অধ্যায় ০.১ · Sets, Functions, Logic & Proof¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
কল্পনা করুন আপনি একটা coin দুইবার toss করছেন। কী কী হতে পারে? — HH, HT, TH, TT। এই চারটি সম্ভাব্য ফলাফলের সংগ্রহ-কেই গণিতবিদরা বলেন একটি set (সেট — কিছু জিনিসের একটা সংগ্রহ)। এখন যদি জিজ্ঞেস করি "অন্তত একটা head পড়ার event (ঘটনা)", তাহলে সেটা ওই বড় সংগ্রহের একটা অংশ: \(\{HH, HT, TH\}\) — একে বলে subset (সাবসেট — অংশ-সেট)। আর "মোট কয়টা head পড়ল" — এটা প্রতিটি ফলাফলকে একটা সংখ্যায় পাঠায় (\(HH \mapsto 2\), \(HT \mapsto 1\), …); এই "পাঠানো"-র নিয়মটাই একটা function (ফাংশন — একটা নিয়ম যা input-কে output-এ পাঠায়)।
লক্ষ করুন, পরিসংখ্যানের তিনটি একদম মৌলিক বস্তু এখানে লুকিয়ে আছে:
| Statistics-এর ধারণা | আসলে যা | এই অধ্যায়ে শিখব |
|---|---|---|
| sample space \(\Omega\) (নমুনাক্ষেত্র) | সব সম্ভাব্য ফলাফলের set | set |
| event (ঘটনা) | sample space-এর subset | subset |
| random variable (দৈব চলক) | ফলাফল → সংখ্যা, একটা function | function |
তাই sets, functions আর logic শেখা মানে শুধু "math করা" নয় — এটা পুরো probability ও statistics-এর ভাষা (language) শেখা। ভাষাটা না জানলে পরের অধ্যায়গুলোতে যখন \(P(A \cup B)\), \(\{X \le x\}\), বা "\(\forall \varepsilon > 0\ \exists N\)" লেখা দেখবেন, সেটা দুর্বোধ্য প্রতীকের সারি মনে হবে। ভাষাটা জানলে ওগুলো সাবলীল বাক্যের মতো পড়া যাবে।
আর proof কেন? পরিসংখ্যান শুধু সূত্র মুখস্থ করার বিষয় নয়। "কেন variance কখনো negative হয় না?", "কেন গড় (mean) সব data point-এর মাঝখানে বসে?" — এসব প্রশ্নের উত্তর একটা যুক্তিশৃঙ্খল (logical argument) দিয়ে নিশ্চিতভাবে দেওয়া যায়। সেই যুক্তি গাঁথার চারটি মৌলিক কৌশল — direct, contrapositive, contradiction, induction — এই অধ্যায়ে হাতে-কলমে শিখব।
hook: ধরা যাক আমি দাবি করি — "যেকোনো \(n\) সংখ্যক মানুষের একটা দলে যদি কারো জন্মদিন না জানি, তবু \(1+2+\dots+n = \frac{n(n+1)}{2}\) জোড়া handshake হবে।" এটা \(n=2\), \(n=10\), \(n=1000\) — সব ক্ষেত্রে সত্য, কিন্তু সব \(n\) আলাদা করে যাচাই তো অসম্ভব (অসীম সংখ্যক \(n\))। induction নামের কৌশল দিয়ে আমরা একবারে সব \(n\)-এর জন্য এটা প্রমাণ করব। এই power-টাই গণিতের সৌন্দর্য।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Set (সেট) ও সদস্যপদ (membership)¶
একটি set হলো সুনির্দিষ্ট, পরস্পর-আলাদা কিছু বস্তুর সংগ্রহ। বস্তুগুলোকে বলে set-এর element (উপাদান) বা member (সদস্য)। আমরা curly braces \(\{\ \}\) দিয়ে লিখি:
- \(3 \in A\) পড়া হয় "\(3\), \(A\)-এর সদস্য" (\(\in\) চিহ্নটি "belongs to / সদস্য")।
- \(7 \notin A\) মানে "\(7\), \(A\)-এর সদস্য নয়"।
দুটি গুরুত্বপূর্ণ নিয়ম: (১) ক্রম (order) গুরুত্বপূর্ণ নয় — \(\{1,2,3\}\) আর \(\{3,1,2\}\) একই set; (২) পুনরাবৃত্তি (repetition) গোনা হয় না — \(\{1,1,2\}\) আসলে \(\{1,2\}\)।
খালি set: যে set-এ কোনো সদস্য নেই, তাকে বলে empty set (শূন্য সেট), লেখা হয় \(\varnothing\) বা \(\{\}\)।
কিছু standard সংখ্যা-set, যেগুলো বারবার লাগবে:
২.২ Set-builder notation (নিয়ম দিয়ে set লেখা)¶
সব সদস্য তালিকা করা সবসময় সম্ভব নয় (যেমন "সব জোড় সংখ্যা")। তখন আমরা একটা শর্ত দিয়ে set বানাই — এটাকে বলে set-builder notation:
পড়া হয়: "\(E\) হলো সেইসব \(x\) যারা integer এবং জোড়।" এখানে \(\mid\) (বা কোথাও \(:\)) চিহ্নটি পড়া হয় "such that" (এমন যে)। বাঁদিকে "কী ধরনের বস্তু", ডানদিকে "কোন শর্ত মানে"।
২.৩ Subset (সাবসেট) ও সমতা¶
\(A\) যদি \(B\)-এর subset হয় (লেখা \(A \subseteq B\)), তার মানে \(A\)-এর প্রতিটি সদস্য \(B\)-তেও আছে:
(এই \(\forall\), \(\Rightarrow\) চিহ্ন দুটো §২.৭-এ ব্যাখ্যা করছি — আপাতত পড়ুন "প্রতিটি \(x\)-এর জন্য, \(x \in A\) হলে \(x \in B\)"।)
- \(\{1,2\} \subseteq \{1,2,3\}\) — সত্য।
- \(\varnothing \subseteq B\) — সবসময় সত্য, যেকোনো \(B\)-এর জন্য (খালি set-এর কোনো সদস্য নেই বলে "প্রতিটি সদস্য \(B\)-তে আছে" শর্তটা খালিভাবে পূরণ হয়ে যায়)।
- দুটি set সমান, \(A = B\), যদি ও কেবল যদি \(A \subseteq B\) এবং \(B \subseteq A\) — দুদিকেই অন্তর্ভুক্তি। (পরে কোনো set-সমতা প্রমাণ করতে এই কৌশলটাই ব্যবহার করব।)
- \(A \subsetneq B\) ("proper subset") মানে \(A \subseteq B\) কিন্তু \(A \ne B\)।
২.৪ Set operations (সেটের ক্রিয়া)¶
দুটি set \(A, B\) নিয়ে নতুন set বানানোর চারটি মৌলিক উপায় (একটা সর্বজনীন set / universal set \(U\)-এর ভেতরে কাজ করছি ভাবুন — যেমন প্রসঙ্গের সব সম্ভাব্য বস্তু):
| ক্রিয়া | চিহ্ন | সংজ্ঞা | বাংলায় |
|---|---|---|---|
