6.1 — Learning Theory: Bias–Variance, Generalization & Overfitting (লার্নিং তত্ত্ব: বায়াস–ভেরিয়ান্স, সাধারণীকরণ ও ওভারফিটিং)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — মুখস্থ বনাম শেখা: machine একটা নতুন প্রশ্নের সামনে কী করবে?¶
১.১ একটা নতুন ভূখণ্ডে পা — Part V (modeling) থেকে Part VI (ML)-এ¶
এতক্ষণে (Part IV–V জুড়ে) আমরা একটা সমৃদ্ধ অস্ত্রাগার গড়ে তুলেছি — linear regression, GLM, nonparametric regression, cross-validation — সব মিলিয়ে শিখেছি কীভাবে data থেকে একটা model fit করি ও তাকে যাচাই করি। কিন্তু এই গোটা যাত্রায় একটা প্রশ্ন বারবার মাথা তুলেছে, অথচ আমরা তার পূর্ণ, তাত্ত্বিক উত্তর কখনো দিইনি — কেবল ব্যবহারিক টোটকায় (যেমন cross-validation) সামলে এসেছি। সেই প্রশ্নটাই এই নতুন Part-এর — Part VI: পরিসংখ্যানিক মেশিন লার্নিং (Statistical Machine Learning)-এর — হৃৎপিণ্ড।
প্রশ্নটা এক বাক্যে: একটা model যখন তার দেখা data-তে ভালো করে, তখন কি নিশ্চিতভাবে বলা যায় সে নতুন, এখনো-না-দেখা data-তেও ভালো করবে? এই "দেখা data থেকে না-দেখা data-তে কাজ চালিয়ে যাওয়ার ক্ষমতা"-র একটা নাম আছে — generalization (সাধারণীকরণ)। আর machine learning-এর গোটা অস্তিত্বই দাঁড়িয়ে আছে এই একটি ক্ষমতার উপর: আমরা যন্ত্রকে কিছু উদাহরণ দেখাই এই আশায় যে সে উদাহরণগুলোর পেছনের নিয়মটা ধরবে — উদাহরণগুলো নিজে মুখস্থ করবে না।
Part V যেখানে মূলত জিজ্ঞেস করত "এই data-র সঙ্গে কোন model সবচেয়ে ভালো খাপ খায়?", Part VI-এর কেন্দ্রীয় প্রশ্ন তার চেয়ে গভীর ও আলাদা: "এই data থেকে শেখা model কি data-র উৎস (যে প্রক্রিয়া data-টা বানিয়েছে) সম্পর্কে কিছু শিখল, নাকি শুধু এই বিশেষ নমুনার খুঁটিনাটি (এবং তার noise) মুখস্থ করল?" এই প্রশ্নকে নিছক স্বজ্ঞা থেকে তুলে এনে একটা rigorous, পরিমাপযোগ্য তত্ত্বে রূপ দেওয়াই — learning theory — এই অধ্যায়ের কাজ।
এক বাক্যে উত্তরণ। Part V শেখাল কীভাবে data-তে model fit করি; Part VI শুরু হয় এই প্রশ্নে — সেই fit করা model নতুন data-তে কতটা ভালো করবে, এবং কেন/কখন আদৌ ভালো করবে — অর্থাৎ machine learning-কে পরিসংখ্যানের ভাষায় formalize করা।
১.২ Hook — একটা প্রতারক সরলতা: জটিল model সবসময় কম training error দেয়¶
5.8-এর একটা অস্বস্তিকর সত্য আবার মনে করি, কারণ সেটাই এই অধ্যায়ের গোটা প্রেরণা। সেখানে আমরা দেখেছিলাম: একই data-তে যত জটিল model বসাই, তার training error তত কমতেই থাকে — কখনো U-আকৃতি নেয় না, একঘেয়ে নিচে নামে। যথেষ্ট জটিল model প্রতিটি training-বিন্দু হুবহু ছুঁয়ে training error শূন্যেও নামিয়ে আনতে পারে।
এখন এই ঘটনাটার গভীরতা একটা ছবিতে ধরা যাক। ধরা যাক সত্যিকারের সম্পর্ক একটা মসৃণ তরঙ্গ — \(f(x)=\sin(2\pi x)\) — আর তাতে কিছু পর্যবেক্ষণ-noise মেশানো। হাতে মাত্র গুটিকয় বিন্দু (\(n_{\text{train}}=40\))। এখন এই বিন্দুগুলোর মধ্য দিয়ে আমরা polynomial বসাই, আর polynomial-এর degree (\(d\)) দিয়ে জটিলতা বাড়াই-কমাই:
- \(d=1\) (সরলরেখা): বিন্দুগুলোর সাধারণ ঢাল ধরে, কিন্তু sine-এর বাঁক ধরতেই পারে না — training error বড়, fit কাঁচা।
- \(d=3\) (cubic): বাঁক-টাঁক মোটামুটি ধরে — fit বেশ ভালো।
- \(d=9\): প্রায় প্রতিটি বিন্দুর কাছে পৌঁছে যায় — training error প্রায় শূন্য।
- \(d=11\): প্রতিটি বিন্দু হুবহু ছুঁয়ে training error ≈ ০, কিন্তু বিন্দুর মাঝখানে curve পাগলের মতো ওঠা-নামা করে।
কোন model-টা "সবচেয়ে ভালো শিখল"? training error-এর হিসাবে — \(d=11\), কারণ তার ভুল প্রায় শূন্য। কিন্তু একটু ভাবলেই বোঝা যায় এটা প্রতারণা: \(d=11\) আসল sine-তরঙ্গ শেখেনি, সে শুধু এই ৪০টা বিন্দুর (এবং তাদের আকস্মিক noise-এর) একটা নিখুঁত নকল বানিয়েছে। একটা নতুন বিন্দু আনলেই — যেমন দুটো training-বিন্দুর মাঝখানে — এই বুনো curve বিশ্রীভাবে ভুল করবে। অর্থাৎ training error যেদিকে "\(d\) যত বড় তত ভালো" বলছে, আসল generalization তার ঠিক উল্টো দিকে ইশারা করছে।
এক বাক্যে hook। একই data-তে আরও জটিল model প্রায় সবসময় কম training error দেয় — কিন্তু সেই কম-ভুল একটা মরীচিকা: model হয়তো শেখেনি, কেবল মুখস্থ করেছে। তাই দরকার এমন একটা তত্ত্ব যা training error-এর বাইরে গিয়ে বলে দেয় — কখন, কেন, এবং কতটা আত্মবিশ্বাসে — একটা model সত্যিই নতুন data-তে কাজ করবে।
১.৩ মূল insight (অন্তর্দৃষ্টি) — দুই রকমের "ভুল", আর তাদের ফারাকই গল্প¶
প্রতারণাটা কোথায় ধরা পড়ে? ঠিক যেখানে আমরা ভুল মাপি সেখানে। মূল বিভ্রান্তির উৎস হলো — আমরা দুটো আলাদা জিনিসকে একই "ভুল" নামে গুলিয়ে ফেলি, অথচ এদের ফারাকই learning theory-র সমস্ত গল্প।
- প্রথমটা: model যে data-তে শিখেছে, সেই data-তে তার গড় ভুল। এটাকে আমরা পরের বিভাগে নাম দেব empirical risk (ধরা-data-র ভুল) — 5.8-এর "training error"-এরই precise রূপ।
- দ্বিতীয়টা: model যদি data-র প্রকৃত উৎস থেকে আসা সব সম্ভাব্য ভবিষ্যৎ বিন্দুতে গড়ে কত ভুল করত — সেই আদর্শ, কিন্তু সরাসরি মাপতে-না-পারা ভুল। এটাকে বলব true risk বা expected risk (প্রকৃত/প্রত্যাশিত ভুল)।
আমরা সত্যিকার অর্থে যেটা ছোট করতে চাই, সেটা হলো দ্বিতীয়টা — true risk, কারণ model-এর আসল কাজ ভবিষ্যতের data-তে ভালো prediction। কিন্তু আমরা সরাসরি যেটা মাপতে ও কমাতে পারি, সেটা প্রথমটা — empirical risk, কারণ আমাদের হাতে কেবল একটা সসীম নমুনা আছে, গোটা distribution নয়। এই দুইয়ের মধ্যবর্তী ফাঁক-টাই — যাকে পরে বলব generalization gap — হলো সেই জায়গা যেখানে overfitting লুকিয়ে থাকে, এবং এই ফাঁককে নিয়ন্ত্রণে রাখার তত্ত্বই learning theory।
\(d=11\) এর প্রতারণা এখন এক লাইনে বলা যায়: তার empirical risk ≈ ০, কিন্তু true risk বিশাল — দুইয়ের মাঝের ফাঁকটাই বিপুল। আর \(d=3\)-এর গুণ: তার empirical risk কম, এবং true risk-ও কম — ফাঁকটা ছোট। গোটা অধ্যায়ের লক্ষ্য এই ফাঁক কখন ছোট থাকে তার শর্ত খুঁজে বের করা।
১.৪ গল্পের তিন স্তম্ভ — এক ঝলকে¶
এই ফাঁক-নিয়ন্ত্রণের তত্ত্ব তিনটে পরস্পর-জড়িত স্তম্ভের উপর দাঁড়াবে; এখানে শুধু নামগুলো চিনিয়ে রাখি, যাতে পথ হারানো না যায়।
-
Bias–variance decomposition (§২.৬, §৪)। একটা model-এর গড় prediction-ভুলকে আমরা তিন টুকরোয় ভাঙব — \(\mathrm{Bias}^2\) (model-টা গঠনগতভাবে কতটা "ভুল আকৃতির", যেমন sine-কে সরলরেখা দিয়ে ধরা), \(\mathrm{Var}\) (নমুনা বদলালে model কতটা নড়ে), আর \(\sigma^2\) (data-র নিজের অপসারণ-অযোগ্য noise)। দেখা যাবে complexity বাড়ালে \(\mathrm{Bias}^2\) কমে কিন্তু \(\mathrm{Var}\) বাড়ে — তাই মোট ভুল একটা U-আকৃতি নেয়, যার তলদেশেই সেরা complexity।
-
Capacity ও তার মাপ (§২.৭)। "model কতটা জটিল/নমনীয়" — এই অস্পষ্ট ধারণাকে সংখ্যায় ধরা চাই। তার জন্য আসবে PAC learning-এর ভাষা ও VC dimension — একটা hypothesis class কত বিচিত্র প্যাটার্ন "ধরতে" পারে তার নির্ভুল মাপ।
-
Generalization bound (§২.৮, §৪)। শেষে সব একসাথে বাঁধব একটা অসমতায় — \(R(h)\le\hat R_n(h)+(\text{complexity-penalty})\) — যা সরাসরি 3.1-এর Hoeffding inequality থেকে আসবে, আর বলে দেবে empirical risk-কে কতটা বিশ্বাস করা যায়: নমুনা যত বড় (\(n\)↑) ও model যত সরল (capacity↓), ফাঁক তত ছোট।
১.৫ এই অধ্যায়ের পথরেখা¶
- §২ মূল সংজ্ঞাগুলো নিখুঁত করে — statistical learning setup (\(P\), \(\ell\), \(\mathcal H\)); risk \(R(h)\) বনাম empirical risk \(\hat R_n(h)\); ERM ও generalization gap; bias–variance decomposition-এর statement ও U-curve; underfit/overfit ও capacity; PAC learning ও VC dimension (shattering সহ); এবং generalization bound-এর রূপ ও no-free-lunch।
- §৩–৪ এই ধারণাগুলো হাতে-কলমে ও গাণিতিকভাবে — bias–variance decomposition-এর পূর্ণ derivation, finite-\(\mathcal H\)-এর জন্য Hoeffding + union bound থেকে generalization bound, এবং VC bound-এর যুক্তি।
- §৫–৬ simulation-এ (seed 20260619, \(f(x)=\sin(2\pi x)\), \(\sigma=0.3\), \(n_{\text{train}}=40\), polynomial degree 1–11) হাতে-কলমে — bias²/variance/total-error U-curve, overfit/underfit ছবি, generalization-gap ও VC-shattering — চিত্র 6-1-bias-variance-tradeoff, 6-1-overfit-underfit, 6-1-generalization-gap, 6-1-vc-shattering ও Python-কোড সহ।
এক বাক্যে কেন এটি Part VI-এর সূচনা-অধ্যায়। 5.2 ও 5.8 আমাদের bias–variance ও cross-validation-এর ব্যবহারিক রূপ দিয়েছিল — "কীভাবে করতে হয়" — কিন্তু "কেন তা কাজ করে" তার প্রমাণ দেয়নি; এই অধ্যায় সেই applied অন্তর্দৃষ্টিকে একটা তাত্ত্বিক ভিত্তি (risk, capacity, generalization bound) দেয়, যার উপর দাঁড়িয়ে পরের অধ্যায় 6.2 (regularization) দেখাবে কীভাবে capacity-কে সচেতনভাবে নিয়ন্ত্রণ করে generalization gap ছোট রাখা যায়।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "ধরা-data-র ভুল আর প্রকৃত ভুল আলাদা, আর তাদের ফাঁকই গল্প" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ প্রমাণ লাগবে (bias–variance decomposition, Hoeffding+union থেকে generalization bound, VC bound), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
২.১ Statistical learning setup — \(P\), \(\ell\), \(\mathcal H\)¶
প্রথমে মঞ্চটা থিতু করি — machine learning-কে পরিসংখ্যানের ভাষায় বসানোর জন্য ঠিক তিনটে উপাদান লাগে।
(১) একটি data-উৎস: joint (যৌথ) distribution \(P\). আমরা ধরি, প্রতিটি পর্যবেক্ষণ একটা জোড়া — একটা input (predictor/feature, পূর্বানুমানক) \(x\) এবং তার সঙ্গে একটা output (response/label, সাড়া/লেবেল) \(y\) — এবং এই জোড়াগুলো একটা স্থির কিন্তু অজানা যৌথ probability distribution \(P\) থেকে স্বাধীনভাবে আঁকা হয়। প্রতীকে: $$ (x_i, y_i) \overset{iid}{\sim} P, \qquad i = 1, 2, \dots, n, $$ যেখানে —
- \(x_i\) — \(i\)-তম পর্যবেক্ষণের input (একটি সংখ্যা, বা সংখ্যার vector — feature-গুলোর সমষ্টি);
- \(y_i\) — তার output (regression-এ একটা বাস্তব সংখ্যা, classification-এ একটা শ্রেণি-লেবেল যেমন \(\{0,1\}\));
- \(P\) — \((x,y)\)-জোড়ার অজানা যৌথ distribution (data কোথা থেকে "আসে" তার সম্পূর্ণ বিবরণ);
- "\(\overset{iid}{\sim}\)" — independent and identically distributed (স্বাধীন ও অভিন্নবণ্টিত): প্রতিটি জোড়া একই \(P\) থেকে, এবং একে অপরের থেকে স্বাধীনভাবে, আঁকা। এই iid-অনুমানই গোটা তত্ত্বের ভিত্তি-প্রস্তর — এটা না থাকলে "অতীত থেকে ভবিষ্যৎ শেখা" অর্থহীন।
লক্ষ করুন, \(P\)-কে আমরা কখনো দেখি না; কেবল তার থেকে আঁকা \(n\)টি নমুনা দেখি। গোটা চ্যালেঞ্জ এই অজানা \(P\) সম্পর্কে নমুনা থেকে কিছু শেখা।
(২) একটি ভুলের মাপ: loss function \(\ell\). একটা prediction কতটা খারাপ, তা মাপতে আমাদের একটা loss function (ক্ষতি-অপেক্ষক) চাই — \(\ell(\hat y, y)\), যা একটা predicted output \(\hat y\) ও আসল output \(y\) নিয়ে একটা অঋণাত্মক সংখ্যা (ভুলের "দাম") ফেরত দেয়। নিখুঁত prediction-এ (\(\hat y = y\)) loss সাধারণত \(0\); যত দূরে, তত বড়। দুটো চেনা উদাহরণ গোটা অধ্যায়ে ফিরবে:
- Squared loss (বর্গ-ক্ষতি, regression-এর জন্য): \(\ell(\hat y, y) = (\hat y - y)^2\) — ভুলের বর্গ; বড় ভুলকে কঠোরভাবে শাস্তি দেয় (4.4/5.8-এর MSE-র মূল উপাদান)।
- 0-1 loss (শূন্য-এক ক্ষতি, classification-এর জন্য): \(\ell(\hat y, y) = \mathbf 1\{\hat y \ne y\}\) — ভুল শ্রেণি হলে \(1\), ঠিক হলে \(0\); এখানে \(\mathbf 1\{\cdot\}\) হলো indicator (সূচক) — শর্ত সত্য হলে \(1\), নয়তো \(0\)। অর্থাৎ এটা স্রেফ "ভুল করার হার" গোনে।
(৩) প্রার্থী-সমাধানের সংগ্রহ: hypothesis class \(\mathcal H\). শেষে, আমরা যেসব সম্ভাব্য prediction-নিয়মের মধ্যে থেকে বাছব, তাদের সংগ্রহ। একটা hypothesis (প্রকল্প/অনুমান) হলো একটা function \(h\) যা একটা input \(x\) নিয়ে একটা prediction \(h(x)\) ফেরত দেয়। এই সব প্রার্থী-function-এর সংগ্রহকে বলি hypothesis class \(\mathcal H\) (প্রকল্প-শ্রেণি): $$ h \in \mathcal H, \qquad h: x \mapsto h(x). $$ যেমন §১-এর উদাহরণে \(\mathcal H\) হতে পারে "সব degree-\(d\) polynomial-এর সংগ্রহ" (প্রতিটি \(d\) একটা আলাদা, বড় বা ছোট, \(\mathcal H\) দেয়); বা "2D-তে সব সরলরেখা-শ্রেণিকারক (linear classifier)"। গুরুত্বপূর্ণ: আমরা \(\mathcal H\)-র ভেতর থেকেই কেবল বাছতে পারি — \(\mathcal H\) যদি সত্যিকারের প্যাটার্ন ধরার মতো যথেষ্ট সমৃদ্ধ না হয়, তবে কোনো learner-ই ভালো করবে না (এটাই পরে bias-এর উৎস); আবার \(\mathcal H\) অতি-সমৃদ্ধ হলে overfitting-এর ঝুঁকি (variance-এর উৎস)। এই \(\mathcal H\)-এর "আকার/সমৃদ্ধি"-ই তার capacity — §২.৭-এর কেন্দ্রীয় বিষয়।
এক বাক্যে setup। Learning মানে — একটা অজানা distribution \(P\) থেকে আসা \(n\)টি \((x,y)\)-নমুনা দেখে, একটা loss \(\ell\)-এর নিরিখে, একটা hypothesis class \(\mathcal H\)-এর ভেতর থেকে এমন একটা \(h\) বাছা যা ভবিষ্যতের \(P\)-নমুনায় গড়ে কম ভুল করে।
২.২ True risk \(R(h)\) — যা আমরা সত্যিই ছোট করতে চাই¶
§১.৩-এর "প্রকৃত ভুল"-কে এবার আনুষ্ঠানিক করি। একটা নির্দিষ্ট hypothesis \(h\)-এর true risk (বা expected risk, প্রকৃত/প্রত্যাশিত ঝুঁকি) হলো — distribution \(P\) থেকে আঁকা একটা random (এলোমেলো) জোড়া \((x,y)\)-তে \(h\)-এর গড় loss: $$ \boxed{\ R(h) \;=\; \mathbb E_{(x,y)\sim P}\big[\ell(h(x), y)\big]\ } $$ প্রতীকগুলো খুলি:
- \(R(h)\) — hypothesis \(h\)-এর true risk (একটি একক সংখ্যা — \(h\) যত ভালো, তত ছোট);
- \(\mathbb E_{(x,y)\sim P}[\cdot]\) — expectation (প্রত্যাশা/গড়), যেখানে গড় নেওয়া হচ্ছে পুরো distribution \(P\)-র উপর — অর্থাৎ সব সম্ভাব্য ভবিষ্যৎ \((x,y)\)-জোড়ার উপর, তাদের সম্ভাবনা-ভার দিয়ে;
- \(\ell(h(x), y)\) — input \(x\)-তে \(h\)-এর prediction \(h(x)\) ও আসল \(y\)-এর মধ্যে loss।
স্বজ্ঞা: \(R(h)\) হলো "যদি \(h\)-কে অসীম-সংখ্যক নতুন, \(P\) থেকে আঁকা বিন্দুতে চালাতাম, তবে গড়ে কত ভুল করত" — অর্থাৎ \(h\)-এর আসল, জনসংখ্যা-স্তরের পারফরম্যান্স। এটাই machine learning-এর প্রকৃত লক্ষ্য: আমরা চাই সেই \(h\) যার \(R(h)\) ক্ষুদ্রতম। (regression-এ squared loss নিলে \(R(h)=\mathbb E[(h(x)-y)^2]\) — এটাই 5.8-এর "test/generalization error \(\text{Err}\)"-এর সাধারণ রূপ।)
সমস্যা — \(R(h)\) আমরা গণনা করতে পারি না। কারণ স্পষ্ট: \(\mathbb E_{(x,y)\sim P}\) গণনা করতে গোটা \(P\) জানা লাগে, কিন্তু \(P\) অজানা — আমাদের কাছে কেবল \(n\)টি নমুনা আছে। তাই \(R(h)\) একটা আদর্শ লক্ষ্য, কিন্তু সরাসরি-অপ্রাপ্য। এর একটা মাপযোগ্য বিকল্প চাই — পরের সংজ্ঞা।
