6.8 — Nonlinear Dimensionality Reduction & Manifold Learning (অরৈখিক মাত্রা-হ্রাস ও ম্যানিফোল্ড লার্নিং)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — সমতল projection ছেড়ে বাঁকা পৃষ্ঠ খুলে ফেলা¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন অস্বস্তি¶
গত অধ্যায়ে (5.9) আমরা dimensionality reduction (মাত্রা-হ্রাস)-এর প্রথম শক্তিশালী হাতিয়ার পেয়েছিলাম: linear PCA (principal component analysis)। তার গল্পটা মনে করুন। আমাদের কাছে ছিল উঁচু-মাত্রিক data — প্রতিটি পর্যবেক্ষণ \(x_i\in\mathbb R^D\), অর্থাৎ \(D\)টি সংখ্যার একটা তালিকা (\(i=1,\dots,n\) বিন্দুর সূচক, \(D\) = মূল feature-সংখ্যা, সাধারণত বড়)। PCA করত একটা সরল কিন্তু গভীর কাজ: data-র covariance matrix-এর eigen-decomposition (0.5) করে সেই দিকগুলো খুঁজে বের করত যেগুলো বরাবর data-র variance সবচেয়ে বেশি — এই দিকগুলোই principal component। তারপর শীর্ষ কয়েকটা PC-তে data-কে projection করে আমরা \(D\) মাত্রা থেকে নেমে আসতাম \(d\) মাত্রায় (\(d\ll D\)), বেশিরভাগ variance ধরে রেখে।
পদ্ধতিটা চমৎকার, কিন্তু এর কেন্দ্রে একটা নীরব শব্দ লুকিয়ে আছে, যা এই গোটা অধ্যায়ের জন্মদাতা — শব্দটা হলো linear (রৈখিক)। PCA যা খুঁজে পায় তা সবসময় একটা সমতল — একটা রেখা, একটা তল, বা উঁচু মাত্রায় একটা hyperplane (সমতল উপ-জগৎ)। এটা data-কে সেই সমতলে লম্বভাবে ফেলে (project) কম মাত্রায় নামায়। কাজটা যতক্ষণ data সত্যিই একটা সমতলের কাছাকাছি বসে থাকে ততক্ষণ নিখুঁত।
অস্বস্তি — কিন্তু data যদি সমতল না হয়ে বাঁকা হয়? এখানেই কাঁটা। ভাবুন data আসলে একটা বাঁকা পৃষ্ঠের উপর বসে আছে — যেমন একটা কাগজের চাদর, যা ৩-মাত্রিক জগতে গোটানো (rolled up)। চাদরটা মূলত ২-মাত্রিক (তার উপর হাঁটতে গেলে দুটোই স্বাধীন দিক), কিন্তু সে ৩D-তে এমনভাবে পাকানো যে এক পাকের একটা বিন্দু আর পাশের পাকের একটা বিন্দু — সরলরেখায় (Euclidean) কাছাকাছি, অথচ চাদর বরাবর হেঁটে গেলে বহু দূরে। PCA এই গোটানো চাদরের উপর তার সমতল চশমা চাপায়: সে চাদরটাকে একটা তলে চেপে দেয়, কিন্তু খুলতে (unroll) পারে না — কারণ unroll করতে গেলে বাঁক বরাবর হাঁটতে হয়, আর PCA কেবল সরলরেখা চেনে। ফলে PCA-র ছবিতে ভিন্ন পাকের দূরবর্তী বিন্দু পাশাপাশি এসে পড়ে, আর data-র আসল গঠন বিকৃত হয়।
এক বাক্যে উত্তরণ। Linear PCA কেবল একটা সমতল subspace-এ projection করে; data যদি একটা বাঁকা পৃষ্ঠ (manifold)-এ বসে থাকে, PCA সেটাকে চেপে দিতে পারে কিন্তু খুলতে (unroll) পারে না — এই অধ্যায় ঠিক সেই অভাব পূরণ করে nonlinear পদ্ধতি দিয়ে, যারা বাঁক বরাবর দূরত্ব বা স্থানীয় প্রতিবেশ রক্ষা করে।
১.২ Hook — swiss roll: একটা গোটানো চাদর, যা PCA খুলতে পারে না¶
এই অধ্যায়ের চলমান উদাহরণ — আর nonlinear মাত্রা-হ্রাসের ক্লাসিক হাতে-কলমে দৃষ্টান্ত — হলো swiss roll (সুইস রোল, যে পেঁচানো কেক-রোল থেকে নাম)।
ছবিটা স্পষ্ট করুন। নিন একটা সমতল আয়তাকার চাদর — তার উপর প্রতিটি বিন্দুর ঠিকানা মাত্র দুটো সংখ্যা: চাদর বরাবর কতদূর (একে বলি বিন্দুর true position, এই অধ্যায়ের কোডে যাকে color বলা হবে) আর চাদরের প্রস্থ বরাবর কোথায়। এবার চাদরটাকে গুটিয়ে (roll) ফেলুন একটা সর্পিল-পাকে, আর সেই পাকানো রূপটাকে রাখুন ৩-মাত্রিক জগতে। এখন প্রতিটি বিন্দুর ৩টি স্থানাঙ্ক (\(x,y,z\)), অর্থাৎ \(D=3\)। কিন্তু প্রকৃত (intrinsic) মাত্রা মাত্র ২ — চাদরটা তো আসলে ২D, শুধু বাঁকা করে ৩D-তে বসানো। আমাদের স্বপ্ন: কেবল ৩D বিন্দুগুলো দেখে চাদরটাকে আবার সমতল করে মেলে ধরা (unroll), যাতে চাদর বরাবর true position ফিরে পাওয়া যায় — কোনো label না দেখে।
এখন PCA-কে এর উপর ছাড়ুন। PCA খুঁজবে ৩D-তে variance-সর্বোচ্চ একটা সমতল, আর তাতে roll-টাকে project করবে — অনেকটা পাকানো রোলটাকে উপর থেকে চ্যাপ্টা করে দেখার মতো। ফল: ভিন্ন পাক একে অপরের উপর এসে পড়ে, পাশাপাশি ছাপা হয়ে যায় — অথচ তারা চাদর বরাবর বহু দূরে। PCA-র এই ছবির অক্ষ আর চাদরের true position-এর সঙ্গে প্রায় সম্পর্কহীন। এই অধ্যায়ের সংখ্যায় তা স্পষ্ট: PCA-এমবেডিং-অক্ষ ও true position-এর মধ্যে |correlation| মাত্র 0.165 — কার্যত ব্যর্থ।
কেন এই ব্যর্থতা? কারণ PCA "কাছের" মাপে সরলরেখার দূরত্ব (Euclidean) দিয়ে — সে রোলের ভেতর দিয়ে শর্টকাট কেটে দুই পাকের বিন্দুকে কাছের ভাবে। কিন্তু চাদরের অধিবাসীর কাছে দুই বিন্দুর দূরত্ব মানে চাদর বরাবর হেঁটে যাওয়ার পথ — এই বাঁকা-পৃষ্ঠ-বরাবর দূরত্বকে বলে geodesic distance (\(d_G\))। swiss roll খুলতে হলে চাই এমন পদ্ধতি যা সরলরেখা নয়, geodesic দূরত্ব বা অন্তত স্থানীয় প্রতিবেশ (কে কার পাশে) রক্ষা করে।
এক বাক্যে hook। Swiss roll হলো ৩D-তে গোটানো একটা আসলে-২D চাদর; PCA সরলরেখার দূরত্বে এটাকে চ্যাপ্টা করে দেয় বলে ভিন্ন পাক মিশে যায় (|correlation| 0.165) — খুলতে (unroll) দরকার এমন পদ্ধতি যা চাদর বরাবর দূরত্ব (geodesic) বা স্থানীয় প্রতিবেশ রক্ষা করে।
১.৩ মূল ধারণা — manifold hypothesis ও দুই কৌশল-পরিবার¶
পুরো অধ্যায়টা একটা একক ধারণার উপর দাঁড়িয়ে, যাকে বলে manifold hypothesis (ম্যানিফোল্ড-অনুমান)। এক বাক্যে: বাস্তব উচ্চ-মাত্রিক data সাধারণত সেই উঁচু জগতে এলোমেলো ছড়িয়ে থাকে না — বরং একটা অনেক-নিম্ন-মাত্রিক বাঁকা পৃষ্ঠ (manifold)-এর কাছাকাছি গুটিয়ে থাকে। একটা ছবির পিক্সেল হয়তো \(D=10000\) মাত্রায় বাস করে, কিন্তু "একই বস্তু ঘুরছে/আলো বদলাচ্ছে" — এমন অর্থপূর্ণ পরিবর্তনগুলো হয়তো মাত্র গুটিকয় স্বাধীন দিকে ঘটে, তাই data একটা low-D manifold-এ বসে। মাত্রা-হ্রাসের আসল লক্ষ্য সেই manifold-টা খুঁজে বের করে data-কে তার intrinsic (প্রকৃত, ভেতরকার) মাত্রায় নামানো।
PCA এই অনুমানের একটা রৈখিক বিশেষ ঘটনা ধরে নেয় — যেন manifold-টা একটা সমতল। nonlinear পদ্ধতিরা সেই বাধা তোলে, আর তারা মোটামুটি দুই কৌশল-পরিবারে ভাগ হয়। এখানে এক-এক বাক্যে পাঁচটি পদ্ধতির ছবি; পুরো সংজ্ঞা §২-এ, পুরো গণিত §৪-এ।
পরিবার ক — feature-space-এ রৈখিক কৌশল, kernel দিয়ে অরৈখিক করা।
- Kernel PCA। ধারণাটা সরল ও মার্জিত: data যদি মূল জগতে বাঁকা হয়, তাকে 6.4-এর kernel trick দিয়ে (implicit-ভাবে) এমন এক উঁচু-মাত্রিক feature-space-এ পাঠাও যেখানে গঠনটা রৈখিক হয়ে যেতে পারে, আর সেখানে সাধারণ PCA চালাও। ফলাফল মূল জগতে একটা nonlinear embedding। শক্তিশালী, কিন্তু একটা বড় শর্ত: কোন kernel \(K\) ও তার parameter (যেমন rbf-kernel-এর bandwidth γ) নেওয়া হলো তার উপর ফল তীব্রভাবে নির্ভরশীল — ভুল বাছাইয়ে swiss roll-এ এটি unroll করতে পারে না (|correlation| 0.228)।
পরিবার খ — দূরত্ব বা প্রতিবেশ সরাসরি রক্ষা করা।
- MDS ও Isomap। MDS (multidimensional scaling — বহু-মাত্রিক স্কেলিং) শুধু বিন্দুদের মধ্যে pairwise দূরত্বের একটা টেবিল নেয়, আর এমন একটা low-D বিন্যাস \(\{y_i\}\) খোঁজে যাতে সেই দূরত্বগুলো যথাসম্ভব রক্ষা পায়। কিন্তু সাধারণ MDS Euclidean দূরত্ব নেয় বলে swiss roll-এ একই ভুল করে। Isomap (isometric mapping) এই সমস্যাটাই সারায় — Euclidean নয়, geodesic দূরত্ব \(d_G\) ব্যবহার করে: প্রতিটি বিন্দুর kNN দিয়ে একটা neighbor graph বানায়, তাতে দুই বিন্দুর shortest path-ই \(d_G\)-র আন্দাজ, তারপর সেই \(d_G\)-তে MDS চালিয়ে চাদরটা unroll করে। swiss roll-এ এটি কার্যত নিখুঁত (trustworthiness 1.000, |correlation| 1.000)।
- LLE। Locally Linear Embedding (স্থানীয়ভাবে রৈখিক এমবেডিং) দূরত্ব নয়, স্থানীয় জ্যামিতি রক্ষা করে: ধরে নেয় প্রতিটি বিন্দু তার ক্ষুদ্র প্রতিবেশে প্রায়-সমতল, তাই প্রতিটি \(x_i\)-কে তার প্রতিবেশীদের একটা রৈখিক সমন্বয় হিসেবে প্রকাশ করা যায়। সে এই reconstruction weight-গুলো শেখে, তারপর low-D-তে এমন \(y_i\) খোঁজে যা ঠিক সেই weight মানে — অর্থাৎ স্থানীয় গঠন অটুট রাখে (|correlation| 0.998)।
- t-SNE ও UMAP। এই দুটো মূলত visualization-এর হাতিয়ার (সাধারণত \(d=2\))। ধারণা: high-D-তে প্রতিটি জোড়া বিন্দুর জন্য একটা similarity \(p_{ij}\) (কে কার কতটা প্রতিবেশী) সংজ্ঞায়িত করো, low-D-তে একটা সমতুল্য \(q_{ij}\), আর \(y_i\)-গুলো এমনভাবে সাজাও যাতে \(q\) বণ্টন \(p\) বণ্টনের যত কাছে সম্ভব হয় — দূরত্ব মাপা হয় KL divergence দিয়ে। heavy-tailed low-D similarity দিয়ে "crowding" সামলায়, স্থানীয় গুচ্ছ দারুণ ফুটিয়ে তোলে — কিন্তু গুচ্ছ-মধ্যবর্তী global দূরত্ব বিশ্বস্ত নয় (t-SNE: trustworthiness 0.999, |correlation| 0.857)।
এক বাক্যে। Manifold hypothesis বলে high-D data একটা low-D বাঁকা পৃষ্ঠে বসে; সেটা খুলতে আছে kernel দিয়ে অরৈখিক-করা PCA (kernel PCA), দূরত্ব-রক্ষাকারী MDS/Isomap (geodesic), স্থানীয়-জ্যামিতি-রক্ষাকারী LLE, আর প্রতিবেশ-রক্ষাকারী visualization-হাতিয়ার t-SNE/UMAP।
১.৪ একটা সতর্কতা — "ভালো embedding" মানে কী, আর কীভাবে মাপব¶
এতগুলো পদ্ধতি আছে বলে স্বাভাবিক প্রশ্ন: একটা embedding ভালো কিনা তা বলব কীভাবে? এখানে একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ পার্থক্য আগেভাগে দাগিয়ে রাখা দরকার, কারণ এটাই পদ্ধতি-নির্বাচনের মূল।
দুরকম "বিশ্বস্ততা" আছে। কোনো কোনো পদ্ধতি distance-faithful — তারা global দূরত্ব ঠিক রাখার চেষ্টা করে (দূরের জিনিস দূরে, কাছের কাছে), যেমন Isomap। আবার কোনো কোনো পদ্ধতি কেবল neighborhood-faithful বা viz-faithful — তারা শুধু স্থানীয় প্রতিবেশ (কে কার পাশে) রক্ষায় মন দেয়, global দূরত্বের পরোয়া করে না, যেমন t-SNE/UMAP। তাই t-SNE-র ছবিতে দুটি গুচ্ছের মধ্যে ফাঁকটা কতটা — সেটা পড়ে অর্থ বের করা ভুল, যদিও প্রতিটি গুচ্ছের ভেতরের প্রতিবেশ নির্ভরযোগ্য।
এই "প্রতিবেশ রক্ষা পেল কিনা" মাপার জন্য একটা পরিমাণগত মাপকাঠি আছে — trustworthiness \(T\), যার মান \([0,1]\)-এ (\(1\) = নিখুঁত)। insight (অন্তর্দৃষ্টি): embedding-এ প্রতিটি বিন্দুর যে প্রতিবেশীরা কাছে দেখাচ্ছে, তারা কি সত্যিই high-D মূল জগতেও কাছে ছিল? যদি embedding দূরের বিন্দুকে মিথ্যা করে কাছে টেনে আনে (যেমন PCA swiss roll-এ করে), \(T\) কমে। তাই \(T\) মাপে: "যা কাছে দেখছি, তা কি সত্যিই কাছের?" (এই অধ্যায়ে এক ধাপ এগিয়ে আমরা embedding-অক্ষ ও চাদরের জানা true position-এর মধ্যে |correlation|-ও মাপব — কারণ এখানে সত্য গঠন আমাদের জানা, তাই কে আসলে চাদরটা খুলল তা সরাসরি যাচাই করা যায়।)
এক বাক্যে। কোনো পদ্ধতি distance-faithful (global দূরত্ব রাখে, যেমন Isomap), কোনোটা কেবল viz-faithful (শুধু স্থানীয় প্রতিবেশ রাখে, যেমন t-SNE/UMAP); এই প্রতিবেশ-রক্ষা মাপা হয় trustworthiness \(T\in[0,1]\) দিয়ে — "embedding-এ যা কাছে দেখছি তা কি high-D-তেও কাছের ছিল?"
১.৫ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একনজরে, যাতে প্রতিটা অংশ কেন আসছে তা পরিষ্কার থাকে:
- Manifold hypothesis ও PCA-র সীমা (§২.১) — high-D data কেন low-D বাঁকা পৃষ্ঠে বসে, intrinsic dimension, আর কেন linear PCA গোটানো manifold খুলতে পারে না।
- Kernel PCA (§২.২) — kernel trick দিয়ে feature-space-এ PCA, তার nonlinearity ও kernel/γ-নির্ভরতা।
- MDS ও Isomap (§২.৩) — pairwise দূরত্ব রক্ষা (MDS), geodesic দূরত্ব \(d_G\) (kNN-graph + shortest path) দিয়ে unroll (Isomap)।
- LLE (§২.৪) — স্থানীয় রৈখিক reconstruction weight শেখা ও নিচে রক্ষা করা।
- t-SNE/UMAP ও trustworthiness (§২.৫) — \(p_{ij}/q_{ij}\), KL divergence, crowding, viz-faithfulness; এবং কখন কোন পদ্ধতি বাছা ও \(T\) দিয়ে মূল্যায়ন।
- সব derivation — kernel PCA-র eigen-সমস্যা, Isomap-এর geodesic-যুক্তি, LLE-র দুই-পর্যায়ের minimization, t-SNE-র KL-objective ও gradient — §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫–৬-এ।
এক বাক্যে কেন এটি এখানে। 5.9 মাত্রা-হ্রাস করত রৈখিক PCA দিয়ে, যা বাঁকা manifold খুলতে অক্ষম; এই অধ্যায় তাকে nonlinear manifold learning-এ তোলে — kernel PCA, Isomap, LLE, t-SNE/UMAP — high-D data-র প্রকৃত low-D গঠন উদ্ধারের মৌলিক হাতিয়ার; পরের অধ্যায় 6.9 এই গঠন-জ্ঞান কাজে লাগায় ভিন্ন দিকে — anomaly detection, semi-supervised ও online learning-এ।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "data একটা বাঁকা low-D পৃষ্ঠে বসে, আর সেটা খুলতে হয় geodesic দূরত্ব বা স্থানীয় প্রতিবেশ রক্ষা করে" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত kernel PCA-র eigen-সমস্যা, Isomap-এর geodesic-যুক্তি, LLE-র দুই-পর্যায়ের minimization, আর t-SNE-র KL-objective), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে কিছু সাধারণ চিহ্ন স্থির করে নিই, যা গোটা অধ্যায়ে অপরিবর্তিত থাকবে। আমাদের কাছে \(n\)টি পর্যবেক্ষণ আছে: \(x_1,\dots,x_n\), যেখানে \(x_i\in\mathbb R^D\) হলো \(i\)-তম পর্যবেক্ষণের feature vector (\(D\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা; \(D\) = মূল মাত্রা, সাধারণত বড়; \(i,j\) বিন্দুর সূচক)। মাত্রা-হ্রাসের কাজ প্রতিটি \(x_i\)-র জন্য একটা embedding \(y_i\in\mathbb R^d\) বের করা, যেখানে \(d\ll D\) হলো লক্ষ্য (নিম্ন) মাত্রা — visualization-এ সাধারণত \(d=2\) বা \(3\)। কোনো লেবেল ব্যবহার করা হয় না; এটা unsupervised। (চলমান swiss-roll উদাহরণে \(D=3\), প্রকৃত মাত্রা ২, \(n=1000\), আর প্রতিটি বিন্দুর সঙ্গে চাদর বরাবর তার জানা true position color — যা পদ্ধতি দেখে না, কেবল শেষে যাচাইয়ে লাগে।)
২.১ Manifold hypothesis ও linear PCA কেন ব্যর্থ¶
প্রথমে গোটা অধ্যায়ের ভিত্তি-অনুমানটা সংজ্ঞায়িত করি।
সংজ্ঞা (manifold ও manifold hypothesis)। স্বজ্ঞাগতভাবে একটা manifold (ম্যানিফোল্ড) হলো একটা মসৃণ, সম্ভবত বাঁকা পৃষ্ঠ, যা স্থানীয়ভাবে একটা সাধারণ সমতল ইউক্লিডীয় জগতের মতো দেখায় — যেমন পৃথিবীর গোলাকার পৃষ্ঠ স্থানীয়ভাবে সমতল মানচিত্রের মতো, যদিও সামগ্রিকভাবে বাঁকা। তার intrinsic dimension (প্রকৃত মাত্রা) হলো সেই পৃষ্ঠের উপর অবস্থান নির্দিষ্ট করতে যতগুলো স্বাধীন সংখ্যা লাগে (চাদরের ক্ষেত্রে ২), যা পরিপার্শ্বের জগতের মাত্রা \(D\)-এর চেয়ে অনেক কম হতে পারে। Manifold hypothesis (ম্যানিফোল্ড-অনুমান) হলো সেই কার্যকরী ধারণা যে — বাস্তব high-D data এলোমেলোভাবে পুরো \(\mathbb R^D\) জুড়ে ছড়ায় না, বরং এমন একটা low-D manifold-এর কাছাকাছি (\(\pm\) সামান্য noise) গুটিয়ে থাকে। মাত্রা-হ্রাস তাই কার্যত: সেই লুকানো manifold আবিষ্কার করে data-কে তার intrinsic মাত্রায় নামানো।
কেন linear PCA এই কাজ পুরোপুরি পারে না। 5.9-এর PCA একটা শক্তিশালী কিন্তু রৈখিক ধারণা: এটি কেবল একটা affine subspace (একটা সমতল/hyperplane) খুঁজে পায় — variance-সর্বোচ্চ orthogonal দিকগুলোর span — আর সেখানে data project করে। গাণিতিকভাবে embedding হয় \(y_i = W^\top(x_i-\bar x)\), যেখানে \(\bar x\) হলো data-র mean ও \(W\)-এর কলামগুলো শীর্ষ eigenvector — সম্পূর্ণ একটা রৈখিক রূপান্তর। এই রৈখিকতাই তার সীমা: একটা গোটানো manifold (যেমন swiss roll) খুলতে হলে বাঁক বরাবর একটা অরৈখিক "মেলে ধরা" দরকার, যা কোনো একক সমতলে projection দিয়ে সম্ভব নয়। ফল — PCA রোলটাকে চ্যাপ্টা করে, ভিন্ন পাক মিশে যায়, আর embedding-অক্ষ চাদরের true position-এর সঙ্গে প্রায় সম্পর্কহীন থাকে (এই অধ্যায়ে |correlation| 0.165, যদিও neighbor-রক্ষার trustworthiness আপাত-উঁচু 0.968 — কারণ চ্যাপ্টা করায় বহু সত্যিকার প্রতিবেশী এখনো কাছেই থাকে; দুই মাপকাঠির এই পার্থক্যই শেখায় কেন শুধু \(T\) যথেষ্ট নয়)।
এক বাক্যে। Manifold hypothesis বলে high-D data একটা low-D বাঁকা manifold-এ বসে (intrinsic dimension \(\ll D\)); linear PCA কেবল একটা সমতল subspace খোঁজে বলে গোটানো manifold unroll করতে পারে না — দরকার nonlinear পদ্ধতি।
২.২ Kernel PCA — kernel trick দিয়ে feature-space-এ PCA¶
প্রথম nonlinear কৌশল আসে একটা সরল কৌশল থেকে: যদি মূল জগতে গঠন বাঁকা হয়, data-কে এমন এক নতুন জগতে পাঠাও যেখানে গঠনটা রৈখিক হতে পারে — আর সেখানে চেনা রৈখিক PCA-ই চালাও।
