5.4 — GLM: Logistic Regression (লজিস্টিক রিগ্রেশন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "যখন উত্তরটা সংখ্যা নয়, বরং হ্যাঁ/না"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
Part V-এর শুরু থেকে (5.1–5.3) আমরা একটা সুন্দর, একীভূত গল্প গেঁথে এসেছি: একটা response চলক \(y\)-কে এক বা একাধিক predictor \(x\)-এর রৈখিক সমন্বয় দিয়ে মডেল করা। 5.1-এ মূল সমীকরণটা দাঁড়িয়েছিল
যেখানে \(y\) হলো \(n\times 1\) response-vector (প্রতিটি ব্যক্তি/এককের জন্য একটা মান), \(X\) হলো \(n\times(p+1)\) design matrix (প্রতিটি সারি এক একক, প্রথম কলাম সব-এক — intercept-এর জন্য, বাকি কলামগুলো predictor), \(\beta\) হলো \((p+1)\times 1\) coefficient-vector, আর \(\varepsilon\) হলো random error (যা ধরে নেওয়া হয়েছিল \(\mathcal{N}(0,\sigma^2)\) — গড় শূন্য, ধ্রুব ভেদ \(\sigma^2\))। OLS দিয়ে আমরা \(\hat\beta=(X^\top X)^{-1}X^\top y\) পেয়েছি, এবং 5.3-এ দেখেছি ANOVA-ও আসলে categorical predictor সহ এই একই regression।
এই গোটা কাঠামোর একটা নীরব কিন্তু গুরুত্বপূর্ণ অনুমান ছিল: response \(y\) একটা সংখ্যাগত (continuous), অবাধ চলক — বাড়ির দাম, ফসলের ফলন, রক্তচাপ। \(y\) যেকোনো বাস্তব মান নিতে পারে, আর আমরা তার গড়কে \(x^\top\beta\) দিয়ে আন্দাজ করি।
কিন্তু বাস্তবে অগুনতি প্রশ্নে response মোটেও সংখ্যা নয় — উত্তরটা হ্যাঁ অথবা না, ঘটেছে অথবা ঘটেনি, দুটো শ্রেণির একটা। এই অধ্যায়ের পুরো বিষয় এটাই: response যখন binary (দ্বি-মান), তখন কী করব।
১.২ Hook — outcome যখন শুধুই হ্যাঁ/না¶
কয়েকটা চেনা পরিস্থিতি ভাবুন, যেখানে যা ভবিষ্যদ্বাণী করতে চাই সেটা একটা সংখ্যা নয়, একটা দুই-মুখো ফলাফল:
- শিক্ষার্থী পরীক্ষায় পাস করবে, না ফেল? — কতক্ষণ পড়েছে আর কত শতাংশ ক্লাসে উপস্থিত ছিল, তা দিয়ে। (এই উদাহরণটাই গোটা অধ্যায়ে আমাদের সঙ্গী থাকবে।)
- বিজ্ঞাপনে ব্যবহারকারী ক্লিক করবে, না করবে না? — তার বয়স, আগের আচরণ, দিনের সময় দিয়ে।
- রোগীর একটা নির্দিষ্ট রোগ আছে, না নেই? — কিছু রক্ত-পরীক্ষার মান ও উপসর্গ দিয়ে।
- ঋণগ্রহীতা ঋণ শোধ করবে (good), না খেলাপি হবে (default)? — আয়, ঋণের পরিমাণ, ইতিহাস দিয়ে।
প্রতিটি ক্ষেত্রেই response-কে আমরা একটা সংখ্যায় লিখি — কিন্তু সেই সংখ্যা শুধু দুটো মান-ই নেয়:
যেখানে \(y_i\) হলো \(i\)-তম এককের (শিক্ষার্থী/ব্যবহারকারী/রোগী) ফলাফল, আর প্রথা অনুযায়ী \(1\) = "হ্যাঁ"/আগ্রহের ঘটনা (যেমন পাস, ক্লিক, রোগ-আছে), \(0\) = "না" (ফেল, ক্লিক-নয়, রোগ-নেই)। কোনটাকে \(1\) ধরব সেটা আমাদের পছন্দ, কিন্তু একবার ঠিক করলে গোটা বিশ্লেষণে স্থির রাখতে হয়।
এখন আসল প্রশ্ন: এই \(y_i\in\{0,1\}\)-কে predictor \(x_i\) দিয়ে মডেল করতে চাইলে আসলে আমরা কী আন্দাজ করতে চাই? একটা শিক্ষার্থীর জন্য "পাস করবে কি না" সম্পর্কে সবচেয়ে স্বাভাবিক, তথ্যবহুল উত্তর কোনো শক্ত হ্যাঁ/না নয় — বরং একটা probability (সম্ভাবনা):
অর্থাৎ "\(i\)-তম এককের predictor \(x_i\) জানা থাকলে তার ফলাফল \(1\) (হ্যাঁ) হওয়ার শর্তাধীন সম্ভাবনা"। এই \(p_i\in[0,1]\)-ই আমাদের আসল লক্ষ্য — "৩ ঘণ্টা পড়া আর ৭০% উপস্থিতি যে শিক্ষার্থীর, তার পাস করার সম্ভাবনা মোটামুটি কত?"। শক্ত শ্রেণিবিভাগ (পাস বলে দেওয়া, না ফেল) আসে পরে, এই সম্ভাবনার ওপর একটা সীমা (threshold) বসিয়ে।
এক বাক্যে লক্ষ্য: binary outcome-এ আমরা সরাসরি \(0\) বা \(1\) ভবিষ্যদ্বাণী করতে চাই না, বরং predictor-নির্ভর সম্ভাবনা \(p_i = P(y_i=1\mid x_i)\) আন্দাজ করতে চাই — আর সেটাকে predictor-দের সাথে এমনভাবে বাঁধতে চাই যা গাণিতিকভাবে সঙ্গত থাকে।
১.৩ সবচেয়ে সরল চেষ্টা — আর কেন 5.1-এর linear regression এখানে ভেঙে পড়ে¶
স্বাভাবিক প্রথম চেষ্টা: যা জানি তা-ই খাটাই। 5.1-এর linear regression তো ঠিক এই কাজই করে — response-কে \(x^\top\beta\) দিয়ে মডেল করে। তাহলে \(y_i\in\{0,1\}\)-কেই response ধরে সরাসরি OLS চালাই না কেন? অর্থাৎ ধরি
আর \(\hat\beta\) বের করি সেই পুরোনো OLS দিয়ে। এই সরল পদ্ধতিটার একটা নামও আছে — linear probability model (রৈখিক সম্ভাবনা-মডেল)। শুনতে নির্দোষ, কিন্তু এর ভেতরে তিনটি আলাদা ও গুরুতর সমস্যা আছে, যা ঠিক 5.1-এর তিনটি ভিত্তিকে আঘাত করে। একে একে দেখি।
সমস্যা ১ — fitted মান \([0,1]\)-এর বাইরে চলে যায় (range লঙ্ঘন)। \(x_i^\top\beta\) একটা রৈখিক ফাংশন — predictor যথেষ্ট বড় বা ছোট হলে এর মান অবাধে \(+\infty\) বা \(-\infty\)-এর দিকে যায়; পুরো পরিসর \((-\infty, +\infty)\)। কিন্তু আমরা যেটা মডেল করছি, \(p_i\), সেটা একটা সম্ভাবনা — তাকে থাকতেই হবে \([0,1]\)-এ। যে শিক্ষার্থী ১০ ঘণ্টা পড়েছে আর ১০০% উপস্থিত, রৈখিক মডেল দিব্যি তার পাসের "সম্ভাবনা" \(1.3\) বলে দিতে পারে; যে কম পড়েছে, \(-0.2\)। সম্ভাবনা \(1.3\) বা \(-0.2\) অর্থহীন। রৈখিক ফাংশনের পরিসর আর সম্ভাবনার পরিসরের মধ্যে এই মৌলিক অমিলটাই প্রথম দেয়াল।
সমস্যা ২ — error আর normal নয় (distribution লঙ্ঘন)। 5.1-এ অনুমান ছিল \(\varepsilon_i = y_i - x_i^\top\beta \sim \mathcal{N}(0,\sigma^2)\) — একটা মসৃণ, ঘণ্টা-আকৃতির বণ্টন। কিন্তু এখন \(y_i\) শুধু \(0\) বা \(1\) — তাই যেকোনো নির্দিষ্ট \(x_i\)-তে error \(\varepsilon_i\) কেবল দুটো মান নিতে পারে: \(y_i=1\) হলে \(1 - x_i^\top\beta\), আর \(y_i=0\) হলে \(0 - x_i^\top\beta\)। একটা দুই-বিন্দুর (two-point) বণ্টন কোনোভাবেই normal নয়। ফলে normal-error-নির্ভর সব ফলাফল — যেগুলো 5.2-এর t-test, F-test, confidence interval-এর ভিত্তি — এখানে আর সরাসরি খাটে না।
সমস্যা ৩ — variance ধ্রুব নয়, \(p(1-p)\) (heteroskedasticity)। এটি সবচেয়ে সূক্ষ্ম, কিন্তু গভীর। 2.3 থেকে জানি, একটা Bernoulli চলক \(y_i\) যার \(P(y_i=1)=p_i\), তার ভেদ (variance):
লক্ষ করুন, এই ভেদ \(p_i\)-এর ওপর নির্ভর করে — মানে \(x_i\)-এর ওপর নির্ভর করে। যেখানে \(p_i\approx 0.5\) (ফলাফল সবচেয়ে অনিশ্চিত), সেখানে ভেদ সর্বোচ্চ (\(0.25\)); আর যেখানে \(p_i\) প্রায় \(0\) বা প্রায় \(1\) (ফলাফল প্রায় নিশ্চিত), সেখানে ভেদ প্রায় শূন্য। অর্থাৎ বিভিন্ন এককের error-এর ভেদ এক নয় — একে বলে heteroskedasticity (অসম-ভেদ; hetero = ভিন্ন, skedasis = বিচ্ছুরণ)। কিন্তু OLS-এর "সবচেয়ে ভালো" হওয়ার পুরো যুক্তি (5.1-এর Gauss–Markov কাঠামো) দাঁড়িয়ে আছে ঠিক উল্টো অনুমানের ওপর — সমান ভেদ (homoskedasticity, LINE-এর "E")। সেই ভিত্তি এখানে ভেঙে পড়ে।
তিনটিকে একসাথে সাজালে ছবিটা পরিষ্কার:
| 5.1-এর যে স্তম্ভ | binary \(y\)-তে কী ঘটে | ফল |
|---|---|---|
| fitted মান = \(x^\top\beta\), পরিসর \((-\infty,\infty)\) | কিন্তু \(p\) থাকতে হবে \([0,1]\)-এ | "সম্ভাবনা" \(>1\) বা \(<0\) — অর্থহীন |
| error \(\varepsilon\sim\mathcal{N}(0,\sigma^2)\) | \(y\in\{0,1\}\) → error দুই-বিন্দুর | normal-ভিত্তিক inference ভাঙে |
| ধ্রুব ভেদ \(\sigma^2\) (homoskedastic) | \(\operatorname{Var}(y)=p(1-p)\), \(p\)-নির্ভর | heteroskedastic, OLS-এর optimality হারায় |
এক বাক্যে সমস্যা: binary outcome-এ সরাসরি linear regression চাপালে তিনটি ভিত্তিই ভাঙে — fitted "সম্ভাবনা" \([0,1]\)-এর বাইরে যায়, error normal থাকে না, আর ভেদ \(p(1-p)\) হওয়ায় তা আর ধ্রুব থাকে না।
১.৪ সমাধানের মূল insight (অন্তর্দৃষ্টি) — probability-কে নয়, তার logit-কে রৈখিক করো¶
তিনটি সমস্যার শিকড় আসলে একটাই: আমরা একটা সীমাবদ্ধ রাশি (\(p\in[0,1]\))-কে সরাসরি একটা অসীম-পরিসরের রাশি (\(x^\top\beta\in(-\infty,\infty)\))-এর সমান বসাতে চাইছি। দুই পরিসর মেলে না — তাই দ্বন্দ্ব।
সমাধানের ধারণাটা চমৎকার রকম সরল: \(p\)-কে সরাসরি রৈখিক না করে, \(p\)-এর এমন একটা রূপান্তর (transformation)-কে রৈখিক করি, যার পরিসর গোটা \((-\infty,\infty)\)। তাহলে দুই পক্ষের পরিসর মিলে যাবে, আর range-লঙ্ঘনের সমস্যাটাই উবে যাবে।
এমন রূপান্তর আমরা দুই ধাপে বানাই (পূর্ণ সংজ্ঞা §২-এ):
- প্রথমে \(p\) (পরিসর \([0,1]\)) থেকে odds \(\dfrac{p}{1-p}\) — "হওয়ার সম্ভাবনা বনাম না-হওয়ার সম্ভাবনার অনুপাত"। \(p\) যখন \(0\to 1\), odds তখন \(0\to +\infty\)। অর্ধেক পথ পেরোনো হলো: নিচের সীমা খুলে গেল, কিন্তু এখনও ঋণাত্মক হতে পারে না।
- তারপর odds-এর logarithm নিই — log-odds বা logit:
এবার \(p\) যখন \(0\to 1\), logit \(\eta\) তখন \(-\infty \to +\infty\) — পুরো বাস্তব রেখা ঢেকে ফেলল। এখানে \(\eta\) (গ্রিক "eta") হলো এই log-odds, এবং একে বলা হয় linear predictor (রৈখিক ভবিষ্যদ্বক্তা), কারণ এটাকেই আমরা predictor-দের রৈখিক সমন্বয়ের সমান বসাব।
এবার সেতুটা স্পষ্ট: পরিসর যখন দুই পক্ষেই \((-\infty,\infty)\), তখন নির্দ্বিধায় লিখতে পারি
এটাই logistic regression-এর হৃদয়। আমরা \(p\)-কে রৈখিক করিনি, করেছি তার logit-কে — আর তাতেই তিনটি সমস্যাই একসাথে মেটে: (১) যেকোনো \(x^\top\beta\)-এর জন্য উল্টো রূপান্তরে পাওয়া \(p\) স্বয়ংক্রিয়ভাবে \([0,1]\)-এ থাকে (পরের অনুচ্ছেদে দেখা যাবে এই উল্টো রূপান্তরই sigmoid); (২) আমরা আর \(y\)-কে normal ধরছি না, ধরছি Bernoulli — তার সঠিক বণ্টন; (৩) সেই Bernoulli কাঠামোই \(p(1-p)\) ভেদকে স্বাভাবিকভাবে ধারণ করে, তাই heteroskedasticity আর সমস্যা নয়, বরং মডেলেরই অংশ।
এই \(p \leftrightarrow \eta\) সেতু-ফাংশনটার — যেটা \(p\)-কে নিয়ে গিয়ে রৈখিক স্কেলে বসায় — একটা সাধারণ নাম আছে: link function (যোজক ফাংশন)। logit এখানে সেই link। আর এই "response-এর কোনো রূপান্তরকে \(x^\top\beta\)-এর সমান বসানো"-র ধারণাটা শুধু logistic-এই থেমে নেই; এটা একটা বড় পরিবারের কেন্দ্রীয় নকশা — Generalized Linear Models (GLM)। logistic regression সেই পরিবারের একটি সদস্য (Bernoulli response + logit link), আর পরের অধ্যায় 5.5-এ আমরা একই নকশায় Poisson (গণনা-data) মডেল গড়ব। সেই সাধারণ কাঠামোটা §২-এর শেষে এবং পূর্ণরূপে পরের অংশগুলোতে খোলা হবে।
এই অধ্যায়ের বাকি পথটা মোটামুটি এমন: - §২ মূল সংজ্ঞাগুলো নিখুঁত করে — odds, log-odds, logit link, sigmoid, logistic মডেল, coefficient-এর odds-ratio ব্যাখ্যা, এবং GLM-এর সাধারণ ত্রিত্ব। - §৩–৪ মডেলটা কীভাবে data থেকে fit হয় — Bernoulli likelihood, কেন MLE (OLS নয়), score equation, এবং বদ্ধ-রূপ না থাকায় Newton–Raphson/IRLS; সাথে deviance, pseudo-\(R^2\), Wald ও LR inference। - §৫–৬ পূর্ণ exam-pass dataset-এ হাতে-কলমে — fitted probability curve, decision boundary, এবং classification মূল্যায়ন (confusion matrix, precision/recall, ROC, AUC) চিত্রসহ।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে আমরা §১-এর insight (অন্তর্দৃষ্টি)-গুলোকে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; পূর্ণ derivation (likelihood, score equation, fitting) §৪-এ।
ধরে রাখি, আমাদের কাছে \(n\)টি একক, \(i=1,\dots,n\)। \(i\)-তম এককের জন্য: - \(y_i \in \{0,1\}\) — পর্যবেক্ষিত binary outcome (\(1\) = আগ্রহের ঘটনা, \(0\) = নয়)। - \(x_i = (1, x_{i1}, \dots, x_{ip})^\top\) — predictor-vector, প্রথম উপাদান \(1\) (intercept-এর জন্য), পরের \(p\)টি বাস্তব predictor। - \(\beta = (\beta_0, \beta_1, \dots, \beta_p)^\top\) — coefficient-vector; \(\beta_0\) হলো intercept, \(\beta_j\) (\(j\ge 1\)) হলো \(j\)-তম predictor-এর coefficient। - \(p_i = P(y_i = 1 \mid x_i)\) — predictor জানা থাকলে outcome \(1\) হওয়ার শর্তাধীন সম্ভাবনা; এটাই আমরা মডেল করি।
২.১ odds ও log-odds — সম্ভাবনার আরেক ভাষা¶
প্রতিদিনের জীবনে আমরা সম্ভাবনাকে দুইভাবে বলি। একভাবে: "পাসের সম্ভাবনা ০.৭৫"। আরেকভাবে (বিশেষত বাজি/খেলার ভাষায়): "পাসের পক্ষে বাজি ৩-এর বিপরীতে ১", মানে পাস-না-করার চেয়ে পাস-করার সম্ভাবনা তিন গুণ। এই দ্বিতীয় রূপটাই odds (অনুপাত-সম্ভাবনা):
যেখানে \(p\) = ঘটনার সম্ভাবনা, \(1-p\) = না-ঘটার সম্ভাবনা। এটা "হওয়া বনাম না-হওয়া"-র অনুপাত। যেমন \(p=0.75\) হলে odds \(=\frac{0.75}{0.25}=3\) ("৩-এর বিপরীতে ১"); \(p=0.5\) হলে odds \(=1\) (সমান-সমান); \(p=0.2\) হলে odds \(=\frac{0.2}{0.8}=0.25\)।
odds-এর তিনটি দরকারি বৈশিষ্ট্য: - \(p\in[0,1)\) যখন বাড়ে, odds \(\in[0,\infty)\) তখন একঘেয়েভাবে (monotonically) বাড়ে — তাই odds জানা আর \(p\) জানা সমতুল্য, কোনো তথ্য হারায় না। - \(p=0 \Rightarrow\) odds \(=0\); \(p\to 1 \Rightarrow\) odds \(\to +\infty\)। অর্থাৎ odds নিচে \(0\)-তে আটকানো কিন্তু ওপরে অসীম — নিচের সীমাটা ভেঙেছে, ওপরেরটা নয়। - odds থেকে \(p\) ফিরে পাওয়া যায়: \(p = \dfrac{\text{odds}}{1+\text{odds}}\)।
এই "নিচে আটকানো, ওপরে অসীম" অসামঞ্জস্যটা দূর করার ধ্রুপদী উপায় — logarithm। odds-এর log নিলে পাই log-odds, যার প্রাতিষ্ঠানিক নাম logit:
এখানে \(\log\) হলো প্রাকৃতিক লগারিদম (natural log, ভিত্তি \(e\)) — পরিসংখ্যানে এটাই প্রথা, কারণ এর derivative সরল এবং পরে \(e^{\beta}\)-রূপে সুন্দরভাবে ফেরত আসে। logit-এর জাদুকরি বৈশিষ্ট্য — এর পরিসর গোটা বাস্তব রেখা:
তাই logit হলো ঠিক সেই সেতু যা §১.৪-এ আমরা খুঁজছিলাম: একটা \([0,1]\)-বদ্ধ সম্ভাবনাকে নিয়ে \((-\infty,\infty)\) স্কেলে ছড়িয়ে দেয়, যেখানে \(p=0.5\) মানে logit \(=0\) (নিরপেক্ষ বিন্দু), \(p>0.5\) মানে ধনাত্মক logit, \(p<0.5\) মানে ঋণাত্মক।
২.২ logit link, sigmoid, এবং logistic regression মডেল¶
এখন মূল সমীকরণ। logistic regression ধরে নেয় যে outcome-এর logit রৈখিক predictor-দের সাপেক্ষে:
এখানে \(\eta_i\) ("eta") হলো \(i\)-তম এককের linear predictor — predictor-দের রৈখিক সমন্বয়, একটা বাস্তব সংখ্যা যা যেকোনো মান নিতে পারে। আর যে ফাংশন \(p_i\)-কে \(\eta_i\)-তে নিয়ে যায়, অর্থাৎ \(g(p) = \log\frac{p}{1-p}\), তাকে বলে link function (যোজক ফাংশন) — এখানে নির্দিষ্টভাবে logit link। "link" নামটা যথার্থ: এটা response-এর সম্ভাবনা-স্কেলকে predictor-দের রৈখিক স্কেলের সাথে যুক্ত করে।
কিন্তু আমরা তো শেষমেশ \(p_i\)-ই চাই (সম্ভাবনাই আমাদের লক্ষ্য), \(\eta_i\) নয়। তাই উপরের সমীকরণটা \(p_i\)-এর জন্য উল্টে নিই। \(\log\frac{p}{1-p}=\eta\) থেকে দু-পাশে \(\exp\) নিয়ে, তারপর \(p\)-এর জন্য সমাধান করে (পূর্ণ বীজগণিত §৪-এ) পাই:
এই ফাংশন — \(\sigma(\eta) = \dfrac{1}{1+e^{-\eta}}\) — কে বলে sigmoid (অথবা logistic) ফাংশন; এটাই logit link-এর inverse। নামটা গ্রিক "sigma"-র আকৃতি থেকে — এর গ্রাফ একটা মসৃণ, প্রসারিত S। এর আচরণ দেখুন, এবং খেয়াল করুন কীভাবে এটা §১-এর range-সমস্যাকে নিঃশব্দে মিটিয়ে দেয়:
অর্থাৎ linear predictor \(\eta = x^\top\beta\) যত বড় (বা ছোট) হোক না কেন — সম্পূর্ণ অবাধ — sigmoid তাকে চেপে এনে সবসময় \((0,1)\)-এর মধ্যে রাখে। range-লঙ্ঘনের সমস্যা মূল থেকেই অসম্ভব হয়ে যায়। \(\eta=0\) (অর্থাৎ log-odds শূন্য, odds \(=1\)) বিন্দুতে \(p=0.5\) — sigmoid-এর কেন্দ্র, যেখানে বক্ররেখা সবচেয়ে খাড়া। এই বিন্দুর দু-পাশে গ্রাফ ক্রমে চ্যাপ্টা হয়ে \(0\) ও \(1\)-এর দিকে মসৃণভাবে স্যাচুরেট করে — যা §৬-এর 5-4-sigmoid চিত্রে স্পষ্ট দেখা যাবে।
দুই রূপ একসাথে রাখলে logistic regression মডেলের সম্পূর্ণ ছবি:
বাঁ দিকের প্রথম রাশিটি বলে দিচ্ছে, প্রতিটি \(y_i\) আসলে একটা Bernoulli চলক (2.3) যার সাফল্য-সম্ভাবনা \(p_i\) — এবং সেই \(p_i\) predictor-দের মধ্য দিয়ে আসছে। দুটি রূপ (logit-রৈখিক ও sigmoid) একই মডেলের দুই মুখ: একটা fitting ও ব্যাখ্যার জন্য সুবিধাজনক, অন্যটা ভবিষ্যদ্বাণীর জন্য।
২.৩ coefficient-এর অর্থ — odds ও odds ratio¶
5.1-এ coefficient-এর ব্যাখ্যা ছিল সরল ও যোগাত্মক: \(\beta_j\) = "\(x_j\) এক একক বাড়লে \(y\)-এর প্রত্যাশিত মান গড়ে \(\beta_j\) যোগ হয়"। logistic regression-এ ব্যাখ্যাটা বদলে যায় — হয়ে ওঠে গুণাত্মক, এবং তা odds-এর ভাষায়। কেন, দেখা যাক।
মডেল বলছে log-odds রৈখিক:
এখন ধরা যাক একটিমাত্র predictor \(x_j\)-কে এক একক বাড়ানো হলো (\(x_j \to x_j + 1\)), বাকি সব predictor স্থির। তাহলে log-odds-এ যোগ হয় ঠিক \(\beta_j\)। কিন্তু log-odds-এ যোগ মানে odds-এ গুণ (কারণ \(\log a + \log b = \log(ab)\)):
এই অনুপাতটাকে — দুটি ভিন্ন অবস্থার odds-এর ভাগফল — বলে odds ratio (OR, অনুপাত-সম্ভাবনার অনুপাত)। তাই logistic coefficient পড়ার নিয়ম:
\(x_j\) এক একক বাড়লে (বাকি সব স্থির রেখে), \(y=1\) হওয়ার odds গুণিতকভাবে \(e^{\beta_j}\) গুণ হয়।
এখান থেকে কয়েকটা পরিষ্কার পাঠ: - \(\beta_j > 0 \Rightarrow e^{\beta_j} > 1\): \(x_j\) বাড়লে odds (এবং সম্ভাবনা) বাড়ে। - \(\beta_j = 0 \Rightarrow e^{\beta_j} = 1\): \(x_j\) odds-এ কোনো প্রভাব ফেলে না (odds অপরিবর্তিত — তাই \(H_0: \beta_j=0\) মানে "predictor-টির কোনো প্রভাব নেই", যা §৪-এর Wald/LR test-এর লক্ষ্য)। - \(\beta_j < 0 \Rightarrow e^{\beta_j} < 1\): \(x_j\) বাড়লে odds কমে।
একটা মূর্ত উদাহরণ (যা §৫-এ পুরো খুলবে): exam-pass মডেলে যদি hours-এর coefficient \(\hat\beta_{\text{hours}} = 0.922\) হয়, তবে odds ratio \(e^{0.922} \approx 2.52\) — অর্থাৎ প্রতি অতিরিক্ত ১ ঘণ্টা পড়ায়, পাসের odds প্রায় ২.৫ গুণ হয় (উপস্থিতি স্থির রেখে)। আবার attend-এর coefficient \(0.0405\) হলে প্রতি +১% উপস্থিতিতে OR \(=e^{0.0405}\approx 1.041\); আর তাকে +১০%-এর জন্য মাপলে \(e^{0.0405\times 10}=e^{0.405}\approx 1.50\) — অর্থাৎ উপস্থিতি ১০% বাড়লে পাসের odds দেড় গুণ। লক্ষণীয়, ব্যাখ্যাটা odds-এর ওপর গুণিতক, সরাসরি সম্ভাবনার ওপর যোগাত্মক নয় — কারণ সম্ভাবনায় প্রভাবটা অরৈখিক (sigmoid-এর কোথায় আছি তার ওপর নির্ভরশীল)।
২.৪ Bernoulli likelihood ও কেন MLE লাগে (OLS নয়)¶
পরের স্বাভাবিক প্রশ্ন: \(\beta\)-কে data থেকে কীভাবে আন্দাজ করব? 5.1-এ উত্তর ছিল OLS — residual sum of squares ছোট করা, যার একটা সুন্দর বদ্ধ-রূপ \(\hat\beta=(X^\top X)^{-1}X^\top y\)। কিন্তু সেই যুক্তি দাঁড়িয়ে ছিল normal error-এর ওপর। এখন error normal নয়, \(y_i\) Bernoulli — তাই আমরা ফিরে যাই 4.3-এর সবচেয়ে সাধারণ, নীতিগত হাতিয়ারে: maximum likelihood।
ধারণাটা: যে \(\beta\) পর্যবেক্ষিত data-টাকে সবচেয়ে সম্ভাব্য করে তোলে, সেটাই বেছে নাও। একটিমাত্র Bernoulli outcome-এর probability mass সংক্ষেপে লেখা যায় (2.3):
— \(y_i=1\) হলে এটা \(p_i\), \(y_i=0\) হলে \(1-p_i\) দেয়, যেখানে \(p_i = \sigma(x_i^\top\beta)\)। ধরে নিচ্ছি একক-গুলো স্বাধীন, তাই গোটা data-র likelihood হলো এদের গুণফল, আর log-likelihood \(\ell(\beta)\) সেই গুণফলের log (গুণফলকে যোগফলে ভাঙে, derivative নেওয়া সহজ হয়):
এই \(\ell(\beta)\)-কে যে \(\beta\) সর্বোচ্চ করে, সেটাই MLE \(\hat\beta\)। (মেশিন লার্নিং-এ এই \(-\ell(\beta)\)-কেই log-loss বা cross-entropy loss বলা হয় — সর্বোচ্চ করার বদলে এর ঋণাত্মককে ন্যূনতম করা, একই জিনিস।)
কিন্তু এখানে একটা মৌলিক পার্থক্য: \(\ell(\beta)\)-এর derivative শূন্য করলে যে সমীকরণ (score equation) পাওয়া যায়, তা \(\beta\)-তে অরৈখিক (কারণ \(p_i\) নিজেই \(\beta\)-এর অরৈখিক — sigmoid — ফাংশন)। ফলে 5.1-এর মতো কোনো বদ্ধ-রূপ (closed-form) সমাধান নেই — \(\hat\beta\)-কে সরাসরি একটা সূত্রে লিখে ফেলা যায় না। তার বদলে সমীকরণটা পুনরাবৃত্তভাবে (iteratively) সমাধান করতে হয়: একটা আন্দাজ থেকে শুরু করে ক্রমে উন্নত করতে করতে এগোনো। এর আদর্শ পদ্ধতি Newton–Raphson, যা logistic-এর ক্ষেত্রে একটা মার্জিত রূপ নেয় — IRLS (Iteratively Reweighted Least Squares, পুনরাবৃত্ত পুনঃভারিত ন্যূনতম-বর্গ): প্রতিটি পুনরাবৃত্তিতে আসলে একটা ভারিত OLS সমস্যা সমাধান হয়, যেখানে ভার (weight) আসে সেই \(p_i(1-p_i)\) ভেদ থেকে — যা §১.৩-এ "সমস্যা" ছিল, এখানে fitting-এরই অংশ হয়ে যায়। পূর্ণ derivation (score, Hessian, Newton–Raphson ও IRLS) §৪-এ।
এক বাক্যে: logistic regression-এ \(\hat\beta\) আসে Bernoulli log-likelihood সর্বোচ্চ করে (MLE), OLS নয়; আর যেহেতু score equation অরৈখিক, বদ্ধ-রূপ সমাধান নেই — তাই Newton–Raphson/IRLS দিয়ে পুনরাবৃত্তভাবে সমাধান হয়।
২.৫ deviance ও pseudo-\(R^2\) — fit কতটা ভালো, তার স্বজ্ঞা¶
5.1-এ মডেল কত ভালো খাপ খেল তা মাপতাম \(R^2\) দিয়ে ("response-এর কত ভগ্নাংশ তারতম্য মডেল ব্যাখ্যা করে"), যা SSE-ভিত্তিক। কিন্তু logistic-এ আমরা SSE ছোট করি না, করি log-likelihood বড় — তাই fit-এর মাপও likelihood-ভিত্তিক হওয়া স্বাভাবিক। কেন্দ্রীয় রাশি deviance:
এখানে \(\ell(\hat\beta)\) হলো fitted মডেলের সর্বোচ্চ log-likelihood। \(\ell\) সবসময় ঋণাত্মক (সম্ভাবনার log), তাই \(-2\ell\) একটা ধনাত্মক রাশি যা মডেলের misfit (অসঙ্গতি) মাপে — ছোট deviance মানে ভালো fit (data বেশি সম্ভাব্য)। "\(-2\)" গুণাঙ্কটা শখের নয়: এতে দুই মডেলের deviance-পার্থক্য সরাসরি 4.7-এর likelihood-ratio (LR) test-এর statistic হয়ে যায় এবং \(\chi^2\)-বণ্টন অনুসরণ করে — তাই deviance আর LR test একই মুদ্রার দুই পিঠ (বিস্তারিত §৪)।
deviance থেকে একটা \(R^2\)-সদৃশ, \([0,1]\)-মাপা সংখ্যা বানাতে ব্যবহার হয় McFadden's pseudo-\(R^2\):
যেখানে \(\ell(\hat\beta)\) = পূর্ণ মডেলের log-likelihood, আর \(\ell_0\) = null model-এর (শুধু intercept, কোনো predictor নেই — অর্থাৎ সবার জন্য একই \(p\) = সামগ্রিক pass rate) log-likelihood। স্বজ্ঞাটা ঠিক \(R^2\)-এর মতোই: predictor-গুলো যোগ করে আমরা log-likelihood কতটা উন্নত করলাম, base-line null model-এর তুলনায়, তার ভগ্নাংশ। \(R^2_{\text{McF}}=0\) মানে predictor কিছুই যোগ করেনি; \(1\)-এর দিকে গেলে fit তত ভালো। (সতর্কতা: linear \(R^2\)-এর তুলনায় McFadden-এর মান স্বভাবতই ছোট হয় — \(0.2\)–\(0.4\) প্রায়ই "ভালো" ধরা হয়।) §৫-এর exam-pass মডেলে আমরা পাব \(R^2_{\text{McF}} \approx 0.489\) — predictor দুটি (পড়ার সময় ও উপস্থিতি) যে শক্তিশালীভাবে পাস-সম্ভাবনা ব্যাখ্যা করে, তার ইঙ্গিত।
২.৬ বড় ছবি — GLM trinity, এবং logistic তার মধ্যে কোথায়¶
এতক্ষণে একটা প্যাটার্ন উঁকি দিচ্ছে, যা logistic-এর চেয়ে অনেক বড়। logistic regression আসলে একটা সাধারণ নকশার বিশেষ রূপ — Generalized Linear Model (GLM)। 5.1-এর সাধারণ linear regression-ও এই নকশার আরেক রূপ; পরের অধ্যায় 5.5-এর Poisson regression-ও তাই। প্রতিটি GLM তিনটি অংশ দিয়ে গড়া — যাকে বলা যায় GLM trinity (ত্রিত্ব):
-
Random component (এলোমেলো উপাদান) — response \(y_i\) কোন বণ্টন থেকে আসে, যা exponential family (সূচকীয় পরিবার) নামের একটা বড় বণ্টন-শ্রেণির সদস্য। এই পরিবারে আছে Normal, Bernoulli, Binomial, Poisson, Gamma — অনেকেই। logistic-এ random component হলো Bernoulli\((p_i)\) (2.3), যার mean \(p_i\) আর variance \(p_i(1-p_i)\)।
-
Systematic component (সুসংবদ্ধ উপাদান) — predictor-গুলো একটা linear predictor-এ ঢোকে, ঠিক 5.1-এর মতোই রৈখিকভাবে: $$ \eta_i \;=\; x_i^\top\beta \;=\; \beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}. $$ এই অংশটা সব GLM-এ অভিন্ন — তাই নাম "linear model"; "generalized" অংশটা আসে পরের উপাদান থেকে।
-
Link function (যোজক ফাংশন) \(g\) — random component-এর mean \(\mu_i = \mathbb{E}[y_i]\)-কে linear predictor \(\eta_i\)-এর সাথে যুক্ত করে: \(g(\mu_i) = \eta_i\)। link-ই ঠিক করে দেয় mean-কে কোন স্কেলে রৈখিক ধরা হবে। logistic-এ mean হলো \(\mu_i = p_i\), আর link হলো logit: \(g(p_i)=\log\frac{p_i}{1-p_i}=\eta_i\)।
এই তিন অংশে বসিয়ে দিলে পরিচিত মডেলগুলো এক টেবিলে ধরা পড়ে:
| মডেল | random component | mean \(\mu\) | link \(g(\mu)=\eta\) | inverse (mean-রূপ) |
|---|---|---|---|---|
| Linear (5.1) | Normal \(\mathcal{N}(\mu,\sigma^2)\) | \(\mu\) | identity: \(\mu=\eta\) | \(\mu = \eta\) |
| Logistic (5.4) | Bernoulli\((p)\) | \(p\) | logit: \(\log\frac{p}{1-p}=\eta\) | \(p = \dfrac{1}{1+e^{-\eta}}\) |
| Poisson (5.5) | Poisson\((\lambda)\) | \(\lambda\) | log: \(\log\lambda=\eta\) | \(\lambda = e^{\eta}\) |
এই টেবিলটাই অধ্যায়ের একীভূত দৃষ্টি: logistic regression = Bernoulli random component + logit link, আর সাধারণ linear regression = Normal + identity link। দুটোই একই কাঠামোর সদস্য — শুধু random component ও link আলাদা। এই অভিন্নতাই কারণ যে logistic বোঝা মানে শুধু একটা আলাদা কৌশল শেখা নয়, বরং একটা সাধারণ ভাষা আয়ত্ত করা — যে ভাষায় পরের অধ্যায় 5.5-এ আমরা শুধু "Bernoulli + logit"-কে "Poisson + log" দিয়ে বদলে দিয়েই গণনা-data (count data) মডেল করতে পারব, বাকি কাঠামো (linear predictor, likelihood, deviance, IRLS) প্রায় অপরিবর্তিত রেখে।
এক বাক্যে GLM trinity: প্রতিটি GLM = একটা exponential-family random component (response-এর বণ্টন) + একটা linear predictor \(\eta=x^\top\beta\) (systematic component) + একটা link function \(g\) যা mean-কে \(\eta\)-এর সাথে বাঁধে — আর logistic regression হলো ঠিক Bernoulli + logit-link-এর ঘটনা।
পরবর্তী অংশে (§৩–৪) আমরা এই মডেলটাকে পূর্ণরূপে data-য় fit করব — Bernoulli likelihood-এর derivation, score equation, Newton–Raphson/IRLS, এবং deviance, Wald ও LR test-এর গাণিতিক ভিত্তি সহ।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে আমরা একটি একক, পূর্ণাঙ্গ data set-এর উপর logistic regression-এর গোটা চক্রটি ধাপে ধাপে দেখব — model fit করা, coefficient পড়া, সেগুলোকে odds ratio-তে রূপান্তর করে ব্যাখ্যা করা, হাতে-কলমে একটি prediction করা, এবং সবশেষে model কতটা ভালো fit করল ও classification কতটা নির্ভুল তা যাচাই করা।
সমস্যাটি। ধরা যাক একদল ছাত্রের জন্য আমাদের কাছে দুটি predictor আছে — সেমিস্টার জুড়ে গড়ে দৈনিক পড়ার ঘণ্টা (hours) এবং উপস্থিতির হার শতাংশে (attend) — এবং একটি binary outcome: ছাত্রটি পরীক্ষায় pass করল কি না (passed \(\in\{0,1\}\))। আমরা \(n=200\) জন ছাত্রের একটি কৃত্রিম data set তৈরি করেছি যেখানে প্রকৃত data-generating process হলো
পুরো data set-এ pass rate হলো \(124/200 = 0.62\) — অর্থাৎ ৬২% ছাত্র pass করেছে। লক্ষ করুন, এটিই হলো কোনো predictor ছাড়াই "বেস-লাইন" অনুমান: যদি আমাদের কাছে hours বা attend সম্পর্কে কিছুই না জানা থাকত, আমরা প্রতিটি ছাত্রের জন্য \(\hat p = 0.62\) বলতাম। logistic regression-এর কাজ হলো predictor ব্যবহার করে এই অনুমানকে ছাত্র-ভেদে আরও ধারালো করা।
E1 · Model fit ও coefficient পড়া¶
আমরা logit link সহ একটি GLM fit করি, যার formula হলো passed ~ hours + attend। linear predictor
Maximum likelihood estimation (statsmodels-এর Logit) চালিয়ে নিচের coefficient table পাওয়া যায়:
| Parameter | \(\hat\beta\) | SE | \(z\) | \(P>\lvert z\rvert\) |
|---|---|---|---|---|
| Intercept | \(-6.320\) | \(1.173\) | \(-5.39\) | \(<0.001\) |
hours |
\(0.9224\) | \(0.1239\) | \(7.44\) | \(<0.001\) |
attend |
\(0.04047\) | \(0.01278\) | \(3.17\) | \(0.0016\) |
Sign পড়া। logit model-এ একটি coefficient-এর চিহ্নই বলে দেয় predictor বাড়লে pass হওয়ার সম্ভাবনা বাড়ে না কমে:
hours-এর coefficient \(\hat\beta_1 = 0.9224 > 0\) — অর্থাৎ পড়ার ঘণ্টা বাড়লে \(\eta\) বাড়ে, ফলে \(p\) বাড়ে। বেশি পড়া বেশি pass-এর সঙ্গে যুক্ত — যা স্বজ্ঞার সঙ্গে মেলে।attend-এর coefficient \(\hat\beta_2 = 0.04047 > 0\) — উপস্থিতি বাড়লেও pass হওয়ার সম্ভাবনা বাড়ে। coefficient-টি ছোট দেখালেও মনে রাখতে হবে এটি প্রতি এক শতাংশ উপস্থিতির প্রভাব, আরattend৪০ থেকে ১০০ পর্যন্ত বিস্তৃত — তাই পরিসরজুড়ে মোট প্রভাব নগণ্য নয়।
দুটি coefficient-ই অত্যন্ত significant (\(z = 7.44\) ও \(3.17\), উভয়েই \(\lvert z\rvert > 1.96\)), তাই কোনোটিই শূন্য বলে ধরে নেওয়া যায় না।
Intercept-এর অর্থ। \(\hat\beta_0 = -6.320\) হলো সেই \(\eta\) যখন hours \(=0\) এবং attend \(=0\) — অর্থাৎ যে ছাত্র মোটেও পড়ে না এবং কখনো ক্লাসে আসে না। সেক্ষেত্রে \(p = \text{sigmoid}(-6.320) = 1/(1+e^{6.320}) \approx 0.0018\) — কার্যত শূন্য pass-সম্ভাবনা। তবে সাবধান: এখানে attend \(=0\) data-র পরিসরের (৪০–১০০) সম্পূর্ণ বাইরে, তাই intercept-এর এই আক্ষরিক ব্যাখ্যাটি একটি extrapolation — সংখ্যাটির ভূমিকা মূলত গাণিতিক, baseline ঠিক করা; একে বাস্তব কোনো ছাত্রের ভবিষ্যদ্বাণী হিসেবে না দেখাই ভালো।
E2 · Odds ratio দিয়ে ব্যাখ্যা — এটিই মূল¶
logit model-এর coefficient সরাসরি probability-র ভাষায় কথা বলে না — কারণ sigmoid অরৈখিক, একই \(\Delta\eta\) probability-র মাঝখানে (০.৫-এর কাছে) বড় পরিবর্তন আনে কিন্তু প্রান্তে (০ বা ১-এর কাছে) সামান্য। তাই coefficient-এর স্বাভাবিক, সুসংগত ব্যাখ্যাটি আসে odds-এর ভাষায়।
কোনো ঘটনার odds হলো ঘটার সম্ভাবনা বনাম না-ঘটার সম্ভাবনার অনুপাত:
logit model-এ ঠিক এই odds-এর logarithm-ই \(\eta\)-র সমান: \(\log\frac{p}{1-p} = \eta = \beta_0 + \beta_1\,\text{hours} + \beta_2\,\text{attend}\)। এর সরাসরি ফল হলো — যদি একটি predictor \(x_j\) এক একক বাড়ে (বাকি সব স্থির রেখে), তবে log-odds ঠিক \(\beta_j\) পরিমাণ বাড়ে, অর্থাৎ odds নিজে \(e^{\beta_j}\) গুণিতকে গুণিত হয়। এই \(e^{\beta_j}\)-কেই বলা হয় odds ratio।
আমাদের estimate থেকে:
এদের ব্যাখ্যা:
- প্রতি \(+1\) ঘণ্টা পড়ায় pass-এর odds \(\times\,2.52\)। অন্য সব স্থির রেখে দৈনিক পড়া এক ঘণ্টা বাড়লে pass বনাম fail-এর odds প্রায় আড়াই গুণ হয়ে যায়। অর্থাৎ যদি কোনো পড়ার-স্তরে pass:fail odds হয় \(1:1\), তবে আরও এক ঘণ্টা পড়লে তা হয় প্রায় \(2.52:1\)।
- প্রতি \(+1\%\) উপস্থিতিতে odds \(\times\,1.0413\) — প্রতি শতাংশে মাত্র ~৪% বৃদ্ধি, ছোট শোনায়। কিন্তু একক-একক ধরা বিভ্রান্তিকর; বাস্তবে উপস্থিতি ১০ শতাংশ-বিন্দুর ধাপে নড়ে। সেই হিসাবে প্রতি \(+10\%\) উপস্থিতিতে odds \(\times\,e^{10\cdot 0.04047} = e^{0.4047} = 1.499 \approx 1.50\) — অর্থাৎ উপস্থিতি ১০ শতাংশ বাড়লে pass-এর odds দেড় গুণ হয়। (লক্ষণীয়: ১০ এককের প্রভাব একক-প্রভাবকে ১০ দিয়ে গুণ নয়, বরং \(e^{\beta}\)-কে দশম ঘাতে তোলা — কারণ odds গুণিতকভাবে জমে: \(1.0413^{10} \approx 1.50\)।)
Odds বনাম probability — সতর্কতা। "odds দ্বিগুণ" আর "probability দ্বিগুণ" এক জিনিস নয়। odds ratio constant — predictor যেখানেই থাকুক, \(+1\) ঘণ্টা সবসময় odds-কে \(2.52\) গুণ করে। কিন্তু এর ফলে probability-তে কত পরিবর্তন আসবে তা নির্ভর করে শুরুর অবস্থানের উপর। উদাহরণ: যদি শুরুতে \(p=0.10\) (odds \(\approx 0.111\)), তবে \(+1\) ঘণ্টায় odds \(= 0.111\times 2.515 = 0.279\), যা থেকে \(p = 0.279/(1+0.279) = 0.218\) — probability প্রায় দ্বিগুণ। কিন্তু যদি শুরুতে \(p=0.80\) (odds \(=4\)) হয়, তবে নতুন odds \(= 4\times 2.515 = 10.06\), \(p = 10.06/11.06 = 0.909\) — probability বাড়ল মাত্র ০.৮০ থেকে ০.৯১। একই odds ratio, কিন্তু probability-তে প্রভাব ভিন্ন; প্রান্তে গিয়ে probability সম্পৃক্ত (saturate) হয়। এই কারণেই logit-এর coefficient-কে odds-এর ভাষায় ব্যাখ্যা করা পরিচ্ছন্ন ও সর্বত্র সত্য, আর probability-র ভাষায় বলতে হলে সবসময় "কোন বিন্দু থেকে" তা উল্লেখ করতে হয়।
E3 · হাতে-কলমে একটি prediction¶
ধরা যাক একজন ছাত্র দৈনিক \(\text{hours}=5\) ঘণ্টা পড়ে এবং তার উপস্থিতি \(\text{attend}=75\%\)। সে pass করবে কি না — model অনুসারে দুই ধাপে বের করি।
ধাপ ১ — linear predictor \(\eta\)। coefficient বসিয়ে:
ধাপ ২ — sigmoid দিয়ে probability।
Classification (শ্রেণিবিন্যাস)। \(0.5\) threshold ব্যবহার করলে, যেহেতু \(p = 0.790 \ge 0.5\), model এই ছাত্রকে pass হিসেবে চিহ্নিত করে। শুধু hard label নয়, model একটি ক্রমাঙ্কিত আত্মবিশ্বাসও দেয় — pass হওয়ার সম্ভাবনা প্রায় ৭৯%। এই \(\eta \to p \to\) label পথটিই হলো logistic regression-এর প্রতিটি prediction-এর সম্পূর্ণ যন্ত্রপাতি।
E4 · Model fit ও classification মূল্যায়ন¶
Overall fit। model কতটা ভালো খাপ খেল তা প্রথমে likelihood-ভিত্তিক পরিমাপে দেখি। fitted model-এর log-likelihood \(\ell = -67.92\), আর শুধু intercept-যুক্ত null model-এর \(\ell_0 = -132.81\)। দুটোর তুলনায়:
- Residual deviance \(= -2\ell = 135.83\) — যত ছোট, fit তত ভালো (null deviance ছিল \(-2\ell_0 = 265.62\), অর্থাৎ predictor যোগ করে deviance অনেকটা কমেছে)।
- McFadden pseudo-\(R^2\) \(= 1 - \dfrac{\ell}{\ell_0} = 1 - \dfrac{-67.92}{-132.81} = 0.489\)। linear regression-এর \(R^2\)-এর মতো হুবহু "ব্যাখ্যাকৃত variance" নয়, কিন্তু একই চেতনায় বড় মান ভালো fit বোঝায়; McFadden-এর স্কেলে \(0.2\)–\(0.4\) ইতিমধ্যেই খুব ভালো fit ধরা হয়, তাই \(0.489\) যথেষ্ট শক্তিশালী।
- Likelihood-ratio test। null model-এর তুলনায় predictor-দুটি একত্রে অর্থবহ কি না তা LLR test বলে; এখানে LLR \(p\text{-value} \approx 6.5\times 10^{-29}\) — কার্যত শূন্য, অর্থাৎ model সামগ্রিকভাবে অত্যন্ত significant।
Classification ক্ষমতা। \(0.5\) threshold-এ প্রতিটি ছাত্রকে pass/fail-এ ভাগ করে প্রকৃত label-এর সঙ্গে মিলিয়ে confusion matrix:
| Predicted fail | Predicted pass | |
|---|---|---|
| Actual fail | TN \(=61\) | FP \(=15\) |
| Actual pass | FN \(=14\) | TP \(=110\) |
এ থেকে মূল metric:
অর্থাৎ model যাদের pass বলে তাদের ৮৮% সত্যিই pass (precision), আর প্রকৃত pass-দের ৮৯% model ধরতে পারে (recall) — দুটিই উঁচু ও ভারসাম্যপূর্ণ। বেস-লাইন (সবাইকে pass বলা, যাতে accuracy হতো ০.৬২) থেকে \(0.855\) accuracy স্পষ্ট উন্নতি।
Threshold-নিরপেক্ষ পরিমাপ — AUC। উপরের সব metric \(0.5\) threshold-এর উপর নির্ভরশীল। AUC (area under the ROC curve) সব সম্ভাব্য threshold জুড়ে model-এর pass ও fail আলাদা করার ক্ষমতা একটি সংখ্যায় ধরে; এখানে \(\text{AUC} = 0.924\)। ব্যাখ্যা: এলোমেলোভাবে নেওয়া একজন প্রকৃত pass-ছাত্রকে model একজন প্রকৃত fail-ছাত্রের চেয়ে বেশি pass-probability দেবে — এমন ঘটনার সম্ভাবনা ৯২.৪%। \(0.5\) মানে নিছক অনুমান, \(1.0\) মানে নিখুঁত পৃথকীকরণ; \(0.924\) চমৎকার discrimination নির্দেশ করে।
Threshold trade-off। \(0.5\) কোনো পবিত্র সংখ্যা নয় — threshold কমালে (যেমন \(0.3\)) model বেশি ছাত্রকে pass বলবে, ফলে recall বাড়ে কিন্তু precision পড়ে (বেশি false positive); threshold বাড়ালে উল্টোটা ঘটে। সঠিক threshold বাস্তব খরচের উপর নির্ভর করে — কোন ভুলটি বেশি ক্ষতিকর, একজন pass-যোগ্য ছাত্রকে fail বলা না একজন দুর্বল ছাত্রকে pass বলা — সেই বিচারে threshold বেছে নিতে হয়।
যাচাই (statsmodels Logit, seed 20260619, n=200):
সব canonical সংখ্যা হুবহু মিলেছে।pass rate: 0.62 (124/200) Coef. Std.Err. z P>|z| Intercept -6.32042 1.17323 -5.38720 0.00000 hours 0.92244 0.12394 7.44251 0.00000 attend 0.04046 0.01278 3.16519 0.00155 llf: -67.92 llnull: -132.81 McFadden pseudo R2: 0.489 LLR p: 6.5e-29 resid deviance: 135.83 OR hours: 2.515 OR attend(+1%): 1.0413 OR attend(+10%): 1.499 hours=5, attend=75 -> eta: 1.327 p: 0.790 accuracy: 0.855 confusion [[61,15],[14,110]] precision: 0.88 recall: 0.887 AUC: 0.924
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে আমরা logistic regression-এর সম্পূর্ণ গাণিতিক কাঠামো ধাপে ধাপে গড়ে তুলব — sigmoid ও logit-এর inverse সম্পর্ক থেকে শুরু করে log-likelihood, score equation, Newton–Raphson/IRLS, asymptotic inference, এবং সবশেষে generalized linear model (GLM)-এর সাধারণ কাঠামো। প্রতিটি ফলাফল আগেরটির উপর দাঁড়িয়ে আছে, তাই ক্রম মেনে পড়াই ভালো।
পুরো অংশে notation একই থাকবে: \(y_i\in\{0,1\}\) হলো observation \(i\)-এর binary outcome, \(x_i\in\mathbb{R}^p\) হলো তার covariate vector, \(p_i=P(y_i=1\mid x_i)\) হলো success probability, \(\eta_i=x_i^\top\beta\) হলো linear predictor (যাকে log-odds বা logit-ও বলা হবে), এবং $$ \sigma(z)=\frac{1}{1+e^{-z}} $$ হলো sigmoid (logistic) function, যাতে \(p_i=\sigma(\eta_i)\)।
৪.১ ★ Sigmoid ও logit: inverse pair এবং মূল derivative identity¶
প্রেরণা। Linear regression (5.1)-এ আমরা \(\mathbb{E}[y\mid x]=x^\top\beta\) ধরেছিলাম — অর্থাৎ response-এর mean সরাসরি linear predictor-এর সমান। কিন্তু এখন \(y_i\in\{0,1\}\), তাই \(\mathbb{E}[y_i\mid x_i]=p_i\in[0,1]\) একটি probability, যা অবশ্যই \([0,1]\)-এর মধ্যে থাকতে হবে। অথচ \(x_i^\top\beta\) যেকোনো বাস্তব সংখ্যা \((-\infty,\infty)\) হতে পারে। তাহলে কীভাবে একটি unbounded linear predictor-কে একটি bounded probability-র সাথে যুক্ত করা যায়? উত্তর হলো একটি link function যা \([0,1]\)-কে \((-\infty,\infty)\)-তে মানচিত্রিত করে।
স্বাভাবিক পছন্দ হলো odds এবং তারপর log-odds (logit)। কোনো ঘটনার odds হলো success ও failure-এর অনুপাত: $$ \text{odds}=\frac{p}{1-p}\in(0,\infty), \qquad \text{logit}(p)=\log\frac{p}{1-p}=\eta\in(-\infty,\infty). $$ এখানে \(p\in(0,1)\) হলে \(\frac{p}{1-p}\in(0,\infty)\), আর তার logarithm পুরো বাস্তব রেখা cover করে। অর্থাৎ logit ঠিক যা চাই — probability scale থেকে linear-predictor scale-এ একটি monotone, smooth, এক-এক mapping।
Inverse বের করা। আমরা মডেল করি \(\eta=\operatorname{logit}(p)=\log\frac{p}{1-p}\)। inference-এর জন্য উল্টোটা দরকার: \(\eta\) জানা থাকলে \(p\) কত? নিচে ধাপে ধাপে solve করি।
ধাপ ১ — দুই পাশে exponentiate: $$ e^{\eta}=\exp!\Big(\log\frac{p}{1-p}\Big)=\frac{p}{1-p}. $$
ধাপ ২ — denominator গুণ করে \(p\) আলাদা করি: $$ e^{\eta}(1-p)=p \;\Longrightarrow\; e^{\eta}-e^{\eta}p=p \;\Longrightarrow\; e^{\eta}=p+e^{\eta}p=p\,(1+e^{\eta}). $$
ধাপ ৩ — \(p\)-এর জন্য সমাধান: $$ p=\frac{e^{\eta}}{1+e^{\eta}}. $$
ধাপ ৪ — উপর-নিচ \(e^{-\eta}\) দিয়ে গুণ করলে স্ট্যান্ডার্ড sigmoid রূপ: $$ p=\frac{e^{\eta}}{1+e^{\eta}}\cdot\frac{e^{-\eta}}{e^{-\eta}} =\frac{1}{e^{-\eta}+1} =\frac{1}{1+e^{-\eta}}=\sigma(\eta). $$
অর্থাৎ logit ও sigmoid পরস্পরের inverse: $$ \boxed{\;\eta=\log\frac{p}{1-p}\quad\Longleftrightarrow\quad p=\sigma(\eta)=\frac{1}{1+e^{-\eta}}\;} $$ \(\sigma\)-কে তাই inverse-logit বা expit-ও বলা হয়।
দুটো ছোট কিন্তু পরে কাজে-লাগা পরিচয়: $$ 1-\sigma(z)=1-\frac{1}{1+e^{-z}}=\frac{e^{-z}}{1+e^{-z}}=\frac{1}{1+e^{z}}=\sigma(-z), $$ যা দেখায় \(\sigma\) এই অর্থে symmetric যে \(\sigma(-z)=1-\sigma(z)\)। ফলে $$ \frac{\sigma(z)}{1-\sigma(z)}=\frac{1/(1+e^{-z})}{e^{-z}/(1+e^{-z})}=\frac{1}{e^{-z}}=e^{z}, $$ অর্থাৎ odds ঠিক \(e^{\eta}\) — coefficient \(\beta_j\)-এর ব্যাখ্যা পরে এখান থেকেই আসবে (§৩ ও §৫ দ্রষ্টব্য: \(x_j\)-এ এক একক বাড়লে odds \(e^{\beta_j}\) গুণ হয়)।
মূল derivative identity। Logistic regression-এর প্রায় সব gradient-গণিত একটিমাত্র সুন্দর identity-র উপর দাঁড়ায়: $$ \sigma'(z)=\sigma(z)\,\bigl(1-\sigma(z)\bigr). $$ এটি প্রমাণ করি। \(\sigma(z)=(1+e^{-z})^{-1}\) লিখে chain rule প্রয়োগ করি: $$ \sigma'(z)=-\,(1+e^{-z})^{-2}\cdot\frac{d}{dz}\bigl(1+e^{-z}\bigr) =-\,(1+e^{-z})^{-2}\cdot(-e^{-z}) =\frac{e^{-z}}{(1+e^{-z})^{2}}. $$ এখন ডান পাশকে দুই ভাগ করে চিনি: $$ \frac{e^{-z}}{(1+e^{-z})^{2}} =\underbrace{\frac{1}{1+e^{-z}}}{=\,\sigma(z)}\cdot\underbrace{\frac{e^{-z}}{1+e^{-z}}} =\sigma(z)\bigl(1-\sigma(z)\bigr). $$ সুতরাং $$ \boxed{\;\sigma'(z)=\sigma(z)\bigl(1-\sigma(z)\bigr)\;} $$ লক্ষণীয়: এই derivative সর্বদা \(\ge 0\) (তাই \(\sigma\) monotone increasing), \(z=0\)-তে সর্বোচ্চ মান \(\tfrac14\) নেয় (যেখানে \(\sigma=\tfrac12\)), এবং \(\lvert z\rvert\to\infty\)-তে \(0\)-তে যায় (saturation — দূরের প্রান্তে gradient প্রায় শূন্য, যা optimization-এ গুরুত্বপূর্ণ)। \(p=\sigma(\eta)\) লিখলে identity-টি হয় \(\dfrac{\partial p}{\partial\eta}=p(1-p)\), যা ঠিক Bernoulli variance — পরে Hessian/Fisher information-এ এই \(p(1-p)\) বারবার ফিরে আসবে।
৪.২ ★★ Log-likelihood এবং exponential-family রূপ¶
Bernoulli likelihood। প্রতিটি \(y_i\mid x_i\sim\text{Bernoulli}(p_i)\) ধরা হয়, যার probability mass function এক লাইনে লেখা যায়: $$ P(y_i\mid x_i)=p_i^{\,y_i}\,(1-p_i)^{\,1-y_i},\qquad y_i\in{0,1}. $$ এই চতুর রূপটি যাচাই করুন: \(y_i=1\) হলে exponent গুলো দাঁড়ায় \(p_i^{1}(1-p_i)^{0}=p_i\); \(y_i=0\) হলে \(p_i^{0}(1-p_i)^{1}=1-p_i\) — ঠিক যা চাই।
Observation গুলো independent ধরে নিলে joint likelihood হলো গুণফল: $$ L(\beta)=\prod_{i=1}^{n}p_i^{\,y_i}(1-p_i)^{1-y_i}, \qquad p_i=\sigma(x_i^\top\beta). $$ গুণফল নিয়ে কাজ করা কঠিন, তাই logarithm নিই (log monotone, তাই argmax অপরিবর্তিত)। log-likelihood: $$ \ell(\beta)=\log L(\beta) =\sum_{i=1}^{n}\Bigl[y_i\log p_i+(1-y_i)\log(1-p_i)\Bigr]. $$ এটিই brief-এ দেওয়া রূপ। (পরিসংখ্যান-শিক্ষায় এর negative-কে binary cross-entropy loss বলা হয় — machine learning-এর সাথে এখানেই সেতু।)
Exponential-family / canonical রূপে রূপান্তর। এখন আমরা \(p_i=\sigma(\eta_i)\) প্রতিস্থাপন করে \(\ell\)-কে সরাসরি \(\eta_i\)-এর ফাংশন হিসেবে লিখব — এই রূপ পরে derivative নেওয়া অসাধারণ সহজ করে দেবে। একটি observation-এর contribution ধরি: $$ \ell_i=y_i\log p_i+(1-y_i)\log(1-p_i). $$ ধাপে ধাপে এগোই।
ধাপ ১ — পদ পুনর্বিন্যাস করে \(\log\frac{p_i}{1-p_i}\) বের করি: $$ \ell_i=y_i\log p_i+\log(1-p_i)-y_i\log(1-p_i) =y_i\log\frac{p_i}{1-p_i}+\log(1-p_i). $$
ধাপ ২ — প্রথম পদে §৪.১-এর ফলাফল \(\log\frac{p_i}{1-p_i}=\eta_i\) বসাই: $$ \ell_i=y_i\,\eta_i+\log(1-p_i). $$
ধাপ ৩ — \(\log(1-p_i)\)-কে \(\eta_i\)-এ প্রকাশ করি। §৪.১ থেকে \(1-\sigma(\eta_i)=\dfrac{1}{1+e^{\eta_i}}\), তাই $$ \log(1-p_i)=\log\frac{1}{1+e^{\eta_i}}=-\log\bigl(1+e^{\eta_i}\bigr). $$
ধাপ ৪ — একত্র করি: $$ \ell_i=y_i\,\eta_i-\log\bigl(1+e^{\eta_i}\bigr). $$
সমস্ত \(i\)-এর উপর যোগ করলে পুরো log-likelihood-এর exponential-family রূপ: $$ \boxed{\;\ell(\beta)=\sum_{i=1}^{n}\Bigl[\,y_i\,\eta_i-\log\bigl(1+e^{\eta_i}\bigr)\Bigr],\qquad \eta_i=x_i^\top\beta\;} $$
ব্যাখ্যা — কেন এই রূপ গুরুত্বপূর্ণ। Exponential family-র canonical form হলো \(f(y\mid\theta)=\exp\!\bigl(\theta\,T(y)-A(\theta)+c(y)\bigr)\), যেখানে \(\theta\) হলো natural (canonical) parameter, \(T(y)\) sufficient statistic, এবং \(A(\theta)\) হলো log-partition (cumulant) function। উপরের রূপের সাথে মিলিয়ে দেখুন: $$ \theta=\eta_i\ (\text{natural parameter}),\qquad T(y_i)=y_i,\qquad A(\eta_i)=\log\bigl(1+e^{\eta_i}\bigr). $$ অর্থাৎ logit হলো Bernoulli-র canonical link — natural parameter \(\eta_i\) ঠিক linear predictor \(x_i^\top\beta\)-এর সমান। এই কাকতালীয় নয়; §৪.৬-এ দেখব এটিই GLM-এর "canonical link" সংজ্ঞা। আরও, exponential family-র সাধারণ তত্ত্ব অনুযায়ী \(A'(\eta)=\mathbb{E}[T(y)]=\mathbb{E}[y]=p\) এবং \(A''(\eta)=\operatorname{Var}(y)=p(1-p)\) — এই দুটি ফলাফল পরের অংশের score ও Hessian-কে প্রায় বিনা পরিশ্রমে দেবে। যাচাই: \(A(\eta)=\log(1+e^\eta)\) হলে \(A'(\eta)=\frac{e^\eta}{1+e^\eta}=\sigma(\eta)=p\) ✓ এবং \(A''(\eta)=\sigma'(\eta)=p(1-p)\) ✓।
