Part I — বর্ণনামূলক পরিসংখ্যান ও EDA · Integrative Demos¶
পরিসংখ্যানের প্রথম কাজ হলো data-কে বর্ণনা করা ও চেনা। এই module-এ descriptive statistics ও exploratory data analysis (EDA)-র পাঁচটি flagship ধারণা পাঁচ ধাপে দেখানো হয়েছে — (১) ধারণা, (২) scratch (শুধু numpy), (৩) library check (assert close(...)), (৪) empirical demonstration/"proof" (printed real numbers), (৫) visualization। সব হিসাব real open data (iris ও wine)-এর উপর, fixed seed 20260619। নিচের সব সংখ্যা executed notebook (notebooks/01-descriptive-eda.ipynb) থেকে সরাসরি নেওয়া।
চালানো:
cd notebooks && python3 -m nbconvert --to notebook --execute --inplace 01-descriptive-eda.ipynb --ExecutePreprocessor.timeout=900
1.1 — Data types · population vs sample · sampling distribution of the mean¶
ধারণা। একটি population-এর সব সদস্য জানা থাকলে তার parameter (mean \(\mu\), sd \(\sigma\)) নির্দিষ্ট সংখ্যা; কিন্তু বাস্তবে আমরা শুধু একটি sample দেখি, তাই sample statistic নিজেই একটি random variable। বারবার sample নিলে statistic-এর মান বদলায়, আর তার বণ্টনকে বলে sampling distribution। iris-এর sepal length-কে POPULATION ধরে, size \(n=10\)-এর হাজার হাজার sample টেনে sample mean-এর sampling distribution বানিয়ে দেখানো হয়েছে এটি population mean-এ কেন্দ্রীভূত এবং তার SD (standard error) \(\approx \sigma/\sqrt{n}\)।
