4.6 — Confidence Intervals (আস্থা ব্যবধান)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — একটিমাত্র সংখ্যা কখনো ঠিক সত্য নয়; তবে কতটা নিশ্চিত?¶
১.১ আগের অধ্যায়গুলো কোথায় রেখে এসেছিল — আর এখন কোন প্রশ্ন¶
Part IV-এর এ পর্যন্ত আমরা point estimation (বিন্দু-অনুমান) শিখেছি — অজানা parameter \(\theta\)-র জন্য data থেকে একটিমাত্র সংখ্যা \(\hat\theta\) বানানো। সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়ের গল্পটা ঠিক সেখান থেকেই শুরু:
- 4.1-এ আমরা শিখেছি কোথাও একটা population (সমগ্রক / জনসমষ্টি) আছে, যার ভেতরে একটা স্থির কিন্তু অজানা সংখ্যা লুকিয়ে — তার নাম parameter (প্যারামিটার / প্রাচল), প্রতীকে \(\theta\) ("থিটা")। আমরা পুরো population দেখি না; পাই কেবল একটা sample (নমুনা) — \(n\)টি পর্যবেক্ষণ \(X_1, X_2, \dots, X_n\)। data থেকে \(\theta\) আন্দাজ করার সূত্রকে বলি estimator (আনুমানক), প্রতীকে "টুপি" দিয়ে \(\hat\theta\)। যেহেতু \(\hat\theta\) random data-র উপর নির্ভর করে, \(\hat\theta\) নিজেও একটা random variable — নমুনা বদলালে এর মানও বদলায়, আর তার নিজস্ব একটা বণ্টন আছে, যাকে বলি sampling distribution (স্যাম্পলিং বণ্টন)।
- 4.4-এ (Properties of Estimators) আমরা estimator-এর মান বিচার করার যন্ত্র গড়েছি — bias, variance, এবং সবচেয়ে কাজে লাগবে এখানে: standard error (\(\mathrm{SE}\)), যা estimator-এর standard deviation, অর্থাৎ "\(\hat\theta\) নমুনা-থেকে-নমুনায় গড়ে কতখানি ওঠানামা করে" তার মাপ। সবচেয়ে পরিচিত: \(\mathrm{SE}(\bar X) = \sigma/\sqrt n\)।
- 3.4-এ (CLT) আমরা পেয়েছি একটা শক্তিশালী সত্য: যথেষ্ট বড় \(n\)-এ নমুনা গড় \(\bar X\) প্রায় Normal — \(\bar X \approx \mathcal{N}\!\big(\mu,\ \sigma^2/n\big)\) (\(\mathcal{N}\) = Normal বণ্টন)। এই Normal-আকৃতিই এই অধ্যায়ে আমাদের সব হিসাবের ভিত্তি হবে।
তাহলে এখন আমাদের হাতে কী আছে? অজানা \(\theta\) আর তার একটা best-guess সংখ্যা \(\hat\theta\)। কিন্তু একটা অস্বস্তি রয়ে গেছে, যা গত অধ্যায়গুলো সযত্নে এড়িয়ে গেছে — আর সেই অস্বস্তি থেকেই এই অধ্যায়ের প্রশ্ন জন্ম নেয়:
আমি যে একটিমাত্র সংখ্যা \(\hat\theta\) রিপোর্ট করলাম, সেটা তো প্রায় নিশ্চিতভাবেই সত্য \(\theta\)-র সমান নয়। তাহলে সেই অনিশ্চয়তাটা আমি কীভাবে সংখ্যায় প্রকাশ করব — যাতে পাঠক জানে আমার আন্দাজ কতটা ভরসাযোগ্য, আর সত্য মান কোন পরিসরে থাকার কথা?
লক্ষ করুন, এতদিন আমরা কেবল \(\hat\theta\) বানিয়ে এক সংখ্যা হাতে ধরিয়ে দিয়েছি — তার সাথে কোনো "অনিশ্চয়তার ছাপ" দিইনি। এই অধ্যায়ের কাজ ঠিক সেই ছাপ যোগ করা: একটা সংখ্যার বদলে একটা ব্যবধান (interval) দেওয়া, আর সেই ব্যবধানের সাথে একটা পরিমাপযোগ্য আস্থা (confidence) জুড়ে দেওয়া।
১.২ Hook — একটিমাত্র বিন্দু বনাম একটি জাল¶
একটা ছবি দিয়ে শুরু করি। কল্পনা করুন আপনি একটা অন্ধকার ঘরে দেয়ালের কোথাও একটা পেরেক (= সত্য \(\theta\)) আছে জেনে সেটায় ঢিল ছুঁড়ছেন। আপনার কাছে দুটো কৌশল:
- একটিমাত্র সুচালো তীর ছোঁড়া (= point estimate \(\hat\theta\))। সমস্যা: পেরেকটা ঠিক যেখানে, তীরের ডগা হুবহু সেখানে পড়ার সম্ভাবনা কার্যত শূন্য — continuous পরিমাপে কোনো একটা নির্দিষ্ট বিন্দুতে আঘাতের সম্ভাবনা \(0\)। তীর প্রায় সবসময়ই একটু এদিক-ওদিক পড়বে, আর আপনি জানবেনও না কতটা ফসকালো।
- একটা জাল বা চওড়া আঠালো পট্টি ছোঁড়া (= confidence interval)। এবার আপনি একটা বিন্দু নয়, একটা এলাকা ঢাকছেন। পট্টিটা যথেষ্ট চওড়া হলে পেরেক তার ভেতরে ধরা পড়ার একটা ভালো সম্ভাবনা থাকে — আর সেই সম্ভাবনাটা আপনি পট্টির চওড়াই দিয়ে নিয়ন্ত্রণ করতে পারেন।
পরিসংখ্যানে এই "জাল" বা "পট্টি"-ই হলো confidence interval — সত্য parameter \(\theta\)-কে ঘিরে রাখার জন্য data থেকে গড়া একটা ব্যবধান। আর "পট্টিটা কতটা চওড়া করলে কত শতাংশ বার পেরেক ধরা পড়বে" — সেই শতাংশটাই confidence level।
একটা বাস্তব উদাহরণ যা সবাই কোথাও না কোথাও দেখেছে: কোনো জনমত-জরিপের রিপোর্টে লেখা থাকে —
"প্রার্থী A-র সমর্থন ৫২% ± ৩% (৯৫% confidence)।"
এখানে \(52\%\) হলো point estimate \(\hat p\), \(\pm 3\%\) হলো margin of error (ত্রুটির সীমা), আর গোটা ব্যবধান \([49\%,\ 55\%]\) হলো confidence interval — "৯৫% confidence" সহ। এই এক লাইনের বাক্যেই এই অধ্যায়ের সব উপাদান লুকিয়ে: একটা কেন্দ্র, একটা \(\pm\) চওড়াই, আর একটা শতাংশ-আস্থা। আমাদের কাজ এই প্রতিটি টুকরো from scratch বোঝা — এবং সবচেয়ে গুরুত্বপূর্ণ, সেই "৯৫%" আসলে কী মানে, তা নিখুঁতভাবে ধরা।
১.৩ "৯৫% confidence" আসলে কী মানে — আর কী মানে নয়¶
এই অধ্যায়ের সবচেয়ে সূক্ষ্ম, সবচেয়ে বেশি ভুল-বোঝা, এবং সবচেয়ে গুরুত্বপূর্ণ ধারণাটা এখানেই — তাই একদম গোড়াতেই স্বজ্ঞার স্তরে গেঁথে দিই (§২.৪-এ আনুষ্ঠানিকভাবে ফিরব)।
প্রায় সবাই প্রথমবার "৯৫% confidence interval \([49\%,\ 55\%]\)" শুনে ভাবে:
❌ (ভুল ব্যাখ্যা) "সত্য সমর্থন \(p\) ৯৫% সম্ভাবনায় \(49\%\) আর \(55\%\)-এর মধ্যে আছে।"
শুনতে নিরীহ, কিন্তু এটা ভুল — এবং কেন ভুল, সেটাই এই অধ্যায়ের আসল শিক্ষা। সমস্যাটা একটা গভীর জায়গায়: এই বাক্য ধরে নিচ্ছে সত্য \(p\) একটা random জিনিস যা "৯৫% সময় এখানে, ৫% সময় ওখানে" থাকে। কিন্তু আমাদের পুরো কাঠামোয় (4.1 থেকে) —
সত্য parameter \(\theta\) (এখানে \(p\)) একটা স্থির সংখ্যা — random নয়, শুধু অজানা। সে একটাই নির্দিষ্ট মান, যেটা হয় ওই ব্যবধানের ভেতরে আছে, নয়তো নেই। কোনো "সম্ভাবনা" এখানে নেই — একটা স্থির সংখ্যা একটা স্থির ব্যবধানের ভেতরে থাকা বা না-থাকা একটা হ্যাঁ/না ব্যাপার, \(0\) বা \(1\), ৯৫% নয়।
তাহলে "৯৫%" কোথা থেকে আসে, আর সেটা কীসের সম্ভাবনা? উত্তর: randomness-টা parameter-এ নেই, আছে ব্যবধানটায়। ব্যবধানের দুই প্রান্ত (\(\hat\theta - m\) আর \(\hat\theta + m\)) data থেকে গণনা করা, তাই নমুনা বদলালে ব্যবধানটাই নড়ে — প্রতিবার নতুন নমুনায় একটা নতুন ব্যবধান। কাজেই সঠিক ব্যাখ্যাটা ব্যবধানের পদ্ধতি নিয়ে, কোনো একটা নির্দিষ্ট ব্যবধান নিয়ে নয়:
✅ (সঠিক ব্যাখ্যা) "এই পদ্ধতি — অর্থাৎ এভাবে নমুনা নিয়ে এভাবে ব্যবধান বানানো — বারবার চালালে, তৈরি হওয়া ব্যবধানগুলোর ৯৫% সত্য \(p\)-কে নিজের ভেতরে ধরবে (আর ৫% ফসকাবে)। হাতে-পাওয়া এই একটা ব্যবধান সেই ৯৫%-এর একটা কি না, তা আমরা জানি না — শুধু জানি পদ্ধতিটা দীর্ঘমেয়াদে ৯৫% বার সফল।"
পার্থক্যটা সূক্ষ্ম কিন্তু আকাশ-পাতাল: ৯৫% হলো ব্যবধান-তৈরির পদ্ধতির সাফল্যের হার, কোনো নির্দিষ্ট ব্যবধানে সত্যের "থাকার সম্ভাবনা" নয়। parameter স্থির; ব্যবধানটা random — তাই "ধরা পড়া/না-পড়া" ঘটনাটার randomness ব্যবধানের দিক থেকে আসে, parameter-এর দিক থেকে নয়।
একটা রূপক দিয়ে গেঁথে নিন: ভাবুন পেরেকটা (সত্য \(\theta\)) দেয়ালে স্থির পেরেক-ই — সে নড়ে না। আপনি বারবার চোখ বুজে একটা নির্দিষ্ট-চওড়ার আংটা ছুঁড়ছেন। আংটাটাই প্রতিবার একটু আলাদা জায়গায় পড়ে (random)। "৯৫% confidence" মানে আপনার ছোঁড়ার কৌশলটা এমন যে ছোঁড়া আংটার ৯৫% পেরেককে ঘিরে ফেলে। একটা নির্দিষ্ট আংটা পেরেক ঘিরেছে কি না — সেটা ছোঁড়ার পর হ্যাঁ অথবা না, ৯৫% কিছু নয়। (Figure 4-6-ci-interpretation এই বহু-ব্যবধানের ছবিটা — কিছু সত্যকে ধরে, কিছু ফসকায় — চোখে দেখাবে।)
এক বাক্যে যা সারা জীবন মনে রাখবেন: confidence level সত্য parameter-এর গুণ নয়, পদ্ধতির গুণ। "৯৫%" বলে পদ্ধতিটা কত ভরসাযোগ্য, ওই একটা ব্যবধানে সত্য কতটা "সম্ভাব্য" তা নয়।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — CI-র শব্দভাণ্ডার from scratch: confidence level \(1-\alpha\), confidence interval, margin of error \(m=z_{\alpha/2}\cdot\mathrm{SE}\), pivot, critical value \(z_{\alpha/2}\) / \(t_{n-1,\alpha/2}\); pivot থেকে CI গড়ার সাধারণ রেসিপি; সঠিক বনাম ভুল interpretation (ব্যবধান random, parameter স্থির); এবং z বনাম t কখন। প্রতিটি প্রতীক খোলা হবে।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 (Normal mean, σ জানা → z-interval), E2 (Normal mean, σ অজানা → t-interval), E3 (proportion-এর CI), E4 (MLE থেকে asymptotic CI, \(\mathrm{SE}=1/\sqrt{nI}\))।
- §৪–৫ — pivot-পদ্ধতির পূর্ণ যৌক্তিক ভিত্তি, coverage probability-র নিখুঁত গণনা, one-sided CI, sample-size নির্ধারণ (\(m\) থেকে \(n\)), এবং interpretation-এর গভীরতর আলোচনা ও Bayesian credible interval-এর সাথে পার্থক্য।
- §৬–৮ — চিত্র (coverage, interpretation, z-vs-t, width-vs-n), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর গুরুত্বপূর্ণ ধাপ। 4.2–4.4 দিয়েছে একটা বিন্দু-আন্দাজ (\(\hat\theta\)) আর তার অনিশ্চয়তার মাপ (\(\mathrm{SE}\)); এই অধ্যায় সেই দুটোকে একত্র করে একটা ব্যবধান-আন্দাজে রূপ দেয় — point estimate \(+\) margin of error। আর ঠিক একই pivot-যুক্তি সামান্য ঘুরিয়ে দিলেই জন্ম নেয় পরের অধ্যায় 4.7-এর hypothesis testing — কাজেই CI আর hypothesis test একই মুদ্রার দুই পিঠ, যা পরে দেখব।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামোটা স্থির: আমাদের কাছে একটি i.i.d. নমুনা \(X_1, X_2, \dots, X_n\) আছে (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা), একটি common distribution থেকে, যার ভেতরে একটি অজানা স্থির parameter \(\theta\) আছে। আমরা একটি point estimator \(\hat\theta = \hat\theta(X_1,\dots,X_n)\) বেছেছি (যেমন \(\bar X\)), এবং তার standard error \(\mathrm{SE}(\hat\theta)\) জানি (4.4)। প্রশ্ন: এই \(\hat\theta\)-কে ঘিরে কীভাবে একটা ব্যবধান বানাব যা সত্য \(\theta\)-কে নির্দিষ্ট আস্থায় ধরে?
