3.3 — Law of Large Numbers (বৃহৎ সংখ্যার সূত্র)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "বেশি data = বেশি নির্ভরযোগ্য গড়", কেন?¶
১.১ একটা পরিচিত অভিজ্ঞতা দিয়ে শুরু¶
একটা ন্যায্য (fair) ছক্কা বারবার গড়ান আর প্রতিবারের ফলের চলমান গড় (running average — এ পর্যন্ত আসা সব ফলের গড়) লিখে রাখুন। শুরুতে এই গড় খুব এলোমেলো লাফায় — প্রথম গড়ানে \(2\) এলে গড় \(2\), পরেরবার \(6\) এলে গড় \((2+6)/2 = 4\), এমন ওঠানামা। কিন্তু আপনি যদি ধৈর্য ধরে \(100\) বার, \(1000\) বার, \(10000\) বার গড়ান, একটা আশ্চর্য জিনিস ঘটে: চলমান গড়টা ধীরে ধীরে থিতু হতে থাকে — আর সেই থিতু-মান হলো ঠিক \(3.5\)। অর্থাৎ যত বেশি বার গড়াই, গড় তত নির্ভরযোগ্যভাবে \(3.5\)-এর কাছে গিয়ে বসে।
এই \(3.5\) সংখ্যাটা আকাশ থেকে পড়েনি — এটা একটামাত্র গড়ানের theoretical গড়, যাকে আমরা বলি population mean (সমগ্রক গড়) বা expectation (প্রত্যাশা): একটা ছক্কার ছয়টা মুখ \(1,2,3,4,5,6\), প্রতিটির সম্ভাবনা \(1/6\), তাই $$ \mu \;=\; \frac{1+2+3+4+5+6}{6} \;=\; \frac{21}{6} \;=\; 3.5. $$ এখানে \(\mu\) ("mu") হলো সেই একক, স্থির, "সত্য" গড় — যা আমরা পেতাম যদি অসীমবার গড়াতে পারতাম। বাস্তবে আমরা অসীমবার গড়াতে পারি না; আমরা \(n\) বার গড়াই আর sample mean (নমুনা গড়) বের করি। এই অধ্যায়ের পুরো গল্প একটি বাক্যে: sample mean, \(n\) বড় করলে, population mean \(\mu\)-তে গিয়ে থিতু হয় — এবং এই দাবিটাকেই গাণিতিকভাবে নিখুঁত করে বলা হলো Law of Large Numbers (LLN) বা বৃহৎ সংখ্যার সূত্র।
স্বজ্ঞাটা সরল আর প্রায় সবাই-জানা: "বেশি data মানে বেশি নির্ভরযোগ্য গড়।" কিন্তু "নির্ভরযোগ্য" শব্দটার পেছনে আসলে কী ঘটছে, কেন ঘটছে, আর কোন শর্তে ঘটছে — সেটাই আমরা এই অধ্যায়ে খুলে দেখব।
১.২ প্রতীকগুলো একবার গুছিয়ে নিই¶
পুরো অধ্যায়ে আমাদের হাতে থাকবে একই কাঠামো। ধরা যাক আমাদের কাছে আছে $$ X_1,\ X_2,\ \dots,\ X_n $$ — এমন কতগুলো random variable (এলোমেলো চলক), যারা i.i.d. (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত)। এই দুই শব্দ ভেঙে বলি, কারণ এরাই LLN-এর প্রাণ:
- independent (স্বাধীন) — একটা গড়ানের ফল পরেরটাকে প্রভাবিত করে না; প্রতিটি \(X_i\) আলাদা, নিজের মতো।
- identically distributed (অভিন্নভাবে বণ্টিত) — প্রতিটি \(X_i\) একই distribution থেকে আসে, অর্থাৎ একই "নিয়মে" এলোমেলো (একই ছক্কা, একই কয়েন)। তাই সবার একই population mean \(\mu\) ও একই বিস্তার।
এই i.i.d. গুচ্ছের জন্য তিনটি সংখ্যা বারবার আসবে:
- \(\mathbb{E}[X_i] = \mu\) — প্রতিটি \(X_i\)-এর population mean (একটাই, কারণ সবাই অভিন্নভাবে বণ্টিত)। এখানে \(\mathbb{E}[\,\cdot\,]\) মানে expectation (2.5-এ শেখা): সম্ভাব্য মানগুলোর সম্ভাবনা-ওজন-করা গড়।
- \(\mathrm{Var}(X_i) = \sigma^2\) — প্রতিটি \(X_i\)-এর variance (ভেদাঙ্ক): একক একটা মান গড় থেকে গড়ে কতটা ছড়ানো; \(\sigma\) ("sigma") তার standard deviation।
- \(\bar X_n = \dfrac{1}{n}\sum_{i=1}^{n} X_i\) — sample mean (নমুনা গড়): এ পর্যন্ত আসা \(n\)টি মানের গড়। মাথার উপর দাগ ("bar") মানে "গড়", আর নিচের \(n\) মনে করায় এটা \(n\)টি পদের গড়।
আরেকটা প্রতীক বারবার লাগবে: \(\varepsilon > 0\) ("epsilon") — একটি ক্ষুদ্র ধনাত্মক সহনসীমা (tolerance): "\(\bar X_n\) আর \(\mu\)-এর পার্থক্য এর চেয়ে ছোট হলেই আমরা খুশি।" (এই \(\varepsilon\)–ভাষা 3.2-এ convergence সংজ্ঞায়িত করতে ব্যবহার করেছিলাম; এখানেও তা-ই কাজে লাগবে।)
খুব জরুরি একটা পার্থক্য গোড়াতেই গেঁথে নিন: \(\mu\) একটা স্থির সংখ্যা (একটা ধ্রুবক, যেমন \(3.5\)), কিন্তু \(\bar X_n\) একটা random variable — প্রতিবার পরীক্ষা চালালে এর মান বদলায়। তাই "\(\bar X_n \to \mu\)" বলতে একটা random জিনিস একটা স্থির জিনিসের দিকে যাওয়া বোঝায় — আর ঠিক এই কারণেই (3.2-এ যেমন দেখেছি) এই "\(\to\)" তীরের একাধিক অর্থ হতে পারে, যা §২-এ স্পষ্ট করব।
১.৩ hook — কেন এই সূত্রের ওপর গোটা পৃথিবী দাঁড়িয়ে¶
LLN নিছক একটা গাণিতিক কৌতূহল নয়; বাস্তব দুনিয়ার অজস্র সিদ্ধান্ত নীরবে এর ওপর ভর করে আছে। তিনটে ছবি দেখুন:
-
ক্যাসিনো (casino) কেন সবসময় জেতে। একটা roulette চাকায় প্রতিটি বাজির গড় ফল ক্যাসিনোর সামান্য পক্ষে — ধরুন প্রতি ১ টাকায় গড়ে ক্যাসিনোর লাভ ৫ পয়সা (\(\mu = 0.05\))। একটামাত্র খেলায় খেলোয়াড় বড় জিততেই পারে; ক্যাসিনো হারতেও পারে। কিন্তু লক্ষ লক্ষ বাজির পর ক্যাসিনোর প্রতি-বাজি গড় লাভ LLN-এর জোরে ঠিক ঐ \(0.05\)-এ থিতু হয় — তাই বহু খেলায় ক্যাসিনোর লাভ কার্যত নিশ্চিত। জুয়াড়ির ভাগ্য random; ক্যাসিনোর লাভ গণিত।
-
জনমত জরিপ (polling) কেন কাজ করে। পুরো দেশের কোটি মানুষকে জিজ্ঞেস না করে জরিপকারী মাত্র কয়েক হাজারকে জিজ্ঞেস করেন, আর তাঁদের "হ্যাঁ"-এর অনুপাত (একটা sample mean) দিয়ে পুরো দেশের প্রকৃত অনুপাত \(\mu\) আন্দাজ করেন। কেন এই অল্প নমুনার গড় গোটা দেশের সত্যির কাছাকাছি হবে? কারণ LLN: যথেষ্ট বড় (ও নিরপেক্ষভাবে বাছা) নমুনার গড় সত্য অনুপাতে থিতু হয়। (নমুনা কতটা কাছে — সেই হার বলে দেয় 3.4-এর CLT; কিন্তু আদৌ যে কাছে যায়, সেই নিশ্চয়তা দেয় এই অধ্যায়ের LLN।)
-
Monte Carlo simulation কেন কঠিন অঙ্ক মেলায়। অনেক সময় একটা সংখ্যা (যেমন \(\pi\), বা একটা জটিল integral, বা একটা ঝুঁকির গড় ক্ষতি) সরাসরি হিসাব করা কঠিন, কিন্তু সেটাকে যদি কোনো random পরীক্ষার expectation \(\mu\) হিসেবে লেখা যায়, তবে কম্পিউটারে সেই পরীক্ষা লক্ষবার চালিয়ে তাদের গড় (\(\bar X_n\)) নিলেই উত্তর পাওয়া যায় — কারণ LLN বলে \(\bar X_n \to \mu\)। আধুনিক পদার্থবিজ্ঞান, finance, মেশিন লার্নিং-এ এই কৌশল সর্বত্র; এর গোটা বৈধতা একমাত্র LLN-এর উপর দাঁড়িয়ে। (§৩-এ আমরা নিজ হাতে \(\pi\) এভাবে আন্দাজ করব।)
তিন ছবিতেই একই মূল সুর: একটা একক ফল অনিশ্চিত, কিন্তু বহু ফলের গড় নিশ্চিত-প্রায়। randomness ব্যক্তি-পর্যায়ে রাজত্ব করে, কিন্তু গড় নিলে সে শৃঙ্খলায় বাঁধা পড়ে। LLN ঠিক এই "ব্যক্তিতে বিশৃঙ্খলা, গড়ে শৃঙ্খলা"-কেই গাণিতিক বাক্যে ধরে।
এক বাক্যে ধরে রাখুন। Law of Large Numbers বলে: i.i.d. sample-এর sample mean \(\bar X_n\), \(n\) বড় করলে, population mean \(\mu\)-তে গিয়ে স্থিত হয়। বাকি পুরো অধ্যায় এই বাক্যকে তিনভাবে পূর্ণ করে — (i) "স্থিত হয়" বলতে ঠিক কী (দুই রকম: weak ও strong), (ii) কেন তা সত্য (3.1-এর inequality দিয়ে প্রমাণ), আর (iii) কোন শর্তে তা ভেঙে পড়ে (যেমন variance বা mean না থাকলে)।
২ · মূল ধারণা ও সংজ্ঞা¶
§১-এ আমরা স্বজ্ঞায় বললাম "\(\bar X_n\) গিয়ে \(\mu\)-তে থিতু হয়।" এবার সেই "থিতু হওয়া"-কে নিখুঁত করি। মনে রাখুন (3.2 থেকে) — যেহেতু \(\bar X_n\) একটা random variable, "\(\bar X_n \to \mu\)"-এর একাধিক অর্থ আছে। LLN আসলে দুটি আলাদা theorem, যারা দুটি আলাদা অর্থে এই থিতু-হওয়া দাবি করে: একটি দুর্বলতর (Weak Law, in probability), একটি কড়াকড়ি (Strong Law, almost surely)। দুটোকেই from scratch গড়ি।
পুরো বিভাগে কাঠামো একই: \(X_1, X_2, \dots\) হলো i.i.d. random variable, প্রত্যেকের \(\mathbb{E}[X_i] = \mu\), এবং (যেখানে দরকার) \(\mathrm{Var}(X_i) = \sigma^2 < \infty\); sample mean \(\bar X_n = \frac1n\sum_{i=1}^n X_i\); আর \(\varepsilon > 0\) একটি ক্ষুদ্র সহনসীমা।
২.১ একটি গুরুত্বপূর্ণ পূর্ব-ফল — \(\bar X_n\)-এর mean ও variance¶
দুই আইনই বোঝার আগে একটা ছোট কিন্তু কেন্দ্রীয় হিসাব দরকার: sample mean নিজে কতটা এলোমেলো? দুটো প্রশ্ন — গড়ে \(\bar X_n\) কোথায় থাকে, আর কতটা ছড়ায়।
(ক) \(\bar X_n\)-এর expectation। expectation-এর linearity (2.5) ব্যবহার করে: $$ \mathbb{E}[\bar X_n] \;=\; \mathbb{E}!\left[\frac1n\sum_{i=1}^n X_i\right] \;=\; \frac1n\sum_{i=1}^n \mathbb{E}[X_i] \;=\; \frac1n \cdot n\mu \;=\; \mu. $$ অর্থাৎ গড়ে sample mean ঠিক \(\mu\)-তেই বসে — কোনো \(n\)-এর জন্যই এটা \(\mu\) থেকে পক্ষপাতদুষ্ট (biased) নয়। এটা ভালো খবর, কিন্তু যথেষ্ট নয়: গড়ে ঠিক জায়গায় থাকা মানে এই নয় যে কোনো একটি পরীক্ষায় \(\bar X_n\) কাছে থাকবে — তার জন্য ছড়ানোও ছোট হতে হবে।
(খ) \(\bar X_n\)-এর variance। এখানেই \(n\)-এর জাদু। যেহেতু \(X_i\)-রা স্বাধীন, স্বাধীন variable-এর যোগফলের variance যোগ হয় (2.6-এ দেখা: \(\mathrm{Var}(\sum X_i) = \sum \mathrm{Var}(X_i) = n\sigma^2\)), আর ধ্রুবক \(1/n\) variance-এ বর্গ হয়ে ঢোকে: $$ \boxed{\ \mathrm{Var}(\bar X_n) \;=\; \mathrm{Var}!\left(\frac1n\sum_{i=1}^n X_i\right) \;=\; \frac{1}{n^2}\sum_{i=1}^n \mathrm{Var}(X_i) \;=\; \frac{1}{n^2}\cdot n\sigma^2 \;=\; \frac{\sigma^2}{n}.\ } $$ এই একটি লাইনই LLN-এর গাণিতিক হৃদয়। খেয়াল করুন: \(\mathrm{Var}(\bar X_n) = \sigma^2/n\) — \(n\) বাড়লে \(\bar X_n\)-এর ছড়ানো \(0\)-এর দিকে যায়। অর্থাৎ যত বেশি data, sample mean তত শক্ত করে তার গড় (\(\mu\))-এর চারপাশে জড়ো হয়। standard deviation-এ এটা \(\sigma/\sqrt{n}\) — তাই নির্ভুলতা \(\sqrt{n}\)-হারে বাড়ে (এই \(\sqrt{n}\) পরে 3.4-এ আবার ফিরবে)।
স্বজ্ঞা: একটা একক গড়ান বুনো লাফায়, কিন্তু অনেক স্বাধীন গড়ানের গড়ে উপরের আর নিচের ভুলগুলো একে অপরকে কাটে — তাই গড়ের ছড়ানো কমে। "গড়ে ঠিক \(\mu\)-তে" + "ছড়ানো \(\to 0\)" — এই দুই মিলেই বলে দেবে \(\bar X_n\) আটকে যায় \(\mu\)-তে। এখন এটাকে দুই ভাষায় formal করি।
২.২ Weak Law of Large Numbers (WLLN) — \(\bar X_n \xrightarrow{P} \mu\)¶
স্বজ্ঞা। Weak Law প্রতিটি বড় \(n\)-কে আলাদা একটা snapshot হিসেবে দেখে আর জিজ্ঞেস করে: "এই নির্দিষ্ট \(n\)-এ, \(\bar X_n\) আর \(\mu\) অনেক দূরে থাকার সম্ভাবনা কি ছোট?" Weak Law বলে — হ্যাঁ, আর \(n\) যত বাড়ে সেই "দূরে থাকার সম্ভাবনা" তত \(0\)-এর দিকে যায়। অর্থাৎ যথেষ্ট বড় \(n\)-এর জন্য \(\bar X_n\) প্রায় নিশ্চয়ই \(\mu\)-এর \(\varepsilon\)-প্রতিবেশে; দূরে ছিটকে যাওয়াটা বিরল ঘটনা।
সংজ্ঞা (Weak Law of Large Numbers — দুর্বল বৃহৎ সংখ্যার সূত্র)। ধরা যাক \(X_1, X_2, \dots\) i.i.d., \(\mathbb{E}[X_i] = \mu\) (এবং সসীম)। তখন sample mean \(\mu\)-তে converge করে in probability (3.2-এ শেখা অর্থে), অর্থাৎ যেকোনো \(\varepsilon > 0\)-এর জন্য $$ \boxed{\ \lim_{n\to\infty} P\big(\lvert \bar X_n - \mu \rvert > \varepsilon\big) \;=\; 0, \qquad\text{সংক্ষেপে}\quad \bar X_n \xrightarrow{P} \mu.\ } $$
প্রতিটি প্রতীক খুলে বলি:
- \(\lvert \bar X_n - \mu \rvert\) — sample mean আর সত্য গড়ের মধ্যে দূরত্ব (absolute value — পরমমান, চিহ্ন বাদ দিয়ে কত দূরে)। এটা একটি random variable, কারণ \(\bar X_n\) random।
- \(\lvert \bar X_n - \mu \rvert > \varepsilon\) — একটি event (ঘটনা): "এবার sample mean সত্য গড় থেকে \(\varepsilon\)-এর বেশি দূরে।" কোনো পরীক্ষায় ঘটে, কোনোটায় ঘটে না।
- \(P(\,\cdot\,)\) — সেই ঘটনার probability (সম্ভাবনা — একটি সংখ্যা, \(0\) ও \(1\)-এর মাঝে)।
- \(\lim_{n\to\infty} \dots = 0\) — এই সম্ভাবনা \(n = 1, 2, 3, \dots\)-এর সাথে একটা সংখ্যা-ক্রম বানায়, আর সেই সংখ্যা-ক্রম \(0\)-তে নামে।
