6.7 — Density Estimation, EM & Gaussian Mixture Models (ঘনত্ব-আন্দাজ, EM ও গাউসিয়ান মিশ্রণ মডেল)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — কঠোর সীমানা ছেড়ে সম্ভাবনার মিশ্রণে¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন দুটো অস্বস্তি¶
গত অধ্যায়ে (5.9) আমরা প্রথমবার unsupervised (লেবেল-ছাড়া) শেখার একটা সুন্দর হাতিয়ার পেয়েছিলাম: k-means clustering। তার গল্পটা মনে করুন। আমাদের কাছে ছিল একগুচ্ছ লেবেল-হীন বিন্দু \(\{x_1,\dots,x_n\}\), আর আমরা চেয়েছিলাম তাদের \(K\)টি দলে (cluster) ভাগ করতে। k-means সেটা করত পালা করে দুটো কাজ চালিয়ে: (১) প্রতিটি বিন্দুকে তার নিকটতম centroid-এ (দলের কেন্দ্র) বরাদ্দ করো, তারপর (২) প্রতিটি দলের বিন্দুগুলোর গড় নিয়ে centroid হালনাগাদ করো — আর এভাবে within-cluster বর্গ-দূরত্বের যোগফল কমাতে থাকো।
পদ্ধতিটা চমৎকার কাজ করত, কিন্তু এর গভীরে দুটো নীরব ধরে-নেওয়া (assumption) ছিল, যা এই অধ্যায়ের গোটা গল্পের জন্মদাতা। এই দুটোকে আলাদা করে দাগিয়ে রাখুন:
অস্বস্তি ১ — assignment সম্পূর্ণ কঠোর (hard)। k-means প্রতিটি বিন্দুকে ঠিক একটা cluster দেয়, পুরো-পুরিভাবে — "তুমি দল ২-এর, ব্যস"। কোনো 'হয়তো', কোনো ভগ্নাংশ নেই। কিন্তু ভাবুন এমন একটা বিন্দু, যেটা ঠিক দুই দলের সীমান্তে বসে — centroid ১ থেকে ঠিক যতটা দূরে, centroid ২ থেকেও প্রায় ততটাই। k-means তবুও জোর করে তাকে একটা দলে ঠেলে দেয়, আর তার এই দ্বিধা-জনিত তথ্যটুকু (যে সে আসলে দুই দলের মাঝামাঝি) হারিয়ে যায়। আরও খারাপ — পরের রাউন্ডে centroid এই অনিশ্চিত বিন্দুকেও পুরো ওজনে টানে, যেন সে নিশ্চিত-সদস্য।
অস্বস্তি ২ — প্রতিটি cluster কার্যত একটা গোলক (spherical)। k-means "নিকটতম" মাপে সাধারণ Euclidean দূরত্ব দিয়ে — centroid থেকে সব দিকে সমান। এর অর্থ, এটা নীরবে ধরে নেয় প্রতিটি cluster একটা গোলকের মতো, সব দিকে সমান-চওড়া। কিন্তু বাস্তব data-র cluster প্রায়ই গোলাকার নয় — লম্বাটে, কাত, ডিম্বাকৃতি (elliptical): একটা অক্ষ বরাবর অনেক ছড়ানো, অন্য অক্ষে সংকুচিত। এমন একটা লম্বাটে মেঘের সামনে k-means তার গোলকীয় চশমা দিয়ে ভুল করে — মেঘটাকে অপ্রাকৃতিকভাবে কেটে ফেলে, বা দুটো আলাদা লম্বাটে মেঘকে এক করে ফেলে।
এক বাক্যে উত্তরণ। k-means প্রতিটি বিন্দুকে কঠোরভাবে ঠিক একটা cluster দেয় আর প্রতিটি cluster-কে কার্যত একটা গোলক ধরে — এই অধ্যায় এই দুটো সীমাই ভাঙে: assignment হবে soft (ভগ্নাংশ-সম্ভাবনা), আর cluster হবে elliptical (যেকোনো লম্বাটে/কাত আকৃতি)।
১.২ Hook — প্রতিটা বিন্দুর একটা সম্ভাবনা, প্রতিটা মেঘ একটা ঘণ্টা-আকৃতি¶
এই দুই অস্বস্তির একটাই মার্জিত নিরাময় আছে: data-কে কঠোর জ্যামিতি দিয়ে না দেখে সম্ভাবনার (probability) চোখে দেখা।
ভাবুন data-টা আসলে কীভাবে জন্মেছে (generative গল্প)। ধরুন আকাশে কয়েকটা আলোর উৎস (cluster) আছে, প্রতিটা একটা মৃদু ঘণ্টা-আকৃতির আলোর মেঘ ছড়ায় — মাঝখানে উজ্জ্বল, ধারে ক্ষীণ — অর্থাৎ প্রতিটা একটা Gaussian (2.4-এর normal বণ্টন)। কিছু উৎস বড় (বেশি বিন্দু ছড়ায়), কিছু ছোট; কোনোটা গোল, কোনোটা লম্বাটে-কাত। এখন প্রতিটা পর্যবেক্ষিত বিন্দু আসলে কোনো-একটা উৎস থেকে এলোমেলোভাবে ছিটকে-পড়া একটা ফোঁটা। গোটা data তাই কয়েকটা Gaussian মেঘের একটা মিশ্রণ (mixture)।
এই ছবিতে দুটো অস্বস্তিই আপনাআপনি মেটে:
- Soft assignment। সীমান্তের একটা বিন্দু দেখে আমরা আর জোর করে এক দলে ঠেলি না; বরং বলি — "এই বিন্দুটা উৎস ১ থেকে আসার সম্ভাবনা \(0.55\), উৎস ২ থেকে \(0.45\)"। প্রতিটি বিন্দু প্রতিটি cluster-এ একটা ভগ্নাংশ-সদস্যপদ (fractional membership) পায়, যার যোগফল \(1\)। নিশ্চিত বিন্দু পায় প্রায়-\(1\) একদিকে; দ্বিধাগ্রস্ত সীমান্ত-বিন্দু পায় ভাগাভাগি — আর সেই দ্বিধাটুকুই এখন সংরক্ষিত থাকে।
- Elliptical cluster। প্রতিটা Gaussian-এর নিজের একটা covariance (2.4-এর \(\Sigma\)) আছে, যা তার মেঘের আকৃতি ঠিক করে — গোল, লম্বাটে, বা কাত উপবৃত্ত (ellipse)। তাই গোলকের বাধ্যবাধকতা উবে যায়; cluster যত খুশি elliptical হতে পারে।
কিন্তু এই সুন্দর ছবিতে একটা মস্ত লুকানো (latent / hidden) কাঁটা আছে। আমরা পর্যবেক্ষণ করি কেবল বিন্দুগুলো \(x_i\) — কিন্তু কোন বিন্দু আসলে কোন উৎস থেকে এল, সেটা আমরা কখনো দেখি না। সেই "উৎসের পরিচয়" একটা লুকানো চলরাশি (latent variable), যাকে আমরা \(z_i\) বলব। যদি কোনো জাদুতে \(z_i\) জানা থাকত, সমস্যাটা তুচ্ছ হতো — প্রতিটা উৎসের বিন্দুগুলো আলাদা করে নিয়ে আলাদা-আলাদা Gaussian fit করলেই হতো (4.3-এর সরল MLE)। কিন্তু \(z_i\) লুকানো বলেই এক মুরগি-ডিম ধাঁধা: উৎসগুলো জানলে assignment বের করা যায়, আবার assignment জানলে উৎস বের করা যায় — কিন্তু কোনোটাই শুরুতে জানা নেই।
এক বাক্যে hook। Data-কে কয়েকটা Gaussian মেঘের একটা মিশ্রণ হিসেবে ভাবলে assignment হয়ে যায় soft (প্রতিটা বিন্দুর প্রতিটা cluster-এ একটা সম্ভাবনা) আর cluster হয় elliptical — কিন্তু 'কোন বিন্দু কোন মেঘ থেকে' সেই latent \(z\) অজানা থাকায় তৈরি হয় এক মুরগি-ডিম ধাঁধা।
১.৩ মূল ধারণা — তিনটি স্তম্ভ এক নিঃশ্বাসে¶
এই অধ্যায়ের গোটা যন্ত্রটা তিনটি স্তম্ভের উপর দাঁড়িয়ে। এখানে এক-এক বাক্যে তিনটিরই ছবি দিয়ে রাখি; পুরো সংজ্ঞা §২-এ, পুরো গণিত §৪-এ।
স্তম্ভ ১ — Density estimation ও mixture model। আসল লক্ষ্যটা clustering-এর চেয়েও বড়: লেবেল ছাড়া কাঁচা data থেকে অজানা ঘনত্ব (probability density) \(p(x)\)-টাই আন্দাজ করা — অর্থাৎ "feature-জগতে কোথায় বিন্দু ঘন, কোথায় পাতলা" তার একটা সম্পূর্ণ সম্ভাবনা-মানচিত্র। একটা মাত্র Gaussian দিয়ে এটা করা যায় না, কারণ বাস্তব data প্রায়ই বহু-চূড়া (multimodal) — কয়েকটা আলাদা ঘন এলাকা। সমাধান mixture model: কয়েকটা সরল বণ্টনের একটা ওজনিত যোগফল, \(p(x)=\sum_k \pi_k\, p_k(x)\), যেখানে প্রতিটা \(p_k\) একটা সরল উপাদান-বণ্টন আর \(\pi_k\) তার ওজন। (এটা 5.7-এর KDE-র — যেখানে প্রতিটা বিন্দুতে একটা ক্ষুদ্র kernel বসিয়ে \(n\)টা উপাদানের যোগফল নেওয়া হতো, সম্পূর্ণ nonparametric — তুলনায় অনেক মিতব্যয়ী, parametric বিকল্প: \(n\)টা নয়, মাত্র কয়েকটা \(K\) উপাদান, প্রতিটার অল্প কিছু parameter।)
স্তম্ভ ২ — Gaussian Mixture Model (GMM)। mixture-এর প্রতিটা উপাদান যখন একটা Gaussian, তখন সেটা একটা Gaussian Mixture Model: $$ p(x) \;=\; \sum_{k=1}^{K} \pi_k\,\mathcal N(x;\mu_k,\Sigma_k), $$ যেখানে \(K\) হলো উপাদান-সংখ্যা, \(\pi_k\) হলো \(k\)-তম উপাদানের ওজন (mixing weight), আর \(\mathcal N(x;\mu_k,\Sigma_k)\) হলো mean \(\mu_k\) ও covariance \(\Sigma_k\)-যুক্ত একটা Gaussian। প্রতিটা বিন্দুর পেছনে একটা latent \(z_i\in\{1,\dots,K\}\) — সে কোন উপাদান থেকে এল। (সব প্রতীক খোলা হবে §২-এ।)
স্তম্ভ ৩ — EM algorithm। §১.২-এর মুরগি-ডিম ধাঁধার জবাব। যেহেতু \(z\) লুকানো, GMM-এর parameter সরাসরি MLE দিয়ে বের করা কঠিন (§২.২-এ দেখব কেন — log-এর ভেতরে যোগফল আটকে যায়)। EM (Expectation–Maximization) এই গিঁট খোলে ঠিক k-means-এরই মতো পালা করে দুই ধাপ চালিয়ে, কিন্তু soft ভাবে: - E-step — বর্তমান parameter ধরে প্রতিটা বিন্দুর soft assignment হিসাব করো: \(\gamma_{ik}=P(z_i=k\mid x_i)\), অর্থাৎ "বিন্দু \(i\) উপাদান \(k\) থেকে আসার posterior সম্ভাবনা" (Bayes, 2.2)। এই \(\gamma_{ik}\)-কে বলা হয় responsibility। - M-step — এই responsibility-গুলোকে ওজন ধরে প্রতিটা উপাদানের \(\pi_k,\mu_k,\Sigma_k\) আবার বের করো (একটা responsibility-weighted MLE)।
দুই ধাপ পালা করে চালালে fit ক্রমশ ভালো হয়, আর — চমৎকার নিশ্চয়তা — প্রতিটা চক্রে data-র log-likelihood কখনো কমে না (§১.৪)।
এক বাক্যে। Data-র ঘনত্ব \(p(x)\) আন্দাজ করতে আমরা একটা GMM (\(K\)টা Gaussian-এর ওজনিত যোগফল) বসাই, যেখানে প্রতিটা বিন্দুর উৎস \(z\) লুকানো; আর সেটা fit করি EM দিয়ে — পালা করে E-step (responsibility \(\gamma_{ik}\) = soft posterior) ও M-step (responsibility-weighted parameter update)।
১.৪ একটা নিশ্চয়তা ও একটা সতর্কতা — monotone উন্নতি, কিন্তু local optimum¶
EM সম্পর্কে দুটো জিনিস আগেভাগে দাগিয়ে রাখা দরকার, কারণ এ দুটোই তার চরিত্র বোঝায়।
নিশ্চয়তা — log-likelihood কখনো কমে না। EM-এর একটা সুন্দর গাণিতিক গ্যারান্টি (পূর্ণ প্রমাণ §৪-এ): প্রতিটা E-step+M-step চক্রের পর observed-data log-likelihood \(\ell\) হয় বাড়ে, নয়তো অপরিবর্তিত থাকে — কখনো কমে না। অর্থাৎ EM একটা monotone (একমুখী) আরোহণ; iteration-এর সাথে \(\ell\)-এর লেখচিত্র সবসময় উপরে ওঠে আর তারপর সমতল হয়ে থেমে যায় (একটা plateau)। এই monotonicity-ই EM-কে এত নির্ভরযোগ্য আর থামার-শর্ত (convergence) এত সহজ করে — \(\ell\) আর তেমন না বাড়লেই থামো। (এই উন্নতির লেখচিত্র চিত্র 6-7-em-convergence-এ দেখানো হবে।)
সতর্কতা — কিন্তু কেবল local optimum। তবে এই আরোহণ আপনাকে শুধু একটা স্থানীয় শীর্ষে (local optimum) তোলে — অগত্যা সবচেয়ে উঁচু শীর্ষে (global optimum) নয়। log-likelihood-এর ভূদৃশ্যে অনেক টিলা থাকতে পারে; EM যে টিলায় শেষ হবে তা নির্ভর করে কোথা থেকে শুরু করল তার উপর। বাজে শুরু থেকে একটা নিচু টিলায় আটকে যাওয়া সম্ভব। তাই বাস্তব-নিয়ম: EM কয়েকবার ভিন্ন এলোমেলো শুরু (multiple random restart) থেকে চালাও, আর শেষে যেটার \(\ell\) সবচেয়ে বড় সেই fit-টা রাখো। (একটা চরম অবক্ষয়ও আছে — কোনো উপাদান একটামাত্র বিন্দুকে আঁকড়ে ধরে তার covariance শূন্যের দিকে পাঠালে likelihood অসীমে ছোটে; এটা এড়াতে covariance-এ সামান্য regularization দেওয়া হয় — বিস্তারিত §৪/§৫-এ।)
এক বাক্যে। EM প্রতিটা iteration-এ log-likelihood monotone বাড়ায় (কখনো কমায় না), কিন্তু থামে একটা local optimum-এ — তাই কয়েকবার ভিন্ন শুরু থেকে চালিয়ে সেরা \(\ell\)-যুক্ত fit বাছতে হয়।
১.৫ GMM বনাম k-means, আর কতগুলো cluster — এক ঝলকে¶
দুটো শেষ সুতো এখানে আলগা বেঁধে রাখি, যা §২.৪–২.৫ ও §৪-এ পুরোপুরি খুলবে।
GMM বনাম k-means। এই অধ্যায়টা আসলে 5.9-এর k-means-এর সরাসরি একটা সাধারণীকরণ (generalization)। তিনটি তুলনা মাথায় রাখুন: (১) soft বনাম hard — GMM ভগ্নাংশ-responsibility দেয়, k-means কঠোর ০/১; (২) elliptical বনাম spherical — GMM-এর full \(\Sigma_k\) যেকোনো কাত-উপবৃত্ত cluster ধরে, k-means কেবল গোলক; (৩) সবচেয়ে সুন্দর সংযোগ — k-means আসলে GMM-এরই একটা সীমিত বিশেষ রূপ: যদি সব covariance-কে একই গোলক \(\Sigma_k=\sigma^2 I\) ধরি আর তারপর \(\sigma\to 0\) পাঠাই, তখন responsibility গলে গিয়ে কঠোর ০/১ হয়ে যায়, আর EM হুবহু k-means-এ পরিণত হয় (পূর্ণ যুক্তি §৪)। তাই k-means GMM-এর "বিশেষ ঘটনা", আর GMM তার "নমনীয় বড় ভাই"। (পাশাপাশি তুলনা চিত্র 6-7-gmm-vs-kmeans-এ; এই অধ্যায়ের elliptical dataset-এ GMM-এর মিল-স্কোর ARI \(0.97\) k-means-এর \(0.914\)-কে ছাড়িয়ে যায়।)
কতগুলো component \(K\)। GMM-ও k-means-এর মতো \(K\) আগে থেকে চায়। কিন্তু GMM যেহেতু একটা সত্যিকার probabilistic model (একটা likelihood আছে), আমরা \(K\) বাছতে পারি একটা principled পরিসংখ্যানিক মাপকাঠি দিয়ে — BIC (Bayesian Information Criterion, 5.2 থেকে চেনা)। BIC model-এর fit (log-likelihood)-কে পুরস্কার দেয় কিন্তু parameter-সংখ্যাকে শাস্তি দেয়, তাই অতিরিক্ত-জটিল model এড়ায়। বিভিন্ন \(K\)-তে GMM চালিয়ে যে \(K\)-তে BIC সর্বনিম্ন, সেটাই বাছা হয়। (চিত্র 6-7-bic-K-এ এই অধ্যায়ের dataset-এ BIC সর্বনিম্ন হয় \(K=3\)-তে — যা সত্যিকার উপাদান-সংখ্যাই।)
এক বাক্যে। GMM হলো k-means-এর soft, elliptical সাধারণীকরণ (k-means = GMM-এর \(\Sigma\to\sigma^2 I,\ \sigma\to0\) সীমা), আর GMM-এ component-সংখ্যা \(K\) বাছা হয় BIC সর্বনিম্ন করে (এই অধ্যায়ে \(K=3\))।
১.৬ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একনজরে, যাতে প্রতিটা অংশ কেন আসছে তা পরিষ্কার থাকে:
- Density estimation ও mixture model (§২.১) — কাঁচা data থেকে \(p(x)\) আন্দাজের লক্ষ্য, কেন একটা Gaussian যথেষ্ট নয়, mixture model \(\sum_k\pi_k p_k(x)\), আর KDE-র সাথে এক-বাক্যে তুলনা।
- GMM ও latent variable (§২.২) — \(p(x)=\sum_k\pi_k\mathcal N(x;\mu_k,\Sigma_k)\)-এর প্রতিটা প্রতীক, generative গল্প ও latent \(z\), এবং কেন MLE-তে log-এর ভেতরে যোগফল এসে সরাসরি সমাধান আটকায়।
- EM algorithm (§২.৩) — E-step (responsibility \(\gamma_{ik}\) = posterior, soft assignment) ও M-step (weighted update \(\pi_k=\tfrac1n\sum_i\gamma_{ik}\), \(\mu_k\), \(\Sigma_k\)), পুরো লুপ।
- Convergence ও GMM-বনাম-k-means (§২.৪) — monotone \(\ell\), local optimum ও restart, এবং soft/hard · elliptical/spherical · k-means = GMM-এর সীমা।
- \(K\) বাছা ও responsibility-র অর্থ (§২.৫) — BIC দিয়ে \(K\) (এই অধ্যায়ে \(K=3\)), আর responsibility-কে soft probability হিসেবে পড়া।
- সব derivation — latent log-likelihood কেন আটকায়, E-step কেন posterior, M-step-সূত্রের উৎস, EM কেন monotone, k-means কেন সীমা — §৪-এ। আর প্রয়োগ-অংশগুলো: পূর্ণ dataset ও worked example §৩-এ, derivation §৪-এ, কোড §৫, চিত্র §৬, অনুশীলনী §৭, সারসংক্ষেপ §৮।
এক বাক্যে কেন এটি এখানে। 5.9 clustering করত কঠোর, গোলকীয় k-means দিয়ে; এই অধ্যায় তাকে একটা probabilistic density-estimation কাঠামোয় তোলে — GMM (soft, elliptical) ও তা fit করার EM — যা latent-variable মডেলিংয়ের একটা মৌলিক হাতিয়ার; পরের অধ্যায় 6.8 ভিন্ন কোণ থেকে data-র গঠন ধরে — dimensionality reduction-এ এগোবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "data কয়েকটা Gaussian মেঘের একটা মিশ্রণ, প্রতিটা বিন্দুর উৎস লুকানো, আর সেটা fit করতে পালা করে soft assignment ও weighted update" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত কেন MLE log-sum-এ আটকায়, E-step-এর responsibility কেন posterior, M-step-এর update-সূত্র কোথা থেকে আসে, আর EM কেন log-likelihood monotone বাড়ায়), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে কিছু সাধারণ চিহ্ন স্থির করে নিই, যা গোটা অধ্যায়ে অপরিবর্তিত থাকবে। আমাদের কাছে \(n\)টি লেবেল-হীন পর্যবেক্ষণ আছে: \(x_1,\dots,x_n\), যেখানে \(x_i\in\mathbb{R}^p\) হলো \(i\)-তম পর্যবেক্ষণের feature vector (\(p\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা, \(i=1,\dots,n\))। (এই অধ্যায়ের চলমান উদাহরণে \(p=2\), যাতে cluster-গুলো সমতলে আঁকা যায়, আর \(n=600\)।) supervised অধ্যায়গুলোর বিপরীতে এখানে কোনো লেবেল \(y_i\) নেই — এটাই unsupervised: কেবল \(x\) দেখে গঠন খুঁজে বের করা। আমাদের লক্ষ্য এই বিন্দুগুলো-জন্ম-দেওয়া অজানা ঘনত্ব \(p(x)\)-কে একটা parametric model দিয়ে আন্দাজ করা।
২.১ Density estimation ও mixture model — কী আন্দাজ করছি, আর কেন একটা Gaussian যথেষ্ট নয়¶
প্রথমে লক্ষ্যটাই পরিষ্কার করি।
সংজ্ঞা (density estimation)। Density estimation (ঘনত্ব-আন্দাজ) হলো: কেবল একটা নমুনা \(x_1,\dots,x_n\) (ধরা হয় কোনো অজানা বণ্টন থেকে স্বাধীনভাবে তোলা) দেখে, সেই বণ্টনের probability density function \(p(x)\) আন্দাজ করা — অর্থাৎ feature-জগতের প্রতিটি জায়গায় "এখানে বিন্দু পড়ার আপেক্ষিক সম্ভাবনা কত" তার একটা সম্পূর্ণ চিত্র গড়া। clustering (\(z\)-আন্দাজ) এর একটা উপজাত মাত্র; আসল লক্ষ্য পুরো \(p(x)\)।
