8.4 — Where Next: Research Readiness (এরপর কোথায় — গবেষণার পথ)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
১.১ একটা যাত্রার শেষ ধাপ — এবং একটা নতুন যাত্রার প্রথম¶
এই অধ্যায়টা গোটা পথের শেষ অধ্যায় — Part 0-এর প্রথম পাতা থেকে যে যাত্রা শুরু হয়েছিল (একটা সংখ্যা, একটা set, একটা function), তা Part VII-এর measure-তাত্ত্বিক central limit theorem-এর পূর্ণ কঠোর প্রমাণে পৌঁছে, তারপর Part VIII-এর ক্যাপস্টোন প্রকল্পে (একটা end-to-end বিশ্লেষণ, একটা simulation-study, একটা ধ্রুপদী ফল পুনরুৎপাদন) হাতে-কলমে পরীক্ষিত হয়েছে। এখন একটাই প্রশ্ন বাকি — এরপর কোথায়?
এই অধ্যায় বাকিগুলোর মতো নয়, আর সেটা ইচ্ছাকৃত। এখানে নতুন কোনো theorem নেই, নতুন কোনো প্রমাণ নেই, ভারী কোনো derivation নেই। এটা কোডে হালকা, দিকনির্দেশনায় ভারী — কারণ এর কাজ শেখানো নয়, বরং চেনানো: এতদিনের অর্জিত ভিত্তির উপর দাঁড়িয়ে এখন কোন দিগন্তগুলো খোলা, সেই মানচিত্রটা হাতে তুলে দেওয়া। একজন শিক্ষার্থী যখন scratch থেকে শুরু করে measure-তাত্ত্বিক probability পর্যন্ত পৌঁছায়, তখন সে আর \"শিক্ষার্থী\" থাকে না — সে একজন সম্ভাব্য গবেষক, আর গবেষকের প্রথম দরকার একটা মানচিত্র: কোথায় কী আছে, কোন পথ কোথায় যায়, আর নিজের পরের পা কোথায় ফেলা।
এক বাক্যে সূচনা। এটি সম্পূর্ণ scratch→PhD পথের শেষ অধ্যায় — নতুন theorem নয়, বরং একটা গবেষণা-মানচিত্র ও পথরেখা: কোন frontier-ক্ষেত্র এখন খোলা, কী পড়তে হবে, কীভাবে reproducible কাজ করতে হবে, আর পরের প্রকল্প কী।
১.২ কেন একটা \"মানচিত্র\" অধ্যায় দরকার¶
গণিত ও পরিসংখ্যানের একটা নিষ্ঠুর সত্য: বিষয়টা এত বিশাল যে যেকোনো একজনের পক্ষে তার সম্পূর্ণটা জানা অসম্ভব। একজন PhD-গবেষক তাঁর সারা জীবনে হয়তো একটা-দুটো উপ-ক্ষেত্রে (subfield) গভীরে যান, বাকিটার সাথে পরিচিত থাকেন কেবল দূর থেকে। তাই \"সব শিখে ফেলা\" কখনোই লক্ষ্য নয় — লক্ষ্য হলো একটা শক্ত, সাধারণ ভিত্তি (যা এই curriculum দিয়েছে) এবং তার উপর দাঁড়িয়ে যেকোনো একটা দিকে দ্রুত গভীরে যাওয়ার ক্ষমতা।
এই অধ্যায় ঠিক সেই ক্ষমতার সেবায়। §২ একটা মানচিত্র আঁকে — statistics/ML-এর মূল frontier-ক্ষেত্রগুলো, প্রতিটির এক-অনুচ্ছেদ পরিচয় এবং এই curriculum-এর কোন অধ্যায় তার দরজা খুলে দিয়েছে তার সরাসরি সুতো। §৩ একটা পড়ার-তালিকা — যে সিঁড়ি বেয়ে foundational বই থেকে ক্ষেত্র-বই, ক্ষেত্র-বই থেকে ল্যান্ডমার্ক paper, আর paper থেকে সেই journal-এ ওঠা যায় যেখানে জীবন্ত গবেষণা ছাপা হয়। §৪ একজন কর্মরত বিজ্ঞানীর কর্মপদ্ধতি — কীভাবে কাজটা reproducible, সৎ, ও ভাগ-করার-যোগ্য রাখা যায়। §৫–৭ চিত্র ও প্রকল্প-প্রম্পট, আর §৮ পুরো যাত্রার একটা সংহত হিসাব।
এক বাক্যে। \"সব শেখা\" লক্ষ্য নয় — লক্ষ্য একটা শক্ত ভিত্তি (curriculum) ও তার উপর যেকোনো দিকে গভীরে যাওয়ার ক্ষমতা; এই অধ্যায় সেই দিকগুলোর মানচিত্র, সিঁড়ি, ও কর্মপদ্ধতি দেয়।
১.৩ শিক্ষার্থী এখন কোথায় দাঁড়িয়ে¶
একটা সৎ হিসাব নেওয়া যাক — এই পথ সম্পূর্ণ করা একজন শিক্ষার্থী কী পারে যা সে শুরুতে পারত না:
- একটা গবেষণা-paper পড়া — কেবল abstract নয়, তার theorem, প্রমাণের কাঠামো, ও ধারণাগত অবদান বোঝা (কারণ probability, inference, ML ও measure theory-র ভাষা এখন পরিচিত);
- একটা ফল প্রমাণ করা — measure-তাত্ত্বিক কঠোরতাসহ (Part VII একটা পূর্ণ CLT-প্রমাণে শেষ হয়েছে, তাই ε–δ থেকে σ-algebra পর্যন্ত প্রমাণের ভাষা আয়ত্তে);
- একটা rigorous বিশ্লেষণ শূন্য থেকে চালানো — data ঢোকানো থেকে model, যাচাই, ও ব্যাখ্যা পর্যন্ত (Part VIII-এর end-to-end প্রকল্প ঠিক এটাই মহড়া দিয়েছে);
- একটা দাবিকে সংখ্যা ও প্রমাণে দাঁড় করানো — Monte-Carlo সিমুলেশনে যাচাই, canonical সংখ্যার সাথে মেলানো, ও reproducible কোডে বেঁধে রাখা।
এই চারটে — paper পড়া, ফল প্রমাণ, বিশ্লেষণ চালানো, দাবি যাচাই — ঠিক একজন গবেষকের কেন্দ্রীয় দক্ষতা। বাকিটা (একটা নির্দিষ্ট ক্ষেত্রের গভীর জ্ঞান) সময় ও অনুশীলনের ব্যাপার, ভিত্তির নয়। ভিত্তি তৈরি।
এক বাক্যে। এই পথ শেষে শিক্ষার্থী পারে — paper পড়া ও যাচাই, ফল প্রমাণ (measure-তাত্ত্বিক কঠোরতাসহ), rigorous বিশ্লেষণ শূন্য থেকে চালানো, ও দাবিকে সংখ্যা-প্রমাণে দাঁড় করানো — একজন গবেষকের কেন্দ্রীয় দক্ষতা।
১.৪ এই অধ্যায়ের পথরেখা¶
- §২ গবেষণা-ক্ষেত্রের মানচিত্র — আটটি frontier-ক্ষেত্রের এক-অনুচ্ছেদ জরিপ (causal inference, Bayesian nonparametrics, high-dimensional statistics, statistical learning theory, stochastic process ও SDE, computational statistics, information theory ও statistics, applied ML ও fairness), প্রতিটির \"কী / কেন / কোন অধ্যায় প্রস্তুত করল\"।
- §৩ পড়ার তালিকা — foundational বই (ইতিমধ্যে ব্যবহৃত), ক্ষেত্র-বই, ল্যান্ডমার্ক paper, ও মূল journal/venue — একটা সৎ, স্তরভিত্তিক সিঁড়ি।
- §৪ reproducibility ও open science — git, seed, environment-pinning, literate notebook, data/code ভাগ, preregistration, reproducibility-সংকট ও তা এড়ানো — এই curriculum-এর প্রকল্পের সাথে মিলিয়ে।
- §৫–৬ কোড ও চিত্র —
_code/lab_8-4.py(seed 20260619) দুটি schematic চিত্র আঁকে: 8-4-field-map (statistics-এর মানচিত্র, ক্ষেত্র→Part তীর) ও 8-4-roadmap (ভিত্তি→গবেষণা পথরেখা)। - §৭ অনুশীলনী ও পরবর্তী প্রকল্প — একটা paper পুনরুৎপাদন, একটা simulation-study নকশা, একটা research proposal — কাঠামো solutions-এ।
- §৮ মহাসমাপ্তি — Part 0→VIII পুরো চাপ ফিরে দেখা, একটা উৎসাহী কিন্তু সৎ বিদায়।
২ · গবেষণা-ক্ষেত্রের মানচিত্র¶
এই curriculum একটা সাধারণ ভিত্তি — probability, inference, modeling, ML, ও measure-তাত্ত্বিক কঠোরতা। তার উপর দাঁড়িয়ে আধুনিক পরিসংখ্যান ও machine learning-এর বহু frontier-ক্ষেত্র এখন নাগালে। নিচে আটটি মূল ক্ষেত্র — প্রতিটির জন্য এটা কী, কেন গুরুত্বপূর্ণ, এবং এই curriculum কোন অধ্যায়ে তার দরজা খুলে দিয়েছে — একটা করে অনুচ্ছেদে। এগুলো পরস্পর-বিচ্ছিন্ন নয় (causal inference-এ high-dimensional পদ্ধতি লাগে, learning theory-তে concentration inequality লাগে) — মানচিত্রটা একটা জাল, তালিকা নয়।
২.১ Causal inference (কার্যকারণ-অনুমান)¶
কী। সাধারণ পরিসংখ্যান correlation (সহ-সম্পর্ক) মাপে; causal inference (কার্যকারণ-অনুমান) প্রশ্ন করে কারণ — \"\(X\) বদলালে \(Y\) বদলাবে কি?\" তার আনুষ্ঠানিক ভাষা তিনটি স্তম্ভে দাঁড়ায়: potential outcomes (সম্ভাব্য-ফলাফল কাঠামো — প্রতিটি একক-ইউনিটের জন্য treatment ও control উভয় অবস্থার একটা কল্পিত ফলাফল \(Y(1),Y(0)\), যার একটাই দেখা যায় — \"causal inference-এর মৌলিক সমস্যা\"), DAG (directed acyclic graph — কার্যকারণ-সম্পর্কের একটা গ্রাফ যা confounding, mediation ও collider চেনায়), এবং instrumental variable (IV — যখন treatment ও outcome-এর মধ্যে লুকানো confounder আছে, তখন একটা \"instrument\" চলক দিয়ে causal effect বের করা)। মূল লক্ষ্য — observational data থেকেও, randomised experiment ছাড়াই, বৈধ কার্যকারণ-দাবি করার শর্ত ও পদ্ধতি।