| union | \(A \cup B\) | \(\{x \mid x \in A \text{ অথবা } x \in B\}\) | "যা \(A\)-তে আছে বা \(B\)-তে আছে" |
| intersection | \(A \cap B\) | \(\{x \mid x \in A \text{ এবং } x \in B\}\) | "যা \(A\)-তেও আছে এবং \(B\)-তেও আছে" |
| difference | \(A \setminus B\) | \(\{x \mid x \in A \text{ এবং } x \notin B\}\) | "\(A\)-তে আছে কিন্তু \(B\)-তে নেই" |
| complement | \(A^{c}\) (বা \(\bar{A}\)) | \(\{x \in U \mid x \notin A\} = U \setminus A\) | "\(U\)-এর মধ্যে যা \(A\)-তে নেই" |
আরও একটা প্রায়ই-লাগে: symmetric difference \(A \triangle B = (A \setminus B) \cup (B \setminus A)\) — "একটার মধ্যে আছে কিন্তু দুটোতেই একসাথে নেই।"
দুটি set-এর কোনো সাধারণ সদস্য না থাকলে (\(A \cap B = \varnothing\)) তাদের বলে disjoint (পরস্পর-বিচ্ছিন্ন) — probability-তে "mutually exclusive events"-এর ভিত্তি ঠিক এটাই।
দুটো অসাধারণ গুরুত্বপূর্ণ পরিচয় (পরে probability-তে বহুবার লাগবে), De Morgan's laws (ডি মরগ্যানের সূত্র):
অর্থাৎ "union-এর complement = complement-গুলোর intersection", আর "intersection-এর complement = complement-গুলোর union"। §৪-এ এর একটা পূর্ণ প্রমাণ করব।
২.৫ Cartesian product (কার্তেসীয় গুণফল)¶
দুটি set \(A\) ও \(B\)-এর Cartesian product হলো সব ordered pair (ক্রমিক জোড়া) \((a,b)\)-এর set, যেখানে প্রথম উপাদান \(A\) থেকে, দ্বিতীয়টি \(B\) থেকে:
উদাহরণ: \(\{1,2\} \times \{x, y\} = \{(1,x), (1,y), (2,x), (2,y)\}\) — মোট \(2 \times 2 = 4\)টি জোড়া। সাধারণভাবে \(|A \times B| = |A|\cdot|B|\) (এখানে \(|S|\) মানে set \(S\)-এর সদস্য সংখ্যা, cardinality)। দুবার coin toss-এর sample space আসলে \(\{H,T\} \times \{H,T\}\) — তাই \(4\)টি ফলাফল। সমতল \(\mathbb{R}^2 = \mathbb{R} \times \mathbb{R}\)ও এভাবেই তৈরি।
২.৬ Relation ও Function¶
একটা relation (সম্পর্ক) \(A\) থেকে \(B\)-তে হলো শুধু \(A \times B\)-এর একটা subset — অর্থাৎ কোন কোন \((a,b)\) জোড়া "সম্পর্কিত" তার একটা তালিকা।
একটা function (ফাংশন) \(f : A \to B\) একটা বিশেষ relation, যেখানে প্রতিটি \(a \in A\)-এর জন্য \(B\)-তে ঠিক একটিমাত্র সঙ্গী \(f(a)\) আছে। অর্থাৎ function = "প্রতিটি input-এর একটা ও কেবল একটা output।" পরিভাষা:
- \(A\) = domain (ডোমেইন — যেখান থেকে input আসে),
- \(B\) = codomain (কোডোমেইন — যেখানে output থাকতে পারে),
- \(f(A) = \{ f(a) \mid a \in A \}\) = range (রেঞ্জ — আসলে যত output পাওয়া যায়; এটা codomain-এর subset, সমান নাও হতে পারে)।
লেখার রীতি (mapping notation): "\(f : A \to B,\ x \mapsto f(x)\)" — যেমন \(f : \mathbb{R} \to \mathbb{R},\ x \mapsto x^2\)। তীর \(\to\) বসে দুটো set-এর মাঝে, আর \(\mapsto\) ("maps to") বসে একটা উপাদান কোথায় যায় তা দেখাতে।
তিন রকম বিশেষ function (পরে inverse, change-of-variable, একে-একে গণনায় লাগবে):
- injective (one-to-one, এক-এক): আলাদা input → আলাদা output। অর্থাৎ \(f(a_1) = f(a_2) \Rightarrow a_1 = a_2\)। (কোনো দুটো input একই জায়গায় পড়ে না।)
- surjective (onto, উপরিচ্ছাদী): codomain-এর প্রতিটি element-ই কোনো-না-কোনো input থেকে আসে, অর্থাৎ range = codomain।
- bijective (এক-এক ও উপরিচ্ছাদী): একই সাথে injective এবং surjective। শুধু bijective function-এরই একটা inverse \(f^{-1}\) থাকে।
২.৭ Logic (যুক্তি): connective ও quantifier¶
একটা proposition (বচন) হলো এমন একটা বাক্য যা সত্য (T) বা মিথ্যা (F) — দুটোর একটা। "\(3 > 2\)" সত্য; "\(5\) জোড়" মিথ্যা। বচন জোড়া লাগানোর logical connective (যোগসূত্র):
| নাম | চিহ্ন | পড়া | কখন সত্য |
|---|---|---|---|
| negation (নঞর্থক) | \(\neg P\) | "not \(P\)" | \(P\) মিথ্যা হলে |
| conjunction (যৌগিক) | \(P \wedge Q\) | "\(P\) and \(Q\)" | দুটোই সত্য হলে |
| disjunction (বিকল্প) | \(P \vee Q\) | "\(P\) or \(Q\)" | অন্তত একটা সত্য হলে |
| implication (অন্তর্ভাব) | \(P \Rightarrow Q\) | "\(P\) হলে \(Q\)" | \(P\) সত্য অথচ \(Q\) মিথ্যা — শুধু এই ক্ষেত্রে মিথ্যা, বাকি সব ক্ষেত্রে সত্য |
| biconditional (উভয়মুখী) | \(P \Leftrightarrow Q\) | "\(P\) iff \(Q\)" | \(P,Q\)-এর সত্যমান একই হলে |
implication নিয়ে দুটো শব্দ মনে রাখুন: \(P \Rightarrow Q\)-এর জন্য — - contrapositive (বিপরীত-প্রতিজ্ঞা): \(\neg Q \Rightarrow \neg P\) — এটি মূল implication-এর logically equivalent (সমতুল্য), সবসময় একসাথে সত্য/মিথ্যা। - converse (বিপরীত): \(Q \Rightarrow P\) — এটি মূলটির সমান নয়, এদের গুলিয়ে ফেলা খুব সাধারণ ভুল।
Quantifier (পরিমাণজ্ঞাপক) — কত উপাদানের জন্য কথাটা খাটে তা বলে:
- universal \(\forall\) পড়া হয় "for all / প্রত্যেকের জন্য": \(\forall x \in \mathbb{R},\ x^2 \ge 0\) ("প্রতিটি বাস্তব \(x\)-এর জন্য \(x^2 \ge 0\)") — সত্য।
- existential \(\exists\) পড়া হয় "there exists / এমন কিছু আছে যে": \(\exists x \in \mathbb{R},\ x^2 = 2\) ("এমন একটা \(x\) আছে যার বর্গ \(2\)") — সত্য (\(x=\sqrt2\))।
খুব দরকারি নিয়ম — quantifier-এর negation (অস্বীকারে \(\forall \leftrightarrow \exists\) পাল্টে যায়):
মানে: "সবাই লম্বা" — এর মিথ্যা হওয়া মানে "কেউ একজন লম্বা নয়।" এই rule-টাই পরে "একটা estimator consistent নয়" জাতীয় বাক্যকে নিখুঁতভাবে লিখতে সাহায্য করবে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ১ — set operations হাতে-কলমে¶
ধরা যাক universal set \(U = \{1,2,\dots,10\}\), আর $\(A = \{1,2,3,4\}, \qquad B = \{3,4,5,6\}.\)$
ধাপে ধাপে:
- union: \(A\) বা \(B\)-তে আছে এমন সব — \(A \cup B = \{1,2,3,4,5,6\}\)।
- intersection: দুটোতেই আছে — শুধু \(3\) আর \(4\) — \(A \cap B = \{3,4\}\)।
- difference: \(A\)-তে আছে কিন্তু \(B\)-তে নেই — \(3,4\) বাদ — \(A \setminus B = \{1,2\}\)।
- complement: \(U\)-তে আছে কিন্তু \(A\)-তে নেই — \(A^{c} = \{5,6,7,8,9,10\}\)।
- symmetric difference: \((A\setminus B)\cup(B\setminus A) = \{1,2\}\cup\{5,6\} = \{1,2,5,6\}\)।
De Morgan যাচাই: \((A \cup B)^c = U \setminus \{1,\dots,6\} = \{7,8,9,10\}\)। আবার \(A^c \cap B^c = \{5,\dots,10\} \cap \{1,2,7,8,9,10\} = \{7,8,9,10\}\)। দুটো মিলল — যেমনটা সূত্র বলে।
উদাহরণ ২ — power set গণনা¶
\(S = \{a, b, c\}\)-এর power set \(\mathcal{P}(S)\) = \(S\)-এর সব subset-এর set। প্রতিটি element-কে "ভেতরে নেব / নেব না" — দুটো করে পছন্দ, তাই \(2^3 = 8\)টি subset:
সাধারণভাবে \(|S| = n\) হলে \(|\mathcal{P}(S)| = 2^n\) — §৪-এ এটা induction দিয়ে প্রমাণ করব। (লক্ষ করুন \(\varnothing\) ও \(S\) নিজে — দুটোই subset হিসেবে গোনা হয়।)
উদাহরণ ৩ — function শ্রেণিবিন্যাস ও statistics-সংযোগ¶
(ক) \(f : \mathbb{R} \to \mathbb{R},\ f(x) = x^2\) — - injective নয়: \(f(-2) = f(2) = 4\), অথচ \(-2 \ne 2\) (দুটো ভিন্ন input একই output)। - surjective নয় (\(\mathbb{R}\)-এ): কোনো \(x\)-এর জন্যই \(f(x) = -1\) হয় না (range = \([0, \infty)\), পুরো \(\mathbb{R}\) নয়)।
(খ) কিন্তু domain ও codomain বদলে দিলে চরিত্র বদলায়: \(g : [0,\infty) \to [0,\infty),\ g(x) = x^2\) এখন bijective — তাই এর inverse \(g^{-1}(y) = \sqrt{y}\) ভালোভাবে সংজ্ঞায়িত। পাঠ: injective/surjective হওয়া শুধু সূত্রের উপর নয়, domain ও codomain-এর উপরেও নির্ভর করে।
(গ) random variable হিসেবে: দুবার coin toss, \(\Omega = \{HH, HT, TH, TT\}\)। ধরা যাক $X(\omega) = $ (head-এর সংখ্যা)। তাহলে \(X\) একটা function \(X : \Omega \to \{0,1,2\} \subset \mathbb{R}\): $\(X(HH)=2,\quad X(HT)=1,\quad X(TH)=1,\quad X(TT)=0.\)$ এটি injective নয় (\(HT, TH\) দুটোই \(1\)-এ যায়) — এবং সেটাই ঠিক আছে, random variable-কে injective হতে হয় না। এখন "ঠিক একটা head" ঘটনাটা হলো \(\{\omega \mid X(\omega) = 1\} = \{HT, TH\}\) — sample space-এর একটা subset, অর্থাৎ একটা event। ন্যায্য coin হলে এর probability (সম্ভাব্যতা) \(|\{HT,TH\}| / |\Omega| = 2/4 = 0.5\)। এভাবেই "set + subset + function" তিনটে মিলে probability-র গোটা ব্যাকরণ গড়ে।
৪ · প্রমাণ ও derivation (উৎপাদন)¶
Part 0-এ আমরা proof-কে elementary রাখব — উদ্দেশ্য চারটি কৌশলের স্বাদ পাওয়া, যাতে পরের অধ্যায়ে theorem-এর প্রমাণ পড়লে ভয় না লাগে।
৪.১ Direct proof — "\(n\) জোড় হলে \(n^2\) জোড়" (★)¶
দাবি: যদি \(n\) একটা জোড় integer হয়, তবে \(n^2\)-ও জোড়।
Direct proof মানে: ধরে নাও hypothesis সত্য, তারপর সরাসরি সংজ্ঞা ও বীজগণিত দিয়ে conclusion-এ পৌঁছাও।
ধরা যাক \(n\) জোড়। জোড় হওয়ার সংজ্ঞা অনুযায়ী কোনো integer \(k\)-এর জন্য \(n = 2k\)। তাহলে $\(n^2 = (2k)^2 = 4k^2 = 2\,(2k^2).\)$ যেহেতু \(2k^2\) একটা integer, \(n^2\)-কে \(2 \times (\text{integer})\) আকারে লেখা গেল — অর্থাৎ \(n^2\) জোড়। \(\blacksquare\)
৪.২ Contrapositive — "\(n^2\) জোড় হলে \(n\) জোড়" (★)¶
দাবি: \(n^2\) জোড় হলে \(n\) জোড়।
সরাসরি (\(n^2\) জোড় ধরে \(n\)-এ পৌঁছানো) করা ঝামেলার। কিন্তু \(P \Rightarrow Q\) আর তার contrapositive \(\neg Q \Rightarrow \neg P\) সমতুল্য (§২.৭)। এখানে contrapositive: "\(n\) জোড় নয় (অর্থাৎ বিজোড়) হলে \(n^2\)-ও বিজোড়।" — এটা প্রমাণ করলেই হবে।
ধরা যাক \(n\) বিজোড়, অর্থাৎ \(n = 2k+1\) কোনো integer \(k\)-এর জন্য। তাহলে $\(n^2 = (2k+1)^2 = 4k^2 + 4k + 1 = 2\,(2k^2 + 2k) + 1,\)$ যা \(2 \times (\text{integer}) + 1\) — অর্থাৎ \(n^2\) বিজোড়। contrapositive সত্য হলো, তাই মূল দাবিও সত্য। \(\blacksquare\)
