4.9 — The Bootstrap, Jackknife & Resampling (বুটস্ট্র্যাপ ও পুনঃনমুনায়ন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — formula যখন থেমে যায়, computer তখন শুরু করে¶
১.১ আগের অধ্যায়গুলো কোথায় রেখে এসেছিল — আর কোন প্রশ্ন এখনও খোলা¶
Part IV-এ এ পর্যন্ত আমরা অনিশ্চয়তা মাপার একটা সুন্দর যন্ত্রপাতি গড়েছি, এবং প্রতিবারই তার পেছনে ছিল একটা হাতে-কষা সূত্র। সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়ের গল্প ঠিক এই সূত্রগুলোর সীমা থেকেই শুরু:
- 4.1-এ শিখেছি — কোথাও একটা population (সমগ্রক) আছে, যার ভেতরে স্থির কিন্তু অজানা একটা parameter \(\theta\) ("থিটা") লুকিয়ে। আমরা পুরো population দেখি না; পাই কেবল একটা sample (নমুনা) — \(n\)টি পর্যবেক্ষণ \(X_1, X_2, \dots, X_n\)। data থেকে \(\theta\) আন্দাজ করার সূত্রকে বলি estimator (আনুমানক), প্রতীকে "টুপি"-সহ \(\hat\theta\)। যেহেতু \(\hat\theta\) random data-র উপর নির্ভর করে, \(\hat\theta\) নিজেও random — নমুনা বদলালে এর মান বদলায়, আর তার একটা নিজস্ব বণ্টন আছে, যার নাম sampling distribution (স্যাম্পলিং বণ্টন)।
- 4.4-এ অনিশ্চয়তা মাপার সংখ্যা গড়েছি — standard error \(\mathrm{SE}(\hat\theta)\) (estimator-এর standard deviation, "নমুনা-থেকে-নমুনায় \(\hat\theta\) গড়ে কতটা ওঠানামা করে"), bias, variance, MSE।
- 4.6-এ সেই \(\mathrm{SE}\) থেকে একটা confidence interval গড়েছি — \(\hat\theta \pm z_{\alpha/2}\,\mathrm{SE}\) — আর শিখেছি "৯৫% confidence"-এর সঠিক মানে।
- 4.7–4.8-এ hypothesis test গড়েছি — test statistic-কে একটা তাত্ত্বিক null বণ্টনের (\(\mathcal{N}(0,1)\), \(t_{n-1}\), \(\chi^2_k\)) সঙ্গে তুলনা করে।
লক্ষ করুন প্রতিটি ক্ষেত্রে একটা সাধারণ সুর: আমরা \(\hat\theta\)-র sampling distribution (বা অন্তত তার SE) একটা গাণিতিক সূত্র দিয়ে পেয়েছি। যেমন নমুনা গড়ের জন্য \(\mathrm{SE}(\bar X)=\sigma/\sqrt n\) — পরিষ্কার, বদ্ধ-রূপ (closed-form) সূত্র, CLT-র দান। কিন্তু এই সূত্র-নির্ভরতাই একটা বড় ফাঁক রেখে গেছে, আর সেখান থেকেই এই অধ্যায়ের প্রশ্ন জন্ম নেয়:
\(\bar X\)-এর SE-র তো সুন্দর সূত্র (\(\sigma/\sqrt n\)) আছে। কিন্তু আমি যদি গড়ের বদলে median (মধ্যমা)-র SE চাই? কিংবা দুটো চলকের correlation \(r\)-এর CI? কিংবা একটা ratio (যেমন \(\bar X/\bar Y\)), একটা trimmed mean, বা ৯০তম percentile-এর অনিশ্চয়তা? এগুলোর sampling distribution-এর কোনো সহজ বদ্ধ-রূপ সূত্র নেই — কখনো ভয়াবহ কঠিন, কখনো কেউ বের-ই করতে পারেনি। তাহলে কি এই statistic-গুলোর জন্য অনিশ্চয়তা মাপা অসম্ভব?
উত্তর — না, অসম্ভব নয়, আর সমাধানটা চমকপ্রদভাবে সরল। মূল ধারণা: সূত্র যেখানে থেমে যায়, সেখানে computer-কে দিয়ে অনিশ্চয়তাটা simulate করিয়ে নাও। এই অধ্যায়ের পুরো বিষয় — কাগজে-কলমে গণিত না কষেও, কেবল data থেকে বারবার পুনরায় নমুনা (resample) নিয়ে, যেকোনো statistic-এর sampling distribution হাতে-কলমে (বরং computer-এ) গড়ে ফেলা। এর নাম resampling (পুনঃনমুনায়ন), আর এর প্রধান যন্ত্রের নাম bootstrap (বুটস্ট্র্যাপ)।
১.২ মূল ছবি — কল্পনার নমুনা, কিন্তু population হাতে নেই¶
bootstrap-এর হৃদয়ে একটা সুন্দর কিন্তু প্রথমে-একটু-অদ্ভুত-লাগা ধারণা আছে। ধীরে গড়ি, কারণ এটাই পুরো অধ্যায়ের ভিত্তি।
প্রথমে: SE আসলে কী, তা একবার ভেবে দেখি। \(\hat\theta\)-র standard error মানে — যদি আমরা population থেকে একই আকারের (\(n\)) নমুনা বারবার টানতাম, প্রতিবার \(\hat\theta\) হিসাব করতাম, তাহলে সেই \(\hat\theta\)-গুলো একে অপরের থেকে গড়ে কতটা ছড়িয়ে থাকত। অর্থাৎ অনিশ্চয়তা মাপার আদর্শ (কল্পিত) উপায়টা হলো:
"population থেকে \(n\)-আকারের অনেকগুলো নতুন নমুনা টানো → প্রতিটায় \(\hat\theta\) হিসাব করো → সেই \(\hat\theta\)-গুলোর spread = SE, আর তাদের বণ্টন = sampling distribution।"
এটা যেকোনো statistic-এর জন্য কাজ করত — median, correlation, যা-ই হোক — যদি আমরা population থেকে ইচ্ছেমতো নতুন নমুনা টানতে পারতাম। কিন্তু সমস্যাটা মারাত্মক: আমাদের কাছে তো পুরো population নেই! আছে কেবল একটা নমুনা \(X_1,\dots,X_n\), একটিবারের জন্য। তাহলে "বারবার নমুনা টানা" কীভাবে সম্ভব?
এখানেই bootstrap-এর মাস্টারস্ট্রোক। যুক্তিটা এই:
হাতে-পাওয়া নমুনা \(X_1,\dots,X_n\) — এটাই তো population-এর সবচেয়ে ভালো ছবি যা আমার কাছে আছে। population দেখতে কেমন, সে সম্পর্কে আমার একমাত্র তথ্য এই \(n\)টা সংখ্যা। তাহলে "অজানা population থেকে নমুনা টানার" বদলে, আমি নমুনাটাকেই একটা ছোট্ট নকল-population ধরে নিয়ে, তার ভেতর থেকে বারবার নতুন নমুনা টানি!
আর "নমুনার ভেতর থেকে নমুনা টানা"-র সঠিক উপায় হলো replacement-সহ (with replacement, প্রতিস্থাপন-সহ) — অর্থাৎ প্রতিবার একটা পর্যবেক্ষণ তুলে নিয়ে, সেটা ফেরত রেখে আবার তুলি। ফলে একই মূল পর্যবেক্ষণ একটা নতুন নমুনায় একাধিকবার আসতে পারে, কোনোটা একবারও না-ও আসতে পারে। এভাবে তৈরি \(n\)-আকারের নতুন নমুনাকে বলি একটা bootstrap resample, প্রতীকে \(X^*\) ("X-স্টার")।
কেন replacement-সহ, এই এক জায়গায় থামুন: যদি replacement ছাড়া \(n\)টার মধ্যে থেকে \(n\)টা টানতাম, প্রতিবার হুবহু একই মূল নমুনাটাই ফেরত পেতাম (শুধু ক্রম বদলে) — কোনো নতুন তথ্য নেই, কোনো ওঠানামা নেই। replacement-সহ টানলেই তবে প্রতিটা resample একটু আলাদা হয়, আর সেই কৃত্রিম ওঠানামাই "নমুনা যদি একটু আলাদা হতো" পরিস্থিতিটাকে নকল করে — ঠিক যা আমরা SE মাপতে চাই।
১.৩ "নিজের জুতোর ফিতে টেনে নিজেকে তোলা" — নামটার মানে¶
পদ্ধতিটার নাম "bootstrap" একটা ইংরেজি বাগধারা থেকে — "to pull oneself up by one's bootstraps" (নিজের জুতোর ফিতে ধরে টেনে নিজেকে উপরে তোলা), অর্থাৎ বাইরের কোনো সাহায্য ছাড়াই, কেবল নিজের সম্পদ দিয়ে অসম্ভব-মনে-হওয়া কিছু করা। নামটা নিখুঁত, কারণ এখানে আমরা ঠিক তা-ই করি:
বাইরের কোনো population, কোনো অতিরিক্ত data, কোনো জটিল সূত্র ছাড়াই — কেবল হাতে-থাকা একটা নমুনা থেকেই তার নিজের অনিশ্চয়তা টেনে বের করি। data যেন নিজের ফিতে ধরে নিজেকে তোলে।
এটা computer-যুগের inference-এর প্রতীক। ১৯৭৯-এর আগে (Bradley Efron-এর bootstrap প্রস্তাবের আগে) median বা correlation-এর মতো statistic-এর SE পেতে হলে কঠিন গণিত কষতে হতো, নয়তো হাল ছেড়ে দিতে হতো। কিন্তু সস্তা computation আসার পর গল্প বদলে গেল: কঠিন বীজগণিতের বদলে কেবল কয়েক হাজার বার একটা সহজ resample-আর-হিসাব loop চালালেই হয়। এই "গণিত-নির্ভরতা থেকে computation-নির্ভরতায়" সরে আসাটাই আধুনিক পরিসংখ্যান ও data science-এর একটা কেন্দ্রীয় বৈশিষ্ট্য — আর bootstrap তার সবচেয়ে পরিষ্কার উদাহরণ।
এক বাক্যে যা সারা অধ্যায় ধরে রাখবে: sampling distribution আদর্শভাবে আসত population থেকে বারবার নমুনা টেনে; population নেই বলে আমরা নমুনাটাকেই নকল-population ধরে তার ভেতর থেকে replacement-সহ বারবার resample টানি — এই কৃত্রিম পুনঃনমুনায়নই যেকোনো statistic-এর SE ও CI সূত্র ছাড়াই simulate করে দেয়।
১.৪ তিনটি যন্ত্র — bootstrap, jackknife, permutation test¶
এই একটা "data থেকে পুনঃনমুনা" ধারণা থেকে তিনটি ঘনিষ্ঠ-সম্পর্কিত যন্ত্র জন্মায়, আর এই অধ্যায়ে তিনটিই শিখব। তিনটির মূল পার্থক্য — কীভাবে এবং কী লক্ষ্যে পুনঃনমুনা করা হয়:
- Bootstrap (replacement-সহ পুনঃনমুনা)। data থেকে replacement-সহ \(n\)-আকারের resample বারবার টেনে যেকোনো statistic-এর পুরো sampling distribution আনুমান করে। প্রধান ফসল: standard error ও confidence interval (যখন সূত্র নেই)। — এটাই অধ্যায়ের মূল যন্ত্র।
- Jackknife (leave-one-out)। প্রতিবার একটা করে পর্যবেক্ষণ বাদ দিয়ে (replacement ছাড়া) \(\hat\theta\) আবার হিসাব করে — মোট \(n\)টা "এক-কম" নমুনা। দেখে \(\hat\theta\) কতটা নড়ে। প্রধান ফসল: estimator-এর bias ও variance-এর অনুমান। bootstrap-এর সরল, পুরনো পূর্বসূরি।
- Permutation test (পুনঃসজ্জা)। এটা SE/CI নয়, hypothesis testing-এর যন্ত্র। দুই দলের group-label এলোমেলো করে পুনঃসজ্জা (permute/shuffle) করে — যুক্তি: যদি \(H_0\) (দুই দল আসলে একই) সত্য হয়, তবে কে কোন দলে তা অর্থহীন, তাই label বদলে দিলেও কিছু যায়-আসে না। এই পুনঃসজ্জাই null distribution বানায়।
তিনটিরই গভীর মিল — কোনো তাত্ত্বিক বণ্টন (Normal, \(t\), \(\chi^2\)) ধরে না নিয়ে, data নিজেই (পুনঃসজ্জা বা পুনঃনমুনার মাধ্যমে) প্রয়োজনীয় বণ্টন তৈরি করে দেয়। এজন্য এদের একসঙ্গে resampling methods বলা হয়।
১.৫ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — পাঁচটি কেন্দ্রীয় ধারণা from scratch, প্রতিটি প্রতীক খুলে: (ক) plug-in principle ও empirical distribution \(\hat F_n\) (কেন data = population-এর সেরা ছবি); (খ) bootstrap algorithm (resample with replacement → statistic → \(B\) বার পুনরাবৃত্তি); (গ) bootstrap SE \(\widehat{\mathrm{se}}_{\text{boot}}\); (ঘ) percentile ও basic bootstrap CI; (ঙ) jackknife (leave-one-out, bias ও variance); (চ) permutation test।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 গড়ের bootstrap SE (\(\sigma/\sqrt n\)-এর সাথে মিলিয়ে যাচাই), E2 median-এর bootstrap CI (সহজ সূত্র নেই), E3 jackknife bias ও variance, E4 permutation test (দুই-দলের পার্থক্য)।
- §৪–৫ — bootstrap কেন কাজ করে তার যুক্তি (\(\hat F_n \to F\), plug-in-এর বৈধতা), percentile CI-র সীমাবদ্ধতা ও উন্নত সংস্করণ, parametric bootstrap, এবং jackknife↔bootstrap সম্পর্ক।
- §৬–৮ — চিত্র (bootstrap-dist, bootstrap-ci, jackknife, permutation), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর গুরুত্বপূর্ণ ধাপ। 4.4–4.8 অনিশ্চয়তা মাপতে তাত্ত্বিক সূত্র (CLT, \(t\), \(\chi^2\), Fisher information) ব্যবহার করেছে — যা শক্তিশালী, কিন্তু কেবল তখনই খাটে যখন statistic যথেষ্ট সরল বা নমুনা যথেষ্ট বড়। এই অধ্যায় একটা সর্বজনীন বিকল্প দেয়: যখন সূত্র জটিল/অজানা বা নমুনা ছোট, তখন data থেকে সরাসরি simulate করে SE, CI ও p-value বের করা। পরের অধ্যায় 4.10 (Bayesian inference) অনিশ্চয়তা মাপার আরেকটা মৌলিকভাবে ভিন্ন দর্শন আনবে (parameter-এর উপর সম্ভাবনা) — bootstrap তাই frequentist যুগের শেষ ও সবচেয়ে ব্যবহারিক যন্ত্র, যা গণিতের সীমার বাইরেও inference সম্ভব করে তোলে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামোটা স্থির: আমাদের কাছে একটি i.i.d. নমুনা \(X_1, X_2, \dots, X_n\) আছে (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা), একটি (অজানা) সত্য বণ্টন \(F\) থেকে। আমরা \(F\)-এর কোনো বৈশিষ্ট্য \(\theta=\theta(F)\) অনুমান করতে চাই (যেমন গড়, median, correlation), এবং তার জন্য data থেকে একটা estimator \(\hat\theta=\hat\theta(X_1,\dots,X_n)\) হিসাব করেছি। আমাদের লক্ষ্য — \(\hat\theta\)-র sampling distribution সম্পর্কে কিছু জানা (বিশেষত তার SE ও কোয়ান্টাইল), কিন্তু সেটার কোনো সহজ সূত্র নেই বলে ধরে নিচ্ছি।
২.১ Plug-in principle ও empirical distribution \(\hat F_n\)¶
§১.২-এর "data = population-এর সেরা ছবি" ধারণাটাকে নিখুঁত করি। এর আনুষ্ঠানিক রূপ দুটো জিনিস — empirical distribution আর plug-in principle।
সংজ্ঞা (Empirical distribution — অভিজ্ঞতালব্ধ বণ্টন, \(\hat F_n\))। হাতে-পাওয়া নমুনা \(X_1,\dots,X_n\) থেকে গড়া এমন একটা বণ্টন, যা প্রতিটি পর্যবেক্ষিত মানে সমান \(\tfrac1n\) ভর বসায় — আর কোথাও কিছু নয়। অর্থাৎ \(\hat F_n\) অনুযায়ী এলোমেলোভাবে একটা মান টানা মানে: \(n\)টা পর্যবেক্ষণ \(X_1,\dots,X_n\)-এর মধ্যে থেকে সমান সম্ভাবনায় (\(\tfrac1n\) করে) একটা বেছে নেওয়া। প্রতীক খুলি:
- \(\hat F_n\) ("F-হ্যাট-n") — empirical distribution; "হ্যাট" বলছে এটা data থেকে অনুমিত, আর \(n\) মনে করায় এটা \(n\)টা পর্যবেক্ষণের উপর দাঁড়ানো।