কেন গুরুত্বপূর্ণ। ওষুধ কি রোগ সারায়? নীতি কি দারিদ্র্য কমায়? বিজ্ঞাপন কি বিক্রি বাড়ায়? — সব \"কেন/কী-হলে\" প্রশ্ন causal, correlational নয়। epidemiology, economics (econometrics), policy, ও আধুনিক tech-শিল্পের A/B testing — সর্বত্র এটি কেন্দ্রীয়।
curriculum কীভাবে প্রস্তুত করল। সরাসরি Part IV (inference — estimation, hypothesis testing, confidence interval: causal effect-ও একটা parameter, তার estimation ও uncertainty) ও Part V (modeling — regression হলো confounder-সমন্বয়ের প্রাথমিক হাতিয়ার; IV ও propensity-score পদ্ধতি regression-এর সম্প্রসারণ)। conditional expectation (Part VII 7.7) causal estimand-এর আনুষ্ঠানিক ভিত্তি — \(\mathbb E[Y\mid \text{do}(X)]\) বোঝার জন্য conditional expectation-এর কঠোর সংজ্ঞা লাগে।
২.২ Bayesian nonparametrics (বেইজীয় অ-প্যারামিতি)¶
কী। সাধারণ Bayesian মডেল একটা সসীম-মাত্রিক parameter-এ prior বসায় (যেমন \(\theta\sim N(0,\tau^2)\))। Bayesian nonparametrics (বেইজীয় অ-প্যারামিতি) prior বসায় অসীম-মাত্রিক বস্তুর উপর — একটা সম্পূর্ণ distribution, বা একটা সম্পূর্ণ function-এর উপর — যাতে model-এর জটিলতা ডেটার সাথে বাড়তে পারে। দুটি স্তম্ভ: Dirichlet process (একটা \"distribution-এর উপর distribution\" — অজানা distribution-কে nonparametric-ভাবে estimate করা, clustering-এ component-সংখ্যা আগে থেকে না বেঁধে) এবং Gaussian process (একটা \"function-এর উপর distribution\" — যেকোনো সসীম বিন্দু-সেটে যার মান যৌথভাবে multivariate normal; regression ও optimisation-এ নমনীয় prior)।
কেন গুরুত্বপূর্ণ। যখন সত্যিকারের model-form অজানা, তখন একটা স্থির parametric রূপ চাপানো ঝুঁকিপূর্ণ; nonparametric prior ডেটাকে নিজের জটিলতা বেছে নিতে দেয়। Gaussian process আধুনিক Bayesian optimisation (hyperparameter-tuning, experimental design)-এর মেরুদণ্ড।
curriculum কীভাবে প্রস্তুত করল। Part IV-এর Bayesian inference (4.10) — prior, likelihood, posterior, conjugacy-র মূল যন্ত্র এখানেই শেখা; Gaussian process বুঝতে Part II-এর multivariate normal ও Part VII-এর \(L^2\)/Hilbert-space কাঠামো (7.5) লাগে (Gaussian process একটা function-space-এর Gaussian measure)। Dirichlet process-এর কঠোর নির্মাণে measure-তাত্ত্বিক ভিত্তি (Part VII) অপরিহার্য।
২.৩ High-dimensional statistics (উচ্চ-মাত্রিক পরিসংখ্যান)¶
কী। ধ্রুপদী পরিসংখ্যানে ধরে নেওয়া হয় নমুনা-সংখ্যা \(n\) অনেক বড়, parameter-সংখ্যা \(p\) ছোট। আধুনিক ডেটায় প্রায়ই উল্টো — \(p\gtrsim n\) বা \(p\gg n\) (হাজার হাজার gene, লক্ষ লক্ষ feature)। High-dimensional statistics (উচ্চ-মাত্রিক পরিসংখ্যান) এই শাসনে estimation ও inference-এর তত্ত্ব: sparsity (কম-সংখ্যক অ-শূন্য coefficient ধরে নেওয়া), lasso-তত্ত্ব (\(\ell_1\)-নিয়মিতকরণ কখন সঠিক support পুনরুদ্ধার করে, তার শর্ত ও ত্রুটি-সীমা), এবং minimax rate (একটা estimation-সমস্যার সর্বোত্তম-সম্ভব অভিসারণ-হার — কোনো estimator যার চেয়ে ভালো করতে পারে না)।
কেন গুরুত্বপূর্ণ। genomics, imaging, text, finance — সর্বত্র feature-সংখ্যা নমুনার চেয়ে বেশি; ধ্রুপদী পদ্ধতি এখানে ভেঙে পড়ে (overfitting, অ-সংজ্ঞায়িত estimator)। sparsity-ভিত্তিক তত্ত্ব এই ভাঙন সামলানোর গাণিতিক ভিত্তি।
curriculum কীভাবে প্রস্তুত করল। সরাসরি Part V ও VI-এর regularization (6.2 — ridge/lasso: shrinkage ও sparsity-র হাতিয়ার); এবং Part VIII-এর 8.3 (James–Stein shrinkage — উচ্চ-মাত্রায় shrinkage কেন অপরিহার্য তার আদি-উদাহরণ, minimax-চিন্তার সূচনা)। ত্রুটি-সীমা প্রমাণে Part III-এর concentration inequality (Chebyshev, Hoeffding-ধাঁচ) মূল যন্ত্র।
২.৪ Statistical learning theory (পরিসংখ্যানিক শিখন-তত্ত্ব)¶
কী। কেন একটা model যা training-data-য় ভালো করে, সে অদেখা data-তেও ভালো করবে? Statistical learning theory (পরিসংখ্যানিক শিখন-তত্ত্ব) এই generalisation-এর গাণিতিক ভিত্তি: VC dimension (Vapnik–Chervonenkis মাত্রা — একটা model-শ্রেণির \"ক্ষমতা\"/জটিলতার একটা মাপ, কতগুলো বিন্দু সে যেকোনোভাবে আলাদা করতে পারে), Rademacher complexity (একটা model-শ্রেণি এলোমেলো noise-এর সাথে কতটা খাপ খায় তার একটা মাপ — generalisation-ত্রুটির শক্ত সীমা দেয়), এবং সাম্প্রতিক deep-learning theory (গভীর নেটওয়ার্ক কেন over-parametrised হয়েও generalise করে — একটা সক্রিয়, অমীমাংসিত গবেষণা-সীমান্ত)।
কেন গুরুত্বপূর্ণ। এটি machine learning-এর তাত্ত্বিক হৃদয় — কেন শেখা আদৌ সম্ভব, কতটা data লাগবে, ও একটা algorithm-এর ভরসাযোগ্যতার গ্যারান্টি। deep learning-এর empirical সাফল্য ও তত্ত্বের ফাঁক এখন সবচেয়ে উত্তপ্ত গবেষণা-এলাকাগুলোর একটা।
curriculum কীভাবে প্রস্তুত করল। Part VI (statistical ML — bias–variance, model-জটিলতা, empirical vs. true risk-এর স্বজ্ঞা) ও Part III (convergence — generalisation-সীমা মূলত concentration inequality ও uniform law of large numbers, যা Part III-এর LLN/inequality-র সরাসরি সম্প্রসারণ)। empirical-process তত্ত্বের কঠোর রূপে Part VII-এর measure-তাত্ত্বিক ভিত্তি লাগে।
২.৫ Stochastic processes ও SDE (দৈব-প্রক্রিয়া ও স্টোকাস্টিক অন্তরকল সমীকরণ)¶
কী। একটা random variable একটা এলোমেলো সংখ্যা; একটা stochastic process (দৈব-প্রক্রিয়া) সময়-জুড়ে বিবর্তিত এলোমেলো একটা পথ। কেন্দ্রীয় বস্তু Brownian motion (ব্রাউনীয় গতি — অবিচ্ছিন্ন, কোথাও-অবকলনযোগ্য-নয় একটা random path, সব অবিচ্ছিন্ন martingale-এর ভিত্তি) এবং stochastic differential equation (SDE — স্টোকাস্টিক অন্তরকল সমীকরণ: একটা random-চালিকা-সহ অন্তরকল সমীকরণ, \(dX_t=\mu\,dt+\sigma\,dW_t\)), যার জন্য একটা নতুন calculus — Itô calculus (ইতো-ক্যালকুলাস) — লাগে, কারণ Brownian path সাধারণ calculus-এর নিয়ম মানে না।
কেন গুরুত্বপূর্ণ। finance (option-pricing, Black–Scholes), physics (diffusion), biology (population-dynamics), ও আধুনিক generative model (diffusion model — যা SDE-ভিত্তিক) — সর্বত্র অবিচ্ছিন্ন-সময় random dynamics। এটি সম্ভাব্যতা-তত্ত্বের সবচেয়ে গভীর ও প্রয়োগ-সমৃদ্ধ শাখাগুলোর একটা।
curriculum কীভাবে প্রস্তুত করল। এটি Part VII-এর সরাসরি ধারাবাহিকতা: martingale (7.8), martingale-অভিসারণ (7.9), ও conditional expectation (7.7) — Brownian motion ও Itô integral-এর গোটা নির্মাণ এই measure-তাত্ত্বিক যন্ত্রের উপর দাঁড়ায়। Part VII শেষ করা মানে এই ক্ষেত্রের সঠিক ভাষা (filtration, adapted process, quadratic variation) ইতিমধ্যে হাতে।
