3.2 — Types of Convergence (অভিসারণের প্রকারভেদ)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
১.১ সংখ্যার sequence-এর limit — যা আমরা ইতিমধ্যে জানি¶
একটা সাধারণ সংখ্যার ক্রম (sequence — ক্রম) দিয়ে শুরু করি। ধরুন
এখানে \(n\) হলো ক্রমের অবস্থান-সূচক (index — সূচক): \(1, 2, 3, \dots\), আর \(a_n\) হলো সেই অবস্থানের সংখ্যা। \(n\) যত বড় হয়, \(a_n\) তত ছোট হয়ে শূন্যের কাছে যায়। এটাকে আমরা লিখি \(a_n \to 0\), বা \(\lim_{n\to\infty} a_n = 0\) ("limit") — এবং সবাই এর মানে স্বজ্ঞায় (intuitively) বুঝি: "\(n\) বড় করলে \(a_n\) আর \(0\)-এর পার্থক্য যত খুশি ছোট করা যায়।"
Part 0-এ আমরা এর precise সংজ্ঞাও দেখেছি (\(\varepsilon\)–\(N\) ভাষায়): যেকোনো ছোট সহনসীমা \(\varepsilon > 0\) নিন; একটা অবস্থান \(N\) পাওয়া যাবে যার পর (অর্থাৎ সব \(n > N\)-এর জন্য) \(\lvert a_n - 0 \rvert < \varepsilon\) থাকবেই। এখানে প্রতিটি প্রতীকের অর্থ:
- \(\varepsilon\) ("epsilon") — আমরা যে কোনো ক্ষুদ্র ধনাত্মক সহনসীমা বেছে নিই; "\(a_n\) আর limit-এর পার্থক্য এর চেয়ে ছোট হলেই খুশি।"
- \(\lvert a_n - 0 \rvert\) — \(a_n\) আর limit \(0\)-এর মধ্যে দূরত্ব (absolute value — পরমমান), অর্থাৎ "কত দূরে আছে, চিহ্ন বাদ দিয়ে।"
- \(N\) — এমন একটা সূচক যার পরে দূরত্ব আর কখনও \(\varepsilon\) ছাড়ায় না।
মূল কথা: সংখ্যার ক্রমে প্রতিটি \(a_n\) একটিমাত্র নির্দিষ্ট সংখ্যা — সেখানে কোনো এলোমেলোপনা (randomness) নেই। তাই limit-এর একটাই সরল অর্থ।
১.২ এখন ধরুন প্রতিটি পদই একটি random variable¶
পরিসংখ্যানে আমরা যে ক্রম নিয়ে কাজ করি, তা সংখ্যার ক্রম নয় — তা random variable-এর ক্রম। অর্থাৎ আমাদের কাছে আছে
যেখানে প্রতিটি \(X_n\) একটি random variable (এলোমেলো চলক — যার মান পরীক্ষার ফলাফলের ওপর নির্ভর করে, একটি নির্দিষ্ট সংখ্যা নয়)। এবং আমরা জানতে চাই: এই ক্রম কি কোনো limit random variable \(X\)-এর "দিকে যাচ্ছে"? প্রতীকে: \(X_n \to X\) — কিন্তু এই তীরের (\(\to\)) মানে এখন আর পরিষ্কার নয়।
কেন পরিষ্কার নয়? একটা ছোট গল্প দিয়ে দেখি। ধরুন
হলো \(n\)টি কয়েন-টসের চলমান গড় (sample mean — নমুনা গড়), যেখানে প্রতিটি টসে head এলে \(X_i = 1\), tail এলে \(X_i = 0\)। এখানে প্রতিটি প্রতীক:
- \(X_i\) — \(i\)-তম টসের ফলাফল (random variable: \(0\) বা \(1\))।
- \(\sum_{i=1}^{n} X_i\) — প্রথম \(n\) টসে মোট কয়টা head এল।
- \(\bar X_n\) — সেই মোটকে \(n\) দিয়ে ভাগ, অর্থাৎ এ পর্যন্ত head-এর ভগ্নাংশ (fraction)।
স্বজ্ঞা বলে: \(n\) বড় হলে \(\bar X_n\) যাবে \(0.5\)-এর দিকে (ন্যায্য কয়েনের ক্ষেত্রে)। কিন্তু লক্ষ করুন — \(\bar X_n\) নিজে একটা random variable! একবার পরীক্ষা চালালে হয়তো \(\bar X_{100} = 0.47\) পাব, আবার চালালে \(\bar X_{100} = 0.53\)। তাহলে "\(\bar X_n \to 0.5\)" বলতে আমরা ঠিক কী বোঝাব?
এখানেই সমস্যা। সংখ্যার ক্রমে \(a_n\) আর limit-এর "দূরত্ব" একটাই নির্দিষ্ট সংখ্যা। কিন্তু random variable-এর ক্রমে \(\lvert X_n - X \rvert\) নিজেই random — কখনো ছোট, কখনো (কদাচিৎ) বড়। তাই "\(X_n\) আর \(X\) কাছে চলে আসে" কথাটার একটিমাত্র অর্থ নেই; একাধিক যুক্তিসঙ্গত অর্থ আছে, আর কোনটা বোঝাচ্ছি তা স্পষ্ট করে বলতে হয়।
১.৩ কেন একাধিক অর্থ লাগে — আসল প্রশ্নগুলো আলাদা¶
"\(X_n\) converge করে" বলতে আমরা আসলে কয়েকটা আলাদা প্রশ্ন করতে পারি, আর প্রতিটি প্রশ্নের নিজস্ব convergence-ধারণা আছে:
-
"যেকোনো নির্দিষ্ট বড় \(n\)-এ, \(X_n\) আর \(X\) অনেক দূরে থাকার সম্ভাবনা কি ছোট?" — এটা convergence in probability (\(X_n \xrightarrow{P} X\))। আমরা প্রতিটি \(n\)-এ একটা সম্ভাবনার দিকে তাকাই; দূরে থাকার সম্ভাবনা \(0\)-এর দিকে গেলেই খুশি।
-
"পুরো পরীক্ষা-যাত্রা (entire infinite sequence of outcomes) ধরলে, \(X_n\) কি প্রায় নিশ্চিতভাবে শেষপর্যন্ত \(X\)-এ থিতু হয়?" — এটা almost sure convergence (\(X_n \xrightarrow{a.s.} X\))। এখানে আমরা একটা গোটা random পথের (path) দিকে তাকাই — সেই পথটা সংখ্যার ক্রমের মতো \(X\)-এ যায় কিনা।
-
"\(X_n\)-এর distribution (বণ্টন — যে আকৃতিতে এর মান ছড়ানো) কি \(X\)-এর distribution-এর আকৃতিতে গিয়ে দাঁড়ায়?" — এটা convergence in distribution (\(X_n \xrightarrow{d} X\))। এখানে \(X_n\) ও \(X\) একই মান নেয় কিনা সেটা প্রশ্ন নয় — শুধু তাদের histogram/CDF-এর আকৃতি মেলে কিনা।
-
"\(X_n\) আর \(X\)-এর গড় বর্গ-পার্থক্য (average squared error) কি \(0\)-এ যায়?" — এটা convergence in \(L^p\) (বিশেষত \(p=2\) হলে mean-square convergence, \(X_n \xrightarrow{L^2} X\))। এটা একটা সংখ্যায় (expectation-এ) সব ভুল গড় করে দেখে।
এই চারটি প্রশ্ন একে অপরের চেয়ে আলাদা, আর তাদের উত্তরও আলাদা হতে পারে — একটা ক্রম একভাবে converge করতে পারে কিন্তু অন্যভাবে নয়। ঠিক যেমন "দুটো শহর কাছাকাছি" বলতে সড়কপথে দূরত্ব, না সরলরেখায় দূরত্ব, না ভ্রমণ-সময় — কোনটা বোঝাচ্ছি তার ওপর উত্তর বদলায়।
কেন statistics-এ এটাই মেরুদণ্ড। পরের দুই অধ্যায়ের দুটো বিখ্যাত theorem আসলে এই ভাষাতেই বলা: Law of Large Numbers (3.3) বলে sample mean \(\bar X_n\) সত্য গড় \(\mu\)-তে যায় — কিন্তু কোন অর্থে? Weak law বলে in probability (\(\xrightarrow{P}\)), strong law বলে almost sure (\(\xrightarrow{a.s.}\))। আর Central Limit Theorem (3.4) বলে standardized sum একটি Normal-এ যায় — সেটা in distribution (\(\xrightarrow{d}\))। অর্থাৎ এই অধ্যায় ছাড়া পরের দুটো theorem নিখুঁতভাবে বিবৃতই করা যায় না। তাই এটা আগে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে আমরা চারটি convergence একে একে from scratch সংজ্ঞায়িত করব। প্রতিটির জন্য একই কাঠামো: আগে স্বজ্ঞা, তারপর formal সংজ্ঞা, তারপর প্রতিটি প্রতীক খোলা। শেষে এদের পারস্পরিক সম্পর্ক — hierarchy — বিবৃত করব।
পুরো বিভাগে আমাদের কাছে আছে একটি random variable sequence \(X_1, X_2, \dots\) এবং একটি সম্ভাব্য limit \(X\) (যা নিজেও একটি random variable, বা মাঝে মাঝে একটি ধ্রুবক — যেমন \(X = \mu\))। আর \(\varepsilon > 0\) মানে সবসময় একটি ক্ষুদ্র ধনাত্মক সহনসীমা।
২.১ Convergence in probability (\(X_n \xrightarrow{P} X\))¶
স্বজ্ঞা। "যত \(n\) বাড়ে, \(X_n\) আর \(X\)-এর মধ্যে দৃশ্যমান পার্থক্য থাকার সম্ভাবনা তত ছোট হয়।" অর্থাৎ একটা নির্দিষ্ট বড় \(n\) ধরলে, \(X_n\) প্রায় নিশ্চয়ই \(X\)-এর কাছাকাছি; দূরে যাওয়াটা বিরল ঘটনা — আর \(n\) যত বাড়ে, ততই বিরল।
সংজ্ঞা (convergence in probability — সম্ভাবনায় অভিসারণ)। আমরা বলি \(X_n\) converge করে \(X\)-এ in probability, লিখি \(X_n \xrightarrow{P} X\), যদি যেকোনো \(\varepsilon > 0\)-এর জন্য
প্রতিটি প্রতীক খুলে বলি:
- \(\lvert X_n - X \rvert\) — \(X_n\) ও \(X\)-এর মধ্যে দূরত্ব (একটি random variable, কারণ \(X_n, X\) দুটোই random)।
- \(\lvert X_n - X \rvert > \varepsilon\) — এমন একটি event (ঘটনা): "\(X_n\) আর \(X\) অন্তত \(\varepsilon\) দূরে।" এটা কখনো ঘটে, কখনো ঘটে না।
- \(P(\,\cdot\,)\) — সেই event-এর probability (সম্ভাবনা) (একটি সংখ্যা, \(0\) আর \(1\)-এর মাঝে)।
- \(\lim_{n\to\infty} \dots = 0\) — এই সম্ভাবনাটা একটি সংখ্যার ক্রম তৈরি করে (\(n = 1, 2, 3, \dots\)), আর §১.১-এর সাধারণ অর্থে সেই সংখ্যা-ক্রম \(0\)-তে যায়।
খেয়াল করুন এখানে কৌশলটা: আমরা random জিনিস (\(\lvert X_n - X\rvert\))-কে সরাসরি limit নিই না; বরং তা থেকে একটা সংখ্যা (সম্ভাবনা) বানাই, তারপর সেই সংখ্যার সাধারণ limit নিই। এভাবেই randomness সামলানো হয়।
২.২ Almost sure convergence (\(X_n \xrightarrow{a.s.} X\))¶
স্বজ্ঞা। এবার একটা গোটা পরীক্ষা-যাত্রা কল্পনা করুন: একবার পরীক্ষা শুরু করলে আপনি পুরো অসীম ক্রম \(X_1, X_2, X_3, \dots\)-এর প্রতিটি মান দেখতে পান (যেমন কয়েন একটানা টস করে যাচ্ছেন, কখনো থামছেন না)। এই একটি গোটা যাত্রাকে বলি একটি outcome \(\omega\) ("omega")। প্রতিটি \(\omega\)-র জন্য \(X_1(\omega), X_2(\omega), \dots\) হলো নির্দিষ্ট সংখ্যার একটা সাধারণ ক্রম — যার §১.১-অর্থে limit থাকতেও পারে, নাও পারে। almost sure convergence বলে: "প্রায় সব যাত্রায় (সম্ভাবনা-\(1\) পরিমাণ যাত্রায়) এই সংখ্যার ক্রমটা সত্যিই \(X\)-এ গিয়ে থিতু হয়।"
সংজ্ঞা (almost sure convergence — প্রায় নিশ্চিত অভিসারণ)। আমরা বলি \(X_n\) converge করে \(X\)-এ almost surely, লিখি \(X_n \xrightarrow{a.s.} X\), যদি
প্রতিটি প্রতীক খুলে বলি:
- \(\omega\) — একটি গোটা outcome (পুরো অসীম যাত্রা); সব \(\omega\)-র সংগ্রহকে বলে sample space।
