অধ্যায় ২.৫ · Expectation, Variance, Moments & MGF¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
আগের দুই অধ্যায়ে (2.3, 2.4) আমরা একটি random variable \(X\)-এর সম্পূর্ণ বর্ণনা শিখেছি — discrete হলে pmf \(p(x)\), continuous হলে pdf \(f(x)\)। কিন্তু বাস্তবে আমরা প্রায়ই পুরো distribution না চেয়ে একটি-দুটি সারসংখ্যা (summary number) চাই: "গড়ে কত আশা করি?", "কতটা ছড়ানো?"। এই অধ্যায় সেই সারসংখ্যাগুলোর — expectation (প্রত্যাশা / গড়), variance (ভেদাঙ্ক / বিস্তার), এবং তাদের সাধারণীকরণ moment ও moment-generating function (MGF)-এর।
একটি গল্প দিয়ে শুরু করি।
ধরুন একটি ক্যাসিনো-খেলায় আপনি একটি ছক্কা (die) ছুঁড়বেন; ফলাফল যত আসবে তত টাকা পাবেন। খেলাটা একবার খেললে কী পাবেন তা অনিশ্চিত — ১ থেকে ৬ যেকোনো কিছু। কিন্তু খেলাটা হাজার বার খেললে গড়ে প্রতিবার কত পাবেন? insight (অন্তর্দৃষ্টি) বলে: সম্ভাব্য মানগুলোকে তাদের probability দিয়ে ওজন করে যোগ করো। প্রতিটি মুখের probability \(1/6\), তাই গড়ে
লক্ষ করুন \(3.5\) ছক্কার কোনো প্রকৃত মুখ নয় — কেউ কখনো ৩.৫ পায় না। তবু এটাই "দীর্ঘমেয়াদি গড়" বা expected value \(\mathbb{E}[X]\)। এই "probability দিয়ে ওজন-করা গড়"-ই expectation-এর কেন্দ্রীয় ধারণা।
Hook — সিসঅ (seesaw) ও ভারসাম্য। expectation-কে শুধু "গড়" না ভেবে একটা ভৌত ছবি ভাবুন। কল্পনা করুন একটি ওজনহীন লাঠির ওপর বিভিন্ন বিন্দুতে ভর (mass) বসানো — বিন্দু \(x\)-এ যত probability, তত ভর। লাঠিটি কোন বিন্দুতে আঙুল দিলে ভারসাম্যে (balance) থাকবে? ঠিক সেই বিন্দুটাই \(\mathbb{E}[X]\) — distribution-এর center of mass (ভরকেন্দ্র)। ডান দিকে বেশি ভর থাকলে ভারসাম্যবিন্দু ডানে সরে — অর্থাৎ বড় মানের probability বেশি হলে গড় বড় হয়। এই "ভারসাম্যবিন্দু" রূপকটা §৬-এর প্রথম ছবিতে দেখব, আর এটা মনে রাখলে expectation কখনো বিমূর্ত মনে হবে না।
কিন্তু কেবল গড় জানলেই হয় না। ধরুন দুটি বিনিয়োগ — দুটোরই গড় রিটার্ন বছরে ৮%। একটির রিটার্ন প্রতি বছর ৭%–৯%-এর মধ্যে দোলে, অন্যটির −৪০% থেকে +৫৬%! গড় এক হলেও এদের ঝুঁকি (risk) আকাশ-পাতাল। এই "গড়ের চারপাশে কতটা ছড়ানো" মাপতেই variance ও তার বর্গমূল standard deviation। আর গড় ও ছড়ানোর পরেও distribution-এর আকৃতি নিয়ে প্রশ্ন থাকে — ডানে না বাঁয়ে হেলানো (skewness)? প্রান্তে (tail) কত ভারী (kurtosis)? এই সব আকৃতি-বৈশিষ্ট্য এক সুতোয় গাঁথে moment-এর ধারণা, আর সব moment-কে একসাথে এক function-এ ধরে রাখে MGF — যা পরে sums ও limit theorem-এ অস্ত্র হয়ে উঠবে।
কেন statistics-এ এটাই মেরুদণ্ড? কারণ Part IV-এ আমরা data থেকে estimator বানাব (যেমন sample mean \(\bar X\))। একটি estimator ভালো কিনা তা মাপি দুটি সংখ্যায়: bias (এর expectation সত্য মান থেকে কতটা সরে) এবং variance (নমুনা বদলালে কতটা দোলে)। দুটোই এই অধ্যায়ের expectation ও variance। আর MGF দিয়ে আমরা চিনব sample mean বা sum কোন distribution মানে — যা Central Limit Theorem (Part III)-এর পথ খুলে দেয়।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Expectation — discrete ও continuous¶
একটি random variable \(X\)-এর expectation (প্রত্যাশা; প্রতিশব্দ: expected value, mean, প্রথম moment) হলো তার সম্ভাব্য মানগুলোর probability-ওজন-করা গড়।
Discrete ক্ষেত্রে (pmf \(p(x)\)): $$ \boxed{\ \mathbb{E}[X] \;=\; \sum_{x} x\,p(x)\ } $$ যোগফল \(X\)-এর সব সম্ভাব্য মান \(x\)-এর ওপর। প্রতিটি মান \(x\)-কে তার "ওজন" \(p(x)\) দিয়ে গুণ।
Continuous ক্ষেত্রে (pdf \(f(x)\)): যোগফলের জায়গায় integral (0.4-এর continuous সংস্করণ): $$ \boxed{\ \mathbb{E}[X] \;=\; \int_{-\infty}^{\infty} x\,f(x)\,dx\ } $$ এখানে \(f(x)\,dx\) হলো \([x, x+dx]\) টুকরোর "ওজন", আর তা \(x\) দিয়ে গুণ করে সব টুকরো জুড়ে যোগ (integrate)।
দুটোই একই ভৌত ছবি: density (বা mass) দিয়ে ওজন করে position-এর গড় = center of mass। তাই \(\mathbb{E}[X]\)-কে প্রায়ই \(\mu\) ("mu") লেখা হয়।
সতর্কতা — expectation সবসময় থাকে না। যোগফল বা integral absolutely convergent না হলে (অর্থাৎ \(\sum \lvert x\rvert p(x)\) বা \(\int \lvert x\rvert f(x)\,dx\) অসীম হলে) \(\mathbb{E}[X]\) সংজ্ঞায়িত হয় না। বিখ্যাত উদাহরণ Cauchy distribution — তার mean নেই (heavy tail)। এই rigorous শর্ত Part VII-এ; আপাতত আমরা ভালো-আচরণের distribution ধরব।
ছোট উদাহরণ (continuous)। \(X \sim \text{Uniform}(0,1)\), অর্থাৎ \(f(x)=1\) for \(0\le x\le 1\): $$ \mathbb{E}[X] = \int_0^1 x\cdot 1\,dx = \Big[\tfrac{x^2}{2}\Big]_0^1 = \tfrac12. $$ ঠিক যেমন প্রত্যাশিত — \(0\) ও \(1\)-এর ঠিক মাঝখান।
২.২ Law of the Unconscious Statistician (LOTUS) — \(\mathbb{E}[g(X)]\)¶
প্রায়ই আমরা \(X\)-এর নয়, \(X\)-এর কোনো function \(g(X)\)-এর গড় চাই — যেমন \(g(X)=X^2\) বা \(g(X)=e^{X}\)। এক উপায়: \(Y=g(X)\)-এর নতুন distribution বের করে \(\mathbb{E}[Y]\) গণনা। কিন্তু সেটা ঝামেলার। LOTUS (law of the unconscious statistician — "অসচেতন পরিসংখ্যানবিদের সূত্র") বলে আমরা সরাসরি মূল distribution দিয়েই গড় নিতে পারি:
অর্থাৎ §২.১-এর সূত্রে \(x\)-এর জায়গায় \(g(x)\) বসিয়ে দিন — \(g(X)\)-এর distribution বের করার দরকার নেই। নামটি মজার: পরিসংখ্যানবিদ "না জেনেই" (unconsciously) ঠিক কাজটা করেন, কারণ সূত্রটা এত স্বাভাবিক দেখায়। (কেন এটা বৈধ — §৪.১-এ।)
উদাহরণ। \(X\sim\text{Uniform}(0,1)\) হলে $$ \mathbb{E}[X^2] = \int_0^1 x^2\cdot 1\,dx = \Big[\tfrac{x^3}{3}\Big]_0^1 = \tfrac13. $$ লক্ষ করুন \(\mathbb{E}[X^2]=\tfrac13 \neq \big(\mathbb{E}[X]\big)^2 = \tfrac14\) — সাধারণভাবে \(\mathbb{E}[g(X)] \neq g(\mathbb{E}[X])\) (এটাই Jensen's inequality-র বীজ, Part III)।
২.৩ Linearity of expectation¶
expectation-এর সবচেয়ে শক্তিশালী ধর্ম — linearity (রৈখিকতা)। যেকোনো ধ্রুবক \(a, b\) এবং random variable \(X, Y\)-এর জন্য:
দ্বিতীয়টি যেকোনো \(X, Y\)-র জন্য খাটে — তারা independent না হলেও! এটা অসাধারণ এবং প্রচণ্ড কাজের: কঠিন গড়কে সহজ টুকরোর গড়ের যোগফলে ভাঙা যায়। সাধারণভাবে: $$ \mathbb{E}!\left[\sum_{i=1}^n a_i X_i\right] = \sum_{i=1}^n a_i\,\mathbb{E}[X_i]. $$
ব্যাখ্যা: \(\mathbb{E}[\cdot]\) আসলে একটি ওজন-করা যোগফল/integral, আর যোগফল ও integral দুটোই linear (0.2, 0.4) — তাই তাদের থেকে গড়া expectation-ও linear। (প্রমাণ §৪.২।)
২.৪ Variance ও standard deviation¶
expectation কেন্দ্র (center) মাপে; variance মাপে কেন্দ্রের চারপাশে কতটা ছড়ানো (spread)। স্বাভাবিক ধারণা: প্রতিটি মান \(X\) গড় \(\mu=\mathbb{E}[X]\) থেকে কত দূরে, অর্থাৎ "deviation" \(X-\mu\)। কিন্তু গড় deviation \(\mathbb{E}[X-\mu]=0\) (ধনাত্মক ও ঋণাত্মক কাটাকাটি)। তাই deviation-কে বর্গ করি (যেন চিহ্ন না থাকে) তারপর গড় নিই:
variance-কে প্রায়ই \(\sigma^2\) ("sigma-squared") লেখা হয়। এটি LOTUS দিয়ে গণনাযোগ্য — discrete-এ \(\sum (x-\mu)^2 p(x)\), continuous-এ \(\int (x-\mu)^2 f(x)\,dx\)।
variance-এর একক মূল রাশির বর্গ (টাকা মাপলে variance টাকা²) — তাই ব্যাখ্যা কঠিন। বর্গমূল নিয়ে মূল এককে ফেরা যায়:
\(\sigma\) বলে "গড়ে মানগুলো \(\mu\) থেকে মোটামুটি কত দূরে"।
গণনা-সূত্র (computational formula)। সংজ্ঞা থেকে সরাসরি না গিয়ে প্রায়ই সুবিধাজনক: $$ \boxed{\ \mathrm{Var}(X) = \mathbb{E}[X^2] - \big(\mathbb{E}[X]\big)^2\ } $$ "mean of square minus square of mean"। (উৎপাদন §৪.৩।)
উদাহরণ (ছক্কা)। \(\mathbb{E}[X]=3.5\), আর \(\mathbb{E}[X^2]=\tfrac{1^2+2^2+\cdots+6^2}{6}=\tfrac{91}{6}\approx 15.17\)। তাই $$ \mathrm{Var}(X) = \tfrac{91}{6} - 3.5^2 = \tfrac{91}{6}-\tfrac{49}{4} = \tfrac{35}{12} \approx 2.917, \qquad \sigma \approx 1.708. $$
২.৫ Variance-এর properties: \(\mathrm{Var}(aX+b)\)¶
linearity expectation-এর জন্য সরল ছিল; variance-এর জন্য একটু আলাদা, কারণ variance বর্গ-ভিত্তিক:
দুটি অংশ পড়ুন: (১) \(+b\) অদৃশ্য — সব মানকে একই \(b\) সরালে ছড়ানো বদলায় না (পুরো distribution ডানে/বাঁয়ে সরে কিন্তু একই আকারে)। (২) \(a\) বর্গ হয়ে আসে — সব মান \(a\) গুণে stretch করলে deviation \(a\) গুণ হয়, তাই বর্গ-deviation \(a^2\) গুণ। ফলে standard deviation-এ: \(\mathrm{SD}(aX+b)=\lvert a\rvert\,\sigma\) (এখানে \(\lvert a\rvert\), কারণ SD ঋণাত্মক হয় না)।
independent (স্বাধীন) \(X, Y\)-র জন্য একটি গুরুত্বপূর্ণ যোগ-নিয়ম (পূর্ণ আলোচনা 2.6-এ): $$ X \perp Y \;\Rightarrow\; \mathrm{Var}(X+Y) = \mathrm{Var}(X) + \mathrm{Var}(Y). $$ সতর্কতা: expectation-এর যোগ-নিয়ম সবসময় খাটে, কিন্তু variance-এর যোগ-নিয়ম কেবল independence-এ (নয়তো একটি covariance পদ যোগ হয়)।
২.৬ Moments — raw ও central¶
expectation (\(k=1\)) ও variance (বর্গ-deviation) আসলে একটি বড় পরিবারের সদস্য — moments (ভ্রামক)। দুই ধরনের:
-
\(k\)-th raw moment (মূল-বিন্দু-ভ্রামক; \(0\)-এর সাপেক্ষে): $$ \mu_k' = \mathbb{E}[X^k]. $$ \(\mu_1' = \mathbb{E}[X]\) হলো mean।
-
\(k\)-th central moment (কেন্দ্রীয় ভ্রামক; \(\mu\)-এর সাপেক্ষে): $$ \mu_k = \mathbb{E}\big[(X-\mu)^k\big]. $$ \(\mu_2 = \mathrm{Var}(X)\) হলো variance। (\(\mu_1=0\) সবসময়।)
নাম "moment" পদার্থবিদ্যা থেকে — ভরের distribution (বণ্টন) বর্ণনায় moment ব্যবহার হয়, ঠিক যেমন এখানে probability-ভরের distribution বর্ণনায়। যত বেশি moment জানা যায়, distribution-এর আকৃতি তত নিখুঁতভাবে চেনা যায়: \(\mu_1'\) কেন্দ্র, \(\mu_2\) ছড়ানো, \(\mu_3\) হেলানো, \(\mu_4\) tail-এর ভার।
২.৭ Skewness ও kurtosis — standardized moment হিসেবে¶
raw central moment scale-নির্ভর (এককসহ)। তুলনার জন্য আমরা standardize করি — central moment-কে \(\sigma\)-এর উপযুক্ত power দিয়ে ভাগ করে একক-মুক্ত (dimensionless) সংখ্যা পাই।
Skewness (বঙ্কিমতা — অসমতা/হেলান) তৃতীয় standardized moment: $$ \boxed{\ \gamma_1 = \frac{\mu_3}{\sigma^3} = \mathbb{E}!\left[\Big(\tfrac{X-\mu}{\sigma}\Big)^3\right]\ } $$ - \(\gamma_1 > 0\): right-skewed (positive skew) — ডান দিকে লম্বা tail (যেমন আয়, বাড়ির দাম)। তখন সাধারণত mean > median। - \(\gamma_1 < 0\): left-skewed — বাঁ দিকে লম্বা tail। - \(\gamma_1 = 0\): symmetric (যেমন normal)।
বিজোড় power \(3\) চিহ্ন ধরে রাখে — তাই দিক (direction) বোঝায়।
Kurtosis (কুর্তোসিস — চূড়া ও tail-এর ভার) চতুর্থ standardized moment: $$ \boxed{\ \beta_2 = \frac{\mu_4}{\sigma^4} = \mathbb{E}!\left[\Big(\tfrac{X-\mu}{\sigma}\Big)^4\right]\ } $$ normal distribution-এর kurtosis ঠিক \(3\)। তুলনার সুবিধার্থে প্রায়ই excess kurtosis ব্যবহার করি: $$ \text{excess kurtosis} = \beta_2 - 3. $$ - excess \(> 0\) (leptokurtic): normal-এর চেয়ে ভারী tail ও সূচালো চূড়া (যেমন Laplace, finance return)। - excess \(= 0\) (mesokurtic): normal-সদৃশ। - excess \(< 0\) (platykurtic): হালকা tail, চ্যাপ্টা (যেমন uniform, excess \(=-1.2\))।
জোড় power \(4\) চিহ্ন মুছে দেয় — তাই দিক নয়, "প্রান্ত কত ভারী" তা-ই মাপে। (§৬-এ skewness ও kurtosis-এর তুলনামূলক ছবি।)
২.৮ Moment-generating function (MGF)¶
সব moment আলাদা আলাদা গণনা করা ক্লান্তিকর। Moment-generating function (MGF; ভ্রামক-উৎপাদক ফাংশন) একটি একক function-এ সব moment প্যাক করে রাখে:
এখানে \(t\) একটি সহায়ক variable। MGF সংজ্ঞায়িত তখনই যখন এই গড় \(t=0\)-এর কোনো খোলা অন্তর্বর্তী \((-h, h)\)-তে সসীম (finite) থাকে।
MGF কেন "moment-generating"? কারণ \(e^{tX}\)-এর Taylor series (0.3) থেকে: $$ M_X(t) = \mathbb{E}\Big[1 + tX + \tfrac{(tX)^2}{2!} + \cdots\Big] = 1 + t\,\mathbb{E}[X] + \tfrac{t^2}{2!}\mathbb{E}[X^2] + \cdots $$ এটাকে \(t=0\)-তে \(k\) বার derivative নিলে \(k\)-th raw moment বেরিয়ে আসে: $$ \boxed{\ \mathbb{E}[X^k] = M_X^{(k)}(0) = \frac{d^k}{dt^k}M_X(t)\Big|_{t=0}\ } $$ অর্থাৎ MGF একটি moment factory (ভ্রামক-কারখানা) — derivative নিন, moment পান। (§৪.৪-এ উৎপাদন।)
MGF-এর তিনটি প্রধান শক্তি:
-
Moment বের করা — উপরের derivative-সূত্র। যেমন Exponential(\(\lambda\))-এর \(M(t)=\dfrac{\lambda}{\lambda - t}\) (for \(t<\lambda\)); \(M'(0)=1/\lambda=\mathbb{E}[X]\), \(M''(0)=2/\lambda^2\), তাই \(\mathrm{Var}=2/\lambda^2 - (1/\lambda)^2 = 1/\lambda^2\)।
-
Distribution চেনা (uniqueness) — MGF যদি \(t=0\)-এর আশেপাশে থাকে, তবে তা distribution-কে একতরফাভাবে নির্ধারণ করে: দুই random variable-এর MGF একই হলে তাদের distribution একই। তাই MGF distribution-এর "আঙুলের ছাপ" (fingerprint)।
-
Independent sum — \(X \perp Y\) হলে $$ \boxed{\ M_{X+Y}(t) = M_X(t)\cdot M_Y(t)\ } $$ কারণ \(\mathbb{E}[e^{t(X+Y)}] = \mathbb{E}[e^{tX}e^{tY}] = \mathbb{E}[e^{tX}]\mathbb{E}[e^{tY}]\) (independence)। অর্থাৎ যোগফলের MGF = MGF-দের গুণফল। uniqueness-এর সাথে মিলিয়ে এটা sum-এর distribution চেনায় — যেমন দুটি independent normal-এর যোগ আবার normal, দুটি independent Poisson-এর যোগ Poisson। এই দুই অস্ত্র (uniqueness + গুণফল) Central Limit Theorem-এর (Part III) মূল হাতিয়ার।
নোট — characteristic function। MGF কখনো কখনো থাকে না (heavy-tail distribution-এ \(\mathbb{E}[e^{tX}]\) অসীম)। তখন ব্যবহার করি characteristic function \(\varphi_X(t)=\mathbb{E}[e^{itX}]\) (\(i=\sqrt{-1}\)), যা সবসময় থাকে। এর rigorous তত্ত্ব Part VII-এ; এই অধ্যায়ে MGF-ই যথেষ্ট।
৩ · পূর্ণাঙ্গ উদাহরণ¶
ধাপে ধাপে একটি discrete ও একটি continuous উদাহরণ — প্রতিটিতে expectation, variance, একটি moment, ও MGF সবগুলো একসাথে গণনা করব।
উদাহরণ A (discrete) — Bernoulli ও তার MGF¶
একটি পরীক্ষা সফল হয় probability \(p\)-তে। \(X=1\) (সফল) probability \(p\), \(X=0\) (ব্যর্থ) probability \(1-p\)। এটি Bernoulli(\(p\))।
ধাপ ১ — expectation। $$ \mathbb{E}[X] = 0\cdot(1-p) + 1\cdot p = p. $$
ধাপ ২ — \(\mathbb{E}[X^2]\) (LOTUS)। যেহেতু \(0^2=0,\ 1^2=1\): $$ \mathbb{E}[X^2] = 0^2(1-p) + 1^2\,p = p. $$ (\(X\) শুধু \(0/1\) নেয় বলে \(X^2=X\), তাই গড়ও সমান।)
ধাপ ৩ — variance (গণনা-সূত্র)। $$ \mathrm{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 = p - p^2 = p(1-p). $$ লক্ষণীয়: \(p=0.5\)-এ variance সর্বোচ্চ (\(0.25\)) — সবচেয়ে বেশি অনিশ্চয়তা; \(p\to 0\) বা \(1\)-এ variance \(\to 0\) (প্রায় নিশ্চিত ফল)।
ধাপ ৪ — MGF। $$ M_X(t) = \mathbb{E}[e^{tX}] = e^{t\cdot 0}(1-p) + e^{t\cdot 1}p = (1-p) + p\,e^{t}. $$
ধাপ ৫ — MGF থেকে moment যাচাই। $$ M_X'(t) = p\,e^{t} \;\Rightarrow\; M_X'(0) = p = \mathbb{E}[X]. \checkmark $$ $$ M_X''(t) = p\,e^{t} \;\Rightarrow\; M_X''(0) = p = \mathbb{E}[X^2]. \checkmark $$ সব মিলে যাচ্ছে।
বোনাস — Binomial সংযোগ। \(n\)টি independent Bernoulli(\(p\))-এর যোগফল \(S=\sum X_i\) হলো Binomial(\(n,p\))। MGF-গুণফল-নিয়মে: $$ M_S(t) = \big[(1-p)+p\,e^{t}\big]^n. $$ এর থেকে \(M_S'(0) = np = \mathbb{E}[S]\), এবং (linearity ও independence থেকেও) \(\mathrm{Var}(S)=np(1-p)\)। একটি Bernoulli-র গড়/variance থেকেই পুরো Binomial-এর গড়/variance বেরিয়ে এলো — এটাই linearity + MGF-এর সৌন্দর্য।
উদাহরণ B (continuous) — Exponential(\(\lambda\))¶
\(X\sim\text{Exponential}(\lambda)\) মানে pdf \(f(x)=\lambda e^{-\lambda x}\) for \(x\ge 0\) (অপেক্ষার সময়, 2.4)। ধরা যাক rate \(\lambda > 0\)।
ধাপ ১ — expectation (integration by parts, 0.4): $$ \mathbb{E}[X] = \int_0^\infty x\,\lambda e^{-\lambda x}\,dx = \frac{1}{\lambda}. $$ অন্তর্দৃষ্টি: rate বেশি (event ঘন ঘন) মানে গড় অপেক্ষা কম — তাই \(1/\lambda\)।
ধাপ ২ — \(\mathbb{E}[X^2]\) (LOTUS, আবার by parts): $$ \mathbb{E}[X^2] = \int_0^\infty x^2\,\lambda e^{-\lambda x}\,dx = \frac{2}{\lambda^2}. $$
ধাপ ৩ — variance। $$ \mathrm{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 = \frac{2}{\lambda^2} - \frac{1}{\lambda^2} = \frac{1}{\lambda^2}, \qquad \sigma = \frac{1}{\lambda}. $$ চমৎকার: Exponential-এ mean ও standard deviation সমান (\(1/\lambda\))।
ধাপ ৪ — MGF (for \(t<\lambda\)): $$ M_X(t) = \int_0^\infty e^{tx}\,\lambda e^{-\lambda x}\,dx = \lambda\int_0^\infty e^{-(\lambda-t)x}\,dx = \frac{\lambda}{\lambda - t}. $$ (\(t<\lambda\) লাগে যেন integral converge করে — নয়তো \(e^{tx}\) অসীমে বেড়ে যায়।)
ধাপ ৫ — MGF থেকে moment। $$ M_X'(t) = \frac{\lambda}{(\lambda-t)^2} \;\Rightarrow\; M_X'(0)=\frac{1}{\lambda}=\mathbb{E}[X]. \checkmark $$ $$ M_X''(t) = \frac{2\lambda}{(\lambda-t)^3} \;\Rightarrow\; M_X''(0)=\frac{2}{\lambda^2}=\mathbb{E}[X^2]. \checkmark $$
ধাপ ৬ — skewness। Exponential-এর তৃতীয় central moment \(\mu_3 = 2/\lambda^3\) (MGF থেকে বের করা যায়), তাই $$ \gamma_1 = \frac{\mu_3}{\sigma^3} = \frac{2/\lambda^3}{(1/\lambda)^3} = 2. $$ \(\lambda\)-নিরপেক্ষ ভাবে skewness \(=2 > 0\) — Exponential সবসময় right-skewed (ডানে লম্বা tail), যা §৬-এর ছবিতেও দেখা যাবে।
§৫-এ এই দুটো উদাহরণের প্রতিটি সংখ্যা NumPy simulation ও SymPy দিয়ে যাচাই করা হবে।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশের প্রমাণ intro-probability স্তরের (rigor → Part VII)। difficulty: ★ সহজ, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং।
৪.১ LOTUS কেন বৈধ (difficulty ★★)¶
দাবি: \(Y=g(X)\) হলে \(\mathbb{E}[Y]=\sum_x g(x)p(x)\) — \(Y\)-এর pmf আলাদা করে বের না করেও।
discrete প্রমাণ। সংজ্ঞা অনুসারে \(\mathbb{E}[Y]=\sum_y y\,p_Y(y)\), যেখানে \(p_Y(y)=P(g(X)=y)=\sum_{x:\,g(x)=y}p(x)\) (সব \(x\) যাদের \(g(x)=y\))। বসিয়ে: $$ \mathbb{E}[Y] = \sum_y y!!\sum_{x:\,g(x)=y}!!p(x) = \sum_y \sum_{x:\,g(x)=y} g(x)\,p(x), $$ (কারণ ভেতরের যোগে \(g(x)=y\), তাই \(y\)-কে \(g(x)\) দিয়ে বদলানো যায়)। এখন \(y\) ও তার নিচের \(x\)-গুলোর দ্বৈত-যোগ আসলে প্রতিটি \(x\)-কে ঠিক একবার গোনে (প্রতিটি \(x\)-এর একটিই \(g(x)\) মান), তাই দ্বৈত-যোগ একটি একক যোগে গুটিয়ে যায়: $$ \mathbb{E}[Y] = \sum_x g(x)\,p(x). \qquad\blacksquare $$ continuous সংস্করণে যোগের জায়গায় integral, আর সাবধানে change-of-variable লাগে (rigorous রূপ Part VII)। মূল অন্তর্দৃষ্টি একই: \(g(x)\)-এর ওজন \(x\)-এর ওজন \(p(x)\)/\(f(x)\,dx\) থেকেই আসে।
