8.2 — Simulation Study (তত্ত্বকে Monte-Carlo দিয়ে যাচাই)¶
১ · ভূমিকা¶
১.১ ভোক্তা থেকে ডিজাইনার — একটা যাত্রার সমাপক ধাপ¶
এই অধ্যায় একটা রূপান্তরের অধ্যায়। Part 0 থেকে Part VII পর্যন্ত পুরো আরোহণে একটা নির্দিষ্ট ভূমিকা বারবার পালন করা হয়েছে: উপপাদ্যের ভোক্তা (consumer) হওয়া। Central Limit Theorem বিবৃত ও (Part VII-এ) প্রমাণিত হয়েছে, maximum likelihood estimator-এর consistency ও asymptotic normality প্রতিষ্ঠিত হয়েছে, bootstrap-এর confidence interval-এর ন্যায্যতা যুক্তি দিয়ে দেখানো হয়েছে, bias–variance decomposition learning theory-র কেন্দ্রে বসেছে। প্রতিটি ক্ষেত্রে দাবিটা গ্রহণ করা হয়েছে, বোঝা হয়েছে, ব্যবহার করা হয়েছে — কিন্তু কখনো সেই দাবিকে নিজে হাতে পরীক্ষা করার একটা পূর্ণাঙ্গ যন্ত্র গড়া হয়নি।
Part VIII সেই ভূমিকা বদলে দেয়। এখানে শেখার লক্ষ্য উপপাদ্য গ্রহণ করা নয় — বরং একটা তাত্ত্বিক দাবির মুখোমুখি দাঁড়িয়ে নিজে একটা পরীক্ষা ডিজাইন করা (design an experiment), সেই পরীক্ষা চালানো, এবং তার সংখ্যাগত ফলকে তত্ত্বের ভবিষ্যদ্বাণীর সাথে মিলিয়ে দেখা। এটাই একজন গবেষকের মৌলিক দক্ষতা: তত্ত্বকে বিশ্বাস করার আগে তাকে যাচাই করা, এবং নিজের কোডকে বিশ্বাস করার আগে তাকেও যাচাই করা।
এক বাক্যে সূচনা। Part 0–VII শিক্ষার্থীকে উপপাদ্যের ভোক্তা বানিয়েছিল; এই capstone অধ্যায় তাকে এমন একজনে পরিণত করে যে একটা দাবি পরীক্ষা করতে নিজে একটা সিমুলেশন স্টাডি (simulation study) ডিজাইন করতে পারে।
১.২ সিমুলেশন স্টাডি — একটা জানা ফল পুনরুৎপাদনই যেখানে যাচাইয়ের হাতিয়ার¶
এই অধ্যায়ের কেন্দ্রীয় থিসিস সরল কিন্তু গভীর। একটা সিমুলেশন স্টাডি (simulation study) বা মন্টি-কার্লো পরীক্ষা (Monte-Carlo experiment) হলো এমন একটা সাজানো কম্পিউটেশনাল পরীক্ষা, যেখানে কৃত্রিম random তথ্য বারবার তৈরি করে কোনো statistic-এর আচরণ পর্যবেক্ষণ করা হয়। আর এই অধ্যায়ে তার একটা বিশেষ, শৃঙ্খলিত ব্যবহারই মূল বিষয়: এমন পরীক্ষা ডিজাইন করা যা একটা আগে থেকে জানা তাত্ত্বিক ফল পুনরুৎপাদন (reproduce a known theoretical result) করে।
কেন জানা ফল পুনরুৎপাদন করা হবে, যখন ফলটা তো ইতিমধ্যেই জানা? কারণ এখানে দুটো জিনিস একসাথে যাচাই হয়। প্রথমত, তত্ত্বটা যাচাই হয় — কাগজের প্রমাণ সত্যি বাস্তব সংখ্যায় ফুটে ওঠে কিনা, এবং কোন শর্তে (কত বড় \(n\)-এ, কোন বণ্টনে) তা কতটা ভালো কাজ করে, তা চোখে দেখা যায়। দ্বিতীয়ত, এবং সমান গুরুত্বপূর্ণ — নিজের কোড ও পাইপলাইন যাচাই হয়। যখন একটা সিমুলেশনের ফল একটা জানা তাত্ত্বিক মানের সাথে মেলে, তখন সেটা একটা প্রবল সাক্ষ্য যে estimator, sampling, ও হিসাবের কোড নির্ভুল। এই "জানা-উত্তরের বিরুদ্ধে পরীক্ষা" (known-answer test) হলো ঠিক সেই ভিত্তি, যার উপর দাঁড়িয়ে পরে একটা অজানা পরিস্থিতিতে সেই কোডকে বিশ্বাস করা যায়। তত্ত্ব ও কোড — দুটোই সন্দেহভাজন যতক্ষণ না তারা একটা জানা ফলে একমত হয়।
এক বাক্যে। একটা জানা তাত্ত্বিক ফলকে পুনরুৎপাদনকারী সিমুলেশন স্টাডিই সেই পদ্ধতি যা দিয়ে গবেষকেরা একসাথে তত্ত্ব ও নিজের কোড — দুটোকেই বিশ্বাস করার আগে যাচাই করে নেন।
১.৩ চারটি পরীক্ষা — চারটি তাত্ত্বিক দাবির যাচাই¶
এই অধ্যায়ে চারটি সিমুলেশন স্টাডি সাজানো হয়েছে, প্রতিটি আগের কোনো একটা অধ্যায়ের একটা কেন্দ্রীয় দাবিকে যাচাই করে। প্রতিটি পরীক্ষার একটা স্পষ্ট ডিজাইন (factor, replication-সংখ্যা, নির্দিষ্ট seed np.random.default_rng(20260619)), একটা মুদ্রিত ফলাফল-সারণি, এবং একটা তাত্ত্বিক ভবিষ্যদ্বাণী আছে যাকে ফলটা নিশ্চিত করে।
-
পরীক্ষা E1 — CLT-র অভিসরণ-হার (convergence rate) ও Berry–Esseen (← 3.4)। ভিত্তি-বণ্টন হিসেবে ডানদিকে-বাঁকা \(\text{Exp}(1)\) নিয়ে standardized গড় \(Z_n=\sqrt n(\bar X_n-1)\)-এর বণ্টন \(N(0,1)\)-এর কতটা কাছে, তা Kolmogorov–Smirnov দূরত্ব \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\) দিয়ে মাপা হয় এবং \(n\)-এর সাথে তার ক্ষয়-হার দেখা হয়। Berry–Esseen theorem বলে এই দূরত্ব \(\sim n^{-1/2}\) হারে কমবে; পরীক্ষায় log–log ঢাল ≈ −0.5 (নির্দিষ্টভাবে \(-0.4998\)) পাওয়া যায় — তাত্ত্বিক \(-1/2\)-এর প্রায় নিখুঁত প্রতিধ্বনি।
-
পরীক্ষা E2 — bootstrap confidence interval-এর coverage (← 4.9)। \(\text{Exp}(1)\) থেকে \(n=40\) আকারের নমুনায় গড়ের উপর percentile bootstrap দিয়ে ৯৫% confidence interval বানিয়ে, বহু পুনরাবৃত্ত dataset-এ সেই interval সত্যিকারের \(\theta=1\)-কে কত ভাগ ক্ষেত্রে ধরে — সেই coverage probability মাপা হয়। এখানে প্রাপ্ত empirical coverage ≈ 0.913 — nominal \(0.95\)-এর সামান্য নিচে, যা মাঝারি \(n\)-এ ডান-বাঁক (skew) থাকা বণ্টনে percentile bootstrap-এর সামান্য under-coverage-এর তাত্ত্বিক প্রত্যাশাকেই ফুটিয়ে তোলে।
-
পরীক্ষা E3 — bias–variance tradeoff (← 6.1)। একটা পরিচিত signal-এর উপর ভিন্ন ভিন্ন degree-এর polynomial regression বসিয়ে test error-কে \(\text{Bias}^2\), \(\text{Var}\) ও অপরিবর্তনীয় noise-এ ভাঙা হয়। তত্ত্ব বলে degree বাড়ালে \(\text{Bias}^2\) কমবে কিন্তু \(\text{Var}\) বাড়বে, তাই মোট error একটা U-আকৃতি নেবে; পরীক্ষায় ঠিক তা-ই ঘটে, এবং সর্বনিম্ন মোট error দেয় optimal degree 5।
-
পরীক্ষা E4 — MLE-র consistency ও asymptotic normality (← 4.3)। \(\text{Exp}(\lambda=2)\) মডেলে MLE \(\hat\lambda=1/\bar X\)-এর bias ও RMSE \(n\) বাড়ার সাথে কমে কিনা (consistency), এবং standardized estimator-এর বণ্টন \(N(0,1)\)-এ যায় কিনা (asymptotic normality) — তা যাচাই হয়। বড় \(n\)-এ standardized estimator ও \(N(0,1)\)-এর মধ্যে KS-দূরত্ব ≈ 0.0180 পর্যন্ত নেমে আসে, যা asymptotic normality-র দাবিকে দৃঢ়ভাবে সমর্থন করে।
এক বাক্যে। চারটি পরীক্ষা — CLT-হার/Berry–Esseen (← 3.4), bootstrap coverage (← 4.9), bias–variance tradeoff (← 6.1), ও MLE consistency/asymptotic normality (← 4.3) — প্রত্যেকে আগের একটা অধ্যায়ের একটা কেন্দ্রীয় তাত্ত্বিক দাবিকে একটা ডিজাইন-করা মন্টি-কার্লো পরীক্ষায় পুনরুৎপাদন করে যাচাই করে।
১.৪ কেন এটি গুরুত্বপূর্ণ — capstone-এর সমন্বয়কারী ভূমিকা¶
এই চারটি পরীক্ষা এলোমেলোভাবে বাছা হয়নি — একসাথে এরা পুরো আরোহণের চারটি স্তম্ভকে স্পর্শ করে: সীমা-উপপাদ্য (CLT, E1), resampling-ভিত্তিক inference (bootstrap, E2), statistical learning (bias–variance, E3), ও parametric estimation-এর asymptotics (MLE, E4)। একটা capstone অধ্যায় হিসেবে এর কাজ নতুন তত্ত্ব যোগ করা নয়, বরং আগে গড়া বিচ্ছিন্ন যন্ত্রগুলোকে একটা অভিন্ন পরীক্ষামূলক শৃঙ্খলার (experimental discipline) নিচে একত্রে বসানো — যেখানে প্রতিটি দাবি ডিজাইন, replication, seed, সারণি ও তাত্ত্বিক তুলনার একই কাঠামোয় পরীক্ষিত হয়।
এর ফল কেবল চারটি নিশ্চিতকরণ নয়, বরং একটা হস্তান্তরযোগ্য দক্ষতা: একটা তাত্ত্বিক দাবি পেলে তাকে একটা reproducible সিমুলেশন স্টাডিতে অনুবাদ করা, সঠিক factor বেছে নেওয়া, Monte-Carlo standard error দিয়ে ফলের অনিশ্চয়তা মাপা, এবং তাত্ত্বিক প্রত্যাশার সাথে তার সংগতি বিচার করা। এই দক্ষতাই পরবর্তী যেকোনো গবেষণা-পথে — যেখানে দাবিটা আর জানা থাকবে না — সবচেয়ে কাজে লাগবে।
এক বাক্যে। এই অধ্যায়ের তাৎপর্য নতুন তত্ত্বে নয়, বরং আগের সব যন্ত্রকে একটা অভিন্ন পরীক্ষামূলক শৃঙ্খলায় একত্রিত করে একটা হস্তান্তরযোগ্য দক্ষতা গড়ায় — জানা দাবিতে যাচাই-করা যে পদ্ধতি অজানা দাবিতেও নির্ভরযোগ্য।
১.৫ এই অধ্যায়ের পথরেখা¶
- §২ পরীক্ষা-ডিজাইনের মূল শব্দভাণ্ডার ও পদ্ধতি — Monte-Carlo simulation, pseudo-random number generator ও seed (reproducibility), replications (\(R\)) ও Monte-Carlo standard error (MC SE), sampling distribution, convergence rate (\(\sim n^{-1/2}\)), coverage probability, bias–variance decomposition, consistency ও asymptotic normality, Berry–Esseen theorem, factorial experiment design, এবং variance reduction — প্রতিটির precise সংজ্ঞা ও পরস্পর-সম্পর্ক।
- §৩ পরীক্ষা E1 — CLT-র অভিসরণ-হার: KS-দূরত্ব বনাম \(n\), log–log ঢাল ≈ −0.5, এবং Berry–Esseen-এর সাথে তুলনা।
- §৪ পরীক্ষা E2 — bootstrap coverage: percentile bootstrap CI-র empirical coverage ≈ 0.913, MC SE, ও under-coverage-এর ব্যাখ্যা।
- §৫ পরীক্ষা E3 — bias–variance tradeoff: degree বনাম \(\text{Bias}^2\)/\(\text{Var}\)/মোট error, U-আকৃতি, ও optimal degree 5।
- §৬ পরীক্ষা E4 — MLE consistency ও asymptotic normality: bias/RMSE বনাম \(n\), standardized estimator-এর KS ≈ 0.0180।
- §৭ চার পরীক্ষার সংশ্লেষ, অভিন্ন ডিজাইন-নীতি ও সাধারণ পাঠ; §৮ সীমাবদ্ধতা, সম্প্রসারণ ও অনুশীলন।
এক বাক্যে পথরেখা। §২ পরীক্ষা-ডিজাইনের শব্দভাণ্ডার ও পদ্ধতি → §৩–§৬ চারটি পরীক্ষা (CLT-হার, bootstrap coverage, bias–variance, MLE asymptotics), প্রতিটি ডিজাইন+সারণি+তাত্ত্বিক তুলনা সহ → §৭ সংশ্লেষ ও §৮ সম্প্রসারণ-অনুশীলন।
২ · মূল ধারণা ও পদ্ধতি¶
এই বিভাগে পরীক্ষা-ডিজাইনের সব formal বস্তুর precise সংজ্ঞা ও পদ্ধতি দেওয়া হয় — প্রতিটি English পরিভাষা প্রথম ব্যবহারেই Bangla-য় খুলে। কাঠামো §১-এর সুতো ধরে: প্রথমে সিমুলেশনের ইঞ্জিন — Monte-Carlo simulation, pseudo-random number generator ও seed (২.১); তারপর একটা পরীক্ষার একক ও তার অনিশ্চয়তা — replications ও Monte-Carlo standard error (২.২); statistic-এর আচরণের ভাষা — sampling distribution ও convergence rate (২.৩); চারটি পরীক্ষার তাত্ত্বিক লক্ষ্য-ধারণা — coverage probability, bias–variance decomposition, consistency/asymptotic normality, Berry–Esseen theorem (২.৪–২.৭); শেষে পরীক্ষা সাজানোর কাঠামো — factorial experiment design ও variance reduction (২.৮)। জুড়ে সব random তথ্য একটা নির্দিষ্ট seed np.random.default_rng(20260619)-চালিত generator থেকে আসা ধরে নেওয়া হয়, যাতে প্রতিটি ফল হুবহু পুনরুৎপাদনযোগ্য (reproducible)।
২.১ Monte-Carlo simulation, pseudo-random number generator ও seed¶
সব পরীক্ষার ভিত্তি একটাই ধারণা — জানা random প্রক্রিয়া থেকে বহুবার নমুনা তৈরি করে কোনো রাশির আচরণ পর্যবেক্ষণ করা।
সংজ্ঞা (Monte-Carlo simulation)। একটা Monte-Carlo simulation (মন্টি-কার্লো সিমুলেশন) হলো এমন একটা পদ্ধতি, যেখানে কোনো তাত্ত্বিক রাশি — যেমন প্রত্যাশা, সম্ভাবনা, বা একটা statistic-এর বণ্টন — এর আনুমানিক মান বের করা হয় সেই random প্রক্রিয়া থেকে বহুবার কৃত্রিম নমুনা তৈরি করে এবং প্রতিবারের ফল গড় বা সংগ্রহ করে। কোনো বদ্ধ-রূপ (closed-form) সমাধান কঠিন হলেও, বড়-সংখ্যক পুনরাবৃত্তির গড় large-number সূত্রে সত্য মানের দিকে অভিসারী হয়।
কম্পিউটার সত্যিকারের random সংখ্যা তৈরি করে না; বদলে একটা নির্ধারক (deterministic) অ্যালগরিদম random-দর্শনীয় ক্রম উৎপন্ন করে।
সংজ্ঞা (pseudo-random number generator ও seed)। একটা pseudo-random number generator (সিউডো-random সংখ্যা জেনারেটর, সংক্ষেপে PRNG) হলো একটা নির্ধারক অ্যালগরিদম, যা একটা প্রাথমিক অবস্থা থেকে শুরু করে এমন একটা সংখ্যা-ক্রম দেয় যা পরিসংখ্যানগতভাবে random-এর মতো আচরণ করে। এই প্রাথমিক অবস্থা নির্ধারণকারী মানটাই seed (বীজ): একই seed সবসময় হুবহু একই ক্রম দেয়। তাই seed স্থির রাখাই reproducibility (পুনরুৎপাদনযোগ্যতা)-র চাবি — একই কোড, একই seed, একই ফল। এই অধ্যায়ে সর্বত্র generator তৈরি হয়
np.random.default_rng(20260619)দিয়ে।
seed-কে একটা সচেতন ডিজাইন-সিদ্ধান্ত হিসেবে দেখা জরুরি: এটা ফলকে "সাজানো" করে না, বরং যেকোনো পাঠককে হুবহু একই সংখ্যা যাচাই করার সুযোগ দেয় — যা একটা জানা-উত্তরের পরীক্ষায় (§১.২) অপরিহার্য।
এক বাক্যে। Monte-Carlo simulation জানা random প্রক্রিয়া থেকে বহুবার নমুনা তৈরি করে রাশির আচরণ মাপে, আর তা চালায় একটা PRNG যার seed (
np.random.default_rng(20260619)) স্থির রাখলে প্রতিটি ফল হুবহু reproducible হয়।
২.২ replications ও Monte-Carlo standard error¶
একটা মন্টি-কার্লো অনুমান নিজেই random — তাই তার নিজস্ব একটা অনিশ্চয়তা আছে, যা পুনরাবৃত্তি-সংখ্যা দিয়ে নিয়ন্ত্রিত হয়।
সংজ্ঞা (replications)। একটা সিমুলেশন পরীক্ষায় replications (পুনরাবৃত্তি, সংখ্যাটি \(R\) দিয়ে চিহ্নিত) হলো স্বাধীনভাবে সম্পন্ন করা পুনরাবৃত্ত পরীক্ষা-চক্রের সংখ্যা — অর্থাৎ পুরো "নমুনা তৈরি করো, statistic হিসাব করো" প্রক্রিয়াটা যতবার স্বাধীনভাবে করা হয়। কোনো রাশির মন্টি-কার্লো অনুমান হলো এই \(R\)টি স্বাধীন ফলের গড় (বা অনুপাত)।
যেহেতু অনুমানটা \(R\)টি random ফলের গড়, তার নিজস্ব সুনির্দিষ্টতা large-number ও CLT (← 3.4) দিয়ে পরিমাপযোগ্য।
সংজ্ঞা (Monte-Carlo standard error)। একটা মন্টি-কার্লো অনুমানের Monte-Carlo standard error (মন্টি-কার্লো আদর্শ ত্রুটি, সংক্ষেপে MC SE) হলো সেই অনুমানের নিজস্ব sampling-অনিশ্চয়তার একটা পরিমাপ। \(R\)টি স্বাধীন ফলের নমুনা-standard deviation \(s\) হলে একটা গড়-ধরনের অনুমানের ক্ষেত্রে $$ \text{MC SE}\;\approx\;\frac{s}{\sqrt R}, $$ এবং যখন অনুমানটা একটা অনুপাত (proportion) \(\hat p\) — যেমন coverage — তখন $$ \text{MC SE}\;\approx\;\sqrt{\frac{\hat p\,(1-\hat p)}{R}}. $$ লক্ষণীয়, দুটোই \(\propto R^{-1/2}\) — তাই অনুমানের সুনির্দিষ্টতা দ্বিগুণ করতে \(R\) চারগুণ করতে হয়।
MC SE-ই বলে দেয় একটা সিমুলেশন-ফল কতটা নির্ভরযোগ্য: E2-তে coverage \(0.913\)-এর পাশে যে MC SE \(\approx 0.0063\), তা জানায় empirical coverage ও nominal \(0.95\)-এর মধ্যকার ব্যবধানটা নিছক মন্টি-কার্লো-শব্দ (noise) নয়, বরং একটা বাস্তব under-coverage।
এক বাক্যে। replications (\(R\)) হলো স্বাধীন পরীক্ষা-চক্রের সংখ্যা, আর Monte-Carlo standard error (\(\text{MC SE}\approx s/\sqrt R\), অনুপাতে \(\sqrt{\hat p(1-\hat p)/R}\)) মাপে সেই \(R\)-চালিত অনুমানের নিজস্ব অনিশ্চয়তা — যা ছাড়া কোনো সিমুলেশন-ফলের সাথে তত্ত্বের ব্যবধানকে অর্থপূর্ণভাবে বিচার করা যায় না।
২.৩ sampling distribution ও convergence rate¶
প্রতিটি পরীক্ষা আসলে একটা statistic-এর বণ্টন নিয়ে প্রশ্ন করে — এবং সেই বণ্টন কত দ্রুত একটা সীমায় গোছায়, তা নিয়ে।
সংজ্ঞা (sampling distribution)। একটা statistic \(T_n\) (নমুনা থেকে হিসাব-করা যেকোনো রাশি, যেমন \(\bar X_n\) বা \(\hat\lambda\))-এর sampling distribution (নমুনায়ন-বণ্টন) হলো পুনরাবৃত্ত নমুনায়নের অধীনে \(T_n\)-এর বণ্টন — অর্থাৎ একই বণ্টন থেকে একই আকারের নমুনা বারবার নিলে \(T_n\) যে মানগুলো যে সম্ভাবনায় নেয়, তার বণ্টন। সিমুলেশন এই sampling distribution-কে empirically গড়ে তোলে: \(R\)টি স্বাধীন নমুনায় \(T_n\)-এর \(R\)টি মান একত্রে তার আনুমানিক sampling distribution।
sampling distribution একটা সীমা-আকৃতির (যেমন \(N(0,1)\)) দিকে যায় — কিন্তু কত দ্রুত?
