Part VI — পরিসংখ্যানিক মেশিন লার্নিং · Integrative Demos¶
Part VI পরিসংখ্যান ও statistical machine learning (মেশিন লার্নিং)-এর সংযোগস্থল ধরে: learning theory ও bias–variance tradeoff, regularization (ridge/lasso), generative ও instance-based classifier (LDA/QDA/Naive Bayes/kNN), SVM ও kernel, decision tree → bagging → random forest, boosting (AdaBoost), EM ও Gaussian mixture, manifold learning (PCA/Isomap/t-SNE), এবং anomaly detection ও semi-supervised learning। প্রতিটি ধারণা চারভাবে দেখানো — (b) scratch (শুধু numpy, যেখানে সম্ভব), (c) library check (sklearn), (d) demonstrate/"prove" (ছাপা real সংখ্যা), (e) visualization — সবই real open data (diabetes, wine, breast_cancer, digits)-এর উপর, fixed seed 20260619 সহ। প্রতিবার train/test split (fixed seed) ও প্রয়োজনে standardize করা হয়েছে। নিচের সব সংখ্যা executed notebook (notebooks/06-statistical-ml.ipynb) থেকে সরাসরি নেওয়া।
6.1 — Learning theory: bias–variance tradeoff¶
ধারণা। যেকোনো estimator-এর expected test error ভাঙা যায় bias² + variance + irreducible noise-এ। সরল model (নিচু-degree polynomial) underfit করে (উঁচু bias, নিচু variance); জটিল model overfit করে (নিচু bias, উঁচু variance)। এই bias–variance tradeoff (বায়াস-ভ্যারিয়ান্স আপস) test error-কে model complexity-র সাপেক্ষে U-আকৃতি দেয়, আর train error একটানা কমতে থাকে — train/test gap-ই overfitting-এর চিহ্ন।