Scratch-এর মূল ধারণা। population = iris['sepal length (cm)'] (\(N=150\))। seeded generator দিয়ে \(B=5000\) বার g.choice(population, size=10, replace=True) টেনে প্রতিবারের mean রাখা হয় sample_means-এ। এই array-এর mean দেয় sampling distribution-এর কেন্দ্র, আর তার std(ddof=0) দেয় empirical standard error।
Demonstrated result (প্রমাণ)। population parameter: \(\mu=5.843333\), \(\sigma=0.825301\)। sampling distribution (\(n=10,\ B=5000\))-এর কেন্দ্র \(=5.847106\) (কার্যত \(\mu\)-র সমান, bias \(=0.003773\)), আর empirical SE \(=0.260022\) — CLT-র তত্ত্ব \(\sigma/\sqrt{n}=0.260983\)-এর সঙ্গে প্রায় হুবহু মিলেছে (পার্থক্য \(=0.000961\))। \(\sqrt{n}\)-সূত্রও যাচাই হয়েছে: \(n\) চারগুণ করলে SE প্রায় অর্ধেক হয় —
| \(n\) | empirical SE | \(\sigma/\sqrt{n}\) |
|---|---|---|
| 5 | 0.37505 | 0.36909 |
| 10 | 0.26268 | 0.26098 |
| 20 | 0.18122 | 0.18454 |
| 40 | 0.12984 | 0.13049 |
| 80 | 0.09262 | 0.09227 |
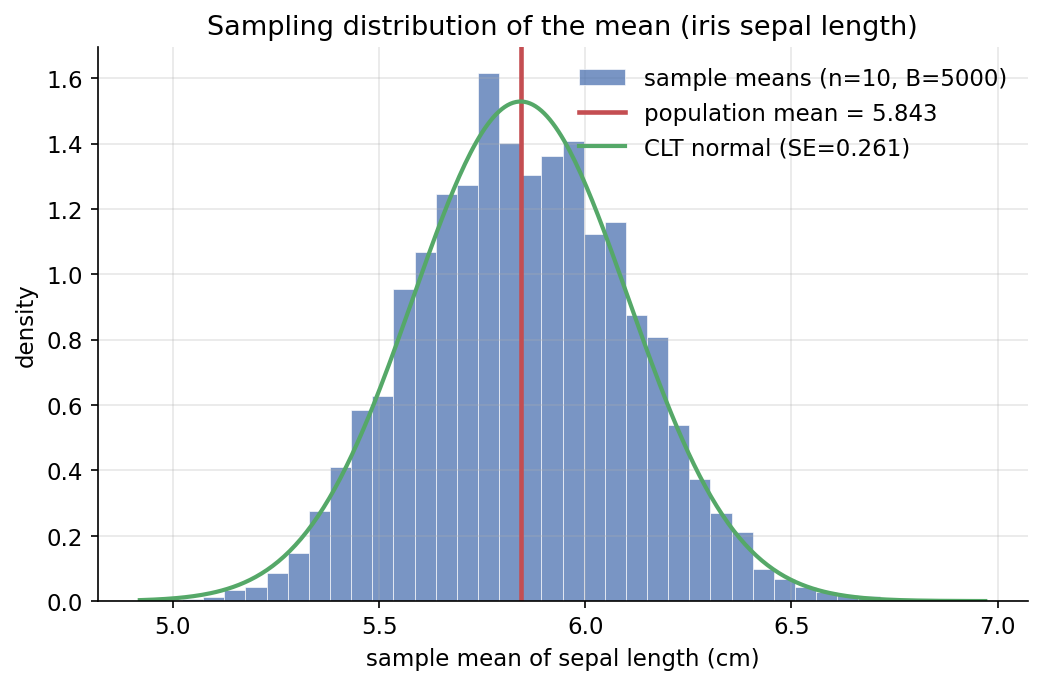
চিত্র: iris sepal length থেকে টানা \(5000\)টি sample mean-এর histogram; লাল রেখা population mean \(=5.843\), সবুজ curve হলো CLT-র normal approximation \(\mathcal N(\mu,\ \text{SE}^2)\) যেখানে \(\text{SE}=0.261\)।
1.2 — Location & variability · robustness¶
ধারণা। Location (কেন্দ্র) মাপে mean ও median; variability (বিস্তার) মাপে variance/sd, IQR ও MAD (median absolute deviation)। Variance-এ \(\text{ddof}=0\) দিলে population সূত্র (\(\div n\)), \(\text{ddof}=1\) দিলে unbiased sample estimate (\(\div (n-1)\))। এদের মূল পার্থক্য robustness: একটি extreme outlier-এ mean ও sd প্রবলভাবে টলে যায়, কিন্তু median ও MAD প্রায় অনড় — কারণ এরা rank-নির্ভর, মানের আকার-নির্ভর নয়।