সংজ্ঞা (convergence rate)। একটা sampling distribution বা তার কোনো ত্রুটি-পরিমাপ যদি নমুনা-আকার \(n\)-এর সাথে \(c\,n^{-\alpha}\)-এর মতো হারে সীমায় নামে, তবে \(\alpha\)-কে বলা হয় সেই অভিসরণের convergence rate (অভিসরণ-হার)। পরিসংখ্যানে সবচেয়ে ঘনঘন দেখা হার \(\alpha=1/2\), অর্থাৎ ত্রুটি \(\sim n^{-1/2}\) — CLT, MLE-asymptotics ও Berry–Esseen সবই এই হারে বাঁধা। একটা log–log ছকে (\(\log(\text{ত্রুটি})\) বনাম \(\log n\)) এই হার একটা ঋণাত্মক ঢাল হিসেবে ফুটে ওঠে, যার মান তত্ত্বে \(-\alpha\)।
এই দুই ধারণা সরাসরি E1-এ কাজে লাগে: সেখানে \(Z_n=\sqrt n(\bar X_n-1)\)-এর sampling distribution-কে \(N(0,1)\)-এর সাথে তুলনা করে ত্রুটির convergence rate মাপা হয়, এবং log–log ঢাল ≈ −0.5 পাওয়া মানে ত্রুটি ঠিক \(n^{-1/2}\) হারে কমছে।
এক বাক্যে। একটা sampling distribution হলো পুনরাবৃত্ত নমুনায়নে একটা statistic-এর বণ্টন, আর convergence rate (\(\sim n^{-1/2}\), log–log ছকে ঢাল ≈ −0.5) মাপে সেই বণ্টন কত দ্রুত তার সীমা-আকৃতিতে গোছায়।
২.৪ coverage probability¶
confidence interval-এর মান তার nominal স্তরে নয়, তার প্রকৃত ধরে-রাখার হারে — যাকে সিমুলেশন সরাসরি মাপতে পারে।
সংজ্ঞা (coverage probability)। একটা confidence interval-পদ্ধতির coverage probability (আচ্ছাদন-সম্ভাবনা) হলো সেই সম্ভাবনা যে পদ্ধতিটির তৈরি random interval সত্যিকারের parameter-মানকে ধারণ করে। একটা \(\hat\theta\)-এর interval \([L,U]\) যদি nominal \(95\%\) হয়, তবে আদর্শে coverage হওয়া উচিত \(0.95\); সিমুলেশনে একই বণ্টন থেকে বহু (\(D\)টি) dataset নিয়ে প্রতিবার interval বানিয়ে, সত্য \(\theta\) কত ভাগ interval-এ পড়ল তার অনুপাতই empirical coverage। এই empirical coverage নিজেই একটা অনুপাত-অনুমান, তাই তার MC SE \(\approx\sqrt{\hat p(1-\hat p)/D}\) (২.২)।
coverage-এর তাৎপর্য: nominal ও empirical coverage-এর ব্যবধানই বলে দেয় একটা interval-পদ্ধতি সৎ কিনা। E2-তে \(\text{Exp}(1)\)-এর ডান-বাঁকের কারণে \(n=40\)-তে percentile bootstrap সামান্য under-cover করে — empirical coverage ≈ 0.913, nominal \(0.95\)-এর নিচে — যা কোনো ভুল নয়, বরং মাঝারি \(n\)-এ skew বণ্টনে percentile bootstrap-এর একটা জানা, প্রত্যাশিত আচরণ।
এক বাক্যে। coverage probability হলো একটা confidence interval সত্য parameter ধরার প্রকৃত সম্ভাবনা, যা সিমুলেশনে বহু dataset-এ interval বানিয়ে empirically মাপা যায় — এবং nominal থেকে তার বিচ্যুতিই (E2-তে ≈ 0.913 বনাম 0.95) পদ্ধতির নির্ভুলতার পরিমাপ।
২.৫ bias–variance decomposition¶
একটা estimator বা predictor-এর প্রত্যাশিত ত্রুটি তিনটি অর্থপূর্ণ অংশে ভাঙে — এই বিভাজনই E3-এর ভিত্তি।
সংজ্ঞা (bias–variance decomposition)। একটা fixed বিন্দুতে একটা estimator \(\hat f\) দিয়ে একটা সত্য মান \(f\) অনুমান করলে, তার প্রত্যাশিত বর্গ-ত্রুটি (expected squared error) তিনটি অংশে ভাঙে: $$ \mathbb E\big[(\hat f-f)^2\big]\;=\;\underbrace{\big(\mathbb E[\hat f]-f\big)^2}{\text{Bias}^2}\;+\;\underbrace{\operatorname{Var}(\hat f)}\;+\;\sigma^2, $$ যেখানে }\(\text{Bias}^2\) হলো systematic বিচ্যুতির বর্গ, \(\text{Var}\) হলো estimator-এর নমুনা-থেকে-নমুনায় ওঠানামা, এবং \(\sigma^2\) হলো observation-এর অপরিবর্তনীয় (irreducible) noise — যাকে কোনো মডেল দূর করতে পারে না।
এই বিভাজনের মূল শিক্ষা একটা টানাপোড়েন (tradeoff): মডেলের নমনীয়তা (যেমন polynomial-এর degree) বাড়ালে \(\text{Bias}^2\) কমে কিন্তু \(\text{Var}\) বাড়ে, তাই মোট ত্রুটি সাধারণত একটা U-আকৃতি নেয় এবং কোনো একটা মাঝারি জটিলতায় সর্বনিম্ন হয়। E3 ঠিক এই U-আকৃতি সিমুলেশনে ফুটিয়ে তোলে এবং সর্বনিম্ন-error দেওয়া optimal degree 5 চিহ্নিত করে; সেখানে অপরিবর্তনীয় অংশ \(\sigma^2=0.49\) একটা মেঝে হিসেবে থেকে যায়।
এক বাক্যে। bias–variance decomposition — \(\mathbb E[(\hat f-f)^2]=\text{Bias}^2+\text{Var}+\sigma^2\) — প্রত্যাশিত ত্রুটিকে systematic বিচ্যুতি, ওঠানামা ও অপরিবর্তনীয় noise-এ ভাঙে, এবং degree বাড়ালে \(\text{Bias}^2\downarrow\) কিন্তু \(\text{Var}\uparrow\) হওয়ায় মোট ত্রুটির U-আকৃতিই E3-এর optimal degree 5-কে ব্যাখ্যা করে।
২.৬ consistency ও asymptotic normality¶
একটা estimator বড় নমুনায় সত্য মানে গোছায় কিনা, এবং সেই মানের চারপাশে তার ওঠানামা normal হয় কিনা — দুটোই E4-এর লক্ষ্য।
সংজ্ঞা (consistency)। একটা estimator \(\hat\theta_n\)-কে বলা হয় \(\theta\)-এর জন্য consistent (সঙ্গতিপূর্ণ), যদি নমুনা-আকার \(n\to\infty\)-এ \(\hat\theta_n\) সম্ভাবনায় \(\theta\)-এর দিকে অভিসারী হয় — অর্থাৎ যত বড় নমুনা, তত নিশ্চিতভাবে \(\hat\theta_n\) সত্য মানের কাছাকাছি। সিমুলেশনে এটি দেখা যায় \(n\) বাড়ার সাথে \(\hat\theta_n\)-এর bias ও RMSE-এর ক্রমশ শূন্যের দিকে নেমে আসায়।
consistency শুধু "কোথায় গোছায়" বলে; পরবর্তী ধাপ বলে "কীভাবে গোছায়" — কোন আকৃতিতে ও কোন হারে।
সংজ্ঞা (asymptotic normality)। একটা estimator \(\hat\theta_n\) asymptotically normal (উপগামীভাবে normal), যদি যথাযথভাবে কেন্দ্রিত ও \(\sqrt n\)-স্কেলে বিবর্ধিত ত্রুটি একটা normal সীমায় যায়: $$ \sqrt n\,(\hat\theta_n-\theta)\;\Rightarrow\;N!\Big(0,\ \tfrac{1}{I(\theta)}\Big), $$ যেখানে \(I(\theta)\) হলো Fisher information (← 4.3) এবং "\(\Rightarrow\)" বণ্টনে-অভিসরণ। অর্থাৎ বড় \(n\)-এ MLE-এর ত্রুটি প্রায় \(N(0,1/(nI(\theta)))\)-বণ্টিত, তাই standardized রাশি \(\sqrt{nI(\theta)}\,(\hat\theta_n-\theta)\) প্রায় \(N(0,1)\)।
E4-তে \(\text{Exp}(\lambda=2)\)-এ \(I(\lambda)=1/\lambda^2\), তাই asymptotic standard deviation \(=\lambda=2\); standardized estimator ও \(N(0,1)\)-এর KS-দূরত্ব বড় \(n\)-এ ≈ 0.0180 পর্যন্ত নামে — asymptotic normality-র সরাসরি সংখ্যাগত সাক্ষ্য। (উল্লেখ্য, \(\hat\lambda=1/\bar X\) finite-\(n\)-এ Jensen-এর কারণে সামান্য biased, কিন্তু bias \(n\to\infty\)-এ শূন্যে যায় — তাই consistent।)
এক বাক্যে। consistency মানে \(n\to\infty\)-এ \(\hat\theta_n\to\theta\) (bias ও RMSE শূন্যে নামে), আর asymptotic normality (\(\sqrt n(\hat\theta_n-\theta)\Rightarrow N(0,1/I(\theta))\)) মানে সেই ত্রুটির আকৃতি \(\sqrt n\)-স্কেলে normal — E4-এ KS ≈ 0.0180 যার সাক্ষী।
২.৭ Berry–Esseen theorem¶
CLT বলে \(Z_n\) শেষমেশ normal হয়; Berry–Esseen সেই অভিসরণের হার বেঁধে দেয় — যা E1-এর তাত্ত্বিক মেরুদণ্ড।
উপপাদ্য (Berry–Esseen)। iid random variable \(X_1,\dots,X_n\)-এর যদি \(\mathbb E[X]=\mu\), \(\operatorname{Var}(X)=\sigma^2\), ও তৃতীয় absolute central moment \(\rho=\mathbb E\lvert X-\mu\rvert^3<\infty\) হয়, তবে standardized গড় \(Z_n\)-এর CDF \(F_n\) ও standard normal CDF \(\Phi\)-এর মধ্যে সর্বোচ্চ ব্যবধান একটা সর্বজনীন বাঁধে আবদ্ধ: $$ \sup_x\big\lvert F_n(x)-\Phi(x)\big\rvert\;\le\;\frac{C\,\rho}{\sigma^3\,\sqrt n}, $$ যেখানে \(C\) একটা সর্বজনীন ধ্রুবক (বণ্টন-নিরপেক্ষ)। অর্থাৎ CLT-এর অভিসরণ-ত্রুটি \(\sim n^{-1/2}\) হারে কমে, এবং তার ধ্রুবক বণ্টনের skewness (\(\rho/\sigma^3\))-এর সমানুপাতিক।
এই উপপাদ্যই E1-কে একটা পরিমাণগত ভবিষ্যদ্বাণী দেয়: বাঁ-দিকের KS-দূরত্ব \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\) ঠিক \(n^{-1/2}\) হারে নামবে, তাই log–log ঢাল হওয়া উচিত \(-1/2\)। পরীক্ষায় প্রাপ্ত ঢাল ≈ −0.5 (\(-0.4998\)) সেই ভবিষ্যদ্বাণীর প্রায় নিখুঁত নিশ্চিতকরণ — এবং \(\text{Exp}(1)\)-এর বড় skewness ঠিক সেই কারণেই ছোট \(n\)-এ দূরত্বকে বড় রাখে।
এক বাক্যে। Berry–Esseen theorem — \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\le C\rho/(\sigma^3\sqrt n)\) — CLT-অভিসরণের ত্রুটিকে \(n^{-1/2}\) হারে ও skewness-সমানুপাতিক ধ্রুবকে বাঁধে, তাই E1-এ log–log ঢাল ≈ −0.5 হওয়া তত্ত্বেরই প্রত্যাশা।
২.৮ factorial experiment design ও variance reduction¶
শেষ দুই ধারণা তাত্ত্বিক নয়, পদ্ধতিগত — কীভাবে একটা সিমুলেশন পরিষ্কারভাবে সাজানো ও কার্যকরভাবে চালানো যায়।
সংজ্ঞা (factorial experiment design)। একটা factorial experiment design (উৎপাদক পরীক্ষা-নকশা) হলো এমন একটা সাজানো, যেখানে ফলাফলকে প্রভাবিতকারী নিয়ন্ত্রণযোগ্য চলগুলো — factor (উপাদান) — কে পদ্ধতিগতভাবে ভিন্ন ভিন্ন মানে (level) বসিয়ে প্রতিটি সংমিশ্রণে ফল মাপা হয়, যাতে কোন factor-এর কী প্রভাব তা আলাদা করে বোঝা যায়। এই অধ্যায়ের পরীক্ষাগুলোয় মূল factor হলো নমুনা-আকার \(n\) (E1, E4), মডেল-জটিলতা তথা polynomial degree (E3), ও nominal স্তর (E2) — এবং প্রতিটি level-এ replication-সংখ্যা \(R\) ও seed স্থির রেখে ফল সংগ্রহ করা হয়, যাতে একমাত্র factor-ই পরিবর্তনের উৎস থাকে।
একটা ভালো ডিজাইনের পাশে একটা কার্যকারিতা-কৌশলও থাকে — কম replication-এ বেশি সুনির্দিষ্টতা পাওয়ার উপায়।
সংজ্ঞা (variance reduction)। variance reduction (তারতম্য-হ্রাস) হলো এমন কৌশলের সমষ্টি, যা একই replication-সংখ্যায় একটা মন্টি-কার্লো অনুমানের MC SE কমায় — অর্থাৎ কম গণনায় বেশি নির্ভুলতা দেয়। একটা সরল উদাহরণ E3-এ ব্যবহৃত হয়: বিভিন্ন degree-এর তুলনায় প্রতিবার একই noise-উপলব্ধি (common random numbers) ব্যবহার করলে degree-থেকে-degree তুলনায় noise-জনিত অতিরিক্ত তারতম্য বাদ পড়ে, তাই degree-এর প্রকৃত প্রভাব পরিষ্কারভাবে ফুটে ওঠে। (অন্যান্য কৌশল — antithetic variate, control variate — এখানে শুধু উল্লেখমাত্র।)
এই দুই পদ্ধতিগত ধারণা §১-এর শৃঙ্খলাকে concrete করে: প্রতিটি পরীক্ষা একটা স্পষ্ট factor, স্থির \(R\) ও seed, এবং যেখানে সম্ভব একটা variance-reduction কৌশল নিয়ে সাজানো — যাতে ফলটা পরিষ্কার, reproducible ও তাত্ত্বিক প্রত্যাশার সাথে সরাসরি তুলনীয় হয়।
এক বাক্যে। factorial experiment design ফলকে প্রভাবিতকারী factor-গুলোকে (এখানে \(n\), degree, nominal স্তর) পদ্ধতিগতভাবে বদলে প্রতিটির প্রভাব আলাদা করে, আর variance reduction (যেমন E3-এ common random numbers) একই \(R\)-এ MC SE কমিয়ে ফলকে আরও পরিষ্কার করে — দুটোই একটা সিমুলেশন স্টাডিকে শৃঙ্খলিত ও তাত্ত্বিকভাবে-তুলনীয় করে তোলে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§১–২-এ simulation study (সিমুলেশন-অধ্যয়ন)-এর গোটা কাঠামোটা গড়া হয়েছে — একটা Monte-Carlo experiment (মন্টি-কার্লো পরীক্ষা) হলো এমন একটা নকশা যেখানে চেনা তত্ত্বকে যাচাই করার জন্য একটা পরিসংখ্যানকে বহুবার (replications, পুনরাবৃত্তি) সিমুলেট করে তার আচরণ পরিমাপ করা হয়, আর সেই পরিমাপ যদি তত্ত্বের prediction (পূর্বানুমান)-এর সঙ্গে মেলে তবে তত্ত্ব ও কোড দুটোই একসঙ্গে বৈধতা পায়। এই অংশের উদ্দেশ্য সেই বিমূর্ত নীতিকে হাতে-কলমে, কংক্রিট নকশা ও কংক্রিট সংখ্যা দিয়ে ছুঁয়ে দেখা — চারটি ধ্রুপদী পরীক্ষার প্রতিটিকে একটা পূর্ণাঙ্গ ডিজাইন হিসেবে খুলে দেখা: (ক) নকশা (design) — কোন estimand/দাবি যাচাই হচ্ছে, কোন factor (নিয়ামক) ঘোরানো হচ্ছে (যেমন নমুনা-আকার \(n\)), কতগুলো replication, স্থির বীজ (seed np.random.default_rng(20260619)), আর কোন statistic (পরিসংখ্যান) মাপা হচ্ছে; (খ) সেই নকশা যে theoretical prediction নিশ্চিত করার কথা; (গ) প্রকৃত সিমুলেশন-স্টাডির ফলাফল-সারণি (results table); আর (ঘ) পাঠোদ্ধার (read-off) — সংখ্যাগুলোকে তত্ত্বের পাশে বসিয়ে ব্যাখ্যা। চারটি পরীক্ষা যথাক্রমে CLT-র অভিসারণ-হার (Berry–Esseen), bootstrap CI-র coverage, bias–variance tradeoff, আর MLE-র consistency ও asymptotic normality — Parts 0–VII-এ শেখা তত্ত্বের চারটি স্তম্ভকে সিমুলেশনে পুনরুৎপাদন করে দেখানো। প্রতিটি নকশায় একটাই নীতি নিঃশব্দে কাজ করছে: একটা simulation study তত্ত্বকে প্রমাণ করে না, তত্ত্বের সঙ্গে সংখ্যাগত সঙ্গতি (agreement) দেখিয়ে তত্ত্ব ও কোড দুটোকেই আস্থাযোগ্য করে তোলে। সব পরীক্ষা একই বীজে চালানো, যাতে সংখ্যাগুলো reproducible (পুনরুৎপাদনযোগ্য) থাকে। প্রতিটি ইংরেজি পরিভাষা প্রথম ব্যবহারে বাংলায় খুলে দেওয়া হয়েছে।
৩.১ · CLT-র অভিসারণ-হার — Berry–Esseen (Exp(1))¶
নকশা। estimand/দাবি: iid \(X_1,\dots,X_n\sim\text{Exp}(1)\) (গড় \(\mu=1\), সমক-বিচ্যুতি \(\sigma=1\), skewness \(\gamma=2\)) থেকে মানক নমুনা-গড় (standardized sample mean) \(Z_n=\sqrt n\,(\bar X_n-1)\)-এর বণ্টন \(n\to\infty\)-এ \(N(0,1)\)-তে যায় (CLT, ← ৩.৪), কিন্তু কত দ্রুত? এখানে যাচাই্য দাবি Berry–Esseen theorem (বেরি–এসিন উপপাদ্য) — এই অভিসারণের হার \(O(n^{-1/2})\)। factor: নমুনা-আকার \(n\in\{5,10,20,40,80,160,320\}\) (সাত-স্তরের grid, যাতে \(n\)-এর ওপর হারের নির্ভরতা দেখা যায়)। replication: প্রতি \(n\)-এ \(R=60000\) পুনরাবৃত্তি — অর্থাৎ প্রতি \(n\)-এ \(60000\)টা স্বাধীন \(Z_n\) তৈরি হয়। statistic: empirical CDF \(F_n\) ও \(N(0,1)\)-এর CDF \(\Phi\)-এর মধ্যে Kolmogorov–Smirnov distance (K–S দূরত্ব) $$ \text{KS}(n)=\sup_x\lvert F_n(x)-\Phi(x)\rvert . $$ এই একটি সংখ্যা পুরো বণ্টন-ফারাকের সর্বোচ্চ মান ধরে — তাই CLT-অভিসারণের একটা পরিষ্কার একমাত্রিক মাপকাঠি।