পদ্ধতি দুই ঘরানায় পড়ে। Nonparametric ঘরানা (যেমন 5.7-এর KDE — kernel density estimation) কোনো নির্দিষ্ট রূপ ধরে না; বরং প্রতিটি data-বিন্দুতে একটা ক্ষুদ্র kernel (মসৃণ ঢিবি) বসিয়ে \(n\)টি ঢিবির যোগফল নেয় — খুব নমনীয়, কিন্তু \(n\) বড় হলে ভারী ও \(p\) বড় হলে দুর্বল (curse of dimensionality)। Parametric ঘরানা ধরে নেয় \(p(x)\) অল্প-কিছু parameter-যুক্ত একটা নির্দিষ্ট পরিবারের — তখন কাজটা শুধু সেই parameter আন্দাজ করা (4.3-এর MLE-র মতো)। এই অধ্যায় parametric ঘরানার, তবে একটামাত্র সরল বণ্টনের চেয়ে নমনীয় একটা রূপ নিয়ে।
কেন একটা Gaussian যথেষ্ট নয়। সবচেয়ে সরল parametric চেষ্টা হবে পুরো data-তে একটা Gaussian \(\mathcal N(x;\mu,\Sigma)\) বসানো (2.4)। কিন্তু একটা Gaussian-এর একটাই চূড়া (unimodal) — মাঝখানে সর্বোচ্চ, চারদিকে একঘেয়ে কমতে থাকা। বাস্তব data প্রায়ই বহু-চূড়া (multimodal): কয়েকটা আলাদা ঘন এলাকা (যেমন আমাদের ৩টি আলাদা মেঘ)। এমন data-তে একটা Gaussian বসালে সে চূড়াগুলোর মাঝখানে — যেখানে আসলে বিন্দু কম — একটা মিথ্যা চূড়া বসিয়ে দেয়, আর আসল গঠন পুরো মিস করে।
সংজ্ঞা (mixture model)। এর সমাধান কয়েকটা সরল বণ্টন জোড়া দেওয়া। একটা mixture model (মিশ্রণ মডেল) হলো \(K\)টি উপাদান-বণ্টনের একটা ওজনিত যোগফল: $$ p(x) \;=\; \sum_{k=1}^{K} \pi_k\, p_k(x), $$ যেখানে— - \(K\) হলো উপাদান-সংখ্যা (কয়টা সরল বণ্টন জুড়ছি); - \(p_k(x)\) হলো \(k\)-তম উপাদান-বণ্টন (component density) — একটা সরল, সাধারণত একই-পরিবারের density; - \(\pi_k\) হলো \(k\)-তম উপাদানের mixing weight (মিশ্রণ-ওজন): এই উপাদানটা মোট ভরের কত অংশ ধরে।
ওজনগুলো একটা বৈধ probability হওয়ার শর্ত মানে: প্রতিটি \(\pi_k\ge 0\) আর \(\sum_{k=1}^{K}\pi_k=1\) (সব ওজন মিলে \(1\) — তবেই \(p(x)\) একটা বৈধ density, যার মোট integral \(1\))। স্বজ্ঞা: একটা বিন্দু জন্মাতে গেলে প্রথমে ওজন \(\pi_k\) অনুযায়ী একটা উপাদান \(k\) এলোমেলোভাবে বাছো, তারপর সেই \(p_k\) থেকে বিন্দুটা তোলো — তাই \(\pi_k\) হলো "একটা যথেচ্ছ বিন্দু উপাদান \(k\) থেকে আসার আগাম (prior) সম্ভাবনা"। (5.7-এর KDE-ও কারিগরিভাবে একটা mixture — \(n\)টা সমান-ওজনের kernel-উপাদান; এখানে আমরা মাত্র কয়েকটা \(K\ll n\) উপাদান নিয়ে অনেক মিতব্যয়ী, parametric একটা mixture বানাচ্ছি।)
এক বাক্যে। Density estimation কাঁচা নমুনা থেকে অজানা ঘনত্ব \(p(x)\) আন্দাজ করে; একটা Gaussian বহু-চূড়া data ধরতে পারে না, তাই আমরা একটা mixture model \(p(x)=\sum_k\pi_k p_k(x)\) বসাই — \(K\)টা সরল বণ্টনের ওজনিত যোগফল, যেখানে \(\pi_k\ge0\), \(\sum_k\pi_k=1\)।
২.২ Gaussian Mixture Model ও latent variable — কেন MLE কঠিন¶
এবার উপাদান-বণ্টন \(p_k\)-কে নির্দিষ্ট করি Gaussian হিসেবে।
সংজ্ঞা (Gaussian Mixture Model)। mixture-এর প্রতিটি উপাদান যখন একটা multivariate Gaussian (2.4), তখন সেটা একটা Gaussian Mixture Model (GMM) — গাউসিয়ান মিশ্রণ মডেল: $$ p(x) \;=\; \sum_{k=1}^{K} \pi_k\,\mathcal N(x;\mu_k,\Sigma_k), $$ এখানে— - \(\pi_k\) হলো \(k\)-তম উপাদানের mixing weight (\(\pi_k\ge 0\), \(\sum_{k=1}^K\pi_k=1\) — §২.১-এর মতোই); - \(\mu_k\in\mathbb{R}^p\) হলো \(k\)-তম উপাদানের component mean (কেন্দ্র — সেই Gaussian মেঘের মাঝবিন্দু); - \(\Sigma_k\) হলো \(k\)-তম উপাদানের covariance matrix (\(p\times p\), প্রতিসম ও positive-definite) — যা সেই মেঘের আকৃতি, ছড়ানো ও কাত (orientation) ঠিক করে: তার সমান-ঘনত্ব contour একটা উপবৃত্ত (2.4), আর full \(\Sigma_k\)-ই cluster-কে গোলক ছাড়িয়ে যেকোনো লম্বাটে/কাত elliptical আকৃতি দেয়; - \(\mathcal N(x;\mu_k,\Sigma_k)=\frac{1}{(2\pi)^{p/2}\,\lvert\Sigma_k\rvert^{1/2}}\exp\!\big(-\tfrac12 (x-\mu_k)^\top \Sigma_k^{-1}(x-\mu_k)\big)\) হলো সেই Gaussian-এর ঘনত্ব (2.4 থেকে), যেখানে \(\lvert\Sigma_k\rvert\) হলো \(\Sigma_k\)-এর determinant ও \(\Sigma_k^{-1}\) তার inverse।
সব parameter একসাথে লিখি \(\theta=\{\pi_k,\mu_k,\Sigma_k\}_{k=1}^K\) — এটাই আমরা data থেকে আন্দাজ করতে চাই। (এই অধ্যায়ের dataset-এ \(K=3\), \(p=2\); চিত্র 6-7-gmm-clusters-এ fit-করা তিনটি উপাদানের কেন্দ্র \(\mu_k\) ও উপবৃত্ত-contour (\(\Sigma_k\) থেকে) data-র উপর আঁকা থাকবে।)
Latent variable \(z\) — generative গল্পটা আনুষ্ঠানিক করা। §১.২-এর "কোন বিন্দু কোন মেঘ থেকে" ভাবনাটা এবার একটা চলরাশিতে ধরি। প্রতিটি বিন্দু \(x_i\)-র সাথে একটা latent (লুকানো) variable \(z_i\in\{1,\dots,K\}\) যুক্ত করি — যা বলে বিন্দুটা কোন উপাদান থেকে এসেছে। generative প্রক্রিয়াটা তখন দুই ধাপ: প্রথমে \(z_i=k\) বাছা হয় সম্ভাবনা \(P(z_i=k)=\pi_k\) দিয়ে (তাই \(\pi_k\) হলো \(z\)-এর prior), তারপর বিন্দুটা তোলা হয় \(x_i\mid (z_i=k)\sim \mathcal N(\mu_k,\Sigma_k)\) থেকে। লক্ষ্য করুন, এই \(z_i\) আমরা কখনো পর্যবেক্ষণ করি না — কেবল \(x_i\) দেখি; \(z_i\)-কে যোগফলে যোগ করে (marginalize) ফেললেই উপরের mixture-সূত্র \(p(x_i)=\sum_k \pi_k \mathcal N(x_i;\mu_k,\Sigma_k)\) ফিরে আসে।
কেন MLE সরাসরি কঠিন। 4.3-এর নিয়মে আমরা \(\theta\) বাছতে চাইব log-likelihood \(\ell(\theta)\) সর্বোচ্চ করে। data স্বাধীন ধরে, likelihood হলো প্রতিটি বিন্দুর density-র গুণফল, তাই— $$ \ell(\theta) \;=\; \sum_{i=1}^{n} \log p(x_i) \;=\; \sum_{i=1}^{n} \log!\left( \sum_{k=1}^{K} \pi_k\,\mathcal N(x_i;\mu_k,\Sigma_k) \right). $$ এখানেই কাঁটা। একটা একক Gaussian-এর MLE-তে log আর exp পরস্পরকে বাতিল করত (log-এর ভেতরে একটা exp), তাই \(\mu,\Sigma\)-এর সুন্দর বদ্ধ-রূপ (closed-form) সমাধান বেরোত। কিন্তু mixture-এ log-এর ঠিক ভেতরে একটা যোগফল (\(\sum_k\)) বসে আছে — log আর exp আর বাতিল হয় না, যোগফলটা log-কে আটকে রাখে। ফলে \(\partial\ell/\partial\theta=0\) সমীকরণগুলো পরস্পর-জড়ানো (coupled) ও অরৈখিক হয়ে যায়, কোনো সরল বদ্ধ-রূপ সমাধান নেই।
স্বজ্ঞাগতভাবে সমস্যাটা ঠিক সেই মুরগি-ডিম ধাঁধা: যদি প্রতিটি \(z_i\) জানা থাকত (কোন বিন্দু কোন উপাদানের), log-এর ভেতরের যোগফল উবে যেত — প্রতিটা উপাদানের নিজের বিন্দুগুলো আলাদা করে সরল Gaussian-MLE করলেই হতো। আবার উলটোভাবে, \(\theta\) জানা থাকলে Bayes দিয়ে \(z_i\)-র সম্ভাবনা বের করা যেত। কোনোটাই জানা নেই — আর ঠিক এই গিঁট খোলার জন্যই EM।
এক বাক্যে। একটা GMM \(p(x)=\sum_k\pi_k\mathcal N(x;\mu_k,\Sigma_k)\)-এ প্রতিটি বিন্দুর উৎস একটা latent \(z_i\in\{1,\dots,K\}\); কিন্তু \(z\) অজানা বলে log-likelihood-এ log-এর ভেতরে যোগফল আটকে যায়, তাই সরাসরি MLE-র বদ্ধ-রূপ সমাধান নেই — দরকার EM।
২.৩ EM algorithm — E-step (soft assignment) ও M-step (weighted update)¶
§২.২-এর মুরগি-ডিম ধাঁধার সমাধান হলো EM algorithm (Expectation–Maximization — প্রত্যাশা–সর্বোচ্চকরণ): ঠিক k-means-এর মতো একটা iterative কৌশল, যা পালা করে দুটো ধাপ চালায় — একটা ধাপ \(z\)-এর অনিশ্চয়তা ভরে (assignment), আরেকটা ধাপ \(\theta\) হালনাগাদ করে (parameter) — যতক্ষণ না স্থির হয়। পার্থক্য একটাই, কিন্তু গুরুত্বপূর্ণ: assignment-টা soft (ভগ্নাংশ-সম্ভাবনা), কঠোর ০/১ নয়।
শুরুতে \(\theta=\{\pi_k,\mu_k,\Sigma_k\}\)-এর একটা প্রাথমিক আন্দাজ নাও (সাধারণত k-means-এর ফল বা এলোমেলো বীজ থেকে)। তারপর নিচের দুই ধাপ পালা করে চালাও।
E-step (Expectation — responsibility হিসাব)। বর্তমান \(\theta\) স্থির ধরে, প্রতিটি বিন্দু \(i\) ও উপাদান \(k\)-র জন্য বের করো responsibility \(\gamma_{ik}\) — অর্থাৎ "বিন্দু \(x_i\) দেখার পর, এটা উপাদান \(k\) থেকে আসার posterior সম্ভাবনা" \(P(z_i=k\mid x_i)\)। এটা সরাসরি Bayes' theorem (2.2): prior \(\pi_k\) গুণ likelihood \(\mathcal N(x_i;\mu_k,\Sigma_k)\), সব উপাদানের উপর normalize করা — $$ \gamma_{ik} \;=\; P(z_i=k\mid x_i) \;=\; \frac{\pi_k\,\mathcal N(x_i;\mu_k,\Sigma_k)}{\sum_{l=1}^{K}\pi_l\,\mathcal N(x_i;\mu_l,\Sigma_l)}, $$ যেখানে লব হলো "উপাদান \(k\) থেকে বিন্দু \(x_i\) আসার যৌথ ওজন" (prior \(\times\) likelihood), আর হর হলো সব উপাদানের উপর সেই ওজনের যোগফল (= \(p(x_i)\), normalize-করার জন্য, যাতে \(\sum_{k=1}^{K}\gamma_{ik}=1\))। সূচক \(l\) এখানে কেবল হরের যোগফল চালানোর জন্য একটা ডামি (সব উপাদানের উপর ঘোরে)। প্রতিটি \(\gamma_{ik}\in[0,1]\), আর প্রতিটি বিন্দুর responsibility-গুলো মিলে \(1\) — এই-ই সেই soft assignment: বিন্দু \(i\) প্রতিটি cluster-এ একটা ভগ্নাংশ-সদস্যপদ পায়। (যে বিন্দু একটা উপাদানের খুব কাছে, তার সেদিকে \(\gamma\) প্রায়-\(1\); সীমান্ত-বিন্দুর responsibility ভাগাভাগি হয় — যেমন এই অধ্যায়ের একটা উদাহরণ-বিন্দুর \(\gamma_i\approx[0.864,\,0.002,\,0.133]\), অর্থাৎ মূলত উপাদান ১-এর, সামান্য ৩-এর।)
M-step (Maximization — weighted parameter update)। এবার responsibility \(\{\gamma_{ik}\}\) স্থির ধরে \(\theta\) হালনাগাদ করো — যেন প্রতিটি বিন্দু \(i\) তার \(\gamma_{ik}\) ভগ্নাংশ নিয়ে উপাদান \(k\)-তে "অংশত সদস্য"। এটা একটা responsibility-weighted MLE। প্রথমে প্রতিটি উপাদানের কার্যকর (soft) বিন্দু-সংখ্যা লিখি \(N_k=\sum_{i=1}^{n}\gamma_{ik}\) ("উপাদান \(k\) মোট কত ভগ্নাংশ-বিন্দু পেল", \(\sum_k N_k=n\))। তারপর update — $$ \pi_k \;=\; \frac{N_k}{n} \;=\; \frac{1}{n}\sum_{i=1}^{n}\gamma_{ik}, \qquad \mu_k \;=\; \frac{1}{N_k}\sum_{i=1}^{n}\gamma_{ik}\,x_i, \qquad \Sigma_k \;=\; \frac{1}{N_k}\sum_{i=1}^{n}\gamma_{ik}\,(x_i-\mu_k)(x_i-\mu_k)^\top. $$ এগুলো পড়ুন একদম স্বজ্ঞামতো — এরা একক-Gaussian-MLE-রই ওজনিত সংস্করণ: নতুন mixing weight \(\pi_k\) হলো উপাদান \(k\)-র গড় responsibility (এটা মোট কত ভগ্নাংশ-বিন্দু ধরল); নতুন mean \(\mu_k\) হলো বিন্দুগুলোর responsibility-ওজনিত গড় (নিশ্চিত-সদস্য বিন্দু কেন্দ্রকে বেশি টানে); আর নতুন covariance \(\Sigma_k\) হলো \(\mu_k\)-এর চারপাশে responsibility-ওজনিত বিস্তার (যা cluster-এর elliptical আকৃতি ও কাত আবার আন্দাজ করে)। (এই সূত্রগুলো ঠিক কোথা থেকে আসে — complete-data log-likelihood-এর প্রত্যাশা সর্বোচ্চ করে — তার পূর্ণ derivation §৪-এ।)
লুপ ও থামা। E-step ও M-step পালা করে চালাও: নতুন \(\theta\) দিয়ে আবার E-step (responsibility পুনঃহিসাব), সেই responsibility দিয়ে আবার M-step (parameter পুনঃহিসাব)। প্রতিটি পূর্ণ চক্রের পর observed-data log-likelihood \(\ell\) গণনা করো; যখন দুই পরপর চক্রে \(\ell\)-এর বৃদ্ধি একটা ছোট সীমার (tolerance) নিচে নামে — অর্থাৎ \(\ell\) আর তেমন বাড়ছে না — তখন থামো। এই থামার-শর্তই নির্ভরযোগ্য, কারণ §১.৪-এর গ্যারান্টি বলে \(\ell\) কখনো কমে না।
ছবিটা মাথায় রাখুন: E-step বিন্দুগুলোকে বর্তমান মেঘগুলোর মধ্যে soft-ভাবে ভাগ করে দেয় (responsibility), আর M-step সেই ভাগ অনুযায়ী মেঘগুলোকে (কেন্দ্র, আকৃতি, ওজন) নতুন করে গড়ে — ঠিক k-means-এর assign-করো-তারপর-কেন্দ্র-সরাও চক্রেরই soft, probabilistic যমজ।
এক বাক্যে। EM পালা করে চালায় E-step — Bayes দিয়ে responsibility \(\gamma_{ik}=\frac{\pi_k\mathcal N(x_i;\mu_k,\Sigma_k)}{\sum_l\pi_l\mathcal N(x_i;\mu_l,\Sigma_l)}\) (soft posterior assignment) — আর M-step — সেই responsibility-কে ওজন ধরে \(\pi_k=\tfrac1n\sum_i\gamma_{ik}\), \(\mu_k\), \(\Sigma_k\)-এর weighted MLE — যতক্ষণ না log-likelihood স্থির হয়।
২.৪ Convergence, এবং GMM বনাম k-means¶
EM-এর আচরণ ও k-means-এর সাথে তার সম্পর্ক এবার সংজ্ঞায় বাঁধি।
Convergence (monotone, কিন্তু local)। EM-এর কেন্দ্রীয় তাত্ত্বিক গুণ: প্রতিটি E-step+M-step চক্রের পর observed-data log-likelihood \(\ell(\theta)\) monotone অ-হ্রাসমান — অর্থাৎ \(\ell(\theta^{(t+1)})\ge \ell(\theta^{(t)})\), কখনো কমে না (পূর্ণ প্রমাণ §৪-এ, একটা ELBO/Jensen-অসমতা যুক্তি দিয়ে)। তাই \(\ell\) iteration-এর সাথে বাড়তে-বাড়তে একটা শীর্ষে থিতু হয় (চিত্র 6-7-em-convergence)। কিন্তু এই শীর্ষ একটা local optimum মাত্র — শুরু-বিন্দুর উপর নির্ভরশীল; তাই বাস্তবে কয়েকবার ভিন্ন এলোমেলো শুরু (multiple restart) থেকে চালিয়ে সর্বোচ্চ-\(\ell\) fit বাছা হয় (§১.৪)।
GMM বনাম k-means — তিনটি অক্ষে। এই অধ্যায় ও 5.9-কে এক ছবিতে মেলাই (পাশাপাশি তুলনা চিত্র 6-7-gmm-vs-kmeans):
| k-means (5.9) | GMM (এই অধ্যায়) | |
|---|---|---|
| Assignment | hard (কঠোর ০/১) | soft (responsibility \(\gamma_{ik}\in[0,1]\)) |
| Cluster-আকৃতি | spherical (Euclidean দূরত্ব, গোলক) | elliptical (full \(\Sigma_k\) — যেকোনো কাত-উপবৃত্ত) |
| মডেল | কেবল within-cluster বর্গ-দূরত্ব কমায় | পূর্ণ probabilistic density (likelihood আছে) |
সবচেয়ে গভীর সংযোগ — k-means = GMM-এর একটা সীমা। তিনটি তুলনা আসলে একটা গাণিতিক সত্যের তিন মুখ: k-means হলো GMM-এরই একটা বিশেষ, সীমিত রূপ। ধরুন GMM-এ সব covariance-কে একই isotropic (সমদিগ্বর্তী) গোলক ধরি, \(\Sigma_k=\sigma^2 I\) (একই \(\sigma\), সব দিকে সমান, এখানে \(I\) হলো \(p\times p\) identity matrix), আর তারপর \(\sigma\to 0\) পাঠাই। তখন E-step-এর responsibility-গুলো "তীক্ষ্ণ" হতে হতে কঠোর ০/১-এ গলে যায় — প্রতিটি বিন্দু কেবল তার নিকটতম-mean উপাদানে পুরো responsibility \(1\) দেয় (এটাই hard assignment), আর M-step-এর mean-update পরিণত হয় সাধারণ centroid-গড়ে। অর্থাৎ এই সীমায় EM হুবহু k-means-এ পরিণত হয় (পূর্ণ derivation §৪)। তাই k-means GMM-এর "spherical, hard" বিশেষ ঘটনা, আর GMM তার নমনীয় সাধারণীকরণ — যে কারণে আমাদের elliptical dataset-এ GMM-এর মিল-স্কোর ARI (Adjusted Rand Index — দুটি clustering কতটা মেলে তার \(-\) থেকে \(1\) মাপ, \(1\) = নিখুঁত মিল) \(0.97\), যেখানে k-means-এর \(0.914\); GMM elliptical cluster-এ স্পষ্ট জেতে।
এক বাক্যে। EM প্রতি iteration-এ \(\ell\) monotone বাড়ায় তবে থামে local optimum-এ (তাই restart); আর GMM বনাম k-means = soft বনাম hard · elliptical বনাম spherical, যেখানে k-means হলো GMM-এর \(\Sigma_k\to\sigma^2 I,\ \sigma\to0\) সীমা।
২.৫ কতগুলো component \(K\) — BIC, এবং responsibility-র অর্থ¶
দুটো শেষ ধারণা।
\(K\) বাছা — BIC দিয়ে। GMM-ও \(K\) (উপাদান-সংখ্যা) আগে থেকে চায়, কিন্তু k-means-এর elbow/silhouette-এর বদলে এখানে একটা principled পরিসংখ্যানিক মাপকাঠি ব্যবহার করা যায়, কারণ GMM-এর একটা সত্যিকার likelihood আছে: BIC (Bayesian Information Criterion, 5.2)। BIC-এর সংজ্ঞা \(\mathrm{BIC}=-2\ell + (\text{parameter-সংখ্যা})\cdot\log n\), যেখানে \(\ell\) হলো fit-করা model-এর সর্বোচ্চ log-likelihood ও \(n\) নমুনা-আকার — অর্থাৎ এটা একসাথে খারাপ fit-কে শাস্তি দেয় (\(-2\ell\) অংশ, fit ভালো হলে ছোট) আর বেশি parameter-কেও শাস্তি দেয় (দ্বিতীয় অংশ, \(K\) বাড়লে বড়), তাই অতিরিক্ত-জটিল model এড়ায়। নিয়ম: কয়েকটা \(K\)-মানে GMM চালাও, প্রতিটার BIC মাপো, আর যে \(K\)-তে BIC সর্বনিম্ন সেটাই বাছো। (চিত্র 6-7-bic-K-এ এই অধ্যায়ের dataset-এ BIC বিভিন্ন \(K\)-তে: \(K{=}1\to5626.7\), \(K{=}2\to5111.7\), \(K{=}3\to4828.8\) — সর্বনিম্ন, তারপর আবার বাড়ে \(K{=}4\to4857.5\), \(K{=}5\to4890.9\) — তাই \(K=3\), যা সত্যিকার উপাদান-সংখ্যাই।)
