2.2 · Conditional Independence Bayes
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
একটা সত্যি ঘটনা দিয়ে শুরু করি। ধরো একটা রোগের জন্য একটা test আছে যেটা ৯৯% নির্ভুল — যার রোগ আছে তার ৯৯% ক্ষেত্রে test "positive" বলে, আর যার রোগ নেই তার ৯৫% ক্ষেত্রে "negative" বলে। তোমার test positive এলো। প্রশ্ন: তোমার আসলে রোগ থাকার probability (সম্ভাবনা) কত?
প্রায় সবাই বলে "৯৯%"। কিন্তু সঠিক উত্তর — যদি রোগটা বিরল হয় (ধরো population (জনসংখ্যা)-র মাত্র ১% আক্রান্ত) — মাত্র প্রায় ১৭%! অর্থাৎ positive test-এর পরও তোমার রোগ না থাকার সম্ভাবনাই বেশি। এই চমকপ্রদ ফলাফলটার নাম false-positive paradox, আর এটা বোঝার চাবিকাঠি হলো এই অধ্যায়ের তিনটে ধারণা: conditional probability (শর্তাধীন সম্ভাব্যতা), independence (স্বাধীনতা), এবং সবার উপরে Bayes' theorem (বেইজের উপপাদ্য)।
মূল অন্তর্দৃষ্টিটা এই: নতুন তথ্য (information) আমাদের সম্ভাবনার হিসাব বদলে দেয়। Test করার আগে তোমার রোগ থাকার সম্ভাবনা ছিল ১% (গোটা population-এর base rate)। Test positive আসার পরে সেই সম্ভাবনা বাড়ে — কিন্তু কতটা বাড়ে তা নির্ভর করে test কতটা ভালো এবং রোগটা কতটা বিরল, দুটোর ওপরেই। এই "তথ্যের আলোকে বিশ্বাস হালনাগাদ (update) করা"-র গণিতই হলো conditional probability ও Bayes' theorem।
Statistics-এ এর গুরুত্ব কোথায়? এই অধ্যায়টা গোটা পরিসংখ্যানের অন্যতম ভিত্তি, কারণ —
- Bayes' theorem হলো Part IV-এর Bayesian inference-এর হৃদয়: data দেখার পর কোনো parameter সম্পর্কে আমাদের বিশ্বাস কীভাবে বদলায়, তার নিয়ম।
- একই theorem Part VI-এর Naive Bayes classifier-এর ভিত্তি — spam filter, document classification, medical diagnosis সবই এর ওপর দাঁড়িয়ে।
- Independence ধারণাটা ছাড়া আমরা random sample, i.i.d. data, কিংবা কোনো probabilistic model লিখতেই পারি না — পরের প্রায় সব অধ্যায়ে এটা লাগবে।
Hook। একটা পরিবারে দুটো বাচ্চা। তুমি জানো অন্তত একটা ছেলে। তাহলে দুটোই ছেলে হওয়ার সম্ভাবনা কত? স্বজ্ঞা বলে \(1/2\), কিন্তু সঠিক উত্তর \(1/3\)! আবার যদি জানো "বড় বাচ্চাটা ছেলে", উত্তর হয়ে যায় \(1/2\)। একই শব্দ "ছেলে", অথচ ভিন্ন তথ্য — ভিন্ন উত্তর। এই সূক্ষ্ম পার্থক্যগুলোই conditional probability-র মূল খেলা, যা আমরা §৩-এ পুরোপুরি খুলব।
২ · মূল ধারণা ও সংজ্ঞা¶
আমরা ধরে নিচ্ছি (২.১ থেকে) একটা sample space \(\Omega\), event-গুলো তার subset, আর একটা probability measure \(P\) আছে যা axioms মেনে চলে। এখন তথ্যের প্রবেশ ঘটাই।
২.১ Conditional probability (শর্তাধীন সম্ভাব্যতা)¶
Event \(B\) ঘটেছে — এই তথ্য জানার শর্তে event \(A\) ঘটার conditional probability (শর্তাধীন সম্ভাব্যতা) হলো $$ P(A \mid B) = \frac{P(A \cap B)}{P(B)}, \qquad \text{যেখানে } P(B) > 0. $$
পড়ো: "\(P(A \mid B)\) = probability of \(A\) given \(B\)"। ওই উল্লম্ব দাগ "\(\mid\)" পড়ো "given" (দেওয়া আছে / শর্তে)। লক্ষ করো \(P(B)>0\) লাগে — যা ঘটতেই পারে না, তা ঘটেছে ধরে শর্ত দেওয়ার কোনো মানে নেই।
