4.3 — Maximum Likelihood Estimation (সর্বোচ্চ সম্ভাব্যতা অনুমান)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "কোন parameter এই data-কে সবচেয়ে সম্ভাব্য করত?"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল¶
অধ্যায় 4.2-এ আমরা point estimation-এর প্রথম recipe শিখেছি — method of moments (MoM)। সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়টা তার ঠিক পাশেই দাঁড়ানো একটা ভিন্ন দর্শন। আমাদের হাতে আছে একটা sample (নমুনা): একটা অজানা distribution থেকে এলোমেলোভাবে তোলা \(n\)টি পর্যবেক্ষণ
এখানে প্রতিটি \(X_i\) একটি random variable (যাদৃচ্ছিক চলক) — কোন মান আসবে তা আগে থেকে নিশ্চিত নয় — আর আমরা ধরে নিই এরা i.i.d. (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা)। distribution-টার ভেতরে এক বা একাধিক অজানা সংখ্যা লুকিয়ে আছে, যাকে আমরা বলি parameter (প্যারামিটার / প্রাচল) এবং চিহ্নিত করি গ্রিক অক্ষর \(\theta\) ("থিটা") দিয়ে। লক্ষ্য একটাই: এই data থেকে অজানা \(\theta\)-র জন্য একটিমাত্র best-guess সংখ্যা \(\hat\theta\) ("থিটা-হ্যাট", মাথার টুপি মানে "এটা data থেকে বানানো আন্দাজ") তৈরি করা।
MoM-এর উত্তরটা ছিল: "তত্ত্বের moment আর data-র moment সমান হওয়া উচিত" — অর্থাৎ population mean-কে sample mean-এর সমান ধরো, দরকার হলে দ্বিতীয় moment-ও মেলাও, তারপর সেই সমীকরণ থেকে \(\theta\) solve করো। সরল, দ্রুত, এবং বেশি data-য় সত্যের কাছে যায় (consistent)। কিন্তু 4.2-এর শেষেই আমরা একটা অস্বস্তিকর ফাটল দেখেছিলাম: Uniform\((0,\theta)\) distribution-এ data \(1,1,1,9\) পেলে MoM বলে \(\hat\theta_{\text{MoM}} = 2\bar X = 6\) — অথচ data-তেই একটা \(9\) আছে, যা \(\theta=6\) হলে আসতেই পারত না! MoM একটা অসম্ভব উত্তর দিল। তখন বলেছিলাম, "এখানে \(\hat\theta=\max_i X_i\) অনেক ভালো হতো — এই তুলনা MLE-তে ফিরে আসবে।" আজ সেই ঋণ শোধ করব।
১.২ Hook — উল্টো দিক থেকে ভাবা¶
MoM data-কে দেখে জিজ্ঞেস করে: "তোমার গড় কত? আচ্ছা, তাহলে সেই গড় মেলানো \(\theta\)-টাই নিলাম।" এটা data-র একটা সারমর্ম (গড়) ধরে কাজ করে। কিন্তু একটা সম্পূর্ণ ভিন্ন, এবং সম্ভবত আরও স্বাভাবিক, প্রশ্ন করা যায়:
আমার হাতে তো ঠিক এই data-টাই এসেছে — \(X_1,\dots,X_n\), যা যা মান, ঠিক যেমন যেমন। এখন প্রশ্ন: \(\theta\)-র কোন মান ধরলে ঠিক এই data-টা ঘটার সম্ভাবনা সবচেয়ে বেশি হতো?
এই প্রশ্নটাই maximum likelihood-এর পুরো আত্মা। ধরুন আপনার বন্ধু একটা মুদ্রা ছুঁড়ে আপনাকে বলল ফলাফল: \(10\) বার ছুঁড়ে \(9\) বার head এসেছে। আপনি যদি অনুমান করতে বলা হয় মুদ্রাটার head-হার \(p\) কত, আপনি কি বলবেন \(p=0.1\)? কখনোই না — কারণ \(p=0.1\) হলে \(9\)টা head পড়া ভীষণ অসম্ভব ব্যাপার। আপনি স্বভাবতই বলবেন "\(p\) মোটামুটি \(0.9\)" — কারণ \(p=0.9\) ধরলেই এই দেখা-ফলাফলটা (৯টা head) সবচেয়ে বেশি সম্ভাব্য হয়। আপনি মনে মনে \(p\)-কে নাড়াচাড়া করে দেখলেন কোন মানে "৯টা head, ১টা tail" ঘটার সম্ভাবনা চূড়ায় ওঠে — আর সেটাকেই best-guess ধরলেন।
ব্যস — এর নাম না জেনেই আপনি maximum likelihood estimation (MLE, সর্বোচ্চ সম্ভাব্যতা অনুমান) চালিয়ে ফেললেন। এক বাক্যে:
MLE বলে — যে parameter-মান হাতে-পাওয়া data-টাকে সবচেয়ে সম্ভাব্য করে তোলে, সেটাই সবচেয়ে যুক্তিসঙ্গত আন্দাজ।
১.৩ MoM আর MLE — দুই দর্শনের পার্থক্য¶
দুটো পদ্ধতিই একই কাজ করে (data থেকে \(\hat\theta\) বানায়), কিন্তু ভিন্ন প্রশ্ন জিজ্ঞেস করে। পার্থক্যটা গোড়াতেই গেঁথে নিন:
| Method of Moments (4.2) | Maximum Likelihood (এই অধ্যায়) | |
|---|---|---|
| মূল প্রশ্ন | কোন \(\theta\)-তে তত্ত্বের গড় = data-র গড়? | কোন \(\theta\) এই পুরো data-টাকে সবচেয়ে সম্ভাব্য করে? |
| data-র কতটা ব্যবহার | কয়েকটা moment (গড়, বর্গের গড়) | প্রতিটি পর্যবেক্ষণের পূর্ণ অবদান |
| হাতিয়ার | সমীকরণ মেলানো (algebra) | একটা function-এর চূড়া খোঁজা (optimization, 0.3) |
| গুণ | সরল, দ্রুত, প্রায়ই closed-form | সাধারণত বেশি দক্ষ; অসম্ভব উত্তর দেয় না |
লক্ষ করুন — MLE পুরো data-র "আকৃতি" ব্যবহার করে, কেবল গড় নয়। এই কারণেই Uniform উদাহরণে MLE-র উত্তর (\(\max_i X_i\)) যুক্তিসঙ্গত হবে আর MoM-এর নয়: MLE জানে \(\theta\) অবশ্যই সব data-র চেয়ে বড় হতে হবে (নইলে এই data আসতই না), MoM শুধু গড় দেখে সেটা টের পায় না।
এক লাইনে ধরে রাখুন: MoM জিজ্ঞেস করে "তোমার গড় কী?"; MLE জিজ্ঞেস করে "কে তোমাকে সবচেয়ে সম্ভাব্য করত?"
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই:
- Likelihood function \(L(\theta)\) কী, এবং "likelihood বনাম probability" পার্থক্য (§২.১–২.২)।
- কেন product-এর বদলে log-likelihood \(\ell(\theta)\) নিয়ে কাজ করি, আর MLE-র precise সংজ্ঞা (§২.৩)।
- MLE বের করার recipe — log নাও → differentiate → score শূন্য → solve → second-order check, এবং invariance property (§২.৪–২.৫)।
- recipe-টা চারটি বাস্তব distribution-এ সংখ্যাসহ চালানো — E1 Bernoulli, E2 Normal, E3 Exponential, E4 Uniform (§৩)।
- তারপর MLE-র properties, কোড, MoM-এর সঙ্গে পূর্ণ তুলনা ও অনুশীলনী (§৪ থেকে — পরবর্তী অংশে)।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো অধ্যায়ের সাধারণ কাঠামো স্থির করি: হাতে একটি i.i.d. sample \(X_1,\dots,X_n\), একটি common distribution থেকে আসা, যার ভেতরে এক বা একাধিক অজানা parameter আছে — সাধারণভাবে \(\theta\)। distribution-টা যদি continuous (অবিচ্ছিন্ন) হয়, তবে তাকে বর্ণনা করে একটি probability density function (pdf, সম্ভাব্যতা ঘনত্ব ফাংশন), যাকে লিখি \(f(x;\theta)\) — অর্থাৎ "\(x\) বিন্দুতে ঘনত্ব, যখন parameter \(\theta\)"। distribution discrete (বিচ্ছিন্ন) হলে তার জায়গায় থাকে probability mass function (pmf, সম্ভাব্যতা ভর ফাংশন) \(P(X=x;\theta)\) — অর্থাৎ "\(X\)-এর মান ঠিক \(x\) হওয়ার সম্ভাবনা।" নিচে সাধারণভাবে \(f(x;\theta)\) লিখব; discrete হলে মনে মনে pmf বসিয়ে নিন (পদ্ধতি হুবহু এক)।
২.১ Likelihood function — data স্থির, parameter পরিবর্তনশীল¶
এখানে একটা সূক্ষ্ম কিন্তু সমগ্র অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ দৃষ্টিভঙ্গি-পরিবর্তন ঘটবে। মন দিয়ে পড়ুন।
এতদিন (Part II–III, probability-তে) আমরা pdf \(f(x;\theta)\)-কে দেখেছি \(x\)-এর function হিসেবে — \(\theta\) জানা-স্থির, আর আমরা জিজ্ঞেস করতাম "বিভিন্ন \(x\)-এ ঘনত্ব কত?" এক observation-এর সম্ভাব্যতা-অবদান \(f(x;\theta)\); আর \(n\)টা i.i.d. observation একসাথে ঘটার যৌথ ঘনত্ব (independence-এর কারণে গুণফল):
এখানে \(\prod_{i=1}^{n}\) ("পাই", capital pi) মানে "\(i=1\) থেকে \(n\) পর্যন্ত সব পদ গুণ করো" — যেমন \(\sum\) যোগের চিহ্ন, তেমনি \(\prod\) গুণের চিহ্ন।
এবার inference-এর তীরটা উল্টে দিই (4.1-এর সেই বড় মোড়)। বাস্তবে data তো ঘটে গেছে — \(X_1,\dots,X_n\)-এর মান হাতে এসে স্থির হয়ে বসে আছে। যা আমরা জানি না তা হলো \(\theta\)। তাই আমরা ঠিক একই গুণফলটা লিখি, কিন্তু এবার \(\theta\)-কে পরিবর্তনশীল আর data-কে স্থির ধরে — এবং নতুন নাম দিই:
সংজ্ঞা (Likelihood function — সম্ভাব্যতা ফাংশন)। observed data \(X_1,\dots,X_n\) স্থির রেখে, likelihood function হলো এই গুণফলটাকে \(\theta\)-র function হিসেবে দেখা:
প্রতিটি প্রতীক খুলি:
- \(L(\theta)\) ("L of theta") — likelihood; এটা \(\theta\)-র একটা ফাংশন, একটা সংখ্যা ফেরত দেয়। বড় \(L(\theta)\) মানে "এই \(\theta\)-তে হাতে-পাওয়া data-টা বেশি সম্ভাব্য ছিল।"
- \(\prod_{i=1}^{n}\) — সব \(n\)টা পদের গুণফল (i.i.d. বলে যৌথ ঘনত্ব = পৃথক ঘনত্বগুলোর গুণফল)।
- \(f(X_i;\theta)\) — \(i\)-তম observation \(X_i\) (যা এখন একটা স্থির সংখ্যা) সেই \(\theta\)-তে যতটা ঘনত্ব/সম্ভাবনা পায়।
খেয়াল করুন আমি ইচ্ছে করেই বড় হাতের \(X_i\) রেখেছি — মনে রাখতে যে এগুলো নমুনা থেকে আসা, যদিও likelihood-এর ভেতরে এদের মান স্থির ধরা হচ্ছে।
২.২ Likelihood বনাম probability — একই সংখ্যা, উল্টো দৃষ্টি¶
নামটা ("likelihood" = সম্ভাব্যতা) আর "probability" শুনতে প্রায় একই, আর সংখ্যাটাও আক্ষরিক অর্থে একই গুণফল — তাহলে পার্থক্য কোথায়? পার্থক্য কোনটা স্থির আর কোনটা পরিবর্তনশীল, তাতে:
- Probability: \(\theta\) স্থির (জানা), \(x\) পরিবর্তনশীল। প্রশ্ন: "এই process থেকে নানা রকম data-র সম্ভাবনা কত?" — আমরা \(x\) জুড়ে যোগ/integrate করলে \(1\) পাই।
- Likelihood: \(x\) (data) স্থির (যা ঘটেছে), \(\theta\) পরিবর্তনশীল। প্রশ্ন: "এই দেখা-data-টা বিভিন্ন \(\theta\)-তে কতটা সম্ভাব্য ছিল?" — \(L(\theta)\) \(\theta\) জুড়ে যোগ করলে \(1\) হওয়ার কোনো বাধ্যবাধকতা নেই। তাই \(L(\theta)\) কোনো probability distribution নয়, এটা শুধু \(\theta\)-গুলোর তুলনামূলক "ব্যাখ্যাক্ষমতা" মাপে।
মূল কথা: likelihood আর probability সংখ্যায় একই সূত্র, কিন্তু likelihood-এ আমরা data-কে সাক্ষী ধরে রাখি আর \(\theta\)-কে বিচার করি — কোন \(\theta\) এই সাক্ষ্যকে সবচেয়ে ভালো ব্যাখ্যা করে। ঠিক এই কারণেই \(L\)-কে probability না বলে "likelihood" বলা হয়।
এই দৃষ্টিভঙ্গি একবার গেঁথে গেলে MLE-র সংজ্ঞা একদম স্বাভাবিক হয়ে যাবে: যে \(\theta\)-তে \(L(\theta)\) সবচেয়ে বড়, সেটাই data-কে সবচেয়ে ভালো ব্যাখ্যা করে — সেটাই আমাদের best-guess।
২.৩ Log-likelihood ও MLE-র সংজ্ঞা¶
কেন product সরাসরি ব্যবহার করি না। \(L(\theta) = \prod_i f(X_i;\theta)\) একটা গুণফল, আর গুণফল নিয়ে দুটো সমস্যা। (১) এর derivative নিতে হলে product rule বারবার লাগে — \(n=100\) পদে দুঃস্বপ্ন। (২) \(100\)টা ছোট ছোট সংখ্যা (যেমন প্রতিটি \(\approx 0.3\)) গুণ করলে ফল এত ক্ষুদ্র হয় যে কম্পিউটারে শূন্যে মিলিয়ে যায় (numerical underflow)। দুটো সমস্যারই একটাই সুন্দর সমাধান — logarithm নাও। কারণ \(\log\) গুণফলকে যোগফলে ভাঙে: \(\log(ab)=\log a+\log b\)।
সংজ্ঞা (Log-likelihood — লগ-সম্ভাব্যতা)। likelihood-এর স্বাভাবিক লগারিদম (natural log, \(\log = \ln\), base \(e\)):
প্রতীক খুলি: \(\ell(\theta)\) ("ছোট হাতের ell of theta", লিপি অক্ষর \(\ell\)) হলো log-likelihood; শেষ ধাপে \(\log\) গুণফলকে যোগফল \(\sum_{i=1}^{n}\)-এ ভেঙে দিয়েছে — এটাই পুরো সুবিধা: গুণ → যোগ, তাই derivative নেওয়া সহজ (যোগের derivative = derivative-গুলোর যোগ)।
একটা সূক্ষ্ম কিন্তু নিশ্চিন্ত করা সত্য। \(\log\) একটা কঠোরভাবে বাড়মুখী (strictly increasing) function — অর্থাৎ \(a\) বাড়লে \(\log a\)-ও বাড়ে, কখনো উল্টোয় না (0.3-এ দেখা)। ফলে \(L(\theta)\) যেখানে চূড়ায় ওঠে, \(\ell(\theta)=\log L(\theta)\)-ও ঠিক সেখানেই চূড়ায় ওঠে। চূড়ার উচ্চতা বদলায়, কিন্তু চূড়ার অবস্থান (\(\theta\)-মান) এক — তাই \(L\)-এর বদলে \(\ell\) maximize করা সম্পূর্ণ নিরাপদ, এবং অনেক সহজ।
\[\arg\max_{\theta} L(\theta) \;=\; \arg\max_{\theta} \ell(\theta).\]
এখন মূল সংজ্ঞা:
সংজ্ঞা (Maximum Likelihood Estimate — MLE, সর্বোচ্চ সম্ভাব্যতা অনুমান)। \(\theta\)-র maximum likelihood estimate হলো সেই মান যা likelihood (সমতুল্যভাবে log-likelihood)-কে সর্বোচ্চ করে:
প্রতীক খুলি: \(\arg\max_{\theta}\) ("argument of the maximum") মানে — যে function-টা সর্বোচ্চ করে তার মান নয়, বরং সেই সর্বোচ্চ-ঘটানো \(\theta\)-টা ফেরত দাও। অর্থাৎ আমরা \(L\)-এর সর্বোচ্চ মান চাই না, চাই কোন \(\theta\)-তে সেই সর্বোচ্চ ঘটে। আর \(\hat\theta_{\text{MLE}}\) যেহেতু random data \(X_i\)-দের ওপর নির্ভর করে, এটা নিজেও একটা random variable (§4.2-এর সাধারণ estimator-এরই একটা নির্দিষ্ট রূপ)।
২.৪ Recipe — হাতে-কলমে MLE বের করার ধাপ¶
বেশিরভাগ মসৃণ (smooth) distribution-এ চূড়াটা একটা "টিলার চূড়া"-র মতো — সেখানে slope (ঢাল) শূন্য। তাই optimization-এর চেনা কৌশল (0.3): derivative শূন্য করো। ধাপগুলো:
- Likelihood লেখো: \(L(\theta) = \prod_{i=1}^{n} f(X_i;\theta)\) — distribution-এর pdf/pmf বসিয়ে।
- Log নাও: \(\ell(\theta) = \sum_{i=1}^{n} \log f(X_i;\theta)\) — গুণফলকে যোগফলে ভাঙো, \(\log\)-এর নিয়ম (\(\log(ab)=\log a+\log b\), \(\log a^b = b\log a\), \(\log e^x = x\)) দিয়ে যতটা পারো সরল করো।
- Differentiate করো (score বানাও): \(\theta\)-র সাপেক্ষে \(\ell\)-এর derivative নাও। এই derivative-এরই একটা বিশেষ নাম —
সংজ্ঞা (Score function — স্কোর ফাংশন)। log-likelihood-এর derivative-কে বলে score: $$ \ell'(\theta) \;=\; \frac{d}{d\theta}\,\ell(\theta) \;=\; \sum_{i=1}^{n}\frac{d}{d\theta}\log f(X_i;\theta). $$ (এখানে \(\ell'(\theta)\) মানে \(\ell\)-এর প্রথম derivative; \(\frac{d}{d\theta}\) মানে "\(\theta\)-র সাপেক্ষে অন্তরকলন"।) 4. Score শূন্য করে solve করো: চূড়ায় ঢাল শূন্য, তাই likelihood equation \(\ell'(\theta)=0\) লিখে \(\theta\)-র জন্য সমাধান করো। যে \(\theta\) এটা মেটায় তাকে বলি \(\hat\theta_{\text{MLE}}\) (একাধিক parameter থাকলে প্রতিটির সাপেক্ষে partial derivative শূন্য করে সমীকরণ-জোড়া)। 5. Second-order check (চূড়া না খাদ?): \(\ell'(\theta)=0\) চূড়া (maximum) বা খাদ (minimum) — দুটোই হতে পারে। নিশ্চিত হতে দেখো second derivative \(\ell''(\hat\theta)<0\) (অর্থাৎ function-টা সেখানে নিচের দিকে বাঁকা, concave — তবেই চূড়া)। অথবা সহজভাবে যুক্তি দাও যে \(\ell\) পুরোটা concave।
মনে রাখুন: "log নাও → derivative নাও → শূন্য করো → solve → চূড়া যাচাই।" — এই পাঁচ-ধাপই বেশিরভাগ MLE-র মেরুদণ্ড।
একটা জরুরি সতর্কতা। এই derivative-recipe কেবল তখনই খাটে যখন (ক) \(\ell\) মসৃণ ও differentiable, এবং (খ) চূড়াটা parameter-পরিসরের ভেতরে পড়ে, প্রান্তে নয়। কিছু distribution-এ — বিশেষত Uniform\((0,\theta)\) — এই দুই শর্তের একটাও মানে না; সেখানে derivative শূন্য করার বদলে সরাসরি likelihood-এর আকার দেখে চূড়া খুঁজতে হয় (§৩-এর E4-এ চোখে দেখব)।
২.৫ Invariance property — রূপান্তরিত parameter-এর MLE¶
MLE-র একটা চমৎকার ও অত্যন্ত ব্যবহারিক ধর্ম দিয়ে এই অংশ শেষ করি। প্রায়ই আমরা \(\theta\) নয়, বরং \(\theta\)-র কোনো রূপান্তর \(g(\theta)\) অনুমান করতে চাই — যেমন Exponential-এ rate \(\lambda\)-র বদলে গড় আয়ু \(1/\lambda\), বা variance \(\sigma^2\)-র বদলে standard deviation \(\sigma\)। প্রশ্ন: \(g(\theta)\)-র MLE আলাদা করে বের করতে হবে, নাকি \(\hat\theta\) থেকেই পাওয়া যাবে?
