১.৫ · EDA Workflow: A Case Study¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
এই অধ্যায়টি Part I-এর capstone (চূড়ান্ত সংশ্লেষ)। 1.1-এ আমরা শিখেছি data-র ধরন (numeric, categorical) ও population বনাম sample; 1.2-এ location ও variability (mean, median, variance, এবং outlier-সহিষ্ণু robust statistics — MAD, IQR); 1.3-এ distribution দেখার tool (histogram, density, boxplot, ECDF); আর 1.4-এ দুটি variable-এর সম্পর্ক (correlation, scatter, group comparison)। এগুলো এতদিন আলাদা আলাদা শিখেছি। এখন প্রশ্ন: একটা সত্যিকারের dataset হাতে পেলে, এই সব tool কোন ক্রমে, কোন যুক্তিতে প্রয়োগ করব?
সেই ক্রমবদ্ধ, পুনরাবৃত্তিযোগ্য প্রক্রিয়াটির নাম EDA (Exploratory Data Analysis, অর্থাৎ অন্বেষণমূলক উপাত্ত বিশ্লেষণ)। শব্দটি ও দর্শনটি দিয়েছিলেন পরিসংখ্যানবিদ John W. Tukey (১৯৭৭)। তাঁর মূল বার্তা ছিল বিপ্লবী: data বিশ্লেষণ শুরু হয় সূত্র বা hypothesis test দিয়ে নয় — শুরু হয় চোখ দিয়ে data-কে দেখা, প্যাটার্ন খোঁজা, অস্বাভাবিকতা ধরা, প্রশ্ন তৈরি করা দিয়ে। তাঁর বিখ্যাত তুলনা: EDA হলো গোয়েন্দাগিরির (detective work) মতো — confirmatory analysis (নিশ্চিতকরণমূলক বিশ্লেষণ, যেমন hypothesis test) শুরুর আগে আপনাকে অপরাধস্থল ঘুরে সূত্র জোগাড় করতে হয়।
Tukey-র মূল insight (অন্তর্দৃষ্টি): "The greatest value of a picture is when it forces us to notice what we never expected to see." — সূত্র চাপিয়ে দেওয়ার আগে data-কে কথা বলতে দিন।
কেন এটি এত গুরুত্বপূর্ণ? কারণ EDA হলো যেকোনো modeling বা inference-এর আবশ্যক প্রথম ধাপ। Section 4-এ আমরা Anscombe-সদৃশ যুক্তি দিয়ে দেখাব: শুধু summary statistic দেখে data বুঝে ফেলা ভয়ংকর বিভ্রান্তিকর হতে পারে — চোখে না দেখলে ভুল model বানাবেন। Part IV (inference) ও Part V (regression/modeling)-এ আমরা ঠিক এই dataset-সদৃশ চিন্তাই ফিরে দেখব: confidence interval, hypothesis test বা regression চালানোর আগে EDA দিয়ে data বুঝে নেওয়াই পেশাদার অভ্যাস।
এই অধ্যায়ে আমরা একটি synthetic কিন্তু বাস্তবঘেঁষা "city housing" dataset কোডে তৈরি করব (numpy default_rng, fixed seed — কোনো download নেই, পুরোপুরি reproducible)। এতে থাকবে কয়েকটি correlated numeric column, একটি categorical column, কিছু missing value, এবং কয়েকটি outlier (data-entry error ও বৈধ চরম মান) — যাতে EDA-র প্রতিটি ধাপ বাস্তবের মতো দেখানো যায়। তারপর ধাপে ধাপে পুরো pipeline চালাব এবং শেষে data থেকে কয়েকটি সিদ্ধান্ত টানব।
২ · মূল ধারণা ও সংজ্ঞা: EDA methodology¶
EDA কোনো একক কৌশল নয়, একটি iterative workflow (পুনরাবৃত্ত কর্মপ্রবাহ)। আমরা একে পাঁচটি ধাপে সাজাব। প্রতিটি ধাপ একটি প্রশ্ন দিয়ে শুরু হয় — এটাই Tukey-দর্শনের কেন্দ্র।
২.১ ধাপ ০ — Question (প্রশ্ন স্থির করা)¶
বিশ্লেষণের আগে জিজ্ঞেস করুন: এই data দিয়ে আমি কী জানতে চাই? আমাদের case study-তে প্রশ্ন হবে — "একটি বাড়ির দাম (price) কীসের ওপর নির্ভর করে? location, area, age, rooms-এর মধ্যে কোনটি দামের সাথে সবচেয়ে জোরালোভাবে যুক্ত?" প্রশ্ন স্পষ্ট হলে কোন variable-এ কতটা মনোযোগ দিতে হবে তা ঠিক করা সহজ হয়।
২.২ ধাপ ১ — Load ও Inspect (লোড ও পরিদর্শন)¶
data হাতে পেয়ে প্রথমেই তার আকার ও গঠন জানতে হয়:
- shape — কত সারি (observation/sample), কত কলাম (variable)? (1.1-এর population vs sample মনে করুন: এটি একটি sample।)
- dtype — প্রতিটি কলামের data type (numeric নাকি categorical/object)? এটি ঠিক করে কোন কলামে কোন summary প্রযোজ্য (1.1)।
- head — প্রথম কয়েকটি সারি চোখে দেখা — মান যুক্তিসঙ্গত দেখাচ্ছে কি?