২.১ Confidence level ও confidence interval — সংজ্ঞা¶
প্রথমে দুটো মূল বস্তু সংজ্ঞায়িত করি: কত আস্থা চাই (confidence level), আর সেই আস্থার ব্যবধানটা কী (confidence interval)।
সংজ্ঞা (Confidence level — আস্থার মাত্রা, \(1-\alpha\))। আমরা আগে থেকে একটা লক্ষ্য-আস্থা ঠিক করি, যাকে লিখি \(1-\alpha\) — একটা সংখ্যা \(0\) আর \(1\)-এর মধ্যে (সাধারণত \(0.90\), \(0.95\), বা \(0.99\))। এখানে —
- \(\alpha\) ("আলফা") হলো significance level বা ব্যর্থতার অনুমোদিত হার — যত ভগ্নাংশ বার আমরা পদ্ধতিটিকে সত্য ফসকাতে দিতে রাজি। যেমন \(\alpha = 0.05\) মানে আমরা মেনে নিই পদ্ধতি ৫% বার ফসকাবে।
- \(1-\alpha\) হলো confidence level — যত ভগ্নাংশ বার পদ্ধতি সত্যকে ধরবে। \(\alpha = 0.05 \Rightarrow 1-\alpha = 0.95\), অর্থাৎ ৯৫% আস্থা।
সংজ্ঞা (Confidence interval — আস্থা ব্যবধান, CI)। parameter \(\theta\)-র একটি \(1-\alpha\) স্তরের confidence interval হলো data থেকে গণনা করা দুটি প্রান্ত \(L = L(X_1,\dots,X_n)\) (lower, নিম্নসীমা) ও \(U = U(X_1,\dots,X_n)\) (upper, ঊর্ধ্বসীমা) দিয়ে গড়া একটি ব্যবধান \([L,\ U]\), যা এই শর্ত মেটায়:
এই সমীকরণটা মন দিয়ে পড়ুন, কারণ এর ভেতরেই §১.৩-এর পুরো সূক্ষ্মতা লুকিয়ে। প্রতিটি অংশ খুলি:
- \(\theta\) — সত্য, স্থির, অজানা parameter (random নয়)।
- \(L\) ও \(U\) — ব্যবধানের দুই প্রান্ত; এরা data-র function, তাই এরাই random (নমুনা বদলালে এদের মান বদলায়)।
- \(P(L \le \theta \le U)\) — এই সম্ভাবনাটা \(L\) ও \(U\)-র randomness-এর উপর নেওয়া (অর্থাৎ "সব সম্ভাব্য নমুনার উপর"), \(\theta\)-র উপর নয়। কথায়: "এলোমেলো প্রান্তওয়ালা ব্যবধান \([L,U]\) স্থির \(\theta\)-কে ঢেকে ফেলার সম্ভাবনা \(1-\alpha\)।"
সবচেয়ে গুরুত্বপূর্ণ পঠন-নির্দেশ: উপরের ঘটনাটা "\(\theta\) এদিক-ওদিক যায়" নয় — \(\theta\) পেরেকের মতো স্থির। বরং \([L,U]\) ব্যবধানটাই random, আর সম্ভাবনাটা সেই random ব্যবধান স্থির \(\theta\)-কে ধরতে পারার। তাই \(P(\cdot) = 1-\alpha\)-কে পড়তে হবে "পদ্ধতি \(1-\alpha\) ভগ্নাংশ বার ধরে", "এই ব্যবধানে \(\theta\) \(1-\alpha\) সম্ভাবনায় আছে" নয়। (হাতে নমুনা এসে গেলে \(L,U\) নির্দিষ্ট সংখ্যা হয়ে যায়, তখন আর কোনো randomness নেই — তাই তখন "৯৫% সম্ভাবনা" বলা অর্থহীন।)
বেশিরভাগ পরিচিত CI প্রতিসম (symmetric) — point estimate \(\hat\theta\)-কে কেন্দ্রে রেখে দুই দিকে সমান দূরত্ব \(m\)। তখন \(L = \hat\theta - m\), \(U = \hat\theta + m\), আর ব্যবধান লেখা হয় সংক্ষেপে:
এই \(m\)-এরই একটা নাম আছে — margin of error, পরের উপবিভাগের বিষয়।
২.২ Margin of error — ব্যবধানের অর্ধ-চওড়াই¶
সংজ্ঞা (Margin of error — ত্রুটির সীমা, \(m\))। প্রতিসম CI \(\hat\theta \pm m\)-এ \(m\)-কে বলে margin of error — point estimate থেকে প্রতিটি প্রান্তের দূরত্ব, অর্থাৎ ব্যবধানের অর্ধ-চওড়াই (half-width)। বেশিরভাগ ক্ষেত্রে এর রূপ:
প্রতিটি প্রতীক খুলি:
- \(\mathrm{SE}(\hat\theta)\) — estimator-এর standard error (4.4), অর্থাৎ তার standard deviation; এটা বলে \(\hat\theta\) স্বভাবতই কতখানি ওঠানামা করে। যত বড় \(\mathrm{SE}\), তত চওড়া ব্যবধান লাগবে — স্বজ্ঞায় সরল: আন্দাজ যত অনিশ্চিত, জাল তত চওড়া।
- \(z_{\alpha/2}\) — একটা critical value (সংকট-মান), যা confidence level-এর উপর নির্ভর করে; এটা ঠিক করে "কত-গুণ \(\mathrm{SE}\) দূরে গেলে আমরা \(1-\alpha\) ভগ্নাংশ ভর ঢেকে ফেলব"। (এর precise সংজ্ঞা §২.৩-এ।)
এই একটা সমীকরণেই margin of error-এর তিন নিয়ন্ত্রকের সম্পর্ক স্পষ্ট, যা গোটা অধ্যায়ে ফিরে আসবে:
- বেশি আস্থা চাইলে (\(1-\alpha\) বাড়ালে, যেমন ৯৫% → ৯৯%) → \(z_{\alpha/2}\) বড় হয় → \(m\) বড় → চওড়া ব্যবধান। অর্থাৎ বেশি নিশ্চিত হতে চাইলে কম নির্দিষ্ট হতে হয় (চওড়া জাল)। এটা একটা মৌলিক আপস: precision বনাম confidence।
- বেশি data নিলে (\(n\) বাড়ালে) → সাধারণত \(\mathrm{SE} \propto 1/\sqrt n\) কমে → \(m\) ছোট → সরু ব্যবধান। তাই \(n\) চারগুণ করলে ব্যবধান অর্ধেক সরু (\(\sqrt n\) নিয়ম)। (Figure
4-6-ci-width-vs-nএই সংকোচন দেখাবে।) - কম ছড়ানো data (ছোট \(\sigma\)) → ছোট \(\mathrm{SE}\) → সরু ব্যবধান।
মনে রাখুন: margin of error \(=\) critical value \(\times\) standard error। CI-র গোটা কাঠামোটা তাই দুই টুকরো — একটা কেন্দ্র (\(\hat\theta\), point estimate, 4.2–4.3 থেকে) আর একটা ব্যাসার্ধ (\(m = z_{\alpha/2}\,\mathrm{SE}\), এই অধ্যায়)। CI = point estimate \(\pm\) (critical value \(\times\) SE)।
২.৩ Pivot ও critical value — ব্যবধানটা কোথা থেকে আসে¶
§২.১-এ আমরা CI-র সংজ্ঞা দিয়েছি (\(P(L\le\theta\le U)=1-\alpha\)), কিন্তু এমন \(L,U\) আসলে কীভাবে খুঁজে পাব তা বলিনি। এখানেই pivot ধারণাটা — CI গড়ার সবচেয়ে সাধারণ ও সুন্দর কৌশল।
মূল ধারণা। আমরা এমন একটা পরিমাণ চাই যেটা (ক) data ও অজানা \(\theta\) — দুটোর উপরই নির্ভর করে, অথচ (খ) যার বণ্টন \(\theta\)-র উপর নির্ভর করে না — একটা সর্বজনবিদিত, ছকে-দেখা বণ্টন। তাহলে সেই জানা বণ্টন থেকে দুটো প্রান্ত বের করে, ভেতরের \(\theta\)-কে আলাদা করে নিলেই CI পেয়ে যাব।
সংজ্ঞা (Pivot / pivotal quantity — মুখ্যাবলম্ব)। একটি pivot হলো data ও parameter-এর একটা function \(Q = Q(X_1,\dots,X_n;\ \theta)\) যার probability distribution \(\theta\)-র উপর নির্ভর করে না (সব \(\theta\)-তে একই বণ্টন)।
সবচেয়ে গুরুত্বপূর্ণ উদাহরণ — যেটা E1-এ সরাসরি কাজে লাগবে। ধরুন \(X_i \sim \mathcal{N}(\mu,\sigma^2)\), \(\sigma\) জানা, \(\mu\) অজানা। তখন standardize-করা নমুনা গড়:
একটা pivot — কারণ (\(\bar X\)-এর sampling distribution Normal হওয়ায়, 4.1) এটা সবসময় standard normal \(\mathcal{N}(0,1)\), \(\mu\) যা-ই হোক না কেন। প্রতীক খুলি: লব \(\bar X - \mu\) মাপে point estimate সত্য থেকে কত দূরে, আর হর \(\sigma/\sqrt n = \mathrm{SE}(\bar X)\) সেই দূরত্বকে "কত SE দূরে"-তে রূপ দেয়; ফল \(Z\) একক-হীন, বণ্টন স্থির। (যথেষ্ট বড় \(n\)-এ CLT-র জোরে এটা Normal না হলেও প্রায় Normal — তাই pivot-যুক্তি অ-Normal data-তেও আসন্নভাবে খাটে।)
সংজ্ঞা (Critical value — সংকট-মান, \(z_{\alpha/2}\))। standard normal বণ্টনের upper-\(\alpha/2\) quantile-কে বলি \(z_{\alpha/2}\) — অর্থাৎ সেই সংখ্যা যার ডানে standard normal-এর ঠিক \(\alpha/2\) ভর পড়ে:
প্রতীক ও স্বজ্ঞা খুলি:
- নিচের সূচক \(\alpha/2\) মানে ভরটা দুই লেজে সমান ভাগে (\(\alpha/2\) বাঁয়ে, \(\alpha/2\) ডানে) ভাগ করা — কারণ আমরা দুই-পাশে সমান প্রতিসম ব্যবধান চাই। মাঝখানে তাই \(1-\alpha\) ভর থাকে।
- সবচেয়ে চেনা মান: \(1-\alpha = 0.95 \Rightarrow \alpha/2 = 0.025 \Rightarrow z_{0.025} = 1.96\) (প্রায় \(2\))। তাই বিখ্যাত "\(\pm 2\) SE" নিয়ম আসলে ৯৫% CI।
- অন্য পরিচিত মান: \(z_{0.05} = 1.645\) (৯০% CI), \(z_{0.005} = 2.576\) (৯৯% CI)।
এই দুই সংজ্ঞা মিলিয়ে এখন CI-র জন্ম দেখি। যেহেতু মাঝের \(1-\alpha\) ভর \([-z_{\alpha/2},\ z_{\alpha/2}]\)-এর মধ্যে:
এবার ভেতরের অসমতা থেকে \(\mu\)-কে আলাদা করি (তিন অংশকে \(\sigma/\sqrt n\) দিয়ে গুণ করে, তারপর \(\bar X\) বিয়োগ করে চিহ্ন উল্টে সাজিয়ে):
এটাই ঠিক §২.১-এর CI-সংজ্ঞার আকার (\(P(L\le\theta\le U)=1-\alpha\)), যেখানে \(L = \bar X - z_{\alpha/2}\sigma/\sqrt n\) আর \(U = \bar X + z_{\alpha/2}\sigma/\sqrt n\)। অর্থাৎ pivot \(Z\) থেকে আমরা CI গড়ে ফেললাম।
CI গড়ার সাধারণ রেসিপি (যা E1–E4-এ বারবার লাগবে):
- একটা pivot \(Q(\text{data};\theta)\) বানাও যার বণ্টন জানা ও \(\theta\)-নিরপেক্ষ (যেমন \(Z\) বা পরে \(T\))।
- সেই জানা বণ্টন থেকে এমন দুই প্রান্ত নাও যাদের মাঝে \(1-\alpha\) ভর: \(P(-c \le Q \le c) = 1-\alpha\), যেখানে \(c\) = critical value।
- ভেতরের অসমতা থেকে \(\theta\) আলাদা করো (বীজগণিতে সাজিয়ে), যাতে \(\theta\) একা মাঝখানে আসে।
- বাকি দুই প্রান্তই হলো \(L\) ও \(U\) — তোমার confidence interval।
এক বাক্যে: pivot হলো সেই সেতু — একটা জানা, \(\theta\)-নিরপেক্ষ বণ্টনওয়ালা পরিমাণ — যাকে "উল্টে" দিলে অজানা \(\theta\)-র চারপাশে একটা ব্যবধান বেরিয়ে আসে। প্রায় সব CI-ই কোনো-না-কোনো pivot থেকে এভাবেই জন্মায়।
২.৪ সঠিক বনাম ভুল interpretation — আনুষ্ঠানিকভাবে¶
§১.৩-এর সতর্কবার্তাটা এবার §২.১-এর সংজ্ঞার আলোকে পাকা করি, কারণ এটাই এই অধ্যায়ের সবচেয়ে পরীক্ষায়-আসা এবং বাস্তবে-ভুল-করা বিন্দু।
সমীকরণ \(P(L \le \theta \le U) = 1-\alpha\)-এ randomness থাকে \(L\) ও \(U\)-তে (data-র function), \(\theta\)-তে নয় (\(\theta\) স্থির)। এর সরাসরি ফল দুটো ব্যাখ্যার পার্থক্য:
| সঠিক ✅ | ভুল ❌ | |
|---|---|---|
| randomness কোথায় | ব্যবধান \([L,U]\)-তে (data থেকে আসা) | (ভুলভাবে) parameter \(\theta\)-তে |
| "৯৫%" কীসের | পদ্ধতির দীর্ঘমেয়াদি সাফল্য-হার | এই ব্যবধানে \(\theta\)-র "থাকার সম্ভাবনা" |
| বাক্য | "এভাবে বানানো ব্যবধানগুলোর ৯৫% সত্যকে ধরে" | "সত্য \(\theta\) ৯৫% সম্ভাবনায় এই ব্যবধানে" |
| হাতে-পাওয়া ব্যবধানে | হয় সত্যকে ধরেছে, নয় ধরেনি (জানি না কোনটা) | (ভুলভাবে) ৯৫% সম্ভাবনা ধার্য করা |
কেন ভুলটা সত্যিই ভুল, তা একটা চূড়ান্ত যুক্তিতে দেখি: ধরুন একটা নির্দিষ্ট নমুনায় আপনি CI পেলেন \([49,\ 55]\)। এখন এই দুই সংখ্যা (\(49\) ও \(55\)) আর সত্য \(p\) — তিনটেই স্থির (যদিও \(p\) অজানা)। একটা স্থির সংখ্যা (\(p\)) একটা স্থির ব্যবধান (\([49,55]\))-এর ভেতরে হয় আছে, নয় নেই — এটা একটা সত্য/মিথ্যা ব্যাপার, এর "সম্ভাবনা" \(0\) বা \(1\), কখনো \(0.95\) নয়। "\(0.95\)" কেবল তখনই অর্থপূর্ণ যখন ব্যবধানটা এখনও random — অর্থাৎ নমুনা টানার আগে, পদ্ধতির বর্ণনা হিসেবে। নমুনা এসে গেলে randomness শেষ, তাই "এই ব্যবধানে ৯৫% সম্ভাবনা" বলা অর্থহীন।
সঠিক মানসিক ছবি (Figure
4-6-ci-coverage): কল্পনা করুন একই পদ্ধতিতে ১০০টা আলাদা নমুনা থেকে ১০০টা CI আঁকা হলো — একটা উল্লম্ব রেখায় (সত্য \(\theta\)) বরাবর সাজানো অনুভূমিক দণ্ড। এদের মধ্যে গড়ে ৯৫টা দণ্ড সেই রেখা ছেদ করবে (সত্যকে ধরবে), ৫টা ধরবে না। "৯৫% confidence" = এই ৯৫/১০০ ধরা-পড়ার হার। কোন দণ্ডটা আপনার হাতে এসেছে, আর সেটা ধরেছে কি না — তা আপনি জানেন না।
একটা ব্যবহারিক ভাষা যা সঠিক ও নিরাপদ: "আমরা ৯৫% confident যে সত্য মান \([49,55]\)-এ" — যেখানে "confident" শব্দটাই পদ্ধতির আস্থা বোঝায়, "৯৫% probability" নয়। (পরে 5.x-এ Bayesian credible interval দেখব, যেখানে "parameter-এর উপর সম্ভাবনা" বৈধ — কিন্তু সেটা একটা ভিন্ন কাঠামো, ভিন্ন অনুমানসহ; frequentist CI-তে নয়।)
২.৫ z বনাম t — কখন কোনটা, আর কেন¶
এতক্ষণ pivot \(Z = (\bar X - \mu)/(\sigma/\sqrt n)\) ব্যবহার করেছি — কিন্তু সেখানে একটা লুকানো অনুমান ছিল: \(\sigma\) জানা। বাস্তবে \(\sigma\) প্রায় কখনোই জানা থাকে না (population-এর variance জানলে তো গড়ও জানতাম!)। তাহলে কী করব? — \(\sigma\)-র জায়গায় তার data-থেকে-গোনা অনুমান \(S\) বসাই, যেখানে
হলো sample standard deviation (\(S^2\) = sample variance, 4.4-এর সেই \(n-1\)-ভাজক unbiased estimator)। কিন্তু এই প্রতিস্থাপন একটা মূল্য চায়, আর সেখান থেকেই \(t\)-distribution আসে।
কেন σ-কে S দিয়ে বদলালে \(z\) আর খাটে না। যখন \(\sigma\) জানা, কেবল লব \(\bar X\) random; হর \(\sigma/\sqrt n\) একটা স্থির সংখ্যা — তাই অনুপাত পরিচ্ছন্ন Normal। কিন্তু \(S\) বসালে এখন লব ও হর দুটোই random (\(S\)-ও নমুনা থেকে গোনা, তাই ওঠানামা করে)। একটা random সংখ্যাকে আরেকটা random সংখ্যা দিয়ে ভাগ করায় অতিরিক্ত একটা অনিশ্চয়তা ঢোকে — ফলে অনুপাতটা Normal-এর চেয়ে একটু বেশি ছড়ানো, বিশেষত লেজে ভারী। এই নতুন বণ্টনের নাম Student's \(t\)-distribution।
সংজ্ঞা (t-statistic ও \(t\)-distribution)। σ-র জায়গায় \(S\) বসানো standardize-করা গড়:
(যখন \(X_i\) Normal)। এখানে —