- \(\xrightarrow{P}\) — "converges in probability" তীর (3.2-এর সংজ্ঞা); উপরের পুরো লাইনটাই এর সংক্ষিপ্ত রূপ।
কৌশলটা 3.2-এর মতোই: random জিনিস \(\lvert \bar X_n - \mu\rvert\)-কে সরাসরি limit না নিয়ে, তা থেকে একটা সংখ্যা (দূরে থাকার সম্ভাবনা) বানাই, তারপর সেই সংখ্যার সাধারণ limit নিই।
কেন এটা §২.১ থেকে প্রায় বিনামূল্যে আসে (finite-variance ক্ষেত্রে)। ধরা যাক variance-ও সসীম, \(\sigma^2 < \infty\)। 3.1-এর Chebyshev's inequality \(\bar X_n\)-এ প্রয়োগ করুন (এর mean \(\mu\), variance \(\sigma^2/n\)): $$ P\big(\lvert \bar X_n - \mu\rvert > \varepsilon\big) \;\le\; \frac{\mathrm{Var}(\bar X_n)}{\varepsilon^2} \;=\; \frac{\sigma^2}{n\,\varepsilon^2}. $$ এখন \(n\to\infty\) নিলে ডান পাশ \(\to 0\) (কারণ \(\sigma^2\) ও \(\varepsilon\) স্থির, শুধু \(n\) বাড়ছে)। তাই বাঁ পাশও \(\to 0\) — WLLN প্রমাণ হয়ে গেল! এই সংক্ষিপ্ত যুক্তিই দেখায় কেন 3.1-এর inequality-গুলো ছিল LLN-এর ভিত্তি-পাথর। (এটি শুধু sketch; পূর্ণ ও সাবধানী প্রমাণ §৪-এ দেওয়া হবে। উল্লেখ্য, finite variance আসলে দরকারি নয় — শুধু \(\mu\) সসীম হলেই WLLN খাটে, তবে সেই সাধারণ প্রমাণ কঠিনতর; এখানে variance-পথটাই সহজবোধ্য।)
২.৩ Strong Law of Large Numbers (SLLN) — \(\bar X_n \xrightarrow{a.s.} \mu\)¶
স্বজ্ঞা। Strong Law আরও কড়া দাবি করে। এটা একটা গোটা অসীম পরীক্ষা-যাত্রা কল্পনা করে — যেন আপনি ছক্কা একটানা গড়িয়েই চলেছেন, কখনো থামছেন না, আর পুরো অসীম ক্রম \(X_1, X_2, X_3, \dots\) দেখতে পাচ্ছেন। এই একটি গোটা যাত্রার জন্য চলমান গড়ের সংখ্যা-ক্রম \(\bar X_1, \bar X_2, \bar X_3, \dots\) তৈরি হয়। Strong Law বলে: প্রায় প্রতিটি এমন যাত্রায় (সম্ভাবনা-\(1\) পরিমাণ যাত্রায়) এই সংখ্যা-ক্রম সত্যিই \(\mu\)-তে গিয়ে স্থায়ীভাবে থিতু হয় — একবার কাছে এলে আর কখনো দূরে ছিটকায় না।
সংজ্ঞা (Strong Law of Large Numbers — শক্তিশালী বৃহৎ সংখ্যার সূত্র)। ধরা যাক \(X_1, X_2, \dots\) i.i.d., \(\mathbb{E}[X_i] = \mu\) (সসীম)। তখন sample mean \(\mu\)-তে converge করে almost surely (3.2-এর অর্থে), অর্থাৎ $$ \boxed{\ P\Big(\big{\,\omega : \lim_{n\to\infty} \bar X_n(\omega) = \mu \,\big}\Big) \;=\; 1, \qquad\text{সংক্ষেপে}\quad \bar X_n \xrightarrow{a.s.} \mu.\ } $$
প্রতিটি প্রতীক খুলে বলি:
- \(\omega\) ("omega") — একটি গোটা outcome (পুরো অসীম পরীক্ষা-যাত্রা; সব \(\omega\)-র সংগ্রহ হলো sample space)।
- \(\bar X_n(\omega)\) — সেই নির্দিষ্ট যাত্রায় \(n\)টি ফলের প্রকৃত গড় (একটি নির্দিষ্ট সংখ্যা, কারণ \(\omega\) স্থির ধরা)।
- \(\lim_{n\to\infty} \bar X_n(\omega) = \mu\) — এই নির্দিষ্ট যাত্রার সংখ্যা-ক্রমটি সাধারণ (deterministic) অর্থে \(\mu\)-তে converge করে।
- \(\{\omega : \dots\}\) — যত যাত্রায় উপরের limit সত্যি, তাদের সবার সংগ্রহ (একটি ঘটনা)।
- \(P(\dots) = 1\) — সেই "ভালো-যাত্রা" সংগ্রহের সম্ভাবনা পুরো \(1\); অর্থাৎ যেসব যাত্রায় থিতু হয় না, তাদের মোট সম্ভাবনা \(0\)।
- \(\xrightarrow{a.s.}\) — "converges almost surely" তীর (3.2)।
"almost" শব্দটা কেন। ব্যতিক্রম-যাত্রা থাকতেই পারে — যেমন (কল্পনায়) এমন যাত্রা যেখানে চিরকাল কেবল \(6\)-ই পড়ে, যার গড় \(\mu\)-তে যায় না — কিন্তু এমন যাত্রাগুলোর মোট সম্ভাবনা ঠিক \(0\)। সম্ভাবনা-\(0\) মানে "অসম্ভব" নয়, "এত বিরল যে সম্ভাবনার হিসাবে গণনায় আসে না।" (এর পুরো rigorous রূপ — measure-zero — Part VII-এ; এখানে স্বজ্ঞাই যথেষ্ট, ঠিক 3.2-এ যেমন।)
২.৪ Weak বনাম Strong — পার্থক্যটা ঠিক কোথায়¶
এটাই এ অধ্যায়ের সবচেয়ে সূক্ষ্ম বিন্দু, তাই ধীরে। দুই আইনই বলে "\(\bar X_n\) গিয়ে \(\mu\)-তে বসে," কিন্তু কতটা কঠোরভাবে বসে — সেখানে পার্থক্য:
- Weak Law (in probability) প্রতিটি \(n\)-কে আলাদা snapshot হিসেবে মাপে: "এই নির্দিষ্ট \(n\)-এ \(\bar X_n\) দূরে থাকার সম্ভাবনা কত?" — সেই সংখ্যা \(0\)-এ যাক, ব্যস। এটা অনুমতি দেয় যে \(\bar X_n\) মাঝে মাঝে দূরে লাফাক — শুধু লাফানোর সম্ভাবনা \(n\)-এর সাথে কমলেই হলো; লাফগুলো (ভিন্ন ভিন্ন যাত্রায়) অসীমবার ঘটতেও পারে।
- Strong Law (almost sure) পুরো অসীম পথ একসাথে দেখে: "একটা গোটা যাত্রা ধরলে, এক জায়গার পর কি \(\bar X_n\) চিরকালের জন্য \(\mu\)-এর কাছে আটকে থাকে?" — এটা দাবি করে যে প্রায় প্রতিটি নির্দিষ্ট যাত্রায় দূরে-লাফানো একসময় পুরোপুরি বন্ধ হয়ে যায়। অনেক কঠোর শর্ত।
একটা চিত্রকল্পে: Weak Law বলে "যেকোনো নির্দিষ্ট দেরিতে দেখা মুহূর্তে \(\bar X_n\) প্রায় নিশ্চয় \(\mu\)-এর কাছে"; Strong Law বলে "প্রায় প্রতিটি গোটা যাত্রা শেষমেশ \(\mu\)-তে স্থায়ীভাবে গেঁথে যায়।" Strong বেশি দাবি করে — তাই এর নাম "strong"।
দিকটাও মনে রাখুন: এই দুই আইন আসলে 3.2-এর hierarchy-র একটা উদাহরণ। সেখানে দেখেছি \(a.s. \Rightarrow P\) (almost sure convergence থাকলে in probability আপনাআপনি আসে, উল্টোটা নয়)। তাই — $$ \underbrace{\bar X_n \xrightarrow{a.s.} \mu}{\text{Strong Law (কড়া)}} \quad\Longrightarrow\quad \underbrace{\bar X_n \xrightarrow{P} \mu}. $$ অর্থাৎ }Strong Law প্রমাণ করলে Weak Law বিনামূল্যে পাওয়া যায়। তবু দুটো আলাদা করে শেখার কারণ আছে: Weak Law-এর প্রমাণ সহজ (§২.২-এর Chebyshev-যুক্তি, এক লাইন) আর অনেক প্রয়োগে যথেষ্ট; Strong Law-এর প্রমাণ অনেক কঠিন (পুরো পথের আচরণ সামলাতে হয়, §৪-এ আংশিক স্কেচ), কিন্তু Monte Carlo-র মতো জায়গায় "একটা যাত্রা চালালেই সেটা সত্যি গন্তব্যে পৌঁছাবে" — এই গ্যারান্টি দরকার, যা শুধু Strong Law-ই দেয়।
২.৫ finite-variance শর্ত ও 3.2-এর সাথে সংযোগ — এক নজরে¶
দুই-একটা সূক্ষ্মতা গুছিয়ে রাখি, যেগুলো প্রায়ই বিভ্রান্ত করে:
- কী লাগে আর কী লাগে না। WLLN ও SLLN দুটোরই আসল একমাত্র অপরিহার্য শর্ত হলো \(\mu = \mathbb{E}[X_i]\) সসীম (অর্থাৎ expectation আদৌ থাকতে হবে)। finite variance (\(\sigma^2 < \infty\)) দরকারি নয় — তবে variance সসীম হলে WLLN-এর প্রমাণ এক লাইনে নেমে আসে (Chebyshev, §২.২)। এই পার্থক্যটা §৩-এর E4 (Cauchy)-তে প্রাণে এসে দাঁড়াবে: সেখানে mean-ই নেই, তাই দুই আইনের কোনোটাই খাটে না।
- 3.2-এর ভাষাই এখানে আইন হয়ে উঠল। 3.2-এ আমরা চারটি convergence ধরন (in probability, almost sure, in distribution, \(L^p\)) শিখেছিলাম — সেগুলো ছিল নিছক ভাষা, খালি পাত্র। এই অধ্যায়ে সেই দুটো পাত্র (in probability, almost sure) ভরে গেল একটা গভীর সত্য দিয়ে: sample mean সত্যিই এই দুই অর্থে \(\mu\)-তে যায়। আর পরের অধ্যায় (3.4) তৃতীয় পাত্রটা (in distribution) ভরবে — standardized sum যে Normal-এ যায়, সেই CLT দিয়ে।
- LLN বনাম CLT, এক বাক্যে। LLN বলে \(\bar X_n\) কোথায় যায় (\(\mu\)-তে); CLT (3.4) বলে সেই যাওয়ার সময় ভুলটা কেমন আকৃতির ও কত বড় (Normal, \(\sigma/\sqrt{n}\) স্কেলে)। LLN আগে আসে, কারণ "কোথায় যায়" না জানলে "কীভাবে যায়" প্রশ্নই ওঠে না।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এবার চারটি concrete উদাহরণে (E1–E4) LLN-কে সংখ্যাসহ দেখি। প্রথম তিনটি (E1–E3) দেখায় LLN কীভাবে কাজ করে; শেষেরটি (E4 — Cauchy) দেখায় শর্ত ভাঙলে কীভাবে LLN ভেঙে পড়ে — যা সমান গুরুত্বপূর্ণ একটি সতর্কতা।
৩.১ E1 — Fair die: \(\bar X_n \to \mu = 3.5\)¶
কাঠামো। \(X_1, X_2, \dots\) হলো একটা ন্যায্য ছক্কার পরপর গড়ান, প্রতিটি \(X_i \in \{1,2,3,4,5,6\}\), প্রতিটি মান সমান সম্ভাবনা \(1/6\)। তাই (§১.১-এ যা পেয়েছি): $$ \mu = \mathbb{E}[X_i] = \frac{1+2+3+4+5+6}{6} = 3.5. $$ variance-ও বের করে রাখি (পরে \(\bar X_n\)-এর ছড়ানো বুঝতে): \(\mathbb{E}[X_i^2] = \frac{1^2+2^2+\dots+6^2}{6} = \frac{91}{6} \approx 15.17\), তাই $$ \sigma^2 = \mathbb{E}[X_i^2] - \mu^2 = \frac{91}{6} - 3.5^2 = 15.1\overline{6} - 12.25 = 2.91\overline{6} \approx 2.92. $$
LLN কী বলছে। যেহেতু \(\mu = 3.5\) সসীম (এবং \(\sigma^2 \approx 2.92\) সসীম), দুই আইনই খাটে: \(\bar X_n \xrightarrow{a.s.} 3.5\) (তাই \(\xrightarrow{P} 3.5\)-ও)। চলমান গড় থিতু হবে ঠিক \(3.5\)-এ।
সংখ্যা-অনুভূতি — ছড়ানো কত দ্রুত কমে। §২.১ থেকে \(\mathrm{Var}(\bar X_n) = \sigma^2/n \approx 2.92/n\), তাই standard deviation \(\approx \sqrt{2.92/n} = 1.71/\sqrt{n}\):
| গড়ান সংখ্যা \(n\) | \(\bar X_n\)-এর std \(\approx 1.71/\sqrt{n}\) | ব্যাখ্যা |
|---|---|---|
| \(n = 10\) | \(\approx 0.54\) | গড় এখনো \(3.5\) থেকে আধ-ঘর এদিক-ওদিক দোলে |
| \(n = 100\) | \(\approx 0.17\) | অনেক শক্ত, সাধারণত \(3.3\)–\(3.7\) |
| \(n = 1000\) | \(\approx 0.054\) | কার্যত \(3.5\)-এ গেঁথে, \(\pm 0.1\)-এর ভেতর |
| \(n = 10000\) | \(\approx 0.017\) | \(3.5\) থেকে আলাদা করা কঠিন |
স্পষ্ট দেখা যাচ্ছে: \(n\) যত বড়, \(\bar X_n\) তত নিবিড়ভাবে \(3.5\)-এর চারপাশে — std কমে \(1/\sqrt{n}\)-হারে। এই থিতু-হওয়াটাই হবে Figure 3-3-running-mean: কয়েকটা random যাত্রার চলমান গড় শুরুতে এলোমেলো লাফিয়ে ধীরে ধীরে \(3.5\)-রেখায় মিশে যায়।
Chebyshev দিয়ে একটা concrete গ্যারান্টি। ধরা যাক \(n = 1000\), আর জানতে চাই \(\bar X_{1000}\) সত্য গড় থেকে \(0.1\)-এর বেশি দূরে যাওয়ার সম্ভাবনা। §২.২-এর সীমা (\(\varepsilon = 0.1\)): $$ P\big(\lvert \bar X_{1000} - 3.5\rvert > 0.1\big) \;\le\; \frac{\sigma^2}{n\varepsilon^2} \;=\; \frac{2.92}{1000 \times 0.1^2} \;=\; \frac{2.92}{10} \;=\; 0.292. $$ অর্থাৎ ১০০০ গড়ানে চলমান গড় \(3.4\)–\(3.6\)-এর বাইরে যাওয়ার সম্ভাবনা সর্বোচ্চ ~২৯%। (এটি Chebyshev-এর আলগা সীমা — প্রকৃত সম্ভাবনা অনেক কম; কিন্তু \(n\to\infty\) নিলে এই সীমা \(\to 0\), যা ঠিক WLLN।)
৩.২ E2 — Fair coin: heads-অনুপাত \(\to 0.5\)¶
কাঠামো। এটি LLN-এর সবচেয়ে পরিচিত মুখ। \(X_1, X_2, \dots\) হলো পরপর কয়েন-টস, প্রতিবার head এলে \(X_i = 1\), tail এলে \(X_i = 0\) (এমন variable-কে বলে Bernoulli, 2.3)। ন্যায্য কয়েনে head ও tail সমান সম্ভাবনা \(1/2\), তাই $$ \mu = \mathbb{E}[X_i] = 1\cdot\tfrac12 + 0\cdot\tfrac12 = 0.5, \qquad \sigma^2 = \mu(1-\mu) = 0.5 \times 0.5 = 0.25. $$ এখানে sample mean-এর একটা সুন্দর অর্থ আছে: \(\bar X_n = \frac1n\sum_i X_i\) = প্রথম \(n\) টসে head-এর অনুপাত (fraction of heads)।
LLN কী বলছে। \(\mu = 0.5\) সসীম, তাই \(\bar X_n \xrightarrow{a.s.} 0.5\) — অর্থাৎ head-এর অনুপাত \(0.5\)-এ স্থিত হয়। এটাই সবার চেনা "অনেকবার ছুঁড়লে অর্ধেক head" — কিন্তু এখন আমরা জানি এটা নিছক প্রবাদ নয়, এটা SLLN-এর সরাসরি ফল, আর "স্থিত হওয়া" মানে almost surely।
একটা জরুরি ভুল-ধারণা ভাঙা — LLN ≠ "ভারসাম্য রক্ষাকারী শক্তি"। অনেকে ভাবেন: ১০টা টসে যদি ৮টা head এসে যায়, তবে "ভারসাম্য ফেরাতে" এখন বেশি tail আসবে। এটা ভুল (এই ভুলকে বলে gambler's fallacy)। কয়েনের কোনো স্মৃতি নেই — পরের টস সবসময় ৫০-৫০। তাহলে অনুপাত \(0.5\)-এ যায় কীভাবে? কারণ শুরুর ৩টা বাড়তি head পরের হাজার হাজার টসে লঘু হয়ে (diluted) যায়, মুছে যায় না। যেমন \(\bar X_{10} = 0.8\) হলেও, পরে আরও ৯৯০ টসে যদি ঠিক অর্ধেক head আসে (\(495\)টি), তবে \(\bar X_{1000} = (8+495)/1000 = 0.503\) — শুরুর ভারসাম্যহীনতা প্রায় মিলিয়ে গেছে, কোনো "ক্ষতিপূরণ" ছাড়াই, নিছক বড় \(n\)-এ ভাগ হয়ে। LLN টানে না, লঘু করে।