- \(X_n(\omega)\) — সেই নির্দিষ্ট যাত্রায় \(n\)-তম পদের প্রকৃত সংখ্যা-মান।
- \(\lim_{n\to\infty} X_n(\omega) = X(\omega)\) — এই নির্দিষ্ট যাত্রার সংখ্যা-ক্রমটি §১.১-এর সাধারণ অর্থে \(X(\omega)\)-এ converge করে (এটা একটি সাধারণ deterministic limit, কারণ \(\omega\) স্থির ধরা)।
- \(\{\omega : \dots\}\) — যত \(\omega\)-র জন্য উপরের সংখ্যা-limit সত্যি, তাদের সবার সংগ্রহ (একটি ঘটনা)।
- \(P(\dots) = 1\) — সেই "ভালো-যাত্রা" সংগ্রহের সম্ভাবনা পুরো \(1\); অর্থাৎ যে যাত্রাগুলোয় converge করে না তাদের মোট সম্ভাবনা \(0\)।
"almost" শব্দটা কেন। "প্রায় নিশ্চিত" বলতে বোঝায় ব্যতিক্রম-যাত্রা থাকতে পারে — যেখানে limit হয় না — কিন্তু তাদের মোট সম্ভাবনা ঠিক \(0\)। সম্ভাবনা-\(0\) মানে "অসম্ভব" নয়, "এত বিরল যে সম্ভাবনার হিসাবে গণনায় আসে না।" (এই "সম্ভাবনা-\(0\) সেট" ধারণার পুরো rigorous রূপ — measure-zero — Part VII-এ; এখানে স্বজ্ঞাই যথেষ্ট।)
দুটো convergence-এর মূল পার্থক্য (in probability বনাম almost sure)। এটাই এ অধ্যায়ের সবচেয়ে সূক্ষ্ম বিন্দু, তাই ধীরে:
- In probability প্রতিটি \(n\)-কে আলাদা করে দেখে: "এই \(n\)-এ ব্যর্থতার (দূরে থাকার) সম্ভাবনা কত?" — একটা সংখ্যা; সেই সংখ্যা \(0\)-এ যাক। এটা ক্রমের পদগুলোকে এক-এক করে (snapshot হিসেবে) মাপে।
- Almost sure পুরো লেজ একসাথে দেখে: "একটা গোটা যাত্রা ধরলে, এক জায়গার পর কি \(X_n\) চিরকালের জন্য \(X\)-এর কাছে আটকে থাকে?" — এটা পুরো অসীম পথের আচরণ দাবি করে, অনেক কঠোর।
পার্থক্যটা এমন: in probability-তে \(X_n\) মাঝে মাঝে দূরে লাফাতে পারে — শুধু লাফানোর সম্ভাবনা সময়ের সাথে কমলেই হলো; কিন্তু লাফগুলো অসীমবার ঘটতে পারে (ভিন্ন ভিন্ন \(\omega\)-তে)। almost sure দাবি করে যে প্রায় প্রতিটি নির্দিষ্ট যাত্রায় লাফানো একসময় পুরোপুরি বন্ধ হয়ে যায়। §৩-এর typewriter example-এ এই পার্থক্যটা একদম চোখে দেখা যাবে।
২.৩ Convergence in distribution (\(X_n \xrightarrow{d} X\))¶
স্বজ্ঞা। আগের দুটো convergence জানতে চায় \(X_n\) ও \(X\) কি একই মান-এর কাছাকাছি। কিন্তু অনেক সময় আমরা মান নিয়ে মাথা ঘামাই না — শুধু জানতে চাই \(X_n\)-এর বণ্টনের আকৃতি (shape of the distribution) \(X\)-এর আকৃতির মতো হয়ে যাচ্ছে কিনা। যেমন: "\(X_n\)-এর histogram কি ক্রমে একটা bell curve-এর আকার নিচ্ছে?" — তখন \(X_n\) আর \(X\) আদৌ কাছাকাছি মান নিক বা না নিক, তাতে কিছু আসে যায় না।
বণ্টনের আকৃতি ধরার আদর্শ হাতিয়ার হলো CDF (cumulative distribution function — সঞ্চিত বণ্টন ফাংশন, 2.4-এ শেখা): \(F_n(x) = P(X_n \le x)\) আর \(F(x) = P(X \le x)\)।
সংজ্ঞা (convergence in distribution — বণ্টনে অভিসারণ)। আমরা বলি \(X_n\) converge করে \(X\)-এ in distribution, লিখি \(X_n \xrightarrow{d} X\), যদি
প্রতিটি প্রতীক খুলে বলি:
- \(F_n(x) = P(X_n \le x)\) — \(X_n\)-এর CDF: "\(X_n\) এর মান \(x\) বা তার কম হওয়ার সম্ভাবনা।" প্রতিটি নির্দিষ্ট \(x\)-এ এটা একটা সংখ্যা।
- \(F(x) = P(X \le x)\) — limit random variable \(X\)-এর CDF।
- \(\lim_{n\to\infty} F_n(x) = F(x)\) — প্রতিটি স্থির \(x\)-এর জন্য, সংখ্যা-ক্রম \(F_1(x), F_2(x), \dots\) গিয়ে \(F(x)\)-এ পৌঁছায়।
- "যেখানে \(F\) continuous" শর্তটা কারিগরি কিন্তু জরুরি: \(F\)-এর যেসব বিন্দুতে লাফ (jump) আছে, ঠিক সেই বিন্দুতে মিল না হলেও চলে; আমরা শুধু \(F\)-এর মসৃণ অংশে মিল দাবি করি। (এই খুঁটিনাটি ও কেন দরকার — §৪-এ ব্যাখ্যা করা হবে; স্বজ্ঞায়: "আকৃতি মেলে, শুধু লাফের বিন্দুতে সীমানা নিয়ে কড়াকড়ি নয়।")
সবচেয়ে দুর্বল অর্থ — এবং তাই সবচেয়ে আলাদা। খেয়াল করুন in distribution-এ \(X_n\) আর \(X\) একই sample space-এ থাকার দরকারও নেই — শুধু তাদের CDF তুলনা হয়। তাই \(X_n \xrightarrow{d} X\) মোটেই বলে না যে \(X_n\) আর \(X\) কাছাকাছি মান নেয়; বলে শুধু তাদের পরিসংখ্যানিক প্রোফাইল (probabilistic profile) মিলে যাচ্ছে। এই কারণেই এটা চারটির মধ্যে দুর্বলতম (weakest) — সবচেয়ে কম দাবি করে।
২.৪ Convergence in \(L^p\) / mean-square (\(X_n \xrightarrow{L^p} X\))¶
স্বজ্ঞা। আরেকটা স্বাভাবিক প্রশ্ন: "\(X_n\) আর \(X\)-এর গড় ভুল কি \(0\)-এ যায়?" এখানে ভুল মাপি \(\lvert X_n - X \rvert\) দিয়ে, সেটাকে \(p\)-ঘাত করি (যেন বড় ভুলে বেশি শাস্তি, আর চিহ্ন না থাকে), তারপর তার expectation (গড়) নিই। \(p = 2\) হলে এটা "গড় বর্গ-ভুল" (mean squared error) — পরিসংখ্যানে সবচেয়ে পরিচিত মাপকাঠি।
সংজ্ঞা (convergence in \(L^p\) — \(L^p\)-অর্থে অভিসারণ)। ধরা যাক \(p \ge 1\) একটি স্থির সংখ্যা। আমরা বলি \(X_n\) converge করে \(X\)-এ in \(L^p\), লিখি \(X_n \xrightarrow{L^p} X\), যদি
বিশেষত \(p = 2\) হলে একে বলে mean-square convergence (গড়-বর্গ অভিসারণ), \(X_n \xrightarrow{L^2} X\), এবং শর্তটা দাঁড়ায় \(\mathbb{E}\big[(X_n - X)^2\big] \to 0\)।
প্রতিটি প্রতীক খুলে বলি:
- \(\lvert X_n - X \rvert^{p}\) — দূরত্বের \(p\)-তম ঘাত (একটি random variable)। \(p = 2\) হলে এটা \((X_n - X)^2\), যা সবসময় \(\ge 0\)।
- \(\mathbb{E}[\,\cdot\,]\) — expectation (গড়, 2.5-এ শেখা): সব সম্ভাব্য \(\omega\) জুড়ে ওজন-করা গড়। এটা random জিনিসকে একটি সংখ্যায় পরিণত করে।
- \(\mathbb{E}\big[\lvert X_n - X\rvert^p\big]\) — তাই একটি সংখ্যা: "গড়ে দূরত্বের \(p\)-ঘাত কত।"
- \(\lim_{n\to\infty} \dots = 0\) — সেই সংখ্যার ক্রম \(0\)-এ যায়, অর্থাৎ গড় ভুল মুছে যায়।
এখানে কৌশলটা §২.১-এর মতোই: random জিনিসকে আগে একটি সংখ্যায় (এবার expectation দিয়ে) নামাই, তারপর সেই সংখ্যার সাধারণ limit নিই — কিন্তু "সম্ভাবনা" নয়, "গড় বর্গ-ভুল" দিয়ে।
কেন \(L^2\) পরিসংখ্যানে এত প্রিয়। variance, mean squared error (MSE), least squares — সবই বর্গ-ভুলের ভাষায় বলা। তাই estimator \(\hat\theta_n\) সত্য মান \(\theta\)-তে "\(L^2\)-অর্থে যায়" মানে তার MSE \(\to 0\) — যা Part IV-এ consistency-র খুব ব্যবহারিক একটা রূপ। (\(L^2\) space-এর গভীর জ্যামিতি — inner product, projection — Part VII §৭.৫-এ।)
২.৫ Hierarchy — চার convergence-এর পারস্পরিক সম্পর্ক¶
এবার মূল প্রশ্ন: এই চারটি কি স্বাধীন, নাকি একটা থেকে আরেকটা আসে? উত্তর — এদের মধ্যে একটা শক্তি-ক্রম (hierarchy — পদসোপান) আছে: কিছু convergence অন্যদের চেয়ে কড়া (stronger), আর কড়াটা সত্যি হলে দুর্বলটা আপনাআপনি সত্যি হয়। নিচের তীরগুলো ("\(\Rightarrow\)" মানে "তাহলে এটাও সত্যি") মনে রাখার মতো:
কথায়:
- \(a.s. \Rightarrow P\) — almost sure convergence সবচেয়ে কড়া (পুরো পথ থিতু হওয়া দাবি করে); তা থাকলে প্রতিটি \(n\)-এ দূরে থাকার সম্ভাবনাও স্বাভাবিকভাবে \(0\)-এ যায়। কিন্তু উল্টোটা নয় — শুধু in probability থেকে almost sure আসে না (এর জ্বলন্ত counterexample §৩-এর typewriter sequence)।
- \(L^p \Rightarrow P\) — গড় বর্গ-ভুল \(0\)-এ গেলে দূরে থাকার সম্ভাবনাও \(0\)-এ যায় (স্বজ্ঞা: গড় ভুল ছোট হলে বড় ভুল বিরল হতে বাধ্য — এর পেছনে Markov/Chebyshev inequality, যা 3.1-এ শেখা; পূর্ণ যুক্তি §৪-এ)। কিন্তু উল্টোটা নয় — in probability হলেও গড় বর্গ-ভুল বিস্ফোরিত হতে পারে (যদি বিরল কিন্তু বিশাল মান থাকে)।
- \(P \Rightarrow d\) — convergence in probability থাকলে CDF-ও মিলে যায়, তাই in distribution আসে। কিন্তু উল্টোটা নয় — in distribution সবচেয়ে দুর্বল, আকৃতি মিললেও মান মিলতে হয় না। (একটি ব্যতিক্রম: limit \(X\) যদি একটি ধ্রুবক \(c\) হয়, তবে \(\xrightarrow{d} c\) থেকে \(\xrightarrow{P} c\)-ও আসে — এই বিশেষ ক্ষেত্রটা 3.4-এ Slutsky-র সাথে কাজে লাগবে।)
এই সম্পর্কগুলো একটা ছবিতে গাঁথা যায় — কড়া থেকে দুর্বলের দিকে তীর:
অর্থাৎ \(a.s.\) আর \(L^p\) — দুটোই (আলাদা আলাদাভাবে, একে অপরকে না বোঝালেও) in probability-তে নামে; আর in probability সবার শেষে in distribution-এ নামে। এই পুরো ছবিটাই Figure 3-2-hierarchy — একটা একমুখী পদসোপান, যেখানে তীর কখনো উল্টোদিকে যায় না।
সতর্কতা — \(a.s.\) আর \(L^p\)-এর মধ্যে কোনো সরাসরি তীর নেই। almost sure থেকে \(L^p\) আসে না (পথ থিতু হলেও গড় বর্গ-ভুল বড় থাকতে পারে), আবার \(L^p\) থেকে almost sure-ও আসে না। এরা দুটো আলাদা পথে একই গন্তব্যে (in probability-তে) নামে — একটাকে অন্যটায় রূপান্তর করা যায় না।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এবার চারটি convergence-কে চারটি concrete উদাহরণে দেখি (E1–E4)। বিশেষ মনোযোগ E1-এ — typewriter sequence — কারণ সেটাই hierarchy-র সবচেয়ে গুরুত্বপূর্ণ পাঠ দেয়: in probability হয়েও almost sure না-হওয়া কেমন দেখতে।
