4.1 — The Inference Problem & Sampling Distributions (পরিসংখ্যানিক অনুমান ও স্যাম্পলিং বণ্টন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — probability ও inference: একই মুদ্রার দুই পিঠ, কিন্তু উল্টো দিকে চলা¶
১.১ একটা বড় মোড় — এতদিন আমরা কোন দিকে হাঁটছিলাম¶
এই অধ্যায়ে আমরা পুরো curriculum-এর সবচেয়ে গুরুত্বপূর্ণ মোড়টা নিচ্ছি। তাই শুরুতেই একটু থেমে দেখা দরকার — এতদিন আমরা ঠিক কোন দিকে হাঁটছিলাম, আর এখন কোন দিকে ঘুরছি।
Part II ও Part III জুড়ে (probability, random variable, distribution, LLN, CLT) আমরা প্রায় সবসময় একটাই ধরনের প্রশ্ন করেছি। প্রশ্নটা ছিল এরকম:
"distribution-টা যদি আমি জানি (অর্থাৎ parameter জানা), তাহলে data কেমন আচরণ করবে?"
উদাহরণ মনে করুন: "একটা ন্যায্য ছক্কা (\(p=1/6\) প্রতিটি মুখে — parameter জানা) \(600\) বার ছুড়লে কতবার '৬' পড়ার সম্ভাবনা কত?" কিংবা "\(X\sim\mathcal N(\mu,\sigma^2)\), \(\mu\) ও \(\sigma^2\) দেওয়া আছে; \(P(X>c)\) কত?" — এখানে process (যন্ত্রটা, distribution-টা) সম্পূর্ণ জানা, আর আমরা সেখান থেকে data-র সম্ভাব্য আচরণ হিসেব করছি। এটাই probability-র স্বাভাবিক দিক: process → data (যন্ত্র থেকে ফলাফল)।
প্রতীক স্থির করে নিই, কারণ পুরো Part IV জুড়ে এগুলোই ফিরে আসবে:
- \(\theta\) ("theta") — distribution-টিকে নিয়ন্ত্রণকারী parameter (স্থিতিমাপ): একটি স্থির কিন্তু (বাস্তবে প্রায়ই) অজানা সংখ্যা, যেমন একটা মুদ্রার head-হার \(p\), বা একটা population-এর গড় \(\mu\)। এটি random নয় — শুধু আমাদের অজানা।
- \(X_1, X_2, \dots, X_n\) — data (উপাত্ত): সেই distribution থেকে নেওয়া \(n\)টি পর্যবেক্ষণ। আমরা ধরব এগুলো iid (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত, 2.6 ও 3.3-এ পরিচিত): প্রত্যেকটি একই distribution থেকে, এবং একে অপরের উপর নির্ভরশীল নয়।
probability-র ভাষায় তাহলে আমরা জানি \(\theta\), আর হিসেব করি \(X_1,\dots,X_n\) সম্পর্কে — যেমন \(P(\bar X_n \le c \mid \theta)\) জাতীয় কিছু।
১.২ এবার তীরটা উল্টে যায় — inference হলো probability-র উল্টো যাত্রা¶
এখন বাস্তব জগতের আসল সমস্যাটা দেখুন। বাস্তবে আমরা \(\theta\) জানি না — সেটাই তো আমরা জানতে চাই! আমাদের হাতে যা আছে তা হলো data: কিছু পর্যবেক্ষণ \(X_1,\dots,X_n\)। আর আমাদের লক্ষ্য সেই data থেকে অজানা \(\theta\) সম্পর্কে শেখা। অর্থাৎ তীরটা ঠিক উল্টো দিকে:
Inference (অনুমান): "data যদি দেখি, তাহলে process (অর্থাৎ অজানা \(\theta\)) সম্পর্কে কী শিখতে পারি?" — এটি data → process (ফলাফল থেকে যন্ত্র)।
এই উল্টো সম্পর্কটাই এই অধ্যায়ের — এবং পুরো Part IV-এর — হৃদয়। এক বাক্যে মনে রাখার মতো করে:
Probability process থেকে data-র দিকে যায় (\(\theta\) জানা → data-র সম্ভাবনা); inference ঠিক উল্টো — data থেকে process-এর দিকে (\(\theta\) অজানা → data দেখে \(\theta\) সম্পর্কে সিদ্ধান্ত)।
একটা রূপক সাহায্য করতে পারে। ভাবুন একটা বন্ধ কারখানা (factory) — ভেতরে কী যন্ত্র চলছে আপনি দেখতে পান না (এটাই অজানা process, parameter \(\theta\))। কিন্তু কারখানার বেল্ট থেকে বেরিয়ে আসা পণ্যগুলো (products) আপনি গুনে-মেপে দেখতে পান (এটাই data \(X_1,\dots,X_n\))।
- probability প্রশ্ন করে: "যন্ত্রটা যদি জানি, পণ্যগুলো কেমন হবে?" — ভেতর থেকে বাইরে।
- inference প্রশ্ন করে: "পণ্যগুলো দেখে যন্ত্রটা সম্পর্কে কী বলতে পারি?" — বাইরে থেকে ভেতরে।
আরেকটা গুরুত্বপূর্ণ কথা: inference কখনোই \(\theta\)-কে নিশ্চিতভাবে জানতে পারে না — কারণ data শুধু একটা সীমিত, এলোমেলো নমুনা। তাই inference-এর প্রতিটি উত্তরের সাথে সবসময় একটা অনিশ্চয়তার মাপ (measure of uncertainty) থাকে। "\(\theta\) ঠিক কত" নয়, বরং "\(\theta\) আনুমানিক কত, এবং সেই আনুমানে কতটা ভুল থাকতে পারে" — এটাই পরিসংখ্যানকে নিছক আন্দাজ থেকে আলাদা করে। (1.1-এ একে বলেছিলাম "ঝুঁকি-নিয়ন্ত্রিত অনুমানের কাঠামো"।)
১.৩ দুটি hook — কেন এই উল্টো প্রশ্নটা সর্বত্র¶
ধারণাটা কেন এত গুরুত্বপূর্ণ, দুটো বাস্তব দৃষ্টান্তে দেখি। দুটোই এই Part জুড়ে বারবার ফিরবে।
(ক) জনমত জরিপ (opinion poll). একটা নির্বাচনের আগে আপনি জানতে চান: দেশের সব ভোটারের মধ্যে কত ভাগ প্রার্থী A-কে সমর্থন করেন? সেই সত্য ভগ্নাংশটাই অজানা parameter — ধরা যাক \(p\) (এটিই আমাদের \(\theta\))। সব ভোটারকে জিজ্ঞেস করা অসম্ভব, তাই আপনি এলোমেলোভাবে \(n=1000\) জনকে জিজ্ঞেস করলেন — এটাই data। ধরুন \(520\) জন "হ্যাঁ" বললেন, তাই sample-এ সমর্থনের হার \(520/1000 = 0.52\)। প্রশ্ন: এই \(0.52\) থেকে সত্য \(p\) সম্পর্কে কী বলতে পারি? "\(p = 0.52\)" বলা কি নিরাপদ, নাকি \(p\) আসলে \(0.49\) বা \(0.55\)-ও হতে পারে? আর কতটা নিশ্চিত হতে পারি? — এটাই inference, আর এর উত্তরই হলো সেই বিখ্যাত "\(52\% \pm 3\%\)"। সেই "\(\pm 3\%\)"-এর পেছনে যে যন্ত্র লুকিয়ে, তা এই অধ্যায়ের standard error ও sampling distribution (CLT থেকে, 3.4)।
(খ) ওষুধের পরীক্ষা (drug trial). একটা নতুন ওষুধ কি সত্যিই রক্তচাপ কমায়? আপনি কিছু রোগীকে ওষুধ দিলেন, কিছুকে placebo (নিষ্ক্রিয় বড়ি) দিলেন, তারপর দুই দলের রক্তচাপের পরিবর্তন মাপলেন। ধরা যাক ওষুধ-দলে গড় কমেছে \(8\) একক, placebo-দলে \(3\) একক — পার্থক্য \(5\)। অজানা parameter এখানে দুই দলের সত্য গড় পার্থক্য \(\theta\)। প্রশ্ন: এই \(5\)-একক পার্থক্যটা কি ওষুধের আসল প্রভাব, নাকি নিছক এলোমেলো ওঠানামা (random fluctuation) — অর্থাৎ ওষুধ আদৌ কাজ না করলেও কেবল নমুনা-ভাগ্যে এমন পার্থক্য আসতে পারত? এই "আসল প্রভাব বনাম এলোমেলো ওঠানামা" আলাদা করার জন্যই আমাদের জানতে হবে: ওষুধ কাজ না করলে পার্থক্যটা স্বাভাবিকভাবে কতটা ওঠানামা করত — অর্থাৎ ওই পার্থক্য-statistic-এর sampling distribution। (পূর্ণ hypothesis testing 4.4-এ; এখানে শুধু দেখছি কেন sampling distribution লাগে।)
দুটো hook-এই একই সুর: আমরা একটা সংখ্যা data থেকে হিসেব করি (sample হার \(0.52\), পার্থক্য \(5\)), কিন্তু সেই সংখ্যা থেকে অজানা সত্য সম্পর্কে সিদ্ধান্ত নিতে হলে জানতে হবে — সংখ্যাটা নিজে নমুনা-থেকে-নমুনায় কতটা ওঠানামা করে। সেই ওঠানামার গাণিতিক রূপই sampling distribution, আর এই অধ্যায় তা from scratch গড়ে তুলবে।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — মূল শব্দভাণ্ডার from scratch: population/parameter/sample/statistic, তারপর কেন্দ্রীয় জুটি estimand (\(\theta\)) বনাম estimator (\(\hat\theta\)); এরপর এই অধ্যায়ের প্রধান নতুন ধারণা — একটি statistic নিজেই random, তাই তার sampling distribution; তার ছড়ানোর মাপ standard error; আর Normal থেকে জন্ম নেওয়া তিন distribution chi-square, Student's t, F ও degrees of freedom।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 (\(\bar X_n\)-এর sampling distribution, \(\mathrm{SE}=\sigma/\sqrt n\)), E2 (\((n-1)S^2/\sigma^2\sim\chi^2_{n-1}\)), E3 (Student's t, যখন \(\sigma\) অজানা), E4 (দুই variance-এর অনুপাত, F)।
- §৪–৫ — sampling distribution ও standard error নিয়ে গভীরতর আলোচনা, \(S^2\)-এর distribution-এর উৎপত্তি, এবং t/F-এর বৈশিষ্ট্য ও প্রয়োগ।
- §৬–৮ — চিত্র, সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর ভিত্তি। 3.4 (CLT) আমাদের দিয়েছে \(\bar X_n\)-এর fluctuation-এর আকৃতি (\(\mathcal N(\mu,\sigma^2/n)\))। এই অধ্যায় সেই ধারণাকে সাধারণীকরণ করে যেকোনো statistic-এ (শুধু \(\bar X_n\) নয়), এবং Normal থেকে আরও তিনটি বণ্টন (\(\chi^2, t, F\)) বের করে — যেগুলো ছাড়া পরের অধ্যায়গুলোর confidence interval (4.3) ও hypothesis test (4.4–4.6) দাঁড়াতেই পারে না।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে আমরা inference-এর পুরো শব্দভাণ্ডার নিচ থেকে গড়ব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না। পুরো বিভাগে \(X_1, X_2, \dots, X_n\) মানে একই (সাধারণত অজানা) distribution থেকে নেওয়া iid নমুনা।
২.১ চার মূল চরিত্র — population, parameter, sample, statistic¶
1.1-এ এদের সাথে প্রথম পরিচয় হয়েছিল; এখানে inference-এর দৃষ্টিকোণ থেকে ঝালিয়ে নিই, কারণ পুরো Part IV এদের ওপর দাঁড়িয়ে।
- Population (জনসমষ্টি) — আমরা যে গোটা গোষ্ঠী বা যে সম্পূর্ণ distribution সম্পর্কে জানতে চাই। গাণিতিকভাবে এটি একটি distribution; এই distribution থেকেই \(X_1,\dots,X_n\) আসে। আকার \(N\) দিয়ে লেখা হয় (প্রায়ই বিশাল, এমনকি ধারণাগতভাবে অসীম)।
- Parameter (স্থিতিমাপ) — সেই population/distribution-কে বর্ণনাকারী একটি স্থির সংখ্যা, প্রতীকে \(\theta\)। যেমন population গড় \(\mu\), population variance \(\sigma^2\), বা সাফল্যের হার \(p\)। মূল কথা: parameter একটি নির্দিষ্ট, অপরিবর্তনীয় সংখ্যা — random নয়, শুধু (সাধারণত) অজানা। নমুনা বদলালেও \(\theta\) বদলায় না; \(\theta\) population-এর সম্পত্তি, নমুনার নয়।
- Sample (নমুনা) — population থেকে আসলে পর্যবেক্ষিত \(n\)টি একক: \(X_1,\dots,X_n\)। আকার \(n\), এবং প্রায় সবসময় \(n \ll N\)।
- Statistic (পরিসংখ্যান) — শুধুমাত্র data থেকে গণনা করা যেকোনো সংখ্যা, প্রতীকে সাধারণভাবে \(T\): $$ T = T(X_1, X_2, \dots, X_n). $$ উদাহরণ: sample mean \(\bar X_n=\frac1n\sum_{i=1}^n X_i\), sample variance \(S^2\), সর্বোচ্চ মান \(\max_i X_i\) ইত্যাদি। সংজ্ঞাগত শর্ত: একটি statistic-এর সূত্রে কোনো অজানা parameter থাকতে পারবে না — তা কেবল হাতে-থাকা data-র উপর নির্ভরশীল ফাংশন, যাতে আমরা সত্যিই তা সংখ্যায় হিসেব করতে পারি।
পার্থক্যটা একটা ছকে স্পষ্ট হয়:
| বিষয় | Parameter (\(\theta\)) | Statistic (\(T\)) |
|---|---|---|
| কীসের সম্পত্তি | population/distribution-এর | sample-এর |
| উৎস | প্রকৃতির দেওয়া, স্থির | data থেকে গণনা করা |
| random? | না (স্থির সংখ্যা) | হ্যাঁ (নমুনা বদলালে বদলায়) |
| জানা? | সাধারণত অজানা | সবসময় হিসেবযোগ্য (জানা) |
| উদাহরণ | \(\mu,\ \sigma^2,\ p\) | \(\bar X_n,\ S^2,\ \hat p\) |
এই ছকের শেষ-থেকে-দ্বিতীয় সারিটি (random কি না) এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ অন্তর্দৃষ্টির বীজ — §২.৪-এ ফিরব।
প্রসঙ্গত, sample mean ও sample variance-এর সংজ্ঞা (1.2 থেকে) এখানে স্থির করে রাখি, কারণ এরা অধ্যায়জুড়ে লাগবে: $$ \bar X_n = \frac{1}{n}\sum_{i=1}^{n} X_i, \qquad S^2 = \frac{1}{n-1}\sum_{i=1}^{n} \big(X_i - \bar X_n\big)^2 . $$ (\(S^2\)-এ ভাগ হয় \(n-1\) দিয়ে, \(n\) দিয়ে নয় — এই "\(n-1\)" কেন, তার একটা গভীর কারণ §২.৭-এর degrees of freedom-এ ও E2-তে পরিষ্কার হবে; §৪-এ পূর্ণ যুক্তি দেওয়া হবে।)
