3.4 — Central Limit Theorem & Delta Method (কেন্দ্রীয় সীমা উপপাদ্য)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — bell curve কেন সর্বত্র?¶
১.১ একটা রহস্য দিয়ে শুরু — একই ঘণ্টা-আকৃতি বারবার ফিরে আসে কেন?¶
একটা সাধারণ পর্যবেক্ষণ দিয়ে শুরু করি, যা একবার চোখে পড়লে আর ভোলা যায় না। নিচের জিনিসগুলোর কোনো আপাত মিল নেই:
- বহু মানুষের উচ্চতা (height) — একটা শহরের সবার;
- একটা কারখানায় তৈরি বহু বোল্টের মাপের সামান্য ভুল (manufacturing error);
- একটা পরীক্ষায় বহু ছাত্রের নম্বর;
- বহুবার একটা ছক্কা ছুড়ে মোট যোগফল (sum of many dice)।
অথচ এদের প্রত্যেকটির histogram (পরিসংখ্যান-চিত্র, 1.3-এ শেখা) আঁকলে বারবার একই আকৃতি ফুটে ওঠে — মাঝখানে উঁচু, দুপাশে প্রতিসমভাবে নামা একটা মসৃণ ঘণ্টা (bell curve)। এই ঘণ্টা-আকৃতিটিই Normal distribution (প্রসামান্য বণ্টন, 2.4-এ পরিচিত), প্রতীকে \(\mathcal{N}(\mu,\sigma^2)\)।
প্রশ্নটা স্বাভাবিক: এত আলাদা আলাদা উৎস (source) থেকে একই আকৃতি আসছে কেন? উচ্চতা তো ছক্কার যোগফলের মতো কিছু নয়; বোল্টের ভুল তো পরীক্ষার নম্বরের মতো কিছু নয়। তবু আকৃতি এক। এটা নিছক কাকতাল নয় — এর পেছনে একটিমাত্র গভীর গাণিতিক কারণ আছে, আর সেই কারণটার নামই এই অধ্যায়ের বিষয়: Central Limit Theorem (CLT)।
এক বাক্যে অন্তর্দৃষ্টিটা এই: যেখানেই বহু ছোট, স্বাধীন প্রভাব যোগ হয়ে একটা ফল তৈরি করে, সেখানেই সেই যোগফলের আকৃতি Normal-এর দিকে যায় — মূল প্রভাবগুলো নিজে যে আকৃতিরই হোক না কেন। একজন মানুষের উচ্চতা বহু জিনের ছোট ছোট অবদান + বহু পরিবেশগত ছোট প্রভাবের যোগ; একটা বোল্টের ভুল বহু ক্ষুদ্র যান্ত্রিক কম্পনের যোগ; ছক্কার মোট যোগফল তো আক্ষরিকভাবেই বহু ছক্কার যোগ। যেহেতু সবগুলোই "বহু ছোট স্বাধীন জিনিসের যোগ", সেহেতু সবগুলোর আকৃতি একই — Normal। এই একটিমাত্র বাক্য কেন সত্যি, সেটাই আমরা precise করব।
১.২ আগের দুই অধ্যায় কী বলেছিল — আর ঠিক কোথায় থামল¶
এই অধ্যায়টা শূন্য থেকে আসছে না; এটা 3.2 আর 3.3-এর সরাসরি পরবর্তী ধাপ। তাই আগে মনে করিয়ে দিই আমরা কোথায় দাঁড়িয়ে আছি।
পুরো গল্পের কেন্দ্রে আছে sample mean (নমুনা গড়)। ধরা যাক আমাদের কাছে আছে i.i.d. (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত) random variable-এর একটা ক্রম \(X_1, X_2, \dots, X_n\), প্রত্যেকের একই mean \(\mu\) ও একই variance \(\sigma^2\)। তাদের গড়
প্রতিটি প্রতীক খুলে বলি (পরে সব আবার §২-এ আনুষ্ঠানিকভাবে আসবে, এখানে শুধু মনে করানো):
- \(X_i\) — \(i\)-তম পর্যবেক্ষণ (random variable), যেমন \(i\)-তম ছক্কার ফল বা \(i\)-তম মানুষের উচ্চতা।
- \(\mu\) ("mu") — প্রতিটি \(X_i\)-এর সত্য গড় (mean), \(\mu=\mathbb{E}[X_i]\) — একটি নির্দিষ্ট (অজানা হলেও স্থির) সংখ্যা।
- \(\sigma^2\) ("sigma squared") — প্রতিটি \(X_i\)-এর variance, ছড়ানোর মাপ; \(\sigma\) হলো তার বর্গমূল, standard deviation।
- \(\sum_{i=1}^{n} X_i\) — প্রথম \(n\)টি পর্যবেক্ষণের যোগফল।
- \(\bar X_n\) — সেই যোগফলকে \(n\) দিয়ে ভাগ, অর্থাৎ নমুনা গড়। নিজে একটি random variable, কারণ নতুন নমুনায় নতুন মান।
3.3 (Law of Large Numbers) যা বলেছিল। LLN-এর বার্তা ছিল সরল ও শক্তিশালী: \(n\) বড় হলে \(\bar X_n\) গিয়ে সত্য গড় \(\mu\)-তে থিতু হয়,
অর্থাৎ LLN আমাদের বলে দেয় গন্তব্য — "নমুনা গড় শেষ পর্যন্ত কোথায় গিয়ে দাঁড়ায়।" উত্তর: ঠিক \(\mu\)-তে। এটুকুই; এর বেশি LLN বলে না।
কিন্তু LLN একটা জরুরি প্রশ্ন অমীমাংসিত রেখে যায়। ভাবুন: \(n\) যত বাড়ে, \(\bar X_n\) আর \(\mu\)-এর পার্থক্য \(\bar X_n - \mu\) ক্রমে ছোট হয়ে \(0\)-এর দিকে যায়। ভালো কথা — কিন্তু:
- এই পার্থক্য কত দ্রুত ছোট হয়? \(n\) দ্বিগুণ করলে ভুল অর্ধেক হয়, না চার ভাগের এক, না অন্য কিছু?
- একটা নির্দিষ্ট \(n\)-এ (ধরুন \(n=100\)) \(\bar X_n\) আর \(\mu\)-এর পার্থক্যের আকৃতি কেমন — পার্থক্যটা কোন distribution মেনে ছড়ায়?
LLN এই দুটোর কোনোটারই উত্তর দেয় না; সে শুধু বলে "শেষমেশ পার্থক্য \(0\)।" এখানেই CLT আসে, আর ঠিক এই দুটো শূন্যস্থান পূরণ করে।
১.৩ এক লাইনের সারমর্ম — LLN বলে "কোথায়", CLT বলে "কত দ্রুত ও কী আকৃতিতে"¶
পুরো অধ্যায়ের অন্তর্দৃষ্টি একটা তুলনায় ধরা যায়, এবং এটিই মনে রাখার মতো মূল বাক্য:
LLN বলে নমুনা গড় কোথায় গিয়ে দাঁড়ায় (\(\mu\)-তে)। CLT বলে সেই দাঁড়ানোর কত দ্রুত ও সেখানে পৌঁছানোর আগে পার্থক্যটা কী আকৃতিতে ছড়ায় (Normal আকৃতিতে, \(\sqrt n\) হারে সরু হতে হতে)।
একটু রূপকে: LLN একটা ভ্রমণ-মানচিত্রের মতো — শুধু গন্তব্য চিহ্নিত করে। CLT হলো সেই ভ্রমণের বিস্তারিত বিবরণ — গন্তব্যের কতটা কাছে পৌঁছেছেন, আর আশপাশে ছড়িয়ে-থাকা সম্ভাব্য অবস্থানগুলোর আকৃতি কেমন। দুটো মিলেই পুরো ছবি।
কেন এই "আকৃতি ও হার" জানা এত গুরুত্বপূর্ণ? কারণ পরিসংখ্যানের প্রায় পুরো inference (অনুমান) এর ওপর দাঁড়িয়ে। যখন আমরা বলি "এই জরিপ অনুযায়ী জনসমর্থন \(52\% \pm 3\%\)", সেই "\(\pm 3\%\)" আসে সরাসরি CLT থেকে — কারণ CLT-ই জানায় নমুনা গড় সত্য মানের চারপাশে কোন আকৃতিতে, কত ছড়িয়ে থাকে। CLT ছাড়া confidence interval (CI — আস্থা-ব্যবধি, Part IV) বা hypothesis test (প্রকল্প-পরীক্ষা)-এর কোনো ভিত্তিই থাকে না। তাই অনেকে CLT-কে বলেন "পরিসংখ্যানের মূল স্তম্ভ"।
এই অধ্যায়ে আমরা চারটি ধাপে এগোব:
- §২-এ CLT-এর precise statement — কী বলে, প্রতিটি প্রতীকসহ — এবং কেন \(\sqrt n\) দিয়েই scale করতে হয়, তার অন্তর্দৃষ্টি। তারপর Delta method — যখন আমরা গড় নয়, গড়ের একটা function \(g(\bar X_n)\)-এর আকৃতি জানতে চাই।
- §৩-এ চারটি পূর্ণাঙ্গ উদাহরণ — ছক্কা থেকে sample proportion পর্যন্ত — সংখ্যাসহ।
- §৪–৫ — CLT-এর গভীরতর ব্যাখ্যা, শর্ত, ও Delta method-এর প্রয়োগ।
- §৬–৮ — চিত্র, common ভুল-ধারণা, ও অনুশীলন।
এক বাক্যে কেন এটা পরের সব অধ্যায়ের ভিত্তি। 3.2 আমাদের \(\xrightarrow{d}\) (convergence in distribution)-এর ভাষা দিয়েছে; 3.3 sample mean-এর গন্তব্য \(\mu\) দিয়েছে। CLT এই দুটোকে জোড়া লাগায়: এটি একটি \(\xrightarrow{d}\)-বিবৃতি যা sample mean-এর fluctuation-এর আকৃতি (\(\mathcal{N}(0,1)\)) নির্দিষ্ট করে। এর ওপরেই Part IV-এর estimation ও Part V-এর hypothesis testing দাঁড়াবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে আমরা দুটো জিনিস from scratch তৈরি করব: প্রথমে Central Limit Theorem-এর precise statement (§২.১–২.৪), তারপর Delta method (§২.৫)। প্রতিটির জন্য একই কাঠামো — আগে স্বজ্ঞা, তারপর formal statement, তারপর প্রতিটি প্রতীক খোলা। পুরো বিভাগে \(X_1, X_2, \dots\) মানে i.i.d. random variable, প্রত্যেকের mean \(\mu\) ও variance \(\sigma^2\) (যেখানে \(0 < \sigma^2 < \infty\), অর্থাৎ variance সসীম ও শূন্য নয়)।
২.১ সমস্যাটা ঠিক করে বসানো — গড়কে "ঠিক মাপে" বড় করা¶
CLT বুঝতে হলে আগে একটা সূক্ষ্ম কিন্তু কেন্দ্রীয় ব্যাপার পরিষ্কার করতে হবে: আমরা ঠিক কোন জিনিসের distribution দেখছি? তিনটি স্বাভাবিক প্রার্থী আছে, আর কেবল তৃতীয়টিই কাজ করে।
ধরা যাক \(\sigma^2\) মানে প্রতিটি \(X_i\)-এর variance। আগে দুটো সহজ তথ্য মনে করি (2.5 থেকে):
- \(\bar X_n\)-এর গড়: \(\mathbb{E}[\bar X_n] = \mu\) (নমুনা গড়ের গড় সত্য গড়ই)।
- \(\bar X_n\)-এর variance: \(\mathrm{Var}(\bar X_n) = \dfrac{\sigma^2}{n}\) (স্বাধীন পদের গড়ের variance, \(n\) দিয়ে ছোট হয়)। তাই \(\bar X_n\)-এর standard deviation \(\dfrac{\sigma}{\sqrt n}\)।
এখন তিন প্রার্থী:
প্রার্থী ১ — সরাসরি \(\bar X_n\)। এর distribution দেখলে কী হয়? LLN বলছে \(\bar X_n \to \mu\) — অর্থাৎ পুরো distribution একটা একটিমাত্র বিন্দুতে (\(\mu\)-তে) গুটিয়ে আসে, সব ছড়ানো মুছে যায়। আকৃতি বলে কিছু থাকে না; পাওয়া যায় শুধু একটা spike \(\mu\)-তে। তথ্যহীন। ❌
প্রার্থী ২ — কেন্দ্রায়িত পার্থক্য \(\bar X_n - \mu\)। এবার \(\mu\) বাদ দিয়ে fluctuation-টুকু দেখছি। কিন্তু এরও variance \(\sigma^2/n \to 0\) — তাই এটাও \(0\)-তে গুটিয়ে আসে, আবার spike (এবার \(0\)-তে)। আকৃতি দেখা গেল না। ❌
প্রার্থী ৩ — scaled পার্থক্য। সমস্যা পরিষ্কার: \(\bar X_n - \mu\) "খুব দ্রুত" \(0\)-তে গুটিয়ে আসছে, তাই আকৃতি দেখার আগেই মিলিয়ে যায়। সমাধান — একে একটা ক্রমবর্ধমান factor দিয়ে বড় করে ধরা, যেন গুটিয়ে আসা ঠিক ভারসাম্যে থামে। কত দিয়ে বড় করব? variance \(\sigma^2/n\), তাই standard deviation \(\sigma/\sqrt n\) — মানে fluctuation-এর "স্বাভাবিক মাপ" \(1/\sqrt n\) হারে ছোট হচ্ছে। কাজেই ঠিক \(\sqrt n\) দিয়ে গুণ করলে সেই ছোট হওয়া পুরোপুরি বাতিল হয়ে যাবে। এটিই সঠিক প্রার্থী — এবং একে standardize করলে পাই \(Z_n\) (§২.২)। ✓
এই \(\sqrt n\)-এর তাৎপর্য §২.৩-এ আরও খুলব; আপাতত মূল কথা: CLT সরাসরি \(\bar X_n\)-এর কথা বলে না, বলে "ঠিক \(\sqrt n\) দিয়ে বড় করে দেখা" fluctuation-এর কথা।
২.২ CLT-এর statement — standardized sample mean \(Z_n\)¶
এবার সেই সঠিক প্রার্থীকে standardize করি — অর্থাৎ গড় বাদ দিয়ে standard deviation দিয়ে ভাগ করি, ঠিক যেমন 2.4-এ যেকোনো Normal-কে \(Z=(X-\mu)/\sigma\) দিয়ে standard Normal-এ আনতাম। এখানে "\(X\)" জায়গায় \(\bar X_n\), তার গড় \(\mu\), তার standard deviation \(\sigma/\sqrt n\):
(দুটো রূপ একই জিনিস — শুধু \(\sigma/\sqrt n\) দিয়ে ভাগকে \(\sqrt n/\sigma\) দিয়ে গুণে লিখলাম।) এই \(Z_n\)-কে বলে standardized sample mean (প্রমিতকৃত নমুনা গড়)। নির্মাণ অনুযায়ী এর গড় \(0\) এবং variance \(1\) — যেকোনো \(n\)-এ।
এবার মূল উপপাদ্য:
Central Limit Theorem (CLT — কেন্দ্রীয় সীমা উপপাদ্য)। ধরা যাক \(X_1, X_2, \dots\) i.i.d., প্রত্যেকের mean \(\mu\) এবং সসীম, শূন্য-নয় variance \(\sigma^2\) (\(0<\sigma^2<\infty\))। তাহলে
সমতুল্যভাবে, CDF-এর ভাষায় (যা \(\xrightarrow{d}\)-এর প্রকৃত সংজ্ঞা, 3.2 থেকে): প্রতিটি বাস্তব সংখ্যা \(z\)-এর জন্য
যেখানে \(\Phi\) হলো standard Normal-এর CDF।
প্রতিটি প্রতীক খুলে বলি:
- \(\bar X_n = \frac1n\sum_{i=1}^n X_i\) — নমুনা গড় (random variable)।
- \(\mu = \mathbb{E}[X_i]\) — প্রতিটি \(X_i\)-এর সত্য গড় (স্থির সংখ্যা)।
- \(\sigma = \sqrt{\mathrm{Var}(X_i)}\) — প্রতিটি \(X_i\)-এর standard deviation (স্থির ধনাত্মক সংখ্যা)।
- \(\sqrt n\) — নমুনা-আকারের বর্গমূল; এটিই সেই "ঠিক মাপের" বিবর্ধক যা §২.১-এ বের করলাম।
- \(Z_n\) — standardized sample mean: গড় \(0\), variance \(1\) প্রতিটি \(n\)-এ।
- \(\mathcal{N}(0,1)\) — standard Normal distribution (mean \(0\), variance \(1\), ঘণ্টা-আকৃতি)।