পরিভাষা টীকা (★). \(A(\eta)=\log(1+e^{\eta})\) ফাংশনটিকে softplus বলা হয়; এটি \(\max(0,\eta)\)-এর smooth approximation এবং সর্বত্র convex (কারণ \(A''=p(1-p)>0\))। \(\ell\)-এ এর সামনে ঋণচিহ্ন থাকায় \(\ell\) concave হবে — §৪.৩-এ ঠিক এটাই দেখব।
৪.৩ ★★ Score equations, OLS-এর সাথে সমান্তরাল, এবং Hessian¶
Score (gradient) নির্ণয়। MLE পেতে \(\ell(\beta)\)-কে \(\beta\)-এর সাপেক্ষে সর্বোচ্চ করতে হবে, অর্থাৎ gradient (score) \(=0\) সমাধান করতে হবে। §৪.২-এর exponential-family রূপ থেকে শুরু করি, কারণ সেখানে \(\beta\)-নির্ভরতা কেবল \(\eta_i=x_i^\top\beta\)-এর মাধ্যমে — তাই chain rule সরল।
একটি observation-এর contribution \(\ell_i=y_i\eta_i-\log(1+e^{\eta_i})\) থেকে \(\eta_i\)-এর সাপেক্ষে derivative: $$ \frac{\partial \ell_i}{\partial \eta_i} =y_i-\frac{e^{\eta_i}}{1+e^{\eta_i}} =y_i-\sigma(\eta_i) =y_i-p_i. $$ এখানে মাঝের পদে আমরা \(\dfrac{d}{d\eta}\log(1+e^{\eta})=\dfrac{e^{\eta}}{1+e^{\eta}}=\sigma(\eta)\) ব্যবহার করেছি (অর্থাৎ §৪.১-এর \(A'(\eta)=p\))। এখন chain rule, যেহেতু \(\dfrac{\partial \eta_i}{\partial \beta}=\dfrac{\partial (x_i^\top\beta)}{\partial\beta}=x_i\): $$ \frac{\partial \ell_i}{\partial \beta} =\frac{\partial \ell_i}{\partial \eta_i}\cdot\frac{\partial \eta_i}{\partial \beta} =(y_i-p_i)\,x_i. $$ সব observation-এর উপর যোগ করে score vector: $$ U(\beta)\equiv\frac{\partial \ell}{\partial \beta}=\sum_{i=1}^{n}(y_i-p_i)\,x_i . $$ Design matrix \(X=\begin{bmatrix}x_1^\top\\ \vdots\\ x_n^\top\end{bmatrix}\in\mathbb{R}^{n\times p}\), এবং vector \(y=(y_1,\dots,y_n)^\top\), \(p=(p_1,\dots,p_n)^\top\) লিখলে যোগফলটি একটি পরিচ্ছন্ন matrix রূপ নেয় (\(\sum_i (y_i-p_i)x_i = X^\top(y-p)\)): $$ \boxed{\;U(\beta)=X^\top(y-p)=0\;} \qquad\text{(score / likelihood equations)}. $$
OLS normal equations-এর সাথে সমান্তরাল — এবং মূল পার্থক্য। 5.1-এ OLS-এর normal equations ছিল \(X^\top(y-\hat y)=0\) যেখানে \(\hat y=X\hat\beta\) (fitted mean)। এখানেও ঠিক একই গঠন: residual \((y-p)\) প্রতিটি column of \(X\)-এর সাথে orthogonal হতে হবে, যেখানে \(p=\mathbb{E}[y\mid X]\) হলো fitted mean। অর্থাৎ উভয় ক্ষেত্রেই MLE/least-squares fitted mean residual-কে predictor-space-এ orthogonal করে। এটি GLM-তত্ত্বের সৌন্দর্য: একই geometric নীতি।
তবে সিদ্ধান্তমূলক পার্থক্য হলো — OLS-এ \(\hat y=X\hat\beta\) linear in \(\beta\), তাই \(X^\top(y-X\beta)=0\) থেকে closed-form \(\hat\beta=(X^\top X)^{-1}X^\top y\) পাওয়া যায়। কিন্তু এখানে \(p_i=\sigma(x_i^\top\beta)\) — sigmoid-এর কারণে \(p\) হলো nonlinear in \(\beta\)। তাই \(X^\top(y-p(\beta))=0\) হলো একগুচ্ছ অরৈখিক সমীকরণ, যার সাধারণভাবে কোনো closed-form সমাধান নেই। ফলে আমাদের iterative numerical পদ্ধতি — Newton–Raphson বা তার সমতুল্য IRLS — প্রয়োজন (§৪.৪)।
Hessian নির্ণয়। Newton-এর জন্য এবং concavity প্রমাণের জন্য দ্বিতীয় derivative দরকার। \(U(\beta)=\sum_i (y_i-p_i)x_i\)-কে আবার \(\beta\)-এর সাপেক্ষে differentiate করি। কেবল \(p_i=\sigma(\eta_i)\) পদই \(\beta\)-নির্ভর, এবং $$ \frac{\partial p_i}{\partial \beta} =\sigma'(\eta_i)\,\frac{\partial \eta_i}{\partial\beta} =p_i(1-p_i)\,x_i, $$ যেখানে §৪.১-এর identity \(\sigma'=\sigma(1-\sigma)\) ব্যবহৃত হয়েছে। সুতরাং (একটি observation-এর Hessian হলো outer product \(x_i x_i^\top\)-এর scalar গুণিতক): $$ H(\beta)=\frac{\partial U}{\partial \beta^\top} =\frac{\partial}{\partial\beta^\top}\sum_i(y_i-p_i)x_i =-\sum_{i=1}^{n}x_i\,\frac{\partial p_i}{\partial\beta^\top} =-\sum_{i=1}^{n}p_i(1-p_i)\,x_i x_i^\top. $$ weight \(w_i\equiv p_i(1-p_i)\) এবং diagonal weight matrix \(W=\operatorname{diag}(w_1,\dots,w_n)=\operatorname{diag}\bigl(p_i(1-p_i)\bigr)\) সংজ্ঞায়িত করি। তখন \(\sum_i w_i x_i x_i^\top=X^\top W X\), তাই $$ \boxed{\;H(\beta)=\frac{\partial^2 \ell}{\partial\beta\,\partial\beta^\top}=-X^\top W X,\qquad W=\operatorname{diag}\bigl(p_i(1-p_i)\bigr)\;} $$
Concavity ও MLE-র একত্ব (uniqueness)। যেকোনো nonzero vector \(v\in\mathbb{R}^p\)-এর জন্য quadratic form: $$ v^\top(-H)v=v^\top X^\top W X\,v=(Xv)^\top W (Xv)=\sum_{i=1}^{n}w_i\,(x_i^\top v)^2\ \ge 0, $$ কারণ প্রতিটি \(w_i=p_i(1-p_i)>0\) যখন \(0<p_i<1\) (যা logistic মডেলে সবসময় সত্য, যেহেতু \(\sigma\) কখনো ঠিক \(0\) বা \(1\) ছোঁয় না)। তাই \(-H=X^\top W X\) অন্তত positive semi-definite; এবং যদি \(X\)-এর full column rank থাকে (অর্থাৎ \(Xv\ne 0\) যখন \(v\ne 0\)), তবে যোগফলটি strictly positive, অর্থাৎ \(-H\) positive-definite \(\Rightarrow\) \(H\) negative-definite। ফলে \(\ell(\beta)\) strictly concave। Strictly concave function-এর সর্বোচ্চ বিন্দু (যদি থাকে) একমাত্র — তাই MLE \(\hat\beta\) unique, এবং কোনো local maximum-এ আটকে যাওয়ার আশঙ্কা নেই। (ব্যতিক্রম: perfect separation — যখন কোনো hyperplane দুই শ্রেণিকে নিখুঁত আলাদা করে — তখন MLE \(\pm\infty\)-তে চলে যায়; এই corner case §৬-এ আলোচ্য।)
৪.৪ ★★ এক ধাপ Newton–Raphson এবং IRLS-রূপে ব্যাখ্যা¶
যেহেতু score equation \(X^\top(y-p)=0\) অরৈখিক, আমরা Newton–Raphson দিয়ে iteratively সমাধান করি। স্মরণ করুন (4.3 / সংখ্যাবিশ্লেষণ), \(U(\beta)=0\) সমাধানের Newton update হলো current point-এ \(U\)-কে linearize করে: $$ 0\approx U(\beta^{(t)})+H(\beta^{(t)})\,(\beta^{(t+1)}-\beta^{(t)}) \;\Longrightarrow\; \beta^{(t+1)}=\beta^{(t)}-H^{-1}\,U\big|_{\beta^{(t)}}. $$ এখন \(H=-X^\top W X\) এবং \(U=X^\top(y-p)\) বসাই (সব কিছু \(\beta^{(t)}\)-এ মূল্যায়িত, অর্থাৎ \(p,W\) গণনা হয় \(\beta^{(t)}\) দিয়ে): $$ \boxed{\;\beta^{(t+1)}=\beta^{(t)}+\bigl(X^\top W X\bigr)^{-1}X^\top(y-p)\;} $$ দুটো ঋণচিহ্ন মিলে যোগচিহ্ন হলো (কারণ \(-H^{-1}=+(X^\top WX)^{-1}\))। concavity-র (§৪.৩) কারণে \(X^\top W X\succ 0\), তাই এর inverse বিদ্যমান এবং প্রতিটি Newton step \(\ell\) বাড়ায় — সাধারণত মাত্র ৫–১০ iteration-এই convergence হয় (quadratic convergence)।
IRLS রূপে পুনর্লিখন। এই Newton update আসলে একটি weighted least squares (WLS) সমস্যার সমাধান — এই দৃষ্টিভঙ্গিকে বলে Iteratively Reweighted Least Squares (IRLS)। দেখি কীভাবে। Update-এর ভেতর \(\beta^{(t)}\)-কে টেনে আনি: $$ \beta^{(t+1)}=(X^\top W X)^{-1}\Bigl[(X^\top W X)\beta^{(t)}+X^\top(y-p)\Bigr] =(X^\top W X)^{-1}X^\top W\Bigl[\underbrace{X\beta^{(t)}+W^{-1}(y-p)}_{\displaystyle z}\Bigr]. $$ এখানে আমরা \(X^\top(y-p)=X^\top W\,W^{-1}(y-p)\) লিখে \(X^\top W\) বাইরে নিয়েছি। সংজ্ঞায়িত করি working response (adjusted dependent variable): $$ z=X\beta^{(t)}+W^{-1}(y-p), \qquad\text{অর্থাৎ}\quad z_i=\eta_i^{(t)}+\frac{y_i-p_i}{p_i(1-p_i)}. $$ তখন update দাঁড়ায়: $$ \boxed{\;\beta^{(t+1)}=\bigl(X^\top W X\bigr)^{-1}X^\top W z\;} $$ এটি ঠিক weighted least squares-এর normal equation: response \(z\), design \(X\), weight \(W\) দিয়ে \(\sum_i w_i (z_i-x_i^\top\beta)^2\) minimize করার সমাধান (তুলনা করুন 5.1-এর WLS: \(\hat\beta=(X^\top W X)^{-1}X^\top W z\))। পার্থক্য শুধু — এখানে \(z\) ও \(W\) প্রতিটি iteration-এ বর্তমান \(\beta^{(t)}\) থেকে পুনর্গণনা হয়, তাই নাম "iteratively reweighted"।
স্বজ্ঞা। Working response \(z_i=\eta_i^{(t)}+\frac{y_i-p_i}{p_i(1-p_i)}\) হলো current linear predictor \(\eta_i\)-এর উপর residual \((y_i-p_i)\)-এর একটি linearized সংশোধন — \(\frac{1}{p_i(1-p_i)}=\frac{d\eta}{dp}\) হলো link-এর local slope, যা probability-scale residual-কে logit-scale-এ রূপান্তর করে। আর weight \(w_i=p_i(1-p_i)\) বেশি (অর্থাৎ \(p_i\approx\tfrac12\), সবচেয়ে অনিশ্চিত observation) সেখানে fit বেশি গুরুত্ব দেয়, আর \(p_i\approx0\) বা \(1\) (নিশ্চিত observation) সেখানে weight প্রায় শূন্য। এভাবে অরৈখিক MLE সমস্যা ভেঙে যায় পরপর কতগুলো linear WLS সমস্যায় — এটিই GLM fitting-এর একীভূত algorithm (R-এর glm() ভেতরে এটিই চালায়)।
৪.৫ ★★ Inference: Fisher information, Wald test, এবং deviance/LR test¶
Fisher information. 4.3 থেকে, observed information হলো \(-H\), আর expected (Fisher) information হলো \(\mathcal{I}(\beta)=-\mathbb{E}[H]\)। এখানে \(H=-X^\top W X\), যেখানে \(W=\operatorname{diag}(p_i(1-p_i))\) কেবল \(\beta\) ও fixed \(x_i\)-এর উপর নির্ভর করে, \(y_i\)-এর উপর নয় — অর্থাৎ \(H\) random নয় (given \(X\))। তাই expectation নিলে কিছু বদলায় না: $$ \boxed{\;\mathcal{I}(\beta)=-\mathbb{E}[H]=X^\top W X\;} $$ (এটিই কারণ — canonical link-এ Newton–Raphson আর Fisher scoring অভিন্ন: observed ও expected information সমান হওয়ায় দুই algorithm একই update দেয়।) বিকল্পভাবে, exponential family-র সাধারণ ফলাফল \(\operatorname{Var}\!\big(\partial\ell_i/\partial\eta_i\big)=A''(\eta_i)=p_i(1-p_i)\) থেকেও একই \(\mathcal{I}=X^\top W X\) আসে।
Asymptotic distribution of \(\hat\beta\). MLE-র সাধারণ asymptotic তত্ত্ব (4.3) অনুযায়ী, regularity conditions-এ $$ \boxed{\;\hat\beta\ \stackrel{\cdot}{\sim}\ \mathcal{N}!\Bigl(\beta,\ \mathcal{I}(\beta)^{-1}\Bigr)=\mathcal{N}!\Bigl(\beta,\ (X^\top W X)^{-1}\Bigr)\;} $$ অর্থাৎ \(\hat\beta\) asymptotically unbiased, normal, এবং তার covariance হলো inverse Fisher information (Cramér–Rao bound অর্জন করে — MLE asymptotically efficient)। প্রায়োগিক ক্ষেত্রে \(\beta\) অজানা, তাই \(W\) মূল্যায়ন করি \(\hat\beta\)-তে: \(\widehat{W}=\operatorname{diag}\big(\hat p_i(1-\hat p_i)\big)\), এবং estimated covariance \(\widehat{\operatorname{Cov}}(\hat\beta)=(X^\top \widehat{W} X)^{-1}\)। এর diagonal-এর বর্গমূল হলো standard error: $$ \mathrm{SE}(\hat\beta_j)=\sqrt{\bigl[(X^\top \widehat{W} X)^{-1}\bigr]_{jj}}. $$
Wald test। কোনো একক coefficient-এর জন্য \(H_0:\beta_j=0\) (covariate \(x_j\)-এর কোনো প্রভাব নেই) পরীক্ষা করতে asymptotic normality ব্যবহার করে Wald statistic (cf. 4.7): $$ \boxed{\;z_j=\frac{\hat\beta_j}{\mathrm{SE}(\hat\beta_j)}\ \stackrel{\cdot}{\sim}\ \mathcal{N}(0,1)\ \text{under }H_0\;} $$ অথবা সমতুল্যভাবে \(z_j^2\stackrel{\cdot}{\sim}\chi^2_1\)। বড় \(\lvert z_j\rvert\) (অর্থাৎ ছোট \(p\)-value) \(H_0\) প্রত্যাখ্যান করে। \(\beta_j\)-এর approximate \((1-\alpha)\) confidence interval: \(\hat\beta_j\pm z_{1-\alpha/2}\,\mathrm{SE}(\hat\beta_j)\); এর দুই প্রান্ত exponentiate করলে odds ratio \(e^{\beta_j}\)-এর CI পাওয়া যায় (§৪.১-এর odds\(=e^\eta\) ব্যাখ্যা অনুযায়ী)।
Deviance এবং Likelihood-Ratio test। Logistic regression-এ goodness-of-fit ও model comparison-এর কেন্দ্রীয় পরিমাপ হলো deviance: $$ D=-2\,\ell(\hat\beta). $$ (আরও সঠিকভাবে, residual deviance হলো saturated model-এর সাপেক্ষে: \(D=2\bigl[\ell_{\text{sat}}-\ell(\hat\beta)\bigr]\); binary data-তে \(\ell_{\text{sat}}=0\) যখন প্রতিটি \(\hat p_i=y_i\), তাই \(D=-2\ell(\hat\beta)\)।) এর ভূমিকা ঠিক linear regression-এর residual sum of squares-এর সমতুল্য — যত ছোট, তত ভালো fit।
দুটি nested model তুলনা করতে (model 0 ⊂ model 1, ধরা যাক \(q\)টি অতিরিক্ত parameter) likelihood-ratio (LR) test ব্যবহার করি (4.7)। দুই model-এর deviance-এর পার্থক্যই হলো test statistic: $$ \boxed{\;G^{2}=D_0-D_1=-2\bigl[\ell_0-\ell_1\bigr]=2\bigl[\ell(\hat\beta_1)-\ell(\hat\beta_0)\bigr]\ \stackrel{\cdot}{\sim}\ \chi^{2}_{q}\ \text{under }H_0\;} $$ যেখানে \(\ell_0=\ell(\hat\beta_0)\) হলো restricted (ছোট) model-এর সর্বোচ্চ log-likelihood, \(\ell_1\) full model-এর, এবং \(q\) হলো parameter-সংখ্যার পার্থক্য (degrees of freedom)। বড় \(G^2\) মানে অতিরিক্ত predictor গুলো fit উল্লেখযোগ্য উন্নত করেছে \(\Rightarrow\) \(H_0\) প্রত্যাখ্যান। বিশেষ ক্ষেত্রে intercept-only null model \(\ell_0\)-র বিরুদ্ধে full model-এর test হলো overall model significance (linear regression-এর overall \(F\)-test-এর GLM-সংস্করণ)।
Wald বনাম LR: ছোট sample-এ LR test সাধারণত বেশি নির্ভরযোগ্য (invariant under reparameterization, এবং separation-এর প্রতি কম সংবেদনশীল); Wald কেবল একটি fit থেকেই দ্রুত হিসাব করা যায় বলে সুবিধাজনক। দুটোই asymptotically সমতুল্য।
৪.৬ ★ GLM সাধারণীকরণ: তিন উপাদান এবং পরবর্তী সংযোগ¶
এতক্ষণ যা করলাম তা একটি অনেক বড় কাঠামোর একটি দৃষ্টান্তমাত্র — Generalized Linear Model (GLM)। Nelder ও Wedderburn (১৯৭২)-এর এই একীভূত তত্ত্ব linear regression, logistic regression, Poisson regression প্রভৃতিকে একই ছাতার নিচে আনে। প্রতিটি GLM তিনটি উপাদান দিয়ে সংজ্ঞায়িত:
-
Random component (random/distributional অংশ) — response \(y_i\) একটি exponential-family distribution অনুসরণ করে, যার mean \(\mu_i=\mathbb{E}[y_i\mid x_i]\)। (logistic-এ: Bernoulli, \(\mu_i=p_i\)।) এই অংশই variance structure ঠিক করে: exponential family-তে \(\operatorname{Var}(y_i)=A''(\eta_i)=V(\mu_i)\) — variance mean-এর একটি ফাংশন (Bernoulli-তে \(V(\mu)=\mu(1-\mu)\))।
-
Systematic component — covariate গুলো একটি linear predictor-এর মাধ্যমে প্রবেশ করে: $$ \eta_i=x_i^\top\beta=\beta_0+\beta_1 x_{i1}+\dots+\beta_{p-1}x_{i,p-1}. $$ এই অংশ সব GLM-এ অভিন্ন — সর্বদা linear in \(\beta\)।
-
Link function — mean আর linear predictor-কে যুক্ত করে একটি monotone, differentiable function \(g\): $$ g(\mu_i)=\eta_i,\qquad\text{সমতুল্যভাবে}\quad \mu_i=g^{-1}(\eta_i). $$ Link-ই হলো GLM-এর "জোড়": এটি bounded mean (\(\mu_i\in[0,1]\) Bernoulli-তে) আর unbounded linear predictor (\(\eta_i\in\mathbb{R}\))-এর মধ্যে সেতু গড়ে।
