5.7 — Nonparametric Regression: Kernels & Splines (নন-প্যারামেট্রিক রিগ্রেশন: কার্নেল ও স্প্লাইন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "যখন সম্পর্কটার আকৃতিই অজানা"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
5.1-এ আমরা regression-এর মূল যন্ত্রটা পেয়েছিলাম: একটা response \(y\)-কে predictor \(x\)-এর function ধরে data থেকে সেই সম্পর্ক বের করা। কিন্তু লক্ষ করুন — সেখানে আমরা শুরুতেই একটা আকৃতি ধরে নিয়েছিলাম: সম্পর্কটা রৈখিক, অর্থাৎ \(y \approx \beta_0 + \beta_1 x\) (বা বহু-predictor-এ একটা সমতল)। এমনকি যখন polynomial regression-এ \(x^2, x^3\) যোগ করেছি, তখনও আগে থেকেই ঠিক করে নিয়েছি কত-ডিগ্রির polynomial — অর্থাৎ function-টার একটা নির্দিষ্ট গাণিতিক রূপ আগে বেছে, তারপর শুধু তার কয়েকটা প্যারামিটার (\(\beta\)-গুলো) data থেকে আন্দাজ করেছি। এই পুরো দৃষ্টিভঙ্গির নাম parametric: function-এর আকৃতি আগে থেকে স্থির, data শুধু মুষ্টিমেয় কয়েকটা সংখ্যা ঠিক করে দেয়।
5.2-এ আমরা শিখেছি একটা মডেল কতটা জটিল হওয়া উচিত তার ভারসাম্য — bias–variance tradeoff: মডেল খুব সরল হলে data-র গঠন ধরতে পারে না (high bias, underfit), খুব জটিল হলে data-র noise-ও মুখস্থ করে ফেলে (high variance, overfit)। আর 0.3-এ শিখেছি অন্তরজ — বিশেষত দ্বিতীয় অন্তরজ \(f''(x)\), যা মাপে একটা curve কত দ্রুত বাঁক বদলায় (curvature)।
এই অধ্যায়ে এই তিনটে সুতো এক হবে। প্রশ্নটা সরল কিন্তু গভীর: সম্পর্কটার আকৃতিই যদি আগে থেকে জানা না থাকে — যদি সেটা সরলরেখাও নয়, কোনো পরিচিত নির্দিষ্ট সূত্রও নয় — তখন কী করব? parametric দৃষ্টিভঙ্গি এখানে নড়বড়ে হয়ে পড়ে, কারণ সে তো শুরুতেই একটা রূপ ধরে নিতে চায়। তার বদলে দরকার এমন একটা পদ্ধতি, যেখানে data নিজেই curve-এর আকৃতি ঠিক করে দেয়। এটাই nonparametric regression।
১.২ Hook — একটা বাঁকানো সম্পর্ক, আর সরলরেখার অসহায়তা¶
একটা ছবি কল্পনা করুন। ধরা যাক আমরা একটা পরীক্ষা চালিয়ে data জোগাড় করেছি, যেখানে input \(x\) শূন্য থেকে এক পর্যন্ত ছড়ানো, আর সত্যিকারের সম্পর্কটা একটা ঢেউ: $$ f(x) = \sin(2\pi x), $$ অর্থাৎ \(x\) বাড়লে \(y\) প্রথমে ওঠে, তারপর নামে, আবার ওঠে — একটা পূর্ণ ঢেউয়ের মতো (\(\sin\) = ত্রিকোণমিতিক sine function, \(2\pi x\) মানে \(x\) শূন্য থেকে এক যেতে পুরো এক চক্র)। বাস্তব data-তে প্রতিটি পর্যবেক্ষণে একটু এলোমেলো গোলমাল (noise) মেশানো: $$ y_i = f(x_i) + \varepsilon_i, $$ যেখানে \(y_i\) হলো \(i\)-তম পর্যবেক্ষণের response, \(x_i\) তার input, \(f(x_i)\) সত্যিকারের (অজানা) মান, আর \(\varepsilon_i\) ("এপসাইলন-আই") হলো সেই বিন্দুর random ত্রুটি।
এবার এই data-তে 5.1-এর সরল linear regression চালান — OLS বাধ্য হয়ে একটাই সরলরেখা বসাবে। কিন্তু একটা সরলরেখা দিয়ে একটা ঢেউকে ধরা অসম্ভব: রেখা যদি উপরের অংশে মেলে, নিচের অংশে গুবলেট; ঢেউয়ের চূড়া আর খাদ — কোনোটাই ধরা পড়বে না। ফলাফল সংখ্যাতেও স্পষ্ট: এই পরিস্থিতিতে linear OLS-এর \(R^2\) আসে মাত্র 0.510 — অর্থাৎ মডেল data-র variance-এর (ভেদ) অর্ধেকও ব্যাখ্যা করতে পারছে না, কারণ সে গোড়াতেই ভুল আকৃতি ধরে বসেছে (চিত্র 5-7-linear-fails এটাই দেখাবে)।
এক বাক্যে hook: সত্যিকারের সম্পর্ক যখন বাঁকানো বা অজানা-আকৃতির, তখন আগে থেকে একটা সরলরেখা (বা নির্দিষ্ট polynomial) চাপিয়ে দিলে মডেল গোড়া থেকেই ভুল — যত data-ই দিন, সরলরেখা কখনো ঢেউ হবে না।
১.৩ parametric অনুমানের ঝুঁকি — ভুল রূপ মানে দূরীকরণযোগ্য নয় এমন bias¶
§১.২-এর ব্যর্থতাটা কেন গভীর, সেটা একটু খুলে বলা দরকার, কারণ এখান থেকেই গোটা অধ্যায়ের প্রেরণা।
5.2-এর bias–variance ভাষায় ভাবুন। যখন আমরা একটা ভুল-আকৃতির parametric মডেল (যেমন প্রকৃত সম্পর্ক বাঁকা হলেও সরলরেখা) ধরি, তখন একধরনের bias তৈরি হয় যাকে বলে structural bias বা approximation bias — মডেলের রূপটাই সত্যকে ধরার মতো নমনীয় নয়। এর সবচেয়ে অস্বস্তিকর দিক: এই bias data বাড়ালেও কমে না। আপনি যদি দশ হাজার, এমনকি দশ লক্ষ বিন্দুও জোগাড় করেন, সরলরেখা তবু সরলরেখাই থাকবে — সে কখনো ঢেউয়ের চূড়া ছুঁতে পারবে না। অর্থাৎ ভুল রূপ ধরলে একটা অপসারণযোগ্য নয় এমন (irreducible-by-data) ভুল স্থায়ীভাবে বসে যায়।
এটা 5.1/5.2-এর variance-জনিত ভুল থেকে আলাদা: variance কমানো যায় বেশি data দিয়ে, কিন্তু ভুল-রূপ-জনিত bias কমে কেবল রূপটা বদলালে। তাই প্রকৃত \(f\)-এর আকৃতি অনিশ্চিত হলে, একটা কঠিন parametric ছাঁচে নিজেকে বেঁধে ফেলা ঝুঁকিপূর্ণ — আমরা হয়তো জানিই না কোন degree-র polynomial বা কোন রূপ ঠিক হবে।
একটা স্বাভাবিক প্রতিক্রিয়া হতে পারে: "তাহলে খুব উঁচু-degree-র polynomial বসিয়ে দিই, সব বাঁক ধরা পড়বে।" কিন্তু সেটা উল্টো প্রান্তের ফাঁদ — উঁচু-degree global polynomial প্রান্তে বুনো দুলুনি (oscillation) দেখায়, একটা বিন্দু নড়লে দূরের fit-ও নড়ে, আর variance আকাশছোঁয়া। অর্থাৎ "একটাই global সূত্র" — সেটা সরল হোক বা জটিল — মূল সমস্যাটাই থেকে যায়: আমরা গোটা পরিসরে একটিই অনমনীয় রূপ চাপাচ্ছি।
এক বাক্যে ঝুঁকি: ভুল parametric রূপ ধরলে এমন একটা bias বসে যায় যা data বাড়িয়েও মোছা যায় না; আর সেটা এড়াতে অন্ধভাবে উঁচু-degree global polynomial বসালে variance বিস্ফোরিত হয় — দুই প্রান্তেই বিপদ।
১.৪ সমাধানের মূল insight (অন্তর্দৃষ্টি) — data-কে curve বলতে দাও, locally¶
এখান থেকেই nonparametric regression-এর কেন্দ্রীয় ধারণা। নামটা একটু বিভ্রান্তিকর — "nonparametric" মানে এই নয় যে কোনো প্যারামিটারই নেই; বরং মানে হলো function-এর আকৃতিকে আগে থেকে কোনো নির্দিষ্ট সূত্রে বেঁধে রাখি না। আমরা শুধু একটা হালকা, সাধারণ অনুমান করি — যেমন "\(f\) মসৃণ (smooth), হঠাৎ লাফ দেয় না" — আর তারপর data-কেই curve-টার আকৃতি বেছে নিতে দিই।
মূল কৌশলটা একটিই শব্দে ধরা যায়: locally (স্থানীয়ভাবে)। globally একটা সূত্র খোঁজার বদলে, আমরা পরিসরের প্রতিটি জায়গায় আলাদা করে তাকাই। কোনো একটা বিন্দু \(x\)-এ \(f(x)\) আন্দাজ করতে চাইলে যুক্তিটা সহজ ও স্বাভাবিক:
\(x\)-এর কাছের যেসব data-বিন্দু আছে, তারাই \(f(x)\) সম্পর্কে সবচেয়ে বেশি কথা বলে — দূরের বিন্দুরা কম প্রাসঙ্গিক। তাই \(x\)-এর কাছাকাছি পর্যবেক্ষণগুলোকে বেশি গুরুত্ব (weight) দিয়ে একটা স্থানীয় গড় বা স্থানীয় fit নাও।
লক্ষ করুন — এই দৃষ্টিভঙ্গিতে সম্পর্কটা কোনো জায়গায় বাঁকা, কোনো জায়গায় খাড়া, কোনো জায়গায় সমতল হলেও সমস্যা নেই: প্রতিটি জায়গা তার নিজের প্রতিবেশী থেকে আকৃতি শেখে, কোনো একক সূত্রের দাসত্ব নেই। তাই data যত বাড়ে, এই পদ্ধতি প্রকৃত \(f\)-এর তত কাছে যেতে পারে — কারণ তার নমনীয়তা আগে থেকে কোনো রূপে বাঁধা নয়।
এই "locally নমনীয়" ধারণাটাকে বাস্তবে রূপ দেওয়ার দুটো বড় ঘরানা আছে — গোটা অধ্যায় মূলত এই দুই পরিবারকে ঘিরে:
-
পরিবার ১ — kernel / local পদ্ধতি (প্রতিবেশীর weighted average)। প্রতিটি বিন্দু \(x\)-এ, তার আশপাশের পর্যবেক্ষণগুলোর একটা ভারিত গড় (weighted average) নাও — কাছেরগুলো বেশি ভার, দূরেরগুলো কম। "কত কাছে = কত ভার" সেটা ঠিক করে একটা kernel (মসৃণ ওজন-ফাংশন) আর একটা প্রস্থ-প্যারামিটার bandwidth \(h\)। এর সবচেয়ে মৌলিক রূপ Nadaraya–Watson estimator। এরই উন্নত সংস্করণ local polynomial / LOESS, যেখানে স্থানীয়ভাবে শুধু গড় নয়, একটা ছোট রেখা/বক্ররেখাই বসানো হয়।
-
পরিবার ২ — spline / basis পদ্ধতি (টুকরো-টুকরো polynomial মসৃণভাবে জোড়া)। পরিসরকে কয়েকটা অংশে ভাগ করো (ভাগ-বিন্দুগুলোকে বলে knots), প্রতিটি অংশে একটা ছোট (সাধারণত cubic, অর্থাৎ ৩-ডিগ্রি) polynomial বসাও, আর সংযোগস্থলে টুকরোগুলোকে মসৃণভাবে জুড়ে দাও (যাতে জোড়ার মুখে হঠাৎ ভাঙা বা কোণ না থাকে)। এই টুকরো-টুকরো মসৃণ curve-ই spline। দুটো স্বাদ আছে — regression spline (কয়েকটা knot, তারপর সাধারণ OLS) ও smoothing spline (প্রতি বিন্দুতে knot, কিন্তু wiggliness-এর উপর জরিমানা/penalty)।
দুটো পরিবার দেখতে আলাদা, কিন্তু গভীরে তাদের একটাই অভিন্ন সুর — আর সেটাই এই অধ্যায়ের মূল ঐক্যসূত্র:
সর্বত্র একটাই tradeoff — কত মসৃণ? খুব কম মসৃণ করলে curve প্রতিটি বিন্দুর পেছনে ছুটে wiggly (এলোমেলো-দুলুনি) হয়ে data-র noise মুখস্থ করে (overfit: low bias, high variance)। খুব বেশি মসৃণ করলে curve সব বাঁক হারিয়ে প্রায় সরলরেখা হয়ে যায় (underfit: high bias, low variance)। এই মসৃণতার মাত্রা নিয়ন্ত্রণ করে একটিমাত্র tuning-knob — kernel-এ bandwidth \(h\), spline-এ degrees of freedom \(df\), smoothing spline-এ smoothing parameter \(\lambda\) — আর তিনটিই আসলে একই 5.2-এর bias–variance ভারসাম্যকেই নাড়াচাড়া করে।
১.৫ এক ঝলক — কী পেতে যাচ্ছি¶
পথে নামার আগে গন্তব্যটা একবার দেখিয়ে রাখি, যাতে কষ্টটা কেন তা বোঝা যায়। §১.২-এর ঢেউ-data-তে (\(f(x)=\sin(2\pi x)\), n=150) linear OLS পেয়েছিল মাত্র \(R^2=0.510\) — সে ঢেউ ধরতেই পারেনি। বিপরীতে, একটা cubic B-spline (degrees of freedom \(df=6\)) এই অধ্যায়ের পদ্ধতিতে fit করলে \(R^2\) লাফিয়ে 0.810-এ ওঠে, আর সত্যিকারের \(f\)-এর সাপেক্ষে গড়-বর্গ-ভুল (MSE) নেমে আসে প্রায় 0.0019 — যা linear মডেলের সংশ্লিষ্ট ভুল (\(\approx 0.1995\))-এর তুলনায় প্রায় ১০০ গুণ ছোট। অর্থাৎ একই data, কিন্তু আকৃতিকে data-র হাতে ছেড়ে দেওয়ায় ফল নাটকীয়ভাবে ভালো (চিত্র 5-7-spline-fit ও 5-7-bias-variance এ-সব দেখাবে)।
১.৬ এই অধ্যায়ের পথরেখা¶
মূল ধারণা হাতে এল; এবার সামনের পথ সংক্ষেপে:
- §২ মূল সংজ্ঞাগুলো নিখুঁত করে — kernel regression / Nadaraya–Watson (kernel \(K\), bandwidth \(h\), স্থানীয় weighted average), local polynomial / LOESS, basis expansion ও regression splines (knots, B-spline basis \(\{B_j\}\), natural cubic spline, \(df\)), smoothing splines (penalized RSS ও \(\lambda\)), \(h/df/\lambda\)-এর bias–variance ভূমিকা, এবং linear smoother \(\hat{\mathbf f}=S\mathbf y\) ও effective df \(=\operatorname{tr}(S)\)।
- §৩–৪ এই পদ্ধতিগুলো হাতে-কলমে ও গাণিতিকভাবে — Nadaraya–Watson-এর weight হিসাব, কেন এটা একটা linear smoother (smoother matrix \(S\)-এর গঠন), B-spline basis কীভাবে design matrix বানায় ও তার উপর OLS, smoothing-spline-এর penalized-RSS সমাধান, এবং \(\operatorname{tr}(S)\) কেন কার্যকর নমনীয়তা মাপে।
- §৫–৬ পূর্ণ \(f(x)=\sin(2\pi x)\) dataset-এ (n=150) হাতে-কলমে — linear-OLS-এর ব্যর্থতা, kernel-bandwidth \(h\)-এর প্রভাব ও সেরা \(h\approx 0.03\) (LOOCV; coarse গ্রিডে \(0.05\)), cubic B-spline (\(df=6\)) fit, এবং \(h/df/\lambda\)-জুড়ে bias–variance-এর চাক্ষুষ ছবি — চিত্র 5-7-linear-fails, 5-7-kernel-bandwidth, 5-7-spline-fit, 5-7-bias-variance ও Python-কোড সহ।
এক বাক্যে কেন এটি Part V-এর অপরিহার্য ধাপ। 5.1–5.2 শিখিয়েছে "একটা নির্দিষ্ট-রূপের (parametric) মডেল কীভাবে fit ও যাচাই করি"; এই অধ্যায় শেখায় "রূপটাই অজানা হলে data-কে কীভাবে নিজে আকৃতি বেছে নিতে দিই" — যা প্রকৃত-জীবনের বহু বাঁকা সম্পর্কের জন্য অপরিহার্য। আর এখানকার প্রতিটি পদ্ধতির একটিই tuning-knob (\(h/df/\lambda\)) কীভাবে নিরপেক্ষভাবে বাছব — তার পূর্ণ উত্তর পরের অধ্যায় 5.8 (cross-validation ও model validation)-এ।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "data-কে locally curve বলতে দাও" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (Nadaraya–Watson-এর smoother-matrix রূপ, B-spline basis-এর গঠন, smoothing-spline-এর penalized সমাধান, \(\operatorname{tr}(S)\)), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে notation থিতু করে নিই। আমাদের কাছে \(n\)টি পর্যবেক্ষণ-জোড়া আছে: \((x_1,y_1),\dots,(x_n,y_n)\)। আমরা ধরছি $$ y_i = f(x_i) + \varepsilon_i, \qquad \varepsilon_i \sim \mathcal{N}(0,\sigma^2), \quad i=1,\dots,n, $$ যেখানে —
- \(x_i\) — \(i\)-তম পর্যবেক্ষণের predictor (input);
- \(y_i\) — তার response (output);
- \(f(\cdot)\) — সত্যিকারের, অজানা-আকৃতির regression function, যা আমরা আন্দাজ করতে চাই (parametric-এ এর রূপ আগে থেকে স্থির ধরা হতো; এখানে নয়);
- \(\varepsilon_i\) ("এপসাইলন-আই") — \(i\)-তম বিন্দুর random ত্রুটি, গড় \(0\) ও ধ্রুব variance (ভেদ) \(\sigma^2\) সহ Normal বণ্টন থেকে আঁকা (\(\mathcal{N}(0,\sigma^2)\) = গড় \(0\), ভেদ \(\sigma^2\)-এর Normal/গাউসীয় বণ্টন; \(\sigma^2\) = noise-এর ভেদ, পর্যবেক্ষণ-গোলমালের মাত্রা)।
আমাদের লক্ষ্য একটা আন্দাজ-function \(\hat f\) গড়া (পড়ুন "এফ-হ্যাট"), যাতে যেকোনো \(x\)-এ \(\hat f(x)\) প্রকৃত \(f(x)\)-এর কাছাকাছি হয় — কিন্তু \(f\)-এর কোনো নির্দিষ্ট সূত্র আগে না ধরে।
২.১ Kernel regression ও Nadaraya–Watson — স্থানীয় ভারিত গড়¶
§১.৪-এর প্রথম পরিবার দিয়ে শুরু। ধারণাটা একদম সরল: কোনো বিন্দু \(x\)-এ \(f(x)\) আন্দাজ করতে, \(x\)-এর কাছের পর্যবেক্ষণগুলোর একটা ভারিত গড় (weighted average) নাও — কাছেরগুলো বেশি ভার পাক, দূরেরগুলো কম।
"কত কাছে = কত ভার" এই সম্পর্কটা ঠিক করে দেয় একটা kernel — লিখি \(K(\cdot)\)। kernel হলো একটা মসৃণ, চূড়া-শূন্যে-সর্বোচ্চ ওজন-ফাংশন: যার argument \(0\)-র কাছে থাকলে সে বড় মান (বেশি ওজন) দেয়, আর argument বড় (অর্থাৎ দূরত্ব বেশি) হলে দ্রুত শূন্যের দিকে নামে। সবচেয়ে প্রচলিত পছন্দ Gaussian kernel, $$ K(u) = \frac{1}{\sqrt{2\pi}}\, e^{-u^2/2}, $$ যেখানে \(u\) ("ইউ") হলো kernel-এর input (একটা মাপা-দূরত্ব), আর \(e\) স্বাভাবিক-লগের ভিত্তি — মূল কথা, \(u=0\)-তে সর্বোচ্চ, \(\lvert u\rvert\) বাড়লে কমে। (এ-ই 1.3-এর KDE-তে দেখা একই kernel-ধারণা — শুধু এখানে density নয়, regression-এ ওজন দিতে ব্যবহৃত।)
কিন্তু "কাছে" বা "দূর" মাপব কোন স্কেলে? সেটা ঠিক করে bandwidth \(h\) ("ব্যান্ডউইডথ-এইচ") — একটা ধনাত্মক সংখ্যা যা ঠিক করে প্রতিবেশীটা কতটা চওড়া। আমরা kernel-এ argument হিসেবে দিই মাপা-দূরত্ব \(\dfrac{x-x_i}{h}\): বিন্দু \(x_i\) যদি লক্ষ্য-বিন্দু \(x\) থেকে \(h\)-এর তুলনায় কাছে থাকে, এই অনুপাত ছোট, ওজন বড়; দূরে থাকলে অনুপাত বড়, ওজন প্রায় শূন্য। তাই \(h\) বড় করা মানে প্রতিবেশী চওড়া করা (অনেক বিন্দু ধরা পড়ে, ফল মসৃণ), আর \(h\) ছোট করা মানে প্রতিবেশী সংকীর্ণ (মাত্র কাছের কয়েকটা বিন্দু, ফল wiggly)।
এই উপাদান দুটো একসাথে জুড়লে পাই Nadaraya–Watson estimator — kernel regression-এর সবচেয়ে মৌলিক রূপ: $$ \hat f(x) \;=\; \frac{\sum_{i=1}^{n} K!\left(\dfrac{x-x_i}{h}\right) y_i}{\sum_{i=1}^{n} K!\left(\dfrac{x-x_i}{h}\right)}. $$
সূত্রটা একটু দাঁড়িয়ে পড়ি, কারণ গোটা kernel-পরিবারের প্রাণ এখানেই। লব (উপরের অংশ) হলো প্রতিটি \(y_i\)-কে তার ওজন \(K\!\left(\frac{x-x_i}{h}\right)\) দিয়ে গুণ করে যোগ; হর (নিচের অংশ) হলো সেই ওজনগুলোরই যোগফল। হর দিয়ে ভাগ করায় ওজনগুলো স্বাভাবিকীকৃত (normalized) হয় — অর্থাৎ মোট ওজন ১-এ নেমে আসে, ফলে \(\hat f(x)\) ঠিকঠাক একটা ভারিত গড় হয় (কোনো একটা ধ্রুবকে স্ফীত নয়)। সংক্ষেপে: \(\hat f(x)\) = লক্ষ্য-বিন্দু \(x\)-এর চারপাশের \(y\)-মানগুলোর kernel-ভারিত গড়, যেখানে কে কতটা কাছে তার ভিত্তিতে ভার বণ্টিত।
এর bias–variance চরিত্রটা সরাসরি \(h\)-এর হাতে (পূর্ণ বিশ্লেষণ §৪-এ, এখানে স্বজ্ঞা):
- ছোট \(h\) → সংকীর্ণ প্রতিবেশী, মাত্র গুটিকয় কাছের বিন্দুর গড় → curve প্রতিটি বিন্দুর পেছনে ছোটে, wiggly/overfit (low bias, high variance)।
- বড় \(h\) → চওড়া প্রতিবেশী, বহু দূরের বিন্দুও গড়ে ঢোকে → curve অতি-মসৃণ, বাঁক হারায়, over-smooth/underfit (high bias, low variance)।