- \(\xrightarrow{d}\) — convergence in distribution (3.2): \(Z_n\)-এর CDF গিয়ে \(\Phi\)-এ মেলে, প্রতিটি বিন্দুতে যেখানে \(\Phi\) continuous (আর \(\Phi\) সর্বত্রই continuous, তাই প্রতিটি \(z\)-এ)।
- \(\Phi(z) = P(Z\le z)\) যেখানে \(Z\sim\mathcal{N}(0,1)\) — standard Normal CDF, একটি নির্দিষ্ট মসৃণ বর্ধমান ফাংশন।
statement-টা কথায়: যেকোনো i.i.d. source থেকে (যার variance সসীম ও শূন্য নয়), নমুনা গড়কে ঠিক ঐ standardized উপায়ে দেখলে, বড় \(n\)-এ তার distribution গিয়ে দাঁড়ায় একটিমাত্র সর্বজনীন আকৃতিতে — standard Normal-এ। মূল \(X_i\) কী distribution মানত — Uniform, Exponential, Bernoulli, ছক্কা — তাতে কিছুই আসে যায় না। এটাই §১.১-এর রহস্যের উত্তর: bell curve সর্বত্র, কারণ যোগফল/গড়কে standardize করলে উৎস ভুলে গিয়ে সবাই একই \(\mathcal{N}(0,1)\)-এ মেলে।
২.৩ "যেকোনো source → Normal" এবং \(\sqrt n\) scaling-এর তাৎপর্য¶
দুটো জিনিস এই statement-এ সবচেয়ে আশ্চর্যজনক, এবং দুটোতেই একটু থামা দরকার।
(ক) "মূল distribution ভুলে যাওয়া" (universality)। CLT-এর সবচেয়ে চমকপ্রদ দিক — উত্তরে মূল source-এর আকৃতির কোনো চিহ্ন থাকে না। শুধু দুটো সংখ্যা — \(\mu\) আর \(\sigma\) — limit-এ ঢোকে, আর তারা তো কেবল standardize করতেই ব্যবহৃত হয়। মূল distribution যত অদ্ভুতই হোক (তীব্রভাবে অপ্রতিসম, একপাশে লম্বা লেজ, এমনকি ছক্কার মতো বিচ্ছিন্ন), যথেষ্ট অনেকগুলো যোগ করে standardize করলে আকৃতি Normal-এ গিয়ে দাঁড়ায়। একে বলে universality (সর্বজনীনতা): বহু ভিন্ন শুরু, একটিই গন্তব্য-আকৃতি। §৩-এর E2 এটা তিনটে একদম আলাদা source-এ চোখে দেখাবে।
কেন এমনটা ঘটে — তার পূর্ণ অন্তর্দৃষ্টি (যোগ করলে প্রতিটি source-এর "খুঁটিনাটি আকৃতি" পরস্পরকে মসৃণ করে দেয়, শুধু প্রথম দুই moment — mean ও variance — টিকে থাকে) §৪-এ moment-অন্তর্দৃষ্টিসহ খোলা হবে। এখানে statement-স্তরে এটুকু মনে রাখুন: finite variance থাকলেই Normal; বাকি বিস্তারিত মুছে যায়।
(খ) ঠিক \(\sqrt n\) কেন — না বেশি, না কম। §২.১-এ দেখলাম \(\bar X_n - \mu\)-এর "স্বাভাবিক মাপ" (standard deviation) \(\sigma/\sqrt n\)। এখন তিনটি সম্ভাব্য বিবর্ধক \(n^{a}\) ভাবি এবং দেখি কী হয় — এটাই \(\sqrt n\)-এর তাৎপর্য সবচেয়ে পরিষ্কার করে:
- খুব ছোট বিবর্ধক (যেমন কিছু দিয়ে গুণ না করা, বা \(a<\tfrac12\)): fluctuation যত দ্রুত \(0\)-তে গুটিয়ে আসছে, বিবর্ধক তত দ্রুত বড় হচ্ছে না — তাই scaled জিনিসও \(0\)-তে গুটিয়ে যায়। আকৃতি দেখার আগেই spike। (এই অর্থেই \(\bar X_n - \mu \xrightarrow{P} 0\) — degenerate limit।)
- খুব বড় বিবর্ধক (\(a>\tfrac12\), যেমন \(n\) দিয়ে গুণ): বিবর্ধক fluctuation-এর ছোট হওয়াকে ছাপিয়ে যায় — তাই scaled জিনিসের ছড়ানো অসীমে চলে যায় (বিস্ফোরণ, blow up)। আবার stable আকৃতি নেই।
- ঠিক \(\sqrt n\) (\(a=\tfrac12\)): বিবর্ধকের বৃদ্ধি আর fluctuation-এর সংকোচন ঠিক ভারসাম্যে মেলে। ফলে \(\sqrt n(\bar X_n-\mu)\)-এর ছড়ানো একটা স্থির, সসীম, শূন্য-নয় মাপে থিতু হয় (এর variance ঠিক \(\sigma^2\)), আর সেই স্থির ছড়ানোর আকৃতিই Normal।
মূল কথা: \(\sqrt n\) হলো সেই একমাত্র scaling যেখানে limit "না-শূন্য, না-অসীম" — অর্থাৎ একমাত্র scaling যেখানে একটা অর্থপূর্ণ আকৃতি দেখা যায়। আর সেই আকৃতি সবসময় Normal। (এজন্যই CLT-কে অনেক সময় বলা হয় "\(\sqrt n\)-হারে convergence": ভুল \(\bar X_n - \mu\) মোটামুটি \(1/\sqrt n\) হারে ছোট হয় — \(n\) চারগুণ করলে সাধারণ ভুল অর্ধেক। এই হারই §১.২-এর প্রথম প্রশ্নের উত্তর।)
২.৪ 3.2 ও 3.3-এর সাথে সংযোগ — এক ছবিতে তিন অধ্যায়¶
এবার পরিষ্কার করি CLT কীভাবে আগের দুই অধ্যায়ের ঠিক ওপরে বসে।
- 3.2 থেকে আমরা \(\xrightarrow{d}\)-এর সংজ্ঞা পেয়েছি — "CDF গিয়ে মেলে"। CLT-এর উপসংহার ঠিক একটি \(\xrightarrow{d}\)-বিবৃতি; এর precise অর্থ ঐ সংজ্ঞা ছাড়া বলাই যেত না। লক্ষ করুন এখানে limit \(\mathcal{N}(0,1)\) একটা ধ্রুবক নয়, একটা সত্যিকারের distribution — তাই এটা in-distribution convergence-এর সবচেয়ে স্বাভাবিক ও গুরুত্বপূর্ণ উদাহরণ (যেখানে limit একটা বিন্দুতে গুটিয়ে যায় না)।
- 3.3 থেকে আমরা পেয়েছি \(\bar X_n \to \mu\)। CLT সেটিকে অস্বীকার করে না — পরিমার্জিত করে। দুটো একসাথে এক ছবিতে: LLN বলছে কেন্দ্র \(\mu\)-তে স্থির; CLT বলছে সেই কেন্দ্রের চারপাশে fluctuation, \(\sqrt n\) দিয়ে বড় করে দেখলে, \(\mathcal{N}(0,1)\) আকৃতির। প্রকৃতপক্ষে CLT থেকে LLN-এর (দুর্বল রূপ) অনুসিদ্ধান্ত হিসেবে বেরও করা যায় — fluctuation Normal-আকৃতিতে থিতু হলে scale-না-করা \(\bar X_n - \mu\) অবশ্যই \(0\)-তে যায়।
একটা পরিভাষাগত সেতু এখানে গেঁথে রাখি, কারণ §৪–৫-এ কাজে লাগবে: CLT প্রায়ই asymptotic (অসীম-আচরণমূলক) রূপে লেখা হয় — বড় \(n\)-এ "approximately"
এটি উপরের boxed statement-এরই অনানুষ্ঠানিক, ব্যবহারিক ভাষান্তর: "\(\bar X_n\) মোটামুটি একটা Normal, যার কেন্দ্র \(\mu\) আর variance \(\sigma^2/n\)।" এই রূপটিই পরে confidence interval বানাতে সরাসরি লাগবে (E3-এ ঝলক দেখব)। তবে মনে রাখা ভালো — কড়া অর্থে limit-টা \(Z_n\)-এর, \(\bar X_n\)-এর নিজের নয়; "\(\overset{\text{approx}}{\sim}\)" হলো বড়-\(n\) আসন্নতার সংক্ষিপ্ত লিখন।
২.৫ Delta method — গড়ের function-এর approximate distribution¶
এতক্ষণ আমরা \(\bar X_n\) (বা তার standardized রূপ)-এর distribution জেনেছি। কিন্তু বাস্তব পরিসংখ্যানে আমরা প্রায়ই গড় নিজে নয়, গড়ের একটা function-এ আগ্রহী।
কেন এটা দরকার — একটা উদাহরণ। ধরুন প্রতিটি \(X_i\) একটা যন্ত্রের আয়ুষ্কাল, আর তার গড় \(\bar X_n\)। কিন্তু আমার রিপোর্টে দরকার গড় আয়ুর লগ \(\log \bar X_n\) (বা variance estimate-এর বর্গমূল \(\sqrt{\cdot}\), বা একটা rate \(1/\bar X_n\))। এখন \(\log \bar X_n\)-এর distribution কেমন? CLT তো সরাসরি বলে \(\bar X_n\)-এর কথা, \(\log \bar X_n\)-এর নয়। এখানেই Delta method (ডেল্টা পদ্ধতি) দরকার — এটি বলে দেয় smooth function \(g\) প্রয়োগ করলে \(g(\bar X_n)\)-ও approximately Normal থাকে, এবং তার approximate variance কত।
মূল অন্তর্দৃষ্টি — linearization (রৈখিকীকরণ)। LLN বলছে \(\bar X_n\) প্রায় নিশ্চয়ই \(\mu\)-এর খুব কাছে (বড় \(n\)-এ)। আর একটা smooth function \(g\) একটা ছোট অঞ্চলে প্রায় সরলরেখার মতো আচরণ করে — এটাই calculus-এর first-order Taylor approximation (প্রথম-ক্রম টেলর আসন্নতা, Part 0-এ শেখা)। অর্থাৎ \(\mu\)-এর কাছে:
যেখানে \(g'(\mu)\) হলো \(g\)-এর derivative (অন্তরজ, ঢাল) ঠিক \(\mu\) বিন্দুতে। এখন \(x\)-এর জায়গায় \(\bar X_n\) বসাই (যা \(\mu\)-এর কাছেই থাকে):
ডান পাশটা পড়ুন: \(g(\mu)\) একটা ধ্রুবক, আর \(g'(\mu)\)ও একটা ধ্রুবক (সংখ্যা)। অর্থাৎ \(g(\bar X_n)\) মোটামুটি = ধ্রুবক + (ধ্রুবক) × \((\bar X_n - \mu)\) — একটা random জিনিসের রৈখিক রূপান্তর (linear transformation)। আর আমরা জানি (2.5): Normal-এর রৈখিক রূপান্তরও Normal, শুধু গড় ও variance বদলায়। যেহেতু \((\bar X_n - \mu)\) approximately Normal (CLT), তাই \(g(\bar X_n)\)-ও approximately Normal।
variance কীভাবে বদলায়? রৈখিক রূপান্তরে ধ্রুবক-গুণক variance-এ বর্গ হয়ে ঢোকে: \(\mathrm{Var}(a + bY) = b^2\,\mathrm{Var}(Y)\)। এখানে \(b = g'(\mu)\), আর \(\mathrm{Var}(\bar X_n - \mu) = \sigma^2/n\)। তাই:
Delta method (statement)। যদি \(g\) একটি function হয় যা \(\mu\)-বিন্দুতে differentiable এবং \(g'(\mu)\neq 0\), তবে বড় \(n\)-এ
সমতুল্য standardized রূপে (CLT-র মতো করে):
প্রতিটি প্রতীক খুলে বলি:
- \(g\) — আমরা যে smooth রূপান্তর প্রয়োগ করছি (যেমন \(g(x)=\sqrt x\), বা \(g(x)=\log x\), বা \(g(x)=1/x\))।
- \(g(\mu)\) — সেই function-এর মান সত্য গড় \(\mu\)-তে; এটিই \(g(\bar X_n)\)-এর approximate কেন্দ্র।
- \(g'(\mu)\) — \(g\)-এর derivative (\(\mu\)-তে মূল্যায়িত); function-টা \(\mu\)-এর কাছে কত খাড়া, তার মাপ।
- \(\big(g'(\mu)\big)^2\) — সেই ঢালের বর্গ; রৈখিক রূপান্তরে variance-এ এভাবেই ঢোকে।
- \(\sigma^2/n\) — মূল \(\bar X_n\)-এর variance, যা ঢাল-বর্গ দিয়ে গুণ হয়ে \(g(\bar X_n)\)-এর approximate variance দেয়।
- \(\lvert g'(\mu)\rvert\) — ঢালের পরমমান (standardize করতে standard deviation লাগে, যা সর্বদা ধনাত্মক)।
এক বাক্যে Delta method: একটা smooth function-কে \(\mu\)-এর কাছে সরলরেখা ধরে নাও; তাহলে \(g(\bar X_n)\)-ও approximately Normal, যার কেন্দ্র \(g(\mu)\) আর variance মূল variance-কে ঢালের বর্গ দিয়ে গুণ। (শর্ত \(g'(\mu)\neq 0\) কেন লাগে — যখন ঢাল শূন্য, তখন first-order term মুছে যায় এবং দ্বিতীয়-ক্রম term লাগে; এই বিশেষ ক্ষেত্র ও Delta method-এর পূর্ণ প্রয়োগ §৪–৫-এ। এখানে statement ও linearization-অন্তর্দৃষ্টিই যথেষ্ট।)
কেন statistics-এ Delta method অপরিহার্য। আমরা খুব কমই কেবল কাঁচা গড় রিপোর্ট করি; প্রায়ই দরকার গড়ের রূপান্তর — odds-এর log, rate-এর reciprocal, variance-এর বর্গমূল (standard error)। Delta method এক ধাপে এদের প্রত্যেকের approximate distribution (ও তাই standard error ও confidence interval) দিয়ে দেয় — CLT-কে নতুন করে প্রমাণ না করেই। তাই এটি CLT-এর সবচেয়ে কাজের সঙ্গী, এবং Part IV-এ estimator-এর uncertainty মাপার মূল হাতিয়ার।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এবার চারটি concrete উদাহরণে (E1–E4) §২-এর ধারণাগুলো দেখি। E1 bell আকৃতি কীভাবে ফোটে তা দেখায়; E2 universality তিন source-এ; E3 sample proportion-এ CLT (confidence interval-এর প্রস্তুতি); E4 Delta method সংখ্যাসহ।
৩.১ E1 — ছক্কার যোগফল/গড়: bell আকৃতি কীভাবে ফোটে¶
একটা ন্যায্য ছক্কা (fair die) ধরি: প্রতিটি \(X_i\) সমসম্ভাব্যে \(\{1,2,3,4,5,6\}\) থেকে একটি মান নেয়। এর histogram flat (সমতল) — ছয়টি সমান দণ্ড, ঘণ্টার কোনো চিহ্ন নেই। mean ও variance (2.5-এর সূত্রে):
তাই \(\sigma=\sqrt{35/12}\approx 1.7078\)।
এখন \(n\)টি ছক্কার যোগফল \(S_n = \sum_{i=1}^n X_i\) (বা সমতুল্যভাবে গড় \(\bar X_n = S_n/n\))-এর distribution দেখি যত \(n\) বাড়াই:
- \(n=1\) (একটি ছক্কা): distribution একদম flat — ছয়টি সমান দণ্ড। কোনো bell নেই।
- \(n=2\) (দুই ছক্কার যোগ, \(S_2\in\{2,\dots,12\}\)): আর flat নয় — একটা ত্রিভুজ আকৃতি! যোগফল \(7\) সবচেয়ে সম্ভাব্য (কারণ \(7\) পাওয়ার উপায় সবচেয়ে বেশি: \(1{+}6, 2{+}5, 3{+}4, \dots\) — ছয় উপায়), আর \(2\) বা \(12\) সবচেয়ে কম (মাত্র এক উপায়)। ইতিমধ্যেই মাঝখানে উঁচু, দুপাশে নিচু।