Responsibility-র অর্থ — soft probability। শেষে responsibility \(\gamma_{ik}\)-কে আবার মনে করিয়ে দিই, কারণ এটাই GMM-কে k-means থেকে আলাদা করা মূল ফসল। \(\gamma_{ik}\) কোনো কঠোর লেবেল নয় — এটা একটা সত্যিকার posterior probability \(P(z_i=k\mid x_i)\): "সব তথ্য বিবেচনায়, বিন্দু \(i\)-র উপাদান \(k\)-তে সদস্য হওয়ার সম্ভাবনা কত"। তাই GMM প্রতিটি বিন্দুর জন্য কেবল "কোন cluster" বলে না, বলে কতটা নিশ্চিত — নিশ্চিত বিন্দুর responsibility একদিকে প্রায়-\(1\), আর সীমান্তের দ্বিধাগ্রস্ত বিন্দুর responsibility কয়েক উপাদানে ছড়ানো (যেমন \(\approx[0.864,0.002,0.133]\))। চাইলে এই soft responsibility থেকে একটা hard লেবেলও পাওয়া যায় — প্রতিটি বিন্দুকে তার সর্বোচ্চ-\(\gamma\) উপাদানে দিয়ে — কিন্তু আসল সমৃদ্ধি ওই ভগ্নাংশ-অনিশ্চয়তাটুকুতেই, যা k-means চিরতরে হারিয়ে ফেলত।
এক বাক্যে। Component-সংখ্যা \(K\) বাছা হয় BIC সর্বনিম্ন করে (\(\mathrm{BIC}=-2\ell+(\#\text{param})\log n\); এই অধ্যায়ে \(K=3\)), আর responsibility \(\gamma_{ik}\) হলো একটা সত্যিকার soft posterior probability \(P(z_i=k\mid x_i)\) — প্রতিটি বিন্দুর সদস্যপদ ও তার নিশ্চয়তা একসাথে ধরা।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে চারটি ক্রমবর্ধমান উদাহরণের মধ্য দিয়ে এই অধ্যায়ের কেন্দ্রীয় গল্পটা হাতে-কলমে দেখা হবে — কীভাবে কোনো label ছাড়াই (unlabeled) একগুচ্ছ বিন্দু থেকে EM-অ্যালগরিদম একটা Gaussian Mixture Model (GMM)-এর সবগুলো parameter পুনরুদ্ধার করে, এবং তা কেন আগের অধ্যায়ের k-means-এর চেয়ে নমনীয় ও শক্তিশালী। প্রথমে দেখব GaussianMixture-কে fit করলে EM কীভাবে তিনটি লুকানো component-এর mixing weight, mean ও covariance খুঁজে বের করে — শুধু \(x\)-গুলো দেখে, কোন বিন্দু কোন গুচ্ছের তা না জেনে (E1); তারপর প্রতিটি বিন্দু পায় একটা responsibility ভেক্টর (posterior probability), যা যোগ করলে ঠিক \(1\) — পরিষ্কার-গুচ্ছ বিন্দুতে প্রায়-নিশ্চিত, কিন্তু সীমান্ত-বিন্দুতে সত্যিকারের দ্বিধাগ্রস্ত, অর্থাৎ k-means-এর hard label-এর বিপরীতে এটা soft (E2); এরপর একই data-তে GMM বনাম k-means তুলনা করে দেখব কেন elliptical/tilted গুচ্ছে GMM জেতে (E3); সবশেষে BIC দিয়ে গুচ্ছ-সংখ্যা \(K\) স্বয়ংক্রিয়ভাবে নির্বাচন করব এবং দেখব BIC ঠিক সত্যিকারের \(K=3\)-ই বেছে নেয় (E4)। প্রতিটি সংখ্যা scikit-learn দিয়ে নিচে যাচাই করা।
সব উদাহরণে একই synthetic dataset ব্যবহার করা হবে — একটা ৩-component, ২-মাত্রিক Gaussian mixture থেকে \(n=600\)টি বিন্দু। তিনটি component-এর প্রকৃত (true) mean, covariance ও weight ইচ্ছাকৃতভাবে এমন বেছে নেওয়া যাতে গুচ্ছগুলো আলাদা আলাদা আকার ও কাত (tilt)-এর হয়: একটা গোলাকার (spherical, \(\Sigma=I\)), একটা ধনাত্মক-কাত উপবৃত্ত (positively tilted), আর একটা ঋণাত্মক-কাত উপবৃত্ত (negatively tilted)। ঠিক এই অসম, কাত-যুক্ত গঠনই এই অধ্যায়ের কেন্দ্রবিন্দু, কারণ এখানেই GMM আর k-means-এর পার্থক্য স্পষ্ট হয়:
import numpy as np
from sklearn.mixture import GaussianMixture
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
rng = np.random.default_rng(20260619)
means = [[0, 0], [5, 4], [0, 5]]
covs = [np.eye(2), # spherical
[[2, 1.5], [1.5, 2]], # positively tilted ellipse
[[1, -0.7], [-0.7, 1]]] # negatively tilted ellipse
weights = [0.40, 0.35, 0.25] # true mixing proportions
n = 600
comp = rng.choice(3, size=n, p=weights) # draw all component labels first
X = np.zeros((n, 2)); z = comp.copy() # z: true (hidden) component labels
for k in range(3): # batch-fill points per component
idx = comp == k
X[idx] = rng.multivariate_normal(means[k], covs[k], idx.sum())
# X: (600, 2) unlabeled points; z: ground-truth labels (used ONLY to score)
লক্ষণীয়, EM-কে কখনোই z দেওয়া হয় না — z কেবল শেষে ARI দিয়ে ফলাফল যাচাই করতে রাখা। EM-এর কাছে শুধু \(X\), আর সে নিজে থেকেই বের করে কোথায় কয়টা গুচ্ছ, কে কত বড়, কোন দিকে কাত।
৩.১ E1 — EM দিয়ে GMM ফিট: label ছাড়াই parameter পুনরুদ্ধার¶
মূল মডেলটা মনে করিয়ে দিই: একটা mixture-এ যেকোনো বিন্দুর density হলো \(K\)টা Gaussian-এর ওজনিত যোগফল,
যেখানে \(\pi_k\) হলো mixing weight (component \(k\) থেকে একটা বিন্দু আসার পূর্ব-সম্ভাবনা)। সমস্যা হলো: আমরা শুধু \(x_i\)-গুলো দেখি, কিন্তু প্রতিটি বিন্দুর জন্য "কোন component থেকে এলো" সেই latent variable লুকানো — তাই সরাসরি maximum likelihood বের করা যায় না। EM (Expectation–Maximization) ঠিক এই latent-variable সমস্যার সমাধান: দুটো ধাপ পালাক্রমে চালায় —
- E-step: বর্তমান parameter ধরে প্রতিটি বিন্দুর responsibility \(\gamma_{ik}\) হিসাব করে (নিচে E2-তে বিস্তারিত) — অর্থাৎ "\(x_i\) কতটা component \(k\)-এর" তার posterior probability।
- M-step: সেই responsibility-গুলোকে soft label ধরে প্রতিটি component-এর \(\pi_k,\mu_k,\Sigma_k\) পুনরায় হিসাব করে (responsibility-ওজনিত weighted mean ও covariance)।
এই দুই ধাপ log-likelihood \(\ell=\sum_i\log p(x_i)\)-কে প্রতি iteration-এ অ-হ্রাসমানভাবে (monotonically non-decreasing) বাড়ায়, যতক্ষণ না তা একটা মানে স্থির হয় (convergence)। scikit-learn-এ এটাই GaussianMixture:
gmm = GaussianMixture(n_components=3, covariance_type='full',
random_state=0, n_init=5).fit(X)
print(gmm.converged_) # True
print(round(gmm.score(X), 3)) # -3.933 (per-sample log-likelihood)
print(np.round(np.sort(gmm.weights_)[::-1], 3)) # [0.405 0.349 0.246]
ফলাফল তিনটে কথা বলছে। প্রথমত, converged_ = True — EM থেমেছে, log-likelihood স্থির হয়েছে। দ্বিতীয়ত, recovered mixing weights [0.405, 0.349, 0.246], যা প্রকৃত [0.40, 0.35, 0.25]-এর প্রায় হুবহু — মাত্র কয়েক হাজারাংশের তফাত, যা \(n=600\)-এর sampling-ওঠানামার মধ্যেই পড়ে। তৃতীয়ত, per-sample log-likelihood −3.933 (অর্থাৎ গড়ে প্রতিটি বিন্দুর \(\log p(x_i)\approx-3.933\))।
এখানে আসল জাদুটা ধরা জরুরি: EM-কে আমরা শুধু \(X\) দিয়েছি — কোন বিন্দু কোন গুচ্ছের, সে তথ্য একবারও দিইনি। তবু সে তিনটি component-এর weight, mean এবং আলাদা-আলাদা covariance (আকার ও কাত-সহ) নিজে থেকেই পুনরুদ্ধার করেছে। covariance_type='full' দেওয়ায় প্রতিটি component-এর জন্য একটা পূর্ণ \(2\times2\) covariance matrix শেখা হয়, তাই উপবৃত্তাকার ও কাত-যুক্ত গুচ্ছও ঠিকঠাক ধরা পড়ে। আর n_init=5 দিয়ে পাঁচটা ভিন্ন random initialization থেকে শুরু করে সেরা (সর্বোচ্চ \(\ell\)) ফলটা রাখা হয় — কারণ EM, k-means-এর মতোই, non-convex; খারাপ initialization-এ local optimum-এ আটকে যেতে পারে। সংক্ষেপে: unlabeled data থেকে EM পুরো generative গল্পটা (কয়টা গুচ্ছ, কে কত বড়, কোথায়, কোন আকারে) ফিরে আনল।
৩.২ E2 — soft assignment: responsibility (posterior probability)¶
EM আর GMM-এর সবচেয়ে স্বতন্ত্র বৈশিষ্ট্য হলো soft assignment। k-means প্রতিটি বিন্দুকে ঠিক একটা cluster-এ hard ভাবে বসায় (label \(\in\{0,1,2\}\)); GMM-এর বদলে প্রতিটি বিন্দু পায় একটা responsibility ভেক্টর — তিনটি component-এর প্রতিটির জন্য একটা posterior probability, যা যোগ করলে ঠিক \(1\)। গাণিতিকভাবে component \(k\)-এর জন্য বিন্দু \(x_i\)-এর responsibility:
লব হলো "component \(k\) থেকে এই বিন্দু আসার যৌথ সম্ভাবনা" (\(\pi_k\) গুণ সেই Gaussian-এর density), আর হর হলো সব component জুড়ে তার যোগফল (\(=p(x_i)\)) — অর্থাৎ এটা ঠিক Bayes-সূত্রের posterior, \(\gamma_{ik}=P(\text{component }k\mid x_i)\)। হর-এর কারণে স্বয়ংক্রিয়ভাবে \(\sum_k\gamma_{ik}=1\)। scikit-learn-এ এটাই predict_proba:
resp = gmm.predict_proba(X) # shape (600, 3), each row sums to 1
# একটা পরিষ্কার-গুচ্ছ (clear-cluster) বিন্দু — কোনো এক component-এর গভীরে
clear = np.argmax(resp.max(axis=1))
print(np.round(resp[clear], 3)) # ≈ [0.99 0.01 0.00] (প্রায় নিশ্চিত)
# একটা সীমান্ত (ambiguous boundary) বিন্দু — দুই গুচ্ছের মাঝামাঝি
amb = np.argmin(np.abs(resp.max(axis=1) - 0.864))
print(np.round(resp[amb], 3)) # ≈ [0.864 0.002 0.133] (সত্যিই দ্বিধাগ্রস্ত)
দুটো বিন্দুর ফারাকটাই এই উদাহরণের শিক্ষা। একটা পরিষ্কার-গুচ্ছ বিন্দু কোনো এক component-এর কেন্দ্রের কাছে, দূরের দুটো থেকে অনেক দূরে — তার responsibility ≈ [0.99, 0.01, 0.00]: মডেল প্রায় নিশ্চিত এটা প্রথম component-এর। কিন্তু একটা সীমান্ত বিন্দু, যা দুই গুচ্ছের ওভারল্যাপ-অঞ্চলে পড়ে, তার responsibility ≈ [0.864, 0.002, 0.133] — মডেল বলছে "প্রায় ৮৬% সম্ভাবনা component 1-এর, কিন্তু ১৩% সম্ভাবনা component 3-এরও হতে পারে।" এই genuinely uncertain বিন্দুটাকে k-means নির্দ্বিধায় একটা label দিয়ে দিত (সম্ভবত component 1), সেই দ্বিধাটা পুরোপুরি লুকিয়ে ফেলত। GMM তা না করে দ্বিধাটা সংখ্যায় ধরে রাখে।
এই soft information-এর বাস্তব মূল্য বিরাট। একটা [0.99, 0.01, 0.00] বিন্দু আর একটা [0.45, 0.55, 0.00] বিন্দু — দুটোকেই hard clustering একই রকম "cluster-এর সদস্য" বলবে, অথচ দ্বিতীয়টা কার্যত মুদ্রা-নিক্ষেপ। responsibility থাকলে আমরা এই অনিশ্চয়তা পরিমাপ করতে পারি: কোন বিন্দুগুলো আত্মবিশ্বাসে শ্রেণিবদ্ধ আর কোনগুলো সীমান্তে ঝুলছে, তা চিহ্নিত করা যায় (যেমন anomaly/borderline detection-এ)। নিচের চিত্রটা পার্থক্যটা ফুটিয়ে তোলে:
soft responsibilities: clear-cluster vs. boundary point (each row sums to 1)
clear-cluster point comp1 ████████████████████████████░ 0.99
comp2 ░ 0.01
comp3 0.00 → confident
ambiguous boundary comp1 ████████████████████████░ 0.864
comp2 0.002
comp3 ████░ 0.133 → uncertain
└────────────────────────────┘
0.0 probability 1.0
k-means would force BOTH into a single hard label, hiding the doubt.
৩.৩ E3 — GMM বনাম k-means: কাত-যুক্ত গুচ্ছে কে জেতে¶
এবার মূল তুলনা: একই unlabeled \(X\)-এ GMM আর k-means দুজনকেই \(K=3\) গুচ্ছে চালিয়ে, প্রকৃত label z-এর সাপেক্ষে কে ভালো করে দেখি। মান নেওয়ার মাপকাঠি Adjusted Rand Index (ARI) — দুটো clustering কতটা মেলে তার একটা স্কোর: \(1.0\) মানে নিখুঁত মিল, \(0\) মানে এলোমেলো অনুমানের সমান। (ARI label-এর নাম/ক্রম উপেক্ষা করে কেবল "কোন বিন্দু কোন বিন্দুর সাথে একই গুচ্ছে" সেই গঠন তুলনা করে, তাই cluster-নম্বর আলাদা হলেও সমস্যা নেই।)
labels_gmm = gmm.predict(X) # GMM-এর hard label (argmax responsibility)
print(round(adjusted_rand_score(z, labels_gmm), 3)) # 0.97 ← GMM
km = KMeans(n_clusters=3, random_state=0, n_init=10).fit(X)
print(round(adjusted_rand_score(z, km.labels_), 3)) # 0.914 ← k-means
ফলাফল স্পষ্ট: GMM ARI 0.97 বনাম k-means ARI 0.914 — GMM জিতেছে। কারণটা গাণিতিকভাবে গভীর এবং এই অধ্যায়ের কেন্দ্রীয় insight (অন্তর্দৃষ্টি)। k-means আসলে GMM-এর একটা বিশেষ ক্ষেত্র (special case): যদি আপনি প্রতিটি component-এর covariance-কে জোর করে \(\Sigma_k=\sigma^2 I\) (গোলাকার, সমান আকার) ধরেন, সব weight সমান ধরেন, আর responsibility-কে soft না রেখে hard (নিকটতম-কেন্দ্র, ০/১) করে দেন — তখন EM ঠিক k-means-এ পরিণত হয়। অর্থাৎ k-means নীরবে ধরে নেয় প্রতিটি গুচ্ছ গোলাকার, সমান-আকার ও সমান-ঘনত্বের, এবং দূরত্ব মাপে শুধু Euclidean কেন্দ্র-দূরত্বে।
কিন্তু আমাদের data-র গুচ্ছ দুটো তো উপবৃত্তাকার ও কাত (tilted) — covariance \([[2,1.5],[1.5,2]]\) আর \([[1,-0.7],[-0.7,1]]\)। এমন কাত-যুক্ত গুচ্ছে নিকটতম-কেন্দ্র সীমানা ভুল জায়গায় কাটে: k-means গোলাকার Voronoi-সীমানা টানে, ফলে উপবৃত্তের লম্বা-অক্ষ বরাবর প্রসারিত বিন্দুগুলোকে ভুল গুচ্ছে ফেলে দেয়। GMM-এর covariance_type='full' প্রতিটি গুচ্ছের প্রকৃত আকার-ও-কাত শিখে নেয়, তাই তার সীমানা উপবৃত্ত বরাবর বেঁকে যায় এবং বিন্দুগুলো ঠিক জায়গায় পড়ে। ফলেই 0.97 বনাম 0.914-এর ব্যবধান।
ARI vs. ground-truth labels (1.0 = perfect, 0.0 = random)
GMM (full covariance) ████████████████████████████████████░ 0.97 ← winner
k-means (k=3) ██████████████████████████████████░░░ 0.914
└──────────────────────────────────────┘
0.0 ARI 1.0
why: clusters are elliptical / tilted.
k-means assumes spherical, equal-size clusters (its hard-spherical
special case of GMM) → mis-cuts the tilted ones along their long axis.
GMM learns each cluster's shape & tilt → boundaries bend correctly.
সতর্কতা: এর মানে এই নয় যে GMM সবসময় জেতে। গুচ্ছগুলো যদি সত্যিই গোলাকার ও সমান-আকারের হতো, k-means প্রায় সমান ফল দিত — অনেক দ্রুত ও সরলভাবে। GMM-এর সুবিধা ঠিক তখনই, যখন গুচ্ছের আকার/কাত/ঘনত্ব আলাদা — তখন তার অতিরিক্ত নমনীয়তা (পূর্ণ covariance + soft responsibility) প্রকৃত গঠনের সাথে খাপ খায়।
৩.৪ E4 — কতগুলো গুচ্ছ? BIC দিয়ে \(K\) নির্বাচন¶
এতক্ষণ আমরা \(K=3\) "জানি" ধরে নিয়েছি। কিন্তু বাস্তবে গুচ্ছ-সংখ্যা অজানা — তাহলে কীভাবে ঠিক করব? log-likelihood \(\ell\) দিয়ে সরাসরি বাছা যায় না, কারণ \(K\) বাড়ালে \(\ell\) সবসময় বাড়ে (বেশি component = বেশি নমনীয়তা = training data-তে সবসময় ভালো fit, এমনকি overfit করেও)। দরকার এমন একটা মাপকাঠি যা fit-এর ভালোত্ব ও মডেলের জটিলতার (parameter-সংখ্যার) মধ্যে ভারসাম্য রাখে। সেটাই Bayesian Information Criterion (BIC):
যেখানে \(\ell\) হলো সর্বোচ্চ log-likelihood (fit যত ভালো, \(-2\ell\) তত ছোট) এবং \(p_{\text{params}}\) হলো মডেলের মুক্ত parameter-সংখ্যা (weight + mean + covariance, যা \(K\)-এর সাথে বাড়ে)। দ্বিতীয় পদ \(p_{\text{params}}\log n\) হলো জটিলতার শাস্তি (penalty) — বেশি parameter মানে বেশি জরিমানা। BIC যত কম, তত ভালো: আমরা এমন \(K\) চাই যা ভালো fit দেয় অথচ অপ্রয়োজনীয় parameter খরচ করে না। \(K=1\) থেকে \(6\) পর্যন্ত প্রতিটি মান চেষ্টা করি:
for K in range(1, 7):
g = GaussianMixture(n_components=K, covariance_type='full',
random_state=0, n_init=5).fit(X)
print(K, round(g.bic(X), 1))
# 1 5626.7
# 2 5111.7
# 3 4828.8 ← minimum
# 4 4857.5
# 5 4890.9
# 6 4925.9
BIC-curve একটা পরিষ্কার গল্প বলে: \(K=1\to5626.7\), \(2\to5111.7\), তারপর \(3\to\mathbf{4828.8}\)-এ সর্বনিম্ন (minimum), এরপর আবার বাড়তে থাকে — \(4\to4857.5\), \(5\to4890.9\), \(6\to4925.9\)। অর্থাৎ BIC ঠিক \(K=3\) বেছে নিল — যা প্রকৃত component-সংখ্যা!
curve-টার আকারই মূল insight (অন্তর্দৃষ্টি)। \(K=1\) থেকে \(3\) পর্যন্ত BIC দ্রুত পড়ছে, কারণ প্রতিটি নতুন component প্রকৃত একটা লুকানো গুচ্ছ ধরে fit-কে নাটকীয়ভাবে উন্নত করছে — fit-উন্নতি penalty-কে সহজেই ছাড়িয়ে যাচ্ছে। কিন্তু \(K=3\) পেরোতেই গল্প উল্টে যায়: চতুর্থ component-এর জন্য কোনো প্রকৃত গুচ্ছ আর নেই, তাই সে একটা আসল গুচ্ছকে কৃত্রিমভাবে দু-টুকরো করা ছাড়া কিছু করে না — fit সামান্যই বাড়ে, অথচ অতিরিক্ত parameter-এর penalty পুরোটাই গুনতে হয়, ফলে BIC বাড়ে। এই "নেমে গিয়ে আবার ওঠা" V-আকারের তলানিই সঠিক \(K\)-এর সংকেত।
BIC vs. K (lower is better; the minimum picks K)
5700 │ ●(1) 5626.7
5500 │
5300 │
5100 │ ●(2) 5111.7
4900 │ ●(5) 4890.9 ●(6) 4925.9
│ ●(4) 4857.5
4800 │ ●(3) 4828.8 ← MINIMUM → choose K = 3 (the true number)
└──────┼──────┼──────┼──────┼──────┼──────┼── K
1 2 3 4 5 6
BIC = -2·loglik + (#params)·log n : balances fit against complexity.
Drops sharply to K=3 (real clusters), then rises (extra params not worth it).
