Part II — probability (সম্ভাব্যতা): ভিত্তি · Integrative Demos¶
Part II পরিসংখ্যানের সেই ভিত্তি ধরে যেখানে অনিশ্চয়তাকে সংখ্যায় বাঁধা হয়: sample space ও probability axioms থেকে শুরু করে conditional probability ও Bayes, discrete ও continuous random variable, expectation-moment-MGF, joint distribution ও covariance, এবং transformation ও order statistics পর্যন্ত। এই module-এ প্রতিটি ধারণা চারভাবে দেখানো — (b) scratch (শুধু numpy), (c) library check (assert/মিল), (d) demonstrate/"prove" (ছাপা real সংখ্যা), (e) visualization — সবই real open data (iris, breast_cancer, sunspots)-এর উপর, fixed seed 20260619 সহ। নিচের সব সংখ্যা executed notebook (notebooks/02-probability.ipynb) থেকে সরাসরি নেওয়া।
চালানো:
cd notebooks && python3 -m nbconvert --to notebook --execute --inplace 02-probability.ipynb --ExecutePreprocessor.timeout=900
2.1 — Sample space, event ও probability axioms¶
ধারণা। একটা random experiment-এর সব ফলাফলের সেট \(\Omega\) হলো sample space (নমুনা-স্থান); তার যেকোনো subset \(A\subseteq\Omega\) একটা event (ঘটনা)। Kolmogorov-এর axioms: (i) \(P(A)\ge 0\), (ii) \(P(\Omega)=1\), (iii) disjoint হলে \(P(A\cup B)=P(A)+P(B)\)। এখান থেকে inclusion–exclusion (অন্তর্ভুক্তি–বর্জন): \(P(A\cup B)=P(A)+P(B)-P(A\cap B)\)। law of large numbers অনুযায়ী নমুনা \(n\) বাড়লে event-এর relative frequency (আপেক্ষিক কম্পাঙ্ক) true probability-তে যায়।
Scratch-এর মূল ধারণা। iris-এ দুটো event — \(A=\{\text{petal length} > \text{median}\}\), \(B=\{\text{sepal length} > \text{median}\}\) — indicator array হিসেবে বানানো। empirical \(\hat P(A)=\text{mean}(\mathbb 1_A)\); \(\hat P(A\cup B)\) সরাসরি গুনে inclusion–exclusion মেলানো; তারপর row shuffle করে prefix-এ running frequency এঁকে convergence।