Invariance property (অপরিবর্তনীয়তা ধর্ম)। যদি \(\hat\theta_{\text{MLE}}\) হয় \(\theta\)-র MLE এবং \(g\) হয় যেকোনো function, তবে \(g(\theta)\)-র MLE হলো ঠিক \(g(\hat\theta_{\text{MLE}})\):
স্বজ্ঞাটা সরল: MLE মানে "যে parameter-মান data-কে সবচেয়ে সম্ভাব্য করে।" \(\theta\)-কে যদি \(g(\theta)\) নামে নতুন মোড়কে লিখি, তবু যে data সবচেয়ে সম্ভাব্য সেই বিন্দুটা একই থাকে — শুধু তার লেবেল \(\hat\theta\) থেকে বদলে \(g(\hat\theta)\) হয়। অর্থাৎ চূড়া যেখানে ছিল সেখানেই, কেবল অক্ষের নাম পাল্টেছে। উদাহরণ: Exponential-এ যদি \(\hat\lambda_{\text{MLE}} = 1/\bar X\) হয়, তবে গড় আয়ু \(\mu = 1/\lambda\)-র MLE আলাদা হিসাব ছাড়াই \(\hat\mu_{\text{MLE}} = 1/\hat\lambda_{\text{MLE}} = \bar X\)। (লক্ষণীয় — MoM-এর এমন সাফসুতরো invariance নেই; এটা MLE-র একটা স্বতন্ত্র সুবিধা।)
৩ · পূর্ণাঙ্গ উদাহরণ — হাতে-কলমে MLE নির্ণয়¶
এবার §২-এর recipe চারটি বাস্তব distribution-এ সংখ্যাসহ চালাব। প্রতিটিতে একই ছন্দ: pdf/pmf → likelihood → log-likelihood → score শূন্য → \(\hat\theta\) → একটা সংখ্যা। সর্বত্র \(\bar X = \frac1n\sum_{i=1}^n X_i\) মানে sample mean (নমুনা গড়)।
৩.১ E1 — Bernoulli / Binomial: \(\hat p = \bar X\)¶
পরিস্থিতি। \(n\) বার একটা মুদ্রা ছোঁড়া। প্রতিটি \(X_i \in \{0,1\}\): head হলে \(1\), tail হলে \(0\) (এটাই Bernoulli\((p)\), যেখানে অজানা \(p = P(X_i=1)\) = head-হার)। pmf এক লাইনে লেখা যায়:
(যাচাই: \(x=1\) দিলে \(p\), \(x=0\) দিলে \(1-p\) — ঠিক।)
ধাপ ১–২ (likelihood ও log)। independence-এ গুণ করি, তারপর log:
ধরি \(k = \sum_{i=1}^n X_i\) = মোট head সংখ্যা। তাহলে
ধাপ ৩–৪ (score শূন্য)। \(p\)-র সাপেক্ষে derivative (\(\frac{d}{dp}\log p = 1/p\), এবং chain rule-এ \(\frac{d}{dp}\log(1-p) = -1/(1-p)\)):
solve: \(\dfrac{k}{p} = \dfrac{n-k}{1-p} \Rightarrow k(1-p) = (n-k)p \Rightarrow k - kp = np - kp \Rightarrow k = np\), তাই
ধাপ ৫ (চূড়া যাচাই)। \(\ell''(p) = -\frac{k}{p^2} - \frac{n-k}{(1-p)^2} < 0\) সব \(p\in(0,1)\)-এ — সদা ঋণাত্মক, তাই \(\ell\) concave, এটা সত্যিই চূড়া। ✓
সংখ্যা। \(10\) বারে \(9\) head (\(n=10,\ k=9\)): \(\hat p_{\text{MLE}} = 9/10 = 0.9\) — ঠিক §১.২-এ স্বজ্ঞায় যা বলেছিলাম। (লক্ষণীয়: এখানে MLE আর MoM একই উত্তর দেয়, কারণ Bernoulli-তে \(\mathbb{E}[X]=p\) বলে moment-মেলানোও \(\hat p = \bar X\) দিত — সব distribution-এ এই মিল হবে না, পরেই দেখব।)
৩.২ E2 — Normal \((\mu,\sigma^2)\): \(\hat\mu=\bar X,\ \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\)¶
পরিস্থিতি। \(X_i \sim \mathcal N(\mu,\sigma^2)\), দুটো অজানা parameter — গড় \(\mu\) ও variance \(\sigma^2\)। Normal-এর pdf:
ধাপ ১–২ (log-likelihood)। গুণফলের log = log-গুলোর যোগ; প্রতিটি পদে \(\log\big(\frac{1}{\sqrt{2\pi\sigma^2}}\big) = -\frac12\log(2\pi\sigma^2)\) আর \(\log\exp(\cdot) = (\cdot)\):
দুই parameter, তাই দুটো partial derivative শূন্য করব।
ধাপ ৩–৪ক (\(\mu\)-র সাপেক্ষে)। কেবল শেষ পদে \(\mu\) আছে; chain rule-এ
\(\sigma^2>0\) বলে \(\sum(X_i-\mu)=0 \Rightarrow \sum X_i = n\mu\), তাই
ধাপ ৩–৪খ (\(\sigma^2\)-র সাপেক্ষে)। \(\sigma^2\)-কে একটা চলক ভেবে derivative (\(\frac{\partial}{\partial\sigma^2}\log\sigma^2 = 1/\sigma^2\), এবং \(\frac{\partial}{\partial\sigma^2}\frac{1}{\sigma^2} = -\frac{1}{\sigma^4}\)):
\(2\sigma^4\) দিয়ে গুণ করে: \(-n\sigma^2 + \sum(X_i-\mu)^2 = 0\), আর \(\mu\)-র জায়গায় তার MLE \(\bar X\) বসিয়ে:
একটা গুরুত্বপূর্ণ মন্তব্য (পরে কাজে লাগবে)। লক্ষ করুন ভাজক \(n\), \(n-1\) নয়। অর্থাৎ MLE হলো সেই variance-অনুমান যার নাম আমরা \(\hat\sigma^2\) রেখেছি (\(n\)-ভাজক), 1.2-এর "নিরপেক্ষ" \(S^2\) (\(n-1\)-ভাজক) নয়। এর মানে MLE সত্য \(\sigma^2\)-কে গড়ে সামান্য কম আন্দাজ করে (biased) — MLE-র একটা স্বভাব, যা §৪-এ properties-এ খতিয়ে দেখা হবে। (\(\mu\)-র MLE অবশ্য \(\bar X\), যা নিরপেক্ষ।)
সংখ্যা। ধরি data \(4, 6, 8\) (\(n=3\))। \(\bar X = 18/3 = 6\), তাই \(\hat\mu = 6\)। বিচ্যুতি: \((4-6),(6-6),(8-6) = -2,0,2\); বর্গ \(4,0,4\); যোগ \(8\)। তাই \(\hat\sigma^2 = 8/3 \approx 2.67\) (তুলনায় \(S^2 = 8/2 = 4\))।
৩.৩ E3 — Exponential\((\lambda)\): \(\hat\lambda = 1/\bar X\)¶
পরিস্থিতি। \(X_i \sim \text{Exponential}(\lambda)\), \(\lambda>0\) = rate (হার); যেমন একটা যন্ত্রের ভাঙার মধ্যবর্তী সময়। pdf (\(x\ge 0\)):
ধাপ ১–২ (log-likelihood)। \(\log f(X_i;\lambda) = \log\lambda - \lambda X_i\), যোগ করে:
ধাপ ৩–৪ (score শূন্য)।
যেহেতু \(\sum X_i = n\bar X\):
ধাপ ৫ (চূড়া যাচাই)। \(\ell''(\lambda) = -\frac{n}{\lambda^2} < 0\) — সদা ঋণাত্মক, তাই চূড়া। ✓
Invariance-এর ঝলক। গড় আয়ু \(\mu = 1/\lambda\) অনুমান করতে চাইলে নতুন কিছু করতে হয় না — §২.৫-এর invariance বলে \(\hat\mu_{\text{MLE}} = 1/\hat\lambda_{\text{MLE}} = \bar X\)।
সংখ্যা। ভাঙার সময় (ঘণ্টা) \(2, 4, 6\) (\(n=3\)): \(\bar X = 12/3 = 4\), তাই \(\hat\lambda = 1/4 = 0.25\) প্রতি ঘণ্টা, আর গড় আয়ু \(\hat\mu = 4\) ঘণ্টা।
৩.৪ E4 — Uniform\((0,\theta)\): \(\hat\theta = \max_i X_i\) (derivative খাটে না!)¶
এই উদাহরণটাই §১.১-এর শোধ-করা ঋণ — এখানে recipe-র ধাপ ৩–৪ (derivative শূন্য) সম্পূর্ণ ব্যর্থ হবে, এবং MLE আর MoM আলাদা পথে যাবে।
পরিস্থিতি। \(X_i \sim \text{Uniform}(0,\theta)\) — \(0\) থেকে \(\theta\)-র মধ্যে সমান-সম্ভাব্য, \(\theta>0\) অজানা ঊর্ধ্বসীমা। pdf:
ধাপ ১ (likelihood — এখানেই মোচড়)। প্রতিটি পদ \(1/\theta\) — কিন্তু কেবল যদি \(\theta \ge X_i\) হয়; যদি কোনো \(X_i > \theta\) হয়, সেই পদ \(0\), পুরো গুণফল \(0\)। অর্থাৎ likelihood শূন্য না হওয়ার শর্ত: \(\theta\) অবশ্যই সব \(X_i\)-র চেয়ে বড়/সমান, মানে \(\theta \ge \max_i X_i\)। তাই:
ধাপ ৩–৪ ব্যর্থ — কেন। যেখানে \(L\) শূন্য নয় সেখানে \(L(\theta)=\theta^{-n}\), এর derivative \(-n\theta^{-n-1}\) কখনো \(0\) হয় না (সদা ঋণাত্মক)! "score = 0" সমাধান নেই। কারণটা ছবিতে স্পষ্ট: \(L(\theta)\) একটানা কমছে (\(\theta\) বাড়লে \(1/\theta^n\) ছোট হয়), কোনো মসৃণ চূড়া নেই। derivative-recipe ধরে নিয়েছিল চূড়া পরিসরের ভেতরে মসৃণভাবে বসে — এখানে তা ভুল।
সরাসরি যুক্তিতে চূড়া। \(L\) যেহেতু \(\theta\)-র সাথে কমে, তাকে যত ছোট রাখা যায় তত \(L\) বড়। কিন্তু \(\theta\) ইচ্ছেমতো ছোট করা যাবে না — শর্ত \(\theta \ge \max_i X_i\)। তাই \(L\) সর্বোচ্চ হয় ঠিক সবচেয়ে ছোট অনুমোদিত \(\theta\)-তে, অর্থাৎ:
(\(X_{(n)}\) মানে সাজানো data-র সবচেয়ে বড়টা।)
স্বজ্ঞা — কেন এটা গভীরভাবে যুক্তিসঙ্গত। \(\theta\) হলো সর্বোচ্চ সম্ভাব্য মান; data-তে যেহেতু \(\max_i X_i\) মানটা ইতিমধ্যে দেখা গেছে, \(\theta\) অন্তত ততটা বড় হতেই হবে (নইলে ওই মানটা আসত না)। আবার তার চেয়ে বড় করলে শুধু "ফাঁকা জায়গা" বাড়ে যেখানে কোনো data পড়েনি — তাতে likelihood কমে। তাই সবচেয়ে আঁটোসাঁটো ঊর্ধ্বসীমা, ঠিক \(\max_i X_i\), সবচেয়ে সম্ভাব্য।
MLE বনাম MoM — এখানেই পার্থক্য চোখে পড়ে। §১.১-এর data \(1,1,1,9\) নিন (\(n=4\), \(\bar X = 3\)):
- MoM: \(\hat\theta_{\text{MoM}} = 2\bar X = 6\) — কিন্তু data-তে \(9\) আছে, \(\theta=6\) অসম্ভব! (গড় ছাড়া MoM কিছু "দেখে" না।)
- MLE: \(\hat\theta_{\text{MLE}} = \max\{1,1,1,9\} = 9\) — সম্পূর্ণ যুক্তিসঙ্গত, কখনো অসম্ভব নয়, কারণ MLE পুরো data-র সীমা দেখে।
এই একটা উদাহরণেই MLE-র মূল সুবিধাটা ধরা পড়ে: পুরো data-র আকৃতি ব্যবহার করে বলে এটা অসম্ভব উত্তর দেয় না, যেখানে MoM শুধু গড় মিলিয়ে পথ হারায়। (MLE-র এই \(\max_i X_i\) সামান্য biased — সত্য \(\theta\)-কে গড়ে একটু কম আন্দাজ করে, কারণ নমুনার সর্বোচ্চ সাধারণত সত্য ঊর্ধ্বসীমার চেয়ে একটু ছোট; এই bias ও তার সংশোধন §৪-এ আলোচ্য।)
§৩-এর সার: চারটির মধ্যে তিনটিতে (E1–E3) মসৃণ "log → derivative → শূন্য" recipe সরাসরি \(\hat\theta\) দিল; চতুর্থটিতে (E4) likelihood-এর আকৃতি সরাসরি বিচার করে চূড়া পেতে হলো — এবং সেখানেই MLE-র শ্রেষ্ঠত্ব MoM-এর ওপর স্পষ্ট হলো।
৪ · প্রমাণ ও উৎপাদন¶
§৩-এ চারটি উদাহরণে আমরা সংখ্যায় MLE পেয়েছি; এই অংশে সেই উত্তরগুলোর পেছনের rigor — score-equation derivation, second-order (maximum) যাচাই, Uniform-এর non-differentiable যুক্তি ও invariance — scratch থেকে প্রমাণ করব। মনে রাখি Maximum Likelihood-এর নীতি: "যে parameter-এর মান হাতে-পাওয়া data-কে সবচেয়ে সম্ভাব্য করে তোলে, সেটাই আমার আন্দাজ।" গাণিতিকভাবে — likelihood \(L(\theta)=\prod_{i=1}^n f(X_i;\theta)\), এবং $$ \hat\theta_{\text{MLE}} \;=\; \arg\max_{\theta}\, L(\theta) \;=\; \arg\max_{\theta}\, \ell(\theta), \qquad \ell(\theta) \;=\; \sum_{i=1}^n \log f(X_i;\theta) . $$ এই অংশে সেই নীতিকে scratch থেকে কাজে লাগিয়ে আসল estimator-গুলো বের করব — কোনো ধাপ লুকানো হবে না, প্রতিটি লাইনের পেছনে কারণ বাংলায় থাকবে। কাজটা পাঁচ টুকরোয় ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে):
- (a) E1 Bernoulli — \(\ell(p)=k\log p+(n-k)\log(1-p)\) থেকে \(\ell'(p)=0\) সমাধান করে \(\hat p=\bar X\) বের করা, second-order check সহ। ★
- (b) E2 Normal\((\mu,\sigma^2)\) — দুই-parameter: \(\partial\ell/\partial\mu=0 \Rightarrow \hat\mu=\bar X\) এবং \(\partial\ell/\partial\sigma^2=0 \Rightarrow \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\)। ★★
- (c) E3 Exponential\((\lambda)\) — \(\ell'(\lambda)=0\) থেকে \(\hat\lambda=1/\bar X\)। ★
- (d) E4 Uniform\((0,\theta)\) — এখানে derivative চলবে না; likelihood \(=\theta^{-n}\cdot\mathbf 1\{\theta\ge \max_i X_i\}\), যা \(\theta\)-তে হ্রাসমান — তাই MLE \(=\max_i X_i\), যুক্তি আসবে monotonicity থেকে, derivative থেকে নয়। ★★
- (e) Invariance — যেকোনো function \(g\)-এর জন্য \(g(\theta)\)-এর MLE হলো \(g(\hat\theta_{\text{MLE}})\); কেন, এবং কীভাবে কাজে লাগে। ★★
এক নজরে যা মনে রাখবেন। MLE বের করার গোটা যন্ত্রটা প্রায় সবসময় একই তিন ধাপ: (i) \(\ell(\theta)=\sum_i\log f(X_i;\theta)\) লেখো (product-কে log করলে sum হয়, আর sum-এর derivative নেওয়া সহজ); (ii) score \(\ell'(\theta)=0\) বসিয়ে candidate বের করো; (iii) second-order (\(\ell''<0\)) দিয়ে নিশ্চিত করো এটা সত্যিই সর্বোচ্চ, সর্বনিম্ন বা inflection নয়। এই recipe-টা smooth, ভেতরের (interior) maximum-এর জন্য — কিন্তু (d) Uniform দেখাবে recipe-টা সর্বজনীন নয়: যেখানে maximum সীমানায় (boundary) বা likelihood non-differentiable, সেখানে derivative নয়, সরাসরি monotonicity-ই পথ দেখায়। সেটাই (d)-র মূল শিক্ষা।
পুরো অংশে নোটেশন এক রাখছি: \(f(x;\theta)\) হলো একটি observation-এর pmf/pdf (parameter \(\theta\)-সহ); i.i.d. ধরে নেওয়ায় যৌথ density factor হয়ে যায়, তাই $$ L(\theta) \;=\; \prod_{i=1}^n f(X_i;\theta), \qquad \ell(\theta) \;=\; \log L(\theta) \;=\; \sum_{i=1}^n \log f(X_i;\theta) , $$ আর score function \(\ell'(\theta)=\dfrac{d\ell}{d\theta}\) (একাধিক parameter হলে partial derivative-গুলোর vector)। মনে রাখুন — \(\log\) একটা কঠোরভাবে বর্ধমান (strictly increasing) function, তাই \(L\)-কে সর্বোচ্চ করা আর \(\ell=\log L\)-কে সর্বোচ্চ করা হুবহু একই \(\theta\)-তে ঘটে (এটা §২–৩-এ প্রতিষ্ঠিত); সেজন্যই আমরা নিশ্চিন্তে সহজতর \(\ell\) নিয়ে কাজ করি।
৪.১ · (a) E1 Bernoulli\((p)\) — score শূন্য করে \(\hat p=\bar X\) — ★¶