Scratch idea. diabetes-এর bmi \(\to\) target (\(1\)-feature regression, \(x\) standardized)। fixed test set (\(n=120\)) রেখে training pool থেকে \(B=200\) বার bootstrap resample করে প্রতিটি degree \(d=1..10\)-এ polynomial least-squares (np.linalg.lstsq) fit; test point-এ prediction জমিয়ে — \(\text{bias}^2=(\bar f(x_0)-y_0)^2\), \(\text{variance}=\operatorname{Var}_B[\hat f(x_0)]\), আর total test MSE \(=\) দুটোর যোগফল (হুবহু মেলে)।
Demonstrated result (প্রমাণ)। test error U-আকৃতির, সর্বনিম্ন degree \(=7\)-এ (test MSE \(=4534.0\)); অতিরিক্ত degree-এ আবার বাড়ে (deg 10 → \(4661.2\))। train MSE একটানা নামে (\(3635.4 \to 3459.4\)), আর variance একটানা বাড়ে (\(19.1 \to 104.3\)) — অর্থাৎ জটিল model বেশি volatile। প্রতিটি degree-এ \(\text{bias}^2+\text{variance}\) ঠিক total test MSE-র সমান (decomposition-এর যাচাই)। bmi→target প্রায় linear বলে U অগভীর, কিন্তু train/test gap ও variance-বৃদ্ধি স্পষ্ট।
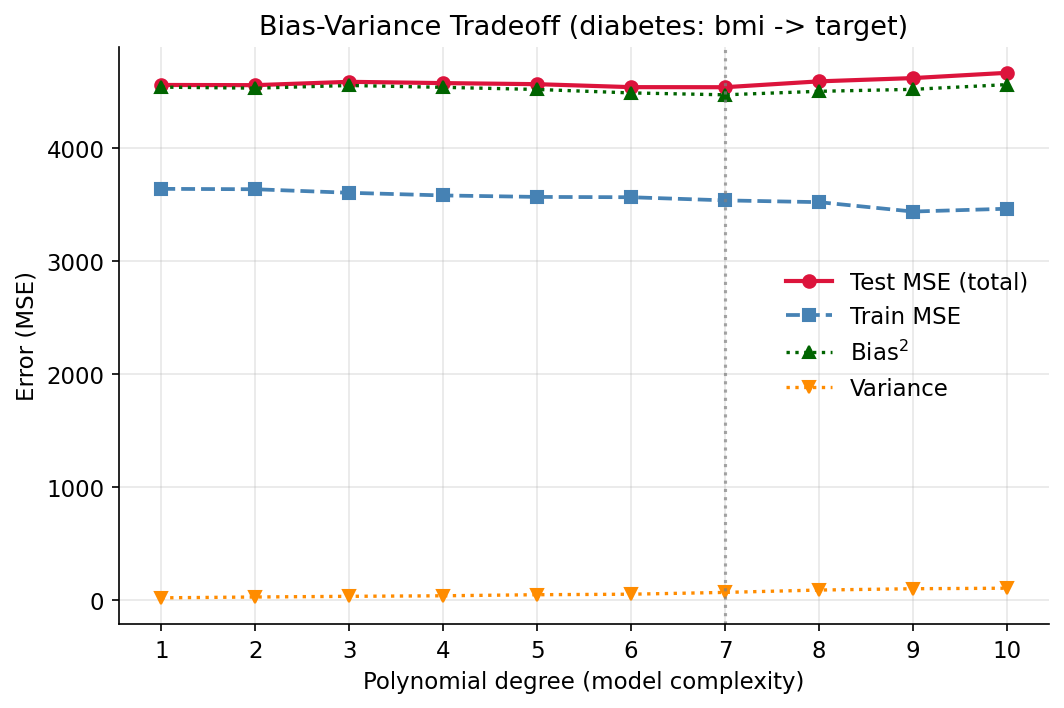
চিত্র: degree-র সাপেক্ষে train MSE (নামছে), test MSE (U-আকৃতি), bias² ও variance।
6.2 — Regularization: ridge ও lasso coefficient paths¶
ধারণা। Regularization (নিয়মিতকরণ) loss-এ penalty যোগ করে coefficient shrink করে variance কমায়। Ridge (\(L_2\)): \(\min_\beta \lVert y-X\beta\rVert^2 + \lambda\lVert\beta\rVert_2^2\), closed form \(\hat\beta=(X^\top X+\lambda I)^{-1}X^\top y\) — coefficient মসৃণভাবে ছোট হয় কিন্তু ঠিক \(0\) হয় না। Lasso (\(L_1\)): penalty \(\lambda\lVert\beta\rVert_1\) — কিছু coefficient ঠিক \(0\) করে (sparsity/বিরলতা, স্বয়ংক্রিয় feature selection)।
Scratch idea. diabetes-এর ১০টি standardized feature (target centered)। Ridge: \(\lambda\)-grid-এ closed-form সমাধান করে path। Lasso: coordinate descent — প্রতিটি \(\beta_j\)-কে বাকিদের fixed রেখে soft-threshold \(S(\rho_j,\lambda)=\operatorname{sign}(\rho_j)\max(\lvert\rho_j\rvert-\lambda,0)\) দিয়ে convergence পর্যন্ত update।