২.২ Estimand বনাম estimator বনাম estimate — তিনটিকে আলাদা রাখা¶
inference-এর কাজ হলো একটি অজানা parameter "আন্দাজ" করা। কিন্তু এই "আন্দাজ" প্রক্রিয়ায় তিনটি আলাদা জিনিস জড়িত, আর এদের গুলিয়ে ফেলা শিক্ষানবিশদের সবচেয়ে সাধারণ ভুল। তাই তিনটিকে যত্ন করে আলাদা করি।
- Estimand (যা অনুমান করতে চাই) — সেই অজানা parameter \(\theta\) নিজে, যাকে আমরা জানতে চাই। যেমন: population গড় \(\mu\)। এটি একটি স্থির সংখ্যা, লক্ষ্যবস্তু (target)।
- Estimator (যা দিয়ে অনুমান করি) — একটি নিয়ম বা সূত্র, যা data নিয়ে \(\theta\)-র একটা আন্দাজ ফেরত দেয়। এটি একটি statistic, প্রতীকে \(\hat\theta\) ("theta-hat" — মাথার উপর hat "\(\hat{}\)" মানে "এটি অজানা \(\theta\)-র একটি অনুমান")। সূত্র হিসেবে এটি random variable: $$ \hat\theta = \hat\theta(X_1, \dots, X_n). $$ যেমন \(\mu\)-কে অনুমান করার একটি স্বাভাবিক estimator হলো \(\hat\mu = \bar X_n\)।
- Estimate (একটি নির্দিষ্ট আন্দাজ) — একটি বিশেষ নমুনায় estimator-এর প্রকৃত সংখ্যাগত মান। যেমন এক জরিপে \(\bar X_n = 168.3\) সেমি। এটি একটি নির্দিষ্ট সংখ্যা — আর random নয়, কারণ data এসে গেছে।
পার্থক্যটা ধরার সবচেয়ে সহজ উপায়: estimator হলো একটা যন্ত্র (random — চালালে এক-একবার এক-এক ফল), estimate হলো সেই যন্ত্র একবার চালিয়ে পাওয়া একটি নির্দিষ্ট ফল (random নয়), আর estimand হলো যন্ত্রটা যা মাপতে চাইছে সেই স্থির লক্ষ্য। একই estimator \(\hat\theta=\bar X_n\) ভিন্ন ভিন্ন নমুনায় ভিন্ন estimate দেবে (\(168.3\), তারপর অন্য নমুনায় \(167.9\), ...), কিন্তু সবগুলোরই লক্ষ্য একই estimand \(\mu\)।
প্রতীক-চুক্তি (পুরো Part IV-এ এক): অজানা সত্য parameter \(\theta\) (hat ছাড়া); তার estimator \(\hat\theta\) (hat সহ)। সাধারণভাবে: \(\mu \leftrightarrow \hat\mu=\bar X_n\), \(\sigma^2 \leftrightarrow \hat{\sigma}^2\) (প্রায়ই \(S^2\)), \(p \leftrightarrow \hat p\)। "hat" দেখলেই বুঝবেন: এটি data থেকে গণনা-করা একটি অনুমান, সত্য মান নয়।
২.৩ পুরো ছবিটা এক জায়গায় — inference-loop¶
উপরের ধারণাগুলো একসাথে জুড়লে inference-এর পুরো চক্রটা দাঁড়ায়। 1.1-এর loop-টাই এখানে parameter–estimator-এর ভাষায় ফিরে আসে:
ডান প্রান্তের প্রশ্নচিহ্নটাই মূল: \(\hat\theta\) কি \(\theta\)-র কাছাকাছি? কতটা কাছে? কতবার? — এই প্রশ্নের উত্তর দিতে হলে জানতে হবে \(\hat\theta\) নিজে নমুনা-থেকে-নমুনায় কেমন ওঠানামা করে। সেটাই পরের উপবিভাগের বিষয়, এবং এই অধ্যায়ের প্রধান নতুন ধারণা।
২.৪ মূল নতুন ধারণা — একটি statistic নিজেই একটি random variable, আর তার distribution = sampling distribution¶
এবার পুরো অধ্যায়ের কেন্দ্রীয় ধারণা। এটি প্রথমে একটু বিস্ময়কর শোনায়, তাই ধীরে গড়ি।
আমরা সাধারণত \(\bar X_n\) বা \(S^2\)-কে "একটা সংখ্যা" ভাবি — যেমন "\(168.3\)"। কিন্তু খেয়াল করুন: সেই সংখ্যাটা এসেছে একটি নির্দিষ্ট নমুনা থেকে। যদি আমরা population থেকে আবার, নতুন করে \(n\)টি একক টানতাম, তাহলে নতুন \(X_1,\dots,X_n\) পেতাম, আর তাদের গড় হতো আলাদা — হয়তো \(167.9\), তার পরের নমুনায় \(169.1\), ইত্যাদি। অর্থাৎ:
statistic \(T=T(X_1,\dots,X_n)\) নিজেই একটি random variable — কারণ তার ইনপুট \(X_1,\dots,X_n\) random, তাই আউটপুটও random। নমুনা বদলালে \(T\)-ও বদলায়।
আর random variable হলেই (Part II থেকে) তার একটি নিজস্ব distribution আছে — একটি probability নিয়ম যা বলে \(T\) কোন মান কত সম্ভাবনায় নেয়। এই distribution-টিরই একটা বিশেষ নাম আছে:
সংজ্ঞা (sampling distribution — স্যাম্পলিং বণ্টন)। একটি statistic \(T=T(X_1,\dots,X_n)\)-এর sampling distribution হলো \(T\)-এর probability distribution, যা জন্ম নেয় random নমুনা \(X_1,\dots,X_n\)-এর ওঠানামা থেকে। অর্থাৎ: "যদি একই population থেকে বারবার (কাল্পনিকভাবে) আকার-\(n\) নমুনা টানতাম এবং প্রতিবার \(T\) হিসেব করতাম, তাহলে সেই \(T\)-মানগুলো যে distribution মেনে ছড়াত — তাই \(T\)-এর sampling distribution।"
দুটো জোর-দিয়ে-বলার মতো সূক্ষ্মতা:
- "Sampling" শব্দটা কীসের? এটি data-র distribution নয় (data \(X_i\)-এর নিজস্ব distribution আলাদা — যেমন উচ্চতার distribution)। এটি statistic-এর distribution, যা নমুনা-গ্রহণ (sampling) প্রক্রিয়ার পুনরাবৃত্তি থেকে আসে। নাম তাই "sampling distribution"।
- বাস্তবে আমরা একটাই নমুনা নিই। "বারবার নমুনা টানা" বেশিরভাগ সময় কল্পনা — আমরা সাধারণত একটিই নমুনা পাই, একটিই estimate। তবু sampling distribution একটি বাস্তব গাণিতিক বস্তু: এটি বলে আমাদের ওই একটিমাত্র estimate কতটা বিশ্বাসযোগ্য, কতটা ওঠানামার শিকার হতে পারত। ঠিক এখানেই গণিত (CLT, ও §২.৬-এর distribution-গুলো) আমাদের উদ্ধার করে — বারবার নমুনা না টেনেই sampling distribution বলে দেয়।
এই দ্বিতীয় বিন্দুটি 3.4-এর সাথে সরাসরি জুড়ছে: CLT আসলে একটা statistic (\(\bar X_n\))-এর sampling distribution সম্পর্কেই একটা উপপাদ্য। এই অধ্যায় সেই দৃষ্টিভঙ্গিকে সাধারণ করে তুলছে।
২.৫ Standard error — একটি estimator-এর ওঠানামার মাপ¶
sampling distribution-এর সবচেয়ে গুরুত্বপূর্ণ একটিমাত্র সংখ্যা হলো তার ছড়ানোর মাপ — estimate-টা নমুনা-থেকে-নমুনায় কতটা ওঠানামা করে। যেহেতু (Part II থেকে) ছড়ানোর স্বাভাবিক মাপ হলো standard deviation, আমরা সংজ্ঞা দিই:
সংজ্ঞা (standard error — আদর্শ ত্রুটি)। একটি estimator \(\hat\theta\)-এর standard error, প্রতীকে \(\mathrm{SE}(\hat\theta)\) বা সংক্ষেপে \(\mathrm{SE}\), হলো তার sampling distribution-এর standard deviation: $$ \mathrm{SE}(\hat\theta) \;=\; \sqrt{\,\mathrm{Var}(\hat\theta)\,}. $$
কয়েকটি কথা মাথায় রাখার মতো:
- "Error" শব্দটা ভুল-বোঝার ফাঁদ। এটি কোনো হিসেবের ভুল নয়, এবং অবশ্যই একটি নির্দিষ্ট estimate \(\theta\) থেকে কত দূরে — তা নয়। এটি কেবল estimator-এর অন্তর্নিহিত ওঠানামা-র মাপ: estimate-গুলো নমুনায়-নমুনায় কতটা ছড়ায়। "error" এসেছে কারণ এই ওঠানামাই আমাদের অনুমানের অনিশ্চয়তার উৎস।
- standard deviation বনাম standard error। \(\sigma\) (population standard deviation) বলে একটিমাত্র data-বিন্দু কতটা ছড়ায়; \(\mathrm{SE}\) বলে একটি statistic (যেমন গড়) কতটা ছড়ায়। দুটো ভিন্ন জিনিস — §৩-এর E1-এ দেখব \(\mathrm{SE}(\bar X_n)=\sigma/\sqrt n\), অর্থাৎ গড়ের ছড়ানো একটি বিন্দুর ছড়ানোর চেয়ে \(\sqrt n\) গুণ ছোট।
- বাস্তবে \(\mathrm{SE}\)-ও প্রায়ই অজানা, কারণ সূত্রে অজানা parameter (\(\sigma\)) থাকে। তখন আমরা তার একটি estimated standard error \(\widehat{\mathrm{SE}}\) ব্যবহার করি (\(\sigma\)-র জায়গায় \(S\) বসিয়ে)। এই "\(\sigma\)-কে \(S\) দিয়ে বদলানো"-র মূল্য কী — তা থেকেই Student's t জন্ম নেবে (§২.৬.২ ও E3)।
২.৬ Normal থেকে জন্ম নেওয়া তিন বণ্টন — chi-square, Student's t, F¶
এতক্ষণ ধারণা ছিল সাধারণ (যেকোনো statistic)। এবার একটি বিশেষ অথচ অতি-গুরুত্বপূর্ণ পরিস্থিতি: যখন মূল data Normal (বা CLT-র কল্যাণে আনুমানিক Normal)। তখন কিছু স্বাভাবিক statistic-এর sampling distribution ঠিক তিনটি নির্দিষ্ট আকৃতি নেয়, যেগুলো Normal থেকে গণিত দিয়ে বের করা যায়। এই তিনটিই Part IV-এর প্রায় সব CI ও test-এর ভিত্তি, তাই এদের from scratch গড়ি।
পুরো জুড়ে \(Z, Z_1, Z_2, \dots\) মানে independent standard Normal, অর্থাৎ প্রত্যেকে \(\mathcal N(0,1)\) এবং পরস্পর স্বাধীন (2.4 ও 2.6)।
২.৬.১ Chi-square বণ্টন \(\chi^2_k\) — independent standard Normal-এর বর্গের যোগ¶
সবচেয়ে মৌলিকটি দিয়ে শুরু। প্রশ্ন: কয়েকটি independent \(\mathcal N(0,1)\)-কে বর্গ করে যোগ করলে কী distribution পাই?
সংজ্ঞা (chi-square — কাই-বর্গ বণ্টন)। \(Z_1, Z_2, \dots, Z_k\) যদি \(k\)টি independent \(\mathcal N(0,1)\) হয়, তবে তাদের বর্গের যোগফল $$ Q \;=\; Z_1^2 + Z_2^2 + \cdots + Z_k^2 \;=\; \sum_{i=1}^{k} Z_i^2 $$ -এর distribution-কে বলে \(k\) degrees of freedom-এর chi-square distribution, প্রতীকে \(Q \sim \chi^2_k\)। এখানে \(k\) একটি ধনাত্মক পূর্ণসংখ্যা — কতগুলো independent Normal বর্গ-যোগ হলো তার সংখ্যা।
প্রতিটি অংশ খুলি:
- \(\chi^2\) ("chi-squared") — গ্রিক অক্ষর "chi"-এর বর্গ; নামটাই মনে করায় ব্যাপারটা বর্গ নিয়ে।
- \(k\) — degrees of freedom (df): এখানে = যোগে কতগুলো independent standard-Normal পদ আছে।
- কেন এটি গুরুত্বপূর্ণ? কারণ variance-জাতীয় রাশিতে বর্গের যোগ স্বাভাবিকভাবেই আসে (\(S^2\)-এ \(\sum(X_i-\bar X_n)^2\) দেখুন)। তাই sample variance-এর sampling distribution chi-square হবে — ঠিক E2-তে।
কয়েকটি দ্রুত বৈশিষ্ট্য (অন্তর্দৃষ্টির জন্য; পূর্ণ ব্যুৎপত্তি §৪): \(Q\ge 0\) সবসময় (বর্গের যোগ ঋণাত্মক হতে পারে না), distribution-টি ডানদিকে লম্বা-লেজী (right-skewed), এবং \(\mathbb{E}[Q]=k\) (প্রতিটি \(\mathbb{E}[Z_i^2]=\mathrm{Var}(Z_i)=1\), তাই \(k\)টির যোগ \(k\))।
২.৬.২ Student's t বণ্টন \(t_k\) — Normal-কে scaled chi-square দিয়ে ভাগ¶
এবার সবচেয়ে ব্যবহারিক distribution-টি, যা সরাসরি §২.৫-এর "\(\sigma\) অজানা" সমস্যা থেকে জন্মায়।
স্মরণ করুন: CLT বলেছিল \(\dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\approx\mathcal N(0,1)\)। কিন্তু এতে \(\sigma\) লাগে, যা বাস্তবে অজানা! স্বাভাবিক সমাধান — \(\sigma\)-র জায়গায় তার estimate \(S\) বসানো: \(\dfrac{\bar X_n-\mu}{S/\sqrt n}\)। কিন্তু এখন হরেও একটা random রাশি (\(S\)) ঢুকল, তাই এটি আর হুবহু Normal থাকে না — একটু বেশি ছড়ায় (কারণ \(S\) নিজেই ওঠানামা করে, বাড়তি অনিশ্চয়তা যোগ করে)। সেই নতুন আকৃতিটাই Student's t।
সংজ্ঞা (Student's t — t বণ্টন)। \(Z\sim\mathcal N(0,1)\) এবং \(Q\sim\chi^2_k\) যদি independent হয়, তবে $$ T \;=\; \frac{Z}{\sqrt{Q/k}} $$ -এর distribution-কে বলে \(k\) degrees of freedom-এর Student's t distribution, প্রতীকে \(T\sim t_k\)।
খুলে বলি:
- লব \(Z\) — একটি standard Normal (আমাদের ক্ষেত্রে standardized গড়)।
- হর \(\sqrt{Q/k}\) — একটি scaled chi-square-এর বর্গমূল (আমাদের ক্ষেত্রে এটিই হবে \(S/\sigma\)-জাতীয় রাশি)। \(Q/k\)-কে \(k\) দিয়ে ভাগ করায় তার গড় \(1\)-এর কাছাকাছি থাকে, তাই হর "\(1\)-এর আশপাশে" ওঠানামা করে।