Logistic = Bernoulli + canonical logit link। এই তিন উপাদানে আমাদের মডেলকে বসালে: $$ \text{random: } y_i\sim\text{Bernoulli}(p_i), \qquad \text{systematic: } \eta_i=x_i^\top\beta, \qquad \text{link: } g(p)=\log\frac{p}{1-p}=\eta. $$ এখানে logit link দৈবচয়ন নয় — এটি Bernoulli-র canonical (natural) link, কারণ §৪.২-এ দেখেছি logit ঠিক natural parameter \(\eta\)-কে দেয় (\(\theta=\eta\), link \(g=\theta(\mu)\))। Canonical link বেছে নিলেই score-এর সুন্দর রূপ \(X^\top(y-p)=0\), observed = expected information, এবং Newton = Fisher scoring — এই সব সরলতা পাওয়া যায়। (Logistic-এর জন্য অন্য link-ও সম্ভব, যেমন probit \(g=\Phi^{-1}\) বা complementary log-log; কিন্তু logit-ই canonical ও সবচেয়ে ব্যবহৃত।)
একই কাঠামো, ভিন্ন distribution — পরবর্তী ধাপের সেতু। এই তিন-উপাদান টেমপ্লেটের সৌন্দর্য: distribution আর link বদলেই নতুন মডেল পাওয়া যায়, কিন্তু fitting (IRLS, §৪.৪) ও inference (Fisher information, Wald, deviance, §৪.৫) প্রায় হুবহু একই থাকে। নিচের সারণি তিনটি কেন্দ্রীয় GLM-এর তুলনা:
| Component | Linear (5.1) | Logistic (5.4) | Poisson (5.5) |
|---|---|---|---|
| Random | \(\mathcal{N}(\mu,\sigma^2)\) | \(\text{Bernoulli}(p)\) | \(\text{Poisson}(\lambda)\) |
| Mean \(\mu\) | \(\mu\in\mathbb{R}\) | \(p\in(0,1)\) | \(\lambda>0\) |
| Canonical link \(g(\mu)\) | identity: \(\mu\) | logit: \(\log\frac{\mu}{1-\mu}\) | log: \(\log\mu\) |
| Variance \(V(\mu)\) | \(1\) (constant) | \(\mu(1-\mu)\) | \(\mu\) |
| Score | \(X^\top(y-\hat y)=0\) | \(X^\top(y-p)=0\) | \(X^\top(y-\lambda)=0\) |
লক্ষ করুন তিন কলামেই score-এর গঠন একই: \(X^\top(y-\hat\mu)=0\) — fitted mean residual predictor-space-এ orthogonal। কেবল \(\hat\mu\) আর \(W=\operatorname{diag}(V(\mu_i))\)-এর সূত্র বদলায়। 5.5-এ Poisson regression ঠিক এই কাঠামোতেই গড়া হবে: random = Poisson, canonical link = log (\(\eta=\log\lambda\), তাই \(\lambda=e^{\eta}\) সবসময় ধনাত্মক — count data-র জন্য আদর্শ), variance \(V(\mu)=\mu\) (mean = variance, Poisson-এর স্বাক্ষর)। এই অংশে গড়া sigmoid–logit–score–IRLS–deviance যন্ত্রপাতি সেখানে প্রায় বিনা পরিবর্তনে পুনর্ব্যবহৃত হবে — কেবল \(\sigma\)-এর জায়গায় \(\exp\), আর \(p(1-p)\)-এর জায়গায় \(\lambda\)। এটিই GLM-এর একীভূত শক্তি।
সারসংক্ষেপ (★). Logistic regression = Bernoulli random component + linear systematic component + canonical logit link। MLE solve হয় score equation \(X^\top(y-p)=0\) থেকে (অরৈখিক, তাই closed-form নেই), iteratively IRLS/Newton দিয়ে: \(\beta^{(t+1)}=\beta^{(t)}+(X^\top W X)^{-1}X^\top(y-p)\)। Inference আসে Fisher information \(\mathcal{I}=X^\top W X\) থেকে — Wald \(z_j=\hat\beta_j/\mathrm{SE}_j\) এবং deviance-ভিত্তিক LR test \(G^2\sim\chi^2\)। সবটাই GLM কাঠামোর একটি দৃষ্টান্ত, যা পরের অধ্যায়ে Poisson-এ সম্প্রসারিত হবে।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা logistic regression-কে দুই দিক থেকে দাঁড় করাব। প্রথমে স্ক্র্যাচ থেকে — sigmoid, log-likelihood, gradient ও Hessian নিজ হাতে লিখে Newton–Raphson / IRLS দিয়ে \(\hat{\boldsymbol\beta}\) বের করব। তারপর সেই ফল মিলিয়ে নেব statsmodels-এর সঙ্গে, এবং sklearn দিয়ে classification (শ্রেণিবিন্যাস) যাচাই করব। মূল উদ্দেশ্য একটাই: maximum likelihood estimate-এর পেছনের যন্ত্রটা যেন কালো বাক্স না থাকে।
ডেটাসেটটি কৃত্রিম — hours (পড়ার ঘণ্টা) ও attend (উপস্থিতির শতাংশ) থেকে একজন শিক্ষার্থী পাশ করবে কি না (passed, 0/1) তার log-odds তৈরি করা হয়েছে \(\eta = -6.0 + 0.9\,\text{hours} + 0.04\,\text{attend}\) সূত্রে, তারপর \(p=\sigma(\eta)\) থেকে Bernoulli নমুনা টানা হয়েছে। অর্থাৎ "সত্যিকারের" coefficient আমরা আগে থেকেই জানি, ফলে estimation কতটা কাছাকাছি পৌঁছায় তা সরাসরি দেখা যাবে।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# -*- coding: utf-8 -*-
# Chapter 5.4 — GLM: Logistic Regression — Code Lab
import numpy as np, pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
from sklearn.metrics import (confusion_matrix, accuracy_score,
precision_score, recall_score, roc_auc_score)
np.set_printoptions(precision=4, suppress=True)
# ----------------------------------------------------------------------
# DATASET
# ----------------------------------------------------------------------
rng = np.random.default_rng(20260619); n = 200
hours = rng.uniform(0, 10, n); attend = rng.uniform(40, 100, n)
eta = -6.0 + 0.9*hours + 0.04*attend
p = 1/(1+np.exp(-eta)); passed = rng.binomial(1, p)
df = pd.DataFrame({'passed': passed, 'hours': hours, 'attend': attend})
print("="*64)
print("DATASET overview")
print("="*64)
print("shape:", df.shape)
print("pass rate:", round(df['passed'].mean(), 4),
f"({int(df['passed'].sum())}/{n})")
print(df.head())
# ----------------------------------------------------------------------
# PART 1 — from-scratch logistic regression via Newton–Raphson / IRLS
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 1 — From scratch: Newton–Raphson / IRLS")
print("="*64)
def sigmoid(z):
# numerically stable logistic
return np.where(z >= 0, 1/(1+np.exp(-z)),
np.exp(z)/(1+np.exp(z)))
# design matrix with intercept column
X = np.column_stack([np.ones(n), df['hours'].values, df['attend'].values])
y = df['passed'].values.astype(float)
def loglik(beta):
z = X @ beta
# log-likelihood: sum[ y*z - log(1+e^z) ] (stable via logaddexp)
return np.sum(y*z - np.logaddexp(0.0, z))
beta = np.zeros(X.shape[1]) # start at 0
print(f"{'iter':>4} {'b0':>10} {'b_hours':>10} {'b_attend':>10} {'loglik':>12}")
for it in range(1, 11):
pi = sigmoid(X @ beta) # fitted probabilities
grad = X.T @ (y - pi) # gradient X^T (y - p)
W = pi*(1-pi) # weights
H = -(X.T * W) @ X # Hessian -X^T W X
step = np.linalg.solve(H, grad) # Newton step: H^{-1} grad
beta = beta - step # update (minus because H negative def.)
print(f"{it:>4} {beta[0]:>10.4f} {beta[1]:>10.4f} "
f"{beta[2]:>10.4f} {loglik(beta):>12.4f}")
# standard errors from observed information (-H)^{-1}
covb = np.linalg.inv(-H)
se = np.sqrt(np.diag(covb))
print()
print("Converged beta_hat (scratch):", beta)
print("Std. errors (scratch):", se)
print("Final log-likelihood (scratch):", round(loglik(beta), 4))
# ----------------------------------------------------------------------
# PART 2 — statsmodels Logit
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 2 — statsmodels Logit (MLE)")
print("="*64)
model = smf.logit('passed ~ hours + attend', df).fit(disp=False)
print(model.summary())
print()
print("Match check (scratch vs statsmodels):")
print(" scratch beta_hat :", np.round(beta, 4))
print(" statsmodels params :", np.round(model.params.values, 4))
print(" max abs difference :", np.max(np.abs(beta - model.params.values)))
print()
print("Odds ratios exp(beta):")
orr = np.exp(model.params)
for name, val in orr.items():
print(f" {name:>10}: {val:.4f}")
# attendance OR for a +10 percentage-point change
print(f" attend per +10 points: {np.exp(model.params['attend']*10):.4f}")
print()
print(f"Pseudo R-squared (McFadden): {model.prsquared:.4f}")
print(f"Log-likelihood : {model.llf:.4f} Null LL: {model.llnull:.4f}")
print(f"LLR p-value : {model.llr_pvalue:.3e}")
# deviance = -2 * loglik
print(f"Deviance (-2*LL): {(-2*model.llf):.4f}")
# ----------------------------------------------------------------------
# PART 3 — prediction + classification
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 3 — Prediction & classification (threshold 0.5)")
print("="*64)
phat = model.predict(df) # predicted probabilities
yhat = (phat >= 0.5).astype(int) # 0.5 threshold
cm = confusion_matrix(y, yhat)
acc = accuracy_score(y, yhat)
prec = precision_score(y, yhat)
rec = recall_score(y, yhat)
auc = roc_auc_score(y, phat)
print("Confusion matrix [rows=true 0/1, cols=pred 0/1]:")
print(cm)
print(f"Accuracy : {acc:.4f}")
print(f"Precision: {prec:.4f}")
print(f"Recall : {rec:.4f}")
print(f"ROC AUC : {auc:.4f}")
# ----------------------------------------------------------------------
# PART 4 — single prediction: hours=5, attend=75
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 4 — Single prediction (hours=5, attend=75)")
print("="*64)
b0, b1, b2 = model.params['Intercept'], model.params['hours'], model.params['attend']
eta_new = b0 + b1*5 + b2*75
p_new = 1/(1+np.exp(-eta_new))
print(f"eta = {b0:.4f} + {b1:.4f}*5 + {b2:.4f}*75 = {eta_new:.4f}")
print(f"p(pass) = sigmoid(eta) = {p_new:.4f}")
৫.২ · কোডের গঠন: চারটি অংশ¶
PART 1 — স্ক্র্যাচ থেকে IRLS। logistic regression-এ closed-form সমাধান নেই (linear regression-এর মতো \((X^\top X)^{-1}X^\top y\) পাওয়া যায় না), কারণ score equation \(X^\top(\mathbf y - \mathbf p)=\mathbf 0\) এ \(\mathbf p\) নিজেই \(\boldsymbol\beta\)-এর nonlinear function। তাই আমরা Newton–Raphson চালাই। প্রতি ধাপে দরকার দুটো জিনিস:
যেখানে \(W = \operatorname{diag}\bigl(p_i(1-p_i)\bigr)\) একটা diagonal weight matrix। কোডে W = pi*(1-pi) একটা vector, আর H = -(X.T * W) @ X সেই vector দিয়ে \(X\)-এর row scale করে \(-X^\top W X\) তৈরি করে — পুরো \(n\times n\) diagonal matrix বানানোর দরকার পড়ে না। Newton update হলো \(\boldsymbol\beta^{(t+1)} = \boldsymbol\beta^{(t)} - H^{-1}\nabla\ell\); এখানে np.linalg.solve(H, grad) সরাসরি \(H^{-1}\nabla\ell\) হিসাব করে (inverse আলাদা করে বের করার চেয়ে সংখ্যাগতভাবে নিরাপদ)। যেহেতু \(H\) negative-definite, এই update-ই log-likelihood বাড়ায়। ঠিক এই কারণেই একে IRLS (Iteratively Reweighted Least Squares) বলা হয় — প্রতি iteration আসলে নতুন weight \(W\) নিয়ে একটা weighted least-squares সমস্যার সমাধান।
সংখ্যাগত স্থিতিশীলতা (numerical stability)।
sigmoid-এ আমরা \(z\ge 0\) ও \(z<0\) ভাগে ভাগ করেছি যাতে \(\exp\) overflow না করে; আর log-likelihood-এ \(\log(1+e^z)\)-এর বদলেnp.logaddexp(0, z)ব্যবহার করেছি, যা বড় \(\lvert z\rvert\)-এও নিরাপদ। এগুলো logistic regression লেখার সময় ছোট কিন্তু জরুরি অভ্যাস।
PART 2 — statsmodels। smf.logit('passed ~ hours + attend', df) formula-interface দিয়ে intercept স্বয়ংক্রিয়ভাবে যোগ করে এবং .fit() ভেতরে একই Newton-ধরনের optimizer চালিয়ে MLE বের করে। আমরা .summary() ছাপি — coefficient, standard error, \(z\)-stat, \(p\)-value, pseudo-\(R^2\), log-likelihood সব এক জায়গায়। তারপর np.exp(model.params) দিয়ে odds ratio বের করি, এবং স্ক্র্যাচের \(\hat{\boldsymbol\beta}\)-র সঙ্গে মিলিয়ে নিই।
PART 3 — classification। model.predict(df) প্রতিটি সারির জন্য \(\hat p\) দেয়। 0.5 threshold দিয়ে আমরা class label বানাই, তারপর sklearn দিয়ে confusion matrix, accuracy, precision, recall হিসাব করি। AUC বের করি roc_auc_score-এ — লক্ষণীয়, AUC-তে threshold লাগে না, কারণ এটি ranking-quality মাপে (সম্ভাব্যতা \(\hat p\) সরাসরি দিতে হয়, label নয়)।
PART 4 — একক পূর্বাভাস। একজন নতুন শিক্ষার্থী যে ৫ ঘণ্টা পড়ে ও ৭৫% উপস্থিত — তার \(\eta\) ও \(p\) হাতে-কলমে বসিয়ে দেখাই, যাতে coefficient → log-odds → probability শৃঙ্খলটা স্পষ্ট হয়।
৫.৩ · আউটপুট¶
================================================================
DATASET overview
================================================================
shape: (200, 3)
pass rate: 0.62 (124/200)
passed hours attend
0 1 5.438988 90.767972
1 1 9.488079 43.435687
2 1 4.512806 69.649486
3 1 7.107940 89.260557
4 1 7.539280 78.940964
================================================================
PART 1 — From scratch: Newton–Raphson / IRLS
================================================================
iter b0 b_hours b_attend loglik
1 -3.4388 0.4889 0.0217 -77.6005
2 -5.2029 0.7475 0.0334 -69.1543
3 -6.1096 0.8885 0.0392 -67.9578
4 -6.3120 0.9211 0.0404 -67.9166
5 -6.3204 0.9224 0.0405 -67.9165
6 -6.3204 0.9224 0.0405 -67.9165
7 -6.3204 0.9224 0.0405 -67.9165
8 -6.3204 0.9224 0.0405 -67.9165
9 -6.3204 0.9224 0.0405 -67.9165
10 -6.3204 0.9224 0.0405 -67.9165
Converged beta_hat (scratch): [-6.3204 0.9224 0.0405]
Std. errors (scratch): [1.1732 0.1239 0.0128]
Final log-likelihood (scratch): -67.9165
================================================================
PART 2 — statsmodels Logit (MLE)
================================================================
Logit Regression Results
==============================================================================
Dep. Variable: passed No. Observations: 200
Model: Logit Df Residuals: 197
Method: MLE Df Model: 2
Date: Fri, 19 Jun 2026 Pseudo R-squ.: 0.4886
Time: 22:11:24 Log-Likelihood: -67.916
converged: True LL-Null: -132.81
Covariance Type: nonrobust LLR p-value: 6.545e-29
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -6.3204 1.173 -5.387 0.000 -8.620 -4.021
hours 0.9224 0.124 7.443 0.000 0.680 1.165
attend 0.0405 0.013 3.165 0.002 0.015 0.066