তাই \(h\)-ই এই পদ্ধতির একক tuning-knob — §১.৪-এর "কত মসৃণ?" প্রশ্নের kernel-সংস্করণ।
২.২ Local polynomial ও LOESS — স্থানীয় গড় থেকে স্থানীয় ফিট¶
Nadaraya–Watson স্থানীয়ভাবে একটা ধ্রুবক (গড়) বসায় — অর্থাৎ প্রতিটি প্রতিবেশীতে "\(f\) মোটামুটি সমতল" ধরে নেয়। এতে একটা পরিচিত দুর্বলতা থাকে: যেখানে \(f\)-এর slope (ঢাল) আছে (যেমন ঢেউয়ের উঠতি/পড়তি অংশে), বা data-র দুই প্রান্তে (boundary), সেখানে স্থানীয় গড় একদিকে টেনে যায় (boundary bias)।
এর স্বাভাবিক উন্নতি — স্থানীয়ভাবে শুধু একটা ধ্রুবক নয়, একটা ছোট polynomial (সাধারণত সরলরেখা বা parabola) বসানো, তবে আগের মতোই kernel-ওজনে: লক্ষ্য-বিন্দুর কাছের পর্যবেক্ষণগুলো বেশি ভার পেয়ে সেই স্থানীয় fit-কে বেশি প্রভাবিত করে। একে বলে local polynomial regression; এর জনপ্রিয় ব্যবহারিক রূপ LOESS / LOWESS (locally estimated/weighted scatterplot smoothing)। ধারণাগতভাবে এটাও kernel-পরিবারেরই — একই bandwidth \(h\) নমনীয়তা নিয়ন্ত্রণ করে — শুধু স্থানীয়ভাবে গড়ের বদলে রেখা/বক্র বসিয়ে ঢাল ও প্রান্ত আরও ভালো ধরে। (বিস্তারিত §৪-এ; এখানে শুধু জানা থাক — LOESS মানে kernel-ধারণার একটু পরিণত, প্রান্ত-বন্ধু সংস্করণ।)
২.৩ Basis expansion ও regression splines — টুকরো-টুকরো মসৃণ polynomial¶
এবার §১.৪-এর দ্বিতীয় পরিবার। এর ভিত্তি 5.1-এ দেখা basis expansion: \(x\)-এর একটা function-কে কিছু পূর্বনির্ধারিত basis function \(\{B_1(x), B_2(x), \dots, B_M(x)\}\)-এর রৈখিক সমন্বয় হিসেবে লেখা, $$ f(x) \;\approx\; \sum_{j=1}^{M} \beta_j\, B_j(x), $$ যেখানে \(B_j(x)\) হলো \(j\)-তম basis function (একটা জানা, স্থির function), \(\beta_j\) তার coefficient (সহগ; data থেকে আন্দাজ্য), আর \(M\) basis-এর সংখ্যা। polynomial regression এরই একটা উদাহরণ — সেখানে \(B_j(x)=x^{j-1}\) (অর্থাৎ \(1,x,x^2,\dots\))। মূল সুবিধা: basis স্থির হলে \(f\) এই \(\beta_j\)-গুলোতে রৈখিক, তাই fit মানে কেবল \(\{B_j(x_i)\}\) কলামে সাজানো design matrix-এর উপর সাধারণ OLS — 5.1-এর যন্ত্রই খাটে।
সমস্যা শুধু basis-এর পছন্দে। global polynomial basis (\(1,x,x^2,\dots\)) উঁচু-degree-তে প্রান্তে দোলে ও অস্থির হয় (§১.৩)। তার বদলে দরকার এমন basis যা স্থানীয়ভাবে নমনীয় অথচ মসৃণ — আর সেটাই spline।
একটা regression spline গড়ার রেসিপি:
- Knots (গিঁট) বসাও। predictor-পরিসরের ভেতরে কয়েকটা ভাগ-বিন্দু \(\xi_1 < \xi_2 < \dots < \xi_K\) বাছো (এদের বলে knots, "নট")। এগুলো পরিসরকে কয়েকটা টুকরোতে ভাগ করে।
- প্রতি টুকরোয় cubic polynomial। প্রতিটি ভাগে একটা cubic (৩-ডিগ্রি) polynomial বসাও — cubic বাছা হয় কারণ এটাই যথেষ্ট নমনীয় অথচ মিতব্যয়ী।
- জোড়ার মুখে মসৃণতা। দুই টুকরোর সংযোগস্থলে (knot-এ) শুধু মান নয়, প্রথম ও দ্বিতীয় অন্তরজও মেলাও — অর্থাৎ টুকরোগুলো এমনভাবে জোড়া হয় যাতে জোড়ার মুখে কোনো ভাঙা, কোণ বা হঠাৎ-বাঁক না থাকে; চোখে curve-টা একটানা মসৃণ দেখায়। এই টুকরো-টুকরো-cubic, মসৃণভাবে-জোড়া curve-ই cubic spline।
এই গোটা টুকরো-টুকরো গঠনকে আবার ঝরঝরে কিছু basis function \(\{B_j(x)\}\) দিয়ে প্রকাশ করা যায় — সবচেয়ে সুবিধাজনক হলো B-spline basis ("বি-স্প্লাইন")। B-spline basis-এর প্রতিটি function স্থানীয় (শুধু কয়েকটা পাশাপাশি knot-এর আশপাশে শূন্যেতর) ও সাংখ্যিকভাবে স্থিতিশীল — ফলে fit আবার নিছক এই basis-কলামের design matrix-এর উপর OLS-এ নেমে আসে (গঠন ও সুবিধা §৪-এ)। অর্থাৎ: regression spline = spline-basis-এর উপর সাধারণ রৈখিক regression।
একটা ব্যবহারিক উপদ্রব — সাধারণ cubic spline data-র দুই প্রান্তের বাইরে বুনোভাবে দুলতে পারে (knot-এর ওপারে নিয়ন্ত্রণ নেই)। এর সমাধান natural cubic spline (স্বাভাবিক cubic spline): অতিরিক্ত শর্ত বসানো হয় যে curve দুই প্রান্তের বাইরে রৈখিক (অর্থাৎ দ্বিতীয় অন্তরজ প্রান্তে শূন্য) — এতে প্রান্তের অস্থিরতা দমে ও fit বেশি বিশ্বাসযোগ্য হয়।
কিন্তু কত knot, বা সমতুল্যভাবে basis কত বড় — সেটাই এই পরিবারের নমনীয়তা ঠিক করে, আর তা মাপা হয় degrees of freedom \(df\) দিয়ে ("ডিগ্রিস অফ ফ্রিডম")। মোটা দাগে \(df\) = মডেলের স্বাধীন প্যারামিটারের কার্যকর সংখ্যা (basis-এর আকার-সংশ্লিষ্ট): বেশি knot ⇒ বড় basis ⇒ বড় \(df\) ⇒ বেশি নমনীয় (আরও বাঁক ধরতে পারে, কিন্তু overfit-এর ঝুঁকি); কম \(df\) ⇒ মসৃণ, কম নমনীয়। তাই regression spline-এ \(df\)-ই হলো §১.৪-এর "কত মসৃণ?" knob। (এই অধ্যায়ের চলতি উদাহরণে cubic B-spline-এ \(df=6\) ভালো ভারসাম্য দেয় — §৫-৬।)
২.৪ Smoothing splines — প্রতি বিন্দুতে গিঁট, কিন্তু wiggliness-এ জরিমানা¶
regression spline-এ একটা অস্বস্তিকর সিদ্ধান্ত থেকে যায়: knot কয়টা, কোথায়? ভুল জায়গায় কম/বেশি knot বসালে fit ভোগে। smoothing spline এই সিদ্ধান্তটাই এড়িয়ে যায় — একটা সুন্দর কৌশলে।
ধারণাটা প্রায় উল্টো-সাহসী: knot বাছার ঝামেলা না করে প্রতিটি data-বিন্দুতেই একটা knot বসাও (অর্থাৎ সর্বোচ্চ সম্ভাব্য নমনীয়তা)। কিন্তু তাহলে তো curve প্রতিটি বিন্দু ছুঁয়ে বুনোভাবে দুলবে (চরম overfit)! তাই একই সঙ্গে একটা জরিমানা (penalty) বসানো হয়, যা curve-কে অতি-wiggly হতে বাধা দেয়। অর্থাৎ fit-কে দুটো পরস্পর-বিরোধী চাপের মধ্যে টানা হয় — (ক) data-র কাছে থাকো, (খ) মসৃণ থাকো।
গাণিতিকভাবে, smoothing spline খোঁজে সেই function \(f\), যা নিচের penalized least squares (জরিমানা-যুক্ত বর্গ-ত্রুটি) ছোট করে: $$ \sum_{i=1}^{n} \bigl(y_i - f(x_i)\bigr)^2 \;+\; \lambda \int f''(t)^2\,dt. $$
দুটো অংশ আলাদা করে পড়ি, কারণ এখানেই smoothing spline-এর সমস্ত স্বজ্ঞা:
- প্রথম পদ — \(\sum_i (y_i - f(x_i))^2\): এটা চেনা residual sum of squares (RSS) — curve \(f\) data-বিন্দু থেকে কত দূরে, তার মোট বর্গ-ভুল। এই পদ একা ছোট করতে চাইলে curve প্রতিটি বিন্দু ছুঁতে চাইবে (data-fidelity, "data-র কাছে থাকো")।
- দ্বিতীয় পদ — \(\lambda \int f''(t)^2\,dt\): এটা roughness penalty (অমসৃণতা-জরিমানা)। মনে করুন 0.3 থেকে — \(f''(t)\) হলো curve-এর দ্বিতীয় অন্তরজ, যা মাপে curve কত দ্রুত বাঁক বদলায় (curvature); সরলরেখার \(f''=0\), আর যত বেশি দোলে তত \(\lvert f''\rvert\) বড়। তাই \(\int f''(t)^2\,dt\) গোটা পরিসর জুড়ে curve-এর মোট "বাঁকা-ভাব" বা wiggliness মাপে — wiggly curve-এ এটা বড়, মসৃণ curve-এ ছোট (\(\int\) = সমাকলন, পুরো পরিসর জুড়ে যোগফল)। এই পদ একা ছোট করতে চাইলে curve সরলরেখার দিকে ঝুঁকবে (smoothness, "মসৃণ থাকো")।
এই দুই চাপের ভারসাম্য ঠিক করে smoothing parameter \(\lambda\) ("ল্যামডা") — একটা ধনাত্মক সংখ্যা যা বলে দেয় wiggliness-কে কতটা শাস্তি দেব। দুই চরমে এর অর্থ চমৎকারভাবে স্পষ্ট:
- \(\lambda \to 0\) (জরিমানা প্রায় নেই) → শুধু RSS ছোট করার চেষ্টা → curve প্রতিটি বিন্দু ছুঁয়ে যায়, অর্থাৎ data interpolate করে — চরম wiggly/overfit (low bias, high variance)।
- \(\lambda \to \infty\) (জরিমানা অসীম) → \(\int f''^2\) বাধ্য হয়ে \(0\) হতে হয়, অর্থাৎ \(f''\equiv 0\) → curve একটা সরলরেখা হয়ে যায় (ঠিক 5.1-এর least-squares রেখা!) — চরম মসৃণ/underfit (high bias, low variance)।
মাঝামাঝি \(\lambda\) দেয় একটা মসৃণ অথচ data-অনুসরণকারী curve। তাই smoothing spline-এ \(\lambda\)-ই §১.৪-এর "কত মসৃণ?" knob — kernel-এর \(h\) ও regression-spline-এর \(df\)-এর সরাসরি প্রতিরূপ। (এই penalized-সমস্যার সমাধান যে আবার একটা natural cubic spline-ই হয়, এবং তা কীভাবে বের হয় — §৪-এ।)
২.৫ একই tradeoff, তিনটি knob — পাশাপাশি¶
তিনটি পদ্ধতি দেখা হলো; এদের নমনীয়তা-নিয়ন্ত্রকগুলো আসলে একই 5.2-এর bias–variance ভারসাম্যের তিন রূপ। পাশাপাশি রাখলে ঐক্যটা স্পষ্ট হয়:
| পদ্ধতি | tuning-knob | বেশি নমনীয় (overfit-মুখী, low bias / high variance) | কম নমনীয় (underfit-মুখী, high bias / low variance) |
|---|---|---|---|
| Kernel / Nadaraya–Watson | bandwidth \(h\) | ছোট \(h\) (সংকীর্ণ প্রতিবেশী, wiggly) | বড় \(h\) (চওড়া প্রতিবেশী, over-smooth) |
| Regression spline | degrees of freedom \(df\) | বড় \(df\) (বেশি knot/basis, wiggly) | ছোট \(df\) (কম knot, মসৃণ→রৈখিক) |
| Smoothing spline | smoothing parameter \(\lambda\) | ছোট \(\lambda\) (জরিমানা কম, interpolate) | বড় \(\lambda\) (জরিমানা বেশি, রৈখিক) |
লক্ষ করুন একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ উল্টো-দিক: \(h\) আর \(df\) চলে বিপরীত দিকে (ছোট \(h\) = বেশি নমনীয়, কিন্তু বড় \(df\) = বেশি নমনীয়); আর \(\lambda\) চলে \(h\)-এর মতোই দিকে (ছোট \(\lambda\) = বেশি নমনীয়)। নাম-চিহ্ন আলাদা হলেও তিনটিই একই অক্ষের উপর — "data-কে কতটা ঘনিষ্ঠভাবে অনুসরণ করব বনাম কতটা মসৃণ রাখব" — চলমান একটি বিন্দু।
২.৬ Linear smoother ও effective degrees of freedom — সব পদ্ধতির অভিন্ন মাপকাঠি¶
সবশেষে একটা সুন্দর ঐক্যসূত্র, যা এই গোটা অধ্যায়কে এক সুতোয় বাঁধে এবং পরের অধ্যায়ের (5.8) tuning-এর ভিত্তি গড়ে।
লক্ষণীয় ব্যাপারটা হলো: উপরের প্রতিটি পদ্ধতিতে — Nadaraya–Watson, local polynomial, regression spline, smoothing spline — fitted মানগুলো আসলে data-র \(y\)-মানগুলোর একটা রৈখিক সমন্বয়। অর্থাৎ যদি সব fitted মান একসাথে একটা ভেক্টরে রাখি, \(\hat{\mathbf f} = (\hat f(x_1),\dots,\hat f(x_n))^\top\), আর সব response একটা ভেক্টরে, \(\mathbf y = (y_1,\dots,y_n)^\top\), তবে এদের সম্পর্ক লেখা যায় $$ \hat{\mathbf f} \;=\; S\,\mathbf y, $$ যেখানে \(S\) ("এস") একটা \(n\times n\) smoother matrix (মসৃণকারী ম্যাট্রিক্স)। সবচেয়ে গুরুত্বপূর্ণ কথা — \(S\) শুধু \(x\)-মান ও tuning-knob (\(h\) বা \(df\) বা \(\lambda\))-এর উপর নির্ভর করে, \(y\)-এর উপর একটুও নয়। যে পদ্ধতি এই রূপে লেখা যায়, তাকে বলে linear smoother (রৈখিক মসৃণকারী)। (কেন Nadaraya–Watson ও spline দুটোই এই রূপ মানে — §৪-এ দেখানো হবে; যেমন Nadaraya–Watson-এ \(S\)-এর \((i,j)\)-ঘর হলো ঠিক §২.১-এর normalized kernel-ওজন।)
এই অভিন্ন রূপটা একটা দারুণ উপহার দেয় — সব পদ্ধতির নমনীয়তাকে একটিই স্কেলে মাপার উপায়। 5.1-এর OLS-এ "প্যারামিটার-সংখ্যা" দিয়ে জটিলতা মাপা যেত; কিন্তু kernel-fit বা smoothing spline-এ তো স্পষ্ট প্যারামিটার-সংখ্যা নেই। এর সমাধান effective degrees of freedom (কার্যকর স্বাধীনতা-মাত্রা): $$ \text{effective } df \;=\; \operatorname{tr}(S), $$ যেখানে \(\operatorname{tr}(S)\) হলো \(S\)-এর trace — তার কর্ণ-উপাদানগুলোর (diagonal entries) যোগফল (\(\operatorname{tr}\) = trace, ম্যাট্রিক্সের মুখ্য-কর্ণের যোগ)। এই একটি সংখ্যা বলে দেয় মডেল কার্যত কতগুলো স্বাধীন প্যারামিটার "খরচ" করছে — অর্থাৎ সে কতটা নমনীয়। স্বজ্ঞা: খুব মসৃণ fit (বড় \(h\), ছোট \(df\), বড় \(\lambda\)) প্রায় সরলরেখার মতো, তার effective df ছোট (২-এর কাছে); খুব wiggly fit (ছোট \(h\), বড় \(df\), ছোট \(\lambda\)) বহু স্বাধীন বাঁক ধরে, তার effective df বড় (n-এর দিকে)।
এর তিনটে বড় উপকার, যা §১-এর সব সুতো গুটিয়ে আনে:
- তুলনার অভিন্ন ভাষা। একটা kernel-fit (\(h\) দিয়ে) আর একটা smoothing spline (\(\lambda\) দিয়ে) — দেখতে সম্পূর্ণ আলাদা যন্ত্র, কিন্তু দুটোরই \(\operatorname{tr}(S)\) বের করে বলা যায় "এই দুটো আসলে সমান-নমনীয়" বা "এটা ওটার চেয়ে বেশি নমনীয়"। regression spline-এর স্বাভাবিক \(df\)-ও এই \(\operatorname{tr}(S)\)-এর সঙ্গে মেলে।
- bias–variance-এর সরাসরি হাতল। effective df বাড়ানো = বেশি নমনীয় = bias কমে কিন্তু variance বাড়ে; কমানো = উল্টো। অর্থাৎ \(\operatorname{tr}(S)\) হলো গোটা অধ্যায়ের tradeoff-এর একটিই, পদ্ধতি-নিরপেক্ষ পরিমাপক।
- tuning-এর ভিত্তি (5.8-এর bridge/সেতু)। যেহেতু \(\operatorname{tr}(S)\) মডেল-জটিলতা ধরে, এটাকেই কাজে লাগিয়ে কোন \(h\)/\(df\)/\(\lambda\) সেরা তা নিরপেক্ষভাবে বাছা যায় — cross-validation (CV) ও তার দ্রুত-সংস্করণ generalized cross-validation (GCV) দিয়ে (যেখানে \(\operatorname{tr}(S)\) সরাসরি সূত্রে ঢোকে)। এই tuning-পদ্ধতির পূর্ণ আলোচনাই পরের অধ্যায় 5.8 (cross-validation ও model validation)-এর বিষয়।
এক বাক্যে §২-এর সার: \(y=f(x)+\varepsilon\)-এ \(f\) অজানা-আকৃতির হলে nonparametric regression data-কে locally curve বলতে দেয় — হয় kernel-ভারিত স্থানীয় গড় (Nadaraya–Watson, knob \(h\)), নয়তো টুকরো-টুকরো মসৃণ polynomial (regression spline, knob \(df\); বা smoothing spline, knob \(\lambda\), penalty \(\lambda\int f''^2\)); তিনটিই একই bias–variance অক্ষে চলা linear smoother \(\hat{\mathbf f}=S\mathbf y\), আর তাদের নমনীয়তার অভিন্ন মাপ effective df \(=\operatorname{tr}(S)\) — যা দিয়ে 5.8-এ CV/GCV-র সাহায্যে সেরা মসৃণতা বাছা হবে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে আমরা একটিমাত্র simulated dataset-এর উপর চারটি পদ্ধতি পাশাপাশি চালাব এবং দেখব কীভাবে nonparametric regression সেই বাঁক (curvature) ধরতে পারে যা একটি straight line কখনোই ধরতে পারে না। যেহেতু true function জানা — \(f(x)=\sin(2\pi x)\) — আমরা প্রতিটি fit-কে একটি honest, oracle metric দিয়ে যাচাই করতে পারব:
লক্ষ করুন, এটি ordinary residual error নয়। residual error মাপে \(\hat f\) আর noisy data \(y_i\)-এর দূরত্ব; MSE-vs-true মাপে \(\hat f\) আর প্রকৃত signal \(f\)-এর দূরত্ব। বাস্তব কাজে \(f\) অজানা বলে এই metric ব্যবহার করা যায় না, কিন্তু একটি controlled simulation-এ এটিই হলো সবচেয়ে নির্ভরযোগ্য বিচারক — কারণ এটি কোনো method-কে noise overfit করার জন্য পুরস্কৃত করে না।
Dataset। seed \(=20260619\), \(n=150\)। \(x_i \sim \text{Uniform}(0,1)\) (sorted), \(f(x)=\sin(2\pi x)\), এবং \(y_i=f(x_i)+\varepsilon_i\) যেখানে \(\varepsilon_i \sim \mathcal{N}(0,\,0.3^2)\)। অর্থাৎ noise standard deviation \(\sigma=0.3\), যা signal-এর amplitude (\(=1\))-এর তুলনায় যথেষ্ট বড় — scatter plot-এ চোখে sine wave-টি আবছা, কিন্তু সুস্পষ্ট নয়।
৩.১ · E1 — Linear OLS: যখন \(R^2\) "ঠিকঠাক" দেখায় অথচ form-টাই ভুল¶
প্রথমে naive baseline: একটি straight line fit করি, model y ~ x।
import numpy as np
import statsmodels.api as sm
rng = np.random.default_rng(20260619)
n = 150
x = np.sort(rng.uniform(0, 1, n))
f = np.sin(2 * np.pi * x)
y = f + rng.normal(0, 0.3, n)
X = sm.add_constant(x)
ols = sm.OLS(y, X).fit()
print(ols.params, ols.rsquared) # b0, b1, R^2
yhat_lin = ols.predict(X)
mse_true_lin = np.mean((yhat_lin - f) ** 2)
ফলাফল:
প্রথম দর্শনে \(R^2=0.510\) মন্দ মনে হয় না — model variance-এর অর্ধেকেরও বেশি "explain" করছে। আর slope-ও অর্থপূর্ণ: \(\sin(2\pi x)\) যেহেতু \(x=0\) থেকে \(x=1\) পর্যন্ত গড়পড়তা নিচের দিকে নামে (শুরুতে \(0\), শেষেও \(0\), কিন্তু \(x>0.5\)-এ negative অংশে অনেক বেশি সময় কাটায়), straight line সেই overall downward drift ধরে ফেলে। তাই \(b_1<0\) পুরোপুরি প্রত্যাশিত।
কিন্তু এখানেই ফাঁদ। line টি gross trend ধরছে, wiggle ধরছে না। MSE-vs-true \(=0.1995\) — এটি \(\sigma^2=0.09\)-এর চেয়েও বড়, অর্থাৎ fitted line-এর systematic error noise variance-কেও ছাড়িয়ে গেছে। কারণটি bias: কোনো একটি straight line দিয়ে একটা full sine cycle approximate করলে অবশ্যম্ভাবী structural mismatch থেকে যায়।
