6.6 — Boosting: AdaBoost & Gradient Boosting (বুস্টিং: অ্যাডাবুস্ট ও গ্রেডিয়েন্ট বুস্টিং)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — সমান্তরাল ভোট ছেড়ে ক্রমিক ভুল-শোধরানোর দল¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন উল্টো ভাবনা¶
গত অধ্যায়ে (6.5) আমরা একটা সুন্দর কৌশল শিখেছিলাম: একটা decision tree (ডিসিশন ট্রি / সিদ্ধান্ত-বৃক্ষ) একা কাজ করলে কুখ্যাতভাবে অস্থির — গভীর গাছের bias কম (যেকোনো জটিল pattern ধরে), কিন্তু variance বিশাল (training-data সামান্য বদলালেই গোটা গাছ পাল্টে যায়)। তার দাওয়াই ছিল ensemble (সমষ্টি): বহু গাছকে একসাথে কাজে লাগানো। আর সেই ensemble আমরা গড়েছিলাম bagging (bootstrap aggregating) ও random forest দিয়ে — যার মূল কথা ছিল:
বহু গাছ সমান্তরালে (parallel), পরস্পর-স্বাধীনভাবে গড়ো (প্রত্যেকে আলাদা bootstrap-নমুনায়), তারপর তাদের ভোট/গড় নাও — আলাদা আলাদা ভুল গড়ে গিয়ে বাতিল হয়, আর variance নেমে আসে।
এখানে দুটো শব্দ আলাদা করে দাগিয়ে রাখুন, কারণ এই অধ্যায়ের গোটা গল্প এই দুই শব্দের বিপরীতে দাঁড়িয়ে: সমান্তরাল (গাছগুলো একে অপরকে চেনে না, যেকোনো ক্রমে লাগানো যায়) এবং variance (bagging ঠিক এই অংশটাই কমায়, bias প্রায় অপরিবর্তিত রেখে)।
এই অধ্যায়ে আমরা ensemble-এর একটা সম্পূর্ণ উল্টো দর্শন শিখব। এখানে গাছগুলো সমান্তরালে নয় — আসে একে একে, ক্রমান্বয়ে (sequentially); আর প্রত্যেকে স্বাধীন নয় — প্রত্যেকে তার আগের সবাইকে দেখে, ঠিক তাদের ছেড়ে-যাওয়া ভুলের উপর মন দেয়। ফল: এটা variance নয়, মূলত bias কমায়। এই ঘরানার নাম boosting (বুস্টিং / উন্নয়ন)।
এক বাক্যে উত্তরণ। Bagging/random forest গাছ গড়ে সমান্তরালে, স্বাধীনভাবে এবং কমায় variance; boosting গাছ (বা যেকোনো দুর্বল model) গড়ে ক্রমান্বয়ে, নির্ভরশীলভাবে — প্রতিটি নতুন learner আগেরগুলোর ভুল শুধরে — এবং কমায় মূলত bias।
১.২ Hook — দুর্বল ছাত্রদের দল, প্রত্যেকে আগের জনের ভুল শুধরে দেয়¶
একটা ছবি দিয়ে শুরু করি। ধরুন একটা কঠিন পরীক্ষার প্রস্তুতি নিচ্ছে একদল ছাত্র, যাদের প্রত্যেকেই দুর্বল — একা কেউই খুব ভালো করতে পারে না, কিন্তু প্রত্যেকে অন্তত আন্দাজের (random guess) চেয়ে সামান্য ভালো। এদের একসাথে কাজে লাগানোর দুটো পথ আছে।
পথ ১ (bagging-এর ছবি)। প্রত্যেক ছাত্রকে আলাদা-আলাদা ঘরে বসিয়ে স্বাধীনভাবে গোটা পরীক্ষাটা দিতে দিন, তারপর প্রতিটি প্রশ্নে তাদের সংখ্যাগরিষ্ঠ উত্তর নিন। কেউ এক জায়গায় ভুল করল, কেউ অন্য জায়গায় — গড়ে নিলে এলোমেলো ভুল বাতিল হয়ে যায়। এটা আগের অধ্যায়ের গল্প।
পথ ২ (boosting-এর ছবি)। এবার ছাত্রদের একে একে ডাকুন, ক্রমান্বয়ে। প্রথম ছাত্র গোটা পরীক্ষাটা দিল; সে কিছু প্রশ্ন পারল, কিছু ভুল করল। এবার দ্বিতীয় ছাত্রকে ডেকে বলুন: "প্রথম জন যে প্রশ্নগুলো ভুল করেছে, তুমি বিশেষভাবে ঠিক সেগুলোতে মন দাও।" দ্বিতীয় জন সেই কঠিন প্রশ্নগুলোতে জোর দিয়ে কিছু শুধরে দিল, কিন্তু নিজেও কিছু নতুন ভুল রেখে গেল। তৃতীয় জনকে ডেকে বলুন: "প্রথম-দ্বিতীয় মিলে এখনও যেগুলো ভুল, এবার তুমি ঠিক সেগুলোতে নজর দাও।" — এভাবে চলতে থাকে। প্রতিটি নতুন ছাত্র আগের দলটার রেখে-যাওয়া ভুলের উপর মন দেয়, আর দল ক্রমশ শক্তিশালী হয়।
এটাই boosting-এর হৃদয়: একগুচ্ছ weak learner (দুর্বল-শিক্ষার্থী — চান্সের চেয়ে সামান্য ভালো model) ক্রমান্বয়ে জুড়ে এমন একটা দল বানানো, যা সম্মিলিতভাবে একটা strong learner (সবল-শিক্ষার্থী — যথেষ্ট নির্ভুল model) হয়ে ওঠে। আশ্চর্য সত্য হলো: প্রতিটি সদস্য আলাদাভাবে সামান্য-ভালো হলেও, ঠিকভাবে জুড়লে সম্মিলিত ফলটা প্রায়-নিখুঁত হতে পারে।
এক বাক্যে hook। Boosting হলো দুর্বল ছাত্রদের একটা দল — প্রত্যেকে ক্রমান্বয়ে এসে আগের জনের রেখে-যাওয়া ভুলের উপর মন দেয় — যা সম্মিলিতভাবে একটা সবল model (strong learner) গড়ে তোলে।
১.৩ Weak learner ও decision stump — দলের সদস্য কে¶
"weak learner" কথাটা একটু নির্দিষ্ট করি, কারণ এই অধ্যায়ের গাণিতিক জাদু এর উপরই দাঁড়িয়ে। একটা weak learner (দুর্বল model) হলো এমন একটা classifier যার নির্ভুলতা সামান্য — শুধু random guess-এর চেয়ে একটু ভালো। দুই-শ্রেণির সমস্যায় random guess-এর নির্ভুলতা ৫০%, তাই একটা weak learner-এর কাজ ৫০%-এর চেয়ে অল্প হলেও বেশি — হয়তো ৫৫%, ৬০%। একা সে প্রায় অকেজো; কিন্তু boosting-এর মূল উপপাদ্য বলে, এমন বহু weak learner ক্রমান্বয়ে জুড়লে নির্ভুলতা ইচ্ছেমতো বাড়ানো যায়।
boosting-এ সবচেয়ে চেনা weak learner হলো decision stump (সিদ্ধান্ত-গুঁড়ি)। মনে করুন 6.5-এর decision tree — কিন্তু একদম অগভীর, মাত্র এক স্তর (depth \(1\)): একটামাত্র প্রশ্ন "\(x_j > t\)?" (feature \(x_j\) একটা সীমা \(t\)-এর বেশি কিনা), আর সঙ্গে সঙ্গে দুটো পাতা, দুটো রায়। এটা গাছের সবচেয়ে ক্ষুদ্র, সবচেয়ে দুর্বল সংস্করণ — তাই নাম "stump" (গুঁড়ি, যেন গাছটা প্রায় গোড়া থেকে কাটা)। এমন একটা গুঁড়ি একা feature-space-কে কেবল একটা সরল রেখায় কাটে, তাই তার ক্ষমতা সীমিত — এই অধ্যায়ের dataset-এ একটা decision stump-এর test-নির্ভুলতা মোটে \(0.739\)।
এই \(0.739\) সংখ্যাটা মনে রাখুন — এটাই আমাদের শুরুর বিন্দু, একজন একক দুর্বল ছাত্র। অধ্যায়ের শেষে দেখব, এমন বহু stump ক্রমান্বয়ে জুড়ে boosting এই নির্ভুলতাকে \(0.850\)-এ তুলে আনে — অর্থাৎ দুর্বল গুঁড়ির একটা দল, ঠিকভাবে সাজালে, 6.5-এর শক্তিশালী random forest (\(0.839\))-কেও ছাড়িয়ে যেতে পারে।
এক বাক্যে। একটা weak learner হলো random guess-এর চেয়ে সামান্য ভালো model (যেমন decision stump — মাত্র এক-প্রশ্ন গভীর গাছ, এই অধ্যায়ে test-নির্ভুলতা \(0.739\)), আর boosting-এর কাজ এমন বহু weak learner ক্রমান্বয়ে জুড়ে একটা strong learner বানানো।
১.৪ মূল insight (অন্তর্দৃষ্টি) — কোথায় মন দিতে হবে, সেটাই আসল প্রশ্ন¶
boosting-এর সব সংস্করণ একই কঙ্কালের উপর দাঁড়িয়ে: একটা additive model (যোগাত্মক model) ধাপে ধাপে গড়ে তোলা। অর্থাৎ চূড়ান্ত model হলো weak learner-গুলোর একটা ওজন-যুক্ত যোগফল —
যেখানে \(h_t(x)\) হলো \(t\)-তম weak learner (যেমন \(t\)-তম stump-এর রায়), \(\alpha_t\) তার ওজন (এই সদস্যের রায়ের গুরুত্ব), আর \(T\) হলো মোট কতগুলো round/learner আমরা জুড়ব। গাছগুলো একে একে যোগ হয়: \(F_1 = \alpha_1 h_1\), তারপর \(F_2 = F_1 + \alpha_2 h_2\), এভাবে \(F_t = F_{t-1} + \alpha_t h_t\)। মূল প্রশ্ন একটাই: পরের learner \(h_t\) ঠিক কোন দিকে মন দেবে, আর তার ওজন \(\alpha_t\) কত হবে? — এই একটা প্রশ্নের দুটো ভিন্ন উত্তরই হলো boosting-এর দুই মহান ঘরানা।
ঘরানা ১ — AdaBoost: ভুল বিন্দুর ওজন বাড়াও। প্রথম ভাবনাটা সরাসরি §১.২-এর গল্প থেকে। প্রতিটা training-বিন্দুকে একটা ওজন \(w_i\) দাও (বিন্দুটা কতটা "গুরুত্বপূর্ণ")। শুরুতে সব বিন্দুর ওজন সমান। একটা learner লাগানোর পর — যে বিন্দুগুলো সে ভুল শ্রেণিবদ্ধ করল, তাদের ওজন বাড়িয়ে দাও, আর যেগুলো ঠিক করল তাদের ওজন কমাও। ফলে পরের learner যখন আসে, সে এই ভারী-ওজনের (এখনও-ভুল) বিন্দুগুলোতেই বেশি মন দেয় — ঠিক সেই "প্রথম জনের ভুল প্রশ্নে নজর দাও" নির্দেশের মতো। এটাই AdaBoost (Adaptive Boosting — অভিযোজিত বুস্টিং)। প্রতিটি learner-এর চূড়ান্ত vote-এ ওজন \(\alpha_t\) নির্ধারিত হয় তার নিজের ভুলের হার দিয়ে — কম-ভুল learner বেশি ভোট পায়।
ঘরানা ২ — Gradient boosting: ভুলের দিকে (gradient-এ) একটা পদক্ষেপ নাও। দ্বিতীয় ভাবনাটা আরও সাধারণ ও মার্জিত, আর সরাসরি 0.3-এর gradient descent-এর সঙ্গে জোড়া। মনে করুন একটা loss \(L(y, F)\) আছে যা মাপে আমাদের বর্তমান ensemble \(F\) কত খারাপ। gradient descent বলত: loss কমাতে হলে তার negative gradient-এর দিকে একটা পদক্ষেপ নাও। gradient boosting ঠিক তাই করে — কিন্তু parameter-space-এ নয়, function-space-এ। প্রতিটি নতুন গাছ \(h_t\)-কে fit করা হয় আগের ensemble-এর loss-এর negative gradient-এ, যাকে আমরা residual (অবশিষ্ট) বলব: \(r_i = -\partial L/\partial F\)। সাধারণ ভাষায়: "এখন পর্যন্ত কোথায় কতটা ভুল করছ — ঠিক সেই ভুলটাকে (residual) পরের গাছ দিয়ে fit করো, আর একটা ছোট পদক্ষেপ নিয়ে যোগ করো।" এটাই gradient boosting — function-space-এ চালানো gradient descent।
দুটো ঘরানাকে এক বাক্যে মেলালে: AdaBoost ভুল বিন্দুর ওজন বাড়িয়ে পরের learner-কে সেদিকে ঠেলে, আর gradient boosting ভুলটাকে সরাসরি একটা residual হিসেবে লিখে পরের learner দিয়ে সেটাকে fit করে — দুটোই আসলে "এখনকার ভুলের উপর মন দাও" নীতিরই দুই রূপ। (এই গভীর সংযোগ — AdaBoost আসলে exponential loss-এর উপর gradient boosting-এর একটা বিশেষ ঘটনা — পুরোপুরি §৪-এ খুলবে।)
এক বাক্যে insight (অন্তর্দৃষ্টি)। Boosting-এর প্রতিটি নতুন learner আগের ensemble-এর ভুলের উপর মন দেয় — AdaBoost ভুল বিন্দুর ওজন বাড়িয়ে, আর gradient boosting ভুলকে একটা negative gradient/residual হিসেবে লিখে পরের গাছ দিয়ে fit করে (function-space-এ gradient descent)।
১.৫ একটা সতর্কবার্তা — boosting overfit করতে পারে¶
এখানে একটা গুরুত্বপূর্ণ বৈসাদৃশ্য আগে থেকেই দাগিয়ে রাখা দরকার, কারণ এটা boosting-কে 6.5-এর random forest থেকে আলাদা করে। random forest-এ আপনি যত খুশি গাছ যোগ করতে পারেন — নির্ভুলতা একটা সীমায় গিয়ে স্থির হয়, কখনো খারাপ হয় না (বেশি গাছ random forest-কে overfit করায় না)। boosting এমন নয়।
যেহেতু boosting ক্রমাগত আগের ভুলের উপর মন দেয়, যথেষ্ট বেশি round চালালে সে শেষে training-data-র noise-কেও (এলোমেলো ভুল-লেবেল, যা আসল pattern নয়) মুখস্থ করতে শুরু করে — অর্থাৎ overfit করে (6.1)। ফলে test-নির্ভুলতা প্রথমে বাড়ে, একটা চূড়ায় পৌঁছয়, তারপর আবার পড়তে থাকে। এই অধ্যায়ের dataset-এ এটা স্পষ্ট চোখে পড়বে: AdaBoost-এর নির্ভুলতা ৫০টা stump-এ চূড়ায় ওঠে (\(0.850\)), তারপর আরও stump যোগ করলে নামতে থাকে — ১০০-তে \(0.794\), ২০০-তে \(0.783\), ৫০০-তে \(0.778\)। বিশেষত AdaBoost label-noise-সংবেদী (noise-sensitive): কারণ সে ভুল বিন্দুর ওজন বাড়ায়, আর একটা ভুল-লেবেল-করা (corrupted) বিন্দুর ওজন round-এর পর round ক্রমাগত বাড়তে থাকে — দল সেই একটা বাজে বিন্দুর পেছনে অযথা সময় নষ্ট করে।
এর মানে boosting-এ কোথায় থামতে হবে (round-সংখ্যা) আর প্রতিটি পদক্ষেপ কত ছোট রাখতে হবে (learning rate, regularization) — এগুলো random forest-এর চেয়ে অনেক বেশি যত্নের দাবি রাখে। এই যত্নটাই §২.৩ ও §৪-এর gradient boosting-এ learning rate \(\nu\), tree-depth ও subsample হিসেবে ফিরে আসবে, আর বাস্তব-জগতের XGBoost/LightGBM ঠিক এই নিয়ন্ত্রণগুলোকেই সুসংগঠিত করে।
এক বাক্যে সতর্কতা। Random forest-এর বিপরীতে boosting বেশি round-এ overfit করতে পারে (test-নির্ভুলতা একটা চূড়ার পর পড়ে), আর AdaBoost বিশেষভাবে label-noise-সংবেদী — তাই round-সংখ্যা, learning rate ও regularization যত্ন করে বাছা জরুরি।
১.৬ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Weak learner ও additive model (§২.১) — weak/strong learner-এর সংজ্ঞা, decision stump, আর \(F_T(x)=\sum_t \alpha_t h_t(x)\) কীভাবে ক্রমান্বয়ে (forward stagewise) গড়ে ওঠে।
- AdaBoost (§২.২) — round-এ ভুল বিন্দুর ওজন \(w_i^{(t)}\) বাড়ানো, weighted error \(\varepsilon_t\), learner-weight \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\), weighted vote, ও exponential loss-এর সঙ্গে যোগসূত্রের ইশারা।
- Gradient boosting (§২.৩) — loss \(L(y,F)\), negative gradient/residual \(r_i=-\partial L/\partial F\)-এ tree-fit, function-space gradient descent, learning rate \(\nu\) (shrinkage), ও depth/subsample regularization।
- Bagging বনাম boosting (§২.৪) — সমান্তরাল/variance বনাম ক্রমিক/bias-এর পরিষ্কার তুলনা, এবং boosting-এর overfitting ও noise-সংবেদনশীলতা।
- XGBoost / LightGBM (§২.৫) — regularized gradient boosting-এর বাস্তব, প্রভাবশালী রূপের ধারণাগত স্থান।
- সব derivation — \(\alpha_t\)-এর সূত্র, exponential-loss minimization, gradient boosting কেন function-space gradient descent ও কেন residual-fit, shrinkage-এর যুক্তি — §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫–৬ থেকে।
এক বাক্যে কেন এটি এখানে। 6.5 ensemble-কে গড়ত সমান্তরালে (bagging/random forest, variance↓); এই অধ্যায় ensemble-এর ক্রমিক, ভুল-কেন্দ্রিক ঘরানা (boosting, bias↓) আনে — AdaBoost ও gradient boosting — আর তার overfitting-ঝুঁকি ও বাস্তব রূপ (XGBoost) চেনায়; পরের অধ্যায় 6.7 model-fitting-এর আরেকটা মৌলিক হাতিয়ার — density estimation ও EM — এ এগোবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর অন্তর্দৃষ্টি — "দুর্বল learner-দের একটা দল ক্রমান্বয়ে গড়ো, প্রতিটি নতুন জন আগেরগুলোর ভুলের উপর মন দিয়ে" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত \(\alpha_t\)-এর সূত্র কোথা থেকে আসে, exponential loss, আর gradient boosting কেন function-space gradient descent), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে কিছু সাধারণ চিহ্ন স্থির করে নিই, যা গোটা অধ্যায়ে অপরিবর্তিত থাকবে। আমাদের কাছে \(n\)টি লেবেল-করা পর্যবেক্ষণ আছে: \((x_1,y_1),\dots,(x_n,y_n)\), যেখানে \(x_i\in\mathbb{R}^p\) হলো \(i\)-তম পর্যবেক্ষণের feature vector (\(p\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা, \(i=1,\dots,n\)), আর \(y_i\) হলো তার শ্রেণি-লেবেল। মূল আলোচনা দুই-শ্রেণির (binary) classification ঘিরে, আর AdaBoost-এর প্রচলিত সুবিধার জন্য আমরা লেবেলকে লিখব \(y_i\in\{-1,+1\}\) (দুই শ্রেণিকে \(-1\) ও \(+1\) ধরে — এতে "ঠিক/ভুল" সহজে \(y_i\,h(x_i)\)-এর চিহ্ন দিয়ে বলা যায়: একই চিহ্ন হলে গুণফল ধনাত্মক মানে সঠিক, বিপরীত চিহ্ন হলে ঋণাত্মক মানে ভুল)। প্রতিটি weak learner-এর রায়ও তাই \(h_t(x)\in\{-1,+1\}\)। (gradient boosting-এ আমরা regression-ও ছোঁব, যেখানে \(y_i\in\mathbb{R}\) একটা সংখ্যা; সেখানে চিহ্ন আলাদা করে বলা হবে।)
২.১ Weak learner ও additive model — boosting-এর কঙ্কাল¶
§১.৩–১.৪-এর ছবিটাকে এবার আনুষ্ঠানিক করি।
সংজ্ঞা (weak ও strong learner)। একটা weak learner (দুর্বল model) হলো এমন একটা classifier \(h(x)\) যার নির্ভুলতা random guess-এর চেয়ে সামান্য বেশি — দুই-শ্রেণির সমস্যায়, যার error-হার \(\tfrac12\)-এর সামান্য কম (অর্থাৎ অর্ধেকের চেয়ে কিছু বেশি বিন্দু সে ঠিক বলে)। বিপরীতে একটা strong learner (সবল model) হলো যথেষ্ট-নির্ভুল একটা classifier (যত খুশি কম error-এ পৌঁছনো যায়)। boosting-এর মৌলিক প্রতিশ্রুতি: বহু weak learner ঠিকভাবে জুড়ে একটা strong learner বানানো সম্ভব।
সংজ্ঞা (decision stump)। একটা decision stump (সিদ্ধান্ত-গুঁড়ি) হলো গভীরতা-\(1\) একটা decision tree (6.5): একটামাত্র split "\(x_j > t\)?" — একটা feature \(x_j\) (\(j\in\{1,\dots,p\}\)) ও একটা threshold \(t\in\mathbb{R}\) — যা সরাসরি দুটো পাতায় দুটো রায় (\(-1\) বা \(+1\)) দেয়। এটাই boosting-এর সবচেয়ে চেনা weak learner; feature-space-কে একটা মাত্র অক্ষ-সমান্তরাল রেখায় কাটে বলে এর ক্ষমতা ইচ্ছাকৃতভাবে সীমিত।
সংজ্ঞা (additive model / ensemble)। boosting-এর চূড়ান্ত model একটা additive model (যোগাত্মক model) — weak learner-গুলোর একটা ওজন-যুক্ত যোগফল:
এখানে— - \(h_t(x)\) হলো \(t\)-তম weak learner-এর রায় (যেমন \(t\)-তম stump-এর output \(\in\{-1,+1\}\)), \(t=1,\dots,T\); - \(\alpha_t\in\mathbb{R}\) হলো \(t\)-তম learner-এর ওজন (coefficient) — এই সদস্যের রায় চূড়ান্ত যোগফলে কতটা ভার পাবে; - \(T\) হলো মোট round-সংখ্যা (কতগুলো weak learner জোড়া হলো)।
binary classification-এ চূড়ান্ত শ্রেণি-রায় হয় এই যোগফলের চিহ্ন দিয়ে: \(\hat y(x) = \operatorname{sign}\!\big(F_T(x)\big)\) (যোগফল ধনাত্মক হলে \(+1\), ঋণাত্মক হলে \(-1\)) — অর্থাৎ এটা একটা weighted vote (ওজন-যুক্ত ভোট): প্রতিটি learner \(h_t\) তার ওজন \(\alpha_t\) অনুযায়ী ভোট দেয়, আর সংখ্যাগরিষ্ঠ ওজন যেদিকে, সেদিকেই রায়।