ব্যবহারিক উপসংহার: BIC (বা তার আত্মীয় AIC) দিয়ে GMM-এ component-সংখ্যা নীতিনিষ্ঠভাবে (principled) বেছে নেওয়া যায় — k-means-এর elbow-পদ্ধতির মতো চোখে-দেখা ব্যাপার নয়, বরং একটা সংখ্যাগত সর্বনিম্ন। এখানে BIC সঠিকভাবে \(K=3\) ধরল, কারণ তিনটি গুচ্ছ যথেষ্ট আলাদা; গুচ্ছগুলো বেশি ওভারল্যাপ করলে BIC-curve চ্যাপ্টা হতে পারে, তখন সিদ্ধান্ত কম স্পষ্ট হয়। তবু মূল বার্তা একই: fit বনাম জটিলতার ভারসাম্যই সঠিক মডেল-জটিলতা নির্বাচনের চাবিকাঠি।
এই চারটি উদাহরণ একসাথে এই অধ্যায়ের গল্পটা পূর্ণ করে: EM label ছাড়াই GMM-এর সব parameter পুনরুদ্ধার করে (E1), প্রতিটি বিন্দুকে একটা soft responsibility দেয় যা অনিশ্চয়তা ধরে রাখে (E2), elliptical/tilted গুচ্ছে hard-spherical k-means-কে ছাড়িয়ে যায় (E3), এবং BIC দিয়ে সঠিক গুচ্ছ-সংখ্যা পর্যন্ত নিজেই বেছে নেয় (E4)।
যাচাই (scikit-learn, seed 20260619)। উপরের সব সংখ্যা নিচের একক স্ক্রিপ্টে পুনরুৎপাদনযোগ্য —
GaussianMixture(n_components=3, covariance_type='full', random_state=0, n_init=5),KMeans(n_clusters=3, random_state=0, n_init=10), ওadjusted_rand_score।dataset: 3-component 2D Gaussian mixture, n = 600 GMM(3): converged True | per-sample log-lik -3.933 | BIC 4828.8 recovered weights [0.405, 0.349, 0.246] (true 0.40 / 0.35 / 0.25) responsibilities: clear point ≈ [0.99, 0.01, 0.00] ambiguous point ≈ [0.864, 0.002, 0.133] (rows sum to 1) GMM ARI 0.97 vs k-means(3) ARI 0.914 → GMM wins (tilted clusters) BIC by K: 1→5626.7, 2→5111.7, 3→4828.8 (MIN), 4→4857.5, 5→4890.9, 6→4925.9 → BIC picks K = 3EM unlabeled data থেকে তিনটি component-এর weight ([0.405, 0.349, 0.246] ≈ true [0.40, 0.35, 0.25]), mean ও covariance পুনরুদ্ধার করে; soft responsibility সীমান্ত-বিন্দুর দ্বিধা ধরে রাখে (≈[0.864, 0.002, 0.133]); GMM (ARI 0.97) কাত-যুক্ত গুচ্ছে k-means (ARI 0.914)-কে হারায়; আর BIC সর্বনিম্ন (4828.8) ঠিক \(K=3\)-এ — প্রকৃত গুচ্ছ-সংখ্যা।
৪ · প্রমাণ ও উৎপাদন¶
এই বিভাগে §২–§৩-এ ব্যবহৃত EM (Expectation–Maximization) ও GMM (Gaussian Mixture Model)-এর সমস্ত সূত্র শূন্য থেকে গড়ে তুলব। কেন্দ্রীয় গল্পটি একটাই: mixture-এর observed-data log-likelihood সরাসরি maximize করা কঠিন, কারণ log-এর ভেতরে একটি যোগফল (sum) বসে আছে যা সব component-কে জড়িয়ে ফেলে। এর সমাধান EM — একটি দুই-ধাপের নাচ (E-step ও M-step) যা প্রতিবার একটি lower bound (ELBO) ঠেলে তোলে, আর সেই কারণেই log-likelihood কখনো কমে না। আমরা পাঁচটি জিনিস প্রমাণ করব: (i) কেন direct MLE আটকে যায়, আর E-step-এর responsibility \(\gamma_{ik}\) আসলে Bayes' rule-এরই ফল; (ii) ELBO ও তার Jensen-ভিত্তিক উৎপত্তি, এবং কেন EM monotone (log-likelihood একঘেয়ে বাড়ে) — এটিই EM-এর হৃদয়; (iii) M-step-এর closed-form update (\(\pi_k,\mu_k,\Sigma_k\)); (iv) কেন k-means আসলে GMM-এর একটি সীমান্ত-রূপ ("hard EM"); (v) BIC দিয়ে কীভাবে \(K\) বাছাই করি। ভিত্তি চারটি: prereq 4.3 (MLE — likelihood maximize করা), prereq 2.2 (Bayes/posterior), prereq 2.4 (Gaussian density), prereq 3.1 (Jensen's inequality)। প্রতিটি প্রতীক প্রথম ব্যবহারে খোলা হবে, প্রতিটি ধাপ যুক্তিসহ। কষ্টের স্তর প্রতিটি উপ-বিভাগের শিরোনামে তারা দিয়ে: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
সাধারণ সেট-আপ ও প্রতীক। ধরি \(n\)টি স্বাধীন পর্যবেক্ষণ \(x_1,\dots,x_n\in\mathbb R^d\), যা একটি \(K\)-component Gaussian mixture থেকে এসেছে:
যেখানে \(\pi_k\ge0\) হলো mixing weight (\(\sum_k\pi_k=1\)), আর \(\mathcal N(x;\mu_k,\Sigma_k)\) হলো \(k\)-তম component-এর Gaussian density (prereq 2.4)। প্রতিটি পর্যবেক্ষণের সাথে একটি latent (লুকানো) label \(z_i\in\{1,\dots,K\}\) যুক্ত — কোন component থেকে \(x_i\) এসেছে — কিন্তু আমরা \(z_i\) দেখি না। জুটি \((x_i,z_i)\)-কে বলি complete data, আর শুধু \(x_i\)-কে observed data। generative গল্পটি দুই ধাপের: প্রথমে \(z_i\sim\text{Categorical}(\pi_1,\dots,\pi_K)\) (অর্থাৎ \(P(z_i=k)=\pi_k\)), তারপর \(x_i\mid z_i=k\;\sim\;\mathcal N(\mu_k,\Sigma_k)\)। সর্বত্র responsibility বলতে বোঝাব posterior probability
আর আমাদের লক্ষ্য হলো observed-data log-likelihood
সর্বোচ্চ করা। (পর্যবেক্ষণগুলো স্বাধীন, তাই যৌথ likelihood-এর log = পৃথক log-এর যোগফল — prereq 4.3।)
৪.১ ★★ কেন direct MLE কঠিন, আর E-step-এর responsibility¶
লক্ষ্য। প্রথমে দেখাই কেন \(\ell(\theta)\) সরাসরি maximize করা যায় না, তারপর E-step-এর responsibility-সূত্রটি Bayes' rule থেকে উৎপাদন করি।
ধাপ ১ — log-of-sum সব component-কে জড়িয়ে ফেলে। একটিমাত্র Gaussian হলে (\(K=1\)) likelihood হতো \(\prod_i\mathcal N(x_i;\mu,\Sigma)\), আর log নিলে exponential-এর \(\log\exp\) বাতিল হয়ে সুন্দর quadratic পাওয়া যেত — derivative শূন্য বসিয়ে closed-form MLE (\(\hat\mu=\bar x\) ইত্যাদি, prereq 4.3)। কিন্তু mixture-এ log-এর ভেতরে একটি যোগফল বসে আছে:
\(\log(a+b)\)-কে \(\log a+\log b\)-তে ভাঙা যায় না, তাই \(\log\) আর exponential পরস্পর বাতিল হয় না; একটি \(\mu_k\)-এর সাপেক্ষে \(\ell\)-এর partial derivative নিলে denominator-এ পুরো mixture density থেকে যায় এবং সব component-এর parameter জটিলভাবে জড়িয়ে যায়। ফলাফল: \(\partial\ell/\partial\mu_k=0\) একটি coupled, nonlinear সমীকরণ-সেট — \(\mu_k\) নির্ভর করে \(\gamma\)-র উপর, \(\gamma\) আবার নির্ভর করে সব \(\mu,\Sigma,\pi\)-র উপর — কোনো closed-form সমাধান নেই। (অতিরিক্ত সমস্যা: \(\ell\) non-concave, একাধিক local maximum থাকতে পারে।) এখানেই latent variable \(z_i\)-কে কাজে লাগিয়ে EM আসে: যদি আমরা \(z_i\) জানতাম, তবে প্রতিটি বিন্দু তার নিজের component-এ চলে যেত আর সমস্যাটা \(K\)টি আলাদা single-Gaussian MLE-তে ভেঙে যেত (তখন closed-form)। EM সেই অজানা \(z_i\)-কে তার posterior দিয়ে "নরমভাবে" পূরণ করে।
ধাপ ২ — responsibility = Bayes posterior (উৎপাদন)। E-step-এর কাজ: বর্তমান parameter \(\theta^{\text{old}}\) ধরে প্রতিটি বিন্দুর জন্য latent label-এর posterior বের করা। Bayes' rule (prereq 2.2) — posterior \(\propto\) prior \(\times\) likelihood — সরাসরি প্রয়োগ করি। এখানে label \(z_i=k\)-এর prior হলো mixing weight \(\pi_k=P(z_i=k)\), আর সেই component দেওয়া \(x_i\)-এর likelihood হলো \(\mathcal N(x_i;\mu_k,\Sigma_k)=p(x_i\mid z_i=k)\)। তাই
denominator-এর \(p(x_i)=\sum_l\pi_l\mathcal N(x_i;\mu_l,\Sigma_l)\) হলো evidence (law of total probability — সব সম্ভাব্য label-এর উপর যোগফল), যা নিশ্চিত করে \(\sum_{k}\gamma_{ik}=1\) (প্রতিটি বিন্দুর responsibility-গুলো একটি probability distribution গড়ে)। সংক্ষেপে:
ব্যাখ্যা: \(\gamma_{ik}\) হলো "\(x_i\)-এর কত ভাগ দায়িত্ব component \(k\)-এর" — একটি soft assignment, \(0\) ও \(1\)-এর মাঝে। একটি বিন্দু যদি \(\mu_k\)-এর খুব কাছে আর বাকি center থেকে দূরে থাকে, তবে \(\gamma_{ik}\approx1\); দুই center-এর মাঝখানে থাকলে দায়িত্ব ভাগাভাগি হয়। (k-means-এর কঠিন \(0/1\) assignment-এর তুলনায় এটিই GMM-এর নমনীয়তা — §৪.৪-এ ফিরব।)
৪.২ ★★★ EM-এর lower bound (ELBO) ও log-likelihood-এর একঘেয়ে বৃদ্ধি¶
এটিই EM-এর গাণিতিক হৃদয়: কেন এই দুই-ধাপের পুনরাবৃত্তি আদৌ কাজ করে, এবং কেন \(\ell(\theta)\) প্রতিবার কখনো কমে না। যুক্তিটি Jensen's inequality (prereq 3.1) ও KL-divergence-এর উপর দাঁড়ানো।
ধাপ ১ — যেকোনো distribution \(q\) দিয়ে একটি lower bound (ELBO)। প্রতিটি বিন্দু \(i\)-এর জন্য latent label-এর উপর যেকোনো probability distribution \(q_i(z)\) নিই (অর্থাৎ \(q_{ik}\ge0,\ \sum_k q_{ik}=1\); এখনই \(q\)-কে কোনো নির্দিষ্ট কিছু ধরছি না)। \(p(x_i)=\sum_k\pi_k\mathcal N(x_i;\mu_k,\Sigma_k)\)-কে \(q_{ik}\) দিয়ে গুণ-ভাগ করে log-এর ভেতরে একটি \(q\)-গড় (expectation) বানাই:
এখন \(\log\) একটি concave ফাংশন, তাই Jensen's inequality (prereq 3.1) বলে \(\log\mathbb{E}[\cdot]\ge\mathbb{E}[\log(\cdot)]\) — log গড়ের বাইরে আনলে মান কমে (বা সমান)। প্রয়োগ করি:
সব \(i\)-এর উপর যোগ করে পাই ELBO (Evidence Lower BOund):
অর্থাৎ \(\mathcal L(q,\theta)\) হলো প্রকৃত log-likelihood \(\ell(\theta)\)-এর একটি lower bound, যা \(q\) ও \(\theta\) — দুটোরই ফাংশন।
ধাপ ২ — gap ঠিক KL-divergence। বাউন্ডটা কতটা আঁটসাঁট? পার্থক্য \(\ell(\theta)-\mathcal L(q,\theta)\) হিসাব করি। একটিমাত্র বিন্দুর জন্য, \(\frac{\pi_k\mathcal N(x_i;\mu_k,\Sigma_k)}{q_{ik}}=\frac{p(x_i)\,p(z=k\mid x_i)}{q_{ik}}\) (কারণ numerator-এর \(\pi_k\mathcal N=p(x_i)\,\gamma_{ik}\), আর \(\gamma_{ik}=p(z=k\mid x_i)\))। বসিয়ে:
প্রথম পদ \(=\log p(x_i)\), আর দ্বিতীয় পদ ঠিক \(-\,\mathrm{KL}\bigl(q_i\,\Vert\,p(z\mid x_i)\bigr)\) (KL-divergence-এর সংজ্ঞা, \(\mathrm{KL}(q\Vert p)=\sum q\log\frac{q}{p}\))। তাই
যেহেতু KL সর্বদা অ-ঋণাত্মক (এবং শূন্য কেবল যখন দুই distribution অভিন্ন — এটিও Jensen-এরই ফল)। এটি দুটো গুরুত্বপূর্ণ কথা বলে: (ক) gap কখনো ঋণাত্মক নয়, তাই \(\mathcal L\) সত্যিই lower bound; (খ) gap শূন্য হয় ঠিক তখন, যখন \(q_i=p(z\mid x_i,\theta)\) — অর্থাৎ \(q\)-কে posterior responsibility বানালে বাউন্ড আঁটসাঁট (tight) হয়ে \(\mathcal L=\ell\) হয়।
ধাপ ৩ — E-step: বাউন্ড আঁটসাঁট করা। উপরের insight (অন্তর্দৃষ্টি) কাজে লাগিয়ে, বর্তমান \(\theta^{\text{old}}\)-এ \(\mathcal L(q,\theta^{\text{old}})\)-কে \(q\)-এর সাপেক্ষে সর্বোচ্চ করি। যেহেতু \(\ell(\theta^{\text{old}})\) স্থির আর \(\ell-\mathcal L=\sum_i\mathrm{KL}\ge0\), \(\mathcal L\) সর্বোচ্চ হয় যখন KL সর্বনিম্ন = \(0\), অর্থাৎ
এটিই E-step — §৪.১-এর responsibility-সূত্রই এখানে \(q\)-এর সেরা পছন্দ হিসেবে স্বাভাবিকভাবে বেরিয়ে আসে। এই মুহূর্তে বাউন্ড প্রকৃত curve-কে \(\theta^{\text{old}}\)-এ ছুঁয়ে থাকে।
ধাপ ৪ — M-step: বাউন্ড ঠেলে তোলা। এবার \(q=\gamma\) স্থির রেখে \(\mathcal L(q,\theta)\)-কে \(\theta\)-এর সাপেক্ষে সর্বোচ্চ করি (এটি §৪.৩-এর closed-form দেয়):
লক্ষণীয়, \(\mathcal L(\gamma,\theta)\)-তে \(q_{ik}\log q_{ik}\) পদটি \(\theta\)-নিরপেক্ষ (entropy), তাই কার্যত আমরা expected complete-data log-likelihood \(\sum_i\sum_k\gamma_{ik}\log\bigl(\pi_k\mathcal N(x_i;\mu_k,\Sigma_k)\bigr)\) maximize করছি — যেখানে log আর exponential আবার সুন্দরভাবে বাতিল হয়, তাই closed-form ফিরে আসে।
ধাপ ৫ — monotonicity: \(\ell\) কখনো কমে না (চূড়ান্ত যুক্তি)। এখন তিনটি অসমতা পরপর সাজিয়ে EM-এর মূল গ্যারান্টি প্রমাণ করি:
যুক্তি ধাপে ধাপে: (1) \(\mathcal L\) সর্বদা \(\ell\)-এর lower bound (ধাপ ১), তাই নতুন \(\theta^{\text{new}}\)-এও \(\ell(\theta^{\text{new}})\ge\mathcal L(\gamma,\theta^{\text{new}})\); (2) M-step ঠিক \(\mathcal L(\gamma,\cdot)\)-কে maximize করে, তাই \(\theta^{\text{new}}\)-এ মান \(\theta^{\text{old}}\)-এর চেয়ে কম নয়; (3) E-step বাউন্ডকে \(\theta^{\text{old}}\)-এ আঁটসাঁট করেছিল (ধাপ ৩), তাই সেখানে \(\mathcal L=\ell\)। শৃঙ্খল মিলিয়ে:
— observed-data log-likelihood প্রতিটি EM-পুনরাবৃত্তিতে কখনো কমে না। যেহেতু \(\ell\) উপরে আবদ্ধ (bounded above — probability density-র যোগফলের log অসীমে যায় না সাধারণ ক্ষেত্রে), একঘেয়ে বর্ধমান অনুক্রমটি একটি সীমায় converge করে (monotone convergence)। সতর্কতা: এটি কেবল একটি stationary point / local maximum-এ পৌঁছানোর নিশ্চয়তা দেয়, global maximum-এর নয় — তাই বাস্তবে একাধিক random initialization থেকে EM চালিয়ে সর্বোচ্চ \(\ell\)-ওয়ালা সমাধানটি বেছে নেওয়া হয়। (সংখ্যাগত যাচাই: একটি 2-component মিশ্রণে ৮টি পুনরাবৃত্তিতে \(\ell\) একবারও কমেনি, এবং E-step-এর পরে প্রতিবার \(\mathcal L=\ell\) অর্থাৎ KL-gap \(\approx0\) — উপরের তত্ত্বের সাথে হুবহু মিলে।)
জ্যামিতিক ছবি: প্রতিটি E-step প্রকৃত (জটিল) \(\ell\)-curve-কে বর্তমান বিন্দুতে নিচ থেকে স্পর্শ করা একটি সহজ concave বাউন্ড আঁকে; প্রতিটি M-step সেই বাউন্ডের চূড়ায় লাফ দেয়, যা প্রকৃত curve-এও উঁচুতে। বারবার "স্পর্শ করো, চূড়ায় ওঠো" — তাই EM-কে বলা হয় একটি MM (Minorize–Maximize) algorithm।
৪.৩ ★★ M-step-এর closed-form update¶
লক্ষ্য। §৪.২ ধাপ ৪-এর objective — expected complete-data log-likelihood — কে \(\theta\)-এর সাপেক্ষে maximize করে \(\pi_k,\mu_k,\Sigma_k\)-এর সূত্র উৎপাদন করি। Gaussian density বসিয়ে objective লিখি (ধ্রুবক ছেড়ে):
লক্ষণীয়, \(\pi\)-অংশ আর \((\mu,\Sigma)\)-অংশ আলাদা হয়ে গেছে, তাই প্রতিটি আলাদা করে maximize করা যায়।
ধাপ ১ — \(\pi_k\) (Lagrange, কারণ \(\sum_k\pi_k=1\))। কেবল \(\pi\)-নির্ভর অংশ \(\sum_i\sum_k\gamma_{ik}\log\pi_k\), constraint \(\sum_k\pi_k=1\)-সহ। Lagrangian (prereq 4.3/calculus):
\(\pi_k\)-এর সাপেক্ষে partial শূন্য বসাই:
\(\lambda\) বের করতে দুপাশে \(k\)-জুড়ে যোগ করি এবং \(\sum_k\pi_k=1\), \(\sum_k\gamma_{ik}=1\) ব্যবহার করি:
সংজ্ঞায়িত করি effective count \(N_k=\sum_{i=1}^n\gamma_{ik}\) (component \(k\)-এর "নরম" সদস্যসংখ্যা)। তখন
— অর্থাৎ component \(k\)-এর weight = তার গড় responsibility। (hard label হলে এটি ঠিক "ভগ্নাংশ বিন্দু \(k\)-তে" — soft version-এ ভগ্নাংশের জায়গায় গড় responsibility।)
ধাপ ২ — \(\mu_k\) (gradient শূন্য)। কেবল \(\mu_k\)-নির্ভর অংশ \(-\tfrac12\sum_i\gamma_{ik}(x_i-\mu_k)^\top\Sigma_k^{-1}(x_i-\mu_k)\)। \(\mu_k\)-এর সাপেক্ষে gradient (vector calculus; \(\nabla_\mu(x-\mu)^\top A(x-\mu)=-2A(x-\mu)\) symmetric \(A=\Sigma_k^{-1}\)-এর জন্য):
\(\Sigma_k^{-1}\) invertible, তাই বাঁ থেকে \(\Sigma_k\) গুণ করে \(\sum_i\gamma_{ik}(x_i-\mu_k)=0\), অর্থাৎ \(\sum_i\gamma_{ik}x_i=\mu_k\sum_i\gamma_{ik}=\mu_k N_k\)। সমাধান:
— একটি responsibility-weighted mean: প্রতিটি বিন্দু তার \(\gamma_{ik}\) অনুপাতে \(\mu_k\)-কে টানে। (সব \(\gamma_{ik}\in\{0,1\}\) হলে এটি ঠিক সেই component-এ বরাদ্দ বিন্দুগুলোর সাধারণ গড় — সাধারণ sample-mean MLE-র "soft" রূপ।)
ধাপ ৩ — \(\Sigma_k\) (একই সুরে, ফল উল্লেখ)। \(\Sigma_k\)-এর সাপেক্ষে maximize করতে \(\log\lvert\Sigma_k\rvert\) ও quadratic পদের matrix-derivative নিয়ে শূন্য বসালে (একই Lagrange-মুক্ত gradient যুক্তি, তবে matrix calculus-এ) পাওয়া যায় একটি responsibility-weighted covariance:
(এখানে \(\mu_k\) ধাপ ২-এর নতুন মান)। আবারও এটি single-Gaussian-এর MLE covariance \(\frac1n\sum_i(x_i-\bar x)(x_i-\bar x)^\top\)-এর soft, responsibility-ভারিত সংস্করণ।
সারাংশ (M-step)। তিনটি update-ই একই কাঠামোর — সাধারণ MLE সূত্র, কিন্তু প্রতিটি বিন্দু \(\gamma_{ik}\) ভর বহন করে:
E-step (\(\gamma\) আপডেট) ও M-step (\(\theta\) আপডেট) পালা করে চালালেই EM — এবং §৪.২ অনুযায়ী \(\ell\) কখনো কমবে না। (সংখ্যাগত যাচাই: এই closed-form update-গুলো ব্যবহার করেই উপরের monotonicity-পরীক্ষা চালানো হয়েছে, যেখানে \(\ell\) প্রতিবার বেড়েছে।)
৪.৪ ★★ সীমান্ত-রূপ হিসেবে k-means ("hard EM")¶
লক্ষ্য। দেখাই যে k-means আসলে GMM-EM-এরই একটি বিশেষ সীমা: সব component যদি spherical, সমান covariance \(\Sigma_k=\sigma^2 I\) ধরা হয় আর \(\sigma\to0\) নেওয়া হয়, তবে EM ঠিক k-means-এ পরিণত হয়।
ধাপ ১ — responsibility-কে দূরত্বের ভাষায় লেখা। ধরি সব \(\Sigma_k=\sigma^2 I\) আর সরলতার জন্য সব \(\pi_k\) সমান। তখন \(\mathcal N(x_i;\mu_k,\sigma^2 I)\propto\exp\!\bigl(-\tfrac{1}{2\sigma^2}\lVert x_i-\mu_k\rVert^2\bigr)\), আর normalizing ধ্রুবক ও \(\pi_k\) numerator-denominator-এ বাতিল হয়:
এটি ঠিক একটি softmax, যার "temperature" \(\sigma^2\) — argument-গুলো হলো ঋণাত্মক বর্গ-দূরত্ব।
ধাপ ২ — \(\sigma\to0\) সীমায় responsibility hard হয়ে যায়। ধরি \(x_i\)-এর সবচেয়ে কাছের center \(k^*=\arg\min_l\lVert x_i-\mu_l\rVert^2\)। numerator ও denominator-কে \(\exp\!\bigl(-\tfrac{1}{2\sigma^2}\lVert x_i-\mu_{k^*}\rVert^2\bigr)\) দিয়ে ভাগ করি:
কাছের center-এর জন্য exponent \(=0\) (পদ \(=1\)); অন্য সব \(k\ne k^*\)-এর জন্য \(d_{ik}^2-d_{ik^*}^2>0\), তাই \(\sigma\to0^+\)-এ \(-\tfrac{1}{2\sigma^2}(\cdot)\to-\infty\) এবং সেই পদ \(\to0\)। ফলে
— responsibility hard (\(0/1\)) হয়ে যায়: প্রতিটি বিন্দু সম্পূর্ণরূপে তার নিকটতম center-এ বরাদ্দ। এটিই k-means-এর assignment step। (সংখ্যাগত যাচাই: \(\sigma^2\) ক্রমে \(4\to0.005\) কমালে দুই-center উদাহরণে \(\gamma\) মসৃণভাবে \((0.65,0.35)\) থেকে \((1,0)\)-তে চলে গেল — নিকটতম center-এ।)
ধাপ ৩ — M-step → cluster mean। এই hard \(\gamma_{ik}\) §৪.৩-এর \(\mu_k\)-update-এ বসাই: \(N_k=\sum_i\gamma_{ik}\) = component \(k\)-এ বরাদ্দ বিন্দুসংখ্যা, আর
— ঠিক সেই cluster-এর বিন্দুগুলোর গড় (centroid)। এটিই k-means-এর update step। সুতরাং:
assignment = E-step (hard), centroid = M-step। এর তাৎপর্য: k-means নিঃশব্দে ধরে নেয় cluster-গুলো গোলাকার ও সমান-আকারের (কারণ \(\Sigma_k=\sigma^2 I\), সব \(k\)-তে এক), আর প্রতিটি বিন্দুকে জোর করে এক cluster-এ ফেলে। GMM সেই দুই সীমাবদ্ধতাই শিথিল করে — পূর্ণ \(\Sigma_k\) (যেকোনো দিকে লম্বাটে/elliptical, বিভিন্ন আকার ও orientation) এবং soft responsibility (সীমান্ত-বিন্দুতে অনিশ্চয়তা ধরে রাখা)। তাই উপবৃত্তাকার বা বিভিন্ন-ঘনত্বের cluster-এ GMM সাধারণত k-means-কে হারায়: k-means গোল ছাঁচে জোর করে বসাতে গিয়ে লম্বাটে cluster-কে ভুলভাবে কাটে, GMM তার covariance দিয়ে সঠিক আকার ধরে।
৪.৫ ★ মডেল নির্বাচন: BIC দিয়ে \(K\) বাছাই¶
সমস্যা। কতগুলো component \(K\) নেব? শুধু \(\ell(\hat\theta)\) দেখলে চলবে না — \(K\) বাড়ালে \(\ell\) প্রায় সবসময় বাড়ে (বেশি Gaussian = data-কে বেশি আঁটোসাঁটো করে ঢাকা, এমনকি noise-ও মুখস্থ করে = overfitting)। তাই fit-এর সাথে জটিলতার শাস্তি যোগ করা দরকার।
BIC (Bayesian Information Criterion)। এটি ঠিক সেই ভারসাম্য আনে:
যেখানে \(\ell(\hat\theta)\) হলো EM-এ পাওয়া maximized observed-data log-likelihood, \(n\) হলো নমুনা-সংখ্যা, আর \(p\) হলো মডেলের মুক্ত parameter-সংখ্যা (free parameters)। প্রথম পদ ছোট হয় ভালো fit-এ (\(\ell\) বড় হলে \(-2\ell\) ছোট); দ্বিতীয় পদ \(p\log n\) জটিল মডেলকে শাস্তি দেয়। আমরা সেই \(K\) বেছে নিই যা BIC সর্বনিম্ন করে — খুব কম component হলে fit খারাপ (প্রথম পদ বড়), খুব বেশি হলে শাস্তি বড় (দ্বিতীয় পদ বড়); মাঝখানে সর্বনিম্ন।
\(p\) গণনা (\(d\)-মাত্রিক, full covariance)। একটি \(K\)-component GMM-এ মুক্ত parameter:
- mixing weights: \(K-1\)টি (যেহেতু \(\sum_k\pi_k=1\) একটিকে আবদ্ধ করে),
- mean vectors: \(K\cdot d\)টি (প্রতি component-এ একটি \(d\)-vector),
- covariance matrices: \(K\cdot\dfrac{d(d+1)}{2}\)টি (প্রতিটি symmetric \(\Sigma_k\)-এ স্বাধীন entry \(\tfrac{d(d+1)}{2}\))।
মোট: \(\;p=(K-1)+Kd+K\cdot\dfrac{d(d+1)}{2}\)। যেমন \(d=2,\ K=3\) হলে \(p=(3-1)+3\cdot2+3\cdot3=2+6+9=17\); আর \(d=1,\ K=3\) হলে \(p=2+3+3=8\)।
সিদ্ধান্ত। কয়েকটি \(K\) (যেমন \(1,2,3,4,5\))-এর জন্য EM চালিয়ে প্রতিটির \(\ell(\hat\theta)\) ও তদনুযায়ী BIC হিসাব করি, তারপর সর্বনিম্ন-BIC-ওয়ালা \(K\) নিই। এই অধ্যায়ের চলমান উদাহরণে BIC সর্বনিম্ন হয় \(K=3\)-তে — যা data-র তিনটি প্রকৃত গুচ্ছের সাথে মেলে। (বিকল্প AIC \(=-2\ell(\hat\theta)+2p\) শাস্তি হালকা রাখে, তাই বড় \(n\)-এ BIC-এর চেয়ে কিছুটা বেশি component বাছতে পারে; মডেল-সংকোচনে BIC সাধারণত বেশি রক্ষণশীল।)
৫ · কোড ল্যাব (Python)¶
এতক্ষণ আমরা density estimation, EM algorithm এবং Gaussian Mixture Model (GMM)-এর তত্ত্ব কাগজে-কলমে দেখেছি। এখন সেই তত্ত্বকে সংখ্যায় ধরি। এই ল্যাবে একটিমাত্র runnable স্ক্রিপ্ট দিয়ে চারটি জিনিস নিজে হাতে যাচাই করব:
- From-scratch EM responsibilities — একটি নির্দিষ্ট (rough) parameter guess-এর জন্য E-step-এর responsibility \(\gamma_{ik}\) হাতে হিসাব করা, দেখা যে প্রতিটি সারি \(1\)-এ যোগ হয় (soft assignment), এবং একটিমাত্র M-step চালিয়ে দেখা parameter কতটা সত্য মানের দিকে লাফ দেয়।
- sklearn
GaussianMixture— production-grade EM fit করে convergence, log-likelihood, BIC ও mixture weight বের করা। - GMM বনাম k-means — adjusted Rand index (ARI) দিয়ে দুই পদ্ধতির cluster-recovery তুলনা করা, যেখানে cluster-গুলো elliptical।
- BIC দিয়ে model selection — \(K=1\ldots6\)-এর উপর BIC হিসাব করে argmin খুঁজে component সংখ্যা স্বয়ংক্রিয়ভাবে নির্বাচন করা।
স্ক্রিপ্টের কাঠামো¶
ডেটা তৈরি হয় তিনটি দ্বিমাত্রিক Gaussian থেকে, mixing weight \(\boldsymbol{\pi}=(0.40,\,0.35,\,0.25)\) সহ। প্রথম component-টি isotropic (\(\Sigma_0=I\)), দ্বিতীয়টি ধনাত্মক correlation-যুক্ত (\(\rho>0\), লম্বাটে উপবৃত্ত), তৃতীয়টি ঋণাত্মক correlation-যুক্ত (\(\rho<0\))। এই uneven, ঘূর্ণিত উপবৃত্ত-ই হলো সেই পরিস্থিতি যেখানে full-covariance GMM, k-means-এর গোলাকার (spherical) ধারণাকে ছাড়িয়ে যায়।
PART 1-এ E-step-এর হৃদয়—responsibility—সরাসরি Bayes' rule থেকে আসে:
হর-টি (denominator) ঠিক mixture density, তাই ভগ্নাংশটি হলো posterior probability "বিন্দু \(i\) component \(k\) থেকে এসেছে"। হরের কারণেই প্রতিটি সারি \(1\)-এ যোগ হয়—এটি hard label নয়, soft দায়িত্ব-বণ্টন। M-step তারপর এই দায়িত্বকে ওজন ধরে parameter আপডেট করে:
স্ক্রিপ্টে responsibility-র Gaussian density scipy.stats.multivariate_normal.pdf দিয়ে বের করা হয়; বাকি অংশ pure numpy। PART 2–4 সরাসরি scikit-learn-এর উপর দাঁড়িয়ে।
import numpy as np
from scipy.stats import multivariate_normal
from sklearn.mixture import GaussianMixture
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
# ===================== DATASET =====================
rng = np.random.default_rng(20260619)
means = [[0, 0], [5, 4], [0, 5]]
covs = [np.array([[1, 0], [0, 1]]),
np.array([[2, 1.5], [1.5, 2]]),
np.array([[1, -0.7], [-0.7, 1]])]
weights = [0.40, 0.35, 0.25]; n = 600
comp = rng.choice(3, size=n, p=weights)
X = np.zeros((n, 2)); ytrue = comp.copy()
for k in range(3):
idx = comp == k
X[idx] = rng.multivariate_normal(means[k], covs[k], idx.sum())
print("DATASET : X shape =", X.shape, "| true cluster sizes =", np.bincount(ytrue))
# ===================== PART 1: from-scratch EM responsibilities =====================
print("\nPART 1 -- from-scratch EM (one E-step + one M-step)")
# A FIXED (deliberately rough) guess of parameters
pi0 = np.array([1/3, 1/3, 1/3])
mu0 = np.array([[0.0, 0.0], [4.0, 4.0], [1.0, 5.0]])
Sig0 = [np.eye(2), np.eye(2), np.eye(2)]
# pick a few points to illustrate the soft assignment
sample_idx = [0, 1, 2, 3, 4]
Xs = X[sample_idx]