Demonstrated result (প্রমাণ)। \(N=150\); median petal length \(=4.350\), median sepal length \(=5.800\)। \(P(A)=0.500000,\ P(B)=0.466667,\ P(A\cap B)=0.433333\)। direct count-এ \(P(A\cup B)=0.533333\), আর identity ঠিক মেলে:
তিন axiom-ই ধরে (\(0\le P(A)\le 1\), \(P(\Omega)=1\), disjoint additivity)। LLN দৃশ্যমান: running frequency \(\hat P(A)\) যায় \(0.400\ (n{=}10)\to 0.467\ (n{=}30)\to 0.493\ (n{=}75)\to 0.500\ (n{=}150)\) — অর্থাৎ \(\lvert\hat P(A)-P(A)\rvert\) ক্রমশ শূন্যের দিকে।
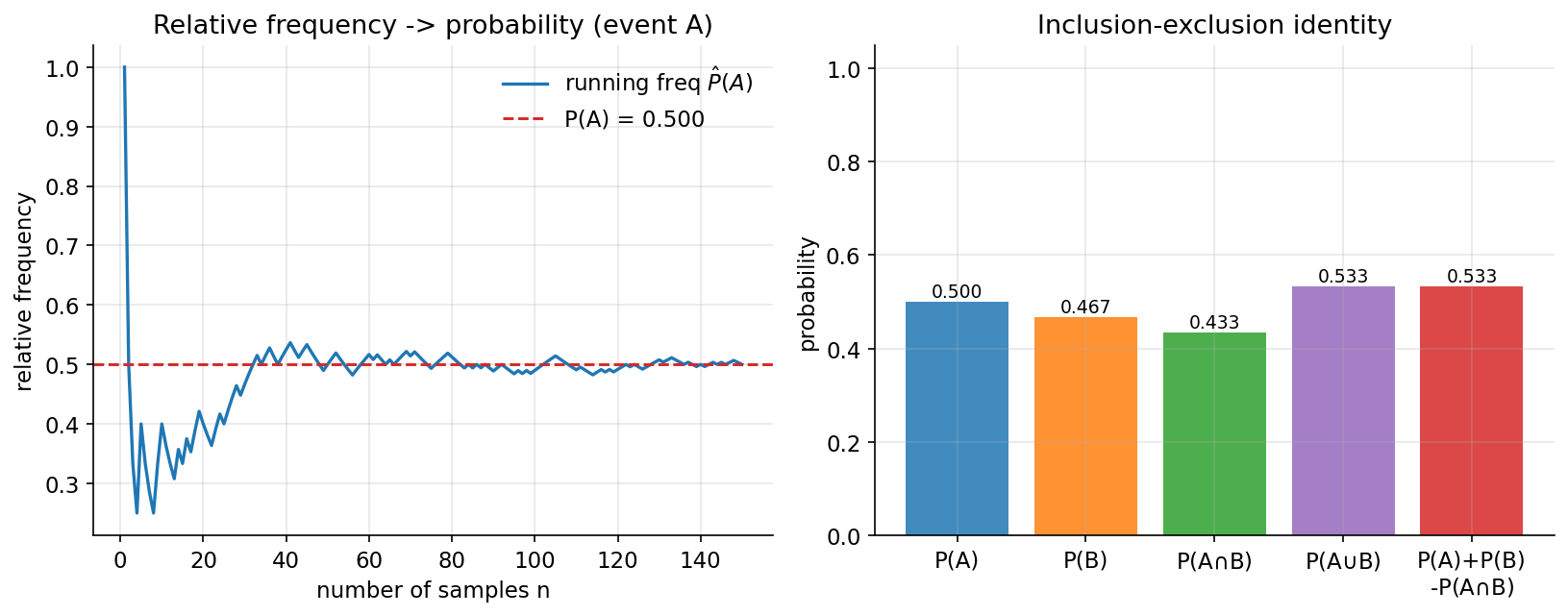
চিত্র: (বাঁ) event \(A\)-এর running relative frequency \(\to P(A)=0.5\); (ডান) inclusion–exclusion বার — \(P(A\cup B)\) ঠিক \(P(A)+P(B)-P(A\cap B)\)-এর সমান।
2.2 — Conditional probability ও Bayes (Gaussian naive Bayes হাতে)¶
ধারণা। conditional probability (শর্তাধীন সম্ভাব্যতা) \(P(A\mid B)=P(A\cap B)/P(B)\); এখান থেকে Bayes' theorem \(P(y\mid \mathbf x)\propto P(\mathbf x\mid y)\,P(y)\)। Gaussian naive Bayes-এ feature-গুলো class দিলে conditionally independent ও প্রতিটি Gaussian ধরা হয়; underflow এড়াতে সব হিসাব log space-এ: \(\log P(y\mid\mathbf x)\propto \log P(y)+\sum_j \log\mathcal N(x_j;\mu_{jy},\sigma_{jy}^2)\), তারপর log-sum-exp দিয়ে normalize।
Scratch-এর মূল ধারণা। breast_cancer (\(0=\) malignant, \(1=\) benign; \(30\) feature) — প্রতি class-এ per-feature mean/var; log-likelihood \(-\tfrac12\log(2\pi\sigma^2)-\tfrac{(x-\mu)^2}{2\sigma^2}\) যোগ; log-prior যোগ; normalize করে posterior \(P(\text{malignant}\mid\mathbf x)\); predict = argmax।