ক্রমিক (forward stagewise) গঠন। boosting-এর সংজ্ঞায়ক বৈশিষ্ট্য: এই যোগফল একসঙ্গে নয়, এক round-এ একটা পদ করে গড়ে ওঠে, আর আগের পদগুলো স্থির রেখে। অর্থাৎ ensemble বাড়ে ক্রমান্বয়ে —
যেখানে \(F_{t-1}\) হলো আগের \(t-1\)টা learner নিয়ে গড়া ensemble (যা এখন আর বদলায় না), আর প্রতিটি round-এ আমরা কেবল নতুন জোড়া \((\alpha_t, h_t)\) বাছি — এমনভাবে যাতে এটা আগের ensemble-এর রেখে-যাওয়া ভুল সবচেয়ে ভালো শোধরায়। এই "আগেরগুলো ধরে রেখে এক পদ করে যোগ" কৌশলের নাম forward stagewise additive modeling (ক্রমিক যোগাত্মক modeling)। ঠিক কোন অর্থে "ভুল শোধরানো" — সেটাই AdaBoost ও gradient boosting-এ দুই ভাবে নির্দিষ্ট হয়, যা পরের দুই উপবিভাগে আসছে। (এই দুই পছন্দ একই forward stagewise কাঠামোর দুই loss — যথাক্রমে exponential ও সাধারণ — তা §৪-এ দেখানো হবে।)
এক বাক্যে। Boosting একটা additive model \(F_T(x)=\sum_{t=1}^T \alpha_t h_t(x)\) গড়ে ক্রমান্বয়ে (\(F_t=F_{t-1}+\alpha_t h_t\)), প্রতিটি round-এ আগেরগুলো স্থির রেখে কেবল নতুন weak learner \(h_t\) ও তার ওজন \(\alpha_t\) বেছে — যাতে আগের ensemble-এর ভুল শোধরায়।
২.২ AdaBoost — ভুল বিন্দুর ওজন বাড়াও, কম-error learner-কে বেশি ভোট দাও¶
প্রথম concrete boosting-পদ্ধতি: AdaBoost (Adaptive Boosting)। এর সংজ্ঞায়ক চাল §১.৪-এর গল্প থেকেই — প্রতিটি training-বিন্দুকে একটা ওজন দাও, আর ভুল বিন্দুর ওজন round-এ-round বাড়াও।
বিন্দু-ওজন \(w_i^{(t)}\)। প্রতিটি বিন্দু \(i\)-র জন্য একটা ওজন রাখি \(w_i^{(t)} \ge 0\) ("round \(t\)-তে বিন্দু \(i\) কতটা গুরুত্বপূর্ণ", \(i=1,\dots,n\))। শুরুতে সব বিন্দু সমান-গুরুত্বের: \(w_i^{(1)} = \tfrac1n\) (প্রতিটির ওজন \(1/n\), যোগফল \(1\))। মূল ভাবনা: যে বিন্দুতে বর্তমান ensemble বারবার ভুল করছে, তার ওজন বড় হবে, যাতে পরের learner সেদিকে মন দিতে বাধ্য হয়।
Round \(t\)-এর তিন ধাপ। প্রতিটি round-এ AdaBoost ঠিক তিনটে কাজ করে।
-
ওজন-সচেতনভাবে একটা weak learner লাগাও। বর্তমান ওজন \(\{w_i^{(t)}\}\) ধরে একটা weak learner \(h_t\) (যেমন একটা stump) train করো, যা ভারী-ওজনের বিন্দুগুলো ঠিক করায় বেশি জোর দেয়। (ব্যবহারিকভাবে: weighted error minimize করে এমন stump বাছা।)
-
এর weighted error মাপো। learner \(h_t\) যে বিন্দুগুলো ভুল করল, তাদের ওজনের যোগফলই এর weighted error:
যেখানে \(\mathbf{1}[\cdot]\) হলো indicator (নির্দেশক ফাংশন: ভেতরের শর্ত সত্য হলে \(1\), নয়তো \(0\)), তাই লব হলো কেবল ভুল-করা বিন্দুগুলোর ওজনের যোগ, আর হর হলো মোট ওজন (normalize করার জন্য)। \(\varepsilon_t\) মানে "এই learner বর্তমান-গুরুত্ব-অনুযায়ী মোট ভরের কত অংশ ভুল করল" — একটা weak learner-এ এটা \(\tfrac12\)-এর সামান্য কম।
- এই learner-এর ওজন \(\alpha_t\) ঠিক করো, আর বিন্দু-ওজন হালনাগাদ করো। learner \(h_t\) চূড়ান্ত vote-এ কত ভার পাবে, সেই \(\alpha_t\) নির্ধারিত হয় তার নিজের error দিয়ে:
(এখানে \(\log\) স্বাভাবিক লগারিদম)। এই সূত্রের স্বজ্ঞা পরিষ্কার, যদিও এর পূর্ণ derivation §৪-এ (exponential loss থেকে): error যত কম (\(\varepsilon_t\) ছোট), অনুপাত \(\frac{1-\varepsilon_t}{\varepsilon_t}\) তত বড়, তাই \(\alpha_t\) তত বড় — অর্থাৎ ভালো learner চূড়ান্ত ভোটে বেশি ওজন পায়; ঠিক \(\varepsilon_t=\tfrac12\) (চান্স-প্রায়) হলে \(\alpha_t=0\) (এই learner কোনো ভোট দেয় না); আর \(\varepsilon_t<\tfrac12\) হলে \(\alpha_t>0\) (যেকোনো better-than-chance learner ধনাত্মক ভোট পায়)। এরপর বিন্দু-ওজন হালনাগাদ হয় — ভুল বিন্দুর ওজন বাড়ে, ঠিক বিন্দুর ওজন কমে:
যেখানে \(\propto\) মানে "সমানুপাতিক" (এরপর আবার normalize করা হয় যাতে যোগফল \(1\))। এই সূত্রটা পড়ুন \(y_i h_t(x_i)\)-এর চিহ্ন দিয়ে: বিন্দু ঠিক হলে \(y_i h_t(x_i)=+1\), তখন গুণক \(e^{-\alpha_t}<1\) — ওজন কমে; বিন্দু ভুল হলে \(y_i h_t(x_i)=-1\), তখন গুণক \(e^{+\alpha_t}>1\) — ওজন বাড়ে। ফলে পরের round-এ learner ঠিক এই ভুল বিন্দুগুলোর দিকেই বেশি মন দেবে। (\(T\) round শেষে চূড়ান্ত model সেই \(F_T(x)=\sum_t \alpha_t h_t(x)\) ও রায় \(\operatorname{sign}(F_T(x))\) — §২.১-এর weighted vote।)
এই reweighting-চক্রটা — সমান ওজন → learner → ভুল বিন্দুর ওজন বাড়ানো → পরের learner সেদিকে — চিত্র 6-6-adaboost-reweighting-এ ধাপে ধাপে দেখানো হবে। আগেই বলা সতর্কতা এখান থেকেই বোঝা যায়: যদি একটা বিন্দুর লেবেল আসলে noise (ভুল করে রাখা) হয়, কোনো learner-ই সেটা "ঠিক" করতে পারবে না, তাই তার ওজন round-এর পর round ক্রমাগত বাড়তেই থাকবে — দল সেই একটা বাজে বিন্দুর পেছনে অযথা শক্তি ঢালবে। এটাই AdaBoost-এর label-noise-সংবেদনশীলতার উৎস।
এক বাক্যে। AdaBoost প্রতিটি round-এ ভুল-শ্রেণিবদ্ধ বিন্দুর ওজন \(w_i\) বাড়ায় (গুণক \(e^{\pm\alpha_t}\)) যাতে পরের learner সেদিকে মন দেয়, আর প্রতিটি learner চূড়ান্ত weighted vote-এ ওজন \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) পায় — কম-error learner বেশি ভোট (derivation §৪)।
২.৩ Gradient boosting — residual-এ গাছ লাগাও, function-space-এ gradient descent¶
দ্বিতীয়, আরও সাধারণ ঘরানা: gradient boosting (গ্রেডিয়েন্ট বুস্টিং)। এর সৌন্দর্য হলো এটা boosting-কে সরাসরি 0.3-এর gradient descent-এর ভাষায় ফেলে — শুধু আমরা parameter নয়, গোটা function \(F\)-কে optimize করি।
একটা loss দিয়ে শুরু। ধরা যাক একটা loss function \(L(y, F)\) আছে — এটা মাপে আমাদের বর্তমান prediction \(F\) সত্যিকার লেবেল \(y\) থেকে কত দূরে (যত ছোট, তত ভালো)। regression-এ চেনা উদাহরণ squared loss \(L(y,F)=\tfrac12 (y-F)^2\); classification-এ অন্য loss (যেমন log-loss) ব্যবহার হয়। আমাদের লক্ষ্য মোট loss \(\sum_{i=1}^n L(y_i, F(x_i))\) ছোট করা।
মূল চাল — function-space-এ gradient descent। 0.3 মনে করুন: একটা parameter \(\theta\)-কে optimize করতে আমরা \(\theta \leftarrow \theta - \nu\,\partial L/\partial\theta\) ধাপে নামতাম — negative gradient-এর দিকে একটা ছোট পদক্ষেপ। gradient boosting ঠিক একই কাজ করে, কিন্তু \(\theta\)-র বদলে পুরো prediction-function \(F\)-কে নামায়। প্রতিটি বিন্দু \(i\)-তে বর্তমান loss-এর negative gradient হলো:
যেখানে \(r_i\) হলো \(i\)-তম বিন্দুর residual (অবশিষ্ট / pseudo-residual), আর derivative-টা নেওয়া হচ্ছে বর্তমান ensemble \(F_{t-1}\)-তে (অর্থাৎ "এখন এই বিন্দুতে loss কোন দিকে সবচেয়ে দ্রুত কমবে")। বিশেষ করে squared loss-এ এই gradient হিসাব করলে দাঁড়ায় ঠিক \(r_i = y_i - F_{t-1}(x_i)\) — অর্থাৎ সাধারণ residual, সত্যিকার মান বিয়োগ বর্তমান prediction (এই কারণেই \(r_i\)-কে "residual" বলা)। এটা সরাসরি সেই স্বজ্ঞা: "এখন পর্যন্ত প্রতিটি বিন্দুতে কতটা ভুল রয়ে গেছে।"
পরের গাছ এই residual-এ fit করো। এবার round \(t\)-এর কাজ সরল: একটা নতুন গাছ \(h_t\)-কে train করো যাতে সে এই residual-গুলো \(\{r_i\}\) যথাসম্ভব ভালো fit করে (অর্থাৎ গাছটা ভবিষ্যদ্বাণী করুক "কোন বিন্দুতে কতটা ভুল বাকি")। তারপর সেই গাছকে একটা ছোট পদক্ষেপ নিয়ে ensemble-এ যোগ করো:
যেখানে \(\nu > 0\) হলো learning rate (শিখন-হার / পদক্ষেপের আকার) — ঠিক 0.3-এর সেই \(\nu\), কিন্তু এখানে প্রতিটি গাছের অবদান কতটা ছোট করে যোগ হবে তা নিয়ন্ত্রণ করে। এটাই gradient boosting: প্রতিটি নতুন গাছ আগের ensemble-এর loss-এর negative gradient (residual)-এ fit, আর একটা ছোট learning-rate পদক্ষেপে যোগ — function-space-এ চালানো gradient descent। (least-squares-এ residual-এ গাছ লাগানো কেন ঠিক negative-gradient পদক্ষেপ — তার পূর্ণ derivation §৪-এ।)
Learning rate ও shrinkage — ছোট পদক্ষেপ কেন ভালো। \(\nu\)-কে shrinkage (সংকোচন)-ও বলে, কারণ এটা প্রতিটি গাছের অবদানকে "সংকুচিত" করে ছোট করে দেয়। স্বজ্ঞা: বড় পদক্ষেপ (\(\nu\) বড়, যেমন \(1.0\)) ensemble-কে দ্রুত training-data-র দিকে টানে — কম গাছেই কাজ হয়, কিন্তু overfit-এর ঝুঁকি বেশি। ছোট পদক্ষেপ (\(\nu\) ছোট, যেমন \(0.05\)–\(0.1\)) প্রতিবার সামান্য করে শোধরায় — তাই অনেক বেশি গাছ লাগে, কিন্তু সাধারণত আরও মসৃণভাবে, ভালো generalize করে। তাই বাস্তবে নিয়ম: ছোট \(\nu\) + বেশি গাছ। এই অধ্যায়ের dataset-এ এর প্রভাব সংখ্যায় চিত্র 6-6-learning-rate-এ দেখানো হবে (২০০ গাছ স্থির রেখে \(\nu\) বদলালে test-নির্ভুলতা বদলায়: \(0.01\to0.794\), \(0.1\to0.850\))।
Regularization — overfitting ঠেকানোর হাতিয়ার। §১.৫-এর সতর্কতা মনে রেখে, gradient boosting-এ overfitting নিয়ন্ত্রণের আরও দুটো প্রধান চাবি আছে, learning rate ছাড়াও: (i) tree-depth — প্রতিটি গাছ কত গভীর/জটিল হবে (অগভীর গাছ = দুর্বল learner = ধীর কিন্তু নিরাপদ; এই অধ্যায়ের reference GradientBoosting-এ depth \(3\)); (ii) subsample — প্রতিটি গাছ training-data-র একটা random উপ-অংশে (subset) লাগানো (একে stochastic gradient boosting বলে), যা গাছে-গাছে কিছুটা randomness এনে overfitting কমায় ও গতি বাড়ায়। round-সংখ্যা (\(T\)), \(\nu\), depth ও subsample — এই চারটে মিলেই boosting-এর bias–variance ভারসাম্য ঠিক করে।
এক বাক্যে। Gradient boosting প্রতিটি নতুন গাছকে আগের ensemble-এর loss-এর negative gradient/residual \(r_i=-\partial L/\partial F\)-এ fit করে (\(F_t=F_{t-1}+\nu h_t\)) — function-space-এ gradient descent — যেখানে learning rate \(\nu\) (shrinkage) প্রতিটি গাছের অবদান ছোট করে, আর depth/subsample regularize করে; ছোট \(\nu\) + বেশি গাছ সাধারণত ভালো generalize করে।
২.৪ Bagging বনাম boosting — দুই দর্শন পাশাপাশি¶
এবার §১-এর কেন্দ্রীয় বৈসাদৃশ্যটা এক জায়গায় গুছিয়ে রাখি, কারণ এটাই 6.5 ও 6.6-কে একসূত্রে বাঁধে। দুটোই ensemble (বহু model মিলিয়ে একটা ভালো model), কিন্তু দর্শন বিপরীত — যা চিত্র 6-6-bagging-vs-boosting-এ পাশাপাশি দেখানো হবে।
- গঠনের ক্রম। Bagging/random forest গাছ গড়ে সমান্তরালে — প্রতিটি গাছ স্বাধীন, পরস্পরকে চেনে না, যেকোনো ক্রমে লাগানো যায়। Boosting গাছ গড়ে ক্রমান্বয়ে — প্রতিটি গাছ আগের সবাইকে দেখে তবেই তৈরি হয় (নির্ভরশীল, ক্রম গুরুত্বপূর্ণ)।
- কী কমায়। Bagging মূলত variance কমায় (অস্থির low-bias/high-variance গাছকে গড় করে স্থির করা)। Boosting মূলত bias কমায় (দুর্বল, high-bias learner-গুলোকে ক্রমান্বয়ে জুড়ে ভুল শোধরে শক্তিশালী করা)।
- সদস্যের ধরন। Bagging সাধারণত পূর্ণ-বৃদ্ধি, কম-bias গাছ ব্যবহার করে (যাদের সমস্যা variance, যা averaging কমায়)। Boosting সাধারণত অগভীর, weak learner (যেমন stump বা depth-3 গাছ) ব্যবহার করে (যাদের সমস্যা bias, যা ক্রমিক যোগ কমায়)।
- Overfitting-আচরণ। Random forest-এ আরও গাছ যোগ করলে নির্ভুলতা স্থির হয় (overfit করায় না)। Boosting বেশি round-এ overfit করতে পারে — test-নির্ভুলতা একটা চূড়ার পর পড়তে থাকে; তাই round-সংখ্যা ও learning rate যত্নে বাছতে হয়। বিশেষত AdaBoost label-noise-সংবেদী (ভুল-লেবেল বিন্দুর ওজন ক্রমাগত বাড়ে), random forest তুলনায় অনেক বেশি noise-সহনশীল।
এক লাইনের স্মৃতি-সূত্র: bagging — সমান্তরাল, স্বাধীন, variance↓, noise-সহনশীল; boosting — ক্রমিক, নির্ভরশীল, bias↓, overfit/noise-সংবেদী। কোনটা ভালো তা data-নির্ভর — boosting প্রায়ই উচ্চতর নির্ভুলতা দেয় (যদি যত্নে tune করা হয়), random forest tune করা সহজ ও বেশি robust।
এক বাক্যে। Bagging গাছ গড়ে সমান্তরালে ও স্বাধীনভাবে এবং কমায় variance (noise-সহনশীল, overfit করে না); boosting গাছ গড়ে ক্রমান্বয়ে ও নির্ভরশীলভাবে এবং কমায় bias (যত্নে না থামালে overfit করতে পারে, AdaBoost noise-সংবেদী)।
২.৫ XGBoost ও LightGBM — gradient boosting-এর বাস্তব, প্রভাবশালী রূপ¶
শেষে সংক্ষেপে আধুনিক বাস্তবতার একটা ইশারা — কারণ "gradient boosting" নামটা প্রায়ই যে দুটো নির্দিষ্ট, অত্যন্ত প্রভাবশালী implementation-এর সঙ্গে শোনা যায়, সেগুলো হলো XGBoost (eXtreme Gradient Boosting) ও LightGBM (Light Gradient Boosting Machine)। বিশদ implementation এই অধ্যায়ের লক্ষ্য নয়; কেবল ধারণাগত স্থানটুকু চিনে রাখি।
মূলত এরা §২.৩-এর gradient boosting-ই — কিন্তু কয়েকটা গুরুত্বপূর্ণ উন্নতিসহ, যা এদের দ্রুত, scalable ও বাস্তবে আরও নির্ভুল করে: - Regularized objective — loss-এর সঙ্গে একটা স্পষ্ট regularization-পদ যোগ করা (গাছের পাতার সংখ্যা ও পাতা-মানের আকারকে শাস্তি দিয়ে), যা overfitting আরও সরাসরি নিয়ন্ত্রণ করে — এ-কারণেই "regularized gradient boosting" নামটা। - Second-order তথ্য — শুধু gradient (প্রথম derivative) নয়, loss-এর দ্বিতীয় derivative-ও (curvature) কাজে লাগিয়ে প্রতিটি গাছ আরও ভালো বাছা। - দক্ষ tree-construction ও গতি — split খোঁজা, missing value সামলানো, এবং বড় data-তে সমান্তরাল/দক্ষ হিসাব — যাতে কোটি-নমুনাতেও চলে (LightGBM বিশেষভাবে দ্রুত, histogram-ভিত্তিক split দিয়ে)।
ব্যবহারিক তাৎপর্য একটাই: tabular data-তে (সারি-কলামের ছকে সাজানো data) XGBoost/LightGBM আজও সবচেয়ে শক্তিশালী, প্রতিযোগিতা-জয়ী হাতিয়ারগুলোর একটি — boosting-এর তত্ত্ব ঠিক এই বাস্তব শক্তিতে রূপ নেয়। (এদের ব্যবহার ও tuning §৫-এ কোডে ছোঁয়া হবে।)
এক বাক্যে। XGBoost ও LightGBM হলো gradient boosting-এর regularized, দ্রুত, scalable রূপ (regularized objective, second-order তথ্য, দক্ষ tree-construction) — tabular data-তে বাস্তবে সবচেয়ে প্রভাবশালী boosting-হাতিয়ার।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে চারটি ক্রমবর্ধমান উদাহরণের মধ্য দিয়ে এই অধ্যায়ের কেন্দ্রীয় গল্পটা হাতে-কলমে দেখা হবে — কীভাবে একটা দুর্বল (weak) base learner-কে boosting দিয়ে ক্রমান্বয়ে শক্তিশালী করে তোলা যায়, এবং তার সাথে কোন কোন বিপদ জড়িত। আগের অধ্যায়ে (bagging / random forest) আমরা দেখেছিলাম কীভাবে variance কমানো যায়; এখানে গল্পটা উল্টো দিক থেকে — boosting মূলত bias কমায়, একটা too-simple model-কে ধাপে ধাপে ভুল শুধরে জটিল করে তোলে। প্রথমে দেখব একটা single decision stump কীভাবে কোনোমতে chance-কে হারায়, এবং AdaBoost সেই stump-গুলোকে stack করে কত বড় উন্নতি ঘটায় (E1); তারপর round-সংখ্যা বাড়ালে AdaBoost কীভাবে label noise-এ overfit করতে শুরু করে (E2); এরপর gradient boosting কীভাবে প্রতিটি নতুন গাছকে residual-এ ফিট করে আরও মসৃণভাবে এগোয় (E3); সবশেষে learning rate \(\nu\) আর tree-সংখ্যার tradeoff এবং সব পদ্ধতির একটা সারাংশ টেবিল (E4)। প্রতিটি সংখ্যা scikit-learn দিয়ে নিচে যাচাই করা।
সব উদাহরণে আগের অধ্যায়ের (৬.৫) একই synthetic dataset ব্যবহার করা হবে — make_classification-এর ২০টি feature, যার মধ্যে মাত্র ৬টি informative, ২টি redundant, আর বাকি ১২টি প্রায় বিশুদ্ধ noise। শ্রেণি দুটো কিছুটা overlap করে (\(\text{class\_sep}=0.8\)) এবং ৫% label ইচ্ছাকৃতভাবে উল্টে দেওয়া (\(\text{flip\_y}=0.05\)) — এই শেষ শর্তটাই এই অধ্যায়ে বিশেষভাবে গুরুত্বপূর্ণ, কারণ boosting-এর সবচেয়ে বড় দুর্বলতা ঠিক এই ধরনের noisy label-এ ধরা পড়ে:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import (AdaBoostClassifier, GradientBoostingClassifier,
RandomForestClassifier)
X, y = make_classification(
n_samples=600, n_features=20, n_informative=6, n_redundant=2,
n_repeated=0, n_classes=2, class_sep=0.8, flip_y=0.05,
random_state=20260619)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
# 420 train / 180 test, label y ∈ {0, 1}
৩.১ E1 — weak learner থেকে boost: এক ধাক্কায় বড় লাফ¶
শুরু করি সবচেয়ে দুর্বল সম্ভাব্য base learner দিয়ে — একটা decision stump, অর্থাৎ মাত্র max_depth=1-এর একটা গাছ যা একটাই split করে, একটাই feature-এ একটাই threshold দিয়ে পুরো dataset-কে দুই ভাগে কাটে। এত সরল model একটা ২০-মাত্রিক, partially overlapping সমস্যায় কতটুকুই বা পারবে?