- \(n=3\): ত্রিভুজের কোণাগুলো মসৃণ হতে শুরু করে — ঘণ্টার দিকে প্রথম ইঙ্গিত।
- \(n=5\): স্পষ্ট ঘণ্টা-আভাস; কেন্দ্র \(5\times 3.5 = 17.5\)-এর কাছে।
- \(n=30\): histogram প্রায় নিখুঁত bell — চোখে Normal থেকে আলাদা করা কঠিন।
এই ক্রমটাই CLT-এর জীবন্ত রূপ: flat (একটি ছক্কা) → ত্রিভুজ (দুই) → ক্রমে মসৃণ ঘণ্টা (অনেক)। মূল distribution flat হলেও, যথেষ্ট যোগ করলে আকৃতি Normal। (এই পাঁচটি histogram-এর ক্রমিক বিবর্তন Figure 3-4-clt-convergence।)
standardize করে মেলানো: \(n=30\)-এ যোগফলের গড় \(30\times 3.5=105\), standard deviation \(\sqrt{30}\times 1.7078\approx 9.35\)। তাই
-এর distribution বড় \(n\)-এ \(\mathcal{N}(0,1)\)-এর খুব কাছে — boxed CLT statement ঠিক যা বলে। ছোট্ট সিমুলেশনে এটা যাচাই করা যায়:
import numpy as np
rng = np.random.default_rng(0)
n, reps = 30, 100_000
mu, sigma = 3.5, np.sqrt(35/12)
# reps বার: ৩০টি ছক্কার যোগফল
S = rng.integers(1, 7, size=(reps, n)).sum(axis=1)
Z = (S - n*mu) / (np.sqrt(n) * sigma) # standardized
print(Z.mean(), Z.var()) # ≈ 0 এবং ≈ 1
# P(Z ≤ 1) তুলনা Φ(1) ≈ 0.8413-এর সাথে
print((Z <= 1).mean()) # ≈ 0.84
আউটপুট: গড় \(\approx 0\), variance \(\approx 1\), আর \(P(Z_{30}\le 1)\approx 0.84\) — যা standard Normal-এর \(\Phi(1)\approx 0.8413\)-এর সাথে মেলে। flat ছক্কা থেকে শুরু করেও standardized যোগফল \(\mathcal{N}(0,1)\)।
৩.২ E2 — তিন আলাদা source, একই \(\mathcal{N}(0,1)\) (universality)¶
এবার §২.৩-এর universality সরাসরি দেখি: তিনটে একদম আলাদা আকৃতির source নিই, প্রত্যেকটির গড়কে standardize করি, আর দেখি তিনটেই একই \(\mathcal{N}(0,1)\)-এ মেলে।
| source | আকৃতি | \(\mu\) | \(\sigma^2\) |
|---|---|---|---|
| Uniform \(U(0,1)\) | flat (সমতল আয়তক্ষেত্র) | \(0.5\) | \(1/12\approx 0.0833\) |
| Exponential (\(\lambda=1\)) | তীব্র অপ্রতিসম, ডানে লম্বা লেজ | \(1\) | \(1\) |
| Bernoulli (\(p=0.3\)) | বিচ্ছিন্ন, দুই দণ্ড (\(0\) ও \(1\)) | \(0.3\) | \(0.21\) |
লক্ষ করুন আকৃতি তিনটে যত আলাদা হতে পারে: একটা সমতল ও অবিচ্ছিন্ন, একটা তীব্রভাবে একপাশে হেলানো, একটা মাত্র দুটো মান নেয়। তবু প্রত্যেকের জন্য \(Z_n=\dfrac{\sqrt n(\bar X_n-\mu)}{\sigma}\) গণনা করে histogram আঁকলে — \(n\) মোটামুটি বড় হলে (\(n=30\)) — তিনটেই একই ঘণ্টা, \(\mathcal{N}(0,1)\)।
import numpy as np
rng = np.random.default_rng(1)
n, reps = 30, 100_000
def standardized_mean(samples, mu, sigma): # samples: (reps, n)
xbar = samples.mean(axis=1)
return np.sqrt(n) * (xbar - mu) / sigma
# তিন source
U = standardized_mean(rng.uniform(0, 1, (reps, n)), 0.5, np.sqrt(1/12))
E = standardized_mean(rng.exponential(1.0, (reps, n)), 1.0, 1.0)
B = standardized_mean(rng.binomial(1, 0.3, (reps, n)), 0.3, np.sqrt(0.21))
for name, Z in [("Uniform", U), ("Exponential", E), ("Bernoulli", B)]:
print(name, round(Z.mean(), 3), round(Z.var(), 3), round((Z <= 0).mean(), 3))
# তিনটেরই: mean ≈ 0, var ≈ 1, P(Z ≤ 0) ≈ 0.5 → সবাই N(0,1)
তিন লাইনের আউটপুটই কাছাকাছি: গড় \(\approx 0\), variance \(\approx 1\), \(P(Z\le 0)\approx 0.5\)। অর্থাৎ মূল source-এর সব স্বাতন্ত্র্য মুছে গিয়ে একটিই আকৃতি — ঠিক যা CLT-র universality দাবি করে। (একটা সতর্কতা যা §৪–৫-এ গভীর করা হবে: Exponential-এর মতো তীব্র অপ্রতিসম source-এ "যথেষ্ট বড় \(n\)" একটু বেশি লাগে — ছোট \(n\)-এ approximation দুর্বল। তিন source-কে পাশাপাশি দেখানো histogram হবে Figure 3-4-clt-sources, এবং মিল কতটা ভালো তা Figure 3-4-qq (Q–Q plot)-এ দেখা যাবে।)
৩.৩ E3 — sample proportion-এর Normal approximation (CI-এর প্রস্তুতি)¶
এখন একটা সরাসরি ব্যবহারিক ক্ষেত্র, যা §১.৩-এর জরিপ-উদাহরণের ভিত্তি। ধরুন একটা জরিপে প্রতিটি উত্তরদাতা হয় একটা প্রার্থীকে সমর্থন করে (\(X_i=1\)) নয় করে না (\(X_i=0\))। অর্থাৎ \(X_i \sim\) Bernoulli(\(p\)), যেখানে \(p\) হলো সত্য (অজানা) জনসমর্থনের হার।
এখানে sample proportion (নমুনা অনুপাত) \(\hat p_n\) আসলে sample mean-ই:
Bernoulli-র জন্য (2.3 থেকে): \(\mu = p\) এবং \(\sigma^2 = p(1-p)\)। তাই CLT সরাসরি প্রয়োগ করলে (§২.৪-এর asymptotic রূপে):
অর্থাৎ sample proportion বড় \(n\)-এ approximately Normal, কেন্দ্র সত্য হার \(p\), আর standard deviation \(\sqrt{p(1-p)/n}\)।
সংখ্যায়। ধরুন \(n=1000\) জনকে জিজ্ঞেস করা হলো, \(520\) জন সমর্থন করল — তাই \(\hat p_n = 0.52\)। তাহলে আনুমানিক standard deviation (যাকে standard error বলে):
Normal approximation-এর empirical rule (68–95–99.7, 2.4) বলে \(\hat p_n\) সত্য \(p\)-এর প্রায় \(\pm 2\) standard deviation-এর মধ্যে \(\approx 95\%\) সময় থাকে। \(2\times 0.0158 \approx 0.0316 \approx 3\%\) — ঠিক §১.৩-এর "\(52\% \pm 3\%\)"। এই "\(\pm 3\%\)" সরাসরি CLT-এর দান।
খেয়াল রাখুন এটা confidence interval-এর কঙ্কাল মাত্র — পূর্ণ নির্মাণ, ব্যাখ্যা, ও \(p\)-কে \(\hat p_n\) দিয়ে বদলানোর যুক্তি (যেখানে Slutsky/Delta-চিন্তা লাগে) Part IV-এ; এখানে শুধু দেখলাম CLT কীভাবে সরাসরি একটা margin of error-এর সংখ্যা দেয়।
৩.৪ E4 — Delta method একটি concrete \(g\)-তে: \(g(p)=\sqrt p\)¶
শেষ উদাহরণে §২.৫-এর Delta method সংখ্যাসহ চালাই। উপরের E3-এর সেটিং-ই রাখি: \(X_i\sim\) Bernoulli(\(p\)), \(\hat p_n = \bar X_n\), \(\mu = p\), \(\sigma^2 = p(1-p)\)। ধরা যাক আমরা \(\hat p_n\) নিজে নয়, তার বর্গমূল \(g(\hat p_n) = \sqrt{\hat p_n}\)-এর distribution চাই (variance-stabilizing রূপান্তর হিসেবে বর্গমূল খুব সাধারণ)।
Delta method-এর তিন ধাপ:
ধাপ ১ — function ও তার derivative। \(g(x) = \sqrt{x} = x^{1/2}\), তাই
ধাপ ২ — Delta method-এর সূত্রে বসানো। §২.৫-এর boxed সূত্রে \(g(\mu)=\sqrt p\), \(\big(g'(\mu)\big)^2 = \dfrac{1}{4p}\), \(\sigma^2 = p(1-p)\):
লক্ষণীয়: variance সরল হয়ে দাঁড়াল \(\dfrac{1-p}{4n}\) — মূল \(p(1-p)/n\) থেকে আলাদা, কারণ ঢাল-বর্গ \(\tfrac{1}{4p}\) দিয়ে গুণ হয়ে \(p\) আংশিক কাটাকুটি হলো। (এটাই "variance-stabilizing"-এর সূচনা: \(\sqrt{\cdot}\) রূপান্তরে variance-এর \(p\)-নির্ভরতা অনেকটা কমে যায়।)
ধাপ ৩ — সংখ্যায়। ধরা যাক \(p=0.36\) ও \(n=400\)। তাহলে:
তাই approximate standard deviation \(\sqrt{0.0004}=0.02\)। অর্থাৎ
ব্যাখ্যা: বড় নমুনায় \(\sqrt{\hat p_n}\)-এর মান প্রায় \(0.6\)-এর চারপাশে ঘণ্টা-আকৃতিতে ছড়ায়, সাধারণ বিচ্যুতি \(\approx 0.02\)। একটা সিমুলেশনে যাচাই:
import numpy as np
rng = np.random.default_rng(2)
p, n, reps = 0.36, 400, 200_000
phat = rng.binomial(n, p, size=reps) / n # প্রতিবার sample proportion
g_phat = np.sqrt(phat) # √p̂
print(round(g_phat.mean(), 4)) # ≈ 0.60 = √p
print(round(g_phat.std(), 4)) # ≈ 0.020 = Delta-method SD
সিমুলেশন-আউটপুট: গড় \(\approx 0.60\) ও standard deviation \(\approx 0.020\) — Delta method-এর ভবিষ্যদ্বাণীর সাথে মেলে। এক ছোট smooth function \(g\)-কে \(\mu\)-এর কাছে সরলরেখা ধরেই \(g(\bar X_n)\)-এর পুরো approximate distribution পেয়ে গেলাম, CLT নতুন করে প্রমাণ না করেই। (এই linearization-এর জ্যামিতি — \(\mu\)-তে স্পর্শক রেখা কীভাবে fluctuation-কে বহন করে — হবে Figure 3-4-delta। অন্য function যেমন \(g=\log\)-এর কেস ও Delta method-এর শর্ত-বিশ্লেষণ §৪–৫-এ।)
৪ · প্রমাণ ও উৎপাদন¶
এই অধ্যায়ের প্রাণভোমরা একটাই বাক্য — যেকোনো (যথেষ্ট-ভালো) উৎস থেকে আসা i.i.d. নমুনার গড় standardize করলে সেটা \(\mathcal{N}(0,1)\)-এর দিকে যায়: $$ Z_n \;=\; \frac{\sqrt n\,(\bar X_n - \mu)}{\sigma} \;\xrightarrow{\;d\;}\; Z \sim \mathcal{N}(0,1), \qquad\text{অর্থাৎ}\quad P(Z_n \le z) \;\xrightarrow[n\to\infty]{}\; \Phi(z)\ \ \forall z . $$ এই উপধারায় আমরা তিনটে জিনিস ধাপে ধাপে খুলব, প্রতিটার পাশে difficulty-tag বসিয়ে (★ = সরাসরি, ★★ = কিছু কৌশল লাগে, ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে, একটা ধাপ অনুমান হিসেবে নেওয়া হবে):
- (a) CLT-র প্রমাণ — moment-generating function (MGF) দিয়ে: দেখাব \(Z_n\)-এর MGF গিয়ে \(e^{t^2/2}\)-তে মেলে, যা ঠিক standard Normal-এর MGF। ★★★
- (b) কেন কেন্দ্রে \(\mu\) আর কেন স্কেল \(\sqrt n\) — 3.3-এর \(\mathrm{Var}(\bar X_n)=\sigma^2/n\)-এর সাথে জুড়ে। ★
- (c) Delta method — first-order Taylor দিয়ে \(g(\bar X_n)\)-এর asymptotic বণ্টন বের করা। ★★
এক নজরে সততা-নোট। (b) ও (c) এখানে পূর্ণাঙ্গভাবে যুক্তিসিদ্ধ — কেবল প্রাথমিক বীজগণিত, Taylor, আর 3.3-এর ভ্যারিয়েন্স-সূত্র লাগে। (a)-তে কাঠামোটা পুরো দেওয়া হবে, কিন্তু একটিমাত্র গাঁট — "MGF বিন্দু-বিন্দু মিললে বণ্টনও মেলে" (continuity theorem) — আমরা অনুমান হিসেবে নেব; তার পূর্ণ প্রমাণে characteristic function ও complex analysis লাগে, যা এই বইয়ের পরিধির বাইরে। তাই (a)-কে আমরা সৎভাবে honest sketch with one assumed step বলছি — কঙ্কাল সম্পূর্ণ, একটি গাঁট ধার করা।
৪.১ · (a) CLT-র প্রমাণ — MGF দিয়ে ★★★¶
প্রস্তুতি: MGF জিনিসটা কী, আর কেন সে এখানে আদর্শ হাতিয়ার¶
কোনো random variable \(Y\)-এর moment-generating function হলো $$ M_Y(t) \;=\; \mathbb{E}!\left[\,e^{tY}\,\right], $$ যেখানে \(t\) একটা বাস্তব সংখ্যা (আমরা ধরে নিচ্ছি \(0\)-এর চারপাশে কোনো খোলা ব্যবধানে এই প্রত্যাশা সসীম — যেমন Uniform, Exponential, Bernoulli সবার জন্য সত্য)। MGF এখানে তিনটে জাদুকরী ধর্ম-এর জন্য আদর্শ, যেগুলো ছাড়া প্রমাণ এগোয় না:
-
স্বাধীনের যোগফল → MGF-এর গুণফল। \(Y_1,\dots,Y_n\) স্বাধীন হলে $$ M_{Y_1+\cdots+Y_n}(t) = \mathbb{E}\big[e^{t\sum_i Y_i}\big] = \mathbb{E}\Big[\textstyle\prod_i e^{tY_i}\Big] \overset{\text{indep}}{=} \prod_i \mathbb{E}\big[e^{tY_i}\big] = \prod_i M_{Y_i}(t). $$ এই পদক্ষেপটাই গড়/যোগফলের সাথে MGF-কে এত মানানসই করে তোলে।
-
রৈখিক রূপান্তর। যেকোনো ধ্রুবক \(a,b\)-এর জন্য \(M_{aY+b}(t) = e^{bt}\,M_Y(at)\), কারণ \(\mathbb{E}[e^{t(aY+b)}]=e^{bt}\mathbb{E}[e^{(at)Y}]\)।
-
MGF → বণ্টন (uniqueness + continuity)। যদি দুটো চলকের MGF একটা ব্যবধানে সমান হয়, তাদের বণ্টনও সমান। আরও যা আমাদের লাগবে: যদি \(M_{Z_n}(t)\to M_Z(t)\) প্রতিটা \(t\)-এ (একটা open interval জুড়ে), তবে \(Z_n \xrightarrow{d} Z\)। এই শেষ অংশটিই (continuity theorem) আমরা অনুমান হিসেবে নিচ্ছি — এটাই (a)-র একমাত্র ধার-করা গাঁট।
