6.4 — Classification II: Support Vector Machines & Kernel Methods (শ্রেণিবিন্যাস II: সাপোর্ট ভেক্টর মেশিন ও কার্নেল পদ্ধতি)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — boundary শুধু আলাদা করলেই হবে না: চাই সবচেয়ে চওড়া রাস্তা¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
6.3-এ আমরা classification (শ্রেণিবিন্যাস)-এর একগুচ্ছ যন্ত্র দেখেছি — LDA, QDA, Naive Bayes, k-NN — এবং তাদের সবাইকে এক সুতোয় গেঁথেছিলাম একটা আদর্শ-মানদণ্ড দিয়ে: সম্ভব-সেরা classifier হলো Bayes classifier, যা প্রতিটি বিন্দুকে তার সর্বোচ্চ-posterior শ্রেণিতে পাঠায়। সেই অধ্যায়ের প্রতিটি পদ্ধতিই ছিল ওই posterior \(P(y\mid x)\)-কে কোনো-না-কোনোভাবে আন্দাজ করার চেষ্টা — কেউ প্রতিটি শ্রেণির density (ঘনত্ব) model করে Bayes rule-এ উল্টে, কেউ প্রতিবেশীর ভোটে।
এখানে একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ কথা লুকিয়ে আছে। ওই পদ্ধতিগুলোতে শেষমেশ একটা decision boundary (সিদ্ধান্ত-সীমানা) তৈরি হতো — সেই পৃষ্ঠ, যা feature-space-কে শ্রেণি-অঞ্চলে ভাগ করে — কিন্তু boundary-টা ছিল ওই posterior-আন্দাজের পার্শ্বপ্রতিক্রিয়া, সরাসরি লক্ষ্য নয়। অর্থাৎ আমরা কখনো সরাসরি জিজ্ঞেস করিনি: "সব সম্ভাব্য boundary-র মধ্যে কোনটা জ্যামিতিকভাবে সবচেয়ে ভালো জায়গায় আছে?"
এই অধ্যায় ঠিক সেই প্রশ্নটাই তোলে, এবং একটা আশ্চর্যরকম পরিষ্কার, সরাসরি-জ্যামিতিক উত্তর দেয়। এখানে আমরা আর কোনো posterior বা density model করব না; বদলে boundary-টাকেই সরাসরি এবং একটা নির্দিষ্ট, সুন্দর নীতিতে বাছব। সেই নীতির নাম max-margin (সর্বোচ্চ-প্রান্ত), আর তার মূর্ত রূপ এই অধ্যায়ের নায়ক — support vector machine (সাপোর্ট ভেক্টর মেশিন, সংক্ষেপে SVM)।
এক বাক্যে উত্তরণ। 6.3-এ boundary ছিল posterior-আন্দাজের উপজাত; এই অধ্যায়ে boundary-ই মূল লক্ষ্য — এবং সব আলাদা-করা boundary-র মধ্যে আমরা সেইটাই বাছব, যা দুই শ্রেণির মাঝে সবচেয়ে চওড়া ফাঁকা জায়গা রাখে (max-margin)।
১.২ Hook — একই data, অনেক রেখা: কোনটা বাছব?¶
একটা ছোট ছবি কল্পনা করুন। কাগজে দুই রঙের কিছু বিন্দু আঁকা — নীল আর লাল — আর তারা এমনভাবে ছড়ানো যে একটা সরলরেখা দিয়ে দুই রঙকে পুরোপুরি আলাদা করা যায়। এমন data-কে বলে linearly separable (রৈখিকভাবে পৃথকযোগ্য)। এখন প্রশ্ন: দুই রঙকে আলাদা করার মতো রেখা তো একটাই নয় — অসংখ্য রেখা টানা যায়, যাদের প্রতিটিই নীল আর লালকে নিখুঁতভাবে দুই পাশে রাখে। কোনটা বাছব?
6.3-এর কোনো পদ্ধতি এই প্রশ্নের সরাসরি উত্তর দেয় না — তারা একটা নির্দিষ্ট রেখা দেয়, কিন্তু "কেন এই রেখাটাই, ওই রেখাটা নয়" সেই বাছাইয়ের নীতি স্পষ্ট নয়। অথচ স্বজ্ঞা বলে, সব রেখা সমান-ভালো নয়। ভাবুন একটা রেখা যা নীল বিন্দুদের একদম গা ঘেঁষে গেছে — সে নীলদের ঠিক আলাদা করেছে বটে, কিন্তু এক চুল এদিক-ওদিক হলেই (যেমন একটা নতুন নীল বিন্দু সামান্য বাঁ দিকে এলে) সে ভুল করে বসবে। তার তুলনায় এমন একটা রেখা — যা নীল আর লাল, দুই দলের থেকেই যথাসম্ভব দূরে, ঠিক মাঝখান দিয়ে গেছে — অনেক বেশি নিরাপদ: দুই পাশেই তার হাতে ফাঁকা জায়গা আছে, তাই ছোটখাটো নড়াচড়ায় সে টলে না।
এই "দুই দলের মাঝখান দিয়ে, যথাসম্ভব ফাঁকা জায়গা রেখে" যাওয়া রেখাটাই max-margin classifier বাছে। আর সেই ফাঁকা রাস্তার প্রস্থই হলো margin (প্রান্ত/ব্যবধান)। অধ্যায়ের একটা চিত্রে (নাম: max-margin) এই ছবিটাই আঁকা থাকবে — একই data-র উপর কয়েকটা সম্ভাব্য রেখা, আর তাদের মধ্যে সেইটা চিহ্নিত যা সবচেয়ে চওড়া করিডোর রাখে।
এক বাক্যে hook। linearly separable data-কে আলাদা করা যায় অসংখ্য রেখায় — কিন্তু সবচেয়ে নিরাপদ রেখা সেইটা, যা দুই শ্রেণির মাঝে সবচেয়ে চওড়া ফাঁকা করিডোর (margin) রেখে ঠিক মাঝখান দিয়ে যায়; SVM সেই রেখাটাই বেছে নেয়।
১.৩ মূল insight (অন্তর্দৃষ্টি) — কেন বড় margin "ভালো" boundary¶
"সবচেয়ে চওড়া রাস্তা বাছো" — এটা কেবল নান্দনিক খেয়াল নয়, এর পেছনে শক্ত যুক্তি আছে, এবং সেই যুক্তি সরাসরি 6.1-এর learning theory থেকে আসে। তিনটি কোণ থেকে দেখা যাক কেন বড় margin ভালো।
(ক) Robustness — ছোট নড়াচড়ায় টলে না। boundary-র চারপাশে যত বেশি ফাঁকা জায়গা, তত বেশি একটা বিন্দু সরে গেলেও সে ভুল পাশে পড়বে না। margin আসলে একটা "নিরাপত্তা-অঞ্চল": training-বিন্দুগুলো boundary থেকে অন্তত margin-প্রস্থ দূরে থাকে, তাই পরিমাপে সামান্য ত্রুটি বা noise সত্ত্বেও শ্রেণি-রায় স্থির থাকে। সরু margin মানে boundary কোনো-না-কোনো শ্রেণির গা ঘেঁষে — সেখানে এক চিমটে noise-ই বিপর্যয়।
(খ) Generalization — নতুন data-তেও কাজ করে। এটাই গভীরতম যুক্তি। 6.1-এ আমরা শিখেছিলাম, একটা classifier-পরিবারের capacity (কত বিচিত্র boundary সে আঁকতে পারে) যত বেশি, overfitting-এর ঝুঁকি তত বেশি; আর ভালো generalization-এর জন্য চাই কম-capacity, কিন্তু-যথেষ্ট-নমনীয় পরিবার। বড় margin দাবি করাটা আসলে একটা পরোক্ষ capacity-নিয়ন্ত্রণ: যেসব hyperplane চওড়া margin রাখতে পারে, তারা সংখ্যায় কম ও "সংযত"। স্বজ্ঞাগতভাবে — চওড়া করিডোর-সহ boundary কম-জটিল, তাই সে training-data-র খুঁটিনাটি (ও noise) মুখস্থ না করে আসল আলাদা-করা-প্রবণতাটা ধরে। তত্ত্বে এটা margin-নির্ভর generalization bound হিসেবে প্রকাশ পায় (§৪-এ ছোঁয়া হবে): margin যত বড়, bound তত আঁটো — অর্থাৎ training-performance থেকে test-performance তত কম দূরে সরবে।
(গ) মাত্র কয়েকটা বিন্দুই গুরুত্বপূর্ণ। আরেকটা চমকপ্রদ ফল, যা পরে গোটা গণিতকে সরল করবে: max-margin boundary আসলে নির্ভর করে কেবল ওই কয়েকটা বিন্দুর উপর, যারা margin-করিডোরের প্রান্তে বসে — এদের নাম support vector। করিডোর থেকে দূরের বিন্দুগুলো (যত বেশিই হোক) boundary-কে এতটুকু প্রভাবিত করে না; চাইলে তাদের সরিয়ে দিলেও একই boundary পাওয়া যায়। অর্থাৎ SVM data-র গভীরে না তাকিয়ে কেবল সীমান্ত-বিন্দুগুলোর উপর মন দেয় — এটাই তার নামের উৎস ("machine that is supported by a few vectors")।
এক বাক্যে অন্তর্দৃষ্টি। বড় margin মানে একসঙ্গে তিন জিনিস — boundary-র চারপাশে নিরাপত্তা-অঞ্চল (robustness), পরোক্ষ capacity-নিয়ন্ত্রণ (ভালো generalization, 6.1), এবং boundary কেবল গুটিকয় সীমান্ত-বিন্দুর (support vector) উপর নির্ভর; এই তিনটিই max-margin নীতিকে কেবল সুন্দর নয়, পরিসংখ্যানিকভাবে যুক্তিযুক্ত করে তোলে।
১.৪ আসল সমস্যা — data যখন সরলরেখায় আলাদা হয় না: kernel trick¶
এতক্ষণের গল্পে একটা বড় "যদি" লুকিয়ে ছিল: যদি data সরলরেখায় (বা সমতল hyperplane-এ) আলাদা করা যেত। কিন্তু বাস্তব data প্রায়ই তেমন নয়। কল্পনা করুন এমন দুই শ্রেণি, যাদের একটা অন্যটাকে অর্ধচন্দ্রাকারে জড়িয়ে আছে — যেমন এই অধ্যায়ের প্রধান dataset make_moons (দুটো পরস্পর-জড়ানো অর্ধচন্দ্র)। এখানে কোনো সরলরেখাই দুই শ্রেণিকে ভালোভাবে আলাদা করতে পারে না — যেকোনো রেখা টানলেই দুই পাশে দুই রঙ মিশে থাকবে। (অধ্যায়ের সংখ্যাগুলো এটাই দেখাবে: এই data-তে একটা রৈখিক SVM-এর নির্ভুলতা মোটে \(0.811\)-এ আটকে যায় — সে ব্যর্থ, কারণ moons রৈখিকভাবে পৃথকযোগ্য নয়।)
তাহলে max-margin-এর গোটা সুন্দর কাঠামো কি অরৈখিক data-তে অকেজো? — এখানেই SVM-এর সবচেয়ে মার্জিত চমক, একটা ধারণা যার নাম kernel trick (কার্নেল কৌশল)।
মূল স্বজ্ঞাটা এক বাক্যে: মূল space-এ যা সরলরেখায় আলাদা হয় না, তা একটা উচ্চ-মাত্রিক space-এ তুলে নিলে অনেক সময় সরল (রৈখিক) boundary-তেই আলাদা হয়ে যায়। একটা সাদামাটা ছবি: এক রঙের বিন্দুগুলো একটা বৃত্তের ভেতরে, অন্য রঙ বাইরে — সমতলে এদের কোনো সরলরেখা আলাদা করতে পারে না। কিন্তু যদি প্রতিটি বিন্দুকে তার কেন্দ্র-থেকে-দূরত্ব অনুযায়ী একটা তৃতীয় মাত্রায় উপরে তুলে দিই (ভেতরের বিন্দু নিচে, বাইরের বিন্দু উপরে), তাহলে ত্রিমাত্রিক space-এ একটা সমতল (hyperplane) দিয়েই অনায়াসে দুই দলকে আলাদা করা যায়। এই "উপরে তুলে নেওয়া"-র কাজ করে একটা feature map \(\phi\) — যা প্রতিটি \(x\)-কে উচ্চ-মাত্রিক \(\phi(x)\)-তে পাঠায়।
সমস্যা হলো, এই \(\phi(x)\) স্পষ্টভাবে বানানো প্রায়ই অসম্ভব-রকম ব্যয়সাধ্য (কখনো মাত্রা অসীমও)। আর ঠিক এখানেই trick-টা কাজ করে: §৪-এ দেখা যাবে SVM-এর গোটা সমাধান লেখা যায় কেবল বিন্দু-জোড়ার inner product \(\langle x_i,x_j\rangle\) দিয়ে — কোথাও আলাদাভাবে \(x_i\) লাগে না, কেবল তাদের জোড়ায়-জোড়ায় গুণফল লাগে। তাই উচ্চ-মাত্রায় কাজ করতে গেলে আমাদের \(\phi(x)\) বানানোরই দরকার নেই; কেবল দরকার \(\langle\phi(x_i),\phi(x_j)\rangle\)-এর মান — আর সেইটা প্রায়ই একটা সরল সূত্রে সরাসরি হিসাব করা যায়, \(\phi\)-কে স্পর্শ না করেই। সেই সূত্রটাই kernel \(K(x,x')=\langle\phi(x),\phi(x')\rangle\)।
ফল: একটা kernel বেছে দিলেই (যেমন RBF kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\)) আমরা কার্যত একটা বিশাল feature-space-এ max-margin hyperplane খুঁজি, অথচ সব হিসাব হয় মূল space-এ — আর মূল space-এ ফিরে এলে সেই hyperplane একটা সুন্দর nonlinear boundary হয়ে দাঁড়ায়, যা অনায়াসে অর্ধচন্দ্র-জড়ানো moons-কেও আলাদা করে। (সংখ্যায়: একই moons-data-তে RBF-kernel SVM নির্ভুলতা তুলে দেয় \(0.900\)-তে, এবং উপযুক্ত \(C\)-তে \(0.944\)-এ — রৈখিকের \(0.811\)-এর তুলনায় স্পষ্ট জয়।)
এক বাক্যে kernel-অন্তর্দৃষ্টি। যা মূল space-এ সরলরেখায় আলাদা হয় না, তা উচ্চ-মাত্রায় তুলে নিলে রৈখিকভাবে আলাদা হতে পারে — আর kernel trick সেই উচ্চ-মাত্রিক feature-map \(\phi\) স্পষ্টভাবে না বানিয়েই, কেবল inner product-কে একটা kernel \(K(x,x')\) দিয়ে বদলে, মূল space-এ nonlinear boundary গড়ে তোলে।
১.৫ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Separating hyperplane ও margin (§২.১) — boundary-কে \(w^\top x+b=0\) রূপে লেখা, এবং margin \(=2/\lVert w\rVert\) কীভাবে এর সঙ্গে যুক্ত।
- Max-margin (hard-margin) classifier (§২.২) — max-margin-কে একটা পরিষ্কার optimization হিসেবে গঠন: \(\min\frac12\lVert w\rVert^2\) s.t. \(y_i(w^\top x_i+b)\ge1\)।
- Support vectors (§২.৩) — যেসব বিন্দুর constraint tight, boundary কেবল তাদের উপর নির্ভর।
- Soft-margin (§২.৪) — slack \(\xi_i\) ও penalty \(C\) দিয়ে overlapping/noisy data সামলানো; \(C\)-এর ভূমিকা; সমতুল্য hinge loss।
- Dual ও \(\alpha_i\) (§২.৫) — Lagrange multiplier \(\alpha_i\), সমাধান কেবল inner product-নির্ভর, \(w=\sum_i\alpha_i y_i x_i\) যেখানে কেবল SV-দের \(\alpha>0\)।
- Kernel trick (§২.৬) — \(\langle x,x'\rangle\to K(x,x')\), feature-map \(\phi\) ছাড়াই nonlinear boundary; RBF ও polynomial kernel; \(\gamma\)-এর অর্থ।
- \(C\) ও \(\gamma\) tuning (§২.৭) — cross-validation দিয়ে bias–variance ভারসাম্য।
- সব derivation (primal → Lagrangian → dual, KKT, kernel-শর্ত) §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫ থেকে।
এক বাক্যে কেন এটি এখানে। 6.3 শ্রেণিবিন্যাসের boundary-কে posterior-আন্দাজের উপজাত হিসেবে পেয়েছিল; এই অধ্যায় সেই boundary-কেই একটা সরাসরি, জ্যামিতিক নীতিতে — max-margin — বাছে এবং kernel trick দিয়ে তাকে অরৈখিক data-তেও প্রসারিত করে; পরের অধ্যায় 6.5 (decision trees, bagging, random forests) boundary গড়ার আরও একটা সম্পূর্ণ ভিন্ন, নিয়ম-ভিত্তিক ঘরানা আনবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর অন্তর্দৃষ্টি — "সব আলাদা-করা boundary-র মধ্যে সবচেয়ে চওড়া-margin-ওয়ালাটা বাছো, আর অরৈখিক হলে kernel দিয়ে উচ্চ-মাত্রায় তুলে নাও" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত primal থেকে dual-এ যাওয়া ও kernel-এর বৈধতা-শর্ত), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে কিছু সাধারণ চিহ্ন স্থির করে নিই, যা গোটা অধ্যায়ে অপরিবর্তিত থাকবে। আমাদের কাছে \(n\)টি লেবেল-করা পর্যবেক্ষণ আছে: \((x_1,y_1),\dots,(x_n,y_n)\), যেখানে \(x_i\in\mathbb{R}^p\) হলো \(i\)-তম পর্যবেক্ষণের feature vector (\(p\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা, \(i=1,\dots,n\)), আর \(y_i\) হলো তার শ্রেণি-লেবেল। এই অধ্যায়ে একটা গুরুত্বপূর্ণ নিয়মবদল: লেবেলগুলো আমরা লিখব \(\{-1,+1\}\) দিয়ে —
অর্থাৎ এক শ্রেণিকে \(+1\) আর অন্যটিকে \(-1\) ধরা হবে। (6.3-এ আমরা \(\{1,\dots,C\}\) বা logistic-এ \(\{0,1\}\) ব্যবহার করতাম; এখানে \(\pm1\) বাছার একমাত্র কারণ — এতে SVM-এর সমস্ত সূত্র অসাধারণ পরিচ্ছন্ন হয়ে যায়, যা একটু পরেই দেখা যাবে।) আপাতত আমরা দুই-শ্রেণি (\(C=2\)) ক্ষেত্রেই থাকব।
২.১ Separating hyperplane ও margin¶
Hyperplane (অধিসমতল)। একটা \(p\)-মাত্রিক feature-space-এ একটা সমতল-জাতীয় সীমানাকে গণিতে বলে hyperplane। তাকে আমরা লিখি
যেখানে \(x\in\mathbb{R}^p\) হলো space-এর যেকোনো বিন্দু, \(w\in\mathbb{R}^p\) হলো একটা স্থির ভেক্টর যাকে বলে weight vector বা normal vector (এটা hyperplane-এর উপর লম্বভাবে দাঁড়িয়ে থাকে — তাই "normal"), আর \(b\in\mathbb{R}\) একটা স্থির সংখ্যা যাকে বলে bias বা intercept (এটা hyperplane-কে মূলবিন্দু থেকে কতদূরে সরানো তা ঠিক করে)। চিহ্ন \(w^\top x\) মানে \(w\) ও \(x\)-এর inner product (অন্তর্গুণফল, dot product), অর্থাৎ \(w^\top x=\sum_{j=1}^p w_j x_j\) — এক সংখ্যা। (২-মাত্রায়, \(p=2\), এই সমীকরণ একটা সরলরেখা; ৩-মাত্রায় একটা সমতল; উচ্চতর মাত্রায় তার সাধারণীকরণ।)
এই hyperplane পুরো space-কে দুই অর্ধে ভাগ করে, আর তার ভিত্তিতে আমরা একটা classifier বানাই — যেকোনো নতুন \(x\)-এর জন্য প্রথমে স্কোর \(w^\top x+b\) হিসাব করি, তারপর শ্রেণি বলি তার চিহ্ন (sign) দেখে:
যেখানে \(\operatorname{sign}(\cdot)\) ধনাত্মক হলে \(+1\), ঋণাত্মক হলে \(-1\) ফেরায়, আর \(\hat y(x)\) হলো \(x\)-এর অনুমিত শ্রেণি। কথায়: hyperplane-এর যে পাশে বিন্দু পড়ে, সেই পাশের শ্রেণিই তার রায়। (লক্ষ্য করুন এটা 5.4-এর logistic regression-এর সেই একই রৈখিক স্কোর \(w^\top x+b\) — পার্থক্য কেবল, পরে আমরা \(w,b\)-কে ভিন্ন নীতিতে বাছব।)
একটা পর্যবেক্ষণ ঠিক পাশে আছে কি না — পরিচ্ছন্ন রূপ। \(y_i\in\{-1,+1\}\) বাছার সুবিধা এখানেই প্রথম ঝিলিক দেয়। একটা বিন্দু \((x_i,y_i)\) সঠিকভাবে ও আত্মবিশ্বাসের সঙ্গে শ্রেণিবদ্ধ হবে যদি তার স্কোর ও তার আসল লেবেল একই চিহ্নের হয় — অর্থাৎ যদি \(y_i(w^\top x_i+b)>0\) হয় (কারণ লেবেল \(+1\) হলে স্কোর ধনাত্মক চাই, লেবেল \(-1\) হলে ঋণাত্মক; দুই ক্ষেত্রেই গুণফল ধনাত্মক)। এই একটিমাত্র রাশি \(y_i(w^\top x_i+b)\) — যাকে বলে functional margin (ক্রিয়াগত প্রান্ত) — একসঙ্গে বলে দেয় বিন্দুটা ঠিক পাশে আছে কি না (চিহ্ন) এবং boundary থেকে কতটা আত্মবিশ্বাসে দূরে (মান)।
Margin (প্রান্ত / পৃথকীকরণ-ব্যবধান)। এবার মূল ধারণা। একটা separating hyperplane ঠিক করার পর, দুই শ্রেণির বিন্দুদের মধ্যে যে নিকটতমরা boundary-র সবচেয়ে কাছে, তাদের boundary থেকে দূরত্বই করিডোরের "অর্ধেক-প্রস্থ" ঠিক করে; পুরো করিডোরের প্রস্থকে বলে margin। জ্যামিতিতে (0.5-এর বিন্দু-থেকে-hyperplane দূরত্বের সূত্র ব্যবহার করে) এটা একটা চমৎকার সরল রূপ নেয়। যদি আমরা \(w\) ও \(b\)-এর মাপ এমনভাবে স্থির করি যে নিকটতম বিন্দুগুলোর জন্য \(\lvert w^\top x_i+b\rvert=1\) (এটাকে বলে canonical বা প্রামাণিক স্কেলিং — কেবল একটা সুবিধাজনক মাপ-বাছাই, সাধারণতা হারায় না), তখন দুই শ্রেণির নিকটতম বিন্দুদের মাঝের পুরো ব্যবধান দাঁড়ায়
যেখানে \(\lVert w \rVert\) হলো weight vector \(w\)-এর Euclidean norm (দৈর্ঘ্য), অর্থাৎ \(\lVert w\rVert=\sqrt{w^\top w}=\sqrt{\sum_{j=1}^p w_j^2}\) (0.5-এর norm)। এই একটিমাত্র সূত্রে গোটা অধ্যায়ের চাবি লুকিয়ে: margin বড় করা মানে \(\lVert w\rVert\) ছোট করা — দুটো একই জিনিস, কারণ একে অপরের উল্টো। (সূত্রটার পূর্ণ ব্যুৎপত্তি — কেন ঠিক \(2/\lVert w\rVert\) — §৪-এ; এখানে কেবল এর অর্থটুকু ধরে রাখা যথেষ্ট।) এই ছবিটা — boundary, দুই পাশের margin-সীমা, আর তাদের মাঝের \(2/\lVert w\rVert\) চওড়া করিডোর — অধ্যায়ের max-margin চিত্রে আঁকা থাকবে।
এক বাক্যে। boundary হলো একটা hyperplane \(w^\top x+b=0\), রায় হয় স্কোরের চিহ্নে \(\operatorname{sign}(w^\top x+b)\), আর দুই শ্রেণির মাঝের ফাঁকা করিডোরের প্রস্থ — margin — ঠিক \(2/\lVert w\rVert\); কাজেই বড় margin আর ছোট \(\lVert w\rVert\) একই দাবি।
২.২ Max-margin (hard-margin) classifier — একটা optimization¶
এবার §১.৩-এর নীতিটাকে — "সবচেয়ে চওড়া margin বাছো" — সরাসরি একটা গাণিতিক optimization-এ রূপ দিই। আমরা চাই margin \(=2/\lVert w\rVert\) সর্বোচ্চ করতে, এই শর্তে যে প্রতিটি training-বিন্দু সঠিক পাশে এবং করিডোরের বাইরে (অন্তত প্রান্তে) থাকে।
আগের অনুচ্ছেদের canonical স্কেলিং-এ "সঠিক পাশে ও করিডোরের প্রান্তে-বা-বাইরে" শর্তটা প্রতিটি বিন্দুর জন্য পরিষ্কার এক অসমতায় ধরা পড়ে:
পড়ুন: প্রতিটি বিন্দুর functional margin অন্তত \(1\) — অর্থাৎ কোনো বিন্দুই করিডোরের ভেতরে ঢোকে না, সবাই তার সঠিক পাশে নিরাপদ দূরত্বে। (লেবেল \(+1\) হলে এটা \(w^\top x_i+b\ge1\), লেবেল \(-1\) হলে \(w^\top x_i+b\le-1\) — দুই পাশের দুই সীমা।)
এবার "\(2/\lVert w\rVert\) সর্বোচ্চ করা" আর "\(\lVert w\rVert\) সর্বনিম্ন করা" একই কথা; আর গাণিতিক সুবিধার জন্য \(\lVert w\rVert\)-এর বদলে \(\frac12\lVert w\rVert^2\) সর্বনিম্ন করি (বর্গ ও \(\frac12\) কেবল derivative-কে পরিচ্ছন্ন করে, সর্বনিম্ন-বিন্দু বদলায় না)। ফলে গোটা hard-margin SVM দাঁড়ায় একটা সাফসুতরো constrained optimization হিসেবে:
যেখানে "s.t." মানে "subject to" (এই শর্তে), \(w\in\mathbb{R}^p\) ও \(b\in\mathbb{R}\) হলো আমরা যা খুঁজছি (boundary-র normal ও bias), আর objective \(\frac12\lVert w\rVert^2\) ছোট করা মানেই margin বড় করা। এই রূপটাকে বলে primal (মূল) সমস্যা — একটা convex quadratic program (উত্তল দ্বিঘাত প্রোগ্রাম: objective দ্বিঘাত ও উত্তল, constraint রৈখিক), তাই এর একটাই বিশ্বব্যাপী সর্বনিম্ন আছে এবং তা নির্ভরযোগ্যভাবে বের করা যায়।
এই গঠনকে "hard-margin" বলা হয় কারণ constraint-গুলো কঠোর: প্রতিটি বিন্দুকে নিখুঁতভাবে সঠিক পাশে ও করিডোরের বাইরে থাকতেই হবে, একটিও ব্যতিক্রম নেই। স্পষ্টতই এটা তখনই সম্ভব যখন data linearly separable — নইলে এমন কোনো \((w,b)\) থাকেই না যা সব শর্ত মেটায়, আর সমস্যাটার কোনো সমাধান নেই। এই দুর্বলতা সামলাতেই একটু পরে soft-margin আসবে। অধ্যায়ের একটা ছোট linearly-separable demo-তে এই hard-margin সমাধান হাতে-কলমে দেখানো হবে (যেখানে মাত্র ৩টি support vector boundary ঠিক করে এবং margin-প্রস্থ দাঁড়ায় \(2.678\))।
এক বাক্যে। hard-margin SVM হলো একটা পরিষ্কার optimization — \(\min\frac12\lVert w\rVert^2\) এই শর্তে যে \(y_i(w^\top x_i+b)\ge1\) সব \(i\)-এর জন্য — যা "সব বিন্দু সঠিক পাশে রেখে margin সর্বোচ্চ করো" দাবিটাকে নিখুঁতভাবে ধরে, কিন্তু কেবল রৈখিকভাবে-পৃথকযোগ্য data-তেই চলে।
২.৩ Support vectors — boundary কেবল কয়েকটা বিন্দুর হাতে¶
§২.২-এর optimization-এর একটা গভীর জ্যামিতিক বৈশিষ্ট্য আছে, যা §১.৩(গ)-তে আভাসে বলা হয়েছিল। সমাধানে প্রতিটি constraint \(y_i(w^\top x_i+b)\ge1\) হয় আঁটো (tight / active) — অর্থাৎ ঠিক সমতা \(y_i(w^\top x_i+b)=1\) — নয়তো শিথিল (slack / inactive) — অর্থাৎ কড়া অসমতা \(y_i(w^\top x_i+b)>1\)।
- যেসব বিন্দুতে constraint আঁটো (\(=1\)): এরা ঠিক margin-করিডোরের প্রান্তের উপর বসে — boundary-র সবচেয়ে কাছের বিন্দু। এদেরই নাম support vector (সাপোর্ট ভেক্টর)।
- যেসব বিন্দুতে constraint শিথিল (\(>1\)): এরা করিডোর থেকে দূরে, নিরাপদ গভীরে।
মূল ফলটা চমকপ্রদ: চূড়ান্ত boundary নির্ভর করে কেবল support vector-দের উপর; বাকি সব (দূরের) বিন্দু সরিয়ে দিলেও একই boundary পাওয়া যায়। স্বজ্ঞা সরল — করিডোরের প্রস্থ ও অবস্থান তো ঠিক করে দেয় তার প্রান্তে-ছুঁয়ে-থাকা বিন্দুরাই; ভেতরের দিকে দূরে কে আছে তাতে করিডোরের কিছু যায়-আসে না। এর ফলে SVM একটা sparse (বিরল) সমাধান দেয়: হাজার হাজার training-বিন্দুর মধ্যে হয়তো গুটিকয়ই support vector, আর কার্যত boundary-র পুরো তথ্য ওই কয়টাতেই ধরা। (§৪-এ dual-রূপে এটা আরও পরিষ্কার হবে — দেখা যাবে কেবল support vector-দের \(\alpha_i>0\), বাকিদের \(\alpha_i=0\)।) এই কয়টা বিন্দু চিহ্নিত-করা ছবি অধ্যায়ের একাধিক চিত্রে (যেমন max-margin, linear-vs-rbf) দেখা যাবে।
এক বাক্যে। support vector হলো সেই গুটিকয় বিন্দু, যাদের constraint আঁটো (\(y_i(w^\top x_i+b)=1\)) — তারা margin-করিডোরের প্রান্তে বসে এবং একা-হাতেই boundary ঠিক করে; বাকি সব বিন্দু সরিয়ে দিলেও SVM-এর সমাধান অপরিবর্তিত থাকে।
২.৪ Soft-margin — slack, penalty \(C\), ও hinge loss¶
hard-margin-এর দুটো সমস্যা: (এক) data যদি রৈখিকভাবে পৃথকযোগ্য না হয় (overlapping শ্রেণি), তবে কোনো সমাধানই নেই; আর (দুই) এমনকি পৃথকযোগ্য হলেও, একটিমাত্র বিচ্যুত বিন্দু (outlier) বা noise গোটা boundary-কে টেনে বিকৃত করে দিতে পারে, কারণ প্রতিটি বিন্দুকে নিখুঁতভাবে শর্ত মানতেই হয়। বাস্তব data-র জন্য চাই একটা নমনীয় সংস্করণ, যা কিছু বিন্দুকে করিডোরে ঢুকতে — এমনকি ভুল পাশে যেতে — অনুমতি দেয়, তবে তার জন্য একটা দাম নেয়। এটাই soft-margin (নরম-প্রান্ত) SVM।
ধারণাটা: প্রতিটি বিন্দুর জন্য একটা slack variable (শিথিলতা-চলক) \(\xi_i\ge0\) ("xi", \(i=1,\dots,n\)) চালু করি, যা মাপে বিন্দুটা তার নিজের margin-শর্ত কতটা লঙ্ঘন করেছে। constraint শিথিল হয়ে দাঁড়ায়
পড়ুন: বিন্দুটাকে আর পুরো \(1\) margin দিতে হবে না, \(\xi_i\) পরিমাণ ছাড় দেওয়া যাবে। এর তিনটি অবস্থা: \(\xi_i=0\) মানে বিন্দুটা ঠিকঠাক করিডোরের বাইরে (কোনো লঙ্ঘন নেই); \(0<\xi_i\le1\) মানে সে করিডোরের ভেতরে ঢুকেছে কিন্তু এখনও সঠিক পাশে; আর \(\xi_i>1\) মানে সে boundary পেরিয়ে ভুল পাশে চলে গেছে (ভুল শ্রেণিবিন্যাস)। কিন্তু এই ছাড় বিনামূল্যে নয় — আমরা মোট লঙ্ঘন \(\sum_i\xi_i\)-কে objective-এ জরিমানা হিসেবে যোগ করি। সম্পূর্ণ soft-margin সমস্যা:
যেখানে \(C>0\) একটা ব্যবহারকারী-নির্ধারিত স্থির সংখ্যা — penalty বা regularization parameter (জরিমানা-গুণাঙ্ক)। এই \(C\) হলো গোটা soft-margin-এর নিয়ন্ত্রক ঘুঁটি, কারণ সে দুটো পরস্পর-বিরোধী চাওয়ার মধ্যে ভারসাম্য বসায়: একদিকে \(\frac12\lVert w\rVert^2\) ছোট রাখা (চওড়া margin), অন্যদিকে \(\sum_i\xi_i\) ছোট রাখা (কম লঙ্ঘন)।
\(C\)-এর দুই প্রান্তের অর্থ (এই স্বজ্ঞাটা পরে hyperparameter-tuning-এর কেন্দ্র):
- ছোট \(C\) (যেমন \(C\to0\)): লঙ্ঘনের জরিমানা হালকা, তাই model আরও বেশি বিন্দুকে করিডোরে ঢুকতে দিয়ে বদলে চওড়া margin রাখে — সহনশীল, কিন্তু কিছু বিন্দু ভুল হতে পারে (বেশি bias, কম variance)।
- বড় \(C\) (যেমন \(C\to\infty\)): লঙ্ঘন প্রায়-অসহনীয়, তাই model সরু margin নিয়ে হলেও যথাসম্ভব সব বিন্দু সঠিকভাবে আলাদা করতে চায় — hard-margin-এর কাছাকাছি, outlier-সংবেদনশীল (কম bias, বেশি variance)।
(অধ্যায়ের সংখ্যাগুলো এটা স্পষ্ট দেখাবে — RBF-kernel-এ moons-data-তে: \(C=0.1\)-এ নির্ভুলতা \(0.833\) ও support vector \(121\)টি, \(C=1\)-এ \(0.900\)/\(63\), \(C=10\)-এ \(0.944\)/\(45\), \(C=100\)-এ \(0.933\)/\(37\) — অর্থাৎ \(C\) বাড়ার সঙ্গে margin সরু হয়, support vector কমে, কিন্তু খুব বড় \(C\)-তে overfit-প্রবণতায় নির্ভুলতা ফের সামান্য নামে।)
Hinge loss — একই জিনিসের loss-রূপ। soft-margin-কে আরেকভাবে দেখা যায়, যা 6.1-এর "risk = loss-এর গড়" কাঠামোর সঙ্গে সরাসরি মেলে। প্রতিটি বিন্দুর সর্বনিম্ন প্রয়োজনীয় slack হলো \(\xi_i=\max\{0,\ 1-y_i(w^\top x_i+b)\}\) (যদি functional margin \(\ge1\) হয় তবে কোনো slack লাগে না, নইলে যতটা কম পড়ল ততটা)। এই রাশিটাকেই বলে hinge loss (কব্জা-ক্ষতি):
নামটা "hinge" (কব্জা) কারণ এর আকৃতি — functional margin \(\ge1\) হলে loss ঠিক শূন্য (সমতল অংশ), আর \(<1\) হলে রৈখিকভাবে বাড়ে (ঢালু অংশ) — দেখতে একটা কব্জা বা দরজার-কড়ার মতো ভাঁজ-খাওয়া। এটা ব্যবহার করে গোটা soft-margin সমস্যাকে slack ও constraint ছাড়াই, একটা পরিচিত regularized loss-minimization রূপে লেখা যায়:
যা ঠিক 6.1–6.2-এর সেই চেনা ছাঁচ — "data-তে ভুল কমাও + model-জটিলতা (\(\lVert w\rVert^2\)) দমন করো" — যেখানে \(C\) এই দুইয়ের আপেক্ষিক ওজন নিয়ন্ত্রণ করে। এই দৃষ্টিকোণ logistic regression-এর সঙ্গে SVM-কে এক ছাদের নিচে আনে: দুটোই রৈখিক স্কোর \(w^\top x+b\)-এর উপর একটা loss minimize করে, কেবল loss-এর আকৃতি আলাদা (logistic-এ log-loss, SVM-এ hinge loss)।
এক বাক্যে। soft-margin SVM প্রতিটি বিন্দুকে slack \(\xi_i\ge0\) পরিমাণ margin-লঙ্ঘনের ছাড় দেয় কিন্তু penalty \(C\) দিয়ে তার দাম নেয় — ছোট \(C\) ⇒ চওড়া margin বেশি violation, বড় \(C\) ⇒ সরু margin কম violation — এবং সমতুল্যভাবে এটি hinge loss \(\max(0,1-y_i(w^\top x_i+b))\)-এর regularized minimization, যা SVM-কে logistic-এর মতোই একটা loss-ভিত্তিক classifier বানায়।
২.৫ Dual ও \(\alpha_i\) — সমাধান কেবল inner product-এর ভাষায়¶
এ পর্যন্ত আমরা SVM-কে \((w,b)\)-এর উপর একটা optimization হিসেবে লিখেছি (একে বলে primal রূপ)। কিন্তু 0.3-এর Lagrange-পদ্ধতি দিয়ে একই সমস্যাকে একটা সম্পূর্ণ ভিন্ন, অসাধারণ উপকারী রূপে লেখা যায় — তার নাম dual (দ্বৈত) রূপ। এখানে আমরা কেবল চূড়ান্ত ছবিটা ও তার তাৎপর্য দেব; পুরো ব্যুৎপত্তি (Lagrangian গঠন, KKT শর্ত হয়ে dual-এ পৌঁছানো) §৪-এ।
ধারণাটা: §২.২-এর প্রতিটি constraint \(y_i(w^\top x_i+b)\ge1\)-এর সঙ্গে আমরা একটা Lagrange multiplier \(\alpha_i\ge0\) ("alpha", \(i=1,\dots,n\)) জুড়ি — প্রতিটি training-বিন্দুর জন্য একটা করে dual-চলক। Lagrangian-কে \(w\) ও \(b\)-এর সাপেক্ষে অপ্টিমাইজ করে সরিয়ে দিলে (§৪) সমস্যাটা কেবল \(\alpha_i\)-গুলোর উপর একটা optimization-এ পরিণত হয়, এবং দুটো চাবিকাঠি-ফল বেরিয়ে আসে।
ফল ১ — weight vector হলো support vector-দের ওজনযুক্ত যোগফল। চূড়ান্ত সমাধানে
অর্থাৎ boundary-র normal \(w\) আসলে training-বিন্দুগুলোরই একটা রৈখিক সমাহার, যেখানে \(i\)-তম বিন্দুর অবদানের ওজন \(\alpha_i y_i\) (\(\alpha_i\) তার "গুরুত্ব", \(y_i\) তার দিক)। এবং এখানেই §২.৩-এর sparsity পরিষ্কার গাণিতিক রূপ পায়: কেবল support vector-দের \(\alpha_i>0\), আর অন্য সব (করিডোর থেকে দূরের) বিন্দুর \(\alpha_i=0\)। কাজেই উপরের যোগফলে কার্যত কেবল কয়েকটা পদই টেকে — boundary সত্যিই গুটিকয় বিন্দুর হাতে।
ফল ২ — সর্বত্র কেবল inner product। dual সমস্যায় (এবং নতুন বিন্দুর রায়েও) training-বিন্দুগুলো কখনো একা আসে না — সবসময় আসে জোড়ায়-জোড়ায় inner product \(\langle x_i, x_j\rangle = x_i^\top x_j\) হিসেবে। একইভাবে, একটা নতুন বিন্দু \(x\)-এর জন্য স্কোর \(w^\top x+b\) লেখা যায় কেবল \(\langle x_i, x\rangle\)-গুলোর ভাষায় (যেহেতু \(w^\top x=\sum_i\alpha_i y_i\,x_i^\top x\))। অর্থাৎ গোটা SVM চালাতে আমাদের আসলে বিন্দুগুলোর স্থানাঙ্ক \(x_i\) আলাদাভাবে দরকার নেই — কেবল দরকার তাদের জোড়ায়-জোড়ায় inner product-এর মান।
এই দ্বিতীয় ফলটা আপাতনিরীহ মনে হলেও, এটাই পরের অনুচ্ছেদের kernel trick-এর গোটা দরজা খুলে দেয়: যদি সমাধানে কেবল \(\langle x_i,x_j\rangle\)-ই লাগে, তবে সেই inner product-কে অন্য-কিছু দিয়ে বদলে দিলে কী হয়?