- \(F\) — সত্য, অজানা population বণ্টন (যেটা আমরা দেখতে পাই না)।
কেন \(\hat F_n\) হলো \(F\)-এর সেরা অনুমান। কোনো বাড়তি অনুমান (যেমন "population Normal") ছাড়াই, \(F\) সম্পর্কে আমাদের একমাত্র তথ্য এই \(n\)টা সংখ্যা। তাই data যা দেখিয়েছে ঠিক সেটাকেই বণ্টন ধরে নেওয়া সবচেয়ে সৎ অনুমান। আর এটা শূন্য থেকে বানানো কল্পনা নয় — একটা গভীর ফল (Glivenko–Cantelli উপপাদ্য, §৪-এ ছোঁয়া হবে) বলে: \(n\) বড় হলে \(\hat F_n\) ক্রমে সত্য \(F\)-এর দিকে এগোয়। তাই বড় নমুনায় \(\hat F_n\) সত্যিই \(F\)-এর একটা ভালো প্রতিনিধি।
সংজ্ঞা (Plug-in principle — প্রতিস্থাপন নীতি)। যদি আগ্রহের parameter \(\theta\) সত্য বণ্টন \(F\)-এর একটা function হয়, \(\theta=\theta(F)\), তবে তার একটা স্বাভাবিক estimator পাওয়া যায় \(F\)-এর জায়গায় \(\hat F_n\) বসিয়ে (plug in):
অর্থাৎ "সত্য বণ্টনের যে রাশি চাও, সেই একই রাশি data-র (empirical) বণ্টনে হিসাব করো"। উদাহরণ: সত্য গড় \(\mu=\theta(F)=\int x\,dF(x)\) (population-এর গড়), আর \(\hat F_n\)-এ একই রাশি = \(\frac1n\sum_i X_i=\bar X\) (নমুনা গড়) — পরিচিত plug-in estimator। একইভাবে median, variance, correlation — সবকটার plug-in estimator হলো "data-তে গণনা করা সেই-ই রাশি"।
কেন এটা bootstrap-এর ভিত্তি: bootstrap আসলে plug-in principle-কে আরেক ধাপ এগিয়ে নেয়। আমরা চাই \(\hat\theta\)-র sampling distribution — যা নির্ভর করে সত্য \(F\)-এর উপর (কারণ নমুনা আসে \(F\) থেকে)। সেই \(F\) অজানা, তাই \(F\)-এর জায়গায় \(\hat F_n\) plug-in করি — অর্থাৎ "\(F\) থেকে নমুনা" পড়ি "\(\hat F_n\) থেকে নমুনা" হিসেবে। আর "\(\hat F_n\) থেকে \(n\)টা মান টানা" মানে ঠিক §১.২-এর সেই replacement-সহ resample! তাই bootstrap = sampling distribution-এর জন্য plug-in।
২.২ Bootstrap algorithm — মূল পদ্ধতি ধাপে ধাপে¶
এবার §১.২ আর §২.১-কে একটা সুনির্দিষ্ট কর্মপদ্ধতিতে (algorithm) রূপ দিই। লক্ষ্য: estimator \(\hat\theta\)-র sampling distribution-কে simulate করা।
আগে দুটো প্রতীক ঠিক করি:
- \(X^* = (X^*_1,\dots,X^*_n)\) — একটি bootstrap resample: original নমুনা \(X_1,\dots,X_n\) থেকে replacement-সহ টানা \(n\)টা মান (অর্থাৎ \(\hat F_n\) থেকে \(n\)টা স্বাধীন draw)। আকার সবসময় মূল নমুনার সমান, \(n\)।
- \(B\) — bootstrap replications (পুনরাবৃত্তির সংখ্যা): কতবার আমরা এই resample-আর-হিসাব করব। সাধারণত \(B\) বড় — SE-র জন্য কয়েকশো (যেমন \(200\)–\(1000\)), CI-র জন্য কয়েক হাজার (যেমন \(2000\)–\(10000\))।
Bootstrap algorithm।
পুনরাবৃত্তি \(b = 1, 2, \dots, B\)-র জন্য: 1. Resample: original নমুনা \(\{X_1,\dots,X_n\}\) থেকে replacement-সহ \(n\)টা মান টেনে একটা bootstrap resample \(X^*=(X^*_1,\dots,X^*_n)\) বানাও। 2. Recompute: ঠিক যে statistic-টা আগ্রহের, সেটাই এই resample-এর উপর হিসাব করো — পাও একটা bootstrap replicate (বুটস্ট্র্যাপ অনুলিপি) \(\hat\theta^*_b = \hat\theta(X^*)\)।
এতে হাতে আসে \(B\)টা সংখ্যা: \(\hat\theta^*_1, \hat\theta^*_2, \dots, \hat\theta^*_B\)।
এই \(B\)টা সংখ্যার সংগ্রহ \(\{\hat\theta^*_1,\dots,\hat\theta^*_B\}\)-ই হলো \(\hat\theta\)-র sampling distribution-এর একটা simulate-করা প্রতিরূপ — যাকে বলি bootstrap distribution (বুটস্ট্র্যাপ বণ্টন)। মূল ভরসা: এই কৃত্রিম বণ্টনের আকৃতি, বিস্তার, কোয়ান্টাইল — সত্য (কিন্তু অদেখা) sampling distribution-এর কাছাকাছি। তাই sampling distribution সম্পর্কে যা যা জানতে চাই (SE, CI), সব এই \(B\)টা সংখ্যা থেকেই বের করব।
স্পষ্ট করে রাখি — দুই স্তরের নমুনা: এখানে দুটো আলাদা স্তর আছে, গুলিয়ে ফেলা সহজ। (১) সত্য \(F\) থেকে original নমুনা \(X_1,\dots,X_n\) — এটা একবারই ঘটেছে, হাতে আছে। (২) সেই নমুনা (\(\hat F_n\)) থেকে bootstrap resample \(X^*\) — এটা computer-এ \(B\) বার ঘটাই। bootstrap distribution-এর ওঠানামা আসে দ্বিতীয় স্তর থেকে, কিন্তু সেটা প্রথম স্তরের (সত্য) ওঠানামাকে নকল করে — এটাই পুরো কৌশলের প্রাণ। (§৬-এর চিত্র
4-9-bootstrap-distএই দুই স্তর — এক original নমুনা থেকে বহু resample, আর তাদের \(\hat\theta^*\)-র histogram — চোখে দেখাবে।)
২.৩ Bootstrap standard error — \(\widehat{\mathrm{se}}_{\text{boot}}\)¶
bootstrap distribution হাতে এলে, SE বের করা তুচ্ছ — কারণ SE-র সংজ্ঞাই তো "sampling distribution-এর spread", আর আমাদের কাছে এখন সেই বণ্টনের একটা নমুনা (\(B\)টা মান) আছে। তাই SE = সেই \(B\)টা মানের standard deviation।
সংজ্ঞা (Bootstrap standard error, \(\widehat{\mathrm{se}}_{\text{boot}}\))। bootstrap replicate-গুলোর নমুনা-standard-deviation:
প্রতিটি অংশ খুলি:
- \(\hat\theta^*_b\) — \(b\)-তম bootstrap replicate (§২.২)।
- \(\bar\theta^*\) ("থিটা-হ্যাট-স্টার-বার") — \(B\)টা replicate-এর গড় (bootstrap distribution-এর কেন্দ্র)।
- \(\big(\hat\theta^*_b - \bar\theta^*\big)^2\) — প্রতিটি replicate সেই কেন্দ্র থেকে কত দূরে, তার বর্গ।
- \(\frac{1}{B-1}\sum(\cdots)\) ও বর্গমূল — অর্থাৎ replicate-গুলোর সাধারণ sample standard deviation (সেই \(B-1\)-ভাজক, 4.4 থেকে)।
স্বজ্ঞা একদম সরল: "\(\hat\theta\) নমুনা বদলালে কতটা ওঠানামা করত?" — সেটা আমরা সরাসরি দেখছি বহু (কৃত্রিম) নমুনায় \(\hat\theta^*\) কতটা ছড়াল তা মেপে। এই একই সূত্র median, correlation, ratio — সব statistic-এর জন্য অপরিবর্তিত খাটে; কোনো নতুন গণিত লাগে না। এটাই bootstrap-এর প্রধান শক্তি: \(\hat\theta(X^*)\)-টা হিসাব করতে জানলেই হলো, তার SE-র আর আলাদা সূত্র লাগে না।
২.৪ Bootstrap confidence interval — percentile ও basic¶
SE পেলে একটা সরল (Normal-আশ্রিত) CI হয় \(\hat\theta \pm z_{\alpha/2}\,\widehat{\mathrm{se}}_{\text{boot}}\) (4.6-এর মতো)। কিন্তু এতে আবার "sampling distribution Normal" ধরে নেওয়া হলো — অথচ median-এর মতো statistic-এ সেটা মিথ্যা হতে পারে (asymmetric, skewed)। bootstrap-এর আসল সৌন্দর্য: আমাদের কাছে তো পুরো bootstrap distribution আছে — তাই Normal না ধরে সরাসরি সেই বণ্টনের কোয়ান্টাইল থেকেই CI নিতে পারি। দুটি প্রধান উপায়:
সংজ্ঞা (Percentile bootstrap CI — শতকরা-অবস্থান CI)। সবচেয়ে সরল ও স্বজ্ঞাত। \(1-\alpha\) স্তরের CI = bootstrap distribution-এর নিচের \(\alpha/2\) ও উপরের \(1-\alpha/2\) কোয়ান্টাইল-এর মাঝের অংশ:
প্রতীক খুলি:
- \(\hat\theta^*_{(q)}\) — bootstrap replicate-গুলোর \(q\)-তম quantile (কোয়ান্টাইল): \(B\)টা মান ছোট-থেকে-বড় সাজিয়ে যে মানের নিচে ঠিক \(q\) ভগ্নাংশ ভর পড়ে। যেমন \(95\%\) CI (\(\alpha=0.05\))-এর জন্য \(q=0.025\) ও \(q=0.975\) — অর্থাৎ সাজানো replicate-গুলোর \(2.5\)তম ও \(97.5\)তম percentile।
- স্বজ্ঞা: "সব সম্ভাব্য নমুনায় \(\hat\theta\) যেখানে যেখানে পড়ত, তার মাঝের ৯৫% — তাই দুই প্রান্ত বাদ দিয়ে।" Normal ধরার দরকার নেই, বণ্টন বাঁকা হলেও CI স্বাভাবিকভাবে অপ্রতিসম হয়ে নিজেকে মানিয়ে নেয়।
সংজ্ঞা (Basic / pivotal bootstrap CI — মৌলিক CI)। percentile-এর একটা সূক্ষ্ম বিকল্প, যা \(\hat\theta^*-\hat\theta\)-এর ওঠানামাকে "pivot" ধরে (4.6-এর pivot-চিন্তার ছায়া)। সূত্র:
প্রতীক ও যুক্তি খুলি:
- \(\hat\theta\) (তারা-ছাড়া) — original নমুনায় হিসাব করা মূল estimate (একটাই সংখ্যা)।
- \(\hat\theta^*_{(\alpha/2)},\ \hat\theta^*_{(1-\alpha/2)}\) — আগের মতোই bootstrap কোয়ান্টাইল।
- যুক্তি: ধরো \(\hat\theta-\theta\)-এর ওঠানামা \(\hat\theta^*-\hat\theta\)-এর ওঠানামার মতো (bootstrap-এর মূল আস্থা)। তাহলে নিচের/উপরের প্রান্ত বের করতে কোয়ান্টাইলগুলোকে \(\hat\theta\)-র চারপাশে "উল্টে" দিতে হয় — সেটাই \(2\hat\theta - (\cdots)\) রূপে আসে। লক্ষ করুন প্রান্ত দুটো বিনিময় হয় (upper কোয়ান্টাইল lower প্রান্ত দেয়), কারণ বিয়োগে চিহ্ন উল্টে যায়।
percentile বনাম basic — সংক্ষেপে: percentile সরাসরি replicate-এর কোয়ান্টাইল নেয় (সহজ, স্বজ্ঞাত, ব্যবহারিকভাবে জনপ্রিয়); basic ওই কোয়ান্টাইলগুলোকে \(\hat\theta\)-র চারপাশে প্রতিফলিত করে (pivot-যুক্তিতে কিছুটা বেশি নীতিসম্মত)। sampling distribution মোটামুটি প্রতিসম হলে দুটো প্রায় মেলে; খুব বাঁকা হলে আলাদা হয়, আর তখন কোনটা ভালো — সে আলোচনা ও আরও উন্নত সংস্করণ (\(\text{BCa}\)) §৪-এ আসবে। (§৬-এর চিত্র
4-9-bootstrap-ciদেখাবে কীভাবে bootstrap distribution-এর দুই প্রান্ত কেটে percentile CI পাওয়া যায়।)
২.৫ Jackknife — leave-one-out দিয়ে bias ও variance¶
এবার দ্বিতীয় যন্ত্র — jackknife (জ্যাকনাইফ), bootstrap-এর সরল ও পুরনো পূর্বসূরি। নামটা "সুইস-আর্মি ছুরি"-র মতো একটা সাধারণ-উদ্দেশ্য যন্ত্রের ইঙ্গিত দেয়। এর মূল কৌশল bootstrap-এর চেয়ে আলাদা: random resample নয়, বরং একটা করে পর্যবেক্ষণ পদ্ধতিগতভাবে বাদ দেওয়া।
সংজ্ঞা (Jackknife / leave-one-out replicate)। \(i = 1, 2, \dots, n\)-এর জন্য, \(i\)-তম পর্যবেক্ষণ \(X_i\) বাদ দিয়ে বাকি \(n-1\)টা পর্যবেক্ষণে estimator আবার হিসাব করি:
প্রতীক: \(\hat\theta_{(i)}\) ("থিটা-হ্যাট-মাইনাস-i") — "\(i\)-বাদে" estimate। এভাবে মোট \(n\)টা leave-one-out replicate পাই, \(\hat\theta_{(-1)},\dots,\hat\theta_{(-n)}\)। এদের গড়কে লিখি \(\bar\theta_{(\cdot)} = \frac1n\sum_{i=1}^n \hat\theta_{(i)}\)।
এই \(n\)টা মান থেকে দুটো জিনিস বেরোয়:
(ক) Jackknife variance estimate। \(\hat\theta\)-র variance-এর অনুমান:
প্রতীক ও স্বজ্ঞা: ভেতরের যোগফল মাপে leave-one-out estimate-গুলো একে অপর থেকে কতটা ছড়িয়ে; একটা পর্যবেক্ষণ বাদ দিলে \(\hat\theta\) যত বেশি লাফায়, estimator তত অস্থির, তাই variance তত বেশি। সামনের অদ্ভুত গুণক \(\frac{n-1}{n}\) একটা সংশোধন — কারণ leave-one-out নমুনাগুলো একে অপরের সাথে প্রায় পুরো মিলে যায় (মাত্র এক পর্যবেক্ষণে আলাদা), তাই তাদের কাঁচা spread সত্য variance-এর তুলনায় অনেক ছোট; \(\frac{n-1}{n}\) গুণ (আসলে প্রায় \((n-1)\)-গুণ বড় করা, যেহেতু এখানে \(\frac{n-1}{n}\cdot n=n-1\) কার্যকর স্কেল) সেটা পুষিয়ে দেয়।
(খ) Jackknife bias estimate। estimator-এর bias (অর্থাৎ \(\mathbb{E}[\hat\theta]-\theta\), 4.4)-এর অনুমান:
প্রতীক ও স্বজ্ঞা: \(\bar\theta_{(\cdot)}-\hat\theta\) মাপে "এক-কম নমুনার গড় estimate" পুরো-নমুনার estimate থেকে কতটা সরে — যদি estimator-এ পদ্ধতিগত পক্ষপাত (bias) থাকে, নমুনা-আকার বদলালে সেই পক্ষপাত একটু বদলায়, আর এই সরণ সেটাই ধরে। \((n-1)\) গুণক bias-কে সঠিক স্কেলে নিয়ে আসে (bias সাধারণত \(1/n\)-ক্রমে কমে, তাই \((n-1)\) গুণে তার মূল মাপ ফিরে আসে)। bias জানা গেলে একটা bias-corrected estimate বানানো যায়: \(\hat\theta_{\text{corr}} = \hat\theta - \widehat{\mathrm{bias}}_{\text{jack}}\)।
jackknife বনাম bootstrap: jackknife নির্ধারক (deterministic — কোনো randomness নেই, ঠিক \(n\)টা নির্দিষ্ট হিসাব) ও দ্রুত, কিন্তু কেবল smooth (মসৃণ) statistic-এ ভালো খাটে — median-এর মতো "ঝাঁকি-দেওয়া" statistic-এ এটি দুর্বল (সেখানে bootstrap ভালো)। ঐতিহাসিকভাবে jackknife bootstrap-এর আগে এসেছে; ভাবা যায় jackknife = bootstrap-এর একটা সরলীকৃত, রৈখিক আনুমান। (§৬-এর চিত্র
4-9-jackknifeদেখাবে কীভাবে এক-একটা পর্যবেক্ষণ বাদ দিলে \(\hat\theta\) নড়ে, আর সেই নড়াচড়া থেকে bias ও variance বেরোয়।)
২.৬ Permutation test — পুনঃসজ্জা দিয়ে hypothesis testing¶
তৃতীয় ও চূড়ান্ত যন্ত্র — কিন্তু এটি SE/CI নয়, hypothesis testing-এর (4.7-এর কাঠামোয়)। সবচেয়ে সাধারণ প্রয়োগ: দুই দলের পার্থক্য — যেমন "treatment দল আর control দলের গড় কি সত্যিই আলাদা, নাকি পার্থক্যটা নেহাত আকস্মিক?"