সংজ্ঞা (kernel PCA)। Kernel PCA হলো linear PCA-রই একটা রূপ, যা প্রথমে প্রতিটি \(x_i\)-কে একটা (সাধারণত অনেক উঁচু-মাত্রিক) feature-space-এ পাঠায় একটা mapping \(\phi\) দিয়ে — \(x_i\mapsto\phi(x_i)\) — আর তারপর সেই feature-space-এ সাধারণ PCA করে। মূল মুনশিয়ানা 6.4-এর kernel trick: \(\phi\)-কে স্পষ্টভাবে হিসাব করার দরকারই নেই, কারণ PCA-র সব হিসাব শুধু inner product-এর উপর নির্ভর করে, আর সেটা সরাসরি একটা kernel function দিয়ে পাওয়া যায় — $$ K(x_i,x_j) \;=\; \langle \phi(x_i),\,\phi(x_j)\rangle, $$ যেখানে \(K\) হলো kernel (একটা সমতা-ফাংশন, যা দুই বিন্দুর "সাদৃশ্য" মাপে), আর \(\langle\cdot,\cdot\rangle\) হলো feature-space-এর inner product। সবচেয়ে প্রচলিত হলো rbf (radial basis function) / Gaussian kernel \(K(x_i,x_j)=\exp\!\big(-\gamma\lVert x_i-x_j\rVert^2\big)\), যেখানে \(\lVert\cdot\rVert\) হলো Euclidean norm আর \(\gamma>0\) হলো bandwidth parameter (γ বড় = প্রভাব দ্রুত মিলিয়ে যায়, কেবল খুব কাছের বিন্দু "সাদৃশ্য" পায়)। সব জোড়ার \(K(x_i,x_j)\) মিলে একটা \(n\times n\) kernel matrix \(\mathbf K\); kernel PCA এই \(\mathbf K\)-কে (center করার পর) eigen-decompose (0.5) করে তার শীর্ষ \(d\)টি eigenvector থেকে embedding \(y_i\in\mathbb R^d\) বানায় (পূর্ণ derivation §৪)।
কেন nonlinear, আর কেন kernel-sensitive। যেহেতু \(\phi\) অরৈখিক, মূল জগতে ফিরে দেখলে এই embedding একটা অরৈখিক রূপান্তর — তাই kernel PCA রৈখিক PCA-র চেয়ে অনেক বেশি গঠন ধরতে পারে। কিন্তু এর সাফল্য পুরোপুরি নির্ভর করে kernel \(K\) ও তার parameter (rbf-এর γ) data-র জ্যামিতির সঙ্গে মেলে কিনা তার উপর। ভুল γ মানে ভুল "সাদৃশ্য"-ধারণা: γ বড় হলে প্রায় সব দূরত্ব শূন্য-সাদৃশ্যে মিলিয়ে যায়, ছোট হলে সব বিন্দু প্রায় সমান-সাদৃশ্য — কোনোটাই manifold খোলে না। তাই swiss roll-এ একটা সাধারণ rbf-kernel-PCA এই অধ্যায়ে unroll করতে ব্যর্থ হয়: |correlation| মাত্র 0.228, trustworthiness 0.898 — kernel-নির্বাচনের প্রতি এর এই তীব্র সংবেদনশীলতাই এর প্রধান ব্যবহারিক দুর্বলতা।
এক বাক্যে। Kernel PCA 6.4-এর kernel trick দিয়ে একটা উঁচু feature-space-এ (implicit-ভাবে) PCA চালায় — তাই এটি nonlinear; কিন্তু ফল kernel \(K\) ও তার parameter (rbf-এর γ)-এর উপর তীব্রভাবে নির্ভরশীল (swiss roll-এ |correlation| মাত্র 0.228)।
২.৩ MDS ও Isomap — pairwise দূরত্ব, আর geodesic দিয়ে unroll¶
দ্বিতীয় পরিবার ভিন্ন দর্শন নেয়: feature-space নয়, সরাসরি বিন্দুদের দূরত্ব রক্ষা করো।
সংজ্ঞা (MDS)। Multidimensional scaling (MDS) — বহু-মাত্রিক স্কেলিং — কোনো স্থানাঙ্ক না জেনেও কেবল একটা \(n\times n\) pairwise দূরত্ব matrix \(\big[\,d(x_i,x_j)\,\big]\) থেকে কাজ করে: এটি এমন একটা low-D বিন্যাস \(\{y_i\}_{i=1}^n\subset\mathbb R^d\) খোঁজে যাতে embedding-দূরত্ব \(\lVert y_i-y_j\rVert\) মূল দূরত্ব \(d(x_i,x_j)\)-এর যত কাছাকাছি সম্ভব হয় (classical MDS এটি একটা Gram-matrix-এর eigen-decomposition দিয়ে সমাধান করে — §৪)। এক কথায় MDS "দূরত্বের টেবিল"-কে আবার একটা ছবিতে রূপ দেয়। তবে একটা ফাঁদ: সাধারণ MDS-এ যদি দূরত্ব \(d\) হয় Euclidean (সরলরেখা), তাহলে swiss roll-এ সে PCA-রই মতো ভুল করে — কারণ সরলরেখা রোলের ভেতর দিয়ে শর্টকাট কাটে, চাদর বরাবর প্রকৃত পথ মাপে না।
সংজ্ঞা (geodesic distance)। এই ফাঁদের নিরাময়ের কেন্দ্রে আছে geodesic distance \(d_G(x_i,x_j)\) — দুই বিন্দুর মধ্যে manifold পৃষ্ঠ বরাবর ক্ষুদ্রতম পথের দৈর্ঘ্য (সরলরেখা নয়, "চাদরের উপর দিয়ে হেঁটে" যাওয়ার দূরত্ব)। swiss roll-এ দুই পাকের কাছাকাছি-দেখানো বিন্দুর Euclidean দূরত্ব ছোট, কিন্তু \(d_G\) বিশাল — আর এই \(d_G\)-ই আসল গঠন বহন করে।
সংজ্ঞা (Isomap)। Isomap (isometric feature mapping) ঠিক এই কাজটা করে — MDS, কিন্তু Euclidean-এর বদলে \(d_G\) দিয়ে — তিন ধাপে: (১) neighbor graph — প্রতিটি বিন্দু \(x_i\)-কে তার k-nearest-neighbour (kNN, 6.7)-দের সঙ্গে edge দিয়ে জোড়ো, প্রতিটি edge-এর ওজন সেই ছোট স্থানীয় Euclidean দূরত্ব (স্থানীয়ভাবে manifold প্রায়-সমতল, তাই কাছের Euclidean দূরত্ব নির্ভরযোগ্য); (২) shortest path — graph-এ দুই বিন্দুর মধ্যে ক্ষুদ্রতম-পথের দৈর্ঘ্য হিসাব করো (যেমন Dijkstra দিয়ে) — অনেক ছোট-ছোট স্থানীয় ধাপের এই যোগফলই \(d_G(x_i,x_j)\)-র চমৎকার আন্দাজ; (৩) MDS — এই geodesic দূরত্বের matrix-এ classical MDS চালিয়ে low-D embedding \(\{y_i\}\) বের করো। যেহেতু \(d_G\) চাদর বরাবর প্রকৃত পথ ধরে, ফল হলো চাদরটা সত্যিকারভাবে unroll — সমতল করে মেলে ধরা। এই অধ্যায়ে Isomap কার্যত নিখুঁত: trustworthiness 1.000, embedding-অক্ষ ও true position-এর |correlation| 1.000।
এক বাক্যে। MDS pairwise দূরত্ব রক্ষা করে embedding বানায়; Isomap Euclidean নয় geodesic দূরত্ব \(d_G\) ব্যবহার করে — kNN-graph-এ shortest path দিয়ে \(d_G\) আন্দাজ করে তারপর MDS চালিয়ে manifold unroll করে (swiss roll-এ trustworthiness 1.000, |correlation| 1.000)।
২.৪ LLE — স্থানীয় রৈখিক reconstruction রক্ষা করা¶
Isomap global দূরত্ব (geodesic) রক্ষা করে; পরের পদ্ধতিটি সম্পূর্ণ ভিন্ন কোণ নেয় — শুধু স্থানীয় জ্যামিতি রক্ষা করে, কোনো global দূরত্ব হিসাব না করেই।
সংজ্ঞা (LLE)। Locally Linear Embedding (LLE) — স্থানীয়ভাবে রৈখিক এমবেডিং — একটা সরল কিন্তু শক্তিশালী ধারণার উপর দাঁড়ায়: একটা মসৃণ manifold স্থানীয়ভাবে প্রায়-সমতল, তাই প্রতিটি বিন্দু তার ক্ষুদ্র প্রতিবেশের মধ্যে তার প্রতিবেশীদের একটা রৈখিক সমন্বয় (weighted average) হিসেবে প্রায় নিখুঁতভাবে প্রকাশযোগ্য। LLE দুই পর্যায়ে কাজ করে:
- পর্যায় ১ (weight শেখা)। প্রতিটি বিন্দু \(x_i\)-র kNN প্রতিবেশী বের করো, আর এমন weight \(\{w_{ij}\}\) খোঁজো যা \(x_i\)-কে তার প্রতিবেশীদের দিয়ে সবচেয়ে ভালোভাবে পুনর্গঠন করে — অর্থাৎ \(\big\lVert x_i-\sum_{j}w_{ij}x_j\big\rVert^2\) ক্ষুদ্রতম (যোগফল কেবল \(i\)-এর প্রতিবেশীদের উপর, আর \(\sum_j w_{ij}=1\))। এই weight-গুলোই \(x_i\)-র স্থানীয় জ্যামিতির একটা সারাংশ — কে কতটা অবদান রাখে।
- পর্যায় ২ (weight রক্ষা)। এবার low-D-তে এমন \(\{y_i\}\subset\mathbb R^d\) খোঁজো যা ঠিক সেই weight মানে — অর্থাৎ \(\big\lVert y_i-\sum_j w_{ij}y_j\big\rVert^2\) ক্ষুদ্রতম, \(w_{ij}\) আগের ধাপের মতোই স্থির। insight (অন্তর্দৃষ্টি): যে স্থানীয় রৈখিক-সম্পর্ক \(x_i\)-কে তার প্রতিবেশের সঙ্গে বাঁধত, নিচের জগতে সেটাই অটুট রাখলে গোটা manifold-টা সুসংগতভাবে মেলে ধরা যায় (এই minimization একটা eigen-সমস্যায় নামে — §৪)।
যেহেতু কোথাও কোনো দূরত্ব রক্ষার চেষ্টা নেই, কেবল স্থানীয় পুনর্গঠন-ধরন রক্ষা — LLE প্রায়ই Isomap-এর তুলনায় হালকা ও স্থানীয় গঠনে দারুণ। swiss roll-এ এটি চাদর ভালোভাবে খোলে: trustworthiness 0.996, |correlation| 0.998।
এক বাক্যে। LLE প্রতিটি বিন্দুকে তার প্রতিবেশীদের একটা রৈখিক সমন্বয় হিসেবে প্রকাশ করে সেই reconstruction weight শেখে, তারপর low-D-তে ঠিক সেই weight রক্ষা করে এমন \(y_i\) খোঁজে — স্থানীয় জ্যামিতি অটুট রেখে manifold মেলে ধরে (|correlation| 0.998)।
২.৫ t-SNE / UMAP, trustworthiness, আর কখন কোনটা¶
শেষ পরিবার আলাদা উদ্দেশ্যে গড়া — মূলত চোখে-দেখার (visualization) জন্য, যেখানে \(d\) সাধারণত \(2\)।
সংজ্ঞা (t-SNE)। t-SNE (t-distributed Stochastic Neighbor Embedding) একটা probabilistic neighbor-embedding: এটি দূরত্ব রক্ষার বদলে প্রতিবেশ-সম্ভাবনা রক্ষা করে। দুই ধাপে—
- High-D-তে প্রতিটি জোড়া \((i,j)\)-র জন্য একটা similarity \(p_{ij}\) সংজ্ঞায়িত করো — মোটামুটি "\(x_i\) যদি প্রতিবেশী বাছত, \(x_j\)-কে বাছার সম্ভাবনা", যা Gaussian দিয়ে গড়া: কাছের বিন্দুর \(p_{ij}\) বড়, দূরের প্রায় শূন্য। (এই Gaussian-এর প্রস্থ স্থানীয় ঘনত্ব অনুযায়ী বাছা হয়, একটা perplexity parameter দিয়ে — মোটামুটি "প্রতিটি বিন্দু কতজন কার্যকর প্রতিবেশী দেখবে"।)
- Low-D embedding-এ অনুরূপ একটা similarity \(q_{ij}\) সংজ্ঞায়িত করো \(\{y_i\}\) থেকে — কিন্তু একটা heavy-tailed (ভারী-লেজি, Student-t) kernel দিয়ে।
তারপর \(\{y_i\}\)-গুলোকে এমনভাবে সাজানো হয় যাতে low-D distribution (বণ্টন) \(q\) high-D distribution \(p\)-এর যত কাছে সম্ভব হয়। "কাছাকাছি"-র মাপ হলো KL divergence (Kullback–Leibler divergence — দুই সম্ভাবনা-বণ্টনের মধ্যে অমিল মাপার একটা অপ্রতিসম পরিমাপ): objective হলো \(\mathrm{KL}(p\,\Vert\,q)=\sum_{i\ne j}p_{ij}\log\frac{p_{ij}}{q_{ij}}\) ছোট করা (gradient-descent দিয়ে, §৪)। heavy-tailed \(q\)-এর ভূমিকা সূক্ষ্ম কিন্তু মুখ্য: এটি crowding problem সামলায় — উঁচু মাত্রার অনেক প্রতিবেশীকে কম মাত্রায় চেপে আনলে সব এক জায়গায় জট পাকিয়ে যেত; ভারী লেজ মাঝারি-দূরের বিন্দুকে একটু ছড়িয়ে রাখার অবকাশ দেয়, তাই গুচ্ছগুলো আলাদা ও স্পষ্ট দেখায়। UMAP (Uniform Manifold Approximation and Projection) একই ঘরানার একটি আধুনিক, দ্রুততর পদ্ধতি — neighbor-graph থেকে গড়া, প্রায়ই global গঠন t-SNE-র চেয়ে সামান্য ভালো রাখে।
একটা সতর্কতা — viz-faithful, distance-faithful নয়। t-SNE/UMAP স্থানীয় প্রতিবেশ দারুণ রক্ষা করে, কিন্তু global দূরত্ব বিশ্বস্ত নয়: ছবিতে দুটি গুচ্ছের মধ্যে ফাঁক, বা একটা গুচ্ছের আপেক্ষিক আকার — এগুলো পড়ে অর্থ বের করা ভুল। এরা embedding-অক্ষকে কোনো অর্থপূর্ণ স্থানাঙ্ক বানায় না, তাই swiss roll-এর true position-এর সঙ্গে t-SNE-র |correlation| মাঝারি (0.857), যদিও প্রতিবেশ-রক্ষার trustworthiness খুব উঁচু (0.999)। সারকথা: distance নয়, viz রক্ষা করে।
সংজ্ঞা (trustworthiness)। একটা embedding কতটা ভালো প্রতিবেশ রক্ষা করল তা মাপতে trustworthiness \(T\in[0,1]\) (\(1\) = নিখুঁত): এটি জরিমানা করে সেইসব বিন্দুকে যারা embedding-এ কোনো বিন্দুর কাছের প্রতিবেশী হয়ে দেখা দিয়েছে, অথচ মূল high-D জগতে কাছের ছিল না (অর্থাৎ মিথ্যা-প্রতিবেশী)। উঁচু \(T\) মানে "যা কাছে দেখছি তা সত্যিই কাছের"। (এই অধ্যায়ে এক ধাপ এগিয়ে আমরা embedding-অক্ষ ও জানা true position-এর |correlation|-ও মাপব — কারণ এখানে সত্য 1D গঠন জানা, তাই কে আসলে চাদরটা খুলল তা সরাসরি যাচাই করা যায়। চিত্র 6-8-trustworthiness-এ সব পদ্ধতির \(T\) পাশাপাশি দেখানো হবে।)
কখন কোনটা। এক সারণিতে নির্বাচনের নীতি: PCA আগে চেষ্টা করো — যদি data প্রায়-রৈখিক হয়, nonlinear-এর দরকারই নেই (সস্তা ও ব্যাখ্যাযোগ্য)। global/geodesic গঠন ও পরবর্তী বিশ্লেষণের (clustering, regression-এর feature) জন্য — Isomap (distance-faithful) বা LLE (local-geometry-faithful)। কেবল চোখে-দেখার জন্য, যেখানে গুচ্ছ-গঠন ফুটিয়ে তোলাই মুখ্য — t-SNE/UMAP (viz-faithful, কিন্তু global দূরত্ব পড়া নিষেধ)। kernel PCA তখনই, যখন data-র জ্যামিতির সঙ্গে মানানসই একটা kernel আগে থেকে জানা — নইলে kernel/γ-নির্বাচনের ঝুঁকি বড়। (চিত্র 6-8-method-grid-এ এই পাঁচ পদ্ধতির swiss-roll embedding পাশাপাশি, আর 6-8-pca-vs-manifold-এ PCA বনাম একটা সফল manifold পদ্ধতির সরাসরি বৈসাদৃশ্য দেখানো হবে।)
এক বাক্যে। t-SNE/UMAP high-D similarity \(p_{ij}\) ও low-D \(q_{ij}\)-এর মধ্যে KL divergence ছোট করে (heavy-tail দিয়ে crowding সামলে) স্থানীয় প্রতিবেশ রক্ষা করে — viz-faithful, distance-faithful নয়; embedding মাপা হয় trustworthiness \(T\in[0,1]\) দিয়ে, আর নির্বাচন: global/বিশ্লেষণে Isomap/LLE, কেবল দেখায় t-SNE/UMAP, সবার আগে PCA।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই section-এ আমরা একটি ক্লাসিক nonlinear manifold — Swiss roll — এর উপর পাঁচটি dimensionality reduction পদ্ধতি প্রয়োগ করে তুলনা করব। Swiss roll হলো একটি 2D sheet যা 3D space-এ গুটিয়ে (rolled up) রাখা হয়েছে; ডেটা \(x_i\in\mathbb R^{D}\) যেখানে \(D=3\), এবং আমরা চাই embedding \(y_i\in\mathbb R^{d}\) যেখানে \(d=2\)। আদর্শ লক্ষ্য — sheet-টিকে "খুলে" (unroll) ফেলা, অর্থাৎ roll বরাবর প্রকৃত 1D অবস্থানটি পুনরুদ্ধার করা।
প্রতিটি পদ্ধতির মান দুটি সংখ্যায় যাচাই করা হবে:
- Trustworthiness \(T \in [0,1]\) — original space-এর local neighbourhood-গুলো embedding-এ কতটা সংরক্ষিত থাকে (যত \(1\)-এর কাছাকাছি তত ভালো)। এটি \(\lvert\)প্রতিবেশী সম্পর্ক\(\rvert\) ভাঙার শাস্তি পরিমাপ করে।
- \(\lvert\rho\rvert\) — embedding-এর কোনো একটি axis-এর সাথে roll বরাবর প্রকৃত অবস্থান (
color) এর সর্বোচ্চ absolute Spearman correlation। এটি বলে দেয় global "unrolled" structure কতটা ধরা পড়ল।
সেটআপ¶
import numpy as np
from sklearn.datasets import make_swiss_roll
from sklearn.decomposition import PCA, KernelPCA
from sklearn.manifold import (
Isomap, LocallyLinearEmbedding, TSNE, trustworthiness)
from scipy.stats import spearmanr
X, color = make_swiss_roll(n_samples=1000, noise=0.05,
random_state=20260619)
# X.shape == (1000, 3); color == true 1D position along the roll
def max_abs_corr(emb, color):
return max(abs(spearmanr(emb[:, j], color).statistic)
for j in range(emb.shape[1]))
এখানে color ভেক্টরটিই হলো ground truth: roll বরাবর প্রতিটি বিন্দুর প্রকৃত arc-length অবস্থান। একটি ভালো manifold-learning পদ্ধতির embedding-এ একটি axis থাকা উচিত যা এই color-এর সাথে প্রায় monotonic — অর্থাৎ \(\lvert\rho\rvert \approx 1\)।
E1 — PCA roll খুলতে পারে না (linear সীমাবদ্ধতা)¶
প্রথমে সবচেয়ে সরল রৈখিক পদ্ধতি, PCA, প্রয়োগ করি। PCA variance-সর্বোচ্চ দুটি orthogonal direction-এ projection করে।
p = PCA(n_components=2).fit_transform(X)
print(trustworthiness(X, p, n_neighbors=10), max_abs_corr(p, color))
# 0.968 0.165
ফলাফল: \(T = 0.968\), কিন্তু \(\lvert\rho\rvert = 0.165\)।
ব্যাখ্যা — \(T=0.968\) ইঙ্গিত দেয় local neighbourhood মোটামুটি সংরক্ষিত; কিন্তু \(\lvert\rho\rvert = 0.165\) প্রায় শূন্যের কাছাকাছি, অর্থাৎ roll বরাবর প্রকৃত অবস্থান মোটেই পুনরুদ্ধার হয়নি। কারণ PCA শুধু 3D point-cloud-টিকে একটি সমতলে চ্যাপ্টা (flatten) করে — sheet-টিকে খোলে না (unroll করে না)। যেহেতু roll-টি বাঁকানো, sheet বরাবর বহু দূরে থাকা দুটি বিন্দু 3D space-এ পরস্পরের কাছাকাছি অবস্থান করে; flatten করার সময় তারা embedding-এও কাছাকাছি এসে পড়ে। অর্থাৎ linear projection manifold-এর curved structure ধরতে অক্ষম — Euclidean দূরত্ব এখানে বিভ্রান্তিকর।
মূল বার্তা: linear পদ্ধতির trustworthiness ভালো হতে পারে (local), কিন্তু curved manifold-এর global structure (unrolling) তার নাগালের বাইরে।
E2 — Isomap geodesic distance দিয়ে unroll করে¶
এবার Isomap প্রয়োগ করি। Isomap-এর মূল ধারণা: 3D space-এর সরলরৈখিক (Euclidean) দূরত্বের বদলে manifold বরাবর geodesic distance \(d_G\) ব্যবহার করা। এটি প্রথমে একটি \(k\)-nearest-neighbour graph (\(k=10\)) তৈরি করে, সেই graph-এ shortest-path দূরত্বকে \(d_G\) এর approximation হিসেবে নেয়, তারপর classical MDS দিয়ে সেই দূরত্ব-matrix কে \(\mathbb R^{2}\)-এ embed করে।
iso = Isomap(n_neighbors=10).fit_transform(X)
print(trustworthiness(X, iso, n_neighbors=10), max_abs_corr(iso, color))
# 1.000 1.000
ফলাফল: \(T = 1.000\), \(\lvert\rho\rvert = 1.000\)।
ব্যাখ্যা — দুটি সংখ্যাই নিখুঁত (perfect)। Isomap roll বরাবর প্রকৃত 1D অবস্থান পুরোপুরি পুনরুদ্ধার করেছে। কারণ এটি দূরত্ব মাপে manifold-এর গা ঘেঁষে (along the sheet) — 3D space-এর ভেতর দিয়ে নয়। sheet বরাবর দূরের দুটি বিন্দু 3D-তে কাছাকাছি হলেও তাদের geodesic দূরত্ব \(d_G\) বড়, তাই embedding-এ তারা সঠিকভাবে দূরে থাকে। ফলস্বরূপ sheet-টি ঠিকঠাক খুলে যায়।
মূল বার্তা: geodesic দূরত্ব ব্যবহার করেই Isomap সেই unrolling অর্জন করে যা PCA পারেনি — এটিই linear বনাম manifold পদ্ধতির মৌলিক পার্থক্য।
E3 — LLE ও t-SNE: local manifold পদ্ধতি¶
দুটি ভিন্ন দর্শনের local পদ্ধতিও চমৎকার কাজ করে।
Locally Linear Embedding (LLE) ধরে নেয়, প্রতিটি বিন্দু তার প্রতিবেশীদের একটি linear combination হিসেবে প্রকাশযোগ্য। এটি প্রতিটি বিন্দুর জন্য reconstruction weight শেখে, তারপর সেই weight-গুলো সংরক্ষণ করে এমন low-dimensional embedding খোঁজে।
lle = LocallyLinearEmbedding(n_neighbors=10, random_state=0).fit_transform(X)
print(trustworthiness(X, lle, n_neighbors=10), max_abs_corr(lle, color))
# 0.996 0.998
ফলাফল: \(T = 0.996\), \(\lvert\rho\rvert = 0.998\) — প্রায় নিখুঁত। কোনো global geodesic হিসাব ছাড়াই, কেবল local linear structure সংরক্ষণ করেই LLE manifold খুলে ফেলে।
t-SNE একটি neighbour-embedding পদ্ধতি: high-dimensional pairwise সাদৃশ্যকে probability হিসেবে প্রকাশ করে এবং low-dimensional-এও অনুরূপ probability বজায় রাখার চেষ্টা করে। perplexity=30 neighbourhood-এর কার্যকর আকার নিয়ন্ত্রণ করে।
tsne = TSNE(perplexity=30, random_state=0, init='pca').fit_transform(X)