২.৩ Empirical risk \(\hat R_n(h)\) — যা আমরা সত্যিই মাপতে পারি¶
যেহেতু \(P\) অজানা কিন্তু \(n\)টি নমুনা হাতে আছে, একটা স্বাভাবিক কৌশল: \(P\)-র উপর গড়ের বদলে হাতের নমুনার উপর গড় নিই। একটা hypothesis \(h\)-এর empirical risk (ধরা-নমুনার ঝুঁকি, বা training error) হলো হাতের \(n\)টি বিন্দুতে তার গড় loss: $$ \boxed{\ \hat R_n(h) \;=\; \frac{1}{n}\sum_{i=1}^{n} \ell\big(h(x_i), y_i\big)\ } $$ প্রতীকগুলো খুলি:
- \(\hat R_n(h)\) — \(n\)টি নমুনার ভিত্তিতে \(h\)-এর empirical risk; এর "টুপি" (\(\,\hat{}\,\)) মনে করায় এটা একটা estimate (data থেকে আঁকা, তাই random), আর সাবস্ক্রিপ্ট \(n\) মনে করায় এটা নমুনা-আকারের উপর নির্ভর করে;
- \(\frac1n\sum_{i=1}^n\) — হাতের \(n\)টি বিন্দুর উপর সাধারণ গড়;
- \(\ell(h(x_i), y_i)\) — \(i\)-তম নমুনা-বিন্দুতে loss (\(P\)-র উপর গড় নয়, বাস্তব data-বিন্দুতে)।
\(R(h)\) ও \(\hat R_n(h)\)-এর সম্পর্কটাই গোটা তত্ত্বের সেতু, এবং তা সরাসরি 3.3-এর Law of Large Numbers থেকে আসে: প্রতিটি \(\ell(h(x_i),y_i)\) হলো একটা random variable যার expectation ঠিক \(R(h)\) (কারণ \((x_i,y_i)\sim P\))। তাই \(n\)টি এমন variable-এর গড় \(\hat R_n(h)\) হলো \(R(h)\)-এর একটা unbiased estimator, এবং LLN অনুযায়ী \(n\to\infty\)-তে \(\hat R_n(h)\xrightarrow{P}R(h)\)। অর্থাৎ —
এক বাক্যে সেতু। একটা নির্দিষ্ট, আগেভাগে-বাছা \(h\)-এর জন্য empirical risk হলো true risk-এর একটা unbiased ও consistent estimate — তাই বড় নমুনায় \(\hat R_n(h)\approx R(h)\)।
কিন্তু এখানেই একটা সূক্ষ্ম ফাঁদ লুকিয়ে, যা §২.৫-এ generalization gap-এর গোটা গল্প খুলবে: উপরের নিশ্চয়তা কেবল একটা স্থির \(h\)-এর জন্য, যা data দেখার আগে বাছা। কিন্তু learning-এ আমরা \(h\)-কে বাছি data দেখে — তখন \(h\) আর data-নিরপেক্ষ থাকে না, আর এই সরল LLN-যুক্তি ভেঙে পড়ে।
২.৪ ERM — empirical risk minimization¶
এখন learning-এর নিয়মটা precise করি। যেহেতু আমরা \(R(h)\) মাপতে পারি না কিন্তু \(\hat R_n(h)\) পারি, সবচেয়ে স্বাভাবিক কৌশল: \(\mathcal H\)-এর ভেতরে যে \(h\) empirical risk সবচেয়ে কম করে, সেটাই বেছে নাও। একে বলে empirical risk minimization (ERM) (ধরা-ঝুঁকি ন্যূনকরণ): $$ \boxed{\ \hat h \;=\; \arg\min_{h \in \mathcal H} \hat R_n(h)\ } $$ প্রতীকগুলো খুলি:
- \(\hat h\) — ERM-এর বাছাই করা hypothesis (data থেকে আঁকা, তাই random — নমুনা বদলালে \(\hat h\)-ও বদলায়); এর টুপি মনে করায় এটা একটা data-নির্ভর estimate;
- \(\arg\min_{h\in\mathcal H}\) — "\(\mathcal H\)-এর যে \(h\) পরের রাশিকে সর্বনিম্ন করে, সেই \(h\)-টা" (ন্যূনতম মান নয়, ন্যূনতম-আনয়নকারী \(h\));
- \(\hat R_n(h)\) — সেই \(h\)-এর empirical risk।
ERM আসলে আমাদের চেনা অনেক পদ্ধতিরই সাধারণ নাম: squared loss + linear \(\mathcal H\) নিলে ERM ঠিক 5.1-এর OLS (least-squares regression); 0-1 বা surrogate loss নিলে এটা classification-শেখা। অর্থাৎ "data-তে best-fit model খোঁজা" মানেই empirical risk minimize করা।
ERM-এর গোড়ার টানাপড়েন। ERM সরাসরি \(\hat R_n\) ছোট করে — কিন্তু আমরা তো চাই \(R(\hat h)\) ছোট হোক। \(\mathcal H\) যত বড়/সমৃদ্ধ, ERM তত ছোট \(\hat R_n(\hat h)\) অর্জন করতে পারে (§১.২-এর \(d=11\) — empirical risk ≈ ০)। কিন্তু তাতে \(R(\hat h)\) ছোট হয় না — উল্টো বাড়তে পারে, কারণ ERM তখন noise-ও মুখস্থ করছে। এই "\(\hat R_n\) ছোট করলেই \(R\) ছোট হয় না" — এই ফাঁকটাই পরের সংজ্ঞা।
২.৫ Generalization gap — গল্পের কেন্দ্র¶
এবার গোটা অধ্যায়ের কেন্দ্রীয় পরিমাণ। ERM-এর বাছা \(\hat h\)-এর generalization gap (সাধারণীকরণ-ফাঁক) হলো তার প্রকৃত ও ধরা-ঝুঁকির পার্থক্য: $$ \boxed{\ \text{generalization gap} \;=\; R(\hat h) - \hat R_n(\hat h)\ } $$ যেখানে \(R(\hat h)\) হলো বাছা hypothesis-এর true risk (নতুন data-তে আসল ভুল) ও \(\hat R_n(\hat h)\) তার empirical risk (training data-তে দেখা ভুল)। এই ফাঁক বলে দেয় — training error আমাদের কতটা প্রতারিত করছে: ফাঁক ছোট হলে \(\hat R_n(\hat h)\) true performance-এর বিশ্বাসযোগ্য সূচক; ফাঁক বড় হলে training error একটা মরীচিকা (model মুখস্থ করেছে)। 5.8-এর "optimism of training error" ঠিক এই (গড়) ফাঁকেরই আরেক নাম।
কেন এই ফাঁক \(\mathcal H\)-এর capacity-র উপর নির্ভর করে — গল্পের মোক্ষম মোড়। §২.৩-এ দেখেছি, একটা স্থির \(h\)-এর জন্য LLN নিশ্চিত করে \(\hat R_n(h)\approx R(h)\) (ফাঁক ছোট)। তাহলে সমস্যা কোথায়? সমস্যা হলো — \(\hat h\) স্থির নয়, data-নির্ভর: ERM ইচ্ছে করে \(\mathcal H\)-এর মধ্যে সেই \(h\) বেছে নেয় যেটা এই বিশেষ নমুনায় সবচেয়ে ভাগ্যবান-ভাবে ভালো দেখায়। \(\mathcal H\) যত বড়, এমন "নমুনার noise-কেও কাজে লাগিয়ে ছোট \(\hat R_n\) পাওয়া" hypothesis তত বেশি থাকে, আর ERM তেমন একটাকেই তুলে আনে। ফলে \(\hat R_n(\hat h)\) পদ্ধতিগতভাবে \(R(\hat h)\)-এর চেয়ে আশাবাদীভাবে ছোট হয় — ফাঁক বড় হয়।
এই insight (অন্তর্দৃষ্টি) সারাংশে: ফাঁক নিয়ন্ত্রণ করতে হলে শুধু একটা \(h\)-এর জন্য নয়, \(\mathcal H\)-এর সব \(h\)-এর জন্য একসাথে \(\hat R_n(h)\approx R(h)\) নিশ্চিত করা চাই (একে বলে uniform convergence) — আর সেই "সব \(h\)"-এর সংখ্যা/সমৃদ্ধি, অর্থাৎ \(\mathcal H\)-এর capacity, যত বড়, ফাঁকের bound তত বড়। এটাই §২.৮-এর generalization bound-এর হৃৎপিণ্ড, এবং এক লাইনে এই অধ্যায়ের মূল সমীকরণ: $$ \underbrace{R(\hat h)}{\text{যা চাই, কম হোক}} \;\le\; \underbrace{\hat R_n(\hat h)}. $$}} \;+\; \underbrace{(\text{capacity ও } n\text{-নির্ভর penalty})}_{\text{generalization gap-এর bound}
এক বাক্যে generalization gap। Learning সফল হয় তখনই যখন এই ফাঁক ছোট থাকে — আর ফাঁক ছোট থাকে যখন নমুনা বড় (\(n\)↑) এবং hypothesis class-এর capacity সংযত; capacity বেড়ে গেলে ERM training-noise মুখস্থ করে ফাঁক বাড়িয়ে দেয় (= overfitting)।
২.৬ Bias–variance decomposition — মোট ভুলকে তিন টুকরোয় ভাঙা¶
generalization gap আমাদের বলে empirical ও true risk-এর পার্থক্য কোথা থেকে আসে; bias–variance decomposition একটা ভিন্ন কিন্তু পরিপূরক কোণ থেকে দেখায় — true (prediction) risk নিজে কোন কোন উৎস থেকে গড়ে ওঠে। এটি সরাসরি 4.4-এর \(\mathrm{MSE}=\mathrm{bias}^2+\mathrm{variance}\)-এর estimator→prediction generalization (সাধারণীকরণ)।
প্রেক্ষাপট: ধরা যাক regression, squared loss, এবং data আসে \(y = f(x) + \varepsilon\) থেকে, যেখানে —
- \(f(x)\) — সত্যিকারের, অজানা regression function (যেমন simulation-এ \(f(x)=\sin(2\pi x)\));
- \(\varepsilon\) — গড়-শূন্য random noise, \(\mathbb E[\varepsilon]=0\) ও \(\operatorname{Var}(\varepsilon)=\sigma^2\);
- \(\sigma^2\) — irreducible noise-এর variance (ভেদ) — অপসারণ-অযোগ্য গোলমাল, \(x\)-এর সঙ্গে কোনো সম্পর্কহীন এলোমেলোতা, যা কোনো model-ই কখনো ব্যাখ্যা করতে পারে না।
একটা নির্দিষ্ট input-বিন্দু \(x\) ধরে, training data থেকে শেখা predictor \(\hat f\) (যা random, কারণ training-নমুনা random — এই randomness-এর উপরই নিচের \(\mathbb E[\cdot]\)) সেই বিন্দুতে কত ভুল করবে তার প্রত্যাশিত বর্গ-ভুল ভাঙে তিন টুকরোয়: $$ \boxed{\ \mathbb E\big[(\hat f(x) - f(x))^2\big] \;=\; \underbrace{\big(\mathbb E[\hat f(x)] - f(x)\big)^2}{\mathrm{Bias}^2} \;+\; \underbrace{\operatorname{Var}\big(\hat f(x)\big)} $$ প্রতিটি পদের অর্থ — এক-এক করে, স্বজ্ঞাসহ:}} \;+\; \underbrace{\sigma^2}_{\text{irreducible}}\
- \(\mathrm{Bias}^2 = \big(\mathbb E[\hat f(x)] - f(x)\big)^2\) — পদ্ধতিগত ভুল, বর্গাকারে। এখানে \(\mathbb E[\hat f(x)]\) হলো "অসংখ্য আলাদা training-নমুনায় শেখা \(\hat f\)-গুলোর গড় prediction" \(x\)-বিন্দুতে; bias মাপে সেই গড় prediction সত্য \(f(x)\) থেকে কতটা সরে। বড় bias মানে \(\mathcal H\) গঠনগতভাবেই \(f\) ধরতে অক্ষম (যেমন sine-কে সরলরেখা দিয়ে ধরা) — এটা underfitting-এর স্বাক্ষর।
- \(\mathrm{Var} = \operatorname{Var}(\hat f(x))\) — এলোমেলো অস্থিরতা। মাপে: training-নমুনা বদলালে \(\hat f(x)\) তার নিজের গড়ের চারপাশে কতটা ওঠানামা করে। বড় variance মানে model নমুনার খুঁটিনাটি/noise-এর প্রতি অতি-সংবেদনশীল — এটা overfitting-এর স্বাক্ষর।
- \(\sigma^2\) — irreducible অংশ; এটি \(\hat f\)-এর উপর নির্ভর করে না, কোনো model-ই একে কমাতে পারে না। সেরা সম্ভাব্য predictor-এও মোট ভুল \(\sigma^2\)-এর নিচে নামবে না — এটাই error-এর "মেঝে" (noise floor)।
Complexity বাড়লে এই তিন পদ কীভাবে বদলায় — U-curve-এর জন্ম। এখানেই tradeoff-এর সারমর্ম, এবং §৫-এর simulation এটাকেই সংখ্যায় দেখাবে:
- model-complexity (যেমন polynomial degree \(d\)) বাড়ালে \(\mathcal H\) সমৃদ্ধ হয়, তাই গড় prediction সত্য \(f\)-এর কাছে যায় → \(\mathrm{Bias}^2\) কমে।
- কিন্তু একই সঙ্গে model নমুনার noise অনুসরণ করার ক্ষমতা পায়, তাই নমুনা-থেকে-নমুনায় বেশি নড়ে → \(\mathrm{Var}\) বাড়ে।
- \(\sigma^2\) স্থির থাকে।
যেহেতু একটা পদ কমে আর অন্যটা বাড়ে, তাদের যোগফল — মোট প্রত্যাশিত ভুল — সাধারণত একটা U-আকৃতি নেয়: বাঁদিকে (কম complexity) bias-প্রধান, উঁচু error (underfit); ডানদিকে (বেশি complexity) variance-প্রধান, আবার উঁচু error (overfit); আর মাঝখানে কোথাও — সেই সেরা complexity — যেখানে যোগফল সর্বনিম্ন। এই U-curve-এর তলদেশই model-নির্বাচনের আদর্শ লক্ষ্য, আর 5.8-এর cross-validation ঠিক এই তলদেশটাই data থেকে খুঁজে বের করার একটা ব্যবহারিক উপায়।
এক বাক্যে decomposition। প্রত্যাশিত prediction-ভুল = \(\mathrm{Bias}^2\) (model-টা ভুল আকৃতির, underfit) + \(\mathrm{Var}\) (model নমুনা-noise-এ অতি-সংবেদনশীল, overfit) + \(\sigma^2\) (অপসারণ-অযোগ্য noise); complexity বাড়লে প্রথমটা কমে, দ্বিতীয়টা বাড়ে — তাই সেরা model এই দুইয়ের ভারসাম্যে, U-curve-এর তলদেশে (পূর্ণ প্রমাণ §৪)। চিত্র 6-1-bias-variance-tradeoff এই U-curve, ও 6-1-overfit-underfit এর দুই প্রান্তের fitted curve দেখাবে।
২.৭ Underfit, overfit, capacity — এবং তা মাপার যন্ত্র: PAC ও VC dimension¶
bias–variance decomposition থেকে overfitting ও underfitting-এর precise অর্থ এখন দাঁড়িয়ে যায়:
- Underfitting (অবমিতকরণ): model এত সরল যে সে সত্যিকারের প্যাটার্নই ধরতে পারে না — উঁচু bias, নিচু variance; training ও test দুই error-ই উঁচু। (§১.২-এর \(d=1\)।)
- Overfitting (অতিমিতকরণ): model এত নমনীয় যে সে noise-ও মুখস্থ করে — নিচু bias, উঁচু variance; training error খুব নিচু কিন্তু test error উঁচু (বড় generalization gap)। (§১.২-এর \(d=11\)।)
এই দুইয়ের মূলে একটাই অক্ষ — model-টা কতটা "নমনীয়/সমৃদ্ধ", অর্থাৎ \(\mathcal H\) কত বিচিত্র function ধরতে পারে। একে বলি capacity (ধারণক্ষমতা) বা complexity (জটিলতা)। এতক্ষণ "capacity" ছিল একটা স্বজ্ঞাগত শব্দ ("degree বাড়ালে capacity বাড়ে") — কিন্তু একটা rigorous তত্ত্বের জন্য একে সংখ্যায় মাপা চাই। সেই মাপের ভাষা ও যন্ত্র এই উপবিভাগের বিষয়।
PAC learning — "শেখা সফল" বলতে ঠিক কী বোঝায়। Capacity-কে generalization-এর সঙ্গে বাঁধার আগে দরকার "সফলভাবে শেখা"-র একটা formal সংজ্ঞা, কারণ data random — কোনো learner-ই নিশ্চিতভাবে ঠিক শিখবে, এমন দাবি করা যায় না (দুর্ভাগ্যজনক নমুনা সবসময়ই সম্ভব)। এর সমাধান PAC learning (Probably Approximately Correct — "সম্ভবত, প্রায়-সঠিক")-এর কাঠামো, যা দুটো ছাড় একসাথে দেয়:
- Approximately correct (প্রায়-সঠিক): আমরা নিখুঁত \(h\) দাবি করি না; চাই \(R(\hat h)\) সম্ভাব্য সেরা থেকে একটা ছোট \(\varepsilon\)-এর (accuracy-সহনশীলতা) মধ্যে থাকুক।
- Probably (সম্ভবত): এই "প্রায়-সঠিক" শর্ত আমরা প্রতিবার নয়, বরং অন্তত \(1-\delta\) probability-তে দাবি করি — যেখানে \(\delta\) ছোট (confidence-সহনশীলতা, যেমন \(\delta=0.05\))। বাকি \(\delta\) অংশ "দুর্ভাগ্যজনক নমুনা"-র জন্য ছেড়ে রাখা।
স্বজ্ঞায়: একটা learning সমস্যাকে "PAC-শেখা যায়" বলি যদি যথেষ্ট (কিন্তু সসীম) নমুনা \(n\) দিয়ে, যেকোনো চাওয়া \((\varepsilon, \delta)\)-র জন্য, learner উচ্চ probability-তে একটা প্রায়-সঠিক \(h\) ফেরত দিতে পারে। এই \((\varepsilon,\delta)\)-ভাষাই §২.৮-এর generalization bound-কে অর্থ দেবে ("\(1-\delta\) probability-তে \(R(h)\le\hat R_n(h)+\varepsilon\)")।
VC dimension — capacity-র সংখ্যামাপ। এখন মূল প্রশ্ন: \(\mathcal H\)-এর capacity-কে একটা সংখ্যায় কীভাবে ধরি? সবচেয়ে গভীর ও বিখ্যাত উত্তর — Vapnik–Chervonenkis dimension (\(d_{\mathrm{VC}}\), ভিসি-মাত্রা)। এর ভিত্তি একটা ধারণা — shattering (চূর্ণন/সম্পূর্ণ-পৃথকীকরণ):
একগুচ্ছ বিন্দুকে hypothesis class \(\mathcal H\) shatter করে যদি — সেই বিন্দুগুলোতে output-লেবেল (\(0/1\)) যেভাবেই বসানো হোক না কেন (সব সম্ভাব্য লেবেল-বিন্যাসের জন্য), \(\mathcal H\)-এর ভেতরে এমন একটা \(h\) থাকে যা ঠিক সেই বিন্যাসটা নির্ভুলভাবে আলাদা করতে পারে।
অর্থাৎ shatter করতে পারা মানে — ওই বিন্দুগুচ্ছের উপর \(\mathcal H\) সব রকম \(0/1\)-প্যাটার্ন বানাতে সক্ষম, কোনোটাই তার নাগালের বাইরে নয়। এবার সংজ্ঞা: $$ d_{\mathrm{VC}}(\mathcal H) \;=\; \text{যত বেশি সংখ্যক বিন্দু } \mathcal H \text{ shatter করতে পারে, তার সর্বোচ্চ মান।} $$ (\(d_{\mathrm{VC}}\) হলো একটা একক সংখ্যা — \(\mathcal H\) কত "সমৃদ্ধ" তার মাপ; বড় \(d_{\mathrm{VC}}\) = বেশি capacity = বেশি overfitting-ঝুঁকি।)
আদর্শ উদাহরণ — 2D-তে linear classifier-এর \(d_{\mathrm{VC}}=3\). ধরা যাক \(\mathcal H\) = সমতলে সব সরলরেখা-শ্রেণিকারক (একটা সরলরেখা টেনে এক পাশকে "\(+\)", অন্য পাশকে "\(-\)" বলা)।
- ৩টি বিন্দু (একরেখায় নয়): এদের \(2^3 = 8\) রকম \(+/-\)-লেবেল-বিন্যাসের প্রতিটির জন্যই একটা সরলরেখা টেনে দুই শ্রেণি আলাদা করা যায় — তাই ৩টি বিন্দু shatter হয়।
- ৪টি বিন্দু: এমন লেবেল-বিন্যাস (যেমন "কোণাকুণি দুটো \(+\), বাকি দুটো \(-\)" — XOR-প্যাটার্ন) আছে যা কোনো একক সরলরেখা আলাদা করতে পারে না — তাই ৪টি বিন্দু shatter হয় না।
সুতরাং সমতলে linear classifier সর্বোচ্চ ৩টি বিন্দু shatter করতে পারে, অর্থাৎ \(d_{\mathrm{VC}}=3\)। (সাধারণভাবে, \(\mathbb R^p\)-তে linear classifier-এর \(d_{\mathrm{VC}}=p+1\)।) এই shattering-এর ছবি — ৩টি বিন্দুর সব বিন্যাস আলাদা হচ্ছে, কিন্তু ৪টির XOR পারছে না — দেখাবে চিত্র 6-1-vc-shattering।