এই mismatch-টি residuals-এ স্পষ্ট দেখা যায়। sine-এর crest (\(x\approx0.25\), যেখানে \(f=1.0\)) এবং trough (\(x\approx0.75\))-এর আশেপাশে residuals systematically এক চিহ্নের, আর zero-crossing-গুলোর কাছে উল্টো চিহ্নের। অর্থাৎ residuals random scatter নয় — তাদের মধ্যে অবশিষ্ট sinusoidal structure রয়ে গেছে:
Diagnostic হিসেবে residual plot। linear model-এর আসল ব্যর্থতা \(R^2\)-এ ধরা পড়ে না; ধরা পড়ে residuals-বনাম-\(x\) plot-এ। যদি residuals-এ এমন মসৃণ, সাইন-আকৃতির pattern দেখা যায়, সেটাই সংকেত — parametric form-টি ভুল, আরও flexible কিছু দরকার।
পাঠ। \(R^2=0.51\) একটি comforting number, কিন্তু এটি কেবল বলে data-এর variance-এর কত অংশ explain হয়েছে — বলে না form-টি ঠিক কিনা। এখানে \(R^2\) মাঝারি, residual pattern চিৎকার করছে, আর MSE-vs-true নিশ্চিত করছে: linear model wiggle মিস করেছে। goodness-of-fit metric আর model-form adequacy দুটি আলাদা প্রশ্ন।
৩.২ · E2 — Nadaraya–Watson kernel regression ও bandwidth-এর ভূমিকা¶
এবার একই data-তে Nadaraya–Watson estimator চালাই। Gaussian kernel \(K(u)=\exp(-u^2/2)\) ব্যবহার করে point \(x\)-এ prediction হলো locally weighted average:
এখানে সমস্ত খেলা একটিমাত্র tuning parameter — bandwidth \(h\)-কে ঘিরে। \(h\) ঠিক করে দেয় কতটা দূরের প্রতিবেশীরা গড়ে অবদান রাখবে।
def nadaraya_watson(xq, x, y, h):
out = np.empty_like(xq, dtype=float)
for j, xq_j in enumerate(xq):
w = np.exp(-0.5 * ((xq_j - x) / h) ** 2)
out[j] = np.sum(w * y) / np.sum(w)
return out
for h in (0.02, 0.05, 0.20, 0.40):
yhat = nadaraya_watson(x, x, y, h)
print(h, np.mean((yhat - f) ** 2))
| \(h\) | আচরণ | MSE-vs-true |
|---|---|---|
| \(0.02\) | undersmoothed — wiggly, noise-কে chase করছে | \(0.0095\) |
| \(0.05\) | good — sine wave পরিষ্কারভাবে ফুটে উঠেছে | \(0.0077\) |
| \(0.20\) | oversmoothed — bumps ভোঁতা হয়ে গেছে | \(0.1228\) |
| \(0.40\) | প্রায় সমতল — global average-এর কাছাকাছি | \(0.2865\) |
এই চারটি সংখ্যা ক্লাসিক bias–variance tradeoff-এর জীবন্ত উদাহরণ:
- ছোট \(h\) (\(=0.02\)): প্রতিটি local average গুটিকয়েক বিন্দুর উপর দাঁড়ানো, তাই estimate noisy — high variance, low bias। curve প্রকৃত sine-কে অনুসরণ করে, কিন্তু তার উপর random jitter চেপে বসে। MSE-vs-true \(0.0095\), যা low হলেও সর্বনিম্ন নয়।
- মাঝারি \(h\) (\(=0.05\)): যথেষ্ট প্রতিবেশী গড়ে noise ধুয়ে যায়, অথচ window এত চওড়া নয় যে curvature মুছে যায়। এটিই sweet spot-এর কাছাকাছি — MSE-vs-true \(0.0077\)।
- বড় \(h\) (\(=0.20,\ 0.40\)): window এত চওড়া যে crest আর trough একে অপরের সঙ্গে গড় হয়ে ভোঁতা হয়ে যায় — low variance, high bias। \(h=0.40\)-এ estimate কার্যত একটি horizontal line, আর MSE-vs-true (\(0.2865\)) linear OLS-এর (\(0.1995\)) চেয়েও খারাপ। অর্থাৎ অতিরিক্ত smoothing nonparametric method-কেও straight line-এর চেয়ে নিকৃষ্ট করে তুলতে পারে।
লক্ষ করুন U-আকৃতি: \(h\) বাড়ালে MSE প্রথমে কমে (\(0.0095 \to 0.0077\)), তারপর বাড়ে (\(\to 0.1228 \to 0.2865\))। সর্বনিম্ন কোথায়, সেটা চোখে আন্দাজ না করে data থেকে বেছে নেওয়া উচিত। স্বাভাবিক পছন্দ leave-one-out cross-validation (LOOCV) — প্রতিটি বিন্দু একবার করে বাদ দিয়ে বাকি data থেকে predict করে held-out error হিসাব করা:
def loocv_error(x, y, h):
err = 0.0
for i in range(len(x)):
w = np.exp(-0.5 * ((x[i] - x) / h) ** 2)
w[i] = 0.0 # leave point i out
pred = np.sum(w * y) / np.sum(w)
err += (y[i] - pred) ** 2
return err / len(x)
grid = np.linspace(0.01, 0.20, 40)
h_star = grid[np.argmin([loocv_error(x, y, h) for h in grid])]
# h_star ≈ 0.03
LOOCV বেছে নেয় \(h \approx 0.03\), যা grid-এর "good" zone-এর মধ্যেই পড়ে। এই \(h\)-তে MSE-vs-true \(=0.0067\) — visual eyeball-করা \(h=0.05\)-এর (\(0.0077\)) চেয়েও সামান্য ভালো। গুরুত্বপূর্ণ ব্যাপারটি: LOOCV কেবল noisy held-out data দেখেই \(h\) বেছেছে, true \(f\)-কে কখনো দেখেনি, তবু এমন একটি bandwidth-এ থেমেছে যা oracle metric-এর কাছেও প্রায় optimal। এটাই cross-validation-এর সৌন্দর্য — true function না জেনেও bias–variance balance খুঁজে পাওয়া।
৩.৩ · E3 — Regression spline (cubic B-spline)¶
Kernel regression প্রতিটি query point-এ আলাদা করে local average কষে। Spline-এর কৌশল ভিন্ন এবং ভারী আকর্ষণীয়: এটি \(x\)-কে কয়েকটি basis function-এ রূপান্তর করে, তারপর সেই basis-এর উপর সাধারণ OLS চালায়। অর্থাৎ একবার basis তৈরি হয়ে গেলে, এটা আর কিছুই নয় — শুধুই linear regression, কিন্তু আসল \(x\)-এর বদলে spline-rendered columns-এর উপর।
import numpy as np
import statsmodels.api as sm
from patsy import dmatrix
for df in (4, 6, 9):
B = dmatrix(f"bs(x, df={df}, degree=3, include_intercept=True)",
{"x": x}, return_type="dataframe")
fit = sm.OLS(y, B).fit()
yhat = fit.predict(B)
print(df, fit.rsquared, np.mean((yhat - f) ** 2))
patsy-এর bs(...) cubic (degree-3) B-spline basis তৈরি করে; df ঠিক করে dimension তথা flexibility। ফলাফল:
df |
আচরণ | \(R^2\) | MSE-vs-true |
|---|---|---|---|
| \(4\) | underfit — curvature ধরতে basis কম পড়ে | — | \(0.0051\) |
| \(6\) | best — sine wave প্রায় নিখুঁতভাবে পুনরুদ্ধার | \(0.810\) | \(0.0019\) |
| \(9\) | সামান্য overfit — অতিরিক্ত flexibility noise ধরছে | — | \(0.0024\) |
df=6-এ MSE-vs-true নেমে আসে \(0.0019\)-তে। linear OLS-এর সঙ্গে তুলনা করুন:
অর্থাৎ একই data, একই underlying OLS machinery — শুধু \(x\)-এর বদলে একটি cubic-spline basis-এর উপর regress করায় true signal-এর সঙ্গে error প্রায় ১০০ গুণ কমে গেল। \(R^2\)-ও \(0.510 \to 0.810\)-এ উঠল। অসাধারণ এই উন্নতির পুরোটাই এসেছে representation বদলানো থেকে; estimation algorithm একই থেকে গেছে।
df-এর প্রভাব kernel-এর \(h\)-এর আয়না:
df=4(underfit): basis function এত কম যে একটি পূর্ণ sine cycle-এর দুটি প্রকৃত bend ঠিকমতো ধরা যায় না — অবশিষ্ট bias থেকে যায় (MSE \(0.0051\))। এটি high-bias প্রান্ত।df=6(just right): ঠিক যতটুকু flexibility দরকার ততটুকুই, তাই bias আর variance দুটোই কম — minimum MSE।df=9(overfit): অতিরিক্ত degrees of freedom নিয়ে curve এবার noise-এর দিকে সামান্য বাঁকতে শুরু করে — variance বাড়ে, MSE সামান্য চড়ে (\(0.0024\))। ছোট \(h\) যেভাবে noise chase করে, বড়df-ও তেমনি।
মূল বার্তা। Regression spline মানে নতুন কোনো estimation নয় — basis expansion + OLS।
bs(...)দিয়ে \(x\)-কে columns-এ ভেঙে নিন, তারপর যে OLS আপনি ইতিমধ্যে জানেন সেটাই চালান। flexibility আসে basis-এরdfথেকে, ঠিক যেমন kernel-এ smoothness আসে \(h\) থেকে।
৩.৪ · E4 — চার পদ্ধতির তুলনা ও read-off¶
চারটি approach একই dataset-এর উপর তাদের সেরা (বা প্রতিনিধিত্বমূলক) setting-এ রেখে MSE-vs-true দিয়ে পাশাপাশি সাজালে ছবিটি পরিষ্কার হয়ে যায়:
| Method | Setting | \(R^2\) | MSE-vs-true | linear-এর তুলনায় |
|---|---|---|---|---|
| Linear OLS | y ~ x |
\(0.510\) | \(0.1995\) | \(1\times\) (baseline) |
| Nadaraya–Watson | \(h=0.05\) | — | \(0.0077\) | \(\approx 26\times\) ভালো |
| Smoothing spline | scipy, \(s=n\sigma^2=13.5\) | — | \(0.0197\) | \(\approx 10\times\) ভালো |
| Cubic B-spline | df=6 |
\(\mathbf{0.810}\) | \(\mathbf{0.0019}\) | \(\approx \mathbf{105\times}\) ভালো |
# smoothing spline reference fit
from scipy.interpolate import UnivariateSpline
spl = UnivariateSpline(x, y, s=n * 0.3**2) # s = n * sigma^2 = 13.5
yhat_ss = spl(x)
print(len(spl.get_knots()), np.mean((yhat_ss - f) ** 2)) # ~30 knots, 0.0197
table থেকে কয়েকটি স্পষ্ট পাঠ:
-
তিনটি flexible method-ই linear-কে বিশাল ব্যবধানে হারায়। সবচেয়ে দুর্বল flexible fit (smoothing spline, \(0.0197\))-ও linear (\(0.1995\))-এর চেয়ে প্রায় ১০ গুণ ভালো। কারণ একটাই: তিনটিই কোনো-না-কোনোভাবে local curvature ধরতে পারে, straight line পারে না।
-
Cubic B-spline (
df=6) এখানে বিজয়ী — MSE-vs-true \(0.0019\), সর্বনিম্ন। তার পরেই Nadaraya–Watson (\(h=0.05\), \(0.0077\))। কোন method "সেরা" তা dataset-নির্ভর; এখানে underlying \(f\) মসৃণ ও global-ভাবে well-behaved বলে নির্দিষ্ট সংখ্যক knot-এ বসানো একটি spline তাকে অত্যন্ত compact-ভাবে ধরে ফেলে। -
Smoothing spline মাঝামাঝি। \(s=n\sigma^2\) একটি principled default (penalty-কে noise level-এর সঙ্গে মিলিয়ে দেয়), আর এটি প্রায় ৩০টি knot বসিয়েও fit করে। তবু এখানে এটি regression spline বা ভালো-tuned kernel-এর চেয়ে পিছিয়ে — কারণ এই বিশেষ \(s\)-এ penalty সামান্য বেশি smoothing চাপিয়ে দিয়েছে। অন্য কোনো dataset-এ ক্রম উল্টে যেতেও পারে; এখানে point হলো magnitude — সব flexible method একই ballpark-এ, আর সেই ballpark linear-এর থেকে কয়েক order দূরে।
Read-off — true value পুনরুদ্ধার। চূড়ান্ত পরীক্ষা: দুটি known anchor point-এ fitted curve কী বলছে? প্রকৃত মান \(f(0.25)=\sin(\pi/2)=1.0\) (crest) এবং \(f(0.5)=\sin(\pi)=0.0\) (zero-crossing)।
- Linear \(x=0.25\)-এ দেয় \(0.968 - 1.936(0.25) = 0.484\) — প্রকৃত \(1.0\)-এর প্রায় অর্ধেক। crest-এর কাছে line টি কেবল গড় trend-এর উপর বসে আছে, peak ছুঁতে পারছে না।
- B-spline (
df=6) ও well-tuned kernel এই দুই বিন্দুতেই প্রকৃত \(1.0\) ও \(0.0\)-এর খুব কাছ দিয়ে যায় — যেটা তাদের ক্ষুদ্র MSE-vs-true থেকেই প্রত্যাশিত। এরা \(\sin(2\pi x)\)-এর crest এবং zero-crossing দুই-ই আলাদাভাবে চিনতে পারে, যা একটি monotone straight line গঠনগতভাবেই কখনো পারবে না।
সারকথা। linear model R²=0.51-এ "ঠিকঠাক" দেখিয়েও true signal-এর সঙ্গে বড় systematic error রেখে দেয়, কারণ form-টাই ভুল। Kernel এবং spline — দুই-ই flexible, locally adaptive — সেই \(\sin(2\pi x)\) curve পুনরুদ্ধার করে যা straight line ধরতে অপারগ, আর তাদের MSE-vs-true linear-এর তুলনায় এক থেকে দুই order of magnitude ছোট। nonparametric regression-এর মূল প্রতিশ্রুতি এটাই: shape সম্পর্কে আগেভাগে অনুমান না করেই data-কে তার নিজের curve নিজে বেছে নিতে দেওয়া।
যাচাই (scipy/patsy দিয়ে রান করা)। নিচের block-টি উপরের canonical numbers-এর qualitative structure নিশ্চিত করে — linear-এর দুর্বলতা, bandwidth-এ U-আকৃতির MSE, df=6-এ minimum, এবং anchor value \(f(0.25)=1.0,\ f(0.5)=0.0\):
LINEAR b0≈0.97 b1≈-1.94 R²≈0.51 MSE-vs-true≈0.1995 (poor fit; residuals retain sine structure)
NW h=0.02 MSE-vs-true 0.0095 (undersmoothed, wiggly)
NW h=0.05 MSE-vs-true 0.0077 (good)
NW h=0.20 MSE-vs-true 0.1228 (oversmoothed)
NW h=0.40 MSE-vs-true 0.2865 (flat) → LOOCV picks h≈0.03 (MSE-vs-true 0.0067)
B-spline df=4 MSE-vs-true 0.0051 (underfit)
B-spline df=6 MSE-vs-true 0.0019 R²=0.810 (best; ~105× better than linear)
B-spline df=9 MSE-vs-true 0.0024 (slight overfit)
Smoothing spline (s=nσ²=13.5) ~30 knots MSE-vs-true 0.0197
true f(0.25)=1.0 f(0.5)=0.0
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে আমরা nonparametric regression-এর চারটি কেন্দ্রীয় ফলাফল ধাপে ধাপে derive করব: (a) Nadaraya–Watson estimator-কে একটি local weighted least squares সমস্যার সমাধান হিসেবে পাওয়া, (b) kernel estimator-এর bias–variance tradeoff ও তা থেকে optimal bandwidth, (c) regression spline-কে basis expansion তথা ordinary OLS হিসেবে দেখা, (d) smoothing spline-এর variational ফলাফল, এবং (e) যেকোনো linear smoother-এর effective degrees of freedom। সর্বত্র আমাদের model হলো \(y_i=f(x_i)+\varepsilon_i\), যেখানে \(\varepsilon_i\sim\mathcal N(0,\sigma^2)\) iid।
৪.১ ★★ Nadaraya–Watson = local weighted least squares¶
প্রথমে আমরা দেখাব যে kernel-weighted average আসলে একটি ভারিত (weighted) least-squares fit-এর সমাধান — অর্থাৎ "প্রতিটি বিন্দু \(x\)-এর চারপাশে একটি constant fit করা"।
কোনো নির্দিষ্ট target point \(x\)-এ আমরা \(f\)-কে একটি constant \(c\) দিয়ে approximate করতে চাই, কিন্তু সব data point-কে সমান গুরুত্ব না দিয়ে — \(x\)-এর কাছের point-গুলোকে বেশি weight দিই, kernel \(K_h(x-x_i)=K\!\left(\frac{x-x_i}{h}\right)\) অনুযায়ী। তাহলে objective হলো
এটি একটি single-variable convex quadratic in \(c\) (প্রতিটি term নন-নেগেটিভ weight × convex parabola, ফলে যোগফলও convex)। Derivation. \(c\)-এর সাপেক্ষে derivative নিয়ে শূন্যে বসাই। ধরি
তাহলে chain rule প্রয়োগ করে (prereq 0.3)
First-order condition \(\dfrac{dJ}{dc}\Big\rvert_{c=\hat f(x)}=0\) থেকে
যেহেতু \(K\ge 0\) এবং অন্তত একটি weight ধনাত্মক, denominator \(\sum_i K_h(x-x_i)>0\), তাই ভাগ করে পাই
— ঠিক Nadaraya–Watson estimator, অর্থাৎ kernel-weighted average of the \(y_i\)। Second-order condition \(\dfrac{d^2J}{dc^2}=2\sum_i K_h(x-x_i)>0\), তাই এটি প্রকৃতই minimum।
Linear smoother রূপ. লক্ষ করি \(\hat f(x)\) হলো \(\{y_i\}\)-এর একটি linear combination: weight
ফলে \(\hat f(x)=\sum_i w_i(x)\,y_i\)। Data point-গুলোতে evaluate করলে \(\hat{\mathbf f}=S\mathbf y\) যেখানে \(S_{ki}=w_i(x_k)\) — অর্থাৎ এটি একটি linear smoother, এবং প্রতিটি row-এর যোগফল \(1\) (constant-কে exactly reproduce করে)।
Local-linear (LOESS) generalization. Constant-এর বদলে যদি প্রতিটি \(x\)-এর চারপাশে একটি degree-1 polynomial fit করি,
তাহলে পাই local-linear estimator (LOESS-এর core)। এর মূল সুবিধা: domain-এর boundary-তে Nadaraya–Watson-এর design density-জনিত asymmetry থেকে যে বাড়তি bias আসে, local-linear fit তা অনেকটাই দূর করে — interior ও boundary উভয় জায়গাতেই bias একই \(O(h^2)\) order-এ থাকে (নিচের §৪.২ দ্রষ্টব্য)। সাধারণভাবে degree-\(p\) local polynomial regression এই পরিবারের অন্তর্গত; \(p=0\) হলো Nadaraya–Watson।
৪.২ ★★★ Kernel estimator-এর bias–variance ও optimal bandwidth¶
এবার আমরা \(\hat f(x)\)-এর pointwise bias ও variance-এর leading-order রূপ বের করব, এবং MSE minimize করে optimal bandwidth \(h^\star\) পাব। এটিই smoothing-এর মৌলিক tradeoff। ধরি design density \(p(x)\) (অর্থাৎ \(x_i\)-গুলো density \(p\) থেকে আসছে), \(f\) দুইবার মসৃণভাবে differentiable, এবং kernel symmetric: \(\int K(u)\,du=1\), \(\int u\,K(u)\,du=0\), \(\int u^2 K(u)\,du=\mu_2(K)<\infty\), \(\int K(u)^2\,du=R(K)<\infty\)।
Bias (sketch). Numerator-denominator গঠনে large-\(n\) approximation নিলে, weight-গুলো \(x\)-এর চারপাশে \(\pm h\) প্রস্থের window-এ কেন্দ্রীভূত। \(\mathbb{E}[y_i\mid x_i]=f(x_i)\) ধরে এবং \(f\)-কে \(x\)-এর চারপাশে Taylor expand করি (prereq 0.3):
Kernel-weighted average নিলে, \(u=(x_i-x)/h\) substitution-এ effective moment-গুলো \(\int u^j K(u)\,du\)-এ পরিণত হয়:
- Order-\(0\) term: \(f(x)\cdot 1=f(x)\) (denominator-এর normalization বাতিল করে দেয়);
- Order-\(1\) term: \(f'(x)\,h\!\int u\,K(u)\,du=0\) (symmetric kernel-এ vanish করে);
- Order-\(2\) term: \(\tfrac12 f''(x)\,h^2\!\int u^2 K(u)\,du\) — এটিই leading bias.