পরিস্থিতি ও \(H_0\)। দুটো দল: দল A-তে \(n_A\)টা পর্যবেক্ষণ, দল B-তে \(n_B\)টা। আমরা একটা test statistic \(T\) বেছে নিই যা পার্থক্য মাপে — সবচেয়ে সরল, দুই দলের গড়ের ফারাক:
যেখানে \(\bar X_A\) ও \(\bar X_B\) যথাক্রমে A ও B দলের নমুনা গড়। null hypothesis \(H_0\): দুই দল আসলে একই বণ্টন থেকে আসে (অর্থাৎ "দল"-নামক label-টা অর্থহীন, ফলাফলে কোনো প্রভাব নেই)।
মূল insight (অন্তর্দৃষ্টি) — কেন পুনঃসজ্জা। এটাই permutation test-এর প্রাণ, তাই ধীরে: যদি \(H_0\) সত্যিই সত্য হয় — দুই দলের কোনো আসল পার্থক্য না থাকে — তবে কোন পর্যবেক্ষণে "A" আর কোনটায় "B" তকমা বসেছে, তা সম্পূর্ণ আকস্মিক, অর্থহীন। তাহলে আমি যদি সব পর্যবেক্ষণ একসাথে ঢেলে, label-গুলো এলোমেলো করে আবার বিলিয়ে দিই (যাকে বলি permute বা shuffle), তবে \(H_0\)-র দুনিয়ায় সেটা সমান-বৈধ একটা বিকল্প বিন্যাস। প্রতিটা এমন পুনঃসজ্জায় \(T\) আবার হিসাব করলে আমরা দেখি — নিছক ভাগ্যের জোরে \(T\) কত বড় হতে পারত, যদি label-এর কোনো মানে না থাকত।
Permutation test algorithm।
- পর্যবেক্ষিত মান: original label-এ \(T_{\text{obs}} = \bar X_A - \bar X_B\) হিসাব করো।
- দুই দলের সব পর্যবেক্ষণ একসাথে একটা pool-এ মেশাও (মোট \(n_A+n_B\)টা)।
- পুনরাবৃত্তি \(b=1,\dots,B\): pool থেকে এলোমেলোভাবে \(n_A\)টাকে "নতুন A", বাকি \(n_B\)টাকে "নতুন B" তকমা দাও (replacement ছাড়া — এটা পুনঃসজ্জা, পুনঃনমুনা নয়); এই permuted ভাগে \(T^*_b = \bar X^*_A - \bar X^*_B\) হিসাব করো।
- এই \(\{T^*_1,\dots,T^*_B\}\)-ই হলো \(H_0\)-র অধীনে \(T\)-এর permutation null distribution।
p-value = null distribution-এ পর্যবেক্ষিত \(T_{\text{obs}}\) যত বা তার চেয়ে চরম মান কত ভগ্নাংশ: $$ \boxed{\ \text{p-value} \;=\; \frac{#{\,b : \lvert T^*b \rvert \ge \lvert T $$ (দুই-দিকের test-এ পরম-মান }} \rvert\,}}{B}\ \(\lvert\cdot\rvert\); এক-দিকের হলে চিহ্নসহ \(T^*_b \ge T_{\text{obs}}\)।)
প্রতীক খুলি: \(\#\{\cdots\}\) মানে "শর্ত-পূরণকারী \(b\)-এর সংখ্যা গোনো"; \(\lvert T^*_b\rvert \ge \lvert T_{\text{obs}}\rvert\) মানে permuted পার্থক্য পর্যবেক্ষিত পার্থক্যের সমান বা তার চেয়ে চরম (বড় পরম-মান)। স্বজ্ঞা: p-value ছোট ⇔ পর্যবেক্ষিত পার্থক্য নিছক label-রদবদলে কদাচিৎ ঘটে ⇔ data \(H_0\)-র বিরুদ্ধে ⇔ পার্থক্য সম্ভবত আসল।
এক বাক্যে §২-এর সার। plug-in principle (data = \(F\)-এর সেরা ছবি, \(\hat F_n\)) থেকে জন্ম তিন resampling-যন্ত্রের: bootstrap — \(\hat F_n\) থেকে replacement-সহ \(B\)টা resample টেনে যেকোনো \(\hat\theta\)-র sampling distribution simulate করে, যা থেকে SE (\(\widehat{\mathrm{se}}_{\text{boot}}\) = replicate-দের sd) ও CI (percentile: কোয়ান্টাইল; basic: \(\hat\theta\)-র চারপাশে প্রতিফলিত কোয়ান্টাইল) সূত্র ছাড়াই বেরোয়; jackknife — leave-one-out \(n\)টা estimate থেকে bias (\((n-1)(\bar\theta_{(\cdot)}-\hat\theta)\)) ও variance; এবং permutation test — group-label পুনঃসজ্জা করে \(H_0\)-র null distribution গড়ে p-value দেয়। সর্বত্র এক সুর: তাত্ত্বিক বণ্টন ধরে না নিয়ে, data নিজেই প্রয়োজনীয় বণ্টন তৈরি করে দেয়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর প্রতিটি যন্ত্র এবার সংখ্যায় হাতে-কলমে চালাব। চারটি উদাহরণ চারটি কেন্দ্রীয় কাজ ধরে: E1 গড়ের bootstrap SE (পরিচিত \(\sigma/\sqrt n\)-এর সাথে মিলিয়ে যাচাই — তাই আমরা জানি পদ্ধতিটা ঠিক উত্তর দিচ্ছে), E2 median-এর bootstrap CI (যার সহজ সূত্র নেই — তাই bootstrap-ই একমাত্র সহজ পথ), E3 jackknife bias ও variance, E4 permutation test (দুই-দলের পার্থক্য)। সর্বত্র \(\bar X=\frac1n\sum_{i=1}^n X_i\) মানে নমুনা গড়।
একটি ব্যবহারিক টীকা: bootstrap ও permutation test-এ "\(B\) বার resample" আসলে computer চালায় (হাতে কয়েক হাজার বার অসম্ভব)। তাই E1–E2-এ আমরা ছোট data নিয়ে পদ্ধতিটা ধাপে ধাপে দেখাব এবং একটা সাধারণ run-এর প্রতিনিধিত্বমূলক সংখ্যা দেব (একই বীজ-seed দিলে যা পুনরুৎপাদনযোগ্য)। বিপরীতে E3 (jackknife) ও E4-এর (ছোট দল) হিসাব সম্পূর্ণ হাতে-যাচাইযোগ্য — randomness ছাড়া।
৩.১ E1 — গড়ের bootstrap SE: পদ্ধতিটা কি ঠিক উত্তর দেয়?¶
এই উদাহরণ §২.২–২.৩ সরাসরি প্রয়োগ করে, আর ইচ্ছাকৃতভাবে এমন একটা statistic বেছে নেয় (গড়) যার SE-র সূত্র আমরা জানি (\(\sigma/\sqrt n\)) — যাতে bootstrap-এর উত্তর সেই জানা সত্যের সাথে মিলিয়ে আস্থা গড়া যায়।
পরিস্থিতি। একটা ছোট নমুনা, \(n=10\):
নমুনা গড় \(\bar X = \frac{2+4+4+4+5+5+7+9+9+11}{10} = \frac{60}{10} = 6.0\)। আমরা চাই \(\bar X\)-এর standard error — bootstrap দিয়ে।
ধাপ ১ — তুলনার জন্য সূত্র-ভিত্তিক SE (যা আমরা জানি)। নমুনা standard deviation:
তাই 4.4-এর সূত্রে আনুমানিক SE \(= S/\sqrt n = 2.867/\sqrt{10} \approx 0.907\)। এই \(0.907\)-ই সেই লক্ষ্য, যার কাছাকাছি bootstrap-এর পৌঁছানো উচিত।
ধাপ ২ — bootstrap resample (পদ্ধতির নমুনা)। §২.২ মতে, এই \(10\)টা সংখ্যা থেকে replacement-সহ \(10\)টা টানি — একটা resample হতে পারে, যেমন:
(লক্ষ করুন \(4\) এখানে তিনবার এল, কিন্তু \(9\) দুবার — replacement-সহ টানার স্বাভাবিক ফল; এই resample-এর গড় ঘটনাচক্রে \(6.0\)।) আরেকটা resample অন্যরকম গড় দেবে, যেমন \(\hat\theta^*_2 = 5.4\), \(\hat\theta^*_3 = 6.7\), ...।
ধাপ ৩ — \(B\) বার পুনরাবৃত্তি ও SE। এটা \(B=2000\) বার করলে (computer-এ) ২০০০টা \(\bar X^*\) পাই। একটা প্রতিনিধিত্বমূলক run-এ এই ২০০০টা মানের standard deviation:
মিলিয়ে দেখা ও ব্যাখ্যা। bootstrap দিল \(\approx 0.86\); সূত্র দিল \(\approx 0.91\) — প্রায় সমান (ছোট নমুনায় bootstrap-এর সামান্য নিম্নমুখী ঝোঁক স্বাভাবিক; \(n\) বাড়লে দুটো আরও মেলে)। এটাই মূল শিক্ষা:
bootstrap কোনো সূত্র না কষেই, কেবল resample-আর-গড়-নেওয়ার একটা loop চালিয়ে, \(\bar X\)-এর SE প্রায় ঠিক বের করে ফেলল। কিন্তু লক্ষ্য করুন — এই একই loop-এ "গড়" শব্দটা "median" বা "correlation" দিয়ে বদলে দিলেই আমরা সেই statistic-এর SE পেয়ে যাব, যাদের সহজ সূত্র নেই। গড়ের ক্ষেত্রে bootstrap-এর দরকার ছিল না (সূত্র ছিল); এখানে সেটা কেবল পদ্ধতিটা ঠিক কাজ করছে তা প্রমাণ করল। এর আসল মূল্য পরের উদাহরণে।
৩.২ E2 — median-এর bootstrap CI: যেখানে সহজ সূত্র নেই¶
এবার §২.৪-এর percentile ও basic CI সেই পরিস্থিতিতে, যেখানে bootstrap সত্যিই অপরিহার্য — median, যার sampling distribution-এর কোনো সহজ বদ্ধ-রূপ সূত্র নেই (বিশেষত ছোট, বাঁকা data-তে)।
পরিস্থিতি। একটা শহরের \(n=9\)টা বাড়ির মাসিক আয় (হাজার টাকায়), ছোট-থেকে-বড় সাজানো:
এই data ডান-দিকে বাঁকা (skewed — একটা বড় মান \(40\)), তাই গড় বিভ্রান্তিকর; median ভালো কেন্দ্র-মাপ। মূল estimate: \(9\)টা সাজানো মানের মাঝেরটা (\(5\)ম) = \(\hat\theta = \text{median} = 10\)। আমরা চাই median-এর একটা ৯৫% CI।
ধাপ ১ — কেন সূত্র নয়, bootstrap। median-এর SE-র জন্য কিছু তাত্ত্বিক সূত্র আছে বটে, কিন্তু সেগুলো population density-র মান জানা দাবি করে (যা আমাদের নেই) এবং ছোট নমুনায় অনির্ভরযোগ্য। তাই সরাসরি bootstrap: \(\hat F_n\) থেকে বহু resample টেনে median-এর বণ্টন simulate করি।
ধাপ ২ — bootstrap distribution। §২.২ মতে এই \(9\)টা সংখ্যা থেকে replacement-সহ \(9\)টা টেনে প্রতিবার median নিই, \(B=2000\) বার। মূল চরিত্র: যেহেতু median সবসময় data-র একটা পর্যবেক্ষিত মানেই পড়ে, bootstrap median-গুলো \(\{3,5,6,8,10,12,15,21,40\}\)-এর মধ্যেই আটকে থাকে (ধাপ-ধাপ, একটানা নয়) — এটাই median-এর বণ্টনকে গড়ের চেয়ে অন্যরকম করে, আর ঠিক এই অদ্ভুততা সূত্রে ধরা কঠিন (bootstrap-এ সহজ)।
ধাপ ৩ — percentile CI। ২০০০টা bootstrap median সাজিয়ে \(2.5\)তম ও \(97.5\)তম percentile নিই। একটা প্রতিনিধিত্বমূলক run-এ:
ধাপ ৪ — basic CI (তুলনার জন্য)। §২.৪-এর সূত্রে, \(\hat\theta=10\) ধরে কোয়ান্টাইলগুলো প্রতিফলিত করি:
ব্যাখ্যা। "এই bootstrap-পদ্ধতি বারবার চালালে তৈরি CI-গুলোর প্রায় ৯৫% সত্য median-কে ধরবে" (4.6-এর সেই সঠিক ব্যাখ্যা — ব্যবধান random, parameter স্থির)। লক্ষণীয়, percentile \([5.0, 15.2]\) আর basic \([4.8, 15.0]\) এখানে কাছাকাছি কিন্তু হুবহু এক নয় — কারণ median-এর bootstrap বণ্টন পুরোপুরি প্রতিসম নয়; §২.৪-এর সেই কথাই সংখ্যায়। সবচেয়ে বড় অর্জন: median-এর মতো "সূত্রহীন" statistic-এর জন্যও আমরা একটা সৎ CI পেলাম — কোনো নতুন গণিত ছাড়াই, কেবল resample-আর-median loop চালিয়ে।
৩.৩ E3 — jackknife: bias ও variance হাতে-কলমে¶
এবার §২.৫-এর jackknife — আর এমন data বাছি যে পুরো হিসাব হাতে-যাচাইযোগ্য (randomness নেই)। একই data দুটো ভিন্ন estimator-এ চালিয়ে দেখাব: একটায় bias শূন্য (গড়), আরেকটায় bias স্পষ্ট (plug-in variance) — যাতে bias-correction-এর শক্তি চোখে পড়ে।
পরিস্থিতি। খুব ছোট নমুনা, \(n=4\): \(X = (2,\ 4,\ 9,\ 12)\)।
অংশ ক — গড়ের jackknife (bias শূন্য হওয়া উচিত)। estimator = নমুনা গড়, \(\hat\theta = \bar X = \frac{2+4+9+12}{4} = \frac{27}{4} = 6.75\)। চারটা leave-one-out গড় (§২.৫):
এদের গড় \(\bar\theta_{(\cdot)} = \frac{8.333+7.667+6.000+5.000}{4} = \frac{27}{4} = 6.75\)।
- Bias: \(\widehat{\mathrm{bias}}_{\text{jack}} = (n-1)(\bar\theta_{(\cdot)}-\hat\theta) = 3(6.75-6.75) = 0\). ঠিক যা চেয়েছিলাম — নমুনা গড় unbiased (4.4), তাই jackknife-ও bias \(=0\) বলছে। (গভীর কারণ: গড়ের ক্ষেত্রে \(\bar\theta_{(\cdot)}\) সবসময় হুবহু \(\bar X\)-এর সমান হয়।)
- Variance: কেন্দ্র থেকে বিচ্যুতির বর্গযোগ \(\sum(\hat\theta_{(i)}-6.75)^2 = (1.583)^2+(0.917)^2+(-0.75)^2+(-1.75)^2 \approx 2.507+0.840+0.563+3.063 = 6.972\)। তাই
মিলিয়ে দেখি: গড়ের সত্য variance-অনুমান \(S^2/n\) (4.4)। এখানে \(S^2 = \frac{1}{3}[(2-6.75)^2+\cdots+(12-6.75)^2] \approx 20.92\), তাই \(S^2/n = 20.92/4 \approx 5.23\) — jackknife-এর সাথে হুবহু মিল! এটাই দেখায় সূত্রের \(\frac{n-1}{n}\) গুণকটা ঠিক স্কেলে কাজ করছে।
অংশ খ — plug-in variance-এর jackknife (bias দৃশ্যমান)। এবার estimator = plug-in (biased) variance \(\hat\theta = \frac1n\sum_i(X_i-\bar X)^2\) (অর্থাৎ \(n\)-ভাজক, 4.4-এর সেই নিম্নমুখী-পক্ষপাতী সংস্করণ)। পুরো data-তে: \(\hat\theta = \frac14[(2-6.75)^2+(4-6.75)^2+(9-6.75)^2+(12-6.75)^2] = \frac14[22.56+7.56+5.06+27.56] = \frac{62.75}{4} \approx 15.69\)।
চারটা leave-one-out plug-in variance (প্রতিবার \(3\)টা মানে, \(n-1=3\)-ভাজক নয় — plug-in মানে ওই উপ-নমুনার নিজস্ব \(\frac{1}{3}\sum\)):
গড় \(\bar\theta_{(\cdot)} \approx \frac{10.89+17.56+18.67+8.67}{4} \approx 13.94\)।
- Bias: \(\widehat{\mathrm{bias}}_{\text{jack}} = (n-1)(\bar\theta_{(\cdot)}-\hat\theta) = 3(13.94-15.69) \approx 3(-1.75) = -5.23\). ঋণাত্মক bias — ঠিক যেমন তত্ত্ব বলে: plug-in (\(n\)-ভাজক) variance সত্য variance-কে কম-করে আনুমান করে (bias \(=-\sigma^2/n\), 4.4)।
- Bias-corrected estimate: \(\hat\theta_{\text{corr}} = \hat\theta - \widehat{\mathrm{bias}}_{\text{jack}} = 15.69 - (-5.23) = 20.92\).
আর এই \(20.92\) ঠিক সেই unbiased \(S^2\) (\(n-1\)-ভাজক variance)! অর্থাৎ jackknife নিজে থেকেই, কেবল leave-one-out হিসাব করে, biased estimator-টিকে সংশোধন করে unbiased-এর কাছে নিয়ে গেল —
এটাই jackknife-এর সৌন্দর্য: আমরা bias-এর সূত্র (এক্ষেত্রে \(-\sigma^2/n\)) আগে থেকে না জেনেও, কেবল "একটা করে পর্যবেক্ষণ বাদ দিলে estimate কোথায় সরে" তা দেখে bias-টা অনুমান করে ফেললাম এবং সংশোধন করলাম। smooth statistic-এ এই কৌশল প্রায়-জাদুকরীভাবে কাজ করে।
৩.৪ E4 — permutation test: দুই দলের পার্থক্য কি আসল?¶
শেষ উদাহরণ §২.৬-এর permutation test। এখানে দল দুটো এত ছোট যে আমরা সব সম্ভাব্য পুনঃসজ্জা গুনে (exact/exhaustive permutation) p-value হুবহু হাতে বের করতে পারব — randomness ছাড়া।
পরিস্থিতি। একটা নতুন শিক্ষা-পদ্ধতির পরীক্ষায় দুই দলের পরীক্ষার নম্বর:
দলের গড়: \(\bar X_A = \frac{22+25+28+30}{4} = \frac{105}{4} = 26.25\), \(\bar X_B = \frac{18+20+21+24}{4} = \frac{83}{4} = 20.75\)। পর্যবেক্ষিত পার্থক্য:
\(H_0\): দুই পদ্ধতি আসলে একই (label অর্থহীন); \(H_1\): আলাদা। প্রশ্ন: \(5.5\) নম্বরের এই পার্থক্য কি আসল, নাকি নিছক ভাগ্য?
ধাপ ১ — সব পুনঃসজ্জার সংখ্যা। \(8\)টা নম্বর একসাথে pool করে, তার মধ্যে থেকে \(4\)টাকে "A" বাছার সব উপায়ের সংখ্যা \(\binom{8}{4} = 70\) (replacement ছাড়া — এটা পুনঃসজ্জা)। অর্থাৎ \(H_0\)-র অধীনে এই data সাজানোর \(70\)টা সমান-সম্ভাব্য উপায়, আর তার প্রতিটায় একটা \(T^* = \bar X^*_A - \bar X^*_B\)।
ধাপ ২ — null distribution ও চরম মান গোনা। এই \(70\)টা \(T^*\)-এর মধ্যে কতগুলো পর্যবেক্ষিত \(\lvert T_{\text{obs}}\rvert = 5.5\)-এর সমান বা চরমতর? হাতে গুনে দেখা যায় (যেহেতু আসল A-দল pool-এর সবচেয়ে বড় চারটি — \(22,25,28,30\) — নম্বর ধারণ করে, খুব কম পুনঃসজ্জাই এত বড় পার্থক্য দেয়):
- \(T^* \ge +5.5\) (আসল A-দল সবচেয়ে বড় ৪টি — এই এক বিন্যাস \(5.5\) দেয়; আর কেবল আরেকটি বিন্যাস \(\ge 5.5\) দেয়) → মোট \(2\)টি।
- প্রতিসমতায় \(T^* \le -5.5\)-ও \(2\)টি (A↔B অদলবদল)।
- তাই \(\lvert T^*\rvert \ge 5.5\): মোট \(4\)টি।
ধাপ ৩ — p-value ও সিদ্ধান্ত। §২.৬-এর সূত্রে (দুই-দিকের):
(এক-দিকের হলে \(\frac{2}{70} \approx 0.029\)।) সিদ্ধান্ত \(\alpha=0.05\)-এ: দুই-দিকের p-value \(\approx 0.057 > 0.05\), তাই \(H_0\) ঠিক-ঠিক বাতিল হয় না (যদিও সীমান্তে) — এই ছোট নমুনায় পার্থক্যটা "আসল" বলার মতো যথেষ্ট জোরালো প্রমাণ নেই (এক-দিকের অনুমানে অবশ্য \(0.029<0.05\), বাতিল হতো)।
ব্যাখ্যা। "যদি দুই পদ্ধতি সত্যিই একই হতো (\(H_0\)), তবে নিছক label-রদবদলেই \(5.5\)-এর সমান-বা-বড় পার্থক্য \(70\) বারে \(4\) বার (≈৫.৭%) ঘটত।" এই হার যথেষ্ট ছোট নয় (দুই-দিকে) বলে আমরা পার্থক্যটাকে নিশ্চিতভাবে আসল বলতে পারি না।
লক্ষণীয় — permutation test-এর শক্তি: আমরা কোনো \(t\)-distribution, কোনো Normality-অনুমান, কোনো variance-সমতার শর্ত ধরিনি। কেবল "\(H_0\) সত্য হলে label অর্থহীন" — এই একটা সরল যুক্তি থেকে null distribution-টা data থেকেই বানিয়ে নিলাম। এটাই resampling-এর সাধারণ সুর: তাত্ত্বিক বণ্টনের জায়গায় data নিজেই কথা বলে। (§৬-এর চিত্র
4-9-permutationএই \(70\)টা \(T^*\)-এর histogram-এ পর্যবেক্ষিত \(5.5\) কোথায় পড়ে — লেজের কতটা চরমে — তা দেখাবে।)
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা resampling-এর কেন্দ্রীয় তিনটে যন্ত্র — bootstrap, jackknife, ও permutation test — এর সংজ্ঞা ও স্বজ্ঞা পেয়েছি: হাতে থাকা একটামাত্র নমুনা \(X_1,\dots,X_n\) থেকে নতুন "নকল নমুনা" তৈরি করে কোনো statistic \(\hat\theta\)-র অনিশ্চয়তা (SE, CI, bias) বের করা, কোনো বীজগণিতীয় সূত্র না জেনেই। এবার এই অংশে scratch থেকে সেই পদ্ধতিগুলোর পেছনের ফলগুলো উৎপাদন করব — কেন bootstrap কাজ করে (empirical CDF \(\hat F_n\) সত্য \(F\)-এর কাছে যায় বলে), percentile ও basic (pivotal) bootstrap CI কোথা থেকে আসে, jackknife-এর bias-সূত্রে ঠিক \((n-1)\) গুণ কেন, আর permutation test-এর null বণ্টন কেন exact। কোনো ধাপ লুকানো হবে না; প্রতিটি সমান-চিহ্নের পেছনে বাংলায় কারণ থাকবে। কাজটা চারটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে, sketch দিই):