২.৬ Computational statistics (গণনামূলক পরিসংখ্যান)¶
কী। অনেক আধুনিক model-এ posterior বা likelihood বদ্ধ-রূপে (closed form) বের করা যায় না — তখন গণনাই একমাত্র পথ। Computational statistics (গণনামূলক পরিসংখ্যান) সেই algorithm-এর তত্ত্ব ও অনুশীলন: MCMC (Markov chain Monte Carlo — একটা Markov chain বানিয়ে যার stationary distribution ঠিক target posterior, তারপর তা থেকে নমুনা টানা), Hamiltonian Monte Carlo (HMC — physics-অনুপ্রাণিত একটা চতুর MCMC যা gradient ব্যবহার করে উচ্চ-মাত্রায় দ্রুত mixing করে), এবং variational inference (একটা কঠিন posterior-কে একটা সরল, নিয়ন্ত্রণযোগ্য distribution-শ্রেণি দিয়ে approximate করা — sampling-এর বদলে optimisation)।
কেন গুরুত্বপূর্ণ। আধুনিক Bayesian statistics ও probabilistic ML পুরোপুরি এই যন্ত্রের উপর নির্ভরশীল (Stan, PyMC, বড়-মাপের deep generative model)। sampling ও optimisation-এর মধ্যে trade-off চেনা একজন প্রায়োগিক গবেষকের অপরিহার্য দক্ষতা।
curriculum কীভাবে প্রস্তুত করল। Part IV-এর Bayesian inference (posterior, যা এই algorithm-গুলো approximate করে) ও Part VI-এর EM/optimisation (variational inference একটা lower-bound সর্বোচ্চকরণ, EM-এর সাধারণীকরণ)। MCMC-র কঠোর ভিত্তিতে (stationary distribution, ergodicity) Part III-এর Markov chain ও Part VII-এর measure-তাত্ত্বিক অভিসারণ লাগে।
২.৭ Information theory ও statistics (তথ্য-তত্ত্ব ও পরিসংখ্যান)¶
কী। Information theory (তথ্য-তত্ত্ব) একটা random variable-এ কতটা \"তথ্য\"/অনিশ্চয়তা আছে তা মাপে — entropy (\(H\), একটা distribution-এর গড় অনিশ্চয়তা) ও KL divergence (Kullback–Leibler অপসারণ, \(D_{KL}(P\Vert Q)\) — দুটি distribution কতটা \"আলাদা\", একটা asymmetric মাপ)। পরিসংখ্যানের সাথে সংযোগ গভীর: maximum-likelihood আসলে KL-অপসারণ ন্যূনতমকরণ; hypothesis testing-এর ক্ষমতা KL-এ প্রকাশ পায়; আর minimax bound (একটা estimation-সমস্যার তথ্য-তাত্ত্বিক নিম্নসীমা — কোনো পদ্ধতি যার চেয়ে ভালো করতে পারে না) প্রায়ই entropy/KL-ভিত্তিক যুক্তিতে (Fano, Le Cam) প্রমাণিত হয়।
কেন গুরুত্বপূর্ণ। এটি statistics, communication, ও machine learning-এর একটা গভীর একীকরণকারী ভাষা — feature-selection, model-নির্বাচন, ও তাত্ত্বিক নিম্নসীমা সর্বত্র entropy/KL-এ কথা বলে; আধুনিক deep learning-এর অনেক loss (cross-entropy, variational bound) সরাসরি তথ্য-তাত্ত্বিক।
curriculum কীভাবে প্রস্তুত করল। Part II (probability — entropy একটা expectation, KL একটা log-ratio-র expectation) ও Part III (convergence — Sanov/large-deviation ধাঁচের ফল, minimax নিম্নসীমার তথ্য-তাত্ত্বিক যুক্তি Part III-এর inequality-র সম্প্রসারণ)। KL ও likelihood-এর সংযোগ Part IV-এর MLE-তত্ত্বে অন্তর্নিহিত।
২.৮ আধুনিক applied ML ও algorithmic fairness (প্রায়োগিক ML ও অ্যালগরিদমিক ন্যায্যতা)¶
কী। সব তত্ত্ব শেষে প্রয়োগে নামে — এবং প্রয়োগ শুধু নির্ভুলতা নয়, দায়িত্বও। আধুনিক applied ML বাস্তব সিস্টেমে model মোতায়েন করে (recommendation, ভাষা-model, চিকিৎসা-নির্ণয়), আর algorithmic fairness (অ্যালগরিদমিক ন্যায্যতা) প্রশ্ন করে — এই model কি বিভিন্ন গোষ্ঠীর প্রতি ন্যায্য? বিভিন্ন fairness-সংজ্ঞা (demographic parity, equalised odds, ইত্যাদি) গাণিতিকভাবে পরস্পর-অসঙ্গত হতে পারে — এটি একটা তত্ত্ব-ও-নীতি-মিশ্রিত সক্রিয় ক্ষেত্র। সাথে জড়িত interpretability (model-এর সিদ্ধান্ত ব্যাখ্যা করা), robustness (adversarial-দৃঢ়তা), ও calibration।
কেন গুরুত্বপূর্ণ। ML এখন লক্ষ লক্ষ মানুষের জীবনকে প্রভাবিত করে (ঋণ, চাকরি, জামিন, চিকিৎসা); ন্যায্যতা, স্বচ্ছতা ও জবাবদিহি আর ঐচ্ছিক নয়। এটি সবচেয়ে দ্রুত-বর্ধমান ও সামাজিকভাবে জরুরি গবেষণা-এলাকাগুলোর একটা।
curriculum কীভাবে প্রস্তুত করল। Part VI (statistical ML-এর পূর্ণ টুলকিট — classification, evaluation, calibration) ও Part I (EDA — গোষ্ঠী-ভিত্তিক বৈষম্য চেনার প্রথম ধাপ সবসময় সৎ, সতর্ক exploratory বিশ্লেষণ)। fairness-metric-এর আনুষ্ঠানিক সংজ্ঞা conditional probability ও decision-theory (Part IV)-এর উপর দাঁড়ায়।
এক বাক্যে (§২)। আটটি frontier — causal inference (←IV,V), Bayesian nonparametrics (←IV 4.10, VII 7.5), high-dimensional statistics (←V,VI 6.2, III), learning theory (←VI, III), stochastic process/SDE (←VII martingale), computational statistics (←IV,VI), information theory (←II,III), applied ML/fairness (←VI,I) — প্রতিটি এই curriculum-এর নির্দিষ্ট অধ্যায়ে বাঁধা একটা খোলা দরজা।
৩ · পড়ার তালিকা: বই, paper, journal¶
একটা সৎ কথা দিয়ে শুরু: একটা curriculum আপনাকে ভিত্তি দেয়, সীমান্ত নয়। সীমান্তে পৌঁছাতে হয় বই থেকে paper-এ, paper থেকে journal-এ উঠে — যেখানে জীবন্ত, অমীমাংসিত গবেষণা ঘটছে। নিচে একটা স্তরভিত্তিক সিঁড়ি — foundational (যা এই পথ ব্যবহার করেছে), পরের-স্তরের ক্ষেত্র-বই, ল্যান্ডমার্ক paper, ও মূল প্রকাশ-ক্ষেত্র। এটি সম্পূর্ণ নয় (কোনো তালিকাই নয়), কিন্তু একটা নির্ভরযোগ্য সূচনা।
৩.১ ভিত্তি-বই (যা এই curriculum-এর মেরুদণ্ড ছিল)¶
এই বইগুলো ইতিমধ্যে পথের অংশ — এদের গভীরে ফিরে যাওয়াই প্রথম \"পরের ধাপ\":
- Rice, Mathematical Statistics and Data Analysis — core spine (Part II–V); probability থেকে inference থেকে regression পর্যন্ত ভারসাম্যপূর্ণ, প্রয়োগ-ঘেঁষা।
- Wasserman, All of Statistics — দ্রুত, rigorous, বিস্তৃত (Part III–IV); decision theory ও nonparametric-এর সংক্ষিপ্ত অথচ ধারালো পরিচয়।
- Klenke, Probability Theory: A Comprehensive Course — measure-তাত্ত্বিক শিখর (Part VII); martingale ও limit theorem-এর পূর্ণ কঠোর গ্রন্থ।
- Kolmogorov–Fomin, Introductory Real Analysis ও Axler, Measure, Integration & Real Analysis — real-analysis ও measure-ভিত্তি; Part VII-এর গণিত-প্রাক্শর্ত।
- applied on-ramp — Bruce–Bruce–Gedeck, Dangeti, Fernández-Granda, Furrer, Sugiyama (intuition, code, ও stats↔ML সেতু)।
৩.২ পরের-স্তরের ক্ষেত্র-বই (§২-এর প্রতিটি দরজার পরের ধাপ)¶
- Causal inference — Hernán & Robins, Causal Inference: What If (আধুনিক, বিনামূল্যে, potential-outcomes-কেন্দ্রিক); Imbens & Rubin, Causal Inference for Statistics, Social, and Biomedical Sciences (গভীর, রেফারেন্স); Pearl, Causality (DAG ও do-calculus-এর উৎস)।
- Bayesian nonparametrics — Rasmussen & Williams, Gaussian Processes for Machine Learning (GP-এর আদর্শ, বিনামূল্যে); Wasserman, All of Nonparametric Statistics (nonparametric ভিত্তি)।