- "Student" — এটি কোনো ছাত্র নয়! W. S. Gosset ছদ্মনামে "Student" নামে এটি প্রকাশ করেছিলেন (Guinness brewery-তে কাজের সময়)।
- মূল অন্তর্দৃষ্টি: যদি হরটা ঠিক \(1\) হতো (অর্থাৎ \(\sigma\) জানা থাকত), পেতাম হুবহু \(Z\sim\mathcal N(0,1)\)। কিন্তু হর random হওয়ায় t-distribution Normal-এর চেয়ে একটু চ্যাপ্টা ও মোটা-লেজী (heavier-tailed) — বাড়তি অনিশ্চয়তার ছাপ।
- df বাড়লে t → Normal। \(k\) বড় হলে \(Q/k\to 1\) (LLN, কারণ \(Q/k\) হলো \(k\)টি \(Z_i^2\)-এর গড়), তাই হর \(\to 1\) এবং \(t_k \to \mathcal N(0,1)\)। অর্থাৎ বড় নমুনায় "\(\sigma\) অজানা" আর "\(\sigma\) জানা" প্রায় একই — যা স্বজ্ঞাসম্মত। (Figure 4-1-t-vs-normal এই তুলনা দেখাবে।)
২.৬.৩ F বণ্টন \(F_{d_1,d_2}\) — দুই scaled chi-square-এর অনুপাত¶
শেষ distribution-টি জন্মায় যখন আমরা দুটি variance তুলনা করতে চাই — তাদের অনুপাত নিই।
সংজ্ঞা (F বণ্টন)। \(Q_1\sim\chi^2_{d_1}\) এবং \(Q_2\sim\chi^2_{d_2}\) যদি independent হয়, তবে দুটিকে নিজ নিজ df দিয়ে ভাগ করে নেওয়া অনুপাত $$ F \;=\; \frac{Q_1/d_1}{Q_2/d_2} $$ -এর distribution-কে বলে \((d_1, d_2)\) degrees of freedom-এর F distribution, প্রতীকে \(F\sim F_{d_1,d_2}\)।
খুলে বলি:
- \(d_1\) — লবের chi-square-এর df (numerator df); \(d_2\) — হরের chi-square-এর df (denominator df)। ক্রম গুরুত্বপূর্ণ: \(F_{d_1,d_2}\) আর \(F_{d_2,d_1}\) এক নয়।
- "F" — Ronald A. Fisher-এর সম্মানে (G. W. Snedecor নামকরণ করেন)।
- কেন df দিয়ে ভাগ? যাতে লব ও হর দুটিরই গড় \(1\)-এর কাছাকাছি থাকে; ফলে দুই variance সমান হলে \(F\) প্রায় \(1\)-এর আশপাশে ঘোরে — যা তুলনার স্বাভাবিক মানদণ্ড দেয় (\(F\gg1\) মানে প্রথম variance বড়, \(F\ll1\) মানে দ্বিতীয়টি বড়)।
- \(F\ge 0\) সবসময় (দুই অ-ঋণাত্মক রাশির অনুপাত), এবং right-skewed।
- t ও F-এর সম্পর্ক: \(T\sim t_k\) হলে \(T^2\sim F_{1,k}\) — কারণ \(T^2=\dfrac{Z^2}{Q/k}=\dfrac{Z^2/1}{Q/k}\), আর \(Z^2\sim\chi^2_1\) (একটি Normal-এর বর্গ)। এই সম্পর্কটি পরে two-sided t-test ও ANOVA জুড়বে (§৪)।
২.৬.৪ Degrees of freedom (df) — শব্দটার মানে কী¶
তিন distribution-এই "degrees of freedom" এসেছে; ধারণাটা আলাদা করে একটু স্পষ্ট করি, কারণ এটি Part IV জুড়ে ফিরবে।
স্বজ্ঞাগতভাবে, degrees of freedom = কতগুলো স্বাধীনভাবে-ওঠানামা-করা সংখ্যা একটি রাশি গঠনে অবদান রাখছে। chi-square-এ এটি সরাসরি = কতগুলো independent \(Z_i\) বর্গ-যোগ হলো।
কিন্তু একটা সূক্ষ্মতা: যখন আমরা \(\sum(X_i-\bar X_n)^2\)-এর মতো রাশি দেখি (যেখানে \(\mu\)-র জায়গায় তার estimate \(\bar X_n\) বসেছে), তখন df \(n\) নয়, \(n-1\) হয়। কারণ \(X_1-\bar X_n,\dots,X_n-\bar X_n\) এই \(n\)টি বিচ্যুতি (deviation) সম্পূর্ণ স্বাধীন নয় — তাদের যোগফল সবসময় ঠিক শূন্য (\(\sum_i(X_i-\bar X_n)=0\), কারণ \(\bar X_n\) গড়ের সংজ্ঞাই তাই)। এই একটি constraint (বাঁধন) একটি স্বাধীনতা কেড়ে নেয়: \(n-1\)টি বিচ্যুতি জানলে শেষটি আপনাআপনি নির্ধারিত। তাই "\(n-1\) degrees of freedom"। ঠিক একই কারণে \(S^2\)-এ ভাগ হয় \(n-1\) দিয়ে — এই যোগসূত্রটি E2-তে সংখ্যাসহ দেখব, পূর্ণ যুক্তি §৪-এ।
এক বাক্যে df: df হলো constraint বাদ দেওয়ার পর কতগুলো রাশি এখনো স্বাধীনভাবে ওঠানামা করতে পারে — chi-square/t/F-এর আকৃতি ঠিক এই সংখ্যাটিই নিয়ন্ত্রণ করে।
৩ · পূর্ণাঙ্গ উদাহরণ — E1 থেকে E4, সংখ্যাসহ¶
এবার §২-এর প্রতিটি ধারণা চারটি concrete উদাহরণে সংখ্যা বসিয়ে দৃঢ় করি। প্রতিটিতে আগে কোন statistic, তারপর তার sampling distribution, তারপর সংখ্যা।
৩.১ E1 — sample mean-এর sampling distribution ও \(\mathrm{SE}=\sigma/\sqrt n\)¶
সেটিং। ধরা যাক একটা population থেকে iid নমুনা \(X_1,\dots,X_n\), প্রত্যেকের mean \(\mu\) ও variance \(\sigma^2\) (3.4-এর মতোই)। আমাদের statistic হলো sample mean \(\bar X_n=\frac1n\sum_i X_i\), যা \(\mu\)-র estimator: \(\hat\mu=\bar X_n\)।
Sampling distribution। §২.৪ বলছে \(\bar X_n\) নিজে random — তার distribution কী? দুটো স্তরে:
- যেকোনো population-এ (বড় \(n\)): CLT (3.4) দেয় approximately $$ \bar X_n \;\overset{\text{approx}}{\sim}\; \mathcal N!\left(\mu,\ \frac{\sigma^2}{n}\right). $$
- Normal population-এ (যেকোনো \(n\)): যদি মূল \(X_i\sim\mathcal N(\mu,\sigma^2)\) হয়, তবে এটি হুবহু (approximation নয়) সত্য — independent Normal-এর যোগ আবার Normal (2.6/3.4)। তাই \(\bar X_n\sim\mathcal N(\mu,\sigma^2/n)\) ঠিক ঠিক।
দুই ক্ষেত্রেই কেন্দ্র \(\mu\) এবং variance \(\sigma^2/n\) — মূল data-র variance \(\sigma^2\)-এর চেয়ে \(n\) গুণ ছোট। তাই standard error: $$ \boxed{\ \mathrm{SE}(\bar X_n) \;=\; \sqrt{\mathrm{Var}(\bar X_n)} \;=\; \sqrt{\frac{\sigma^2}{n}} \;=\; \frac{\sigma}{\sqrt n}\ } $$
সংখ্যায়। ধরা যাক একটা population-এর \(\sigma = 15\) (যেমন IQ-জাতীয় স্কোর), এবং আমরা \(n=100\) আকারের নমুনা নিই। তাহলে: $$ \mathrm{SE}(\bar X_n) = \frac{15}{\sqrt{100}} = \frac{15}{10} = 1.5 . $$ ব্যাখ্যা: একটিমাত্র ব্যক্তির স্কোর \(\sigma=15\) একক ছড়ায়, কিন্তু \(100\) জনের গড় মাত্র \(1.5\) একক ছড়ায় — \(10=\sqrt{100}\) গুণ সংকুচিত। নমুনা \(n=400\) করলে \(\mathrm{SE}=15/20=0.75\) — আরও অর্ধেক। এই "\(1/\sqrt n\) হারে সংকোচন"-ই কেন বড় নমুনা ভালো তার গাণিতিক হৃদয় (Figure 4-1-se-shrink এটি দেখাবে)।
এক ছোট সিমুলেশনে যাচাই — population থেকে বারবার নমুনা টেনে গড়ের ছড়ানো মাপি:
import numpy as np
rng = np.random.default_rng(0)
mu, sigma, n, reps = 50, 15, 100, 100_000
means = rng.normal(mu, sigma, size=(reps, n)).mean(axis=1) # প্রতিবার X̄ₙ
print(round(means.mean(), 3)) # ≈ 50.0 = μ (কেন্দ্র)
print(round(means.std(), 3)) # ≈ 1.5 = σ/√n (standard error)
৩.২ E2 — sample variance ও chi-square: \((n-1)S^2/\sigma^2\sim\chi^2_{n-1}\)¶
সেটিং। এবার estimand হলো population variance \(\sigma^2\), estimator হলো sample variance \(S^2=\frac{1}{n-1}\sum_i(X_i-\bar X_n)^2\)। ধরা যাক মূল data Normal: \(X_i\sim\mathcal N(\mu,\sigma^2)\)।
Sampling distribution। \(S^2\) নিজে random; তার আকৃতি কী? একটা মৌলিক ফল (Normal থেকে, §২.৬.১-এর chi-square এখানে আসে): $$ \boxed{\ \frac{(n-1)\,S^2}{\sigma^2} \;\sim\; \chi^2_{n-1}\ } $$ কেন chi-square? কারণ ভেতরের রাশি \(\sum_i(X_i-\bar X_n)^2\) হলো (standardize করলে) Normal-বিচ্যুতির বর্গের যোগ — ঠিক §২.৬.১-এর গঠন। আর কেন df \(=n-1\), \(n\) নয়? কারণ বিচ্যুতিগুলোর যোগ শূন্য — একটি constraint, একটি df কম (§২.৬.৪)। এই left-side রাশিটিকে scaled/normalized sample variance বলা চলে।
সংখ্যায় (df ও গড় যাচাই)। ধরা যাক \(n=10\), তাই \((n-1)S^2/\sigma^2\sim\chi^2_9\)। chi-square-এর গড় = তার df (§২.৬.১), তাই $$ \mathbb{E}!\left[\frac{(n-1)S^2}{\sigma^2}\right] = n-1 = 9 . $$ বাঁ পাশ থেকে \(\dfrac{n-1}{\sigma^2}\,\mathbb{E}[S^2] = n-1\), অর্থাৎ \(\mathbb{E}[S^2]=\sigma^2\)। এটিই "\(n-1\) দিয়ে ভাগ"-এর পুরস্কার: তবেই \(S^2\)-এর গড় ঠিক \(\sigma^2\) হয় (একে বলে unbiased — পক্ষপাতহীন, 4.2-এ বিশদ)। যদি \(n\) দিয়ে ভাগ করতাম, গড় হতো \(\frac{n-1}{n}\sigma^2<\sigma^2\) — একটু কম, পক্ষপাতী। সংখ্যায়: \(\sigma^2=4\) হলে \(\mathbb{E}[S^2]=4\) (\(n-1\)-ভাগে), কিন্তু \(n\)-ভাগে হতো \(\frac{9}{10}\times4=3.6\)।
import numpy as np
rng = np.random.default_rng(1)
mu, sigma2, n, reps = 0, 4.0, 10, 200_000
sigma = np.sqrt(sigma2)
X = rng.normal(mu, sigma, size=(reps, n))
S2 = X.var(axis=1, ddof=1) # ddof=1 ⇒ n−1 ভাগ
stat = (n - 1) * S2 / sigma2 # ≈ χ²₉
print(round(stat.mean(), 3)) # ≈ 9.0 = df = n−1
print(round(S2.mean(), 3)) # ≈ 4.0 = σ² (unbiased)
৩.৩ E3 — Student's t: \(\sigma\) অজানা হলে \(\dfrac{\bar X_n-\mu}{S/\sqrt n}\sim t_{n-1}\)¶
সেটিং। বাস্তবে \(\sigma\) অজানা (§২.৫)। E1-এ standardize করতে \(\sigma\) লাগত; তার বদলে \(S\) বসালে কী হয়? ধরা যাক \(X_i\sim\mathcal N(\mu,\sigma^2)\)।
Sampling distribution। \(\sigma\) জানা থাকলে \(\dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\sim\mathcal N(0,1)\) (হুবহু, Normal data-য়)। কিন্তু \(\sigma\)-র জায়গায় \(S\) বসালে: $$ \boxed{\ \frac{\bar X_n-\mu}{S/\sqrt n} \;\sim\; t_{n-1}\ } $$ কেন ঠিক \(t_{n-1}\)? §২.৬.২-এর সংজ্ঞায় বসিয়ে দেখা যায়: রাশিটিকে লেখা যায় \(\dfrac{Z}{\sqrt{Q/(n-1)}}\) আকারে, যেখানে লব \(Z=\dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\sim\mathcal N(0,1)\), আর হরে \(Q=(n-1)S^2/\sigma^2\sim\chi^2_{n-1}\) (E2 থেকে!), এবং Normal data-য় \(\bar X_n\) ও \(S^2\) independent (একটি সুন্দর Normal-বিশেষ ধর্ম; §৪-এ ব্যাখ্যা করা হবে)। অর্থাৎ E2-এর chi-square আর E1-এর Normal একসাথে জুড়ে Student's t জন্ম দেয়। df \(=n-1\) আসে \(S^2\)-এর df থেকেই।
সংখ্যায় — কেন এটা গুরুত্বপূর্ণ। \(n=10\) (\(t_9\)) ধরা যাক। Normal হলে কেন্দ্রীয় \(95\%\) ধরতে \(\pm 1.96\) standard deviation লাগত। কিন্তু \(t_9\) একটু মোটা-লেজী, তাই একই \(95\%\) ধরতে লাগে \(\pm 2.262\) (t-সারণি থেকে) — বেশি চওড়া। অর্থাৎ \(\sigma\) অজানা থাকায় (এবং \(S\) দিয়ে অনুমান করায়) আমাদের অনিশ্চয়তা বাড়ে, তাই ব্যবধি চওড়া করতে হয়:
| df \(=n-1\) | t-এর \(97.5\%\) বিন্দু | Normal \(97.5\%\) বিন্দু |
|---|---|---|
| \(9\) (\(n=10\)) | \(2.262\) | \(1.960\) |
| \(29\) (\(n=30\)) | \(2.045\) | \(1.960\) |
| \(99\) (\(n=100\)) | \(1.984\) | \(1.960\) |
লক্ষ করুন df বাড়লে t-বিন্দু Normal-এর \(1.960\)-র দিকে নামছে — ঠিক §২.৬.২-এর "\(t_k\to\mathcal N(0,1)\)" বাস্তবে। এই বাড়তি চওড়াই হলো "\(\sigma\) অজানা থাকার মূল্য", আর এটিই 4.3-এর confidence interval-এ সরাসরি কাজে লাগবে। (Figure 4-1-t-vs-normal এই মোটা-লেজ ও অভিসরণ দেখাবে।)
৩.৪ E4 — F distribution: দুই variance-এর অনুপাত¶
সেটিং। এবার দুটি স্বাধীন Normal population তুলনা: প্রথম থেকে \(n_1\)টি নমুনা (\(\sigma_1^2\) variance, sample variance \(S_1^2\)), দ্বিতীয় থেকে \(n_2\)টি নমুনা (\(\sigma_2^2\), \(S_2^2\))। প্রশ্ন (ওষুধ-পরীক্ষা বা গুণমান-নিয়ন্ত্রণে সাধারণ): দুই population-এর variance কি সমান, নাকি একটি বেশি ছড়ানো?
