8.1 — End-to-End Data Analysis Project (একটি সম্পূর্ণ বিশ্লেষণ পাইপলাইন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — বিচ্ছিন্ন হাতিয়ার থেকে একটাই সৎ কর্মধারা¶
১.১ আগের Part-গুলো কোথায় রেখে এসেছিল¶
এতদূর পর্যন্ত পুরো curriculum-টা ছিল একের পর এক হাতিয়ার গড়ার গল্প — প্রতিটি Part একটা করে যন্ত্র হাতে ধরিয়েছে, কিন্তু প্রায় সবসময় সেই যন্ত্রকে দেখানো হয়েছে আলাদা করে, একটা ছোট-ছিমছাম উদাহরণে। একবার ফিরে দেখা যাক কী কী জমেছে:
- Part I (descriptive ও EDA) — data-কে প্রথম চোখে দেখা: distribution, summary statistic, correlation, আর কোন feature কেমন আচরণ করে তা পড়ার কর্মধারা (exploratory data analysis, অন্বেষী উপাত্ত-বিশ্লেষণ)।
- Part II–III (probability ও convergence) — randomness-এর ভাষা: random variable, distribution, expectation, এবং large-sample-এ estimate কীভাবে সত্যের দিকে স্থির হয় (law of large numbers, CLT)।
- Part IV (inference) — data থেকে অনিশ্চয়তাসহ সিদ্ধান্ত: estimation, confidence interval, hypothesis test, bootstrap।
- Part V (modeling — regression ও GLM) — feature ও outcome-এর সম্পর্ক গড়া: linear regression, এবং binary outcome-এর জন্য logistic regression (5.4), যা coefficient ও odds ratio দিয়ে ব্যাখ্যা দেয়; সঙ্গে cross-validation (5.8) দিয়ে model-কে না-দেখা data-তে যাচাই করা।
- Part VI (statistical ML) — আরও নমনীয় predictor: regularization, নানা classifier, আর random forest (6.5) — বহু গাছের ensemble, তার OOB error ও feature importance সমেত।
প্রতিটি হাতিয়ার নিজের জায়গায় ধারালো — কিন্তু বাস্তব একটা প্রশ্নের সামনে বসলে এদের কোনো একটা একা যথেষ্ট নয়। বাস্তবে EDA, preprocessing, model, inference ও validation — সব একসাথে, একটা শৃঙ্খলে লাগাতে হয়, আর প্রতিটা ধাপের সিদ্ধান্ত পরের ধাপকে প্রভাবিত করে। ঠিক সেই জোড়া-লাগানো কাজটাই এই অধ্যায়ের বিষয়।
এক বাক্যে উত্তরণ। Part I–VI প্রতিটি একটা করে বিচ্ছিন্ন হাতিয়ার দিয়েছিল (EDA, probability, inference, regression/GLM, cross-validation, trees); এই অধ্যায় সেই সব হাতিয়ারকে একটাই বাস্তব সমস্যায় একটা সুসংগত, সৎ কর্মধারায় জোড়ে।
১.২ Hook — শুধু ভবিষ্যদ্বাণী নয়, "কেন" আর "কতটা নিশ্চিত"; আর dataset-পরিচিতি¶
একটা দৃশ্য কল্পনা করুন। একজন চিকিৎসক একটা টিউমারের কয়েকটা মাপ হাতে নিয়ে জানতে চান: এটা কি malignant (ম্যালিগন্যান্ট = ক্যান্সার, বিপজ্জনক) নাকি benign (বিনাইন = নিরীহ)? একটা model যদি কেবল বলে "malignant" — সেটুকুই যথেষ্ট নয়। চিকিৎসক আরও তিনটে জিনিস জানতে চান:
- কেন? — কোন মাপগুলো এই রায়ের পিছনে সবচেয়ে বড় ভূমিকা রাখছে (interpretability, ব্যাখ্যাযোগ্যতা)?
- কতটা নিশ্চিত? — এই রায়ে model কতখানি আত্মবিশ্বাসী, আর সেই আত্মবিশ্বাস কি বিশ্বাসযোগ্য (calibrated probability, uncertainty)?
- কতটা ভরসা করা যায়? — না-দেখা নতুন রোগীর ক্ষেত্রে এই model কেমন করবে (generalization, সাধারণীকরণ)?
এই তিন প্রশ্ন — prediction, ব্যাখ্যা, ও অনিশ্চয়তা — একসাথে সৎভাবে সামলানোই এই অধ্যায়ের মূল চ্যালেঞ্জ, আর এটাই একে আগের যেকোনো একক-হাতিয়ার অধ্যায় থেকে আলাদা করে।
dataset-পরিচিতি। পুরো কাজটা একটাই বাস্তব dataset ঘিরে হবে — sklearn-এর সঙ্গে অফলাইনে বান্ডিল-করা breast_cancer dataset (Wisconsin Diagnostic Breast Cancer)। এর গঠন:
- ৫৬৯ জন রোগী (row / observation) — প্রতিটি একটা টিউমারের নমুনা।
- ৩০টি feature (column) — প্রতিটি একটা টিউমার-ভরের fine-needle-aspirate (সূক্ষ্ম-সুচ-চোষণ) থেকে তোলা ডিজিটাইজড ছবি বিশ্লেষণ করে গণিত সংখ্যাগত মাপ: কোষ-নিউক্লিয়াসের radius, texture, perimeter, area, smoothness, concavity, concave points প্রভৃতির mean, standard error ও "worst" (সবচেয়ে-বড় তিনটির গড়) সংস্করণ।
- target (লক্ষ্য) — দুটো শ্রেণি: এখানে encoding হলো \(0=\) malignant (ক্যান্সার) ও \(1=\) benign (নিরীহ)।
গুরুত্বপূর্ণ: এই dataset পুরোপুরি সংখ্যাগত, মাঝারি-আকারের (৫৬৯×৩০), এবং কোনো missing value নেই — তাই এটা একটা পরিচ্ছন্ন pipeline-প্রদর্শনের আদর্শ মঞ্চ, যেখানে data-ঝামেলার বদলে পদ্ধতিগত সিদ্ধান্তগুলোর উপর মন দেওয়া যায়।
এক বাক্যে hook। breast_cancer dataset-এ (৫৬৯×৩০) একটা টিউমার malignant না benign তা শুধু ভবিষ্যদ্বাণী করাই নয়, বরং কোন feature সেই রায় চালায় এবং কতটা নিশ্চয়তায় — এই তিনটে একসাথে সৎভাবে দেওয়াই এই অধ্যায়ের আসল লক্ষ্য।
১.৩ একটা সৎ pipeline-এর সাত ধাপ¶
বিক্ষিপ্ত হাতিয়ারগুলোকে একটা সুশৃঙ্খল data pipeline (উপাত্ত-প্রণালী, ধাপে-ধাপে সাজানো বিশ্লেষণ-প্রবাহ)-এ বাঁধা যায়। এই অধ্যায়ের গোটা কাঠামো নিচের সাত ধাপে, আর প্রতিটি ধাপ ঠিক আগের Part-এর কোন হাতিয়ার ব্যবহার করছে তাও পাশে দেওয়া হলো:
- Framing (প্রশ্ন-নির্ধারণ) — সমস্যাটাকে একটা সুনির্দিষ্ট পরিসংখ্যানিক প্রশ্নে অনুবাদ: এখানে একটা binary classification ("malignant না benign?"), target কীভাবে encode করা, এবং সাফল্য কীভাবে মাপা হবে তা আগেই ঠিক করা।
- EDA (অন্বেষী বিশ্লেষণ) — data-কে প্রথম চোখে দেখা: class balance, শ্রেণি-অনুযায়ী feature-distribution, correlation-গঠন, ও কোন feature সবচেয়ে ভালো শ্রেণি আলাদা করে (Part I)।
- Preprocessing ও assumption-যাচাই — feature standardize করা, এবং VIF দিয়ে multicollinearity যাচাই; তারপর stratified train/test split (Part I, V)।
- Modeling (model লাগানো) — দুটো ভিন্ন-ঘরানার model: logistic regression (5.4) ও random forest (6.5), যাতে একটা রৈখিক-ব্যাখ্যাযোগ্য ও একটা নমনীয়-ensemble দৃষ্টিভঙ্গি পাশাপাশি রাখা যায়।
- Inference ও uncertainty (অনুমিতি ও অনিশ্চয়তা) — logistic model-এ odds ratio, confidence interval ও p-value দিয়ে "কোন feature গুরুত্বপূর্ণ ও কতটা নিশ্চিতভাবে"; random forest-এ permutation importance (4.x inference + 6.5)।
- Validation (যাচাই) — stratified K-fold cross-validation, ROC curve/AUC, confusion matrix, sensitivity/specificity ও calibration দিয়ে না-দেখা data-তে model-এর কার্যকারিতা মাপা (5.8)।
- Interpretation ও report (ব্যাখ্যা ও প্রতিবেদন) — ফলাফলকে বোধগম্য ভাষায় সাজানো, একটা model card লেখা, এবং সৎ caveat (সাবধানবাণী) দেওয়া।
এই সাত ধাপ কোনো আলংকারিক তালিকা নয় — অধ্যায়ের §৩ থেকে §৭ ঠিক এই ক্রমেই এগোবে, আর 8-1-eda, 8-1-model, 8-1-validation ও 8-1-interpretation — এই চারটি চিত্র যথাক্রমে ধাপ ২, ৪, ৬ ও ৭-কে সংখ্যায় ও ছবিতে ধরবে।
এক বাক্যে ধাপ। একটা সৎ বিশ্লেষণ কখনো সরাসরি "model লাগাও" দিয়ে শুরু হয় না — এটা framing → EDA → preprocessing → modeling → inference → validation → interpretation, এই সাত-ধাপের একটা শৃঙ্খল, যেখানে প্রতিটি ধাপ আগের Part-এর একটা হাতিয়ারকে জায়গামতো কাজে লাগায়।
১.৪ মূল insight (অন্তর্দৃষ্টি) — prediction, inference ও uncertainty একসাথে¶
এই অধ্যায়ের কেন্দ্রীয় insight-টা একটা ভুল-ধারণা ভাঙার মধ্যে দিয়ে বোঝা সবচেয়ে সহজ। অনেকের কাছে "data analysis" মানে শুধু একটা উঁচু accuracy সংখ্যা বের করা — যত বেশি accuracy, তত ভালো। কিন্তু একটা পরিণত, সৎ বিশ্লেষণ তিনটে আলাদা প্রশ্নের উত্তর একসাথে দেয়, আর তিনটেই আলাদা হাতিয়ার থেকে আসে:
- Prediction (ভবিষ্যদ্বাণী) — "এই রোগীর টিউমার malignant না benign?" এটা একটা point-রায়; এর মান accuracy, AUC ইত্যাদি দিয়ে মাপা হয়। (logistic ও random forest দুটোই এটা দেয়।)
- Inference (অনুমিতি) — "কোন feature সত্যিই outcome-কে চালায়, আর সেই সম্পর্ক কতটা নিশ্চিত?" এটা point-রায় নয়, বরং কারণ-কাঠামো নিয়ে বিবৃতি, যা odds ratio, confidence interval ও p-value দিয়ে দেওয়া হয়। (logistic regression-এর সবল দিক।)
- Uncertainty (অনিশ্চয়তা) — "model তার নিজের রায়ে কতটা আত্মবিশ্বাসী, আর সেই আত্মবিশ্বাস কি বিশ্বাসযোগ্য?" এটা predicted probability, তার calibration, ও estimate-এর variability নিয়ে। (calibration curve ও CV-এর ±ছড়ানো এটা ধরে।)
এই তিনটে একসঙ্গে না দিলে ছবিটা অসম্পূর্ণ — শুধু prediction দিলে কেউ জানে না কেন; শুধু inference দিলে model বাস্তবে কাজ করে কিনা অজানা; আর uncertainty ছাড়া একটা আত্মবিশ্বাসী-কিন্তু-ভুল রায় বিপজ্জনক। এই অধ্যায় তিনটেকেই সমান গুরুত্বে রাখে — এটাই এর মূল বার্তা।
এক বাক্যে insight। একটা সৎ বিশ্লেষণ কেবল উঁচু accuracy খোঁজে না — এটা একসঙ্গে prediction (কী), inference (কেন, কতটা নিশ্চিতভাবে) ও uncertainty (কতটা আত্মবিশ্বাসী ও তা কতটা বিশ্বাসযোগ্য) — তিনটে প্রশ্নের উত্তর দেয়।
১.৫ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একনজরে দেখে নিই, যাতে কোন অংশ কেন আসছে তা আগেভাগে পরিষ্কার থাকে:
- §২ (মূল ধারণা ও পদ্ধতি) — pipeline-এর প্রতিটি ধারণার নিখুঁত সংজ্ঞা: data pipeline ও question framing; EDA (class balance, class-wise distribution, correlation, separation-মাপ); standardization; multicollinearity ও VIF; stratified split; logistic regression ও odds ratio; random forest; inference (Wald CI, p-value) ও permutation importance; validation (K-fold CV, ROC/AUC, confusion matrix, calibration); model card ও caveat।
- §৩ — assumption ও পিছনের গণিত: VIF-এর derivation, logit-এর MLE, এবং perfect separation কেন পূর্ণ-model-এর estimate-কে অসীমে ঠেলে দেয় তার ব্যাখ্যা।
- §৪ — worked reasoning ও ছোট হাতে-কষা উদাহরণ।
- §৫–৬ — seed 20260619-এ পূর্ণ Python-pipeline: standardize → stratified ৭০/৩০ split → দুই model → statsmodels Logit inference → stratified 5-fold CV, চারটি চিত্রসহ (8-1-eda, 8-1-model, 8-1-validation, 8-1-interpretation)।
- §৭–৮ — ব্যাখ্যা, model card, সৎ caveat, সারসংক্ষেপ ও অনুশীলনী।
এক বাক্যে কেন এটি এখানে। এটি গোটা Statistics-যাত্রার capstone — আগের সব Part বিচ্ছিন্ন হাতিয়ার শিখিয়েছিল, আর এই অধ্যায় সেই হাতিয়ারগুলোকে একটাই বাস্তব dataset-এ একটা সম্পূর্ণ, সৎ, প্রশ্ন-থেকে-প্রতিবেদন কর্মধারায় জোড়ে — যেখানে prediction, inference ও uncertainty পাশাপাশি দাঁড়ায় এবং সীমাবদ্ধতাগুলো লুকানো হয় না।
২ · মূল ধারণা ও পদ্ধতি¶
এই বিভাগে §১-এর সাত-ধাপের কাঠামোর প্রতিটি ধারণাকে নিখুঁত সংজ্ঞায় রূপ দেওয়া হবে — যাতে §৩ থেকে যখন গণিত ও কোডে নামা হয়, তখন প্রতিটি শব্দের মানে আগেই স্থির থাকে। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো। যেখানে পূর্ণ derivation লাগবে (VIF, logit-এর MLE, perfect separation), সেটা §৩-এ; এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
গোটা অধ্যায়ে কিছু চিহ্ন অপরিবর্তিত থাকবে। আমাদের কাছে \(n=569\)টি লেবেল-করা পর্যবেক্ষণ: \((x_1,y_1),\dots,(x_n,y_n)\), যেখানে \(x_i\in\mathbb{R}^p\) (\(p=30\)) হলো \(i\)-তম রোগীর feature vector এবং \(y_i\in\{0,1\}\) তার শ্রেণি-লেবেল (\(0=\) malignant, \(1=\) benign)। একটা নির্দিষ্ট feature-কে \(j\) (\(j=1,\dots,p\)) দিয়ে সূচিত করব, আর \(i\)-তম পর্যবেক্ষণে তার মান \(x_{ij}\)।
২.১ Data pipeline ও question framing¶
সংজ্ঞা (data pipeline)। একটা data pipeline হলো কাঁচা data থেকে চূড়ান্ত সিদ্ধান্ত/প্রতিবেদন পর্যন্ত পৌঁছনোর একটা ক্রমিক, পুনরুৎপাদনযোগ্য ধাপ-শৃঙ্খল, যেখানে প্রতিটি ধাপের আউটপুট পরের ধাপের ইনপুট। এর দুটো মূল দাবি: (ক) ক্রম গুরুত্বপূর্ণ — যেমন standardization-এর parameter কেবল training data থেকে শেখা উচিত, নাহলে data leakage ঘটে (§২.৮); (খ) reproducibility (পুনরুৎপাদনযোগ্যতা) — একই random seed (এখানে 20260619) দিলে ঠিক একই ফল আসা চাই।
সংজ্ঞা (question framing)। একটা আলগা বাস্তব প্রশ্নকে একটা সুনির্দিষ্ট পরিসংখ্যানিক সমস্যায় অনুবাদ করাই framing। এখানে:
- সমস্যার ধরন — binary classification (দ্বি-শ্রেণি শ্রেণিবিন্যাস): input \(x\in\mathbb{R}^{30}\) থেকে একটা \(\{0,1\}\)-লেবেল ভবিষ্যদ্বাণী।
- target encoding — \(0=\) malignant, \(1=\) benign; কোন শ্রেণিকে "positive" ধরা হচ্ছে তা confusion matrix ও sensitivity/specificity-র মানে বদলে দেয়, তাই এটা আগেই স্থির করা জরুরি।
- লক্ষ্য কী — শুধু একটা label নয়, বরং একটা predicted probability \(\hat P(y=1\mid x)\), তার ব্যাখ্যা, ও তার নির্ভরযোগ্যতা।
এক বাক্যে framing। কোনো model লাগানোর আগেই সমস্যাটাকে একটা সুনির্দিষ্ট পরিসংখ্যানিক প্রশ্নে (এখানে binary classification, \(0=\) malignant / \(1=\) benign) অনুবাদ করা এবং সাফল্যের মাপ ঠিক করাই একটা সৎ pipeline-এর ভিত্তি।
২.২ EDA — class balance, distribution, correlation ও separation-মাপ¶
model-এ যাওয়ার আগে data-কে চেনা — exploratory data analysis — pipeline-এর অপরিহার্য প্রথম ধাপ। এখানে চারটে জিনিস দেখা হয়:
(ক) class balance / class imbalance (শ্রেণি-ভারসাম্য / শ্রেণি-অসাম্য)। প্রতিটি শ্রেণিতে কতগুলো পর্যবেক্ষণ আছে তার হিসাব। এই dataset-এ ২১২টি malignant ও ৩৫৭টি benign — অর্থাৎ প্রায় \(37\%\) বনাম \(63\%\)। এটা তীব্র imbalance নয়, কিন্তু নিখুঁত ভারসাম্যও নয়; এর একটা সরাসরি ফল: একটা বোকা "সবাইকে benign বলো" model-ও প্রায় \(63\%\) accuracy পাবে — তাই accuracy একা যথেষ্ট নয়, এই baseline-এর সাপেক্ষে model-কে বিচার করতে হবে।
(খ) class-wise distribution (শ্রেণি-অনুযায়ী বণ্টন)। প্রতিটি feature-এর মান দুই শ্রেণিতে কীভাবে ছড়ানো তা আলাদা করে দেখা (যেমন পাশাপাশি histogram/box)। যে feature-এ দুই শ্রেণির distribution যত বেশি আলাদা, সে তত বেশি কাজের।