- \(t_{n-1}\) — \(t\)-distribution with \(n-1\) degrees of freedom (স্বাধীনতার মাত্রা)। সূচক \(n-1\) আসে \(S\) গণনায় (যেহেতু \(\bar X\) অনুমান করতে একটা degree of freedom খরচ হয়, 4.4-এর সেই \(n-1\))।
- \(T\)-ও একটা pivot — এর বণ্টন \(t_{n-1}\), যা \(\mu,\sigma\) কোনোটার উপরই নির্ভর করে না; তাই §২.৩-এর একই রেসিপিতে এটা থেকেও CI গড়া যায়, শুধু \(z_{\alpha/2}\)-র জায়গায় \(t\)-critical value নিয়ে।
\(t\)-এর critical value ও আকৃতি। \(t\)-interval-এর critical value হলো \(t_{n-1,\alpha/2}\) — \(t_{n-1}\) বণ্টনের upper-\(\alpha/2\) quantile (\(P(T > t_{n-1,\alpha/2}) = \alpha/2\))। দুটো মূল বৈশিষ্ট্য:
- \(t_{n-1,\alpha/2} > z_{\alpha/2}\) সবসময় — \(t\) ভারী-লেজ বলে একই মাঝের-ভর ঢাকতে একটু বেশি দূরে যেতে হয়; ফলে t-interval সর্বদা z-interval-এর চেয়ে সামান্য চওড়া। এই বাড়তি চওড়াই σ-না-জানার অতিরিক্ত অনিশ্চয়তার মাশুল। (Figure
4-6-z-vs-t-ciদুই বণ্টন ও তাদের critical value পাশাপাশি দেখাবে।) - \(n\) বড় হলে \(S \to \sigma\) (LLN), তাই \(t_{n-1}\) ক্রমে \(\mathcal{N}(0,1)\)-এ মিলিয়ে যায়: \(t_{n-1,\alpha/2} \to z_{\alpha/2}\)। যেমন \(n=2\)-এ \(t_{1,0.025}=12.71\) (বিশাল!), \(n=11\)-এ \(t_{10,0.025}=2.23\), \(n=31\)-এ \(t_{30,0.025}=2.04\), আর \(n\to\infty\)-এ \(\to 1.96\)। তাই বড় নমুনায় (\(n \gtrsim 30\)) দুটো প্রায় অভিন্ন।
সিদ্ধান্তের নিয়ম — কখন কোনটা:
| পরিস্থিতি | pivot | critical value | ব্যবহার |
|---|---|---|---|
| \(\sigma\) জানা, data Normal (বা বড় \(n\)) | \(Z = \dfrac{\bar X - \mu}{\sigma/\sqrt n}\) | \(z_{\alpha/2}\) | z-interval (E1) |
| \(\sigma\) অজানা, \(S\) দিয়ে অনুমান, data ~Normal | \(T = \dfrac{\bar X - \mu}{S/\sqrt n}\) | \(t_{n-1,\alpha/2}\) | t-interval (E2) |
| \(\sigma\) অজানা কিন্তু \(n\) বিশাল | \(T \approx Z\) | \(\approx z_{\alpha/2}\) | দুটোই কাছাকাছি; প্রায়ই \(z\) |
এক বাক্যে: σ জানা থাকলে \(z\); σ-কে \(S\) দিয়ে বদলালে সেই বাড়তি অনিশ্চয়তার জন্য \(t\) (একটু চওড়া) — আর বড় নমুনায় দুটো মিলে যায়, কারণ তখন \(S\) প্রায় \(\sigma\)।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর রেসিপি এবার চারটি বাস্তব পরিস্থিতিতে সংখ্যাসহ চালাব। প্রতিটিতে একই ছন্দ: pivot বাছো → critical value নাও → \(\hat\theta \pm (\text{critical value})\times\mathrm{SE}\) লিখে সংখ্যা বসাও → ব্যাখ্যা করো। চারটি উদাহরণ চারটি কেন্দ্রীয় কেস ধরে: E1 z-interval (σ জানা), E2 t-interval (σ অজানা), E3 proportion-এর CI, E4 MLE থেকে asymptotic CI।
E1 · Normal mean, σ known — z-interval¶
এই উদাহরণটা §২.৩-এ গড়া রেসিপির সরাসরি সংখ্যা-প্রয়োগ।
সেটআপ। একটা কারখানার যন্ত্র প্যাকেটে চিনি ভরে; প্যাকেট-ওজন আনুমানিক Normal, এবং দীর্ঘ ইতিহাস থেকে population standard deviation জানা: \(\sigma = 10\) গ্রাম। আজ \(n = 100\)টি প্যাকেট মেপে নমুনা গড় পাওয়া গেল \(\bar X = 50\) গ্রাম। সত্য গড় ওজন \(\mu\)-র একটি ৯৫% confidence interval চাই।
ধাপ ১–২ (pivot ও critical value)। \(\sigma\) জানা ও data Normal, তাই pivot \(Z = (\bar X - \mu)/(\sigma/\sqrt n) \sim \mathcal{N}(0,1)\), আর confidence level \(1-\alpha = 0.95 \Rightarrow \alpha/2 = 0.025 \Rightarrow z_{\alpha/2} = z_{0.025} = 1.96\)।
ধাপ ৩ (margin of error)। প্রথমে standard error:
তাই margin of error:
ধাপ ৪ (CI)। point estimate \(\pm\) margin:
সঠিক ব্যাখ্যা (§২.৪ মতে)। "এই পদ্ধতিতে বারবার ১০০-প্যাকেট নমুনা নিয়ে CI বানালে, ব্যবধানগুলোর ৯৫% সত্য গড় ওজন \(\mu\)-কে ধরবে। হাতে-পাওয়া এই \([48.04, 51.96]\) তাদের একটা — হয় সত্যকে ধরেছে, নয় ধরেনি।" ভুল হবে বলা "\(\mu\) ৯৫% সম্ভাবনায় \([48.04, 51.96]\)-এ" — \(\mu\) স্থির, ব্যবধানটা random।
একটু নাড়াচাড়া (নিয়ন্ত্রকের প্রভাব দেখা): যদি ৯৯% চাইতাম, \(z_{0.005}=2.576\), তখন \(m = 2.576\), CI \(= [47.42, 52.58]\) — চওড়া (বেশি আস্থার মাশুল)। আর \(n=400\) হলে \(\mathrm{SE}=10/20=0.5\), ৯৫% CI \(= 50\pm0.98 = [49.02, 50.98]\) — অর্ধেক সরু (\(n\) চারগুণ, \(\sqrt n\) দ্বিগুণ)।
E2 · Normal mean, σ unknown — t-interval¶
এবার বাস্তবসম্মত কেস: σ জানা নয়, data থেকে \(S\) অনুমান করতে হবে — তাই \(z\) নয়, \(t\)।
সেটআপ। একটা নতুন ওষুধ রক্তচাপ কতটা কমায় তা মাপতে \(n = 16\) জন রোগীর উপর পরীক্ষা। নমুনা গড় হ্রাস \(\bar X = 8\) mmHg, sample standard deviation \(S = 4\) mmHg (population \(\sigma\) অজানা)। সত্য গড় হ্রাস \(\mu\)-র ৯৫% CI চাই। (ছোট নমুনা, σ অজানা — t-interval-এর আদর্শ ক্ষেত্র।)
ধাপ ১–২ (pivot ও critical value)। σ অজানা, \(S\) দিয়ে প্রতিস্থাপিত, তাই pivot \(T = (\bar X - \mu)/(S/\sqrt n) \sim t_{n-1} = t_{15}\)। degrees of freedom \(= n-1 = 15\)। ৯৫% মানে \(\alpha/2 = 0.025\), আর \(t\)-ছক থেকে \(t_{15,\,0.025} = 2.131\) (লক্ষ করুন: \(z_{0.025}=1.96\)-এর চেয়ে বড় — t চওড়া)।
ধাপ ৩ (margin of error)। standard error (এখন \(S\) দিয়ে অনুমিত):
তাই
ধাপ ৪ (CI)।
তুলনা — t বনাম z এখানে। যদি ভুল করে (σ জানা ভেবে) \(z_{0.025}=1.96\) ব্যবহার করতাম, CI হতো \(8 \pm 1.96 = [6.04, 9.96]\) — সরু। t-interval \([5.87, 10.13]\) একটু চওড়া, আর এই বাড়তি চওড়াই সৎ: σ না-জানার অনিশ্চয়তা ধরা আছে। ছোট \(n\)-এ পার্থক্যটা গুরুত্বপূর্ণ; \(n\) বড় হলে (\(t_{n-1}\to z\)) মিলে যেত।
ব্যাখ্যা। "এই পদ্ধতিতে বানানো CI-গুলোর ৯৫% সত্য গড় রক্তচাপ-হ্রাস ধরবে।" যেহেতু পুরো ব্যবধান \([5.87, 10.13]\) শূন্যের ডানে, এটা ইঙ্গিত দেয় ওষুধটা সত্যিই রক্তচাপ কমায় (এই সংযোগ — CI ও "শূন্য ব্যবধানে আছে কি না" — 4.7-এ hypothesis test-এর সাথে গাঁটছড়া বাঁধবে)।
E3 · Proportion — \(\hat p \pm z_{\alpha/2}\sqrt{\hat p(1-\hat p)/n}\)¶
§১.২-এর সেই জরিপ-উদাহরণে ফিরি — একটা অনুপাত (proportion) \(p\)-র CI।
সেটআপ। একটা নির্বাচনী জরিপে \(n = 1000\) জনকে জিজ্ঞেস করা হলো; \(520\) জন প্রার্থী A-কে সমর্থন করল। সত্য সমর্থন-অনুপাত \(p\)-র ৯৫% CI চাই।
point estimate ও তার SE। point estimate হলো নমুনা-অনুপাত:
এখানে প্রতিটি উত্তর একটা Bernoulli\((p)\) (\(1\) = সমর্থন, \(0\) = না), তাই \(\hat p = \bar X\) আসলে একটা নমুনা গড়! 4.4 থেকে এর standard error:
কিন্তু এতে অজানা \(p\) আছে — তাই বাস্তবে \(p\)-র জায়গায় \(\hat p\) বসিয়ে estimated SE নিই (যা বড় \(n\)-এ বৈধ, কারণ \(\hat p \approx p\)):
critical value ও CI। এখানে কেন \(z\) (t নয়)? কারণ pivot-টা \(\hat p\)-র CLT-আশ্রিত Normal আসন্নায়নের উপর দাঁড়ায় (\(\hat p \approx \mathcal{N}(p,\ p(1-p)/n)\) বড় \(n\)-এ, 3.4) — কোনো \(t\)-গঠন এখানে নেই, তাই critical value \(z_{\alpha/2} = 1.96\)। margin:
তাই
— অর্থাৎ ৫২% ± ৩.১%, ঠিক §১.২-এর "৫২% ± ৩%" এর উৎস! সঠিক ব্যাখ্যা: "এই জরিপ-পদ্ধতি বারবার চালালে CI-গুলোর ৯৫% সত্য সমর্থন \(p\)-কে ধরবে।" (লক্ষণীয়: ব্যবধান \(50\%\)-এর দুপাশে ছড়ানো, তাই এই data থেকে "A নিশ্চিত জিতবে" বলা যায় না — সত্য \(p\) \(50\%\)-এর নিচেও হতে পারে।)
একটা ব্যবহারিক সতর্কতা। এই "\(\hat p \pm z\sqrt{\hat p(1-\hat p)/n}\)" সূত্র (Wald interval) বড় \(n\) ও মাঝারি \(\hat p\)-তে ভালো, কিন্তু \(\hat p\) যদি \(0\) বা \(1\)-এর খুব কাছে, বা \(n\) ছোট হয়, তখন এটা দুর্বল (এমনকি \([\,\cdot\,]\) প্রান্ত \(0\)–\(1\) ছাড়িয়ে যেতে পারে)। তখন উন্নত সংস্করণ (Wilson বা Agresti–Coull interval) লাগে — §৪/অনুশীলনীতে আসবে।
E4 · MLE থেকে asymptotic CI — \(\mathrm{SE} = 1/\sqrt{nI}\)¶
শেষ উদাহরণ সবচেয়ে সাধারণ ও শক্তিশালী: যেকোনো MLE-র চারপাশে একটা CI, যা 4.3 (MLE) ও 4.4–4.5 (Fisher information) কে CI-র সাথে জোড়ে।
পটভূমি (4.3–4.5 থেকে এক লাইনে)। maximum likelihood estimator \(\hat\theta_{\text{MLE}}\)-র একটা চমৎকার বড়-নমুনা (asymptotic) ধর্ম আছে: যথেষ্ট নিয়মিত পরিস্থিতিতে, বড় \(n\)-এ এটা প্রায় Normal —
যেখানে \(I(\theta)\) হলো Fisher information (এক observation-এ data কতটা "তথ্য" বহন করে তার মাপ, 4.5)। অর্থাৎ MLE-ও asymptotically একটা point estimate যার standard error:
(বাস্তবে অজানা \(\theta\)-র জায়গায় \(\hat\theta\) বসাই)। যেহেতু আকৃতি Normal, এখানেও pivot \(\approx \mathcal{N}(0,1)\) — তাই z-interval-এর সেই একই রেসিপি খাটে।
সাধারণ সূত্র (asymptotic CI from MLE):
সংখ্যায় (Bernoulli/proportion আবার, MLE-চোখে)। ধরা যাক Bernoulli\((p)\) data — যেমন E3। 4.5-এ দেখানো হবে (বা যাচাইযোগ্য) Bernoulli-র Fisher information \(I(p) = \dfrac{1}{p(1-p)}\)। তাহলে MLE \(\hat p = \bar X\) (4.3-এর E1), আর তার asymptotic SE:
লক্ষ করুন — এটা হুবহু E3-এর সেই SE! অর্থাৎ proportion-এর CI আসলে এই সাধারণ MLE-সূত্রের একটা বিশেষ ঘটনা। E3-এর সংখ্যা (\(n=1000,\ \hat p=0.52\)) বসালে সেই একই CI \([0.489,\ 0.551]\) পাই। এটাই দেখায় asymptotic-MLE পদ্ধতিটা কত একীভূত: z-interval, proportion-interval — সবই এর ছায়ায়।
আরেকটা ঝলক (Exponential)। \(X_i \sim \text{Exponential}(\lambda)\)-তে MLE \(\hat\lambda = 1/\bar X\) (4.3-এর E3), আর Fisher information \(I(\lambda) = 1/\lambda^2\), তাই \(\mathrm{SE}(\hat\lambda) = \frac{1}{\sqrt{n\cdot 1/\hat\lambda^2}} = \hat\lambda/\sqrt n\)। ধরা যাক \(n=100\) যন্ত্রের গড় আয়ু থেকে \(\hat\lambda = 0.25\)/ঘণ্টা; তখন \(\mathrm{SE} = 0.25/10 = 0.025\), আর ৯৫% CI \(= 0.25 \pm 1.96\times0.025 = 0.25 \pm 0.049 = [0.201,\ 0.299]\) প্রতি ঘণ্টা।
§৩-এর সার: চারটি উদাহরণই একই কঙ্কাল — point estimate \(\pm\) (critical value) \(\times\) SE — শুধু (ক) SE-র সূত্র আর (খ) critical value (\(z\) না \(t\)) পরিস্থিতি-ভেদে বদলায়। σ জানা → \(z\) ও \(\sigma/\sqrt n\) (E1); σ অজানা → \(t\) ও \(S/\sqrt n\) (E2); proportion → \(z\) ও \(\sqrt{\hat p(1-\hat p)/n}\) (E3); যেকোনো MLE → \(z\) ও \(1/\sqrt{nI}\) (E4)। আর প্রতিটিরই ব্যাখ্যা একই সাবধানতা মেনে: ব্যবধান random, parameter স্থির।
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা confidence interval (CI, আস্থা-অন্তর) কী, কেন দরকার, আর তার তিনটে দৈনন্দিন রূপ — z-interval, t-interval, proportion interval — স্বজ্ঞাগতভাবে দেখেছি। এবার এই অংশে আমরা scratch থেকে সেই সূত্রগুলো উৎপাদন করব: কোথা থেকে \(z_{\alpha/2}\) আসে, কেন margin ঠিক \(z_{\alpha/2}\,\mathrm{SE}\), আর সবচেয়ে গুরুত্বপূর্ণ — "\(95\%\) confidence" বাক্যটার নিখুঁত অর্থ কী। কোনো ধাপ লুকানো হবে না; প্রতিটি সমান-চিহ্নের পেছনে বাংলায় কারণ থাকবে। কাজটা চারটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে):
- (a) মূল যন্ত্র — pivot (অক্ষদণ্ড) থেকে z-interval উৎপাদন: \(Z=\dfrac{\bar X-\mu}{\sigma/\sqrt n}\sim\mathcal N(0,1)\) ধরে \(P(-z_{\alpha/2}\le Z\le z_{\alpha/2})=1-\alpha\), তারপর ভেতরের অসমতা \(\mu\)-কে ঘিরে উল্টে এনে \([\bar X - z_{\alpha/2}\sigma/\sqrt n,\ \bar X + z_{\alpha/2}\sigma/\sqrt n]\) (E1)। ★★
- (b) \(\sigma\) অজানা হলে কেন z নয়, t — pivot \(\dfrac{\bar X-\mu}{S/\sqrt n}\sim t_{n-1}\), আর কেন \(S\) বসানোয় বাড়তি অনিশ্চয়তা tail-কে মোটা করে (E2)। ★★
- (c) proportion-এর CI CLT থেকে — \(\hat p\)-র approximate Normality ধরে \(\hat p \pm z_{\alpha/2}\sqrt{\hat p(1-\hat p)/n}\) (E3)। ★
- (d) "coverage"-এর নিখুঁত ব্যাখ্যা — interval-টাই random, তাই \(P(\text{interval covers }\mu)=1-\alpha\) পুনঃপুন নমুনার উপর; এটা "এই নির্দিষ্ট interval-এ \(\mu\) আছে এমন সম্ভাবনা \(1-\alpha\)" নয় (E1–E4-এর ভিত্তি)। ★★
