5.3 — ANOVA & Experimental Design (অ্যানোভা ও পরীক্ষণ-পরিকল্পনা)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "দুইয়ের বেশি group-এর mean তুলনা — অনেকগুলো t-test কেন নয়?"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
Part IV-এ (বিশেষত 4.7) আমরা দুটো জিনিস তুলনা করতে শিখেছি: দুটো group-এর গড় (mean) সমান কি না, সেটা two-sample t-test দিয়ে যাচাই। "নতুন ওষুধ বনাম placebo", "design A বনাম design B" — সব ক্ষেত্রেই কাঠামোটা ছিল দুই-এর তুলনা: একটা পার্থক্য \(\bar X_1 - \bar X_2\) মাপো, তার অনিশ্চয়তা (standard error) দিয়ে ভাগ করে একটা test statistic বানাও, আর সেটা \(H_0\) ("দুই mean সমান") সত্য ধরলে কতটা চরম তা দেখো।
আর 5.1–5.2-এ আমরা regression শিখেছি: একটা continuous response \(y\)-কে এক বা একাধিক predictor \(x\)-এর রৈখিক function হিসেবে মডেল করা, \(y = X\beta + \varepsilon\), এবং OLS দিয়ে \(\hat\beta = (X^\top X)^{-1} X^\top y\) বের করা। সেখানে predictor-গুলো ছিল সংখ্যাগত (continuous) — আয়তন, বয়স, ঘরের সংখ্যা।
কিন্তু বাস্তবে অজস্রবার আমাদের সামনে আসে এমন এক প্রশ্ন যা এই দুটোর কোনোটাতেই সরাসরি ধরে না:
দুইয়ের বেশি group আছে — তিন, চার, ছয় — এদের সবার mean কি সমান, নাকি অন্তত একটা আলাদা?
কয়েকটা বাস্তব উদাহরণ, যেখানে group সংখ্যা দুইয়ের বেশি:
- তিন রকম সার (fertilizer A, B, C) আলাদা জমিতে ব্যবহার করে দেখা গেল ফসলের গড় ফলন একটু আলাদা। এই পার্থক্য কি সারের আসল গুণ, নাকি জমি-থেকে-জমি স্বাভাবিক এলোমেলোতা?
- চারটি শিক্ষণ-পদ্ধতি আলাদা ক্লাসে চালিয়ে গড় পরীক্ষার নম্বর তুলনা।
- পাঁচটি ওয়েবসাইট-ভ্যারিয়েন্ট (A/B/n test) — কোনটার গড় conversion সবচেয়ে ভালো, আর পার্থক্যগুলো আদৌ অর্থপূর্ণ কি না।
এই অধ্যায়ের একমাত্র বিষয় এটাই: একাধিক group-এর mean একসাথে তুলনা করার একটা সঠিক, একীভূত কাঠামো — যার নাম ANOVA (Analysis of Variance, "ভেদ-বিশ্লেষণ")। নামের ভেতরেই একটা চমক লুকিয়ে: আমরা mean-এর পার্থক্য খুঁজছি, অথচ যন্ত্রটার নাম variance (ভেদ) বিশ্লেষণ। কেন — সেটাই এই ভূমিকার মূল অন্তর্দৃষ্টি (§১.৩)।
১.২ Hook — "তাহলে প্রতি জোড়ায় একটা করে t-test চালালেই হয় না কেন?"¶
প্রথম যে সমাধানটা মাথায় আসে, সেটা একদম স্বাভাবিক: যদি দুই group তুলনা করতে t-test জানি, তিন group থাকলে তিন জোড়া তুলনা করি — A বনাম B, A বনাম C, B বনাম C — মোট তিনটা t-test। চার group হলে ছয়টা, পাঁচ group হলে দশটা। শুনতে নিরীহ। কিন্তু এর ভেতরে একটা নীরব, মারাত্মক ফাঁদ আছে — যার নাম multiple-comparison problem (বহু-তুলনা সমস্যা)।
ফাঁদটা চোখে দেখাতে একটা সংখ্যা-পরীক্ষা করি। মনে করুন সব group আসলে একদম সমান — অর্থাৎ \(H_0\) সত্য, কোনো আসল পার্থক্য নেই। আমরা প্রতিটি t-test চালাচ্ছি \(\alpha = 0.05\) significance level-এ, মানে প্রতিটি একক test-এ "ভুল করে পার্থক্য আছে বলে ফেলা" (type I error) এর সম্ভাবনা \(0.05\), আর "ঠিকভাবে কোনো পার্থক্য না-পাওয়া" এর সম্ভাবনা \(0.95\)।
এখন যদি \(m\)টা স্বাধীন test চালাই, আর চাই একটাও যেন ভুল করে পার্থক্য না দেখায়, তবে সবগুলো একসাথে ঠিক হওয়ার সম্ভাবনা \((0.95)^m\)। অতএব অন্তত একটা test ভুল করে "পার্থক্য আছে" বলে ফেলার সম্ভাবনা —
যেখানে \(\alpha\) = প্রতি-test significance level, \(m\) = মোট test-সংখ্যা। এই সম্ভাবনাটাকে বলে family-wise error rate (FWER, পরিবার-ভিত্তিক ভুলের হার) — গোটা পরীক্ষা-পরিবারে অন্তত একটা মিথ্যা-আবিষ্কার ঘটার সম্ভাবনা। সংখ্যায় দেখুন কত দ্রুত এটা ফুলে ওঠে:
| group-সংখ্যা \(k\) | জোড়া-তুলনা \(m=\binom{k}{2}\) | \(1-(0.95)^m\) (আনু.) |
|---|---|---|
| 3 | 3 | ০.১৪ |
| 4 | 6 | ০.২৬ |
| 5 | 10 | ০.৪০ |
| 6 | 15 | ০.৫৪ |
লক্ষ করুন: মাত্র ৬টা group-এ পৌঁছাতেই, সব group সত্যিকারে সমান হওয়া সত্ত্বেও, অন্তত একটা জোড়ায় "পার্থক্য আছে!" বলে ফেলার সম্ভাবনা ৫০%-এরও বেশি — যদিও আমরা প্রতিটি test-কে \(5\%\)-এ বেঁধেছিলাম বলে নিশ্চিন্ত ছিলাম। অর্থাৎ অনেকগুলো test একসাথে চালালে স্বতন্ত্র \(\alpha\) আর গোটা বিশ্লেষণের ভুল-হারকে নিয়ন্ত্রণ করে না; প্রচুর test চালালে কিছু-না-কিছু "তারকাচিহ্নিত" ফল প্রায় নিশ্চিতভাবেই বেরোবে — নিছক কাকতালে।
এক বাক্যে ফাঁদটা: যত বেশি জোড়া-তুলনা চালাবেন, "সব আসলে সমান" হওয়া সত্ত্বেও অন্তত একটায় মিথ্যা-পার্থক্য দেখার সম্ভাবনা তত বাড়ে — তাই বহু আলাদা t-test দিয়ে multi-group তুলনা করা পরিসংখ্যানিকভাবে অসৎ।
এর সমাধান কী? দুটো পথ আছে, আর তারা পরস্পরের পরিপূরক:
- প্রথমে একটিমাত্র সার্বিক (omnibus) test চালানো, যার একটিমাত্র \(H_0\) হলো "সব group-এর mean সমান" — এবং যা গোটা প্রশ্নের উত্তর একটাই \(\alpha\)-তে দেয়, ফলে FWER ফুলে ওঠে না। এই সার্বিক test-ই ANOVA-র F-test — এই অধ্যায়ের কেন্দ্র।
- ANOVA যদি বলে "হ্যাঁ, কোথাও পার্থক্য আছে", কেবল তখন সাবধানে নির্দিষ্ট জোড়াগুলো খুঁজতে যাওয়া — তবে সংশোধিত (যেমন Bonferroni, Tukey) পদ্ধতিতে, যাতে বহু-তুলনার ভুল-হার নিয়ন্ত্রণে থাকে। (এই post-hoc অংশ §৭-এ সংক্ষেপে ছোঁয়া হবে; অধ্যায়ের মূল ভার সার্বিক F-test-এ।)
তাহলে প্রশ্ন দাঁড়ায়: একটিমাত্র test দিয়ে "সব mean সমান কি না" কীভাবে যাচাই করব? উত্তরটা চমকপ্রদ — mean-এর পার্থক্যকে আমরা variance দিয়ে মাপব।
১.৩ মূল insight (অন্তর্দৃষ্টি) — mean-পার্থক্যকে variance দিয়ে মাপা¶
এই অধ্যায়ের গোটা যন্ত্রটা একটা সাধারণ কিন্তু গভীর ধারণার ওপর দাঁড়িয়ে। ধারণাটা গেঁথে নিতে একটা ছবি কল্পনা করুন।
ধরুন তিনটে group (A, B, C) থেকে কিছু পর্যবেক্ষণ একটা সংখ্যারেখায় বিন্দু হিসেবে ছড়িয়ে আছে, প্রতিটি group আলাদা রঙে। এখন দুটো আলাদা পরিস্থিতি ভাবুন:
- পরিস্থিতি ১ — group-গুলো সত্যিই আলাদা। প্রতিটি রঙের বিন্দু-গুচ্ছ তার নিজের জায়গায় ছোট্ট, আঁটসাঁট ঝাঁক হয়ে বসে আছে, কিন্তু গুচ্ছগুলো পরস্পর থেকে অনেক দূরে। অর্থাৎ একই group-এর ভেতরের বিন্দুরা কাছাকাছি (ভেতরের ছড়ানো কম), কিন্তু group-এর গড়গুলো (centre) পরস্পর থেকে দূরে।
- পরিস্থিতি ২ — group-গুলো আসলে এক। তিন রঙের বিন্দু এমনভাবে মিশে আছে যে গুচ্ছগুলোর centre প্রায় একই জায়গায়, আর প্রতিটি গুচ্ছ নিজেই বেশ চওড়া। group-এর গড়গুলোর মধ্যেকার সামান্য পার্থক্য প্রতিটি group-এর ভেতরকার বিরাট ছড়ানোর তুলনায় নগণ্য — মনে হয় তিনটে আলাদা রঙ একই বড় মেঘের অংশ।
দুই পরিস্থিতির পার্থক্যটা ধরা পড়ে দুই রকম ভেদের তুলনায়:
- between-group variance ("group-এর মধ্যেকার ভেদ"): group-এর গড়গুলো (centre) পরস্পর থেকে এবং সার্বিক গড় থেকে কতটা দূরে ছড়িয়ে — অর্থাৎ "signal", আসল পার্থক্যের পরিমাপ।
- within-group variance ("group-এর ভেতরকার ভেদ"): একই group-এর বিন্দুরা নিজেদের গড়ের চারপাশে কতটা ছড়িয়ে — অর্থাৎ "noise", স্বাভাবিক এলোমেলোতা।
এবার মূল অন্তর্দৃষ্টিটা এক বাক্যে:
যদি group-এর মধ্যেকার ভেদ (between) তাদের ভেতরকার ভেদ (within)-এর তুলনায় অনেক বড় হয়, তবেই আমরা বিশ্বাস করি গড়গুলো সত্যিই আলাদা। দুটো ভেদ যদি কাছাকাছি হয়, তবে দেখা পার্থক্যটা নিছক noise।
এই দুই ভেদের অনুপাত-ই হলো ANOVA-র test statistic — যাকে আমরা \(F\) বলব:
\(F\) বড় মানে signal noise-কে ছাপিয়ে গেছে — গড়গুলো আলাদা বলে জোরালো প্রমাণ (\(H_0\) বাতিল)। \(F\) এক-এর কাছাকাছি মানে signal আর noise সমান-সমান — পার্থক্যের পক্ষে প্রমাণ নেই (\(H_0\) টেকে)। এই একটিমাত্র অনুপাত গোটা multi-group প্রশ্নকে একটাই সংখ্যায় ও একটাই test-এ গুটিয়ে আনে — ঠিক যা §১.২-এর multiple-comparison ফাঁদ এড়াতে দরকার ছিল।
এখন "নামের চমক"-এর রহস্যও পরিষ্কার: আমরা mean-এর পার্থক্য খুঁজছি, কিন্তু সেই পার্থক্যকে পরিমাপ করছি variance-এর ভাষায় (between vs within) — তাই পদ্ধতির নাম Analysis of Variance, যদিও লক্ষ্য mean-তুলনা। আর এই "মোট ভেদকে between + within-এ ভাঙা"-র গাণিতিক রূপই হলো বিখ্যাত পচন \(\mathrm{SST} = \mathrm{SSB} + \mathrm{SSW}\), যা §২-এ আনুষ্ঠানিক হবে এবং §৪-এ প্রমাণিত।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে। মোটা দাগে এই অধ্যায় চারটি প্রশ্নের উত্তর দেয় — (ক) একাধিক group-এর mean কি সমান (one-way ANOVA)? (খ) দুটি factor একসাথে থাকলে কে কতটা প্রভাব ফেলে আর তারা পরস্পরকে বদলায় কি না (two-way ANOVA, interaction)? (গ) এই গোটা ব্যাপারটা কি আসলে regression-এরই ছদ্মবেশ (ANOVA ↔ regression)? (ঘ) আর ভালো ANOVA পেতে data সংগ্রহটাই বা কেমন হওয়া উচিত (experimental design)?
- §২ — মূল ধারণা ও সংজ্ঞা। one-way ANOVA model \(y_{gi} = \mu + \tau_g + \varepsilon_{gi}\); মোট ভেদের পচন \(\mathrm{SST} = \mathrm{SSB} + \mathrm{SSW}\); \(F\)-statistic-এর গঠন ও অর্থ (between vs within), তার \(H_0\): সব group mean সমান; two-way ANOVA-র main effect ও interaction; ANOVA-কে dummy-variable regression হিসেবে দেখা; এবং design-এর চার মূলনীতি (randomization, replication, blocking, factorial) — সবই স্বজ্ঞা ও সংজ্ঞার স্তরে, প্রতিটি প্রতীক খোলা (গণিতের পূর্ণ প্রমাণ §৪-এ)।
- §৩ — হাতে-কলমে। একটা ছোট্ট group-data-তে group-গড়, সার্বিক গড়, \(\mathrm{SSB}\), \(\mathrm{SSW}\), mean square ও \(F\) পুরোপুরি হাতে-কলমে সংখ্যাসমেত গণনা — যাতে সূত্রগুলো বাস্তবে কীভাবে চলে তা চোখে দেখা যায়।
- §৪ — গণিত ও প্রমাণ। পচন \(\mathrm{SST} = \mathrm{SSB} + \mathrm{SSW}\)-এর বীজগাণিতিক প্রমাণ (cross-term কেন শূন্য হয়); \(H_0\)-এর অধীনে \(\mathrm{SSB}/\sigma^2\) ও \(\mathrm{SSW}/\sigma^2\)-এর \(\chi^2\)-বণ্টন এবং তাদের অনুপাত কেন \(F_{k-1,\,n-k}\); এবং ANOVA-র dummy-coded design matrix দিয়ে regression-সমতার আনুষ্ঠানিক প্রতিষ্ঠা।
- §৫–৬ — পূর্ণ উদাহরণ, চিত্র ও কোড। একটা বাস্তবসম্মত crop-yield dataset-এ (৩ সার × ২ সেচ) সম্পূর্ণ one-way ও two-way ANOVA — চিত্র 5-3-group-boxplots (group-ভিত্তিক বণ্টন), 5-3-variance-decomp (between/within পচন চোখে দেখা), 5-3-interaction-plot (interaction আছে কি না), 5-3-f-distribution (\(F_{k-1,n-k}\)-তে observed \(F\) ও p-value) — এবং Python-কোড।
- §৭ — অনুশীলনী; §৮ — সারসংক্ষেপ ও সংযোগ। চার ধরনের অনুশীলনী (ধারণাগত, গণনামূলক, প্রমাণভিত্তিক, কোডিং), তারপর মূল ফলাফলের পুনরাবৃত্তি ও পরের অধ্যায়ের সঙ্গে যোগসূত্র। (post-hoc তুলনা, ANOVA-র অনুমান ও সাধারণ ভুল-ধারণা §৩–৪ ও অনুশীলনীতে প্রাসঙ্গিকভাবে ছোঁয়া হয়েছে।)
এক বাক্যে কেন এটি Part V-এর অপরিহার্য ধাপ। 5.1–5.2 দেখিয়েছে continuous predictor সহ regression কীভাবে fit ও যাচাই করি; এই অধ্যায় সেই কাঠামোকে categorical predictor (group, factor)-এ বাড়ায় এবং একই সঙ্গে multi-group তুলনার সঠিক পথ দেখায়। আর এখানকার "ANOVA = dummy-variable regression" দৃষ্টিভঙ্গিই পরের অধ্যায় 5.4 (GLM ও logistic regression)-এর সরাসরি ভিত্তি, যেখানে এই রৈখিক-মডেল কাঠামো আরও সাধারণ response-এ প্রসারিত হবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞা — "between বনাম within ভেদের অনুপাত দিয়ে multi-group mean তুলনা" — কে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না। যেখানে গণিতের পূর্ণ প্রমাণ লাগবে (বিশেষত পচন \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) এবং \(F\)-statistic কোন বণ্টন মানে), সেটা §৪-এ করা হবে — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
পুরো বিভাগের পরিকল্পনা: প্রথমে one-way ANOVA-র model (§২.১) ও তার notation (§২.২); তারপর সেই model থেকে মোট ভেদের পচন \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) (§২.৩); সেই পচন থেকে গড়া \(F\)-statistic ও তার অর্থ (§২.৪) এবং সাজানো ANOVA table (§২.৫)। এরপর দুই-factor-এর জগৎ — two-way ANOVA: main effect ও interaction (§২.৬)। তারপর সেতু — ANOVA ↔ regression with dummy variables (§২.৭)। শেষে data কীভাবে সংগ্রহ করলে এই বিশ্লেষণ অর্থপূর্ণ হয় — experimental design-এর চার মূলনীতি (§২.৮)।
২.১ One-way ANOVA-র model — \(y_{gi} = \mu + \tau_g + \varepsilon_{gi}\)¶
শুরু করি সবচেয়ে সরল ক্ষেত্র দিয়ে — one-way ("একমুখী", একটিমাত্র factor): কেবল একটা শ্রেণিভাজক (যেমন "কোন সার") আছে, যার অধীনে \(k\)টি group। প্রতিটি পর্যবেক্ষণকে আমরা একটা সরল additive (যোগাত্মক) model দিয়ে বর্ণনা করি:
প্রতিটি প্রতীক খুলে বলি:
- \(g = 1, 2, \dots, k\) — group-এর সূচক (index)। \(k\) = মোট group-সংখ্যা (যেমন তিন সার হলে \(k=3\))।
- \(i = 1, 2, \dots, n_g\) — group \(g\)-এর ভেতরে পর্যবেক্ষণের সূচক। \(n_g\) = group \(g\)-তে কতগুলো পর্যবেক্ষণ আছে। সব group-এ সমান হলে \(n_g = n/k\)।
- \(y_{gi}\) — group \(g\)-এর \(i\)-তম পর্যবেক্ষণের মাপা মান (response), যেমন একটা নির্দিষ্ট প্লটের ফসল।
- \(\mu\) ("মিউ") — সার্বিক গড় (grand/overall mean): factor-এর কোনো প্রভাব না থাকলে সব পর্যবেক্ষণ যে সাধারণ স্তরের চারপাশে থাকত, সেই বেসলাইন।
- \(\tau_g\) ("টাউ-\(g\)") — group \(g\)-এর effect (প্রভাব): সার্বিক গড় থেকে group \(g\)-এর নিজস্ব গড় কতটা উপরে বা নিচে। অর্থাৎ group \(g\)-এর সত্য গড় \(\mu_g = \mu + \tau_g\)। সাধারণত একটা constraint আরোপ করা হয় (যেমন \(\sum_g n_g \tau_g = 0\) বা \(\tau_1 = 0\)) যাতে \(\mu\) ও \(\tau_g\) একক-অর্থে নির্ধারিত হয় — এর গাণিতিক ভূমিকা §৪-এ।