- High-dimensional statistics — Wainwright, High-Dimensional Statistics: A Non-Asymptotic Viewpoint (আধুনিক তত্ত্বের রেফারেন্স); Bühlmann & van de Geer, Statistics for High-Dimensional Data (lasso-তত্ত্ব ও প্রয়োগ); Hastie–Tibshirani–Wainwright, Statistical Learning with Sparsity।
- Statistical learning theory — Shalev-Shwartz & Ben-David, Understanding Machine Learning (স্পষ্ট, স্বয়ংসম্পূর্ণ); Mohri–Rostamizadeh–Talwalkar, Foundations of Machine Learning; Vershynin, High-Dimensional Probability (concentration — তত্ত্বের যন্ত্র)।
- Stochastic processes ও SDE — Øksendal, Stochastic Differential Equations (মৃদু, স্ট্যান্ডার্ড সূচনা); Karatzas & Shreve, Brownian Motion and Stochastic Calculus (কঠোর, গভীর); Le Gall, Brownian Motion, Martingales, and Stochastic Calculus।
- Computational statistics — Robert & Casella, Monte Carlo Statistical Methods (MCMC-এর রেফারেন্স); Gelman et al., Bayesian Data Analysis (প্রায়োগিক Bayesian ও গণনা); Bishop, Pattern Recognition and Machine Learning (variational inference)।
- Information theory — Cover & Thomas, Elements of Information Theory (আদর্শ পাঠ্য); Polyanskiy & Wu, Information Theory (statistics-সংযোগে আধুনিক, বিনামূল্যে লেকচার-নোট)।
- Applied ML ও fairness — Hastie–Tibshirani–Friedman, The Elements of Statistical Learning (ML-এর রেফারেন্স); Barocas–Hardt–Narayanan, Fairness and Machine Learning (fairness-এর আধুনিক, বিনামূল্যে গ্রন্থ)।
৩.৩ কয়েকটি ল্যান্ডমার্ক paper (মূল ধারণার উৎসে ফেরা)¶
গবেষণা-অভ্যাসের একটা মূল অংশ — মূল paper পড়া, পাঠ্যবইয়ের সরলীকৃত রূপ নয়। কয়েকটি ঐতিহাসিক দিকচিহ্ন:
- Stein (1956) ও James–Stein (1961) — shrinkage-এর জন্ম (Part VIII 8.3-এ পুনরুৎপাদিত)।
- Tibshirani (1996), Regression Shrinkage and Selection via the Lasso — sparsity-বিপ্লবের সূচনা।
- Efron (1979), Bootstrap Methods — resampling-inference-এর জন্ম।
- Cover & Hart (1967), Nearest Neighbor Pattern Classification; Cortes & Vapnik (1995), Support-Vector Networks — ML-ভিত্তির দিকচিহ্ন।
- Rubin (1974) ও Pearl-এর কাজ — আধুনিক causal-কাঠামোর ভিত্তি।
মূল paper পড়ার একটা কৌশল: প্রথমে abstract ও উপসংহার, তারপর মূল theorem-এর বিবৃতি, তারপর (দরকারে) প্রমাণ — এবং সর্বদা প্রশ্ন করা \"এটা কি আমি নিজে যাচাই/পুনরুৎপাদন করতে পারি?\" (§৭-এর প্রকল্প ঠিক এই অভ্যাস গড়ে)।
৩.৪ মূল journal ও venue (কোথায় জীবন্ত গবেষণা ছাপা হয়)¶
সীমান্তে থাকতে হলে জানতে হয় কোথায় দেখতে হয়। এক-লাইন করে:
- Annals of Statistics — পরিসংখ্যান-তত্ত্বের সর্বোচ্চ-মর্যাদার journal; গভীর তাত্ত্বিক ফল (minimax, high-dimensional, asymptotics)।
- Journal of the American Statistical Association (JASA) — তত্ত্ব ও প্রয়োগ-পদ্ধতির বিস্তৃত, প্রভাবশালী journal।
- Biometrika — পরিসংখ্যান-পদ্ধতির ধ্রুপদী, উচ্চমানের journal (বিশেষত biostatistics-ঘেঁষা)।
- Journal of the Royal Statistical Society: Series B (JRSS-B) — পদ্ধতিগত পরিসংখ্যানের নেতৃস্থানীয় journal (lasso-paper এখানেই)।
- Journal of Machine Learning Research (JMLR) — ML-তত্ত্ব ও পদ্ধতির মুক্ত-প্রবেশ (open-access) প্রধান journal।
- NeurIPS ও ICML proceedings — আধুনিক machine-learning গবেষণার প্রধান সম্মেলন; দ্রুত-চলমান সীমান্ত এখানেই প্রথম প্রকাশ পায়।
এক বাক্যে (§৩)। সিঁড়িটা — ভিত্তি-বই (Rice, Wasserman, Klenke…) → ক্ষেত্র-বই (Hernán–Robins, Wainwright, Øksendal, Cover–Thomas…) → ল্যান্ডমার্ক paper (Stein, Tibshirani, Efron…) → journal/venue (Annals, JASA, Biometrika, JRSS-B, JMLR, NeurIPS/ICML) — বই থেকে জীবন্ত গবেষণায় ওঠার পথ।
৪ · Reproducibility ও open science¶
একটা ফল যদি অন্য কেউ (বা ছয় মাস পরে আপনি নিজেই) পুনরুৎপাদন করতে না পারেন, তবে তা বিজ্ঞান নয় — উপাখ্যান। Reproducibility (পুনরুৎপাদনযোগ্যতা) — একই ডেটা ও একই কোডে একই ফল পাওয়া — আধুনিক গবেষণার একটা অ-আলোচনাযোগ্য মান। এই অংশ একজন কর্মরত বিজ্ঞানীর সরঞ্জাম ও অভ্যাস সংক্ষেপে দেয়, এবং দেখায় এই curriculum-এর নিজের প্রকল্প ঠিক এই নীতিতেই গড়া।
৪.১ কর্মরত বিজ্ঞানীর সরঞ্জাম¶
- Version control (git) — কোড ও লেখার প্রতিটি পরিবর্তনের ইতিহাস রাখা; \"কী বদলেছি, কখন, কেন\" ফিরে দেখা ও নিরাপদে পরীক্ষা করা যায়। প্রতিটি গবেষণা-প্রকল্প একটা git-repository দিয়ে শুরু হওয়া উচিত।
- স্থির random seed — যেকোনো এলোমেলোতা (সিমুলেশন, নমুনা-বিভাজন, initialisation) একটা নির্দিষ্ট seed দিয়ে বাঁধা, যাতে ফল হুবহু পুনরুৎপাদনযোগ্য। (এই curriculum জুড়ে একটাই master seed — 20260619 — প্রতিটি চিত্র ও সংখ্যার পেছনে।)
- Environment-pinning (নির্ভরতা-সংস্করণ লক) — কোন library-র কোন সংস্করণ ব্যবহৃত হয়েছে তা লিপিবদ্ধ করা (যেমন একটা
requirements.txt), যাতে ভবিষ্যতে বা অন্য মেশিনে একই পরিবেশ পুনর্গঠন করা যায় — নাহলে একটা library-আপডেটই ফল বদলে দিতে পারে। - Literate notebook — কোড, ফলাফল ও ব্যাখ্যা একসাথে বোনা (Jupyter-ধাঁচ), যাতে যুক্তির সুতো ও তার সংখ্যাগত সাক্ষ্য একই জায়গায় থাকে। (এই curriculum-এর প্রতিটি অধ্যায় ঠিক এই আদর্শে — prose, LaTeX, চালানো-যায় কোড, ও তার আসল output একত্রে।)
- Data ও code ভাগ করা — ফল প্রকাশের সাথে ডেটা ও কোড উন্মুক্ত করা (একটা public repository-তে), যাতে অন্যরা যাচাই ও গড়তে পারে — open science-এর মূল।
- Preregistration — একটা বিশ্লেষণ চালানোর আগে তার hypothesis ও পদ্ধতি (কী মাপব, কীভাবে, কোন test) লিখে রাখা ও নথিভুক্ত করা, যাতে ফল-দেখে-পরে-গল্প-বানানো (post-hoc rationalisation) এড়ানো যায়।
৪.২ Reproducibility crisis ও তা এড়ানো¶
একটা অস্বস্তিকর বাস্তবতা: বহু ক্ষেত্রে (মনোবিজ্ঞান, জীববিজ্ঞান, এমনকি পরিসংখ্যান-নিবিড় গবেষণায়) প্রকাশিত ফলের একটা বড় অংশ স্বাধীনভাবে পুনরুৎপাদন করা যায় না — এটাই reproducibility crisis (পুনরুৎপাদন-সংকট)। এর মূলে কয়েকটি চেনা ফাঁদ:
- p-hacking / multiple testing — বহু test চালিয়ে কেবল \"তাৎপর্যপূর্ণ\"গুলো জানানো (← Part IV-এর multiple-comparison সতর্কতা এখানে সরাসরি প্রাসঙ্গিক);
- selective reporting — কেবল যে বিশ্লেষণ \"কাজ করল\" তা জানানো, বাকিগুলো চেপে যাওয়া;
- অপর্যাপ্ত ক্ষমতা (underpowered study) — এত ছোট নমুনায় কাজ করা যে ফল আসলে গোলমাল (← Part IV-এর power-বিশ্লেষণ);
- অ-ভাগকৃত কোড/ডেটা — যাচাই করার উপায়ই না থাকা।
এড়ানোর পথ ঠিক §৪.১-এর অভ্যাসগুলোই: seed দিয়ে determinism, git দিয়ে ইতিহাস, environment-pinning দিয়ে পুনর্গঠন, preregistration দিয়ে সততা, ও open code/data দিয়ে যাচাইযোগ্যতা। মূল মানসিকতা — নিজের ফলের সবচেয়ে কঠোর সমালোচক নিজে হওয়া: \"এটা কি সত্যিই দাঁড়ায়, নাকি আমি গোলমালকে সংকেত ভাবছি?\"
৪.৩ এই curriculum নিজে কীভাবে গড়া¶