ধরা যাক \(X_1,\dots,X_n\) i.i.d. Bernoulli\((p)\) থেকে — প্রতিটি \(X_i\in\{0,1\}\) (যেমন মুদ্রা-ছোঁড়ায় head\(=1\)/tail\(=0\)), যেখানে \(p=P(X_i=1)\) একমাত্র অজানা parameter, \(0<p<1\)। লক্ষ্য: এই data থেকে \(\hat p_{\text{MLE}}\) বের করা।
ধাপ ১ — একটি observation-এর pmf এক সূত্রে লেখা। Bernoulli-র pmf-কে দুই-ক্ষেত্রের বদলে একটিমাত্র চটপটে সূত্রে লেখা যায় (2.3-এর সেই কৌশল): $$ f(x;p) \;=\; p^{\,x}\,(1-p)^{\,1-x}, \qquad x\in{0,1}. $$ যাচাই করুন কেন এটা ঠিক: \(x=1\) বসালে \(p^1(1-p)^0=p\) ✓; \(x=0\) বসালে \(p^0(1-p)^1=1-p\) ✓। দুটো ক্ষেত্রই এক সূত্রে ধরা পড়ল — এই compact রূপটাই product নেওয়ার সময় সোনার মতো কাজে দেবে।
ধাপ ২ — likelihood ও log-likelihood। i.i.d. ধরে product নিই: $$ L(p) \;=\; \prod_{i=1}^n p^{\,X_i}(1-p)^{\,1-X_i} \;=\; p^{\sum_i X_i}\,(1-p)^{\,n-\sum_i X_i} . $$ (কেন: একই ভিত্তি \(p\)-এর ঘাতগুলো যোগ হয়, \(\sum X_i\) পাই; আর \(1-p\)-এর ঘাতগুলো যোগ হয়ে \(\sum(1-X_i)=n-\sum X_i\)।) এবার সংক্ষেপ \(k:=\sum_{i=1}^n X_i\) লিখি — এটাই মোট "সাফল্য" সংখ্যা (কতবার \(1\) এল)। তাহলে \(L(p)=p^{k}(1-p)^{n-k}\)। log নিই (product → sum, ঘাত → গুণক): $$ \boxed{\;\ell(p) \;=\; k\log p \;+\; (n-k)\log(1-p)\;}. $$ এটাই brief-এ দেওয়া রূপ — এবং এখান থেকেই পুরো derivation।
ধাপ ৩ — score function বের করি (\(\ell'(p)\))। \(p\)-এর সাপেক্ষে derivative নিই। মনে রাখুন \(\frac{d}{dp}\log p=\frac1p\), আর chain rule-এ \(\frac{d}{dp}\log(1-p)=\frac{1}{1-p}\cdot(-1)=-\frac{1}{1-p}\): $$ \ell'(p) \;=\; \frac{k}{p} \;-\; \frac{n-k}{1-p} . $$
ধাপ ৪ — score শূন্য করে candidate বের করি। maximum-এর শর্ত \(\ell'(p)=0\): $$ \frac{k}{p} \;=\; \frac{n-k}{1-p} . $$ আড়াআড়ি গুণ (cross-multiply) করি: $$ k\,(1-p) \;=\; (n-k)\,p \quad\Longrightarrow\quad k - kp \;=\; np - kp \quad\Longrightarrow\quad k \;=\; np . $$ (\(-kp\) দুদিকে কাটাকাটি গেল।) তাই $$ \boxed{\;\hat p_{\text{MLE}} \;=\; \frac{k}{n} \;=\; \frac{1}{n}\sum_{i=1}^n X_i \;=\; \bar X\;}. $$ চমৎকার স্বজ্ঞাময় — head আসার probability-র সেরা আন্দাজ হলো head আসার সাধারণ ভগ্নাংশ (\(k/n\))। §১.২-এর সেই "১০ বারে ৯ head ⇒ \(\hat p=0.9\)" এখন গাণিতিকভাবে MLE হিসেবে প্রমাণিত।
ধাপ ৫ — second-order check: এটা কি সত্যিই সর্বোচ্চ? \(\ell'(p)=0\) শুধু একটা stationary point চিহ্নিত করে — তা সর্বোচ্চ, সর্বনিম্ন, না inflection, তা নিশ্চিত করতে দ্বিতীয় derivative লাগে। আবার derivative নিই: $$ \ell''(p) \;=\; \frac{d}{dp}!\left(\frac{k}{p} - \frac{n-k}{1-p}\right) \;=\; -\frac{k}{p^2} \;-\; \frac{n-k}{(1-p)^2} . $$ (এখানে \(\frac{d}{dp}\frac{1}{1-p}=\frac{1}{(1-p)^2}\), তাই দ্বিতীয় পদে \(-(n-k)\cdot\frac{1}{(1-p)^2}\)।) লক্ষ করুন — \(0<p<1\) এবং \(k\ge0,\ n-k\ge0\) হওয়ায় উভয় পদই ঋণাত্মক, তাই $$ \ell''(p) \;<\; 0 \qquad \text{সর্বত্র } (0,1)\text{-তে}. $$ \(\ell\) পুরো ব্যবধানে strictly concave — মানে এর একটিমাত্র চূড়া, আর আমাদের পাওয়া \(\hat p=\bar X\) ঠিক সেই global maximum। (concavity নিশ্চিত করে আমরা কোনো ভুল চূড়ায় আটকাইনি।) \(\;\blacksquare\)
সীমানার দিকে এক ঝলক। যদি \(k=0\) (একটিও সাফল্য নয়) হয়, \(\hat p=0\); \(k=n\) হলে \(\hat p=1\) — এরা প্যারামিটার-স্থানের প্রান্তে, যেখানে \(\ell\) (\(\log 0\)-এর কারণে) \(-\infty\)-এর দিকে যায়, তবু \(k/n\) সূত্রটা ঠিকই সীমা-মান দেয়। interior \(0<k<n\)-এ derivation নির্ঝঞ্ঝাট।
৪.২ · (b) E2 Normal\((\mu,\sigma^2)\) — দুই parameter, দুই partial derivative — ★★¶
ধরা যাক \(X_1,\dots,X_n\) i.i.d. \(\mathcal N(\mu,\sigma^2)\) থেকে — গড় \(\mu\) ও variance \(\sigma^2\) দুটোই অজানা (\(\theta=(\mu,\sigma^2)\))। দুই অজানা, তাই দুটো শর্ত লাগবে: \(\ell\)-কে \(\mu\) ও \(\sigma^2\) — উভয়ের সাপেক্ষে stationary করতে হবে। এটাই MLE-র multi-parameter রূপের প্রথম পূর্ণ উদাহরণ।
ধাপ ১ — একটি observation-এর pdf, তারপর log-likelihood। Normal density (2.4): $$ f(x;\mu,\sigma^2) \;=\; \frac{1}{\sqrt{2\pi\sigma^2}}\,\exp!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right). $$ এর log নিই — এখানেই \(\log\)-এর জাদু: exponential মুছে যায়, ভগ্নাংশ যোগ-বিয়োগে ভাঙে। $$ \log f(x;\mu,\sigma^2) \;=\; -\tfrac12\log(2\pi) \;-\; \tfrac12\log\sigma^2 \;-\; \frac{(x-\mu)^2}{2\sigma^2} . $$ (\(\log\frac{1}{\sqrt{2\pi\sigma^2}} = -\tfrac12\log(2\pi\sigma^2) = -\tfrac12\log(2\pi)-\tfrac12\log\sigma^2\); আর \(\log e^{(\cdot)}=(\cdot)\)।) এবার \(n\)টা পদ যোগ করি: $$ \boxed{\;\ell(\mu,\sigma^2) \;=\; -\frac n2\log(2\pi) \;-\; \frac n2\log\sigma^2 \;-\; \frac{1}{2\sigma^2}\sum_{i=1}^n (X_i-\mu)^2\;}. $$ প্রথম পদ (\(-\frac n2\log 2\pi\)) একটা ধ্রুবক — \(\mu,\sigma^2\)-এর উপর নির্ভর করে না, তাই derivative নিলে শূন্য হবে; তবু সম্পূর্ণতার জন্য রাখলাম।
ধাপ ২ — \(\mu\)-এর সাপেক্ষে partial derivative (\(\sigma^2\) স্থির ধরে)। শুধু শেষ পদে \(\mu\) আছে। chain rule: \(\frac{\partial}{\partial\mu}(X_i-\mu)^2 = 2(X_i-\mu)\cdot(-1) = -2(X_i-\mu)\)। তাই $$ \frac{\partial\ell}{\partial\mu} \;=\; -\frac{1}{2\sigma^2}\sum_{i=1}^n \big(!-2(X_i-\mu)\big) \;=\; \frac{1}{\sigma^2}\sum_{i=1}^n (X_i-\mu) . $$
ধাপ ৩ — \(\partial\ell/\partial\mu=0\) সমাধান। \(\sigma^2>0\), তাই শূন্য হতে গেলে যোগফলটাই শূন্য হতে হবে: $$ \sum_{i=1}^n (X_i-\mu) \;=\; 0 \quad\Longrightarrow\quad \sum_{i=1}^n X_i \;-\; n\mu \;=\; 0 \quad\Longrightarrow\quad \boxed{\;\hat\mu_{\text{MLE}} \;=\; \frac1n\sum_{i=1}^n X_i \;=\; \bar X\;}. $$ লক্ষ করুন — এটা \(\sigma^2\)-এর মান যা-ই হোক, একই (\(\sigma^2\) কেটে গেল)। অর্থাৎ গড়ের MLE হলো sample mean, variance যত বড়-ছোটই হোক। এটাই প্রত্যাশিত: Normal-এ \(\mu\) হলো কেন্দ্র, আর data-র কেন্দ্রের সেরা আন্দাজ গড়।
ধাপ ৪ — \(\sigma^2\)-এর সাপেক্ষে partial derivative (\(\mu\) স্থির ধরে)। সুবিধার জন্য \(v:=\sigma^2\) লিখি (একটা একক চলক হিসেবে ভাবলে derivative পরিষ্কার)। \(\ell\)-এ \(v\) আছে দুই পদে: \(-\frac n2\log v\) আর \(-\frac{1}{2v}\sum(X_i-\mu)^2\)। derivative: $$ \frac{\partial\ell}{\partial v} \;=\; -\frac n2\cdot\frac1v \;+\; \Big(-\tfrac12\sum_i(X_i-\mu)^2\Big)\cdot\frac{d}{dv}\Big(\frac1v\Big). $$ এখানে \(\frac{d}{dv}(v^{-1})=-v^{-2}\), তাই দ্বিতীয় পদ \(=-\tfrac12\sum(X_i-\mu)^2\cdot(-v^{-2})=+\frac{1}{2v^2}\sum(X_i-\mu)^2\)। সব মিলিয়ে: $$ \frac{\partial\ell}{\partial v} \;=\; -\frac{n}{2v} \;+\; \frac{1}{2v^2}\sum_{i=1}^n (X_i-\mu)^2 . $$
ধাপ ৫ — \(\partial\ell/\partial v=0\) সমাধান (এবং \(\mu=\hat\mu\) বসানো)। শূন্য করি, দুই পাশে \(2v^2\) গুণ (যেহেতু \(v>0\)): $$ -\,n v \;+\; \sum_{i=1}^n (X_i-\mu)^2 \;=\; 0 \quad\Longrightarrow\quad v \;=\; \frac1n\sum_{i=1}^n (X_i-\mu)^2 . $$ এখন \(\mu\)-এর জায়গায় তার নিজের MLE \(\hat\mu=\bar X\) বসাই (দুটো শর্ত একসাথে সমাধান করছি — এটাই joint maximisation): $$ \boxed{\;\hat\sigma^2_{\text{MLE}} \;=\; \frac1n\sum_{i=1}^n (X_i-\bar X)^2\;}. $$
খেয়াল করুন — হরে \(n\), \(n-1\) নয় (4.2-এর সেই সুর আবার)। MLE ঠিক MoM-এর মতোই \(\frac1n\) দেয় (4.2 §৪.১-এ MoM-ও এই \(\frac1n\) পেয়েছিল)। দুই ভিন্ন নীতি — moment-matching ও likelihood — Normal-এর variance-এ একই উত্তরে এসে মিলল, এটা সুন্দর সমাপতন। কিন্তু এই \(\hat\sigma^2\) সামান্য biased: \(\mathbb E[\hat\sigma^2]=\frac{n-1}{n}\sigma^2<\sigma^2\) (গড়ে একটু কম আঁচ, কারণ একই data থেকে \(\bar X\) অনুমান করায় এক "degree of freedom" খরচ হয়)। তাই অনেকে unbiased \(\frac{1}{n-1}\)-রূপ ব্যবহার করেন। MLE unbiasedness-এর প্রতিশ্রুতি দেয় না — এটা §৬-এর property-আলোচনায় ফিরবে; এখানে মূল বার্তা: likelihood-সমীকরণ সরাসরি \(\frac1n\)-ই দেয়।
ধাপ ৬ — maximum যাচাই (স্কেচ, ★★)। দুই-চলকের ক্ষেত্রে maximum নিশ্চিত করতে Hessian (দ্বিতীয়-derivative-এর matrix) negative-definite হওয়া দরকার। স্থির \(\sigma^2\)-এ \(\ell\) হলো \(\mu\)-তে একটা ঊর্ধ্বমুখী-খোলা parabola-র ঋণাত্মক — অর্থাৎ \(\frac{\partial^2\ell}{\partial\mu^2}=-\frac{n}{\sigma^2}<0\) (concave in \(\mu\))। আর \((\hat\mu,\hat\sigma^2)\)-তে বসিয়ে দেখা যায় cross-term (\(\partial^2\ell/\partial\mu\partial v\), যেখানে \(\sum(X_i-\hat\mu)=0\)) শূন্য হয়ে যায়, ফলে Hessian কর্ণীয় (diagonal) ও উভয় কর্ণ-পদ ঋণাত্মক — তাই negative-definite, অর্থাৎ \((\bar X,\ \frac1n\sum(X_i-\bar X)^2)\) সত্যিই একটি local (এবং একমাত্র, তাই global) maximum। পূর্ণ Hessian-হিসাব ★★-এর সীমার একটু বাইরে, তাই কাঠামোটা দিলাম; §৫-এ আমরা 2-D log-likelihood সরাসরি plot-করে চোখেও দেখব এর একটিমাত্র চূড়া। \(\;\blacksquare\)
৪.৩ · (c) E3 Exponential\((\lambda)\) — score শূন্য করে \(\hat\lambda=1/\bar X\) — ★¶
ধরা যাক \(X_1,\dots,X_n\) i.i.d. Exponential\((\lambda)\) থেকে (rate-parametrization) — যেমন পরপর দুটো request-এর মধ্যেকার অপেক্ষা-সময়, বা একটা যন্ত্রাংশের আয়ু। একমাত্র অজানা rate \(\lambda>0\)।
ধাপ ১ — pdf ও log-likelihood। Exponential density (2.4): \(f(x;\lambda)=\lambda e^{-\lambda x}\) (\(x\ge0\))। log নিই: $$ \log f(x;\lambda) \;=\; \log\lambda \;-\; \lambda x . $$ \(n\)টা পদ যোগ করি (\(\sum_i x_i\) এক জায়গায় জড়ো হয়): $$ \boxed{\;\ell(\lambda) \;=\; n\log\lambda \;-\; \lambda\sum_{i=1}^n X_i\;}. $$ লক্ষ করুন — পুরো data-র মধ্যে দরকার শুধু একটা সংখ্যা: যোগফল \(\sum X_i\) (একে বলে sufficient statistic, §৬-এ পরিচয়)।
ধাপ ২ — score। $$ \ell'(\lambda) \;=\; \frac{n}{\lambda} \;-\; \sum_{i=1}^n X_i . $$ (\(\frac{d}{d\lambda}(n\log\lambda)=\frac n\lambda\); আর \(\frac{d}{d\lambda}\big(-\lambda\sum X_i\big)=-\sum X_i\), যেহেতু \(\sum X_i\) ধ্রুবক।)
ধাপ ৩ — score শূন্য করে সমাধান। $$ \frac{n}{\lambda} \;=\; \sum_{i=1}^n X_i \quad\Longrightarrow\quad \lambda \;=\; \frac{n}{\sum_i X_i} \;=\; \frac{1}{\frac1n\sum_i X_i} \quad\Longrightarrow\quad \boxed{\;\hat\lambda_{\text{MLE}} \;=\; \frac{1}{\bar X}\;}. $$ স্বজ্ঞাময় — rate-এর সেরা আন্দাজ হলো গড় অপেক্ষা-সময়ের উল্টো। গড়ে প্রতি \(2\) মিনিটে একটা request এলে (\(\bar X=2\)) rate-এর আন্দাজ \(\hat\lambda=0.5\)/মিনিট। (এবং লক্ষণীয় — এটাও 4.2-এর MoM-উত্তর \(1/\bar X\)-এর হুবহু সমান; Exponential-এ MoM ও MLE মিলে যায়।)
ধাপ ৪ — second-order check। $$ \ell''(\lambda) \;=\; \frac{d}{d\lambda}!\left(\frac n\lambda - \sum_i X_i\right) \;=\; -\frac{n}{\lambda^2} \;<\;0 \qquad(\lambda>0). $$ সর্বত্র ঋণাত্মক, তাই \(\ell\) strictly concave — আমাদের পাওয়া \(\hat\lambda=1/\bar X\) নিশ্চিতভাবে global maximum। \(\;\blacksquare\)
৪.৪ · (d) E4 Uniform\((0,\theta)\) — derivative নয়, monotonicity — ★★¶
এবার একটি সাবধানতার উদাহরণ — যেখানে "score শূন্য করো" recipe-টা ভেঙে পড়ে, আর সঠিক উত্তর আসে সম্পূর্ণ ভিন্ন যুক্তিতে। ধরা যাক \(X_1,\dots,X_n\) i.i.d. Uniform\((0,\theta)\) থেকে — \(0\) থেকে \(\theta\)-র মধ্যে সমভাবে ছড়ানো, যেখানে উপরের সীমা \(\theta>0\) অজানা।