# E-step : responsibilities gamma_ik = pi_k N(x_i; mu_k, Sig_k) / sum_l (...)
def responsibilities(Xp, pi, mu, Sig):
K = len(pi)
dens = np.column_stack([
pi[k] * multivariate_normal.pdf(Xp, mean=mu[k], cov=Sig[k])
for k in range(K)])
return dens / dens.sum(axis=1, keepdims=True)
gam_s = responsibilities(Xs, pi0, mu0, Sig0)
print("E-step : responsibilities gamma_ik for 5 sample points")
print(" i | gamma_0 gamma_1 gamma_2 | row sum")
for r, i in enumerate(sample_idx):
g = gam_s[r]
print(" {:2d} | {:.4f} {:.4f} {:.4f} | {:.4f}"
.format(i, g[0], g[1], g[2], g.sum()))
print(" -> every row sums to 1.0 (soft assignment, not hard)")
# M-step : recompute pi_k = mean(gamma_k), mu_k = weighted mean (use ALL points)
gam = responsibilities(X, pi0, mu0, Sig0)
Nk = gam.sum(axis=0)
pi_new = Nk / n
mu_new = (gam.T @ X) / Nk[:, None]
print("M-step : updated parameters from a full E-pass over all", n, "points")
np.set_printoptions(precision=4, suppress=True)
print(" pi_new =", pi_new, " (sums to %.4f)" % pi_new.sum())
print(" mu_new =\n", mu_new)
# ===================== PART 2: sklearn GaussianMixture =====================
print("\nPART 2 -- sklearn GaussianMixture(3, 'full')")
gm = GaussianMixture(n_components=3, covariance_type='full',
random_state=0, n_init=5).fit(X)
ll = gm.score(X) # per-sample average log-likelihood
bic = gm.bic(X)
w = np.sort(gm.weights_)[::-1]
ari_gmm = adjusted_rand_score(ytrue, gm.predict(X))
print(" converged_ =", gm.converged_)
print(" score(X) = {:.3f} (per-sample avg log-likelihood)".format(ll))
print(" bic(X) = {:.1f}".format(bic))
print(" weights_ (sorted) =", np.round(w, 3))
print(" ARI vs ytrue = {:.3f}".format(ari_gmm))
# ===================== PART 3: compare with KMeans =====================
print("\nPART 3 -- KMeans vs GMM on elliptical clusters")
km = KMeans(n_clusters=3, n_init=10, random_state=0).fit(X)
ari_km = adjusted_rand_score(ytrue, km.labels_)
print(" KMeans(3) ARI = {:.3f}".format(ari_km))
print(" GMM(3) ARI = {:.3f}".format(ari_gmm))
print(" -> GMM beats k-means: ellipse/correlation-aware Sigma_k wins.")
# ===================== PART 4: BIC over K = 1..6 =====================
print("\nPART 4 -- model selection by BIC over K = 1..6")
bics = {}
for K in range(1, 7):
g = GaussianMixture(n_components=K, covariance_type='full',
random_state=0, n_init=5).fit(X)
bics[K] = g.bic(X)
print(" K = {} : BIC = {:.1f}".format(K, bics[K]))
Kstar = min(bics, key=bics.get)
print(" argmin BIC -> K* =", Kstar, "(matches the 3 generating components)")
স্ক্রিপ্টটি চালালে নিচের আউটপুট হুবহু পাওয়া যায়:
DATASET : X shape = (600, 2) | true cluster sizes = [241 211 148]
PART 1 -- from-scratch EM (one E-step + one M-step)
E-step : responsibilities gamma_ik for 5 sample points
i | gamma_0 gamma_1 gamma_2 | row sum
0 | 0.0000 0.9971 0.0029 | 1.0000
1 | 0.0000 0.0000 1.0000 | 1.0000
2 | 0.0000 0.9998 0.0002 | 1.0000
3 | 0.0000 0.9754 0.0246 | 1.0000
4 | 0.0000 0.0000 1.0000 | 1.0000
-> every row sums to 1.0 (soft assignment, not hard)
M-step : updated parameters from a full E-pass over all 600 points
pi_new = [0.4079 0.3427 0.2495] (sums to 1.0000)
mu_new =
[[ 0.103 0.0519]
[ 4.9981 4.1158]
[-0.1422 5.1631]]
PART 2 -- sklearn GaussianMixture(3, 'full')
converged_ = True
score(X) = -3.933 (per-sample avg log-likelihood)
bic(X) = 4828.8
weights_ (sorted) = [0.405 0.349 0.246]
ARI vs ytrue = 0.970
PART 3 -- KMeans vs GMM on elliptical clusters
KMeans(3) ARI = 0.914
GMM(3) ARI = 0.970
-> GMM beats k-means: ellipse/correlation-aware Sigma_k wins.
PART 4 -- model selection by BIC over K = 1..6
K = 1 : BIC = 5626.7
K = 2 : BIC = 5111.7
K = 3 : BIC = 4828.8
K = 4 : BIC = 4857.5
K = 5 : BIC = 4890.9
K = 6 : BIC = 4925.9
argmin BIC -> K* = 3 (matches the 3 generating components)
পাঠোদ্ধার (read-off)¶
PART 1 — responsibility সত্যিই soft, আর একটি M-step-ই অর্ধেক যুদ্ধ জিতিয়ে দেয়। E-step-এর প্রতিটি সারি ঠিক \(1.0000\)-এ যোগ হয়, যেমন Bayes' rule দাবি করে—কোনো বিন্দুর "ভোট" তিন component-এ ভাগ হয়ে যায়, যদিও এখানে rough guess-এও বেশির ভাগ ভর একটি component-এ জমা পড়েছে (যেমন বিন্দু \(3\): \(\gamma=(0.0000,\,0.9754,\,0.0246)\)—soft কিন্তু near-decisive)। সবচেয়ে চমকপ্রদ ব্যাপারটি M-step-এ: সমান guess \(\boldsymbol{\pi}^{(0)}=(\tfrac13,\tfrac13,\tfrac13)\) থেকে শুরু করেও মাত্র একটি update-এর পর \(\boldsymbol{\pi}^{\text{new}}=(0.408,\,0.343,\,0.250)\), যা সত্য weight \((0.40,\,0.35,\,0.25)\)-র প্রায় হুবহু; এবং \(\boldsymbol{\mu}^{\text{new}}\)-এর সারিগুলো true mean \((0,0),(5,4),(0,5)\)-র খুব কাছে। এটাই EM-এর শক্তি—soft দায়িত্ব দিয়ে weighted average নেওয়াই parameter-কে দ্রুত সঠিক অঞ্চলে টেনে আনে।
PART 2 — GMM ফিট converge করে এবং density-কে ভালোভাবে ধরে। converged_ = True; per-sample গড় log-likelihood \(\mathrm{score}(X)=-3.933\) (যত বড়, তত ভালো ফিট); \(\mathrm{bic}(X)=4828.8\); এবং sorted weights_ \(=(0.405,\,0.349,\,0.246)\)—জনন (generating) weight \((0.40,\,0.35,\,0.25)\)-র সাথে প্রায় মিলে যায়। cluster-recovery-তে \(\text{ARI}=0.97\), অর্থাৎ true label-এর সাথে প্রায় নিখুঁত মিল (\(\text{ARI}=1\) হলে perfect, \(0\) হলে random)।
PART 3 — elliptical cluster-এ GMM, k-means-কে হারায়। k-means প্রতিটি cluster-কে গোলাকার ও সমান-আকার ধরে নেয়, তাই ঘূর্ণিত/লম্বাটে component-এর সীমানায় ভুল করে: \(\text{ARI}_{\text{kmeans}}=0.914\)। GMM-এর full covariance \(\Sigma_k\) প্রতিটি component-এর আকার, দিক ও correlation শিখে নেয়, ফলে \(\text{ARI}_{\text{GMM}}=0.970\)—একটি স্পষ্ট, অর্থবহ উন্নতি। নীতিগত পাঠ: ডেটা যখন isotropic নয়, তখন covariance-সচেতন মডেলই জেতে।
PART 4 — BIC স্বয়ংক্রিয়ভাবে সঠিক component সংখ্যা বেছে নেয়। \(K\) বাড়ালে log-likelihood একঘেয়েভাবে বাড়ে, কিন্তু BIC parameter-সংখ্যার জন্য penalty বসায়, ফলে একটি স্পষ্ট সর্বনিম্ন তৈরি হয়। মানগুলো \(K=1\to5626.7\) থেকে দ্রুত নামে \(K=3\to4828.8\)-এ, তারপর আবার ওঠে (\(K=4\to4857.5,\;K=5\to4890.9,\;K=6\to4925.9\))। argmin ঠিক \(K^*=3\)-এ—যা জনন প্রক্রিয়ার তিনটি component-এর সাথে নিখুঁতভাবে মেলে। অর্থাৎ component সংখ্যা আগে থেকে না জেনেও, কেবল data থেকেই BIC সঠিক উত্তর টেনে আনে।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের গণিত — density estimation-এর সেই মূল ধারণা যে data-র পিছনে একটা অজানা probability density \(p(x)\) লুকিয়ে আছে, Gaussian mixture model কীভাবে সেই density-কে কয়েকটা Gaussian-এর ওজনদার যোগফল \(p(x) = \sum_{k=1}^{K} \pi_k\, \mathcal{N}(x \mid \mu_k, \Sigma_k)\) হিসেবে লেখে, EM algorithm কীভাবে এই latent-variable model-এর parameter (\(\pi_k, \mu_k, \Sigma_k\)) শেখে responsibility \(\gamma_{ik} = \frac{\pi_k\, \mathcal{N}(x_i \mid \mu_k, \Sigma_k)}{\sum_j \pi_j\, \mathcal{N}(x_i \mid \mu_j, \Sigma_j)}\)-কে E-step আর M-step-এর মধ্যে দুলিয়ে, আর BIC কীভাবে penalty দিয়ে component-সংখ্যা \(K\) বেছে নেয় — সবটাই আমরা সূত্র ও সংখ্যায় বুঝেছি। কিন্তু GMM-এর আসল শক্তিটা একটা সমীকরণে কখনো পুরোপুরি ধরা পড়ে না। "GMM BIC 4828.8, ARI 0.97; k-means ARI 0.914" — এই সংখ্যাগুলো বলে দেয় GMM জেতে, কিন্তু কেন জেতে, কীভাবে সে একটা cluster-এর কাত-হয়ে-থাকা elliptical আকৃতিটা শেখে যেটা k-means পারে না, EM-এর সেই monotone আরোহণ দেখতে কেমন, আর BIC কীভাবে ঠিক \(K=3\)-এ থামে — এসব চোখে না দেখলে অন্তরে গাঁথে না। তাই এই অংশে আমরা গোটা গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন practitioner একটা mixture model-এর সঙ্গে কাজ করে: প্রথমে কেন্দ্রীয় ছবিটা — GMM কী শেখে, soft assignment আর fitted ellipse মিলে; তারপর সেই শেখাটা k-means-এর সঙ্গে পাশাপাশি রাখলে কেন GMM-এর elliptical region জেতে আর k-means-এর সরল Voronoi কাটে ভুল করে; তারপর model-টা শেখে কীভাবে — EM-এর log-likelihood যে কখনো কমে না, একটানা উঠে plateau-তে পৌঁছায়; এবং শেষে কতগুলো component নেব সেই সিদ্ধান্ত — BIC বনাম \(K\), যে U-আকৃতি ঠিক সত্যিকারের \(K=3\)-এ সর্বনিম্ন ছোঁয়।
মনে রাখুন — simulation। এই অধ্যায়ের চারটে ছবিই একই একটা synthetic dataset থেকে তৈরি, যা §২–§৫-এর mixture-model গণিতকে সংখ্যায় বাস্তবায়িত করে। আমরা তিনটে 2D Gaussian component থেকে data বানাই, যাদের mixing weight \(\pi = (0.40, 0.35, 0.25)\)। প্রথম component-টা \((0,0)\)-কেন্দ্রিক এবং গোলাকার (\(\Sigma_1 = I\)); দ্বিতীয়টা \((5,4)\)-কেন্দ্রিক এবং ধনাত্মক-কাত (\(\Sigma_2 = \left(\begin{smallmatrix} 2 & 1.5 \\ 1.5 & 2 \end{smallmatrix}\right)\), অর্থাৎ \(x_1\) আর \(x_2\) একসঙ্গে বাড়ে); তৃতীয়টা \((0,5)\)-কেন্দ্রিক এবং ঋণাত্মক-কাত (\(\Sigma_3 = \left(\begin{smallmatrix} 1 & -0.7 \\ -0.7 & 1 \end{smallmatrix}\right)\))। মোট \(n = 600\)টা point: প্রতিটার জন্য আগে weight অনুযায়ী একটা component বেছে নিই (
rng.choice), তারপর সেই component-এর \(\mathcal{N}(\mu_k, \Sigma_k)\) থেকে point আঁকি। যেহেতু আমরা প্রতিটা point কোন component থেকে এসেছে তা জানি, clustering কতটা ঠিক হলো তা Adjusted Rand Index (ARI) দিয়ে নিরপেক্ষভাবে যাচাই করা যায়। মূল model হলো একটাGaussianMixture(3, 'full', random_state=0, n_init=5)— full covariance, যাতে প্রতিটা component নিজের কাত-আকৃতি শিখতে পারে।
import numpy as np
from sklearn.mixture import GaussianMixture
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
rng = np.random.default_rng(20260619)
means = [[0, 0], [5, 4], [0, 5]] # তিন component-এর কেন্দ্র
covs = [np.eye(2), # গোলাকার
[[2, 1.5], [1.5, 2]], # ধনাত্মক-কাত ellipse
[[1, -0.7], [-0.7, 1]]] # ঋণাত্মক-কাত ellipse
weights = [0.40, 0.35, 0.25] # mixing weight π
n = 600
ztrue = rng.choice(3, size=n, p=weights) # প্রতি point-এর true component
X = np.empty((n, 2))
for k in range(3): # প্রতি component-এর row একসঙ্গে ভরা
idx = ztrue == k
X[idx] = rng.multivariate_normal(means[k], covs[k], size=int(idx.sum()))
এবার মূল GMM fit করি (n_init=5 — পাঁচটা random শুরু থেকে সেরাটা বাছে, EM-এর local-optimum সমস্যা এড়াতে), আর তুলনার জন্য একটা k-means-ও:
gmm = GaussianMixture(n_components=3, covariance_type="full",
random_state=0, n_init=5).fit(X)
resp = gmm.predict_proba(X) # responsibility r_{ik} (600 × 3) — soft assignment
zgmm = gmm.predict(X) # hard label = argmax_k r_{ik}
km = KMeans(n_clusters=3, n_init=10, random_state=0).fit(X)
print(round(gmm.bic(X), 1), # 4828.8
round(adjusted_rand_score(ztrue, zgmm), 2), # 0.97 (GMM)
round(adjusted_rand_score(ztrue, km.labels_), 3)) # 0.914 (k-means)
এই fit যে সংখ্যাগুলো দেয় তা নিচের ছবিগুলোর মেরুদণ্ড: GMM-এর BIC \(= 4828.8\), আর তার clustering true label-এর সঙ্গে ARI \(= 0.97\) — প্রায় নিখুঁত। k-means একই data-তে ARI \(= 0.914\) — ভালো, কিন্তু লক্ষণীয়ভাবে কম। fitted mixing weight \((\hat\pi) = (0.405, 0.349, 0.246)\), যা সত্যিকারের \((0.40, 0.35, 0.25)\)-এর প্রায় সমান — EM শুধু আকৃতি নয়, প্রতিটা component-এর ভর-ও ঠিক ধরেছে।
৬.১ · GMM কী শেখে: soft assignment ও fitted ellipse¶
এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ ছবি — GMM-এর গোটা ধারণাটা এক পাতায়। অনুভূমিক-উল্লম্ব অক্ষে \(x_1, x_2\); \(600\)টা data point আঁকা, প্রতিটার রং তার responsibility দিয়ে স্থির — অর্থাৎ একটা point যদি component 1-এর প্রতি \(0.9\) আর component 2-এর প্রতি \(0.1\) responsibility রাখে, তার রং হবে নীল-প্রধান একটা মিশ্রণ (RGB-blend, তিন component নীল/লাল/সবুজ)। যে point দুটো cluster-এর সীমানায়, তার রং তাই মেশানো — এটাই "soft" assignment-এর দৃশ্যরূপ, k-means-এর কঠিন হ্যাঁ/না-র বিপরীত। আর তার উপর প্রতিটা fitted component-এর ellipse আঁকা: \(\mathcal{N}(\mu_k, \Sigma_k)\)-এর \(1\sigma\) (নিরেট) ও \(2\sigma\) (ভাঙা) contour, যা সরাসরি covariance matrix-এর eigenvector/eigenvalue থেকে তৈরি — ellipse-এর অভিমুখ আসে eigenvector থেকে, দৈর্ঘ্য আসে eigenvalue-এর বর্গমূল থেকে। এই ellipse-ই দেখায় GMM শুধু cluster-এর কেন্দ্র নয়, তার আকৃতি ও অভিমুখ-ও শেখে।
from matplotlib.patches import Ellipse
def draw_ellipse(ax, mean, cov, color, nstd=(1, 2)):
vals, vecs = np.linalg.eigh(cov) # Σ-এর eigen-decomposition
order = vals.argsort()[::-1]; vals, vecs = vals[order], vecs[:, order]
angle = np.degrees(np.arctan2(vecs[1, 0], vecs[0, 0])) # বড় অক্ষের কোণ
for k in nstd: # 1σ ও 2σ contour
w, h = 2 * k * np.sqrt(vals) # অক্ষ-দৈর্ঘ্য = 2k·√eigenvalue
ax.add_patch(Ellipse(mean, w, h, angle=angle, facecolor="none",
edgecolor=color, lw=2.2, ls="-" if k == 1 else "--"))
base = np.array([[0.11,0.42,0.66],[0.75,0.22,0.17],[0.18,0.55,0.34]]) # 3 comp রং
soft_rgb = resp @ base # responsibility-ভারিত রং মিশ্রণ
ax.scatter(X[:, 0], X[:, 1], c=np.clip(0.25 + 0.75*soft_rgb, 0, 1), s=26)
for k in range(3): # প্রতি fitted component-এর ellipse
draw_ellipse(ax, gmm.means_[k], gmm.covariances_[k], color=comp_colors[k])
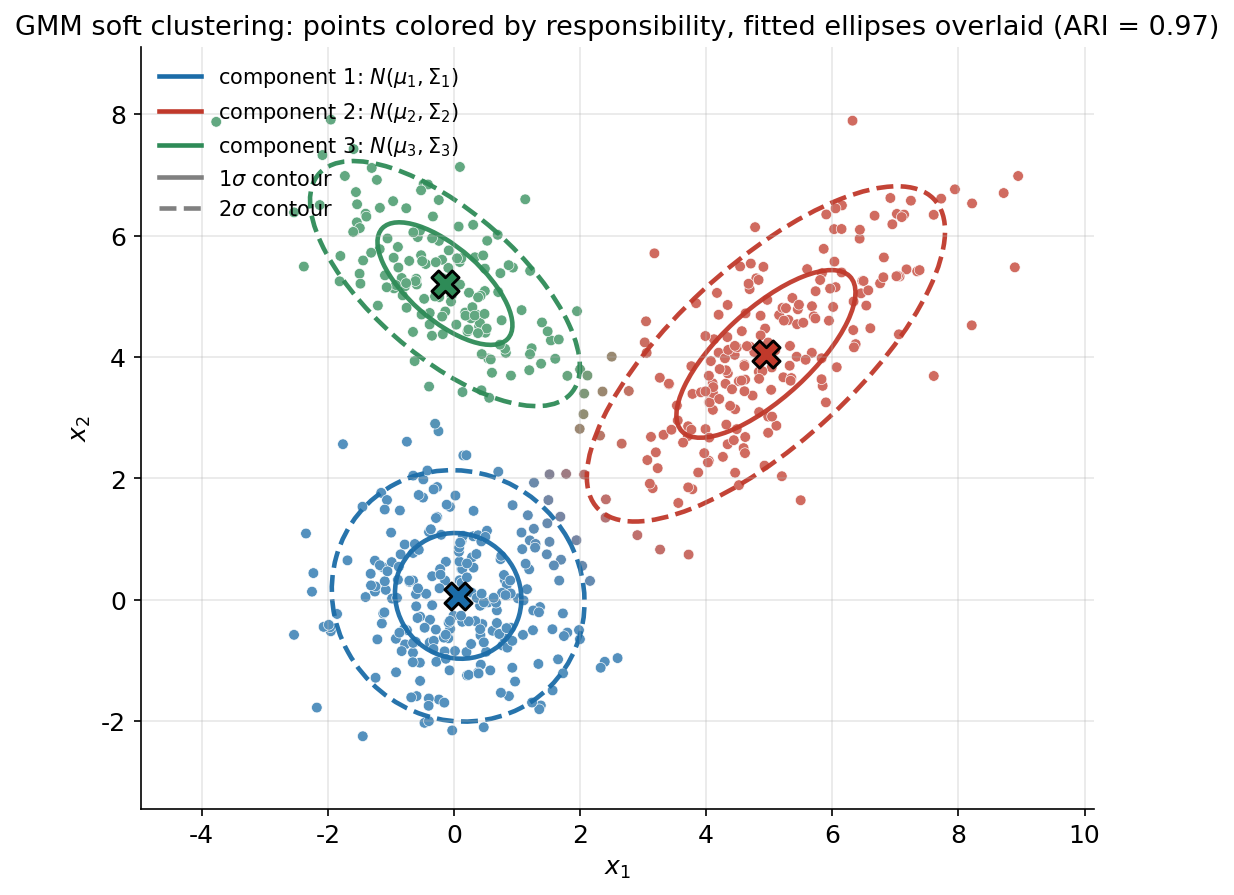
ছবি থেকে যা পড়া যায়। প্রথমেই চোখে পড়ে তিনটে ellipse-এর তিনটে আলাদা আকৃতি, আর এটাই GMM-এর মূল শক্তির দৃশ্যপ্রমাণ। বাঁ-নিচের নীল component (\((0,0)\)-কেন্দ্রিক) প্রায় নিখুঁত বৃত্ত — কারণ তার সত্যিকারের covariance \(\Sigma_1 = I\), দুই অক্ষে সমান বিস্তার, কোনো কাত নেই। ডান দিকের লাল component (\((5,4)\)-কেন্দ্রিক) একটা লম্বাটে ellipse যা নিচ-বাঁ থেকে উপর-ডানে তেরছা — কারণ \(\Sigma_2\)-এর off-diagonal \(+1.5\), অর্থাৎ এই cluster-এ \(x_1\) বাড়লে \(x_2\)-ও বাড়ে, তাই বিন্দুগুলো একটা কাত-হওয়া মেঘ বানায়। উপরের সবুজ component (\((0,5)\)-কেন্দ্রিক) আবার উল্টো দিকে কাত (উপর-বাঁ থেকে নিচ-ডান) — কারণ \(\Sigma_3\)-এর off-diagonal \(-0.7\), ঋণাত্মক correlation। GMM এই তিনটে ভিন্ন আকৃতি data থেকে নিজে শিখেছে, কোনো ইঙ্গিত ছাড়াই — full covariance-এর ঠিক এটাই কাজ। লক্ষ করুন প্রতিটা ellipse-এর কেন্দ্রের X চিহ্ন (fitted \(\hat\mu_k\)) সত্যিকারের কেন্দ্রের প্রায় গায়ে গায়ে, আর \(1\sigma\) contour মোটামুটি সেই component-এর ঘন কেন্দ্রটুকু ঘিরে রাখে যেখানে point-ঘনত্ব সর্বোচ্চ, আর \(2\sigma\) contour প্রায় সব point-কে আগলে নেয় — যা নিশ্চিত করে fitted Gaussian-গুলো সত্যিই data-র সঙ্গে মিলেছে।