Scratch-এর মূল ধারণা। iris-এর sepal width-এর উপর numpy-primitive দিয়ে: mean = sum/n, median = sorted array-এর মাঝের মান, var(ddof) = Σ(x−mean)²/(n−ddof), IQR = Q3 − Q1, আর MAD = median(\lvert x − median(x)\rvert)। তারপর একটি বিশাল outlier (\(30.0\)) যোগ করে চারটি statistic-এর shift তুলনা করা হয়।
Demonstrated result (প্রমাণ)। sepal width-এ: mean \(=3.057333\), median \(=3.000000\), variance \(=0.188713\) (\(\text{ddof}=0\)) ও \(0.189979\) (\(\text{ddof}=1\)), sd \(=0.435866\), IQR \(=0.500000\), MAD \(=0.300000\) — সবই numpy-র সঙ্গে machine precision-এ মিলেছে। একটি outlier (\(30.0\)) যোগ করলে:
| statistic | before | after | abs shift |
|---|---|---|---|
| mean | 3.0573 | 3.2358 | 0.1784 |
| sd | 0.4359 | 2.2352 | 1.7993 |
| median | 3.0000 | 3.0000 | 0.0000 |
| MAD | 0.3000 | 0.3000 | 0.0000 |
অর্থাৎ mean সরে \(0.178\) ও sd সরে \(1.799\) (non-robust), কিন্তু median ও MAD একটুও সরে না (\(0.000\)) — এটাই robustness-এর প্রমাণ।
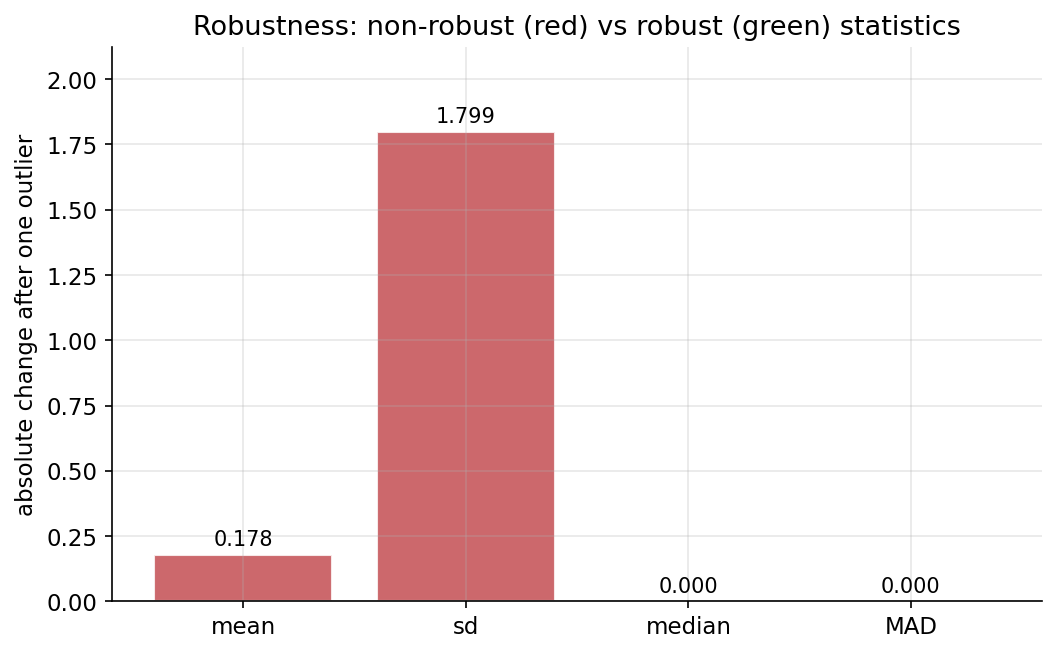
চিত্র: একটি outlier যোগের পর প্রতিটি statistic-এর absolute shift — লাল (mean, sd) প্রবলভাবে টলে, সবুজ (median, MAD) অনড়।
1.3 — Distributions & visualization · histogram, KDE, ECDF, Q–Q¶