Demonstrated result (প্রমাণ)। scratch দুটোই sklearn-এর সাথে মেলে — Ridge (\(\alpha=10\)): max \(\lvert\text{diff}\rvert = 8.2\times10^{-14}\) (close=True); Lasso (\(\alpha=0.5\)): max \(\lvert\text{diff}\rvert = 5.9\times10^{-8}\) (close=True)। shrinkage: ridge coefficient-এর \(L_2\) norm \(65.4 \to 8.82\) (\(\lambda\) বাড়ার সাথে)। sparsity: lasso nonzero count \(10 \to 3\); \(\alpha=0.5\)-এ scratch ও sklearn দুটোই \(8/10\) রাখে, একই feature দুটো (\(\lvert\text{age}\rvert\), s2) \(0\) করে।
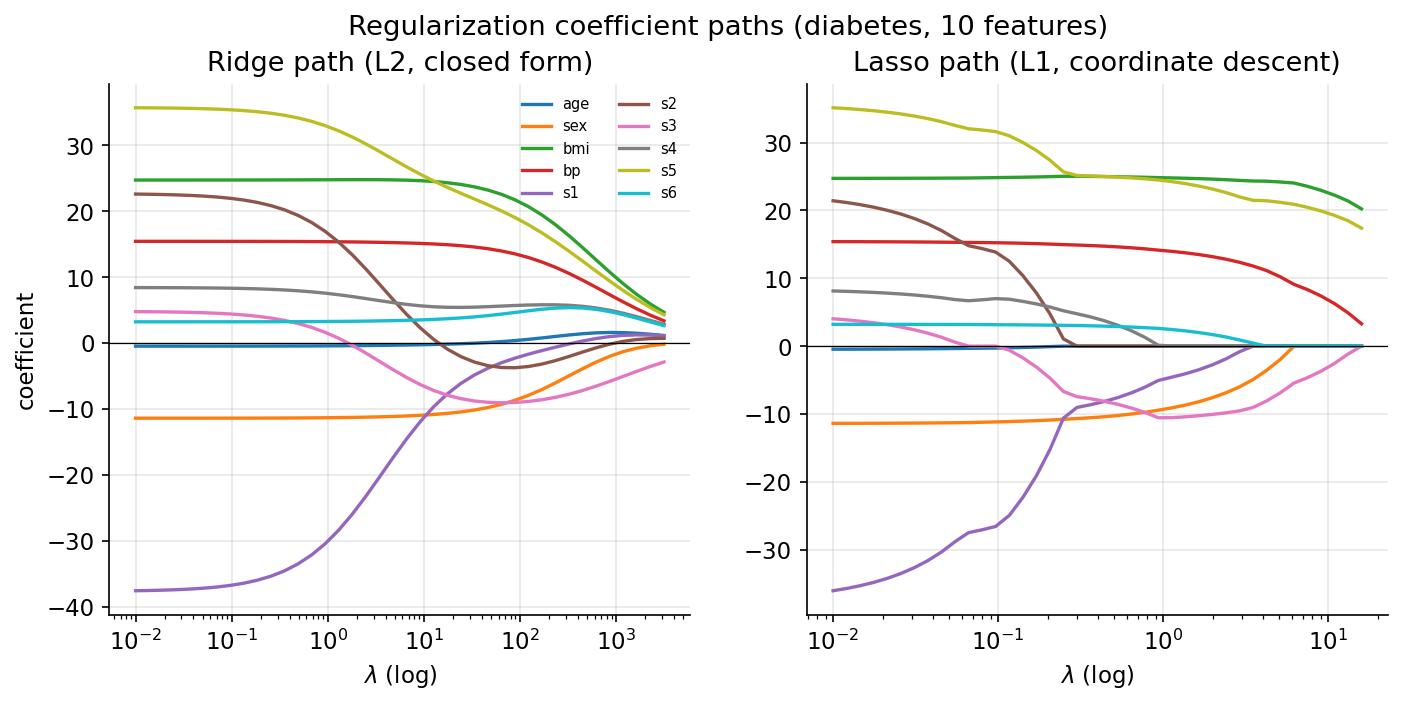
চিত্র: ridge path (বাঁ, মসৃণ shrink) ও lasso path (ডান, coefficient একে একে ঠিক \(0\)-তে)।
6.3 — Generative ও instance-based classifiers: LDA / QDA / NB / kNN¶
ধারণা। চারটি ধ্রুপদী classifier — LDA: প্রতি class Gaussian, shared covariance \(\Sigma\), boundary linear; QDA: প্রতি class-এর নিজস্ব \(\Sigma_k\), boundary quadratic; Gaussian NB: feature class-এর ভেতর স্বাধীন (diagonal \(\Sigma_k\)); kNN: parametric নয়, test point-এর \(k\) নিকটতম প্রতিবেশীর majority vote। প্রথম তিনটি posterior \(\propto\) prior \(\times\) likelihood; kNN distance-ভিত্তিক।
Scratch idea. wine (৩ class, ১৩ standardized feature)। LDA/QDA/NB: প্রতি class-এর \(\hat\mu_k,\hat\Sigma_k\) থেকে log-posterior \(\log\pi_k - \tfrac12\log\lvert\Sigma_k\rvert - \tfrac12(x-\mu_k)^\top\Sigma_k^{-1}(x-\mu_k)\)-এর argmax। kNN: Euclidean distance-এর argsort করে majority vote।