৪.৩ Contradiction — "\(\sqrt{2}\) irrational" (★★)¶
Proof by contradiction (অসম্ভবে-প্রমাণ): যা প্রমাণ করতে চাই তার উল্টোটা ধরে নাও, তারপর দেখাও সেটা একটা অসম্ভব পরিস্থিতি (contradiction) ডেকে আনে — তাই উল্টোটা মিথ্যা, মূলটা সত্য।
দাবি: \(\sqrt{2}\) একটা irrational সংখ্যা (অর্থাৎ দুই integer-এর ভগ্নাংশ হিসেবে লেখা যায় না)।
ধরা যাক উল্টোটা সত্য — \(\sqrt2\) rational, অর্থাৎ \(\sqrt2 = \dfrac{p}{q}\) যেখানে \(p,q\) integer, \(q \ne 0\), এবং ভগ্নাংশটি সবচেয়ে সরল রূপে (অর্থাৎ \(p,q\)-এর কোনো সাধারণ উৎপাদক নেই)। বর্গ করি: $\(2 = \frac{p^2}{q^2} \;\Rightarrow\; p^2 = 2q^2.\)$ তাহলে \(p^2\) জোড়, আর §৪.২ অনুযায়ী \(p\)-ও জোড় — ধরা যাক \(p = 2m\)। বসিয়ে: \((2m)^2 = 2q^2 \Rightarrow 4m^2 = 2q^2 \Rightarrow q^2 = 2m^2\)। তাই \(q^2\) জোড়, অতএব \(q\)-ও জোড়।
কিন্তু এখন \(p\) আর \(q\) দুটোই জোড় — অর্থাৎ দুজনেরই উৎপাদক \(2\) আছে। এটা সরাসরি বিরোধ করে আমাদের ধরে-নেওয়া "\(p,q\)-এর সাধারণ উৎপাদক নেই" শর্তটাকে। contradiction পেলাম — অতএব ধরে-নেওয়াটা ভুল ছিল; \(\sqrt2\) irrational। \(\blacksquare\)
৪.৪ Induction — "\(\displaystyle\sum_{i=1}^{n} i = \frac{n(n+1)}{2}\)" (★)¶
Mathematical induction দিয়ে আমরা "প্রতিটি \(n \in \mathbb{N}\)-এর জন্য \(P(n)\) সত্য" — এমন বিবৃতি প্রমাণ করি দুই ধাপে, ডমিনো ফেলার মতো: (১) প্রথম ডমিনো ফেলো; (২) দেখাও যেকোনো ডমিনো পড়লে তার পরেরটাও পড়ে — তাহলে সব পড়বে।
ধরি \(P(n):\ \displaystyle\sum_{i=1}^{n} i = \frac{n(n+1)}{2}\)।
Base case (\(n=1\)): বাঁদিক \(= 1\); ডানদিক \(= \frac{1\cdot 2}{2} = 1\)। মিলল, তাই \(P(1)\) সত্য।
Inductive step: ধরে নাও কোনো \(n = k\)-এর জন্য \(P(k)\) সত্য (একে বলে inductive hypothesis): $\(\sum_{i=1}^{k} i = \frac{k(k+1)}{2}.\)$ দেখাতে হবে \(P(k+1)\)-ও সত্য। বাঁদিকে \((k+1)\)তম পদ যোগ করি: $\(\sum_{i=1}^{k+1} i = \underbrace{\sum_{i=1}^{k} i}_{\text{hypothesis}} + (k+1) = \frac{k(k+1)}{2} + (k+1).\)$ ডান পাশটা একসাথে করি (\(\,k+1\,\) সাধারণ নিয়ে): $\(= (k+1)\!\left(\frac{k}{2} + 1\right) = (k+1)\cdot\frac{k+2}{2} = \frac{(k+1)\big((k+1)+1\big)}{2}.\)$ ঠিক এটাই \(P(k+1)\)-এর দাবি। base case + inductive step দুটোই হলো, তাই সব \(n \in \mathbb{N}\)-এর জন্য \(P(n)\) সত্য। \(\blacksquare\)
এই একই কৌশলে উদাহরণ ২-এর দাবি — "\(|S|=n \Rightarrow |\mathcal{P}(S)| = 2^n\)" — প্রমাণ করা যায় (অনুশীলনী P3 দেখুন)।
৪.৫ Set-সমতা: De Morgan-এর একটা সূত্র (★★)¶
দাবি: \((A \cup B)^c = A^c \cap B^c\)।
দুটো set সমান প্রমাণ করতে দেখাই দুদিকেই subset (§২.৩)। আসলে এখানে প্রতিটি ধাপ "iff" (যদি ও কেবল যদি), তাই একবারেই দুদিক ধরা যায়। যেকোনো \(x\) নিই: $$ \begin{aligned} x \in (A \cup B)^c &\iff x \notin (A \cup B) && (\text{complement-এর সংজ্ঞা})\ &\iff \neg\,(x \in A \ \text{বা}\ x \in B) && (\text{union-এর সংজ্ঞা})\ &\iff (x \notin A)\ \text{এবং}\ (x \notin B) && (\text{logic: } \neg(P \vee Q) \equiv \neg P \wedge \neg Q)\ &\iff x \in A^c \ \text{এবং}\ x \in B^c && (\text{complement-এর সংজ্ঞা})\ &\iff x \in A^c \cap B^c && (\text{intersection-এর সংজ্ঞা}). \end{aligned} $$ যেহেতু যেকোনো \(x\)-এর জন্য বাঁ ও ডান দুই দিকের সদস্যপদ একই, set দুটো সমান। \(\blacksquare\) লক্ষ করুন — set-তত্ত্বের De Morgan আসলে logic-এর De Morgan-এরই অনুবাদ।
৫ · কোড ল্যাব (Python)¶
Python-এর built-in set type আমাদের গাণিতিক set-এর প্রায় হুবহু প্রতিরূপ — তাই উপরের সব ধারণা কোডে যাচাই করা যায়। নিচের সব snippet চালানো-যোগ্য (runnable)।
৫.১ Set operations — from scratch (built-in set)¶
from itertools import product
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}
U = set(range(1, 11)) # universal set {1,...,10}
print("A | B =", sorted(A | B)) # union -> [1, 2, 3, 4, 5, 6]
print("A & B =", sorted(A & B)) # intersection -> [3, 4]
print("A - B =", sorted(A - B)) # difference -> [1, 2]
print("A ^ B =", sorted(A ^ B)) # symmetric diff -> [1, 2, 5, 6]
print("U - A =", sorted(U - A)) # complement A^c -> [5, 6, 7, 8, 9, 10]
print("A subset of U?", A <= U) # subset test -> True
# Cartesian product A x {0,1}
print("A x {0,1} =", sorted(product(A, {0, 1})))
আউটপুট (উদাহরণ ১-এর হাতে-কষা মানের সাথে অবিকল মেলে):
A | B = [1, 2, 3, 4, 5, 6]
A & B = [3, 4]
A - B = [1, 2]
A ^ B = [1, 2, 5, 6]
U - A = [5, 6, 7, 8, 9, 10]