- describe — numeric কলামের দ্রুত summary (count, mean, std, min, quartile, max)।
এই ধাপেই প্রথম সতর্ক-সংকেত (red flag) ধরা পড়ে: count কম মানে missing value; অসম্ভব min/max (যেমন ঋণাত্মক দাম) মানে error।
২.৩ ধাপ ২ — Clean (পরিষ্কার করা)¶
বাস্তব data কখনো নিখুঁত নয়। দুটি প্রধান সমস্যা:
(ক) Missing value (অনুপস্থিত মান): কিছু ঘর ফাঁকা (NaN)। প্রথমে কত ও কোথায় তা মাপুন (missingness chart)। তারপর সিদ্ধান্ত:
- drop — যদি খুব অল্প সারি প্রভাবিত হয় এবং randomly (MCAR — Missing Completely At Random) অনুপস্থিত হয়।
- impute (পূরণ করা) — ফাঁকা ঘরে একটি যুক্তিসঙ্গত মান বসানো; সাধারণ পছন্দ হলো সেই কলামের median (1.2-এর robust statistic, কারণ outlier-এর প্রভাবে কম বিকৃত হয়)। আরও ভালো — group-ভিত্তিক median (যেমন প্রতি location-এর median)।
(খ) Outlier (চরম/বিচ্ছিন্ন মান): কয়েকটি মান বাকিদের থেকে অনেক দূরে। দুই ধরনের outlier আলাদা করা জরুরি: - error outlier — data-entry ভুল বা অসম্ভব মান (ঋণাত্মক দাম, ১৩০ বছরের বাড়ি, sqft-কে sqm ভেবে ঢোকানো)। এগুলো domain knowledge দিয়ে সংশোধন বা বাদ দেওয়া উচিত। - genuine outlier — বৈধ কিন্তু বিরল মান (সত্যিকারের luxury flat)। এগুলো মূল্যবান তথ্য; অন্ধভাবে মুছবেন না।
outlier শনাক্ত করার একটি robust নিয়ম হলো IQR fence (1.2/1.3): \(Q_1\) ও \(Q_3\) যথাক্রমে ২৫তম ও ৭৫তম percentile হলে, \(\mathrm{IQR} = Q_3 - Q_1\), এবং
এই সীমার বাইরের মানকে boxplot "outlier" হিসেবে চিহ্নিত করে। লক্ষ রাখুন — IQR fence শুধু flag করে; মুছবেন কি না সেটি domain-নির্ভর সিদ্ধান্ত।
২.৪ ধাপ ৩ — Univariate analysis (একক চলক বিশ্লেষণ) — 1.2/1.3 প্রয়োগ¶
প্রতিটি variable আলাদাভাবে বুঝুন: - numeric: center (mean/median), spread (std/IQR/MAD), shape (skew, modality) — histogram, density, boxplot দিয়ে। skew থাকলে median ও IQR বেশি নির্ভরযোগ্য (robust)। - categorical: প্রতিটি শ্রেণিতে কতটি (frequency/proportion) — bar chart দিয়ে।
২.৫ ধাপ ৪ — Bivariate ও multivariate analysis — 1.4 প্রয়োগ¶
variable-দের সম্পর্ক: - numeric–numeric: scatter plot + correlation। পুরো correlation matrix একসাথে heatmap-এ দেখা সবচেয়ে দক্ষ। Pearson \(r\) linear (রৈখিক) সম্পর্ক মাপে; Spearman \(\rho\) (rank-ভিত্তিক) monotonic (একঘাতী) সম্পর্ক ও outlier-সহিষ্ণুতা মাপে — দুটোর পার্থক্য নিজেই একটি সূত্র। - categorical–numeric: group comparison — প্রতিটি শ্রেণির জন্য numeric variable-এর distribution তুলনা (group-wise boxplot, group mean ± sd)।
২.৬ ধাপ ৫ — Insight (সিদ্ধান্ত) ও Reproducibility¶
সব মিলিয়ে: কোন প্যাটার্ন স্পষ্ট? কোন সম্পর্ক জোরালো? পরবর্তী modeling-এ কী মাথায় রাখতে হবে (যেমন collinearity, nonlinearity)? এবং সবচেয়ে গুরুত্বপূর্ণ — পুরো pipeline যেন reproducible হয়: fixed seed, deterministic ধাপ, যাতে অন্য কেউ হুবহু একই ফল পায় (0.6-এর reproducibility নীতি)।
এক নজরে EDA pipeline:
Question → Load/Inspect → Clean → Univariate → Bivariate/Multivariate → Insight— প্রয়োজনে যেকোনো ধাপ থেকে আগের ধাপে ফেরা যায় (iterative)।
৩ · পূর্ণাঙ্গ উদাহরণ — সম্পূর্ণ EDA case study (ধাপে ধাপে)¶
এই Section-এ আমরা পুরো pipeline-টি বর্ণনা ও ব্যাখ্যাসহ চালাই। সম্পূর্ণ runnable কোড Section 5-এ একত্রে; এখানে আমরা যুক্তি ও আউটপুট পড়ি।
৩.১ Dataset পরিচিতি (build)¶
আমরা একটি কাল্পনিক শহরের ৬০০টি ফ্ল্যাটের data তৈরি করেছি (default_rng(2025))। কলাম পাঁচটি:
| কলাম | ধরন (1.1) | অর্থ |
|---|---|---|
location |
categorical (nominal) | central / suburb / outer |
area_sqm |
numeric (continuous) | আয়তন, বর্গমিটার |
age_years |
numeric (continuous) | বাড়ির বয়স, বছর |
rooms |
numeric (discrete) | ঘরের সংখ্যা |
price_lakh |
numeric (continuous) | দাম, লাখ টাকায় (লক্ষ্য variable) |
গঠনে আমরা ইচ্ছাকৃতভাবে রেখেছি: price মোটামুটি area, rooms-এর সাথে ধনাত্মক, age-এর সাথে ঋণাত্মক সম্পর্কে; area ও rooms-এ জোরালো collinearity; কিছু missing value; এবং কয়েকটি outlier (luxury unit + data-entry error)।
৩.২ Load ও Inspect¶
df.shape, df.dtypes, df.head(), df.describe() চালিয়ে যা পেলাম:
shape : (600, 5)
dtypes:
location object
area_sqm float64
age_years float64
rooms float64
price_lakh float64
head:
location area_sqm age_years rooms price_lakh
0 outer 187.3 9.0 7.0 223.3
1 suburb 144.3 23.9 6.0 220.1
2 outer 157.5 13.8 7.0 225.5
3 outer 163.8 8.3 5.0 175.2
4 outer 189.3 10.4 6.0 231.6
describe (numeric):
area_sqm age_years rooms price_lakh
count 600.00 552.00 570.00 582.00
mean 126.72 15.71 4.49 187.60
std 51.82 11.42 1.52 42.63
min 40.00 0.50 1.00 -15.00
25% 97.88 8.10 3.00 163.22
50% 122.30 13.15 4.00 187.05
75% 152.33 20.82 5.00 211.82
max 980.00 130.00 9.00 575.85
গোয়েন্দার চোখে যা ধরা পড়ল (red flags):
1. count অসমান: area_sqm = 600 কিন্তু age_years = 552, rooms = 570, price_lakh = 582 → missing value আছে।
2. price_lakh min = −15 → দাম ঋণাত্মক হতে পারে না → error outlier।
3. area_sqm max = 980 → একটি ফ্ল্যাট ৯৮০ বর্গমিটার? সম্ভবত sqft-কে sqm ভেবে ঢোকানো typo।
4. age_years max = 130 → ১৩০ বছরের বাড়ি অসম্ভব এই data-তে → error outlier।
এই চারটি সংকেত পরের ধাপের (cleaning) এজেন্ডা ঠিক করে দিল।
৩.৩ Clean — missing ও outlier handling¶
Missing: কলামভিত্তিক missing fraction (Figure 1): age_years ≈ 8%, rooms ≈ 5%, price_lakh ≈ 3%, বাকিগুলো 0%। যেহেতু অনুপস্থিতি random-সদৃশ (MCAR) ও পরিমাণ মাঝারি, আমরা location-group median দিয়ে impute করব (drop করলে অনেক সারি হারাতাম)।
Outlier: domain rule প্রয়োগ করি —
- price_lakh > 0 (ঋণাত্মক দাম বাদ),
- age_years ≤ 100 (অসম্ভব বয়স বাদ),
- area_sqm ≤ 400 (sqft-typo বাদ)।
এই error outlier-গুলো বাদ দিলাম। কিন্তু luxury unit-এর মতো বৈধ চরম দাম (≈ 489, 575 লাখ) আমরা রেখে দিলাম — কারণ এগুলো সত্যিকারের তথ্য (Section 4-এ এই সিদ্ধান্তের যুক্তি)। cleaning-এর পর: shape (597, 5) — অর্থাৎ ৬০০ থেকে ৩টি সারি বাদ পড়ল। Figure 4-এ raw বনাম cleaned price boxplot পাশাপাশি দেখুন: ঋণাত্মক ও অতি-নিম্ন error মানগুলো চলে গেছে, কিন্তু উপরের দিকের বৈধ চরম মান টিকে আছে।
৩.৪ Univariate (1.2/1.3 প্রয়োগ)¶
cleaned data-তে price_lakh-এর histogram (Figure 2a) মোটামুটি সমমিত (symmetric), ঘণ্টা-আকার, median ≈ 187 লাখ। age_years ডানদিকে কিছুটা skewed (gamma থেকে তৈরি)। categorical location-এ suburb সবচেয়ে বেশি, outer সবচেয়ে কম (Figure 1-এর data থেকেও তিন শ্রেণির উপস্থিতি স্পষ্ট)।
৩.৫ Bivariate (1.4 প্রয়োগ)¶
Correlation heatmap (Figure 2c) এক নজরে সম্পর্ক দেখায়:
area_sqm age_years rooms price_lakh
area_sqm 1.000 0.049 0.879 0.529
age_years 0.049 1.000 0.010 -0.313
rooms 0.879 0.010 1.000 0.514
price_lakh 0.529 -0.313 0.514 1.000
পাঠ:
- area_sqm ↔ price_lakh: \(r = 0.53\) (মাঝারি ধনাত্মক) — বড় ফ্ল্যাট সাধারণত দামি।
- rooms ↔ price_lakh: \(r = 0.51\) — প্রায় একই, কারণ...