স্বজ্ঞা — নমুনাক্ষেত্র সংকোচন (sample-space restriction): "\(B\) ঘটেছে" জানা মানে গোটা \(\Omega\) আর প্রাসঙ্গিক নয় — এখন আমাদের জগৎ কেবল \(B\)। তাই আমরা \(\Omega\)-এর বদলে \(B\)-কেই নতুন সম্পূর্ণ নমুনাক্ষেত্র ধরি, আর তার ভেতরে \(A\)-র অংশ মানে \(A \cap B\)। ভগ্নাংশের হরে \(P(B)\) দিয়ে ভাগ করা হলো এই সংকুচিত জগতে probability আবার \(1\)-এ স্বাভাবিক করা (renormalize)। ছবিতে: \(\Omega\)-র একটা টুকরো \(B\)-তে zoom-in করে, সেই টুকরোর মধ্যে \(A\) কতটা জায়গা নেয় তা মাপা।
সরল উদাহরণ: একটা ন্যায্য ছক্কা গড়ালে। \(A = \{\)সংখ্যা \(=2\}\), \(B = \{\)জোড় সংখ্যা\(\} = \{2,4,6\}\)। তথ্য ছাড়া \(P(A)=1/6\)। কিন্তু "জোড় এসেছে" জানলে সম্ভাব্য জগৎ মাত্র \(\{2,4,6\}\), তার মধ্যে \(2\) একটা — তাই \(P(A \mid B) = 1/3\)। সূত্রেও: \(P(A\cap B)=P(\{2\})=1/6\), \(P(B)=3/6\), ভাগফল \((1/6)/(1/2)=1/3\) ✓।
২.২ Multiplication rule (গুণনের নিয়ম)¶
সংজ্ঞাটা উল্টে লিখলেই joint probability-র সূত্র পাই: $$ P(A \cap B) = P(B)\,P(A \mid B) = P(A)\,P(B \mid A). $$ অর্থাৎ "দুটোই ঘটার" সম্ভাবনা = "প্রথমটা ঘটার" সম্ভাবনা \(\times\) "প্রথমটা ঘটেছে ধরে দ্বিতীয়টা ঘটার" সম্ভাবনা। এটা probability tree-এর প্রতিটি ডাল বরাবর গুণ করার নিয়ম (§৬, চিত্র ১)। তিনটি event-এ বাড়ালে (chain rule): $$ P(A \cap B \cap C) = P(A)\,P(B \mid A)\,P(C \mid A \cap B). $$
২.৩ Independence (স্বাধীনতা)¶
দুটো event \(A\) ও \(B\) পরস্পর independent (স্বাধীন) যদি একটার ঘটা অন্যটার সম্ভাবনাকে না বদলায়: $$ P(A \mid B) = P(A) \quad\Longleftrightarrow\quad P(A \cap B) = P(A)\,P(B). $$
ডানদিকের গুণফল-রূপটাই আনুষ্ঠানিক সংজ্ঞা (এতে \(P(B)=0\)-তেও সমস্যা হয় না, আর symmetric)। স্বজ্ঞা: \(B\) জানলেও \(A\) সম্পর্কে আমাদের জ্ঞান একটুও বদলায় না — দুটো ঘটনা একে অপরের সম্পর্কে কোনো information বহন করে না।
⚠️ সাবধান — দুটো ভিন্ন জিনিস গুলিয়ে ফেলো না: - Mutually exclusive / disjoint (\(A \cap B = \varnothing\)): একসাথে ঘটতে পারে না। এরা সাধারণত independent নয় — বরং চরম নির্ভরশীল (একটা ঘটলে অন্যটা নিশ্চিত ঘটে না)। যদি \(P(A),P(B)>0\) হয়, disjoint হলে \(P(A\cap B)=0 \ne P(A)P(B)\), তাই independent নয়। - Independent: একে অপরের সম্ভাবনাকে প্রভাবিত করে না।
তিন বা ততোধিক event-এর জন্য mutual independence আরও কড়া: শুধু জোড়ায় জোড়ায় (pairwise) নয়, প্রতিটি উপগোষ্ঠীর জন্য গুণফল-নিয়ম খাটতে হবে — \(P(A\cap B\cap C)=P(A)P(B)P(C)\) এবং তিনটে pairwise শর্তও। (Pairwise independent কিন্তু mutually independent নয় — এমন উদাহরণ §৭-এ।)
২.৪ Conditional independence (শর্তাধীন স্বাধীনতা)¶
\(A\) ও \(B\) একটা তৃতীয় event \(C\)-এর শর্তে conditionally independent যদি $$ P(A \cap B \mid C) = P(A \mid C)\,P(B \mid C). $$
অর্থাৎ \(C\) জেনে ফেলার পর \(A\) ও \(B\) আর কোনো অতিরিক্ত তথ্য বহন করে না একে অপরের সম্পর্কে। এটা Naive Bayes-এর প্রাণভোমরা (Part VI): একটা ইমেল spam কিনা (\(C\)) জানলে তার মধ্যে "free" আর "winner" শব্দ থাকা (\(A, B\)) — এদের আমরা conditionally independent ধরি, যা গণনা বিপুলভাবে সহজ করে।
🔑 গুরুত্বপূর্ণ: conditional independence আর (marginal) independence আলাদা — একটা থাকলে আরেকটা থাকতেই হবে এমন নয়। দুটো মোমবাতি একই দেশলাই থেকে জ্বলতে পারে; "আগুন লেগেছে" না জানলে একটার জ্বলা অন্যটার সম্পর্কে তথ্য দেয় (নির্ভরশীল), কিন্তু "দেশলাই জ্বেলেছে" (\(C\)) জানলে তারা স্বাধীন হয়ে যায়। উদাহরণ §৩.৩-এ।