(সংখ্যা-অনুভূতি E1-এর মতোই: std \(= \sqrt{0.25/n} = 0.5/\sqrt{n}\), তাই \(n=100\)-এ \(\approx 0.05\), \(n=10000\)-এ \(\approx 0.005\) — দ্রুত \(0.5\)-এ আঁটো।)
৩.৩ E3 — Monte Carlo: \(\pi\)-এর মান average দিয়ে আন্দাজ¶
এবার LLN-কে একটা যন্ত্র হিসেবে ব্যবহার করি — একটা সংখ্যা (\(\pi\)) আন্দাজ করতে, যা সরাসরি হিসাব করা কঠিন। কৌশলটার নাম Monte Carlo, আর এর পুরো ভিত্তি LLN।
ধারণা। একটা \(2\times 2\) বর্গক্ষেত্র কল্পনা করুন, কেন্দ্র মূলবিন্দুতে, কোণ \((-1,-1)\) থেকে \((1,1)\) — এর ক্ষেত্রফল \(4\)। এর ভেতরে আঁকা একক বৃত্ত (ব্যাসার্ধ \(1\), ক্ষেত্রফল \(\pi\))। এবার বর্গক্ষেত্রের ভেতর একটা random বিন্দু \((U, V)\) ফেলুন, যেখানে \(U, V\) স্বাধীনভাবে \([-1, 1]\)-এ Uniform। সেই বিন্দু বৃত্তের ভেতরে পড়ার সম্ভাবনা = (বৃত্তের ক্ষেত্রফল)/(বর্গের ক্ষেত্রফল) \(= \pi/4\)।
এবার একটা চতুর random variable বানাই — একটি indicator (নির্দেশক, 2.3): $$ X_i = \begin{cases} 1 & \text{যদি } i\text{-তম বিন্দু বৃত্তের ভেতরে (অর্থাৎ } U_i^2 + V_i^2 \le 1\text{)} \ 0 & \text{নচেৎ.} \end{cases} $$ এর expectation ঠিক ঐ সম্ভাবনা: $$ \mu = \mathbb{E}[X_i] = P(\text{বৃত্তের ভেতরে}) = \frac{\pi}{4}. $$
LLN-এর প্রয়োগ। \(X_i\)-রা i.i.d. Bernoulli, \(\mu = \pi/4\) সসীম — তাই LLN বলে $$ \bar X_n = \frac{1}{n}\sum_{i=1}^n X_i \;=\; (\text{বৃত্তের ভেতরে পড়া বিন্দুর অনুপাত}) \;\xrightarrow{a.s.}\; \frac{\pi}{4}. $$ অর্থাৎ অনেক random বিন্দু ফেলে, বৃত্তের-ভেতরের অনুপাত গুনে, \(4\) দিয়ে গুণ করলেই \(\pi\)-এর আন্দাজ: $$ \widehat{\pi}_n \;=\; 4\,\bar X_n \;\xrightarrow{a.s.}\; \pi. $$
সংখ্যায় (একটি নমুনা run)। ধরা যাক একবার চালিয়ে এই ফল পেলাম (random, তাই প্রতিবার একটু আলাদা হবে):
| বিন্দু সংখ্যা \(n\) | বৃত্তে পড়া অনুপাত \(\bar X_n\) | \(\widehat\pi_n = 4\bar X_n\) | প্রকৃত \(\pi = 3.14159\dots\) থেকে ভুল |
|---|---|---|---|
| \(n = 100\) | \(0.81\) | \(3.24\) | \(\approx 0.10\) |
| \(n = 1{,}000\) | \(0.792\) | \(3.168\) | \(\approx 0.027\) |
| \(n = 10{,}000\) | \(0.7861\) | \(3.1444\) | \(\approx 0.003\) |
| \(n = 1{,}000{,}000\) | \(0.785419\) | \(3.14168\) | \(\approx 0.00009\) |
স্পষ্ট: \(n\) বাড়ার সাথে আন্দাজ \(\pi\)-এর দিকে থিতু হচ্ছে — কোনো calculus বা \(\pi\)-এর সূত্র ছাড়াই, নিছক random বিন্দু ছুঁড়ে আর গড় নিয়ে। এটাই Monte Carlo-র সৌন্দর্য, আর এর প্রতিটি ধাপ LLN-এর গ্যারান্টিতে চলছে। (এই থিতু-হওয়া হবে Figure 3-3-monte-carlo: বর্গে ছড়ানো বিন্দু, বৃত্তে-ভেতর/বাইরে রঙে আলাদা, পাশে \(\widehat\pi_n\) ক্রমে \(\pi\)-রেখায় মিশছে।)
বড় ছবি। এখানে \(\pi\) ছিল উদাহরণ মাত্র। যেকোনো পরিমাণ যদি কোনো random পরীক্ষার expectation \(\mu = \mathbb{E}[X_i]\) হিসেবে লেখা যায় — একটা integral, একটা গড় মুনাফা, একটা ভৌত ধ্রুবক — তবে সেই পরীক্ষা বহুবার চালিয়ে গড় নিলেই উত্তর; LLN বলে গড় সত্যি মানে পৌঁছাবে। এই একটিমাত্র নীতি আধুনিক simulation-এর গোটা ক্ষেত্রটাকে ধরে রেখেছে।
৩.৪ E4 — Cauchy distribution: যখন LLN ভেঙে পড়ে¶
এতক্ষণ দেখলাম LLN কীভাবে কাজ করে। এবার সমান-গুরুত্বপূর্ণ উল্টো পাঠ: শর্ত ভাঙলে LLN ব্যর্থ হয়। এই সতর্কতা না জানলে কেউ অন্ধভাবে "বেশি data নিলেই গড় থিতু হবে" ধরে নিয়ে মারাত্মক ভুল করতে পারে।
কাঠামো। ধরা যাক \(X_1, X_2, \dots\) i.i.d., কিন্তু এবার তারা একটা standard Cauchy distribution থেকে আসে — যার probability density function $$ f(x) = \frac{1}{\pi\,(1 + x^2)}, \qquad x \in (-\infty, \infty). $$ দেখতে এটা Normal-এর মতোই একটা সুষম, ঘণ্টা-আকৃতির, কেন্দ্র-\(0\) বণ্টন। কিন্তু এর লেজ (tail) অনেক ভারী — দূরের চরম মান (যেমন \(x = 100\) বা \(1000\)) Normal-এর তুলনায় বহুগুণ বেশি সম্ভব।
আসল সমস্যা — mean-ই নেই। Cauchy-র জন্য expectation \(\mathbb{E}[X_i]\) সংজ্ঞায়িতই হয় না — integral \(\int_{-\infty}^{\infty} x\, f(x)\,dx\) অভিসারী (convergent) নয়, কারণ লেজ এত ভারী যে \(x \cdot \frac{1}{\pi(1+x^2)}\)-এর area দুই দিকে \(\pm\infty\)-এ ছুটে যায়, বাতিল হয় না। অর্থাৎ Cauchy-র কোনো \(\mu\) নেই (variance তো নেই-ই)। আর §২.৫-এ বলেছিলাম LLN-এর একমাত্র অপরিহার্য শর্ত হলো "\(\mu\) সসীম হতে হবে" — এখানে ঠিক সেই শর্তই ভাঙছে।
ফল — running mean কখনো থিতু হয় না। যেহেতু কোনো \(\mu\)-ই নেই, \(\bar X_n\) কোনো নির্দিষ্ট মানে যাওয়ার প্রশ্নই ওঠে না। আরও আশ্চর্য একটা গাণিতিক সত্য: Cauchy variable-এর sample mean \(\bar X_n\) আসলে আবার ঠিক সেই একই standard Cauchy distribution মেনে চলে — অর্থাৎ \(1000\)টা মানের গড় নিলেও সেটা একটা একক Cauchy মানের চেয়ে এতটুকু কম এলোমেলো নয়! বেশি data এখানে কোনো নির্ভুলতা কেনে না।
স্বজ্ঞা — কেন ভারী লেজ সব ভেস্তে দেয়। E1–E3-এ LLN কাজ করছিল কারণ উপরের ও নিচের ভুলগুলো গড়ে একে অপরকে কাটছিল আর ছড়ানো (\(\sigma^2/n\)) কমছিল। কিন্তু Cauchy-তে লেজ এত ভারী যে যেকোনো মুহূর্তে একটা বিশাল মান (যেমন \(X_i = 5000\)) এসে পড়তে পারে — আর সেই একটা দানব মান পুরো চলমান গড়কে ছিটকে দেয়, এতদিনের জমানো ভারসাম্য নষ্ট করে। যত \(n\) বাড়ে, তত বড় বড় মান আসার সুযোগও বাড়ে, তাই গড় কখনো শান্ত হয় না — বারবার নতুন দানব এসে তাকে লাফ করায়। কাটাকাটির বদলে এখানে মাঝে মাঝের অতিকায় মান রাজত্ব করে, তাই গড় থিতু হওয়ার কোনো উপায় থাকে না।
সংখ্যায় তুলনা (E1 die-র উল্টো ছবি)। একটা নমুনা Cauchy যাত্রার চলমান গড় এমন দেখাতে পারে:
| \(n\) | fair die-র \(\bar X_n\) (E1) | Cauchy-র \(\bar X_n\) (নমুনা) |
|---|---|---|
| \(n = 10\) | \(3.6\) | \(-2.7\) |
| \(n = 100\) | \(3.42\) | \(11.3\) |
| \(n = 1000\) | \(3.51\) | \(-4.8\) |
| \(n = 10000\) | \(3.498\) | \(63.0\) |
বাঁ কলামে (die) গড় সুন্দর করে \(3.5\)-এ আঁটো হচ্ছে; ডান কলামে (Cauchy) গড় কোনো নিয়ম ছাড়াই লাফাচ্ছে — \(n\) বাড়লেও থিতু তো হয়ই না, বরং একটা দানব মান এলে আরও বড় লাফ দেয় (\(n=10000\)-এ \(63\)!)। এই থিতু-না-হওয়া ছবিটাই হবে Figure 3-3-cauchy-fail: die-র মসৃণ অভিসারী চলমান গড়ের পাশে Cauchy-র চিরচঞ্চল, কখনো-না-বসা চলমান গড় — পাশাপাশি রেখে পার্থক্যটা চোখে দেখা।
মনে রাখার সতর্কতা। LLN কোনো জাদুমন্ত্র নয় যা "বেশি data" পেলেই খেটে যায়। এর একটা শর্ত আছে — population mean \(\mu\) অন্তত সসীমভাবে থাকতে হবে। ভারী-লেজ (heavy-tailed) data-তে — যেমন কিছু আর্থিক রিটার্ন, নেটওয়ার্ক ট্র্যাফিক, বা চরম-ঘটনার বণ্টন — এই শর্ত ভাঙতে পারে, আর তখন sample mean নিয়ে কাজ করা বিপজ্জনক। শর্ত যাচাই না করে LLN-এ ভরসা কোরো না — এটাই E4-এর স্থায়ী পাঠ।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে আমরা Law of Large Numbers-কে scratch থেকে (একদম শুরু থেকে) দাঁড় করাব। কোনো বীজগণিতের ধাপ লুকানো হবে না, প্রতিটি লাইনের পেছনে কারণ বাংলায় থাকবে। কাজটা চারটি ধাপে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সহজ · ★★ = মাঝারি · ★★★ = উন্নত):
- (ক) \(\bar X_n\)-এর mean ও variance হিসাব করা — \(\mathbb{E}[\bar X_n]=\mu\) আর \(\mathrm{Var}(\bar X_n)=\sigma^2/n\) (এখানেই independence আসল কাজ করে; from scratch দেখাব)। ★
- (খ) এই দুই ফল আর 3.1-এর Chebyshev সরাসরি জুড়ে Weak Law (WLLN) প্রমাণ করা। ★
- (গ) Strong Law (SLLN) বিবৃত করা ও কেন এটি weak-এর চেয়ে কড়া তা ব্যাখ্যা করা (পূর্ণ প্রমাণ নয়, সৎ proof-sketch)। ★★★
- (ঘ) শর্তগুলো খতিয়ে দেখা — finite variance বনাম finite mean, এবং E4 (Cauchy) দিয়ে দেখা যে mean না থাকলে LLN ভেঙে পড়ে।
পুরো অংশের ভিত্তি দুটো জিনিস, যা আগের অধ্যায়ে শেখা: (i) expectation linear — \(\mathbb{E}[aU+bV]=a\,\mathbb{E}[U]+b\,\mathbb{E}[V]\) (2.5); আর (ii) independent হলে covariance শূন্য — \(\mathrm{Cov}(X_i,X_j)=0\) যখন \(i\ne j\) (2.6)। এই দুই হাতিয়ার দিয়েই পুরো অধ্যায়ের গাণিতিক মেরুদণ্ড দাঁড়াবে।
৪.১ · (ক) \(\bar X_n\)-এর mean ও variance — ★¶
ধরা যাক \(X_1, X_2, \dots, X_n\) হলো i.i.d. (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত) random variable, প্রত্যেকের একই mean ও variance:
এবং sample mean (নমুনা গড়)
আমাদের লক্ষ্য দুটো সংখ্যা: \(\bar X_n\) "গড়ে" কোথায় থাকে (\(\mathbb{E}[\bar X_n]\)) এবং কতটা ছড়ায় (\(\mathrm{Var}(\bar X_n)\))। এই দুটোই WLLN-এর সরাসরি কাঁচামাল।
দাবি ১ — \(\mathbb{E}[\bar X_n] = \mu\) (unbiased: গড়ের গড় সত্য গড়েই বসে)¶
প্রমাণ। শুরু করি সংজ্ঞা থেকে, তারপর expectation-এর linearity ব্যবহার করি ধাপে ধাপে।
প্রতিটি ধাপের কারণ:
- (1) \(\frac1n\) একটি ধ্রুবক (constant, \(n\) স্থির), আর expectation ধ্রুবক-গুণে রৈখিক — তাই ধ্রুবকটা বাইরে আনা যায়: \(\mathbb{E}[cZ]=c\,\mathbb{E}[Z]\)।
- (2) expectation যোগফলের ওপরও রৈখিক — "যোগফলের expectation = expectation-এর যোগফল" (\(\mathbb{E}[\sum Z_i]=\sum \mathbb{E}[Z_i]\), 2.5)। লক্ষণীয়: এই ধাপে independence লাগেনি — linearity সবসময়ই খাটে, variable-গুলো independent হোক বা না হোক।
- (3) প্রতিটি \(X_i\)-এর expectation একই, \(\mu\) ("identically distributed" শর্ত)।
- (4) একই সংখ্যা \(\mu\) মোট \(n\) বার যোগ করলে \(n\mu\); তারপর \(\frac1n\cdot n\mu=\mu\)।
অর্থ। \(\bar X_n\) একটি random variable — একেক বার একেক মান দেয় — কিন্তু তার expectation ঠিক \(\mu\), নমুনা-আকার \(n\) যা-ই হোক। এই ধর্মকে বলে unbiasedness (পক্ষপাতহীনতা): sample mean গড়ে সত্য গড়ের চেয়ে বেশিও নয়, কমও নয় (Part IV-এ গভীরভাবে আসবে)। অর্থাৎ \(\bar X_n\) ইতিমধ্যেই "ঠিক জায়গায় কেন্দ্রিত"; এখন শুধু দেখা বাকি যে \(n\) বাড়লে এর ছড়ানো কমে — সেটাই দাবি ২। \(\;\blacksquare\)
দাবি ২ — \(\mathrm{Var}(\bar X_n) = \dfrac{\sigma^2}{n}\) (এখানেই independence আসল কাজ করে)¶
এটাই পুরো অধ্যায়ের চাবি-ফল। variance \(1/n\) হারে কমে — আর ঠিক এই কমাটাই LLN-কে সম্ভব করে। প্রমাণে independence কোথায় ঢোকে, তা আমরা স্পষ্ট করে দেখাব।
ধাপ ১ — ধ্রুবক বাইরে আনা। variance-এর একটি মৌলিক ধর্ম: \(\mathrm{Var}(cZ)=c^2\,\mathrm{Var}(Z)\) — ধ্রুবক বাইরে এলে বর্গ হয়ে আসে (কারণ variance বর্গ-এককে মাপা; 2.5)। এখানে \(c=\frac1n\):
ধাপ ২ — যোগফলের variance খোলা (সাধারণ সূত্র, এখনো independence ছাড়া)। এবার \(\mathrm{Var}\big(\sum_i X_i\big)\) খুলি। সাবধান — variance যোগফলের ওপর সবসময় রৈখিক নয়; সাধারণ সূত্রে covariance-পদ থাকে (2.6):
ছোট করে মনে করিয়ে দিই কেন এই সূত্র (2.6-এর ফল): \(\sum_i X_i\)-এর variance মানে \(\mathbb{E}\big[(\sum_i (X_i-\mu))^2\big]\); বর্গ খুললে \(n\)টি "নিজের সাথে নিজের" পদ (\((X_i-\mu)^2\), যাদের expectation = \(\mathrm{Var}(X_i)\)) আর সব "ভিন্ন জোড়া" পদ (\((X_i-\mu)(X_j-\mu)\), \(i\ne j\), যাদের expectation = \(\mathrm{Cov}(X_i,X_j)\)) আসে। তাই উপরের দুই অংশ।