Sampling distribution। স্বাভাবিক statistic হলো দুই sample variance-এর অনুপাত। E2 থেকে \((n_1-1)S_1^2/\sigma_1^2\sim\chi^2_{n_1-1}\) এবং \((n_2-1)S_2^2/\sigma_2^2\sim\chi^2_{n_2-1}\), দুটি independent। §২.৬.৩-এর F-সংজ্ঞায় বসালে: $$ \boxed{\ \frac{S_1^2/\sigma_1^2}{S_2^2/\sigma_2^2} \;\sim\; F_{\,n_1-1,\ n_2-1}\ } $$ (কারণ প্রতিটি \(\chi^2\)-কে তার df \(n_i-1\) দিয়ে ভাগ করলে \(S_i^2/\sigma_i^2\) পাওয়া যায়, আর তাদের অনুপাতই F-এর সংজ্ঞা।) বিশেষ ক্ষেত্র — variance সমান হলে (\(\sigma_1^2=\sigma_2^2\)), \(\sigma\)-গুলো কাটাকুটি হয়ে সরাসরি পর্যবেক্ষণযোগ্য রাশি দাঁড়ায়: $$ \frac{S_1^2}{S_2^2} \;\sim\; F_{\,n_1-1,\ n_2-1}. $$ এটিই সুবিধা: \(\sigma\) জানা না থাকলেও, "variance সমান" অনুমানের অধীনে কেবল data থেকে গণনাযোগ্য \(S_1^2/S_2^2\)-এর distribution জানা।
সংখ্যায়। ধরা যাক \(n_1=n_2=11\) (তাই \(F_{10,10}\)), এবং নমুনায় পেলাম \(S_1^2=12\), \(S_2^2=4\)। তাহলে পর্যবেক্ষিত অনুপাত: $$ \frac{S_1^2}{S_2^2} = \frac{12}{4} = 3.0 . $$ যদি দুই সত্য variance সমান হতো, আমরা আশা করতাম অনুপাত \(\approx 1\) (§২.৬.৩)। পাওয়া গেল \(3.0\) — অনেক বড়। প্রশ্ন: এটা কি সত্যিই প্রথম population-এর বেশি ছড়ানোর প্রমাণ, নাকি \(F_{10,10}\)-এর স্বাভাবিক ওঠানামাতেই \(3.0\) আসা সম্ভব? \(F_{10,10}\)-এর \(95\%\) বিন্দু \(\approx 2.98\) (F-সারণি) — অর্থাৎ variance সমান হলে অনুপাত \(2.98\) ছাড়ানোর সম্ভাবনা মাত্র \(5\%\)। যেহেতু \(3.0 > 2.98\), এটি (সামান্য হলেও) "variance সমান" ধারণার বিরুদ্ধে প্রমাণ। এই যুক্তিটাই পূর্ণরূপে F-test ও ANOVA-তে গড়াবে (4.6; §৪-এ পরিচিতি)।
import numpy as np
rng = np.random.default_rng(3)
n1, n2, reps = 11, 11, 200_000 # σ₁²=σ₂² ধরে নিচ্ছি (null)
X1 = rng.normal(0, 1, size=(reps, n1)); S1 = X1.var(axis=1, ddof=1)
X2 = rng.normal(0, 1, size=(reps, n2)); S2 = X2.var(axis=1, ddof=1)
Fstat = S1 / S2 # ≈ F₁₀,₁₀ যখন σ₁²=σ₂²
print(round(np.quantile(Fstat, 0.95), 3)) # ≈ 2.98 (95% বিন্দু)
print(round((Fstat > 3.0).mean(), 4)) # ≈ 0.05 (3.0 ছাড়ানোর হার)
§৩-এর সারসংক্ষেপ। চারটি উদাহরণ চারটি মূল ধারণা ছুঁয়েছে: E1 — statistic random, তার \(\mathrm{SE}=\sigma/\sqrt n\); E2 — variance-এর sampling distribution chi-square, ও "\(n-1\)"-এর অর্থ; E3 — \(\sigma\) অজানা হলে Normal-এর বদলে t (চওড়া, মোটা-লেজ); E4 — দুই variance তুলনায় F। এই তিন বণ্টন (\(\chi^2, t, F\))-ই পরের অধ্যায়গুলোর CI ও hypothesis test-এর কাঁচামাল। sampling distribution ও standard error-এর গভীরতর তত্ত্ব, \(S^2\)-এর distribution ও \(\bar X_n\perp S^2\)-এর ব্যুৎপত্তি, এবং t/F-এর আরও প্রয়োগ — §৪–৫-এ।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে আমরা চারটি মৌলিক sampling distribution-কে scratch থেকে গড়ে তুলব। প্রতিটি ফলাফলের পাশে একটি difficulty-tag থাকবে — ★ (সহজ), ★★ (মাঝারি), ★★★ (কঠিন) — যাতে তুমি বুঝতে পারো কোনটা প্রথম পাঠে গভীরভাবে বুঝতেই হবে আর কোনটা আপাতত "মেনে নিয়ে" এগোলেও চলবে। চলমান উদাহরণ E1–E4 ধরে ধরে এগোব।
মনে রাখো আমাদের সেটআপ: \(X_1,\dots,X_n\) একটি iid নমুনা, কোনো population থেকে যার সত্যিকারের mean \(\mu\) আর variance \(\sigma^2\) (দুটোই অজানা ধ্রুবক)। আমরা চাই এই নমুনা থেকে গণিত-করা statistic \(T=T(X_1,\dots,X_n)\)-এর distribution জানতে — কারণ §১–৩-এ দেখেছি, এই sampling distribution-ই inference-এর gateway।
৪.১ · \(\bar X_n\)-এর mean, variance, SE এবং sampling distribution ★¶
Recap (3.3 থেকে): এই তিনটি ফলাফল 3.3-এ এসেছিল; এখানে আমরা দ্রুত আবার দাঁড় করিয়ে দিচ্ছি, কারণ পুরো Part IV এদের ওপর দাঁড়িয়ে আছে।
নমুনা-গড়ের সংজ্ঞা: $$ \bar X_n \;=\; \frac{1}{n}\sum_{i=1}^{n} X_i . $$
(ক) প্রত্যাশা (unbiasedness)। Expectation linear, তাই যোগফল আর ধ্রুবক-গুণ ভেতরে-বাইরে করা যায়: $$ \mathbb{E}[\bar X_n] = \mathbb{E}!\left[\frac{1}{n}\sum_{i=1}^{n} X_i\right] = \frac{1}{n}\sum_{i=1}^{n} \mathbb{E}[X_i] = \frac{1}{n}\cdot n\mu = \mu . $$ এখানে \(\mathbb{E}[X_i]=\mu\) প্রতিটি \(i\)-এর জন্য, কারণ সব \(X_i\) একই population থেকে এসেছে (identically distributed)। ফল: \(\bar X_n\) হলো \(\mu\)-এর একটি unbiased estimator — গড়পড়তায় ঠিক লক্ষ্যেই বসে।
(খ) Variance। এখানেই iid-এর "independent" শর্তটা কাজে লাগে। Variance যোগফলের ওপর সরাসরি ভাঙে শুধু যদি পদগুলো uncorrelated হয় (independence ⇒ uncorrelated): $$ \mathrm{Var}(\bar X_n) = \mathrm{Var}!\left(\frac{1}{n}\sum_{i=1}^{n} X_i\right) \stackrel{(1)}{=} \frac{1}{n^2}\,\mathrm{Var}!\left(\sum_{i=1}^{n} X_i\right) \stackrel{(2)}{=} \frac{1}{n^2}\sum_{i=1}^{n}\mathrm{Var}(X_i) \stackrel{(3)}{=} \frac{1}{n^2}\cdot n\sigma^2 = \frac{\sigma^2}{n} . $$ ধাপগুলোর যুক্তি: - \((1)\): \(\mathrm{Var}(cY)=c^2\,\mathrm{Var}(Y)\) — ধ্রুবক বর্গ হয়ে বেরোয় (\(c=1/n\))। - \((2)\): independence-এর কারণে সব covariance-পদ শূন্য, তাই \(\mathrm{Var}(\sum X_i)=\sum \mathrm{Var}(X_i)\)। এই ধাপেই "independent" শর্তটা অপরিহার্য — নয়তো \(\sum_{i\neq j}\mathrm{Cov}(X_i,X_j)\) পদগুলো বেঁচে থাকত। - \((3)\): \(\mathrm{Var}(X_i)=\sigma^2\) প্রতিটির জন্য, যোগফলে \(n\sigma^2\)।
(গ) Standard error। Estimator-এর standard deviation-কেই তার standard error বলি: $$ \boxed{\;\mathrm{SE}(\bar X_n)=\sqrt{\mathrm{Var}(\bar X_n)}=\frac{\sigma}{\sqrt n}\;} $$ লক্ষ করো: \(n\) বাড়লে SE কমে, কিন্তু কমে \(\sqrt n\)-এর হারে — \(n\) চারগুণ করলে SE অর্ধেক হয়। এই "\(\sqrt n\)-হারে সংকোচন"-ই large-sample inference-এর ইঞ্জিন (§৫-এর Lab 4-এ চোখে দেখব)।
(ঘ) \(\bar X_n\)-এর সম্পূর্ণ distribution — CLT (E1)। উপরের তিনটি শুধু দুটি সংখ্যা (mean, variance) দিল; কিন্তু inference-এর জন্য চাই গোটা distribution। এখানে দুটো ক্ষেত্র:
-
যদি population নিজেই Normal হয় — অর্থাৎ \(X_i\sim\mathcal N(\mu,\sigma^2)\) — তবে normal random variable-গুলোর linear combination আবার normal, কাজেই ঠিক ঠিক (exact): $$ \bar X_n \;\sim\; \mathcal N!\left(\mu,\ \frac{\sigma^2}{n}\right). \tag{E1} $$
-
যদি population Normal না-ও হয় — যেকোনো distribution, কেবল \(\sigma^2<\infty\) থাকলেই — তবে Central Limit Theorem (CLT) বলে, বড় \(n\)-এর জন্য \(\bar X_n\) আনুমানিকভাবে normal: $$ \bar X_n \;\stackrel{\text{approx}}{\sim}\; \mathcal N!\left(\mu,\ \frac{\sigma^2}{n}\right), \qquad\text{সমতুল্যভাবে}\qquad Z_n=\frac{\bar X_n-\mu}{\sigma/\sqrt n}\;\xrightarrow{d}\;\mathcal N(0,1). $$ এটিই E1-কে সর্বজনীন করে: parent যত বিদঘুটে (skewed, multimodal) হোক, যথেষ্ট বড় \(n\)-এ নমুনা-গড়ের sampling distribution ঘণ্টা-আকৃতির normal-এর দিকে গড়ায়। §৫-এর Lab 1-এ আমরা ইচ্ছে করে একটি skewed Exponential parent নিয়ে এটি simulate করে দেখাব — তবু \(\bar X_n\) সুন্দর normal হয়ে যায়।
স্বজ্ঞা: mean হলো ছোট ছোট স্বাধীন ওঠানামার যোগফল-গড়; এমন যোগফল-গড়ে আলাদা আলাদা অনিয়ম পরস্পরকে কেটে গড়পড়তা মসৃণ ঘণ্টা গড়ে তোলে — এটাই CLT-র হৃদয়।
৪.২ · Chi-square distribution \(\chi^2_k\) এবং \(S^2\)-এর sampling distribution ★★★¶
এটি অধ্যায়ের সবচেয়ে কঠিন (★★★) অংশ — তাই ধাপে ধাপে।
(ক) \(\chi^2_k\)-এর সংজ্ঞা (scratch থেকে)। ধরো \(Z_1,\dots,Z_k\) পরস্পর-স্বাধীন standard normal, অর্থাৎ প্রত্যেকে \(\mathcal N(0,1)\)। তাদের বর্গের যোগফল-কেই বলি chi-square with \(k\) degrees of freedom: $$ \boxed{\;\chi^2_k \;\stackrel{d}{=}\; Z_1^2 + Z_2^2 + \cdots + Z_k^2,\qquad Z_i \stackrel{\text{iid}}{\sim}\mathcal N(0,1).\;} $$ এটাই সংজ্ঞা — আর কিছু নয়। "Degrees of freedom (df)" \(k\) মানে কতগুলো স্বাধীন squared-normal যোগ হচ্ছে।
(খ) Mean ও variance (সংজ্ঞা থেকে সরাসরি)। প্রথমে একটিমাত্র \(Z\sim\mathcal N(0,1)\)-এর জন্য: $$ \mathbb{E}[Z^2] = \mathrm{Var}(Z) + (\mathbb{E}[Z])^2 = 1 + 0 = 1, $$ কারণ \(\mathrm{Var}(Z)=\mathbb{E}[Z^2]-(\mathbb{E}[Z])^2\) আর \(\mathbb{E}[Z]=0,\ \mathrm{Var}(Z)=1\)। তাহলে যোগফলে, linearity দিয়ে: $$ \mathbb{E}[\chi^2_k] = \sum_{i=1}^{k}\mathbb{E}[Z_i^2] = k . $$ আর independence-এর কারণে variance যোগ হয়; standard normal-এর জন্য \(\mathrm{Var}(Z^2)=2\) (এটি \(\mathbb{E}[Z^4]=3\) ব্যবহার করে পাওয়া যায়: \(\mathrm{Var}(Z^2)=\mathbb{E}[Z^4]-(\mathbb{E}[Z^2])^2=3-1=2\)), কাজেই $$ \mathrm{Var}(\chi^2_k) = \sum_{i=1}^{k}\mathrm{Var}(Z_i^2) = 2k . $$ সংক্ষেপে: \(\chi^2_k\)-এর mean \(=k\), variance \(=2k\)। এই দুটিই §৫-এর Lab 2-তে empirically যাচাই করব।
(গ) আকৃতি। \(\chi^2_k\) কেবল \(\ge 0\) মানে নেয় (বর্গের যোগফল কখনো ঋণাত্মক হয় না), ডানদিকে লেজ-টানা (right-skewed)। \(k\) বাড়লে (mean \(k\) ডানে সরে, CLT-প্রভাবে) এটি ধীরে ধীরে symmetric normal-এর দিকে যায়।
(ঘ) মূল ফলাফল — \(S^2\)-এর sampling distribution (E2)। Sample variance-এর সংজ্ঞা (\(n-1\) ভাগ, যাতে unbiased হয়): $$ S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar X_n)^2 . $$ দাবি (E2): যদি \(X_1,\dots,X_n \stackrel{\text{iid}}{\sim}\mathcal N(\mu,\sigma^2)\), তবে $$ \boxed{\;\frac{(n-1)S^2}{\sigma^2}\;\sim\;\chi^2_{\,n-1}\;} \tag{E2} $$ অর্থাৎ scaled sample variance ঠিক একটি chi-square, কিন্তু df \(=n-1\) — পুরো \(n\) নয়।
(ঙ) প্রমাণের রূপরেখা (sketch) এবং df কেন \(n-1\)। পূর্ণ প্রমাণ অরথোগোনাল রূপান্তর চায়; এখানে যুক্তির কঙ্কালটি দিই —
ধরো \(Z_i=(X_i-\mu)/\sigma \sim \mathcal N(0,1)\) iid। তাহলে শুরুতে আমাদের হাতে \(n\)টি স্বাধীন squared-normal, যাদের যোগফল \(\sum_{i=1}^n Z_i^2\sim\chi^2_n\) — অর্থাৎ df \(=n\)। এবার একটি বীজগাণিতিক পরিচয় (sum-of-squares decomposition): $$ \underbrace{\sum_{i=1}^{n}(X_i-\mu)^2}{\text{\(\sigma^2\) ভাগে }\chi^2_n} \;=\; \underbrace{\sum}^{n}(X_i-\bar X_n)^2{=\,(n-1)S^2} \;+\; \underbrace{n(\bar X_n-\mu)^2}{\text{\(\sigma^2\) ভাগে }\chi^2_1} . $$ দুপাশকে \(\sigma^2\) দিয়ে ভাগ করলে: $$ \underbrace{\frac{1}{\sigma^2}\sum_{i=1}^{n}(X_i-\mu)^2}{\chi^2_n} = \underbrace{\frac{(n-1)S^2}{\sigma^2}} + \underbrace{\frac{n(\bar X_n-\mu)^2}{\sigma^2}}_{\chi^2_1}. $$ শেষ পদটি \(\chi^2_1\), কারণ \(\bar X_n\sim\mathcal N(\mu,\sigma^2/n)\) (E1) মানে \(\dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\sim\mathcal N(0,1)\), আর তার বর্গ হলো একটিমাত্র squared standard normal \(=\chi^2_1\)।