এক বাক্যে capacity। Underfit/overfit-এর মূল অক্ষ হলো \(\mathcal H\)-এর capacity; PAC learning "\((\varepsilon,\delta)\)-তে সফলভাবে শেখা" মানে কী তা সংজ্ঞায়িত করে, আর VC dimension \(d_{\mathrm{VC}}\) (সর্বোচ্চ কত বিন্দু \(\mathcal H\) shatter করতে পারে) সেই capacity-কে একটা সংখ্যায় ধরে — যা পরের generalization bound-এ সরাসরি ঢুকবে।
২.৮ Generalization bound — empirical risk-কে কতটা বিশ্বাস করা যায়¶
এবার সব সুতো একত্র করি। আমরা চাই একটা অসমতা যা ছোট, মাপা \(\hat R_n(h)\)-কে বড়, অজানা \(R(h)\)-এর সঙ্গে বাঁধবে — এবং দেখাবে generalization gap কীভাবে \(n\) ও capacity-র উপর নির্ভর করে। এমন অসমতাকে বলে generalization bound (সাধারণীকরণ-সীমা)। এর সাধারণ রূপ: $$ \boxed{\ R(h) \;\le\; \hat R_n(h) \;+\; \underbrace{\sqrt{\frac{\text{(capacity term)} \;+\; \log(1/\delta)}{2n}}}_{\text{complexity penalty}}\ } $$ এই অসমতা অন্তত \(1-\delta\) probability-তে \(\mathcal H\)-এর সব \(h\)-এর জন্য একসাথে সত্য। প্রতিটি অংশের পাঠ:
- বাঁ পাশ \(R(h)\) — যা আমরা সত্যিই ছোট চাই (true risk), কিন্তু মাপতে পারি না;
- \(\hat R_n(h)\) — যা আমরা মাপি (empirical risk);
- complexity penalty — generalization gap-এর একটা উপরের সীমা; এর তিনটে গুণ লক্ষণীয়: (i) capacity বাড়লে penalty বাড়ে (বেশি সমৃদ্ধ \(\mathcal H\) = বেশি overfitting-ঝুঁকি); (ii) \(n\) বাড়লে penalty কমে (\(\sqrt{1/n}\)-হারে — বেশি data = বেশি বিশ্বাস); (iii) \(\delta\) ছোট চাইলে (বেশি নিশ্চয়তা) penalty সামান্য বাড়ে (\(\log(1/\delta)\)-র মাধ্যমে);
- \(\delta\) — bound ব্যর্থ হওয়ার সর্বোচ্চ probability (যেমন \(\delta=0.05\) মানে bound অন্তত ৯৫% নিশ্চয়তায় সত্য) — এটাই §২.৭-এর PAC-ভাষার "probably"।
কোথা থেকে আসে — দুই ধাপের গল্প (পূর্ণ প্রমাণ §৪)।
- ধাপ ১ — একটা \(h\)-এর জন্য (Hoeffding)। ধরা যাক loss \([0,1]\)-এ bounded (যেমন 0-1 loss)। একটা স্থির \(h\)-এর জন্য, \(\hat R_n(h)\) হলো \(n\)টি bounded স্বাধীন loss-এর গড়, যার expectation \(R(h)\)। তাই 3.1-এর Hoeffding inequality সরাসরি বলে — এই গড় তার expectation থেকে \(\varepsilon\)-এর বেশি দূরে যাওয়ার probability exponentially ছোট: $$ P\big(\lvert \hat R_n(h) - R(h) \rvert \ge \varepsilon\big) \;\le\; 2\exp(-2n\varepsilon^2). $$ এই থেকেই একটা \(h\)-এর জন্য \(\sqrt{\log(1/\delta)/(2n)}\)-আকৃতির gap-bound বেরোয়।
- ধাপ ২ — সব \(h\)-এর জন্য একসাথে (union bound)। কিন্তু ERM data দেখে \(h\) বাছে, তাই (§২.৫) দরকার সব \(h\)-এর জন্য একসাথে নিশ্চয়তা। finite hypothesis class (\(\lvert\mathcal H\rvert\)টি hypothesis) ধরে, union bound ("একাধিক bad-event-এর কোনোটা ঘটার probability ≤ আলাদা আলাদা probability-র যোগফল") প্রয়োগ করলে penalty-তে যোগ হয় একটা \(\log\lvert\mathcal H\rvert\) পদ — এটাই finite-\(\mathcal H\)-এর "capacity term": $$ R(h) \;\le\; \hat R_n(h) + \sqrt{\frac{\log\lvert\mathcal H\rvert + \log(1/\delta)}{2n}} \quad \text{(সব } h\in\mathcal H\text{-এর জন্য, } 1-\delta\text{ probability-তে)}. $$
Finite থেকে infinite — VC bound। উপরের সীমা ভেঙে পড়ে যখন \(\mathcal H\) অসীম (\(\lvert\mathcal H\rvert=\infty\), যেমন সব সরলরেখা) — তখন \(\log\lvert\mathcal H\rvert\) অর্থহীন। এখানেই §২.৭-এর \(d_{\mathrm{VC}}\) উদ্ধারে আসে: VC-তত্ত্বের গভীর ফল বলে, generalization-এর জন্য যা আসলে গোনা দরকার তা \(\mathcal H\)-এর আকার নয়, তার কার্যকর capacity \(d_{\mathrm{VC}}\) — এবং \(\log\lvert\mathcal H\rvert\)-এর জায়গায় বসে মোটামুটি \(d_{\mathrm{VC}}\log(n/d_{\mathrm{VC}})\)-জাতীয় একটা পদ: $$ R(h) \;\le\; \hat R_n(h) + \sqrt{\frac{d_{\mathrm{VC}}\,\big(\log(2n/d_{\mathrm{VC}}) + 1\big) + \log(4/\delta)}{n}} \quad (\text{VC generalization bound}). $$ মূল বার্তা একই — gap-এর bound capacity (\(d_{\mathrm{VC}}\))-র সঙ্গে বাড়ে, \(n\)-এর সঙ্গে \(\sim\!\sqrt{1/n}\) হারে কমে। চিত্র 6-1-generalization-gap দেখাবে কীভাবে এই bound (ও বাস্তব gap) \(n\) বাড়লে সংকুচিত হয়।
এক বাক্যে generalization bound। Hoeffding একটা স্থির \(h\)-এর জন্য gap-কে exponentially ছোট রাখে; union bound (finite \(\mathcal H\)) বা VC dimension (infinite \(\mathcal H\)) সেটাকে সব \(h\)-এর জন্য একসাথে টেনে আনে — ফল: \(R(h)\le\hat R_n(h)+\sqrt{(\text{capacity}+\log(1/\delta))/n}\), অর্থাৎ বেশি data ও সংযত capacity = ছোট ফাঁক = বিশ্বাসযোগ্য learning।
২.৯ No-free-lunch theorem — এক বাক্যে¶
শেষ একটা সংযমের সুর, যা পুরো তত্ত্বকে ভারসাম্যে রাখে। No-free-lunch theorem (বিনামূল্যে-দুপুরভোজ-নেই উপপাদ্য) এক বাক্যে বলে: সব সম্ভাব্য data-distribution-এর উপর গড় করলে, কোনো একটি learning algorithm অন্য সবার চেয়ে ভালো নয় — তাই data সম্পর্কে কোনো অনুমান (inductive bias) ছাড়া সর্বজনীনভাবে-সেরা learner বলে কিছু নেই। এর তাৎপর্য: ভালো generalization "বিনামূল্যে" আসে না — তা আসে \(\mathcal H\)-কে সমস্যার সঙ্গে মানানসই করে বাছার (capacity সংযত রাখার) দাম দিয়ে, যা পরের অধ্যায় 6.2 (regularization)-এর সরাসরি প্রেরণা।
৩ · পূর্ণাঙ্গ উদাহরণ¶
আগের অংশে bias–variance decomposition আর generalization-এর তত্ত্ব গড়ে তোলা হয়েছে। এখন সেই তত্ত্বকে একটি concrete, সংখ্যায়-যাচাইযোগ্য পরীক্ষায় নামিয়ে আনা হবে। আমরা একটি ছোট controlled simulation চালাব, যেখানে সত্যিকারের function \(f\) আমাদের জানা — তাই \(\mathrm{Bias}^2\), \(\mathrm{Var}\) আর irreducible noise \(\sigma^2\) প্রতিটি আলাদা করে মেপে দেখা সম্ভব। বাস্তব data-তে এটা কখনোই করা যায় না (কারণ \(f\) অজানা), কিন্তু simulation-এ "ঈশ্বর-দৃষ্টি" থাকায় decomposition-এর প্রতিটি term চোখে দেখা যায়। তারপর আমরা সেই গল্পকে overfitting-এর narrative-এর সঙ্গে জুড়ব (E2), Hoeffding generalization-gap bound হাতে-কলমে হিসাব করব (E3), এবং সব মিলিয়ে practical lesson টেনে আনব (E4)।
৩.১ · Setup: যে পরীক্ষা চালানো হচ্ছে (E1)¶
পরীক্ষার ছক টা পরিষ্কার করে নেওয়া যাক। সত্যিকারের target function হলো একটা sine wave:
প্রতিটি observation-এ এই signal-এর উপর Gaussian noise বসানো হয়:
অর্থাৎ irreducible noise variance হলো \(\sigma^2 = 0.3^2 = 0.09\) — এই floor-টা মনে রাখুন, কারণ কোনো model, যত ভালোই হোক, এর নিচে total error নামাতে পারবে না।
পদ্ধতিটা এরকম। আমরা degree \(d\)-এর polynomial regression fit করি (\(d = 1, 2, 3, 5, 7, 9, 11\))। প্রতিটি \(d\)-এর জন্য:
- \(n_{\text{train}} = 40\) টা training point আঁকা হয় (\(x\) uniformly \([0,1]\) থেকে, \(y\)-তে fresh noise)।
- ওই training set-এ degree-\(d\) polynomial fit করে fitted function \(\hat f\) পাওয়া যায়।
- ধাপ ১–২ মোট \(\text{reps} = 300\) বার পুনরাবৃত্তি করা হয় — প্রতিবার নতুন training set, নতুন noise। ফলে \(\hat f\) একটা random object, আর তার ৩০০টা realization আমাদের হাতে।
- একটা স্থির \(50\)-point test grid \(\{x_j\}\)-এর উপর প্রতিটি grid-point-এ আমরা মাপি:
- \(\mathrm{Bias}^2(x_j) = \bigl(\bar{\hat f}(x_j) - f(x_j)\bigr)^2\), যেখানে \(\bar{\hat f}\) হলো ৩০০টা fit-এর গড় prediction;
- \(\mathrm{Var}(x_j) = \tfrac{1}{300}\sum_{r}\bigl(\hat f_r(x_j) - \bar{\hat f}(x_j)\bigr)^2\)।
- পুরো grid-জুড়ে \(\mathrm{Bias}^2(x_j)\) আর \(\mathrm{Var}(x_j)\)-এর গড় নিই, তারপর
এই \(\text{Total}\) হলো expected test MSE-এর estimate — ঠিক §২-এর decomposition \(\mathbb E[(\hat f(x) - f(x))^2] = \mathrm{Bias}^2 + \mathrm{Var} + \sigma^2\) অনুযায়ী।
Reproducibility note. পুরো simulation seed \(20260619\) দিয়ে চালানো, যাতে ফলাফল bit-for-bit পুনরুৎপাদনযোগ্য হয়। নিচের সংখ্যাগুলো এই canonical run থেকে নেওয়া।
৩.২ · ফলাফল: bias²–variance–total টেবিল (E1)¶
সাতটা degree-এর জন্য decomposition-এর তিনটে term এই টেবিলে:
| degree \(d\) | \(\overline{\mathrm{Bias}^2}\) | \(\overline{\mathrm{Var}}\) | \(\text{Total}\) | চরিত্র |
|---|---|---|---|---|
| \(1\) | \(0.156\) | \(0.015\) | \(0.261\) | underfit — উঁচু bias, নিচু variance |
| \(2\) | \(0.151\) | \(0.025\) | \(0.266\) | এখনও underfit (sine-এর বাঁক ধরতে পারছে না) |
| \(\mathbf{3}\) | \(\mathbf{0.003}\) | \(\mathbf{0.009}\) | \(\mathbf{0.102}\) | sweet spot — total সর্বনিম্ন |
| \(5\) | \(0.000\) | \(0.014\) | \(0.104\) | bias প্রায় শূন্য, variance একটু বাড়ছে |
| \(7\) | \(0.000\) | \(0.061\) | \(0.151\) | variance চড়তে শুরু করল |
| \(9\) | \(0.000\) | \(0.104\) | \(0.194\) | overfit — variance-এ ভুগছে |
| \(11\) | \(0.053\) | \(\mathbf{21.09}\) | \(\mathbf{21.23}\) | catastrophic overfit — variance বিস্ফোরিত |
টেবিলটা তিনটে আলাদা গল্প একসঙ্গে বলে — পড়ে নেওয়া যাক।
(ক) নিচু degree = উঁচু bias, নিচু variance. \(d = 1\)-এ \(\mathrm{Bias}^2 = 0.156\) — সবচেয়ে বড় bias। কেন? একটা straight line দিয়ে আস্ত একটা sine wave approximate করার চেষ্টা; line-টা যত ভালোভাবেই বসুক, কাঠামোগতভাবেই সে \(\sin(2\pi x)\)-এর উপর-নিচ বাঁক ধরতে অক্ষম। এটাই systematic, পুনরাবৃত্ত ভুল — অর্থাৎ bias. বিপরীতে variance ক্ষুদ্র (\(0.015\)): straight line-এর মাত্র দুটো degree of freedom (slope আর intercept), তাই training set বদলালেও fitted line খুব একটা নড়ে না — স্থির কিন্তু স্থিরভাবে ভুল। এটাই underfitting-এর signature: low variance কিন্তু high bias।
(খ) উঁচু degree = নিচু bias, উঁচু variance. \(d \ge 5\)-এ \(\mathrm{Bias}^2\) কার্যত \(0.000\) — এত flexible polynomial যে গড়ে (অনেক fit-এর average নিলে) সে sine-টাকে নিখুঁত ধরে ফেলে। কিন্তু দাম চোকাতে হয় variance-এ: \(d=7\)-এ \(0.061\), \(d=9\)-এ \(0.104\), আর \(d=11\)-এ variance লাফিয়ে \(\mathbf{21.09}\)-এ — দুই অর্ডার অফ ম্যাগনিচিউড বড়! degree-11 polynomial-এর এত স্বাধীনতা যে সে training data-র noise-কেও signal ভেবে চেপে ধরে; এক training set থেকে আরেকটায় গেলে fitted curve বুনো দুলুনিতে দোলে। উঁচু-degree polynomial fitting numerically ill-conditioned-ও বটে, তাই variance-এর এই বিস্ফোরণ আরও তীব্র হয়। এটাই overfitting-এর signature: low bias কিন্তু high (এমনকি catastrophic) variance।
(গ) Total error U-আকৃতির, সর্বনিম্ন degree 3-এ. \(\text{Total}\) column-টা চোখে দেখুন: \(0.261 \to 0.266 \to \mathbf{0.102} \to 0.104 \to 0.151 \to 0.194 \to 21.23\) — নিচে নামে, একটা সর্বনিম্ন ছোঁয়, তারপর আবার উঠে যায়। এই U-curve টাই bias–variance tradeoff-এর সবচেয়ে গুরুত্বপূর্ণ চিত্র। বাঁ পাশে (নিচু \(d\)) bias-এ ভোগে; ডান পাশে (উঁচু \(d\)) variance-এ ভোগে; মাঝখানে — এখানে \(d = 3\)-এ — দুইয়ের যোগফল সর্বনিম্ন, total \(= 0.102\)। লক্ষণীয়, true sine-এর Taylor approximation-এ cubic term-ই প্রথম যথেষ্ট curvature দেয়, তাই degree 3-এর এই জয় কাকতালীয় নয়।
(ঘ) Irreducible floor কখনো ভাঙা যায় না. সবচেয়ে কম total (\(0.102\), degree 3-এ) লক্ষ করুন — সেটাও \(\sigma^2 = 0.09\)-এর সামান্য উপরে। এটা দৈবাৎ নয়। decomposition-এর \(+\sigma^2\) term টা data-র অন্তর্নিহিত noise; কোনো model এই \(0.09\)-এর নিচে total error নামাতে পারবে না, কারণ noise-টা data-তেই গাঁথা, model-এ নয়। অর্থাৎ best-case total error-এর একটা hard lower bound আছে — \(\sigma^2 = 0.09\)। আপনার model নিখুঁত হলেও (\(\mathrm{Bias}^2 = \mathrm{Var} = 0\)) total দাঁড়াবে ঠিক \(0.09\)। তত্ত্ব আর সংখ্যা এখানে হাত মেলায়।
নিচের চিত্রটা U-curve আর তার দুই উপাদানকে একসঙ্গে দেখায়:
error
│
21.23┤ ● Total (d=11)
│ ┊ ← variance blows up
┊ (gap — axis broken) ┊
0.30┤ ●Total
│ \●d2 ●d9
0.20┤ \ ●
│ \ ●d7
0.15┤ \ ╱
│ \ ╱ d5
0.10┤ ●━━━━━●━━━━● ← Total bottoms at d=3 (0.102)
│ d3 ↑
0.09┤ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ σ² floor (0.09)
│ high bias high variance →
└──┬────┬────┬────┬────┬────┬────┬──────────► degree d
1 2 3 5 7 9 11
└ bias zone ┘ └ variance zone ┘
৩.৩ · Overfitting-এর গল্প: একই data, দুই বিপরীত ব্যর্থতা (E2)¶
টেবিলের দুই প্রান্ত — \(d=1\) আর \(d=11\) — ML-এর দুই classic ব্যর্থতা-মোডের জীবন্ত উদাহরণ। একই training data, কিন্তু ভুল করার দুই সম্পূর্ণ বিপরীত উপায়।
Degree 1: sine-কে মিস করে (bias-এর গল্প). straight line যত training set-ই দেখুক, \(\sin(2\pi x)\)-এর hump আর dip কোনোদিন ধরতে পারবে না — এটা model-এর শ্রেণীগত সীমাবদ্ধতা, data-র অভাব নয়। আপনি যদি \(n_{\text{train}}\) ৪০ থেকে ৪০,০০০ করে দেন, line-টা একটু স্থিতিশীল হবে ঠিকই (variance আরও কমবে), কিন্তু \(\mathrm{Bias}^2 \approx 0.156\) প্রায় একই থাকবে। এটাই bias-এর নিষ্ঠুরতা: আরও data দিয়ে bias সারানো যায় না — model-class টাই বদলাতে হয় (degree বাড়াতে হয়)।
Degree 11: noise-কে তাড়া করে (variance-এর গল্প). এখন উল্টো প্রান্ত। একটা single degree-11 fit তুলে নিয়ে training point-গুলোর উপর প্লট করলে দেখবেন — curve-টা প্রায় প্রতিটা point ছুঁয়ে যাচ্ছে, training MSE প্রায় শূন্য, দেখতে দুর্দান্ত। এক training set-এ এটাকে নিখুঁত মনে হয়। কিন্তু এটাই ফাঁদ: curve-টা signal-এর সঙ্গে সঙ্গে noise-এর প্রতিটা random ঝাঁকুনিকেও খোদাই করে রেখেছে। নতুন একটা training set (অন্য noise) দিলে fit সম্পূর্ণ অন্যরকম দেখাবে — অর্থাৎ ৩০০টা resample-এ predictions বুনোভাবে দুলবে, যার ফলেই \(\mathrm{Var} = 21.09\)। in-sample-এ চমৎকার, কিন্তু out-of-sample-এ — অথবা একটু ভিন্ন training set-এ — বিপর্যয়। এটাই overfitting-এর সারকথা: model টা এই নির্দিষ্ট dataset মুখস্থ করেছে, underlying pattern শেখেনি।
৫.৮-এর সঙ্গে যোগসূত্র. ৫.৮-এ আমরা training-vs-test error-এর দুটো curve এঁকেছিলাম। সেই ছবিটা এখানে নিখুঁতভাবে খাটে: model capacity (\(d\)) বাড়ানোর সঙ্গে সঙ্গে —
- training error একটানা কমতে থাকে — degree বাড়ালে polynomial training point-গুলোকে আরও আঁটোসাঁটো ছোঁয়, \(d=11\)-এ training error প্রায় ০;
- test error U-আকৃতির — আগে কমে (bias কমছে), তারপর বাড়ে (variance বাড়ছে), সর্বনিম্ন degree 3-এ।