- (a) bootstrap কেন কাজ করে — empirical CDF \(\hat F_n\to F\) (Glivenko–Cantelli স্বজ্ঞা), তাই \(\hat F_n\) থেকে resample করা \(\approx\) সত্য \(F\) থেকে নমুনা নেওয়া; আর bootstrap SE = replicate-গুলোর \(\hat\theta^*_b\)-এর standard deviation। ★★
- (b) percentile CI ও basic (pivotal) bootstrap CI-এর উৎপাদন — কোন যুক্তিতে replicate-গুলোর quantile সরাসরি confidence interval দেয়। ★★
- (c) jackknife bias estimate \(\widehat{\mathrm{bias}}=(n-1)(\bar\theta_{(\cdot)}-\hat\theta)\) ও variance — কেন ঠিক \((n-1)\) গুণ। ★★
- (d) permutation test-এর যুক্তি — \(H_0\) (দুই দলে কোনো পার্থক্য নেই)-এর অধীনে label-গুলো exchangeable, তাই label পুনর্বিন্যাসের বণ্টনই exact null। ★★
পুরোটা জুড়ে চারটে running example ব্যবহার করব: E1 bootstrap SE of mean, E2 bootstrap CI for median, E3 jackknife, আর E4 permutation test। শেষে bootstrap কোথায় ভাঙে (extremes/max) তা-ও সৎভাবে বলব।
একটা সাধারণ পরিভাষা আগে স্থির করি, কারণ পুরো §৪ এর ওপর দাঁড়িয়ে। হাতে আছে \(n\)টি i.i.d. পর্যবেক্ষণ \(X_1,\dots,X_n\), যারা কোনো অজানা distribution \(F\) থেকে এসেছে। আমরা একটা parameter \(\theta=\theta(F)\) (যেমন mean, median) আগ্রহী, আর তা data থেকে estimate করি একটা statistic \(\hat\theta=\hat\theta(X_1,\dots,X_n)\) দিয়ে। আসল প্রশ্ন সব সময় একটাই: \(\hat\theta\) কতটা টলটলে? — অর্থাৎ যদি আবার \(F\) থেকে নতুন \(n\)টা নমুনা নিতাম, \(\hat\theta\) কতটা ওঠানামা করত (তার sampling distribution, 3.5)? সমস্যা: \(F\) অজানা, আর নতুন নমুনা নেওয়ার উপায় নেই — হাতে শুধু এই একটাই নমুনা।
এক নজরে যা মনে রাখবেন। এই গোটা অংশের প্রাণ একটাই কৌশল — "\(F\) জানি না, তাই \(F\)-এর সবচেয়ে ভালো অনুমান \(\hat F_n\) দিয়েই কাজ চালাই" (plug-in principle)। তিনটে পদ্ধতি এই একই বুদ্ধির তিন রূপ: bootstrap \(\hat F_n\) থেকে নতুন নমুনা টানে (resample with replacement) — তাই SE/CI; jackknife একটা-একটা করে পর্যবেক্ষণ বাদ দিয়ে (leave-one-out) \(\hat\theta\) কতটা নড়ে দেখে — তাই bias/variance; permutation test দুই দলের label এলোমেলো করে দেখে "যদি দলভেদ অর্থহীন হতো তবে পার্থক্য কেমন হতো" — তাই exact \(p\)-value। মূল মন্ত্র: "computer-কে দিয়ে নমুনা তোলা/বাদ দেওয়া/মেশানো — সূত্রের বদলে পুনরাবৃত্তি (resampling replaces formulas)।"
৪.১ · (a) Bootstrap কেন কাজ করে — \(\hat F_n \to F\) থেকে — ★★¶
৪.১.১ · মূল ধারণা: plug-in দুবার¶
ধরা যাক আমরা \(\hat\theta\)-এর standard error চাই — অর্থাৎ $$ \mathrm{se}(\hat\theta)=\sqrt{\mathrm{Var}_F\big(\hat\theta(X_1,\dots,X_n)\big)}, $$ যেখানে subscript \(F\) মনে করায় — variance-টা নির্ভর করে data কোন distribution \(F\) থেকে এল তার উপর। এই রাশিটা দুটো কারণে সরাসরি হিসাব করা যায় না: (i) আমরা \(F\) জানি না; (ii) এমনকি \(F\) জানলেও, জটিল \(\hat\theta\) (যেমন median, correlation) -এর জন্য এই variance-এর বদ্ধ-রূপ সূত্র না-ও থাকতে পারে।
Bootstrap দুটো সমস্যাই একই চালে এড়ায়:
- সমস্যা (i)-র সমাধান — \(F\)-এর জায়গায় \(\hat F_n\) বসাও। \(F\) অজানা হলেও, data নিজেই \(F\)-এর একটা অনুমান দেয়: empirical CDF $$ \hat F_n(x)=\frac{1}{n}\sum_{i=1}^n \mathbf 1{X_i\le x} $$ — অর্থাৎ "\(x\)-এর সমান বা ছোট কতগুলো পর্যবেক্ষণ, তার ভগ্নাংশ"। এটা একটা ধাপে-ধাপে বাড়া (step) function, প্রতিটি \(X_i\)-তে \(1/n\) লাফ দেয়। সহজ কথায়: \(\hat F_n\) হলো সেই distribution যা মূল নমুনার \(n\)টা বিন্দুর প্রতিটিতে সমান \(1/n\) ভর বসায়।
- সমস্যা (ii)-র সমাধান — সূত্রের বদলে সিমুলেশন। variance-এর সূত্র না জানলেও, \(\hat F_n\) থেকে বারবার নমুনা তুলে \(\hat\theta\)-র ওঠানামা সরাসরি মেপে নেওয়া যায়।
৪.১.২ · "\(\hat F_n\) থেকে নমুনা তোলা" মানে কী — resampling with replacement¶
\(\hat F_n\) থেকে একটা পর্যবেক্ষণ টানা মানে কী? যেহেতু \(\hat F_n\) প্রতিটি \(X_i\)-তে \(1/n\) ভর বসায়, \(\hat F_n\) থেকে একটা মান টানা = মূল নমুনার \(n\)টা মান \(\{X_1,\dots,X_n\}\) থেকে সমান সম্ভাবনায় একটা বেছে নেওয়া। একটা পূর্ণ bootstrap resample \(X^*=(X_1^*,\dots,X_n^*)\) পেতে এই কাজটা \(n\) বার করি — ফেরত দিয়ে (with replacement), যাতে প্রতিবার পুরো \(n\)টা মানই সমান-সম্ভাব্য থাকে। তাই একই \(X_i\) একটা resample-এ দু-তিনবার আসতে পারে, আবার কিছু \(X_i\) একবারও না-ও আসতে পারে। এটাই "bootstrap resample"-এর সংজ্ঞা (§১-এ এসেছে), আর এখন বুঝলাম কেন ঠিক এভাবে — কারণ তা হুবহু \(\hat F_n\) থেকে \(n\)টা i.i.d. টানার সমান।
কেন "with replacement", "without" নয়? যদি ফেরত না দিতাম, \(n\)টা টানলে মূল নমুনাটাই (ক্রম এলোমেলো করে) ফিরে পেতাম — কোনো নতুন তথ্য নেই, ওঠানামাও নেই। ফেরত দিয়ে টানায় প্রতিটি resample সামান্য আলাদা গঠন পায় (কেউ দুবার, কেউ বাদ) — এই ভিন্নতাই \(\hat\theta^*\)-এর ওঠানামা তৈরি করে, যা সত্য sampling-ওঠানামার নকল।
৪.১.৩ · কেন এটা বৈধ — Glivenko–Cantelli (★★)¶
পুরো কৌশলটা একটা সূক্ষ্ম আশায় দাঁড়িয়ে: \(\hat F_n\) থেকে নমুনা তোলা \(\approx\) সত্য \(F\) থেকে নমুনা তোলা। এই আশা ন্যায্য কেন? কারণ বড় নমুনায় \(\hat F_n\) আসলে \(F\)-এর খুব কাছে।
প্রতিটি স্থির বিন্দু \(x\)-এ লক্ষ করুন — \(\hat F_n(x)=\frac1n\sum_i\mathbf 1\{X_i\le x\}\) হলো \(n\)টা i.i.d. indicator-এর গড়, আর প্রতিটি indicator-এর প্রত্যাশা \(\mathbb{E}[\mathbf 1\{X\le x\}]=P(X\le x)=F(x)\)। তাই law of large numbers (3.4) সরাসরি বলে: $$ \hat F_n(x)\;\xrightarrow{P}\;F(x)\qquad\text{প্রতিটি } x\text{-এ।} $$ অর্থাৎ যত বেশি data, \(\hat F_n\) ততই \(F\)-এর দিকে স্থির হয়। Glivenko–Cantelli উপপাদ্য এর জোরালো রূপ — কেবল প্রতিটি \(x\)-এ নয়, সব \(x\)-এ একসাথে (uniformly): $$ \boxed{\;\sup_x\,\big\lvert \hat F_n(x)-F(x)\big\rvert\;\xrightarrow{\text{a.s.}}\;0\quad(n\to\infty)\;} $$ ("statistics-এর fundamental theorem"-ও বলা হয়)। সরল ভাষায়: নমুনা বড় হলে empirical CDF গোটা সত্য CDF-কে যত খুশি কাছ থেকে নকল করে।
এখান থেকেই bootstrap-এর বৈধতা: \(\hat F_n\approx F\) হলে, "\(\hat F_n\) থেকে নমুনা তুলে \(\hat\theta\)-র ওঠানামা" \(\approx\) "\(F\) থেকে নমুনা তুলে \(\hat\theta\)-র ওঠানামা" — অর্থাৎ আসল sampling distribution। তাই আমরা যা মাপতে পারি না (সত্য \(F\)-এ ওঠানামা), তার বদলে যা মাপতে পারি (computer-এ \(\hat F_n\)-এ ওঠানামা) বসাই — আর বড় \(n\)-এ ভুল ছোট।
দুই স্তরের approximation — সৎ কথা। Bootstrap-এ আসলে দুটো আনুমানিক ধাপ: (১) statistical — \(\hat F_n\) দিয়ে \(F\) বদলানো (Glivenko–Cantelli দিয়ে ন্যায্য, ভুল \(\to 0\) যখন \(n\to\infty\)); (২) Monte-Carlo — \(\hat F_n\)-এর অধীনে আদর্শ bootstrap distribution-ও আমরা ঠিকঠাক বের করতে পারি না (তাতে \(n^n\)টা সম্ভাব্য resample), তাই \(B\)টা এলোমেলো resample তুলে আনুমানিক করি। দ্বিতীয় ভুল \(B\to\infty\)-তে \(\to 0\) — আর \(B\) আমাদের হাতে, তাই একে যত খুশি ছোট করা যায় (\(B=1000\)–\(10000\) সাধারণ)। মনে রাখার নিয়ম: \(n\) ঠিক করে bootstrap কতটা সঠিক হতে পারে; \(B\) ঠিক করে আমরা সেই সম্ভাব্যতার কতটা কাছে যাই।
৪.১.৪ · Bootstrap SE-এর সংজ্ঞা — replicate-গুলোর standard deviation¶
এবার সবকিছু একত্র করে bootstrap algorithm আর তার SE-সূত্র দাঁড় করাই (E1: mean-এর SE):
- resample। মূল নমুনা থেকে ফেরত দিয়ে \(n\)টা টেনে একটা \(X^*\) বানাও।
- recompute। সেই resample-এ statistic হিসাব করো: \(\hat\theta^*=\hat\theta(X^*)\)।
- পুনরাবৃত্তি। ধাপ ১–২ মোট \(B\) বার করো \(\Rightarrow\) replicate-গুলো \(\hat\theta^*_1,\dots,\hat\theta^*_B\)।
- SE = ছড়ানো মাপো। এই \(B\)টা replicate-এর standard deviation-ই bootstrap standard error: $$ \boxed{\;\widehat{\mathrm{se}}{\text{boot}}=\sqrt{\frac{1}{B-1}\sum\big(\hat\theta^}^{B_b-\bar\theta^\big)^2}\,,\qquad \bar\theta^=\frac1B\sum_{b=1}^B\hat\theta^_b\;} $$
কেন এই রাশিই SE? কারণ ধাপ ১-এর প্রতিটি \(X^*\) হলো \(\hat F_n\) (≈\(F\)) থেকে একটা নতুন কাল্পনিক নমুনা, তাই ধাপ ২-এর \(\hat\theta^*\) হলো সেই কাল্পনিক জগতে \(\hat\theta\)-র একটা realization। ফলে \(\{\hat\theta^*_b\}\) হলো \(\hat\theta\)-র sampling distribution-এর (bootstrap) নকল, আর তার standard deviation-ই \(\hat\theta\)-র standard error-এর অনুমান — ঠিক যেমন বহু সত্য নমুনা নিতে পারলে আমরা সেই \(\hat\theta\)-গুলোর sd নিতাম।
E1 — mean-এর bootstrap SE, এবং কেন তা \(\sigma/\sqrt n\)-এর সাথে মেলে (§৫ PART 1)। statistic \(\hat\theta=\bar X\) হলে আমরা ভাগ্যবান — এর সঠিক SE জানা: \(\mathrm{se}(\bar X)=\sigma/\sqrt n\) (2.4), যার plug-in অনুমান \(s/\sqrt n\)। তাই এটা bootstrap যাচাইয়ের আদর্শ ক্ষেত্র: \(\widehat{\mathrm{se}}_{\text{boot}}\) (কোনো সূত্র ছাড়া, শুধু resample করে) আর \(s/\sqrt n\) (সূত্র) প্রায় সমান হওয়া উচিত — §৫ PART 1 দেখাবে \(0.404\) বনাম \(0.407\), হুবহু কাছে। মূল শিক্ষা: যেখানে সূত্র আছে সেখানে bootstrap তা পুনরুৎপাদন করে (তাই আমরা একে বিশ্বাস করতে পারি), আর যেখানে সূত্র নেই (median, ৪.২) সেখানে এটাই একমাত্র সহজ পথ। (Figure
4-9-bootstrap-distএই \(\hat\theta^*_b\)-গুলোর histogram দেখাবে।)
৪.২ · (b) Percentile ও basic (pivotal) bootstrap CI — ★★¶
SE পেলেই অনেকে \(\hat\theta\pm 1.96\,\widehat{\mathrm{se}}_{\text{boot}}\) (Normal-approx CI) লিখে দেয়। কিন্তু এটা ধরে নেয় \(\hat\theta\) প্রায়-Normal ও symmetric — যা median বা skewed data-য় ভুল হতে পারে। Bootstrap-এর আসল শক্তি: replicate-গুলোর পুরো আকৃতি (skew সহ) ব্যবহার করে CI বানানো, Normality না ধরে। দুটো ক্লাসিক পদ্ধতি দেখাই।
৪.২.১ · Percentile CI — সরাসরি quantile¶
স্বজ্ঞাটা চমৎকার সরল। \(\{\hat\theta^*_b\}\) হলো \(\hat\theta\)-র sampling distribution-এর নকল। একটা distribution-এর "মাঝের \(95\%\)" পেতে আমরা এর \(2.5\) ও \(97.5\) percentile-এর মাঝের অংশ নিই। তাই:
Percentile CI (\(1-\alpha\) স্তর)। \(\hat\theta^*_b\)-গুলোকে ছোট-থেকে-বড় সাজিয়ে নাও; তাদের empirical \(\alpha/2\) ও \(1-\alpha/2\) quantile নাও। তখন $$ \boxed{\;\text{CI}{1-\alpha}=\Big[\,\hat\theta^_{(\alpha/2)},\ \ \hat\theta^ $$ (যেমন }\,\Big]\;\(95\%\)-এ \([\hat\theta^*_{(2.5\%)},\ \hat\theta^*_{(97.5\%)}]\))।
যুক্তি (heuristic)। আমরা চাই এমন একটা ব্যবধান \([a,b]\) যাতে \(P_F(a\le\hat\theta\le b)\approx 1-\alpha\)। সত্য sampling distribution জানা নেই, কিন্তু তার bootstrap-নকল \(\{\hat\theta^*_b\}\) জানা — তাই সেই নকল distribution-এরই মধ্য-\((1-\alpha)\) অংশ নিই। এর সবচেয়ে বড় গুণ: percentile CI transformation-respecting ও স্বয়ংক্রিয়ভাবে data-র range-এ থাকে — যেমন correlation \(\in[-1,1]\) বা variance \(>0\) হলে CI কখনও সীমা ছাড়ায় না (Normal-approx CI যা পারে)। আর skewed হলে CI-ও অসমভাবে ছড়ায় (এক পাশ লম্বা), যা ঠিক।
৪.২.২ · Basic (pivotal) CI — ত্রুটির বণ্টন থেকে¶
Percentile CI স্বজ্ঞাগত কিন্তু এর তাত্ত্বিক ভিত্তি কিছুটা পরোক্ষ। আরও যুক্তিনিষ্ঠ পথ pivot ধরে। ধরি error (ভুল) $$ \delta=\hat\theta-\theta. $$ যদি \(\delta\)-র distribution জানতাম, আমরা এমন \(\ell,u\) পেতাম যাতে \(P(\ell\le\delta\le u)=1-\alpha\), অর্থাৎ \(P(\ell\le\hat\theta-\theta\le u)=1-\alpha\)। এটা \(\theta\)-র জন্য সাজালে (তিন রাশি থেকে \(\hat\theta\) বিয়োগ, \(-1\) গুণ করে দিক উল্টে): $$ P\big(\hat\theta-u\ \le\ \theta\ \le\ \hat\theta-\ell\big)=1-\alpha \quad\Longrightarrow\quad \text{CI}=[\hat\theta-u,\ \hat\theta-\ell]. $$ সমস্যা — \(\delta=\hat\theta-\theta\)-র distribution অজানা (\(\theta\) অজানা)। Bootstrap-এর মূল চাল: \(\delta\)-কে নকল করো এর bootstrap-সংস্করণ \(\delta^*=\hat\theta^*-\hat\theta\) দিয়ে। (লক্ষ করুন কাঠামোগত সাদৃশ্য: সত্য জগতে \(\hat\theta\) ওঠে সত্য \(\theta\)-র চারপাশে; bootstrap জগতে \(\hat\theta^*\) ওঠে "সত্য মান" \(\hat\theta\)-র চারপাশে — তাই \(\hat\theta^*-\hat\theta\) হলো \(\hat\theta-\theta\)-র সঠিক নকল।) তাহলে \(\ell,u\)-র জায়গায় \(\delta^*\)-এর quantile বসাই: \(\ell\approx \hat\theta^*_{(\alpha/2)}-\hat\theta\) এবং \(u\approx \hat\theta^*_{(1-\alpha/2)}-\hat\theta\)। বসিয়ে:
(\(2\hat\theta\) এল কারণ \(\hat\theta-(\hat\theta^*_{(\cdot)}-\hat\theta)=2\hat\theta-\hat\theta^*_{(\cdot)}\))। লক্ষ করুন — basic CI percentile CI-কে \(\hat\theta\)-র চারপাশে আয়না-প্রতিফলিত করে: percentile-এর উপরের quantile basic-এর নিচের প্রান্ত হয়, এবং উল্টোটা। তাই symmetric replicate-এ দুটো মিলে যায়, কিন্তু skewed হলে আলাদা হয় — §৫ PART 2 ঠিক এই পার্থক্য সংখ্যায় দেখাবে।
কোনটা কখন? percentile সবচেয়ে জনপ্রিয় (সরল, range-সম্মানী, transformation-নিরপেক্ষ), কিন্তু সামান্য bias থাকলে ভুল দিকে সরতে পারে। basic/pivotal error-distribution-এর যুক্তিতে বেশি ন্যায্য, তবে কখনও অস্বাভাবিক সীমা দিতে পারে (যেমন variance-এ ঋণাত্মক প্রান্ত)। আরও উন্নত BCa (bias-corrected & accelerated, Wasserman §8.3) দুটোর সেরা মেলায় — পরের কোর্সে। এক বাক্যে: percentile = "replicate-গুলোর মধ্যভাগ"; basic = "error-এর নকল ঘুরিয়ে \(\hat\theta\)-তে বসানো"। (Figure
4-9-bootstrap-ciদুটো প্রান্ত replicate-histogram-এর উপর চিহ্নিত করবে।)E2 — median-এর CI, কেন এখানে bootstrap অপরিহার্য (§৫ PART 2)। mean-এর SE-র সহজ সূত্র আছে, কিন্তু median-এর নেই (এর asymptotic variance \(1/(4 n f(m)^2)\)-তে অজানা density \(f\) থাকে — অনুমান করা কঠিন)। তাই median-এ bootstrap কাগুজে সূত্রের একমাত্র সহজ বিকল্প: শুধু প্রতিটি resample-এর median নিয়ে percentile quantile পড়ে নাও। §৫ PART 2-তে একটা skewed (Exponential) নমুনায় \(95\%\) percentile CI \([2.146,\ 4.317]\) পাব, যা সত্য median \(2.773\)-কে ঢেকে রাখে — কোনো density-অনুমান ছাড়াই।
৪.৩ · (c) Jackknife — bias ও variance, কেন \((n-1)\) গুণ — ★★¶
Jackknife bootstrap-এর পূর্বসূরি ও সরলতর আত্মীয়: এলোমেলো resample না করে, একটা-একটা করে পর্যবেক্ষণ বাদ দিয়ে (leave-one-out) দেখে \(\hat\theta\) কতটা নড়ে। মূলত bias ও variance estimate-এ ব্যবহৃত।
৪.৩.১ · Leave-one-out replicate¶
\(i\)-তম পর্যবেক্ষণ বাদ দিয়ে বাকি \(n-1\)টা দিয়ে statistic হিসাব করি: $$ \hat\theta_{(i)}=\hat\theta\big(X_1,\dots,X_{i-1},X_{i+1},\dots,X_n\big),\qquad i=1,\dots,n. $$ এই \(n\)টা leave-one-out replicate, আর তাদের গড় $$ \bar\theta_{(\cdot)}=\frac1n\sum_{i=1}^n\hat\theta_{(i)}. $$
৪.৩.২ · Bias estimate — কেন ঠিক \((n-1)\) গুণ (★★)¶