৪.২ Linearity of expectation (difficulty ★★)¶
দাবি: \(\mathbb{E}[aX+b]=a\mathbb{E}[X]+b\) এবং \(\mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y]\)।
প্রথম অংশ (continuous, LOTUS দিয়ে)। \(g(x)=ax+b\) ধরে LOTUS: $$ \mathbb{E}[aX+b]=\int (ax+b)f(x)\,dx = a!\int x f(x)\,dx + b!\int f(x)\,dx = a\,\mathbb{E}[X] + b\cdot 1, $$ কারণ integral linear (0.4) এবং \(\int f(x)\,dx=1\) (normalization)। discrete-এ যোগফলের linearity দিয়ে একইভাবে। \(\blacksquare\)
দ্বিতীয় অংশ (যোগের নিয়ম)। এর জন্য joint distribution লাগে (2.6-এ পূর্ণ)। অন্তর্দৃষ্টি: continuous joint pdf \(f(x,y)\) ধরে, $$ \mathbb{E}[X+Y]=\iint (x+y)f(x,y)\,dx\,dy = \iint x f\,dx\,dy + \iint y f\,dx\,dy = \mathbb{E}[X]+\mathbb{E}[Y], $$ যেখানে \(\iint x f(x,y)\,dy\,dx = \int x f_X(x)\,dx=\mathbb{E}[X]\) (ভেতরের integral marginal density দেয়)। লক্ষণীয়, কোথাও independence লাগেনি — তাই linearity universal। \(\blacksquare\)
৪.৩ গণনা-সূত্র \(\mathrm{Var}(X)=\mathbb{E}[X^2]-(\mathbb{E}[X])^2\) (difficulty ★)¶
\(\mu=\mathbb{E}[X]\) ধরি (একটি ধ্রুবক)। সংজ্ঞা থেকে শুরু করে বর্গ খুলি এবং linearity প্রয়োগ: $$ \mathrm{Var}(X)=\mathbb{E}[(X-\mu)^2]=\mathbb{E}[X^2 - 2\mu X + \mu^2]. $$ linearity ব্যবহার করে (\(\mu\) ধ্রুবক, তাই বের করা যায়): $$ = \mathbb{E}[X^2] - 2\mu\,\mathbb{E}[X] + \mu^2 = \mathbb{E}[X^2] - 2\mu\cdot\mu + \mu^2 = \mathbb{E}[X^2] - \mu^2. \qquad\blacksquare $$ এই সূত্র গণনায় সুবিধাজনক — \((x-\mu)^2\) আগে বের করতে হয় না।
৪.৪ Variance scaling \(\mathrm{Var}(aX+b)=a^2\mathrm{Var}(X)\) (difficulty ★)¶
\(Y=aX+b\) ধরি। প্রথমে §৪.২ থেকে \(\mathbb{E}[Y]=a\mu+b\)। তাই deviation: $$ Y-\mathbb{E}[Y] = (aX+b)-(a\mu+b) = a(X-\mu). $$ \(b\) কাটাকাটি হয়ে গেল (তাই shift অদৃশ্য)। এখন variance: $$ \mathrm{Var}(Y)=\mathbb{E}\big[(Y-\mathbb{E}[Y])^2\big]=\mathbb{E}\big[a^2(X-\mu)^2\big]=a^2\,\mathbb{E}[(X-\mu)^2]=a^2\,\mathrm{Var}(X). \qquad\blacksquare $$
৪.৫ MGF moment-generating কেন (difficulty ★★)¶
দাবি: \(M_X^{(k)}(0)=\mathbb{E}[X^k]\)।
\(M_X(t)=\mathbb{E}[e^{tX}]\)-এ \(e^{tX}\)-এর Taylor expansion (0.3) বসাই এবং (যথেষ্ট ভালো শর্তে) expectation ও যোগফলের ক্রম বদলাই: $$ M_X(t)=\mathbb{E}\Big[\sum_{k=0}^\infty \frac{(tX)^k}{k!}\Big]=\sum_{k=0}^\infty \frac{t^k}{k!}\,\mathbb{E}[X^k]. $$ এটি \(t\)-এর একটি power series যার \(t^k\)-এর coefficient (সহগ) \(\dfrac{\mathbb{E}[X^k]}{k!}\)। কিন্তু যেকোনো function-এর Taylor series-এ \(t^k\)-এর coefficient \(\dfrac{M^{(k)}(0)}{k!}\)। দুই coefficient মিলিয়ে: $$ \frac{M_X^{(k)}(0)}{k!}=\frac{\mathbb{E}[X^k]}{k!} \;\Rightarrow\; M_X^{(k)}(0)=\mathbb{E}[X^k]. \qquad\blacksquare $$ (expectation ও অসীম-যোগের ক্রম বদলানোর rigorous ন্যায্যতা Part VII-এ; এখানে আমরা ভালো-আচরণ ধরে নিচ্ছি।)
৪.৬ Independent sum-এর MGF গুণফল (difficulty ★)¶
\(X\perp Y\) ধরি। independence-এর মূল ধর্ম: independent random variable-এর function-দেরও product-expectation আলাদা হয়ে যায় (2.6-এ formal), অর্থাৎ \(\mathbb{E}[g(X)h(Y)]=\mathbb{E}[g(X)]\,\mathbb{E}[h(Y)]\)। \(g(X)=e^{tX},\,h(Y)=e^{tY}\) নিয়ে: $$ M_{X+Y}(t)=\mathbb{E}[e^{t(X+Y)}]=\mathbb{E}[e^{tX}e^{tY}]=\mathbb{E}[e^{tX}]\,\mathbb{E}[e^{tY}]=M_X(t)\,M_Y(t). \qquad\blacksquare $$ এই সরল গুণফল-নিয়মই sum-of-independent random variable বিশ্লেষণের মূল চাবি।
৫ · কোড ল্যাব (Python)¶
আমরা প্রথমে from-scratch (NumPy দিয়ে definition হাতে প্রয়োগ ও Monte Carlo simulation) করব, তারপর library (scipy.stats ও sympy) দিয়ে মিলিয়ে যাচাই করব। সব simulation reproducible — default_rng ও fixed seed।
৫.১ from-scratch — definition + Monte Carlo¶
import numpy as np
rng = np.random.default_rng(2505) # reproducible
# ---- (ক) discrete die: definition দিয়ে E[X], Var(X) ----
x = np.arange(1, 7) # মুখ 1..6
p = np.full(6, 1/6) # প্রতিটি probability 1/6
EX = np.sum(x * p) # Σ x p(x)
EX2 = np.sum(x**2 * p) # LOTUS: Σ x^2 p(x)
varX = EX2 - EX**2 # গণনা-সূত্র
print(f"die E[X] = {EX:.4f} (theory 3.5)")
print(f"die E[X^2]= {EX2:.4f} (theory 91/6 = {91/6:.4f})")
print(f"die Var = {varX:.4f} (theory 35/12 = {35/12:.4f})")
print(f"die SD = {np.sqrt(varX):.4f}")
# ---- (খ) Monte Carlo: sample mean -> E[X] (Law of Large Numbers feel) ----
draws = rng.integers(1, 7, size=1_000_000) # দশ লাখ বার ছক্কা
print(f"\nMonte Carlo sample mean (1e6 rolls) = {draws.mean():.4f} (-> 3.5)")
print(f"Monte Carlo sample var = {draws.var():.4f} (-> 2.9167)")
# ---- (গ) linearity যাচাই: E[2X+3] = 2 E[X] + 3 ----
print(f"\nE[2X+3] sim = {(2*draws+3).mean():.4f} theory = {2*EX+3:.4f}")
print(f"Var(2X+3) sim = {(2*draws+3).var():.4f} theory a^2 Var = {4*varX:.4f}")
প্রত্যাশিত আউটপুট (সংখ্যা মেলে, simulation সামান্য দোলে):
die E[X] = 3.5000 (theory 3.5)
die E[X^2]= 15.1667 (theory 91/6 = 15.1667)
die Var = 2.9167 (theory 35/12 = 2.9167)
die SD = 1.7078
Monte Carlo sample mean (1e6 rolls) = 3.4999 (-> 3.5)
Monte Carlo sample var = 2.9170 (-> 2.9167)
E[2X+3] sim = 9.9999 theory = 10.0000
Var(2X+3) sim = 11.6680 theory a^2 Var = 11.6667
Var(2X+3) ≈ \(4\times 2.9167\) আর E[2X+3] ≈ \(10\) — §২.৩ ও §২.৫-এর নিয়ম সংখ্যায় নিশ্চিত হলো।
৫.২ from-scratch — MGF থেকে moment (numeric derivative)¶