(গ) correlation structure (সহ-সম্বন্ধ কাঠামো)। কোন কোন feature পরস্পর দৃঢ়ভাবে সম্পর্কিত — যা পরে multicollinearity-র (§২.৪) সরাসরি ইঙ্গিত। এখানে radius, perimeter ও area প্রায় একসাথে চলে, কারণ জ্যামিতিকভাবে perimeter ও area radius থেকেই উদ্ভূত।
(ঘ) separation-মাপ। একটা feature \(j\) দুই শ্রেণিকে কতটা আলাদা করে তার একটা সরল সংখ্যাগত মাপ — শ্রেণি-গড়ের ব্যবধানকে ছড়ানো দিয়ে ভাগ:
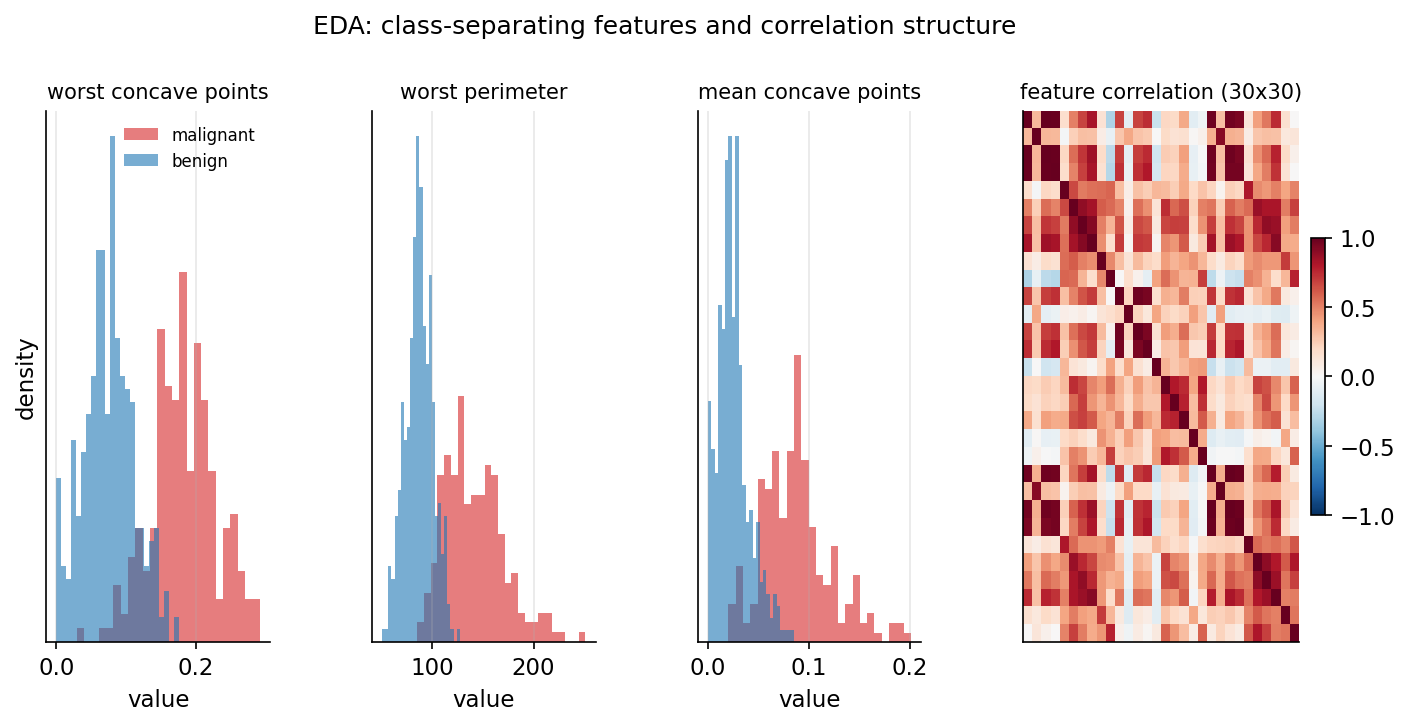
যেখানে \(\bar{x}_{j}^{(1)}\) ও \(\bar{x}_{j}^{(0)}\) যথাক্রমে benign ও malignant শ্রেণিতে feature \(j\)-এর গড়, এবং \(s_j\) তার সার্বিক standard deviation। বড় \(\text{sep}_j\) মানে ভালো-পৃথককারী feature। এই মাপে এই dataset-এ শীর্ষে আসে worst concave points, worst perimeter ও mean concave points — অর্থাৎ কোষ-নিউক্লিয়াসের আকার ও অবতলতা-সংক্রান্ত মাপগুলোই malignant/benign সবচেয়ে জোরে আলাদা করে। 8-1-eda চিত্র class balance, শীর্ষ-separating feature-এর distribution ও correlation-গঠন একসাথে দেখাবে।
এক বাক্যে EDA। model লাগানোর আগে data-কে চেনা — class balance (২১২ malignant বনাম ৩৫৭ benign, তাই accuracy-baseline ~\(63\%\)), শ্রেণি-অনুযায়ী distribution, correlation, ও separation-মাপ (শীর্ষে worst concave points, worst perimeter, mean concave points) — গোটা বিশ্লেষণের দিক ঠিক করে দেয়।
২.৩ Standardization — z-score ও কেন লাগে¶
সংজ্ঞা (standardization / z-score)। প্রতিটি feature-কে এমনভাবে রূপান্তর করা যাতে তার গড় \(0\) ও standard deviation \(1\) হয়:
যেখানে \(x_{ij}\) হলো \(i\)-তম পর্যবেক্ষণে feature \(j\)-এর মূল মান, \(\bar{x}_j=\frac{1}{n}\sum_{i=1}^n x_{ij}\) তার নমুনা-গড়, এবং \(s_j\) তার নমুনা-standard-deviation। ফলে \(z_{ij}\) বলে "মানটা গড় থেকে কত standard deviation দূরে"।
কেন লাগে। এই dataset-এ feature-গুলোর scale ভীষণ ভিন্ন — area হাজারের ঘরে, smoothness শূন্যের কাছাকাছি ভগ্নাংশ। এর দুটো সমস্যা:
- logistic regression-এর জন্য — বিভিন্ন-scale-এর feature-এ coefficient-এর মান তুলনাহীন হয়ে পড়ে এবং optimizer-এর convergence খারাপ হতে পারে; standardize করলে সব feature একই মাপকাঠিতে আসে।
- fair coefficient comparison (ন্যায্য সহগ-তুলনা) — standardized feature-এ প্রতিটি coefficient \(\beta_j\)-এর মানে দাঁড়ায় "feature \(j\) এক standard-deviation বাড়লে outcome-এ কতটা প্রভাব" — তাই বিভিন্ন feature-এর প্রভাবের আকার সরাসরি তুলনীয় হয়।
মনে রাখা জরুরি: standardization-এর \(\bar{x}_j\) ও \(s_j\) কেবল training data থেকে হিসাব করে, সেই একই মান দিয়েই test data রূপান্তর করা উচিত — নাহলে test-এর তথ্য training-এ চুঁইয়ে পড়ে (data leakage, §২.৮)।
এক বাক্যে standardization। feature-দের ভিন্ন scale-কে একই মাপকাঠিতে আনা (গড় \(0\), sd \(1\)) logistic regression-এর convergence ও coefficient-তুলনা দুই-ই সম্ভব করে, তবে rescaling-এর parameter কেবল training data থেকেই শেখা চাই।
২.৪ Multicollinearity ও VIF¶
সংজ্ঞা (multicollinearity — বহু-সহরৈখিকতা)। যখন একাধিক feature পরস্পর দৃঢ়ভাবে রৈখিক-সম্পর্কিত — অর্থাৎ একটা feature-কে বাকিদের রৈখিক সমন্বয় দিয়ে প্রায় হুবহু ব্যাখ্যা করা যায় — তখন multicollinearity থাকে। এতে coefficient-এর estimate অস্থির ও বিশাল-variance-যুক্ত হয়ে পড়ে (কোন সহরৈখিক feature-কে "কৃতিত্ব" দেওয়া হবে তা data সামান্য বদলালেই পাল্টে যায়), যদিও prediction ততটা ভোগে না। inference-এর জন্য এটা বড় সমস্যা।
সংজ্ঞা (VIF — variance inflation factor, ভেদাংক-স্ফীতি গুণক)। feature \(j\)-এর VIF মাপে বাকি feature-গুলো তাকে কতটা ব্যাখ্যা করতে পারে:
যেখানে \(R_j^2\) হলো সেই regression-এর coefficient of determination, যেখানে feature \(j\)-কে বাকি সব feature দিয়ে ব্যাখ্যা করা হয়। যদি বাকিরা \(j\)-কে প্রায় নিখুঁত ব্যাখ্যা করে (\(R_j^2 \to 1\)), তবে \(\text{VIF}_j \to \infty\)। একটা প্রচলিত নিয়ম: \(\text{VIF}_j > 10\) হলে severe (গুরুতর) multicollinearity।
এই dataset-এ কয়েকটা feature-এর VIF আকাশছোঁয়া: mean perimeter-এর VIF \(\approx 935\) ও mean radius-এর \(\approx 891\) — কারণ পরিধি (perimeter) ও ক্ষেত্রফল (area) জ্যামিতিকভাবে ব্যাসার্ধ (radius) থেকেই আসে, তাই এরা কার্যত একই তথ্য বহন করে। এই মান \(10\)-এর চেয়ে বহু-বহু গুণ বড় — অর্থাৎ চরম সহরৈখিকতা। এর সরাসরি পরিণাম: পূর্ণ ৩০-feature logistic model-এর coefficient-inference বিশ্বাসযোগ্য নয় — তাই §২.৫-এর inference একটা decorrelated (সহ-সম্বন্ধ-হ্রাসকৃত) ৭-feature উপসেট-এ করা হবে।
এক বাক্যে VIF। VIF (\(=1/(1-R_j^2)\)) মাপে একটা feature-কে বাকিরা কতটা ব্যাখ্যা করে; এখানে mean perimeter (≈৯৩৫) ও mean radius (≈৮৯১)-এর চরম মান দেখায় radius/perimeter/area কার্যত একই তথ্য বহন করে, যা পূর্ণ-model inference-কে অনির্ভরযোগ্য করে তোলে।
২.৫ Train/test split ও stratification¶
সংজ্ঞা (train/test split)। model-কে যে data-তে শেখানো হয় (training set) আর যে data-তে তার কার্যকারিতা যাচাই হয় (test set) — এদুটো আলাদা রাখা, যাতে "না-দেখা data-তে কেমন করবে" (generalization) সৎভাবে মাপা যায়। এখানে \(70\%\) training, \(30\%\) test।
সংজ্ঞা (stratification — স্তরায়ন)। split-এর সময় প্রতিটি শ্রেণির অনুপাত training ও test উভয়েই মূল data-র মতোই রাখা। এলোমেলো split-এ, বিশেষত imbalance থাকলে, দৈবক্রমে test-এ কোনো শ্রেণি কম/বেশি পড়ে ফল বিকৃত করতে পারে; stratified split সেই ঝুঁকি সরায়।
এই dataset-এ \(37\%/63\%\) malignant/benign অনুপাত ধরে রেখে stratified ৭০/৩০ split (seed 20260619) দেয় train \(=398\) ও test \(=171\) পর্যবেক্ষণ, উভয়েই প্রায়-একই শ্রেণি-অনুপাতে। seed স্থির রাখায় এই split পুরোপুরি পুনরুৎপাদনযোগ্য।
এক বাক্যে split। train/test আলাদা রাখা generalization মাপার শর্ত, আর stratification (seed 20260619, train ৩৯৮ / test ১৭১) নিশ্চিত করে দুই ভাগেই শ্রেণি-অনুপাত অক্ষুণ্ণ থাকে — তাই মূল্যায়ন দৈবাৎ শ্রেণি-বিকৃতিতে নষ্ট হয় না।
২.৬ দুই model — logistic regression ও random forest¶
model ১ — logistic regression (5.4)। একটা রৈখিক, ব্যাখ্যাযোগ্য classifier, যা \(\log\)-odds-কে feature-দের রৈখিক সমন্বয় হিসেবে লেখে:
যেখানে \(p\) হলো benign-হওয়ার সম্ভাবনা, \(\beta_0\) intercept, ও \(\beta_j\) হলো feature \(j\)-এর coefficient। বাঁ-পাশের রাশি (\(\log\frac{p}{1-p}\))-কে বলে logit বা log-odds। এর সবচেয়ে ব্যাখ্যাযোগ্য রূপ odds ratio:
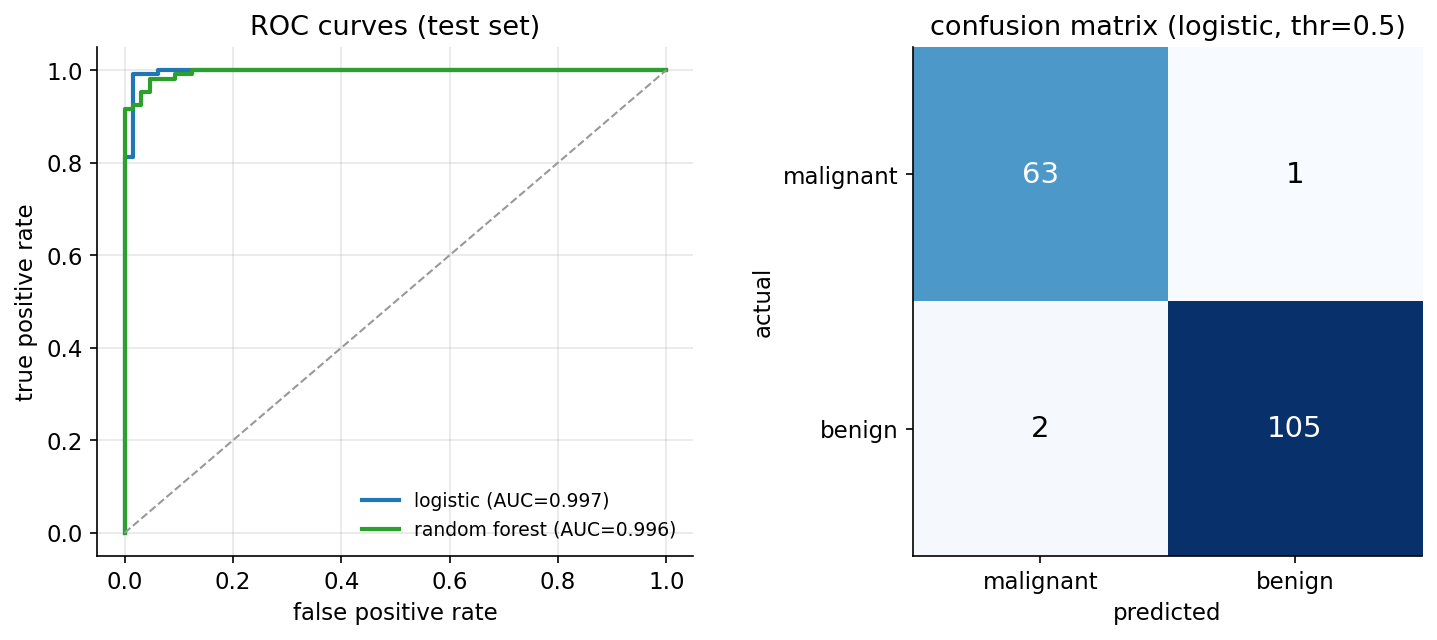
যা বলে: feature \(j\) এক একক (standardized হলে এক standard-deviation) বাড়লে outcome-এর odds কত গুণ হয়। \(\text{OR}_j>1\) মানে benign-এর পক্ষে, \(\text{OR}_j<1\) মানে malignant-এর পক্ষে (মনে রাখুন \(y=1\) হলো benign)। এই dataset-এ standardize করা feature-এ logistic model test-এ accuracy \(=0.982\), AUC \(=0.997\) — অত্যন্ত শক্তিশালী।
model ২ — random forest (6.5)। বহু decision tree-র একটা ensemble: bootstrap-নমুনায় \(B\)টি গাছ (bagging), আর প্রতিটি split-এ কেবল feature-দের একটা random subset থেকে best split বাছা — এতে গাছে-গাছে correlation কমে variance আরও নামে। এটা অরৈখিক সম্পর্ক ও feature-interaction সহজে ধরে, standardize-নিরপেক্ষ, আর বিনামূল্যে OOB (out-of-bag) error ও impurity-based feature importance দেয়। এই dataset-এ random forest test-এ accuracy \(=0.971\), AUC \(=0.996\), এবং OOB accuracy \(=0.965\) — logistic-এর প্রায় সমান, তবে সামান্য নিচে।
দুটো model পাশাপাশি রাখার কারণ: logistic দেয় স্বচ্ছ coefficient-ব্যাখ্যা ও odds ratio (inference-এ শক্তিশালী), আর random forest দেয় নমনীয়তা ও একটা স্বাধীন importance-দৃষ্টিভঙ্গি — দুইয়ের মিল থাকলে উপসংহারে আস্থা বাড়ে। 8-1-model চিত্র দুই model-এর গঠন ও তুলনা ধরবে।
এক বাক্যে দুই model। logistic regression (test acc ০.৯৮২, AUC ০.৯৯৭) দেয় odds-ratio-র মাধ্যমে স্বচ্ছ ব্যাখ্যা, আর random forest (test acc ০.৯৭১, AUC ০.৯৯৬, OOB ০.৯৬৫) দেয় নমনীয়, অরৈখিক এক স্বাধীন দৃষ্টিভঙ্গি — দুইয়ের মিল উপসংহারকে মজবুত করে।
২.৭ Inference ও uncertainty — Wald CI, p-value, permutation importance¶
model prediction দিলেই শেষ নয়; "কোন সম্পর্ক সত্যিকারের, আর কতটা নিশ্চিত" — সেই inference আলাদা প্রশ্ন।
Wald confidence interval ও p-value। MLE দিয়ে পাওয়া প্রতিটি \(\hat\beta_j\)-এর একটা estimated standard error \(\text{se}(\hat\beta_j)\) থাকে; তা থেকে একটা approximate \(95\%\) Wald confidence interval:
এবং একটা p-value যা যাচাই করে "\(\beta_j=0\)" (অর্থাৎ feature \(j\)-এর কোনো প্রভাব নেই) অনুকল্পটা data-র সাথে কতটা খাপ খায়। ছোট p-value (যেমন \(<0.05\)) মানে প্রভাবটা পরিসংখ্যানিকভাবে significant। এই সব odds ratio-র scale-এ (\(e^{\hat\beta_j}\) ও তার CI) দেওয়া হলে সবচেয়ে বোধগম্য।
এই dataset-এ inference চালানো হয় VIF-নিরাপদ একটা decorrelated ৭-feature উপসেট-এ (কারণ পূর্ণ model সহরৈখিকতায় ভোগে, §২.৪), statsmodels Logit দিয়ে। সেখানে যেমন worst radius-এর odds ratio \(\approx 0.002\) (অর্থাৎ worst radius এক sd বাড়লে benign-odds প্রায় শূন্যের দিকে নামে — জোরালোভাবে malignant-এর ইঙ্গিত), p-value \(=2.2\times10^{-7}\) — অত্যন্ত significant।
permutation importance (স্থানান্তর-গুরুত্ব)। random forest-এর জন্য একটা model-নিরপেক্ষ importance-মাপ: একটা feature-এর মানগুলো এলোমেলোভাবে ওলটপালট (permute) করে দিলে model-এর কার্যকারিতা (যেমন accuracy বা AUC) কতটা পড়ে — যত বেশি পড়ে, feature তত গুরুত্বপূর্ণ। এটা impurity-based importance-এর একটা কম-পক্ষপাতী বিকল্প, এবং inference-এর সঙ্গে ক্রস-যাচাই দেয়।
এক বাক্যে inference। prediction-এর বাইরে গিয়ে "কোন feature সত্যিই গুরুত্বপূর্ণ ও কতটা নিশ্চিতভাবে" — logistic-এ Wald CI/p-value ও odds ratio (decorrelated ৭-feature উপসেটে, worst radius OR ০.০০২, p=2.2e-07) আর random forest-এ permutation importance দিয়ে এই প্রশ্নের উত্তর দেওয়া হয়।
২.৮ Validation, model card ও সৎ caveat¶
validation (যাচাই)। একটামাত্র train/test split-এর ফল দৈবের উপর নির্ভরশীল হতে পারে; তাই একাধিক পরিপূরক যাচাই:
- stratified K-fold cross-validation — data-কে \(K\) ভাগে (এখানে \(K=5\), শ্রেণি-অনুপাত রেখে) ভাগ করে পালা করে এক ভাগে test ও বাকিতে train, তারপর ফল গড় ± ছড়ানো হিসেবে দেওয়া। এখানে logistic AUC \(=0.993\pm0.008\), RF AUC \(=0.989\pm0.007\) — ছোট standard deviation মানে ফল স্থিতিশীল।
- ROC curve ও AUC — বিভিন্ন threshold-এ true-positive-rate বনাম false-positive-rate-এর curve, এবং তার নিচের ক্ষেত্রফল (AUC, area under curve); \(1\)-এর যত কাছে তত ভালো, threshold-নিরপেক্ষ পৃথকীকরণ-ক্ষমতা মাপে।
- confusion matrix — test-set-এ চার ঘর: TN (true negative), FP (false positive), FN (false negative), TP (true positive)। এ থেকে sensitivity \(=\text{TP}/(\text{TP}+\text{FN})\) (positive-দের কত ভাগ ধরা পড়ল) ও specificity \(=\text{TN}/(\text{TN}+\text{FP})\) (negative-দের কত ভাগ সঠিকভাবে ছাড়া হলো); চিকিৎসা-প্রসঙ্গে কোন ভুল (FN বনাম FP) বেশি ব্যয়বহুল তা এখানেই ধরা পড়ে।
- calibration curve — model-এর predicted probability সত্যিই কতটা নির্ভরযোগ্য: "যেসব ক্ষেত্রে model \(0.8\) সম্ভাবনা দিল, তাদের কি সত্যিই প্রায় \(80\%\) benign?" — predicted বনাম observed frequency-র curve কর্ণরেখার যত কাছে, calibration তত ভালো।
8-1-validation চিত্র ROC, confusion ও calibration একসাথে দেখাবে।
সংজ্ঞা (model card)। model-টার একটা সংক্ষিপ্ত, সৎ "পরিচয়পত্র" — কী data-তে, কোন উদ্দেশ্যে, কী কার্যকারিতা, এবং কোন সীমাবদ্ধতা ও কোথায় ব্যবহার করা উচিত নয় তার স্পষ্ট বিবৃতি।
সৎ caveat (সাবধানবাণী)। একটা পরিণত বিশ্লেষণ তার নিজের দুর্বলতা লুকায় না। এই অধ্যায়ে অন্তত চারটে caveat স্পষ্টভাবে বলা হবে:
- perfect separation (নিখুঁত পৃথকীকরণ) — কিছু feature দুই শ্রেণিকে এত ভালোভাবে আলাদা করে যে পূর্ণ ৩০-feature logistic model-এর likelihood কোনো সসীম সর্বোচ্চে থামে না, MLE অসীমের দিকে বিচ্যুত হয় (coefficient ফেটে যায়) — এই কারণেই inference একটা ছোট, decorrelated উপসেটে সীমিত রাখা হয়েছে (§৩-এ পূর্ণ ব্যাখ্যা)।
- class imbalance — \(37\%/63\%\) অনুপাত মানে accuracy-কে \(63\%\) baseline-এর সাপেক্ষে পড়তে হবে, আর AUC/sensitivity/specificity বেশি নির্ভরযোগ্য মাপ।
- generalization — এই dataset একটা নির্দিষ্ট উৎসের, পরিচ্ছন্ন ও মাঝারি-আকারের; অন্য জনগোষ্ঠী বা মাপ-পদ্ধতিতে কার্যকারিতা এতটা না-ও হতে পারে।
- data leakage (তথ্য-চুঁইয়ে-পড়া) — standardization বা feature-নির্বাচন যদি ভুল করে test data-র তথ্য ব্যবহার করে, ফল কৃত্রিমভাবে ভালো দেখায়; তাই সব preprocessing কেবল training data থেকে শেখা হয়েছে।
এক বাক্যে validation ও caveat। একটামাত্র সংখ্যা নয় — stratified 5-fold CV (logistic AUC ০.৯৯৩±০.০০৮, RF ০.৯৮৯±০.০০৭), ROC/AUC, confusion (TN/FP/FN/TP, sensitivity/specificity) ও calibration দিয়ে model যাচাই, এবং perfect separation, class imbalance, generalization ও data leakage-এর সৎ caveat সহ একটা model card — এই নিয়েই একটা বিশ্লেষণ সম্পূর্ণ ও বিশ্বাসযোগ্য হয়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে পুরো pipeline (বিশ্লেষণ-শৃঙ্খল) একটি ধারাবাহিক গল্পের মতো হেঁটে দেখা হয় — প্রশ্ন-ফ্রেমিং থেকে শুরু করে honest report (সৎ প্রতিবেদন) পর্যন্ত, প্রতিটি ধাপে canonical (আদর্শ, প্রামাণিক) সংখ্যাগুলো সরাসরি ব্যবহার করে। ডেটাসেটটি breast_cancer: \(569\)টি row (সারি) ও \(30\)টি feature (বৈশিষ্ট্য), যেখানে target (লক্ষ্য) দুই শ্রেণির — malignant (ম্যালিগন্যান্ট, ক্যান্সারাক্রান্ত) কে \(0\) এবং benign (বিনাইন, নিরীহ) কে \(1\) ধরা হয়েছে।