৩.১ E1 — Typewriter / sliding-indicator sequence (in probability, কিন্তু NOT almost sure)¶
কাঠামো। ধরা যাক আমাদের sample space হলো \([0,1]\) ব্যবধি (interval), আর একটি random point \(U\) সেখানে Uniform-ভাবে বাছা হয় — অর্থাৎ \(U\)-র \([0,1]\)-এর যেকোনো উপ-ব্যবধিতে পড়ার সম্ভাবনা ঠিক সেই উপ-ব্যবধির দৈর্ঘ্যের সমান। (এই \(U\)-ই হলো আমাদের outcome \(\omega\)।)
এবার \([0,1]\)-কে ক্রমে ছোট ছোট টুকরোয় ভাগ করি — আগে \(1\)টা গোটা টুকরো, তারপর \(2\)টা অর্ধেক, তারপর \(4\)টা... — আর প্রতিটি টুকরোর জন্য একটি indicator random variable বানাই, যা ঐ টুকরোতে \(U\) পড়লে \(1\), না পড়লে \(0\):
| \(n\) | টুকরো (block) | \(X_n = 1\) যদি \(U\) এখানে পড়ে |
|---|---|---|
| \(X_1\) | \([0, 1]\) | পুরো ব্যবধি (দৈর্ঘ্য \(1\)) |
| \(X_2\) | \([0, \tfrac12]\) | বাঁ অর্ধেক (দৈর্ঘ্য \(\tfrac12\)) |
| \(X_3\) | \([\tfrac12, 1]\) | ডান অর্ধেক (দৈর্ঘ্য \(\tfrac12\)) |
| \(X_4\) | \([0, \tfrac14]\) | (দৈর্ঘ্য \(\tfrac14\)) |
| \(X_5\) | \([\tfrac14, \tfrac12]\) | (দৈর্ঘ্য \(\tfrac14\)) |
| \(X_6\) | \([\tfrac12, \tfrac34]\) | (দৈর্ঘ্য \(\tfrac14\)) |
| \(X_7\) | \([\tfrac34, 1]\) | (দৈর্ঘ্য \(\tfrac14\)) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) |
নামটা "typewriter" কারণ সক্রিয় টুকরোটি (যেখানে \(X_n = 1\)) বাঁ থেকে ডানে স্লাইড করে যায়, ডানপ্রান্তে পৌঁছে আবার বাঁয়ে ফিরে আসে আরও সরু হয়ে — পুরোনো টাইপরাইটারের carriage-এর মতো। প্রতিটি "পাস"-এ টুকরো অর্ধেক হয়। আমাদের প্রস্তাবিত limit হলো \(X = 0\) (অর্থাৎ "\(X_n\) কি \(0\)-এ যায়?")।
দাবি ১ — \(X_n \xrightarrow{P} 0\) (in probability সত্যি)। যেকোনো \(\varepsilon \in (0,1)\) ধরি। \(X_n\) হয় \(0\) নয় \(1\); তাই \(\lvert X_n - 0 \rvert > \varepsilon\) ঘটনাটি ঘটে কেবল তখনই যখন \(X_n = 1\), অর্থাৎ \(U\) ঐ \(n\)-তম টুকরোয় পড়ে। সেই সম্ভাবনা ঠিক টুকরোর দৈর্ঘ্য:
আর টুকরোর দৈর্ঘ্য \(n\) বাড়ার সাথে \(\to 0\) (প্রতি পাসে অর্ধেক: \(1, \tfrac12, \tfrac14, \dots\))। কাজেই
দাবি ২ — \(X_n \xrightarrow{a.s.} 0\) মিথ্যা (almost sure ব্যর্থ)। এবার একটা নির্দিষ্ট যাত্রা ধরি — অর্থাৎ একটা নির্দিষ্ট মান \(U = u\) স্থির করি (\(u\) যেকোনো বিন্দু \([0,1]\)-এ)। প্রশ্ন: এই নির্দিষ্ট \(u\)-র জন্য সংখ্যা-ক্রম \(X_1(u), X_2(u), X_3(u), \dots\) কি \(0\)-এ যায়?
লক্ষ করুন — প্রতিটি পাসে (\([0,1]\)-এর প্রতিটি সম্পূর্ণ বিভাজনে) ঠিক একটা টুকরো \(u\)-কে ঢাকবেই (কারণ টুকরোগুলো মিলে পুরো \([0,1]\))। সেই টুকরোর \(X_n(u) = 1\)। অর্থাৎ যত বড় \(n\)-ই ধরি, তার পরেও এমন আরও \(n\) আসবে যেখানে \(X_n(u) = 1\) — অসীমবার \(X_n(u) = 1\) ঘটে, আবার অসীমবার \(X_n(u) = 0\) ঘটে। তাই সংখ্যা-ক্রম \(X_n(u)\) \(0\) আর \(1\)-এর মধ্যে চিরকাল দুলতে থাকে — কোনো limit নেই, \(0\)-এ তো নয়ই।
এটা প্রতিটি \(u \in [0,1]\)-এর জন্য সত্যি। অর্থাৎ যে \(\omega\)-গুলোর জন্য \(\lim X_n(\omega) = 0\), তাদের সংগ্রহ আসলে খালি (সম্ভাবনা \(0\), \(1\) নয়)। সংজ্ঞা §২.২ দাবি করত এই সম্ভাবনা \(= 1\); এখানে তা \(= 0\)। কাজেই
পাঠ — কেন এটাই hierarchy-র হৃদয়। এক নজরে পার্থক্যটা ধরুন:
- In probability খুশি, কারণ প্রতিটি বড় \(n\)-এ "এই মুহূর্তে \(X_n = 1\)" হওয়ার সম্ভাবনা ছোট (টুকরো সরু)। snapshot হিসেবে \(X_n\) প্রায় সবসময়ই \(0\)।
- Almost sure অসন্তুষ্ট, কারণ একটা গোটা যাত্রা ধরলে \(X_n = 1\) লাফ কখনো পুরোপুরি বন্ধ হয় না — অসীমবার ফিরে আসে (শুধু ভিন্ন ভিন্ন \(n\)-এ)। পথ কখনো \(0\)-এ থিতু হয় না।
এই উদাহরণটাই দেখায় কেন \(P \Rightarrow a.s.\) নয় — convergence in probability "মাঝে মাঝে দূরে লাফানো" সহ্য করে যতক্ষণ লাফের সম্ভাবনা কমে, কিন্তু almost sure সেই লাফ চিরতরে থামতে বাধ্য করে। (চলমান সরু টুকরোর এই ছবিই Figure 3-2-typewriter।)
৩.২ E2 — Sample mean \(\bar X_n \to \mu\) (almost sure; SLLN-এর পূর্বাভাস)¶
ধরা যাক \(X_1, X_2, \dots\) হলো i.i.d. (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত) random variable, প্রত্যেকের expectation \(\mathbb{E}[X_i] = \mu\)। sample mean
§১.২-এর কয়েন-উদাহরণে যা দেখেছিলাম। Strong Law of Large Numbers (SLLN) বলে — যা পরের অধ্যায় (3.3)-এ প্রমাণ হবে —
কেন এটা almost sure (শুধু in probability নয়)? কারণ SLLN দাবি করে প্রায় প্রতিটি নির্দিষ্ট যাত্রায় চলমান গড়ের পথটা সত্যিই \(\mu\)-তে গিয়ে থিতু হয় — একবার কাছে এলে আর দূরে লাফায় না। typewriter-এর ঠিক উল্টো ছবি: এখানে পথ স্থায়ীভাবে থিতু হয়। (Weak Law দুর্বলতর — শুধু \(\bar X_n \xrightarrow{P} \mu\); hierarchy অনুসারে strong থেকে weak আপনাআপনি আসে।)
সংখ্যা-অনুভূতি। ন্যায্য কয়েনে \(\mu = 0.5\)। একটা একক অসীম টস-যাত্রা কল্পনা করুন: শুরুতে \(\bar X_n\) লাফায় (\(\bar X_1 \in \{0,1\}\)), কিন্তু \(n\) বড় হলে সেই নির্দিষ্ট যাত্রার গড় \(0.5\)-এ গিয়ে আটকে যায় এবং থাকে। প্রায় সব যাত্রাই এমন — তাই a.s.।
৩.৩ E3 — Standardized / sample-max → in distribution¶
E3a (sum → Normal)। ধরা যাক \(S_n = X_1 + \dots + X_n\) হলো \(n\)টি i.i.d. পদের যোগফল (\(\mu, \sigma^2\) সহ)। standardize করি (গড় সরিয়ে, স্কেলে ভাগ করে):
Central Limit Theorem (3.4) বলে \(Z_n \xrightarrow{d} Z\), যেখানে \(Z \sim \mathcal{N}(0,1)\) (standard Normal)। লক্ষণীয় — এটা অবশ্যই in distribution, কারণ \(Z_n\)-এর প্রকৃত মান \(Z\)-এর প্রকৃত মানের কাছে যায় না (তারা ভিন্ন random variable, এমনকি আলাদা পরীক্ষা থেকেও আসতে পারে); শুধু \(Z_n\)-এর CDF \(F_n\) গিয়ে Normal-এর CDF \(\Phi\)-তে মেলে। অর্থাৎ histogram-এর আকৃতি bell curve হয়ে যায়, মান নয়। concrete রূপ: Binomial\((n, p)\) যথেষ্ট বড় \(n\)-এ Normal-এর মতো দেখায় — এটাই §৬-এর Figure 3-2-in-dist-এ দেখা যাবে।
E3b (sample-max)। আরেকটা in-distribution উদাহরণ: \(X_1,\dots,X_n \sim \text{Uniform}(0,1)\) হলে maximum \(M_n = \max(X_1,\dots,X_n)\) ক্রমে \(1\)-এর দিকে ঠেলে যায়, আর \(n(1 - M_n)\) একটি Exponential বণ্টনে converge করে in distribution। আবারও — আমরা আকৃতির কথা বলছি, নির্দিষ্ট মানের নয়।
৩.৪ E4 — \(X_n \to \mu\) in \(L^2\) (mean-square)¶
ধরা যাক একটি estimator \(X_n\) এমন যে তার expectation \(\mu\)-এর দিকে যায় এবং তার ছড়ানো (variance) \(0\)-এর দিকে যায়; concrete-ভাবে ধরুন গড় ঠিক \(\mu\) এবং \(\mathrm{Var}(X_n) = \sigma^2 / n\) (যেমন sample mean-এর ক্ষেত্রে, 3.3-এ দেখা যাবে \(\mathrm{Var}(\bar X_n) = \sigma^2/n\))। তখন গড় বর্গ-ভুল:
(এখানে \(\mathbb{E}[(X_n - \mu)^2] = \mathrm{Var}(X_n)\) কারণ \(\mathbb{E}[X_n] = \mu\), অর্থাৎ ভুলের গড়টাই variance — 2.5-এর সংজ্ঞা।) যেহেতু গড় বর্গ-ভুল \(0\)-এ যায়, সংজ্ঞা §২.৪ অনুসারে
এবং hierarchy (\(L^2 \Rightarrow P\)) থেকে এর সাথে সাথে \(X_n \xrightarrow{P} \mu\)-ও পাওয়া গেল — অর্থাৎ "MSE \(\to 0\)" একটা সহজ-যাচাইযোগ্য শর্ত যা থেকে in-probability convergence বিনামূল্যে আসে। পরিসংখ্যানে estimator-এর consistency দেখানোর এটাই সবচেয়ে ব্যবহারিক একটা পথ (Part IV)।
চার উদাহরণ এক নজরে। E1 (typewriter): \(P\) আছে, \(a.s.\) নেই — দুর্বলতর কিন্তু \(a.s.\) নয়। E2 (sample mean): \(a.s.\) — কড়া। E3 (standardized sum / max): কেবল \(d\) — দুর্বলতম, শুধু আকৃতি। E4 (MSE \(\to 0\)): \(L^2\), তাই \(P\)-ও। এই চারটি মিলিয়ে hierarchy-র প্রতিটি স্তর একবার করে ছোঁয়া হলো — §৪ থেকে এদের পারস্পরিক প্রমাণ ও আরও counterexample আসবে।
৪ · প্রমাণ ও পাল্টা-উদাহরণ¶
এই অধ্যায়ের কেন্দ্রীয় ফলাফল হলো convergence-এর চার ধরনের মধ্যেকার শ্রেণিবিন্যাস (hierarchy)। কথায় বললে:
অর্থাৎ — \(L^p\)-convergence এবং almost-sure convergence, দুটোই আলাদা আলাদাভাবে convergence in probability-কে টেনে আনে; আর convergence in probability নিজে টেনে আনে convergence in distribution। এই তীরগুলো একমুখী: উল্টোদিকে সাধারণত যাওয়া যায় না। নিচে আমরা প্রতিটা তীর আলাদা করে প্রমাণ করব, প্রতিটার পাশে difficulty-tag (★ = সরাসরি, ★★ = কিছু কৌশল লাগে, ★★★ = কারিগরি/পূর্ণ প্রমাণ এই পর্যায়ের বাইরে) বসিয়ে দেব, এবং কোনটা সম্পূর্ণ প্রমাণ আর কোনটা শুধু স্কেচ — তা পরিষ্কার করে বলব।