এক নজরে যা মনে রাখবেন। এই গোটা অংশের প্রাণ একটাই কৌশল — pivot: এমন একটা রাশি যা data ও অজানা parameter দুটো থেকেই বানানো, অথচ যার বণ্টন parameter-এর উপর নির্ভর করে না (z-এ \(\mathcal N(0,1)\), t-এ \(t_{n-1}\))। একবার pivot হাতে এলে বাকি সব যান্ত্রিক: pivot-এর জানা বণ্টন থেকে দুটো critical value নাও, মাঝে \(1-\alpha\) probability আটকাও, তারপর অসমতাটা \(\mu\)-কে ঘিরে উল্টে দাও — তাহলেই random দুই প্রান্ত \([\hat\theta - m,\ \hat\theta + m]\) বেরিয়ে আসে। তাই মূল মন্ত্র: "CI মানে point estimate-কে কেন্দ্র করে \(\pm\) একটা margin, আর সেই margin = critical value × standard error।"
পুরো অংশে নোটেশন এক রাখছি: \(\theta\) (এখানে প্রধানত \(\mu\) বা \(p\)) অজানা স্থির parameter — কোনো random variable নয়, তার কোনো বণ্টন নেই, সে শুধু একটা (আমাদের অজানা) সংখ্যা। \(\bar X,\ S,\ \hat p,\ \hat\theta\) সবই data-র function, তাই random। \(1-\alpha\) হলো আমাদের চাওয়া confidence level (যেমন \(0.95\)), আর \(\alpha\) তার পরিপূরক (যেমন \(0.05\))। \(z_{\alpha/2}\) হলো standard Normal-এর সেই বিন্দু যার ডানদিকে ঠিক \(\alpha/2\) probability পড়ে; \(t_{n-1,\alpha/2}\) তেমনি \(t_{n-1}\) বণ্টনের জন্য। আর \(\mathrm{SE}\) (standard error) হলো estimator-এর standard deviation (4.4-এ সংজ্ঞায়িত)।
৪.১ · (a) Pivot থেকে z-interval — সূত্রটা কোথা থেকে আসে — ★★¶
এটাই গোটা অধ্যায়ের কেন্দ্রবিন্দু, তাই ধীরে, প্রতিটা ধাপের কারণসহ যাব। লক্ষ্য: E1-এর সূত্র
আকাশ থেকে না পড়ে কীভাবে একটিমাত্র normal-table থেকে স্বাভাবিকভাবে গজায় তা দেখা।
প্রেক্ষাপট ও অনুমান। ধরা যাক \(X_1,\dots,X_n\) i.i.d., প্রত্যেকের mean \(\mu\) (অজানা — এটাই আমরা ধরতে চাই) আর variance \(\sigma^2\) জানা (এই subsection-এর কৃত্রিম কিন্তু শিক্ষণীয় ধরা; (b)-তে এটা শিথিল করব)। দুটো জিনিস আগের অধ্যায় থেকে হাতে আছে:
- 3.4 (CLT) / Normal হলে অবিকল: যদি প্রতিটি \(X_i\) ঠিক Normal হয়, তবে \(\bar X\sim\mathcal N\!\big(\mu,\ \sigma^2/n\big)\) অবিকল (exactly)। আর Normal না হলেও, \(n\) মাঝারি-বড় হলে CLT অনুযায়ী \(\bar X\) approximately Normal — সূত্রটা তখন approximate CI দেয়।
- Standardization (2.4): যেকোনো \(\mathcal N(a,b^2)\) থেকে \(a\) বিয়োগ করে \(b\) দিয়ে ভাগ করলে \(\mathcal N(0,1)\) পাওয়া যায়।
ধাপ ১ — pivot তৈরি করি। \(\bar X\)-কে standardize করি। যেহেতু \(\mathbb E[\bar X]=\mu\) আর \(\mathrm{Var}(\bar X)=\sigma^2/n\) (তাই \(\mathrm{sd}(\bar X)=\sigma/\sqrt n\)), সংজ্ঞা মেনে
এই \(Z\)-ই আমাদের pivot। কেন একে "pivot" বলি, তা এখানে চোখে দেখুন: \(Z\)-এর ভেতরে \(\mu\) (অজানা) আর \(\bar X\) (random) দুটোই আছে, অথচ \(Z\)-এর বণ্টন (\(\mathcal N(0,1)\)) \(\mu\)-র উপর মোটেই নির্ভর করে না — \(\mu\) যা-ই হোক, \(Z\) সবসময় standard Normal। ঠিক এই ধর্মটাই আমাদের পরে \(\mu\)-কে "বের করে আনতে" দেবে।
ধাপ ২ — pivot-এর জন্য একটা central probability statement লিখি। \(\mathcal N(0,1)\)-এর জন্য \(z_{\alpha/2}\)-এর সংজ্ঞা: এটা সেই ধনাত্মক সংখ্যা যার ডানদিকে ঠিক \(\alpha/2\) ক্ষেত্রফল (probability) পড়ে, অর্থাৎ \(P(Z > z_{\alpha/2}) = \alpha/2\)। symmetry-র কারণে বাঁদিকেও তাই: \(P(Z < -z_{\alpha/2}) = \alpha/2\)। তাহলে দুই প্রান্তের মাঝে যা থাকে:
(\(95\%\)-এর জন্য \(\alpha=0.05\), তাই \(z_{\alpha/2}=z_{0.025}\approx 1.96\) — এই সংখ্যাটাই §৫-এ যন্ত্র ছাপাবে।) লক্ষ করুন: এই লাইনটা নিশ্চিত সত্য, কারণ এটা শুধু \(\mathcal N(0,1)\)-এর একটা ধর্ম — এখনো \(\mu\) নিয়ে কিছু "দাবি" করিনি।
ধাপ ৩ — pivot-এর সংজ্ঞা বসাই। এবার \(Z\)-এর জায়গায় তার মান বসাই:
ধাপ ৪ — ভেতরের অসমতাটা \(\mu\)-কে ঘিরে উল্টাই (এটাই মূল কৌশল)। আমরা চাই মাঝখানে \(\mu\) একা দাঁড়াক। তিন ধাপে বীজগণিত — মনে রাখবেন \(\sigma/\sqrt n > 0\), তাই গুণ-ভাগে অসমতার মুখ বদলায় না:
প্রথমে তিন দিকে \(\sigma/\sqrt n\) দিয়ে গুণ:
এবার তিন দিক থেকে \(\bar X\) বিয়োগ:
শেষে \(-1\) দিয়ে গুণ — এখানে অসমতার দুই মুখ উল্টে যায় (ঋণাত্মক দিয়ে গুণের নিয়ম), আর দুই প্রান্ত জায়গা বদলায়:
এই তিনটে রূপান্তর প্রতিটা ধাপে একই ঘটনাকে (event) বর্ণনা করে — মানে probability অপরিবর্তিত। তাই:
ধাপ ৫ — পড়ে নিই কী পেলাম। ডান-বাঁ প্রান্ত দুটো — \(\bar X \mp z_{\alpha/2}\sigma/\sqrt n\) — সম্পূর্ণভাবে data থেকে গণনাযোগ্য (কারণ এখানে \(\sigma\) জানা, আর \(\bar X\) নমুনা থেকে পাওয়া)। এদের আমরা নাম দিই random interval
এখানে \(\mathrm{SE}=\sigma/\sqrt n\) হলো \(\bar X\)-এর standard error, আর \(m\) (margin of error, ত্রুটি-প্রান্ত) = critical value × SE। এটাই E1-এর z-interval, আর আমরা দেখলাম এটা কোনো জাদু নয় — কেবল একটা pivot-এর central probability statement-কে \(\mu\)-র চারপাশে উল্টে লেখা।
স্বজ্ঞা — দুই কেন্দ্রের নাচ। ধাপ ২-এর statement "\(\mu\) কেন্দ্রে, \(\bar X\) ঘোরে": \(P(\lvert \bar X - \mu\rvert \le z_{\alpha/2}\sigma/\sqrt n)=1-\alpha\) — অর্থাৎ random \(\bar X\) স্থির \(\mu\)-র \(m\)-দূরত্বের মধ্যে পড়ার সম্ভাবনা \(1-\alpha\)। ধাপ ৪-এ আমরা একই দূরত্ব-শর্তকে "\(\bar X\) কেন্দ্রে, \(\mu\) ঘেরা" দৃষ্টিতে লিখলাম: \(\mu\) যদি \(\bar X\)-এর \(m\)-দূরত্বে থাকে, তবে \(\bar X\)-ও \(\mu\)-র \(m\)-দূরত্বে — একই ঘটনা! কিন্তু সাবধান, "\(\mu\) ঘেরা" বলতে \(\mu\) নড়ছে না (সে স্থির), নড়ছে interval-টাই (কারণ তার দুই প্রান্ত random \(\bar X\) থেকে)। এই সূক্ষ্মতা (d)-তে নিখুঁত করব — এটাই CI-র সবচেয়ে ভুল-বোঝা বিন্দু।
সংখ্যায় যাচাই (§৫ PART 1)। \(\sigma=8,\ n=25\)-তে \(\mathrm{SE}=8/\sqrt{25}=1.6\), margin \(=1.96\times1.6=3.136\) — যন্ত্র ঠিক এই সংখ্যাই ছাপাবে, আর interval-টা সত্য \(\mu=50\)-কে ঘিরে রাখবে।
৪.২ · (b) σ অজানা হলে কেন t-interval — ★★¶
ধাপে-ধাপে z-interval পেলাম, কিন্তু সেখানে একটা অবাস্তব অনুমান ছিল — \(\sigma\) জানা। বাস্তবে \(\mu\) যদি অজানা হয়, \(\sigma\)-ও প্রায় সবসময় অজানা! তাহলে \(\mathrm{SE}=\sigma/\sqrt n\) আমরা গণনাই করতে পারি না। স্বাভাবিক সমাধান: \(\sigma\)-র জায়গায় তার estimate — sample standard deviation \(S=\sqrt{\frac{1}{n-1}\sum_i (X_i-\bar X)^2}\) (4.4-এ unbiased \(S^2\) দেখা) — বসিয়ে দাও।
ধাপ ১ — একটা নতুন pivot, আর তার অসুবিধা। \(\sigma\)-কে \(S\) দিয়ে বদলে দিলে আমাদের রাশি দাঁড়ায়
প্রশ্ন: এটাও কি \(\mathcal N(0,1)\)? না — আর এই "না"-টাই গোটা t-গল্পের কারণ। কেন না, তা স্বজ্ঞায় ধরুন: \(Z\)-এ হর \(\sigma/\sqrt n\) একটা স্থির সংখ্যা (random নয়, কারণ \(\sigma\) জানা)। কিন্তু \(T\)-এ হর \(S/\sqrt n\) নিজেই random — \(S\) নমুনা-থেকে-নমুনায় ওঠানামা করে। ফলে \(T\)-তে দুই উৎসের এলোমেলোতা: লব \(\bar X\) থেকে, আর হর \(S\) থেকে। বিশেষত ছোট নমুনায় কখনো \(S\) সত্য \(\sigma\)-র চেয়ে অনেক ছোট আসে — তখন হর ছোট হওয়ায় \(T\) অস্বাভাবিক বড় (দুই দিকেই) হয়ে যায়। তাই \(T\)-এর বণ্টন \(\mathcal N(0,1)\)-এর চেয়ে বেশি ছড়ানো, tail মোটা (heavier tails)।
ধাপ ২ — সঠিক বণ্টন: Student's t. এক চমৎকার ফল (Normal data-র জন্য অবিকল, 4.1-এ sampling distribution হিসেবে দেখা; এখানে statement হিসেবে ধরছি — পূর্ণ প্রমাণ \(\chi^2\) ও স্বাধীনতা লাগে, ★★★):
এখানে \(t_{n-1}\) হলো \(n-1\) degrees of freedom-যুক্ত Student's t-distribution। তার আকৃতি \(\mathcal N(0,1)\)-এর মতোই — শূন্যে কেন্দ্রিত, প্রতিসম, ঘণ্টা-আকার — শুধু tail মোটা, ঠিক যেমন ধাপ ১-এ যুক্তি দিল। আর \(df=n-1\) কেন? কারণ \(S\) হিসাব করতে \(\bar X\) লেগেছে, যাতে একটা degree of freedom খরচ হয়েছে (4.4-এ "\(n-1\) কেন" প্রসঙ্গে দেখা একই হিসাব)।
ধাপ ৩ — একই pivot-কৌশল, শুধু critical value বদলে। \(T\)-ও একটা pivot (এর বণ্টন \(t_{n-1}\) — \(\mu,\sigma\)-র উপর নির্ভর করে না)। তাই (a)-র গোটা ধাপ ২–৪ হুবহু পুনরাবৃত্তি, কেবল \(z_{\alpha/2}\)-র জায়গায় \(t_{n-1,\alpha/2}\) (= \(t_{n-1}\)-এর ডানদিকে \(\alpha/2\) রেখে যাওয়া বিন্দু):
এটাই E2-এর t-interval: কাঠামো z-interval-এর সঙ্গে অভিন্ন — \(\hat\theta \pm (\text{critical})\times \mathrm{SE}\) — শুধু (i) \(\sigma\)-র জায়গায় \(S\) (তাই \(\mathrm{SE}\) এখন estimated, \(S/\sqrt n\)), আর (ii) \(z_{\alpha/2}\)-র জায়গায় বড় critical value \(t_{n-1,\alpha/2}\)।
কেন t সবসময় চওড়া, আর কখন z-এ মিশে যায়। যেহেতু \(t_{n-1}\)-এর tail মোটা, মাঝের \(1-\alpha\) probability ধরতে আমাদের আরও দূরে যেতে হয় — তাই সবসময় \(t_{n-1,\alpha/2} > z_{\alpha/2}\), অর্থাৎ t-interval সবসময় z-interval-এর চেয়ে চওড়া। এটা ন্যায্য মূল্য: \(\sigma\) না-জানার বাড়তি অনিশ্চয়তার জন্য আমরা একটু বেশি প্রশস্ত interval দিয়ে "সততা" রক্ষা করি। আর \(n\) বড় হলে \(S\) ক্রমে \(\sigma\)-র কাছাকাছি স্থির হয়, হরের এলোমেলোতা কমে — তাই \(t_{n-1}\to\mathcal N(0,1)\), এবং \(t_{n-1,\alpha/2}\to z_{\alpha/2}\)। (\(df=1000\)-এ \(t\approx1.962\), প্রায় \(1.96\) — §৫ PART 3 ঠিক এই অভিসরণ ছাপাবে।) এজন্যই বড় নমুনায় z আর t কার্যত এক, কিন্তু ছোট নমুনায় t বাধ্যতামূলক।
সতর্কতা ★★। \(T\sim t_{n-1}\) ফলটা অবিকল কেবল data Normal হলে। Normal না হলেও \(n\) বড় হলে CLT + \(S\xrightarrow{P}\sigma\) মিলে \(T\) approximately Normal থাকে, তাই t-interval তখনো approximate কাজ চালায় — কিন্তু খুব ছোট, খুব skewed নমুনায় coverage নড়তে পারে (§৬-এর ভুল-ধারণায় ছোঁয়া হবে)।
৪.৩ · (c) Proportion-এর CI — CLT থেকে — ★¶
তৃতীয় দৈনন্দিন রূপ: একটা অজানা অনুপাত \(p\) (যেমন ভোটে সমর্থনের হার, ক্লিকের হার)। data হলো \(n\)টা স্বাধীন হ্যাঁ/না — \(X_1,\dots,X_n\) i.i.d. \(\mathrm{Bernoulli}(p)\), যেখানে \(X_i=1\) মানে "সফল"। স্বাভাবিক estimator হলো নমুনা-অনুপাত \(\hat p = \frac1n\sum_i X_i\) (সফলতার ভগ্নাংশ)।
ধাপ ১ — \(\hat p\)-এর mean ও variance। Bernoulli-র জন্য \(\mathbb E[X_i]=p\) ও \(\mathrm{Var}(X_i)=p(1-p)\) (2.3-এ দেখা)। তাই i.i.d. গড়ের নিয়মে:
ধাপ ২ — CLT প্রয়োগ (এখানেই 3.4-এর E3 ফিরে আসে)। \(\hat p\) তো \(n\)টা i.i.d. Bernoulli-র গড়, তাই CLT অনুযায়ী \(n\) মাঝারি-বড় হলে \(\hat p\) approximately Normal:
ধাপ ৩ — একটা ছোট সমস্যা, আর তার সমাধান (plug-in)। এটা প্রায়-pivot, কিন্তু একটা কাঁটা: হরে \(\sqrt{p(1-p)/n}\)-তে অজানা \(p\) বসে আছে! z-interval-এ হর জানা ছিল; এখানে নয়। সমাধান — হরের \(p\)-কে তার estimate \(\hat p\) দিয়ে বদলাই (plug-in / Wald পদ্ধতি)। \(n\) বড় হলে \(\hat p\xrightarrow{P}p\) (LLN), তাই এই বদল approximately বণ্টন নষ্ট করে না (Slutsky-র যুক্তি, 3.2):
এই রাশির হর এখন পুরোটাই data থেকে গণনাযোগ্য — তাই একে approximate pivot ধরে (a)-র যন্ত্র চালাই:
এটাই E3-এর proportion CI — আবার সেই একই অবয়ব \(\hat\theta \pm z_{\alpha/2}\,\widehat{\mathrm{SE}}\), যেখানে এবার \(\hat\theta=\hat p\) আর \(\widehat{\mathrm{SE}}=\sqrt{\hat p(1-\hat p)/n}\)।
মনে রাখার বিন্দু। তিনটে interval-ই (z, t, proportion) একই টেমপ্লেটের তিন রূপ: estimate \(\pm\) critical-value \(\times\) SE। পার্থক্য শুধু — SE কী, আর critical value কোন বণ্টন থেকে (\(z\) না \(t\))। proportion-এ critical value \(z\) (CLT-ভিত্তিক বলে), SE-তে plug-in \(\hat p\)। (একটা সতর্কতা ★★: এই "Wald" interval \(p\) চরম-কাছাকাছি \(0\) বা \(1\) হলে বা \(n\) ছোট হলে দুর্বল — তখন Wilson বা Agresti–Coull interval ভালো; এটা §৬/পরের অধ্যায়ে।)
৪.৪ · (d) "Coverage" বলতে ঠিক কী — interval random, μ নয় — ★★¶
এখন অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ — এবং সবচেয়ে বেশি ভুল-বোঝা — ধারণাটা নিখুঁত করি। আমরা বারবার লিখেছি "\(95\%\) confidence interval"। প্রশ্ন: এই "\(95\%\)" সংখ্যাটা ঠিক কীসের probability?