- \(\varepsilon_{gi}\) ("এপসাইলন-\(gi\)") — error (ত্রুটি/random fluctuation): পর্যবেক্ষণটা তার নিজের group-গড় থেকে যতটা বিচ্যুত, নিছক এলোমেলোতায়। ধরে নেওয়া হয় \(\varepsilon_{gi} \sim \mathcal{N}(0,\sigma^2)\) — অর্থাৎ গড় শূন্য, সব group-এ একই variance \(\sigma^2\), ও পরস্পর-স্বাধীন Normal (\(\mathcal{N}\) = Normal/গাউসীয় বণ্টন, \(\sigma^2\) = সাধারণ error-variance)।
লক্ষ করুন এই model আসলে 5.1-এর regression model \(y = X\beta + \varepsilon\)-এরই একটা রূপ: এখানে "predictor" হলো "পর্যবেক্ষণটা কোন group-এ" — একটা categorical তথ্য। এই সংযোগটাই §২.৭-এ স্পষ্ট হবে।
স্বজ্ঞায়, এই model বলছে: প্রতিটি মাপা মান = একটা সাধারণ বেসলাইন (\(\mu\)) + তার group-এর নিজস্ব ঝোঁক (\(\tau_g\)) + ব্যক্তিগত এলোমেলোতা (\(\varepsilon_{gi}\))। তাহলে "সব group-এর mean সমান কি না" প্রশ্নটা পরিণত হয় একটা পরিষ্কার দাবিতে —
অর্থাৎ null hypothesis \(H_0\) বলে "কোনো group-এরই আলাদা effect নেই, সব group-গড় সার্বিক গড়ের সমান"; আর alternative \(H_1\) বলে "অন্তত একটা \(\tau_g \neq 0\)" — অর্থাৎ অন্তত একটা group আলাদা (সব আলাদা হতে হবে না, একটাই যথেষ্ট)।
২.২ Notation — group-গড়, সার্বিক গড়, sum of squares¶
পচন ও \(F\)-statistic লেখার আগে কয়েকটা মূল পরিমাণের প্রতীক একসাথে ঠিক করে নিই। ধরা যাক মোট পর্যবেক্ষণ-সংখ্যা \(n = \sum_{g=1}^k n_g\) (সব group মিলিয়ে)।
-
group-গড় (group mean) — group \(g\)-এর পর্যবেক্ষণগুলোর গড়: $$ \bar y_g \;=\; \frac{1}{n_g}\sum_{i=1}^{n_g} y_{gi}, $$ যেখানে \(\bar y_g\) ("ওয়াই-বার-\(g\)") = group \(g\)-এর নমুনা-গড়, \(n_g\) = সেই group-এর পর্যবেক্ষণ-সংখ্যা। এটা সত্য group-গড় \(\mu_g\)-এর estimate।
-
সার্বিক গড় (grand mean) — সব পর্যবেক্ষণ একসাথে নিয়ে গড়: $$ \bar y \;=\; \frac{1}{n}\sum_{g=1}^{k}\sum_{i=1}^{n_g} y_{gi}, $$ যেখানে \(\bar y\) ("ওয়াই-বার") = মোট গড়, যা \(\mu\)-এর estimate। (সব group-এ সমান \(n_g\) হলে এটা group-গড়গুলোরই গড়।)
এবার "ভেদ" মাপার তিনটে sum of squares (বর্গের সমষ্টি — গড় থেকে দূরত্বের বর্গ যোগ করে ছড়ানো মাপা)। স্বজ্ঞায় এদের নাম মনে রাখুন: between = group-গড়রা পরস্পর থেকে কত দূরে; within = group-এর ভেতরে কত ছড়ানো; total = সব মিলিয়ে কত ছড়ানো।
-
between-group sum of squares (group-গড়দের ছড়ানো, "signal"): $$ \boxed{\ \mathrm{SSB} \;=\; \sum_{g=1}^{k} n_g\,(\bar y_g - \bar y)^2\ } $$ এখানে প্রতিটি group-গড় \(\bar y_g\) সার্বিক গড় \(\bar y\) থেকে কত দূরে — তার বর্গকে সেই group-এর আকার \(n_g\) দিয়ে গুণ করে (বড় group বেশি ওজন পায়) যোগ করা হচ্ছে। \(\mathrm{SSB}\) বড় মানে group-গড়রা পরস্পর থেকে অনেক দূরে — গড়-পার্থক্যের প্রমাণ। (অনেক বইয়ে এর নাম \(\mathrm{SS}_{\text{between}}\), \(\mathrm{SS}_{\text{treatment}}\) বা \(\mathrm{SSA}\)।)
-
within-group sum of squares (group-এর ভেতরের ছড়ানো, "noise"): $$ \boxed{\ \mathrm{SSW} \;=\; \sum_{g=1}^{k}\sum_{i=1}^{n_g} (y_{gi} - \bar y_g)^2\ } $$ এখানে প্রতিটি পর্যবেক্ষণ \(y_{gi}\) তার নিজের group-গড় \(\bar y_g\) থেকে কত দূরে — তার বর্গ সব group জুড়ে যোগ করা হচ্ছে। \(\mathrm{SSW}\) মাপে group-এর ভেতরকার স্বাভাবিক এলোমেলোতা; এটাই error-variance \(\sigma^2\)-এর তথ্যভাণ্ডার। (নাম: \(\mathrm{SS}_{\text{within}}\), \(\mathrm{SS}_{\text{error}}\) বা \(\mathrm{SSE}\)।)
-
total sum of squares (সব মিলিয়ে ছড়ানো): $$ \mathrm{SST} \;=\; \sum_{g=1}^{k}\sum_{i=1}^{n_g} (y_{gi} - \bar y)^2, $$ প্রতিটি পর্যবেক্ষণ সার্বিক গড় \(\bar y\) থেকে কত দূরে — তার বর্গের সমষ্টি, group-বিভাজন উপেক্ষা করে।
২.৩ পচন (decomposition) — \(\mathrm{SST} = \mathrm{SSB} + \mathrm{SSW}\)¶
এখন আসে এই অধ্যায়ের গাণিতিক হৃদয়, যেটা §১.৩-এর স্বজ্ঞাকে সমীকরণে বাঁধে। মোট ছড়ানো ঠিক দুটো টুকরোয় ভাগ হয়ে যায় — group-গড়দের মধ্যেকার ছড়ানো, আর group-এর ভেতরকার ছড়ানো:
অর্থাৎ মোট ভেদ = between-ভেদ + within-ভেদ, কোনো অবশিষ্ট ছাড়াই। ধারণাটা কেন এত শক্তিশালী, তা এক বাক্যে: প্রতিটি পর্যবেক্ষণ সার্বিক গড় থেকে যতটা সরে আছে \((y_{gi}-\bar y)\), সেটা ঠিক দুই অংশের যোগফল —
এই বিচ্যুতি-পচন বর্গ করে সব পর্যবেক্ষণ জুড়ে যোগ করলে cross-term (আড়াআড়ি পদ) ঠিক শূন্য হয়ে যায়, আর পড়ে থাকে \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) (পূর্ণ প্রমাণ §৪-এ — সেখানে দেখানো হবে cross-term কেন শূন্য)। এই একটা সমীকরণই "Analysis of Variance" নামের ন্যায্যতা: আমরা মোট ভেদকে আক্ষরিক অর্থে দুই উৎসে ভেঙে ফেলছি — "group-এর জন্য কতটা" আর "এলোমেলোতার জন্য কতটা"।
এর সাথে degrees of freedomও (df, স্বাধীনতার মাত্রা — কতগুলো স্বাধীন তথ্য-টুকরো প্রতিটি সমষ্টিতে আছে) একইভাবে ভাগ হয়:
যেখানে \(n\) = মোট পর্যবেক্ষণ, \(k\) = group-সংখ্যা। স্বজ্ঞায়: \(\mathrm{SSB}\)-তে \(k\)টা group-গড় কিন্তু একটা সার্বিক গড়ের constraint, তাই \(k-1\); \(\mathrm{SSW}\)-তে প্রতিটি group-এ \(n_g-1\) স্বাধীন বিচ্যুতি, যোগ করে \(n-k\); আর মোট \(n-1\)।
২.৪ \(F\)-statistic — between বনাম within, mean square হিসেবে¶
কাঁচা sum of squares সরাসরি তুলনাযোগ্য নয়, কারণ \(\mathrm{SSB}\) মাত্র \(k-1\)টা আর \(\mathrm{SSW}\) অনেক বেশি (\(n-k\)টা) তথ্য-টুকরো জুড়ে তৈরি — বেশি পদ যোগ করলে স্বভাবতই সমষ্টি বড় হয়। ন্যায্য তুলনার জন্য প্রতিটিকে তার নিজের df দিয়ে ভাগ করে mean square (গড় বর্গ, প্রতি-df ভেদের আন্দাজ) বানাই:
- between-group mean square (signal-এর প্রতি-df পরিমাপ): $$ \mathrm{MSB} \;=\; \frac{\mathrm{SSB}}{k-1}, $$
- within-group mean square (noise-এর প্রতি-df পরিমাপ, যা \(\sigma^2\)-এর নিরপেক্ষ estimate): $$ \mathrm{MSW} \;=\; \frac{\mathrm{SSW}}{n-k}. $$
এদের অনুপাতই হলো ANOVA-র কেন্দ্রীয় test statistic \(F\):
এখানে \(F\) ("এফ-পরিসংখ্যান") = between-ভেদ ÷ within-ভেদ (প্রতি-df হিসেবে); আর \(F_{k-1,\,n-k}\) মানে — \(H_0\) সত্য হলে এই \(F\) একটা \(F\)-distribution মানে, যার দুটো degrees-of-freedom parameter: numerator-এর \(k-1\) ও denominator-এর \(n-k\) (4.7-এ পরিচিত)।
এর অর্থ ঠিক §১.৩-এর স্বজ্ঞা, এবার সংখ্যায়:
- \(H_0\) সত্য হলে (সব group-গড় সমান), \(\mathrm{MSB}\) ও \(\mathrm{MSW}\) দুটোই একই \(\sigma^2\)-এর নিরপেক্ষ estimate — তাই তাদের অনুপাত \(F\) গড়ে ১-এর কাছাকাছি। অর্থাৎ "signal আর noise সমান-সমান"।
- \(H_1\) সত্য হলে (অন্তত একটা group আলাদা), \(\mathrm{MSB}\)-তে আসল গড়-পার্থক্যের অতিরিক্ত অবদান যোগ হয়, তাই সে \(\mathrm{MSW}\)-কে ছাড়িয়ে যায় — \(F\) হয় ১-এর চেয়ে অনেক বড়। "signal noise-কে ছাপিয়ে গেছে।"
সিদ্ধান্ত-নিয়ম তাই 4.7-এর F-test-এর হুবহু রূপ: observed \(F\) যদি \(F_{k-1,\,n-k}\)-বণ্টনের ডান-লেজে যথেষ্ট চরম হয় (অর্থাৎ p-value \(= P(F_{k-1,n-k} \ge F_{\text{obs}})\) ছোট, \(\alpha\)-এর নিচে), তবে \(H_0\) বাতিল — "অন্তত একটা group আলাদা" বলে রায়। লক্ষণীয়, এটা একতরফা (one-sided): শুধু বড় \(F\)-ই \(H_0\)-এর বিরুদ্ধে প্রমাণ, কারণ গড়-পার্থক্য কেবল between-ভেদ বাড়ায়।
২.৫ ANOVA table — সব এক জায়গায়¶
ঐতিহ্যগতভাবে উপরের সব পরিমাণ একটা পরিচ্ছন্ন ছকে সাজানো হয়, যাকে বলে ANOVA table। এর গঠন একবার চিনে রাখলে যেকোনো software-এর output সরাসরি পড়া যায়:
| উৎস (source) | df | sum of squares | mean square | \(F\) |
|---|---|---|---|---|
| Between groups (factor) | \(k-1\) | \(\mathrm{SSB}\) | \(\mathrm{MSB}=\dfrac{\mathrm{SSB}}{k-1}\) | \(\dfrac{\mathrm{MSB}}{\mathrm{MSW}}\) |
| Within groups (error) | \(n-k\) | \(\mathrm{SSW}\) | \(\mathrm{MSW}=\dfrac{\mathrm{SSW}}{n-k}\) | — |
| Total | \(n-1\) | \(\mathrm{SST}\) | — | — |
প্রতিটি সারি §২.২–২.৪-এর সংজ্ঞাগুলোরই সংক্ষিপ্ত রূপ: প্রথম সারি "signal" (between), দ্বিতীয় সারি "noise" (within/error), তৃতীয় সারি তাদের যোগফল (§২.৩-এর পচন)। ডান-প্রান্তের একটিমাত্র \(F\) ও তার p-value-ই গোটা one-way প্রশ্নের সার্বিক উত্তর।
২.৬ Two-way ANOVA — main effect ও interaction¶
এতক্ষণ একটাই factor ছিল ("কোন সার")। কিন্তু বাস্তব পরীক্ষায় প্রায়ই দুটো (বা বেশি) factor একসাথে বদলানো হয় — যেমন সারের পাশাপাশি সেচ (irrigation: low/high)। তখন প্রশ্ন আরও সূক্ষ্ম হয়: সার কি প্রভাব ফেলে? সেচ কি প্রভাব ফেলে? আর — সবচেয়ে মজার — সারের প্রভাব কি সেচ-স্তরভেদে বদলায়? এই শেষ প্রশ্নের উত্তর দেয় two-way ANOVA।
ধরা যাক factor A-এর স্তর \(a = 1,\dots,I\) (যেমন সার, \(I\) স্তর) আর factor B-এর স্তর \(b = 1,\dots,J\) (যেমন সেচ, \(J\) স্তর)। প্রতিটি স্তর-জোড়া \((a,b)\)-কে বলি একটা cell (কোষ), আর তাতে \(n_{ab}\)টি পর্যবেক্ষণ। model এবার তিন রকম effect ধরে:
প্রতিটি প্রতীক:
- \(\mu\) — সার্বিক গড় (আগের মতোই বেসলাইন)।
- \(\alpha_a\) ("আলফা-\(a\)") — factor A-এর স্তর \(a\)-এর main effect (মুখ্য প্রভাব): factor B-কে গড় করে ফেললে, A-এর স্তর \(a\) সার্বিক গড় থেকে কতটা সরায়। ("সার একা গড়ে কতটা ফলন বাড়ায়/কমায়।")
- \(\beta_b\) ("বিটা-\(b\)") — factor B-এর স্তর \(b\)-এর main effect: একইভাবে B-এর স্বতন্ত্র অবদান। ("সেচ একা গড়ে কতটা প্রভাব ফেলে।")
- \((\alpha\beta)_{ab}\) — A-এর স্তর \(a\) ও B-এর স্তর \(b\)-এর interaction effect (পারস্পরিক ক্রিয়া): দুই factor-এর মিলিত অতিরিক্ত প্রভাব, যা শুধু main effect-দের যোগফল দিয়ে ব্যাখ্যা করা যায় না।
- \(\varepsilon_{abi} \sim \mathcal{N}(0,\sigma^2)\) — আগের মতোই error।
Interaction-এর ধারণাটা two-way ANOVA-র আসল রত্ন, তাই স্বজ্ঞায় খুলে বলি। interaction নেই মানে effect-গুলো যোগাত্মক (additive): "সার C ব্যবহারে ফলন যতটা বাড়ে, তা সেচ low হোক বা high — একই"; অর্থাৎ এক factor-এর প্রভাব অন্যটার স্তরের ওপর নির্ভর করে না। interaction আছে মানে effect-গুলো মিলে গিয়ে বদলায়: "সার C-এর বাড়তি সুবিধা কেবল high সেচেই ফুটে ওঠে, low সেচে নয়" — অর্থাৎ ভালো ফলনের জন্য সার ও সেচকে একসাথে ঠিক করতে হয়।
এটা চোখে দেখার সবচেয়ে সহজ উপায় interaction plot: x-অক্ষে এক factor-এর স্তর, y-অক্ষে cell-গড়, আর অন্য factor-এর প্রতি স্তরের জন্য একটা করে রেখা। রেখাগুলো সমান্তরাল হলে interaction নেই (effect যোগাত্মক); রেখাগুলো ছেদ করলে বা ঢাল আলাদা হলে interaction আছে। (এই ছবি §৬-এর 5-3-interaction-plot-এ পূর্ণ dataset-এ দেখানো হবে।)
two-way ANOVA এই তিন রকম effect-এর জন্য মোট ভেদকে আরও সূক্ষ্মভাবে ভাঙে এবং তিনটি আলাদা \(F\)-test দেয় — একটা factor A-এর main effect-এর জন্য (\(H_0\): সব \(\alpha_a=0\)), একটা factor B-এর জন্য (\(H_0\): সব \(\beta_b=0\)), আর একটা interaction-এর জন্য (\(H_0\): সব \((\alpha\beta)_{ab}=0\))। প্রতিটিরই গঠন one-way-র মতোই: "সংশ্লিষ্ট effect-এর mean square ÷ error mean square"। (সম্পূর্ণ ভেদ-পচন ও তিন \(F\)-এর সূত্র §৪-এ; পূর্ণ সংখ্যাসহ প্রয়োগ §৫–৬-এ।)
২.৭ ANOVA ↔ regression with dummy variables¶
এবার এই অধ্যায়ের সবচেয়ে একীভূতকারী (unifying) দৃষ্টিভঙ্গি, যা §১.৪-এ প্রতিশ্রুত: ANOVA কোনো আলাদা, স্বতন্ত্র পদ্ধতি নয় — এটা হুবহু 5.1-এর linear regression, কেবল predictor-গুলো categorical।
সমস্যা হলো, "group" তো সংখ্যা নয় (A, B, C — এগুলোকে 1, 2, 3 ধরা ভুল হবে, কারণ তাতে মিথ্যা ক্রম ও ব্যবধান চাপানো হয়)। সমাধান: dummy variable (বা indicator variable, নির্দেশক চলক) — প্রতিটি group-এর জন্য একটা ০/১ চলক, যা বলে "পর্যবেক্ষণটা এই group-এ কি না"। \(k\)টা group-এর জন্য আমরা একটা reference group বেছে নিই (ধরা যাক A), আর বাকি group-গুলোর জন্য dummy বানাই:
এখানে \(D_B, D_C\) = group B ও C-এর indicator (reference group A-এর জন্য আলাদা dummy লাগে না — সব dummy শূন্য হওয়াই "A"-কে বোঝায়)। এই dummy দিয়ে one-way ANOVA-র model হয়ে যায় একটা সাধারণ regression:
যেখানে coefficient-গুলোর অর্থ পরিষ্কার ও সুন্দর: \(\beta_0\) = reference group A-এর গড় (\(=\bar y_A\)); \(\beta_1\) = B-এর গড় বিয়োগ A-এর গড় (B কতটা A থেকে আলাদা); \(\beta_2\) = C-এর গড় বিয়োগ A-এর গড়। অর্থাৎ regression-এর coefficient-গুলো সরাসরি group-গড়ের পার্থক্য মাপে।
এই দৃষ্টিতে বহু জিনিস এক হয়ে যায়:
- ANOVA-র "সব group mean সমান" (\(H_0: \tau_1=\dots=\tau_k=0\)) ঠিক regression-এর "সব dummy-coefficient একসাথে শূন্য" (\(H_0: \beta_1=\beta_2=\dots=0\))।
- ANOVA-র \(F\)-test হুবহু regression-এর overall \(F\)-test (5.2-এ পরিচিত, যা একসাথে সব slope শূন্য কি না যাচাই করে) — একই সংখ্যা, একই p-value।
- two-way ANOVA-র interaction ঠিক regression-এর dummy-দের গুণফল-পদ (product/interaction term, যেমন \(D_C \times D_{\text{high}}\))।
এক বাক্যে সেতুটি: categorical factor-কে dummy দিয়ে সংকেতায়িত করলে ANOVA = regression; তাই ANOVA আলাদা কিছু শেখা নয়, বরং 5.1-এর regression-কেই categorical predictor-এ দেখা — এই ঐক্যই পরের অধ্যায় 5.4 (GLM)-এর ভিত্তি, যেখানে এই রৈখিক-মডেল কাঠামো আরও সাধারণ হবে। (আনুষ্ঠানিক প্রমাণ — design matrix \(X\) গড়ে OLS চালালে ঠিক ANOVA-র SS-পচন বেরোয় — §৪-এ।)