ধাপ ৩ — এখানেই independence ব্যবহার (covariance-পদ মুছে যাওয়া)। এই ধাপটাই কেন্দ্রবিন্দু। \(X_i\)-গুলো independent, তাই যেকোনো \(i \ne j\)-এর জন্য
কেন? independence-এর সংজ্ঞা থেকে (\(i\ne j\) হলে \(\mathbb{E}[X_iX_j]=\mathbb{E}[X_i]\,\mathbb{E}[X_j]\), 2.6), তাই
অর্থাৎ \((৪.২)\)-এর গোটা covariance-যোগফল পুরোপুরি শূন্য হয়ে যায়:
এই এক লাইনই অধ্যায়ের হৃদয়। independence ছাড়া covariance-পদ থেকে যেত, এবং তা ধনাত্মক হলে \(\mathrm{Var}(\sum X_i)\) অনেক বড় হতে পারত — তখন গড় আর \(1/n\) হারে শক্ত হতো না, LLN ভেঙে যেতে পারত। স্বাধীনতাই নিশ্চিত করে যে variance-গুলো শুধু "যোগ" হয়, একে অপরকে বাড়িয়ে দেয় না। (টীকা: আসলে শুধু uncorrelated — অর্থাৎ \(\mathrm{Cov}=0\) — হলেই এই ধাপ খাটে; full independence-এর চেয়ে এটি দুর্বল শর্ত। কিন্তু i.i.d. ধরায় আমরা independence-ই ব্যবহার করছি।)
ধাপ ৪ — identically distributed: সব variance সমান। প্রতিটি \(X_i\)-এর variance একই, \(\sigma^2\) ("identically distributed")। তাই \((৪.৩)\)-এর যোগফল \(n\)টি একই \(\sigma^2\)-এর যোগ:
ধাপ ৫ — সব জোড়া দেওয়া। \((৪.১)\)-এ এই মান বসাই:
ফল কী বলছে — LLN-এর গোটা গল্প এই এক সূত্রে। \(\mathrm{Var}(\bar X_n)=\sigma^2/n\) মানে: নমুনা-আকার \(n\) বাড়লে \(\bar X_n\)-এর ছড়ানো \(1/n\) হারে কমে (standard deviation \(\sigma/\sqrt n\) হারে — অর্থাৎ \(1/\sqrt n\) হারে)। \(n\to\infty\) নিলে variance \(\to 0\) — \(\bar X_n\) তার কেন্দ্র \(\mu\)-এর চারপাশে আরও আরও শক্ত করে জড়ো হয় (concentration)। দাবি ১ বলেছিল কেন্দ্র ঠিক \(\mu\); দাবি ২ বলছে সেই কেন্দ্রের চারপাশের কম্পন মুছে যাচ্ছে। দুটো একসাথে মানে — \(\bar X_n\) ক্রমে \(\mu\)-তে বসে পড়ছে। এটাকেই এখন Chebyshev দিয়ে আনুষ্ঠানিক করব।
সংখ্যায় ঝলক (§৫-এর পূর্বাভাস)। fair die-তে \(\sigma^2 = \tfrac{35}{12}\approx 2.92\), তাই \(\mathrm{Var}(\bar X_{1000})=2.92/1000\approx 0.0029\) — অর্থাৎ standard deviation মাত্র \(\approx 0.054\)। তাই \(1000\) বার ছুঁড়লে গড় \(3.5\)-এর খুব কাছেই থাকার কথা — LAB 1-এ ঠিক তা-ই দেখব (\(n=1000\)-এ গড় \(\approx 3.49\))।
৪.২ · (খ) Weak Law of Large Numbers — Chebyshev দিয়ে প্রমাণ — ★¶
এবার মূল ফল। §৪.১-এর দুটো ছোট হিসাব (mean \(=\mu\), variance \(=\sigma^2/n\)) আর 3.1-এর Chebyshev inequality — এই দুই উপাদান জুড়ে দিলেই Weak Law তিন লাইনে বেরিয়ে আসে। নতুন কোনো কৌশল লাগবে না; এটাই দেখায় 3.1-এর অসমতাগুলো কেন এত যত্ন করে প্রমাণ করা হয়েছিল।
বিবৃতি (Weak Law of Large Numbers — দুর্বল বৃহৎ সংখ্যার সূত্র)। ধরা যাক \(X_1, X_2, \dots\) i.i.d., \(\mathbb{E}[X_i]=\mu\) এবং সসীম variance \(\mathrm{Var}(X_i)=\sigma^2<\infty\)। তবে যেকোনো \(\varepsilon>0\)-এর জন্য
অর্থাৎ সংজ্ঞা অনুযায়ী (3.2 §২.১) \(\bar X_n \xrightarrow{P} \mu\) — sample mean সত্য গড়ে converge করে in probability।
মনে করিয়ে দেওয়া — 3.1-এর Chebyshev (a-রূপ)। যেকোনো random variable \(Y\)-এর mean \(\mathbb{E}[Y]\) ও variance \(\mathrm{Var}(Y)\) থাকলে, যেকোনো \(a>0\)-এর জন্য
(3.1-এ এটি \((X-\mu)^2\)-এর ওপর Markov প্রয়োগ করে প্রমাণ করা হয়েছিল; এখানে সরাসরি ব্যবহার করছি।)
প্রমাণ (সম্পূর্ণ)। চালটা সহজ: Chebyshev-কে \(Y=\bar X_n\)-এ প্রয়োগ করি। এর জন্য \(\bar X_n\)-এর mean ও variance লাগবে — যা §৪.১-এ কষাই হয়ে গেছে।
ধাপ ১ — Chebyshev-এ \(Y=\bar X_n\) বসানো। §৪.১ থেকে আমরা জানি
তাই \((\text{Chebyshev})\)-এ \(Y=\bar X_n\) এবং \(a=\varepsilon\) বসাই (যেহেতু \(\varepsilon>0\), শর্ত ঠিক আছে)। ডান পাশের \(\mathbb{E}[Y]\)-এর জায়গায় \(\mu\) আর \(\mathrm{Var}(Y)\)-এর জায়গায় \(\sigma^2/n\):
এই \((৪.৪)\) একটা পরিষ্কার, ব্যবহারযোগ্য bound — মনে রাখার মতো: "\(\bar X_n\) সত্য গড় থেকে \(\varepsilon\) বা বেশি দূরে যাওয়ার probability সর্বোচ্চ \(\sigma^2/(n\varepsilon^2)\)।"
ধাপ ২ — \(n\to\infty\) সীমা নেওয়া। \((৪.৪)\)-এর ডান পাশে তাকাই: লব \(\sigma^2\) স্থির (নমুনা-আকারের ওপর নির্ভর করে না), হর \(\varepsilon^2\)-ও স্থির (\(\varepsilon\) আগে থেকে বাছা)। শুধু \(n\) হরে বাড়ছে। তাই
কারণ \(\frac1n\to 0\) (একটি স্থির ধনাত্মক সংখ্যাকে অসীম-বড় কিছু দিয়ে ভাগ করলে শূন্যে যায়)।
ধাপ ৩ — squeeze (চাপা)। probability সবসময় \(\ge 0\), তাই বাঁ পাশ দুই সীমার মাঝে চাপা পড়ে:
বাঁ ও ডান — দুই দিকই \(0\)-তে যাচ্ছে, তাই মাঝেরটিও \(0\)-তে যেতে বাধ্য (squeeze theorem, Part 0)। যেহেতু \(\varepsilon>0\) ছিল যেকোনো, এটি সব \(\varepsilon\)-এর জন্যই সত্য। সংজ্ঞা অনুযায়ী এটাই \(\bar X_n \xrightarrow{P} \mu\)। \(\;\blacksquare\)
মন্তব্য — প্রমাণটা কেন এত ছোট হলো। সমস্ত ভারী কাজ আগেই করা হয়ে গেছে: §৪.১-এ \(\mathrm{Var}(\bar X_n)=\sigma^2/n\) (যেখানে independence ব্যবহৃত), আর 3.1-এ Chebyshev। WLLN আসলে এই দুটোর এক লাইনের ফলাফল। এজন্যই অনেকে বলেন "Chebyshev হলো LLN-এর ইঞ্জিন।" (এই bound বনাম empirical probability §৫-এর LAB 3-এ সংখ্যায় দেখব — figure 3-3-wlln-chebyshev-এ দৃশ্যমান করা হবে।)
স্পষ্ট করি — convergence কত দ্রুত? \((৪.৪)\) বলে bound \(\sim 1/n\) হারে নামে — ভালো, কিন্তু তেমন দ্রুত নয়। যদি data bounded হয় (যেমন coin বা die), 3.1-এর Hoeffding দিত exponential-হারে (\(e^{-2n\varepsilon^2}\)-জাতীয়) আরও অনেক শক্ত bound। অর্থাৎ একই WLLN বিভিন্ন অসমতা দিয়ে প্রমাণ করা যায়; Chebyshev সবচেয়ে সাধারণ (শুধু finite variance লাগে), Hoeffding দ্রুততর (কিন্তু boundedness চায়)।
৪.৩ · (গ) Strong Law of Large Numbers — বিবৃতি ও proof-sketch — ★★★¶
Weak Law বলে \(\bar X_n \xrightarrow{P} \mu\) — অর্থাৎ প্রতিটি বড় \(n\)-এ "\(\bar X_n\) দূরে থাকার সম্ভাবনা ছোট।" কিন্তু 3.2-এ আমরা শিখেছি convergence in probability একটি দুর্বলতর ধারণা: এটা মাঝে মাঝে দূরে লাফানো সহ্য করে, যতক্ষণ লাফের সম্ভাবনা কমে। Strong Law আরও কড়া কিছু দাবি করে — প্রায় প্রতিটি নির্দিষ্ট যাত্রায় গড় স্থায়ীভাবে \(\mu\)-তে থিতু হয়।
বিবৃতি (Strong Law of Large Numbers — সবল বৃহৎ সংখ্যার সূত্র)। ধরা যাক \(X_1, X_2, \dots\) i.i.d. এবং finite mean \(\mathbb{E}[\lvert X_i\rvert]<\infty\) (অর্থাৎ \(\mathbb{E}[X_i]=\mu\) সুসংজ্ঞায়িত)। তবে
অর্থাৎ সংজ্ঞা অনুযায়ী (3.2 §২.২) \(\bar X_n \xrightarrow{a.s.} \mu\) — sample mean সত্য গড়ে converge করে almost surely।
weak বনাম strong — ঠিক পার্থক্যটা কী? এটা এ অধ্যায়ের সবচেয়ে সূক্ষ্ম বিন্দু, তাই ধীরে (3.2-এর ভাষায়):
- Weak (in probability): প্রতিটি স্থির \(n\)-কে আলাদা "snapshot" হিসেবে দেখে — "এই \(n\)-এ \(\bar X_n\) দূরে থাকার সম্ভাবনা কত?" সেই সংখ্যা \(0\)-তে যায়। কিন্তু এটা একটামাত্র যাত্রার পুরো ভবিষ্যৎ নিয়ে কিছু বলে না; দূরে-লাফ মাঝে মাঝে ফিরে আসতে পারে (ভিন্ন ভিন্ন যাত্রায়)।
- Strong (almost sure): একটা গোটা অসীম যাত্রা \(\bar X_1(\omega), \bar X_2(\omega), \dots\) ধরে — "এই নির্দিষ্ট পথটা কি সত্যিই \(\mu\)-তে গিয়ে আটকে যায়?" উত্তর: প্রায় প্রতিটি যাত্রায় (সম্ভাবনা-\(1\)) হ্যাঁ — একবার কাছে এলে আর কখনো দূরে যায় না।
3.2-এর hierarchy থেকে আমরা জানি \(a.s. \Rightarrow P\) — তাই Strong Law থেকে Weak Law আপনাআপনি আসে (strong দিলে weak বিনামূল্যে)। উল্টোটা নয়: শুধু WLLN থেকে SLLN টানা যায় না; SLLN-এর জন্য আলাদা, গভীরতর যুক্তি লাগে। এটাই দুটোকে আলাদা theorem বানায়।
একটা চমকপ্রদ ব্যাপার — শর্ত আসলে দুর্বলতর। খেয়াল করুন: Weak Law-এ আমরা finite variance (\(\sigma^2<\infty\)) ধরেছিলাম (Chebyshev-এর জন্য দরকার ছিল)। কিন্তু Strong Law-এর জন্য শুধু finite mean (\(\mathbb{E}[\lvert X_i\rvert]<\infty\)) লাগে — variance অসীম হলেও চলে! অর্থাৎ কড়া উপসংহার (a.s.) আসলে কম অনুমানে পাওয়া যায়। এটা প্রথমে অদ্ভুত শোনালেও সত্য — তবে এর মূল্য হলো প্রমাণটা অনেক কঠিন (Chebyshev আর যথেষ্ট নয়)।
সততা-নোট। নিচে আমরা SLLN-এর একটি proof-sketch দিচ্ছি — পূর্ণ কঠোর প্রমাণ নয়। কারণ সৎভাবে বললে: সাধারণ finite-mean ক্ষেত্রে SLLN-এর পূর্ণ প্রমাণে measure-theoretic যন্ত্রপাতি (Borel–Cantelli lemma, truncation, Kolmogorov-এর maximal inequality) লাগে, যা Part VII-এর আগে হাতে আসবে না। তাই এখানে আমরা একটি সরলীকৃত পথ (finite 4th moment ধরে নিয়ে) স্কেচ করছি — মূল কৌশলটা দেখানোর জন্য — এবং স্পষ্ট করে বলছি কোথায় শর্টকাট নিচ্ছি। কোনো ফাঁকি লুকানো নেই; শুধু গভীরতম ধাপগুলো নির্দেশ করে এগিয়ে যাচ্ছি।
Proof-sketch (সরলীকৃত — finite 4th moment ধরে)। ধরে নিই (শুধু এই স্কেচের জন্য, মূল theorem-এ যা লাগে না) যে \(\mathbb{E}[X_i^4]<\infty\), এবং সরলতার জন্য \(\mu=0\) (নইলে \(X_i-\mu\) দিয়ে কাজ করুন)। মূল ধারণা চার ধাপে:
- চতুর্থ moment-এর হিসাব। \(\bar X_n = \frac1n\sum_i X_i\)-এর জন্য একটু বীজগণিতে দেখানো যায় (independence ব্যবহার করে, যেমন §৪.১-এ variance কষা হয়েছিল, কিন্তু এবার বর্গের বদলে চতুর্থ ঘাত নিয়ে) যে একটি ধ্রুবক \(C\) আছে যেন
স্বজ্ঞা: variance যেমন \(1/n\) হারে নামে, চতুর্থ moment তেমন \(1/n^2\) হারে নামে — আরও দ্রুত। এই দ্রুততাই চাবি।
- সম্ভাবনার যোগফল সসীম। Markov inequality (3.1) চতুর্থ ঘাতে প্রয়োগ করি: যেকোনো \(\varepsilon>0\)-এ
এখন সব \(n\)-এর জন্য এই সম্ভাবনাগুলো যোগ করি:
কারণ \(\sum 1/n^2\) একটি converge করা series (এর মান \(\pi^2/6\), Part 0-এ দেখা)। লক্ষণীয় — Chebyshev দিত \(1/n\), আর \(\sum 1/n\) diverge করে; তাই এখানে চতুর্থ moment-এর \(1/n^2\) দরকার হলো। এটাই স্কেচে boundedness/4th-moment ধরার আসল কারণ।
-
Borel–Cantelli lemma। এখানে একটি গভীর ফল ব্যবহার করি (পূর্ণ প্রমাণ Part VII): যদি কোনো ঘটনাসমূহের সম্ভাবনার যোগফল সসীম হয় (\(\sum_n P(A_n)<\infty\)), তবে সম্ভাবনা-\(1\)-এ সেই ঘটনাগুলোর মধ্যে কেবল সসীম-সংখ্যক ঘটে (অর্থাৎ একটা জায়গার পর আর ঘটে না)। এখানে \(A_n=\{\lvert\bar X_n\rvert\ge\varepsilon\}\)। যোগফল সসীম (ধাপ ২), তাই প্রায় প্রতিটি যাত্রায় "\(\bar X_n\) দূরে" ঘটনা একসময় চিরতরে বন্ধ হয়ে যায় — অর্থাৎ এক জায়গার পর সব \(n\)-এ \(\lvert\bar X_n\rvert<\varepsilon\)।
-
সব \(\varepsilon\)-এর জন্য জোড়া। ধাপ ৩ প্রতিটি স্থির \(\varepsilon\)-এর জন্য খাটে। \(\varepsilon=1, \tfrac12, \tfrac13,\dots\) ক্রমে নিয়ে (একটা countable সংগ্রহ, তাই union-ও সম্ভাবনা-\(1\)) উপসংহার টানা যায়: প্রায় প্রতিটি যাত্রায় \(\bar X_n\to 0\) — যেহেতু যেকোনো সহনসীমার চেয়ে গড় একসময় কাছাকাছি থাকে। এটাই \(\bar X_n\xrightarrow{a.s.}0\) (এবং \(\mu=0\) ফিরিয়ে নিলে \(\bar X_n\xrightarrow{a.s.}\mu\))। \(\;\square\)