- area_sqm ↔ rooms: \(r = 0.88\) (খুব জোরালো) → এই দুটি প্রায় একই তথ্য বহন করে — multicollinearity (বহু-সহরৈখিকতা)। Part V-এ regression-এ এটি সমস্যা তৈরি করতে পারে; এখনই চিহ্নিত করে রাখলাম।
- age_years ↔ price_lakh: \(r = -0.31\) (ঋণাত্মক) — পুরনো বাড়ি সস্তা, প্রত্যাশিত।
Key bivariate highlight (Figure 3): area_sqm বনাম price_lakh scatter, location-অনুযায়ী রঙিন, একটি least-squares fit রেখাসহ। সম্পর্ক স্পষ্টভাবে ধনাত্মক ও মোটামুটি রৈখিক। তবে একটি সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ লক্ষণ: Pearson \(r = 0.53\) কিন্তু Spearman \(\rho = 0.61\)। rank-ভিত্তিক Spearman বেশি হওয়ার অর্থ — কয়েকটি চরম মান Pearson-কে কিছুটা টেনে নামাচ্ছে এবং সম্পর্কটি নিখুঁত রৈখিক নয় (slightly monotonic-nonlinear)। এটিই Tukey-র "চোখে দেখার" মূল্য — শুধু একটি \(r\) সংখ্যা পুরো গল্প বলত না।
Group comparison (Figure 2b, 2d): location অনুযায়ী price-এর boxplot ও mean ± sd:
mean median std count
location
central 184.45 180.5 48.17 204
outer 205.47 210.2 35.09 153
suburb 179.55 181.2 34.93 240
আকর্ষণীয় ফল: outer location-এর গড় দাম সবচেয়ে বেশি (≈ 205), suburb সবচেয়ে কম (≈ 179)। কেন? কারণ আমাদের data-গঠনে outer ফ্ল্যাটগুলো গড়ে বড় (বেশি area), আর দামে area-র ভূমিকা বড়। অর্থাৎ location-এর "প্রভাব" আসলে area-র মাধ্যমে আসছে — একটি confounding-সদৃশ ইঙ্গিত, যা multivariate চিন্তা ছাড়া বোঝা যেত না। লক্ষ করুন central-এর std সবচেয়ে বড় (48.2) — কারণ luxury outlier-গুলো central-এ।
৩.৬ Insight (সিদ্ধান্ত)¶
- price-এর সবচেয়ে জোরালো একক predictor হলো
area_sqm(\(r \approx 0.53\), Spearman \(0.61\)), তার সাথেrooms(\(0.51\)) ও ঋণাত্মকভাবেage_years(\(-0.31\))। area_sqmওroomsপ্রায় একই তথ্য (collinear, \(r=0.88\)) — modeling-এ দুটোই একসাথে রাখলে coefficient অস্থির হতে পারে।- location-এর আপাত প্রভাব মূলত area-র মধ্য দিয়ে আসছে — কাঁচা গড় তুলনা বিভ্রান্তিকর হতে পারে; multivariate model লাগবে (Part V)।
- data quality: ৩.৫% সারি error outlier/typo ছিল — clean না করলে correlation ও mean সবই বিকৃত হতো।
৪ · প্রমাণ ও উৎপাদন: কেন EDA model-এর আগে আবশ্যক¶
এই অধ্যায়ে আনুষ্ঠানিক গাণিতিক proof-এর বদলে আমরা দুটি গুরুত্বপূর্ণ পদ্ধতিগত দাবি যুক্তি ও পরিমাপ দিয়ে প্রতিষ্ঠা করব। এগুলোই EDA-র দার্শনিক ভিত্তি।
৪.১ দাবি: একই summary statistic, সম্পূর্ণ ভিন্ন data — তাই চোখে দেখা আবশ্যক · কাঠিন্য ★¶
দাবি: শুধু mean, variance ও correlation দেখে দুটি dataset-কে "একই" ভাবা ভুল হতে পারে; তাদের আকৃতি সম্পূর্ণ ভিন্ন হতে পারে।
এটি Anscombe's quartet (১৯৭৩)-এর কেন্দ্রীয় শিক্ষা। Anscombe চারটি dataset বানিয়েছিলেন যাদের mean (\(\bar{x},\bar{y}\)), variance, correlation (\(r\)), এমনকি least-squares fit রেখা — সব প্রায় হুবহু এক, অথচ scatter আঁকলে একটি রৈখিক, একটি বক্র, একটিতে একটি outlier পুরো \(r\) নিয়ন্ত্রণ করছে, আরেকটিতে সব \(x\) একই মান ছাড়া একটি বিন্দু।
যুক্তি (কেন এমন হয়): mean ও variance distribution-এর কেবল প্রথম দুটি moment ধরে; correlation কেবল রৈখিক সহপরিবর্তন ধরে। কিন্তু একটি distribution-এর আকৃতিতে অসীম স্বাধীনতা আছে — skew, modality, nonlinearity, outlier — যা এই কয়েকটি সংখ্যায় ধরা পড়ে না। গাণিতিকভাবে, একই \((\bar{x},\bar{y},s_x,s_y,r)\) মেনেও অসংখ্য ভিন্ন যুগ্ম-distribution সম্ভব। অতএব summary statistic একটি lossy (তথ্য-ক্ষয়ী) সংকোচন — হারানো তথ্য কেবল ছবিতে ফিরে আসে।