A subset of U? True
A x {0,1} = [(1, 0), (1, 1), (2, 0), (2, 1), (3, 0), (3, 1), (4, 0), (4, 1)]
Python operator ↔ গাণিতিক চিহ্ন: | = \(\cup\), & = \(\cap\), - = \(\setminus\), ^ = \(\triangle\), <= = \(\subseteq\)।
৫.২ Power set — নিজে বানানো (bit-mask দিয়ে)¶
প্রতিটি subset-কে একটা binary সংখ্যার সাথে মেলানো যায়: \(n\) element হলে \(2^n\)টি সংখ্যা (\(0\) থেকে \(2^n-1\)), প্রতিটার bit বলে দেয় কোন element নেওয়া হলো।
def power_set(s):
s = list(s)
n = len(s)
out = []
for mask in range(2 ** n): # 0 .. 2^n - 1
subset = frozenset(s[i] for i in range(n) if (mask >> i) & 1)
out.append(subset)
return out
ps = power_set({1, 2, 3})
print("number of subsets =", len(ps)) # -> 8 (= 2^3)
print(sorted([sorted(x) for x in ps], key=lambda z: (len(z), z)))
# -> [[], [1], [2], [3], [1, 2], [1, 3], [2, 3], [1, 2, 3]]
len(ps) ঠিক \(2^3 = 8\) — §৪.৪-এর induction-দাবির computational সাক্ষ্য।
৫.৩ Function: injective / surjective / bijective যাচাই¶
def classify(f, domain, codomain):
images = [f(x) for x in domain]
injective = len(set(images)) == len(images) # কোনো output পুনরাবৃত্তি নেই?
surjective = set(images) == set(codomain) # codomain পুরো ঢাকা পড়ল?
return injective, surjective, (injective and surjective)
dom = [0, 1, 2, 3]
print("x^2 on {0..3}:", classify(lambda x: x**2, dom, [0, 1, 4, 9]))
# -> (True, True, True) : নিজের range-এ bijective
print("x mod 2 :", classify(lambda x: x % 2, dom, [0, 1]))
# -> (False, True, False) : surjective কিন্তু injective নয় (0,2 -> 0; 1,3 -> 1)
৫.৪ Random variable = function (theory ↔ computation)¶
import itertools
Omega = ["".join(w) for w in itertools.product("HT", repeat=2)] # sample space
X = lambda w: w.count("H") # number of heads
print("Omega =", Omega) # ['HH', 'HT', 'TH', 'TT']
print("X values =", {w: X(w) for w in Omega}) # {'HH':2,'HT':1,'TH':1,'TT':0}
# event {X = 1} = sample space-এর subset
event = {w for w in Omega if X(w) == 1}
print("event {X=1} =", sorted(event), " P =", len(event) / len(Omega))
# -> event {X=1} = ['HT', 'TH'] P = 0.5
পাওয়া গেল \(P\{X=1\} = 0.5\) — উদাহরণ ৩(গ)-এর সাথে মিল। এখানেই প্রথমবার দেখা গেল কীভাবে set, subset আর function একসাথে একটা সম্ভাব্যতা হিসাব করে।
৫.৫ De Morgan brute-force যাচাই (random simulation)¶
import random
U = set(range(6))
comp = lambda S: U - S
ok = True
for _ in range(2000): # 2000 random জোড়া
A = set(random.sample(list(U), random.randint(0, 6)))
B = set(random.sample(list(U), random.randint(0, 6)))
if comp(A | B) != comp(A) & comp(B): ok = False # (A∪B)^c = A^c ∩ B^c
if comp(A & B) != comp(A) | comp(B): ok = False # (A∩B)^c = A^c ∪ B^c
print("De Morgan holds on 2000 random pairs:", ok) # -> True
True — §৪.৫-এর প্রমাণের সাথে সঙ্গতিপূর্ণ। (মনে রাখবেন: simulation প্রমাণ নয়, কিন্তু প্রমাণ ভুল হলে এটা ধরিয়ে দিত — তাই এটা একটা ভালো sanity check।)
লাইব্রেরি প্রসঙ্গে: set ও function এতটাই মৌলিক যে Python-এর core ভাষাতেই (
set,lambda) এরা আছে — আলাদা library লাগে না। তবে symbolic set/logic নিয়ে কাজ করতে চাইলেsympy.FiniteSet,sympy.Unionইত্যাদি আছে; পরের অধ্যায়গুলোতেnumpy/scipyআসবে যখন বড় সংখ্যাগত কাজ লাগবে।
৬ · ভিজ্যুয়ালাইজেশন¶
নিচের সব ছবি একটিমাত্র স্ক্রিপ্ট (_code/0-1-figs.py) থেকে তৈরি; in-figure লেখা ইংরেজিতে (Bengali-font সমস্যা এড়াতে), ব্যাখ্যা বাংলায়।
Figure 1 — Set operations (Venn diagram)¶
বড় আয়তক্ষেত্র \(U\) (universal set), ভেতরে দুটো বৃত্ত \(A\) ও \(B\)। রঙিন অংশটাই ফলাফল-set: union (পুরো ছায়া), intersection (মাঝের ফালি), difference \(A\setminus B\) (শুধু \(A\)-এর একলা অংশ), complement \(A^c\) (\(A\)-এর বাইরের সব)।
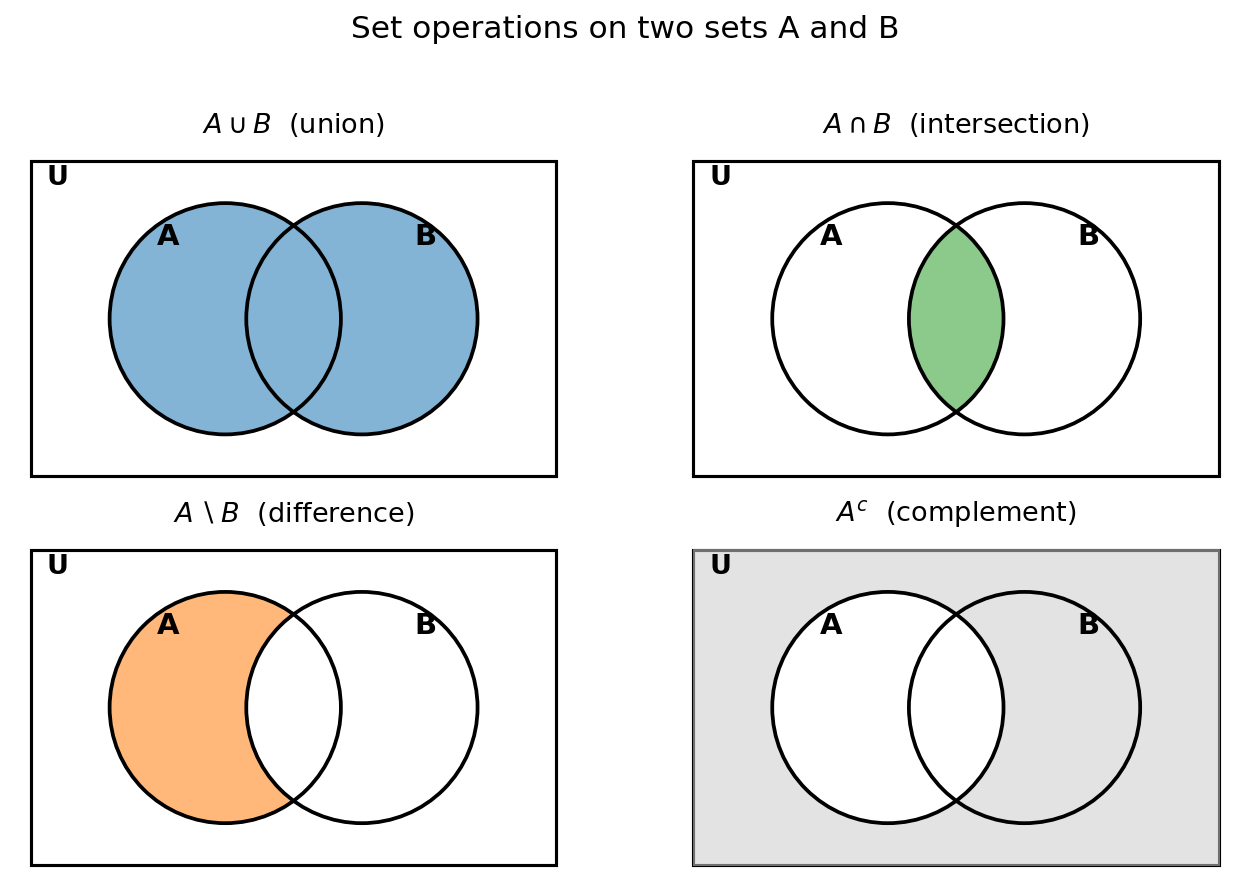
Figure 2 — Function as mapping: injective vs surjective vs bijective¶
দুই কলাম বিন্দু (বাঁয়ে domain \(X\), ডানে codomain \(Y\)), তীর দেখায় কে কোথায় যায়। injective: কোনো দুই তীর একই \(Y\)-বিন্দুতে মেলে না (কিন্তু \(Y\)-এর 4 কেউ ধরে না — তাই onto নয়)। surjective: \(Y\)-এর প্রতিটি বিন্দুতে অন্তত একটা তীর আসে (কিন্তু a,b দুটোই 1-এ — তাই one-to-one নয়)। bijective: নিখুঁত জোড়ায়-জোড়ায় মিল — তখনই inverse থাকে।
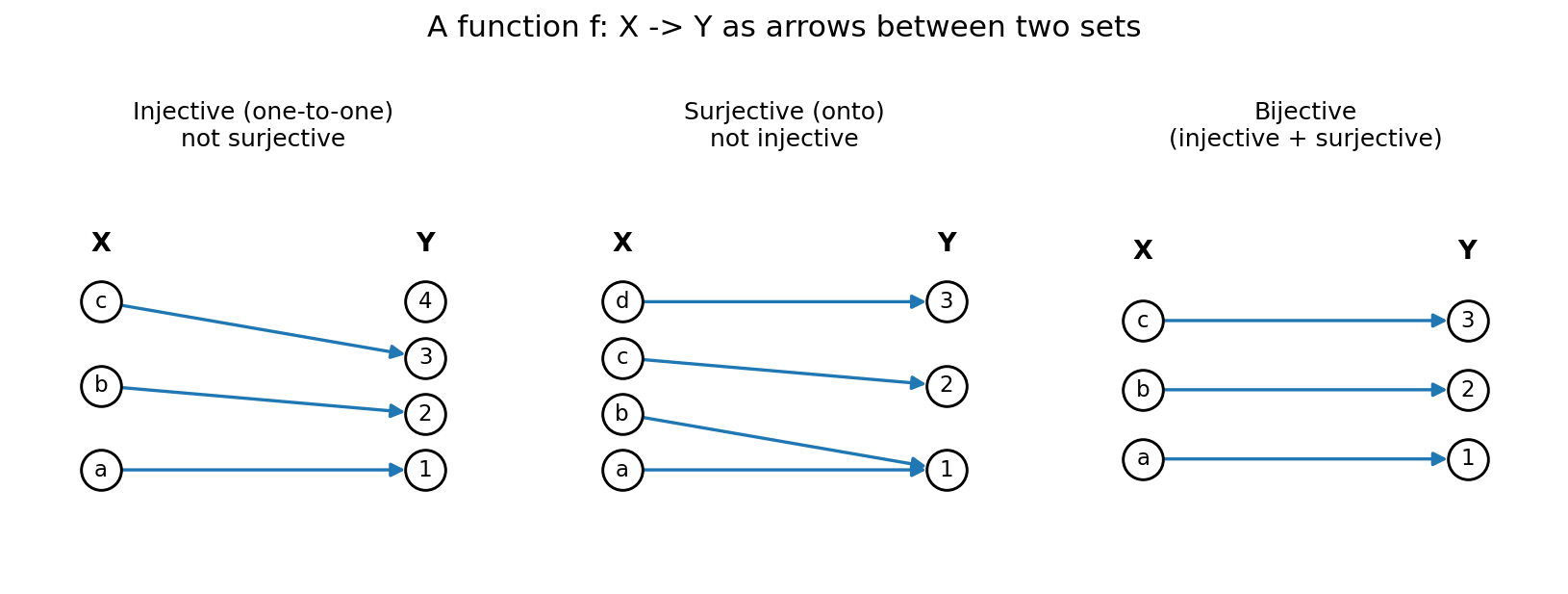
Figure 3 — কখন একটা curve function, আর কখন নয় (vertical line test)¶