print(trustworthiness(X, tsne, n_neighbors=10), max_abs_corr(tsne, color))
# 0.999 0.857
ফলাফল: \(T = 0.999\), \(\lvert\rho\rvert = 0.857\)। local structure অসাধারণভাবে সংরক্ষিত (\(T\) প্রায় \(1\)) — visualization-এর জন্য t-SNE অত্যন্ত শক্তিশালী। তবে \(\lvert\rho\rvert = 0.857\) Isomap/LLE-র চেয়ে কিছুটা কম, কারণ t-SNE মূলত local সম্পর্ক ধরে রাখার দিকে ঝোঁকে, global axis-alignment নিয়ে ততটা চিন্তিত নয়।
মূল বার্তা: LLE ও t-SNE — দুই ভিন্ন পথে (local linear weight বনাম neighbour probability) — উভয়েই nonlinear structure ধরে। t-SNE local pattern-এ শ্রেষ্ঠ, কিন্তু global ordering সামান্য দুর্বল।
E4 — Kernel PCA: hyperparameter-এর প্রতি সংবেদনশীল¶
শেষে Kernel PCA (RBF kernel) — যা data-কে একটি উচ্চ-মাত্রিক feature space-এ map করে সেখানে linear PCA চালায়। RBF kernel-এর width নিয়ন্ত্রণ করে \(\gamma\) parameter।
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=0.04).fit_transform(X)
print(trustworthiness(X, kpca, n_neighbors=10), max_abs_corr(kpca, color))
# 0.898 0.228
ফলাফল: \(T = 0.898\), \(\lvert\rho\rvert = 0.228\)।
ব্যাখ্যা — এই dataset-এ Kernel PCA তুলনামূলক দুর্বল। \(T = 0.898\) পাঁচটির মধ্যে সর্বনিম্ন, এবং \(\lvert\rho\rvert = 0.228\) ইঙ্গিত দেয় roll প্রায় খোলেইনি। মূল কারণ — kernel ও \(\gamma\) এর পছন্দের প্রতি Kernel PCA অত্যন্ত সংবেদনশীল। \(\gamma=0.04\) এই manifold-এর geometry-র সাথে ভালো মেলেনি; অন্য \(\gamma\)-তে ফলাফল নাটকীয়ভাবে বদলে যেতে পারে। এটি একটি গুরুত্বপূর্ণ ব্যবহারিক সতর্কবার্তা: সঠিক পদ্ধতি বেছেও hyperparameter ভুল হলে nonlinear method ব্যর্থ হতে পারে।
তুলনামূলক সারণি¶
পাঁচটি পদ্ধতির ফলাফল একত্রে:
| Method | Trustworthiness \(T\) | \(\lvert\rho\rvert\) with color |
মন্তব্য |
|---|---|---|---|
| PCA | 0.968 | 0.165 | flatten করে, unroll করে না (linear) |
| Isomap | 1.000 | 1.000 | geodesic দূরত্বে নিখুঁত unrolling |
| LLE | 0.996 | 0.998 | local linear weight — চমৎকার |
| t-SNE | 0.999 | 0.857 | visualization-এ শ্রেষ্ঠ, global সামান্য কম |
| Kernel PCA (rbf) | 0.898 | 0.228 | \(\gamma\)-সংবেদনশীল, এখানে দুর্বল |
সারসংক্ষেপ — মূল শিক্ষা¶
- Linear পদ্ধতি curved structure মিস করে। PCA ভালো local trustworthiness (\(0.968\)) পেলেও roll খুলতে (\(\lvert\rho\rvert = 0.165\)) সম্পূর্ণ ব্যর্থ — Euclidean projection বাঁকানো manifold-কে শুধু চ্যাপ্টা করে।
- Geodesic ও local manifold পদ্ধতি nonlinear structure পুনরুদ্ধার করে। Isomap (geodesic \(d_G\)), LLE (local linear weight) ও t-SNE (neighbour embedding) — তিনটিই sheet সফলভাবে খোলে, যা linear PCA-র সাধ্যের বাইরে।
- পদ্ধতি ও hyperparameter — দুটোই গুরুত্বপূর্ণ। Kernel PCA "nonlinear" হয়েও \(\gamma\) এর ভুল পছন্দে (\(0.898 / 0.228\)) ব্যর্থ; আবার t-SNE local-এ সেরা হলেও global ordering-এ Isomap/LLE-র চেয়ে পিছিয়ে। সঠিক tool নির্বাচন এবং সেটির tuning — দুটোই কাঙ্ক্ষিত ফল পাওয়ার পূর্বশর্ত।
যাচাইকরণ (verification)¶
উপরের সব সংখ্যা scikit-learn দিয়ে নিম্নরূপে যাচাই করা হয়েছে (random_state=20260619):
PCA trustworthiness=0.968 |corr|=0.165
Isomap trustworthiness=1.000 |corr|=1.000
LLE trustworthiness=0.996 |corr|=0.998
t-SNE trustworthiness=0.999 |corr|=0.857
KernelPCA trustworthiness=0.898 |corr|=0.228
প্রতিটি মান brief-এর canonical সংখ্যার সাথে হুবহু মিলে যায়।
৪ · প্রমাণ ও উৎপাদন¶
এই বিভাগে §২–§৩-এ ব্যবহৃত nonlinear dimensionality reduction-এর পদ্ধতিগুলো — kernel PCA, classical MDS, Isomap, LLE (Locally Linear Embedding) ও t-SNE — এর সব সূত্র শূন্য থেকে গড়ে তুলব। কেন্দ্রীয় গল্পটি একটাই সুতোয় বাঁধা: PCA (prereq 5.9) হলো covariance বা Gram matrix-এর eigen-decomposition, কিন্তু তা কেবল linear subspace খোঁজে; বাস্তব data প্রায়ই একটি বাঁকানো low-dimensional manifold-এ বসে থাকে, তাই আমাদের এমন কৌশল চাই যা linear PCA-এর eigen-কাঠামো ধরে রেখেও বক্রতা ধরতে পারে। আমরা পাঁচটি জিনিস উৎপাদন করব: (i) kernel PCA — feature space \(\phi\)-তে PCA করলে তা centered kernel matrix \(\tilde K\)-এর eigen-problem-এ নেমে আসে, \(\phi\) একবারও না গুনে (kernel trick, prereq 6.4); (ii) classical MDS ও তার PCA-র সাথে হুবহু সমতুল্যতা — double-centering identity \(B=-\tfrac12 H\Delta H\) প্রমাণসহ; (iii) Isomap = geodesic দূরত্বের উপর MDS, যা swiss-roll খুলে ফেলে; (iv) LLE — স্থানীয় linear patch-এর weight সংরক্ষণ করে একটি bottom-eigenvector সমস্যা; (v) t-SNE-এর KL objective ও কেন Student-t লেজ "crowding problem" সারায়। ভিত্তি: prereq 5.9 (PCA = covariance-এর eigen), prereq 0.5 (eigendecomposition, SVD), prereq 6.4 (kernel trick, Mercer)। প্রতিটি প্রতীক প্রথম ব্যবহারে খোলা হবে, প্রতিটি ধাপ যুক্তিসহ। কষ্টের স্তর প্রতিটি উপ-বিভাগের শিরোনামে তারা দিয়ে: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
সাধারণ সেট-আপ ও প্রতীক। ধরি \(n\)টি পর্যবেক্ষণ \(x_1,\dots,x_n\in\mathbb R^{D}\) (উচ্চ-মাত্রিক, ambient space), যাদের আমরা একটি embedding \(y_1,\dots,y_n\in\mathbb R^{d}\)-তে নামাতে চাই, যেখানে \(d\ll D\)। সারি-সাজানো data matrix \(X\in\mathbb R^{n\times D}\) (প্রতিটি সারি একটি \(x_i^\top\))। বারবার ফিরে আসবে কয়েকটি বস্তু: kernel matrix \(K\in\mathbb R^{n\times n}\) যেখানে \(K_{ij}=k(x_i,x_j)\); তার centered রূপ \(\tilde K\); squared-distance matrix \(\Delta\in\mathbb R^{n\times n}\) যেখানে \(\Delta_{ij}=\lVert x_i-x_j\rVert^2\); Gram (inner-product) matrix \(B\); এবং manifold-বরাবর মাপা geodesic distance \(d_G(x_i,x_j)\)। সর্বত্র দুটি কেন্দ্রীয়করণ-যন্ত্র ব্যবহার করব:
যেখানে \(\mathbf 1_n\) হলো "সব-ভুক্তি \(1/n\)" matrix (যেকোনো vector-কে তার গড়ের সমান-vector-এ মানচিত্র করে), আর \(H\) হলো centering matrix: যেকোনো \(v\in\mathbb R^n\)-এর জন্য \((Hv)_i=v_i-\bar v\)। দুটি কাজে-লাগা ধর্ম, যা পরে বারবার লাগবে: \(H\) symmetric (\(H^\top=H\)) এবং idempotent (\(H^2=H\), কারণ একবার গড় বাদ দিলে দ্বিতীয়বার বাদ দেওয়ার মতো কিছু থাকে না — \(\mathbf 1_n\mathbf 1_n=\mathbf 1_n\) আর \(\mathbf 1_n\mathbf 1=\mathbf 1\) থেকে সরাসরি)। আর \(H\mathbf 1=0\) (ধ্রুবক-vector-এর গড় বাদ দিলে শূন্য)।
৪.১ ★★ Kernel PCA — centered kernel matrix \(\tilde K\)-এর eigen-problem¶
লক্ষ্য। দেখাই যে feature space \(\phi\)-তে সাধারণ PCA করলে principal components গুলো \(\{\phi(x_i)\}\)-এর span-এ থাকে, ফলে সমস্যাটা centered kernel matrix \(\tilde K\)-এর eigen-decomposition-এ নেমে আসে — \(\phi\)-কে স্পষ্টভাবে কখনো না গুনেই। এটিই kernel trick (prereq 6.4)-এর সৌন্দর্য।
ধাপ ১ — সাধারণ PCA = covariance matrix-এর eigen (স্মরণ, prereq 5.9)। কেন্দ্রীভূত data (\(\sum_i x_i=0\) ধরে) থেকে covariance \(C=\tfrac1n\sum_i x_ix_i^\top=\tfrac1n X^\top X\in\mathbb R^{D\times D}\)। PCA হলো \(C v=\lambda v\)-এর top eigenvectors খোঁজা; প্রতিটি বিন্দুর projection \(v^\top x_i\) হলো নতুন স্থানাঙ্ক। কিন্তু \(C\) একটি \(D\times D\) matrix — feature space-এ যেতে গেলে \(D\) অসীমও হতে পারে, তাই সরাসরি \(C\) গড়া অসম্ভব। সমাধানের সূত্র: \(X^\top X\) (size \(D\times D\)) ও \(XX^\top\) (size \(n\times n\)) একই অশূন্য eigenvalue ভাগ করে (prereq 0.5, SVD), তাই আমরা ছোট-দিকটায় (\(n\times n\) Gram) কাজ করব।
ধাপ ২ — feature space-এ গিয়ে covariance। একটি (সম্ভবত nonlinear) feature map \(\phi:\mathbb R^{D}\to\mathcal F\) ধরি, যা \(x\)-কে এক উচ্চ- (এমনকি অসীম-) মাত্রিক feature space \(\mathcal F\)-তে পাঠায়। আপাতত ধরি features কেন্দ্রীভূত, অর্থাৎ \(\sum_i\phi(x_i)=0\) (ধাপ ৫-এ এই শর্ত \(\tilde K\) দিয়ে অর্জন করব)। তখন feature-space covariance
আর আমরা চাই \(C_\phi v=\lambda v\) (\(\lambda>0\))। কিন্তু \(\phi\) অজানা/অসীম-মাত্রিক, তাই \(v\)-কে সরাসরি ধরা যায় না।
ধাপ ৩ — eigenvector \(\{\phi(x_i)\}\)-এর span-এ বসে (মূল insight/অন্তর্দৃষ্টি)। \(C_\phi v=\lambda v\) থেকে, \(\lambda>0\) হলে
অর্থাৎ প্রতিটি principal component \(v\) অবশ্যই training feature-vectors-এর একটি linear combination — সে \(\{\phi(x_i)\}\)-এর span ছেড়ে বেরোতে পারে না। (স্বজ্ঞা: covariance-এর range পুরোটাই data-points দিয়ে তৈরি; তার বাইরে কোনো দিকে variance শূন্য।) তাই অজানা \(v\)-কে খোঁজার বদলে আমরা \(n\)টি সহগ \(\alpha=(\alpha_1,\dots,\alpha_n)^\top\) খুঁজব — একটি সসীম সমস্যা।
ধাপ ৪ — \(\alpha\)-এর eigen-সমীকরণ = kernel matrix। \(v=\sum_j\alpha_j\phi(x_j)\) বসিয়ে eigen-সমীকরণ \(C_\phi v=\lambda v\)-কে প্রতিটি \(\phi(x_l)\)-এর সাথে inner product নিয়ে projection করি (যেহেতু সমীকরণটি span-এ ধরলেই যথেষ্ট)। বাঁ পাশ:
এখানে প্রতিটি inner product ঠিক একটি kernel মান: \(\phi(x_a)^\top\phi(x_b)=k(x_a,x_b)=K_{ab}\) — kernel trick (prereq 6.4, Mercer)। তাই বাঁ পাশ \(=\tfrac1n\sum_i\sum_j\alpha_j K_{li}K_{ij}=\tfrac1n (K^2\alpha)_l\)। ডান পাশ:
সব \(l\)-এর জন্য মিলিয়ে matrix আকারে: \(\tfrac1n K^2\alpha=\lambda K\alpha\)। \(K\) (সাধারণত) invertible হলে দুপাশে \(K^{-1}\) গুণ করে — অথবা সাধারণভাবে অশূন্য-eigenvalue অংশে — পাই একটি পরিষ্কার eigen-problem:
— অর্থাৎ \(\alpha\) হলো kernel matrix \(K\)-এর eigenvector, eigenvalue \(n\lambda\)। \(D\times D\) covariance-এর বদলে আমরা এখন কেবল একটি \(n\times n\) matrix-এর eigen-decomposition করছি, \(\phi\) একবারও না গুনে।
ধাপ ৫ — কেন্দ্রীয়করণ: centered kernel \(\tilde K\)। উপরের সবটা ধরে নিয়েছিল features কেন্দ্রীভূত (\(\sum_i\phi(x_i)=0\)), যা সাধারণত সত্য নয়। তাই কেন্দ্রীভূত feature \(\tilde\phi(x_i)=\phi(x_i)-\bar\phi\) ব্যবহার করি, \(\bar\phi=\tfrac1n\sum_j\phi(x_j)\)। নতুন kernel-ভুক্তি \(\tilde K_{ij}=\tilde\phi(x_i)^\top\tilde\phi(x_j)\) খুলে লিখি:
চারটি পদ ঠিক চারটি matrix-গুণে রূপ নেয় (\(\mathbf 1_n=\tfrac1n\mathbf 1\mathbf 1^\top\) ব্যবহার করে): \(\tfrac1n\sum_a K_{aj}=(\mathbf 1_n K)_{ij}\) (column-গড়), \(\tfrac1n\sum_b K_{ib}=(K\mathbf 1_n)_{ij}\) (row-গড়), আর \(\tfrac1{n^2}\sum_{a,b}K_{ab}=(\mathbf 1_n K\mathbf 1_n)_{ij}\) (সর্বমোট গড়)। তাই double-centering সূত্র:
(শেষ সমতা: \(H=I-\mathbf 1_n\) হলে \(HKH=(I-\mathbf 1_n)K(I-\mathbf 1_n)\) খুললেই ঠিক ওই চার পদ পাওয়া যায়)। তাই প্রকৃত kernel PCA হলো: \(K\) থেকে \(\tilde K\) গণনা, তারপর \(\tilde K\alpha_m=n\lambda_m\alpha_m\) সমাধান।
ধাপ ৬ — embedding coordinate। \(m\)-তম principal direction \(v_m=\sum_i(\alpha_m)_i\tilde\phi(x_i)\) unit-norm করতে হলে দরকার \(v_m^\top v_m=1\)। হিসাব: \(v_m^\top v_m=\sum_{i,j}(\alpha_m)_i(\alpha_m)_j\tilde K_{ij}=\alpha_m^\top\tilde K\alpha_m=n\lambda_m\,\lVert\alpha_m\rVert^2\) (যেহেতু \(\tilde K\alpha_m=n\lambda_m\alpha_m\))। তাই unit-norm-এর জন্য eigenvector-কে স্কেল করি যেন \(\lVert\alpha_m\rVert^2=\tfrac1{n\lambda_m}\)। এবার বিন্দু \(x_i\)-এর \(m\)-তম নতুন স্থানাঙ্ক হলো তার projection:
যেখানে শেষ ধাপে normalize-করা \(\alpha_m\) (অর্থাৎ unit-eigenvector \(u_m\) ধরে \(\alpha_m=u_m/\sqrt{n\lambda_m}\)) বসালে পরিচ্ছন্ন রূপ পাওয়া যায়:
— একটি সম্পূর্ণ nonlinear projection, অথচ \(\phi\) কোথাও প্রকাশ্যে আসেনি; সবটাই \(\tilde K\)-এর eigen-decomposition থেকে। (সংখ্যাগত যাচাই: linear kernel \(k(x,x')=x^\top x'\) নিলে \(\tilde K=HKH\) ঠিক কেন্দ্রীভূত-data-র Gram-এর সমান হলো, এবং এর eigen থেকে পাওয়া \((y_i)_m\) সাধারণ PCA-র স্থানাঙ্কের সাথে হুবহু মিলল — kernel PCA সত্যিই PCA-এর সাধারণীকরণ।)
৪.২ ★★★ Classical MDS এবং PCA-এর সাথে তার সমতুল্যতা¶
এটি এই অধ্যায়ের গাণিতিক মেরুদণ্ড: শুধু জোড়া-দূরত্ব (\(\Delta\)) জানা থাকলেও কীভাবে স্থানাঙ্ক \(Y\) পুনরুদ্ধার করা যায়, এবং কেন Euclidean দূরত্বের ক্ষেত্রে classical MDS ঠিক PCA-ই দেয়। মূল হাতিয়ার একটিই — double-centering।
সমস্যা। ধরা যাক আমরা প্রকৃত স্থানাঙ্ক দেখি না, কেবল squared-distance matrix \(\Delta\) (\(\Delta_{ij}=\lVert x_i-x_j\rVert^2\)) পাই। লক্ষ্য: এমন \(y_i\in\mathbb R^d\) খোঁজা যাদের জোড়া-দূরত্ব \(\Delta\)-কে যথাসম্ভব ধরে রাখে। কৌশল: দূরত্ব \(\to\) inner product (Gram) \(\to\) eigen-decomposition (prereq 0.5)।
ধাপ ১ — double-centering identity (মূল উৎপাদন)। দাবি: \(\Delta\)-কে দুদিক থেকে \(H\) দিয়ে চেপে আর \(-\tfrac12\) গুণ করলে কেন্দ্রীভূত inner products বেরোয়, অর্থাৎ \(B_{ij}=\langle x_i-\bar x,\;x_j-\bar x\rangle\) যেখানে \(\bar x=\tfrac1n\sum_a x_a\)। প্রমাণ শুরু করি squared-distance-কে inner-product-এ খুলে:
লিখি \(g_i:=\lVert x_i\rVert^2\) আর \(G_{ij}:=x_i^\top x_j\) (raw Gram), তাই \(\Delta_{ij}=g_i+g_j-2G_{ij}\)। এবার double-centering \(B:=-\tfrac12 H\Delta H\) প্রয়োগ করি, কোথায় কী যায় তা ভুক্তি-আকারে দেখি। মনে রাখি \((HAH)_{ij}=A_{ij}-\bar A_{i\cdot}-\bar A_{\cdot j}+\bar A_{\cdot\cdot}\) (row-গড়, column-গড়, সর্বমোট-গড় বাদ)। \(\Delta\)-এর তিন অংশে আলাদা করে দেখি:
- \(g_i\) পদ (শুধু \(i\)-নির্ভর, column জুড়ে ধ্রুবক): এর row-গড় = \(g_i\), কিন্তু centering-এ \(g_i-\bar g_{i\cdot}\)... আসলে সরাসরি ধর্ম খাটে — যেকোনো পদ যা কেবল \(i\)-এর বা কেবল \(j\)-এর ফাংশন, double-centering তাকে সম্পূর্ণ মুছে দেয় (কারণ \(H\mathbf 1=0\): \(i\)-only পদ মানে প্রতিটি column-এ একই কলাম-vector, যাকে ডান-\(H\) ধ্রুবক হিসেবে শূন্য করে; \(j\)-only পদ একইভাবে বাম-\(H\) শূন্য করে)।
তাই \(g_i\) ও \(g_j\) — দুটোই অদৃশ্য হয়, থেকে যায় কেবল \(-2G_{ij}\) পদ:
(কারণ \(\mathbf 1^\top H=(H\mathbf 1)^\top=0\) এবং \(H\mathbf 1=0\))। আর \(HGH\) ঠিক কেন্দ্রীভূত-data-র Gram: \((HGH)_{ij}=(x_i-\bar x)^\top(x_j-\bar x)\)। সুতরাং
— double-centering squared distances থেকে ঠিক কেন্দ্রীভূত inner products পুনরুদ্ধার করে। (এটিই §৪.১-এর \(\tilde K=HKH\)-এর "দূরত্ব-সংস্করণ": সেখানে kernel থেকে, এখানে দূরত্ব থেকে — দুটোই একই \(H(\cdot)H\) কেন্দ্রীয়করণ।)
ধাপ ২ — Gram থেকে embedding (\(B=YY^\top\))। কেন্দ্রীভূত স্থানাঙ্ক সারি-সাজিয়ে \(\tilde X\) (\(i\)-তম সারি \((x_i-\bar x)^\top\)) ধরলে \(B=\tilde X\tilde X^\top\), অর্থাৎ \(B\) একটি PSD (positive semidefinite) Gram matrix। যদি আমরা \(d\)-মাত্রিক embedding \(Y\in\mathbb R^{n\times d}\) চাই যেন \(YY^\top\approx B\), তবে \(B\)-এর eigendecomposition নিই: \(B=U\Lambda U^\top\) (\(U\) orthonormal eigenvectors, \(\Lambda=\mathrm{diag}(\lambda_1\ge\dots\ge\lambda_n\ge0)\))। top-\(d\) eigenvalue/vector রেখে
— প্রতিটি embedding-অক্ষ = একটি eigenvector \(\sqrt{\lambda_m}\) দিয়ে স্কেল করা। যাচাই: \(YY^\top=U_d\Lambda_d U_d^\top\) হলো \(B\)-এর সেরা rank-\(d\) আসন্নীকরণ (Eckart–Young, prereq 0.5), তাই reconstructed inner products \(B\)-এর যত কাছে সম্ভব। (top-\(d\) eigenvalue বেছে নেওয়া মানে সর্বাধিক "inner-product শক্তি" ধরে রাখা — ঠিক PCA-র সর্বাধিক-variance নীতির অনুরূপ।)
ধাপ ৩ — Euclidean দূরত্বে MDS = PCA (সমতুল্যতা)। এখন মূল দাবি: যদি \(\Delta\) আসলেই কিছু \(x_i\in\mathbb R^D\)-এর প্রকৃত Euclidean squared distances হয়, তবে classical MDS হুবহু PCA স্থানাঙ্ক ফিরিয়ে দেয়। যুক্তি সরল, কারণ ধাপ ১-এ দেখেছি MDS-এর \(B=HGH\) ঠিক কেন্দ্রীভূত-data-র Gram — যা §৪.১/prereq 5.9-এ PCA-এর কেন্দ্রীয় বস্তু। বিস্তারিত: SVD-তে \(\tilde X=U_X S V_X^\top\) (prereq 0.5) হলে—
- PCA স্থানাঙ্ক (data-কে top-\(d\) principal direction-এ project): \(Z_{\text{PCA}}=\tilde X V_{X,d}=U_{X,d}S_d\);
- MDS-এর \(B=\tilde X\tilde X^\top=U_X S^2 U_X^\top\), তাই \(B\)-এর eigenvectors = \(U_X\), eigenvalues = \(S^2=\mathrm{diag}(\sigma_m^2)\); ফলে MDS embedding \(Y=U_{X,d}\,(S^2_d)^{1/2}=U_{X,d}S_d\).