এক নজরে সততা-নোট। (a) ও (d) এখানে পূর্ণাঙ্গভাবে প্রমাণিত। (b) ও (c)-এর বিবৃতি (statement) ও মূল ধারণা (intuition) দেওয়া হবে, কিন্তু একদম শেষ কারিগরি ধাপ (measure-theoretic limit বা subsequence argument) আমরা সংক্ষেপে স্কেচ করব — সম্পূর্ণ rigorous প্রমাণ অধ্যায় 3.3-এ measure-theoretic যন্ত্রপাতি হাতে এলে আসবে।
৪.১ · (a) \(L^p \Rightarrow\) in probability ★¶
বিবৃতি। যদি কোনো \(p\ge 1\)-এর জন্য \(X_n \xrightarrow{L^p} X\) হয় — অর্থাৎ \(\mathbb{E}\big[\,\lvert X_n - X\rvert^{\,p}\,\big] \to 0\) — তবে \(X_n \xrightarrow{P} X\)।
এটাই হলো hierarchy-র সবচেয়ে সহজ ও সবচেয়ে কাজে-লাগা তীর, কারণ পরিসংখ্যানে আমরা প্রায়ই mean-squared error (\(p=2\)) ছোট করি, আর তা থেকে বিনামূল্যে convergence in probability পেয়ে যাই। প্রমাণের একমাত্র উপাদান হলো অধ্যায় 3.1-এ পাওয়া Markov inequality (এবং তার বিশেষ রূপ Chebyshev)। সেটা মনে করিয়ে দিই — যেকোনো অঋণাত্মক random variable \(Y \ge 0\) এবং \(a>0\)-এর জন্য:
প্রমাণ (সম্পূর্ণ)। একটা \(\varepsilon>0\) স্থির করি। আমাদের দেখাতে হবে \(P\big(\lvert X_n - X\rvert > \varepsilon\big) \to 0\)।
ধাপ ১ — সঠিক অঋণাত্মক চলক বেছে নেওয়া। \(Y_n := \lvert X_n - X\rvert^{\,p}\) ধরি। যেহেতু absolute value-এর \(p\)-তম ঘাত, \(Y_n \ge 0\) — Markov লাগানোর শর্ত মেটে।
ধাপ ২ — ঘটনাটিকে \(Y_n\)-এর ভাষায় লেখা। লক্ষ্য করো, \(p\ge 1\) হওয়ায় \(t \mapsto t^{p}\) অপেক্ষকটি \([0,\infty)\)-তে বর্ধমান (increasing)। তাই দুই দিকেই \(p\)-তম ঘাত নিলে অসমতার দিক বদলায় না:
অর্থাৎ ঘটনা দুটো হুবহু একই — সুতরাং তাদের সম্ভাবনাও সমান: $$ P\big(\lvert X_n - X\rvert > \varepsilon\big) \;=\; P\big(Y_n > \varepsilon^{\,p}\big). $$
ধাপ ৩ — Markov প্রয়োগ। এবার \((\text{Markov})\)-তে \(Y = Y_n\) এবং \(a = \varepsilon^{\,p}\) বসাই (যেহেতু \(\varepsilon>0\), তাই \(\varepsilon^p>0\) — শর্ত ঠিক আছে):
(প্রথম "\(\le\)" এসেছে কারণ "\(>\)"-ঘটনা "\(\ge\)"-ঘটনার অন্তর্ভুক্ত।)
ধাপ ৪ — সীমা নেওয়া। অনুমান অনুযায়ী \(\mathbb{E}\big[\lvert X_n - X\rvert^{p}\big] \to 0\), আর হরের \(\varepsilon^{p}\) একটি স্থির ধনাত্মক সংখ্যা (যা \(n\)-এর সাথে বদলায় না)। তাই ডানপাশের ভগ্নাংশ \(\to 0\)। মাঝখানে চাপা পড়ে (squeeze, যেহেতু বাঁপাশ \(\ge 0\)):
যেহেতু \(\varepsilon>0\) ছিল যেকোনো, এটি সব \(\varepsilon\)-এর জন্যই খাটে — সংজ্ঞা অনুযায়ী \(X_n \xrightarrow{P} X\)। \(\;\blacksquare\)
\(p=2\)-এর বিশেষ রূপ (Chebyshev) — চোখে আঙুল দিয়ে। \(p=2\) বসালে পাই $\(P\big(\lvert X_n - X\rvert > \varepsilon\big) \le \dfrac{\mathbb{E}[(X_n - X)^2]}{\varepsilon^2}.\)$ এটাই running example E4-কে সরাসরি hierarchy-র সাথে জোড়ে: যদি \(\mathbb{E}[(X_n-\mu)^2]\to 0\) (অর্থাৎ \(X_n \xrightarrow{L^2}\mu\)), তবে উপরের অসমতা বলে \(X_n \xrightarrow{P}\mu\) — কোনো বাড়তি পরিশ্রম ছাড়াই। কোড ল্যাবে (§৫) আমরা সংখ্যায় দেখব এই MSE আসলে \(\sigma^2/n\) হারে শূন্যে নামছে।
৪.২ · (b) almost sure \(\Rightarrow\) in probability ★★¶
বিবৃতি। যদি \(X_n \xrightarrow{a.s.} X\) হয়, তবে \(X_n \xrightarrow{P} X\)।
মূল ধারণা (intuition) — আগে অনুভব করি, পরে প্রমাণ। Almost-sure convergence একটা খুব শক্তিশালী শর্ত: এটা বলে, প্রায় প্রতিটা ফলাফল-পথ (sample path) \(\omega\)-এর জন্য সংখ্যাক্রম \(X_n(\omega)\) আসল \(X(\omega)\)-তে গিয়ে থামে। অর্থাৎ একটা নির্দিষ্ট পথ ধরলে, একটা সময়ের পর সে পথ আর \(\varepsilon\)-এর বাইরে যায়ই না। অন্যদিকে convergence in probability একটা দুর্বল, প্রতিটা-\(n\)-এ-আলাদা শর্ত: শুধু চায়, প্রতিটা নির্দিষ্ট \(n\)-এ "\(\varepsilon\)-এর বাইরে থাকা \(\omega\)-দের পরিমাপ" ছোট হোক। স্বজ্ঞাতভাবে, যদি প্রায় সব পথ একসময় চিরতরে ভিতরে ঢুকে পড়ে, তবে যেকোনো নির্দিষ্ট বড় \(n\)-এ এখনো বাইরে থাকা পথের পরিমাণও নিশ্চয়ই ছোট হতে বাধ্য — তাই শক্তিশালী শর্ত দুর্বলটাকে টেনে আনে।
প্রমাণ (স্কেচ — মূল ধাপ সততার সাথে চিহ্নিত)। almost-sure convergence-কে "tail event"-এর ভাষায় লেখা হলো প্রমাণের আসল চাবি। নিচের "টেইল-ঘটনা" বানাই:
অর্থাৎ \(A_n(\varepsilon)\) হলো সেই পথগুলোর সংগ্রহ যারা \(n\)-এর পর কোথাও-না-কোথাও এখনো \(\varepsilon\)-এর বাইরে লাফ দেয়।
ধাপ ১ — almost-sure মানে টেইল-পরিমাপ শূন্যে নামে। \(X_n \xrightarrow{a.s.} X\) হওয়ার একটা সমতুল্য (এবং standard) রূপ হলো: প্রতিটা \(\varepsilon>0\)-এর জন্য \(P\big(A_n(\varepsilon)\big) \to 0\) যখন \(n\to\infty\)। (এই সমতুল্যতাটিই measure-theoretic ধাপ — এটি আমরা এখানে অনুমান হিসেবে নিচ্ছি; পূর্ণ যাচাই 3.3-এ।) কারণটা স্বজ্ঞাত: পথ \(\omega\) যদি converge করে, তবে যথেষ্ট বড় \(n\)-এর পর সে \(\varepsilon\)-গণ্ডির ভিতরেই থাকে, তাই সে \(A_n(\varepsilon)\)-তে আর থাকে না; ফলে \(A_n(\varepsilon)\) ক্রমশ "খালি"-র দিকে সংকুচিত হয় এবং তার পরিমাপ শূন্যে যায়।
ধাপ ২ — এক-\(n\)-এর ঘটনা টেইল-ঘটনার ভিতরে। এবার একদম সরল পর্যবেক্ষণ — যে পথ নির্দিষ্ট \(n\)-এ বাইরে, সে অবশ্যই "\(\ge n\) কোথাও বাইরে"-দের একজন: $$ \big{\lvert X_n - X\rvert > \varepsilon\big} \;\subseteq\; A_n(\varepsilon). $$ কারণ \(m=n\) ধরলেই \(\sup_{m\ge n}\lvert X_m - X\rvert \ge \lvert X_n - X\rvert > \varepsilon\)। উপসেট হলে পরিমাপও ছোট (monotonicity, 3.1): $$ P\big(\lvert X_n - X\rvert > \varepsilon\big) \;\le\; P\big(A_n(\varepsilon)\big). $$
ধাপ ৩ — সীমা। ধাপ ১ বলে ডানপাশ \(\to 0\); squeeze করলে বাঁপাশও \(\to 0\) — অর্থাৎ \(X_n \xrightarrow{P} X\)। \(\;\square\)
স্কেচ কেন, পূর্ণ নয়? শুধু ধাপ ১-এর সমতুল্যতা ("\(a.s.\Leftrightarrow P(A_n)\to 0\)") প্রমাণে continuity-of-measure লাগে, যা measure theory-র ফল। বাকি দুই ধাপ (set-inclusion ও squeeze) সম্পূর্ণ এবং elementary। তাই এটিকে আমরা honest sketch বলছি — কঙ্কাল পুরো, একটি গাঁট 3.3-এ শক্ত হবে।
৪.৩ · (c) in probability \(\Rightarrow\) in distribution ★★¶
বিবৃতি। যদি \(X_n \xrightarrow{P} X\) হয়, তবে \(X_n \xrightarrow{d} X\) — অর্থাৎ \(F\)-এর প্রতিটা continuity point \(x\)-এ \(F_n(x) \to F(x)\), যেখানে \(F_n, F\) যথাক্রমে \(X_n, X\)-এর CDF।
মূল ধারণা। Convergence in probability বলে \(X_n\) ও \(X\) "প্রায় একই জায়গায়" থাকে (পার্থক্য \(\varepsilon\)-এর বাইরে যাওয়ার সম্ভাবনা ছোট)। দুটো চলক যদি প্রায় একই জায়গায় থাকে, তবে "\(X_n \le x\)" আর "\(X \le x\)" ঘটনা দুটোও প্রায় একই — শুধু \(x\)-এর একদম গা-ঘেঁষা সীমানায় (boundary) সামান্য গরমিল হতে পারে। সেই সীমানা-গরমিলটাই continuity point-এ মিলিয়ে যায়, তাই সেখানে \(F_n(x)\to F(x)\)।
প্রমাণ (sandwich — মূল অংশ সম্পূর্ণ, শেষ ধাপ স্কেচ)। \(x\) হোক \(F\)-এর একটা continuity point, আর \(\varepsilon>0\) যেকোনো ছোট সংখ্যা।
ধাপ ১ — উপরের বেড়া (upper bound)। ঘটনা \(\{X_n \le x\}\)-কে দুই টুকরোয় ভাঙি — হয় \(X\)-ও কাছাকাছি ছোট, নয়তো \(X_n\) আর \(X\) অনেক দূরে: $$ {X_n \le x} \;\subseteq\; {X \le x+\varepsilon} \;\cup\; {\lvert X_n - X\rvert > \varepsilon}. $$ (যুক্তি: যদি \(X_n \le x\) অথচ \(X > x+\varepsilon\) হয়, তবে \(X - X_n > \varepsilon\), অর্থাৎ \(\lvert X_n - X\rvert > \varepsilon\) — তাই বাঁদিকের যেকোনো ফলাফল ডানদিকের কোনো-না-কোনো ঘটনায় পড়ে।) পরিমাপ নিয়ে (union bound, 3.1): $$ F_n(x) = P(X_n \le x) \;\le\; P(X \le x+\varepsilon) + P(\lvert X_n - X\rvert > \varepsilon) = F(x+\varepsilon) + r_n, $$ যেখানে \(r_n := P(\lvert X_n - X\rvert > \varepsilon)\)।
ধাপ ২ — নিচের বেড়া (lower bound)। হুবহু একই কায়দায়, ভূমিকা উল্টে \(\{X \le x-\varepsilon\}\) থেকে শুরু করি: $$ {X \le x-\varepsilon} \;\subseteq\; {X_n \le x} \;\cup\; {\lvert X_n - X\rvert > \varepsilon}, $$ যা দেয় $$ F(x-\varepsilon) \;\le\; F_n(x) + r_n \qquad\Longrightarrow\qquad F(x-\varepsilon) - r_n \;\le\; F_n(x). $$
ধাপ ৩ — দুই বেড়া একসাথে (sandwich)। ধাপ ১ ও ২ মিলিয়ে: $$ F(x-\varepsilon) - r_n \;\le\; F_n(x) \;\le\; F(x+\varepsilon) + r_n. $$
ধাপ ৪ — সীমা, দুই পর্যায়ে। অনুমান \(X_n \xrightarrow{P} X\) বলে \(r_n \to 0\)। তাই \(n\to\infty\) নিলে (liminf/limsup নিয়ে): $$ F(x-\varepsilon) \;\le\; \liminf_n F_n(x) \;\le\; \limsup_n F_n(x) \;\le\; F(x+\varepsilon). $$ এবার \(\varepsilon \downarrow 0\) পাঠাই। যেহেতু \(x\) একটা continuity point, সংজ্ঞা অনুযায়ী \(F(x-\varepsilon)\to F(x)\) এবং \(F(x+\varepsilon)\to F(x)\) — দুই বেড়াই \(F(x)\)-তে এসে মেলে। ফলে \(\liminf\) ও \(\limsup\) চাপা পড়ে সমান হয়: $$ \lim_{n\to\infty} F_n(x) = F(x). \qquad \blacksquare\ (\text{continuity point-এ}) $$