এক বাক্যে। Lagrange multiplier \(\alpha_i\) ব্যবহার করে SVM-কে dual রূপে লেখা যায়, যেখানে \(w=\sum_i\alpha_i y_i x_i\) (কেবল support vector-দের \(\alpha_i>0\)) এবং প্রশিক্ষণ ও রায় — দুটোই — কেবল বিন্দু-জোড়ার inner product \(\langle x_i,x_j\rangle\)-এর উপর নির্ভর করে, যা kernel trick-এর ভিত্তি।
২.৬ Kernel trick — inner product বদলে nonlinear boundary¶
§২.৫-এর শেষ পর্যবেক্ষণ — "SVM-এ কেবল inner product \(\langle x_i,x_j\rangle\)-ই লাগে" — কে এবার একটা শক্তিশালী যন্ত্রে পরিণত করি। §১.৪-এর স্বজ্ঞা ছিল: অরৈখিক data-কে একটা feature map \(\phi\) দিয়ে উচ্চ-মাত্রিক space-এ তুলে নিলে সেখানে রৈখিকভাবে আলাদা করা যায়। ধরা যাক তেমন একটা map আছে, \(\phi:\mathbb{R}^p\to\mathcal{F}\), যা প্রতিটি \(x\)-কে একটা (সম্ভবত বিশাল বা অসীম-মাত্রিক) feature-space \(\mathcal{F}\)-এর বিন্দু \(\phi(x)\)-তে পাঠায়। ওই space-এ SVM চালাতে গেলে, §২.৫ অনুযায়ী, আমাদের কেবল দরকার \(\langle\phi(x_i),\phi(x_j)\rangle\) — অর্থাৎ তোলা-বিন্দুগুলোর জোড়ায়-জোড়ায় inner product, কখনো \(\phi(x_i)\) আলাদাভাবে নয়।
Kernel-এর সংজ্ঞা। এই inner product-কে একটা ফাংশনের নাম দিই — kernel (কার্নেল):
যেখানে \(x,x'\in\mathbb{R}^p\) মূল space-এর যেকোনো দুই বিন্দু, আর \(K(x,x')\) একটা সংখ্যা — তোলা-space-এ তাদের inner product। এখন trick-টা: বহু গুরুত্বপূর্ণ \(\phi\)-এর জন্য, \(K(x,x')\) মূল \(x,x'\)-এর একটা সরল সূত্রে সরাসরি হিসাব করা যায় — \(\phi(x)\) বা \(\phi(x')\) কখনো গণনা না করেই। তাই আমরা SVM-এর প্রতিটি \(\langle x_i,x_j\rangle\)-কে নিছক \(K(x_i,x_j)\) দিয়ে বদলে দিই, ব্যস — কোনো \(\phi\) স্পষ্টভাবে না বানিয়েই কার্যত উচ্চ-মাত্রিক \(\mathcal{F}\)-এ max-margin hyperplane খুঁজে ফেলি। মূল space-এ ফিরে এলে সেই hyperplane একটা nonlinear decision boundary হয়ে দাঁড়ায়। এই "নিচ থেকে উপরে তুলে, সেখানে সমতলে আলাদা করে, ফিরে এসে বাঁকা boundary" — এই গোটা গল্পটা অধ্যায়ের kernel-trick চিত্রে আঁকা থাকবে।
দুটো প্রধান kernel। ব্যবহারিকভাবে সবচেয়ে চেনা দুটি:
-
RBF kernel (radial basis function, ব্যাসার্ধ-ভিত্তিক; একে Gaussian kernel-ও বলে): $$ K(x, x') \;=\; \exp!\big(-\gamma \,\lVert x - x' \rVert^2\big), $$ যেখানে \(\lVert x-x'\rVert^2\) হলো দুই বিন্দুর মধ্যে Euclidean দূরত্বের বর্গ, আর \(\gamma>0\) ("gamma") একটা hyperparameter। এর অর্থ স্বজ্ঞাগত: \(K(x,x')\) মাপে দুই বিন্দু কতটা "কাছাকাছি/সদৃশ" — খুব কাছের বিন্দুর জন্য \(K\approx1\), দূরের জন্য \(K\approx0\)। আর \(\gamma\) ঠিক করে কত দ্রুত এই সাদৃশ্য দূরত্বের সঙ্গে মিলিয়ে যায় (এর গভীর প্রভাব §২.৭-এ)। RBF kernel-ই এই অধ্যায়ের প্রধান অস্ত্র — moons-এর মতো অরৈখিক data-তে এটাই জয় এনে দেয়।
-
Polynomial kernel (বহুপদী): $$ K(x, x') \;=\; \big(\langle x, x'\rangle + c\big)^{d}, $$ যেখানে \(d\) একটা ধনাত্মক পূর্ণসংখ্যা — বহুপদীর degree (ঘাত), আর \(c\ge0\) একটা স্থির সংখ্যা। এই kernel কার্যত মূল feature-গুলোর সমস্ত \(d\)-ঘাত পর্যন্ত গুণফল-সংমিশ্রণকে feature হিসেবে যোগ করার সমতুল্য — অর্থাৎ \(d=2\) হলে boundary দ্বিঘাত (বৃত্ত/উপবৃত্ত-জাতীয়), উচ্চতর \(d\)-তে আরও জটিল।
(যেকোনো ফাংশনই বৈধ kernel নয় — \(K\)-কে একটা সত্যিকারের inner product-এর সঙ্গে মিলতে হলে তাকে একটা শর্ত — Mercer condition — মানতে হয়, যা §৪-এ আলোচিত হবে। RBF ও polynomial — দুটোই এই শর্ত মেনে চলে, তাই বৈধ।)
এক বাক্যে। kernel trick হলো — SVM-এ প্রতিটি inner product \(\langle x,x'\rangle\)-কে একটা kernel \(K(x,x')=\langle\phi(x),\phi(x')\rangle\) দিয়ে বদলে দেওয়া, যা feature-map \(\phi\) স্পষ্টভাবে না বানিয়েই উচ্চ-মাত্রিক space-এ রৈখিক (অথচ মূল space-এ nonlinear) boundary গড়ে; দুই প্রধান kernel হলো RBF \(\exp(-\gamma\lVert x-x'\rVert^2)\) ও polynomial \((\langle x,x'\rangle+c)^d\)।
২.৭ \(C\) ও \(\gamma\) tuning — bias–variance ভারসাম্য¶
kernel-যুক্ত SVM-এ এখন দুটো গুরুত্বপূর্ণ hyperparameter আছে (যেগুলো data থেকে শেখা হয় না, ব্যবহারকারীকে বাইরে থেকে বাছতে হয়): penalty \(C\) আর RBF-এর \(\gamma\)। এদের ভূমিকা আলাদা কিন্তু পরস্পর-জড়িত, এবং দুটোই সরাসরি 6.1-এর bias–variance ভারসাম্যের সঙ্গে যুক্ত।
-
\(C\) (§২.৪ থেকে): margin-প্রস্থ বনাম violation নিয়ন্ত্রণ করে। ছোট \(C\) ⇒ চওড়া margin, বেশি ছাড়, মসৃণ/সরল boundary (বেশি bias, কম variance); বড় \(C\) ⇒ সরু margin, কম ছাড়, training-data আঁকড়ে ধরা boundary (কম bias, বেশি variance — overfit-প্রবণ)।
-
\(\gamma\) (RBF-এর প্রভাব-পরিসর): এটি ঠিক করে প্রতিটি training-বিন্দুর প্রভাব feature-space-এ কতদূর পৌঁছায়। ছোট \(\gamma\) ⇒ প্রতিটি বিন্দুর প্রভাব বহুদূর বিস্তৃত ⇒ boundary খুব মসৃণ ও সরল (অতি-ছোট \(\gamma\)-তে প্রায় রৈখিক, underfit-প্রবণ — বেশি bias)। বড় \(\gamma\) ⇒ প্রতিটি বিন্দুর প্রভাব কেবল তার নিজের চারপাশে সীমাবদ্ধ ⇒ boundary প্রতিটি বিন্দুকে আলাদাভাবে ঘিরে ধরা, অত্যন্ত এবড়োখেবড়ো (overfit-প্রবণ — বেশি variance, প্রায় k-NN-এর মতো আচরণ)।
(অধ্যায়ের সংখ্যাগুলো এটা স্পষ্ট দেখাবে — moons-data, RBF, \(\gamma\)-এর প্রভাব: \(\gamma=0.1\)-এ নির্ভুলতা \(0.800\) (অতি-মসৃণ, underfit), \(\gamma=5\)-এ \(0.956\) (ভালো ভারসাম্য), \(\gamma=20\)-এ \(0.956\) কিন্তু support vector লাফিয়ে \(132\)টিতে — অর্থাৎ boundary data-কে মুখস্থ করছে, overfit।)
যেহেতু \(C\) আর \(\gamma\) একসঙ্গে boundary-র জটিলতা ঠিক করে, এদের আলাদাভাবে নয়, একসাথে বাছতে হয় — সাধারণত একটা মান-জোড়ার জাল (grid) ধরে প্রতিটি \((C,\gamma)\) জোড়ায় cross-validation (5.8-এর — data-কে fold-এ ভাগ করে বারবার held-out অংশে পরখ) চালিয়ে, যে জোড়া সর্বোচ্চ গড় validation-নির্ভুলতা দেয় সেটা নেওয়া হয়। এই প্রক্রিয়াটাই (একে বলে grid search with cross-validation) মূলত একটা bias–variance খোঁজ — খুব-সরল (underfit) ও খুব-জটিল (overfit) boundary-র মাঝামাঝি সেই "মিষ্টি বিন্দু" খুঁজে বের করা। এই \(C\)–\(\gamma\) জালের প্রভাব অধ্যায়ের C-gamma চিত্রে দেখানো হবে।
এক বাক্যে। \(C\) নিয়ন্ত্রণ করে margin-প্রস্থ বনাম violation, আর \(\gamma\) নিয়ন্ত্রণ করে RBF-kernel-এর প্রভাব-পরিসর (ছোট \(\gamma\) ⇒ মসৃণ/underfit, বড় \(\gamma\) ⇒ এবড়োখেবড়ো/overfit) — দুটোই boundary-র জটিলতা ঠিক করে, তাই এদের একসাথে cross-validation দিয়ে বাছা মানে আসলে একটা bias–variance ভারসাম্য খোঁজা।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে চারটি ক্রমবর্ধমান উদাহরণের মধ্য দিয়ে SVM-এর মূল ধারণাগুলো হাতে-কলমে দেখা হবে। প্রথমে একটা ছোট, perfectly separable dataset-এ max-margin ও support vector-এর জ্যামিতি (E1); তারপর একটা non-linear dataset-এ linear SVM ব্যর্থ হলে kernel trick কীভাবে উদ্ধার করে (E2); এরপর soft-margin penalty \(C\)-এর ভূমিকা (E3); সবশেষে RBF kernel-এর \(\gamma\) এবং overfitting, এবং একটা সারাংশ টেবিল (E4)। প্রতিটি সংখ্যা scikit-learn-এ SVC দিয়ে নিচে যাচাই করা।
সব non-linear উদাহরণে একই dataset ব্যবহার করা হবে — make_moons-এর দুটো জড়ানো অর্ধচন্দ্র, যা ইচ্ছাকৃতভাবে linearly inseparable:
import numpy as np
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = make_moons(n_samples=300, noise=0.25, random_state=20260619)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
# 210 train / 90 test, label y ∈ {0, 1} (SVM-এর ভেতরে ±1-এ ম্যাপ হয়)
৩.১ E1 — Max-margin এবং support vector-এর জ্যামিতি¶
আগে একটা পরিষ্কার, perfectly separable পরিস্থিতি দেখা যাক, যেখানে hard-margin SVM কোনো ভুল ছাড়াই দুই শ্রেণিকে আলাদা করতে পারে। দুটো আলাদা cluster তৈরি করে তাতে hard-margin (অর্থাৎ খুব বড় \(C\), কার্যত \(C\to\infty\)) linear SVM ফিট করি:
rng = np.random.default_rng(20260619)
A = rng.normal([0, 0], 0.5, (30, 2)) # class -1
B = rng.normal([3, 3], 0.5, (30, 2)) # class +1
Xb = np.vstack([A, B]); yb = np.r_[np.full(30, -1), np.full(30, 1)]
hard = SVC(kernel="linear", C=1e6).fit(Xb, yb) # C বিশাল → কোনো slack নেই
margin = 2.0 / np.linalg.norm(hard.coef_[0]) # 2 / ‖w‖
print(hard.support_vectors_.shape[0], round(margin, 3)) # 3 2.678
ফলাফল: hyperplane \(w^\top x + b = 0\) এমনভাবে বসে যে দুই cluster-এর মাঝখানের "রাস্তা" (street) সবচেয়ে চওড়া হয়। এই street-এর প্রস্থ ঠিক \(2/\lVert w\rVert = 2.678\)। এখানেই SVM-এর কেন্দ্রীয় নীতি: সব hyperplane যা দুই শ্রেণিকে আলাদা করে, তাদের মধ্যে SVM সেটাকেই বেছে নেয় যার margin সর্বোচ্চ — এটাই maximum-margin classifier।
সবচেয়ে গুরুত্বপূর্ণ পর্যবেক্ষণ: এই উদাহরণে ৬০টি বিন্দুর মধ্যে কেবল ৩টি support vector boundary-টা নির্ধারণ করছে। Support vector হলো সেই বিন্দুগুলো যারা ঠিক margin-এর কিনারায় বসে আছে — যাদের জন্য \(y_i(w^\top x_i + b) = 1\)। বাকি ৫৭টি বিন্দু margin-এর "ভেতরের" দিকে নিরাপদ দূরত্বে থাকায় solution-এ তাদের কোনো অবদান নেই: dual formulation-এ তাদের \(\alpha_i = 0\)। এর একটা চমকপ্রদ পরিণতি আছে — যদি কোনো non-support-vector বিন্দু সরিয়ে দেওয়া হয় বা একটু নাড়ানো হয়, hyperplane এক চুলও নড়বে না। Decision boundary সম্পূর্ণভাবে শুধু support vector-গুলোর উপর নির্ভরশীল; এ কারণেই SVM-কে memory-efficient ও outlier-এর প্রতি (margin-এর বাইরের বিন্দুর ক্ষেত্রে) দৃঢ় বলা হয়।
জ্যামিতিটা নিচে চিত্রিত:
x₂
│ ◇ ◇ ◇ ← class +1 (◇)
│ ◇ ●◇ ◇ ● = support vector (on margin edge)
│ ╲ ◇ ╲ ◇
upper │ · · · ╲· · · · ╲· · · · · margin edge: wᵀx + b = +1
margin│ ╲ ╲ ╲
│ ╲ ╲ decision boundary: wᵀx + b = 0
lower │· · · · ╲· ·●· · · ╲· · · · margin edge: wᵀx + b = −1
margin│ △ ╲ ╲ ╲
│ △ △ △ ╲ ◀── street width = 2/‖w‖ = 2.678
│ △ ●△ △ ╲ (only 3 ● support vectors fix the street)
│ △ △ △
└──────────────────────────── x₁
class −1 (△)
৩.২ E2 — Linear SVM ব্যর্থ হয়, kernel জেতে¶
এবার make_moons dataset-এ ফিরি, যেখানে দুটো শ্রেণি একে অপরের মধ্যে আঁকাবাঁকাভাবে জড়ানো। প্রথমে straight-line (linear) SVM চেষ্টা করি:
lin = SVC(kernel="linear", C=1).fit(X_train, y_train)
print(round(lin.score(X_test, y_test), 3), # 0.811
lin.support_vectors_.shape[0]) # 74
Test accuracy মাত্র 0.811 — এবং ২১০টি train বিন্দুর মধ্যে ৭৪টি support vector, যা একটা স্পষ্ট সংকেত যে কোনো সরলরেখা এই দুই অর্ধচন্দ্রকে ভালোভাবে আলাদা করতে পারছে না। ডেটা linearly separable নয়; একটা একক straight line দিয়ে এই বাঁকানো সীমানা ধরা অসম্ভব।
এখানেই kernel trick আসে। RBF kernel $\(K(x, x') = \exp\!\big(-\gamma\,\lVert x - x'\rVert^2\big)\)$ ব্যবহার করলে, SVM যেন বিন্দুগুলোকে একটা উচ্চ-মাত্রিক feature space-এ ম্যাপ করে সেখানে একটা hyperplane বসায় — অথচ কখনো সেই উচ্চ-মাত্রিক স্থানে স্পষ্টভাবে যেতে হয় না (শুধু inner product \(K(x,x')\) লাগে)। মূল 2D-তে এর ফল হলো একটা বাঁকানো decision boundary:
rbf1 = SVC(kernel="rbf", C=1, gamma="scale").fit(X_train, y_train)
print(round(rbf1.score(X_test, y_test), 3), # 0.900
rbf1.support_vectors_.shape[0]) # 63
rbf10 = SVC(kernel="rbf", C=10, gamma="scale").fit(X_train, y_train)
print(round(rbf10.score(X_test, y_test), 3), # 0.944
rbf10.support_vectors_.shape[0]) # 45
RBF kernel-সহ accuracy লাফ দিয়ে 0.900-তে (\(C=1\)) এবং penalty বাড়িয়ে 0.944-তে (\(C=10\)) পৌঁছায় — linear-এর 0.811 থেকে বড় উন্নতি। একই সঙ্গে support vector কমে 74 → 63 → 45, কারণ একটা ভালো-মানানো boundary-র আশেপাশে কম বিন্দুকেই "সীমান্তরক্ষী" হিসেবে রাখতে হয়। সংক্ষেপে: kernel trick 2D ছাড়াই boundary-টাকে বাঁকিয়ে দেয়, আর তাতেই non-linear pattern ধরা পড়ে।
তুলনার জন্য একটা polynomial kernel-ও দেখা যাক:
poly = SVC(kernel="poly", degree=3, C=1, gamma="scale").fit(X_train, y_train)
print(round(poly.score(X_test, y_test), 3)) # 0.833
Degree-3 polynomial kernel 0.833 দেয় — linear-এর চেয়ে ভালো, কিন্তু এই moon-আকৃতির জন্য RBF-এর 0.900-এর চেয়ে দুর্বল। তাই এই dataset-এ RBF-ই স্বাভাবিক পছন্দ।
linear (straight cut) RBF kernel (curved boundary)
●●●╲ ●● ●●● ╭─╮ ●●
●●●● ╲●● ●●●●╱ ╰╮●
●●●●● ╲ ●●●●● │ ← boundary bends
────── ╲ ── line can't ╭────────╯ around the moons
△△△ ╲ △ separate the │ △△△△△
△△△△ ╲△△ two moons ╰─╮ △△△△△△
△△△△ ╲ ╰── △△△△
acc = 0.811 acc = 0.900 (C=1) / 0.944 (C=10)
৩.৩ E3 — Soft-margin: penalty \(C\)-এর ভূমিকা¶
বাস্তব (noisy) ডেটায় hard margin প্রায়ই অসম্ভব, তাই soft margin slack variable \(\xi_i \ge 0\) চালু করে কিছু বিন্দুকে margin লঙ্ঘন বা ভুল-শ্রেণিভুক্ত হতে দেয়। objective হয় $\(\min_{w,b,\xi}\;\tfrac12\lVert w\rVert^2 + C\sum_i \xi_i,\)$ যেখানে penalty \(C\) ঠিক করে দেয় margin চওড়া রাখার (\(\lVert w\rVert\) ছোট) আর violation কমানোর (\(\sum\xi_i\) ছোট) মধ্যে কোনটাকে প্রাধান্য দেওয়া হবে। RBF kernel (gamma='scale') রেখে \(C\) পাল্টে দেখি:
for C in [0.1, 1, 10, 100]:
m = SVC(kernel="rbf", C=C, gamma="scale").fit(X_train, y_train)
print(C, round(m.score(X_test, y_test), 3), m.support_vectors_.shape[0])
# 0.1 0.833 121
# 1 0.900 63
# 10 0.944 45
# 100 0.933 37
| \(C\) | margin | test acc | #SV | চরিত্র |
|---|---|---|---|---|
| 0.1 | চওড়া | 0.833 | 121 | অনেক violation সহ্য করে; high bias |
| 1 | মাঝারি | 0.900 | 63 | ভারসাম্যপূর্ণ |
| 10 | সরু | 0.944 | 45 | কঠোর; এই ডেটায় সেরা |
| 100 | খুব সরু | 0.933 | 37 | সামান্য overfit; acc নামে |
প্যাটার্নটা পরিষ্কার এবং SVM বোঝার জন্য কেন্দ্রীয়:
- ছোট \(C\) (যেমন 0.1): violation-এর শাস্তি কম, তাই margin চওড়া হয়, অনেক বিন্দু margin-এর ভেতরে ঢুকে support vector হয়ে যায় (121 SV) — মডেল বেশি tolerant, high bias, accuracy কম (0.833)।
- বড় \(C\) (যেমন 100): প্রতিটি violation-এর শাস্তি চড়া, margin সরু হয়ে training data-কে যথাসম্ভব নিখুঁতভাবে ফিট করতে চায়; support vector কমে 37-এ নামে — high variance, সামান্য overfit, তাই test accuracy 0.944 থেকে 0.933-এ নেমে আসে।
অর্থাৎ ছোট \(C\) = চওড়া margin / বেশি SV / বেশি bias; বড় \(C\) = সরু margin / কম SV / বেশি variance। এই উদাহরণে \(C=10\) মিষ্টি বিন্দু (0.944)।
৩.৪ E4 — RBF-এর \(\gamma\), overfitting, এবং সারাংশ¶