আমাদের case study-তেই এর প্রমাণ: আমরা দেখলাম Pearson \(r = 0.53\) কিন্তু Spearman \(\rho = 0.61\) — দুটি সংখ্যার এই ব্যবধান শুধু তখনই অর্থপূর্ণ হলো যখন আমরা scatter (Figure 3) দেখলাম এবং বুঝলাম সম্পর্কটি নিখুঁত রৈখিক নয় ও চরম মানে সংবেদনশীল। উপসংহার: যেকোনো \(r\) বা mean রিপোর্ট করার আগে অন্তত একটি histogram/scatter দেখা বাধ্যতামূলক। \(\blacksquare\)
৪.২ দাবি: outlier ও missing handling model-এর আগে না করলে inference পক্ষপাতদুষ্ট হয় · কাঠিন্য ★¶
দাবি: error outlier বা NaN অসংশোধিত রেখে summary/model চালালে ফলাফল উল্লেখযোগ্যভাবে বিকৃত হয়।
পরিমাপ (আমাদের data থেকে): raw price_lakh-এর mean ছিল 187.60 (একটি −15 ও কয়েকটি অতি-উচ্চ typo-প্রভাবিত), আর IQR fence \([90.3,\ 284.7]\)-এর বাইরে ৯টি মান flag হলো। cleaning-এর পর distribution-এর নিচের লেজ থেকে error মান চলে গেল (Figure 4)। আরও তীব্র উদাহরণ — area_sqm-এ একটিমাত্র ৯৮০-এর typo mean-কে ও area↔price correlation-কে কৃত্রিমভাবে টেনে নিত; mean (outlier-সংবেদনশীল) বনাম median (robust, 1.2) এর পার্থক্যই এই বিকৃতির সাক্ষী।
যুক্তি: mean, variance, Pearson \(r\), এবং least-squares regression — সবই non-robust: এদের গণনায় প্রতিটি বিন্দু (বিশেষত দূরবর্তী বিন্দু) বর্গ-দূরত্বের ওজনে প্রভাব ফেলে, তাই একটিমাত্র চরম error পুরো ফল টানতে পারে। NaN থাকলে অনেক function নীরবে সারি বাদ দেয় বা NaN ফেরত দেয় — ফলে গণনা ভুল বা অসম্পূর্ণ হয়। EDA-র cleaning ধাপ এই বিপদগুলো model-এর আগে সরিয়ে দেয়। \(\blacksquare\)
৪.৩ সতর্কতা: data leakage ও "peeking" · কাঠিন্য ★★¶
EDA শক্তিশালী, কিন্তু একটি গুরুতর ফাঁদ আছে যা Part IV/VI-তে কেন্দ্রীয় হবে। Data leakage (তথ্য চুঁইয়ে পড়া) ঘটে যখন আপনি অজান্তে test/future data-র তথ্য বিশ্লেষণ বা model-এ ঢুকিয়ে ফেলেন।
- Imputation leakage: যদি পুরো dataset-এর (train + test একসাথে) median দিয়ে impute করেন, তবে test-এর তথ্য train-এ ঢুকে গেল। সঠিক অভ্যাস: train/test split আগে করুন, তারপর কেবল train থেকে median হিসাব করে উভয়ে প্রয়োগ করুন।
- Outlier/scaling leakage: একই কারণে IQR fence বা standardization-এর parameter কেবল train থেকে শেখা উচিত।
- "Peeking" বা multiple-comparisons বিপদ: EDA-তে অসংখ্য plot/correlation দেখে যদি আপনি "যেটা সবচেয়ে চমকপ্রদ" সেটাকেই hypothesis বানিয়ে পরে সেই একই data-তে test করেন, তবে p-value অর্থহীন (এটি circular, বা data dredging)। Tukey-ও এ বিষয়ে সতর্ক ছিলেন: EDA সূত্র তৈরি করে (hypothesis-generating), কিন্তু সেই সূত্র নিশ্চিত করতে হয় স্বাধীন data-তে confirmatory analysis দিয়ে।
মূল নীতি: EDA → hypothesis তৈরি; নতুন/পৃথক data → hypothesis যাচাই। একই data-তে দুটোই করলে আত্মপ্রতারণা। (বিস্তারিত: Part IV — hypothesis testing, Part VI — train/test, cross-validation।) \(\blacksquare\)
৫ · কোড ল্যাব (Python) — সম্পূর্ণ reproducible EDA pipeline¶
নিচের কোড একটানা চালালে পুরো case study পুনরুৎপাদিত হয়। আমরা default_rng(2025) ব্যবহার করছি — তাই প্রতিবার হুবহু একই ফল (0.6-এর reproducibility নীতি)। ছবি তৈরির অংশ Section 6-এ।
৫.১ Build — synthetic dataset তৈরি¶
import numpy as np
import pandas as pd
def build_housing(seed=2025, n=600):
rng = np.random.default_rng(seed) # reproducible
location = rng.choice(["central", "suburb", "outer"],
size=n, p=[0.35, 0.40, 0.25])
base_area = {"central": 95, "suburb": 130, "outer": 165}
area = np.array([rng.normal(base_area[g], 28) for g in location])
area = np.clip(area, 40, None) # area ≥ 40 sqm
age = rng.gamma(shape=2.2, scale=7.0, size=n) # right-skewed age
rooms = np.clip(np.round(area / 28 + rng.normal(0, 0.6, n)), 1, 9).astype(int)
loc_premium = np.array([{"central":55,"suburb":30,"outer":12}[g] for g in location])