MGF-এর derivative হাতে নিয়ে moment বের করা যায় (finite difference, 0.3):
import numpy as np
# Exponential(lambda=2): theory E[X]=1/2, E[X^2]=2/4=0.5, Var=0.25
lam = 2.0
def mgf_exp(t): # M(t) = lambda / (lambda - t), t < lambda
return lam / (lam - t)
h = 1e-4
# central finite-difference derivatives at t=0
M1 = (mgf_exp(h) - mgf_exp(-h)) / (2*h) # M'(0) = E[X]
M2 = (mgf_exp(h) - 2*mgf_exp(0) + mgf_exp(-h)) / h**2 # M''(0) = E[X^2]
print(f"M'(0) = {M1:.4f} (E[X] theory 1/lambda = {1/lam:.4f})")
print(f"M''(0) = {M2:.4f} (E[X^2] theory 2/lambda^2 = {2/lam**2:.4f})")
print(f"Var = {M2 - M1**2:.4f} (theory 1/lambda^2 = {1/lam**2:.4f})")
প্রত্যাশিত আউটপুট:
M'(0) = 0.5000 (E[X] theory 1/lambda = 0.5000)
M''(0) = 0.5000 (E[X^2] theory 2/lambda^2 = 0.5000)
Var = 0.2500 (theory 1/lambda^2 = 0.2500)
MGF সত্যিই "moment factory" — শুধু derivative নিয়েই moment পাওয়া গেল।
৫.৩ library — scipy.stats (built-in moments) ও sympy (closed form)¶
from scipy import stats
import sympy as sp
import numpy as np
# ---- (ক) scipy.stats: distribution-এর mean/var/skew/kurtosis সরাসরি ----
print("--- scipy.stats analytic moments ---")
m, v, s, k = stats.expon.stats(scale=1/2.0, moments='mvsk') # Exp(lambda=2)
print(f"Exp(2): mean={m:.4f} var={v:.4f} skew={s:.4f} exkurt={k:.4f}")
# Bernoulli(0.3)
m, v, s, k = stats.bernoulli.stats(p=0.3, moments='mvsk')
print(f"Bern(.3): mean={m:.4f} var={v:.4f} skew={s:.4f} exkurt={k:.4f}")
# Normal: skew 0, excess kurtosis 0
m, v, s, k = stats.norm.stats(loc=0, scale=1, moments='mvsk')
print(f"N(0,1): mean={m:.4f} var={v:.4f} skew={s:.4f} exkurt={k:.4f}")
# Laplace (heavy tail): excess kurtosis +3
print(f"Laplace excess kurtosis = {stats.laplace.stats(moments='k'):.4f} (heavy tail)")
print(f"Uniform excess kurtosis = {stats.uniform.stats(moments='k'):.4f} (light tail)")
# ---- (খ) sympy: MGF থেকে symbolic moment ----
print("\n--- sympy symbolic MGF ---")
t, lam = sp.symbols('t lambda', positive=True)
M = lam / (lam - t) # Exponential MGF
EX = sp.diff(M, t).subs(t, 0)
EX2 = sp.diff(M, t, 2).subs(t, 0)
print("Exp MGF: E[X] =", sp.simplify(EX)) # 1/lambda
print("Exp MGF: E[X^2] =", sp.simplify(EX2)) # 2/lambda^2
print("Exp MGF: Var =", sp.simplify(EX2 - EX**2))# 1/lambda^2
# Normal MGF: exp(mu t + sigma^2 t^2 / 2)
mu, sig = sp.symbols('mu sigma', real=True, positive=True)
Mn = sp.exp(mu*t + sig**2 * t**2 / 2)
print("Normal MGF: E[X] =", sp.simplify(sp.diff(Mn, t).subs(t, 0))) # mu
print("Normal MGF: E[X^2] =", sp.simplify(sp.diff(Mn, t, 2).subs(t, 0))) # mu^2 + sigma^2
প্রকৃত আউটপুট (চালিয়ে যাচাই করা):
--- scipy.stats analytic moments ---
Exp(2): mean=0.5000 var=0.2500 skew=2.0000 exkurt=6.0000
Bern(.3): mean=0.3000 var=0.2100 skew=0.8729 exkurt=-1.2381
N(0,1): mean=0.0000 var=1.0000 skew=0.0000 exkurt=0.0000
Laplace excess kurtosis = 3.0000 (heavy tail)
Uniform excess kurtosis = -1.2000 (light tail)
--- sympy symbolic MGF ---
Exp MGF: E[X] = 1/lambda
Exp MGF: E[X^2] = 2/lambda**2
Exp MGF: Var = lambda**(-2)
Normal MGF: E[X] = mu
Normal MGF: E[X^2] = mu**2 + sigma**2
লক্ষ করুন Exp(2)-এর skewness \(=2\) (§৩ উদাহরণ B মিলে গেল), Normal-এর skew ও excess kurtosis দুটোই \(0\), এবং sympy-র closed-form moment হাতের গণনার সাথে হুবহু এক।
৫.৪ library — independent sum-এর MGF গুণফল (simulation দিয়ে)¶
import numpy as np
from scipy import stats
rng = np.random.default_rng(11)
# X ~ Gamma(2,1), Y ~ Gamma(3,1), independent -> X+Y ~ Gamma(5,1) (shapes add)
X = rng.gamma(shape=2.0, scale=1.0, size=500_000)
Y = rng.gamma(shape=3.0, scale=1.0, size=500_000)
S = X + Y
print(f"E[X]+E[Y] = {X.mean()+Y.mean():.3f} E[X+Y] sim = {S.mean():.3f} (theory 5)")
print(f"Var(X)+Var(Y) = {X.var()+Y.var():.3f} Var(X+Y) sim = {S.var():.3f} (theory 5, indep)")
# theory: X+Y ~ Gamma(5,1) -> mean 5, var 5
print(f"Gamma(5,1) theory mean/var = {stats.gamma.mean(5):.1f} / {stats.gamma.var(5):.1f}")
প্রত্যাশিত আউটপুট:
E[X]+E[Y] = 5.001 E[X+Y] sim = 5.001 (theory 5)
Var(X)+Var(Y) = 5.005 Var(X+Y) sim = 5.005 (theory 5, indep)
Gamma(5,1) theory mean/var = 5.0 / 5.0
independent sum-এ mean যোগ হয় (linearity, সবসময়) এবং variance-ও যোগ হয় (independence-এ); আর MGF-গুণফল-নিয়ম বলে যোগফল আবার Gamma — §৬-এর শেষ ছবিতে এই সমান্তরাল (simulation বনাম theory) দেখব।
৬ · ভিজ্যুয়ালাইজেশন¶
নিচের প্রতিটি figure-এর কোড ঠিক যা দিয়ে ছবিটি বানানো হয়েছে তা-ই (একটি script থেকে)। in-figure লেখা English; ব্যাখ্যা বাংলায়। reproducible: default_rng(2505)।
Figure 1 — Expectation = balance point (center of mass)¶
বাঁয়ে discrete pmf-এর নিচে একটি ত্রিভুজাকার fulcrum (ঠেকনা) ঠিক \(\mathbb{E}[X]\)-এ — distribution সেখানে ভারসাম্যে। ডানে একটি skewed continuous density-র center of mass একই অর্থে \(\mathbb{E}[X]\)। এটাই §১-এর "seesaw" রূপক।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
BLUE, RED, GREEN, GREY = "#2f6db5", "#c0392b", "#27ae60", "#34495e"
fig, axes = plt.subplots(1, 2, figsize=(11, 4.4))
xs = np.array([1, 2, 3, 4, 5, 6])
ps = np.array([0.05, 0.10, 0.15, 0.20, 0.25, 0.25])
mu = np.sum(xs * ps)
ax = axes[0]
ax.bar(xs, ps, width=0.55, color=BLUE, alpha=0.55, edgecolor=GREY, zorder=2)
ax.axhline(0, color="black", lw=1.4)
ax.plot([mu], [-0.03], marker="^", markersize=18, color=RED, zorder=3)
ax.axvline(mu, color=RED, lw=1.6, ls="--")