Demonstrated result (প্রমাণ)। priors \(P(\text{malignant})=0.3726,\ P(\text{benign})=0.6274\)। scratch GNB train-accuracy \(=0.942004\) (\(536/569\)), যা sklearn GaussianNB-র \(0.942004\)-এর সাথে হুবহু মেলে; prediction সম্পূর্ণ identical, আর posterior-এর সর্বোচ্চ পার্থক্য মাত্র \(2.3\times10^{-15}\) (float-দ্বারা সীমিত)। posterior সত্যিই দুই class আলাদা করে: mean \(P(\text{malignant}\mid\mathbf x)\) true-malignant-এ \(0.8915\) বনাম true-benign-এ \(0.0306\)। সবচেয়ে অনিশ্চিত case-এ posterior \(0.548994\) (\(0.5\)-এর কাছে)।
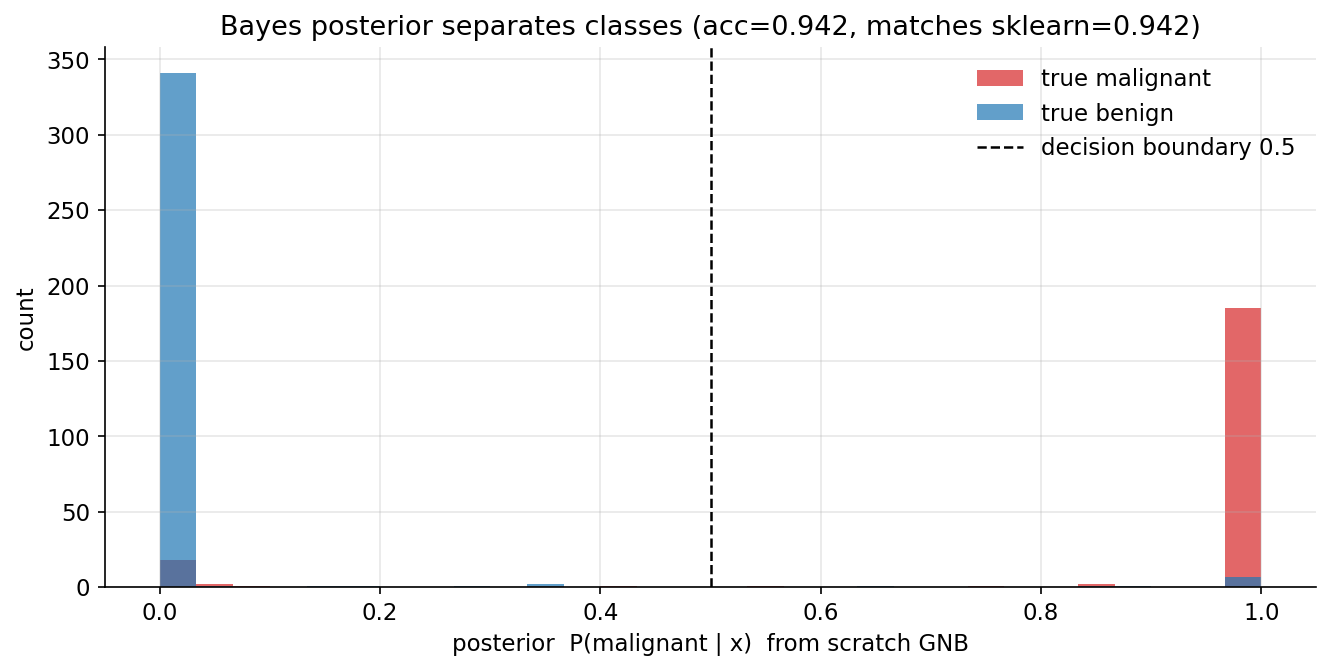
চিত্র: scratch GNB-র posterior \(P(\text{malignant}\mid \mathbf x)\)-এর histogram — true-malignant (ডানে জমা) ও true-benign (বাঁয়ে জমা) \(0.5\) boundary-র দুই পাশে; accuracy sklearn-এর সমান।
2.3 — Discrete random variables (Binomial ও Poisson)¶
ধারণা। discrete random variable-এর distribution তার pmf (probability mass function) দিয়ে সম্পূর্ণ। Binomial \(\text{Bin}(n,p)\): \(P(X=k)=\binom nk p^k(1-p)^{n-k}\)। Poisson \(\text{Pois}(\lambda)\): \(P(X=k)=e^{-\lambda}\lambda^k/k!\), যেখানে mean \(=\) var \(=\lambda\); MLE \(\hat\lambda=\bar X\)। dispersion index \(\text{var}/\text{mean}\) True-Poisson-এ \(1\); তার চেয়ে বড় হলে overdispersion।
Scratch-এর মূল ধারণা। log-gamma (gammaln) দিয়ে সংখ্যাগতভাবে স্থিতিশীল binomial coefficient ও pmf; একইভাবে Poisson pmf। sunspots বার্ষিক SUNACTIVITY পূর্ণসংখ্যায় round করে \(\hat\lambda=\text{mean}\); observed frequency histogram বনাম fitted Poisson pmf overlay।