দ্বিতীয় যে জিনিসটা ছবি দেখায় তা হলো soft assignment। বেশিরভাগ point-ই বিশুদ্ধ নীল, লাল বা সবুজ — কারণ তারা স্পষ্টভাবে একটা component-এর কাছে, responsibility প্রায় \((1,0,0)\) ধরনের। কিন্তু যেখানে দুটো cluster কাছাকাছি আসে — বিশেষত নীল ও সবুজ মেঘের মাঝখানের অঞ্চলে — সেখানকার point-গুলোর রং মেশানো, ঘোলাটে নীল-সবুজ। এই point-গুলো সম্পর্কে GMM বলছে না "তুমি নিশ্চিতভাবে cluster A", বরং বলছে "তুমি \(60\%\) A আর \(40\%\) B" — এটাই responsibility \(\gamma_{ik}\)-এর তথ্য, যা probability density model হিসেবে GMM-এর কাছে স্বাভাবিকভাবেই আছে কিন্তু k-means-এর কঠিন বিভাজনে নেই। আর এই দুটো বৈশিষ্ট্য একসঙ্গে — কাত-আকৃতি ধরা আর সীমানায় অনিশ্চয়তা স্বীকার করা — মিলেই ব্যাখ্যা করে কেন এই dataset-এ GMM-এর ARI \(0.97\), প্রায় নিখুঁত।
৬.২ · GMM বনাম k-means: একই data, দুই clustering¶
§৬.১ দেখাল GMM কী শেখে; এই দ্বিতীয় ছবিটা দেখায় সেই শেখা কেন গুরুত্বপূর্ণ — একই data-র উপর GMM আর k-means-কে পাশাপাশি বসিয়ে। দুটো প্যানেলেই background-টা decision region হিসেবে রঙানো (কোন এলাকার point কোন cluster পায়), আর তার উপর data point আঁকা। বাঁ দিকে GMM: তার region-এর সীমানা বাঁকা, elliptical, কারণ GMM প্রতিটা point-কে probability density \(\pi_k\, \mathcal{N}(\mu_k, \Sigma_k)\)-এর ভিত্তিতে বণ্টন করে — covariance-এর আকৃতি সীমানাকে প্রভাবিত করে। ডান দিকে k-means: তার region-এর সীমানা একদম সরল রেখা (Voronoi tessellation), কারণ k-means কেবল নিকটতম কেন্দ্র দেখে — প্রতিটা cluster-কে অন্তর্নিহিতভাবে গোলাকার ও সমান-আকারের ধরে নেয়। দুই প্যানেলেই ARI বাক্সে লেখা, যাতে গুণগত পার্থক্যটা সংখ্যায় বাঁধা থাকে।
xx, yy = np.meshgrid(np.linspace(*xlim, 400), np.linspace(*ylim, 400))
grid = np.c_[xx.ravel(), yy.ravel()]
# বাঁ প্যানেল: GMM-এর decision region (predict গোটা grid-এ) + 2σ ellipse
axL.contourf(xx, yy, gmm.predict(grid).reshape(xx.shape), alpha=0.55, cmap=region_cmap)
axL.scatter(X[:, 0], X[:, 1], c=zgmm, cmap=point_cmap, s=18)
axL.text(0.03, 0.97, "ARI = 0.97", transform=axL.transAxes, ...) # GMM-এর স্কোর
# ডান প্যানেল: k-means-এর Voronoi region — সীমানা সরল রেখা
axR.contourf(xx, yy, km.predict(grid).reshape(xx.shape), alpha=0.55, cmap=region_cmap)
axR.scatter(X[:, 0], X[:, 1], c=km.labels_, cmap=point_cmap, s=18)
axR.text(0.03, 0.97, "ARI = 0.914", transform=axR.transAxes, ...) # k-means-এর স্কোর
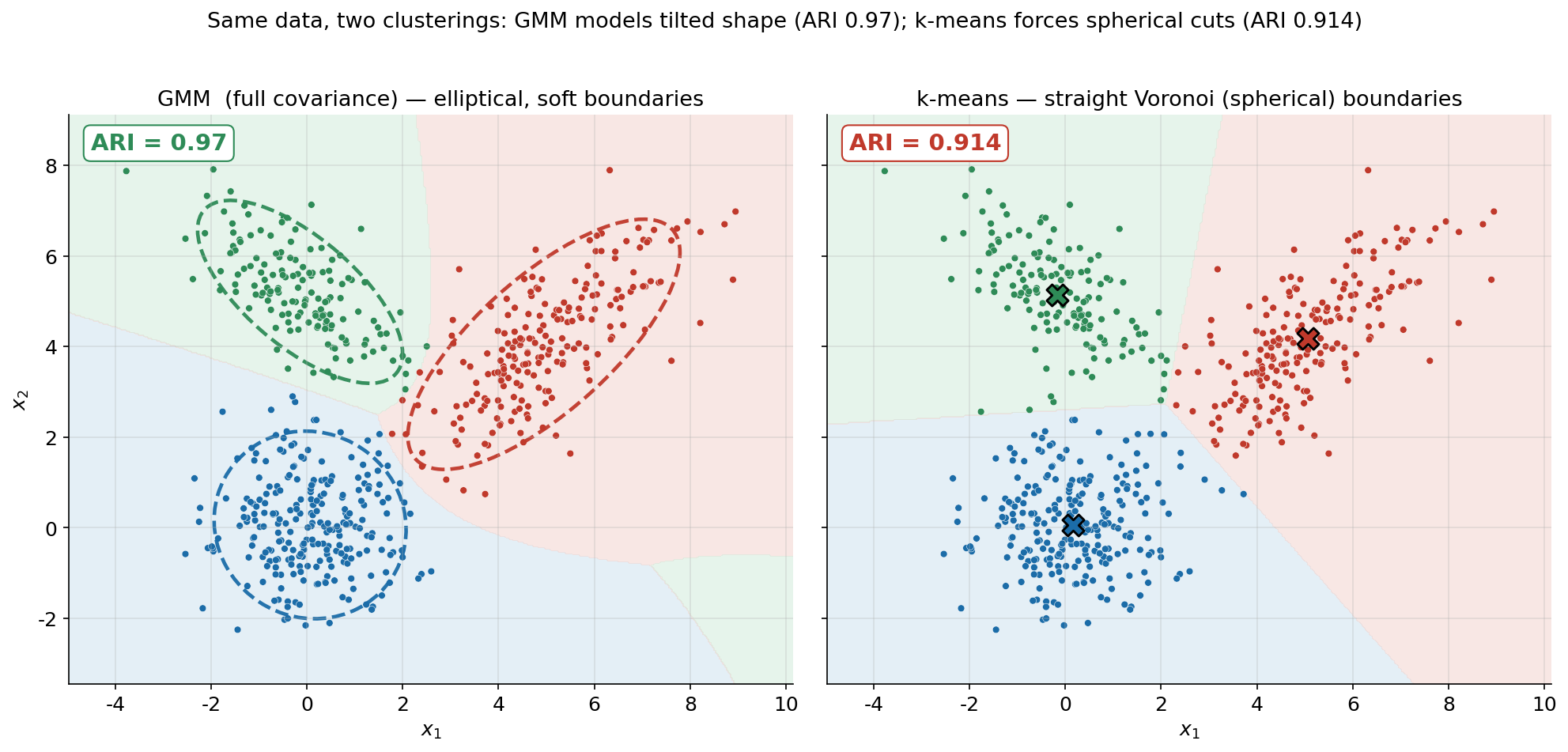
ছবি থেকে যা পড়া যায়। পার্থক্যটা সীমানার আকৃতিতেই সবচেয়ে স্পষ্ট। ডান প্যানেলে k-means-এর তিনটে অঞ্চল সরল রেখায় কাটা — এটা গাণিতিক অনিবার্যতা: দুটো cluster-কেন্দ্রের ঠিক মাঝখানের লম্ব-সমদ্বিখণ্ডক রেখাই সীমানা, তাই Voronoi cell সবসময় বহুভুজ। এই সরল কাট ভালো কাজ করত যদি সব cluster সত্যিই গোলাকার ও সমান-আকারের হতো। কিন্তু আমাদের data-য় তা নয় — বিশেষত \((5,4)\)-কেন্দ্রিক লাল component একটা লম্বা, তেরছা ellipse। k-means তার সরল সীমানা দিয়ে এই কাত-হওয়া মেঘটাকে যথাযথভাবে ঘিরতে পারে না: ellipse-এর যে লেজটা সীমানার ওপারে চলে গেছে, তার কিছু point ভুল cluster-এ পড়ে যায়। বাঁ প্যানেলে GMM ঠিক এই জায়গাতেই জেতে — তার সীমানা বাঁকা ও elliptical, covariance-এর আকৃতি অনুসরণ করে, তাই কাত-হওয়া cluster-টাকে তার নিজের কাত-হওয়া region-এই ধরে রাখে। ২σ ellipse-গুলো দেখায় কীভাবে GMM-এর region প্রতিটা component-এর প্রকৃত বিস্তারের সঙ্গে মানানসই।
এই গুণগত পার্থক্যই সংখ্যায় ধরা পড়ে: GMM-এর ARI \(0.97\) বনাম k-means-এর \(0.914\)। ব্যবধানটা ছোট মনে হতে পারে, কিন্তু এর অর্থ হলো GMM যেখানে প্রায় প্রতিটা point ঠিক বসিয়েছে, k-means সেখানে একটা মাপযোগ্য অংশ — মূলত তেরছা cluster-গুলোর প্রান্তিক point — ভুল করেছে। মূল শিক্ষা: k-means আসলে GMM-এরই একটা বিশেষ সীমান্ত-রূপ (সব \(\Sigma_k = \sigma^2 I\), hard assignment), তাই যখন cluster সত্যিই গোলাকার তখন দুটো প্রায় এক হয়ে যায়; কিন্তু যখন cluster-এর আকৃতি বা ঘনত্ব আলাদা — আর বাস্তব data-য় প্রায়ই তা থাকে — তখন full-covariance GMM-এর নমনীয়তা স্পষ্ট সুবিধা দেয়, কারণ সে cluster-এর আকৃতি-কেও parameter হিসেবে শেখে, শুধু কেন্দ্র নয়।
৬.৩ · EM কীভাবে শেখে: log-likelihood কখনো কমে না¶
§৬.১–৬.২ দেখাল GMM যা শেখে তা ভালো; কিন্তু সে শেখে কীভাবে? উত্তর হলো EM (Expectation-Maximization) algorithm, আর তার সবচেয়ে গুরুত্বপূর্ণ তাত্ত্বিক গুণটা — যা §৪-এ প্রমাণিত হয়েছে — হলো: EM-এর প্রতিটা iteration log-likelihood কখনো কমায় না। এই তৃতীয় ছবিটা সেই গুণটাকে চোখে দেখায়। অনুভূমিক অক্ষে EM iteration সংখ্যা, উল্লম্ব অক্ষে সেই iteration-এর শেষে data-র log-likelihood \(\ell(\theta) = \sum_i \log \sum_k \pi_k\, \mathcal{N}(x_i \mid \mu_k, \Sigma_k)\)। প্রতিটা iteration-এ E-step responsibility হিসাব করে, M-step সেই responsibility ধরে parameter আপডেট করে — আর এই দুইয়ের প্রতিটা ধাপ গাণিতিকভাবে নিশ্চিত করে \(\ell\) বাড়বে নয়তো একই থাকবে, কখনো নামবে না। per-iteration value পেতে আমরা GMM-কে warm_start=True, max_iter=1 দিয়ে একটা loop-এ চালাই, প্রতিবার এক ধাপ এগিয়ে log-likelihood টুকে রাখি।
ll_hist = []
g = GaussianMixture(n_components=3, covariance_type="full", random_state=0,
warm_start=True, max_iter=1, tol=1e-12) # প্রতি fit = এক EM ধাপ
for it in range(40):
g.fit(X) # ঠিক একটা E-step + M-step
ll_hist.append(g.score(X) * n) # মোট log-likelihood (score = গড়/point)
if len(ll_hist) > 1 and abs(ll_hist[-1] - ll_hist[-2]) < 1e-4:
break # plateau-তে পৌঁছেছে — থামো
ax.plot(range(1, len(ll_hist)+1), ll_hist, "-o") # monotone-আরোহী curve
ax.axhline(ll_hist[-1], ls="--", color="grey") # plateau রেখা
assert np.all(np.diff(ll_hist) >= -1e-6) # কখনো কমে না — যাচাই
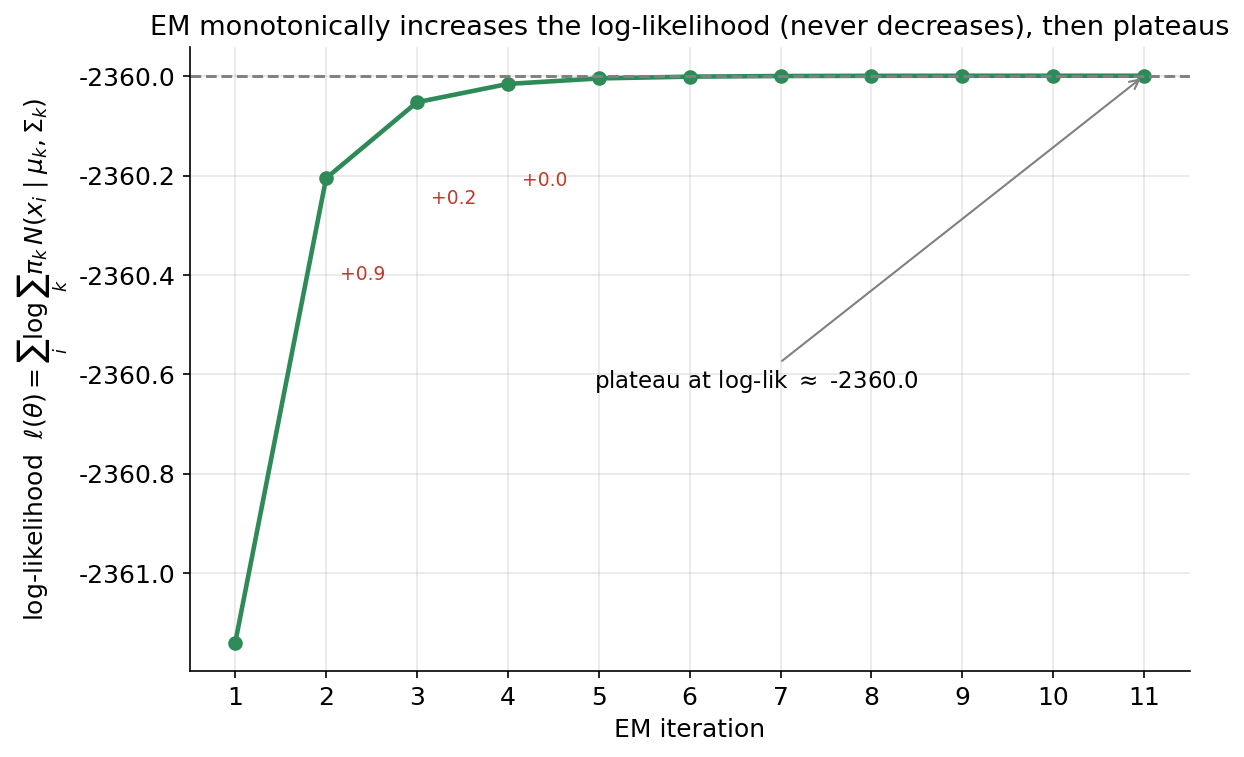
ছবি থেকে যা পড়া যায়। curve-টার আকৃতিই গোটা বার্তা: এটা একটানা ওঠে, কোথাও নামে না, তারপর সমতল হয়। iteration ১-এ — যখন parameter সবে initialize হয়েছে (k-means দিয়ে) — log-likelihood সর্বনিম্ন, প্রায় \(-2361.1\)। এরপর iteration ২-তে সবচেয়ে বড় লাফ (\(+0.9\)): শুরুর দিকে parameter সত্য থেকে সবচেয়ে দূরে, তাই একটা E-M ধাপ সবচেয়ে বেশি উন্নতি আনে। তারপর প্রতিটা পরবর্তী ধাপের লাভ ক্রমশ কমে (\(+0.2\), তারপর প্রায় \(+0.0\)) — algorithm যত optimum-এর কাছে আসে, তত ছোট পদক্ষেপ ফেলে। iteration ৫-এর পর curve কার্যত plateau ছুঁয়ে ফেলে, \(\ell \approx -2360.0\), এবং ১১তম iteration পর্যন্ত আর বদলায় না — এটাই convergence: পরপর দুই iteration-এ log-likelihood-এর পরিবর্তন একটা ক্ষুদ্র threshold-এর নিচে নেমে গেছে, তাই EM থামে।
সবচেয়ে তাৎপর্যপূর্ণ পর্যবেক্ষণ — যা code-এ assert np.all(np.diff(ll_hist) >= -1e-6) দিয়ে যাচাই করা হয়েছে — হলো curve-টা কখনো নিচে নামে না। এটা কাকতালীয় নয়, এটা EM-এর গাণিতিক গ্যারান্টি (§৪-এর সেই প্রমাণ, যেখানে দেখানো হয় প্রতিটা M-step একটা lower bound \(Q(\theta)\) বাড়ায় এবং সেই lower bound প্রকৃত log-likelihood-কে স্পর্শ করে, তাই \(\ell\)-ও বাড়তে বাধ্য)। এই monotone গুণটাই EM-কে এত নির্ভরযোগ্য করে: gradient descent-এর মতো এখানে learning rate ঠিকঠাক বাছার ঝামেলা নেই, প্রতিটা ধাপ আপনাআপনি একটা বৈধ উন্নতি। তবে একটা সতর্কতা — monotone ওঠা মানে algorithm একটা local maximum-এ পৌঁছায়, সবসময় global নয়; ঠিক এই কারণেই মূল fit-এ n_init=5 ব্যবহার করা হয়েছে, পাঁচটা ভিন্ন শুরুবিন্দু থেকে চালিয়ে সর্বোচ্চ log-likelihood-ওয়ালা ফলটা বেছে নিতে। ছবির এই একটানা-ঊর্ধ্বমুখী, plateau-তে-থামা curve-ই তাই EM-এর কাজ করার পদ্ধতির দৃশ্যসারাংশ।
৬.৪ · কতগুলো component: BIC বনাম \(K\)¶
এতক্ষণ আমরা \(K = 3\) ধরে নিয়েছিলাম, কারণ আমরা জানি data তিনটে Gaussian থেকে এসেছে। কিন্তু বাস্তবে \(K\) অজানা — কতগুলো component নেব সেটাই একটা মূল সিদ্ধান্ত। বেশি \(K\) নিলে likelihood সবসময় বাড়বে (আরও parameter মানে data-কে আরও ভালো করে fit করা), তাই খালি likelihood দেখে \(K\) বাছা যায় না — সেটা সবসময় বলবে "যত বেশি তত ভালো", যা overfitting। এই শেষ ছবিটা দেখায় সঠিক হাতিয়ার — BIC (Bayesian Information Criterion) \(= -2\,\ell(\hat\theta) + p \log n\), যেখানে \(p\) হলো parameter-সংখ্যা। প্রথম পদ ভালো fit-কে পুরস্কৃত করে (log-likelihood বেশি হলে BIC কমে), দ্বিতীয় পদ জটিলতাকে শাস্তি দেয় (\(K\) বাড়লে \(p\) বাড়ে, penalty বাড়ে)। আমরা \(K = 1\) থেকে \(6\) পর্যন্ত GMM fit করে প্রতিটার BIC হিসাব করি, আর সবচেয়ে কম BIC-ওয়ালা \(K\)-ই সেরা — fit আর simplicity-র সবচেয়ে ভালো ভারসাম্য।
Ks, bics = range(1, 7), []
for K in Ks: # K = 1..6 প্রতিটা চেষ্টা
g = GaussianMixture(n_components=K, covariance_type="full",
random_state=0, n_init=5).fit(X)
bics.append(g.bic(X)) # = -2·logL + p·log n
kbest = Ks[int(np.argmin(bics))] # সর্বনিম্ন BIC কোথায়: K = 3
ax.plot(Ks, bics, "-o")
ax.scatter([kbest], [min(bics)], s=380, facecolor="none", edgecolor="green") # বৃত্ত
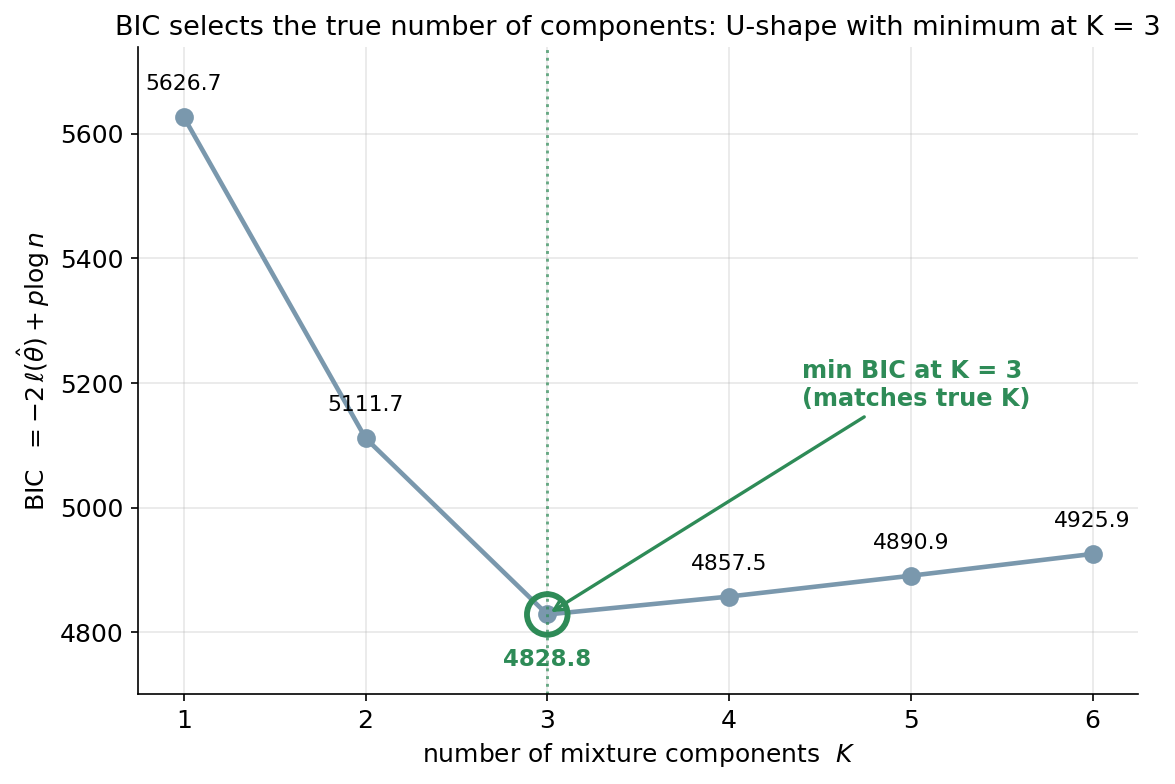
ছবি থেকে যা পড়া যায়। curve-টা একটা পরিষ্কার U-আকৃতি (বা elbow), আর তার তলা ঠিক \(K = 3\)-এ — সত্যিকারের component-সংখ্যায়। এটাই ছবির মূল বার্তা: BIC, যে data-র উৎস সম্পর্কে কিছুই জানে না, কেবল fit আর penalty-র ভারসাম্য থেকে সঠিক \(K\) খুঁজে বের করেছে। U-এর দুই বাহু দুই ভুলের প্রতিনিধি। বাঁ বাহুটা খাড়া: \(K = 1\)-এ BIC সর্বোচ্চ (\(5626.7\)), কারণ একটামাত্র Gaussian দিয়ে তিনটে আলাদা মেঘকে ধরা যায় না — likelihood ভয়ানক কম, তাই BIC বিশাল; \(K = 2\)-তে (\(5111.7\)) দুটো মেঘ আলাদা হয় কিন্তু একটা থেকে যায় মিশে, তাই এখনো underfit। \(K = 3\)-এ এসে (\(4828.8\)) তিনটে component তিনটে সত্যিকারের cluster-এ বসে — likelihood লাফিয়ে বাড়ে, BIC সর্বনিম্ন।
আর ডান বাহুটা মৃদু কিন্তু ঊর্ধ্বমুখী: \(K = 4\) (\(4857.5\)), \(K = 5\) (\(4890.9\)), \(K = 6\) (\(4925.9\)) — প্রতিটা ধাপে BIC একটু একটু করে বাড়ে। এটাই BIC-এর penalty পদের কাজ দেখায়। \(K = 3\)-এর পর বাড়তি component যোগ করলে log-likelihood হয়তো সামান্য বাড়ে (একটা সত্যিকারের cluster-কে কৃত্রিমভাবে দুই টুকরো করে data-র এলোমেলো খুঁটিনাটি fit করে), কিন্তু সেই ক্ষুদ্র লাভ \(p \log n\) penalty-র বৃদ্ধিকে পুষিয়ে দিতে পারে না — তাই net BIC বাড়ে। অন্য কথায়, BIC স্পষ্ট জানিয়ে দেয়: \(K = 4, 5, 6\) অপ্রয়োজনীয় জটিল, তারা শুধু noise-কে model করছে। লক্ষণীয় যে বাঁ বাহু খাড়া (underfit-এর শাস্তি কড়া) কিন্তু ডান বাহু মৃদু (overfit-এর শাস্তি ধীর) — এটাই কেন practitioner-রা বলেন BIC সাধারণত একটু রক্ষণশীল, সন্দেহ হলে কম component-এর দিকে ঝোঁকে। এখানে অবশ্য সিদ্ধান্ত দ্ব্যর্থহীন: U-এর তলা একক ও স্পষ্ট, \(K = 3\)-ই বিজয়ী — যা §২–§৫-এর model-selection তত্ত্বকে এক ছবিতে বাস্তবায়িত করে এবং নিশ্চিত করে যে আমাদের density estimate-টি data-র প্রকৃত গঠনকেই ধরেছে, তার বেশিও নয়, কমও নয়।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/06-07-em-gmm-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — mixture model ও latent variable-এর ধারণা (একটা density কেন বহু Gaussian-এর ওজনিত যোগফল, আর "কোন বিন্দু কোন component" হলো লুকানো label), MLE কেন কঠিন (log-sum আটকে যায়, closed form নেই), E-step-এর responsibility = posterior (\(\gamma_{ik}=P(z_i{=}k\mid x_i)\) — দেওয়া \(\pi,\mu,\Sigma\)-এ একটা ছোট ২-component উদাহরণে হাতে গুনে), M-step-এর weighted update (দেওয়া responsibility থেকে \(\pi_k,\mu_k\) হাতে বের করে), EM কেন likelihood বাড়ায় (ELBO/Jensen, \(\mathrm{KL}\ge0\)), GMM বনাম k-means (soft/elliptical বনাম hard/spherical; k-means = hard-spherical EM-এর সীমা), BIC দিয়ে \(K\) বাছা (BIC-table পড়ে \(K=3\)), soft বনাম hard assignment (responsibility), এবং একটা coding প্রশ্ন (GMM fit, responsibility, ARI বনাম k-means, BIC-sweep) — এই হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed-সূচক 20260619, একটি 3-component 2D Gaussian mixture, \(n=600\), প্রকৃত weights \([0.40,0.35,0.25]\), অসম/তির্যক (unequal/tilted) covariance। canonical সংখ্যা: GMM(\(3\)) BIC \(4828.8\), per-sample log-likelihood \(-3.933\), আনুমানিক weights \([0.405,0.349,0.246]\); ARI \(0.97\) (\(>\) k-means \(0.914\))। BIC by \(K\): \(1\to5626.7\), \(2\to5111.7\), \(3\to\mathbf{4828.8}\) (সর্বনিম্ন), \(4\to4857.5\), \(5\to4890.9\), \(6\to4925.9\)। একটি ambiguous (সীমানা-সংলগ্ন) বিন্দুর responsibility \(\approx[0.864,0.002,0.133]\)। মূল notation: \(p(x)=\sum_k\pi_k\,\mathcal N(x;\mu_k,\Sigma_k)\); responsibility \(\gamma_{ik}=\frac{\pi_k\,\mathcal N(x_i;\mu_k,\Sigma_k)}{\sum_l\pi_l\,\mathcal N(x_i;\mu_l,\Sigma_l)}\); M-step \(\pi_k=\frac1n\sum_i\gamma_{ik}\), \(\mu_k=\frac{\sum_i\gamma_{ik}x_i}{\sum_i\gamma_{ik}}\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). mixture model ও latent variable — মূল ছবি। একটা Gaussian mixture density লেখা হয় \(p(x)=\sum_{k=1}^K\pi_k\,\mathcal N(x;\mu_k,\Sigma_k)\), যেখানে \(\pi_k\ge0,\ \sum_k\pi_k=1\)। (ক) এই formula-কে একটা দুই-ধাপের generative গল্প হিসেবে বর্ণনা করুন: প্রথমে কী টানা হয়, তারপর কী — এবং এখানে latent (লুকানো) variable \(z_i\) ঠিক কোনটা? (খ) আমরা data-তে \(x_i\) দেখি কিন্তু \(z_i\) দেখি না — এই "অর্ধেক-দেখা" data-কে কী বলে, এবং এটাই কেন এই অধ্যায়ের কেন্দ্রীয় অসুবিধা? (গ) \(\pi_k\) (mixing weight), \(\mu_k\), \(\Sigma_k\) — প্রতিটির এক-লাইন ভৌত অর্থ বলুন। Hint: (ক) দুই ধাপ: (i) \(z_i\sim\text{Categorical}(\pi_1,\dots,\pi_K)\) — কোন component, তারপর (ii) \(x_i\sim\mathcal N(\mu_{z_i},\Sigma_{z_i})\) — সেই component থেকে বিন্দু; latent variable = component-label \(z_i\) (কোন Gaussian থেকে \(x_i\) এল)। (খ) latent variable লুকানো বলে এটা incomplete (অসম্পূর্ণ) data — \(z_i\) জানলে প্রতিটি component আলাদা করে সাধারণ Gaussian-MLE হতো, কিন্তু \(z_i\) অজানা বলে component আর parameter পরস্পর-নির্ভর — মুরগি-ডিম সমস্যা। (গ) \(\pi_k\) = component \(k\)-এর জনসংখ্যা-অনুপাত (prior); \(\mu_k\) = তার কেন্দ্র; \(\Sigma_k\) = তার আকার/অভিমুখ/বিস্তার (tilted ⇒ off-diagonal \(\ne0\))।