ধারণা। একটি feature-এর বণ্টন দেখার চারটি হাতিয়ার: histogram (bin-count), Gaussian KDE (প্রতিটি বিন্দুতে একটি normal kernel বসিয়ে মসৃণ density), ECDF \(\hat F(x)=\frac1n\sum_i \mathbf 1\{X_i\le x\}\) (ক্রমযোজিত অনুপাত), ও Q–Q plot (data-quantile বনাম normal-quantile — সরলরেখা হলে normal)। iris-এর petal length এখানে বিশেষ শিক্ষণীয় কারণ এটি bimodal (setosa বনাম বাকিরা), যা KDE ও Q–Q দুটোই ধরে ফেলে।
Scratch-এর মূল ধারণা। KDE: bw = n^(−1/5)·std(ddof=1) (Scott's rule), তারপর \(\hat f(x)=\frac1{n\,h}\sum_i \phi\!\big(\tfrac{x-x_i}{h}\big)\) যেখানে \(\phi\) standard normal। ECDF: sorted মান বনাম \(i/n\)। Q–Q: sample standardize করে sort, বনাম theoretical quantile \(\sqrt2\cdot\mathrm{erf}^{-1}(2p-1)\) (একটি scratch erfinv দিয়ে), \(p=(i-0.5)/n\)।
Demonstrated result (প্রমাণ)। petal length (\(n=150\))-এ Scott bandwidth \(=0.648037\), KDE-র peak density \(=0.2504\) ঘটে \(x=4.804\)-এ, আর ECDF median-এ \(F=0.5067\)। scratch KDE scipy-র gaussian_kde-এর সঙ্গে মিলেছে max পার্থক্য মাত্র \(5.27\times10^{-16}\)-এ (কার্যত হুবহু), আর ECDF np.sort-এর সঙ্গে অভিন্ন। bimodality-র formal প্রমাণ: Q–Q correlation \(r=0.9380\) (১-এর থেকে স্পষ্ট কম) এবং Shapiro–Wilk test \(W=0.8763,\ p=7.41\times10^{-10}\) (\(p\ll0.05\), তাই normality নাকচ)। KDE integrates to \(0.9939\approx1\) — একটি বৈধ density।
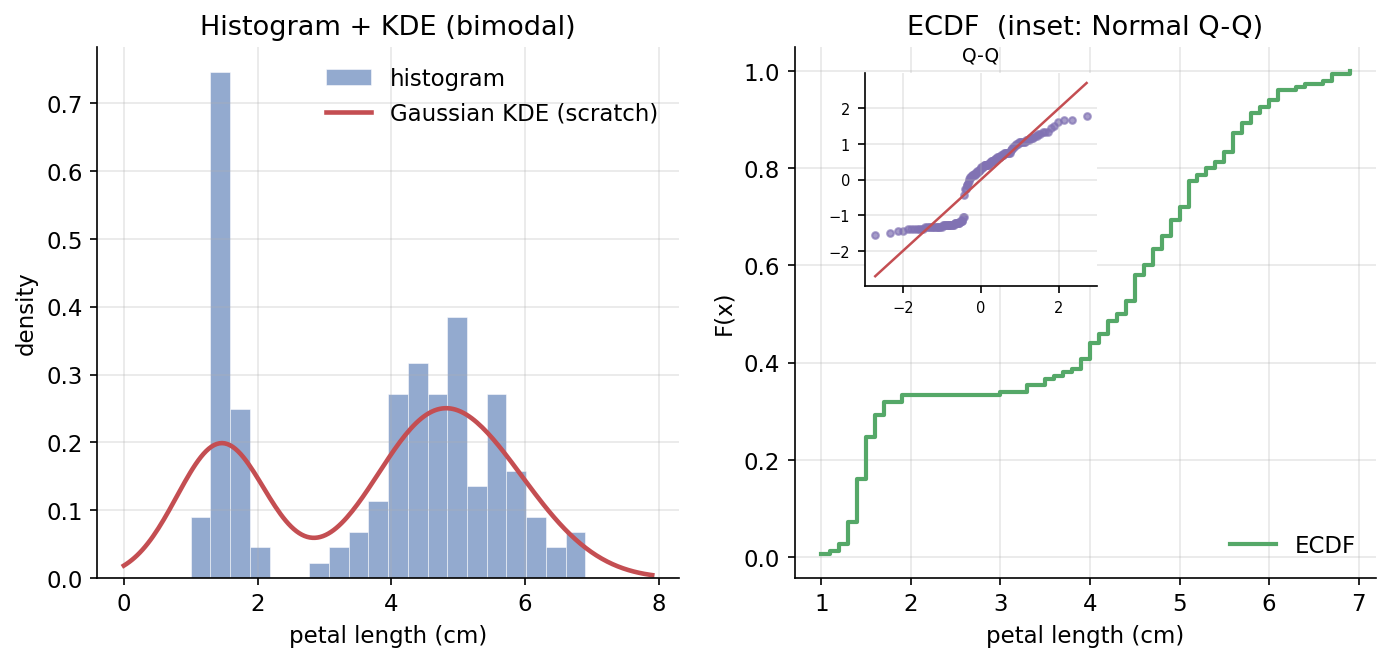