stump = DecisionTreeClassifier(max_depth=1, random_state=0).fit(X_train, y_train)
print(round(stump.score(X_test, y_test), 3)) # 0.739
ফলাফল 0.739 — random guessing (০.৫) থেকে ভালো হলেও বেশ দুর্বল। এটাই weak learner-এর সংজ্ঞা: এমন একটা classifier যা কেবল chance-এর সামান্য উপরে থাকে। একটা stump-এর capacity এত কম যে সে এই সমস্যার বেশিরভাগ গঠন ধরতেই পারে না — এটা একটা high-bias model, too simple to fit।
এখন AdaBoost-এর জাদু। আমরা ঠিক এই একই দুর্বল stump-কে base estimator হিসেবে দিয়ে অনেকগুলো stump পরপর (sequentially) ফিট করি, যেখানে প্রতিটি নতুন stump আগের round-এ যে বিন্দুগুলো ভুল হয়েছিল সেগুলোর উপর বেশি ওজন (weight) দেয়। চূড়ান্ত predictor হলো এই stump-গুলোর weighted ভোট, \(F_T(x)=\sum_t \alpha_t h_t(x)\), যেখানে প্রতিটি stump-এর ভোটের ওজন \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) — যত কম ভুল করা stump, তত বেশি তার বক্তব্যের ওজন।
ada = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50, random_state=0).fit(X_train, y_train)
print(round(ada.score(X_test, y_test), 3)) # 0.850
৫০টা stump একসাথে → test accuracy 0.850! একটা একক stump যেখানে 0.739, সেখানে সেই একই দুর্বল উপাদান পরপর সাজিয়ে আমরা 0.850-এ পৌঁছে গেলাম — এগারো পয়েন্টের বিশাল উন্নতি, base learner-এ কোনো পরিবর্তন ছাড়াই। মূল insight (অন্তর্দৃষ্টি) এই: প্রতিটি stump আলাদাভাবে দুর্বল হলেও, প্রত্যেকে আগের সবার ভুলের দিকে মনোযোগ দেয়, ফলে ensemble হিসেবে তারা একটা অনেক জটিল decision boundary গড়ে তোলে। boosting এখানে bias কমাচ্ছে — একক stump যে অংশগুলো ধরতে পারছিল না, পরবর্তী stump-রা সেগুলোকেই লক্ষ্য করে শোধরাচ্ছে। এটাই bagging-এর সাথে দার্শনিক পার্থক্য: bagging স্বাধীন full-grown গাছ গড় করে variance কমায়, আর boosting নির্ভরশীল weak learner সাজিয়ে bias কমায়।
৩.২ E2 — AdaBoost ও noise-sensitivity: যেখানে বেশি মানে খারাপ¶
E1-এ দেখলাম ৫০টা stump দারুণ কাজ করে। স্বাভাবিক প্রশ্ন: তাহলে আরও বেশি round দিলে কি আরও ভালো হবে? Random forest-এর ক্ষেত্রে গাছ যত বেশি, ফল তত স্থিতিশীল — গাছ বাড়ালে কখনো ক্ষতি হয় না। boosting-এ কি একই কথা খাটে? দেখি n_estimators ১ থেকে ৫০০ পর্যন্ত বাড়িয়ে:
for n in [1, 10, 50, 100, 200, 500]:
m = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=n, random_state=0).fit(X_train, y_train)
print(n, round(m.score(X_test, y_test), 3))
# 1 0.739
# 10 0.789
# 50 0.850 ← peak
# 100 0.794
# 200 0.783
# 500 0.778
curve-টা আগে ওঠে, তারপর নামে: \(1 \to 0.739\), \(10 \to 0.789\), ৫০-এ 0.850-এ চূড়া (peak), তারপর \(100 \to 0.794\), \(200 \to 0.783\), \(500 \to 0.778\) — ক্রমাগত অবনতি। এটা একটা গুরুত্বপূর্ণ এবং কিছুটা বিস্ময়কর ফল: boosting overfit করতে পারে, এবং এখানে বেশি round মানে খারাপ generalization।
কেন? কারণ AdaBoost-এর কেন্দ্রীয় mechanism-ই হলো ভুল-হওয়া বিন্দুর ওজন বাড়িয়ে দেওয়া। আমাদের dataset-এ \(\text{flip\_y}=0.05\)-এর কারণে training-এর প্রায় ৫% label নিজেই ভুল (mislabeled noise)। এই noisy বিন্দুগুলো প্রকৃতিগতভাবে অসম্ভব — কোনো সৎ classifier-ই এগুলো ঠিক করতে পারে না, কারণ এদের label-ই এলোমেলো। কিন্তু AdaBoost তা জানে না; সে এই বিন্দুগুলোকে বারবার ভুল হতে দেখে, আর প্রতি round-এ এদের ওজন আরও বাড়িয়ে দেয়। round যত বাড়ে, ensemble তত বেশি শক্তি ব্যয় করে এই কয়েকটা noisy outlier-কে "শেখার" পেছনে, ফলে boundary বিকৃত হয়ে যায় এবং প্রকৃত signal ক্ষতিগ্রস্ত হয়। ৫০ round পর্যন্ত লাভ সর্বোচ্চ; তারপর থেকে noise মুখস্থ করার ক্ষতিই বড় হতে থাকে।
এর থেকে তিনটে শিক্ষা: (১) random forest-এর বিপরীতে, boosting CAN overfit — n_estimators একটা genuine hyperparameter, যাকে বেশি দিলেই ভালো নয়; (২) AdaBoost বিশেষভাবে noise-sensitive, কারণ exponential loss mislabeled বিন্দুকে অত্যধিক শাস্তি দেয়, তাই outlier-এর উপর অসঙ্গতভাবে বেশি ফোকাস করে; (৩) প্রতিকার হলো early stopping বা কম round — validation accuracy-র উপর নজর রেখে যেখানে curve নামতে শুরু করে সেখানে থামা। এখানে validation দিয়ে আমরা ৫০-এর আশেপাশে থামতাম, ৫০০-তে নয়।
৩.৩ E3 — gradient boosting: residual-এ ফিট করা¶
AdaBoost ওজন পুনর্বণ্টন (reweighting) দিয়ে কাজ করে; gradient boosting একই boosting-ধারণাকে আরও সাধারণ ও মসৃণ একটা কাঠামোতে রাখে। এখানে প্রতিটি নতুন গাছ আগের ensemble-এর residual-এ ফিট হয় — অর্থাৎ loss function-এর negative gradient, \(r_i=-\partial L/\partial F\)-এ। স্বজ্ঞাগতভাবে: এ পর্যন্ত যা ভবিষ্যদ্বাণী করা হয়েছে তার "যেখানে যেটুকু ভুল রয়ে গেছে" (the leftover error), পরের গাছ ঠিক সেটাকেই predict করার চেষ্টা করে, এবং তাকে একটা ছোট learning rate \(\nu\) দিয়ে গুণ করে ensemble-এ যোগ করা হয়: \(F_t(x)=F_{t-1}(x)+\nu\,h_t(x)\)। এই \(\nu\)-গুণিত ক্ষুদ্র ধাপ (shrinkage) generalization-এর জন্য অত্যন্ত গুরুত্বপূর্ণ, যা E4-এ দেখা যাবে। AdaBoost যেখানে depth-1 stump ব্যবহার করত, gradient boosting সাধারণত একটু গভীর গাছ (depth-3) ব্যবহার করে, যাতে প্রতিটি গাছ feature-এর মধ্যে কিছু interaction ধরতে পারে।
gb = GradientBoostingClassifier(
n_estimators=200, learning_rate=0.1, max_depth=3,
random_state=0).fit(X_train, y_train)
print(round(gb.score(X_test, y_test), 3), # 0.850
round(gb.score(X_train, y_train), 3)) # 1.000
২০০টা depth-3 গাছ, \(\nu=0.1\) → test 0.850, train 1.000। এখানে দুটো জিনিস একসাথে লক্ষণীয়। প্রথমত, train accuracy পুরো 1.000 — মডেল training data পূর্ণভাবে fit করে ফেলেছে, ঠিক যেমন একটা overfit full tree করত। অথচ test accuracy 0.850-এ বেশ ভালো থেকে যায়! এই আপাত-বিরোধটা shrinkage-এর কৃতিত্ব: প্রতিটি গাছকে \(\nu=0.1\) দিয়ে ছোট করে যোগ করায় কোনো একক গাছ ensemble-কে আমূল টানতে পারে না; ফল ধীরে, নিয়ন্ত্রিতভাবে গড়ে ওঠে। তাই training-এ সম্পূর্ণ fit হওয়া সত্ত্বেও মডেল noise মুখস্থ করার বদলে মসৃণ, generalizable একটা function শেখে।
দ্বিতীয়ত, তুলনার জন্য আগের অধ্যায়ের সেরা পদ্ধতি — random forest:
rf = RandomForestClassifier(n_estimators=300, random_state=0).fit(X_train, y_train)
print(round(rf.score(X_test, y_test), 3)) # 0.839
RandomForest(300) → 0.839, আর gradient boosting 0.850-এ তাকে সামান্য টপকে যায়। অর্থাৎ এই সমস্যায় bias-কমানো boosting ensemble (GB) variance-কমানো bagging ensemble (RF)-এর চেয়ে একটু এগিয়ে — যদিও পার্থক্য ছোট, এবং তা এসেছে এই মূল্যে যে boosting-এর hyperparameter (round-সংখ্যা, learning rate, depth) অনেক বেশি সতর্কভাবে tune করতে হয়, যেখানে RF প্রায় out-of-the-box ভালো চলে।
৩.৪ E4 — learning rate, overfitting ও চূড়ান্ত তুলনা¶
gradient boosting-এর সবচেয়ে গুরুত্বপূর্ণ hyperparameter হলো learning rate \(\nu\) (shrinkage)। এটা ঠিক করে প্রতিটি নতুন গাছ ensemble-এ কতটুকু অবদান রাখবে। ছোট \(\nu\) = ছোট, সতর্ক ধাপ; বড় \(\nu\) = বড়, আক্রমণাত্মক ধাপ। গাছের সংখ্যা ২০০ ও depth-3 স্থির রেখে \(\nu\) পরিবর্তন করে দেখি:
for lr in [0.01, 0.05, 0.1, 0.5, 1.0]:
m = GradientBoostingClassifier(
n_estimators=200, learning_rate=lr, max_depth=3,
random_state=0).fit(X_train, y_train)
print(lr, round(m.score(X_test, y_test), 3))
# 0.01 0.794 ← too slow, underfits (200 trees কম পড়ে)
# 0.05 0.833
# 0.1 0.850 ← good
# 0.5 0.844
# 1.0 0.878 ← fast, এই বিশেষ ক্ষেত্রে সর্বোচ্চ কিন্তু ঝুঁকিপূর্ণ
প্যাটার্নটা শিক্ষণীয়। \(\nu=0.01\)-এ test মাত্র 0.794 — ধাপ এত ছোট যে ২০০টা গাছ দিয়ে ensemble এখনো যথেষ্ট দূর এগোতেই পারেনি, অর্থাৎ এটা underfit (too slow)। \(\nu\) বাড়ার সাথে accuracy উন্নত হয়: \(0.05 \to 0.833\), \(0.1 \to 0.850\) (নিরাপদ default, একটা ভালো ভারসাম্য)। বড় \(\nu\)-তে এই dataset-এ সংখ্যা আরও বাড়ে — \(0.5 \to 0.844\), \(1.0 \to 0.878\) — কিন্তু এখানে সাবধানতা জরুরি: বড় learning rate fast convergence দেয়, তবে তা ঝুঁকিপূর্ণ, কারণ প্রতিটি বড় ধাপ overshoot করে noise মুখস্থ করার সম্ভাবনা বাড়ায়। একটা single random_state-এ 1.0-এর উচ্চ মান অনেকটা ভাগ্য; অন্য split-এ এটা সহজেই অস্থির হয়ে পড়তে পারে। তাই বাস্তবে ছোট \(\nu\) (০.০৫–০.১) আর বেশি গাছের সংমিশ্রণই বেশি নির্ভরযোগ্য বলে পছন্দ করা হয়।
এখান থেকেই উঠে আসে boosting-এর কেন্দ্রীয় tradeoff — learning rate × tree-সংখ্যা। ছোট \(\nu\) মানে প্রতিটি গাছ কম অবদান রাখে, তাই একই জায়গায় পৌঁছাতে আরও বেশি গাছ লাগে; বড় \(\nu\) কম গাছে দ্রুত পৌঁছায় কিন্তু overfit-এর ঝুঁকি বাড়ায়। এই দুটো প্রায় বিনিময়যোগ্য (learning_rate অর্ধেক করলে n_estimators মোটামুটি দ্বিগুণ করতে হয়)। আর গাছ-সংখ্যা ও গাছের গভীরতা — দুটোই একসাথে বাড়ালে capacity দ্রুত বাড়ে, যা overfit ডেকে আনতে পারে:
deep = GradientBoostingClassifier(
n_estimators=500, learning_rate=0.5, max_depth=5,
random_state=0).fit(X_train, y_train)
print(round(deep.score(X_train, y_train), 3), # 1.000
round(deep.score(X_test, y_test), 3)) # 0.856
৫০০টা depth-5 গাছ, \(\nu=0.5\) → train 1.000, test 0.856। train পুরোপুরি fit, test ০.৮৫-এর আশেপাশে — অর্থাৎ আরও গভীর গাছ আর বড় learning rate একসাথে দিলে capacity অনেক বেড়ে যায়, এবং shrinkage-এর সুরক্ষা সত্ত্বেও মডেল overfit-এর দিকে ঝুঁকতে থাকে; train ও test-এর মধ্যে ফাঁক চওড়া হয়।
সব ফলাফল একসাথে রাখলে এই অধ্যায়ের গল্পটা পরিষ্কার হয়:
| পদ্ধতি | configuration | test accuracy |
|---|---|---|
| Decision stump | max_depth=1 (weak base) |
0.739 |
| AdaBoost | stump, n_estimators=50 |
0.850 |
| Gradient boosting | n=200, lr=0.1, depth=3 |
0.850 |
| Random forest | n_estimators=300 |
0.839 |
একটা দুর্বল stump (0.739) থেকে শুরু করে boosting ধাপে ধাপে bias কমিয়ে AdaBoost ও gradient boosting দুটোকেই 0.850-এ তুলে আনে, এবং সেরা bagging ensemble (RandomForest 0.839)-কে সামান্য টপকায়। সঙ্গে আসে boosting-এর দুটো সতর্কবার্তা: এটা noisy label-এ overfit করতে পারে (E2), এবং এর শক্তি পুরোপুরি কাজে লাগাতে learning rate, round-সংখ্যা ও depth সাবধানে balance করতে হয় (E4)। সংক্ষেপে — bagging variance কমায়, boosting bias কমায়, এবং নিয়ন্ত্রিতভাবে tune করা boosting এই ধরনের কঠিন সমস্যায় সাধারণত একটু এগিয়ে থাকে।
যাচাই (verification) — উপরের সব সংখ্যা scikit-learn দিয়ে নিচের মতো করে পুনরুৎপাদন করা যায় (seed 20260619, train/test split
random_state=0, stratify=y→ 420/180):shapes (420, 20) (180, 20) stump test 0.739 AdaBoost n=1 test 0.739 AdaBoost n=10 test 0.789 AdaBoost n=50 test 0.850 ← peak AdaBoost n=100 test 0.794 AdaBoost n=200 test 0.783 AdaBoost n=500 test 0.778 GB(200, lr=0.1, depth=3) test 0.850 train 1.000 RF(300) test 0.839 GB lr=0.01 test 0.794 GB lr=0.05 test 0.833 GB lr=0.1 test 0.850 GB lr=0.5 test 0.844 GB lr=1.0 test 0.878 GB(500, lr=0.5, depth=5) train 1.000 test 0.856
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে boosting-এর গাণিতিক ভিত্তি ধাপে ধাপে গড়ে তুলি। প্রথমে দেখাই যে AdaBoost আসলে একটা নির্দিষ্ট loss — exponential loss — কে greedy ভাবে minimize করার একটা পদ্ধতি, আর এই দৃষ্টিকোণ থেকে learner-weight \(\alpha_t\)-এর সূত্র নিজে থেকেই বেরিয়ে আসে। তারপর সেই \(\alpha_t\)-এর আচরণ ব্যাখ্যা করি (কেন better-than-chance learner positive vote পায়) এবং training error যে exponentially নামে তা দেখাই। এরপর gradient boosting-কে function space-এর উপর gradient descent হিসেবে বুঝি — যেখানে পরের গাছ আগের ensemble-এর pseudo-residual-এ ফিট করা হয়, আর squared loss-এ এটা ঠিক "যা বাকি আছে তাতে ফিট করো"-তে নেমে আসে। শেষে shrinkage / learning rate-কে regularization হিসেবে দেখি এবং bagging বনাম boosting-এর তফাতটা bias–variance ভাষায় গুছিয়ে রাখি।
পুরো অংশে দুর্বল শিক্ষক (weak learner) \(h_t(x)\in\{-1,+1\}\), additive model
label \(y_i\in\{-1,+1\}\), AdaBoost-এর sample-weight \(w_i^{(t)}\), weighted error
learner-weight \(\alpha_t\), loss \(L(y,F)\) আর learning rate \(\nu\) — এই notation ধরে চলব।
৪.১ ★★★ AdaBoost = exponential loss-এর forward stagewise minimization¶
AdaBoost-কে প্রায়ই কেবল একটা algorithm হিসেবে শেখানো হয় ("ভুল-শ্রেণিকৃত point-এর ওজন বাড়াও")। কিন্তু এর পেছনে একটা পরিষ্কার optimization লুকিয়ে আছে: AdaBoost হলো exponential loss-এর উপর forward stagewise additive modeling। এই দাবিটাই এখন ধাপে ধাপে প্রমাণ করি — আর প্রমাণের উপজাত হিসেবে \(\alpha_t\)-এর সূত্র বেরিয়ে আসবে।
লক্ষ্য (objective). আমরা এমন additive model \(F\) খুঁজছি যা পুরো training set-এ exponential loss minimize করে:
কেন exponential loss? margin \(y_iF(x_i)\) যত বড় (অর্থাৎ সঠিক দিকে যত আত্মবিশ্বাসী), \(e^{-y_iF(x_i)}\) তত ছোট; ভুল হলে (\(y_iF<0\)) এটা exponentially বেড়ে যায়। এটা \(0/1\) misclassification loss-এর একটা মসৃণ, উপর-থেকে-বাঁধা (upper-bounding) surrogate — কারণ \(\mathbb 1\{yF<0\}\le e^{-yF}\) সব \(yF\)-এর জন্য (চিত্র দেখুন)।
loss
|\ . . . 0/1 loss (step at margin 0)
| \ ___ exp loss e^{-m}
3 | \__
| \__
1 |........\__.........______________ <- 0/1 jumps 1 -> 0 here
| \___
0 +----+----+----+----+----+----+----> margin m = y*F(x)
-2 -1 0 1 2 3
exp loss সবসময় 0/1 loss-এর উপরে -> তাই surrogate
Forward stagewise: এক ধাপে একটা পদ যোগ। পুরো \(F\)-কে একসাথে optimize করা কঠিন, তাই আমরা লোভী (greedy) ভাবে এক ধাপে একটা পদ যোগ করি। ধরা যাক \(t-1\) ধাপ পরে আমাদের কাছে আছে
এখন আমরা একটা নতুন পদ \(\alpha\,h\) যোগ করতে চাই — অর্থাৎ \(F_t=F_{t-1}+\alpha h\) — যেখানে \(\alpha>0\) আর \(h(x)\in\{-1,+1\}\) এমন ভাবে বাছব যাতে objective যতটা সম্ভব নামে, আগের পদগুলো নড়াচড়া না করিয়ে (এটাই "forward stagewise"-এর মর্ম: পুরোনো coefficient পুনঃসমন্বয় করা হয় না)। যা minimize করতে হবে:
Exponent ভাঙি — exponential-এর গুণ-ধর্ম কাজে লাগিয়ে:
এখানে আবির্ভাব ঘটল sample-weight-এর:
লক্ষণীয় — \(w_i^{(t)}\) মোটেই \(\alpha\) বা \(h\)-এর উপর নির্ভর করে না (এটা সম্পূর্ণভাবে অতীত \(F_{t-1}\)-এর দ্বারা নির্ধারিত), তাই এই ধাপের optimization-এ এটা ধ্রুবক। objective দাঁড়াল
Correct / incorrect-এ ভাগ। যেহেতু \(y_i,h(x_i)\in\{-1,+1\}\), তাদের গুণফল \(y_i h(x_i)\) মাত্র দুটো মান নেয়:
তাই যোগফলটাকে দুই দলে ভাগ করি — সঠিক (\(y_ih=+1\Rightarrow e^{-\alpha\cdot(+1)}=e^{-\alpha}\)) আর ভুল (\(y_ih=-1\Rightarrow e^{-\alpha\cdot(-1)}=e^{\alpha}\)):
দুটো যোগফলকে weighted error দিয়ে লিখি। ধরা যাক ওজনগুলো normalized (\(\sum_i w_i^{(t)}=1\) — না হলে দুই পাশেই একই ধ্রুবক, যা minimizer বদলায় না), তাহলে ভুল-অংশের ওজন-যোগই হলো weighted error:
ফলে objective একটা চমৎকার সরল রূপ পায়:
(equivalent (সমতুল্য) রূপে \(J(\alpha)=(e^{\alpha}-e^{-\alpha})\,\varepsilon_t+e^{-\alpha}\) — শুধু \(e^{-\alpha}(1-\varepsilon_t)=e^{-\alpha}-e^{-\alpha}\varepsilon_t\) খুলে গুছিয়ে নিলেই হয়।)
\(h_t\) বাছাই. \(\alpha>0\) স্থির রাখলে \((\ast)\)-এ \(e^{\alpha}>e^{-\alpha}\), তাই \(J\) কমাতে চাইলে \(\varepsilon_t\) যতটা সম্ভব ছোট করতে হবে। অর্থাৎ — যা-ই \(\alpha\) হোক — সেরা \(h_t\) হলো সেইটা যা weighted error \(\varepsilon_t\) সর্বনিম্ন করে। ঠিক এই কাজটাই AdaBoost করে: প্রতিটা round-এ বর্তমান ওজন \(w_i^{(t)}\) নিয়ে একটা weak learner ফিট করে যা weighted misclassification কমায়।
\(\alpha_t\) বাছাই — derivative শূন্য। এবার \(h_t\) (তথা \(\varepsilon_t\)) স্থির ধরে \((\ast)\)-কে \(\alpha\)-এর সাপেক্ষে minimize করি। \(J(\alpha)\) অন্তরকলন:
শূন্যে বসাই:
দুই পাশে natural log নিয়ে \(2\alpha=\log\frac{1-\varepsilon_t}{\varepsilon_t}\), অর্থাৎ
এটাই AdaBoost-এর সেই বিখ্যাত learner-weight সূত্র — এখানে কোনো অনুমান হিসেবে নয়, exponential loss minimize করার ফলাফল হিসেবে এল।
এটা সত্যিই minimum কিনা? দ্বিতীয় অন্তরজ \(\dfrac{d^2J}{d\alpha^2}=e^{-\alpha}(1-\varepsilon_t)+e^{\alpha}\varepsilon_t=J(\alpha)>0\) (ওজন ও \(\varepsilon_t\in(0,1)\) ধনাত্মক), তাই \(J\) strictly convex এবং stationary point-টা সত্যিকারের minimum। optimal মানে objective দাঁড়ায় \(J(\alpha_t)=2\sqrt{\varepsilon_t(1-\varepsilon_t)}\) — এই সংখ্যাটা §৪.২-এ error-bound-এ ফিরে আসবে।
Weight update — ভুল point-এর ওজন বাড়ে। \(w_i^{(t)}=e^{-y_iF_{t-1}(x_i)}\) আর \(F_t=F_{t-1}+\alpha_t h_t\) থেকে পরের round-এর ওজন:
অর্থাৎ (normalization ধ্রুবক \(Z_t=\sum_i w_i^{(t)}e^{-\alpha_t y_i h_t(x_i)}\) বাদ দিয়ে)
এখন \(\alpha_t>0\) ধরে (better-than-chance learner, §৪.২) ব্যাখ্যা করি:
- সঠিক point (\(y_ih_t=+1\)): গুণক \(e^{-\alpha_t}<1\) → ওজন কমে।
- ভুল point (\(y_ih_t=-1\)): গুণক \(e^{+\alpha_t}>1\) → ওজন বাড়ে।
ফলে পরের weak learner বর্তমানে যে point-গুলো ভুল হচ্ছে তাদের উপর বেশি মনোযোগ দিতে বাধ্য হয় — এটাই AdaBoost-এর সেই স্বজ্ঞাত "কঠিন উদাহরণে জোর দাও" আচরণ, যা এখন আমরা দেখলাম exponential-loss minimization থেকে স্বাভাবিকভাবেই উদ্ভূত। সংক্ষেপে:
৪.২ ★★ \(\alpha_t\)-এর অর্থ ও training error-এর exponential পতন¶
§৪.১-এ পাওয়া \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) সূত্রটা কেবল ঠিক দেখতে নয় — এর প্রতিটা সীমা আচরণ স্বজ্ঞার সাথে মেলে। যেহেতু \(\alpha_t\) হলো learner-এর "ভোটের ওজন", আমরা চাই ভালো learner বেশি বলুক, খারাপ learner চুপ থাকুক।
\(\alpha_t\)-এর চিহ্ন ও সীমা। \(\log\) monotone (একঘাতী) বলে \(\alpha_t\)-এর চিহ্ন নির্ভর করে \(\frac{1-\varepsilon_t}{\varepsilon_t}\) কত — অর্থাৎ \(\varepsilon_t\) কত-র উপর:
| \(\varepsilon_t\) | \(\dfrac{1-\varepsilon_t}{\varepsilon_t}\) | \(\alpha_t=\tfrac12\log(\cdot)\) | ব্যাখ্যা |
|---|---|---|---|
| \(\varepsilon_t<\tfrac12\) | \(>1\) | \(\alpha_t>0\) | chance-এর চেয়ে ভালো → ধনাত্মক ভোট |
| \(\varepsilon_t\to 0^+\) | \(\to+\infty\) | \(\alpha_t\to+\infty\) | নিখুঁত learner → একাই আধিপত্য |
| \(\varepsilon_t=\tfrac12\) | \(=1\) | \(\alpha_t=0\) | এলোমেলো অনুমান → সম্পূর্ণ উপেক্ষা |
| \(\varepsilon_t>\tfrac12\) | \(<1\) | \(\alpha_t<0\) | chance-এর চেয়ে খারাপ → চিহ্ন উল্টে দাও |
সংখ্যায় দেখা যাক: \(\varepsilon_t=0.5\Rightarrow\alpha_t=\tfrac12\log 1=0\); \(\varepsilon_t=0.4\Rightarrow\alpha_t=\tfrac12\log 1.5\approx0.203\); \(\varepsilon_t=0.1\Rightarrow\alpha_t=\tfrac12\log 9\approx1.099\); \(\varepsilon_t=0.01\Rightarrow\alpha_t\approx2.298\)। ত্রুটি যত শূন্যের দিকে, ওজন তত আকাশছোঁয়া — যেমনটা চাই।
\(\varepsilon_t>\tfrac12\) হলে \(\alpha_t<0\) — তখন AdaBoost কার্যত learner-টার ভবিষ্যদ্বাণী উল্টে নেয় (\(-h_t\) ব্যবহার করে), কারণ অর্ধেকের বেশি ভুল করা learner-এর বিপরীতটা অর্ধেকের বেশি সঠিক। binary সেটিংয়ে "chance-এর চেয়ে খারাপ" বলে আসলে কিছু নেই — শুধু চিহ্ন ভুল।
Weak-learning assumption। Boosting "কাজ করে" — অর্থাৎ প্রতি round-এ অগ্রগতি হয় — যদি প্রতিটা weak learner অন্তত chance-এর চেয়ে সামান্য ভালো হয়। আনুষ্ঠানিকভাবে ধরে নিই কোনো \(\gamma>0\)-র জন্য
(\(\gamma\)-কে বলে edge — chance থেকে কতটা ভালো)। এটাই weak-learning assumption। এর অধীনে প্রতিটা \(\alpha_t>0\), তাই প্রতিটা round ensemble-এ অর্থপূর্ণ অবদান রাখে।
Training error exponentially নামে। §৪.১-এ দেখেছি optimal \(\alpha_t\)-তে round-\(t\) objective ছোট হয় একটা গুণক \(Z_t=2\sqrt{\varepsilon_t(1-\varepsilon_t)}\)-এ। এদিকে exponential loss যেহেতু \(0/1\) loss-কে উপর থেকে বাঁধে, \(\mathbb 1\{y_iF_T(x_i)<0\}\le e^{-y_iF_T(x_i)}\), তাই training error (গড় ভুল-হার) উপরে বাঁধা পড়ে loss-এর গড়ে — আর সেই গড় round-গুলোর গুণফলে ভেঙে যায়:
এখন \(\varepsilon_t\le\tfrac12-\gamma\) বসিয়ে প্রতিটা পদ আবদ্ধ করি। \(2\sqrt{\varepsilon(1-\varepsilon)}=\sqrt{1-4(\tfrac12-\varepsilon)^2}\le\sqrt{1-4\gamma^2}\le e^{-2\gamma^2}\) (শেষ ধাপে \(1-u\le e^{-u}\)):
অর্থাৎ যতক্ষণ প্রতিটা weak learner-এর edge \(\gamma>0\), training error round-সংখ্যা \(T\)-এর সাথে exponentially শূন্যের দিকে যায়। এটাই boosting-এর মূল প্রতিশ্রুতি: অনেকগুলো সামান্য-ভালো learner মিলে একটা প্রায়-নিখুঁত (training-এ) classifier বানানো যায়। (test error অবশ্য আলাদা গল্প — §৪.৪-এ overfitting আসবে।)
৪.৩ ★★★ Gradient boosting = function space-এ gradient descent¶
AdaBoost কেবল exponential loss-এ কাজ করে। Gradient boosting হলো এর generalization (সাধারণীকরণ) — যেকোনো differentiable loss \(L(y,F)\)-এর জন্য। মূল ধারণাটা চমৎকার: পুরো ensemble \(F\)-কে একটা সংখ্যা নয়, বরং function space-এর একটা "বিন্দু" হিসেবে ভাবি, আর সেই বিন্দুকে negative-gradient দিকে এক ধাপ সরিয়ে loss কমাই — ঠিক যেমন §০.৩-এর সাধারণ gradient descent parameter space-এ করে।
Gradient descent-এর সাদৃশ্য। parameter space-এ একটা ফাংশন \(J(\theta)\) minimize করতে আমরা করি \(\theta\leftarrow\theta-\eta\,\nabla_\theta J\)। এখন আমরা minimize করতে চাই
কিন্তু "চলক" এখন স্বয়ং ফাংশন \(F\)। সরলীকরণের জন্য \(F\)-কে কেবল training point-এ এর মানগুলোর vector হিসেবে ভাবি: \(\big(F(x_1),\dots,F(x_N)\big)\)। তাহলে \(J\) এই \(N\)টা সংখ্যার একটা সাধারণ ফাংশন, আর তার gradient-এর \(i\)-তম উপাদান:
Pseudo-residual। gradient descent-এর পদক্ষেপ হলো negative gradient-এর দিকে যাওয়া। তাই প্রতিটা point-এ আমরা যে দিকে \(F(x_i)\) সরাতে চাই তা হলো
এই \(r_i\)-কে বলে pseudo-residual — round \(t\)-এ point \(i\)-তে loss সবচেয়ে দ্রুত যেদিকে নামে। (parameter space-এ \(\nabla J\) একটা vector; এখানে \(\{r_i\}\) হলো training point-গুলোর উপর negative-gradient "vector"।)
সমস্যা: gradient শুধু training point-এ সংজ্ঞায়িত। \(r_i\) আমরা কেবল \(N\)টা training point-এ জানি, কিন্তু নতুন \(x\)-এ predict করতে গেলে এর একটা সাধারণীকরণ দরকার — একটা ফাংশন। তাই আমরা একটা base learner \(h_t\) (যেমন একটা ছোট regression tree) least squares-এ fit করি এই pseudo-residual-গুলোর উপর, যাতে \(h_t(x)\approx r\) সর্বত্র:
অর্থাৎ — যেদিকে নামতে চাই (negative gradient) সেদিকের একটা মসৃণ, সাধারণীকরণযোগ্য আনুমানিক রূপ পেলাম। (লক্ষণীয়: loss \(L\) যা-ই হোক, base learner-টা সবসময় squared-error-এ ফিট হয় — এটাই gradient boosting-কে এক ছাঁচে নানা loss চালাতে দেয়।)
Update — এক ধাপ এগোও। তারপর ensemble-কে এই দিকে এক ধাপ এগিয়ে দিই। একটা step-size \(\gamma_t\) (line search-এ best, অথবা সরল বাস্তবায়নে \(1\)) আর learning rate \(\nu\) গুণ করে:
এটাই "function space-এ gradient descent": পুরোনো ensemble \(+\) \(\nu\times\)(negative-gradient দিকের approximate step)। \(\nu\) হলো learning rate (§৪.৪)।
Squared loss → ordinary residual. এবার দেখি সবচেয়ে সরল ক্ষেত্রে এই বিমূর্ত pseudo-residual কী রূপ নেয়। regression-এর squared loss
এর \(F\)-এর সাপেক্ষে অন্তরজ (chain rule, ভেতরের \(-1\) সহ):
তাই pseudo-residual:
এটা ঠিক সাধারণ residual — বর্তমান prediction-এর পরে "যা বাকি থেকে গেল"! সুতরাং squared loss-এ gradient boosting-এর পুরো রহস্যটা একটা সরল বাক্যে দাঁড়ায়:
প্রতিটা নতুন tree বাকি ভুলটুকু একটু একটু করে শুষে নেয়, আর ensemble সত্যের দিকে এগোয়।
অন্য loss → অন্য residual. কিন্তু এই "ordinary residual" রূপটা squared loss-এরই বিশেষ সৌভাগ্য — অন্য loss ভিন্ন pseudo-residual দেয়, তাই gradient boosting শুধু regression-এর বাইরেও খাটে:
- Absolute loss \(L=\lvert y-F\rvert\): \(\dfrac{\partial L}{\partial F}=-\operatorname{sign}(y-F)\), তাই \(r_i=\operatorname{sign}\big(y_i-F_{t-1}(x_i)\big)\in\{-1,0,+1\}\) — মাত্রা নয়, কেবল দিক। এটাই gradient boosting-কে outlier-এর প্রতি বেশি সহনশীল (robust) করে, কারণ বিশাল residual-ও আর বিশাল gradient টানে না।
- Logistic / binomial deviance (classification, \(y\in\{-1,+1\}\), \(L=\log\!\big(1+e^{-2yF}\big)\)): অন্তরকলন করলে $$ r_i=-\frac{\partial L}{\partial F}\Big\rvert_{F_{t-1}}=\frac{2\,y_i}{1+e^{\,2\,y_i F_{t-1}(x_i)}} . $$ এটা একধরনের "probability residual" — point-টা সঠিক দিকে যত আত্মবিশ্বাসী, \(r_i\) তত শূন্যের দিকে (gradient মিইয়ে যায়); ভুল ও আত্মবিশ্বাসী হলে \(r_i\) বড় হয়ে \(\pm2\)-র দিকে যায়। এই loss-এ চালালে gradient boosting আসলে probabilistic classifier (এটাই gradient boosting machine / GBM-এর classification রূপ)।
সারকথা: AdaBoost হলো gradient boosting-এরই একটা বিশেষ দৃষ্টান্ত — exponential loss নিলে negative gradient ঠিক সেই reweighting-এ ফিরে আসে যা §৪.১-এ পেয়েছিলাম।
৪.৪ ★ Learning rate / shrinkage — regularization হিসেবে¶
§৪.৩-এর update-এ \(\nu\) ফাংশনটা শুধু একটা গুণক নয় — এটাই gradient boosting-এর সবচেয়ে গুরুত্বপূর্ণ regularizer। পুনরায়:
এই \(\nu\)-কে বলে learning rate বা shrinkage। প্রতিটা নতুন গাছের অবদানকে \(\nu\) দিয়ে সংকুচিত (shrink) করা হয় — অর্থাৎ পুরো পদক্ষেপ না নিয়ে তার একটা ভগ্নাংশ নেওয়া হয়।
ছোট \(\nu\) কেন ভালো generalize করে। \(\nu\) বড় (\(\nu=1\)) মানে প্রতিটা গাছ বর্তমান residual-এ আগ্রাসীভাবে ঝাঁপিয়ে পড়ে — দ্রুত training error নামে কিন্তু training set-এর গোলমাল (noise) সহ মুখস্থ করে ফেলার ঝুঁকি বাড়ে (overfitting)। \(\nu\) ছোট (\(0.01\)–\(0.1\)) মানে ছোট ছোট, সাবধানি পদক্ষেপ — প্রতিটা গাছ সামান্য সংশোধন করে, তাই কোনো একটা গাছ ভুল দিকে নিয়ে গেলেও ক্ষতি সীমিত, আর ensemble মসৃণভাবে সত্যের দিকে এগোয়। ফল: ছোট \(\nu\) সাধারণত ভালো test-performance দেয়।
\(\nu\)–\(T\) tradeoff। কিন্তু ছোট পদক্ষেপ মানে একই দূরত্ব পৌঁছাতে বেশি পদক্ষেপ — অর্থাৎ ছোট \(\nu\)-র জন্য চাই বেশি গাছ \(T\)। মোটামুটি, একই training fit পেতে \(\nu\) আর \(T\) বিপরীত-অনুপাতে চলে (\(\nu\!\downarrow\Rightarrow T\!\uparrow\))। তাই বাস্তবে: \(\nu\) ছোট রাখো (যেমন \(0.05\)), \(T\) বড় রাখো, আর early stopping (validation error যেখানে বাড়তে শুরু করে সেখানে থামা) দিয়ে \(T\) বেছে নাও।
test
error | high nu (nu=1): দ্রুত নামে, তাড়াতাড়ি overfit, U গভীর
| \ _____ low nu (nu=0.05): ধীরে নামে, চ্যাপ্টা min,
| \ ___---/ ভালো generalize
| V ___---
| \ ___/
+----------------------------------> number of trees T
small T large T
(ছোট nu-তে min ডানে সরে, কিন্তু নিচু)
আরও regularizer। shrinkage একা নয়; gradient boosting-এ আরও কয়েকটা নিয়ন্ত্রক একসাথে কাজ করে:
- Tree depth (বা leaf-সংখ্যা): অগভীর গাছ = দুর্বল learner = feature-এর মধ্যে কম interaction; depth \(1\) (stump) মানে কেবল additive effect, বেশি depth মানে উচ্চ-ক্রম interaction ধরা যায় কিন্তু overfit-এর ঝুঁকি বাড়ে।
- Subsample (stochastic gradient boosting): প্রতিটা round-এ training data-র একটা random ভগ্নাংশ (যেমন \(50\)–\(80\%\)) নিয়ে গাছ ফিট করা। এই randomness গাছগুলোর মধ্যে correlation কমায় এবং variance নামায় (bagging-এর সাথে মিল), পাশাপাশি গণনাও দ্রুত করে।
- Feature subsampling, L1/L2 penalty on leaf-weights (যেমন XGBoost-এ): প্রতিটা গাছকে আরও সংযত করে।
সব মিলিয়ে gradient boosting-এর শক্তি যেমন বড়, overfit-এর ঝুঁকিও তেমন — তাই এই regularizer-গুলোর সাবধানি tuning-ই ভালো boosting model-এর আসল কারিগরি।
৪.৫ ★ Bagging বনাম Boosting — bias–variance ছবিতে¶
এই অধ্যায় (boosting) আর পূর্ববর্তী §৬.৫ (bagging / random forest) দুটোই ensemble — অনেক গাছ মিলিয়ে একটা শক্তিশালী predictor। কিন্তু এরা bias–variance decomposition (§৬.১) এর ভিন্ন অংশকে লক্ষ্য করে। তফাতটা গুছিয়ে রাখা জরুরি, কারণ এটাই ঠিক করে কোনটা কখন ব্যবহার করব।
| দিক | Bagging / Random Forest | Boosting (AdaBoost / GBM) |
|---|---|---|
| base learner | শক্তিশালী, low-bias, high-variance (পূর্ণ গাছ) | দুর্বল, high-bias, low-variance (stump/অগভীর গাছ) |
| গাছগুলোর সম্পর্ক | স্বাধীন (parallel) — bootstrap sample-এ আলাদা আলাদা ফিট | পরাধীন (sequential) — প্রতিটা গাছ আগেরগুলোর ভুলের উপর নির্ভর |
| একত্রীকরণ | সরল গড়/vote (সমান ওজন) | ওজনযুক্ত যোগ (\(\alpha_t\) বা \(\nu\)) |
| মূলত কমায় | variance (bias প্রায় অপরিবর্তিত) | bias (variance বাড়তে পারে) |
| overfit-প্রবণতা | কম — গাছ বাড়ালে সাধারণত খারাপ হয় না | বেশি — গাছ বাড়ালে শেষে overfit করতে পারে |
| সমান্তরালকরণ | সহজ (গাছ স্বাধীন) | কঠিন (ক্রমিক নির্ভরতা) |
মূল বৈপরীত্য। Bagging নেয় অনেকগুলো স্বাধীন, high-variance learner আর তাদের গড় করে; গড় করায় variance নামে (§৬.৫-এ দেখানো \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) সূত্র), কিন্তু প্রতিটা learner আগে থেকেই low-bias বলে bias প্রায় একই থাকে। অর্থাৎ bagging-এর লক্ষ্য variance term।