Demonstrated result (প্রমাণ)। self-check: \(\sum\) binom pmf (\(n{=}10,p{=}0.3\)) \(=1.0000000000\), \(\sum\) Poisson pmf (\(\lambda{=}50\)) \(=1.0000000000\); দুই scratch pmf scipy-র সাথে মেলে (True)। sunspots (\(N=309\)): \(\hat\lambda=49.779935\) কিন্তু sample variance \(=1632.37\) — তাই dispersion \(=32.79 \gg 1\), অর্থাৎ ডেটা Poisson-এর তুলনায় ভীষণ overdispersed (sunspot cycle-এ boom-bust থাকায় স্বাভাবিক)। মডেল-পক্ষে mean\(=\)var identity ঠিক আছে: simulated \(\text{Pois}(49.78)\)-এর mean \(49.75\), var \(49.58\) — দুটোই \(\approx\lambda\)।
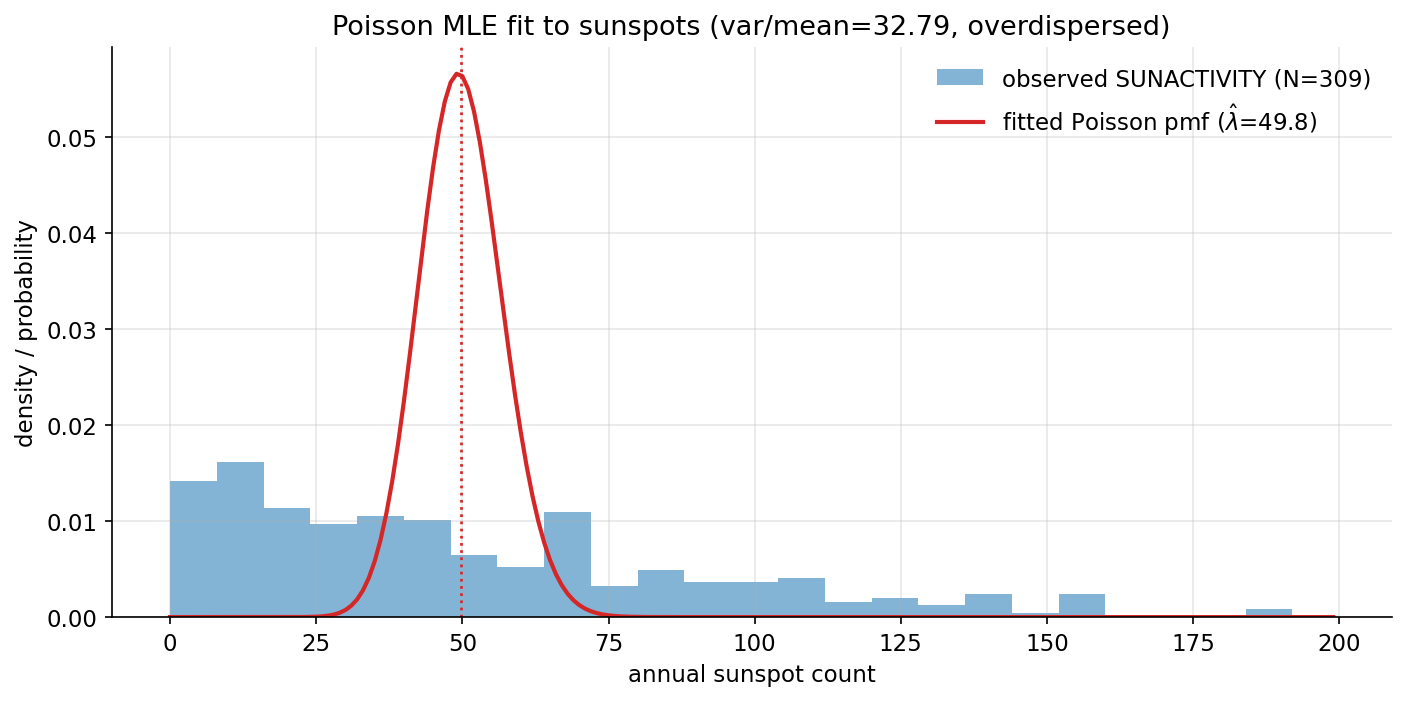
চিত্র: sunspot বার্ষিক count-এর observed density বনাম fitted Poisson pmf (\(\hat\lambda=49.8\)); Poisson একঘেয়ে সরু, ডেটা অনেক চওড়া — overdispersion স্পষ্ট।
2.4 — Continuous distributions (Normal ও Exponential)¶
ধারণা। continuous random variable-এর distribution তার pdf \(f(x)\) ও cdf \(F(x)=\int_{-\infty}^x f\) দিয়ে বর্ণিত। Normal \(\mathcal N(\mu,\sigma^2)\)-এর MLE \(\hat\mu=\bar X,\ \hat\sigma^2=\tfrac1N\sum(x_i-\bar X)^2\)। 68–95–99.7 rule বলে Normal-এ \(P(\mu-\sigma<X<\mu+\sigma)\approx 0.6827\)। Exponential \(\text{Exp}(\lambda)\): \(f(x)=\lambda e^{-\lambda x}\), cdf \(1-e^{-\lambda x}\)।
Scratch-এর মূল ধারণা। Normal pdf হাতে, cdf-এ erf; iris sepal length-এ \(\hat\mu,\hat\sigma\); fine grid-এ pdf-কে np.trapezoid দিয়ে cumulative integrate করে cdf reconstruct এবং closed-form cdf-এর সাথে মেলানো; \(1\sigma\)-coverage analytic ও empirical দুইভাবে।