২.৫ Law of total probability (পূর্ণ সম্ভাব্যতার নিয়ম)¶
\(B_1, B_2, \dots, B_n\) যদি \(\Omega\)-র একটা partition হয় (পরস্পর-বিচ্ছিন্ন এবং একসাথে গোটা \(\Omega\) ঢাকে, প্রতিটির \(P(B_i)>0\)), তবে যেকোনো event \(A\)-র জন্য $$ P(A) = \sum_{i=1}^{n} P(A \mid B_i)\,P(B_i). $$
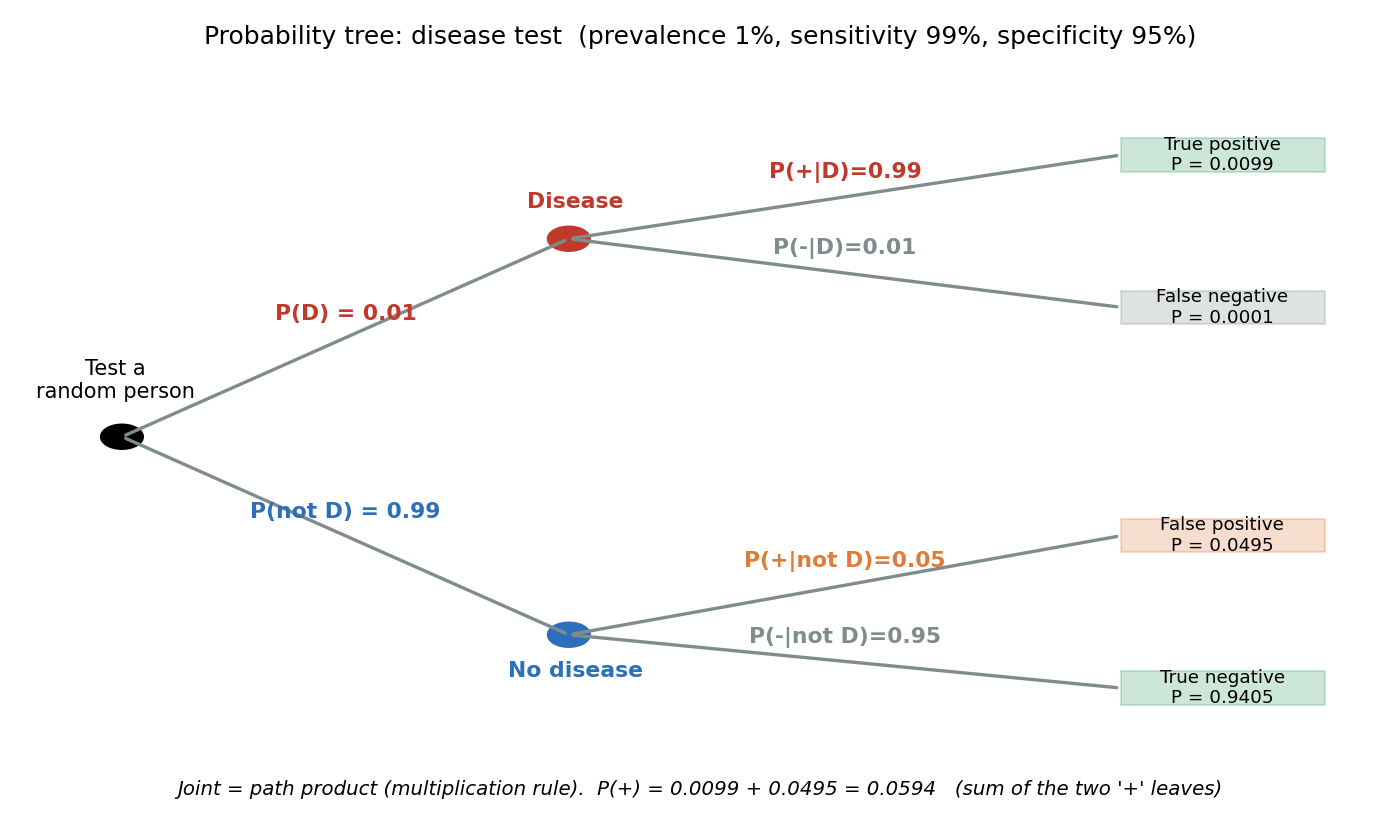
স্বজ্ঞা: \(A\)-তে পৌঁছানোর সব রাস্তা \(B_i\)-গুলোর মধ্য দিয়ে যায়। প্রতিটা রাস্তার "ওজন" \(P(B_i)\) আর সেই রাস্তায় \(A\)-তে পৌঁছানোর সম্ভাবনা \(P(A\mid B_i)\) — সবগুলোর weighted average-ই মোট \(P(A)\)। সরলতম রূপে (\(B\) ও তার complement \(B^c\)): $$ P(A) = P(A \mid B)P(B) + P(A \mid B^c)P(B^c). $$ রোগ-test-এ: \(P(+) = P(+\mid D)P(D) + P(+\mid D^c)P(D^c) = 0.99\cdot0.01 + 0.05\cdot0.99 = 0.0594\) — এটাই tree-এর দুটো "\(+\)" পাতার যোগফল (§৬, চিত্র ১)।
২.৬ Bayes' theorem (বেইজের উপপাদ্য)¶
\(B_1,\dots,B_n\) একটা partition হলে, যেকোনো event \(A\) (with \(P(A)>0\)) দেখার পর $$ \boxed{\,P(B_k \mid A) = \frac{P(A \mid B_k)\,P(B_k)}{\sum_{i=1}^{n} P(A \mid B_i)\,P(B_i)} = \frac{P(A \mid B_k)\,P(B_k)}{P(A)}\,.}$$
দুটো event-এর সরল রূপ: $$ P(B \mid A) = \frac{P(A \mid B)\,P(B)}{P(A \mid B)P(B) + P(A \mid B^c)P(B^c)}. $$
এই সূত্রটা conditional-এর দিক উল্টে দেয়: আমরা সাধারণত জানি \(P(A \mid B)\) ("কারণ থেকে ফলাফল" — রোগ থাকলে test positive), কিন্তু চাই \(P(B \mid A)\) ("ফলাফল থেকে কারণ" — test positive হলে রোগ)। প্রতিটা অংশের নাম আছে, যা Part IV-এ বারবার ফিরবে:
| পদ | নাম | অর্থ |
|---|---|---|
| \(P(B_k)\) | prior (পূর্ব-সম্ভাবনা) | data দেখার আগে \(B_k\)-তে বিশ্বাস |
| \(P(A \mid B_k)\) | likelihood (সম্ভাব্যতা/সাক্ষ্য) | \(B_k\) সত্য হলে এই data দেখার সম্ভাবনা |
| \(P(A)\) | evidence / marginal | data-র মোট সম্ভাবনা (normalizing constant) |
| \(P(B_k \mid A)\) | posterior (উত্তর-সম্ভাবনা) | data দেখার পর \(B_k\)-তে হালনাগাদ বিশ্বাস |
এক বাক্যে: posterior \(\propto\) likelihood \(\times\) prior। অর্থাৎ নতুন বিশ্বাস = (পুরোনো বিশ্বাস) কে (সাক্ষ্য কতটা মানানসই) দিয়ে গুণ, তারপর normalize। এই এক লাইনই গোটা Bayesian পরিসংখ্যানের সারকথা।
৩ · পূর্ণাঙ্গ উদাহরণ¶
৩.১ Disease test — false-positive paradox (পূর্ণ গণনা)¶
§১-এর সমস্যাটা এবার ধাপে ধাপে শেষ করি। ধরা যাক — - Prevalence (ব্যাপকতা): \(P(D) = 0.01\) (জনসংখ্যার ১% আক্রান্ত), তাই \(P(D^c)=0.99\)। - Sensitivity (সংবেদনশীলতা): \(P(+ \mid D) = 0.99\) (রোগীকে test ধরতে পারে ৯৯%)। - Specificity (নির্দিষ্টতা): \(P(- \mid D^c) = 0.95\), তাই false-positive rate \(P(+ \mid D^c)=0.05\)।
আমরা চাই \(P(D \mid +)\)। Bayes' theorem (with \(D, D^c\) partition): $$ P(D \mid +) = \frac{P(+ \mid D)\,P(D)}{P(+ \mid D)P(D) + P(+ \mid D^c)P(D^c)} = \frac{0.99 \times 0.01}{0.99 \times 0.01 + 0.05 \times 0.99}. $$ হিসাব করি: হরে \(0.0099 + 0.0495 = 0.0594\), তাই $$ P(D \mid +) = \frac{0.0099}{0.0594} = \frac{1}{6} \approx 0.1667 = 16.7\%. $$
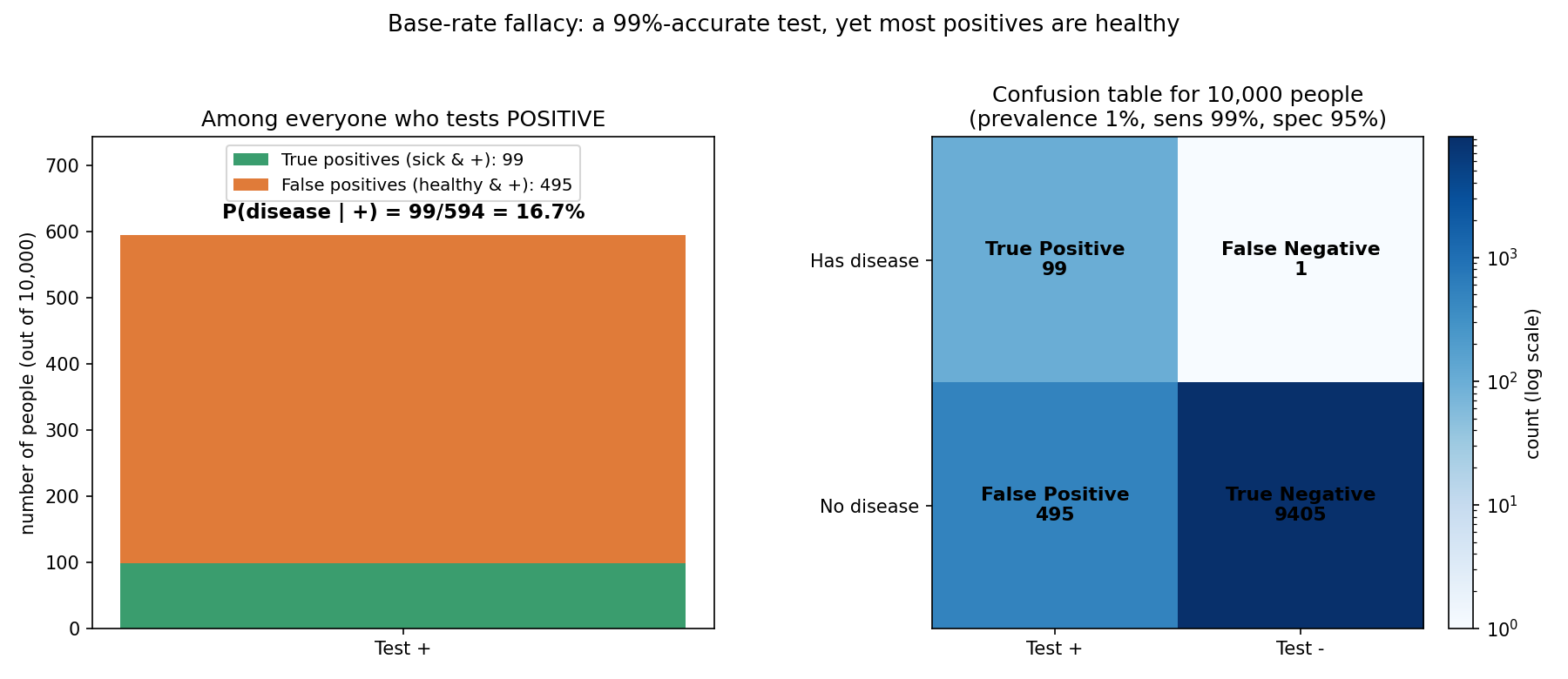