Boosting উল্টোটা করে: শুরু করে দুর্বল, high-bias learner দিয়ে, আর তাদের ক্রমান্বয়ে যোগ করে — প্রতিটা নতুন learner আগের ensemble-এর অবশিষ্ট ভুল (residual / reweighted error) ঠিক করে, ফলে ধাপে ধাপে bias নামে। কিন্তু গাছগুলো পরস্পর-নির্ভর ও training-fit ক্রমশ আঁটসাঁট হওয়ায় ensemble-এর variance বাড়তে পারে — তাই অতিরিক্ত round শেষে overfit-এর দিকে নিয়ে যেতে পারে (§৪.৪-এর regularizer-গুলো ঠিক এই variance-বৃদ্ধি সামলাতেই)।
এক বাক্যে: bagging variance-এর শত্রু, boosting bias-এর শত্রু। তাই আপনার মডেল যদি under-fit করে (high bias) — boosting; যদি একটা শক্তিশালী মডেল over-fit করে (high variance) — bagging। আর gradient boosting + shrinkage + subsample আসলে দুই জগতের সেরাটা ছোঁয়ার চেষ্টা: বেশিরভাগ bias boosting-এ নামাও, বাকি variance subsampling-এর randomness দিয়ে সামলাও।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা boosting-এর কেন্দ্রীয় গল্পটা একটাই script-এ চোখের সামনে দাঁড় করাব: একটা weak learner (এমন একটা মডেল যা কোনোমতে random guessing-এর চেয়ে সামান্য ভালো) কীভাবে boosting-এর মধ্য দিয়ে strong learner-এ রূপ নেয়। তারপর দুটো প্রধান বাস্তবায়ন — AdaBoostClassifier ও GradientBoostingClassifier — হাতে নিয়ে দেখব কীভাবে n_estimators (round-এর সংখ্যা) আর learning_rate (প্রতি round-এর contribution-এর shrinkage) সরাসরি bias–variance trade-off নিয়ন্ত্রণ করে। সবশেষে একটা পরিষ্কার demonstration: bagging (random forest) যেখানে গাছ বাড়ালে সচরাচর overfit করে না, boosting সেখানে overfit করতে পারে — round বেশি বা গাছ গভীর হলে train accuracy ১.০০-তে আটকে গিয়ে test accuracy পিছিয়ে পড়ে।
আমরা একটা synthetic binary-classification dataset ব্যবহার করছি যেখানে ইচ্ছাকৃতভাবে flip_y=0.05 দিয়ে label noise ঢোকানো হয়েছে — অর্থাৎ প্রায় ৫% label উল্টে দেওয়া। এই noise-ই boosting-এর দুর্বলতা (noisy point-গুলোকে বারবার বেশি weight দেওয়া) সবচেয়ে স্পষ্টভাবে ফুটিয়ে তোলে।
চালানোর নির্দেশ —
numpyওscikit-learnইনস্টল থাকলেই script চলবে। না থাকলে এক লাইনে:pip install scikit-learn --break-system-packages -q। নিচের সম্পূর্ণ code একটানা runnable।
import numpy as np
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# ---- dataset: label-noise (flip_y=0.05) ঢোকানো binary classification ----
X, y = make_classification(
n_samples=600, n_features=20, n_informative=6, n_redundant=2, n_repeated=0,
n_classes=2, class_sep=0.8, flip_y=0.05, random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.3, random_state=0, stratify=y)
print(f"shapes: Xtr={Xtr.shape} Xte={Xte.shape}")
print("=" * 60)
# ===== PART 1: weak learner -> boosting করলে strong =====
print("PART 1 -- weak learner -> boosting")
stump = DecisionTreeClassifier(max_depth=1, random_state=0).fit(Xtr, ytr)
acc_stump = accuracy_score(yte, stump.predict(Xte))
print(f" decision stump (max_depth=1) test acc = {acc_stump:.3f}")
ada50 = AdaBoostClassifier(estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50, random_state=0).fit(Xtr, ytr)
acc_ada50 = accuracy_score(yte, ada50.predict(Xte))
print(f" AdaBoost (50 stumps) test acc = {acc_ada50:.3f}")
print(f" lift from boosting = {acc_ada50 - acc_stump:+.3f}")
print("=" * 60)
# ===== PART 2: AdaBoost-এ n_estimators বাড়ালে কী হয় =====
print("PART 2 -- AdaBoost n_estimators sweep")
print(f" {'n_estimators':>12} | {'test acc':>8}")
print(f" {'-'*12}-+-{'-'*8}")
for M in [1, 10, 50, 100, 200, 500]:
clf = AdaBoostClassifier(estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=M, random_state=0).fit(Xtr, ytr)
a = accuracy_score(yte, clf.predict(Xte))
print(f" {M:>12} | {a:>8.3f}")
print(" peak at M=50; rises then DEGRADES (label-noise overfitting)")
print("=" * 60)
# ===== PART 3: GradientBoosting বনাম RandomForest, এবং lr sweep =====
print("PART 3 -- GradientBoosting vs RandomForest")
gb = GradientBoostingClassifier(n_estimators=200, learning_rate=0.1,
max_depth=3, random_state=0).fit(Xtr, ytr)
gb_tr = accuracy_score(ytr, gb.predict(Xtr))
gb_te = accuracy_score(yte, gb.predict(Xte))
print(f" GB(200, lr=0.1, depth=3) train = {gb_tr:.3f} test = {gb_te:.3f}")
rf = RandomForestClassifier(n_estimators=300, random_state=0).fit(Xtr, ytr)
rf_te = accuracy_score(yte, rf.predict(Xte))
print(f" RandomForest(300) test = {rf_te:.3f}")
print()
print(" GB learning_rate sweep (n=200, depth=3)")
print(f" {'learning_rate':>13} | {'test acc':>8}")
print(f" {'-'*13}-+-{'-'*8}")
for lr in [0.01, 0.05, 0.1, 0.5, 1.0]:
clf = GradientBoostingClassifier(n_estimators=200, learning_rate=lr,
max_depth=3, random_state=0).fit(Xtr, ytr)
a = accuracy_score(yte, clf.predict(Xte))
print(f" {lr:>13} | {a:>8.3f}")
print("=" * 60)
# ===== PART 4: boosting-ও overfit করতে পারে =====
print("PART 4 -- boosting CAN overfit")
gbof = GradientBoostingClassifier(n_estimators=500, learning_rate=0.5,
max_depth=5, random_state=0).fit(Xtr, ytr)
of_tr = accuracy_score(ytr, gbof.predict(Xtr))
of_te = accuracy_score(yte, gbof.predict(Xte))
print(f" GB(500, lr=0.5, depth=5) train = {of_tr:.3f} test = {of_te:.3f}")
print(f" train-test gap = {of_tr - of_te:.3f} (overfit signature)")
print("=" * 60)
আউটপুট¶
shapes: Xtr=(420, 20) Xte=(180, 20)
============================================================
PART 1 -- weak learner -> boosting
decision stump (max_depth=1) test acc = 0.739
AdaBoost (50 stumps) test acc = 0.850
lift from boosting = +0.111
============================================================
PART 2 -- AdaBoost n_estimators sweep
n_estimators | test acc
-------------+---------
1 | 0.739
10 | 0.789
50 | 0.850
100 | 0.794
200 | 0.783
500 | 0.778
peak at M=50; rises then DEGRADES (label-noise overfitting)
============================================================
PART 3 -- GradientBoosting vs RandomForest
GB(200, lr=0.1, depth=3) train = 1.000 test = 0.850
RandomForest(300) test = 0.839
GB learning_rate sweep (n=200, depth=3)
learning_rate | test acc
--------------+---------
0.01 | 0.794
0.05 | 0.833
0.1 | 0.850
0.5 | 0.844
1.0 | 0.878
============================================================
PART 4 -- boosting CAN overfit
GB(500, lr=0.5, depth=5) train = 1.000 test = 0.856
train-test gap = 0.144 (overfit signature)
============================================================
পাঠোদ্ধার¶
PART 1 — weak থেকে strong. একটা single decision stump (max_depth=1, অর্থাৎ মাত্র একটা split — একটা feature-এর একটা threshold) test-এ পায় 0.739। এটাই আমাদের weak learner: ২-class সমস্যায় random guessing দেয় ০.৫, তাই ০.৭৩৯ "random-এর চেয়ে সামান্য ভালো" — একটা গাছের পক্ষে দুর্বল, কিন্তু boosting-এর কাঁচামাল হিসেবে যথেষ্ট। ঠিক সেই একই stump-কে weak learner হিসেবে নিয়ে AdaBoost-এ ৫০ round চালালে test accuracy লাফিয়ে 0.850 — এক ধাক্কায় \(+0.111\) উন্নতি। এটাই boosting-এর মূল দাবির হাতে-গরম প্রমাণ: stump একা \(0.739\), কিন্তু ৫০টা stump-কে ক্রমান্বয়ে আগের ভুলের ওপর জোর দিয়ে যোগ করলে তৈরি হয় একটা strong learner। গুরুত্বপূর্ণ পার্থক্য মনে রাখুন — bagging-এ গাছগুলো সমান্তরালে, স্বাধীনভাবে তৈরি হয়; boosting-এ প্রতিটা নতুন গাছ আগের গাছগুলোর residual ভুলের ওপর নির্ভরশীল, ক্রমিকভাবে (sequentially) যুক্ত হয়।
PART 2 — n_estimators বাড়ালে monotonic উন্নতি হয় না। sweep-টা দেখুন: \(M=1\) মানে কার্যত একটা stump, তাই \(0.739\)। তারপর \(M=10 \to 0.789\), \(M=50 \to 0.850\) — এ পর্যন্ত round বাড়ানো bias কমাচ্ছে, ensemble আরও সূক্ষ্ম decision boundary শিখছে। কিন্তু peak আসে \(M=50\)-তে; এর পর \(M=100 \to 0.794\), \(M=200 \to 0.783\), \(M=500 \to 0.778\) — accuracy ক্রমাগত নামতে থাকে। কারণটা \(\texttt{flip\_y}=0.05\)-এ লুকানো: AdaBoost প্রতি round-এ ভুল-classify হওয়া point-এর weight বাড়ায়। কিন্তু flipped label-গুলো আসলেই শেখার অযোগ্য (তারা noise), তাই AdaBoost এদের weight অসীমের দিকে ঠেলে দিতে থাকে এবং পরের stump-গুলো এই noisy point-গুলোকেই খুশি করার চেষ্টায় signal থেকে সরে যায়। ফল — round বাড়লে model noise মুখস্থ করে, generalization ক্ষতিগ্রস্ত হয়। এটা একটা ক্লাসিক পাঠ: boosting-এ n_estimators একটা regularization knob, একে validation দিয়ে tune করতে হয় — যত বেশি তত ভালো নয়।
PART 3 — Gradient Boosting এবং shrinkage (learning_rate)। এবার ভিন্ন কৌশল: GradientBoostingClassifier weight পুনর্বণ্টন করে না, বরং প্রতি round-এ আগের ensemble-এর loss-এর negative gradient (residual) fit করে এবং নতুন গাছকে learning_rate দিয়ে scale করে যোগ করে। GB(n_estimators=200, learning_rate=0.1, max_depth=3) দেয় train \(= 1.000\), test \(= 0.850\) — train একদম perfect, অর্থাৎ ensemble training data সম্পূর্ণ মুখস্থ করেছে, তবু test \(0.850\)-তে স্থিতিশীল। তুলনায় RandomForest(300) দেয় \(0.839\); এখানে GB সামান্য এগিয়ে। এরপর learning_rate sweep মূল trade-off-টা দেখায়: \(0.01 \to 0.794\) (এত ছোট step যে ২০০ round-এও মডেল underfit, প্রতিটা গাছের অবদান নগণ্য), \(0.05 \to 0.833\), \(0.1 \to 0.850\), \(0.5 \to 0.844\), \(1.0 \to 0.878\)। ছোট learning_rate মানে বেশি shrinkage, বেশি regularization, কিন্তু একই accuracy পেতে তখন বেশি round লাগে — এটাই fewer-but-bigger steps vs. more-but-smaller steps এর সেই মৌলিক বিনিময়। বাস্তবে learning_rate ও n_estimators সবসময় জোড়ায় tune করা হয় (ছোট lr + বেশি estimators সাধারণত সবচেয়ে নির্ভরযোগ্য)।
PART 4 — boosting overfit করতে পারে (RF যেখানে সচরাচর করে না)। আরও গভীর গাছ (max_depth=5), আরও বেশি round (n_estimators=500), আর বড় step (learning_rate=0.5) — তিনটাই capacity বাড়ায়। ফল: train \(= 1.000\), test \(= 0.856\), আর train–test gap \(= 0.144\)। train perfect হওয়া + বড় gap = পরিষ্কার overfit signature। এখানে test (\(0.856\)) coincidentally মন্দ নয়, কিন্তু gap-টাই সতর্কবার্তা: এই configuration training noise-এ অতিরিক্ত fit করছে এবং নতুন একটু ভিন্ন data-তে এর performance ভঙ্গুর। মূল conceptual পার্থক্য — random forest-এ গাছ বাড়ালে variance averaging-এর মধ্য দিয়ে কমে, তাই বেশি গাছ সাধারণত ক্ষতি করে না; কিন্তু boosting sequentially loss কমায়, তাই round/depth অতিরিক্ত বাড়ালে সে training data (noise সহ) মুখস্থ করার দিকে এগোয়। অর্থাৎ "more trees never hurt" — এই প্রবাদ bagging-এর জন্য মোটামুটি খাটে, boosting-এর জন্য নয়। boosting-কে regularize করতে হয়: ছোট learning_rate, অগভীর গাছ (max_depth ছোট রাখা — stump বা শালো tree), validation-নির্ভর early stopping, এবং subsampling।
এক বাক্যে নির্যাস — boosting একগুচ্ছ weak learner-কে ক্রমিকভাবে যোগ করে strong learner বানায় (\(0.739 \to 0.850\)), কিন্তু
n_estimators,learning_rateও গাছের depth — এই তিন knob মূলত regularization নিয়ন্ত্রণ করে, এবং অসতর্ক হলে boosting (bagging-এর বিপরীতে) noise মুখস্থ করে overfit করে।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে আমরা boosting-এর গণিত দেখেছি — AdaBoost কীভাবে প্রতি round-এ ভুল-শ্রেণিবদ্ধ বিন্দুর sample weight বাড়িয়ে পরের weak learner-কে কঠিন উদাহরণের দিকে ঠেলে দেয়, আর Gradient Boosting কীভাবে আগের ensemble-এর residual (negative gradient)-এ একের পর এক ছোট tree fit করে loss কমায়। কিন্তু এই দুই algorithm-এর আসল চরিত্র — round বাড়ালে accuracy কীভাবে বদলায়, reweighting আসলে চোখে কেমন দেখায়, learning rate \(\nu\) কী ভূমিকা রাখে, আর সবশেষে boosting আর bagging মৌলিকভাবে কোথায় আলাদা — এসব সমীকরণে যতটা ধরা পড়ে, ছবিতে দেখলে তার চেয়ে ঢের স্পষ্ট হয়। এই অংশে আমরা একটাই প্রধান synthetic dataset (এবং reweighting দেখানোর জন্য একটি ছোট 2D dataset) ব্যবহার করে চারটি ছবি তৈরি করব, যেগুলো একসাথে boosting-এর গল্পটা বলে।
প্রধান ছবিগুলোর ভিত্তি হলো নিচের নিয়ন্ত্রিত classification পরীক্ষা: \(n = 600\) observation, \(20\) feature (যার মধ্যে মাত্র \(6\)টি সত্যিকার অর্থে informative, \(2\)টি redundant), দুই class, মাঝারি class separation (\(\text{class\_sep} = 0.8\)), এবং গুরুত্বপূর্ণভাবে \(5\%\) label noise (flip_y=0.05) — অর্থাৎ প্রায় প্রতি কুড়িতে একটি observation-এর label ইচ্ছাকৃতভাবে উল্টে দেওয়া। এই noise-টুকুই পরে boosting-এর overfitting আচরণ দেখানোর চাবিকাঠি হবে, কারণ AdaBoost ঠিক এই উল্টানো বিন্দুগুলোকেই বারবার "কঠিন" ভেবে আঁকড়ে ধরবে। data-কে আমরা ৭০:৩০ অনুপাতে train/test-এ ভাগ করেছি, stratify=y দিয়ে যাতে দুই split-এ class-অনুপাত সমান থাকে।
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=600, n_features=20, n_informative=6, n_redundant=2,
n_repeated=0, n_classes=2, class_sep=0.8, flip_y=0.05, # 5% label noise
random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
reference-বিন্দু হিসেবে একটিমাত্র decision stump (গভীরতা-১ গাছ, যা boosting-এর weak learner) এই data-তে test accuracy পায় মাত্র ০.৭৩৯ — random-এর চেয়ে সামান্য ভালো, একটি দুর্বল শিক্ষার্থীর প্রত্যাশিত মান। boosting-এর পুরো প্রতিশ্রুতি হলো বহু এমন দুর্বল stump-কে বুদ্ধি করে জুড়ে দিয়ে একটি শক্তিশালী classifier বানানো — ছবিগুলো ঠিক এই রূপান্তরটাই, এবং তার সীমাবদ্ধতাগুলোও, চোখের সামনে দেখাবে।
৬.১ · boosting round বাড়ালে কী হয়¶
প্রথম ছবিটি boosting-এর সবচেয়ে গুরুত্বপূর্ণ ব্যবহারিক প্রশ্নের উত্তর দেয়: আরও round মানেই কি আরও ভালো? এতে test accuracy আঁকা হয়েছে boosting round সংখ্যার (n_estimators) বিপরীতে — একটি লাল curve AdaBoost-এর (কয়েকটি নির্দিষ্ট \(n\)-এ, প্রতিবার নতুন করে fit করে), আর একটি নীল curve Gradient Boosting-এর (একই fitted model থেকে staged_predict দিয়ে প্রতি round-এর পূর্বাভাস বের করে)। নিচে ধূসর রেখায় একক stump-এর baseline ০.৭৩৯।