ধাপ ১ — একটি observation-এর pdf, এবং তার লুকানো শর্ত। Uniform\((0,\theta)\)-এর density: $$ f(x;\theta) \;=\; \begin{cases} \dfrac{1}{\theta}, & 0\le x\le \theta,\[4pt] 0, & \text{অন্যথায়.} \end{cases} $$ এই "অন্যথায় \(0\)" অংশটাই গোটা গল্পের নায়ক — সাধারণত যা উপেক্ষা করি, এখানে সেটাই নির্ণায়ক। indicator (নির্দেশক) চিহ্ন দিয়ে এক সূত্রে লিখি: $$ f(x;\theta) \;=\; \frac{1}{\theta}\,\mathbf 1{0\le x\le \theta}, $$ যেখানে \(\mathbf 1\{A\}\) মানে — শর্ত \(A\) সত্য হলে \(1\), নইলে \(0\)।
ধাপ ২ — likelihood ও তার সীমানা-শর্ত। product নিই: $$ L(\theta) \;=\; \prod_{i=1}^n \frac{1}{\theta}\,\mathbf 1{0\le X_i\le\theta} \;=\; \frac{1}{\theta^n}\,\prod_{i=1}^n \mathbf 1{0\le X_i\le\theta} . $$ এখন মূল পর্যবেক্ষণ — indicator-গুলোর গুণফল \(1\) হবে কেবল তখনই, যখন প্রতিটি \(X_i\le\theta\), অর্থাৎ যখন সবচেয়ে বড় observation-ও \(\theta\)-র নিচে থাকে। আর "সব \(X_i\le\theta\)" মানে ঠিক "\(\max_i X_i\le\theta\)"। (যেহেতু সব data ধনাত্মক, \(0\le X_i\) আপনিই সত্য।) তাই $$ \prod_{i=1}^n \mathbf 1{0\le X_i\le\theta} \;=\; \mathbf 1{\theta\ge \max_i X_i}, $$ এবং likelihood দাঁড়ায়: $$ \boxed{\;L(\theta) \;=\; \theta^{-n}\,\cdot\,\mathbf 1{\theta\ge \max_i X_i}\;}. $$ এই রূপটা brief-এর দেওয়া রূপ — এবং এর আকৃতিই সব বলে দেয়।
ধাপ ৩ — কেন derivative এখানে চলবে না। স্বাভাবিক প্রবৃত্তিতে আমরা \(\frac{dL}{d\theta}=0\) বসাতে যাব। কিন্তু দেখুন \(L(\theta)\)-এর চেহারা:
- \(\theta < \max_i X_i\) হলে indicator \(=0\), তাই \(L(\theta)=0\) (এই \(\theta\) অসম্ভব — কারণ তাহলে একটা \(X_i\) থাকত যা \(\theta\) ছাড়িয়ে গেছে, অথচ Uniform\((0,\theta)\) তা হতে দেয় না);
- \(\theta \ge \max_i X_i\) হলে indicator \(=1\), তাই \(L(\theta)=\theta^{-n}\)।
অর্থাৎ \(L\) ঠিক \(\theta=\max_i X_i\) বিন্দুতে \(0\) থেকে এক লাফে \((\max_i X_i)^{-n}\)-এ ওঠে — সেখানে function-টা অবিচ্ছিন্ন নয়, derivative নেই। আর \(\theta>\max_i X_i\) অঞ্চলে \(L(\theta)=\theta^{-n}\) একটা মসৃণ হ্রাসমান curve, যার derivative \(-n\theta^{-n-1}\) কোথাও \(0\) হয় না (সর্বত্র ঋণাত্মক)। সুতরাং "\(\ell'=0\)" সমীকরণের কোনো সমাধানই নেই — recipe সম্পূর্ণ নিরুত্তর। maximum এখানে derivative-এর জায়গায় নয়, সীমানায় (boundary)।
ধাপ ৪ — সঠিক যুক্তি: monotonicity। derivative বাদ দিয়ে সরাসরি function-এর আকৃতি দেখি। কোন \(\theta\) \(L\)-কে সর্বোচ্চ করে?
- \(\theta\)-কে \(\max_i X_i\)-এর নিচে নেওয়া যাবে না — তাহলে \(L=0\) (সবচেয়ে খারাপ)। তাই feasible \(\theta\) অবশ্যই \(\ge\max_i X_i\)।
- feasible অঞ্চলে (\(\theta\ge\max_i X_i\)) \(L(\theta)=\theta^{-n}\), যা \(\theta\) বাড়লে কঠোরভাবে কমে (যেহেতু \(n\ge1\), বড় হর মানে ছোট মান)।
দুটো মিলিয়ে: \(L\) সর্বোচ্চ হবে feasible অঞ্চলের সবচেয়ে বাঁ-প্রান্তে — অর্থাৎ যত ছোট \(\theta\) নেওয়া যায় ততই ভালো, কিন্তু \(\max_i X_i\)-এর নিচে নামা নিষেধ। তাই সর্বোচ্চ ঠিক সীমানায়: $$ \boxed{\;\hat\theta_{\text{MLE}} \;=\; \max_{1\le i\le n} X_i\;}. $$ স্বজ্ঞাটা অপূর্ব: আমরা \(\theta\)-কে যতটা সম্ভব ছোট রাখতে চাই (কারণ \(\theta^{-n}\) ছোট \(\theta\)-তে বড়), কিন্তু এত ছোট নয় যে কোনো observed data অসম্ভব হয়ে পড়ে — তাই ঠিক বৃহত্তম data-বিন্দুতে থামি। এটাই সেই "smallest box that still contains all the data" নীতি।
MoM-এর সাথে তীক্ষ্ণ তুলনা (4.2-এর সুতো ধরে)। 4.2 §৪.১-এ Uniform-এর জন্য MoM দিয়েছিল \(\hat\theta_{\text{MoM}}=2\bar X\), আর সেখানেই সতর্ক করা হয়েছিল — \(2\bar X\) অনায়াসে কোনো observed \(X_i\)-এর চেয়ে ছোট হতে পারে, যা অসম্ভব (\(\theta\ge\max_i X_i\) সর্বদা সত্য)। MLE সেই দোষ থেকে মুক্ত: \(\max_i X_i\) সংজ্ঞা থেকেই সর্বদা feasible। তবু একটা সূক্ষ্মতা — \(\max_i X_i\) সর্বদা সত্য \(\theta\)-র সামান্য নিচে থাকে (কোনো নমুনাই \(\theta\) ছাড়াতে পারে না), তাই এটা একটু biased; কিন্তু §৫-এ সংখ্যায় দেখব এর MSE তবু \(2\bar X\)-এর চেয়ে নাটকীয়ভাবে ছোট — কারণ এর ভ্যারিয়েন্স \(1/n^2\)-হারে কমে (\(2\bar X\) কমে ধীর \(1/n\)-হারে)। এই তুলনাটাই §৫-এর Part 4-এর প্রাণ। \(\;\blacksquare\)
এক বাক্যে শিক্ষা। যখন parameter density-র support-কে (যে অঞ্চলে density শূন্য নয়) নিয়ন্ত্রণ করে — যেমন Uniform-এর উপরের সীমা \(\theta\) — তখন likelihood প্রায়ই সীমানায় সর্বোচ্চ, derivative নিরুপায়, আর সঠিক অস্ত্র monotonicity। এই ধরনের সমস্যাকে বলে non-regular (অনিয়মিত) estimation, যেখানে standard "score=0" তত্ত্ব খাটে না।
৪.৫ · (e) Invariance — \(g(\theta)\)-এর MLE = \(g(\hat\theta_{\text{MLE}})\) — ★★¶
MLE-র সবচেয়ে কাজের ধর্মগুলোর একটা হলো এর invariance (অপরিবর্তনীয়তা): একবার \(\hat\theta_{\text{MLE}}\) পেয়ে গেলে, \(\theta\)-র যেকোনো function-এর MLE পেতে আর নতুন করে কিছু optimize করতে হয় না — শুধু সেই function-টা \(\hat\theta\)-তে বসিয়ে দিলেই হয়।
বিবৃতি (Invariance property)। ধরা যাক \(\hat\theta_{\text{MLE}}\) হলো \(\theta\)-র MLE, আর \(\tau=g(\theta)\) হলো \(\theta\)-র একটা function (আমরা যে নতুন রাশিতে আগ্রহী)। তবে \(\tau\)-এর MLE হলো $$ \boxed{\;\hat\tau_{\text{MLE}} \;=\; g(\hat\theta_{\text{MLE}})\;}. $$
কেন — সরল ক্ষেত্র (\(g\) one-to-one)। ধরা যাক \(g\) একটা এক-এক (invertible) function, তাই \(\theta=g^{-1}(\tau)\)। আমরা likelihood-কে নতুন parameter \(\tau\)-এর ভাষায় লিখি: \(L^\ast(\tau):=L\big(g^{-1}(\tau)\big)\)। এখন মূল যুক্তি — \(\tau\)-এর উপর \(L^\ast\) সর্বোচ্চ হয় ঠিক তখন, যখন ভেতরের \(\theta=g^{-1}(\tau)\) মান \(L\)-কে সর্বোচ্চ করে; কিন্তু \(L\) সর্বোচ্চ হয় \(\theta=\hat\theta_{\text{MLE}}\)-তে (সংজ্ঞা)। তাই \(L^\ast\)-এর চূড়া ঐ \(\tau\)-তে, যেখানে \(g^{-1}(\tau)=\hat\theta\), অর্থাৎ \(\tau=g(\hat\theta)\)। সংক্ষেপে — reparametrize করলে চূড়ার অবস্থান বদলায় না, শুধু তার "label" বদলায়: পুরোনো label \(\hat\theta\), নতুন label \(g(\hat\theta)\)। \(\;\blacksquare\)
কেন এটা গভীর (general \(g\))। \(g\) যদি এক-এক না-ও হয় (যেমন \(g(\theta)=\theta^2\), যা \(+\theta\) ও \(-\theta\)-কে একই জায়গায় পাঠায়), তখন "\(\tau\)-এর likelihood" সরাসরি সংজ্ঞায়িত করা যায় না। সমাধান — induced (আরোপিত) likelihood: \(\tau\)-এর জন্য likelihood ধরা হয় \(L^\ast(\tau)=\sup_{\{\theta:\,g(\theta)=\tau\}} L(\theta)\) (যে সব \(\theta\) একই \(\tau\) দেয়, তাদের মধ্যে সর্বোচ্চ likelihood)। এই সংজ্ঞা-সহ উপরের ফল হুবহু টেকে — পূর্ণ প্রমাণ ★★-এর একটু বাইরে, তাই এখানে এক-এক ক্ষেত্রের পরিষ্কার যুক্তিটাই মূল, আর general ক্ষেত্রে ফলটা একই থাকে বলে জানিয়ে রাখছি।
running examples-এ invariance — তাৎক্ষণিক ফসল:
- E1 (Bernoulli). \(\hat p=\bar X\)। ধরা যাক আমরা চাই odds \(\tau=\dfrac{p}{1-p}\)-এর MLE। আলাদা করে কিছু না করে, সরাসরি: \(\hat\tau=\dfrac{\hat p}{1-\hat p}=\dfrac{\bar X}{1-\bar X}\)। (logistic regression-এর odds ঠিক এভাবেই আসে।)
- E2 (Normal). \(\hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\) থেকে standard deviation \(\sigma=\sqrt{\sigma^2}\)-এর MLE সরাসরি \(\hat\sigma=\sqrt{\hat\sigma^2}=\sqrt{\frac1n\sum(X_i-\bar X)^2}\) — কোনো নতুন optimization নয়। (যেহেতু \(g(v)=\sqrt v\) এক-এক ও বর্ধমান \(v>0\)-তে, সরল ক্ষেত্রটাই খাটে।)
- E3 (Exponential). \(\hat\lambda=1/\bar X\)। Exponential-এর গড় \(\mu=1/\lambda\), তাই গড়ের MLE \(\hat\mu=1/\hat\lambda=\bar X\) — চমৎকারভাবে আবার sample mean। আবার, median \(=\frac{\ln 2}{\lambda}\), তাই median-এর MLE সরাসরি \(\frac{\ln 2}{\hat\lambda}=\bar X\ln 2\)। একটাই \(\hat\lambda\) থেকে যত খুশি derived রাশির MLE বিনা পরিশ্রমে। (§৫-এ এই "\(1/\hat\lambda=\bar X\)" সমতা আমরা সংখ্যায় ছাপিয়েও দেখব।)
কেন invariance এত মূল্যবান। বাস্তবে আমরা প্রায়ই original parameter-এ নয়, তার কোনো রূপান্তরে আগ্রহী — rate নয় বরং mean, variance নয় বরং SD, probability নয় বরং odds বা log-odds। invariance বলে: মূল parameter-এর MLE একবার বের করো, তারপর যত function লাগে সব ওই একই উত্তরে বসিয়ে নাও — প্রতিবার নতুন করে maximize করতে হবে না। MoM-এর এমন কোনো সাধারণ গ্যারান্টি নেই; এটা MLE-র একটা স্বতন্ত্র সুবিধা।
৪.৬ · সারমর্ম: পাঁচটি ফল এক টেবিলে¶
| ফল | difficulty | মূল পদ্ধতি | \(\hat\theta_{\text{MLE}}\) |
|---|---|---|---|
| (a) E1 Bernoulli | ★ | \(\ell'(p)=\frac kp-\frac{n-k}{1-p}=0\), \(\ell''<0\) | \(\hat p=\bar X\) |
| (b) E2 Normal | ★★ | \(\partial_\mu\ell=0\) ও \(\partial_{\sigma^2}\ell=0\) (joint) | \(\hat\mu=\bar X,\ \ \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\) |
| (c) E3 Exponential | ★ | \(\ell'(\lambda)=\frac n\lambda-\sum X_i=0\), \(\ell''<0\) | \(\hat\lambda=1/\bar X\) |
| (d) E4 Uniform\((0,\theta)\) | ★★ | derivative নয় — \(L=\theta^{-n}\mathbf 1\{\theta\ge\max\}\) হ্রাসমান, তাই boundary | \(\hat\theta=\max_i X_i\) |
| (e) Invariance | ★★ | reparametrize-এ চূড়ার label বদলায়, অবস্থান নয় | \(\widehat{g(\theta)}=g(\hat\theta_{\text{MLE}})\) |
মূল ছবি দুই স্তরে। প্রথম স্তর — smooth, interior maximum (a,b,c): recipe একই — \(\ell=\sum\log f\) লেখো, score \(=0\) বসিয়ে candidate পাও, \(\ell''<0\) (বা Hessian negative-definite) দিয়ে সর্বোচ্চ নিশ্চিত করো। এতে Bernoulli, Normal, Exponential-এর সব MLE বেরিয়ে এল, এবং লক্ষণীয়ভাবে তিনটেই 4.2-এর MoM-উত্তরের সাথে মিলে গেল। দ্বিতীয় স্তর — boundary maximum (d): Uniform দেখাল recipe সর্বজনীন নয় — support যখন parameter-নির্ভর, derivative নিরুপায়, আর monotonicity-ই সঠিক অস্ত্র; উত্তর \(\max_i X_i\), যা MoM-এর \(2\bar X\)-এর চেয়ে শ্রেয়। শেষে (e) invariance পুরো কাঠামোকে বহুগুণ ফলপ্রসূ করে — একটা MLE থেকে অসংখ্য derived রাশির MLE বিনা শ্রমে। পরের §৫-এ আমরা এই পাঁচটিই সংখ্যায় যাচাই করব: grid ও scipy.optimize দিয়ে argmax খুঁজে closed-form-এর সাথে মিলিয়ে।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর ফলগুলোকে আমরা সংখ্যায় যাচাই করব — যাতে MLE কাগজে নয় শুধু, computer-এও বিশ্বাসযোগ্য হয়। মূল কৌশল: প্রতিটা ক্ষেত্রে log-likelihood \(\ell(\theta)\) সরাসরি বানিয়ে তার argmax তিন স্বাধীন উপায়ে বের করব — (a) ঘন grid-এ সব মান গুনে সর্বোচ্চ, (b) scipy.optimize দিয়ে (negative log-likelihood মিনিমাইজ করে), আর (c) §৪-এ derive-করা closed form — তারপর দেখব তিনটে এক জায়গায় মেলে। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয়।)
চারটে অংশ, ঠিক §৪-এর উদাহরণ অনুসরণ করে:
- Part 1 — Bernoulli (§৪.১)। \(\ell(p)=k\log p+(n-k)\log(1-p)\)-এর argmax grid ও optimizer দিয়ে বের করে closed form \(\hat p=k/n=\bar X\)-এর সাথে মেলানো।
- Part 2 — Exponential (§৪.৩ + invariance §৪.৫)। \(\ell(\lambda)=n\log\lambda-\lambda\sum X_i\)-এর argmax তিন উপায়ে; closed form \(\hat\lambda=1/\bar X\) যাচাই; আর invariance দিয়ে গড়ের MLE \(1/\hat\lambda=\bar X\) মিলিয়ে দেখা।
- Part 3 — Normal 2-D (§৪.২)। দুই-parameter \(\ell(\mu,\sigma^2)\)-কে \((\mu,\sigma^2)\)-grid-এ maximize করে closed form \(\hat\mu=\bar X,\ \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\)-এর সাথে মেলানো।
- Part 4 — Uniform\((0,\theta)\) (§৪.৪)। প্রথমে দেখানো likelihood \(\theta^{-n}\) \(\theta\ge\max\)-এ হ্রাসমান (তাই argmax \(=\max\)); তারপর Monte-Carlo-তে MLE \(=\max_i X_i\) বনাম MoM \(=2\bar X\)-এর bias/variance/MSE পাশাপাশি — MLE ভালো তা সংখ্যায় ধরা।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.3 — Maximum Likelihood Estimation (MLE) : Code Lab