এখন মূল চাবিকাঠি — Cochran/Fisher-এর স্বাধীনতা-উপপাদ্য: normal নমুনায় \(\bar X_n\) আর \(S^2\) পরস্পর স্বাধীন (কেন এটি বিশেষ, নিচের নোট দেখো)। ফলে ডানপাশের দুই পদ স্বাধীন, আর chi-square-এর df যোগধর্মী (additive) — দুই স্বাধীন \(\chi^2_a,\chi^2_b\)-এর যোগ \(\chi^2_{a+b}\)। df-এর বইখাতা মিলিয়ে: $$ n \;=\; (?) \;+\; 1 \quad\Longrightarrow\quad (?) \;=\; n-1 . $$ তাই \(\dfrac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}\)। df একটি হারানোর কারণ: আমরা অজানা \(\mu\)-কে নমুনা থেকে আঁকা \(\bar X_n\) দিয়ে প্রতিস্থাপন করেছি; এই একটি estimated parameter একটি স্বাধীনতার একটি মাত্রা (a degree of freedom) খেয়ে ফেলে — তাই \(n\)-এর বদলে \(n-1\)।
\(\bar X_n \perp S^2\) কেন বিশেষ? সাধারণত যেকোনো population-এ মানে আর বিস্তার সম্পর্কিত হতে পারে; কিন্তু শুধু Normal distribution-এর এই অনন্য বৈশিষ্ট্য যে নমুনা-গড় আর নমুনা-variance পরিসংখ্যানগতভাবে স্বাধীন। জ্যামিতিকভাবে: \(\bar X_n\) বহন করে data-vector-এর "all-ones দিকের" projection, আর \((X_i-\bar X_n)\) অবশিষ্টগুলো তার লম্ব (orthogonal) উপ-জগতে বাস করে; Gaussian-এর rotational symmetry-র কারণে এই দুই orthogonal অংশ স্বাধীন। এই স্বাধীনতাই পরের t-distribution গঠনে অপরিহার্য।
৪.৩ · Student's t-distribution \(t_k\) এবং ভারী লেজ ★★¶
(ক) সমস্যা যা t-কে জন্ম দেয়। E1 থেকে আমরা পাই \(\dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\sim\mathcal N(0,1)\) — চমৎকার, কিন্তু এতে \(\sigma\) লাগে, যা বাস্তবে অজানা! স্বাভাবিক সমাধান: \(\sigma\)-এর জায়গায় তার estimate \(S\) বসাও। তখন যা পাই সেটি আর normal থাকে না — সেটিই Student's t: $$ T = \frac{\bar X_n-\mu}{S/\sqrt n}\;\sim\; t_{\,n-1}. \tag{E3} $$ এখানে হরে এখন একটি random পরিমাণ (\(S\)) — সে নিজে ওঠানামা করে — তাই অতিরিক্ত অনিশ্চয়তা ঢোকে, distribution-এর লেজ মোটা হয়।
(খ) সাধারণ সংজ্ঞা (scratch থেকে)। Student's t-কে সংজ্ঞায়িত করি একটি অনুপাত হিসেবে: এক standard normal-কে এক স্বাধীন scaled chi-square-এর বর্গমূল দিয়ে ভাগ — $$ \boxed{\;t_k \;\stackrel{d}{=}\; \frac{Z}{\sqrt{\,V/k\,}},\qquad Z\sim\mathcal N(0,1),\ \ V\sim\chi^2_k,\ \ Z\perp V.\;} $$ এখন (গ)-এ মিলিয়ে দিই এটি কীভাবে E3 হয়।
(গ) E3-কে এই ছাঁচে ফেলা। ভগ্নাংশের লব-হরকে \(\sigma\) দিয়ে ভাগ করি: $$ T=\frac{\bar X_n-\mu}{S/\sqrt n} =\frac{(\bar X_n-\mu)\big/(\sigma/\sqrt n)}{(S/\sqrt n)\big/(\sigma/\sqrt n)} =\frac{\;\overbrace{(\bar X_n-\mu)/(\sigma/\sqrt n)}^{Z\,\sim\,\mathcal N(0,1)}\;}{\;\underbrace{S/\sigma}_{=\,\sqrt{\,[(n-1)S^2/\sigma^2]/(n-1)\,}}\;} =\frac{Z}{\sqrt{V/(n-1)}}, $$ যেখানে \(V=(n-1)S^2/\sigma^2\sim\chi^2_{n-1}\) (E2 থেকে), আর লবের \(Z\) ও হরের \(V\) স্বাধীন — কারণ ৪.২-এ দেখা \(\bar X_n\perp S^2\)। কাজেই \(T\sim t_{n-1}\), df \(=n-1\)। (লক্ষ করো: df আবার \(n-1\), কারণ একই estimated \(\mu\)।)
(ঘ) লেজ ভারী কেন (heavier tails)। স্বজ্ঞা: normal-এ হর একটি স্থির ধ্রুবক \(\sigma\); t-তে হর একটি random \(S\) যে মাঝে মাঝে স্বাভাবিকের চেয়ে ছোট মান নেয়। ছোট হর দিয়ে ভাগ করলে অনুপাত হঠাৎ বড় হয়ে যায় — তাই চরম (বড়) মান normal-এর চেয়ে বেশি ঘন ঘন আসে, distribution-এর লেজ পুরু হয়। ফলে দুটো বাস্তব পরিণতি: - একই কেন্দ্রীয় এলাকার জন্য t-এর critical value normal-এর চেয়ে বড় (95% interval চওড়া)। - df \(\to\infty\) হলে \(S\to\sigma\) (large-sample-এ \(S\) নিখুঁত হয়), random-হরের ওঠানামা মিলিয়ে যায়, আর \(t_k \to \mathcal N(0,1)\)।
§৫-এর Lab 3-এ আমরা সংখ্যায় দেখব: df \(=2\)-এ লেজ অনেক ভারী, df \(=100\)-এ প্রায় normal। উদাহরণস্বরূপ দুপাশের 95% critical value: \(t^*_{2}\approx 4.30\), \(t^*_{5}\approx 2.57\), \(t^*_{30}\approx 2.04\), \(t^*_{100}\approx 1.98\) — ক্রমে normal-এর \(z^*=1.96\)-এর দিকে নামছে।
৪.৪ · F-distribution \(F_{d_1,d_2}\) — দুই variance-এর অনুপাত ★★¶
(ক) সংজ্ঞা (scratch থেকে)। দুটি স্বাধীন chi-square নাও, যথাক্রমে \(d_1\) ও \(d_2\) df-এর; প্রত্যেকটিকে নিজের df দিয়ে ভাগ করো (অর্থাৎ "per-df average" নাও), তারপর অনুপাত করো: $$ \boxed{\;F_{d_1,d_2}\;\stackrel{d}{=}\;\frac{U/d_1}{V/d_2},\qquad U\sim\chi^2_{d_1},\ V\sim\chi^2_{d_2},\ U\perp V.\;} $$ এখানে \(d_1\) হলো numerator df, \(d_2\) হলো denominator df। \(F\ge 0\) সর্বদা (দুই অঋণাত্মক রাশির অনুপাত), আর সাধারণভাবে অসমমিত (right-skewed)।
(খ) E4 — দুই Normal নমুনার variance তুলনা। ধরো দুটি স্বাধীন normal নমুনা: প্রথমটি \(n_1\) আকারের, sample variance \(S_1^2\), সত্যিকারের variance \(\sigma_1^2\); দ্বিতীয়টি \(n_2\) আকারের, \(S_2^2\), \(\sigma_2^2\)। E2 থেকে আমরা জানি $$ \frac{(n_1-1)S_1^2}{\sigma_1^2}\sim\chi^2_{n_1-1}, \qquad \frac{(n_2-1)S_2^2}{\sigma_2^2}\sim\chi^2_{n_2-1}, $$ এবং দুই নমুনা স্বাধীন বলে এই দুই chi-square স্বাধীন। প্রতিটিকে নিজ df (\(n_1-1\), \(n_2-1\)) দিয়ে ভাগ করে অনুপাত নিলে (সংজ্ঞা মিলিয়ে) পাই: $$ \frac{S_1^2/\sigma_1^2}{S_2^2/\sigma_2^2}\;\sim\;F_{\,n_1-1,\;n_2-1}. \tag{E4} $$ বিশেষ ও সবচেয়ে কাজের রূপ: যদি দুই population-এর variance সমান হয় (\(H_0:\sigma_1^2=\sigma_2^2\)), তবে \(\sigma\)-গুলো কাটাকাটি হয়ে যায় এবং পর্যবেক্ষিত অনুপাত সরল হয়ে দাঁড়ায় $$ \frac{S_1^2}{S_2^2}\;\sim\;F_{\,n_1-1,\;n_2-1}. $$ এটিই variance-সমতা পরীক্ষা ও (পরে) ANOVA-র মূল statistic — "দুই গোষ্ঠীর বিচ্ছুরণ কি একই?" প্রশ্নটিকে একটি জানা distribution-এ ফেলে দেয়।
চারটি একসূত্রে গাঁথা। লক্ষ করো গোটা পরিবারটি একটিই বীজ থেকে জন্মায় — standard normal \(Z\): \(\;Z^2\) যোগ করলে \(\Rightarrow \chi^2\); \(\;Z/\sqrt{\chi^2/k}\Rightarrow t\); \(\;(\chi^2/d_1)\big/(\chi^2/d_2)\Rightarrow F\)। এবং পরিচয়গুলো একে অপরের সাথে জড়িত: \(t_k^2 = F_{1,k}\) (t-কে বর্গ করলেই numerator-df \(=1\)-এর F)। এই একতাই Part IV-এর confidence interval ও hypothesis test-গুলোর ভিত।
৫ · কোড ল্যাব (Python)¶
নিচের সম্পূর্ণ script-টি runnable: শুধু numpy ও scipy লাগে, randomness reproducible (fixed seed default_rng(2024))। চারটি lab চারটি running example-কে সংখ্যায় যাচাই করে। নিচে প্রতিটি অংশের পর আসল (real) output হুবহু বসানো আছে — তুমি নিজে চালালে একই সংখ্যা পাবে।
চালানোর নিয়ম: সম্পূর্ণ কোড একটি ফাইলে (যেমন
figs_4-1_B.py) রেখেpython3 figs_4-1_B.pyদাও। histogram দেখতে চাইলে শেষে দেওয়া (ঐচ্ছিক) plotting block-টি আনকমেন্ট করো।
৫.০ · সাধারণ সেটআপ¶
import numpy as np
from scipy import stats
rng = np.random.default_rng(2024) # fixed seed -> reproducible
৫.১ · Lab 1 — \(\bar X_n\)-এর sampling distribution (E1, CLT)¶
আমরা ইচ্ছে করে একটি skewed parent নিচ্ছি — Exponential(scale \(=5\)), যার mean \(=5\), variance \(=25\) — যাতে দেখানো যায় parent normal না হলেও CLT-র কল্যাণে \(\bar X_n\) আনুমানিক \(\mathcal N(\mu,\sigma^2/n)\) হয়ে যায়। প্রতিটি replication-এ \(n=30\) মানের নমুনা নিই, গড় করি, এই গড়টির empirical mean/variance/SE-কে তত্ত্বের সাথে মেলাই।
print("=" * 60)
print("LAB 1: Sampling distribution of Xbar_n (E1)")
print("=" * 60)
mu, sigma, n = 5.0, 2.0, 30
reps = 20000
# Parent: Exponential(scale=mu) -> mean=mu=5, var=mu^2=25 (skewed, NON-normal)
scale = mu
samples = rng.exponential(scale=scale, size=(reps, n))
xbars = samples.mean(axis=1)
pop_var = scale ** 2 # variance of Exponential(scale) = scale^2
print(f"Parent: Exponential(scale={scale}) -> mean={scale}, var={pop_var}")
print(f"n = {n}, reps = {reps}")
print(f"Empirical mean of Xbar : {xbars.mean():.4f} (theory mu = {mu})")
print(f"Empirical var of Xbar : {xbars.var(ddof=1):.4f} (theory sigma^2/n = {pop_var/n:.4f})")
print(f"Empirical SE of Xbar : {xbars.std(ddof=1):.4f} (theory sigma/sqrt(n) = {np.sqrt(pop_var)/np.sqrt(n):.4f})")
আসল output:
============================================================
LAB 1: Sampling distribution of Xbar_n (E1)
============================================================
Parent: Exponential(scale=5.0) -> mean=5.0, var=25.0
n = 30, reps = 20000
Empirical mean of Xbar : 5.0037 (theory mu = 5.0)
Empirical var of Xbar : 0.8402 (theory sigma^2/n = 0.8333)
Empirical SE of Xbar : 0.9166 (theory sigma/sqrt(n) = 0.9129)
পাঠ: parent তীব্র-skewed হওয়া সত্ত্বেও empirical mean (\(5.0037\)) ≈ \(\mu=5\), আর empirical variance (\(0.8402\)) ≈ \(\sigma^2/n=0.8333\) — দুটোই তত্ত্বের প্রায় গায়ে গায়ে। histogram আঁকলে (ঐচ্ছিক block) দেখা যেত \(\mathcal N(5,\,25/30)\) ঘণ্টা-curve প্রায় ছাপিয়ে বসে — এটিই Figure 4-1-sampling-dist-এর সংখ্যাগত ভিত্তি।
৫.২ · Lab 2 — \((n-1)S^2/\sigma^2 \sim \chi^2_{n-1}\) (E2)¶
প্রতিটি replication-এ \(n=8\) মানের normal নমুনা থেকে \(S^2\) গণনা করি, scaled statistic \((n-1)S^2/\sigma^2\) বানাই, আর দেখি এটি সত্যিই \(\chi^2_{7}\) অনুসরণ করে কিনা — mean (\(=\) df), variance (\(=2\cdot\)df), এবং একটি Kolmogorov–Smirnov goodness-of-fit test দিয়ে।
print("=" * 60)
print("LAB 2: (n-1)S^2/sigma^2 ~ chi^2_{n-1} (E2)")
print("=" * 60)
mu2, sigma2, n2 = 0.0, 3.0, 8
reps2 = 20000
norm_samples = rng.normal(loc=mu2, scale=sigma2, size=(reps2, n2))
S2 = norm_samples.var(axis=1, ddof=1) # sample variance (ddof=1 -> divide by n-1)
stat = (n2 - 1) * S2 / sigma2**2 # should be chi^2_{n-1}
df = n2 - 1
print(f"Parent: Normal(mu={mu2}, sigma={sigma2}), n = {n2}, df = {df}")
print(f"Empirical mean of (n-1)S^2/sigma^2 : {stat.mean():.4f} (theory df = {df})")
print(f"Empirical var of (n-1)S^2/sigma^2 : {stat.var(ddof=1):.4f} (theory 2*df = {2*df})")
ks = stats.kstest(stat, 'chi2', args=(df,))
print(f"KS test vs chi2_{df}: statistic = {ks.statistic:.4f}, p-value = {ks.pvalue:.4f}")
আসল output:
============================================================
LAB 2: (n-1)S^2/sigma^2 ~ chi^2_{n-1} (E2)
============================================================
Parent: Normal(mu=0.0, sigma=3.0), n = 8, df = 7
Empirical mean of (n-1)S^2/sigma^2 : 7.0016 (theory df = 7)
Empirical var of (n-1)S^2/sigma^2 : 13.8739 (theory 2*df = 14)
KS test vs chi2_7: statistic = 0.0073, p-value = 0.2427
পাঠ: empirical mean \(7.0016 \approx \text{df}=7\) এবং variance \(13.87 \approx 2\,\text{df}=14\) — ঠিক যেমন ৪.২(খ)-তে প্রমাণ করেছিলাম। KS p-value \(=0.2427\) (\(\gg 0.05\)) মানে data আর \(\chi^2_7\)-এর মধ্যে কোনো তাৎপর্যপূর্ণ ফারাক নেই — অর্থাৎ E2 simulation-এ দাঁড়িয়ে গেল। (লক্ষ করো df \(=n-1=7\), পুরো \(n=8\) নয় — সেই হারানো এক df!)
