১.২ · Location & Variability¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
ধরুন আপনার হাতে একটি ক্লাসের ৫০ জন শিক্ষার্থীর পরীক্ষার নম্বর আছে — ৫০টি সংখ্যা। কেউ যদি জিজ্ঞেস করে "ক্লাসটা কেমন করল?", আপনি কি ৫০টি সংখ্যা একে একে বলবেন? না। আপনি বলবেন দুটো জিনিস: গড়ে নম্বর কত (কোথায় data-র কেন্দ্র), আর নম্বরগুলো কতটা ছড়ানো (সবাই কাছাকাছি, নাকি কেউ ৯০ কেউ ৩০)। এই দুটো প্রশ্নই হলো descriptive statistics-এর প্রাণ — location (অবস্থান, অর্থাৎ কেন্দ্র কোথায়) আর variability (পরিবর্তনশীলতা, অর্থাৎ ছড়ানো কতটা)।
Insight (অন্তর্দৃষ্টি): যেকোনো সংখ্যাগত data-কে দুটি প্রশ্ন দিয়ে শুরু করা যায় — "এটা সাধারণত কত?" (location) এবং "এটা কতটা এদিক-ওদিক হয়?" (variability)। প্রায় সব পরিসংখ্যান এই দুটি প্রশ্নের চারপাশেই গড়ে ওঠে।
কেন একটিমাত্র সংখ্যা যথেষ্ট নয়, তা বোঝা জরুরি। দুটি ক্লাসের গড় নম্বর হুবহু ৭০ হতে পারে — কিন্তু একটিতে সবাই ৬৮–৭২-এর মধ্যে, অন্যটিতে কেউ ৪০ কেউ ৯৫। গড় এক, কিন্তু গল্প সম্পূর্ণ আলাদা। তাই location ছাড়া variability অর্থহীন, আর variability ছাড়া location অসম্পূর্ণ — দুটো একসাথে চাই।
আরও একটি সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ ব্যাপার: কোন পরিমাপটি "ভালো" তা নির্ভর করে data-র চরিত্রের উপর। যদি একজন বিল গেটস কোনো ছোট পাড়ার বাড়িতে এসে বসেন, পাড়ার "গড় সম্পদ" আকাশছোঁয়া হয়ে যাবে — অথচ পাড়ার আর কারো অবস্থা বদলায়নি। এখানে গড় (mean) প্রতারণা করছে; বরং median (মধ্যমা) সত্যিকারের "সাধারণ মানুষ"-এর ছবি দেয়। এই robustness-এর ধারণাই এই অধ্যায়ের অন্যতম মূল শিক্ষা।
statistics-এর সাথে যোগসূত্রটিও এখনই স্পষ্ট করে নিই। এই অধ্যায়ে আমরা যা গণনা করব — sample mean \(\bar{x}\), sample variance \(s^2\) — এগুলো হলো হাতে থাকা sample থেকে বের করা সংখ্যা। কিন্তু আমাদের আসল লক্ষ্য প্রায়ই থাকে অজানা population (যেমন সব শিক্ষার্থী, কেবল এই ৫০ জন নয়)। তাই \(\bar{x}\) আসলে population-এর গড় \(\mu\)-এর একটি estimate (আনুমানিক মান), আর \(s^2\) হলো population variance \(\sigma^2\)-এর estimate। আজকের descriptive statistic-গুলোই Part IV-তে গিয়ে estimator হয়ে উঠবে — তখন প্রশ্ন হবে "এই estimate কতটা নির্ভরযোগ্য?"। আপাতত আমরা শুধু সঠিকভাবে গণনা ও ব্যাখ্যা করা শিখব।
২ · মূল ধারণা ও সংজ্ঞা¶
ধরা যাক আমাদের কাছে \(n\)টি সংখ্যাগত observation আছে: \(x_1, x_2, \dots, x_n\)। এদের sorted (ছোট থেকে বড় সাজানো) রূপকে লিখি \(x_{(1)} \le x_{(2)} \le \dots \le x_{(n)}\) — এদের order statistics (ক্রম-পরিসংখ্যান) বলে।
২.১ Location-এর পরিমাপ¶
Mean (গড়): সবচেয়ে পরিচিত। সব মান যোগ করে সংখ্যা দিয়ে ভাগ — $$ \bar{x} \;=\; \frac{1}{n}\sum_{i=1}^{n} x_i . $$ ভৌতভাবে mean হলো data-র ভারসাম্য বিন্দু (balance point): যদি প্রতিটি বিন্দুকে একটি সমান ওজনের পুঁতি ভাবা হয় আর একটি দাঁড়িপাল্লায় বসানো হয়, mean-এর জায়গাতেই পাল্লাটা ভারসাম্য পাবে।
Median (মধ্যমা): sorted data-র ঠিক মাঝখানের মান — যে মানের নিচে ৫০% data, উপরে ৫০%। $$ \text{median} = \begin{cases} x_{((n+1)/2)} & n \text{ বিজোড় হলে},\[4pt] \dfrac{x_{(n/2)} + x_{(n/2 + 1)}}{2} & n \text{ জোড় হলে}. \end{cases} $$ median data-র মাত্র "অবস্থান" দেখে — মান কত বড় তা নয়। তাই একটি বিশাল outlier median-কে নাড়াতে পারে না।
Mode (সংখ্যাগুরু মান): যে মান সবচেয়ে বেশিবার আসে। সংখ্যাগত data-র চেয়ে categorical data-তে (যেমন "সবচেয়ে জনপ্রিয় রং") এটি বেশি কাজে লাগে; একটি data-র একাধিক mode থাকতে পারে (bimodal, multimodal)।
Weighted mean (ভারযুক্ত গড়): সব observation সমান গুরুত্ব না-ও পেতে পারে। প্রতিটি \(x_i\)-এর সাথে একটি weight \(w_i \ge 0\) থাকলে — $$ \bar{x}w \;=\; \frac{\sum. $$ উদাহরণ: course grade যেখানে বেশি credit-এর বিষয় বেশি ওজন পায়; বা survey যেখানে কম-প্রতিনিধিত্বকারী দলকে বেশি weight দেওয়া হয়। সব }^{n} w_i\,x_i}{\sum_{i=1}^{n} w_i\(w_i\) সমান হলে এটি সাধারণ mean-এ ফিরে যায়।
Trimmed mean (ছাঁটা গড়): দুই প্রান্ত থেকে একটি নির্দিষ্ট ভগ্নাংশ \(p\) (যেমন ১০%) বাদ দিয়ে বাকিগুলোর mean। এটি mean-এর সরলতা আর median-এর robustness-এর মাঝামাঝি একটি আপস — অলিম্পিকে বিচারকদের সর্বোচ্চ ও সর্বনিম্ন স্কোর বাদ দেওয়া এর বাস্তব উদাহরণ।
২.২ Variability/Dispersion-এর পরিমাপ¶
Range (পরিসর): সবচেয়ে সরল — সর্বোচ্চ বিয়োগ সর্বনিম্ন: \(\text{range} = x_{(n)} - x_{(1)}\)। মাত্র দুটি বিন্দুর উপর নির্ভর করে বলে outlier-এ অত্যন্ত সংবেদনশীল।