RBF kernel-এ \(\gamma\) নিয়ন্ত্রণ করে প্রতিটি training বিন্দুর প্রভাব কতটা দূর পর্যন্ত ছড়ায়: ছোট \(\gamma\) মানে প্রশস্ত, মসৃণ প্রভাব; বড় \(\gamma\) মানে প্রতিটি বিন্দুর প্রভাব খুব সংকীর্ণ, ফলে boundary অত্যন্ত আঁকাবাঁকা হয়ে individual বিন্দু ঘিরে ফেলে। \(C=1\) স্থির রেখে \(\gamma\) পাল্টাই:
for g in [0.1, 0.5, 1, 5, 20]:
m = SVC(kernel="rbf", C=1, gamma=g).fit(X_train, y_train)
print(g, round(m.score(X_test, y_test), 3), m.support_vectors_.shape[0])
# 0.1 0.800 (too smooth — underfit)
# 0.5 0.900
# 1 0.900
# 5 0.956
# 20 0.956 132 (overfit — almost every point is an SV)
- \(\gamma = 0.1\): boundary খুব মসৃণ, moon-এর বাঁক ধরতে পারে না — accuracy কমে 0.800 (underfit)।
- \(\gamma = 5\): যথেষ্ট নমনীয়, accuracy 0.956।
- \(\gamma = 20\): accuracy এখনও 0.956, কিন্তু support vector বেড়ে 132 (210 train-এর প্রায় ৬৩%!) — কার্যত প্রতিটি বিন্দুই support vector হয়ে যাচ্ছে। এটা overfitting-এর স্পষ্ট সংকেত: মডেল আর সাধারণ pattern শিখছে না, প্রতিটি training বিন্দু মুখস্থ করছে। test accuracy এখানে দৈবক্রমে ভালো থাকলেও এত বেশি #SV মডেলকে ভঙ্গুর ও generalization-এর জন্য ঝুঁকিপূর্ণ করে তোলে।
লক্ষণীয়: #SV মডেলের জটিলতার একটা সরাসরি সূচক। \(C\) বা \(\gamma\) যা-ই হোক, support vector-এর সংখ্যা যখন প্রায় গোটা training set-এর সমান হয়ে যায়, তখন বুঝতে হবে মডেল overfit করছে।
সারাংশ টেবিল — make_moons (210 train / 90 test):
| মডেল | kernel | \(C\) | \(\gamma\) | test acc | #SV | মন্তব্য |
|---|---|---|---|---|---|---|
| Linear SVM | linear | 1 | — | 0.811 | 74 | linearly inseparable → ব্যর্থ |
| Poly (deg 3) | poly | 1 | scale | 0.833 | — | linear-এর চেয়ে ভালো, RBF-এর চেয়ে দুর্বল |
| RBF | rbf | 1 | scale | 0.900 | 63 | kernel trick → বাঁকানো boundary |
| RBF | rbf | 10 | scale | 0.944 | 45 | এই ডেটায় সেরা |
| RBF (small \(C\)) | rbf | 0.1 | scale | 0.833 | 121 | চওড়া margin, high bias |
| RBF (large \(C\)) | rbf | 100 | scale | 0.933 | 37 | সরু margin, সামান্য overfit |
| RBF (\(\gamma\) small) | rbf | 1 | 0.1 | 0.800 | — | too smooth, underfit |
| RBF (\(\gamma\) large) | rbf | 1 | 20 | 0.956 | 132 | overfit — প্রায় সব বিন্দুই SV |
মূল takeaway: linear SVM শুধু linearly separable ডেটায় কাজ করে (এখানে মাত্র 0.811); tuned \(C\) ও \(\gamma\)-সহ RBF SVM non-linear pattern অনায়াসে ধরে (0.944 পর্যন্ত)। \(C\) ভারসাম্য রাখে bias আর variance-এর মধ্যে, \(\gamma\) নিয়ন্ত্রণ করে boundary-র নমনীয়তা, আর support vector-এর সংখ্যা মডেল-জটিলতার একটা স্বচ্ছ সংকেত — খুব বেশি হলে overfitting-এর সাবধানবাণী।
যাচাই (scikit-learn 1.x, উপরের কোড চালিয়ে):
সব canonical সংখ্যা মিলেছে।train/test : 210 / 90 Linear C=1 : acc 0.811, #SV 74 RBF C=1, gamma=scale : acc 0.900, #SV 63 RBF C=10, gamma=scale : acc 0.944, #SV 45 Poly deg=3, C=1 : acc 0.833 C-effect (RBF, gamma=scale): C=0.1 → 0.833 / 121 SV C=1 → 0.900 / 63 SV C=10 → 0.944 / 45 SV C=100 → 0.933 / 37 SV gamma-effect (RBF, C=1): γ=0.1 → 0.800 γ=0.5 → 0.900 γ=1 → 0.900 γ=5 → 0.956 γ=20 → 0.956 / 132 SV Hard-margin demo (np-rng দুই গুচ্ছ, 60 points, separable): 3 support vectors, margin 2.678
৪ · প্রমাণ ও উৎপাদন¶
আগের sections-এ আমরা Support Vector Machine-এর ছবিটা intuition-এর স্তরে দেখেছি: দুই ক্লাসের মাঝখানে যত চওড়া সম্ভব একটা "রাস্তা" (margin) বসিয়ে তার মাঝবরাবর একটা separating hyperplane টানা। এবার আমরা সেই ছবিটাকে কলম-হাতে গণিতে রূপান্তর করব — ধাপে ধাপে, কোনো ফাঁক না রেখে। গল্পের কাঠামোটা এরকম: প্রথমে দেখাব "সবচেয়ে চওড়া margin" চাওয়াটা আসলে একটা সুনির্দিষ্ট convex quadratic program (QP); তারপর Lagrange duality দিয়ে সেই সমস্যাটাকে এমন রূপে আনব যেখানে data শুধু inner product-এর মধ্য দিয়ে ঢোকে — আর ঠিক এই বৈশিষ্ট্যই kernel trick-এর দরজা খুলে দেয়, যা একটা linear classifier-কে input-space-এ বাঁকানো (nonlinear) boundary আঁকতে দেয় কোনো high-dimensional feature কখনো হিসাব না করেই।
প্রতিটি উপ-section-এর শিরোনামে difficulty tag দেওয়া (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং)। notation শুরু থেকে শেষ পর্যন্ত একই: training data \(\{(x_i,y_i)\}_{i=1}^n\) যেখানে \(x_i\in\mathbb R^p\) আর label \(y_i\in\{-1,+1\}\); separating hyperplane \(\{x:w^\top x+b=0\}\) যেখানে \(w\in\mathbb R^p\) তার normal vector আর \(b\in\mathbb R\) একটা offset; classifier-এর সিদ্ধান্ত \(\hat y(x)=\operatorname{sign}(w^\top x+b)\)। dual/Lagrange variable হবে \(\alpha_i\ge0\), slack হবে \(\xi_i\ge0\), penalty constant হবে \(C>0\), আর kernel হবে \(K(x,x')=\langle\phi(x),\phi(x')\rangle\)।
৪.১ Margin \(=2/\lVert w\rVert\) এবং primal QP ★★¶
লক্ষ্য¶
আমরা দেখাব: canonical scaling-এ (যেখানে নিকটতম বিন্দুগুলোর জন্য \(\lvert w^\top x_i+b\rvert=1\)) দুই ক্লাসের margin-সীমানা ঠিক \(2/\lVert w\rVert\) দূরত্বে থাকে। ফলে "margin সর্বোচ্চ করা" মানে \(\lVert w\rVert\) সর্বনিম্ন করা, এবং পুরো সমস্যাটা দাঁড়ায়
এটাই hard-margin SVM-এর primal QP — একটা convex objective (quadratic) আর linear constraints।
ধাপ ১ — একটা বিন্দু থেকে hyperplane-এর দূরত্ব¶
ধরুন একটা hyperplane \(H=\{x:w^\top x+b=0\}\) আর একটা বিন্দু \(x_0\)। \(H\)-এর উপর \(x_0\)-এর লম্ব-প্রক্ষেপণ (foot of perpendicular) থেকে \(x_0\) পর্যন্ত দূরত্বটা চাই। \(w\) যেহেতু \(H\)-এর সাথে লম্ব (normal), \(x_0\) থেকে \(H\)-এ পৌঁছানো যায় \(w\)-এর দিকেই একটু সরে: কোনো scalar \(t\)-এর জন্য projection হবে \(x_0-t\,w\), আর সেটা \(H\)-এ থাকতে হবে —
তাহলে \(x_0\) থেকে \(H\) পর্যন্ত দূরত্ব হলো প্রক্ষেপণ-সরণের দৈর্ঘ্য \(\lVert t\,w\rVert=\lvert t\rvert\,\lVert w\rVert\):
অর্থাৎ যেকোনো বিন্দুর hyperplane থেকে দূরত্ব \(=\dfrac{\lvert w^\top x_0+b\rvert}{\lVert w\rVert}\) — সংখ্যাটার লব হলো "signed score"-এর পরম-মান, আর হর normal-এর দৈর্ঘ্য দিয়ে তাকে সঠিক স্কেলে আনে।
ধাপ ২ — canonical scaling এবং margin-প্রস্থ¶
লক্ষ করুন একটা সূক্ষ্ম স্বাধীনতা: \((w,b)\) আর \((\kappa w,\kappa b)\) যেকোনো \(\kappa>0\)-এর জন্য একই hyperplane বর্ণনা করে (সমীকরণ \(w^\top x+b=0\) দুদিকে \(\kappa\) গুণ করলে অপরিবর্তিত)। এই স্বাধীনতা কাজে লাগিয়ে আমরা স্কেল এমনভাবে স্থির করি যেন hyperplane-এর সবচেয়ে কাছের বিন্দুগুলোর জন্য
একে বলে canonical (বা canonical-form) scaling। এর ফলে সব training বিন্দুর জন্য \(\lvert w^\top x_i+b\rvert\ge1\), আর label-চিহ্ন ব্যবহার করে (\(y_i\) আর \(w^\top x_i+b\) একই চিহ্নের হলে সঠিক শ্রেণিবিন্যাস) এটা পরিষ্কার linear constraint-এ লেখা যায়:
যেখানে সমতা ঘটে ঠিক সেই নিকটতম বিন্দুগুলোতে যারা margin-সীমানার গায়ে বসে। দুই ক্লাসের margin-সীমানা তাই দুটো সমান্তরাল hyperplane: \(w^\top x+b=+1\) আর \(w^\top x+b=-1\)। ধাপ ১-এর দূরত্ব-সূত্র প্রয়োগ করে এদের প্রতিটির কেন্দ্রীয় hyperplane (\(w^\top x+b=0\)) থেকে দূরত্ব
তাই দুই সীমানার মধ্যে মোট ব্যবধান — অর্থাৎ margin-প্রস্থ —
ধাপ ৩ — maximize margin \(=\) minimize \(\tfrac12\lVert w\rVert^2\)¶
margin \(=2/\lVert w\rVert\) সর্বোচ্চ করা মানে হর \(\lVert w\rVert\) সর্বনিম্ন করা (যেহেতু লব ধ্রুবক)। \(\lVert w\rVert\ge0\)-তে \(\lVert w\rVert\) সর্বনিম্ন করা আর \(\tfrac12\lVert w\rVert^2\) সর্বনিম্ন করা একই কাজ (\(t\mapsto\tfrac12 t^2\) ফাংশনটা \(t\ge0\)-তে strictly increasing, তাই argmin বদলায় না)। বর্গ-রূপটা বেছে নিই দুটি কারণে: এটা differentiable (কোনো \(\lVert\cdot\rVert\)-জাত non-smooth kink নেই), আর এটা \(w\)-তে convex quadratic — ফলে constraints-গুলো linear হওয়ায় গোটা সমস্যা একটা সুন্দর convex QP, যার একটাই global minimum। তাই hard-margin SVM-এর primal:
জ্যামিতিক যাচাই। সহজ এক-মাত্রিক উদাহরণ: \(x_1=+1\) (\(y_1=+1\)), \(x_2=-1\) (\(y_2=-1\)), আর প্রতিসাম্যে \(w=(a),\,b=0\)। canonical constraint \(y_i(w^\top x_i+b)=a\cdot1\ge1\), নিকটতম বিন্দুতে সমতা দিলে \(a=1\), তাই \(\lVert w\rVert=1\) এবং margin \(=2/\lVert w\rVert=2\) — যা সরাসরি দেখা যায়, কারণ দুই বিন্দু \(+1\) ও \(-1\)-এর মাঝে দূরত্বই \(2\), আর সীমানা মাঝবরাবর \(x=0\)-তে। যেকোনো অন্য বৈধ \((w,b)\) এর চেয়ে সরু margin দেবে।
এই QP-র সীমা। এটা সুন্দর কিন্তু দুটো সমস্যা আছে: (১) constraint-গুলো data-র মধ্য দিয়ে সরাসরি \(x_i\)-তে আসছে — high-dimensional বা nonlinear feature যোগ করতে গেলে এটা অসুবিধাজনক; (২) data linearly separable না হলে কোনো বৈধ \((w,b)\)-ই থাকে না (feasible set ফাঁকা)। পরের উপ-section duality দিয়ে প্রথম সমস্যার সমাধানের পথ খুলবে, আর §৪.৩ slack দিয়ে দ্বিতীয়টা সামলাবে।
৪.২ Lagrangian dual ও support vectors ★★★¶
লক্ষ্য¶
primal QP-টাকে আমরা এর Lagrangian dual-এ রূপান্তর করব এবং দেখাব দুটো গুরুত্বপূর্ণ ব্যাপার: (১) optimal weight vector হলো data-র একটা ভারিত যোগফল \(w=\sum_i\alpha_i y_i x_i\), আর (২) KKT complementary slackness-এর কারণে \(\alpha_i>0\) হয় কেবল সেই বিন্দুগুলোর জন্য যারা margin-সীমানার ঠিক উপর — এদেরই বলে support vectors। ফলে boundary নির্ধারিত হয় গুটিকয় বিন্দু দিয়ে, পুরো dataset দিয়ে নয়। dual সমস্যাটা দাঁড়াবে
ধাপ ১ — Lagrangian গঠন¶
primal-এর প্রতিটি inequality constraint \(y_i(w^\top x_i+b)-1\ge0\)-এর জন্য একটা multiplier \(\alpha_i\ge0\) বসিয়ে Lagrangian (prereq 0.3):
স্বরণ করুন duality-র যুক্তি: constraint লঙ্ঘিত হলে (\(y_i(w^\top x_i+b)-1<0\)) ওই পদটা ধনাত্মক \(\alpha_i\) দিয়ে গুণ হয়ে \(L\)-কে বাড়াতে চায়, তাই \(\alpha_i\)-এর উপর sup আর \((w,b)\)-এর উপর inf নিলে শাস্তি স্বয়ংক্রিয়ভাবে আরোপিত হয়। যেহেতু primal convex আর constraints linear (Slater-শর্ত পূর্ণ, separable ক্ষেত্রে), strong duality ধরে — তাই dual-এর সমাধান primal-এর সমাধান হুবহু দেয়।
ধাপ ২ — stationarity (KKT-র প্রথম শর্ত)¶
minimum-এ \(L\)-এর \(w\) ও \(b\)-এর সাপেক্ষে gradient শূন্য হতে হবে।
\(w\)-এর সাপেক্ষে (\(\nabla_w\tfrac12\lVert w\rVert^2=w\), আর \(\nabla_w(w^\top x_i)=x_i\)):
এটাই প্রথম মূল ফল: optimal \(w\) হলো training বিন্দুগুলোর একটা linear combination, যেখানে প্রতিটি বিন্দুর অবদান তার label \(y_i\) আর ওজন \(\alpha_i\)-নির্ভর।
\(b\)-এর সাপেক্ষে (\(L\)-এ \(b\) আসে শুধু \(-\sum_i\alpha_i y_i b\) পদে):
এটা dual-এর একটা সমতা-constraint হিসেবে টিকে থাকবে।
ধাপ ৩ — substitute করে dual বের করা¶
ধাপ ২-এর দুটো সম্পর্ক \(L\)-এ ফেরত বসাই। প্রথমে \(\lVert w\rVert^2=w^\top w\) পদটা \(w=\sum_i\alpha_i y_i x_i\) দিয়ে:
এবার Lagrangian-এর দ্বিতীয় অংশ খুলি:
মাঝের পদটা শূন্য (ধাপ ২), আর প্রথম পদ \(=w^\top w=\lVert w\rVert^2=\sum_{i,j}\alpha_i\alpha_j y_i y_j x_i^\top x_j\)। সব একসাথে বসিয়ে:
অর্থাৎ dual objective
যাকে \(\alpha_i\ge0\) ও \(\sum_i\alpha_i y_i=0\)-এর অধীনে maximize করতে হয় (box-এর dual)। দুটো ব্যাপার এখানে চোখে রাখুন: (১) dual-এ আর \(w,b\) নেই — শুধু \(\alpha\), আর সংখ্যায় constraint সরল (একটা box \(\alpha_i\ge0\) + একটা linear সমতা); (২) data ঢুকেছে কেবল inner product \(x_i^\top x_j\)-এর মধ্য দিয়ে — §৪.৪-এ এটাই সব বদলে দেবে।
ধাপ ৪ — complementary slackness ও support vectors¶
KKT-শর্তের শেষ অংশ complementary slackness: প্রতিটি constraint-multiplier জোড়ার জন্য optimum-এ
অর্থাৎ প্রতিটি \(i\)-তে দুটোর অন্তত একটা শূন্য। এর থেকে দুটো ঘটনা:
- যদি বিন্দু \(i\) margin-সীমানার ভেতরে (অর্থাৎ \(y_i(w^\top x_i+b)>1\), কড়া অসমতা), তবে বর্গাকার-বন্ধনীর রাশি ধনাত্মক, তাই বাধ্যতামূলকভাবে \(\alpha_i=0\) — এই বিন্দু \(w=\sum_i\alpha_i y_i x_i\)-এ কোনো অবদান রাখে না।
- \(\alpha_i>0\) কেবল তখনই সম্ভব যখন \(y_i(w^\top x_i+b)=1\), অর্থাৎ বিন্দুটা margin-সীমানার ঠিক উপর।
এই দ্বিতীয় শ্রেণির বিন্দুগুলোকেই বলে support vectors:
ফলে separating hyperplane নির্ধারিত হয় কেবল margin-এর উপর বসা গুটিকয় বিন্দু দিয়ে — বাকি (প্রায়ই বেশিরভাগ) বিন্দু সরালেও সমাধান অপরিবর্তিত থাকে। এটাই "support vector" নামের উৎস: এরাই margin-কে "ঠেকনা" দিয়ে রাখে। (\(b\) যেকোনো একটা support vector থেকে পাওয়া যায়: \(y_s(w^\top x_s+b)=1\Rightarrow b=y_s-w^\top x_s\), কারণ \(y_s\in\{-1,+1\}\) তাই \(1/y_s=y_s\)।) \(\;\blacksquare\)
যাচাইয়ের স্কেচ। আগের এক-মাত্রিক উদাহরণে (\(x_1=+1,x_2=-1\)) প্রতিসাম্যে \(\alpha_1=\alpha_2=\alpha\); সমতা-constraint \(\sum_i\alpha_i y_i=\alpha-\alpha=0\) আপনা-আপনি পূর্ণ। dual objective দাঁড়ায় \(2\alpha-\tfrac12\alpha^2\!\sum_{i,j}y_iy_j x_i^\top x_j\); এখানে \(\sum_{i,j}y_iy_jx_i^\top x_j=(x_1-x_2)^\top(x_1-x_2)=\lVert x_1-x_2\rVert^2=4\), তাই \(g(\alpha)=2\alpha-2\alpha^2\), \(g'(\alpha)=2-4\alpha=0\Rightarrow\alpha=\tfrac12\)। তখন \(w=\alpha y_1 x_1+\alpha y_2 x_2=\tfrac12(1)-\tfrac12(-1)=1\) — primal-এর \(w=1\)-এর সাথে হুবহু মিলল, আর দুই বিন্দুই support vector।
দুটো পুরস্কার একসাথে। dual আমাদের দুটো জিনিস দিল যা §৪.৪-এ গুরুত্বপূর্ণ হবে: প্রথমত, সমাধানটা data-তে কেবল inner product-নির্ভর; দ্বিতীয়ত, সমাধানটা sparse (শুধু SV-গুলো গোনে), তাই decision function হিসাব করা সস্তা।
৪.৩ Soft margin: slack, hinge loss ও \(C\) ★★¶
লক্ষ্য¶
বাস্তব data প্রায়ই linearly separable নয় — কিছু বিন্দু ভুল দিকে বা margin-এর ভেতরে পড়ে যায়, তখন §৪.১-এর hard constraint \(y_i(w^\top x_i+b)\ge1\) একসাথে সবার জন্য পূরণ করা অসম্ভব। সমাধান: প্রতিটি বিন্দুকে constraint একটু লঙ্ঘনের অনুমতি দেওয়া, কিন্তু সেই লঙ্ঘনের জন্য জরিমানা নেওয়া। আমরা দেখাব এই "soft margin" SVM হুবহু সমান hinge loss + L2 regularization, এবং \(C\) হলো margin-প্রস্থ বনাম লঙ্ঘনের মধ্যেকার ভারসাম্য-নব।
ধাপ ১ — slack variable যোগ¶
প্রতিটি বিন্দুর জন্য একটা slack \(\xi_i\ge0\) আনি, যা constraint কতটা লঙ্ঘিত হলো তা মাপে:
ব্যাখ্যা: \(\xi_i=0\) হলে বিন্দুটা margin-এর সঠিক পাশে নিরাপদে (\(\ge1\)); \(0<\xi_i<1\) হলে সঠিক দিকে কিন্তু margin-এর ভেতরে; \(\xi_i>1\) হলে সরাসরি ভুল দিকে (misclassified)। objective-এ \(C\sum_i\xi_i\) পদটা মোট লঙ্ঘন-পরিমাণে জরিমানা চাপায়, আর \(\tfrac12\lVert w\rVert^2\) আগের মতোই margin চওড়া রাখতে চায়।
ধাপ ২ — optimal slack \(=\) hinge¶
\(w,b\) স্থির ধরে প্রতিটি \(\xi_i\)-এর সর্বোত্তম মান কী, দেখি। দুটো constraint একসাথে: \(\xi_i\ge0\) এবং \(\xi_i\ge 1-y_i(w^\top x_i+b)\) (দ্বিতীয়টা প্রথম constraint পুনর্বিন্যাস করে)। objective যেহেতু \(\xi_i\)-তে বাড়ছে (\(+C\xi_i\), \(C>0\)), minimum-এ \(\xi_i\) যতটা ছোট রাখা যায় ততটাই রাখবে — অর্থাৎ দুটো নিচের-সীমার বড়টার সমান:
এটাই বিখ্যাত hinge function। যাচাই করুন: যদি \(1-y_i(w^\top x_i+b)\le0\) (বিন্দু নিরাপদে সঠিক পাশে), তবে \(\xi_i^\star=0\), কোনো জরিমানা নেই; নাহলে \(\xi_i^\star=1-y_i(w^\top x_i+b)>0\), ঠিক ততটুকু যতটুকু constraint পূরণে দরকার।
ধাপ ৩ — SVM \(=\) hinge loss \(+\) L2 regularization¶
এবার \(\xi_i^\star\)-এর এই মান objective-এ ফেরত বসাই — slack চলক বিলুপ্ত হয়ে যায়, থাকে শুধু \(w,b\):
\(f(x):=w^\top x+b\) লিখে, আর পুরো objective-কে \(C\) দিয়ে ভাগ করলে (positive scalar, argmin অপরিবর্তিত) এটা চেনা regularized-loss রূপে দাঁড়ায়:
এটাই মূল উপলব্ধি: SVM হলো hinge loss-এর সমষ্টি \(+\) একটা L2 regularization পদ, যেখানে \(y_i f(x_i)\) হলো \(i\)-তম বিন্দুর "margin score"। তুলনা করুন 6.3-এর logistic regression-এর সাথে (যা log-loss + (ঐচ্ছিক) regularization minimize করে) — SVM আসলে একই কাঠামোয়, কেবল loss-টা hinge। hinge-এর বিশেষত্ব: এটা margin \(\ge1\) হলে ঠিক শূন্য (সঠিক-ও-নিরাপদ বিন্দুতে কোনো শাস্তি নেই), আর margin কমলে রৈখিকভাবে শাস্তি বাড়ায় — এই "kink at 1"-ই SVM-কে margin-সচেতন করে। \(\;\blacksquare\)
\(C\)-এর ভূমিকা: bias–variance নব¶
\(C\) ঠিক করে দেয় দুই উদ্দেশ্যের আপেক্ষিক গুরুত্ব — চওড়া margin (ছোট \(\lVert w\rVert\)) বনাম কম লঙ্ঘন (ছোট \(\sum_i\xi_i\)):
- বড় \(C\): লঙ্ঘনে কড়া জরিমানা, তাই optimizer যেকোনো মূল্যে \(\xi_i\) ছোট রাখতে চায় — margin সরু হলেও প্রায় সব বিন্দু সঠিকভাবে শ্রেণিবদ্ধ করার চেষ্টা। ফলে bias কম, variance বেশি (training data-র খুঁটিনাটিতে, এমনকি noise-এ, fit হয়ে যায়; \(C\to\infty\)-তে hard-margin SVM ফিরে আসে)।
- ছোট \(C\): লঙ্ঘনে নরম জরিমানা, তাই কিছু বিন্দুকে margin-এর ভেতরে বা ভুল দিকে যেতে দিয়ে হলেও চওড়া, মসৃণ margin বজায় রাখে। ফলে variance কম, bias বেশি (boundary সরল ও স্থিতিশীল, কিন্তু কিছু বিন্দু ভুল হতে পারে)।
তাই \(C\) হলো এই অধ্যায়ের প্রথম bias–variance নব (prereq 6.1) — সাধারণত cross-validation দিয়ে বাছা হয়। (§৪.৫-এ kernel-এর \(\gamma\) হবে দ্বিতীয় নব, আর দুটো একসাথে SVM-এর capacity নিয়ন্ত্রণ করে।)
৪.৪ Kernel trick ও RBF kernel ★★★¶
লক্ষ্য¶
§৪.২-এর dual-এ আমরা দেখেছি data ঢোকে কেবল inner product \(x_i^\top x_j\)-এর মধ্য দিয়ে। এই একটিমাত্র পর্যবেক্ষণ থেকে জন্ম নেয় kernel trick: \(x_i^\top x_j\)-এর জায়গায় একটা feature-map \(\phi\)-এর inner product \(K(x_i,x_j)=\langle\phi(x_i),\phi(x_j)\rangle\) বসিয়ে দিলে আমরা পাই feature space \(\phi\)-তে একটা linear SVM — যা input space-এ একটা nonlinear boundary, অথচ \(\phi\) কখনো স্পষ্টভাবে হিসাব না করেই। আমরা এটা প্রতিষ্ঠা করব, valid kernel-এর শর্ত (Mercer) বলব, আর দেখাব RBF kernel এক অসীম-মাত্রিক \(\phi\)-এর সমতুল্য।
ধাপ ১ — feature map ও replacement¶
ধরুন একটা map \(\phi:\mathbb R^p\to\mathcal H\) feature-গুলোকে কোনো (সম্ভবত বিশাল) space \(\mathcal H\)-এ পাঠায়। \(\phi(x)\)-space-এ একটা linear SVM মানে dual-এ সর্বত্র \(x_i\)-কে \(\phi(x_i)\) দিয়ে প্রতিস্থাপন — অর্থাৎ \(x_i^\top x_j\) হয়ে যায় \(\phi(x_i)^\top\phi(x_j)=\langle\phi(x_i),\phi(x_j)\rangle\)। এই inner-product ফাংশনটাকেই বলি kernel:
এখন গুরুত্বপূর্ণ ব্যাপারটা: dual objective আর decision function — দুটোই \(\phi\)-কে কেবল inner product হিসেবে চায়, কখনো একা \(\phi(x)\) vector হিসেবে নয়। dual:
আর decision function (\(w=\sum_i\alpha_i y_i\phi(x_i)\) বসিয়ে, \(w^\top\phi(x)=\sum_i\alpha_i y_i\langle\phi(x_i),\phi(x)\rangle\)):
অর্থাৎ পুরো প্রশিক্ষণ ও পূর্বাভাস কেবল \(K(\cdot,\cdot)\) মান হিসাব করেই করা যায়। যদি \(K\) সরাসরি (cheaply) হিসাব করা যায় অথচ তার অন্তর্নিহিত \(\phi\) বিশাল-বা-অসীম-মাত্রিক হয়, তবে আমরা কখনো \(\phi\) না বানিয়েই সেই বিশাল feature-space-এর সুবিধা পেলাম — এটাই "trick"। আর যেহেতু \(f(x)\)-এ শুধু SV-গুলো গোনে (§৪.২), পূর্বাভাসও sparse ও সস্তা।
ধাপ ২ — কোন \(K\) বৈধ? Mercer-এর শর্ত¶
যেকোনো দুই-চলক ফাংশন \(K(x,x')\) কি কোনো না কোনো \(\phi\)-এর inner product হতে পারে? না — দরকার একটা শর্ত। Mercer-এর শর্ত বলে: \(K\) একটা বৈধ kernel (অর্থাৎ কোনো \(\phi\)-এর জন্য \(K(x,x')=\langle\phi(x),\phi(x')\rangle\)) তখনই যখন এটা symmetric (\(K(x,x')=K(x',x)\)) এবং positive semi-definite (PSD) — যার বাস্তব রূপ: যেকোনো সসীম বিন্দু-সেট \(\{x_1,\dots,x_m\}\)-এর জন্য Gram matrix
সর্বদা positive semi-definite হবে, অর্থাৎ যেকোনো vector \(c\in\mathbb R^m\)-এর জন্য
কেন এটা স্বাভাবিক: যদি সত্যিই \(K(x_i,x_j)=\langle\phi(x_i),\phi(x_j)\rangle\) হয়, তবে \(c^\top\mathbf K c=\big\lVert\sum_i c_i\phi(x_i)\big\rVert^2\ge0\) — একটা norm-এর বর্গ কখনো ঋণাত্মক নয়। তাই PSD-হওয়াটা kernel-বৈধতার অপরিহার্য শর্ত, আর Mercer বলে এটা যথেষ্টও। এই PSD-শর্তের আরেকটা গুরুত্বপূর্ণ ফল: dual objective-এ \(-\tfrac12\sum_{ij}\alpha_i\alpha_j y_iy_j K(x_i,x_j)\) পদটা concave থাকে, তাই kernelized সমস্যাও একটা সুন্দর convex QP — একটাই global optimum।
ধাপ ৩ — RBF kernel: অসীম-মাত্রিক \(\phi\)¶
সবচেয়ে জনপ্রিয় kernel হলো Radial Basis Function (Gaussian) kernel:
এটা যে এক অসীম-মাত্রিক \(\phi\)-এর সমতুল্য, তা exponential-এর power series দিয়ে দেখা যায়। বর্গ খুলি: \(\lVert x-x'\rVert^2=\lVert x\rVert^2-2x^\top x'+\lVert x'\rVert^2\), তাই
এখন মূল গুণক \(e^{2\gamma\,x^\top x'}\)-কে তার Taylor series দিয়ে লিখি:
প্রতিটি পদ \((x^\top x')^k\) আবার নিজেই \(x\) ও \(x'\)-এর \(k\)-মাত্রার সব সম্ভাব্য monomial-গুণফলের একটা inner product (multinomial বিস্তার দিয়ে) — অর্থাৎ এক-একটা \(k\)-এর জন্য সব degree-\(k\) polynomial feature। সব \(k=0,1,2,\dots,\infty\) একসাথে যোগ হওয়ায় অন্তর্নিহিত feature map \(\phi\)-এ সব মাত্রার অসীম-সংখ্যক polynomial feature ঢুকে পড়ে — তাই \(\phi(x)\) একটা অসীম-মাত্রিক ভেক্টর, যার একটা উপাদান (scale-সহ)
এটাই RBF-এর শক্তির উৎস: একটা মাত্র scalar \(K(x,x')\) হিসাব করেই আমরা কার্যত একটা অসীম-মাত্রিক feature-space-এ linear SVM চালাচ্ছি, যা input-space-এ অত্যন্ত নমনীয় বাঁকানো boundary দিতে পারে — অথচ \(\phi\) কখনো স্পর্শ না করেই। (RBF সব \(x,x'\)-এর জন্য PSD Gram matrix দেয়, তাই Mercer-বৈধ — ধাপ ২।) \(\;\blacksquare\)
সিরিজ-যাচাই (এক-মাত্রিক)। \(x,x'\) scalar ধরলে \(K=e^{-\gamma(x-x')^2}=e^{-\gamma x^2}e^{-\gamma x'^2}\sum_{k\ge0}\frac{(2\gamma)^k}{k!}(xx')^k\)। উদাহরণ \(\gamma=0.7,\ x=0.4,\ x'=-0.3\): বাঁদিক \(e^{-0.7(0.7)^2}=e^{-0.343}\approx0.7096\); ডানদিকের series কয়েক পদ (\(k=0,1,2,\dots\)) যোগ করলে দ্রুত \(0.7096\)-তেই অভিসৃত হয় (কারণ \(\lvert 2\gamma\,xx'\rvert\) ছোট), যা দুই রূপের সমতা নিশ্চিত করে।
দুটো চেনা kernel। RBF ছাড়াও ব্যবহারিকভাবে গুরুত্বপূর্ণ: linear kernel \(K(x,x')=x^\top x'\) (এখানে \(\phi(x)=x\), অর্থাৎ §৪.২-এর মূল linear SVM), আর polynomial kernel \(K(x,x')=(x^\top x'+c)^d\) (\(\phi\)-তে degree-\(\le d\) পর্যন্ত সব monomial feature)। একই dual যন্ত্রে শুধু \(K\) পাল্টে দিলেই linear থেকে নানা-রকম nonlinear boundary পাওয়া যায় — এটাই kernel methods-এর সৌন্দর্য।
৪.৫ \(\gamma\) ও capacity ★¶
§৪.৪-এ RBF kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\)-এর \(\gamma\) শুধু একটা ধ্রুবক নয় — এটা প্রতিটি support vector-এর চারপাশে বসা "প্রভাব-বলয়"-এর প্রস্থ নিয়ন্ত্রণ করে, তাই এটাই decision boundary-র মসৃণতা তথা মডেলের capacity-র নব। মনে রাখুন decision function \(f(x)=\sum_{i\in\text{SV}}\alpha_i y_i\,e^{-\gamma\lVert x_i-x\rVert^2}+b\) আসলে প্রতিটি SV-তে কেন্দ্রীভূত Gaussian "bump"-এর একটা ভারিত যোগফল; \(\gamma\) সেই bump-গুলো কতটা চওড়া বা সরু, তা ঠিক করে:
- ছোট \(\gamma\): \(\lVert x_i-x\rVert^2\)-এর গুণক ছোট, তাই Gaussian bump চওড়া — একটা SV-এর প্রভাব দূর পর্যন্ত ছড়ায়, ফলে বহু SV-এর অবদান মসৃণভাবে মিশে যায়। boundary মসৃণ ও সরল, প্রায় linear-এর কাছাকাছি। এটা high bias, low variance — মডেল কম নমনীয়, সূক্ষ্ম গঠন ধরতে পারে না, কিন্তু noise-এ স্থিতিশীল।
- বড় \(\gamma\): bump সরু — প্রতিটি SV-এর প্রভাব কেবল তার গা-ঘেঁষা ছোট্ট অঞ্চলে। boundary এবড়োখেবড়ো ও কুঁকড়ানো, প্রায় প্রতিটি training বিন্দুকে আলাদাভাবে ঘিরে ধরে, আর সাধারণত অনেক বেশি SV লাগে। এটা low bias, high variance — চরমে প্রতিটি বিন্দুর চারপাশে একটা সরু দ্বীপ বানিয়ে training data মুখস্থ করে ফেলে (overfit)।
তাই \(\gamma\) হলো §৪.৩-এর \(C\)-র পাশে দ্বিতীয় bias–variance নব, এবং দুটো একসাথে কাজ করে: \(C\) ঠিক করে margin-লঙ্ঘন কতটা সহ্য করা হবে, আর \(\gamma\) ঠিক করে boundary কতটা স্থানীয়ভাবে বাঁকতে পারবে। ব্যবহারিকভাবে \((C,\gamma)\) জোড়াটা একসাথে cross-validation grid-search দিয়ে বাছা হয় (পরবর্তী section) — কারণ একটার সেরা মান অন্যটার উপর নির্ভর করে। এভাবে kernel SVM ঘুরেফিরে সেই একই কেন্দ্রীয় প্রশ্নেই ফেরে যা এই Part-জুড়ে আমাদের পথ দেখাচ্ছে: মডেলকে কতটা নমনীয় হতে দেব, আর সেই নমনীয়তার বিনিময়ে কতটা variance মেনে নেব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা SVM-এর তত্ত্বকে কোডে রূপ দেব। data হিসেবে নেব make_moons — দুটো ইন্টারলকিং অর্ধচন্দ্র, যা লিনিয়ারলি সেপারেবল নয়: একটিমাত্র সরলরেখা দিয়ে দুই শ্রেণিকে ভাগ করা অসম্ভব। ঠিক এখানেই kernel trick-এর মাহাত্ম্য ফুটে ওঠে। পুরো ল্যাবে আমরা শুধু sklearn.svm.SVC ব্যবহার করব এবং চারটি জিনিস দেখব:
- Linear বনাম RBF kernel — একই \(C=1\)-এ linear SVM moons-এ হোঁচট খায়, কিন্তু RBF kernel feature space-এ তুলে নিয়ে জিতে যায়।
- Soft-margin \(C\) sweep (RBF) — ছোট \(C\) মানে প্রশস্ত margin ও বেশি support vector; বড় \(C\) মানে সংকীর্ণ margin ও কম support vector।
- \(\gamma\) sweep (RBF) — ছোট \(\gamma\) মানে মসৃণ ও underfit-প্রবণ boundary; বড় \(\gamma\) মানে প্রতিটি বিন্দুর চারপাশে সরু "spike", যেখানে প্রায় সব training point-ই support vector হয়ে overfit করে।
- Decision function-এ support vector-এর ভূমিকা — দেখব \(f(\mathbf{x})\) শুধুমাত্র support vector-গুলোর উপরই নির্ভর করে।
মূল ফল আগেভাগে মনে রাখুন: linear \(\to 0.811\), RBF \(\to 0.900\), আর \(C=10\)-এ RBF \(\to 0.944\)। নিচে এর প্রতিটি যাচাই হবে।
স্ক্রিপ্ট¶
# -*- coding: utf-8 -*-
# কোড ল্যাব ৬.৪ — SVM & Kernel Methods
# সব মডেল sklearn.svm.SVC; linear vs RBF, C ও gamma-র প্রভাব, #SV গণনা।
import numpy as np
from sklearn.datasets import make_moons
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# ----------------------------------------------------------------------
# DATA: two interlocking moons — NOT linearly separable
# ----------------------------------------------------------------------
X, y = make_moons(n_samples=300, noise=0.25, random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
def n_sv(clf):
"""ফিট করা SVC থেকে support vector-এর সংখ্যা।"""
return int(clf.support_vectors_.shape[0])
# ======================================================================
# PART 1 — Linear vs RBF kernel (একই C = 1)
# linear: feature space = input space, তাই moons-এ ব্যর্থ।
# RBF : K(x, x') = exp(-gamma * ||x - x'||^2), kernel trick-এ জয়ী।
# ======================================================================
print("=== PART 1 : Linear vs RBF kernel (C=1) ===")
lin = SVC(kernel="linear", C=1).fit(Xtr, ytr)
rbf = SVC(kernel="rbf", C=1, gamma="scale").fit(Xtr, ytr)
print(f"Linear C=1 acc={accuracy_score(yte, lin.predict(Xte)):.3f} #SV={n_sv(lin)}")
print(f"RBF C=1 gamma=scale acc={accuracy_score(yte, rbf.predict(Xte)):.3f} #SV={n_sv(rbf)}")
poly = SVC(kernel="poly", degree=3, C=1, gamma="scale").fit(Xtr, ytr)
print(f"Poly deg=3 C=1 acc={accuracy_score(yte, poly.predict(Xte)):.3f} #SV={n_sv(poly)}")
# ======================================================================
# PART 2 — Soft-margin C sweep (RBF, gamma = scale)
# ছোট C -> regularization বেশি -> প্রশস্ত margin -> বেশি #SV
# বড় C -> regularization কম -> সংকীর্ণ margin -> কম #SV
# ======================================================================
print("\n=== PART 2 : Soft-margin C sweep (RBF, gamma=scale) ===")
print(f"{'C':>6} | {'acc':>6} | {'#SV':>4}")
print("-" * 22)
for C in [0.1, 1, 10, 100]:
m = SVC(kernel="rbf", C=C, gamma="scale").fit(Xtr, ytr)
print(f"{C:>6} | {accuracy_score(yte, m.predict(Xte)):>6.3f} | {n_sv(m):>4}")
# ======================================================================
# PART 3 — gamma sweep (RBF, C = 1)
# ছোট gamma -> চওড়া kernel -> মসৃণ boundary (underfit-প্রবণ)
# বড় gamma -> সরু kernel -> প্রায় প্রতি point-ই SV (overfit)
# ======================================================================
print("\n=== PART 3 : gamma sweep (RBF, C=1) ===")
print(f"{'gamma':>6} | {'acc':>6} | {'#SV':>4}")
print("-" * 22)
for g in [0.1, 0.5, 1, 5, 20]:
m = SVC(kernel="rbf", C=1, gamma=g).fit(Xtr, ytr)
print(f"{g:>6} | {accuracy_score(yte, m.predict(Xte)):>6.3f} | {n_sv(m):>4}")
# ======================================================================
# PART 4 — Decision function uses ONLY support vectors
# f(x) = sum_i (alpha_i * y_i) K(x_i, x) + b , শুধু support vector x_i-র উপর।
# sklearn-এ dual_coef_ = (alpha_i * y_i), support_vectors_ = x_i।
# ======================================================================
print("\n=== PART 4 : Decision function uses only support vectors ===")
best = SVC(kernel="rbf", C=10, gamma="scale").fit(Xtr, ytr)
print(f"RBF C=10 : #SV={n_sv(best)} out of {Xtr.shape[0]} training points")
print(f"dual_coef_ shape = {best.dual_coef_.shape} (= alpha_i * y_i)")
print(f"support_vectors_ shape = {best.support_vectors_.shape}")
print(f"intercept b = {best.intercept_[0]:.4f}")
df = best.decision_function(Xte[:3])
print(f"decision_function(Xte[:3]) = {np.round(df, 4)}")