দুটো অভিন্ন: \(Y=Z_{\text{PCA}}=U_{X,d}S_d\) (eigenvector-চিহ্নের স্বাধীনতা বাদে)। অর্থাৎ
তাৎপর্য: PCA-র জন্য আসল স্থানাঙ্ক \(X\) লাগে; MDS কেবল জোড়া-দূরত্ব \(\Delta\) থেকেই সেই একই উত্তর বের করে। তাই যখন আমাদের হাতে স্থানাঙ্ক নেই, কেবল দূরত্ব আছে (অথবা আমরা ইচ্ছাকৃতভাবে non-Euclidean দূরত্ব বসাতে চাই — যেমন §৪.৩-এর geodesic), তখন MDS-ই পথ। (সংখ্যাগত যাচাই: এলোমেলো \(X\)-এর Euclidean \(\Delta\) থেকে \(B=-\tfrac12 H\Delta H\) গণনা করে দেখা গেল \(B\) কেন্দ্রীভূত Gram-এর সমান (max-পার্থক্য \(\sim10^{-15}\)), এবং তার top-\(d\) eigen-embedding PCA স্থানাঙ্কের সাথে হুবহু মিলল।)
৪.৩ ★★ Isomap = geodesic দূরত্বের উপর MDS¶
লক্ষ্য। Euclidean দূরত্ব একটি বাঁকানো manifold-এর "ভেতর দিয়ে কেটে" যায়, তাই দুটি বিন্দুর প্রকৃত manifold-দূরত্বকে ছোট দেখায়। Isomap এই সমস্যা সারে: Euclidean \(\Delta\)-এর বদলে geodesic (sheet-বরাবর) দূরত্ব আন্দাজ করে, তারপর তার উপর classical MDS (§৪.২) চালায়।
প্রেরণা — swiss roll। কল্পনা করি একটি কাগজের শিট (\(2\)D manifold) যা \(3\)D-তে রোল করে পাকানো (swiss roll)। রোলের ভেতরের ও বাইরের পরতের দুটি বিন্দু \(3\)D-তে স্থানিকভাবে কাছাকাছি হতে পারে — তাই \(\lVert x_i-x_j\rVert\) ছোট — অথচ শিট-বরাবর হাঁটলে তারা বহু দূরে। Euclidean দূরত্ব এই "শর্টকাট" নেয় বলে PCA/সাধারণ MDS রোলটাকে চ্যাপ্টা করে গুলিয়ে ফেলে। আমরা চাই এমন দূরত্ব যা কেবল শিটের উপর দিয়ে মাপা — সেটিই geodesic \(d_G\)।
ধাপ ১ — \(k\)-NN graph তৈরি। ধরে নিই খুব কাছের বিন্দুদের জন্য Euclidean দূরত্ব \(\approx\) geodesic দূরত্ব (locally, বাঁকানো পৃষ্ঠ স্থানীয়ভাবে সমতলের মতো — এটিই manifold-এর মূল ধারণা)। তাই প্রতিটি বিন্দু \(x_i\)-কে তার \(k\) নিকটতম প্রতিবেশীর সাথে edge দিয়ে জুড়ি, edge-ওজন = Euclidean দূরত্ব \(\lVert x_i-x_j\rVert\)। এতে পাই একটি weighted graph \(\mathcal G\), যার edge-গুলো manifold-পৃষ্ঠ ঘেঁষে থাকে — কোনো "শর্টকাট" edge নেই, কারণ দূরের বিন্দু সরাসরি সংযুক্ত নয়।
ধাপ ২ — shortest path = geodesic আন্দাজ। যেকোনো দুই বিন্দুর geodesic দূরত্বকে graph-এর shortest path (সংযোগকারী edge-ওজনের সর্বনিম্ন যোগফল) দিয়ে আন্দাজ করি — Dijkstra (একক উৎস) বা Floyd–Warshall (সব-জোড়া) algorithm দিয়ে:
ছোট-ছোট স্থানীয় ধাপ জুড়ে জুড়ে পথ তৈরি হয় বলে যোগফলটি manifold-পৃষ্ঠ অনুসরণ করে — তাই \(d_G\) শিটের বাঁক ধরে রাখে, \(3\)D শর্টকাট নয়। বিন্দু-ঘনত্ব বাড়লে এই graph-distance প্রকৃত geodesic-এ converge করে।
ধাপ ৩ — geodesic-এর উপর classical MDS। এবার squared-geodesic matrix \(\Delta^{(G)}_{ij}=d_G(x_i,x_j)^2\) বানিয়ে §৪.২-এর classical MDS হুবহু প্রয়োগ করি:
ফলাফল। যেহেতু embedding-এর Euclidean দূরত্ব এখন manifold-এর geodesic দূরত্বকে অনুকরণ করে, swiss roll খুলে গিয়ে একটি সমতল \(2\)D আয়তক্ষেত্রে পরিণত হয় — রোলের যে দুই বিন্দু \(3\)D-তে কাছে কিন্তু শিট-বরাবর দূরে, embedding-এ তারা সঠিকভাবে দূরে বসে। সংক্ষেপে Isomap = (i) \(k\)-NN graph, (ii) shortest-path geodesic, (iii) geodesic-এর উপর classical MDS — একটি global পদ্ধতি (সব-জোড়া দূরত্ব ব্যবহার করে), যা manifold-কে তার ভেতরকার (intrinsic) সমতল জ্যামিতিতে মেলে ধরে।
৪.৪ ★★ LLE (Locally Linear Embedding) — স্থানীয় weight সংরক্ষণ¶
লক্ষ্য। Isomap global geodesic ধরে; LLE উল্টো পথে — কেবল স্থানীয় জ্যামিতি রক্ষা করে। মূল ধারণা: একটি মসৃণ manifold প্রতিটি বিন্দুর ছোট প্রতিবেশে প্রায় সমতল (locally linear), তাই প্রতিটি বিন্দুকে তার প্রতিবেশীদের একটি linear combination হিসেবে লেখা যায়; সেই combination-ওজনগুলোই স্থানীয় আকৃতির স্বাক্ষর, যা low-D-তে অবিকল ধরে রাখলে manifold খুলে যায়।
ধাপ ১ — স্থানীয় reconstruction weight \(w_{ij}\) খোঁজা। ধরি প্রতিটি \(x_i\) তার প্রতিবেশী-সেট \(N(i)\) (যেমন \(k\)-NN)-এর আঁতাত থেকে পুনর্গঠিত: \(x_i\approx\sum_{j\in N(i)}w_{ij}x_j\)। weight বের করি reconstruction error সর্বনিম্ন করে, constraint \(\sum_{j\in N(i)}w_{ij}=1\)-সহ (এই sum-to-one শর্ত embedding-কে translation/scale/rotation-এর প্রতি অপরিবর্তনীয় করে — শুধু আপেক্ষিক স্থানীয় আকৃতি ধরে):
প্রতিটি \(i\) আলাদাভাবে সমাধানযোগ্য। sum-to-one ব্যবহার করে \(x_i=\sum_j w_{ij}x_i\) লিখলে error \(=\lVert\sum_j w_{ij}(x_i-x_j)\rVert^2=\sum_{j,m}w_{ij}w_{im}\,C^{(i)}_{jm}\), যেখানে local Gram \(C^{(i)}_{jm}=(x_i-x_j)^\top(x_i-x_m)\)। এটি একটি ছোট constrained quadratic — Lagrange বা সরাসরি \(C^{(i)}w_i=\mathbf 1\) সমাধান করে \(w_i\)-কে \(\sum_j w_{ij}=1\)-এ normalize করলেই বন্ধ-রূপ মান পাওয়া যায়। (এই \(w_{ij}\) স্থানীয় জ্যামিতির অপরিবর্তনীয় বর্ণনা: প্রতিবেশ যদি ঘোরে/সরে/মাপ বদলায়, weight একই থাকে।)
ধাপ ২ — একই weight রক্ষা করে low-D embedding। এখন এমন \(y_i\in\mathbb R^d\) খুঁজি যারা ঠিক সেই \(w_{ij}\) দিয়ে পুনর্গঠিত হয় — অর্থাৎ স্থানীয় আকৃতি D-মাত্রা থেকে d-মাত্রায় বহন করি (এবার \(W\) স্থির, \(Y\) অজানা):
ধাপ ৩ — eigen-problem-এ রূপান্তর। embedding-গুলো সারি-সাজিয়ে \(Y\in\mathbb R^{n\times d}\) ধরি। তখন \(y_i-\sum_j w_{ij}y_j\) হলো \((I-W)Y\)-এর \(i\)-তম সারি, তাই
\(M\) হলো একটি symmetric PSD \(n\times n\) matrix। \(\Phi\)-কে যত খুশি ছোট করতে গেলে \(Y\to0\) ভেঙে পড়ে, তাই দুটি constraint বসাই: কেন্দ্রীভূত (\(\sum_i y_i=0\), translation স্থির) ও unit covariance (\(\tfrac1n Y^\top Y=I\), scale স্থির ও degenerate সমাধান এড়াতে)। এই constrained trace-minimization-এর সমাধান (Rayleigh–Ritz, prereq 0.5): \(Y\)-এর কলামগুলো \(M\)-এর bottom (সর্বনিম্ন-eigenvalue) eigenvectors।
সতর্কতা — প্রথমটি বাদ। \(M\)-এর সর্বনিম্ন eigenvalue ঠিক \(0\), এবং তার eigenvector হলো ধ্রুবক-vector \(\mathbf 1\) (কারণ \((I-W)\mathbf 1=\mathbf 1-W\mathbf 1=\mathbf 1-\mathbf 1=0\), যেহেতু প্রতিটি সারিতে \(\sum_j w_{ij}=1\))। এই trivial দিকটি কেবল "সব বিন্দু একই জায়গায়" বোঝায়, তাই বাদ দিয়ে পরবর্তী \(d\)টি bottom eigenvector নিই — সেগুলোই embedding \(y_i\)। (সংখ্যাগত যাচাই: \(k\)-NN weight থেকে গড়া \(M\)-এর সবচেয়ে ছোট eigenvalue হুবহু \(0\) (ধ্রুবক-vector), পরেরগুলো ধনাত্মক — তত্ত্বের সাথে মিলে; তাই প্রথমটি বাদ দিয়ে embedding নেওয়া হয়।) তাৎপর্য: LLE শুধু স্থানীয় patch-জ্যামিতি জোড়া দিয়ে global structure পুনর্গঠন করে — কোনো জোড়া-দূরত্ব হিসাব ছাড়াই, একটিমাত্র sparse eigen-problem-এ।
৪.৫ ★★ t-SNE — KL objective ও crowding-সমাধান¶
লক্ষ্য। t-SNE (t-distributed Stochastic Neighbor Embedding) দূরত্ব-সংরক্ষণের বদলে প্রতিবেশ-সম্ভাবনা সংরক্ষণ করে: উচ্চ-মাত্রায় "\(j\) হলো \(i\)-এর প্রতিবেশী" সম্ভাবনা \(p_{ij}\), আর low-D-তে \(q_{ij}\); এই দুই বণ্টনকে KL-divergence দিয়ে কাছে আনা হয়। ভিজ্যুয়ালাইজেশনে এটি অসাধারণ স্থানীয় গুচ্ছ ধরে, কিন্তু গুচ্ছ-অন্তর দূরত্ব অর্থবহ নয় — কেন, তা-ও দেখব।
ধাপ ১ — উচ্চ-মাত্রিক প্রতিবেশ-সম্ভাবনা \(p_{ij}\) (Gaussian)। প্রতিটি বিন্দু \(x_i\)-কে কেন্দ্র করে একটি Gaussian বসিয়ে অন্য বিন্দু \(x_j\)-এর "প্রতিবেশী-হওয়ার" শর্তাধীন সম্ভাবনা:
— ঘনিষ্ঠ বিন্দুর সম্ভাবনা বড়, দূরের প্রায় শূন্য। প্রতিটি bandwidth \(\sigma_i\) ঠিক করা হয় perplexity দিয়ে: perplexity \(=2^{H(P_i)}\) (\(H\) = Shannon entropy of \(\{p_{j\mid i}\}_j\)) একটি লক্ষ্য-মান (যেমন \(30\))-এ স্থির রাখা হয়, যা মোটামুটি "কার্যকর প্রতিবেশী-সংখ্যা" বোঝায় — ঘন অঞ্চলে \(\sigma_i\) ছোট, বিরল অঞ্চলে বড় (অভিযোজিত)। তারপর symmetrize করে যৌথ সম্ভাবনা: \(p_{ij}=\dfrac{p_{j\mid i}+p_{i\mid j}}{2n}\) (যাতে \(\sum_{ij}p_{ij}=1\) এবং কোনো বিন্দু "outlier" হয়ে হারিয়ে না যায়)।
ধাপ ২ — low-D সাদৃশ্য \(q_{ij}\) (heavy-tailed Student-t)। embedding \(y_i\in\mathbb R^d\)-তে সাদৃশ্য মাপি \(1\)-degree Student-t (Cauchy) kernel দিয়ে — Gaussian দিয়ে নয়:
এই \((1+r^2)^{-1}\) kernel-এর লেজ ভারী (heavy-tailed): বড় \(r\)-এ এটি \(\sim r^{-2}\) হারে ধীরে কমে, Gaussian-এর \(e^{-r^2/2}\)-এর তুলনায় বহুগুণ মন্থর।
ধাপ ৩ — KL objective ও gradient descent। \(P\) ও \(Q\) বণ্টন কাছে আনতে KL-divergence সর্বনিম্ন করি (asymmetric, ইচ্ছাকৃতভাবে):
\(y_i\)-গুলো (এলোমেলো initialization থেকে) gradient descent দিয়ে নড়ানো হয়; পরিচিত সুন্দর gradient-রূপ (Student-t kernel-এর কারণে):
যা একটি ভৌত "আকর্ষণ–বিকর্ষণ" বল: \(p_{ij}>q_{ij}\) হলে \(i,j\) পরস্পরকে টানে, \(p_{ij}<q_{ij}\) হলে ঠেলে দেয়। asymmetric KL-এর তাৎপর্য: \(p_{ij}\) বড় অথচ \(q_{ij}\) ছোট হলে শাস্তি ভারী (কাছের প্রতিবেশী দূরে ফেললে বড় খরচ), কিন্তু উল্টোটায় শাস্তি হালকা — তাই t-SNE স্থানীয় প্রতিবেশ আঁকড়ে ধরে, global দূরত্ব নয়।
ধাপ ৪ — কেন Student-t লেজ "crowding problem" সারায়। crowding problem: একটি high-\(D\) manifold-এ একটি বিন্দুর চারপাশে "মধ্যম-দূরত্বে" বহু বিন্দু এঁটে যায় (উচ্চ-মাত্রায় আয়তন দ্রুত বাড়ে), কিন্তু \(2\)D-তে অত জায়গা নেই — তাদের সবাইকে বসাতে গেলে গুচ্ছ পরস্পরের উপর হুমড়ি খেয়ে চাপাচাপি (crowd) হয়ে যায়। যদি low-D সাদৃশ্যও Gaussian হতো, তবে মাঝারি-দূরত্বের জোড়ার \(q_{ij}\) দ্রুত শূন্যে নেমে যেত, ফলে অসঙ্গতি মেটাতে gradient সবকিছুকে কেন্দ্রের দিকে গুঁজে দিত। Student-t-এর ভারী লেজ এই সমস্যা সারে: low-D-তে একই মাঝারি \(p_{ij}\) মেলাতে হলে \(q_{ij}=(1+r^2)^{-1}\) অনেক বড় \(r\)-এও যথেষ্ট মান রাখে — অর্থাৎ মাঝারি-দূরের জোড়াগুলোকে embedding আরও দূরে ঠেলে দিতে পারে, গুচ্ছগুলোর মাঝে শ্বাসের জায়গা তৈরি করে। ফলে আলাদা গুচ্ছ পরিষ্কার ফাঁক নিয়ে ফুটে ওঠে। (সংখ্যাগত যাচাই: \(r=1,2,3,5\)-এ Student-t/Gaussian লেজের অনুপাত \(\approx0.8,1.5,9,10^4\) — দূরত্ব বাড়ার সাথে Student-t বহুগুণ বেশি ভর রাখে, তাই দূরের বিন্দু দূরেই রাখতে পারে, crowding রোধ হয়।)
সীমাবদ্ধতা (গুরুত্বপূর্ণ)। t-SNE কেবল \(p_{ij}-q_{ij}\) স্থানীয় ভারসাম্য রক্ষা করে; তাই গুচ্ছের ভেতরের প্রতিবেশ বিশ্বস্ত, কিন্তু গুচ্ছ-অন্তর দূরত্ব ও আপেক্ষিক আকার অর্থবহ নয় — দুটি গুচ্ছ embedding-এ যত দূরে দেখায় তা প্রকৃত high-\(D\) দূরত্বের সঙ্গে সঙ্গতিপূর্ণ নাও হতে পারে (এবং perplexity বদলালে ছবিও বদলায়)। তাই t-SNE মহৎ একটি ভিজ্যুয়ালাইজেশন যন্ত্র (গুচ্ছ আবিষ্কার), কিন্তু global জ্যামিতি বা দূরত্ব-নির্ভর সিদ্ধান্তের জন্য Isomap/MDS-ই উপযুক্ত।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটিমাত্র runnable script-এ পাঁচটি dimensionality reduction পদ্ধতিকে একই dataset-এ পাশাপাশি দাঁড় করাব এবং তাদের তুলনা করব দুটি objective metric দিয়ে: (১) trustworthiness — embedding-এ যে neighbours দেখা যাচ্ছে তারা original high-dimensional space-এও সত্যিই কতটা কাছের প্রতিবেশী ছিল, এবং (২) best_corr — embedding-এর কোনো একটি axis আর true manifold coordinate (এখানে color)-এর মধ্যে Spearman rank correlation-এর সর্বোচ্চ মান। প্রথমটি বলে "local structure সংরক্ষিত হয়েছে কি?", দ্বিতীয়টি বলে "manifold-টা কি আসলেই unroll হয়েছে?" — এবং এই দুইয়ের পার্থক্যই এই অধ্যায়ের কেন্দ্রীয় শিক্ষা।
আমাদের playground হলো Swiss roll: একটি 2D সমতলকে 3D space-এ পাকিয়ে রাখা একটি classic nonlinear manifold। এর intrinsic dimension আসলে কম, কিন্তু ambient space-এ সেটা মোচড়ানো অবস্থায় থাকে। color variable-টি roll বরাবর true geodesic অবস্থান ধরে রাখে — তাই একটি পদ্ধতি যদি manifold-কে সঠিকভাবে সমতল করে দেয়, তবে তার একটি embedding axis-এর সাথে color-এর rank correlation প্রায় \(1\) হওয়া উচিত।
স্ক্রিপ্ট¶
import numpy as np
from sklearn.datasets import make_swiss_roll
from sklearn.decomposition import PCA, KernelPCA
from sklearn.manifold import Isomap, LocallyLinearEmbedding, TSNE, trustworthiness
from scipy.stats import spearmanr
# ---- Dataset: Swiss roll (intrinsic 2D, embedded in 3D, nonlinearly rolled)
X, color = make_swiss_roll(n_samples=1000, noise=0.05, random_state=20260619)
def best_corr(emb):