# Numerically illustrates / verifies:
# PART 1 — Bernoulli: log-likelihood argmax by (grid) and (scipy.optimize),
# checked against the closed form phat = k/n = Xbar.
# PART 2 — Exponential: same three ways, closed form lambdahat = 1/Xbar;
# invariance check MLE of mean = 1/lambdahat = Xbar.
# PART 3 — Normal(mu, sigma^2): 2-D log-likelihood; grid argmax over (mu, sigma^2)
# vs closed forms muhat = Xbar, sigma2hat = (1/n) sum (X-Xbar)^2.
# PART 4 — Uniform(0,theta): likelihood theta^-n is DECREASING for theta >= max,
# so MLE = max(X_i); Monte-Carlo shows it beats MoM = 2*Xbar (bias/var/MSE).
import numpy as np
from scipy import optimize
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=6, suppress=True)
# ===============================================================
# PART 1 — BERNOULLI(p): l(p) = k log p + (n-k) log(1-p), k = sum X_i.
# Closed form hat(p)_MLE = k/n = Xbar.
# ===============================================================
print("=" * 66)
print("PART 1 — Bernoulli(p): log-likelihood argmax (grid / optimizer / closed form)")
print("=" * 66)
p_true = 0.30
n = 200
X = (rng.random(n) < p_true).astype(float)
k = int(X.sum())
print(f" data: n = {n}, successes k = {k}, Xbar = k/n = {k/n:.6f}")
def loglik_bern(p, k, n):
p = np.clip(p, 1e-12, 1 - 1e-12) # keep log finite on the open interval (0,1)
return k * np.log(p) + (n - k) * np.log(1.0 - p)
# (a) GRID search over p in (0,1)
grid = np.linspace(1e-4, 1 - 1e-4, 200_001)
p_grid = grid[np.argmax(loglik_bern(grid, k, n))]
# (b) scipy.optimize: minimize the NEGATIVE log-likelihood
res = optimize.minimize_scalar(lambda p: -loglik_bern(p, k, n),
bounds=(1e-9, 1 - 1e-9), method="bounded")
p_opt = res.x
# (c) CLOSED FORM
p_closed = k / n
print(f" (a) grid argmax hat(p) = {p_grid:.6f}")
print(f" (b) scipy.optimize hat(p) = {p_opt:.6f}")
print(f" (c) closed form k/n hat(p) = {p_closed:.6f}")
print(f" all agree to 4 dp? {np.allclose([p_grid, p_opt], p_closed, atol=1e-4)}")
# ===============================================================
# PART 2 — EXPONENTIAL(lambda): l(lambda) = n log lambda - lambda * sum X_i.
# Closed form hat(lambda)_MLE = n / sum X_i = 1/Xbar.
# ===============================================================
print("\n" + "=" * 66)
print("PART 2 — Exponential(lambda): log-likelihood argmax")
print("=" * 66)
lam_true = 0.5
n = 200
Xe = rng.exponential(scale=1.0 / lam_true, size=n) # numpy 'scale' = 1/lambda = mean
S = Xe.sum()
print(f" data: n = {n}, sum X_i = {S:.6f}, Xbar = {Xe.mean():.6f}")
def loglik_exp(lam, n, S):
lam = np.clip(lam, 1e-12, None)
return n * np.log(lam) - lam * S
glam = np.linspace(1e-3, 3.0, 300_001)
lam_grid = glam[np.argmax(loglik_exp(glam, n, S))]
res_e = optimize.minimize_scalar(lambda l: -loglik_exp(l, n, S),
bounds=(1e-6, 100.0), method="bounded")
lam_opt = res_e.x
lam_closed = n / S
print(f" (a) grid argmax hat(lambda) = {lam_grid:.6f}")
print(f" (b) scipy.optimize hat(lambda) = {lam_opt:.6f}")
print(f" (c) closed form 1/Xbar hat(lambda) = {lam_closed:.6f}")
print(f" all agree to 3 dp? {np.allclose([lam_grid, lam_opt], lam_closed, atol=1e-3)}")
# Invariance: MLE of the MEAN mu = g(lambda) = 1/lambda equals 1/hat(lambda) = Xbar.
print(f" invariance: MLE of mean = 1/hat(lambda) = {1.0/lam_closed:.6f} vs Xbar = {Xe.mean():.6f}")
# ===============================================================
# PART 3 — NORMAL(mu, sigma^2): TWO-parameter log-likelihood.
# l(mu,s2) = -n/2 log(2 pi) - n/2 log(s2) - 1/(2 s2) sum (X_i - mu)^2.
# Closed forms: hat(mu)=Xbar, hat(sigma^2)=(1/n) sum (X-Xbar)^2.
# ===============================================================
print("\n" + "=" * 66)
print("PART 3 — Normal(mu, sigma^2): 2-D log-likelihood argmax")
print("=" * 66)
mu_true, sig_true = 5.0, 2.0
n = 300
Xn = rng.normal(mu_true, sig_true, size=n)
xbar = Xn.mean()
s2_hat = Xn.var() # ddof=0 => (1/n) sum (X-Xbar)^2
mu_grid = np.linspace(xbar - 1.0, xbar + 1.0, 401)
s2_grid = np.linspace(max(1e-3, s2_hat - 1.5), s2_hat + 1.5, 401)
best = (-np.inf, None, None)
for mu in mu_grid: # vectorize over s2 for speed
ll = (-0.5 * n * np.log(2 * np.pi) - 0.5 * n * np.log(s2_grid)
- np.sum((Xn - mu) ** 2) / (2.0 * s2_grid))
j = np.argmax(ll)
if ll[j] > best[0]:
best = (ll[j], mu, s2_grid[j])
_, mu_gridmax, s2_gridmax = best
print(f" data: n = {n}")
print(f" grid argmax hat(mu) = {mu_gridmax:.4f} , hat(sigma^2) = {s2_gridmax:.4f}")
print(f" closed form Xbar = {xbar:.4f} , (1/n)sum(X-Xbar)^2 = {s2_hat:.4f}")
print(f" (true mu = {mu_true}, true sigma^2 = {sig_true**2:.1f})")
# ===============================================================
# PART 4 — UNIFORM(0, theta): MLE = max(X_i) vs MoM = 2*Xbar.
# L(theta) = theta^(-n) * 1{theta >= max X_i} is DECREASING for theta >= max,
# so the maximiser is the smallest feasible theta = max(X_i) (non-differentiable).
# ===============================================================
print("\n" + "=" * 66)
print("PART 4 — Uniform(0,theta): MLE = max(X_i) vs MoM = 2*Xbar")
print("=" * 66)
theta_true = 10.0
n = 40
Xu = rng.uniform(0.0, theta_true, size=n)
mx = Xu.max()
print(f" one sample (n={n}): max X_i = {mx:.4f}, 2*Xbar = {2*Xu.mean():.4f} (true theta {theta_true})")
print(" likelihood L(theta)=theta^-n for theta>=max (must DECREASE as theta grows):")
for th in [mx, mx * 1.05, mx * 1.25, mx * 1.5, mx * 2.0]:
rel = np.exp(-n * (np.log(th) - np.log(mx))) # L(theta)/L(max) in (0,1]
print(f" theta = {th:7.4f} L(theta)/L(max) = {rel:.6e}")
print(" => ratio strictly decreasing, so the maximiser is theta = max(X_i)")
print("\n Monte-Carlo bias / variance / MSE (REP = 20000 samples each):")
print(f" {'n':>6} | {'MLE bias':>10} {'MLE var':>10} {'MLE MSE':>10} | "
f"{'MoM bias':>10} {'MoM var':>10} {'MoM MSE':>10} | {'MSE ratio':>9}")
REP = 20_000
for n in [5, 20, 100, 500]:
U = rng.uniform(0.0, theta_true, size=(REP, n))
mle = U.max(axis=1) # MLE = max X_i
mom = 2.0 * U.mean(axis=1) # MoM = 2 Xbar
b_mle = mle.mean() - theta_true; v_mle = mle.var(); mse_mle = b_mle**2 + v_mle
b_mom = mom.mean() - theta_true; v_mom = mom.var(); mse_mom = b_mom**2 + v_mom
print(f" {n:>6} | {b_mle:>10.5f} {v_mle:>10.5f} {mse_mle:>10.5f} | "
f"{b_mom:>10.5f} {v_mom:>10.5f} {mse_mom:>10.5f} | {mse_mom/mse_mle:>9.3f}")
print(" MLE(max) is slightly biased low but its MSE shrinks ~1/n^2 (MoM ~1/n) => MLE far better.")
৫.২ · বাস্তব আউটপুট¶
উপরের স্ক্রিপ্ট চালালে (seed 20260619, numpy 2.2.6, scipy 1.15.3) ঠিক নিচের আউটপুট আসে — সত্যিই চালিয়ে পাওয়া (দুবার চালালেও হুবহু এক, কারণ seed স্থির):
==================================================================
PART 1 — Bernoulli(p): log-likelihood argmax (grid / optimizer / closed form)
==================================================================
data: n = 200, successes k = 60, Xbar = k/n = 0.300000
(a) grid argmax hat(p) = 0.300000
(b) scipy.optimize hat(p) = 0.300000
(c) closed form k/n hat(p) = 0.300000
all agree to 4 dp? True
==================================================================
PART 2 — Exponential(lambda): log-likelihood argmax
==================================================================
data: n = 200, sum X_i = 384.175176, Xbar = 1.920876
(a) grid argmax hat(lambda) = 0.520597
(b) scipy.optimize hat(lambda) = 0.520596
(c) closed form 1/Xbar hat(lambda) = 0.520596
all agree to 3 dp? True
invariance: MLE of mean = 1/hat(lambda) = 1.920876 vs Xbar = 1.920876
==================================================================
PART 3 — Normal(mu, sigma^2): 2-D log-likelihood argmax
==================================================================
data: n = 300
grid argmax hat(mu) = 5.1492 , hat(sigma^2) = 4.1008
closed form Xbar = 5.1492 , (1/n)sum(X-Xbar)^2 = 4.1008
(true mu = 5.0, true sigma^2 = 4.0)
==================================================================
PART 4 — Uniform(0,theta): MLE = max(X_i) vs MoM = 2*Xbar
==================================================================
one sample (n=40): max X_i = 9.9485, 2*Xbar = 11.3975 (true theta 10.0)
likelihood L(theta)=theta^-n for theta>=max (must DECREASE as theta grows):
theta = 9.9485 L(theta)/L(max) = 1.000000e+00
theta = 10.4459 L(theta)/L(max) = 1.420457e-01
theta = 12.4357 L(theta)/L(max) = 1.329228e-04
theta = 14.9228 L(theta)/L(max) = 9.043773e-08
theta = 19.8970 L(theta)/L(max) = 9.094947e-13
=> ratio strictly decreasing, so the maximiser is theta = max(X_i)
Monte-Carlo bias / variance / MSE (REP = 20000 samples each):
n | MLE bias MLE var MLE MSE | MoM bias MoM var MoM MSE | MSE ratio
5 | -1.66142 1.99746 4.75778 | -0.00876 6.77539 6.77547 | 1.424
20 | -0.47928 0.21082 0.44053 | 0.00194 1.67053 1.67054 | 3.792
100 | -0.09999 0.00980 0.01979 | 0.00288 0.33752 0.33753 | 17.053
500 | -0.01985 0.00040 0.00079 | 0.00262 0.06684 0.06685 | 84.396
MLE(max) is slightly biased low but its MSE shrinks ~1/n^2 (MoM ~1/n) => MLE far better.