কেন এত কম? কারণ সুস্থ মানুষ অনেক বেশি (৯৯%)। তাদের মাত্র ৫% ভুল positive হলেও সংখ্যাটা বিশাল। \(10{,}000\) জনের ছবিতে দেখলে স্ফটিকস্বচ্ছ হয় (চিত্র ২): - রোগী \(100\) জন → তাদের \(\approx 99\) জন true positive। - সুস্থ \(9{,}900\) জন → তাদের \(5\% = 495\) জন false positive। - মোট positive \(= 99 + 495 = 594\) জন, যাদের মধ্যে সত্যিকারের রোগী মাত্র \(99\) — অনুপাত \(99/594 = 16.7\%\)।
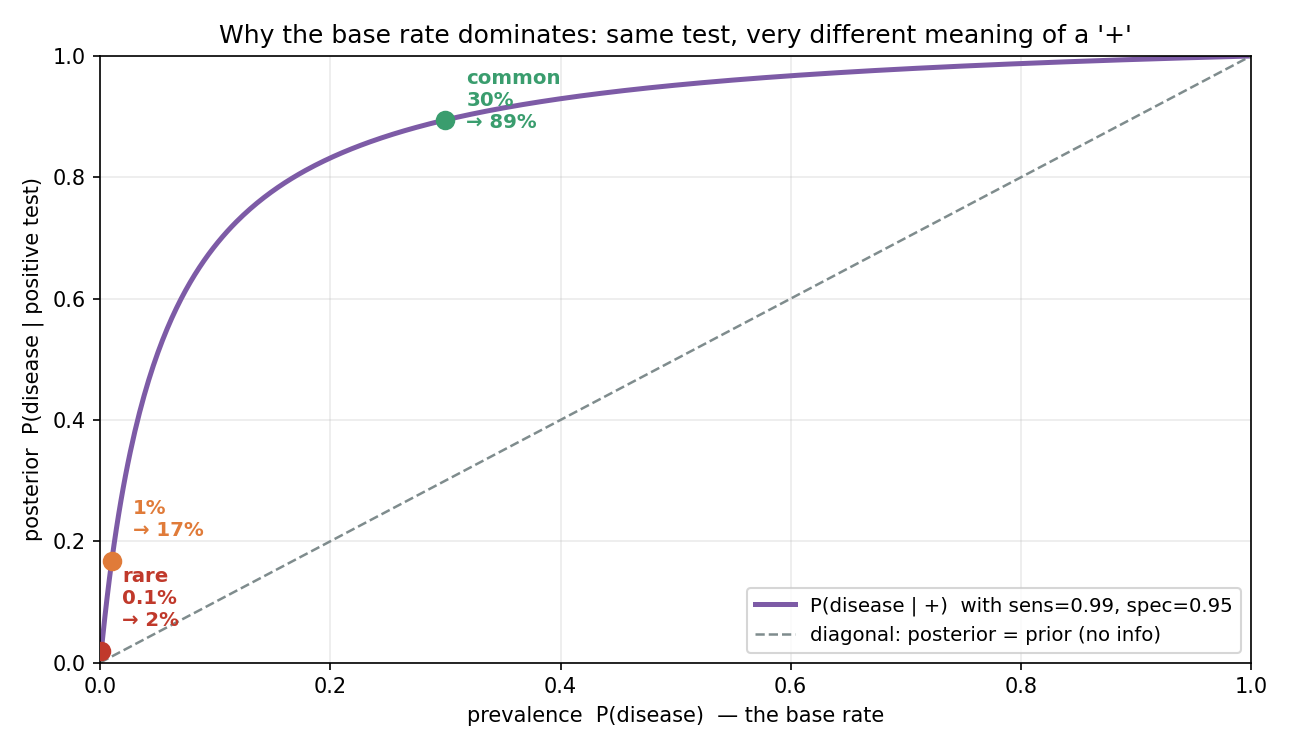
এটাই base-rate fallacy (ভিত্তি-হার ভ্রান্তি): মানুষ prevalence (\(P(D)\), base rate) উপেক্ষা করে শুধু test-এর নির্ভুলতা (\(P(+\mid D)\)) দেখে — তাই ভুল করে \(99\%\) ভাবে। সঠিক উত্তর prior-এর ওপর প্রবলভাবে নির্ভরশীল (চিত্র ৪)।
৩.২ দুটো ছেলে — তথ্যের সূক্ষ্মতা¶
§১-এর hook শেষ করি। দুটো বাচ্চা, প্রতিটি সমসম্ভাব্যভাবে ছেলে (B) বা মেয়ে (G)। নমুনাক্ষেত্র (বড়, ছোট ক্রমে): \(\Omega = \{BB, BG, GB, GG\}\), প্রতিটি \(1/4\)।
ঘটনা ক — "অন্তত একটা ছেলে": \(B_1 = \{BB, BG, GB\}\)। চাই \(P(BB \mid B_1)\): $$ P(BB \mid B_1) = \frac{P(BB \cap B_1)}{P(B_1)} = \frac{P(BB)}{P(B_1)} = \frac{1/4}{3/4} = \frac{1}{3}. $$ ঘটনা খ — "বড় বাচ্চাটা ছেলে": \(B_2 = \{BB, BG\}\)। তাহলে $$ P(BB \mid B_2) = \frac{P(BB)}{P(B_2)} = \frac{1/4}{2/4} = \frac{1}{2}. $$ দুটো তথ্যই "একটা ছেলে আছে" বলে, কিন্তু খ আরও নির্দিষ্ট (কোনটা ছেলে তা জানায়), তাই বেশি নমুনা বাদ দেয় — উত্তর বদলে যায়। শিক্ষা: conditional probability-তে ঠিক কী জানা গেল তার সংজ্ঞা অত্যন্ত সতর্কভাবে করতে হয়।
৩.৩ Conditional vs marginal independence — একটা ছোট মডেল¶
দুটো ল্যাম্প একই switch-এ। \(C=\{\)switch on\(\}\) with \(P(C)=0.5\)। Switch on থাকলে প্রতিটা ল্যাম্প স্বাধীনভাবে \(0.9\) সম্ভাবনায় জ্বলে; off থাকলে কোনোটাই জ্বলে না। \(A=\{\)ল্যাম্প ১ জ্বলছে\(\}\), \(B=\{\)ল্যাম্প ২ জ্বলছে\(\}\)।
\(C\)-র শর্তে: \(P(A\cap B \mid C) = 0.9 \times 0.9 = 0.81 = P(A\mid C)P(B\mid C)\) — conditionally independent ✓।
কিন্তু marginally? \(P(A) = P(A\mid C)P(C) + P(A\mid C^c)P(C^c) = 0.9(0.5)+0(0.5)=0.45\)। একইভাবে \(P(B)=0.45\)। আর $$ P(A\cap B) = \underbrace{0.81 \times 0.5}{C} + \underbrace{0 \times 0.5} = 0.405. $$ কিন্তু \(P(A)P(B) = 0.45 \times 0.45 = 0.2025 \ne 0.405\)। তাই \(A, B\) marginally নির্ভরশীল (NOT independent)! কারণ ল্যাম্প ১ জ্বলছে দেখলে switch on হওয়ার সম্ভাবনা বাড়ে, যা ল্যাম্প ২-এর সম্ভাবনাও বাড়ায়। সিদ্ধান্ত: conditional independence ≠ marginal independence — দুটোই আলাদাভাবে যাচাই করতে হয়।
৩.৪ Bayesian updating — দুটো test (sequential)¶
ধরো প্রথম test positive আসার পর একই ব্যক্তির আরেকটা স্বাধীন test করা হলো, সেটাও positive। এখন রোগের সম্ভাবনা? এখানে কৌশল: প্রথম posterior-ই দ্বিতীয় test-এর prior হয়ে যায়।
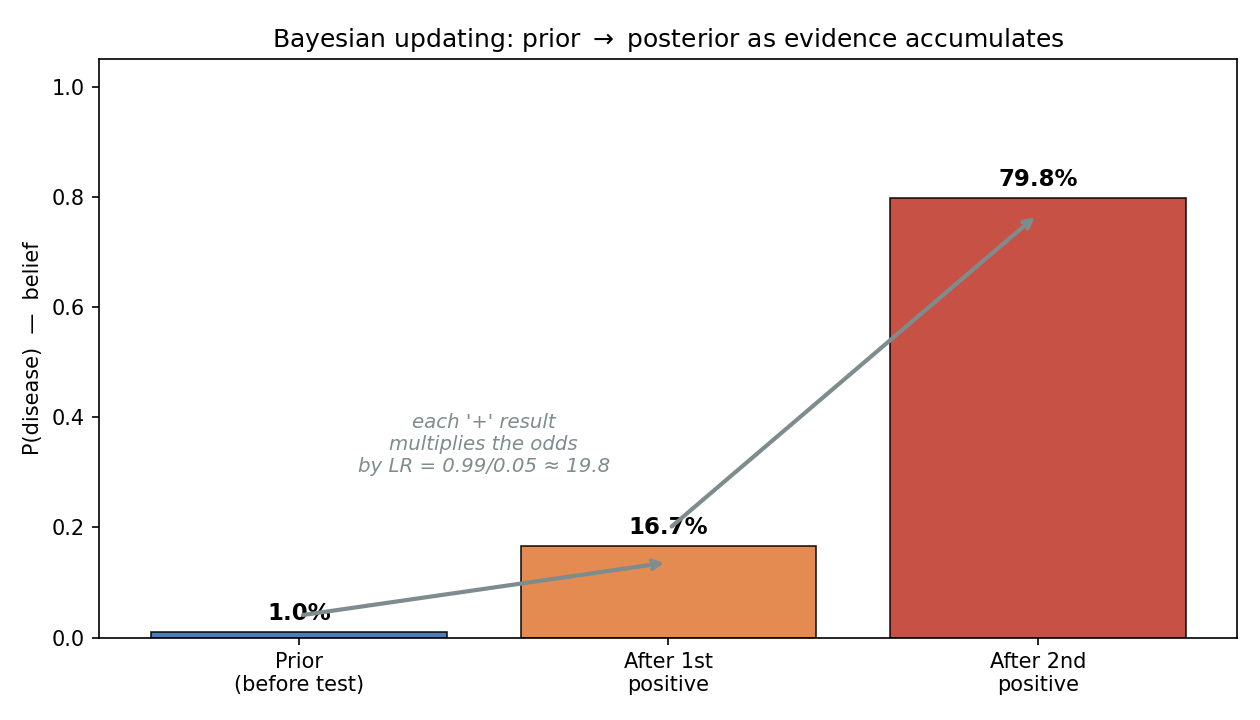