আউটপুট¶
=== PART 1 : Linear vs RBF kernel (C=1) ===
Linear C=1 acc=0.811 #SV=74
RBF C=1 gamma=scale acc=0.900 #SV=63
Poly deg=3 C=1 acc=0.833 #SV=90
=== PART 2 : Soft-margin C sweep (RBF, gamma=scale) ===
C | acc | #SV
----------------------
0.1 | 0.833 | 121
1 | 0.900 | 63
10 | 0.944 | 45
100 | 0.933 | 37
=== PART 3 : gamma sweep (RBF, C=1) ===
gamma | acc | #SV
----------------------
0.1 | 0.800 | 93
0.5 | 0.900 | 72
1 | 0.900 | 62
5 | 0.956 | 74
20 | 0.956 | 132
=== PART 4 : Decision function uses only support vectors ===
RBF C=10 : #SV=45 out of 210 training points
dual_coef_ shape = (1, 45) (= alpha_i * y_i)
support_vectors_ shape = (45, 2)
intercept b = -0.5937
decision_function(Xte[:3]) = [-2.3751 1.2308 -2.6998]
পাঠোদ্ধার¶
PART 1 — kernel trick-ই পার্থক্য গড়ে দেয়। linear SVM moons-এ মাত্র \(0.811\) accuracy পায়, কারণ একটি hyperplane এই বাঁকা সীমানা ধরতে পারে না — তবু \(74\)টি support vector "টানাটানি" করে সেরা সরলরেখাটা খোঁজে। একই \(C=1\)-এ শুধু kernel "linear" থেকে "rbf"-এ বদলেই accuracy লাফিয়ে \(0.900\)-এ ওঠে এবং #SV কমে \(63\) হয়। RBF kernel \(K(\mathbf{x},\mathbf{x}')=\exp\!\big(-\gamma\,\lVert \mathbf{x}-\mathbf{x}'\rVert^{2}\big)\) ডেটাকে এক উঁচু-মাত্রার feature space-এ মানসিকভাবে তুলে নেয়, যেখানে দুই moon লিনিয়ারলি সেপারেবল হয়ে যায় — অথচ আমরা কখনও সেই space-এ স্পষ্টভাবে coordinate বানাই না, শুধু inner product হিসাব করি। এটিই "kernel trick"। degree-3 polynomial kernel মাঝামাঝি — \(0.833\), RBF-এর চেয়ে দুর্বল।
PART 2 — \(C\) হলো margin বনাম ভুলের দরাদরি। \(C\) ছোট মানে objective-এ slack-এর শাস্তি কম, তাই optimizer প্রশস্ত margin বেছে নেয় এবং অনেক বিন্দুকে margin-এর ভেতরে/ভুল দিকে থাকতে দেয় — এরা সবাই support vector হয়, তাই \(C=0.1\)-এ #SV অনেক বেশি (\(121\)) এবং model কিছুটা underfit (\(0.833\))। \(C\) বাড়ালে margin সংকুচিত হয়, কম বিন্দু violate করে, #SV কমে: \(1\to 63\), \(10\to 45\), \(100\to 37\)। সবচেয়ে ভালো এখানে \(C=10\) → accuracy \(0.944\); এর পরে \(C=100\)-এ training noise-কে অতিরিক্ত গুরুত্ব দিয়ে accuracy সামান্য পড়ে \(0.933\)। অর্থাৎ ছোট \(C\) = বেশি SV/প্রশস্ত margin, বড় \(C\) = কম SV/সংকীর্ণ margin — আর চরমে গেলে overfit।
PART 3 — \(\gamma\) নিয়ন্ত্রণ করে boundary কতটা "wiggly"। \(\gamma\) প্রতিটি RBF "গাউসিয়ান টিলা"-র প্রস্থ ঠিক করে। খুব ছোট \(\gamma=0.1\) মানে প্রতিটি টিলা চওড়া, boundary অতিমসৃণ, model underfit — accuracy কমে \(0.800\)। \(\gamma\) বাড়ালে boundary moons-এর বাঁক ধরতে শেখে: \(0.5\to 0.900\), \(5\to 0.956\)। কিন্তু \(\gamma=20\)-এ প্রতিটি টিলা এত সরু যে কার্যত প্রতিটি বিন্দুর নিজস্ব দ্বীপ তৈরি হয় — #SV বেড়ে \(132\) (প্রায় সব training point!), যা ক্ল্যাসিক overfitting-এর চিহ্ন; test accuracy এখানে কাকতালীয়ভাবে \(0.956\)-তে থাকলেও model টি অস্থির ও generalize করতে দুর্বল। অর্থাৎ বড় \(\gamma\) = প্রায় প্রতিটি বিন্দুই SV = overfit।
PART 4 — decision function বাঁচে শুধু support vector-এ। সেরা মডেল (\(C=10\))-এ মাত্র \(45\)টি support vector \(210\)টি training point-এর মধ্যে; বাকি \(165\)টি বিন্দু decision boundary-তে কোনো প্রভাবই রাখে না। প্রেডিকশন নিয়মটি হলো
যেখানে যোগফলটি শুধুমাত্র support vector-এর উপর চলে — তাই sklearn dual_coef_-এ আকার \((1,45)\) (অর্থাৎ \(\alpha_i y_i\) মান) এবং support_vectors_-এ আকার \((45,2)\) রাখে, পুরো \(210\) নয়। এটিই SVM-কে memory-দক্ষ ও sparse করে: model আসলে কয়েকটি সীমান্ত-বিন্দু আর একটি bias \(b\approx-0.5937\) মাত্র। decision_function-এর মান (যেমন \(-2.3751,\ 1.2308,\ -2.6998\)) ঋণাত্মক হলে শ্রেণি \(0\), ধনাত্মক হলে শ্রেণি \(1\) — আর এর পরম মান বিন্দুটি boundary থেকে কত "নিরাপদ" দূরত্বে তা বোঝায়।
এক লাইনে সারমর্ম: moons-এ linear SVM (\(0.811\)) ব্যর্থ, RBF kernel (\(0.900\)) সফল; \(C\) বাড়িয়ে margin আঁটসাঁট করলে \(C=10\)-এ সেরা \(0.944\) মেলে; \(\gamma\) বাড়ালে boundary তীক্ষ্ণ হয়ে শেষমেশ প্রায় প্রতিটি বিন্দুই support vector হয়ে overfit-এর দিকে যায় — আর গোটা decision function জুড়ে কাজ করে কেবল মুষ্টিমেয় support vector।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে আমরা SVM-এর গণিত ধাপে ধাপে গড়েছি — কীভাবে max-margin classifier দুই class-এর মাঝে সবচেয়ে চওড়া রাস্তা খোঁজে, কীভাবে hard-margin শর্ত শিথিল করে soft-margin ও \(C\) আসে, এবং কীভাবে kernel trick data-কে স্পষ্টভাবে উঁচু মাত্রায় না তুলেও সেখানকার linear separator-এর সুফল এনে দেয়। কিন্তু এই ধারণাগুলোর জ্যামিতিক চরিত্র — margin আসলে দেখতে কেমন, support vector-গুলো কোথায় বসে, একটা সরলরেখা কেন বাঁকা data-তে হার মানে আর RBF kernel কীভাবে সীমানা বাঁকিয়ে দেয়, আর \(C\) ও \(\gamma\) ঘোরালে boundary কীভাবে সরল থেকে জটিল হয়ে ওঠে — এসব সমীকরণে যতটা ধরা পড়ে, decision-region ছবিতে দেখলে তার চেয়ে অনেক বেশি স্পষ্ট হয়। এই অংশে আমরা চারটি ছবি তৈরি করব, যেগুলো একসাথে SVM ও kernel method-এর পুরো গল্পটা চোখের সামনে মেলে ধরে।
ছবিগুলো দুটি নিয়ন্ত্রিত dataset-এর ওপর দাঁড়িয়ে আছে। প্রথমটি একটি ছোট, linearly separable দুই-গুচ্ছ demo — দুটি Gaussian blob, একটি \((0,0)\)-র চারপাশে আর অন্যটি \((3,3)\)-র চারপাশে, প্রতিটিতে ৩০টি বিন্দু — যেখানে একটিমাত্র সরলরেখা দুই class-কে নিখুঁতভাবে আলাদা করতে পারে; এই demo দিয়ে আমরা hard-margin SVM-এর max-margin ধারণাটা সবচেয়ে পরিষ্কার ভাবে দেখাব। দ্বিতীয়টি আরও কঠিন: make_moons থেকে তৈরি দুটি পরস্পর-জড়ানো অর্ধচন্দ্রাকার class (\(n = 300\), \(\text{noise} = 0.25\)), যেখানে কোনো সরলরেখাই কাজ করে না — এখানেই kernel trick-এর প্রয়োজন ফুটে ওঠে। make_moons data-কে আমরা ৭০:৩০ অনুপাতে train/test-এ ভাগ করেছি, stratify=y দিয়ে যাতে দুই class দুই split-এই সমানুপাতে থাকে।
import numpy as np
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
# (১) max-margin demo: linearly separable দুই গুচ্ছ
rng = np.random.default_rng(20260619)
A = rng.normal([0, 0], 0.5, (30, 2)) # class -1
B = rng.normal([3, 3], 0.5, (30, 2)) # class +1
# (২) মূল benchmark: পরস্পর-জড়ানো দুই moon
X, y = make_moons(n_samples=300, noise=0.25, random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.3,
random_state=0, stratify=y)
এই দুই setup মিলিয়ে আমরা SVM-এর দুই মুখ একসাথে দেখাতে পারব — সরল demo-তে margin ও support vector-এর মূল জ্যামিতি, আর কঠিন moons-এ kernel-এর শক্তি ও তার hyperparameter (\(C\), \(\gamma\))-নির্ভরতা। প্রতিটি SVM-এর accuracy একই test set-এ মাপা, তাই সংখ্যাগুলো সরাসরি তুলনাযোগ্য।
৬.১ · max-margin hyperplane ও support vector¶
প্রথম ছবিটি SVM-এর একদম মূল ধারণাটা — সবচেয়ে চওড়া রাস্তা (widest street) — সরল demo-তে দেখায়। দুই গুচ্ছ এখানে স্পষ্টভাবে আলাদা, তাই অসংখ্য সরলরেখা তাদের ভাগ করতে পারত; SVM তাদের মধ্যে সেই একটিই বেছে নেয় যার দু-পাশের margin সবচেয়ে চওড়া। ছবিতে কঠিন (solid) রেখাটি হলো decision boundary (\(\mathbf{w}^\top \mathbf{x} + b = 0\)), আর তার দু-পাশের ছেদরেখা (dashed) দুটি হলো margin (\(\mathbf{w}^\top \mathbf{x} + b = \pm 1\))। সবুজ বৃত্তে ঘেরা বিন্দুগুলোই support vector — কেবল এরাই margin ছুঁয়ে আছে এবং একাই boundary-র অবস্থান নির্ধারণ করে।
from sklearn.svm import SVC
# §৬-এর setup-এর দুই গুচ্ছ A, B থেকে design matrix ও label বানাই
Xs = np.vstack([A, B]); ys = np.r_[np.full(30, -1), np.full(30, 1)]
# বড় C ⇒ hard-margin (কোনো ভুল সহ্য নয়), linearly separable data-তে নিখুঁত
clf = SVC(kernel="linear", C=1e6).fit(Xs, ys)
w, b = clf.coef_[0], clf.intercept_[0]
margin = 2.0 / np.linalg.norm(w) # = 2.678
# decision boundary ও margin দুটি রেখা
x2 = -(w[0]*x1 + b) / w[1] # w·x + b = 0
x2_up = -(w[0]*x1 + b - 1) / w[1] # w·x + b = +1
x2_dn = -(w[0]*x1 + b + 1) / w[1] # w·x + b = -1
ax.scatter(*clf.support_vectors_.T, s=240, facecolors="none",
edgecolors="green") # support vector-গুলো বৃত্তে ঘেরা
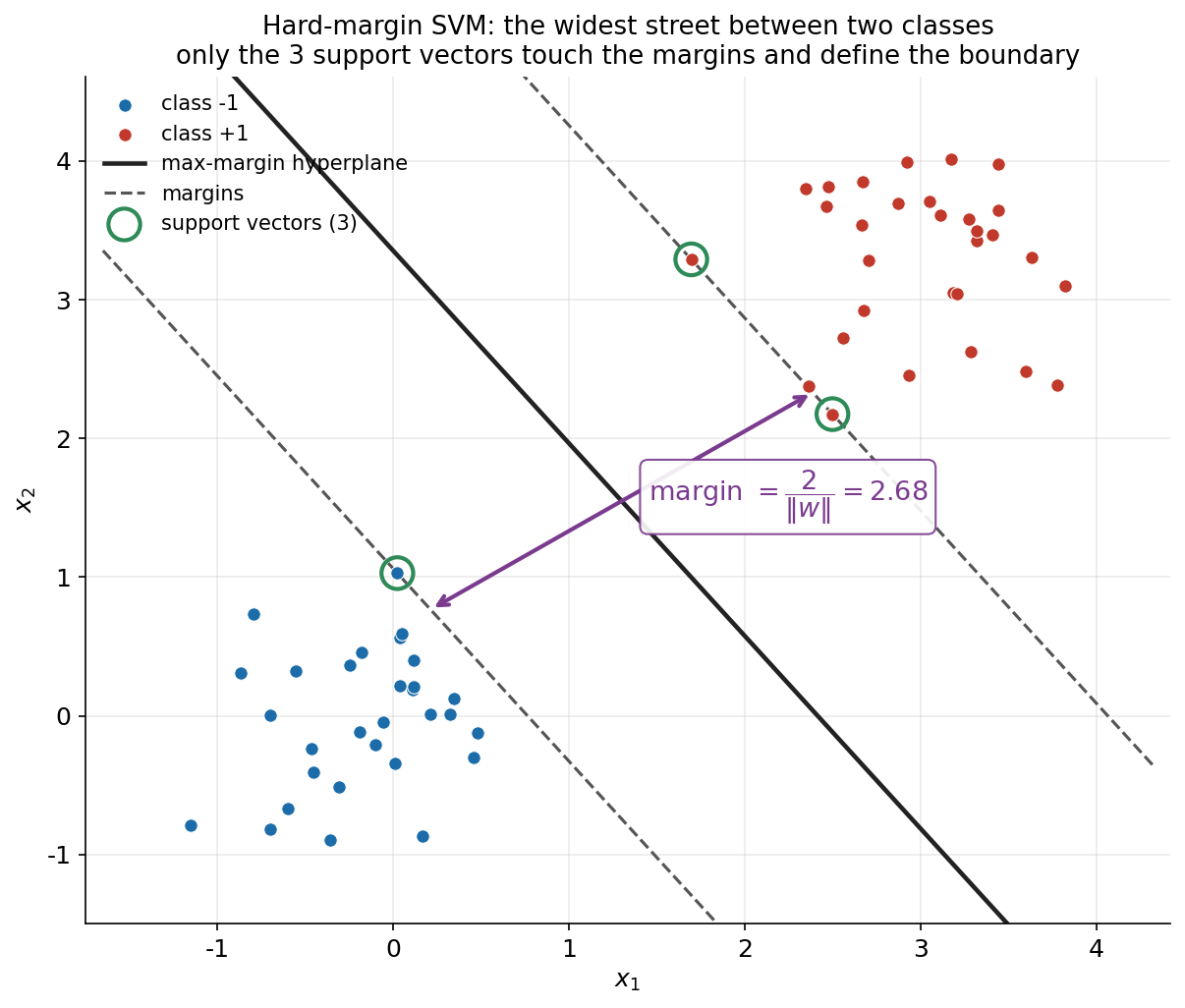
ছবিটি SVM-এর তিনটি কেন্দ্রীয় ধারণা একসাথে চাক্ষুষ করে। প্রথমত, margin = সবচেয়ে চওড়া রাস্তা: অসংখ্য সম্ভাব্য বিভাজক-রেখার মধ্যে SVM সেটিই বাছে যা দু-পাশে সর্বোচ্চ ফাঁকা জায়গা (\(\dfrac{2}{\lVert \mathbf{w} \rVert}\)) রাখে — এখানে এই প্রস্থ \(2.678\)। স্বজ্ঞাত যুক্তি হলো, রাস্তা যত চওড়া, নতুন (unseen) বিন্দু সীমানার ভুল দিকে পড়ার আশঙ্কা তত কম, অর্থাৎ বড় margin মানে ভালো generalization। দ্বিতীয়ত, margin-কে চওড়া করা মানে \(\lVert \mathbf{w} \rVert\)-কে ছোট করা: যেহেতু প্রস্থ \(\dfrac{2}{\lVert \mathbf{w} \rVert}\), margin সর্বোচ্চ করা আর \(\lVert \mathbf{w} \rVert^2\) ন্যূনতম করা একই কথা — আর এটিই SVM-এর optimization-এর মূল objective, যা আমরা তত্ত্ব-অংশে দেখেছি।
তৃতীয় এবং সবচেয়ে আকর্ষণীয় বার্তাটি support vector নিয়ে। লক্ষ করুন, এখানে \(60\)টি বিন্দুর মধ্যে মাত্র ৩টিই (সবুজ বৃত্তে ঘেরা) margin ছুঁয়ে আছে — এই তিনটিই support vector। SVM-এর একটি গভীর সম্পত্তি হলো, decision boundary সম্পূর্ণরূপে কেবল এই কয়েকটি support vector দিয়েই নির্ধারিত হয়: বাকি \(57\)টি বিন্দু margin-এর নিরাপদ দূরত্বে আছে বলে তাদের যেকোনো একটিকে সরিয়ে দিলেও (যতক্ষণ তা margin-এর ভেতরে না ঢোকে) boundary একচুলও নড়বে না। এই কারণেই SVM-কে বলা হয় sparse model — সিদ্ধান্ত নেয় কেবল গুটিকয় সীমান্তবর্তী বিন্দুর ওপর নির্ভর করে, পুরো dataset-এর ওপর নয়। এই demo-তে data নিখুঁতভাবে আলাদা বলে আমরা hard-margin (বড় \(C\)) ব্যবহার করেছি; বাস্তব data-তে, যেখানে class-গুলো একে অপরের মধ্যে ছড়িয়ে থাকে, এই কঠোর শর্ত শিথিল করে soft-margin ও \(C\) আসে — যার প্রভাব আমরা ৬.৩-এ দেখব।
৬.২ · linear বনাম RBF: kernel trick কাজে¶
দ্বিতীয় ছবিটি এবার কঠিন make_moons data-তে যায়, এবং SVM-এর সবচেয়ে গুরুত্বপূর্ণ সীমাবদ্ধতা ও তার সমাধান পাশাপাশি দেখায়। বাঁ panel-এ একটি linear SVM — যা কেবল একটি সরলরেখা টানতে পারে; ডান panel-এ একটি RBF-kernel SVM — যা একই data-তে বাঁকা সীমানা আঁকতে পারে। দুটি panel-এই একই দুই-moon data (দুই class দুই রঙে), পেছনে প্রতিটি classifier-এর decision region হালকা রঙে ভরাট।
svm_lin = SVC(kernel="linear", C=1.0).fit(Xtr, ytr) # সরলরেখা
svm_rbf = SVC(kernel="rbf", C=1.0, gamma="scale").fit(Xtr, ytr) # বাঁকা সীমানা
accuracy_score(yte, svm_lin.predict(Xte)) # 0.811
accuracy_score(yte, svm_rbf.predict(Xte)) # 0.900
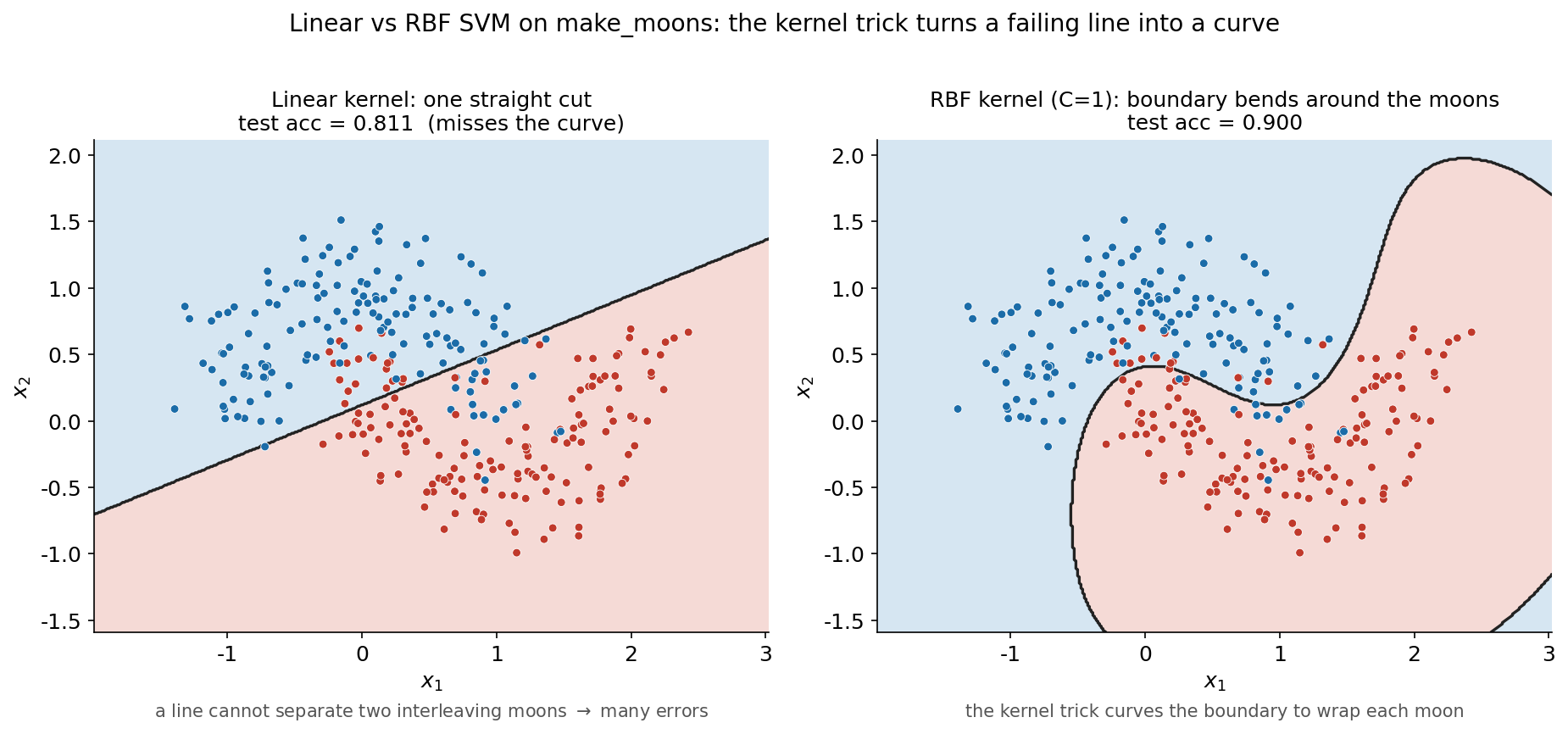
দুটি panel-এর বৈসাদৃশ্যই এই অংশের কেন্দ্রীয় শিক্ষা। বাঁ দিকে (linear SVM) model কেবল একটি সরলরেখা টানতে বাধ্য। কিন্তু দুটি moon তো একে অপরের মধ্যে আঙুলের মতো ঢুকে আছে — কোনো সরলরেখাই এদের পরিষ্কার ভাগ করতে পারে না, তাই linear SVM যেখানেই রেখা টানুক, প্রতিটি moon-এর একটা অংশ ভুল দিকে পড়েই যায়। ফল: test accuracy মাত্র \(0.811\)। এটি SVM-এর ভুল নয়, বরং এই data-র মৌলিক চরিত্র — input space-এ class দুটি linearly separable নয়।
ডান দিকে (RBF SVM) ঠিক এই সমস্যাটিই kernel trick দিয়ে সমাধান হয়। RBF (Radial Basis Function / Gaussian) kernel কার্যত data-কে একটি অসীম-মাত্রিক feature space-এ তুলে নেয়, যেখানে moon দুটি linearly separable হয়ে ওঠে; সেখানে টানা সরল সীমানা যখন আমাদের আসল 2D space-এ ফিরিয়ে আনা হয়, তখন তা হয়ে দাঁড়ায় একটি বাঁকা S-আকৃতির সীমানা যা প্রতিটি moon-কে আলাদা করে ঘিরে ধরে। আশ্চর্যের ব্যাপার হলো, এই পুরো উঁচু-মাত্রিক উত্তোলন আসলে কখনো গণনা করতে হয় না — kernel function \(K(\mathbf{x}_i, \mathbf{x}_j) = \exp(-\gamma \lVert \mathbf{x}_i - \mathbf{x}_j \rVert^2)\) কেবল বিন্দু-জোড়ার মধ্যকার সাদৃশ্য মেপেই সেই উঁচু space-এর dot product-এর সমান ফল দেয়। এটাই বিখ্যাত kernel trick: উঁচু মাত্রায় না গিয়েও উঁচু মাত্রার linear separator-এর সব সুবিধা পাওয়া। ফল: accuracy \(0.811 \to 0.900\)-এ লাফ — কেবল kernel বদলেই। \(C\) বাড়িয়ে \(10\) করলে (margin আরও শক্ত) accuracy আরও উঠে \(0.944\) হয়, যা পরবর্তী ছবিতে স্পষ্ট হবে।
৬.৩ · \(C\) ও \(\gamma\): bias–variance ভারসাম্য¶
তৃতীয় ছবিটি RBF SVM-এর দুটি মূল hyperparameter — \(C\) (margin কতটা শক্ত/নরম) ও \(\gamma\) (kernel কতটা সরু/মসৃণ) — একসাথে ঘুরিয়ে দেখায় তারা কীভাবে decision boundary-র জটিলতা, তথা bias–variance ভারসাম্য, নিয়ন্ত্রণ করে। ছবিটি একটি \(3 \times 3\) grid: উপর থেকে নিচে \(\gamma\) বাড়ছে (\(0.5 \to 5 \to 20\)), বাঁ থেকে ডানে \(C\) বাড়ছে (\(0.1 \to 1 \to 100\))। প্রতিটি cell-এর শিরোনামে তার test accuracy লেখা।
for gamma in [0.5, 5, 20]: # সারি: kernel-এর প্রসার
for C in [0.1, 1, 100]: # কলাম: margin-এর কোমলতা
m = SVC(kernel="rbf", C=C, gamma=gamma).fit(Xtr, ytr)
acc = accuracy_score(yte, m.predict(Xte))
plot_regions(ax, m, f"γ={gamma}, C={C} acc={acc:.3f}")
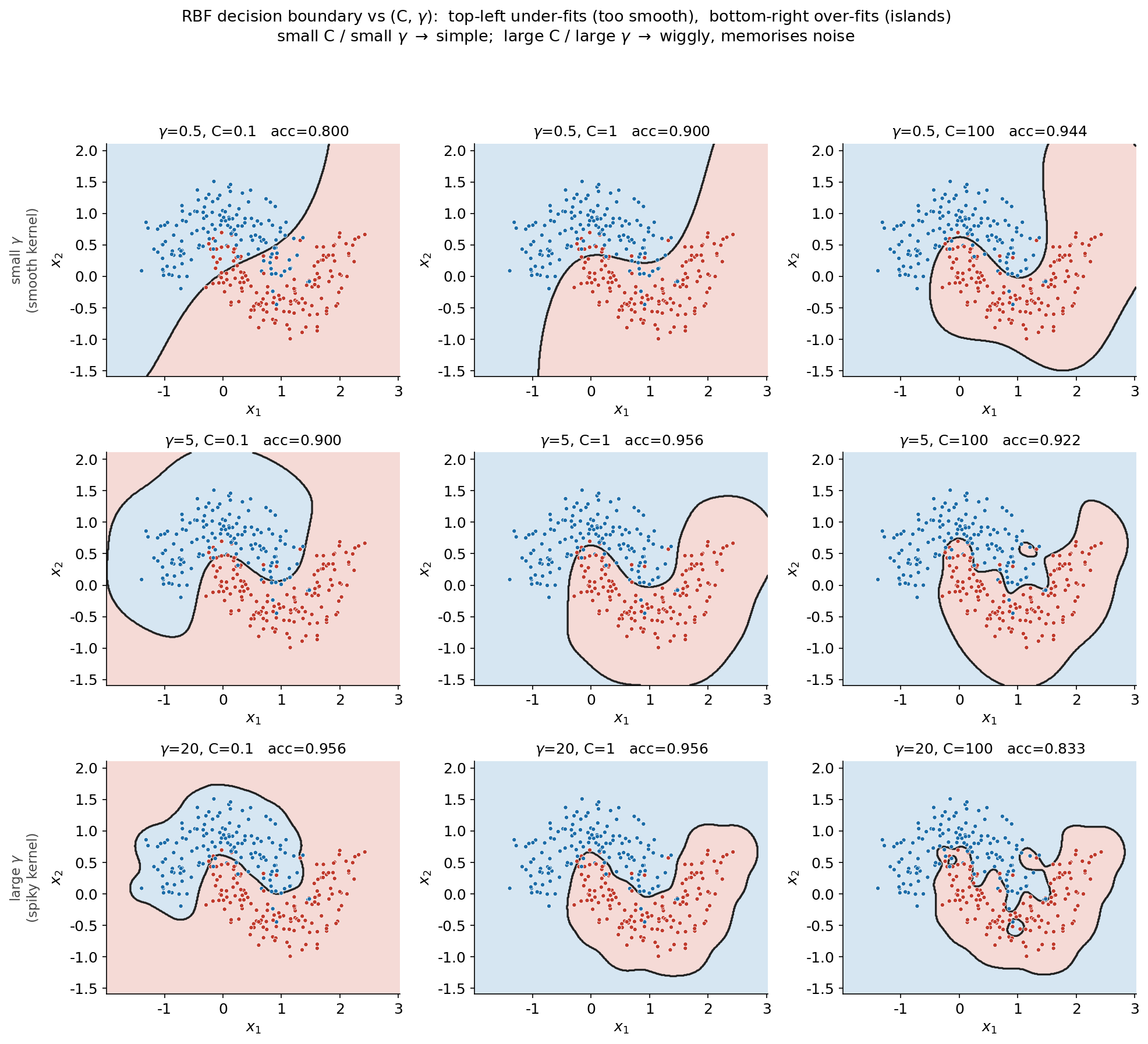
এই grid-টি SVM-এর hyperparameter-tuning-এর পুরো insight (অন্তর্দৃষ্টি) একটি ছবিতে গুটিয়ে আনে। প্রথমে \(\gamma\) (উপর-থেকে-নিচ): \(\gamma\) নিয়ন্ত্রণ করে একটি training বিন্দুর প্রভাব কতদূর পৌঁছায়। ছোট \(\gamma\) (উপরের সারি, \(0.5\)): প্রতিটি বিন্দুর প্রভাব দূর পর্যন্ত ছড়ায়, তাই kernel মসৃণ আর সীমানা প্রায় সরল ও সাধারণ — সবচেয়ে উপরের-বাঁ cell-এ (\(\gamma=0.5, C=0.1\)) এটি এতটাই সরল যে moon-এর গঠন ভালো ধরতে পারে না, accuracy মাত্র \(0.800\) (underfit / high bias)। বড় \(\gamma\) (নিচের সারি, \(20\)): প্রতিটি বিন্দুর প্রভাব কেবল তার অতি-নিকটেই সীমিত, তাই সীমানা প্রতিটি বিন্দুর চারপাশে তীব্রভাবে বাঁক নেয় — নিচের-ডান cell-এ (\(\gamma=20, C=100\)) এটি এমনকি বিপরীত class-এর এলাকার ভেতরে বিচ্ছিন্ন ছোট দ্বীপ তৈরি করে noise-বিন্দু মুখস্থ করে ফেলে, accuracy পড়ে \(0.833\) (overfit / high variance)।