চিত্র (বাঁ): petal length-এর histogram ও তার উপর scratch Gaussian KDE — দুটি চূড়া (bimodal) স্পষ্ট। (ডান): ECDF (step), inset-এ normal Q–Q — বিন্দুগুলো সরলরেখা থেকে সরে গিয়ে non-normality দেখাচ্ছে।
1.4 — Correlation & bivariate analysis¶
ধারণা। Pearson \(r\) দুই variable-এর linear সম্পর্ক মাপে (covariance-কে দুই sd দিয়ে ভাগ), মান \([-1,1]\)। Spearman \(\rho\) হলো rank-এর উপর Pearson — তাই এটি যেকোনো monotone সম্পর্ক ধরে ও outlier-এ robust। সতর্কতা (Anscombe): একই \(r\) সম্পূর্ণ ভিন্ন আকৃতির data থেকে আসতে পারে, আবার কম \(r\) একটি জোরালো non-linear সম্পর্ক লুকাতে পারে — তাই সংখ্যার পাশাপাশি ছবি দেখা অপরিহার্য।
Scratch-এর মূল ধারণা। Pearson: \(r=\dfrac{\sum(u-\bar u)(v-\bar v)}{\sqrt{\sum(u-\bar u)^2\sum(v-\bar v)^2}}\)। Spearman: প্রথমে average-rank (tie সামলে) বের করে, তারপর সেই rank-এর উপর একই Pearson সূত্র। চারটি iris feature-এর জন্য np.corrcoef দিয়ে \(4\times4\) correlation matrix।
Demonstrated result (প্রমাণ)। sepal length বনাম petal length: scratch Pearson \(r=0.871754\), Spearman \(\rho=0.881898\) — scipy-র সঙ্গে হুবহু মিলেছে (দুটোই match: True)। পূর্ণ correlation matrix:
| sepLen | sepWid | petLen | petWid | |
|---|---|---|---|---|
| sepLen | +1.000 | −0.118 | +0.872 | +0.818 |
| sepWid | −0.118 | +1.000 | −0.428 | −0.366 |
| petLen | +0.872 | −0.428 | +1.000 | +0.963 |
| petWid | +0.818 | −0.366 | +0.963 | +1.000 |