==============================================================================
Match check (scratch vs statsmodels):
scratch beta_hat : [-6.3204 0.9224 0.0405]
statsmodels params : [-6.3204 0.9224 0.0405]
max abs difference : 3.552713678800501e-15
Odds ratios exp(beta):
Intercept: 0.0018
hours: 2.5154
attend: 1.0413
attend per +10 points: 1.4988
Pseudo R-squared (McFadden): 0.4886
Log-likelihood : -67.9165 Null LL: -132.8128
LLR p-value : 6.545e-29
Deviance (-2*LL): 135.8330
================================================================
PART 3 — Prediction & classification (threshold 0.5)
================================================================
Confusion matrix [rows=true 0/1, cols=pred 0/1]:
[[ 61 15]
[ 14 110]]
Accuracy : 0.8550
Precision: 0.8800
Recall : 0.8871
ROC AUC : 0.9236
================================================================
PART 4 — Single prediction (hours=5, attend=75)
================================================================
eta = -6.3204 + 0.9224*5 + 0.0405*75 = 1.3266
p(pass) = sigmoid(eta) = 0.7903
৫.৪ · পাঠোদ্ধার (read-off)¶
(ক) IRLS দ্রুত মেশে এবং MLE-ই বের করে। \(\boldsymbol\beta=\mathbf 0\) থেকে শুরু করে মাত্র ৫ iteration-এই \(\hat{\boldsymbol\beta}\) স্থির — log-likelihood \(-77.60 \to -69.15 \to -67.96 \to -67.92\) ক্রমে দ্রুত ওপরে উঠে থেমে যায়। এটাই Newton–Raphson-এর quadratic convergence-এর স্বাক্ষর: optimum-এর কাছে প্রতি ধাপে সঠিক অঙ্কসংখ্যা মোটামুটি দ্বিগুণ হয়।
(খ) স্ক্র্যাচ ≡ statsmodels। আমাদের হাতে-লেখা \(\hat{\boldsymbol\beta} = [-6.3204,\ 0.9224,\ 0.0405]\) এবং statsmodels-এর মান হুবহু এক — max abs difference ≈ 3.6e-15, অর্থাৎ machine precision। standard error-ও মেলে: \(\mathrm{SE} = (1.173,\ 0.124,\ 0.0128)\), যা আমরা observed information \((-H)^{-1}\)-এর diagonal থেকে পেয়েছি — ঠিক যেমন statsmodels দেয়। এতেই বোঝা যায় library-টা কোনো জাদু করছে না, একই IRLS চালাচ্ছে।
(গ) coefficient ও odds ratio। তিনটি coefficient-ই সংখ্যাগতভাবে তাৎপর্যপূর্ণ (significant): \(z = -5.39,\ 7.44,\ 3.17\) এবং সব \(p<0.01\)। ব্যাখ্যা odds- এর ভাষায় —
- hours: \(e^{0.9224} = 2.52\) — পড়ার সময় ১ ঘণ্টা বাড়লে পাশের odds প্রায় ২.৫ গুণ।
- attend: \(e^{0.04047}=1.041\) প্রতি ১ শতাংশে; ১০ শতাংশ বাড়লে \(e^{0.4047}=1.50\), অর্থাৎ odds প্রায় দেড় গুণ।
লক্ষণীয়, এই estimate "সত্যিকারের" generating coefficient \((-6.0,\ 0.9,\ 0.04)\)-এর খুব কাছাকাছি — ২০০ নমুনায় MLE মূল মান ভালোভাবেই উদ্ধার করেছে।
(ঘ) মডেল কতটা ভালো। \(\text{LL-Null}=-132.81\) থেকে \(\ell=-67.92\)-তে নামা মানে predictor-গুলো সত্যিই কাজ করছে; pseudo-\(R^2_{\text{McFadden}} = 1 - \ell/\ell_0 = 0.489\), এবং likelihood-ratio test-এর \(p = 6.5\times10^{-29}\) — null model (শুধু intercept) চূড়ান্তভাবে বাতিল। Deviance \(= -2\ell = 135.83\)।
(ঙ) শ্রেণিবিন্যাস (0.5 threshold)। confusion matrix \(\begin{pmatrix}61 & 15\\ 14 & 110\end{pmatrix}\) থেকে accuracy \(=\frac{61+110}{200}=0.855\), precision \(=0.880\), recall \(=0.887\)। ROC AUC \(=0.924\) — threshold-নিরপেক্ষ এই মান দেখায় মডেলটি পাশ ও ফেল শ্রেণিকে চমৎকারভাবে আলাদা করতে পারে (একজন এলোমেলো পাশ-করা শিক্ষার্থীকে এলোমেলো ফেল-করা শিক্ষার্থীর চেয়ে বেশি \(\hat p\) দেওয়ার সম্ভাবনা ৯২%)।
(চ) একক পূর্বাভাস। hours \(=5\), attend \(=75\)-এ \(\eta = -6.3204 + 0.9224(5) + 0.04047(75) = 1.327\), তাই \(p = \sigma(1.327) = 0.790\)। অর্থাৎ এই শিক্ষার্থীর পাশের সম্ভাবনা প্রায় ৭৯% — \(\eta>0\) হওয়ায় \(p>0.5\), এবং 0.5 threshold-এ সে "পাশ" শ্রেণিতে পড়বে। এটাই coefficient → log-odds → probability পুরো শৃঙ্খলের একটিমাত্র সংখ্যায় সারসংক্ষেপ।
মূল পাঠ। logistic regression-এর fit মানে log-likelihood-কে Newton–Raphson/IRLS দিয়ে maximize করা; হাতে-লেখা কোড আর
statsmodelsএকই উত্তর দেয় বলে library-র ভেতরটা আর রহস্য নয়। মডেলের মান odds ratio-তে পড়তে হয়, আর তার classification-ক্ষমতা threshold-নির্ভর (accuracy/confusion) ও threshold-নিরপেক্ষ (AUC) — দুই চোখেই দেখা উচিত।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটিমাত্র স্ক্রিপ্ট
_code/figs_5-4.py-তে তৈরি; PNG_assets/-এ (prefix5-4, dpi=150)। in-figure সব লেখা ইংরেজিতে (matplotlib-এ Bengali-font rendering সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। সব ছবি একই synthetic exam-pass dataset থেকে (\(n=200\) শিক্ষার্থী; দুটি predictor —hours\(\sim \text{Uniform}(0,10)\) পড়ার ঘণ্টা, আরattend\(\sim \text{Uniform}(40,100)\) উপস্থিতি-শতাংশ; সত্যিকারের linear predictor \(\eta=-6.0+0.9\,\text{hours}+0.04\,\text{attend}\), এরপর \(p=\sigma(\eta)\) আরpassed\(\sim \text{Bernoulli}(p)\))। এই data-তেLogit('passed ~ hours + attend')fit করে পাওয়া \(\hat\beta=[-6.320,\ 0.9224,\ 0.04047]\), যার AUC \(=0.924\) আর accuracy \(=0.855\) — নিচের সব ছবিতে এই ফিট-করা সংখ্যাগুলোই ব্যবহৃত। প্রতিটি ছবির আসল plotting-code-ও দেওয়া আছে, যাতে আপনি হুবহু পুনরুৎপাদন করতে পারেন।
logistic regression-এর গাণিতিক কঙ্কালটা §২–§৫-এ দাঁড় করানো হয়েছে — কেন 0/1 outcome-এ সরলরেখা (OLS) খাটে না, logit link \(\log\frac{p}{1-p}=\eta\) আর তার বিপরীত sigmoid \(\sigma(\eta)=\frac{1}{1+e^{-\eta}}\), coefficient-গুলোর log-odds / odds-ratio ব্যাখ্যা, maximum likelihood দিয়ে \(\hat\beta\) আঁদাজ, আর শেষে threshold বসিয়ে শ্রেণিবিভাজন ও তার মূল্যায়ন (confusion matrix, ROC, AUC)। কিন্তু এই সব ধারণা জীবন্ত হয়ে ওঠে তখনই, যখন আমরা সেগুলোকে চোখে দেখি। এই বিভাগে চারটি ছবি দিয়ে logistic regression-এর চারটি কেন্দ্রীয় প্রশ্ন ধরা হয়েছে: (১) কেন সরলরেখা নয়, S-curve — sigmoid-এর আকৃতি বনাম binary data-তে OLS-এর \([0,1]\) ছাড়িয়ে যাওয়া (Figure 1); (২) probability কীভাবে predictor-এর সাথে বাড়ে — fit-করা \(\hat P(\text{pass})\) S-curve, পড়ার ঘণ্টার সাপেক্ষে (Figure 2); (৩) classifier-টা কতটা ভালো ranks করে — ROC curve আর AUC (Figure 3); আর (৪) সিদ্ধান্ত-রেখাটা দেখতে কেমন — predictor-space-এ \(p=0.5\) decision boundary (Figure 4)। প্রথম ছবি কেন logistic-ই দরকার, দ্বিতীয়টি model কী predict করছে, তৃতীয়টি সেই prediction কতটা নির্ভরযোগ্য, আর শেষটি কোথায় গিয়ে "pass" আর "fail" আলাদা হয় — চার কোণ থেকে একই model-কে দেখা।
Figure 1 — sigmoid বনাম সরলরেখা: কেন 0/1-এ OLS খাটে না?¶
একদম শুরুর ছবি — logistic regression-এর গোটা অস্তিত্বের কারণটাই চোখে দেখায়, দুই প্যানেলে। বাঁ প্যানেল নিছক গাণিতিক logistic (sigmoid) function \(\sigma(\eta)=\frac{1}{1+e^{-\eta}}\) আঁকে \(\eta\in[-8,8]\) জুড়ে: একটা মসৃণ S-আকৃতির নীল curve, যা \(\eta\to-\infty\)-তে \(0\)-এ আর \(\eta\to+\infty\)-তে \(1\)-এ গিয়ে চ্যাপ্টা হয় (দুটো ধূসর dotted asymptote-রেখা), আর \(\eta=0\)-তে ঠিক \(0.5\) ছুঁয়ে যায় (কমলা বিন্দু ও cross-hair)। এটাই সেই "squashing" — যেকোনো বাস্তব সংখ্যা \(\eta\)-কে একটা বৈধ probability \((0,1)\)-তে চেপে আনা। ডান প্যানেল ঠিক একই binary data-তে (passed বনাম hours, দৃশ্যমানতার জন্য jitter করা) দুটো প্রতিদ্বন্দ্বী fit তুলনা করে: লাল সরলরেখা হলো naive OLS (least-squares) fit, আর নীল S-curve হলো logistic fit। যা লক্ষ করতে হবে: (ক) বাঁ প্যানেলে sigmoid কখনোই \(0\)-র নিচে বা \(1\)-র উপরে যায় না — গঠনগতভাবেই (by construction) এটা সবসময় বৈধ probability দেয়। (খ) ডান প্যানেলে লাল OLS-রেখা সোজা, তাই বড় hours-এ সেটা \(1\) ছাড়িয়ে উপরে আর ছোট hours-এ \(0\)-র নিচে নেমে যায় (লাল ছায়া-অঞ্চল দুটো এই "অসম্ভব" পূর্বাভাস চিহ্নিত করে) — অথচ probability \(1\)-এর বেশি বা \(0\)-র কম হতে পারে না, এটাই OLS-এর মৌলিক ব্যর্থতা। (গ) নীল logistic S-curve একই data-তে সুন্দরভাবে \([0,1]\)-এর ভেতরে থাকে এবং প্রান্তে (data-র নিচের ও উপরের মেঘে) আরও ভালো বসে — কারণ এটা বাস্তবেই probability হিসেবে আচরণ করে। (ঘ) মূল শিক্ষা: 0/1 outcome-এ আমরা সরাসরি \(y\)-কে নয়, \(y=1\) হওয়ার probability-কে model করি, আর সেই probability-কে \([0,1]\)-এ বেঁধে রাখতেই sigmoid link — logistic regression মানে আসলে "একটা সরলরেখা \(\eta\), তারপর তাকে sigmoid দিয়ে probability-তে রূপান্তর"।
z = np.linspace(-8, 8, 400)
axL.plot(z, sigmoid(z), color=BLUE, lw=2.6) # the S-curve
axL.axhline(0.5, ls="--"); axL.axvline(0, ls="--") # sigma(0)=0.5
# RIGHT: naive OLS straight line vs logistic, on the SAME 0/1 data
coef, *_ = np.linalg.lstsq(np.vstack([np.ones(n), hours]).T,
passed.astype(float), rcond=None)
ols = coef[0] + coef[1] * xx
axR.plot(xx, ols, color=RED) # escapes [0, 1]
axR.fill_between(xx, 1, ols, where=(ols > 1), color=RED, alpha=0.18) # P>1 region
axR.fill_between(xx, 0, ols, where=(ols < 0), color=RED, alpha=0.18) # P<0 region
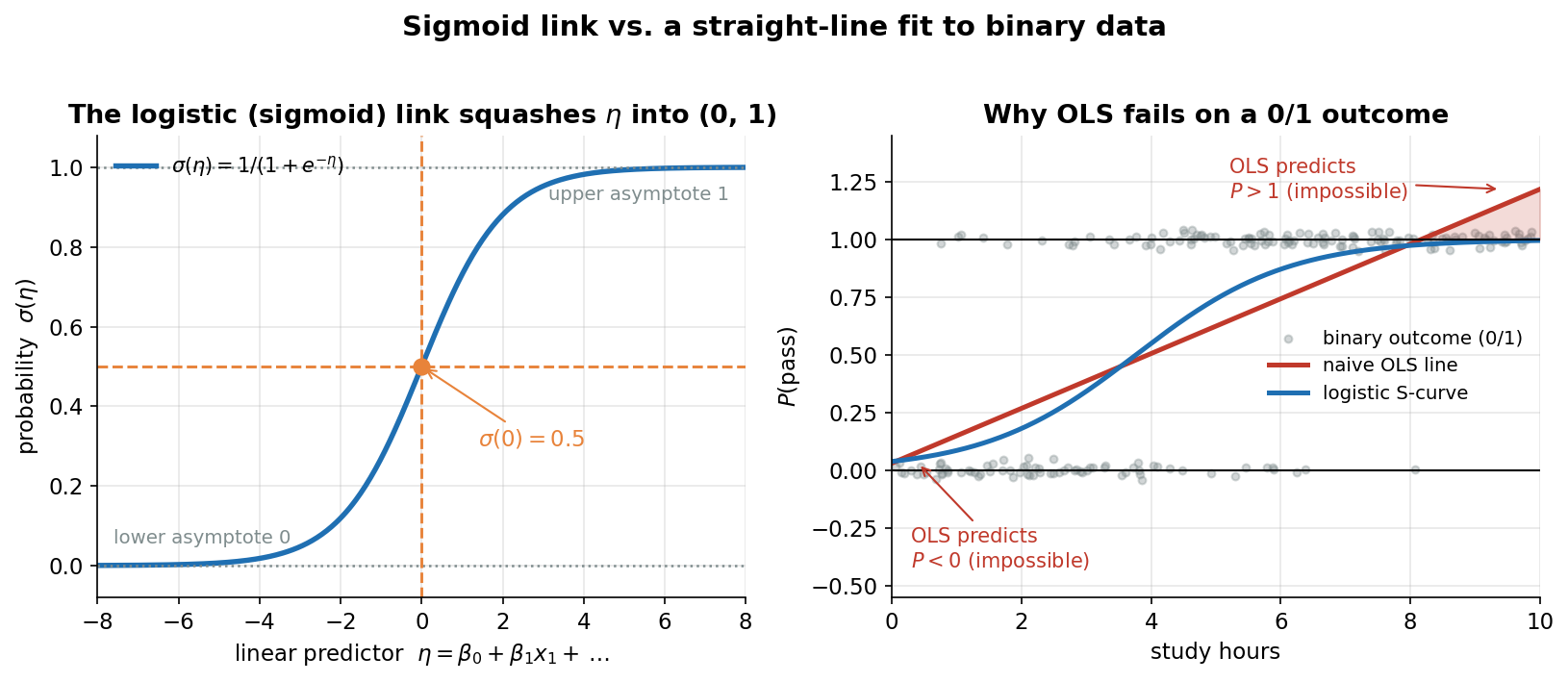
Figure 2 — fit-করা probability-curve: ঘণ্টা বাড়লে pass-সম্ভাবনা?¶
দ্বিতীয় ছবি model-টা আসলে কী predict করছে সেটা দেখায় — আমাদের নিজস্ব data-তে fit-করা logistic curve। অনুভূমিক অক্ষে পড়ার ঘণ্টা (hours), উল্লম্ব অক্ষে \(P(\text{pass})\)। নিচে-উপরে দুই সারিতে jitter করা কাঁচা বিন্দু: লাল বিন্দুগুলো passed = 0 (fail, \(y\) প্রায় \(0\)), নীল বিন্দুগুলো passed = 1 (pass, \(y\) প্রায় \(1\))। তাদের মাঝখান দিয়ে কালো S-curve-টা হলো পূর্ণ model-এর fit-করা \(\hat P(\text{pass}\mid \text{hours})\), যেখানে দ্বিতীয় predictor attend-কে তার গড় মান \(\approx 69\%\)-এ স্থির রাখা হয়েছে (তাই এটা hours-এর একমাত্র-ফাংশন হিসেবে আঁকা যায়)। কমলা cross-hair দেখায় curve-টা ঠিক কোথায় \(\hat P=0.5\) অতিক্রম করে — এখানে \(\text{hours}\approx 3.83\), অর্থাৎ গড়-উপস্থিতির একজন শিক্ষার্থীর জন্য এই ঘণ্টার বেশি পড়লে model "pass" দিকে ঝুঁকবে। যা লক্ষ করতে হবে: (ক) curve-টা বাঁ থেকে ডানে একদিকে বাড়ে (monotone increasing) — ঘণ্টা বাড়লে pass-সম্ভাবনা বাড়ে, যা \(\hat\beta_{\text{hours}}=0.9224>0\) ধনাত্মক হওয়ারই দৃশ্যরূপ। (খ) এটা সরলরেখা নয়, S-আকৃতির: খুব কম বা খুব বেশি ঘণ্টায় curve প্রায় চ্যাপ্টা (\(0\) বা \(1\)-এর কাছে স্যাচুরেটেড), আর মাঝখানে (\(\hat P=0.5\)-এর আশপাশে) সবচেয়ে খাড়া — অর্থাৎ একই "১ ঘণ্টা বেশি পড়া" probability-তে সবচেয়ে বড় বদল আনে এই সিদ্ধান্ত-সীমানার কাছেই, প্রান্তে নয়। (গ) curve-টা data-র সাথে সঙ্গতিপূর্ণ: যেখানে নীল (pass) বিন্দু ঘন (বেশি ঘণ্টা), সেখানে curve উঁচুতে; যেখানে লাল (fail) বিন্দু ঘন (কম ঘণ্টা), সেখানে নিচুতে — দুই মেঘের মাঝখানের overlap-অঞ্চলেই curve খাড়াভাবে ০.৫ পার হয়। (ঘ) মূল শিক্ষা: logistic regression কোনো কঠিন "হ্যাঁ/না" দেয় না, দেয় একটা মসৃণ probability; "pass/fail" সিদ্ধান্ত আসে পরে, এই curve-এর উপর একটা threshold (এখানে \(0.5\)) বসিয়ে।
# fitted full-model P(pass) as a function of hours, with attend fixed at its mean
xx = np.linspace(0, 10, 300)
pcurve = sigmoid(b0 + b1 * xx + b2 * attend.mean()) # b = [-6.320, 0.9224, 0.04047]
ax.plot(xx, pcurve, color="black", lw=2.8) # the fitted S-curve
# jittered raw 0/1 outcome, coloured by class
for cls, col in [(0, C0), (1, C1)]: # red = fail, blue = pass
m = passed == cls
ax.scatter(hours[m], passed[m] + jitter[m], color=col, alpha=0.45)
h_star = (0.0 - b0 - b2 * attend.mean()) / b1 # where P = 0.5 -> hours ~ 3.83
ax.axhline(0.5, ls="--"); ax.axvline(h_star, ls="--")
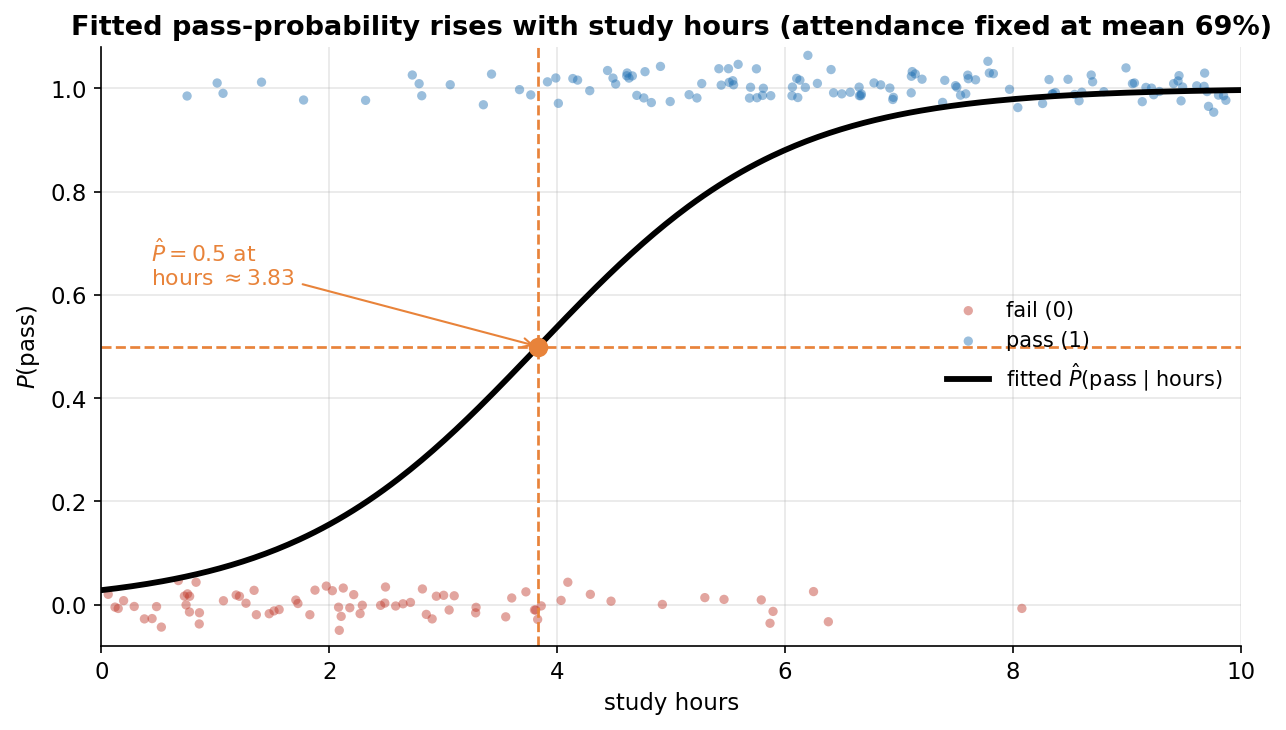
Figure 3 — ROC curve: classifier কতটা ভালো ranks করে?¶
তৃতীয় ছবি model-এর শ্রেণিবিভাজন-গুণমান মূল্যায়নের প্রধান হাতিয়ার — ROC (Receiver Operating Characteristic) curve। অনুভূমিক অক্ষে False Positive Rate (FPR \(= 1-\) specificity, অর্থাৎ আসল fail-দের মধ্যে কত ভুল করে "pass" বলা হলো), উল্লম্ব অক্ষে True Positive Rate (TPR \(=\) sensitivity / recall, আসল pass-দের মধ্যে কত ঠিকভাবে ধরা পড়ল)। নীল curve-টা \(0\) থেকে \(1\) পর্যন্ত প্রতিটি সম্ভাব্য threshold-এ এই দুই হারের জোড়া এঁকে তৈরি — threshold কড়া করলে (উঁচু) দুটোই কমে, ঢিলা করলে দুটোই বাড়ে, আর সেই trade-off-টাই curve-এর আকৃতিতে ধরা। ধূসর তির্যক ভাঙা-রেখা হলো chance baseline (এলোমেলো অনুমান, AUC \(=0.50\))। নীল ছায়াঘেরা অঞ্চলের ক্ষেত্রফলই AUC \(=0.92\) — curve-এর নিচের মোট এলাকা। লাল বিন্দুটি দেখায় আমাদের default threshold \(=0.5\)-এ operating point কোথায় বসে। যা লক্ষ করতে হবে: (ক) curve-টা তির্যক রেখার অনেক উপরে, বাঁ-উপরের কোণার দিকে ঝুঁকে — একটা ভালো classifier-এর চিহ্ন; আদর্শ (perfect) classifier বাঁ-উপরের কোণা \((0,1)\) ছুঁত (শূন্য ভুল), আর এলোমেলো অনুমান তির্যক রেখায় পড়ত। (খ) AUC \(=0.92\) একটা একক, threshold-নিরপেক্ষ সংখ্যা: এর অর্থ "এলোমেলোভাবে এক pass আর এক fail শিক্ষার্থী তুলে নিলে, model ৯২% ক্ষেত্রে pass-জনকে বেশি probability দেবে" — অর্থাৎ model-টা দুই শ্রেণিকে কত ভালো ক্রমে সাজায় (ranks) তারই পরিমাপ, কোনো নির্দিষ্ট cutoff নয়। (গ) লাল বিন্দু (\(0.5\)-threshold) curve-এর বাঁ-উপরের কোণার কাছাকাছি — মোটামুটি উঁচু TPR (অনেক pass ধরা পড়ছে) আর তুলনায় কম FPR (অল্প fail ভুলভাবে "pass")। (ঘ) সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ: ROC গোটা curve দেখায়, কিন্তু বাস্তবে আপনাকে একটা একটি বিন্দু বেছে নিতে হয় (threshold ঠিক করে) — সেই পছন্দ নির্ভর করে ভুলের মূল্যের উপর: false-positive বেশি ক্ষতিকর হলে threshold বাড়ান, false-negative বেশি ক্ষতিকর হলে কমান। মূল শিক্ষা: accuracy (\(0.855\)) একটিমাত্র threshold-এর ফল, কিন্তু AUC সব threshold জুড়ে model-এর সহজাত বিভাজন-ক্ষমতা সংক্ষেপে বলে — তাই ভারসাম্যহীন (imbalanced) data-তেও এটি নির্ভরযোগ্য।