ভুল ব্যাখ্যা (যা প্রায় সবাই প্রথমে ভাবে)। "আমার হাতে-পাওয়া interval \([44.40,\ 50.67]\)-এর ভেতরে সত্য \(\mu\) থাকার সম্ভাবনা \(95\%\)।" — এই বাক্যটা frequentist কাঠামোয় অর্থহীন, এবং তা বোঝা জরুরি। কেন? কারণ এই বাক্যে দুটোই স্থির সংখ্যা: (i) \(\mu\) একটা নির্দিষ্ট অজানা ধ্রুবক, আর (ii) একবার নমুনা টেনে ফেলার পর \([44.40,\ 50.67]\)-ও দুটো নির্দিষ্ট সংখ্যা — random কিছু নেই! দুটো স্থির সংখ্যার মধ্যে একটা স্থির সংখ্যা হয় আছে (probability \(1\)) নয় নেই (probability \(0\)) — মাঝের "\(0.95\)" বলে কিছু নেই। (\(\mu=50\) সত্যিই \([44.40,50.67]\)-এ আছে, তাই এখানে উত্তর \(1\); কিন্তু আমরা \(\mu\) জানি না বলে কোনটা — \(0\) না \(1\) — তা বলতে পারি না, তবু "\(0.95\)" কখনোই নয়।)
সঠিক ব্যাখ্যা — randomness কোথায় তা ঠিকভাবে চিহ্নিত করা। \(\mu\) স্থির; random জিনিসটা হলো interval-টাই। ধাপ (a)-র দুই প্রান্ত \(\bar X \mp z_{\alpha/2}\sigma/\sqrt n\) random \(\bar X\)-এর function, তাই নতুন নমুনা = নতুন (ভিন্ন) interval। কল্পনা করুন একই population থেকে বারবার (ধরা যাক \(1000\) বার) নতুন নমুনা টানছেন, প্রতিবার সূত্রটা চালিয়ে একটা interval বানাচ্ছেন — পাবেন \(1000\)টা ভিন্ন interval, এদিক-ওদিক ছড়ানো, এক একটার দুই প্রান্ত এক এক জায়গায়। সত্য \(\mu\) একটা স্থির উল্লম্ব রেখা; কিছু interval সেই রেখাকে ঢেকে ফেলে (cover করে), কিছু মিস করে। ধাপ (a)-র boxed সমীকরণ ঠিক এটাই বলে:
যেখানে probability-টা পুনঃপুন-নমুনার (interval-এর randomness-এর) উপর, \(\mu\)-র উপর নয়। অর্থাৎ:
"\(95\%\) confidence" মানে: এই পদ্ধতিতে বানানো interval-গুলোর দীর্ঘমেয়াদে প্রায় \(95\%\) সত্য \(\mu\)-কে ঢেকে ফেলবে। এটা পদ্ধতির (procedure-এর) একটা ধর্ম — কোনো একক interval-এর নয়।
কেন এই পার্থক্য তুচ্ছ নয়। "\(95\%\)" কথাটা একটা নির্ভরযোগ্যতার রেটিং — যেমন "এই ছাতা \(95\%\) বৃষ্টিতে টেকে"। একবার বৃষ্টিতে নেমে গেলে হয় ভিজলেন, নয় ভিজলেন না; কিন্তু ছাতার রেটিং তবু "\(95\%\)" — সেটা বহু-বৃষ্টির গড় পারফরম্যান্স। তেমনি, আপনার হাতের নির্দিষ্ট interval হয় \(\mu\)-কে ঢেকেছে নয় ঢাকেনি (আপনি জানেন না কোনটা), কিন্তু যে পদ্ধতিতে এটা বানালেন তার coverage \(95\%\)।
এটাই E1–E4-এর সাধারণ মেরুদণ্ড, আর §৫-এ চোখে দেখব। §৫ PART 2-তে আমরা ঠিক এই "\(1000\) বার নমুনা" কাজটা \(100{,}000\) বার করব, প্রতিবার \(95\%\) interval বানাব, আর গুনব কত ভাগ সত্য \(\mu\)-কে ঢাকল — উত্তর আসবে \(\approx 0.949\), ঠিক \(0.95\)-এর গায়ে। এটাই coverage-এর সংজ্ঞার সরাসরি সংখ্যা-প্রমাণ। (Figure
4-6-ci-coverageও4-6-ci-interpretationএই বহু-interval ছবিটা — কোনগুলো \(\mu\)-রেখা ঢাকে, কোনগুলো মিস করে — চোখে দেখাবে।)শেষ সতর্কতা — coverage বনাম confidence level। আমরা যা চাই তা \(1-\alpha\) (nominal coverage, যেমন \(0.95\)); পদ্ধতি যা আসলে অর্জন করে তা actual coverage। সঠিক pivot ব্যবহার করলে এ-দুই মেলে (PART 2-এর (a),(b) দেখাবে coverage \(\approx0.95\))। কিন্তু ভুল pivot — যেমন \(\sigma\) অজানা হলেও z-interval চালানো — actual coverage-কে \(0.95\)-এর নিচে নামিয়ে দেয় (PART 2-এর (c) দেখাবে \(\approx 0.917\), ছোট \(n\)-এ)। এই under-coverage ঠিক কেন (b)-র t-interval (চওড়া বলে) দরকার তার সংখ্যাগত প্রমাণ — তাত্ত্বিক যুক্তি (b)-তে, সংখ্যা §৫-এ।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর চারটে ফলকে আমরা সিমুলেশনে যাচাই করব — যাতে confidence interval-এর ধর্মগুলো কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সবচেয়ে গুরুত্বপূর্ণ যাচাইটা হলো coverage (§৪.৪): আমরা একই population থেকে হাজার-হাজার বার নতুন নমুনা টেনে প্রতিবার একটা \(95\%\) CI বানাব, তারপর গুনব কত ভাগ interval সত্য \(\mu\)-কে ঢাকল — উত্তর আসবে \(\approx 0.95\), যা "\(95\%\) confidence"-এর সংজ্ঞারই সরাসরি সংখ্যা-প্রমাণ। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। critical value (z, t) আসে scipy.stats থেকে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া।)
আমরা চারটে জিনিস মাপব, ঠিক §৪-এর চার অংশ অনুসরণ করে:
- PART 1 — তিনটে CI একটা নমুনা থেকে (§৪.১–৪.৩)। একটা নমুনা টেনে E1 (z-interval, \(\sigma\) জানা), E2 (t-interval, \(\sigma\) অজানা → \(S\)), E3 (proportion CI) — তিনটে গড়ে তুলব, প্রতিটায় \(\mathrm{SE}\), margin ও interval ছাপাব, আর সত্য parameter ভেতরে কি না দেখাব।
- PART 2 — Monte Carlo coverage (§৪.৪)। \(100{,}000\) বার নমুনা টেনে দেখাব (a) সঠিক z-interval ও (b) সঠিক t-interval-এর coverage \(\approx 0.95\), কিন্তু (c) ভুল pivot (\(\sigma\) অজানা হলেও z) coverage-কে \(0.95\)-এর নিচে নামায়। সাথে দেখাব REP বাড়লে coverage কীভাবে \(0.95\)-এ থিতু হয়।
- PART 3 — z বনাম t প্রস্থ (§৪.২)। বিভিন্ন \(n\)-এ \(z_{\alpha/2}\) vs \(t_{n-1,\alpha/2}\) ছাপিয়ে দেখাব t সবসময় বড় (interval চওড়া), আর তাদের অনুপাত \(n\) বাড়লে \(1\)-এর দিকে যায়।
- PART 4 — CI প্রস্থ বনাম \(n\) (§৪.১)। margin \(m=z_{\alpha/2}\sigma/\sqrt n\) কীভাবে \(1/\sqrt n\) হারে কমে — \(n\) চারগুণ করলে প্রস্থ ঠিক অর্ধেক — তা সংখ্যায় দেখাব।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.6 — Confidence Intervals : Code Lab
# Numerically illustrates:
# PART 1 — Build z / t / proportion CIs from ONE sample.
# PART 2 — Monte Carlo COVERAGE: ~95% of 95%-CIs contain the true mu
# (z and t correct; wrong z-with-S under-covers at small n).
# PART 3 — z vs t WIDTH: t is always wider; gap shrinks as n grows.
# PART 4 — CI WIDTH vs n: margin m = z*sigma/sqrt(n) shrinks like 1/sqrt(n).
import numpy as np
from scipy import stats
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=4, suppress=True)
# -----------------------------------------------------------------
# PART 1 — Build z / t / proportion CIs from a single sample.
# -----------------------------------------------------------------
print("=" * 72)
print("PART 1 — Three confidence intervals from ONE sample (1-alpha = 0.95)")
print("=" * 72)
alpha = 0.05
z_crit = stats.norm.ppf(1 - alpha/2) # z_{alpha/2} = 1.96 for 95%
print(f"\n z_(alpha/2) = {z_crit:.4f} (alpha = {alpha}, 1-alpha = {1-alpha})")
# --- E1 : z-interval (sigma KNOWN) ---
mu_true, sigma_known = 50.0, 8.0
n1 = 25
x1 = rng.normal(mu_true, sigma_known, size=n1)
xbar1 = x1.mean()
se_z = sigma_known / np.sqrt(n1) # SE = sigma/sqrt(n) (sigma known)
m_z = z_crit * se_z # margin = z * SE
ci_z = (xbar1 - m_z, xbar1 + m_z)
print("\n E1 z-interval (sigma known = 8):")
print(f" n={n1}, xbar={xbar1:.4f}, SE={se_z:.4f}, margin={m_z:.4f}")
print(f" 95% CI = [{ci_z[0]:.4f}, {ci_z[1]:.4f}] (true mu={mu_true} inside: {ci_z[0] <= mu_true <= ci_z[1]})")
# --- E2 : t-interval (sigma UNKNOWN, use S) ---
n2 = 25
x2 = rng.normal(mu_true, sigma_known, size=n2) # same DGP, but pretend sigma unknown
xbar2 = x2.mean()
S2 = x2.std(ddof=1) # sample SD with (n-1) divisor
t_crit = stats.t.ppf(1 - alpha/2, df=n2 - 1) # t_{n-1, alpha/2}
se_t = S2 / np.sqrt(n2)
m_t = t_crit * se_t
ci_t = (xbar2 - m_t, xbar2 + m_t)
print("\n E2 t-interval (sigma unknown, use S):")
print(f" n={n2}, xbar={xbar2:.4f}, S={S2:.4f}, t_(n-1,a/2)={t_crit:.4f}, margin={m_t:.4f}")
print(f" 95% CI = [{ci_t[0]:.4f}, {ci_t[1]:.4f}] (true mu={mu_true} inside: {ci_t[0] <= mu_true <= ci_t[1]})")
# --- E3 : proportion CI (Wald, via CLT) ---
p_true = 0.40
n3 = 200
x3 = rng.binomial(1, p_true, size=n3) # n3 Bernoulli(p) trials
phat = x3.mean()
se_p = np.sqrt(phat * (1 - phat) / n3) # plug-in SE
m_p = z_crit * se_p
ci_p = (phat - m_p, phat + m_p)
print("\n E3 proportion CI (Wald / CLT):")
print(f" n={n3}, phat={phat:.4f}, SE={se_p:.4f}, margin={m_p:.4f}")
print(f" 95% CI = [{ci_p[0]:.4f}, {ci_p[1]:.4f}] (true p={p_true} inside: {ci_p[0] <= p_true <= ci_p[1]})")
# -----------------------------------------------------------------
# PART 2 — Monte Carlo COVERAGE: fraction of 95%-CIs covering true mu.
# Key teaching point: the INTERVAL is random; coverage ~ 0.95 over
# repeated samples is the meaning of "95% confidence".
# -----------------------------------------------------------------
print("\n" + "=" * 72)
print("PART 2 — Monte Carlo coverage of 95% CIs (true mu fixed; intervals random)")
print("=" * 72)
REP = 100_000
n = 10 # SMALL n so z-vs-t difference shows
# vectorised: REP samples, each of size n, from Normal(mu_true, sigma_known^2)
samp = rng.normal(mu_true, sigma_known, size=(REP, n))
xbar = samp.mean(axis=1)
Sn = samp.std(axis=1, ddof=1) # sample SD per row
# (a) z-interval with KNOWN sigma -> should cover ~0.95 (it is exact here)
m_zc = z_crit * sigma_known / np.sqrt(n)
covz = np.mean((xbar - m_zc <= mu_true) & (mu_true <= xbar + m_zc))
# (b) t-interval with sigma UNKNOWN (S) -> should cover ~0.95 (correct pivot)
tcn = stats.t.ppf(1 - alpha/2, df=n - 1)
m_tc = tcn * Sn / np.sqrt(n)
covt = np.mean((xbar - m_tc <= mu_true) & (mu_true <= xbar + m_tc))
# (c) WRONG: z-interval but sigma UNKNOWN (use S with z crit) -> UNDER-covers
m_wrong = z_crit * Sn / np.sqrt(n)
covw = np.mean((xbar - m_wrong <= mu_true) & (mu_true <= xbar + m_wrong))
print(f"\n REP={REP}, n={n}, nominal coverage = {1-alpha:.2f}")
print(f" (a) z-interval, sigma KNOWN : coverage = {covz:.4f} (correct -> ~0.95)")
print(f" (b) t-interval, sigma unknown(S): coverage = {covt:.4f} (correct -> ~0.95)")
print(f" (c) z-interval BUT sigma unknown: coverage = {covw:.4f} (WRONG -> under 0.95)")
print("\n Read-off: (a),(b) sit on 0.95; (c) the z-with-S shortcut under-covers at small n,")
print(" which is exactly WHY the t-interval (wider) is needed when sigma is unknown.")
# show coverage converging to 0.95 as REP grows (the frequentist meaning)
print("\n Coverage of the t-interval as REP grows (converges to 0.95):")
print(f" {'REP':>8} {'coverage':>10}")
hits_t = (xbar - m_tc <= mu_true) & (mu_true <= xbar + m_tc)
for r in [100, 1000, 10_000, 100_000]:
print(f" {r:>8} {hits_t[:r].mean():>10.4f}")
# -----------------------------------------------------------------
# PART 3 — z vs t WIDTH comparison (full width = 2*margin), same data scale.
# t_crit > z_crit always; the ratio -> 1 as n grows (t_{n-1} -> Normal).
# -----------------------------------------------------------------
print("\n" + "=" * 72)
print("PART 3 — z vs t critical values and CI half-width (per unit SE)")
print("=" * 72)
print(f"\n {'n':>5} {'z_crit':>8} {'t_(n-1)':>9} {'t/z ratio':>11}")
print(" " + "-" * 38)
for nn in [3, 5, 10, 30, 100, 1000]:
tc = stats.t.ppf(1 - alpha/2, df=nn - 1)
print(f" {nn:>5} {z_crit:>8.4f} {tc:>9.4f} {tc/z_crit:>11.4f}")
print("\n Read-off: t_crit always exceeds z_crit=1.96 (heavier tails), so the t-interval is")
print(" always WIDER; the t/z ratio falls toward 1 as n grows (t_{n-1} -> N(0,1)).")
# -----------------------------------------------------------------
# PART 4 — CI WIDTH vs n: margin m = z*sigma/sqrt(n) ~ 1/sqrt(n).
# Quadrupling n halves the width. (Diminishing returns of more data.)
# -----------------------------------------------------------------
print("\n" + "=" * 72)
print("PART 4 — z-interval half-width m = z*sigma/sqrt(n) shrinks like 1/sqrt(n)")
print(f" sigma = {sigma_known}, 1-alpha = {1-alpha}")
print("=" * 72)
print(f"\n {'n':>6} {'margin m':>10} {'full width 2m':>14} {'m(n)/m(4n)':>12}")
print(" " + "-" * 46)
ns = [25, 100, 400, 1600, 6400]
margins = [z_crit * sigma_known / np.sqrt(nn) for nn in ns]
for i, nn in enumerate(ns):
ratio = (margins[i] / margins[i+1]) if i + 1 < len(ns) else float('nan')
rtxt = f"{ratio:.4f}" if i + 1 < len(ns) else " -- "
print(f" {nn:>6} {margins[i]:>10.4f} {2*margins[i]:>14.4f} {rtxt:>12}")
print("\n Read-off: each 4x in n halves the margin (ratio ~ 2.0), i.e. width ~ 1/sqrt(n).")
print(" To shrink the interval 10x you need 100x the data -> precision is expensive.")
print("\n[done] all parts ran.")
৫.২ · প্রকৃত আউটপুট (স্ক্রিপ্ট চালিয়ে পাওয়া)¶
========================================================================
PART 1 — Three confidence intervals from ONE sample (1-alpha = 0.95)
========================================================================
z_(alpha/2) = 1.9600 (alpha = 0.05, 1-alpha = 0.95)
E1 z-interval (sigma known = 8):
n=25, xbar=47.5335, SE=1.6000, margin=3.1359
95% CI = [44.3975, 50.6694] (true mu=50.0 inside: True)
E2 t-interval (sigma unknown, use S):
n=25, xbar=47.8655, S=8.5981, t_(n-1,a/2)=2.0639, margin=3.5491
95% CI = [44.3164, 51.4146] (true mu=50.0 inside: True)
E3 proportion CI (Wald / CLT):
n=200, phat=0.4200, SE=0.0349, margin=0.0684
95% CI = [0.3516, 0.4884] (true p=0.4 inside: True)
========================================================================
PART 2 — Monte Carlo coverage of 95% CIs (true mu fixed; intervals random)
========================================================================
REP=100000, n=10, nominal coverage = 0.95
(a) z-interval, sigma KNOWN : coverage = 0.9488 (correct -> ~0.95)
(b) t-interval, sigma unknown(S): coverage = 0.9490 (correct -> ~0.95)
(c) z-interval BUT sigma unknown: coverage = 0.9173 (WRONG -> under 0.95)
Read-off: (a),(b) sit on 0.95; (c) the z-with-S shortcut under-covers at small n,
which is exactly WHY the t-interval (wider) is needed when sigma is unknown.
Coverage of the t-interval as REP grows (converges to 0.95):
REP coverage
100 0.9900
1000 0.9580
10000 0.9500
100000 0.9490
========================================================================
PART 3 — z vs t critical values and CI half-width (per unit SE)
========================================================================
n z_crit t_(n-1) t/z ratio
--------------------------------------
3 1.9600 4.3027 2.1953
5 1.9600 2.7764 1.4166
10 1.9600 2.2622 1.1542
30 1.9600 2.0452 1.0435
100 1.9600 1.9842 1.0124
1000 1.9600 1.9623 1.0012
Read-off: t_crit always exceeds z_crit=1.96 (heavier tails), so the t-interval is
always WIDER; the t/z ratio falls toward 1 as n grows (t_{n-1} -> N(0,1)).