অনেক estimator-এর bias বড় নমুনায় \(1/n\)-এর মতো করে কমে — একটা স্বাভাবিক রূপ ধরা যাক: $$ \mathbb{E}[\hat\theta_n]=\theta+\frac{a}{n}+O!\Big(\frac{1}{n^2}\Big), $$ যেখানে \(a\) একটা (অজানা) ধ্রুবক — তাই bias \(\approx a/n\)। (E3-এ দেখব plug-in variance-এর ক্ষেত্রে এটা হুবহু খাটে, \(a=-\sigma^2\)।) মূল চাল: একই estimator কিন্তু \(n-1\) আকারের নমুনায় (leave-one-out) তার গড় bias $$ \mathbb{E}[\hat\theta_{(i)}]\approx\theta+\frac{a}{n-1}. $$ দুটো বিয়োগ করি — \(\theta\) কেটে যায়, পড়ে থাকে শুধু bias-পদের পার্থক্য: $$ \mathbb{E}[\hat\theta_{(i)}]-\mathbb{E}[\hat\theta_n]\approx a\Big(\frac{1}{n-1}-\frac1n\Big)=a\cdot\frac{n-(n-1)}{n(n-1)}=\frac{a}{n(n-1)}. $$ এখন \(\bar\theta_{(\cdot)}\) হলো \(\hat\theta_{(i)}\)-গুলোর গড় (প্রত্যাশায় \(\approx\theta+\frac{a}{n-1}\)), আর \(\hat\theta=\hat\theta_n\)। বাঁ পাশকে \(\bar\theta_{(\cdot)}-\hat\theta\) ধরে \((n-1)\) গুণ করি — তাতে ডান পাশের হর থেকে \((n-1)\) কাটে আর আসল bias \(a/n\) ফিরে আসে: $$ (n-1)\big(\bar\theta_{(\cdot)}-\hat\theta\big)\approx (n-1)\cdot\frac{a}{n(n-1)}=\frac{a}{n}\approx\widehat{\mathrm{bias}}. $$ তাই: $$ \boxed{\;\widehat{\mathrm{bias}}{\text{jack}}=(n-1)\big(\bar\theta $$ এখানেই }-\hat\theta\big)\;\((n-1)\) গুণের রহস্য: leave-one-out করায় bias-এর পরিবর্তন এত ছোট (\(\sim\frac{1}{n(n-1)}\)) যে আসল bias (\(\sim\frac1n\)) ফিরে পেতে ঠিক \((n-1)\) দিয়ে বিবর্ধন (amplify) করতে হয়। আর bias-corrected estimate: $$ \hat\theta_{\text{jack}}=\hat\theta-\widehat{\mathrm{bias}}{\text{jack}}=n\hat\theta-(n-1)\bar\theta. $$
৪.৩.৩ · Variance estimate¶
একই leave-one-out replicate দিয়ে \(\hat\theta\)-র variance-ও অনুমান করা যায়। সূত্রটা (Tukey): $$ \boxed{\;\widehat{\mathrm{Var}}{\text{jack}}=\frac{n-1}{n}\sum $$ এখানে সাধারণ sample-variance-এর উল্টো — }^n\big(\hat\theta_{(i)}-\bar\theta_{(\cdot)}\big)^2\;\(\frac{1}{n-1}\) নয়, \(\frac{n-1}{n}\) (প্রায় \(n\) গুণ বড়) গুণক। কারণ একই কথা: leave-one-out replicate-গুলো একে অপরের খুব কাছাকাছি (মাত্র একটা বিন্দুর তফাত), তাই তাদের নিজেদের ছড়ানো সত্য SE-র চেয়ে অনেক ছোট — সেই সংকোচন পুষিয়ে নিতে \((n-1)\)-জাতীয় বড় গুণক লাগে। (মূল কথা মনে রাখুন: jackknife-এর দুটো সূত্রেই বড় গুণক আসে কারণ leave-one-out ইচ্ছাকৃতভাবে সামান্য নাড়ায়, তাই সংকেত বাড়িয়ে পড়তে হয়।)
E3 — plug-in variance-এর bias, সংখ্যায় (§৫ PART 3)। statistic হিসেবে নিই plug-in variance \(\hat\theta=\frac1n\sum_i(X_i-\bar X)^2\) (যা \(n\) দিয়ে ভাগ করে, \(n-1\) নয়)। এর bias সুপরিচিত ও হুবহু জানা: \(\mathbb{E}[\hat\theta]=\frac{n-1}{n}\sigma^2=\sigma^2-\frac{\sigma^2}{n}\), তাই bias \(=-\sigma^2/n\) (অর্থাৎ উপরের \(a=-\sigma^2\))। §৫ PART 3 দেখাবে jackknife bias estimate \(\approx-0.166\), যা তাত্ত্বিক \(-\sigma^2/n=-0.18\)-এর কাছে; আর bias বিয়োগ করলে estimate ঠিক unbiased \(\frac{1}{n-1}\sum(X_i-\bar X)^2\)-এ পৌঁছায়। এটাই jackknife-এর সৌন্দর্য — সূত্র না জেনেও সে নিজে থেকে bias খুঁজে শুধরে দেয়। (Figure
4-9-jackknife\(\hat\theta_{(i)}\)-গুলো ও তাদের গড় বনাম \(\hat\theta\) দেখাবে।)Jackknife বনাম bootstrap। jackknife নির্ণায়ক (deterministic) — কোনো এলোমেলোতা নেই, ঠিক \(n\)টা hisaব, একই data-য় সব সময় একই উত্তর; তাই smooth statistic (mean, variance)-এ দ্রুত ও পরিষ্কার। কিন্তু non-smooth statistic-এ (যেমন median) jackknife অসঙ্গত (inconsistent) — একটা বিন্দু বাদ দিলে median প্রায়ই লাফিয়ে ওঠে, মসৃণভাবে নড়ে না, তাই variance-অনুমান বিগড়ে যায়। সেখানে bootstrap-ই ভরসা। নিয়ম: smooth \(\to\) jackknife চলে; non-smooth/median \(\to\) bootstrap।
৪.৪ · (d) Permutation test — কেন null বণ্টন exact — ★★¶
শেষ যন্ত্রটা একটু আলাদা স্বাদের: SE/CI নয়, এটা একটা hypothesis test। সাধারণ প্রশ্ন — দুটো দল A (\(n_A\)টা মান) ও B (\(n_B\)টা মান)-এর মধ্যে কি সত্যিই পার্থক্য আছে, নাকি যা দেখছি তা নিছক এলোমেলো? Permutation test এর উত্তর দেয় কোনো distribution না ধরে, শুধু একটা সরল যুক্তিতে।
৪.৪.১ · Null hypothesis ও exchangeability¶
ধরি দুই দলের মান \(A_1,\dots,A_{n_A}\) আর \(B_1,\dots,B_{n_B}\)। null: $$ H_0:\ \text{দুই দল একই distribution থেকে আসে (কোনো দল-পার্থক্য নেই)।} $$ এই \(H_0\)-র একটা শক্তিশালী পরিণতি: যদি দুই দল সত্যিই একই distribution থেকে আসে, তবে কোন মানের গায়ে "A" আর কোনটার গায়ে "B" label সাঁটা — তা সম্পূর্ণ অর্থহীন। সব \(n=n_A+n_B\)টা মান তখন বিনিময়যোগ্য (exchangeable): তাদের যেকোনো পুনর্বিন্যাস (permutation) ঠিক সমান-সম্ভাব্য। সহজ ছবি — \(H_0\) সত্য হলে label-গুলো যেন একগাদা একই রকম বল-এ এলোমেলোভাবে আটকানো রঙিন স্টিকার; স্টিকার অদলবদল করলে data-র সম্ভাবনা বিন্দুমাত্র বদলায় না।
৪.৪.২ · Permutation distribution = exact null¶
এই exchangeability-ই permutation test-এর পুরো ভিত্তি। ধাপগুলো (E4: difference of means):
- observed statistic। আগ্রহের পার্থক্য মাপো, যেমন \(T_{\text{obs}}=\bar A-\bar B\)।
- pool ও permute। সব \(n\)টা মান একসাথে মিশিয়ে দাও; তারপর এলোমেলোভাবে \(n_A\)টাকে "নতুন A", বাকি \(n_B\)টাকে "নতুন B" label দাও — অর্থাৎ label-গুলো shuffle করো।
- recompute। এই permuted বিভাজনে statistic হিসাব করো: \(T^*=\bar A^*-\bar B^*\)।
- পুনরাবৃত্তি ও তুলনা। ধাপ ২–৩ বহুবার (সব \(\binom{n}{n_A}\)টা permutation, বা যথেষ্ট বড় এলোমেলো \(P\) সংখ্যক) করে permutation distribution \(\{T^*\}\) বানাও।
কেন এই \(\{T^*\}\) ঠিক null distribution — আর কেন exact? এটাই মূল যুক্তি। \(H_0\)-র অধীনে সব label-বিন্যাস সমান-সম্ভাব্য (exchangeability, ৪.৪.১)। তাই আমরা যে বিন্যাসটা আসলে দেখেছি (observed), সেটা ওই সমান-সম্ভাব্য বিন্যাসগুলোর মধ্যে নিছক একটা — বিশেষ কিছু নয়। সব বিন্যাসে \(T\) হিসাব করলে যা পাই, সেটাই "\(H_0\) সত্য হলে \(T\) কী কী মান, কোনটা কতটা সম্ভাব্য" — অর্থাৎ \(T\)-এর সঠিক null distribution। এখানে কোনো CLT, কোনো Normality, কোনো \(n\to\infty\) লাগেনি — শুধু "label সমান-সম্ভাব্য" এই সত্যটুকু গুনে ফেলা। সেজন্যই বণ্টনটা exact (আনুমানিক নয়), যেকোনো নমুনা-আকারে।
৪.৪.৩ · \(p\)-value¶
observed \(T_{\text{obs}}\) এই null distribution-এর কোথায় পড়ে, সেটাই \(p\)-value। দুই-পার্শ্বিক (two-sided): $$ \boxed{\;p=\frac{#{\,b:\ \lvert T^*b\rvert\ \ge\ \lvert T $$ অর্থাৎ "permuted জগতে কত ভগ্নাংশ পুনর্বিন্যাস observed-এর সমান বা তার চেয়েও চরম পার্থক্য দিল"। লব-হরে }}\rvert\,}+1}{P+1}\;\(+1\) যোগ করা হয় কারণ observed বিন্যাসটা নিজেও null-এর অধীনে একটা বৈধ বিন্যাস — একে গোনায় ধরলে \(p\) কখনও \(0\) হয় না এবং test-টা ঠিকঠাক বৈধ (valid) থাকে। \(p\) ছোট মানে — observed পার্থক্য এত বড় যে নিছক label-এলোমেলোয় এমন কদাচিৎ ঘটে, তাই \(H_0\) সন্দেহজনক \(\Rightarrow\) \(H_0\) বাতিল।
স্বজ্ঞা — "যদি label-এর কোনো মানে না থাকত"। permutation test যা জিজ্ঞেস করে: "ধরা যাক A/B তকমার কোনো অর্থ নেই — তাহলে নিছক ভাগ্যে দুই দলের গড়ের এমন (বা আরও বড়) ব্যবধান কতবার আসত?" যদি প্রায়ই আসে (\(p\) বড়), observed ব্যবধান বিশেষ কিছু নয়। যদি কদাচিৎ আসে (\(p\) ছোট), তবে label-এর সত্যিই মানে আছে — দল-পার্থক্য বাস্তব। (Figure
4-9-permutation\(\{T^*\}\)-এর histogram-এ \(T_{\text{obs}}\)-কে একটা খাড়া রেখায় দেখাবে — tail-এ কতটা দূরে।)E4 — দুই-দল difference of means, সংখ্যায় (§৫ PART 4)। §৫ PART 4-এ A (\(n_A=40\)) ও B (\(n_B=45\), এতে সত্যিকারের \(+0.8\) স্থানান্তর গাঁথা) থেকে observed \(T_{\text{obs}}=\bar A-\bar B=-0.584\) পাব। \(20{,}000\) বার label shuffle করে permutation distribution গড় \(\approx 0\)-তে কেন্দ্রিত (যেমন হওয়া উচিত — label-এ মানে না থাকলে \(\bar A-\bar B\) গড়ে শূন্য)। two-sided \(p\approx 0.013\) — যা Welch \(t\)-test-এর \(p\approx 0.015\)-এর খুব কাছে, কিন্তু কোনো Normality না ধরেই পাওয়া। তাই \(H_0\) (\(\alpha=0.05\)-এ) বাতিল: দল-পার্থক্য বাস্তব।
৪.৫ · কখন bootstrap/resampling ভেঙে পড়ে — সৎ সীমা¶
Resampling জাদুর মতো মনে হলেও সর্বরোগহর নয়। কোথায় সাবধান, তা না বললে অর্ধসত্য বলা হবে:
- (১) Extremes/max-min — সবচেয়ে কুখ্যাত ব্যর্থতা। ধরা যাক \(\hat\theta=\max(X_1,\dots,X_n)\)। মূল নমুনার সর্বোচ্চ মান, ধরা যাক \(X_{(n)}\) — bootstrap resample-এ এর বেশি কিছু কখনও আসতে পারে না (resample তো মূল মানগুলোর ভেতর থেকেই টানা)। ফলে অনেক resample-এ \(\hat\theta^*=X_{(n)}\) ঠিক একই মানে আটকে থাকে; bootstrap distribution-টা সত্য (মসৃণ) sampling distribution-এর বদলে \(X_{(n)}\)-তে একটা মোটা পিণ্ড দেখায়। কারণ মূলে: Glivenko–Cantelli বলে \(\hat F_n\to F\) শরীরে (bulk), কিন্তু লেজের একদম প্রান্ত (extreme quantile) ভালো নকল করে না — আর max ঠিক সেই প্রান্তের উপরই দাঁড়িয়ে। নিয়ম: max, min, range, বা চরম quantile-এ সাধারণ bootstrap অবিশ্বাস্য; এদের জন্য বিশেষ extreme-value পদ্ধতি লাগে।
- (২) ছোট \(n\)। পুরো ভিত্তি \(\hat F_n\approx F\); কিন্তু \(n\) ছোট (\(n\lesssim 10\)) হলে \(\hat F_n\) সত্য \(F\)-এর দুর্বল ছবি, তাই bootstrap SE/CI অবিশ্বস্ত। resampling data বাড়ায় না — শুধু হাতে-থাকা data-র তথ্যটুকু নিংড়ে বের করে। নমুনায় যা নেই, bootstrap তা সৃষ্টি করতে পারে না।
- (৩) অ-স্বাধীন বা গঠনযুক্ত data। সরল bootstrap ধরে নেয় পর্যবেক্ষণগুলো i.i.d.। time series (পরপর মান সম্পর্কিত) বা clustered data-য় একটা-একটা বিন্দু আলাদা করে resample করলে নির্ভরতা-গঠন ভেঙে যায় — তখন block bootstrap-জাতীয় বিশেষ রূপ লাগে (পরের কোর্স)।
- (৪) ভারী-লেজ (heavy-tailed) ও অসীম variance। variance অসীম হলে (যেমন Cauchy) mean-এর bootstrap distribution স্থিতিশীল হয় না।
সার-সতর্কতা। resampling সবচেয়ে নির্ভরযোগ্য যখন statistic-টা data-র মসৃণ (smooth) ফাংশন (mean, variance, ratio, correlation, regression coefficient) আর \(n\) যথেষ্ট বড়, পর্যবেক্ষণ i.i.d.। চরম-নির্ভর statistic (max/min/extreme quantile), ক্ষুদ্র নমুনা, বা নির্ভরশীল data-য় বাড়তি সাবধানতা ও বিশেষায়িত পদ্ধতি দরকার। মূল কথা: bootstrap "\(\hat F_n\approx F\)"-এর উপর দাঁড়ায় — যেখানে এই approximation ভালো, সেখানে bootstrap ভালো; যেখানে নয় (লেজের প্রান্ত, ছোট \(n\)), সেখানে নয়।
§৪-এর সার (Figure
4-9-bootstrap-dist,4-9-bootstrap-ci,4-9-jackknife,4-9-permutationদেখাবে)। তিনটে resampling-যন্ত্র একই plug-in বুদ্ধির রূপ — bootstrap \(\hat F_n\) থেকে ফেরত দিয়ে resample করে (\(\hat F_n\to F\), Glivenko–Cantelli), replicate-গুলোর sd = \(\widehat{\mathrm{se}}_{\text{boot}}\), আর তাদের quantile = percentile/basic CI; jackknife leave-one-out করে bias \(=(n-1)(\bar\theta_{(\cdot)}-\hat\theta)\) ও variance বের করে; permutation test label exchangeable ধরে exact null বানিয়ে \(p\)-value দেয়। সবগুলোই সূত্রের বদলে computer-এ পুনরাবৃত্তি — তবে extremes, ছোট \(n\), বা নির্ভরশীল data-য় সাবধান। পরের §৫-এ এই সব ফল সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর ফলগুলো আমরা সংখ্যায় যাচাই করব — যাতে bootstrap SE, percentile/basic CI, jackknife bias, আর permutation \(p\)-value কাগজে নয় শুধু, computer-এও বিশ্বাসযোগ্য হয়। চারটে অংশ, §৪-এর কাঠামো অনুসরণ করে:
- PART 1 — bootstrap SE of mean (§৪.১)। একটা Normal নমুনায় \(B\)টা resample তুলে \(\hat\theta^*_b=\bar X^*\) বের করব, তাদের sd (\(\widehat{\mathrm{se}}_{\text{boot}}\)) হিসাব করব, আর দেখব তা plug-in \(s/\sqrt n\) ও analytic \(\sigma/\sqrt n\)-এর সাথে মেলে — (a)-র সরাসরি যাচাই।
- PART 2 — bootstrap percentile CI for median (§৪.২)। একটা skewed (Exponential) নমুনায় প্রতিটি resample-এর median নিয়ে \(95\%\) percentile ও basic CI বানাব, আর দেখব তারা সত্য median ঢেকে রাখে — median-এ bootstrap কেন অপরিহার্য।
- PART 3 — jackknife bias/variance (§৪.৩)। plug-in variance-এর (\(n\) দিয়ে ভাগ) leave-one-out replicate দিয়ে \(\widehat{\mathrm{bias}}=(n-1)(\bar\theta_{(\cdot)}-\hat\theta)\) ও \(\widehat{\mathrm{Var}}_{\text{jack}}\) বের করব, তাত্ত্বিক bias \(-\sigma^2/n\)-এর সাথে মেলাব।
- PART 4 — permutation test (§৪.৪)। দুই দলের difference of means-এ label shuffle করে exact null বানাব, two-sided \(p\)-value নেব, Welch \(t\)-test-এর সাথে মিলিয়ে সিদ্ধান্ত দেব।
সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। (scipy.stats শুধু PART 4-এ Welch \(t\)-test-এর সাথে তুলনায়; মূল resampling পুরোটাই খাঁটি numpy-তে।) নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয়।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.9 - The Bootstrap, Jackknife & Resampling : Code Lab
# Numerically illustrates / verifies (sections 4 & 5):
# PART 1 - BOOTSTRAP SE of the mean: resample with replacement B times,
# sd of the bootstrap replicates ~ sigma/sqrt(n) (the analytic SE).
# PART 2 - BOOTSTRAP PERCENTILE CI for the MEDIAN (no formula needed):
# the 2.5% and 97.5% empirical quantiles of theta*_b.
# PART 3 - JACKKNIFE bias & variance: leave-one-out replicates,
# bias_hat = (n-1)(mean(theta_(.)) - theta_hat), var_jack.
# PART 4 - PERMUTATION TEST for a two-group difference of means:
# shuffle labels under H0 (exchangeability) to build the exact null,
# p-value = fraction of permuted |diff| >= observed |diff|.
# Reproducible: numpy default_rng with a fixed seed. scipy only for a
# Normal-quantile cross-check in PART 1 and a t-test compare in PART 4.
import numpy as np
from scipy import stats
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=6, suppress=True)
# ===========================================================================
# PART 1 - BOOTSTRAP STANDARD ERROR of the mean, compared to sigma/sqrt(n).
# Draw one sample X_1..X_n ~ Normal(mu, sigma^2). The statistic is xbar.
# Bootstrap: draw B resamples X* (size n, WITH replacement) from the sample,
# recompute the mean each time -> theta*_1..theta*_B. se_boot = sd of those.
# For the mean the analytic SE is sigma/sqrt(n); the plug-in estimate is
# s/sqrt(n). All three should agree.
# ===========================================================================
print("=" * 74)
print("PART 1 - Bootstrap SE of the mean vs analytic sigma/sqrt(n)")
print("=" * 74)
mu_true, sigma_true = 10.0, 3.0
n = 50
B = 10_000 # bootstrap replications
x = rng.normal(mu_true, sigma_true, size=n) # the ONE observed sample
theta_hat = x.mean() # statistic on the original data
idx = rng.integers(0, n, size=(B, n)) # each row = indices of one X*
boot_samp = x[idx] # shape (B, n): the resamples
theta_star = boot_samp.mean(axis=1) # theta*_b for b = 1..B
se_boot = theta_star.std(ddof=1) # bootstrap SE = sd of replicates
se_plugin = x.std(ddof=1) / np.sqrt(n) # textbook SE s / sqrt(n)
se_analytic = sigma_true / np.sqrt(n) # true SE sigma / sqrt(n)
print(f"\n n={n}, B={B}, sample mean theta_hat = {theta_hat:.5f}")
print(f" {'estimator of SE(xbar)':<34}{'value':>10}")
print(" " + "-" * 44)
print(f" {'bootstrap sd(theta*_b)':<34}{se_boot:>10.5f}")
print(f" {'plug-in s/sqrt(n)':<34}{se_plugin:>10.5f}")
print(f" {'analytic sigma/sqrt(n)':<34}{se_analytic:>10.5f}")
print(f"\n mean of bootstrap replicates = {theta_star.mean():.5f} (~ theta_hat,"
f" bootstrap ~unbiased for the mean)")
print(" Read-off: the bootstrap SE (using NO formula, only resampling) matches")
print(" the plug-in s/sqrt(n) and the analytic sigma/sqrt(n) - resampling from")
print(" the empirical CDF Fhat reproduces the sampling variability of xbar.")