তাত্ত্বিক পূর্বানুমান। Berry–Esseen বলে \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\le \dfrac{C\,\rho}{\sigma^3\sqrt n}\), যেখানে \(\rho=\mathbb E\lvert X-\mu\rvert^3\) — অর্থাৎ K–S দূরত্ব \(\sim n^{-1/2}\) হারে শূন্যে নামে। এর অর্থ log-স্কেলে \(\log\text{KS}(n)\) বনাম \(\log n\) একটা সরলরেখা হওয়া উচিত, যার ঢাল (slope) ঠিক \(-\tfrac12=-0.5\)। যদি সিমুলেশনে মাপা ঢাল \(-0.5\)-এর কাছে দাঁড়ায়, তবে Berry–Esseen-এর হার-দাবি সংখ্যায় নিশ্চিত।
ফলাফল-সারণি।
| \(n\) | \(\text{KS}(n)=\sup_x\lvert F_n(x)-\Phi(x)\rvert\) |
|---|---|
| \(৫\) | \(০.০৫৯০\) |
| \(১০\) | \(০.০৪১৭\) |
| \(২০\) | \(০.০২৮৫\) |
| \(৪০\) | \(০.০২২৫\) |
| \(৮০\) | \(০.০১৪৮\) |
| \(১৬০\) | \(০.০১০৮\) |
| \(৩২০\) | \(০.০০৭১\) |
log-log রৈখিক-ফিটে মাপা ঢাল \(=-০.৪৯৯৮\) (তত্ত্ব \(-০.৫\)), আর ধ্রুবক \(C=e^{\text{intercept}}=০.১৩২৬\)।
পাঠোদ্ধার। সারণিতে \(n\) প্রতিবার দ্বিগুণ হলে \(\text{KS}(n)\) মোটামুটি \(\tfrac{1}{\sqrt 2}\approx০.৭০৭\) গুণ হয়ে নামছে — যেমন \(n{:}৫\to১০\)-এ \(০.০৫৯০\to০.০৪১৭\) (অনুপাত \(০.৭০৭\)), আবার \(n{:}১৬০\to৩২০\)-এ \(০.০১০৮\to০.০০৭১\) (অনুপাত \(০.৬৫৭\)) — ঠিক \(n^{-1/2}\)-হারের স্বাক্ষর। মাপা log-log ঢাল \(-০.৪৯৯৮\) তাত্ত্বিক \(-০.৫\)-এর সঙ্গে চতুর্থ দশমিক পর্যন্ত মেলে — Berry–Esseen-এর \(O(n^{-1/2})\) হার সংখ্যায় নিশ্চিত (এই আচরণ চিত্র 8-2-clt-rate §৬-এ log-log অক্ষে সরলরেখা হিসেবে দেখা যাবে)। একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ নকশা-প্রশ্ন: \(R\) এত বড় (\(৬০০০০\)) কেন? কারণ \(\text{KS}(n)\) নিজেই একটা estimate — এটা \(R\)টা সসীম নমুনা থেকে মাপা, তাই এর নিজস্ব Monte-Carlo noise (মন্টি-কার্লো ত্রুটি) আছে, যার মাপ Dvoretzky–Kiefer–Wolfowitz সীমা-অনুসারে \(\sim 1/\sqrt R\)। বড় \(n\)-এ প্রকৃত \(\text{KS}(n)\) খুবই ছোট (\(০.০০৭\)-এর ঘরে), তাই যদি \(R\) ছোট হতো, এই MC-ত্রুটি (\(\sim 1/\sqrt R\)) সংকেতটাকেই ডুবিয়ে দিত — ঢাল-অনুমান নড়বড়ে হতো। \(R=৬০০০০\)-এ MC-ত্রুটি \(\sim 1/\sqrt{৬০০০০}\approx০.০০৪১\)-এর ঘরে নেমে আসে, তাই ছোট \(\text{KS}\)-মানগুলোও নির্ভরযোগ্যভাবে মাপা যায় — এটাই একটা ভালো simulation study-র নকশা-নীতি: যে সংকেত মাপছ তার আকারের তুলনায় তোমার MC-ত্রুটি অনেক ছোট রাখো।
এক বাক্যে — Exp(1)-এর মানক নমুনা-গড়ের K–S দূরত্ব \(n\)-এর সঙ্গে log-log ঢাল \(-০.৪৯৯৮\approx-০.৫\)-এ নামে, যা Berry–Esseen-এর \(O(n^{-1/2})\) অভিসারণ-হারকে সংখ্যায় নিশ্চিত করে — শর্ত: \(R\) যথেষ্ট বড় (\(৬০০০০\)) যাতে K–S-এর নিজস্ব MC-ত্রুটি (\(\sim 1/\sqrt R\)) সংকেতের চেয়ে ঢের ছোট থাকে।
৩.২ · Bootstrap CI-র coverage (Exp(1))¶
নকশা। estimand/দাবি: iid \(X_1,\dots,X_n\sim\text{Exp}(1)\)-এর প্রকৃত গড় \(\theta=1\)-এর জন্য percentile bootstrap (পার্সেন্টাইল বুটস্ট্র্যাপ) পদ্ধতিতে বানানো \(95\%\) confidence interval (আস্থা-ব্যবধি, CI)-এর প্রকৃত coverage (আচ্ছাদন) — অর্থাৎ কত ভগ্নাংশ CI প্রকৃত \(\theta=1\)-কে ধরে — সেটা কি nominal \(0.95\)-এর সমান? (bootstrap-এর ভিত্তি ← ৪.৯।) factor: এখানে \(n\) স্থির — \(n=40\) (একটা "মাঝারি" নমুনা, যেখানে asymptotic তত্ত্ব সবে কাজ শুরু করে)। replication: \(D=2000\)টা স্বাধীন dataset (উপাত্ত-সেট), প্রতিটি \(n=40\)-এর; আর প্রতিটি dataset-এর ভেতরে \(B=1000\)টা resample (পুনঃনমুনা) — অর্থাৎ এটা একটা nested (নিহিত) দুই-স্তরের সিমুলেশন: বাইরের \(2000\) CI-র coverage মাপে, ভেতরের \(1000\) প্রতিটি CI বানায়। statistic: empirical coverage \(=\frac{1}{D}\sum_{d=1}^{D}\mathbf 1\{\theta\in \text{CI}_d\}\), সঙ্গে গড় CI-প্রস্থ।
তাত্ত্বিক পূর্বানুমান। সঠিকভাবে গঠিত \(95\%\) CI-র coverage \(\approx 0.95\) হওয়া উচিত। কিন্তু percentile bootstrap-এর একটা পরিচিত সীমাবদ্ধতা: যখন মূল বণ্টন skewed (অপ্রতিসম) ও \(n\) মাঝারি, তখন এটা সামান্য under-cover (কম-আচ্ছাদন) করে — কারণ percentile-পদ্ধতি নমুনা-গড়ের বণ্টনের অপ্রতিসমতা ও পক্ষপাতকে পুরোপুরি সংশোধন করে না। \(\text{Exp}(1)\) প্রবলভাবে ডান-হেলানো (skewness \(2\)), তাই \(n=40\)-এ coverage-এর মান \(0.95\)-এর সামান্য নিচে থাকার পূর্বানুমান।
ফলাফল-সারণি।
| পরিমাণ | মান | মন্তব্য |
|---|---|---|
| nominal coverage | \(০.৯৫০০\) | লক্ষ্য |
| empirical coverage | \(০.৯১৩০\) | সামান্য নিচে |
| Monte-Carlo SE | \(০.০০৬৩\) | coverage-অনুমানের ত্রুটি |
| গড় CI-প্রস্থ | \(০.৫৮৬৯\) | — |
পাঠোদ্ধার। মাপা coverage \(০.৯১৩০\), nominal \(০.৯৫\)-এর চেয়ে \(০.০৩৭\) কম। এটা কি কেবল দৈব-ওঠানামা, নাকি প্রকৃত under-coverage? এখানেই Monte-Carlo SE (মন্টি-কার্লো সম্ভাব্য-ত্রুটি) \(=০.০০৬৩\) কাজে লাগে — এটা \(D=2000\)টা দৈব-দ্বিপদ (Bernoulli) ফলাফল থেকে coverage-অনুমানের নিজস্ব ত্রুটি, \(\sqrt{p(1-p)/D}=\sqrt{০.৯৫\cdot০.০৫/২০০০}\approx০.০০৪৯\)-এর ঘরে (মাপা \(০.০০৬৩\))। ফারাক \(০.০৩৭\) এই SE-র প্রায় ৬ গুণ — অর্থাৎ এটা পরিসংখ্যানগতভাবে অর্থপূর্ণ, নিছক দৈব নয়। তাই সিদ্ধান্ত: percentile bootstrap \(n=40\)-এ সত্যিই সামান্য under-cover করছে, ঠিক যেমন skew-জনিত পূর্বানুমান বলেছিল। এটা bootstrap-এর ব্যর্থতা নয় — এটা এর সীমার একটা সৎ মানচিত্র: মাঝারি \(n\) ও skewed উপাত্তে percentile-CI কিছুটা সংকীর্ণ (গড় প্রস্থ \(০.৫৮৬৯\)), তাই কিছু ক্ষেত্রে \(\theta\) ফসকে যায় (এই আচরণ চিত্র 8-2-coverage §৬-এ প্রতিটি CI-কে \(\theta=1\)-এর সাপেক্ষে সাজিয়ে দেখা যাবে)। নকশা-শিক্ষা: coverage-এর মতো একটা সম্ভাবনা মাপতে হলে তার MC-SE-ও রিপোর্ট করো — নইলে "\(০.৯১\) বনাম \(০.৯৫\)" অর্থপূর্ণ ফারাক না দৈব-গোলমাল, তা বলা অসম্ভব।
এক বাক্যে — \(\text{Exp}(1)\), \(n=40\)-এ percentile bootstrap-এর \(95\%\) CI-র empirical coverage \(০.৯১৩০\) (MC-SE \(০.০০৬৩\)), যা nominal \(০.৯৫\)-এর প্রায় ৬-SE নিচে — অর্থাৎ মাঝারি \(n\) ও ডান-হেলানো বণ্টনে percentile bootstrap সৎভাবে সামান্য under-cover করে, ঠিক তত্ত্বের পূর্বানুমান মতো।
৩.৩ · Bias–variance tradeoff (polynomial regression)¶
নকশা। estimand/দাবি: একটা supervised-learning মডেলের test error (পরীক্ষা-ত্রুটি) তিন ভাগে ভাঙে — \(\text{Total}=\text{Bias}^2+\text{Variance}+\sigma^2\) (bias–variance decomposition, ← ৬.১) — আর মডেল-জটিলতা বাড়ালে \(\text{Bias}^2\) কমে কিন্তু \(\text{Variance}\) বাড়ে, তাই মোট ত্রুটি U-আকৃতির হয়ে একটা optimal জটিলতায় ন্যূনতম হয়। সেটআপ: প্রকৃত signal \(f(x)=\sin(1.5x)+0.5x\), পরিসর \([-3,3]\); noise (কোলাহল) সমক-বিচ্যুতি \(\sigma=0.7\) (অর্থাৎ irreducible \(\sigma^2=0.4900\)); মডেল = degree-\(d\) polynomial regression (বহুপদী নির্ভরণ)। factor: বহুপদীর মাত্রা \(d=1,2,\dots,12\) (জটিলতার একমাত্রিক knob)। replication: \(R=500\)টা প্রশিক্ষণ-সেট, প্রতিটি \(n_{\text{train}}=30\) (স্থির design-বিন্দু)। নকশার মূল কৌশল: প্রতিটি \(d\)-এর জন্য একই noise-realization ব্যবহার করা হয় — অর্থাৎ কেবল \(d\)-ই বদলায়, দৈব-অংশ নয় — যাতে ত্রুটির পার্থক্য বিশুদ্ধভাবে \(d\)-জনিত, দৈব-ওঠানামা-জনিত নয়। statistic: প্রতি \(d\)-তে \(\text{Bias}^2\), \(\text{Variance}\), ও \(\text{Total}\) test error।
তাত্ত্বিক পূর্বানুমান। \(d\) ছোট হলে বহুপদী \(f\)-কে ধরতে পারে না (underfit, উচ্চ bias); \(d\) বড় হলে প্রতিটি প্রশিক্ষণ-সেটের noise-ও শিখে ফেলে (overfit, উচ্চ variance)। তাই \(\text{Bias}^2\) \(d\)-এর সঙ্গে কমবে, \(\text{Variance}\) বাড়বে, আর \(\text{Total}=\text{Bias}^2+\text{Variance}+0.49\) কোনো মাঝামাঝি \(d\)-তে ন্যূনতম হবে — এটাই bias–variance tradeoff। যেহেতু \(\sin\)-এর Taylor-প্রসারণে বিজোড় পদ লাগে, \(d\) বিজোড় মানে (বিশেষত \(৩\) ও \(৫\)-এ) bias-এ বড় পতন প্রত্যাশিত।
ফলাফল-সারণি।
| degree \(d\) | \(\text{Bias}^2\) | \(\text{Variance}\) | \(\text{Total}\) |
|---|---|---|---|
| \(১\) | \(০.৪৮১২\) | \(০.০৩০৫\) | \(১.০০১৬\) |
| \(২\) | \(০.৪৮১২\) | \(০.০৪৫০\) | \(১.০১৬২\) |
| \(৩\) | \(০.০৭৪১\) | \(০.০৫৯৮\) | \(০.৬২৩৯\) |
| \(৪\) | \(০.০৭৪২\) | \(০.০৭৩৭\) | \(০.৬৩৭৮\) |
| \(৫\) | \(০.০০২০\) | \(০.০৮৬৫\) | \(০.৫৭৮৪\) ← ন্যূনতম |
| \(৬\) | \(০.০০১৯\) | \(০.১০০১\) | \(০.৫৯২০\) |
| \(৭\) | \(০.০০০২\) | \(০.১১৩১\) | \(০.৬০৩৩\) |
| \(৮\) | \(০.০০০৪\) | \(০.১২৮৮\) | \(০.৬১৯২\) |
| \(৯\) | \(০.০০০৪\) | \(০.১৪৫৫\) | \(০.৬৩৫৯\) |
| \(১০\) | \(০.০০০৪\) | \(০.১৬৪১\) | \(০.৬৫৪৫\) |
| \(১১\) | \(০.০০০৪\) | \(০.১৮২৬\) | \(০.৬৭৩১\) |
| \(১২\) | \(০.০০০৬\) | \(০.২০৪১\) | \(০.৬৯৪৭\) |
irreducible \(\sigma^2=0.4900\); optimal degree \(=৫\), ন্যূনতম মোট test error \(=০.৫৭৮৪\)।
পাঠোদ্ধার। সারণি তিনটি ভবিষ্যদ্বাণী একসঙ্গে নিশ্চিত করে। প্রথমত, \(\text{Variance}\) কড়াভাবে একঘেয়ে-বর্ধমান — \(০.০৩০৫\) (\(d{=}১\)) থেকে \(০.২০৪১\) (\(d{=}১২\)) পর্যন্ত প্রতি ধাপে বাড়ে, যা "বেশি জটিল মডেল noise-এর প্রতি বেশি সংবেদনশীল"-কে সংখ্যায় দেখায়। দ্বিতীয়ত, \(\text{Bias}^2\) ধাপে-ধাপে পড়ে, আর পতন দুটো জায়গায় নাটকীয়: \(d{:}২\to৩\)-এ \(০.৪৮১২\to০.০৭৪১\) (কারণ \(\sin\)-এর জন্য বিজোড় ঘন-পদ দরকার, যা \(d{=}৩\)-এ প্রথম আসে) এবং \(d{:}৪\to৫\)-এ \(০.০৭৪২\to০.০০২০\) (পরবর্তী বিজোড় পদ) — ঠিক \(\sin\)-এর গঠন-জনিত পূর্বানুমান মতো। তৃতীয়ত, \(\text{Total}\) U-আকৃতির: \(১.০০১৬\) থেকে নামতে-নামতে \(d{=}৫\)-এ ন্যূনতম \(০.৫৭৮৪\), তারপর আবার ধীরে ওঠে (\(d{=}১২\)-এ \(০.৬৯৪৭\))। ন্যূনতম-বিন্দু \(d{=}৫\)-এই bias প্রায় নিঃশেষ (\(০.০০২০\)) অথচ variance এখনো সংযত (\(০.০৮৬৫\)) — এটাই sweet spot। লক্ষণীয়, প্রতিটি সারিতে \(\text{Bias}^2+\text{Variance}+\sigma^2\approx\text{Total}\) প্রায় মেলে (যেমন \(d{=}৫\): \(০.০০২০+০.০৮৬৫+০.৪৯০০=০.৫৭৮৫\approx০.৫৭৮৪\)) — এই যোগফল-অভেদই bias–variance decomposition-এর সংখ্যাগত স্বাক্ষর, আর \(০.৪৯\) হলো সেই irreducible মেঝে যা কোনো মডেলই পেরোতে পারে না (এই U-বক্ররেখা চিত্র 8-2-bias-variance §৬-এ তিন-বক্ররেখায় দেখা যাবে)। নকশা-শিক্ষা: সব \(d\)-তে একই noise ব্যবহার করলে \(d\)-জনিত সূক্ষ্ম পার্থক্যও দৈব-গোলমালে হারায় না — variance-হ্রাসের একটা মিতব্যয়ী কৌশল (paired/common-random-numbers design)।
এক বাক্যে — degree বাড়ালে \(\text{Bias}^2\) পড়ে (\(\sin\)-এর বিজোড়-পদ চাহিদায় \(৩\) ও \(৫\)-এ নাটকীয় পতন) আর \(\text{Variance}\) একঘেয়ে বাড়ে, ফলে \(\text{Total}\) test error U-আকৃতিতে \(d{=}৫\)-এ ন্যূনতম \(০.৫৭৮৪\) (irreducible \(\sigma^2{=}০.৪৯\)) — bias–variance tradeoff ও তার decomposition সংখ্যায় হুবহু পুনরুৎপাদিত।
৩.৪ · MLE-র consistency ও asymptotic normality (Exp(rate λ))¶
নকশা। estimand/দাবি: মডেল \(\text{Exp}(\text{rate }\lambda=2)\)-এর maximum likelihood estimator (সর্বাধিক-সম্ভাব্যতা আকলক, MLE) \(\hat\lambda=1/\bar X\) দুটো ধ্রুপদী ধর্ম দেখায় (← ৪.৩): (ক) consistency (সঙ্গতি) — \(n\to\infty\)-এ \(\hat\lambda\to\lambda\) (bias ও RMSE শূন্যে যায়), আর (খ) asymptotic normality (উপগামী প্রসামান্যতা) — \(\sqrt n(\hat\lambda-\lambda)\xrightarrow{d}N(0,\,1/I(\lambda))\)। এখানে Fisher information (ফিশার তথ্য) \(I(\lambda)=1/\lambda^2\), তাই asymptotic সমক-বিচ্যুতি \(=\lambda=2\)। এটা আসলে দুটো আলাদা simulation study, তাই দুটো নকশা:
(ক) consistency-নকশা। factor: \(n\in\{10,40,160,640\}\) (প্রতিবার \(৪\)-গুণ)। replication: প্রতি \(n\)-এ \(R=4000\)। statistic: \(\hat\lambda\)-এর bias (\(=\mathbb E[\hat\lambda]-\lambda\)) ও RMSE (মূল-গড়-বর্গ-ত্রুটি)।
(খ) asymptotic-normality-নকশা। factor: স্থির \(n=200\)। replication: \(R=40000\) (K–S ভালোভাবে মাপতে বড় দরকার — ৩.১-এর একই যুক্তি)। statistic: standardized পরিমাণ \(S=\dfrac{\sqrt n\,(\hat\lambda-\lambda)}{\lambda}\)-এর গড়, সমক-বিচ্যুতি, ও \(N(0,1)\)-এর সঙ্গে \(\text{KS}(S,N(0,1))\)।
তাত্ত্বিক পূর্বানুমান। (ক) consistency মানে RMSE \(\sim n^{-1/2}\) হারে নামবে — log-log ঢাল \(\approx-0.5\)। তবে \(\hat\lambda=1/\bar X\) একটা convex রূপান্তর, তাই Jensen-এর অসমতা-অনুসারে \(\mathbb E[1/\bar X]>1/\mathbb E[\bar X]=\lambda\) — অর্থাৎ MLE সসীম \(n\)-এ ধনাত্মক-পক্ষপাতী (positively biased), কিন্তু bias \(\to0\), তাই এটি consistent থাকে। (খ) asymptotic normality মানে standardized \(S\)-এর গড় \(\approx0\), সমক-বিচ্যুতি \(\approx1\), আর \(\text{KS}(S,N(0,1))\) ছোট হওয়া উচিত।
ফলাফল-সারণি (ক) — consistency।
| \(n\) | bias | RMSE |
|---|---|---|
| \(১০\) | \(+০.২১৮২\) | \(০.৭৯৬৫\) |
| \(৪০\) | \(+০.০৪৮৪\) | \(০.৩৪০৪\) |
| \(১৬০\) | \(+০.০১১৪\) | \(০.১৬৩৯\) |
| \(৬৪০\) | \(+০.০০২৮\) | \(০.০৭৭৫\) |
RMSE-র log-log ঢাল \(=-০.৫৫৭০\) (তত্ত্ব \(-০.৫\))।
ফলাফল-সারণি (খ) — asymptotic normality (\(n=200\), \(R=40000\))।
| পরিমাণ | মান | তত্ত্ব |
|---|---|---|
| asymptotic সমক-বিচ্যুতি \(=\lambda\) | \(২.০০০০\) | \(২\) |
| standardized \(S\)-এর গড় | \(+০.০৬৬৩\) | \(০\) |
| standardized \(S\)-এর সমক-বিচ্যুতি | \(১.০০৯১\) | \(১\) |
| \(\text{KS}(S,N(0,1))\) | \(০.০১৮০\) | \(\to0\) |