এই নীতিগুলো এখানে কেবল উপদেশ নয় — এই curriculum-এর প্রতিটি অধ্যায় ঠিক এই আদর্শে নির্মিত, একটা জীবন্ত উদাহরণ হিসেবে:
- একটা master seed — সমস্ত সিমুলেশন ও চিত্রের পেছনে একটাই generator (
np.random.default_rng(20260619)), নির্দিষ্ট ক্রমে টানা, তাই প্রতিটি সংখ্যা হুবহু পুনরুৎপাদনযোগ্য। - চালানো-যায় কোড — প্রতিটি চিত্র একটা স্বয়ংসম্পূর্ণ, চালানো-যায় স্ক্রিপ্ট থেকে (এই অধ্যায়ের
_code/lab_8-4.py-সহ); কোনো চিত্র হাতে-আঁকা বা অ-পুনরুৎপাদনযোগ্য নয়। - canonical সংখ্যা-যাচাই — মূল সংখ্যাগুলো অধ্যায়, solutions ও glossary-জুড়ে এক রাখা হয় (একটা \"canonical\" মান, একাধিক জায়গায় মিলিয়ে), যাতে কোনো অসঙ্গতি না থাকে — ঠিক একটা reproducible গবেষণা-প্রকল্পের মতো।
- environment-pinning — একটা
requirements.txtনির্ভরতা-সংস্করণ লিপিবদ্ধ করে, যাতে পরিবেশ পুনর্গঠন করা যায়।
অর্থাৎ, এই পথ কেবল reproducibility সম্পর্কে পড়ায়নি — এটি নিজেই একটা reproducible প্রকল্পের মহড়া দিয়েছে। পরের গবেষণা-কাজে এই অভ্যাস সঙ্গে নিয়ে যাওয়াই লক্ষ্য।
এক বাক্যে (§৪)। Reproducibility অ-আলোচনাযোগ্য — git, স্থির seed, environment-pinning, literate notebook, open code/data ও preregistration দিয়ে reproducibility-সংকটের ফাঁদ (p-hacking, selective reporting) এড়ানো যায়; এই curriculum নিজেই (এক master seed 20260619, চালানো-যায় কোড, canonical সংখ্যা) এই আদর্শের একটা জীবন্ত উদাহরণ।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায় নতুন কোনো পরিসংখ্যানিক দাবি সিমুলেট করে না — তার কাজ দিকনির্দেশনা, তাই কোড-ল্যাবটাও ইচ্ছাকৃতভাবে হালকা: একটাই ছোট, চালানো-যায় স্ক্রিপ্ট দুটি schematic (ব্যাখ্যামূলক, ডেটা-চালিত নয়) চিত্র আঁকে যা গোটা যাত্রা ও তার সামনের দিগন্ত এক নজরে দেখায় — (১) statistics-এর একটা মানচিত্র (§২-এর frontier-ক্ষেত্রগুলো node হিসেবে, প্রতিটি থেকে curriculum-Part-এ prereq তীর), আর (২) একটা শেখার পথরেখা (ভিত্তি→inference→modeling→ML→measure theory→গবেষণা, পরবর্তী-ধাপ ট্যাগসহ)। নির্ভরতা কেবল numpy ও matplotlib (Agg)।
স্ক্রিপ্টের কাঠামো ও পুনরুৎপাদনযোগ্যতা (reproducibility)¶
পুরো ল্যাবটা একটাই স্ক্রিপ্ট — _code/lab_8-4.py (Part VIII-এর part-8-capstone/_code/ ডিরেক্টরিতে)। এখানে এলোমেলোতার ভূমিকা নগণ্য ও কেবল আলংকারিক: field-map চিত্রে একটা ম্লান, পেছন-পটের \"ধারণার ছিটে\" (decorative scatter) আঁকতে একটাই generator np.random.default_rng(20260619) ব্যবহৃত হয় — কোনো পরিসংখ্যানিক দাবি এই এলোমেলোতার উপর দাঁড়ায় না, তবু চিত্রটা byte-পুনরুৎপাদনযোগ্য থাকে। বাকি সবটা নির্ধারক (deterministic) layout। set-up লাইন:
import numpy as np
import matplotlib
matplotlib.use("Agg") # write PNGs, never show
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
SEED = 20260619
rng = np.random.default_rng(SEED) # one generator; decorative use only
দুটো সহায়ক ফাংশন — একটা rounded label-box আঁকে, একটা বাঁকানো তীর আঁকে — পুরো ভিজ্যুয়াল-ভাষা এই দুটোর উপর:
def _box(ax, xy, w, h, text, face, fg="white", fs=10, ...):
"""একটা rounded label box কেন্দ্র xy-তে আঁকে।"""
x, y = xy
p = FancyBboxPatch((x - w/2, y - h/2), w, h, boxstyle="round,pad=0.03",
facecolor=face, edgecolor="none", zorder=3)
ax.add_patch(p)
ax.text(x, y, text, ha="center", va="center", color=fg, fontsize=fs,
fontweight="bold", zorder=4)
return (x, y)
def _arrow(ax, a, b, color="#8d99ae", lw=1.6, rad=0.0, ...):
"""a থেকে b-তে একটা বাঁকানো তীর আঁকে।"""
ar = FancyArrowPatch(a, b, arrowstyle="-|>", mutation_scale=14,
linewidth=lw, color=color,
connectionstyle=f"arc3,rad={rad}", zorder=2)
ax.add_patch(ar)
৫.১ · চিত্র ১ — statistics-এর মানচিত্র (frontier-ক্ষেত্র → curriculum-Part)¶
কেন্দ্রে একটা hub — \"this curriculum, Parts 0–VIII\" — আর তার চারপাশে একটা বলয়ে §২-এর আটটি frontier-ক্ষেত্র node হিসেবে; প্রতিটি node থেকে hub-এ একটা মৃদু তীর, এবং প্রতিটির নিচে একটা italic ট্যাগ যা সেই ক্ষেত্রের prereq-Part নাম করে (যেমন causal inference ← Part IV,V):
fig, ax = plt.subplots(figsize=(13.6, 9.8))
ax.set_xlim(0, 100); ax.set_ylim(-8, 100); ax.axis("off")
hub = _box(ax, (50, 50), 26, 9,
"This curriculum\nParts 0-VIII (scratch -> PhD-ready)", C_PART)
fields = [ # (label, prereq-Part tag, position) -- আটটি frontier
("Causal inference\n(potential outcomes,\nDAGs, IV)", "Part IV,V", (18, 84)),
("Bayesian\nnonparametrics ...", "Part IV (4.10)", (50, 90)),
("High-dimensional\nstatistics ...", "Part V,VI (6.2)", (82, 84)),
# ... learning theory, SDE, computational, information theory, applied ML
]
for label, part_tag, pos in fields:
_box(ax, pos, 18.5, 12.5, label, C_FIELD)
_arrow(ax, hub, pos, rad=0.06) # hub -> field
ax.text(pos[0], pos[1]-8.4, f"<- {part_tag}", ha="center",
style="italic", color=C_PART) # prereq tag
fig.savefig(f"{ASSETS}/8-4-field-map.png", bbox_inches="tight")
৫.২ · চিত্র ২ — শেখার পথরেখা (ভিত্তি → গবেষণা)¶
একটা বাম-থেকে-ডান মেরুদণ্ড (spine) বরাবর নয়টি \"স্টপ\" — Part 0 থেকে Part VIII — প্রতিটি একটা milestone-বিন্দু ও উপরে/নিচে পালা করে বসানো label-box (ভিড় এড়াতে), একটা উপ-শিরোনামে সেই Part-এর মূল বিষয়; শেষে একটা \"→ Research\" তীর, আর নিচে পাঁচটি \"suggested next step\" ট্যাগ:
stops = [("Part 0\nFoundations", "algebra, logic, ..."),
("Part I\nEDA", "data, plots, ..."), ...,
("Part VIII\nCapstone", "end-to-end, simulation, papers")]
xs = np.linspace(9, 91, len(stops)); y_spine = 60.0
ax.plot([xs[0], xs[-1]], [y_spine, y_spine], color=C_GY, lw=3) # spine
for i, (title, sub) in enumerate(stops):
face = C_PART if i < len(stops)-1 else C_HL # capstone highlighted
ax.scatter([xs[i]], [y_spine], s=260, color=face, zorder=3)
up = (i % 2 == 0) # alternate above/below
_box(ax, (xs[i], y_spine + (14 if up else -14)), 11.6, 11.0, title, face)
_arrow(ax, (xs[-1]+1, y_spine), (97, y_spine), color=C_HL) # -> Research
next_steps = ["Reproduce a recent paper", "Design a simulation study",
"Write a research proposal", "Read Annals / JMLR / JASA",
"Pick one field, go deep"]
fig.savefig(f"{ASSETS}/8-4-roadmap.png", bbox_inches="tight")
বাস্তব আউটপুট (real stdout):
wrote 8-4-field-map.png (map of research fields <- curriculum parts)
wrote 8-4-roadmap.png (foundations -> ... -> research roadmap)
DONE -- both schematic figures for chapter 8.4 written to _assets/.