ax.text(mu, max(ps)*1.02, f"E[X] = {mu:.2f}", color=RED, ha="center", fontsize=11)
ax.set_title("Discrete: E[X] is the balance point of the pmf")
ax.set_xlabel("value x"); ax.set_ylabel("probability p(x)")
ax.set_ylim(-0.06, max(ps)*1.18)
x = np.linspace(0, 8, 600)
y = stats.gamma.pdf(x, a=2.0, scale=1.0); mu_c = 2.0
ax = axes[1]
ax.plot(x, y, color=GREEN, lw=2.3); ax.fill_between(x, 0, y, color=GREEN, alpha=0.22)
ax.axhline(0, color="black", lw=1.4)
ax.plot([mu_c], [-0.022], marker="^", markersize=18, color=RED, zorder=3)
ax.axvline(mu_c, color=RED, lw=1.6, ls="--")
ax.text(mu_c+0.15, max(y)*0.9, f"E[X] = {mu_c:.2f}", color=RED, fontsize=11)
ax.set_title("Continuous: E[X] is the center of mass of the density")
ax.set_xlabel("value x"); ax.set_ylabel("density f(x)")
ax.set_ylim(-0.05, max(y)*1.15)
fig.suptitle("Expectation as a balance point (center of mass)", fontsize=14)
fig.tight_layout(rect=[0, 0, 1, 0.95])
fig.savefig("../_assets/2-5-expectation-balance.png", dpi=150)
![বাঁয়ে একটি discrete pmf-এর নিচে লাল ত্রিভুজ-ঠেকনা ঠিক E[X]=4.20-তে, যেন distribution সেখানে ভারসাম্যে; ডানে একটি ডান-হেলানো continuous density-র center of mass E[X]=2.00 — expectation মানেই probability-ভরের ভারসাম্যবিন্দু।](../_assets/2-5-expectation-balance.png)
Figure 2 — Same mean, different variance¶
তিনটি normal density, সবার একই mean (\(0\)), কিন্তু variance ভিন্ন (\(\sigma=1, 2, 3.5\))। দেখায় mean কেন্দ্র ঠিক করে, আর variance ঠিক করে কেন্দ্রের চারপাশে কতটা ছড়ানো — §১-এর "একই গড়, ভিন্ন ঝুঁকি" রূপক।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
BLUE, ORANGE, RED, GREY = "#2f6db5", "#e67e22", "#c0392b", "#34495e"
fig, ax = plt.subplots(figsize=(9, 4.6))
x = np.linspace(-9, 9, 800)
for sd, c in zip([1.0, 2.0, 3.5], [BLUE, ORANGE, RED]):
y = stats.norm.pdf(x, loc=0, scale=sd)
ax.plot(x, y, color=c, lw=2.3, label=f"sigma = {sd:.1f} (Var = {sd**2:.2f})")
ax.fill_between(x, 0, y, color=c, alpha=0.10)
ax.axvline(0, color=GREY, lw=1.4, ls="--")
ax.set_title("Same mean (0), different variance: spread around the center")
ax.set_xlabel("value x"); ax.set_ylabel("density f(x)")
ax.legend(loc="upper right", fontsize=10)
fig.tight_layout()
fig.savefig("../_assets/2-5-same-mean-diff-var.png", dpi=150)
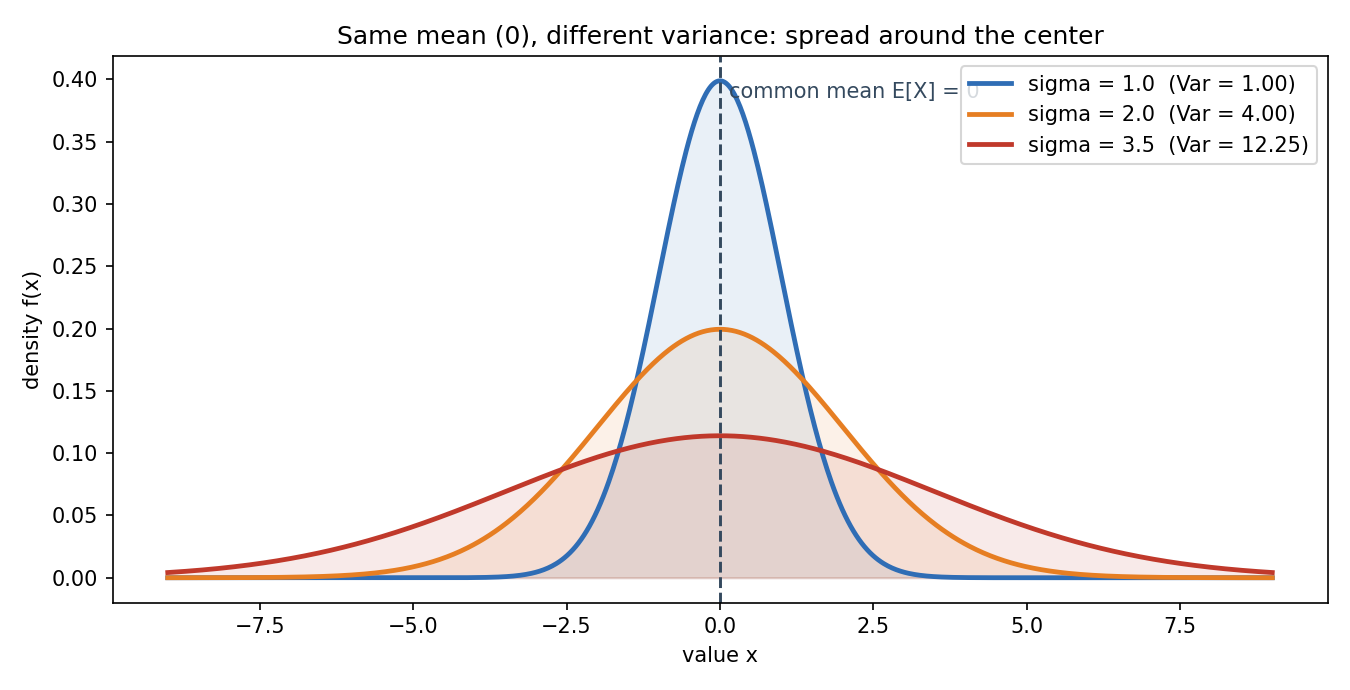
Figure 3 — Skewness: direction of the long tail¶
বাঁ থেকে ডানে: left-skewed (\(\gamma_1<0\)), symmetric (\(\gamma_1=0\)), right-skewed (\(\gamma_1>0\))। প্রতিটিতে mean (কালো ড্যাশ) ও median (বেগুনি ডট) দেখানো — skew-এ mean tail-এর দিকে টানে, তাই mean ও median আলাদা হয়।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
BLUE, RED, GREEN, PURPLE, GREY = "#2f6db5", "#c0392b", "#27ae60", "#7d3c98", "#34495e"
fig, axes = plt.subplots(1, 3, figsize=(12, 4.0))
x1 = np.linspace(-1, 9, 600)
y_right = stats.gamma.pdf(x1, a=2.0, scale=1.0)
y_left = stats.gamma.pdf(8 - x1, a=2.0, scale=1.0)
y_sym = stats.norm.pdf(x1, loc=4, scale=1.2)
panels = [(axes[0], y_left, "Left-skewed (skewness < 0)", RED, "long tail to the LEFT"),
(axes[1], y_sym, "Symmetric (skewness = 0)", BLUE, "balanced tails"),
(axes[2], y_right, "Right-skewed (skewness > 0)", GREEN, "long tail to the RIGHT")]
for ax, yy, title, c, note in panels:
ax.plot(x1, yy, color=c, lw=2.3); ax.fill_between(x1, 0, yy, color=c, alpha=0.22)
dx = x1[1]-x1[0]; area = np.sum(yy)*dx
mean = np.sum(x1*yy)*dx/area
cdf = np.cumsum(yy)*dx/area; median = x1[np.searchsorted(cdf, 0.5)]
ax.axvline(mean, color="black", lw=1.5, ls="--", label="mean")
ax.axvline(median, color=PURPLE, lw=1.5, ls=":", label="median")
ax.set_title(title, fontsize=11); ax.set_xlabel("x"); ax.set_yticks([])
ax.text(0.5, -0.18, note, transform=ax.transAxes, ha="center", fontsize=9, color=GREY)
ax.legend(loc="upper right", fontsize=8)
axes[0].set_ylabel("density")
fig.suptitle("Skewness: direction of the long tail (mean vs median)", fontsize=13)
fig.tight_layout(rect=[0, 0.04, 1, 0.94])
fig.savefig("../_assets/2-5-skewness.png", dpi=150)
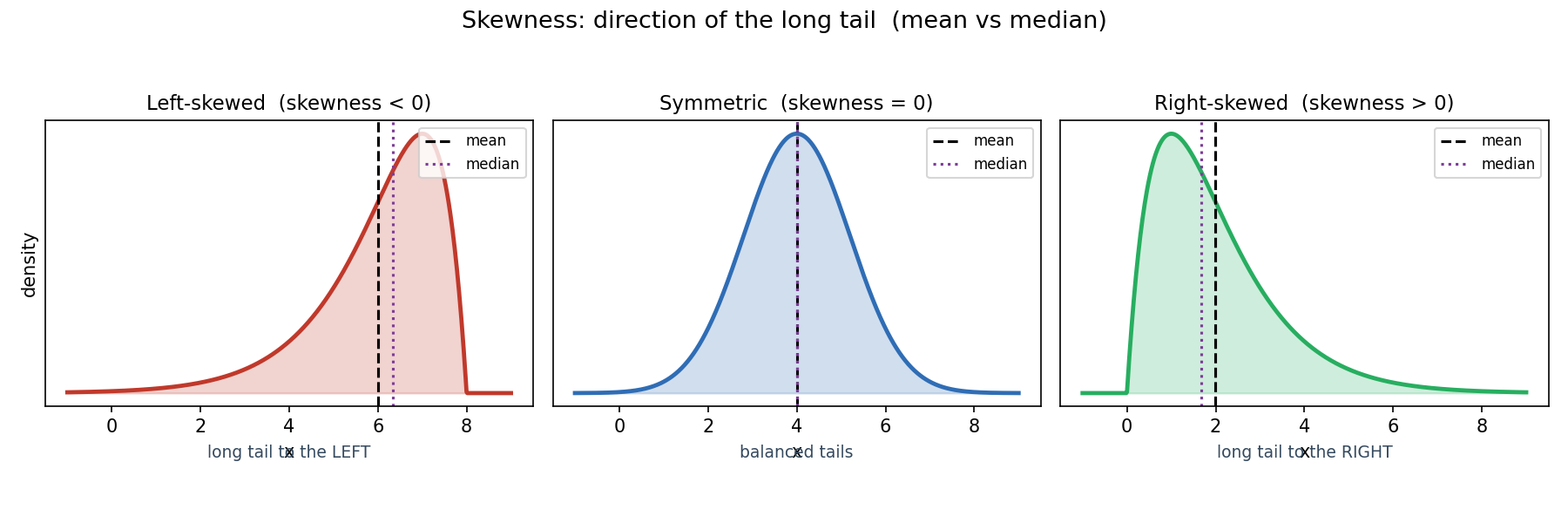
Figure 4 — Kurtosis: peakedness ও tail-এর ভার¶
তিনটি density — Laplace (heavy tail, excess \(+3\)), Normal (excess \(0\)), Uniform (light tail, excess \(-1.2\)) — সবার variance \(=1\) (standardized)। বাঁয়ে linear scale-এ চূড়া তুলনা; ডানে log scale-এ tail তুলনা (heavy tail log-এ স্পষ্ট)।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
BLUE, RED, GREEN = "#2f6db5", "#c0392b", "#27ae60"
fig, axes = plt.subplots(1, 2, figsize=(11, 4.4))
x = np.linspace(-6, 6, 800)
normal = stats.norm.pdf(x, 0, 1)
laplace = stats.laplace.pdf(x, 0, 1/np.sqrt(2)) # var 1
uniform = stats.uniform.pdf(x, -np.sqrt(3), 2*np.sqrt(3)) # var 1
for ax, log in zip(axes, [False, True]):
ax.plot(x, laplace, color=RED, lw=2.3, label="Laplace (heavy tail, excess +3)")
ax.plot(x, normal, color=BLUE, lw=2.3, label="Normal (excess kurtosis 0)")
ax.plot(x, uniform, color=GREEN, lw=2.3, label="Uniform (light tail, excess -1.2)")
ax.set_xlabel("standardized value z")
if log:
ax.set_yscale("log"); ax.set_ylim(1e-4, 1.0)
ax.set_title("Log scale: tails compared"); ax.set_ylabel("density (log)")
else:
ax.set_title("Linear scale: peak compared"); ax.set_ylabel("density")
ax.legend(loc="upper right", fontsize=8.5)
fig.suptitle("Kurtosis: peakedness and tail heaviness (all variance = 1)", fontsize=13)
fig.tight_layout(rect=[0, 0, 1, 0.94])