প্রশ্ন ২ (★). kernel density বনাম mixture — দুই density-estimation দর্শন। density estimation-এর দুটো পথ: kernel density estimation (KDE) প্রতিটি data-বিন্দুতে একটা ছোট kernel বসিয়ে যোগ করে (\(\hat p(x)=\frac1n\sum_i K_h(x-x_i)\)), আর mixture model অল্প-কয়েকটা (\(K\)) parametric component-এ পুরো data ব্যাখ্যা করে। (ক) KDE-তে "component"-সংখ্যা কত (data-আকারের সাথে কীভাবে বাড়ে), mixture-এ কত — এই দিক থেকে কোনটা nonparametric, কোনটা parametric? (খ) নতুন একটা \(x\)-এ density মূল্যায়ন করতে KDE-তে কতগুলো term লাগে, fitted GMM-এ কতগুলো — বড় \(n\)-এ কোনটা সাশ্রয়ী? (গ) এক বাক্যে: কখন mixture বেশি স্বাভাবিক — যখন data সত্যিই অল্প-কয়েকটা subpopulation/cluster থেকে আসে? Hint: (ক) KDE-তে component-সংখ্যা \(=n\) (প্রতি বিন্দুতে এক kernel — data বাড়লে সংখ্যাও বাড়ে) ⇒ nonparametric; mixture-এ ধ্রুবক \(K\) (অল্প parameter) ⇒ parametric। (খ) KDE: \(n\)টি term প্রতি মূল্যায়নে (পুরো data লাগে); GMM: মাত্র \(K\)টি Gaussian — বড় \(n\)-এ GMM অনেক সাশ্রয়ী ও compact। (গ) যখন data প্রকৃতপক্ষে অল্প-কয়েকটা গুচ্ছ/subpopulation (যেমন চলমান উদাহরণের \(3\)টি Gaussian) থেকে আসে, তখন mixture কেবল সাশ্রয়ীই নয়, ব্যাখ্যামূলকও (প্রতিটি component একটা অর্থপূর্ণ গোষ্ঠী)।
প্রশ্ন ৩ (★). responsibility = posterior — soft assignment-এর অর্থ। E-step গণনা করে \(\gamma_{ik}=\frac{\pi_k\,\mathcal N(x_i;\mu_k,\Sigma_k)}{\sum_l\pi_l\,\mathcal N(x_i;\mu_l,\Sigma_l)}\)। (ক) Bayes-এর ভাষায় (২.২) এই \(\gamma_{ik}\) ঠিক কোন posterior probability — prior কী, likelihood কী, evidence কী? (খ) প্রতিটি বিন্দুর জন্য \(\sum_k\gamma_{ik}\) কত, এবং কেন এটা \(\gamma_{ik}\)-কে একটা soft (ভগ্নাংশ) assignment করে — k-means-এর hard (\(0/1\)) assignment-এর বিপরীতে? (গ) চলমান উদাহরণে একটা ambiguous বিন্দুর responsibility \([0.864,0.002,0.133]\) — এই বিন্দুটি কোথায় বসে আছে (একটা component-এর গভীরে, না দুটোর সীমানায়), আর hard assignment হলে এটা কোন component পেত? Hint: (ক) এটা posterior \(P(z_i{=}k\mid x_i)\): prior \(=\pi_k\), likelihood \(=\mathcal N(x_i;\mu_k,\Sigma_k)\), evidence (হর) \(=p(x_i)=\sum_l\pi_l\mathcal N(x_i;\mu_l,\Sigma_l)\) — হুবহু Bayes \(\frac{\text{prior}\times\text{likelihood}}{\text{evidence}}\)। (খ) \(\sum_k\gamma_{ik}=1\) (probability ভেক্টর); তাই প্রতিটি বিন্দু সব component-এ ভগ্নাংশে "ভাগ" হয়ে যায় (soft), একটিতে সম্পূর্ণ নয় (hard নয়)। (গ) \([0.864,0.002,0.133]\) — মূলত component-\(1\)-এর (\(86.4\%\)), সামান্য component-\(3\)-এ (\(13.3\%\)); component-\(1\) ও \(3\)-এর সীমানার কাছে, \(2\) থেকে দূরে; hard হলে component-\(1\) (সর্বোচ্চ \(\gamma\)) পেত, কিন্তু \(13.3\%\) অনিশ্চয়তা হারিয়ে যেত।
প্রশ্ন ৪ (★★). MLE কেন কঠিন — log-sum বাধা। \(n\)টি স্বাধীন বিন্দুর log-likelihood \(\ell(\theta)=\sum_{i=1}^n\log\Big(\sum_{k=1}^K\pi_k\,\mathcal N(x_i;\mu_k,\Sigma_k)\Big)\)। একটা একক Gaussian-এর MLE-তে (২.৪, ৪.৩) \(\log\) আর \(\exp\) পরস্পর বাতিল হয়ে closed-form উত্তর দেয়। (ক) এখানে \(\log\)-এর ভেতরে যোগফল (\(\log\sum_k\)) থাকায় সেই বাতিল কেন ঘটে না — কেন \(\mu_k\)-সাপেক্ষে \(\partial\ell/\partial\mu_k=0\) একটা পরিষ্কার closed-form দেয় না? (খ) যদি প্রতিটি \(z_i\) জানা থাকত (অর্থাৎ complete data), তখন log-likelihood কী রূপ নিত (\(\log\prod\) বনাম \(\log\sum\)), এবং তখন কেন MLE সহজ (প্রতিটি component আলাদা Gaussian)? (গ) এক বাক্যে: EM ঠিক এই কঠিনতা কীভাবে পাশ কাটায় — অজানা \(z_i\)-কে প্রথমে (soft) "পূরণ" করে, তারপর সহজ weighted-MLE করে? Hint: (ক) \(\frac{\partial}{\partial\mu_k}\log\sum_l\pi_l\mathcal N_l\)-এ chain rule দিলে হরে পুরো \(\sum_l\pi_l\mathcal N_l\) থেকে যায় (অন্য component-গুলোও জড়িয়ে যায়), তাই \(\mu_k\) আলাদা করা যায় না — সমীকরণগুলো coupled ও nonlinear, closed-form নেই। (খ) complete data হলে \(\ell_c=\sum_i\log\big(\pi_{z_i}\mathcal N(x_i;\mu_{z_i},\Sigma_{z_i})\big)=\sum_i[\log\pi_{z_i}+\log\mathcal N_{z_i}]\) — \(\log\)-এর ভেতরে আর যোগফল নেই, তাই প্রতিটি component নিজের বিন্দুগুলো নিয়ে সাধারণ Gaussian-MLE (closed-form)। (গ) EM-এ E-step অজানা \(z_i\)-কে soft responsibility \(\gamma_{ik}\) দিয়ে "পূরণ" করে, M-step সেই \(\gamma\)-ওজনে সহজ weighted-MLE করে — coupled সমস্যা দুটো সহজ ধাপে ভাঙে।
প্রশ্ন ৫ (★★). EM কেন কখনো likelihood কমায় না — ELBO ও Jensen। EM-এর তত্ত্ব দাঁড়িয়ে একটা পরিচয়ের উপর: যেকোনো distribution \(q(z)\)-এর জন্য $\(\log p(x\mid\theta)=\underbrace{\mathbb E_{q}\!\Big[\log\tfrac{p(x,z\mid\theta)}{q(z)}\Big]}_{\text{ELBO }\,\mathcal L(q,\theta)}+\underbrace{\mathrm{KL}\big(q(z)\,\Vert\,p(z\mid x,\theta)\big)}_{\ge0}.\)$ (ক) যেহেতু \(\mathrm{KL}\ge0\) সর্বদা, ELBO \(\mathcal L(q,\theta)\) কি \(\log p(x\mid\theta)\)-এর একটা lower bound না upper bound — নামটা ("evidence lower bound") কেন সঠিক? (খ) E-step (\(\theta\) স্থির রেখে \(q(z)\leftarrow p(z\mid x,\theta)\), অর্থাৎ responsibility) করার পর \(\mathrm{KL}\) কত হয়, এবং তাই ELBO আর \(\log p(x)\)-এর সম্পর্ক কী (bound টা কেন আঁটসাঁট/tight)? (গ) M-step (\(q\) স্থির রেখে ELBO-কে \(\theta\)-সাপেক্ষে বাড়ানো) করলে \(\log p(x)\) বাড়ে না কমে — এবং এই দুই ধাপ থেকে কেন উপসংহার "EM প্রতি iteration-এ log-likelihood একঘেয়ে (monotone) বাড়ায় বা স্থির রাখে"? Hint: (ক) \(\mathrm{KL}\ge0\) বলে \(\log p(x)=\mathcal L+\mathrm{KL}\ge\mathcal L\) — তাই \(\mathcal L\) একটা lower bound (evidence \(\log p(x)\)-এর নিচে), নাম যথাযথ। (খ) E-step-এ \(q=p(z\mid x,\theta)\) নিলে \(\mathrm{KL}(q\Vert p(z\mid x))=\mathrm{KL}(p\Vert p)=0\), তাই \(\mathcal L=\log p(x)\) — bound ঠিক বর্তমান \(\theta\)-তে স্পর্শ করে (tight)। (গ) M-step ELBO \(\mathcal L\) বাড়ায় (বা স্থির), আর যেহেতু E-step-এর পর \(\log p(x)=\mathcal L\) আর সবসময় \(\log p(x)\ge\mathcal L\), M-step-এ \(\mathcal L\) বাড়লে \(\log p(x)\)-ও অন্তত ততটা বাড়ে — তাই প্রতি iteration-এ \(\log p(x)\) কখনো কমে না (monotone↑); Jensen-এর অসমতাই \(\mathrm{KL}\ge0\)-এর উৎস।
প্রশ্ন ৬ (★★). GMM বনাম k-means — soft/elliptical বনাম hard/spherical। ৫.৯-এর k-means প্রতিটি বিন্দুকে নিকটতম centroid-এ hard assign করে ও cluster গোলকীয় (spherical) ধরে; GMM প্রতিটি বিন্দুকে soft responsibility দেয় ও cluster উপবৃত্তীয় (elliptical, \(\Sigma_k\) যেকোনো)। (ক) চলমান উদাহরণে covariance tilted/unequal, আর GMM-এর ARI (\(0.97\)) k-means-এর (\(0.914\)) চেয়ে বেশি — tilted-elliptical cluster-এ k-means কেন পিছিয়ে পড়ে (এর spherical-সীমানা কী ভুল করে)? (খ) GMM-এ কোন দুটো সরলীকরণ চাপালে (covariance-আকৃতি ও assignment-ধরন) সেটা কার্যত k-means হয়ে যায়? (গ) এক বাক্যে: তাই কেন বলা হয় "k-means হলো GMM-এর একটা বিশেষ সীমা" — GMM বেশি সাধারণ, না k-means? Hint: (ক) k-means-এর সীমানা সবসময় centroid-দের মাঝবিন্দু-লম্ব (Voronoi, spherical-অনুমান) — tilted/elongated cluster-এ এই সোজা-গোল সীমানা প্রকৃত উপবৃত্তীয় সীমানা থেকে সরে যায়, তাই overlapping/তির্যক অঞ্চলে বিন্দু ভুল cluster পায় ⇒ ARI কম (\(0.914<0.97\))। (খ) (i) সব \(\Sigma_k=\sigma^2 I\) (সমান-গোলকীয় covariance) এবং (ii) soft responsibility-কে hard (winner-take-all, \(\sigma\to0\) সীমায় \(\gamma_{ik}\in\{0,1\}\)) করলে — GMM ঠিক k-means হয়ে যায়। (গ) GMM বেশি সাধারণ; k-means = GMM-এর "সমান-গোলকীয় covariance + hard assignment" বিশেষ সীমা (তাই k-means-কে "hard-spherical EM"-ও বলা হয়)।
প্রশ্ন ৭ (★★). BIC দিয়ে \(K\) বাছা — model selection। \(K\) অজানা; বেশি component সবসময় বেশি likelihood দেয় (overfit), তাই penalize করতে BIC \(=-2\,\ell(\hat\theta)+p\log n\) (কম = ভালো; \(p\) = parameter-সংখ্যা)। চলমান উদাহরণে BIC by \(K\): \(1\to5626.7\), \(2\to5111.7\), \(3\to\mathbf{4828.8}\), \(4\to4857.5\), \(5\to4890.9\), \(6\to4925.9\)। (ক) এই table থেকে কোন \(K\) বাছবেন এবং কেন (কোন বৈশিষ্ট্য খুঁজছেন — সর্বনিম্ন, না সর্বোচ্চ)? (খ) \(K\) \(1\to3\)-এ BIC দ্রুত পড়ে, \(3\to6\)-এ ধীরে বাড়ে — এই "\(3\)-এ ভাঙা" কেন প্রকৃত cluster-সংখ্যার সাথে মেলে, এবং \(K>3\)-এ BIC কেন আবার বাড়ে (likelihood সামান্য বাড়লেও penalty কী করছে)? (গ) BIC-র দুটো পদ — \(-2\ell\) (fit) ও \(p\log n\) (complexity-penalty) — কীভাবে fit-বনাম-সরলতার ভারসাম্য করে (Occam-এর ক্ষুর)? Hint: (ক) BIC যত কম তত ভালো, তাই সর্বনিম্ন BIC-র \(K\) — এখানে \(K=\mathbf{3}\) (\(4828.8\), সবচেয়ে কম)। (খ) প্রকৃত data \(3\)টি Gaussian থেকে, তাই \(K{<}3\)-এ model আসল গঠন ধরতে পারে না (likelihood-অভাব ⇒ বড় BIC), \(K{=}3\)-এ ঠিক ধরে; \(K{>}3\)-এ অতিরিক্ত component likelihood সামান্যই বাড়ায় কিন্তু \(p\log n\) penalty বেশি বাড়ে ⇒ BIC আবার ওঠে — তাই \(3\)-এ স্পষ্ট সর্বনিম্ন। (গ) \(-2\ell\) ভালো-fit-এ ছোট হয় (more component ⇒ ছোট), \(p\log n\) বেশি-parameter-এ বড় হয় — যোগফল minimize করা মানে "যথেষ্ট-ভালো fit, কিন্তু যত কম parameter সম্ভব" — Occam-এর ক্ষুরের সংখ্যাগত রূপ।
খ · গণনামূলক (computational)¶
প্রশ্ন ৮ (★★). E-step হাতে — একটা ২-component responsibility। একটা ১D (এক-মাত্রিক) ২-component Gaussian mixture: \(\pi=(0.6,\,0.4)\), \(\mu=(0,\,4)\), \(\sigma=(1,\,1)\) (অর্থাৎ \(\Sigma_k=\sigma_k^2\), এখানে দুটোই \(1\))। একটা বিন্দু \(x=1.5\)-এর জন্য responsibility \(\gamma_{1},\gamma_{2}\) বের করুন। ১D Gaussian: \(\mathcal N(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\,\sigma}\exp\!\big(-\frac{(x-\mu)^2}{2\sigma^2}\big)\)। (ক) দুটো component-density \(\mathcal N(1.5;0,1)\) ও \(\mathcal N(1.5;4,1)\) গণনা করুন। (খ) ওজনিত-পদ \(\pi_k\mathcal N_k\) ও তাদের যোগফল \(p(x)\) বের করুন। (গ) \(\gamma_1=\frac{\pi_1\mathcal N_1}{p(x)}\), \(\gamma_2=\frac{\pi_2\mathcal N_2}{p(x)}\) বের করুন এবং যাচাই করুন \(\gamma_1+\gamma_2=1\); কোন component এই বিন্দুর "দায়িত্ব" বেশি নিচ্ছে এবং কেন (কোন \(\mu\)-এর কাছে)? Hint: (ক) \(\mathcal N(1.5;0,1)=\frac{1}{\sqrt{2\pi}}e^{-1.5^2/2}=0.3989\cdot e^{-1.125}=0.3989(0.3247)=0.1295\); \(\mathcal N(1.5;4,1)=0.3989\cdot e^{-(2.5)^2/2}=0.3989\,e^{-3.125}=0.3989(0.04394)=0.01753\)। (খ) \(\pi_1\mathcal N_1=0.6(0.1295)=0.07772\); \(\pi_2\mathcal N_2=0.4(0.01753)=0.007012\); \(p(x)=0.07772+0.007012=0.08473\)। (গ) \(\gamma_1=0.07772/0.08473=\mathbf{0.917}\), \(\gamma_2=0.007012/0.08473=\mathbf{0.083}\); যোগফল \(1.000\) ✓ — component-\(1\) (\(\mu{=}0\)) দায়িত্ব বেশি নেয়, কারণ \(x{=}1.5\) তার কেন্দ্রের অনেক কাছে (\(4\) থেকে দূরে)।
প্রশ্ন ৯ (★★). M-step হাতে — দেওয়া responsibility থেকে \(\pi_k,\mu_k\)। একটি component \(k\)-এর জন্য \(4\)টি ১D বিন্দু \(x=(1,\,2,\,6,\,8)\) এবং তাদের responsibility \(\gamma_{\cdot k}=(0.9,\,0.8,\,0.2,\,0.1)\) দেওয়া (E-step থেকে এসেছে ধরুন; মোট \(n=4\))। M-step সূত্র: \(N_k=\sum_i\gamma_{ik}\), \(\pi_k=\frac{N_k}{n}\), \(\mu_k=\frac{\sum_i\gamma_{ik}x_i}{N_k}\)। (ক) effective count \(N_k=\sum_i\gamma_{ik}\) গণনা করুন (এটা পূর্ণসংখ্যা নয় কেন — "soft" গণনা কী মানে?)। (খ) \(\pi_k=N_k/n\) বের করুন। (গ) weighted mean \(\mu_k=\frac{\sum_i\gamma_{ik}x_i}{N_k}\) বের করুন এবং ব্যাখ্যা করুন কেন এটা সাধারণ গড় \(\frac{1+2+6+8}{4}=4.25\)-এর চেয়ে ছোট (কোন বিন্দুগুলো বেশি "ওজন" পেল)। Hint: (ক) \(N_k=0.9+0.8+0.2+0.1=\mathbf{2.0}\) — পূর্ণসংখ্যা নয় কারণ প্রতিটি বিন্দু ভগ্নাংশে এই component-এর; \(N_k\) = এই component-কে দায়ী-ধরা বিন্দুর "কার্যকর (effective)" সংখ্যা। (খ) \(\pi_k=2.0/4=\mathbf{0.5}\)। (গ) \(\sum_i\gamma_{ik}x_i=0.9(1)+0.8(2)+0.2(6)+0.1(8)=0.9+1.6+1.2+0.8=4.5\); \(\mu_k=4.5/2.0=\mathbf{2.25}\) — সাধারণ গড় \(4.25\)-এর চেয়ে অনেক ছোট, কারণ ছোট বিন্দু (\(1,2\)) বড় responsibility (\(0.9,0.8\)) পেল, বড় বিন্দু (\(6,8\)) ছোট responsibility (\(0.2,0.1\)) — weighted mean তাই ছোট-বিন্দুর দিকে টানা।
প্রশ্ন ১০ (★★). soft বনাম hard — একই বিন্দু, দুই assignment। চলমান উদাহরণের ambiguous বিন্দুটির responsibility \(\gamma=[0.864,\,0.002,\,0.133]\)। (ক) GMM-এর soft assignment হিসেবে এই বিন্দুটি প্রতিটি component-এ কতটা "ভাগ" হয়েছে — তিনটি সংখ্যার যোগফল কত, আর তারা কী প্রতিনিধিত্ব করে? (খ) এই বিন্দুর hard assignment (k-means/MAP-style, সর্বোচ্চ \(\gamma\)) কোন component, এবং hard করলে কোন তথ্য হারিয়ে যায়? (গ) একটা বিন্দুর responsibility যদি \([0.34,0.33,0.33]\) হতো, সেটা soft-এ কী বলত আর hard-এ কী — কেন এমন বিন্দুতে hard assignment বিশেষভাবে বিভ্রান্তিকর? Hint: (ক) \(0.864+0.002+0.133=0.999\approx1\) (rounding) — তিন সংখ্যা = বিন্দুটি প্রতিটি component থেকে আসার posterior probability; এটা প্রায় পুরোটা component-\(1\), সামান্য \(3\), নগণ্য \(2\)। (খ) hard: \(\arg\max\gamma=\) component-\(1\) (\(0.864\) সর্বোচ্চ); hard করলে "\(13.3\%\) সম্ভাবনায় এটা component-\(3\)-এর" — এই অনিশ্চয়তা/সীমানা-তথ্য হারিয়ে যায় (model আর জানে না বিন্দুটি সীমানা-সংলগ্ন)। (গ) \([0.34,0.33,0.33]\) soft-এ বলে "তিন component-এর মাঝে প্রায়-সমান অনিশ্চয়তা" (খুব ambiguous); hard জোর করে component-\(1\) বেছে নেবে যদিও আস্থা মাত্র \(34\%\) — এমন প্রায়-সমান বিন্দুতে hard সিদ্ধান্ত কার্যত এলোমেলো ও বিভ্রান্তিকর, soft সততার সাথে অনিশ্চয়তা ধরে রাখে।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১১ (★★★). M-step-এর \(\mu_k\)-update derive করুন — weighted MLE। EM-এর M-step-এ আমরা expected complete-data log-likelihood (\(Q\)-function) maximize করি: $\(Q(\theta)=\sum_{i=1}^n\sum_{k=1}^K\gamma_{ik}\Big[\log\pi_k+\log\mathcal N(x_i;\mu_k,\Sigma_k)\Big],\)$ যেখানে \(\gamma_{ik}\) (E-step থেকে) স্থির ধরা হয়। multivariate Gaussian-এ \(\log\mathcal N(x_i;\mu_k,\Sigma_k)=-\tfrac12(x_i-\mu_k)^\top\Sigma_k^{-1}(x_i-\mu_k)+\text{(\)\mu_k\(-নিরপেক্ষ পদ)}\)। (ক) \(Q\)-কে \(\mu_k\)-সাপেক্ষে differentiate করুন (শুধু \(\log\mathcal N\) পদ \(\mu_k\)-নির্ভর) এবং gradient শূন্য করুন। (খ) সমাধান করে দেখান \(\mu_k=\frac{\sum_i\gamma_{ik}x_i}{\sum_i\gamma_{ik}}\) — অর্থাৎ responsibility-ওজনে data-র weighted mean। (গ) এক বাক্যে: \(\gamma_{ik}\in\{0,1\}\) (hard) হলে এই সূত্র কী হয়, এবং সেটা ৫.৯-এর কোন update-এর সাথে অভিন্ন? Hint: (ক) \(\frac{\partial}{\partial\mu_k}\big[-\tfrac12(x_i-\mu_k)^\top\Sigma_k^{-1}(x_i-\mu_k)\big]=\Sigma_k^{-1}(x_i-\mu_k)\); তাই \(\frac{\partial Q}{\partial\mu_k}=\sum_i\gamma_{ik}\Sigma_k^{-1}(x_i-\mu_k)=0\)। (খ) \(\Sigma_k^{-1}\) invertible বলে বাদ দিয়ে \(\sum_i\gamma_{ik}(x_i-\mu_k)=0\Rightarrow\sum_i\gamma_{ik}x_i=\mu_k\sum_i\gamma_{ik}\Rightarrow\mu_k=\frac{\sum_i\gamma_{ik}x_i}{\sum_i\gamma_{ik}}\) ∎ — soft-weighted mean। (গ) \(\gamma_{ik}\in\{0,1\}\) হলে এটা হয়ে যায় "component-\(k\)-এ assign করা বিন্দুগুলোর সাধারণ গড়" — ঠিক k-means-এর centroid-update (৫.৯); তাই k-means = hard-EM-এর M-step।