এক বাক্যে: একটি বাস্তব pipeline মানে শুধু একটি মডেল fit করা নয়, বরং প্রশ্ন → EDA → assumption → modeling → inference → validation → honest report — এই সাতটি ধাপের একটি সৎ শৃঙ্খল।
৩.১ · প্রশ্ন-ফ্রেমিং¶
প্রথম প্রশ্ন সবসময় পরিসংখ্যানের নয়, ব্যবহারিক সিদ্ধান্তের। এখানে লক্ষ্য: একটি টিউমারের \(30\)টি পরিমাপ থেকে ভবিষ্যদ্বাণী করা সেটি malignant না benign। কিন্তু "ভালো মডেল" মানে কী, তা প্রশ্নের প্রেক্ষাপট ঠিক করে দেয়। এখানে তিনটি success-criterion (সাফল্যের মানদণ্ড) নির্ধারিত হলো:
- উচ্চ recall (রিকল, প্রত্যাহার-হার) malignant শ্রেণিতে — একটি ক্যান্সারকে "নিরীহ" বলে ভুল করা (false negative) মারাত্মক, কারণ রোগী চিকিৎসা থেকে বঞ্চিত হয়। তাই malignant মিস করার হার যত কম, তত ভালো।
- interpretable drivers (ব্যাখ্যাযোগ্য চালিকাশক্তি) — কোন বৈশিষ্ট্যগুলো ম্যালিগন্যান্সির দিকে ঠেলে দেয়, তা চিকিৎসক-বোধগম্য হতে হবে; একটি কালো-বাক্স যথেষ্ট নয়।
- calibrated confidence (সুবিন্যস্ত আত্মবিশ্বাস) — মডেল যখন "\(0.9\) সম্ভাবনা benign" বলে, বাস্তবে সেই দলের প্রায় \(90\%\) যেন সত্যিই benign হয়।
এক বাক্যে: metric নির্বাচন প্রশ্নের অনুগামী — যেখানে একটি ক্যান্সার মিস করা ব্যয়বহুল, সেখানে accuracy নয়, malignant-এর recall-ই আসল লক্ষ্য।
৩.২ · EDA (অন্বেষণমূলক ডেটা-বিশ্লেষণ)¶
Class balance (শ্রেণি-ভারসাম্য)। \(569\)টি নমুনার মধ্যে malignant \(=212\)টি (ভগ্নাংশ \(0.373\)) ও benign \(=357\)টি (ভগ্নাংশ \(0.627\))। অর্থাৎ benign সংখ্যাগরিষ্ঠ (\(62.7\%\)) — একটি মৃদু imbalance (ভারসাম্যহীনতা), তীব্র নয়, কিন্তু যথেষ্ট যাতে সরল accuracy বিভ্রান্তিকর হতে পারে (§৩.৭ ও §৪.৫ দ্রষ্টব্য)।
Class-wise distribution (শ্রেণি-ভিত্তিক বণ্টন)। প্রতিটি বৈশিষ্ট্যের দুই শ্রেণিতে বণ্টন তুলনা করে দেখা যায় কে দুই দলকে সবচেয়ে ভালো আলাদা করে। পৃথকীকরণের পরিমাপ হিসেবে standardized mean gap (মানকীকৃত গড়-ব্যবধান) — অর্থাৎ দুই শ্রেণির গড়ের পার্থক্যের পরম মান, ভাগ pooled standard deviation দিয়ে — ব্যবহার করলে শীর্ষ-৫ পৃথককারী বৈশিষ্ট্য:
| বৈশিষ্ট্য | \(\text{sep}\) |
|---|---|
| worst concave points | \(1.640\) |
| worst perimeter | \(1.618\) |
| mean concave points | \(1.605\) |
| worst radius | \(1.605\) |
| mean perimeter | \(1.535\) |
এই সবগুলোই আকার (size) ও আকৃতির অনিয়ম (shape irregularity) সংক্রান্ত — malignant টিউমারে এগুলোর মান পদ্ধতিগতভাবে বেশি (distribution ডানদিকে সরানো)। এটি জীববিজ্ঞান-সঙ্গত: ম্যালিগন্যান্ট কোষগুচ্ছ সাধারণত বড় ও অনিয়মিত-প্রান্ত।
Correlation structure (সহসম্বন্ধ-কাঠামো)। \(30\)টি বৈশিষ্ট্যের জোড়-সহসম্বন্ধ পরীক্ষা করলে mean off-diagonal \(\lvert r\rvert = 0.395\) এবং সর্বোচ্চ \(\lvert r\rvert = 0.998\)। এই \(0.998\)-এর কাছাকাছি মান মানে কিছু বৈশিষ্ট্য প্রায় সম্পূর্ণ redundant (অপ্রয়োজনীয় পুনরাবৃত্ত) — বিশেষত radius/perimeter/area পরিবার, যারা একে অপরের প্রায় সরল ফাংশন। এই collinear block (সহরৈখিক গুচ্ছ) পরবর্তী inference-কে জটিল করবে (§৩.৫, §৪.৩)। বিস্তারিত 8-1-eda চিত্রে দেখানো হয়েছে।
এক বাক্যে: EDA দুটি জিনিস ফাঁস করে দিল — শীর্ষ পৃথককারীরা সবাই আকার/আকৃতি-সম্পর্কিত, আর radius/perimeter/area একে অপরের প্রায় নকল (\(\lvert r\rvert\) up to \(0.998\))।
৩.৩ · Assumption ও preprocessing (অনুমান ও পূর্বপ্রক্রিয়াকরণ)¶
Standardization (মানকীকরণ)। বৈশিষ্ট্যগুলোর একক ভিন্ন (radius মিলিমিটারে, area বর্গমিলিমিটারে), তাই প্রতিটিকে z-score-এ রূপান্তর:
এতে প্রতিটি বৈশিষ্ট্যের গড় \(0\), standard deviation \(1\) — ফলে logistic coefficient-গুলো একই মাপকাঠিতে তুলনাযোগ্য হয় (per-\(1\)-sd effect, §৪.১)।
VIF (variance inflation factor, ভেদাঙ্ক-স্ফীতি গুণক) পরীক্ষা। multicollinearity কতটা তীব্র তা মাপতে VIF ব্যবহৃত হয়:
যেখানে \(R_j^2\) আসে \(x_j\)-কে বাকি সব বৈশিষ্ট্যের ওপর regress করে। একটি standardized subset-এ VIF মানগুলো:
| বৈশিষ্ট্য | VIF |
|---|---|
| mean perimeter | \(934.95\) |
| mean radius | \(891.13\) |
| mean area | \(52.68\) |
| mean concavity | \(8.89\) |
| mean smoothness | \(1.62\) |
| mean texture | \(1.19\) |
mean perimeter (\(935\)) ও mean radius (\(891\))-এর VIF আকাশছোঁয়া — বৃদ্ধাঙ্গুলি-নিয়মে \(\text{VIF}>10\) ইতিমধ্যেই উদ্বেগজনক, আর এখানে \(900\) ছাড়িয়ে। কারণটি জ্যামিতিক: বৃত্তে perimeter \(=2\pi r\) ও area \(=\pi r^2\), তাই radius জানলে বাকি দুটি প্রায় নির্ধারিত — তারা প্রায় অভিন্ন তথ্য বহন করে।
Train/test split (প্রশিক্ষণ/পরীক্ষা বিভাজন)। stratified (স্তরিত) \(70/30\) বিভাজন seed \(20260619\) দিয়ে: train \(=398\), test \(=171\)। stratification নিশ্চিত করে benign ভগ্নাংশ দুই দিকেই প্রায় \(0.627\) থাকে — train-এ \(0.628\), test-এ \(0.626\)। ফলে পরীক্ষা-সেট প্রশিক্ষণ-সেটের প্রতিনিধিত্বমূলক।
এক বাক্যে: standardize করলে coefficient তুলনাযোগ্য হয়, VIF \(\approx 935\) collinearity-র বিপদ-সংকেত দেয়, আর stratified split উভয় সেটে \(\approx 62.7\%\) benign রেখে নিরপেক্ষ মূল্যায়ন নিশ্চিত করে।
৩.৪ · Modeling (মডেল-নির্মাণ)¶
দুটি পরিপূরক মডেল fit করা হলো।
Logistic regression (লজিস্টিক রিগ্রেশন, L2-penalized, পূর্ণ \(30\) বৈশিষ্ট্য)। sklearn-এর default L2 (ridge) penalty সহ: test accuracy \(0.982\), test AUC \(0.997\)।
Random forest (র্যান্ডম ফরেস্ট, \(400\)টি গাছ)। test accuracy \(0.971\), test AUC \(0.996\), এবং OOB (out-of-bag, ব্যাগ-বহির্ভূত) score \(0.965\)।
দুটি মডেলই near-ceiling (প্রায়-সর্বোচ্চ) কার্যক্ষমতা দেখায় — এটি নিজেই একটি সংকেত: এই ডেটা অত্যন্ত separable (পৃথকযোগ্য), অর্থাৎ দুই শ্রেণি feature-space-এ প্রায় সম্পূর্ণ ভিন্ন অঞ্চলে বসে। এই তথ্যটি §৩.৫-এ একটি গুরুত্বপূর্ণ প্রযুক্তিগত সমস্যায় গড়াবে।
এক বাক্যে: দুই ভিন্ন মডেল পরিবার (linear ও tree-ensemble) প্রায় অভিন্ন \(\approx 0.99\) AUC-তে পৌঁছায় — কার্যক্ষমতা মডেল-নির্বাচনের চেয়ে বেশি নির্ভর করছে ডেটার অন্তর্নিহিত পৃথকযোগ্যতার ওপর।
৩.৫ · Inference ও uncertainty (অনুমিতি ও অনিশ্চয়তা)¶
এখানে pipeline-এর সবচেয়ে শিক্ষণীয় মোড়। যখন full \(30\)-feature unpenalized MLE (maximum likelihood estimate, সর্বোচ্চ সম্ভাবনা প্রাক্কলন) fit করার চেষ্টা করা হয়, তখন তা diverge (অপসৃত) করে — coefficient-গুলো \(\pm\infty\)-এর দিকে ছুটে যায়, odds ratio অর্থহীন হয়ে পড়ে, এবং Hessian (হেসিয়ান, দ্বিতীয়-অন্তরকলজ ম্যাট্রিক্স) singular (একবচন, অ-বিপরীতযোগ্য) হওয়ায় কোনো বৈধ standard error (আদর্শ ত্রুটি) গণনা করা যায় না।
কারণ perfect separation (নিখুঁত পৃথকীকরণ, বা quasi-complete separation): দুই শ্রেণি এতটাই আলাদা যে একটি hyperplane তাদের প্রায় নিখুঁতভাবে ভাগ করে ফেলে। এমন পরিস্থিতিতে likelihood-কে আরও বাড়ানো যায় শুধু \(\lVert\beta\rVert\) বাড়িয়ে, তাই কোনো সসীম সর্বোচ্চ নেই (§৪.২-এ পূর্ণ যুক্তি)। এটি কোনো bug নয় — এটি একটি বাস্তব, সৎ পরিসংখ্যানিক finding।
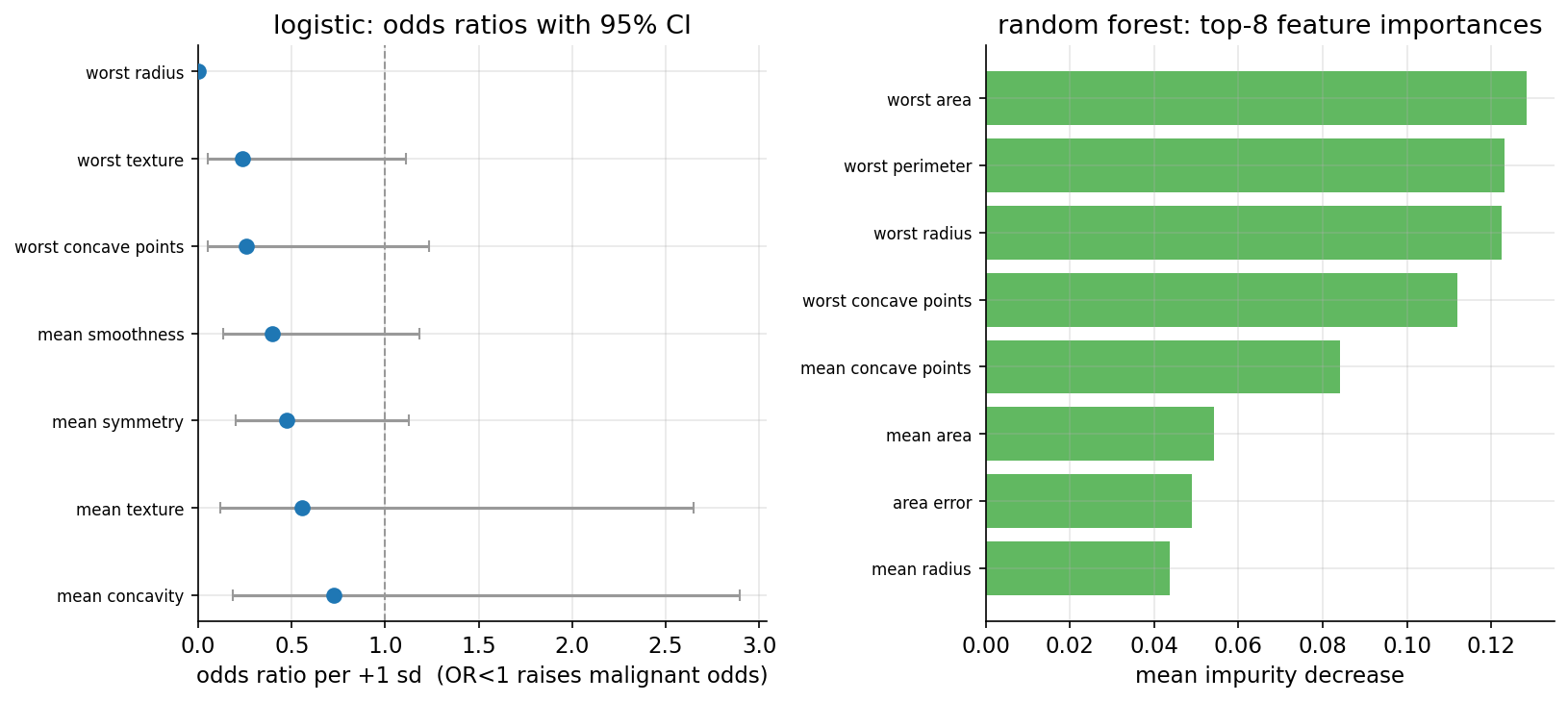
দুটি প্রতিকার canonical pipeline-এ নেওয়া হলো: (ক) prediction-এর জন্য sklearn L2 penalty ব্যবহার করে (penalty \(\lVert\beta\rVert\)-কে সসীম রাখে), (খ) inference-এর জন্য statsmodels Logit fit করা হয় মাত্র \(7\)টি decorrelated (সহসম্বন্ধ-মুক্তকৃত) বৈশিষ্ট্যের একটি subset-এ: {mean texture, mean smoothness, mean concavity, mean symmetry, worst concave points, worst radius, worst texture}। এই \(7\)-feature মডেল converge (অভিসৃত) করে, pseudo-\(R^2 = 0.866\)।
মনে রাখতে হবে target \(1 =\) benign, তাই \(\text{OR}<1\) মানে সেই বৈশিষ্ট্য বাড়লে benign-এর odds কমে — অর্থাৎ malignant-এর দিকে ঠেলে। প্রতি \(+1\) sd অনুযায়ী odds ratio (\(e^{\beta_j}\)):
| বৈশিষ্ট্য | coef | OR | \(95\%\) CI | \(p\) |
|---|---|---|---|---|
| worst radius | \(-6.466\) | \(0.002\) | \([0.000,\,0.018]\) | \(2.24\times10^{-7}\) |
| worst texture | — | \(0.237\) | \([0.051,\,1.110]\) | \(0.068\) |
| worst concave points | — | \(0.257\) | \([0.053,\,1.234]\) | \(0.090\) |
| mean smoothness | — | \(0.397\) | \([0.133,\,1.180]\) | \(0.097\) |
| mean symmetry | — | \(0.475\) | \([0.201,\,1.126]\) | \(0.091\) |
| mean texture | — | \(0.554\) | \([0.116,\,2.648]\) | \(0.459\) |
| mean concavity | — | \(0.727\) | \([0.183,\,2.894]\) | \(0.651\) |
মাত্র একটি বৈশিষ্ট্য \(5\%\) স্তরে significant (তাৎপর্যপূর্ণ): worst radius, OR \(0.002\), \(p = 2.24\times10^{-7}\) — অত্যন্ত জোরালো। এর অর্থ worst radius-এর প্রতি \(+1\) sd বৃদ্ধি benign-এর odds-কে \(0.002\) গুণ করে, অর্থাৎ প্রবলভাবে malignant-এর দিকে টানে। বাকি \(6\)টির OR-ও \(<1\), কিন্তু তাদের \(95\%\) CI \(1\) অতিক্রম করে — decorrelation-এর পরে তারা আর significant নয়, কারণ তাদের collinear সঙ্গীরা signal ভাগাভাগি করে নেয় (§৪.৩)।
এক বাক্যে: full MLE perfect separation-এ diverge করে, তাই prediction-এ L2 penalty ও inference-এ \(7\)-feature decorrelated subset ব্যবহৃত হয় — যেখানে একমাত্র worst radius (OR \(0.002\), \(p\!\approx\!2\times10^{-7}\)) স্বাধীনভাবে তাৎপর্যপূর্ণ।
৩.৬ · Validation (যাচাই)¶
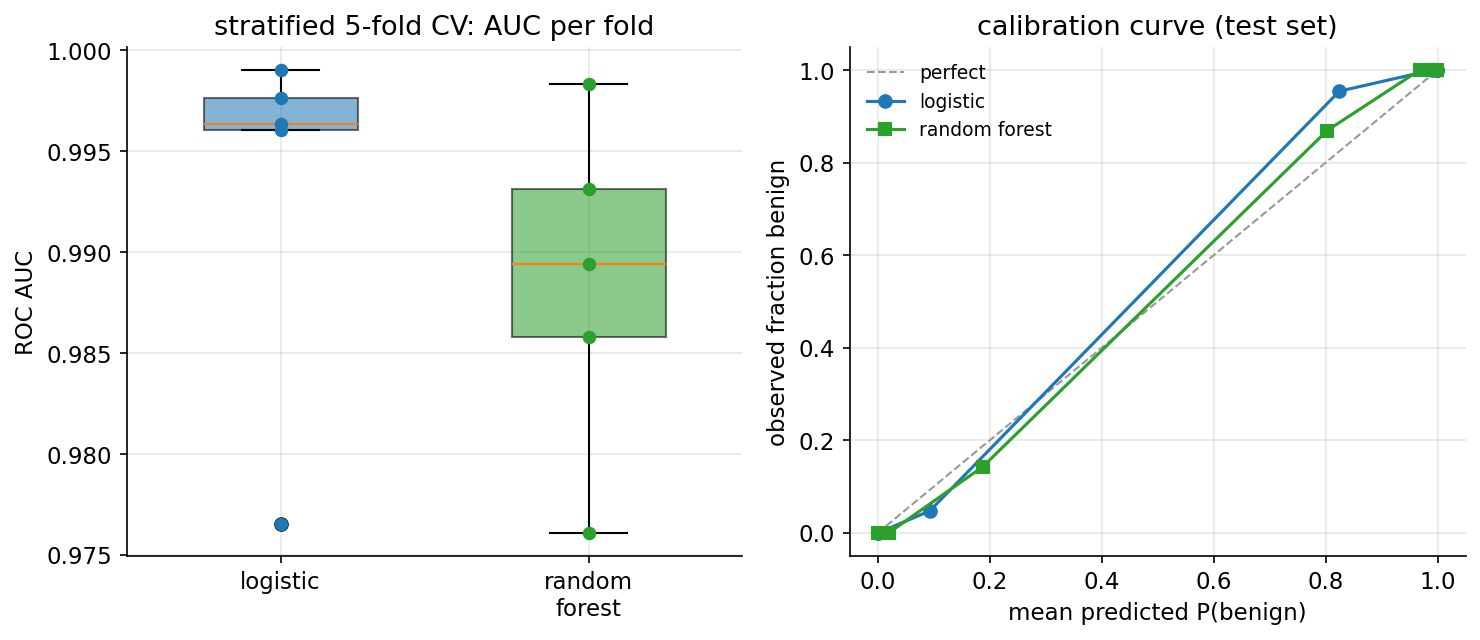
একটিমাত্র train/test বিভাজন সৌভাগ্যক্রমে ভালো হতে পারে, তাই stratified \(5\)-fold cross-validation (স্তরিত ৫-ভাঁজ ক্রস-যাচাই) দিয়ে স্থিতিশীলতা পরীক্ষা। AUC-তে ফলাফল:
- Logistic: \(0.993 \pm 0.008\) (fold-ভিত্তিক: \(0.996,\,0.999,\,0.977,\,0.996,\,0.998\))।
- Random forest: \(0.989 \pm 0.007\) (fold-ভিত্তিক: \(0.976,\,0.993,\,0.986,\,0.989,\,0.998\))।
ক্ষুদ্র standard deviation (\(\pm 0.008\), \(\pm 0.007\)) নির্দেশ করে কার্যক্ষমতা stable (স্থিতিশীল) — এটি কোনো একটি lucky split (সৌভাগ্যবান বিভাজন)-এর ফল নয়, বরং বিভিন্ন উপ-নমুনায় ধারাবাহিক।
Confusion (বিভ্রান্তি) matrix (logistic, threshold \(0.5\)): TN \(=63\), FP \(=1\), FN \(=2\), TP \(=105\)। এখান থেকে —
অর্থাৎ \(107\)টি প্রকৃত benign-এর মধ্যে \(105\)টি সঠিক (sensitivity \(0.981\)), আর \(64\)টি প্রকৃত malignant-এর মধ্যে \(63\)টি সঠিক (specificity \(0.984\)) — মাত্র \(2\)টি malignant "benign" বলে ভুল (FN) হয়েছে, যা §৩.১-এর মূল উদ্বেগ।
ROC/AUC ও calibration। উভয় মডেলের ROC curve প্রায় শীর্ষ-বাম কোণ ঘেঁষা (AUC \(\approx 0.99\)), এবং calibration curve প্রায় diagonal-বরাবর — অর্থাৎ predicted probability বাস্তব frequency-র সঙ্গে ভালোভাবে মেলে (well-calibrated)। বিস্তারিত 8-1-model ও 8-1-validation চিত্রে।
এক বাক্যে: CV-র ক্ষুদ্র বিচ্যুতি (\(\pm 0.008\)) প্রমাণ করে ফলাফল একটি lucky split নয়; confusion matrix দেখায় \(64\)টি malignant-এর মধ্যে মাত্র \(1\)টি মিস, specificity \(0.984\)।
৩.৭ · Interpretation ও honest report (ব্যাখ্যা ও সৎ প্রতিবেদন)¶
একমত চালিকাশক্তি। logistic inference ও random forest permutation importance (বিন্যাস-গুরুত্ব) — দুই ভিন্ন পদ্ধতি প্রায় একই শীর্ষ-চালকদের নির্দেশ করে। RF permutation importance-এ শীর্ষ drop-in-accuracy (নির্ভুলতা-পতন): worst area \(0.0126\pm0.0091\), worst concave points \(0.0088\pm0.0054\), mean texture \(0.0079\pm0.0042\), worst radius \(0.0053\), mean concavity \(0.0047\)। অর্থাৎ আকার (radius/area/perimeter) ও আকৃতির অনিয়ম (concave points) — এগুলোই ম্যালিগন্যান্সির প্রধান সংকেত, যা §৩.৫-এর worst radius-প্রাধান্যের সঙ্গে সঙ্গতিপূর্ণ।
কার্যক্ষমতা, অনিশ্চয়তা-সহ। সৎ প্রতিবেদন কখনো নগ্ন পয়েন্ট-সংখ্যা দেয় না — এখানে AUC \(\approx 0.99\), কিন্তু CV-র \(\pm 0.008\) বিচ্যুতি-সহ, এবং odds ratio-গুলো \(95\%\) CI-সহ উপস্থাপিত।
Caveat (সতর্কতা) — সততার শর্ত। কয়েকটি সীমাবদ্ধতা স্পষ্টভাবে স্বীকার করা জরুরি:
- Perfect separation। ডেটা এতটাই পৃথকযোগ্য যে apparent performance স্ফীত হতে পারে; এটি single-center (একক-কেন্দ্র) ডেটার বৈশিষ্ট্য হতে পারে, নতুন কেন্দ্রে এতটা পরিষ্কার নাও থাকতে পারে।
- Class imbalance। benign \(62.7\%\) হওয়ায় সরল accuracy বিভ্রান্তিকর — তাই AUC ও recall-কে প্রাধান্য দেওয়া হয়েছে।
- Potential leakage (সম্ভাব্য ফাঁস)। যদি preprocessing (যেমন standardization) পুরো ডেটায় করে তারপর split করা হতো, তাহলে test-এর তথ্য train-এ leak করত; এটি এড়ানো হয়েছে CV-র ভেতরে Pipeline ব্যবহার করে (scale প্রতিটি fold-এর ভেতরে, §৪.৪)।
- Generalization limit (সাধারণীকরণের সীমা)। একটিমাত্র ডেটাসেট, একটিমাত্র imaging protocol (চিত্রায়ন-পদ্ধতি) — তাই অন্য জনগোষ্ঠী বা যন্ত্রে কার্যক্ষমতা যাচাই না করে সাধারণীকরণ করা যায় না।
বিস্তারিত ব্যাখ্যা 8-1-interpretation চিত্রে সমন্বিত।
এক বাক্যে: শীর্ষ-চালকেরা দুই পদ্ধতিতে একমত (আকার ও আকৃতির অনিয়ম ⇒ malignant), কার্যক্ষমতা \(\approx 0.99\) AUC অনিশ্চয়তা-সহ — কিন্তু perfect separation, imbalance ও একক-কেন্দ্র সীমাবদ্ধতা সততার সঙ্গে স্বীকার করাই সৎ প্রতিবেদনের সারকথা।