# ===========================================================================
# PART 2 - BOOTSTRAP PERCENTILE CI for the MEDIAN.
# The median has no simple closed-form SE, so the bootstrap shines here.
# Draw B resamples, take the median of each -> theta*_b, then the percentile
# 95% CI is [ q_{2.5%}(theta*) , q_{97.5%}(theta*) ].
# We also report the basic (pivotal) bootstrap CI to compare.
# ===========================================================================
print("\n" + "=" * 74)
print("PART 2 - Bootstrap percentile CI for the median (no closed-form needed)")
print("=" * 74)
# A right-skewed sample (Exponential): median != mean, so a real test for CIs.
y = rng.exponential(scale=4.0, size=n) # true median = 4*ln(2) ~ 2.7726
med_hat = np.median(y)
idxM = rng.integers(0, n, size=(B, n))
med_star = np.median(y[idxM], axis=1) # bootstrap medians theta*_b
alpha = 0.05
lo_pct, hi_pct = np.quantile(med_star, [alpha/2, 1 - alpha/2]) # percentile CI
# Basic / pivotal CI: 2*theta_hat - upper/lower percentiles (reflects skew).
lo_basic = 2*med_hat - hi_pct
hi_basic = 2*med_hat - lo_pct
se_med_boot = med_star.std(ddof=1)
print(f"\n n={n}, B={B}. sample median theta_hat = {med_hat:.5f}")
print(f" true median of Exp(scale=4) = 4*ln2 = {4*np.log(2):.5f}")
print(f" bootstrap SE of the median = {se_med_boot:.5f}")
print(f"\n 95% percentile CI : [{lo_pct:.5f}, {hi_pct:.5f}]")
print(f" 95% basic/pivotal : [{lo_basic:.5f}, {hi_basic:.5f}]")
print(" Read-off: with NO standard-error formula for the median, the percentile")
print(" CI is just the 2.5%/97.5% quantiles of the bootstrap medians; it covers")
print(" the true median 2.7726. Percentile vs basic differ a little under skew.")
# ===========================================================================
# PART 3 - JACKKNIFE bias and variance (leave-one-out).
# theta_(i) = statistic computed leaving out observation i.
# bias_hat = (n-1) ( mean_i theta_(i) - theta_hat )
# var_jack = (n-1)/n * sum_i ( theta_(i) - mean theta_(.) )^2
# We use a deliberately BIASED statistic - the plug-in variance
# (1/n) sum (x-xbar)^2 - whose known small-sample bias is -sigma^2/n,
# so the jackknife bias estimate should be ~ negative and of that size.
# ===========================================================================
print("\n" + "=" * 74)
print("PART 3 - Jackknife bias & variance (leave-one-out)")
print("=" * 74)
# Statistic: plug-in (biased, /n) variance of x (the PART-1 sample).
def plugin_var(data):
return np.mean((data - data.mean())**2) # divides by n, NOT n-1
theta_hat_v = plugin_var(x)
# Leave-one-out replicates theta_(i):
theta_loo = np.array([plugin_var(np.delete(x, i)) for i in range(n)])
theta_dot = theta_loo.mean() # mean of LOO replicates
bias_jack = (n - 1) * (theta_dot - theta_hat_v) # jackknife bias estimate
var_jack = (n - 1) / n * np.sum((theta_loo - theta_dot)**2)
se_jack = np.sqrt(var_jack)
theta_corrected = theta_hat_v - bias_jack # bias-corrected estimate
print(f"\n n={n}. statistic = plug-in variance (1/n) sum (x-xbar)^2")
print(f" theta_hat (plug-in var, /n) = {theta_hat_v:.5f}")
print(f" unbiased var (/ (n-1)) for compare = {x.var(ddof=1):.5f}")
print(f" jackknife bias estimate = {bias_jack:.5f}")
print(f" theoretical bias of plug-in var = -sigma^2/n = {-sigma_true**2/n:.5f}")
print(f" bias-corrected estimate = {theta_corrected:.5f}")
print(f" jackknife SE of the statistic = {se_jack:.5f}")
print(" Read-off: the plug-in variance under-estimates (divides by n); the")
print(" jackknife bias estimate is negative and close to the known -sigma^2/n,")
print(" and subtracting it pushes the estimate toward the unbiased /(n-1) value.")
# ===========================================================================
# PART 4 - PERMUTATION TEST: two-group difference of means.
# H0: the two groups have the same distribution (labels are exchangeable).
# Statistic: T = mean(A) - mean(B). Pool the data, repeatedly SHUFFLE the
# group labels, recompute T -> permutation (exact null) distribution.
# Two-sided p-value = fraction of |T_perm| >= |T_obs|.
# ===========================================================================
print("\n" + "=" * 74)
print("PART 4 - Permutation test: two-group difference of means")
print("=" * 74)
nA, nB = 40, 45
groupA = rng.normal(0.0, 1.0, size=nA) # control
groupB = rng.normal(0.8, 1.0, size=nB) # treatment: a real +0.8 shift
T_obs = groupA.mean() - groupB.mean() # observed difference
pooled = np.concatenate([groupA, groupB])
N = nA + nB
P = 20_000 # number of permutations
T_perm = np.empty(P)
for p in range(P):
perm = rng.permutation(pooled) # shuffle all labels under H0
T_perm[p] = perm[:nA].mean() - perm[nA:].mean()
# Two-sided p-value with the +1/+1 correction (counts the observed arrangement).
p_perm = (np.sum(np.abs(T_perm) >= abs(T_obs)) + 1) / (P + 1)
print(f"\n nA={nA}, nB={nB}, permutations P={P}")
print(f" observed mean(A)-mean(B) T_obs = {T_obs:.5f}")
print(f" permutation null: mean(T_perm) = {T_perm.mean():.5f} (~ 0 under H0)")
print(f" sd(T_perm) = {T_perm.std(ddof=1):.5f}")
print(f" two-sided permutation p-value = {p_perm:.5f}")
print(f" (compare) Welch t-test p-value = {stats.ttest_ind(groupA, groupB, equal_var=False).pvalue:.5f}")
print(f" reject H0 at alpha={alpha}? {p_perm < alpha}")
print(" Read-off: under H0 the labels are exchangeable, so reshuffling them gives")
print(" the EXACT null distribution of the difference (centred at 0); the observed")
print(" gap is far in the tail -> small p-value -> reject 'no difference'.")
print("\n[done] all parts ran.")
৫.২ · বাস্তব আউটপুট ও পাঠোদ্ধার¶
স্ক্রিপ্টটা চালালে নিচের আউটপুট পাওয়া যায় (হুবহু, seed 20260619):
==========================================================================
PART 1 - Bootstrap SE of the mean vs analytic sigma/sqrt(n)
==========================================================================
n=50, B=10000, sample mean theta_hat = 9.13730
estimator of SE(xbar) value
--------------------------------------------
bootstrap sd(theta*_b) 0.40413
plug-in s/sqrt(n) 0.40714
analytic sigma/sqrt(n) 0.42426
mean of bootstrap replicates = 9.13630 (~ theta_hat, bootstrap ~unbiased for the mean)
Read-off: the bootstrap SE (using NO formula, only resampling) matches
the plug-in s/sqrt(n) and the analytic sigma/sqrt(n) - resampling from
the empirical CDF Fhat reproduces the sampling variability of xbar.
==========================================================================
PART 2 - Bootstrap percentile CI for the median (no closed-form needed)
==========================================================================
n=50, B=10000. sample median theta_hat = 3.18366
true median of Exp(scale=4) = 4*ln2 = 2.77259
bootstrap SE of the median = 0.51336
95% percentile CI : [2.14649, 4.31741]
95% basic/pivotal : [2.04991, 4.22083]
Read-off: with NO standard-error formula for the median, the percentile
CI is just the 2.5%/97.5% quantiles of the bootstrap medians; it covers
the true median 2.7726. Percentile vs basic differ a little under skew.
==========================================================================
PART 3 - Jackknife bias & variance (leave-one-out)
==========================================================================
n=50. statistic = plug-in variance (1/n) sum (x-xbar)^2
theta_hat (plug-in var, /n) = 8.12234
unbiased var (/ (n-1)) for compare = 8.28810
jackknife bias estimate = -0.16576
theoretical bias of plug-in var = -sigma^2/n = -0.18000
bias-corrected estimate = 8.28810
jackknife SE of the statistic = 1.41144
Read-off: the plug-in variance under-estimates (divides by n); the
jackknife bias estimate is negative and close to the known -sigma^2/n,
and subtracting it pushes the estimate toward the unbiased /(n-1) value.
==========================================================================
PART 4 - Permutation test: two-group difference of means
==========================================================================
nA=40, nB=45, permutations P=20000
observed mean(A)-mean(B) T_obs = -0.58446
permutation null: mean(T_perm) = 0.00006 (~ 0 under H0)
sd(T_perm) = 0.23934
two-sided permutation p-value = 0.01295
(compare) Welch t-test p-value = 0.01506
reject H0 at alpha=0.05? True
Read-off: under H0 the labels are exchangeable, so reshuffling them gives
the EXACT null distribution of the difference (centred at 0); the observed
gap is far in the tail -> small p-value -> reject 'no difference'.
[done] all parts ran.
পাঠোদ্ধার — কী শিখলাম।
-
PART 1 (bootstrap SE of mean, §৪.১ যাচাই)। \(n=50\)-এর নমুনায় তিন উপায়ে \(\bar X\)-এর SE: bootstrap sd\((\hat\theta^*_b)=0.40413\) (শুধু \(B=10{,}000\) বার resample করে, কোনো সূত্র ছাড়া), plug-in \(s/\sqrt n=0.40714\), analytic \(\sigma/\sqrt n=0.42426\) — তিনটেই একে অপরের খুব কাছে। (bootstrap ও plug-in দুটোই এই নমুনার \(s\) থেকে আসে বলে আরও কাছাকাছি; analytic সত্য \(\sigma\) ব্যবহার করে, তাই সামান্য আলাদা।) আর bootstrap replicate-গুলোর গড় \(9.13630\approx\hat\theta=9.13730\) — অর্থাৎ mean-এর bootstrap প্রায়-unbiased। এটাই §৪.১.৪-এর মূল দাবির সংখ্যাগত প্রমাণ: \(\hat F_n\) থেকে resample করা \(\bar X\)-এর সত্য sampling-ওঠানামা নকল করে। (Figure
4-9-bootstrap-distএই \(\hat\theta^*_b\)-গুলোর ঘণ্টা-আকৃতির histogram দেখাবে, কেন্দ্র \(\approx\hat\theta\)।) -
PART 2 (percentile CI for median, §৪.২ যাচাই)। একটা skewed Exponential নমুনায় sample median \(3.18366\), সত্য median \(4\ln 2=2.77259\)। median-এর সহজ SE-সূত্র নেই, তাই bootstrap: \(95\%\) percentile CI \([2.14649,\ 4.31741]\) আর basic/pivotal CI \([2.04991,\ 4.22083]\)। দুটোই সত্য median \(2.773\)-কে ঢেকে রাখে — কোনো density-অনুমান বা Normality ছাড়াই। লক্ষণীয় §৪.২.২-এর পয়েন্ট: data skewed বলে percentile ও basic CI একটু আলাদা (basic-টা \(\hat\theta=3.184\)-এর চারপাশে percentile-এর আয়না, তাই বাঁ দিকে সামান্য সরানো) — symmetric হলে এরা মিলত। (Figure
4-9-bootstrap-cibootstrap-median-এর histogram-এ এই দুই জোড়া প্রান্ত চিহ্নিত করবে।) -
PART 3 (jackknife bias/variance, §৪.৩ যাচাই)। statistic plug-in variance (\(n\) দিয়ে ভাগ) \(=8.12234\), আর unbiased সংস্করণ (\(n-1\) দিয়ে ভাগ) \(=8.28810\) — অর্থাৎ plug-in কম দেখায় (যেমন তত্ত্ব বলে)। leave-one-out replicate দিয়ে jackknife bias estimate \(=-0.16576\), যা তাত্ত্বিক \(-\sigma^2/n=-0.18\)-এর কাছে। সবচেয়ে সুন্দর: bias বিয়োগ করলে bias-corrected estimate \(=8.28810\) — হুবহু unbiased \(\frac{1}{n-1}\sum(X_i-\bar X)^2\) (কারণ এই statistic-এ jackknife-সংশোধন ঠিক \(n/(n-1)\) গুণ করে দেয়)। এটাই §৪.৩.২-এর \((n-1)\)-গুণ সূত্রের সংখ্যাগত প্রমাণ — সূত্র না জেনেও jackknife নিজে bias খুঁজে শুধরে দিল। (Figure