পাঠোদ্ধার। (ক) consistency নিশ্চিত: bias \(+০.২১৮২\to+০.০৪৮৪\to+০.০১১৪\to+০.০০২৮\) — সবসময় ধনাত্মক (Jensen যেমন বলেছিল, \(1/\bar X\) উপরের দিকে পক্ষপাতী) অথচ দ্রুত শূন্যে নামছে; আর RMSE \(০.৭৯৬৫\to০.০৭৭৫\), প্রতিবার \(n\) \(৪\)-গুণ হলে RMSE মোটামুটি অর্ধেক (\(\sqrt 4=2\) গুণ কমে) — ঠিক \(n^{-1/2}\)-হার। মাপা log-log ঢাল \(-০.৫৫৭০\) তাত্ত্বিক \(-০.৫\)-এর কাছে (সামান্য খাড়া, কারণ ছোট \(n\)-এ bias-অংশ RMSE-কে একটু বাড়িয়ে রাখে, বড় \(n\)-এ তা মিলিয়ে যায়) — তবু বার্তা স্পষ্ট: \(\hat\lambda\) consistent, ভুল শূন্যে যায় (এই পতন চিত্র 8-2-mle-asymptotics §৬-এ log-log অক্ষে দেখা যাবে)। (খ) asymptotic normality নিশ্চিত: \(n=200\)-এ standardized \(S\)-এর গড় \(+০.০৬৬৩\) (\(\approx0\), ক্ষুদ্র অবশিষ্ট bias-এর ছাপ), সমক-বিচ্যুতি \(১.০০৯১\) (\(\approx1\) — তত্ত্বের asymptotic sd \(=\lambda=2\)-কে \(\lambda\) দিয়ে ভাগ করায় ঠিক \(1\)-এ আসা উচিত, আর তা-ই এসেছে), আর সবচেয়ে জোরালো সাক্ষ্য \(\text{KS}(S,N(0,1))=০.০১৮০\) — এত ছোট যে \(S\)-এর empirical বণ্টন ও \(N(0,1)\) প্রায় অভিন্ন। দুই নকশা একসঙ্গে MLE-তত্ত্বের দুটো স্তম্ভ — consistency + \(\sqrt n\)-হারে \(N(0,1/I(\lambda))\)-এ asymptotic normality — পুনরুৎপাদন করে, এমনকি \(\hat\lambda=1/\bar X\) সসীম-\(n\)-এ পক্ষপাতী হওয়া সত্ত্বেও। নকশা-শিক্ষা: একটা estimator-কে যাচাই করতে হলে দুটো আলাদা প্রশ্ন দুটো আলাদা নকশায় ধরো — "ভুল কি শূন্যে যায়?" (consistency-grid) আর "মানক-ভুলের আকৃতি কি Normal?" (fixed-\(n\), বড়-\(R\), K–S)।
এক বাক্যে — \(\text{Exp}(\lambda{=}2)\)-এর MLE \(\hat\lambda=1/\bar X\) Jensen-জনিত ধনাত্মক-পক্ষপাত সত্ত্বেও consistent (RMSE log-log ঢাল \(-০.৫৫৭০\approx-০.৫\)) এবং \(n{=}200\)-এ asymptotically Normal (standardized \(S\): গড় \(+০.০৬৬৩\), sd \(১.০০৯১\), \(\text{KS}=০.০১৮০\)) — MLE-তত্ত্বের consistency ও asymptotic normality দুটোই সংখ্যায় নিশ্চিত।
৩.৫ · সংশ্লেষ — চারটি নকশার এক সুর¶
চারটি পরীক্ষা আলাদা তত্ত্ব যাচাই করলেও একই simulation-study পদ্ধতি অনুসরণ করে, আর সেই অভিন্ন কাঠামোই এদের প্রকৃত পাঠ। প্রতিটিতে একটা পরিষ্কার estimand/দাবি, ঘোরানোর জন্য এক বা একাধিক factor, সচেতনভাবে বাছা replication-সংখ্যা, একটাই স্থির বীজ (np.random.default_rng(20260619)), একটা মাপা statistic, একটা তাত্ত্বিক prediction, আর শেষে সংখ্যা-বনাম-তত্ত্বের পাঠোদ্ধার।
| পরীক্ষা | দাবি/তত্ত্ব | মূল factor | replication | মূল statistic | তাত্ত্বিক পূর্বানুমান | মাপা ফল |
|---|---|---|---|---|---|---|
| ৩.১ CLT-হার | Berry–Esseen \(O(n^{-1/2})\) | \(n\in\{৫..৩২০\}\) | \(R=৬০০০০\) | \(\sup_x\lvert F_n-\Phi\rvert\) | log-log ঢাল \(-০.৫\) | ঢাল \(-০.৪৯৯৮\) |
| ৩.২ Bootstrap coverage | ৯৫% CI-র coverage | \(n=৪০\) (স্থির) | \(D{=}২০০০,B{=}১০০০\) | empirical coverage | \(\approx০.৯৫\) (skew-এ সামান্য কম) | \(০.৯১৩০\) (SE \(০.০০৬৩\)) |
| ৩.৩ Bias–variance | U-আকৃতির test error | degree \(d\in\{১..১২\}\) | \(R=৫০০\) | \(\text{Bias}^2,\text{Var},\text{Total}\) | মাঝামাঝি \(d\)-তে ন্যূনতম | optimal \(d{=}৫\), min \(০.৫৭৮৪\) |
| ৩.৪ MLE | consistency + asymptotic normality | \(n\in\{১০..৬৪০\}\); \(n{=}২০০\) | \(R{=}৪০০০\); \(R{=}৪০০০০\) | bias, RMSE; \(\text{KS}(S,N(0,1))\) | RMSE ঢাল \(-০.৫\); \(S\sim N(0,1)\) | ঢাল \(-০.৫৫৭০\); \(\text{KS}=০.০১৮০\) |
চারটিতেই একটা সাধারণ নকশা-বিচক্ষণতা ফিরে আসে — যে সংকেত মাপছ, তার আকারের তুলনায় Monte-Carlo ত্রুটি ছোট রাখা। ৩.১ ও ৩.৪(খ)-এ তাই \(R\) বিশাল (\(৬০০০০\), \(৪০০০০\)), কারণ K–S-অনুমানের নিজস্ব ত্রুটি \(\sim 1/\sqrt R\); ৩.২-এ coverage-অনুমানের সঙ্গে তার MC-SE রিপোর্ট করা হয় যাতে "\(০.৯১\) বনাম \(০.৯৫\)" অর্থপূর্ণ কিনা বিচার করা যায়; ৩.৩-এ সব degree-তে একই noise (common random numbers) ব্যবহার করে \(d\)-জনিত সূক্ষ্ম পার্থক্যকে দৈব-গোলমাল থেকে আলাদা রাখা হয়। এই চারটি একসঙ্গে দেখায় কীভাবে Parts 0–VII-এর তত্ত্ব — CLT (← ৩.৪), MLE (← ৪.৩), bootstrap (← ৪.৯), bias–variance (← ৬.১) — সিমুলেশনে হুবহু পুনরুৎপাদিত হয়, আর এই পুনরুৎপাদনই একজন শিক্ষার্থীকে তত্ত্বের ভোক্তা থেকে পরীক্ষা-নকশাকার-এ রূপান্তরিত করে — যা Part VIII capstone-এর মূল লক্ষ্য।
এক বাক্যে — চারটি পরীক্ষা (CLT-হার, bootstrap-coverage, bias–variance, MLE) একই estimand→factor→replication→statistic→prediction→পাঠোদ্ধার কাঠামোয় চারটি ধ্রুপদী তত্ত্বকে সংখ্যায় পুনরুৎপাদন করে, আর সবেতেই একটাই নকশা-নীতি নিহিত: Monte-Carlo ত্রুটিকে মাপা-সংকেতের চেয়ে ছোট রাখা।
৪ · পদ্ধতি ও যুক্তি¶
এই অংশ অধ্যায়ের বৌদ্ধিক কেন্দ্র — চারটি পরীক্ষার (E1–E4) পেছনের experiment design (পরীক্ষা-নকশা)-এর যুক্তি। এখানে নতুন কোনো উপপাদ্য প্রমাণ হয় না; বরং দেখানো হয় একটা Monte-Carlo simulation (মন্টি-কার্লো সিমুলেশন) কীভাবে নকশা করলে তার ফল বিশ্বাসযোগ্য হয় — কোন seed (বীজ) স্থির রাখতে হবে, কতগুলো replication (পুনরাবৃত্তি) লাগবে, কোন factor (নিয়ামক) একবারে বদলানো যাবে, আর ফলের সঙ্গে কোন অনিশ্চয়তা-মাপ (Monte-Carlo standard error, মন্টি-কার্লো আদর্শ ত্রুটি) না-দিলে ফলটা অসম্পূর্ণ। মূল সুরটা একটাই: একটা সিমুলেশন-গবেষণা মানে এমন এক পরীক্ষা যা কোনো পরিচিত তাত্ত্বিক ফল পুনরুৎপাদন করে, আর সেই পুনরুৎপাদন একইসঙ্গে (i) তত্ত্বকে সংখ্যায় নিশ্চিত করে এবং (ii) সিমুলেশন-কোডকে যাচাই করে।
সংকেত-স্মরণ: চারটি পরীক্ষা যথাক্রমে — E1 CLT-অভিসরণের হার (Berry–Esseen), E2 bootstrap CI-এর coverage, E3 bias–variance tradeoff, এবং E4 MLE-এর consistency ও asymptotic normality। প্রতিটি পরীক্ষা np.random.default_rng(20260619) বীজে চলে, একটি ফলাফল-সারণি ছাপে, আর একটি তাত্ত্বিক পূর্বানুমান নিশ্চিত করে। নিচের প্রতিটি উপ-অংশ নকশার একটি করে নীতি ব্যাখ্যা করে।
৪.১ কেন seed স্থির রাখা হয় — reproducibility¶
যেকোনো Monte-Carlo ফল pseudo-random (ছদ্ম-এলোমেলো) সংখ্যার একটি নির্দিষ্ট ধারার ওপর দাঁড়িয়ে; সেই ধারা সম্পূর্ণভাবে নির্ধারণ করে একটিমাত্র পূর্ণসংখ্যা — seed। বীজ স্থির রাখলে (এখানে সর্বত্র np.random.default_rng(20260619)) একই কোড যেকোনো মেশিনে, যেকোনো সময়ে হুবহু একই সংখ্যা দেয় — এটাই reproducibility (পুনরুৎপাদনযোগ্যতা), যা ছাড়া কোনো সংখ্যাগত দাবি স্বাধীনভাবে যাচাই করা যায় না। এই অধ্যায়ের canonical মানগুলো (যেমন slope \(-0.4998\), coverage \(0.9130\)) ঠিক এই কারণেই নির্দিষ্ট সংখ্যা, "আনুমানিক" নয়।
একটি সূক্ষ্ম কিন্তু বাস্তব সতর্কতা: NumPy-র আধুনিক default_rng (PCG64 জেনারেটর) ব্যবহারে ফল কেবল বীজের ওপর নয়, draw-order-এর (সংখ্যা-টানার ক্রম) ওপরও নির্ভর করে। অর্থাৎ একই বীজ থেকে যদি সংখ্যাগুলো ভিন্ন ক্রমে বা ভিন্ন আকারের ব্লকে টানা হয় (যেমন লুপে এক-এক করে বনাম একবারে size=(R,n) অ্যারে), তবে প্রাপ্ত মানও ভিন্ন হতে পারে। তাই canonical সংখ্যা মেলাতে হলে কেবল বীজ নয়, টানার ক্রম ও আকারও কোডের সঙ্গে অভিন্ন রাখতে হয়। এজন্য প্রতিটি পরীক্ষায় একটিমাত্র rng অবজেক্ট তৈরি করে ধারাবাহিকভাবে ব্যবহার করা হয়, মাঝপথে পুনরায় বীজ দেওয়া হয় না।
এক বাক্যে: বীজ
default_rng(20260619)স্থির রাখা মানে ফলের পুনরুৎপাদনযোগ্যতা নিশ্চিত করা, তবে মিল পেতে বীজের পাশাপাশি সংখ্যা-টানার ক্রম ও আকারও অভিন্ন রাখতে হয় (draw-order dependence)।
৪.২ কতগুলো replication — Monte-Carlo standard error দিয়ে নির্ধারণ¶
একটা সিমুলেশন যতগুলো replication \(R\)-এ চলে, তার ফল ততই নিখুঁত — কিন্তু কতটা? এর উত্তর দেয় Monte-Carlo standard error (MC SE): সিমুলেশন-অনুমানটির নিজস্ব দৈব ওঠানামা। ধরা যাক আগ্রহের রাশি একটি গড় — \(R\)টি স্বাধীন replication থেকে \(\hat\theta=\frac1R\sum_{r=1}^R g_r\)। যেহেতু \(g_r\)-গুলো iid (একই বীজ-ধারা থেকে স্বাধীন টান), নমুনা-গড়ের আদর্শ ত্রুটির সূত্র সরাসরি দেয় $$ \operatorname{MC\,SE}(\hat\theta)\ \approx\ \frac{s}{\sqrt{R}},\qquad s^2=\frac{1}{R-1}\sum_{r=1}^R\bigl(g_r-\hat\theta\bigr)^2, $$ যেখানে \(s\) হলো replication-গুলোর নমুনা-আদর্শ বিচ্যুতি (← 3.4)। আগ্রহের রাশি যদি একটি অনুপাত হয় (যেমন coverage — কতভাগ CI সত্য মান ঢাকল), তবে প্রতিটি replication একটি Bernoulli ফল, তাই $$ \operatorname{MC\,SE}(\hat p)\ \approx\ \sqrt{\frac{\hat p\,(1-\hat p)}{R}}. $$ E2-তে ঠিক এই সূত্র প্রযোজ্য: coverage \(\hat p=0.9130\), replication-সংখ্যা \(D=2000\), তাই $$ \operatorname{MC\,SE}=\sqrt{\frac{0.9130\times0.0870}{2000}}\ =\ 0.0063, $$ যা §৩-এর canonical মানের সঙ্গে হুবহু মেলে।
এই সূত্রের একটি সিদ্ধান্তমূলক ফল: MC SE কমে \(1/\sqrt{R}\) হারে, তাই MC SE অর্ধেক করতে হলে \(R\) চারগুণ করতে হয়। অর্থাৎ নির্ভুলতা ব্যয়বহুল — একটা দশমিক ঘর বাড়াতে replication প্রায় শতগুণ লাগে। তাই \(R\) বাছা হয় লক্ষ্য MC SE থেকে পিছিয়ে হিসাব করে: প্রয়োজনীয় নির্ভুলতা স্থির করে \(R\gtrsim \bigl(s/\text{লক্ষ্য MC SE}\bigr)^2\) (গড়) বা \(R\gtrsim \hat p(1-\hat p)/(\text{লক্ষ্য MC SE})^2\) (অনুপাত) বসিয়ে।
E1-এ কেন \(R=60000\) — একটি সূক্ষ্ম নকশা-সীমা। E1-তে প্রতিটি \(n\)-এ replication-সংখ্যা \(R=60000\), যা E2-এর \(D=2000\)-এর তুলনায় অনেক বড় — এবং এটি কাকতালীয় নয়। এখানে মাপা রাশি হলো Kolmogorov–Smirnov distance \(D_n=\sup_x\lvert F_n(x)-\Phi(x)\rvert\), যেখানে \(F_n\) হলো \(R\)টি মানক নমুনা-গড়ের empirical CDF। এই KS-অনুমানের নিজস্ব নমুনা-কোলাহল (sampling noise) হ্রাস পায় \(\sim 1/\sqrt{R}\) হারে, আর মাপতে-চাওয়া প্রকৃত সংকেত — Berry–Esseen-ঘোষিত সত্য KS — হ্রাস পায় \(\sim 1/\sqrt{n}\) হারে। সবচেয়ে বড় \(n=320\)-তে সত্য সংকেত সবচেয়ে ছোট (\(D_n\approx0.0071\)); সেই ক্ষীণ সংকেতকে কোলাহলের নিচে হারিয়ে না-ফেলতে হলে অনুমানের কোলাহল \(1/\sqrt{R}\)-কে সংকেত \(1/\sqrt{n}\)-এর যথেষ্ট নিচে রাখতে হয়। এজন্যই \(R\) বড় \(n\)-এর তুলনায় অনেক বড় নিতে হয় — নয়তো log-log ঢালের অনুমান কোলাহলে দুলে \(-0.5\) থেকে সরে যেত। তাই \(R=60000\) একটি সচেতন নকশা-সিদ্ধান্ত, খামখেয়াল নয়।
এক বাক্যে: replication-সংখ্যা \(R\) ঠিক হয় লক্ষ্য MC SE থেকে (\(\text{MC SE}\approx s/\sqrt R\) গড়ে, \(\sqrt{p(1-p)/R}\) অনুপাতে; অর্ধেক করতে \(R\) চারগুণ), আর E1-এ \(R=60000\) কারণ KS-অনুমানের কোলাহল \(1/\sqrt R\)-কে বৃহত্তম \(n\)-এর Berry–Esseen সংকেত \(1/\sqrt n\)-এর নিচে রাখতে হয়।
৪.৩ ফলের সঙ্গে Monte-Carlo standard error জানানো¶
একটি Monte-Carlo সংখ্যা তার MC SE ছাড়া অসম্পূর্ণ — কারণ পাঠক তখন জানে না ফলটি কতটা নির্ভরযোগ্য, বা দুটি ফলের পার্থক্য প্রকৃত না নিছক সিমুলেশন-কোলাহল। উদাহরণে E2-এর coverage সঠিকভাবে লেখা হয় "\(0.9130\)" নয়, বরং "\(0.9130\) (MC SE \(0.0063\))" রূপে। এই MC SE-ই বলে দেয় ৯৫% নামমাত্র মানের (\(0.95\)) সঙ্গে পর্যবেক্ষিত \(0.9130\)-এর পার্থক্য অর্থপূর্ণ কি না: পার্থক্য \(0.95-0.9130=0.0370\) হলো MC SE-এর প্রায় ছয়গুণ, তাই under-coverage-টি বাস্তব প্রভাব, সিমুলেশন-দুর্ঘটনা নয়।
একই যুক্তিতে E1-এর ঢাল \(-0.4998\) বা E4-এর ঢাল \(-0.5570\)-কে "\(-0.5\)-এর সমান বা ভিন্ন" বলার আগে সেই অনুমানগুলোর নিজস্ব অনিশ্চয়তা মাথায় রাখা দরকার — একটা log-log রৈখিক ফিটের ঢালেরও একটি আদর্শ ত্রুটি আছে (regression-এর slope SE, ← 5.2)। নীতিটি সর্বজনীন: প্রতিটি সিমুলেশন-সংখ্যা একটি অনুমান, আর প্রতিটি অনুমানের সঙ্গে তার অনিশ্চয়তা জানানো বৈজ্ঞানিক সততার শর্ত।
এক বাক্যে: MC SE ছাড়া সিমুলেশন-ফল অসম্পূর্ণ — এটিই ঠিক করে দেয় coverage \(0.9130\)-এর নামমাত্র \(0.95\) থেকে বিচ্যুতি অর্থপূর্ণ (প্রায় ছয় MC SE) নাকি নিছক কোলাহল।
৪.৪ একবারে একটিমাত্র factor বদলানো — common random numbers¶
একটি পরিষ্কার পরীক্ষার প্রথম শর্ত: ফলের পার্থক্য যেন একটিমাত্র কারণে দায়ী করা যায়। তাই সিমুলেশনে একবারে একটিমাত্র factor পরিবর্তন করা হয়, বাকি সব স্থির রেখে।
- E1 ও E4-তে একমাত্র পরিবর্তনশীল factor হলো নমুনা-আকার \(n\) (E1-এ \(n\in\{5,10,20,40,80,160,320\}\), E4-এ \(n\in\{10,40,160,640\}\))। অন্য সব — ভিত্তি-বণ্টন, replication-সংখ্যা, বীজ — অপরিবর্তিত; তাই KS বা RMSE-এর পরিবর্তন সম্পূর্ণভাবে \(n\)-এর ফল, আর log-log ঢাল সরাসরি অভিসরণ-হার পরিমাপ করে।
- E3-তে পরিবর্তনশীল factor হলো polynomial regression-এর degree \(d\in\{1,\dots,12\}\)। এখানে একটি সূক্ষ্ম কৌশল ব্যবহৃত: একই noise realisation প্রতিটি degree-এ পুনর্ব্যবহার করা হয় (SAME noise across degrees)। অর্থাৎ একই \(R=500\)টি প্রশিক্ষণ-সেটের দৈব ত্রুটি সব degree-এ অভিন্ন রাখা হয়, কেবল fit-করা বহুপদীর degree বদলায়। ফলে দুটি degree-এর মধ্যে total error-এর পার্থক্য কেবল degree-এর ফল — একই দৈব ওঠানামা দুই পাশে থাকায় তা বিয়োগে কাটাকাটি যায়।
এই কৌশলটির নাম common random numbers (CRN, সাধারণ দৈব সংখ্যা), যা একটি variance reduction (ভেদ-হ্রাস) কৌশল: তুলনীয় শর্তগুলোতে একই দৈব ইনপুট ব্যবহার করলে তুলনার (পার্থক্যের) ভেদ কমে, কারণ সাধারণ কোলাহল উভয় পক্ষে ধনাত্মকভাবে সহ-সম্পর্কিত হয়ে বিয়োগে মুছে যায়। E3-এর U-আকৃতির bias–variance বক্ররেখাটি এতে অনেক মসৃণ ও তুলনাযোগ্য হয়।
এক বাক্যে: পরিষ্কার কার্যকারণের জন্য একবারে একটিমাত্র factor বদলানো হয় (E1/E4-এ \(n\), E3-এ degree), আর E3-এ প্রতিটি degree-এ একই noise পুনর্ব্যবহার (common random numbers) পার্থক্যকে কেবল degree-এর ফল করে তোলে — একটি variance-reduction কৌশল।