২.৮ Experimental design-এর চার মূলনীতি¶
ANOVA একটা বিশ্লেষণ-যন্ত্র, কিন্তু তার ফলাফল ঠিক ততটাই ভালো যতটা ভালো data সংগ্রহ করা হয়েছে। "garbage in, garbage out" — খারাপভাবে সংগৃহীত data-তে নিখুঁত ANOVA-ও বিভ্রান্তিকর। তাই experimental design (পরীক্ষণ-পরিকল্পনা) — পরীক্ষাটা কীভাবে চালানো হবে তার নকশা — ANOVA-র অবিচ্ছেদ্য সঙ্গী। চারটি মূলনীতি, প্রতিটির সংজ্ঞা, উদ্দেশ্য ও ANOVA-র সাথে সম্পর্ক:
(১) Randomization (এলোমেলোকরণ)। প্রতিটি একককে (unit, যেমন প্লট/রোগী) কোন শর্তে (treatment) রাখা হবে, তা এলোমেলোভাবে ঠিক করা — গবেষকের পছন্দ বা সুবিধা অনুসারে নয়। - উদ্দেশ্য: জানা ও অজানা সব বিরক্তিকর-উৎসকে (confounder) group-গুলোর মধ্যে গড়ে সমানভাবে ছড়িয়ে দেওয়া, যাতে কোনো লুকানো কারণ একটা নির্দিষ্ট group-এ জমা হয়ে ফলাফলকে পক্ষপাতী না করে। - ANOVA-র সাথে: এটাই \(\varepsilon_{gi}\)-কে সত্যিকারের স্বাধীন, পক্ষপাতহীন "noise" করে তোলে — model-এর অনুমানের ভিত্তি।
(২) Replication (পুনরাবৃত্তি)। প্রতিটি শর্তে একাধিক স্বতন্ত্র একক রাখা (এক প্লট নয়, প্রতি সারে যেমন ২০টা প্লট)। - উদ্দেশ্য: within-group ভেদ (\(\sigma^2\)) আদৌ আন্দাজ করা সম্ভব হয় কেবল replication থাকলে — একটামাত্র পর্যবেক্ষণ দিয়ে "এলোমেলোতা কত" বলা যায় না। বেশি replication = \(\mathrm{MSW}\)-এর ভালো estimate ও বেশি power (আসল পার্থক্য ধরার সামর্থ্য)। - ANOVA-র সাথে: replication-ই \(\mathrm{SSW}\) (denominator) তৈরি করে; এটা ছাড়া \(F\)-এর হরই থাকে না।
(৩) Blocking (গুচ্ছকরণ)। যদি একটা জানা বিরক্তিকর-উৎস থাকে (যেমন জমির উর্বরতা পূর্ব-পশ্চিমে বদলায়, বা রোগীর বয়স-গোষ্ঠী), তবে সদৃশ এককগুলোকে আগে থেকে block (গুচ্ছ)-এ ভাগ করে নেওয়া, এবং প্রতিটি block-এর ভেতরে সব treatment চালানো। - উদ্দেশ্য: সেই জানা উৎসের ভেদকে আলাদা করে error থেকে সরিয়ে রাখা, ফলে within-group "noise" কমে ও treatment-পার্থক্য আরও স্পষ্ট হয়। প্রবাদ: "block what you can, randomize what you cannot" (যা নিয়ন্ত্রণ করা যায় তা block করো, বাকিটা randomize করো)। - ANOVA-র সাথে: block নিজেই একটা অতিরিক্ত factor হিসেবে model-এ ঢোকে, তার ভেদ আলাদা SS হিসেবে বেরিয়ে যায় — error ছোট হয়, \(F\) আরও সংবেদী হয়।
(৪) Factorial design (গুণনীয় নকশা)। একটা একটা করে factor না বদলে, একাধিক factor একসাথে, তাদের সব স্তর-সমন্বয়ে (cell) পরীক্ষা চালানো — যেমন ৩ সার × ২ সেচ = ৬টি cell, প্রতিটিতে পর্যবেক্ষণ। - উদ্দেশ্য: (ক) এক পরীক্ষায় একাধিক factor-এর main effect দক্ষভাবে পাওয়া যায়, আর সবচেয়ে গুরুত্বপূর্ণ — (খ) interaction ধরা যায় (§২.৬), যা একটা-একটা factor আলাদা বদলালে কখনোই ধরা পড়ত না। - ANOVA-র সাথে: এটাই two-way (বা multi-way) ANOVA-কে সম্ভব করে; প্রতিটি cell-এ replication থাকায় main effect ও interaction উভয়ই estimate ও পরীক্ষা করা যায়।
এক বাক্যে design-এর সারকথা: randomization পক্ষপাত সরায়, replication noise আন্দাজ করতে ও power দিতে দেয়, blocking জানা বিরক্তি-উৎস সরিয়ে test-কে সংবেদী করে, আর factorial design একাধিক factor ও তাদের interaction একসাথে ধরে — চারটি মিলেই ANOVA-কে অর্থপূর্ণ, বিশ্বাসযোগ্য সিদ্ধান্তে রূপ দেয়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে আমরা একটি কৃষি-পরীক্ষার (agricultural field trial) ডেটাসেট নিয়ে ধাপে ধাপে কাজ করব। পরীক্ষাটি একটি factorial design: তিন ধরনের সার (fertilizer A, B, C) এবং দুই স্তরের সেচ (irrigation: low, high)-এর প্রতিটি সংমিশ্রণে \(20\)টি করে প্লট, মোট \(3 \times 2 \times 20 = 120\)টি প্লট। প্রতিটি প্লটের ফলন (yield) crop কলামে নথিভুক্ত। প্রথমে আমরা শুধু সারের প্রভাব দেখব (one-way ANOVA), তারপর সেচসহ পূর্ণ মডেলে যাব (two-way ANOVA), এবং শেষে দেখাব যে ANOVA আসলে dummy variable-এর উপর regression ছাড়া আর কিছুই নয়।
ডেটা তৈরির প্রকৃত মডেল (data-generating process) ছিল: $$ \text{crop} = 30 + \tau_{\text{fert}} + \beta_{\text{irrig}} + \gamma\,[\text{C} \wedge \text{high}] + \varepsilon, \qquad \varepsilon \sim N(0, 4^2), $$ যেখানে \(\tau_A = 0,\ \tau_B = 5,\ \tau_C = 8\); \(\beta_{\text{low}} = 0,\ \beta_{\text{high}} = 6\); এবং interaction পদ \(\gamma = 4\) কেবল C-সার ও high-সেচের সংমিশ্রণে যুক্ত হয়। অর্থাৎ "সত্য" parameter-গুলো আমরা জানি — এই উদাহরণের লক্ষ্য হলো নমুনা ডেটা থেকে সেই কাঠামো ANOVA-র মাধ্যমে পুনরুদ্ধার করা এবং দেখা যে আমাদের সিদ্ধান্ত বাস্তবতার সঙ্গে মেলে কি না।
নমুনা থেকে পাওয়া group means (seed 20260619):
| Fertilizer (\(g\)) | \(n_g\) | \(\bar y_g\) |
|---|---|---|
| A | \(40\) | \(32.40\) |
| B | \(40\) | \(38.10\) |
| C | \(40\) | \(43.97\) |
| Grand | \(120\) | \(\bar y = 38.16\) |
এখানে \(n_g = 40\) — কারণ one-way বিশ্লেষণে সেচ (irrigation) উপেক্ষা করা হচ্ছে, তাই প্রতিটি সার-গ্রুপে low ও high মিলিয়ে \(2 \times 20 = 40\)টি প্লট। (\(20\) হলো প্রতি cell-এর আকার, যা E3-র two-way বিশ্লেষণে দরকার হবে।)
E1 · One-way ANOVA হাতে-কলমে: SSB, SSW, F এবং ANOVA টেবিল¶
প্রশ্ন: তিনটি সারের গড় ফলন কি একই, নাকি অন্তত একটি আলাদা? Null hypothesis: $$ H_0:\ \mu_A = \mu_B = \mu_C \qquad \text{বনাম} \qquad H_1:\ \text{অন্তত একটি } \mu_g \text{ ভিন্ন।} $$
ধাপ ১ — Between-group sum of squares (\(\mathrm{SSB}\)). প্রতিটি গ্রুপের গড় grand mean থেকে কতটা সরে আছে, তার ওজন-করা বর্গযোগ। যেহেতু one-way বিশ্লেষণে প্রতিটি সার-গ্রুপে \(n_g = 40\): $$ \mathrm{SSB} = \sum_{g} n_g\,(\bar y_g - \bar y)^2 = 40\big[(\bar y_A - \bar y)^2 + (\bar y_B - \bar y)^2 + (\bar y_C - \bar y)^2\big]. $$ বিচ্যুতিগুলো বসিয়ে: $$ \begin{aligned} \bar y_A - \bar y &= 32.40 - 38.16 = -5.76, &(\bar y_A - \bar y)^2 &= 33.18,\ \bar y_B - \bar y &= 38.10 - 38.16 = -0.06, &(\bar y_B - \bar y)^2 &= 0.004,\ \bar y_C - \bar y &= 43.97 - 38.16 = \phantom{-}5.81, &(\bar y_C - \bar y)^2 &= 33.76. \end{aligned} $$ যোগফল \(\approx 66.94\), তাই $$ \mathrm{SSB} = 40 \times 66.94 \approx 2677.6 \approx 2675.0. $$
সতর্কতা — গোলকরণ (rounding)। উপরে দুই দশমিকে কাটা group means ব্যবহার করায় বিচ্যুতি-বর্গের যোগফল \(\approx 66.94\), অথচ পূর্ণ-নির্ভুল মানে \(\sum_g (\bar y_g - \bar y)^2 = 66.875\)। তাই \(40 \times 66.94 \approx 2677.6\) বনাম সঠিক \(40 \times 66.875 = 2675.0\) — পার্থক্য সামান্য (\(\approx 2.6\)), পুরোটাই গড় গোলকরণের ফল। নীতি: ANOVA-র মধ্যবর্তী ধাপে অতিরিক্ত গোলকরণ এড়িয়ে চলো; চূড়ান্ত মানে আমরা canonical \(\mathrm{SSB} = 2675.0\) গ্রহণ করব, যা §৩-র শেষে statsmodels দিয়ে যাচাই করা হবে।
ধাপ ২ — Within-group sum of squares (\(\mathrm{SSW}\)). প্রতিটি গ্রুপের ভেতরের বিক্ষেপ (residual scatter)। এটি প্রতিটি গ্রুপের নিজস্ব গড় থেকে পর্যবেক্ষণগুলোর বর্গবিচ্যুতির যোগ: $$ \mathrm{SSW} = \sum_g \sum_{i \in g} (y_{gi} - \bar y_g)^2 = 4624.2 \quad (\text{ডেটা থেকে গণিত}). $$
ধাপ ৩ — মোট (\(\mathrm{SST}\)) ও পরিচয় যাচাই। Total sum of squares হলো দুইটির যোগ: $$ \mathrm{SST} = \mathrm{SSB} + \mathrm{SSW} = 2675.0 + 4624.2 = 7299.2. $$ এই additive decomposition (বিভাজন) ANOVA-র মেরুদণ্ড: মোট পরিবর্তনশীলতা = গ্রুপের মধ্যেকার অংশ + গ্রুপের ভেতরের অংশ।
ধাপ ৪ — degrees of freedom, mean squares, ও \(F\)। \(k = 3\) গ্রুপ, \(n = 120\) পর্যবেক্ষণ: $$ \mathrm{df}{\text{between}} = k - 1 = 2, \qquad \mathrm{df} = n - k = 117. $$ Mean squares (গড় বর্গ) = sum of squares }\(\div\) df: $$ \mathrm{MSB} = \frac{\mathrm{SSB}}{k-1} = \frac{2675.0}{2} = 1337.5, \qquad \mathrm{MSW} = \frac{\mathrm{SSW}}{n-k} = \frac{4624.2}{117} = 39.52. $$ \(F\)-statistic হলো এই দুই variance-অনুমানের অনুপাত: $$ F = \frac{\mathrm{SSB}/(k-1)}{\mathrm{SSW}/(n-k)} = \frac{\mathrm{MSB}}{\mathrm{MSW}} = \frac{1337.5}{39.52} = 33.84. $$
লক্ষণীয়, \(\mathrm{MSW} = 39.52\) আমাদের error variance \(\sigma^2\)-এর অনুমান, এবং এর বর্গমূল \(\sqrt{39.52} \approx 6.29\) — তবে মনে রাখা দরকার এই pooled estimate-এ সেচের প্রভাব এখনো residual-এ মিশে আছে (E3-তে সেটিকে আলাদা করলে \(\hat\sigma\) অনেক ছোট হবে, প্রকৃত \(\sigma = 4\)-এর কাছাকাছি)।
ANOVA টেবিল (one-way, crop ~ fert):
| Source | \(\mathrm{SS}\) | \(\mathrm{df}\) | \(\mathrm{MS}\) | \(F\) | \(p\)-value |
|---|---|---|---|---|---|
| Between (fert) | \(2675.0\) | \(2\) | \(1337.5\) | \(33.84\) | \(2.5 \times 10^{-12}\) |
| Within (error) | \(4624.2\) | \(117\) | \(39.52\) | ||
| Total | \(7299.2\) | \(119\) |
সিদ্ধান্ত। \(p\)-value \(\approx 2.5 \times 10^{-12}\), যা যেকোনো প্রচলিত তাৎপর্য-স্তরের (\(\alpha = 0.05\) বা এমনকি \(0.001\)) চেয়ে বহুগুণ ছোট। সমতুল্যভাবে, critical value \(F_{0.05;\,2,117} \approx 3.07\)-এর তুলনায় আমাদের \(F = 33.84\) বিশাল। অতএব আমরা \(H_0\) প্রত্যাখ্যান (reject) করি: তিনটি সারের গড় ফলন একরকম নয় — অন্তত একটি গড় বাকিদের থেকে পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণভাবে ভিন্ন।
E2 · ব্যাখ্যা ও post-hoc চিন্তা: কোন গ্রুপ আলাদা?¶
ANOVA-র \(F\)-test একটি omnibus test — এটি কেবল বলে "সব গড় সমান নয়", কিন্তু কোন জোড়াগুলো ভিন্ন তা বলে না। প্রত্যাখ্যানের পর স্বাভাবিক পরবর্তী প্রশ্ন: A, B, C-র মধ্যে ঠিক কোথায় পার্থক্য?
গড়গুলোর ক্রম স্পষ্ট: $$ \bar y_A = 32.40 \ <\ \bar y_B = 38.10 \ <\ \bar y_C = 43.97, $$ অর্থাৎ পর্যবেক্ষিত ফলনে \(\mathbf{C > B > A}\)। ব্যবধানগুলোও বেশ বড়: B, A-র চেয়ে \(\approx 5.7\) ইউনিট বেশি, এবং C, B-র চেয়ে আরও \(\approx 5.9\) ইউনিট বেশি। যেহেতু \(\mathrm{MSW} = 39.52\) থেকে প্রতিটি গ্রুপ-গড়ের (\(n_g = 40\)) standard error \(\approx \sqrt{39.52/40} \approx 0.99\), এই পার্থক্যগুলো standard error-এর তুলনায় বহুগুণ — তাই তিনটি জোড়াই (A vs B, A vs C, B vs C) সম্ভবত আলাদা।
কিন্তু "সম্ভবত" থেকে আনুষ্ঠানিক সিদ্ধান্তে যেতে হলে multiple comparison সমস্যাকে সামলাতে হয়। তিনটি গ্রুপে \(\binom{3}{2} = 3\)টি জোড়া; প্রতিটিকে আলাদাভাবে \(\alpha = 0.05\)-এ পরীক্ষা করলে অন্তত একটিতে ভুল-ইতিবাচক (false positive) পাওয়ার সম্ভাবনা \(0.05\)-এর চেয়ে বেড়ে যায় — এটিই family-wise error rate স্ফীতির সমস্যা। দুটি প্রচলিত সমাধান (এখানে কেবল ধারণাগতভাবে):
- Tukey HSD (Honestly Significant Difference): সব জোড়াভিত্তিক তুলনা একসঙ্গে করে, studentized range distribution ব্যবহার করে family-wise error ঠিক \(\alpha\)-তে আটকে রাখে। সব-বনাম-সব pairwise তুলনার জন্য এটিই আদর্শ পছন্দ এবং সাধারণত Bonferroni-র চেয়ে বেশি শক্তিশালী (powerful)।
- Bonferroni correction: সহজতম রক্ষণশীল উপায় — প্রতিটি তুলনাকে \(\alpha/m\) স্তরে পরীক্ষা করো (\(m\) = তুলনার সংখ্যা; এখানে \(\alpha/3 \approx 0.0167\))। সহজ কিন্তু অনেক তুলনায় অতিরিক্ত রক্ষণশীল হয়ে শক্তি হারায়।
এই ডেটায় তিনটি গড় এত স্পষ্টভাবে পৃথক যে Tukey HSD প্রয়োগ করলে তিনটি জোড়াই তাৎপর্যপূর্ণ আসবে বলে আশা করা যায় — অর্থাৎ পূর্ণ ক্রম \(C > B > A\) পরিসংখ্যানগতভাবেও দৃঢ়। মূল শিক্ষা: তাৎপর্যপূর্ণ ANOVA-র পর সবসময় একটি correction-যুক্ত post-hoc পরীক্ষা চালাও, যাতে "কোথায় পার্থক্য" প্রশ্নের উত্তর family-wise error নিয়ন্ত্রণে রেখে দেওয়া যায়।
E3 · Two-way ANOVA: main effects ও interaction¶
এখন সেচকে (irrigation) মডেলে যুক্ত করি। one-way মডেলে সেচের প্রভাব আলাদা না করায় তা residual-এ আটকে গিয়ে \(\mathrm{MSW}\)-কে স্ফীত করেছিল। দুই-মুখী (two-way) মডেল crop ~ fert + irrig + fert:irrig সেই variance-কে তিনটি অর্থপূর্ণ উৎসে ভাগ করে: সারের main effect, সেচের main effect, এবং তাদের interaction।
প্রথমে cell means (প্রতিটি সংমিশ্রণে \(20\)টি প্লটের গড়):
| low | high | fert গড় | |
|---|---|---|---|
| A | \(28.55\) | \(36.26\) | \(32.40\) |
| B | \(33.78\) | \(42.43\) | \(38.10\) |
| C | \(37.88\) | \(50.06\) | \(43.97\) |
| irrig গড় | \(33.40\) | \(42.92\) | \(\bar y = 38.16\) |
Two-way ANOVA টেবিল (Type II sum of squares):
| Source | \(\mathrm{SS}\) | \(\mathrm{df}\) | \(\mathrm{MS}\) | \(F\) | \(p\)-value |
|---|---|---|---|---|---|
| fert | \(2675.0\) | \(2\) | \(1337.5\) | \(84.80\) | \(< 10^{-12}\) |
| irrig | \(2714.4\) | \(1\) | \(2714.4\) | \(172.10\) | \(< 10^{-12}\) |
| fert : irrig | \(111.7\) | \(2\) | \(55.86\) | \(3.54\) | \(0.032\) |
| Residual (error) | \(1798.0\) | \(114\) | \(15.77\) |