Variance (ভেদাঙ্ক) ও standard deviation: প্রতিটি বিন্দু mean থেকে কতটা দূরে — সেই দূরত্বের গড়। দূরত্বের চিহ্ন বাদ দিতে আমরা বর্গ করি (deviation-গুলো যোগ করলে এমনিতেই \(0\) হয় — দেখুন §৪.১)। Sample variance: $$ s^2 \;=\; \frac{1}{n-1}\sum_{i=1}^{n} (x_i - \bar{x})^2 . $$ এখানে \(n-1\) দেখে অবাক হবেন না — কেন \(n\) নয় তা §৪.৩-এ ব্যাখ্যা করা হয়েছে (সংক্ষেপে: এটি \(\sigma^2\)-এর unbiased estimate দেয়)। Population variance-এ আমরা \(n\) দিয়ে ভাগ করি: $$ \sigma^2 \;=\; \frac{1}{N}\sum_{i=1}^{N} (x_i - \mu)^2 . $$ variance-এর একক মূল data-র এককের বর্গ (যেমন "টাকা\(^2\)") — যা ব্যাখ্যা করা কঠিন। তাই আমরা বর্গমূল নিই, পাই standard deviation (পরিমিত ব্যবধান): $$ s \;=\; \sqrt{s^2}, \qquad \sigma \;=\; \sqrt{\sigma^2}. $$ \(s\)-এর একক মূল data-র মতোই, তাই এটিই দৈনন্দিন ব্যাখ্যায় সবচেয়ে বেশি ব্যবহৃত spread-এর পরিমাপ।
Percentile ও quantile: \(p\)-তম percentile হলো সেই মান যার নিচে data-র \(p\%\) পড়ে। যেমন ৯০তম percentile-এর নিচে ৯০% data। Quantile একই ধারণা, কিন্তু ভগ্নাংশে প্রকাশ করা (\(0.90\) quantile = ৯০তম percentile)। বিশেষ নাম: median = \(0.5\) quantile; quartile (চতুর্থক) হলো \(Q_1\) (২৫তম), \(Q_2\) (median), \(Q_3\) (৭৫তম)।
IQR (interquartile range, আন্তঃচতুর্থক পরিসর): মাঝের ৫০% data কতটা ছড়ানো — $$ \text{IQR} = Q_3 - Q_1 . $$ এটি দুই প্রান্তের আত্যন্তিক মান পুরোপুরি উপেক্ষা করে, তাই range-এর তুলনায় অনেক বেশি robust।
MAD (median absolute deviation, মধ্যমা-পরম-বিচ্যুতি): median থেকে প্রতিটি বিন্দুর পরম দূরত্বের median — $$ \text{MAD} \;=\; \operatorname{median}\big(\lvert x_i - \operatorname{median}(x)\rvert\big). $$ এটি standard deviation-এর একটি অত্যন্ত robust বিকল্প। normal distribution-এর সাথে তুলনীয় করতে প্রায়ই \(1.4826 \times \text{MAD}\) ব্যবহার করা হয় (এই scale-factor MAD-কে \(\sigma\)-র estimate বানায়)।
সতর্কতা — দুটো MAD: কিছু বই "MAD" বলতে mean absolute deviation (\(\frac{1}{n}\sum \lvert x_i - \bar{x}\rvert\)) বোঝায়, যা mean-ভিত্তিক ও কম robust। আমরা এই অধ্যায়ে MAD = median absolute deviation ধরছি (Practical Statistics-এর কনভেনশন)। নাম দেখে নয়, সংজ্ঞা দেখে কাজ করুন।
২.৩ Robustness, outlier ও standardization¶
Robust statistic হলো সেই পরিমাপ যা কিছু আত্যন্তিক বা ভুল মান (outlier) থাকলেও বেশি বদলায় না। median, IQR, MAD, trimmed mean — robust; mean, range, standard deviation — non-robust। একটি দরকারি ধারণা breakdown point: একটি statistic-কে অর্থহীন (অসীম) করে দিতে সর্বনিম্ন কত ভগ্নাংশ data নষ্ট করতে হয়। mean-এর breakdown point \(0\) (একটিমাত্র বিন্দু অসীম করলেই mean অসীম); median-এর \(50\%\) — তাই median অসাধারণভাবে শক্তপোক্ত।
Standardization (z-score, প্রমিতকরণ): প্রতিটি মানকে "mean থেকে কত standard deviation দূরে" সেই এককে রূপান্তর — $$ z_i \;=\; \frac{x_i - \bar{x}}{s}. $$ z-score একক-নিরপেক্ষ (টাকা বা সেন্টিমিটার যা-ই হোক): \(z=2\) মানে মানটি mean থেকে ২ standard deviation উপরে। গঠনগতভাবে z-score-এর mean সর্বদা \(0\) ও standard deviation সর্বদা \(1\) হয় (§৪.৪)। ভিন্ন এককের দুটি variable তুলনা করতে — যেমন উচ্চতা (cm) আর ওজন (kg) — z-score অপরিহার্য, এবং পরে অনেক machine learning algorithm-এর pre-processing-এর মূল ধাপ।
৩ · পূর্ণাঙ্গ উদাহরণ¶
একটি ছোট, হাতে-গোনা data দিয়ে সব ধারণা একসাথে দেখি। ১০ জন শিক্ষার্থীর পরীক্ষার নম্বর (sorted): $$ x = (62,\; 70,\; 71,\; 73,\; 75,\; 75,\; 78,\; 82,\; 88,\; 96). $$
Mean. যোগফল \(\sum x_i = 770\), তাই $$ \bar{x} = \frac{770}{10} = 77.0 . $$
Median. \(n=10\) জোড়, মাঝের দুটি মান \(x_{(5)}=75,\ x_{(6)}=75\), তাই $$ \text{median} = \frac{75 + 75}{2} = 75.0 . $$ লক্ষ করুন \(\bar{x} = 77 > \text{median} = 75\) — সামান্য ডানে-হেলানো (right-skewed), কারণ উপরের দিকে \(88, 96\) গড়কে একটু টেনে তুলেছে।
Mode. \(75\) একবারের বেশি (দুইবার) এসেছে; বাকি সব একবার। তাই mode \(= 75\)।
Range. \(96 - 62 = 34\)।
Variance ও standard deviation. প্রথমে বর্গ-বিচ্যুতির যোগফল। প্রতিটি \((x_i - 77)\): \(-15, -7, -6, -4, -2, -2, 1, 5, 11, 19\)। এদের বর্গের যোগফল $$ \sum (x_i - \bar{x})^2 = 225 + 49 + 36 + 16 + 4 + 4 + 1 + 25 + 121 + 361 = 842 . $$ তাহলে $$ s^2 = \frac{842}{n-1} = \frac{842}{9} \approx 93.56, \qquad s = \sqrt{93.56} \approx 9.67 . $$ (population সূত্রে \(\sigma^2 = 842/10 = 84.2,\ \sigma \approx 9.18\) — পার্থক্যটি \(n\) বনাম \(n-1\) থেকে আসে।)