প্রথম test-এর পর: \(P(D \mid +) = 1/6 \approx 0.1667\) (§৩.১)। এটাকে নতুন prior ধরে, দ্বিতীয় positive (\(+_2\))-কে conditionally independent ধরে (রোগ-অবস্থা জানা থাকলে test দুটো স্বাধীন): $$ P(D \mid +_1, +_2) = \frac{0.99 \times 0.1667}{0.99 \times 0.1667 + 0.05 \times 0.8333} = \frac{0.1650}{0.1650 + 0.0417} \approx 0.798. $$ দুটো positive মিলে বিশ্বাস \(1\% \to 17\% \to 80\%\)-তে লাফ দিল (চিত্র ৩)। প্রতিটা positive একই likelihood ratio \(\mathrm{LR} = 0.99/0.05 \approx 19.8\) দিয়ে odds গুণ করে — এটাই Bayesian updating-এর গুণনাত্মক সৌন্দর্য, যা §৪.৫-এ দেখব। data যত জমে, posterior তত দৃঢ় হয় — Part IV-এর Bayesian inference-এর পুরো গল্প এখান থেকেই শুরু।
৪ · প্রমাণ ও উৎপাদন¶
এগুলো intro-probability প্রমাণ — শুধু conditional probability-র সংজ্ঞা ও axioms লাগবে (পূর্ণ measure-theoretic rigor Part VII-এ)।
৪.১ Multiplication rule ★¶
সংজ্ঞা \(P(A\mid B) = P(A\cap B)/P(B)\)-এর দুপাশকে \(P(B)\) দিয়ে গুণ করলেই $$ P(A \cap B) = P(B)\,P(A \mid B). $$ ভূমিকাগুলো বদলে (সংজ্ঞায় \(A,B\) অদলবদল) একইভাবে \(P(A\cap B)=P(A)P(B\mid A)\)। \(\;\blacksquare\)
৪.২ Chain rule (induction দিয়ে) ★★¶
দাবি: \(P(A_1 \cap \cdots \cap A_n) = P(A_1)\,P(A_2\mid A_1)\,P(A_3 \mid A_1\cap A_2)\cdots P(A_n \mid A_1\cap\cdots\cap A_{n-1})\)।
প্রমাণ (induction): \(n=2\) হলো §৪.১। ধরা যাক দাবিটি \(n-1\) ধাপে সত্য। ধরি \(E = A_1\cap\cdots\cap A_{n-1}\)। তাহলে §৪.১ প্রয়োগ করে $$ P(E \cap A_n) = P(E)\,P(A_n \mid E). $$ আর induction hypothesis দিয়ে \(P(E)\)-কে প্রথম \(n-1\)টা পদের গুণফলে ভাঙি; ফলে পুরো \(n\)-পদের গুণফল পাই। \(\;\blacksquare\)
৪.৩ Law of total probability ★¶
\(B_1,\dots,B_n\) partition বলে event \(A\)-কে বিচ্ছিন্ন টুকরোয় ভাঙা যায়: $$ A = A \cap \Omega = A \cap \Big(\bigcup_i B_i\Big) = \bigcup_i (A \cap B_i), $$ এবং \(B_i\)-গুলো পরস্পর-বিচ্ছিন্ন বলে \((A\cap B_i)\)-গুলোও পরস্পর-বিচ্ছিন্ন। তাই axiom (countable/finite additivity) অনুসারে $$ P(A) = \sum_i P(A \cap B_i) = \sum_i P(A \mid B_i)\,P(B_i), $$ শেষ ধাপে multiplication rule (§৪.১)। \(\;\blacksquare\)
৪.৪ Bayes' theorem ★¶
posterior-এর সংজ্ঞা থেকে শুরু করি এবং numerator-এ multiplication rule দুইভাবে লিখি: $$ P(B_k \mid A) = \frac{P(B_k \cap A)}{P(A)} = \frac{P(A \mid B_k)\,P(B_k)}{P(A)}. $$ এখন হরের \(P(A)\)-কে law of total probability (§৪.৩) দিয়ে বদলালেই সম্পূর্ণ রূপ: $$ P(B_k \mid A) = \frac{P(A \mid B_k)\,P(B_k)}{\sum_i P(A \mid B_i)\,P(B_i)}. \qquad\blacksquare $$ লক্ষ করো প্রমাণটা ত্রিবিধ অংশের সাজানো প্রয়োগ মাত্র: conditional-এর সংজ্ঞা \(+\) multiplication rule \(+\) total probability।
৪.৫ Odds রূপ ও likelihood ratio ★★¶
দুটো hypothesis \(H\) vs \(H^c\)-এর জন্য Bayes' theorem-এর অনুপাত নিলে normalizing constant \(P(A)\) কেটে যায়: $$ \underbrace{\frac{P(H \mid A)}{P(H^c \mid A)}}{\text{posterior odds}} = \underbrace{\frac{P(A \mid H)}{P(A \mid H^c)}} \times \underbrace{\frac{P(H)}{P(H^c)}}_{\text{prior odds}}. $$ অর্থাৎ }posterior odds = LR × prior odds। §৩.১-এ prior odds \(= 0.01/0.99 \approx 1/99\), \(\mathrm{LR} = 0.99/0.05 = 19.8\), তাই posterior odds \(= 19.8/99 = 0.2\), যা \(P = 0.2/(1+0.2) = 1/6\) — আগের উত্তরের সাথে মেলে ✓। দ্বিতীয় positive আবার \(\times 19.8\) করে — এজন্যই §৩.৪-এ লাফটা গুণনাত্মক। এই odds-রূপ পরিসংখ্যানে evidence পরিমাপের আদর্শ ভাষা।