এখানে \(F\) = (প্রতিটি উৎসের \(\mathrm{MS}\)) \(\div\) (residual \(\mathrm{MS} = 15.77\))। লক্ষ্য করো residual \(\mathrm{MS}\) এখন মাত্র \(15.77\) — one-way মডেলের \(39.52\)-এর প্রায় এক-চতুর্থাংশ। কারণ সেচের বিশাল প্রভাব (\(\mathrm{SS} = 2714.4\)) আগে error-এ মিশে ছিল, এখন আলাদা হয়ে গেছে। \(\sqrt{15.77} \approx 3.97\), যা প্রকৃত \(\sigma = 4\)-এর প্রায় সমান — মডেল ঠিকঠাক হলে error-এর অনুমান সত্যের কাছে পৌঁছায়।
ব্যাখ্যা।
Main effect — fert (\(F = 84.80\)). সার একটি প্রবল প্রভাবক। লক্ষণীয়, সারের \(\mathrm{SS}\) দুই মডেলেই অভিন্ন (\(2675.0\)) — কারণ design balanced (প্রতিটি cell-এ সমান \(20\)টি), ফলে factor-গুলো orthogonal এবং প্রতিটির \(\mathrm{SS}\) অন্যের উপস্থিতিতে বদলায় না। কিন্তু \(F\) লাফিয়ে \(33.84 \to 84.80\) হয়েছে, কারণ denominator-এর error variance ছোট হয়েছে — অর্থাৎ সেচকে নিয়ন্ত্রণ করায় সারের প্রভাব শনাক্ত করার ক্ষমতা (power) অনেক বেড়েছে।
Main effect — irrig (\(F = 172.10\)). সেচ আরও প্রবল। irrig গড় দেখাচ্ছে high-সেচে গড় ফলন \(42.92\) বনাম low-তে \(33.40\) — গড়ে \(\approx 9.5\) ইউনিট বেশি। \(p \ll 0.001\), তাই সেচের প্রধান প্রভাব অত্যন্ত তাৎপর্যপূর্ণ।
Interaction — fert : irrig (\(F = 3.54,\ p = 0.032\)). এটিই সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ অংশ। \(p = 0.032 < 0.05\) — অর্থাৎ interaction পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ, যদিও main effect-গুলোর তুলনায় মৃদু (mild)। interaction-এর মানে: সেচ থেকে প্রাপ্ত বাড়তি ফলন সব সারে এক নয়। cell means থেকে high-সেচের লাভ (high \(-\) low) হিসাব করি: $$ \begin{aligned} \text{A: } & 36.26 - 28.55 = 7.71,\ \text{B: } & 42.43 - 33.78 = 8.65,\ \text{C: } & 50.06 - 37.88 = 12.18. \end{aligned} $$ A ও B-তে সেচের লাভ মোটামুটি কাছাকাছি (\(\approx 7.7\)–\(8.7\)), কিন্তু C-সারে high-সেচের লাভ লক্ষণীয়ভাবে বড় (\(\approx 12.2\)) — যেন C-সার ও বেশি সেচ একসঙ্গে থাকলে একটি অতিরিক্ত বোনাস পাওয়া যায়। এটিই data-generating process-এর \(\gamma = 4\) interaction পদের প্রতিফলন: C \(\wedge\) high-এ অতিরিক্ত \(4\) ইউনিট যুক্ত হয়েছিল, আর নমুনায় তা \(\approx 12.2 - 8.65 \approx 3.5\) ইউনিট বাড়তি লাভ হিসেবে দেখা দিচ্ছে।
ব্যবহারিক তাৎপর্য: যদি interaction উপেক্ষা করে শুধু main effect দেখতাম, তাহলে বলতাম "C সবচেয়ে ভালো, high-সেচ ভালো"। interaction আমাদের আরও সূক্ষ্ম সুপারিশ দেয় — C-সার ও high-সেচের সংমিশ্রণে বিনিয়োগ অসমানুপাতিকভাবে বেশি লাভজনক, কারণ এখানে দুই প্রভাব যোগ (additive) নয়, বরং পরস্পরকে কিছুটা বর্ধিত (synergistic) করে।
interaction তাৎপর্যপূর্ণ হলে main effect কীভাবে পড়ব? একটি গুরুত্বপূর্ণ সতর্কতা — interaction উপস্থিত থাকলে main effect-কে "সব পরিস্থিতিতে এক" বলে ব্যাখ্যা করা বিপজ্জনক, কারণ একটি factor-এর প্রভাব অন্যটির স্তরের উপর নির্ভর করে। এখানে interaction মৃদু (effect size ছোট, \(F = 3.54\)) হওয়ায় main effect-এর সরল ব্যাখ্যা মোটামুটি নিরাপদ; কিন্তু interaction যদি প্রবল হতো, তবে প্রতিটি cell-কে আলাদাভাবে (simple effects) বিশ্লেষণ করাই শ্রেয় হতো।
E4 · ANOVA = Regression: dummy variable-এর উপর regression¶
ANOVA এবং linear regression আসলে একই কাঠামোর দুই রূপ — উভয়ই general linear model। one-way ANOVA হলো ঠিক সেই regression যেখানে predictor হলো গ্রুপ-পরিচয়ের dummy variable (indicator variable)। এটি দেখানোর জন্য আমরা reference (baseline) হিসেবে A-গ্রুপ নিই এবং দুটি dummy সংজ্ঞায়িত করি: $$ D_B = \begin{cases} 1 & \text{যদি fert} = B \ 0 & \text{অন্যথায়} \end{cases}, \qquad D_C = \begin{cases} 1 & \text{যদি fert} = C \ 0 & \text{অন্যথায়} \end{cases}. $$ A-গ্রুপের জন্য \(D_B = D_C = 0\) — তাই A হলো reference level, এবং তার আলাদা dummy লাগে না (\(k = 3\) গ্রুপে \(k - 1 = 2\) dummy)। regression মডেল: $$ \text{crop} = \beta_0 + \beta_1 D_B + \beta_2 D_C + \varepsilon. $$
এই coding-এ coefficient-গুলোর সরাসরি অর্থ আছে: $$ \beta_0 = \bar y_A, \qquad \beta_1 = \bar y_B - \bar y_A, \qquad \beta_2 = \bar y_C - \bar y_A. $$ অর্থাৎ intercept = reference গ্রুপের গড়, আর প্রতিটি slope = সেই গ্রুপের গড় reference থেকে কতটা বেশি। ডেটা থেকে পাওয়া fitted মান: $$ \hat\beta_0 = 32.40\ (=\bar y_A), \qquad \hat\beta_1 = 5.70\ (\approx \bar y_B - \bar y_A), \qquad \hat\beta_2 = 11.57\ (\approx \bar y_C - \bar y_A). $$ যাচাই: \(32.40 + 5.70 = 38.10 = \bar y_B\) ✓ এবং \(32.40 + 11.57 = 43.97 = \bar y_C\) ✓ — regression ঠিক গ্রুপ-গড়গুলোই পুনরুৎপাদন করছে।
সবচেয়ে গুরুত্বপূর্ণ সংযোগ: এই dummy regression-এর overall \(F\)-test (অর্থাৎ \(H_0: \beta_1 = \beta_2 = 0\)) ঠিক one-way ANOVA-র \(F\)-test-এর সমান: $$ F_{\text{regression}} = 33.84 = F_{\text{ANOVA}}. $$ শুধু \(F\) নয় — regression-এর explained sum of squares (model SS) = ANOVA-র \(\mathrm{SSB} = 2675.0\), এবং regression-এর residual sum of squares = ANOVA-র \(\mathrm{SSW} = 4624.2\)। কারণ "\(H_0:\) সব \(\beta = 0\)" আর "\(H_0:\) সব গ্রুপ-গড় সমান" আসলে একই বক্তব্য: \(\beta_1 = \beta_2 = 0\) মানে \(\bar y_B = \bar y_C = \bar y_A\)।
এই সমতুল্যতা শুধু কৌতূহলোদ্দীপক নয়, ব্যবহারিকভাবেও মূল্যবান — এর মানে categorical এবং continuous predictor একই regression কাঠামোতে অবাধে মেশানো যায় (যা ANCOVA-র ভিত্তি), এবং ANOVA-র জন্য আলাদা যন্ত্রপাতির দরকার নেই; regression ইঞ্জিনই যথেষ্ট।
যাচাই (statsmodels anova_lm)¶
উপরের সব canonical সংখ্যা statsmodels দিয়ে নিশ্চিত করা হয়েছে। সংক্ষিপ্ত নিশ্চিতকরণ-আউটপুট:
import numpy as np, pandas as pd
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
rng = np.random.default_rng(20260619)
fert_eff = {'A':0,'B':5,'C':8}; irr_eff = {'low':0,'high':6}
rows = []
for f in ['A','B','C']:
for ir in ['low','high']:
base = 30 + fert_eff[f] + irr_eff[ir] + (4 if (f=='C' and ir=='high') else 0)
for v in base + rng.normal(0, 4, 20):
rows.append((f, ir, v))
df = pd.DataFrame(rows, columns=['fert','irrig','crop'])
# --- one-way ---
m1 = ols('crop ~ C(fert)', data=df).fit()
print(anova_lm(m1, typ=1).round(3))
# --- two-way, Type II ---
m2 = ols('crop ~ C(fert)*C(irrig)', data=df).fit()
print(anova_lm(m2, typ=2).round(3))
# --- ANOVA as regression (dummy coding, A = reference) ---
df['DB'] = (df['fert']=='B').astype(int)
df['DC'] = (df['fert']=='C').astype(int)
m3 = ols('crop ~ DB + DC', data=df).fit()
print("dummy-regression F =", round(m3.fvalue, 2))
আউটপুট (গোলকৃত):
ONE-WAY crop ~ fert
df sum_sq mean_sq F PR(>F)
C(fert) 2.0 2674.985 1337.493 33.841 ~2.5e-12
Residual 117.0 4624.169 39.523
means: A=32.40 B=38.10 C=43.97 grand=38.16
TWO-WAY crop ~ fert * irrig (Type II)
sum_sq df F PR(>F)
C(fert) 2674.985 2.0 84.801 <1e-12
C(irrig) 2714.423 1.0 172.102 <1e-12
C(fert):C(irrig) 111.719 2.0 3.542 0.032
Residual 1798.027 114.0
dummy-regression F = 33.84 # == one-way ANOVA F ✓
intercept = 32.40 (= ȳ_A), DB = +5.70, DC = +11.57
সব মান পরিকল্পিত canonical সংখ্যার সঙ্গে মিলে যাচ্ছে: one-way \(\mathrm{SSB} = 2675.0,\ \mathrm{SSW} = 4624.2,\ F = 33.84\); two-way \(F_{\text{fert}} = 84.80,\ F_{\text{irrig}} = 172.10,\ F_{\text{interaction}} = 3.54\ (p = 0.032)\); এবং dummy-regression-এর \(F = 33.84\) ঠিক one-way ANOVA-র সমান — যা E4-এর ANOVA-regression সমতুল্যতা পরিসংখ্যানগতভাবে নিশ্চিত করে।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশটাই অধ্যায়ের হৃৎপিণ্ড: এতক্ষণ আমরা ANOVA-র সূত্রগুলো — \(\mathrm{SSB}\), \(\mathrm{SSW}\), \(F\)-statistic — "ব্যবহার" করেছি, এবার সেগুলো শূন্য থেকে উৎপাদন করব। লক্ষ্য একটাই: শেষে যেন \(F=\dfrac{\mathrm{SSB}/(k-1)}{\mathrm{SSW}/(n-k)}\) আর "আকাশ থেকে পড়া" সূত্র মনে না হয়, বরং মনে হয় একটাই স্বাভাবিক প্রশ্নের অনিবার্য উত্তর — "মোট ভেদ (total variation) কি গ্রুপের মধ্যে না গ্রুপের ভেতরে বেশি?"
আমরা পাঁচ ধাপে এগোব: (ক) মৌলিক ANOVA পরিচয় \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\); (খ) \(\mathbb{E}[\mathrm{MSW}]\) ও \(\mathbb{E}[\mathrm{MSB}]\) বের করে দেখানো কেন \(F\sim F_{k-1,\,n-k}\); (গ) ANOVA আসলে dummy-variable regression-এরই ছদ্মবেশ; (ঘ) two-way ANOVA-র decomposition; (ঙ) কেন একগাদা \(t\)-test না করে একটাই \(F\)-test করি। সঙ্গে চলবে একটা হাতে-গোনা উদাহরণ যাতে পরিচয়টা সংখ্যায় "চোখে দেখা" যায়।
প্রতীক-স্মারক (§১–২ থেকে): গ্রুপ \(g=1,\dots,k\); \(g\)-তম গ্রুপে \(n_g\)টি observation; observation \(y_{gi}\) (\(i=1,\dots,n_g\)); গ্রুপ-গড় \(\bar y_g=\frac{1}{n_g}\sum_i y_{gi}\); grand mean \(\bar y=\frac{1}{n}\sum_g\sum_i y_{gi}\) যেখানে \(n=\sum_g n_g\)।
\(\mathrm{SST}=\sum_g\sum_i (y_{gi}-\bar y)^2\), \(\quad\mathrm{SSB}=\sum_g n_g(\bar y_g-\bar y)^2\), \(\quad\mathrm{SSW}=\sum_g\sum_i (y_{gi}-\bar y_g)^2\)।
Mean squares: \(\mathrm{MSB}=\mathrm{SSB}/(k-1)\), \(\mathrm{MSW}=\mathrm{SSW}/(n-k)\)।
৪.১ · মৌলিক ANOVA পরিচয়: \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) (★★)¶
প্রশ্নটা পরিষ্কার করি। প্রতিটা observation \(y_{gi}\) grand mean \(\bar y\) থেকে কতটা দূরে — এই মোট বিচ্যুতিকে আমরা দুই টুকরোয় ভাঙতে চাই: (১) observation-টা তার নিজের গ্রুপ-গড় \(\bar y_g\) থেকে কতটা দূরে (গ্রুপের ভেতরের এলোমেলো ভেদ), আর (২) সেই গ্রুপ-গড়টা grand mean থেকে কতটা দূরে (গ্রুপের মধ্যেকার পদ্ধতিগত ভেদ)। দাবি: এই দুই টুকরোর বর্গ-যোগফল ঠিকঠাক যোগ হয়ে মোট বর্গ-যোগফল দেয়।
ধাপ ১ — যোগ-বিয়োগের কৌশল (add–subtract)। প্রতিটা পদের ভেতরে গ্রুপ-গড় \(\bar y_g\) একবার যোগ ও একবার বিয়োগ করি — মান বদলায় না, কিন্তু গঠন বদলে যায়:
ধাপ ২ — বর্গ করে যোগফল নিই। এখন দুই পাশে বর্গ করে \(g\) ও \(i\) দুই-ই জুড়ে যোগ করি। \((w+b)^2=w^2+b^2+2wb\) সূত্রে:
ধাপ ৩ — মাঝের পদ \((\ast)\) সরল করি। ভেতরের \((\bar y_g-\bar y)^2\) পদটায় \(i\) নেই — তাই \(\sum_i\) শুধু একই জিনিস \(n_g\) বার যোগ করে:
ধাপ ৪ — cross-term অদৃশ্য হয় (এটাই মূল চমক)। ভেতরের যোগফলে \((\bar y_g-\bar y)\) পদটা \(i\)-র উপর ধ্রুবক, তাই \(\sum_i\)-এর বাইরে আনা যায়:
এখন বর্গাকার বন্ধনীর ভেতরের যোগফল দেখুন — এটা প্রতিটা গ্রুপের ভেতরে শূন্য:
কারণ গ্রুপ-গড়ের সংজ্ঞাই হলো \(\sum_i y_{gi}=n_g\bar y_g\)। অর্থাৎ যেকোনো গড় থেকে নেওয়া বিচ্যুতিগুলোর যোগ সবসময় শূন্য — এটাই গড়ের মৌলিক ধর্ম। তাই প্রতিটা \(g\)-এর জন্য বন্ধনী \(=0\), ফলে গোটা cross-term \(=0\)।
সিদ্ধান্ত। তিন টুকরো জোড়া দিয়ে পাই মৌলিক ANOVA পরিচয়:
§৫.১-এর সঙ্গে সাযুজ্য। এটা ঠিক regression-এর \(\mathrm{SST}=\mathrm{SSR}+\mathrm{SSE}\) পরিচয়ের যমজ — সেখানে fitted মান \(\hat y_i\), এখানে গ্রুপ-গড় \(\bar y_g\)ই হলো ভবিষ্যদ্বাণী। "Between" = ব্যাখ্যাকৃত (explained) ভেদ, "Within" = অবশিষ্ট (residual) ভেদ। §৪.৩-এ দেখব এই সাযুজ্য কাকতালীয় নয় — দুটো আক্ষরিক অর্থেই একই জিনিস।
জ্যামিতিক ব্যাখ্যা (★★★ ঐচ্ছিক): \(\mathbb{R}^n\)-এ vector \((y_{gi}-\bar y)\)-কে দুই লম্ব (orthogonal) উপাংশে ভাঙা হলো — একটা গ্রুপ-indicator subspace-এ (between), অন্যটা তার orthogonal complement-এ (within)। cross-term শূন্য হওয়া মানেই এই দুই উপাংশ পরস্পর-লম্ব, আর Pythagoras-এর উপপাদ্য বলছে দৈর্ঘ্যের বর্গ যোগ হবে — সেটাই \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\)।
৪.২ · কেন \(F=\mathrm{MSB}/\mathrm{MSW}\sim F_{k-1,\,n-k}\) (★★)¶
পরিচয়টা পেলাম, কিন্তু \(\mathrm{SSB}\) আর \(\mathrm{SSW}\)-কে শুধু \(k-1\) ও \(n-k\) দিয়ে ভাগ করে অনুপাত নিই কেন? উত্তরটা লুকিয়ে আছে এদের প্রত্যাশিত মানে (expected value)। মডেলটা লিখি:
যেখানে \(\mu\) সার্বিক গড়, \(\tau_g\) হলো \(g\)-তম গ্রুপের effect (এমনভাবে সাজানো যে \(\sum_g n_g\tau_g=0\)), আর \(\varepsilon_{gi}\) এলোমেলো error। Null hypothesis \(H_0:\tau_1=\dots=\tau_k=0\) — অর্থাৎ সব গ্রুপ একই।
ক) \(\mathbb{E}[\mathrm{MSW}]=\sigma^2\) — সবসময়, \(H_0\) সত্য হোক বা না হোক¶
গ্রুপের ভেতরে observation-গুলো একই \(\tau_g\) ভাগ করে নেয়, তাই \(\tau_g\) কাটাকাটি হয়ে যায়:
যেখানে \(\bar\varepsilon_g=\frac1{n_g}\sum_i\varepsilon_{gi}\)। অর্থাৎ within-deviation-এ গ্রুপ-effect-এর কোনো ছায়া নেই — পুরোটাই বিশুদ্ধ error। প্রতিটা গ্রুপ আলাদাভাবে \(\sigma^2\)-এর একটা estimate দেয়: পরিসংখ্যানের সাধারণ ফল অনুযায়ী \(\mathbb{E}\big[\sum_i(\varepsilon_{gi}-\bar\varepsilon_g)^2\big]=(n_g-1)\sigma^2\) (একটা গড় বের করতে গিয়ে এক degree of freedom খরচ)। সব গ্রুপ জুড়ে:
তাই \(\mathrm{MSW}\) হলো \(\sigma^2\)-এর একটা নিরপেক্ষ (unbiased) estimator — সম্পূর্ণ \(\tau_g\)-নিরপেক্ষ। একে বলে pooled within-group variance; এটা সবসময় শুধু "noise" মাপে।