Quartile ও IQR. linear-interpolation পদ্ধতিতে (NumPy-র default) \(Q_1 = 71.5,\ Q_3 = 81.0\), তাই $$ \text{IQR} = 81.0 - 71.5 = 9.5 . $$
MAD. median \(=75\) থেকে পরম দূরত্ব: \(\lvert x_i - 75\rvert = 13, 5, 4, 2, 0, 0, 3, 7, 13, 21\)। এদের median (sorted: \(0,0,2,3,4,5,7,13,13,21\) → মাঝের দুটি \(4,5\)) \(= 4.5\)। scaled: \(1.4826 \times 4.5 \approx 6.67\)।
Weighted mean (ভিন্ন প্রসঙ্গ). ধরুন তিনটি course-এ নম্বর \(80, 90, 70\) এবং credit-hour (weight) যথাক্রমে \(3, 4, 1\): $$ \bar{x}_w = \frac{3(80) + 4(90) + 1(70)}{3+4+1} = \frac{240 + 360 + 70}{8} = \frac{670}{8} = 83.75 . $$ বেশি credit-এর course (৯০, weight ৪) ফলাফলকে নিজের দিকে বেশি টেনেছে।
z-score। সবচেয়ে বড় মান \(96\)-এর z-score (sample \(s\approx 9.67\) ধরে): $$ z_{96} = \frac{96 - 77}{9.67} \approx 1.96 , $$ অর্থাৎ \(96\) নম্বরটি গড় থেকে প্রায় ২ standard deviation উপরে — তুলনামূলকভাবে খুব ভালো ফল।
Outlier-এর প্রভাব (mean বনাম median)। এবার একটি ভিন্ন data নিই যেখানে একটি চরম মান আছে: $$ y = (41, 43, 44, 45, 46, 47, 48, 50, 52, 400). $$ এখানে \(\bar{y} = 81.6\) কিন্তু \(\text{median} = 46.5\)। বাস্তবে ৯ জনের মান ৪০–৫২-এর মধ্যে, একজন ৪০০ — তবু mean বলছে "গড় ৮২", যা বিভ্রান্তিকর। median (৪৬.৫) সত্যিকারের "সাধারণ" মান অনেক ভালো ধরছে। ১০% trimmed mean (দুই প্রান্তের একটি করে বাদ) দেয় \(\approx 46.88\) — median-এর কাছাকাছি, কারণ চরম \(400\) ছাঁটা পড়েছে। এটাই robustness-এর মূল পাঠ।
৪ · প্রমাণ ও উৎপাদন¶
৪.১ ★ Mean থেকে নেওয়া deviation-এর যোগফল সর্বদা শূন্য¶
দাবি: \(\displaystyle\sum_{i=1}^{n}(x_i - \bar{x}) = 0\)।
প্রমাণ. যোগফলকে ভেঙে লিখি এবং \(\sum \bar{x} = n\bar{x}\) ব্যবহার করি: $$ \sum_{i=1}^{n}(x_i - \bar{x}) = \sum_{i=1}^{n} x_i - \sum_{i=1}^{n}\bar{x} = \sum_{i=1}^{n} x_i - n\bar{x} = n\bar{x} - n\bar{x} = 0, $$ কারণ সংজ্ঞা অনুযায়ী \(\sum x_i = n\bar{x}\)। \(\blacksquare\)
এই কারণেই variance-এ আমরা deviation-গুলো সরাসরি যোগ করি না (যোগফল সবসময় \(0\), কোনো তথ্য দেয় না) — বরং বর্গ করে যোগ করি, যাতে চিহ্ন বাদ গিয়ে প্রকৃত ছড়ানো ধরা পড়ে।
৪.২ ★ Mean হলো সেই বিন্দু যা বর্গ-দূরত্বের যোগফল সর্বনিম্ন করে¶
দাবি: ফাংশন \(g(c) = \sum_{i=1}^{n}(x_i - c)^2\) সর্বনিম্ন হয় ঠিক \(c = \bar{x}\)-তে।
উৎপাদন (calculus, 0.3-এর derivative). \(c\)-এর সাপেক্ষে অন্তরীকরণ করি: $$ g'(c) = \sum_{i=1}^{n} 2(x_i - c)(-1) = -2\sum_{i=1}^{n}(x_i - c) = -2\Big(\sum x_i - nc\Big). $$ \(g'(c) = 0\) বসালে \(\sum x_i - nc = 0 \Rightarrow c = \frac{1}{n}\sum x_i = \bar{x}\)। দ্বিতীয় derivative \(g''(c) = 2n > 0\) — তাই এটি সত্যিই minimum। \(\blacksquare\)
এটি গভীর: mean হলো "least squares" অর্থে সবচেয়ে কাছের কেন্দ্রবিন্দু, এবং ঠিক এই নীতিই পরে linear regression-এর ভিত্তি (Part V)। তুলনায়, median হলো সেই বিন্দু যা পরম দূরত্বের যোগফল \(\sum\lvert x_i - c\rvert\) সর্বনিম্ন করে — এজন্যই বর্গ না-করা, robust পরিমাপগুলো median-কেন্দ্রিক।
৪.৩ ★★ কেন sample variance-এ \(n-1\) (Bessel's correction)¶
দাবি: \(s^2 = \frac{1}{n-1}\sum(x_i - \bar{x})^2\) population variance \(\sigma^2\)-এর একটি unbiased estimator, অর্থাৎ \(\mathbb{E}[s^2] = \sigma^2\); কিন্তু \(n\) দিয়ে ভাগ করলে গড়ে \(\sigma^2\)-এর চেয়ে ছোট মান পাওয়া যায়।
স্বজ্ঞামূলক উৎপাদন। যদি আমরা প্রকৃত \(\mu\) জানতাম, তবে \(\frac{1}{n}\sum(x_i-\mu)^2\) হতো \(\sigma^2\)-এর সঠিক estimate। কিন্তু আমরা \(\mu\) জানি না — তার বদলে একই data থেকে বের করা \(\bar{x}\) ব্যবহার করি। §৪.২ অনুযায়ী \(\bar{x}\) হলো সেই বিন্দু যা \(\sum(x_i - c)^2\)-কে সর্বনিম্ন করে। তাই $$ \sum(x_i - \bar{x})^2 \;\le\; \sum(x_i - \mu)^2 $$ — অর্থাৎ \(\bar{x}\) ব্যবহার করলে বর্গ-যোগফল সবসময় একটু কম আসে। ফলে \(\frac{1}{n}\sum(x_i-\bar{x})^2\) গড়ে \(\sigma^2\)-কে কম মূল্যায়ন (underestimate) করে। হিসাব করে দেখা যায় ঠিক যতটা কম, তা পূরণ হয় যদি \(n\)-এর বদলে \(n-1\) দিয়ে ভাগ করি। সূক্ষ্মভাবে: \(\bar{x}\) আনুমান করতে data থেকে একটি "degree of freedom" (স্বাধীনতার মাত্রা) খরচ হয়েছে, তাই \(n-1\)টি স্বাধীন তথ্য বাকি। আনুষ্ঠানিক expectation-ভিত্তিক প্রমাণ Part IV-তে দেওয়া হবে। \(\blacksquare\)