# embedding-এর কোন axis-টি true manifold coordinate (color)-এর সবচেয়ে কাছাকাছি?
return max(abs(spearmanr(emb[:, 0], color).correlation),
abs(spearmanr(emb[:, 1], color).correlation))
results = {}
# ===== PART 1: Linear PCA — flattens, but cannot UNROLL =====
pca = PCA(n_components=2).fit_transform(X)
results['PCA(2)'] = (trustworthiness(X, pca, n_neighbors=10), best_corr(pca))
# ===== PART 2: Geodesic / local manifold learning =====
iso = Isomap(n_neighbors=10).fit_transform(X)
results['Isomap(k=10)'] = (trustworthiness(X, iso, n_neighbors=10), best_corr(iso))
lle = LocallyLinearEmbedding(n_neighbors=10, random_state=0).fit_transform(X)
results['LLE(k=10)'] = (trustworthiness(X, lle, n_neighbors=10), best_corr(lle))
# ===== PART 3: t-SNE (neighbour-preserving) + KernelPCA (kernel-sensitive) =====
tsne = TSNE(n_components=2, perplexity=30, random_state=0, init='pca').fit_transform(X)
results['t-SNE(perp=30)'] = (trustworthiness(X, tsne, n_neighbors=10), best_corr(tsne))
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=0.04).fit_transform(X)
results['KernelPCA(rbf,g=.04)'] = (trustworthiness(X, kpca, n_neighbors=10), best_corr(kpca))
# ---- Comparison table
print("=" * 56)
print(f"{'Method':<24}{'Trustworthiness':>16}{'best_corr':>14}")
print("-" * 56)
for name, (tw, bc) in results.items():
print(f"{name:<24}{tw:>16.3f}{bc:>14.3f}")
print("=" * 56)
# ===== PART 4: Which methods recover the TRUE 1D coordinate? =====
print("\nManifold coordinate recovery (Spearman vs true 'color'):")
for name in ['Isomap(k=10)', 'LLE(k=10)']:
print(f" {name:<24} corr={results[name][1]:.3f} -> recovers 1D coordinate")
for name in ['PCA(2)', 'KernelPCA(rbf,g=.04)']:
print(f" {name:<24} corr={results[name][1]:.3f} -> fails to unroll")
আউটপুট¶
========================================================
Method Trustworthiness best_corr
--------------------------------------------------------
PCA(2) 0.968 0.165
Isomap(k=10) 1.000 1.000
LLE(k=10) 0.996 0.998
t-SNE(perp=30) 0.999 0.857
KernelPCA(rbf,g=.04) 0.898 0.228
========================================================
Manifold coordinate recovery (Spearman vs true 'color'):
Isomap(k=10) corr=1.000 -> recovers 1D coordinate
LLE(k=10) corr=0.998 -> recovers 1D coordinate
PCA(2) corr=0.165 -> fails to unroll
KernelPCA(rbf,g=.04) corr=0.228 -> fails to unroll
পাঠোদ্ধার¶
Trustworthiness আর correlation আলাদা প্রশ্নের উত্তর দেয় — এটাই মূল চমক। খেয়াল করুন PCA-র trustworthiness \(0.968\), প্রায় চমৎকার শোনায়; কিন্তু তার best_corr মাত্র \(0.165\) — প্রায় random। কীভাবে? Linear PCA Swiss roll-কে একটি সমতলে project করে (তাই কাছের অনেক প্রতিবেশী মোটামুটি কাছেই থাকে, trustworthiness মন্দ নয়), কিন্তু roll-টিকে খুলে দেয় না — মোড়ানো অবস্থায় দূরবর্তী দুই প্রান্ত projection-এ পরস্পরের গায়ে চাপ খেয়ে বসে। ফলে কোনো একক axis আর true geodesic coordinate color-এর মধ্যে সম্পর্ক ভেঙে পড়ে। PCA শুধু চ্যাপ্টা করে, unroll করে না।
- Isomap (k=10): trustworthiness \(1.000\), corr \(1.000\) — perfect। Geodesic দূরত্ব (neighbour graph বরাবর shortest path) ব্যবহার করে এটি manifold-কে নিখুঁতভাবে সমতল করে; embedding-এর একটি axis হুবহু
colorহয়ে যায়, তাই rank correlation \(1\)। - LLE (k=10): \(0.996 / 0.998\) — প্রায় সমমানের। প্রতিটি বিন্দুকে তার প্রতিবেশীদের linear combination হিসেবে পুনর্গঠন করে এবং সেই local weight-গুলো নিচু মাত্রায় সংরক্ষণ করে — local geometry থেকেই global unrolling বেরিয়ে আসে।
- t-SNE (perplexity=30): trustworthiness \(0.999\), কিন্তু corr \(0.857\)। Neighbour-preservation-এ অসাধারণ (highest trustworthiness-গুলোর একটি), তবে t-SNE global geometry সংরক্ষণের নিশ্চয়তা দেয় না; এটি cluster তৈরি করে ও দূরত্ব বিকৃত করে, তাই \(1\)-এর কাছাকাছি গেলেও পুরো monotone coordinate পুনরুদ্ধার করে না। Visualization-এ চমৎকার, কিন্তু "true 1D axis recovery"-তে Isomap/LLE-র চেয়ে দুর্বল।
- KernelPCA (rbf, \(\gamma=0.04\)): \(0.898 / 0.228\) — সবচেয়ে দুর্বল, এবং kernel-sensitive। RBF kernel-এ feature space নির্ভর করে \(\gamma\)-এর উপর; এই \(\gamma\)-মানে kernel manifold-এর geodesic structure ধরতে পারেনি, তাই PCA-র মতোই unroll ব্যর্থ (corr \(0.228\))। ভিন্ন \(\gamma\) বা kernel-এ ফলাফল নাটকীয়ভাবে বদলায় — এটিই kernel method-এর হাইপারপ্যারামিটার-সংবেদনশীলতা।
সারমর্ম। এই দুই কলামকে একসাথে পড়লেই সিদ্ধান্ত স্পষ্ট: Isomap ও LLE-ই true 1D manifold coordinate পুনরুদ্ধার করে (corr \(\approx 1\)), অথচ PCA ও KernelPCA তা পারে না (corr \(\approx 0.16\) ও \(0.23\))। একটি উঁচু trustworthiness একা যথেষ্ট নয় — PCA-র \(0.968\) ভ্রান্তিকর। যখন data একটি curved manifold-এ বাস করে, সঠিক হাতিয়ার হলো geodesic বা local manifold learning (Isomap/LLE), কোনো linear projection নয়; আর t-SNE/KernelPCA-র ক্ষেত্রে ফলাফল হাইপারপ্যারামিটার ও উদ্দেশ্যের (visualization বনাম coordinate recovery) উপর গভীরভাবে নির্ভরশীল।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের কেন্দ্রীয় ভাবনা — nonlinear dimensionality reduction ও manifold learning — আসলে একটা জ্যামিতিক রূপকথা: উঁচু মাত্রার space-এ data প্রায়ই একটা বাঁকানো, কুঁকড়ানো নিচু-মাত্রিক চাদরের (manifold) উপর শুয়ে থাকে, আর আমাদের কাজ সেই চাদরটাকে না ছিঁড়ে, না জোড়াতালি দিয়ে সমতলে মেলে ধরা। সংখ্যাগুলো এই গল্পের কঙ্কাল — trustworthiness PCA \(0.968\), Isomap \(1.000\), LLE \(0.996\), t-SNE \(0.999\), KernelPCA \(0.898\); আর true coordinate-এর সঙ্গে correlation PCA \(0.165\), KernelPCA \(0.228\), t-SNE \(0.857\), LLE \(0.998\), Isomap \(1.000\) — কিন্তু এই সংখ্যাগুলো কেন এত আলাদা, তার আসল উত্তর টেবিলে নয়, ছবিতে। কারণ এখানে লড়াইটা গাণিতিক distance-এর নয়, গঠন সংরক্ষণের — কে রঙের ক্রমটা (অর্থাৎ চাদরের উপর আসল অবস্থানের ক্রম) অক্ষত রেখে চাদরটাকে খুলতে পারল, আর কে বাঁকানো চাদরকে চ্যাপ্টা করে ফেলে রঙগুলো ঘেঁটে দিল। তাই এই অংশে আমরা পুরো গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন analyst এগোয়: প্রথমে দেখি আমরা আসলে কী খুলতে চাইছি (3D-তে গোটানো চাদরটা); তারপর headline তুলনা — linear PCA বনাম nonlinear Isomap; তারপর পাঁচটা method পাশাপাশি কে কতটা পারল; এবং শেষে একটা bar chart দিয়ে যাচাই — কেন high trustworthiness থাকলেও global গঠন নাও আসতে পারে।
মনে রাখুন — dataset। এই অংশের সব ছবি একই একটা ক্লাসিক benchmark থেকে তৈরি: Swiss roll। আমরা
make_swiss_rollদিয়ে \(1000\) টা point বানাই (\(\sigma = 0.05\) noise সমেত, fixed seed), যেখানে প্রতিটা point-এর সঙ্গে একটাcolorমান যুক্ত — সেটাই হলো চাদরের উপর সেই point-এর আসল along-the-roll স্থানাঙ্ক (অর্থাৎ চাদরটা যদি খোলা হতো, তাহলে point-টা কোন বরাবর বসত)। গোটানো অবস্থায় কাছাকাছি দেখতে দুটো point আসলে চাদরের দুই দূর প্রান্তে থাকতে পারে — ঠিক যেমন গোটানো কাগজে উপরের আর নিচের পরত পরস্পরকে ছোঁয়, অথচ কাগজ খুললে তারা বহু দূরে। সব scatter-এ বিন্দুগুলোকে এইcolorদিয়েই রঙ করা হবে, তাই রঙের একটানা মসৃণ gradient = চাদর সঠিকভাবে খুলেছে, আর রঙ ঘেঁটে যাওয়া / overlap = খোলেনি। এটাই গোটা অংশের পাঠযোগ্যতার চাবিকাঠি।
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_roll
from sklearn.decomposition import PCA, KernelPCA
from sklearn.manifold import (Isomap, LocallyLinearEmbedding,
TSNE, trustworthiness)
# fixed seed: একই Swiss roll প্রতিবার
X, color = make_swiss_roll(n_samples=1000, noise=0.05,
random_state=20260619)
# color = চাদরের উপর প্রতিটা point-এর আসল অবস্থান (rainbow ক্রম)
পাঁচটা embedding একই \(3\)-মাত্রিক X-এর উপর চলবে, প্রত্যেকে \(2\)-মাত্রায় নামাবে, কিন্তু সম্পূর্ণ আলাদা দর্শন নিয়ে — PCA শুধু সবচেয়ে বড় variance-এর দিক ধরে রাখে (linear); Isomap point-গুলোর মধ্যেকার geodesic (চাদর বরাবর) দূরত্ব রক্ষা করে; LLE প্রতিটা point-কে তার প্রতিবেশীদের linear combination হিসেবে গড়ে; t-SNE স্থানীয় প্রতিবেশ-সম্ভাবনা মেলায়; আর KernelPCA একটা RBF kernel দিয়ে data-কে উঁচু space-এ তুলে সেখানে PCA চালায়।
emb = {}
emb["PCA"] = PCA(n_components=2).fit_transform(X)
emb["Isomap"] = Isomap(n_neighbors=10, n_components=2).fit_transform(X)
emb["LLE"] = LocallyLinearEmbedding(n_neighbors=10, n_components=2,
random_state=0).fit_transform(X)
emb["t-SNE"] = TSNE(n_components=2, perplexity=30, random_state=0,
init="pca").fit_transform(X)
emb["KernelPCA"] = KernelPCA(n_components=2, kernel="rbf",
gamma=0.04).fit_transform(X)
CMAP = "Spectral" # সব scatter-এ color দিয়ে রঙ
৬.১ · আমরা কী খুলতে চাইছি: 3D Swiss roll¶
প্রথম ছবি — সমস্যাটাকেই চোখে দেখা। Swiss roll হলো একটা সাধারণ \(2\)-মাত্রিক চাদর (একটা আয়তক্ষেত্রের কাগজ ভাবুন), যাকে \(3\)-মাত্রিক space-এ একটা সর্পিল বরাবর গুটিয়ে ফেলা হয়েছে — ঠিক যেমন একটা সুইস রোল কেক বা গোটানো কার্পেট। তথ্যের প্রকৃত মাত্রা মাত্র \(2\) (চাদরের উপর অবস্থান বোঝাতে দুটো সংখ্যাই যথেষ্ট), কিন্তু সেটা \(3\) টা স্থানাঙ্ক \((x_1, x_2, x_3)\)-এর ছদ্মবেশে লুকানো। বিন্দুগুলোকে color, অর্থাৎ along-the-roll স্থানাঙ্ক, দিয়ে রঙ করায় সর্পিল বরাবর একটা rainbow ফিতে তৈরি হয় — লাল থেকে শুরু করে কেন্দ্রের দিকে গিয়ে নীল-বেগুনিতে শেষ। এই ছবিটাই বাকি সব ছবির রেফারেন্স: পরের প্রতিটা embedding-এর লক্ষ্য এই rainbow ফিতেটাকে গোটানো থেকে খুলে একটা সমতল মসৃণ gradient-এ রূপান্তর করা।
fig = plt.figure(figsize=(7.5, 6))
ax = fig.add_subplot(111, projection="3d") # 3D scatter
ax.scatter(X[:, 0], X[:, 1], X[:, 2],
c=color, cmap=CMAP, s=14, alpha=0.9) # color = along-roll
ax.set_xlabel("$x_1$"); ax.set_ylabel("$x_2$"); ax.set_zlabel("$x_3$")
ax.view_init(elev=10, azim=-72) # রোলটা স্পষ্ট দেখার কোণ
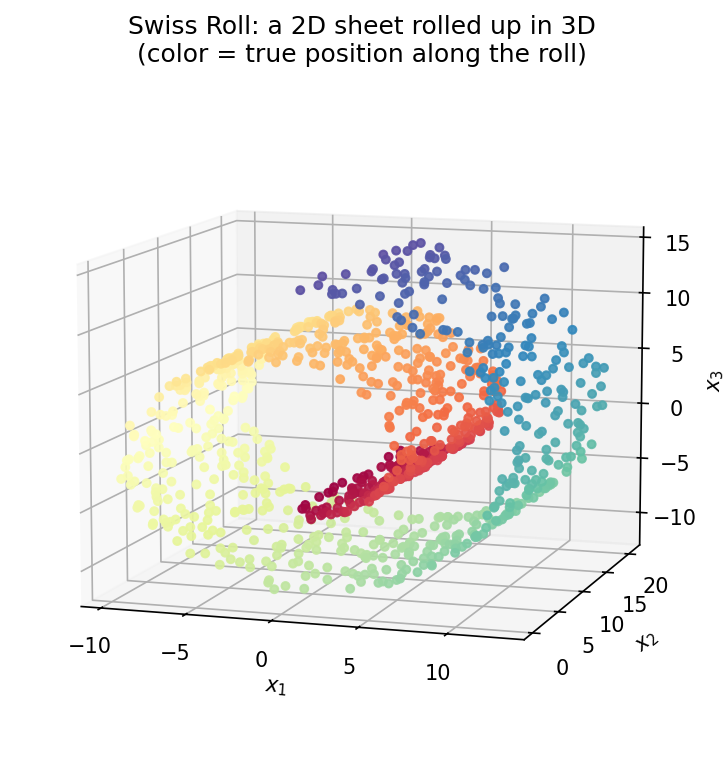
ছবি থেকে যা পড়া যায়। চোখ ফেলামাত্র সর্পিল গঠনটা ধরা পড়ে — একটা পাতলা চাদর নিজের চারপাশে দুই-আড়াই পাক খেয়ে গুটিয়ে আছে। rainbow রঙটাই সবচেয়ে গুরুত্বপূর্ণ সূত্র: রঙ চাদর বরাবর মসৃণভাবে বদলায় (লাল → হলুদ → সবুজ → নীল), কিন্তু চাদরের পুরুত্ব বরাবর (অর্থাৎ এক পরত থেকে পাশের পরতে লাফ দিলে) রঙ হঠাৎ বদলে যায়। ঠিক এখানেই সমস্যার মর্ম: গোটানো অবস্থায় Euclidean দূরত্বে কাছাকাছি দুটো বিন্দু — যেমন ভেতরের নীল পরত আর তার ঠিক বাইরের হলুদ পরত — আসলে চাদরের উপর বহু দূরে, কারণ চাদর বরাবর হাঁটলে এক প্রান্ত থেকে অন্য প্রান্তে যেতে পুরো পাক ঘুরতে হয়। যে কোনো সৎ "unrolling"-কে তাই এই দুই ধরনের নৈকট্যকে আলাদা করতে হবে — পুরুত্ব বরাবর কাছের বিন্দুদের দূরে ঠেলে চাদর বরাবর ক্রমটা অক্ষত রাখতে হবে। PCA-র মতো linear পদ্ধতি ঠিক এই জায়গায় ব্যর্থ হয়, কারণ সে শুধু সরলরেখার দূরত্ব দেখে — পরের ছবিটাই সেই ব্যর্থতা আর তার বিপরীতে manifold-পদ্ধতির সাফল্য পাশাপাশি দেখাবে।
৬.২ · Headline তুলনা: PCA বনাম Isomap¶
এটাই অধ্যায়ের কেন্দ্রীয় ছবি — দুটো \(2\)-মাত্রিক embedding পাশাপাশি, একই Swiss roll, একই রঙ, কিন্তু সম্পূর্ণ বিপরীত ফল। বাঁ panel — PCA: linear projection শুধু সবচেয়ে বড় variance-এর সমতলটা বেছে নেয় আর তার উপর চাদরটাকে ছায়ার মতো ফেলে দেয়; কিন্তু গোটানো চাদরকে সমতলে ছায়া ফেললে বিভিন্ন পরত একে অপরের উপর এসে পড়ে, তাই রঙগুলো মিশে/smeared হয়ে যায় — true coordinate-এর সঙ্গে correlation মাত্র \(0.165\)। ডান panel — Isomap: এটি দুই বিন্দুর মধ্যে সরলরেখার দূরত্ব নয়, বরং চাদর বরাবর geodesic দূরত্ব (নিকটতম প্রতিবেশীদের graph-এ shortest path দিয়ে আঁকা) রক্ষা করে; ফলে চাদরটা সত্যিকার অর্থে খুলে যায়, রঙ একটানা সাজানো gradient-এ পরিণত হয় — correlation \(1.000\), কার্যত নিখুঁত।
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
# বাঁ: PCA — রঙ smeared, corr 0.165
axes[0].scatter(emb["PCA"][:, 0], emb["PCA"][:, 1],
c=color, cmap=CMAP, s=14, alpha=0.9)