বাঁয়ে \(f(x)=x^2\): একই অনুভূমিক রেখা (\(y=4\)) দুই জায়গায় (\(x=-2,2\)) কাটে — তাই injective নয়। ডানে একটা বৃত্ত: একটা খাড়া (vertical) রেখা curve-কে দুবার কাটে, মানে এক \(x\)-এর জন্য দুটো \(y\) — তাই এটা function-ই নয়। এই "vertical line test" function চেনার দ্রুততম চাক্ষুষ উপায়।
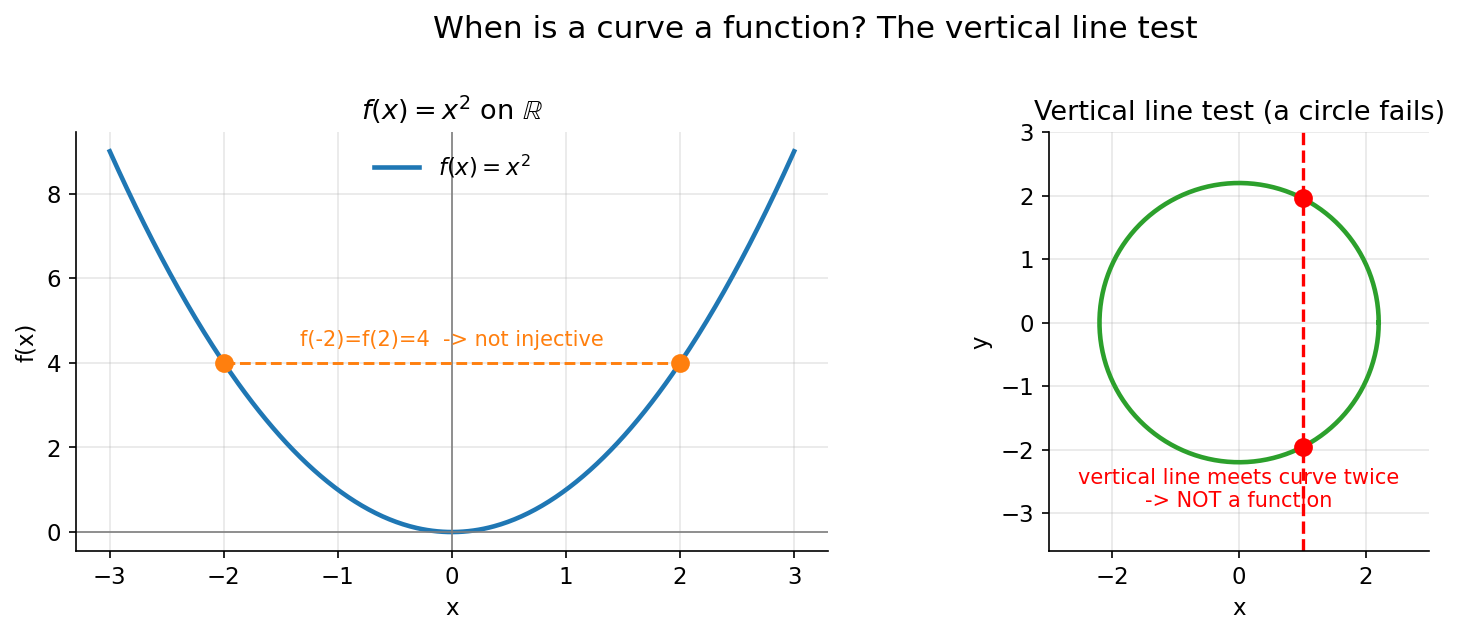
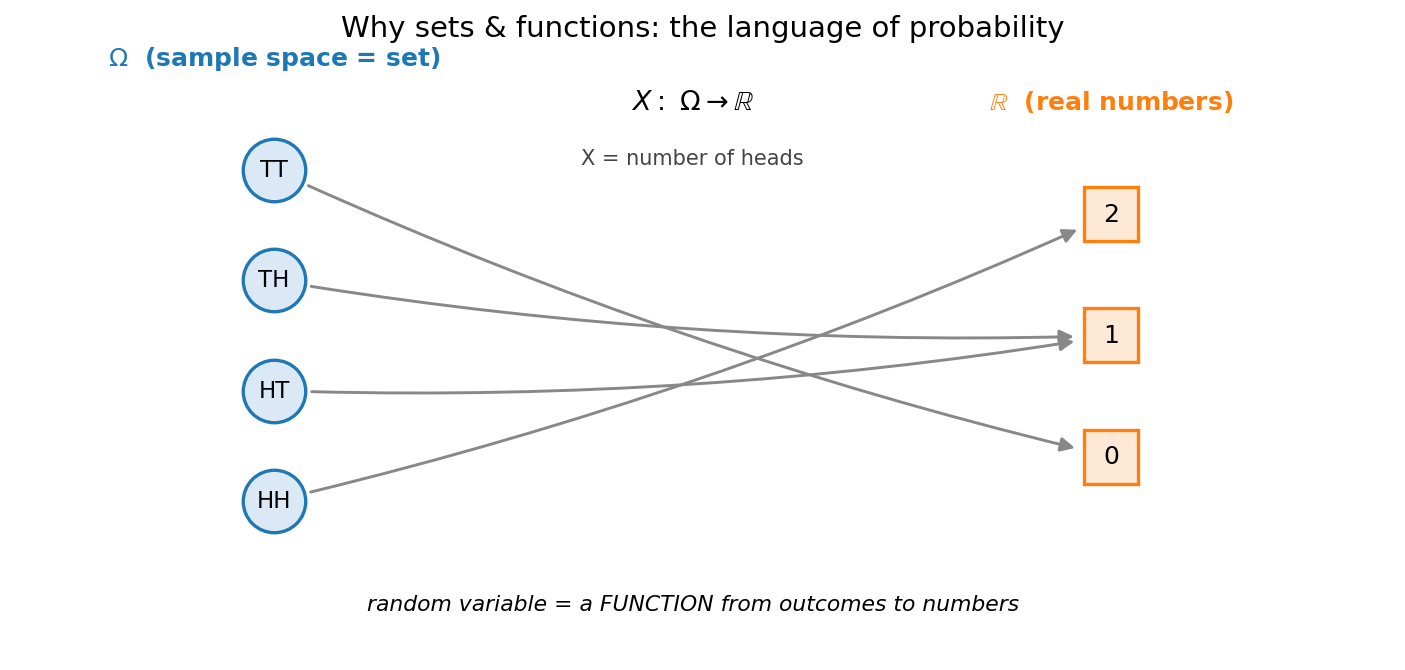
Figure 4 — কেন sets ও functions: probability-র ভাষা¶
বাঁয়ে sample space \(\Omega = \{HH,HT,TH,TT\}\) (একটা set)। ডানে সংখ্যারেখা \(\mathbb{R}\)। ধূসর তীরগুলো random variable \(X\) (= head-সংখ্যা), যা প্রতিটি ফলাফলকে একটা সংখ্যায় পাঠায় — অর্থাৎ একটা function \(X:\Omega\to\mathbb{R}\)। এই একটা ছবিই গোটা অধ্যায়ের statistics-সংযোগ ধরে রাখে।
ছবি তৈরির পূর্ণ কোড (চালালে চারটি PNG-ই পুনরুৎপাদিত হয়)
import sys
sys.path.append(".../Statistics/curriculum/_code") # figstyle-এর পথ
import numpy as np
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Circle, Rectangle, FancyArrowPatch
from figstyle import set_style
set_style()
ASSETS = ".../Statistics/curriculum/_assets"
BLUE, ORANGE, GREEN, GREY = "#1f77b4", "#ff7f0e", "#2ca02c", "#cccccc"
# ---- FIGURE 1: Venn (union / intersection / difference / complement) ----
def venn_panel(ax, shade):
ax.add_patch(Rectangle((0, 0), 10, 6, fill=False, ec="black", lw=1.5))
ax.text(0.3, 5.55, "U", fontsize=13, fontweight="bold")
cA, cB, r = (3.7, 3.0), (6.3, 3.0), 2.2
xs, ys = np.linspace(0, 10, 400), np.linspace(0, 6, 400)
X, Y = np.meshgrid(xs, ys)
inA = (X - cA[0])**2 + (Y - cA[1])**2 <= r**2
inB = (X - cB[0])**2 + (Y - cB[1])**2 <= r**2
mask, col = {"union": (inA | inB, BLUE), "inter": (inA & inB, GREEN),
"diff": (inA & ~inB, ORANGE), "comp": (~inA, GREY)}[shade]
ax.contourf(X, Y, mask.astype(float), levels=[0.5, 1.5], colors=[col], alpha=0.55)
ax.add_patch(Circle(cA, r, fill=False, ec="black", lw=1.8))
ax.add_patch(Circle(cB, r, fill=False, ec="black", lw=1.8))
ax.text(2.4, 4.4, "A", fontsize=14, fontweight="bold")
ax.text(7.3, 4.4, "B", fontsize=14, fontweight="bold")
ax.set_xlim(-0.3, 10.3); ax.set_ylim(-0.3, 6.3)
ax.set_aspect("equal"); ax.axis("off")
fig, axes = plt.subplots(2, 2, figsize=(9, 6))
for ax, (sh, t) in zip(axes.ravel(),
[("union", r"$A \cup B$ (union)"), ("inter", r"$A \cap B$ (intersection)"),
("diff", r"$A \setminus B$ (difference)"), ("comp", r"$A^{c}$ (complement)")]):
venn_panel(ax, sh); ax.set_title(t, fontsize=13)
fig.suptitle("Set operations on two sets A and B", fontsize=15, y=0.99)
fig.tight_layout(rect=[0, 0, 1, 0.96]); fig.savefig(f"{ASSETS}/0-1-venn.png", bbox_inches="tight")
# ---- FIGURE 2: mapping (injective / surjective / bijective) ----
def mapping_panel(ax, title, dom, cod, edges):
nD, nC = len(dom), len(cod)
yd = np.linspace(0, max(nD, nC) - 1, nD); yd -= yd.mean()
yc = np.linspace(0, max(nD, nC) - 1, nC); yc -= yc.mean()
posL = {dom[i]: (0.0, yd[i]) for i in range(nD)}
posR = {cod[i]: (3.0, yc[i]) for i in range(nC)}
for a, b in edges:
ax.add_patch(FancyArrowPatch(posL[a], posR[b], arrowstyle="-|>",
mutation_scale=14, color=BLUE, lw=1.6, shrinkA=10, shrinkB=10))
for d, (x, y) in {**posL, **posR}.items():
ax.plot(x, y, "o", ms=20, color="white", mec="black", mew=1.4, zorder=3)
ax.text(x, y, d, ha="center", va="center", fontsize=11, zorder=4)
top = max(yd.max(), yc.max()) + 0.9
ax.text(0.0, top, "X", ha="center", fontsize=13, fontweight="bold")
ax.text(3.0, top, "Y", ha="center", fontsize=13, fontweight="bold")
ax.set_title(title, fontsize=12)
ax.set_xlim(-0.8, 3.8); ax.set_ylim(-max(nD, nC) / 1.4 - 0.6, max(nD, nC) / 1.4 + 1.2)
ax.axis("off")
fig, axes = plt.subplots(1, 3, figsize=(11, 4))
mapping_panel(axes[0], "Injective (one-to-one)\nnot surjective",
["a", "b", "c"], ["1", "2", "3", "4"], [("a","1"),("b","2"),("c","3")])
mapping_panel(axes[1], "Surjective (onto)\nnot injective",
["a", "b", "c", "d"], ["1", "2", "3"], [("a","1"),("b","1"),("c","2"),("d","3")])
mapping_panel(axes[2], "Bijective\n(injective + surjective)",
["a", "b", "c"], ["1", "2", "3"], [("a","1"),("b","2"),("c","3")])
fig.suptitle("A function f: X -> Y as arrows between two sets", fontsize=15, y=1.02)