স্ক্রিপ্টটি চালাতে (Part VIII-এর _code/ থেকে): python lab_8-4.py। এটি _assets/8-4-field-map.png ও _assets/8-4-roadmap.png লেখে — §৬-এ প্রদর্শিত।
এক বাক্যে (§৫)। একটা হালকা, প্রায়-নির্ধারক স্ক্রিপ্ট (
lab_8-4.py, seed 20260619 কেবল আলংকারিক পটভূমিতে) দুটি schematic চিত্র আঁকে — একটা মানচিত্র (frontier-ক্ষেত্র→Part) ও একটা পথরেখা (ভিত্তি→গবেষণা) —FancyBboxPatch/FancyArrowPatchদিয়ে।
৬ · ভিজ্যুয়ালাইজেশন¶
দুটি চিত্র গোটা অধ্যায়ের — এবং গোটা যাত্রার — সারাংশ: একটা কোথায় যাওয়া যায় (মানচিত্র), আরেকটা কোথা থেকে এলাম (পথরেখা)।
৬.১ · চিত্র ১ — statistics-এর মানচিত্র¶
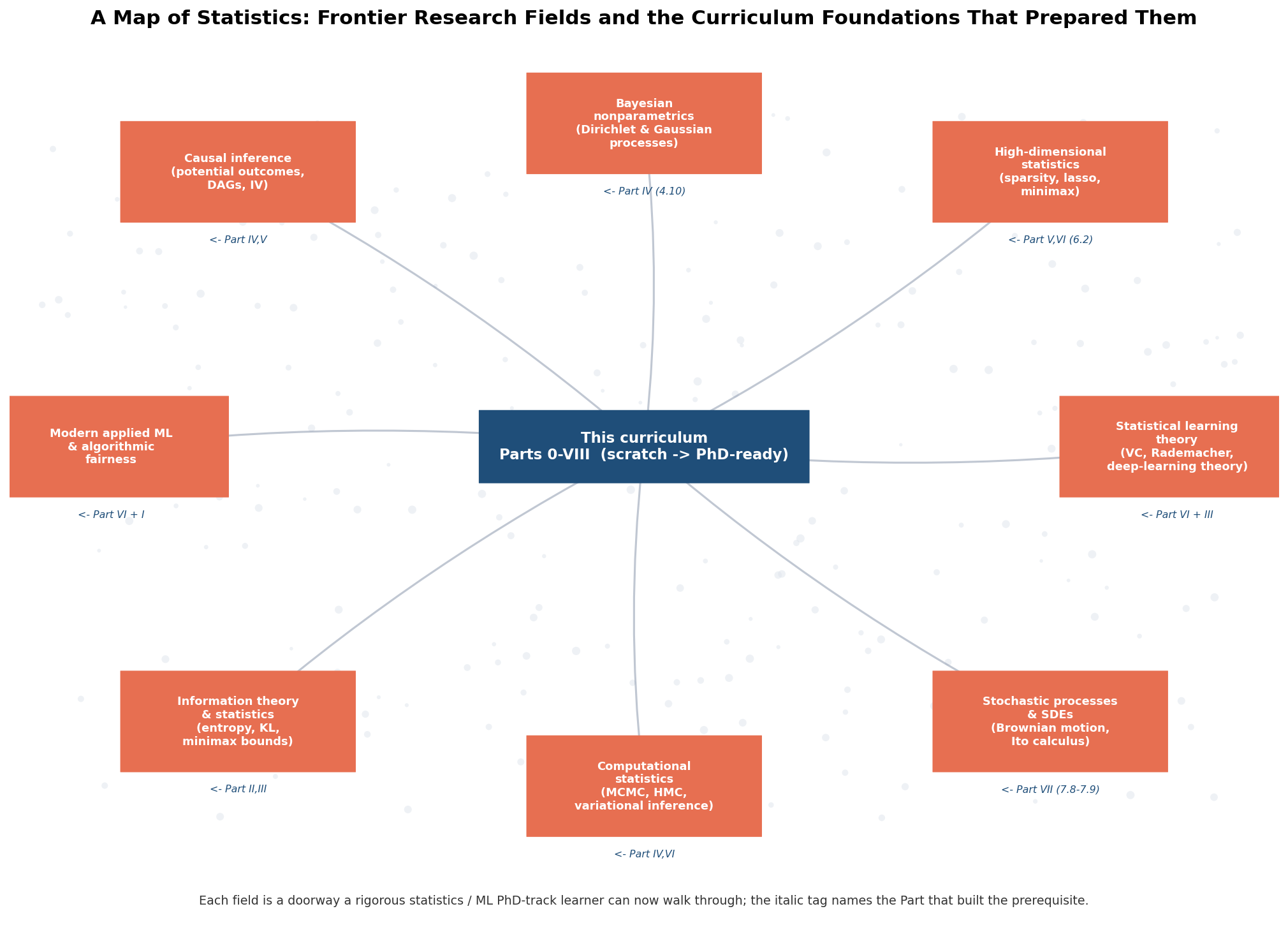
এই মানচিত্র §২-এর গল্পটাই একটা ছবিতে বলে: এই curriculum একটা কেন্দ্রীয় ভিত্তি, আর প্রতিটি frontier-ক্ষেত্র তার থেকে বেরোনো একটা দরজা — italic ট্যাগ দেখায় কোন Part সেই দরজার চাবি দিল। খেয়াল করার মতো: কোনো ক্ষেত্রই বিচ্ছিন্ন নয়, সবই একই hub থেকে; আর একটা ক্ষেত্র প্রায়ই একাধিক Part-এর উপর দাঁড়ায় (learning theory ← Part VI + III), মনে করিয়ে দেয় সীমান্তগুলো পরস্পর-বোনা।
৬.২ · চিত্র ২ — শেখার পথরেখা¶
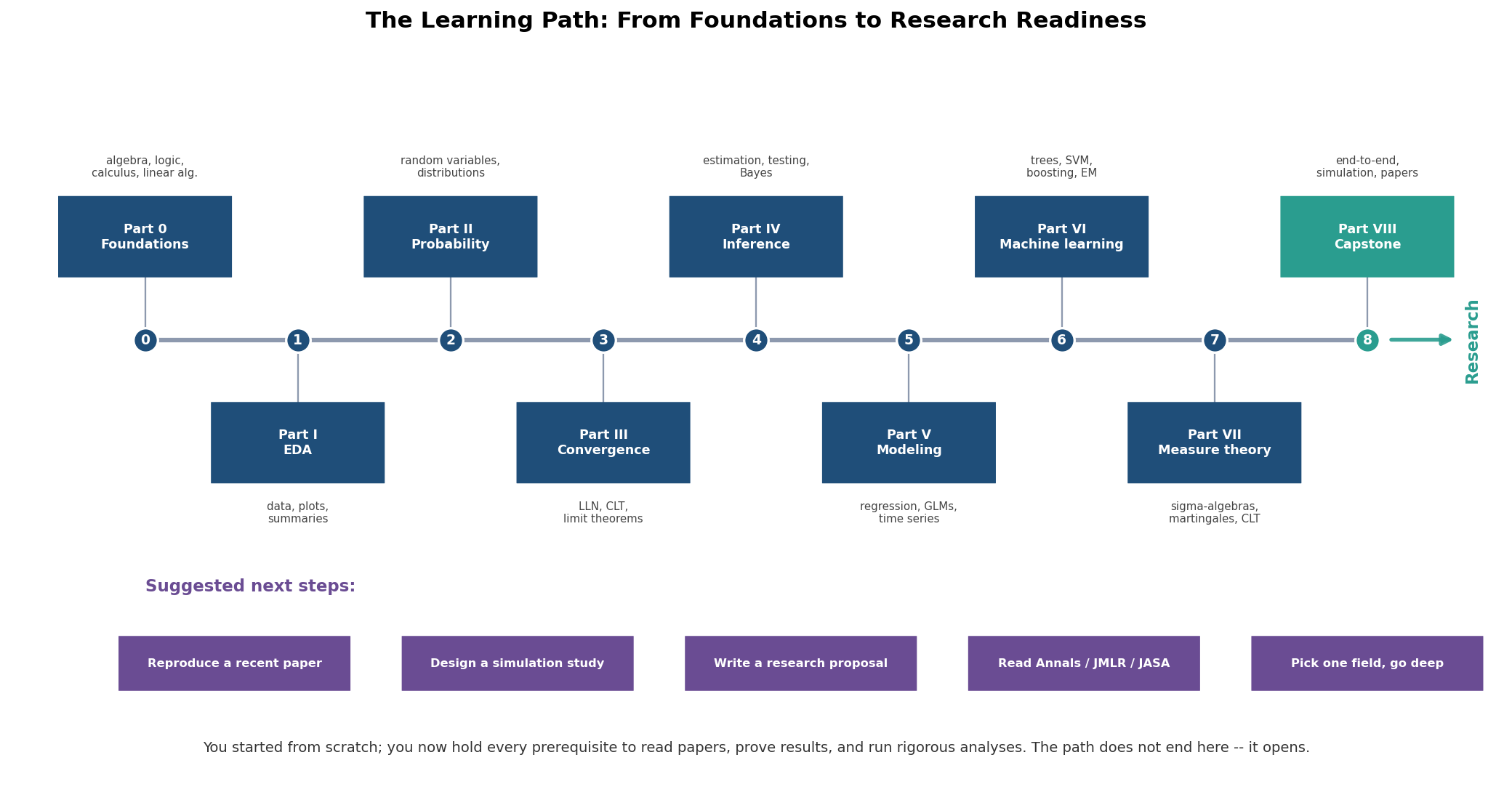
এই পথরেখা পুরো চাপটা একনজরে দেখায় — শূন্য (Part 0-এর algebra ও logic) থেকে শুরু করে ধাপে ধাপে EDA, probability, convergence, inference, modeling, ML, measure theory পেরিয়ে capstone-এ (হাইলাইট করা, কারণ এখানেই তত্ত্ব প্রয়োগে নামে), তারপর তীরটা গবেষণার দিকে খোলে। নিচের পাঁচটি ট্যাগ §৭-এর প্রকল্পগুলোরই সারাংশ — পরের সুনির্দিষ্ট পা।
এক বাক্যে (§৬)। দুটি চিত্র — একটা মানচিত্র (এই curriculum-hub থেকে আটটি frontier-দরজা, প্রতিটির prereq-Part ট্যাগসহ) ও একটা পথরেখা (Part 0→VIII মেরুদণ্ড, capstone হাইলাইট করা, তারপর → Research) — গোটা যাত্রা ও তার সামনের দিগন্ত এক ছবিতে ধরে।
৭ · অনুশীলনী ও পরবর্তী প্রকল্প¶
এই অধ্যায়ের অনুশীলনী অন্যদের মতো নয় — এগুলো গণিত-সমস্যা নয়, বরং পরবর্তী-প্রকল্পের প্রম্পট: একজন শুরুয়াতি গবেষকের প্রথম বাস্তব কাজগুলো। এদের কোনো একক \"সঠিক উত্তর\" নেই; solutions-ফাইল প্রতিটির জন্য একটা কাঠামো ও দিকনির্দেশনা দেয় — কীভাবে শুরু করা, কী কী ধাপ, ও কোথায় সতর্ক থাকা। কঠিনতা-চিহ্ন: ★ সূচনা-প্রকল্প, ★★ মাঝারি, ★★★ উচ্চাকাঙ্ক্ষী। এগুলো সময় নিয়ে, নিজের গতিতে করার জন্য — একটাই যথেষ্ট একটা মাস-ব্যাপী প্রকল্প হতে।
পূর্ণাঙ্গ দিকনির্দেশনা (কাঠামো, ধাপ, সতর্কতা):
_solutions/08-04-where-next-solutions.md। এগুলো প্রকল্প-প্রম্পট, তাই \"সমাধান\" মানে একটা রোডম্যাপ, একটা চূড়ান্ত উত্তর নয়।
প্রসঙ্গত, §৪-এর reproducibility-অভ্যাস (git, স্থির seed, environment-pinning, চালানো-যায় কোড, canonical সংখ্যা) প্রতিটি প্রকল্পে সঙ্গে নিন — একজন গবেষকের অভ্যাস প্রথম প্রকল্প থেকেই গড়া উচিত।
ক · পুনরুৎপাদন ও যাচাই¶
অনুশীলন ১ (★) — একটা সাম্প্রতিক paper পুনরুৎপাদন¶
§২-এর যেকোনো একটা ক্ষেত্র বেছে, তার একটা মূল paper (§৩.৩-এর ল্যান্ডমার্ক, বা একটা সাম্প্রতিক JMLR/Annals paper) নিন এবং তার কেন্দ্রীয় empirical বা তাত্ত্বিক দাবিটি নিজে পুনরুৎপাদন করুন। (ক) paper-এর মূল theorem বা মূল চিত্র/টেবিলটি চিহ্নিত করুন। (খ) একটা reproducible স্ক্রিপ্ট (git, স্থির seed) লিখে সেই ফল ফিরে পান। (গ) canonical সংখ্যার সাথে মিলিয়ে (paper-এর মান বনাম আপনার মান) একটা সংক্ষিপ্ত \"reproduction report\" লিখুন — কী মিলল, কী মিলল না, কেন।
Hint: Part VIII 8.3 (James–Stein) ঠিক এই মহড়া — একটা ধ্রুপদী ফল পড়া→বোঝা→কোডে যাচাই। শুরুতে একটা সরল, সু-নথিভুক্ত ফল বাছুন (যেমন lasso-র support-recovery একটা toy setting-এ, বা bootstrap-CI-এর coverage); সম্পূর্ণ deep-learning paper নয়। মূল দক্ষতা — paper-এর দাবিকে একটা যাচাইযোগ্য সংখ্যায় নামানো।
অনুশীলন ২ (★★) — একটা reproducibility-audit¶
একটা প্রকাশিত ফল (বা আপনার নিজের একটা পুরোনো বিশ্লেষণ) নিয়ে §৪-এর মানদণ্ডে একটা reproducibility-audit চালান। (ক) কোড ও ডেটা কি উপলব্ধ? seed কি স্থির? environment কি pinned? (খ) ফলটি কি হুবহু পুনরুৎপাদনযোগ্য — নাকি একটা library-সংস্করণ বা একটা অ-স্থির seed তা বদলে দেয়? (গ) কী কী পরিবর্তন (git, seed, requirements.txt, একটা README) ফলটিকে সম্পূর্ণ reproducible করত — একটা সংক্ষিপ্ত checklist।