এবার \(C\) (বাঁ-থেকে-ডান): \(C\) নিয়ন্ত্রণ করে margin-violation কতটা শাস্তিযোগ্য, অর্থাৎ margin কতটা নরম। ছোট \(C\) (বাঁ কলাম, \(0.1\)): ভুল সহ্য করার শাস্তি কম, তাই margin চওড়া ও নরম, সীমানা মসৃণ ও সরল — regularization বেশি। বড় \(C\) (ডান কলাম, \(100\)): প্রতিটি ভুলের শাস্তি ভারী, তাই model প্রতিটি training বিন্দু ঠিক করতে মরিয়া হয়ে margin সরু ও সীমানা আঁকাবাঁকা করে ফেলে — regularization কম, overfit-প্রবণ। দুটি knob মিলে একই গল্প বলে: ছোট \(C\) ও ছোট \(\gamma\) → সরল সীমানা (high bias), বড় \(C\) ও বড় \(\gamma\) → জটিল সীমানা (high variance), আর সেরা performance মাঝামাঝি কোথাও। লক্ষণীয়, এই data-তে সর্বোচ্চ accuracy (\(0.956\)) মেলে মাঝারি \(\gamma=5\)-এ — যেখানে সীমানা যথেষ্ট বাঁকা যে দুই moon ধরতে পারে, কিন্তু এত আঁকাবাঁকা নয় যে noise মুখস্থ করে। ঠিক এই কারণেই বাস্তবে \(C\) ও \(\gamma\) একসাথে cross-validation দিয়ে খোঁজা হয় (যেমন grid search) — কারণ এই grid-ই দেখাচ্ছে, ভুল কোণে গেলে accuracy \(0.956\) থেকে \(0.800\) বা \(0.833\)-এ নেমে যেতে পারে।
৬.৪ · kernel trick-এর জ্যামিতি: উঁচু মাত্রায় উত্তোলন¶
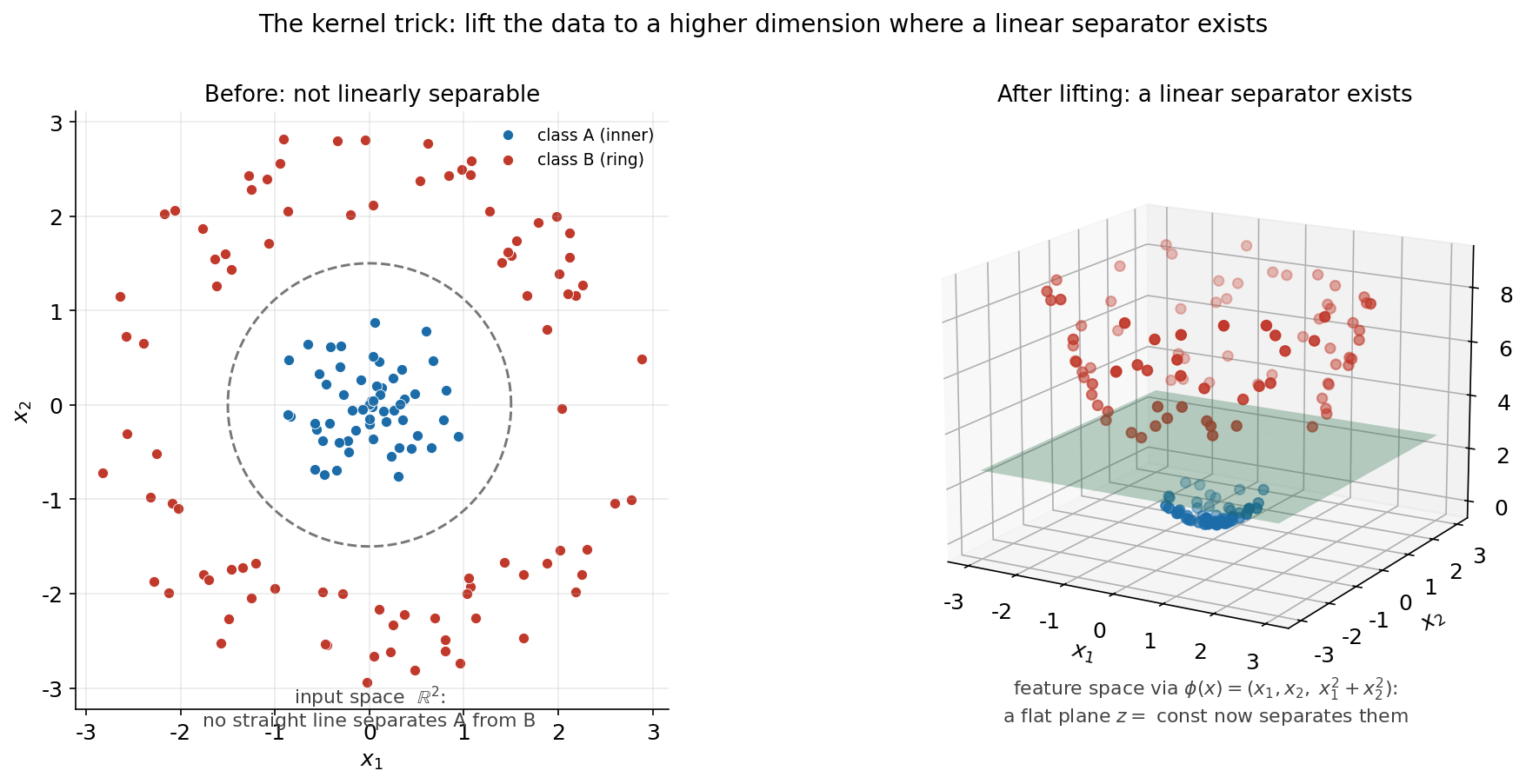
শেষ ছবিটি একটি schematic — এটি কোনো নির্দিষ্ট SVM fit নয়, বরং kernel trick-এর মূল ধারণাটি কেন কাজ করে তার জ্যামিতিক ছবি। বাঁ panel-এ একটি 2D data যেখানে একটি class কেন্দ্রে গুটিয়ে আছে আর অন্যটি তাকে ঘিরে একটি বলয়ে — কোনো সরলরেখাই এদের আলাদা করতে পারে না। ডান panel-এ একই data-কে একটি তৃতীয় মাত্রায় (\(z = x_1^2 + x_2^2\)) উত্তোলন (lift) করা হয়েছে, আর সেই উঁচু space-এ একটি সমতল (flat plane) এখন দুই class-কে নিখুঁতভাবে আলাদা করছে।
# φ: প্রতিটি বিন্দুকে একটি তৃতীয় মাত্রা যোগ করে উঁচু space-এ তোলা
def phi(P):
return P[:, 0], P[:, 1], P[:, 0]**2 + P[:, 1]**2 # z = x1² + x2²
# কেন্দ্রের গুচ্ছ (z ছোট) আর বলয় (z বড়) এখন উচ্চতায় আলাদা হয়ে যায়;
# z = const একটি সমতল তাদের মাঝে বসিয়ে দিলেই linear separator
ax3d.plot_surface(gx, gy, np.full_like(gx, 2.6), alpha=0.3) # সমতল z = 2.6
এই schematic-টি ৬.২-এ দেখা RBF-এর "জাদু"-র পেছনের আসল কারণটি উন্মোচন করে। বাঁ দিকে (input space, \(\mathbb{R}^2\)): কেন্দ্রের class ও বলয়ের class এমনভাবে সাজানো যে যেকোনো সরলরেখা টানলেই দুই class-এর কিছু না কিছু বিন্দু একই পাশে পড়ে যায় — এরা মৌলিকভাবে linearly separable নয়। কোনো linear classifier (linear SVM সহ) এখানে অসহায়। ডান দিকে (feature space): কিন্তু একটি সরল mapping \(\phi(\mathbf{x}) = (x_1, x_2, x_1^2 + x_2^2)\) প্রতিটি বিন্দুতে একটি তৃতীয় স্থানাঙ্ক \(z = x_1^2 + x_2^2\) (অর্থাৎ কেন্দ্র থেকে দূরত্বের বর্গ) যোগ করে। এই নতুন মাত্রায়, কেন্দ্রের বিন্দুগুলো (ছোট ব্যাসার্ধ) নিচে নেমে যায় আর বলয়ের বিন্দুগুলো (বড় ব্যাসার্ধ) উপরে উঠে যায় — দুই class এখন উচ্চতায় পরিষ্কার আলাদা। ফলে একটি সাধারণ অনুভূমিক সমতল ($z = $ ধ্রুবক) তাদের নিখুঁতভাবে ভাগ করে দেয়, যেটি কিনা সেই উঁচু space-এ একটি linear separator।
এটাই kernel method-এর সারকথা, একটি বাক্যে: যে data নিম্ন মাত্রায় বাঁকা সীমানা চায়, তাকে উপযুক্ত উঁচু মাত্রায় তুললে সেখানে একটি সরল (linear) সীমানাই যথেষ্ট হয়ে যায়। আর kernel trick-এর সৌন্দর্য হলো, SVM-কে কখনো এই \(\phi(\mathbf{x})\) স্পষ্টভাবে গণনা করতে হয় না — kernel function \(K(\mathbf{x}_i, \mathbf{x}_j)\) সরাসরি সেই উঁচু space-এর dot product \(\phi(\mathbf{x}_i)^\top \phi(\mathbf{x}_j)\)-এর সমান মান দেয়, ফলে আমরা উঁচু (এমনকি অসীম) মাত্রার সুবিধা পাই অথচ গণনা থেকে যায় আসল data-র মাত্রাতেই। বাঁ দিকের বৃত্তাকার সমস্যাটি \(z = x_1^2 + x_2^2\) দিয়ে যেমন সমাধান হলো, ঠিক তেমনি ৬.২-এর moons-সমস্যাটি RBF kernel সমাধান করে — পার্থক্য কেবল, RBF কার্যত একটি অসীম-মাত্রিক \(\phi\) ব্যবহার করে, যা এই একটি ছবিতে আঁকা সম্ভব নয়, কিন্তু এর পেছনের ধারণাটি ঠিক এটাই।
সারসংক্ষেপ¶
চারটি ছবি একসাথে SVM ও kernel method-এর একটি সম্পূর্ণ জ্যামিতিক গল্প তৈরি করে। max-margin (৬.১) দেখাল SVM-এর মূল ধারণা — সবচেয়ে চওড়া রাস্তা (\(\dfrac{2}{\lVert \mathbf{w} \rVert} = 2.678\)) আর তাকে ধরে রাখা মাত্র ৩টি support vector, অর্থাৎ model-টি sparse। linear বনাম RBF (৬.২) দেখাল কেন একটি সরলরেখা জড়ানো moons-এ হারে (\(0.811\)) আর kernel trick কীভাবে সীমানা বাঁকিয়ে তা \(0.900\) (এবং \(C=10\)-এ \(0.944\))-এ তোলে। \(C\) ও \(\gamma\)-র grid (৬.৩) এই kernel-এর দুই knob-এর bias–variance প্রকাশ করল — ছোট \(C\)/\(\gamma\) সরল সীমানা (underfit, acc \(0.800\)), বড় \(C\)/\(\gamma\) আঁকাবাঁকা সীমানা ও বিচ্ছিন্ন দ্বীপ (overfit, acc \(0.833\)), আর মাঝামাঝি \(\gamma=5\)-এ সেরা (\(0.956\))। শেষে kernel-trick schematic (৬.৪) এই সবকিছুর পেছনের নীতিটি উন্মোচন করল: নিম্ন-মাত্রায় বাঁকা-সীমানা সমস্যাকে উপযুক্ত উঁচু মাত্রায় তুলে একটি সরল সমতল দিয়েই সমাধান করা যায়, আর kernel trick সেই উত্তোলন স্পষ্টভাবে না করেই এর সুফল এনে দেয়। এই ছবিগুলো তৈরির সম্পূর্ণ, পুনরুৎপাদনযোগ্য কোড আছে _code/figs_6-4.py-তে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও সংক্ষিপ্ত hint। (★ সহজ, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং।) data-নির্ভর প্রশ্নগুলো এই অধ্যায়ের চলমান simulation-এর canonical সংখ্যা ব্যবহার করে — seed np.random.default_rng(20260619)-সূচক, make_moons (\(n=300\), \(\text{noise}=0.25\)), \(70/30\) train–test split। মূল notation: separating hyperplane \(w^\top x+b=0\), label \(y_i\in\{-1,+1\}\), geometric margin \(2/\lVert w\rVert\), slack \(\xi_i\ge 0\), penalty \(C\), dual coefficient \(\alpha_i\), RBF kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\), hinge loss \(\max(0,\,1-y_i f(x_i))\) যেখানে \(f(x)=w^\top x+b\)। পূর্ণ সমাধান _solutions/06-04-svm-kernel-methods-solutions.md-এ।
প্রসঙ্গের সুবিধার্থে নিচের canonical টেবিলগুলো কয়েকটি প্রশ্নে বারবার লাগবে (সবই একই test-set; accuracy ↑ মানে বেশি-ই-ভালো, #SV = support vector-এর সংখ্যা)।
(ক) kernel-ভেদে তুলনা (\(C=1\), RBF-এ উপযুক্ত \(\gamma\)):
| classifier | boundary | test accuracy | #SV |
|---|---|---|---|
| Linear SVM | linear | 0.811 | 74 |
| RBF SVM (\(C=1\)) | nonlinear | 0.900 | 63 |
| RBF SVM (\(C=10\)) | nonlinear | 0.944 | 45 |
| Polynomial (deg \(3\)) | nonlinear | 0.833 | — |
(খ) RBF-এ \(C\)-sweep (\(\gamma\) স্থির, soft-margin penalty বদলে):
| \(C\) | test accuracy | #SV |
|---|---|---|
| 0.1 | 0.833 | 121 |
| 1 | 0.900 | 63 |
| 10 | 0.944 | 45 |
| 100 | 0.933 | 37 |
(গ) RBF-এ \(\gamma\)-sweep (\(C\) স্থির, kernel-প্রস্থ বদলে):
| \(\gamma\) | test accuracy | #SV |
|---|---|---|
| 0.1 | 0.800 | — |
| 5 | 0.956 | — |
| 20 | 0.956 | 132 |
(লক্ষণীয়: make_moons দুই অর্ধচন্দ্রাকৃতি শ্রেণি linearly inseparable, তাই linear SVM দুর্বল (\(0.811\)); RBF kernel nonlinear boundary এঁকে অনেক ভালো করে, এবং \(C\) বাড়ালে (\(0.1\to10\)) margin সংকুচিত হয়ে #SV কমে ও accuracy বাড়ে, কিন্তু খুব বড় \(C\) (\(=100\)) সামান্য overfit করে (\(0.933\)); \(\gamma\) ছোট হলে boundary প্রায়-linear (\(0.800\)), \(\gamma\) বড় হলে boundary প্রতিটি বিন্দুকে আঁকড়ে অতি-নমনীয় ও #SV বিপুল (\(\gamma{=}20\to132\))।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). দুই linearly separable শ্রেণির মাঝখানে অসংখ্য separating hyperplane টানা যায় যেগুলো training data-তে শূন্য-ভুল করে। SVM তবু এদের মধ্যে একটিকেই — maximum-margin hyperplane-কে — বেছে নেয়। (ক) এক-দুই বাক্যে যুক্তি দিন কেন "সবচেয়ে চওড়া রাস্তা" বেছে নেওয়া generalization-এর (test data-তে ভালো করার) দিক থেকে যুক্তিযুক্ত। (খ) এটি ৬.১-এর কোন ধারণার সঙ্গে মেলে? Hint: (ক) margin যত চওড়া, boundary দুই শ্রেণির নিকটতম বিন্দু থেকে তত দূরে — তাই data সামান্য সরলেও (নতুন/noisy বিন্দু) ভুল-শ্রেণিবিন্যাসের সম্ভাবনা কম; চওড়া margin কার্যত classifier-এর "নিরাপত্তা-অঞ্চল"। (খ) এটি একধরনের capacity নিয়ন্ত্রণ/regularization (৬.১) — সম্ভাব্য boundary-গুলোর মধ্যে সবচেয়ে "সরল/স্থিতিশীল"টা বাছাই, যা variance কমায়।
প্রশ্ন ২ (★). support vector কাকে বলে এবং কেন এই কয়েকটি বিন্দুই SVM-এর "মেরুদণ্ড"? (ক) সংজ্ঞা দিন: কোন training-বিন্দুগুলোকে support vector বলা হয় (margin/dual-এর ভাষায়)? (খ) দাবিটি ব্যাখ্যা করুন: যদি একটি non-support-vector বিন্দু মুছে ফেলে SVM আবার train করা হয়, decision boundary অপরিবর্তিত থাকে — কিন্তু একটি support vector মুছলে boundary বদলে যেতে পারে। (গ) canonical টেবিল থেকে দেখান RBF(\(C{=}10\))-এ মাত্র \(45\)টি বিন্দুই (মোট training-এর ক্ষুদ্র অংশ) boundary নির্ধারণ করে। Hint: (ক) support vector হলো সেই training-বিন্দু যাদের dual coefficient \(\alpha_i>0\) — জ্যামিতিকভাবে যারা margin-এর উপর বা ভিতরে (বা ভুল পাশে) বসে। (খ) decision function \(f(x)=\sum_i \alpha_i y_i K(x_i,x)+b\)-এ যাদের \(\alpha_i=0\) তারা যোগফলে কোনো অবদান রাখে না; তাই তাদের অপসারণে \(f\) বদলায় না। support vector-এর \(\alpha_i>0\) — তারা যোগফলে সক্রিয়, তাই তাদের সরালে boundary নড়ে। (গ) \(210\)টি training-বিন্দুর মধ্যে মাত্র \(45\)টি SV — boundary "অল্প কয়েকটি গুরুত্বপূর্ণ বিন্দু"-নির্ভর, এটাই SVM-এর sparsity।
প্রশ্ন ৩ (★★). hinge loss বনাম 0–1 loss। (ক) margin \(m=y_i f(x_i)\)-এর ফাংশন হিসেবে hinge loss \(\max(0,1-m)\) ও 0–1 loss (\(m\le 0\) হলে \(1\), নইলে \(0\)) — দুটোর আকৃতি বর্ণনা করুন (কোথায় শূন্য, কোথায় বাড়ে)। (খ) কেন আমরা সরাসরি 0–1 loss minimize করি না, বরং hinge ব্যবহার করি? (গ) hinge loss-এ একটি বিন্দু সঠিক পাশে থেকেও (\(m>0\)) শাস্তি পেতে পারে — কখন, এবং এটি support vector-এর সঙ্গে কীভাবে সম্পর্কিত? Hint: (ক) 0–1 loss একটি ধাপ — \(m\le0\) (ভুল পাশে) হলে \(1\), \(m>0\) হলে \(0\); hinge \(m\ge1\) হলে \(0\), \(m<1\) হলে রৈখিকভাবে \(1-m\) বাড়ে (slope \(-1\))। (খ) 0–1 loss অবিচ্ছিন্ন নয়, non-convex, gradient প্রায় সর্বত্র শূন্য — optimize করা NP-কঠিন; hinge হলো এর convex surrogate (উপরের সীমা), যা দক্ষ optimization দেয় ও margin-কে পুরস্কৃত করে। (গ) \(0<m<1\) মানে বিন্দু সঠিক পাশে কিন্তু margin-এর ভিতরে — তখনও \(1-m>0\) শাস্তি; ঠিক এই বিন্দুরাই (margin-এ বা ভিতরে) support vector।
প্রশ্ন ৪ (★★). kernel trick কেন কাজ করে। SVM-এর dual সমস্যায় training-বিন্দুরা কেবল inner product \(x_i^\top x_j\) আকারে ঢোকে — কোথাও আলাদাভাবে \(x_i\) লাগে না। (ক) এই পর্যবেক্ষণ থেকে এক বাক্যে ব্যাখ্যা করুন কীভাবে আমরা feature map \(\phi\)-কে স্পষ্টভাবে গণনা না করেও উচ্চমাত্রিক feature-space-এ linear SVM চালাতে পারি (শুধু \(K(x_i,x_j)=\phi(x_i)^\top\phi(x_j)\) জেনে)। (খ) RBF kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\)-এর অন্তর্নিহিত feature-space-এর মাত্রা কত — এবং তবু কেন এটি গণনাযোগ্য? Hint: (ক) যেহেতু dual ও decision function-এ data কেবল inner product হিসেবে আসে, যেকোনো inner product \(x_i^\top x_j\)-কে একটা kernel \(K(x_i,x_j)\) দিয়ে প্রতিস্থাপন করলেই গণনা অপরিবর্তিত থাকে — অথচ গোপনে আমরা \(\phi\)-space-এ linear boundary বসাচ্ছি, \(\phi\) কখনো স্পষ্ট না করেই। (খ) RBF-এর feature-space অসীম-মাত্রিক (exponential-এর Taylor-বিস্তারে সব ক্রমের বহুপদ); তবু \(K\) মূল-space-এ একটি সহজ scalar সূত্র, তাই \(\phi\) ছাড়াই গণনাযোগ্য — এটাই kernel trick-এর মূল লাভ।
প্রশ্ন ৫ (★★). valid kernel ও Mercer-শর্ত। যেকোনো দুই-চলকের ফাংশন \(K(x,x')\)-কে কি SVM-এ kernel হিসেবে ব্যবহার করা যায়? (ক) "valid kernel" হতে হলে \(K\)-কে কোন শর্ত মানতে হয় (Mercer-শর্ত, gram matrix-এর ভাষায়)? (খ) এই শর্ত পূরণ হওয়াটা কেন গুরুত্বপূর্ণ — অর্থাৎ valid না হলে কী ভেঙে পড়ে? (গ) RBF ও polynomial — দুটোই valid; এক বাক্যে বলুন কেন valid kernel-দের যোগফল/গুণফলও সাধারণত valid। Hint: (ক) \(K\) symmetric এবং যেকোনো সসীম বিন্দু-সেট \(\{x_1,\dots,x_n\}\)-এর জন্য gram matrix \(K_{ij}=K(x_i,x_j)\) অবশ্যই positive semi-definite (PSD) হতে হবে — এটিই Mercer-শর্ত, যা নিশ্চিত করে \(K(x,x')=\phi(x)^\top\phi(x')\) রূপে কোনো feature map \(\phi\) আদৌ আছে। (খ) PSD না হলে কোনো \(\phi\)-inner-product রূপ নেই — dual আর উত্তল (convex) থাকে না, optimization অর্থ হারায়। (গ) valid kernel-এর gram matrix PSD; PSD matrix-দের যোগফল PSD, এবং element-wise গুণফল (Schur product) PSD থাকে — তাই kernel-দের যোগ/গুণও valid।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★) [E-margin]. margin \(=2/\lVert w\rVert\) হাতে। একটি 2D linear classifier-এর parameter \(w=(0.6,\,0.8)\), \(b=-1\) (অর্থাৎ boundary \(0.6x_1+0.8x_2-1=0\))। (ক) \(\lVert w\rVert\) বের করুন। (খ) geometric margin (পূর্ণ "রাস্তার প্রস্থ") \(2/\lVert w\rVert\) গণনা করুন। (গ) ধরুন আমরা সব parameter দ্বিগুণ করি (\(w=(1.2,1.6)\), \(b=-2\)) — boundary-র অবস্থান কি বদলায়? margin-এর সূত্রগত মান কি বদলায়, না অপরিবর্তিত থাকে, এবং কেন এই কারণেই SVM-এ scale স্থির করতে \(y_i(w^\top x_i+b)\ge 1\) শর্ত আরোপ করা হয়? Hint: (ক) \(\lVert w\rVert=\sqrt{0.6^2+0.8^2}=\sqrt{0.36+0.64}=\sqrt{1}=1\)। (খ) margin \(=2/1=2\)। (গ) \(w,b\) দ্বিগুণ করলে hyperplane \(\{x:w^\top x+b=0\}\) একই সেট (সমীকরণ scale-invariant), কিন্তু \(\lVert w\rVert=2\) হয়ে সূত্র "margin"\(=2/2=1\) দেখায় — অর্থাৎ margin-এর সংজ্ঞা scale-নির্ভর; তাই SVM canonical scale (\(y_i f(x_i)\ge1\), নিকটতম বিন্দুতে সমতা) ধরে, যাতে margin দ্ব্যর্থহীনভাবে \(2/\lVert w\rVert\)।
প্রশ্ন ৭ (★) [E-rbf-K]. RBF kernel-মান গণনা করুন। দুই বিন্দু \(x=(1,\,2)\) ও \(x'=(2,\,0)\), এবং RBF kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\)। (ক) প্রথমে \(\lVert x-x'\rVert^2\) (squared Euclidean দূরত্ব) বের করুন। (খ) \(\gamma=0.2\)-এ \(K(x,x')\) গণনা করুন। (গ) এবার \(\gamma\) অনেক বড় (\(\gamma=5\)) ধরে \(K\) গণনা করুন, এবং এক বাক্যে বলুন বড় \(\gamma\) কীভাবে দূরের দুই বিন্দুর "মিল"-কে দ্রুত শূন্যের দিকে ঠেলে দেয় (এটাই কেন বড় \(\gamma\) = সংকীর্ণ, স্থানীয় kernel = বেশি capacity)। Hint: (ক) \(\lVert x-x'\rVert^2=(1-2)^2+(2-0)^2=1+4=5\)। (খ) \(K=\exp(-0.2\times5)=\exp(-1)\approx0.368\)। (গ) \(\gamma=5\): \(K=\exp(-25)\approx1.4\times10^{-11}\approx0\) — বড় \(\gamma\)-তে সামান্য দূরত্বেও মিল প্রায় শূন্য, তাই প্রতিটি বিন্দুর প্রভাব অতি-স্থানীয় (সংকীর্ণ "টিলা"), boundary বেশি wiggly।