from sklearn.metrics import roc_curve, roc_auc_score
fpr, tpr, thr = roc_curve(passed, phat) # phat = model.predict(df)
AUC = roc_auc_score(passed, phat) # 0.9236
ax.plot(fpr, tpr, color=BLUE, lw=2.8) # ROC curve
ax.fill_between(fpr, tpr, color=BLUE, alpha=0.12) # area under curve = AUC
ax.plot([0, 1], [0, 1], ls="--", color=GREY) # chance baseline (AUC 0.50)
idx = np.argmin(np.abs(thr - 0.5)) # the 0.5-threshold operating point
ax.scatter([fpr[idx]], [tpr[idx]], color=RED, s=70)
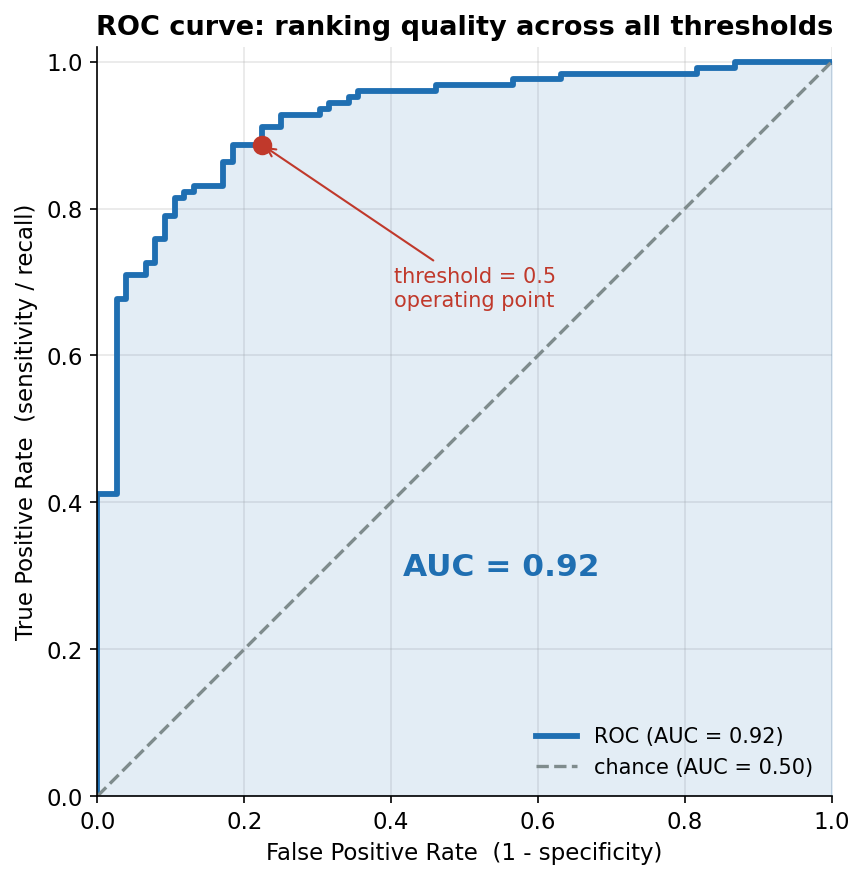
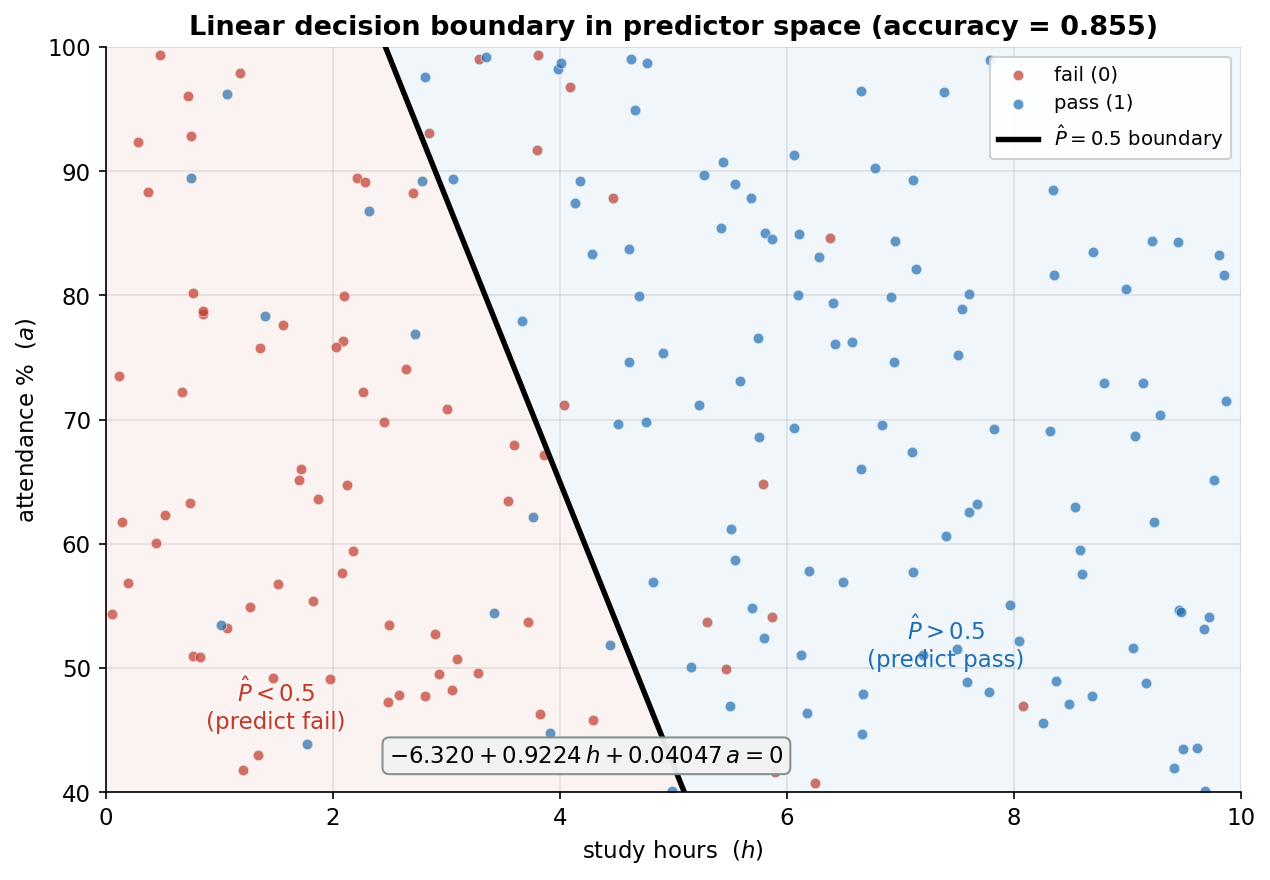
Figure 4 — decision boundary: predictor-space-এ pass আর fail কোথায় আলাদা?¶
শেষ ছবি — logistic regression-এর সিদ্ধান্তটা দুই-মাত্রিক predictor-space-এ ছবি করে দেখায়। অনুভূমিক অক্ষে পড়ার ঘণ্টা (\(h\)), উল্লম্ব অক্ষে উপস্থিতি-শতাংশ (\(a\)); প্রতিটি বিন্দু একজন শিক্ষার্থী, লাল হলে আসলে fail (\(\text{passed}=0\)), নীল হলে আসলে pass (\(\text{passed}=1\))। কালো সরলরেখা-টা হলো \(\hat P=0.5\) decision boundary — যেখানে fit-করা \(\hat\beta_0+\hat\beta_1 h+\hat\beta_2 a=0\), অর্থাৎ \(-6.320+0.9224\,h+0.04047\,a=0\) (নিচের box-এ সমীকরণ লেখা)। এই রেখার ডান-দিকে হালকা নীল অঞ্চলে model "pass" predict করে (\(\hat P>0.5\)), বাঁ-দিকে হালকা লাল অঞ্চলে "fail" (\(\hat P<0.5\))। যা লক্ষ করতে হবে: (ক) boundary-টা একটা সরলরেখা — predictor-space-এ logistic regression সবসময় রৈখিক সীমানা টানে (linear classifier), কারণ \(\hat P=0.5\) মানে \(\text{logit}=\eta=0\), আর \(\eta\) predictor-গুলোর রৈখিক যোগফল; এটাই এই model-এর শক্তি (সরল, ব্যাখ্যাযোগ্য) এবং সীমাবদ্ধতা (বাঁকা সীমানা ধরতে পারে না)। (খ) দুই শ্রেণি predictor-space-এ মোটামুটি ভালোভাবে আলাদা — নীল বিন্দুরা বেশিরভাগ ডান-উপরে (বেশি ঘণ্টা ও/বা বেশি উপস্থিতি), লাল বিন্দুরা বাঁ-নিচে — কিন্তু নিখুঁত নয়: সীমানার ভুল দিকে কিছু বিন্দু পড়ে (লাল অঞ্চলে কয়েকটি নীল, নীল অঞ্চলে কয়েকটি লাল), আর এই ভুল-শ্রেণিবদ্ধ বিন্দুগুলোই \(1-0.855=0.145\) ভুল-হারের (misclassification) উৎস (title-এ accuracy \(=0.855\))। (গ) রেখাটি নিচের দিকে ঢালু (ঋণাত্মক ঢাল): কম ঘণ্টা পড়লেও বেশি উপস্থিতি দিয়ে কিছুটা পুষিয়ে দেওয়া যায়, আবার কম উপস্থিতি বেশি ঘণ্টা পড়ে — দুই predictor পরস্পরকে trade-off করতে পারে, যা \(\hat\beta_1,\hat\beta_2\) দুটোই ধনাত্মক হওয়ার সরাসরি ফল। (ঘ) ঢালের তীক্ষ্ণতা \(-\hat\beta_1/\hat\beta_2=-0.9224/0.04047\approx-22.8\) বলে দেয় ১ ঘণ্টা বেশি পড়া প্রায় \(22.8\) শতাংশ-বিন্দু বেশি উপস্থিতির সমান প্রভাব ফেলে — অর্থাৎ এই data-তে pass-করতে পড়ার ঘণ্টা উপস্থিতির চেয়ে অনেক বেশি গুরুত্বপূর্ণ, যা §৪-এর coefficient-ব্যাখ্যাকেই দৃশ্যে নিশ্চিত করে। মূল শিক্ষা: একটা probability-curve (Figure 2) দুই predictor-এর space-এ একটা সরল decision boundary-তে রূপ নেয়, আর সেই রেখার ঢাল ও অবস্থান সরাসরি fit-করা coefficient থেকেই আসে।
# p = 0.5 boundary: b0 + b1*h + b2*a = 0 -> a = -(b0 + b1*h) / b2
hh = np.linspace(0, 10, 200)
aa = -(b0 + b1 * hh) / b2 # the decision line
ax.plot(hh, aa, color="black", lw=2.6) # -6.320 + 0.9224 h + 0.04047 a = 0
for cls, col in [(0, C0), (1, C1)]: # colour points by true class
m = passed == cls
ax.scatter(hours[m], attend[m], color=col)
ax.fill_between(hh, aa, 100, color=C1, alpha=0.06) # predicted-pass half-plane
ax.fill_between(hh, 40, aa, color=C0, alpha=0.06) # predicted-fail half-plane
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-04-logistic-regression-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — logit link কীভাবে probability-কে \((-\infty,\infty)\)-তে টেনে আনে আর \(e^{\hat\beta}\) কীভাবে odds-এ অনুবাদ হয়, তা হাতে গুনে দেখাটাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — পরীক্ষায় পাস-prediction, seed np.random.default_rng(20260619), \(n=200\): predictor hours (অধ্যয়নের ঘণ্টা, uniform \(0\)–\(10\)) ও attend (উপস্থিতি %, uniform \(40\)–\(100\)); true \(\eta=-6+0.9\cdot\text{hours}+0.04\cdot\text{attend}\), \(p=\sigma(\eta)\), response passed \(\sim\text{Bernoulli}(p)\)। canonical সংখ্যা: pass rate \(0.62\); \(\hat\beta=[-6.320,\,0.9224,\,0.04047]\) (intercept, hours, attend), \(\mathrm{SE}=[1.173,\,0.1239,\,0.01278]\), Wald \(z=[-5.39,\,7.44,\,3.17]\); odds ratio: hours-এর \(e^{\hat\beta_1}=2.515\) (per \(+1\) ঘণ্টা), attend-এর \(+10\) point-এ \(e^{10\hat\beta_2}=1.499\); log-likelihood \(\ell=-67.92\), null \(\ell_0=-132.81\), McFadden pseudo-\(R^2=0.489\), deviance \(D=135.83\), LLR \(p=6.5\times10^{-29}\); threshold \(0.5\)-এ accuracy \(0.855\), confusion \(\begin{bmatrix}\text{TN }61 & \text{FP }15\\ \text{FN }14 & \text{TP }110\end{bmatrix}\), AUC \(0.924\); উদাহরণ-পূর্বাভাস hours\(=5\), attend\(=75\Rightarrow\eta=1.327,\ p=0.790\)। মূল সম্পর্ক: \(p=\sigma(\eta)=\dfrac{1}{1+e^{-\eta}}\), \(\;\operatorname{logit}(p)=\log\dfrac{p}{1-p}=\eta=x^\top\beta\), \(\;\text{odds}=\dfrac{p}{1-p}=e^{\eta}\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). binary outcome (\(y_i\in\{0,1\}\)) থাকলে কেউ পরামর্শ দিল: "GLM-এর ঝামেলা কেন? সরাসরি ৫.১-এর OLS দিয়ে passed ~ hours + attend fit করো — linear probability model।" এই পদ্ধতির অন্তত তিনটি মৌলিক সমস্যা নাম দিয়ে ব্যাখ্যা করুন। বিশেষ করে: (ক) fitted \(\hat y\) কেন probability হিসেবে অর্থহীন হতে পারে; (খ) error-এর variance নিয়ে LINE-এর কোন অনুমান ভাঙে; (গ) hours \(\to\infty\) গেলে কোন আচরণ বাস্তবসম্মত নয়।
Hint: (ক) \(x^\top\hat\beta\) যেকোনো বাস্তব মান নিতে পারে, তাই \(\hat y<0\) বা \(\hat y>1\) — যা "probability" নয়। (খ) Bernoulli-তে \(\operatorname{Var}(y\mid x)=p(1-p)\), যা \(p\)-নির্ভর — অর্থাৎ heteroscedasticity, LINE-এর 'E' (equal variance) ভাঙে; error Normal-ও নয় (দুটো মাত্র মান)। (গ) OLS-এ প্রভাব রৈখিক ও অসীমভাবে বাড়ে; বাস্তবে probability \(1\)-তে saturate করা উচিত — logistic curve ঠিক সেটাই দেয়।
প্রশ্ন ২ (★). logit link আর sigmoid (logistic) function একে অপরের inverse — এটি স্পষ্ট করুন। (ক) \(\operatorname{logit}(p)=\log\frac{p}{1-p}\) থেকে শুরু করে বীজগণিতে দেখান \(p=\sigma(\eta)=\frac{1}{1+e^{-\eta}}\) যখন \(\eta=\operatorname{logit}(p)\)। (খ) \(\eta=0,\ \pm\infty\) হলে \(p\) কত? (গ) "log-odds স্কেলে মডেলটা রৈখিক, কিন্তু probability স্কেলে S-আকৃতির" — এই বাক্যটা একটা বাক্যে নিজের ভাষায় ব্যাখ্যা করুন। Hint: \(\eta=\log\frac{p}{1-p}\Rightarrow e^{\eta}=\frac{p}{1-p}\Rightarrow p=\frac{e^{\eta}}{1+e^{\eta}}=\frac{1}{1+e^{-\eta}}\)। \(\eta=0\Rightarrow p=0.5\); \(\eta\to+\infty\Rightarrow p\to1\); \(\eta\to-\infty\Rightarrow p\to0\)। logit link \(\eta=x^\top\beta\)-কে রৈখিক রাখে, \(\sigma(\cdot)\) তাকে \((0,1)\)-তে চেপে S-curve বানায়।
প্রশ্ন ৩ (★★). "odds" আর "odds ratio" — এই দুটো একই জিনিস নয়; পার্থক্যটা logistic regression-এর interpretation-এর কেন্দ্রে। (ক) odds-এর সংজ্ঞা দিন এবং \(p=0.79\) হলে odds কত (উদাহরণ-পূর্বাভাসের মান) তা বলুন। (খ) \(e^{\hat\beta_1}=2.515\) ("hours-এর odds ratio") বাক্যে ব্যাখ্যা করুন — এটা ঠিক কী-র সাপেক্ষে কী গুণে বদলায়? (গ) odds ratio \(>1\), \(=1\), \(<1\) হওয়া predictor-এর প্রভাব সম্পর্কে কী বলে? attend-এর coefficient \(\hat\beta_2=0.04047\) ছোট — তবু কেন তা significant হতে পারে? Hint: odds \(=\frac{p}{1-p}\); \(p=0.79\Rightarrow\) odds \(=\frac{0.79}{0.21}\approx3.76\) ("পাসের পক্ষে প্রায় \(3.76{:}1\)")। odds ratio \(e^{\hat\beta_1}\) = hours \(1\) একক বাড়লে odds কত গুণ হয় (attend স্থির রেখে) — এখানে \(2.515\) গুণ, অর্থাৎ \(\sim152\%\) বৃদ্ধি। \(e^{\hat\beta}>1\) মানে predictor বাড়লে event-এর odds বাড়ে; \(=1\) মানে কোনো প্রভাব নেই; \(<1\) মানে কমে। ছোট coefficient-ও SE আরও ছোট হলে (\(z\) বড়) significant হয়; তাছাড়া attend-এর scale বড় (\(40\)–\(100\)), তাই \(+10\) point-এ প্রভাব \(e^{10\hat\beta_2}=1.499\) — মোটেও ছোট নয়।
প্রশ্ন ৪ (★★). logistic regression কেন MLE দিয়ে fit হয়, OLS-এর মতো closed-form least-squares দিয়ে নয়? (ক) Bernoulli observation-দের জন্য likelihood \(L(\beta)=\prod_i p_i^{y_i}(1-p_i)^{1-y_i}\) থেকে log-likelihood \(\ell(\beta)\) লিখুন (যেখানে \(p_i=\sigma(x_i^\top\beta)\))। (খ) এই \(\ell(\beta)\)-কে \(\beta\)-র সাপেক্ষে সর্বোচ্চ করার সমীকরণ কেন বীজগণিতে সরাসরি সমাধানযোগ্য নয় — এক বাক্যে। (গ) ফলে কোন iterative algorithm ব্যবহৃত হয়, এবং তার সাথে weighted least squares-এর সম্পর্ক কী? Hint: \(\ell(\beta)=\sum_i[y_i\log p_i+(1-y_i)\log(1-p_i)]=\sum_i[y_i\,\eta_i-\log(1+e^{\eta_i})]\), \(\eta_i=x_i^\top\beta\)। score-সমীকরণ \(\nabla\ell=X^\top(y-p)=0\)-তে \(p\) নিজেই \(\beta\)-র অরৈখিক (\(\sigma\)) function — তাই \(\beta\) আলাদা করা যায় না (no closed form)। সমাধান: Newton–Raphson, যা প্রতিটি ধাপে একটা weighted least-squares solve-এ পরিণত হয় ⇒ IRLS (iteratively reweighted least squares)।
প্রশ্ন ৫ (★★). logistic regression-কে GLM (generalized linear model) কাঠামোয় ফেলা — তিনটি উপাদান চিহ্নিত করুন: (ক) random component (response-এর distribution); (খ) systematic component (linear predictor); (গ) link function। প্রতিটির জন্য logistic regression-এ নির্দিষ্ট রূপটা লিখুন, এবং ব্যাখ্যা করুন কীভাবে ৫.১-এর ordinary linear regression-ও এই একই তিন-উপাদান ছাঁচের একটা বিশেষ ক্ষেত্র (কোন distribution, কোন link?)। Hint: (ক) random: \(y_i\sim\text{Bernoulli}(p_i)\) (exponential family-র সদস্য); (খ) systematic: \(\eta_i=x_i^\top\beta\); (গ) link: \(g(p)=\operatorname{logit}(p)=\log\frac{p}{1-p}=\eta\) (canonical link for Bernoulli)। ordinary regression = random Normal + systematic \(x^\top\beta\) + identity link (\(g(\mu)=\mu\))। অর্থাৎ GLM শুধু link ও distribution বদলে একই linear-predictor কাঠামোকে বিভিন্ন outcome-এ বিস্তৃত করে।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★). চলমান মডেলের fitted coefficient \(\hat\beta=[-6.320,\,0.9224,\,0.04047]\) (intercept, hours, attend)। হাতে (ক্যালকুলেটরে) করুন: (ক) একজন শিক্ষার্থী যে hours\(=5\) ঘণ্টা পড়েছে আর attend\(=75\%\) উপস্থিত — তার linear predictor \(\eta=\hat\beta_0+\hat\beta_1\cdot5+\hat\beta_2\cdot75\) বের করুন; (খ) তারপর \(p=\sigma(\eta)=\frac{1}{1+e^{-\eta}}\) গণনা করে পাসের সম্ভাব্যতা বলুন; (গ) এই \(p\) থেকে odds \(\frac{p}{1-p}\) বের করুন এবং দেখান তা \(e^{\eta}\)-এর সমান। canonical-এর সাথে মিলছে কি? Hint: \(\eta=-6.320+0.9224(5)+0.04047(75)=-6.320+4.612+3.035=1.327\)। \(p=\frac{1}{1+e^{-1.327}}=\frac{1}{1+0.265}\approx0.790\)। odds \(=\frac{0.790}{0.210}\approx3.76\), আর \(e^{1.327}\approx3.77\) — rounding বাদে সমান ✓।
প্রশ্ন ৭ (★). odds ratio হাতে। (ক) hours-এর coefficient \(\hat\beta_1=0.9224\) থেকে per-\(1\)-ঘণ্টা odds ratio \(e^{\hat\beta_1}\) গণনা করুন এবং বাক্যে ব্যাখ্যা করুন। (খ) attend-এর coefficient \(\hat\beta_2=0.04047\) থেকে \(10\) point বৃদ্ধির odds ratio \(e^{10\hat\beta_2}\) বের করুন। (গ) একজন শিক্ষার্থী আরও \(2\) ঘণ্টা বেশি পড়লে (attend স্থির) তার পাসের odds কত গুণ হবে — \(\left(e^{\hat\beta_1}\right)^2\) হিসাব করে বলুন। Hint: \(e^{0.9224}\approx2.515\) — "প্রতি অতিরিক্ত ঘণ্টায় পাসের odds \(2.515\) গুণ" (attend ধরে রেখে)। \(e^{10\times0.04047}=e^{0.4047}\approx1.499\) — "attend \(10\) point বাড়লে odds \(\sim1.5\) গুণ"। \(2\) ঘণ্টা \(\Rightarrow e^{2\hat\beta_1}=2.515^2\approx6.33\) গুণ (odds ratio-গুলো additive predictor-এ multiplicative)।
প্রশ্ন ৮ (★★). Wald test ও significance। coefficient-summary: \(\hat\beta=[-6.320,\,0.9224,\,0.04047]\), \(\mathrm{SE}=[1.173,\,0.1239,\,0.01278]\)। (ক) প্রতিটি predictor-এর Wald statistic \(z_j=\hat\beta_j/\mathrm{SE}_j\) গণনা করে canonical \([-5.39,\,7.44,\,3.17]\)-এর সাথে মেলান। (খ) \(\lvert z\rvert>1.96\) rule দিয়ে \(\alpha=0.05\)-এ কোন কোন predictor significant? (গ) hours-এর জন্য \(\hat\beta_1\)-এর approximate \(95\%\) confidence interval \(\hat\beta_1\pm1.96\,\mathrm{SE}_1\) বের করুন, তারপর তা odds-ratio স্কেলে রূপান্তর করুন (\(e^{\text{lower}},\,e^{\text{upper}}\)) এবং ব্যাখ্যা করুন কেন এই interval \(1\)-কে অন্তর্ভুক্ত করা না-করাটা গুরুত্বপূর্ণ। Hint: \(z_1=0.9224/0.1239\approx7.44\); \(z_2=0.04047/0.01278\approx3.17\); \(z_0=-6.320/1.173\approx-5.39\) — তিনটাই \(\lvert z\rvert>1.96\), সব significant। CI: \(0.9224\pm1.96(0.1239)=[0.6796,\,1.1652]\); odds-ratio CI \(=[e^{0.6796},e^{1.1652}]=[1.97,\,3.21]\)। \(1\)-এর বাইরে থাকায় (পুরোটা \(>1\)) hours-এর প্রভাব \(\alpha=0.05\)-এ significant ও positive।
প্রশ্ন ৯ (★★). deviance, likelihood-ratio test ও pseudo-\(R^2\)। fitted মডেলের \(\ell=-67.92\), intercept-only (null) মডেলের \(\ell_0=-132.81\)। (ক) residual deviance \(D=-2\ell\) এবং null deviance \(D_0=-2\ell_0\) গণনা করুন; canonical \(D=135.83\) মিলছে কি? (খ) likelihood-ratio statistic \(G^2=2(\ell-\ell_0)=D_0-D\) বের করুন; এটি \(df=2\)-এর \(\chi^2\) (দুই predictor) — \(\chi^2_{0.95,2}=5.99\)-এর সাথে তুলনা করে global significance-এর সিদ্ধান্ত দিন। (গ) McFadden pseudo-\(R^2=1-\ell/\ell_0\) গণনা করে canonical \(0.489\)-এর সাথে মেলান, এবং এটি \(5.1\)-এর \(R^2\) থেকে অর্থে কীভাবে আলাদা তা এক বাক্যে বলুন। Hint: \(D=-2(-67.92)=135.83\) ✓; \(D_0=-2(-132.81)=265.63\)। \(G^2=2(-67.92-(-132.81))=2(64.89)=129.78=265.63-135.83\) ✓। \(129.78\gg5.99\), তাই দুই predictor মিলিয়ে অত্যন্ত significant (canonical LLR \(p=6.5\times10^{-29}\))। pseudo-\(R^2=1-(-67.92)/(-132.81)=1-0.5114=0.489\); এটি variance-ব্যাখ্যার অংশ নয় বরং log-likelihood-উন্নতির আপেক্ষিক পরিমাপ — তাই OLS-\(R^2\)-এর মতো করে পড়া যায় না।