Hint: §৪.১-এর ছয়টি সরঞ্জাম আপনার checklist। একটা ভালো test — কোডটা একটা নতুন, পরিষ্কার পরিবেশে (fresh virtual environment) চালিয়ে দেখুন হুবহু একই সংখ্যা আসে কিনা; না এলে ঠিক কোথায় ভাঙল তা-ই audit-এর মূল খুঁজে বের করা।
খ · নকশা ও পরিকল্পনা¶
অনুশীলন ৩ (★★) — একটা simulation-study নকশা¶
§২-এর একটা প্রশ্ন বেছে (যেমন \"lasso কখন সঠিক support পুনরুদ্ধার করে?\" বা \"এই দুটি estimator-এর মধ্যে কোনটা ছোট নমুনায় ভালো?\") তার জন্য একটা পূর্ণ simulation-study নকশা করুন। (ক) প্রশ্ন ও estimand স্পষ্ট করুন; কোন কোন factor পরিবর্তন করবেন (\(n\), \(p\), sparsity, noise) তা তালিকাভুক্ত করুন। (খ) কোন metric মাপবেন (bias, variance, MSE, coverage, support-recovery-হার) ও কতগুলো replication তা ঠিক করুন। (গ) reproducibility-পরিকল্পনা লিখুন (master seed, draw-ক্রম, চিত্র) — Part VIII 8.2-এর কাঠামো অনুসরণ করে।
Hint: Part VIII 8.2 (simulation study) হুবহু এই নকশার একটা কার্যকর নমুনা — একটা factorial grid, প্রতি cell-এ replication, canonical সংখ্যা, ও reproducible seed। মূল শৃঙ্খলা — সিমুলেশন চালানোর আগে কী মাপবেন তা ঠিক করা (একটা mini-preregistration, §৪.১), যাতে ফল-দেখে-গল্প এড়ানো যায়।
অনুশীলন ৪ (★★★) — একটা research proposal লেখা¶
§২-এর একটা ক্ষেত্রে একটা ছোট (২–৩ পাতা) research proposal লিখুন — একজন শুরুয়াতি গবেষকের প্রথম প্রস্তাবের মতো। (ক) একটা সুনির্দিষ্ট, উত্তরযোগ্য প্রশ্ন বলুন (\"সব শেখা\" নয়, একটা সরু ফাটল)। (খ) কেন এটি গুরুত্বপূর্ণ ও কী কী ইতিমধ্যে জানা (একটা সংক্ষিপ্ত literature-প্রেক্ষাপট, §৩-এর venue থেকে ২–৩টি রেফারেন্স)। (গ) একটা পদ্ধতি ও একটা যাচাই-পরিকল্পনা (তত্ত্ব? simulation? বাস্তব-ডেটা?) — এবং সম্ভাব্য বাধা ও সীমাবদ্ধতা সৎভাবে।
Hint: একটা ভালো proposal-এর মূল হলো সুযোগ সংকীর্ণ করা — একটা বিশাল ক্ষেত্র নয়, একটা নির্দিষ্ট, সীমিত, উত্তরযোগ্য প্রশ্ন। §২-এর কোন ক্ষেত্রটা আপনাকে সবচেয়ে টানে তা দিয়ে শুরু করুন, তারপর সেখানে একটা ছোট, অমীমাংসিত বা অল্প-অন্বেষিত কোণ খুঁজুন। এই অনুশীলনটাই একজন গবেষকের কেন্দ্রীয় দক্ষতা — একটা ভালো প্রশ্ন প্রণয়ন।
গ · প্রতিফলন¶
অনুশীলন ৫ (★) — নিজের যাত্রার মানচিত্র¶
§৬-এর দুটি চিত্র সামনে রেখে নিজের যাত্রার একটা ব্যক্তিগত হিসাব লিখুন। (ক) Part 0→VIII-এর মধ্যে কোন অংশ সবচেয়ে কঠিন লেগেছিল, কোনটা সবচেয়ে সুন্দর — এবং কেন। (খ) §২-এর আটটি ক্ষেত্রের মধ্যে কোন দুটি আপনাকে সবচেয়ে টানে, ও কেন (কোন অধ্যায় সেই আকর্ষণের বীজ বুনেছিল)। (গ) একটা সৎ পরের-ধাপ পরিকল্পনা — পরের তিন মাসে কোন একটা বই (§৩) বা প্রকল্প (অনুশীলন ১–৪) নেবেন।
Hint: এটি একটা প্রতিফলন, কোনো \"ভুল উত্তর\" নেই। মূল উদ্দেশ্য — মানচিত্রটা নিজের করে নেওয়া: কোন দরজা দিয়ে ঢুকবেন তা ঠিক করা। §৮-এর মহাসমাপ্তি এই প্রতিফলনের একটা সঙ্গী।
৮ · সারসংক্ষেপ — গোটা যাত্রার সমাপ্তি¶
এই অধ্যায় একটা যাত্রার শেষ — কিন্তু, যেমন §৬-এর পথরেখা দেখায়, তীরটা শেষে থামে না, খোলে। চলুন পুরো চাপটা এক জায়গায় গেঁথে নিই — শূন্য থেকে যেখানে এসে দাঁড়ালাম।
৮.১ পুরো চাপের পুনরাবৃত্তি — Part 0 থেকে Part VIII।
- Part 0 — গাণিতিক ভিত্তি। algebra, logic, set, calculus, linear algebra — যতটুকু লাগবে, ঠিক ততটুকু, \"just-in-time\"। এখান থেকেই প্রমাণের ভাষা ও গণনার হাতিয়ার।
- Part I — বর্ণনামূলক পরিসংখ্যান ও EDA। data, plot, summary — সংখ্যার সাথে সৎ, চোখ-খোলা পরিচয়; যেকোনো বিশ্লেষণের প্রথম, অপরিহার্য ধাপ।
- Part II — সম্ভাব্যতা: ভিত্তি। random variable, distribution, expectation — অনিশ্চয়তার ভাষা, বাকি সবকিছুর ব্যাকরণ।
- Part III — অসমতা, অভিসারণ ও random process। LLN, CLT, inequality — কেন নমুনা জনসংখ্যা সম্পর্কে বলে, কেন গড় স্থিতিশীল; পরিসংখ্যানের তাত্ত্বিক হৃৎস্পন্দন।
- Part IV — পরিসংখ্যানিক অনুমান। estimation, testing, confidence interval, Bayesian — ডেটা থেকে সিদ্ধান্ত ও তার অনিশ্চয়তার পরিমাপ; পরিসংখ্যানের কেন্দ্র।
- Part V — পরিসংখ্যানিক মডেলিং। regression, GLM, time series — চলকের মধ্যে সম্পর্ক ধরা ও ভবিষ্যদ্বাণী; তত্ত্ব থেকে প্রয়োগে প্রথম বড় সেতু।