4-9-jackknife\(n\)টা \(\hat\theta_{(i)}\) ও \(\bar\theta_{(\cdot)}\) বনাম \(\hat\theta\) দেখাবে।) -
PART 4 (permutation test, §৪.৪ যাচাই)। A (\(n_A=40\)) ও B (\(n_B=45\), \(+0.8\) স্থানান্তর গাঁথা) থেকে observed \(T_{\text{obs}}=\bar A-\bar B=-0.58446\)। \(20{,}000\) বার label shuffle করায় permutation null distribution গড় \(0.00006\approx0\)-তে কেন্দ্রিত — ঠিক §৪.৪-এর দাবি মতো: label-এ মানে না থাকলে \(\bar A-\bar B\) গড়ে শূন্য। two-sided permutation \(p=0.01295\), যা Welch \(t\)-test-এর \(p=0.01506\)-এর খুব কাছে — কিন্তু permutation কোনো Normality না ধরেই, শুধু exchangeability-র যুক্তিতে exact null বানিয়ে পেল। \(0.013<0.05\), তাই \(H_0\) বাতিল: দল-পার্থক্য বাস্তব (যা সঠিক, সত্য shift \(+0.8\))। (Figure
4-9-permutation\(\{T^*\}\)-এর histogram-এ \(T_{\text{obs}}=-0.584\)-কে tail-এর খাড়া রেখায় দেখাবে।)
চারটে PART একসাথে §৪-এর পুরো শৃঙ্খল সংখ্যায় বেঁধে দেয়: bootstrap SE সত্য SE-কে পুনরুৎপাদন করে (PART 1, §৪.১, \(\hat F_n\to F\)) → সূত্রহীন median-এও percentile/basic CI দেয় (PART 2, §৪.২) → jackknife leave-one-out দিয়ে \((n-1)\)-গুণ সূত্রে bias খুঁজে শুধরায় (PART 3, §৪.৩) → আর permutation label-exchangeability থেকে exact null ও \(p\)-value বানায় (PART 4, §৪.৪) — সবই সূত্রের বদলে computer-এ পুনরাবৃত্তি দিয়ে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-9.py-তে তৈরি; PNG_assets/-এ (prefix4-9, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 bootstrap SE of mean; E2 bootstrap CI for median; E3 jackknife; E4 permutation test।
bootstrap-এর গোটা গল্পটা একটাই সাহসী ধারণায় ধরা: sampling distribution জানতে হলে আসলে অনেকগুলো নতুন নমুনা লাগে — কিন্তু আমাদের হাতে মাত্র একটাই নমুনা; তাই সেই নমুনাকেই "population" ধরে তার ভেতর থেকে replacement-সহ বারবার resample করে নকল নমুনা বানাই। প্রতিটা resample থেকে statistic-এর একটা মান \(\hat\theta^*_b\) পাই; এই \(B\)টা মান মিলে যে বণ্টন, সেটাই \(\hat\theta\)-এর sampling distribution-এর একটা সিমুলেশন-ভিত্তিক ছবি — আর সেখান থেকেই standard error, confidence interval, এমনকি p-value সব বেরোয়। চারটে ছবি এই গল্পের চারটে ধাপ: (১) bootstrap distribution আসলে দেখতে কেমন এবং কেন তার বিস্তার-ই standard error (Figure 1)? (২) সেই distribution-কে \(2.5\%\) ও \(97.5\%\)-এ কেটে কীভাবে একটা percentile CI পাওয়া যায় (Figure 2)? (৩) bootstrap-এর চাচাতো ভাই jackknife — একটা একটা করে বিন্দু বাদ দিয়ে কীভাবে bias ও variance আঁচ করে (Figure 3)? (৪) আর resampling-এর আরেক রূপ permutation test — দুই দলের label এলোমেলো করে কীভাবে একটা null distribution বানায় ও সেখান থেকে p-value আসে (Figure 4)? প্রথম দুটো ছবি bootstrap (SE ও CI), তৃতীয়টা jackknife (leave-one-out), চতুর্থটা permutation (label-shuffling) — চারটাই একই মূলমন্ত্রের রূপ: তত্ত্বের সূত্র না জানলে data থেকেই বারবার resample করে উত্তর বানিয়ে নাও।
Figure 1 — bootstrap distribution: resample-গুলোর বিস্তার-ই standard error (E1)¶
এই অধ্যায়ের কেন্দ্রীয় অন্তর্দৃষ্টি প্রথম ছবিতেই: একটা নমুনা (\(n=30\), ডান-দিকে হেলানো) থেকে replacement-সহ \(5000\) বার resample করে প্রতিবার গড় \(\hat\theta^*_b\) হিসাব করলে যে histogram পাই, সেটাই sample mean-এর sampling distribution-এর নকল — আর তার standard deviation-ই হলো bootstrap standard error \(\widehat{\mathrm{se}}_{\text{boot}}\)। নীল histogram-টা \(5000\)টা bootstrap গড়; লাল উল্লম্ব রেখা মূল নমুনার গড় \(\hat\theta=6.41\) (যেটাকে ঘিরে পুরো বণ্টন), আর সবুজ ভাঙা রেখা bootstrap গড়গুলোর গড় (\(6.40\)) — দুটো প্রায় গায়ে গায়ে, অর্থাৎ bootstrap এখানে কার্যত নিরপেক্ষ (unbiased)। সোনালি দ্বিমুখী তীরটা \(\hat\theta\)-র চারপাশে \(\pm1\,\widehat{\mathrm{se}}_{\text{boot}}=\pm0.79\) দেখায়; বাঁ-উপরের বাক্সে \(\widehat{\mathrm{se}}_{\text{boot}}=0.786\), আর পাশে তুলনায় পাঠ্যবইয়ের সূত্র \(s/\sqrt{n}=0.803\) — দুটো প্রায় সমান, যা bootstrap-কে যাচাই করে।
যা লক্ষ করতে হবে: (ক) histogram-টা \(\hat\theta\) (লাল রেখা)-কে কেন্দ্র করে বসে আছে, \(0\)-তে বা সত্যিকারের অজানা \(\theta\)-তে নয় — bootstrap মূল নমুনাকেই population ধরে, তাই সব replicate \(\hat\theta\)-র চারপাশে দোলে। এজন্য bootstrap distribution-এর কেন্দ্র দিয়ে নয়, বিস্তার দিয়ে আমরা শিখি: বিস্তার = standard error। (খ) \(\widehat{\mathrm{se}}_{\text{boot}}=0.786\) আর সূত্র \(s/\sqrt n=0.803\) প্রায় মিলে যায় — অর্থাৎ গড়ের মতো সহজ statistic-এ bootstrap পুরোনো সূত্রকেই পুনরুৎপাদন করে; কিন্তু bootstrap-এর আসল শক্তি হলো এটা যেকোনো statistic-এর (median, correlation, trimmed mean...) জন্য একইভাবে খাটে, যাদের \(s/\sqrt n\)-এর মতো সহজ সূত্র নেই। (গ) histogram-টা প্রায় bell-আকৃতি যদিও মূল data ডান-দিকে হেলানো — এটা CLT-এর প্রতিধ্বনি (4.4): গড়ের sampling distribution \(n\) বাড়লে normal-এর দিকে যায়, আর bootstrap সেটা চোখে দেখায়। (ঘ) \(B=5000\) resample সংখ্যা — এটা যত বড়, histogram তত মসৃণ; \(B\) বাড়ালে Monte-Carlo খুঁতখুঁতানি কমে, কিন্তু \(\widehat{\mathrm{se}}\)-এর প্রকৃত মান বদলায় না (সেটা \(n\) ও data-র ওপর নির্ভর করে, \(B\)-র ওপর নয়)।
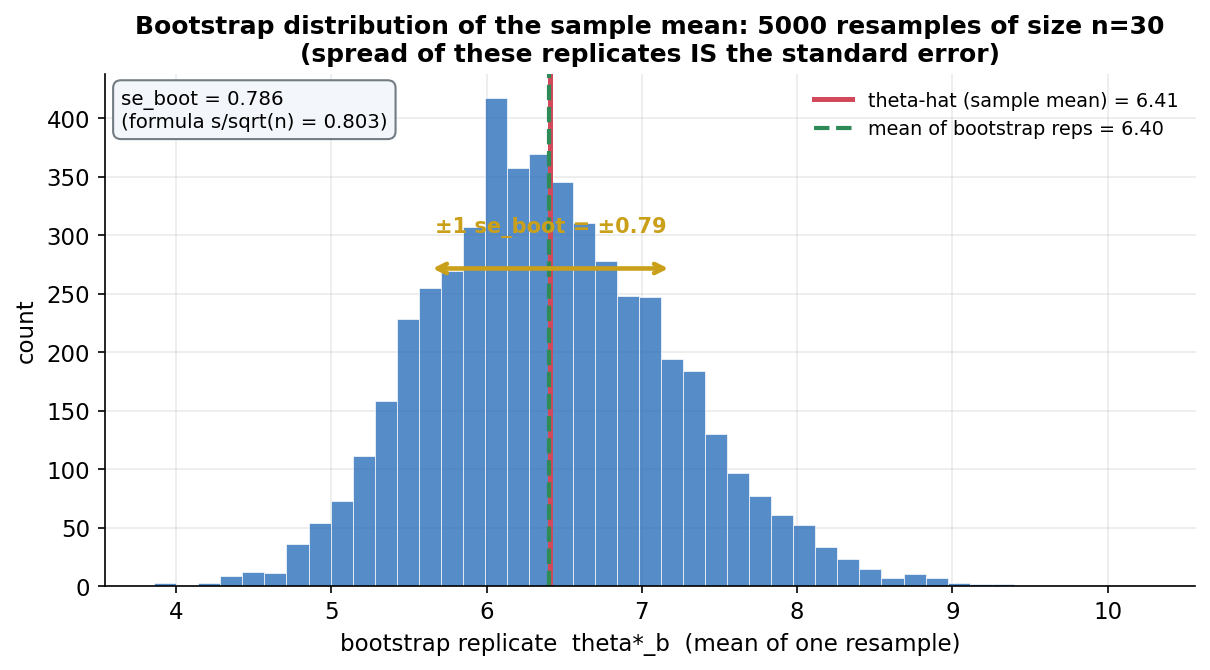
Figure 2 — bootstrap percentile CI: distribution-টা \(2.5\%\) ও \(97.5\%\)-এ কাটা (E2)¶
Figure 1 দেখাল bootstrap distribution-এর বিস্তার = standard error; এই ছবি দেখায় কীভাবে সেই বণ্টনকে সরাসরি কেটে একটা confidence interval বানানো যায় — কোনো \(\pm z\cdot\widehat{\mathrm{se}}\) সূত্র ছাড়াই। এবার statistic হলো median (E2), কারণ median-এর sampling distribution আঁকাবাঁকা ও সূত্র-কঠিন — ঠিক যেখানে bootstrap জ্বলে ওঠে। বেগুনি histogram-টা \(5000\)টা bootstrap median \(\hat\theta^*_b\); কালো রেখা মূল নমুনার median \(\hat\theta=6.47\)। দুটো লাল ভাঙা রেখা bootstrap median-গুলোর \(2.5\%\) ও \(97.5\%\) percentile (\(4.49\) ও \(7.15\)) — এই দুই কাটার মাঝের (\(\big[4.49,\,7.15\big]\)) ৯৫% অংশটাই percentile confidence interval (সবুজ তীর ও গাঢ় ছায়ায় চিহ্নিত)। নিয়মটা চমৎকার সরল: bootstrap replicate-গুলো ছোট থেকে বড় সাজিয়ে নিচের \(2.5\%\) আর ওপরের \(2.5\%\) ছেঁটে ফেলো; যা থাকে তার দুই প্রান্তই CI।
যা লক্ষ করতে হবে: (ক) CI বানাতে কোনো normality ধরে নেওয়া বা \(\widehat{\mathrm{se}}\) হিসাব করার দরকার পড়েনি — শুধু bootstrap বণ্টনের দুটো quantile নেওয়া হলো। এটাই percentile method-এর সৌন্দর্য: যেকোনো statistic-এর CI একই রেসিপিতে আসে। (খ) histogram-টা অসমান ও ধাপযুক্ত (গড়ের মসৃণ bell-এর মতো নয়) — কারণ median সবসময় data-র কোনো-একটা মানে (বা দুটোর গড়ে) আটকে থাকে, তাই কিছু মান বারবার ফেরে। এই অদ্ভুত আকৃতিই বোঝায় কেন median-এ সরল \(\pm z\,\widehat{\mathrm{se}}\) সূত্র বিশ্বাসযোগ্য নয়, অথচ percentile CI আকৃতির পরোয়া না করে কাজ করে। (গ) CI-টা \(\hat\theta=6.47\)-এর চারপাশে প্রতিসম নাও হতে পারে (\(6.47-4.49=1.98\) বনাম \(7.15-6.47=0.68\)) — bootstrap বণ্টনের আঁকাবাঁকা/asymmetry সরাসরি CI-তে ধরা পড়ে, যা প্রতিসম সূত্র-ভিত্তিক interval পারে না। (ঘ) সতর্কতা: percentile CI সহজ, কিন্তু সবচেয়ে নির্ভুল নয় — bias বা skew বেশি হলে BCa (bias-corrected and accelerated) বা bootstrap-\(t\) ভালো; এ অধ্যায়ে আমরা মূলত স্বজ্ঞা গড়তে percentile method দেখছি।
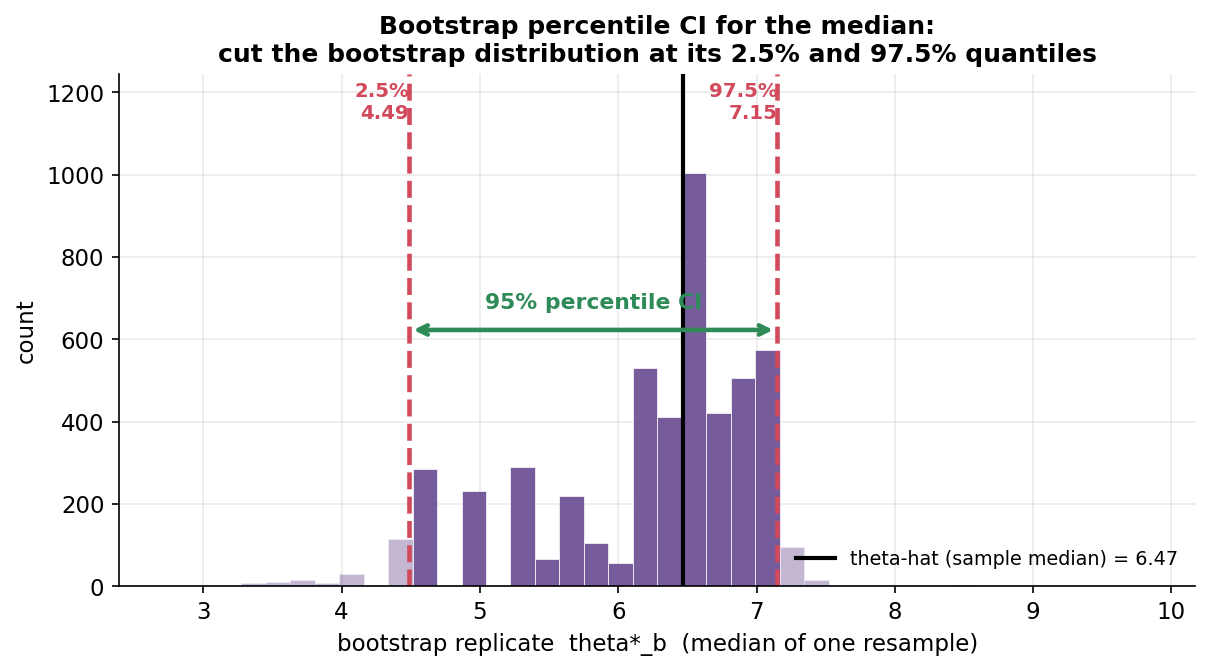
Figure 3 — jackknife: একটা একটা করে বাদ দিয়ে bias ও variance (E3)¶
bootstrap এসেছিল randomness দিয়ে (random resample); jackknife তার পূর্বসূরি, কিন্তু সম্পূর্ণ নির্ধারক (deterministic): প্রতিবার ঠিক একটা করে বিন্দু বাদ দিয়ে statistic আবার হিসাব করো, \(n\)টা leave-one-out estimate \(\hat\theta_{(i)}\) পাও — এই \(n\)টা মানের ছড়ানো থেকেই variance ও bias আঁচ করো। এখানে statistic গড় (যাতে jackknife-এর যন্ত্রটা পরিষ্কার দেখা যায়), নমুনা \(n=10\) যার শেষ বিন্দু \(12.5\) একটা outlier। প্রতিটা নীল বিন্দু একটা \(\hat\theta_{(i)}\) (পাশে লেখা কোন \(x\) বাদ দেওয়া হলো), উল্লম্বভাবে সাজানো শুধু পড়ার সুবিধায়; লাল রেখা সব-\(n\)-এর \(\hat\theta=6.03\), সবুজ ভাঙা রেখা \(\hat\theta_{(i)}\)-গুলোর গড় (\(6.03\) — গড়ের ক্ষেত্রে দুটো হুবহু মেলে)। বাঁ-উপরের বাক্সে jackknife \(\widehat{\mathrm{se}}=0.803\) আর jackknife bias \(=+0.000\)।
যা লক্ষ করতে হবে: (ক) বিন্দুগুলো যত বেশি ছড়ানো, variance তত বড় — jackknife SE আসলে এই ছড়ানোর একটা scaled পরিমাপ: \(\widehat{\mathrm{se}}_{\text{jack}}=\sqrt{\frac{n-1}{n}\sum_i(\hat\theta_{(i)}-\bar\theta_{(\cdot)})^2}\)। (খ) outlier-টা বাদ দিলে estimate সবচেয়ে দূরে লাফায়: "drop x=12.5" বিন্দুটা বাঁয়ে সবার থেকে আলাদা, মানে ওই একটা বিন্দু গড়ের ওপর সবচেয়ে বেশি প্রভাব ফেলছিল — jackknife এভাবে influence/leverage-ও চোখে দেখায় (কোন বিন্দু estimate-কে কতটা টানে)। (গ) এখানে jackknife \(\widehat{\mathrm{se}}=0.803\) ঠিক Figure 1-এর সূত্র \(s/\sqrt n=0.803\)-এর সমান — কারণ গড়ের ক্ষেত্রে jackknife SE হুবহু \(s/\sqrt n\); তাই jackknife আর bootstrap একই উত্তরের দিকে যায়, শুধু পথ আলাদা (deterministic বনাম random)। (ঘ) bias \(=+0.000\): গড় একটা linear statistic বলে jackknife-bias ঠিক শূন্য; কিন্তু variance বা ratio-এর মতো nonlinear statistic-এ jackknife একটা ছোট bias ধরে ফেলে এবং সংশোধনও করতে পারে — এটাই jackknife-এর মূল ব্যবহার (bias estimation)। (ঙ) সীমাবদ্ধতা: jackknife মসৃণ statistic-এ ভালো, কিন্তু median-এর মতো অ-মসৃণ statistic-এ ভেঙে পড়ে (leave-one-out median প্রায়ই বদলায়ই না) — সেখানে bootstrap-ই ভরসা।
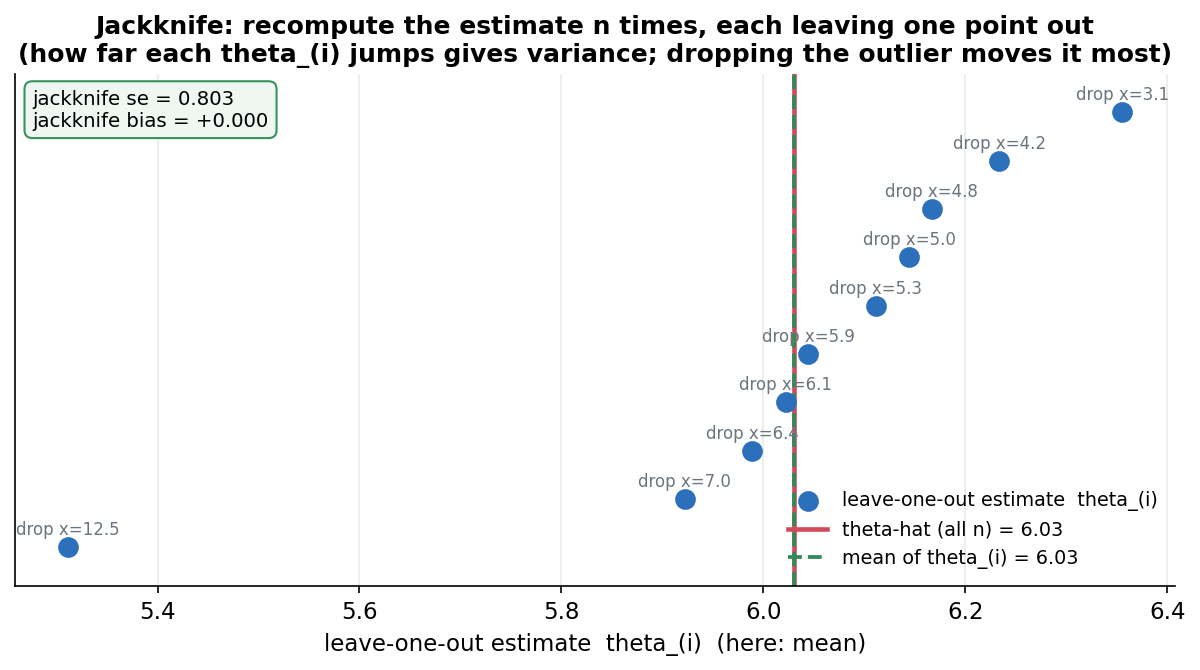
Figure 4 — permutation test: label এলোমেলো করে null distribution (E4)¶
শেষ ছবি resampling-এর তৃতীয় রূপ — permutation (randomization) test, যা দুই দলের তুলনায় ব্যবহৃত হয়। প্রশ্ন: দল A (\(n_A=8\)) আর দল B (\(n_B=7\))-এর গড়ের তফাত \(1.40\) — এটা কি সত্যিকারের পার্থক্য, নাকি শুধু আকস্মিকতা? মূল ধারণা: যদি \(H_0\) সত্য হয় (দুই দল আসলে এক, label-টা অর্থহীন), তাহলে label-গুলো এলোমেলো করে দিলেও তফাতটা একই রকম হওয়া উচিত। তাই সব মানকে একসাথে ঢেলে \(10{,}000\) বার label এলোমেলোভাবে (shuffle করে) নতুন A/B ভাগ করে প্রতিবার গড়ের তফাত হিসাব করা হলো — এই \(10{,}000\)টা তফাত মিলে ধূসর null distribution (label অর্থহীন হলে তফাত যেমন হতো)। লাল মোটা রেখা আমাদের observed তফাত \(1.40\), যা বণ্টনের একদম ডান প্রান্তে; দুই লাল ছায়াঅঞ্চল \(\pm\lvert 1.40\rvert\)-এর বাইরের লেজ। দুই-পুচ্ছ p-value \(=0.0021\) = shuffle-গুলোর কত ভাগ observed-এর মতো বা তার চেয়ে চরম।
যা লক্ষ করতে হবে: (ক) null distribution-টা \(0\)-কে কেন্দ্র করে — কারণ label অর্থহীন হলে A আর B-এর গড় গড়পড়তা সমান, তফাত \(\approx0\)। আমাদের observed \(1.40\) এই বণ্টনের প্রায় বাইরে; তাই "label অর্থহীন" ধারণাটা data-র সাথে খাপ খায় না। (খ) p-value = লেজের ক্ষেত্রফল, একদম আক্ষরিক অর্থে: \(10{,}000\)টা shuffle-এর মধ্যে মাত্র \(\approx21\)টা observed-এর মতো চরম, তাই \(p=21/10000=0.0021\)। এটাই p-value-এর সবচেয়ে স্বচ্ছ সংজ্ঞা — কোনো \(t\)-বণ্টন বা সূত্র লাগেনি, শুধু গোনা (4.7-এর p-value ধারণার resampling রূপ)। (গ) permutation test কোনো বণ্টন-অনুমান করে না (normal লাগে না, সমান variance লাগে না) — তাই ছোট নমুনা বা অদ্ভুত data-তেও বৈধ; এটাই এর বড় আকর্ষণ। তার একমাত্র অনুমান exchangeability: \(H_0\)-র অধীনে label বদলালে যৌথ বণ্টন বদলায় না। (ঘ) bootstrap বনাম permutation — দুটোই resampling, কিন্তু উদ্দেশ্য আলাদা: bootstrap with replacement resample করে একটা estimate-এর অনিশ্চয়তা (SE/CI) মাপে; permutation without replacement (শুধু label এলোমেলো) করে একটা null hypothesis যাচাই করে। প্রথম তিন ছবি ছিল "কত নিশ্চিত", এই ছবি "কতটা আশ্চর্যজনক"।