Demonstrated result (প্রমাণ)। চারটির scratch test accuracy sklearn-এর সাথে হুবহু মেলে (test size \(=54\)): LDA \(0.9815\) / QDA \(0.9815\) / kNN \(0.9815\) / NB \(0.9630\)। wine feature-গুলো প্রায় Gaussian ও class ভালো-আলাদা বলে সবাই ভালো করে; NB-র independence-অনুমান সামান্য দুর্বল বলে সে একটু পিছিয়ে। সেরা scratch model: LDA (\(0.9815\))।
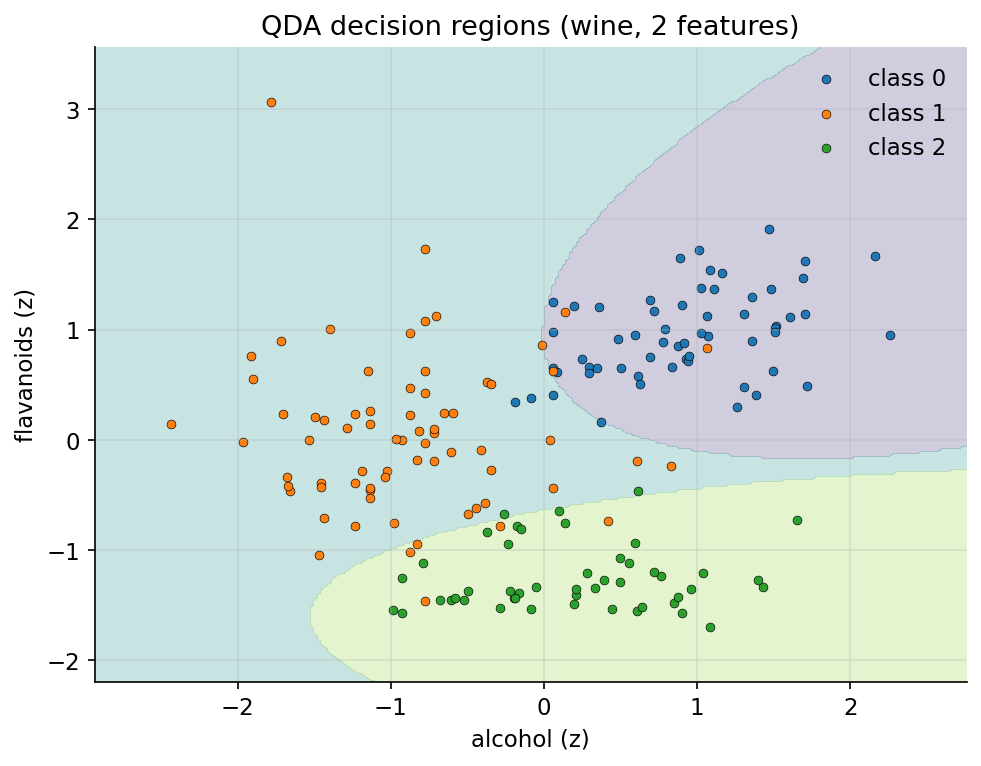
চিত্র: wine-এর ২ feature (alcohol, flavanoids)-এ QDA-র quadratic decision region ও তিন class।
6.4 — Support Vector Machines ও kernels¶
ধারণা। SVM দুই class-এর মাঝে margin (মার্জিন) সর্বোচ্চ করা hyperplane খোঁজে; কেবল support vector (margin-এর উপর/ভেতরে থাকা point) boundary নির্ধারণ করে। Kernel trick-এ data-কে উচ্চ-মাত্রায় map করে non-linear boundary পাওয়া যায় — RBF kernel \(K(x,x')=\exp(-\gamma\lVert x-x'\rVert^2)\)। \(C\) margin-বনাম-ভুলের আপস (বড় \(C\) = কম ভুল, সরু margin); \(\gamma\) প্রতিটি point-এর প্রভাবের ব্যাপ্তি।
Library idea (sklearn). breast_cancer-এর ২ standardized feature (mean radius, mean texture)। linear বনাম RBF SVC; margin, support vector, ও \(C,\gamma\)-র প্রভাব।
Demonstrated result (প্রমাণ)। linear SVM test acc \(=0.9181\) (\(118/398\) support vector); weight \(w=[-2.2230,-0.5900]\), geometric margin width \(2/\lVert w\rVert = 0.8696\)। RBF (\(C{=}1,\gamma{=}0.5\)) test acc \(0.9064\); খুব aggressive RBF (\(C{=}100,\gamma{=}2\)) train acc বাড়ে (\(0.9020\)) কিন্তু test acc নামে (\(0.9006\)) — বড় \(C,\gamma\) overfit-এর দিকে টানে। এই projection-এ linear boundary-ই সবচেয়ে ভালো generalize করে।
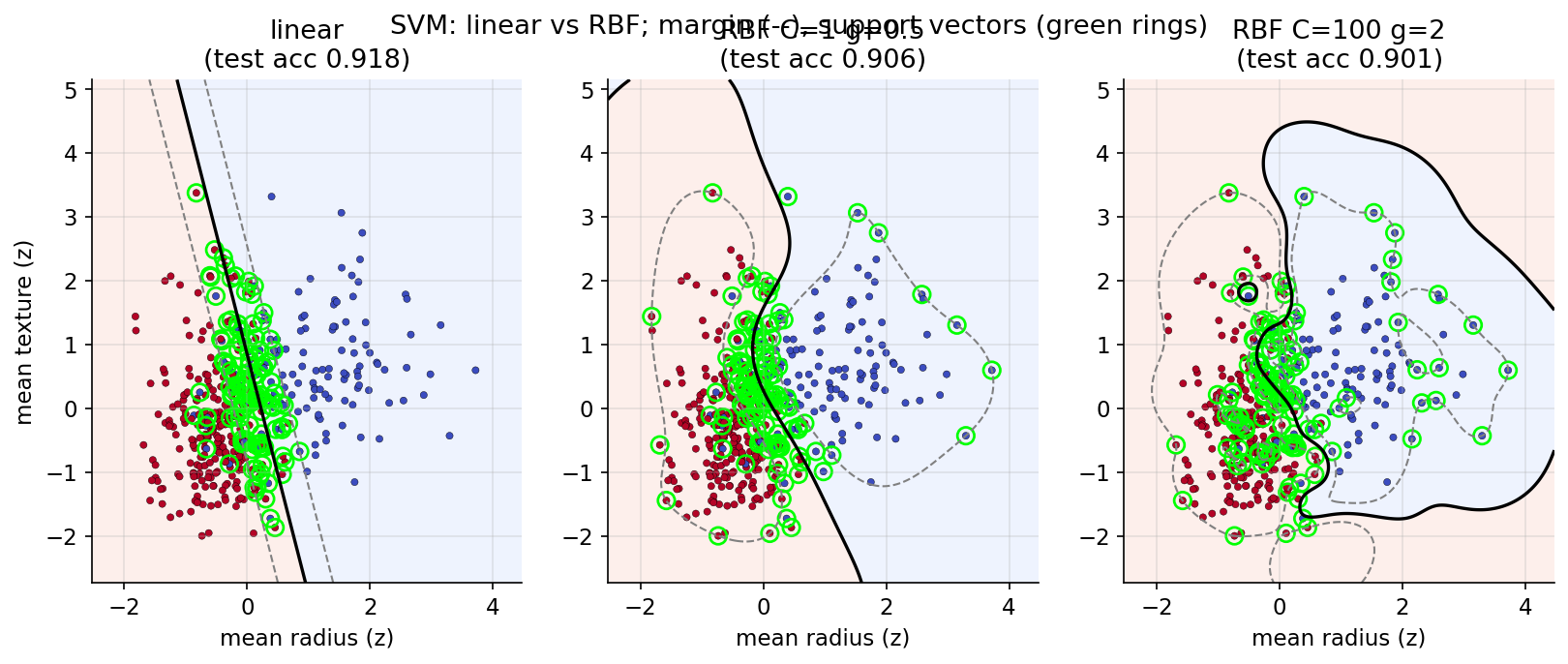
চিত্র: তিন config-এ decision boundary, margin (--), ও support vector (সবুজ রিং)।