আর আমাদের লক্ষ্য-MGF — standard Normal \(Z\sim \mathcal{N}(0,1)\)-এর MGF — হলো $$ M_Z(t) = \mathbb{E}[e^{tZ}] = \int_{-\infty}^{\infty} e^{tz}\,\frac{1}{\sqrt{2\pi}}e^{-z^2/2}\,dz = e^{t^2/2}. \tag{\(\star\)} $$ (এক লাইনে কেন: exponent-এ \(tz - \tfrac{z^2}{2} = -\tfrac12(z-t)^2 + \tfrac{t^2}{2}\) — "complete the square"; বাকি integral একটা shifted Normal-এর ঘনত্ব, তাই \(1\), পড়ে থাকে \(e^{t^2/2}\)।) আমাদের পুরো খাটনি এখন একটাই দাবি প্রমাণে গিয়ে দাঁড়ায়: \(M_{Z_n}(t) \to e^{t^2/2}\)।
ধাপ ১ — কেন্দ্রায়িত-মানক চলকে নামিয়ে আনা¶
হিসাব সরল রাখতে প্রথমেই i.i.d. চলকগুলোকে কেন্দ্রায়িত ও মানক (standardized) করি: $$ W_i \;:=\; \frac{X_i - \mu}{\sigma}, \qquad \text{তাহলে}\quad \mathbb{E}[W_i]=0,\ \ \mathrm{Var}(W_i)=\mathbb{E}[W_i^2]=1 . $$ এদের MGF-কে ডাকি \(m(t):=M_{W_i}(t)=\mathbb{E}[e^{tW_i}]\) (সব \(i\)-তে একই, কারণ identically distributed)। এবার \(Z_n\)-কে এই \(W_i\)-দের ভাষায় লিখি: $$ Z_n = \frac{\sqrt n(\bar X_n - \mu)}{\sigma} = \frac{\sqrt n}{\sigma}\cdot\frac{1}{n}\sum_{i=1}^n (X_i-\mu) = \frac{1}{\sqrt n}\sum_{i=1}^n \frac{X_i-\mu}{\sigma} = \frac{1}{\sqrt n}\sum_{i=1}^n W_i . $$ অর্থাৎ \(Z_n\) হলো স্বাধীন মানক চলকদের যোগফলকে \(\sqrt n\) দিয়ে ভাগ — ঠিক যে রূপে ধর্ম ১ ও ২ একসাথে খাটানো যায়।
ধাপ ২ — \(Z_n\)-এর MGF-কে \(m(t)\)-এর ভাষায় লেখা¶
প্রথমে ধর্ম ২ (রৈখিকতা, এখানে \(a=1/\sqrt n,\ b=0\)): প্রতিটা পদ \(\frac{W_i}{\sqrt n}\)-এর MGF হলো \(m\!\big(t/\sqrt n\big)\)। এরপর ধর্ম ১ (স্বাধীনের যোগফল → গুণফল), আর যেহেতু সব \(W_i\) একই বণ্টনের, \(n\)টা একই factor: $$ M_{Z_n}(t) = \mathbb{E}!\left[\exp!\Big(\tfrac{t}{\sqrt n}\textstyle\sum_i W_i\Big)\right] = \prod_{i=1}^n \mathbb{E}!\left[e^{(t/\sqrt n)\,W_i}\right] = \left[\, m!\left(\tfrac{t}{\sqrt n}\right)\right]^{\,n}. \tag{4.1} $$ এখন পুরো প্রশ্নটা একটাই হয়ে গেল: \(n\to\infty\) হলে \(\big[m(t/\sqrt n)\big]^n\) কোথায় যায়? এখানেই Taylor expansion ঢোকে।
ধাপ ৩ — \(m\)-এর Taylor expansion (\(0\)-এর চারপাশে)¶
\(m(s)=\mathbb{E}[e^{sW}]\)-কে \(s=0\)-এর চারপাশে তিন পদ পর্যন্ত খুলি। মূল সুবিধা: MGF-এর derivative-গুলো \(0\)-তে ঠিক moments দেয় (নাম থেকেই — moment-generating): $$ m(0)=\mathbb{E}[1]=1,\qquad m'(0)=\mathbb{E}[W]=0,\qquad m''(0)=\mathbb{E}[W^2]=1 . $$ (কেন: \(m'(s)=\mathbb{E}[W e^{sW}]\), তাই \(m'(0)=\mathbb{E}[W]\); আবার \(m''(s)=\mathbb{E}[W^2 e^{sW}]\), তাই \(m''(0)=\mathbb{E}[W^2]\) — প্রত্যাশা ও derivative অদলবদলের বৈধতা ওই "\(0\)-র কাছে MGF সসীম" শর্ত থেকে আসে।) সুতরাং Taylor (Peano remainder-সহ): $$ m(s) \;=\; 1 + \underbrace{m'(0)}{0}\,s + \tfrac12\,\underbrace{m''(0)}\,s^2 + o(s^2) \;=\; 1 + \tfrac{s^2}{2} + o(s^2)\qquad (s\to 0). \tag{4.2} $$ এখানে \(o(s^2)\) মানে এমন একটা অবশিষ্ট যে \(s\to 0\) হলে তা \(s^2\)-এর তুলনায় উপেক্ষ্য, অর্থাৎ \(o(s^2)/s^2 \to 0\)। এই "\(0+0+\tfrac{s^2}{2}\)" রূপটাই — first moment শূন্য, second moment এক — শেষমেশ \(e^{t^2/2}\)-এর জন্ম দেবে।
ধাপ ৪ — (4.2)-কে (4.1)-এ বসানো, তারপর \(n\)-তম ঘাত নেওয়া¶
(4.1)-এ \(s=t/\sqrt n\) বসাই; \(n\) বড় হলে \(s\to 0\), তাই (4.2) খাটে: $$ m!\left(\frac{t}{\sqrt n}\right) = 1 + \frac12\left(\frac{t}{\sqrt n}\right)^{!2} + o!\left(\frac{1}{n}\right) = 1 + \frac{t^2}{2n} + o!\left(\frac{1}{n}\right). $$ সুতরাং $$ M_{Z_n}(t) = \left[\, m!\left(\tfrac{t}{\sqrt n}\right)\right]^{n} = \left[\, 1 + \frac{t^2/2}{n} + o!\left(\frac1n\right)\right]^{\,n}. \tag{4.3} $$ এই রূপটা ভয়ানক চেনা — \(\big(1+\tfrac{c}{n}\big)^n\) ধরনের, যা \(e^{c}\)-তে যায়। নিচে সেটাই আঁটঘাট করে দেখাই।
ধাপ ৫ — সীমা: \(\big(1+\tfrac{c}{n}+o(\tfrac1n)\big)^n \to e^{c}\), এখানে \(c=\tfrac{t^2}{2}\) (সততার মূল গাঁট এখানে)¶
স্থির \(t\) ধরো, লিখি \(a_n := \dfrac{t^2/2}{n} + o\!\left(\dfrac1n\right)\) — অর্থাৎ \(n\,a_n \to \tfrac{t^2}{2}\)। লগারিদম নিই (যেহেতু বড় \(n\)-এ \(1+a_n>0\)): $$ \ln M_{Z_n}(t) = n\,\ln(1+a_n). $$ এবার \(\ln(1+a_n)\)-কে খুলি। যেহেতু \(a_n\to 0\), আমরা জানি \(\ln(1+a)=a - \tfrac{a^2}{2}+\cdots = a + O(a^2)\), তাই $$ n\,\ln(1+a_n) = n\Big(a_n + O(a_n^2)\Big) = \underbrace{n\,a_n}{\to\, t^2/2} + \underbrace{n\cdot O(a_n^2)}. $$ শেষ পদটা শূন্যে যায় কারণ \(a_n = O(1/n)\), তাই \(a_n^2=O(1/n^2)\), আর \(n\cdot O(1/n^2)=O(1/n)\to 0\)। সুতরাং $$ \ln M_{Z_n}(t) \xrightarrow[n\to\infty]{} \frac{t^2}{2} \qquad\Longrightarrow\qquad M_{Z_n}(t) \xrightarrow[n\to\infty]{} e^{t^2/2}. \tag{4.4} $$
ধাপ ৬ — উপসংহার (এখানেই অনুমানটা ব্যবহার করি)¶
(4.4) বলে: প্রতিটা \(t\)-এ \(Z_n\)-এর MGF গিয়ে মেলে \(e^{t^2/2}\)-তে, যা (\(\star\)) অনুসারে ঠিক \(\mathcal{N}(0,1)\)-এর MGF। এবার continuity theorem (প্রস্তুতির ধর্ম ৩, যা আমরা অনুমান হিসেবে নিয়েছি) প্রয়োগ করি — MGF বিন্দু-বিন্দু মিললে বণ্টনও মেলে — তাই $$ Z_n = \frac{\sqrt n(\bar X_n - \mu)}{\sigma} \;\xrightarrow{\;d\;}\; \mathcal{N}(0,1). \qquad \blacksquare\ (\text{honest sketch}) $$
স্কেচ কোথায়, পূর্ণ কোথায়? ধাপ ১–৫ সম্পূর্ণ ও প্রাথমিক — শুধু রৈখিকতা, স্বাধীনতা, Taylor আর \(\ln(1+a)\)-র প্রসারণ লেগেছে, কোনো ফাঁক নেই। একমাত্র ধার-করা ধাপ হলো ধাপ ৬-এর continuity theorem ("\(M_{Z_n}\to M_Z\) পয়েন্টওয়াইজ \(\Rightarrow Z_n\xrightarrow{d}Z\)")। এর পূর্ণ প্রমাণে MGF-এর বদলে characteristic function \(\varphi_Y(t)=\mathbb{E}[e^{itY}]\) ব্যবহার করতে হয় (কারণ characteristic function সবসময়ই বিদ্যমান, MGF নয়) এবং Lévy-র continuity theorem + Fourier inversion লাগে — তা একটা পূর্ণ measure-theoretic probability কোর্সের বিষয়। তাই এটিকে ★★★ ট্যাগ দিলাম: কাঠামো পুরো বুঝে নাও, ওই একটি গাঁট পরে শক্ত হবে।
MGF বনাম characteristic function — এক বাক্যে। যদি কোনো উৎসের MGF \(0\)-র কাছে নাই-ই থাকে (যেমন ভারী-লেজি Cauchy, যার এমনকি \(\mu\)-ই নেই), উপরের প্রমাণ অচল — কিন্তু characteristic function দিয়ে হুবহু একই ছয় ধাপ চলে, শুধু \(e^{tW}\)-র জায়গায় \(e^{itW}\) আর \(e^{t^2/2}\)-র জায়গায় \(e^{-t^2/2}\)। ধারণাটা অভিন্ন; শুধু যন্ত্রটা বেশি টেকসই।
running examples-এ এক ঝলক¶
- E1 (dice-sum). একটা ছক্কার ফলাফল \(X_i\in\{1,\dots,6\}\), যেখানে \(\mu=3.5\), \(\sigma^2=\tfrac{35}{12}\)। \(n\)টা ছক্কার যোগফল \(S_n=\sum X_i\); standardize করলে \(Z_n=(S_n - 3.5n)/\sqrt{35n/12}\)। উপরের প্রমাণ বলে \(Z_n\xrightarrow{d}\mathcal{N}(0,1)\) — তাই বহু-ছক্কার যোগফলের histogram ঘণ্টা-আকৃতি নেয় (§৫-এও আমরা একই ছবি skewed উৎসে দেখব)।
- E2 (Uniform/Exponential/Bernoulli). তিনটেরই MGF \(0\)-র কাছে বিদ্যমান, তাই উপরের ছয় ধাপ অক্ষরে অক্ষরে খাটে — উৎস যত আলাদাই হোক, গন্তব্য একই \(\mathcal{N}(0,1)\)। এটাই CLT-র universality: প্রমাণে উৎসের একমাত্র যে দুটো তথ্য ঢুকেছে তা হলো \(m'(0)=0\) ও \(m''(0)=1\) — অর্থাৎ শুধু প্রথম দুই moment; আকৃতির বাকি সব বিবরণ \(o(s^2)\)-তে চাপা পড়ে মুছে যায়।
৪.২ · (b) কেন কেন্দ্রে \(\mu\), আর কেন স্কেল \(\sqrt n\) ★¶
CLT-র বিবৃতিতে দুটো "কেন" প্রায়ই খটকা লাগে: (i) কেন \(\bar X_n\) থেকে \(\mu\) বিয়োগ করি, আর (ii) কেন গুণ করি ঠিক \(\sqrt n\) দিয়ে — \(n\) নয়, \(n^{1/3}\) নয়। দুটোরই উত্তর আসে সরাসরি 3.3-এ পাওয়া দুটো তথ্য থেকে: $$ \mathbb{E}[\bar X_n] = \mu, \qquad \mathrm{Var}(\bar X_n) = \frac{\sigma^2}{n}. \tag{3.3} $$ (মনে করিয়ে দিই — \(\mathbb{E}[\bar X_n]=\tfrac1n\sum\mathbb{E}[X_i]=\mu\); আর স্বাধীনতার দরুন \(\mathrm{Var}(\bar X_n)=\tfrac{1}{n^2}\sum\mathrm{Var}(X_i)=\tfrac{n\sigma^2}{n^2}=\tfrac{\sigma^2}{n}\)।)
কেন \(\mu\) বিয়োগ (কেন্দ্রায়ন)। যেকোনো সার্থক limiting বণ্টনের একটা স্থির কেন্দ্র দরকার। কিন্তু \(\bar X_n\)-এর কেন্দ্র \(\mathbb{E}[\bar X_n]=\mu\) — সেটা নিজেই \(n\)-নিরপেক্ষ একটা সংখ্যা, যা সরে যায় না, শুধু ছড়ানো কমে। তাই \(\bar X_n - \mu\) নিলে আমরা চলকটিকে শূন্যকেন্দ্রিক করি; এখন এর গড় ঠিক \(0\), যা \(\mathcal{N}(0,1)\)-এর কেন্দ্রের সাথে মেলে। কেন্দ্রায়ন না করলে রাশিটা \(\mu\)-তে গিয়ে জমে (LLN), কোনো ঘণ্টা-আকৃতি ফুটত না।
কেন ভাগ \(\sigma\) দিয়ে (মানকীকরণ)। \(\bar X_n - \mu\)-এর variance (ভ্যারিয়েন্স) (3.3) থেকে \(\sigma^2/n\)। একে \(\sigma\) দিয়ে ভাগ করলে ভ্যারিয়েন্স হয় \(\tfrac{1}{\sigma^2}\cdot\tfrac{\sigma^2}{n}=\tfrac1n\) — উৎসের নিজস্ব scale (\(\sigma\)) সরে গিয়ে একটা সর্বজনীন রাশি পড়ে থাকে, যা শুধু \(n\)-এর উপর নির্ভর করে। তাই গন্তব্য \(\mathcal{N}(0,1)\) — উৎস-নিরপেক্ষ একটাই বণ্টন।
কেন গুণ ঠিক \(\sqrt n\) (স্কেলিং — এটাই আসল রহস্য)। এবার চলক \(\bar X_n - \mu\), যার \(\mathrm{Var}=\sigma^2/n\), আর আমরা একে \(n^\alpha\) দিয়ে গুণ করব; দেখি কোন \(\alpha\) "ঠিক" ফল দেয়। গুণনে ভ্যারিয়েন্স \(n^{2\alpha}\) গুণ হয় (ধর্ম: \(\mathrm{Var}(cY)=c^2\mathrm{Var}(Y)\)): $$ \mathrm{Var}!\big(n^{\alpha}(\bar X_n - \mu)\big) = n^{2\alpha}\cdot \frac{\sigma^2}{n} = \sigma^2\, n^{2\alpha-1}. \tag{4.5} $$ এখন তিনটে সম্ভাবনা ওজন করি — limiting বণ্টন নন-ট্রিভিয়াল (না শূন্যে চুপসে, না অসীমে বিস্ফোরিত) হতে গেলে এই ভ্যারিয়েন্সকে একটা স্থির, ধনাত্মক সংখ্যায় থিতু হতে হবে:
| স্কেল \(n^\alpha\) | (4.5)-এর ভ্যারিয়েন্স | \(n\to\infty\)-এ আচরণ | ফলাফল |
|---|---|---|---|
| খুব ছোট, \(\alpha<\tfrac12\) | \(\sigma^2 n^{2\alpha-1}\to 0\) | ছড়ানো মুছে যায় | চলক \(0\)-তে চুপসে যায় (degenerate) — কোনো আকৃতি নেই |
| খুব বড়, \(\alpha>\tfrac12\) | \(\sigma^2 n^{2\alpha-1}\to \infty\) | ছড়ানো বিস্ফোরিত | বণ্টন অসীমে ছিটকে যায় — কোনো সীমা নেই |
| ঠিক \(\alpha=\tfrac12\) | \(\sigma^2 n^{0}=\sigma^2\) | স্থির | একমাত্র "ঠিক" স্কেল |