========================================================================
PART 4 — z-interval half-width m = z*sigma/sqrt(n) shrinks like 1/sqrt(n)
sigma = 8.0, 1-alpha = 0.95
========================================================================
n margin m full width 2m m(n)/m(4n)
----------------------------------------------
25 3.1359 6.2719 2.0000
100 1.5680 3.1359 2.0000
400 0.7840 1.5680 2.0000
1600 0.3920 0.7840 2.0000
6400 0.1960 0.3920 --
Read-off: each 4x in n halves the margin (ratio ~ 2.0), i.e. width ~ 1/sqrt(n).
To shrink the interval 10x you need 100x the data -> precision is expensive.
[done] all parts ran.
৫.৩ · আউটপুট কীভাবে পড়বেন — §৪-এর সঙ্গে মিলিয়ে¶
প্রতিটি PART সরাসরি §৪-এর একটা ফল সংখ্যায় প্রমাণ করল। সংক্ষেপে মিলিয়ে নিই:
- PART 1 — তিনটে interval, একটাই টেমপ্লেট (§৪.১–৪.৩)। তিনটে CI-ই estimate \(\pm\) critical \(\times\) SE অবয়বে। E1-এ \(\mathrm{SE}=\sigma/\sqrt n=8/5=1.6\), margin \(=1.96\times1.6=3.136\) — ঠিক §৪.১-এর হিসাব। E2-তে একই data-স্কেলে \(S=8.60\) (\(\sigma=8\)-এর কাছাকাছি, কিন্তু random), আর critical value \(t_{24,0.025}=2.064 > 1.96\) — তাই margin একটু বড় (\(3.55\)); এটাই §৪.২-এর "t সবসময় চওড়া"-র এক-নমুনা দৃষ্টান্ত। E3-এ \(\hat p=0.42\), \(\widehat{\mathrm{SE}}=\sqrt{0.42\cdot0.58/200}=0.0349\) — §৪.৩-এর CLT-ভিত্তিক proportion CI। তিনটে interval-ই এই নির্দিষ্ট নমুনায় সত্য parameter-কে ঢাকল (
inside: True) — তবে মনে রাখুন (§৪.৪), এটা এই নমুনার ভাগ্য, পদ্ধতির গ্যারান্টি নয়। - PART 2 — coverage = "\(95\%\)"-এর আসল অর্থ (§৪.৪)। এটাই ল্যাবের মূল ফল। \(100{,}000\) বার নতুন নমুনা টেনে: সঠিক z-interval coverage \(0.9488\), সঠিক t-interval \(0.9490\) — দুটোই nominal \(0.95\)-এর গায়ে। অর্থাৎ random interval সত্য (স্থির) \(\mu\)-কে দীর্ঘমেয়াদে \(\approx95\%\) সময় ঢাকে — §৪.৪-এর boxed সংজ্ঞার সরাসরি সংখ্যা-প্রমাণ। REP-টেবিল দেখাচ্ছে এই \(0.95\) ধীরে ধীরে স্থির হয় (\(100\) বারে \(0.99\), কিন্তু \(10{,}000\)+ বারে \(0.95\)) — frequentist "দীর্ঘমেয়াদি হার"-এর চেহারা। আর (c): \(\sigma\) অজানা হলেও জোর করে z চালালে coverage \(0.9173\) — \(0.95\)-এর স্পষ্ট নিচে (under-coverage)। এই একটা সংখ্যাই §৪.২-এর গোটা যুক্তির প্রমাণ: \(\sigma\) না-জানার অনিশ্চয়তা উপেক্ষা করলে interval বড্ড সরু হয়, তাই সত্য \(\mu\) বেশি বার ফসকে যায় — আর সেই ফাঁক পোষাতেই চওড়া t-interval দরকার।
- PART 3 — z বনাম t প্রস্থ (§৪.২)। \(t_{n-1,0.025}\) সবসময় \(1.96\)-এর বড় (\(n=3\)-এ বিশাল \(4.30\), অর্থাৎ interval দ্বিগুণেরও বেশি চওড়া!), আর \(n\) বাড়লে \(t/z\) অনুপাত \(1\)-এর দিকে নামে (\(n=1000\)-এ \(1.001\))। এটাই §৪.২-এর "t-interval সবসময় চওড়া, কিন্তু বড় \(n\)-এ z-এ মিশে যায়" — সংখ্যায়।
- PART 4 — প্রস্থ বনাম \(n\) (§৪.১)। margin \(m=z_{\alpha/2}\sigma/\sqrt n\) ঠিক \(1/\sqrt n\) হারে কমে: \(n\) চারগুণ করলে \(m\) ঠিক অর্ধেক (অনুপাত কলামে নিখুঁত \(2.0000\))। ব্যবহারিক বার্তা: interval \(10\) গুণ সরু করতে চাইলে \(100\) গুণ data লাগে — precision ব্যয়বহুল, আর এটাই sample-size পরিকল্পনার (পরের অধ্যায় 4.7) মূল সমীকরণ। (Figure
4-6-ci-width-vs-nও4-6-z-vs-t-ciPART 3–4-এর এই দুই প্রবণতা চোখে দেখাবে।)
এক বাক্যে ল্যাবের শিক্ষা। CI মানে point estimate-কে ঘিরে \(\pm\) margin; margin = critical × SE; "\(95\%\)" interval-টার ধর্ম নয়, পদ্ধতির ধর্ম (coverage \(\approx0.95\) — PART 2 দেখাল); সঠিক pivot (σ অজানা হলে t) না নিলে coverage ভেঙে পড়ে; আর interval সরু করার একমাত্র সৎ পথ — বেশি data, কিন্তু কেবল \(1/\sqrt n\) হারে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-6.py-তে তৈরি; PNG_assets/-এ (prefix4-6, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 z-interval; E2 t-interval; E3 proportion CI; E4 MLE-based CI।
confidence interval-এর গোটা গল্পটা চারটা প্রশ্নে ধরা যায়, আর প্রতিটার একটা ছবি আছে। (১) "৯৫% confidence" কথাটার আসল মানে কী — অর্থাৎ একটা CI কাকে cover করে, আর "৯৫%" সংখ্যাটা ঠিক কীসের ওপর প্রতিশ্রুতি (Figure 1)? (২) এই ৯৫% নিয়ে যে সবচেয়ে সাধারণ ভুলটা সবাই করে — "আমার এই interval-এ \(\mu\) থাকার ৯৫% সম্ভাবনা" — সেটা কেন ভুল, আর সঠিক ব্যাখ্যাটা দেখতে কেমন (Figure 2)? (৩) ছোট নমুনায় \(\sigma\) অজানা থাকলে z-interval-এর বদলে কেন t-interval (চওড়া) লাগে, আর \(n\) বাড়লে দুটো কীভাবে মিলে যায় (Figure 3)? (৪) interval-টা কত সরু করা যায়, আর সরু করতে গেলে কত data লাগে — half-width-এর সাথে \(n\)-এর সম্পর্ক (Figure 4)? প্রথম দুটো ছবি ব্যাখ্যা (cover-এর মানে আর তার ভুল-পাঠ), তৃতীয়টা কোন critical value (\(z\) না \(t\)), আর চতুর্থটা interval কত চওড়া (\(1/\sqrt n\) নিয়ম)।
Figure 1 — coverage: "৯৫%" আসলে কীসের প্রতিশ্রুতি¶
এই অধ্যায়ের কেন্দ্রীয় অন্তর্দৃষ্টি একটাই ছবিতে: "৯৫% confidence" মানে interval-টা নয়, পদ্ধতিটা ৯৫% সময় ঠিক হয়। এখানে সত্যি \(\mu=50\) (কালো খাড়া রেখা) স্থির, আর আমরা একই population থেকে ১০০ বার আলাদা নমুনা (\(n=25\), \(\sigma=10\) জানা) নিয়ে প্রতিবার একটা ৯৫% z-interval \(\bar x\pm z_{\alpha/2}\,\mathrm{SE}\) বানিয়েছি — প্রতিটা অনুভূমিক দণ্ড একেকটা interval, মাঝের বিন্দু সেই নমুনার \(\bar x\)। যে interval সত্যি \(\mu=50\)-কে ধরে (cover করে) তা নীল; যেগুলো ফসকে যায় (একদম ডানে বা বাঁয়ে সরে গিয়ে রেখাটা ছোঁয় না) তা লাল। এখানে \(100\)-র মধ্যে \(96\)টা ধরেছে, \(4\)টা ফসকেছে।
যা লক্ষ করতে হবে: (ক) দণ্ডগুলো এদিক-ওদিক লাফাচ্ছে কারণ প্রতিটা নতুন নমুনায় \(\bar x\) বদলায় — অর্থাৎ interval-টাই random, \(\mu\) নয় (কালো রেখা স্থির)। এটাই পরের ছবির মূল কথা। (খ) লাল দণ্ডগুলো ফসকেছে কারণ সেই নমুনায় \(\bar x\) ঘটনাক্রমে \(\mu\) থেকে \(z_{\alpha/2}\mathrm{SE}\)-এর বেশি দূরে পড়েছে — এটা "ভুল" নয়, পদ্ধতির অনিবার্য \(5\%\) ব্যর্থতা। (গ) cover-হার এখানে \(96/100=96\%\), প্রতিশ্রুত \(95\%\)-এর কাছাকাছি; অসীম সংখ্যক নমুনায় এটা ঠিক \(95\%\)-এ গিয়ে দাঁড়াবে (এটাই confidence level-এর সংজ্ঞা)। শিক্ষা: "৯৫%" হলো long-run coverage — বহু interval-এর মধ্যে কত ভাগ সত্যি প্যারামিটারকে ধরে, কোনো একটা নির্দিষ্ট interval-এর সম্পর্কে নয়।
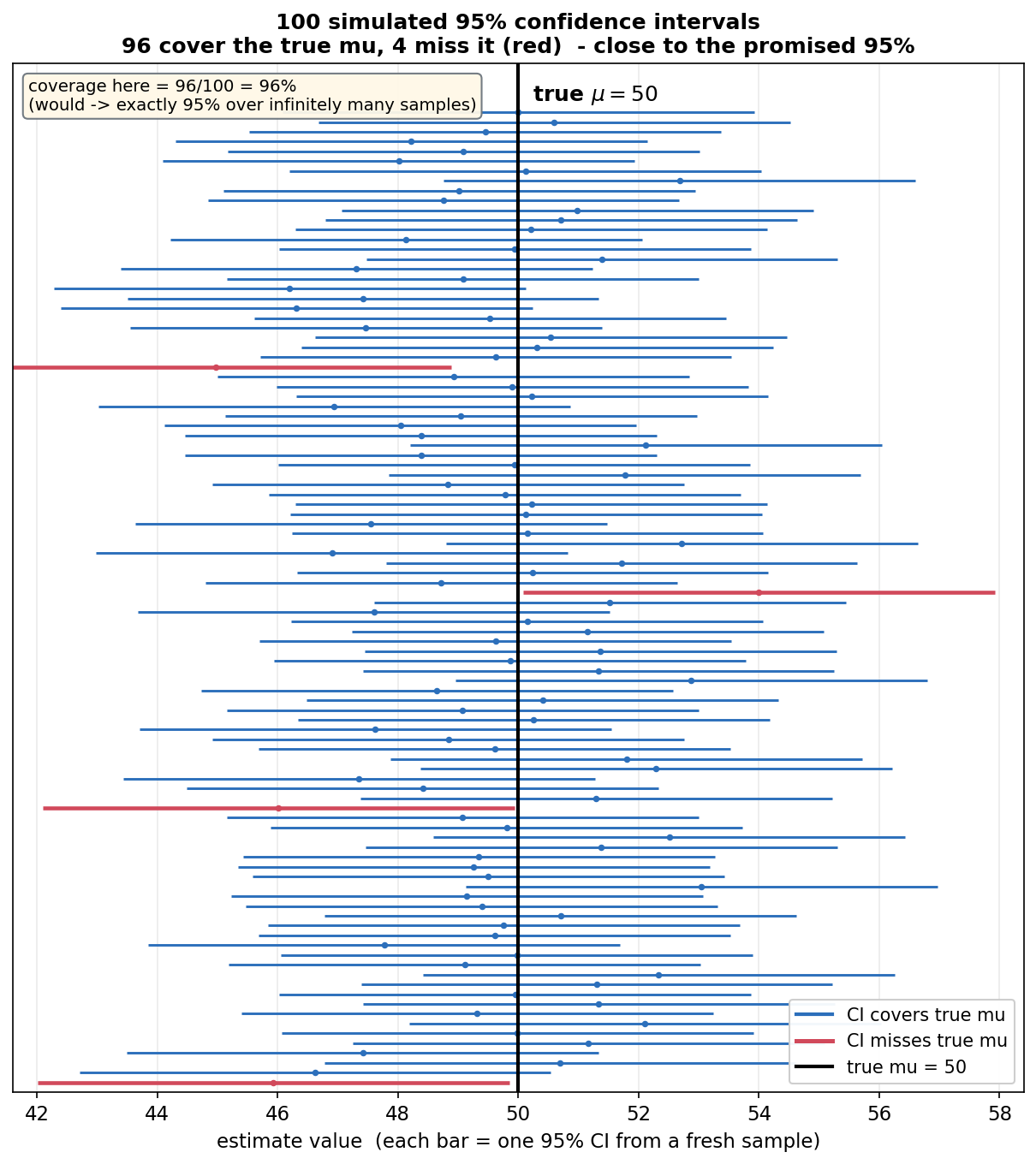
Figure 2 — সঠিক বনাম ভুল ব্যাখ্যা: ৯৫% কীসের সম্ভাবনা?¶
Figure 1 দেখাল interval-টাই random; এই ছবি সেই সূত্র থেকে সবচেয়ে সাধারণ ভুল ব্যাখ্যাটা সরাসরি খণ্ডন করে। বাঁ দিক (সঠিক, সবুজ): ঠিক Figure 1-এর মতো বহু interval; \(\mu\) একটা স্থির খাড়া রেখা, আর প্রায় \(95\%\) interval (\(20\)-র মধ্যে \(19\)টা সবুজ) তাকে ধরে, \(1\)টা লাল ফসকায়। এখানে "৯৫%" বলতে বোঝায় পদ্ধতিটা ৯৫% সময় সফল — random জিনিসটা interval। ডান দিক (ভুল, লাল ✗): এখানে শুধু একটা computed interval (নীল দণ্ড) আর তার ওপর একটা লোভনীয় কিন্তু ভুল ছবি — যেন \(\mu\) নিজে একটা সম্ভাবনার "মেঘ" (লাল ছায়া) যার \(95\%\) এই interval-এর ভেতরে পড়ে। বড় লাল ✗ মনে করিয়ে দেয়: \(\mu\) random নয়, এটা একটা স্থির (অজানা) সংখ্যা।
যা লক্ষ করতে হবে: (ক) বাঁয়ে অনেক interval, ডানে একটা — এই পার্থক্যটাই আসল। confidence-এর বিবৃতি (probability statement) interval বানানোর আগে সত্য: "যে interval আমি বানাব, তা ৯৫% সম্ভাবনায় \(\mu\)-কে ধরবে।" (খ) কিন্তু একবার data দেখে নির্দিষ্ট সংখ্যা বসিয়ে ফেললে (ডান দিকের নীল দণ্ড, যেমন \([\,0.10,\,0.46\,]\)), interval-টা হয় \(\mu\)-কে ধরেছে নয়তো ধরেনি — এখানে আর কোনো "৯৫% সম্ভাবনা" বাস করে না (তাই ডানে লাল ✗)। (গ) সঠিক ভাষা: "৯৫% confident" = "এই পদ্ধতি ৯৫% interval-এ সঠিক"; ভুল ভাষা: "\(\mu\) এই নির্দিষ্ট interval-এ থাকার সম্ভাবনা ৯৫%"। frequentist কাঠামোয় \(\mu\)-কে কোনো probability দেওয়া যায় না — সেটা করতে গেলে Bayesian credible interval লাগবে (4.x-এ আলাদা ধারণা)। এই একটাই ভুল CI-শিক্ষার সবচেয়ে বড় ফাঁদ, তাই ছবিটা মন দিয়ে দেখুন।
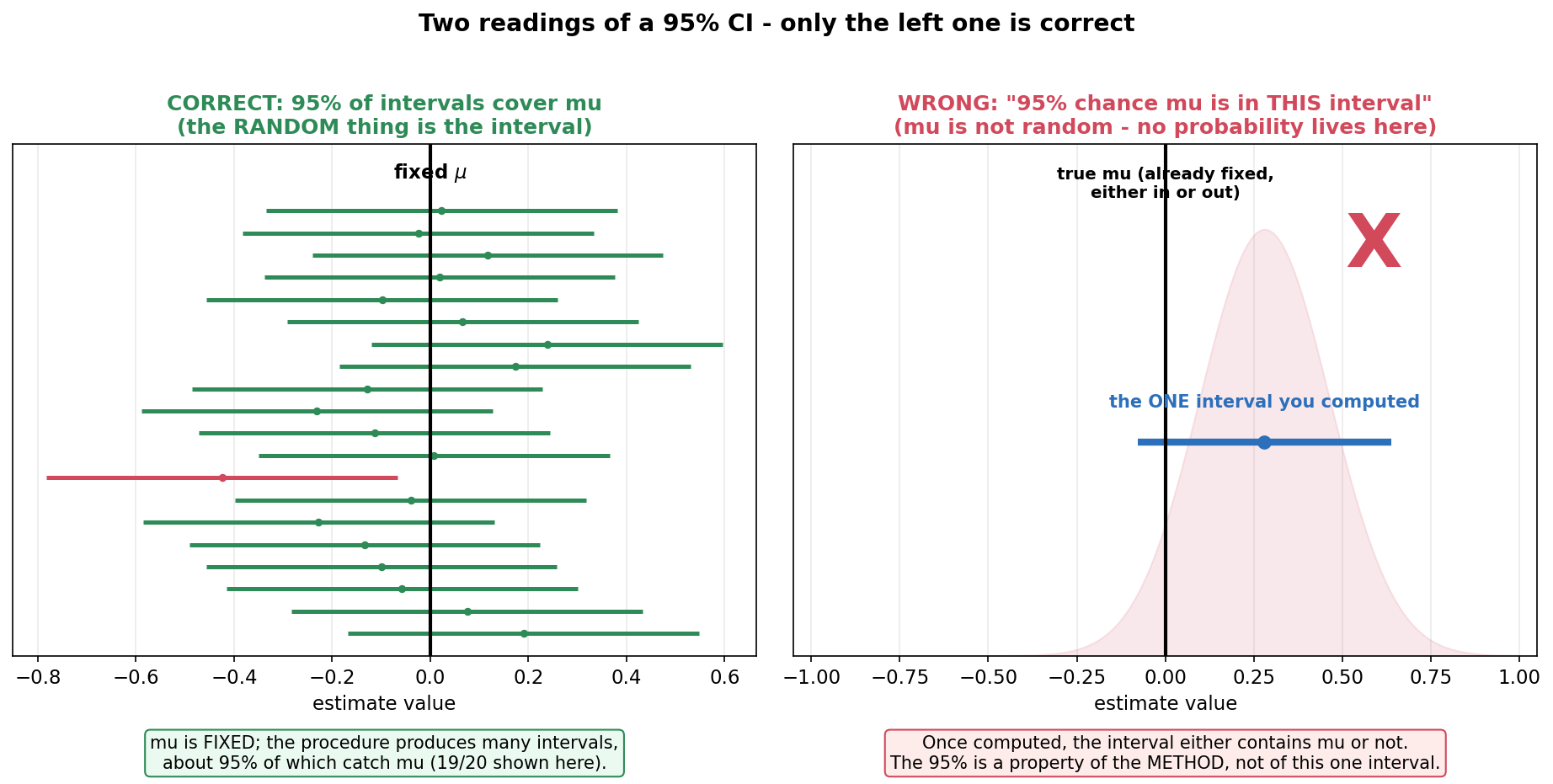
Figure 3 — z-interval বনাম t-interval: \(\sigma\) অজানা হলে দাম দিতে হয়¶
এবার E1 বনাম E2-র পার্থক্য একছবিতে: \(\sigma\) জানা থাকলে multiplier \(z_{\alpha/2}\) (z-interval), কিন্তু \(\sigma\) অজানা হয়ে \(s\) দিয়ে অনুমান করলে multiplier \(t_{n-1,\alpha/2}\) (t-interval) — আর এই \(t\) সবসময় \(z\)-এর চেয়ে বড়, বিশেষত ছোট \(n\)-এ, যা interval-কে চওড়া করে। প্যানেল (a): অনুভূমিক অক্ষ \(n\); নীল রেখা স্থির \(z_{0.025}=1.96\), কমলা রেখা \(t_{n-1,\,0.025}\) — যা \(n=2\)-তে বিশাল (\(12.7\), চার্টের ওপরে কাটা) থেকে নেমে \(n=5\)-এ \(2.78\), \(n=10\)-এ \(2.26\), হয়ে \(n\) বড় হলে \(1.96\)-এর গায়ে মিশে যায়। প্যানেল (b): একই \(\sigma\)-তে কয়েকটা \(n\)-এর জন্য জোড়া-দণ্ড — উপরে নীল z-interval, নিচে কমলা t-interval (চওড়া); \(n=3\)-এ কমলা দণ্ড অনেক লম্বা, \(n=30\)-এ প্রায় সমান।