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# AdaBoost: প্রতিটি n-এ আলাদা করে fit করে test accuracy
ada_ns = [1, 10, 25, 50, 75, 100, 150, 200, 300, 500]
ada_acc = [accuracy_score(yte, AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=n, random_state=0).fit(Xtr, ytr).predict(Xte))
for n in ada_ns]
# GradientBoosting: একবার fit করে প্রতি round-এর staged prediction
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.1,
max_depth=3, random_state=0).fit(Xtr, ytr)
gb_test = [accuracy_score(yte, p) for p in gb.staged_predict(Xte)]
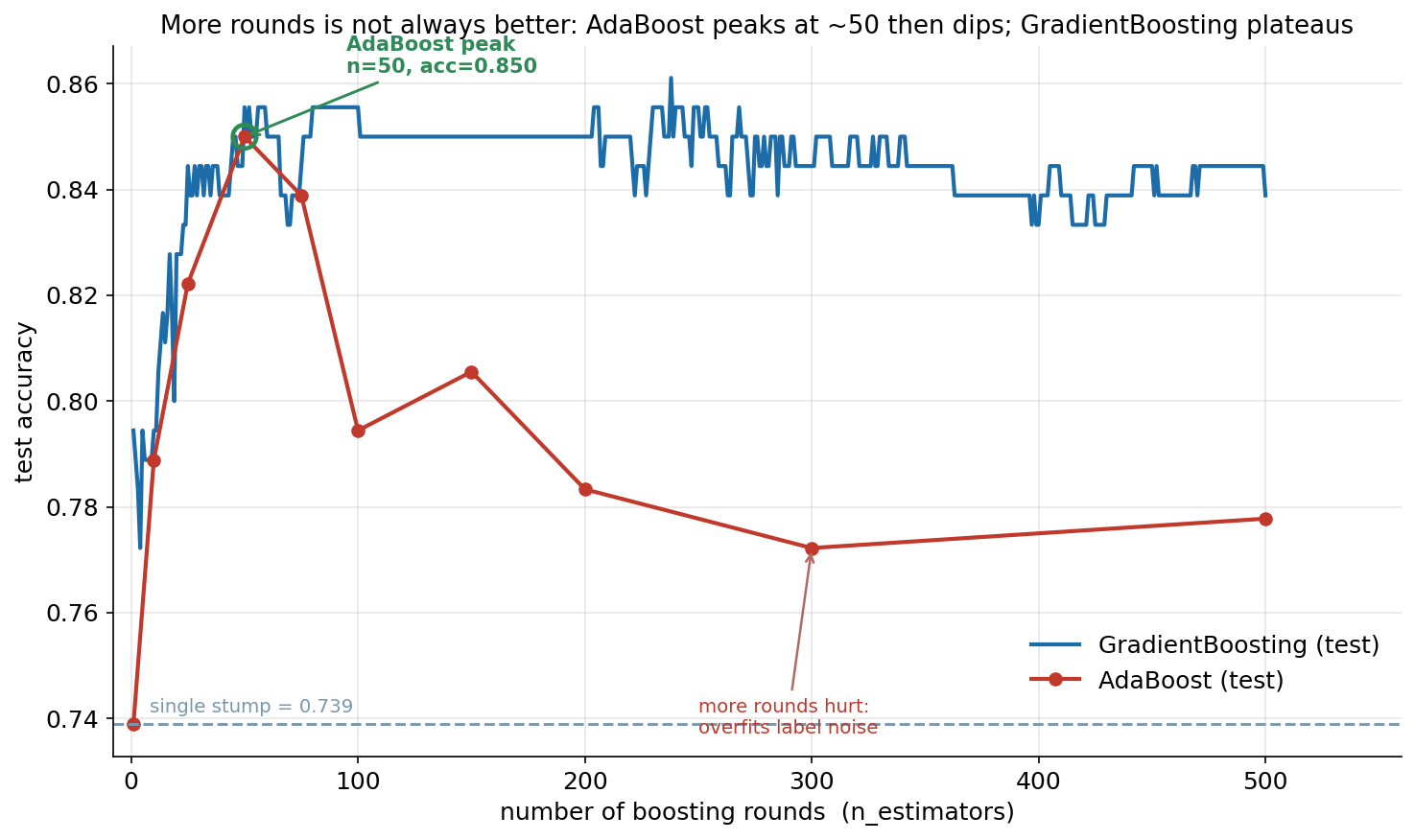
এই ছবিটি boosting সম্পর্কে একটি প্রচলিত ভুল ধারণা ভাঙে। লাল AdaBoost curve-এর গল্পটা তিন অংকের: প্রথমে দ্রুত উত্থান — মাত্র একটি stump থেকে (\(n=1\), accuracy ০.৭৩৯) শুরু করে \(n=10\)-এ ০.৭৮৯, \(n=25\)-এ ০.৮২২, আর \(n=50\)-এ এটি সর্বোচ্চ ০.৮৫০-এ পৌঁছায় (সবুজ বৃত্তে চিহ্নিত peak)। এই পর্যায়ে প্রতিটি নতুন stump সত্যিকার signal ধরছে, ভুলগুলো শুধরে নিচ্ছে। কিন্তু এরপর শুরু হয় পতন: \(n=100\)-এ accuracy নেমে ০.৭৯৪, \(n=200\)-এ ০.৭৮৩, এমনকি \(n=500\)-এ ০.৭৭৮ — অর্থাৎ peak-এর তুলনায় প্রায় সাত শতাংশ-বিন্দু খারাপ। কারণটি আমাদের dataset-এর সেই \(5\%\) label noise: এতগুলো round পেরিয়ে গেলে সত্যিকার ভুল আর ফুরিয়ে যায়, তখন AdaBoost তার exponential reweighting দিয়ে সেই উল্টানো-label noise-বিন্দুগুলোকেই বারবার "কঠিন" ভেবে আঁকড়ে ধরে — noise মুখস্থ করে ফেলে, যা test-এ ক্ষতি করে। এ কারণেই AdaBoost-এ n_estimators নিজেই একটি গুরুত্বপূর্ণ, tune-করার-যোগ্য hyperparameter।
নীল Gradient Boosting curve-এর আচরণ স্পষ্টভাবে আলাদা ও মসৃণতর: এটিও দ্রুত ওঠে, প্রায় ০.৮৫-এর কাছাকাছি গিয়ে plateau করে এবং বহু round পরেও ভেঙে পড়ে না (অল্প ওঠানামা থাকে, কিন্তু AdaBoost-এর মতো নাটকীয় পতন নয়)। এর কারণ Gradient Boosting-এর তুলনামূলক ছোট learning rate (\(\nu=0.1\)) প্রতিটি step-কে সংযত রাখে, ফলে noise-এর দিকে ছুটে যাওয়ার প্রবণতা কম। সংক্ষেপে এই ছবির বার্তা: boosting-এ "আরও round" সর্বদা "আরও ভালো" নয় — বিশেষত AdaBoost-এ একটি optimal round-সংখ্যা থাকে, যার পরে overfitting শুরু হয়।
৬.২ · AdaBoost-এর reweighting যন্ত্রটি চোখে দেখা¶
দ্বিতীয় ছবিটি AdaBoost-এর হৃদয় — sample reweighting — কে দৃশ্যমান করে। এখানে আমরা একটি সরল 2D make_moons data ব্যবহার করি (\(n=150\), \(\text{noise}=0.3\)) যাতে decision boundary এবং প্রতিটি বিন্দু একসাথে আঁকা যায়। তিনটি panel তিনটি পর্যায়ের ছবি — \(t=1\), \(t=5\), \(t=20\) round পরে। প্রতিটি panel-এ বিন্দুর আকার = তার চলতি AdaBoost sample weight: যে বিন্দু এখনো ভুল-শ্রেণিবদ্ধ হচ্ছে সে round-এ-round বড় হয়, আর পেছনে চলতি ensemble-এর decision boundary তাদের দিকে বেঁকে যায়।
from sklearn.datasets import make_moons
X2, y2 = make_moons(n_samples=150, noise=0.3, random_state=20260619)
# প্রতিটি round-এর জন্য discrete-AdaBoost sample weight নিজে হাতে হিসাব করা
def adaboost_weights(X, y, T):
w = np.full(len(y), 1.0 / len(y)) # সমান weight দিয়ে শুরু
ys = np.where(y == 1, 1.0, -1.0)
for _ in range(T):
st = DecisionTreeClassifier(max_depth=1).fit(X, y, sample_weight=w)
pred = np.where(st.predict(X) == 1, 1.0, -1.0)
err = np.clip((w * (pred != ys)).sum() / w.sum(), 1e-10, 1 - 1e-10)
alpha = 0.5 * np.log((1 - err) / err) # ভুল কম হলে বেশি ওজন
w *= np.exp(-alpha * ys * pred) # ভুলের weight বাড়ে, ঠিকের কমে
w /= w.sum()
return w
# point size = 18 + w/w.max()*320 -> ভুল বিন্দুগুলো বড় দেখায়
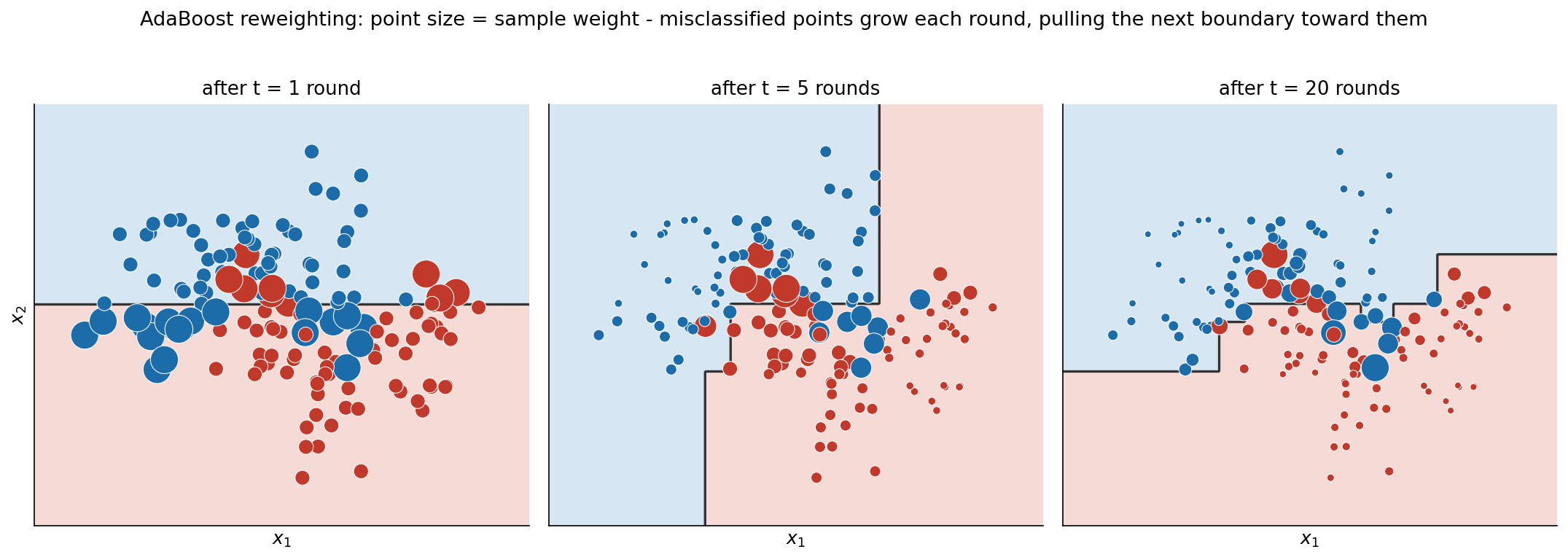
তিনটি panel পাশাপাশি দেখলে AdaBoost-এর adaptive নামের অর্থ স্পষ্ট হয়ে ওঠে। \(t=1\) (বাঁ): এখনো মাত্র একটি stump, তাই সব বিন্দুর weight প্রায় সমান (প্রায় একই আকার), আর boundary একটি অক্ষ-সমান্তরাল সরলরেখা — যা দুই বাঁকা চাঁদকে আলাদা করতে বহু বিন্দু ভুল করে। \(t=5\) (মাঝ): পাঁচ round পরে চিত্র বদলে গেছে — যে বিন্দুগুলো বারবার ভুল-পাশে পড়ছিল (বিশেষত দুই চাঁদের overlap অঞ্চলে ও noise-বিন্দুগুলো) তারা লক্ষণীয়ভাবে বড় হয়ে গেছে, কারণ প্রতিটি round-এ তাদের weight গুণিতকভাবে বেড়েছে। boundary আর সরলরেখা নেই — এটি ভাঁজ খেয়ে সেই কঠিন বিন্দুগুলোর দিকে এগিয়ে গেছে। \(t=20\) (ডান): কুড়ি round পরে সবচেয়ে একগুঁয়ে (প্রায়শই noise) বিন্দুগুলো সবচেয়ে বড়, আর boundary একটি জটিল staircase যা দুই চাঁদের প্রকৃত সীমানা ঘনিষ্ঠভাবে অনুসরণ করছে।
এই ক্রমটাই AdaBoost-এর মূল চক্রের ছবি: (১) চলতি weight-এ একটি weak learner fit করো; (২) যা ভুল হলো তার weight বাড়াও; (৩) তাই পরের learner বাধ্য হয় সেই ভুলগুলোর দিকে মন দিতে। বিন্দুর আকারই এখানে weight-এর সরাসরি প্রতিনিধি, তাই "ভুল বিন্দু বড় হয়, পরের boundary তার দিকে বাঁকে" — এই বাক্যটি আর বিমূর্ত থাকে না, চোখে দেখা যায়। তবে খেয়াল করুন, এই একই প্রক্রিয়া যখন সত্যিকার noise-বিন্দুকেও "কঠিন" ভেবে আঁকড়ে ধরে বড় করে তোলে, তখন সেটাই ৬.১-এ দেখা overfitting-এর উৎস — শক্তি ও দুর্বলতা একই যন্ত্রের দুই পিঠ।
৬.৩ · learning rate \(\nu\) এবং shrinkage-overfitting বিনিময়¶
তৃতীয় ছবিটি Gradient Boosting-এর সবচেয়ে গুরুত্বপূর্ণ regularization knob — learning rate \(\nu\) (shrinkage) — কে আতশকাচের নিচে রাখে। প্রতিটি round-এ Gradient Boosting নতুন tree-র অবদানকে \(\nu\) দিয়ে গুণ করে যোগ করে; ছোট \(\nu\) মানে প্রতিটি step ছোট, সংযত। ছবিতে দুটি সেটিং তুলনা করা হয়েছে — \(\nu=0.1\) (সংযত) বনাম \(\nu=1.0\) (কোনো shrinkage নেই) — এবং প্রতিটির জন্য staged_predict দিয়ে train ও test accuracy দুটোই round-সংখ্যার বিপরীতে আঁকা, মোট চারটি curve।
gb_lo = GradientBoostingClassifier(n_estimators=200, learning_rate=0.1,
max_depth=3, random_state=0).fit(Xtr, ytr)
gb_hi = GradientBoostingClassifier(n_estimators=200, learning_rate=1.0,
max_depth=3, random_state=0).fit(Xtr, ytr)
# প্রতিটির train ও test staged accuracy (4 curve)
lo_tr = [accuracy_score(ytr, p) for p in gb_lo.staged_predict(Xtr)]
lo_te = [accuracy_score(yte, p) for p in gb_lo.staged_predict(Xte)]
hi_tr = [accuracy_score(ytr, p) for p in gb_hi.staged_predict(Xtr)]
hi_te = [accuracy_score(yte, p) for p in gb_hi.staged_predict(Xte)]
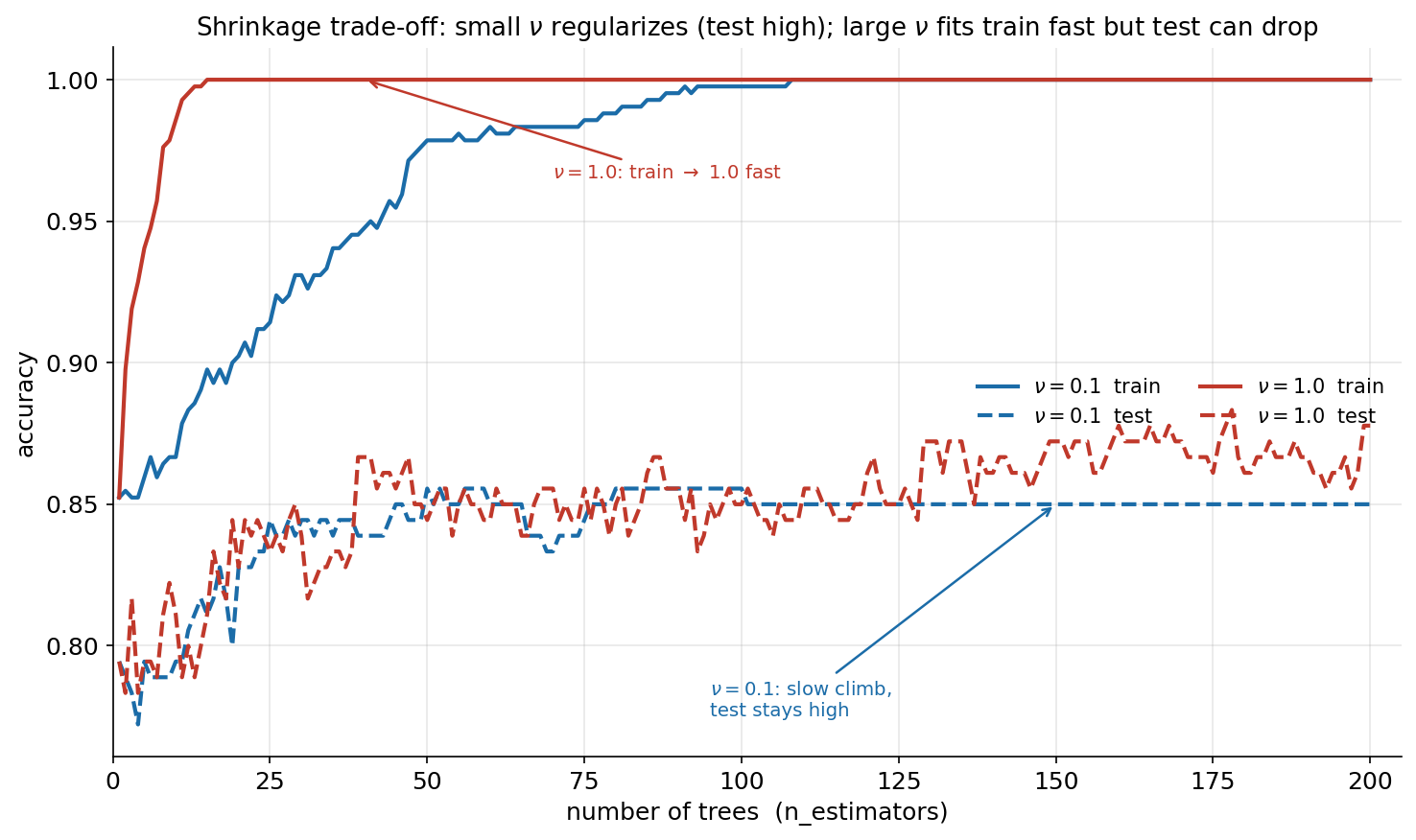
চারটি curve একসাথে shrinkage-এর মূল বিনিময়টি দেখায়। \(\nu=1.0\) (লাল, কোনো shrinkage নেই): train accuracy অত্যন্ত দ্রুত — মাত্র ১৫-২০টি tree-তেই — পূর্ণ ১.০-তে পৌঁছে যায়, অর্থাৎ model training data নিখুঁতভাবে মুখস্থ করে ফেলে। কিন্তু এর test curve (ভাঙা লাল রেখা) ০.৮৫-এর আশেপাশে জোরালোভাবে ওঠানামা করে — কখনো ০.৮৭ পর্যন্ত উঠলেও স্থিতিশীল নয়, কারণ বড় বড় step model-কে noise-এর দিকে ঠেলে দেয়। প্রতিটি tree পূর্ণ মাত্রায় residual-এ fit হওয়ায় ensemble মোটা, ঝাঁকুনিপূর্ণ পদক্ষেপে এগোয়।
\(\nu=0.1\) (নীল, সংযত shrinkage): train accuracy অনেক ধীরে ওঠে — প্রতিটি tree-র অবদান এক-দশমাংশে নামিয়ে আনায় ১.০-তে পৌঁছাতে অনেক বেশি tree লাগে। কিন্তু এর পুরস্কার test curve-এ (ভাঙা নীল রেখা): এটি মসৃণভাবে উঠে ০.৮৫-এর কাছাকাছি একটি স্থিতিশীল plateau-তে বসে যায়, প্রায় ঝাঁকুনিহীন। অর্থাৎ ছোট \(\nu\) একপ্রকার regularizer — প্রতিটি ছোট, সাবধানী step generalization-কে রক্ষা করে, আর train-test ফাঁক বড় হলেও test performance অটুট থাকে। এই ছবির বার্তা: shrinkage একটি বিনিময় — ছোট \(\nu\) ধীর কিন্তু নিরাপদ (বেশি tree চাই, কিন্তু test স্থিতিশীল ও সাধারণত ভালো), বড় \(\nu\) দ্রুত কিন্তু ঝুঁকিপূর্ণ (train চটজলদি ১.০ ছোঁয়, test অস্থির)। ব্যবহারিক নিয়মও তাই: ছোট \(\nu\) নাও, আর সেই ক্ষতিপূরণে বেশি n_estimators দাও — early stopping দিয়ে কোথায় থামবে ঠিক করে।
একটি সতর্কবার্তা — পাঠ্য সংখ্যা বনাম ছবির সংখ্যা। এই অধ্যায়ের তত্ত্ব-অংশের anchor table-এ \(\nu=1.0\) (n=200)-এ চূড়ান্ত test accuracy ০.৮৭৮ লেখা — যা \(\nu=0.1\)-এর ০.৮৫০-এর চেয়ে সামান্য বেশি। এটি স্ববিরোধ নয়: ০.৮৭৮ হলো একটিমাত্র, \(200\)-তম round-এর বিন্দু-মান, যা লাল test curve-এর তীব্র ওঠানামার মধ্যে কাকতালীয়ভাবে একটি উঁচু বিন্দুতে পড়েছে। ছবিটি ঠিক এ কারণেই পুরো curve দেখায়, কেবল শেষ বিন্দু নয় — আর সেই curve বলে দেয় বড় \(\nu\)-এর test performance অস্থির ও অনির্ভরযোগ্য, ছোট \(\nu\)-এর তুলনায় কম নিরাপদ। এই পার্থক্যই shrinkage-এর আসল শিক্ষা।
৬.৪ · bagging বনাম boosting: দুই দর্শন¶
শেষ ছবিটি একটি ধারণাগত schematic — কোনো data-plot নয়, বরং এই Part-এর দুই মহান ensemble-দর্শনের একটি পাশাপাশি তুলনা: bagging (যেমন Random Forest) বনাম boosting (AdaBoost ও Gradient Boosting)। বাঁ দিকে bagging-এর সমান্তরাল গঠন, ডান দিকে boosting-এর ক্রমিক গঠন, আর নিচে একটি ছোট accuracy-bar inset যা এই data-তে চার method-কে সংখ্যায় তুলনা করে।
# inset bar: এই অধ্যায়ের চার anchor (test accuracy)
methods = ["stump", "AdaBoost", "GB", "RF"]
accs = [0.739, 0.850, 0.850, 0.839] # একক stump থেকে ensemble-এর লাফ
ax_inset.bar(methods, accs,
color=["#7a98ad", "#c0392b", "#1b6ca8", "#8e44ad"])
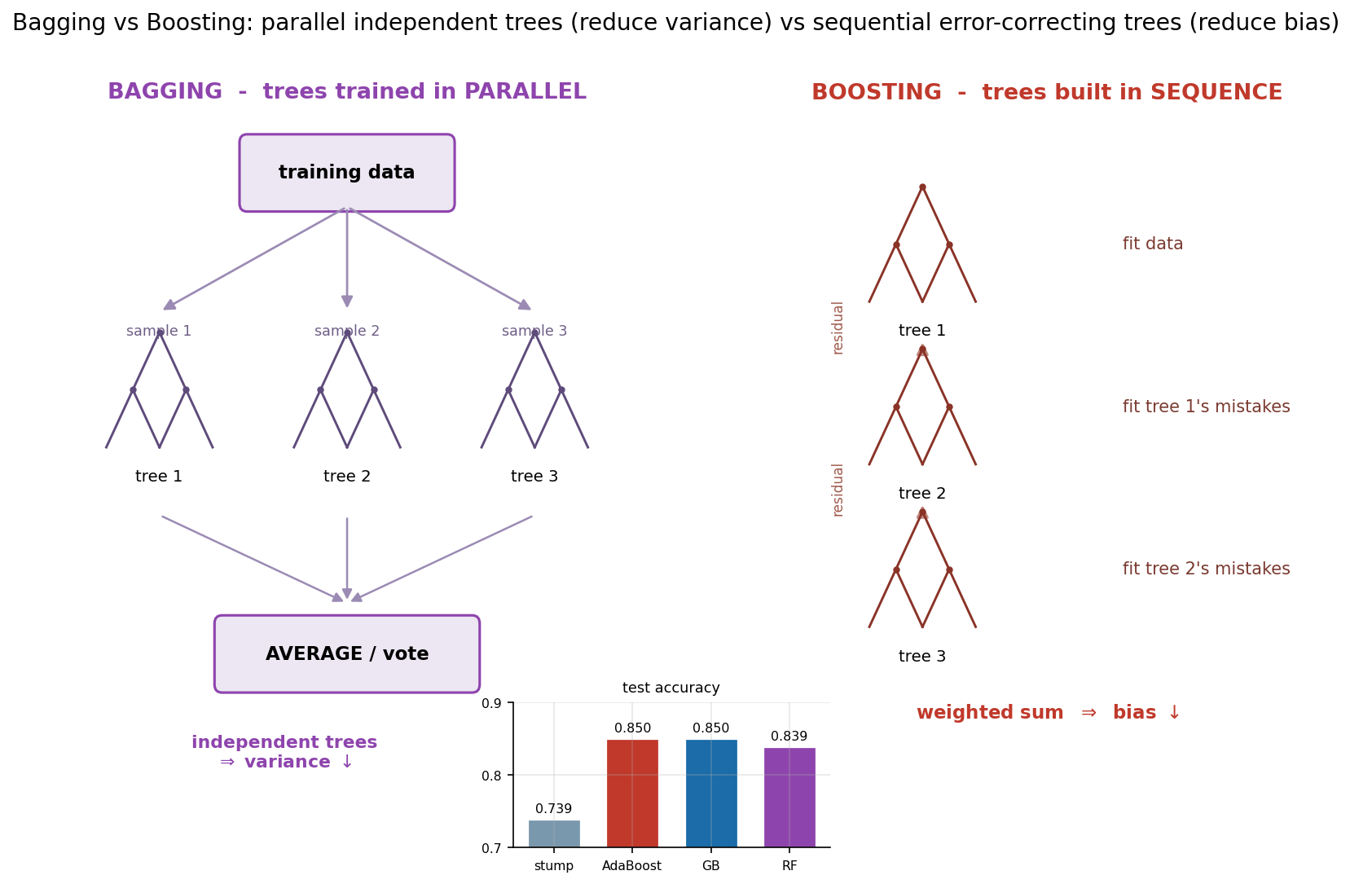
এই schematic-টি গোটা Part-এর তুলনামূলক মেরুদণ্ড। বাঁ দিকে (BAGGING): একই training data থেকে bootstrap sampling করে কয়েকটি আলাদা subset বানানো হয়, প্রতিটিতে একটি গাছ স্বাধীনভাবে ও সমান্তরালে প্রশিক্ষিত হয় (একটি গাছ অন্যটির কথা জানে না), তারপর সব গাছের পূর্বাভাস average বা vote করে চূড়ান্ত সিদ্ধান্ত নেওয়া হয়। যেহেতু গাছগুলো স্বাধীন এবং তাদের ভুল আংশিকভাবে পরস্পরকে বাতিল করে, এই কৌশলের মূল লাভ variance কমানো — একক গভীর গাছের অস্থিরতা গড়ে গিয়ে মিলিয়ে যায়। Random Forest ঠিক এই পরিবারের, এখানে accuracy ০.৮৩৯।
ডান দিকে (BOOSTING): এখানে গাছগুলো সমান্তরাল নয়, বরং একটি শৃঙ্খলে ক্রমিকভাবে তৈরি হয় — প্রথম গাছ মূল data-তে fit হয়, দ্বিতীয় গাছ প্রথমটির ভুল/residual-এ fit হয়, তৃতীয়টি দ্বিতীয়টির অবশিষ্ট ভুলে, এভাবে চলতে থাকে; প্রতিটি নতুন গাছ পূর্ববর্তী ensemble-এর যেখানে দুর্বলতা ঠিক সেখানে মন দেয়। চূড়ান্ত পূর্বাভাস হলো এদের একটি weighted sum। যেহেতু প্রতিটি step আগের সম্মিলিত ভুল শোধরায়, boosting-এর মূল লাভ bias কমানো — দুর্বল, high-bias learner-দের জুড়ে একটি শক্তিশালী, কম-bias model গড়ে তোলা। AdaBoost ও Gradient Boosting দুটোই এই পরিবারের, এখানে দুজনেই ০.৮৫০।
নিচের accuracy-bar inset পুরো গল্পটাকে একটি সংখ্যা-শৃঙ্খলে বাঁধে: একক stump মাত্র ০.৭৩৯ থেকে শুরু করে ensemble-গুলো লাফিয়ে উঠেছে — AdaBoost ০.৮৫০, GB ০.৮৫০, RF ০.৮৩৯। অর্থাৎ একটি দুর্বল শিক্ষার্থীকে (variance কমিয়ে হোক — bagging, বা bias কমিয়ে — boosting) বহুগুণে জুড়ে দিলে প্রায় এগারো শতাংশ-বিন্দু উন্নতি মেলে। লক্ষণীয় যে এই নির্দিষ্ট data-তে boosting (০.৮৫০) আর bagging (০.৮৩৯) প্রায় সমান-সমান — সর্বজনীন কোনো বিজয়ী নেই; কোন দর্শন এগিয়ে থাকবে তা নির্ভর করে data-র চরিত্রের ওপর (signal বনাম noise, base learner কতটা দুর্বল ইত্যাদি)। schematic-টির আসল শিক্ষা পরিসংখ্যান নয়, বরং স্থাপত্য: bagging সমান্তরালে variance-এর বিরুদ্ধে লড়ে, boosting ক্রমে bias-এর বিরুদ্ধে — আর এই মৌলিক পার্থক্যই ঠিক করে দেয় কখন কোনটি বাছবে।
সারসংক্ষেপ¶
চারটি ছবি একসাথে boosting-এর একটি সম্পূর্ণ চিত্র তৈরি করে। Round বনাম accuracy (৬.১) দেখাল যে boosting-এ আরও round সর্বদা ভালো নয় — AdaBoost \(n=50\)-এ ০.৮৫০-এ peak করে তারপর label noise-এ overfit করে নেমে আসে, যেখানে Gradient Boosting মসৃণভাবে plateau করে। Reweighting (৬.২) AdaBoost-এর হৃদয়টি চোখে দেখাল — ভুল বিন্দুগুলো round-এ-round বড় হয়, boundary তাদের দিকে বাঁকে। Learning rate (৬.৩) shrinkage-এর বিনিময় উন্মোচন করল — ছোট \(\nu\) ধীর কিন্তু test-এ স্থিতিশীল, বড় \(\nu\) দ্রুত train ১.০ ছোঁয় কিন্তু test অস্থির। শেষে bagging বনাম boosting (৬.৪) দুই দর্শনকে পাশাপাশি রাখল — সমান্তরাল গাছ variance কমায়, ক্রমিক গাছ bias কমায়, আর একক stump-এর ০.৭৩৯ থেকে ensemble-গুলো ০.৮৪-০.৮৫-এ পৌঁছায়। এই ছবিগুলো তৈরির সম্পূর্ণ, পুনরুৎপাদনযোগ্য কোড আছে _code/figs_6-6.py-তে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/06-06-boosting-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — boosting-এর মূল ধারণা (ক্রমিক weak learner, bias↓; bagging-এর সমান্তরাল variance↓-এর বিপরীত), AdaBoost-এর learner-ওজন \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) (দেওয়া \(\varepsilon_t\)-এ \(\alpha_t\) হাতে গুনে, এবং \(\varepsilon=0.5\) ও \(\varepsilon\to0\) চরমে কী হয়), ভুল-বিন্দুর reweighting (কেন ভুল-শ্রেণিবদ্ধ বিন্দুর ওজন বাড়ে), কেন AdaBoost noise-sensitive (n_estimators-curve পড়া — \(50\)-এ চূড়া তারপর পতন), gradient boosting = negative-gradient/residual-এ গাছ fit (\(r=y-F\) squared loss-এ হাতে দেখানো), learning-rate shrinkage ও \(\nu\)–\(T\) tradeoff (lr-sweep পড়া), boosting overfit করতে পারে (train \(1.000\)/test \(0.850\)), এবং bagging বনাম boosting বৈসাদৃশ্য — এই হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed-সূচক 20260619 (৬.৫-এর অভিন্ন dataset), make_classification(n_samples=600, n_features=20, n_informative=6), \(70/30\) split (\(420\) train, \(180\) test)। canonical test accuracy: decision stump (depth-\(1\)) \(0.739\); AdaBoost (stump base), n_estimators \(1\to0.739\), \(10\to0.789\), \(50\to\mathbf{0.850}\) (চূড়া), \(100\to0.794\), \(200\to0.783\), \(500\to0.778\) (চূড়ার পর পতন — noise-sensitivity); GradientBoosting (\(n{=}200\), lr \(0.1\), depth \(3\)) test \(0.850\) / train \(1.000\) (overfit-চিহ্ন); RF (\(300\)) \(0.839\) (তুলনা); GB learning-rate sweep (\(n{=}200\), depth \(3\)): lr \(0.01\to0.794\), \(0.05\to0.833\), \(0.1\to0.850\), \(0.5\to0.844\), \(1.0\to0.878\)। মূল notation: additive model \(F_T(x)=\sum_t\alpha_t h_t(x)\); AdaBoost weighted error \(\varepsilon_t=\sum_i w_i\,\mathbf 1[h_t(x_i)\ne y_i]\), learner-ওজন \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\); gradient-boosting pseudo-residual \(r_i=-\big[\partial L/\partial F(x_i)\big]_{F=F_{t-1}}\); learning rate \(\nu\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). boosting কী — weak learner-এর ক্রমিক সমষ্টি। boosting একগুচ্ছ weak learner (যেমন decision stump — সবে chance-এর চেয়ে ভালো, এখানে \(0.739\)) ক্রমিকভাবে যোগ করে একটা strong learner \(F_T(x)=\sum_t\alpha_t h_t(x)\) বানায়, যেখানে প্রতিটি নতুন \(h_t\) আগের সমষ্টির ভুল সংশোধন করতে শেখে। (ক) "weak learner" বলতে আনুষ্ঠানিকভাবে কী বোঝায় — একটা stump-এর accuracy (\(0.739\)) এই সংজ্ঞা কীভাবে মেটায়? (খ) boosting-এ গাছগুলো স্বাধীন না পরস্পর-নির্ভর — অর্থাৎ \(h_t\) গড়তে আগের কোন তথ্য লাগে, এবং এজন্য boosting কেন সমান্তরালভাবে (parallel) train করা কঠিন? (গ) এক বাক্যে বলুন boosting মূলত কোনটা কমায় — bias না variance (bagging-এর বিপরীতে), এবং কেন weak/high-bias base learner বাছা হয়। Hint: (ক) weak learner = এমন classifier যার error random guessing-এর (\(50\%\), binary-তে) চেয়ে ধারাবাহিকভাবে একটু কম (\(\varepsilon<0.5\)); stump-এর \(0.739>0.5\) মানে error \(0.261<0.5\) — দুর্বল কিন্তু chance-এর চেয়ে ভালো, তাই বৈধ weak learner। (খ) পরস্পর-নির্ভর — \(h_t\) গড়তে আগের সমষ্টি \(F_{t-1}\)-এর ভুল (AdaBoost-এ reweighted data, GB-তে residual) লাগে; তাই \(h_t\) গড়ার আগে \(h_{t-1}\) শেষ হতেই হবে — ক্রমিক, সমান্তরাল নয়। (গ) boosting মূলত bias কমায় (ধারাবাহিকভাবে ভুল সংশোধন করে); high-bias/low-variance base learner (অগভীর stump) বাছা হয় যাতে যোগফল overfit না করেই ধীরে ধীরে complexity বাড়ে — RF-এর low-bias/high-variance গাছের ঠিক উল্টো।