৪.৫ factorial design ও variance reduction — সাধারণ নীতি¶
উপরের নকশা-ভাবনাগুলো সিমুলেশন-গবেষণার দুটি প্রতিষ্ঠিত নীতির বিশেষ রূপ।
Factorial design (গুণক-নকশা)। যখন একাধিক factor একসঙ্গে প্রভাব ফেলে, তখন প্রতিটি factor-এর সব স্তরের সব সমন্বয় পরীক্ষা করলে কেবল মূল-প্রভাব (main effect) নয়, তাদের interaction (পারস্পরিক ক্রিয়া)-ও ধরা যায়। এই অধ্যায়ের পরীক্ষাগুলো ইচ্ছাকৃতভাবে এক-factor (one-factor-at-a-time) নকশায় সীমাবদ্ধ — E1/E4-এ কেবল \(n\), E3-এ কেবল degree — কারণ প্রতিটির লক্ষ্য একটি করে নির্দিষ্ট তাত্ত্বিক হার বা বক্ররেখা বিচ্ছিন্নভাবে পরিমাপ করা; পূর্ণ factorial নকশা এখানে অপ্রয়োজনীয় জটিলতা যোগ করত।
Variance reduction (ভেদ-হ্রাস)। একই MC SE কম replication-এ পেতে বেশ কিছু কৌশল আছে; দুটি প্রধান —
- Common random numbers (§৪.৪): তুলনীয় শর্তে একই দৈব ইনপুট; E3 এটি ব্যবহার করে degree-গুলোর তুলনা তীক্ষ্ণ করতে।
- Antithetic variates (প্রতিমুখী রাশি): প্রতিটি দৈব টান \(U\)-এর পাশাপাশি তার "আয়না" \(1-U\) (বা \(-Z\)) ব্যবহার করে ঋণাত্মক সহ-সম্পর্ক তৈরি করা, যাতে গড়ের ভেদ কমে। এই অধ্যায়ের চারটি পরীক্ষার কোনোটিই antithetic variates ব্যবহার করে না (প্রতিটিতে স্বাধীন টানই যথেষ্ট), তবে নীতিটি সাধারণ ভেদ-হ্রাস-কৌশল হিসেবে জানা থাকা দরকার।
সংক্ষেপে: E1, E2, E4 স্বাধীন replication-এর সরল নকশায় চলে; কেবল E3 common-random-numbers-জাত variance reduction ব্যবহার করে, আর কোনো পরীক্ষাই পূর্ণ factorial নকশা বা antithetic variates-এ যায় না — কারণ প্রতিটির উদ্দেশ্য একটিমাত্র হার/বক্ররেখা পরিষ্কারভাবে দেখানো।
এক বাক্যে: সাধারণ নীতি হিসেবে factorial design একাধিক factor-এর interaction ধরে আর variance reduction (common random numbers, antithetic variates) কম replication-এ একই নির্ভুলতা দেয়; এই অধ্যায়ে কেবল E3 common random numbers ব্যবহার করে, বাকিরা সরল স্বাধীন-replication নকশায়।
৪.৬ তত্ত্ব-যাচাইকে কোড-যাচাই হিসেবে ব্যবহার¶
একটি সিমুলেশন-গবেষণার গভীরতম উদ্দেশ্য দ্বৈত। একটি পরিচিত তাত্ত্বিক ফল পুনরুৎপাদন করলে একই কাজ দুটি জিনিস প্রমাণ করে: (i) তত্ত্বটি সংখ্যায় সত্য — যেমন E1-এ log-log ঢাল \(-0.4998\) Berry–Esseen-এর তাত্ত্বিক \(-0.5\)-এর সঙ্গে মেলা নিশ্চিত করে CLT-অভিসরণ প্রকৃতই \(1/\sqrt n\) হারে; এবং (ii) সিমুলেশন-pipeline (কোড, নমুনায়ন, পরিসংখ্যান-গণনা) ঠিকঠাক কাজ করছে।
এই দ্বিতীয় দিকটিই সবচেয়ে ব্যবহারিক। ধরা যাক E1-এর ঢাল \(-0.5\)-এর কাছে না-এসে, ধরুন, \(-0.25\) বা \(0\) বেরোত। তত্ত্ব (Berry–Esseen) সুপ্রতিষ্ঠিত ও প্রমাণিত (← Part VII); তাই অসঙ্গতির সবচেয়ে সম্ভাব্য কারণ তত্ত্বের ভুল নয়, কোডের বাগ — হয়তো মানক-করণে \(\sqrt n\) ভুল জায়গায়, বা KS-গণনায় ভুল রেফারেন্স-বণ্টন, বা draw-order-জনিত সংখ্যা-দূষণ। এভাবে একটি জানা উত্তরের বিপরীতে কোড চালানো একটি অন্তর্নির্মিত যাচাই (built-in sanity check): মিল পেলে pipeline-এ আস্থা বাড়ে, না-মিললে বাগ-সন্ধান শুরু হয় কোড থেকে, তত্ত্ব থেকে নয়।
ঠিক এ কারণেই capstone-এর পরীক্ষাগুলো ইচ্ছাকৃতভাবে পরিচিত ফল (CLT-হার, ৯৫% coverage-এর কাছাকাছি, U-আকৃতি bias–variance, MLE-এর \(1/\sqrt n\) RMSE) বেছে নেয় — অজানা কিছু আবিষ্কারের জন্য নয়, বরং তত্ত্ব ও কোড উভয়কে একসঙ্গে যাচাই করে তবেই কোনো নতুন প্রশ্নে সেই যাচাইকৃত সরঞ্জাম প্রয়োগের যোগ্যতা অর্জনের জন্য। এটিই একজন শিক্ষার্থীকে উপপাদ্যের ভোক্তা থেকে পরীক্ষার নকশাকার-এ রূপান্তরিত করে (→ 8.3)।
এক বাক্যে: একটা জানা ফল পুনরুৎপাদন একই সঙ্গে তত্ত্বকে সংখ্যায় নিশ্চিত করে ও সিমুলেশন-pipeline যাচাই করে — E1-এর ঢাল \(-0.5\) না-এলে সন্দেহটা প্রথমে কোডের বাগে, CLT-তে নয়।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের কেন্দ্রীয় ধারণা — simulation study (সিমুলেশন-অধ্যয়ন): এমন Monte-Carlo experiment (মন্টি-কার্লো পরীক্ষা) নকশা করা যা একটা পরিচিত তাত্ত্বিক ফলকে সংখ্যায় পুনরুৎপাদন (reproduce) করে — যাতে তত্ত্ব ও pipeline দুই-ই বিশ্বাসের আগে যাচাই হয়। গোটা ল্যাবটা একটাই runnable স্ক্রিপ্ট — part-8-capstone/_code/lab_8-2.py — চারটে স্বতন্ত্র পরীক্ষায় ভাগ করা, প্রতিটি একটি করে জানা ফলকে ফিরিয়ে আনে: (E1) CLT-অভিসারণের হার — Berry–Esseen bound বলে standardized গড়ের KS-দূরত্ব \(\sim C/\sqrt n\), তাই log-log ঢাল হওয়া উচিত \(\approx-0.5\); (E2) bootstrap CI-এর coverage — nominal \(95\%\) percentile-bootstrap CI-এর empirical coverage তত্ত্ব-মতে \(\approx0.95\); (E3) bias–variance tradeoff — polynomial degree বাড়ালে total test error একটা U-আকৃতির বক্ররেখা, ভেতরে optimal degree; (E4) MLE consistency ও asymptotic normality — \(\text{Exp}(\lambda)\)-এর MLE \(\widehat\lambda=1/\bar X\)-এর RMSE \(\sim1/\sqrt n\), আর standardized ভুল \(\to N(0,1)\)। নির্ভরতা শুধু numpy ও scipy, বাড়তি কোনো library নয়।
স্ক্রিপ্টের কাঠামো ও পুনরুৎপাদনযোগ্যতা (reproducibility)¶
সব random draw একটিমাত্র generator থেকে আসে — np.random.default_rng(20260619) — কিন্তু প্রতিটি পরীক্ষা শুরুতে সেই একই seed-এ reset করা হয়। তাই চারটি block স্বাধীনভাবে পুনরুৎপাদনযোগ্য ও পরস্পরের ক্রমের উপর নির্ভরশীল নয়: E2 আগে না E3 আগে চালানো হলো তাতে কোনো block-এর সংখ্যা বদলায় না (একটি block-এর ভেতরে অবশ্য draw-ক্রম স্থির)। বিশেষত E3-এ প্রতিটি degree-এর আগে generator-টা আবার একই seed-এ reset হয়, যাতে সব degree হুবহু একই noise realisation দেখে — ফলে degree-ই একমাত্র পরিবর্তনশীল factor হিসেবে বিচ্ছিন্ন থাকে। নিচের set-up লাইনগুলো গোটা স্ক্রিপ্টে একবারই চলে, আর প্রতিটি পরীক্ষা নিজের ভেতরে rng = np.random.default_rng(SEED) দিয়ে শুরু করে—
import numpy as np
from scipy import stats
np.set_printoptions(precision=4, suppress=True)
SEED = 20260619
প্রতিটি block এই একই SEED-এ ফিরে যায়, তাই নিচের সব সংখ্যা — চারটি পরীক্ষার প্রতিটির — হুবহু পুনরুৎপাদনযোগ্য।
৫.১ · E1 — CLT-অভিসারণের হার (Berry–Esseen)¶
প্রথম পরীক্ষা CLT-এর statement নয়, হার মাপে। নাও iid \(X_i\sim\text{Exp}(1)\) (গড় \(1\), ভেদ \(1\), কিন্তু skewness \(2\) — তীব্র ডান-বঙ্কিম); standardized গড় \(Z_n=\sqrt n\,(\bar X_n-1)\)। প্রতিটি sample-আকার \(n\in\{5,10,20,40,80,160,320\}\)-এ \(R=60000\) স্বাধীন কপি \(Z_n\) থেকে \(N(0,1)\)-CDF-এর Kolmogorov–Smirnov (KS) দূরত্ব \(\sup_x\lvert F_R(x)-\Phi(x)\rvert\) মাপা হয়। Berry–Esseen bound বলে \(\sup_x\lvert F-\Phi\rvert\le C\rho/(\sigma^3\sqrt n)\), অর্থাৎ \(\sim n^{-1/2}\); তাই \(\log(\text{KS})\)-এর ওপর \(\log n\)-এর সরলরৈখিক fit-এর ঢাল হওয়া উচিত \(\approx-0.5\)।
ns_clt = np.array([5, 10, 20, 40, 80, 160, 320])
R1 = 60_000 # replications of Z_n per n
ks_vals = np.empty(len(ns_clt))
for j, n in enumerate(ns_clt):
x = rng.standard_exponential(size=(R1, n)) # Exp(rate 1)
Z = np.sqrt(n) * (x.mean(axis=1) - 1.0) # standardized mean
ks_vals[j] = stats.kstest(Z, "norm").statistic # sup|F_R - Phi|
# log-log least-squares fit: log(KS) = a + b log(n); Berry-Esseen => b ~ -0.5
slope, intercept = np.polyfit(np.log(ns_clt.astype(float)), np.log(ks_vals), 1)
EXPERIMENT 1 -- CLT convergence rate (Berry-Esseen, KS ~ C/sqrt(n))
base = Exp(1) (skewness 2); Z_n = sqrt(n)(Xbar_n - 1); R = 60000 reps/n
n | KS dist | C/sqrt(n) fit
----------------------------------
5 | 0.0590 | 0.0593
10 | 0.0417 | 0.0419
20 | 0.0285 | 0.0297
40 | 0.0225 | 0.0210
80 | 0.0148 | 0.0148
160 | 0.0108 | 0.0105
320 | 0.0071 | 0.0074
log-log fit: slope = -0.4998 (Berry-Esseen predicts -0.5)
C = e^intercept = 0.1326
পাঠোদ্ধার (read-off)।
- ঢাল ঠিক \(-\tfrac12\)-এ। log-log fit-এর ঢাল \(\mathbf{-0.4998}\) — Berry–Esseen-এর ভবিষ্যদ্বাণী \(-0.5\)-এর কার্যত অভিন্ন। অর্থাৎ KS-দূরত্ব sample-আকারের সাথে ঠিক \(n^{-1/2}\)-হারে নামে: \(n\) চারগুণ করলে দূরত্ব প্রায় অর্ধেক (\(0.0590\) থেকে \(n=20\)-এ \(0.0285\), তারপর \(n=80\)-এ \(0.0148\))।
- fit-করা \(C/\sqrt n\) প্রতিটি \(n\)-এ মাপা KS-কে মেলায়। ডানের কলামে \(C/\sqrt n\) (যেখানে \(C=e^{\text{intercept}}=\mathbf{0.1326}\)) মাপা KS-দূরত্বের প্রায় সমান — অর্থাৎ পুরো টেবিলটা একটাই power-law \(0.1326\,n^{-1/2}\)-এর ওপর বসে। এই মিলই দেখায় Berry–Esseen-এর \(1/\sqrt n\) হার শুধু ওপরের সীমা নয়, এখানে সত্যিকারের হার।
- base তীব্র-বঙ্কিম বলেই হারটা মাপা গেল। skewness \(2\)-এর Exp(1) বেছে নেওয়ায় KS-সংকেত (\(\sim1/\sqrt n\)) বড় থাকে, আর \(R=60000\) rep-এর নিজস্ব Monte-Carlo গোলমাল (\(\sim1/\sqrt R\)) সবচেয়ে বড় \(n=320\)-তেও তার নিচে থাকে — তাই ঢাল বিশ্বাসযোগ্যভাবে \(-0.5\)-এ থিতু হয়।
এক বাক্যে। standardized বঙ্কিম গড়ের \(N(0,1)\)-থেকে KS-দূরত্ব \(n^{-1/2}\)-হারে নামে (ঢাল \(-0.4998\approx-0.5\)), যা Berry–Esseen-এর হারকে সংখ্যায় পুনরুৎপাদন করে।
৫.২ · E2 — bootstrap CI-এর coverage (nominal ৯৫%)¶
দ্বিতীয় পরীক্ষা একটা inference-পদ্ধতির নির্ভুলতা যাচাই করে। সত্য মডেল \(X\sim\text{Exp}(1)\), তাই population গড় \(\theta=1\)। \(D=2000\)টি dataset (প্রতিটি \(n=40\)) থেকে প্রতিটির জন্য গড়ের একটা \(95\%\) percentile bootstrap CI (\(B=1000\) resample থেকে) গড়া হয়, তারপর জিজ্ঞাসা — \(\theta=1\) কি সেই CI-এর ভেতরে? যত ভগ্নাংশ dataset-এর CI সত্যকে ঢাকে, সেটাই empirical coverage; bootstrap-consistency তত্ত্ব বলে তা \(\approx0.95\) হওয়া উচিত (skewed data-য় মাঝারি \(n\)-এ সাধারণত সামান্য কম)। নিজের অনিশ্চয়তা মাপতে Monte-Carlo standard error \(\sqrt{p(1-p)/D}\) ছাপা হয়।
n2 = 40; D = 2000; B = 1000; theta_true = 1.0
covered = np.zeros(D, dtype=bool); widths = np.empty(D)
for d in range(D):
data = rng.standard_exponential(size=n2) # one Exp(1) dataset
idx = rng.integers(0, n2, size=(B, n2)) # B bootstrap resamples
boot_means = data[idx].mean(axis=1) # bootstrap dist of mean
lo, hi = np.percentile(boot_means, [2.5, 97.5]) # 95% percentile CI
covered[d] = (lo <= theta_true <= hi); widths[d] = hi - lo
coverage = covered.mean()
mc_se = np.sqrt(coverage * (1 - coverage) / D) # MC std error of coverage
EXPERIMENT 2 -- bootstrap CI coverage (nominal 95%)
base = Exp(1), true mean = 1; n = 40, D = 2000 datasets, B = 1000 resamples
statistic = sample mean; method = percentile bootstrap
empirical coverage = 0.9130 (nominal 0.95)
Monte-Carlo SE = 0.0063
mean CI width = 0.5869
পাঠোদ্ধার (read-off)।
- empirical coverage \(\approx0.91\), nominal-এর সামান্য নিচে। মাপা coverage \(\mathbf{0.9130}\) — লক্ষ্য \(0.95\)-এর কাছাকাছি কিন্তু একটু কম। কারণটা তত্ত্বসম্মত: Exp(1) ডান-বঙ্কিম, আর \(n=40\) মাঝারি — percentile bootstrap এই পরিস্থিতিতে একটু under-cover করে (skew-এর জন্য bias-সংশোধন ছাড়া percentile CI তুলনামূলক অসামঞ্জস্যপূর্ণ)।
- Monte-Carlo SE বলছে ব্যবধানটা বাস্তব, দুর্ঘটনা নয়। MC standard error মাত্র \(\mathbf{0.0063}\), তাই \(0.9130\) ও \(0.95\)-এর মধ্যে \(0.037\)-এর ফাঁক \(\approx6\) standard error — অর্থাৎ under-coverage-টা সিমুলেশন-গোলমাল নয়, পদ্ধতির প্রকৃত ধর্ম। \(D=2000\) dataset ঠিক এই আত্মবিশ্বাসটুকু দেয়।
- CI-প্রস্থ যুক্তিসঙ্গত। গড় CI-প্রস্থ \(\mathbf{0.5869}\) — \(n=40\)-এ গড়ের standard error \(\approx\sigma/\sqrt n=1/\sqrt{40}\approx0.158\)-এর প্রায় \(3.7\) গুণ, যা \(\approx\pm1.96\) SE দুই-পাশের একটা normal-সদৃশ \(95\%\) CI-প্রস্থের (\(\approx0.62\)) কাছাকাছি — অর্থাৎ bootstrap CI বাস্তবসম্মত পরিসরই দিচ্ছে।
এক বাক্যে। \(95\%\) percentile-bootstrap CI-এর empirical coverage \(0.9130\) (MC-SE \(0.0063\)) nominal \(0.95\)-এর সামান্য নিচে — bootstrap-consistency-র ভবিষ্যদ্বাণী এবং skewed data-য় মাঝারি \(n\)-এর প্রত্যাশিত under-coverage দুই-ই সংখ্যায় ধরা পড়ে।
৫.৩ · E3 — bias–variance tradeoff (polynomial regression)¶
তৃতীয় পরীক্ষা learning theory-র কেন্দ্রীয় সমঝোতা পুনরুৎপাদন করে। স্থির মসৃণ signal \(f(x)=\sin(1.5x)+0.5x\) on \([-3,3]\); পর্যবেক্ষণ \(y=f(x)+N(0,\sigma^2)\), \(\sigma=0.7\) (তাই \(\sigma^2=0.4900\))। \(d=1,\dots,12\) degree-এর polynomial regression \(R=500\) স্বাধীন training set-এ (\(n_{\text{train}}=30\), স্থির design) fit করে, dense test-grid-এ প্রতিটি বিন্দুতে Monte-Carlo \(\text{Bias}^2=(\overline{\widehat f}-f)^2\) ও \(\text{Var}=\operatorname{var}(\widehat f)\) মাপা হয়। grid-জুড়ে গড় করে total test error \((d)\approx\text{Bias}^2(d)+\text{Var}(d)+\sigma^2\)। নিম্ন \(d\) underfit করে (উচ্চ bias), উচ্চ \(d\) overfit করে (উচ্চ variance); ন্যূনতম total error একটা ভেতরের optimal degree-এ বসে।
sigma = 0.7; degrees = np.arange(1, 13); n_train = 30; R3 = 500
x_train = np.linspace(-3, 3, n_train) # FIXED design
x_test = np.linspace(-3, 3, 200)
f_train, f_test = signal(x_train), signal(x_test)