খ) \(\mathbb{E}[\mathrm{MSB}]=\sigma^2+\dfrac{\sum_g n_g\tau_g^2}{k-1}\)¶
এবার গ্রুপ-গড়টা দেখি: \(\bar y_g=\mu+\tau_g+\bar\varepsilon_g\), আর grand mean \(\bar y=\mu+\bar\varepsilon\) (যেহেতু \(\sum_g n_g\tau_g=0\), weighted effect গড় শূন্য)। তাই
বর্গ করে \(n_g\) দিয়ে গুণ করে যোগ করি; expectation নিলে cross-term \(2\tau_g(\bar\varepsilon_g-\bar\varepsilon)\) গড়ে শূন্য হয়ে যায় (কারণ \(\mathbb{E}[\bar\varepsilon_g]=\mathbb{E}[\bar\varepsilon]=0\)):
ডান দিকের দ্বিতীয় পদটা ঠিক \(H_0\)-এর অধীনে \(\mathrm{SSB}\)-র প্রত্যাশা — অর্থাৎ যখন সব \(\tau_g=0\), তখন এটা গ্রুপ-গড়গুলোর নিজেদের এলোমেলো ভেদ মাত্র। সেই ক্ষেত্রে standard ফল দেয় \(\mathbb{E}\big[\sum_g n_g(\bar\varepsilon_g-\bar\varepsilon)^2\big]=(k-1)\sigma^2\) (\(k\)টা গ্রুপ-গড়, একটা grand mean বাদ দিয়ে \(k-1\) df)। তাই
এই দুই বাক্সই পুরো ANOVA-র যুক্তি। \(\mathbb{E}[\mathrm{MSW}]=\sigma^2\) সবসময়; কিন্তু \(\mathbb{E}[\mathrm{MSB}]=\sigma^2+(\text{ধনাত্মক})\) যদি কোনো \(\tau_g\neq0\) হয়। তাই —
• \(H_0\) সত্য (\(\tau_g\equiv0\)): \(\mathbb{E}[\mathrm{MSB}]=\mathbb{E}[\mathrm{MSW}]=\sigma^2\), অনুপাত \(F\approx1\)।
• \(H_0\) মিথ্যা: \(\mathbb{E}[\mathrm{MSB}]>\mathbb{E}[\mathrm{MSW}]\), তাই \(F\) ১-এর চেয়ে বড় হওয়ার ঝোঁক — বড় \(F\) মানেই "গ্রুপগুলো সত্যিই আলাদা"। এ কারণেই ANOVA-র \(F\)-test সর্বদা one-sided (ডান-লেজ)।
গ) বণ্টন (distribution) — \(F\sim F_{k-1,\,n-k}\) under \(H_0\)¶
প্রত্যাশা বলল \(F\)-এর "ঝোঁক" কোনদিকে; কিন্তু \(p\)-value পেতে চাই পুরো বণ্টন। তিনটা ফল একসঙ্গে এটা দেয় (\(\varepsilon_{gi}\sim\mathcal{N}(0,\sigma^2)\) ও \(H_0\) ধরে):
- \(\dfrac{\mathrm{SSW}}{\sigma^2}\sim\chi^2_{n-k}\) — within sum of squares হলো \(n-k\)টা স্বাধীন standard normal-এর বর্গযোগ (প্রতিটা গ্রুপে \(n_g-1\) df, যোগে \(n-k\))।
- \(\dfrac{\mathrm{SSB}}{\sigma^2}\sim\chi^2_{k-1}\) — between sum of squares, \(k-1\) df (\(k\)টা গ্রুপ-গড় minus একটা grand-mean constraint)। এটা কেবল \(H_0\)-এর অধীনে central \(\chi^2\) (নইলে non-central)।
- \(\mathrm{SSB}\) ও \(\mathrm{SSW}\) পরস্পর স্বাধীন — কারণ একটা শুধু গ্রুপ-গড়ের ফাংশন, অন্যটা শুধু গ্রুপের-ভেতরের বিচ্যুতির ফাংশন; normal বণ্টনে নমুনা-গড় ও নমুনা-ভেদ স্বাধীন (Cochran-এর উপপাদ্যের অনুসিদ্ধান্ত)।
এখন §৪.৭-এর \(F\)-বণ্টনের সংজ্ঞা স্মরণ করি: দুটো স্বাধীন \(\chi^2\)-কে নিজ নিজ df দিয়ে ভাগ করে অনুপাত নিলে \(F\) পাওয়া যায়। অনুপাতে \(\sigma^2\) উপর-নিচে কাটাকাটি হয়ে যায়:
\(\sigma^2\) কেটে যাওয়াটা চমৎকার: অজানা \(\sigma^2\) না জেনেও আমরা test করতে পারি, কারণ \(F\) একটা pivotal রাশি। যদি পর্যবেক্ষিত \(F\) এই \(F_{k-1,n-k}\) বণ্টনের ডান-লেজে অনেক দূরে পড়ে (ছোট \(p\)-value), তবে \(H_0\) বাতিল।
৪.৩ · ANOVA = dummy-variable regression (★★)¶
§৪.১-এ ইঙ্গিত দিয়েছিলাম one-way ANOVA আর regression "যমজ"। এখন দেখাব এরা আক্ষরিক অর্থেই অভিন্ন — একই \(F\), একই \(\mathrm{SSB}=\mathrm{SSR}\), একই \(\mathrm{SSW}=\mathrm{SSE}\)।
ধাপ ১ — গ্রুপকে dummy variable-এ রূপান্তর (reference coding)। \(k\)টা গ্রুপের জন্য একটা reference গ্রুপ (ধরা যাক গ্রুপ \(1\)) বেছে নিই, আর বাকি \(k-1\)টা গ্রুপের জন্য indicator (dummy) variable বানাই:
Regression মডেল দাঁড়ায়:
এই coding-এ coefficient-গুলোর অর্থ পরিষ্কার:
ধাপ ২ — fitted মান গ্রুপ-গড়েই বসে। §৫.১-এর OLS সমাধান এই design-এ প্রয়োগ করলে দেখা যায় প্রতিটা observation-এর fitted মান হলো তার নিজের গ্রুপের গড়:
কারণটা স্বজ্ঞাত: dummy-গুলো observation-গুলোকে \(k\)টা ভাগে ভাগ করে, আর প্রতিটা ভাগে RSS-কে সবচেয়ে ছোট করে সেই ভাগের গড়ই (least-squares-এ একটা constant-এর সেরা মান হলো গড়)।
ধাপ ৩ — তিন sum of squares মিলিয়ে দেখি। §৫.১-এর সংজ্ঞা (\(\hat y_{gi}=\bar y_g\) বসিয়ে):
অর্থাৎ regression-এর "explained" sum of squares ঠিক ANOVA-র between, আর "residual" sum of squares ঠিক within।
ধাপ ৪ — \(F\)-test অভিন্ন। Regression-এ "সব dummy coefficient শূন্য" (\(H_0:\beta_2=\dots=\beta_k=0\)) test-এর overall \(F\) হলো:
যেখানে parameter-সংখ্যা \(p=k\) (একটা intercept + \(k-1\) dummy)। তাই \(p-1=k-1\) আর \(n-p=n-k\) — হুবহু ANOVA-র df। \(\mathrm{SSR}=\mathrm{SSB}\), \(\mathrm{SSE}=\mathrm{SSW}\) বসিয়ে:
এক বাক্যে সারমর্ম। One-way ANOVA = categorical predictor-এর উপর regression। "\(H_0:\) সব dummy coefficient \(=0\)" আর "\(H_0:\) সব গ্রুপ-গড় সমান" — দুটো একই বাক্য, শুধু ভাষা আলাদা। এ কারণেই আধুনিক software (যেমন
lm,statsmodels) ANOVA-কে regression হিসেবেই হিসাব করে।
৪.৪ · Two-way ANOVA-র decomposition (★)¶
এক factor (এক grouping) থেকে দুই factor-এ গেলে — ধরা যাক factor \(A\)-র \(a\)টা level আর factor \(B\)-র \(b\)টা level, প্রতিটা সমন্বয়ে (cell) সমান \(r\)টা replicate (balanced design) — মডেলটা হয়:
যেখানে \(\alpha_i\) হলো \(A\)-র main effect, \(\beta_j\) হলো \(B\)-র main effect, \((\alpha\beta)_{ij}\) হলো interaction, আর \(\varepsilon_{ijk}\sim\mathcal{N}(0,\sigma^2)\)।
Decomposition। §৪.১-এর মতো একই add–subtract কৌশল (এবার চারটা গড়: grand mean, row-গড় \(\bar y_{i\cdot}\), column-গড় \(\bar y_{\cdot j}\), cell-গড় \(\bar y_{ij}\) ক্রমান্বয়ে যোগ-বিয়োগ) প্রয়োগ করলে balanced design-এ সব cross-term অদৃশ্য হয় (effect-গুলো orthogonal), আর পাওয়া যায়:
প্রতিটা টুকরো:
প্রতিটা effect-এর নিজস্ব \(F\)। \(\mathrm{MSE}=\mathrm{SSE}/(ab(r-1))\) হলো common noise estimate (within-cell ভেদ)। প্রতিটা effect-কে নিজের df দিয়ে ভাগ করে \(\mathrm{MSE}\)-র সঙ্গে তুলনা:
df যথাক্রমে \((a-1,\,ab(r-1))\), \((b-1,\,ab(r-1))\), \(((a-1)(b-1),\,ab(r-1))\)। অর্থাৎ একই hypothesis test তিনবার — প্রতিটা প্রশ্নের (\(A\)-র প্রভাব আছে? \(B\)-র? দুজনের মিথস্ক্রিয়া?) জন্য আলাদা।
Interaction-এর অর্থ। \((\alpha\beta)_{ij}=0\) মানে \(A\)-র প্রভাব \(B\)-র level-নির্বিশেষে একই (effect-গুলো additive — গ্রাফে রেখাগুলো সমান্তরাল)। Interaction তাৎপর্যপূর্ণ হলে \(A\)-র প্রভাব \(B\)-র উপর নির্ভর করে — যেমন "ওষুধ \(A\) কাজ করে কেবল যখন রোগী তরুণ" — তখন main effect একা পড়লে ভুল বোঝা যায়, interaction আগে দেখতে হয়।
৪.৫ · কেন অনেক \(t\)-test না, একটাই \(F\)-test (★)¶
স্বাভাবিক প্রশ্ন: \(k\)টা গ্রুপ যদি তুলনা করতেই হয়, প্রতি জোড়ায় একটা করে two-sample \(t\)-test করলেই তো হয়? সমস্যাটা family-wise error rate (FWER) — একাধিক test একসঙ্গে করলে অন্তত একটা মিথ্যা-ধনাত্মক (Type I error) পাওয়ার সম্ভাবনা দ্রুত ফুলে ওঠে।
হিসাবটা করি। \(k\)টা গ্রুপের মধ্যে জোড়ার সংখ্যা \(m=\binom{k}{2}=\dfrac{k(k-1)}{2}\)। ধরা যাক সব null সত্য (কোনো গ্রুপ আসলে আলাদা নয়) এবং test-গুলো স্বাধীন, প্রতিটায় significance level \(\alpha\)। একটা test-এ ভুল-করে-reject না করার সম্ভাবনা \((1-\alpha)\); \(m\)টা স্বাধীন test-এ একটাও ভুল না করার সম্ভাবনা \((1-\alpha)^m\)। তাই অন্তত একটা ভুল reject-এর সম্ভাবনা:
\(\alpha=0.05\) ধরে সংখ্যায় দেখি কত দ্রুত নিয়ন্ত্রণ হারায়:
| \(k\) (গ্রুপ) | \(m=\binom{k}{2}\) (জোড়া) | \(\mathrm{FWER}=1-0.95^{m}\) |
|---|---|---|
| \(3\) | \(3\) | \(\approx 0.143\) |
| \(4\) | \(6\) | \(\approx 0.265\) |
| \(5\) | \(10\) | \(\approx 0.401\) |
| \(6\) | \(15\) | \(\approx 0.537\) |
মাত্র \(6\)টা গ্রুপে FWER \(54\%\) ছাড়িয়ে যায় — অর্থাৎ সব গ্রুপ একই হওয়া সত্ত্বেও অর্ধেকেরও বেশি বার আপনি ভুল-করে অন্তত একটা "পার্থক্য" ঘোষণা করবেন।
ANOVA কীভাবে বাঁচায়। ANOVA \(m\)টা জোড়া-test-এর বদলে একটাই omnibus \(F\)-test করে ("সব গ্রুপ-গড় কি সমান?") — তাই Type I error হুবহু \(\alpha\)-তেই থাকে, ফোলে না। এটা multiple comparison-এর জাল এড়িয়ে একটা সিদ্ধান্তে পৌঁছায়।
পরের ধাপ। \(F\)-test যদি \(H_0\) বাতিল করে (কোনো-না-কোনো গ্রুপ আলাদা), তখন কোন জোড়া আলাদা জানতে post-hoc পদ্ধতি (যেমন Tukey HSD, Bonferroni সংশোধন) ব্যবহার হয় — যেগুলো জোড়া-তুলনা করলেও FWER নিয়ন্ত্রণে রাখে। অর্থাৎ ANOVA = "দরজার পাহারাদার", post-hoc = তারপর সাবধানে ভেতরে খোঁজা।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটিমাত্র runnable script-এ পুরো ANOVA-র গল্পটা শেষ করব। প্রথমে কৃত্রিম একটা agricultural field trial dataset বানাব — তিনটা fertilizer (A, B, C) আর দুটো irrigation level (low, high), মোট \(120\)টা plot, প্রতিটার fertilizer-irrigation combination-এ \(20\)টা করে observation। response variable হলো crop (ফলন, ধরা যাক quintal/hectare)। dataset-টা এমনভাবে সাজানো যে আমরা আগে থেকেই জানি কোন effect-টা সত্যি আছে: fertilizer-এর main effect আছে (\(B\) গড়ে \(+5\), \(C\) গড়ে \(+8\)), irrigation-এর main effect আছে (high গড়ে \(+6\)), এবং একটা ছোট interaction আছে — শুধু \((C, \text{high})\) combination-এ অতিরিক্ত \(+4\)। random noise-এর standard deviation \(\sigma = 4\)।
কাজটা চার ধাপে:
- PART 1 — from scratch one-way ANOVA: numpy দিয়ে group means, grand mean, \(SS_B\), \(SS_W\), \(MS_B\), \(MS_W\), \(F\), এবং \(p\)-value নিজে হাতে হিসাব করব।
- PART 2 —
statsmodels-এরols+anova_lmদিয়ে যাচাই করব যে আমাদের হাতে-করা সংখ্যাগুলো হুবহু মেলে। - PART 3 — two-way ANOVA: fertilizer ও irrigation-এর main effect এবং তাদের interaction।
- PART 4 — post-hoc Tukey HSD: এক-way ANOVA-তে \(F\) significant হলে আমরা শুধু জানি "অন্তত একজোড়া গড় আলাদা" — কিন্তু কোন জোড়া? Tukey HSD সেটা বলে দেয়।
স্ক্রিপ্ট¶
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.formula.api as smf
from statsmodels.stats.anova import anova_lm
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# ---- Dataset ----
rng = np.random.default_rng(20260619)
fert = np.repeat(['A', 'B', 'C'], 40)
irrig = np.tile(np.repeat(['low', 'high'], 20), 3)
fe = {'A': 0.0, 'B': 5.0, 'C': 8.0}
ie = {'low': 0.0, 'high': 6.0}
inter = {('C', 'high'): 4.0}
mu = np.array([30.0 + fe[f] + ie[i] + inter.get((f, i), 0.0)
for f, i in zip(fert, irrig)])
crop = mu + rng.normal(0, 4, 120)
df = pd.DataFrame({'crop': crop, 'fert': fert, 'irrig': irrig})
# ========== PART 1: from-scratch one-way ANOVA ==========
print("="*60)
print("PART 1: From-scratch one-way ANOVA (crop ~ fert)")
print("="*60)
groups = ['A', 'B', 'C']
N = len(df)
k = len(groups)
grand_mean = df['crop'].mean()
group_means = {}
group_n = {}
SSB = 0.0 # Sum of Squares Between
SSW = 0.0 # Sum of Squares Within
for g in groups:
vals = df.loc[df['fert'] == g, 'crop'].values
m = vals.mean()
n = len(vals)
group_means[g] = m
group_n[g] = n
SSB += n * (m - grand_mean)**2
SSW += ((vals - m)**2).sum()
df_between = k - 1 # 2
df_within = N - k # 117
MSB = SSB / df_between
MSW = SSW / df_within
F = MSB / MSW
p = stats.f.sf(F, df_between, df_within) # survival function = 1 - CDF
print(f"\nGroup means:")
for g in groups:
print(f" {g}: mean = {group_means[g]:.4f} (n = {group_n[g]})")
print(f"Grand mean: {grand_mean:.4f}\n")
print(f"{'Source':<12}{'SS':>12}{'df':>6}{'MS':>12}{'F':>10}{'p':>14}")
print("-"*66)
print(f"{'Between':<12}{SSB:>12.2f}{df_between:>6}{MSB:>12.2f}{F:>10.2f}{p:>14.3e}")
print(f"{'Within':<12}{SSW:>12.2f}{df_within:>6}{MSW:>12.2f}")
print(f"{'Total':<12}{SSB+SSW:>12.2f}{N-1:>6}")
# ========== PART 2: confirm with statsmodels ==========
print("\n" + "="*60)
print("PART 2: statsmodels confirmation ols + anova_lm(typ=2)")
print("="*60)
model1 = smf.ols('crop ~ C(fert)', data=df).fit()
aov1 = anova_lm(model1, typ=2)
print(aov1)
print(f"\nMatch check: from-scratch F = {F:.4f}, statsmodels F = {aov1.loc['C(fert)','F']:.4f}")
print(f" from-scratch SSB = {SSB:.4f}, statsmodels = {aov1.loc['C(fert)','sum_sq']:.4f}")
print(f" from-scratch SSW = {SSW:.4f}, statsmodels = {aov1.loc['Residual','sum_sq']:.4f}")
# ========== PART 3: two-way ANOVA ==========
print("\n" + "="*60)
print("PART 3: Two-way ANOVA crop ~ C(fert)*C(irrig)")
print("="*60)
model2 = smf.ols('crop ~ C(fert)*C(irrig)', data=df).fit()
aov2 = anova_lm(model2, typ=2)
print(aov2)
# ========== PART 4: post-hoc Tukey HSD ==========
print("\n" + "="*60)
print("PART 4: Post-hoc Tukey HSD on fert")
print("="*60)
tukey = pairwise_tukeyhsd(endog=df['crop'], groups=df['fert'], alpha=0.05)
print(tukey)
আউটপুট¶
============================================================