৪.৬ Independence ⇒ symmetric ★¶
দাবি: \(P(A\mid B)=P(A)\) (with \(P(B)>0\)) হলে \(P(B\mid A)=P(B)\) (with \(P(A)>0\))। প্রমাণ: শর্ত থেকে \(P(A\cap B)=P(A)P(B)\) (গুণফল-রূপ), যা symmetric; তাই \(P(B\mid A)=P(A\cap B)/P(A)=P(A)P(B)/P(A)=P(B)\)। অর্থাৎ "\(B\), \(A\)-কে প্রভাবিত করে না" ⟺ "\(A\), \(B\)-কে প্রভাবিত করে না" — independence পারস্পরিক। \(\;\blacksquare\)
৫ · কোড ল্যাব (Python)¶
আমরা প্রথমে simulation দিয়ে Bayes' theorem যাচাই করব (theory যা বলে, এলোমেলো নমুনাও তাই বলে কিনা), তারপর independence ও conditional independence সংখ্যায় পরীক্ষা করব। reproducible — default_rng + স্থির seed; কোনো download নেই।
৫.১ Monte-Carlo যাচাই — Bayes' theorem¶
কৌশল: লক্ষ লক্ষ "ব্যক্তি" simulate করি, প্রত্যেকের রোগ-অবস্থা ও test-ফল এলোমেলোভাবে ঠিক করি। তারপর শুধু positive-দের মধ্যে কত শতাংশের সত্যিই রোগ আছে গুনি — সেটা \(P(D \mid +)\)-এর empirical অনুমান, যা Bayes-এর exact মানের সাথে মেলা উচিত।
import numpy as np
rng = np.random.default_rng(2025) # reproducible
M = 200_000 # সংখ্যা যত বড়, অনুমান তত নিখুঁত
prev, sens, fpr = 0.01, 0.99, 0.05 # P(D), P(+|D), P(+|not D)
disease = rng.random(M) < prev # True = রোগ আছে
# রোগ থাকলে sens সম্ভাবনায় +, না থাকলে fpr সম্ভাবনায় +
test_pos = np.where(disease, rng.random(M) < sens, rng.random(M) < fpr)
# empirical conditional probability: positive-দের মধ্যে রোগীর ভগ্নাংশ
p_D_given_pos = disease[test_pos].mean()
# Bayes' theorem-এর exact মান
analytic = (sens * prev) / (sens * prev + fpr * (1 - prev))
print(f"P(+) empirical = {test_pos.mean():.4f} (theory 0.0594)")
print(f"P(D | +) Monte-Carlo = {p_D_given_pos:.4f}")
print(f"P(D | +) Bayes (exact) = {analytic:.4f}")
আউটপুট:
P(+) empirical = 0.0589 (theory 0.0594)
P(D | +) Monte-Carlo = 0.1708
P(D | +) Bayes (exact) = 0.1667
Monte-Carlo অনুমান (\(0.1708\)) exact মানের (\(0.1667\)) খুব কাছে — সংখ্যা (\(M\)) বাড়ালে আরও কাছে যাবে (law of large numbers, Part III)। চিত্র ৫-এ positive-সংখ্যার সাথে এই অনুমানের অভিসরণ (convergence) দেখানো আছে।
৫.২ Bayesian updating — sequential function¶
def bayes_update(prior, likelihood_if_true, likelihood_if_false):
"""একটা positive evidence-এ posterior হিসাব; পরের ধাপের prior হিসেবে ব্যবহার্য।"""
num = likelihood_if_true * prior
den = num + likelihood_if_false * (1 - prior)
return num / den
belief = prev # শুরুর prior = prevalence = 0.01
print(f"prior : {belief:.4f}")
for k in (1, 2, 3):
belief = bayes_update(belief, sens, fpr) # প্রতিটা স্বাধীন positive
print(f"after positive {k}: {belief:.4f}")
আউটপুট:
লক্ষ করো posterior-ই পরের prior — তিনটে positive মিলে বিশ্বাস \(1\% \to 99\%\)। এটাই Bayesian inference-এর recursive কাঠামো।
৫.৩ Independence vs conditional independence যাচাই¶
§৩.৩-এর দুই-ল্যাম্প মডেল simulate করে দেখি — \(C\)-র শর্তে স্বাধীন, কিন্তু marginally নির্ভরশীল।
rng = np.random.default_rng(7)
M = 500_000
C = rng.random(M) < 0.5 # switch on?