যা লক্ষ করতে হবে: (ক) t সবসময় z-এর ওপরে (প্যানেল a) — কারণ \(\sigma\)-কে একই ছোট নমুনা থেকে আঁচ করার বাড়তি অনিশ্চয়তা পুষিয়ে দিতে interval-কে চওড়া করতে হয়; এই বাড়তি চওড়াই "\(\sigma\) অজানা থাকার দাম।" (খ) \(n\to\infty\)-এ কমলা নীলে মিশে যায় — কারণ বড় নমুনায় \(s\to\sigma\), তখন t-distribution normal-এ রূপ নেয় (Student-t-এর লেজ মোটা, কিন্তু df বাড়লে পাতলা হয়)। তাই practical নিয়ম: \(n\gtrsim 30\) হলে z আর t-এর ফারাক নগণ্য, কিন্তু ছোট \(n\)-এ অবশ্যই t ব্যবহার করুন, নইলে interval ভুলভাবে সরু হবে ও coverage ৯৫%-এর নিচে নামবে। (গ) প্যানেল (b)-তে দণ্ডগুলো \(\bar x\) ঘিরে symmetric; \(n=3\)-এ t-দণ্ড নীল-দণ্ডের চেয়ে স্পষ্ট লম্বা — এই অতিরিক্ত দৈর্ঘ্যই Figure 4-এর width-আলোচনার সাথে জোড়া (t হলে half-width একটু বেশি)।
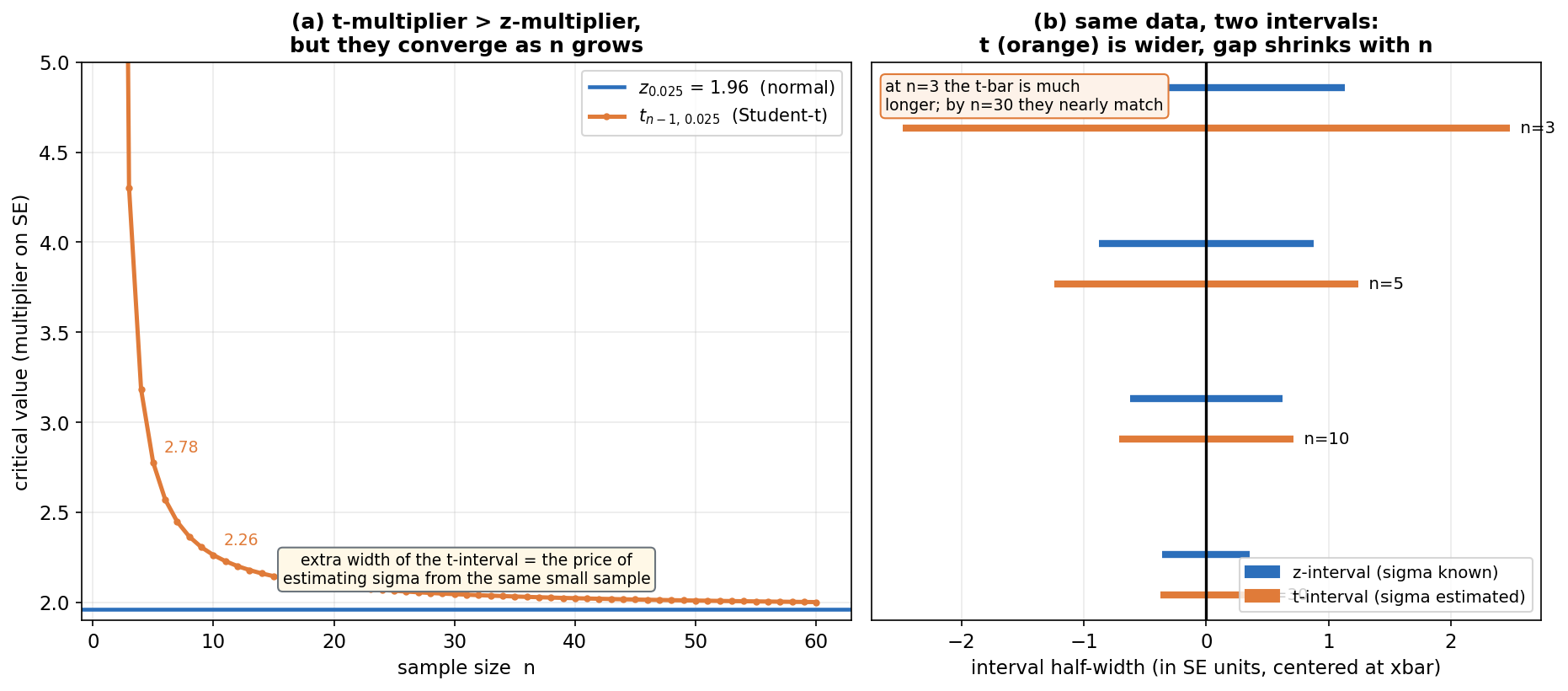
Figure 4 — CI half-width \(\propto 1/\sqrt n\): সরু করতে চাইলে data চারগুণ¶
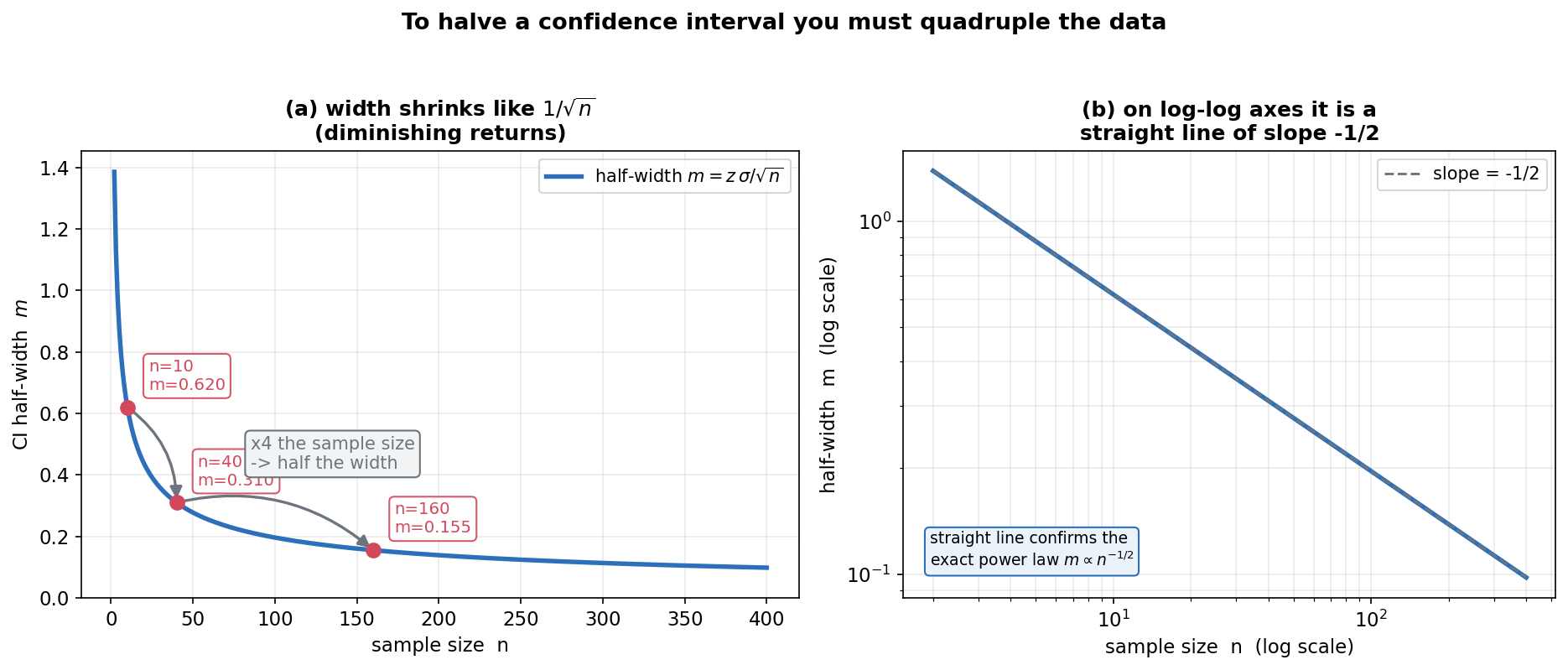
শেষ ছবি practical প্রশ্নের উত্তর দেয়: margin of error \(m=z_{\alpha/2}\,\sigma/\sqrt n\) — অর্থাৎ interval-এর অর্ধ-প্রস্থ \(n\)-এর বর্গমূলের বিপরীত আনুপাতিক (\(m\propto 1/\sqrt n\))। প্যানেল (a): অনুভূমিক অক্ষ \(n\), উল্লম্ব অক্ষ half-width \(m\); নীল curve দ্রুত নামে তারপর সমতল হয় (diminishing returns)। তিনটা লাল বিন্দু \(n=10,40,160\)-এ: \(m=0.620,\,0.310,\,0.155\) — প্রতিবার \(n\) চারগুণ হলে \(m\) ঠিক অর্ধেক (বাঁকা ধূসর তীর দেখাচ্ছে)। প্যানেল (b): একই জিনিস log-log অক্ষে — সরলরেখা, ঢাল \(-1/2\), যা power law \(m\propto n^{-1/2}\) নিশ্চিত করে।
যা লক্ষ করতে হবে: (ক) curve-টা প্রথমে খাড়া নামে, তারপর চ্যাপ্টা হয়ে যায় — অর্থাৎ ছোট \(n\)-এ নমুনা একটু বাড়ালেই interval অনেক সরু হয়, কিন্তু \(n\) আগে থেকেই বড় হলে আরও সরু করতে বিশাল data লাগে (diminishing returns)। (খ) মূল নিয়ম: interval অর্ধেক সরু করতে \(n\) চারগুণ করতে হয় (\(n\to 4n \Rightarrow \sqrt n \to 2\sqrt n \Rightarrow m\to m/2\)); \(0.620\to0.310\to0.155\) এই সংখ্যাগুলোই তা দেখায়। তাই কেউ যদি বলে "precision দ্বিগুণ চাই", বুঝতে হবে খরচ (নমুনা-আকার) চারগুণ। (গ) log-log-এ সরলরেখা ও ঢাল \(-1/2\) — এটা power law-এর স্বাক্ষর: \(\log m = \log(z\sigma) - \tfrac12\log n\), তাই ঢাল ঠিক \(-\tfrac12\)। (এই \(1/\sqrt n\) হার সরাসরি Part III-এর CLT/standard-error থেকে আসে, আর sample-size planning-এ ব্যবহৃত হয়: চাহিদা-মাফিক \(m\) পেতে দরকারি \(n\ge (z_{\alpha/2}\sigma/m)^2\)।)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-06-confidence-intervals-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: confidence level \(1-\alpha\); margin of error \(m=z_{\alpha/2}\,\mathrm{SE}\); z-interval \(\bar x\pm z_{\alpha/2}\,\sigma/\sqrt n\) (\(\sigma\) জানা); t-interval \(\bar x\pm t_{n-1,\alpha/2}\,s/\sqrt n\) (\(\sigma\) অজানা); proportion CI \(\hat p\pm z_{\alpha/2}\sqrt{\hat p(1-\hat p)/n}\); pivot = এমন quantity যার distribution \(\theta\)-নিরপেক্ষ। চলমান উদাহরণ: E1 z-interval; E2 t-interval; E3 proportion CI; E4 MLE-based CI।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন confidence level \(1-\alpha\), margin of error \(m\), আর critical value \(z_{\alpha/2}\) — এই তিনটা কী। একটা \(95\%\) CI-তে \(\alpha\) কত, আর \(z_{\alpha/2}\)-এর আনুমানিক মান কত? Hint: \(1-\alpha\) = পদ্ধতির long-run coverage; \(m=z_{\alpha/2}\mathrm{SE}\) = কেন্দ্র থেকে দুই প্রান্তের দূরত্ব; \(z_{\alpha/2}\) = standard normal-এর সেই বিন্দু যার ডানে \(\alpha/2\) ভর। \(95\%\Rightarrow\alpha=0.05,\ \alpha/2=0.025,\ z_{0.025}\approx1.96\)।
প্রশ্ন ২ (★★) — [CI-এর সঠিক ব্যাখ্যা যাচাই]. একজন গবেষক একটা নমুনা থেকে গড়ের \(95\%\) CI পেলেন \([\,12.1,\,15.9\,]\) এবং লিখলেন: "সত্যি \(\mu\) এই interval-এ থাকার সম্ভাবনা \(95\%\)।" এই বাক্যটা কেন ভুল? সঠিক ব্যাখ্যাটা এক-দুই বাক্যে লিখুন। Figure 1 ও Figure 2 থেকে যুক্তি টানুন। (frequentist কাঠামোয় \(\mu\)-কে কি কোনো probability দেওয়া যায়?) Hint: \(\mu\) স্থির (random নয়); একবার interval বসানো হলে তা হয় \(\mu\)-কে ধরেছে নয় ধরেনি — কোনো \(0.95\) সম্ভাবনা থাকে না। "৯৫%" হলো পদ্ধতির long-run coverage (random জিনিস = interval, Figure 1-এর লাফানো দণ্ড)। সঠিক: "যদি বহুবার নমুনা নিয়ে এভাবে interval বানাই, ~৯৫% তাদের সত্যি \(\mu\)-কে ধরবে।"
প্রশ্ন ৩ (★★). কখন z-interval ব্যবহার করবেন আর কখন t-interval? Figure 3 থেকে ব্যাখ্যা করুন কেন একই নমুনায় t-interval z-interval-এর চেয়ে চওড়া, এবং \(n\) বড় হলে কী ঘটে। Hint: \(\sigma\) জানা (বা \(n\) খুব বড়) ⇒ z; \(\sigma\) অজানা, \(s\) দিয়ে আঁচ ⇒ t। \(t_{n-1,\alpha/2}>z_{\alpha/2}\) কারণ \(\sigma\) আঁচের বাড়তি অনিশ্চয়তা; \(n\to\infty\)-এ \(s\to\sigma\), \(t\to z\), দুই interval মেলে।
প্রশ্ন ৪ (★★). একটা \(95\%\) CI আর একটা \(99\%\) CI একই data থেকে বানালে কোনটা চওড়া হবে, এবং কেন? "বেশি confidence" আর "বেশি precision (সরু interval)"-এর মধ্যে কী tradeoff আছে? কীভাবে এই tradeoff না ভেঙে দুটোই উন্নত করা যায়? Hint: \(99\%\) চওড়া (\(z_{0.005}=2.576>z_{0.025}=1.96\), তাই \(m\) বড়)। একই \(n\)-এ confidence ↑ ⇒ width ↑ — সরাসরি tradeoff। দুটো একসাথে পেতে চাইলে \(n\) বাড়াতে হবে (Figure 4: \(m\propto1/\sqrt n\))।
খ · গাণনিক (computational)¶
প্রশ্ন ৫ (★) — E1 (z-interval). একটা মেশিন-ভরা প্যাকেটের ওজন \(\mathcal{N}(\mu,\sigma^2)\), \(\sigma=4\) গ্রাম জানা। \(n=16\) প্যাকেটে \(\bar x=502\) গ্রাম। \(\mu\)-এর একটা \(95\%\) z-interval বের করুন। (ব্যবহার করুন \(z_{0.025}=1.96\)।) Hint: \(\mathrm{SE}=\sigma/\sqrt n=4/4=1\); \(m=1.96\times1=1.96\); CI \(=502\pm1.96=[\,500.04,\,503.96\,]\)।
প্রশ্ন ৬ (★★) — E2 (t-interval). এক ব্যাচ ব্যাটারির আয়ু (ঘণ্টা) থেকে \(n=10\) নমুনায় \(\bar x=210\), \(s=15\) (\(\sigma\) অজানা)। \(\mu\)-এর \(95\%\) t-interval বের করুন। (\(t_{9,\,0.025}=2.262\)।) এই interval একটা \(z\)-interval-এর চেয়ে চওড়া না সরু হতো, এবং কেন? Hint: \(\mathrm{SE}=s/\sqrt n=15/\sqrt{10}=4.743\); \(m=2.262\times4.743=10.73\); CI \(=210\pm10.73=[\,199.27,\,220.73\,]\)। z হলে \(1.96\) ব্যবহার করত — সরু হতো, কিন্তু \(\sigma\) অজানা বলে coverage কমে যেত; তাই t সঠিক।
প্রশ্ন ৭ (★★) — E3 (proportion CI). একটা A/B-টেস্টে \(n=400\) ব্যবহারকারীর \(\hat p=0.30\) ক্লিক করল। click-rate \(p\)-এর \(95\%\) (Wald) CI বের করুন: \(\hat p\pm z_{\alpha/2}\sqrt{\hat p(1-\hat p)/n}\)। margin of error কত শতাংশ-বিন্দু? Hint: \(\sqrt{0.30\times0.70/400}=\sqrt{0.000525}=0.02291\); \(m=1.96\times0.02291=0.0449\); CI \(=0.30\pm0.045=[\,0.255,\,0.345\,]\), অর্থাৎ \(\pm4.5\) শতাংশ-বিন্দু।
প্রশ্ন ৮ (★★) — sample size planning। প্রশ্ন ৭-এর A/B টেস্টে margin of error \(\pm2\) শতাংশ-বিন্দু (\(m=0.02\)) চাই \(95\%\) confidence-এ। কমপক্ষে কত \(n\) লাগবে? (\(\hat p\) অজানা হলে worst-case \(\hat p=0.5\) ধরুন।) Hint: \(n\ge\big(z_{\alpha/2}/m\big)^2\,\hat p(1-\hat p)\)। worst case \(\hat p(1-\hat p)=0.25\): \(n\ge(1.96/0.02)^2\times0.25=9604\times0.25=2401\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★) — pivot পদ্ধতি। \(X_1,\dots,X_n\overset{iid}{\sim}\mathcal{N}(\mu,\sigma^2)\), \(\sigma\) জানা। দেখান যে \(Z=\dfrac{\bar X-\mu}{\sigma/\sqrt n}\sim\mathcal{N}(0,1)\) একটা pivot (এর distribution \(\mu\)-নিরপেক্ষ)। এরপর \(P(-z_{\alpha/2}\le Z\le z_{\alpha/2})=1-\alpha\) থেকে শুরু করে বীজগণিতে \(\mu\)-কে মাঝে এনে z-interval \(\bar X\pm z_{\alpha/2}\,\sigma/\sqrt n\)-টি derive করুন। Hint: \(\bar X\sim\mathcal{N}(\mu,\sigma^2/n)\) standardize করলে \(Z\) — এর distribution \(\mu,\sigma\)-এর ওপর নির্ভর করে না, তাই pivot। অসমতার ভেতরে \(-z_{\alpha/2}\le\frac{\bar X-\mu}{\sigma/\sqrt n}\le z_{\alpha/2}\) থেকে \(\mu\) isolate: \(\bar X-z_{\alpha/2}\frac{\sigma}{\sqrt n}\le\mu\le\bar X+z_{\alpha/2}\frac{\sigma}{\sqrt n}\)।