6.5 — Decision trees, bagging, ও random forest¶
ধারণা। CART tree প্রতিটি node-এ Gini impurity \(G=1-\sum_k p_k^2\) সবচেয়ে কমানো (feature, threshold) বেছে split করে; গভীর tree কম bias কিন্তু উঁচু variance। Bagging অনেক tree কে আলাদা bootstrap sample-এ fit করে vote — variance কমায়। Random forest bagging-এর সাথে প্রতি split-এ feature-এর random subset যোগ করে tree de-correlate করে; OOB (out-of-bag) sample দিয়ে বিনা-hold-out validation ও feature importance।
Scratch idea. breast_cancer-এ Gini-ভিত্তিক recursive CART (max depth \(=3\))। তারপর sklearn BaggingClassifier, RandomForestClassifier।
Demonstrated result (প্রমাণ)। scratch CART (depth 3) test acc \(=0.9532\) — sklearn tree-র সাথে হুবহু (\(0.9532\))। variance হ্রাস: একটি deep tree test acc \(0.9415\) (resample-এ std \(0.0117\), উঁচু variance) → bagging(200) \(0.9532\) (OOB \(0.9447\)) → random forest \(0.9708\) (OOB \(0.9523\))। top feature importance: worst area (\(0.1391\)), worst concave points (\(0.1194\)), worst perimeter (\(0.1187\)) — টিউমারের আকার-সম্পর্কিত feature-ই সবচেয়ে গুরুত্বপূর্ণ।
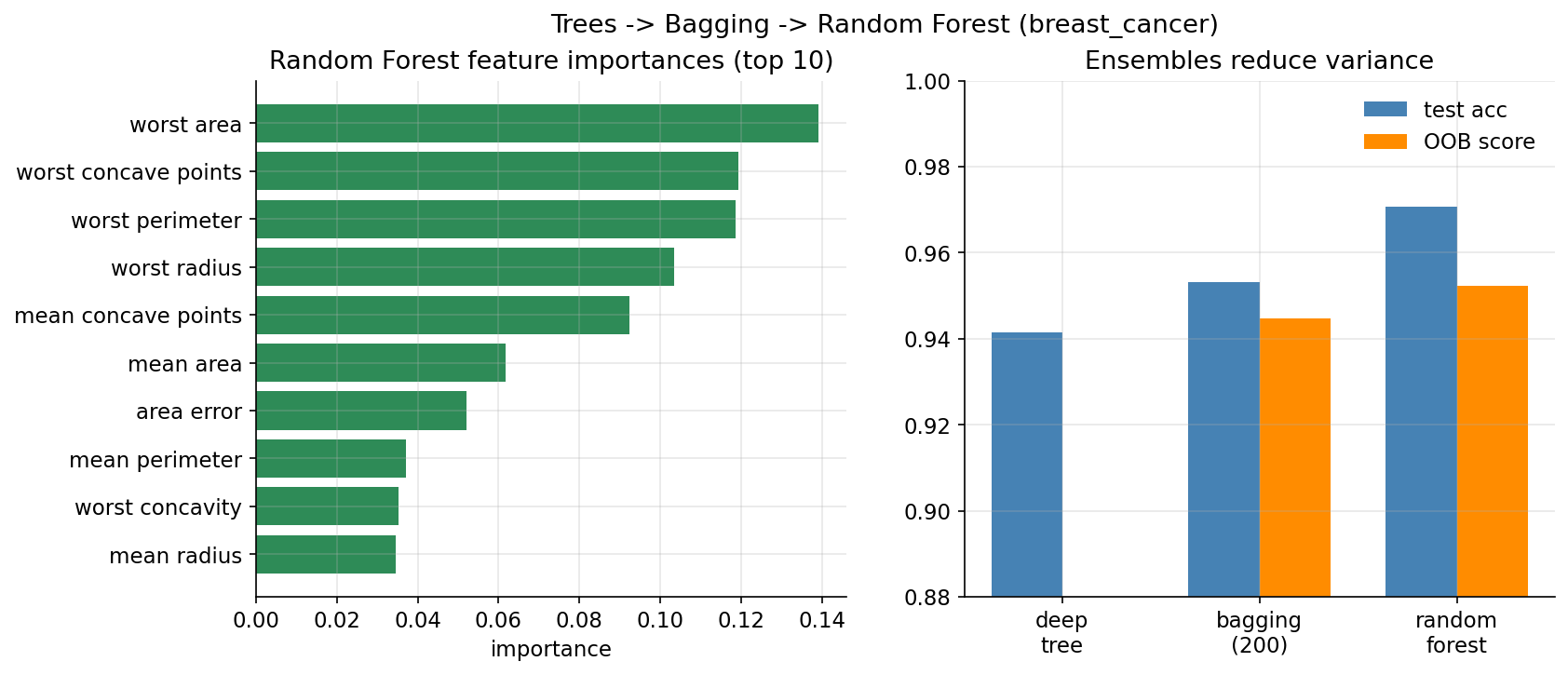
চিত্র: বাঁয়ে top-10 RF feature importance; ডানে deep tree/bagging/RF-এর test ও OOB accuracy।
6.6 — Boosting: AdaBoost from scratch¶
ধারণা। Boosting (বুস্টিং) দুর্বল learner ক্রমান্বয়ে যোগ করে — প্রতিটি নতুন learner আগের ভুলগুলোতে বেশি মন দেয়। AdaBoost (\(y\in\{-1,+1\}\)): weighted error \(\varepsilon_t=\sum_i w_i\mathbb{1}[h_t(x_i)\ne y_i]\); learner weight \(\alpha_t=\tfrac12\ln\frac{1-\varepsilon_t}{\varepsilon_t}\); ভুল point-এর weight বাড়িয়ে \(w_i\leftarrow w_i e^{-\alpha_t y_i h_t(x_i)}\) renormalize; চূড়ান্ত \(\operatorname{sign}\big(\sum_t\alpha_t h_t(x)\big)\)।