অর্থাৎ \(\alpha=\tfrac12\), তথা গুণক \(\sqrt n\), হলো সেই একমাত্র হার যাতে ভ্যারিয়েন্স \(n\)-এর সাথে না বাড়ে না কমে — একটা স্থির \(\sigma^2\)-এ দাঁড়ায়। (এরপর \(\sigma\) দিয়ে ভাগ করলে সেটা ঠিক \(1\), \(\mathcal{N}(0,1)\)-এর ভ্যারিয়েন্স।) এক বাক্যে: \(\bar X_n\)-এর ছড়ানো \(1/\sqrt n\) হারে কমে, তাই ছড়ানোটাকে আবার দৃশ্যমান করতে হলে ঠিক \(\sqrt n\) দিয়েই বড় করতে হয় — এই দুই হার একে অপরকে হুবহু কাটে। \(\;\blacksquare\)
স্বজ্ঞা — একই কথা ছবিতে। \(\bar X_n\)-এর histogram \(\mu\)-র চারপাশে \(\propto 1/\sqrt n\) চওড়া। \(n\) চারগুণ করলে চওড়া অর্ধেক। \(\sqrt n\) দিয়ে গুণ মানে microscope-এর zoom ঠিক ওই হারে বাড়ানো — তাই যত বড় \(n\), তত বেশি zoom, আর প্রতিবার একই আকারের ঘণ্টা চোখে পড়ে। কম zoom (ছোট \(\alpha\)) করলে সব এক বিন্দুতে; বেশি zoom (বড় \(\alpha\)) করলে কিছুই ফ্রেমে আঁটে না।
৪.৩ · (c) Delta method — first-order Taylor দিয়ে ★★¶
প্রশ্নটা কী। CLT আমাদের দেয় \(\bar X_n\)-এর asymptotic বণ্টন। কিন্তু বাস্তবে আমরা প্রায়ই \(\bar X_n\) নয়, তার একটা function (অপেক্ষক) \(g(\bar X_n)\)-এর বণ্টন চাই — যেমন গড়ের লগারিদম, গড়ের বর্গ, কিংবা proportion থেকে odds। Delta method ঠিক এই প্রশ্নের উত্তর: যদি \(\sqrt n(\bar X_n-\mu)\xrightarrow{d}\mathcal{N}(0,\sigma^2)\) হয় আর \(g\) মসৃণ (differentiable) হয়, তবে $$ \sqrt n\,\big(g(\bar X_n)-g(\mu)\big) \;\xrightarrow{\;d\;}\; N!\big(0,\; g'(\mu)^2\,\sigma^2\big). \tag{Delta} $$
মূল ধারণা — আগে অনুভব। \(n\) বড় হলে \(\bar X_n\) প্রায় নিশ্চিতভাবে \(\mu\)-এর খুব কাছে থাকে (LLN, 3.3)। তাই \(g\)-কে আমরা কেবল \(\mu\)-এর একদম পাশের এক টুকরোতেই দেখি — আর মসৃণ যেকোনো অপেক্ষক ছোট পরিসরে প্রায় সরলরেখা (তার tangent)। সরলরেখা random variable-এর আকৃতি বদলায় না, শুধু scale করে — তাই \(\bar X_n\)-এর Normal আকৃতি \(g\)-র ভিতর দিয়ে গিয়েও Normal-ই থাকে, কেবল ভ্যারিয়েন্স \(g'(\mu)^2\) গুণে বদলায়।
ধাপ ১ — \(g\)-কে \(\mu\)-এর চারপাশে first-order Taylor-এ খোলা¶
\(g\) যদি \(\mu\)-তে differentiable হয়, তবে Taylor-এর first-order রূপ (Lagrange/Peano remainder সহ): \(\bar X_n\)-এর মান \(x\)-এ $$ g(x) = g(\mu) + g'(\mu)\,(x-\mu) + R(x), \qquad \text{যেখানে}\ \ \frac{R(x)}{x-\mu}\to 0\ \ \text{যখন}\ x\to\mu. \tag{4.6} $$ অর্থাৎ অবশিষ্ট \(R(x)\) হলো \((x-\mu)\)-এর তুলনায় উচ্চতর-ক্রম ক্ষুদ্র — চলক \(\mu\)-এর যত কাছে, \(R\) তত নগণ্য। এবার \(x=\bar X_n\) বসাই: $$ g(\bar X_n) = g(\mu) + g'(\mu)\,(\bar X_n-\mu) + R(\bar X_n). \tag{4.7} $$
ধাপ ২ — \(g(\mu)\) সরিয়ে \(\sqrt n\) দিয়ে গুণ¶
(4.7) থেকে \(g(\mu)\) বিয়োগ করে \(\sqrt n\) দিয়ে গুণ করি (ঠিক CLT-র মতো কেন্দ্রায়ন + স্কেলিং): $$ \sqrt n\,\big(g(\bar X_n)-g(\mu)\big) = g'(\mu)\cdot \underbrace{\sqrt n\,(\bar X_n-\mu)}{=:\,U_n} \;+\; \underbrace{\sqrt n\,R(\bar X_n)} $$ ডানপাশটা দুই টুকরো: একটা পরিচিত মূল পদ }. \tag{4.8\(g'(\mu)\,U_n\), আর একটা অবশিষ্ট পদ \(V_n\)। কৌশল হলো — মূল পদ থেকে উত্তর বেরোয়, আর \(V_n\) "মিলিয়ে যায়"।
ধাপ ৩ — মূল পদ: CLT সরাসরি লাগাই¶
ভিতরের \(U_n=\sqrt n(\bar X_n-\mu)\) ঠিক সেই রাশি যার সীমা CLT দেয়: $$ U_n \xrightarrow{\;d\;} \mathcal{N}(0,\sigma^2)\qquad(\text{4.1-এর CLT, কারণ }Z_n=U_n/\sigma). $$ এবার ধ্রুবক \(g'(\mu)\) দিয়ে গুণ। একটা Normal-কে ধ্রুবক \(c\) দিয়ে গুণলে আবার Normal পাই, ভ্যারিয়েন্স \(c^2\) গুণ হয় (\(\mathrm{Var}(cU)=c^2\mathrm{Var}(U)\) — এবং সীমা-বণ্টনের ক্ষেত্রে এটা বৈধ কারণ \(u\mapsto c u\) একটা continuous map): $$ g'(\mu)\,U_n \xrightarrow{\;d\;} g'(\mu)\cdot \mathcal{N}(0,\sigma^2) = N!\big(0,\,g'(\mu)^2\sigma^2\big). \tag{4.9} $$ উত্তরের কঙ্কাল এখানেই তৈরি; এখন কেবল দেখাতে হবে \(V_n\) এটা নষ্ট করে না।
ধাপ ৪ — অবশিষ্ট পদ \(V_n\) মিলিয়ে যায় (এখানে একটু কৌশল — ★★-র কারণ)¶
দাবি: \(V_n = \sqrt n\,R(\bar X_n) \xrightarrow{P} 0\)। যুক্তিটা দুই অংশ:
(ক) \(\bar X_n - \mu\) ছোট। LLN (3.3) বলে \(\bar X_n \xrightarrow{P}\mu\), অর্থাৎ \(\bar X_n-\mu\xrightarrow{P}0\)। আরও সূক্ষ্মভাবে, CLT বলে \(\sqrt n(\bar X_n-\mu)=U_n\) একটা সীমাবদ্ধ (stochastically bounded, \(O_P(1)\)) রাশি — অসীমে ছিটকে যায় না।
(খ) \(R\) আরও দ্রুত ছোট। (4.6) অনুসারে \(R(\bar X_n)=(\bar X_n-\mu)\cdot \varepsilon(\bar X_n)\), যেখানে \(\bar X_n\to\mu\) হলে \(\varepsilon(\bar X_n)\to 0\)। তাই $$ V_n = \sqrt n\,R(\bar X_n) = \underbrace{\sqrt n\,(\bar X_n-\mu)}{U_n\,=\,O_P(1)} \cdot \underbrace{\varepsilon(\bar X_n)}\; 0 . $$ অর্থাৎ "সীমাবদ্ধ × শূন্যে-যাওয়া = শূন্যে-যাওয়া" — }\,0} \;\xrightarrow{P\(V_n\) অদৃশ্য হয়ে যায়। (এই ধাপে "\(O_P(1)\times o_P(1)=o_P(1)\)" নিয়মটি ও Slutsky-র উপপাদ্য ব্যবহার হলো — এদের পূর্ণ বিবৃতি 3.3-এ; এখানে স্বজ্ঞাগতভাবে নিচ্ছি, তাই ★★।)
ধাপ ৫ — দুই টুকরো জোড়া (Slutsky) ও উপসংহার¶
(4.8)-এ ডানপাশ = \(g'(\mu)U_n + V_n\), যেখানে \(g'(\mu)U_n \xrightarrow{d} \mathcal{N}(0,g'(\mu)^2\sigma^2)\) আর \(V_n\xrightarrow{P}0\)। Slutsky-র উপপাদ্য (3.3) বলে — converging-in-distribution রাশির সাথে converging-in-probability-to-constant রাশি যোগ করলে যোগফলও একই বণ্টনে যায় (ধ্রুবক \(0\) যোগে বণ্টন বদলায় না)। তাই $$ \sqrt n\,\big(g(\bar X_n)-g(\mu)\big) \;\xrightarrow{\;d\;}\; N!\big(0,\; g'(\mu)^2\,\sigma^2\big). \qquad \blacksquare $$
এক বাক্যে মন্ত্র। "Variance multiplies by \(g'(\mu)^2\)." — Delta method মানে শুধু এই: তোমার কাছে \(\bar X_n\)-এর asymptotic ভ্যারিয়েন্স \(\sigma^2/n\) আছে; \(g(\bar X_n)\)-এর asymptotic ভ্যারিয়েন্স হবে ঠিক \(g'(\mu)^2\) গুণ, অর্থাৎ \(g'(\mu)^2\sigma^2/n\)।
সতর্কতা — \(g'(\mu)=0\) হলে। তখন (Delta)-র limiting ভ্যারিয়েন্স \(0\) — first-order পদ মুছে যায়, আর আসল ওঠানামা আসে second-order (\(\tfrac12 g''(\mu)(\bar X_n-\mu)^2\)) পদ থেকে। তখন সঠিক স্কেল \(\sqrt n\) নয়, \(n\), আর সীমা Normal নয়, \(\chi^2\)-ঘেঁষা — একে বলে second-order delta method। এই বইয়ে আমরা সাধারণ \(g'(\mu)\ne 0\) ক্ষেত্রেই থাকব।
running examples-এ Delta method (E3 ও E4)¶
- E3 (sample proportion). \(X_i\sim\text{Bernoulli}(p)\), তাই \(\hat p=\bar X_n\), \(\mu=p\), \(\sigma^2=p(1-p)\)। সরাসরি CLT: \(\sqrt n(\hat p-p)\xrightarrow{d}N\big(0,\,p(1-p)\big)\)। এবার Delta দিয়ে log-odds \(g(p)=\ln\frac{p}{1-p}\)-এর বণ্টন চাইলে: \(g'(p)=\frac{1}{p(1-p)}\), তাই $$ \sqrt n\Big(\ln\tfrac{\hat p}{1-\hat p}-\ln\tfrac{p}{1-p}\Big)\xrightarrow{d}N!\Big(0,\ \underbrace{\tfrac{1}{p^2(1-p)^2}}{g'(p)^2}\cdot \underbrace{p(1-p)}\Big). $$ পরিসংখ্যানে logistic regression-এর standard error ঠিক এখান থেকেই আসে।}\Big)=N!\Big(0,\ \tfrac{1}{p(1-p)
- E4 (delta method, মূল চলমান উদাহরণ). ধরো উৎস Exponential, \(\mu=1\), \(\sigma^2=1\), আর আমরা \(g(\bar X_n)\) চাই।
- \(g(x)=\ln x\): \(g'(1)=1/1=1\), তাই asymptotic ভ্যারিয়েন্স \(=1^2\cdot 1=1\) → \(\sqrt n(\ln\bar X_n - 0)\xrightarrow{d}\mathcal{N}(0,1)\)।
- \(g(x)=x^2\): \(g'(1)=2\cdot 1=2\), তাই ভ্যারিয়েন্স \(=2^2\cdot 1=4\) → \(\sqrt n(\bar X_n^2-1)\xrightarrow{d}\mathcal{N}(0,4)\)।
এই দুই সংখ্যা (\(1\) ও \(4\)) আমরা §৫-এ সিমুলেশনে হুবহু যাচাই করব — কাগজ ও কম্পিউটার একই উত্তর দেবে।
৪.৪ · সারমর্ম: কোনটা পূর্ণ, কোনটা ধার-করা গাঁট¶
| ফল | difficulty | অবস্থা | মূল যন্ত্র |
|---|---|---|---|
| (a) CLT (MGF \(\to e^{t^2/2}\)) | ★★★ | honest sketch — ১টি গাঁট (continuity theorem) ধার-করা | MGF গুণফল-সূত্র, Taylor, \((1+\tfrac cn)^n\to e^c\) |
| (b) কেন্দ্র \(\mu\) ও স্কেল \(\sqrt n\) | ★ | সম্পূর্ণ যুক্তি | \(\mathrm{Var}(\bar X_n)=\sigma^2/n\) (3.3) |
| (c) Delta method | ★★ | সম্পূর্ণ (Slutsky/\(O_P\) 3.3-থেকে ধার) | first-order Taylor + CLT + Slutsky |
মূল ছবি: (a) CLT-র ইঞ্জিন — Taylor-এ প্রথম দুই moment (\(0,1\)) ছাড়া সব মুছে যাওয়ায় উৎস-নিরপেক্ষ \(\mathcal{N}(0,1)\) জন্মায়; (b) \(\sqrt n\) হলো সেই একমাত্র স্কেল যা \(\bar X_n\)-এর \(1/\sqrt n\)-ছড়ানোকে ঠিক কাটে; (c) মসৃণ \(g\)-র ভিতর দিয়ে গেলে Normal আকৃতি টেকে, শুধু ভ্যারিয়েন্স \(g'(\mu)^2\) গুণ হয়। পরের §৫-এ আমরা এই তিনটেই সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর তিনটে দাবিকে আমরা সিমুলেশনে যাচাই করব — যাতে CLT ও Delta method কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে।
আমরা চারটে জিনিস মাপব:
- Part 1 — skewed উৎসে CLT যত \(n\) বাড়ে। \(X_i\sim\text{Exponential}(1)\) (ভয়ানক ডান-বাঁকা, skewness \(=2\))। \(Z_n=\sqrt n(\bar X_n-\mu)/\sigma\) standardize করে দেখব এর histogram/CDF ক্রমশ \(N(0,1)\)-এ বসে; পরিমাপ হিসেবে \(Z_n\)-এর skewness (\(\to 0\)) আর \(\sup_x\lvert F_n(x)-\Phi(x)\rvert\) (\(\to 0\))।
- Part 2 — তিনটে আলাদা উৎসে CLT (E2)। Uniform, Exponential, Bernoulli — তিনটেই standardize-এর পর \(N(0,1)\)-এ যায় কিনা (universality)।
- Part 3 — Delta method ভ্যারিয়েন্স যাচাই (E4)। Exponential উৎসে \(g(x)=\ln x\) ও \(g(x)=x^2\)-এর জন্য \(\sqrt n(g(\bar X_n)-g(\mu))\)-এর empirical ভ্যারিয়েন্স তত্ত্বের \(g'(\mu)^2\sigma^2\) (\(=1\) ও \(4\))-এর সাথে মেলে কিনা।
- Part 4 — sample proportion (E3)। \(\hat p=\bar X_n\) Bernoulli থেকে; standardize করে CLT, আর \(\mathrm{Var}(\hat p)=p(1-p)/n\) যাচাই।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 3.4 — Central Limit Theorem & Delta Method : Code Lab
# Numerically illustrates: (1) CLT for a skewed source as n grows,
# (2) CLT across 3 different sources,
# (3) Delta-method asymptotic variance.
import numpy as np
from math import erf
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => reproducible
# Standard-normal CDF Phi via erf (no scipy dependency).
def Phi(x):
x = np.asarray(x, dtype=float)
return 0.5 * (1.0 + np.vectorize(lambda t: erf(t / np.sqrt(2.0)))(x))
# Kolmogorov-Smirnov style distance: sup_x |F_n(x) - Phi(x)| on a grid.
def sup_cdf_gap(Z, grid):
Zs = np.sort(Z)
F_emp = np.searchsorted(Zs, grid, side="right") / Z.size
return np.max(np.abs(F_emp - Phi(grid)))
GRID = np.linspace(-4.0, 4.0, 161)