৫.৩ · আউটপুট কীভাবে পড়ব — দাবি মিলিয়ে দেখা¶
- Part 1 — Bernoulli (§৪.১)। তিনটে পথ — grid, scipy.optimize, closed form \(k/n\) — সবাই হুবহু \(\hat p=0.300000\) দিল (
all agree to 4 dp? True)। এটাই §৪.১-এর কাগুজে derivation-এর সরাসরি সাক্ষ্য: যে \(\hat p=\bar X\) আমরা \(\ell'(p)=0\) থেকে পেলাম, computer স্বাধীনভাবে \(\ell(p)\)-এর চূড়া খুঁজেও ঠিক সেখানেই পৌঁছাল। (এখানে data-য় \(k=60\) সাফল্য \(200\)-তে, তাই \(\hat p=0.30\) — true \(p=0.30\)-র সাথেও মিলে গেছে, যা সুখকর সমাপতন।) - Part 2 — Exponential + invariance (§৪.৩, §৪.৫)। grid ও optimizer দুটোই closed form \(\hat\lambda=1/\bar X=0.520596\)-এর সাথে ৩ দশমিক পর্যন্ত মিলল (
all agree to 3 dp? True; grid-এর \(0.520597\) ও optimizer-এর \(0.520596\)-এর সামান্য পার্থক্য কেবল grid-এর সসীম ঘনত্বের দানা)। আর শেষ লাইনটা invariance যাচাই করে: গড়ের MLE \(=1/\hat\lambda=1.920876\) হুবহু \(\bar X=1.920876\)-এর সমান — ঠিক যা §৪.৫ বলেছিল (\(\mu=1/\lambda\), তাই \(\hat\mu=1/\hat\lambda=\bar X\))। নতুন optimization ছাড়াই derived রাশির MLE মিলে গেল। - Part 3 — Normal 2-D (§৪.২)। দুই-parameter surface-এ grid-argmax দিল \(\hat\mu=5.1492,\ \hat\sigma^2=4.1008\) — যা closed form \(\bar X=5.1492\) ও \(\frac1n\sum(X_i-\bar X)^2=4.1008\)-এর সাথে শেষ অঙ্ক পর্যন্ত মিলল। অর্থাৎ §৪.২-এর দুটো partial-derivative সমীকরণ একসাথে সমাধান করে পাওয়া \((\bar X,\ \frac1n\sum(X_i-\bar X)^2)\) সত্যিই 2-D log-likelihood-এর চূড়া — computer তা grid-এ স্বাধীনভাবে খুঁজে নিশ্চিত করল। (লক্ষণীয় — \(\hat\sigma^2=4.10\), true \(\sigma^2=4.0\)-র সামান্য ওপরে এই নির্দিষ্ট নমুনায়; §৪.২-এর bias-নোট মনে রাখলে গড়ে \(\frac{n-1}{n}\sigma^2\) সামান্য নিচে থাকার কথা, কিন্তু একক নমুনায় ওঠানামা স্বাভাবিক।)
- Part 4 — Uniform, MLE বনাম MoM (§৪.৪)। দুই অংশে পড়ুন।
- (i) likelihood হ্রাসমান। এই নমুনায় \(\max_i X_i=9.9485\)। ছকটা দেখায় \(\theta\) যত \(\max\)-এর ওপরে ওঠে, \(L(\theta)/L(\max)\) তত দ্রুত \(0\)-র দিকে নামে (\(1\to 0.142\to 1.3\times10^{-4}\to\dots\))। অর্থাৎ \(L\) feasible অঞ্চলে কঠোরভাবে হ্রাসমান — তাই argmax ঠিক সবচেয়ে বাঁ-প্রান্তে, \(\theta=\max_i X_i\)। এটাই §৪.৪-এর monotonicity-যুক্তির সংখ্যাগত রূপ: derivative লাগেনি, function-এর পতনটাই উত্তর দিল। (আর খেয়াল করুন এই নমুনায় MoM \(=2\bar X=11.40\), যা \(\max=9.95\)-এর ওপরে বটে — কিন্তু MoM-এর এমন কোনো গ্যারান্টি নেই; MLE-র \(\max\) সর্বদা feasible।)
- (ii) MSE তুলনা। Monte-Carlo টেবিলে দুই estimator-এর গুণ-দোষ স্পষ্ট। MLE \(=\max\) সর্বদা একটু biased নিচে (bias ঋণাত্মক: \(-1.66\to-0.48\to-0.10\to-0.02\), কারণ কোনো নমুনাই \(\theta\) ছাড়াতে পারে না) — যেখানে MoM \(=2\bar X\) কার্যত unbiased। কিন্তু আসল গল্প MSE-তে: MLE-র MSE (\(4.76\to0.44\to0.0198\to0.0008\)) কমছে প্রায় \(1/n^2\)-হারে, MoM-এর MSE (\(6.78\to1.67\to0.34\to0.067\)) কমছে ধীর \(1/n\)-হারে। ফলে MSE-অনুপাত (MoM/MLE) \(n\)-এর সাথে বাড়তেই থাকে: \(1.4\to3.8\to17\to84\) — \(n=500\)-এ MLE প্রায় ৮৪ গুণ ছোট MSE! এটাই §৪.৪-এর দাবির নাটকীয় নিশ্চিতকরণ: biased হয়েও \(\max\) অনেক শ্রেয়, কারণ ভ্যারিয়েন্স-লাভ bias-ক্ষতিকে বিপুলভাবে ছাপিয়ে যায় — আর "unbiased = ভালো" ধারণাটা এখানে স্পষ্টভাবে ভুল।
সততা-নোট। এই সিমুলেশন MLE-র closed-form গুলো "প্রমাণ" করে না — আসল প্রমাণ §৪-এর calculus ও monotonicity-যুক্তির কাজ; কোড শুধু চোখে দেখায় যে স্বাধীন সংখ্যাগত optimization ঠিক একই উত্তরে পৌঁছায়। আর Part 4-এর Monte-Carlo সংখ্যাগুলো (\(20{,}000\) replication-এর) সসীম-নমুনার দানা বহন করে — যেমন MoM-এর bias ঠিক \(0\) না হয়ে \(\pm0.003\), বা MLE-র bias তত্ত্বের \(-\theta/(n+1)\)-এর কাছাকাছি কিন্তু হুবহু নয়; আসল মান এই আনুমানিকতার সীমায়। মূল তিনটে বার্তা — (১) grid/optimizer/closed-form তিন পথের মিল (Part 1–3), (২) invariance-এর সংখ্যাগত যাচাই (Part 2), (৩) MLE-র MSE-আধিপত্য \(n\)-এর সাথে বেড়ে চলা (Part 4) — সবই §৪-কে নিশ্ছিদ্রভাবে সমর্থন করে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-3.py-তে তৈরি; PNG_assets/-এ (prefix4-3, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 Bernoulli (\(\hat p=\bar X\)); E2 Normal (\(\hat\mu=\bar X,\ \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\)); E3 Exponential (\(\hat\lambda=1/\bar X\)); E4 Uniform\((0,\theta)\) (\(\hat\theta=\max_i X_i\))।
MLE-র পুরো গল্পটা আসলে একটাই বাক্যে ধরা যায়: "যে \(\theta\)-মান এই observed data-কে সবচেয়ে সম্ভাব্য করে, সেটাই বেছে নাও।" কিন্তু এই বাক্যটা সূত্রে যত শুকনো শোনায়, ছবিতে তত জীবন্ত — কারণ "সবচেয়ে সম্ভাব্য করা" মানে আসলে একটা পাহাড়ের চূড়া খোঁজা। আমরা চারটি ছবি দিয়ে চারটি কেন্দ্রীয় ব্যাপার "চোখে দেখব": (১) চূড়া খোঁজার মুহূর্ত — likelihood \(L(\theta)\) আর log-likelihood \(\ell(\theta)\) একই \(\theta\)-তে চূড়ায় পৌঁছায়, আর সেই argmax-ই \(\hat\theta_{\text{MLE}}\) (Figure 1); (২) দুই-প্যারামিটার ক্ষেত্রে চূড়াটা একটা পাহাড়ের শিখর — Normal-এর log-likelihood surface, যার একটিমাত্র শীর্ষ ঠিক \((\bar X,\hat\sigma^2)\)-তে (Figure 2); (৩) MLE আর MoM-এর sampling distribution পাশাপাশি — কোনটা সত্যিকারের \(\theta\)-র চারপাশে বেশি আঁটসাঁট (Figure 3); আর (৪) যেখানে calculus খাটে না — Uniform\((0,\theta)\)-এর likelihood একটা লাফ ও পতন, তাই MLE = max, MoM = \(2\bar X\) থেকে আলাদা (Figure 4)। প্রথম দুটো ছবি MLE আসলে কী খোঁজে, পরের দুটো সেই খোঁজার ফল কতটা ভালো ও কোথায় আলাদা — কয়েকটা ভিন্ন কোণ থেকে।
Figure 1 — likelihood ও log-likelihood: চূড়াই MLE¶
এই অধ্যায়ের কেন্দ্রীয় ছবি, একটা সত্যিকারের Exponential নমুনায় (\(n=12\), true \(\lambda=0.7\))। উপরের প্যানেলে scaled likelihood \(L(\lambda)\) — একটা কমলা ঘণ্টা-মতো বক্ররেখা, যার সর্বোচ্চ বিন্দু (চূড়া) ঠিক \(\hat\lambda_{\text{MLE}}=1/\bar x=0.764\)-তে (সবুজ রেখা ও বিন্দু)। নিচের প্যানেলে একই data-র log-likelihood \(\ell(\lambda)\) — একটা মসৃণ অবতল (concave) বক্ররেখা, আর তার চূড়াও ঠিক একই \(\lambda\)-তে: সবুজ রেখা দুই প্যানেলে এক জায়গায়। নিচের প্যানেলে চূড়ায় একটা annotation — "slope = 0 here (score equation)" — মনে করিয়ে দেয় MLE বের করার calculus-চাল: \(\ell'(\lambda)=0\) সমাধান করা (score function শূন্য)। লাল ভাঙা-রেখা সত্যিকারের \(\lambda=0.7\)। যা লক্ষ করতে হবে: (ক) \(L\) আর \(\ell\)-এর চূড়া একই জায়গায় — কারণ \(\log\) একটা কঠোরভাবে বর্ধমান (monotonic) ফাংশন, তাই যেখানে \(L\) সর্বোচ্চ সেখানেই \(\ell\) সর্বোচ্চ; আমরা \(\ell\) নিয়ে কাজ করি শুধু কারণ গুণফল \(\prod_i f\) যোগফল \(\sum_i\log f\)-এ পরিণত হয়ে অন্তরকলন (differentiation) সহজ হয়ে যায়। (খ) চূড়ায় ঢাল শূন্য — এটাই MLE-র "first-order condition", যা থেকে \(\hat\lambda=1/\bar x\) সমীকরণ বেরোয় (§৪-এ উৎপাদিত)। (গ) \(\hat\lambda=0.764\) সত্যি \(0.7\)-এর সামান্য ডানে — কারণ \(n=12\), নমুনায় ওঠানামা (sampling variability) আছে; বড় \(n\)-এ চূড়া সত্যিকারের \(\lambda\)-র দিকে সরে আসবে (পরের অধ্যায় 4.4-এ consistency)।
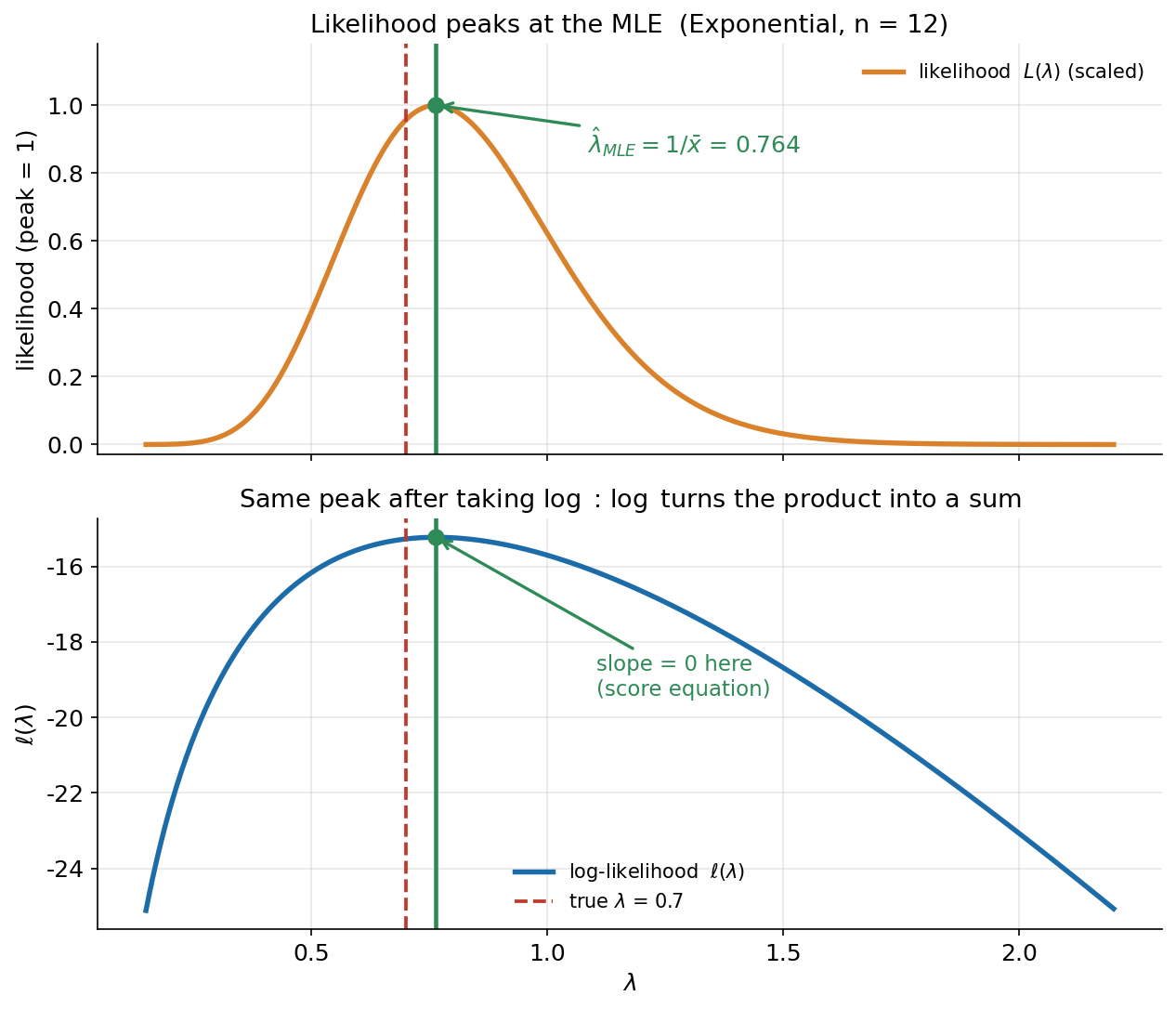
Figure 2 — দুই প্যারামিটারে MLE: log-likelihood-র পাহাড়ের শিখর¶
এক প্যারামিটারে চূড়া ছিল একটা বিন্দু; দুই প্যারামিটারে চূড়া হয়ে যায় একটা পাহাড়ের শিখর। এই ছবি E2 Normal\((\mu,\sigma^2)\)-এর log-likelihood surface, একটা \(n=40\) নমুনায়। অনুভূমিক অক্ষে \(\mu\) (mean parameter), উল্লম্ব অক্ষে \(\sigma\) (sd parameter); রঙ ও contour-রেখা দেখায় প্রতিটি \((\mu,\sigma)\)-জোড়ে \(\ell(\mu,\sigma^2)\)-এর মান — উজ্জ্বল হলুদ মানে উঁচু (high log-likelihood), গাঢ় নীল-বেগুনি মানে নিচু। লাল তারা-চিহ্ন (★) হলো শিখর — MLE — যা ঠিক \((\hat\mu,\hat\sigma)=(\bar x,\hat\sigma)=(4.60,\ 1.90)\)-তে; সাদা বিন্দু-রেখাগুলো শিখর থেকে দুই অক্ষে নেমে দেখায় \(\hat\mu=\bar x\) আর \(\hat\sigma\) কোথায়। যা লক্ষ করতে হবে: (ক) পুরো surface-এ একটিমাত্র শিখর (single peak / unimodal) — তাই MLE অনন্য, আর যেকোনো দিক থেকে "উপরে ওঠা" (hill-climbing) সেই একই শিখরে পৌঁছায়; এই মসৃণ একক-চূড়া আকৃতিই অনেক optimization algorithm-কে কাজ করতে দেয়। (খ) শিখরটা ঠিক \(\mu=\bar x\)-এ — অর্থাৎ Normal-এ mean-এর MLE হলো sample mean, যেটা আমরা §৪-এ \(\partial\ell/\partial\mu=0\) থেকে পেয়েছি। (গ) contour-গুলো শিখরের কাছে ঘন ও প্রায় উপবৃত্তাকার (elliptical), দূরে গেলে পাতলা — এই বক্রতা (curvature) আসলে পরে (4.4-এ) MLE-র variance/precision-এর সাথে যুক্ত হবে: যত খাড়া চূড়া, তত নিশ্চিত estimate।
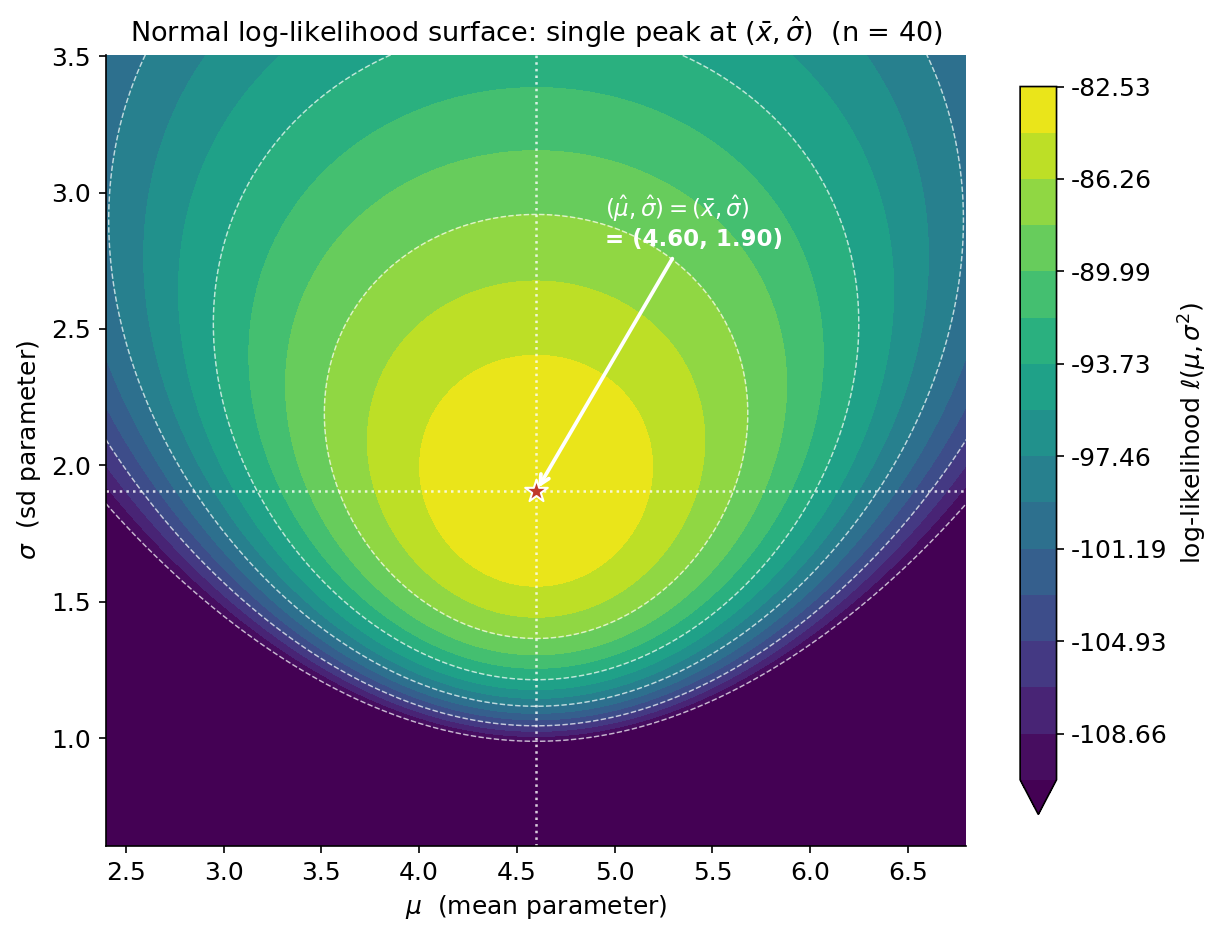
Figure 3 — MLE বনাম MoM: কার sampling distribution বেশি আঁটসাঁট?¶