L1 = C & (rng.random(M) < 0.9) # on হলে 0.9 সম্ভাবনায় জ্বলে
L2 = C & (rng.random(M) < 0.9)
# marginal: P(L1,L2) বনাম P(L1)P(L2)
joint = (L1 & L2).mean()
product = L1.mean() * L2.mean()
print(f"P(L1,L2) = {joint:.4f}")
print(f"P(L1)*P(L2) = {product:.4f} -> অসমান => marginally নির্ভরশীল")
# conditional on C: P(L1,L2|C) বনাম P(L1|C)P(L2|C)
on = C
j_c = (L1 & L2)[on].mean()
p_c = L1[on].mean() * L2[on].mean()
print(f"P(L1,L2|C) = {j_c:.4f}")
print(f"P(L1|C)*P(L2|C)= {p_c:.4f} -> প্রায় সমান => conditionally স্বাধীন")
আউটপুট:
P(L1,L2) = 0.4050
P(L1)*P(L2) = 0.2024 -> অসমান => marginally নির্ভরশীল
P(L1,L2|C) = 0.8104
P(L1|C)*P(L2|C)= 0.8100 -> প্রায় সমান => conditionally স্বাধীন
সংখ্যাগুলো §৩.৩-এর হাতে-করা হিসাবের সাথে মেলে: \(0.405\) ও \(0.2025\) marginally আলাদা, কিন্তু \(C\)-র শর্তে \(0.81 \approx 0.9\times0.9\)। সিদ্ধান্ত পরিষ্কার: conditional independence থাকা সত্ত্বেও marginal independence নাও থাকতে পারে।
৬ · ভিজ্যুয়ালাইজেশন¶
চিত্র ১ — Probability tree (রোগ-test)¶
Tree-তে প্রথম শাখা রোগ-অবস্থা (\(D\) vs \(D^c\), prior), দ্বিতীয় শাখা test-ফল (likelihood)। প্রতিটি পাতার joint probability = পথ বরাবর গুণ (multiplication rule, §২.২)। দুটো "\(+\)" পাতার যোগফল \(0.0099+0.0495=0.0594 = P(+)\) — এটাই law of total probability-র চাক্ষুষ রূপ (§২.৫)। Bayes' theorem মানে: positive পাতাগুলোর মধ্যে কেবল উপরেরটা (true positive) রোগীর — তার অনুপাতই \(P(D\mid +)\)।
চিত্র ২ — Confusion / population-square (false-positive paradox)¶
\(10{,}000\) জনের ছবি। বাঁ-প্যানেল: যারা positive তাদের মধ্যে সবুজ (true positive, \(99\)) বনাম কমলা (false positive, \(495\)) — অধিকাংশই সুস্থ! তাই \(P(D\mid +)=99/594=16.7\%\)। ডান-প্যানেল: পূর্ণ confusion table (TP/FN/FP/TN), যা পরে classification-এ (Part VI) precision-recall-এর ভিত্তি হবে।
চিত্র ৩ — Prior → posterior update (bar chart)¶
তিনটে bar: prior (\(1\%\)), এক positive-এর পর posterior (\(16.7\%\)), দ্বিতীয় positive-এর পর (\(79.8\%\))। প্রতিটা "\(+\)" odds-কে likelihood ratio \(\approx 19.8\) দিয়ে গুণ করে (§৪.৫) — তাই বিশ্বাস ধাপে ধাপে লাফায়। এটাই sequential Bayesian updating (§৩.৪)।
চিত্র ৪ — Base-rate-এর প্রভাব¶
একই test (sens \(0.99\), spec \(0.95\)), কিন্তু prevalence ভিন্ন। বক্ররেখা দেখায় \(P(D\mid +)\) কীভাবে base rate-এর সাথে বাড়ে: বিরল রোগে (\(0.1\%\)) positive-এর মানে মাত্র \(\approx 2\%\), \(1\%\)-এ \(17\%\), কিন্তু সাধারণ রোগে (\(30\%\)) \(89\%\)। ধূসর কর্ণরেখা "তথ্য নেই" অবস্থা — বক্ররেখা সবসময় তার উপরে (positive কিছু তথ্য দেয়ই), কিন্তু কতটা তা base rate-নির্ভর। base-rate fallacy-র মূল ছবি।
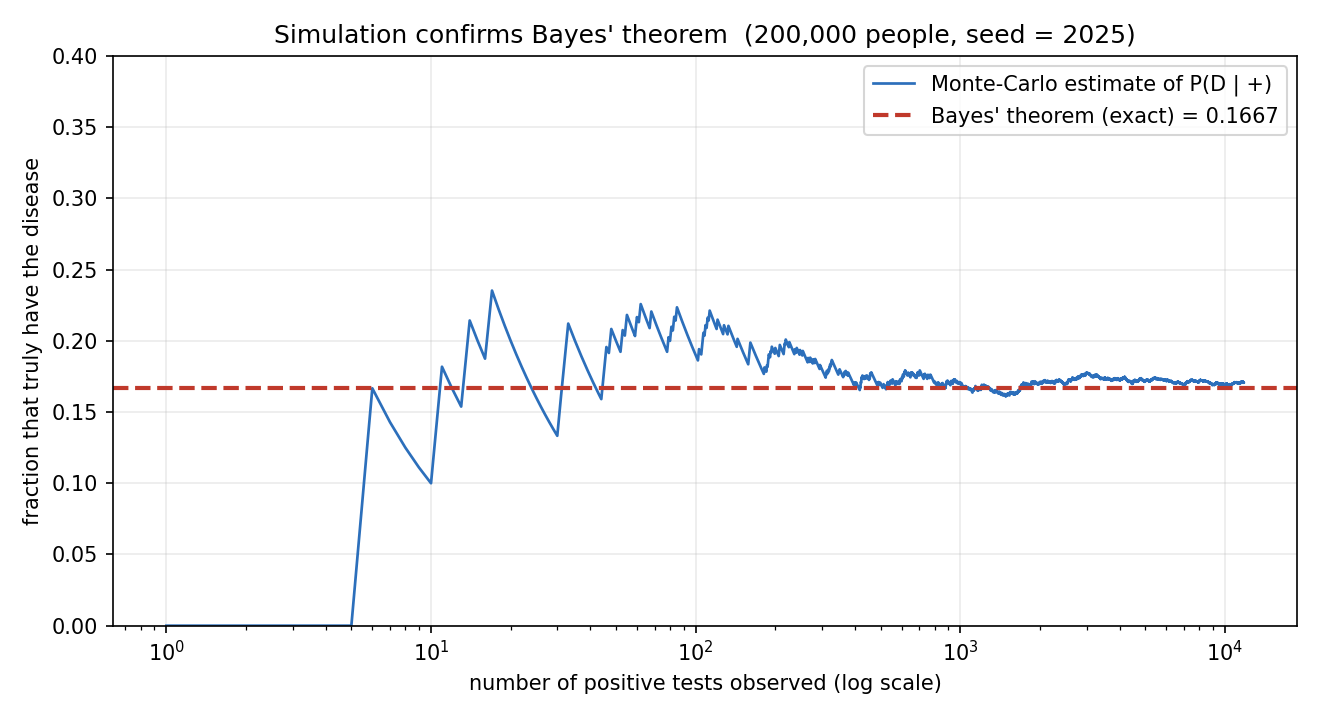
চিত্র ৫ — Simulation Bayes-কে নিশ্চিত করে¶
\(200{,}000\) ব্যক্তির simulation (seed \(2025\))। নীল রেখা: positive-সংখ্যা বাড়ার সাথে \(P(D\mid +)\)-এর running empirical অনুমান; লাল ড্যাশ: Bayes-এর exact মান \(0.1667\)। শুরুতে অনুমান অস্থির (অল্প নমুনা), কিন্তু positive-সংখ্যা বাড়লে exact মানে স্থির হয় — তত্ত্ব ও simulation মিলল (§৫.১)।
৭ · অনুশীলনী¶
difficulty: ★ সহজ, ★★ মাঝারি, ★★★ কঠিন। পূর্ণ সমাধান: _solutions/02-02-conditional-independence-bayes-solutions.md।
৭.১ Conceptual (ধারণাগত)¶
Q1 (★) নিজের ভাষায় ব্যাখ্যা করো কেন "mutually exclusive" আর "independent" সম্পূর্ণ ভিন্ন ধারণা। \(P(A),P(B)>0\) হলে দুটো event কি একই সাথে disjoint এবং independent হতে পারে? Hint: disjoint হলে \(P(A\cap B)\) কত? independent হলে কত হওয়া উচিত?