# ===============================================================
# PART 1 — CLT for a SKEWED source (Exponential) as n grows.
# X_i ~ Exp(rate=1): mu = 1, sigma = 1, but heavily right-skewed.
# Z_n = sqrt(n)*(Xbar_n - mu)/sigma should approach N(0,1).
# ===============================================================
print("=== PART 1 CLT for skewed source X_i ~ Exponential(1) ===")
print(" mu = 1, sigma = 1, skewness = 2 (right-skewed)")
print(f"{'n':>6} {'mean(Z_n)':>10} {'var(Z_n)':>9} {'skew(Z_n)':>10} {'sup|Fn-Phi|':>12}")
REP = 200_000
mu_exp, sd_exp = 1.0, 1.0
for n in [1, 2, 5, 30, 100]:
X = rng.exponential(scale=1.0, size=(REP, n)) # mean = scale = 1
Xbar = X.mean(axis=1)
Zn = np.sqrt(n) * (Xbar - mu_exp) / sd_exp
m, v = Zn.mean(), Zn.var()
sk = np.mean(((Zn - m) / np.sqrt(v)) ** 3) # sample skewness
print(f"{n:>6} {m:>10.4f} {v:>9.4f} {sk:>10.4f} {sup_cdf_gap(Zn, GRID):>12.5f}")
print(" note: theoretical skew(Z_n) = 2/sqrt(n) -> 0; sup-gap -> 0 confirms CLT")
# ===============================================================
# PART 2 — CLT for THREE different sources at a fixed n.
# Uniform(0,1), Exponential(1), Bernoulli(0.3). All -> N(0,1).
# ===============================================================
print("\n=== PART 2 CLT for THREE sources (standardized, n = 50) ===")
n = 50
sources = {
"Uniform(0,1)": (lambda size: rng.random(size), 0.5, np.sqrt(1/12)),
"Exponential(1)": (lambda size: rng.exponential(1.0, size), 1.0, 1.0),
"Bernoulli(0.3)": (lambda size: (rng.random(size) < 0.3)*1.0, 0.3, np.sqrt(0.3*0.7)),
}
print(f"{'source':>16} {'mean(Z_n)':>10} {'var(Z_n)':>9} {'sup|Fn-Phi|':>12}")
for name, (draw, mu_s, sd_s) in sources.items():
X = draw((REP, n))
Zn = np.sqrt(n) * (X.mean(axis=1) - mu_s) / sd_s
print(f"{name:>16} {Zn.mean():>10.4f} {Zn.var():>9.4f} {sup_cdf_gap(Zn, GRID):>12.5f}")
print(" all three sup-gaps are small => CLT is source-agnostic (universality)")
# ===============================================================
# PART 3 — DELTA METHOD variance check.
# Source: Exponential(1), so mu = 1, sigma^2 = 1.
# g(x) = log(x): g'(x) = 1/x, g'(mu) = 1.
# => sqrt(n)(g(Xbar) - g(mu)) -> N(0, g'(mu)^2 * sigma^2) = N(0, 1).
# g(x) = x^2 : g'(x) = 2x, g'(mu) = 2.
# => asymptotic variance = (2)^2 * 1 = 4.
# ===============================================================
print("\n=== PART 3 Delta method: Var of sqrt(n)*(g(Xbar)-g(mu)) ===")
print(" source Exponential(1): mu = 1, sigma^2 = 1")
n = 500
REP3 = 300_000
Xbar = rng.exponential(1.0, size=(REP3, n)).mean(axis=1)
for gname, g, gprime_mu in [("g(x)=log x", np.log, 1.0),
("g(x)=x^2", lambda x: x**2, 2.0)]:
T = np.sqrt(n) * (g(Xbar) - g(mu_exp)) # g(mu)=log1=0 or 1^2=1
emp_var = T.var()
theory = (gprime_mu ** 2) * (sd_exp ** 2)
print(f" {gname:>12}: empirical Var = {emp_var:7.4f} theory g'(mu)^2*sigma^2 = {theory:6.4f}")
print(" empirical variances match the delta-method prediction")
# ===============================================================
# PART 4 — Sample PROPORTION (E3) as a special CLT/Delta case.
# X_i ~ Bernoulli(p): phat = Xbar, sqrt(n)(phat - p) -> N(0, p(1-p)).
# ===============================================================
print("\n=== PART 4 Sample proportion phat, p = 0.3, n = 200 ===")
p = 0.3
n = 200
phat = (rng.random((REP, n)) < p).mean(axis=1)
Zn = (phat - p) / np.sqrt(p * (1 - p) / n)
print(f" mean(Z_n) = {Zn.mean():.4f}, var(Z_n) = {Zn.var():.4f}, "
f"sup|Fn-Phi| = {sup_cdf_gap(Zn, GRID):.5f}")
print(f" theory Var(phat) = p(1-p)/n = {p*(1-p)/n:.6f}, empirical = {phat.var():.6f}")
৫.২ · বাস্তব আউটপুট¶
উপরের স্ক্রিপ্ট চালালে (seed 20260619, numpy 2.2.6) ঠিক নিচের আউটপুট আসে — এগুলো সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয় (দুবার চালালেও হুবহু এক, কারণ seed স্থির):
=== PART 1 CLT for skewed source X_i ~ Exponential(1) ===
mu = 1, sigma = 1, skewness = 2 (right-skewed)
n mean(Z_n) var(Z_n) skew(Z_n) sup|Fn-Phi|
1 0.0014 1.0042 2.0155 0.15866
2 0.0032 0.9959 1.3903 0.09201
5 -0.0010 1.0016 0.8898 0.06134
30 -0.0010 0.9986 0.3583 0.02494
100 0.0012 0.9992 0.1918 0.01344
note: theoretical skew(Z_n) = 2/sqrt(n) -> 0; sup-gap -> 0 confirms CLT
=== PART 2 CLT for THREE sources (standardized, n = 50) ===
source mean(Z_n) var(Z_n) sup|Fn-Phi|
Uniform(0,1) 0.0033 1.0017 0.00179
Exponential(1) -0.0035 0.9973 0.02010
Bernoulli(0.3) 0.0002 0.9975 0.06919
all three sup-gaps are small => CLT is source-agnostic (universality)
=== PART 3 Delta method: Var of sqrt(n)*(g(Xbar)-g(mu)) ===
source Exponential(1): mu = 1, sigma^2 = 1
g(x)=log x: empirical Var = 1.0024 theory g'(mu)^2*sigma^2 = 1.0000
g(x)=x^2: empirical Var = 4.0268 theory g'(mu)^2*sigma^2 = 4.0000
empirical variances match the delta-method prediction
=== PART 4 Sample proportion phat, p = 0.3, n = 200 ===
mean(Z_n) = 0.0018, var(Z_n) = 0.9994, sup|Fn-Phi| = 0.03456
theory Var(phat) = p(1-p)/n = 0.001050, empirical = 0.001049
৫.৩ · আউটপুট কীভাবে পড়ব — দাবি মিলিয়ে দেখা¶
- Part 1 — skewed উৎসে CLT (§৪.১)। এটাই অধ্যায়ের প্রধান দাবির সরাসরি সাক্ষ্য। উৎস Exponential ভীষণ অসমমিত (skewness \(=2\)), অথচ standardize-করা \(Z_n\)-এর
mean(Z_n)সর্বদা \(\approx 0\) আরvar(Z_n)সর্বদা \(\approx 1\) — যা §৪.২-র কেন্দ্রায়ন+মানকীকরণের কাজ। আসল চমক দুই কলামে:skew(Z_n)\(2.02\to 0.19\)-এ নামছে (তত্ত্ব বলে ঠিক \(2/\sqrt n\) — যাচাই করো: \(n=100\)-এ \(2/10=0.20\), মিলে যাচ্ছে), আরsup|Fn-Phi|\(0.159\to 0.013\)-এ নামছে। দুটোই \(N(0,1)\)-এর দিকে convergence (অভিসরণ)-এর সংখ্যাগত স্বাক্ষর: \(n\) বাড়ার সাথে \(Z_n\)-এর বাঁকা-ভাব মুছে গিয়ে CDF \(\Phi\)-এর গায়ে বসছে — ঠিক যা MGF-প্রমাণ (4.4) প্রতিশ্রুতি দিয়েছিল। - Part 2 — তিন উৎসে CLT, universality (§৪.১ E2)। একই \(n=50\)-এ তিনটে সম্পূর্ণ আলাদা উৎস — সবার
mean(Z_n)\(\approx 0\),var(Z_n)\(\approx 1\), আরsup|Fn-Phi|ছোট। অভিসরণের গতি আলাদা: Uniform (সমমিত, হালকা-লেজি) সবচেয়ে দ্রুত (\(0.0018\)), Exponential মাঝারি (\(0.020\)), Bernoulli(0.3) সবচেয়ে ধীর (\(0.069\)) — কারণ Bernoulli বিচ্ছিন্ন ও অসমমিত, তাই একই \(n\)-এ ঘণ্টা-আকৃতিতে পৌঁছাতে বেশি সময় নেয়। কিন্তু গন্তব্য সবার এক: এটাই §৪.১-এ যা বলেছিলাম — প্রমাণে উৎসের কেবল প্রথম দুই moment (\(0,1\)) ঢোকে, বাকি সব \(o(s^2)\)-তে মুছে যায়, তাই \(N(0,1)\) সর্বজনীন। - Part 3 — Delta method ভ্যারিয়েন্স (§৪.৩ E4)। এটাই §৪.৩-র মূল সূত্রের সরাসরি যাচাই। Exponential উৎসে (\(\mu=1,\sigma^2=1\)):
- \(g(x)=\ln x\): empirical Var \(=1.0024\) বনাম তত্ত্ব \(g'(\mu)^2\sigma^2=1^2\cdot1=1\) — মিলে গেছে।
- \(g(x)=x^2\): empirical Var \(=4.0268\) বনাম তত্ত্ব \(2^2\cdot1=4\) — মিলে গেছে।
অর্থাৎ "variance multiplies by \(g'(\mu)^2\)" মন্ত্রটা সংখ্যায় সত্য: একই \(\bar X_n\)-কে দুটো আলাদা \(g\)-র ভিতর দিয়ে চালালে asymptotic ছড়ানো বদলায় ঠিক \(g'(\mu)^2\) অনুপাতে (\(1\) বনাম \(4\), অর্থাৎ চারগুণ)। কাগজের first-order Taylor আর কম্পিউটারের \(300{,}000\) সিমুলেশন একই উত্তরে এসে দাঁড়াল।
- Part 4 — sample proportion (§৪.৩ E3)। \(\hat p\) Bernoulli(\(0.3\)) থেকে: standardize-করা চলকের mean\(\approx 0\), var\(\approx 1\), sup|Fn-Phi|\(=0.035\) ছোট — অর্থাৎ \(\sqrt n(\hat p-p)\xrightarrow{d}N(0,p(1-p))\) খাটছে। আর সরাসরি ভ্যারিয়েন্স-যাচাই: empirical \(\mathrm{Var}(\hat p)=0.001049\) বনাম তত্ত্ব \(p(1-p)/n=0.001050\) — কার্যত অভিন্ন। এটাই proportion-এর confidence interval ও hypothesis test-এর ভিত্তি (পরের 3.5-এ কাজে লাগবে)।