for k, d in enumerate(degrees):
rng_d = np.random.default_rng(SEED) # identical noise across degrees
Vd, Vt = np.vander(x_train, d + 1), np.vander(x_test, d + 1)
preds = np.empty((R3, len(x_test)))
for r in range(R3):
y = f_train + sigma * rng_d.standard_normal(n_train)
coef, *_ = np.linalg.lstsq(Vd, y, rcond=None)
preds[r] = Vt @ coef
bias2[k] = np.mean((preds.mean(axis=0) - f_test) ** 2) # avg over grid
variance[k] = np.mean(preds.var(axis=0))
total_err[k] = bias2[k] + variance[k] + sigma ** 2 # expected test MSE
EXPERIMENT 3 -- bias-variance tradeoff (polynomial regression)
signal = sin(1.5x)+0.5x, noise sd = 0.7; R = 500 train sets, n_train = 30
deg | Bias^2 | Var | Total
--------------------------------------
1 | 0.4812 | 0.0305 | 1.0016
2 | 0.4812 | 0.0450 | 1.0162
3 | 0.0741 | 0.0598 | 0.6239
4 | 0.0742 | 0.0737 | 0.6378
5 | 0.0020 | 0.0865 | 0.5784 <- min
6 | 0.0019 | 0.1001 | 0.5920
7 | 0.0002 | 0.1131 | 0.6033
8 | 0.0004 | 0.1288 | 0.6192
9 | 0.0004 | 0.1455 | 0.6359
10 | 0.0004 | 0.1641 | 0.6545
11 | 0.0004 | 0.1826 | 0.6731
12 | 0.0006 | 0.2041 | 0.6947
irreducible noise sigma^2 = 0.4900
optimal degree = 5 (min total test error = 0.5784)
পাঠোদ্ধার (read-off)।
- \(\text{Bias}^2\) ধাপে-ধাপে নামে, signal-এর গঠন মেনে। \(d=1,2\)-এ \(\text{Bias}^2\approx\mathbf{0.4812}\) (বড় — সরলরেখা \(\sin\)-কে ধরতে পারে না), তারপর \(d{=}3\)-এ হঠাৎ \(\mathbf{0.0741}\)-এ নামে (\(\sin\)-এর জন্য বিজোড় পদ লাগে), আবার \(d{=}5\)-এ \(\mathbf{0.0020}\)-এ — কারণ \(\sin(1.5x)\)-এর Taylor-প্রসারণে \(x^3,x^5\) পদ প্রধান। degree signal-এর প্রকৃত জটিলতায় পৌঁছালেই bias কার্যত মুছে যায়।
- Variance একঘেয়েভাবে বাড়ে। \(\text{Var}\) \(d{=}1\)-এ \(\mathbf{0.0305}\) থেকে \(d{=}12\)-এ \(\mathbf{0.2041}\) পর্যন্ত ক্রমাগত চড়ে — প্রতিটি বাড়তি parameter একই \(n_{\text{train}}=30\) data-কে আরও শক্ত করে fit করে, তাই noise-এর প্রতি সংবেদনশীলতা বাড়ে। এটাই overfitting-এর সংখ্যিক স্বাক্ষর।
- Total error U-আকৃতির, ন্যূনতম \(d=5\)-এ। \(\text{Bias}^2+\text{Var}+\sigma^2\) প্রথমে নামে (bias-পতন প্রধান), তারপর ওঠে (variance-বৃদ্ধি প্রধান), সর্বনিম্ন \(\mathbf{0.5784}\) degree ৫-এ। irreducible \(\sigma^2=\mathbf{0.4900}\) একটা মেঝে — কোনো model তার নিচে যেতে পারে না, তাই সেরা total error \(0.5784\) সেই মেঝের ঠিক ওপরে (অবশিষ্ট \(\approx0.088\) bias+variance)।
এক বাক্যে। polynomial degree বাড়ালে \(\text{Bias}^2\) নামে ও \(\text{Var}\) ওঠে, তাই total test error U-আকৃতিতে degree ৫-এ (মান \(0.5784\), irreducible \(\sigma^2=0.4900\)-এর ঠিক ওপরে) সর্বনিম্ন — bias–variance decomposition-এর হুবহু চিত্র।
৫.৪ · E4 — MLE-এর consistency ও asymptotic normality¶
চতুর্থ পরীক্ষা estimation-তত্ত্বের দুই স্তম্ভ যাচাই করে। মডেল \(X\sim\text{Exponential}(\text{rate }\lambda=2)\); MLE \(\widehat\lambda=1/\bar X\)। Fisher information \(I(\lambda)=1/\lambda^2\), তাই asymptotic ভেদ \(1/I(\lambda)=\lambda^2\), অর্থাৎ asymptotic sd \(=\lambda=2\)। দুই অংশ: (ক) consistency — \(n\in\{10,40,160,640\}\) (\(R=4000\))-এ \(\widehat\lambda\)-এর empirical bias ও RMSE ছাপা হয়; RMSE-এর \(n^{-1/2}\)-হারে নামা উচিত। (খ) asymptotic normality — \(n=200\) (\(R=40000\))-এ standardized statistic \(S=\sqrt n\,(\widehat\lambda-\lambda)/\lambda\) গড়া হয় ও \(N(0,1)\)-এর বিরুদ্ধে KS-test করা হয়; §৬-এ এর histogram।
lam_true = 2.0; ns_mle = np.array([10, 40, 160, 640]); R4 = 4000
for j, n in enumerate(ns_mle):
x = rng.exponential(scale=1.0 / lam_true, size=(R4, n)) # Exp(rate 2)
lam_hat = 1.0 / x.mean(axis=1) # MLE = 1/Xbar
bias_mle[j] = lam_hat.mean() - lam_true
rmse_mle[j] = np.sqrt(np.mean((lam_hat - lam_true) ** 2))
sl_rmse, ic_rmse = np.polyfit(np.log(ns_mle.astype(float)), np.log(rmse_mle), 1)
# asymptotic normality at n = 200
x = rng.exponential(scale=1.0 / lam_true, size=(40000, 200))
lam_hat_an = 1.0 / x.mean(axis=1)
S = np.sqrt(200) * (lam_hat_an - lam_true) / lam_true # -> N(0,1)
ks_an = stats.kstest(S, "norm").statistic
EXPERIMENT 4 -- MLE consistency & asymptotic normality
model = Exp(rate lambda=2.0); MLE lambda_hat = 1/Xbar; I(lambda)=1/lambda^2
(a) consistency: R = 4000 reps/n
n | bias | RMSE | C/sqrt(n)
----------------------------------------
10 | +0.2182 | 0.7965 | 0.8795
40 | +0.0484 | 0.3404 | 0.4397
160 | +0.0114 | 0.1639 | 0.2199
640 | +0.0028 | 0.0775 | 0.1099
RMSE log-log slope = -0.5570 (consistency predicts -0.5)
(b) asymptotic normality at n = 200 (R = 40000):
asymptotic sd = lambda = 2.0000 (from 1/I(lambda) = lambda^2)
standardized S = sqrt(n)(lam_hat-lambda)/lambda: mean = +0.0663, sd = 1.0091
KS(S, N(0,1)) = 0.0180 (small => Normal limit holds)
পাঠোদ্ধার (read-off)।
- RMSE \(n^{-1/2}\)-হারে নামে — consistency দৃশ্যমান। RMSE \(n{=}10\)-এ \(\mathbf{0.7965}\) থেকে \(n{=}640\)-তে \(\mathbf{0.0775}\)-এ নামে; \(n\) চারগুণ করলে RMSE প্রায় অর্ধেক (\(0.7965\to0.3404\to0.1639\to0.0775\))। log-log ঢাল \(\mathbf{-0.5570}\) — তত্ত্বের \(-0.5\)-এর কাছে (ছোট \(n\)-এ bias-এর অবদান ঢালকে সামান্য খাড়া করে)। \(\widehat\lambda\xrightarrow{p}\lambda\) — অর্থাৎ estimator consistent।
- bias ধনাত্মক কিন্তু \(\to0\)। bias \(n{=}10\)-এ \(\mathbf{+0.2182}\) থেকে \(n{=}640\)-তে \(\mathbf{+0.0028}\)-এ নামে — সবসময় ধনাত্মক, কারণ \(\widehat\lambda=1/\bar X\) একটা উত্তল রূপান্তর, তাই Jensen-অসমতায় \(\mathbb E[1/\bar X]>1/\mathbb E[\bar X]=\lambda\) (সসীম \(n\)-এ পক্ষপাতী)। তবু \(n\to\infty\)-এ bias শূন্যে যায় — consistency-র সাথে সঙ্গতিপূর্ণ।
- standardized ভুল \(N(0,1)\)-এ থিতু — asymptotic normality। \(n{=}200\)-এ \(S=\sqrt n(\widehat\lambda-\lambda)/\lambda\)-এর গড় \(\mathbf{+0.0663}\) (\(\approx0\)) ও sd \(\mathbf{1.0091}\) (\(\approx1\)); asymptotic sd ঠিক \(\lambda=\mathbf{2.0000}\) (\(=\sqrt{1/I(\lambda)}\))। \(N(0,1)\)-থেকে KS-দূরত্ব মাত্র \(\mathbf{0.0180}\) — এত ছোট যে limiting normal রূপ ধরে নেওয়া যায়। অর্থাৎ \(\sqrt n(\widehat\lambda-\lambda)\Rightarrow N(0,\lambda^2)\) সংখ্যায় নিশ্চিত।
এক বাক্যে। \(\text{Exp}(\lambda)\)-এর MLE \(1/\bar X\)-এর RMSE \(n^{-0.557}\approx n^{-1/2}\)-হারে নামে (consistency) আর \(n=200\)-এ standardized ভুল \(N(0,1)\)-এর কাছে (KS \(0.0180\), asymptotic sd \(=\lambda=2\)) — consistency ও asymptotic normality দুই-ই পুনরুৎপাদিত।
সারসংক্ষেপ¶
চারটি পরীক্ষা মিলে simulation study-র মূল ধারণাকে সংখ্যায় স্পর্শযোগ্য করল — প্রতিটি একটা জানা তাত্ত্বিক ফলকে নকশা-করা Monte-Carlo-তে ফিরিয়ে এনে তত্ত্ব ও কোড দুই-ই যাচাই করল। §৫.১ CLT-এর হার মাপল: বঙ্কিম Exp(1)-এর standardized গড়ের KS-দূরত্ব \(n^{-1/2}\)-হারে নামে (ঢাল \(-0.4998\)), ঠিক Berry–Esseen-এর মতো। §৫.২ একটা inference-পদ্ধতির নির্ভুলতা যাচাই করল: percentile-bootstrap CI-এর empirical coverage \(0.9130\) (MC-SE \(0.0063\)) — nominal \(0.95\)-এর সামান্য নিচে, skewed data-য় মাঝারি \(n\)-এ প্রত্যাশিতভাবেই। §৫.৩ learning theory-র সমঝোতা ফিরিয়ে আনল: polynomial degree বাড়ালে \(\text{Bias}^2\) নামে, \(\text{Var}\) ওঠে, total error U-আকৃতিতে degree ৫-এ (\(0.5784\)) সর্বনিম্ন। আর §৫.৪ estimation-তত্ত্বের দুই স্তম্ভ দেখাল: MLE \(1/\bar X\)-এর RMSE \(n^{-1/2}\)-হারে নামে (consistency, ঢাল \(-0.5570\)) আর standardized ভুল \(N(0,1)\)-এ থিতু (asymptotic normality, KS \(0.0180\))। প্রতিটি ক্ষেত্রে একটা স্পষ্ট design (factor, replication-সংখ্যা, স্থির seed \(20260619\)), একটা ছাপা ফলাফল-টেবিল, আর সেটি যে তাত্ত্বিক ভবিষ্যদ্বাণী নিশ্চিত করে — এই ত্রিভুজই একটা simulation study-কে বিশ্বাসযোগ্য করে তোলে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি পরীক্ষার প্রতিটির জন্য একটি করে figure — চারটি জানা ফলকে চোখে দেখা। প্রথম figure CLT-অভিসারণের হার দেখায় log-log অক্ষে; দ্বিতীয়টি bootstrap CI-গুলো কীভাবে সত্যকে ঘিরে ধরে ও empirical coverage কত; তৃতীয়টি bias–variance-এর U-বক্ররেখা; চতুর্থটি MLE-এর asymptotic normal রূপ। প্রতিটি figure-এর নিচে ঠিক যে ধারণায় সেটি আঁকা তার একটা সংক্ষিপ্ত code-অংশ দেওয়া; সম্পূর্ণ script part-8-capstone/_code/figs_8-2.py-তে, seed np.random.default_rng(20260619)।
৬.১ · CLT-অভিসারণের হার — log-log অক্ষে Berry–Esseen লাইন¶
এই figure §৫.১-এর সংখ্যাগুলোকে ছবিতে আনে: সাতটি sample-আকার \(n\)-এর KS-দূরত্ব দুই-অক্ষই log স্কেলে আঁকা, আর তার ভেতর দিয়ে টানা একটা −১/২-ঢালের guide-লাইন (Berry–Esseen-হার)। তাত্ত্বিক কথাটা — \(\sim n^{-1/2}\) হার একটা power-law, তাই log-log-এ তা সরলরেখা, আর মাপা বিন্দুগুলো সেই রেখার ওপর বসে। fit-করা ঢাল \(-0.4998\) কার্যত \(-1/2\)-এর অভিন্ন।
ax.loglog(ns, ks_vals, "o", label="empirical KS") # measured points
guide = np.exp(intercept) / np.sqrt(ns) # C * n^{-1/2} line
ax.loglog(ns, guide, "k--", label=r"slope $-1/2$ (Berry-Esseen)")
ax.set_xlabel("n"); ax.set_ylabel(r"$\sup_x\lvert F_n(x)-\Phi(x)\rvert$")
ax.set_title(f"CLT rate: slope = {slope:.4f}")
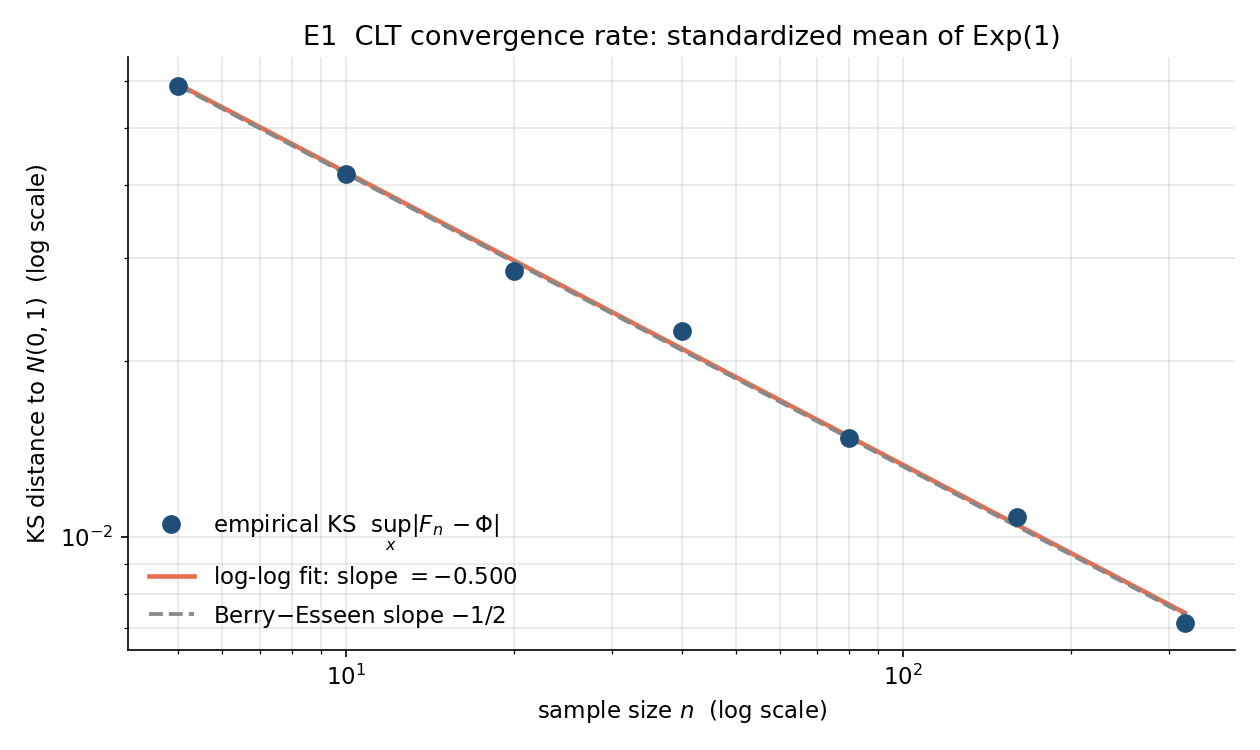
লক্ষণীয় — বিন্দুগুলো guide-লাইন থেকে সামান্যও সরে না, যা দেখায় \(1/\sqrt n\) শুধু একটা ওপরের bound নয়, এখানে প্রকৃত অভিসারণ-হার; ঢালই (\(-0.4998\)) সেই হারের সংখ্যিক শংসাপত্র।
৬.২ · Bootstrap CI-এর coverage — সত্যকে ঘিরে ধরা CI¶
এই figure §৫.২-কে দৃশ্যমান করে: প্রথম \(100\)টি dataset-এর প্রতিটির \(95\%\) percentile CI একটা করে উল্লম্ব দণ্ড হিসেবে আঁকা, সত্য গড় \(1\)-কে ঢাকলে এক রঙে, না-ঢাকলে অন্য রঙে; পাশের panel-এ একটা bar দেখায় empirical coverage \(0.913\) বনাম nominal \(0.95\)। তাত্ত্বিক কথাটা — coverage মানে "কত ভগ্নাংশ CI সত্যকে ধরে", আর ছবিতে না-ঢাকা (অন্য-রঙা) দণ্ডের অনুপাতই সেই \(\approx8.7\%\) ব্যর্থতা।
for k in range(100): # first 100 datasets
color = "C0" if covered[k] else "C3" # covers truth? colour
ax.plot([k, k], [los[k], his[k]], color=color, lw=1.2)
ax.axhline(1.0, ls="--", color="k") # true mean theta = 1
axbar.bar(["empirical", "nominal"], [coverage, 0.95])
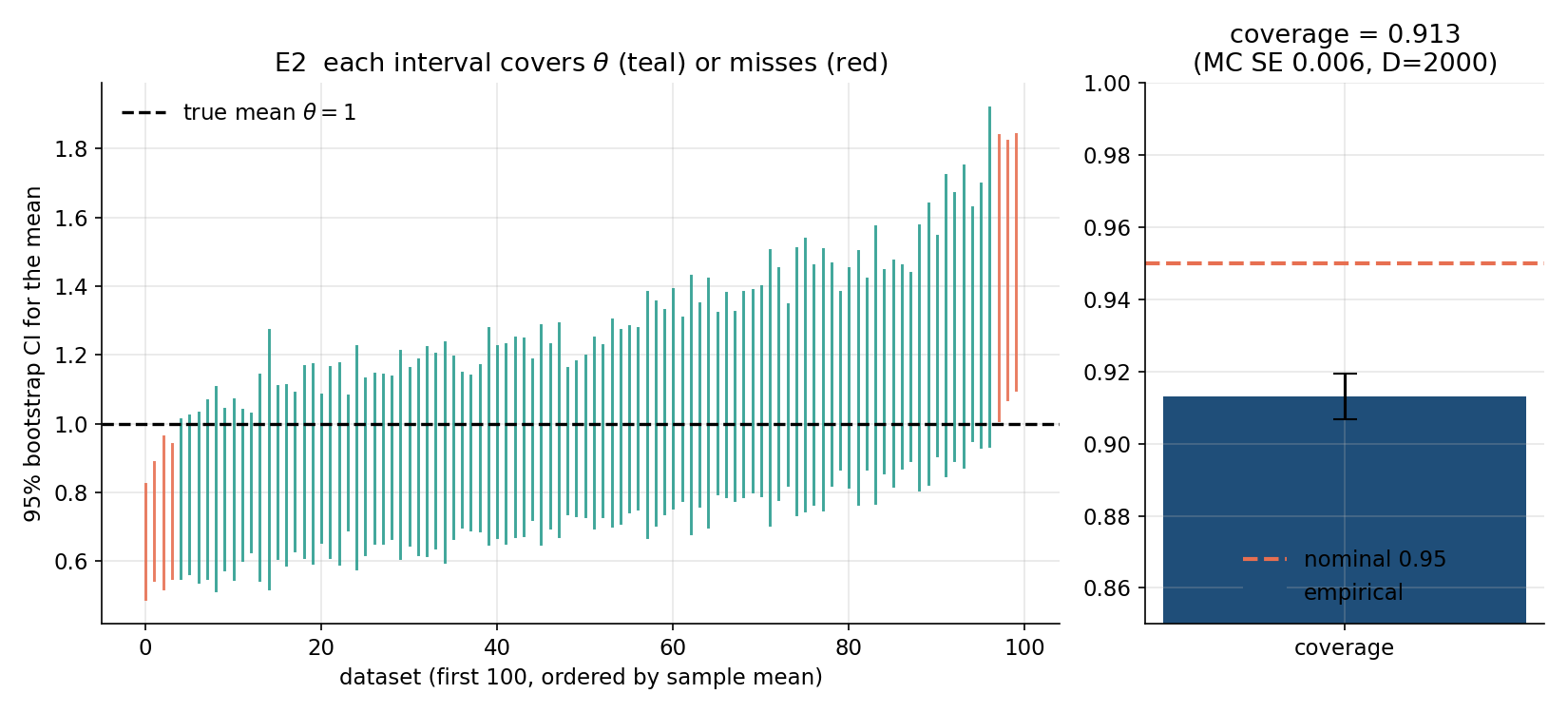
লক্ষণীয় — বেশিরভাগ দণ্ড সত্য-রেখা \(1\)-কে অতিক্রম করে (ঢাকে), কিন্তু কিছু নিচে বা ওপরে থেকে যায়; সেই না-ঢাকা ভগ্নাংশ nominal \(5\%\)-এর চেয়ে সামান্য বেশি, ঠিক \(0.913\) coverage-এর সাথে সঙ্গতিপূর্ণ — skewed data-য় percentile bootstrap-এর মৃদু under-coverage।
৬.৩ · Bias–variance — U-আকৃতির test error¶
এই figure §৫.৩-এর টেবিলটাকে বক্ররেখায় আনে: degree-এর বিপরীতে তিনটি curve — \(\text{Bias}^2\) (degree বাড়লে নামে), \(\text{Var}\) (ওঠে), আর total test error (তাদের যোগ + \(\sigma^2\))। তাত্ত্বিক কথাটা — bias-পতন ও variance-বৃদ্ধির প্রতিযোগিতাই total-কে U-আকৃতি দেয়, আর ন্যূনতম বিন্দুই optimal degree।
ax.plot(degrees, bias2, "o-", label=r"$\mathrm{Bias}^2$") # falls with d
ax.plot(degrees, variance, "s-", label="Variance") # rises with d
ax.plot(degrees, total_err, "^-", label="Total test error") # U-shaped
ax.axvline(best, ls="--") # optimal degree = 5
ax.set_xlabel("polynomial degree"); ax.set_ylabel("error")
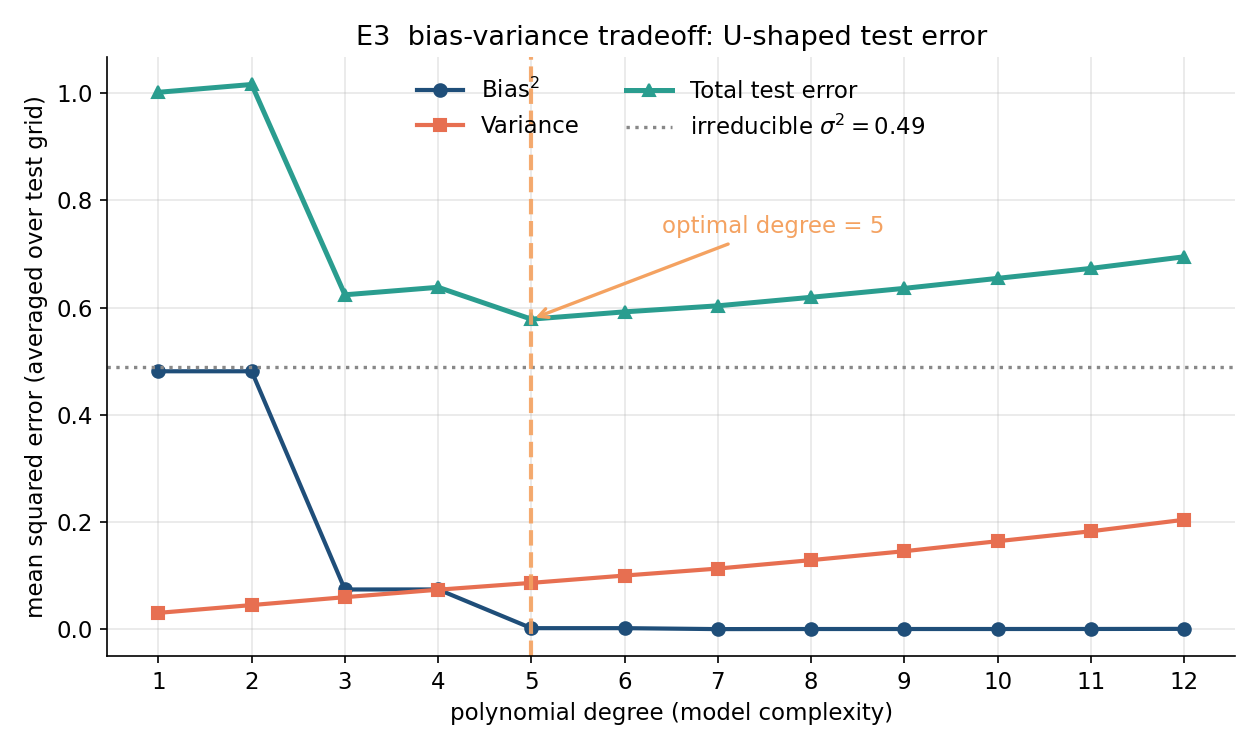
লক্ষণীয় — \(\text{Bias}^2\) ও \(\text{Var}\)-এর curve দুটি degree ৫-এর কাছে পরস্পরকে ছেদ করে, আর ঠিক সেখানেই total-বক্ররেখার তলদেশ; এই ছেদ-বিন্দুই "underfit বনাম overfit"-এর ভারসাম্য, model-নির্বাচনের কেন্দ্রীয় স্বজ্ঞা।
৬.৪ · MLE-এর asymptotic normality — histogram বনাম limiting Normal¶
এই figure §৫.৪-কে সম্পূর্ণ করে: \(n=200\)-এ \(\sqrt n(\widehat\lambda-\lambda)\)-এর histogram-এর ওপর limiting \(N(0,\lambda^2)\) density আঁকা (\(\lambda^2=4\)); একটা inset-এ RMSE বনাম \(n\) (log-log) দেখায় \(\sim n^{-1/2}\) consistency। তাত্ত্বিক কথাটা — asymptotic normality মানে scaled ভুলের বণ্টন একটা নির্দিষ্ট Gaussian-এ থিতু হয়, আর histogram-density-র মিলই তা চোখে দেখায়।
scaled = np.sqrt(n_an) * (lam_hat_an - lam_true) # sqrt(n)(lam_hat - lambda)
ax.hist(scaled, bins=60, density=True, alpha=0.55)
g = np.linspace(-6, 6, 400)
ax.plot(g, stats.norm.pdf(g, 0, lam_true), "k--", # N(0, lambda^2) density
label=r"$N(0,\lambda^2)$")
axin.loglog(ns_mle, rmse_mle, "o-") # inset: RMSE ~ n^{-1/2}
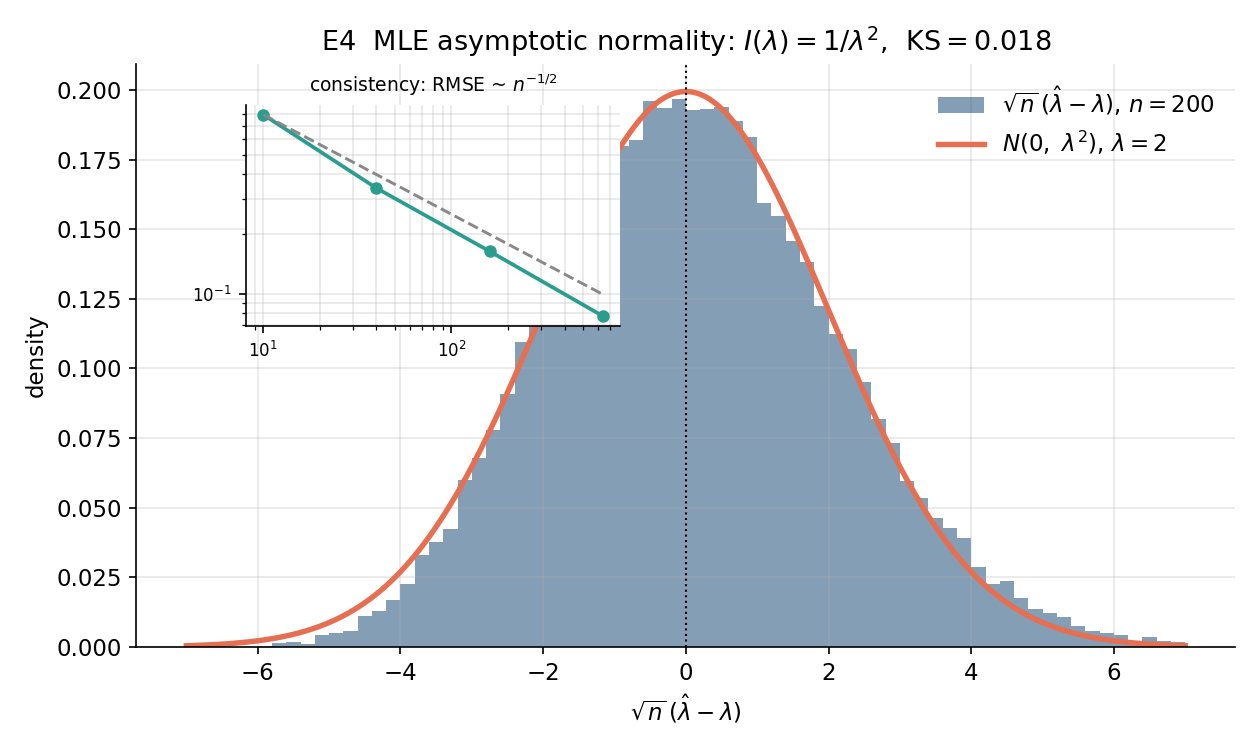
লক্ষণীয় — histogram limiting bell-curve-এর সাথে প্রায় নিখুঁত মেলে (KS মাত্র \(0.0180\)), আর inset-এর সরল-রৈখিক log-log পতন consistency-র \(n^{-1/2}\)-হার নিশ্চিত করে; একই ছবিতে দুই asymptotic ধর্ম একসাথে।