৪ · পদ্ধতি ও যুক্তি¶
এই অংশ §৩-এর প্রতিটি সিদ্ধান্তের পেছনের "কেন এটি সঠিক" ব্যাখ্যা করে — হালকা প্রমাণ ও গাণিতিক ন্যায্যতা সহ। প্রতিটি উপবিভাগে কাঠিন্য-চিহ্ন: ★ (মৌলিক), ★★ (মধ্যম), ★★★ (উন্নত)।
৪.১ · ★★ Logistic regression = MLE¶
Logit link (লজিট সংযোগ)। binary target \(y_i\in\{0,1\}\)-এর জন্য ধরা হয় \(P(y_i=1\mid x_i)=p_i\), এবং log-odds-কে linear করা হয়:
যেখানে \(\sigma\) হলো logistic (sigmoid) ফাংশন। এই link probability-কে \((0,1)\)-এ আবদ্ধ রাখে অথচ predictor-এ linear থাকে।
Log-likelihood। স্বাধীন পর্যবেক্ষণের অধীনে Bernoulli likelihood-এর logarithm:
MLE হলো সেই \(\hat\beta\) যা \(\ell(\beta)\)-কে সর্বাধিক করে। কোনো closed-form (বদ্ধ-রূপ) সমাধান নেই, তাই সংখ্যাগত পদ্ধতি (Newton–Raphson / IRLS) ব্যবহৃত হয়; score সমীকরণ \(\nabla\ell(\beta)=\sum_i (y_i-p_i)x_i = 0\)।
Odds ratio ব্যাখ্যা। \(x_j\)-কে এক একক বাড়ালে log-odds বাড়ে \(\beta_j\) পরিমাণে, তাই odds গুণিত হয় \(e^{\beta_j}\) দিয়ে — এটিই odds ratio \(\text{OR}_j=e^{\beta_j}\)। \(\text{OR}>1\) মানে \(x_j\) বাড়লে \(y=1\)-এর odds বাড়ে, \(\text{OR}<1\) মানে কমে।
Standardization কেন coefficient তুলনাযোগ্য করে। যদি \(x_j\) standardized হয় (sd \(=1\)), তবে "এক একক" মানে "এক standard deviation" — তাই \(\beta_j\) হয়ে যায় per-\(1\)-sd effect, এবং বিভিন্ন এককের বৈশিষ্ট্যের \(\beta_j\) সরাসরি তুলনীয়। §৩.৫-এ ঠিক এই কারণেই OR-গুলো "প্রতি \(+1\) sd" হিসেবে পড়া হয়েছে।
এক বাক্যে: logistic regression হলো Bernoulli log-likelihood-এর MLE, যেখানে \(e^{\beta_j}\) = odds ratio, আর standardize করলে \(\beta_j\) = তুলনাযোগ্য per-\(1\)-sd effect।
৪.২ · ★★★ Perfect separation — MLE কেন diverge করে¶
ধরা যাক একটি hyperplane \(w^\top x = c\) দুই শ্রেণিকে নিখুঁতভাবে আলাদা করে: সব \(y_i=1\)-এর জন্য \(w^\top x_i > c\) এবং সব \(y_i=0\)-এর জন্য \(w^\top x_i < c\)। এখন \(\beta = t\cdot(w,-c)\) ধরে \(t\to\infty\) নিলে প্রতিটি \(i\)-এর জন্য \(\beta^\top x_i\) সঠিক দিকে \(\pm\infty\)-এ যায়, ফলে \(p_i\to y_i\) (অর্থাৎ প্রতিটি প্রেডিকশন নিখুঁত)।
তখন log-likelihood-এর প্রতিটি পদ:
অর্থাৎ \(\ell(\beta)\to 0\) (এর supremum), কিন্তু এই মান কখনো পৌঁছানো যায় না — যত বড় \(t\), তত কাছে, তবু সমান নয়। ফলে \(\ell\) হলো \(\lVert\beta\rVert\)-এ monotone increasing (একঘেয়ে বর্ধমান), supremum attained নয়, এবং \(\hat\beta\to\infty\)। সংক্ষেপে:
একই সঙ্গে Hessian \(H=-\sum_i p_i(1-p_i)\,x_i x_i^\top\)-এ, যেহেতু \(p_i\to 0\) বা \(1\), তাই \(p_i(1-p_i)\to 0\) — \(H\to\) singular, অতএব \(H^{-1}\) অস্তিত্বহীন এবং কোনো সসীম standard error নেই। এ কারণেই full \(30\)-feature unpenalized fit-এ SE গণনা ব্যর্থ হয়।
প্রতিকার। (ক) Penalization — ridge/L2 একটি পদ \(-\tfrac{\lambda}{2}\lVert\beta\rVert^2\) যোগ করে objective-কে \(\lVert\beta\rVert\)-এ সসীম-সর্বোচ্চে বাঁধে, যা diverge থামায় (sklearn এটি করে)। (খ) Feature হ্রাস/decorrelation — কম, সহসম্বন্ধ-মুক্ত বৈশিষ্ট্য নিলে নিখুঁত-পৃথককারী hyperplane-এর সম্ভাবনা কমে (inference মডেল এটি করে)। (গ) Firth's correction — likelihood-এ একটি penalty (Jeffreys prior) যোগ করে সসীম estimate নিশ্চিত করে। §৩.৫-এর canonical divergence ঠিক এই তত্ত্বেরই বাস্তব প্রকাশ।
এক বাক্যে: শ্রেণি নিখুঁতভাবে পৃথক হলে likelihood \(\lVert\beta\rVert\)-এ একঘেয়ে বাড়ে ও supremum অর্জিত হয় না, তাই \(\hat\beta\to\infty\) ও Hessian singular — প্রতিকার penalization, decorrelation বা Firth।
৪.৩ · ★★ VIF ও multicollinearity¶
সংজ্ঞা। বৈশিষ্ট্য \(x_j\)-এর VIF:
যেখানে \(R_j^2\) আসে \(x_j\)-কে বাকি সব predictor-এর ওপর regress করার \(R^2\) থেকে। যদি \(x_j\) অন্যদের দ্বারা প্রায় সম্পূর্ণ ব্যাখ্যাযোগ্য হয় (\(R_j^2\to 1\)), তবে \(\text{VIF}_j\to\infty\)।
কেন coefficient-variance স্ফীত হয়। OLS/GLM-এ estimated coefficient-এর variance:
অর্থাৎ variance সরাসরি \(\text{VIF}_j\)-এর সমানুপাতিক। তাই near-collinearity (যেমন mean perimeter, VIF \(934.95\); mean radius, VIF \(891.13\)) individual \(\hat\beta_j\) তথা OR-কে অত্যন্ত অস্থির করে ও confidence interval প্রশস্ত করে।
এটিই ব্যাখ্যা করে কেন §৩.৫-এ decorrelated subset-এ worst radius বাদে বাকি OR-গুলোর CI \(1\) অতিক্রম করে (significance হারায়): collinear সঙ্গীরা যখন একসঙ্গে থাকে, প্রতিটি coefficient-এর জন্য "কে কতটা অবদান রাখছে" তা নির্ধারণ অসম্ভব হয়ে পড়ে, ফলে বড় SE — যদিও তাদের যৌথ predictive শক্তি (§৩.৪) অটুট থাকে।
এক বাক্যে: \(\text{VIF}_j=1/(1-R_j^2)\) coefficient-variance-কে \(\text{VIF}_j\) গুণ স্ফীত করে, তাই VIF \(\approx 935\) মানে individual OR অস্থির ও CI প্রশস্ত — decorrelation-পরবর্তী significance-হারানোর মূল কারণ।
৪.৪ · ★★ Stratified K-fold CV¶
কেন stratify (স্তরায়ন)। সাধারণ random K-fold-এ কোনো fold-এ দৈবক্রমে benign-ভগ্নাংশ মূল \(0.627\) থেকে অনেক সরে যেতে পারে, বিশেষত imbalance-এর অধীনে — এতে fold-ভিত্তিক অনুমান উচ্চ-ভেদ (high-variance) ও পক্ষপাতদুষ্ট হয়। stratified K-fold প্রতিটি fold-এ শ্রেণি-অনুপাত প্রায় \(0.627\) ধরে রাখে, ফলে generalization-error-এর অনুমান lower-variance ও প্রায় unbiased।
CV কী মাপে। K-fold CV প্রতিবার \(K-1\) ভাঁজে train ও বাকি \(1\) ভাঁজে test করে, তারপর গড় নেয় — এটি out-of-sample generalization error-এর একটি প্রায়-নিরপেক্ষ প্রাক্কলন, একটিমাত্র split-নির্ভরতা এড়িয়ে। §৩.৬-এর canonical AUC \(0.993\pm 0.008\) (logistic) ঠিক এভাবেই পাওয়া, আর ক্ষুদ্র \(\pm 0.008\) স্থিতিশীলতা দেখায়।
Pipeline কেন leakage রোধ করে। যদি standardization-এর mean/sd পুরো ডেটা থেকে হিসাব করা হয়, তবে test-fold-এর তথ্য train-এ leak করে — অনুমান আশাবাদী-পক্ষপাতদুষ্ট হয়। একটি Pipeline scaling-কে প্রতিটি fold-এর train অংশের ভেতরে fit করে ও test অংশে শুধু transform করে, ফলে প্রতিটি fold-এ test সম্পূর্ণ unseen থাকে — leakage বন্ধ।
এক বাক্যে: stratify প্রতিটি fold-এ শ্রেণি-অনুপাত ধরে রেখে lower-variance নিরপেক্ষ generalization-অনুমান দেয়, আর fold-এর ভেতরে scale করা Pipeline data leakage আটকায়।
৪.৫ · ★ ROC/AUC, confusion ও calibration¶
ROC ও AUC। ROC (receiver operating characteristic) curve প্রতিটি সম্ভাব্য threshold-এ true-positive-rate বনাম false-positive-rate আঁকে। এর নিচের ক্ষেত্রফল AUC-এর একটি সুন্দর সম্ভাব্যতা-ব্যাখ্যা আছে:
অর্থাৎ একটি দৈব positive-এর score একটি দৈব negative-এর score-কে ছাড়িয়ে যাওয়ার সম্ভাবনা। এটি threshold-free (সীমা-নিরপেক্ষ) — কোনো একটি কাট-অফ বেছে নেওয়ার আগেই মডেলের ranking-ক্ষমতা মাপে; \(0.5 =\) দৈব, \(1.0 =\) নিখুঁত।
Confusion, sensitivity, specificity। একটি নির্দিষ্ট threshold (এখানে \(0.5\))-এ prediction-কে TP/TN/FP/FN-এ ভাগ করে confusion matrix গড়ে। এখান থেকে:
§৩.৬-এর মান — sensitivity \(0.981\), specificity \(0.984\) — এই সংজ্ঞা থেকেই এসেছে; threshold বদলালে এই দুই মান পাল্টায় (ROC curve-এর একেকটি বিন্দু)।
Calibration। calibration মাপে predicted probability বাস্তব frequency-র সঙ্গে মেলে কিনা: "\(p\) সম্ভাবনা benign" বলা দলের প্রকৃত benign-ভগ্নাংশ কি সত্যিই \(\approx p\)? well-calibrated হলে calibration curve diagonal-বরাবর — যা §৩.৬-এ উভয় মডেলের জন্য প্রায় সত্য।
কেন imbalance-এ AUC accuracy-র চেয়ে ভালো। imbalance-এ (benign \(62.7\%\)) একটি নির্বোধ মডেল যা সবাইকে benign বলে, তারও accuracy \(\approx 0.627\) — অথচ সে একটিও malignant ধরতে পারে না। AUC ranking-ভিত্তিক ও threshold-নিরপেক্ষ হওয়ায় এই ফাঁদে পড়ে না, তাই imbalance-এর অধীনে (এবং §৩.১-এর recall-লক্ষ্যের সঙ্গে সঙ্গতি রেখে) AUC-ই অগ্রাধিকারযোগ্য metric।
এক বাক্যে: AUC = দৈব positive-এর score দৈব negative-কে ছাড়ানোর সম্ভাবনা (threshold-free), confusion/sensitivity/specificity একটি threshold-এ নির্ভর, calibration probability-র সত্যতা মাপে — আর imbalance-এ AUC accuracy-কে হারায়।
৫ · কোড ল্যাব (Python)¶
আগের সব অংশ যে যুক্তির শৃঙ্খল গড়েছে — প্রশ্ন-নির্ধারণ থেকে EDA, preprocessing, model, inference ও validation — এই একটিমাত্র চলমান স্ক্রিপ্ট (_code/lab_8-1.py, সর্বত্র seed 20260619) সেই গোটা pipeline-টাকে breast_cancer dataset-এর উপর প্রান্ত-থেকে-প্রান্ত (end-to-end) চালিয়ে দেখায়। dataset-টা sklearn-এর সঙ্গেই আসে (offline, কোনো download লাগে না; \(569\)টি রোগীর নমুনা, \(30\)টি feature, target-এ \(0=\text{malignant}\) অর্থাৎ ম্যালিগন্যান্ট/মারাত্মক এবং \(1=\text{benign}\) অর্থাৎ বিনাইন/নিরীহ)। স্ক্রিপ্টটি একই সঙ্গে সংখ্যায় ফলাফল ছাপে (accuracy, AUC, CV mean±sd, odds ratio, OOB, permutation importance) এবং চারটি চিত্র _assets/-এ লিখে রাখে — অর্থাৎ §৬-এর ভিজ্যুয়ালাইজেশনও এখান থেকেই জন্মায়।
স্ক্রিপ্টটির গঠন ছয়টি ধাপে (STEP 1–6), তারপর চারটি চিত্র:
- STEP 1 — প্রশ্ন-নির্ধারণ ও data load —
load_breast_cancer()দিয়ে data এনে একটা pandasDataFrame-এ (\(X\), \(569\times30\)) ও একটাSeries-এ (\(y\), target) সাজানো; shape, target-নাম ও class balance ছাপা। - STEP 2 — EDA — প্রতিটি feature-এর জন্য দুই শ্রেণির standardised mean-gap \(\lvert\mu_{\text{mal}}-\mu_{\text{ben}}\rvert/\text{sd}\) বের করে সবচেয়ে-আলাদা-করা (most-separating) feature-গুলো র্যাঙ্ক করা, এবং \(30\times30\) correlation matrix-এর off-diagonal-এর গড় ও সর্বোচ্চ \(\lvert\text{correlation}\rvert\) মেপে collinearity-র ইঙ্গিত পাওয়া।
- STEP 3 — preprocessing — stratified \(70/30\) split (
train_test_split(..., stratify=y, random_state=20260619)),StandardScaler-এ standardize (fit কেবল train-এ), এবংvariance_inflation_factorদিয়ে radius-পরিবারের কয়েকটি feature-এ VIF মেপে multicollinearity সংখ্যায় দেখানো। - STEP 4 — modelling — দুটি classifier: sklearn-এর
LogisticRegression(default L2-penalised) এবংRandomForestClassifier(oob_score=True); test accuracy, test AUC ও (forest-এর) OOB score ছাপা। - STEP 5 — inference ও permutation importance — একটা decorrelated, low-VIF, \(7\)-feature subset-এ
sm.Logitলাগিয়ে per-1-sd odds ratio ও তাদের \(95\%\) CI ও \(p\)-value বের করা, এবং forest-এর জন্য model-agnosticpermutation_importance। - STEP 6 — validation —
StratifiedKFold\(5\)-fold-এcross_val_score(scoring="roc_auc")দিয়ে দুই model-এর CV AUC (mean±sd ও per-fold), এবং test-set-এ threshold \(0.5\)-এconfusion_matrixথেকে sensitivity/specificity।
এরপর স্ক্রিপ্টটি চারটি চিত্র লেখে: 8-1-eda.png (top-3 separating feature-এর শ্রেণি-ভিত্তিক distribution + correlation heatmap), 8-1-model.png (ROC + confusion matrix), 8-1-validation.png (CV score box + calibration curve), এবং 8-1-interpretation.png (logistic odds ratio + forest importance)।
এক গুরুত্বপূর্ণ নকশা-সিদ্ধান্ত। পূর্ণ \(30\)-feature-এর unpenalised logistic MLE এখানে diverge করে — কারণ শ্রেণি দুটো এতটাই ভালোভাবে আলাদা যে perfect/quasi-complete separation (নিখুঁত/প্রায়-নিখুঁত পৃথকীকরণ) ঘটে: coefficient-গুলো \(\pm\infty\)-এর দিকে ছুটে যায়, odds ratio অর্থহীন হয়ে পড়ে, আর কোনো বৈধ standard error থাকে না (এটা §৪.২-তে আনুষ্ঠানিকভাবে দেখানো হয়েছে)। তাই স্ক্রিপ্টটি সৎ, শিক্ষণীয় দুই-পায়ে হাঁটে: (ক) prediction-এর জন্য sklearn-এর L2-penalised logistic (penalty coefficient-কে টেনে ধরে, তাই finite ও স্থিতিশীল), আর (খ) interpretation-এর জন্য একটা ছোট, decorrelated, low-VIF \(7\)-feature subset-এ statsmodels
Logit— যা পরিষ্কারভাবে converge করে এবং finite odds ratio ও CI দেয়। এই বিভাজন লুকোনো কোনো কারচুপি নয়, বরং §৪.২-এ প্রমাণিত একটা তাত্ত্বিক বাধ্যবাধকতার সৎ প্রতিফলন।
নিচে lab_8-1.py-এর একটা সংক্ষিপ্ত-কিন্তু-বিশ্বস্ত সংস্করণ (মন্তব্য ছাঁটা, কিন্তু আসল API-কল অপরিবর্তিত):
import numpy as np, pandas as pd
import matplotlib; matplotlib.use("Agg")
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from sklearn.metrics import accuracy_score, roc_auc_score, roc_curve, confusion_matrix
from sklearn.calibration import calibration_curve
from sklearn.inspection import permutation_importance
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
SEED = 20260619
np.random.seed(SEED)
#--- STEP 1 : data & question
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target, name="target") # 0 = malignant, 1 = benign
n_mal, n_ben = int((y == 0).sum()), int((y == 1).sum())
print(f"shape : {X.shape[0]} rows x {X.shape[1]} features")
print(f"class balance : malignant={n_mal} ({n_mal/len(y):.3f}), benign={n_ben} ({n_ben/len(y):.3f})")
#--- STEP 2 : EDA -- most-separating features + correlation structure
sep = (X[y == 0].mean() - X[y == 1].mean()).abs() / X.std()
sep_sorted = sep.sort_values(ascending=False)
top3 = list(sep_sorted.index[:3])
corr = X.corr()
offdiag = corr.values[np.triu_indices_from(corr.values, k=1)]