noise = rng.normal(0, 22, n)
price = 0.78*area + 4.1*rooms - 1.6*age + loc_premium + 60 + noise # lakh BDT
df = pd.DataFrame({"location": location, "area_sqm": area.round(1),
"age_years": age.round(1), "rooms": rooms,
"price_lakh": price.round(1)})
# inject realistic outliers (data-entry errors / luxury units)
o = rng.choice(n, size=6, replace=False)
df.loc[o[:3], "price_lakh"] *= rng.uniform(2.4, 3.1, 3) # luxury / typo
df.loc[o[3], "area_sqm"] = 980.0 # sqft->sqm typo
df.loc[o[4], "age_years"] = 130.0 # impossible age
df.loc[o[5], "price_lakh"] = -15.0 # negative price
# inject missing values (MCAR-ish)
for col, frac in [("age_years",0.08), ("rooms",0.05), ("price_lakh",0.03)]:
miss = rng.choice(n, size=int(frac*n), replace=False)
df.loc[miss, col] = np.nan
return df
df = build_housing()
৫.২ Inspect — shape, dtype, head, describe¶
print("shape:", df.shape)
print(df.dtypes)
print(df.head())
print(df.describe().round(2))
print("missing per column:\n", df.isna().sum())
আউটপুট Section 3.2-এ দেখানো হয়েছে (shape (600, 5); price_lakh min = −15, area_sqm max = 980, age_years max = 130; এবং age_years/rooms/price_lakh-এ যথাক্রমে 48/30/18টি missing)।
৫.৩ Clean — outlier (domain rule) + missing (group-median impute)¶
def clean(df):
d = df.copy()
# (1) domain-rule outlier removal: শুধু অসম্ভব/error মান বাদ
d = d[(d["price_lakh"] > 0) | d["price_lakh"].isna()] # ঋণাত্মক দাম বাদ
d = d[(d["age_years"] <= 100) | d["age_years"].isna()] # অসম্ভব বয়স বাদ
d = d[d["area_sqm"] <= 400] # sqft-typo বাদ
# (2) missing imputation: location-group median (robust, leakage-সচেতন হলে train-only)
for col in ["age_years", "rooms", "price_lakh"]:
d[col] = d.groupby("location")[col].transform(lambda s: s.fillna(s.median()))
return d
dc = clean(df)
print("cleaned shape:", dc.shape) # (597, 5)
নোট (Section 4.3): বাস্তব modeling-এ
clean-এর median train split থেকে শিখে test-এ প্রয়োগ করতে হবে — তা না হলে data leakage। এখানে EDA-র জন্য পুরো sample ব্যবহার করছি।
৫.৪ Univariate summary (robust + classical)¶
num_cols = ["area_sqm", "age_years", "rooms", "price_lakh"]
def robust_summary(s):
q1, q3 = s.quantile([.25, .75])
return pd.Series({"mean": s.mean(), "median": s.median(),
"std": s.std(), "IQR": q3 - q1,
"MAD": (s - s.median()).abs().median()})
print(dc[num_cols].apply(robust_summary).round(2))
print("\nlocation counts:\n", dc["location"].value_counts())
৫.৫ Bivariate — correlation ও group comparison¶
# numeric-numeric: correlation matrix (Pearson ও Spearman)
print("Pearson:\n", dc[num_cols].corr().round(3))
print("Spearman:\n", dc[num_cols].corr(method="spearman").round(3))
# key pair
r_p = dc["area_sqm"].corr(dc["price_lakh"])
r_s = dc["area_sqm"].corr(dc["price_lakh"], method="spearman")
print(f"area~price : Pearson r={r_p:.3f}, Spearman rho={r_s:.3f}")
# categorical-numeric: group comparison
print(dc.groupby("location")["price_lakh"]
.agg(["mean", "median", "std", "count"]).round(2))
৫.৬ IQR-fence outlier flag (শনাক্তকরণ)¶
q1, q3 = df["price_lakh"].quantile([.25, .75])
iqr = q3 - q1
lo, hi = q1 - 1.5*iqr, q3 + 1.5*iqr
flag = (df["price_lakh"] < lo) | (df["price_lakh"] > hi)
print(f"IQR fence: [{lo:.1f}, {hi:.1f}] -> {int(flag.sum())} outliers flagged")