Demonstrated result (প্রমাণ)। sepal length (\(N=150\)): \(\hat\mu=5.843333,\ \hat\sigma=0.825301\); fitted pdf-এর মোট integral \(=1.00000000\)। scratch pdf/cdf scipy-র সাথে মেলে (True); numeric-integrated cdf বনাম closed-form cdf-এর সর্বোচ্চ পার্থক্য মাত্র \(8.2\times10^{-8}\) — অর্থাৎ integration সত্যিই cdf যাচাই করে। \(1\sigma\) interval \(=(5.0180,\ 6.6686)\): analytic \(P=0.682689\) (textbook \(0.6827\); \(\lvert\cdot-0.6827\rvert=0.000011\)), আর iris-এ empirical \(P=0.600000\) (finite ছোট নমুনা ও sepal length সম্পূর্ণ Normal নয় বলে সামান্য কম)। \(2\sigma\) analytic \(=0.954500\)।
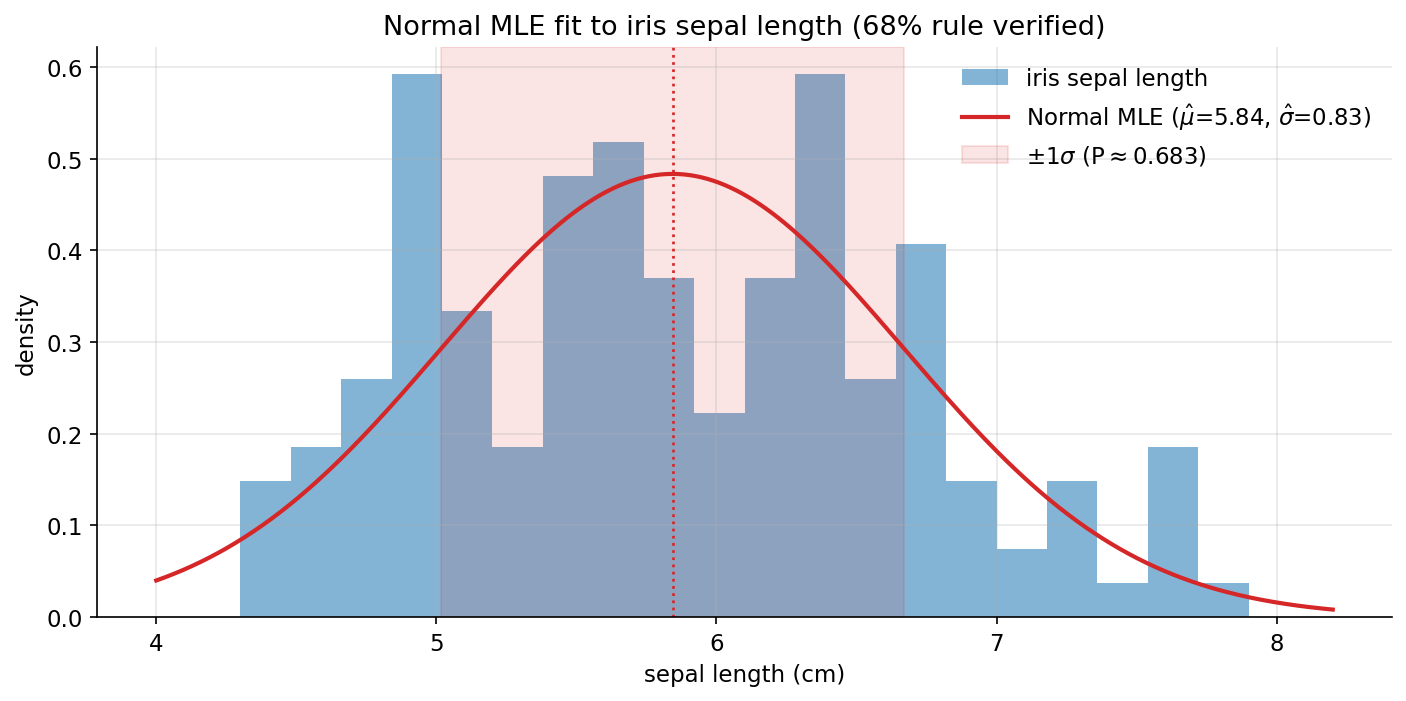
চিত্র: iris sepal length-এর histogram-এ fitted Normal pdf (\(\hat\mu=5.84,\hat\sigma=0.83\)) overlay; ছায়াঢাকা \(\pm1\sigma\) ব্যান্ডে সম্ভাব্যতা \(\approx 0.683\) (68% rule)।
2.5 — Expectation, moments ও moment generating function (MGF)¶
ধারণা। random variable-এর expectation \(E[X]\), variance \(\text{Var}(X)=E[(X-\mu)^2]\), standardized skewness \(E[(\tfrac{X-\mu}{\sigma})^3]\) (অসমতা) ও kurtosis \(E[(\tfrac{X-\mu}{\sigma})^4]\) (লেজের ভার; Normal-এ \(3\))। MGF \(M(t)=E[e^{tX}]\) থেকে সব raw moment: \(M'(0)=E[X],\ M''(0)=E[X^2]\)। overflow এড়াতে centered feature ও ছোট \(t\)-grid \([-0.3,0.3]\) নেওয়া হয়।
Scratch-এর মূল ধারণা। iris petal length centre করে (\(E[X]\approx 0,\ E[X^2]=\text{Var}\)); empirical \(\hat M(t)=\tfrac1N\sum e^{tx_i}\) ছোট grid-এ; central finite difference \(M'(0)\approx\tfrac{M(h)-M(-h)}{2h}\) ও \(M''(0)\approx\tfrac{M(h)-2M(0)+M(-h)}{h^2}\); সরাসরি-হিসাবকৃত moment-এর সাথে মেলানো।