সবচেয়ে জোরালো জুটি petLen ও petWid (\(r=0.9629\), প্রায় collinear)। Anscombe caution এক লাইনে দেখানো হয়েছে: একটি linear cloud-এ \(r=+0.923\), কিন্তু একটি parabolic cloud-এ \(r=+0.038\) — কম \(r\) একটি প্রবল non-linear প্যাটার্ন লুকিয়ে রাখে, তাই সবসময় plot করা উচিত।
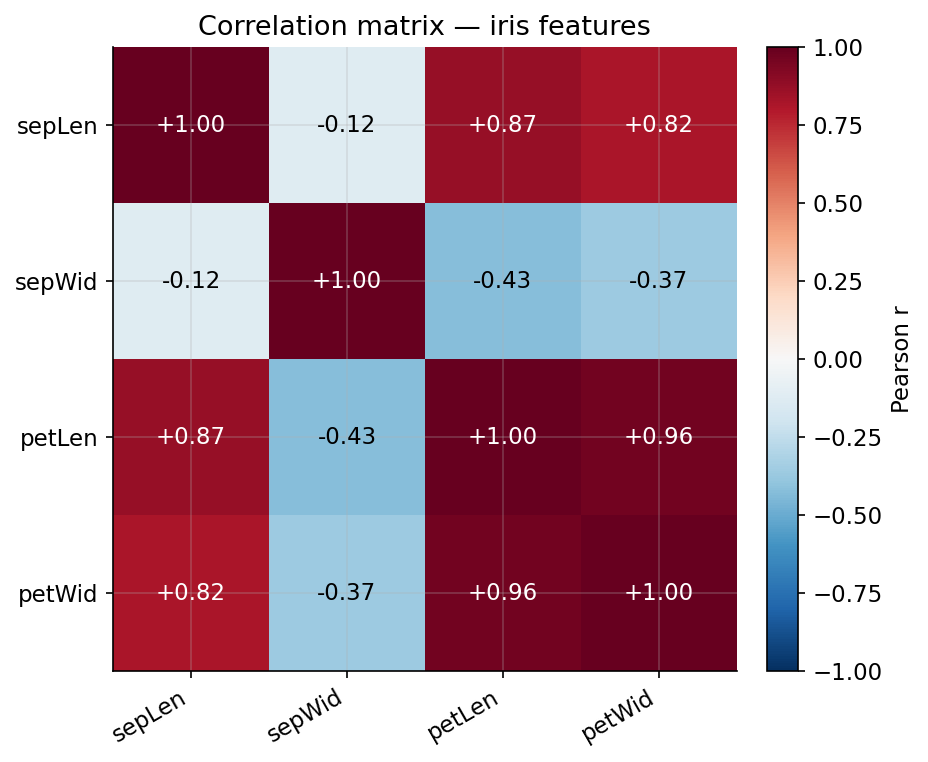
চিত্র: iris-এর চারটি feature-এর Pearson correlation matrix (annotated heatmap); লাল \(=\) ধনাত্মক, নীল \(=\) ঋণাত্মক। petal length–petal width কোষটি সবচেয়ে গাঢ় (\(+0.96\))।
1.5 — EDA case study · the wine dataset¶
ধারণা। একটি সম্পূর্ণ EDA ধাপে ধাপে data চেনায়: (১) shape ও class-balance, (২) missing/constant column খোঁজা, (৩) summary statistics, (৪) সবচেয়ে discriminative feature-এর per-class বণ্টন, (৫) একটি multivariate দৃশ্য — এখানে standardize করে নিজ হাতে computed eigen/SVD দিয়ে PCA-2D projection। wine-এ ১৭৮টি নমুনা, ১৩টি রাসায়নিক feature, ৩টি class।
Scratch-এর মূল ধারণা। class-separation র্যাঙ্ক করতে F-ratio \(=\dfrac{\text{between-class variance}}{\text{within-class variance}}\) প্রতিটি feature-এ। PCA: standardize(X) করে covariance \(\Sigma=\frac1{n-1}Z^\top Z\), তার eigh থেকে বড় দুটি eigenvector-এ project; একই ফল svd(Z) থেকেও যাচাই।
Demonstrated result (প্রমাণ)। wine: \(178\) rows \(\times\) \(13\) features, class counts \([59,71,48]\), missing \(=0\), constant columns \(=0\) (data পরিচ্ছন্ন)। summary — alcohol: mean \(13.001\), sd \(0.812\), range \([11.03,14.83]\); proline: mean \(746.893\), sd \(314.907\); flavanoids: mean \(2.029\), sd \(0.999\)। সবচেয়ে discriminative feature (F-ratio অনুসারে):