৫.৩ · Lab 3 — t vs normal, df বাড়লে (E3)¶
t-distribution যে df বাড়ার সাথে normal-এ মেশে আর ছোট df-এ ভারী লেজ রাখে, তা CDF-মান, দুপাশের লেজ-সম্ভাবনা, এবং 95% critical value তিনভাবে দেখাই।
print("=" * 60)
print("LAB 3: Student's t vs Normal as df grows (E3)")
print("=" * 60)
xs = [0.0, 1.0, 1.96, 2.5]
print("P(T_df <= x) for growing df vs Phi(x):")
header = " x |" + "".join(f" df={d:<4}" for d in [2, 5, 30, 100]) + " | Normal"
print(header)
for x in xs:
row = f" {x:>4.2f} |"
for d in [2, 5, 30, 100]:
row += f" {stats.t.cdf(x, d):.4f} "
row += f" | {stats.norm.cdf(x):.4f}"
print(row)
print()
print("Two-sided tail P(|T_df| > 2) vs P(|Z| > 2):")
for d in [2, 5, 30, 100]:
print(f" df = {d:<4}: P(|T|>2) = {2 * stats.t.sf(2.0, d):.4f}")
print(f" Normal : P(|Z|>2) = {2*stats.norm.sf(2.0):.4f}")
print()
print("0.975 quantile (two-sided 95% critical value):")
for d in [2, 5, 30, 100]:
print(f" df = {d:<4}: t* = {stats.t.ppf(0.975, d):.4f}")
print(f" Normal : z* = {stats.norm.ppf(0.975):.4f}")
আসল output:
============================================================
LAB 3: Student's t vs Normal as df grows (E3)
============================================================
P(T_df <= x) for growing df vs Phi(x):
x | df=2 df=5 df=30 df=100 | Normal
0.00 | 0.5000 0.5000 0.5000 0.5000 | 0.5000
1.00 | 0.7887 0.8184 0.8373 0.8401 | 0.8413
1.96 | 0.9055 0.9464 0.9703 0.9736 | 0.9750
2.50 | 0.9352 0.9728 0.9909 0.9930 | 0.9938
Two-sided tail P(|T_df| > 2) vs P(|Z| > 2):
df = 2 : P(|T|>2) = 0.1835
df = 5 : P(|T|>2) = 0.1019
df = 30 : P(|T|>2) = 0.0546
df = 100 : P(|T|>2) = 0.0482
Normal : P(|Z|>2) = 0.0455
0.975 quantile (two-sided 95% critical value):
df = 2 : t* = 4.3027
df = 5 : t* = 2.5706
df = 30 : t* = 2.0423
df = 100 : t* = 1.9840
Normal : z* = 1.9600
পাঠ: তিন কোণ থেকেই একই গল্প — (i) CDF-মান df বাড়ার সাথে normal column-এর দিকে গড়ায়; (ii) দুপাশের লেজ \(P(\lvert T\rvert>2)\) df \(=2\)-এ \(0.1835\) (normal-এর \(0.0455\)-এর চারগুণ!) থেকে কমে df \(=100\)-এ \(0.0482\); (iii) 95% critical value \(t^*\) \(4.30\to 2.57\to 2.04\to 1.98\), ক্রমে \(z^*=1.96\)-এর দিকে। ছোট df-এ ভারী লেজ ⇒ বড় critical value ⇒ চওড়া confidence interval — এটিই Figure 4-1-t-vs-normal-এর কাহিনি।
৫.৪ · Lab 4 — SE সংকুচিত হয় \(\sigma/\sqrt n\) হারে (E1, SE)¶
প্রতিটি \(n\)-এর জন্য বহু নমুনা-গড়ের empirical standard deviation (= empirical SE) মাপি, আর তত্ত্বের \(\sigma/\sqrt n\)-এর সাথে অনুপাত দেখাই।
print("=" * 60)
print("LAB 4: SE shrinks as sigma/sqrt(n) (E1, SE)")
print("=" * 60)
sigma4 = 2.0
reps4 = 8000
print(f"sigma = {sigma4}. Empirical SE = std of Xbar over {reps4} reps.")
print(" n | empirical SE | theory sigma/sqrt(n) | ratio")
for n4 in [5, 10, 20, 40, 80, 160]:
s = rng.normal(loc=0.0, scale=sigma4, size=(reps4, n4))
xb = s.mean(axis=1)
emp_se = xb.std(ddof=1)
theo_se = sigma4 / np.sqrt(n4)
print(f" {n4:>4} | {emp_se:.4f} | {theo_se:.4f} | {emp_se/theo_se:.3f}")
print()
print("Note: doubling n divides SE by sqrt(2) ~ 1.414, NOT by 2.")
আসল output:
============================================================
LAB 4: SE shrinks as sigma/sqrt(n) (E1, SE)
============================================================
sigma = 2.0. Empirical SE = std of Xbar over 8000 reps.
n | empirical SE | theory sigma/sqrt(n) | ratio
5 | 0.8969 | 0.8944 | 1.003
10 | 0.6252 | 0.6325 | 0.989
20 | 0.4490 | 0.4472 | 1.004
40 | 0.3164 | 0.3162 | 1.000
80 | 0.2280 | 0.2236 | 1.020
160 | 0.1589 | 0.1581 | 1.005
পাঠ: empirical SE প্রতিটি \(n\)-এ তত্ত্বের \(\sigma/\sqrt n\)-এর প্রায় হুবহু (ratio ≈ \(1.0\))। আর সংকোচন \(\sqrt n\)-হারে: \(n=20\to 80\) অর্থাৎ \(n\) চারগুণ হলে SE \(0.449\to 0.228\), ঠিক প্রায় অর্ধেক (\(1/\sqrt 4=1/2\))। বাস্তব শিক্ষা: precision দ্বিগুণ করতে data চারগুণ লাগে — এটিই Figure 4-1-se-shrink-এর মূল বার্তা।
৫.৫ · (ঐচ্ছিক) histogram প্লট¶
ছবি চাইলে নিচের block যোগ করো (Lab 1 ও Lab 2-এর xbars, stat ভেরিয়েবল ব্যবহার করে):
# import matplotlib.pyplot as plt
# fig, ax = plt.subplots(1, 2, figsize=(11, 4))
# # Lab 1: Xbar vs Normal(mu, sigma^2/n)
# ax[0].hist(xbars, bins=60, density=True, alpha=0.6, label="empirical Xbar")
# grid = np.linspace(xbars.min(), xbars.max(), 300)
# ax[0].plot(grid, stats.norm.pdf(grid, mu, np.sqrt(pop_var/n)), 'r-', lw=2,
# label=r"$\mathcal{N}(\mu,\sigma^2/n)$")
# ax[0].set_title("Sampling distribution of Xbar (E1)"); ax[0].legend()
# # Lab 2: scaled S^2 vs chi^2_{n-1}
# ax[1].hist(stat, bins=60, density=True, alpha=0.6, label=r"empirical $(n-1)S^2/\sigma^2$")
# g2 = np.linspace(0, stat.max(), 300)
# ax[1].plot(g2, stats.chi2.pdf(g2, df), 'r-', lw=2, label=r"$\chi^2_{n-1}$")
# ax[1].set_title("Sampling distribution of scaled S^2 (E2)"); ax[1].legend()
# plt.tight_layout(); plt.savefig("fig_4-1_labs.png", dpi=130)
সারসংক্ষেপ। চারটি lab চারটি তত্ত্বকে সংখ্যায় দাঁড় করিয়ে দিল: CLT-তে \(\bar X_n\) skewed parent থেকেও normal (E1); scaled \(S^2\) ঠিক \(\chi^2_{n-1}\), df একটি কম (E2); t df বাড়লে normal-এ মেশে, ছোট df-এ ভারী লেজ (E3); আর SE কমে \(\sqrt n\)-হারে। এই হাতে-কলমে ভিতের ওপরই 4.2-এ confidence interval ও hypothesis test গড়ে উঠবে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-1.py-তে তৈরি; PNG_assets/-এ (prefix4-1, dpi=150)। in-figure লেখা সব ইংরেজিতে। প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা আছে — beginner-এর জন্য এটাই আসল শেখার সূত্র।
inference-এর গোটা গল্পটা একটা ধাঁধার মতো: আমরা একটাই নমুনা হাতে পাই, তা থেকে একটাই সংখ্যা (statistic \(T\), যেমন \(\bar X_n\)) হিসাব করি — কিন্তু সেই একটা সংখ্যার পেছনে লুকিয়ে থাকে একটা আস্ত distribution, কারণ অন্য একটা নমুনা টানলে সংখ্যাটা একটু অন্যরকম হতো। সেই কাল্পনিক "অন্য সব নমুনার" সংখ্যাগুলোর distribution-ই হলো sampling distribution। এটাকে চোখে না দেখলে standard error, confidence interval, \(p\)-value — কিছুই বিশ্বাসযোগ্য হয় না। তাই আমরা চারটি ছবি দিয়ে চারটি জিনিস "দেখব": (১) একটা estimator \(\bar X_n\)-এর sampling distribution আসলে দেখতে কেমন এবং \(n\) বাড়লে কীভাবে সরু ও Normal হয়, (২) Normal থেকে জন্ম নেওয়া তিনটি কাজের distribution — \(\chi^2_k\), \(t_k\), \(F_{d_1,d_2}\), (৩) Student's \(t\) কীভাবে df বাড়লে \(\mathcal N(0,1)\)-এ মিশে যায় (ভারী লেজ সরু হয়), আর (৪) standard error \(\sigma/\sqrt{n}\) কীভাবে \(n\) বাড়লে ছোট হয় — অর্থাৎ বেশি data মানে ধারালো estimator।
Figure 1 — একটা estimator-এর sampling distribution (E1)¶
পুরো অধ্যায়ের কেন্দ্রীয় ছবি। population নেওয়া হয়েছে ডানে-বাঁকানো (right-skewed) — Gamma\((2,\,1.5)\), যার \(\mu=3\), \(\sigma=\sqrt{4.5}\approx 2.12\) — যাতে বোঝা যায় sampling distribution শুধু উৎসের একটা নকল নয়। দুই প্যানেলে \(n=5\) ও \(n=50\)-এর জন্য \(40{,}000\)টি কাল্পনিক নমুনার \(\bar X_n\)-এর histogram (নীল), তার উপর তত্ত্ব-পূর্বাভাস \(\mathcal N(\mu,\,\sigma^2/n)\) (লাল)। যা লক্ষ করতে হবে: (ক) প্রতিটি histogram-এর কেন্দ্র \(\mu=3\)-তেই — অর্থাৎ \(\bar X_n\) গড়ে সঠিক জায়গায় পড়ে (unbiased)। (খ) \(n=5\)-এ histogram এখনো একটু ডানে-বাঁকা (উৎসের skew সম্পূর্ণ মুছে যায়নি), কিন্তু \(n=50\)-এ তা প্রায় নিখুঁত প্রতিসম ঘণ্টা — CLT (3.4) কাজ করছে। (গ) সবচেয়ে গুরুত্বপূর্ণ: \(n=5\)-এর histogram চওড়া (SE \(=0.95\)), \(n=50\)-এর histogram অনেক সরু (SE \(=0.30\)) — বেশি data মানে \(\bar X_n\) সত্যিকার \(\mu\)-র চারপাশে আরও জড়ো হয়ে বসে। এই ছবিটাই inference-এর ভিত্তি: একটা estimator-এর "ভুল কতটা হতে পারে" তা মাপা যায় তার sampling distribution-এর ছড়ানো (= standard error) দিয়ে।
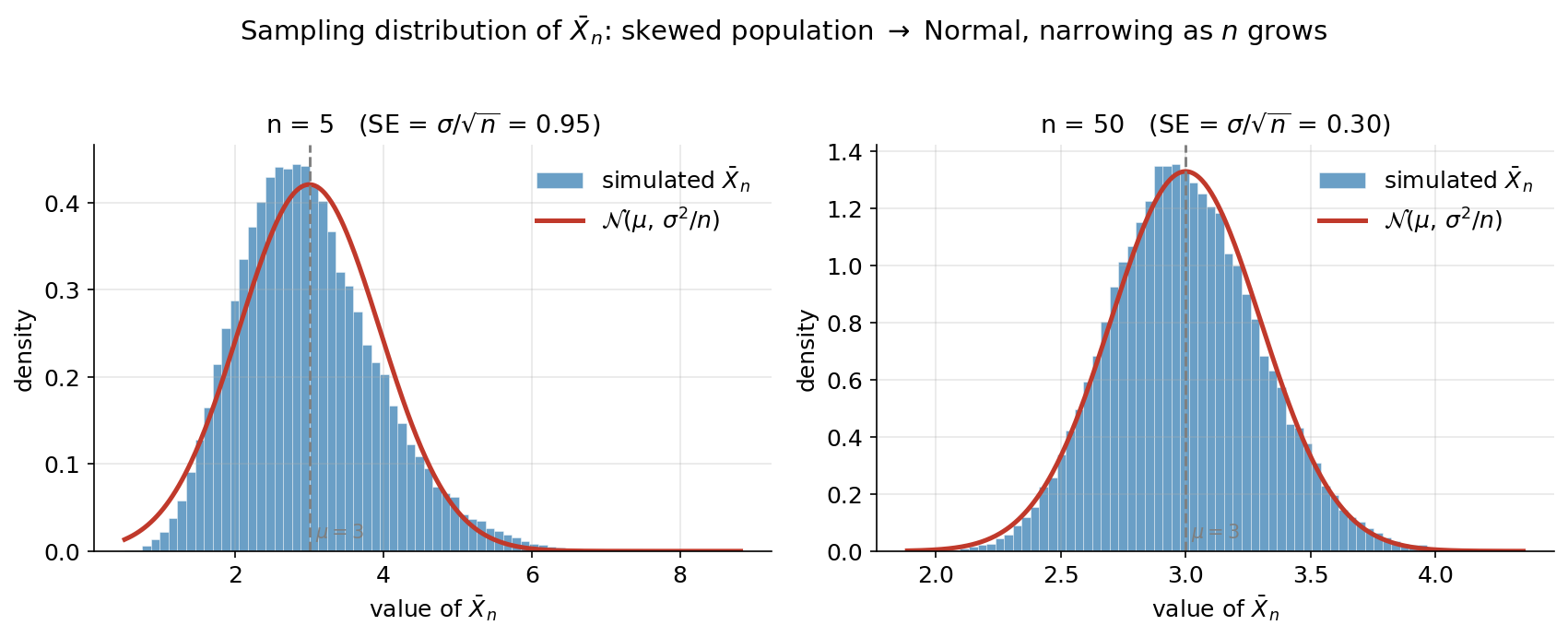
Figure 2 — Normal থেকে জন্মানো তিন distribution: \(\chi^2\), \(t\), \(F\) (E2, E3, E4)¶