প্রশ্ন ১০ (★★). confusion matrix → accuracy/precision/recall। threshold \(0.5\)-এ মডেলের confusion matrix:
| Predicted \(0\) (fail) | Predicted \(1\) (pass) | |
|---|---|---|
| Actual \(0\) (fail) | TN \(=61\) | FP \(=15\) |
| Actual \(1\) (pass) | FN \(=14\) | TP \(=110\) |
(ক) accuracy \(=\frac{\mathrm{TP}+\mathrm{TN}}{n}\) গণনা করুন (\(n=200\)); canonical \(0.855\) মিলছে কি? (খ) "pass" (positive) class-এর জন্য precision \(=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}}\) ও recall \(=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}\) বের করুন। (গ) মডেলটাকে যদি এমন পরিস্থিতিতে ব্যবহার করা হয় যেখানে একজন আসলে-fail শিক্ষার্থীকে "pass" বলে ভুল করা (FP) বেশি ক্ষতিকর — তাহলে threshold \(0.5\) থেকে বাড়াবেন না কমাবেন, এবং তাতে precision/recall-এ কী হবে? Hint: accuracy \(=\frac{110+61}{200}=\frac{171}{200}=0.855\) ✓। precision \(=\frac{110}{110+15}=\frac{110}{125}=0.88\); recall \(=\frac{110}{110+14}=\frac{110}{124}\approx0.887\)। FP বেশি ক্ষতিকর হলে threshold বাড়ান (যেমন \(0.7\)) — তখন কম case-কে "pass" বলা হবে, FP কমে precision বাড়ে, কিন্তু কিছু সত্যিকারের pass মিস হয়ে FN বাড়ে ⇒ recall কমে (classic trade-off)।
প্রশ্ন ১১ (★★). ROC/AUC ও threshold। মডেলের AUC \(=0.924\)। (ক) ROC curve কোন দুটো রাশির বিপরীতে আঁকা হয় (threshold \(0\) থেকে \(1\) ঘোরালে)? axis দুটো নাম দিন। (খ) AUC \(=0.924\)-এর সম্ভাব্যতা-ভিত্তিক অর্থ এক বাক্যে বলুন। (গ) AUC কেন threshold-নিরপেক্ষ একটা পরিমাপ, অথচ accuracy threshold-নির্ভর — এবং কেন class imbalance থাকলে accuracy-র চেয়ে AUC প্রায়ই বেশি নির্ভরযোগ্য? Hint: ROC = \(y\)-অক্ষে TPR (recall/sensitivity) vs \(x\)-অক্ষে FPR (\(=1-\)specificity), threshold ঘুরিয়ে। AUC = "একটা random positive case-কে মডেল একটা random negative case-এর চেয়ে বেশি score দেওয়ার সম্ভাবনা" — \(0.924\) মানে \(92.4\%\) সময়ে সঠিক ranking; \(0.5\) = random, \(1.0\) = perfect। accuracy একটা নির্দিষ্ট cutoff-এ গোনা হয় (তাই threshold-নির্ভর) আর majority class বড় হলে শুধু সেটা predict করেই উঁচু থাকতে পারে; AUC সব threshold জুড়ে ranking-গুণ মাপে বলে imbalance-এ কম বিভ্রান্তিকর।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১২ (★★). sigmoid-derivative identity। logistic function \(\sigma(z)=\frac{1}{1+e^{-z}}\)-এর জন্য প্রমাণ করুন: $\(\sigma'(z)=\sigma(z)\,\bigl(1-\sigma(z)\bigr).\)$ এরপর ব্যাখ্যা করুন এই identity কীভাবে logistic regression-এর variance \(\operatorname{Var}(y\mid x)=p(1-p)\) এবং score/Hessian গণনায় চাবিকাঠি হয়ে ওঠে। Hint: \(\sigma(z)=(1+e^{-z})^{-1}\); chain rule-এ \(\sigma'(z)=-(1+e^{-z})^{-2}\cdot(-e^{-z})=\frac{e^{-z}}{(1+e^{-z})^2}\)। এখন \(\frac{e^{-z}}{1+e^{-z}}=1-\sigma(z)\) আর \(\frac{1}{1+e^{-z}}=\sigma(z)\), তাই \(\sigma'(z)=\sigma(z)(1-\sigma(z))\)। যেহেতু \(p=\sigma(\eta)\), \(\frac{\partial p}{\partial\eta}=p(1-p)\) — ঠিক Bernoulli variance, আর এটি IRLS-এর weight \(w_i=p_i(1-p_i)\)।
প্রশ্ন ১৩ (★★★). score equation \(X^\top(y-p)=0\) প্রমাণ করুন। log-likelihood \(\ell(\beta)=\sum_{i=1}^n\bigl[y_i\,\eta_i-\log(1+e^{\eta_i})\bigr]\), \(\eta_i=x_i^\top\beta\), \(p_i=\sigma(\eta_i)\)। দেখান যে MLE-তে gradient $\(\frac{\partial\ell}{\partial\beta}=\sum_{i=1}^n (y_i-p_i)\,x_i=X^\top(y-p)=\mathbf 0,\)$ যেখানে \(X\) হলো \(n\times(d+1)\) design matrix, \(y=(y_i)\), \(p=(p_i)\)। এর একটি ফলিত অর্থও বলুন: design-এ intercept থাকলে এই সমীকরণ থেকে কী conservation property পাওয়া যায়? Hint: \(\frac{\partial}{\partial\beta}\bigl[y_i\eta_i\bigr]=y_i x_i\) (যেহেতু \(\eta_i=x_i^\top\beta\))। \(\frac{\partial}{\partial\beta}\log(1+e^{\eta_i})=\frac{e^{\eta_i}}{1+e^{\eta_i}}\,x_i=p_i x_i\) (প্রশ্ন ১২-র identity ব্যবহার করে, যেহেতু \(\sigma(\eta_i)=p_i\))। যোগ করলে \(\nabla\ell=\sum_i(y_i-p_i)x_i=X^\top(y-p)\); MLE-তে \(=0\)। conservation: intercept column সব-\(1\) হওয়ায় প্রথম সমীকরণ \(\sum_i(y_i-p_i)=0\Rightarrow\sum_i p_i=\sum_i y_i\) — fitted probability-র যোগফল ঠিক observed positive-সংখ্যার সমান (এখানে \(\sum_i\hat p_i=124\), যেমন \(0.62\times200\))।
প্রশ্ন ১৪ (★★★). Hessian negative-definite ⇒ concavity ও একক MLE। প্রশ্ন ১৩-র score থেকে দেখান যে log-likelihood-এর Hessian $\(\frac{\partial^2\ell}{\partial\beta\,\partial\beta^\top}=-\,X^\top W X,\qquad W=\operatorname{diag}\bigl(p_i(1-p_i)\bigr).\)$ এরপর যুক্তি দিন কেন এই Hessian negative semi-definite, ফলে \(\ell(\beta)\) concave, এবং (যদি \(X\)-এর rank পূর্ণ ও কোনো perfect separation না থাকে) MLE একক ও Newton–Raphson/IRLS অবধারিতভাবে সেই global maximum-এ পৌঁছায়। Hint: \(\frac{\partial p_i}{\partial\beta}=p_i(1-p_i)x_i\) (প্রশ্ন ১২), তাই \(\frac{\partial}{\partial\beta^\top}\sum_i(y_i-p_i)x_i=-\sum_i p_i(1-p_i)x_i x_i^\top=-X^\top W X\)। যেকোনো vector \(v\)-এর জন্য \(v^\top(X^\top W X)v=\sum_i p_i(1-p_i)(x_i^\top v)^2\ge0\) (কারণ \(p_i(1-p_i)>0\)), তাই \(-X^\top W X\preceq0\) ⇒ concave। concave function-এর stationary point-ই global max; full-rank \(X\)-এ strictly concave ⇒ একক MLE। (এ-ই কারণে logistic regression-এ OLS-এর মতো local-minima সমস্যা নেই — তবে perfect separation হলে MLE অসীমে চলে যায়।)
ঘ · কোডিং (Python)¶
প্রশ্ন ১৫ (★★★). পূর্ণ logistic-regression pipeline — fit + odds ratios + diagnostics + ROC। seed np.random.default_rng(20260619) দিয়ে data বানান: hours = rng.uniform(0,10,200), attend = rng.uniform(40,100,200), eta = -6 + 0.9*hours + 0.04*attend, passed = rng.binomial(1, 1/(1+np.exp(-eta)))। তারপর:
1. fit: statsmodels-এর sm.Logit(passed, sm.add_constant(np.column_stack([hours,attend]))).fit() চালিয়ে coefficient summary (β̂, SE, \(z\), \(p\)) ছাপুন; canonical \(\hat\beta=[-6.320,0.9224,0.04047]\), \(z=[-5.39,7.44,3.17]\)-এর সাথে মেলান।
2. odds ratios: প্রতিটি coefficient-এর \(e^{\hat\beta_j}\) ও তার \(95\%\) CI (\(e^{\hat\beta\pm1.96\,\mathrm{SE}}\)) ছাপুন; hours-এর \(2.515\), attend-এর per-\(10\)-point \(e^{10\hat\beta_2}=1.499\) যাচাই করুন।
3. goodness-of-fit: log-likelihood, null log-likelihood, deviance \(=-2\ell\), McFadden pseudo-\(R^2\), LLR \(p\)-value ছাপুন (\(\ell=-67.92\), \(D=135.83\), pseudo-\(R^2=0.489\), \(p=6.5\times10^{-29}\))।
4. classification + ROC: threshold \(0.5\)-এ confusion matrix (\(\begin{bmatrix}61&15\\14&110\end{bmatrix}\)), accuracy (\(0.855\)), precision, recall; এবং sklearn.metrics.roc_auc_score/roc_curve দিয়ে AUC (\(0.924\)) ও ROC curve।
5. by-hand check: hours\(=5\), attend\(=75\)-এ \(\eta\) ও \(p\) হাতে-হিসাবের সূত্রে গণনা করে model.predict-এর সাথে মিলিয়ে দেখান (\(\eta=1.327,\ p=0.790\))।
(সম্ভব হলে ১–৫ এক runnable script-এ; প্রতিটি সংখ্যা canonical-এর সাথে মিলিয়ে নিন।)
Hint: from sklearn.metrics import confusion_matrix, roc_auc_score, roc_curve; phat = model.predict(X), pred = (phat>=0.5).astype(int)। odds-ratio CI: np.exp(model.conf_int())। score-check (ঐচ্ছিক): X.T @ (passed - phat) \(\approx\mathbf 0\) — প্রশ্ন ১৩-র যাচাই। প্রত্যাশিত সব সংখ্যা উপরের canonical তালিকায়।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
কেন এই অধ্যায়। ৫.১–৫.৩ পর্যন্ত response ছিল অবিচ্ছিন্ন ও আনুমানিক Normal, তাই \(\mathbb E[y]=x^\top\beta\) (identity link, Normal error) যথেষ্ট ছিল। কিন্তু outcome যখন binary ("পাস/ফেল", "রোগী বাঁচল/মারা গেল", "ক্লিক হলো/হলো না"), তখন OLS ভেঙে পড়ে — পূর্বাভাস \([0,1]\)-এর বাইরে যায়, error Normal নয়, আর variance \(p(1-p)\) mean-নির্ভর (heteroscedastic)। সমাধান: logistic regression, যা GLM পরিবারের প্রথম সদস্য।
-
logit link (মূল ধারণা)। probability-কে সরাসরি \(x^\top\beta\)-র সমান না-ধরে, তার log-odds-কে রৈখিক ধরা হয়: $\(\operatorname{logit}(p_i)=\log\frac{p_i}{1-p_i}=\eta_i=x_i^\top\beta\quad\Longleftrightarrow\quad p_i=\sigma(\eta_i)=\frac{1}{1+e^{-\eta_i}}.\)$ link function \(\eta_i\)-কে \((-\infty,\infty)\)-তে রাখে, আর inverse (sigmoid) \(p_i\)-কে \((0,1)\)-তে চেপে S-curve বানায় — তাই পূর্বাভাস সবসময় বৈধ probability।
-
MLE / IRLS দিয়ে fit। OLS-এর closed-form নেই; প্রতিটি observation Bernoulli ধরে likelihood $\(L(\beta)=\prod_i p_i^{y_i}(1-p_i)^{1-y_i},\qquad \ell(\beta)=\sum_i\bigl[y_i\eta_i-\log(1+e^{\eta_i})\bigr].\)$ score-সমীকরণ \(\;X^\top(y-p)=0\;\) অরৈখিক (কারণ \(p=\sigma(X\beta)\)), তাই Newton–Raphson দিয়ে সমাধান — যা প্রতিধাপে weighted least squares-এ পরিণত হয় (IRLS, weight \(w_i=p_i(1-p_i)\))। log-likelihood concave (Hessian \(=-X^\top WX\preceq0\)), তাই MLE একক — local-minima সমস্যা নেই।
-
interpretation: odds ও odds ratio। coefficient log-odds স্কেলে — কিন্তু \(e^{\hat\beta_j}\) নিলে তা odds ratio: predictor \(j\) এক একক বাড়লে event-এর odds কত গুণ হয় (বাকি predictor স্থির)। চলমান উদাহরণে hours-এর \(e^{0.9224}=2.515\) (প্রতি ঘণ্টায় পাসের odds \(\sim2.5\) গুণ), attend-এর \(10\)-point-এ \(e^{10\times0.04047}=1.499\)। \(e^{\hat\beta}>1\Rightarrow\) প্রভাব positive, \(=1\Rightarrow\) নিরপেক্ষ, \(<1\Rightarrow\) negative। এটাই logistic regression-কে ব্যাখ্যাযোগ্য রাখে।
-
inference: Wald ও likelihood-ratio। প্রতিটি coefficient-এর Wald \(z=\hat\beta_j/\mathrm{SE}_j\) (৪.৭) — উদাহরণে \(z=[-5.39,7.44,3.17]\), তিনটাই \(\lvert z\rvert>1.96\), সব significant। global fit-এর জন্য deviance \(D=-2\ell=135.83\) ও likelihood-ratio \(G^2=D_0-D=129.78\) (\(\chi^2_2\), \(p=6.5\times10^{-29}\)); McFadden pseudo-\(R^2=1-\ell/\ell_0=0.489\) মডেলের আপেক্ষিক log-likelihood-উন্নতি মাপে (OLS-\(R^2\)-এর মতো নয়)।
-
মূল্যায়ন: confusion matrix, accuracy, AUC। probability-কে threshold (সাধারণত \(0.5\)) দিয়ে \(0/1\)-এ রূপান্তর করে confusion matrix \(\begin{bmatrix}\text{TN }61&\text{FP }15\\\text{FN }14&\text{TP }110\end{bmatrix}\) → accuracy \(0.855\), precision \(0.88\), recall \(0.887\)। কিন্তু accuracy threshold- ও imbalance-নির্ভর; threshold \(0\) থেকে \(1\) ঘোরালে TPR-vs-FPR এঁকে ROC curve, তার নিচের ক্ষেত্রফল AUC \(=0.924\) — threshold-নিরপেক্ষ ranking-গুণ (random positive > random negative হওয়ার সম্ভাবনা)। decision threshold বাছাই FP বনাম FN-এর আপেক্ষিক খরচের উপর নির্ভর।
পূর্ববর্তী সংযোগ (← ৫.১, ৪.৩, ৪.৭):
- ৫.১ (Linear Regression): logistic regression ঠিক ৫.১-এর linear-predictor কাঠামো (\(\eta=x^\top\beta\)) রেখেই দুটো জিনিস বদলায় — response-এর distribution (Normal → Bernoulli) আর link (identity → logit)। অর্থাৎ ৫.১ হলো GLM-এর special case (Normal + identity link), আর logistic regression তারই natural সাধারণীকরণ binary outcome-এর জন্য। design matrix \(X\), coefficient \(\beta\), এমনকি "\(X^\top(y-\hat\mu)=0\)"-জাতীয় orthogonality — সব গঠনগতভাবে চেনা।
- ৪.৩ (MLE): logistic regression-এর হৃদয় হলো ৪.৩-এর maximum likelihood — Bernoulli likelihood লিখে log নিয়ে score-সমীকরণ শূন্য করা। closed form না-থাকায় ৪.৩-এ আলোচিত Newton–Raphson iterative optimization (এখানে IRLS রূপে) সরাসরি ব্যবহৃত। coefficient-এর SE আসে observed/expected Fisher information (\(X^\top WX\))-এর inverse থেকে — ৪.৩/৪.৫-এর asymptotic MLE-তত্ত্বেরই প্রয়োগ।
- ৪.৭ (Wald / LR test): coefficient-significance-এর Wald \(z\) এবং global fit-এর likelihood-ratio \(G^2\) (deviance-পার্থক্য) — দুটোই ৪.৭-এর Wald ও likelihood-ratio framework-এর হুবহু প্রয়োগ, এখানে \(\chi^2\) reference distribution-সহ। large-sample-এ \(z^2\approx\) LR — সেই সমতাও ৪.৭ থেকে চেনা।
পরবর্তী সংযোগ (→ ৫.৫ — GLM: Poisson Regression & Beyond): logistic regression GLM-যাত্রার শুরু মাত্র। ৫.৪-এ outcome ছিল binary (Bernoulli + logit link)। কিন্তু অনেক outcome হলো count — "দিনে কতগুলো দুর্ঘটনা", "ঘণ্টায় কতজন গ্রাহক", "একটি পৃষ্ঠায় কতগুলো ত্রুটি" — যা \(\{0,1,2,\dots\}\)-এ থাকে এবং Bernoulli-ও নয়, Normal-ও নয়। ৫.৫ ঠিক একই GLM যন্ত্র (random component + linear predictor + link + MLE/IRLS) প্রয়োগ করবে, শুধু distribution হবে Poisson আর link হবে log (\(\log\mu=x^\top\beta\)): এ-ই Poisson regression। সংক্ষেপে: ৫.১ linear model বানায়, ৫.২ তাকে বিচার করে, ৫.৩ তাকে categorical/পরীক্ষামূলক জগতে নেয়, ৫.৪ তাকে binary outcome-এ (logit link) বিস্তৃত করে, আর ৫.৫ তাকে count outcome-এ (log link) — সবই একই exponential-family GLM ছাঁচের ভিন্ন রূপ।
সূত্র (sources): R. Furrer, STA121 Statistical Modeling (generalized linear models, logistic regression, link functions, deviance, IRLS); L. Wasserman, All of Statistics, Ch. 13 (Logistic Regression — log-odds model, MLE, Wald inference); J. A. Rice, Mathematical Statistics and Data Analysis (likelihood-based fitting ও GLM-ভিত্তি); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 5 (Classification — logistic regression, confusion matrix, precision/recall, ROC/AUC, threshold choice); P. Dangeti, Statistics for Machine Learning (logistic regression, odds ratio interpretation, classification metrics