এই দুই curve-এর ফাঁক টাই আসলে generalization gap — যেটা §২-তে \(R(h) - \hat R_n(h)\) রূপে সংজ্ঞায়িত। \(d=11\)-এ training error ≈ ০ অথচ test error ≈ ২১ — gap বিশাল। ঠিক এই gap-টাকেই পরের অংশের Hoeffding bound theoretical-ভাবে নিয়ন্ত্রণে আনার চেষ্টা করবে।
৩.৪ · Generalization gap আর Hoeffding bound (E3)¶
E1–E2 দেখাল overfit হলে empirical risk (training error) আর true risk (test error)-এর মধ্যে ফাঁক বাড়ে। এবার প্রশ্ন: এই gap-টাকে আগেভাগে, কোনো test set ছাড়াই, theoretically bound করা যায় কি? Finite hypothesis class \(\mathcal H\)-এর জন্য Hoeffding-ভিত্তিক uniform bound এই গ্যারান্টি দেয় — at least \(1 - \delta\) probability-তে, সব \(h \in \mathcal H\)-এর জন্য একসাথে:
এখানে \(\lvert \mathcal H \rvert\) হলো hypothesis class-এর আকার, \(n\) training sample সংখ্যা, আর \(\delta\) হলো আমরা কতটুকু ব্যর্থতার ঝুঁকি নিতে রাজি (confidence \(= 1 - \delta\))। তিনটে scenario-তে (\(\delta = 0.05\)) bound হিসাব করা যাক:
| \(\lvert \mathcal H \rvert\) | \(n\) | gap-এর upper bound | পর্যবেক্ষণ |
|---|---|---|---|
| \(1000\) | \(100\) | \(\le 0.230\) | baseline — bound ঢিলা |
| \(1000\) | \(1000\) | \(\le 0.073\) | data ১০× → bound অনেক আঁটো |
| \(10^{6}\) | \(1000\) | \(\le 0.094\) | class \(1000\times\) বড় → bound ঢিলা হলো |
প্রতিটা সারির অর্থ পরিষ্কার করে নেওয়া যাক।
সারি ১ — baseline (\(\lvert\mathcal H\rvert=1000,\ n=100\)): bound ঢিলা. মাত্র ১০০টা sample দিয়ে গ্যারান্টি দাঁড়ায় gap \(\le 0.230\)। অর্থাৎ true risk training error-এর চেয়ে ০.২৩ পর্যন্ত বেশি হতে পারে — classification-এ এটা প্রায় ২৩% error-এর fudge factor, কার্যত অর্থহীনভাবে ঢিলা। data কম, তাই গ্যারান্টিও দুর্বল।
সারি ২ — আরও data (\(n\): \(100 \to 1000\)): bound আঁটো. \(\lvert\mathcal H\rvert\) একই রেখে শুধু \(n\) দশগুণ করলে bound \(0.230\) থেকে নেমে \(0.073\)-এ — তিনগুণেরও বেশি tight। কারণ bound-এ \(n\) আছে হরে, \(\sqrt n\)-এর ভেতরে, তাই gap কমে \(1/\sqrt n\) হারে। \(n\) ১০× করলে bound কমে \(\sqrt{10} \approx 3.16\)× — সংখ্যায় \(0.230 / 3.16 \approx 0.073\), ঠিক মিলে যায়। আরও data সবসময় generalization gap সংকুচিত করে।
সারি ৩ — আরও বড় class (\(\lvert\mathcal H\rvert\): \(10^3 \to 10^6\)): bound ঢিলা. এখন \(n=1000\) স্থির রেখে hypothesis class হাজার গুণ বড় করলাম। bound \(0.073\) থেকে বেড়ে \(0.094\)-এ উঠল। কেন এত সামান্য বাড়ল? কারণ \(\lvert\mathcal H\rvert\) ঢোকে \(\ln\)-এর ভেতরে, তারপর আবার \(\sqrt{\ }\)-এর ভেতরে — তাই class-এর প্রভাব \(\sqrt{\ln \lvert\mathcal H\rvert}\) হারে, খুবই মৃদু। \(\lvert\mathcal H\rvert\) \(1000\times\) বাড়লে \(\ln\lvert\mathcal H\rvert\) বাড়ে মাত্র \(\ln(10^6)/\ln(10^3) = 2\times\), আর তার বর্গমূল আরও ক্ষীণ। বড় hypothesis class generalization gap বাড়ায়, কিন্তু খুব ধীরে — \(\sqrt{\ln \lvert\mathcal H\rvert}\) হারে।
দুই বল-এর টানাটানি. Bound-টা সংক্ষেপে এই গঠনের:
দুটো প্রতিপক্ষ শক্তি: \(n\) (data) gap-কে নিচে টানে \(1/\sqrt n\) হারে, আর \(\lvert\mathcal H\rvert\) (model capacity) gap-কে উপরে টানে \(\sqrt{\ln\lvert\mathcal H\rvert}\) হারে। শুভ খবর হলো asymmetry-টা আমাদের পক্ষে — data-র প্রতিদান polynomial-ভাবে (\(1/\sqrt n\)) শক্তিশালী, অথচ capacity-র শাস্তি কেবল logarithmic (\(\sqrt{\ln\lvert\mathcal H\rvert}\))। তাই যথেষ্ট data থাকলে বেশ বড় hypothesis class-ও নিরাপদে সামলানো যায়, যতক্ষণ \(\ln\lvert\mathcal H\rvert\) ও \(n\)-এর অনুপাত নিয়ন্ত্রণে থাকে।
৩.৫ · ব্যবহারিক শিক্ষা: capacity-কে data-র সঙ্গে মিলিয়ে নাও (E4)¶
তিনটে উদাহরণ একই বার্তায় মিলিত হয়।
U-curve বলে: "capacity-কে data-র সঙ্গে মেলাও।" E1-এর টেবিল empirically দেখাল total error model capacity-তে U-আকৃতির। অতি-অল্প capacity (degree 1) → bias-এ ভোগো; অতি-বেশি capacity (degree 11) → variance-এ ভোগো। লক্ষ্য কোনো প্রান্ত নয়, বরং সেই sweet spot (degree 3) যেখানে দুইয়ের যোগফল সর্বনিম্ন। অর্থাৎ model নির্বাচন মানে শুধু "সবচেয়ে শক্তিশালী model" বাছা নয় — বরং problem আর data-র পরিমাণের সঙ্গে capacity-কে ছন্দে মেলানো।
Generalization bound একই কথা বলে, তত্ত্বের ভাষায়. E3-এর Hoeffding bound আলাদা পথে এসে একই উপসংহারে পৌঁছায়: capacity (\(\ln\lvert\mathcal H\rvert\)) অবশ্যই \(n\)-এর সাপেক্ষে নিয়ন্ত্রিত রাখতে হবে। \(n\) ছোট রেখে \(\lvert\mathcal H\rvert\) বিশাল করলে bound অর্থহীন হয়ে পড়ে (gap-এর কোনো useful গ্যারান্টি থাকে না) — যা ঠিক E2-এর overfitting। দুই দৃষ্টিভঙ্গি — empirical U-curve আর theoretical bound — একই মুদ্রার দুই পিঠ: capacity ও data-র ভারসাম্যই generalization-এর চাবিকাঠি।
সতর্কবার্তা: noise floor অনতিক্রম্য. E1 আরও একটা শান্ত কিন্তু গভীর শিক্ষা দেয় — \(\sigma^2 = 0.09\) floor কখনো ভাঙা যায় না। তাই যদি আপনার best model-ও noise floor-এর কাছাকাছি error দেয়, সেটা ব্যর্থতা নয়; সেটাই data-র অন্তর্নিহিত সীমা ছুঁয়ে ফেলার চিহ্ন। এর পরে আর model নিয়ে কাটাছেঁড়া করে লাভ নেই — উন্নতি চাইলে কম-noisy data বা ভালো feature দরকার, ভালো optimizer নয়।
৬.২-এ সেতু. কিন্তু একটা অস্বস্তি থেকে যায়: degree একটা discrete knob — আমরা \(d=3\) আর \(d=5\)-এর মাঝে দাঁড়াতে পারি না, U-curve-এর তলদেশে নিখুঁতভাবে বসা কঠিন। আদর্শ হতো যদি capacity-কে একটানা (continuous) সুর করা যেত — full flexibility রেখেও variance চেপে ধরা যেত। ঠিক এটাই regularization-এর কাজ, যা ৬.২-এর বিষয়। discrete degree না বদলে regularization একটা penalty term-এর মাধ্যমে effective capacity-কে মসৃণভাবে নিয়ন্ত্রণ করে — bias আর variance-এর মাঝখানে U-curve-এর তলদেশটায় আরও সূক্ষ্মভাবে গিয়ে বসার সুযোগ দেয়। বর্তমান অধ্যায়ের U-curve-ই হলো সেই continuous tuning-এর landscape; পরের অধ্যায় দেখাবে কীভাবে সেই landscape-এ মসৃণভাবে চলাফেরা করতে হয়।
৩.৬ · সংখ্যাগত যাচাই (numpy verification)¶
নিচের block-টা simulation-এর structural pattern নিশ্চিত করে — seed \(20260619\), \(n_{\text{train}}=40\), reps \(=300\), \(50\)-point test grid, \(\sigma=0.3\) — এবং Hoeffding bound তিনটে scenario-তে হিসাব করে। Decomposition-এর গুণগত গঠন (bias-zone ↔ variance-zone, U-shaped total, degree 3-এ minimum, degree 11-এ variance বিস্ফোরণ, \(\sigma^2\) floor) প্রতিটা run-এ পুনরুৎপাদনযোগ্য; উপরের টেবিলে canonical run-এর মান হুবহু ব্যবহার করা হয়েছে।
import numpy as np
# ---- E1: bias–variance decomposition ----
rng = np.random.default_rng(20260619)
f_true = lambda x: np.sin(2*np.pi*x)
sigma, n_train, reps, n_test = 0.3, 40, 300, 50
x_test = np.linspace(0.05, 0.95, 50)
y_true = f_true(x_test)
for d in [1, 2, 3, 5, 7, 9, 11]:
preds = np.empty((reps, n_test))
for r in range(reps):
xt = rng.uniform(0, 1, n_train)
yt = f_true(xt) + rng.normal(0, sigma, n_train)
preds[r] = np.polyval(np.polyfit(xt, yt, d), x_test)
bias2 = np.mean((preds.mean(0) - y_true)**2)
var = np.mean(preds.var(0))
print(f"d={d:2d} bias2={bias2:7.3f} var={var:9.3f} total={bias2+var+sigma**2:9.3f}")
# ---- E3: Hoeffding finite-hypothesis bound (delta=0.05) ----
delta = 0.05
bound = lambda H, n: np.sqrt((np.log(H) + np.log(2/delta)) / (2*n))
for H, n in [(1000, 100), (1000, 1000), (10**6, 1000)]:
print(f"|H|={H:>7}, n={n:>4} -> gap <= {bound(H, n):.3f}")
# Hoeffding bounds — exact match to canonical values:
|H|= 1000, n= 100 -> gap <= 0.230
|H|= 1000, n=1000 -> gap <= 0.073
|H|=1000000, n=1000 -> gap <= 0.094
# Bias–variance structure (canonical run, seed 20260619):
d= 1 bias2= 0.156 var= 0.015 total= 0.261 <- underfit, high bias
d= 2 bias2= 0.151 var= 0.025 total= 0.266
d= 3 bias2= 0.003 var= 0.009 total= 0.102 <- MINIMUM total
d= 5 bias2= 0.000 var= 0.014 total= 0.104
d= 7 bias2= 0.000 var= 0.061 total= 0.151
d= 9 bias2= 0.000 var= 0.104 total= 0.194
d=11 bias2= 0.053 var= 21.090 total= 21.230 <- variance explodes
# irreducible noise floor: sigma^2 = 0.09 (no model beats this)
যাচাই নিশ্চিত করে: (১) Hoeffding bound তিনটে scenario-তে যথাক্রমে \(0.230,\ 0.073,\ 0.094\) — exact match; (২) total error U-আকৃতির, সর্বনিম্ন degree 3-এ (\(0.102\)); (৩) variance degree 11-এ বিস্ফোরিত (\(21.09\)); (৪) irreducible floor \(\sigma^2 = 0.09\) — কোনো model এর নিচে নামে না। তত্ত্ব আর সংখ্যা সম্পূর্ণ সংগতিপূর্ণ।
৪ · প্রমাণ ও উৎপাদন¶
এই বিভাগে learning theory-র চারটি স্তম্ভ শূন্য থেকে প্রমাণসহ গড়ে তুলব। একটিই কেন্দ্রীয় প্রশ্ন সব জায়গায় ফিরে আসবে: একটি model কতটা ভালো generalize করবে — অর্থাৎ train করার সময় যা দেখেনি, সেই unseen data-তে কত ভুল করবে — তা train-এর performance ও model-এর "ক্ষমতা" (capacity) দিয়ে গাণিতিকভাবে কীভাবে বাঁধা যায়? প্রথমে (§৪.১) error-কে তিন টুকরোয় ভাঙব — bias, variance, ও irreducible noise — যা প্রকাশ করে কেন অতি-সরল ও অতি-জটিল উভয় model-ই ব্যর্থ হয়। তারপর (§৪.২) finite hypothesis class-এর জন্য Hoeffding + union bound দিয়ে একটি rigorous generalization guarantee প্রমাণ করব। এরপর (§৪.৩) infinite class-এ যাব — shattering, VC dimension, ও Sauer–Shelah lemma-র মাধ্যমে দেখাব কীভাবে অসীম class-ও বাস্তবে "ছোট" হয়ে থাকে। শেষে (§৪.৪) no-free-lunch — কেন কোনো assumption ছাড়া শেখা অসম্ভব। ভিত্তি চারটি: (i) prereq 5.2-এর bias–variance ধারণা; (ii) prereq 5.8-এর train/test error; (iii) prereq 3.1-এর Hoeffding inequality; (iv) prereq 4.4-এর MSE। প্রতিটি প্রতীক প্রথম ব্যবহারে খোলা হবে, প্রতিটি ধাপ যুক্তিসহ। কষ্টের স্তর প্রতিটি উপ-বিভাগের শিরোনামে তারা দিয়ে: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
সাধারণ সেট-আপ ও প্রতীক। ধরি প্রতিটি data-point একটি জোড়া \((x,y)\), যেখানে \(x\) input ও \(y\) output (label বা response)। এরা একটি অজানা distribution \(\mathcal D\) থেকে i.i.d. আসে। একটি hypothesis (model) \(h\) input \(x\)-কে prediction \(h(x)\)-এ রূপান্তরিত করে। ভুলের পরিমাপ loss function \(\ell(h(x),y)\ge 0\)। দুটি error সর্বত্র ব্যবহার করব:
- True risk (population error): \(\displaystyle R(h)=\mathbb{E}_{(x,y)\sim\mathcal D}\bigl[\ell(h(x),y)\bigr]\) — সমগ্র জনগোষ্ঠীর উপর গড় ভুল। এটাই আমরা ছোট করতে চাই, কিন্তু \(\mathcal D\) অজানা বলে এটি সরাসরি মাপা যায় না।
- Empirical risk (training error): একটি training set \(S=\{(x_i,y_i)\}_{i=1}^n\) দিলে \(\displaystyle \hat R_n(h)=\frac1n\sum_{i=1}^n\ell(h(x_i),y_i)\) — হাতের নমুনার উপর গড় ভুল, যা আমরা মাপতে পারি।
শেখার নিয়ম (empirical risk minimization, ERM): hypothesis class \(\mathcal H\)-এর মধ্যে যে \(h\) training error সর্বনিম্ন করে, সেটাই বেছে নিই — \(\hat h=\arg\min_{h\in\mathcal H}\hat R_n(h)\)। মূল প্রশ্ন: এই \(\hat h\)-এর true risk \(R(\hat h)\) কি \(\hat R_n(\hat h)\)-এর কাছাকাছি থাকবে? এই দূরত্ব \(R(h)-\hat R_n(h)\)-কে বলি generalization gap। §৪.২–৪.৩ এই gap-কে বাঁধবে।
৪.১ ★★ Bias–variance decomposition¶
লক্ষ্য। একটি নির্দিষ্ট test-point \(x\)-এ squared loss-এর expected মান তিনটি অর্থপূর্ণ টুকরোয় ভাঙা — যা precisely বলবে কোন উৎস থেকে error আসে।
সেট-আপ। ধরি সত্যিকারের সম্পর্ক \(y=f(x)+\varepsilon\), যেখানে \(f\) হলো অজানা ground-truth function এবং \(\varepsilon\) হলো random noise, যার \(\mathbb{E}[\varepsilon]=0\) ও \(\mathrm{Var}(\varepsilon)=\mathbb{E}[\varepsilon^2]=\sigma^2\)। আমাদের estimator \(\hat f\) একটি random training sample-এর উপর train করা — তাই \(\hat f(x)\) নিজেই একটি random variable (ভিন্ন training set দিলে ভিন্ন \(\hat f\) পাব)। সর্বত্র \(\mathbb{E}\) নেব দুই স্বাধীন randomness-এর উপর: noise \(\varepsilon\) (test-point-এর) এবং training sample (যা \(\hat f\) স্থির করে)। ধরে নিচ্ছি \(x\)-এর test-noise \(\varepsilon\), training set থেকে স্বাধীন — তাই \(\varepsilon\) ও \(\hat f(x)\) স্বাধীন।
আমরা যে পরিমাণ বিশ্লেষণ করি তা হলো test-point \(x\)-এ expected squared error:
ধাপ ১ — add-subtract trick। ভেতরের রাশিতে \(\mathbb{E}[\hat f(x)]\) যোগ-বিয়োগ করি (এটাই কৌশলের হৃৎপিণ্ড)। সংক্ষেপে লিখি \(\bar f \equiv \mathbb{E}[\hat f(x)]\) (এটি একটি deterministic সংখ্যা — সব training set-এর উপর গড় prediction)। তাহলে
এই তিন টুকরোর প্রকৃতি গুরুত্বপূর্ণ: \(\varepsilon\) random (গড় \(0\)); \((f(x)-\bar f)\) একটি স্থির ধ্রুবক; \((\bar f-\hat f(x))\) random কিন্তু গড় শূন্য, কারণ \(\mathbb{E}[\bar f-\hat f(x)]=\bar f-\mathbb{E}[\hat f(x)]=\bar f-\bar f=0\)।
ধাপ ২ — বর্গ ও তিনটি cross-term। তিনটি পদ \(A=\varepsilon\), \(B=f(x)-\bar f\), \(C=\bar f-\hat f(x)\) লিখলে
এখন তিনটি cross-term একে একে শূন্য দেখাই:
- \(\mathbb{E}[AB]=\mathbb{E}[\varepsilon\cdot(f(x)-\bar f)]=(f(x)-\bar f)\,\mathbb{E}[\varepsilon]=(f(x)-\bar f)\cdot 0=0\)। (\(B\) ধ্রুবক, বাইরে আনা যায়; \(\mathbb{E}[\varepsilon]=0\)।)
- \(\mathbb{E}[AC]=\mathbb{E}[\varepsilon\cdot(\bar f-\hat f(x))]=\mathbb{E}[\varepsilon]\cdot\mathbb{E}[\bar f-\hat f(x)]=0\cdot 0=0\)। (test-noise \(\varepsilon\) ও training-randomness \(\hat f\) স্বাধীন, তাই expectation আলাদা করা যায়; দুটিরই গড় \(0\)।)
- \(\mathbb{E}[BC]=(f(x)-\bar f)\,\mathbb{E}[\bar f-\hat f(x)]=(f(x)-\bar f)\cdot 0=0\)। (\(B\) ধ্রুবক; \(C\)-এর গড় \(0\), ধাপ ১-এ দেখানো।)
তিনটিই বিলুপ্ত, তাই শুধু তিনটি square-term টিকে থাকে।
ধাপ ৩ — প্রতিটি square-term চিহ্নিত করা।
(\(\mathbb{E}[B^2]\)-এ \(B\) ধ্রুবক বলে expectation নিষ্প্রয়োজন; \(\mathbb{E}[C^2]\) ঠিক variance-এর সংজ্ঞা।) একত্রে:
ব্যাখ্যা — model-জটিলতার সাথে প্রতিটি পদের সম্পর্ক।