প্রশ্ন ৮ (★) [E-Csweep]. উপরের \(C\)-sweep টেবিল "পড়ুন" (RBF, \(\gamma\) স্থির)। (ক) \(C\) বাড়ার সঙ্গে (#SV) কী হয়, এবং কেন — soft-margin penalty বাড়লে margin চওড়া না সরু হয়? (খ) সর্বোচ্চ test accuracy কোন \(C\)-তে, এবং \(C=100\)-এ accuracy সামান্য পড়ে যাওয়া (\(0.944\to0.933\)) কী নির্দেশ করে? (গ) \(C\to 0\) ও \(C\to\infty\) — দুই চরমে SVM-এর আচরণ এক বাক্যে বর্ণনা করুন (bias–variance ভাষায়)। Hint: (ক) বড় \(C\) মানে slack-এর শাস্তি বেশি ⇒ optimizer কম margin-লঙ্ঘন সহ্য করে ⇒ margin সরু হয়, margin-এর ভিতরে কম বিন্দু পড়ে ⇒ #SV কমে (\(121\to63\to45\to37\))। (খ) সর্বোচ্চ \(0.944\) at \(C=10\); \(C=100\)-এ সামান্য পতন = অতি-কঠোর margin training noise-কে আঁকড়ে সামান্য overfit। (গ) ছোট \(C\) = চওড়া margin, বেশি লঙ্ঘন সহ্য, high bias/low variance (under-fit); বড় \(C\) = সরু margin, প্রায় hard-margin, low bias/high variance (over-fit)।
প্রশ্ন ৯ (★★) [E-gamma]. \(\gamma\)-sweep টেবিল "পড়ুন" (RBF, \(C\) স্থির) এবং RBF-এর bias–variance বুঝুন। (ক) \(\gamma=0.1\)-এ accuracy মাত্র \(0.800\) — kernel তখন প্রশস্ত না সংকীর্ণ, এবং এর ফলে boundary প্রায় কী আকৃতির হয়ে পড়ে? (খ) \(\gamma\) বাড়িয়ে \(5\) করলে accuracy লাফিয়ে \(0.956\); কিন্তু \(\gamma=20\)-তে accuracy আর বাড়ে না (\(0.956\)) অথচ #SV বিপুল বেড়ে \(132\) — এটি কী সমস্যার (over-fit) আগাম সংকেত? (গ) \(\gamma\) ও \(C\) — দুটোই capacity বাড়ায়; এক বাক্যে বলুন এদের ভূমিকা কীভাবে আলাদা। Hint: (ক) ছোট \(\gamma\) = প্রশস্ত (wide) kernel, প্রতিটি বিন্দুর প্রভাব দূর পর্যন্ত ⇒ boundary প্রায় মসৃণ/linear, moons-এর বাঁক ধরতে পারে না ⇒ under-fit (\(0.800\))। (খ) \(\gamma=20\)-এ accuracy না বেড়ে #SV \(132\) (training-এর অর্ধেকের বেশি) মানে boundary প্রতিটি বিন্দুকে আলাদাভাবে আঁকড়াচ্ছে — high variance, over-fit-এর সংকেত (test data বাড়লে পতন হতো)। (গ) \(\gamma\) kernel-এর আকৃতি/স্থানীয়তা নিয়ন্ত্রণ করে (boundary কত wiggly), আর \(C\) margin-লঙ্ঘনের শাস্তি নিয়ন্ত্রণ করে (কত বিন্দু ভুল পাশে সহ্য) — তাই দুটো আলাদা knob, একসঙ্গে tune করতে হয়।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১০ (★★) [P-margin]. margin সূত্র \(2/\lVert w\rVert\) উৎপাদন করুন। ধরুন canonical scale-এ দুই শ্রেণির নিকটতম বিন্দুগুলোতে \(w^\top x+b=+1\) ও \(w^\top x+b=-1\) ধরা হয় (margin-এর দুই প্রান্ত-সমতল)। (ক) একটি বিন্দু থেকে hyperplane \(w^\top x+b=0\)-এর লম্ব-দূরত্বের সূত্র ব্যবহার করে দেখান এই দুই প্রান্ত-সমতলের মধ্যবর্তী লম্ব-দূরত্ব (পূর্ণ margin) ঠিক \(\dfrac{2}{\lVert w\rVert}\)। (খ) এর থেকে যুক্তি দিন কেন "margin সর্বোচ্চ করা" আর "\(\tfrac12\lVert w\rVert^2\) সর্বনিম্ন করা" সমতুল্য — অর্থাৎ SVM-এর primal উদ্দেশ্য। Hint: (ক) \(w^\top x+b=c\) ও \(w^\top x+b=c'\) — দুই সমান্তরাল সমতলের লম্ব-দূরত্ব \(=\dfrac{\lvert c-c'\rvert}{\lVert w\rVert}\); এখানে \(c=+1,\,c'=-1\) ⇒ দূরত্ব \(=\dfrac{\lvert 1-(-1)\rvert}{\lVert w\rVert}=\dfrac{2}{\lVert w\rVert}\)। (খ) margin \(=2/\lVert w\rVert\) সর্বোচ্চ করা \(\Leftrightarrow\) \(\lVert w\rVert\) সর্বনিম্ন করা \(\Leftrightarrow\) \(\tfrac12\lVert w\rVert^2\) সর্বনিম্ন করা (\(y_i(w^\top x_i+b)\ge1\) শর্তে), যা একটি মসৃণ উত্তল quadratic program।
প্রশ্ন ১১ (★★★) [P-dual-sv]. dual থেকে কেন কেবল support vector-এর \(\alpha_i>0\)। hard-margin SVM-এর Lagrangian-দ্বৈত (dual) গঠনে KKT-শর্তের মধ্যে রয়েছে complementary slackness: $$ \alpha_i\big[\,y_i(w^\top x_i+b)-1\,\big]=0,\qquad \alpha_i\ge 0 . $$ (ক) এই শর্ত থেকে যুক্তি দিন: যদি একটি বিন্দু margin-এর কঠোরভাবে বাইরে থাকে (\(y_i(w^\top x_i+b)>1\)), তবে অবশ্যই \(\alpha_i=0\)। (খ) আর \(\alpha_i>0\) হলে অবশ্যই \(y_i(w^\top x_i+b)=1\) — অর্থাৎ বিন্দুটি ঠিক margin-এর উপর (একটি support vector)। (গ) এর ফলেই optimal \(w=\sum_i\alpha_i y_i x_i\) এবং decision function \(f(x)=\sum_i\alpha_i y_i\,x_i^\top x+b\) কেবল support vector-এর উপর নির্ভর করে — এক বাক্যে ব্যাখ্যা করুন। Hint: (ক) margin-এর কঠোর বাইরে হলে বর্গাকার-বন্ধনী \(y_i(w^\top x_i+b)-1>0\) (অশূন্য); গুণফল শূন্য হতে হলে তখন \(\alpha_i=0\)। (খ) \(\alpha_i>0\) হলে গুণফল শূন্য রাখতে বন্ধনীটি \(=0\) লাগে ⇒ \(y_i(w^\top x_i+b)=1\) ⇒ বিন্দু margin-সীমায়। (গ) যেহেতু non-SV-দের \(\alpha_i=0\), \(w=\sum_i\alpha_i y_i x_i\) যোগফলে তারা বাদ — তাই \(w\) ও \(f\) শুধু \(\alpha_i>0\)-যুক্ত বিন্দু (support vector) দিয়ে নির্মিত; এটাই SVM-এর sparsity ও প্রশ্ন ২-এর "non-SV মুছলে boundary অপরিবর্তিত" দাবির ভিত্তি।
প্রশ্ন ১২ (★★) [P-kernel-valid]. valid kernel-এর gram matrix PSD হতে হবে — দেখান কেন এটি অপরিহার্য। ধরুন \(K(x,x')=\phi(x)^\top\phi(x')\) কোনো feature map \(\phi\)-র জন্য। (ক) যেকোনো বিন্দু-সেট \(x_1,\dots,x_n\) ও যেকোনো বাস্তব সহগ \(c_1,\dots,c_n\)-এর জন্য দেখান \(\sum_{i}\sum_{j} c_i c_j K(x_i,x_j)\ge 0\) (অর্থাৎ gram matrix positive semi-definite)। (খ) এর বিপরীত দিকটি (Mercer) এক বাক্যে বলুন: PSD হওয়া কেন যথেষ্টও — অর্থাৎ কোনো \(\phi\)-র অস্তিত্ব নিশ্চিত করে। Hint: (ক) \(\sum_{i,j}c_ic_j K(x_i,x_j)=\sum_{i,j}c_ic_j\,\phi(x_i)^\top\phi(x_j)=\Big\lVert\sum_i c_i\phi(x_i)\Big\rVert^2\ge0\) — একটি ভেক্টরের norm-বর্গ, তাই অঋণাত্মক; সুতরাং gram matrix PSD। (খ) Mercer-উপপাদ্য বলে উল্টোটাও সত্য — symmetric ও PSD \(K\)-র জন্য একটি (সম্ভবত অসীম-মাত্রিক) \(\phi\) সবসময় বিদ্যমান, তাই PSD-ই valid kernel হওয়ার সম্পূর্ণ শর্ত।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৩ (★★) [E-fit]. এই অধ্যায়ের dataset পুনর্গঠন করুন (make_moons, \(n=300\), \(\text{noise}=0.25\), seed-সূচক 20260619, \(70/30\) split) এবং (ক) linear SVM, (খ) RBF SVM (\(C=1\)), (গ) RBF SVM (\(C=10\)), (ঘ) polynomial (degree \(3\)) SVM fit করে প্রত্যেকের test accuracy ও support-vector সংখ্যা (clf.support_.size) ছাপুন। আপনার সংখ্যাগুলো canonical টেবিল (ক)-র কাছাকাছি কি? কেন linear SVM এখানে সবচেয়ে দুর্বল (\(0.811\)), আর RBF(\(C{=}10\)) সেরা (\(0.944\)) — make_moons-এর আকৃতির সঙ্গে মিলিয়ে এক-দুই বাক্যে বলুন।
Hint: from sklearn.svm import SVC; from sklearn.datasets import make_moons; SVC(kernel="linear", C=1), SVC(kernel="rbf", C=1), SVC(kernel="rbf", C=10), SVC(kernel="poly", degree=3, C=1); প্রতিটির .fit(Xtr,ytr).score(Xte,yte) ও .support_.size। প্রত্যাশিত — linear \(\approx0.811\) (74 SV), RBF\(C{=}1\approx0.900\) (63 SV), RBF\(C{=}10\approx0.944\) (45 SV), poly3 \(\approx0.833\)। moons দুই অর্ধচন্দ্র linearly inseparable, তাই সরলরেখা পারে না; RBF বাঁকানো boundary এঁকে পারে। সমাধানে runnable script।
প্রশ্ন ১৪ (★★★) [E-tune-boundary]. \(C\)–\(\gamma\) tune করুন, decision boundary আঁকুন ও support vector চিহ্নিত করুন। (ক) RBF SVM-এ \(C\in\{0.1,1,10,100\}\)-এর প্রতিটির জন্য test accuracy ও #SV ছাপুন এবং canonical \(C\)-sweep টেবিল (খ)-র সঙ্গে মেলান (প্রত্যাশিত \(0.833/121,\ 0.900/63,\ 0.944/45,\ 0.933/37\))। (খ) অনুরূপভাবে \(\gamma\in\{0.1,5,20\}\) (\(C\) স্থির) sweep করে accuracy ছাপুন (প্রত্যাশিত \(0.800,\ 0.956,\ 0.956\))। (গ) সেরা (\(C,\gamma\))-তে 2D grid-এ decision boundary contourf দিয়ে আঁকুন, training-বিন্দু scatter করুন, এবং support vector-গুলোকে (clf.support_vectors_) আলাদা marker-এ চিহ্নিত করুন — যাচাই করুন SV-রা সত্যিই boundary-র কাছে/margin-এ বসে আছে।
Hint: grid: xx,yy=np.meshgrid(...), Z=clf.decision_function(np.c_[xx.ravel(),yy.ravel()]).reshape(xx.shape), plt.contour(xx,yy,Z,levels=[-1,0,1]) (boundary ও দুই margin-সীমা); plt.scatter(clf.support_vectors_[:,0], clf.support_vectors_[:,1], s=120, facecolors="none", edgecolors="k") দিয়ে SV বৃত্তায়িত করুন। \(C\) বাড়লে #SV কমবে, margin সরু হবে; \(\gamma\) বড় হলে boundary wiggly হবে। পূর্ণ plotting-script সমাধানে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- max-margin = সবচেয়ে চওড়া রাস্তা। linearly separable দুই শ্রেণির মধ্যে অসংখ্য শূন্য-ভুল hyperplane থাকতে পারে; SVM তাদের মধ্যে সেইটি বাছে যা দুই শ্রেণিকে সর্বোচ্চ margin-এ আলাদা করে। margin \(=2/\lVert w\rVert\), তাই "margin সর্বোচ্চ করা" \(\Leftrightarrow\) "\(\tfrac12\lVert w\rVert^2\) সর্বনিম্ন করা" (\(y_i(w^\top x_i+b)\ge1\) শর্তে) — একটি উত্তল quadratic program। চওড়া margin = নতুন/noisy বিন্দুতেও স্থিতিশীল সিদ্ধান্ত = ভালো generalization।
- soft-margin ও penalty \(C\)। বাস্তব data প্রায়ই perfectly separable নয় (
make_moonsযেমন), তাই প্রতিটি বিন্দুতে একটি slack \(\xi_i\ge0\) অনুমোদন করে margin-লঙ্ঘন সহ্য করা হয়, এবং উদ্দেশ্যে \(C\sum_i\xi_i\) শাস্তি যোগ হয়। \(C\) একটি bias–variance knob: ছোট \(C\) = চওড়া margin, বেশি লঙ্ঘন সহ্য, low variance/high bias (under-fit); বড় \(C\) = সরু margin, প্রায় hard-margin, low bias/high variance। canonical \(C\)-sweep এটি দেখায় — \(C:0.1\to10\)-এ #SV \(121\to45\) কমে accuracy \(0.833\to0.944\) বাড়ে, কিন্তু \(C=100\)-এ সামান্য over-fit (\(0.933\))। - SVM = hinge loss + L2 regularization। soft-margin SVM-কে সমতুল্যভাবে লেখা যায় একটি loss + penalty রূপে: প্রতিটি বিন্দুর hinge loss \(\max(0,\,1-y_i f(x_i))\) (margin-লঙ্ঘনের উত্তল শাস্তি, 0–1 loss-এর convex surrogate) যোগ একটি L2 penalty \(\tfrac12\lVert w\rVert^2\) (= margin সর্বোচ্চকরণ)। এই দৃষ্টিতে SVM ৬.১/৬.২-এর regularized-loss কাঠামোরই একটি সদস্য — শুধু loss-টি hinge।
- dual কেবল inner product-এ নির্ভর ⇒ kernel trick। primal-কে Lagrangian-দ্বৈতে রূপান্তরিত করলে data কেবল inner product \(x_i^\top x_j\) আকারে ঢোকে, এবং KKT complementary slackness-এর ফলে কেবল support vector-এর \(\alpha_i>0\) — boundary অল্প কয়েকটি বিন্দু-নির্ভর (sparsity)। যেহেতু সর্বত্র data কেবল inner product হিসেবে আসে, যেকোনো inner product-কে একটি kernel \(K(x_i,x_j)=\phi(x_i)^\top\phi(x_j)\) দিয়ে প্রতিস্থাপন করলেই গোপনে এক উচ্চ-(এমনকি অসীম-)মাত্রিক feature-space-এ linear boundary বসানো যায় — \(\phi\) কখনো স্পষ্ট না করেই। এটিই kernel trick, যা nonlinear decision boundary সম্ভব করে।
- RBF kernel: \(C\) ও \(\gamma\) মিলে capacity। সবচেয়ে বহুল-ব্যবহৃত kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\) — অন্তর্নিহিত feature-space অসীম-মাত্রিক, তবু গণনাযোগ্য (kernel trick)। \(\gamma\) kernel-এর প্রস্থ/স্থানীয়তা নিয়ন্ত্রণ করে: ছোট \(\gamma\) = প্রশস্ত kernel = প্রায়-linear, মসৃণ boundary (under-fit, \(\gamma{=}0.1\to0.800\)); বড় \(\gamma\) = সংকীর্ণ kernel = প্রতিটি বিন্দু আঁকড়ানো wiggly boundary (over-fit-প্রবণ, \(\gamma{=}20\)-এ #SV \(132\))। \(C\) ও \(\gamma\) — দুই আলাদা knob, একসঙ্গে tune করতে হয় (canonical সেরা RBF \(C{=}10\): \(0.944\))। valid kernel হতে \(K\)-কে symmetric ও gram-matrix-PSD (Mercer-শর্ত) হতে হয়, যা \(\phi\)-এর অস্তিত্ব নিশ্চিত করে; RBF ও polynomial — দুটোই valid।
একনজরে তুলনা (canonical):
| Linear SVM | RBF SVM (\(C{=}10\)) | Polynomial (deg 3) | |
|---|---|---|---|
| boundary | hyperplane (linear) | nonlinear, মসৃণ | nonlinear, polynomial |
| kernel | \(x^\top x'\) | \(\exp(-\gamma\lVert x-x'\rVert^2)\) | \((x^\top x'+c)^d\) |
| মূল knob | \(C\) | \(C,\ \gamma\) | \(C,\ d\) |
| test accuracy | 0.811 | 0.944 | 0.833 |
| #SV | 74 | 45 | — |
পূর্ববর্তী সংযোগ:
- ← 6.3 (Classification I): ৬.৩-এর classifier-রা হয় density model করত (generative — LDA/QDA/Naive Bayes), নয় প্রতিবেশী গুনত (instance-based — k-NN)। SVM একটি ভিন্ন, discriminative দর্শন — কোনো বিতরণ না ধরে সরাসরি সেরা separating boundary খোঁজে। QDA-র quadratic boundary যেমন nonlinearity আনত, kernel SVM তা আরও সাধারণভাবে (এমনকি অসীম-মাত্রিক feature-space-এ) আনে; আর k-NN-কে যে curse of dimensionality ভোগায়, kernel-পদ্ধতি তা এড়ায় — মাত্রায় না গিয়ে কেবল inner-product-এ কাজ সেরে।
- ← 5.4 (Linear classifier / logistic regression): ৫.৪-এর logistic regression-ও discriminative ও একটি linear decision boundary (\(w^\top x+b\)) আঁকে — কিন্তু তা log-loss (cross-entropy) minimize করে, SVM করে hinge loss + margin। দুটোই একই linear-predictor কাঠামোর উপর দাঁড়ানো; পার্থক্য loss-এ ও SVM-এর margin/sparsity-দৃষ্টিভঙ্গিতে।
- ← 6.1 (capacity / bias–variance): SVM-এর প্রতিটি knob সরাসরি capacity নিয়ন্ত্রণ করে — max-margin নিজেই একটি regularizer (variance↓); \(C\) margin-কঠোরতা ও \(\gamma\) kernel-প্রস্থ মিলে ৬.১-এর U-curve-কেই আবার সামনে আনে (under-fit ↔ over-fit)।
- ← 0.3 (Lagrange / optimization): SVM-এর primal-থেকে-dual রূপান্তর সরাসরি ০.৩-এর Lagrangian multiplier ও KKT-শর্ত (বিশেষত complementary slackness)-এর প্রয়োগ; এই দ্বৈত গঠন ছাড়া "data কেবল inner product-এ আসে" এবং তাই kernel trick — কিছুই দাঁড়ায় না। ০.৫-এর inner-product ধারণাই kernel-এর ভিত্তি।
পরবর্তী সংযোগ (→ 6.5 — Decision Trees, Bagging & Random Forests): SVM একটি মসৃণ, margin-ভিত্তিক, geometry-নির্ভর classifier — একটিমাত্র (kernelized) সীমানা আঁকে। পরের অধ্যায় সম্পূর্ণ ভিন্ন, নিয়ম-ভিত্তিক (rule-based) দর্শন আনে: decision tree feature-space-কে ধাপে ধাপে অক্ষ-সমান্তরাল আয়তখণ্ডে ভাগ করে ("যদি \(x_1>t\) তবে...") — ব্যাখ্যাযোগ্য কিন্তু একা প্রায়ই অস্থির (high variance)। তারপর আসে ensemble ধারণা: অনেক tree-কে একসঙ্গে জুড়ে (bagging — bootstrap নমুনায় বহু tree, তারপর গড়/ভোট; random forest — সঙ্গে feature-randomization) variance কমিয়ে শক্তিশালী predictor গড়া। অর্থাৎ ৬.৪ "একটি সেরা সীমানা খোঁজো"; ৬.৫ "অনেক সরল নিয়ম-গাছ মিলিয়ে সিদ্ধান্ত নাও" — দুই ভিন্ন পথ একই classification-লক্ষ্যে।
source pointer: SVM ও kernel methods-এর statistics-অভিমুখী, গাণিতিকভাবে যত্নশীল উপস্থাপনা — Sugiyama, Introduction to Statistical Machine Learning (margin, soft-margin, dual, kernel trick, RBF/polynomial kernel, Mercer-শর্ত)। Bayes-ঝুঁকি ও classifier-তুলনার বৃহত্তর পটভূমি Wasserman, All of Statistics। data-scientist-মুখী, কোড-সহ ব্যবহারিক দৃষ্টিভঙ্গি (kernel বাছাই, \(C\)/\(\gamma\) tuning, support vector) Bruce & Bruce, Practical Statistics for Data Scientists এবং Dangeti, Statistics for Machine Learning (SVM, kernel, hyperparameter-tuning ও bias–variance)।