MLE আর আগের অধ্যায়ের MoM — দুটোই estimator, কিন্তু একই data থেকে কি একই উত্তর দেয়? আর দিলে, কোনটা সত্যিকারের \(\theta\)-র চারপাশে কম ওঠানামা করে? এই ছবি সেই তুলনা, এমন একটা উদাহরণে যেখানে দুটো নাটকীয়ভাবে আলাদা: E4 Uniform\((0,\theta)\), true \(\theta=10\), \(n=20\)। আমরা \(8000\) বার নতুন নমুনা টেনে প্রতিবার দুটোই হিসাব করেছি — MLE \(\hat\theta=\max_i X_i\) (সবুজ histogram) আর MoM \(\hat\theta=2\bar X\) (বেগুনি histogram); লাল ভাঙা-রেখা সত্যি \(\theta=10\)। যা লক্ষ করতে হবে: (ক) সবুজ (MLE) বণ্টন সত্যি \(10\)-এর ঠিক বাঁ পাশে ঘন হয়ে জমে আছে এবং খুব সরু (SD \(\approx0.46\)) — কারণ \(\max_i X_i\) কখনো \(\theta\) ছাড়াতে পারে না (সব \(X_i\le\theta\)), তাই এটা একটু নিচ থেকে আসে কিন্তু অসম্ভব রকম নিখুঁত। (খ) বেগুনি (MoM) বণ্টন \(10\)-এর চারপাশে প্রতিসমভাবে ছড়ানো কিন্তু অনেক চওড়া (SD \(\approx1.31\)) — গড়ে ঠিক জায়গায় (unbiased) হলেও যেকোনো একটা নমুনায় estimate সত্যি থেকে অনেক দূরে যেতে পারে। (গ) মূল বার্তা box-এ: SD(MLE) \(\approx0.46\) বনাম SD(MoM) \(\approx1.31\) — MLE প্রায় তিন গুণ আঁটসাঁট এই \(n\)-এ (আসলে এখানে MLE-র variance মাত্রায় \(\theta^2/n^2\), MoM-এর \(\theta^2/(3n)\), তাই বড় \(n\)-এ ব্যবধান আরও বাড়ে)। এটাই MLE-র মূল আকর্ষণের পূর্বাভাস: প্রায়ই MoM-এর চেয়ে বেশি efficient (কম variance) — বিস্তারিত 4.4-এ।
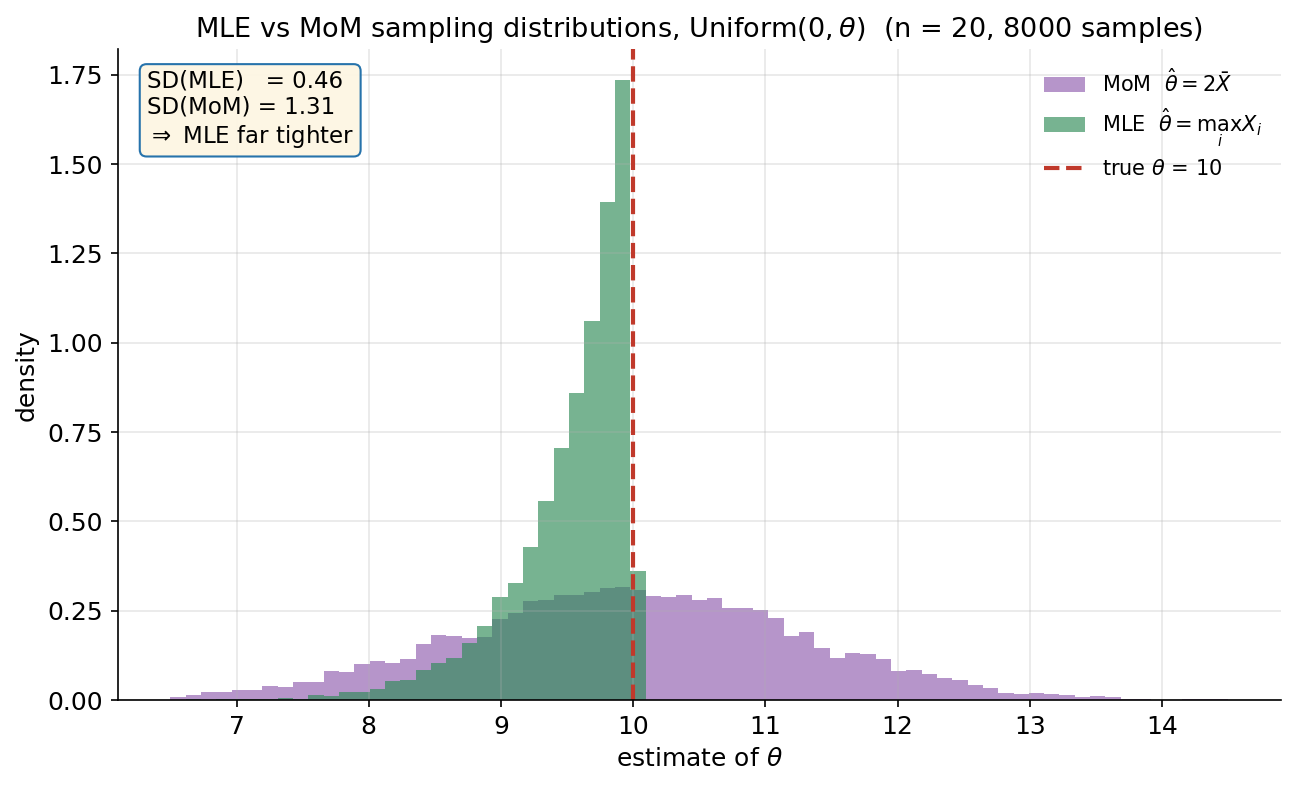
Figure 4 — Uniform\((0,\theta)\): যেখানে calculus খাটে না, MLE = max¶
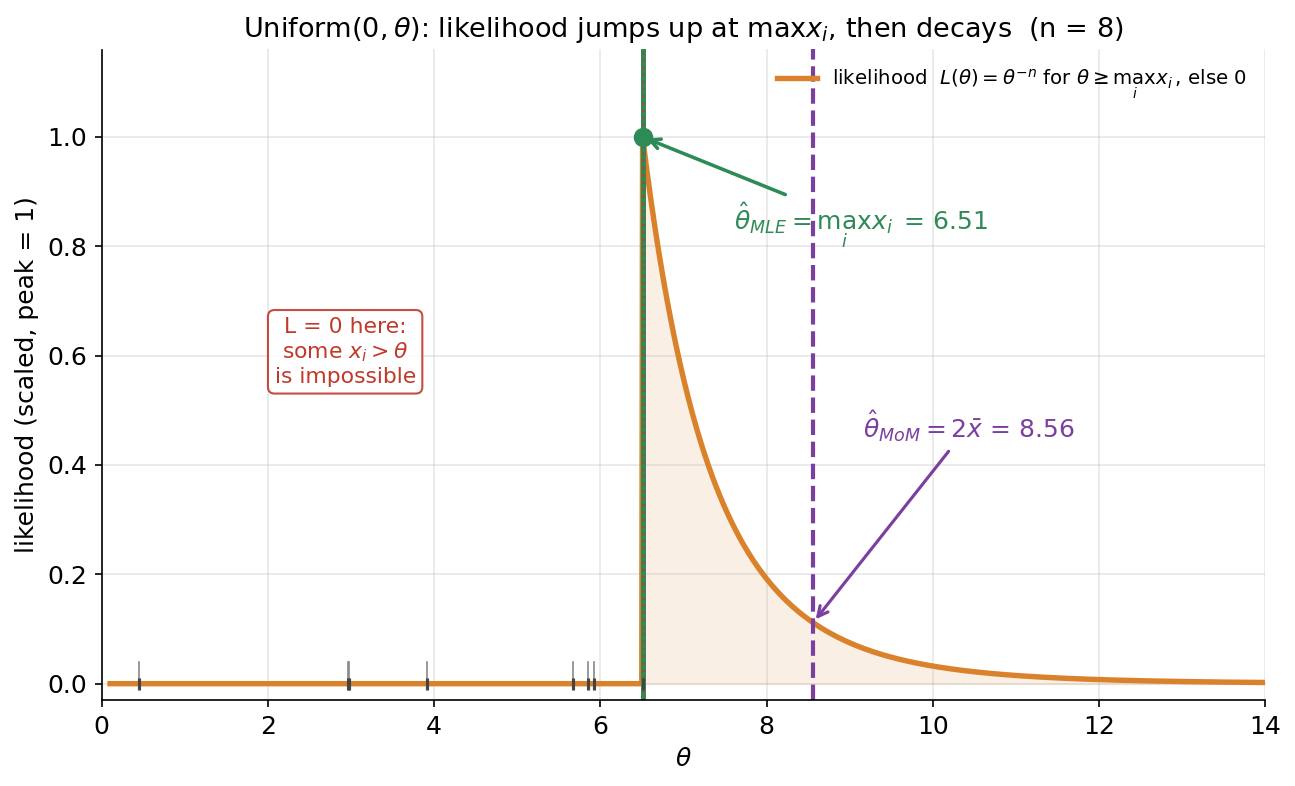
আগের তিন ছবিতে MLE ছিল একটা মসৃণ চূড়া, calculus দিয়ে (\(\ell'=0\)) পাওয়া যেত। কিন্তু সব ক্ষেত্রে তা হয় না — আর এই শেষ ছবি ঠিক সেই ব্যতিক্রমটা দেখায়, যা MLE-র সংজ্ঞাকে গভীরভাবে বোঝায়। E4 Uniform\((0,\theta)\), একটা ছোট নমুনা (\(n=8\), true \(\theta=8\))। কমলা বক্ররেখা হলো likelihood \(L(\theta)\)। তার আকৃতিটাই চমক: \(\theta\) যদি নমুনার সবচেয়ে বড় মান \(\max_i x_i=6.51\)-এর চেয়ে ছোট হয়, তবে \(L(\theta)=0\) (লাল box: "L = 0 here: some \(x_i>\theta\) is impossible" — কারণ কোনো observation \(\theta\) ছাড়িয়ে গেলে সেই \(\theta\) অসম্ভব); ঠিক \(\max_i x_i\)-তে likelihood হঠাৎ লাফিয়ে সর্বোচ্চে ওঠে; তারপর \(\theta\) আরও বাড়লে \(L(\theta)=\theta^{-n}\) ক্রমে কমতে থাকে (বড় \(\theta\) মানে data-কে বেশি ছড়িয়ে দেওয়া, তাই কম সম্ভাব্য)। তাই চূড়া ঠিক প্রান্তে — \(\hat\theta_{\text{MLE}}=\max_i x_i=6.51\) (সবুজ রেখা ও বিন্দু)। তুলনার জন্য বেগুনি ভাঙা-রেখা MoM \(\hat\theta_{\text{MoM}}=2\bar x=8.56\)। যা লক্ষ করতে হবে: (ক) এখানে \(\ell'(\theta)=0\) খাটে না — কোথাও ঢাল শূন্য হয় না; সর্বোচ্চ likelihood একটা প্রান্ত-বিন্দুতে (boundary), তাই MLE বের করতে হয় likelihood-এর আকৃতি সরাসরি বিচার করে, যান্ত্রিকভাবে derivative নিয়ে নয় (একটা গুরুত্বপূর্ণ সাবধান-বার্তা §৪-এ)। (খ) MLE = \(6.51\) আর MoM = \(8.56\) — আলাদা; এখানে MoM আসল \(8\)-এর বেশ কাছে, MLE একটু কম (নিচ থেকে, কারণ \(\max\le\theta\) সর্বদা) — তবে Figure 3 দেখিয়েছে বহু নমুনার গড়ে MLE অনেক বেশি আঁটসাঁট। (গ) নিচের ছোট খাড়া দাগগুলো হলো ৮টা data point; লক্ষ করুন MLE ঠিক সবচেয়ে ডানের point-এ বসে — MLE "data যতটুকু দাবি করছে ঠিক ততটুকু" \(\theta\) বেছে নেয়, তার চেয়ে এক চুলও বড় নয়।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-03-maximum-likelihood-estimation-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (চলমান উদাহরণ: E1 Bernoulli\((p)\), \(\hat p=\bar X\); E2 Normal\((\mu,\sigma^2)\); E3 Exponential\((\lambda)\), \(\hat\lambda=1/\bar X\); E4 Uniform\((0,\theta)\), \(\hat\theta=\max_i X_i\)। স্মারক: \(L(\theta)=\prod_i f(X_i;\theta)\), \(\ell(\theta)=\sum_i\log f(X_i;\theta)\), score \(\ell'(\theta)\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় MLE-র মূল ধাপগুলো বলুন: likelihood লেখা, log নেওয়া, derivative নিয়ে শূন্য বসানো, সমাধান করা। বিশেষত ব্যাখ্যা করুন কেন আমরা \(L(\theta)\) সরাসরি না নিয়ে \(\ell(\theta)=\log L(\theta)\) নিয়ে কাজ করি — দুটো কারণ দিন। Figure 1 দিয়ে যুক্তি দিন কেন \(L\) ও \(\ell\)-এর চূড়া একই জায়গায়। Hint: কারণ ১ — \(\log\) গুণফল \(\prod_i f\)-কে যোগফল \(\sum_i\log f\)-এ বদলায়, তাই derivative নেওয়া অনেক সহজ (প্রতিটা পদ আলাদা)। কারণ ২ — সংখ্যাগত: অনেক ছোট সম্ভাবনার গুণফল underflow করে শূন্য হয়ে যায়, কিন্তু যোগফল স্থিতিশীল। চূড়া একই কারণ \(\log\) কঠোরভাবে বর্ধমান (monotonic), তাই argmax বদলায় না (Figure 1-এ সবুজ রেখা দুই প্যানেলে এক জায়গায়)।
প্রশ্ন ২ (★). "Likelihood হলো data-র দৃষ্টিতে \(\theta\)-র ওপর একটা ফাংশন, probability নয়" — এই বাক্যটা ব্যাখ্যা করুন। \(f(x;\theta)\)-কে \(x\)-এর ফাংশন (data fixed নয়, \(\theta\) fixed) হিসেবে দেখা আর \(\theta\)-এর ফাংশন (\(x\) fixed, \(\theta\) চলক) হিসেবে দেখার পার্থক্য কী? কেন \(L(\theta)\)-কে \(\theta\)-এর ওপর "integrate করলে ১ হয়" — এটা সত্যি নয়? Hint: \(f(x;\theta)\) একই সূত্র, কিন্তু দুই ভূমিকা: \(\theta\) স্থির রেখে \(x\)-এ এটা একটা density (∫ over \(x\) = 1); \(x\) (data) স্থির রেখে \(\theta\)-তে এটা likelihood — এর \(\theta\)-জুড়ে যোগ/integral-এর কোনো অর্থ নেই, ১ হওয়ার দরকার নেই। MLE শুধু এর argmax খোঁজে, area নয় (Figure 1)।
প্রশ্ন ৩ (★★). Figure 4-এ Uniform\((0,\theta)\)-এ MLE বের করতে derivative (\(\ell'(\theta)=0\)) খাটে না — কেন? এই উদাহরণ থেকে MLE সম্পর্কে কী সাধারণ সাবধান-বার্তা বেরোয়? (ইঙ্গিত: likelihood-এর চূড়া কোথায় — মসৃণ অভ্যন্তরে, না প্রান্তে?) Hint: Uniform-এ \(L(\theta)=\theta^{-n}\) for \(\theta\ge\max_i x_i\), else \(0\) — এটা \(\max_i x_i\)-এ লাফ দেয় ও কমতে থাকে, কোথাও ঢাল শূন্য নয়; সর্বোচ্চ একটা প্রান্ত-বিন্দুতে (boundary)। সাধারণ বার্তা: \(\ell'=0\) শুধু তখনই MLE দেয় যখন চূড়া parameter-space-এর অভ্যন্তরে ও likelihood মসৃণ; নয়তো likelihood-এর আকৃতি সরাসরি বিচার করতে হয়।
প্রশ্ন ৪ (★★). Invariance property কী? যদি \(\hat\theta_{\text{MLE}}\) হয় \(\theta\)-র MLE, আর \(g\) একটা ফাংশন, তবে \(g(\theta)\)-র MLE কী? E3 Exponential-এ \(\hat\lambda=1/\bar X\) ব্যবহার করে mean lifetime \(\tau=1/\lambda\)-এর MLE বের করুন — কোনো নতুন optimization ছাড়াই। Hint: invariance: \(\widehat{g(\theta)}_{\text{MLE}}=g(\hat\theta_{\text{MLE}})\) — শুধু MLE-টা \(g\)-তে বসিয়ে দাও। তাই \(\tau=1/\lambda\Rightarrow\hat\tau_{\text{MLE}}=1/\hat\lambda_{\text{MLE}}=1/(1/\bar X)=\bar X\)। (অর্থপূর্ণ: গড় আয়ুর MLE হলো নমুনা-গড় আয়ু।)
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). E1 Bernoulli\((p)\) — একটা মুদ্রা \(n=10\) বার ছুঁড়ে \(7\) বার head: data \(\sum_i x_i=7\)। (ক) log-likelihood \(\ell(p)\) লিখুন। (খ) \(\ell'(p)=0\) সমাধান করে \(\hat p_{\text{MLE}}\) বের করুন। (গ) উত্তরটা কি \(\bar x\)? সংখ্যায় কত? Hint: (ক) \(\ell(p)=\big(\sum x_i\big)\log p+\big(n-\sum x_i\big)\log(1-p)=7\log p+3\log(1-p)\)। (খ) \(\ell'(p)=\frac{7}{p}-\frac{3}{1-p}=0\Rightarrow 7(1-p)=3p\Rightarrow p=7/10\)। (গ) হ্যাঁ, \(\hat p=\bar x=\sum x_i/n=0.7\)।
প্রশ্ন ৬ (★). E3 Exponential\((\lambda)\), নমুনা \(\{0.5,\ 1.5,\ 1.0,\ 2.0,\ 0.5\}\) (\(n=5\))। (ক) \(\bar x\) বের করুন। (খ) \(\hat\lambda_{\text{MLE}}\) হিসাব করুন। (গ) invariance দিয়ে mean lifetime \(\tau=1/\lambda\)-এর MLE বের করুন। Hint: (ক) \(\bar x=(0.5+1.5+1.0+2.0+0.5)/5=5.5/5=1.1\)। (খ) \(\hat\lambda=1/\bar x=1/1.1\approx0.909\)। (গ) \(\hat\tau=1/\hat\lambda=\bar x=1.1\) (invariance — প্রশ্ন ৪)।
প্রশ্ন ৭ (★★). E2 Normal\((\mu,\sigma^2)\) — দুটো প্যারামিটার। নমুনা \(\{4,\ 6,\ 5,\ 7,\ 3\}\) (\(n=5\))। (ক) MLE সূত্র লিখুন: \(\hat\mu=\bar X\), \(\hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\)। (খ) সংখ্যায় \(\hat\mu\) ও \(\hat\sigma^2\) বের করুন। (গ) লক্ষ করুন হরে \(n\) না \(n-1\) — এর মানে MLE-র \(\hat\sigma^2\) সামান্য কী? Hint: (খ) \(\bar x=(4+6+5+7+3)/5=25/5=5\); বিচ্যুতি \(\{-1,1,0,2,-2\}\), বর্গ-যোগ \(=1+1+0+4+4=10\); \(\hat\sigma^2=10/5=2\)। (গ) হরে \(n\) মানে এটা \(s^2\) (যার হরে \(n-1\))-এর চেয়ে ছোট, তাই MLE-র \(\hat\sigma^2\) সামান্য biased (নিচের দিকে) — 4.4-এ আলোচ্য।
প্রশ্ন ৮ (★★). E4 Uniform\((0,\theta)\), নমুনা \(\{2.3,\ 5.1,\ 4.4,\ 1.8,\ 3.9\}\)। (ক) \(\hat\theta_{\text{MLE}}\) বের করুন। (খ) MoM \(\hat\theta_{\text{MoM}}=2\bar x\) বের করুন। (গ) দুটো তুলনা করুন — কোনটা বড়? MLE কি কখনো সবচেয়ে বড় observation-এর চেয়ে ছোট হতে পারে? Hint: (ক) \(\hat\theta_{\text{MLE}}=\max_i x_i=5.1\)। (খ) \(\bar x=(2.3+5.1+4.4+1.8+3.9)/5=17.5/5=3.5\); \(2\bar x=7.0\)। (গ) এখানে MoM (\(7.0\)) > MLE (\(5.1\))। MLE কখনো \(\max_i x_i\)-এর চেয়ে ছোট হতে পারে না (সংজ্ঞাই তাই) — তাই MoM-এর "অবৈধ মান" সমস্যা (4.2 Q4) MLE-তে নেই।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). E1 Bernoulli-র MLE উৎপাদন করুন। \(X_1,\dots,X_n\overset{iid}{\sim}\text{Bernoulli}(p)\)। (ক) \(L(p)\) ও \(\ell(p)\) লিখুন। (খ) score \(\ell'(p)\) বের করে \(0\) বসান, সমাধান করে \(\hat p=\bar X\) দেখান। (গ) দ্বিতীয় derivative দেখে নিশ্চিত করুন এটা সর্বোচ্চ (maximum), সর্বনিম্ন নয়। Hint: (ক) \(L(p)=\prod_i p^{X_i}(1-p)^{1-X_i}=p^{\sum X_i}(1-p)^{n-\sum X_i}\); \(\ell(p)=(\sum X_i)\log p+(n-\sum X_i)\log(1-p)\)। (খ) \(\ell'(p)=\frac{\sum X_i}{p}-\frac{n-\sum X_i}{1-p}=0\Rightarrow p=\frac{\sum X_i}{n}=\bar X\)। (গ) \(\ell''(p)=-\frac{\sum X_i}{p^2}-\frac{n-\sum X_i}{(1-p)^2}<0\) — সর্বত্র অবতল, তাই অনন্য সর্বোচ্চ।