মনে রাখুন: \(n\) বড় হলে \(n\) আর \(n-1\)-এর পার্থক্য নগণ্য; ছোট sample-এ এটি গুরুত্বপূর্ণ। তাই NumPy-র default
ddof=0(\(n\) দিয়ে ভাগ) আর pandas-এর defaultddof=1(\(n-1\)) — এই পার্থক্য জেনে রাখা জরুরি (§৫-এ দেখানো)।
৪.৪ ★ z-score-এর mean সর্বদা \(0\), standard deviation সর্বদা \(1\)¶
দাবি: \(z_i = (x_i - \bar{x})/s\) হলে \(\bar{z} = 0\) এবং \(\text{std}(z) = 1\) (একই ddof ব্যবহার করে)।
প্রমাণ. mean: $$ \bar{z} = \frac{1}{n}\sum_{i} \frac{x_i - \bar{x}}{s} = \frac{1}{s}\cdot\frac{1}{n}\sum_i (x_i - \bar{x}) = \frac{1}{s}\cdot 0 = 0 $$ (§৪.১ অনুসারে ভেতরের যোগফল \(0\))। এখন variance (\(\bar{z}=0\) ব্যবহার করে): $$ \frac{1}{n}\sum_i (z_i - \bar{z})^2 = \frac{1}{n}\sum_i z_i^2 = \frac{1}{n}\sum_i \frac{(x_i - \bar{x})^2}{s^2} = \frac{1}{s^2}\cdot\underbrace{\frac{1}{n}\sum_i (x_i - \bar{x})^2}_{=\,s^2} = 1 . $$ তাই standard deviation \(= 1\)। \(\blacksquare\) — এ কারণেই z-score একক মুছে দেয় ও ভিন্ন variable তুলনাযোগ্য করে।
৫ · কোড ল্যাব (Python)¶
প্রথমে from scratch (শুধু NumPy array operation দিয়ে) প্রতিটি statistic বানাব, তারপর numpy/pandas-এর তৈরি function দিয়ে মিলিয়ে যাচাই করব।
import numpy as np
# --- §3-এর হাতে-গোনা data ---
x = np.array([62, 70, 71, 73, 75, 75, 78, 82, 88, 96], dtype=float)
n = x.size
# ---------- location: from scratch ----------
mean_scratch = x.sum() / n # গড় = Σx / n
xs = np.sort(x) # median-এর জন্য sort
if n % 2 == 1:
median_scratch = xs[n // 2]
else:
median_scratch = (xs[n // 2 - 1] + xs[n // 2]) / 2
vals, counts = np.unique(x, return_counts=True) # mode = সর্বোচ্চ count-এর মান
mode_scratch = vals[np.argmax(counts)]
print("mean scratch =", mean_scratch, " numpy =", x.mean()) # 77.0 77.0
print("median scratch =", median_scratch, " numpy =", np.median(x)) # 75.0 75.0
print("mode scratch =", mode_scratch) # 75.0
# ---------- weighted & trimmed mean ----------
vals = np.array([80, 90, 70], dtype=float)
w = np.array([3, 4, 1], dtype=float) # credit hours হিসেবে weight
wmean_scratch = (w * vals).sum() / w.sum() # Σ w·x / Σ w
print("weighted mean =", wmean_scratch) # 83.75
from scipy import stats
y = np.array([41, 43, 44, 45, 46, 47, 48, 50, 52, 400], dtype=float)
print("y mean =", y.mean()) # 81.6 (outlier-এ টানা)
print("y median =", np.median(y)) # 46.5 (robust)
print("y trim 10% =", stats.trim_mean(y, 0.10)) # 46.875
# ---------- variability: from scratch vs numpy ----------
dev = x - x.mean()
ss = (dev ** 2).sum() # Σ(x - x̄)²
var_pop_scratch = ss / n # population (÷ n)
var_samp_scratch = ss / (n - 1) # sample (÷ n-1)
print("sum sq dev =", ss) # 842.0
print("var pop scratch=", var_pop_scratch, " numpy ddof0 =", x.var())
print("var samp scratch=", var_samp_scratch, " numpy ddof1 =", x.var(ddof=1))
print("std samp scratch=", var_samp_scratch ** 0.5,
" numpy ddof1 =", x.std(ddof=1)) # ≈ 9.672
print("range =", x.max() - x.min()) # 34.0
# ---------- percentile / quartile / IQR ----------
q1, q2, q3 = np.percentile(x, [25, 50, 75]) # linear interpolation (default)
iqr = q3 - q1
print(f"Q1={q1} Q2(median)={q2} Q3={q3} IQR={iqr}") # 71.5 75.0 81.0 9.5
print("90th percentile =", np.percentile(x, 90)) # 88.8
# ---------- MAD (median absolute deviation) from scratch ----------
med = np.median(x)
mad_scratch = np.median(np.abs(x - med))
print("MAD =", mad_scratch) # 4.5
print("MAD scaled =", 1.4826 * mad_scratch) # ≈ 6.672 (~σ estimate)
# ---------- z-score (standardization) ----------
z = (x - x.mean()) / x.std(ddof=1)
print("z of 96 =", round(float(z[np.argmax(x)]), 4)) # 1.9643
print("z mean (≈0) =", round(float(z.mean()), 12)) # 0.0
print("z std (=1) =", round(float(z.std(ddof=1)), 6)) # 1.0
এবার pandas দিয়ে এক লাইনে পুরো summary — বাস্তবে EDA-তে এটাই প্রথম পদক্ষেপ:
import pandas as pd
s = pd.Series(x, name="score")
print(s.describe()) # count, mean, std(ddof=1), min, 25%, 50%, 75%, max
print("\nmedian :", s.median())
print("mode :", s.mode().tolist())
print("var :", s.var()) # pandas default ddof=1 (numpy default ddof=0 — সাবধান!)