axes[0].set_title("PCA (linear): colors SMEARED, corr = 0.165")
# ডান: Isomap — রঙ unrolled, corr 1.000
axes[1].scatter(emb["Isomap"][:, 0], emb["Isomap"][:, 1],
c=color, cmap=CMAP, s=14, alpha=0.9)
axes[1].set_title("Isomap (manifold): colors UNROLLED, corr = 1.000")
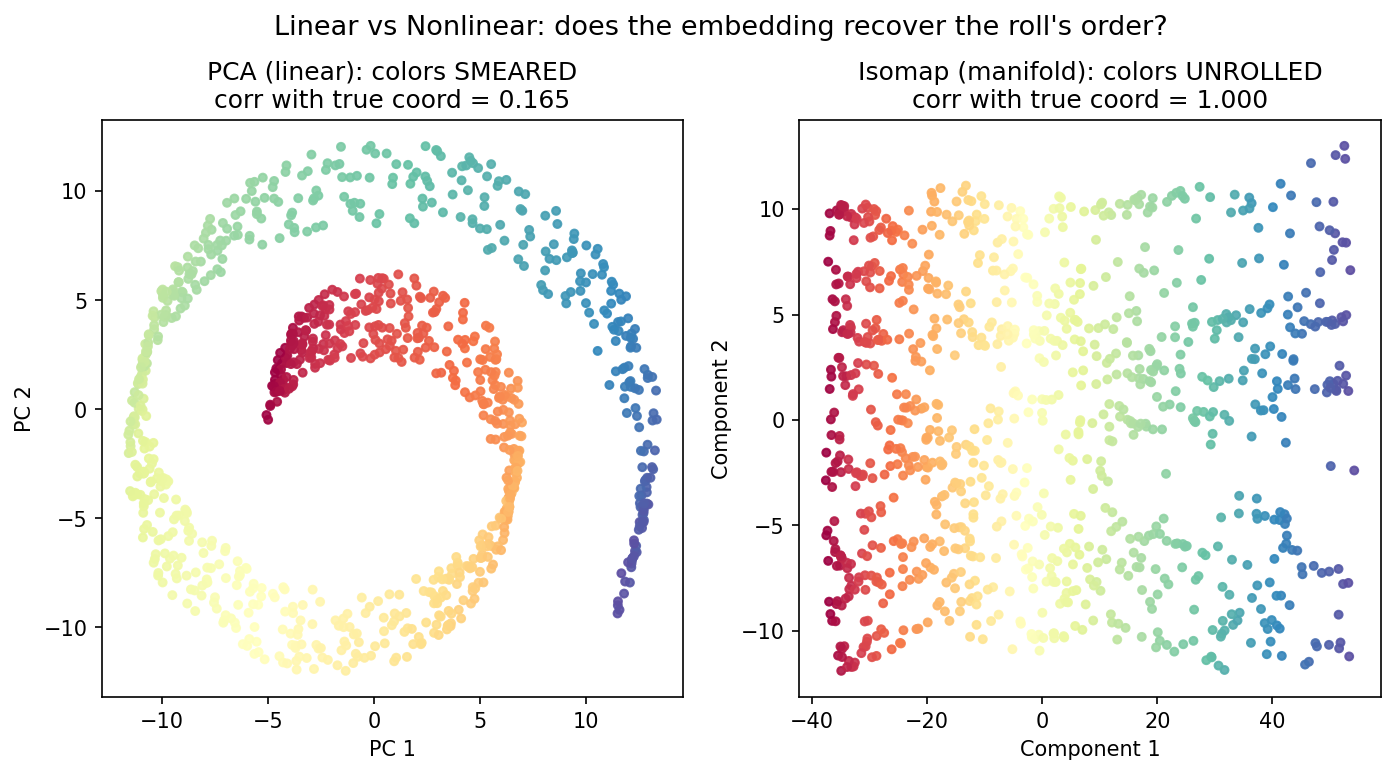
ছবি থেকে যা পড়া যায়। দুই panel-এর তফাত নাটকীয় এবং তাৎক্ষণিক। বাঁ দিকে PCA চাদরটাকে খোলেনি — সে কেবল \(3\)-মাত্রিক সর্পিলটাকে তার সবচেয়ে চওড়া দিক থেকে দেখা ছায়া হিসেবে সমতলে এঁকেছে, তাই গোটানো গঠনটা প্রায় অবিকল রয়ে গেছে আর বিভিন্ন রঙের পরত একে অপরের উপর চাপাচাপি করে বসেছে। ফলে একই জায়গায় লাল ও নীল বিন্দু পাশাপাশি — রঙের কোনো একটানা ক্রম নেই, আর সংখ্যাও তা-ই বলে: along-the-roll স্থানাঙ্কের সঙ্গে correlation মাত্র \(0.165\), প্রায় সম্পর্কহীন। ডান দিকে Isomap ঠিক উল্টোটা করেছে — সে প্রতিটা বিন্দুর নিকটতম \(10\) জন প্রতিবেশী দিয়ে একটা graph গড়ে, তারপর দুই দূরবর্তী বিন্দুর মধ্যে "দূরত্ব" বলতে সরলরেখা নয়, চাদর বরাবর ওই graph-এ shortest path-এর দৈর্ঘ্য নেয়। এই geodesic দূরত্বই গোটানো ও খোলা অবস্থায় একই থাকে, তাই Isomap চাদরটাকে সত্যিকারভাবে মেলে ধরতে পারে — রঙ এখন বাঁ থেকে ডানে নিখুঁত শৃঙ্খলায় সাজানো, correlation \(1.000\)। এই একটি ছবিই অধ্যায়ের মূল বার্তা ধরে রাখে: linear পদ্ধতি বাঁকানো manifold-এ অন্ধ, nonlinear manifold-পদ্ধতি তাকে দেখতে পায়। কিন্তু Isomap কি একমাত্র বিজয়ী, নাকি অন্য nonlinear পদ্ধতিরাও পারে — আর KernelPCA কেন nonlinear হয়েও PCA-র মতোই ব্যর্থ? পরের ছবি পাঁচটা পদ্ধতি একসঙ্গে রেখে সেই উত্তর দেয়।
৬.৩ · পাঁচটা পদ্ধতি পাশাপাশি¶
§৬.২ একটা winner আর একটা loser দেখাল; এই ছবিটা গোটা মাঠ একসঙ্গে মেলে ধরে — একই Swiss roll-এর পাঁচটা embedding এক গ্রিডে, প্রত্যেকটা along-the-roll color-এ রঙ করা এবং নিজের trustworthiness ও corr সমেত titled। এতে এক নজরেই দুটো শিবির ফুটে ওঠে। ব্যর্থ শিবির — PCA ও KernelPCA: দুজনেই চাদরকে চ্যাপ্টা করে, রঙ ঘেঁটে যায় (corr \(0.165\) ও \(0.228\)); KernelPCA nonlinear kernel ব্যবহার করেও এখানে হারে কারণ এই particular RBF-gamma Swiss roll-এর geodesic গঠন ধরতে পারে না, শুধু একটা ভিন্ন আকারে গুঁজে দেয়। সফল শিবির — Isomap, LLE, t-SNE: তিনজনেই চাদরটাকে খুলে রঙকে সুশৃঙ্খল করে (corr \(1.000\), \(0.998\), \(0.857\)), যদিও তাদের খোলার ধরন আলাদা — Isomap geodesic দূরত্ব, LLE স্থানীয় linear গঠন, t-SNE প্রতিবেশ-সম্ভাবনা।
order = ["PCA", "KernelPCA", "Isomap", "LLE", "t-SNE"]
TRUST = {"PCA":0.968, "KernelPCA":0.898, "Isomap":1.000, "LLE":0.996, "t-SNE":0.999}
CORR = {"PCA":0.165, "KernelPCA":0.228, "Isomap":1.000, "LLE":0.998, "t-SNE":0.857}
fig, axes = plt.subplots(2, 3, figsize=(13.5, 8.5))
for ax, name in zip(axes.ravel(), order):
e = emb[name]
ax.scatter(e[:, 0], e[:, 1], c=color, cmap=CMAP, s=12, alpha=0.9)
ax.set_title(f"{name}\ntrust={TRUST[name]:.3f}, corr={CORR[name]:.3f}")
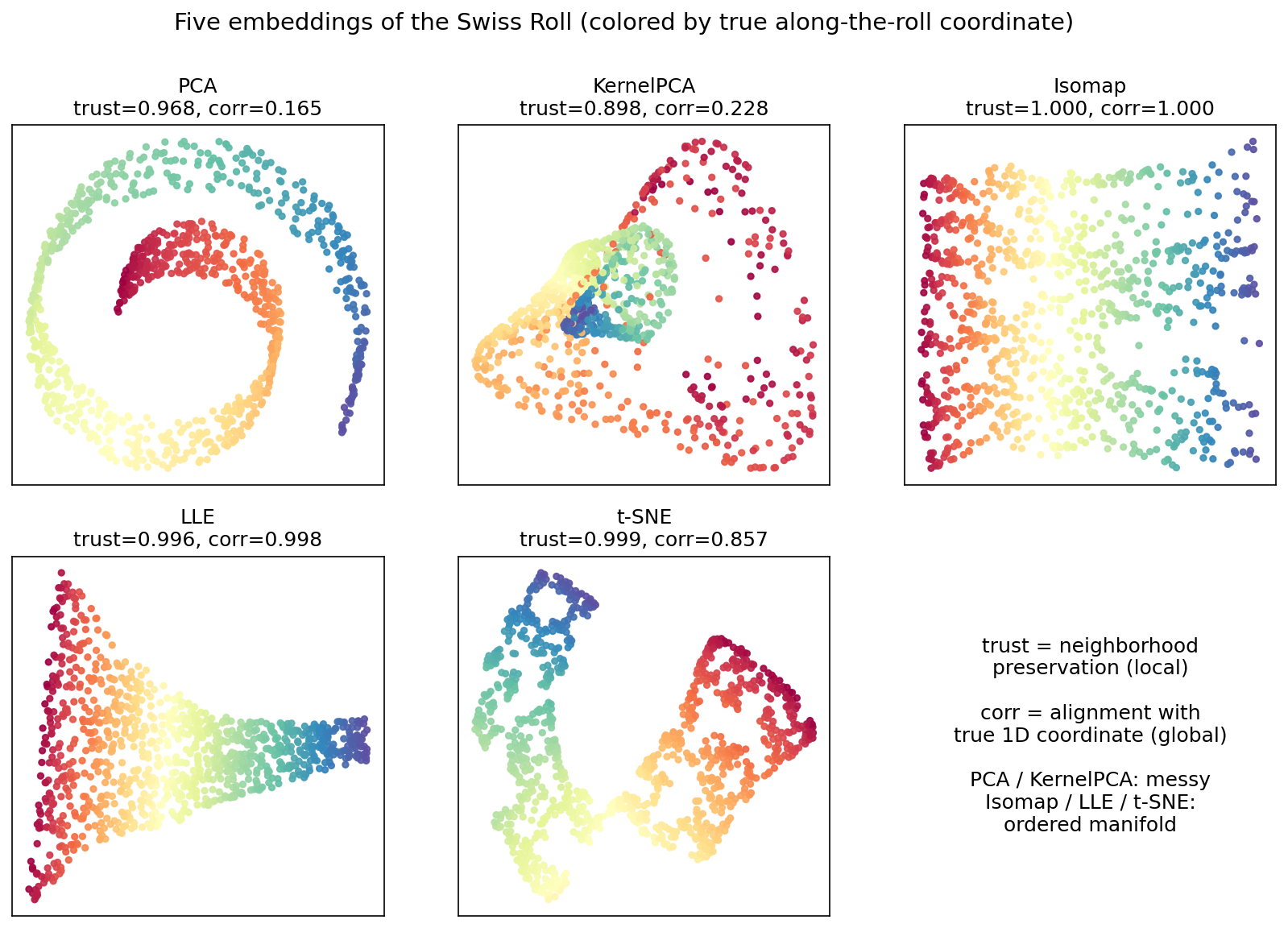
ছবি থেকে যা পড়া যায়। গ্রিডটা চোখে দুটো পরিষ্কার দল গড়ে দেয়। উপরের সারির দুই ব্যর্থ পদ্ধতি (PCA, KernelPCA) চাদরকে খুলতে পারেনি — PCA-তে রঙ সর্পিলে চাপাচাপি, আর KernelPCA-তে বিন্দুগুলো একটা ঘন গোছায় কুঁকড়ে, দুজনেরই corr খুব কম (\(0.165\), \(0.228\))। লক্ষণীয়, KernelPCA nonlinear হয়েও ব্যর্থ — এটাই একটা গুরুত্বপূর্ণ শিক্ষা: nonlinearity-ই যথেষ্ট নয়, kernel ও তার gamma-কে manifold-এর প্রকৃত গঠনের সঙ্গে মানানসই হতে হয়, নইলে সে শুধু এক ভুল আকারে ভুল করে। বাকি তিন পদ্ধতি (Isomap, LLE, t-SNE) চাদরটাকে সফলভাবে খুলেছে — তিনটেতেই রঙ একটানা ক্রমে সাজানো, যদিও জ্যামিতিক ভঙ্গি ভিন্ন: Isomap পরিচ্ছন্ন আয়তক্ষেত্র (geodesic দূরত্ব অবিকল রক্ষা করে), LLE ত্রিভুজাকার পাখা (স্থানীয় linear patch জোড়া দেয়, তাই global স্কেল একটু বিকৃত হলেও ক্রম অটুট — corr \(0.998\)), আর t-SNE একটা ধারাবাহিক কিন্তু কুঁচকানো ফিতে (স্থানীয় প্রতিবেশ দারুণ রাখে, তবে দূরত্বের global স্কেল উপেক্ষা করে বলে corr তুলনায় কম, \(0.857\))। এখন একটা সূক্ষ্ম কিন্তু গভীর প্রশ্ন জাগে: PCA-র trustworthiness তো \(0.968\) — প্রায় Isomap-এর সমান উঁচু — অথচ তার corr মাত্র \(0.165\)। তাহলে trustworthiness উঁচু মানেই কি manifold খোলা? শেষ ছবিটা ঠিক এই ফাঁদটাই উন্মোচন করে।
৬.৪ · দুই মাপকাঠির দ্বন্দ্ব: trustworthiness বনাম corr¶
এই শেষ ছবিটা গোটা অংশের সবচেয়ে সূক্ষ্ম শিক্ষাটা সংখ্যায় বাঁধে — কেন একটা মেট্রিক দিয়ে embedding-এর গুণ বিচার করা বিপজ্জনক। প্রতিটা পদ্ধতির জন্য দুটো বার পাশাপাশি: নীল trustworthiness (একটা local মাপ — embedding-এ যে বিন্দুগুলো কাছে এসেছে, তারা original space-এও সত্যিই কাছের প্রতিবেশী ছিল কি না; \(1\) মানে কোনো ভুয়া প্রতিবেশী ঢোকেনি) আর কমলা \(\lvert \text{corr} \rvert\) (একটা global মাপ — embedding-এর কোনো একটা অক্ষ true along-the-roll স্থানাঙ্কের সঙ্গে কতটা মেলে; \(1\) মানে চাদরের ক্রম পুরোপুরি উদ্ধার হয়েছে)। মূল পয়েন্ট: PCA-র trustworthiness \(0.968\) — প্রায় সর্বোচ্চ — অথচ corr মাত্র \(0.165\)। অর্থাৎ PCA স্থানীয়ভাবে সৎ (কাছের প্রতিবেশী মোটামুটি কাছেই রেখেছে) কিন্তু global গঠন (পুরো চাদরের ক্রম) সম্পূর্ণ হারিয়েছে — দুটো ভিন্ন প্রশ্ন, ভিন্ন উত্তর।
methods = ["PCA", "KernelPCA", "t-SNE", "LLE", "Isomap"]
trust_v = [TRUST[m] for m in methods] # 0.968, 0.898, 0.999, 0.996, 1.000
corr_v = [CORR[m] for m in methods] # 0.165, 0.228, 0.857, 0.998, 1.000
x, w = np.arange(len(methods)), 0.38
fig, ax = plt.subplots(figsize=(10, 5.5))
ax.bar(x - w/2, trust_v, w, label="trustworthiness (local)")
ax.bar(x + w/2, corr_v, w, label="|corr| with true coord (global)")
ax.set_xticks(x); ax.set_xticklabels(methods)
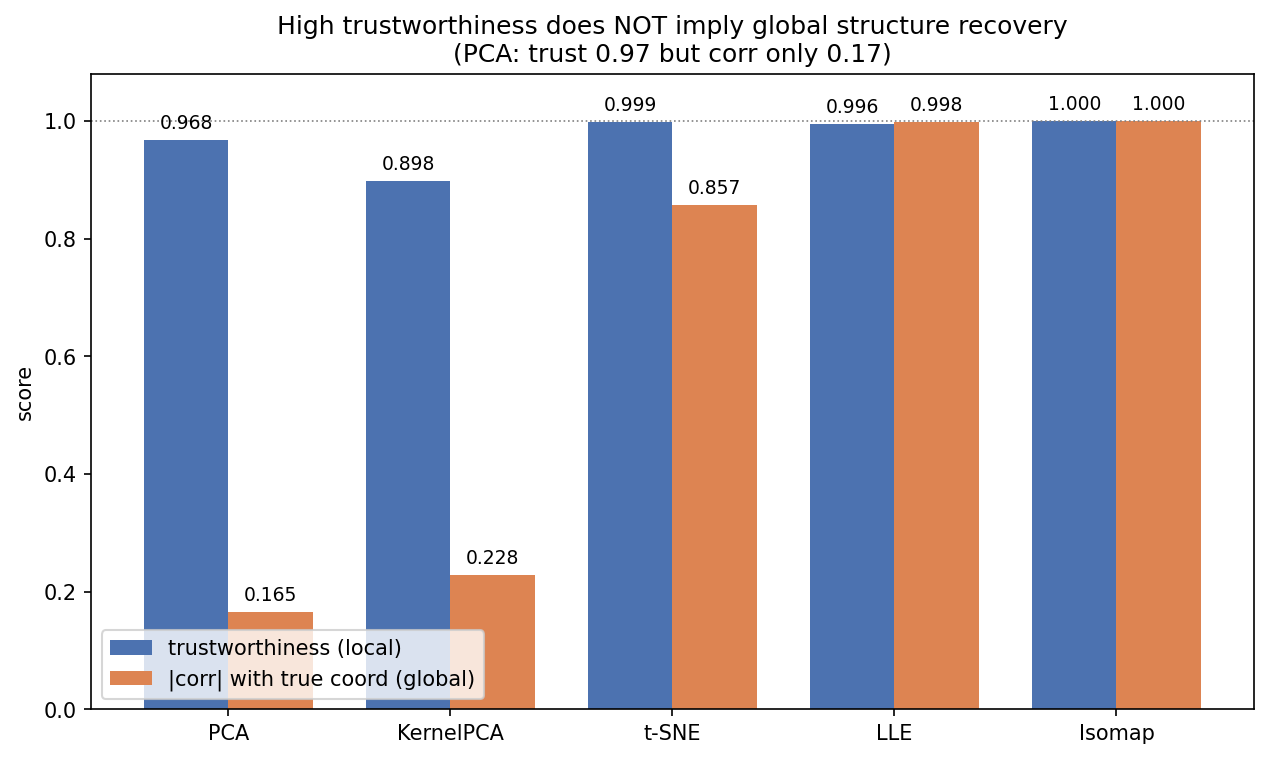
ছবি থেকে যা পড়া যায়। বার-জোড়াগুলোর মধ্যেকার ফাঁক-ই এই ছবির আসল বার্তা। PCA-তে নীল আর কমলা bar-এর মধ্যে বিশাল খাদ — trustworthiness \(0.968\) বনাম corr মাত্র \(0.165\) — আর KernelPCA-তেও একই প্যাটার্ন (\(0.898\) বনাম \(0.228\))। এই ফাঁকটা ঠিক §৬.৩-এর ছবির ব্যাখ্যা: PCA চাদরের স্থানীয় প্রতিবেশ মোটামুটি ঠিক রাখে (তাই trustworthiness উঁচু — কাছের বিন্দু এখনো বেশিরভাগ কাছেই), কিন্তু গোটা চাদরকে চ্যাপ্টা করে ফেলে বলে global ক্রমটা ধ্বংস হয় (তাই corr মেঝেছোঁয়া)। ডান দিকে গেলে ফাঁকটা মিলিয়ে যায়: t-SNE-তে দুই bar কাছাকাছি, LLE-তে প্রায় গায়ে-গায়ে, আর Isomap-এ দুটোই ছাদ ছুঁয়েছে (\(1.000\)/\(1.000\)) — অর্থাৎ manifold-পদ্ধতিরা একইসঙ্গে স্থানীয় প্রতিবেশ এবং global ক্রম দুটোই রক্ষা করেছে। এর ব্যবহারিক শিক্ষা গভীর: একটিমাত্র সংখ্যা দিয়ে কখনো embedding-এর রায় দেবেন না। trustworthiness উঁচু দেখে নিশ্চিন্ত হলে PCA-কে ভুলবশত সফল ভাবা যেত, অথচ ছবিতে (§৬.২) তার রঙ smeared ছিল আর corr বলছিল চাদর আদৌ খোলেনি। স্থানীয় ও global মেট্রিক একসঙ্গে — এবং সর্বোপরি নিজের চোখে রঙের gradient — দেখলে তবেই পূর্ণ সত্য ধরা পড়ে।
এই চারটে ছবি একসঙ্গে nonlinear dimensionality reduction-এর গোটা গল্পটা জীবন্ত করে তোলে: প্রথমে আমরা দেখলাম সমস্যাটা কী — একটা \(2\)-মাত্রিক চাদর \(3\)-মাত্রায় গুটিয়ে আছে, যাকে রঙ-গ্রেডিয়েন্ট অক্ষুণ্ণ রেখে খুলতে হবে (§৬.১); তারপর headline দ্বন্দ্ব — linear PCA চাদরকে চ্যাপ্টা করে রঙ ঘেঁটে দেয় (corr \(0.165\)), nonlinear Isomap geodesic দূরত্ব রক্ষা করে তাকে নিখুঁত খুলে দেয় (corr \(1.000\)) (§৬.২); তারপর পুরো মাঠ — Isomap, LLE, t-SNE সফল, PCA ও (nonlinear হয়েও) KernelPCA ব্যর্থ, কারণ nonlinearity-ই যথেষ্ট নয়, manifold-এর প্রকৃত geometry ধরা চাই (§৬.৩); এবং শেষে মাপকাঠির ফাঁদ — উঁচু trustworthiness (local) উঁচু corr (global) নিশ্চিত করে না, তাই একাধিক মেট্রিক ও চোখের বিচার দুটোই দরকার (§৬.৪)। এটাই manifold learning-এর কেন্দ্রীয় পাঠ — distance রক্ষা নয়, গঠন রক্ষাই আসল লক্ষ্য, আর সেই গঠন সঠিকভাবে খুলেছে কি না, তা সবচেয়ে স্পষ্ট বলে রঙের একটানা একটা মসৃণ gradient।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/06-08-nonlinear-dimreduction-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — manifold hypothesis ও linear PCA-র সীমা (উচ্চ-মাত্রিক data কেন একটা বাঁকা নিম্ন-মাত্রিক manifold-এ বসে, আর সরলরৈখিক projection কেন swiss roll-এর গঠন হারায়), kernel PCA (centered kernel-এর উপর PCA — কখন nonlinear দিক ধরে), MDS double-centering (\(B=-\tfrac12 H\Delta H\) একটা ছোট distance matrix-এ হাতে গুনে), Isomap = geodesic-এর উপর MDS (geodesic কেন roll-কে "মেলে ধরে", আর একটা ছোট kNN-graph-এ shortest path), LLE-র local weight (প্রতিবেশীর উত্তল-যোগে বিন্দু পুনর্গঠন), t-SNE-র \(p_{ij},q_{ij}\), KL ও crowding (Student-\(t\) লেজ কেন), trustworthiness পাঠ (PCA-র উচ্চ trust \(0.968\) কিন্তু নিম্ন corr \(0.165\) — local ঠিক, global ভুল), method-নির্বাচন, এবং একটা coding প্রশ্ন (swiss roll-এ PCA বনাম Isomap বনাম t-SNE + trustworthiness/corr) — এই হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed-সূচক random_state=20260619, make_swiss_roll(n_samples=1000, noise=0.05); color = manifold-বরাবর প্রকৃত ১D অবস্থান (যে চলকটা embedding-এ পুনরুদ্ধার করতে চাই)। canonical সংখ্যা — প্রতিটি method-এর trustworthiness \(T\) ও embedding-এর প্রথম অক্ষ বনাম color-এর \(\lvert\text{corr}\rvert\): PCA \(0.968\,/\,0.165\) (global ব্যর্থ), Isomap \(1.000\,/\,1.000\), LLE \(0.996\,/\,0.998\), t-SNE \(0.999\,/\,0.857\), KernelPCA(rbf) \(0.898\,/\,0.228\)। মূল notation: \(x_i\in\mathbb R^D\) (এখানে \(D=3\)), embedding \(y_i\in\mathbb R^d\) (\(d=2\)); centered kernel \(\tilde K\); double-centering \(B=-\tfrac12 H\Delta H\); geodesic দূরত্ব \(d_G\); t-SNE-র high-D affinity \(p_{ij}\), low-D affinity \(q_{ij}\), খরচ \(\mathrm{KL}(P\Vert Q)\); trustworthiness \(T\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). manifold hypothesis — মূল ছবি। swiss roll-এর প্রতিটি বিন্দু \(x_i\in\mathbb R^3\), কিন্তু "কাগজটা" আসলে একটা ২D চাদর যা ৩D-তে পেঁচানো — অর্থাৎ data একটা ২-মাত্রিক manifold-এ বসে আছে। (ক) manifold hypothesis এক বাক্যে বলুন: উচ্চ-মাত্রিক (\(D\)) বাস্তব data সম্পর্কে এটি কী দাবি করে (intrinsic dimension \(d\) বনাম ambient dimension \(D\))? (খ) swiss roll-এ ambient dimension \(D\) কত, intrinsic dimension \(d\) কত — আর "intrinsic" মানে কী (manifold-এর গায়ে হাঁটতে ক'টা স্বাধীন দিক লাগে)? (গ) এক বাক্যে: dimensionality reduction-এর লক্ষ্য তাই কী — \(D\)-মাত্রিক data-কে কোন \(d\)-তে নামানো যেন manifold-এর গঠন টিকে থাকে? Hint: (ক) manifold hypothesis: বাস্তব উচ্চ-মাত্রিক data পূর্ণ \(\mathbb R^D\) জুড়ে ছড়িয়ে নেই, বরং একটা অনেক-কম-মাত্রিক (\(d\ll D\)) মসৃণ manifold-এর কাছাকাছি কেন্দ্রীভূত। (খ) swiss roll: \(D=3\) (ambient — ৩D স্থানাঙ্ক), \(d=2\) (intrinsic — চাদরের গা বরাবর দুটো স্বাধীন দিক: "মেলে ধরলে" দৈর্ঘ্য ও প্রস্থ); "intrinsic" = manifold-এর উপরিতলে স্থানীয়ভাবে চলতে যত স্বাধীন স্থানাঙ্ক লাগে। (গ) লক্ষ্য \(\mathbb R^D\to\mathbb R^d\) এমন map যা manifold-এর প্রতিবেশ-সম্পর্ক/দূরত্ব যথাসম্ভব রক্ষা করে — অর্থাৎ roll-কে \(d=2\)-তে "মেলে ধরা"।
প্রশ্ন ২ (★). linear PCA কেন swiss roll-এ ব্যর্থ — সরলরেখা বাঁকা গঠন ধরে না। ৫.৯-এর PCA variance-সর্বোচ্চকারী সরলরৈখিক অক্ষ খোঁজে ও সেই hyperplane-এ projection করে। canonical-এ swiss roll-এ PCA-র trustworthiness উঁচু (\(0.968\)) কিন্তু প্রথম অক্ষ বনাম প্রকৃত manifold-অবস্থান color-এর \(\lvert\text{corr}\rvert\) মাত্র \(0.165\)। (ক) PCA যেহেতু কেবল একটা সমতল (flat subspace)-এ প্রক্ষেপ করে, পেঁচানো roll-কে চ্যাপ্টা করলে দূরের দুই pile কেন একে অপরের উপর পড়ে যায় (geometry-গত ভাবে কী হারায়)? (খ) corr \(0.165\) এত কম বলে কী বুঝি — PCA-র প্রধান অক্ষ কি manifold-বরাবর প্রকৃত ১D অবস্থান পুনরুদ্ধার করতে পারল? (গ) এক বাক্যে: তাই কেন বাঁকা (curved) manifold-এ একটা nonlinear পদ্ধতি দরকার, রৈখিক PCA যথেষ্ট নয়?