কী সৎভাবে রেখে দিলাম। (i) ধাপ ১-এর \(\mathbb{E}[\bar X_n^4]\le C/n^2\) — পূর্ণ বীজগণিত (চতুর্থ ঘাত খুলে independence দিয়ে cross-পদ বাদ) এখানে করিনি, শুধু ফল দিয়েছি। (ii) ধাপ ৩-এর Borel–Cantelli lemma — সম্ভাবনা-তত্ত্বের একটি মৌলিক ফল, এর প্রমাণ Part VII-এ। (iii) সবচেয়ে বড় শর্টকাট: finite 4th moment ধরে নিলাম, যেখানে আসল SLLN শুধু finite mean-এ খাটে — সেই সাধারণ ক্ষেত্রে truncation ও Kolmogorov-এর কৌশল লাগে, এই পর্যায়ের বাইরে। মূল গল্পটা (দ্রুত-নামা moment \(\Rightarrow\) সসীম যোগফল \(\Rightarrow\) Borel–Cantelli \(\Rightarrow\) পথ থিতু) কিন্তু সঠিক ও সৎ।
৪.৪ · (ঘ) শর্ত খতিয়ে দেখা — finite variance বনাম finite mean, ও LLN-এর ভাঙন (E4 Cauchy)¶
দুটো theorem-এর শর্ত পাশাপাশি রাখি — এই তুলনাই বোঝায় LLN কখন খাটে, কখন নয়।
| অনুমান | উপসংহার | প্রমাণের হাতিয়ার | |
|---|---|---|---|
| Weak Law | i.i.d. + finite variance \(\sigma^2<\infty\) | \(\bar X_n \xrightarrow{P}\mu\) | Chebyshev (3.1) |
| Strong Law | i.i.d. + finite mean \(\mathbb{E}\lvert X_i\rvert<\infty\) | \(\bar X_n \xrightarrow{a.s.}\mu\) | Borel–Cantelli (Part VII) |
দুটো পর্যবেক্ষণ:
-
Strong-এর শর্ত দুর্বলতর, উপসংহার কড়াতর। finite mean হলো finite variance-এর চেয়ে কম দাবি (variance থাকলে mean থাকেই, উল্টোটা নয়)। তবু Strong Law কড়া (a.s.) ফল দেয় — শুধু প্রমাণ কঠিন। আমাদের Weak-এর প্রমাণে finite variance লেগেছিল কারণ Chebyshev-এর জন্য variance দরকার; কিন্তু সেটা প্রমাণের সুবিধার শর্ত, theorem-এর অপরিহার্য শর্ত নয়। (আসলে finite mean থাকলেই WLLN-ও সত্য, কিন্তু সেই প্রমাণে Chebyshev খাটে না, ভিন্ন কৌশল লাগে।)
-
সবচেয়ে জরুরি শর্ত — mean-টা অন্তত থাকতে হবে। দুই theorem-এই minimum দাবি হলো \(\mu\) সুসংজ্ঞায়িত ও সসীম। mean-ই যদি না থাকে, "\(\bar X_n\to\mu\)" কথাটারই কোনো অর্থ নেই — কোন \(\mu\)-তে যাবে? এই সীমানাটাই E4 নাটকীয়ভাবে দেখায়।
E4 — Cauchy distribution: mean অসংজ্ঞায়িত, তাই LLN ভেঙে পড়ে¶
পটভূমি (3.3 §৩ থেকে)। standard Cauchy distribution-এর pdf
এটি দেখতে ঘণ্টা-আকৃতির, \(0\)-এর চারপাশে প্রতিসম — উপরিভাগে নিরীহ মনে হয়। কিন্তু এর tail এত ভারী যে mean অসংজ্ঞায়িত (undefined)। কেন? mean-এর সংজ্ঞায় লাগে \(\int_{-\infty}^{\infty} \lvert x\rvert f(x)\,dx\) সসীম হওয়া। এখানে বড় \(x\)-এ \(\lvert x\rvert f(x)\approx \frac{\lvert x\rvert}{\pi x^2}=\frac{1}{\pi\lvert x\rvert}\), আর \(\int^{\infty}\frac{1}{x}\,dx\) diverge করে (log-ভাবে অসীমে যায়, Part 0)। তাই
পরিণতি — দুই theorem-ই অকার্যকর। \(\mu\) নেই, তাই Weak Law-ও না (Chebyshev-এর আগে variance তো দূর, mean-ই নেই), Strong Law-ও না (finite-mean শর্ত ভঙ্গ)। অর্থাৎ Cauchy LLN-এর শর্তের বাইরে।
কিন্তু \(\bar X_n\) কি তবু থিতু হয় না? না — এবং এটাই নাটকীয়। Cauchy-র একটি বিখ্যাত ধর্ম: \(n\)টি i.i.d. standard Cauchy-র গড় \(\bar X_n\) নিজেও আবার ঠিক একটি standard Cauchy! অর্থাৎ \(\bar X_{1}, \bar X_{10}, \bar X_{1000}\) — সবার distribution হুবহু একই, \(n\) বাড়ালে একটুও সরু হয় না। তাই গড় কখনো কোনো একটা মানে বসে না; এটা চিরকাল একই-চওড়া Cauchy হয়ে দুলতে থাকে, মাঝে মাঝে বিশাল মান নেয় (ভারী tail-এর কারণে একটা অতি-বড় \(X_i\) পুরো গড়কে টেনে নিয়ে যায়)।
§৫-এর LAB 4-এ চোখে দেখব। running mean প্লট করলে die/coin-এর মতো \(\mu\)-তে থিতু হওয়ার বদলে এটা বারবার বড় লাফ দেবে — এবং দুটো স্বাধীন Cauchy-যাত্রা সম্পূর্ণ ভিন্ন আচরণ করবে, কোনোটাই কোথাও converge করবে না। (figure 3-3-cauchy-fail-এ die-এর শান্ত concentration বনাম Cauchy-র বুনো দোলাচল পাশাপাশি দেখানো হয়েছে।)
মূল পাঠ — LLN জাদু নয়, শর্তসাপেক্ষ। "বেশি data মানে গড় ঠিক হয়ে যায়" — এটা একটা theorem, স্বতঃসিদ্ধ সত্য নয়। এর জন্য অন্তত mean-এর অস্তিত্ব দরকার। ভারী-tail data (যেমন কিছু আর্থিক return, নেটওয়ার্ক load, বা power-law ঘটনা) Cauchy-র মতো আচরণ করতে পারে — সেখানে নমুনা গড় বাড়ালেও স্থিতিশীল হয় না, বরং বিভ্রান্তিকর হতে পারে। তাই বাস্তব data-তে LLN প্রয়োগের আগে moment-শর্ত যাচাই করা জরুরি। এই সতর্কতাই E4-এর আসল শিক্ষা।
৫ · কোড ল্যাব (Python)¶
এই অংশে আমরা §৪-এর তত্ত্বকে চোখে ও সংখ্যায় দেখব। চারটি LAB, প্রতিটি স্বয়ংসম্পূর্ণ ও runnable — numpy-র default_rng ব্যবহার করে fixed seed দিয়ে, যাতে আপনি একই কোড চালালে হুবহু একই সংখ্যা পান (reproducibility — পুনরুৎপাদনযোগ্যতা)। নিচের প্রতিটি output সত্যিকারের চালানো ফল (পুরো স্ক্রিপ্ট একবারে চললে seed-ক্রম অনুযায়ী মান সামান্য বদলাতে পারে; গুরুত্বপূর্ণ হলো প্রবণতা, শেষ-দশমিক নয়)।
কীভাবে চালাবেন। নিচের সব কোড একটি ফাইলে (যেমন
figs_3-3.py) রেখেpython figs_3-3.pyচালান। লাগবে শুধুnumpy। প্লট-সংস্করণ (running-mean curve, Chebyshev bound vs empirical, Cauchy-র বুনো পথ) §৬-এ_code/figs_3-3.py-তে; এখানে আমরা মূলত সংখ্যাগুলো ছাপিয়ে তত্ত্ব যাচাই করছি।
LAB 1 — Running mean: die (E1) ও coin (E2) → \(\mu\)-তে থিতু হওয়া¶
প্রথম ল্যাবে আমরা §৪.১-এর মূল দাবি চোখে দেখি: \(n\) বাড়লে \(\bar X_n\) সত্য গড় \(\mu\)-এর দিকে গড়িয়ে যায়। দুটো running example — fair die (\(\mu=3.5\)) ও fair coin (\(\mu=0.5\))।
import numpy as np
rng = np.random.default_rng(42) # fixed seed -> reproducible
N = 100_000
# --- E1: fair six-sided die, true mean mu = 3.5 ---
die = rng.integers(1, 7, size=N) # values in {1,...,6}
running_mean_die = np.cumsum(die) / np.arange(1, N + 1) # bar X_n for every n
mu_die = 3.5
for n in [10, 100, 1000, 10_000, 100_000]:
rm = running_mean_die[n - 1]
print(f"[die] n={n:>7d}: mean = {rm:.4f} |error| = {abs(rm - mu_die):.4f}")
# --- E2: fair coin, X_i in {0,1}, true mean mu = 0.5 ---
coin = rng.integers(0, 2, size=N) # 0 = tail, 1 = head
running_mean_coin = np.cumsum(coin) / np.arange(1, N + 1)
mu_coin = 0.5
for n in [10, 100, 1000, 10_000, 100_000]:
rm = running_mean_coin[n - 1]
print(f"[coin] n={n:>7d}: mean = {rm:.4f} |error| = {abs(rm - mu_coin):.4f}")
আসল output:
[die] n= 10: mean = 3.1000 |error| = 0.4000
[die] n= 100: mean = 3.6400 |error| = 0.1400
[die] n= 1000: mean = 3.4880 |error| = 0.0120
[die] n= 10000: mean = 3.4752 |error| = 0.0248
[die] n= 100000: mean = 3.4998 |error| = 0.0002
[coin] n= 10: mean = 0.6000 |error| = 0.1000
[coin] n= 100: mean = 0.4600 |error| = 0.0400
[coin] n= 1000: mean = 0.5000 |error| = 0.0000
[coin] n= 10000: mean = 0.5011 |error| = 0.0011
[coin] n= 100000: mean = 0.5016 |error| = 0.0016
কী লক্ষ করবেন। (১) ছোট \(n\)-এ গড় এলোমেলো — die-তে \(n=10\)-এ \(3.10\), coin-এ \(n=10\)-এ \(0.60\)। (২) \(n\) বাড়লে error সামগ্রিকভাবে কমে — die-তে \(n=100{,}000\)-এ মাত্র \(0.0002\)। (৩) তবে কমাটা একঘেয়ে নয় (die-তে \(n=1000\)-এ error \(0.012\), কিন্তু \(n=10{,}000\)-এ সামান্য বেড়ে \(0.025\))। এটা LLN-এর সাথে সঙ্গতিপূর্ণ: LLN বলে দূরে থাকার সম্ভাবনা কমে, প্রতিটি ধাপে error একঘেয়ে কমবে এমন নয় — \(\bar X_n\) random বলে মাঝে মাঝে সামান্য বাড়তে-কমতে পারে, কিন্তু সার্বিক প্রবণতা \(\mu\)-র দিকে। (এই running-mean curve-ই figure 3-3-running-mean-এ দেখানো হয়েছে।)
LAB 2 — Monte Carlo π (E3): error বনাম \(n\)¶
LLN-এর সবচেয়ে সুন্দর প্রায়োগিক রূপ — Monte Carlo integration। ধারণা: \([-1,1]^2\) বর্গক্ষেত্রে এলোমেলো বিন্দু ছুঁড়ি; একক বৃত্তের ভেতরে পড়ার অনুপাত \(\to \pi/4\) (কারণ বৃত্তের ক্ষেত্রফল \(\pi\), বর্গের \(4\))। এই অনুপাত আসলে একটি indicator-এর sample mean, তাই LLN একে \(\pi/4\)-তে নিয়ে যায় — \(4\) দিয়ে গুণে \(\pi\) পাই।
import numpy as np
rng = np.random.default_rng(7)
N = 2_000_000
x = rng.uniform(-1.0, 1.0, size=N)
y = rng.uniform(-1.0, 1.0, size=N)
inside = (x**2 + y**2 <= 1.0).astype(float) # indicator; E[indicator] = pi/4
running_pi = 4.0 * np.cumsum(inside) / np.arange(1, N + 1) # running estimate of pi
for n in [100, 1_000, 10_000, 100_000, 1_000_000, 2_000_000]:
est = running_pi[n - 1]
print(f"n={n:>9d}: pi_hat = {est:.5f} |error| = {abs(est - np.pi):.5f}")
# compare error with the Monte Carlo ~ 1/sqrt(n) rate
for n in [10_000, 100_000, 1_000_000]:
print(f" n={n:>9d}: |error|={abs(running_pi[n-1]-np.pi):.5f}, "
f"1/sqrt(n)={1/np.sqrt(n):.5f}")
আসল output:
n= 100: pi_hat = 3.08000 |error| = 0.06159
n= 1000: pi_hat = 3.15200 |error| = 0.01041
n= 10000: pi_hat = 3.15600 |error| = 0.01441
n= 100000: pi_hat = 3.14176 |error| = 0.00017
n= 1000000: pi_hat = 3.14330 |error| = 0.00171
n= 2000000: pi_hat = 3.14188 |error| = 0.00028
n= 10000: |error|=0.01441, 1/sqrt(n)=0.01000
n= 100000: |error|=0.00017, 1/sqrt(n)=0.00316
n= 1000000: |error|=0.00171, 1/sqrt(n)=0.00100
কী লক্ষ করবেন। (১) estimate সত্য \(\pi=3.14159\ldots\)-এর দিকে যাচ্ছে — \(n=2{,}000{,}000\)-এ \(3.14188\), error মাত্র \(\sim 0.0003\)। (২) error একঘেয়ে নামে না (LLN-এর random প্রকৃতি — \(n=100{,}000\)-এ error যত ছোট, \(n=1{,}000{,}000\)-এ সাময়িকভাবে তার চেয়ে বড়ও হতে পারে)। (৩) তবে error-এর মাপ মোটামুটি \(1/\sqrt n\) হারে ছোট হয় — কারণ §৪.১ থেকে \(\mathrm{Var}(\bar X_n)=\sigma^2/n\), তাই typical error \(\sim\sigma/\sqrt n\)। এই \(1/\sqrt n\) হারই Monte Carlo পদ্ধতির স্বাক্ষর: নির্ভুলতা ১০ গুণ বাড়াতে নমুনা ১০০ গুণ লাগে। (এই error-vs-\(n\) curve figure 3-3-monte-carlo-তে।)
LAB 3 — Chebyshev bound বনাম empirical \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\)¶
এই ল্যাবটি §৪.২-এর সরাসরি যাচাই। WLLN-এর প্রমাণে আমরা bound পেয়েছিলাম \((৪.৪)\): \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\le \sigma^2/(n\varepsilon^2)\)। এখন আমরা (i) সেই তাত্ত্বিক bound আর (ii) প্রকৃত (empirical) probability — দুটো পাশাপাশি রেখে দেখব bound সত্যিই উপরের ছাদ হিসেবে কাজ করে এবং দুটোই \(0\)-তে নামে। source: Uniform\((0,1)\), যার \(\mu=\tfrac12\), \(\sigma^2=\tfrac1{12}\)।
import numpy as np
rng = np.random.default_rng(2024)
mu, sigma2, eps = 0.5, 1.0/12.0, 0.05
REPS = 20_000 # independent replications to estimate the probability
print(f"{'n':>6} | {'Chebyshev bound':>16} | {'empirical prob':>15} | holds?")
for n in [50, 100, 200, 500, 1000]:
samples = rng.uniform(0.0, 1.0, size=(REPS, n))
xbar = samples.mean(axis=1) # one bar X_n per replication
emp = np.mean(np.abs(xbar - mu) >= eps) # empirical P(|Xbar-mu|>=eps)
bound = sigma2 / (n * eps**2) # Chebyshev bound (4.4)
holds = "yes" if emp <= bound + 1e-12 else "NO"
print(f"{n:>6d} | {bound:>16.5f} | {emp:>15.5f} | {holds}")
আসল output:
n | Chebyshev bound | empirical prob | holds?