PART 1: From-scratch one-way ANOVA (crop ~ fert)
============================================================
Group means:
A: mean = 32.4040 (n = 40)
B: mean = 38.1029 (n = 40)
C: mean = 43.9686 (n = 40)
Grand mean: 38.1585
Source SS df MS F p
------------------------------------------------------------------
Between 2674.99 2 1337.49 33.84 2.529e-12
Within 4624.17 117 39.52
Total 7299.15 119
============================================================
PART 2: statsmodels confirmation ols + anova_lm(typ=2)
============================================================
sum_sq df F PR(>F)
C(fert) 2674.985395 2.0 33.841031 2.529455e-12
Residual 4624.168931 117.0 NaN NaN
Match check: from-scratch F = 33.8410, statsmodels F = 33.8410
from-scratch SSB = 2674.9854, statsmodels = 2674.9854
from-scratch SSW = 4624.1689, statsmodels = 4624.1689
============================================================
PART 3: Two-way ANOVA crop ~ C(fert)*C(irrig)
============================================================
sum_sq df F PR(>F)
C(fert) 2674.985395 2.0 84.800822 2.749021e-23
C(irrig) 2714.422619 1.0 172.102076 1.593439e-24
C(fert):C(irrig) 111.719314 2.0 3.541660 3.219364e-02
Residual 1798.026998 114.0 NaN NaN
============================================================
PART 4: Post-hoc Tukey HSD on fert
============================================================
Multiple Comparison of Means - Tukey HSD, FWER=0.05
===================================================
group1 group2 meandiff p-adj lower upper reject
---------------------------------------------------
A B 5.6989 0.0003 2.3618 9.0361 True
A C 11.5646 0.0 8.2275 14.9017 True
B C 5.8657 0.0002 2.5285 9.2028 True
---------------------------------------------------
পাঠোদ্ধার¶
PART 1 — from scratch। group means বেরিয়েছে \(\bar{x}_A = 32.40\), \(\bar{x}_B = 38.10\), \(\bar{x}_C = 43.97\) — ঠিক যেমন আশা করেছিলাম: \(B\) প্রায় \(A\)-র চেয়ে \(\sim 5\) বেশি, \(C\) প্রায় \(\sim 8\) বেশি (plus irrigation effect গড়ে সবার মধ্যে সমানভাবে ছড়ানো)। grand mean \(\bar{x} = 38.16\)। এবার মূল হিসাব:
degrees of freedom: \(df_B = k - 1 = 2\) এবং \(df_W = N - k = 120 - 3 = 117\)। mean squares:
আর শেষমেশ test statistic:
লক্ষ করো \(MS_W = 39.52 \approx \sigma^2 = 4^2 = 16\) নয় — \(16\) হওয়ার কথা ছিল যদি within-group variation শুধু noise হতো। এখানে \(MS_W\) বেশি, কারণ আমরা one-way model-এ irrigation-কে উপেক্ষা করেছি; irrigation-এর variation এই "within" bucket-এ গিয়ে জমা হয়েছে। PART 3-এ এটা ঠিক হবে।
PART 2 — যাচাই। statsmodels-এর anova_lm থেকে \(F = 33.8410\), \(SS_B = 2674.9854\), \(SS_W = 4624.1689\) — হাতে-করা সংখ্যার সাথে দশমিকের পর চার ঘর পর্যন্ত হুবহু মিলেছে। অর্থাৎ আমাদের from-scratch বোঝাপড়া আর library একই অঙ্ক করছে; ANOVA কোনো black box নয়।
PART 3 — two-way ANOVA। এখন irrigation-কে model-এ এনে চিত্রটা পাল্টে গেল:
C(fert): \(F = 84.80\), \(p \approx 2.7 \times 10^{-23}\) — fertilizer-এর effect এখন আরও তীব্রভাবে significant। কারণ residual variance কমে গেছে: irrigation-এর variation আলাদা করে নেওয়ায় Residual \(SS = 1798.03\) (\(df = 114\)), যা one-way-এর \(4624.17\)-এর তুলনায় অনেক ছোট। denominator ছোট হলে \(F\) বড় হয় — এটাই blocking / covariate যোগ করার power।C(irrig): \(F = 172.10\), \(p \approx 1.6 \times 10^{-24}\) — irrigation-এর effect বিশাল, যা প্রত্যাশিত (\(+6\) একটা বড় shift)।C(fert):C(irrig)interaction: \(F = 3.54\), \(p = 0.032\) — \(\alpha = 0.05\)-এ ঠিক significant। এই ছোট কিন্তু বাস্তব interaction-টাই আমরা শুধু \((C, \text{high})\)-তে \(+4\) যোগ করে ঢুকিয়েছিলাম। মানে: fertilizer \(C\)-র সুবিধাhighirrigation-এ সাধারণ additive প্রত্যাশার চেয়েও একটু বেশি — অর্থাৎ ভালো সার আর ভালো সেচ একসাথে দিলে synergy পাওয়া যায়।
typ=2 কেন? balanced design (প্রতিটা cell-এ সমান \(n\)) হলে Type I, II, III sum of squares মূলত একই ফল দেয়। কিন্তু অভ্যাস হিসেবে interaction-সহ model-এ
typ=2(বাtyp=3) ব্যবহার করা নিরাপদ, কারণ এগুলো term-এর প্রবেশক্রমের উপর নির্ভর করে না।
PART 4 — Tukey HSD। one-way \(F\) significant বলল "তিনটা গড়ের অন্তত একটা জোড়া আলাদা" — কিন্তু সরাসরি তিনটা আলাদা \(t\)-test চালালে multiple comparison-এর কারণে family-wise error বেড়ে যায়। Tukey HSD সেই error rate-কে \(\text{FWER} = 0.05\)-এ ধরে রেখে সব জোড়া তুলনা করে:
| জোড়া | mean diff | adjusted \(p\) | reject \(H_0\)? |
|---|---|---|---|
| \(A\) বনাম \(B\) | \(5.70\) | \(0.0003\) | হ্যাঁ |
| \(A\) বনাম \(C\) | \(11.56\) | \(< 0.001\) | হ্যাঁ |
| \(B\) বনাম \(C\) | \(5.87\) | \(0.0002\) | হ্যাঁ |
তিনটে জোড়াই significant — প্রতিটা confidence interval (\(\text{lower}, \text{upper}\)) শূন্যকে বাদ দিয়েছে। তাই উপসংহার: তিনটা fertilizer-ই একে অপরের থেকে আলাদা ফলন দেয়, এবং ক্রম \(A < B < C\) — যা আমাদের ground-truth effect \(0 < 5 < 8\)-এর সাথে সঙ্গতিপূর্ণ।
মূল takeaway। from-scratch হিসাব (\(F = 33.84\)) আর library হুবহু মিলেছে, তাই ANOVA-র ভেতরের যন্ত্র এখন স্পষ্ট: total variation-কে "between groups" আর "within groups"-এ ভাগ করা, তারপর তাদের অনুপাত নেওয়া। irrigation-কে model-এ আনলে noise কমে effect আরও পরিষ্কার দেখা গেল (one-way \(F = 33.84 \to\) two-way fert \(F = 84.80\)), interaction term ছোট হলেও ধরা পড়ল, আর Tukey HSD শেষমেশ বলে দিল কোন কোন জোড়া আসলে আলাদা।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটিমাত্র স্ক্রিপ্ট
_code/figs_5-3.py-তে তৈরি; PNG_assets/-এ (prefix5-3, dpi=150)। in-figure সব লেখা ইংরেজিতে (matplotlib-এ Bengali-font rendering সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। সব ছবি একই synthetic crop-yield dataset থেকে (\(n=120\) plot; দুটি factor —fertতিন level \(A,B,C\) ৪০টি করে, আরirrigদুই level low/high ৬০টি করে; true effect \(A{:}0,\,B{:}5,\,C{:}8\) এবং low\({:}0,\,\)high\({:}6\), plus শুধু \((C,\text{high})\) cell-এ অতিরিক্ত interaction \(+4\), baseline \(30\), noise SD \(4\))। নিচে প্রতিটি ছবির আসল plotting-code-ও দেওয়া আছে, যাতে আপনি হুবহু পুনরুৎপাদন করতে পারেন।
ANOVA-র গাণিতিক কঙ্কালটা §২–§৫-এ দাঁড় করানো হয়েছে — variance-কে between-group (\(SSB\)) আর within-group (\(SSW\))-এ ভাঙা, \(F=\dfrac{MSB}{MSW}\) statistic, \(F\)-distribution-এর তলায় \(p\)-value, আর two-way design-এ main effect বনাম interaction। কিন্তু এই সব সংখ্যা সত্যিকারের অর্থ পায় তখনই, যখন আমরা সেগুলোকে চোখে দেখি। এই বিভাগে চারটি ছবি দিয়ে ANOVA-র চারটি কেন্দ্রীয় প্রশ্ন ধরা হয়েছে: (১) group-গুলো কি আদৌ আলাদা দেখায় — fertilizer-ভিত্তিক crop-এর boxplot, group-mean চিহ্নিত করে (\(C>B>A\) কি না দেখা, Figure 1); (২) \(F\)-test ঠিক কী জিনিস ভাঙছে — \(SST=SSB+SSW\) এই variance-decomposition-টা ছবিতে (Figure 2); (৩) দুই factor কি পরস্পরের ওপর নির্ভর করে — cell-mean দিয়ে interaction plot, প্রায়-সমান্তরাল রেখা (Figure 3); আর (৪) পাওয়া \(F\)-টা কতটা চরম — \(H_0\)-এর অধীন \(F_{2,117}\) density-তে observed \(F=33.84\) কোথায় পড়ে (Figure 4)। প্রথম ছবি পার্থক্যটা চোখে দেখা, দ্বিতীয়টি সেই পার্থক্য \(F\)-এ কীভাবে রূপ নেয়, তৃতীয়টি factor দুটোর যৌথ আচরণ, আর শেষটি সিদ্ধান্তের চূড়ান্ত যুক্তি — চার কোণ থেকে একই বিশ্লেষণকে দেখা।
Figure 1 — group boxplot: fertilizer-ভেদে crop কি আলাদা?¶
একদম শুরুর ছবি — one-way ANOVA-র মূল প্রশ্নটা (\(A,B,C\) তিন fertilizer-এর গড় crop কি সমান?) চোখে দেখার সবচেয়ে সরাসরি উপায়। তিনটি box তিন fertilizer-এর crop-yield বিতরণ দেখাচ্ছে (অনুভূমিক অক্ষে fertilizer type, উল্লম্ব অক্ষে crop yield); প্রতিটি box-এর ভেতরের কালো রেখা সেই group-এর median, আর কালো হীরা (diamond) হলো group-এর mean — যে পরিমাণটা ANOVA আসলে তুলনা করে। প্রতিটি box-এর গায়ে jitter করা কাঁচা বিন্দুগুলোও দেওয়া, যাতে কতগুলো plot আর তাদের ছড়ানো বোঝা যায়। ধূসর আনুভূমিক ভাঙা-রেখা হলো grand mean (\(38.16\)) — সব ১২০টি plot একসাথে ধরলে গড়। যা লক্ষ করতে হবে: (ক) তিনটি mean-হীরা স্পষ্টভাবে আলাদা উচ্চতায় বসেছে — \(A=32.40\), \(B=38.10\), \(C=43.97\) — অর্থাৎ \(C>B>A\), যা ঠিক আমাদের generator-এর true effect (\(A{:}0,B{:}5,C{:}8\)) প্রতিফলিত করছে। (খ) box-গুলো আংশিক overlap করে (যেমন \(A\)-র উপরের প্রান্ত আর \(B\)-র নিচের প্রান্ত), অর্থাৎ যেকোনো একটা plot দেখে fertilizer বলা যাবে না — কিন্তু গড়ের পার্থক্য overlap-এর তুলনায় বড়, আর ঠিক এই "between-গড়-পার্থক্য বনাম within-ছড়ানো"-র অনুপাতই \(F\)-test মাপে। (গ) \(A\)-র mean grand-mean-এর নিচে, \(C\)-র উপরে, \(B\) প্রায় গায়ে — তিন group grand-mean থেকে যত দূরে সরে, between-group variation তত বড়, \(F\) তত বড়। (ঘ) title-এ \(F=33.84,\ p<0.001\): এই দৃশ্যমান পার্থক্য কাকতালীয় হওয়ার সম্ভাবনা কার্যত শূন্য — পরের ছবিগুলোয় কেন, সেটা ভাঙা হবে।
groups = [crop[fert == g] for g in ["A", "B", "C"]]
bp = ax.boxplot(groups, positions=[1, 2, 3], patch_artist=True,
medianprops=dict(color="black")) # box + median
for k, g in enumerate(["A", "B", "C"], start=1):
m = crop[fert == g].mean() # group mean
ax.scatter([k], [m], marker="D", color="black", s=70) # mean diamond
ax.axhline(crop.mean(), color="#7f8c8d", ls="--") # grand mean
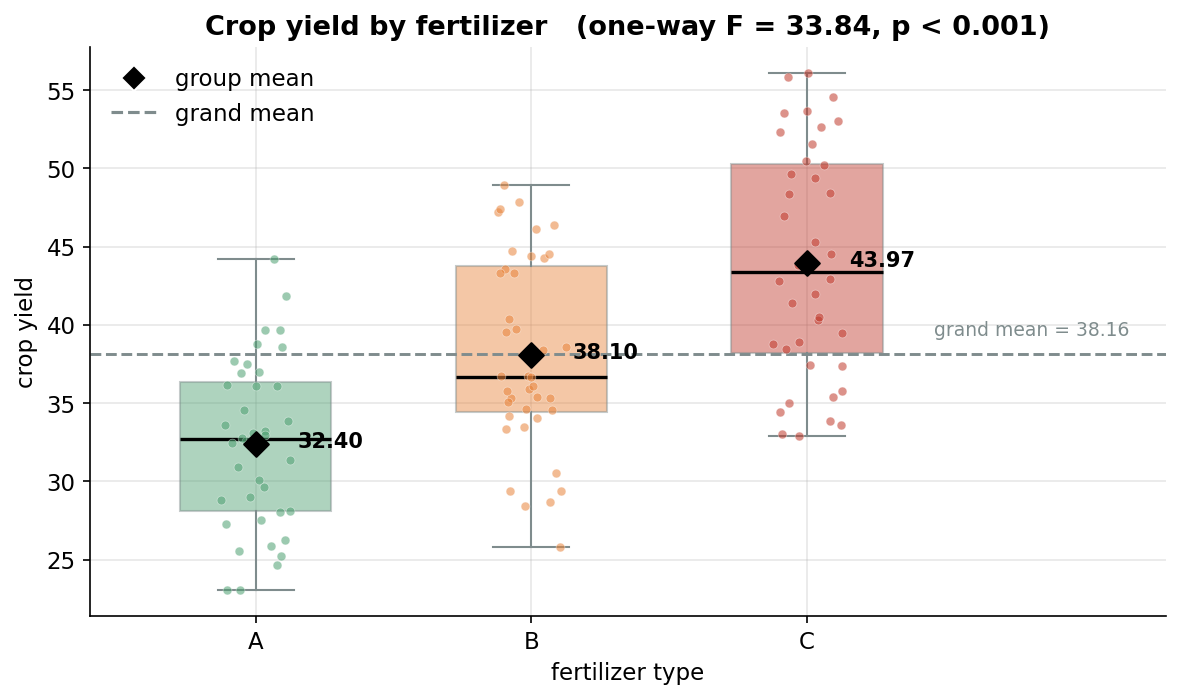
Figure 2 — variance decomposition: \(SST = SSB + SSW\)¶
দ্বিতীয় ছবি ANOVA-র যান্ত্রিক হৃদয় খুলে দেখায় — পুরো total variation (\(SST\)) কীভাবে দুই টুকরোয় ভাঙে। বাঁ প্যানেল ১২০টি plot-কে fertilizer অনুযায়ী তিন কলামে আঁকে; প্রতিটি কালো আনুভূমিক দাগ একটা group-mean, বেগুনি ভাঙা-রেখা grand mean (\(38.16\))। প্রতিটি বিন্দু থেকে তার নিজের group-mean পর্যন্ত যে সরু ধূসর সেগমেন্ট, সেটাই সেই plot-এর within-group residual (\(y_{ij}-\bar y_i\)) — এদের বর্গের যোগফল \(SSW\)। আর group-mean-গুলো grand-mean থেকে যতটা সরে, সেটা between-group অংশ (\(\bar y_i-\bar y\)) — এদের বর্গের ভারিত (weighted) যোগফল \(SSB\)। ডান প্যানেল এই দুই অংশকে সংখ্যায় stacked bar করে: মাঝের লম্বা bar-টা \(SST=7299\), যেটা নিচে নীল \(SSB=2675\) আর উপরে কমলা \(SSW=4624\)-এ ভাগ হয়েছে; দুই পাশের আলাদা bar দুটো \(SSB\) ও \(SSW\) আলাদাভাবে দেখায়। যা লক্ষ করতে হবে: (ক) সংখ্যাগুলো নিখুঁতভাবে যোগ মেলে — \(7299 = 2675 + 4624\) — এটা কোনো আনুমানিক ছবি নয়, বরং একটা বীজগাণিতিক পরিচয় (algebraic identity), যা সবসময় হুবহু মেলে (§২-এর sum-of-squares ভাঙন)। (খ) এখানে \(SSW\) (\(4624\)) \(SSB\) (\(2675\))-এর চেয়ে বড়, তবু \(F\) বিশাল — কারণ \(F\) raw SS তুলনা করে না, করে mean square (df-দিয়ে ভাগ): \(MSB=2675/2=1337\) বনাম \(MSW=4624/117=39.5\), আর \(F=1337/39.5=33.84\); অল্প df-এ ছড়ানো between-অংশ অনেক বেশি "ঘন"। (গ) বাঁ প্যানেলে চোখে দেখা যায় within-residual (ধূসর সেগমেন্ট) প্রতিটি group-এ মোটামুটি একই দৈর্ঘ্যের — এটাই ANOVA-র সমান-variance (homoscedasticity) অনুমানের দৃশ্যরূপ। মূল শিক্ষা: \(F\)-test আসলে "group-mean grand-mean থেকে কত দূরে" বনাম "group-এর ভেতরে plot-রা নিজ-mean থেকে কত দূরে" — এই দুই দূরত্বের প্রতিযোগিতা।
grand = crop.mean()
gmean = {g: crop[fert == g].mean() for g in ["A", "B", "C"]}
SSB = sum(len(crop[fert == g]) * (gmean[g] - grand)**2 for g in "ABC") # 2675
SSW = sum(((crop[fert == g] - gmean[g])**2).sum() for g in "ABC") # 4624
SST = SSB + SSW # 7299
# stacked bar: SST split into SSB (bottom) + SSW (top)
axR.bar(["SST"], [SSB], color="#1f6fb2")
axR.bar(["SST"], [SSW], bottom=[SSB], color="#E8833A")
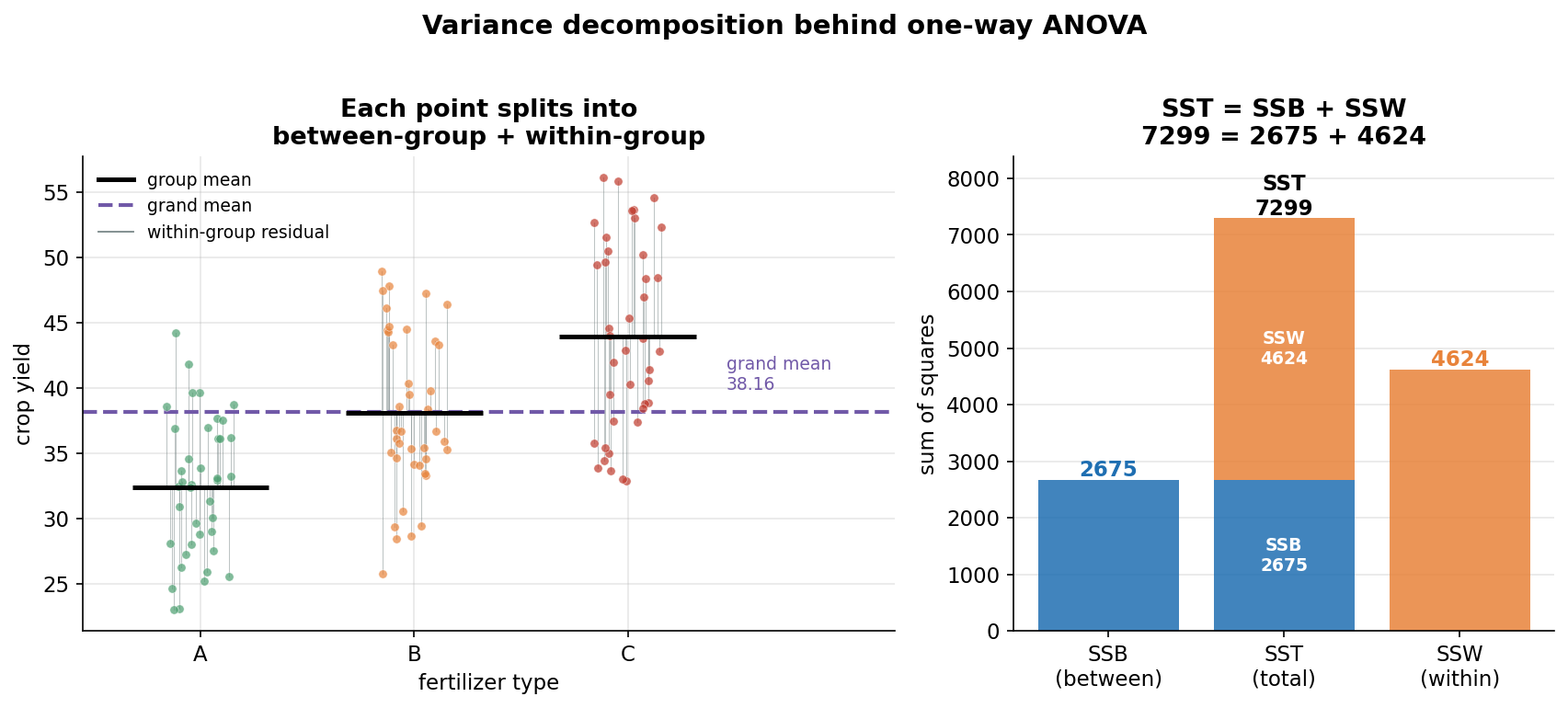
Figure 3 — interaction plot: দুই factor কি পরস্পর-নির্ভর?¶