প্রশ্ন ১০ (★★). confidence level-এর frequentist সংজ্ঞা আনুষ্ঠানিকভাবে লিখুন: একটা interval \(C_n=[\,L(X),\,U(X)\,]\)-এর coverage probability কী, এবং "\(C_n\) একটা \((1-\alpha)\) CI" বলতে ঠিক কী বোঝায়? এরপর ব্যাখ্যা করুন কেন এই সংজ্ঞায় probability-টা interval-এর ওপর (data-র randomness), \(\theta\)-এর ওপর নয় — Figure 2-র সাথে মেলান। Hint: coverage \(=P_\theta\big(L(X)\le\theta\le U(X)\big)\); এটি \(\ge1-\alpha\) সব \(\theta\)-এর জন্য হলে \(C_n\) একটা \((1-\alpha)\) CI। randomness আসে \(X\) থেকে (\(L,U\) random), \(\theta\) স্থির — তাই "interval ধরবে কি না" প্রশ্নটাই random (Figure 2-এর বাঁ দিক)।
প্রশ্ন ১১ (★★★) — E4 (MLE-based / large-sample CI). ধরুন \(\hat\theta\) একটা MLE যার asymptotic বণ্টন \(\hat\theta\approx\mathcal{N}\!\big(\theta,\ \widehat{\mathrm{se}}^2\,\big)\) যেখানে \(\widehat{\mathrm{se}}=1/\sqrt{n\,I(\hat\theta)}\) (\(I\) = Fisher information)। (ক) এই normal approximation থেকে \(\theta\)-এর একটা \((1-\alpha)\) Wald CI লিখুন। (খ) এখন \(\psi=g(\theta)\) একটা মসৃণ রূপান্তর; delta method ব্যবহার করে \(\psi\)-এর জন্য approximate CI লিখুন (এর se = \(\lvert g'(\hat\theta)\rvert\,\widehat{\mathrm{se}}\))। (গ) এই গোটা পদ্ধতিটা §৭ Q9-এর pivot-যুক্তির সাথে কীভাবে মেলে? Hint: (ক) \(\hat\theta\pm z_{\alpha/2}\,\widehat{\mathrm{se}}\)। (খ) \(g(\hat\theta)\pm z_{\alpha/2}\,\lvert g'(\hat\theta)\rvert\,\widehat{\mathrm{se}}\)। (গ) এখানে approximate pivot \(\frac{\hat\theta-\theta}{\widehat{\mathrm{se}}}\xrightarrow{d}\mathcal{N}(0,1)\) — বড় নমুনায় Q9-এর exact normal pivot-এরই asymptotic সংস্করণ। (4.5-এর Fisher information ও asymptotic normality এখানে সরাসরি কাজে লাগছে।)
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★★) — coverage simulation (Figure 1 পুনর্নির্মাণ)। \(\mathcal{N}(\mu=50,\sigma^2=100)\) থেকে \(n=25\)-এর নমুনা \(10{,}000\) বার টেনে প্রতিবার \(95\%\) z-interval বানান, এবং কত ভাগ interval সত্যি \(\mu=50\)-কে ধরে তা গুনুন। empirical coverage কি \(\approx0.95\)? তারপর \(n=25\)-এর বদলে \(n=5\)-এ পুনরাবৃত্তি করুন — coverage কি বদলায় (z-interval, \(\sigma\) জানা)? Hint:
import numpy as np
from scipy import stats
rng = np.random.default_rng(0)
mu, sigma, n, R = 50.0, 10.0, 25, 10000
z = stats.norm.ppf(0.975)
X = rng.normal(mu, sigma, size=(R, n))
xbar = X.mean(1); m = z * sigma / np.sqrt(n)
cover = (xbar - m <= mu) & (mu <= xbar + m)
print("coverage:", cover.mean()) # ~0.95
প্রশ্ন ১৩ (★★) — z বনাম t, \(\sigma\) অজানা হলে coverage। এখন \(\sigma\) অজানা ধরে (\(s\) দিয়ে অনুমান) \(n=5\)-এ \(10{,}000\) বার (ক) z-interval (\(1.96\,s/\sqrt n\)) ও (খ) t-interval (\(t_{4,0.025}\,s/\sqrt n\)) বানিয়ে দুটোর empirical coverage তুলনা করুন। দেখান z-interval-এর coverage \(0.95\)-এর নিচে নামে, কিন্তু t-interval \(\approx0.95\) ফিরিয়ে দেয়।
Hint: s = X.std(axis=1, ddof=1); z-interval m_z = 1.96*s/np.sqrt(n), t-interval m_t = stats.t.ppf(0.975, df=n-1)*s/np.sqrt(n)। ছোট \(n\)-এ z-coverage \(\approx0.88\)–\(0.90\) (under-coverage), t-coverage \(\approx0.95\) — এটাই কেন t লাগে।
প্রশ্ন ১৪ (★★★) — proportion CI (E3) ও MLE-CI (E4)। Bernoulli\((p=0.3)\) থেকে \(n=400\)-এর নমুনা \(5{,}000\) বার টেনে প্রতিবার \(95\%\) Wald proportion-CI বানান; empirical coverage ছাপান (Wald CI ছোট/চরম \(p\)-তে under-cover করে — এখানে \(p=0.3\)-এ কেমন?)। তারপর একই data-কে MLE-কাঠামোয় দেখুন: \(\hat p\) হলো \(p\)-এর MLE, \(\widehat{\mathrm{se}}=\sqrt{\hat p(1-\hat p)/n}\), তাই Wald CI = MLE-based CI — দুটো যে একই, তা যাচাই করুন। Hint:
phat = rng.binomial(n, 0.3, size=5000) / n
se = np.sqrt(phat*(1-phat)/n)
lo, hi = phat - 1.96*se, phat + 1.96*se
print("coverage:", ((lo <= 0.3) & (0.3 <= hi)).mean())
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- CI কী। point estimate একটা সংখ্যা; confidence interval একটা পরিসর \([\,L(X),\,U(X)\,]\) যা estimate-এর সাথে তার অনিশ্চয়তাও বহন করে। গঠন প্রায় সবসময় estimate \(\pm\) margin of error: \(\hat\theta\pm m\), যেখানে \(m=z_{\alpha/2}\,\mathrm{SE}\) (বা ছোট-নমুনায় \(t_{n-1,\alpha/2}\,\mathrm{SE}\))।
- "৯৫%" মানে coverage, interval নয় (Figure 1, 2)। confidence level \(1-\alpha\) হলো পদ্ধতির long-run coverage: বহুবার নমুনা নিয়ে interval বানালে ~\((1-\alpha)\) ভাগ সত্যি \(\theta\)-কে ধরবে। random জিনিসটা interval (\(\theta\) স্থির)। তাই "\(\theta\) এই নির্দিষ্ট interval-এ থাকার সম্ভাবনা ৯৫%" — ভুল: একবার সংখ্যা বসলে interval হয় ধরেছে নয় ধরেনি, কোনো probability বাকি থাকে না (§৭ Q2, Q10)।
- pivot পদ্ধতি (§৭ Q9)। CI বানানোর মূল কৌশল: এমন একটা pivot quantity খোঁজা যার distribution \(\theta\)-নিরপেক্ষ (যেমন \(Z=\frac{\bar X-\mu}{\sigma/\sqrt n}\sim\mathcal{N}(0,1)\)), তারপর \(P(-z_{\alpha/2}\le Z\le z_{\alpha/2})=1-\alpha\) থেকে \(\theta\)-কে isolate করা।
- z বনাম t (Figure 3)। \(\sigma\) জানা (বা \(n\) বড়) ⇒ z-interval \(\bar x\pm z_{\alpha/2}\sigma/\sqrt n\) (E1)। \(\sigma\) অজানা, \(s\) দিয়ে আঁচ ⇒ t-interval \(\bar x\pm t_{n-1,\alpha/2}\,s/\sqrt n\) (E2) — সবসময় চওড়া (\(t>z\)), কারণ \(\sigma\) আঁচের বাড়তি অনিশ্চয়তা; \(n\to\infty\)-এ দুই মিলে যায়। ছোট \(n\)-এ z ব্যবহার করলে coverage ৯৫%-এর নিচে নামে (§৭ Q13)।
- প্রস্থ ও সংখ্যা-নির্ধারণ (Figure 4)। half-width \(m\propto 1/\sqrt n\) — interval অর্ধেক সরু করতে \(n\) চারগুণ (diminishing returns)। তাই sample-size planning: চাহিদা-মাফিক \(m\) পেতে \(n\ge(z_{\alpha/2}\sigma/m)^2\) (§৭ Q8)। confidence ↑ ⇒ width ↑ (একই \(n\)-এ), একটা সরাসরি tradeoff (§৭ Q4)।
- চলমান উদাহরণে সারাংশ। E1 (z): \(\sigma\) জানা, \(\bar x\pm z_{\alpha/2}\sigma/\sqrt n\)। E2 (t): \(\sigma\) অজানা, \(\bar x\pm t_{n-1,\alpha/2}s/\sqrt n\)। E3 (proportion): \(\hat p\pm z_{\alpha/2}\sqrt{\hat p(1-\hat p)/n}\) — যা আসলে Bernoulli-র MLE \(\hat p\)-এর Wald CI। E4 (MLE-based): বড় নমুনায় \(\hat\theta\pm z_{\alpha/2}\,\widehat{\mathrm{se}}\) (\(\widehat{\mathrm{se}}=1/\sqrt{n I(\hat\theta)}\)), আর delta method দিয়ে \(g(\theta)\)-এর CI (§৭ Q11) — E3 এই কাঠামোরই বিশেষ ঘটনা।
পূর্ববর্তী সংযোগ (← 4.5 Fisher Information ও Cramér–Rao, এবং 4.1, 4.4, 3.4): 4.1-এ point estimation আর standard error, 4.4-এ sampling distribution ও MSE, আর 4.5-এ Fisher information \(I(\theta)\) ও asymptotic normality of the MLE — এই অধ্যায় সেই সব উপাদানকে এক করে অনিশ্চয়তাকে একটা পরিসরে প্রকাশ করল। 4.5-এ আমরা জেনেছি MLE বড় নমুনায় \(\mathcal{N}\big(\theta,\,1/[nI(\theta)]\big)\)-এর কাছাকাছি; সেই asymptotic normality-ই E4-এর Wald CI-র সরাসরি ভিত্তি (\(\widehat{\mathrm{se}}=1/\sqrt{nI(\hat\theta)}\))। আর pivot \(\frac{\bar X-\mu}{\sigma/\sqrt n}\sim\mathcal{N}(0,1)\)-এর পেছনে আছে 3.4-এর CLT ও standard-error ধারণা — যেখান থেকে \(1/\sqrt n\) হারটাও আসে (Figure 4)। অর্থাৎ 4.4–4.5 ছিল "estimator কত ভালো ও কত নিখুঁত" মাপা; 4.6 হলো সেই নিখুঁততাকে একটা interval-এ অনুবাদ করা।
পরবর্তী সংযোগ (→ 4.7 — Hypothesis Testing; CI ও test-এর দ্বৈততা): এই অধ্যায়ে আমরা data থেকে \(\theta\)-এর একটা সম্ভাব্য পরিসর বানালাম। পরের অধ্যায় উল্টো প্রশ্ন করবে: "\(\theta\)-এর একটা নির্দিষ্ট মান (যেমন \(\theta=\theta_0\)) কি data-র সাথে সঙ্গতিপূর্ণ?" — এটাই hypothesis testing (null \(H_0:\theta=\theta_0\), p-value, power, Neyman–Pearson)। দুটো গভীরভাবে দ্বৈত (dual): একটা \((1-\alpha)\) CI আসলে সেই সব \(\theta_0\)-এর সংগ্রহ যাদের level-\(\alpha\) test প্রত্যাখ্যান করে না — অর্থাৎ "\(\theta_0\) কি \(95\%\) CI-তে আছে?" আর "\(H_0:\theta=\theta_0\) কি \(5\%\) level-এ প্রত্যাখ্যাত নয়?" — এক প্রশ্নের দুই রূপ। তাই এই অধ্যায়ের pivot-যুক্তি (§৭ Q9) সরাসরি test-statistic-এ রূপ নেবে, আর \(z_{\alpha/2}/t_{n-1,\alpha/2}\) critical value-গুলোই test-এর rejection boundary হবে। CI "কতটা অনিশ্চয়তা" বলে; test "একটা নির্দিষ্ট দাবি টেকে কি না" বলে — 4.7-এ এই দুই দৃষ্টিভঙ্গি একসূত্রে বাঁধা পড়বে।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 6 (§6.3.2 Confidence Sets — coverage, pivot, normal-based interval; §6.3.1 ব্যাখ্যা ও সাধারণ ভুল) ও Ch. 9 (parametric/Wald CI, delta method); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 7 (§7.3–7.4 Survey Sampling ও confidence intervals, sample-size; normal ও large-sample interval); P. Bruce, A. Bruce & P. Gedeck, Practical Statistics for Data Scientists, Ch. 2 ("Confidence Intervals", bootstrap ও margin-of-error-এর ব্যবহারিক দিক)।