fig.savefig("../_assets/2-5-kurtosis.png", dpi=150)
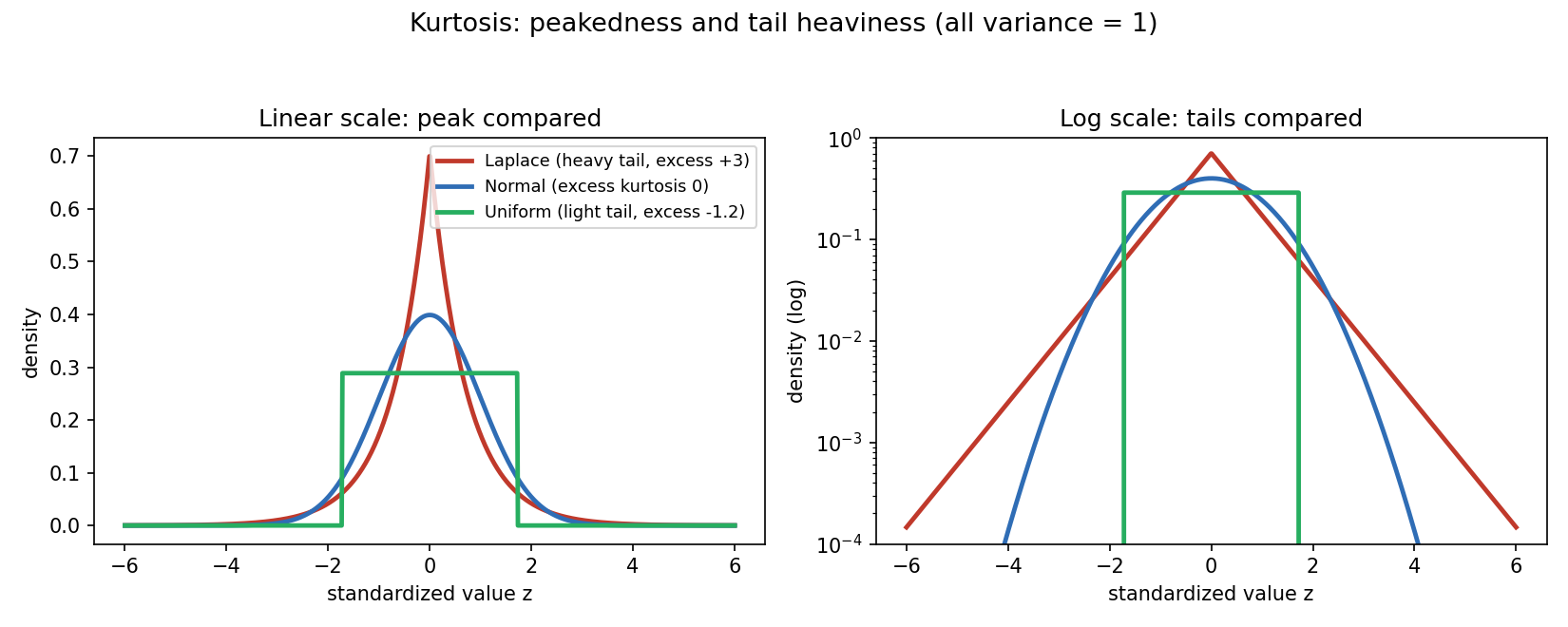
Figure 5 — Sample mean → E[X] (simulation)¶
পাঁচটি independent trial-এ একটি fair die ক্রমাগত ছোঁড়া হচ্ছে; প্রতিটির running sample mean (\(\bar X_n\)) আঁকা। \(n\) বাড়লে সব trial সত্য মান \(\mathbb{E}[X]=3.5\) (কালো ড্যাশ)-এর দিকে স্থির হয় — Law of Large Numbers (Part III)-এর পূর্বাভাস ও §৫.১-এর Monte Carlo-র দৃশ্যরূপ।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(2505)
COLS = ["#2f6db5", "#e67e22", "#27ae60", "#7d3c98", "#c0392b"]
fig, ax = plt.subplots(figsize=(9.2, 4.8))
N = 4000
for trial, c in zip(range(5), COLS):
draws = rng.integers(1, 7, size=N)
running = np.cumsum(draws) / np.arange(1, N + 1)
ax.plot(np.arange(1, N + 1), running, color=c, lw=1.2, alpha=0.8, label=f"trial {trial+1}")
ax.axhline(3.5, color="black", lw=2.0, ls="--", label="E[X] = 3.5 (true)")
ax.set_xscale("log")
ax.set_xlabel("number of rolls n (log scale)"); ax.set_ylabel("running sample mean")
ax.set_title("Sample mean -> E[X] as n grows (fair die, 5 independent trials)")
ax.set_ylim(1, 6); ax.legend(loc="upper right", fontsize=8.5, ncol=2)
fig.tight_layout()
fig.savefig("../_assets/2-5-sample-mean-converges.png", dpi=150)
![পাঁচটি রঙিন running-mean রেখা প্রথমে বুনোভাবে দোলে, তারপর n বাড়লে সবাই E[X]=3.5 কালো-ড্যাশ রেখায় মিলিত হয় — sample mean দীর্ঘমেয়াদে expectation-এ converge করে।](../_assets/2-5-sample-mean-converges.png)
Figure 6 — MGF: moment factory ও sum-identifier¶
বাঁয়ে standard normal-এর MGF \(M(t)=e^{t^2/2}\); \(t=0\)-তে ঢাল \(=\mathbb{E}[X]=0\) (লাল tangent অনুভূমিক), আর \(M(0)=1\) সবসময়। ডানে দুটি independent Gamma-র যোগফল: simulation (কমলা hist) ঠিক theoretical Gamma(5,1)-এর (লাল ড্যাশ) সাথে মেলে — MGF-গুণফল-নিয়মের প্রমাণ।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
rng = np.random.default_rng(2505)
BLUE, RED, GREEN, ORANGE, PURPLE = "#2f6db5", "#c0392b", "#27ae60", "#e67e22", "#7d3c98"
fig, axes = plt.subplots(1, 2, figsize=(11.2, 4.5))
t = np.linspace(-1.5, 1.5, 400); M = np.exp(t**2 / 2)
ax = axes[0]
ax.plot(t, M, color=PURPLE, lw=2.4, label="M(t) = exp(t^2 / 2)")
ax.plot(t, np.ones_like(t), color=RED, lw=1.6, ls="--", label="tangent at 0: slope = E[X] = 0")
ax.scatter([0], [1], color="black", zorder=5); ax.text(0.05, 1.05, "M(0) = 1", fontsize=10)
ax.set_title("MGF of N(0,1): derivatives at t=0 give the moments")
ax.set_xlabel("t"); ax.set_ylabel("M(t)"); ax.legend(loc="upper center", fontsize=9)
x = np.linspace(0, 16, 600)
ax = axes[1]
ax.plot(x, stats.gamma.pdf(x, a=2.0), color=BLUE, lw=2.0, label="X ~ Gamma(2,1)")
ax.plot(x, stats.gamma.pdf(x, a=3.0), color=GREEN, lw=2.0, label="Y ~ Gamma(3,1)")
ssum = rng.gamma(2.0, 1.0, 200000) + rng.gamma(3.0, 1.0, 200000)
ax.hist(ssum, bins=80, density=True, color=ORANGE, alpha=0.35, label="simulated X+Y")
ax.plot(x, stats.gamma.pdf(x, a=5.0), color=RED, lw=2.4, ls="--", label="theory: Gamma(5,1)")
ax.set_title("MGFs multiply for sums: X+Y is Gamma(5,1)")
ax.set_xlabel("value"); ax.set_ylabel("density"); ax.legend(loc="upper right", fontsize=8.5)
fig.suptitle("Moment-generating function: a moment factory and a sum-identifier", fontsize=13)
fig.tight_layout(rect=[0, 0, 1, 0.94])
fig.savefig("../_assets/2-5-mgf.png", dpi=150)
![বাঁ প্যানেলে standard normal-এর MGF curve M(t)=exp(t²/2), t=0-তে অনুভূমিক tangent দেখায় slope=E[X]=0 ও M(0)=1; ডান প্যানেলে Gamma(2,1)+Gamma(3,1)-এর simulated histogram হুবহু theoretical Gamma(5,1)-এ বসে — MGF moment বানায় এবং independent sum-এর distribution চেনায়।](../_assets/2-5-mgf.png)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও hint। পূর্ণ সমাধান _solutions/02-05-expectation-variance-moments-solutions.md-এ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). "expectation একটি balance point" — নিজের ভাষায় ব্যাখ্যা করুন কেন ছক্কার \(\mathbb{E}[X]=3.5\) হলেও ছক্কার কোনো প্রকৃত মুখ ৩.৫ নয়, এবং এতে কোনো অসংগতি নেই। Hint: center of mass কি বস্তুর কোনো প্রকৃত কণার অবস্থানে থাকতেই হবে?
প্রশ্ন ২ (★). কেন variance-এ deviation \(X-\mu\)-কে বর্গ করা হয়, শুধু \(\mathbb{E}[X-\mu]\) নেওয়া হয় না? আর standard deviation কেন variance-এর চেয়ে ব্যাখ্যায় সুবিধাজনক? Hint: \(\mathbb{E}[X-\mu]\)-এর মান কত? একক কী?
প্রশ্ন ৩ (★★). "linearity of expectation independence ছাড়াই খাটে, কিন্তু variance-এর যোগ-নিয়ম খাটে না" — দুই বাক্যে পার্থক্যটা ব্যাখ্যা করুন। কোন রাশি variance-এর যোগ-নিয়মে independence না থাকলে যোগ হয়? Hint: §২.৫ ও 2.6-এর covariance।
প্রশ্ন ৪ (★★). skewness কেন বিজোড় (power 3) এবং kurtosis কেন জোড় (power 4) standardized moment — এর ফলে একটি দিক (direction) মাপে আর অন্যটি মাপে না, ব্যাখ্যা করুন। Hint: বিজোড় power ঋণাত্মক ইনপুটে চিহ্ন ধরে রাখে; জোড় power মুছে দেয়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). \(X\sim\text{Uniform}(0,1)\)-এর জন্য definition দিয়ে \(\mathbb{E}[X]\), \(\mathbb{E}[X^2]\) (LOTUS) এবং \(\mathrm{Var}(X)\) গণনা করুন। Hint: \(f(x)=1\) on \([0,1]\); \(\int_0^1 x^k\,dx = \tfrac{1}{k+1}\)।
প্রশ্ন ৬ (★★). একটি random variable \(X\)-এর pmf: \(p(0)=0.2,\ p(1)=0.5,\ p(2)=0.3\)। \(\mathbb{E}[X]\), \(\mathrm{Var}(X)\), এবং LOTUS দিয়ে \(\mathbb{E}[(X-1)^2]\) গণনা করুন। শেষেরটি কি \(\mathrm{Var}(X)\)-এর সমান হলো? কেন/কেন নয়? Hint: \(\mathbb{E}[(X-c)^2]\) ন্যূনতম হয় \(c=\mu\)-তে; এখানে \(c=1\) কি \(\mu\)?