প্রশ্ন ২ (★). bagging বনাম boosting — দুই বিপরীত ensemble-দর্শন। দুটোই অনেক tree মিলিয়ে ensemble বানায়, কিন্তু আনুমানিক বিপরীত উপায়ে। নিচের প্রতিটির জন্য bagging/RF বনাম boosting-এর পার্থক্য এক লাইনে বলুন: (ক) গাছ গড়ার ক্রম (সমান্তরাল-স্বাধীন বনাম ক্রমিক-নির্ভর); (খ) base learner-এর প্রকৃতি (low-bias/high-variance deep tree বনাম high-bias/low-variance weak stump); (গ) ensemble মূলত কোন error-উপাদান কমায় (variance বনাম bias); (ঘ) আরও গাছ যোগ করার নিরাপত্তা (RF: কখনো overfit করায় না; boosting: অতিরিক্ত গাছ overfit করাতে পারে)। Hint: (ক) bagging সমান্তরাল ও স্বাধীন (প্রতিটি গাছ আলাদা bootstrap), boosting ক্রমিক ও নির্ভরশীল (প্রতিটি গাছ আগেরটার ভুলে)। (খ) bagging: গভীর low-bias/high-variance গাছ গড় করে; boosting: অগভীর high-bias/low-variance weak learner যোগ করে। (গ) bagging/RF variance কমায় (bias প্রায় অপরিবর্তিত); boosting bias কমায়। (ঘ) RF-এ গাছ বাড়ালে variance শুধু কমে/স্থির — নিরাপদ; boosting-এ গাছ training-error fit করতে থাকে, তাই অতিরিক্ত round overfit করাতে পারে (canonical AdaBoost: \(50\to0.850\) চূড়া, এরপর \(500\to0.778\) পতন)।
প্রশ্ন ৩ (★★). AdaBoost-এর learner-ওজন \(\alpha_t\) কী বলছে। AdaBoost প্রতিটি weak learner \(h_t\)-কে ওজন দেয় \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\), যেখানে \(\varepsilon_t\) হলো weighted error। (ক) \(\varepsilon_t\) ছোট (ভালো learner) হলে \(\alpha_t\) বড় না ছোট — অর্থাৎ ভালো learner final vote-এ বেশি না কম প্রভাব রাখে? (খ) \(\varepsilon_t=0.5\) (chance-সমান learner) হলে \(\alpha_t\) কত, এবং final ensemble-এ এই learner কী অবদান রাখে — কেন এটা স্বজ্ঞাত? (গ) \(\varepsilon_t\to0\) (প্রায় নিখুঁত learner) হলে \(\alpha_t\to?\), আর \(\varepsilon_t>0.5\) (chance-এর চেয়ে খারাপ) হলে \(\alpha_t\)-এর চিহ্ন কী হয় এবং এর ব্যাখ্যা কী (learner-এর সিদ্ধান্ত উল্টে নেওয়া)? Hint: (ক) \(\varepsilon_t\) ছোট ⇒ \(\frac{1-\varepsilon_t}{\varepsilon_t}\) বড় ⇒ \(\log\) বড় ⇒ \(\alpha_t\) বড়; ভালো learner বেশি ভোট-ওজন পায় — যৌক্তিক। (খ) \(\varepsilon_t=0.5\): \(\frac{1-0.5}{0.5}=1\), \(\log 1=0\), তাই \(\alpha_t=0\) — chance-সমান learner final vote-এ কোনো অবদানই রাখে না (তথ্যহীন)। (গ) \(\varepsilon_t\to0\): \(\alpha_t\to+\infty\) (প্রায়-নিখুঁত learner-কে বিপুল ওজন); \(\varepsilon_t>0.5\): \(\frac{1-\varepsilon_t}{\varepsilon_t}<1\), \(\log<0\), তাই \(\alpha_t<0\) — ensemble learner-এর সিদ্ধান্ত উল্টে নেয় (anti-correlated learner-ও কাজে লাগে)।
প্রশ্ন ৪ (★★). reweighting — AdaBoost কীভাবে পরের learner-কে নির্দেশ দেয়। প্রতিটি round শেষে AdaBoost নমুনা-ওজন \(w_i\) আপডেট করে: ভুল-শ্রেণিবদ্ধ বিন্দুর ওজন বাড়ায়, ঠিক-শ্রেণিবদ্ধ বিন্দুর ওজন কমায় (\(w_i\leftarrow w_i\exp(\alpha_t)\) ভুলের জন্য, \(w_i\exp(-\alpha_t)\) ঠিকের জন্য, তারপর normalize)। (ক) কেন ভুল-বিন্দুর ওজন বাড়ানো হয় — পরের weak learner \(h_{t+1}\) তখন কোন বিন্দুদের দিকে বেশি মন দেবে? (খ) \(\alpha_t>0\) ধরে দেখান \(\exp(\alpha_t)>1\) এবং \(\exp(-\alpha_t)<1\) — তাই update সত্যিই ভুলের ওজন বাড়ায়, ঠিকের কমায়। (গ) এক বাক্যে বলুন এই reweighting boosting-কে কীভাবে adaptive করে — নামের "Ada" অংশটা এখান থেকেই; এবং কেন এটা boosting-কে label-noise/outlier-এর প্রতি সংবেদনশীল করে তোলে। Hint: (ক) ভুল-বিন্দুর ওজন বাড়লে পরের learner-এর weighted objective-এ ওই বিন্দুগুলো বেশি "দামি" হয়, তাই \(h_{t+1}\) সেগুলো ঠিক করার দিকে বেশি মন দেয় — যেখানে ensemble এখনো দুর্বল সেখানেই মনোযোগ। (খ) \(\alpha_t>0\Rightarrow e^{\alpha_t}>e^0=1\) (ওজন বাড়ে) এবং \(e^{-\alpha_t}<1\) (ওজন কমে)। (গ) প্রতিটি round আগের ভুলের দিকে মানিয়ে নেয় (adapts) বলে "adaptive boosting" — কিন্তু mislabeled বিন্দু/outlier কখনো ঠিক হয় না, তাই তাদের ওজন round-এর পর round বাড়তেই থাকে, ensemble তাদের পেছনে অতিরিক্ত ক্ষমতা ঢালে ⇒ noise-sensitive।
প্রশ্ন ৫ (★★). gradient boosting — residual/negative-gradient-এ গাছ fit। AdaBoost ওজন বদলায়; gradient boosting বদলে প্রতিটি round-এ loss \(L\)-এর negative gradient (pseudo-residual) \(r_i=-\big[\partial L/\partial F(x_i)\big]_{F=F_{t-1}}\)-এ একটা গাছ fit করে, তারপর \(F_t=F_{t-1}+\nu\,h_t\)। (ক) squared loss \(L(y,F)=\tfrac12(y-F)^2\)-এর জন্য \(r_i\) গণনা করে দেখান এটা ঠিক সাধারণ residual \(y_i-F_{t-1}(x_i)\) — তাই "fit the residual" আর "fit the negative gradient" এখানে অভিন্ন। (খ) কেন এটাকে functional gradient descent বলা হয় — সাধারণ gradient descent parameter-space-এ পা ফেলে, এখানে পা ফেলা হয় কোন space-এ? (গ) AdaBoost কি gradient boosting-এর একটা বিশেষ রূপ হিসেবে দেখা যায় — কোন loss function-এর জন্য (এক শব্দে)? Hint: (ক) \(\frac{\partial}{\partial F}\big[\tfrac12(y-F)^2\big]=-(y-F)\), তাই \(r_i=-\big[-(y_i-F_{t-1}(x_i))\big]=y_i-F_{t-1}(x_i)\) — হুবহু residual। (খ) functional gradient descent: প্রতিটি step function-space-এ একটা নতুন function \(h_t\) যোগ করে \(F\)-কে negative-gradient দিকে সরায় (\(F_t=F_{t-1}+\nu h_t\)) — parameter নয়, পুরো function-ই variable; এটা ০.৩-এর gradient descent-এর function-space সংস্করণ। (গ) exponential loss — AdaBoost হলো exponential loss-এর উপর forward stagewise additive modeling, তাই gradient boosting-এর একটা বিশেষ ক্ষেত্র।
প্রশ্ন ৬ (★★). learning rate (shrinkage) ও \(\nu\)–\(T\) tradeoff। gradient boosting আপডেট করে \(F_t=F_{t-1}+\nu\,h_t\), যেখানে \(\nu\in(0,1]\) হলো learning rate / shrinkage। চলমান উদাহরণে GB (\(n{=}200\), depth \(3\)), lr বাড়ালে test accuracy: \(0.01\to0.794\), \(0.05\to0.833\), \(0.1\to0.850\), \(0.5\to0.844\), \(1.0\to0.878\)। (ক) ছোট \(\nu\) মানে প্রতিটি গাছের অবদান কম — তাই একই accuracy পেতে গাছের সংখ্যা \(T\) বেশি না কম লাগবে, এবং এজন্যই \(\nu=0.01\)-এ (\(200\) গাছেই) accuracy মাত্র \(0.794\) কেন? (খ) "\(\nu\) ছোট করো, \(T\) বড় করো" কেন সাধারণত ভালো generalize করে — shrinkage কীভাবে overfitting-এর বিরুদ্ধে regularizer-এর মতো কাজ করে? (গ) এই sweep-এ accuracy একঘেয়ে বাড়ছে না (peak \(1.0\to0.878\) কিন্তু \(0.1\to0.850\), মাঝে ওঠানামা) — এটা কী মনে করিয়ে দেয় \(\nu\) একটা hyperparameter যা (\(T\)-এর সাথে যৌথভাবে) tune করতে হয়, একা বাড়িয়ে/কমিয়ে নয়? Hint: (ক) ছোট \(\nu\)-তে প্রতি step ছোট, তাই floor-এ পৌঁছাতে বেশি গাছ (\(T\)) লাগে; \(\nu=0.01\)-এ \(200\) গাছ যথেষ্ট নয় (under-fit এখনো), তাই \(0.794\) — আরও গাছ দিলে উঠত। (খ) ছোট \(\nu\) + বড় \(T\): প্রতিটি গাছ কেবল সামান্য সংশোধন করে, তাই ensemble ধীরে-ধীরে fit হয়, কোনো একক গাছ data-noise-এ overreact করে না — shrinkage তাই variance-নিয়ন্ত্রক regularizer (ridge-এর মতো, প্রতিটি update ছোট রাখে)। (গ) accuracy \(\nu\)-তে একঘেয়ে নয় (এই বিশেষ data-তে \(1.0\)-ও ভালো করল), তাই \(\nu\) ও \(T\) একসঙ্গে cross-validation দিয়ে tune করা উচিত — কোনো একটা "সবসময়-সেরা" \(\nu\) নেই; ছোট \(\nu\) নিরাপদ default কিন্তু \(T\) বাড়াতে হয়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৭ (★). \(\alpha_t\) হাতে গুনুন — তিনটি error-মান। AdaBoost-এ \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) (natural log)। নিচের প্রতিটি weighted error-এর জন্য \(\alpha_t\) গণনা করুন এবং চিহ্ন/মাত্রা ব্যাখ্যা করুন: (ক) \(\varepsilon_t=0.3\); (খ) \(\varepsilon_t=0.1\); (গ) \(\varepsilon_t=0.5\) এবং \(\varepsilon_t=0.6\) — শেষ দুটির চিহ্ন তুলনা করে বলুন কী ঘটছে। Hint: (ক) \(\frac{0.7}{0.3}=2.333\), \(\ln 2.333=0.847\), \(\alpha=\tfrac12(0.847)=\mathbf{0.424}\) (ধনাত্মক, মাঝারি ওজন)। (খ) \(\frac{0.9}{0.1}=9\), \(\ln 9=2.197\), \(\alpha=\mathbf{1.099}\) (অনেক বড় — ভালো learner বেশি ভোট)। (গ) \(\varepsilon=0.5\): \(\ln 1=0\), \(\alpha=\mathbf{0}\) (তথ্যহীন); \(\varepsilon=0.6\): \(\frac{0.4}{0.6}=0.667\), \(\ln 0.667=-0.405\), \(\alpha=\mathbf{-0.203}\) (ঋণাত্মক — chance-এর চেয়ে খারাপ learner-এর ভোট উল্টে নেওয়া হয়)।
প্রশ্ন ৮ (★★). একটা reweighting round হাতে। \(5\)টি বিন্দু, প্রাথমিক ওজন সমান \(w_i=1/5=0.2\) প্রতিটি। weak learner \(h_1\) বিন্দু \(\#2\) ও \(\#4\) ভুল করে, বাকি তিনটি ঠিক। (ক) weighted error \(\varepsilon_1=\sum_i w_i\mathbf 1[h_1(x_i)\ne y_i]\) এবং \(\alpha_1=\tfrac12\log\frac{1-\varepsilon_1}{\varepsilon_1}\) গণনা করুন। (খ) প্রতিটি বিন্দুর unnormalized নতুন ওজন বের করুন: ভুলের জন্য \(w_i e^{\alpha_1}\), ঠিকের জন্য \(w_i e^{-\alpha_1}\)। (গ) normalization-ধ্রুবক \(Z\) (সব unnormalized ওজনের যোগ) দিয়ে ভাগ করে normalized ওজন বের করুন, এবং যাচাই করুন ভুল-বিন্দুর মোট ওজন এখন ঠিক \(0.5\) — AdaBoost-এর একটা পরিচিত ধর্ম (পরের round-এ আগের learner ঠিক chance-সমান)। Hint: (ক) \(\varepsilon_1=0.2+0.2=0.4\); \(\frac{0.6}{0.4}=1.5\), \(\ln 1.5=0.405\), \(\alpha_1=\mathbf{0.203}\)। (খ) \(e^{0.203}=1.225\), \(e^{-0.203}=0.816\); ভুল (\(\#2,\#4\)): \(0.2(1.225)=0.245\) প্রতিটি; ঠিক (\(\#1,\#3,\#5\)): \(0.2(0.816)=0.163\) প্রতিটি। (গ) \(Z=2(0.245)+3(0.163)=0.490+0.490=0.980\); normalized — ভুল প্রতিটি \(0.245/0.980=0.250\), ঠিক প্রতিটি \(0.163/0.980=0.167\); ভুল-মোট \(=2(0.250)=\mathbf{0.5}\) ✓ (ঠিক-মোট-ও \(3(0.167)=0.5\)) — reweight করে \(h_1\)-কে নতুন বণ্টনে ঠিক \(50\%\) error-এ নামানো হয়।
প্রশ্ন ৯ (★★). squared-loss residual হাতে — gradient boosting-এর প্রথম দুই step। regression-এ squared loss \(L=\tfrac12(y-F)^2\), তাই pseudo-residual \(r_i=y_i-F_{t-1}(x_i)\)। ৩টি বিন্দুর target \(y=(10,\,12,\,20)\)। ধরুন \(F_0(x)=\bar y\) (ধ্রুবক প্রাথমিক ভবিষ্যদ্বাণী)। (ক) \(F_0\) ও প্রথম-round residual \(r_i^{(1)}=y_i-F_0\) গণনা করুন। (খ) ধরুন একটা সরল regression-গাছ এই residual-এ fit করে ভবিষ্যদ্বাণী দিল \(h_1=(-4,\,-4,\,8)\) (অর্থাৎ প্রথম দুটি বিন্দুকে এক leaf, তৃতীয়টিকে আরেক leaf-এ রেখে residual-গড় ফেরত দিল); learning rate \(\nu=0.5\) নিয়ে \(F_1=F_0+\nu h_1\) এবং নতুন residual \(r_i^{(2)}=y_i-F_1\) বের করুন। (গ) এক বাক্যে বলুন কেন residual (\(\max\lvert r\rvert\)) ছোট হয়ে আসছে — boosting-এর "ভুল ধীরে-ধীরে সংশোধন" এখানে কীভাবে দেখা যাচ্ছে। Hint: (ক) \(F_0=\bar y=(10+12+20)/3=14\); \(r^{(1)}=(10-14,\,12-14,\,20-14)=(-4,\,-2,\,6)\)। (খ) \(\nu h_1=0.5(-4,-4,8)=(-2,-2,4)\); \(F_1=(14-2,\,14-2,\,14+4)=(12,\,12,\,18)\); \(r^{(2)}=(10-12,\,12-12,\,20-18)=(-2,\,0,\,2)\)। (গ) \(\max\lvert r\rvert\) \(6\to2\)-এ নামল — প্রতিটি গাছ আগের residual-এর একটা অংশ (shrunk by \(\nu\)) মুছে দিচ্ছে, তাই যোগফল \(F_t\) ক্রমে \(y\)-এর কাছে যাচ্ছে; এটাই functional gradient descent-এর এক-একটা পা।
প্রশ্ন ১০ (★★). AdaBoost n_estimators-curve পড়া — noise-sensitivity। চলমান উদাহরণে AdaBoost (stump base) test accuracy:
| n_estimators | test accuracy |
|---|---|
| 1 | 0.739 |
| 10 | 0.789 |
| 50 | 0.850 (চূড়া) |
| 100 | 0.794 |
| 200 | 0.783 |
| 500 | 0.778 |
(ক) \(1\to50\)-এ accuracy বাড়ে (\(0.739\to0.850\)) কেন — boosting এ সময় কোন error-উপাদান কমাচ্ছে? (খ) \(50\)-এর পর accuracy পড়ে (\(0.850\to0.778\)) — RF-এ যেখানে আরও গাছ কখনো ক্ষতি করে না, এখানে কেন ক্ষতি করছে (boosting অতিরিক্ত round-এ কী fit করতে থাকে)? (গ) এই curve কীভাবে দেখায় AdaBoost-এর n_estimators একটা tune-যোগ্য hyperparameter (early stopping দরকার), RF-এর "যত-বেশি-তত-ভালো" knob-এর বিপরীতে? Hint: (ক) শুরুতে boosting ক্রমিকভাবে bias কমায় — একগুচ্ছ stump-এর যোগফল ধীরে-ধীরে আসল decision boundary ধরে, তাই \(0.739\to0.850\)। (খ) চূড়ার পর ensemble training-data (noise/outlier সমেত) fit করতে থাকে — ভুল-বিন্দুর ওজন বাড়তে-বাড়তে ensemble তাদের পেছনে অতিরিক্ত ক্ষমতা ঢালে ⇒ overfit, test accuracy পড়ে (\(0.850\to0.778\)); এটাই AdaBoost-এর noise-sensitivity। (গ) accuracy n_estimators-এ একঘেয়ে নয় (চূড়া আছে), তাই validation/CV দিয়ে সেরা round (এখানে \(\approx50\)) বেছে early stopping দরকার — RF-এর monotone-নিরাপদ curve-এর বিপরীত।