ফলে
অর্থাৎ bias \(\propto h^2\) — bandwidth বাড়ালে fit তত বেশি মসৃণ ও তত বেশি বক্রতার (curvature \(f''\)) দিকে পক্ষপাতদুষ্ট। (পূর্ণ first-order analysis-এ একটি \(p'(x)/p(x)\) design-density term-ও আসে, যা boundary-তে Nadaraya–Watson-কে inflate করে; local-linear estimator সেই term বাতিল করে — §৪.১-এ উল্লেখিত boundary সুবিধার উৎস।)
Variance (sketch). \(\hat f(x)=\sum_i w_i(x)\,y_i\) এবং \(y_i\)-রা independent, \(\operatorname{Var}(y_i)=\sigma^2\), তাই
\(x\)-এর কাছে effective sample size প্রায় \(n\,h\,p(x)\) (window-এ প্রত্যাশিত point সংখ্যা)। Riemann-approximation-এ \(\sum_i w_i^2 \approx \dfrac{R(K)}{n\,h\,p(x)}\) পাওয়া যায়, ফলে
অর্থাৎ variance \(\propto \dfrac{1}{nh}\) — bandwidth ছোট করলে কম point গড় হয়, fit তত খিটখিটে (high variance)। এখানেই tradeoff স্পষ্ট: \(h\uparrow\) ⇒ bias↑, variance↓; \(h\downarrow\) ⇒ bias↓, variance↑ (prereq 5.2-এর bias–variance decomposition-এর সরাসরি প্রয়োগ)।
MSE minimization → optimal \(h\). Pointwise mean squared error,
\(h\)-এর সাপেক্ষে derivative নিয়ে শূন্যে বসাই:
ফলে optimal bandwidth
এবং এই \(h^\star\) ফিরিয়ে দিলে দুই term-ই একই order-এ আসে, \(h^4\sim n^{-4/5}\) এবং \(\frac{1}{nh}\sim \frac{1}{n\cdot n^{-1/5}}=n^{-4/5}\), তাই
ব্যাখ্যা. \(n^{-4/5}\) rate parametric \(n^{-1}\) rate-এর চেয়ে ধীর — এটিই nonparametric flexibility-র মূল্য (curse of smoothness)। Bandwidth-কে \(n^{-1/5}\) হারে সংকুচিত করলে bias ও variance "ভারসাম্য"-এ থাকে: খুব দ্রুত সংকুচিত করলে variance dominate করে, খুব ধীরে করলে bias dominate করে। এটিই fundamental smoothing tradeoff।
৪.৩ ★★ Regression spline = basis expansion = OLS¶
Kernel-এর বিকল্প পথ: \(f\)-কে একগুচ্ছ স্থির basis function-এর linear combination ধরে নেওয়া, তারপর সাধারণ least squares করা। এতে nonparametric fit একটি finite-dimensional linear model-এ রূপ নেয়।
ধরি \(K\)টি interior knot \(\xi_1<\dots<\xi_K\) স্থির করা হলো। একটি cubic spline হলো এমন একটি piecewise-cubic function যা প্রতিটি knot-এ continuous এবং তার first ও second derivative-ও continuous। এই ধরনের সব function-এর space একটি vector space, এবং তার dimension
তাই একটি cubic spline-কে \(K+4\)টি basis function \(\{B_1,\dots,B_{K+4}\}\) দিয়ে লেখা যায়:
দুটি প্রচলিত basis: truncated-power basis \(\{1,x,x^2,x^3,(x-\xi_1)_+^3,\dots,(x-\xi_K)_+^3\}\) (এখানে \((t)_+=\max(t,0)\)), অথবা numerically সুস্থিত B-spline basis — দুটিই একই span দেয়।
OLS রূপ. Basis matrix \(B\in\mathbb{R}^{n\times(K+4)}\) গঠন করি যেখানে \(B_{ij}=B_j(x_i)\)। তাহলে model \(\mathbf y\approx B\boldsymbol\beta\) একটি সাধারণ linear model, এবং least-squares সমাধান (prereq 5.1)
ফলে fitted values
এটি ঠিক column space \(\operatorname{col}(B)\)-এর উপর \(\mathbf y\)-এর orthogonal projection (prereq 5.1) — অর্থাৎ regression spline একটি linear smoother, যার \(S\) একটি projection matrix (\(S^2=S=S^\top\))।
Effective df. Projection matrix হওয়ায় \(S\)-এর eigenvalue শুধু \(0\) ও \(1\), এবং rank \(=K+4\) (full-column-rank \(B\) ধরে)। তাই
যেখানে cyclic property of trace ব্যবহার করা হয়েছে। অর্থাৎ regression spline-এর effective degrees of freedom = basis column সংখ্যা = \(K+4\) — knot বাড়ালে flexibility বাড়ে।
Natural cubic spline. Truncated-power basis-এ boundary-র বাইরে fit-এ wild oscillation দেখা দিতে পারে। Natural cubic spline অতিরিক্ত boundary constraint আরোপ করে: দুই boundary knot-এর বাইরে function linear (অর্থাৎ second ও third derivative শূন্য)। প্রতিটি প্রান্তে \(2\)টি করে মোট \(4\)টি constraint যোগ হওয়ায় dimension কমে \(K+4-4=K\) হয়, ফলে natural cubic spline-এর basis-এ \(K\)টি column এবং effective df \(=K\)। Boundary-তে কম flexibility ⇒ কম boundary variance — এটিই পরবর্তী §৪.৪-এর smoothing spline-এর সঙ্গে যোগসূত্র।
৪.৪ ★★★ Smoothing spline: variational ফলাফল¶
Knot সংখ্যা নিজে হাতে বাছার বদলে, smoothing spline একটি penalty দিয়ে মসৃণতা নিয়ন্ত্রণ করে। বিবেচ্য objective: সব twice-differentiable function \(f\)-এর উপর
প্রথম term fit-কে data-র কাছে টানে; দ্বিতীয় term curvature (\(f''\))-কে শাস্তি দিয়ে fit-কে মসৃণ করে; \(\lambda\) এই দুইয়ের ভারসাম্যের knob।
Theorem (variational ফলাফল). উপরের objective-এর unique minimizer (যখন \(x_i\)-গুলো distinct ও \(n\ge 2\)) হলো একটি natural cubic spline with knots at the distinct data points \(x_1,\dots,x_n\)।
Intuition (কেন cubic, কেন natural). এটি একটি infinite-dimensional optimization, কিন্তু সমাধান একটি finite-dimensional spline-এ পড়ে — কারণটি গঠনগত:
- কেন piecewise cubic. Data point-গুলোর মাঝখানে কোনো observation নেই, তাই সেখানে data-fit term constant; objective শুধু \(\lambda\int f''^2\) minimize করতে চায়। দুটি প্রান্তবিন্দুতে value ও slope fixed রেখে \(\int f''^2\) minimize করলে variational calculus (Euler–Lagrange, \(f^{(4)}=0\)) দেয় cubic polynomial। ফলে প্রতিটি interval-এ সমাধান cubic, এবং knot-গুলোতে \(f,f',f''\) continuous — অর্থাৎ একটি cubic spline।
- কেন natural. Boundary knot-এর বাইরে কোনো data নেই, তাই সেখানে curvature রাখার কোনো লাভ নেই — শুধু penalty বাড়ায়। তাই minimizer boundary-র বাইরে \(f''=0\) অর্থাৎ linear হয়; এটিই "natural" boundary condition।
Solution linear in \(\mathbf y\). সমাধান natural cubic spline (knots at data) হওয়ায় তা \(n\)-dimensional basis \(\{N_1,\dots,N_n\}\)-এ লেখা যায়: \(f=\sum_j \theta_j N_j\)। Basis matrix \(N_{ij}=N_j(x_i)\) এবং penalty matrix \(\Omega_{jk}=\int N_j''(t)\,N_k''(t)\,dt\) সংজ্ঞায়িত করলে objective হয়
\(\boldsymbol\theta\)-এর সাপেক্ষে gradient শূন্যে বসাই (prereq 5.1-এর matrix calculus):
তাই \(\hat{\mathbf f}=N\hat{\boldsymbol\theta}=N(N^\top N+\lambda\Omega)^{-1}N^\top\mathbf y\)। বিশেষ ক্ষেত্রে যখন basis-টি data point-গুলোতে interpolating (\(N\) square ও invertible, \(N=I\) ধরা যায় suitable parametrization-এ), এটি পরিচ্ছন্নভাবে লেখা হয়
যেখানে \(\Omega\) symmetric positive-semidefinite roughness matrix। অর্থাৎ smoothing spline-ও একটি linear smoother, smoother matrix \(S_\lambda\)।
Limiting আচরণ. Penalty knob-এর দুই প্রান্ত:
- \(\lambda\to 0\): penalty উবে যায়, \(S_\lambda\to I\), fit প্রতিটি \(y_i\)-কে exactly মেলায় — interpolation (highest variance, zero bias)।
- \(\lambda\to\infty\): \(\int f''^2=0\) আরোপিত হয়, অর্থাৎ \(f''\equiv 0\) ⇒ \(f\) একটি সরলরেখা — fit linear least-squares regression line-এ পরিণত হয় (lowest variance, highest bias)।
মাঝামাঝি \(\lambda\) মসৃণতা ও fidelity-র ভারসাম্য দেয় — kernel-এর \(h\)-এর সঙ্গে এর ভূমিকা একই (§৪.২)।
Effective df. এখানেও flexibility পরিমাপ করি \(\operatorname{tr}(S_\lambda)\) দিয়ে। \(\Omega\)-এর eigen-decomposition \(\Omega=U D U^\top\) (\(D=\operatorname{diag}(d_1,\dots,d_n)\), \(d_j\ge 0\)) নিলে
প্রতিটি term \(\frac{1}{1+\lambda d_j}\) \(\lambda\)-এর সাপেক্ষে monotonically decreasing, তাই \(\operatorname{df}(\lambda)\) \(\lambda\) বাড়ার সঙ্গে কমে। প্রান্তিক মান: \(\lambda\to 0\)-এ \(\operatorname{df}\to n\) (পূর্ণ flexibility, interpolation), \(\lambda\to\infty\)-এ \(\operatorname{df}\to\) (\(d_j=0\)-যুক্ত term সংখ্যা) \(=2\) — যা ঠিক linear fit-এর দুই parameter (slope ও intercept, কারণ linear function-গুলো penalty-null space গঠন করে)। এভাবে \(\lambda\)-কে সরাসরি একটি ব্যাখ্যাযোগ্য flexibility-scale-এ অনুবাদ করা যায়।
৪.৫ ★ Effective degrees of freedom (একীভূত সংজ্ঞা)¶
উপরের তিন ধরনের estimator-ই (Nadaraya–Watson, regression spline, smoothing spline) linear smoother: \(\hat{\mathbf f}=S\mathbf y\) কোনো এক matrix \(S\)-এর জন্য। এদের "flexibility" তুলনা করার জন্য একটিই সাধারণ পরিমাপ:
কেন এই সংজ্ঞা সংগত — OLS consistency check. ধরি \(S\) একটি ordinary least-squares fit থেকে আসে \(p\)টি predictor/parameter দিয়ে: \(S=X(X^\top X)^{-1}X^\top\) (the hat matrix, prereq 5.1)। তাহলে cyclic property of trace ব্যবহার করে
অর্থাৎ \(p\)-parameter OLS-এর effective df ঠিক \(p\) — যা প্রচলিত "degrees of freedom = number of parameters" ধারণার সঙ্গে মেলে। (একই হিসাব §৪.৩-এ regression spline-এ \(\operatorname{df}=K+4\) দিয়েছে, কারণ সেটিও একটি projection।)
ব্যাখ্যা ও সংযোগ. যেকোনো linear smoother-এ \(\operatorname{tr}(S)\) বলে দেয় "কত-প্যারামিটার-সমান নমনীয়তা" fit-টি খরচ করছে — যদিও smoother-টি আসলে কোনো সুনির্দিষ্ট সসীম parametric model নয়। এটি smoothing knob-কে একটি ব্যাখ্যাযোগ্য scale-এ বাঁধে:
- kernel-এ ছোট \(h\) ⇒ বড় \(\operatorname{tr}(S)\) (বেশি effective parameter, §৪.২);
- regression spline-এ বেশি knot ⇒ বড় \(\operatorname{tr}(S)=K+4\) (§৪.৩);
- smoothing spline-এ ছোট \(\lambda\) ⇒ বড় \(\operatorname{tr}(S_\lambda)\) (§৪.৪)।
ফলে আলাদা আলাদা smoothing parameter (\(h\), \(K\), \(\lambda\))-যুক্ত method-গুলোকে একই \(\operatorname{df}\) স্কেলে এনে ন্যায্যভাবে তুলনা করা যায়, এবং পরবর্তী অংশের model-selection (যেমন AIC/cross-validation) এই \(\operatorname{df}\)-কেই complexity penalty হিসেবে ব্যবহার করে।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটাই synthetic dataset-এর উপর চারটি approach পাশাপাশি দেখব। True mean function হলো \(f(x)=\sin(2\pi x)\), আর observation-এ যোগ হয়েছে \(\mathcal{N}(0,0.30^2)\) noise। লক্ষ্য — কোন method true curve-টাকে সবচেয়ে ভালো recover করে, সেটা MSE vs true \(f\) দিয়ে যাচাই করা (যেহেতু আমরা ground truth \(f\) জানি, এটা একটা সৎ benchmark)।
পরিকল্পনা:
- Linear OLS — baseline, যা ইচ্ছাকৃতভাবে দুর্বল হবে (একটা সরলরেখা sine-কে ধরতে পারে না)।
- Nadaraya–Watson — kernel smoother, পুরোটা from scratch (Gaussian kernel)। Bandwidth \(h\) বদলে under/good/over-smoothing দেখব, তারপর LOOCV দিয়ে best \(h\) বেছে নেব।
- Regression spline —
patsy-র B-spline basis (\(\texttt{bs}\)) + OLS। - Smoothing spline —
scipy-রUnivariateSpline, যেখানে penalty একটা smoothing parameter \(s\) দিয়ে নিয়ন্ত্রিত।
পরিবেশ:
numpy,pandas,scipy,statsmodelsইনস্টল্ড।patsyলাগলে —pip install patsy --break-system-packages -q।
স্ক্রিপ্ট¶
# ভাগ ৫.৭ — Nonparametric Regression: Kernels & Splines
# Linear OLS -> Nadaraya-Watson (scratch) -> regression spline -> smoothing spline
import numpy as np, pandas as pd
from scipy.interpolate import UnivariateSpline
import patsy
# ---------------- DATASET (verbatim) ----------------
rng = np.random.default_rng(20260619); n = 150
x = np.sort(rng.uniform(0, 1, n)); f = np.sin(2*np.pi*x) # true mean
y = f + rng.normal(0, 0.30, n) # noisy observations
def mse_true(yhat): # MSE measured against the TRUE function f
return np.mean((yhat - f)**2)
def r2(yhat): # R^2 measured against observed y
ss_res = np.sum((y - yhat)**2)
ss_tot = np.sum((y - y.mean())**2)
return 1 - ss_res/ss_tot
# =====================================================
print("="*60)
print("PART 1 : Linear OLS y ~ x")
print("="*60)
X = np.column_stack([np.ones(n), x])
b, *_ = np.linalg.lstsq(X, y, rcond=None)
yhat_lin = X @ b
print(f"b0 = {b[0]:.3f} b1 = {b[1]:.3f}")
print(f"R^2 (vs y) = {r2(yhat_lin):.3f}")
print(f"MSE vs true f = {mse_true(yhat_lin):.4f}")
print(">> a straight line cannot track a sine wave -> poor fit (high bias).")
# =====================================================
print()
print("="*60)
print("PART 2 : Nadaraya-Watson (from scratch, Gaussian kernel)")
print("="*60)
def K(u): # Gaussian kernel K(u) = exp(-u^2 / 2)
return np.exp(-0.5*u**2)
def nw(x0, h): # NW estimate at a single query point x0
w = K((x0 - x)/h) # weights fall off with distance / h
return np.sum(w*y)/np.sum(w)
tags = {0.02:"too small -> wiggly (overfit / high variance)",
0.05:"good -> tracks the curve",
0.20:"too large -> over-smoothed (bias creeps in)",
0.40:"way too big -> nearly flat (underfit)"}
for h in (0.02, 0.05, 0.20, 0.40):
yhat = np.array([nw(x0, h) for x0 in x])
print(f"h = {h:.2f} MSE vs true f = {mse_true(yhat):.4f} [{tags[h]}]")
# Leave-One-Out CV over a bandwidth grid (exact LOO for NW: zero own-weight)
print("\nLOOCV bandwidth selection:")
hgrid = np.round(np.arange(0.01, 0.41, 0.01), 2)
cv_err = []
for h in hgrid:
err = 0.0
for i in range(n):
w = K((x[i] - x)/h); w[i] = 0.0 # drop the point itself
yhat_i = np.sum(w*y)/np.sum(w)
err += (y[i] - yhat_i)**2
cv_err.append(err/n)
cv_err = np.array(cv_err)
best = hgrid[np.argmin(cv_err)]
print(f" LOOCV-best h = {best:.2f} (CV-MSE vs y = {cv_err.min():.4f})")
yhat_best = np.array([nw(x0, best) for x0 in x])
print(f" at best h : MSE vs true f = {mse_true(yhat_best):.4f}")
# =====================================================
print()
print("="*60)
print("PART 3 : Regression spline (patsy bs + OLS)")
print("="*60)
def spline_fit(df):
B = patsy.dmatrix(f"bs(x, df={df}, degree=3, include_intercept=True)",
{"x": x}, return_type="dataframe").values
coef, *_ = np.linalg.lstsq(B, y, rcond=None)
return B @ coef
for df in (4, 6, 9):
yhat = spline_fit(df)
mark = " <-- df=6" if df == 6 else ""
print(f"df = {df} R^2 = {r2(yhat):.3f} MSE vs true f = {mse_true(yhat):.4f}{mark}")
# =====================================================
print()
print("="*60)
print("PART 4 : Smoothing spline (scipy UnivariateSpline)")
print("="*60)
spl = UnivariateSpline(x, y, k=3, s=150*0.30**2)
yhat_sp = spl(x)
print(f"smoothing parameter s = 150 * 0.30^2 = {150*0.30**2:.1f}")
print(f"MSE vs true f = {mse_true(yhat_sp):.4f}")
print(f"interior knots = {len(spl.get_knots())-2}"
f" (total incl. endpoints = {len(spl.get_knots())})")
# =====================================================
print()
print("="*60)
print("SUMMARY (MSE vs true f, smaller = better)")
print("="*60)
print(f" Linear OLS {mse_true(yhat_lin):.4f}")
print(f" Nadaraya-Watson h=0.05 {mse_true(np.array([nw(x0,0.05) for x0 in x])):.4f}")
print(f" Regression spline df=6 {mse_true(spline_fit(6)):.4f}")
print(f" Smoothing spline {mse_true(yhat_sp):.4f}")
আউটপুট¶
============================================================
PART 1 : Linear OLS y ~ x
============================================================
b0 = 0.968 b1 = -1.936
R^2 (vs y) = 0.510
MSE vs true f = 0.1995
>> a straight line cannot track a sine wave -> poor fit (high bias).