প্রশ্ন ৭ (★★). \(Y=3X-2\) এবং জানা আছে \(\mathbb{E}[X]=4,\ \mathrm{Var}(X)=5\)। \(\mathbb{E}[Y]\), \(\mathrm{Var}(Y)\), ও \(\mathrm{SD}(Y)\) বের করুন (properties ব্যবহার করে, নতুন distribution ছাড়াই)। Hint: §২.৩ ও §২.৫; \(\mathrm{SD}=\lvert a\rvert\sigma\)।
প্রশ্ন ৮ (★★). Bernoulli(\(p\))-এর MGF \(M(t)=(1-p)+pe^t\) থেকে \(M'(0)\) ও \(M''(0)\) বের করে \(\mathbb{E}[X]\) ও \(\mathrm{Var}(X)\) যাচাই করুন। Hint: \(M'(t)=pe^t\); \(t=0\) বসান।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). প্রমাণ করুন \(\mathrm{Var}(aX+b)=a^2\mathrm{Var}(X)\) সংজ্ঞা \(\mathbb{E}[(Y-\mathbb{E}[Y])^2]\) থেকে শুরু করে। Hint: \(Y-\mathbb{E}[Y]=a(X-\mu)\) দেখান, তারপর বর্গ ও linearity।
প্রশ্ন ১০ (★★). \(X\perp Y\) হলে MGF-গুণফল-নিয়ম \(M_{X+Y}(t)=M_X(t)M_Y(t)\) প্রমাণ করুন এবং ব্যাখ্যা করুন কেন independence অপরিহার্য। Hint: \(\mathbb{E}[e^{tX}e^{tY}]\) কখন গুণফলে ভাঙে?
প্রশ্ন ১১ (★★★). দুটি independent Poisson, \(X\sim\text{Poisson}(\lambda_1)\) ও \(Y\sim\text{Poisson}(\lambda_2)\)-এর MGF \(M(t)=e^{\lambda(e^t-1)}\) ব্যবহার করে দেখান \(X+Y\sim\text{Poisson}(\lambda_1+\lambda_2)\)। Hint: MGF গুণ করুন; exponent-এ \(\lambda\)-গুলো যোগ হয়; uniqueness প্রয়োগ করুন।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে Binomial(\(n=10, p=0.3\)) থেকে \(10^6\)টি নমুনা টানুন (rng.binomial), sample mean ও sample variance বের করে theory (\(np\) ও \(np(1-p)\))-র সাথে মেলান।
Hint: default_rng(seed); .mean(), .var()।
প্রশ্ন ১৩ (★★). scipy.stats দিয়ে Exponential(\(\lambda=1.5\))-এর mean, var, skewness, excess kurtosis বের করুন এবং বড় simulation থেকে empirical মানের সাথে তুলনা করুন (scipy.stats.skew, scipy.stats.kurtosis)। skewness \(\approx 2\) কি? excess kurtosis \(\approx 6\) কি?
Hint: stats.expon.stats(scale=1/1.5, moments='mvsk')।
প্রশ্ন ১৪ (★★★). sympy দিয়ে Normal(\(\mu,\sigma^2\))-এর MGF \(e^{\mu t+\sigma^2 t^2/2}\) থেকে প্রথম চারটি raw moment বের করুন, এবং তা থেকে central moment \(\mu_3\) ও \(\mu_4\) গণনা করে দেখান skewness \(=0\) ও excess kurtosis \(=0\)।
Hint: sp.diff(M, t, k).subs(t, 0); central moment binomial expansion দিয়ে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Expectation \(\mathbb{E}[X]=\sum x\,p(x)\) (discrete) বা \(\int x f(x)\,dx\) (continuous) — distribution-এর balance point / center of mass। প্রতীক \(\mu\)।
- LOTUS: \(\mathbb{E}[g(X)]=\sum g(x)p(x)\) বা \(\int g(x)f(x)\,dx\) — \(g(X)\)-এর distribution ছাড়াই গড়। সাধারণভাবে \(\mathbb{E}[g(X)]\neq g(\mathbb{E}[X])\)।
- Linearity: \(\mathbb{E}[aX+b]=a\mathbb{E}[X]+b\) এবং \(\mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y]\) — independence ছাড়াই খাটে।
- Variance \(\mathrm{Var}(X)=\mathbb{E}[(X-\mu)^2]=\mathbb{E}[X^2]-\mu^2\) — গড়ের চারপাশে ছড়ানো; SD \(\sigma=\sqrt{\mathrm{Var}(X)}\) মূল এককে।
- Scaling: \(\mathrm{Var}(aX+b)=a^2\mathrm{Var}(X)\) (\(+b\) অদৃশ্য, \(a\) বর্গ হয়ে আসে)। independent হলে \(\mathrm{Var}(X+Y)=\mathrm{Var}(X)+\mathrm{Var}(Y)\)।
- Moments: \(k\)-th raw \(\mu_k'=\mathbb{E}[X^k]\), central \(\mu_k=\mathbb{E}[(X-\mu)^k]\)। Skewness \(=\mu_3/\sigma^3\) (হেলান/দিক), kurtosis \(=\mu_4/\sigma^4\) (excess \(=\beta_2-3\); tail-এর ভার)।
- MGF \(M_X(t)=\mathbb{E}[e^{tX}]\) — (১) \(M^{(k)}(0)=\mathbb{E}[X^k]\) (moment factory), (২) distribution-এর fingerprint (uniqueness), (৩) \(X\perp Y \Rightarrow M_{X+Y}=M_X M_Y\)।
মূল distribution-এর moment (দ্রুত রেফারেন্স):
| Distribution | \(\mathbb{E}[X]\) | \(\mathrm{Var}(X)\) | MGF \(M_X(t)\) |
|---|---|---|---|
| Bernoulli(\(p\)) | \(p\) | \(p(1-p)\) | \((1-p)+pe^t\) |
| Binomial(\(n,p\)) | \(np\) | \(np(1-p)\) | \(\big[(1-p)+pe^t\big]^n\) |
| Poisson(\(\lambda\)) | \(\lambda\) | \(\lambda\) | \(e^{\lambda(e^t-1)}\) |
| Uniform(\(0,1\)) | \(\tfrac12\) | \(\tfrac{1}{12}\) | \(\dfrac{e^t-1}{t}\) |
| Exponential(\(\lambda\)) | \(\dfrac1\lambda\) | \(\dfrac{1}{\lambda^2}\) | \(\dfrac{\lambda}{\lambda-t}\ (t<\lambda)\) |
| Normal(\(\mu,\sigma^2\)) | \(\mu\) | \(\sigma^2\) | \(e^{\mu t+\sigma^2 t^2/2}\) |
statistics-এর সাথে সংযোগ (কেন এত গুরুত্বপূর্ণ):
| এই অধ্যায়ের ধারণা | statistics-এ রূপ (Part IV+) |
|---|---|
| expectation \(\mathbb{E}[\hat\theta]\) | estimator-এর bias \(=\mathbb{E}[\hat\theta]-\theta\) |
| variance \(\mathrm{Var}(\hat\theta)\) | estimator-এর নির্ভরযোগ্যতা; MSE \(=\) bias\(^2+\)variance |
| \(\mathbb{E}[\bar X]=\mu,\ \mathrm{Var}(\bar X)=\sigma^2/n\) | sample mean-এর sampling distribution (Part III–IV) |
| MGF uniqueness + গুণফল | sum/limit-এর distribution; Central Limit Theorem (Part III) |
| skewness, kurtosis | distribution-আকৃতি নির্ণয়, model-fit ও risk (Part V) |
পূর্ববর্তী সংযোগ (← 2.3, 2.4): discrete pmf (\(\sum\)) ও continuous pdf (\(\int\)) — দুটো থেকেই একই expectation/variance সংজ্ঞা গড়া হলো, শুধু \(\sum\) ↔ \(\int\) বদলে। 0.4-এর integration ও 0.3-এর Taylor series এখানে সরাসরি কাজে এলো (MGF, by-parts moment)।
পরবর্তী সংযোগ (→ 2.6): এরপর Joint, marginal ও conditional distribution — একাধিক random variable একসাথে। সেখানে আমরা covariance ও correlation সংজ্ঞায়িত করব (যা variance-এর যোগ-নিয়মের অনুপস্থিত পদ), এবং linearity-র যোগ-অংশ ও MGF-গুণফল-নিয়মের পেছনের independence formally প্রমাণ করব। variance-এর scaling তখন vector-এ গিয়ে covariance matrix-এ রূপ নেবে (multivariate)।
source pointer: এই অধ্যায়ের মূল উৎস Rice (Ch. 4 — Expected Values) ও Wasserman (Ch. 3 — Expectation); intuition ও LOTUS/MGF-এর সেতু Fernández-Granda (Ch. 4)। expectation/integral-এর rigorous (measure-theoretic) সংজ্ঞা ও MGF বনাম characteristic function-এর পূর্ণ তত্ত্ব আসবে Part VII-এ। estimator-এর bias-variance প্রয়োগ **Part IV