50 | 0.66667 | 0.22555 | yes
100 | 0.33333 | 0.08220 | yes
200 | 0.16667 | 0.01440 | yes
500 | 0.06667 | 0.00015 | yes
1000 | 0.03333 | 0.00000 | yes
কী লক্ষ করবেন। (১) প্রতিটি সারিতে empirical ≤ bound — Chebyshev কখনো লঙ্ঘিত হয় না (holds = yes সর্বত্র); এটাই প্রমাণের সততা সংখ্যায় নিশ্চিত করে। (২) bound ঢিলা (loose) — \(n=50\)-এ bound \(0.67\) কিন্তু আসল মাত্র \(0.23\); কারণ Chebyshev কোনো distribution অনুমান করে না, তাই সব ক্ষেত্রে নিরাপদ থাকতে আলগা হয় (3.1-এর চরিত্র)। (৩) দুটোই \(0\)-তে নামে — bound \(\sim 1/n\) হারে, empirical আরও দ্রুত। bound \(\to 0\) হওয়াটাই \((৪.৪)\)-এর squeeze, যা WLLN দেয়। (figure 3-3-wlln-chebyshev-এ bound বনাম empirical দুটো curve একসাথে দেখানো হয়েছে — bound উপরে, empirical নিচে, দুটোই শূন্যমুখী।)
LAB 4 — Cauchy running mean converge করে না (E4)¶
শেষ ল্যাবটি §৪.৪-এর সতর্কবার্তা চোখে দেখায়: mean না থাকলে LLN ভেঙে পড়ে। আমরা standard Cauchy তৈরি করি দুটি independent standard Normal-এর অনুপাত হিসেবে (\(Z_1/Z_2\) standard Cauchy দেয়) — তারপর তার running mean দেখি। die/coin-এর মতো থিতু হওয়ার বদলে এটা বুনোভাবে লাফাবে।
import numpy as np
rng = np.random.default_rng(0)
N = 200_000
cauchy = rng.standard_normal(N) / rng.standard_normal(N) # standard Cauchy
running_mean = np.cumsum(cauchy) / np.arange(1, N + 1)
for n in [10, 100, 1_000, 10_000, 100_000, 200_000]:
print(f"n={n:>7d}: running mean = {running_mean[n-1]:>12.4f}")
# a SECOND independent run -> completely different, also non-converging
rng2 = np.random.default_rng(99)
c2 = rng2.standard_normal(N) / rng2.standard_normal(N)
rm2 = np.cumsum(c2) / np.arange(1, N + 1)
print("--- run-1 vs run-2 (independent) ---")
for n in [1_000, 10_000, 100_000, 200_000]:
print(f"n={n:>7d}: run-1 = {running_mean[n-1]:>11.4f} run-2 = {rm2[n-1]:>11.4f}")
আসল output:
n= 10: running mean = -0.1161
n= 100: running mean = -0.4053
n= 1000: running mean = -37.0552
n= 10000: running mean = -3.4693
n= 100000: running mean = -0.0157
n= 200000: running mean = -0.1468
--- run-1 vs run-2 (independent) ---
n= 1000: run-1 = -37.0552 run-2 = -0.0443
n= 10000: run-1 = -3.4693 run-2 = 2.8268
n= 100000: run-1 = -0.0157 run-2 = -1.2703
n= 200000: run-1 = -0.1468 run-2 = -0.2961
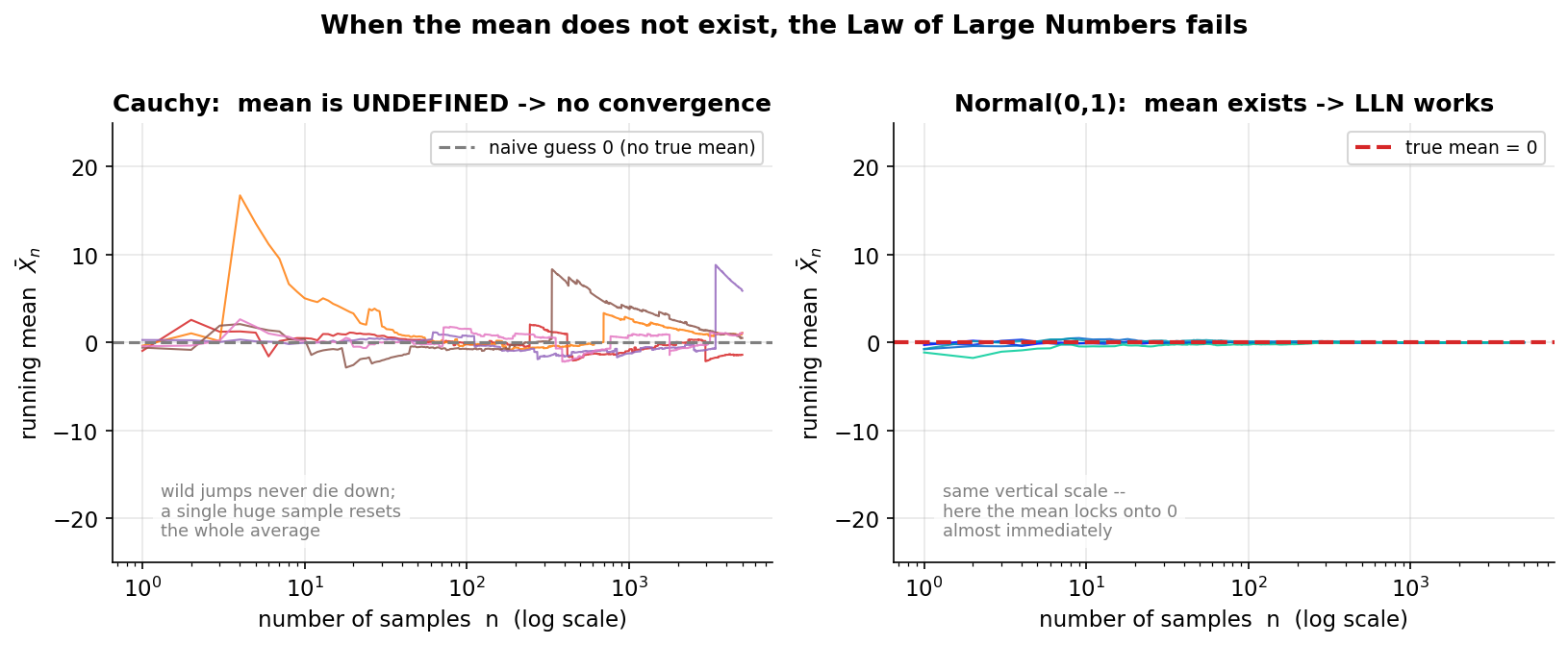
কী লক্ষ করবেন। (১) running mean কোথাও থিতু হয় না — \(n=1000\)-এ হঠাৎ \(-37.05\)-এ লাফ (একটিমাত্র বিশাল \(X_i\) পুরো গড়কে টেনে নিল, ভারী tail-এর সাক্ষাৎ প্রমাণ), তারপর আবার ফিরে আসে। die-তে \(n=1000\)-এ গড় \(3.5\)-এর \(0.01\)-এর মধ্যে ছিল; এখানে গড় \(37\) দূরে! (২) দুটো independent run সম্পূর্ণ ভিন্ন পথে চলে — এমনকি \(n=200{,}000\)-এও run-1 (\(-0.147\)) আর run-2 (\(-0.296\)) মেলে না, আর মাঝপথে (\(n=10{,}000\)) একটা \(-3.47\), আরেকটা \(+2.83\)। যদি LLN খাটত, বড় \(n\)-এ দুটোই একই \(\mu\)-তে বসত — কিন্তু \(\mu\) নেই, তাই বসার জায়গাও নেই। (৩) তুলনায় LAB 1-এর die/coin শান্তভাবে \(\mu\)-তে থিতু হয়েছিল — এই বৈপরীত্যই §৪.৪-এর পাঠ: LLN moment-শর্তের ওপর নির্ভরশীল, স্বতঃসিদ্ধ নয়। (figure 3-3-cauchy-fail-এ die-এর শান্ত convergence বনাম Cauchy-র এই বুনো পথ পাশাপাশি দেখানো হয়েছে।)
চারটি LAB এক নজরে। LAB 1 (die/coin): \(\bar X_n\to\mu\) থিতু হয় — LLN কাজ করছে। LAB 2 (Monte Carlo π): LLN-এর প্রায়োগিক শক্তি, error \(\sim 1/\sqrt n\)। LAB 3 (Chebyshev): প্রমাণের bound সংখ্যায় সত্য — empirical \(\le\) bound, দুটোই \(\to 0\)। LAB 4 (Cauchy): শর্ত ভাঙলে LLN-ও ভাঙে — গড় কখনো থিতু হয় না। এই চারটি মিলে §৪-এর প্রতিটি তাত্ত্বিক দাবি একবার করে সংখ্যায় ছুঁয়ে দেখা হলো।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_3-3.py-তে তৈরি; PNG_assets/-এ (prefix3-3, dpi=150)। in-figure লেখা সব ইংরেজিতে। প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র।
Law of Large Numbers (LLN)-এর কথাগুলো — "running mean \(\bar X_n\) ধীরে ধীরে \(\mu\)-তে থিতু হয়" — চোখে না দেখলে বিমূর্ত শোনায়। তাই চারটি ছবি দিয়ে চারটি জিনিস "দেখব": (১) সত্যিই running mean কীভাবে true mean-এ গড়িয়ে যায় (E1 ছক্কা→3.5, E2 মুদ্রা→0.5), (২) "দূরে-থাকার probability" কীভাবে শূন্যে নামে আর Chebyshev bound তার উপরে ছাদ ধরে রাখে, (৩) LLN-এর একটি বাস্তব প্রয়োগ — Monte Carlo দিয়ে \(\pi\) আনুমান (E3), আর (৪) যখন mean-ই নেই (Cauchy, E4), তখন LLN কীভাবে ভেঙে পড়ে।
Figure 1 — running mean true mean-এ থিতু হয় (E1, E2)¶
এই অধ্যায়ের কেন্দ্রীয় ছবি — LLN-এর হৃদয়। বাঁ প্যানেলে \(8\)টি স্বাধীন ছক্কা-গড়ানোর path: প্রতিটি হলো একটা চলমান গড় \(\bar X_n=\frac1n\sum_{i=1}^n X_i\), আর লাল dashed রেখা হলো true mean \(\mu=3.5\)। ডান প্যানেলে \(8\)টি মুদ্রা-ছোঁড়ার path, যেখানে heads-এর চলমান অনুপাত \(\to 0.5\)। যা লক্ষ করতে হবে: শুরুতে (ছোট \(n\)) সব path বুনোভাবে লাফায় — \(n=2\)-তে গড় \(1\) বা \(6\)-ও হতে পারে; কিন্তু \(n\) বাড়ার সাথে সাথে সব path একটা ফানেলের মতো সরু হয়ে এসে true mean-এর গায়ে চেপে বসে। গুরুত্বপূর্ণ: এটা একটা-দুটো path-এর কাকতাল নয় — প্রতিটি path-ই থিতু হয়, কারণ "ছড়ানো" (spread, অর্থাৎ \(\operatorname{Var}(\bar X_n)=\sigma^2/n\)) \(n\)-এর সাথে কমে। এটাই strong LLN-এর দৃশ্যরূপ: প্রায় প্রতিটি পথ আক্ষরিকভাবে \(\mu\)-তে যায়।
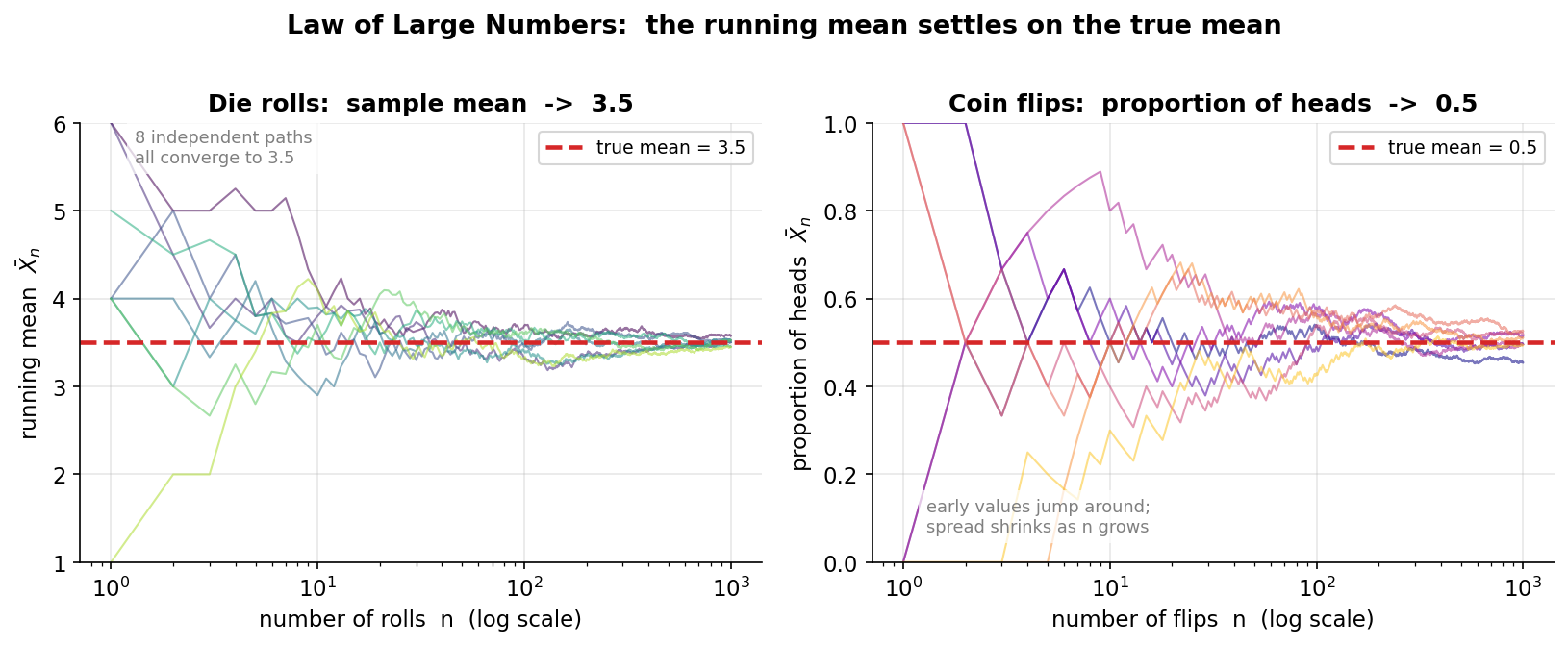
Figure 2 — দূরে-থাকার probability শূন্যে নামে; Chebyshev ছাদ ধরে রাখে¶
weak LLN আসলে কী দাবি করে, আর Chebyshev inequality (3.1) কীভাবে তা প্রমাণ করে — দুটো এক ছবিতে। উৎস Uniform\((0,1)\), তাই \(\mu=0.5\), \(\sigma^2=\tfrac1{12}\), আর আমরা \(\varepsilon=0.05\) নিলাম। নীল রেখা হলো সিমুলেশন থেকে মাপা প্রকৃত probability \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\) — অর্থাৎ কত ভগ্নাংশ পরীক্ষায় গড় এখনো \(\mu\) থেকে \(\varepsilon\)-এর বেশি দূরে। কমলা রেখা হলো Chebyshev bound \(\sigma^2/(n\varepsilon^2)\)। যা লক্ষ করতে হবে: (ক) নীল রেখা সবসময় কমলা রেখার নিচে থাকে — Chebyshev একটা সত্যিকারের ছাদ, কখনো লঙ্ঘিত হয় না; (খ) দুটোই \(n\) বাড়লে \(0\)-তে নামে — এটাই \(\bar X_n\xrightarrow{P}\mu\); (গ) কিন্তু নীল রেখা কমলার চেয়ে অনেক দ্রুত নামে — কারণ Chebyshev একটা সর্বজনীন, ঢিলা (loose) bound, যা distribution-এর বিশেষ আকৃতি কাজে লাগায় না। তাই Chebyshev দিয়ে weak LLN প্রমাণ করা যায়, কিন্তু সে প্রমাণ "কত দ্রুত"-র ব্যাপারে রক্ষণশীল।
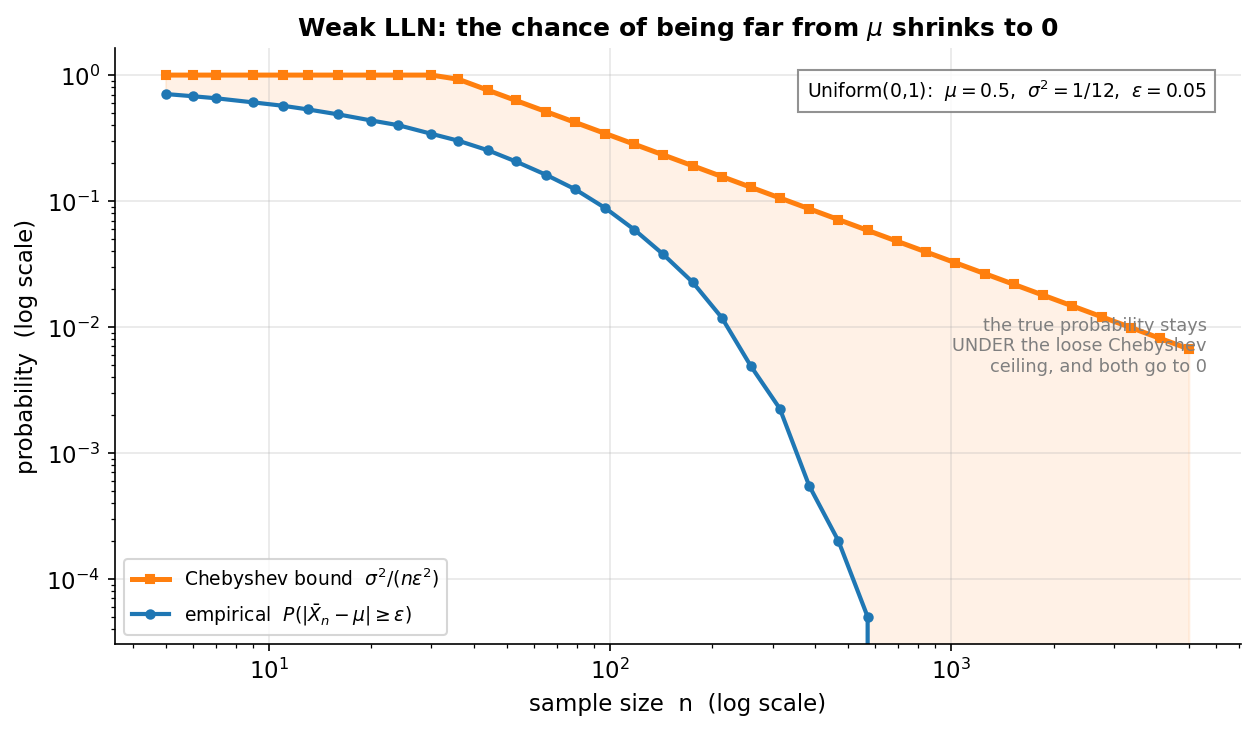
Figure 3 — Monte Carlo: গড় করে \(\pi\) আনুমান (E3)¶
LLN শুধু তত্ত্ব নয় — এটা computational statistics-এর ইঞ্জিন। ধরুন \([-1,1]\times[-1,1]\) বর্গে এলোমেলো বিন্দু ছুঁড়ছি; একক বৃত্তের ভেতরে পড়ার probability \(=\pi/4\)। তাই indicator \(X_i=\mathbf 1\{\)বিন্দু \(i\) বৃত্তের ভেতরে\(\}\)-র গড় \(\bar X_n\to\pi/4\), এবং \(4\bar X_n\to\pi\) — এটাই LLN-এর সরাসরি ফল। ছবিতে \(12\)টি হালকা নীল path (প্রতিটি একটা স্বাধীন সিমুলেশন), একটা মোটা path, লাল dashed রেখায় true \(\pi=3.14159\), আর কমলা ছায়াঘেরা ব্যান্ড হলো তাত্ত্বিক \(\pi\pm 2\,\mathrm{SE}\) (যেখানে \(\mathrm{SE}=\sqrt{16\,p(1-p)/n}\), \(p=\pi/4\))। যা লক্ষ করতে হবে: ছোট \(n\)-এ আনুমান \(\pi\) থেকে দূরে ও অস্থির; \(n\) বাড়লে সব path ব্যান্ডের ভেতরে গুটিয়ে এসে \(\pi\)-তে বসে। ব্যান্ডটা \(1/\sqrt n\) হারে সরু হয় — অর্থাৎ নির্ভুলতা বাড়াতে \(4\) গুণ বিন্দু লাগে প্রতি অর্ধেক error-এ। (এই \(\sqrt n\)-হার আসলে CLT-র ইঙ্গিত — পরের অধ্যায় 3.4।)
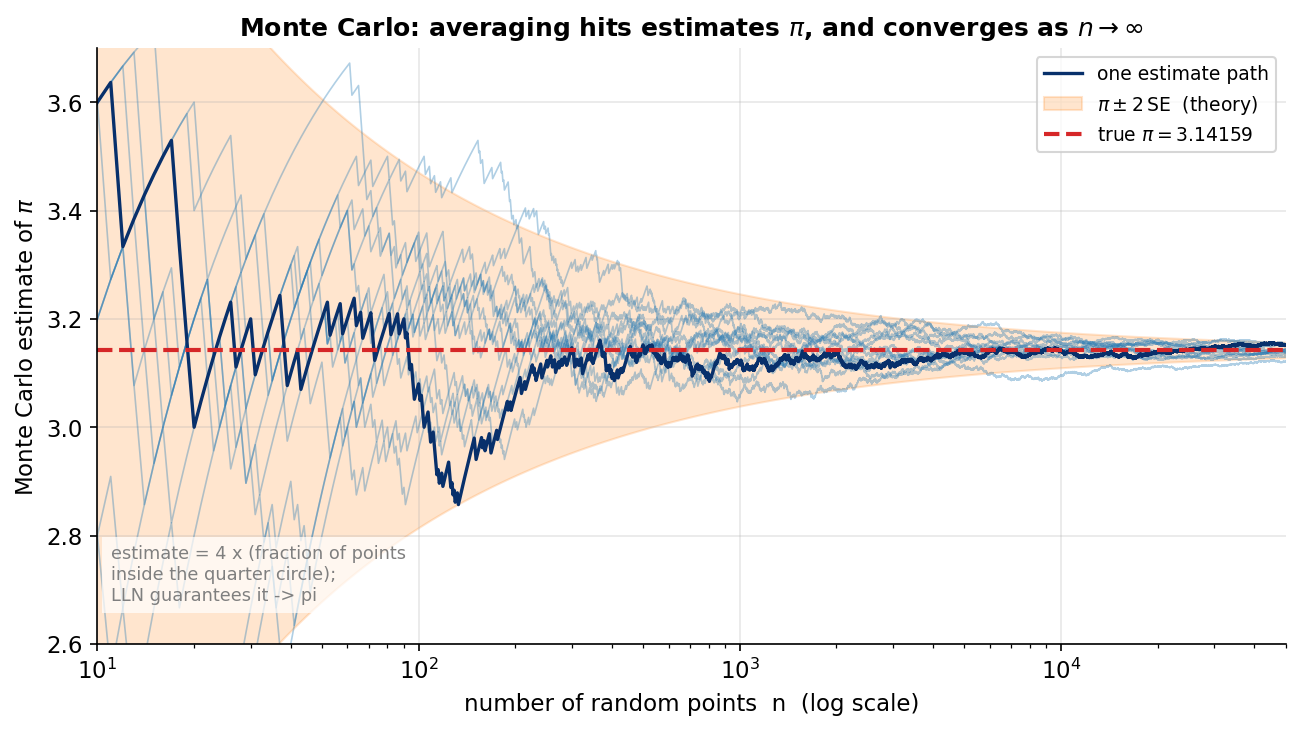
Figure 4 — Cauchy: mean নেই, তাই LLN ভাঙে (E4)¶
LLN-এর শর্ত ভুলে গেলে কী হয়, তা এই ছবি হাড়ে হাড়ে দেখায়। LLN-এর জন্য দরকার \(\mathbb E\lvert X_i\rvert<\infty\) (mean-এর অস্তিত্ব)। Cauchy distribution-এ সেই শর্ত ভাঙে — এর heavy tail এত মোটা যে \(\mathbb E\lvert X\rvert=\infty\), mean অসংজ্ঞায়িত। বাঁ প্যানেলে \(5\)টি Cauchy running-mean path: ধূসর dashed রেখা \(0\) (একটা সরল-মনে অনুমান, কিন্তু true mean নয়)। ডান প্যানেলে — একই উল্লম্ব scale-এ — Normal\((0,1)\)-এর \(5\)টি path তুলনার জন্য। যা লক্ষ করতে হবে: বাঁয়ে path-গুলো কখনো থিতু হয় না — একটা path \(\sim 17\)-তে লাফায়, আরেকটা \(n\approx 300\)-তে হঠাৎ রিসেট হয়ে যায়; কারণ একটা বিশাল sample (heavy tail থেকে) পুরো গড়কে টেনে সরিয়ে দেয়, আর \(n\) বাড়লেও সেই ধাক্কা ছোট হয় না। ডানে, ঠিক উল্টো: Normal-এ mean আছে, তাই path প্রায় সঙ্গে সঙ্গে \(0\)-তে আটকে যায়। পাঠ: LLN একটা শর্তাধীন গ্যারান্টি — "যত data, তত নির্ভুল গড়" সবসময় সত্য নয়; mean না থাকলে averaging-এ কোনো নিরাপত্তা নেই।
চারটি ছবির plotting code (একটি স্ক্রিপ্ট _code/figs_3-3.py)