প্রশ্ন ১১ (★★). boosting overfit করে — train বনাম test। চলমান উদাহরণে GradientBoosting (\(n{=}200\), lr \(0.1\), depth \(3\)): train accuracy \(1.000\), test accuracy \(0.850\)। তুলনায় একই data-তে RF(\(300\)) test \(0.839\)। (ক) train \(1.000\) কিন্তু test \(0.850\) — এই \(0.150\) ব্যবধান কীসের লক্ষণ, এবং কেন যথেষ্ট round/গভীরতা দিলে boosting training-error প্রায় \(0\)-এ নামাতে পারে? (খ) তবু GB-এর test (\(0.850\)) RF-এর (\(0.839\))-এর চেয়ে সামান্য ভালো — train-error \(0\) মানেই কি model খারাপ, না generalization (test) দিয়েই বিচার করতে হবে? (গ) এই overfitting ঠেকাতে gradient boosting-এ ব্যবহৃত তিনটি নিয়ন্ত্রক (regularizer) নাম বলুন। Hint: (ক) train ≫ test (\(1.000\) বনাম \(0.850\)) = overfitting-এর ক্লাসিক চিহ্ন; যথেষ্ট গাছ ও যথেষ্ট গভীরতা থাকলে additive model প্রতিটি training-বিন্দু আলাদা করে fit করতে পারে, তাই training-error \(\to0\) (এখানে \(1.000\))। (খ) train-error \(0\) একা নিন্দনীয় নয় — boosting প্রায়ই train \(1.0\)-তেও ভালো test দেয় (margin বাড়ায়); আসল বিচার test/CV accuracy, আর এখানে GB (\(0.850\)) RF (\(0.839\))-কে সামান্য হারায়। (গ) (i) learning-rate shrinkage (ছোট \(\nu\)), (ii) গাছের গভীরতা/সংখ্যা সীমিত করা + early stopping, (iii) subsampling (stochastic gradient boosting, প্রতি round-এ data/feature-এর উপসেট) — XGBoost-এ অতিরিক্ত L1/L2 regularization-ও।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১২ (★★★). AdaBoost = exponential loss-এ forward stagewise — \(\alpha_t\) ও reweighting উভয়ই বের করুন। AdaBoost-কে exponential loss \(L(y,F)=\exp(-yF(x))\) (\(y\in\{-1,+1\}\))-এর উপর forward stagewise additive modeling হিসেবে দেখা যায়: round \(t\)-এ স্থির \(F_{t-1}\) ধরে আমরা বাছি $\((\alpha_t,h_t)=\arg\min_{\alpha,h}\sum_{i=1}^n \exp\!\big(-y_i\,[F_{t-1}(x_i)+\alpha h(x_i)]\big).\)$ ধরুন \(w_i^{(t)}=\exp(-y_iF_{t-1}(x_i))\) (round \(t\)-এর "ওজন") এবং \(h(x_i)\in\{-1,+1\}\)। (ক) objective-কে \(\sum_i w_i^{(t)}\exp(-\alpha y_i h(x_i))\) রূপে লিখে, \(y_ih(x_i)=+1\) (ঠিক) ও \(-1\) (ভুল) দুই দলে ভেঙে দেখান এটি \(=e^{-\alpha}\!\sum_{\text{ঠিক}}w_i+e^{\alpha}\!\sum_{\text{ভুল}}w_i\)। (খ) weighted error \(\varepsilon_t=\frac{\sum_{\text{ভুল}}w_i}{\sum_i w_i}\) ধরে, \(\alpha\)-সাপেক্ষে derivative শূন্য করে দেখান \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\)। (গ) আপডেট \(F_t=F_{t-1}+\alpha_t h_t\) থেকে দেখান পরের round-এর ওজন \(w_i^{(t+1)}=w_i^{(t)}\exp(-\alpha_t y_i h_t(x_i))\) — অর্থাৎ ভুল-বিন্দু (\(y_ih_t=-1\)) \(e^{\alpha_t}\)-গুণ ওজন পায়, ঠিক-বিন্দু \(e^{-\alpha_t}\)-গুণ — ঠিক AdaBoost-এর reweighting নিয়ম। Hint: (ক) \(-\alpha y_i h(x_i)=-\alpha\) যখন \(y_ih=+1\), \(=+\alpha\) যখন \(y_ih=-1\); তাই objective \(=e^{-\alpha}\sum_{\text{ঠিক}}w_i+e^{\alpha}\sum_{\text{ভুল}}w_i\)। (খ) \(W=\sum_i w_i\), \(\sum_{\text{ভুল}}w_i=\varepsilon_t W\), \(\sum_{\text{ঠিক}}w_i=(1-\varepsilon_t)W\); objective \(=W[(1-\varepsilon_t)e^{-\alpha}+\varepsilon_t e^{\alpha}]\); \(\frac{d}{d\alpha}=W[-(1-\varepsilon_t)e^{-\alpha}+\varepsilon_t e^{\alpha}]=0\Rightarrow e^{2\alpha}=\frac{1-\varepsilon_t}{\varepsilon_t}\Rightarrow\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) ∎। (গ) \(w_i^{(t+1)}=\exp(-y_iF_t(x_i))=\exp(-y_i[F_{t-1}(x_i)+\alpha_t h_t(x_i)])=w_i^{(t)}\exp(-\alpha_t y_i h_t(x_i))\) — exponent \(-\alpha_t\) (ঠিক, \(y_ih_t=1\)) বা \(+\alpha_t\) (ভুল, \(y_ih_t=-1\)), যা AdaBoost-এর multiplicative reweighting (normalize করার পর)।
প্রশ্ন ১৩ (★★★). gradient boosting = function-space-এ steepest descent। loss \(\sum_i L(y_i,F(x_i))\)-কে আমরা সরাসরি প্রতিটি বিন্দুর ভবিষ্যদ্বাণী \(F(x_i)\)-এর সাপেক্ষে minimize করতে চাই। (ক) সাধারণ gradient descent প্রতি step-এ \(F(x_i)\leftarrow F(x_i)-\nu\,g_i\) করত, যেখানে \(g_i=\partial L/\partial F(x_i)\); দেখান squared loss \(L=\tfrac12(y-F)^2\)-এ \(-g_i=y_i-F(x_i)\) — অর্থাৎ negative gradient = residual। (খ) সমস্যা: এই \(-g_i\) কেবল training-বিন্দুতে সংজ্ঞায়িত, নতুন \(x\)-এ নয়। gradient boosting এটা কীভাবে সমাধান করে — pseudo-residual \(\{(x_i,-g_i)\}\)-এ একটা regression tree \(h_t\) fit করে কী অর্জন করা হয় (function-space-এ পা ফেলা বনাম point-wise)? (গ) তাই আপডেট \(F_t=F_{t-1}+\nu h_t\) কেন "functional gradient descent"-এর এক step, এবং learning rate \(\nu\) এখানে gradient-descent-এর কোন parameter-এর ভূমিকা পালন করে? Hint: (ক) \(\frac{\partial}{\partial F}\tfrac12(y-F)^2=-(y-F)\), তাই \(g_i=-(y_i-F(x_i))\), \(-g_i=y_i-F(x_i)\) = residual। (খ) point-wise \(-g_i\) generalize করে না; gradient boosting এতে একটা regression tree \(h_t\) fit করে — গাছটা \(-g_i\)-এর একটা smooth, সর্বত্র-সংজ্ঞায়িত আনুমানিকতা দেয়, তাই negative-gradient দিক পুরো input-space-এ বাড়ানো যায় (point-wise update-কে function-এ রূপান্তর)। (গ) \(F_t=F_{t-1}+\nu h_t\) হলো \(F\)-কে (আনুমানিক) negative-gradient \(h_t\approx-g\) দিকে \(\nu\)-আকারের পা ফেলা — function-space-এ steepest descent; \(\nu\) ঠিক gradient descent-এর step size / learning rate (০.৩), ছোট \(\nu\) ⇒ ছোট সতর্ক পা।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৪ (★★★). পূর্ণ pipeline — stump → AdaBoost (n_est sweep) → GradientBoosting (overfit + lr sweep) → RF তুলনা। seed-সূচক 20260619 দিয়ে ৬.৫-এর অভিন্ন canonical dataset বানান: make_classification(n_samples=600, n_features=20, n_informative=6, random_state=20260619), তারপর \(70/30\) split (random_state=20260619, \(420\) train / \(180\) test)। এবার:
- baseline stump:
DecisionTreeClassifier(max_depth=1, random_state=...)fit করে test accuracy ছাপুন — canonical \(0.739\) (weak learner)। - AdaBoost n_estimators sweep:
AdaBoostClassifier(n_estimators=B, random_state=...)-এর জন্য \(B\in\{1,10,50,100,200,500\}\) test accuracy ছাপুন — canonical \(0.739,0.789,\mathbf{0.850},0.794,0.783,0.778\); চূড়া \(B{=}50\)-এ, তারপর পতন (noise-sensitivity/overfit) — দেখান। - GradientBoosting (default) — overfit-চিহ্ন:
GradientBoostingClassifier(n_estimators=200, learning_rate=0.1, max_depth=3, random_state=...)fit করে train ও test accuracy দুটোই ছাপুন — canonical train \(1.000\), test \(0.850\) (train ≫ test = overfit)। - GB learning-rate sweep: একই (\(n{=}200\), depth \(3\))-এ lr \(\in\{0.01,0.05,0.1,0.5,1.0\}\) test accuracy ছাপুন — canonical \(0.794,0.833,0.850,0.844,0.878\) (\(\nu\)–\(T\) tradeoff)।
- RF তুলনা:
RandomForestClassifier(n_estimators=300, random_state=...)test accuracy ছাপুন — canonical \(0.839\) (boosting-এর bias↓ বনাম bagging-এর variance↓ পাশাপাশি রাখুন)।
Hint: from sklearn.datasets import make_classification; from sklearn.model_selection import train_test_split; from sklearn.tree import DecisionTreeClassifier; from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier; from sklearn.metrics import accuracy_score। সব estimator-এ একই random_state=20260619। সংস্করণ-ভেদে শেষ অঙ্কে সামান্য হেরফের হতে পারে কিন্তু গল্প — stump দুর্বল → AdaBoost ক্রমে bias কমিয়ে \(\approx50\) round-এ চূড়া তারপর overfit → GB train \(1.0\)/test \(0.85\) → lr–T tradeoff → RF তুলনীয় — অপরিবর্তিত। পূর্ণ runnable script _solutions/06-06-boosting-solutions.md-এর §ঘ-তে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
Boosting — ক্রমিক weak learner-এর সমষ্টি, bias↓। boosting একগুচ্ছ weak learner (অগভীর, high-bias/low-variance — যেমন decision stump, এখানে \(0.739\)) ক্রমিকভাবে যোগ করে একটা strong learner \(F_T(x)=\sum_t\alpha_t h_t(x)\) গড়ে, যেখানে প্রতিটি নতুন \(h_t\) আগের সমষ্টির ভুল সংশোধন করতে শেখে। bagging/RF যেখানে স্বাধীন গাছ গড় করে variance কমায়, boosting সেখানে নির্ভরশীল গাছ যোগ করে মূলত bias কমায় — দুই বিপরীত ensemble-দর্শন।
-
AdaBoost — exponential loss + reweighting + learner-ওজন \(\alpha_t\)। প্রতিটি round-এ AdaBoost weighted error \(\varepsilon_t\)-এর weak learner বাছে, তাকে ওজন দেয় \(\alpha_t=\tfrac12\log\frac{1-\varepsilon_t}{\varepsilon_t}\) (ভালো learner ⇒ বড় \(\alpha\); \(\varepsilon=0.5\) ⇒ \(\alpha=0\), তথ্যহীন; \(\varepsilon>0.5\) ⇒ \(\alpha<0\), ভোট উল্টে), এবং ভুল-বিন্দুর ওজন বাড়িয়ে (\(w_i\leftarrow w_ie^{\pm\alpha_t}\)) পরের learner-কে কঠিন বিন্দুর দিকে মন দিতে বাধ্য করে — তাই "adaptive"। গাণিতিকভাবে AdaBoost = exponential loss-এর উপর forward stagewise additive modeling (§৭ প্রশ্ন ১২-তে \(\alpha_t\) ও reweighting দুটোই এই minimization থেকে বেরোয়)।
-
Gradient boosting — negative-gradient residual-এ গাছ fit, shrinkage \(\nu\)। প্রতিটি round-এ loss-এর pseudo-residual \(r_i=-\partial L/\partial F\big\rvert_{F_{t-1}}\)-এ একটা regression tree fit করে \(F_t=F_{t-1}+\nu h_t\) — squared loss-এ \(r_i=y_i-F_{t-1}(x_i)\) (সাধারণ residual), তাই "fit the residual" = "fit the negative gradient"। এটা functional gradient descent (০.৩-এর gradient descent function-space-এ); learning rate \(\nu\) হলো step size — ছোট \(\nu\) + বড় \(T\) regularizer-এর মতো ভালো generalize করে (canonical lr-sweep: \(0.01\to0.794\) … \(0.1\to0.850\), \(\nu\)–\(T\) tradeoff)। AdaBoost হলো এর exponential-loss বিশেষ রূপ।
-
Boosting overfit করতে পারে — AdaBoost noise-sensitive। RF-এ আরও গাছ কখনো ক্ষতি করে না, কিন্তু boosting অতিরিক্ত round-এ training-noise fit করতে থাকে: canonical AdaBoost n_estimators \(1\to0.739\), \(50\to\mathbf{0.850}\) (চূড়া), তারপর \(100\to0.794\), \(500\to0.778\) (পতন — early stopping দরকার); GradientBoosting train \(1.000\)/test \(0.850\) (train ≫ test = overfit-চিহ্ন)। mislabeled বিন্দু/outlier-এর ওজন round-এর পর round বাড়ে বলেই AdaBoost noise/outlier-সংবেদনশীল।
-
XGBoost ও আধুনিক রূপ। বাস্তবে gradient boosting-এর regularized, scalable বাস্তবায়ন XGBoost (এবং LightGBM/CatBoost) — shrinkage, গাছ-গভীরতা/সংখ্যা-সীমা, stochastic subsampling (row/column), এবং অতিরিক্ত L1/L2 penalty দিয়ে overfitting নিয়ন্ত্রণ করে; tabular data-তে এরা প্রায়শই সেরা off-the-shelf predictor।
-
মূল বার্তা। দুর্বল-কিন্তু-পক্ষপাতী (high-bias) learner-কে ক্রমিকভাবে যোগ করে, প্রতিবার আগের ভুল সংশোধন করিয়ে শক্তিশালী low-bias predictor বানানোই boosting-এর সারমর্ম — AdaBoost ওজন বদলে, gradient boosting residual-এ গাছ fit করে। ক্ষমতা boosting-এর শক্তি ও দুর্বলতা একসাথে: যথেষ্ট মন দিলে bias প্রায় শূন্যে নামে, কিন্তু অতিরিক্ত round/বড় \(\nu\) overfit করায় — তাই shrinkage, early stopping ও subsampling অপরিহার্য।
পূর্ববর্তী সংযোগ (← ৬.৫, ৬.১, ০.৩):
-
৬.৫ (decision trees, bagging, random forest): ৬.৫ ছিল সমান্তরাল ensemble — অনেক স্বাধীন, low-bias/high-variance গভীর গাছ একসাথে গড় করে variance কমানো (\(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) floor, decorrelation)। ৬.৬ ঠিক উল্টো প্রান্ত আক্রমণ করে: ক্রমিক boosting অনেক নির্ভরশীল, high-bias/low-variance অগভীর learner যোগ করে bias কমায়। একই base ingredient (tree) দুই বিপরীত উপায়ে — RF গভীর গাছকে গড় করে শান্ত করে, boosting অগভীর গাছকে যোগ করে শক্তিশালী করে; এই দ্বৈততাই (parallel-averaging বনাম sequential-correcting) দুই অধ্যায়কে এক সুতোয় বাঁধে, আর canonical RF \(0.839\) বনাম boosting \(0.850\) পাশাপাশি তুলনার ভিত্তি।
-
৬.১ (bias–variance ও learning theory): boosting ৬.১-এর bias–variance tradeoff-এর আরেকটা সরাসরি প্রয়োগ, কিন্তু bias-প্রান্ত থেকে। একটা stump = high bias, low variance; boosting ক্রমিকভাবে round যোগ করে ensemble-এর capacity বাড়ায়, তাই bias কমে — কিন্তু যথেষ্ট round-এর পর capacity এত বাড়ে যে variance/overfit ফিরে আসে (AdaBoost চূড়ার পর পতন, GB train \(1.0\))। অর্থাৎ n_estimators ও \(\nu\) ঠিক ৬.১-এর "complexity-ডায়াল", আর early stopping/shrinkage সেই ডায়াল sweet-spot-এ থামানোর কৌশল।
-
০.৩ (gradient descent): gradient boosting-এর গোটা যন্ত্রটাই ০.৩-এর gradient descent-এর একটা সুন্দর সাধারণীকরণ। ০.৩-এ parameter \(\theta\leftarrow\theta-\nu\nabla_\theta L\); এখানে variable parameter নয়, পুরো function \(F\) — তাই \(F\leftarrow F-\nu\,g\), যেখানে negative gradient \(-g\) (= residual squared loss-এ) প্রতিটি round-এ একটা গাছ দিয়ে আনুমানিত হয় (functional gradient descent)। ০.৩-এর learning rate \(\nu\) ও step-size-স্বজ্ঞা এখানে হুবহু ফिরে আসে — ছোট সতর্ক পা (ছোট \(\nu\)) বেশি step (বড় \(T\)) চায়, কিন্তু ভালো generalize করে।
পরবর্তী সংযোগ (→ ৬.৭ — density estimation ও EM): ৬.২–৬.৬ জুড়ে আমরা supervised শিক্ষার একটা সম্পূর্ণ toolkit গড়েছি — regularization (৬.২), classification (৬.৩), SVM/kernel (৬.৪), trees/bagging/RF (৬.৫), এবং boosting (৬.৬) — সর্বত্র label \(y\) পরিচিত, লক্ষ্য \(x\mapsto y\) ম্যাপ শেখা। ৬.৭ একটা আমূল ভিন্ন জগতে নিয়ে যায়: unsupervised শিক্ষা, যেখানে কোনো label নেই, শুধু data-র গঠন (density \(p(x)\)) শেখা লক্ষ্য। density estimation (kernel density, mixture model) সরাসরি \(p(x)\) আঁকে, আর EM (Expectation–Maximization) algorithm latent (লুকানো) variable থাকলে (যেমন Gaussian mixture-এ কোন বিন্দু কোন component থেকে এল — অজানা) likelihood maximize করার একটা মার্জিত পুনরাবৃত্ত পদ্ধতি দেয়। অর্থাৎ এ অধ্যায় supervised toolkit সম্পূর্ণ করে, আর ৬.৭ থেকে শুরু হয় label ছাড়া শেখার গল্প — boosting-এর "ভুল সংশোধন" আর residual-fit-এর জায়গায় আসবে "লুকানো গঠন উন্মোচন" ও likelihood-maximization।
সূত্র (sources): P. Dangeti, Statistics for Machine Learning (boosting, AdaBoost, gradient boosting ও XGBoost-এর প্রয়োগমুখী আলোচনা ও Python); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 6 (boosting ও XGBoost-এর ব্যবহারিক দৃষ্টিভঙ্গি, hyperparameter ও overfitting); M. Sugiyama, Introduction to Statistical Machine Learning (boosting, additive model ও bias-হ্রাসের তাত্ত্বিক ভিত্তি); L. Wasserman, All of Statistics, Ch. 22 (boosting ও classification-এর সংক্ষিপ্ত পরিসংখ্যানিক উপস্থাপন)।