# IQR fence: [90.3, 284.7] -> 9 outliers flagged
পুরো script _code/-এ রাখা একটি ফাইলে একত্রে চালালে উপরের সব আউটপুট ও Section 6-এর চারটি ছবি একবারেই তৈরি হবে।
৬ · ভিজ্যুয়ালাইজেশন — multi-panel EDA dashboard¶
প্রতিটি figure-এর সাথে সংক্ষিপ্ত ব্যাখ্যা ও তৈরির মূল কোড। মনে রাখুন: figure-এর ভেতরের লেখা ইংরেজিতে, ব্যাখ্যা বাংলায় (caption-এ)। সব ছবি একটি script-এ matplotlib.use("Agg") দিয়ে dpi=150-এ তৈরি; নিচে relative path-এ embed করা।
Figure 1 — Missingness chart¶
প্রথমেই data quality-র মানচিত্র: কোন কলামে কত শতাংশ মান অনুপস্থিত। এটি cleaning ধাপের এজেন্ডা ঠিক করে।
import matplotlib; matplotlib.use("Agg")
import matplotlib.pyplot as plt
miss = df.isna().mean().sort_values(ascending=False)
fig, ax = plt.subplots(figsize=(7.2, 4.0))
bars = ax.bar(miss.index, miss.values*100, color="#4C72B0", edgecolor="white")
for b, v in zip(bars, miss.values*100):
ax.text(b.get_x()+b.get_width()/2, v+0.15, f"{v:.1f}%", ha="center", fontsize=10)
ax.set_ylabel("Missing values (%)"); ax.set_xlabel("Column")
ax.set_title("Missingness by column (raw data)")
fig.tight_layout(); fig.savefig("../_assets/1-5-missingness.png", dpi=150)
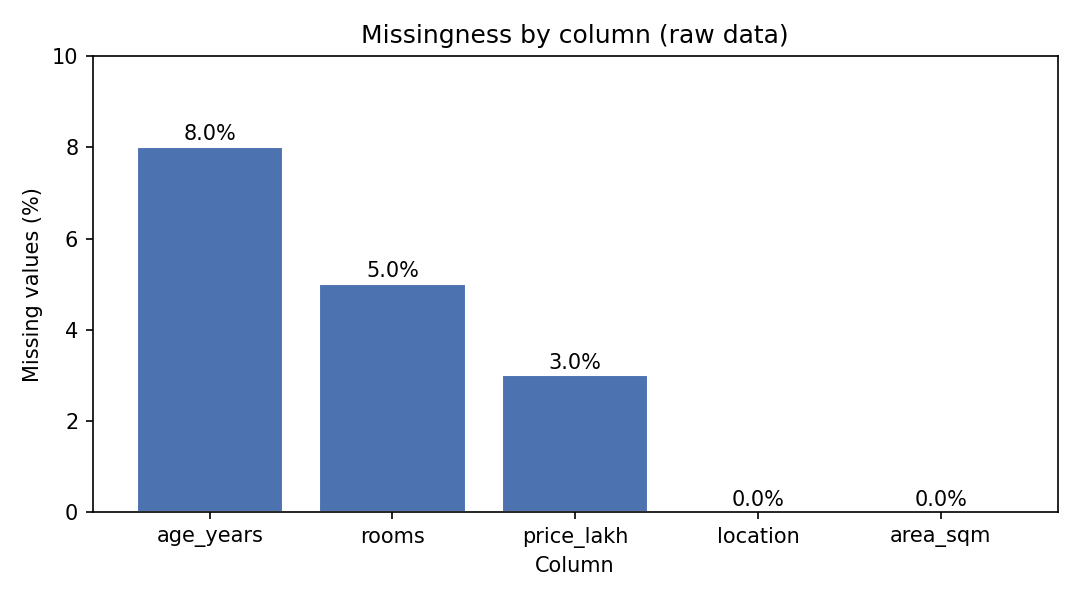
Figure 2 — Multi-panel EDA dashboard (2×2)¶
EDA-র মূল ছবি: একটি Figure-এ চারটি প্যানেল — (a) univariate distribution, (b) group-wise boxplot, (c) correlation heatmap, (d) group mean। বাস্তবে এই চার দৃষ্টিভঙ্গি একসাথে দেখলেই dataset-এর গল্প স্পষ্ট হয়।
import matplotlib.gridspec as gridspec
num_cols = ["area_sqm","age_years","rooms","price_lakh"]
fig = plt.figure(figsize=(11.6, 8.2))
gs = gridspec.GridSpec(2, 2, figure=fig, hspace=0.40, wspace=0.34)
groups = ["central","suburb","outer"]
# (a) price histogram + median
axA = fig.add_subplot(gs[0,0])
axA.hist(dc["price_lakh"], bins=30, color="#4C72B0", edgecolor="white", alpha=0.9)
axA.axvline(dc["price_lakh"].median(), color="#C44E52", ls="--", lw=2,
label=f"median = {dc['price_lakh'].median():.0f}")
axA.set_title("(a) Distribution of price"); axA.set_xlabel("Price (lakh BDT)")
axA.set_ylabel("Count"); axA.legend()
# (b) boxplot of price by location
axB = fig.add_subplot(gs[0,1])
data_by = [dc.loc[dc.location==g, "price_lakh"].values for g in groups]
bp = axB.boxplot(data_by, tick_labels=groups, patch_artist=True)
for patch, c in zip(bp["boxes"], ["#C44E52","#55A868","#CCB974"]):
patch.set_facecolor(c); patch.set_alpha(0.7)
axB.set_title("(b) Price by location"); axB.set_ylabel("Price (lakh BDT)")
# (c) correlation heatmap
axC = fig.add_subplot(gs[1,0])
corr = dc[num_cols].corr()
im = axC.imshow(corr.values, cmap="RdBu_r", vmin=-1, vmax=1)
axC.set_xticks(range(4)); axC.set_xticklabels(num_cols, rotation=30, ha="right")
axC.set_yticks(range(4)); axC.set_yticklabels(num_cols)
for i in range(4):
for j in range(4):
v = corr.values[i,j]
axC.text(j, i, f"{v:.2f}", ha="center", va="center",
color="white" if abs(v)>0.55 else "black")
axC.set_title("(c) Correlation heatmap (Pearson)")
fig.colorbar(im, ax=axC, fraction=0.046, pad=0.06, label="r")
# (d) mean price by location ± sd
axD = fig.add_subplot(gs[1,1])
g = dc.groupby("location")["price_lakh"].agg(["mean","std"]).reindex(groups)
axD.bar(g.index, g["mean"], yerr=g["std"], capsize=5,
color=["#C44E52","#55A868","#CCB974"], alpha=0.8, edgecolor="white")