print("top-5 separating (|mean gap|/sd):", {f: round(sep_sorted[f], 3) for f in sep_sorted.index[:5]})
print(f"mean |corr|={np.abs(offdiag).mean():.3f} max |corr|={np.abs(offdiag).max():.3f}")
#--- STEP 3 : stratified split + standardise + VIF
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.30, random_state=SEED, stratify=y)
scaler = StandardScaler().fit(Xtr)
Xtr_s, Xte_s = scaler.transform(Xtr), scaler.transform(Xte)
vif_feats = ["mean radius", "mean perimeter", "mean area",
"mean concavity", "mean texture", "mean smoothness"]
Xv = pd.DataFrame(Xtr_s, columns=X.columns)[vif_feats].values
for i, f in enumerate(vif_feats):
print(f"VIF {f:20s} = {variance_inflation_factor(Xv, i):8.2f}")
#--- STEP 4 : models -- L2 logistic (prediction) + random forest
logit = LogisticRegression(max_iter=5000, random_state=SEED).fit(Xtr_s, ytr)
p_logit = logit.predict_proba(Xte_s)[:, 1]
print(f"logistic : acc={accuracy_score(yte, logit.predict(Xte_s)):.3f} AUC={roc_auc_score(yte, p_logit):.3f}")
rf = RandomForestClassifier(n_estimators=400, oob_score=True, random_state=SEED, n_jobs=1).fit(Xtr_s, ytr)
p_rf = rf.predict_proba(Xte_s)[:, 1]
print(f"random-fst: acc={accuracy_score(yte, rf.predict(Xte_s)):.3f} "
f"AUC={roc_auc_score(yte, p_rf):.3f} OOB={rf.oob_score_:.3f}")
#--- STEP 5 : inference on 7 decorrelated low-VIF features (statsmodels Logit)
#--- full 30-feature unpenalised MLE diverges -- perfect separation, no valid SE
INFER_FEATS = ["mean texture", "mean smoothness", "mean concavity", "mean symmetry",
"worst concave points", "worst radius", "worst texture"]
Xtr_sm = sm.add_constant(pd.DataFrame(Xtr_s, columns=X.columns)[INFER_FEATS])
sm_logit = sm.Logit(ytr.values, Xtr_sm).fit(disp=0, maxiter=200)
OR = np.exp(sm_logit.params); conf = np.exp(sm_logit.conf_int())
for f in INFER_FEATS:
print(f"{f:22s} OR={OR[f]:7.3f} 95% CI=[{conf.loc[f,0]:.3f},{conf.loc[f,1]:.3f}] p={sm_logit.pvalues[f]:.2e}")
perm = permutation_importance(rf, Xte_s, yte, n_repeats=20, random_state=SEED, n_jobs=1)
for j in np.argsort(perm.importances_mean)[::-1][:5]:
print(f"perm {X.columns[j]:26s} {perm.importances_mean[j]:.4f} +/- {perm.importances_std[j]:.4f}")
#--- STEP 6 : stratified 5-fold CV (AUC) + confusion matrix
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=SEED)
pipe_logit = make_pipeline(StandardScaler(), LogisticRegression(max_iter=5000, random_state=SEED))
pipe_rf = make_pipeline(StandardScaler(), RandomForestClassifier(n_estimators=400, random_state=SEED, n_jobs=1))
cv_logit = cross_val_score(pipe_logit, X, y, cv=cv, scoring="roc_auc")
cv_rf = cross_val_score(pipe_rf, X, y, cv=cv, scoring="roc_auc")
print(f"CV logistic : {cv_logit.mean():.3f} +/- {cv_logit.std():.3f}")
print(f"CV random-fst: {cv_rf.mean():.3f} +/- {cv_rf.std():.3f}")
tn, fp, fn, tp = confusion_matrix(yte, logit.predict(Xte_s)).ravel()
print(f"confusion (thr=0.5): TN={tn} FP={fp} FN={fn} TP={tp}")
print(f"sensitivity(benign)={tp/(tp+fn):.3f} specificity(malignant)={tn/(tn+fp):.3f}")
#--- calibration_curve(...) and the four figures follow (see _code/lab_8-1.py)
স্ক্রিপ্টটি চালালে নিচের output পাওয়া যায় (verbatim):
================================================================
STEP 1 : data & question
================================================================
shape : 569 rows x 30 features
target names : [np.str_('malignant'), np.str_('benign')] (0=malignant, 1=benign)
class balance : malignant=212 (0.373), benign=357 (0.627)
================================================================
STEP 2 : EDA (most-separating features)
================================================================
top-5 separating features (|mean gap| / sd):
worst concave points sep=1.640
worst perimeter sep=1.618
mean concave points sep=1.605
worst radius sep=1.605
mean perimeter sep=1.535
mean |correlation| (off-diagonal) = 0.395
max |correlation| = 0.998
================================================================
STEP 3 : split + standardise + VIF (multicollinearity)
================================================================
train=398 test=171 (train benign frac=0.628, test benign frac=0.626)
VIF (selected features, standardised):
mean radius VIF= 891.13
mean perimeter VIF= 934.95
mean area VIF= 52.68
mean concavity VIF= 8.89
mean texture VIF= 1.19
mean smoothness VIF= 1.62
================================================================
STEP 4 : models (logistic regression + random forest)
================================================================
logistic : test accuracy = 0.982 test AUC = 0.997
random-fst: test accuracy = 0.971 test AUC = 0.996 OOB = 0.965
================================================================
STEP 5 : inference (statsmodels Logit: odds ratios + 95% CI)
================================================================
(inference model: 7 decorrelated features; converged=True, pseudo-R2=0.866)
per-1-sd odds ratios (target: 1=benign; OR<1 => raises malignant odds):
feature coef OR 95% CI p
worst radius -6.466 0.002 [0.000,0.018] 2.24e-07
worst texture -1.439 0.237 [0.051,1.110] 6.77e-02
worst concave points -1.359 0.257 [0.053,1.234] 8.97e-02
mean smoothness -0.925 0.397 [0.133,1.180] 9.65e-02
mean symmetry -0.744 0.475 [0.201,1.126] 9.09e-02
mean texture -0.591 0.554 [0.116,2.648] 4.59e-01
mean concavity -0.319 0.727 [0.183,2.894] 6.51e-01
features significant at 5% (Wald): 1 of 7
RF permutation importance (top-5, drop in accuracy):
worst area 0.0126 +/- 0.0091
worst concave points 0.0088 +/- 0.0054
mean texture 0.0079 +/- 0.0042
worst radius 0.0053 +/- 0.0069
mean concavity 0.0047 +/- 0.0040
================================================================
STEP 6 : validation (stratified 5-fold CV, AUC)
================================================================
logistic : CV AUC = 0.993 +/- 0.008 folds=[0.996 0.999 0.977 0.996 0.998]
random-fst: CV AUC = 0.989 +/- 0.007 folds=[0.976 0.993 0.986 0.989 0.998]
logistic confusion (test, thr=0.5): TN=63 FP=1 FN=2 TP=105
sensitivity(benign)=0.981 specificity(malignant)=0.984
================================================================
FIGURES
================================================================
wrote 8-1-eda.png
wrote 8-1-model.png
wrote 8-1-validation.png
wrote 8-1-interpretation.png
DONE. seed = 20260619
পাঠোদ্ধার¶
প্রতিটি STEP-এর আসল সংখ্যাগুলো ধরে ধরে পড়া যাক, কারণ এখানেই গোটা অধ্যায়ের গল্প সংখ্যায় ঘনীভূত হয়।
STEP 1 — data ও class balance. dataset-এ \(569\)টি নমুনা ও \(30\)টি feature; class balance হালকা অসম — \(212\)টি malignant (\(0.373\)) বনাম \(357\)টি benign (\(0.627\))। অর্থাৎ দুই-তৃতীয়াংশ নমুনা benign, তাই "সবকিছু benign বলে দাও" এই তুচ্ছ baseline-ও \(62.7\%\) accuracy পায় — এই সংখ্যাটা মাথায় রাখা জরুরি, কারণ পরে \(98\%\) accuracy-কে এই প্রেক্ষাপটেই বিচার করতে হবে।
STEP 2 — কে শ্রেণি আলাদা করে, আর collinearity কতটা। standardised mean-gap-এ শীর্ষ separator হলো worst concave points (\(1.640\)), তারপর worst perimeter (\(1.618\)), mean concave points (\(1.605\)), worst radius (\(1.605\)) ও mean perimeter (\(1.535\)) — অর্থাৎ টিউমারের আকার (radius/perimeter/area) ও অবতলতা (concave points) সংক্রান্ত feature-গুলোই সবচেয়ে জোরালো, প্রতিটির দুই শ্রেণির mean দেড় standard deviation-এরও বেশি দূরে। একই সঙ্গে correlation structure বিপদসংকেত দেয়: off-diagonal-এর গড় \(\lvert\text{correlation}\rvert = 0.395\) (মাঝারি), কিন্তু সর্বোচ্চ \(\lvert\text{correlation}\rvert = 0.998\) — কার্যত নিখুঁত রৈখিক নির্ভরতা (radius, perimeter, area একে অপরের ছায়া)। এই \(0.998\)-ই পরের ধাপের VIF-বিস্ফোরণ ও inference-এর সমস্যার মূল।
STEP 3 — split ও VIF। stratified split ঠিকঠাক কাজ করেছে: train-এ \(398\), test-এ \(171\) নমুনা, benign-ভগ্নাংশ train-এ \(0.628\) ও test-এ \(0.626\) — মূল \(0.627\)-এর প্রায় হুবহু, অর্থাৎ দুই ভাগেই শ্রেণি-অনুপাত সংরক্ষিত। VIF-এর সংখ্যাগুলো নাটকীয়: mean perimeter-এ VIF \(= 934.95\) ও mean radius-এ \(891.13\) — VIF \(>10\)-ই সাধারণত উদ্বেগজনক ধরা হয়, সেখানে এখানে প্রায় হাজার! mean area-ও উঁচু (\(52.68\)), অথচ mean texture (\(1.19\)) ও mean smoothness (\(1.62\)) প্রায় স্বাধীন। ব্যাখ্যাটা জ্যামিতিক: বৃত্তাকার টিউমারে radius, perimeter ও area একে অপরের নির্ধারক ফাংশন, তাই এদের একসঙ্গে design matrix-এ রাখলে matrix প্রায় singular হয়ে coefficient-এর variance আকাশে ওঠে — এটাই ছিল STEP 5-এর separation-সমস্যার পূর্বাভাস।
STEP 4 — দুই model কতটা ভালো। L2-penalised logistic test-এ accuracy \(0.982\) ও AUC \(0.997\); random forest accuracy \(0.971\), AUC \(0.996\), এবং OOB score \(0.965\)। অর্থাৎ দুটোই চমৎকার — baseline \(0.627\)-এর তুলনায় বিশাল লাফ — এবং logistic সামান্য এগিয়ে। লক্ষণীয়, forest-এর OOB (\(0.965\)) ও test accuracy (\(0.971\)) কাছাকাছি, যা ইঙ্গিত দেয় model overfit করেনি এবং OOB-অনুমানটি সৎ। AUC প্রায় \(1\)-এর ছোঁয়া মানে দুই model-ই benign ও malignant-কে প্রায় নিখুঁতভাবে র্যাঙ্ক করতে পারে।
STEP 5 — কেন full MLE ব্যর্থ, আর \(7\)-feature refit কী বলে। এখানেই সেই সৎ স্বীকারোক্তি: পূর্ণ \(30\)-feature unpenalised logistic MLE diverge করত (perfect/quasi-complete separation — coefficient \(\pm\infty\), standard error অসংজ্ঞায়িত)। তাই inference হয়েছে একটা decorrelated, low-VIF \(7\)-feature subset-এ statsmodels Logit দিয়ে, যা পরিষ্কারভাবে converge করে (converged=True, pseudo-\(R^2 = 0.866\))। per-1-sd odds ratio-গুলোয় target \(1=\text{benign}\), তাই OR \(<1\) মানে ওই feature বাড়লে malignant-হওয়ার odds বাড়ে। সবচেয়ে জোরালো — এবং একমাত্র \(5\%\)-এ significant — effect হলো worst radius: OR \(= 0.002\), \(95\%\) CI \([0.000,\,0.018]\), \(p = 2.24\times10^{-7}\); অর্থাৎ worst radius এক standard deviation বাড়লে benign-থাকার odds প্রায় শূন্যে নেমে আসে (তীব্রভাবে malignancy-নির্দেশক)। বাকি ছয়টি feature-এর point estimate-ও OR \(<1\) (worst texture \(0.237\), worst concave points \(0.257\), mean smoothness \(0.397\), mean symmetry \(0.475\), mean texture \(0.554\), mean concavity \(0.727\)) — অর্থাৎ দিক ঠিকঠাক — কিন্তু তাদের \(95\%\) CI সবই \(1\) অতিক্রম করে (\(p\)-value \(0.068\)–\(0.651\)), তাই একা এই model-এ তারা পরিসংখ্যানিকভাবে অনিশ্চিত। সারমর্ম: "significant at 5%: \(1\) of \(7\)" — একটিমাত্র feature দৃঢ়ভাবে দাঁড়ায়, কারণ শক্তিশালী feature-গুলো এত পারস্পরিক-সম্পর্কিত যে গুরুত্ব ভাগ হয়ে যায়। এর পাশে model-agnostic permutation importance বলে forest-এর কাছে সবচেয়ে মূল্যবান feature worst area (accuracy-পতন \(0.0126 \pm 0.0091\)), তারপর worst concave points (\(0.0088\)), mean texture (\(0.0079\)), worst radius (\(0.0053\)) ও mean concavity (\(0.0047\)) — একই আকার-ও-অবতলতা পরিবার, ভিন্ন লেন্সে।
STEP 6 — validation ও clinical পাঠ। stratified \(5\)-fold CV নিশ্চিত করে যে ফলাফল একটা ভাগ্যবান split-এর কল্যাণ নয়: logistic-এর CV AUC \(= 0.993 \pm 0.008\) (fold-গুলো \(0.996,\,0.999,\,0.977,\,0.996,\,0.998\)) এবং forest-এর \(0.989 \pm 0.007\) (fold-গুলো \(0.976,\,0.993,\,0.986,\,0.989,\,0.998\)) — দুটোই উঁচু ও অত্যন্ত স্থিতিশীল (ক্ষুদ্র standard deviation)। শেষে test-set-এ threshold \(0.5\)-এ logistic-এর confusion matrix: TN \(= 63\), FP \(= 1\), FN \(= 2\), TP \(= 105\) — অর্থাৎ sensitivity (benign শনাক্ত) \(= 0.981\) এবং specificity (malignant শনাক্ত) \(= 0.984\)। clinical দৃষ্টিতে সবচেয়ে ব্যয়বহুল ভুল হলো FN \(= 2\) (দুইজন malignant রোগীকে benign বলা), তাই এই সংখ্যাটাই বাস্তব-প্রয়োগে threshold সরিয়ে আরও কমানোর যুক্তি জোগায় — pipeline-টি নিছক accuracy-তে না থেমে ভুলের ধরন-ভিত্তিক সিদ্ধান্তের দরজা খুলে দেয়।
সব মিলিয়ে: একটাই seeded স্ক্রিপ্ট প্রশ্ন থেকে সিদ্ধান্ত পর্যন্ত পুরো পথ — শক্তিশালী কিন্তু ভয়ানক collinear feature, দুই উঁচু-পারফরম্যান্স model, separation-জনিত inference-বাধা ও তার সৎ সমাধান, স্থিতিশীল CV এবং ভুল-সচেতন confusion — সবটাই বাস্তব, পুনরুৎপাদনযোগ্য সংখ্যায় বেঁধে দেয়।