print("MAD-ish:", (s - s.median()).abs().median()) # median absolute deviation
Output (সংক্ষেপে): scratch ও library সব জায়গায় হুবহু মেলে — mean \(=77\), median \(=75\), mode \(=75\), \(\sum\!\text{dev}^2 = 842\), sample variance \(\approx 93.56\), sample std \(\approx 9.67\), range \(=34\), \(Q_1{=}71.5,\ Q_3{=}81,\ \text{IQR}{=}9.5\), MAD \(=4.5\); weighted mean \(=83.75\); outlier-data-য় mean \(=81.6\) অথচ median \(=46.5\) ও trimmed mean \(\approx 46.88\); z-score-এর mean \(=0\), std \(=1\) — §৩ ও §৪-এর সব ফল সংখ্যায় যাচাই হলো। একটি ব্যবহারিক সতর্কতা: numpy.var/std-এর default ddof=0 কিন্তু pandas.var/std-এর default ddof=1 — তাই একই data-তে দুটো ভিন্ন উত্তর দেখলে আগে ddof মিলিয়ে নিন।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবিই একটি script-এ, এক রানে তৈরি (seed fixed, synthetic data)। প্রতিটি ছবির নিচে যে কোড দেখানো হলো তা-ই চলেছে।
Figure 1 — skewed distribution-এ mean বনাম median¶
lognormal থেকে তৈরি আয়ের data (ডানদিকে লম্বা লেজ)। লাল রেখা mean, সবুজ ভাঙা রেখা median। লক্ষ করুন লম্বা ডান-লেজ mean-কে ডানে টেনে নিয়েছে, তাই \(\text{mean} > \text{median}\) — right-skewed data-র সর্বজনীন বৈশিষ্ট্য।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(42)
income = rng.lognormal(mean=10.5, sigma=0.6, size=5000) / 1000.0 # হাজার টাকায়
mean_v, median_v = income.mean(), np.median(income)
fig, ax = plt.subplots(figsize=(8.5, 5))
ax.hist(income, bins=60, range=(0, 200), color="#1f77b4", alpha=0.55,
edgecolor="white", linewidth=0.4)
ax.axvline(mean_v, color="#d62728", lw=2.4, label=f"mean = {mean_v:.1f}")
ax.axvline(median_v, color="#2ca02c", lw=2.4, ls="--", label=f"median = {median_v:.1f}")
ax.set_xlim(0, 200); ax.set_xlabel("Monthly income (thousand BDT)")
ax.set_ylabel("Frequency (count)")
ax.set_title("Right-skewed distribution: mean > median")
ax.legend(fontsize=11); ax.grid(True, alpha=0.25)
plt.tight_layout(); plt.savefig("../_assets/1-2-mean-vs-median.png", dpi=150)
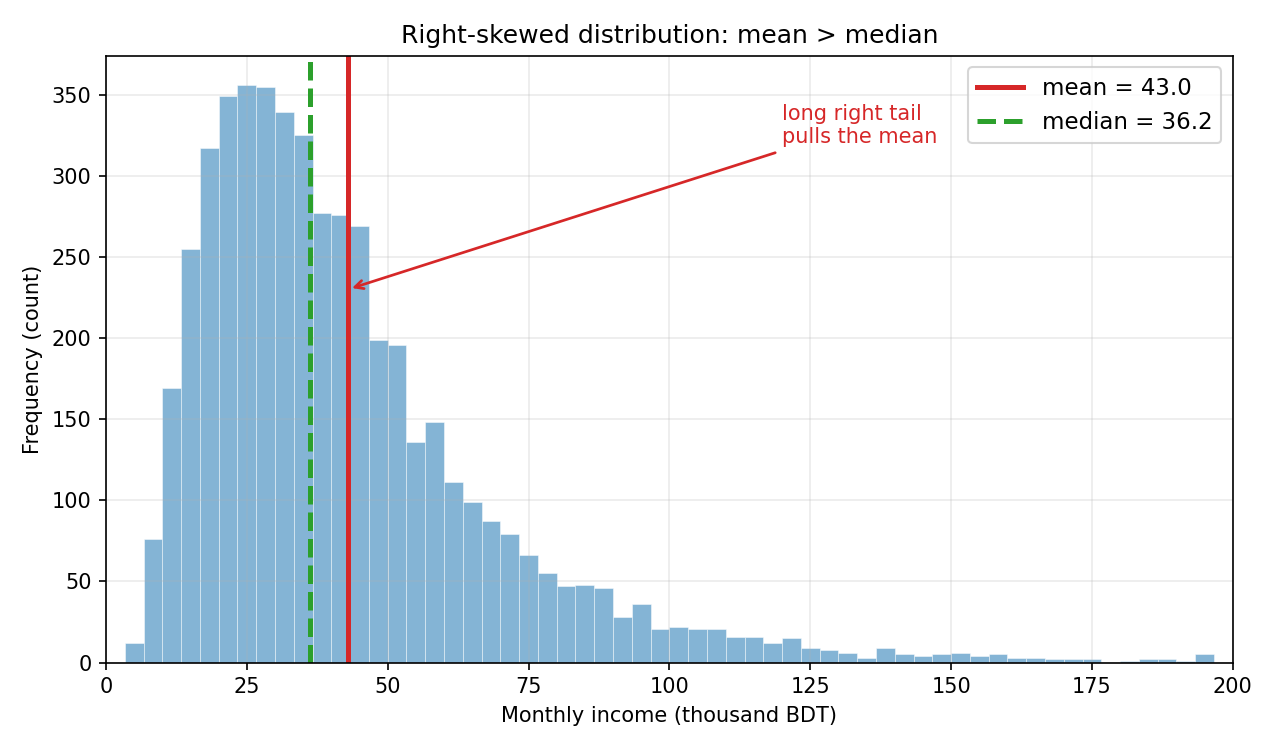
Figure 2 — outlier কীভাবে mean-কে টানে, median স্থির থাকে¶
বাঁয়ে: ১০টি বিন্দুর সাথে একটিমাত্র outlier (\(400\)); mean (লাল) দূরে সরে গেছে, median (সবুজ) ভিড়ের মধ্যেই। ডানে: outlier-এর মান বাড়ানোর সাথে সাথে mean অবিরত উপরে উঠছে, কিন্তু median অপরিবর্তিত — এই হলো robustness-এর দৃশ্যরূপ।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
base = np.array([41,43,44,45,46,47,48,50,52,54], dtype=float)
outliers = [54, 80, 120, 200, 400]
means = [np.append(base, o).mean() for o in outliers]
medians = [np.median(np.append(base, o)) for o in outliers]
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
ax = axes[0]; full = np.append(base, 400)
ax.scatter(base, np.zeros_like(base), s=60, color="#1f77b4", alpha=0.7, zorder=3,