axD.set_title("(d) Mean price by location (± sd)"); axD.set_ylabel("Mean price (lakh BDT)")
fig.suptitle("EDA dashboard: city housing dataset (cleaned)", fontsize=14, y=0.98)
fig.savefig("../_assets/1-5-dashboard.png", dpi=150)
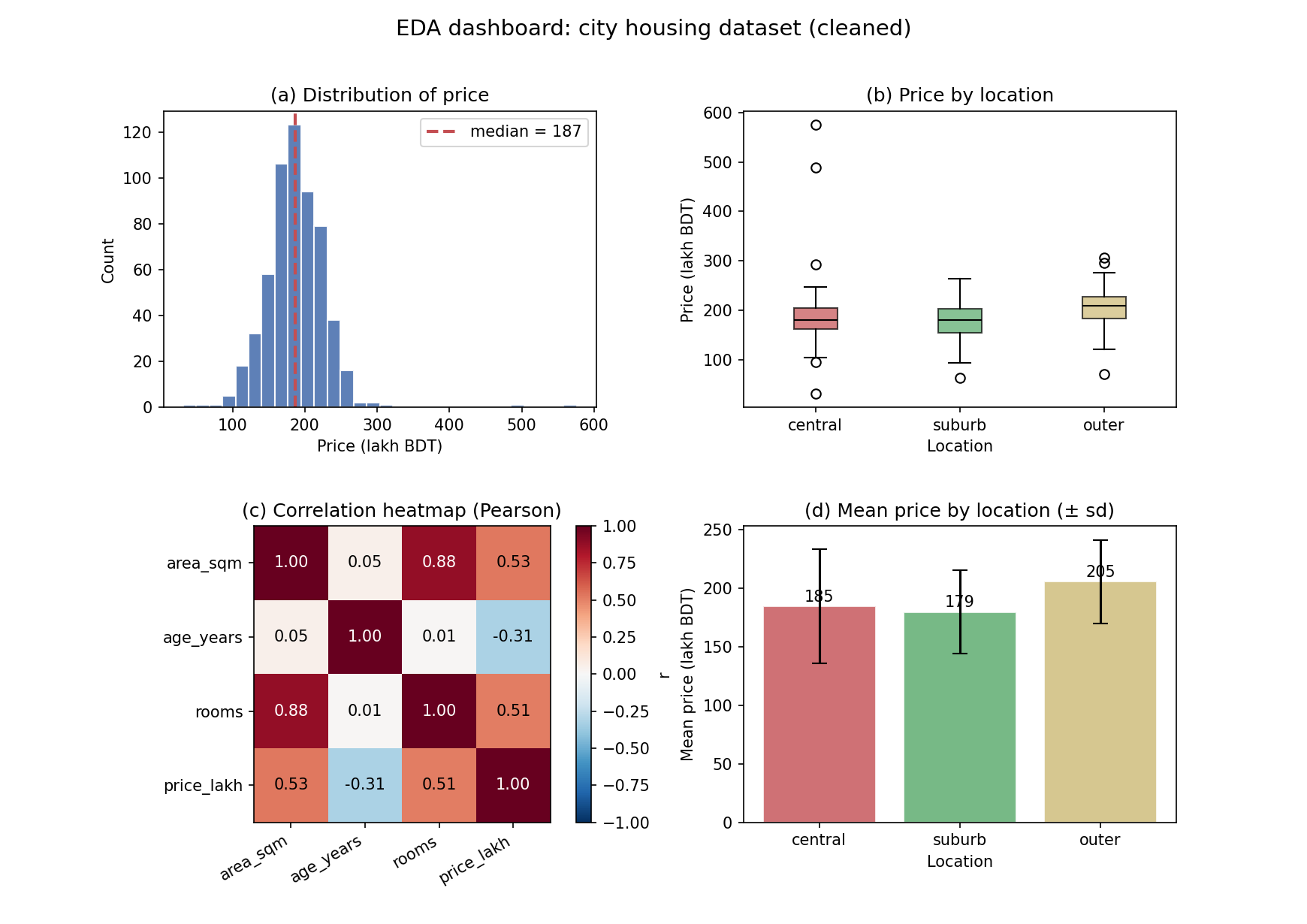
Figure 3 — Key bivariate relationship (area vs price)¶
সবচেয়ে গুরুত্বপূর্ণ সম্পর্কটিকে আলাদা করে highlight: area বনাম price, location অনুযায়ী রঙিন, least-squares fit রেখাসহ।
fig, ax = plt.subplots(figsize=(7.6, 5.2))
colmap = {"central":"#C44E52","suburb":"#55A868","outer":"#CCB974"}
for gname in groups:
sub = dc[dc.location==gname]
ax.scatter(sub["area_sqm"], sub["price_lakh"], s=22, alpha=0.6,
color=colmap[gname], label=gname)
x, y = dc["area_sqm"].values, dc["price_lakh"].values
b1, b0 = np.polyfit(x, y, 1)
xs = np.linspace(x.min(), x.max(), 100)
ax.plot(xs, b0+b1*xs, "k--", lw=2, label=f"fit: price = {b0:.0f} + {b1:.2f}·area")
ax.set_xlabel("Area (sqm)"); ax.set_ylabel("Price (lakh BDT)")
ax.set_title(f"Area vs price by location (Pearson r = {np.corrcoef(x,y)[0,1]:.2f})")
ax.legend(loc="upper left"); fig.tight_layout()
fig.savefig("../_assets/1-5-bivariate.png", dpi=150)
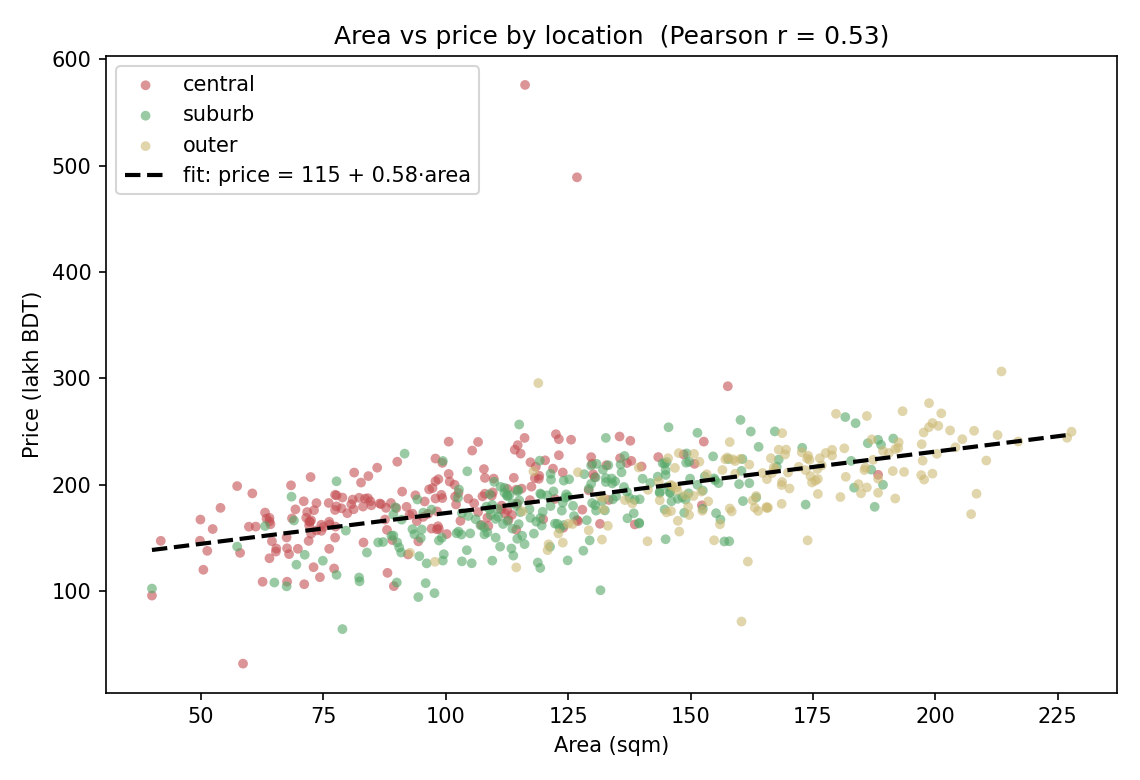
Figure 4 — Outlier handling: raw vs cleaned¶
cleaning-এর প্রভাব দৃশ্যমান করতে price-এর boxplot — পরিষ্কার করার আগে ও পরে পাশাপাশি।
fig, axes = plt.subplots(1, 2, figsize=(9.2, 4.6))
b1 = axes[0].boxplot(df["price_lakh"].dropna().values, patch_artist=True)
b1["boxes"][0].set_facecolor("#C44E52"); b1["boxes"][0].set_alpha(0.6)
axes[0].set_title("(a) Raw price (with outliers)"); axes[0].set_ylabel("Price (lakh BDT)")
axes[0].set_xticks([1]); axes[0].set_xticklabels(["raw"])
b2 = axes[1].boxplot(dc["price_lakh"].values, patch_artist=True)
b2["boxes"][0].set_facecolor("#55A868"); b2["boxes"][0].set_alpha(0.6)
axes[1].set_title("(b) After cleaning (IQR + domain rules)")
axes[1].set_xticks([1]); axes[1].set_xticklabels(["clean"])
fig.suptitle("Effect of outlier handling on the price distribution", fontsize=13)
fig.tight_layout(); fig.savefig("../_assets/1-5-outliers.png", dpi=150)
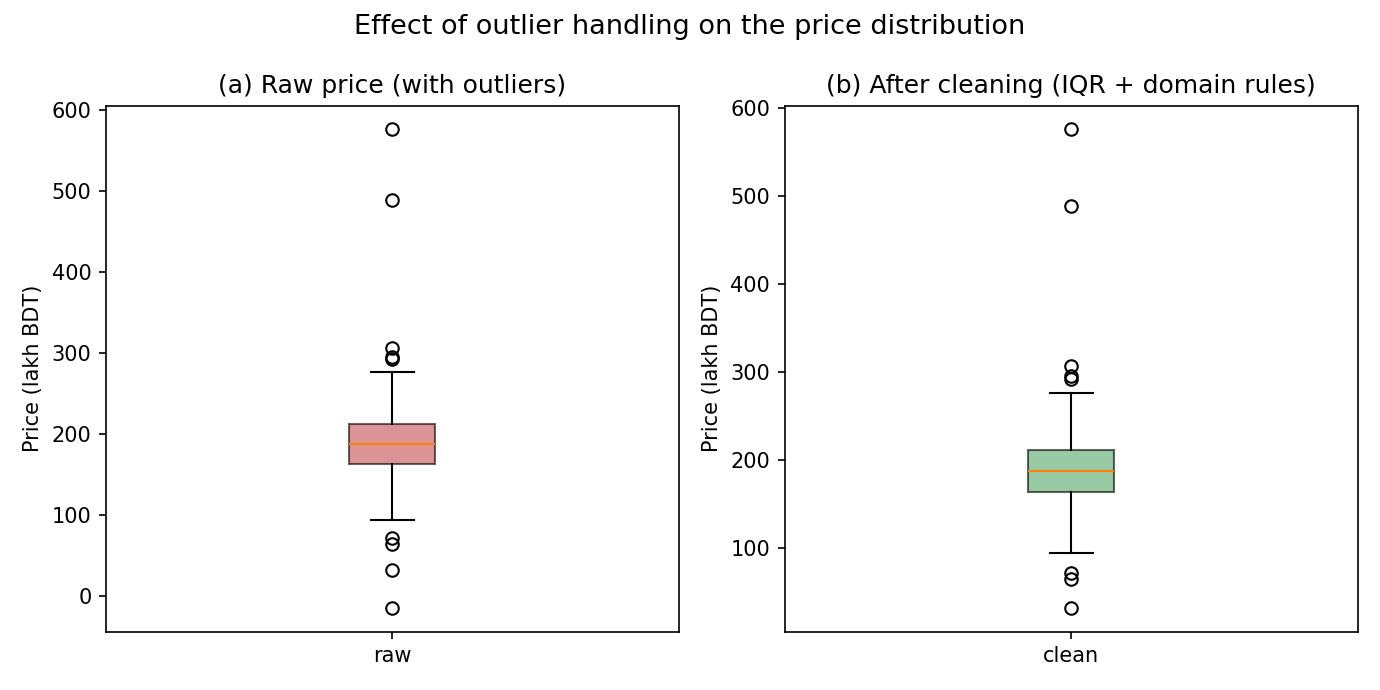
গুরুত্বপূর্ণ পর্যবেক্ষণ: Figure 4(b)-তে এখনও কিছু উঁচু বিন্দু আছে — কারণ আমরা শুধু error outlier মুছেছি, বৈধ luxury unit রেখেছি (Section 4.1-এর নীতি)। boxplot-এর "outlier" বিন্দু মানেই "বাদ দাও" নয়।
৭ · অনুশীলনী — extend the analysis¶
প্রতিটির difficulty tag ও hint দেওয়া। পূর্ণ সমাধান: _solutions/01-05-eda-workflow-casestudy-solutions.md। সব অনুশীলনী Section 5-এর build_housing() ও clean() থেকে চলবে।
Conceptual (ধারণাগত)¶
প্র. ১ [difficulty: easy] নিজের ভাষায় ব্যাখ্যা করুন কেন EDA-তে median ও IQR, mean ও std-এর চেয়ে নিরাপদ যখন data-তে outlier সন্দেহ করেন। আমাদের price_lakh (raw)-এর উদাহরণ দিন।
Hint: mean ও std-এ প্রতিটি বিন্দু বর্গ-দূরত্বে ওজন পায়; median/IQR rank-ভিত্তিক।
প্র. ২ [difficulty: medium] Anscombe-র শিক্ষা এক বাক্যে বলুন, এবং আমাদের case study-র কোন নির্দিষ্ট পর্যবেক্ষণ (একটি সংখ্যা-জোড়া) ঠিক সেই শিক্ষাকেই প্রতিফলিত করেছিল তা ব্যাখ্যা করুন।
Hint: Pearson বনাম Spearman-এর পার্থক্য, এবং কেন তা scatter না দেখলে বোঝা যেত না।
প্র. ৩ [difficulty: medium] "data leakage" কী, এবং আমাদের clean() function-এর group-median imputation কোন পরিস্থিতিতে leakage তৈরি করতে পারে? কীভাবে এড়াবেন?