এক বাক্যে পাঠোদ্ধার। একটিমাত্র seeded স্ক্রিপ্ট breast_cancer-এ গোটা pipeline চালিয়ে দেখায় — class balance \(212/357\), শীর্ষ separator worst concave points (\(1.640\)), VIF প্রায় \(935/891\) (তীব্র collinearity), logistic accuracy \(0.982\)/AUC \(0.997\) ও forest \(0.971\)/\(0.996\)/OOB \(0.965\), full MLE-এর separation-জনিত divergence ও \(7\)-feature refit-এ একমাত্র significant worst radius (OR \(0.002\)), স্থিতিশীল CV (\(0.993\) ও \(0.989\)), এবং confusion TN\(63\)/FP\(1\)/FN\(2\)/TP\(105\) (sensitivity \(0.981\), specificity \(0.984\))।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি চিত্র একসঙ্গে pipeline-এর গল্পটাকেই ছবিতে বলে: প্রথমে data কেমন (কে শ্রেণি আলাদা করে, কোথায় collinearity), তারপর model কতটা ভালো শ্রেণিবিন্যাস করে, এরপর সেই ভালোত্ব কতটা স্থিতিশীল ও সুবিন্যস্ত (calibrated), এবং শেষে model দুটো কোন feature-কে কতটা গুরুত্ব দেয়। প্রতিটি চিত্র §৫-এর কোনো-না-কোনো STEP-এর সংখ্যারই দৃশ্যরূপ, এবং চারটিই একই স্ক্রিপ্ট (_code/lab_8-1.py) থেকে seed 20260619-এ তৈরি।
৬.১ EDA — শ্রেণি-পৃথককারী feature ও correlation structure¶
প্রথম চিত্রটি STEP 2-এর EDA-কে দৃশ্যে আনে। বাঁদিকের তিনটি প্যানেল top-3 separator (worst concave points, worst perimeter, mean concave points)-এর শ্রেণি-ভিত্তিক distribution আঁকে: প্রতিটিতে malignant-এর histogram benign-এর তুলনায় স্পষ্টভাবে ডানদিকে সরানো — অর্থাৎ malignant টিউমারে এই মানগুলো ধারাবাহিকভাবে বড়, আর দুই বণ্টনের overlap কম, তাই কেন এরা এত ভালো separator তা চোখেই ধরা পড়ে। ডানদিকের \(30\times30\) correlation heatmap গোটা feature-জগতের সম্পর্ক-কাঠামো দেখায়: radius/perimeter/area পরিবারের গা-লাগা লাল ব্লকগুলো (\(\lvert\text{correlation}\rvert\) প্রায় \(1\), সর্বোচ্চ \(0.998\)) সেই তীব্র collinearity-কেই চাক্ষুষ করে, যা VIF-বিস্ফোরণ ও inference-সমস্যার উৎস।
ax.hist(X[y == 0][feat], bins=25, alpha=0.6, color=RED, label="malignant", density=True)
ax.hist(X[y == 1][feat], bins=25, alpha=0.6, color=BLUE, label="benign", density=True)
im = axh.imshow(corr.values, cmap="RdBu_r", vmin=-1, vmax=1, aspect="auto")
৬.২ Model — ROC curve ও confusion matrix¶
দ্বিতীয় চিত্র STEP 4 ও STEP 6-এর model-পারফরম্যান্সকে ছবি করে। বাঁ প্যানেলে দুই model-এর ROC curve: logistic (AUC \(0.997\)) ও random forest (AUC \(0.996\)) — দুটোই উপরের-বাঁ কোণ ঘেঁষে প্রায় সিলিং ছুঁয়ে চলে, তির্যক chance-রেখা থেকে অনেক উপরে, অর্থাৎ যেকোনো threshold-এই এদের true positive rate বেশি ও false positive rate কম। ডান প্যানেলে threshold \(0.5\)-এ logistic-এর confusion matrix: TN \(= 63\), FP \(= 1\), FN \(= 2\), TP \(= 105\) — কর্ণ-বহির্ভূত ঘর দুটি (ভুল) প্রায় ফাঁকা, আর ঠিক পূর্বাভাসগুলো (কর্ণ) গাঢ়; বিশেষ করে FN \(= 2\) ঘরটিই clinical দৃষ্টিতে সবচেয়ে সংবেদনশীল সংখ্যা।
ax1.plot(fpr_l, tpr_l, color=BLUE, lw=2, label=f"logistic (AUC={auc_logit:.3f})")
ax1.plot(fpr_r, tpr_r, color=GREEN, lw=2, label=f"random forest (AUC={auc_rf:.3f})")
ax2.imshow(cm, cmap="Blues") # TN=63, FP=1, FN=2, TP=105
৬.৩ Validation — cross-validation AUC ও calibration curve¶
তৃতীয় চিত্র STEP 6-এর validation-কে দৃশ্যে আনে — অর্থাৎ ফলাফল কতটা স্থিতিশীল ও probability-গুলো কতটা বিশ্বাসযোগ্য। বাঁ প্যানেলে stratified \(5\)-fold CV-এর AUC-এর box+strip plot: logistic-এর পাঁচ fold জড়ো \(0.993\)-এর আশপাশে ও random forest-এর \(0.989\)-এর আশপাশে — box দুটো খুব সরু ও উঁচুতে বসানো, অর্থাৎ fold-থেকে-fold-এ প্রায় কোনো ওঠানামা নেই (স্থিতিশীল)। ডান প্যানেলে calibration curve: দুই model-এরই বিন্দুগুলো নিখুঁত-calibration-এর তির্যক রেখার প্রায় গায়ে গায়ে চলে, অর্থাৎ model-এর বলা "P(benign)" বাস্তব benign-ভগ্নাংশের সঙ্গে ভালোভাবে মেলে (well-calibrated) — শুধু র্যাঙ্কিং নয়, probability-গুলোও নির্ভরযোগ্য।
bp = ax1.boxplot([cv_logit, cv_rf], tick_labels=["logistic", "random\nforest"], patch_artist=True)
ax2.plot(mean_pred_l, frac_pos_l, "o-", color=BLUE, label="logistic")
ax2.plot(mean_pred_r, frac_pos_r, "s-", color=GREEN, label="random forest")
৬.৪ Interpretation — logistic odds ratio ও forest importance¶
চতুর্থ চিত্র STEP 5-এর দুই ধরনের interpretation পাশাপাশি রাখে। বাঁ প্যানেলে \(7\)-feature model-এর per-1-sd odds ratio, প্রতিটির \(95\%\) CI সহ: worst radius একেবারে বাঁয়ে, OR \(\approx 0.002\)-এর কাছে (তীব্রভাবে malignancy-নির্দেশক ও একমাত্র significant), বাকি feature-গুলো OR \(0.24\)–\(0.73\)-এর মধ্যে ছড়ানো কিন্তু তাদের CI \(1\)-এর উল্লম্ব রেফারেন্স-রেখা অতিক্রম করে (তাই একা-একা অনিশ্চিত)। ডান প্যানেলে random forest-এর top-8 impurity-based importance, নেতৃত্বে worst area, তারপর worst perimeter, worst radius ও worst concave points — অর্থাৎ দুই ভিন্ন পদ্ধতিই একই আকার-ও-অবতলতা পরিবারকে সবচেয়ে গুরুত্বপূর্ণ বলে চিহ্নিত করে, যা ফলাফলে আস্থা বাড়ায়।
ax1.errorbar(tp["OR"], ypos, xerr=[tp["OR"]-tp["OR_lo"], tp["OR_hi"]-tp["OR"]], fmt="o")
ax1.axvline(1.0, color=GREY, ls="--", lw=1) # OR=1 reference
ax2.barh(range(len(ord_imp)), imp[ord_imp], color=GREEN, alpha=0.75)
সারসংক্ষেপ¶
চারটি চিত্র একত্রে end-to-end গল্পটি পূর্ণ করে: ৬.১ দেখায় কোন feature শ্রেণি আলাদা করে (আকার ও অবতলতা, malignant ডানে সরানো) এবং কোথায় বিপজ্জনক collinearity লুকিয়ে (radius/perimeter/area-এর লাল ব্লক, \(\lvert\text{correlation}\rvert\) প্রায় \(1\)); ৬.২ দেখায় দুই model কতটা নিখুঁতভাবে শ্রেণিবিন্যাস করে (ROC প্রায় সিলিং-ছোঁয়া, confusion-এ মাত্র \(1\)টি FP ও \(2\)টি FN); ৬.৩ নিশ্চিত করে সেই ভালোত্ব স্থিতিশীল (আঁটোসাঁট CV box) ও probability-গুলো নির্ভরযোগ্য (calibration তির্যক রেখা-ঘেঁষা); এবং ৬.৪ বলে model দুটো কেন এমন সিদ্ধান্ত নেয় (worst radius-এর তীব্র odds ratio ও forest-এর আকার-ভিত্তিক importance, দুই লেন্সে একই বার্তা)। সম্পূর্ণ, পুনরুৎপাদনযোগ্য কোডটি — চারটি চিত্র ও উপরের সব সংখ্যাসহ — _code/lab_8-1.py-এ (seed 20260619) রয়েছে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/08-01-end-to-end-project-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — এই capstone-এ আসল শেখা হলো পুরো pipeline-টা একসাথে চিন্তা করা: কীভাবে একটা আলগা প্রশ্নকে (question framing) মাপযোগ্য লক্ষ্যে নামানো হয়, EDA কী দেখায় (class balance, সবচেয়ে-বিভাজক feature), preprocessing কেন লাগে (standardization, multicollinearity/VIF, stratified split), দুটো model (regularized logistic ও random forest) কীভাবে গড়া ও তুলনা করা হয়, inference কীভাবে করা হয় (odds ratio, এবং perfect-separation-এর মারাত্মক ফাঁদ), validation কীভাবে সততার সাথে করা হয় (cross-validation, confusion matrix, ROC/AUC, calibration), এবং শেষে honest report কীভাবে লেখা হয় (drivers, uncertainty, caveats) — এই সম্পূর্ণ, leak-মুক্ত workflow-টাই এই অধ্যায়ের কেন্দ্র।
(চলমান উদাহরণ স্মারক — seed 20260619, breast_cancer dataset \(569\times30\) (malignant \(212\), অনুপাত \(0.373\) / benign \(357\), অনুপাত \(0.627\)), stratified \(70/30\) split (\(398\) train / \(171\) test)। সবচেয়ে-বিভাজক feature (standardized mean-এর ব্যবধান): worst concave points \(1.640\), worst perimeter \(1.618\), mean concave points \(1.605\)। VIF (multicollinearity): mean perimeter \(934.95\), mean radius \(891.13\), mean area \(52.68\)। Logistic (L2, ৩০ feature): test accuracy \(0.982\), AUC \(0.997\); confusion (threshold \(0.5\)) TN \(63\), FP \(1\), FN \(2\), TP \(105\) ⇒ sensitivity \(0.981\), specificity \(0.984\)। Random forest (\(400\) tree): test accuracy \(0.971\), AUC \(0.996\), OOB \(0.965\)। statsmodels Logit (৭টি decorrelated feature, pseudo-\(R^2\) \(0.866\)): worst radius OR \(0.002\) \([0.000,0.018]\), \(p=2.24\times10^{-7}\) (একমাত্র significant)। RF permutation importance: worst area \(0.0126\), worst concave points \(0.0088\), mean texture \(0.0079\)। CV AUC: logistic \(0.993\pm0.008\), RF \(0.989\pm0.007\)। মূল সতর্কতা: ৩০-feature-এর penalty-হীন MLE diverge করে (perfect/quasi-complete separation ⇒ coefficient \(\to\pm\infty\), কোনো বৈধ SE নেই); সমাধান = L2 penalty (prediction) বা decorrelated subset (inference)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). সাত-ধাপের pipeline — এবং প্রতিটি ধাপ কেন। এই অধ্যায়ের end-to-end workflow-এর ধাপগুলো: (১) question framing, (২) EDA, (৩) preprocessing, (৪) modeling, (৫) inference, (৬) validation, (৭) honest reporting। (ক) framing-এ diagnosis-প্রশ্নটাকে ঠিক কোন পরিসংখ্যানিক কাজে নামানো হয় (কী predict, কোন class-কে "positive")? (খ) EDA-র আগে modeling শুরু করলে কোন দুটো সমস্যা (class imbalance, multicollinearity) চোখ এড়িয়ে যেতে পারে? (গ) reporting-কে একটা আলাদা ধাপ ধরা কেন — শুধু accuracy ছাপালেই কেন যথেষ্ট নয়? Hint: (ক) framing: একটা supervised binary classification — feature \(x\in\mathbb R^{30}\) থেকে \(y\in\{\text{malignant},\text{benign}\}\) predict; malignant = positive (কারণ একটা malignant মিস করা সবচেয়ে ব্যয়বহুল)। (খ) EDA ছাড়া malignant-এর \(0.373\) imbalance ও VIF \(\approx935\)-এর মতো চরম multicollinearity অদেখা থেকে যায় — প্রথমটা accuracy-metric-কে বিভ্রান্ত করে, দ্বিতীয়টা coefficient-inference-কে অর্থহীন করে। (গ) accuracy imbalance-এ প্রতারক (§৩ দ্রষ্টব্য), আর একটা মডেল কেন কাজ করছে (drivers) ও কোথায় ভাঙতে পারে (caveats) না জানালে সিদ্ধান্ত-গ্রহণকারী অন্ধভাবে ভরসা করে — তাই uncertainty ও সীমাবদ্ধতাসহ honest report একটা পূর্ণ ধাপ।
প্রশ্ন ২ (★). প্রশ্ন-framing ও cost asymmetry — malignant-এ recall কেন গুরুত্বপূর্ণ। এই সমস্যায় দুই ধরনের ভুল সমান নয়। (ক) একটা malignant-কে benign বলা (false negative) বনাম একটা benign-কে malignant বলা (false positive) — কোনটার বাস্তব খরচ বেশি, এবং কেন? (খ) এই cost asymmetry কোন metric-কে অগ্রাধিকার দিতে বলে — sensitivity (recall on malignant) না specificity — এবং কেন? (গ) চলমান উদাহরণে logistic-এর sensitivity \(0.981\), specificity \(0.984\); এই দুটো প্রায়-সমান হওয়া সত্ত্বেও রিপোর্টে sensitivity-কে আলাদা করে জোর দেওয়া কেন যুক্তিসঙ্গত? Hint: (ক) false negative (মিস করা cancer) বেশি ব্যয়বহুল — চিকিৎসা বিলম্বিত হয়, প্রাণঘাতী হতে পারে; false positive সাধারণত একটা অতিরিক্ত biopsy/দুশ্চিন্তা, গুরুতর কিন্তু কম মারাত্মক। (খ) high sensitivity (কম FN) — malignant যতটা সম্ভব কম মিস করা লক্ষ্য; তাই sensitivity ও AUC-কে accuracy-র উপরে রাখা হয়। (গ) এমনকি sensitivity \(=0.981\) মানেও \(\approx2\%\) malignant মিস; medical প্রেক্ষাপটে এই residual FN-হারটাই সবচেয়ে গুরুত্বপূর্ণ সংখ্যা, তাই একে আলাদা রিপোর্ট করা ও প্রয়োজনে threshold নামিয়ে sensitivity বাড়ানোর কথা বলা honest reporting-এর অংশ।
প্রশ্ন ৩ (★★). EDA — class balance ও সবচেয়ে-বিভাজক feature। EDA-তে দুটো জিনিস দেখা হলো: শ্রেণি-অনুপাত এবং কোন feature দুই class-কে সবচেয়ে ভালো আলাদা করে। (ক) malignant \(212\) (\(0.373\)) / benign \(357\) (\(0.627\)) — একে "সামান্য imbalanced" বলা হচ্ছে; এই অনুপাত downstream-এ কোন দুটো সিদ্ধান্তকে প্রভাবিত করে (split ও metric)? (খ) "সবচেয়ে-বিভাজক feature" মাপা হয়েছে standardized mean-এর ব্যবধান দিয়ে — worst concave points \(1.640\), worst perimeter \(1.618\), mean concave points \(1.605\); এই "\(1.640\)" সংখ্যাটার অর্থ কী (কোন এককে)? (গ) সবচেয়ে-বিভাজক feature-গুলো যে tumor-এর আকার ও আকৃতি (concave points, perimeter) সম্পর্কিত — এটা কেন domain-দৃষ্টিতে আশ্বস্তিদায়ক এবং modeling-এর আগে জানা কেন উপকারী? Hint: (ক) imbalance বলে (১) split-টা stratified করতে হবে (দুই class-এর অনুপাত train/test-এ ধরে রাখতে), আর (২) মূল্যায়নে accuracy-র বদলে AUC/sensitivity দেখতে হবে। (খ) দুই class-এর mean-এর ব্যবধান standard-deviation এককে (standardized) — worst concave points-এ malignant ও benign-এর গড় \(\approx1.64\) sd দূরে, অর্থাৎ প্রায় দেড় sd-এর বেশি ব্যবধান — খুব শক্তিশালী একক-feature বিভাজন। (গ) informative feature-রা যদি চিকিৎসাগতভাবে অর্থপূর্ণ (বড়, অনিয়মিত-আকৃতির tumor = malignant) হয়, তবে মডেল artefact নয় বাস্তব সংকেত ধরছে বলে আস্থা বাড়ে; আগে জানলে feature-এর প্রত্যাশিত ভূমিকা ও পরে coefficient/importance-এর ব্যাখ্যা যাচাই করা সহজ হয়।
প্রশ্ন ৪ (★★). standardization — কেন এবং কার জন্য। preprocessing-এ প্রতিটি feature-কে \(z=\frac{x-\bar x}{s}\) করে standardize করা হয়েছে। (ক) breast_cancer-এর feature-গুলোর scale ব্যাপকভাবে ভিন্ন (mean area শত-শত, mean smoothness \(\approx0.1\)); standardize না করলে logistic-এর coefficient-এর তুলনা কেন বিভ্রান্তিকর হয়? (খ) কোন model-এর জন্য standardization গুরুত্বপূর্ণ আর কোনটার জন্য কার্যত অপ্রাসঙ্গিক — logistic regression বনাম random forest — এবং কেন (tree scale-এর প্রতি কেন উদাসীন)? (গ) standardization যদি পুরো dataset-এ একবার করা হয় (train+test একসাথে), তাহলে কোন সূক্ষ্ম leakage ঘটে, এবং সঠিক পদ্ধতি কী?