fig.tight_layout(); fig.savefig(f"{ASSETS}/0-1-mapping.png", bbox_inches="tight")
# ---- FIGURE 3: real function plot + vertical line test ----
fig, axes = plt.subplots(1, 2, figsize=(11, 4.2))
x = np.linspace(-3, 3, 400)
axes[0].plot(x, x**2, color=BLUE, lw=2.2, label=r"$f(x)=x^2$")
axes[0].axhline(0, color="grey", lw=0.8); axes[0].axvline(0, color="grey", lw=0.8)
axes[0].plot([-2, 2], [4, 4], "o", color=ORANGE, ms=8, zorder=5)
axes[0].hlines(4, -2, 2, color=ORANGE, ls="--", lw=1.4)
axes[0].text(0, 4.4, "f(-2)=f(2)=4 -> not injective", ha="center", color=ORANGE, fontsize=10)
axes[0].set_title(r"$f(x)=x^2$ on $\mathbb{R}$"); axes[0].set_xlabel("x"); axes[0].set_ylabel("f(x)")
axes[0].legend(loc="upper center")
th = np.linspace(0, 2*np.pi, 400)
axes[1].plot(2.2*np.cos(th), 2.2*np.sin(th), color=GREEN, lw=2.2)
axes[1].axvline(1.0, color="red", ls="--", lw=1.6)
axes[1].plot([1, 1], [np.sqrt(2.2**2 - 1), -np.sqrt(2.2**2 - 1)], "o", color="red", ms=8, zorder=5)
axes[1].text(0, -2.9, "vertical line meets curve twice\n-> NOT a function", ha="center", color="red", fontsize=10)
axes[1].set_title("Vertical line test (a circle fails)")
axes[1].set_xlabel("x"); axes[1].set_ylabel("y"); axes[1].set_aspect("equal")
axes[1].set_xlim(-3, 3); axes[1].set_ylim(-3.6, 3)
fig.suptitle("When is a curve a function? The vertical line test", fontsize=15, y=1.0)
fig.tight_layout(); fig.savefig(f"{ASSETS}/0-1-function-plot.png", bbox_inches="tight")
# ---- FIGURE 4: sample space -> random variable -> R ----
fig, ax = plt.subplots(figsize=(9.5, 4.6))
omega = ["HH", "HT", "TH", "TT"]; yL = np.linspace(0, 3, 4); yL -= yL.mean()
for i, w in enumerate(omega):
ax.plot(0.0, yL[i], "o", ms=30, color="#dbe9f6", mec=BLUE, mew=1.6, zorder=3)
ax.text(0.0, yL[i], w, ha="center", va="center", fontsize=11, zorder=4)
ax.text(0.0, yL.max() + 0.95, r"$\Omega$ (sample space = set)", ha="center", fontsize=12, fontweight="bold", color=BLUE)
vals = {"HH": 2, "HT": 1, "TH": 1, "TT": 0}; xR = 4.2
for v in [0, 1, 2]:
yv = (v - 1) * 1.1
ax.plot(xR, yv, "s", ms=26, color="#fde9d6", mec=ORANGE, mew=1.6, zorder=3)
ax.text(xR, yv, str(v), ha="center", va="center", fontsize=12, zorder=4)
ax.text(xR, 2.05, r"$\mathbb{R}$ (real numbers)", ha="center", fontsize=12, fontweight="bold", color=ORANGE)
posR = {0: (xR, -1.1), 1: (xR, 0.0), 2: (xR, 1.1)}
for i, w in enumerate(omega):
ax.add_patch(FancyArrowPatch((0.0, yL[i]), posR[vals[w]], arrowstyle="-|>",
mutation_scale=14, color="#888888", lw=1.4, shrinkA=18, shrinkB=18,
connectionstyle="arc3,rad=0.05"))
ax.text(2.1, 2.05, r"$X:\ \Omega \to \mathbb{R}$", ha="center", fontsize=13, fontweight="bold")
ax.text(2.1, 1.55, "X = number of heads", ha="center", fontsize=10, color="#444")
ax.text(2.1, -2.5, "random variable = a FUNCTION from outcomes to numbers", ha="center", fontsize=10.5, style="italic")
ax.set_xlim(-1.3, 5.6); ax.set_ylim(-2.9, 2.6); ax.axis("off")
ax.set_title("Why sets & functions: the language of probability", fontsize=14)
fig.tight_layout(); fig.savefig(f"{ASSETS}/0-1-rv-bridge.png", bbox_inches="tight")
৭ · অনুশীলনী¶
প্রতিটি সমস্যার সাথে hint ও difficulty (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং)। পূর্ণ সমাধান: _solutions/00-01-sets-functions-logic-solutions.md।
Conceptual (ধারণা যাচাই)¶
- C1 (★). \(A = \{1,2,3,4,5\}\), \(B = \{2,4,6\}\), \(U = \{1,\dots,8\}\) নিয়ে নিচের সবগুলো বের করুন: \(A\cup B\), \(A\cap B\), \(A\setminus B\), \(B\setminus A\), \(A^c\), \(A\triangle B\)। Hint: প্রতিটি সংজ্ঞা শব্দে অনুবাদ করুন ("বা", "এবং", "তে নেই")।
- C2 (★). নিচের প্রতিটি কি সত্য না মিথ্যা, কারণসহ: (ক) \(\varnothing \in \{\varnothing\}\), (খ) \(\varnothing \subseteq \{1,2\}\), (গ) \(\{1\} \in \{\{1\}, 2\}\), (ঘ) \(\{1\} \subseteq \{1, 2\}\)। Hint: "\(\in\)" (সদস্য) আর "\(\subseteq\)" (অংশ-সেট)-এর পার্থক্যে মন দিন।
- C3 (★★). quantifier-যুক্ত এই বাক্যটির negation লিখুন (বাংলায় ও প্রতীকে): "\(\forall x \in \mathbb{R},\ \exists y \in \mathbb{R}\) যেন \(y > x\)।" এটা কি সত্য? Hint: §২.৭-এর negation নিয়ম দুবার লাগান; \(\forall \leftrightarrow \exists\) পাল্টে যায়।