# _code/figs_3-3.py — Chapter 3.3 figures (Law of Large Numbers).
# In-figure text ENGLISH only. Run once; saves 4 PNGs (dpi=150) to _assets/.
import os
import numpy as np
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
ASSETS = "../_assets"
os.makedirs(ASSETS, exist_ok=True)
plt.rcParams.update({
"figure.dpi": 150, "savefig.dpi": 150, "font.size": 11,
"axes.titlesize": 12, "axes.titleweight": "bold", "axes.labelsize": 11,
"axes.grid": True, "grid.alpha": 0.3, "legend.fontsize": 9,
"axes.spines.top": False, "axes.spines.right": False,
})
BLUE="#1f77b4"; ORANGE="#ff7f0e"; RED="#d62728"; PURPLE="#9467bd"; GREY="#7f7f7f"
# --- Figure 1: running mean of die (->3.5) and coin (->0.5) ---
def fig_running_mean():
rng = np.random.default_rng(7); N = 1000; n = np.arange(1, N + 1)
fig, (axd, axc) = plt.subplots(1, 2, figsize=(11, 4.4))
for k in range(8):
run = np.cumsum(rng.integers(1, 7, size=N)) / n
axd.plot(n, run, lw=1.0, alpha=0.55, color=plt.cm.viridis(k / 8))
axd.axhline(3.5, color=RED, lw=2.2, ls="--", label="true mean = 3.5")
axd.set_xscale("log"); axd.set_ylim(1, 6)
axd.set_xlabel("number of rolls n (log scale)")
axd.set_ylabel(r"running mean $\bar{X}_n$")
axd.set_title("Die rolls: sample mean -> 3.5"); axd.legend(loc="upper right")
for k in range(8):
run = np.cumsum(rng.integers(0, 2, size=N)) / n
axc.plot(n, run, lw=1.0, alpha=0.55, color=plt.cm.plasma(k / 8))
axc.axhline(0.5, color=RED, lw=2.2, ls="--", label="true mean = 0.5")
axc.set_xscale("log"); axc.set_ylim(0, 1)
axc.set_xlabel("number of flips n (log scale)")
axc.set_ylabel(r"proportion of heads $\bar{X}_n$")
axc.set_title("Coin flips: proportion of heads -> 0.5"); axc.legend(loc="upper right")
fig.suptitle("Law of Large Numbers: the running mean settles on the true mean",
fontsize=13, fontweight="bold", y=1.01)
fig.tight_layout(); fig.savefig(f"{ASSETS}/3-3-running-mean.png", bbox_inches="tight")
plt.close(fig)
# --- Figure 2: empirical P(|Xbar-mu|>=eps) vs Chebyshev sigma^2/(n eps^2) ---
def fig_wlln_chebyshev():
rng = np.random.default_rng(11)
mu, sigma2, eps, M, Nmax = 0.5, 1/12, 0.05, 20000, 5000
ns = np.unique(np.round(np.logspace(np.log10(5), np.log10(Nmax), 36)).astype(int))
nset = set(int(v) for v in ns); emp_map = {}
running = np.zeros(M) # incremental sum: O(M) memory
for j in range(1, Nmax + 1):
running += rng.uniform(0, 1, size=M)
if j in nset:
emp_map[j] = float(np.mean(np.abs(running / j - mu) >= eps))
emp = np.array([emp_map[int(v)] for v in ns])
cheb = np.minimum(sigma2 / (ns * eps**2), 1.0)
fig, ax = plt.subplots(figsize=(8.5, 5.0))
ax.plot(ns, cheb, color=ORANGE, lw=2.4, marker="s", ms=4,
label=r"Chebyshev bound $\sigma^2/(n\varepsilon^2)$")
ax.plot(ns, emp, color=BLUE, lw=2.0, marker="o", ms=4,
label=r"empirical $P(|\bar{X}_n-\mu|\geq\varepsilon)$")
ax.fill_between(ns, emp, cheb, color=ORANGE, alpha=0.10)
ax.set_xscale("log"); ax.set_yscale("log")
ax.set_xlabel("sample size n (log scale)"); ax.set_ylabel("probability (log scale)")
ax.set_title(r"Weak LLN: the chance of being far from $\mu$ shrinks to 0")
ax.legend(loc="lower left")
fig.tight_layout(); fig.savefig(f"{ASSETS}/3-3-wlln-chebyshev.png", bbox_inches="tight")
plt.close(fig)
# --- Figure 3: Monte Carlo pi estimate with +-2 SE band ---
def fig_monte_carlo():
rng = np.random.default_rng(3); N = 50000; n = np.arange(1, N + 1)
fig, ax = plt.subplots(figsize=(8.8, 5.0))
for k in range(12):
x = rng.uniform(-1, 1, N); y = rng.uniform(-1, 1, N)
est = 4.0 * np.cumsum((x**2 + y**2 <= 1).astype(float)) / n
ax.plot(n, est, lw=0.8, alpha=0.35, color=BLUE)
x = rng.uniform(-1, 1, N); y = rng.uniform(-1, 1, N)
est = 4.0 * np.cumsum((x**2 + y**2 <= 1).astype(float)) / n
ax.plot(n, est, lw=1.6, color="#08306b", label="one estimate path")
p = np.pi / 4; se = np.sqrt(16.0 * p * (1 - p) / n)
ax.fill_between(n, np.pi - 2*se, np.pi + 2*se, color=ORANGE, alpha=0.20,
label=r"$\pi \pm 2\,$SE (theory)")
ax.axhline(np.pi, color=RED, lw=2.0, ls="--", label=r"true $\pi=3.14159$")
ax.set_xscale("log"); ax.set_ylim(2.6, 3.7); ax.set_xlim(10, N)
ax.set_xlabel("number of random points n (log scale)")
ax.set_ylabel(r"Monte Carlo estimate of $\pi$")
ax.set_title(r"Monte Carlo: averaging hits estimates $\pi$, and converges as $n\to\infty$")
ax.legend(loc="upper right")
fig.tight_layout(); fig.savefig(f"{ASSETS}/3-3-monte-carlo.png", bbox_inches="tight")
plt.close(fig)
# --- Figure 4: Cauchy running mean does NOT settle (vs Normal) ---
def fig_cauchy_fail():
rng = np.random.default_rng(0); N = 5000; n = np.arange(1, N + 1)
fig, (axc, axn) = plt.subplots(1, 2, figsize=(11, 4.4))
cols = [RED, ORANGE, PURPLE, "#8c564b", "#e377c2"]
for k in range(5):
run = np.cumsum(rng.standard_cauchy(N)) / n
axc.plot(n, run, lw=1.0, alpha=0.85, color=cols[k])
axc.axhline(0.0, color=GREY, lw=1.5, ls="--", label="naive guess 0 (no true mean)")
axc.set_xscale("log"); axc.set_ylim(-25, 25)
axc.set_xlabel("number of samples n (log scale)")
axc.set_ylabel(r"running mean $\bar{X}_n$")
axc.set_title("Cauchy: mean is UNDEFINED -> no convergence"); axc.legend(loc="upper right")
for k in range(5):
run = np.cumsum(rng.standard_normal(N)) / n
axn.plot(n, run, lw=1.0, alpha=0.85, color=plt.cm.winter(k / 5))
axn.axhline(0.0, color=RED, lw=2.0, ls="--", label="true mean = 0")
axn.set_xscale("log"); axn.set_ylim(-25, 25)
axn.set_xlabel("number of samples n (log scale)")
axn.set_ylabel(r"running mean $\bar{X}_n$")
axn.set_title("Normal(0,1): mean exists -> LLN works"); axn.legend(loc="upper right")
fig.suptitle("When the mean does not exist, the Law of Large Numbers fails",
fontsize=13, fontweight="bold", y=1.01)
fig.tight_layout(); fig.savefig(f"{ASSETS}/3-3-cauchy-fail.png", bbox_inches="tight")
plt.close(fig)
if __name__ == "__main__":
fig_running_mean(); fig_wlln_chebyshev(); fig_monte_carlo(); fig_cauchy_fail()
print("ALL DONE")
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/03-03-law-of-large-numbers-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় weak LLN আর strong LLN-এর পার্থক্য লিখুন। কোনটা \(\bar X_n\xrightarrow{P}\mu\) আর কোনটা \(\bar X_n\xrightarrow{a.s.}\mu\)? Figure 1-এর ছক্কা-প্যানেল দিয়ে বোঝান "প্রায় প্রতিটি পথ থিতু হয়" বলতে কী বোঝায়। Hint: weak — প্রতিটি স্থির \(n\)-এ "দূরে থাকার probability ছোট"; strong — প্রায় প্রতিটি গোটা পথ আক্ষরিকভাবে \(\mu\)-তে যায় (3.2-এর mode-গুলো মনে করুন)।
প্রশ্ন ২ (★). একজন বলল: "LLN বলে পরপর অনেক tail এলে এবার head আসার সম্ভাবনা বেশি — না হলে গড় \(0.5\) হবে কীভাবে?" এই gambler's fallacy কেন ভুল, LLN আসলে কী দাবি করে — ব্যাখ্যা করুন। Hint: মুদ্রা স্মৃতিহীন (independent); LLN ভবিষ্যৎ ছোঁড়াকে "শোধরায়" না, বরং বিশাল \(n\)-এ পুরোনো বিচ্যুতিকে পাতলা করে দেয় (\(\div n\))।
প্রশ্ন ৩ (★). Figure 4 দেখুন: Cauchy-র running mean থিতু হয় না, অথচ Normal-এর হয়। LLN-এর কোন শর্ত Cauchy-তে ভাঙে? "mean undefined" বলতে কী বোঝায়, আর সেটা কীভাবে averaging-এর নিরাপত্তা কেড়ে নেয়? Hint: LLN-এর জন্য দরকার \(\mathbb E\lvert X_i\rvert<\infty\); Cauchy-র heavy tail-এ সেই integral ডাইভার্জ করে, তাই একটা বিশাল sample যেকোনো সময় গড়কে টেনে সরায়।
প্রশ্ন ৪ (★★). "consistency" বলতে statistics-এ \(\hat\theta_n\xrightarrow{P}\theta\) বোঝায়। ব্যাখ্যা করুন কেন LLN সরাসরি বলে দেয় sample mean \(\bar X_n\) হলো population mean \(\mu\)-র একটা consistent estimator। sample variance-এর consistency-ও কি LLN থেকে আসে? কীভাবে? Hint: sample mean-এর consistency = weak LLN-এর সংজ্ঞাই; variance-এর জন্য \(\frac1n\sum X_i^2\) আর \(\bar X_n\) — দুটোতেই LLN লাগান, তারপর continuous mapping।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). E1 (ছক্কা, \(\mu=3.5\), \(\sigma^2=35/12\approx 2.917\))। Chebyshev দিয়ে \(P(\lvert\bar X_n-3.5\rvert\ge 0.1)\)-এর একটা upper bound লিখুন \(n\)-এর function হিসেবে। \(n=1000\)-এ bound-টি কত? এই bound \(\le 0.05\) করতে কমপক্ষে কত \(n\) লাগবে? Hint: \(\operatorname{Var}(\bar X_n)=\sigma^2/n\); Chebyshev: \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\le \frac{\sigma^2}{n\varepsilon^2}\); \(n\ge \frac{\sigma^2}{\varepsilon^2\cdot 0.05}\)।