Normal-ভিত্তিক inference-এর তিনটি কর্মী-distribution একই ছবিতে, তিন প্যানেলে। বাঁ প্যানেল (\(\chi^2_k\)): \(k\)টি স্বাধীন \(\mathcal N(0,1)\)-এর বর্গের যোগফলের distribution; df \(k=1,2,4,8\)। লক্ষণীয় — এটা শুধু \(0\)-এর ডানে বাস করে (বর্গ কখনো ঋণাত্মক নয়), \(k=1,2\)-এ তীব্রভাবে ডানে-বাঁকা, \(k\) বাড়লে চূড়া ডানে সরে গিয়ে ধীরে ধীরে প্রতিসম হয়। sample variance \(S^2\) এই family-তে বাস করে (E2)। মাঝের প্যানেল (\(t_k\)): \(0\)-কেন্দ্রিক, ঘণ্টা-আকৃতির, কিন্তু \(\mathcal N(0,1)\)-এর (লাল ভাঙা-রেখা) চেয়ে ভারী লেজ; df ছোট হলে লেজ যত ভারী। এটাই \(\sigma\) অজানা থাকলে \(\bar X_n\)-এর standardize-রূপের distribution (E3)। ডান প্যানেল (\(F_{d_1,d_2}\)): দুটো scaled \(\chi^2\)-এর অনুপাত; দুই df-জোড়া। ডানে-বাঁকা, \(0\)-এর ডানে, দুই variance-এর তুলনায় ব্যবহৃত (E4)। যা লক্ষ করতে হবে: তিনটিই Normal থেকে নির্মিত — বর্গ করো (\(\chi^2\)), Normal-কে \(\chi^2\) দিয়ে ভাগ করো (\(t\)), দুই \(\chi^2\)-এর অনুপাত নাও (\(F\)) — তাই Normal বোঝা থাকলে তিনটিই হাতের মুঠোয়। প্রতিটির আকৃতি তার degrees of freedom দিয়ে নিয়ন্ত্রিত।
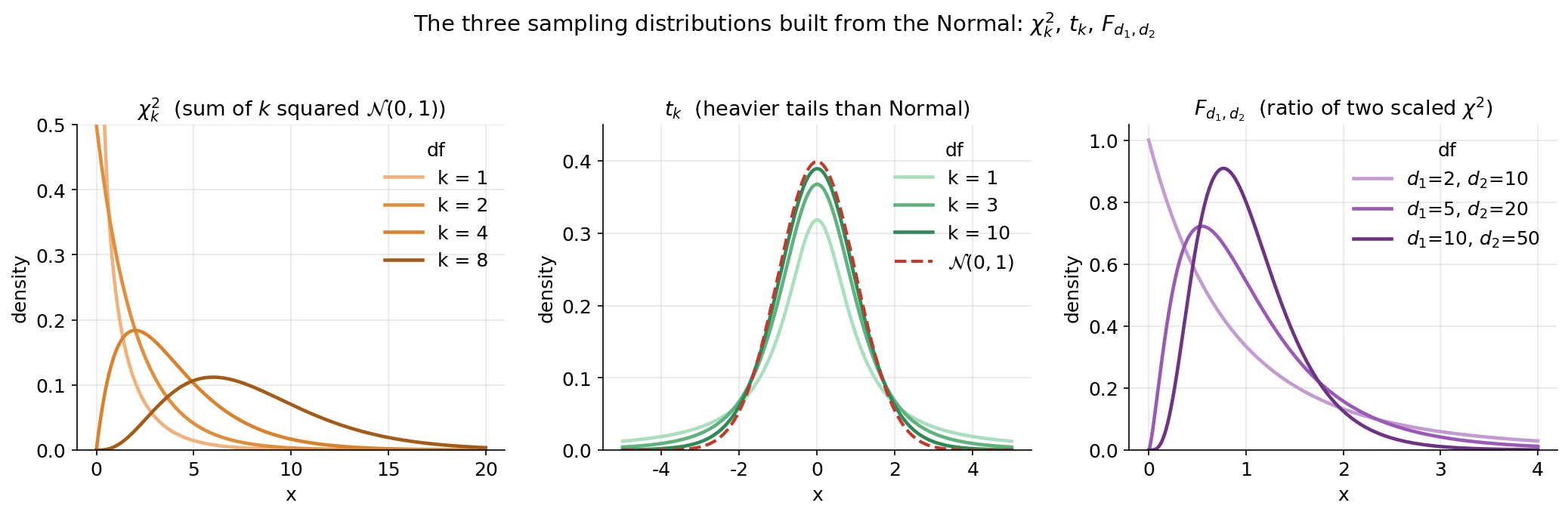
Figure 3 — Student's \(t\) কীভাবে Normal-এ মেশে (E3)¶
আগের ছবির মাঝের প্যানেলটাকে এখানে বড় করে দেখানো হলো, কারণ এই একটা গল্পই inference-এ বারবার ফিরে আসে: df বাড়লে \(t_k\to\mathcal N(0,1)\)। মূল প্যানেলে \(t_1,t_2,t_5,t_{30}\) (সবুজের ক্রমশ গাঢ় ছায়া) আর লাল ভাঙা-রেখায় \(\mathcal N(0,1)\)। ডান কোণে একটা zoom-inset শুধু ডান লেজ (\(x\in[2,5]\)) দেখায়। যা লক্ষ করতে হবে: (ক) মূল চূড়ায় — \(t_1\) (হালকা সবুজ) সবচেয়ে নিচু ও চ্যাপ্টা, কারণ তার ভর লেজে ছড়িয়ে গেছে; df বাড়ার সাথে চূড়া উঁচু হয়ে লাল Normal-curve-এর দিকে ওঠে। (খ) inset-এ স্পষ্ট — সব \(t\)-curve লেজে Normal-এর উপরে বসে (অর্থাৎ চরম মান বেশি সম্ভব), কিন্তু df \(=30\)-এ সেই ফাঁক প্রায় মিলিয়ে যায়। ব্যবহারিক অর্থ: ছোট নমুনায় (df ছোট) \(t\)-এর ভারী লেজ ব্যবহার করে আমরা প্রশস্ততর confidence interval বানাই — কারণ \(\sigma\) অজানা থাকায় বাড়তি অনিশ্চয়তা আছে; নমুনা বড় হলে \(t\) আর Normal-এ কার্যত কোনো তফাত থাকে না (4.2 ও hypothesis testing-এর সরাসরি ভিত্তি)।
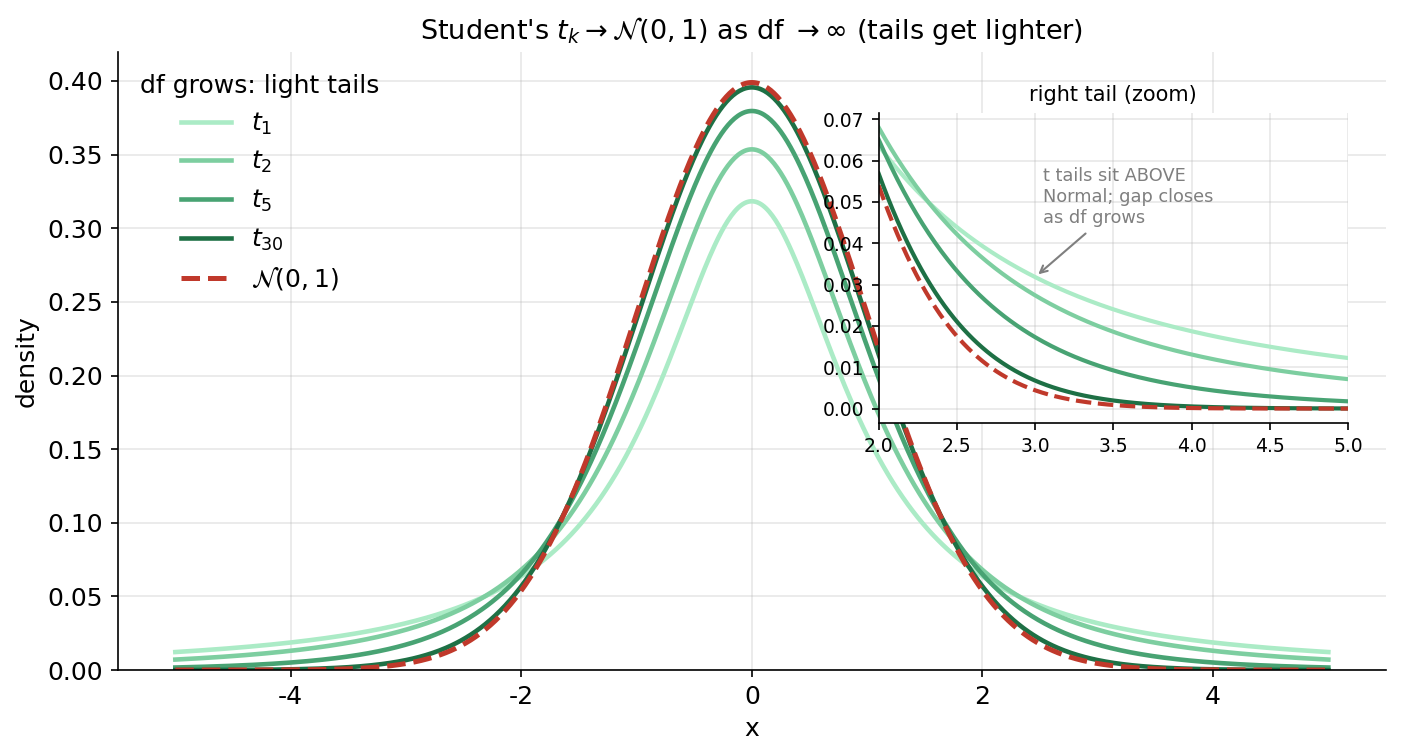
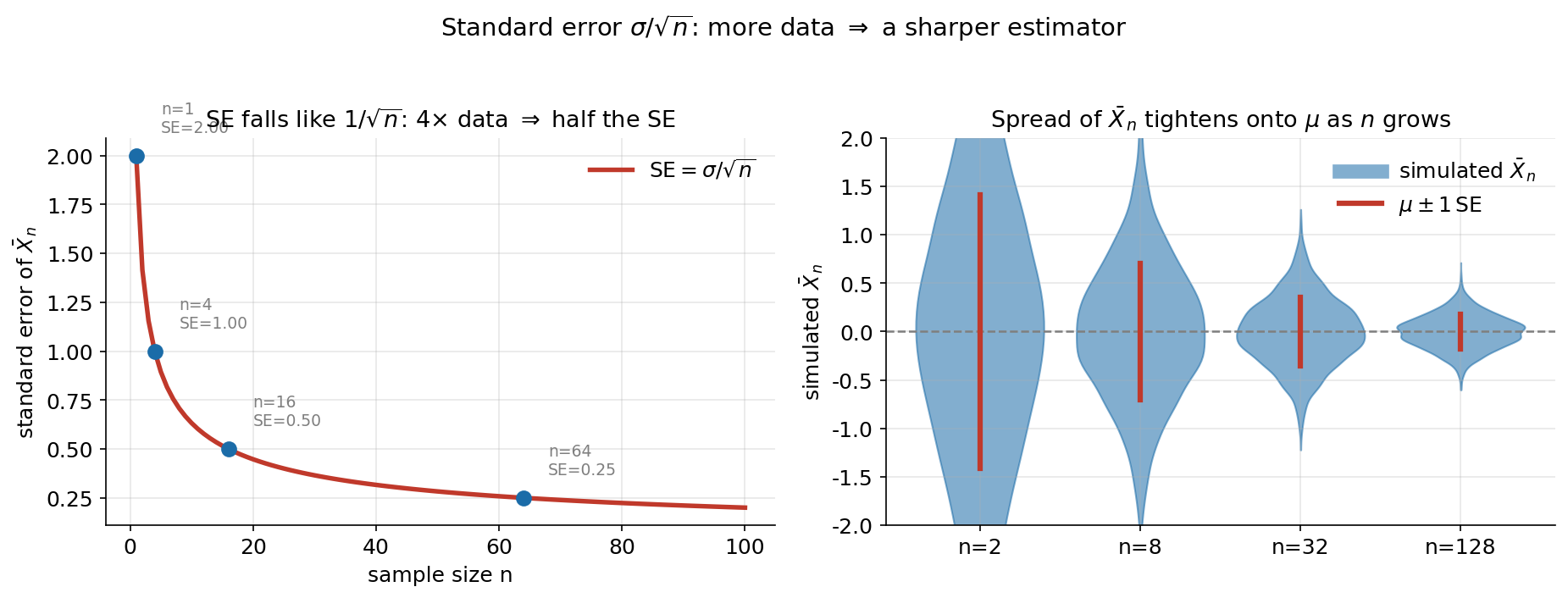
Figure 4 — standard error \(\sigma/\sqrt{n}\) ছোট হয় (E1)¶
inference-এর সবচেয়ে ব্যবহারিক একটা সংখ্যা: একটা estimator কত নির্ভরযোগ্য তা মাপে তার standard error — আর \(\bar X_n\)-এর জন্য সেটা \(\mathrm{SE}=\sigma/\sqrt{n}\)। বাঁ প্যানেলে \(\sigma=2\) ধরে SE-কে \(n\)-এর বিপরীতে আঁকা (লাল curve), কয়েকটা \(n\) চিহ্নিত। ডান প্যানেলে simulation: \(n=2,8,32,128\)-এর প্রতিটির জন্য \(3000\)টি \(\bar X_n\)-এর violin (নীল), পাশে লাল দাগে \(\mu\pm 1\,\mathrm{SE}\)। যা লক্ষ করতে হবে: (ক) বাঁয়ে curve-টা খাড়াভাবে নামে তারপর চ্যাপ্টা হয় — কারণ \(1/\sqrt{n}\) মানে শুরুতে অল্প data যোগ করলেই SE অনেক কমে, কিন্তু পরে কমানো কঠিন: \(n\) চারগুণ করলে তবেই SE অর্ধেক (\(n{=}4{\to}16\)-এ SE \(1.00{\to}0.50\))। (খ) ডানে violin-গুলো \(n\) বাড়ার সাথে সরু হয়ে \(\mu=0\)-এর গায়ে জড়ো হয় — অর্থাৎ বড় নমুনায় \(\bar X_n\) প্রায় সবসময়ই \(\mu\)-র খুব কাছে পড়ে। (গ) লাল \(\pm 1\,\mathrm{SE}\) দাগ violin-এর প্রস্থের সাথে মেলে — তত্ত্বের SE আর simulation-এর ছড়ানো এক। এই \(1/\sqrt{n}\) হারই বলে দেয় জরিপে কত নমুনা লাগবে, আর কেন নিখুঁত হতে গেলে খরচ দ্রুত বাড়ে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-01-inference-sampling-distributions-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় পার্থক্য করুন: estimand (\(\theta\)), estimator (\(\hat\theta\) বা \(T\)), আর একটা estimate (একটা সংখ্যা)। একটা উদাহরণ দিন (যেমন population গড় উচ্চতা অনুমান) যেখানে তিনটিকে আলাদা করে চিহ্নিত করা যায়। Hint: estimand = যা জানতে চাই (অজানা ধ্রুবক, যেমন \(\mu\)); estimator = নমুনার একটা function/নিয়ম (random variable, যেমন \(\bar X_n\)); estimate = একটা নির্দিষ্ট নমুনায় সেই function-এর মান (একটা সংখ্যা, যেমন \(172.4\) সেমি)।
প্রশ্ন ২ (★). "Sampling distribution আর data-র histogram এক জিনিস নয়।" — ব্যাখ্যা করুন কেন। কোনটা একটা নমুনার ভেতরের মানগুলোর ছড়ানো দেখায়, আর কোনটা কাল্পনিক বহু নমুনার statistic-এর ছড়ানো দেখায়? Figure 1-এর দৃষ্টিকোণে উত্তর দিন। Hint: data-histogram = একটাই নমুনার \(X_1,\dots,X_n\)-এর distribution (population-এর আকৃতি অনুমান করে); sampling distribution = \(T=\bar X_n\)-এর distribution বহু নমুনার ওপর — Figure 1-এর প্রতিটা bar একটা গোটা নমুনার গড়, একটা একক মান নয়।
প্রশ্ন ৩ (★★). standard error আর standard deviation — শব্দ দুটো প্রায়ই গুলিয়ে যায়। population SD \(\sigma\), sample SD \(S\), আর \(\bar X_n\)-এর standard error \(\mathrm{SE}=\sigma/\sqrt{n}\) — তিনটির ভূমিকা আলাদা করে বলুন। \(n\to\infty\)-এ কোনটা \(0\)-তে যায় আর কোনটা যায় না, কেন? Hint: \(\sigma\) ও \(S\) ব্যক্তি-পর্যবেক্ষণের ছড়ানো মাপে — population-এর ধর্ম, \(n\) বাড়লেও স্থির (\(S\to\sigma\)); \(\mathrm{SE}\) মাপে estimator \(\bar X_n\)-এর ছড়ানো — \(n\to\infty\)-এ \(\sigma/\sqrt{n}\to 0\) (Figure 4)।
প্রশ্ন ৪ (★★). degrees of freedom (df) ধারণাটা স্বজ্ঞাতভাবে ব্যাখ্যা করুন: কেন sample variance \(S^2=\frac{1}{n-1}\sum(X_i-\bar X)^2\)-এ ভাজক \(n-1\), \(n\) নয়? "একটা df খরচ হয়ে গেছে" কথাটার মানে কী? Figure 2-এর \(\chi^2_{n-1}\)-এর সাথে এর সম্পর্ক কী? Hint: \(\sum(X_i-\bar X)=0\) — এই একটা constraint মানে \(n\)টি বিচ্যুতির মধ্যে \(n-1\)টিই স্বাধীন (শেষটি বাকিগুলো থেকে নির্ধারিত); \(\bar X\) অনুমান করতে গিয়ে "একটা df খরচ", আর সেই কারণেই \((n-1)S^2/\sigma^2\sim\chi^2_{n-1}\) (df \(=n-1\))।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). একটা population-এর \(\sigma=6\)। \(\bar X_n\)-এর standard error \(\mathrm{SE}=\sigma/\sqrt{n}\) ব্যবহার করে: (ক) \(n=9,36,144\)-এর প্রতিটির জন্য SE বের করুন। (খ) SE-কে অর্ধেক করতে \(n\) কতগুণ করতে হয়? (গ) SE \(=0.5\) পেতে কত \(n\) লাগবে? Hint: (ক) \(6/\sqrt{9}=2\), \(6/\sqrt{36}=1\), \(6/\sqrt{144}=0.5\); (খ) \(1/\sqrt{n}\) অর্ধেক হতে \(n\) চারগুণ; (গ) \(6/\sqrt{n}=0.5\Rightarrow\sqrt{n}=12\Rightarrow n=144\)।
প্রশ্ন ৬ (★). Figure 1-এর setup: population Gamma\((2,1.5)\), তাই \(\mu=3\), \(\sigma=\sqrt{4.5}\approx 2.121\)। CLT ধরে \(n=50\)-এ \(\bar X_{50}\)-এর আনুমানিক sampling distribution লিখুন এবং আনুমান করুন \(P(\bar X_{50}>3.4)\)। (\(\Phi(1.33)\approx 0.908\) ব্যবহার করুন।) Hint: \(\bar X_{50}\approx\mathcal N(3,\ 4.5/50)\), \(\mathrm{SE}=\sqrt{0.09}=0.3\); \(P(\bar X_{50}>3.4)\approx 1-\Phi\!\big(\tfrac{3.4-3}{0.3}\big)=1-\Phi(1.33)\)।
প্রশ্ন ৭ (★★). একটা \(\mathcal N(\mu,\sigma^2)\) population থেকে \(n=10\)-এর নমুনা (df \(=n-1=9\))। \(\chi^2\)-table থেকে \(\chi^2_{9,\,0.975}=19.02\) ও \(\chi^2_{9,\,0.025}=2.70\) দেওয়া। তথ্য: \(\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_9\) (E2)। এর থেকে \(P\!\left(2.70\le \frac{9S^2}{\sigma^2}\le 19.02\right)=0.95\)-কে \(\sigma^2\)-এর একটা \(95\%\) ব্যবধানে পুনর্বিন্যাস করুন (যদি \(S^2\) পরিমাপিত হয়)। Hint: অসমতার ভেতরে \(\sigma^2\) আলাদা করুন: \(\frac{9S^2}{19.02}\le\sigma^2\le\frac{9S^2}{2.70}\) — এটাই variance-এর confidence interval-এর কাঠামো, যা \(\chi^2\) sampling distribution থেকে সরাসরি আসে।
প্রশ্ন ৮ (★★). \(t\) বনাম Normal critical value (E3)। একটা \(95\%\) দুই-প্রান্তিক ব্যবধানে Normal ব্যবহার করলে multiplier \(z_{0.975}=1.96\)। কিন্তু ছোট নমুনায় \(t\) লাগে: \(t_{9,\,0.975}=2.262\), \(t_{29,\,0.975}=2.045\), \(t_{\infty}=1.960\)। (ক) কেন \(t\)-multiplier সবসময় \(z\)-এর চেয়ে বড়? (খ) df \(9\to 29\to\infty\)-এ multiplier কীভাবে বদলায় এবং কেন? Figure 3-এর সাথে যুক্ত করুন। Hint: (ক) \(t\)-এর ভারী লেজ (Figure 3) মানে একই \(95\%\) ভর ধরতে আরও চওড়া যেতে হয়; \(\sigma\) অজানা থাকার বাড়তি অনিশ্চয়তা; (খ) df বাড়লে লেজ হালকা হয়, multiplier \(1.96\)-এর দিকে নামে।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★). দেখান যে \(\bar X_n\) হলো \(\mu\)-এর একটা unbiased estimator এবং তার variance \(\sigma^2/n\)। অর্থাৎ iid \(X_i\) (\(\mathbb{E}[X_i]=\mu\), \(\operatorname{Var}(X_i)=\sigma^2\)) হলে \(\mathbb{E}[\bar X_n]=\mu\) ও \(\operatorname{Var}(\bar X_n)=\sigma^2/n\) প্রমাণ করুন। (এখান থেকেই \(\mathrm{SE}=\sigma/\sqrt{n}\)।) Hint: প্রত্যাশার রৈখিকতা: \(\mathbb{E}[\bar X_n]=\frac1n\sum\mathbb{E}[X_i]=\mu\); স্বাধীনতায় variance যোগ হয়: \(\operatorname{Var}\!\big(\frac1n\sum X_i\big)=\frac{1}{n^2}\sum\operatorname{Var}(X_i)=\frac{n\sigma^2}{n^2}\)।