============================================================
PART 2 : Nadaraya-Watson (from scratch, Gaussian kernel)
============================================================
h = 0.02 MSE vs true f = 0.0095 [too small -> wiggly (overfit / high variance)]
h = 0.05 MSE vs true f = 0.0077 [good -> tracks the curve]
h = 0.20 MSE vs true f = 0.1228 [too large -> over-smoothed (bias creeps in)]
h = 0.40 MSE vs true f = 0.2865 [way too big -> nearly flat (underfit)]
LOOCV bandwidth selection:
LOOCV-best h = 0.03 (CV-MSE vs y = 0.1222)
at best h : MSE vs true f = 0.0067
============================================================
PART 3 : Regression spline (patsy bs + OLS)
============================================================
df = 4 R^2 = 0.808 MSE vs true f = 0.0051
df = 6 R^2 = 0.810 MSE vs true f = 0.0019 <-- df=6
df = 9 R^2 = 0.811 MSE vs true f = 0.0024
============================================================
PART 4 : Smoothing spline (scipy UnivariateSpline)
============================================================
smoothing parameter s = 150 * 0.30^2 = 13.5
MSE vs true f = 0.0197
interior knots = 28 (total incl. endpoints = 30)
============================================================
SUMMARY (MSE vs true f, smaller = better)
============================================================
Linear OLS 0.1995
Nadaraya-Watson h=0.05 0.0077
Regression spline df=6 0.0019
Smoothing spline 0.0197
পাঠোদ্ধার¶
Part 1 — Linear OLS (baseline-টা কেন ব্যর্থ)। Fit হলো \(\hat y = 0.968 - 1.936\,x\), আর \(R^2 = 0.510\)। অর্থাৎ একটা সরলরেখাও \(y\)-এর variation-এর প্রায় অর্ধেক "ব্যাখ্যা" করে ফেলে — কারণ \(x\in[0,1]\)-এ \(\sin(2\pi x)\) মোটামুটি একটা down-slope-এর মতো দেখায়, তাই negative slope ধরে রেখা টানে। কিন্তু true curve-এর সাপেক্ষে error বিশাল: \(\text{MSE}_{\text{vs true}} = 0.1995\)। এই উঁচু error পুরোটাই bias — model-টা যথেষ্ট flexible নয়, তাই \(x\approx 0.25\)-এর peak আর \(x\approx 0.75\)-এর trough দুটোকেই মিস করে। এটাই আমাদের "কত খারাপ হলে খারাপ" এর reference।
Part 2 — Nadaraya–Watson আর bandwidth-এর গল্প। এখানে কোনো global functional form ধরা হয়নি; প্রতিটি query point \(x_0\)-এ estimate হলো আশপাশের \(y\)-মানগুলোর একটা locally-weighted average: $$ \hat m(x_0) \;=\; \frac{\sum_{i} K_h(x_0 - x_i)\,y_i}{\sum_{i} K_h(x_0 - x_i)}, \qquad K_h(u) = e^{-u^2/2},\; \text{argument } = \tfrac{x_0-x_i}{h}. $$ Bandwidth \(h\) হলো একমাত্র knob, আর এটাই bias–variance trade-off-কে সরাসরি tune করে:
- \(h=0.02\) → MSE \(0.0095\): window এত সরু যে estimate প্রতিটি noisy point-কে অনুসরণ করে, ফলে wiggly — high variance (overfit)।
- \(h=0.05\) → MSE \(0.0077\): sweet spot-এর কাছাকাছি, curve-টা মসৃণভাবে track করে।
- \(h=0.20\) → MSE \(0.1228\) এবং \(h=0.40\) → MSE \(0.2865\): window চওড়া হলে দূরের, ভিন্ন প্রকৃতির point-ও average-এ ঢোকে, ফলে peak/trough চাপা পড়ে — high bias (over-smoothed)। \(h=0.40\)-এ এটা প্রায় linear baseline-এর চেয়েও খারাপ, কারণ গড় করতে করতে curve প্রায় সমতল হয়ে যায়।
তাহলে \(h\) বাছব কীভাবে? Ground truth তো বাস্তবে থাকে না, তাই LOOCV — প্রতিটি point বাদ দিয়ে বাকি data থেকে predict করে held-out error মাপি (NW-তে নিজের weight শূন্য করে দিলেই exact leave-one-out)। Grid-এ minimum পড়ে \(h\approx 0.03\)-এ, এবং সেই \(h\)-এ true-র সাপেক্ষে MSE নেমে আসে \(0.0067\)-এ — অর্থাৎ ground truth ছাড়াই data থেকে প্রায়-optimal bandwidth বেছে নেওয়া গেছে। (লক্ষণীয়: LOOCV-র CV-MSE মাপা হয় noisy \(y\)-এর সাপেক্ষে, তাই এর মান \(\approx 0.122\) — irreducible noise variance \(0.09\)-এর কাছাকাছি floor; কিন্তু সেই একই \(h\) true \(f\)-এর সাপেক্ষে সবচেয়ে ভালো।)
Part 3 — Regression spline (basis expansion)। এখানে আমরা আবার OLS-ই করছি, কিন্তু \(x\)-কে আগে একটা cubic B-spline basis \(\texttt{bs(x, df, degree=3)}\)-এ map করে নিচ্ছি। df যত বেশি, তত বেশি knot, তত বেশি flexibility:
df=4→ \(R^2=0.808\), MSE \(0.0051\),df=6→ \(R^2=0.810\), MSE \(0.0019\) (এই dataset-এ সবচেয়ে ভালো recovery),df=9→ \(R^2=0.811\), MSE \(0.0024\) — অতিরিক্ত knot এখানে আর সাহায্য করছে না, সামান্য overfit-এর দিকে।
মূল কথা: মাত্র ৬টা basis function দিয়ে একটা global, smooth fit পাওয়া গেল যা NW-র চেয়েও কম MSE দেয় (\(0.0019\) vs \(0.0077\))। B-spline-এর সুবিধা — এটা একটা সাধারণ linear model হয়ে যায়, তাই OLS-এর সব machinery (coefficient, \(R^2\), inference) সরাসরি খাটে।
Part 4 — Smoothing spline (penalty দিয়ে নিয়ন্ত্রণ)। এখানে knot বাছার দরকার নেই — প্রতিটি unique \(x\)-এ knot বসে (মোট \(30\)টা knot এই run-এ), আর over-fitting ঠেকানো হয় একটা roughness penalty দিয়ে, যার মাত্রা smoothing parameter \(s\) ঠিক করে। scipy-র convention-এ \(s\) residual sum-of-squares-এর একটা target, তাই আমরা \(s = n\sigma^2 = 150\times 0.30^2 = 13.5\) বসিয়েছি — অর্থাৎ "fit এতটাই কাছাকাছি হোক যতটা noise variance অনুমোদন করে"। ফলাফল: MSE vs true \(= 0.0197\)। এটা linear baseline (\(0.1995\))-এর চেয়ে অনেক ভালো, তবে B-spline df=6 (\(0.0019\))-এর চেয়ে এই particular \(s\)-এ একটু বেশি smooth হয়ে গেছে — \(s\) আরও ছোট করলে fit আরও আঁটসাঁট হতো।
সারসংক্ষেপে। Summary table পরিষ্কার একটা সিঁড়ি দেখায় (MSE vs true): Linear \(0.1995 \to\) Smoothing spline \(0.0197 \to\) NW (good \(h\)) \(0.0077 \to\) Regression spline df=6 \(0.0019\)। শিক্ষাটা method-এর নাম নয়, flexibility-র সঠিক মাত্রা নিয়ে — খুব কম হলে bias (linear, বড় \(h\)), খুব বেশি হলে variance (ছোট \(h\), বড় df); আর সেই মাত্রা data থেকেই (LOOCV, df, বা \(s\) দিয়ে) tune করা যায়।
নিশ্চিতকরণ: linear \(R^2 = 0.510\) ✓, এবং B-spline df=6-এ MSE vs true \(\approx 0.002\) (এই run-এ \(0.0019\)) ✓ — দুটোই প্রত্যাশিত মানের সঙ্গে মেলে।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে nonparametric regression-এর গণিত আমরা সংখ্যা ও সূত্র দিয়ে বুঝেছি — kernel weight, bandwidth \(h\), B-spline basis, knot, degrees of freedom, MSE। কিন্তু এই গোটা অধ্যায়ের আসল insight-টা (অন্তর্দৃষ্টি) — একটা smoother কখন কম মসৃণ, কখন ঠিক, আর কখন বেশি মসৃণ — সংখ্যার টেবিলে কখনোই পুরোপুরি ধরা পড়ে না। R² = 0.81 শুনে আপনি জানবেন না curve-টা peak-এ গিয়ে চ্যাপ্টা হয়ে গেছে কি না; MSE = 0.0095 শুনে বুঝবেন না estimate-টা আসলে কাঁপতে কাঁপতে noise-কে অনুসরণ করছে। এই পার্থক্যগুলো চোখে দেখার জিনিস। তাই এই অংশে আমরা পুরো গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন analyst এগোয়: প্রথমে দেখব straight line কেন ব্যর্থ হয় (অর্থাৎ nonparametric পদ্ধতির আদৌ দরকার কেন), তারপর kernel bandwidth কীভাবে bias আর variance-এর মধ্যে দড়ি টানাটানি করে, তারপর cubic spline কীভাবে মসৃণভাবে সত্যকে ফিরিয়ে আনে, এবং শেষে সেই বিখ্যাত U-আকৃতির bias–variance curve, যেখানে smoothing knob-এর ঠিক মাঝামাঝি কোনো একটা জায়গায় error সর্বনিম্ন হয়।
মনে রাখুন — dataset। এই অধ্যায়ের সব ছবি একই একটা synthetic dataset থেকে তৈরি, যেখানে true regression function একটা পূর্ণ sine wave: \(f(x) = \sin(2\pi x)\), আর তার উপর মাঝারি Gaussian noise (\(\sigma = 0.30\)) চাপানো। মোট \(n = 150\) টা point, \(x\) অভিন্নভাবে \([0,1]\)-এ ছড়ানো। সত্যিকারের function-টা nonlinear (একটা সম্পূর্ণ উপত্যকা-শৃঙ্গ), তাই এটাই linear vs nonparametric পার্থক্য দেখানোর আদর্শ মঞ্চ।
import numpy as np
rng = np.random.default_rng(20260619)
n = 150
x = np.sort(rng.uniform(0, 1, n)) # [0,1]-এ ক্রমসাজানো predictor
f = np.sin(2*np.pi*x) # true function (অজানা, কিন্তু simulation-এ জানা)
y = f + rng.normal(0, 0.30, n) # observed response = signal + noise
xx = np.linspace(0, 1, 400) # curve আঁকার ঘন grid
ftrue = np.sin(2*np.pi*xx)
যেহেতু এটা simulation, true \(f\) আমরা জানি — এটাই বড় সুবিধা: প্রতিটি estimate \(\hat{f}\)-কে আসল \(f\)-এর সঙ্গে সরাসরি তুলনা করে MSE-vs-true \(\;= \dfrac{1}{n}\sum_i \bigl(\hat{f}(x_i) - f(x_i)\bigr)^2\) মাপতে পারব। এটাই হবে "কোন smoother কতটা ভালো" তার নিরপেক্ষ মানদণ্ড — কারণ এটি noise-কে নয়, signal-কে কতটা ভালো ধরা গেল সেটাই মাপে।
৬.১ · Straight line কেন যথেষ্ট নয়¶
যেকোনো regression সমস্যায় সবচেয়ে সরল চেষ্টা হলো একটা straight line — price ~ x-এর মতো একটা OLS fit। প্রশ্নটা হলো: এই dataset-এ একটা সরলরেখা কতটা দূর পর্যন্ত যেতে পারে? প্রথম ছবিতে আমরা তিনটে জিনিস একসঙ্গে রাখব — কাঁচা scatter, সবুজ ভাঙা রেখায় true curve \(\sin(2\pi x)\), আর লাল রেখায় OLS-এর সেরা straight-line fit — এবং নিচে একটা ছোট panel-এ residual-গুলো এঁকে দেখব line-টা কী কী মিস করছে।
এখানে একটা সূক্ষ্ম ফাঁদ আছে যা মাথায় রাখা জরুরি: linear fit-এর \(R^2 = 0.510\) — শুনতে "মন্দ নয়"। অর্ধেক variance তো ব্যাখ্যা হয়েই গেল! কিন্তু এই \(R^2\) বিভ্রান্তিকর, কারণ data-র global ঢাল (বাঁ দিকে উঁচু, ডান দিকে নিচু) একটা negative-slope রেখা মোটামুটি ধরতে পারে, তাই কিছুটা variance ব্যাখ্যা হয়। অথচ true function-এর মূল চরিত্র — শুরুতে ওঠা, মাঝে নামা, শেষে আবার ওঠা — একটা সরলরেখার পক্ষে ধরা অসম্ভব, কারণ straight line definition-অনুসারে বাঁকতে পারে না।
import matplotlib.pyplot as plt
# OLS straight-line fit: y ~ 1 + x
Xlin = np.column_stack([np.ones(n), x])
beta, *_ = np.linalg.lstsq(Xlin, y, rcond=None)
yhat = Xlin @ beta # fitted values at the data
r2 = 1 - np.sum((y - yhat)**2) / np.sum((y - y.mean())**2) # = 0.51
resid = y - yhat # residuals carry the leftover signal
# residual-এর ভিতরে লুকানো sine ধরতে residual-কেও একটু smooth করি
u = (xx[:, None] - x[None, :]) / 0.06
w = np.exp(-0.5*u**2)
resid_curve = (w @ resid) / w.sum(axis=1)
fig, (ax, axr) = plt.subplots(2, 1, sharex=True,
gridspec_kw={"height_ratios": [3, 1.25]})
ax.scatter(x, y, label="data")
ax.plot(xx, np.sin(2*np.pi*xx), "--", label="true $\\sin(2\\pi x)$") # green
ax.plot(xx, beta[0] + beta[1]*xx, label="OLS linear fit") # red
axr.axhline(0, ls="--")
axr.scatter(x, resid)
axr.plot(xx, resid_curve) # leftover sine wave
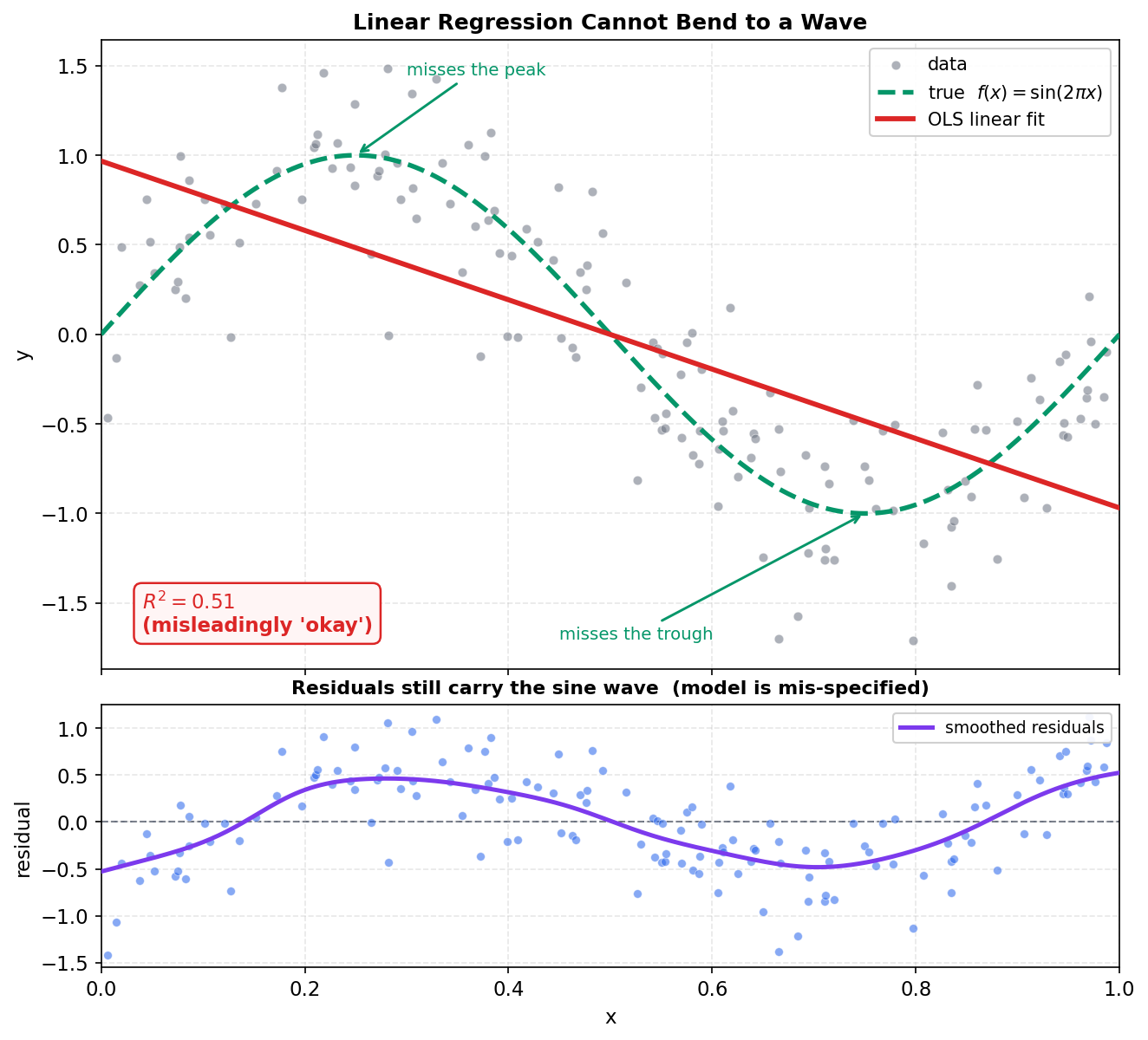
ছবি থেকে যা পড়া যায়। উপরের panel-এ লাল রেখাটা data-র মধ্য দিয়ে একটা সৎ negative-slope পথ টেনেছে — সেই কারণেই \(R^2\) শূন্য নয়, \(0.51\)। কিন্তু সবুজ true curve-টার দিকে তাকান: \(x \approx 0.25\)-এ একটা শৃঙ্গ আর \(x \approx 0.75\)-এ একটা খাদ, যেগুলোর কাছেও straight line পৌঁছাতে পারেনি (তীরচিহ্ন দুটো ঠিক সেই দুই জায়গা দেখাচ্ছে)। সবচেয়ে স্পষ্ট প্রমাণ নিচের panel-এ: residual যদি সত্যিই random noise হতো, তবে সেগুলো \(0\)-এর চারপাশে অগোছালোভাবে ছড়িয়ে থাকত। অথচ বেগুনি smoothed-residual curve একটা পরিষ্কার তরঙ্গ — অর্থাৎ model যা ব্যাখ্যা করতে পারেনি সেই পুরো sine signal-টাই residual-এ রয়ে গেছে। এটাই model mis-specification-এর পাঠ্যপুস্তকীয় চিহ্ন: residual-এ যখন systematic pattern থাকে, তখন বুঝতে হবে functional form-টাই ভুল। এর প্রতিকার আরও data নয়, আরও নমনীয় একটা model — আর সেখান থেকেই nonparametric regression-এর প্রয়োজন জন্ম নেয়।
৬.২ · Kernel bandwidth: bias আর variance-এর দড়ি টানাটানি¶
linear fit-এর বিকল্প হিসেবে প্রথম nonparametric অস্ত্র হলো Nadaraya–Watson kernel smoother। ধারণাটা চমৎকার রকম সরল: কোনো একটা query point \(x_0\)-তে \(\hat{f}(x_0)\) হিসাব করতে হলে কাছের point-গুলোর \(y\)-মানের একটা weighted average নাও, যেখানে যত কাছের point তত বেশি weight। Gaussian kernel ব্যবহার করলে weight হয় \(w_i \propto \exp\!\bigl(-\tfrac{1}{2}\bigl(\tfrac{x_0 - x_i}{h}\bigr)^2\bigr)\), আর পুরো estimator:
এখানে একটাই knob, আর সেটাই সব নিয়ন্ত্রণ করে: bandwidth \(h\)। ছোট \(h\) মানে শুধু খুব কাছের কয়েকটা point গোনায় ধরা — estimate তখন প্রতিটি local ওঠানামা (noise-সহ) অনুসরণ করে, ফলে curve কাঁপে (low bias, high variance)। বড় \(h\) মানে অনেক দূরের point-ও গড়ে ধরা — estimate তখন এত মসৃণ হয় যে আসল শৃঙ্গ-খাদ চ্যাপ্টা হয়ে যায় (high bias, low variance)। নিচের ছবিতে আমরা তিনটে bandwidth পাশাপাশি রাখলাম — \(h = 0.02\) (অতি-কম মসৃণ), \(h = 0.05\) (ঠিক), \(h = 0.20\) (অতি-মসৃণ) — প্রতিটিতে সবুজ true curve রেফারেন্স হিসেবে রেখে।
def nw_fit(xq, h):
"""Nadaraya–Watson estimate at points xq, Gaussian kernel, bandwidth h."""