Demonstrated result (প্রমাণ)। centered petal length (\(N=150\)): \(E[X]=-6.6\times10^{-16}\) (কার্যত \(0\)), \(\text{Var}=3.095503\), sd \(=1.759404\), skewness \(=-0.272128\), kurtosis \(=1.604464\) (Normal-এর \(3\)-এর চেয়ে কম — light-tailed, bimodal iris)। তিনটিই scipy-র সাথে মেলে (True)। \(M(0)=1.000000\) ঠিক। MGF derivative থেকে moment recover: \(M'(0)=-2.47\times10^{-7}\approx E[X]\), আর \(M''(0)=3.095504\) বনাম \(E[X^2]=3.095503\) (পার্থক্য \(1.3\times10^{-6}\)); centered বলে \(E[X^2]=\text{Var}\) ঠিক মেলে।
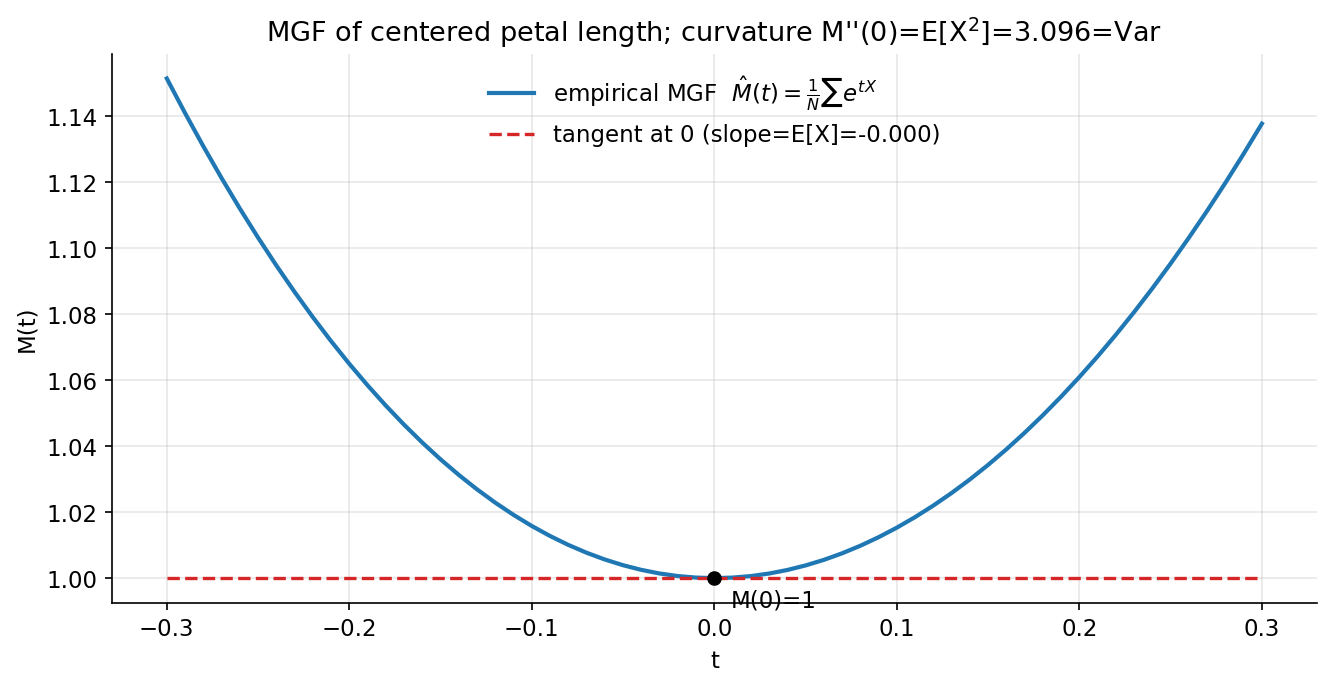
চিত্র: centered petal length-এর empirical MGF \(\hat M(t)\); \(t{=}0\)-তে tangent-এর ঢাল \(=M'(0)=E[X]\approx 0\), আর curvature \(M''(0)=3.0955=\text{Var}\)।
2.6 — Joint distribution ও covariance (bivariate normal)¶
ধারণা। দুই random variable-এর joint distribution একসাথে আচরণ ধরে। covariance \(\text{Cov}(X,Y)=E[(X-\mu_X)(Y-\mu_Y)]\); correlation \(\rho=\text{Cov}/(\sigma_X\sigma_Y)\in[-1,1]\)। bivariate normal সম্পূর্ণ নির্ধারিত হয় mean vector \(\boldsymbol\mu\) ও \(2\times2\) covariance matrix \(\Sigma\) দিয়ে; density-র contour হলো \((\mathbf z-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf z-\boldsymbol\mu)=\text{const}\) ellipse, আর এই Mahalanobis দূরত্বের বর্গ bivariate normal-এ \(\chi^2_2\) অনুসরণ করে।
Scratch-এর মূল ধারণা। iris petal length ও petal width centre করে population \(\text{Cov}=\tfrac1N\sum(x-\bar x)(y-\bar y)\), \(\rho=\text{Cov}/(\sigma_x\sigma_y)\); \(2\times2\) \(\Sigma\)-এর inverse ও determinant দিয়ে bivariate-normal density grid ও contour; np.cov-এর সাথে মেলানো; Mahalanobis coverage বনাম \(\chi^2_2\)।