Scratch idea. wine-এর ২-class সমস্যা (class 0 বনাম বাকি, standardized)। weak learner = decision stump (এক feature, এক threshold, weighted-error minimizing)। stage-wise train/test error, তারপর sklearn AdaBoostClassifier/GradientBoostingClassifier।
Demonstrated result (প্রমাণ)। boosting round বাড়ার সাথে error কমে: round 1 → train \(0.0726\), test \(0.0926\); round 10 → train \(0.0000\), test \(0.0370\); round 40 → train \(0.0000\), test \(0.0370\) (test acc \(0.9630\))। মাত্র ১০ round-এই train error \(0\), test error স্থির — stump-এর ensemble দ্রুত শক্তিশালী। sklearn AdaBoost(40) test acc \(0.9815\), GradientBoosting(40) \(0.9630\) — একই মানের।
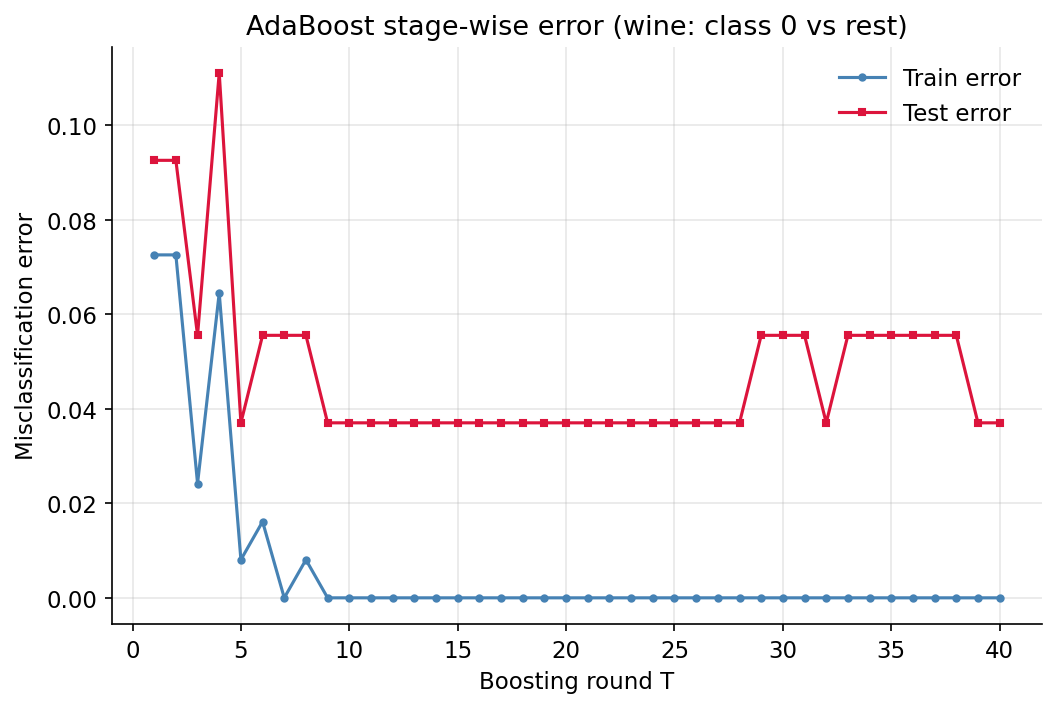
চিত্র: round-এর সাথে train ও test misclassification error কমছে।
6.7 — EM algorithm ও Gaussian mixture model (GMM)¶
ধারণা। Gaussian mixture ধরে data \(K\)টি Gaussian-এর মিশ্রণ থেকে: \(p(x)=\sum_k\pi_k\,\mathcal{N}(x\mid\mu_k,\sigma_k^2)\)। component-membership latent (লুকানো), তাই EM: E-step-এ responsibility \(\gamma_{ik}=\dfrac{\pi_k\mathcal{N}(x_i\mid\mu_k,\sigma_k^2)}{\sum_j\pi_j\mathcal{N}(x_i\mid\mu_j,\sigma_j^2)}\); M-step-এ \(\pi_k,\mu_k,\sigma_k^2\)-কে responsibility-weighted update। প্রতি iteration-এ log-likelihood কখনো কমে না। BIC দিয়ে \(K\) বাছাই।
Scratch idea. wine-এর flavanoids (\(1\)-D, standardized — ৩ class একসাথে মেশানো, স্বাভাবিকভাবেই multimodal)। \(K=2\) EM নিজ হাতে; responsibility, monotone log-likelihood; \(K=1..5\)-এ BIC; sklearn GaussianMixture-এর সাথে যাচাই।