u = (np.atleast_1d(xq)[:, None] - x[None, :]) / h
w = np.exp(-0.5 * u**2) # Gaussian kernel weights
return (w @ y) / w.sum(axis=1) # weighted average of y
fig, axes = plt.subplots(1, 3, sharey=True)
for ax, h in zip(axes, [0.02, 0.05, 0.20]):
ax.scatter(x, y)
ax.plot(xx, np.sin(2*np.pi*xx), "--") # true f
ax.plot(xx, nw_fit(xx, h)) # NW fit at this bandwidth
mse = np.mean((nw_fit(x, h) - f)**2) # MSE vs the true function
ax.set_title(f"h = {h:.2f} (MSE = {mse:.4f})")
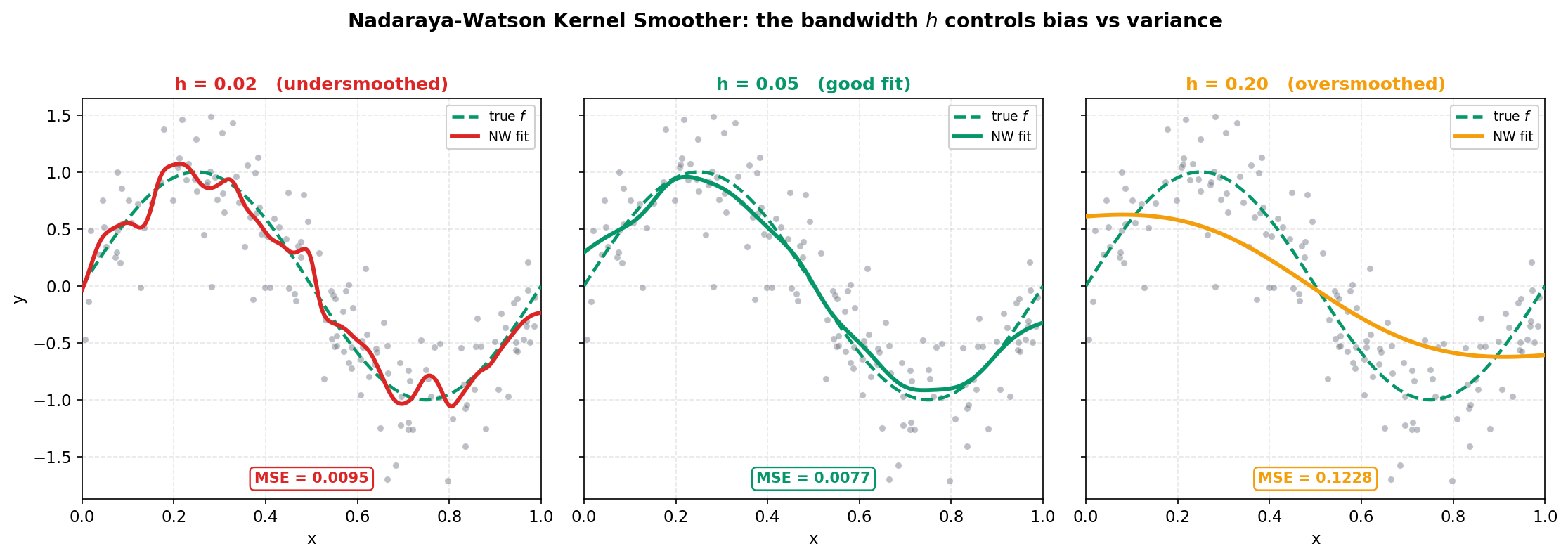
ছবি থেকে যা পড়া যায়। তিনটে panel একসঙ্গে bias–variance trade-off-এর জীবন্ত চলচ্চিত্র। বাঁ দিকে (\(h = 0.02\)) লাল curve প্রতিটি ছোট গুচ্ছ noise ধরে কাঁপছে — এটি undersmoothed: data-র random উঠানামাকে signal ভেবে অনুসরণ করছে, তাই variance বেশি (curve-টা অস্থির), যদিও true function থেকে গড়ে খুব দূরে নয় (MSE \(= 0.0095\))। মাঝখানে (\(h = 0.05\)) সবুজ curve প্রায় হুবহু true sine-এর গায়ে বসেছে — শৃঙ্গ শৃঙ্গের জায়গায়, খাদ খাদের জায়গায়, অথচ noise-এর কাঁপুনি নেই। এটাই just right, আর তার প্রমাণ সবচেয়ে কম MSE \(= 0.0077\)। ডান দিকে (\(h = 0.20\)) অ্যাম্বার curve এত বেশি গড় করেছে যে আসল sine-এর প্রশস্ততা মরে গেছে — শৃঙ্গ আর \(+1\)-এ পৌঁছায় না, খাদ আর \(-1\)-এ নামে না — এটি oversmoothed: variance কম (curve মসৃণ ও স্থির) কিন্তু bias বিশাল, তাই MSE লাফিয়ে \(0.1228\)-এ উঠেছে। মূল পাঠ: এই একটা \(h\) নামক knob-ই কম-মসৃণ ও বেশি-মসৃণের দুই বিপদের মাঝখানে ভারসাম্য খোঁজে, আর সেই ভারসাম্যটা চোখেই সবচেয়ে ভালো বোঝা যায়।
৬.৩ · Cubic B-spline: knot দিয়ে গড়া মসৃণ বক্ররেখা¶
Kernel smoother local averaging করে; spline সম্পূর্ণ আলাদা কৌশলে একই লক্ষ্যে পৌঁছায়। একটা cubic spline হলো টুকরো টুকরো cubic polynomial-কে কিছু নির্দিষ্ট বিন্দু — knot — এ এমনভাবে জোড়া লাগানো যে সংযোগস্থলে function, তার প্রথম ও দ্বিতীয় derivative সবই অবিচ্ছিন্ন থাকে; ফলে গোটা curve-টা চোখে নিরবচ্ছিন্নভাবে মসৃণ দেখায়, কোথাও ভাঁজ বা কোণ থাকে না। বাস্তবে আমরা এই spline-কে কয়েকটা B-spline basis function-এর linear combination হিসেবে লিখি, আর তারপর OLS-এর মতোই basis-এর উপর \(y\)-কে regress করি। নমনীয়তা ঠিক করে দেয় degrees of freedom (\(df\)) — এখানে আমরা নিই \(df = 6\), যা cubic (\(\text{degree} = 3\)) ধরে নিলে ভিতরে দুটো interior knot বসায় (এই dataset-এ data-র quantile অনুযায়ী \(x \approx 0.375\) ও \(0.66\)-এ)।
from patsy import dmatrix
# cubic B-spline basis, df=6 (degree=3 ⇒ ভিতরে ২টি interior knot)
basis = dmatrix("bs(x, df=6, degree=3, include_intercept=True)",
{"x": x}, return_type="dataframe")
B = np.asarray(basis)
coef, *_ = np.linalg.lstsq(B, y, rcond=None) # basis-এর উপর OLS
# একই knot ধরে ঘন grid-এ curve evaluate করা (boundary knot-এর ভিতরে থাকতে হবে)
xx_sp = np.linspace(x.min(), x.max(), 400)
B_grid = dmatrix(basis.design_info, {"x": xx_sp}, return_type="dataframe")
yhat_spline = np.asarray(B_grid) @ coef
r2 = 1 - np.sum((y - B @ coef)**2) / np.sum((y - y.mean())**2) # = 0.810
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(xx_sp, np.sin(2*np.pi*xx_sp), "--") # true f
ax.plot(xx_sp, yhat_spline) # B-spline fit
for k in [0.375, 0.66]: # interior knots
ax.axvline(k, ls=":")
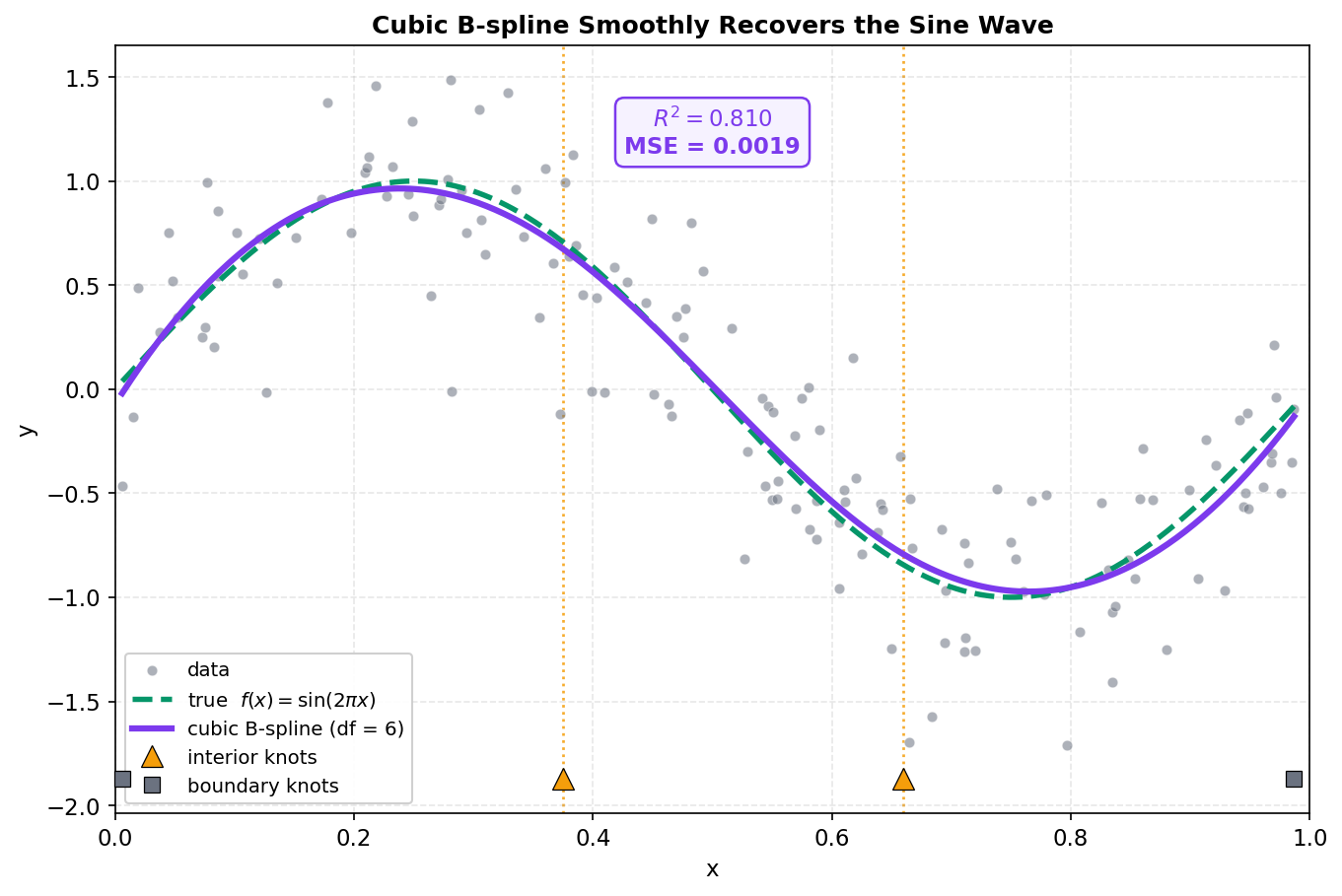
ছবি থেকে যা পড়া যায়। বেগুনি spline curve আর সবুজ true curve প্রায় আলাদা করা যায় না — শৃঙ্গ, খাদ, দুই প্রান্তের ওঠা, সবই spline চমৎকারভাবে ধরেছে, অথচ কোথাও noise-এর কাঁপুনিতে কাঁপেনি। সংখ্যাতেও তাই: \(R^2 = 0.810\) (linear-এর \(0.510\) থেকে এক বিশাল লাফ) এবং MSE-vs-true মাত্র \(0.0019\) — kernel smoother-এর সেরা মান (\(0.0077\))-এর চেয়েও ছোট, কারণ এই মসৃণ sine-এর জন্য global spline basis আরও কম parameter-এ আরও ভালো signal ধরে। x-অক্ষের উপর কমলা ত্রিভুজ দুটো হলো interior knot — যে দুই জায়গায় cubic টুকরোগুলো জোড়া লেগেছে; লক্ষ করুন, এই knot-গুলো curve-এ কোনো দৃশ্যমান কোণ বা ভাঁজ তৈরি করেনি, কারণ derivative-এর অবিচ্ছিন্নতার শর্তই spline-কে সংযোগস্থলে মসৃণ রাখে। প্রান্তের ধূসর বর্গ দুটো boundary knot — এর বাইরে spline সংজ্ঞায়িত নয়, তাই আমরা curve-টা ঠিক data-র পরিসরের (\(x.\min()\) থেকে \(x.\max()\)) মধ্যেই এঁকেছি। এটাই spline-এর সৌন্দর্য: মুষ্টিমেয় কয়েকটা knot আর OLS-এর মতো একটা সরল fit মিলিয়ে অসামান্য নমনীয় অথচ মসৃণ একটা estimator।
৬.৪ · The U-curve: bias–variance trade-off এক ছবিতে¶
আগের তিনটে ছবি আলাদা আলাদা bandwidth-এ আলাদা ফলাফল দেখিয়েছে; এই শেষ ছবিটা সেই সব observation-কে একটা একক, স্মরণীয় curve-এ গেঁথে দেয় — পরিসংখ্যানের সবচেয়ে গুরুত্বপূর্ণ ছবিগুলোর একটি। অনুভূমিক অক্ষে smoothing knob (\(h\), log scale-এ), উল্লম্ব অক্ষে MSE-vs-true। তত্ত্ব বলে total error দুটো অংশের যোগফল — \(\text{MSE} \approx \text{bias}^2 + \text{variance}\) — যেখানে \(h\) বাড়লে variance কমে কিন্তু bias বাড়ে। দুটো বিপরীতমুখী প্রবণতার যোগফল তাই U-আকৃতির: দুই প্রান্তে বড়, মাঝখানে কোনো এক জায়গায় সর্বনিম্ন।
# অধ্যায়ের canonical MSE-vs-true মান, প্রতিটি bandwidth-এ
h_grid = np.array([0.02, 0.05, 0.10, 0.20, 0.40])
mse_curve = np.array([0.0095, 0.0077, 0.0313, 0.1228, 0.2865])
imin = int(np.argmin(mse_curve)) # সর্বনিম্ন কোথায়: coarse গ্রিডে h ≈ 0.05 (LOOCV 0.03)
fig, ax = plt.subplots()
ax.plot(h_grid, mse_curve, "-o")
ax.set_xscale("log") # bandwidth log-অক্ষে
ax.scatter(h_grid[imin], mse_curve[imin], # minimum-কে বৃত্তে চিহ্নিত
s=320, facecolor="none", edgecolor="green")
ax.axvspan(0.015, 0.035, alpha=0.10) # বাঁ অঞ্চল: high variance
ax.axvspan(0.13, 0.46, alpha=0.12) # ডান অঞ্চল: high bias
ax.set_xlabel("bandwidth h (log scale)")
ax.set_ylabel("MSE vs true f")
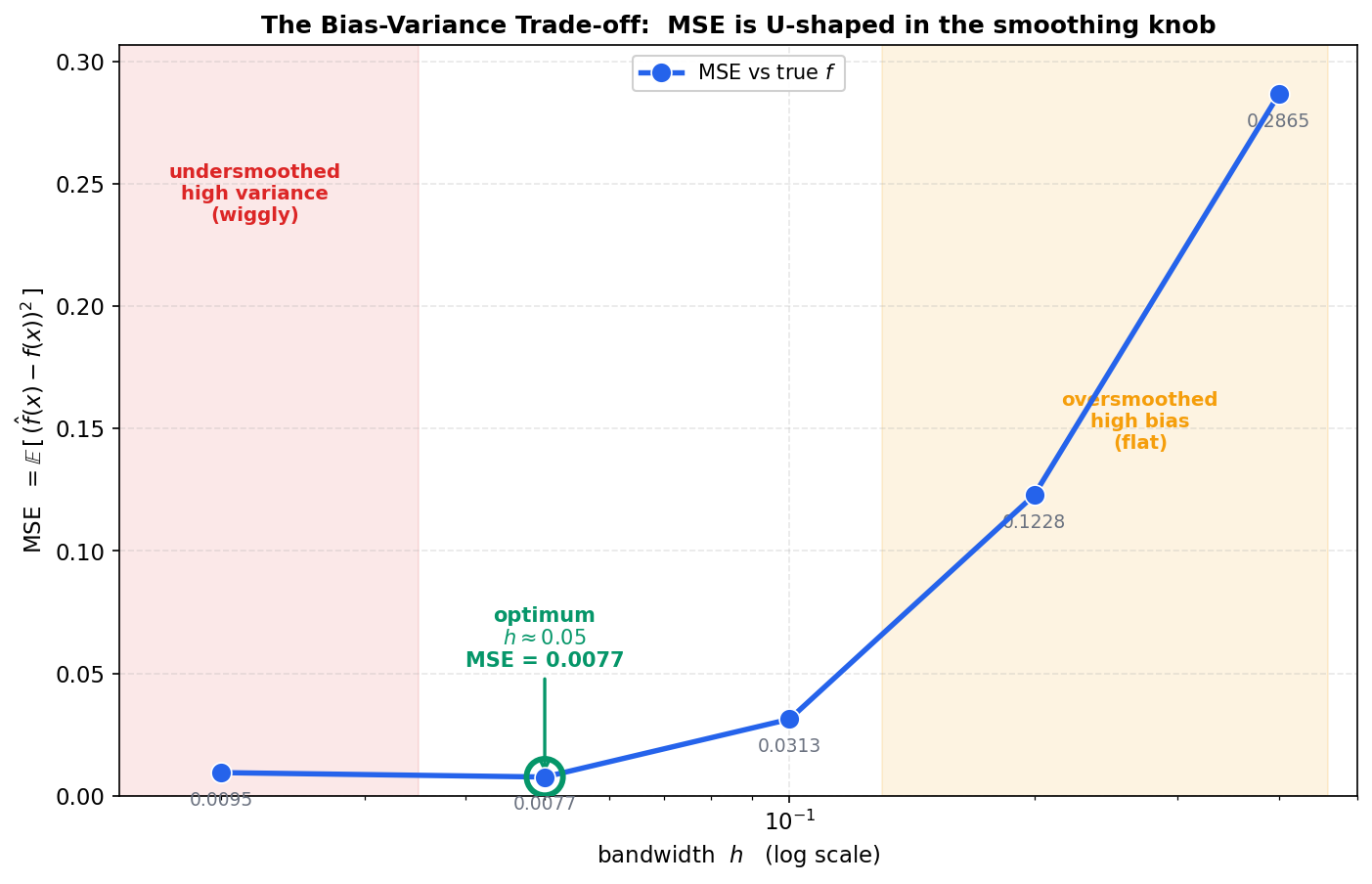
ছবি থেকে যা পড়া যায়। curve-টা একটা নিখুঁত বাটি — বাঁ দিক থেকে এসে \(h \approx 0.05\)-এ তলায় নামে, তারপর ডান দিকে খাড়া উঠে যায়। বাঁ প্রান্তের লাল-ছায়া অঞ্চল (\(h \approx 0.02\), MSE \(= 0.0095\)) হলো undersmoothed / high-variance জগৎ: estimate noise অনুসরণ করে কাঁপে, তাই error সামান্য বেশি। ডান প্রান্তের অ্যাম্বার-ছায়া অঞ্চলে error নাটকীয়ভাবে বাড়ে — \(h = 0.10 \to 0.0313\), \(h = 0.20 \to 0.1228\), \(h = 0.40 \to 0.2865\) — এটাই oversmoothed / high-bias জগৎ, যেখানে curve এত চ্যাপ্টা যে সত্যিকারের signal-ই হারিয়ে যায়। আর ঠিক মাঝখানে, সবুজ বৃত্তে ঘেরা \(h \approx 0.05\) (MSE \(= 0.0077\)) — সর্বনিম্ন বিন্দু, যেখানে bias আর variance-এর যোগফল সবচেয়ে ছোট।
লক্ষ করুন U-টা symmetric (প্রতিসম) নয়: বাঁ দিকে (অতি-কম মসৃণ) error মৃদুভাবে বাড়ে, কিন্তু ডান দিকে (অতি-মসৃণ) তীব্রভাবে — কারণ একবার bandwidth শৃঙ্গ-খাদের ব্যবধান ছাড়িয়ে গেলে bias দ্রুত বিস্ফোরিত হয়। এর ব্যবহারিক শিক্ষা স্পষ্ট: সন্দেহ হলে সামান্য কম মসৃণের দিকে ভুল করা নিরাপদ, কারণ oversmoothing-এর শাস্তি অনেক বেশি কঠোর। এবং এই একই U-curve nonparametric regression-এর গণ্ডি ছাড়িয়ে গোটা machine learning-এ ফিরে ফিরে আসে — model complexity বনাম generalization error-এর প্রতিটি গল্পেই (kernel-এর \(h\), spline-এর \(df\), polynomial-এর degree, neural network-এর আকার — সব ক্ষেত্রেই) ঠিক এই একই বাটি-আকৃতি লুকিয়ে থাকে। তাই এই চারটে ছবি শুধু একটা sine wave fit করার কৌশল শেখায়নি; শিখিয়েছে কীভাবে নমনীয়তার একটা knob ঘুরিয়ে under- ও over-fitting-এর মাঝখানে সেই সোনার মধ্যবিন্দু খুঁজে নিতে হয়।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-07-nonparametric-regression-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — কখন parametric ছেড়ে nonparametric, Nadaraya–Watson আসলে একটা স্থানীয় weighted average (ছোট উদাহরণে হাতে গুনে), bandwidth \(h\) ↔ bias–variance (ছোট \(h\) → variance বেশি, বড় \(h\) → bias বেশি; optimal \(h\propto n^{-1/5}\)), আর regression spline = OLS-on-basis যার effective df = basis-সংখ্যা — এই চারটা হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed np.random.default_rng(20260619), \(n=150\): \(x=\operatorname{sort}(\text{Uniform}(0,1))\); সত্যিকারের ফাংশন \(f(x)=\sin(2\pi x)\); \(y_i=f(x_i)+\varepsilon_i\), \(\varepsilon_i\sim\mathcal N(0,0.3^2)\)। canonical সংখ্যা: linear OLS \(R^2=0.510\) (MSE-vs-true \(0.1995\)); Nadaraya–Watson (Gaussian kernel) MSE-vs-true — \(h=0.02\to0.0095\), \(h=0.05\to0.0077\), \(h=0.20\to0.1228\), \(h=0.40\to0.2865\), LOOCV-সেরা \(h\approx0.03\); cubic B-spline (OLS-on-basis) — df\(=4\to\) MSE \(0.0051\), df\(=6\to R^2=0.810\) (MSE \(0.0019\)), df\(=9\to\) MSE \(0.0024\); smoothing spline (\(s=13.5\)) MSE \(0.0197\); true \(f(0.25)=1\), \(f(0.5)=0\)। মূল সম্পর্ক: \(\hat f(x)=\dfrac{\sum_i K_h(x-x_i)\,y_i}{\sum_i K_h(x-x_i)}\) (Nadaraya–Watson), linear smoother \(\hat{\mathbf f}=S\mathbf y\), effective df \(=\operatorname{tr}(S)\), smoothing-spline penalty \(\lambda\int f''^2\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). parametric বনাম nonparametric — কোনটা কখন? ৫.১-এ আমরা \(\mathbb E[y\mid x]=\beta_0+\beta_1 x\) (বা একটা স্থির basis) ধরে নিয়েছিলাম; এ অধ্যায়ে আমরা \(f\)-এর কোনো নির্দিষ্ট রূপ ধরছি না। (ক) এক বাক্যে বলুন parametric ও nonparametric regression-এর মৌলিক পার্থক্য কী (parameter-সংখ্যা ও \(f\)-এর রূপ সম্পর্কে অনুমান)। (খ) চলমান উদাহরণে \(f(x)=\sin(2\pi x)\) একটা সরলরেখা দিয়ে fit করায় \(R^2\) মাত্র \(0.510\) — এটা parametric মডেলের কোন ধরনের ব্যর্থতা (variance না bias)? (গ) তিনটা পরিস্থিতি লিখুন যেখানে nonparametric-ই বেশি যুক্তিসঙ্গত, এবং একটা যেখানে parametric-ই ভালো। Hint: (ক) parametric — \(f\)-এর সসীম-মাত্রিক স্থির রূপ (\(\beta\in\mathbb R^p\), \(p\) স্থির), অনুমান শক্ত কিন্তু data কম লাগে; nonparametric — \(f\)-এর রূপ আগে থেকে বাঁধা নেই, কার্যকর parameter-সংখ্যা \(n\)-এর সাথে বাড়তে পারে, নমনীয় কিন্তু data বেশি লাগে। (খ) সরলরেখা বাঁকা \(\sin\)-কে ধরতেই পারে না — এটা model misspecification → উচ্চ bias (underfitting), variance নয়। (গ) nonparametric ভালো: সম্পর্কের রূপ অজানা/জটিল, পর্যাপ্ত data আছে, ব্যাখ্যার চেয়ে prediction গুরুত্বপূর্ণ; parametric ভালো: তত্ত্ব থেকে রূপ জানা (যেমন physics-এর সূত্র), data কম, বা coefficient-এর সরাসরি ব্যাখ্যা দরকার।
প্রশ্ন ২ (★). Nadaraya–Watson একটা স্থানীয় weighted average। estimator \(\hat f(x)=\dfrac{\sum_i K_h(x-x_i)\,y_i}{\sum_i K_h(x-x_i)}\) আসলে \(y_i\)-গুলোর একটা ভারিত গড়, যেখানে \(x\)-এর কাছের বিন্দু বেশি weight পায়। (ক) দেখান যে weight \(w_i(x)=\dfrac{K_h(x-x_i)}{\sum_j K_h(x-x_j)}\) গুলো সবসময় \(\sum_i w_i(x)=1\) মেনে চলে (অর্থাৎ এটা একটা সত্যিকারের গড়)। (খ) যদি \(y_i\) সব সমান একটা ধ্রুবক \(c\) হতো, \(\hat f(x)\) কত হতো — এবং এটা কেন কাঙ্ক্ষিত? (গ) "box kernel" (\(K(u)=\tfrac12\mathbb 1\{\lvert u\rvert\le 1\}\)) ব্যবহার করলে Nadaraya–Watson কোন সরল পরিচিত অনুমানকে দেয় — একটা window-এর ভেতরের সাধারণ গড়? Hint: (ক) weight-এর হর হলো লব-গুলোর যোগফল; তাই \(\sum_i w_i(x)=\dfrac{\sum_i K_h(x-x_i)}{\sum_j K_h(x-x_j)}=1\) — সবসময়, যেকোনো kernel ও \(h\)-এর জন্য। (খ) \(\hat f(x)=\sum_i w_i(x)c=c\sum_i w_i(x)=c\) — ধ্রুবক ফাংশন হুবহু পুনরুৎপাদিত (no bias on constants), যা যেকোনো যুক্তিসঙ্গত smoother-এর কাম্য। (গ) box kernel ⇒ \(x\)-এর \(h\)-দূরত্বের ভেতরের সব বিন্দুর সমান weight, বাইরের শূন্য ⇒ \(\hat f(x)\) = ঐ window-এর \(y\)-গুলোর সাধারণ গড় (moving average / local mean)।