label="bulk of data (10 points)")
ax.scatter([400], [0], s=110, color="black", marker="X", zorder=4, label="one outlier = 400")
ax.axvline(full.mean(), color="#d62728", lw=2.2, label=f"mean = {full.mean():.1f}")
ax.axvline(np.median(full),color="#2ca02c", lw=2.2, ls="--", label=f"median = {np.median(full):.1f}")
ax.set_yticks([]); ax.set_xlim(30, 420); ax.set_xlabel("Value")
ax.set_title("One extreme point drags the mean far away")
ax.legend(fontsize=9, loc="upper center"); ax.grid(True, axis="x", alpha=0.25)
ax = axes[1]
ax.plot(outliers, means, "o-", color="#d62728", lw=2, ms=7, label="mean")
ax.plot(outliers, medians, "s--", color="#2ca02c", lw=2, ms=7, label="median")
ax.set_xlabel("Magnitude of the single outlier"); ax.set_ylabel("Statistic value")
ax.set_title("Mean is sensitive; median is robust")
ax.legend(fontsize=11); ax.grid(True, alpha=0.25)
plt.tight_layout(); plt.savefig("../_assets/1-2-outlier-pull.png", dpi=150)
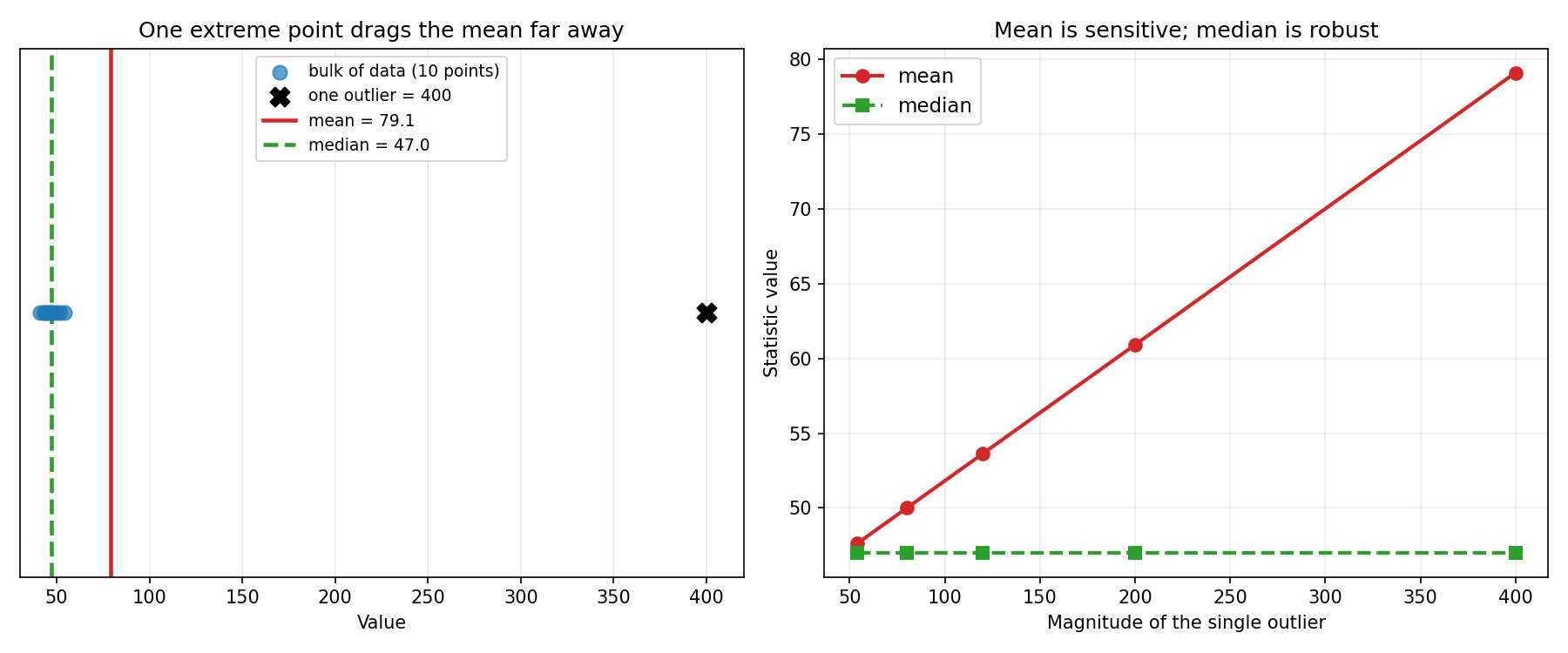
Figure 3 — boxplot দিয়ে quartile ও IQR¶
boxplot-এর শরীর-বৃত্তান্ত: বাক্সের দুই প্রান্ত \(Q_1\) ও \(Q_3\), ভেতরের লাল রেখা median, বাক্সের প্রস্থ IQR; "whisker" \(1.5\times\text{IQR}\) পর্যন্ত যায়, তার বাইরের বিন্দুগুলো outlier (কালো বিন্দু) হিসেবে চিহ্নিত — এটাই বহুল-ব্যবহৃত \(1.5\times\)IQR rule।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(7)
data = np.append(rng.normal(50, 10, size=200), [95, 98, 12, 8]) # planted outliers
q1, q2, q3 = np.percentile(data, [25, 50, 75]); iqr = q3 - q1
fig, ax = plt.subplots(figsize=(9, 5.5))
ax.boxplot(data, vert=False, widths=0.5, patch_artist=True,
boxprops=dict(facecolor="#cfe3f7", edgecolor="#1f77b4", lw=1.6),
medianprops=dict(color="#d62728", lw=2.4),
flierprops=dict(marker="o", markerfacecolor="black",
markeredgecolor="black", markersize=5, alpha=0.7))
ax.annotate(f"Q1 = {q1:.1f}", xy=(q1, 1.27), xytext=(q1-6, 1.42), ha="center",
color="#1f77b4", fontsize=9, arrowprops=dict(arrowstyle="->", color="#1f77b4"))
ax.annotate(f"median (Q2) = {q2:.1f}", xy=(q2, 1.27), xytext=(q2, 1.46), ha="center",
color="#d62728", fontsize=9, arrowprops=dict(arrowstyle="->", color="#d62728"))
ax.annotate(f"Q3 = {q3:.1f}", xy=(q3, 1.27), xytext=(q3+6, 1.42), ha="center",
color="#1f77b4", fontsize=9, arrowprops=dict(arrowstyle="->", color="#1f77b4"))
ax.annotate("", xy=(q1, 0.67), xytext=(q3, 0.67),
arrowprops=dict(arrowstyle="<->", color="#2ca02c", lw=2))
ax.text((q1+q3)/2, 0.56, f"IQR = Q3 - Q1 = {iqr:.1f}", ha="center",
color="#2ca02c", fontsize=10, fontweight="bold")
ax.set_yticks([]); ax.set_xlabel("Value"); ax.set_ylim(0.3, 1.7)
ax.set_title("Anatomy of a boxplot: quartiles, IQR and 1.5xIQR outlier rule")
ax.grid(True, axis="x", alpha=0.25)