Demonstrated result (প্রমাণ)। means: petal length \(=3.7580\), petal width \(=1.1993\); \(\text{Cov}(X,Y)=1.286972\), \(\rho=0.962865\) (দৃঢ় ধনাত্মক)। scratch \(\Sigma\) ও \(\rho\) np.cov(ddof=0)/np.corrcoef-এর সাথে মেলে (True)। \(\det\Sigma=0.130219\), eigenvalue \(0.0358\) ও \(3.6368\) — দুটোই ধনাত্মক, তাই \(\Sigma\) SPD (symmetric positive-definite)। Mahalanobis-coverage তত্ত্বের কাছাকাছি: \(90\%\) ellipse-এ \(0.9133\), \(95\%\) ellipse-এ \(0.9467\) বিন্দু (target \(0.90,\ 0.95\))।
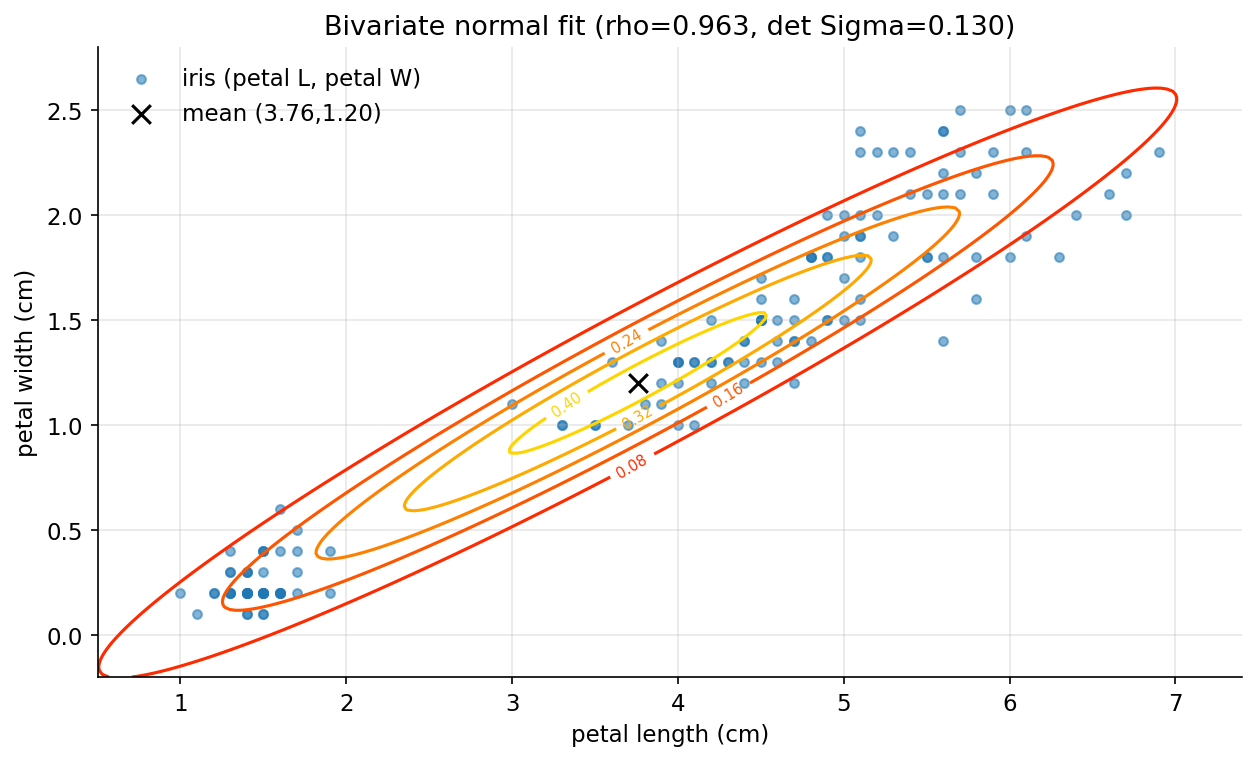
চিত্র: iris (petal length, petal width) scatter-এর উপর fitted bivariate-normal density contour (\(\rho=0.963\)); উপবৃত্তগুলো ঢালু, দৃঢ় positive correlation প্রতিফলিত করে।
2.7 — Transformation ও order statistics¶
ধারণা। (i) Change of variable (রূপান্তর)। \(Y=g(X)\) monotone হলে \(f_Y(y)=f_X(g^{-1}(y))\,\lvert \tfrac{d}{dy}g^{-1}(y)\rvert\); বিশেষভাবে \(Y=X^2\) (\(X>0\))-এ \(f_Y(y)=\dfrac{f_X(\sqrt y)}{2\sqrt y}\)। (ii) Order statistics (ক্রম-পরিসংখ্যান)। \(n\) iid নমুনার maximum \(M=\max_i X_i\)-এর cdf \(F_M(x)=F(x)^n\) (কারণ সব \(X_i\le x\) হতে হবে)।
Scratch-এর মূল ধারণা। (i) iris petal length (\(>0\))-এ Normal-MLE \(f_X\); \(Y=X^2\)-এর empirical histogram বনাম analytic \(f_Y(y)=f_X(\sqrt y)/(2\sqrt y)\)। (ii) feature-এর empirical CDF \(\hat F\) (searchsorted); \(B=60{,}000\) বার \(n=5\)-size resample-এর max নিয়ে empirical max-CDF বনাম \(\hat F(x)^5\) overlay।