এখানে স্কেচ কোথায়? আসলে খুব কম। ধাপ ১–৩ সম্পূর্ণ elementary ও পূর্ণ। একমাত্র সূক্ষ্মতা ধাপ ৪-এ liminf–limsup নিয়ে কারবার — এটা rigorous, তবে "\(\liminf=\limsup\Rightarrow\lim\) exists" তথ্যটি প্রকৃত-বিশ্লেষণের (real analysis) মান ফল ধরে নেওয়া হলো। তাই (c)-কে কার্যত সম্পূর্ণ প্রমাণ ধরাই ন্যায্য — শুধু continuity-point-এ সীমাবদ্ধ থাকার শর্তটা মাথায় রাখলেই হলো। discontinuity point-এ দাবি করা হয়ই না — পরের উপধারায় এর কারণ স্পষ্ট হবে।
৪.৪ · (d) উল্টো তীরগুলো ভাঙে — running examples দিয়ে ★¶
এতক্ষণ চারটে "\(\Rightarrow\)" দেখলাম। এবার দেখাই, এদের কোনোটাই উল্টোভাবে খাটে না — অর্থাৎ hierarchy-টা সত্যিকারের কঠোর (strict)। দুটো পাল্টা-উদাহরণই যথেষ্ট, আর দুটোই আমাদের running examples থেকে।
(d-১) in probability \(\not\Rightarrow\) almost sure — typewriter (E1)¶
এটি hierarchy-র সবচেয়ে বিখ্যাত পাল্টা-উদাহরণ, যা দেখায় (b)-এর তীর উল্টানো যায় না।
গঠন (construction)। \([0,1]\) ব্যবধানে একে একে ছোট-হতে-থাকা টুকরো "স্ক্যান" করি, যেন টাইপরাইটারের ক্যারেজ বাঁ-থেকে-ডানে ছুটছে। চলকগুলো block ধরে সাজাই:
- block \(b=0,1,2,\dots\)-তে ঠিক \(2^b\)টি চলক, প্রতিটি একটি \(\frac{1}{2^b}\)-চওড়া উপব্যবধানের indicator: $$ \text{block }b,\ \text{slot }j\ (j=0,\dots,2^b-1): \quad X^{(b,j)}(\omega) = \mathbf{1}!\left[\, \tfrac{j}{2^b} \le \omega < \tfrac{j+1}{2^b} \,\right],\qquad \omega \sim \text{Uniform}(0,1). $$ এদের লম্বা সারিতে বসালে পাই \(X_1, X_2, X_3, \dots\) — যেখানে block \(0\) দেয় \(X_1\), block \(1\) দেয় \(X_2, X_3\), block \(2\) দেয় \(X_4,X_5,X_6,X_7\), ইত্যাদি।
দাবি ১ — \(X_n \xrightarrow{P} 0\)। \(n\)-তম চলকটি block \(b\)-তে পড়লে সেটি একটি \(\frac{1}{2^b}\)-চওড়া উপব্যবধানের indicator, তাই $$ P\big(X_n > \varepsilon\big) = P\big(X_n = 1\big) = \frac{1}{2^b} \quad (0<\varepsilon<1). $$ \(n\to\infty\) হলে block-সূচক \(b\to\infty\) (কারণ প্রতিটা block শেষ হলেই পরের, আরও বড়, block শুরু), সুতরাং \(\frac{1}{2^b} \to 0\)। অর্থাৎ \(P(\lvert X_n - 0\rvert>\varepsilon)\to 0\) — convergence in probability to \(0\)। (কোড ল্যাবে এই \(\approx 1/2^b\) হ্রাস আমরা সংখ্যায় ধরব।)
দাবি ২ — কিন্তু \(X_n \not\xrightarrow{a.s.} 0\)। স্থির করো যেকোনো একটা ফলাফল \(\omega\in[0,1]\) (ধরা যাক \(\omega\) irrational, যাতে সীমানায় না পড়ে)। প্রতিটা block \(b\)-তে ঠিক একটি slot \(j\) আছে যার উপব্যবধান \([\frac{j}{2^b},\frac{j+1}{2^b})\) এই \(\omega\)-কে ঢেকে রাখে — সেই slot-এ \(X^{(b,j)}(\omega)=1\)। যেহেতু এটা প্রতিটা block-এ ঘটে, সংখ্যাক্রম \(X_n(\omega)\) অসীমবার \(1\)-এ ফিরে আসে (আবার অন্য slot-এ \(0\))। তাই \(X_n(\omega)\) কখনো একটামাত্র সীমায় থিতু হয় না — \(\limsup_n X_n(\omega)=1\) অথচ \(\liminf_n X_n(\omega)=0\)। এটা প্রতিটা \(\omega\)-এর জন্য সত্য, তাই যে \(\omega\)-সেটে convergence ঘটে তার পরিমাপ \(0\) — সংজ্ঞা অনুযায়ী almost-sure convergence ব্যর্থ।
উপসংহার। \(X_n \xrightarrow{P} 0\) অথচ \(X_n \not\xrightarrow{a.s.} 0\) — সুতরাং "in probability \(\Rightarrow\) a.s." মিথ্যা। এই একই উদাহরণ আরও বলে: \(L^p\)-ও জরুরি নয়, কারণ এখানে \(\mathbb{E}[X_n^p]=\frac{1}{2^b}\to 0\), তাই \(X_n\xrightarrow{L^p}0\)ও বটে — তবু a.s. নেই। অর্থাৎ \(L^p \not\Rightarrow a.s.\)ও একই ধাক্কায় দেখা হয়ে গেল। \(\;\blacksquare\)
(d-২) in distribution \(\not\Rightarrow\) in probability — degenerate (সমমিত) উদাহরণ¶
এটি দেখায় (c)-এর তীর উল্টানো যায় না — convergence in distribution সবচেয়ে দুর্বল, সে "মান" নয় শুধু "বণ্টন" মেলায়।
গঠন। একটিমাত্র symmetric চলক নিই: \(Z\) এমন যে \(P(Z=+1)=P(Z=-1)=\tfrac12\) (একটা ন্যায্য মুদ্রা, head=+1, tail=−1)। এখন সংজ্ঞা দিই $$ X_n := (-1)^n Z, \qquad\text{এবং লক্ষ্য চলক}\quad X := Z. $$ অর্থাৎ \(X_1=-Z,\ X_2=+Z,\ X_3=-Z,\dots\) — চিহ্ন পালা করে উল্টায়।
দাবি ১ — \(X_n \xrightarrow{d} X\)। মূল কথা: \(Z\) symmetric, তাই \(-Z\) ও \(+Z\)-এর বণ্টন হুবহু এক (\(-Z\)-ও সমান সম্ভাবনায় \(\pm1\))। ফলে প্রতিটা \(n\)-এর জন্যই \(X_n\)-এর CDF ঠিক \(X\)-এর CDF-এর সমান: \(F_n \equiv F\) (যেখানে \(F\)-এর লাফ \(-1\) ও \(+1\)-এ)। একই CDF মানে \(F_n(x)\to F(x)\) তুচ্ছভাবে সব continuity point-এ — সুতরাং \(X_n \xrightarrow{d} X\)। (খেয়াল করো: \(x=\pm1\) হলো discontinuity point, আর সেখানে \(F_n=F\) হলেও দাবিটা সেখানে লাগেই না — ৪.৩-এর "continuity point-only" শর্তের তাৎপর্য এখানেই।)
দাবি ২ — কিন্তু \(X_n \not\xrightarrow{P} X\)। এবার "মান" দেখি, "বণ্টন" নয়। বিজোড় \(n\)-এর জন্য \(X_n - X = -Z - Z = -2Z\), তাই \(\lvert X_n - X\rvert = 2\lvert Z\rvert = 2\) (সর্বদা, কারণ \(\lvert Z\rvert=1\))। সুতরাং \(\varepsilon=1\) ধরলে, প্রতিটা বিজোড় \(n\)-এ $$ P\big(\lvert X_n - X\rvert > 1\big) = P(2 > 1) = 1 \;\not\to\; 0. $$ যেহেতু সম্ভাবনাটি অসীমবার \(1\)-এ আটকে থাকে, কোনোভাবেই \(\to 0\) হয় না — convergence in probability ব্যর্থ।
উপসংহার। \(X_n \xrightarrow{d} X\) অথচ \(X_n \not\xrightarrow{P} X\) — সুতরাং "in distribution \(\Rightarrow\) in probability" মিথ্যা। (একটামাত্র গুরুত্বপূর্ণ ব্যতিক্রম: যদি সীমা \(X=c\) একটি ধ্রুবক হয়, তবে \(\xrightarrow{d} c\) থেকে \(\xrightarrow{P} c\) ফেরত পাওয়া যায় — এই বিশেষ ফলটি 3.3-এ আসবে; উপরের পাল্টা-উদাহরণ কাজ করল কারণ \(X=Z\) ধ্রুবক নয়।) \(\;\blacksquare\)
৪.৫ · সারমর্ম: কোনটা প্রমাণ, কোনটা স্কেচ¶
| তীর | difficulty | অবস্থা | মূল যন্ত্র |
|---|---|---|---|
| (a) \(L^p \Rightarrow P\) | ★ | সম্পূর্ণ প্রমাণ | Markov/Chebyshev (3.1) |
| (b) \(a.s. \Rightarrow P\) | ★★ | honest স্কেচ (১টি গাঁট 3.3-এ) | tail-event \(A_n(\varepsilon)\), monotonicity |
| (c) \(P \Rightarrow d\) | ★★ | কার্যত সম্পূর্ণ (continuity-point-এ) | sandwich + union bound |
| (d-১) \(P \not\Rightarrow a.s.\) | ★ | সম্পূর্ণ পাল্টা-উদাহরণ | typewriter (E1) |
| (d-২) \(d \not\Rightarrow P\) | ★ | সম্পূর্ণ পাল্টা-উদাহরণ | degenerate \((-1)^n Z\) |
মূল ছবি: \(L^p\) ও \(a.s.\) — দুই শক্তিশালী মোড — গিয়ে মেশে \(P\)-তে; \(P\) গিয়ে মেশে সবচেয়ে দুর্বল \(d\)-তে; আর প্রতিটা তীর কঠোরভাবে একমুখী। পরের §৫-এ আমরা এই পাঁচটা দাবিকেই সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা §৪-এর প্রতিটা দাবি সিমুলেশনে দেখব — যাতে hierarchy শুধু কাগজে নয়, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, এবং একটা স্থির seed (20260619) বসানো — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible), যে যতবার চালাবে একই সংখ্যা পাবে।
আমরা চারটি জিনিস মাপব:
- E1 (typewriter): \(P(\lvert X_n - 0\rvert > \varepsilon) \to 0\) — অথচ a.s. নয় (block-সর্বোচ্চ \(1\)-এ আটকে থাকে)।
- E2 (\(\bar X_n\)): \(P(\lvert \bar X_n - \mu\rvert > \varepsilon) \to 0\), এবং একটিমাত্র পথের tail-sup কমে — almost-sure-এর সাক্ষ্য।
- E3 (in distribution): empirical CDF \(F_n \to F\) অর্থে \(\sup_x \lvert F_n(x) - F(x)\rvert \to 0\) (CLT দিয়ে \(N(0,1)\)-এ)।
- E4 (\(L^2\)): \(\mathbb{E}[(\bar X_n - \mu)^2] \to 0\), আর তা মেলে তত্ত্বের \(\sigma^2/n\)-এর সাথে।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 3.2 — Types of Convergence : Code Lab
# Numerically illustrates the convergence-type hierarchy with the running examples.
import numpy as np
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => reproducible
# ---------------------------------------------------------------
# E1 Typewriter sequence: X_n -> 0 in probability, NOT a.s.
# ---------------------------------------------------------------
# Block b (b = 0,1,2,...) has 2^b indicators, each = 1 on an interval of
# width 1/2^b that sweeps across [0,1]. P(X_n = 1) = 1/2^b -> 0
# => convergence in probability.
# But every point of [0,1] is hit infinitely often => NOT a.s.
def typewriter_index(n):
"""Map global index n (1-based) to (block b, lo, hi) of its indicator.