প্রশ্ন ৬ (★★). E2 (মুদ্রা, \(X_i\sim\text{Bernoulli}(p)\), \(\mu=p\), \(\sigma^2=p(1-p)\))। (ক) Chebyshev দিয়ে দেখান \(\bar X_n\xrightarrow{P}p\)। (খ) \(p\) অজানা হলে \(\sigma^2=p(1-p)\)-এর সর্বোচ্চ মান কত, আর সেটা ব্যবহার করে \(P(\lvert\bar X_n-p\rvert\ge 0.02)\le 0.05\) নিশ্চিত করতে কত \(n\) লাগবে? (এটাই poll-এর "margin of error" হিসাবের কঙ্কাল।) Hint: \(p(1-p)\le \tfrac14\); তাই bound \(\le \frac{1}{4n\varepsilon^2}\); \(n\ge \frac{1}{4\varepsilon^2\cdot 0.05}\)।
প্রশ্ন ৭ (★★). Monte Carlo (E3): \(\hat\pi_n=4\bar X_n\), যেখানে \(X_i=\mathbf 1\{\)বিন্দু বৃত্তে\(\}\sim\text{Bernoulli}(\pi/4)\)। (ক) \(\mathbb E[\hat\pi_n]=\pi\) দেখান। (খ) \(\operatorname{Var}(\hat\pi_n)\) বের করুন এবং দেখান \(\operatorname{SE}(\hat\pi_n)=\sqrt{16\cdot\frac\pi4(1-\frac\pi4)/n}\)। (গ) error \(\le 0.01\) (অর্থাৎ \(2\,\mathrm{SE}\le 0.01\)) পেতে আনুমানিক কত \(n\) লাগবে? Hint: \(\operatorname{Var}(4\bar X_n)=16\,p(1-p)/n\) যেখানে \(p=\pi/4\approx 0.785\); \(2\sqrt{16p(1-p)/n}\le 0.01\) থেকে \(n\) বের করুন।
প্রশ্ন ৮ (★★). ধরুন \(Y_n=\frac1n\sum_{i=1}^n X_i^2\) যেখানে \(X_i\sim\text{Uniform}(0,1)\) iid। (ক) \(Y_n\) কোন সংখ্যায় converge করবে এবং কোন mode-এ? (খ) এই উদাহরণ দিয়ে দেখান LLN শুধু "গড়" নয়, যেকোনো \(g(X_i)\)-র গড়েও খাটে (যতক্ষণ \(\mathbb E\lvert g(X)\rvert<\infty\))। Hint: \(X_i^2\)-ও iid; \(\mathbb E[X^2]=\int_0^1 x^2\,dx=\tfrac13\); তাই \(Y_n\xrightarrow{a.s.}\tfrac13\) (strong LLN, \(X_i^2\)-তে প্রয়োগ)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). Weak LLN (finite variance) প্রমাণ করুন: \(X_1,\dots,X_n\) iid, \(\mathbb E[X_i]=\mu\), \(\operatorname{Var}(X_i)=\sigma^2<\infty\) হলে \(\bar X_n\xrightarrow{P}\mu\)। (Chebyshev-ভিত্তিক আদর্শ প্রমাণ।) Hint: \(\mathbb E[\bar X_n]=\mu\), \(\operatorname{Var}(\bar X_n)=\sigma^2/n\); Chebyshev: \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\le \frac{\sigma^2}{n\varepsilon^2}\to 0\)।
প্রশ্ন ১০ (★★). \(L^2\) (mean-square) LLN প্রমাণ করুন: একই অনুমানে \(\bar X_n\xrightarrow{L^2}\mu\), অর্থাৎ \(\mathbb E[(\bar X_n-\mu)^2]\to 0\)। তারপর 3.2-র hierarchy ব্যবহার করে এখান থেকেই \(\bar X_n\xrightarrow{P}\mu\) পুনরায় বের করুন। Hint: \(\mathbb E[(\bar X_n-\mu)^2]=\operatorname{Var}(\bar X_n)=\sigma^2/n\to 0\); আর \(L^2\Rightarrow P\) (3.2, প্রশ্ন ৯ সেখানে)।
প্রশ্ন ১১ (★★★). Cauchy ব্যর্থতা (E4) আনুষ্ঠানিকভাবে। \(X_1,\dots,X_n\) iid standard Cauchy। একটি বিখ্যাত তথ্য: \(\bar X_n\)-ও standard Cauchy (distribution বদলায় না!)। (ক) characteristic function \(\varphi_X(t)=e^{-\lvert t\rvert}\) ব্যবহার করে দেখান \(\bar X_n\)-এর characteristic function-ও \(e^{-\lvert t\rvert}\)। (খ) এ থেকে যুক্তি দিন কেন \(\bar X_n\) কোনো ধ্রুবকে \(\xrightarrow{P}\) করতে পারে না — অর্থাৎ LLN ব্যর্থ। Hint: (ক) iid হলে \(\varphi_{\sum X_i}(t)=\varphi_X(t)^n=e^{-n\lvert t\rvert}\); \(\bar X_n=\frac1n\sum\) হলে \(\varphi_{\bar X_n}(t)=\varphi_{\sum}(t/n)=e^{-\lvert t\rvert}\)। (খ) ধ্রুবকে গেলে distribution একটা step (degenerate) হতো, কিন্তু এখানে চিরকাল Cauchy-ই থাকে।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে E1 সিমুলেট করুন: একটা ফেয়ার ছক্কার \(N=5000\)টি roll-এ running mean \(\bar X_n\) হিসাব করে \(n\)-এর বিপরীতে plot করুন (default_rng(0)), আর \(\mu=3.5\)-এ একটা অনুভূমিক রেখা টানুন। তিনটি ভিন্ন seed-এ তিনটি path এঁকে দেখান সবাই \(3.5\)-এ থিতু হয় কিন্তু পথ আলাদা।
Hint: rolls = rng.integers(1, 7, N); run = np.cumsum(rolls)/np.arange(1, N+1); log-scale x-axis convergence ভালো দেখায়।
প্রশ্ন ১৩ (★★). Figure 2 পুনরায় বানান: Uniform\((0,1)\) থেকে weak LLN-এর "empirical \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\)" বনাম Chebyshev bound \(\sigma^2/(n\varepsilon^2)\) একই log-log অক্ষে আঁকুন (\(\varepsilon=0.05\), \(\mu=0.5\))। নিশ্চিত করুন empirical curve সবসময় bound-এর নিচে থাকে।
Hint: প্রতিটি \(n\)-এ \(M=20000\) পরীক্ষা; স্মৃতি বাঁচাতে একটা running ভেক্টরে incrementally যোগ করুন (পুরো ম্যাট্রিক্স নয়), নির্দিষ্ট \(n\)-গুলোতে fraction মাপুন।
প্রশ্ন ১৪ (★★★). Monte Carlo দিয়ে একটা integral আনুমান করুন (E3-এর সাধারণীকরণ): \(I=\int_0^1 e^{-x^2}\,dx\)। \(U_i\sim\text{Uniform}(0,1)\) নিয়ে \(\hat I_n=\frac1n\sum e^{-U_i^2}\) হিসাব করুন, running estimate plot করুন, আর true মান (scipy-র erf দিয়ে \(\frac{\sqrt\pi}{2}\operatorname{erf}(1)\)) এর সাথে মেলান। \(\pm 2\,\mathrm{SE}\) ব্যান্ড যোগ করুন এবং দেখান estimate ব্যান্ডের ভেতরে \(I\)-তে যায়।
Hint: \(\hat I_n\) হলো \(g(U)=e^{-U^2}\)-র sample mean, তাই LLN-এ \(\hat I_n\to\mathbb E[g(U)]=I\); \(\mathrm{SE}=s_n/\sqrt n\) যেখানে \(s_n\) হলো sample std of \(g(U_i)\)।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Law of Large Numbers (LLN) একটাই বড় বার্তা দেয়: iid নমুনার sample mean \(\bar X_n\) true mean \(\mu\)-তে থিতু হয় যখন \(n\to\infty\) (E1 ছক্কা→3.5, E2 মুদ্রা→0.5; Figure 1)। এটাই "averaging কাজ করে কেন"-র গাণিতিক ভিত্তি।
- দুই সংস্করণ, দুই শক্তি (3.2-র mode-এ):
- Weak LLN (WLLN): \(\bar X_n\xrightarrow{P}\mu\) — প্রতিটি \(\varepsilon>0\)-এ \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\to 0\)। finite variance থাকলে Chebyshev দিয়ে এক লাইনে প্রমাণ: bound \(=\sigma^2/(n\varepsilon^2)\to 0\) (Figure 2)।
- Strong LLN (SLLN): \(\bar X_n\xrightarrow{a.s.}\mu\) — প্রায় প্রতিটি গোটা পথ আক্ষরিকভাবে \(\mu\)-তে যায়। শক্তিশালীতর; শর্তও হালকা — শুধু \(\mathbb E\lvert X_i\rvert<\infty\) যথেষ্ট (variance লাগে না)।
- একটিমাত্র শর্ত, কিন্তু অপরিহার্য: mean-এর অস্তিত্ব (\(\mathbb E\lvert X_i\rvert<\infty\))। এটা ভাঙলে — যেমন Cauchy (E4, Figure 4) — running mean কখনো থিতু হয় না; LLN একটা শর্তাধীন গ্যারান্টি, সর্বজনীন জাদু নয়।
- প্রয়োগ: consistency (\(\hat\theta_n\xrightarrow{P}\theta\)) — সব ভালো estimator-এর ন্যূনতম দাবি — সরাসরি LLN থেকে আসে; আর Monte Carlo (E3, Figure 3) integration/simulation-এর পুরো ক্ষেত্র দাঁড়িয়ে আছে "গড় করলেই সত্যে পৌঁছাব" — অর্থাৎ LLN-এর উপর।
statistics/ML-এর সাথে সংযোগ:
| ধারণা | LLN কোথায় কাজ করে |
|---|---|
| consistency of estimators | \(\hat\theta_n\xrightarrow{P}\theta\) — sample mean, MLE, method-of-moments সবার ভিত্তি |
| Monte Carlo / simulation | integral ও expectation আনুমান: \(\frac1n\sum g(X_i)\to\mathbb E[g(X)]\) (E3) |
| empirical risk minimization | training loss \(\frac1n\sum \ell(\cdot)\to\) true risk \(\mathbb E[\ell]\) — ML-এ generalization-এর শুরু |
| bootstrap, sample moments | sample mean/variance/quantile → population মান (data বাড়লে) |
| frequentist probability | "probability = দীর্ঘকালীন আপেক্ষিক ফ্রিকোয়েন্সি"-র আনুষ্ঠানিক ন্যায্যতা (E2) |
পূর্ববর্তী সংযোগ (← 3.1, 3.2): এই অধ্যায় আগের দুইটার সরাসরি ফসল। 3.1-এ পাওয়া Chebyshev inequality (\(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\le\sigma^2/(n\varepsilon^2)\)) হলো weak LLN-এর প্রমাণ-যন্ত্র (Figure 2 ঠিক এই bound-ই আঁকে); আর 3.1-এর concentration ধারণা ("data বাড়লে \(\bar X_n\) আরও আঁটসাঁট") LLN-এরই পরিমাণগত রূপ। 3.2-এ সংজ্ঞায়িত convergence-এর mode-গুলো (\(\xrightarrow{P}\), \(\xrightarrow{a.s.}\), \(\xrightarrow{L^2}\)) হলো সেই precise ভাষা যাতে weak vs strong LLN আলাদা করা যায় — WLLN মানে \(\xrightarrow{P}\), SLLN মানে \(\xrightarrow{a.s.}\)।
পরবর্তী সংযোগ (→ 3.4 Central Limit Theorem): LLN আর CLT একসাথে asymptotic statistics-এর দুই স্তম্ভ, আর এদের ভাগাভাগি পরিষ্কার — LLN বলে \(\bar X_n\) কোথায় যায় (উত্তর: \(\mu\)); CLT বলে কত দ্রুত আর কী আকৃতিতে যায়। LLN-এ পার্থক্য \(\bar X_n-\mu\to 0\), কিন্তু সেটা শূন্যে গেলে আর কিছু বলা যায় না; CLT সেই পার্থক্যকে \(\sqrt n\) দিয়ে বড় করে দেখায় যে \(\sqrt n(\bar X_n-\mu)\xrightarrow{d}\mathcal N(0,\sigma^2)\) — অর্থাৎ error আনুমানিক Normal, আর সঙ্কুচিত হয় ঠিক \(1/\sqrt n\) হারে (Figure 3-এর \(\pm 2\,\mathrm{SE}\) ব্যান্ড এরই পূর্বাভাস)। তাই: LLN দেয় নিশ্চয়তা (গড় ঠিক জায়গায় যায়), CLT দেয় নির্ভুলতার মাপ ও আকৃতি (confidence interval, \(z\)/\(t\)-test, \(p\)-value সব এখান থেকে)।
সূত্র (sources): Wasserman, All of Statistics, Ch. 5 (The Law of Large Numbers); Rice, Mathematical Statistics and Data Analysis, §5.2 (The Law of Large Numbers); Cauchy প্রতি-উদাহরণ ও characteristic-function যুক্তির জন্য Wasserman Ch. 5 ও 4।