সততা-নোট। সিমুলেশন CLT "প্রমাণ" করে না — অসীম \(n\) কখনো চালানো যায় না; এটা শুধু সাক্ষ্য দেয় যে আঙুলে-গোনা \(n\)-এই অভিসরণ স্পষ্ট। Part 1-এ skewness ও sup-gap-এর একমুখী পতন, Part 2-তে তিন উৎসের একই গন্তব্য, Part 3-এ Delta-ভ্যারিয়েন্সের হুবহু মিল — তিনটেই §৪-এর প্রমাণকে চোখে দেখায় মাত্র; আসল যুক্তি §৪-এর কাজ। আর ছোট-ছোট অবশিষ্ট গরমিল (যেমন Part 1-এ \(n=100\)-এও sup-gap ঠিক \(0\) নয়, \(0.013\)) হলো সসীম-\(n\) ও সসীম-নমুনার (\(200{,}000\) replication) Monte-Carlo দানা — আসল সীমা \(0\)।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_3-4.py-তে তৈরি; PNG_assets/-এ (prefix3-4, dpi=150)। in-figure লেখা সব ইংরেজিতে। প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা আছে — beginner-এর জন্য এটাই আসল শেখার সূত্র।
Central Limit Theorem-এর জাদুটা ভাষায় বললে অবিশ্বাস্য শোনায়: উৎস যত আঁকাবাঁকাই হোক, যথেষ্ট নমুনার গড় standardize করলে সেটা ঘণ্টা-আকৃতির Normal-এ গিয়ে দাঁড়ায়। কিন্তু এটা ছবিতে দেখলে বিশ্বাসযোগ্য হয়ে ওঠে। আমরা চারটি ছবি দিয়ে চারটি জিনিস "চোখে দেখব": (১) একটা বাঁকানো (skewed) উৎসের standardized গড় কীভাবে \(n\) বাড়লে \(N(0,1)\)-এ গড়িয়ে যায়, (২) সম্পূর্ণ ভিন্ন তিনটি উৎসও standardize করলে একই Normal-এ পৌঁছায়, (৩) QQ-plot দিয়ে সেই Normal-হওয়াটা কত নিখুঁত তা পরিমাপ, আর (৪) Delta method — একটা nonlinear রূপান্তর \(g\) কীভাবে গড়ের ছড়ানোকে তার tangent-এর ঢাল দিয়ে নতুন Normal-এ পাঠায়।
Figure 1 — বাঁকানো উৎসের standardized গড় Normal-এ গড়ায়¶
পুরো অধ্যায়ের কেন্দ্রীয় ছবি। চারটি প্যানেলে \(n=1,2,5,30\)-এর জন্য standardized গড় \(Z_n=\sqrt{n}(\bar X_n-\mu)/\sigma\)-এর histogram — উৎস হলো Exponential\((1)\), যা ভীষণভাবে ডানে-বাঁকানো (right-skewed), মোটেও ঘণ্টা-আকৃতির নয়। প্রতিটি প্যানেলে লাল রেখা হলো লক্ষ্য \(N(0,1)\)-এর density। যা লক্ষ করতে হবে: \(n=1\)-এ histogram-টা ঠিক উৎসের মতোই বাঁকানো — বাঁ দিকে একটা ধারালো প্রাচীর (\(Z_1\) কখনো \(-1\)-এর কম হতে পারে না, কারণ Exponential মান \(0\)-এর নিচে নামে না) আর ডানে লম্বা লেজ। কিন্তু \(n=2,5\)-এ histogram ধীরে ধীরে প্রতিসম (symmetric) হতে শুরু করে, আর \(n=30\)-এ এটা প্রায় নিখুঁতভাবে লাল ঘণ্টা-curve-এর গায়ে বসে যায়। অর্থাৎ Central Limit Theorem উৎসের আকৃতিকে "ভুলিয়ে দেয়" — শুধু \(\mu\) আর \(\sigma^2\) মনে রাখে (E2-এর মূল বার্তা)।
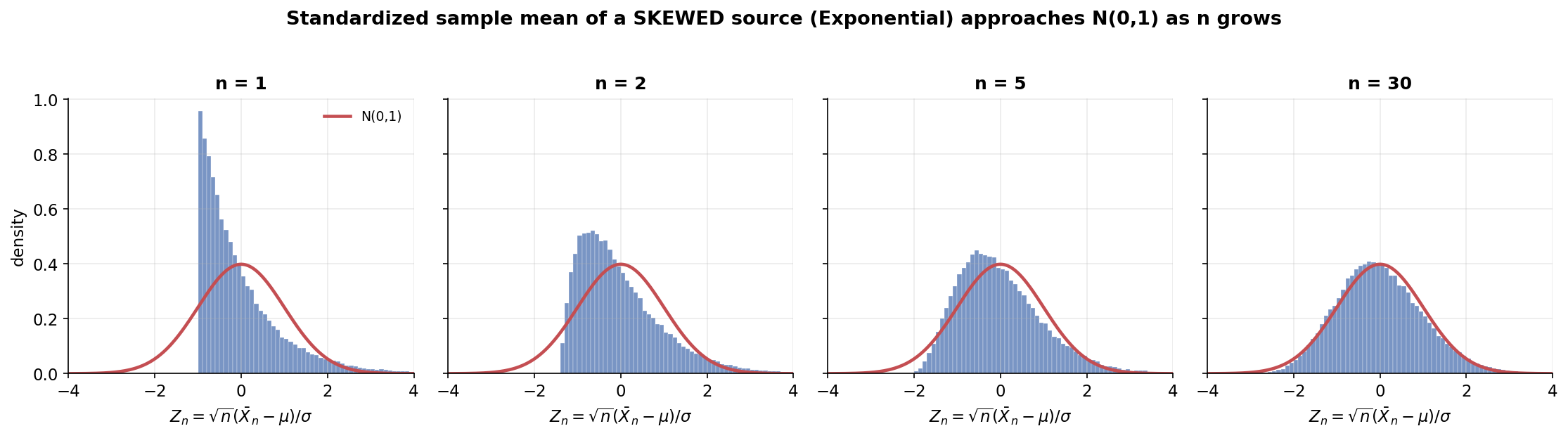
Figure 2 — তিন উৎস, এক গন্তব্য¶
CLT-র সবচেয়ে অবাক-করা দিকটা: উৎস কী তাতে কিছু যায় আসে না (শুধু variance finite হলেই হলো)। তিনটি প্যানেলে তিনটি সম্পূর্ণ ভিন্ন উৎস — Uniform\((0,1)\) (সমতল, flat), Exponential\((1)\) (ডানে-বাঁকানো), আর Bernoulli\((0.3)\) (বিচ্ছিন্ন, শুধু \(0\) ও \(1\) — দুটো spike)। প্রতিটির জন্য \(n=30\)-এ standardized গড় \(Z_{30}\)-এর histogram আঁকা, পাশে লাল \(N(0,1)\)। যা লক্ষ করতে হবে: তিনটি উৎস দেখতে আকাশ-পাতাল আলাদা — একটা সমান, একটা লেজওয়ালা, একটা মাত্র দুই-মানের — তবু standardize করার পরে তিনটি histogram-ই একই ঘণ্টা-curve-এ গিয়ে মেলে। এমনকি Bernoulli-র মতো বিচ্ছিন্ন উৎসও, যেখানে একটা একক মান কখনো ঘণ্টা-আকৃতি নয়, যথেষ্ট যোগফল নিলে মসৃণ Normal দেয় (E3 — sample proportion এর সরাসরি ভিত্তি)। এটাই CLT-কে statistics-এর "universal" হাতিয়ার বানায়।
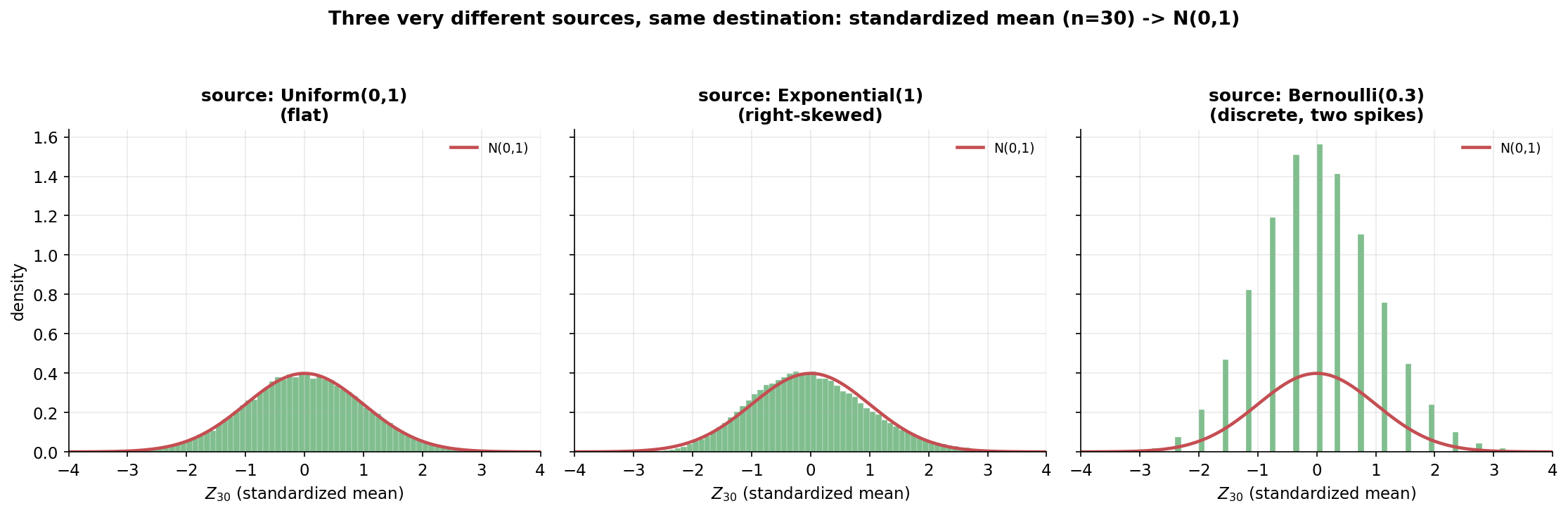
Figure 3 — QQ-plot: Normal-হওয়া কত নিখুঁত?¶
histogram চোখে আন্দাজ দেয়, কিন্তু QQ-plot (quantile–quantile plot) সংখ্যায় বলে দেয় একটা distribution কতটা Normal। অনুভূমিক অক্ষে তাত্ত্বিক Normal quantile, উল্লম্ব অক্ষে আমাদের simulated \(Z_n\)-এর sample quantile; বিন্দুগুলো যদি \(45^\circ\) সরলরেখা (\(y=x\)) বরাবর বসে, তবে distribution-টা ঠিক Normal। বাঁ প্যানেলে \(n=2\), ডান প্যানেলে \(n=30\) — উৎস আবার Exponential। যা লক্ষ করতে হবে: \(n=2\)-এ বিন্দুগুলো রেখার থেকে বেঁকে যায় — বিশেষত দুই প্রান্তে (লেজে), কারণ skewed উৎসের গড় তখনো Normal নয়। কিন্তু \(n=30\)-এ বিন্দুগুলো প্রায় নিখুঁতভাবে সরলরেখার গায়ে শুয়ে পড়ে। QQ-plot তাই CLT-র "convergence" কে চোখে-দেখা পরিমাপে রূপ দেয়; বাস্তব data-তেও এটাই আমরা ব্যবহার করি দেখতে যে normal approximation চলবে কি না (3.5 ও Part IV-এর diagnostic হাতিয়ার)।
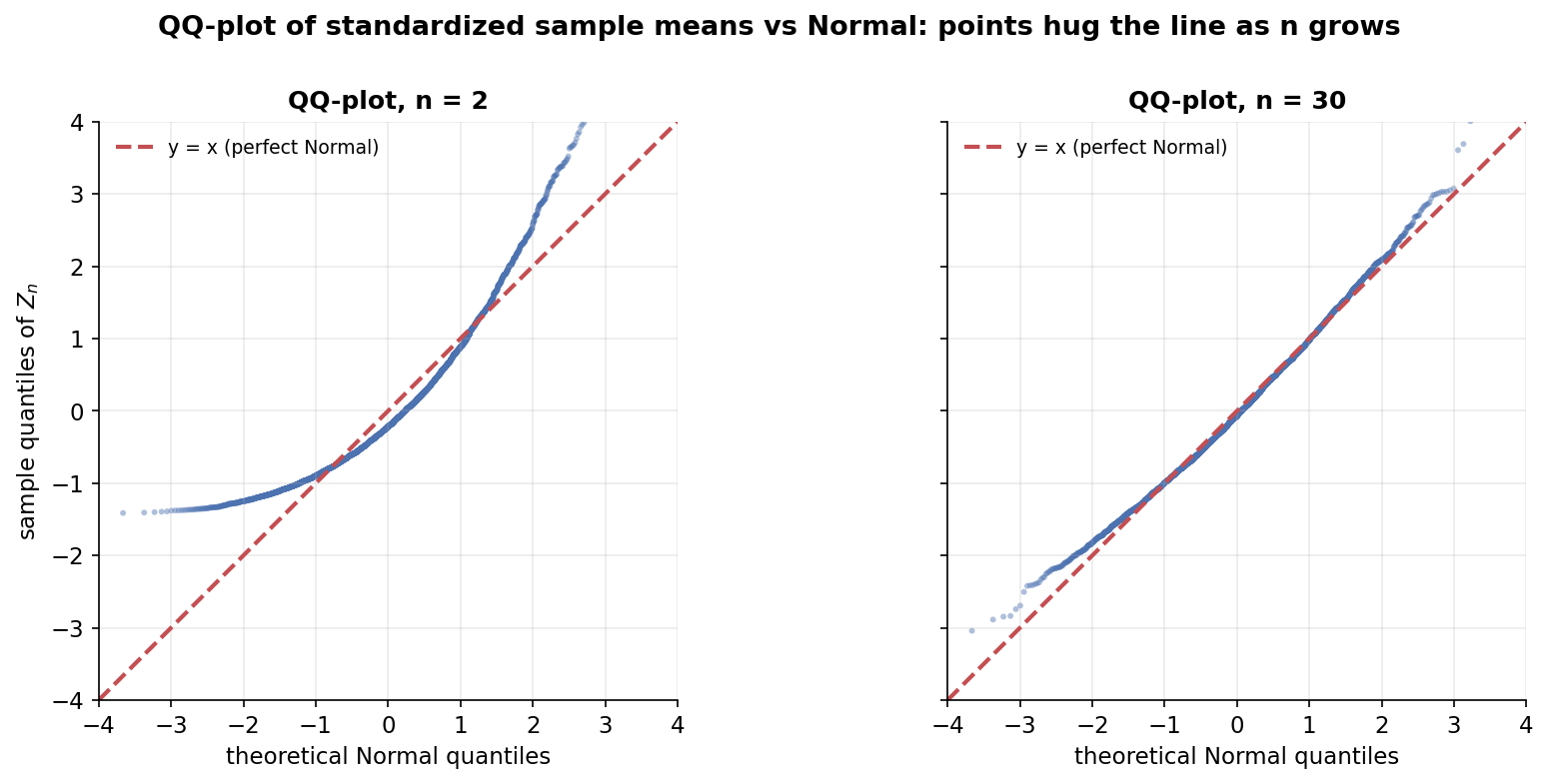
Figure 4 — Delta method: ছড়ানো tangent দিয়ে পাঠানো¶
CLT গড় \(\bar X_n\)-এর জন্য Normal দেয়; কিন্তু আমরা প্রায়ই গড় নয়, গড়ের একটা function \(g(\bar X_n)\)-তে আগ্রহী (যেমন variance, ratio, log)। Delta method বলে: \(\bar X_n\) যদি \(\mu\)-র চারপাশে সরু Normal হয়, তবে \(g(\bar X_n)\)-ও আনুমানিক Normal — শুধু তার ছড়ানো (standard deviation) \(g'(\mu)\) গুণ বেশি বা কম। এই ছবিতে নীল curve হলো একটা nonlinear \(g(x)=x^2\), লাল ভাঙা-রেখা হলো \(\mu=1.2\)-তে তার tangent (ঢাল \(g'(\mu)=2.4\))। নিচে অক্ষে সবুজ একটা ছোট Normal "ঢিবি" — \(\bar X_n\)-এর distribution, ছড়ানো \(\sigma/\sqrt{n}\)। বাঁ অক্ষে বেগুনি ঢিবি — \(g(\bar X_n)\)-এর distribution। যা লক্ষ করতে হবে: সবুজ ঢিবিটা যখন tangent-রেখা বেয়ে উপরে ওঠে, তখন তা চওড়া হয়ে যায় (বেগুনি ঢিবি সবুজটার চেয়ে চওড়া), কারণ এখানে ঢাল \(2.4>1\) — তাই ইনপুটের ছোট ছড়ানো আউটপুটে \(2.4\) গুণ বড় ছড়ানো হয়ে যায়। এটাই Delta method-এর হৃদয়: linearize করো (curve-কে tangent দিয়ে বদলে নাও), তারপর ছড়ানো ঢাল দিয়ে গুণ করো (E4-এর মূল কৌশল)।
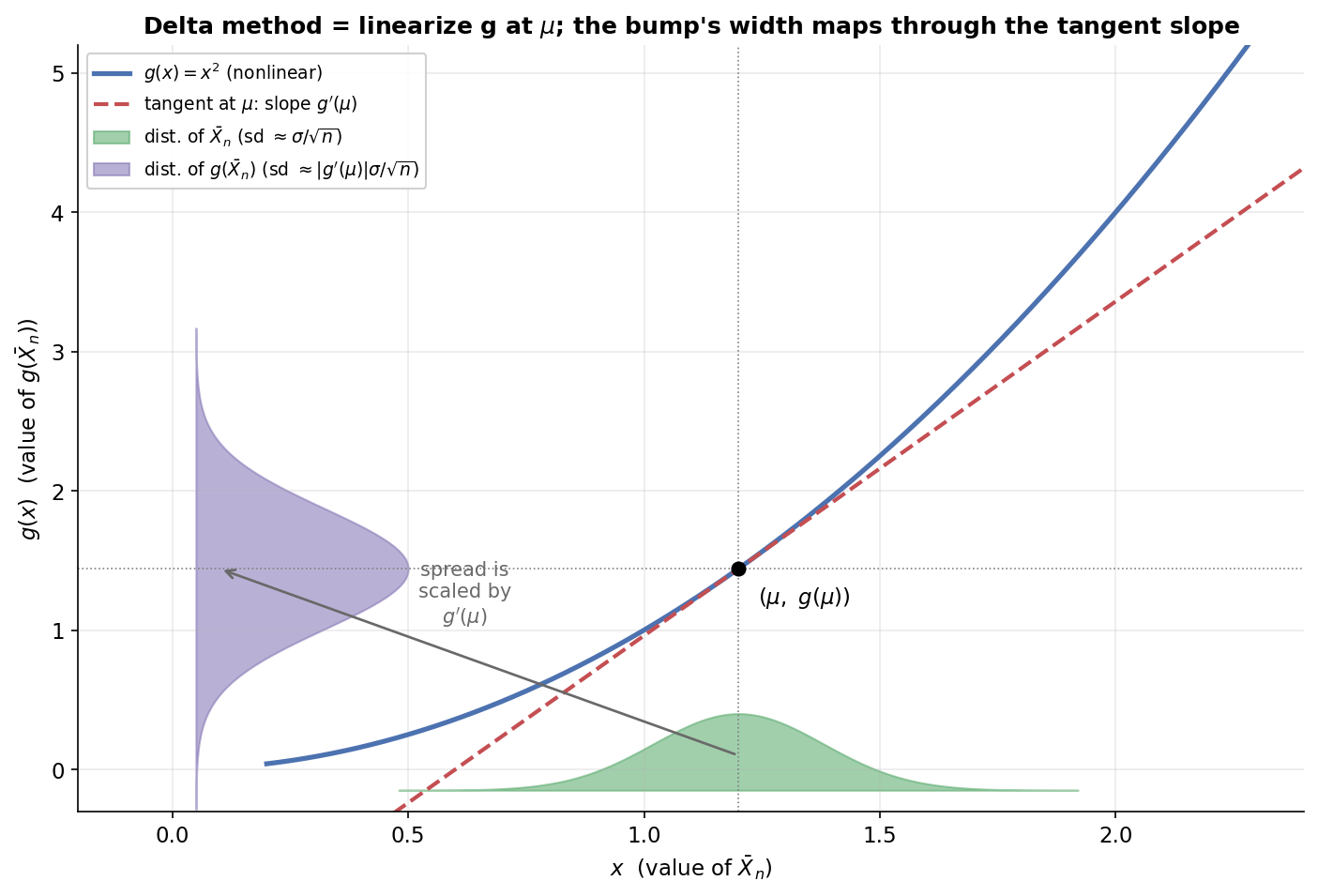
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/03-04-central-limit-theorem-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন Central Limit Theorem আসলে কী দাবি করে এবং কী দাবি করে না। বিশেষত: (ক) এটা কি বলে \(\bar X_n\) নিজে Normal হয়ে যায়, নাকি \(\bar X_n\)-এর কোনো standardize-করা রূপ? (খ) উৎস distribution Normal হতে হবে কি? Figure 1 ও Figure 2 দিয়ে উত্তর সমর্থন করুন। Hint: CLT-র বিষয় হলো \(Z_n=\sqrt{n}(\bar X_n-\mu)/\sigma\), \(\bar X_n\) নিজে নয় (যার ছড়ানো \(0\)-তে সঙ্কুচিত হয়, LLN); উৎস যেকোনো হতে পারে যদি \(\sigma^2<\infty\)।
প্রশ্ন ২ (★). Law of Large Numbers (3.3) বলে \(\bar X_n\xrightarrow{P}\mu\) — অর্থাৎ গড় একটা বিন্দুতে থিতু হয়। তাহলে Central Limit Theorem কী নতুন তথ্য যোগ করে যা LLN দেয় না? (\(\sqrt{n}\) গুণ করার ভূমিকা ব্যাখ্যা করুন।) Hint: LLN বলে কোথায় থিতু হয়; CLT বলে থিতু হওয়ার হার ও আকৃতি — \(\bar X_n-\mu\) প্রায় \(\sigma/\sqrt{n}\) মাপের ওঠানামা, আর সেটা Normal-আকৃতির। \(\sqrt{n}\) গুণ না করলে limit-এ সব ভর \(0\)-তে গুটিয়ে গিয়ে তথ্য হারাত।
প্রশ্ন ৩ (★★). কেউ বলল: "\(n=30\) হলেই CLT খাটে, তার কম হলে নয়।" এই নিয়মের সমস্যা কী? কোন ধরনের উৎসে \(n=30\) যথেষ্ট নয়, আর কোন উৎসে \(n=5\)-ও যথেষ্ট হতে পারে? Figure 1 ও Figure 3-র দৃষ্টিকোণ থেকে যুক্তি দিন। Hint: "\(n=30\)" একটা রুক্ষ আঙুল-গোনা নিয়ম, প্রমাণ নয়; উৎস যত বেশি skewed/heavy-tailed (যেমন Exponential), তত বড় \(n\) লাগে; প্রতিসম bounded উৎসে (যেমন Uniform) অল্প \(n\)-এই ভালো approximation।
প্রশ্ন ৪ (★★). Delta method-এ যদি \(g'(\mu)=0\) হয় (অর্থাৎ \(\mu\)-তে \(g\)-এর tangent অনুভূমিক), তাহলে সাধারণ first-order Delta method ভেঙে পড়ে — কেন? Figure 4-র tangent-ছবি দিয়ে স্বজ্ঞাতভাবে বোঝান, তারপর অনুমান করুন তখন কী করা উচিত। Hint: ঢাল \(0\) হলে linear approximation বলে "ছড়ানো \(\to 0\cdot\sigma/\sqrt{n}\)", যা limiting variance \(0\) দেয় — তথ্য হারিয়ে যায়; তখন second-order (curvature, \(g''(\mu)\)) দরকার, আর limit Normal নয় বরং chi-square-জাতীয় হয়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). একটা নিরপেক্ষ ছয়-পার্শ্ব ছক্কা \(n=100\) বার ফেলা হলো (E1)। একটি ফেলায় \(\mu=3.5\), \(\sigma^2=\tfrac{35}{12}\approx 2.917\)। যোগফল \(S_{100}=\sum_{i=1}^{100}X_i\)-এর জন্য CLT দিয়ে আনুমান করুন \(P(S_{100}>380)\)। (\(\Phi\)-table বা \(\Phi(1.76)\approx 0.961\) ব্যবহার করুন।) Hint: \(S_n\)-এর mean \(=n\mu=350\), sd \(=\sigma\sqrt{n}=\sqrt{2.917}\cdot 10\approx 17.08\); standardize: \(P(S_{100}>380)\approx 1-\Phi\!\big(\tfrac{380-350}{17.08}\big)\)।
প্রশ্ন ৬ (★). sample proportion (E3): একটা মুদ্রা যার head-probability \(p=0.5\), \(n=400\) বার ছোঁড়া হলো। \(\hat p=\bar X_n\) (head-এর ভগ্নাংশ)-এর জন্য CLT দিয়ে \(P(\hat p>0.55)\) আনুমান করুন। Hint: Bernoulli-তে \(\mu=p=0.5\), \(\sigma^2=p(1-p)=0.25\); \(\hat p\)-এর sd \(=\sqrt{0.25/400}=0.025\); \(P(\hat p>0.55)\approx 1-\Phi(2)=1-0.977\)।