- C4 (★). \(f:\{1,2,3\}\to\{a,b\}\) এমন একটা function-এর উদাহরণ দিন যা surjective কিন্তু injective নয়। এমন function-এর কেন কোনো inverse নেই, এক বাক্যে বলুন। Hint: তিনটা input, দুটো output — pigeonhole।
Computational (গণনা)¶
- N1 (★). \(|A| = 5\) হলে \(|\mathcal{P}(A)|\) কত? আর \(|\mathcal{P}(\mathcal{P}(\varnothing))|\) কত? Hint: \(|\mathcal{P}(S)| = 2^{|S|}\); ভেতর থেকে বাইরে হিসাব করুন — \(|\varnothing| = 0\)।
- N2 (★★). \(A = \{1,2,3\}\), \(B = \{x, y\}\)। (ক) \(A\times B\)-এর সব element লিখুন। (খ) \(A\times B\) থেকে \(\{0,1\}\)-তে কয়টি ভিন্ন function সম্ভব? Hint: (খ) প্রতিটি input-এর জন্য \(2\)টি করে পছন্দ, input সংখ্যা \(|A\times B|\)।
- N3 (★★). \(50\) জন শিক্ষার্থীর মধ্যে \(30\) জন চা, \(25\) জন কফি, \(12\) জন দুটোই পছন্দ করে। কতজন অন্তত একটা পছন্দ করে? কতজন একটাও না? Hint: inclusion–exclusion: \(|T\cup C| = |T| + |C| - |T\cap C|\)।
Proof-based (প্রমাণ)¶
- P1 (★). Direct proof দিন: যদি \(a\) ও \(b\) দুটোই জোড় integer হয়, তবে \(a+b\) জোড়। Hint: \(a=2m,\ b=2n\) ধরে যোগফলে \(2\) সাধারণ নিন।
- P2 (★★). Contrapositive দিয়ে প্রমাণ করুন: যদি \(n^2\) বিজোড় হয়, তবে \(n\) বিজোড়। Hint: contrapositive বলুন আগে, তারপর §৪.১-এর মতো \(n=2k\) ধরুন।
- P3 (★★★). Induction দিয়ে প্রমাণ করুন: \(|S| = n\) হলে \(|\mathcal{P}(S)| = 2^n\)। Hint: \(S\)-তে একটা নতুন element \(x\) যোগ করলে প্রতিটি পুরোনো subset দুবার গোনা যায় — "\(x\) ছাড়া" আর "\(x\) সহ"।
Coding (কোড)¶
- K1 (★). এমন একটা Python function
is_subset(A, B)লিখুন যা built-in<=ব্যবহার না করে (শুধু loop দিয়ে) বলে দেয় \(A \subseteq B\) কিনা। তিনটি কেস-এ পরীক্ষা করুন, যার একটাতে \(A = \varnothing\)। Hint: "\(A\)-এর প্রতিটি element কি \(B\)-তে আছে?" — একটাও না থাকলেFalse। - K2 (★★). §৪.৪-এর identity \(\sum_{i=1}^n i = \frac{n(n+1)}{2}\) —
n\(= 1\) থেকে \(1000\) পর্যন্ত প্রতিটি মানে দুই পাশ মিলিয়ে দেখান যে সবসময় সমান (একটাও অমিল হলে print করুন)। Hint:sum(range(1, n+1))বনামn*(n+1)//2; integer ভাগের জন্য//। - K3 (★★★). একটা function
classify(f, domain, codomain)লিখুন (§৫.৩-এর মতো) যা(injective, surjective, bijective)ফেরত দেয়; তারপর \(f(x) = x \bmod 3\) (\(\text{domain}=\{0,\dots,5\}\), \(\text{codomain}=\{0,1,2\}\)) শ্রেণিবদ্ধ করুন এবং উত্তর হাতে যাচাই করুন। Hint:set(images)-এর আকার দিয়ে injective, codomain-এর সাথে সমতা দিয়ে surjective।
৮ · সারসংক্ষেপ ও সংযোগ¶
এক নজরে যা শিখলাম:
- Set = বস্তুর সংগ্রহ; ক্রম/পুনরাবৃত্তি গোনা হয় না। চিহ্ন: \(\in, \subseteq\); ক্রিয়া: \(\cup, \cap, \setminus, {}^c, \times\)। set-builder \(\{x \mid \text{শর্ত}\}\) দিয়ে নিয়ম-ভিত্তিক set লেখা যায়। power set \(\mathcal{P}(S)\)-এ \(2^{|S|}\)টি subset।
- De Morgan: \((A\cup B)^c = A^c\cap B^c\) এবং \((A\cap B)^c = A^c\cup B^c\) — probability-তে complement-নির্ভর হিসাবের মেরুদণ্ড।
- Function \(f:A\to B\) = প্রতিটি input-এর ঠিক একটি output; domain/codomain/range আলাদা ধারণা। injective / surjective / bijective — এবং inverse শুধু bijective-এর জন্যই থাকে।
- Logic: \(\neg, \wedge, \vee, \Rightarrow, \Leftrightarrow\); \(\forall, \exists\) ও তাদের negation। implication-এর contrapositive সমতুল্য, converse নয়।
- চারটি proof কৌশল: direct, contrapositive, contradiction, induction — হাতে-কলমে প্রয়োগ করলাম।
মূল সংযোগ (statistics-এর সাথে): $\(\boxed{\ \text{sample space} = \text{set},\quad \text{event} = \text{subset},\quad \text{random variable} = \text{function}\ }\)$ এই ত্রয়ীই Part II-তে probability-র formal কাঠামো হয়ে উঠবে — যেখানে \(P(A\cup B)\), \(P(A^c) = 1 - P(A)\) (De Morgan + axiom থেকে), আর \(\{X \le x\}\) (একটা event-as-subset) সর্বত্র লাগবে।
পূর্ববর্তী সংযোগ: এটি Part 0-এর প্রথম অধ্যায় — কোনো prerequisite নেই; এখান থেকেই পুরো কারিকুলামের ভাষা শুরু।
পরবর্তী → 0.2 (Summation/Product notation, Combinatorics): "কয়টা উপায়ে?" গোনার শিল্প। power set-এর \(2^n\), Cartesian product-এর \(|A|\cdot|B|\), আর coin-toss outcome-গোনা — এই অধ্যায়ের যে গোনাগুলো এসেছে, 0.2-এ সেগুলোকে permutation, combination ও binomial coefficient-এ পরিণত করব, যা সরাসরি Part II-এর discrete probability-তে কাজে লাগবে।
Source pointer: এই অধ্যায় self-contained (Part 0)। বিষয়বস্তু যেকোনো standard "discrete mathematics / proofs" সূচনা-পাঠের সাথে মেলে এবং বিশেষভাবে Part II (probability foundations)-এর set-theoretic ভিত্তি প্রস্তুত করে।