প্রশ্ন ১০ (★★). \(t\)-distribution-এর সংজ্ঞা থেকে নির্মাণ (E3)। ধরুন \(Z\sim\mathcal N(0,1)\) ও \(V\sim\chi^2_k\) স্বাধীন। \(t\)-distribution সংজ্ঞায়িত: \(T=\dfrac{Z}{\sqrt{V/k}}\)। ব্যাখ্যা করুন কীভাবে এই সংজ্ঞা থেকে one-sample \(t\)-statistic \(\dfrac{\bar X_n-\mu}{S/\sqrt{n}}\) ঠিক \(t_{n-1}\) হয় — কোনটা \(Z\)-এর ভূমিকায়, কোনটা \(V\)-এর, df কত? Hint: \(\frac{\bar X_n-\mu}{\sigma/\sqrt{n}}=Z\sim\mathcal N(0,1)\); \(\frac{(n-1)S^2}{\sigma^2}=V\sim\chi^2_{n-1}\) এবং \(\bar X_n\perp S^2\) (Normal-এ স্বাধীন); ভাগ করলে \(\sigma\) কাটে, পড়ে থাকে \(\frac{Z}{\sqrt{V/(n-1)}}=t_{n-1}\)।
প্রশ্ন ১১ (★★★). \(F\)-distribution ও তার দুই-দিকের সম্পর্ক (E4)। \(F=\dfrac{U/d_1}{V/d_2}\) যেখানে \(U\sim\chi^2_{d_1}\), \(V\sim\chi^2_{d_2}\) স্বাধীন। (ক) দেখান যদি \(T\sim t_k\) তবে \(T^2\sim F_{1,k}\)। (খ) দেখান যদি \(X\sim F_{d_1,d_2}\) তবে \(1/X\sim F_{d_2,d_1}\) — এবং ব্যাখ্যা করুন কেন এটা lower-tail critical value-কে upper-tail দিয়ে পাওয়ার কাজে লাগে। Hint: (ক) \(T=\frac{Z}{\sqrt{V/k}}\) হলে \(T^2=\frac{Z^2/1}{V/k}\), আর \(Z^2\sim\chi^2_1\) — ঠিক \(F_{1,k}\)-এর সংজ্ঞা; (খ) \(1/X=\frac{V/d_2}{U/d_1}\) — শুধু numerator–denominator অদলবদল, তাই df উল্টে \(F_{d_2,d_1}\); এতে \(F_{d_1,d_2,\,\alpha}=1/F_{d_2,d_1,\,1-\alpha}\)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে Figure 1-এর সরল রূপ বানান। Gamma\((2,1.5)\) population (\(\mu=3\)) থেকে \(n=5\) ও \(n=50\)-এর প্রতিটির জন্য \(\bar X_n\)-এর \(30{,}000\)টি নমুনা তুলুন, histogram আঁকুন, তার উপর \(\mathcal N(\mu,\sigma^2/n)\) (এখানে \(\sigma^2=4.5\)) বসান। দুটো ক্ষেত্রে empirical SD তুলনা করুন তত্ত্ব-SE \(\sigma/\sqrt{n}\)-এর সাথে। default_rng(0) ব্যবহার করুন।
Hint: xbar = rng.gamma(2, 1.5, size=(30_000, n)).mean(axis=1); xbar.std() বনাম np.sqrt(4.5)/np.sqrt(n); density-curve-এ scipy.stats.norm.pdf(grid, 3, np.sqrt(4.5/n))।
প্রশ্ন ১৩ (★★). sampling distribution নিজে নির্মাণ করুন একটা কম-পরিচিত statistic-এর জন্য। \(\mathcal N(0,1)\) থেকে \(n=8\)-এর নমুনা বহুবার (\(20{,}000\)) তুলে প্রতিবার sample median হিসাব করুন। (ক) median-এর sampling distribution-এর histogram আঁকুন। (খ) এর empirical SD বের করে \(\bar X_8\)-এর SE \(=1/\sqrt{8}\)-এর সাথে তুলনা করুন — কোনটা বেশি, এবং Normal data-তে এটা কী বলে (median কি mean-এর চেয়ে কম/বেশি efficient)?
Hint: med = np.median(rng.normal(0,1,size=(20_000,8)), axis=1); Normal-এ median-এর SE \(\approx 1.253\,\sigma/\sqrt{n}\) — অর্থাৎ mean-এর চেয়ে বড়, তাই Normal data-তে mean বেশি efficient। (এটাই দেখায় যেকোনো statistic-এরই একটা sampling distribution আছে, শুধু \(\bar X_n\)-এর নয়।)
প্রশ্ন ১৪ (★★★). \(t_{n-1}\) sampling distribution সিমুলেশনে যাচাই (E2+E3)। \(\mathcal N(\mu,\sigma^2)\) (যেকোনো \(\mu,\sigma\), যেমন \(\mu=10,\sigma=3\)) থেকে \(n=6\)-এর নমুনা \(50{,}000\) বার তুলে প্রতিবার \(T=\dfrac{\bar X_n-\mu}{S/\sqrt{n}}\) গণনা করুন। (ক) \(T\)-এর histogram-এ তাত্ত্বিক \(t_{5}\) density বসান এবং \(\mathcal N(0,1)\)-ও বসিয়ে পার্থক্য দেখান। (খ) empirical \(P(\lvert T\rvert>2.571)\) গণনা করে তাত্ত্বিক \(0.05\)-এর সাথে মেলান (\(t_{5,0.975}=2.571\))। (গ) আলাদাভাবে দেখান \(\frac{(n-1)S^2}{\sigma^2}\)-এর histogram \(\chi^2_5\)-এর সাথে মেলে।
Hint: X = rng.normal(10,3,size=(50_000,6)); xbar=X.mean(1); S=X.std(1,ddof=1); T=(xbar-10)/(S/np.sqrt(6)); scipy.stats.t.pdf(grid,5) ও scipy.stats.chi2.pdf(grid,5) দিয়ে overlay; histogram স্পষ্টভাবে \(t_5\)-এর সাথে মিলবে, Normal-এর চেয়ে ভারী লেজ দেখাবে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- inference-এর সমস্যা: আমরা একটা population-এর অজানা estimand \(\theta\) (যেমন \(\mu\), \(\sigma^2\), \(p\)) জানতে চাই, হাতে আছে শুধু একটা নমুনা। নমুনার একটা function \(T=\hat\theta\) (যেমন \(\bar X_n\), \(S^2\)) হলো estimator — এটা random variable, কারণ নমুনা random। একটা নির্দিষ্ট নমুনায় তার মান হলো একটা estimate (একটা সংখ্যা)।
- sampling distribution: একই population থেকে বারবার (কাল্পনিকভাবে) নমুনা তুললে \(T\)-এর যে distribution হয় — এটাই inference-এর কেন্দ্রীয় বস্তু। এর কেন্দ্র বলে estimator কি ঠিক জায়গায় (bias), আর এর ছড়ানো (\(=\) standard error) বলে estimate কতটা নির্ভরযোগ্য (Figure 1)।
- standard error: \(\bar X_n\)-এর জন্য \(\mathrm{SE}=\sigma/\sqrt{n}\) — population SD নয়, estimator-এর SD। এটা \(1/\sqrt{n}\) হারে কমে: \(n\) চারগুণ করলে SE অর্ধেক (Figure 4)। এটাই বলে দেয় নির্ভুলতা কিনতে কত data লাগে।
- Normal থেকে জন্মানো তিন distribution (df-নিয়ন্ত্রিত):
- \(\chi^2_k\) — \(k\)টি স্বাধীন \(\mathcal N(0,1)\)-এর বর্গের যোগফল; \(\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}\) (E2), variance-inference-এর ভিত্তি।
- \(t_k\) — \(\frac{Z}{\sqrt{V/k}}\) (\(Z\sim\mathcal N(0,1)\), \(V\sim\chi^2_k\)); \(\sigma\) অজানা থাকলে \(\frac{\bar X_n-\mu}{S/\sqrt{n}}\sim t_{n-1}\) (E3)। ভারী লেজ, কিন্তু df বাড়লে \(\to\mathcal N(0,1)\) (Figure 2, Figure 3)।
- \(F_{d_1,d_2}\) — দুই scaled \(\chi^2\)-এর অনুপাত; দুই variance তুলনায় (E4)।
- degrees of freedom: প্রতিটি distribution-এর আকৃতি df দিয়ে নিয়ন্ত্রিত; \(S^2\)-এ \(\bar X\) অনুমান করতে "একটা df খরচ" হয় বলে df \(=n-1\)।
পূর্ববর্তী সংযোগ (← 3.4 CLT, ← 1.2): 3.4-এর Central Limit Theorem-ই এই অধ্যায়ের ইঞ্জিন — CLT বলে iid নমুনার গড়ের sampling distribution বড় \(n\)-এ \(\mathcal N(\mu,\sigma^2/n)\), তাই Figure 1-এ skewed population থেকেও \(\bar X_{50}\)-এর histogram Normal ও সরু হয়। CLT না থাকলে "\(\bar X_n\)-এর sampling distribution Normal" দাবিটাই দাঁড়াত না। আর 1.2-এর location ও variability পরিমাপ (mean, variance, SD) এখানে অন্য ভূমিকায় ফিরে এসেছে: তখন সেগুলো ছিল একটা data-set বর্ণনার হাতিয়ার (descriptive), এখন সেগুলো estimator — population-এর অজানা \(\mu,\sigma^2\)-কে অনুমান করার যন্ত্র, যাদের নিজেদেরই sampling distribution আছে। descriptive থেকে inferential-এ এই দৃষ্টিভঙ্গির বদলই Part IV-এর সূচনা।
পরবর্তী সংযোগ (→ 4.2 ও Part IV-এর বাকি): এই অধ্যায় কাঠামো গড়ল; পরের অধ্যায়গুলো তার ওপর inference নির্মাণ করবে — - 4.2 (point estimation — method of moments ও পরে maximum likelihood): কীভাবে ভালো estimator \(\hat\theta\) বানাতে হয় তার প্রথম দুটো নিয়মতান্ত্রিক পদ্ধতি; কিন্তু সেই \(\hat\theta\) কতটা ভালো তা বিচার করতে লাগে তার sampling distribution — অর্থাৎ এই অধ্যায়ের ভাষা। sampling distribution হলো সব inference-এর ভিত্তি: এটা ছাড়া না bias মাপা যায়, না variance, না consistency। - confidence interval (Part IV): \(\bar X_n\pm t_{n-1,\,0.975}\cdot S/\sqrt{n}\) — multiplier আসে \(t\)-distribution থেকে (Figure 3), প্রস্থ আসে SE থেকে (Figure 4)। - hypothesis testing (Part IV): \(z\)-, \(t\)-, \(\chi^2\)-, \(F\)-test — প্রতিটি test-statistic-এর null-distribution হলো এই অধ্যায়ের চারটি sampling distribution-এরই একটি।
সারকথা: একটা estimate কেবল একটা সংখ্যা নয় — তার পেছনে একটা sampling distribution দাঁড়িয়ে, আর সেই distribution-এর কেন্দ্র ও ছড়ানো (standard error) জানা থাকলেই কেবল আমরা বলতে পারি "আমাদের উত্তর কতটা নিশ্চিত।" Part IV-এর গোটা ইমারত — estimation, confidence interval, testing — এই একটি ধারণার ওপর দাঁড়িয়ে।
সূত্র (sources): Wasserman, All of Statistics, Ch. 6 (Models, Statistical Inference and Learning) ও Ch. 7 (Estimating the CDF and Statistical Functionals); Rice, Mathematical Statistics and Data Analysis, Ch. 6 (Distributions Derived from the Normal Distribution — \(\chi^2\), \(t\), \(F\), এবং sample mean ও variance-এর sampling distribution)।