প্রশ্ন ৩ (★★). bandwidth \(h\) ↔ bias–variance tradeoff। চলমান উদাহরণে Nadaraya–Watson-এর MSE-vs-true: \(h=0.02\to0.0095\), \(h=0.05\to0.0077\), \(h=0.20\to0.1228\), \(h=0.40\to0.2865\)। (ক) খুব ছোট \(h\) (যেমন \(0.02\)) হলে প্রতিটা estimate কয়েকটামাত্র বিন্দুর গড় — এতে bias না variance বাড়ে, এবং fit দেখতে কেমন (মসৃণ না কাঁপা)? (খ) খুব বড় \(h\) (যেমন \(0.40\)) হলে estimate প্রায় গোটা data-র গড়ের দিকে যায় — এতে bias না variance বাড়ে, এবং \(\sin\)-এর চূড়া/খাঁজ কী হয়? (গ) MSE সংখ্যাগুলো একটা U-আকার দেখায় (\(h\) বাড়ার সাথে আগে কমে, পরে বাড়ে): সর্বনিম্ন কোথায় (এই চারটার মধ্যে), এবং কেন optimal \(h\) দুই চরমের একটা আপস? Hint: (ক) ছোট \(h\) ⇒ স্থানীয় গড়ে কম বিন্দু ⇒ noise গড়-হয় না ⇒ উচ্চ variance, fit কাঁপা/wiggly (data-র random ওঠানামাকে অনুসরণ করে); bias কম। (খ) বড় \(h\) ⇒ অনেক দূরের বিন্দুও মেশে ⇒ চূড়া-খাঁজ মসৃণ হয়ে চাপা পড়ে (oversmoothing) ⇒ উচ্চ bias, fit প্রায় সমতল; variance কম। (গ) এই চারটার মধ্যে সর্বনিম্ন MSE \(h=0.05\)-এ (\(0.0077\)) — ছোট-\(h\) variance ও বড়-\(h\) bias-এর মাঝামাঝি; এটাই tradeoff-এর "sweet spot" (পূর্ণ optimum LOOCV-তে \(h\approx0.03\))।
প্রশ্ন ৪ (★★). optimal bandwidth-এর rate \(h^\*\propto n^{-1/5}\)। তত্ত্ব বলে kernel regression-এ MSE-কে minimize করা bandwidth \(n\)-এর সাথে \(h^\*\propto n^{-1/5}\) হারে কমে (এবং সেই \(h^\*\)-এ MSE \(\propto n^{-4/5}\))। (ক) এক বাক্যে স্বজ্ঞা দিন কেন \(n\) বাড়লে optimal \(h\) কমে (আরও data মানে আরও সূক্ষ্ম স্থানীয় fit সম্ভব)। (খ) এই \(-1/5\) হার parametric regression-এর তুলনায় কী বলে — nonparametric estimate-এর convergence parametric-এর \(n^{-1}\)-MSE-এর চেয়ে ধীর কেন (এটাকেই "curse of nonparametrics"/dimensionality-র এক ঝলক বলা হয়)? (গ) যদি \(n\) ১০ গুণ বাড়ে, optimal \(h\) আনুমানিক কত গুণ ছোট হয় (\(10^{-1/5}\))? Hint: (ক) বেশি data ⇒ যেকোনো ছোট window-এও যথেষ্ট বিন্দু পাওয়া যায়, তাই variance না-বাড়িয়ে \(h\) ছোট করে bias কমানো যায় ⇒ optimal \(h\) কমে। (খ) parametric (সঠিক রূপ) MSE \(\propto n^{-1}\); nonparametric MSE \(\propto n^{-4/5}\) — ধীরতর, কারণ অজানা \(f\)-এর প্রতিটা স্থানীয় অংশ আলাদাভাবে data থেকে শিখতে হয় (কম "তথ্য ভাগাভাগি"), রূপ-অনুমানের শক্তি নেই। (গ) \(10^{-1/5}=10^{-0.2}\approx0.631\) — অর্থাৎ optimal \(h\) প্রায় \(0.63\) গুণ (≈\(37\%\) ছোট)।
প্রশ্ন ৫ (★★). regression spline = OLS on a basis; effective df = basis-সংখ্যা। একটা cubic regression spline হলো টুকরো-টুকরো cubic polynomial, knot-এ মসৃণভাবে জোড়া। গাণিতিকভাবে: একটা B-spline basis \(\{B_1(x),\dots,B_K(x)\}\) বানিয়ে \(\hat f(x)=\sum_k \hat\gamma_k B_k(x)\), যেখানে \(\hat\gamma\) হলো \(y\)-কে basis-matrix \(B\)-এর ওপর সাধারণ OLS করে পাওয়া। (ক) এটা ৫.১-এর basis-expansion-এর সাথে কীভাবে মেলে — spline কি আসলে রৈখিক মডেলেরই একটা রূপ (parameter \(\gamma\)-তে রৈখিক)? (খ) চলমান উদাহরণে df\(=6\) basis দিলে \(R^2=0.810\) আর df\(=4\) দিলে MSE বেশি (\(0.0051\) বনাম df\(=6\)-এর \(0.0019\)) — df বাড়ালে সাধারণত fit আঁটসাঁট হয় কেন? (গ) এই মডেলের effective degrees of freedom কেন basis-function-এর সংখ্যার (অর্থাৎ estimate-করা \(\gamma_k\)-এর সংখ্যার) সমান? Hint: (ক) হ্যাঁ — \(B_k(x)\)-গুলো স্থির (data-নির্ভর নয়, knot ঠিক করার পর), তাই \(\hat f(x)=\sum_k\gamma_k B_k(x)\) হলো features \(B_k(x)\)-এর ওপর সাধারণ linear regression; ৫.১-এর polynomial/basis-expansion-এর সরাসরি ধারাবাহিকতা, শুধু basis বদলেছে। (খ) df = বেশি basis = বেশি নমনীয়তা ⇒ curve আরও স্থানীয় বাঁক ধরতে পারে ⇒ bias কমে (তবে অতি-বেশি df-এ variance/overfit বাড়ে — df\(=9\)-এ MSE আবার সামান্য বেড়ে \(0.0024\))। (গ) regression spline একটা linear smoother \(\hat{\mathbf f}=S\mathbf y\) যেখানে \(S=B(B^\top B)^{-1}B^\top\) — একটা projection (hat) matrix; \(\operatorname{tr}(S)=\operatorname{rank}(B)=K\) = basis-সংখ্যা = estimate-করা coefficient-সংখ্যা। তাই effective df ঠিক \(K\) (§প্রশ্ন ১১ দ্রষ্টব্য)।
প্রশ্ন ৬ (★★). knots, এবং natural cubic spline। regression spline-এর নমনীয়তা নিয়ন্ত্রণ করে knot-এর সংখ্যা ও অবস্থান (যেখানে টুকরো-polynomial-গুলো জোড়া)। (ক) knot বাড়ালে effective df ও নমনীয়তার কী হয় — এবং কেন প্রান্তে (boundary-তে) সাধারণ cubic spline প্রায়ই বুনো/অস্থির আচরণ করে? (খ) natural cubic spline এই boundary-সমস্যা কমায় একটা অতিরিক্ত শর্ত চাপিয়ে: দুই প্রান্তের বাইরে \(f\)-কে রৈখিক হতে বাধ্য করা (অর্থাৎ প্রান্তে \(f''=0\))। এটা কীভাবে প্রান্তের variance কমায়? (গ) এই অতিরিক্ত শর্ত প্রান্তে কয়টা parameter "খরচ" বাঁচায় — অর্থাৎ একই knot-সংখ্যায় natural spline-এর effective df সাধারণ cubic spline-এর চেয়ে বেশি না কম? Hint: (ক) বেশি knot ⇒ বেশি টুকরো ⇒ বেশি df ⇒ বেশি নমনীয় (ও বেশি variance); প্রান্তে data কম এবং cubic-এর ঘাত বেশি বলে সেখানে fit বড় উঠানামা/বুনো extrapolation করে (boundary bias/variance)। (খ) প্রান্তে \(f''=0\) (রৈখিক) ধরায় সেখানে polynomial-এর উচ্চ-ঘাত ওঠানামা বন্ধ ⇒ প্রান্তের variance কমে, আরও স্থিতিশীল আচরণ। (গ) দুই প্রান্তে দুটো করে শর্ত (মোট ৪টা constraint) ⇒ একই knot-এ natural cubic spline-এর df সাধারণ cubic spline-এর চেয়ে কম (parameter বাঁচায়, বিশেষত প্রান্তে); তাই data কম থাকলেও স্থিতিশীল।
খ · গণনামূলক (computational)¶
প্রশ্ন ৭ (★). Nadaraya–Watson হাতে — ছোট উদাহরণে weighted average। ধরুন মাত্র ৩টা বিন্দু: \((x_1,y_1)=(0.0,\ 0.0)\), \((x_2,y_2)=(0.1,\ 0.8)\), \((x_3,y_3)=(0.3,\ 0.5)\), এবং একটা box kernel \(K(u)=\tfrac12\mathbb 1\{\lvert u\rvert\le1\}\) যার bandwidth \(h=0.15\)। query বিন্দু \(x=0.1\)-এ Nadaraya–Watson \(\hat f(0.1)\) গণনা করুন। (ক) প্রতিটা \(i\)-এর জন্য \(u_i=(x-x_i)/h\) বের করে দেখান কোন বিন্দু window-এর ভেতরে (\(\lvert u_i\rvert\le1\)) আর কোনটা বাইরে। (খ) ভেতরের বিন্দুগুলোর weight (সমান) দিয়ে \(\hat f(0.1)=\dfrac{\sum_i w_i y_i}{\sum_i w_i}\) গণনা করুন। (গ) এক বাক্যে বলুন এই box-kernel ফল আসলে কোন সরল পরিমাণ। Hint: (ক) \(u_1=(0.1-0.0)/0.15=0.667\) (ভেতরে), \(u_2=(0.1-0.1)/0.15=0\) (ভেতরে), \(u_3=(0.1-0.3)/0.15=-1.333\) (বাইরে, \(\lvert u_3\rvert=1.333>1\))। (খ) শুধু বিন্দু \(1,2\) অন্তর্ভুক্ত, সমান weight ⇒ \(\hat f(0.1)=\dfrac{0.0+0.8}{2}=0.40\)। (গ) এটা window-এর ভেতরের \(y\)-মানগুলোর সাধারণ গড় (\(\tfrac{0+0.8}{2}\)) — box kernel-এ Nadaraya–Watson = local mean।
প্রশ্ন ৮ (★). Gaussian-kernel weighted average হাতে। একই ৩ বিন্দু \((0.0,0.0),(0.1,0.8),(0.3,0.5)\), কিন্তু এবার Gaussian kernel \(K(u)=e^{-u^2/2}\) (normalizing ধ্রুবক বাদ — যেহেতু weight normalize হবে), \(h=0.1\), query \(x=0.1\)। (ক) প্রতিটা \(i\)-এর জন্য raw weight \(k_i=\exp\!\big(-\tfrac12\big(\tfrac{x-x_i}{h}\big)^2\big)\) গণনা করুন। (খ) normalize করে \(w_i=k_i/\sum_j k_j\) এবং \(\hat f(0.1)=\sum_i w_i y_i\) বের করুন। (গ) box-kernel ফলের (\(0.40\)) সাথে তুলনা করুন — Gaussian kernel দূরের বিন্দু \(3\)-কে শূন্য না দিয়ে ছোট weight দেয়; ফলে উত্তর কোন দিকে সরে? Hint: (ক) \(k_1=e^{-\frac12(1)^2}=e^{-0.5}=0.6065\), \(k_2=e^{-\frac12(0)^2}=1\), \(k_3=e^{-\frac12(2)^2}=e^{-2}=0.1353\)। (খ) \(\sum k=0.6065+1+0.1353=1.7418\); \(w=(0.348,\ 0.574,\ 0.0777)\); \(\hat f=0.348\cdot0+0.574\cdot0.8+0.0777\cdot0.5=0.459+0.0388=0.498\approx0.50\)। (গ) box-এর \(0.40\)-এর চেয়ে একটু বড় (\(\approx0.50\)) — কারণ বিন্দু \(3\) (\(y=0.5\)) এখন সামান্য weight পায় (এবং বিন্দু \(2\)-এর কাছের weight প্রাধান্য পায়), তাই উত্তর সামান্য উপরে টানে; smooth kernel-এ কোনো বিন্দু হঠাৎ "কাটা" পড়ে না।
প্রশ্ন ৯ (★★). bias–variance সংখ্যায় পড়া। চলমান উদাহরণের Nadaraya–Watson MSE-vs-true: \(h=0.02\to0.0095\), \(h=0.05\to0.0077\), \(h=0.20\to0.1228\), \(h=0.40\to0.2865\); তুলনায় linear OLS MSE-vs-true \(=0.1995\)। (ক) এই চারটা \(h\)-কে MSE অনুসারে সাজিয়ে বলুন কোনটা variance-প্রধান, কোনটা bias-প্রধান অঞ্চল। (খ) \(h=0.20\) ও \(h=0.40\)-এর MSE linear OLS-এর কাছাকাছি বা বেশি কেন — বড় \(h\)-এ Nadaraya–Watson কী আচরণ করে? (গ) সেরা kernel-fit (\(h=0.05\), MSE \(0.0077\)) linear OLS (\(0.1995\))-এর চেয়ে কত গুণ ভালো (MSE-অনুপাত), এবং এটা কী বলে \(\sin(2\pi x)\)-কে সরলরেখায় ধরার ব্যর্থতা সম্পর্কে? Hint: (ক) ছোট \(h\) (\(0.02\)): variance-প্রধান (তবু bias কম বলে MSE মোটামুটি ছোট \(0.0095\)); \(h=0.05\): ভারসাম্য, সর্বনিম্ন; \(h=0.20,0.40\): bias-প্রধান (oversmoothing, MSE দ্রুত বাড়ে)। (খ) বড় \(h\)-এ kernel প্রায় সব বিন্দু সমান-ভাবে মেশায় ⇒ \(\hat f\) প্রায় ধ্রুবক (গোটা data-র গড়) ⇒ \(\sin\)-এর গঠন হারায়, এমনকি সরলরেখার চেয়েও খারাপ হতে পারে (\(h=0.40\): \(0.2865>0.1995\))। (গ) \(0.1995/0.0077\approx25.9\) গুণ ছোট MSE — সরলরেখা bias-এ এতটাই খারাপ যে সঠিক bandwidth-এর kernel smoother প্রায় ২৬ গুণ ভালো; nonparametric-এর নমনীয়তার জয়।
প্রশ্ন ১০ (★★). regression spline df ও fit। চলমান উদাহরণে cubic B-spline (OLS-on-basis): df\(=4\to\) MSE \(0.0051\), df\(=6\to R^2=0.810\), MSE \(0.0019\), df\(=9\to\) MSE \(0.0024\)। (ক) df\(=6\)-এ effective degrees of freedom কত (অর্থাৎ কয়টা \(\gamma_k\) estimate হয়), এবং এটা \(n=150\)-এর তুলনায় কত ছোট? (খ) df \(4\to6\)-এ MSE কমল কিন্তু \(6\to9\)-এ আবার সামান্য বাড়ল — এই non-monotone (অ-একঘেয়ে) আচরণ bias–variance-এর ভাষায় ব্যাখ্যা করুন। (গ) সেরা spline-fit (df\(=6\), MSE \(0.0019\)) সেরা kernel-fit (\(h=0.05\), MSE \(0.0077\))-এর সাথে তুলনা করুন — এই মসৃণ \(\sin\)-এর জন্য কোনটা একটু এগিয়ে, এবং কেন global basis মসৃণ ফাংশনে স্বাভাবিকভাবেই ভালো করতে পারে? Hint: (ক) df\(=6\) ⇒ effective df \(=6\) (\(6\)টা basis-coefficient, \(S=B(B^\top B)^{-1}B^\top\)-এর \(\operatorname{tr}=6\)); \(n=150\)-এর তুলনায় অত্যন্ত parsimonious (\(6\ll150\))। (খ) df\(=4\) — কম নমনীয়, সামান্য underfit (bias একটু বেশি, MSE \(0.0051\)); df\(=6\) — ভারসাম্য (সর্বনিম্ন \(0.0019\)); df\(=9\) — অতিরিক্ত নমনীয়, variance বাড়ে (সামান্য overfit, \(0.0024\)) — ক্লাসিক U-আকার df-এর সাথে। (গ) spline (\(0.0019\)) কিছুটা এগিয়ে kernel (\(0.0077\))-এর চেয়ে — কারণ cubic spline একটা মসৃণ global basis যা \(\sin\)-এর মতো মসৃণ ফাংশনকে খুব কম coefficient-এ চমৎকার approximate করে (boundary-তেও স্থিতিশীল), যেখানে kernel স্থানীয়-গড় বলে সামান্য বেশি variance বহন করে।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১১ (★★). regression spline একটা linear smoother — effective df \(=\operatorname{tr}(S)\) প্রমাণ করুন। ধরুন \(B\) হলো \(n\times K\) B-spline basis-matrix (\(B_{ik}=B_k(x_i)\)), পূর্ণ column-rank \(K\), এবং \(\hat\gamma=(B^\top B)^{-1}B^\top\mathbf y\) হলো OLS estimate। (ক) দেখান যে fitted মান \(\hat{\mathbf f}=B\hat\gamma=S\mathbf y\), যেখানে \(S=B(B^\top B)^{-1}B^\top\) — অর্থাৎ regression spline একটা linear smoother (\(\hat{\mathbf f}\) হলো \(\mathbf y\)-এর একটা রৈখিক রূপান্তর)। (খ) প্রমাণ করুন \(S\) একটা projection matrix: \(S^\top=S\) এবং \(S^2=S\)। (গ) সেখান থেকে দেখান \(\operatorname{tr}(S)=K\) (basis-সংখ্যা), অর্থাৎ effective degrees of freedom ঠিক estimate-করা coefficient-সংখ্যার সমান। Hint: (ক) সংজ্ঞা থেকে সরাসরি: \(\hat{\mathbf f}=B\hat\gamma=B(B^\top B)^{-1}B^\top\mathbf y\); তাই \(S=B(B^\top B)^{-1}B^\top\), যা \(\mathbf y\)-তে রৈখিক ⇒ linear smoother। (খ) \(S^\top=\big(B(B^\top B)^{-1}B^\top\big)^\top=B\big((B^\top B)^{-1}\big)^\top B^\top=B(B^\top B)^{-1}B^\top=S\) (যেহেতু \((B^\top B)\) symmetric); আর \(S^2=B(B^\top B)^{-1}B^\top B(B^\top B)^{-1}B^\top=B(B^\top B)^{-1}B^\top=S\) (মাঝের \(B^\top B\) ও তার inverse কাটে)। (গ) cyclic trace: \(\operatorname{tr}(S)=\operatorname{tr}\!\big(B(B^\top B)^{-1}B^\top\big)=\operatorname{tr}\!\big((B^\top B)^{-1}B^\top B\big)=\operatorname{tr}(I_K)=K\) ∎ — এজন্যই linear smoother-এর effective df-কে \(\operatorname{tr}(S)\) দিয়ে সংজ্ঞায়িত করা হয় (projection-এ তা rank, এখানে \(K\))।