Q2 (★) Bayes' theorem-এ prior, likelihood, posterior — প্রতিটার এক-বাক্যের অর্থ লেখো এবং "posterior \(\propto\) likelihood \(\times\) prior" বাক্যটা ব্যাখ্যা করো। Hint: কোনটা data দেখার আগে, কোনটা পরে?
Q3 (★★) base-rate fallacy কী? একটা বাস্তব উদাহরণ দাও (medical test ছাড়া) যেখানে মানুষ base rate উপেক্ষা করে ভুল সিদ্ধান্ত নেয়। Hint: spam filter, নিরাপত্তা-স্ক্যানার, বিরল ঘটনা শনাক্তকরণ।
৭.২ Computational (গণনামূলক)¶
Q4 (★) একটা প্যাকেট থেকে একটা তাস তোলা হলো। \(A=\{\)তাসটা রাজা (King)\(\}\), \(B=\{\)তাসটা লাল (heart/diamond)\(\}\)। \(P(A\mid B)\), \(P(B\mid A)\) বের করো এবং \(A,B\) independent কিনা যাচাই করো। Hint: \(52\) তাসে \(4\) রাজা, \(26\) লাল, \(2\) লাল রাজা।
Q5 (★★) এক spam filter: ৪০% ইমেল spam। "free" শব্দটা spam-এর \(60\%\)-এ, কিন্তু ভালো ইমেলের মাত্র \(4\%\)-এ থাকে। একটা ইমেলে "free" আছে — সেটা spam হওয়ার probability কত? Hint: Bayes; \(S\) ও \(S^c\) partition; \(P(\text{free}\mid S)=0.6\)।
Q6 (★★) §৩.১-এর test-এ prevalence যদি \(0.01\)-এর বদলে \(0.5\) (সাধারণ রোগ) হয়, \(P(D\mid +)\) কত? এক positive ও দুই positive-এর পর — দুটোই বের করো এবং base rate-এর প্রভাব নিয়ে এক বাক্যে মন্তব্য করো। Hint: একই Bayes সূত্র, শুধু prior বদলাও।
Q7 (★★★) Monty Hall সমস্যা: ৩টা দরজা, একটার পেছনে গাড়ি। তুমি দরজা ১ বাছলে; উপস্থাপক (যে জানে গাড়ি কোথায়) দরজা ৩ খুলে দেখাল ছাগল। দরজা ২-তে switch করলে গাড়ি জেতার probability কত? Bayes/conditional probability দিয়ে যুক্তি দাও। Hint: উপস্থাপকের আচরণ likelihood — তিনি কখনো গাড়ির দরজা খোলেন না, এবং তোমার দরজা খোলেন না।
৭.৩ Proof-based (প্রমাণভিত্তিক)¶
Q8 (★★) প্রমাণ করো: \(A\) ও \(B\) independent হলে \(A\) ও \(B^c\) (complement)-ও independent। Hint: \(P(A) = P(A\cap B)+P(A\cap B^c)\) লেখো, তারপর \(P(A\cap B)=P(A)P(B)\) বসাও।
Q9 (★★★) একটা ন্যায্য ছক্কা দুবার গড়াও। \(A=\{\)প্রথমটা জোড়\(\}\), \(B=\{\)দ্বিতীয়টা জোড়\(\}\), \(C=\{\)দুটোর যোগফল জোড়\(\}\)। দেখাও \(A,B,C\) pairwise independent কিন্তু mutually independent নয় (অর্থাৎ \(P(A\cap B\cap C)\ne P(A)P(B)P(C)\))। Hint: প্রতিটা pair-এর জন্য গুণফল-শর্ত যাচাই করো; তারপর তিনটে একসাথে।
৮ · সারসংক্ষেপ ও সংযোগ¶
যা শিখলাম (recap):
| ধারণা | সূত্র / সংজ্ঞা | মূল কথা |
|---|---|---|
| Conditional probability | \(P(A\mid B)=\dfrac{P(A\cap B)}{P(B)}\) | নমুনাক্ষেত্র \(B\)-তে সংকোচন |
| Multiplication rule | \(P(A\cap B)=P(B)P(A\mid B)\) | tree-এর ডাল বরাবর গুণ |
| Chain rule | \(P(A_1\cap\cdots\cap A_n)=\prod_k P(A_k\mid A_1\cap\cdots\cap A_{k-1})\) | ধাপে ধাপে শর্ত |
| Independence | \(P(A\cap B)=P(A)P(B)\) | একে অন্যকে প্রভাবিত করে না |
| Conditional independence | \(P(A\cap B\mid C)=P(A\mid C)P(B\mid C)\) | \(C\) জানার পর স্বাধীন (Naive Bayes) |
| Law of total probability | \(P(A)=\sum_i P(A\mid B_i)P(B_i)\) | সব পথের weighted average |
| Bayes' theorem | \(P(B_k\mid A)=\dfrac{P(A\mid B_k)P(B_k)}{\sum_i P(A\mid B_i)P(B_i)}\) | conditional-এর দিক উল্টানো |
| Odds form | posterior odds \(=\) LR \(\times\) prior odds | evidence-এর গুণনাত্মক ভাষা |
মূল মন্ত্র: posterior \(\propto\) likelihood \(\times\) prior। আর সাবধানতা — (১) independent ≠ mutually exclusive, (২) conditional independence ≠ marginal independence, (৩) base rate উপেক্ষা করলেই false-positive paradox।
পূর্ববর্তী সংযোগ (২.১): ২.১-এ axioms (\(P(\Omega)=1\), additivity) আর event-এর set-গণিত শিখেছিলে। এই অধ্যায়ের সব প্রমাণ (total probability, Bayes) ঠিক সেই axioms-এর ওপর দাঁড়িয়ে — conditional probability নতুন কোনো axiom নয়, বরং একটা সংজ্ঞা।
পরবর্তী সংযোগ (২.৩ Random Variables): পরের অধ্যায়ে event থেকে আমরা random variable-এ যাব — outcome-কে সংখ্যায় রূপান্তর। সেখানে conditional probability সাধারণীকৃত হবে conditional distribution ও conditional expectation-এ, আর independence হবে independent random variables — i.i.d. data-র ভিত্তি।
Statistics-এ এর গন্তব্য (source pointer): Bayes' theorem এই অধ্যায়ের সবচেয়ে দূরপ্রসারী ধারণা — - Part IV — Bayesian inference: এখানকার prior/likelihood/posterior সরাসরি parameter-এ প্রয়োগ হবে: \(P(\theta \mid \text{data}) \propto P(\text{data}\mid\theta)\,P(\theta)\)। §৩.৪-এর sequential updating-ই সেখানে posterior-কে data-র সাথে পরিমার্জনের নিয়ম। - Part VI — Naive Bayes classifier: §২.৪-এর conditional independence ধরে নিয়ে spam/document classification — feature-গুলো class-এর শর্তে স্বাধীন ধরে likelihood সরল করা হয়। - §৬-এর confusion table Part VI-এ classification metric (precision, recall, ROC)-এর সরাসরি পূর্বসূরি।
(Rice Ch.1; Wasserman Ch.1; Fernández-Granda Ch.1; Dangeti — Naive