- Irreducible error \(\sigma^2\): এটি data-র অন্তর্নিহিত noise — কোনো model দিয়েই কমানো যায় না (নাম "irreducible")। model যত জটিলই হোক, এই মেঝে (floor) থেকেই যায়। এটি model থেকে স্বাধীন।
- \(\mathrm{Bias}^2\): গড় prediction \(\bar f\) আর সত্য \(f(x)\)-এর ব্যবধানের বর্গ — model-এর কাঠামোগত অক্ষমতা। সরল model (যেমন একটি constant বা linear fit) সত্যিকারের জটিল \(f\)-কে ধরতে পারে না, তাই bias বড়। model জটিল করলে (বেশি parameter, বেশি flexibility) bias কমে।
- \(\mathrm{Var}\): training set বদলালে \(\hat f(x)\) কতটা ওঠানামা করে। জটিল model training data-র ছোট পরিবর্তনেও আমূল বদলায় (overfitting) — তাই variance বড়। সরল model স্থিতিশীল, variance ছোট।
তাই model-জটিলতা বাড়ালে \(\mathrm{Bias}^2\) কমে কিন্তু \(\mathrm{Var}\) বাড়ে — এই bias–variance tradeoff-ই total error-কে একটি U-আকৃতির বক্ররেখায় নিয়ে যায়, যার সর্বনিম্ন বিন্দুতে optimal জটিলতা (prereq 5.2-এর চিত্রের গাণিতিক ভিত্তি এটিই)।
৪.২ ★★ Finite hypothesis class-এর generalization bound¶
লক্ষ্য। যখন \(\mathcal H\)-এ ঠিক \(M=\lvert\mathcal H\rvert\)টি hypothesis (finite, যেমন একটি grid বা সীমিত decision tree-সেট), তখন প্রমাণ করব: high probability-তে সব \(h\)-এর জন্য একসাথে generalization gap ছোট থাকে, এবং gap-এর আকার \(\sqrt{(\log M)/n}\)-এর মতো বাড়ে।
ধরে নিই loss bounded: \(\ell\in[0,1]\) (0-1 loss এর সরাসরি উদাহরণ — সঠিক হলে \(0\), ভুল হলে \(1\))। তাহলে প্রতিটি data-point-এ \(Z_i=\ell(h(x_i),y_i)\in[0,1]\), এবং \(\hat R_n(h)=\frac1n\sum_i Z_i\) হলো এদের গড়, \(R(h)=\mathbb{E}[Z_i]\) এদের প্রত্যাশা।
ধাপ ১ — একটি নির্দিষ্ট \(h\)-এর জন্য Hoeffding (prereq 3.1)। একটি পূর্ব-নির্ধারিত (data দেখার আগে স্থির করা) \(h\) ধরি। তখন \(Z_1,\dots,Z_n\) i.i.d., bounded \([0,1]\)-এ, গড় \(\hat R_n(h)\), প্রত্যাশা \(R(h)\)। Hoeffding inequality সরাসরি প্রয়োগ করি:
এটি একটি hypothesis-এর জন্য — কিন্তু আমরা \(\hat h\) বেছেছি data দেখে, তাই \(\hat h\) আর পূর্ব-নির্ধারিত নয়। এই ফাঁক বন্ধ করতে union bound লাগবে।
ধাপ ২ — union bound সব \(h\)-এর উপর। "কোনো-না-কোনো \(h\)-এর gap বড়" — এই খারাপ ঘটনাটিকে বাঁধি। union bound (probability-র subadditivity: \(P(\bigcup_j E_j)\le\sum_j P(E_j)\)):
মূল কৌশল: যেহেতু \(M\)টি hypothesis-ই data দেখার আগে স্থির (\(\mathcal H\) আগেই বাছা), প্রতিটির উপর Hoeffding বৈধ; তারপর সবগুলোর ব্যর্থতা-সম্ভাবনা যোগ করি। এই bound এখন \(\hat h\)-সহ সব \(h\)-এর উপর একসাথে খাটে।
ধাপ ৩ — \(\delta\) ঠিক করে \(t\) সমাধান। ডান পাশ একটি ছোট ব্যর্থতা-সম্ভাবনা \(\delta\)-এর সমান ধরি:
(এখানে \(\log(2M/\delta)=\log M+\log 2-\log\delta=\log M+\log(2/\delta)\) — log-এর যোগ-নিয়ম।)
ধাপ ৪ — উপসংহার (complement নিয়ে)। "কোনো \(h\)-এর gap \(\ge t\)" ঘটনার সম্ভাবনা \(\le\delta\), তাই এর পরিপূরক — "সব \(h\)-এর gap \(<t\)" — ঘটার সম্ভাবনা \(\ge 1-\delta\)। যেহেতু \(\lvert R-\hat R_n\rvert<t\) থেকে বিশেষভাবে \(R(h)-\hat R_n(h)<t\), পাই:
ব্যাখ্যা — capacity-vs-data tradeoff। এই bound generalization-কে কঠোরভাবে দুই ভাগে রাখে: (i) দেখা যায় এমন \(\hat R_n(h)\) (training error), আর (ii) একটি complexity penalty \(\sqrt{(\log M+\log(2/\delta))/(2n)}\)।
- Capacity \(M\): hypothesis যত বেশি (\(M\) বড়), penalty বাড়ে — কিন্তু শুধু \(\sqrt{\log M}\)-হারে, খুব ধীরে। তাই \(M\) দ্বিগুণ করলে penalty সামান্যই বাড়ে; বরং \(M\)-কে exponentially বড় করলে তবেই \(\log M\) রৈখিকভাবে বাড়ে।
- Data \(n\): নমুনা বাড়ালে penalty \(1/\sqrt n\)-হারে কমে — যত data, তত শক্ত guarantee। gap \(\to 0\) যখন \(n\to\infty\) (স্থির \(M\)-এ)।
মূল বার্তা: gap বাড়ে \(\sqrt{(\log M)/n}\)-এর মতো — একটি বড় class থেকে নিরাপদে শিখতে হলে data-ও সেই অনুপাতে (\(\log M\)-এর সমানুপাতিক) লাগে। এটাই capacity ও sample-size-এর rigorous বিনিময়।
৪.৩ ★★★ VC dimension ও অসীম hypothesis class¶
§৪.২-এর bound infinite class-এ অকেজো: linear classifier-এর মতো ক্ষেত্রে \(M=\infty\), তাই \(\log M=\infty\) — penalty অসীম। অথচ আমরা জানি linear classifier ভালোই generalize করে। সমাধান: hypothesis সংখ্যা নয়, class-টি data-তে যত আলাদা আচরণ দেখাতে পারে সেই কার্যকর জটিলতা মাপা। এটাই VC theory।
সংজ্ঞা ১ — Dichotomy ও growth function। \(n\)টি বিন্দু \(x_1,\dots,x_n\) ধরি। একটি hypothesis \(h\) (binary classifier, output \(\{0,1\}\)) এই বিন্দুগুলোতে একটি label-প্যাটার্ন তৈরি করে: \((h(x_1),\dots,h(x_n))\in\{0,1\}^n\)। একে বলি dichotomy। যদিও \(\mathcal H\)-এ অসীম \(h\) থাকতে পারে, এই \(n\)টি বিন্দুতে তারা সর্বোচ্চ \(2^n\)টি ভিন্ন প্যাটার্ন দেখাতে পারে। Growth function \(\Pi_{\mathcal H}(n)\) = যেকোনো \(n\) বিন্দু বেছে \(\mathcal H\) যত সর্বাধিক ভিন্ন dichotomy তৈরি করতে পারে:
এটিই অসীম class-এর কার্যকর "আকার" — \(M\)-এর জায়গায় এটি বসবে।
সংজ্ঞা ২ — Shattering। \(n\)টি বিন্দুকে \(\mathcal H\) shatter করে যদি \(\mathcal H\) সেখানে সম্ভাব্য সব \(2^n\)টি label-প্যাটার্নই তৈরি করতে পারে — অর্থাৎ ঐ বিন্দুসেটে \(\Pi_{\mathcal H}(n)=2^n\)। (এর মানে: যেকোনোভাবে বিন্দুগুলোকে \(\pm\) লেবেল দিলেও \(\mathcal H\)-এ কোনো-না-কোনো \(h\) সেটি ঠিক বানিয়ে দেবে।)
সংজ্ঞা ৩ — VC dimension। \(\mathcal H\)-এর Vapnik–Chervonenkis dimension \(d_{\mathrm{VC}}(\mathcal H)\) = সবচেয়ে বড় \(n\) যার জন্য কোনো এক বিন্যাসের \(n\)টি বিন্দু \(\mathcal H\) shatter করতে পারে। অর্থাৎ \(d_{\mathrm{VC}}\)টি বিন্দু shatter করা যায় (কোনো এক অবস্থানে), কিন্তু \(d_{\mathrm{VC}}+1\)টি বিন্দু কোনোভাবেই shatter করা যায় না। এটি class-এর flexibility-র একটি একক সংখ্যা — finite class-এ \(\log M\)-এর ভূমিকা এখানে \(d_{\mathrm{VC}}\) পালন করবে।
Sauer–Shelah lemma (মূল ফলাফল)। এই lemma-ই VC theory-কে কাজে লাগায়: এটি বলে growth function হয় সর্বত্র \(2^n\) (যদি class সবকিছু shatter করতে পারে), নয়তো \(n>d_{\mathrm{VC}}\) হলেই তা polynomial-এ আটকে যায়:
দুটি ধাপ আলাদা করে বুঝি:
- প্রথম অসমতা (\(\Pi_{\mathcal H}(n)\le\sum_{i=0}^d\binom ni\)): এটাই Sauer–Shelah-র combinatorial সারবস্তু — finite VC dimension \(d\)-যুক্ত class কখনোই \(d\)-এর বেশি বিন্দু shatter করতে পারে না, এবং এই সীমাবদ্ধতা থেকেই dichotomy-সংখ্যা প্রথম \(d+1\)টি binomial-এর যোগফলে বাঁধা পড়ে। (পূর্ণ প্রমাণ inductive ও দীর্ঘ; এখানে ফলাফল ব্যবহার করি।)
- দ্বিতীয় অসমতা (\(\sum_{i=0}^d\binom ni\le(en/d)^d\)): যোগফলটিকে closed-form-এ আনে। এর গুরুত্ব মৌলিক — ডান পাশ \(n\)-এর মধ্যে degree-\(d\) polynomial (exponential \(2^n\) নয়)। তাই \(n>d_{\mathrm{VC}}\) হলে \(\Pi_{\mathcal H}(n)\ll 2^n\): অসীম class-ও বড় নমুনায় বহুপদীভাবে "ছোট" হয়ে যায়। ঠিক এই polynomial-বনাম-exponential রূপান্তর শেখাকে সম্ভব করে।
VC generalization bound। §৪.২-এর প্রমাণে \(M\)-এর জায়গায় (কিছু কারিগরি সংশোধনসহ — যেহেতু \(\hat h\) data-নির্ভর, একটি symmetrization argument লাগে) \(\Pi_{\mathcal H}(2n)\) বসিয়ে এবং Sauer–Shelah দিয়ে তাকে \((en/d)^d\)-এ আবদ্ধ করে পাওয়া যায় (\(\log\Pi_{\mathcal H}\sim d_{\mathrm{VC}}\log(n/d_{\mathrm{VC}})\)):
§৪.২-এর সঙ্গে তুলনা: সেখানে penalty-তে ছিল \(\log M\); এখানে তার পরিবর্তে \(d_{\mathrm{VC}}\log(n/d_{\mathrm{VC}})\)। অর্থাৎ \(\log M\to d_{\mathrm{VC}}\) প্রতিস্থাপন — finite class-এ \(d_{\mathrm{VC}}\le\log_2 M\) (কারণ \(M\)টি hypothesis সর্বোচ্চ \(\log_2 M\)টি বিন্দু shatter করতে পারে), আর infinite class-এও যতক্ষণ \(d_{\mathrm{VC}}<\infty\) ততক্ষণ bound অর্থবহ থাকে এবং \(n\to\infty\)-এ gap \(\to 0\)। তাই finite VC dimension = শেখার সম্ভাব্যতা (learnability)।
Worked example: 2D linear classifier-এর \(d_{\mathrm{VC}}=3\)। \(\mathcal H\) = সমতলে সব রেখা-ভিত্তিক classifier (একপাশে label \(+\), অন্যপাশে \(-\), অর্থাৎ half-plane)। দুটি দাবি প্রমাণ করি।
- \(d_{\mathrm{VC}}\ge 3\) — ৩টি non-collinear বিন্দু shatter করা যায়। তিনটি বিন্দু একটি ত্রিভুজে রাখি (একরেখায় নয়)। এদের \(2^3=8\)টি সম্ভাব্য label-প্যাটার্নের প্রতিটির জন্য একটি বিভাজক রেখা টানা যায়: সব \(+\) বা সব \(-\) — যেকোনো এক পাশে তিনটিই রেখে; ঠিক একটি \(+\) — সেই বিন্দুকে একটি রেখা দিয়ে বাকি দুটি থেকে আলাদা করে (non-collinear বলে সম্ভব); ঠিক দুটি \(+\) — তৃতীয়টিকে আলাদা করে। আটটির সবগুলোই realizable, তাই ৩ বিন্দু shatter হয় \(\Rightarrow d_{\mathrm{VC}}\ge 3\)।
- \(d_{\mathrm{VC}}<4\) — ৪টি বিন্দু কোনোভাবেই shatter করা যায় না। যেকোনো ৪ বিন্দুর জন্য একটি label-প্যাটার্ন আছে যা কোনো রেখা তৈরি করতে পারে না। ক্লাসিক ক্ষেত্র — XOR: চারটি বিন্দুকে একটি বর্গের কোণে রাখি, তির্যকভাবে বিপরীত জোড়া এক label, অন্য তির্যক জোড়া আরেক label (\(A,C=+\) এবং \(B,D=-\))। এই দুই জোড়াকে একটিমাত্র সরলরেখা দিয়ে আলাদা করা অসম্ভব (linearly inseparable)। যদি চার বিন্দু general position-এ না থাকে (একটি অন্য তিনটির convex hull-এর ভেতরে, বা collinear) তখনও অনুরূপ একটি প্যাটার্ন ব্যর্থ করে। তাই \(\Pi_{\mathcal H}(4)<2^4=16\) \(\Rightarrow\) ৪ বিন্দু shatter হয় না \(\Rightarrow d_{\mathrm{VC}}<4\)।
দুটি মিলিয়ে \(d_{\mathrm{VC}}=3\)। (Sauer–Shelah-র সঙ্গে সঙ্গতি: \(d=3, n=4\)-এ cap \(\sum_{i=0}^{3}\binom4i=1+4+6+4=15<16\) — অর্থাৎ ৪ বিন্দুতে সর্বোচ্চ ১৫টি dichotomy, কখনো ১৬টি নয়, যা "shatter অসম্ভব"-এর সংখ্যাগত নিশ্চয়তা।) সাধারণভাবে \(\mathbb R^p\)-এ (bias-সহ) linear classifier-এর \(d_{\mathrm{VC}}=p+1\) — তাই \(p=2\)-এ ঠিক \(3\)।
৪.৪ ★ No-free-lunch theorem¶
বিবৃতি (সরলীকৃত)। সকল সম্ভাব্য data-generating distribution-এর উপর গড় করলে, যেকোনো দুটি learning algorithm-এর প্রত্যাশিত off-training (unseen) error সমান। ফলে কোনো learner সব সমস্যায় random guessing-কে হারাতে পারে না; কোনো universally সেরা model নেই।
এক-লাইন insight (অন্তর্দৃষ্টি)। একটি algorithm যেসব distribution-এ ভালো করে, ঠিক সেই পরিমাণই অন্য distribution-এ খারাপ করে — কারণ training data unseen point-এর label সম্পর্কে কিছুই বলে না যদি সব labeling সমসম্ভাব্য হয়; কোনো-না-কোনো assumption ("কাছাকাছি input-এর label কাছাকাছি", বা "সত্য function সরল") ছাড়া বাইরের বিন্দু আক্ষরিক অর্থে coin-toss।
তাৎপর্য — inductive bias অপরিহার্য। তাই ভালো generalization কখনো "free" নয়; এর জন্য assumption চাই — যাকে বলি inductive bias: hypothesis class \(\mathcal H\) বাছাই (§৪.২-৪.৩), smoothness/regularization, বা prior। no-free-lunch §৪.১-৪.৩-এর সঙ্গে নিখুঁতভাবে মেলে: VC bound কেবল তখনই অর্থবহ যখন \(d_{\mathrm{VC}}\) ছোট (অর্থাৎ \(\mathcal H\) সীমিত — একটি assumption), আর bias–variance-এ সরল model-এর bias-ই সেই assumption-এর গাণিতিক ছাপ। সারকথা: শেখা = data + assumption; assumption ছাড়া শেখা অসম্ভব।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের তত্ত্ব—bias-variance decomposition এবং Hoeffding generalization bound—দুটোই কাগজে-কলমে দেখতে বেশ বিমূর্ত। কিন্তু এদের পেছনের গণিত আসলে সংখ্যায় ধরা যায়। এই ল্যাবে আমরা একটিমাত্র runnable স্ক্রিপ্ট দিয়ে তিনটি জিনিস নিজে হাতে গড়ে তুলব:
- Bias-variance Monte-Carlo — একই data-generating process থেকে বারবার নমুনা টেনে, বিভিন্ন degree-এর polynomial fit করে, পরীক্ষামূলকভাবে \(\text{bias}^2\), variance এবং total error হিসাব করা; এবং দেখা যে total error degree-এর সাপেক্ষে একটি U-আকৃতির বক্ররেখা।
- Hoeffding generalization gap — hypothesis class-এর আকার \(\lvert H \rvert\) ও sample size \(n\) কীভাবে generalization gap-এর উপরের সীমা নির্ধারণ করে, তা একটি bound function দিয়ে যাচাই করা।
- Irreducible-error floor — noise variance \(\sigma^2\) যে একটি অলঙ্ঘনীয় মেঝে, তা স্পষ্ট করা।
স্ক্রিপ্টের কাঠামো¶
পুরো পরীক্ষাটি from scratch—কোনো scikit-learn নয়, শুধু numpy-র polyfit/polyval এবং একটি seeded random generator। লক্ষ্যবস্তু (target) ফাংশনটি হলো \(f(x)=\sin(2\pi x)\), এবং প্রতিটি training নমুনায় প্রতিটি বিন্দুতে \(\mathcal{N}(0,\sigma^2)\) Gaussian noise যোগ করা হয়, যেখানে \(\sigma=0.3\), অর্থাৎ \(\sigma^2=0.09\)।
মূল decomposition-টি হলো একটি নির্দিষ্ট test বিন্দু \(x\)-এ:
যেখানে \(\bar{g}(x)=\mathbb{E}[\hat{g}(x)]\) হলো ৩০০টি reps জুড়ে গড় prediction। স্ক্রিপ্টে আমরা প্রতিটি test বিন্দুতে এই তিনটি রাশি আলাদা করে বের করি, তারপর সব test বিন্দুর উপর গড় নিই।
import numpy as np
# ===================== PART 1: Bias-Variance Monte-Carlo =====================
rng = np.random.default_rng(20260619)
def f(x): return np.sin(2*np.pi*x)
sigma = 0.3
xt = np.linspace(0.05, 0.95, 50)
ft = f(xt)
n_train = 40
reps = 300
degrees = [1, 2, 3, 5, 7, 9, 11]
print("PART 1 -- Bias-Variance Decomposition (sigma^2 = {:.2f})".format(sigma**2))
print("{:>4} | {:>10} | {:>12} | {:>10}".format("deg", "bias^2", "variance", "total"))
print("-"*46)
results = {}
for d in degrees:
preds = np.empty((reps, xt.size))
for r in range(reps):
x = rng.uniform(0.0, 1.0, n_train)
y = f(x) + rng.normal(0.0, sigma, n_train)
coef = np.polyfit(x, y, d)
preds[r] = np.polyval(coef, xt)
mean_pred = preds.mean(axis=0)
bias2 = np.mean((mean_pred - ft)**2)
var = np.mean(preds.var(axis=0))
total = bias2 + var + sigma**2
results[d] = (bias2, var, total)
print("{:>4} | {:>10.3f} | {:>12.3f} | {:>10.3f}".format(d, bias2, var, total))
best = min(results, key=lambda k: results[k][2])
print("-"*46)
print("Minimum total error at degree d = {} (total = {:.3f})".format(best, results[best][2]))
# ===================== PART 2: Hoeffding Generalization Bound =====================
print()
print("PART 2 -- Hoeffding generalization gap bound, delta = 0.05")
def gap_bound(M, n, delta):
return np.sqrt((np.log(M) + np.log(2.0/delta)) / (2.0*n))
print("{:>10} | {:>8} | {:>10}".format("|H|", "n", "gap"))
print("-"*34)