- Part VI — পরিসংখ্যানিক মেশিন লার্নিং। tree, SVM, boosting, EM, dimensionality reduction — pattern-শেখা ও পূর্বাভাসের আধুনিক টুলকিট, পরিসংখ্যানিক ভিত্তিতে।
- Part VII — measure-তাত্ত্বিক সম্ভাব্যতা (শিখর)। σ-algebra, Lebesgue integral, \(L^p\), martingale, characteristic function — এবং একটা পূর্ণ কঠোর CLT-প্রমাণে সমাপ্তি; এখানেই probability তার সবচেয়ে গভীর, নিখুঁত রূপ পায়।
- Part VIII — ক্যাপস্টোন ও গবেষণা-প্রস্তুতি। একটা end-to-end বিশ্লেষণ (8.1), একটা simulation-study (8.2), একটা ধ্রুপদী ফল পুনরুৎপাদন (8.3) — এবং এই অধ্যায় (8.4): সামনের পথের মানচিত্র। এখানেই সব তত্ত্ব হাতে-কলমে গবেষণা-দক্ষতায় রূপ নেয়।
৮.২ শিক্ষার্থী এখন কী পারে (একটা সৎ হিসাব)।
- একটা গবেষণা-paper পড়া ও যাচাই করা — তার theorem, প্রমাণ-কাঠামো ও অবদান বোঝা, এবং তার দাবি নিজে পুনরুৎপাদন করা।
- একটা ফল প্রমাণ করা — ε–δ থেকে σ-algebra পর্যন্ত, measure-তাত্ত্বিক কঠোরতাসহ (Part VII একটা পূর্ণ CLT-প্রমাণে শেষ)।
- একটা rigorous বিশ্লেষণ শূন্য থেকে চালানো — data থেকে model থেকে যাচাই থেকে ব্যাখ্যা, reproducible কোডে বাঁধা।
- একটা দাবিকে সংখ্যা ও প্রমাণে দাঁড় করানো — সিমুলেশনে যাচাই, canonical সংখ্যায় মেলানো, ও নিজের ফলের কঠোর সমালোচক হওয়া।
- §২-এর যেকোনো frontier-ক্ষেত্রে দ্রুত গভীরে যাওয়া — কারণ ভিত্তি (probability, inference, ML, measure theory) সাধারণ, আর প্রতিটি ক্ষেত্র সেই ভিত্তিতেই দাঁড়ায়।
৮.৩ একটা সৎ কথা — এবং একটা উৎসাহ।
সৎ থাকা যাক: এই পথ শেষ করা মানে \"সব জানা\" নয় — measure theory-র গভীরতা, একটা frontier-ক্ষেত্রের জীবন্ত গবেষণা, একটা কঠিন paper-এর প্রতিটি সূক্ষ্মতা — এসবে দখল আসে বছরের অনুশীলনে, একটা curriculum-এ নয়। কিন্তু যা তৈরি হয়েছে তা আরও মূল্যবান: একটা শক্ত, সৎ, সাধারণ ভিত্তি, আর তার উপর দাঁড়িয়ে নিজে শেখার, প্রমাণ করার, ও যাচাই করার ক্ষমতা। একজন গবেষককে যা আলাদা করে তা মুখস্থ জ্ঞান নয় — নতুন কিছুর মুখোমুখি হয়ে তা নিজে বুঝে নেওয়ার অভ্যাস। সেই অভ্যাস এখন গড়া।
শুরুটা ছিল একটা সংখ্যা, একটা set, একটা সরল প্রশ্ন — \"গড় কী?\"। শেষটা একটা কঠোর CLT-প্রমাণ, একটা পুনরুৎপাদিত প্যারাডক্স, আর সামনে-খোলা একটা গবেষণা-দিগন্ত। মাঝের পথটুকু — ধৈর্য, অনুশীলন, ও অনেক প্রমাণ — বৃথা যায়নি। §৬-এর পথরেখার শেষ তীরটা যেখানে \"Research\" লেখা, সেটা এখন আর দূরের কল্পনা নয় — সেটা পরের পা।
পথ এখানে শেষ হয় না। এটা খোলে।
উৎস। এই অধ্যায়ের curated পড়ার-তালিকা (§৩) — ভিত্তি-বই (Rice, Wasserman, Klenke, Kolmogorov–Fomin, Axler); ক্ষেত্র-বই (Hernán–Robins, Imbens–Rubin, Pearl; Rasmussen–Williams, Wasserman; Wainwright, Bühlmann–van de Geer; Shalev-Shwartz–Ben-David, Vershynin; Øksendal, Karatzas–Shreve; Robert–Casella, Gelman et al.; Cover–Thomas; Barocas–Hardt–Narayanan); ল্যান্ডমার্ক paper (Stein 1956, James–Stein 1961, Tibshirani 1996, Efron 1979, Cortes–Vapnik 1995); ও journal/venue (Annals of Statistics, JASA, Biometrika, JRSS-B, JMLR, NeurIPS/ICML)। reproducibility-পটভূমি (§৪) — Ioannidis 2005, Munafò et al. 2017, ও git/preregistration-এর ধারণা।
এক বাক্যে (পুরো অধ্যায়)। এই সমাপ্তি-অধ্যায় নতুন theorem নয় বরং একটা গবেষণা-মানচিত্র দেয় — আটটি frontier-ক্ষেত্র (causal inference, Bayesian nonparametrics, high-dimensional statistics, learning theory, stochastic process/SDE, computational statistics, information theory, applied ML/fairness) প্রতিটির অধ্যায়-সংযোগসহ (§২), একটা স্তরভিত্তিক পড়ার-তালিকা (ভিত্তি-বই→ক্ষেত্র-বই→paper→journal, §৩), reproducibility-ও-open-science-এর কর্মপদ্ধতি (git, seed, environment-pinning, preregistration — এই curriculum যেভাবে গড়া, §৪), দুটি schematic চিত্র (statistics-এর মানচিত্র ও শেখার পথরেখা, §৫–৬), ও পরবর্তী-প্রকল্পের প্রম্পট (paper পুনরুৎপাদন, simulation নকশা, proposal, §৭) — শেষে Part 0→VIII পুরো যাত্রার হিসাব নিয়ে (§৮) একজন শূন্য-থেকে-শুরু শিক্ষার্থীকে একজন গবেষণা-প্রস্তুত ব্যক্তিতে পরিণত দেখিয়ে একটা উৎসাহী কিন্তু সৎ বিদায় জানায় — পথ শেষ নয়, খোলে।