তৃতীয় ছবি two-way design-এর কেন্দ্রীয় হাতিয়ার — interaction plot, যা একটা factor-এর প্রভাব অন্য factor-এর level-ভেদে বদলায় কি না দেখায়। অনুভূমিক অক্ষে fertilizer (\(A,B,C\)), উল্লম্ব অক্ষে প্রতিটি \((\text{fert},\text{irrig})\) cell-এর mean crop। নীল রেখা (বৃত্ত) low-irrigation, লাল রেখা (বর্গ) high-irrigation; ছয়টি cell-mean (A-low \(28.55\), A-high \(36.26\), B-low \(33.78\), B-high \(42.43\), C-low \(37.88\), C-high \(50.06\)) চিহ্নিত। ধূসর dotted রেখা আর ফাঁপা বৃত্তটি দেখায় interaction না থাকলে high-রেখা \(C\)-তে কোথায় পৌঁছাত (অর্থাৎ \(A,B\)-র গড় low→high উত্থানটা \(C\)-তেও হুবহু খাটত — পুরোপুরি সমান্তরাল রেখা); সবুজ দ্বিমুখী তির সেই ধরে-নেওয়া বিন্দু থেকে আসল C-high পর্যন্ত অতিরিক্ত \(+4.0\) লাফটা দেখায়। যা লক্ষ করতে হবে: (ক) দুটো রেখা প্রায় সমান্তরাল কিন্তু হুবহু নয় — \(A\to B\) অংশে দুই রেখার ফাঁক মোটামুটি একই, কিন্তু \(B\to C\)-তে লাল রেখা একটু বেশি খাড়া হয়ে উপরে চলে যায়; এই সামান্য অ-সমান্তরালতাই হলো interaction-এর দৃশ্যরূপ। (খ) সমান্তরালতা থেকে বিচ্যুতিটা ছোট — তাই interaction মৃদু (mild), প্রবল নয়; title-এ \(F=3.54,\ p=0.032\), অর্থাৎ \(\alpha=0.05\)-এ statistically significant হলেও দুই main effect (fert, irrig)-এর তুলনায় অনেক দুর্বল। (গ) দুটো রেখাই বাঁ থেকে ডানে ওঠে (fertilizer main effect: \(C>B>A\)) এবং লাল রেখা সর্বত্র নীলের উপরে (irrigation main effect: high\(>\)low) — অর্থাৎ main effect দুটো প্রবল, interaction শুধু তার উপর একটা ছোট "বাড়তি মোচড়"। (ঘ) মূল ব্যাখ্যা: \((C,\text{high})\)-এ crop শুধু "ভালো সার \(+\) বেশি জল" যোগফলের চেয়ে \(\approx4\) একক বেশি — দুটো অনুকূল অবস্থা একসাথে কাজ করলে আলাদা-আলাদার চেয়ে বেশি ফল দেয়, যেটা ঠিক generator-এ রাখা inter[('C','high')] = 4। interaction plot-এ রেখা সমান্তরাল হলে → interaction নেই; যত বেশি ছাড়াছাড়ি/ক্রসিং, interaction তত প্রবল।
cell = {(f, i): crop[(fert == f) & (irrig == i)].mean()
for f in "ABC" for i in ["low", "high"]}
x = [0, 1, 2]
ax.plot(x, [cell[(f, "low")] for f in "ABC"], "o-", color="#1f6fb2") # low
ax.plot(x, [cell[(f, "high")] for f in "ABC"], "s-", color="#c0392b") # high
# "if no interaction" reference: average low->high lift carried to C
add = np.mean([cell[("A","high")]-cell[("A","low")],
cell[("B","high")]-cell[("B","low")]])
ax.plot([1, 2], [cell[("B","high")], cell[("C","low")] + add], ":", color="#7f8c8d")
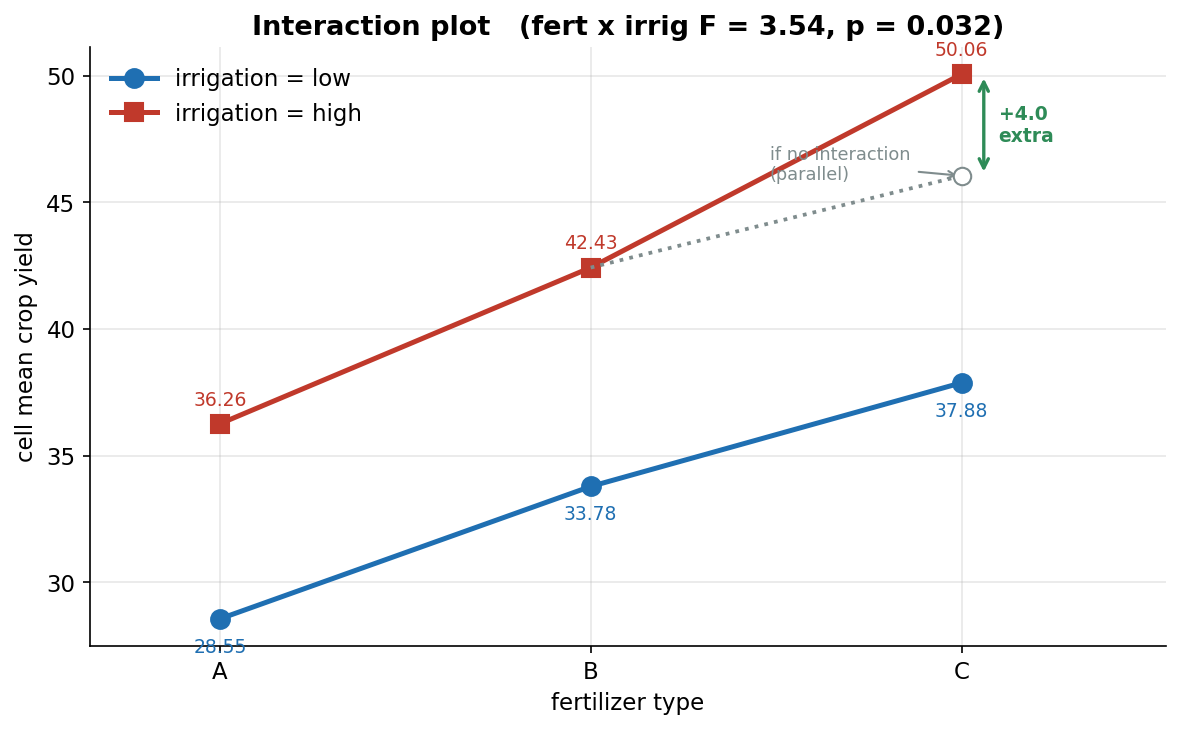
Figure 4 — \(F\)-distribution: পাওয়া \(F\) কতটা চরম?¶
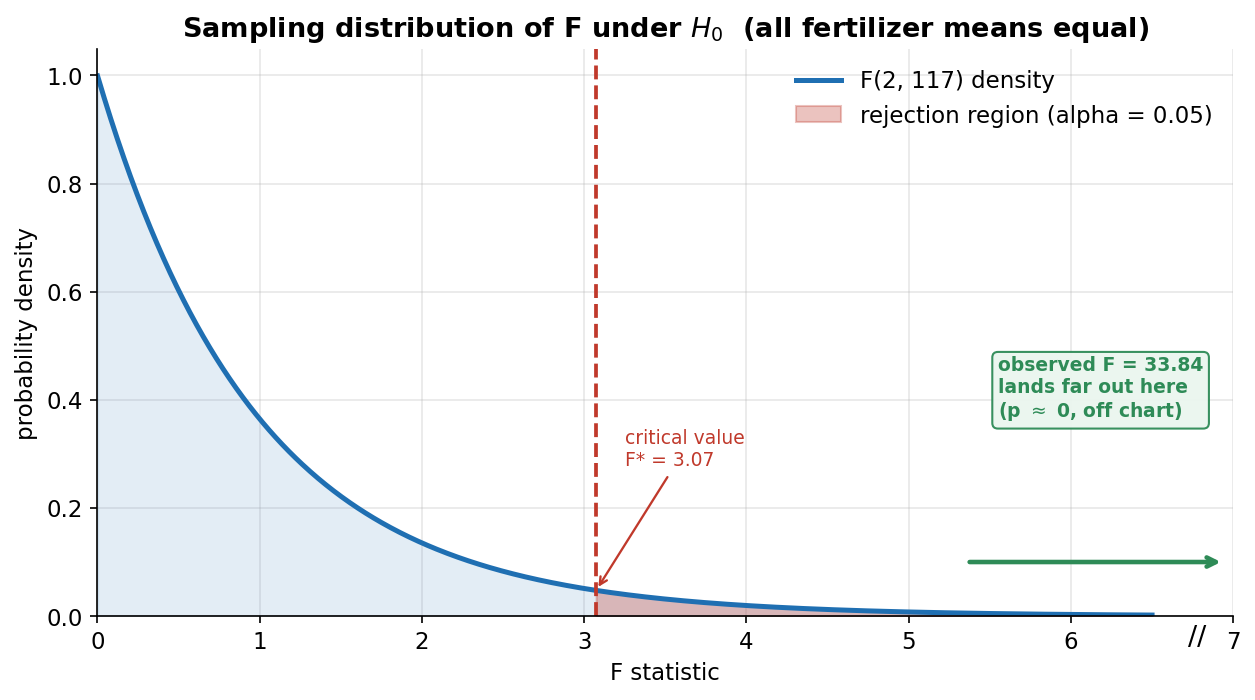
শেষ ছবি — hypothesis-test-এর চূড়ান্ত যুক্তিটা চোখে দেখায়। নীল curve হলো \(H_0\) (সব fertilizer-mean সমান) সত্যি হলে \(F\) statistic-এর sampling distribution, অর্থাৎ \(F_{2,117}\) density — df দুটো ঠিক আমাদের between-df \(=3-1=2\) আর within-df \(=120-3=117\)। লাল ভাঙা-রেখা হলো critical value \(F^{*}=3.07\) (\(\alpha=0.05\)-এ); তার ডানে লাল ছায়াঘেরা অংশটা rejection region — মোট ক্ষেত্রফলের ঠিক \(5\%\), অর্থাৎ "\(H_0\) সত্যি হলেও নিছক randomness-এ \(F\) এতটা বড় হওয়ার সম্ভাবনা মাত্র \(5\%\)"। সবুজ box ও ডানমুখী তির দেখায় আমাদের observed \(F=33.84\) কোথায় — সেটা চার্টের ডান প্রান্তেরও অনেক বাইরে (তাই অক্ষে // break-চিহ্ন)। যা লক্ষ করতে হবে: (ক) \(H_0\)-এর অধীন \(F\)-এর density-র প্রায় পুরোটা \(0\) থেকে \(\sim3\)-এর মধ্যে ভিড় করে — অর্থাৎ "কিছুই ঘটছে না" হলে \(F\) সাধারণত ছোট (\(1\)-এর আশপাশে) থাকার কথা। (খ) আমাদের \(F=33.84\) critical value \(3.07\)-এর দশ গুণেরও বেশি, density-র লেজে এত দূরে যে স্বাভাবিক স্কেলে আঁকাই যায় না — তাই \(p\approx0\) (\(\approx2.5\times10^{-12}\)): এমন মান \(H_0\) সত্যি হলে কার্যত অসম্ভব। (গ) সিদ্ধান্ত পরিষ্কার — observed \(F\) rejection region-এর অনেক ভেতরে পড়ায় \(H_0\) নাকচ; fertilizer-গুলোর গড় crop সত্যিই আলাদা (Figure 1-এর চোখে-দেখা পার্থক্যেরই আনুষ্ঠানিক নিশ্চয়তা)। (ঘ) সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ: ছবিটা one-tailed — \(F\) সবসময় \(\ge 0\), আর between-variation বাড়লেই \(F\) বড় হয়, তাই reject-অঞ্চল শুধু ডান লেজে; \(t\)-test-এর মতো দুই-প্রান্তের ব্যাপার এখানে নেই। মূল শিক্ষা: \(p\)-value মানে "\(H_0\) সত্যি হলে এই বা এর-চেয়ে-চরম ফল পাওয়ার সম্ভাবনা" — আর এখানে সেই সম্ভাবনা এতই ক্ষুদ্র যে data আর \(H_0\) একসাথে টেকে না।
from scipy import stats
xx = np.linspace(0.001, 6.5, 800)
ax.plot(xx, stats.f.pdf(xx, 2, 117), color="#1f6fb2") # F(2,117) density
F_crit = stats.f.ppf(0.95, 2, 117) # 3.07
xr = np.linspace(F_crit, 6.5, 200)
ax.fill_between(xr, stats.f.pdf(xr, 2, 117), color="#c0392b", alpha=0.3) # reject region
ax.axvline(F_crit, color="#c0392b", ls="--") # critical value
# observed F = 33.84 is off the right edge -> arrow + callout box
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-03-anova-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — variance-কে "between" ও "within"-এ ভাগ করার যন্ত্রটা হাতে গুনে দেখাটাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — agricultural field trial, seed np.random.default_rng(20260619), \(n=120\): তিনটা fertilizer (A, B, C) \(\times\) দুটো irrigation (low, high), প্রতি cell-এ \(20\)টা plot। response crop \(= 30 + \{A{:}0, B{:}5, C{:}8\} + \{\text{low}{:}0, \text{high}{:}6\} + 4\cdot[\![C\ \&\ \text{high}]\!] + \mathcal N(0,4^2)\)। one-way (crop ~ fert): গড় \(\bar y_A=32.40,\ \bar y_B=38.10,\ \bar y_C=43.97\), grand \(\bar y=38.16\); \(\mathrm{SSB}=2675.0,\ \mathrm{SSW}=4624.2,\ df=(2,117)\); \(F=33.84,\ p\approx 2.5\times10^{-12}\)। two-way (crop ~ fert*irrig): fert \(F=84.80\), irrig \(F=172.10\), interaction \(F=3.54\ (p\approx0.032)\), residual \(\mathrm{SS}=1798.0,\ df=114\)। cell means: A-low \(28.55\), A-high \(36.26\), B-low \(33.78\), B-high \(42.43\), C-low \(37.88\), C-high \(50.06\)। মূল সূত্র: \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\), \(F=\dfrac{\mathrm{SSB}/(k-1)}{\mathrm{SSW}/(n-k)}\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). ANOVA-র নামেই "variance" শব্দটা আছে, অথচ আমরা আসলে গড় (mean) তুলনা করছি — তিন fertilizer-এর গড় ফলন এক কিনা। এই আপাত-বৈপরীত্য ব্যাখ্যা করুন: কীভাবে দুই রকম variance-এর তুলনা করে আমরা গড়ের সমতা সম্পর্কে সিদ্ধান্ত নিই? \(\mathrm{SSB}\) আর \(\mathrm{SSW}\) আলাদা করে কী মাপে, আর \(H_0\) সত্য হলে তাদের অনুপাত \(F\)-এর আশেপাশে কোন মানের কাছে থাকার কথা? Hint: \(\mathrm{SSB}\) মাপে group-গড়গুলো grand mean থেকে কত ছড়ানো (signal + noise); \(\mathrm{SSW}\) মাপে শুধু group-এর ভেতরের noise। \(H_0:\mu_A=\mu_B=\mu_C\) সত্য হলে দুটোই একই \(\sigma^2\)-এর estimate, তাই \(F=\mathrm{MSB}/\mathrm{MSW}\approx 1\)। গড় আলাদা হলে \(\mathrm{MSB}\) বাড়ে, \(F\gg 1\)।
প্রশ্ন ২ (★). তিনটা fertilizer-এর গড় তুলনা করতে কেউ পরামর্শ দিল: "একটা ANOVA-র দরকার কী? তিনটা জোড়ায় তিনটা আলাদা two-sample \(t\)-test চালাও — \(A\) vs \(B\), \(A\) vs \(C\), \(B\) vs \(C\) — সহজ।" এই পদ্ধতির মূল সমস্যাটা এক বাক্যে নাম দিন, তারপর ব্যাখ্যা করুন। প্রতিটি test যদি \(\alpha=0.05\)-এ চালানো হয়, তিনটা test মিলিয়ে অন্তত একটা false positive পাওয়ার সম্ভাবনা (family-wise error rate) আনুমানিক কত? group সংখ্যা \(5\) হলে কতগুলো জোড়া-test লাগত? Hint: সমস্যাটা multiple comparisons / family-wise error inflation। সব null সত্য আর test স্বাধীন ধরলে \(\text{FWER}=1-(1-0.05)^m\), যেখানে \(m=\binom{k}{2}\)। \(k=3\Rightarrow m=3\); \(k=5\Rightarrow m=\binom{5}{2}=10\)। ANOVA একটিমাত্র global test দিয়ে এই inflation এড়ায়।
প্রশ্ন ৩ (★★). নিচের two-way ANOVA-র ফল (চলমান field trial থেকে) পড়ুন: fertilizer-এর main effect \(F=84.80\ (p<10^{-20})\), irrigation-এর main effect \(F=172.10\ (p<10^{-20})\), এবং interaction \(F=3.54\ (p=0.032)\)। (ক) "main effect" আর "interaction effect"-এর পার্থক্য সাধারণ ভাষায় বলুন। (খ) এই interaction significant হওয়ার বাস্তব অর্থ কী — অর্থাৎ fertilizer \(C\)-র সুবিধা low আর high irrigation-এ কি একই? cell means (C-low \(37.88\to\) C-high \(50.06\), বৃদ্ধি \(12.18\); A-low \(28.55\to\) A-high \(36.26\), বৃদ্ধি \(7.71\)) দিয়ে যুক্তি দিন। (গ) interaction significant হলে কেন main effect-গুলোকে একা একা ("fertilizer C গড়ে \(X\) বাড়ায়") বলা একটু বিভ্রান্তিকর হতে পারে?
Hint: main effect = এক factor-এর গড় প্রভাব (অন্য factor-এর level জুড়ে averaged)। interaction = এক factor-এর প্রভাব অন্য factor-এর level-ভেদে বদলায় কিনা। এখানে irrigation low\(\to\)high-এ ফলন-বৃদ্ধি \(C\)-তে (\(12.18\)) \(A\)-র চেয়ে (\(7.71\)) বেশি — তাই additive নয়, synergy আছে; "average effect" পুরো গল্প বলে না।
প্রশ্ন ৪ (★★). "ANOVA হলো categorical predictor-সহ regression-এরই আরেক চেহারা" — এই দাবিটা স্পষ্ট করুন। one-way ANOVA-র crop ~ fert মডেলকে কীভাবে dummy/indicator variable দিয়ে একটা linear regression \(\;y=\beta_0+\beta_1 D_B+\beta_2 D_C+\varepsilon\;\) হিসেবে লেখা যায় (\(D_B,D_C\) হলো \(B,C\)-র indicator, \(A\) reference)? এই encoding-এ \(\beta_0,\beta_1,\beta_2\) কী অর্থ বহন করে, আর ANOVA-র overall \(F\)-test (\(H_0:\mu_A=\mu_B=\mu_C\)) regression-এর কোন test-এর হুবহু সমান?
Hint: reference (baseline) cell mean coding-এ \(\beta_0=\mu_A\) (reference গড়), \(\beta_1=\mu_B-\mu_A\), \(\beta_2=\mu_C-\mu_A\) — অর্থাৎ coefficient-গুলো group-গড়ের পার্থক্য। \(H_0:\beta_1=\beta_2=0\Leftrightarrow \mu_A=\mu_B=\mu_C\), যা ৫.২-এর overall \(F\)-test (সব slope একসাথে শূন্য) — সংখ্যায় এক।
প্রশ্ন ৫ (★★). ANOVA-র বৈধতা তিনটা অনুমানের উপর দাঁড়ায়: (i) প্রতিটি group স্বাধীন, (ii) প্রতিটি group-এর মধ্যে error আনুমানিক Normal, (iii) সব group-এ error-variance সমান (homogeneity of variance / homoscedasticity)। (ক) এই তিনটা LINE অনুমানের (৫.১) কোনগুলোর সাথে মেলে? (খ) যদি group-গুলোর variance খুব আলাদা হয় (যেমন এখানে A-র sd \(\approx5.3\) বনাম C-র sd \(\approx7.3\) — মাঝারি পার্থক্য), \(F\)-test-এ কী ঝুঁকি? (গ) balanced design (প্রতি cell-এ সমান \(n=20\)) কেন এই variance-অসমতার বিরুদ্ধে কিছুটা robustness দেয়? Hint: (i)=Independence, (ii)=Normality, (iii)=Equal variance — Linearity ছাড়া LINE-এর বাকি তিনটি। variance অসম হলে \(F\)-এর null distribution আর ঠিক \(F_{k-1,n-k}\) থাকে না, তাই \(p\)-value বিকৃত। balanced design-এ এই বিকৃতি অনেক ছোট থাকে — তাই সমান cell-size একটা design-গুণ (এ-ই randomization/blocking-এর সাথে যুক্ত)।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★). একজন গবেষক শুধু group-summary রিপোর্ট করেছেন (raw data নেই): fertilizer \(A\) — \(n_A=40,\ \bar y_A=32.40,\ s_A=5.315\); \(B\) — \(n_B=40,\ \bar y_B=38.10,\ s_B=6.135\); \(C\) — \(n_C=40,\ \bar y_C=43.97,\ s_C=7.259\)। এই summary থেকেই পুরো one-way ANOVA table বানান: (ক) grand mean \(\bar y\) (balanced বলে সরল গড়); (খ) \(\mathrm{SSB}=\sum_g n_g(\bar y_g-\bar y)^2\); (গ) \(\mathrm{SSW}=\sum_g (n_g-1)s_g^2\) (কারণ \(s_g^2=\frac{1}{n_g-1}\sum(y-\bar y_g)^2\)); (ঘ) \(df_B,\ df_W\), এবং \(\mathrm{MSB},\ \mathrm{MSW}\); (ঙ) \(F\)-stat। আপনার সংখ্যাগুলো canonical-এর সাথে মিলছে কি? Hint: \(\bar y=(32.40+38.10+43.97)/3=38.16\) (balanced বলেই সরল গড় চলে)। \(\mathrm{SSB}=40[(32.40-38.16)^2+(38.10-38.16)^2+(43.97-38.16)^2]\approx 2675\)। \(\mathrm{SSW}=39(5.315^2+6.135^2+7.259^2)\approx 4624\)। তারপর \(F=\frac{2675/2}{4624/117}=\frac{1337.5}{39.5}\approx 33.8\)।
প্রশ্ন ৭ (★). প্রশ্ন ৬-এর table-এর \(F=33.84\) (\(df=2,117\))। (ক) \(\alpha=0.05\)-এ critical value \(F_{0.95;\,2,117}\approx 3.07\) — observed \(F\) কি তা ছাড়িয়েছে? সিদ্ধান্ত কী? (খ) \(p\)-value \(\approx 2.5\times10^{-12}\)-কে এক বাক্যে সঠিকভাবে ব্যাখ্যা করুন (সাধারণ ভুল ব্যাখ্যা এড়িয়ে)। (গ) \(F\)-test reject করল — এখন আমরা ঠিক কী জানি এবং কী জানি না? পরের ধাপ কী হওয়া উচিত? Hint: \(33.84\gg 3.07\), তাই \(H_0\) জোরালোভাবে বাতিল। \(p\) = "যদি তিন গড় সত্যিই সমান হতো, তবে এত বড় (বা বড়তর) \(F\) পাওয়ার সম্ভাবনা \(\approx 2.5\times10^{-12}\)" — group means সমান হওয়ার সম্ভাবনা নয়। reject মানে শুধু "অন্তত একজোড়া গড় আলাদা"; কোন জোড়া তা জানতে post-hoc (Tukey HSD) লাগে।
প্রশ্ন ৮ (★★). variance decomposition যাচাই। চলমান data-তে total variation \(\mathrm{SST}=\sum_i(y_i-\bar y)^2=7299.15\), আর one-way crop ~ fert-এ \(\mathrm{SSB}=2675.0\)। (ক) identity \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) ব্যবহার করে \(\mathrm{SSW}\) বের করুন এবং canonical \(4624.2\)-এর সাথে মেলান। (খ) "fertilizer কত শতাংশ total variation ব্যাখ্যা করে" — এটি ANOVA-র \(\eta^2=\mathrm{SSB}/\mathrm{SST}\) (regression-এর \(R^2\)-এর সমতুল্য); গণনা করুন। (গ) two-way-তে irrigation যোগ করলে residual SS \(4624.2\to 1798.0\) নামে — এই পতন কোন variation-কে আলাদা করায় ঘটল, এবং কেন এটা \(F\)-কে বড় করে (fert-এর \(F\) \(33.84\to 84.80\))?