Block b occupies indices 2^b .. 2^(b+1)-1 and has 2^b slots of width 1/2^b."""
b, start = 0, 1
while start + (2 ** b) - 1 < n: # advance until n falls inside block b
start += 2 ** b
b += 1
j = n - start # 0-based slot, 0 <= j < 2^b
m = 2 ** b
return b, j / m, (j + 1) / m
def typewriter_prob_gt_eps(n, eps, M=200_000):
b, lo, hi = typewriter_index(n)
u = rng.random(M) # U ~ Uniform(0,1)
X = ((u >= lo) & (u < hi)).astype(float)
return np.mean(X > eps), (hi - lo)
eps = 0.5
print("--- E1 Typewriter: P(|X_n - 0| > eps) -> 0 ? ---")
print(f"{'n':>6} {'block b':>8} {'width(1/2^b)':>13} {'P(X_n>eps)~':>12}")
for n in [1, 5, 20, 55, 210, 820, 3160]:
p_emp, width = typewriter_prob_gt_eps(n, eps)
b, _, _ = typewriter_index(n)
print(f"{n:>6} {b:>8} {width:>13.5f} {p_emp:>12.5f}")
# ---------------------------------------------------------------
# E2 Sample mean: Xbar_n -> mu almost surely (strong LLN)
# ---------------------------------------------------------------
mu, sigma, eps2 = 3.0, 2.0, 0.2
Nrep, Nmax = 4000, 5000
data = rng.normal(mu, sigma, size=(Nrep, Nmax))
running_mean = np.cumsum(data, axis=1) / np.arange(1, Nmax + 1)
print("\n--- E2 Sample mean: P(|Xbar_n - mu| > eps) -> 0 ---")
print(f"{'n':>6} {'P(|Xbar-mu|>eps)~':>18}")
for n in [10, 50, 200, 1000, 5000]:
print(f"{n:>6} {np.mean(np.abs(running_mean[:, n-1] - mu) > eps2):>18.5f}")
one = running_mean[0] # a single path
tail_sup = [np.max(np.abs(one[n-1:] - mu)) for n in [10, 100, 1000]]
print(" one path sup_{m>=n}|Xbar_m-mu| (n=10,100,1000):",
np.round(tail_sup, 4))
# ---------------------------------------------------------------
# E3 In distribution: empirical CDF F_n -> F (CLT to N(0,1))
# ---------------------------------------------------------------
from math import erf
Phi = np.vectorize(lambda x: 0.5 * (1.0 + erf(x / np.sqrt(2.0))))
sd_unif = 1.0 / np.sqrt(12.0)
grid = np.linspace(-3.5, 3.5, 141)
F_true = Phi(grid)
print("\n--- E3 In distribution: sup_x |F_n(x) - Phi(x)| -> 0 ---")
print(f"{'n':>6} {'sup|Fn - Phi|':>14}")
for n in [1, 2, 5, 30, 200]:
U = rng.random(size=(60_000, n))
Z = (U.mean(axis=1) - 0.5) / (sd_unif / np.sqrt(n)) # standardized
Zs = np.sort(Z)
F_emp = np.searchsorted(Zs, grid, side="right") / Z.size
print(f"{n:>6} {np.max(np.abs(F_emp - F_true)):>14.5f}")
# ---------------------------------------------------------------
# E4 L^2 convergence: E[(Xbar_n - mu)^2] -> 0 ( = sigma^2 / n )
# ---------------------------------------------------------------
print("\n--- E4 L^2: E[(Xbar_n - mu)^2] -> 0 ---")
print(f"{'n':>6} {'emp MSE':>12} {'theory s^2/n':>14}")
for n in [10, 50, 200, 1000, 5000]:
mse = np.mean((running_mean[:, n-1] - mu) ** 2)
print(f"{n:>6} {mse:>12.6f} {sigma**2 / n:>14.6f}")
৫.২ · বাস্তব আউটপুট¶
উপরের স্ক্রিপ্ট চালালে (seed 20260619, numpy 2.2.6) ঠিক নিচের আউটপুট আসে — এগুলো সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয়:
--- E1 Typewriter: P(|X_n - 0| > eps) -> 0 ? ---
n block b width(1/2^b) P(X_n>eps)~
1 0 1.00000 1.00000
5 2 0.25000 0.25150
20 4 0.06250 0.06253
55 5 0.03125 0.03158
210 7 0.00781 0.00766
820 9 0.00195 0.00191
3160 11 0.00049 0.00052
--- E2 Sample mean: P(|Xbar_n - mu| > eps) -> 0 ---
n P(|Xbar-mu|>eps)~
10 0.76475
50 0.47850
200 0.15450
1000 0.00125
5000 0.00000
one path sup_{m>=n}|Xbar_m-mu| (n=10,100,1000): [0.9047 0.1185 0.0807]
--- E3 In distribution: sup_x |F_n(x) - Phi(x)| -> 0 ---
n sup|Fn - Phi|
1 0.05839
2 0.01896
5 0.00642
30 0.00278
200 0.00263
--- E4 L^2: E[(Xbar_n - mu)^2] -> 0 ---
n emp MSE theory s^2/n
10 0.406824 0.400000
50 0.077940 0.080000
200 0.019666 0.020000
1000 0.003966 0.004000
5000 0.000778 0.000800
৫.৩ · আউটপুট কীভাবে পড়ব — দাবি মিলিয়ে দেখা¶
- E1 — typewriter (in prob, not a.s.).
P(X_n>eps)~কলামটা প্রায় হুবহুwidth(1/2^b)-এর সমান, আর block \(b\) বাড়ার সাথে দুটোই \(1.0 \to 0.0005\)-এ নামছে। এটাই §৪.৪-এর দাবি ১-এর সংখ্যাগত রূপ: \(P(\lvert X_n\rvert>\varepsilon)=\frac{1}{2^b}\to 0\) → convergence in probability। অথচ প্রতিটা block-এ একটা-না-একটা slot সর্বদা \(1\) দেয়, তাই কোনো একক path থামে না — সেইজন্য সিমুলেশন a.s. দেখাতে পারে না (এবং দেখানোর কথাও নয়): এটা §৪.৪ দাবি ২-এর সরাসরি প্রতিফলন। - E2 — sample mean (a.s., তাই in prob-ও). \(P(\lvert\bar X_n-\mu\rvert>0.2)\) কলামটা \(0.76 \to 0.00\)-এ নামছে (\(n\) বাড়লে) — convergence in probability স্পষ্ট। বাড়তি সাক্ষ্য: একটিমাত্র path-এর
sup_{m>=n}|Xbar_m-mu|রাশিটা \(0.90 \to 0.12 \to 0.08\)-এ কমছে, অর্থাৎ একটা নির্দিষ্ট path-ও একসময় চিরতরে \(\mu\)-এর কাছে আটকে যাচ্ছে — এটাই almost-sure আচরণের সাক্ষাৎ ছবি (§৪.২-এর tail-event \(A_n(\varepsilon)\) ছোট হওয়া)। - E3 — in distribution (CDF convergence).
sup|Fn - Phi|রাশিটা \(0.058 \to 0.003\)-এ নামছে যখন \(n\) বাড়ে — অর্থাৎ \(\bar U_n\)-কে standardize করা চলকের empirical CDF ক্রমশ \(N(0,1)\)-এর CDF \(\Phi\)-এর গায়ে বসে যাচ্ছে। এটাই \(F_n\to F\) তথা convergence in distribution (CLT-চালিত)। (\(n=200\)-এ \(\approx 0.0026\)-এ থিতু হওয়া Monte-Carlo দানার (sampling noise) ফল — \(60{,}000\) নমুনার সীমা; আসল সীমা \(0\)।) - E4 — \(L^2\).
emp MSEকলাম প্রায় হুবহুtheory s^2/n-এর সমান, আর \(n\) বাড়ার সাথে \(0.41 \to 0.0008\)-এ নামছে — অর্থাৎ \(\mathbb{E}[(\bar X_n-\mu)^2]\to 0\), তথা convergence in \(L^2\)। আর §৪.১-এর Chebyshev-প্রমাণ অনুযায়ী এই \(L^2\)-পতনই E2-র convergence in probability-কে বিনামূল্যে নিশ্চিত করে — কাগজ আর সংখ্যা এখানে একই কথা বলছে।