প্রশ্ন ১০ (★★). E3 Exponential-র MLE উৎপাদন করুন। \(X_i\overset{iid}{\sim}\text{Exp}(\lambda)\), \(f(x;\lambda)=\lambda e^{-\lambda x}\)। (ক) \(\ell(\lambda)\) লিখুন। (খ) score \(=0\) থেকে \(\hat\lambda=1/\bar X\) দেখান। (গ) \(\ell''<0\) যাচাই করুন। Hint: (ক) \(\ell(\lambda)=\sum_i(\log\lambda-\lambda X_i)=n\log\lambda-\lambda\sum_i X_i\)। (খ) \(\ell'(\lambda)=\frac{n}{\lambda}-\sum_i X_i=0\Rightarrow\lambda=\frac{n}{\sum X_i}=\frac{1}{\bar X}\)。 (গ) \(\ell''(\lambda)=-\frac{n}{\lambda^2}<0\) — অবতল, সর্বোচ্চ নিশ্চিত (Figure 1-এর নিচের প্যানেলের আকৃতি)।
প্রশ্ন ১১ (★★★). E4 Uniform\((0,\theta)\)-এ MLE = max প্রমাণ করুন (calculus ছাড়া)। \(X_i\overset{iid}{\sim}\text{Uniform}(0,\theta)\), \(f(x;\theta)=\frac1\theta\) for \(0\le x\le\theta\), else \(0\)। (ক) \(L(\theta)\) লিখুন এবং দেখান এটা \(\theta^{-n}\) যখন \(\theta\ge\max_i X_i\), নয়তো \(0\)। (খ) যুক্তি দিন কেন এটা \(\theta=\max_i X_i\)-এ সর্বোচ্চ। (গ) ব্যাখ্যা করুন কেন এখানে \(\ell'(\theta)=0\) পদ্ধতি ব্যর্থ। Hint: (ক) \(L(\theta)=\prod_i\frac1\theta\mathbf{1}\{0\le X_i\le\theta\}=\theta^{-n}\mathbf{1}\{\theta\ge\max_i X_i\}\) (সব indicator একসাথে = \(\theta\ge\) সবচেয়ে বড়টা)। (খ) \(\theta\ge\max\) অঞ্চলে \(\theta^{-n}\) কঠোরভাবে হ্রাসমান, তাই যত ছোট \(\theta\) তত বড় \(L\) — কিন্তু \(\theta\) অন্তত \(\max_i X_i\) হতেই হবে; তাই সর্বোচ্চ ঠিক \(\theta=\max_i X_i\)-এ (Figure 4)। (গ) \(L\) ওখানে অবিচ্ছিন্নভাবে অন্তরকলনযোগ্য নয় (লাফ আছে), চূড়া অভ্যন্তরে নয় প্রান্তে — তাই derivative-শূন্য পদ্ধতির শর্তই মেটে না।
প্রশ্ন ১২ (★★★). Invariance property প্রমাণ করুন (এক-এক ফাংশনের ক্ষেত্রে)। ধরুন \(\hat\theta=\arg\max_\theta L(\theta)\), আর \(\psi=g(\theta)\) যেখানে \(g\) এক-এক (bijective)। দেখান reparametrized likelihood \(\tilde L(\psi)=L(g^{-1}(\psi))\)-এর সর্বোচ্চ হয় \(\hat\psi=g(\hat\theta)\)-তে। (ব্যাখ্যা করুন কেন এর ফল: \(\widehat{g(\theta)}=g(\hat\theta)\)।) Hint: \(g\) এক-এক হলে \(\psi\)-তে maximize করা = \(\theta=g^{-1}(\psi)\)-তে maximize করা (একই মান, শুধু নাম-বদল)। \(L(g^{-1}(\psi))\) সর্বোচ্চ হয় যখন \(g^{-1}(\psi)=\hat\theta\), অর্থাৎ \(\psi=g(\hat\theta)\)। তাই \(\hat\psi=g(\hat\theta)\) — MLE-টা ফাংশনের ভেতরে "বসিয়ে দেওয়া" যায় (Wasserman §9.5; non-bijective \(g\)-তেও induced-likelihood যুক্তিতে এটা টেকে)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৩ (★). numpy দিয়ে E3 Exponential\((\lambda)\)-এর MLE বানান। true \(\lambda=0.5\) ধরে \(n=200\)-এর নমুনা টানুন (rng.exponential(1/0.5, 200)), \(\hat\lambda_{\text{MLE}}=1/\bar X\) ছাপান, আর সত্যি \(0.5\)-এর সাথে তুলনা করুন। invariance দিয়ে mean lifetime \(\hat\tau=\bar X\)-ও ছাপান।
Hint: rng=np.random.default_rng(0); x=rng.exponential(1/0.5,200); lam_hat=1/x.mean(); print(lam_hat, x.mean())। সাধারণত \(\hat\lambda\) \(0.5\)-এর কাছে; \(\hat\tau=\bar X\approx 2.0\) (যা \(1/0.5\))।
প্রশ্ন ১৪ (★★). Likelihood curve নিজে আঁকুন (Figure 1 পুনরুৎপাদন, Exponential)। true \(\lambda=0.7\), \(n=12\) নমুনা টানুন। \(\lambda\)-grid-এ log-likelihood \(\ell(\lambda)=n\log\lambda-\lambda\sum X_i\) হিসাব করে plot করুন; চূড়া \(1/\bar X\)-তে একটা উল্লম্ব রেখা দিন। দেখান grid-এর argmax আর \(1/\bar X\) মেলে।
Hint: x=rng.exponential(1/0.7,12); g=np.linspace(0.15,2.2,600); ll=12*np.log(g)-g*x.sum(); plt.plot(g,ll); plt.axvline(1/x.mean())। যাচাই: g[ll.argmax()] ≈ 1/x.mean() (grid যত ঘন তত নিখুঁত)।
প্রশ্ন ১৫ (★★★). MLE বনাম MoM sampling distribution নিজে তুলনা করুন (Figure 3 পুনরুৎপাদন, Uniform)। true \(\theta=10\), \(n=20\)। \(5000\) বার নমুনা টেনে প্রতিবার \(\hat\theta_{\text{MLE}}=\max_i X_i\) ও \(\hat\theta_{\text{MoM}}=2\bar X\) হিসাব করুন। (ক) দুটোর histogram একই অক্ষে আঁকুন। (খ) দুটোর mean, SD, আর MSE (= variance + bias²) ছাপান। (গ) কোনটার MSE ছোট, এবং কেন — সংক্ষেপে বলুন। (ঘ) বোনাস: scipy.optimize.minimize_scalar দিয়ে Exponential-এর negative log-likelihood minimize করে দেখান উত্তর হাতে-পাওয়া \(1/\bar X\)-এর সমান।
Hint: ভেক্টরাইজ: S=rng.uniform(0,10,size=(5000,20)); mle=S.max(1); mom=2*S.mean(1); তারপর mle.mean(),mle.std(),mom.mean(),mom.std(); mse=lambda e,t:((e-t)**2).mean()। MLE নিচের দিকে সামান্য biased কিন্তু variance অনেক ছোট, তাই MSE-ও ছোট (Figure 3)। বোনাস: from scipy.optimize import minimize_scalar; nll=lambda L:-(len(x)*np.log(L)-L*x.sum()); minimize_scalar(nll,bounds=(0.01,5),method='bounded').x ≈ 1/x.mean()।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- MLE-র সারমর্ম: যে প্যারামিটার-মান observed data-কে সবচেয়ে সম্ভাব্য করে, সেটাই বেছে নাও। আনুষ্ঠানিকভাবে — likelihood $$ L(\theta)=\prod_{i=1}^n f(X_i;\theta) $$ সর্বোচ্চ করো; কার্যত আমরা log-likelihood \(\ell(\theta)=\sum_{i=1}^n\log f(X_i;\theta)\) সর্বোচ্চ করি (একই argmax, কারণ \(\log\) monotonic — Figure 1), কারণ এতে গুণফল যোগফলে পরিণত হয়ে অন্তরকলন ও সংখ্যাগত স্থিতিশীলতা দুটোই সহজ হয়। মসৃণ, অভ্যন্তরীণ চূড়ার ক্ষেত্রে \(\hat\theta_{\text{MLE}}\) আসে score equation \(\ell'(\theta)=0\) সমাধান করে (এবং \(\ell''<0\) যাচাই করে)।
- চলমান উদাহরণগুলো (closed-form): E1 Bernoulli — \(\hat p_{\text{MLE}}=\bar X\); E2 Normal — \(\hat\mu=\bar X,\ \hat\sigma^2=\frac1n\sum_i(X_i-\bar X)^2\); E3 Exponential — \(\hat\lambda=1/\bar X\) (mean lifetime \(\hat\tau=\bar X\), invariance-এ); E4 Uniform\((0,\theta)\) — \(\hat\theta=\max_i X_i\)। প্রথম তিনটি calculus দিয়ে; চতুর্থটি likelihood-এর আকৃতি বিচার করে (Figure 4), কারণ সেখানে চূড়া প্রান্তে — \(\ell'=0\) খাটে না।
- Likelihood ≠ probability: \(f(X_i;\theta)\)-কে এখানে দেখা হয় \(\theta\)-এর ফাংশন হিসেবে (data fixed), probability density হিসেবে নয়; তাই \(\theta\)-জুড়ে এর integral ১ হওয়ার দরকার নেই, আমরা শুধু এর argmax খুঁজি।
- Invariance property: \(\hat\theta_{\text{MLE}}\) থাকলে যেকোনো ফাংশন \(g\)-এর জন্য \(\widehat{g(\theta)}_{\text{MLE}}=g(\hat\theta_{\text{MLE}})\) — কোনো নতুন optimization ছাড়াই (যেমন \(\hat\tau=1/\hat\lambda=\bar X\))। এটা MLE-র একটা বড় ব্যবহারিক সুবিধা, যা MoM-এর নেই।
- MLE বনাম MoM: কখনো দুটো একই উত্তর দেয় (Exponential-এ দুটোই \(1/\bar X\), Normal-এ mean দুটোই \(\bar X\)), কখনো নাটকীয়ভাবে আলাদা (Uniform-এ MLE = max বনাম MoM = \(2\bar X\) — Figure 3, 4)। যেখানে আলাদা, সেখানে MLE প্রায়ই বেশি efficient (কম variance — Uniform-এ SD প্রায় ৩ গুণ ছোট) এবং সবসময় বৈধ প্যারামিটার দেয় (\(\max_i X_i\) কখনো \(\theta\) ছাড়ায় না), যেখানে MoM মাঝে মাঝে অবৈধ মান দিতে পারে।
পূর্ববর্তী সংযোগ (← 4.2 Method of Moments): 4.2-এ আমরা প্রথম concrete estimation-পদ্ধতি শিখেছিলাম — MoM: sample moment = population moment ধরে \(\theta\) solve করা; সরল, দ্রুত, প্রায়ই closed-form। এই অধ্যায় সেই কাঠামোতেই একটা দ্বিতীয়, সাধারণত উন্নততর পদ্ধতি ভরল — MLE। দুটোই একই প্রশ্নের ("data থেকে একটা best-guess \(\hat\theta\)") দুই উত্তর, কিন্তু ভিন্ন নীতিতে: MoM moment মেলায়, MLE data-কে সবচেয়ে সম্ভাব্য করে। 4.2-এর শেষে আমরা দুটো ইঙ্গিত রেখে এসেছিলাম — (১) Uniform-এ MLE প্রায় \(n\) গুণ কম variance (4.2 §৭ Q11), আর (২) MoM মাঝে মাঝে অবৈধ মান দেয় — এই অধ্যায়ের Figure 3–4 ও §৭ Q8/Q11/Q15 সেই দুটোকেই concrete করে দেখাল। তাই MoM-কে প্রায়ই MLE-র starting point বা দ্রুত-আনুমান হিসেবেই বেশি ব্যবহার করা হয়।
পরবর্তী সংযোগ (→ 4.4 — MLE-র ধর্মাবলি: bias, variance, consistency, efficiency): এই অধ্যায় দেখাল কীভাবে MLE বের করতে হয়; পরের অধ্যায় 4.4 জিজ্ঞেস করবে — "এই estimator-টা কতটা ভালো?" সেখানে আমরা MLE-কে 4.1-এর মানদণ্ডে যাচাই করব: (১) consistency — \(\hat\theta_{\text{MLE}}\xrightarrow{P}\theta\) (যেমন Figure 1-এ \(n\) বাড়লে চূড়া সত্যি \(\lambda\)-তে সরে); (২) asymptotic normality — বড় \(n\)-এ \(\hat\theta_{\text{MLE}}\) আনুমানিক Normal, একটা সুনির্দিষ্ট variance-সহ; (৩) bias — যেমন Normal-এর \(\hat\sigma^2\) (হরে \(n\)) সামান্য নিচে-biased (§৭ Q7); (৪) efficiency — Fisher information ও Cramér–Rao lower bound দিয়ে দেখানো হবে MLE asymptotically সর্বনিম্ন-সম্ভব variance অর্জন করে (asymptotically efficient), যার পূর্বাভাস আমরা Figure 2-এর "খাড়া চূড়া = বেশি precision" ও Figure 3-এর "MLE far tighter"-এ ইতিমধ্যে দেখেছি। অর্থাৎ এই অধ্যায়ের recipe পরের অধ্যায়ে পাবে তার তাত্ত্বিক ন্যায্যতা — কেন MLE-কে statistics-এর "default" estimation-পদ্ধতি বলা হয়।
সূত্র (sources):
- Wasserman, All of Statistics — Ch. 9 (Parametric Inference; §9.3 Maximum Likelihood, §9.4 Properties of the MLE, §9.5 The Delta Method ও Equivariance/Invariance)।
- Rice, Mathematical Statistics and Data Analysis — Ch. 8 (§8.5 The Method of Maximum Likelihood, §8.5.2 Large-Sample Theory)।