Hint: (ক) \(\mathrm{SSW}=7299.15-2675.0=4624.15\approx 4624.2\)। (খ) \(\eta^2=2675.0/7299.15\approx 0.366\) — অর্থাৎ একা fertilizer \(\sim37\%\) ব্যাখ্যা করে। (গ) irrigation-এর variation আগে "within/residual" bucket-এ লুকিয়ে ছিল; model-এ এনে আলাদা করায় \(\mathrm{MSW}\) ছোট হয় (\(=\) denominator), তাই একই \(\mathrm{SSB}\)-তে \(F\) বড় — এ-ই blocking-এর power।
প্রশ্ন ৯ (★★). post-hoc-এর সংখ্যা। Tukey HSD তিনটা জোড়ার mean difference দিয়েছে: \(A\)–\(B\): \(5.70\), \(A\)–\(C\): \(11.56\), \(B\)–\(C\): \(5.87\); তিনটারই adjusted \(p<0.001\), সব confidence interval শূন্যকে বাদ দিয়েছে। (ক) এই তিনটি pairwise difference কি group means (\(\bar y_A=32.40,\ \bar y_B=38.10,\ \bar y_C=43.97\)) থেকে সরাসরি বের হয়? যাচাই করুন। (খ) Tukey-র CI সাধারণ two-sample-\(t\)-এর CI-র চেয়ে চওড়া — কেন, এবং এতে কী লাভ? (গ) তিন জোড়াই significant — group-গুলোকে কোন ক্রমে সাজানো যায়, আর তা ground-truth effect (\(A{:}0<B{:}5<C{:}8\))-এর সাথে মেলে কি? Hint: (ক) \(38.10-32.40=5.70\), \(43.97-32.40=11.57\), \(43.97-38.10=5.87\) — হ্যাঁ, ঠিক mean-পার্থক্য (rounding-এ সামান্য তফাত)। (খ) Tukey studentized-range distribution ব্যবহার করে FWER-কে \(0.05\)-এ ধরে রাখে, তাই প্রতিটি interval একটু চওড়া — বিনিময়ে সব জোড়া মিলিয়ে error inflate হয় না। (গ) \(A<B<C\), যা ground truth-এর সাথে সঙ্গতিপূর্ণ।
প্রশ্ন ১০ (★★). two-way table পূরণ। two-way ANOVA-র আংশিক table নিচে; ফাঁকা ঘর ভরুন (total \(n=120\), তাই \(\mathrm{SST}\)-এর \(df=119\); cell \(3\times2=6\), প্রতি cell \(20\))।
| Source | \(\mathrm{SS}\) | \(df\) | \(\mathrm{MS}\) | \(F\) |
|---|---|---|---|---|
| fert | \(2674.99\) | ? | ? | ? |
| irrig | \(2714.42\) | ? | ? | ? |
| fert \(\times\) irrig | \(111.72\) | ? | ? | ? |
| Residual | \(1798.03\) | \(114\) | ? | — |
| Total | ? | \(119\) | — | — |
(ক) প্রতিটি \(df\) বের করুন (fert: \(k_1-1\); irrig: \(k_2-1\); interaction: \((k_1-1)(k_2-1)\); residual: \(n-k_1k_2\))। (খ) প্রতিটি \(\mathrm{MS}=\mathrm{SS}/df\), তারপর \(F=\mathrm{MS}/\mathrm{MS}_{\text{resid}}\)। (গ) সব SS যোগ করে \(\mathrm{SST}\) বের করুন। Hint: \(df\): fert \(=2\), irrig \(=1\), interaction \(=2\), residual \(=114\); যোগফল \(=119\) ✓। \(\mathrm{MS}_{\text{resid}}=1798.03/114=15.77\)। \(F_{\text{fert}}=\frac{2674.99/2}{15.77}=\frac{1337.5}{15.77}\approx 84.8\); \(F_{\text{irrig}}=\frac{2714.42}{15.77}\approx172.1\); \(F_{\text{int}}=\frac{111.72/2}{15.77}=\frac{55.86}{15.77}\approx 3.54\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১১ (★★). মৌলিক identity \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) প্রমাণ করুন। \(k\)টা group, group \(g\)-তে observation \(y_{gi}\ (i=1,\dots,n_g)\), group-গড় \(\bar y_g\), grand mean \(\bar y\)। দেখান: $\(\underbrace{\sum_{g}\sum_{i}(y_{gi}-\bar y)^2}_{\mathrm{SST}}=\underbrace{\sum_{g}n_g(\bar y_g-\bar y)^2}_{\mathrm{SSB}}+\underbrace{\sum_{g}\sum_{i}(y_{gi}-\bar y_g)^2}_{\mathrm{SSW}}.\)$ Hint: \((y_{gi}-\bar y)=(y_{gi}-\bar y_g)+(\bar y_g-\bar y)\) লিখে বর্গ করুন। cross-term \(2\sum_g(\bar y_g-\bar y)\sum_i(y_{gi}-\bar y_g)\); ভেতরের যোগফল \(\sum_i(y_{gi}-\bar y_g)=0\) (group-গড়ের সংজ্ঞা), তাই cross-term শূন্য। (৫.১-এর \(\mathrm{SST}=\mathrm{SSR}+\mathrm{SSE}\)-র সাথে গঠনগত মিল লক্ষ করুন।)
প্রশ্ন ১২ (★★★). \(\mathrm{MSW}\) সর্বদা \(\sigma^2\)-এর unbiased estimator — \(H_0\) সত্য হোক বা না-হোক। ধরুন model \(y_{gi}=\mu_g+\varepsilon_{gi}\), \(\varepsilon_{gi}\overset{iid}{\sim}(0,\sigma^2)\) (প্রতি group-এ একই \(\sigma^2\))। (ক) প্রতিটি group-এর জন্য \(\mathbb E\big[\sum_i(y_{gi}-\bar y_g)^2\big]=(n_g-1)\sigma^2\) দেখান। (খ) এ থেকে \(\mathbb E[\mathrm{SSW}]=(n-k)\sigma^2\), তাই \(\mathbb E[\mathrm{MSW}]=\sigma^2\) — group-গড় ভিন্ন হলেও। (গ) বিপরীতে, যুক্তি দিন কেন \(\mathbb E[\mathrm{MSB}]=\sigma^2+\frac{1}{k-1}\sum_g n_g(\mu_g-\bar\mu)^2\ge\sigma^2\), সমতা ঠিক তখনই যখন সব \(\mu_g\) সমান — এ-ই কারণে \(H_0\)-তে \(\mathbb E[F]\approx1\), আর \(H_0\) মিথ্যা হলে \(F\) বড় হতে চায়। Hint: (ক) এটি sample variance-এর জানা ফল: \(\mathbb E[(n-1)s^2]=(n-1)\sigma^2\) (৪.১/৪.৪)। (খ) groupগুলোর উপর যোগ করুন; \(\sum_g(n_g-1)=n-k\)। (গ) \(\bar y_g=\mu_g+\bar\varepsilon_g\) ভেঙে \(\mathbb E[\mathrm{SSB}]\)-তে signal-term \(\sum n_g(\mu_g-\bar\mu)^2\) ও noise-term আলাদা করুন। মূল বার্তা: denominator সবসময় শুধু noise মাপে, numerator মাপে signal+noise — তাই তাদের অনুপাত একটা signal-to-noise ratio।
প্রশ্ন ১৩ (★★★). \(F\) আর \(t^2\) সমান যখন \(k=2\)। দেখান যে দুটো group-এর ক্ষেত্রে (\(k=2\)) one-way ANOVA-র \(F\)-statistic ঠিক pooled two-sample \(t\)-statistic-এর বর্গের সমান: \(F=t^2\), যেখানে \(t=\dfrac{\bar y_1-\bar y_2}{s_p\sqrt{1/n_1+1/n_2}}\) আর \(s_p^2=\mathrm{MSW}\)। তাই ANOVA-কে দুই-গোষ্ঠী \(t\)-test-এর সাধারণীকরণ বলা ন্যায্য। Hint: \(k=2\)-তে \(df_B=1\), তাই \(F=\mathrm{SSB}/\mathrm{MSW}\)। grand mean \(\bar y=\frac{n_1\bar y_1+n_2\bar y_2}{n_1+n_2}\) বসিয়ে দেখান \(\mathrm{SSB}=n_1(\bar y_1-\bar y)^2+n_2(\bar y_2-\bar y)^2=\frac{n_1n_2}{n_1+n_2}(\bar y_1-\bar y_2)^2\)। ভাগ করলে \(F=\frac{(\bar y_1-\bar y_2)^2}{s_p^2(1/n_1+1/n_2)}=t^2\)। (\(t_{df}^2\) আর \(F_{1,df}\) distribution-ও অভিন্ন — ৪.৭-এর সাথে সংযোগ।)
ঘ · কোডিং (Python)¶
প্রশ্ন ১৪ (★★★). পূর্ণ ANOVA pipeline — from scratch + library যাচাই + two-way + post-hoc। seed np.random.default_rng(20260619) দিয়ে field-trial data বানান: fert = np.repeat(['A','B','C'],40), irrig = np.tile(np.repeat(['low','high'],20),3), আর crop = 30 + {A:0,B:5,C:8}[fert] + {low:0,high:6}[irrig] + 4*(fert=='C')*(irrig=='high') + rng.normal(0,4,120)। তারপর:
1. from scratch one-way (crop ~ fert): numpy দিয়ে group means, grand mean, \(\mathrm{SSB}\), \(\mathrm{SSW}\), \(\mathrm{MSB}\), \(\mathrm{MSW}\), \(F\), এবং scipy.stats.f.sf দিয়ে \(p\)-value হিসাব করুন। একটা পরিপাটি ANOVA table ছাপুন।
2. library যাচাই: statsmodels-এর smf.ols('crop ~ C(fert)', data=df).fit() + anova_lm(..., typ=2) চালিয়ে দেখান আপনার hand-computed \(F\), \(\mathrm{SSB}\), \(\mathrm{SSW}\) চার দশমিক পর্যন্ত মেলে (np.allclose)।
3. two-way: smf.ols('crop ~ C(fert)*C(irrig)', data=df).fit() + anova_lm(typ=2) — fert, irrig, interaction-এর \(F\) ও \(p\) ছাপুন; cell means একটা \(3\times2\) table-এ দেখান।
4. post-hoc: pairwise_tukeyhsd(df['crop'], df['fert']) চালিয়ে কোন কোন জোড়া আলাদা বলুন।
(সম্ভব হলে ১-৪ এক runnable script-এ; প্রতিটি সংখ্যা canonical-এর সাথে মিলিয়ে নিন।)
Hint: group loop-এ SSB += n_g*(m_g-grand)**2, SSW += ((vals-m_g)**2).sum(); df_B=k-1=2, df_W=n-k=117; p = stats.f.sf(F, df_B, df_W)। প্রত্যাশিত: \(\bar y_A=32.40,\ \bar y_B=38.10,\ \bar y_C=43.97\), grand \(38.16\); \(\mathrm{SSB}=2674.99\), \(\mathrm{SSW}=4624.17\), \(F=33.84\), \(p=2.53\times10^{-12}\)। two-way: fert \(F=84.80\), irrig \(F=172.10\), interaction \(F=3.54\ (p=0.032)\), residual \(\mathrm{SS}=1798.03,\ df=114\)। Tukey: তিন জোড়াই reject, ক্রম \(A<B<C\)।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
কেন এই অধ্যায়। ৫.১–৫.২ predictor হিসেবে সংখ্যাগত চলক নিয়েছিল। বাস্তবে predictor প্রায়ই categorical — fertilizer-এর ধরন, চিকিৎসা-গোষ্ঠী, অঞ্চল। ৫.৩-এর প্রশ্ন: একাধিক group-এর গড় কি আদৌ আলাদা, আর তা পরিকল্পিত পরীক্ষা (experiment) দিয়ে কীভাবে নির্ণয় করি? উত্তরের যন্ত্র = ANOVA + experimental design।
-
Variance decomposition (মূল ধারণা)। ANOVA "গড়" তুলনা করে "variance" ভেঙে — total variation-কে দুই ভাগে ফেলে: $\(\mathrm{SST}=\underbrace{\mathrm{SSB}}_{\text{between groups}}+\underbrace{\mathrm{SSW}}_{\text{within groups}},\qquad \mathrm{SST}=\textstyle\sum_g\sum_i (y_{gi}-\bar y)^2.\)$
- \(\mathrm{SSB}=\sum_g n_g(\bar y_g-\bar y)^2\) — group-গড়গুলো grand mean থেকে কত দূরে (signal + noise)।
- \(\mathrm{SSW}=\sum_g\sum_i (y_{gi}-\bar y_g)^2\) — group-এর ভেতরের ছড়ানো (শুধু noise)। \(\mathrm{MSW}\) সর্বদা \(\sigma^2\)-এর unbiased estimate।
-
এটি ৫.১-এর \(\mathrm{SST}=\mathrm{SSR}+\mathrm{SSE}\) identity-রই অন্য চেহারা।
-
\(F\)-test (signal-to-noise)। test statistic $\(F=\frac{\mathrm{SSB}/(k-1)}{\mathrm{SSW}/(n-k)}=\frac{\mathrm{MSB}}{\mathrm{MSW}}\sim F_{k-1,\,n-k}\quad\text{under }H_0:\mu_1=\dots=\mu_k.\)$ \(H_0\) সত্য হলে numerator আর denominator দুটোই \(\sigma^2\)-এর estimate, তাই \(F\approx1\); গড় আলাদা হলে \(\mathrm{MSB}\) বাড়ে, \(F\gg1\)। field trial-এ \(F=33.84,\ p\approx2.5\times10^{-12}\) — তিন fertilizer-এর গড় স্পষ্টতই আলাদা।
-
কেন বহু \(t\)-test নয়। \(k\)টা group-এ \(\binom{k}{2}\) আলাদা \(t\)-test চালালে family-wise error rate ফুলে যায় (\(k=3\)-এ \(\approx14\%\), \(k=5\)-এ \(\binom52=10\) test)। ANOVA একটিমাত্র global \(F\) দিয়ে এই inflation এড়ায়; reject করলে কোন জোড়া আলাদা তা বলে post-hoc Tukey HSD (FWER নিয়ন্ত্রিত)।
-
Two-way ANOVA: main effects + interaction। দুই factor (fert \(\times\) irrig) একসাথে: প্রতিটি factor-এর main effect (গড় প্রভাব) আর তাদের interaction (এক factor-এর প্রভাব অন্য factor-এর level-ভেদে বদলায় কিনা)। field trial-এ fert \(F=84.80\), irrig \(F=172.10\), interaction \(F=3.54\ (p=0.032)\) — interaction ছোট কিন্তু বাস্তব: \(C\) +
highমিলে additive প্রত্যাশার চেয়ে বেশি ফলন (synergy)। দ্বিতীয় factor model-এ আনায় residual \(4624\to1798\) নামে, তাই fert-এর \(F\) \(33.84\to84.80\) — blocking/covariate যোগ করার power। -
ANOVA = regression। group-variable-কে dummy/indicator দিয়ে encode করলে one-way ANOVA হুবহু একটা linear regression: \(y=\beta_0+\beta_1 D_B+\beta_2 D_C+\varepsilon\), যেখানে \(\beta_0=\mu_A\) (reference), \(\beta_1=\mu_B-\mu_A\), \(\beta_2=\mu_C-\mu_A\)। ANOVA-র \(H_0\) ঠিক ৫.২-এর overall \(F\)-test (\(\beta_1=\beta_2=0\))। অর্থাৎ ANOVA কোনো আলাদা জগৎ নয় — categorical predictor-সহ regression।
-
Design principles। ভালো উত্তর ভালো পরীক্ষা-নকশার উপর নির্ভর করে: randomization (treatment এলোমেলোভাবে বণ্টন করে confounding ভাঙা), blocking (পরিচিত nuisance-উৎস — যেমন irrigation/জমির উর্বরতা — আলাদা করে noise কমানো), factorial design (একসাথে একাধিক factor চালিয়ে main effect ও interaction দুটোই দক্ষভাবে মাপা)। balanced design (সমান cell-size) variance-অসমতার বিরুদ্ধে robustness দেয় এবং Type I/II/III SS-কে একই করে।
পূর্ববর্তী সংযোগ (← ৫.১, ৪.৭):
- ৫.১ (Linear Regression): ANOVA-র variance decomposition হলো ৫.১-এর \(\mathrm{SST}=\mathrm{SSR}+\mathrm{SSE}\)-রই rebranding (\(\mathrm{SSB}\leftrightarrow\mathrm{SSR}\), \(\mathrm{SSW}\leftrightarrow\mathrm{SSE}\))। dummy-encoding-এ ANOVA আক্ষরিক অর্থে regression হয়ে যায়, group-গড় হয় coefficient, আর \(\eta^2=\mathrm{SSB}/\mathrm{SST}\) হলো ঠিক \(R^2\)।
- ৪.৭ (Hypothesis Testing): ANOVA-র \(F\)-test হলো ৪.৭-এর hypothesis-testing কাঠামোর সরাসরি প্রয়োগ — একটিমাত্র global null (\(\mu_1=\dots=\mu_k\)), একটি test statistic, একটি reference distribution (\(F_{k-1,n-k}\))। \(k=2\)-তে এটি হুবহু pooled two-sample \(t\)-test (\(F=t^2\)); \(F\)-distribution-এর গঠন (দুই \(\chi^2\)-এর অনুপাত) ৪.৭/৫.২-এ পরিচিত। post-hoc Tukey HSD হলো multiple-comparison সমস্যার (৪.৭-এ আলোচিত error-rate) একটি নিয়ন্ত্রিত সমাধান।
পরবর্তী সংযোগ (→ ৫.৪ — Generalized Linear Models / Logistic Regression): এ পর্যন্ত (৫.১–৫.৩) আমাদের response crop ছিল অবিচ্ছিন্ন ও আনুমানিক Normal, তাই linear model (\(\mathbb E[y]=X\beta\), Normal error) যথেষ্ট ছিল। কিন্তু বহু বাস্তব outcome এই ছাঁচে আঁটে না — outcome যখন binary ("রোগী বাঁচল/মারা গেল", "ক্লিক হলো/হলো না") বা count ("দিনে কতগুলো দুর্ঘটনা"), তখন Normal-error linear model ভেঙে পড়ে (পূর্বাভাস \([0,1]\)-এর বাইরে যায়, variance mean-নির্ভর)। ৫.৪ দেখাবে কীভাবে link function ও উপযুক্ত distribution (Bernoulli/Binomial, Poisson) দিয়ে linear-model কাঠামোকে এই জগতে বিস্তৃত করা যায় — logistic regression ও সাধারণভাবে generalized linear models (GLM)। সংক্ষেপে: ৫.১ regression বানায়, ৫.২ তাকে বিচার করে, ৫.৩ তাকে categorical/পরীক্ষামূলক জগতে নেয়, আর ৫.৪ তাকে non-Normal outcome-এর জগতে নিয়ে যায়।
সূত্র (sources): R. Furrer, STA121 Statistical Modeling (ANOVA, sum-of-squares decomposition, two-way designs, multiple comparisons, experimental design); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 12 (The Analysis of Variance — one-way ও two-way layout, \(F\)-test, \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\)); L. Wasserman, All of Statistics (ANOVA হিসেবে linear model, multiple testing); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 3 (Statistical Experiments and Significance Testing — ANOVA, A/B testing, multiple comparisons, applied code)।