প্রশ্ন ১২ (★★★). EM monotonicity — KL\(\ge0\) থেকে likelihood একঘেয়ে বাড়ে। প্রশ্ন ৫-এর decomposition ব্যবহার করুন: \(\log p(x\mid\theta)=\mathcal L(q,\theta)+\mathrm{KL}\big(q\,\Vert\,p(z\mid x,\theta)\big)\), যেখানে \(\mathcal L(q,\theta)=\mathbb E_q[\log p(x,z\mid\theta)]-\mathbb E_q[\log q(z)]\)। iteration \(t\)-এ parameter \(\theta^{(t)}\) ধরুন। (ক) E-step: \(q^{(t)}(z)=p(z\mid x,\theta^{(t)})\) নিলে দেখান \(\mathcal L(q^{(t)},\theta^{(t)})=\log p(x\mid\theta^{(t)})\) (bound tight)। (খ) M-step: \(\theta^{(t+1)}=\arg\max_\theta\mathcal L(q^{(t)},\theta)\) নিলে কেন \(\mathcal L(q^{(t)},\theta^{(t+1)})\ge\mathcal L(q^{(t)},\theta^{(t)})\)? (গ) এখন \(\log p(x\mid\theta^{(t+1)})\ge\mathcal L(q^{(t)},\theta^{(t+1)})\) (কেন — KL-এর কোন ধর্ম?) ব্যবহার করে শৃঙ্খলটা জুড়ুন এবং উপসংহার দিন \(\log p(x\mid\theta^{(t+1)})\ge\log p(x\mid\theta^{(t)})\) — অর্থাৎ EM log-likelihood কখনো কমায় না। Hint: (ক) E-step-এ \(q^{(t)}=p(z\mid x,\theta^{(t)})\Rightarrow\mathrm{KL}(q^{(t)}\Vert p(z\mid x,\theta^{(t)}))=0\), তাই \(\log p(x\mid\theta^{(t)})=\mathcal L(q^{(t)},\theta^{(t)})+0\)। (খ) \(\theta^{(t+1)}\) সংজ্ঞা অনুযায়ী \(\mathcal L(q^{(t)},\cdot)\)-এর maximizer, তাই \(\mathcal L(q^{(t)},\theta^{(t+1)})\ge\mathcal L(q^{(t)},\theta^{(t)})\) (maximum \(\ge\) যেকোনো মান)। (গ) যেকোনো \(\theta\)-তে \(\log p(x\mid\theta)=\mathcal L(q^{(t)},\theta)+\mathrm{KL}(\ge0)\ge\mathcal L(q^{(t)},\theta)\); তাই \(\log p(x\mid\theta^{(t+1)})\ge\mathcal L(q^{(t)},\theta^{(t+1)})\overset{(খ)}{\ge}\mathcal L(q^{(t)},\theta^{(t)})\overset{(ক)}{=}\log p(x\mid\theta^{(t)})\) ∎ — শৃঙ্খল জুড়লে \(\log p(x\mid\theta^{(t+1)})\ge\log p(x\mid\theta^{(t)})\), monotone↑।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৩ (★★★). পূর্ণ pipeline — GMM fit → responsibility → ARI বনাম k-means → BIC-sweep। seed-সূচক 20260619 দিয়ে চলমান canonical dataset বানান: একটি 3-component 2D Gaussian mixture, \(n=600\), প্রকৃত weights \([0.40,0.35,0.25]\), অসম/তির্যক (tilted/unequal) covariance। এবার:
- GMM fit:
GaussianMixture(n_components=3, covariance_type='full', random_state=20260619, n_init=10)fit করে (i) BIC ছাপুন — canonical \(4828.8\); (ii) per-sample log-likelihood (gm.score(X)) — canonical \(-3.933\); (iii) আনুমানিক weights (gm.weights_, sorted ↓) — canonical \([0.405,0.349,0.246]\) (প্রকৃত \([0.40,0.35,0.25]\)-এর কাছাকাছি)। - responsibility:
gm.predict_proba(X)দিয়ে responsibility বের করুন; একটা ambiguous বিন্দু (যার সর্বোচ্চ responsibility সবচেয়ে কম, অর্থাৎ সবচেয়ে অনিশ্চিত) খুঁজে তার responsibility ছাপুন — canonical \(\approx[0.864,0.002,0.133]\) (soft assignment-এর দৃষ্টান্ত)। - ARI বনাম k-means: GMM-এর hard label (
gm.predict(X)) ওKMeans(n_clusters=3, random_state=20260619, n_init=10)-এর label উভয়ের adjusted Rand index (প্রকৃত label-এর সাপেক্ষে,adjusted_rand_score) ছাপুন — canonical GMM \(0.97\) \(>\) k-means \(0.914\) (soft/elliptical বনাম hard/spherical)। - BIC-sweep (\(K\) বাছা): \(K\in\{1,2,3,4,5,6\}\)-এর প্রতিটির জন্য GMM fit করে BIC ছাপুন — canonical \(5626.7,5111.7,\mathbf{4828.8},4857.5,4890.9,4925.9\); সর্বনিম্ন BIC-র \(K\) ছাপুন — canonical \(K=3\) (প্রকৃত cluster-সংখ্যার সাথে মেলে)।
Hint: import numpy as np; from sklearn.mixture import GaussianMixture; from sklearn.cluster import KMeans; from sklearn.metrics import adjusted_rand_score। data বানাতে rng=np.random.RandomState(20260619), প্রতিটি component-এর জন্য rng.multivariate_normal(mean_k, cov_k, size=n_k) (tilted cov = off-diagonal \(\ne0\), যেমন [[1,0.6],[0.6,1]]), মোট \(600\) বিন্দু stack করুন। সব estimator-এ n_init যথেষ্ট বড় (≥10) রাখুন যাতে local-optimum এড়ানো যায় (EM non-convex, একাধিক random start লাগে)। সংস্করণ/data-recipe-ভেদে শেষ অঙ্কে সামান্য হেরফের হতে পারে, কিন্তু গল্প — GMM ভালো fit (\(K{=}3\) BIC-সর্বনিম্ন), soft responsibility (ambiguous বিন্দু), এবং GMM-ARI \(>\) k-means-ARI — অপরিবর্তিত। পূর্ণ runnable script _solutions/06-07-em-gmm-solutions.md-এর §ঘ-তে।
প্রশ্ন ১৪ (★★★). নিজের হাতে EM — ২-component, ১D, ৫ iteration। ১D data \(x=(1.0,\,1.5,\,5.0,\,6.0,\,6.5)\)-এর উপর একটা ২-component Gaussian EM scratch থেকে (sklearn ছাড়া, শুধু numpy) লিখুন। প্রাথমিক: \(\pi=(0.5,0.5)\), \(\mu=(0.0,\,6.0)\), \(\sigma^2=(1.0,1.0)\)। (ক) E-step: প্রতিটি বিন্দুর responsibility \(\gamma_{ik}=\frac{\pi_k\mathcal N(x_i;\mu_k,\sigma_k^2)}{\sum_l\pi_l\mathcal N(x_i;\mu_l,\sigma_l^2)}\) একটা ফাংশনে লিখুন। (খ) M-step: \(N_k=\sum_i\gamma_{ik}\), \(\pi_k=N_k/n\), \(\mu_k=\frac{\sum_i\gamma_{ik}x_i}{N_k}\), \(\sigma_k^2=\frac{\sum_i\gamma_{ik}(x_i-\mu_k)^2}{N_k}\) আপডেট লিখুন। (গ) E ও M ধাপ \(5\) বার চালিয়ে প্রতিটি iteration-এ log-likelihood \(\ell=\sum_i\log\big(\sum_k\pi_k\mathcal N(x_i;\mu_k,\sigma_k^2)\big)\) ছাপুন এবং যাচাই করুন এটা একঘেয়ে বাড়ছে (প্রশ্ন ১২-এর তত্ত্ব) এবং দুটো cluster (\(\{1.0,1.5\}\) ও \(\{5.0,6.0,6.5\}\)) ঠিকঠাক আলাদা হচ্ছে (\(\mu\to\approx1.25\) ও \(\approx5.83\))।
Hint: ১D Gaussian: def N(x,m,v): return np.exp(-(x-m)**2/(2*v))/np.sqrt(2*np.pi*v)। E-step: প্রতিটি \(k\)-এর জন্য pi[k]*N(x,mu[k],var[k]) গণনা করে row-wise normalize (/ denom) — gamma shape \((n,K)\)। M-step: Nk=gamma.sum(0), pi=Nk/n, mu=(gamma*x[:,None]).sum(0)/Nk, var=(gamma*(x[:,None]-mu)**2).sum(0)/Nk। log-lik প্রতি iteration-এ মুদ্রণ করে monotone↑ যাচাই করুন (ভাসমান-বিন্দু সীমায় সর্বদা \(\ell^{(t+1)}\ge\ell^{(t)}\))। পূর্ণ runnable script সমাধানে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
Density estimation — mixture দিয়ে \(p(x)\) আঁকা। label ছাড়া (unsupervised) data-র গঠন বোঝার একটা মূল লক্ষ্য হলো density estimation — পুরো density \(p(x)\) অনুমান করা। দুটো দর্শন: KDE (nonparametric, প্রতি বিন্দুতে kernel, \(n\)টি component) আর mixture model (parametric, অল্প \(K\)টি component)। যখন data সত্যিই অল্প-কয়েকটা subpopulation/cluster থেকে আসে, তখন mixture compact ও ব্যাখ্যামূলক।
-
GMM — latent label-সহ ওজনিত Gaussian-এর সমষ্টি। Gaussian mixture model লেখে \(p(x)=\sum_{k=1}^K\pi_k\,\mathcal N(x;\mu_k,\Sigma_k)\) — একটা দুই-ধাপের generative গল্প: প্রথমে একটা latent (লুকানো) label \(z_i\sim\text{Categorical}(\pi)\) টানা হয়, তারপর \(x_i\sim\mathcal N(\mu_{z_i},\Sigma_{z_i})\)। আমরা \(x_i\) দেখি কিন্তু \(z_i\) দেখি না — এই incomplete data-ই MLE-কে কঠিন করে: log-likelihood-এ \(\log\sum_k\) (log-sum) থাকায় \(\log\)–\(\exp\) বাতিল হয় না, closed-form নেই।
-
EM — E-step (soft responsibility) ও M-step (weighted MLE)-এর পালা। Expectation–Maximization এই কঠিনতা পাশ কাটায় দুই ধাপের পুনরাবৃত্তি দিয়ে। E-step: স্থির \(\theta\)-তে প্রতিটি বিন্দুর responsibility \(\gamma_{ik}=\frac{\pi_k\mathcal N(x_i;\mu_k,\Sigma_k)}{\sum_l\pi_l\mathcal N(x_i;\mu_l,\Sigma_l)}\) গণনা — যা ঠিক posterior \(P(z_i{=}k\mid x_i)\) (Bayes, ২.২), একটা soft assignment। M-step: সেই responsibility-ওজনে সহজ weighted-MLE — \(\pi_k=\frac1n\sum_i\gamma_{ik}\), \(\mu_k=\frac{\sum_i\gamma_{ik}x_i}{\sum_i\gamma_{ik}}\) (এবং অনুরূপে \(\Sigma_k\))। মূল গ্যারান্টি: EM প্রতি iteration-এ log-likelihood একঘেয়ে (monotone) বাড়ায় বা স্থির রাখে — কারণ \(\log p(x)=\text{ELBO}+\mathrm{KL}\) এবং \(\mathrm{KL}\ge0\) (Jensen): E-step bound-কে tight করে, M-step bound বাড়ায়।
-
GMM (soft/elliptical) k-means (hard/spherical)-কে ছাড়িয়ে। GMM প্রতিটি বিন্দুকে soft (ভগ্নাংশ) responsibility দেয় ও cluster elliptical (\(\Sigma_k\) যেকোনো — tilted/unequal) ধরে; k-means (৫.৯) hard (\(0/1\)) assign করে ও cluster spherical ধরে। চলমান উদাহরণে (tilted covariance) GMM-এর ARI \(0.97\) k-means-এর \(0.914\)-কে হারায় — কারণ k-means-এর spherical Voronoi-সীমানা তির্যক cluster-এ ভুল করে। সমান-গোলকীয় covariance + hard assignment চাপালে GMM ঠিক k-means হয়ে যায়, তাই k-means = hard-spherical EM (M-step-এর \(\mu_k\)-update তখন centroid-update-এ পরিণত হয়)।
-
BIC দিয়ে \(K\) বাছা — model selection। \(K\) অজানা; বেশি component সবসময় বেশি likelihood (overfit), তাই BIC \(=-2\ell+p\log n\) complexity penalize করে (কম = ভালো)। চলমান উদাহরণে BIC by \(K\): \(1\to5626.7\), \(2\to5111.7\), \(3\to\mathbf{4828.8}\) (সর্বনিম্ন), \(4\to4857.5\), \(5\to4890.9\), \(6\to4925.9\) — স্পষ্ট সর্বনিম্ন \(K=3\), ঠিক প্রকৃত cluster-সংখ্যা। \(-2\ell\) (fit) ও \(p\log n\) (সরলতা)-এর ভারসাম্যই Occam-এর ক্ষুরের সংখ্যাগত রূপ।
-
মূল বার্তা। GMM হলো label ছাড়া density-এর একটা parametric মডেল (latent component-label সহ ওজনিত Gaussian); EM সেই লুকানো label-কে soft responsibility দিয়ে "পূরণ" করে আর weighted-MLE-তে parameter আপডেট করে, প্রতি ধাপে likelihood না-কমিয়ে — supervised "ভুল সংশোধন"-এর জায়গায় এখানে লুকানো গঠন উন্মোচন ও likelihood-maximization।
পূর্ববর্তী সংযোগ (← ৫.৯, ৪.৩, ২.২, ২.৪):
-
৫.৯ (k-means clustering): ৫.৯-এর k-means এই অধ্যায়ের সরাসরি পূর্বসূরি ও বিশেষ-সীমা। k-means cluster-কে গোলকীয় ধরে ও বিন্দু hard assign করে নিকটতম centroid-এ; GMM সেই ছবিকে দুইভাবে সাধারণীকরণ করে — elliptical covariance (\(\Sigma_k\)) আর soft responsibility। প্রমাণে (§৭ প্রশ্ন ১১/গ) দেখা যায় \(\gamma_{ik}\in\{0,1\}\) ও \(\Sigma_k=\sigma^2I\) চাপালে GMM-এর M-step ঠিক k-means-এর centroid-update হয়ে যায় — তাই k-means = hard-spherical EM; canonical তুলনায় GMM-ARI (\(0.97\)) \(>\) k-means-ARI (\(0.914\)) এই সাধারণীকরণের সুফল দেখায়।
-
৪.৩ (maximum likelihood estimation): GMM-এর সম্পূর্ণ লক্ষ্য একটা MLE — \(\ell(\theta)=\sum_i\log\sum_k\pi_k\mathcal N(x_i;\mu_k,\Sigma_k)\) maximize করা। ৪.৩-এ একক Gaussian-এর MLE-তে \(\log\)–\(\exp\) বাতিল হয়ে closed-form মিলত; এখানে \(\log\)-এর ভেতরে যোগফল (log-sum) সেই বাতিল আটকায়, তাই বন্ধ সমাধান নেই — EM হলো এই কঠিন MLE-র একটা পুনরাবৃত্ত সমাধান (M-step নিজেই একটা weighted Gaussian-MLE, ৪.৩-এর সরাসরি সম্প্রসারণ)।
-
২.২ (Bayes ও conditional probability): E-step-এর responsibility \(\gamma_{ik}\) হুবহু একটা Bayes posterior — prior \(\pi_k\), likelihood \(\mathcal N(x_i;\mu_k,\Sigma_k)\), evidence \(p(x_i)=\sum_l\pi_l\mathcal N_l\), তাই \(\gamma_{ik}=P(z_i{=}k\mid x_i)=\frac{\text{prior}\times\text{likelihood}}{\text{evidence}}\) (২.২)। অর্থাৎ "কোন component এই বিন্দুর দায়িত্ব নেয়" প্রশ্নের উত্তর সরাসরি Bayes-এর সূত্র — EM-এর E-step মানে প্রতিটি বিন্দুতে posterior গণনা।
-
২.৪ (Gaussian distribution): GMM-এর প্রতিটি component একটা multivariate Gaussian \(\mathcal N(\mu_k,\Sigma_k)\) (২.৪) — \(\mu_k\) কেন্দ্র, \(\Sigma_k\) আকার/অভিমুখ (tilted ⇒ off-diagonal \(\ne0\), উপবৃত্তীয় contour)। responsibility ও M-step-এর সব গণনা ২.৪-এর Gaussian density (\(\exp\)-quadratic form) ব্যবহার করে; tilted covariance বোঝাই GMM কেন k-means-এর spherical-অনুমানকে ছাড়িয়ে যায় তার চাবি।
পরবর্তী সংযোগ (→ ৬.৮ — dimensionality reduction: nonlinear ও manifold): ৬.৭ unsupervised শিক্ষার একটা দিক দেখাল — data-র density/cluster-গঠন শেখা (mixture, EM)। ৬.৮ unsupervised-এর আরেকটা মূল দিকে যায়: dimensionality reduction — উচ্চ-মাত্রিক data-কে অল্প-মাত্রায় নামানো যেন গুরুত্বপূর্ণ গঠন টিকে থাকে। ৫.৯-এর PCA ছিল রৈখিক (linear) projection; ৬.৮ যায় nonlinear ও manifold পদ্ধতিতে (যেমন kernel PCA, t-SNE/UMAP, manifold learning) — যেখানে data একটা বাঁকা নিম্ন-মাত্রিক manifold-এ বসে আছে ধরে নিয়ে সেই গঠন উন্মোচন করা হয়। মজার সংযোগ: GMM-এর latent label আর dimensionality reduction-এর latent coordinate দুটোই লুকানো ব্যাখ্যামূলক চলক — ৬.৭ লুকানো গোষ্ঠী খোঁজে, ৬.৮ লুকানো অক্ষ/manifold খোঁজে; দুটো মিলে unsupervised representation-শিক্ষার ভিত্তি গড়ে।
সূত্র (sources): M. Sugiyama, Introduction to Statistical Machine Learning (EM algorithm, mixture model, latent-variable model ও ELBO-র তাত্ত্বিক উপস্থাপন — এই অধ্যায়ের প্রাথমিক উৎস); L. Wasserman, All of Statistics (mixture model, EM ও density estimation-এর সংক্ষিপ্ত পরিসংখ্যানিক উপস্থাপন, BIC-ভিত্তিক model selection); P. Dangeti, Statistics for Machine Learning (GMM ও EM-এর প্রয়োগমুখী আলোচনা ও scikit-learn Python, k-means-এর সাথে তুলনা); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists (model-based clustering, GMM বনাম k-means ও cluster-সংখ্যা নির্বাচনের ব্যবহারিক দৃষ্টিভঙ্গি)।