plt.tight_layout(); plt.savefig("../_assets/1-2-boxplot-iqr.png", dpi=150)
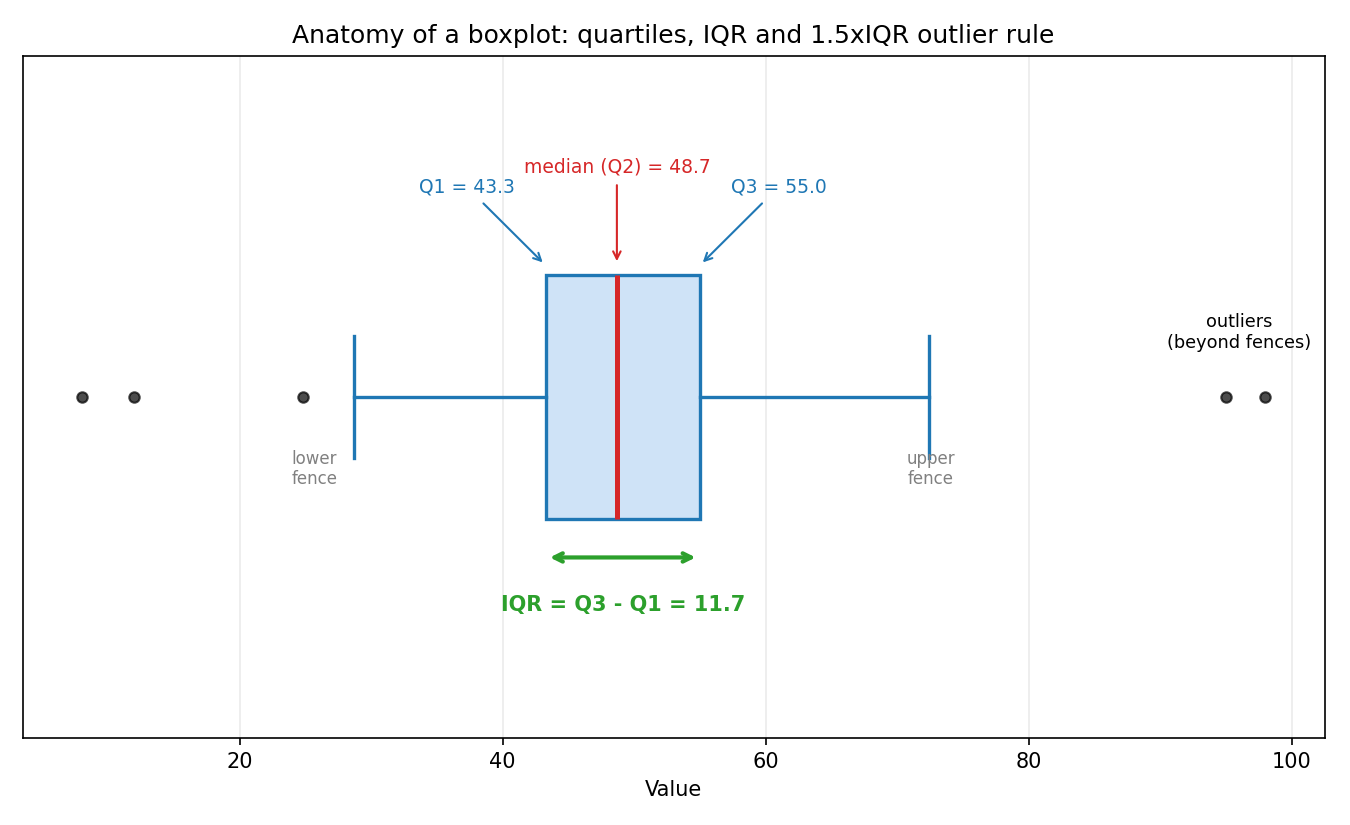
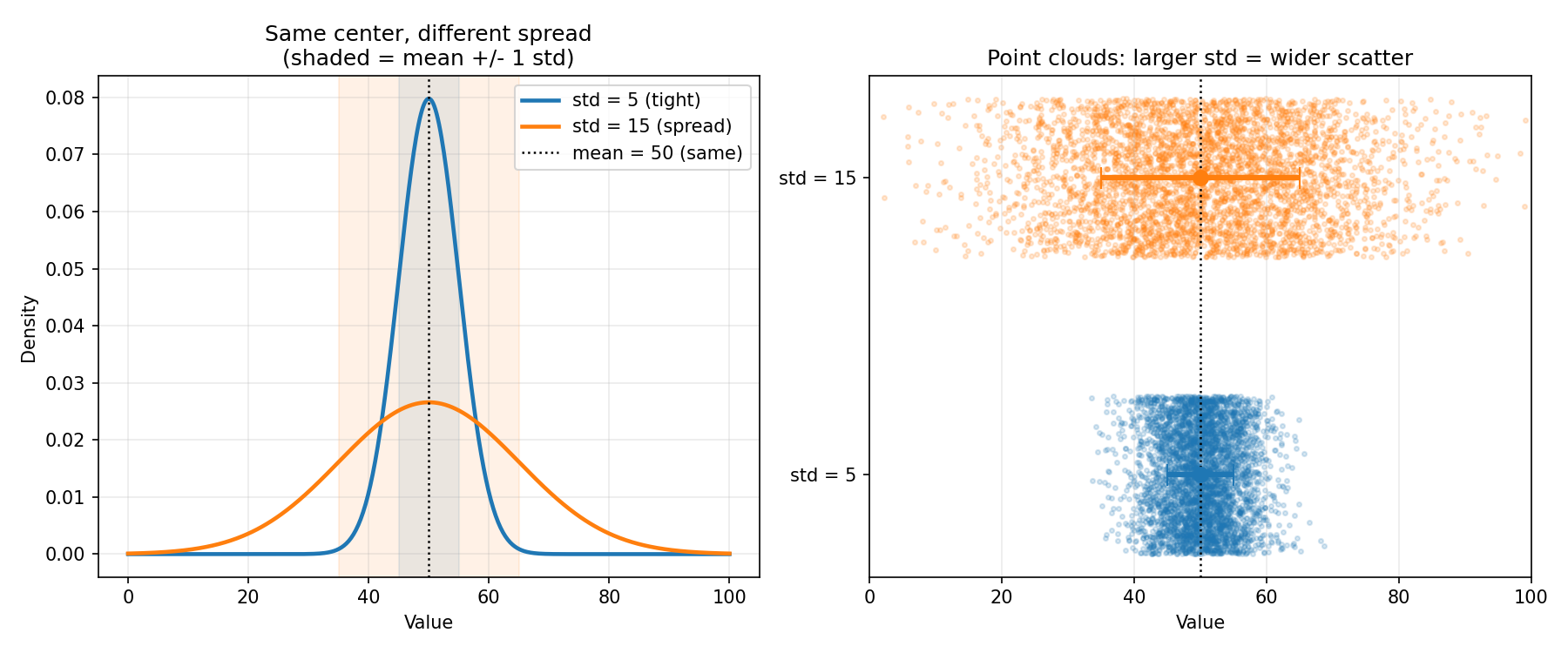
Figure 4 — std/variance: একই কেন্দ্র, ভিন্ন spread¶
দুটি distribution-এর mean হুবহু এক (\(50\)), কিন্তু একটির std \(=5\) (সরু), অন্যটির std \(=15\) (চওড়া)। বাঁয়ে density (ছায়া দেওয়া অঞ্চল = mean \(\pm 1\) std), ডানে point-cloud — বড় standard deviation মানে বেশি ছড়ানো। এই ছবিই দেখায় কেন একা mean যথেষ্ট নয়।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(11); mu = 50
small = rng.normal(mu, 5, size=4000); large = rng.normal(mu, 15, size=4000)
xs = np.linspace(0, 100, 500)
gauss = lambda x, m, s: np.exp(-0.5*((x-m)/s)**2) / (s*np.sqrt(2*np.pi))
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
ax = axes[0]
ax.plot(xs, gauss(xs, mu, 5), color="#1f77b4", lw=2.2, label="std = 5 (tight)")
ax.plot(xs, gauss(xs, mu, 15), color="#ff7f0e", lw=2.2, label="std = 15 (spread)")
for s, c in [(5, "#1f77b4"), (15, "#ff7f0e")]:
ax.axvspan(mu-s, mu+s, color=c, alpha=0.10)
ax.axvline(mu, color="black", lw=1.2, ls=":", label="mean = 50 (same)")
ax.set_xlabel("Value"); ax.set_ylabel("Density")
ax.set_title("Same center, different spread\n(shaded = mean +/- 1 std)")
ax.legend(fontsize=10); ax.grid(True, alpha=0.25)
ax = axes[1]
ax.scatter(small, rng.uniform(0.6, 1.4, small.size), s=6, alpha=0.18, color="#1f77b4")
ax.scatter(large, rng.uniform(2.1, 2.9, large.size), s=6, alpha=0.18, color="#ff7f0e")
for yc, s, c in [(1.0, 5, "#1f77b4"), (2.5, 15, "#ff7f0e")]:
ax.errorbar(mu, yc, xerr=s, fmt="o", color=c, ecolor=c, elinewidth=3, capsize=6, ms=8, zorder=5)
ax.set_yticks([1.0, 2.5]); ax.set_yticklabels(["std = 5", "std = 15"])
ax.set_xlim(0, 100); ax.set_xlabel("Value")
ax.set_title("Point clouds: larger std = wider scatter")
ax.grid(True, axis="x", alpha=0.25)
plt.tight_layout(); plt.savefig("../_assets/1-2-spread.png", dpi=150)
৭ · অনুশীলনী¶
সমাধান
_solutions/01-02-location-variability-solutions.md-এ। আগে নিজে চেষ্টা করুন; কোড-প্রশ্নে seed দিলে আপনার সংখ্যা সমাধানের সাথে মিলবে।
Conceptual¶
১. [easy] একটি কোম্পানির ১০ জন কর্মীর বেতন (হাজার টাকায়): \(30, 32, 33, 35, 36, 38, 40, 42, 45, 800\) (শেষ জন CEO)। কোন পরিমাপ — mean না median — "সাধারণ কর্মীর বেতন" ভালো বোঝাবে এবং কেন? দুটোর আনুমানিক মান যুক্তিসহ বলুন (গণনা ছাড়াই বড়/ছোট কোনটা হবে)।
২. [easy] নিচের প্রতিটি statistic robust না non-robust, এক বাক্যে কারণসহ লিখুন: (ক) range, (খ) median, (গ) standard deviation, (ঘ) IQR, (ঙ) mean।
৩. [medium] variance-এর সংজ্ঞায় deviation-গুলো বর্গ না করে যদি সরাসরি যোগ করতাম, কী পেতাম এবং সেটা spread-এর পরিমাপ হিসেবে কেন অকেজো? (§৪.১-এর ফল ব্যবহার করুন।) বর্গ করার বদলে পরম মান নিলে কোন statistic পাওয়া যায়?