Demonstrated result (প্রমাণ)। EM (\(K=2\)) দুটো component পায় — means \([-1.4076,\ 0.31]\), weights \([0.1805,\ 0.8195]\) — অর্থাৎ একটি ছোট, নিচু-flavanoid গুচ্ছ (মূলত class 2) আর একটি বড় গুচ্ছ। log-likelihood iter0 \(-285.11\) → converged \(-226.44\) (\(71\) iter), monotone non-decreasing = True। BIC: \(K{=}1{:}515.5\), \(K{=}2{:}478.8\) (সর্বনিম্ন) → BIC picks \(K=2\)। sklearn GaussianMixture হুবহু একই means/weights ও log-lik \(-226.4417\) দেয়; sklearn-ও \(K=2\) বেছে নেয়।
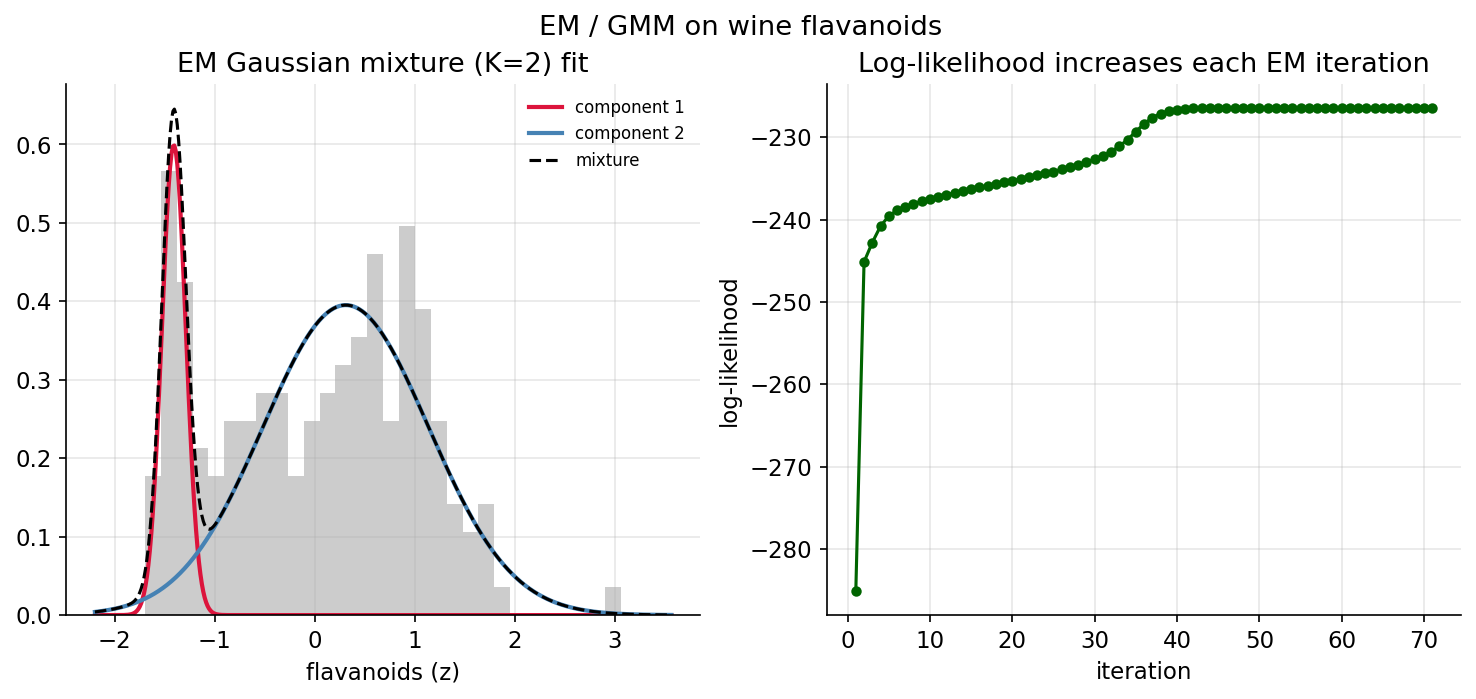
চিত্র: বাঁয়ে histogram-এর উপর \(K=2\) mixture fit; ডানে iteration-এ log-likelihood বাড়ছে।
6.8 — Dimensionality reduction: PCA vs Isomap vs t-SNE¶
ধারণা। উচ্চ-মাত্রার data-কে ২-D-তে নামানোর তিন কৌশল — PCA: linear, সর্বোচ্চ-variance orthogonal দিক ধরে project (global structure রাখে, বাঁকানো manifold খুলতে পারে না); Isomap: neighborhood graph-এ geodesic (জিওডেসিক) দূরত্ব বজায় রেখে unfold; t-SNE: প্রতিবেশীর সম্ভাবনা-বণ্টন মিলিয়ে local cluster আলাদা করে (global দূরত্ব বিকৃত হতে পারে)। Trustworthiness মাপে local neighborhood কতটা রক্ষা পেল।
Library idea (sklearn). digits (64-D → 2-D), digit অনুযায়ী রঙ, গতির জন্য \(700\)-row subset (standardized)।
Demonstrated result (প্রমাণ)। trustworthiness (k\(=\)10) ক্রম PCA \(0.8101\) < Isomap \(0.8465\) < t-SNE \(0.9766\) — যা textbook-প্রত্যাশা: nonlinear manifold-method local structure ভালো রাখে, t-SNE সবচেয়ে বেশি। PCA-র ২ component মাত্র \(22.65\%\) variance ধরে (৬৪-D digit-কে ২ linear দিকে চাপা কঠিন), তবু t-SNE-তে ১০টি digit স্পষ্ট আলাদা গুচ্ছ গড়ে।