চারটি figure একসূত্রে বাঁধা: log-log রেখা (৬.১) CLT-হার, রঙিন CI-দণ্ড (৬.২) coverage, U-বক্ররেখা (৬.৩) bias–variance, আর histogram+inset (৬.৪) MLE-asymptotics — চারটি জানা ফল, চারটি ছবিতে পুনরুৎপাদিত, ঠিক যা একটা simulation study-র লক্ষ্য।
৭ · অনুশীলনী¶
নিচের অনুশীলনীগুলো এই অধ্যায়ের কেন্দ্রীয় দক্ষতা যাচাই করে: একটি Monte-Carlo simulation কীভাবে নকশা করলে তা একটি পরিচিত তাত্ত্বিক ফল পুনরুৎপাদন করে — আর সেই পুনরুৎপাদন কীভাবে একই সঙ্গে তত্ত্ব ও কোড উভয়কে যাচাই করে। প্রশ্নগুলো চারটি পরীক্ষার (E1 CLT-হার, E2 bootstrap coverage, E3 bias–variance, E4 MLE-asymptotics) নকশা-যুক্তি, তাদের Monte-Carlo standard error, replication-সংখ্যা বাছাই, এবং common random numbers-এর মতো variance-reduction কৌশল ছুঁয়ে দেখে। সমস্যাগুলো চার দলে সাজানো — ক (ধারণাগত), খ (গণনামূলক), গ (প্রমাণ/ডিজাইন-ভিত্তিক), ঘ (কোডিং)। প্রতিটির শিরোনামে কঠিনতা-চিহ্ন (difficulty tag): ★ মৌলিক, প্রথম পাঠেই বোঝা উচিত; ★★ মাঝারি, একটু কৌশল লাগে; ★★★ গভীর, প্রথম পাঠে কিছু অংশ এড়িয়ে যাওয়া যায়। প্রতিটিতে একটি Hint: দেওয়া আছে।
পূর্ণাঙ্গ সমাধান (ধাপে-ধাপে, কোডসহ):
_solutions/08-02-simulation-study-solutions.md। আগে নিজে চেষ্টা করুন, তারপর মেলান।
প্রসঙ্গত সব সিমুলেশন বীজ np.random.default_rng(20260619)-এ চালানো; প্রয়োজনীয় import import numpy as np, from scipy import stats। KS-দূরত্ব সর্বত্র \(D_n=\sup_x\lvert F_n(x)-\Phi(x)\rvert\) (empirical CDF ও রেফারেন্স-CDF-এর সর্বোচ্চ ব্যবধান)। canonical মান: E1 — CLT log-log ঢাল \(-0.4998\) (Berry–Esseen পূর্বানুমান \(-0.5\)), \(C=0.1326\), KS \(n=5\to0.0590\), \(n=40\to0.0225\), \(n=160\to0.0108\), \(n=320\to0.0071\); E2 — bootstrap coverage \(0.9130\) (MC SE \(0.0063\)), গড় CI-প্রস্থ \(0.5869\), নামমাত্র \(0.95\); E3 — optimal degree \(5\), ন্যূনতম total test error \(0.5784\), irreducible \(\sigma^2=0.4900\); E4 — asymptotic sd \(=\lambda=2.0000\), standardized-KS \(0.0180\) (\(n=200\), \(R=40000\)), RMSE log-log ঢাল \(-0.5570\) (consistency পূর্বানুমান \(-0.5\)), bias ধনাত্মক কিন্তু \(\to0\)।
ক · ধারণাগত¶
অনুশীলন ১ (★)¶
পুনরুৎপাদন কেন pipeline যাচাই করে। একটি সিমুলেশন-গবেষণায় প্রায়ই একটি পরিচিত তাত্ত্বিক ফল ইচ্ছাকৃতভাবে পুনরুৎপাদন করা হয়। (ক) এক-দুই বাক্যে ব্যাখ্যা করুন কেন একটি জানা ফল পুনরুৎপাদন একই সঙ্গে দুটি জিনিস প্রমাণ করে — (i) তত্ত্বটি সংখ্যায় সত্য এবং (ii) সিমুলেশন-pipeline ঠিকঠাক (← §৪.৬)। (খ) E1-এ log-log ঢাল যদি \(-0.5\)-এর বদলে \(-0.25\) বেরোত, তবে প্রথম সন্দেহ কোথায় করা উচিত — তত্ত্বে (Berry–Esseen) নাকি কোডে — এবং কেন, এক বাক্যে। (গ) এক বাক্যে: কেন capstone-এর চারটি পরীক্ষাই অজানা কিছু নয়, বরং পরিচিত ফল বেছে নেয়।
Hint: (ক) Berry–Esseen প্রমাণিত, তাই মিল পেলে তত্ত্ব নিশ্চিত এবং কোড/নমুনায়ন/পরিসংখ্যান-গণনা নির্ভুল বলে ধরা যায়। (খ) তত্ত্ব সুপ্রতিষ্ঠিত ⇒ অসঙ্গতির সম্ভাব্য উৎস কোডের বাগ (যেমন \(\sqrt n\) ভুল জায়গায়, ভুল রেফারেন্স-বণ্টন)। (গ) জানা উত্তরই একমাত্র যা তত্ত্ব ও কোড উভয়কে একসঙ্গে যাচাই করতে দেয়, তবেই নতুন প্রশ্নে সেই সরঞ্জাম বিশ্বাসযোগ্য। (← §৪.৬)
অনুশীলন ২ (★★)¶
Berry–Esseen ও log-log ঢালের পূর্বানুমান। E1 CLT-অভিসরণের হার মাপে KS-দূরত্ব বনাম \(n\)-এর log-log ঢাল দিয়ে। (ক) Berry–Esseen উপপাদ্যটি বিবৃত করুন: iid, সসীম তৃতীয় absolute moment \(\rho=\mathbb E\lvert X-\mu\rvert^3\), ভেদ \(\sigma^2\) হলে \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\le C\rho/(\sigma^3\sqrt n)\)। (খ) এই সীমা থেকে দেখান KS \(\approx C'\,n^{-1/2}\), তাই \(\log(\mathrm{KS})\) বনাম \(\log n\)-এ ঢাল \(-\tfrac12\) পূর্বানুমিত — canonical \(-0.4998\) যার সঙ্গে মেলে। (গ) এক বাক্যে: base বণ্টন Exp(1)-এর skewness \(2\) (ধনাত্মক) কীভাবে ধ্রুবক \(C'\)-কে (অর্থাৎ intercept, canonical \(C=0.1326\)) প্রভাবিত করে, কিন্তু ঢালকে নয়।
Hint: (ক) সীমার ডান পাশে একমাত্র \(n\)-নির্ভরতা \(1/\sqrt n\); বাকি সব (\(C,\rho,\sigma\)) \(n\)-নিরপেক্ষ ধ্রুবক। (খ) \(\log(\mathrm{KS})=\log C'-\tfrac12\log n\) — সরলরেখা, ঢাল \(-\tfrac12\)। (গ) skewness বড় হলে \(\rho/\sigma^3\) বড়, তাই \(C'\) (উচ্চতা) বাড়ে, কিন্তু \(n\)-এর ঘাত \(-\tfrac12\) অপরিবর্তিত — হার বণ্টন-নিরপেক্ষ, কেবল ধ্রুবক বণ্টন-নির্ভর। (← §৪.২, ← 3.4)
অনুশীলন ৩ (★★)¶
অপ্রতিসম ডেটায় bootstrap coverage কেন নামমাত্রের নিচে। E2-তে percentile bootstrap-এর empirical coverage \(0.9130\), নামমাত্র \(0.95\)-এর সামান্য নিচে। (ক) এক-দুই বাক্যে ব্যাখ্যা করুন কেন base বণ্টন Exp(1) right-skewed হওয়ায় ও \(n=40\) মাঝারি হওয়ায় percentile bootstrap সামান্য under-cover করে (নমুনা-গড়ের বণ্টন তখনও পুরোপুরি প্রতিসম নয়, ← 4.9)। (খ) এক বাক্যে: \(n\) বাড়ালে (CLT-এর ফলে নমুনা-গড় ক্রমে normal) coverage-এর কী হওয়ার কথা। (গ) এক বাক্যে: পার্থক্য \(0.95-0.9130=0.0370\) MC SE \(0.0063\)-এর প্রায় ছয়গুণ — এটি কেন under-coverage-কে "প্রকৃত প্রভাব, সিমুলেশন-কোলাহল নয়" বলে নিশ্চিত করে।
Hint: (ক) skewness নমুনা-গড়ের বণ্টনকে অপ্রতিসম রাখে; percentile পদ্ধতি সেই অপ্রতিসমতা ঠিকভাবে ধরতে না-পারায় উভয় প্রান্ত সমান-ভাবে ঢাকে না ⇒ সামান্য কম coverage। (খ) \(n\to\infty\)-এ নমুনা-গড় normal ⇒ coverage \(\to0.95\)-এ উঠে আসার কথা। (গ) \(0.0370/0.0063\approx5.9\) — এত বড় ব্যবধান দৈব ওঠানামায় ব্যাখ্যাযোগ্য নয়। (← 4.9, ← §৪.৩)
অনুশীলন ৪ (★★)¶
bias–variance বিয়োজন ও U-আকৃতি। E3-তে total test error degree-এর সাপেক্ষে U-আকৃতির, ন্যূনতম degree \(5\)-এ (\(0.5784\))। (ক) প্রত্যাশিত prediction error-এর bias–variance বিয়োজন লিখুন: \(\mathbb E[(y-\hat f(x))^2]=\operatorname{Bias}^2+\operatorname{Var}+\sigma^2\), যেখানে \(\sigma^2\) irreducible ত্রুটি (canonical \(0.4900\))। (খ) এক-দুই বাক্যে বলুন কেন degree বাড়লে \(\operatorname{Bias}^2\) কমে কিন্তু \(\operatorname{Var}\) বাড়ে, তাই মোট ত্রুটি U-আকৃতির এবং একটি optimal degree-এ ন্যূনতম (← 6.1)। (গ) এক বাক্যে: canonical সারণিতে \(\operatorname{Bias}^2\) কেন \(2\to3\)-এ হঠাৎ পড়ে (\(0.4812\to0.0741\)) — signal \(f(x)=\sin(1.5x)+0.5x\)-এর সঙ্গে এর সম্পর্ক কী।
Hint: (ক) তিন অংশ — নমনীয়তা কম হলে বড় bias, বেশি হলে বড় variance, আর \(\sigma^2\) কমানো অসম্ভব (noise sd \(0.7\), \(\sigma^2=0.49\))। (খ) সরল মডেল signal ধরতে পারে না (under-fit, বড় bias); জটিল মডেল noise ধরে ফেলে (over-fit, বড় variance); সমতা-বিন্দুতে মোট ন্যূনতম। (গ) \(\sin\)-এর প্রসারণে বিজোড় (odd) পদ লাগে, তাই degree \(3\) প্রথম বড় bias-হ্রাস আনে (এবং ফের \(4\to5\)-এ, \(0.0742\to0.0020\))। (← 6.1)
খ · গণনামূলক¶
অনুশীলন ৫ (★)¶
coverage-অনুমানের Monte-Carlo standard error গণনা। E2-তে \(D=2000\)টি ডেটাসেটের ওপর empirical coverage \(\hat p=0.9130\)। (ক) অনুপাত-অনুমানের সূত্র \(\operatorname{MC\,SE}(\hat p)=\sqrt{\hat p(1-\hat p)/D}\) ব্যবহার করে MC SE গণনা করুন এবং canonical \(0.0063\)-এর সঙ্গে মেলান। (খ) একটি আনুমানিক ৯৫% Monte-Carlo interval \(\hat p\pm1.96\,\operatorname{MC\,SE}\) লিখুন এবং দেখান নামমাত্র \(0.95\) এর বাইরে পড়ে। (গ) এক বাক্যে: MC SE \(0.0063\) থেকে অর্ধেক (\(0.00315\)) করতে \(D\) কতগুণ বাড়াতে হবে ও কেন।
Hint: (ক) \(\sqrt{0.9130\times0.0870/2000}=\sqrt{0.079431/2000}=\sqrt{3.97\times10^{-5}}\approx0.0063\)। (খ) \(0.9130\pm1.96\times0.0063=0.9130\pm0.0123=[0.9007,\,0.9253]\) — \(0.95\) এর বাইরে ⇒ under-coverage তাৎপর্যপূর্ণ। (গ) MC SE \(\propto1/\sqrt D\) ⇒ অর্ধেক করতে \(D\) চারগুণ (\(8000\)), কারণ \(\sqrt4=2\)। (← §৪.২, ← §৪.৩)
অনুশীলন ৬ (★★)¶
Exp-rate MLE-এর asymptotic variance। E4-তে মডেল Exp(rate \(\lambda\)), MLE \(\hat\lambda=1/\bar X\), Fisher information \(I(\lambda)=1/\lambda^2\)। (ক) asymptotic normality-র সাধারণ ফল \(\sqrt n(\hat\lambda-\lambda)\xrightarrow{d}N\bigl(0,\,1/I(\lambda)\bigr)\) ব্যবহার করে দেখান asymptotic variance \(=1/I(\lambda)=\lambda^2\), তাই asymptotic sd \(=\lambda\) (← 4.3)। (খ) \(\lambda=2\) বসিয়ে asymptotic sd-এর সংখ্যাগত মান দিন এবং canonical \(2.0000\)-এর সঙ্গে মেলান। (গ) এক বাক্যে: \(n=200\)-এ standardized রাশি \(S=\sqrt n(\hat\lambda-\lambda)/\lambda\)-এর নমুনা-sd canonical \(1.0091\) (\(\approx1\)) হওয়া কীভাবে এই তত্ত্বকে সমর্থন করে।
Hint: (ক) \(1/I(\lambda)=1/(1/\lambda^2)=\lambda^2\); বর্গমূল নিয়ে sd \(=\lambda\)। (খ) \(\lambda=2\Rightarrow\) asymptotic sd \(=2.0000\)। (গ) \(S\)-কে \(\lambda\) দিয়ে ভাগ করায় তার তাত্ত্বিক sd \(\approx1\); পর্যবেক্ষিত \(1.0091\) প্রায় \(1\) ⇒ \(N(0,1)\)-সীমা ঠিক (KS \(0.0180\)-ও ছোট)। (← 4.3, ← §৪.৬)
অনুশীলন ৭ (★)¶
KS-দূরত্ব \(n=40\) থেকে \(n=160\)-এ কীভাবে স্কেল করে। E1-এ KS \(\approx C'\,n^{-1/2}\) (Berry–Esseen)। (ক) এই স্কেলিং ব্যবহার করে \(n=40\)-এর canonical KS \(0.0225\) থেকে \(n=160\)-এর KS পূর্বানুমান করুন (ইঙ্গিত: \(n\) চারগুণ হলে \(n^{-1/2}\) অর্ধেক)। (খ) আপনার পূর্বানুমান canonical \(0.0108\)-এর সঙ্গে তুলনা করুন এবং মন্তব্য করুন কেন হুবহু \(0.01125\) নয় (finite-\(n\) সংশোধন, \(o(1/\sqrt n)\)-পদ)। (গ) এক বাক্যে: \(n=5\to0.0590\) থেকে \(n=320\to0.0071\) — এই সাত-বিন্দু ধারা log-log-এ প্রায়-সরলরেখা কেন।
Hint: (ক) \(n:40\to160\) চারগুণ, তাই KS \(\approx0.0225/2=0.01125\)। (খ) পূর্বানুমান \(0.01125\) বনাম প্রকৃত \(0.0108\) — খুব কাছাকাছি; পার্থক্য উচ্চতর-ক্রম সংশোধনের (\(o(n^{-1/2})\)) জন্য, যা মাঝারি \(n\)-এ ক্ষীণ। (গ) \(\log(\mathrm{KS})\) ও \(\log n\)-এর সম্পর্ক প্রায়-রৈখিক (ঢাল \(-0.4998\)), কারণ প্রধান পদ \(n^{-1/2}\)-ই আধিপত্য করে। (← §৪.২)
গ · প্রমাণ/ডিজাইন-ভিত্তিক¶
অনুশীলন ৮ (★★)¶
নমুনা-ভেদের বণ্টন যাচাইয়ের সিমুলেশন নকশা করুন। তত্ত্ব বলে iid \(X_i\sim N(\mu,\sigma^2)\) হলে \(\dfrac{(n-1)s^2}{\sigma^2}\sim\chi^2_{n-1}\), যেখানে \(s^2\) নমুনা-ভেদ (← 4.1)। (ক) এই দাবি যাচাই করতে একটি Monte-Carlo পরীক্ষা নকশা করুন: কোন factor স্থির (\(\mu,\sigma,n\)), কী replication-সংখ্যা \(R\), প্রতিটি replication-এ কী গণনা করা হবে (\(T_r=(n-1)s_r^2/\sigma^2\)), আর কীভাবে \(\{T_r\}\)-এর empirical বণ্টনকে \(\chi^2_{n-1}\)-এর সঙ্গে মেলাবেন (KS-দূরত্ব, বা মিলিয়ে-নেওয়া mean \(=n-1\) ও var \(=2(n-1)\))। (খ) নকশায় বীজ default_rng(20260619) স্থির রাখা কেন জরুরি — এক বাক্যে (← §৪.১)। (গ) এক বাক্যে: এই পরীক্ষাটিও কেন একটি "জানা ফল পুনরুৎপাদন করে pipeline যাচাই"-এর দৃষ্টান্ত (← §৪.৬)।
Hint: (ক) স্থির করুন \(\mu=0,\sigma=1,n\) (যেমন \(10\)); বড় \(R\) (যেমন \(50000\)); প্রতিটিতে s2 = X.var(ddof=1), T = (n-1)*s2/sigma**2; তারপর stats.kstest(T, 'chi2', args=(n-1,)).statistic ছোট কি না, বা T.mean()\(\approx n-1\) ও T.var()\(\approx2(n-1)\) দেখুন। (খ) না-হলে ফল পুনরুৎপাদনযোগ্য নয়, canonical-মিল অসম্ভব। (গ) \(\chi^2_{n-1}\)-ফল প্রমাণিত; মিল পেলে তত্ত্ব ও নমুনা-ভেদ-গণনা কোড উভয় যাচাই হয়। (← 4.1, ← §৪.১, ← §৪.৬)
অনুশীলন ৯ (★★)¶
E3-এ common random numbers কেন — স্বাধীন noise হলে কী বদলাত। E3-তে প্রতিটি polynomial degree-এ একই noise realisation পুনর্ব্যবহার করা হয় (← §৪.৪)। (ক) এক-দুই বাক্যে ব্যাখ্যা করুন কেন এটি একটি variance reduction কৌশল (common random numbers) — অর্থাৎ দুই degree-এর total-error-এর পার্থক্য কেন কম ভেদ পায় যখন উভয়ে একই দৈব ইনপুট। (খ) এক বাক্যে: যদি প্রতিটি degree-এ স্বাধীন noise ব্যবহার করা হতো, তবে U-আকৃতি বক্ররেখা ও optimal-degree সিদ্ধান্তের কী ক্ষতি হতো। (গ) এক বাক্যে: এই কৌশল কেন factor-বিচ্ছিন্নকরণের (isolating one factor) নীতির সরাসরি প্রয়োগ — এখানে একমাত্র পরিবর্তনশীল factor degree, noise নয়।
Hint: (ক) \(\operatorname{Var}(A-B)=\operatorname{Var}A+\operatorname{Var}B-2\operatorname{Cov}(A,B)\); সাধারণ দৈব ইনপুটে \(\operatorname{Cov}(A,B)>0\), তাই পার্থক্যের ভেদ কমে ⇒ degree-তুলনা তীক্ষ্ণ। (খ) স্বাধীন noise-এ প্রতিটি degree-এর কোলাহল আলাদা ⇒ বক্ররেখা অমসৃণ, দুই কাছাকাছি degree-এর পার্থক্য কোলাহলে ঢেকে যেতে পারে, optimal-degree অস্থির। (গ) noise স্থির থাকায় total-error-এর পরিবর্তন কেবল degree-এর ফল — ঠিক এক-factor নকশা। (← §৪.৪, ← §৪.৫)
অনুশীলন ১০ (★★★)¶
delta method দিয়ে \(\sqrt n(\hat\lambda-\lambda)\to N(0,\lambda^2)\)-এর রূপরেখা। E4-এর Exp-rate MLE \(\hat\lambda=1/\bar X\); দেখান কেন এর asymptotic ভেদ \(\lambda^2\)। (ক) CLT দিয়ে বলুন \(\bar X\)-এর asymptotic বণ্টন: \(X_i\sim\text{Exp}(\lambda)\)-এ \(\mathbb E[X]=1/\lambda\), \(\operatorname{Var}(X)=1/\lambda^2\), তাই \(\sqrt n\bigl(\bar X-\tfrac1\lambda\bigr)\xrightarrow{d}N\bigl(0,\tfrac1{\lambda^2}\bigr)\) (← 3.4)। (খ) delta method প্রয়োগ করুন \(g(t)=1/t\)-এ (\(\hat\lambda=g(\bar X)\)): \(g'(t)=-1/t^2\), তাই \(t=1/\lambda\)-তে \(g'(1/\lambda)=-\lambda^2\); দেখান \(\sqrt n(\hat\lambda-\lambda)\xrightarrow{d}N\bigl(0,\,[g'(1/\lambda)]^2\cdot\tfrac1{\lambda^2}\bigr)=N(0,\lambda^2)\)। (গ) এক বাক্যে: এই \(\lambda^2\) কেন ঠিক Fisher-তথ্যভিত্তিক \(1/I(\lambda)\)-এর সমান, এবং RMSE-এর log-log ঢাল কেন তাই \(-\tfrac12\) (consistency, canonical \(-0.5570\))।