Hint: train/test split-এর ক্রম; median কেবল train থেকে শেখা।
Computational (গণনামূলক)¶
প্র. ৪ [difficulty: easy] cleaned dc-তে age_years কলামের জন্য IQR fence বের করে কতটি outlier flag হয় গণনা করুন। price-এর fence-এর সাথে তুলনা করুন।
Hint: Section 5.6-এর কোড অন্য কলামে প্রয়োগ করুন।
প্র. ৫ [difficulty: medium] dc-তে একটি নতুন numeric কলাম price_per_sqm = price_lakh / area_sqm তৈরি করুন। এর univariate summary (median, IQR) বের করুন এবং location অনুযায়ী group-mean তুলনা করুন। location অনুযায়ী per-sqm দাম কি ভিন্ন? (এটি Section 3.6-এর confounding প্রশ্নের একটি উত্তর-চেষ্টা।)
Hint: dc.groupby("location")["price_per_sqm"].mean()।
প্র. ৬ [difficulty: medium] cleaning করার আগে ও পরে area_sqm ↔ price_lakh-এর Pearson \(r\) আলাদাভাবে বের করুন (raw-তে আগে NaN drop করুন)। ৯৮০-typo বাদ দিলে correlation কতটা বদলায়? এক বাক্যে ব্যাখ্যা।
Hint: df.dropna(subset=[...]).corr() বনাম dc[...].corr()।
Mini-project (ছোট প্রকল্প)¶
প্র. ৭ [difficulty: hard] build_housing()-কে seed=7 দিয়ে আবার চালিয়ে একটি ভিন্ন sample তৈরি করুন। তারপর সম্পূর্ণ pipeline (inspect → clean → univariate → bivariate) চালিয়ে একটি ৩-৪ বাক্যের EDA সারাংশ লিখুন: কোন সম্পর্ক জোরালো, কোথায় collinearity, কোন data-quality সমস্যা পেলেন। নতুন seed-এ কি একই গুণগত উপসংহার টিকে থাকে?
Hint: reproducibility মানে seed fixed হলে ফল স্থির; ভিন্ন seed-এ সংখ্যা সামান্য বদলালেও গুণগত প্যাটার্ন (area↔price ধনাত্মক, area↔rooms collinear) টিকে থাকা উচিত।
প্র. ৮ [difficulty: hard] Figure 2-এর dashboard-এ একটি পঞ্চম প্যানেল যোগ করুন: age_years বনাম price_lakh-এর scatter (ঋণাত্মক সম্পর্ক দৃশ্যমান করতে) একটি fit রেখাসহ। ৩×২ grid ব্যবহার করুন এবং figure সংরক্ষণ করুন। সম্পর্কের চিহ্ন (sign) heatmap-এর \(-0.31\)-এর সাথে মেলে কি না যাচাই করুন।
Hint: gridspec.GridSpec(3, 2, ...); np.polyfit(age, price, 1)-এর slope ঋণাত্মক হওয়া উচিত।
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে যা শিখলাম¶
- EDA হলো ক্রমবদ্ধ গোয়েন্দাগিরি (Tukey-দর্শন):
Question → Load/Inspect → Clean → Univariate → Bivariate/Multivariate → Insight— একটি iterative, reproducible pipeline। - Inspect:
shape,dtype,head,describeদিয়ে data-র গঠন বোঝা ও red flag (অসমcount, অসম্ভব min/max) ধরা। - Clean: missingness মেপে group-median দিয়ে impute; outlier-কে error বনাম genuine-এ ভাগ করে domain rule + IQR fence দিয়ে handle — error মুছুন, বৈধ চরম মান রাখুন।
- Univariate (1.2/1.3): robust (median, IQR, MAD) ও classical summary, histogram/boxplot দিয়ে center–spread–shape।
- Bivariate (1.4): correlation heatmap (Pearson ও Spearman), scatter, এবং categorical-অনুযায়ী group comparison (boxplot, mean ± sd)। আমাদের data-তে পেলাম: area↔price মাঝারি ধনাত্মক, area↔rooms জোরালো collinear, age↔price ঋণাত্মক, এবং location-এর আপাত প্রভাব আসলে area-র মধ্য দিয়ে।
- প্রমাণ-অংশে: Anscombe-যুক্তিতে দেখলাম summary statistic lossy — চোখে দেখা আবশ্যক (Pearson ০.৫৩ বনাম Spearman ০.৬১ এর জীবন্ত উদাহরণ); outlier/missing অসংশোধিত রাখলে non-robust statistic বিকৃত হয়; এবং data leakage / peeking এড়াতে EDA সূত্র তৈরি করে, যাচাই করতে হয় পৃথক data-তে।
- Reproducibility: fixed
seed+ deterministic pipeline = অন্য কেউ হুবহু একই ফল পায়।
সংযোগ¶
- পূর্ববর্তী: 1.1 (data/variable type) → কলাম শ্রেণিবদ্ধ করা; 1.2 (robust statistics) → median/IQR/MAD-নির্ভর cleaning ও summary; 1.3 (distribution, boxplot, ECDF) → univariate ছবি ও IQR fence; 1.4 (correlation, bivariate) → heatmap ও group comparison। এই অধ্যায় ঠিক সেগুলোকেই একটি বাস্তব workflow-এ জুড়ল।
- পরবর্তী: 2.1 — Sample space, axioms of probability (Part II — Probability Foundations)। এখানে আমরা data বর্ণনা করেছি; Part II থেকে শুরু হবে data-র পেছনের randomness-এর গণিত, যা পরে inference (Part IV) ও modeling (Part V)-এর ভিত্তি। বিশেষভাবে — এই EDA-তে চিহ্নিত প্রশ্নগুলো (price-এর predictor, collinearity, location-confounding) Part V-এ regression হিসেবে আনুষ্ঠানিকভাবে ফিরে আসবে; cleaning ও leakage-সচেতনতা Part IV/VI-এ inference ও model validation-এর সময় কেন্দ্রীয় হবে। EDA তাই গোটা curriculum-এ বারবার ফিরে দেখার অভ্যাস।
Source pointer¶
EDA workflow ও applied code-on-ramp ভঙ্গি অনুসরণ করেছে Practical Statistics for Data Scientists (Bruce, Bruce & Gedeck) — বিশেষত data exploration ও robust statistics অধ্যায়। মূল দর্শন (detective work, resistance/robustness, re-expression, ছবি-প্রথম) এসেছে John W. Tukey-র Exploratory Data Analysis (১৯৭৭) থেকে; summary-statistic-এর সীমাবদ্ধতার ক্লাসিক উদাহরণ F. J. Anscombe (১৯৭৩)। dataset সম্পূর্ণ synthetic ও reproducible (numpy default_rng, seed=2025) — কোনো বাহ্যিক download নেই।