সততা-নোট। সিমুলেশন কখনো almost-sure convergence "প্রমাণ" করে না (তার জন্য অসীম-লম্বা পথ লাগত); এটা শুধু সাক্ষ্য দেয় — E2-তে tail-sup কমা সেই সাক্ষ্য, আর E1-এ tail কমতে অস্বীকার করা ঠিক উল্টো সাক্ষ্য। প্রকৃত প্রমাণ §৪-এর কাজ; কোড সেই প্রমাণকে চোখে দেখায় মাত্র।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_3-2.py-তে তৈরি; PNG_assets/-এ (prefix3-2, dpi=150)। in-figure লেখা সব ইংরেজিতে। প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা আছে — beginner-এর জন্য এটাই আসল শেখার সূত্র।
এই অধ্যায়ের ভেতরের ধারণাগুলো ভাষায় বললে শক্ত শোনায়, কিন্তু ছবিতে দেখলে স্বচ্ছ হয়ে যায়। আমরা চারটি ছবি দিয়ে চারটি জিনিস "চোখে দেখব": (১) চার ধরনের convergence কীভাবে একে অপরকে imply করে, (২) convergence in probability আসলে দেখতে কেমন, (৩) convergence in distribution-এ CDF কীভাবে ধীরে ধীরে limit-এর দিকে গড়িয়ে যায়, আর (৪) সেই বিখ্যাত typewriter sequence — যা in probability converge করে কিন্তু almost surely করে না।
Figure 1 — convergence-এর শ্রেণীবিন্যাস (hierarchy)¶
পুরো অধ্যায়ের কঙ্কাল এক ছবিতে। চারটি বাক্স — almost sure (\(\xrightarrow{a.s.}\)), \(L^p\) (\(\xrightarrow{L^p}\)), in probability (\(\xrightarrow{P}\)), in distribution (\(\xrightarrow{d}\)) — আর তাদের মধ্যে এক-মুখী তীর। যা লক্ষ করতে হবে: তীরগুলো কেবল একদিকে যায় (strong \(\Rightarrow\) weak), উল্টোদিকে নয়। almost sure ও \(L^p\) — দুটোই "শক্তিশালী" mode আর দুটোই আলাদাভাবে \(\xrightarrow{P}\) imply করে; কিন্তু এদের একটি অন্যটিকে imply করে না (লাল বাক্স)। সবচেয়ে দুর্বল mode convergence in distribution — আর \(\xrightarrow{d}\) থেকে \(\xrightarrow{P}\)-তে ফেরা যায় না, একমাত্র ব্যতিক্রম যখন limit একটা ধ্রুবক (constant)।
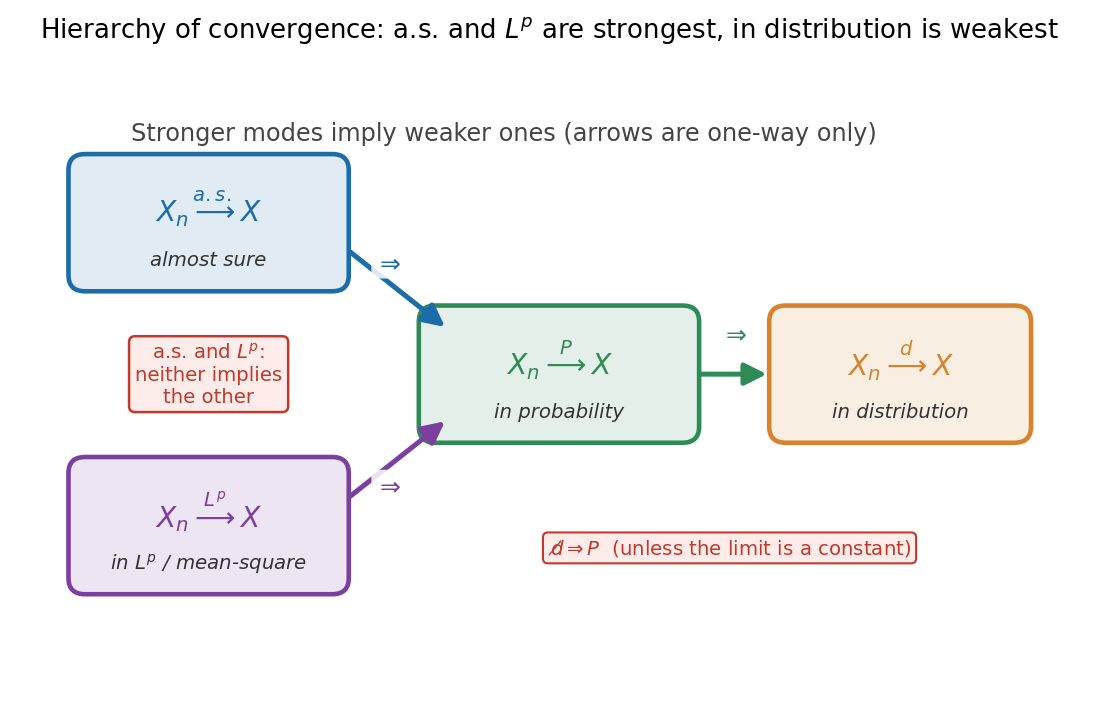
Figure 2 — convergence in probability দেখতে কেমন¶
এই অধ্যায়ের কেন্দ্রীয় ছবি। বাঁ প্যানেলে \(200\)টি simulated path: প্রতিটি হলো iid নমুনার চলমান গড় \(X_n=\bar X_n\) (running mean), যার limit \(X=\mu\) (এখানে \(0\))। চারপাশে সবুজ shaded ব্যান্ড \([\mu-\varepsilon,\ \mu+\varepsilon]\) (\(\varepsilon=0.25\))। যা লক্ষ করতে হবে: শুরুতে path-গুলো এলোমেলো ছড়ানো, কিন্তু \(n\) বাড়ার সাথে সাথে সবাই একটা ফানেলের মতো ব্যান্ডের ভেতরে ঢুকে পড়ে। ডান প্যানেলে সেই "ভেতরে ঢোকা"-টাই সংখ্যায়: যত ভগ্নাংশ path এখনো ব্যান্ডের বাইরে (\(\lvert X_n-X\rvert>\varepsilon\)), সেটা — অর্থাৎ \(P(\lvert X_n-X\rvert>\varepsilon)\)-এর আনুমানিক রূপ — দ্রুত \(0\)-তে নেমে যায়। এটাই convergence in probability-র সংজ্ঞা: প্রতিটি স্থির \(\varepsilon\)-এর জন্য বাইরে-থাকার probability \(\to 0\) (E2)।
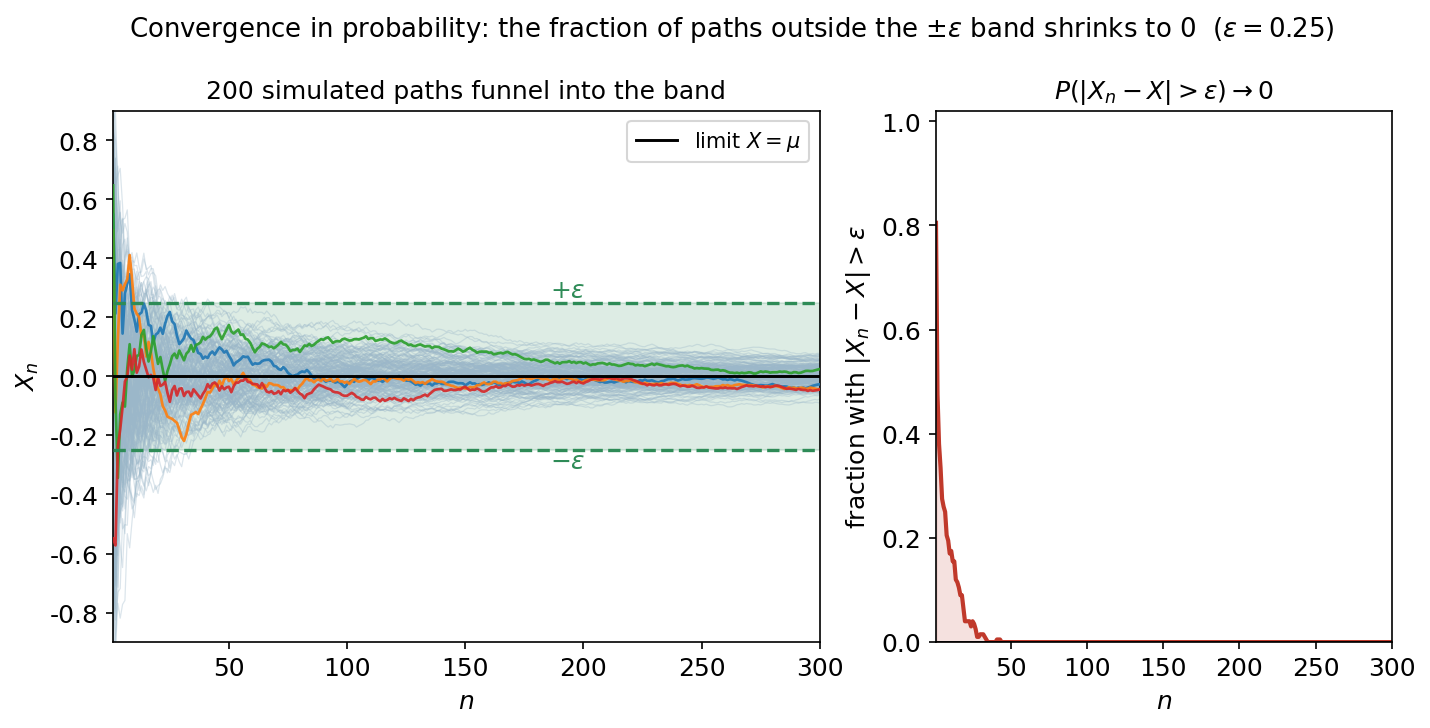
Figure 3 — convergence in distribution: CDF গড়িয়ে যায়¶
convergence in distribution শুধু সংখ্যা নয়, পুরো আকৃতি-র ব্যাপার। কালো মোটা রেখা হলো limit CDF \(F\) (এখানে standard Normal-এর \(\Phi\))। তিনটি ধাপের রঙিন step-curve হলো empirical CDF \(F_n\), তিনটি ভিন্ন নমুনা-আকার \(n=5,30,500\)-এর জন্য — উৎস কিন্তু skewed (Exponential), Normal নয়। যা লক্ষ করতে হবে: \(n\) ছোট হলে \(F_n\) অমসৃণ ও \(F\) থেকে দূরে; \(n\) বাড়লে step-curve মসৃণ হয়ে ঠিক \(\Phi\)-র গায়ে বসে যায়। অর্থাৎ \(F_n(x)\to F(x)\) \(F\)-এর প্রতিটি continuity point-এ — এটাই \(\xrightarrow{d}\) (E3)। চমক: উৎস বাঁকানো হলেও standardized গড়ের CDF ঘণ্টা-curve-এর CDF-এর দিকে গড়ায় (Central Limit Theorem-এর পূর্বাভাস, 3.4)।
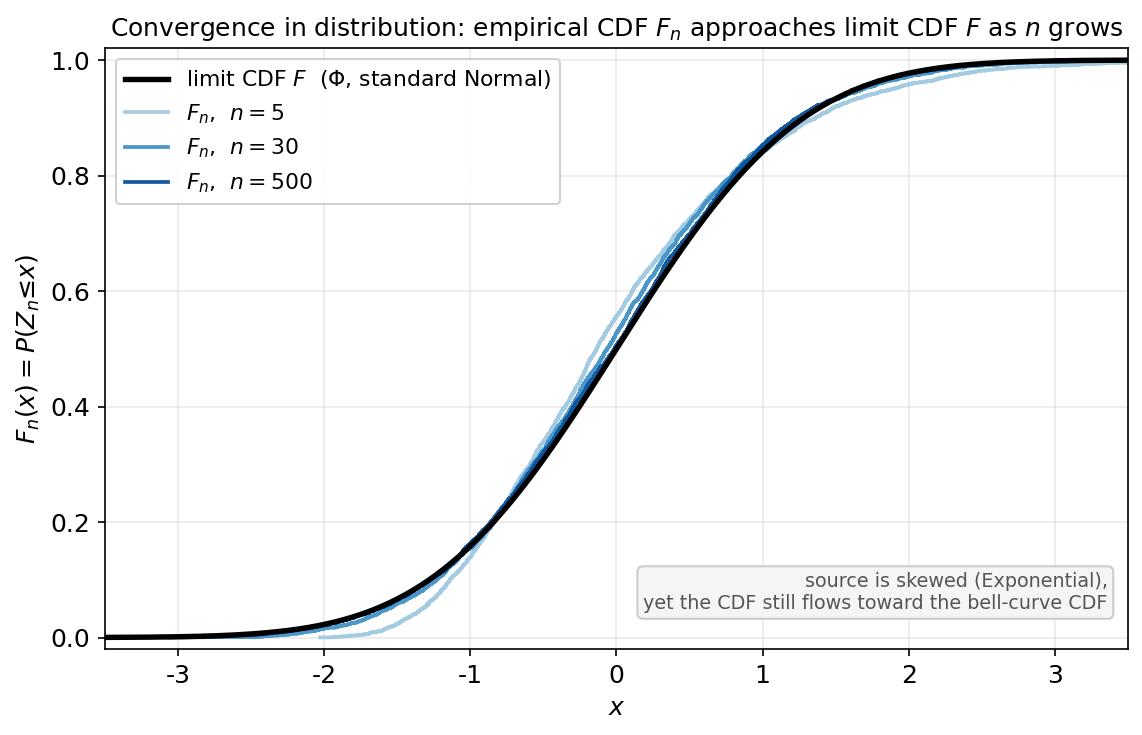
Figure 4 — typewriter sequence: in probability কিন্তু almost surely নয়¶
এই অধ্যায়ের সবচেয়ে শিক্ষণীয় উদাহরণ (E1)। \([0,1]\)-এর উপর একটা "জানালা" পিছলে যায়, তারপর অর্ধেক হয়ে আবার শুরু থেকে; প্রতিটি \(X_n\) হলো ওই জানালার indicator। যা লক্ষ করতে হবে তিনটি প্যানেলে —
- উপরে-বাঁয়ে: প্রতিটি \(X_n\) কোন sub-interval-এ "চালু" তার carpet; জানালা সরছে, তারপর অর্ধেক হয়ে আবার বাঁ থেকে শুরু।
- উপরে-ডানে: একটা স্থির \(\omega=0.3\) ধরলে \(X_n(\omega)\) বারবার \(1\)-এ লাফ দেয় — অসীমবার (infinitely often)। তাই কোনো নির্দিষ্ট বিন্দুতে sequence থিতু হয় না: almost sure limit নেই।
- নিচে: তবু \(P(\lvert X_n\rvert>\varepsilon)=\) জানালার প্রস্থ \(=1/2^b\to 0\)। তাই \(X_n\xrightarrow{P}0\)।
দুটো প্যানেল পাশাপাশি রাখলেই পরিষ্কার: probability-তে যাওয়া (গড়ে ছোট) আর almost surely যাওয়া (প্রতিটি পথে থিতু) — এক জিনিস নয়।
![Typewriter sequence figure with three panels. Top-left: a carpet/bar chart showing which sub-interval of [0,1] each indicator X_1 through X_15 is "on", with the window sliding rightward then halving in width and restarting from the left (coloured by block). Top-right: a stem plot of X_n(omega) at the fixed point omega = 0.3 versus n, where the value spikes to 1 at scattered indices again and again (infinitely often), so there is no almost-sure limit. Bottom (full width): P(|X_n| > epsilon), equal to the window width 1/2^b, plotted against n as a green step-down curve falling toward 0 with block transitions b = 0,1,2,3 annotated, showing X_n converges in probability to 0. Title: converges in probability but NOT almost surely.](../_assets/3-2-typewriter.png)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/03-02-types-of-convergence-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন convergence in probability (\(\xrightarrow{P}\)) আর almost sure convergence (\(\xrightarrow{a.s.}\))-এর মূল পার্থক্য কী। typewriter ছবি (Figure 4)-র দুটি প্যানেল দিয়ে বোঝান কোনটা "গড়ে ছোট হওয়া" আর কোনটা "প্রতিটি পথে থিতু হওয়া।" Hint: "infinitely often \(1\)-এ লাফ" বনাম "\(P(\lvert X_n\rvert>\varepsilon)\to 0\)" — কোনটা পথ-ভিত্তিক, কোনটা probability-ভিত্তিক?