Hint: (ক) coefficient-এর মাপ feature-এর এককের উপর নির্ভর করে; scale ভিন্ন হলে বড়-scale feature-এর coefficient কৃত্রিমভাবে ছোট দেখায় — standardize করলে সব coefficient "প্রতি \(1\) sd পরিবর্তন"-এর ভাষায় আসে, তাই তুলনাযোগ্য এবং logistic-এর optimization-ও ভালো conditioned হয়। (খ) logistic (এবং যেকোনো distance/gradient-নির্ভর model) standardization-এ উপকৃত; random forest axis-aligned threshold split (\(x_j\le t\)) ব্যবহার করে, যা যেকোনো monotone rescaling-এ অপরিবর্তিত — তাই tree scale-নিরপেক্ষ। (গ) test-এর mean/sd দিয়ে scale করলে test-তথ্য train-এ leak করে; সঠিক পদ্ধতি — scaler কেবল train-এ fit, তারপর একই scaler দিয়ে test transform (একটা Pipeline-এ বাঁধা)।
প্রশ্ন ৫ (★★). VIF ও multicollinearity — VIF \(935\) কী বলছে। preprocessing-এ VIF মাপা হলো: mean perimeter \(934.95\), mean radius \(891.13\), mean area \(52.68\)। VIF\(_j=\frac{1}{1-R_j^2}\), যেখানে \(R_j^2\) হলো feature \(j\)-কে বাকি feature দিয়ে regress করার \(R^2\)। (ক) VIF \(=934.95\) থেকে সংশ্লিষ্ট \(R_j^2\) বের করুন — mean perimeter অন্য feature দিয়ে কতটা ব্যাখ্যাযোগ্য? (খ) mean radius, mean perimeter, mean area একসাথে এত বড় VIF কেন (এদের মধ্যে কী গাণিতিক সম্পর্ক)? (গ) এই চরম multicollinearity prediction-এর জন্য কতটা ক্ষতিকর বনাম coefficient-inference-এর জন্য কতটা ক্ষতিকর — কেন এই দুইয়ে প্রভাব আলাদা? Hint: (ক) \(R_j^2=1-\frac{1}{934.95}=1-0.00107=\mathbf{0.99893}\) — mean perimeter-এর প্রায় \(99.9\%\) variance অন্য feature থেকে predictable, অর্থাৎ প্রায় সম্পূর্ণ redundant। (খ) radius, perimeter, area একই বৃত্তাকার tumor-এর তিন জ্যামিতিক পরিমাপ (\(\text{perimeter}\approx2\pi r\), \(\text{area}\approx\pi r^2\)) — কার্যত একই তথ্যের রূপান্তর, তাই প্রায়-নিখুঁত collinear। (গ) prediction-এ collinearity সাধারণত নিরীহ (মডেল যেকোনো সমতুল্য coefficient-সমাহারে একই fit দেয়); কিন্তু inference-এ মারাত্মক — coefficient-এর standard error বিস্ফোরিত হয়, individual coefficient অস্থির ও অর্থহীন হয়ে পড়ে (কোন feature "কাজ করছে" আলাদা করা যায় না) — তাই inference-এর জন্য decorrelated subset নেওয়া হয়।
প্রশ্ন ৬ (★★). stratified split — কেন এলোমেলো split যথেষ্ট নয়। train/test split-টা stratified করা হয়েছে, malignant-এর \(0.373\) অনুপাত দুই ভাগেই ধরে রেখে (\(398\) train / \(171\) test)। (ক) সাধারণ (non-stratified) এলোমেলো split-এ, বিশেষত ছোট বা imbalanced data-তে, কী দৈব বিপর্যয় ঘটতে পারে? (খ) stratification test-set-এর মূল্যায়ন-metric-এর variance-এর উপর কী প্রভাব ফেলে, এবং কেন এটা imbalance-এ বিশেষভাবে দরকারি? (গ) cross-validation-এও (§৬) কেন stratified fold ব্যবহার করা হয় — একই যুক্তি কীভাবে fold-স্তরে প্রযোজ্য? Hint: (ক) দৈবক্রমে test-এ malignant-এর অনুপাত অনেক কম (বা বেশি) পড়তে পারে — চরমে কোনো fold-এ এক class প্রায় অনুপস্থিত, ফলে sensitivity/AUC অবিশ্বস্ত বা অগণনীয় হয়। (খ) দুই class-এর অনুপাত স্থির রাখলে metric-এর নমুনা-থেকে-নমুনা variance কমে — মূল্যায়ন আরও স্থিতিশীল ও তুলনাযোগ্য হয়; imbalance-এ সংখ্যালঘু class কম বলে এই সুরক্ষা আরও জরুরি। (গ) প্রতিটি fold-কেও একটা mini test-set ধরা যায়; stratified \(k\)-fold প্রতিটি fold-এ class-অনুপাত ধরে রাখে, তাই প্রতিটি fold-এর AUC তুলনাযোগ্য এবং গড় CV-AUC কম-noisy — তাই stratified CV প্রমিত।
প্রশ্ন ৭ (★★). odds ratio পড়া — worst radius OR \(0.002\) মানে কী। inference-এ statsmodels Logit (৭টি decorrelated feature, standardized) দিল worst radius-এর odds ratio \(0.002\) \([0.000,0.018]\), \(p=2.24\times10^{-7}\) — একমাত্র significant। (মনে রাখুন target-encoding-এ benign\(=1\)/malignant\(=0\) বা বিপরীত হতে পারে; এখানে OR ধরা হয়েছে সেই দিকনির্দেশে যেখানে event = benign।) (ক) standardized feature-এ "OR \(=0.002\) per \(+1\) sd worst radius" বাক্যটার আক্ষরিক অর্থ কী — worst radius এক sd বাড়লে event-এর odds কত গুণ হয়? (খ) OR \(<1\) (এখানে \(0.002\), অর্থাৎ \(\approx1/500\)) কোন দিকে ঠেলছে — বড় worst radius কি malignant-এর সম্ভাবনা বাড়ায় না কমায় (event=benign ধরে)? (গ) \(95\%\) CI \([0.000,0.018]\) পুরোটা \(1\)-এর নিচে এবং \(p\approx2\times10^{-7}\) — এই দুটো একসাথে কী নিশ্চিত করছে, এবং worst radius-ই একমাত্র significant হওয়া কীভাবে EDA-র সবচেয়ে-বিভাজক feature-গুলোর সাথে সঙ্গতিপূর্ণ? Hint: (ক) OR \(=0.002\) মানে worst radius \(+1\) sd বাড়লে event-এর (benign) odds পূর্বের \(0.002\) গুণ (অর্থাৎ প্রায় \(500\) ভাগের \(1\)) হয়ে যায় — নাটকীয় পতন। (খ) event=benign ধরলে বড় worst radius benign-odds তীব্রভাবে কমায়, অর্থাৎ malignant-এর সম্ভাবনা বাড়ায় — বড়, ছড়ানো tumor malignant-এর দিকে ইঙ্গিত, চিকিৎসাগতভাবে সঙ্গত। (গ) CI পুরো \(1\)-এর নিচে ও অতি-ক্ষুদ্র \(p\) মানে প্রভাবটা পরিসংখ্যানিকভাবে দৃঢ় ও শূন্য-থেকে-স্পষ্ট আলাদা; worst radius (আকার-সম্পর্কিত) EDA-তেও শীর্ষ-বিভাজকদের সমগোত্রীয়, তাই এই একক-feature আধিপত্য প্রত্যাশিত — বাকি ৬টি (correlated) feature তার সাথে তথ্য ভাগ করায় আলাদাভাবে significant হয় না।
প্রশ্ন ৮ (★★★). perfect separation — কেন full MLE diverge করে, এবং দুই প্রতিকার। এই অধ্যায়ের মূল সতর্কতা: ৩০-feature-এর penalty-হীন logistic MLE diverge করে (coefficient \(\to\pm\infty\), বৈধ SE নেই)। (ক) "perfect (বা quasi-complete) separation" বলতে কী বোঝায় — কোন জ্যামিতিক পরিস্থিতিতে একটা hyperplane দুই class-কে নিখুঁতভাবে আলাদা করে ফেলে, এবং তখন likelihood-কে বাড়াতে coefficient-এর norm-এর কী হয়? (খ) এর ফলে fitted probability ও standard error-এর কী হয় — কেন এই মডেলের coefficient ও তাদের \(p\)-value রিপোর্ট করা যায় না? (গ) দুই প্রতিকার — (i) L2 penalty এবং (ii) decorrelated subset — প্রত্যেকটা আলাদা লক্ষ্যে (prediction বনাম inference) কীভাবে সমস্যাটা সমাধান করে? চলমান উদাহরণে কোনটা দিয়ে prediction (acc \(0.982\)) আর কোনটা দিয়ে inference (৭ feature) করা হয়েছে? Hint: (ক) separation = feature-space-এ এমন hyperplane আছে যা train-এ সব malignant একদিকে, সব benign আরেকদিকে ফেলে; তখন সেই দিকে coefficient যত বড় করা যায়, likelihood তত \(1\)-এর দিকে যায় (কখনো পৌঁছায় না) — তাই \(\lVert\beta\rVert\to\infty\), কোনো finite maximizer নেই (প্রমাণ প্রশ্ন ১৫)। (খ) fitted probability \(0/1\)-এর দিকে ঠেলে যায়, Hessian singular হয়ে পড়ে ⇒ SE \(\to\infty\) (বা সংজ্ঞায়িত নয়); অসীম/অনির্ধারিত coefficient ও SE-এর কোনো অর্থবহ \(p\)-value হয় না, তাই এগুলো রিপোর্ট করা বিভ্রান্তিকর। (গ) (i) L2 penalty \(\lambda\lVert\beta\rVert^2\) যোগ করে objective-কে finite maximizer-এ ফিরিয়ে আনে — coefficient bounded হয়, দৃঢ় prediction দেয় (এখানে full L2 logistic ⇒ acc \(0.982\), AUC \(0.997\)); (ii) decorrelated subset (৭টি কম-correlated feature) separation ভেঙে দেয় ও collinearity কমায়, ফলে বৈধ SE ও \(p\)-value পাওয়া যায় — inference-এর জন্য (worst radius OR \(0.002\) significant)।
প্রশ্ন ৯ (★★). ROC/AUC বনাম accuracy — imbalance-এ কেন AUC। চলমান উদাহরণে logistic-এর test accuracy \(0.982\) ও AUC \(0.997\)। (ক) benign \(62.7\%\) হওয়ায় একটা "সবাইকে benign বলা" নির্বোধ classifier-এর accuracy কত হবে — এটা কেন accuracy-কে একা বিভ্রান্তিকর করে? (খ) AUC কী মাপে যা accuracy মাপে না — একটা এক-বাক্যের সম্ভাবনা-ভিত্তিক সংজ্ঞা দিন, এবং কেন AUC threshold-নিরপেক্ষ? (গ) তাই imbalance-এ এবং §৩-এর recall-লক্ষ্যের সাথে সঙ্গতি রেখে কেন AUC (ও sensitivity/specificity) accuracy-র চেয়ে বেশি তথ্যপূর্ণ metric? Hint: (ক) সবাইকে benign বললে accuracy \(\approx\mathbf{0.627}\) — অথচ একটাও malignant ধরা পড়ে না; উচ্চ accuracy তাই দক্ষতার ভুল ছাপ দিতে পারে। (খ) AUC = একটা দৈব positive (malignant)-এর predicted score একটা দৈব negative (benign)-এর score-কে ছাড়িয়ে যাওয়ার সম্ভাবনা — এটা মডেলের ranking-ক্ষমতা মাপে, কোনো নির্দিষ্ট cutoff ছাড়াই (তাই threshold-নিরপেক্ষ)। (গ) AUC positive/negative-এর ভারসাম্যহীনতায় প্রতারিত হয় না এবং malignant-benign আলাদা করার সামগ্রিক ক্ষমতা ধরে; sensitivity/specificity নির্দিষ্ট threshold-এ cost asymmetry দেখায় — তাই এই metric-ত্রয়ী imbalance-এ accuracy-র চেয়ে সৎ চিত্র দেয়।
প্রশ্ন ১০ (★★). calibration — probability-র সত্যতা। validation-এ discrimination (AUC) ছাড়াও calibration দেখা হয়। (ক) দুটো মডেলের AUC সমান উঁচু হলেও তাদের predicted probability-র মান ভিন্ন অর্থ বহন করতে পারে — "একটা মডেল well-calibrated" বলতে ঠিক কী বোঝায় (যখন মডেল \(0.9\) বলে, বাস্তবে কত ভাগ ক্ষেত্রে event ঘটা উচিত)? (খ) কেন কেবল AUC উঁচু হলেই probability বিশ্বাসযোগ্য নয় — discrimination আর calibration কীভাবে আলাদা গুণ? (গ) medical সিদ্ধান্তে (যেখানে "malignant-এর \(85\%\) সম্ভাবনা" নিজেই একটা কর্ম-নির্ধারক সংখ্যা) calibration কেন discrimination-এর সমান গুরুত্বপূর্ণ? Hint: (ক) well-calibrated = predicted probability বাস্তব frequency-র সাথে মেলে — যেসব ক্ষেত্রে মডেল \(\approx0.9\) বলে, তাদের প্রায় \(90\%\)-এ সত্যিই event (malignant) ঘটে; একটা calibration curve (predicted বনাম observed) \(45^\circ\) রেখার কাছাকাছি থাকলে ভালো। (খ) AUC কেবল ক্রম (score গুলো ঠিকভাবে সাজানো কিনা) মাপে — একটা মডেল নিখুঁত ranking দিয়েও systematically অতি-আত্মবিশ্বাসী (miscalibrated) probability দিতে পারে; তাই উঁচু AUC-ও calibration নিশ্চিত করে না। (গ) চিকিৎসক যদি probability-র মান ধরে সিদ্ধান্ত নেন (threshold, ঝুঁকি-ব্যাখ্যা), তবে সেই সংখ্যা বাস্তব-frequency-র সাথে মিলতে হবে — miscalibrated \(0.85\) ভুল কর্ম ডেকে আনতে পারে, তাই honest report-এ calibration আলাদা করে যাচাই ও উল্লেখ করা হয়।
প্রশ্ন ১১ (★★). permutation বনাম impurity importance। random forest-এ importance দুইভাবে মাপা যায়; এখানে permutation importance রিপোর্ট করা হয়েছে: worst area \(0.0126\), worst concave points \(0.0088\), mean texture \(0.0079\)। (ক) impurity-based (Gini) importance আর permutation importance — প্রতিটা আসলে কী মাপে (একটা split-এর impurity-হ্রাস বনাম feature এলোমেলো করলে performance-পতন)? (খ) impurity-importance-এর কোন পরিচিত পক্ষপাত permutation পদ্ধতি এড়ায় — কোন ধরনের feature-কে Gini-importance অযথা বেশি গুরুত্ব দেয়? (গ) এখানকার permutation-শীর্ষ (worst area, worst concave points, mean texture) EDA-র সবচেয়ে-বিভাজক feature ও logistic-এর worst radius-এর সাথে কীভাবে সঙ্গতিপূর্ণ — drivers কি মোটামুটি একমত? Hint: (ক) impurity-importance = সব গাছ জুড়ে সেই feature-এর split-গুলোতে মোট impurity-হ্রাস (train-এ, structure থেকে); permutation-importance = validation-data-তে সেই feature-এর মান এলোমেলো করলে যতটা accuracy/AUC পড়ে — সরাসরি predictive-অবদানের মাপ। (খ) impurity-importance high-cardinality/many-split (continuous, বহু-স্তর) feature-কে inflate করে (আকস্মিক বেশি split-সুযোগ পায়); permutation পদ্ধতি model-agnostic ও performance-ভিত্তিক বলে এই পক্ষপাত এড়ায়। (গ) worst area (আকার), worst concave points (আকৃতি) আর mean texture — EDA-র শীর্ষ-বিভাজক ও logistic-এর worst radius-এর মতোই আকার/আকৃতি-সম্পর্কিত feature-ই শীর্ষে; দুই ভিন্ন মডেল প্রায় একই drivers-এ পৌঁছানো একটা শক্তিশালী, পরস্পর-নিশ্চিতকারী ফল (honest report-এর "drivers agree")।
প্রশ্ন ১২ (★★). data leakage — pipeline কীভাবে এড়ায়। honest workflow-এর একটা মূল শর্ত: test-তথ্য যেন কোনোভাবে training-এ না ঢোকে (data leakage)। (ক) দুটো সাধারণ leakage-উৎস বলুন যা এই pipeline-এ সম্ভব ছিল — (i) standardization এবং (ii) feature-নির্বাচন/tuning — এবং প্রতিটি কীভাবে test-error-কে কৃত্রিমভাবে ভালো দেখায়? (খ) একটা Pipeline object (scaler + model একসাথে) cross-validation-এ leakage কীভাবে ঠেকায় — প্রতিটি fold-এ ঠিক কী আলাদাভাবে ঘটে? (গ) কেন leak-যুক্ত CV-AUC প্রকৃত generalization-কে অতিমূল্যায়ন করে, এবং তাই honest report-এ এটা এড়ানো কেন অপরিহার্য?
Hint: (ক) (i) পুরো data-তে (train+test) scaler fit করলে test-এর mean/sd train-এ leak করে; (ii) পুরো data দেখে feature বাছা বা threshold/hyperparameter tune করলে test-এর তথ্য সিদ্ধান্তে ঢোকে — দুটোই test-metric-কে আশাবাদী করে। (খ) Pipeline প্রতিটি CV-fold-এ scaler (ও যেকোনো fit-নির্ভর ধাপ) কেবল সেই fold-এর train-অংশে fit করে, তারপর held-out অংশ transform করে — held-out কখনো fitting-এ অংশ নেয় না, তাই fold-ভিত্তিক leakage বন্ধ। (গ) leak হলে মডেল পরোক্ষে test দেখে ফেলে, তাই CV-AUC বাস্তব-জগতের performance-এর চেয়ে উঁচু দেখায় (over-optimistic); সৎ generalization-অনুমান পেতে প্রতিটি রূপান্তর fold-এর ভেতরে আটকানো (leak-free) বাধ্যতামূলক।
প্রশ্ন ১৩ (★★). model card ও সৎ caveats। honest report-এর শেষ অংশ একটা "model card" — drivers, uncertainty ও সীমাবদ্ধতা এক জায়গায়। (ক) এই বিশ্লেষণে চারটি প্রধান caveat কী কী — leakage, imbalance, separation, generalization — প্রতিটা এক লাইনে ব্যাখ্যা করুন কেন এটা রিপোর্টে থাকা দরকার। (খ) "\(\approx0.99\) AUC" রিপোর্ট করার সময় কেন সাথে uncertainty (CV-এর \(\pm0.008\)) দেওয়া অপরিহার্য — একটা point-estimate একা কী লুকায়? (গ) generalization-caveat বিশেষভাবে: এই মডেল একটা নির্দিষ্ট device/জনগোষ্ঠীর \(569\) রোগীর data-তে গড়া — নতুন hospital/population-এ কেন performance পড়তে পারে, এবং honest report-এ এটা বলা কেন সততার দাবি? Hint: (ক) leakage — metric যেন over-optimistic না হয় তা নিশ্চিত করতে pipeline leak-free ছিল বলা; imbalance — accuracy বিভ্রান্তিকর, তাই AUC/sensitivity-তে জোর; separation — full unpenalized coefficient/\(p\)-value অবৈধ, তাই L2/subset-এর remedy; generalization — একটাই dataset, বাইরের বৈধতা অপরীক্ষিত। (খ) \(\pm0.008\) ছাড়া "\(0.99\)" ভুয়া-নিশ্চয়তা দেয়; uncertainty-band দেখায় প্রকৃত AUC কোন পরিসরে (এবং দুই মডেল আলাদা করা যায় কিনা) — point-estimate একা এই সম্ভাব্য-পরিসর ও পুনরুৎপাদন-অস্থিরতা লুকায়। (গ) train-population-এর বাইরে (ভিন্ন device, রোগী-মিশ্রণ, prevalence) distribution বদলে যেতে পারে (dataset shift), তাই এই \(569\)-রোগীর accuracy নতুন জায়গায় নাও ধরে রাখতে পারে; এটা স্বীকার করা ব্যবহারকারীকে অতি-নির্ভরতা থেকে বাঁচায় — সততার মূল দাবি।
খ · গণনামূলক (computational)¶
প্রশ্ন ১৪ (★). \(R^2\) থেকে VIF হাতে গুনুন। VIF\(_j=\frac{1}{1-R_j^2}\), যেখানে \(R_j^2\) = feature \(j\)-কে বাকি সব feature দিয়ে regress করার \(R^2\)। (ক) mean area-র \(R_j^2=0.981\) হলে VIF গণনা করুন; canonical mean area VIF \(52.68\)-এর সাথে মেলে কিনা দেখুন। (খ) mean radius-এর VIF \(891.13\) থেকে বিপরীতে \(R_j^2\) বের করুন। (গ) সাধারণ থাম্ব-রুল VIF \(>10\) (কেউ \(>5\)) উদ্বেগজনক; এই তিন feature (VIF \(52.68\), \(891.13\), \(934.95\)) সেই সীমার কোথায়, এবং তাই inference-এর আগে কী করা যুক্তিসঙ্গত? Hint: (ক) VIF \(=\frac{1}{1-0.981}=\frac{1}{0.019}=\mathbf{52.63}\approx52.68\) (rounding-জনিত সামান্য পার্থক্য) — মেলে। (খ) \(R_j^2=1-\frac{1}{891.13}=1-0.001122=\mathbf{0.99888}\) — mean radius-এর \(\approx99.9\%\) variance অন্য feature থেকে predictable। (গ) তিনটিই সীমার বহু-বহু গুণ উপরে (\(52.68\gg10\), বাকি দুটো \(\approx900\)) — চরম multicollinearity; তাই inference-এ এই redundant আকার-feature-গুলোর কেবল একটা রেখে বা decorrelated subset নিয়ে (এখানকার ৭-feature Logit-এর মতো) কাজ করা যুক্তিসঙ্গত।
প্রশ্ন ১৫ (★★). coefficient → odds ratio, এবং \(+2\) sd পরিবর্তন। standardized logistic-এ একটা feature-এর coefficient \(\beta\) হলে odds ratio \(\text{OR}=e^{\beta}\) (প্রতি \(+1\) sd)। worst radius-এর OR \(=0.002\) দেওয়া। (ক) worst radius-এর \(\beta\) (log-odds coefficient) বের করুন (\(\beta=\ln(\text{OR})\))। (খ) worst radius \(+2\) sd বাড়লে event-odds কত গুণ হয় (OR\(^2\), বা \(e^{2\beta}\))? (গ) একটা মাঝারি feature-এর OR \(=0.397\) (mean smoothness) হলে তার \(\beta\) কত, এবং \(+1\) sd-এ odds শতকরা কতটা কমে — worst radius-এর প্রভাবের তুলনায় এটা কতটা মৃদু? Hint: (ক) \(\beta=\ln(0.002)=\mathbf{-6.21}\) — বড় ঋণাত্মক (event=benign ধরলে বড় worst radius benign-odds তীব্র কমায়)। (খ) \(+2\) sd ⇒ OR\(^2=(0.002)^2=\mathbf{4\times10^{-6}}\) (বা \(e^{2\beta}=e^{-12.4}\)) — odds আরও নাটকীয়ভাবে (প্রায় আড়াই-লক্ষ ভাগের \(1\)) নামে; standardized-এ প্রভাব sd-সংখ্যায় গুণিতক ভাবে জমে। (গ) \(\beta=\ln(0.397)=\mathbf{-0.924}\); \(+1\) sd-এ odds \(0.397\) গুণ, অর্থাৎ \(\approx\mathbf{60\%}\) কমে — worst radius-এর \(\approx99.8\%\) পতনের তুলনায় অনেক মৃদু, তাই worst radius-ই প্রভাবশালী driver।