Demonstrated result (প্রমাণ)। petal length \(\mu=3.7580,\ \text{sd}=1.7594\), range \([1.00,6.90]\); \(Y=X^2\) range \([1.000,47.610]\), mean \(17.2181\)। analytic \(f_Y\)-এর observed-range integral \(=0.952412\) (বাকি \(\sim 0.05\) Normal-এর তত্ত্বীয় লেজে, ডেটা-support-এর বাইরে) এবং empirical histogram-এর সাথে RMSE মাত্র \(0.02967\) — রূপান্তর-formula মেলে। max-of-5 ঠিক তত্ত্ব ধরে: প্রতিটি quantile-এ empirical \(F_{\max}\approx \hat F(x)^5\) (যেমন \(x{=}5.000\)-এ \(0.1932\) বনাম \(0.1935\)), আর পুরো grid-এ \(\max\lvert F_{\text{emp}}-\hat F^5\rvert=0.0029\)। order-statistic shift স্পষ্ট: \(E[\max\text{ of }5]=5.6176 > E[X]=3.7580\)।
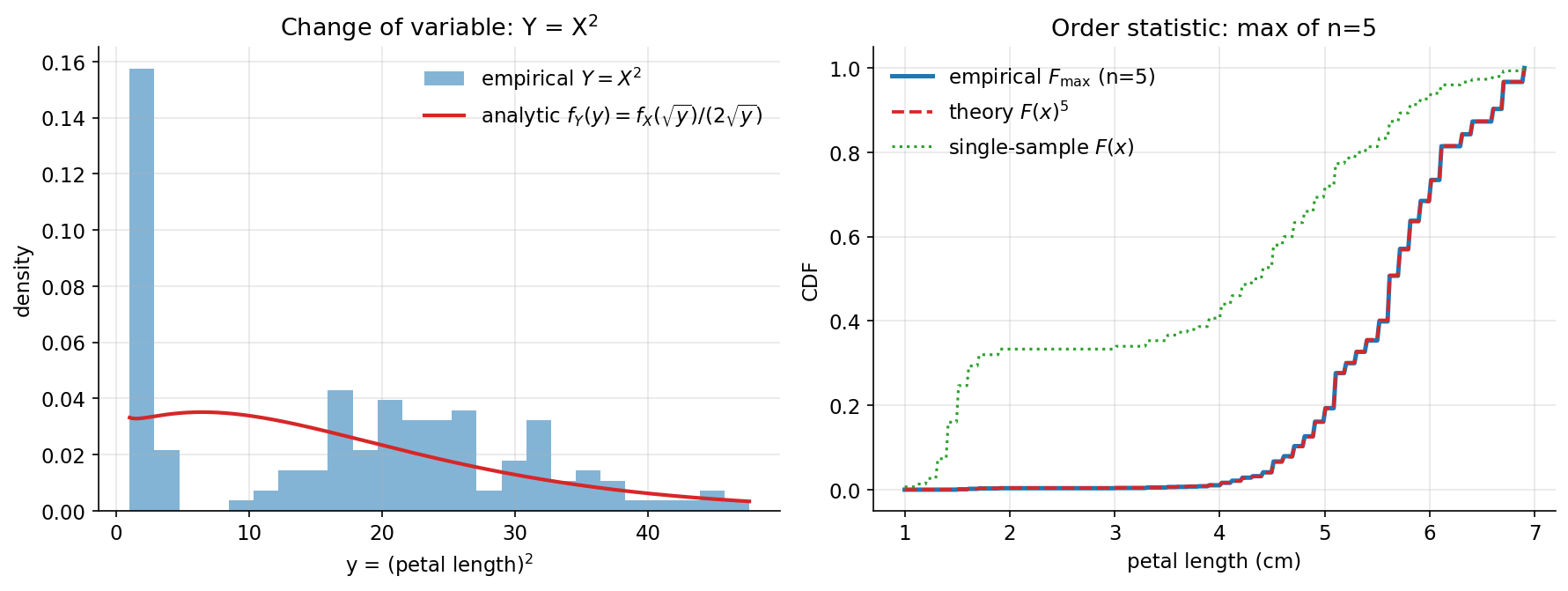
চিত্র: (বাঁ) \(Y=X^2\)-এর empirical histogram বনাম analytic transform density; (ডান) \(n{=}5\)-এর max-এর empirical CDF বনাম theory \(F(x)^5\) (ও single-sample \(F\)) — প্রায় হুবহু মেলে।
সারসংক্ষেপ (Part II)¶
| Demo | Real dataset | Scratch বনাম Library | Headline number |
|---|---|---|---|
| 2.1 axioms | iris | freq == numpy; identity exact | \(P(A\cup B)=0.5333=P(A)+P(B)-P(A\cap B)\) |
| 2.2 Bayes | breast_cancer | acc == sklearn, \(\Delta\)posterior \(2.3e{-}15\) | scratch GNB acc \(=0.942004\) |
| 2.3 Poisson | sunspots | pmf == scipy | \(\hat\lambda=49.78\), dispersion \(32.79\) |
| 2.4 Normal | iris | pdf/cdf == scipy, cdf err \(8e{-}8\) | \(P(1\sigma)=0.6827\) |
| 2.5 MGF | iris | moments == scipy | \(M''(0)=3.0955=\text{Var}\) |
| 2.6 bivariate | iris | \(\Sigma,\rho\) == numpy | \(\rho=0.9629\), SPD \(\Sigma\) |
| 2.7 transform | iris | \(f_Y\) RMSE \(0.030\); \(F^n\) gap \(0.003\) | \(E[\max_5]=5.62>3.76\) |
সব সংখ্যা seed 20260619-এ deterministic; একই notebook re-run করলে হুবহু পুনরুৎপাদনযোগ্য।