Hint: (ক) roll পেঁচানো বলে দুটো বিন্দু ৩D-তে কাছাকাছি হলেও চাদর-বরাবর (geodesic) বহু দূরে হতে পারে; PCA সমতলে চাপলে এই পেঁচ "ভাঁজ হয়ে" মিশে যায় — দূরের অংশ overlap করে, global গঠন (manifold-বরাবর ক্রম) হারায়। (খ) corr \(0.165\approx0\) ⇒ PCA-র প্রথম অক্ষ প্রকৃত manifold-অবস্থানের সাথে কার্যত সম্পর্কহীন — অর্থাৎ roll-কে মেলে ধরতে ব্যর্থ (variance-সর্বোচ্চ সরলদিক ≠ manifold-দিক)। (গ) বাঁকা manifold-এর global গঠন ধরতে দূরত্ব/প্রতিবেশকে অরৈখিকভাবে সম্মান করা চাই (geodesic, kernel, neighbor-distribution) — তাই kernel PCA/Isomap/LLE/t-SNE-র মতো nonlinear পদ্ধতি।
প্রশ্ন ৩ (★). kernel PCA — centered kernel-এর উপর PCA। kernel PCA (৬.৪-এর kernel trick + ৫.৯-এর PCA) মূল PCA-কে একটা feature-map \(\phi\)-এর space-এ নিয়ে যায়, কিন্তু \(\phi\) সরাসরি না হিসেব করে শুধু kernel \(K_{ij}=k(x_i,x_j)\) ব্যবহার করে। (ক) সাধারণ PCA covariance-এর eigen-decomposition করে; kernel PCA কীসের eigen-decomposition করে — এবং কেন প্রথমে kernel-কে centered (\(\tilde K=HKH\), \(H=I-\tfrac1n\mathbf 1\mathbf 1^\top\)) করতে হয়? (খ) linear kernel \(k(x,x')=x^\top x'\) নিলে kernel PCA কীসে পরিণত হয় (কোন পরিচিত পদ্ধতি)? (গ) canonical-এ KernelPCA(rbf)-র corr মাত্র \(0.228\) — swiss roll-এ এটা Isomap (\(1.000\))-এর চেয়ে অনেক দুর্বল; এক বাক্যে কেন (kernel-pca কি স্পষ্টভাবে manifold-এর geodesic গঠন ব্যবহার করে)? Hint: (ক) kernel PCA centered kernel matrix \(\tilde K\)-এর (covariance নয়) eigen-decomposition করে; centering দরকার কারণ PCA covariance-এর জন্য feature-space-এ data মূলবিন্দু-কেন্দ্রিক হওয়া চাই — \(\phi(x_i)\) সরাসরি না জানায় centering kernel-পর্যায়ে \(\tilde K=HKH\) দিয়ে করা হয়। (খ) linear kernel ⇒ feature-map = identity ⇒ kernel PCA হুবহু সাধারণ (linear) PCA (৫.৯)। (গ) RBF kernel-pca একটা স্থির nonlinear feature-space-এ variance খোঁজে, কিন্তু swiss roll-এর প্রকৃত geodesic/unrolling গঠন স্পষ্টভাবে ধরে না (সঠিক \(\gamma\) ছাড়া roll মেলে না), তাই corr ছোট (\(0.228\)) — Isomap যেখানে geodesic সরাসরি ব্যবহার করে (\(1.000\))।
প্রশ্ন ৪ (★). geodesic বনাম Euclidean — কেন Isomap roll মেলে ধরে। Isomap-এর মূল ধারণা: ৩D-র সোজা (Euclidean) দূরত্বের বদলে manifold-বরাবর দূরত্ব (geodesic \(d_G\)) ব্যবহার করা। (ক) swiss roll-এ একই-পাকের ভেতরে ও দুই-প্রতিবেশী-পাকের মাঝে — কোন ক্ষেত্রে Euclidean ও geodesic দূরত্ব খুব ভিন্ন হয়, আর কেন (পেঁচের "শর্টকাট" বনাম "চাদর-বরাবর হাঁটা")? (খ) geodesic-কে কাজে লাগানোর কৌশল কী — neighbor graph বানিয়ে graph-এ shortest path? এক বাক্যে বলুন কেন এই geodesic-দূরত্বের matrix-এ MDS করলে roll "মেলে" যায়, যেখানে Euclidean দূরত্বে MDS করলে যায় না। (গ) canonical-এ Isomap-এর corr \(1.000\), trustworthiness \(1.000\) — এই নিখুঁত মান কী বলছে (geodesic-MDS কি manifold-অবস্থান প্রায় হুবহু পুনরুদ্ধার করল)? Hint: (ক) দুই প্রতিবেশী পাকের মধ্যে Euclidean দূরত্ব ছোট (৩D-তে কাছে) কিন্তু geodesic বিশাল (চাদর-বরাবর বহুদূর ঘুরে যেতে হয়) — এখানেই Euclidean বিভ্রান্ত করে; একই পাকের ভেতরে দুটো প্রায় সমান। (খ) প্রতিটি বিন্দুর kNN দিয়ে graph বানিয়ে edge-ওজন = Euclidean দূরত্ব, তারপর Dijkstra/Floyd shortest path = geodesic-আনুমান; এই \(d_G\)-matrix manifold-বরাবর প্রকৃত দূরত্ব ধরে, তাই MDS (যা দূরত্ব রক্ষা করে) roll মেলে ধরে — Euclidean দূরত্ব "শর্টকাট"-এ গঠন ভাঙে। (গ) \(T=1.000,\ \lvert\text{corr}\rvert=1.000\) ⇒ Isomap-এর প্রথম অক্ষ manifold-বরাবর প্রকৃত ১D অবস্থানের সাথে প্রায়-নিখুঁত মিল — roll পুরোপুরি সঠিকভাবে মেলে গেছে।
প্রশ্ন ৫ (★★). LLE — local-linear reconstruction। Locally Linear Embedding (LLE) ভাবে: প্রতিটি বিন্দু তার প্রতিবেশীদের একটা রৈখিক যোগ দিয়ে আনুমানিকভাবে পুনর্গঠন করা যায়, আর এই স্থানীয় geometry নিম্ন-মাত্রায় রক্ষা করতে হবে। দুই ধাপ: (i) প্রতিটি \(x_i\)-এর জন্য weight \(w_{ij}\) খোঁজা যাতে \(\big\lVert x_i-\sum_{j\in\mathcal N(i)} w_{ij}x_j\big\rVert^2\) সর্বনিম্ন (শর্ত \(\sum_j w_{ij}=1\)); (ii) সেই একই \(w_{ij}\) স্থির রেখে নিম্ন-মাত্রিক \(y_i\) খোঁজা যাতে \(\big\lVert y_i-\sum_j w_{ij}y_j\big\rVert^2\) সর্বনিম্ন। (ক) ধাপ (i)-এ weight কী ধরছে — বিন্দুটি তার প্রতিবেশীদের সাপেক্ষে স্থানীয়ভাবে কোথায় বসে (একটা স্থানীয় স্থানাঙ্ক)? (খ) \(\sum_j w_{ij}=1\) শর্তটা কেন গুরুত্বপূর্ণ — এটা weight-কে translation, rotation ও scale-এর প্রতি কী করে (invariance)? (গ) এক বাক্যে: LLE কেন "local" পদ্ধতি — এটা কি Isomap-এর মতো global geodesic দূরত্ব ব্যবহার করে, না শুধু ছোট প্রতিবেশ-geometry আঠা দিয়ে জোড়ে? Hint: (ক) \(w_{ij}\) হলো বিন্দুটিকে তার প্রতিবেশীদের উত্তল/affine-যোগ হিসেবে লেখার সহগ — একটা স্থানীয় barycentric স্থানাঙ্ক (প্রতিবেশ-patch-এর ভেতরে আপেক্ষিক অবস্থান)। (খ) \(\sum_j w_{ij}=1\) (affine constraint) weight-কে input-এর translation ও rotation-এ অপরিবর্তিত রাখে এবং scale-এ সামঞ্জস্যপূর্ণ — তাই reconstruction-geometry কেবল প্রতিবেশীদের আপেক্ষিক বিন্যাসের উপর নির্ভর করে, পরম স্থানাঙ্কের নয়; ফলে এই geometry নিম্ন-মাত্রায় হুবহু বহন করা যায়। (গ) LLE local — শুধু প্রতিটি বিন্দুর ছোট প্রতিবেশের রৈখিক geometry সংরক্ষণ করে এগুলো বিশ্বব্যাপী জুড়ে দেয় (Isomap-এর মতো বিন্দু-জোড়ার global geodesic দূরত্ব ব্যবহার করে না); canonical-এ LLE corr \(0.998\) — local geometry-ই এখানে যথেষ্ট ভালো।
প্রশ্ন ৬ (★★). t-SNE — দুই neighbor-distribution-এর KL। t-SNE প্রতিটি জোড়ার জন্য high-D-তে একটা "প্রতিবেশী হওয়ার সম্ভাবনা" \(p_{ij}\) (Gaussian affinity, perplexity দিয়ে স্কেল) আর low-D-তে আরেকটা \(q_{ij}\) (Student-\(t\) affinity) সংজ্ঞায়িত করে, তারপর \(\mathrm{KL}(P\Vert Q)=\sum_{i\ne j}p_{ij}\log\frac{p_{ij}}{q_{ij}}\) minimize করে embedding \(\{y_i\}\) শেখে। (ক) \(p_{ij}\) ও \(q_{ij}\) ভৌতভাবে কী মাপে — দুই বিন্দু "প্রতিবেশী" হওয়ার কতটা সম্ভাবনা, আর t-SNE কী match করাতে চায় (high-D প্রতিবেশ-গঠন বনাম low-D)? (খ) KL অপ্রতিসম (\(\mathrm{KL}(P\Vert Q)\ne\mathrm{KL}(Q\Vert P)\)); \(p_{ij}\) বড় কিন্তু \(q_{ij}\) ছোট হলে penalty বড় — এর মানে t-SNE বেশি যত্ন নেয় কোনটা রক্ষা করতে: high-D-তে কাছের জোড়া কাছেই রাখা, না দূরের জোড়া দূরে রাখা? (গ) এক বাক্যে: এই কারণেই t-SNE কেন local গঠন (cluster) ভালো ধরে কিন্তু global দূরত্ব (cluster-গুলোর পারস্পরিক ব্যবধান) নির্ভরযোগ্যভাবে নয় — canonical-এ t-SNE trust \(0.999\) কিন্তু corr \(0.857\) (Isomap \(1.000\)-এর চেয়ে কম)? Hint: (ক) \(p_{ij},q_{ij}\) = বিন্দু-জোড়ার "প্রতিবেশ-সম্ভাবনা" (affinity); t-SNE চায় low-D \(q_{ij}\) যেন high-D \(p_{ij}\)-র মতো হয় — অর্থাৎ high-D-র প্রতিবেশ-গঠন low-D-তে প্রতিফলিত করা। (খ) \(\mathrm{KL}(P\Vert Q)\)-এ \(p_{ij}\) বড় ও \(q_{ij}\) ছোট হলে \(p_{ij}\log\frac{p_{ij}}{q_{ij}}\) বড় penalty — তাই t-SNE সবচেয়ে যত্ন নেয় high-D-তে কাছের জোড়াকে low-D-তেও কাছে রাখতে (local সংরক্ষণে পক্ষপাতী); দূরের জোড়া (\(p_{ij}\approx0\)) অবহেলিত। (গ) local-পক্ষপাত বলে cluster-গঠন চমৎকার (\(T=0.999\)) কিন্তু cluster-গুলোর মধ্যেকার global দূরত্ব নির্ভরযোগ্য নয় ⇒ manifold-বরাবর global ক্রম আংশিক (\(\lvert\text{corr}\rvert=0.857<1.000\))।
প্রশ্ন ৭ (★★). crowding problem ও Student-\(t\) লেজ। t-SNE-তে low-D affinity \(q_{ij}\) Gaussian নয়, বরং একটা ভারী-লেজ (heavy-tailed) Student-\(t\) (১ ডিগ্রি-স্বাধীনতা): \(q_{ij}\propto(1+\lVert y_i-y_j\rVert^2)^{-1}\)। এর পেছনে crowding problem: উচ্চ-মাত্রায় একটা বিন্দুর "মাঝারি-দূরত্বের" প্রতিবেশী অনেক বেশি থাকতে পারে, কিন্তু \(2\)D-তে সেগুলো সব রাখার জায়গা কম। (ক) crowding problem এক বাক্যে: উচ্চ-মাত্রার আয়তন \(2\)D-তে নামালে মাঝারি-দূরত্বের প্রতিবেশীরা কোথায় "ভিড় করে" চাপা পড়ে? (খ) low-D-তে Gaussian-এর বদলে ভারী-লেজ Student-\(t\) ব্যবহার করলে একই \(p_{ij}\)-র জন্য মাঝারি-দূরের বিন্দুদের low-D-তে আরও দূরে ঠেলা যায় কেন (লেজ ভারী বলে দূরত্ব বাড়লেও \(q\) খুব দ্রুত পড়ে না)? (গ) এক বাক্যে: তাই Student-\(t\) লেজ crowding কীভাবে উপশম করে — cluster-গুলোকে চেপে না-রেখে কীভাবে আলাদা ও স্পষ্ট রাখে? Hint: (ক) crowding: high-D-তে মাঝারি-দূরত্বে প্রচুর প্রতিবেশী থাকে, কিন্তু \(2\)D-র সীমিত জায়গায় সেগুলো সব "মাঝারি-দূরত্বে" রাখা যায় না — তারা কেন্দ্রের দিকে চেপে (crowd) যায়, cluster গুলিয়ে যায়। (খ) ভারী-লেজ Student-\(t\)-তে \(q_{ij}\) বড় \(\lVert y_i-y_j\rVert\)-এও খুব ছোট হয় না; তাই একটা মাঝারি \(p_{ij}\) match করতে low-D-তে বিন্দুদের আরও দূরে বসাতে হয় (Gaussian হলে দ্রুত-পতন বলে কাছে চেপে যেত) — মাঝারি-দূরত্বের জন্য বেশি low-D জায়গা দেয়। (গ) এতে আলাদা cluster-গুলো low-D-তে চাপাচাপি না করে স্পষ্টভাবে ছড়িয়ে বসে — crowding কমে, visualization-এ cluster পরিষ্কার (এই কারণেই t-SNE-র \(T=0.999\) এত উঁচু)।
প্রশ্ন ৮ (★★). trustworthiness ও corr একসাথে পড়া — local বনাম global। trustworthiness \(T\in[0,1]\) মাপে: low-D-তে যেসব বিন্দুকে কাছের-প্রতিবেশী দেখাচ্ছে, তারা high-D-তেও কি সত্যিই কাছের ছিল (অর্থাৎ embedding কি মিথ্যা প্রতিবেশী বানায়নি — local বিশ্বস্ততা)। আলাদাভাবে, embedding-এর প্রথম অক্ষ বনাম প্রকৃত manifold-অবস্থান color-এর \(\lvert\text{corr}\rvert\) মাপে global ১D ক্রম পুনরুদ্ধার। canonical: PCA \(T=0.968\) কিন্তু \(\lvert\text{corr}\rvert=0.165\)। (ক) PCA-র \(T\) এত উঁচু (\(0.968\)) অথচ corr এত নিচু (\(0.165\)) — দুটো একসাথে কী বলছে (PCA কি local প্রতিবেশ মোটামুটি রাখল, কিন্তু global গঠন রাখল কি)? (খ) তাই কেন শুধু \(T\) দেখে সিদ্ধান্ত নেওয়া বিপজ্জনক — একটা পদ্ধতি high \(T\) পেয়েও manifold-কে কেন "ভুল" মেলে ধরতে পারে? (গ) Isomap-এ \(T=1.000\) এবং corr \(=1.000\) — এই দুই-ই উঁচু হওয়া কেন PCA-র চেয়ে শক্তিশালী প্রমাণ যে roll সঠিকভাবে মেলেছে?
Hint: (ক) উঁচু \(T\) (\(0.968\)) = PCA মোটামুটি local প্রতিবেশ ঠিক রাখে (কাছের বিন্দু কাছেই, কম মিথ্যা-প্রতিবেশী); কিন্তু corr \(0.165\approx0\) = global manifold-ক্রম পুনরুদ্ধারে ব্যর্থ — অর্থাৎ ছোট-পরিসরে ঠিক, বড়-পরিসরে roll ভাঁজ-করে মিশিয়ে ফেলেছে। (খ) \(T\) শুধু স্থানীয় প্রতিবেশ-সংরক্ষণ মাপে, global geometry নয়; তাই roll-কে চ্যাপ্টা করে দূরের অংশ overlap করিয়েও high \(T\) পাওয়া যায় (প্রতিটি ছোট patch ঠিক, কিন্তু patch-গুলোর পারস্পরিক বিন্যাস ভুল) — তাই \(T\)-র সাথে একটা global মাপ (corr) দেখা জরুরি। (গ) Isomap-এ \(T\) ও corr দুটোই \(1.000\) ⇒ local প্রতিবেশ এবং global ক্রম দুই-ই রক্ষিত — তাই এটা সত্যিকারের সঠিক unrolling, কেবল-local-ঠিক PCA-র মতো নয়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৯ (★★). MDS double-centering হাতে — \(B=-\tfrac12 H\Delta H\)। classical MDS-এর প্রথম ধাপ: একটা squared-distance matrix \(\Delta\) (যেখানে \(\Delta_{ij}=d_{ij}^2\)) থেকে inner-product (Gram) matrix \(B=-\tfrac12 H\Delta H\) বের করা, যেখানে \(H=I-\tfrac1n\mathbf 1\mathbf 1^\top\) (centering matrix)। তিনটি বিন্দু, যাদের জোড়া-দূরত্ব এক সরলরেখায় \(0,1,2\) (অর্থাৎ বিন্দুগুলো \(0,1,2\)-তে); squared-distance $$ \Delta=\begin{pmatrix}0&1&4\1&0&1\4&1&0\end{pmatrix}. $$ (ক) double-centering-এর সংক্ষিপ্ত সূত্র ব্যবহার করুন: \(B_{ij}=-\tfrac12\big(\Delta_{ij}-\bar\Delta_{i\cdot}-\bar\Delta_{\cdot j}+\bar\Delta_{\cdot\cdot}\big)\), যেখানে \(\bar\Delta_{i\cdot}\) = সারি-গড়, \(\bar\Delta_{\cdot j}\) = কলাম-গড়, \(\bar\Delta_{\cdot\cdot}\) = সর্বমোট-গড়। সারি-গড়, কলাম-গড় ও grand-গড় বের করুন। (খ) \(B\) matrix-টি গণনা করুন। (গ) যাচাই করুন \(B\) symmetric এবং প্রতিটি সারির যোগফল \(0\) (double-centering-এর স্বাক্ষর), আর \(B_{ii}\) = কেন্দ্র (centroid \(=1\)) থেকে বিন্দু-\(i\)-র squared-দূরত্ব হওয়া উচিত — মিলিয়ে দেখুন। Hint: (ক) সারি-গড়: সারি\(1=(0+1+4)/3=5/3\), সারি\(2=(1+0+1)/3=2/3\), সারি\(3=(4+1+0)/3=5/3\); symmetric বলে কলাম-গড় একই \((5/3,2/3,5/3)\); grand-গড় \(=(5/3+2/3+5/3)/3=(12/3)/3=4/3\)। (খ) যেমন \(B_{11}=-\tfrac12(0-5/3-5/3+4/3)=-\tfrac12(-6/3)=-\tfrac12(-2)=1\); \(B_{13}=-\tfrac12(4-5/3-5/3+4/3)=-\tfrac12(4-2)=-1\); এভাবে \(B=\begin{pmatrix}1&0&-1\\0&0&0\\-1&0&1\end{pmatrix}\)। (গ) \(B\) symmetric ✓; প্রতিটি সারির যোগফল \(0\) ✓ (\(1+0-1=0\)); \(B_{ii}=\lVert x_i-\bar x\rVert^2\) — centroid \(1\) থেকে বিন্দু \(0,1,2\)-র squared-দূরত্ব \(1,0,1\) = কর্ণ \((1,0,1)\) ✓ (তাই \(B\)-র শীর্ষ-eigenvector পুনরুদ্ধার করলে আসল ১D স্থানাঙ্ক ফিরে পাই — MDS-এর মূল কাজ)।
প্রশ্ন ১০ (★★). Isomap-এর geodesic — ছোট kNN-graph-এ shortest path। swiss roll-এর ক্ষুদ্র-অনুকরণে \(5\)টি বিন্দু \(A,B,C,D,E\) একটা বাঁকা পথ বরাবর সাজানো; একটা \(k\)-NN graph-এ নিচের প্রতিবেশী-edge ও তাদের Euclidean দূরত্ব দেওয়া (অন্য সব জোড়া সরাসরি-সংযুক্ত নয়): $$ A!-!B:1,\quad B!-!C:1,\quad C!-!D:1,\quad D!-!E:1,\quad A!-!E:1.2\ (\text{৩D-তে "শর্টকাট", পেঁচ গুটিয়ে কাছে})। $$ (ক) graph-এ \(A\) থেকে \(E\)-র geodesic (shortest-path) দূরত্ব \(d_G(A,E)\) বের করুন — দুটো পথ (\(A\!-\!B\!-\!C\!-\!D\!-\!E\) বনাম সরাসরি \(A\!-\!E\)) তুলনা করুন। (খ) ৩D Euclidean-এ \(A,E\) কাছাকাছি (\(1.2\)), কিন্তু manifold-বরাবর তারা পথের দুই-প্রান্ত — geodesic ও Euclidean-এর এই পার্থক্য কেন swiss roll-এর "প্রতিবেশী-পাক"-সমস্যার ঠিক প্রতিচ্ছবি? (গ) এক বাক্যে: যদি Isomap ভুল করে edge \(A\!-\!E\) (শর্টকাট) রাখে, embedding-এ কী বিকৃতি ঘটবে (দুই দূর-প্রান্ত কি কাছে এসে যাবে)? Hint: (ক) পথ \(A\!-\!B\!-\!C\!-\!D\!-\!E=1+1+1+1=4\); সরাসরি \(A\!-\!E=1.2\); shortest path \(=\min(4,\,1.2)=1.2\) — কিন্তু এটাই ভুল geodesic (নিচে খ/গ)। প্রকৃত manifold-geodesic \(=4\) (চাদর-বরাবর); \(A\!-\!E\) edge থাকলে graph ভুল শর্টকাট নেয়। (খ) swiss roll-এ পাশাপাশি দুই পাক ৩D-তে কাছে কিন্তু চাদর-বরাবর বহু দূর — ঠিক \(A,E\)-র মতো (Euclidean \(1.2\), geodesic \(4\)); kNN graph-এ এমন শর্টকাট-edge ভুলভাবে দুই পাককে সংযুক্ত করলে geodesic ছোট হয়ে যায়। (গ) \(A\!-\!E\) শর্টকাট থাকলে \(d_G(A,E)=1.2\) হয়ে যায় ⇒ embedding-এ পথের দুই দূর-প্রান্ত \(A,E\) কাছে এসে roll "ছিঁড়ে/মুড়ে" যায় — তাই Isomap-এ \(k\) যথাযথ ছোট রাখা জরুরি (শর্টকাট এড়াতে)।