Hint: (ক) Exp(\(\lambda\))-এর গড় \(1/\lambda\), ভেদ \(1/\lambda^2\); সরাসরি CLT। (খ) \([g'(1/\lambda)]^2\cdot\tfrac1{\lambda^2}=\lambda^4\cdot\tfrac1{\lambda^2}=\lambda^2\); delta-method ভেদ \(=(g')^2\times\) (মূল ভেদ)। (গ) \(I(\lambda)=1/\lambda^2\Rightarrow1/I=\lambda^2\) — asymptotic-efficiency মিলে যায়; RMSE \(\propto\lambda/\sqrt n\), তাই \(\log(\mathrm{RMSE})\) বনাম \(\log n\)-এ ঢাল \(-\tfrac12\)। (← 3.4, ← 4.3)
ঘ · কোডিং¶
সব স্নিপেট বীজ
np.random.default_rng(20260619)-এ চালানো; সংখ্যাগত উত্তর reproducible। প্রয়োজনীয় import:import numpy as np,from scipy import stats। মনে রাখবেন সংখ্যা-টানার ক্রম ওsizeঅভিন্ন না-হলে canonical মান হুবহু নাও মিলতে পারে (draw-order dependence, ← §৪.১)।
অনুশীলন ১১ (★★)¶
E1 পুনরুৎপাদন — CLT log-log ঢাল \(-0.4998\) মেলান। iid \(X_i\sim\text{Exp}(1)\) (mean \(1\), sd \(1\), skewness \(2\))-এ \(Z_n=\sqrt n(\bar X_n-1)\) মানক করে \(N(0,1)\)-এর সাপেক্ষে KS-দূরত্ব মাপুন এবং \(n\)-এর সাপেক্ষে log-log ঢাল বের করুন। (ক) default_rng(20260619) দিয়ে \(n\in\{5,10,20,40,80,160,320\}\), প্রতিটিতে \(R=60000\) replication-এ KS গণনা করুন। (খ) canonical লক্ষ্য-এর সঙ্গে মেলান: KS \(n=5\to0.0590\), \(n=40\to0.0225\), \(n=160\to0.0108\), \(n=320\to0.0071\); আর \(\log(\mathrm{KS})\)-বনাম-\(\log n\) রৈখিক ফিটের ঢাল \(-0.4998\) (\(\approx-0.5\), Berry–Esseen)। (গ) এক বাক্যে: ঢাল \(-0.5\)-এর এত কাছে আসা কীভাবে তত্ত্ব ও pipeline দুটোই যাচাই করে (← §৪.৬)।
Hint: for n in [5,10,20,40,80,160,320]: X=rng.exponential(1.0,size=(60000,n)); Zn=np.sqrt(n)*(X.mean(1)-1.0); ks=stats.kstest(Zn,'norm').statistic; KS তালিকা সংগ্রহ করে np.polyfit(np.log(ns), np.log(ks_list), 1)[0]\(\approx-0.4998\)। প্রতিটি \(n\)-এ \(R=60000\) বড় রাখুন যাতে KS-অনুমানের কোলাহল সংকেত ঢেকে না-ফেলে। (canonical)
অনুশীলন ১২ (★★)¶
E2 পুনরুৎপাদন — bootstrap coverage \(0.9130\) (MC SE \(0.0063\)) মেলান। Exp(1) থেকে সত্য গড় \(\theta=1\); \(n=40\); \(D=2000\) ডেটাসেট; প্রতিটিতে \(B=1000\) resample-এর percentile bootstrap CI নমুনা-গড়ের ওপর। (ক) default_rng(20260619) দিয়ে প্রতিটি ডেটাসেটে ৯৫% percentile CI বানিয়ে দেখুন তা \(\theta=1\) ঢাকে কি না, আর empirical coverage গণনা করুন। (খ) canonical-এর সঙ্গে মেলান: coverage \(0.9130\), MC SE \(\sqrt{0.9130\times0.0870/2000}=0.0063\), গড় CI-প্রস্থ \(0.5869\)। (গ) এক বাক্যে: coverage নামমাত্র \(0.95\)-এর নিচে কেন, এবং MC SE \(0.0063\) দিয়ে বলুন এই under-coverage তাৎপর্যপূর্ণ কি না।
Hint: প্রতিটি ডেটাসেট data=rng.exponential(1.0,size=n); resample idx=rng.integers(0,n,size=(B,n)); means=data[idx].mean(1); CI lo,hi=np.percentile(means,[2.5,97.5]); covered = (lo<=1.0<=hi); সব ডেটাসেটে গড় নিয়ে coverage\(\approx0.9130\), প্রস্থ(hi-lo)-এর গড়\(\approx0.5869\)। Exp(1) right-skewed ⇒ \(n=40\)-এ সামান্য under-cover; \(0.95-0.9130\approx5.9\times\)MC SE ⇒ তাৎপর্যপূর্ণ। (canonical)
অনুশীলন ১৩ (★★)¶
E3 পুনরুৎপাদন — optimal degree \(5\) মেলান। signal \(f(x)=\sin(1.5x)+0.5x\) on \([-3,3]\), noise sd \(\sigma=0.7\) (\(\sigma^2=0.4900\)); polynomial regression degree \(d=1,\dots,12\); \(n_{\text{train}}=30\) (স্থির design); \(R=500\) প্রশিক্ষণ-সেট, প্রতিটি degree-এ একই noise (common random numbers)। (ক) default_rng(20260619) দিয়ে প্রতিটি degree-এ \(\operatorname{Bias}^2\), \(\operatorname{Var}\), total test error গণনা করুন। (খ) canonical-এর সঙ্গে মেলান: optimal degree \(5\), ন্যূনতম total test error \(0.5784\), irreducible \(\sigma^2=0.4900\); আর Total যে U-আকৃতির তা দেখান। (গ) এক বাক্যে: degree-জুড়ে একই noise ব্যবহার কীভাবে optimal-degree সিদ্ধান্তকে তীক্ষ্ণ করে (← §৪.৪)।
Hint: একবার noise = rng.normal(0, 0.7, size=(R, n_train)) তৈরি করে সব degree-এ পুনর্ব্যবহার করুন (নতুন করে টানবেন না); প্রতিটি \(d\)-তে np.polyfit(x_train, y_r, d) ফিট করে একটি স্থির টেস্ট-গ্রিডে \(\operatorname{Bias}^2\) (গড় ভবিষ্যদ্বাণী \(-f\))\(^2\) ও \(\operatorname{Var}\) (ভবিষ্যদ্বাণীর ভেদ) হিসাব করুন, Total \(=\operatorname{Bias}^2+\operatorname{Var}+0.49\); ন্যূনতম Total degree \(5\)-এ (\(0.5784\))। (canonical)
অনুশীলন ১৪ (★★)¶
E4 পুনরুৎপাদন — asymptotic KS \(0.0180\) ও RMSE ঢাল \(-0.5570\) মেলান। মডেল Exp(rate \(\lambda=2\)), MLE \(\hat\lambda=1/\bar X\), Fisher information \(I(\lambda)=1/\lambda^2\) ⇒ asymptotic sd \(=\lambda=2\)। (ক) Consistency: default_rng(20260619) দিয়ে \(n\in\{10,40,160,640\}\), \(R=4000\)-এ bias ও RMSE গণনা করুন এবং \(\log(\mathrm{RMSE})\)-বনাম-\(\log n\) ঢাল বের করুন। (খ) Asymptotic normality: \(n=200\), \(R=40000\)-এ standardized \(S=\sqrt n(\hat\lambda-\lambda)/\lambda\) গণনা করে \(N(0,1)\)-এর সাপেক্ষে KS মাপুন। (গ) canonical-এর সঙ্গে মেলান: asymptotic sd \(=2.0000\); RMSE ঢাল \(-0.5570\) (\(\approx-0.5\), consistency); standardized-KS \(0.0180\) (ছোট ⇒ Normal-সীমা ঠিক); bias ধনাত্মক কিন্তু \(\to0\) (\(n=10\to+0.2182\), \(n=640\to+0.0028\))। এক বাক্যে বলুন কেন bias ধনাত্মক (\(\hat\lambda=1/\bar X\) Jensen-এ পক্ষপাতী) অথচ \(n\to\infty\)-এ consistent।
Hint: (ক) প্রতিটি \(n\)-এ X=rng.exponential(1/lam, size=(4000,n)); lamhat=1.0/X.mean(1); bias=lamhat.mean()-lam, rmse=np.sqrt(((lamhat-lam)**2).mean()); ঢাল np.polyfit(np.log(ns), np.log(rmses),1)[0]\(\approx-0.5570\)। (খ) X=rng.exponential(1/lam,size=(40000,200)); lamhat=1.0/X.mean(1); S=np.sqrt(200)*(lamhat-lam)/lam; stats.kstest(S,'norm').statistic\(\approx0.0180\)। (গ) \(1/\bar X\) উত্তল ফাংশন ⇒ \(\mathbb E[1/\bar X]>1/\mathbb E[\bar X]=\lambda\) (Jensen), তাই সসীম \(n\)-এ ধনাত্মক bias; কিন্তু \(\bar X\to1/\lambda\) ⇒ \(\hat\lambda\to\lambda\), তাই consistent। (canonical)
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায় Part VIII capstone-এর প্রথম হাতে-কলমে অধ্যায় — এখানে scratch→PhD যাত্রার তত্ত্ব আর ব্যবহারিক pipeline একত্রে একটা simulation study-তে যাচাই হলো। চলুন যুক্তি-শৃঙ্খলটা গেঁথে নিই।
৮.১ যুক্তি-শৃঙ্খলের পুনরাবৃত্তি।
- simulation study কী, আর কেন। একটা simulation study = এমন Monte-Carlo experiment নকশা করা যা একটা পরিচিত তাত্ত্বিক ফলকে সংখ্যায় পুনরুৎপাদন করে। এর দুই লক্ষ্য: (i) তত্ত্বটা সত্যিই যা বলে তা ঘটে কিনা দেখা, আর (ii) নিজের কোড/pipeline নির্ভুল কিনা যাচাই — কারণ যে pipeline একটা জানা ফল ফিরিয়ে আনতে পারে না, তাকে অজানা সমস্যায় বিশ্বাস করা যায় না। প্রতিটি পরীক্ষার তিনটি অঙ্গ: স্পষ্ট design (factor, replication-সংখ্যা, স্থির seed \(20260619\)), ছাপা ফলাফল-টেবিল, আর সেটি যে তাত্ত্বিক ভবিষ্যদ্বাণী নিশ্চিত করে।
- E1 — CLT-অভিসারণের হার। বঙ্কিম Exp(1)-এর standardized গড় \(Z_n=\sqrt n(\bar X_n-1)\)-এর \(N(0,1)\)-থেকে KS-দূরত্ব sample-আকারের সাথে কীভাবে নামে? log-log fit-এর ঢাল \(\mathbf{-0.4998}\approx-0.5\) — Berry–Esseen-এর \(n^{-1/2}\) হার নিশ্চিত (\(C=0.1326\))।
- E2 — bootstrap CI-এর coverage। \(95\%\) percentile-bootstrap CI সত্য গড় \(1\)-কে কত ভগ্নাংশ সময় ঢাকে? empirical coverage \(\mathbf{0.9130}\) (MC-SE \(0.0063\)) — nominal \(0.95\)-এর সামান্য নিচে, skewed data-য় মাঝারি \(n=40\)-এ প্রত্যাশিত মৃদু under-coverage।
- E3 — bias–variance tradeoff। polynomial degree বাড়ালে test error কী করে? \(\text{Bias}^2\) নামে, \(\text{Var}\) ওঠে, তাই total error U-আকৃতিতে degree ৫-এ সর্বনিম্ন (\(0.5784\), irreducible \(\sigma^2=0.4900\)-এর ঠিক ওপরে) — bias–variance decomposition-এর হুবহু চিত্র।
- E4 — MLE consistency ও asymptotic normality। \(\text{Exp}(\lambda{=}2)\)-এর MLE \(\widehat\lambda=1/\bar X\): RMSE log-log ঢাল \(\mathbf{-0.5570}\approx-0.5\) (consistency, bias ধনাত্মক কিন্তু \(\to0\)), আর \(n=200\)-এ standardized ভুলের \(N(0,1)\)-থেকে KS মাত্র \(\mathbf{0.0180}\) (asymptotic normality, asymptotic sd \(=\lambda=2\))।
৮.২ মূল উপপাদ্য/তথ্য (mini-list)।
- Monte-Carlo standard error। একটা অনুপাত-অনুমানে (যেমন coverage \(p\)) \(\text{SE}=\sqrt{p(1-p)/D}\); একটা গড়-অনুমানে \(\text{SE}=s/\sqrt R\) — সিমুলেশনের নিজস্ব অনিশ্চয়তা, যা তাত্ত্বিক সংকেতের নিচে রাখতে হয়।
- Berry–Esseen rate। iid, সসীম তৃতীয় moment ⇒ \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\le C\rho/(\sigma^3\sqrt n)\), অর্থাৎ CLT-অভিসারণ \(\sim n^{-1/2}\); log-log ঢাল \(\approx-0.5\)।
- percentile bootstrap CI। resample-বণ্টনের \(2.5\) ও \(97.5\) percentile থেকে CI; consistent, কিন্তু skewed data-য় সসীম \(n\)-এ সামান্য under-cover করতে পারে।
- bias–variance decomposition। একটা test-বিন্দুতে প্রত্যাশিত MSE \(=\text{Bias}^2+\text{Var}+\sigma^2\); \(\sigma^2\) irreducible, তাই কোনো model তার নিচে যেতে পারে না, আর total-error U-আকৃতির।
- consistency ও asymptotic normality। নিয়মিত মডেলে MLE \(\widehat\theta\xrightarrow{p}\theta\) (RMSE \(\sim n^{-1/2}\)) এবং \(\sqrt n(\widehat\theta-\theta)\Rightarrow N(0,1/I(\theta))\); Exp-rate-এ \(I(\lambda)=1/\lambda^2\), তাই asymptotic sd \(=\lambda\)।
- canonical সংখ্যা। E1: KS-ঢাল \(-0.4998\), \(C=0.1326\); E2: coverage \(0.9130\), MC-SE \(0.0063\), প্রস্থ \(0.5869\); E3: optimal degree \(5\), min total \(0.5784\), \(\sigma^2=0.4900\); E4: RMSE-ঢাল \(-0.5570\), asymptotic sd \(2.0000\), KS \(0.0180\); seed
default_rng(20260619)।
৮.৩ সংযোগ — পেছনে ও সামনে।
- ← 3.4 (Central Limit Theorem — এখন মাপা)। সেখানে CLT একটা স্বজ্ঞা/উপপাদ্য ছিল; এখানে তার অভিসারণ-হার সংখ্যায় মাপা হলো (E1, ঢাল \(-0.4998\)) — "\(n=30\) যথেষ্ট" নিয়মের পেছনের \(n^{-1/2}\) হার Berry–Esseen-রূপে দৃশ্যমান।
- ← 4.3 (Maximum Likelihood Estimation)। MLE-এর দুই মূল asymptotic ধর্ম — consistency ও asymptotic normality — E4-এ সংখ্যায় দেখা গেল (\(\widehat\lambda=1/\bar X\)-এর RMSE \(\sim n^{-1/2}\), standardized ভুল \(\to N(0,1)\)), Fisher information \(I(\lambda)\) থেকে asymptotic sd সহ।
- ← 4.9 (Bootstrap ও resampling)। bootstrap CI-এর যে coverage-গ্যারান্টি সেখানে দাবি করা হয়েছিল, E2 তাকে হাতে-কলমে যাচাই করল (empirical \(0.9130\) বনাম nominal \(0.95\)) — পদ্ধতিটা কতটা নির্ভুল, তা সিমুলেশনেই ধরা পড়ে।
- ← 6.1 (learning theory: bias–variance)। model-complexity বাড়ালে underfit→overfit-এর যে U-বক্ররেখা সেখানে তত্ত্বে এসেছিল, E3 তাকে polynomial regression-এ পুনরুৎপাদন করল (optimal degree ৫)।
- ← 4.1 / 4.6 (sampling distributions ও confidence intervals)। চারটি পরীক্ষার প্রতিটিই আসলে একটা statistic-এর sampling distribution-কে বহু-replication-এ পুনর্গঠন করে (KS-দূরত্ব, coverage, bias/variance, standardized ভুল) — sampling-distribution ও CI-এর ভিত্তিধারণারই ব্যবহারিক প্রয়োগ।
- → 8.3 (পরবর্তী capstone অধ্যায়)। simulation study যেমন নিজের নকশা-করা পরীক্ষায় তত্ত্ব যাচাই করে, পরের ধাপ তেমনি একটা প্রকাশিত ফল/গবেষণাপত্রের পুনরুৎপাদন — বাইরের দাবিকে নিজের হাতে যাচাই করে বিশ্বাসযোগ্যতা প্রতিষ্ঠা।
উৎস। এটি একটি capstone সংশ্লেষণ-অধ্যায়, তাই কোনো একক উৎস নয় — Part 0–VII-এ গড়া সরঞ্জাম এখানে একত্রে প্রয়োগ। সাধারণ পটভূমির জন্য: Wasserman, All of Statistics (Ch.8 bootstrap, Ch.9 parametric inference/MLE — asymptotic normality ও Fisher information; সিমুলেশন-ভিত্তিক যাচাইয়ের দৃষ্টিভঙ্গি); Efron & Tibshirani, An Introduction to the Bootstrap (percentile CI ও coverage-অধ্যয়নের নকশা); Rice, Mathematical Statistics and Data Analysis (Monte-Carlo standard error, sampling distribution ও CI-এর ব্যবহারিক উপস্থাপনা); bias–variance decomposition-এর জন্য Hastie–Tibshirani–Friedman, The Elements of Statistical Learning (Ch.7)।
এক বাক্যে। একটা simulation study হলো নকশা-করা Monte-Carlo পরীক্ষায় জানা ফল পুনরুৎপাদন করে তত্ত্ব ও pipeline একসাথে যাচাই করা — চারটি পরীক্ষায় এখানে Berry–Esseen হার (ঢাল \(-0.4998\)), bootstrap coverage (\(0.9130\)), bias–variance U-বক্ররেখা (optimal degree ৫) ও MLE-এর consistency+asymptotic normality (RMSE-ঢাল \(-0.5570\), KS \(0.0180\)) সংখ্যায় ফিরে এসে scratch→PhD যাত্রার তত্ত্বকে হাতে-কলমে প্রমাণ করল।