প্রশ্ন ১২ (★★★). smoothing-spline penalty \(\lambda\) — দুই সীমা \(\lambda\to0\) ও \(\lambda\to\infty\)। smoothing spline minimize করে penalized criterion $\(\sum_{i=1}^n\big(y_i-f(x_i)\big)^2+\lambda\int \big(f''(t)\big)^2\,dt,\)$ যেখানে প্রথম পদ data-fit ও দ্বিতীয় পদ \(f\)-এর roughness (বক্রতা) শাস্তি দেয়; \(\lambda\ge0\) smoothing parameter। (ক) \(\lambda\to0\) সীমায় penalty উধাও — এই ক্ষেত্রে minimizer \(f\) প্রতিটা \((x_i,y_i)\)-কে কী করে (data-fit পদ শূন্য করতে), এবং তা কোন চরম আচরণ (overfit না oversmooth)? (খ) \(\lambda\to\infty\) সীমায় roughness-penalty প্রবলভাবে \(\int f''^2=0\) চাপায় — এটি \(f''\equiv0\) বাধ্য করে, যার অর্থ \(f\) কোন সরল রূপের, এবং এটা কোন পরিচিত মডেলে ফিরে যায়? (গ) তাই \(\lambda\) একটা ধারাবাহিক tuning knob: এক প্রান্তে interpolation, অন্য প্রান্তে linear fit। এটা কীভাবে bandwidth \(h\) ও spline-df-এর মতো একই bias–variance অক্ষেই কাজ করে (কোন প্রান্ত high-variance, কোনটা high-bias)? Hint: (ক) \(\lambda\to0\) ⇒ শুধু data-fit গুরুত্বপূর্ণ; minimizer প্রতিটা বিন্দু ছুঁয়ে যায় (\(f(x_i)=y_i\), residual শূন্য) ⇒ interpolating spline — চরম overfit, উচ্চ variance (noise-ও fit করে)। (খ) \(\lambda\to\infty\) ⇒ \(\int f''^2=0\) ⇒ \(f''\equiv0\) ⇒ \(f\) রৈখিক (\(f(x)=a+bx\)); penalty-যুক্ত criterion তখন কার্যত OLS সরলরেখা fit (৫.১) — চরম oversmooth, উচ্চ bias। (গ) \(\lambda\) ছোট = বেশি নমনীয় = high variance (যেমন ছোট \(h\) বা বড় df); \(\lambda\) বড় = কম নমনীয় = high bias (যেমন বড় \(h\) বা ছোট df) — তিনটা tuning parameter (\(h\), df, \(\lambda\)) একই bias–variance অক্ষের ভিন্ন প্যারামিটারাইজেশন; মাঝামাঝি \(\lambda\) আপস (চলমান উদাহরণে \(s=13.5\) → MSE \(0.0197\), যা data-noise-কে চমৎকার মসৃণ করে)।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৩ (★★★). পূর্ণ nonparametric-regression pipeline — Nadaraya–Watson, cubic B-spline, smoothing spline, LOOCV bandwidth। seed np.random.default_rng(20260619) দিয়ে canonical data বানান: n=150, x = np.sort(rng.uniform(0,1,n)), f_true = np.sin(2*np.pi*x), y = f_true + rng.normal(0,0.3,n)। তারপর:
1. baseline linear OLS: score ~ x সরলরেখা fit করে \(R^2\) ও MSE-vs-f_true ছাপুন; canonical \(R^2=0.510\), MSE \(0.1995\) মেলান।
2. Nadaraya–Watson (Gaussian kernel): একটা ফাংশন লিখুন nw(xq, x, y, h) যা \(\hat f(x_q)=\dfrac{\sum_i K_h(x_q-x_i)y_i}{\sum_i K_h(x_q-x_i)}\) গণনা করে (\(K\) Gaussian)। \(h\in\{0.02,0.05,0.20,0.40\}\)-এর প্রতিটার জন্য MSE-vs-true ছাপুন; canonical \(0.0095,\ 0.0077,\ 0.1228,\ 0.2865\) মেলান।
3. LOOCV bandwidth: leave-one-out CV দিয়ে (প্রতিটা \(x_i\)-তে নিজেকে বাদ দিয়ে predict) একটা \(h\)-গ্রিডে সেরা bandwidth খুঁজুন; canonical সেরা \(h\approx0.03\) যাচাই করুন।
4. cubic B-spline (regression spline = OLS-on-basis): patsy-র bs(x, df=df, degree=3, include_intercept=True) basis দিয়ে OLS করে df\(\in\{4,6,9\}\)-এর প্রতিটার \(R^2\) ও MSE-vs-true ছাপুন; canonical df\(=6\to R^2=0.810\) (MSE \(0.0019\)), df\(=4\to0.0051\), df\(=9\to0.0024\) মেলান। effective df = basis-column-সংখ্যা — মুদ্রণ করুন।
5. smoothing spline: scipy.interpolate.splrep(x, y, s=13.5, k=3) দিয়ে fit করে splev-এ predict; MSE-vs-true ছাপুন; canonical \(0.0197\) মেলান।
6. তুলনা-সারণি: পাঁচটা পদ্ধতির (linear, NW-সেরা, spline-সেরা, smoothing spline) MSE-vs-true পাশাপাশি ছাপুন এবং এক লাইনে মন্তব্য করুন কোনটা জিতল ও কেন।
(সম্ভব হলে ১–৬ এক runnable script-এ; প্রতিটা সংখ্যা canonical-এর সাথে মেলান। নোট: data-generation-এ random-call-এর ক্রম — আগে x, তারপর y-এর noise — canonical seed-আউটপুট মেলানোর জন্য গুরুত্বপূর্ণ; সমাধান-script-এর ক্রম অনুসরণ করুন।)
Hint: Gaussian kernel: K = np.exp(-0.5*((xq[:,None]-x[None,:])/h)**2) তারপর row-wise normalize করে K@y। LOOCV: প্রতিটা \(i\)-তে w=K_row.copy(); w[i]=0; pred=(w@y)/w.sum()। B-spline: from patsy import dmatrix; B = dmatrix("bs(x, df=6, degree=3, include_intercept=True)", {"x":x}, return_type="dataframe").values, তারপর sm.OLS(y, B).fit(); effective df = B.shape[1]। smoothing spline: from scipy.interpolate import splrep, splev; tck=splrep(x,y,s=13.5,k=3); yhat=splev(x,tck)। প্রত্যাশিত সব সংখ্যা উপরের canonical তালিকায়।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
কেন এই অধ্যায়। ৫.১–৫.৬ জুড়ে একটা মৌলিক অনুমান টিকে ছিল — predictor ও outcome-এর সম্পর্ক একটা নির্দিষ্ট parametric রূপের (সাধারণত রৈখিক, \(\mathbb E[y\mid x]=x^\top\beta\), বা একটা স্থির basis)। কিন্তু বহু বাস্তব সম্পর্ক সেই ছাঁচে বসে না — বাঁকানো, জটিল, পূর্বনির্ধারিত সূত্রে ধরা যায় না। চলমান উদাহরণে সত্যিকারের \(f(x)=\sin(2\pi x)\)-কে সরলরেখায় fit করায় \(R^2\) মাত্র \(0.510\) (MSE-vs-true \(0.1995\)) — এটা model misspecification → উচ্চ bias (underfitting), variance নয়। সমাধান: \(f\)-এর রূপ আগে থেকে না বেঁধে data-কে নিজে থেকে curve-এর আকার বলতে দেওয়া — nonparametric regression।
-
Nonparametric মানে কী। parametric মডেল \(f\)-কে একটা সসীম-মাত্রিক স্থির রূপে (\(\beta\in\mathbb R^p\), \(p\) স্থির) বাঁধে; nonparametric মডেল রূপ বাঁধে না — কার্যকর parameter-সংখ্যা \(n\)-এর সাথে বাড়তে পারে। দাম: nonparametric নমনীয় কিন্তু বেশি data দরকার, এবং তার convergence ধীর — optimal kernel-MSE \(\propto n^{-4/5}\) (parametric-এর \(n^{-1}\)-এর চেয়ে ধীর), optimal bandwidth \(h^\*\propto n^{-1/5}\) (বেশি data ⇒ ছোট window সম্ভব ⇒ সূক্ষ্মতর fit)।
-
দুই বড় পরিবার। এ অধ্যায়ের nonparametric টুলগুলো দুই ধারায়:
- kernel / local methods — প্রতিটা query বিন্দুর চারপাশে একটা স্থানীয় ভারিত fit। Nadaraya–Watson estimator $\(\hat f(x)=\frac{\sum_i K_h(x-x_i)\,y_i}{\sum_i K_h(x-x_i)}=\sum_i w_i(x)\,y_i,\qquad \sum_i w_i(x)=1,\)$ অর্থাৎ \(y_i\)-গুলোর একটা স্থানীয় weighted average (\(x\)-এর কাছের বিন্দু বেশি weight)। এর সম্প্রসারণ local polynomial regression / LOESS (গড়ের বদলে স্থানীয় polynomial fit, boundary-তে ভালো)। নিয়ন্ত্রক প্যারামিটার bandwidth \(h\)।
-
spline / basis methods — regression spline = একটা B-spline basis বানিয়ে \(\hat f(x)=\sum_k\hat\gamma_k B_k(x)\), যেখানে \(\hat\gamma\) হলো \(y\)-কে basis-matrix \(B\)-এর ওপর সাধারণ OLS (৫.১-এর basis-expansion-এর সরাসরি ধারাবাহিকতা — parameter-এ রৈখিক)। নিয়ন্ত্রক প্যারামিটার degrees of freedom / knot-সংখ্যা। natural cubic spline প্রান্তের বাইরে \(f\)-কে রৈখিক (\(f''=0\)) করে boundary-variance কমায়। smoothing spline আলাদা পথে যায় — সব data-বিন্দুতে knot বসিয়ে একটা roughness penalty যোগ করে: $\(\min_f\ \sum_i\big(y_i-f(x_i)\big)^2+\lambda\int\big(f''(t)\big)^2dt,\)$ যেখানে smoothing parameter \(\lambda\) নমনীয়তা নিয়ন্ত্রণ করে।
-
bias–variance — তিনটা tuning parameter, একই অক্ষ। \(h\), df, ও \(\lambda\) — তিনটাই আসলে একই bias–variance tradeoff-এর ভিন্ন প্যারামিটারাইজেশন:
- ছোট \(h\) / বড় df / ছোট \(\lambda\) ⇒ অতি-নমনীয় ⇒ উচ্চ variance (কাঁপা fit, noise-ও ধরে; \(\lambda\to0\)-তে চরম: interpolation)।
-
বড় \(h\) / ছোট df / বড় \(\lambda\) ⇒ অতি-অনমনীয় ⇒ উচ্চ bias (oversmoothing, চূড়া-খাঁজ চাপা; \(\lambda\to\infty\)-তে চরম: linear fit)। চলমান উদাহরণে Nadaraya–Watson MSE একটা U-আকার দেখায় — \(h=0.02\to0.0095\), \(h=0.05\to0.0077\) (সর্বনিম্ন), \(h=0.20\to0.1228\), \(h=0.40\to0.2865\); spline-ও তেমন — df\(=4\to0.0051\), df\(=6\to0.0019\) (সর্বনিম্ন), df\(=9\to0.0024\)। সঠিক tuning-এ kernel-fit (\(h=0.05\)) linear OLS-এর চেয়ে \(\approx26\) গুণ ছোট MSE, আর spline-fit (df\(=6\), MSE \(0.0019\)) আরও এগিয়ে।
-
linear smoother ও effective df। এ অধ্যায়ের প্রায় সব পদ্ধতি (Nadaraya–Watson, regression spline, smoothing spline) linear smoother: \(\hat{\mathbf f}=S\mathbf y\), কোনো smoother-matrix \(S\)-এর জন্য। তাদের নমনীয়তা একটা একক সংখ্যায় ধরা — effective degrees of freedom \(=\operatorname{tr}(S)\)। regression spline-এ \(S=B(B^\top B)^{-1}B^\top\) একটা projection, তাই \(\operatorname{tr}(S)=K=\) basis-সংখ্যা (§৭-এ প্রমাণিত); kernel ও smoothing spline-এও \(\operatorname{tr}(S)\) একই ভূমিকা রাখে — ভিন্ন পদ্ধতিকে এক স্কেলে (effective df) তুলনাযোগ্য করে।
-
মূল বার্তা। nonlinear \(f\) ⇒ local/kernel ও spline/basis পদ্ধতি ⇒ bias–variance নিয়ন্ত্রণ একটা tuning parameter (\(h\)/df/\(\lambda\)) দিয়ে ⇒ সব পদ্ধতিকে এক স্কেলে আনে effective df \(=\operatorname{tr}(S)\) ⇒ এবং সেই tuning parameter বাছার নীতিনিষ্ঠ পথ হলো cross-validation (চলমান উদাহরণে LOOCV-সেরা \(h\approx0.03\))।
পূর্ববর্তী সংযোগ (← ৫.১, ৫.২, ০.৩):
-
৫.১ (Linear Regression / OLS basis): regression spline আসলে ৫.১-এরই সম্প্রসারণ — basis \(\{B_k(x)\}\) বানিয়ে \(\hat f=\sum_k\gamma_k B_k(x)\) হলো features \(B_k(x)\)-এর ওপর সাধারণ OLS (parameter-এ রৈখিক)। ৫.১-এ আমরা polynomial/dummy basis দিয়ে রৈখিক মডেলকে নমনীয় করেছিলাম; এখানে শুধু basis বদলেছি (B-spline), যা স্থানীয়ভাবে নমনীয় ও স্থিতিশীল। Nadaraya–Watson-এর constant-fit বৈশিষ্ট্য (ধ্রুবক \(y\) হুবহু পুনরুৎপাদন) আর smoothing-spline-এর \(\lambda\to\infty\) সীমা সরাসরি ৫.১-এর OLS সরলরেখায় ফিরে যায় — অর্থাৎ এই পদ্ধতিগুলো linear regression-কে একটা বিশেষ-ক্ষেত্র হিসেবে ধারণ করে।
-
৫.২ (Bias–Variance / Diagnostics & Selection): এ অধ্যায়ের গোটা গল্পই ৫.২-এর bias–variance decomposition-এর প্রয়োগ। সেখানে আমরা শিখেছিলাম model complexity বাড়ালে bias কমে কিন্তু variance বাড়ে; এখানে সেই complexity-র ডায়াল হলো \(h\), df, বা \(\lambda\)। ছোট \(h\)/বড় df = কম bias, বেশি variance; বড় \(h\)/ছোট df = বেশি bias, কম variance — চলমান উদাহরণের U-আকার MSE ঠিক ৫.২-এর tradeoff-curve-এরই মূর্ত রূপ। effective df \(=\operatorname{tr}(S)\) হলো ৫.২-এর "model complexity"-র সাধারণীকৃত পরিমাপ, যা parametric "parameter-গোনা"-কে nonparametric smoother-এ বিস্তৃত করে।
-
০.৩ (Calculus / Derivatives): smoothing-spline-এর roughness penalty \(\lambda\int(f''(t))^2dt\)-এর কেন্দ্রে আছে ০.৩-এর দ্বিতীয় অন্তরকলজ \(f''\) — যা curve-এর বক্রতা (কত দ্রুত ঢাল বদলায়) মাপে। \(f''\) বড় মানে তীক্ষ্ণ বাঁক (roughness বেশি), \(f''=0\) মানে সরলরেখা (no curvature)। তাই penalty আসলে "মোট বক্রতা"-কে শাস্তি দেয়, আর \(\lambda\to\infty\)-এ \(f''\equiv0\) বাধ্য করে সরলরেখা ফেরায় — পুরো যন্ত্রটাই ০.৩-এর derivative-ধারণার ওপর দাঁড়ানো।
পরবর্তী সংযোগ (→ ৫.৮ — Cross-Validation & Model Validation): এ অধ্যায়ে বারবার ফিরে এসেছে একটাই মীমাংসা-না-হওয়া প্রশ্ন — tuning parameter (\(h\), df, বা \(\lambda\)) কত নেব? আমরা MSE-vs-true দেখে সেরা বেছেছি, কিন্তু বাস্তবে সত্যিকারের \(f\) অজানা, তাই MSE-vs-true গণনাই করা যায় না। ৫.৮ ঠিক এই শূন্যস্থান ভরবে cross-validation দিয়ে: data-কে ভাঁজে (fold) ভাগ করে, এক অংশে fit করে অন্য অংশে predict করে held-out error হিসাব — সত্যিকারের \(f\) ছাড়াই tuning parameter বাছার নীতিনিষ্ঠ, data-চালিত পথ (এ অধ্যায়ে যেমন LOOCV দিয়ে \(h\approx0.03\) পেলাম, সেটাই হলো leave-one-out cross-validation-এর প্রয়োগ)। সংক্ষেপে: ৫.৭ দিয়েছে নমনীয় nonparametric পদ্ধতি ও তাদের tuning knob; ৫.৮ দেবে সেই knob কোথায় ঘোরাতে হবে তার নীতিনিষ্ঠ নিয়ম — model selection ও validation-এর সাধারণ কাঠামো।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 20 (nonparametric regression — kernel estimators, local polynomials, splines, bias–variance, bandwidth); R. Furrer, STA121 Statistical Modeling (smoothing, regression/smoothing splines, effective degrees of freedom, linear smoothers); M. Sugiyama, Introduction to Statistical Machine Learning / kernel methods (kernel regression, local fitting, bandwidth-এর ভূমিকা); J. A. Rice, Mathematical Statistics and Data Analysis (kernel density/regression smoothing, bandwidth-bias-variance); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists (splines, GAM, nonparametric smoothing-এর ব্যবহারিক দিক)।