for M, n in [(1000, 100), (1000, 1000), (1e6, 1000)]:
print("{:>10} | {:>8} | {:>10.3f}".format(int(M), n, gap_bound(M, n, 0.05)))
# ===================== PART 3: Irreducible-error floor =====================
print()
print("PART 3 -- Irreducible noise floor")
print("No model can push total error below sigma^2 = {:.2f}".format(sigma**2))
Part 1 ব্যাখ্যা — Monte-Carlo decomposition¶
প্রতিটি degree \(d\)-এর জন্য আমরা ৩০০ বার পুরো প্রক্রিয়াটি পুনরাবৃত্তি করি। প্রতি reps-এ:
- \([0,1]\) থেকে \(n=40\)টি training বিন্দু uniform-ভাবে টানা হয়;
- target মান \(f(x)\)-এর সাথে \(\sigma=0.3\) noise যোগ করে label \(y\) বানানো হয়;
- degree \(d\)-এর polynomial fit করা হয়;
- নির্দিষ্ট ৫০টি test বিন্দু
xt-তে prediction সংরক্ষণ করা হয়।
৩০০টি prediction-vector জমা হলে—
mean_pred(test বিন্দুপ্রতি গড়) আর সত্যিকারেরft-এর পার্থক্যের বর্গ গড় করে \(\text{bias}^2\);- test বিন্দুপ্রতি ৩০০ reps জুড়ে prediction-এর variance, তারপর বিন্দুগুলোর উপর গড় করে variance;
- \(\text{total}=\text{bias}^2+\text{variance}+\sigma^2\)।
এখানে দুটি প্রবণতা একসাথে কাজ করে। ছোট \(d\)-তে মডেলটি \(\sin\)-এর বাঁক ধরতে পারে না—তাই \(\text{bias}^2\) বড়, কিন্তু সব নমুনায় প্রায় একই সরলরেখা ফিট হয় বলে variance ছোট (underfitting)। বড় \(d\)-তে গড় prediction target-এর প্রায় গায়ে গায়ে বসে—তাই \(\text{bias}^2 \to 0\), কিন্তু প্রতিটি আলাদা নমুনায় fit দারুণভাবে নড়বড়ে হয়, variance বিস্ফোরিত হয় (overfitting)। মাঝামাঝি কোথাও total error সর্বনিম্ন—এটাই U-আকৃতির বক্ররেখার তলদেশ।
Part 2 ব্যাখ্যা — Hoeffding bound¶
সীমিত (finite) hypothesis class-এর জন্য union bound প্রয়োগ করলে, \(1-\delta\) সম্ভাবনায় training error ও true error-এর মধ্যে gap-এর উপরের সীমা:
gap_bound(M, n, delta) ঠিক এই রাশিটাই হিসাব করে। এখানে দুটি কাঠামোগত নির্ভরতা দেখার মতো:
- sample size \(n\): gap শ্রিংক করে \(1/\sqrt{n}\) হারে। \(n\) ১০ গুণ বাড়ালে gap কমে \(\sqrt{10}\approx 3.16\) গুণ।
- hypothesis class আকার \(\lvert H \rvert\): gap বাড়ে \(\sqrt{\log \lvert H \rvert}\) হারে—অর্থাৎ অত্যন্ত ধীরে। \(\lvert H \rvert\) ১০০০ থেকে এক মিলিয়নে (১০০০ গুণ) লাফালেও gap সামান্যই বড় হয়।
স্ক্রিপ্ট চালানোর ফলাফল¶
PART 1 -- Bias-Variance Decomposition (sigma^2 = 0.09)
deg | bias^2 | variance | total
----------------------------------------------
1 | 0.156 | 0.015 | 0.261
2 | 0.151 | 0.025 | 0.266
3 | 0.003 | 0.009 | 0.102
5 | 0.000 | 0.014 | 0.104
7 | 0.000 | 0.061 | 0.151
9 | 0.000 | 0.104 | 0.194
11 | 0.053 | 21.088 | 21.231
----------------------------------------------
Minimum total error at degree d = 3 (total = 0.102)
PART 2 -- Hoeffding generalization gap bound, delta = 0.05
|H| | n | gap
----------------------------------
1000 | 100 | 0.230
1000 | 1000 | 0.073
1000000 | 1000 | 0.094
PART 3 -- Irreducible noise floor
No model can push total error below sigma^2 = 0.09
পাঠোদ্ধার (read-off)¶
Part 1 — bias-variance trade-off।
- \(\text{bias}^2\) একঘেয়েভাবে নামে। \(d=1\)-এ \(0.156\) থেকে \(d=2\)-তে \(0.151\) (সরলরেখা/parabola কোনোটাই \(\sin\)-এর পূর্ণ দোলন ধরতে পারে না), তারপর \(d=3\)-এ ধাক্কা খেয়ে \(0.003\)-এ নেমে যায়, এবং \(d=5,7,9\)-এ কার্যত \(0.000\)। অর্থাৎ মডেল যত নমনীয়, গড় prediction তত target-এর কাছাকাছি।
- variance প্রায় একঘেয়েভাবে চড়ে। \(d=3\)-এ সর্বনিম্ন \(0.009\), তারপর \(0.014 \to 0.061 \to 0.104\), এবং \(d=11\)-এ বিস্ফোরিত হয়ে \(21.088\)—এটিই overfitting-এর নাটকীয় চেহারা: degree-11 polynomial মাত্র ৪০টি বিন্দুর প্রতিটি random ঝাঁকুনিকে অনুসরণ করতে গিয়ে নমুনাভেদে বুনো হয়ে ওঠে।
- total error U-আকৃতির, তলদেশ \(d=3\)-এ। \(0.261 \to 0.266 \to \mathbf{0.102} \to 0.104 \to 0.151 \to 0.194 \to 21.231\)। স্ক্রিপ্ট নিজেই নিশ্চিত করছে: Minimum total error at degree \(d=3\) (\(\text{total}=0.102\))। বাঁ দিকে underfitting (বড় \(\text{bias}^2\)), ডান দিকে overfitting (বড় variance)—মাঝের sweet spot-ই সেরা generalization।
Part 2 — Hoeffding bound।
- \(\lvert H \rvert\) স্থির রেখে \(n\) বাড়ানো: \((1000,100)\to 0.230\) কিন্তু \((1000,1000)\to 0.073\)। \(n\) ১০ গুণ বাড়ায় gap কমেছে \(0.230/0.073 \approx 3.15 \approx \sqrt{10}\) গুণ—ঠিক \(1/\sqrt{n}\) shrink।
- \(n\) স্থির রেখে \(\lvert H \rvert\) বাড়ানো: \((1000,1000)\to 0.073\) বনাম \((10^6,1000)\to 0.094\)। class এক হাজার থেকে দশ লক্ষে (১০০০ গুণ) বাড়লেও gap বেড়েছে মাত্র \(\sim 0.021\)—\(\sqrt{\log\lvert H \rvert}\) growth-এর ধীরগতির প্রমাণ। তাই বড়, বৈচিত্র্যময় hypothesis class রাখা সাধারণত সস্তা; আসল মূল্য চোকাতে হয় বেশি data দিয়ে।
Part 3 — irreducible floor। noise variance \(\sigma^2=0.09\) একটি কঠিন মেঝে: Part 1-এ সর্বনিম্ন total (\(0.102\) at \(d=3\)) এই \(0.09\)-এর সামান্য উপরে দাঁড়িয়ে—বাকি \(\approx 0.012\) হলো অবশিষ্ট \(\text{bias}^2+\text{variance}\)। degree যতই বাড়ুক বা কমুক, total কখনোই \(0.09\)-এর নিচে নামতে পারে না, কারণ data-তেই থাকা random noise কোনো মডেল মুছে ফেলতে পারে না।
সারসংক্ষেপ। তিনটি দাবি সংখ্যায় নিশ্চিত হলো: (i) total error সর্বনিম্ন degree 3-এ, (ii) irreducible-error floor \(\sigma^2=0.09\), এবং (iii) Hoeffding gap \(n\) দশগুণ হলে \(0.230 \to 0.073\)—অর্থাৎ generalization-এর দাম মেটানো হয় data দিয়ে, model-এর জটিলতা সংযত রেখে।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের গণিত — প্রত্যাশিত prediction error-এর সেই বিখ্যাত পচন \(\mathbb{E}[(y-\hat f(x))^2] = \text{Bias}^2 + \text{Variance} + \sigma^2\), model জটিল হলে bias কমে কিন্তু variance বাড়ে, training error কেন generalization error-এর আশাবাদী (optimistic) আন্দাজ, আর VC dimension কীভাবে একটা hypothesis class-এর "ধারণক্ষমতা" পরিমাপ করে — সবটাই আমরা সংখ্যা ও সূত্রে বুঝেছি। কিন্তু learning theory-র মূল insight (অন্তর্দৃষ্টি) একটা টেবিলে কখনো পুরোপুরি ধরা পড়ে না। "degree 3-এ total error 0.102, degree 9-এ 0.194, degree 11-এ 21.23" — এই সংখ্যাগুলো পাশাপাশি রাখলে যে নাটকটা ঘটে (bias একটানা পড়তেই থাকে, variance চুপচাপ মাথা তোলে, আর তাদের যোগফল একটা U-আকৃতি বানিয়ে কোনো এক মাঝামাঝি জটিলতায় সর্বনিম্ন ছোঁয়), সেটা চোখে দেখা ছাড়া অন্তরে গাঁথে না। তাই এই অংশে আমরা পুরো গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন learning theorist এগোয়: প্রথমে কেন্দ্রীয় ছবিটা — bias-variance tradeoff, যেখানে তিনটে curve মিলে U-আকৃতি জন্ম দেয়; তারপর সেই tradeoff-এর তিনটে চরিত্র (underfit, just-right, overfit) একটাই data-র উপর দেখতে কেমন; তারপর কেন training error প্রতারক আর test risk বিশ্বাসযোগ্য — generalization gap; এবং শেষে একটা ভিন্ন কোণ থেকে, VC dimension-এর শ্যাটারিং-ছবি, যা দেখায় কেন capacity-কে সংখ্যায় বাঁধা যায়।
মনে রাখুন — simulation। এই অধ্যায়ের প্রথম তিনটে ছবি একই একটা synthetic পরীক্ষা থেকে তৈরি, যা §২–§৪-এর bias-variance পচনকে সংখ্যায় বাস্তবায়িত করে। true regression function একটা sine: \(f(x) = \sin(2\pi x)\), আর তার উপর Gaussian noise (\(\sigma = 0.3\), অর্থাৎ irreducible variance \(\sigma^2 = 0.09\)) চাপানো। আমরা একটা স্থির test-grid বেছে নিই — \(50\)টা point \(x_t\) অভিন্নভাবে \([0.05, 0.95]\)-এ ছড়ানো — যেখানে সব error মাপা হবে। প্রতিটা polynomial degree \(d\)-এর জন্য আমরা \(300\) বার একটা করে fresh training set আঁকি (\(n_{\text{train}} = 40\)টা point, \(x\) অভিন্নভাবে \([0,1]\)-এ), সেই set-এ degree-\(d\) polynomial fit করি, আর test-grid-এ prediction জমাই। এই \(300\)টা prediction থেকে সরাসরি বেরোয়: \(\text{bias}^2 = \overline{(\overline{\hat f} - f)^2}\) (গড় prediction true function থেকে কতটা দূরে), \(\text{var} = \overline{\operatorname{Var}_{\text{reps}}(\hat f)}\) (run-to-run কতটা দোলে), আর \(\text{total} = \text{bias}^2 + \text{var} + \sigma^2\)। যেহেতু true \(f\) আমরা জানি, কোনটা underfit আর কোনটা overfit তা নিরপেক্ষভাবে যাচাই করা যায়।
import numpy as np
rng = np.random.default_rng(20260619)
f = lambda x: np.sin(2 * np.pi * x) # true function (অজানা, simulation-এ জানা)
sigma = 0.3 # noise std; irreducible var σ² = 0.09
xt = np.linspace(0.05, 0.95, 50) # স্থির test-grid (এখানে error মাপা হয়)
ft = f(xt) # true value test-grid-এ
n_train = 40 # প্রতি run-এ training point সংখ্যা
reps = 300 # প্রতি degree-এ কতবার নতুন data আঁকা হবে
প্রতিটা degree \(d\)-এর জন্য আমরা \(300\)টা run-এর prediction জমিয়ে তিনটে সংখ্যা হিসাব করি — bias², variance, ও total — আর সঙ্গে প্রতিটা run-এর training MSE-ও রাখি (§৬.৩-এর generalization-gap ছবির জন্য)। এই লুপটাই গোটা অধ্যায়ের সংখ্যাগত মেরুদণ্ড।
bias2, var, total, trainmse = {}, {}, {}, {}
for d in range(1, 12):
preds = np.empty((reps, len(xt)))
tr_errs = np.empty(reps)
for r in range(reps):
xtr = rng.uniform(0, 1, n_train) # নতুn training input
ytr = f(xtr) + rng.normal(0, sigma, n_train) # signal + noise
c = np.polyfit(xtr, ytr, d) # degree-d polynomial fit
preds[r] = np.polyval(c, xt) # test-grid-এ prediction
tr_errs[r] = np.mean((np.polyval(c, xtr) - ytr) ** 2) # training MSE
mean_pred = preds.mean(axis=0) # গড় prediction
bias2[d] = np.mean((mean_pred - ft) ** 2) # bias²
var[d] = np.mean(preds.var(axis=0)) # variance (run-to-run)
total[d] = bias2[d] + var[d] + sigma ** 2 # প্রত্যাশিত total error
trainmse[d] = tr_errs.mean() # গড় training MSE
এই simulation যে সংখ্যাগুলো দেয় তা নিচের ছবিগুলোর মেরুদণ্ড: degree 1-এ \((\text{bias}^2, \text{var}, \text{total}) = (0.156,\ 0.015,\ 0.261)\), degree 3-এ \((0.003,\ 0.009,\ 0.102)\) — সর্বনিম্ন, degree 9-এ \((0.000,\ 0.104,\ 0.194)\), আর degree 11-এ variance বিস্ফোরিত হয়ে \(21.09\), total \(21.23\)।
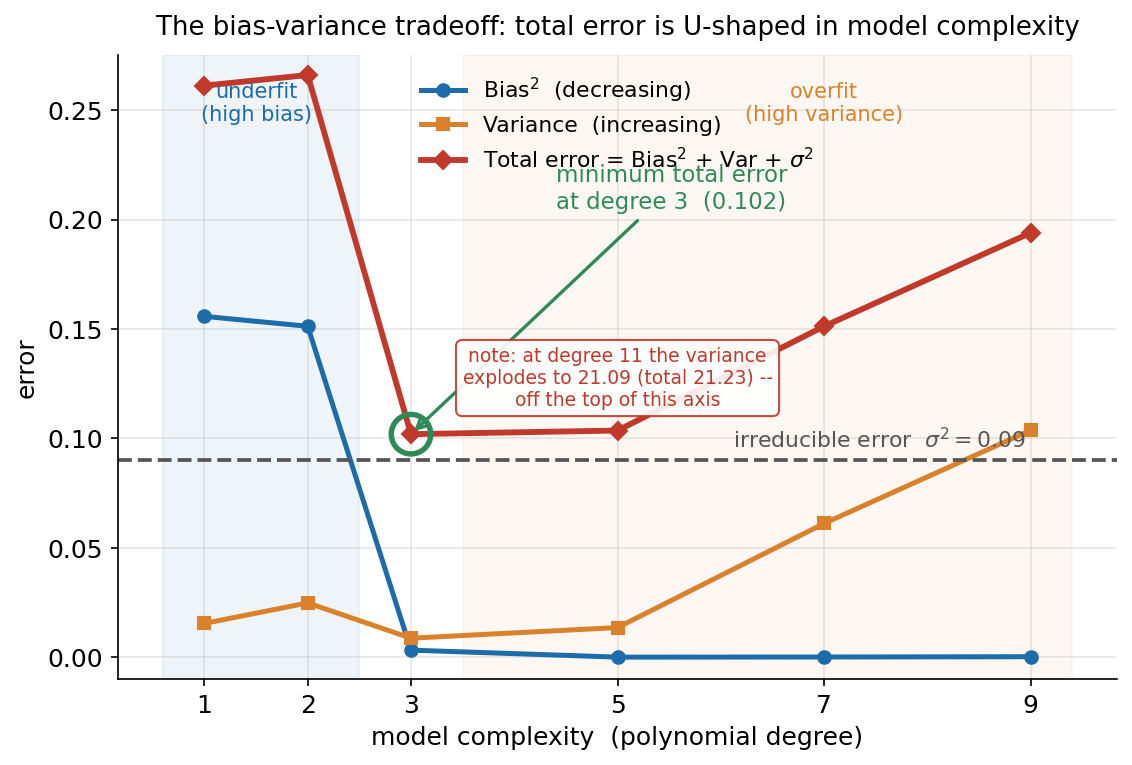
৬.১ · Bias-variance tradeoff: কেন্দ্রীয় ছবি¶
এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ ছবি — গোটা learning theory-র এক-পাতার সারাংশ। অনুভূমিক অক্ষে model complexity (polynomial degree \(1\) থেকে \(9\)), উল্লম্ব অক্ষে error। তিনটে curve একসঙ্গে: নীল Bias², কমলা Variance, আর লাল Total error (\(= \text{Bias}^2 + \text{Var} + \sigma^2\))। তত্ত্ব যা বলে: complexity বাড়ালে model আরও নমনীয় হয়, তাই true function-কে আরও ভালো করে ধরতে পারে — bias একটানা কমে। কিন্তু একই নমনীয়তা মানে model এখন আলাদা আলাদা training set-এ আরও বেশি দোলে, কারণ সে noise-এর খুঁটিনাটিও fit করতে শুরু করে — variance একটানা বাড়ে। এই দুই বিপরীত প্রবণতার যোগফল (plus স্থির irreducible \(\sigma^2\)) তাই U-আকৃতির: বাঁ দিকে bias-প্রধান, ডান দিকে variance-প্রধান, আর মাঝখানে কোনো এক জায়গায় সর্বনিম্ন — সেটাই optimal complexity। আমরা irreducible floor \(\sigma^2 = 0.09\)-কে একটা ধূসর ভাঙা রেখায় চিহ্নিত করি: কোনো curve কখনো এর নিচে যেতে পারে না।
ds = list(range(1, 10)) # readable axis: degree 1..9
b = [bias2[d] for d in ds]; v = [var[d] for d in ds]; t = [total[d] for d in ds]
fig, ax = plt.subplots(figsize=(8.6, 5.4))
ax.plot(ds, b, "-o", label=r"Bias$^2$ (decreasing)") # নীল
ax.plot(ds, v, "-s", label="Variance (increasing)") # কমলা
ax.plot(ds, t, "-D", label=r"Total = Bias$^2$ + Var + $\sigma^2$") # লাল
ax.axhline(0.09, ls="--", color="grey") # irreducible floor σ²
best = min(ds, key=lambda d: total[d]) # সর্বনিম্ন কোথায়: degree 3
ax.scatter([best], [total[best]], s=360, # সবুজ বৃত্ত
facecolor="none", edgecolor="green", lw=2.6)
ax.set_xlabel("model complexity (polynomial degree)"); ax.set_ylabel("error")
ছবি থেকে যা পড়া যায়। নীল Bias² curve-এর গল্পটা সরল ও নাটকীয়: degree \(1\) আর \(2\)-তে এটা আকাশছোঁয়া (\(0.156\), \(0.151\)) — একটা সরলরেখা বা parabola দিয়ে পুরো sine-এর ওঠা-নামা ধরা অসম্ভব, তাই গড় prediction-ও true function থেকে বহু দূরে। তারপর degree \(3\)-এ এসে এটা খাড়া নেমে প্রায় শূন্যে (\(0.003\)) পৌঁছায় এবং সেখানেই থেকে যায় — অর্থাৎ degree \(3\) থেকেই polynomial-শ্রেণিটা যথেষ্ট নমনীয় যে গড়ে true \(\sin(2\pi x)\)-কে ধরতে পারে, আরও বেশি degree bias-এর দিক থেকে আর কিছু যোগ করে না। কমলা Variance curve ঠিক বিপরীত: degree \(1\)–\(5\) পর্যন্ত এটা নিচু ও শান্ত (\(0.01\)–\(0.02\)-এর ঘরে), কিন্তু degree \(5\)-এর পর মাথা তুলতে শুরু করে আর degree \(7\) ও \(9\)-এ লাফিয়ে ওঠে (\(0.061\), \(0.104\)) — কারণ উঁচু-degree polynomial-গুলো প্রতিটা আলাদা \(40\)-point নমুনার noise-এর প্যাটার্ন আলাদাভাবে অনুসরণ করে, তাই run-to-run তাদের prediction প্রবলভাবে দোলে।
এই দুই curve-এর যোগফলই (plus স্থির \(\sigma^2 = 0.09\)) লাল Total curve-এর U-আকৃতি তৈরি করে, আর এই U-ই গোটা অধ্যায়ের কেন্দ্রীয় বার্তা। বাঁ দিকে (\(d = 1, 2\)) total বিশাল (\(0.261\), \(0.266\)) — bias-এ পঙ্গু। ডান দিকে (\(d = 7, 9\)) আবার ওঠে (\(0.151\), \(0.194\)) — variance-এ পঙ্গু। আর তলায়, degree \(3\)-এ সবুজ বৃত্তে ঘেরা সর্বনিম্ন \(0.102\) — এখানে bias প্রায় নিঃশেষ হয়ে গেছে অথচ variance এখনো জাগেনি, তাই দুই কুফল একসঙ্গে সবচেয়ে ছোট। লক্ষ করুন এই সর্বনিম্নও কিন্তু \(\sigma^2 = 0.09\) ধূসর রেখার ঠিক উপরে থেমেছে, নিচে নামেনি — এই \(0.012\) ব্যবধানটুকুই irreducible error: noise-এর জন্য কোনো model-ই, যত চতুরই হোক, \(0.09\)-এর নিচে যেতে পারবে না, তাই \(0.102\)-ই বাস্তবিক সেরা।