প্রশ্ন ২ (★). hierarchy-র (Figure 1) চারটি তীর শব্দে লিখুন: কোন mode কোনটাকে imply করে? এবং বলুন কেন \(\xrightarrow{d}\) সাধারণত \(\xrightarrow{P}\) imply করে না — কোন একটিমাত্র পরিস্থিতিতে করে? Hint: in distribution শুধু CDF মেলায়, \(X_n\) আর \(X\)-কে একই sample point-এ "কাছাকাছি" করে না; ব্যতিক্রম — limit একটা constant।
প্রশ্ন ৩ (★★). কেউ দাবি করল: "\(X_n\xrightarrow{d}c\) (একটা ধ্রুবক) হলে \(X_n\xrightarrow{P}c\)।" এটা কি সত্য? স্বজ্ঞাতভাবে ব্যাখ্যা করুন কেন limit ধ্রুবক হলে distribution-এ মিল আর probability-তে মিল একই হয়ে যায়। Hint: limit-এর CDF একটা step (সব ভর \(c\)-তে); \(F_n\) সেই step-এর কাছে এলে \(X_n\) অবশ্যই \(c\)-র কাছাকাছি ঘন হয়।
প্রশ্ন ৪ (★★). \(L^p\) convergence (\(\mathbb{E}\lvert X_n-X\rvert^p\to 0\)) "গড় ভুল" শূন্যে নেয়। ব্যাখ্যা করুন কেন একটা বিরল কিন্তু বিশাল spike \(L^2\) convergence ভাঙতে পারে, অথচ \(\xrightarrow{P}\) অক্ষত রাখতে পারে। (ইঙ্গিত: spike-এর probability ছোট হলেও তার বর্গ বড় হতে পারে।) Hint: \(P(\lvert X_n\rvert>\varepsilon)\) ছোট হওয়া আর \(\mathbb{E}[X_n^2]\) ছোট হওয়া — মান-এর আকার গুনতি হয় শুধু দ্বিতীয়টায়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). \(X_n\sim\text{Uniform}(0,\tfrac1n)\)। (ক) \(\varepsilon=0.01\)-এ \(P(\lvert X_n\rvert>\varepsilon)\) বের করুন \(n\)-এর function হিসেবে; (খ) দেখান এটা \(0\)-তে যায়, অর্থাৎ \(X_n\xrightarrow{P}0\); (গ) \(\mathbb{E}[X_n]\) ও \(\mathbb{E}[X_n^2]\) বের করে বলুন \(X_n\xrightarrow{L^2}0\) কি না। Hint: Uniform\((0,1/n)\)-এ \(P(X_n>\varepsilon)=1-n\varepsilon\) যতক্ষণ \(\varepsilon<1/n\), নইলে \(0\); \(\mathbb{E}[X_n^2]=\frac{1}{3n^2}\)।
প্রশ্ন ৬ (★★). weak law-এর হাতে-কলমে রূপ: \(X_1,\dots,X_n\) iid, \(\mathbb{E}[X_i]=\mu\), \(\operatorname{Var}(X_i)=\sigma^2\), \(\bar X_n=\frac1n\sum X_i\) (E2)। Chebyshev দিয়ে \(P(\lvert\bar X_n-\mu\rvert>\varepsilon)\)-এর একটা upper bound লিখুন এবং \(n\to\infty\)-এ তা \(0\) দেখিয়ে \(\bar X_n\xrightarrow{P}\mu\) প্রমাণ করুন। \(\sigma^2=4,\ \varepsilon=0.5\) হলে bound \(\le 0.05\) করতে কত \(n\) লাগবে? Hint: \(\operatorname{Var}(\bar X_n)=\sigma^2/n\); Chebyshev: \(P(\lvert\bar X_n-\mu\rvert>\varepsilon)\le \frac{\sigma^2}{n\varepsilon^2}\)।
প্রশ্ন ৭ (★★). ধরুন maximum \(M_n=\max(U_1,\dots,U_n)\) যেখানে \(U_i\) iid Uniform\((0,1)\)। (ক) \(M_n\)-এর CDF \(F_n(x)=x^n\) (\(0\le x\le 1\)) দেখান; (খ) \(n(1-M_n)\)-এর limiting distribution বের করে দেখান \(n(1-M_n)\xrightarrow{d}\text{Exponential}(1)\)। Hint: \(P(n(1-M_n)>t)=P(M_n<1-\tfrac{t}{n})=(1-\tfrac{t}{n})^n\to e^{-t}\)।
প্রশ্ন ৮ (★★). \(Z_n=\frac{\bar X_n-\mu}{\sigma/\sqrt n}\) (standardized sample mean)। Figure 3-এর সংখ্যাগুলো ধরে: উৎস Exponential\((1)\) হলে \(\mu=1,\ \sigma=1\); \(n=30\)-এ \(Z_n\) আনুমানিক কোন distribution-এ যায় এবং কেন? \(P(Z_n\le 1.96)\)-এর আনুমানিক মান বলুন। Hint: CLT অনুযায়ী \(Z_n\xrightarrow{d}\mathcal N(0,1)\); \(\Phi(1.96)\approx 0.975\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). প্রমাণ করুন: \(X_n\xrightarrow{L^2}X\ \Rightarrow\ X_n\xrightarrow{P}X\)। অর্থাৎ mean-square convergence থেকে convergence in probability পাওয়া যায়। Hint: Markov inequality \(L^2\) ভার্সনে — \(P(\lvert X_n-X\rvert>\varepsilon)=P(\lvert X_n-X\rvert^2>\varepsilon^2)\le \frac{\mathbb{E}\lvert X_n-X\rvert^2}{\varepsilon^2}\)।
প্রশ্ন ১০ (★★). প্রমাণ করুন: \(X_n\xrightarrow{P}X\ \Rightarrow\ X_n\xrightarrow{d}X\) — অর্থাৎ hierarchy-র \(P\Rightarrow d\) তীরটি। (sandwich যুক্তি: \(F\)-এর যেকোনো continuity point \(x\)-এ \(\limsup F_n(x)\le F(x)\le \liminf F_n(x)\) দেখান।) Hint: যেকোনো \(\delta>0\)-এ \(\{X_n\le x\}\subseteq\{X\le x+\delta\}\cup\{\lvert X_n-X\rvert>\delta\}\); দ্বিতীয় ঘটনার probability \(\to 0\), তারপর \(\delta\downarrow 0\)।
প্রশ্ন ১১ (★★★). typewriter sequence (E1) আনুষ্ঠানিকভাবে নির্মাণ করুন এবং দুটো দাবি প্রমাণ করুন: (ক) \(X_n\xrightarrow{P}0\); (খ) প্রতিটি \(\omega\in[0,1]\)-এ \(X_n(\omega)\) converge করে না (তাই \(X_n\xrightarrow{a.s.}0\) মিথ্যা)। এর মাধ্যমে দেখান \(\xrightarrow{P}\ \not\Rightarrow\ \xrightarrow{a.s.}\)। Hint: (ক) \(P(X_n\ne 0)=\) জানালার প্রস্থ \(\to 0\); (খ) প্রতিটি \(\omega\) অসীমবার কোনো জানালায় পড়ে, আবার অসীমবার পড়ে না — তাই \(X_n(\omega)\) অসীমবার \(1\) ও অসীমবার \(0\)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে \(X_n\sim\text{Uniform}(0,1/n)\)-এর জন্য \(n=1,\dots,2000\)-এ \(P(\lvert X_n\rvert>0.01)\) Monte Carlo-তে আনুমান করুন (প্রতি \(n\)-এ \(10{,}000\) নমুনা, default_rng(0)) এবং তা \(0\)-র দিকে নামছে কি না plot করুন। তাত্ত্বিক মান \(\max(0,1-n\cdot0.01)\)-এর সাথে মেলান।
Hint: (rng.uniform(0, 1/n, 10000) > 0.01).mean(); tail-এ probability ঠিক \(0\) হওয়া উচিত।
প্রশ্ন ১৩ (★★). weak law সিমুলেট করুন (Figure 2-র মতো): iid Uniform\((-1,1)\) থেকে \(200\)টি running-mean path বানিয়ে একটা \(\pm\varepsilon\) ব্যান্ড আঁকুন এবং "বাইরে-থাকা ভগ্নাংশ" বনাম \(n\) plot করুন। \(\varepsilon\) ছোট করলে নামার হার কীভাবে বদলায় দেখান।
Hint: np.cumsum(x)/np.arange(1,N+1); outside fraction \(=\) (np.abs(paths-0)>eps).mean(axis=0)।
প্রশ্ন ১৪ (★★★). typewriter sequence (E1) কোডে বানান এবং দুটো জিনিস একসাথে plot করুন: (ক) একটা স্থির \(\omega\)-তে \(X_n(\omega)\)-র spike (almost sure-হীনতা), আর (খ) \(P(\lvert X_n\rvert>\varepsilon)=\) জানালার প্রস্থ \(\to 0\) (in probability)। দুই কাহিনি পাশাপাশি দেখান। (চাইলে নিজের স্ক্রিপ্টে — _code/figs_3-2.py-র গঠন অনুসরণ করতে পারেন।)
Hint: block \(b\)-তে \(2^b\)টি interval, প্রতিটির প্রস্থ \(1/2^b\); index \((b,j)\) flatten করুন; fixed \(\omega\) যেই interval-এ পড়ে সেখানে value \(1\)।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- একটা random variable-এর sequence \(X_n\) "limit \(X\)-এর দিকে যায়" — এর চারটি ভিন্ন অর্থ আছে, দুর্বলতম থেকে শক্তিশালী:
- convergence in distribution (\(X_n\xrightarrow{d}X\)): কেবল CDF মেলে — \(F_n(x)\to F(x)\) প্রতিটি continuity point-এ। আকৃতি একই হয়, কিন্তু \(X_n\) আর \(X\) একই sample point-এ কাছাকাছি হওয়ার দরকার নেই (Figure 3)।
- convergence in probability (\(X_n\xrightarrow{P}X\)): প্রতিটি \(\varepsilon>0\)-এ \(P(\lvert X_n-X\rvert>\varepsilon)\to 0\) — "বড় ভুল-এর সম্ভাবনা মুছে যায়" (Figure 2, E2)।
- convergence in \(L^p\) / mean-square (\(X_n\xrightarrow{L^p}X\)): \(\mathbb{E}\lvert X_n-X\rvert^p\to 0\) — "গড় ভুল (p-ঘাতে)" শূন্যে নামে (E4); \(p=2\) হলে mean-square।
- almost sure convergence (\(X_n\xrightarrow{a.s.}X\)): \(P\bigl(\lim_n X_n=X\bigr)=1\) — প্রায় প্রতিটি পথ আক্ষরিকভাবে থিতু হয়।
- শ্রেণীবিন্যাস (Figure 1): \(\;a.s.\Rightarrow P\), এবং \(\;L^p\Rightarrow P\), এবং \(\;P\Rightarrow d\)। উল্টোগুলো সাধারণত মিথ্যা; \(a.s.\) ও \(L^p\) পরস্পরকে imply করে না; \(d\Rightarrow P\) কেবল যখন limit একটা ধ্রুবক।
- মূল প্রতি-উদাহরণ (E1): typewriter sequence (Figure 4) \(\xrightarrow{P}0\) করে কিন্তু \(\xrightarrow{a.s.}0\) করে না — প্রমাণ যে "probability-তে ছোট" আর "প্রতিটি পথে থিতু" এক নয়।
statistics/ML-এর সাথে সংযোগ (কেন এত গুরুত্বপূর্ণ):
| convergence mode | statistics/ML-এ ভূমিকা |
|---|---|
| \(\xrightarrow{P}\) (in probability) | Law of Large Numbers (3.3)-এর ভাষা; estimator consistency-র সংজ্ঞা (\(\hat\theta_n\xrightarrow{P}\theta\)) |
| \(\xrightarrow{a.s.}\) (almost sure) | Strong Law of Large Numbers (3.3); প্রায়-নিশ্চিত গ্যারান্টি |
| \(\xrightarrow{d}\) (in distribution) | Central Limit Theorem (3.4); CI, \(z\)/\(t\)-test, \(p\)-value-এর asymptotic ভিত্তি |
| \(\xrightarrow{L^2}\) (mean-square) | MSE \(\to 0\); estimator-এর \(L^2\)-consistency, projection ও Hilbert-space যুক্তি |
পূর্ববর্তী সংযোগ (← 3.1, 2.4): 3.1-এ আমরা sequence ও limit-এর ধারণা (real number-এর জন্য \(\epsilon\)-\(N\)) দেখেছি; এখানে সেই limit-ধারণাকে random variable-এ তুলে আনা হলো — আর "কাছাকাছি" শব্দটার একাধিক অর্থ বেরোলো বলেই চারটি mode। 2.4-এর CDF (\(F(x)=P(X\le x)\)) সরাসরি convergence in distribution-এর হাতিয়ার, আর 2.5-এর expectation/variance (\(\mathbb{E}\), \(\operatorname{Var}\)) দিয়েই \(L^p\) ও Chebyshev-ভিত্তিক probability convergence সংজ্ঞায়িত ও প্রমাণিত হয়।
পরবর্তী সংযোগ (→ 3.3, 3.4): এই চারটি mode পরের দুই অধ্যায়ের মূল ভাষা। 3.3-এ Law of Large Numbers — weak LLN ঠিক \(\bar X_n\xrightarrow{P}\mu\) (Chebyshev দিয়ে, প্রশ্ন ৬-এর মতো), strong LLN \(\bar X_n\xrightarrow{a.s.}\mu\)। 3.4-এ Central Limit Theorem — standardized গড় \(\frac{\bar X_n-\mu}{\sigma/\sqrt n}\xrightarrow{d}\mathcal N(0,1)\) (Figure 3-এই এর পূর্বাভাস)। অর্থাৎ "estimator ঠিক উত্তরে যায়" বলতে \(\xrightarrow{P}\)/\(\xrightarrow{a.s.}\), আর "তার ভুল আনুমানিক Normal" বলতে \(\xrightarrow{d}\) — পুরো inferential statistics এই দুই স্তম্ভের উপর দাঁড়িয়ে।
সূত্র (sources): Wasserman, All of Statistics, Ch. 5 (Convergence of Random Variables); Fernández-Granda, Probability and Statistics for Data Science (modes of convergence ও LLN/CLT-র প্রস্তুতি)।