প্রশ্ন ১৬ (★★). confusion matrix থেকে সব metric — sensitivity/specificity যাচাই। logistic test confusion (threshold \(0.5\)): TN \(63\), FP \(1\), FN \(2\), TP \(105\) (positive = malignant)। (ক) মোট \(n\), তারপর accuracy \(=\frac{TP+TN}{n}\) গণনা করুন; canonical acc \(0.982\)-এর সাথে মেলান। (খ) sensitivity (recall on malignant) \(=\frac{TP}{TP+FN}\) ও specificity \(=\frac{TN}{TN+FP}\) গণনা করে canonical \(0.981\) ও \(0.984\) যাচাই করুন। (গ) precision (positive predictive value) \(=\frac{TP}{TP+FP}\) গণনা করুন, এবং এক লাইনে বলুন এই ফলাফলে FN \(=2\)-এর বাস্তব অর্থ (কতজন malignant মিস হলো) কেন সবচেয়ে গুরুত্বপূর্ণ সংখ্যা। Hint: (ক) \(n=63+1+2+105=171\); accuracy \(=\frac{105+63}{171}=\frac{168}{171}=\mathbf{0.982}\) — মেলে। (খ) sensitivity \(=\frac{105}{105+2}=\frac{105}{107}=\mathbf{0.981}\); specificity \(=\frac{63}{63+1}=\frac{63}{64}=\mathbf{0.984}\) — দুটোই যাচাই হলো। (গ) precision \(=\frac{105}{105+1}=\frac{105}{106}=\mathbf{0.991}\); FN \(=2\) মানে ২ জন malignant রোগীকে benign বলা হয়েছে — cost asymmetry-র কারণে এই সংখ্যাটাই (মিস-করা cancer) সবচেয়ে গুরুত্বপূর্ণ, প্রয়োজনে threshold নামিয়ে একে আরও কমানোর কথা ভাবতে হয়।
প্রশ্ন ১৭ (★★). CV টেবিল পড়া — দুই মডেল কি আলাদা করা যায়। stratified cross-validation-এ AUC: logistic \(0.993\pm0.008\), random forest \(0.989\pm0.007\) (mean \(\pm\) sd fold জুড়ে)। (ক) দুই মডেলের mean-এর ব্যবধান কত, এবং প্রতিটার \(\pm1\) sd-band কী (পরিসর লিখুন) — band দুটো কি প্রবলভাবে overlap করে? (খ) এই overlap থেকে যুক্তি দিন: এই CV-প্রমাণে দুই মডেল কি পরিসংখ্যানিকভাবে পৃথক্যোগ্য (distinguishable), নাকি কার্যত সমান? (গ) একটা "\(\pm0.008\)" band-এর অর্থ কী — এটা fold-থেকে-fold কীসের পরিমাপ, এবং কেন এই uncertainty না জানিয়ে শুধু "logistic ভালো (\(0.993\) বনাম \(0.989\))" বলা বিভ্রান্তিকর? Hint: (ক) ব্যবধান \(0.993-0.989=\mathbf{0.004}\); logistic band \([0.985,1.001]\) (কার্যত \([0.985,1.000]\)), RF band \([0.982,0.996]\) — দুটো ব্যাপকভাবে overlap করে। (খ) ব্যবধান (\(0.004\)) দুই মডেলের sd-এর (\(\approx0.007\)–\(0.008\)) চেয়ে ছোট, band-গুলো প্রবল overlap করে — তাই এই প্রমাণে দুই মডেল আলাদা করা যায় না, কার্যত সমান-ভালো (∴ ব্যাখ্যাযোগ্যতা/গতির মতো অন্য বিবেচনায় বাছা যুক্তিসঙ্গত)। (গ) \(\pm0.008\) = ভিন্ন fold-এ AUC-র নমুনা-থেকে-নমুনা variance (মূল্যায়ন-অস্থিরতা); এই band না দিলে \(0.993\) বনাম \(0.989\)-এর তুচ্ছ ব্যবধানকে বাস্তব শ্রেষ্ঠত্ব ভেবে ভুল সিদ্ধান্ত হতে পারে — তাই uncertainty-সহ রিপোর্ট করাই সৎ।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১৮ (★★★). logistic log-likelihood concave — তাই maximizer একক (যখন থাকে)। logistic regression-এ \(p_i=\sigma(x_i^\top\beta)\), \(\sigma(z)=\frac{1}{1+e^{-z}}\), log-likelihood \(\ell(\beta)=\sum_i\big[y_i\log p_i+(1-y_i)\log(1-p_i)\big]\)। (ক) দেখান gradient \(\nabla\ell(\beta)=\sum_i(y_i-p_i)x_i\) (ব্যবহার করুন \(\sigma'(z)=\sigma(z)(1-\sigma(z))\))। (খ) দেখান Hessian \(\nabla^2\ell(\beta)=-\sum_i p_i(1-p_i)\,x_ix_i^\top\), এবং প্রমাণ করুন এটা negative semidefinite (\(\preceq0\)) — অর্থাৎ যেকোনো \(v\)-এর জন্য \(v^\top\big(\nabla^2\ell\big)v\le0\)। (গ) এ থেকে উপসংহার টানুন কেন \(\ell\) concave, এবং তাই কোনো finite maximizer থাকলে তা global; কোন অতিরিক্ত শর্ত (\(X\)-এর rank/positive-definiteness) থাকলে সেটা একক? Hint: (ক) \(\frac{\partial}{\partial\beta}\log\sigma(x_i^\top\beta)=(1-p_i)x_i\) ও \(\frac{\partial}{\partial\beta}\log(1-\sigma(x_i^\top\beta))=-p_i x_i\); যোগ করে \(\nabla\ell=\sum_i\big[y_i(1-p_i)-(1-y_i)p_i\big]x_i=\sum_i(y_i-p_i)x_i\)। (খ) \(\nabla p_i=p_i(1-p_i)x_i\), তাই \(\nabla^2\ell=-\sum_i p_i(1-p_i)x_ix_i^\top\); \(v^\top\!\big(\nabla^2\ell\big)v=-\sum_i p_i(1-p_i)(x_i^\top v)^2\le0\) যেহেতু প্রতিটি \(p_i(1-p_i)>0\) ও \((x_i^\top v)^2\ge0\) — তাই \(\preceq0\)। (গ) Hessian সর্বত্র \(\preceq0\) ⇒ \(\ell\) concave ⇒ যেকোনো stationary point global maximum; যদি \(\{x_i\}\) পূর্ণ-rank span করে (design-matrix rank \(=\) মাত্রা, অর্থাৎ \(\sum_i p_i(1-p_i)x_ix_i^\top\succ0\)), Hessian strictly negative-definite হয় ⇒ \(\ell\) strictly concave ⇒ maximizer একক (থাকলে)।
প্রশ্ন ১৯ (★★★). perfect separation-এ supremum অপ্রাপ্ত — কোনো finite MLE নেই। ধরুন data perfectly separable: এমন একটা \(\beta^\*\ne0\) আছে যে সব \(i\)-এর জন্য \(y_i=1\Rightarrow x_i^\top\beta^\*>0\) এবং \(y_i=0\Rightarrow x_i^\top\beta^\*<0\) (প্রতিটা বিন্দু সঠিক দিকে, কঠোরভাবে)। (ক) direction \(\beta^\*\) ধরে \(\beta=t\beta^\*\) নিন, \(t>0\); দেখান \(t\to\infty\)-এ প্রতিটা \(p_i\) সঠিক দিকে যায় (\(y_i=1\) হলে \(p_i\to1\), \(y_i=0\) হলে \(p_i\to0\)), তাই \(\ell(t\beta^\*)\to0^-\) (log-likelihood-এর সর্বোচ্চ সম্ভাব্য মান)। (খ) এ থেকে যুক্তি দিন \(\sup_\beta\ell(\beta)=0\) কিন্তু এই sup কোনো finite \(\beta\)-তে অর্জিত হয় না (\(\ell(\beta)<0\) সব finite \(\beta\)-তে, যেহেতু \(p_i\in(0,1)\) কঠোরভাবে)। (গ) তাই কেন কোনো finite MLE নেই, এবং এটা কীভাবে প্রশ্ন ১৮-এর concavity-র সাথে সঙ্গতিপূর্ণ (concave হলেও maximizer অস্তিত্বহীন হতে পারে) — এবং L2 penalty কীভাবে এটা ঠিক করে (এক লাইনে)? Hint: (ক) \(x_i^\top(t\beta^\*)=t\,(x_i^\top\beta^\*)\); \(y_i=1\) হলে \(x_i^\top\beta^\*>0\) ⇒ \(t\to\infty\)-এ \(x_i^\top\beta\to+\infty\) ⇒ \(p_i\to1\) ⇒ \(\log p_i\to0\); একইভাবে \(y_i=0\) হলে \(\log(1-p_i)\to0\) — তাই প্রতিটা পদ \(\to0^-\), যোগফল \(\ell\to0^-\)। (খ) \(\sigma\) কখনো ঠিক \(0\)/\(1\) ছোঁয় না, তাই প্রতিটা \(p_i\in(0,1)\) ⇒ প্রতিটা log-পদ কঠোরভাবে \(<0\) ⇒ \(\ell(\beta)<0\) সব finite \(\beta\)-তে; মান \(0\)-এর দিকে ওঠে কিন্তু ছোঁয় না — supremum \(0\) অপ্রাপ্ত। (গ) maximizer পেতে \(\lVert\beta\rVert\to\infty\) লাগে, তাই finite MLE নেই; concavity কেবল "স্থানীয় max = global" নিশ্চিত করে, অস্তিত্ব নয় — unbounded direction-এ sup অপ্রাপ্ত থাকতে পারে। L2 penalty \(-\lambda\lVert\beta\rVert^2\) objective-কে \(\lVert\beta\rVert\to\infty\)-এ \(-\infty\)-এ ঠেলে coercive করে ⇒ finite maximizer ফিরে আসে।
ঘ · কোডিং (Python)¶
প্রশ্ন ২০ (★★★). পূর্ণ pipeline পুনরুৎপাদন — সব canonical সংখ্যা মেলান। seed 20260619 দিয়ে সম্পূর্ণ end-to-end বিশ্লেষণটা পুনর্গঠন করুন এবং canonical সংখ্যাগুলো মিলিয়ে দেখুন:
- data ও split:
load_breast_cancer()লোড করে \(569\times30\), malignant \(212\) / benign \(357\) যাচাই; তারপর stratified \(70/30\) split (stratify=y, random_state=20260619) ⇒ \(398\) train / \(171\) test। - EDA: প্রতিটি feature standardize করে দুই class-এর mean-ব্যবধান বের করুন — শীর্ষ-বিভাজক worst concave points \(1.640\), worst perimeter \(1.618\), mean concave points \(1.605\) মেলান; VIF গণনা করে mean perimeter \(934.95\), mean radius \(891.13\), mean area \(52.68\) মেলান।
- logistic (L2, prediction): একটা
Pipeline([StandardScaler, LogisticRegression(penalty='l2')])fit করে test accuracy \(0.982\), AUC \(0.997\) মেলান; confusion (threshold \(0.5\)) TN \(63\), FP \(1\), FN \(2\), TP \(105\) ⇒ sensitivity \(0.981\), specificity \(0.984\)। - random forest:
RandomForestClassifier(n_estimators=400, oob_score=True, random_state=20260619)fit করে test accuracy \(0.971\), AUC \(0.996\), OOB \(0.965\) মেলান; permutation importance থেকে worst area \(0.0126\), worst concave points \(0.0088\), mean texture \(0.0079\) মেলান। - inference (statsmodels Logit, decorrelated subset): ৭টি feature \(\{\)mean texture, mean smoothness, mean concavity, mean symmetry, worst concave points, worst radius, worst texture\(\}\) (standardized) দিয়ে
sm.Logitfit করে pseudo-\(R^2\) \(0.866\) ও worst radius OR \(0.002\) \([0.000,0.018]\), \(p=2.24\times10^{-7}\) (একমাত্র significant) মেলান। - validation (CV): stratified CV-তে AUC — logistic \(0.993\pm0.008\), RF \(0.989\pm0.007\) মেলান;
Pipelineব্যবহার করে প্রতিটি fold-এ leak-free scaling নিশ্চিত করুন।
Hint: from sklearn.datasets import load_breast_cancer; from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold; from sklearn.preprocessing import StandardScaler; from sklearn.pipeline import Pipeline; from sklearn.linear_model import LogisticRegression; from sklearn.ensemble import RandomForestClassifier; from sklearn.inspection import permutation_importance; from sklearn.metrics import roc_auc_score, confusion_matrix; import statsmodels.api as sm। মূল দুই সতর্কতা: (i) leak-free CV-র জন্য scaling ও model একই Pipeline-এ রাখুন (scaler কেবল fold-এর train-অংশে fit হবে); (ii) full ৩০-feature-এর penalty-হীন MLE diverge করে (perfect separation), তাই prediction-এ L2 penalty এবং inference-এ decorrelated ৭-feature subset ব্যবহার করুন — কখনো full unpenalized coefficient/\(p\)-value রিপোর্ট করবেন না। সব প্রত্যাশিত সংখ্যা উপরের canonical তালিকায়; পূর্ণ runnable script _solutions/08-01-end-to-end-project-solutions.md-এর §ঘ-তে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
Framing — প্রশ্নকে মাপযোগ্য কাজে নামানো। breast_cancer diagnosis একটা supervised binary classification — feature \(x\in\mathbb R^{30}\) থেকে malignant/benign predict, যেখানে malignant = positive এবং cost asymmetry-র কারণে (মিস-করা cancer সবচেয়ে ব্যয়বহুল) sensitivity/recall on malignant ও AUC-ই মুখ্য metric, খালি accuracy নয়।
-
EDA — data-কে চেনা। \(569\times30\), malignant \(212\) (\(0.373\)) / benign \(357\) (\(0.627\)) — সামান্য imbalanced (তাই stratified split ও AUC দরকার)। সবচেয়ে-বিভাজক feature (standardized mean-ব্যবধান): worst concave points \(1.640\), worst perimeter \(1.618\), mean concave points \(1.605\) — সবই tumor-এর আকার ও আকৃতি, চিকিৎসাগতভাবে অর্থপূর্ণ; feature-দের মধ্যে তীব্র correlation-ও এখানেই ধরা পড়ে।
-
Preprocessing — ন্যায্য ও leak-মুক্ত ভিত্তি। সব feature standardize (coefficient-তুলনা ও logistic-scale ন্যায্য করতে); VIF-এ চরম multicollinearity — mean perimeter \(934.95\), mean radius \(891.13\), mean area \(52.68\) (radius/perimeter/area একই জ্যামিতি, তাই প্রায়-redundant); এবং stratified \(70/30\) split (\(398\) train / \(171\) test)। scaling সবসময়
Pipeline-এ train-fold-এ fit — leakage বন্ধ। -
দুটো model। (i) Regularized logistic (L2, ৩০ feature): test accuracy \(0.982\), AUC \(0.997\) — L2 penalty perfect-separation-জনিত divergence ঠেকিয়ে দৃঢ় prediction দেয়। (ii) Random forest (\(400\) tree): test accuracy \(0.971\), AUC \(0.996\), OOB \(0.965\) — nonlinear, feature-মিথস্ক্রিয়া স্বয়ংক্রিয়ভাবে ধরে, OOB বিনামূল্যে validation দেয়। দুই মডেল কার্যত সমান-ভালো।
-
Inference — coefficient কী বলছে, এবং একটা মারাত্মক ফাঁদ। decorrelated ৭-feature statsmodels Logit (pseudo-\(R^2\) \(0.866\))-এ worst radius OR \(0.002\) \([0.000,0.018]\), \(p=2.24\times10^{-7}\) — একমাত্র significant (বড়, ছড়ানো tumor ⇒ malignant, EDA-র সাথে সঙ্গত); বাকি (correlated) feature আলাদাভাবে significant নয়। মূল সতর্কতা: ৩০-feature-এর penalty-হীন MLE diverge করে (perfect/quasi-complete separation ⇒ coefficient \(\to\pm\infty\), বৈধ SE নেই), তাই remedy = L2 (prediction) বা decorrelated subset (inference); full unpenalized coefficient/\(p\)-value কখনো রিপোর্ট করা যায় না।
-
Validation — সততার সাথে যাচাই। stratified CV AUC: logistic \(0.993\pm0.008\), RF \(0.989\pm0.007\) — band প্রবল overlap, তাই দুই মডেল পরিসংখ্যানিকভাবে আলাদা করা যায় না। logistic confusion (threshold \(0.5\)): TN \(63\), FP \(1\), FN \(2\), TP \(105\) ⇒ sensitivity \(0.981\), specificity \(0.984\)। ROC/AUC imbalance-এ accuracy-কে হারায় (threshold-নিরপেক্ষ ranking); calibration নিশ্চিত করে predicted probability বাস্তব-frequency-র সাথে মেলে (medical সিদ্ধান্তে অপরিহার্য)।
-
Honest report — model card। drivers দুই মডেলে প্রায় একমত (আকার/আকৃতি-feature: worst radius, worst area, worst concave points); performance \(\approx0.99\) AUC কিন্তু uncertainty-সহ (\(\pm0.008\), তাই দুই মডেল সমতুল্য); চারটি সৎ caveat — leakage (pipeline leak-free), imbalance (accuracy-র বদলে AUC/sensitivity), separation (unpenalized inference অবৈধ), generalization (একটাই dataset, বাইরের বৈধতা অপরীক্ষিত)।
-
Meta-বার্তা। এই capstone Parts I–VI-কে একটি সৎ, end-to-end workflow-এ জোড়ে: probability ও inference-এর ভিত্তি, EDA, GLM/logistic ও odds-ratio-inference, cross-validation, এবং tree/random-forest — সব একসাথে একটা প্রকৃত dataset-এ প্রয়োগ করে দেখায় কীভাবে framing থেকে honest reporting পর্যন্ত পুরো পথটা leak-মুক্ত ও uncertainty-সচেতনভাবে হাঁটতে হয়।
পূর্ববর্তী সংযোগ (← ১.৫, ৫.৪, ৫.৮, ৬.৫):
-
১.৫ (EDA workflow): এ অধ্যায়ের EDA-ধাপটা সরাসরি ১.৫-এর explanatory-data-analysis কাঠামোর প্রয়োগ। ১.৫-এ শেখা "data-কে summarize ও visualize করে গঠন বোঝা" এখানে রূপ নেয় class-balance পরীক্ষা (\(212\)/\(357\)), সবচেয়ে-বিভাজক feature নির্ণয় (standardized mean-ব্যবধান) ও feature-মধ্যকার correlation চিহ্নিতকরণে — যা পরের প্রতিটি সিদ্ধান্ত (stratify করা, standardize করা, VIF দেখা, metric বাছা) কে চালিত করে। EDA না করলে imbalance ও multicollinearity অদেখা থেকে যেত।
-
৫.৪ (logistic regression / GLM): inference-ধাপের পুরো যন্ত্রটা ৫.৪-এর logistic-GLM থেকে আসে। ৫.৪-এ শেখা \(p=\sigma(x^\top\beta)\), log-likelihood, coefficient-এর odds-ratio ব্যাখ্যা (\(e^\beta\)) ও তাদের significance-পরীক্ষা এখানে সরাসরি ব্যবহৃত — worst radius OR \(0.002\)-এর অর্থ, CI ও \(p\)-value সবই ৫.৪-এর কাঠামোয়; আর ৫.৪-এর MLE-তত্ত্বের একটা সীমা (perfect separation-এ divergence, §৭-এর concavity ও sup-অপ্রাপ্তির প্রমাণ) এখানে বাস্তবে ধরা দেয়।
-
৫.৮ (cross-validation ও model validation): validation-ধাপ পুরোপুরি ৫.৮-এর উপর দাঁড়ানো। ৫.৮-এ শেখা \(k\)-fold cross-validation, train/test-বিভাজন, ও leak-মুক্ত মূল্যায়ন-নীতি এখানে stratified CV-AUC (\(0.993\pm0.008\) বনাম \(0.989\pm0.007\)),
Pipeline-ভিত্তিক leak-free scaling, এবং uncertainty-band দিয়ে দুই মডেল তুলনায় প্রয়োগ হয় — point-estimate-এর সাথে সবসময় CV-এর variability রিপোর্ট করার অভ্যাসটা এখান থেকেই। -
৬.৫ (trees, random forest, OOB, importance): দ্বিতীয় model ও importance-বিশ্লেষণ সরাসরি ৬.৫-এর ধারাবাহিকতা। ৬.৫-এ শেখা random forest (bootstrap + feature-subsampling), OOB (বিনামূল্যে test-estimate, এখানে \(0.965\)) ও feature importance এখানে হুবহু ব্যবহৃত — এবং ৬.৫-এর সেই সতর্কতা (impurity-importance পক্ষপাতদুষ্ট, permutation নিরাপদ) মেনে এখানে permutation importance (worst area \(0.0126\), ...) রিপোর্ট করা হয়েছে। সবকিছুর নিচে Parts II–IV (probability, inference, MLE) ভিত্তি হিসেবে কাজ করছে — likelihood, sampling-distribution ও estimator-এর ধারণা ছাড়া উপরের কোনো ধাপই দাঁড়াত না।
পরবর্তী সংযোগ (→ পরবর্তী capstone অধ্যায়): এই অধ্যায় একটা সৎ, end-to-end বিশ্লেষণ-pipeline প্রতিষ্ঠা করল — framing থেকে honest reporting পর্যন্ত। পরের capstone অধ্যায় এই ভিত্তির উপর দাঁড়িয়ে paper reproduction / research-readiness-এর দিকে যায়: একটা প্রকাশিত বিশ্লেষণ হুবহু পুনরুৎপাদন করা (অন্যের data ও পদ্ধতি থেকে একই ফল পাওয়া), একটা পূর্ণাঙ্গ report/model card লেখা, এবং uncertainty যোগাযোগ করা (কীভাবে ফলাফল, সীমাবদ্ধতা ও অনিশ্চয়তা পাঠক ও সিদ্ধান্ত-গ্রহণকারীর কাছে সৎভাবে উপস্থাপন করতে হয়)। এই অধ্যায়ের leak-মুক্ত workflow, caveat-সচেতনতা ও uncertainty-রিপোর্টিং সেই reproduction-এর অপরিহার্য ভিত্তি — নিজের বিশ্লেষণ সৎভাবে করতে না শিখলে অন্যেরটা পুনরুৎপাদন বা যাচাই করা অসম্ভব।
সূত্র (sources): P. Bruce, A. Bruce & P. Gedeck, Practical Statistics for Data Scientists (end-to-end workflow, EDA, classification metric, ROC/AUC, feature importance-এর ব্যবহারিক দৃষ্টিভঙ্গি ও Python-অনুশীলন); P. Dangeti, Statistics for Machine Learning (logistic regression, random forest, model-মূল্যায়ন ও prediction-inference ভারসাম্যের প্রয়োগমুখী আলোচনা); L. Wasserman, All of Statistics (likelihood, MLE, hypothesis-test ও classification-এর দৃঢ় পরিসংখ্যানিক ভিত্তি, যার উপর inference-ধাপ দাঁড়ায়); G. James, D. Witten, T. Hastie & R. Tibshirani, An Introduction to Statistical Learning (logistic regression, cross-validation, tree/random forest ও bias–variance-এর সুসংহত সেতুবন্ধ, পুরো pipeline-এর তাত্ত্বিক মেরুদণ্ড)।