প্রশ্ন ৭ (★★). \(X_1,\dots,X_n\) iid Exponential\((1)\), তাই \(\mu=1,\ \sigma=1\) (Figure 1-র উৎস)। (ক) \(n=30\)-এ CLT দিয়ে \(\bar X_{30}\)-এর আনুমানিক distribution লিখুন। (খ) \(P(\bar X_{30}>1.3)\) আনুমান করুন। (গ) প্রকৃত মান (Gamma-ভিত্তিক) approximation-এর চেয়ে সামান্য বেশি না কম হবে বলে আশা করেন — কেন? (skew-এর দিক ভাবুন।) Hint: (ক) \(\bar X_{30}\approx\mathcal N(1,\ 1/30)\), sd \(\approx 0.1826\); (খ) \(1-\Phi\!\big(\tfrac{1.3-1}{0.1826}\big)=1-\Phi(1.64)\approx 0.05\); (গ) ডানে-skew বলে ডান লেজ আসলে একটু মোটা, তাই প্রকৃত probability সামান্য বেশি।
প্রশ্ন ৮ (★★). Delta method হাতে-কলমে (E4): \(\hat p\approx\mathcal N\!\big(p,\ \tfrac{p(1-p)}{n}\big)\)। odds \(g(p)=\tfrac{p}{1-p}\)-এর জন্য Delta method দিয়ে \(g(\hat p)\)-এর আনুমানিক variance বের করুন। \(p=0.4,\ n=100\) হলে সংখ্যাটি বসান। Hint: \(g'(p)=\tfrac{1}{(1-p)^2}\); Delta method: \(\operatorname{Var}\!\big(g(\hat p)\big)\approx \big(g'(p)\big)^2\cdot\tfrac{p(1-p)}{n}=\tfrac{1}{(1-p)^4}\cdot\tfrac{p(1-p)}{n}=\tfrac{p}{n(1-p)^3}\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). ধরে নিন CLT সত্য: \(Z_n=\sqrt{n}(\bar X_n-\mu)/\sigma\xrightarrow{d}\mathcal N(0,1)\)। Slutsky's theorem ব্যবহার করে প্রমাণ করুন যে \(\sigma\)-কে একটা consistent estimator \(S_n\) (\(S_n\xrightarrow{P}\sigma\)) দিয়ে বদলালেও limit বদলায় না: \(\dfrac{\sqrt{n}(\bar X_n-\mu)}{S_n}\xrightarrow{d}\mathcal N(0,1)\)। Hint: লিখুন \(\dfrac{\sqrt{n}(\bar X_n-\mu)}{S_n}=Z_n\cdot\dfrac{\sigma}{S_n}\); এখানে \(\sigma/S_n\xrightarrow{P}1\); Slutsky: \(X_n\xrightarrow{d}X\) ও \(Y_n\xrightarrow{P}c\) হলে \(X_nY_n\xrightarrow{d}cX\)।
প্রশ্ন ১০ (★★). Delta method-এর বিবৃতি ও প্রমাণ-স্কেচ। ধরুন \(\sqrt{n}(\bar X_n-\mu)\xrightarrow{d}\mathcal N(0,\sigma^2)\) এবং \(g\) একটা function যার \(\mu\)-তে derivative \(g'(\mu)\) আছে ও \(g'(\mu)\ne 0\)। প্রমাণ করুন (first-order Taylor + Slutsky দিয়ে): $$ \sqrt{n}\,\big(g(\bar X_n)-g(\mu)\big)\ \xrightarrow{d}\ \mathcal N!\big(0,\ \big(g'(\mu)\big)^2\sigma^2\big). $$ Hint: \(\mu\)-র চারপাশে first-order Taylor: \(g(\bar X_n)=g(\mu)+g'(\xi_n)(\bar X_n-\mu)\) কোনো \(\xi_n\)-এর জন্য \(\bar X_n\) ও \(\mu\)-র মাঝে; \(\bar X_n\xrightarrow{P}\mu\) বলে \(\xi_n\xrightarrow{P}\mu\) ও \(g'(\xi_n)\xrightarrow{P}g'(\mu)\); এবার \(\sqrt{n}\) গুণ করে Slutsky।
প্রশ্ন ১১ (★★★). CLT-র moment generating function (MGF) প্রমাণ (সরলীকৃত, MGF বিদ্যমান ধরে)। \(Y_i=(X_i-\mu)/\sigma\) (mean \(0\), variance \(1\)) ধরুন, তাই \(Z_n=\tfrac{1}{\sqrt{n}}\sum_{i=1}^n Y_i\)। দেখান যে \(Z_n\)-এর MGF \(M_{Z_n}(t)\to e^{t^2/2}\) (\(N(0,1)\)-এর MGF), তাই \(Z_n\xrightarrow{d}\mathcal N(0,1)\)। Hint: স্বাধীনতায় \(M_{Z_n}(t)=\big[M_Y\!\big(t/\sqrt{n}\big)\big]^n\); \(M_Y(s)=1+\tfrac{s^2}{2}+o(s^2)\) (কারণ \(M_Y(0)=1,\ M_Y'(0)=0,\ M_Y''(0)=1\)); \(s=t/\sqrt{n}\) বসিয়ে \(\big[1+\tfrac{t^2}{2n}+o(1/n)\big]^n\to e^{t^2/2}\)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে Figure 1-র সরল রূপ বানান: Exponential\((1)\) থেকে \(n=1,5,30\)-এর জন্য \(\bar X_n\)-এর \(20{,}000\)টি নমুনা তুলে standardize করুন (\(Z_n=\sqrt{n}(\bar X_n-1)/1\)) এবং তিনটি histogram-এর উপর \(N(0,1)\) density আঁকুন। default_rng(0) ব্যবহার করুন।
Hint: xbar = rng.exponential(1.0, size=(20000, n)).mean(axis=1); z = np.sqrt(n)*(xbar-1); histogram-এ density=True, তারপর scipy.stats.norm.pdf।
প্রশ্ন ১৩ (★★). CLT-র convergence হার পরিমাপ করুন। Exponential\((1)\) উৎসে \(n=2,5,10,30,100\)-এর প্রতিটির জন্য \(Z_n\)-এর \(50{,}000\) নমুনা তুলে empirical \(P(Z_n\le 1.96)\) গণনা করুন এবং \(\Phi(1.96)=0.975\)-এর সাথে পার্থক্য plot করুন (log-scale)। দেখান পার্থক্য আনুমানিক \(1/\sqrt{n}\) হারে কমে (Berry–Esseen-এর পূর্বাভাস)।
Hint: (z <= 1.96).mean() বনাম \(n\); error \(\propto 1/\sqrt{n}\) হলে log-log plot-এ ঢাল \(\approx -0.5\) (skewness থাকায় leading error term first-order)।
প্রশ্ন ১৪ (★★★). Delta method সিমুলেশনে যাচাই করুন। \(\hat p=\bar X_n\), Bernoulli\((0.4)\), \(n=100\)। (ক) \(10{,}000\) বার simulate করে \(g(\hat p)=\log\!\big(\tfrac{\hat p}{1-\hat p}\big)\) (log-odds)-এর empirical variance বের করুন। (খ) Delta-method-পূর্বাভাস \(\operatorname{Var}\approx\tfrac{1}{n\,p(1-p)}\)-এর সাথে মেলান। (গ) \(g(\hat p)\)-এর histogram-এ Delta-predicted Normal বসিয়ে দেখান মিল ভালো। Hint: log-odds-এর \(g'(p)=\tfrac{1}{p(1-p)}\), তাই Delta variance \(=\big(\tfrac{1}{p(1-p)}\big)^2\cdot\tfrac{p(1-p)}{n}=\tfrac{1}{n\,p(1-p)}\); \(p=0.4,n=100\)-এ \(\approx 0.0417\); কোনো sim-এ \(\hat p\in\{0,1\}\) হলে log-odds অসীম — সেগুলো বাদ দিন বা \(n\) বড় রাখুন।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Central Limit Theorem (CLT): \(X_1,\dots,X_n\) iid, \(\mathbb E[X_i]=\mu\), \(0<\operatorname{Var}(X_i)=\sigma^2<\infty\) হলে $$ Z_n=\frac{\sqrt{n}\,(\bar X_n-\mu)}{\sigma}\ \xrightarrow{d}\ \mathcal N(0,1),\qquad\text{সমতুল্যভাবে } \bar X_n\ \overset{\text{approx}}{\sim}\ \mathcal N!\Big(\mu,\ \frac{\sigma^2}{n}\Big). $$ উৎসের আকৃতি যাই হোক — Uniform, Exponential, এমনকি বিচ্ছিন্ন Bernoulli — standardize-করা গড় Normal-এ যায় (Figure 1, Figure 2)।
- CLT vs LLN: LLN (3.3) বলে গড় কোথায় থিতু হয় (\(\bar X_n\xrightarrow{P}\mu\)); CLT বলে থিতু হওয়ার হার ও আকৃতি — ওঠানামা \(\sigma/\sqrt{n}\) মাপের এবং Normal-আকৃতির। তাই LLN consistency দেয়, CLT দেয় distribution (যা ছাড়া error bar আঁকা যায় না)।
- standardization-এর ভূমিকা: \(\sqrt{n}\) গুণ না করলে \(\bar X_n-\mu\) সব \(0\)-তে গুটিয়ে যেত (degenerate limit); \(\sqrt{n}\)-ই ঠিক সেই zoom যা nondegenerate Normal বের করে আনে।
- asymptotic normality: "যথেষ্ট বড় \(n\)-এ আনুমানিক Normal" — এই ধর্মই \(\bar X_n\), \(\hat p\) (E3), এবং বহু estimator-এর বড়-নমুনা আচরণ বর্ণনা করে। QQ-plot (Figure 3) দিয়ে এই Normal-হওয়াটা চোখে যাচাই করা যায়।
- Delta method (E4): \(g\) যদি \(\mu\)-তে differentiable হয় ও \(g'(\mu)\ne 0\), তবে $$ \sqrt{n}\,\big(g(\bar X_n)-g(\mu)\big)\ \xrightarrow{d}\ \mathcal N!\big(0,\ \big(g'(\mu)\big)^2\sigma^2\big). $$ স্বজ্ঞা: curve-কে tangent দিয়ে linearize করো, ছড়ানো \(g'(\mu)\) দিয়ে গুণ হয় (Figure 4)। এটাই গড়ের function-এর (variance, ratio, log-odds...) asymptotic distribution বের করার মূল কৌশল।
পূর্ববর্তী সংযোগ (← 3.3, 3.2): 3.3-এর Law of Large Numbers ছিল CLT-র জোড়া-স্তম্ভের প্রথমটি — weak LLN ঠিক \(\bar X_n\xrightarrow{P}\mu\) বলে; CLT সেই একই \(\bar X_n\)-কে \(\sqrt{n}\) দিয়ে zoom করে তার ওঠানামার আকৃতি দেখায়। আর 3.2-এর convergence in distribution (\(\xrightarrow{d}\)) হলো CLT-র বিবৃতির আক্ষরিক ভাষা — \(Z_n\xrightarrow{d}\mathcal N(0,1)\) মানে \(Z_n\)-এর CDF \(\Phi\)-র প্রতিটি continuity point-এ গড়ায় (3.2-র Figure 3-এই এর পূর্বাভাস ছিল)। Slutsky's theorem ও Delta method-এর প্রমাণে 3.2-এর \(\xrightarrow{P}\)/\(\xrightarrow{d}\)-এর মিথস্ক্রিয়া সরাসরি ব্যবহৃত হয়েছে।
পরবর্তী সংযোগ (→ 3.5 ও Part IV): 3.5-এ (random processes / আরও limit-উপপাদ্য) CLT-র সাধারণীকরণ — multivariate CLT, dependent ও non-identical ক্ষেত্রে (Lindeberg) — আসবে। কিন্তু CLT-র আসল ফসল কাটা হয় Part IV (inference)-এ: - confidence interval: \(\bar X_n\approx\mathcal N(\mu,\sigma^2/n)\) থেকেই \(\bar X_n\pm 1.96\,\sigma/\sqrt{n}\) একটা \(95\%\) CI — পুরো CI-তত্ত্বের asymptotic ভিত্তি CLT। - hypothesis test: \(z\)-statistic, \(t\)-test, \(p\)-value — সবই "null-এর অধীনে statistic আনুমানিক Normal" ধরে নেয়, যা CLT দেয়। - Delta method তখন ব্যবহৃত হয় standard error বের করতে যখন আগ্রহের রাশি গড়ের একটা nonlinear function (যেমন odds ratio, correlation, log-rate)।
সারকথা: LLN বলেছিল estimator "ঠিক উত্তরে যায়"; CLT বলে "তার ভুল আনুমানিক Normal, মাপ \(\sigma/\sqrt{n}\)" — আর এই একটি বাক্যের উপরেই পরিমাপাত্মক (quantitative) inference-এর গোটা ইমারত দাঁড়িয়ে।
সূত্র (sources): Wasserman, All of Statistics, Ch. 5 (The Central Limit Theorem; The Delta Method); Rice, Mathematical Statistics and Data Analysis, §5.3 (Convergence in Distribution and the Central Limit Th