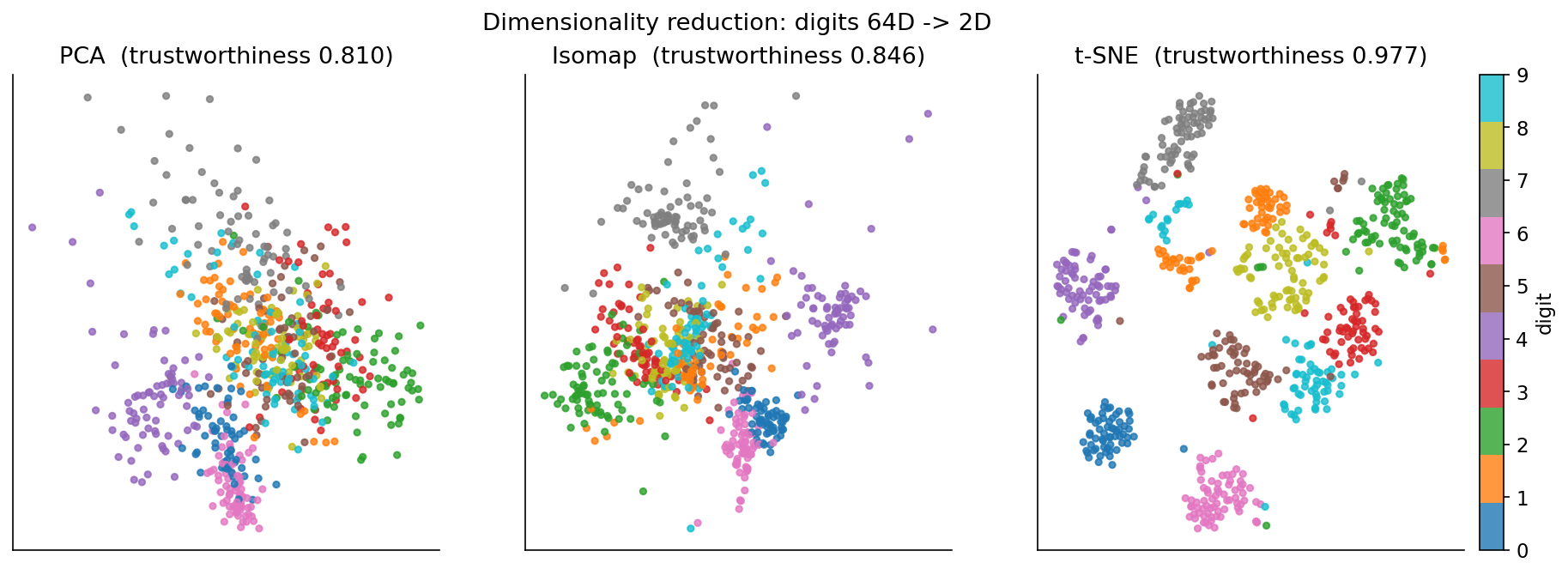
চিত্র: digits 64-D → 2-D তিন panel (PCA, Isomap, t-SNE), digit-অনুযায়ী রঙ।
6.9 — Anomaly detection ও semi-supervised learning¶
ধারণা। Anomaly detection (অস্বাভাবিকতা শনাক্তকরণ): স্বাভাবিক data থেকে দূরবর্তী point চিহ্নিত করা। Mahalanobis distance \(D^2=(x-\mu)^\top\Sigma^{-1}(x-\mu)\) covariance-adjusted দূরত্ব (বড় \(D^2\) = বেশি অস্বাভাবিক); Isolation Forest point-কে random split-এ isolate করতে কত কম split লাগে তা দিয়ে score দেয়। Semi-supervised learning: অল্প labeled + বহু unlabeled থেকে শেখা — label propagation similarity-graph-এ label ছড়ায়।
Scratch + library. breast_cancer-এ benign-centroid থেকে Mahalanobis score (scratch) ও IsolationForest; তারপর LabelPropagation-এ labeled-fraction বনাম accuracy।
Demonstrated result (প্রমাণ)। malignant point অনেক বেশি অস্বাভাবিক দেখায় — mean Mahalanobis score benign \(29.87\) বনাম malignant \(\mathbf{1295.12}\) (~\(43\times\) বেশি)। IsolationForest \(211\) point flag করে; flagged-এর মধ্যে malignant-হার \(0.635\) বনাম overall \(0.373\) — অর্থাৎ anomaly ≈ malignant (দুই score-এর Spearman corr \(0.737\))। semi-supervised: label propagation মাত্র \(2\%\) label (\(7\)টি) দিয়ে acc \(0.6257\), তারপর label বাড়ার সাথে দ্রুত ওঠে — \(10\%\)-এ \(0.9474\), \(50\%\)-এ \(0.9591\); কম-label region-এ unlabeled data-র graph structure সাহায্য করে।
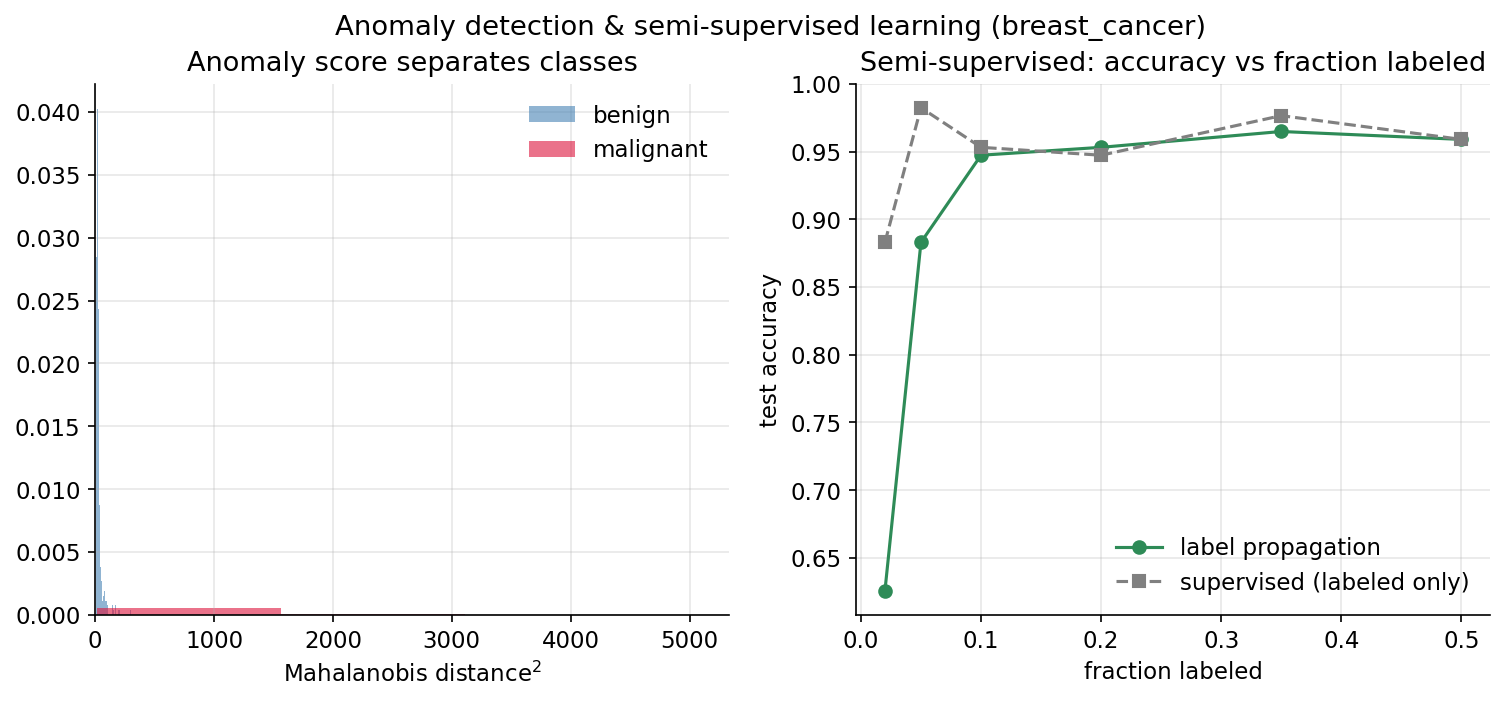
চিত্র: বাঁয়ে benign বনাম malignant-এর Mahalanobis score বণ্টন; ডানে labeled-fraction-এর সাথে label-propagation accuracy।