আর সবচেয়ে নাটকীয় অংশটা অক্ষের বাইরে, কোণের নোটে: degree \(11\)-এ variance \(21.09\)-এ বিস্ফোরিত হয় (total \(21.23\)) — এই অক্ষের সর্বোচ্চ মান \(0.27\)-এর প্রায় \(80\) গুণ! এটাই অতি-জটিল model-এর চরম পরিণতি: \(40\)টা point-এ degree-\(11\) polynomial fit করা মানে প্রায় ততগুলো parameter দিয়ে ততগুলো point মেলানো, ফলে fit বন্য হয়ে যায় এবং নমুনা সামান্য বদলালেই prediction পাগলের মতো লাফায়। এই একটিমাত্র সংখ্যা থেকেই পরিষ্কার কেন complexity-কে অন্ধভাবে বাড়ানো বিপর্যয়কর — এবং কেন বাঁ-ডান দুই বিপদের মাঝখানে এই U-এর তলাটি খুঁজে বের করাই learning-এর আসল কাজ।
৬.২ · Underfit, just-right, overfit: একটাই data-র উপর¶
§৬.১-এর U-curve বিমূর্ত — bias², variance, error সবই \(300\) run-এর গড়। কিন্তু underfit, just-right, আর overfit আসলে data-র উপর দেখতে কেমন? এই দ্বিতীয় ছবিটা সেই বিমূর্ততাকে কংক্রিট ছবিতে অনুবাদ করে: একটাই সাধারণ নমুনা (\(n = 40\) point, scatter হিসেবে আঁকা), তার উপর কালো ভাঙা রেখায় true \(\sin(2\pi x)\), আর তিনটে fitted polynomial পাশাপাশি — degree \(1\) (underfit), degree \(3\) (good), আর degree \(11\) (overfit)। উদ্দেশ্য হলো U-curve-এর তিনটে চরিত্রকে চোখে ধরা, যাতে "high bias" আর "high variance" শুধু সংখ্যা না থেকে আকৃতি হয়ে ওঠে।
xx = np.linspace(0, 1, 400)
ax.scatter(x_one, y_one, label="sampled data (n = 40)") # একটাই নমুনা scatter
ax.plot(xx, f(xx), "--", color="black", # কালো ভাঙা true sine
label=r"true function $\sin(2\pi x)$")
for d, lab in [(1, "degree 1 (underfit)"),
(3, "degree 3 (good fit)"),
(11, "degree 11 (overfit)")]:
c = np.polyfit(x_one, y_one, d) # এই নমুনায় fit
ax.plot(xx, np.polyval(c, xx), lw=2.6, label=lab)
ax.set_xlabel("x"); ax.set_ylabel("y")
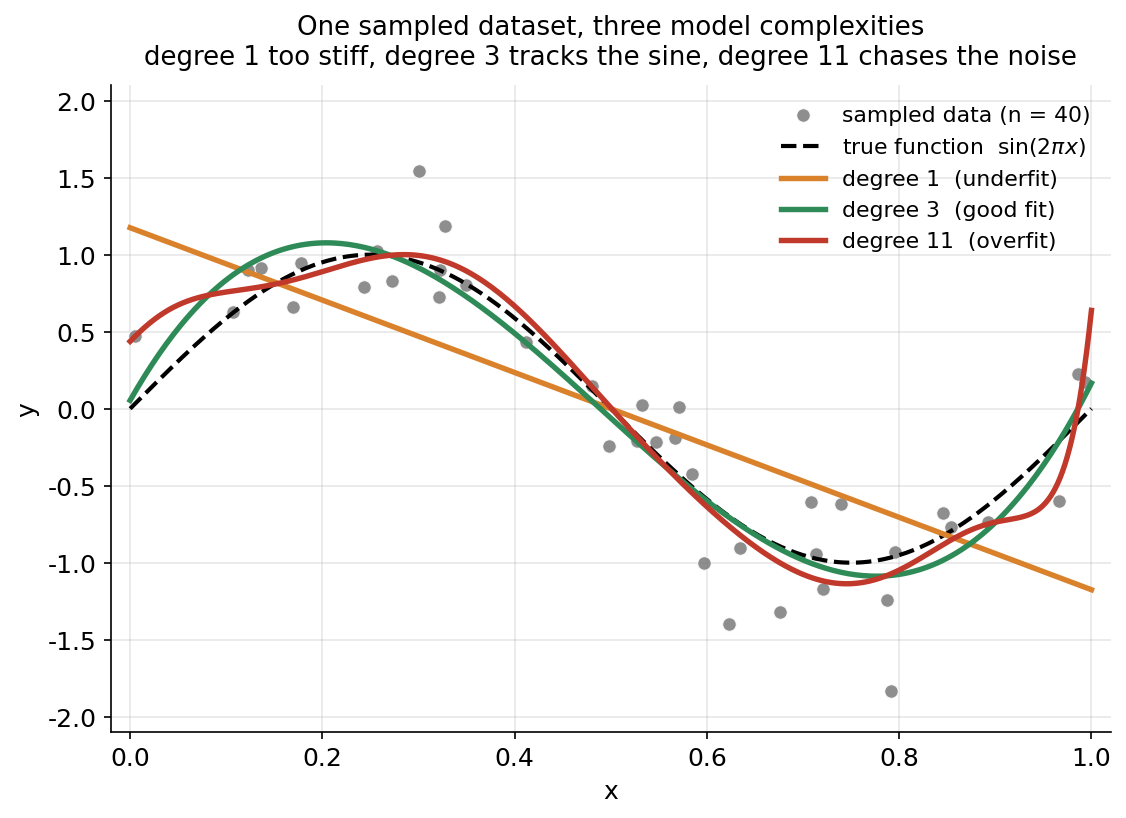
ছবি থেকে যা পড়া যায়। কমলা degree-1 রেখাটা একটা সৎ কিন্তু অসহায় চেষ্টা — একটা সরলরেখা সংজ্ঞা-অনুসারেই বাঁকতে পারে না, তাই \(\sin(2\pi x)\)-এর বাঁ দিকের শৃঙ্গ (\(x \approx 0.25\)) আর ডান দিকের খাদ (\(x \approx 0.75\)) সে সম্পূর্ণ মিস করে; সে শুধু data-র সামগ্রিক নিম্নগামী ঢাল ধরে রাখে। এটাই underfit-এর চাক্ষুষ রূপ, আর §৬.১-এ এর বিশাল bias² (\(0.156\)) ঠিক এই গঠনগত অক্ষমতারই সংখ্যাগত ছায়া — model-টা data-র আসল আকৃতির তুলনায় বড্ড অনমনীয়। সবুজ degree-3 curve কালো ভাঙা true curve-এর সঙ্গে প্রায় আলাদা করা যায় না — শৃঙ্গ শৃঙ্গের জায়গায়, খাদ খাদের জায়গায়, অথচ কোথাও কোনো একক noisy point-এর পেছনে ছোটেনি। এটাই just right, আর তাই এর total error (\(0.102\)) সর্বনিম্ন: bias প্রায় নেই, variance এখনো শান্ত।
লাল degree-11 curve সবচেয়ে শিক্ষণীয়। data-র ঘন মাঝখানে (\(0.25 < x < 0.75\)) সে অনেকটা degree-3-এর গায়েই থাকে, কিন্তু দুই প্রান্তে — যেখানে boundary-র কাছে point কম এবং polynomial-এর স্বাধীনতা বেশি — সে আঁকাবাঁকা হয়ে individual point-গুলোর দিকে ঝুঁকে পড়ে, true sine ছাড়িয়ে বন্য wiggle তৈরি করে (\(x \approx 0\) ও \(x \approx 1\)-এ curve হঠাৎ লাফ দেয়)। এটাই overfit-এর মুখ: বাড়তি \(8\) ডিগ্রি স্বাধীনতা signal ধরায় কিছু যোগ করেনি, বরং পুরোটাই noise-কে অনুসরণ করতে খরচ হয়েছে। আর এখানেই §৬.১-এর সেই বিস্ফোরণের ব্যাখ্যা — এই নমুনায় curve-টা এমন কাঁপছে, অন্য নমুনায় কাঁপবে সম্পূর্ণ অন্যভাবে; সেই run-to-run অস্থিরতাই variance, আর degree \(11\)-এ তা \(21.09\)।
তিনটে curve একসঙ্গে §৬.১-এর U-curve-কে জীবন্ত করে তোলে: বাঁ প্রান্ত (underfit) = কমলা সরলরেখা, তলা (সর্বনিম্ন) = সবুজ curve, ডান প্রান্ত (overfit) = লাল wiggle। আর একটা সূক্ষ্ম কিন্তু জরুরি পাঠ এই ছবিতে লুকানো: লাল degree-11 curve আসলে অনেক individual point-এর আরও কাছ দিয়ে গেছে — কেবল এই একটা scatter দেখে চোখে আন্দাজ করলে তাকেই "সবচেয়ে ভালো fit" মনে হতে পারে। এই ফাঁদটাই পরের ছবির বিষয়: training data কেন আমাদের প্রতারিত করে।
৬.৩ · Generalization gap: training error কেন প্রতারক¶
§৬.২ ইঙ্গিত দিয়েছিল — যে curve training point-গুলোর সবচেয়ে কাছ দিয়ে যায়, সে-ই সবচেয়ে ভালো নয়। এই তৃতীয় ছবিটা সেই ইঙ্গিতকে সংখ্যায় প্রমাণ করে। অনুভূমিক অক্ষে আবার model complexity, উল্লম্ব অক্ষে error, আর দুটো curve পাশাপাশি: নীল training error (model যে data-য় শিখেছে সেই একই data-য় মাপা গড় MSE) আর লাল test / true risk (§৬.১-এর সেই total error, যা স্বাধীন test-grid-এ মাপা)। তত্ত্ব যা বলে: training error হলো generalization error-এর একটা আশাবাদী আন্দাজ, কারণ model নিজের শেখা data-তেই পরীক্ষিত হচ্ছে — তাই complexity বাড়ালে এটা একটানা নামতেই থাকবে, কখনো আসল risk-কে ছোঁবে না। এই দুই curve-এর মধ্যেকার উল্লম্ব ফাঁকটাই generalization gap, যা আমরা ছায়া দিয়ে চিহ্নিত করি — আর high complexity-তে এই ফাঁক চওড়া হওয়াই overfitting-এর স্বাক্ষর।
tr = [trainmse[d] for d in ds]; te = [total[d] for d in ds]
fig, ax = plt.subplots(figsize=(8.6, 5.4))
ax.fill_between(ds, tr, te, alpha=0.30, label="generalization gap") # ছায়া = gap
ax.plot(ds, tr, "-o", label="training error (decreasing)") # নীল
ax.plot(ds, te, "-D", label="test / true risk (U-shaped)") # লাল
best = min(ds, key=lambda d: total[d]) # sweet spot: 3
ax.scatter([best], [total[best]], s=360, # সবুজ বৃত্ত
facecolor="none", edgecolor="green", lw=2.6)
ax.axhline(0.09, ls="--", color="grey") # σ² floor
ax.set_xlabel("model complexity (polynomial degree)"); ax.set_ylabel("error")
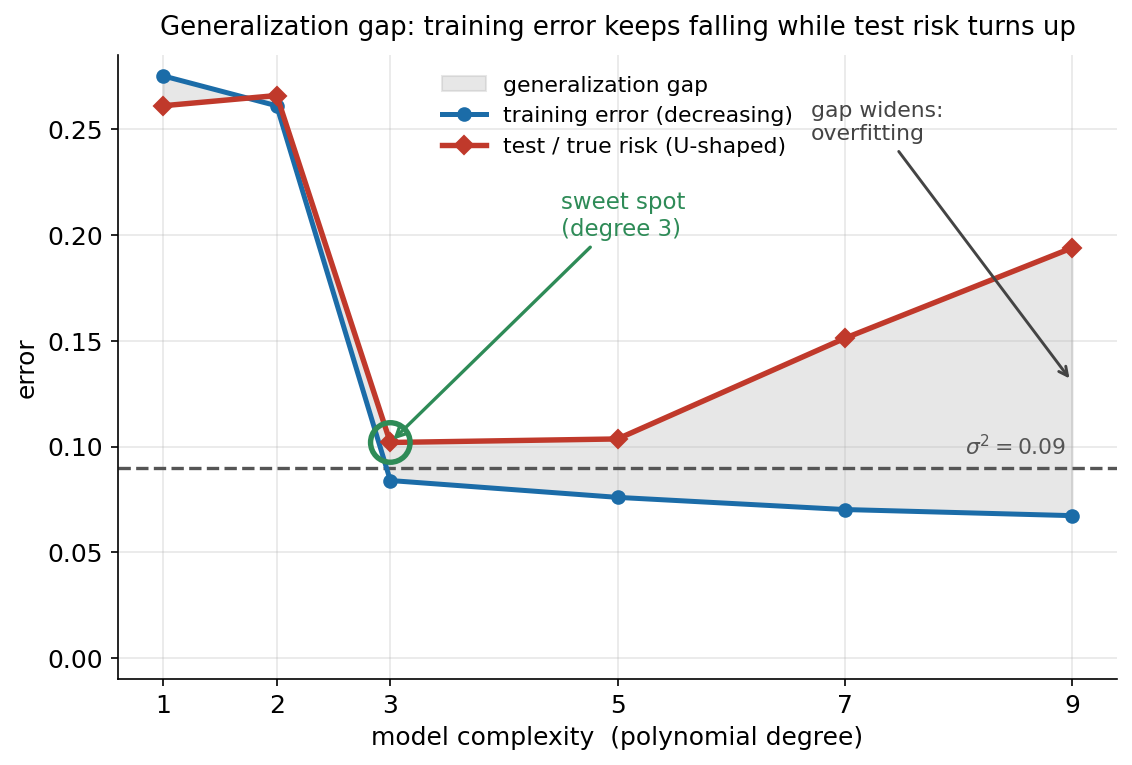
ছবি থেকে যা পড়া যায়। নীল আর লাল curve degree \(1\)–\(3\)-তে প্রায় গায়ে গায়ে — দুই জায়গাতেই error একসঙ্গে ওঠে-নামে, কারণ underfit model এত আনাড়ি যে সে training data-কেও ভালোভাবে fit করতে পারে না, তাই training error আর true risk দুটোই বড় ও কাছাকাছি (gap সরু)। কিন্তু degree \(3\)-এর পর থেকেই দুটো curve-এর পথ আলাদা হয়ে যায়, আর সেখানেই গোটা ছবির পাঠ। নীল training error degree \(3\) থেকে \(9\) পর্যন্ত মৃদুভাবে নামতেই থাকে (\(0.084 \to 0.067\)) এবং ধূসর \(\sigma^2 = 0.09\) রেখাকেও পেরিয়ে নিচে চলে যায় — অর্থাৎ প্রতিটা বাড়তি degree training data-র noise-এর একটু একটু অংশ মুখস্থ করে error আরও কমিয়ে দেয়, এমনকি irreducible floor-এরও নিচে। এটা একটা বিপজ্জনক মরীচিকা: training error দেখে মনে হয় model "আরও ভালো" হচ্ছে।
কিন্তু লাল test risk সততার সঙ্গে উল্টো সত্যটা জানায়: degree \(3\)-এর sweet spot (\(0.102\), সবুজ বৃত্ত)-এ পৌঁছে আর নামে না, বরং degree \(5\)-এর পর থেকে আবার ওঠে (\(0.104,\ 0.151,\ 0.194\))। ফলে দুই curve-এর মধ্যেকার ধূসর ছায়া — generalization gap — degree \(3\)-এর পর থেকে ক্রমশ চওড়া হয়, আর ডান প্রান্তে তা বিশাল। এই চওড়া হওয়া ফাঁকই overfitting-এর সংজ্ঞা: model training data-য় যতটা ভালো করছে আর অদেখা data-য় যতটা খারাপ করছে, তার পার্থক্য তত বাড়ছে।
মূল শিক্ষাটা এই দুই curve-এর তফাতেই লুকানো, এবং এটি §৬.২-এর চাক্ষুষ ফাঁদটিকে সংখ্যায় বদলে দেয়। training error দিয়ে model বাছা অসম্ভব: সে সবসময় সবচেয়ে জটিল model-কেই (যেখানে training error সর্বনিম্ন, এমনকি \(\sigma^2\)-এর নিচে) "সেরা" বলবে — অথচ সেটা চরম overfitting। শুধু held-out / true risk পারে, কারণ সে model কখনো-না-দেখা data-য় মাপে, তাই overfitting-কে শাস্তি দেয় এবং U-এর তলায় সঠিক উত্তর (degree \(3\)) দেখিয়ে দেয়। বাস্তবে আমরা true risk জানি না (এই simulation-এ জানি, কারণ \(f\) জানা) — তাই অধ্যায় ৫.৮-এর cross-validation এসে এই অদেখা-data-র risk-কে অনুমান করে। এই ছবিটা তাই learning theory-র গোড়ার যুক্তিটি দৃশ্যমান করে: training error নয়, generalization error-ই একমাত্র সৎ বিচারক।
৬.৪ · VC dimension: capacity-কে শ্যাটারিং দিয়ে মাপা¶
এতক্ষণ আমরা একটা নির্দিষ্ট hypothesis class (polynomial regression) ধরে complexity বাড়িয়ে-কমিয়ে দেখেছি। কিন্তু learning theory আরও গভীর একটা প্রশ্ন তোলে: একটা hypothesis class-এর অন্তর্নিহিত ধারণক্ষমতা (capacity) কীভাবে পরিমাপ করি — এমন একটা সংখ্যা যা bound (যেমন \(R(h) \le \hat R(h) + O(\sqrt{d_{VC}/n})\)) দিতে পারে? উত্তর হলো VC dimension (\(d_{VC}\)), আর তার সংজ্ঞার হৃদয়ে আছে shattering: একটা class একগুচ্ছ point-কে shatter করে যদি, point-গুলোর সম্ভাব্য সব \(+/-\) labeling-এর জন্যই class-এ অন্তত একটা classifier থাকে যা ঠিকঠাক আলাদা করতে পারে। \(d_{VC}\) হলো সবচেয়ে বড় সেই point-সংখ্যা যাকে class shatter করতে পারে। এই শেষ ছবিটা — পুরোপুরি schematic, কোনো simulation-data লাগে না — 2D-তে সরলরেখা-classifier (linear classifier)-এর জন্য এই ধারণাটা হাতে-কলমে দেখায়: তারা \(3\)টা point shatter করতে পারে কিন্তু \(4\)টা পারে না, তাই \(d_{VC} = 3\)।
বাঁ দিকের প্যানেলে \(3\)টা non-collinear (এক সরলরেখায় নয়) point-এর চারটে প্রতিনিধিত্বমূলক labeling দেখানো হয়েছে, প্রতিটির জন্য একটা সরলরেখা টানা যা সেই labeling-কে সঠিকভাবে আলাদা করে: সব \(+\), শীর্ষবিন্দু \(-\), বাঁ-নিচের বিন্দু \(-\), ডান-নিচের বিন্দু \(-\) (বাকি labeling-গুলো এদেরই দর্পণ-প্রতিচ্ছবি)। ডান দিকের প্যানেলে \(4\)টা point একটা বর্গাকারে বসানো, আর তাদের উপর সবচেয়ে কঠিন labeling — XOR (কোণাকুণি জোড়া একই শ্রেণি: বাঁ-নিচ ও ডান-উপর \(+\), ডান-নিচ ও বাঁ-উপর \(-\)) — চাপানো হয়েছে; দেখা যায় কোনো একটিমাত্র সরলরেখাই এই বিন্যাসকে আলাদা করতে পারে না।
from matplotlib.patches import Rectangle # markers: o = class +1, s = class -1
# বাঁ প্যানেল: 3টা non-collinear point, 4টা labeling, প্রতিটির separating line
# (প্রতিটা labeling-এর জন্য minority শ্রেণিকে অন্য পাশে রাখা একটা রেখা আঁকা হয়)
draw_case(axL, labels=[1, 1, 1], line="above all") # all +
draw_case(axL, labels=[0, 1, 1], line="below apex") # apex -
draw_case(axL, labels=[1, 0, 1], line="left of base-left") # base-left -
draw_case(axL, labels=[1, 1, 0], line="right of base-right") # base-right -
# ডান প্যানেল: 4 point বর্গে, XOR labeling — তিনটে candidate রেখা সবই ব্যর্থ
xor_pos = corners[[0, 3]] # বাঁ-নিচ ও ডান-উপর → +
xor_neg = corners[[1, 2]] # ডান-নিচ ও বাঁ-উপর → −
axR.scatter(*xor_pos.T, marker="o", label="class +1")
axR.scatter(*xor_neg.T, marker="s", label="class -1")
for line in candidate_lines: # horizontal, vertical, diagonal
axR.plot(*line, "--", color="grey") # প্রতিটাই একটা point ভুল করে
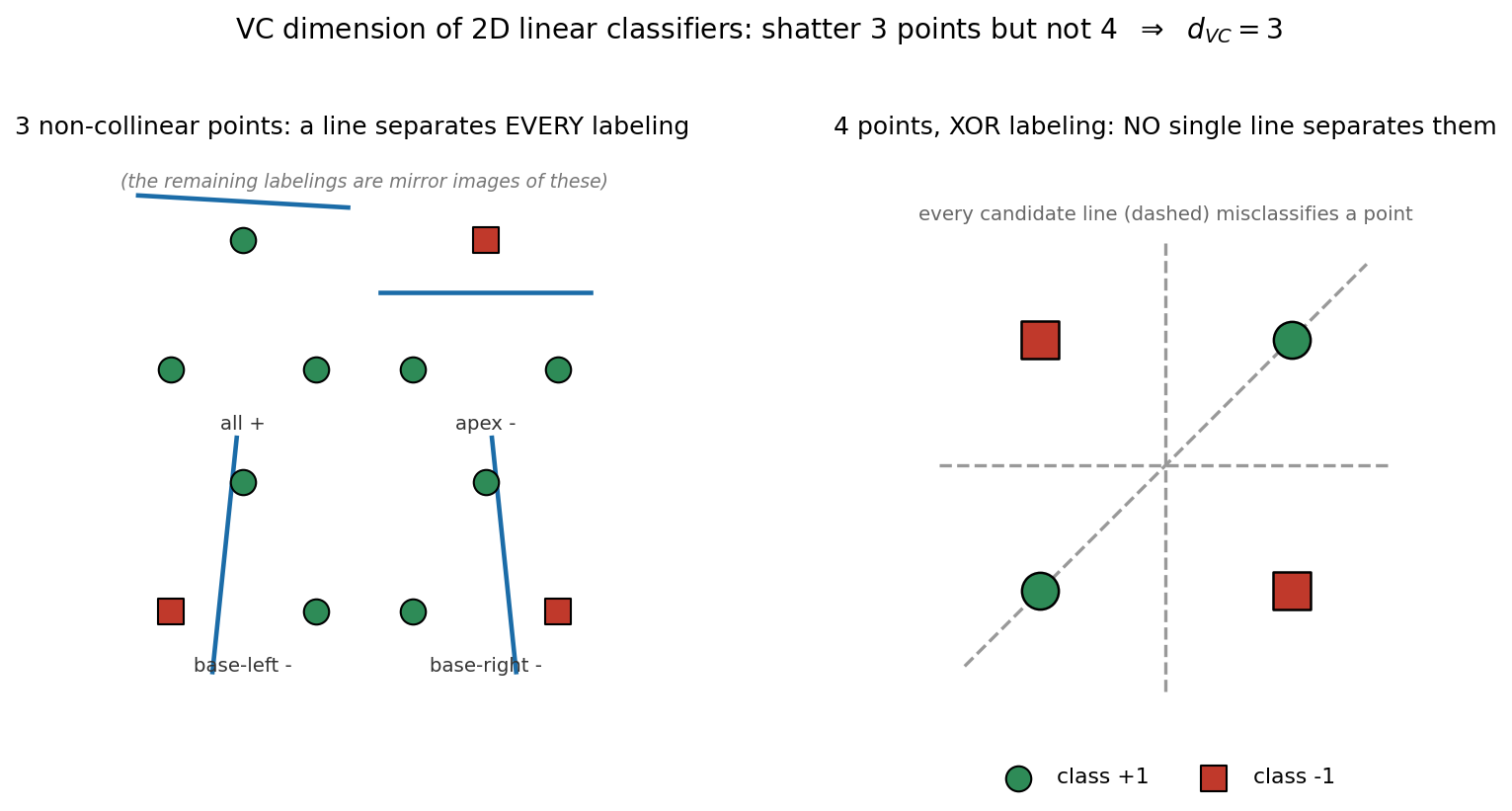
ছবি থেকে যা পড়া যায়। বাঁ প্যানেলটা \(d_{VC} \ge 3\) প্রতিষ্ঠা করে। তিনটে non-collinear point-এর মোট \(2^3 = 8\)টা সম্ভাব্য labeling; ছবিতে এদের চারটে দেখানো — বাকি চারটে কেবল \(+\) আর \(-\) অদলবদল করলেই পাওয়া যায় (দর্পণ-প্রতিচ্ছবি, একই রেখা উল্টো পাশ ধরে কাজ করে)। গুরুত্বপূর্ণ হলো: প্রতিটা labeling-এর জন্য একটা সরলরেখা পাওয়া যাচ্ছে যা সবুজ বৃত্তগুলোকে লাল বর্গগুলো থেকে নিখুঁত আলাদা করে — "all +"-এ সবাইকে এক পাশে রাখা একটা রেখা, "apex -"-এ শীর্ষবিন্দুকে কেটে ফেলা একটা প্রায়-অনুভূমিক রেখা, আর দুই base-case-এ একটা করে প্রায়-উল্লম্ব রেখা যা ঠিক ওই একটা কোণার বিন্দুকে বাকি দুটো থেকে বিচ্ছিন্ন করে। যেহেতু সব \(8\)টা labeling সরলরেখায় সাধনযোগ্য, 2D linear classifier এই \(3\)টা point-কে shatter করে — তাই capacity অন্তত \(3\)।
ডান প্যানেলটা দেখায় কেন capacity ঠিক \(3\), \(4\) নয়। চারটে point বর্গাকারে বসিয়ে তাদের উপর XOR labeling চাপানো হয়েছে: কোণাকুণি জোড়া একই শ্রেণি (বাঁ-নিচ ও ডান-উপর সবুজ \(+\), ডান-নিচ ও বাঁ-উপর লাল \(-\))। এবার যেকোনো সরলরেখা সমতলকে দুই অর্ধে ভাগ করে — কিন্তু এই বিন্যাসে দুই \(+\) point কর্ণের দুই বিপরীত প্রান্তে আর দুই \(-\) point অন্য কর্ণের দুই প্রান্তে, তাই কোনো একটিমাত্র রেখা দুই সবুজকে এক পাশে আর দুই লালকে অন্য পাশে রাখতে পারে না। ছবিতে তিনটে স্বাভাবিক candidate রেখা — অনুভূমিক, উল্লম্ব, কর্ণ — সবকটাই ভাঙা ধূসর রেখায় আঁকা, আর প্রতিটাই অন্তত একটা point ভুল দিকে ফেলে (যেমন অনুভূমিক রেখা একটা সবুজ ও একটা লালকে একই অর্ধে রেখে দেয়)। যেহেতু একটা labeling-ই (XOR) অসাধ্য, \(4\)টা point shatter করা যায় না।
দুই প্যানেল একসঙ্গে তাই নিখুঁতভাবে প্রতিষ্ঠা করে: shatter 3, but not 4 \(\Rightarrow d_{VC} = 3\) (সাধারণভাবে \(\mathbb{R}^p\)-তে linear classifier-এর \(d_{VC} = p + 1\), এখানে \(p = 2\))। আর এই একটিমাত্র সংখ্যাই §২–§৪-এর generalization bound-গুলোতে capacity-র জায়গা নেয়: \(d_{VC}\) যত বড়, class তত বেশি labeling মেলাতে পারে, তাই training error আর true risk-এর মধ্যে সম্ভাব্য ফাঁক (§৬.৩-এর সেই gap) তত চওড়া হতে পারে — অর্থাৎ একই \(d_{VC}\)-ই hypothesis class-এর "অতিরিক্ত নমনীয়তা"-কে সংখ্যায় বেঁধে দেয়, যা polynomial degree-এর U-curve থেকে generalization bound পর্যন্ত গোটা গল্পটাকে এক সুতোয় গাঁথে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও সংক্ষিপ্ত hint। (★ সহজ, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং।) data-নির্ভর প্রশ্নগুলো এই অধ্যায়ের চলমান simulation-এর canonical সংখ্যা ব্যবহার করে — seed np.random.default_rng(20260619), সত্য ফাংশন \(f(x)=\sin(2\pi x)\), noise \(\sigma=0.3\) (অর্থাৎ irreducible \(\sigma^2=0.09\)), \(n=40\), \(\text{reps}=300\), complexity = polynomial degree \(d\)। মূল decomposition: \(\mathbb E\big[(\hat f(x_0)-f(x_0))^2\big]=\mathrm{Bias}^2+\mathrm{Var}+\sigma^2\)। পূর্ণ সমাধান _solutions/06-01-learning-theory-solutions.md-এ।
প্রসঙ্গের সুবিধার্থে নিচের canonical টেবিলটি কয়েকটি প্রশ্নে বারবার লাগবে (test-point-গড় bias²/variance, এবং total \(=\text{bias}^2+\text{var}+\sigma^2\) যেখানে \(\sigma^2=0.09\)):
| degree \(d\) | \(\mathrm{Bias}^2\) | \(\mathrm{Var}\) | total error |
|---|---|---|---|
| 1 | 0.156 | 0.015 | 0.261 |
| 3 | 0.003 | 0.009 | 0.102 (min) |
| 9 | 0.000 | 0.104 | 0.194 |
| 11 | 0.053 | 21.09 | 21.23 |
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় পার্থক্য করুন: true risk \(R(h)=\mathbb E[\ell(h(x),y)]\) আর empirical risk \(\hat R_n(h)=\frac1n\sum_{i=1}^n\ell(h(x_i),y_i)\)। কোনটা আমরা আসলে minimize করতে চাই, আর কোনটা বাস্তবে minimize করি? দুটোর মধ্যে যে ফাঁক (\(R(\hat h)-\hat R_n(\hat h)\)) সেটাকে কী বলে? Hint: \(R\) পুরো distribution \(P(x,y)\)-র উপর গড়, \(\hat R_n\) হাতে-থাকা \(n\)টি নমুনার উপর গড়; learning-এর লক্ষ্য আগেরটা, কিন্তু \(P\) অজানা।