৪. [medium] কেন sample variance-এ \(n-1\) দিয়ে ভাগ করা হয়, এক অনুচ্ছেদে নিজের ভাষায় ব্যাখ্যা করুন। \(n=5\) আর \(n=5000\) — কোন ক্ষেত্রে \(n\) বনাম \(n-1\)-এর পার্থক্য বেশি গুরুত্বপূর্ণ?
৫. [hard] breakdown point-এর সংজ্ঞা মনে রেখে যুক্তি দিন কেন median-এর breakdown point \(50\%\) কিন্তু mean-এর \(0\%\)। এটি কীভাবে §৩-এর outlier-উদাহরণের সাথে মেলে?
Computational¶
৬. [easy] হাতে (ক্যালকুলেটর চলবে, কোড নয়) data \(\{4, 8, 8, 10, 15\}\)-এর জন্য বের করুন: mean, median, mode, range, sample variance (\(n-1\)), sample standard deviation।
৭. [medium] নিচের কোড ব্যবহার করে (seed fixed) from scratch ও library দিয়ে mean, median, sample std, IQR, MAD বের করে মিলিয়ে দেখুন:
৮. [medium] weighted mean: চারটি বিষয়ে নম্বর \(\{75, 88, 92, 60\}\), credit-hour \(\{3, 4, 3, 2\}\)। weighted mean ও সাধারণ (unweighted) mean — দুটোই বের করুন এবং পার্থক্যের কারণ ব্যাখ্যা করুন।
৯. [hard] outlier-এর প্রভাব পরিমাপ করুন। প্রশ্ন ৭-এর data-তে একটি মান \(\,500\) যোগ করুন। যোগ করার আগে ও পরে mean, median, std, IQR, MAD — পাঁচটির প্রতিটি কত শতাংশ বদলাল হিসাব করে একটি ছোট টেবিল বানান। কোন statistic সবচেয়ে কম বদলাল, কোনটি সবচেয়ে বেশি?
১০. [hard] z-score ও তুলনা। দুজন শিক্ষার্থী — Rita গণিতে \(82\) (ক্লাসের mean \(70\), std \(8\)), Karim পদার্থে \(75\) (ক্লাসের mean \(60\), std \(10\))। নিজ-নিজ ক্লাসের তুলনায় কে ভালো করল? z-score বের করে যুক্তি দিন। তারপর কোডে যাচাই করুন যে কোনো data-র z-score-এর mean \(\approx 0\) ও std \(\approx 1\)।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল কথাগুলো একনজরে:
- যেকোনো সংখ্যাগত data-কে দুটি প্রশ্ন দিয়ে ধরা যায় — location (কেন্দ্র কোথায়) ও variability (কতটা ছড়ানো)। একটি ছাড়া অন্যটি অসম্পূর্ণ।
- Location: mean (ভারসাম্য বিন্দু, least-squares কেন্দ্র), median (মাঝের মান, robust), mode (সর্বাধিক-পুনরাবৃত্ত), weighted mean (ভিন্ন গুরুত্ব), trimmed mean (প্রান্ত ছাঁটা আপস)।
- Variability: range (অতি-সংবেদনশীল), variance ও standard deviation (mean থেকে বর্গ-দূরত্বভিত্তিক, একক যথাক্রমে বর্গ ও মূল), IQR (মাঝের ৫০%, robust), MAD (median-ভিত্তিক, খুব robust)।
- Percentile/quantile data-কে অবস্থান-ভিত্তিকভাবে কাটে; quartile ও IQR এদেরই বিশেষ রূপ, আর boxplot এদের চাক্ষুষ ভাষা (\(1.5\times\)IQR rule-এ outlier)।
- Robustness ও outlier: একটিমাত্র চরম মান mean/range/std-কে টেনে নিতে পারে, কিন্তু median/IQR/MAD প্রায় অটল — skewed বা দূষিত data-তে এই পার্থক্য নির্ণায়ক।
- Standardization (z-score): mean বিয়োগ করে std দিয়ে ভাগ; ফলে mean \(0\), std \(1\) — একক মুছে যায়, ভিন্ন variable তুলনাযোগ্য হয়।
প্রমাণ থেকে যা শিখলাম: deviation-এর যোগফল সবসময় \(0\) (তাই বর্গ করা দরকার); mean হলো বর্গ-দূরত্ব-সর্বনিম্নকারী বিন্দু (regression-এর বীজ); \(n-1\) আসে unbiasedness থেকে; z-score-এর mean/std গঠনগতভাবে \(0/1\)।
পেছনের সাথে সংযোগ (1.1): 1.1-এ আমরা data type ও sample বনাম population আলাদা করেছিলাম; এই অধ্যায় সেই sample থেকে গণনাযোগ্য সারাংশ-সংখ্যা দিল। 0.4-এর sum/integral-এর স্বজ্ঞা এখানে \(\sum\)-ভিত্তিক সংজ্ঞায় কাজে এল; 0.6-এর NumPy/pandas দিয়েই সব গণনা করলাম।
সামনের সাথে সংযোগ: পরের অধ্যায় 1.3 — Distributions & Visualization এই location/spread-কে পূর্ণ distribution-এর কাঠামোয় বসাবে — histogram, density, skewness ও kurtosis (আকৃতির পরিমাপ) সহ; mean/median-এর পার্থক্য তখন skewness-এর ভাষায় ধরা পড়বে। আর গভীর যোগসূত্রটি Part IV-তে: আজকের \(\bar{x}\) ও \(s^2\) তখন population-এর \(\mu\) ও \(\sigma^2\)-এর estimator হবে, এবং আমরা প্রশ্ন করব — এই estimate কতটা সঠিক, কতটা পরিবর্তনশীল, কতটা পক্ষপাতহীন? §৪.৩-এর \(n-1\) আর §৪.৪-এর z-score সেখানে confidence interval ও hypothesis testing-এর সরাসরি হাতিয়ার হয়ে উঠবে।
এক বাক্যে: location বলে data সাধারণত কোথায়, variability বলে কতটা বিশ্বাস করা যায় — আর robust বিকল্প জানা থাকলে outlier আপনাকে বোকা বানাতে পারবে না।