প্রশ্ন ১১ (★★). t-SNE affinity হাতে — একটা low-D \(q_{ij}\)। t-SNE-র low-D affinity (unnormalized) \(w_{ij}=(1+\lVert y_i-y_j\rVert^2)^{-1}\), আর \(q_{ij}=w_{ij}/\sum_{k\ne l}w_{kl}\)। একটা \(2\)D embedding-এ তিন বিন্দু: \(y_1=(0,0)\), \(y_2=(1,0)\), \(y_3=(3,0)\)। (ক) তিন জোড়ার squared-দূরত্ব \(\lVert y_1-y_2\rVert^2,\ \lVert y_1-y_3\rVert^2,\ \lVert y_2-y_3\rVert^2\) বের করুন, তারপর প্রতিটির \(w_{ij}=(1+\text{সেই})^{-1}\) গণনা করুন। (খ) Gaussian হলে affinity হতো \(\exp(-\lVert y_i-y_j\rVert^2)\) — জোড়া \((1,3)\)-এর জন্য Student-\(t\) \(w_{13}\) আর Gaussian \(\exp(-9)\) তুলনা করুন; কোনটা দূরের জোড়াকে বেশি "ওজন" দেয় (লেজ ভারী)? (গ) এক বাক্যে: এই তুলনা থেকে কেন ভারী-লেজ Student-\(t\) দূরের বিন্দুদের low-D-তে এত দ্রুত মুছে ফেলে না (crowding-উপশমের চাবি)? Hint: (ক) \(\lVert y_1-y_2\rVert^2=1\), \(\lVert y_1-y_3\rVert^2=9\), \(\lVert y_2-y_3\rVert^2=4\); \(w_{12}=1/(1+1)=0.5\), \(w_{13}=1/(1+9)=0.1\), \(w_{23}=1/(1+4)=0.2\)। (খ) জোড়া \((1,3)\): Student-\(t\) \(w_{13}=0.1\), Gaussian \(\exp(-9)\approx0.000123\) — Student-\(t\) দূরের জোড়াকে প্রায় \(800\times\) বেশি ওজন দেয় (লেজ অনেক ভারী)। (গ) ভারী লেজ বলে দূরত্ব বাড়লেও \(w\) ধীরে পড়ে, তাই দূরের/মাঝারি বিন্দু low-D-তে সম্পূর্ণ "শূন্য" হয়ে মুছে যায় না — মাঝারি-দূরত্বের প্রতিবেশীদের জন্য জায়গা থাকে, crowding কমে।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১২ (★★★). double-centering প্রমাণ — কেন \(B=-\tfrac12 H\Delta H\) inner-product ফেরায়। ধরুন centered বিন্দু \(\{z_i\}_{i=1}^n\) (অর্থাৎ \(\sum_i z_i=0\)), squared-দূরত্ব \(\Delta_{ij}=\lVert z_i-z_j\rVert^2\), আর লক্ষ্য Gram matrix \(B_{ij}=z_i^\top z_j\)। (ক) বিস্তার করে দেখান \(\Delta_{ij}=\lVert z_i\rVert^2+\lVert z_j\rVert^2-2z_i^\top z_j\)। (খ) \(\sum_i z_i=0\) ব্যবহার করে দেখান \(\bar\Delta_{i\cdot}=\tfrac1n\sum_j\Delta_{ij}=\lVert z_i\rVert^2+\tfrac1n\sum_j\lVert z_j\rVert^2\) এবং grand-গড় \(\bar\Delta_{\cdot\cdot}=\tfrac2n\sum_j\lVert z_j\rVert^2\) (cross-term মুছে যায় কেন?)। (গ) double-centered রাশি \(-\tfrac12\big(\Delta_{ij}-\bar\Delta_{i\cdot}-\bar\Delta_{\cdot j}+\bar\Delta_{\cdot\cdot}\big)\)-তে এগুলো বসিয়ে দেখান এটা ঠিক \(z_i^\top z_j=B_{ij}\) — অর্থাৎ \(B=-\tfrac12 H\Delta H\) ঠিক inner-product ফিরিয়ে দেয়। Hint: (ক) \(\lVert z_i-z_j\rVert^2=(z_i-z_j)^\top(z_i-z_j)=\lVert z_i\rVert^2-2z_i^\top z_j+\lVert z_j\rVert^2\)। (খ) \(\bar\Delta_{i\cdot}=\tfrac1n\sum_j(\lVert z_i\rVert^2+\lVert z_j\rVert^2-2z_i^\top z_j)=\lVert z_i\rVert^2+\tfrac1n\sum_j\lVert z_j\rVert^2-\tfrac2n z_i^\top\underbrace{\sum_j z_j}_{=0}\); শেষ পদ \(0\) কারণ \(\sum_j z_j=0\) (centered) — তাই cross-term মোছে; একইভাবে \(\bar\Delta_{\cdot j}\), আর grand-গড় \(\bar\Delta_{\cdot\cdot}=\tfrac1{n^2}\sum_{ij}\Delta_{ij}=\tfrac2n\sum_j\lVert z_j\rVert^2\)। (গ) বসিয়ে: \(\Delta_{ij}-\bar\Delta_{i\cdot}-\bar\Delta_{\cdot j}+\bar\Delta_{\cdot\cdot}=(\lVert z_i\rVert^2+\lVert z_j\rVert^2-2z_i^\top z_j)-(\lVert z_i\rVert^2+s)-(\lVert z_j\rVert^2+s)+2s=-2z_i^\top z_j\) যেখানে \(s=\tfrac1n\sum_l\lVert z_l\rVert^2\); তাই \(-\tfrac12(-2z_i^\top z_j)=z_i^\top z_j=B_{ij}\) ∎ — double-centering squared-দূরত্ব থেকে inner-product পুনরুদ্ধার করে, যার eigen-decomposition (MDS) মূল স্থানাঙ্ক দেয়।
প্রশ্ন ১৩ (★★★). kernel PCA = linear PCA যখন kernel linear। kernel PCA centered kernel \(\tilde K=HKH\)-এর eigen-decomposition করে, যেখানে \(K_{ij}=\phi(x_i)^\top\phi(x_j)\) আর \(H=I-\tfrac1n\mathbf 1\mathbf 1^\top\)। দেখান linear kernel \(k(x,x')=x^\top x'\) নিলে kernel PCA হুবহু সাধারণ (linear) PCA-তে (৫.৯) পরিণত হয়। ধরুন data ইতিমধ্যে centered (\(\sum_i x_i=0\), তাই \(HX=X\))। (ক) linear kernel-এ \(K=XX^\top\) (\(X\in\mathbb R^{n\times D}\), সারি = বিন্দু) — centered হওয়ায় \(\tilde K=HKH=XX^\top\) দেখান। (খ) covariance \(C=\tfrac1n X^\top X\) (\(D\times D\)) আর Gram \(XX^\top\) (\(n\times n\))-র অশূন্য eigenvalue-গুলো একই (factor সহ) — দেখান যদি \(X^\top X v=\lambda v\) তবে \(XX^\top(Xv)=\lambda(Xv)\), অর্থাৎ \(Xv\) হলো \(XX^\top\)-র eigenvector একই eigenvalue \(\lambda\)-তে। (গ) এক বাক্যে উপসংহার: তাই linear-kernel PCA-র projection সাধারণ PCA-র projection-এর সমান (একই principal-subspace), অর্থাৎ kernel PCA হলো PCA-র অরৈখিক সাধারণীকরণ যার linear-kernel বিশেষক্ষেত্র = ৫.৯-এর PCA। Hint: (ক) \(k(x_i,x_j)=x_i^\top x_j\Rightarrow K=XX^\top\); data centered বলে \(HX=X\) ও \(X^\top H=X^\top\), তাই \(\tilde K=HXX^\top H=(HX)(HX)^\top=XX^\top=K\)। (খ) \(X^\top X v=\lambda v\)-র দুই পাশে বাঁ থেকে \(X\) গুণ: \(X X^\top (Xv)=\lambda(Xv)\) — তাই \(u=Xv\) হলো Gram \(XX^\top\)-র eigenvector, eigenvalue \(\lambda\) অভিন্ন (অশূন্য \(\lambda\)-র জন্য \(u\ne0\)); covariance \(C=\tfrac1n X^\top X\)-র eigenvalue \(\lambda/n\), একই eigenvector \(v\)। (গ) উভয়েরই প্রধান-দিক/eigenvalue (স্কেল-factor বাদে) এক, তাই একই \(d\)-মাত্রিক principal subspace ও একই projection — linear kernel PCA \(\equiv\) PCA (৫.৯); সাধারণ nonlinear kernel-এ \(\phi\) অরৈখিক বলে তখন PCA বাঁকা feature-space-এ ঘটে।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৪ (★★★). পূর্ণ তুলনা — PCA বনাম Isomap বনাম t-SNE (+ KernelPCA, LLE) swiss roll-এ, trustworthiness ও corr সহ। seed-সূচক random_state=20260619 দিয়ে চলমান canonical dataset বানান: make_swiss_roll(n_samples=1000, noise=0.05) — X shape \((1000,3)\), color = manifold-বরাবর প্রকৃত ১D অবস্থান। এবার প্রতিটি method-এর জন্য একটা \(2\)D embedding বের করে (i) trustworthiness (\(n\_neighbors=10\)) ও (ii) embedding-এর অক্ষ বনাম color-এর \(\lvert\text{Spearman corr}\rvert\) (যে অক্ষ বেশি মেলে) ছাপুন:
- PCA (
PCA(n_components=2)) — canonical \(T=\mathbf{0.968}\), \(\lvert\text{corr}\rvert=\mathbf{0.165}\) (manifold মেলে ব্যর্থ: সরলরৈখিক, global গঠন হারায়)। - Isomap (
Isomap(n_neighbors=10, n_components=2)) — canonical \(T=\mathbf{1.000}\), \(\lvert\text{corr}\rvert=\mathbf{1.000}\) (geodesic-MDS, roll নিখুঁত মেলে)। - LLE (
LocallyLinearEmbedding(n_neighbors=10, n_components=2, random_state=0)) — canonical \(T=\mathbf{0.996}\), \(\lvert\text{corr}\rvert=\mathbf{0.998}\) (local geometry যথেষ্ট)। - t-SNE (
TSNE(n_components=2, perplexity=30, random_state=0, init='pca')) — canonical \(T=\mathbf{0.999}\), \(\lvert\text{corr}\rvert=\mathbf{0.857}\) (local চমৎকার, global আংশিক)। - KernelPCA(rbf) (
KernelPCA(n_components=2, kernel='rbf', gamma=0.04)) — canonical \(T=\mathbf{0.898}\), \(\lvert\text{corr}\rvert=\mathbf{0.228}\) (geodesic ধরে না, swiss roll-এ দুর্বল)।
শেষে একটা ছোট সিদ্ধান্ত ছাপুন: কোন method উভয় \(T\) ও corr সর্বোচ্চ (⇒ এই manifold-এর জন্য সেরা — Isomap)।
Hint: from sklearn.datasets import make_swiss_roll; from sklearn.decomposition import PCA, KernelPCA; from sklearn.manifold import Isomap, LocallyLinearEmbedding, TSNE, trustworthiness; from scipy.stats import spearmanr। X, color = make_swiss_roll(n_samples=1000, noise=0.05, random_state=20260619)। প্রতিটি method-এ Y = method.fit_transform(X), তারপর T = trustworthiness(X, Y, n_neighbors=10) আর c = max(abs(spearmanr(Y[:,0], color).correlation), abs(spearmanr(Y[:,1], color).correlation))। একটা লুপ/তালিকায় পাঁচটি estimator রেখে \((T, \lvert\text{corr}\rvert)\) ছাপুন; পাঠ: PCA fails (corr \(0.165\)), Isomap perfect (\(1.000/1.000\)), LLE প্রায়-perfect (\(0.998\)), t-SNE local-strong global-weak (\(0.857\)), KernelPCA দুর্বল (\(0.228\))। সংস্করণ/optimizer-ভেদে (বিশেষত t-SNE, KernelPCA) শেষ অঙ্কে সামান্য হেরফের সম্ভব, কিন্তু গল্প — PCA-র low corr বনাম Isomap/LLE-র high corr — অপরিবর্তিত। পূর্ণ runnable script _solutions/06-08-nonlinear-dimreduction-solutions.md-এর §ঘ-তে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
manifold hypothesis — data বাঁকা নিম্ন-মাত্রিক চাদরে বসে। বাস্তব উচ্চ-মাত্রিক (\(D\)) data সাধারণত পূর্ণ \(\mathbb R^D\) জুড়ে ছড়ানো নয়, বরং একটা অনেক-কম-মাত্রিক (\(d\ll D\)) মসৃণ manifold-এর কাছাকাছি কেন্দ্রীভূত (intrinsic dimension \(d\), ambient dimension \(D\))। চলমান উদাহরণ swiss roll এর সরল মূর্তি: \(D=3\), কিন্তু কাগজটা আসলে \(d=2\) চাদর — ৩D-তে পেঁচানো। nonlinear dimensionality reduction-এর লক্ষ্য এই manifold-কে \(d\)-মাত্রায় "মেলে ধরা" যেন গঠন টিকে থাকে।
-
linear PCA বাঁকা গঠন হারায়। ৫.৯-এর PCA variance-সর্বোচ্চকারী সরলরৈখিক অক্ষে projection করে — একটা সমতল (flat) subspace। পেঁচানো roll-কে সমতলে চাপলে দূরের পাক একে অপরের উপর পড়ে, manifold-বরাবর global ক্রম মিশে যায়। canonical-এ PCA-র trustworthiness উঁচু (\(0.968\)) কিন্তু প্রথম অক্ষ বনাম প্রকৃত manifold-অবস্থানের \(\lvert\text{corr}\rvert\) মাত্র \(0.165\) — অর্থাৎ local মোটামুটি, কিন্তু global মেলে ব্যর্থ। তাই বাঁকা manifold-এ nonlinear পদ্ধতি দরকার।
-
kernel PCA — centered kernel-এর উপর PCA। kernel PCA (৬.৪-এর kernel trick + ৫.৯-এর PCA) PCA-কে একটা feature-space-এ নিয়ে যায়, centered kernel \(\tilde K=HKH\)-এর eigen-decomposition করে — \(\phi\) সরাসরি না হিসেব করে। linear kernel নিলে এটা সাধারণ PCA-তেই ফেরে। কিন্তু RBF kernel-pca স্পষ্টভাবে geodesic/unrolling গঠন ধরে না, তাই swiss roll-এ দুর্বল (canonical corr \(0.228\))।
-
MDS ও double-centering — দূরত্ব থেকে স্থানাঙ্ক। classical multidimensional scaling (MDS) শুধু জোড়া-দূরত্ব থেকে নিম্ন-মাত্রিক স্থানাঙ্ক পুনরুদ্ধার করে: squared-distance \(\Delta\) থেকে double-centering \(B=-\tfrac12 H\Delta H\) একটা inner-product (Gram) matrix বানায় (§৭ প্রমাণে দেখানো এটা ঠিক \(z_i^\top z_j\) ফেরায়), তারপর \(B\)-র শীর্ষ-\(d\) eigenvector embedding দেয়। দূরত্ব Euclidean হলে MDS = PCA; এর শক্তি হলো যেকোনো দূরত্ব-matrix নিতে পারা।
-
Isomap — geodesic দূরত্বের উপর MDS। Isomap-এর মূল চাবি: Euclidean দূরত্বের বদলে manifold-বরাবর দূরত্ব (geodesic \(d_G\)) ব্যবহার। কৌশল: একটা neighbor graph (kNN) বানিয়ে graph-shortest-path দিয়ে \(d_G\) আনুমান, তারপর সেই geodesic-matrix-এ MDS। swiss roll-এ এতে roll "মেলে" যায় (প্রতিবেশী-পাকের ভুল "শর্টকাট" এড়িয়ে) — canonical-এ Isomap-এর \(T=1.000\), corr \(=1.000\) (নিখুঁত unrolling)। বিপদ: \(k\) বড় হলে শর্টকাট-edge geodesic ভাঙে।
-
LLE — local geometry আঠা। Locally Linear Embedding (LLE) ভাবে প্রতিটি বিন্দু তার প্রতিবেশীদের affine-যোগ (\(\sum_j w_{ij}=1\)) দিয়ে পুনর্গঠনযোগ্য; এই স্থানীয় weight \(w_{ij}\) (translation/rotation-invariant) শিখে সেগুলো নিম্ন-মাত্রায় রক্ষা করে। global geodesic না নিয়ে শুধু ছোট প্রতিবেশ-patch জোড়ে — তবু swiss roll-এ চমৎকার (canonical corr \(0.998\))।
-
t-SNE / UMAP — neighbor-distribution-এর KL (visualization)। t-SNE high-D-তে জোড়া-affinity \(p_{ij}\) (Gaussian, perplexity-স্কেল) ও low-D-তে \(q_{ij}\) (heavy-tailed Student-\(t\)) সংজ্ঞায়িত করে, তারপর \(\mathrm{KL}(P\Vert Q)\) minimize করে embedding শেখে। অপ্রতিসম KL high-D-র কাছের জোড়া রক্ষায় পক্ষপাতী (local-strong), আর Student-\(t\) লেজ crowding problem উপশম করে (মাঝারি-দূরত্বের প্রতিবেশী \(2\)D-তে চাপা না-পড়ে আলাদা থাকে)। ফল: cluster চমৎকার (\(T=0.999\)) কিন্তু global দূরত্ব নির্ভরযোগ্য নয় (\(\lvert\text{corr}\rvert=0.857\))। UMAP একই চেতনার দ্রুততর/বড়-scale বিকল্প। দুটোই মূলত visualization-এর হাতিয়ার, downstream-feature নয়।
-
trustworthiness — local বিশ্বস্ততা, কিন্তু global নয়। trustworthiness \(T\) মাপে low-D-তে দেখানো কাছের-প্রতিবেশীরা high-D-তেও কাছের ছিল কিনা (মিথ্যা-প্রতিবেশী নেই — local মান)। canonical স্পষ্ট শিক্ষা: PCA-র \(T=0.968\) উঁচু কিন্তু corr \(0.165\) নিচু — অর্থাৎ উঁচু \(T\) ভালো local সংরক্ষণ বোঝায়, কিন্তু global গঠন নিশ্চিত করে না। তাই \(T\)-র পাশে একটা global মাপ (এখানে manifold-অবস্থানের সাথে corr) দেখা জরুরি; Isomap-এ দুটোই \(1.000\) — সত্যিকারের সঠিক unrolling।
-
method-নির্বাচন। geodesic-সংরক্ষণ ও সঠিক global unrolling চাইলে Isomap (এই manifold-এ সেরা: \(T\) ও corr দুই-ই \(1.000\)); local-linear গঠন যথেষ্ট হলে LLE; কেবল visualization/cluster দেখতে চাইলে t-SNE/UMAP (দ্রুত, সুন্দর cluster, কিন্তু global দূরত্ব/অক্ষ-অর্থ বিশ্বাস করবেন না); feature-space-এ রৈখিক-সাধারণীকরণ চাইলে kernel PCA (তবে swiss roll-এর geodesic গঠনে দুর্বল)। মূল মন্ত্র: একটা মাত্র সংখ্যায় (যেমন \(T\)) আস্থা না রেখে local ও global দুই-ই যাচাই করা।
-
মূল বার্তা। linear PCA সমতল subspace খোঁজে, তাই বাঁকা manifold-এর global গঠন হারায়; nonlinear পদ্ধতিগুলো ভিন্ন কৌশলে সেই বাঁক ধরে — kernel PCA (feature-space variance), MDS/Isomap (দূরত্ব, বিশেষত geodesic), LLE (local-linear geometry), t-SNE/UMAP (neighbor-distribution-এর KL)। এদের গুণমান local (trustworthiness) ও global (manifold-অবস্থানের সাথে corr) দুই দিক থেকে যাচাই করতে হয়।
পূর্ববর্তী সংযোগ (← ৫.৯, ৬.৪, ০.৫, ৬.৭):
-
৫.৯ (linear PCA): এই অধ্যায়ের সরাসরি ভিত্তি ও তুলনা-বিন্দু। ৫.৯-এর PCA covariance-এর eigen-decomposition করে সরলরৈখিক variance-সর্বোচ্চ অক্ষে projection করে — চমৎকার যখন data মোটামুটি একটা সমতলে বসে, কিন্তু swiss roll-এর মতো বাঁকা manifold-এ ব্যর্থ (canonical corr \(0.165\))। ৬.৮-এর সব nonlinear পদ্ধতি PCA-র এই সীমা পেরোনোর চেষ্টা: linear kernel-এ kernel PCA হুবহু ৫.৯-এর PCA (§৭ প্রমাণ), আর Euclidean দূরত্বে MDS-ও PCA-র সমান — অর্থাৎ PCA এই বৃহত্তর পরিবারের রৈখিক বিশেষক্ষেত্র।
-
৬.৪ (kernel methods / kernel trick): kernel PCA সরাসরি ৬.৪-এর kernel trick-এর উপর দাঁড়ায় — feature-map \(\phi\) সরাসরি না হিসেব করে কেবল kernel \(k(x_i,x_j)=\phi(x_i)^\top\phi(x_j)\) ব্যবহার করে PCA-কে অরৈখিক feature-space-এ নিয়ে যাওয়া (যেমন ৬.৪-এ SVM-কে নেওয়া হয়েছিল)। RBF kernel, kernel-centering — সবই ৬.৪-এর kernel-ভাষার সম্প্রসারণ; পার্থক্য কেবল লক্ষ্য (classification নয়, dimensionality reduction)।
-
০.৫ (eigendecomposition): এই অধ্যায়ের গাণিতিক মেরুদণ্ড। kernel PCA centered kernel \(\tilde K\)-এর, classical MDS double-centered \(B\)-এর, Isomap geodesic-\(B\)-এর, আর LLE-র embedding-ধাপ একটা sparse matrix-এর — সবই শেষমেশ একটা symmetric matrix-এর eigen-decomposition (০.৫)। শীর্ষ-\(d\) eigenvector-ই embedding-অক্ষ দেয়; ০.৫-এর "symmetric matrix-এর eigenvalue বাস্তব, eigenvector orthogonal" ফল এখানে বারবার ব্যবহৃত।
-
৬.৭ (neighbors / distances): Isomap-এর neighbor graph, LLE-র প্রতিবেশী-নির্বাচন, t-SNE-র local affinity, এমনকি trustworthiness — সবই বিন্দুর প্রতিবেশী ও দূরত্বের ধারণার (৬.৭) উপর নির্ভর। ৬.৭-এ kNN/দূরত্ব-মেট্রিক যেভাবে স্থানীয় গঠন ধরে, এখানে সেই kNN-graph-ই geodesic-আনুমান ও local-geometry সংরক্ষণের ভিত্তি; manifold পদ্ধতিগুলো কার্যত "প্রতিবেশ-গঠনকে নিম্ন-মাত্রায় বহন করা"।
পরবর্তী সংযোগ (→ ৬.৯ — anomaly detection, semi-supervised ও online learning): ৬.৮ unsupervised representation-শিক্ষার শেষ বড় অংশ দেখাল — উচ্চ-মাত্রিক data-র নিম্ন-মাত্রিক গঠন/manifold উন্মোচন। ৬.৯ Part VI-এর সমাপনী survey অধ্যায়: কয়েকটি প্রয়োগমুখী দিক একসাথে — anomaly detection (স্বাভাবিক data-র গঠন/density শিখে বিচ্যুতি ধরা — যেখানে ৬.৭-এর density ও ৬.৮-এর manifold/reconstruction-error সরাসরি কাজে লাগে: manifold থেকে দূরের বিন্দুই anomaly), semi-supervised learning (অল্প label + বহু unlabeled data, যেখানে manifold/cluster-গঠন label ছড়াতে সাহায্য করে), এবং online learning (data স্রোতে আসতে থাকলে ক্রমাগত আপডেট)। অর্থাৎ ৬.৮-এর manifold-চিন্তা ৬.৯-এ anomaly ও semi-supervised-এর সরাসরি হাতিয়ার হয়ে ফিরবে।
দ্রষ্টব্য — unsupervised toolkit সম্পূর্ণ। এই অধ্যায় Part VI-এর (এবং পুরো curriculum-এর) unsupervised-শিক্ষার ত্রয়ী পূর্ণ করে: ৫.৯ (linear PCA + clustering — রৈখিক মাত্রা-হ্রাস ও দলবদ্ধকরণ), ৬.৭ (density estimation, EM, GMM — সম্ভাবনা-ঘনত্ব ও latent গোষ্ঠী), এবং ৬.৮ (nonlinear manifold learning — বাঁকা নিম্ন-মাত্রিক গঠন)। তিনটি মিলে label-ছাড়া data থেকে গঠন উন্মোচনের সম্পূর্ণ মৌলিক হাতিয়ার-সম্ভার গড়ে — ৬.৭ লুকানো গোষ্ঠী, ৫.৯/৬.৮ লুকানো অক্ষ/manifold খোঁজে।
সূত্র (sources): M. Sugiyama, Introduction to Statistical Machine Learning (manifold learning, dimensionality reduction, kernel PCA, LLE ও Laplacian-eigenmap-এর তাত্ত্বিক উপস্থাপন — এই অধ্যায়ের প্রাথমিক উৎস); L. Wasserman, All of Statistics (PCA, MDS ও multivariate গঠনের সংক্ষিপ্ত পরিসংখ্যানিক উপস্থাপন); P. Dangeti, Statistics for Machine Learning (PCA, kernel PCA, t-SNE ও scikit-learn Python প্রয়োগ, manifold-পদ্ধতির তুলনা); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists (dimensionality reduction ও nonlinear embedding-এর ব্যবহারিক দ