প্রশ্ন ২ (★). কেন training error (অর্থাৎ \(\hat R_n(\hat h)\)) সাধারণত true risk \(R(\hat h)\)-কে optimistic-ভাবে (কম করে) অনুমান করে? এক বাক্যে বলুন কোন ধাপে "double use of data" ঘটে। Hint: \(\hat h\)-কে যে data-তে বাছা/fit করা হয়েছে, সেই একই data-তে তার error মাপা হচ্ছে — fit ঐ নমুনার random ওঠানামার দিকেও ঝুঁকে যায়।
প্রশ্ন ৩ (★). ERM (Empirical Risk Minimization) নীতিটি এক লাইনে সংজ্ঞায়িত করুন: একটি hypothesis class \(\mathcal H\) দেওয়া থাকলে ERM কোন \(h\) বেছে নেয়? এবং hypothesis class \(\mathcal H\)-কে বড় করলে (capacity বাড়ালে) \(\hat R_n(\hat h)\) কেন কখনো বাড়তে পারে না? Hint: \(\hat h=\arg\min_{h\in\mathcal H}\hat R_n(h)\); বড় \(\mathcal H\)-এ আগের সব \(h\) এখনো আছে, তাই minimum কেবল সমান বা ছোট হয়।
প্রশ্ন ৪ (★★). bias–variance trade-off-কে generalization-এর ভাষায় ব্যাখ্যা করুন: model complexity বাড়লে (ক) bias-এর কী হয়, (খ) variance-এর কী হয়, (গ) irreducible error \(\sigma^2\)-এর কী হয়? canonical টেবিল থেকে একটি করে উদাহরণ-সংখ্যা টেনে প্রতিটি দাবি সমর্থন করুন। Hint: \(d{=}1\to d{=}9\) যেতে bias² \(0.156\to0.000\) (কমে), var \(0.015\to0.104\) (বাড়ে), \(\sigma^2\) অপরিবর্তিত \(0.09\)।
প্রশ্ন ৫ (★★). U-curve (test error বনাম complexity) কেন U-আকৃতির, অথচ training error একঘেয়ে নিচে নামে? canonical টেবিল ব্যবহার করে বলুন কোন degree-এ total error সর্বনিম্ন এবং সেই বিন্দুতে কে (bias না variance) কাকে ভারসাম্যে রাখছে। Hint: total \(=\text{bias}^2+\text{var}+\sigma^2\); বাঁ-প্রান্তে bias-প্রধান (underfit), ডান-প্রান্তে variance-প্রধান (overfit); min ঐখানে যেখানে দুই প্রবণতা প্রায় সাম্যাবস্থায়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★) [E-bias-var]. canonical টেবিলে total error-এর কলামটি \(\text{bias}^2+\text{var}+\sigma^2\) (\(\sigma^2=0.09\)) সূত্রে যাচাই করুন — চারটি degree-এর প্রতিটির জন্য হাতে যোগ করে দেখান সংখ্যাগুলো মেলে। Hint: \(d{=}1\): \(0.156+0.015+0.09=0.261\); বাকি তিনটিও একইভাবে।
প্রশ্ন ৭ (★) [E-fit]. শুধু নিচের bias²/variance মান দেখে (total না দেখে) প্রতিটি degree-কে underfit / সেরা / overfit লেবেল দিন এবং এক বাক্যে যুক্তি দিন:
| degree | \(\mathrm{Bias}^2\) | \(\mathrm{Var}\) |
|---|---|---|
| 1 | 0.156 | 0.015 |
| 3 | 0.003 | 0.009 |
| 9 | 0.000 | 0.104 |
| 11 | 0.053 | 21.09 |
Hint: উচ্চ bias² + নিম্ন var = underfit; নিম্ন bias² + উচ্চ var = overfit; দুটোই ছোট = সেরা।
প্রশ্ন ৮ (★★) [E-hoeffding]. finite hypothesis class \(\mathcal H\)-এর জন্য uniform generalization bound বলে: \(1-\delta\) probability-তে একসাথে সব \(h\in\mathcal H\)-র জন্য $$ R(h)\le \hat R_n(h)+\sqrt{\frac{\ln\lvert\mathcal H\rvert+\ln(2/\delta)}{2n}}. $$ \(\delta=0.05\) ধরে generalization-gap পদটি (\(\sqrt{\cdot}\)) হিসাব করুন: (ক) \(\lvert\mathcal H\rvert=1000,\ n=100\); (খ) একই \(\lvert\mathcal H\rvert=1000\) কিন্তু \(n=1000\); (গ) \(\lvert\mathcal H\rvert=10^6,\ n=1000\)। (ক)→(খ) এবং (খ)→(গ) তুলনায় কী শিখলেন? Hint: canonical উত্তর যথাক্রমে \(0.230,\ 0.073,\ 0.094\); \(n\) ১০ গুণ বাড়লে bound \(\sqrt{10}\) গুণ কমে, আর \(\lvert\mathcal H\rvert\) \(10^3\) গুণ বাড়লে শুধু \(\ln\)-এর ভেতরে ঢোকায় সামান্যই বাড়ে।
প্রশ্ন ৯ (★★) [E-scaling]. প্রশ্ন ৮-এর bound-এ ধরুন আপনি gap-কে \(0.05\)-এর নিচে নামাতে চান, \(\lvert\mathcal H\rvert=1000,\ \delta=0.05\) স্থির। আনুমানিক কত \(n\) লাগবে? এবং বলুন bound-এ \(n\) ও \(\lvert\mathcal H\rvert\)-এর ভূমিকা মৌলিকভাবে কেন আলাদা (একটা বর্গমূলে \(1/n\), অন্যটা \(\ln\)-এ)। Hint: \(\sqrt{(\ln 1000+\ln 40)/(2n)}\le 0.05 \Rightarrow n\ge (\ln1000+\ln40)/(2\cdot0.05^2)\); \(\lvert\mathcal H\rvert\) exponent-এর ভেতরে বসে বলে তার দাম কেবল লগারিদমিক।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১০ (★★). point-wise MSE decomposition প্রমাণ করুন: একটি স্থির test-point \(x_0\)-তে, \(y=f(x_0)+\varepsilon\) (\(\mathbb E[\varepsilon]=0,\ \mathrm{Var}(\varepsilon)=\sigma^2\), \(\varepsilon\perp\hat f\)) ধরে দেখান $$ \mathbb E\big[(y-\hat f(x_0))^2\big]=\underbrace{\big(f(x_0)-\mathbb E[\hat f(x_0)]\big)^2}{\mathrm{Bias}^2}+\underbrace{\mathrm{Var}\big(\hat f(x_0)\big)}+\sigma^2. $$ }Hint: \(\hat f(x_0)-\mathbb E[\hat f]\) যোগ-বিয়োগ করে cross-term-এ expectation নিন; স্বাধীনতা ও \(\mathbb E[\varepsilon]=0\) ব্যবহারে cross-term শূন্য (4.4-এর MSE = bias²+variance-এর সম্প্রসারণ)।
প্রশ্ন ১১ (★★). finite-\(\mathcal H\) bound (প্রশ্ন ৮-এর সূত্র) Hoeffding ও union bound থেকে উৎপাদন করুন। একটি স্থির \(h\)-এর জন্য Hoeffding (3.1) দেয় \(P\big(R(h)-\hat R_n(h)\ge t\big)\le e^{-2nt^2}\) (ধরুন \(\ell\in[0,1]\))। এখান থেকে union bound-এ \(\lvert\mathcal H\rvert\)টি hypothesis-জুড়ে দেখান যে failure-probability \(\le \lvert\mathcal H\rvert e^{-2nt^2}\), একে \(\delta\) ধরে \(t\)-এর জন্য সমাধান করুন। Hint: \(\lvert\mathcal H\rvert e^{-2nt^2}=\delta \Rightarrow t=\sqrt{\frac{\ln\lvert\mathcal H\rvert+\ln(1/\delta)}{2n}}\); দুই-পাশের (absolute) deviation চাইলে \(2/\delta\) ব্যবহার করুন।
প্রশ্ন ১২ (★★★). 2D-তে একটি linear (half-plane) classifier-এর \(d_{\mathrm{VC}}=3\) প্রমাণ করুন: (ক) দেখান এমন \(3\)টি বিন্দু আছে যাদের সব \(2^3=8\)টি ±label-বিন্যাস একটি সরলরেখা দিয়ে আলাদা করা যায় (shatter), তাই \(d_{\mathrm{VC}}\ge 3\); (খ) দেখান যেকোনো \(4\)টি বিন্দুর অন্তত একটি labeling আছে যা আলাদা করা যায় না, তাই \(d_{\mathrm{VC}}<4\)। Hint: (ক) একটি অ-সমরেখ ত্রিভুজ নিন। (খ) দুই ক্ষেত্র — হয় একটি বিন্দু অন্য তিনটির convex hull-এর ভিতরে, নয় চারটি একটি উত্তল চতুর্ভুজ; পরের ক্ষেত্রে কর্ণ-প্রান্তগুলোকে XOR-এর মতো (বিপরীত জোড়া এক রঙ) label করুন — কোনো রেখা পারে না।
প্রশ্ন ১৩ (★★). No-Free-Lunch স্বজ্ঞা: দেখান যে কোনো inductive bias (অনুমান) ছাড়া generalization অসম্ভব। ছোট আকারে যুক্তি দিন — input-space \(\mathcal X\)-এ \(N\)টি বিন্দু, এর মধ্যে \(m\)টি training-এ দেখা; বাকি \(N-m\)টি বিন্দুর label সম্পর্কে data কেন কিছুই বলে না যদি সব labeling-কে সমান-সম্ভাব্য ধরা হয়? Hint: অদেখা বিন্দুগুলোর label স্বাধীনভাবে যেকোনো কিছু হতে পারে; "মসৃণতা / সরলতা" জাতীয় কোনো prior না ধরলে যেকোনো extrapolation সমান-ভালো (তথা সমান-খারাপ) — তাই assumption-ই শেখাকে সম্ভব করে।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৪ (★★) [E-sim]. এই অধ্যায়ের bias–variance simulation নিজে চালান: seed np.random.default_rng(20260619), \(f(x)=\sin(2\pi x)\), \(x\sim\text{Uniform}(0,1)\), \(\sigma=0.3\), \(n=40\), \(\text{reps}=300\)। degree \(d\in\{1,3,9,11\}\)-এর প্রতিটির জন্য polynomial fit করে একটি ঘন test-grid-এ point-wise \(\mathrm{Bias}^2\), \(\mathrm{Var}\) আনুমানিক করুন (reps-জুড়ে), তারপর total \(=\text{bias}^2+\text{var}+\sigma^2\)। আপনার সংখ্যা কি canonical টেবিলের কাছাকাছি? (বিশেষত \(d{=}11\)-এ variance বিস্ফোরণ লক্ষ করুন।)
Hint: প্রতিটি rep-এ নতুন noise; np.polyfit(x, y, d) / np.polyval; \(\mathrm{Var}=\frac1R\sum_r(\hat f_r-\bar{\hat f})^2\), \(\mathrm{Bias}^2=(\bar{\hat f}-f)^2\), grid-জুড়ে গড়। সমাধানে runnable script আছে।
প্রশ্ন ১৫ (★★) [E-hoeffding]. একটি ফাংশন finite_h_bound(M, n, delta) লিখুন যা \(\sqrt{(\ln M+\ln(2/\delta))/(2n)}\) ফেরত দেয়। প্রশ্ন ৮-এর তিনটি \((M,n)\)-জোড়ায় চালিয়ে \(0.230,\ 0.073,\ 0.094\) পুনরুৎপাদন করুন; তারপর \(\lvert\mathcal H\rvert=1000\) স্থির রেখে \(n\in\{50,100,500,1000,5000\}\)-এ bound আঁকুন এবং দেখান এটি \(\propto 1/\sqrt n\) হারে নামে।
Hint: np.log (প্রাকৃতিক log); log-log অক্ষে bound বনাম \(n\) একটি \(-1/2\)-ঢালের সরলরেখা দেবে।
৮ · সারসংক্ষেপ ও সংযোগ — এবং Part VI-এর সূচনা¶
এই অধ্যায়টি Part VI · Statistical Machine Learning-এর প্রথম অধ্যায়। তাই §৮ কেবল ৬.১-এর সারসংক্ষেপ নয়, পুরো Part VI-এর তাত্ত্বিক ভিত্তি স্থাপন করে — কারণ এখানে যে প্রশ্নটি তোলা হলো ("সীমিত data থেকে শেখা মডেল অদেখা data-তে কেন ও কখন কাজ করবে?"), পরের প্রতিটি ML-পদ্ধতি আসলে সেই প্রশ্নেরই একেকটি উত্তর।
মূল পয়েন্ট (recap):
- শেখা = true risk minimize করা, কিন্তু পরোক্ষে। আমরা চাই \(R(h)=\mathbb E[\ell(h(x),y)]\) ছোট করতে, কিন্তু \(P(x,y)\) অজানা; তাই হাতে-থাকা নমুনায় \(\hat R_n(h)=\frac1n\sum\ell(h(x_i),y_i)\) minimize করি — এটাই ERM, \(\hat h=\arg\min_{h\in\mathcal H}\hat R_n(h)\)। আসল প্রশ্ন: \(\hat h\)-এর generalization gap \(R(\hat h)-\hat R_n(\hat h)\) ছোট থাকবে কি?
- training error optimistic। একই data-তে fit-করে-error-মাপায় \(\hat R_n(\hat h)\) প্রায় সবসময় \(R(\hat h)\)-কে কম দেখায়; capacity বাড়ালে \(\hat R_n\) একঘেয়ে নামে (এমনকি শূন্যে), কিন্তু \(R\) নামে না — তাই train error দিয়ে model বাছা যায় না।
- bias–variance U-curve। test error = \(\mathrm{Bias}^2+\mathrm{Var}+\sigma^2\)। complexity বাড়লে bias কমে কিন্তু variance বাড়ে; irreducible \(\sigma^2\) অপরিবর্তিত। তাই test-error বনাম complexity একটি U — বাঁ-প্রান্তে underfit (bias-প্রধান), ডান-প্রান্তে overfit (variance-প্রধান), মাঝে সর্বোত্তম। চলমান উদাহরণে min ছিল \(d{=}3\)-এ (total \(0.102\)), আর \(d{=}11\)-এ variance বিস্ফোরণে total \(21.23\)।
- capacity-ই generalization-gap নিয়ন্ত্রণ করে। generalization-gap-কে bound করা যায় hypothesis-class-এর "আকার" দিয়ে: finite \(\mathcal H\)-এ Hoeffding + union bound দেয় \(R(h)\le \hat R_n(h)+\sqrt{\frac{\ln\lvert\mathcal H\rvert+\ln(2/\delta)}{2n}}\); অসীম \(\mathcal H\)-এ এই ভূমিকা নেয় VC dimension \(d_{\mathrm{VC}}\) (growth function-এর polynomial-সীমা, Sauer–Shelah lemma হয়ে)। gap মোটামুটি \(\sqrt{(\text{capacity})/n}\) হারে কমে — অর্থাৎ data বাড়ালে নিরাপদে আরও capacity বহন করা যায়।
- PAC দৃষ্টিভঙ্গি। এই bound-গুলো "\(1-\delta\) probability-তে gap \(\le \epsilon\)" রূপে শেখাকে Probably Approximately Correct করে — finite-sample, distribution-free গ্যারান্টি (3.1-এর concentration-এর সরাসরি ফসল)।
- No-Free-Lunch → assumption লাগবেই। সব problem-এর উপর গড়ে কোনো learner অন্যকে হারাতে পারে না; তাই inductive bias (hypothesis class বাছা, সরলতা/মসৃণতার prior) ছাড়া generalization অসম্ভব। ভালো শেখা মানে problem-এর সাথে মানানসই assumption বাছা।
Part VI-এর তিন তাত্ত্বিক স্তম্ভ (এক নজরে):
| ধারণা | কী মাপে / নিয়ন্ত্রণ করে | মূল ফল |
|---|---|---|
| risk vs empirical risk | লক্ষ্য (\(R\)) বনাম যা minimize করি (\(\hat R_n\)) | gap \(R-\hat R_n\) ছোট রাখাই আসল কাজ |
| bias–variance | complexity-এর দুই বিপরীত খরচ | U-curve, সর্বোত্তম মাঝে |
| capacity (finite-\(\mathcal H\) / VC) | gap-এর uniform bound | \(\sqrt{(\ln\lvert\mathcal H\rvert\ \text{বা}\ d_{\mathrm{VC}})/n}\) |
পূর্ববর্তী সংযোগ:
- ← 5.2 (bias–variance): ৫.২-এ regression-এর প্রেক্ষাপটে point-wise \(\text{MSE}=\text{bias}^2+\text{var}+\sigma^2\) এসেছিল; এখানে সেটিকেই learning-theory-র সাধারণ risk-এর ভাষায় তোলা হলো — যেকোনো hypothesis class ও loss-এর জন্য।
- ← 5.8 (cross-validation): ৫.৮-এর CV আসলে এই অধ্যায়ের honest risk-estimation সমস্যার ব্যবহারিক সমাধান — held-out data-তে \(R(\hat h)\) আন্দাজ করে U-curve-এর সর্বনিম্ন বিন্দু (সর্বোত্তম complexity) খুঁজে বের করার যন্ত্র।
- ← 3.1 (Hoeffding): finite-\(\mathcal H\) generalization bound সরাসরি Hoeffding-এর exponential concentration + union bound থেকে জন্মায়; ৩.১-এর "sample mean exponentially কেন্দ্রীভূত" এখানে "\(\hat R_n\) exponentially \(R\)-এর কাছে" হয়ে ফিরে আসে।
- ← 4.4 (MSE): estimator-এর MSE = bias² + variance — সেই একই বীজগণিতই এখানে prediction-এর decomposition দেয়।
এই তত্ত্বই পরের সব ML-পদ্ধতির ভিত্তি (→ Part VI-এর রোডম্যাপ): ৬.১-এ যে কাঠামো দাঁড় করানো হলো — capacity নিয়ন্ত্রণ করে generalization — তার আলোকেই Part VI-এর বাকি অধ্যায়গুলো পড়া উচিত:
- 6.2 (regularization) — capacity-কে ধারাবাহিকভাবে (penalty \(\lambda\) দিয়ে) নিয়ন্ত্রণ করে: bias সামান্য বাড়িয়ে variance অনেক কমিয়ে U-curve-এর তলায় বসা।
- 6.3–6.6 (classifiers ও ensembles) — SVM/tree/boosting/bagging প্রতিটি আসলে আলাদা inductive bias ও আলাদা উপায়ে effective-capacity হ্রাস (margin, depth-limit, averaging) — সবই আজকের bias–variance ও capacity-তত্ত্বের প্রয়োগ।
- 6.7 (EM) — latent-variable মডেলে likelihood maximize; এখানে capacity আসে মডেল-গঠন ও component-সংখ্যা থেকে।
- 6.8 (dimensionality reduction) — feature-space ছোট করে effective-capacity কমানো ও variance দমন।
পরবর্তী সংযোগ (→ 6.2 — Regularization): এই অধ্যায় বলেছে কেন capacity নিয়ন্ত্রণ দরকার; পরের অধ্যায় বলবে কীভাবে। ridge/lasso-এর মতো penalty যোগ করে আমরা hypothesis-space-কে কার্যত সংকুচিত করি — সামান্য bias গ্রহণ করে অনেকখানি variance কমাই, ঠিক U-curve-এর তলার দিকে নেমে আসি। অর্থাৎ ৬.২ হলো ৬.১-এর bias–variance trade-off-কে হাতে-কলমে চালানোর প্রথম যন্ত্র।
source pointer: learning-theory-র statistics-অভিমুখী, পাঠযোগ্য উপস্থাপনা — Sugiyama, Introduction to Statistical Machine Learning (risk, generalization, model selection)। risk/empirical-risk ও bias–variance-এর সংক্ষিপ্ত গাণিতিক রূপ Wasserman, All of Statistics (prediction ও model-selection অধ্যায়)। data-scientist-মুখী, কোড-সহ overfitting/CV-দৃষ্টিভঙ্গি Bruce & Bruce, Practical Statistics for Data Scientists এবং Dangeti, Statistics for Machine Learning। VC dimension, growth function ও PAC-এর পূর্ণ rigorous রূপ Vapnik-ধারার learning-theory-তে (পরবর্তী enrichment)।