| feature | F-ratio | class 0 / 1 / 2 mean |
|---|---|---|
| flavanoids | 2.673 | 2.982 / 2.081 / 0.781 |
| proline | 2.376 | 1115.712 / 519.507 / 629.896 |
| od280/od315 | 2.171 | 3.158 / 2.785 / 1.684 |
| alcohol | 1.544 | 13.745 / 12.279 / 13.154 |
PCA-2D: PC1 variance \(=36.20\%\), PC2 \(=19.21\%\) (প্রথম দুই মিলে \(55.41\%\)), আর eigen-decomposition ও SVD হুবহু একই (True)। PC1-এর class-mean \(-2.283 / 0.039 / 2.748\) — একঘেয়ে ক্রমে সাজানো, অর্থাৎ শুধু PC1 বরাবরই তিন class স্পষ্ট আলাদা হয়।
তিনটি concrete finding।
1. flavanoids একক-হাতে সেরা discriminator (F-ratio \(2.673\)): class means \(2.982 \to 2.081 \to 0.781\) তিন class-কে একঘেয়ে ক্রমে আলাদা করে।
2. data পরিচ্ছন্ন ও নিরাপদ — শূন্য missing ও শূন্য constant column, তাই imputation বা column-drop ছাড়াই modeling-এ যাওয়া যায়।
3. দুই মাত্রাতেই class সুস্পষ্টভাবে পৃথক — মাত্র \(55.41\%\) variance ধরেও PCA-2D scatter-এ তিনটি group প্রায় পরিষ্কারভাবে বিভক্ত (PC1 class-mean \(-2.283/0.039/2.748\)), যা ইঙ্গিত দেয় একটি সরল linear classifier-ই এখানে ভালো কাজ করবে।
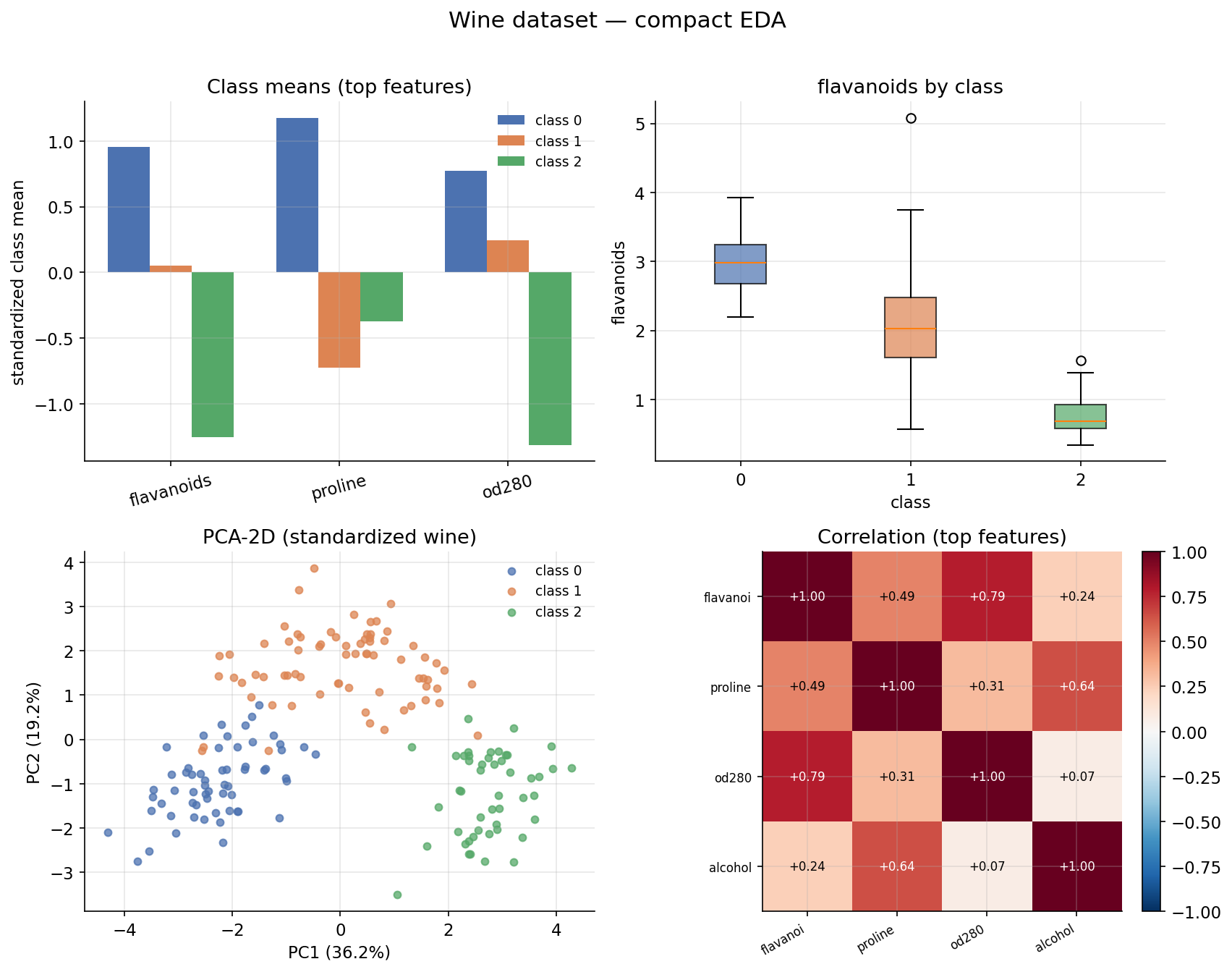
চিত্র (২×২): (উপর-বাঁ) top-3 feature-এর standardized per-class mean bar; (উপর-ডান) সেরা feature flavanoids-এর boxplot-by-class; (নিচ-বাঁ) PCA-2D scatter, class-রং সহ (PC1 \(36.2\%\), PC2 \(19.2\%\)); (নিচ-ডান) top-4 feature-এর correlation snippet।