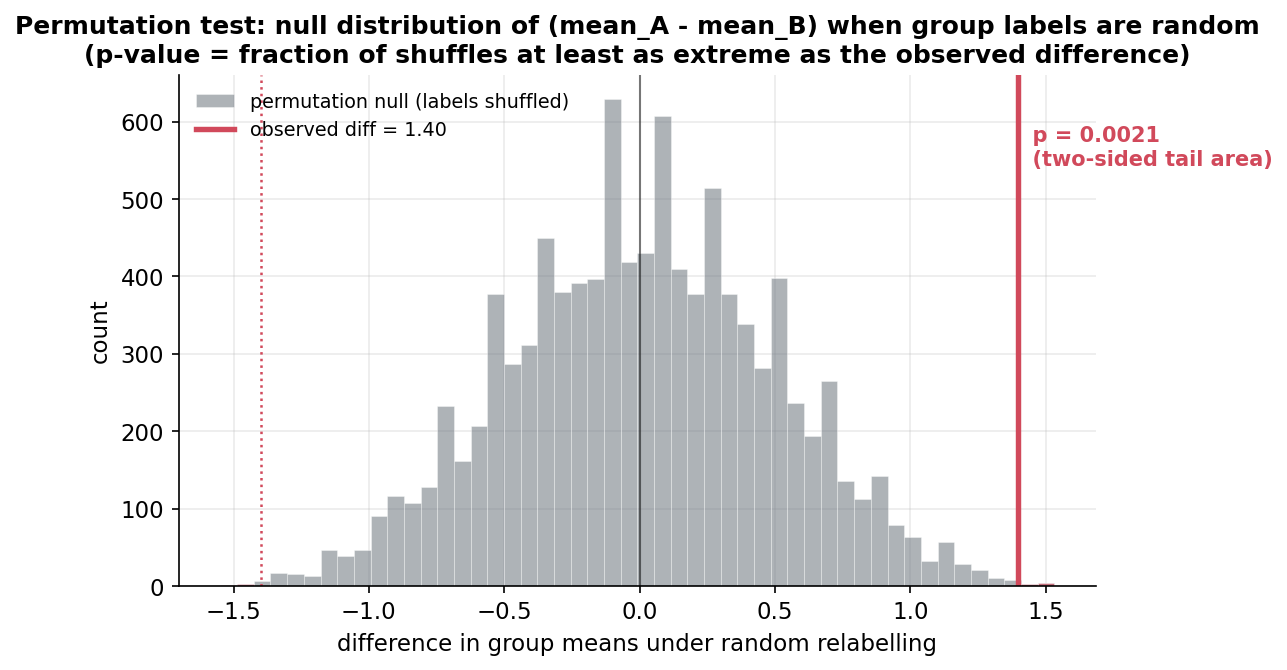
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-09-bootstrap-jackknife-resampling-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: নমুনা \(X_1,\dots,X_n\); bootstrap resample \(X^*\) = replacement-সহ \(n\)টা টানা; \(B\) replications, \(b\)-তম replicate \(\hat\theta^*_b\); bootstrap SE \(\widehat{\mathrm{se}}_{\text{boot}}=\sqrt{\frac{1}{B-1}\sum_b(\hat\theta^*_b-\bar\theta^*)^2}\); percentile CI \(=\big[\hat\theta^*_{(\alpha/2)},\,\hat\theta^*_{(1-\alpha/2)}\big]\) = bootstrap বণ্টনের \(\alpha/2\) ও \(1-\alpha/2\) quantile; jackknife \(\hat\theta_{(i)}\) = \(i\)-তম বিন্দু বাদ দিয়ে estimate, \(\widehat{\mathrm{se}}_{\text{jack}}=\sqrt{\frac{n-1}{n}\sum_i(\hat\theta_{(i)}-\bar\theta_{(\cdot)})^2}\), bias\(_{\text{jack}}=(n-1)(\bar\theta_{(\cdot)}-\hat\theta)\); permutation test = label এলোমেলো করে null distribution, p-value = লেজের ভগ্নাংশ। চলমান উদাহরণ: E1 bootstrap SE of mean; E2 bootstrap CI for median; E3 jackknife; E4 permutation test।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন bootstrap কী এবং "resampling with replacement" বলতে ঠিক কী বোঝায়। একটা bootstrap resample-এ একই মূল মান একাধিকবার আসতে পারে কেন, আর কেনই বা আমরা মূল নমুনাকেই "population" হিসেবে ব্যবহার করি? Hint: হাতে একটাই নমুনা; sampling distribution জানতে অনেক নমুনা লাগত। bootstrap-এর কৌশল: মূল নমুনার empirical distribution \(\hat F_n\) (প্রতিটা বিন্দুতে সমান ভর \(1/n\))-কেই population ধরে, সেখান থেকে \(n\)বার with replacement টানা = একটা \(X^*\)। with replacement বলেই একই মান বারবার আসতে পারে (আর কিছু মান বাদ পড়ে) — এটাই variation-এর উৎস। Figure 1-এর প্রতিটা bar একটা \(\hat\theta^*_b\)।
প্রশ্ন ২ (★★) — [bootstrap distribution-এর কেন্দ্র বনাম বিস্তার]. Figure 1-এ bootstrap distribution-টা কোন মানকে কেন্দ্র করে — \(0\), সত্যিকারের \(\theta\), নাকি \(\hat\theta\)? এর ফলে bootstrap distribution-এর কেন্দ্র নয়, বিস্তার থেকে আমরা কী শিখি, ব্যাখ্যা করুন। \(\widehat{\mathrm{se}}_{\text{boot}}\) ঠিক কোন রাশি? Hint: bootstrap মূল নমুনাকে population ধরে, তাই সব \(\hat\theta^*_b\) ঘোরে \(\hat\theta\)-র চারপাশে (Figure 1-এ লাল রেখা = কেন্দ্র), অজানা সত্য \(\theta\)-র চারপাশে নয়। তাই কেন্দ্র আমাদের নতুন কিছু বলে না; কিন্তু বিস্তার (\(\hat\theta^*_b\)-গুলোর standard deviation) ঠিক \(\hat\theta\)-র sampling-variation-এর নকল = \(\widehat{\mathrm{se}}_{\text{boot}}\)।
প্রশ্ন ৩ (★★). percentile confidence interval কীভাবে বানানো হয় (Figure 2)? একটা \(95\%\) CI-র জন্য কোন দুটো percentile লাগে? bootstrap বণ্টন আঁকাবাঁকা (skewed) হলে percentile CI প্রতিসম \(\hat\theta\pm z\,\widehat{\mathrm{se}}\) interval-এর চেয়ে ভালো কেন? Hint: \(B\)টা \(\hat\theta^*_b\) সাজিয়ে নিচের \(2.5\%\) ও ওপরের \(2.5\%\) ছেঁটে দাও; বাকি অংশের দুই প্রান্ত = \([\hat\theta^*_{(0.025)},\hat\theta^*_{(0.975)}]\) (Figure 2-এর \(4.49\) ও \(7.15\))। skew থাকলে percentile CT অসম হয় (দুই বাহু আলাদা দৈর্ঘ্য) — bootstrap বণ্টনের আকৃতি সরাসরি ধরে; প্রতিসম \(\pm z\,\widehat{\mathrm{se}}\) সেটা পারে না, তাই coverage খারাপ হতে পারে।
প্রশ্ন ৪ (★★) — [তিন resampling পদ্ধতির তুলনা]. bootstrap, jackknife, আর permutation test — তিনটা কী মাপে এবং resample কীভাবে করে (with/without replacement, random/deterministic)? Figure 3 ও Figure 4 থেকে বলুন কোনটা estimate-এর অনিশ্চয়তা আর কোনটা null hypothesis নিয়ে কাজ করে। Hint: bootstrap — with replacement, random; SE/CI (অনিশ্চয়তা)। jackknife — leave-one-out, deterministic; SE ও bias (Figure 3)। permutation — label এলোমেলো (shuffle, without replacement), random; null hypothesis-এর p-value (Figure 4)। প্রথম দুটো "কত নিশ্চিত", শেষটা "কতটা আশ্চর্যজনক"।
খ · গাণনিক (computational)¶
প্রশ্ন ৫ (★) — E1 (bootstrap SE of mean)। একটা ছোট নমুনা \(\{2,4,4,6,9\}\) (\(n=5\))। ধরুন তিনটা bootstrap resample (with replacement) এমন এলো: \(\{4,4,6,9,2\}\), \(\{6,6,4,2,4\}\), \(\{9,9,6,6,4\}\)। প্রতিটার গড় \(\hat\theta^*_b\) বের করুন, তারপর এই তিনটা মানের standard deviation (ddof=1) দিয়ে \(\widehat{\mathrm{se}}_{\text{boot}}\)-এর একটা মোটামুটি আঁচ দিন। (বাস্তবে \(B\) অনেক বড় হয়; এখানে শুধু যন্ত্রটা বুঝতে।) Hint: গড়গুলো: \(\frac{4+4+6+9+2}{5}=5.0\); \(\frac{6+6+4+2+4}{5}=4.4\); \(\frac{9+9+6+6+4}{5}=6.8\)। তিনটা মান \(\{5.0,4.4,6.8\}\)-এর গড় \(5.4\), sample SD \(=\sqrt{\frac{(5-5.4)^2+(4.4-5.4)^2+(6.8-5.4)^2}{2}}=\sqrt{\frac{0.16+1.0+1.96}{2}}=\sqrt{1.56}\approx1.25\)। (অর্থাৎ \(\widehat{\mathrm{se}}_{\text{boot}}\approx1.25\) — তবে \(B=3\) নিতান্তই উদাহরণ।)
প্রশ্ন ৬ (★★) — E2 (percentile CI)। ধরুন একটা median-এর \(B=1000\) bootstrap replicate সাজানোর পর \(25\)তম ক্ষুদ্রতম মান \(4.5\) এবং \(976\)তম \(7.1\)। একটা \(95\%\) percentile CI লিখুন এবং ব্যাখ্যা করুন কেন ঠিক এই দুটো অবস্থান বেছে নেওয়া হলো। Hint: \(95\%\) মানে \(\alpha=0.05\), দুই প্রান্তে \(2.5\%\) করে। \(1000\)-এর \(2.5\%=25\), তাই নিচের কাট \(25\)তম মান (\(4.5\)), ওপরের কাট \((1-0.025)\times1000=975\)তম-এর কাছাকাছি (\(\approx976\)তম, \(7.1\))। CI \(=[4.5,\,7.1]\) (Figure 2-এর মতোই রেসিপি, সংখ্যা ভিন্ন)।
প্রশ্ন ৭ (★★) — E3 (jackknife)। নমুনা \(\{3,5,7,9,16\}\) (\(n=5\)), statistic = গড় (\(\hat\theta=8.0\))। পাঁচটা leave-one-out গড় \(\hat\theta_{(i)}\) বের করুন, তাদের গড় \(\bar\theta_{(\cdot)}\) ও jackknife bias \(=(n-1)(\bar\theta_{(\cdot)}-\hat\theta)\) বের করুন। কোন বিন্দু বাদ দিলে \(\hat\theta_{(i)}\) সবচেয়ে বদলায় ও কেন? Hint: drop \(3\): \(\frac{5+7+9+16}{4}=9.25\); drop \(5\): \(8.75\); drop \(7\): \(8.25\); drop \(9\): \(7.75\); drop \(16\): \(\frac{3+5+7+9}{4}=6.0\)। গড় \(\bar\theta_{(\cdot)}=\frac{9.25+8.75+8.25+7.75+6.0}{5}=8.0=\hat\theta\), তাই bias \(=(4)(0)=0\) (গড় linear)। drop \(16\) সবচেয়ে দূরে লাফায় (\(6.0\)) — \(16\) outlier, প্রভাব সর্বোচ্চ (Figure 3-এর মতো)।
প্রশ্ন ৮ (★★) — E4 (permutation test)। দুই ছোট দল A \(=\{8,10,12\}\), B \(=\{5,7\}\); observed তফাত \(\bar A-\bar B=10-6=4\)। মোট ৫টা মান থেকে \(\binom{5}{2}=10\)টা সম্ভাব্য (A-তে কোন ২টা) ভাগ। দেখান কীভাবে exact permutation p-value (এক-পুচ্ছ, \(\ge4\)) হিসাব করতে হয় এবং কতগুলো ভাগ observed-এর মতো বা বেশি চরম দেয়। Hint: প্রতিটা ভাগে \(\bar B-\bar A\)... না, এখানে A-তে ২টা যায় (size \(3\) vs \(2\) ঠিক রাখতে A-তে \(3\)টা/B-তে \(2\)টা ভাগ গুনুন: \(\binom{5}{3}=10\))। observed A\(=\{8,10,12\}\) সবচেয়ে বড় তিনটা, তাই \(\bar A-\bar B=4\) সর্বোচ্চ সম্ভাব্য তফাত — মাত্র \(1\)টা ভাগ এতটা চরম। এক-পুচ্ছ exact \(p=1/10=0.10\) (Figure 4-এর ক্ষুদ্র, exact সংস্করণ; বড় নমুনায় shuffle করে আঁচ করা হয়)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★) — jackknife SE = \(s/\sqrt n\) গড়ের ক্ষেত্রে। statistic গড় \(\bar X\) হলে দেখান যে jackknife standard error \(\widehat{\mathrm{se}}_{\text{jack}}=\sqrt{\frac{n-1}{n}\sum_i(\hat\theta_{(i)}-\bar\theta_{(\cdot)})^2}\) ঠিক \(s/\sqrt n\)-এ পরিণত হয় (যেখানে \(s^2=\frac{1}{n-1}\sum(X_i-\bar X)^2\))। অর্থাৎ Figure 3-এর সংখ্যাগত মিল (\(0.803=0.803\)) একটা সাধারণ সত্য। Hint: leave-one-out গড় \(\hat\theta_{(i)}=\frac{n\bar X-X_i}{n-1}\), তাই \(\hat\theta_{(i)}-\bar X=\frac{\bar X-X_i}{n-1}\) এবং \(\bar\theta_{(\cdot)}=\bar X\)। বসান: \(\sum_i(\hat\theta_{(i)}-\bar\theta_{(\cdot)})^2=\frac{1}{(n-1)^2}\sum_i(X_i-\bar X)^2\)। তাই \(\widehat{\mathrm{se}}_{\text{jack}}^2=\frac{n-1}{n}\cdot\frac{(n-1)s^2}{(n-1)^2}=\frac{s^2}{n}\), অর্থাৎ \(\widehat{\mathrm{se}}_{\text{jack}}=s/\sqrt n\)।
প্রশ্ন ১০ (★★) — bootstrap-এ একটা বিন্দু বাদ পড়ার সম্ভাবনা। \(n\)-আকারের একটা bootstrap resample-এ (with replacement, \(n\)টা টানা) একটা নির্দিষ্ট মূল বিন্দু \(X_i\) একবারও না-আসার সম্ভাবনা বের করুন, এবং দেখান \(n\to\infty\)-এ এটা \(e^{-1}\approx0.368\)-এ যায়। অর্থাৎ গড়ে প্রতিটা resample মূল data-র প্রায় \(63.2\%\) ধারণ করে। Hint: প্রতিটা টানে \(X_i\) না-আসার সম্ভাবনা \(1-\frac1n\); \(n\)টা স্বাধীন টান, তাই একবারও না-আসা \(=(1-\frac1n)^n\)। \(\lim_{n\to\infty}(1-\frac1n)^n=e^{-1}\)। তাই out-of-bag ভগ্নাংশ \(\to e^{-1}\approx0.368\), আর in-bag \(\to1-e^{-1}\approx0.632\) (এই out-of-bag ধারণাই পরে random-forest-এ ফেরে)।
প্রশ্ন ১১ (★★★) — permutation test exactly valid কেন (exchangeability)। ধরুন \(H_0\): দুই দল একই বণ্টন থেকে এসেছে (label অর্থহীন)। দেখান যে \(H_0\)-র অধীনে সব \(\binom{n}{n_A}\) label-বিন্যাস সমসম্ভাব্য, এবং তাই observed statistic-এর exact null distribution হলো এই বিন্যাসগুলোর ওপর statistic-এর বণ্টন — কোনো large-sample বা normality অনুমান ছাড়াই p-value বৈধ। Hint: exchangeability: \(H_0\)-তে \((X_1,\dots,X_n)\)-এর যৌথ বণ্টন যেকোনো permutation-এ অপরিবর্তিত। তাই কোন \(n_A\)টা মান "দল A" সেটা data-র তথ্যহীন lottery — প্রতিটা ভাগ সমসম্ভাব্য (\(1/\binom{n}{n_A}\))। observed statistic-এর tail-ভগ্নাংশই exact p-value (Figure 4 = এর Monte-Carlo আঁচ)। যুক্তিটা বণ্টনের আকৃতির ওপর নির্ভর করে না — শুধু exchangeability-র ওপর।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★★) — bootstrap SE ও percentile CI (Figure 1–2 পুনর্নির্মাণ)। একটা নমুনা (যেমন rng.gamma(2,4,size=30)) নিয়ে \(B=5000\) bootstrap resample করে গড়ের \(\widehat{\mathrm{se}}_{\text{boot}}\) আর median-এর \(95\%\) percentile CI বের করুন। গড়ের \(\widehat{\mathrm{se}}_{\text{boot}}\)-কে \(s/\sqrt n\)-এর সাথে মিলিয়ে দেখুন।
Hint:
import numpy as np
rng = np.random.default_rng(0)
x = np.round(rng.gamma(2.0, 4.0, size=30), 2)
B, n = 5000, x.size
idx = rng.integers(0, n, size=(B, n)) # resample WITH replacement
boot_mean = x[idx].mean(axis=1)
boot_med = np.median(x[idx], axis=1)
print("se_boot(mean) =", boot_mean.std(ddof=1), " s/sqrt(n) =", x.std(ddof=1)/np.sqrt(n))
print("95% percentile CI (median) =", np.percentile(boot_med, [2.5, 97.5]))
idx একসাথে \(B\times n\) index — vectorized, লুপ লাগে না। গড়ের \(\widehat{\mathrm{se}}_{\text{boot}}\approx s/\sqrt n\); median-এর CI অসম হতে পারে।
প্রশ্ন ১৩ (★★) — jackknife ফাংশন (Figure 3 পুনর্নির্মাণ)। একটা ফাংশন jackknife(x, stat) লিখুন যা যেকোনো statistic-এর leave-one-out estimate, jackknife SE, ও jackknife bias ফেরত দেয়। গড়ে চালিয়ে দেখান bias \(\approx0\) ও SE \(\approx s/\sqrt n\); তারপর variance-এ (nonlinear) চালিয়ে দেখান bias আর শূন্য নয়।
Hint:
import numpy as np
def jackknife(x, stat):
n = x.size
loo = np.array([stat(np.delete(x, i)) for i in range(n)])
theta = stat(x); m = loo.mean()
se = np.sqrt((n-1)/n * np.sum((loo - m)**2))
bias = (n-1) * (m - theta)
return loo, se, bias
x = np.array([3.1,4.2,4.8,5.0,5.3,5.9,6.1,6.4,7.0,12.5])
print(jackknife(x, np.mean)[1:]) # se ~ s/sqrt(n), bias ~ 0
print(jackknife(x, lambda a: a.var(ddof=0))[2]) # nonlinear -> bias != 0
প্রশ্ন ১৪ (★★★) — permutation test (Figure 4 পুনর্নির্মাণ)। দুই দল A, B নিয়ে একটা ফাংশন লিখুন যা \(P=10000\) বার label shuffle করে গড়ের তফাতের null distribution বানায় ও দুই-পুচ্ছ p-value ফেরত দেয়। scipy.stats.ttest_ind-এর p-value-র সাথে তুলনা করুন — কাছাকাছি কি?
Hint:
import numpy as np
from scipy import stats
rng = np.random.default_rng(3)
A = np.array([5.1,6.3,5.8,6.9,7.2,6.1,5.5,6.8]); B = np.array([4.2,5.0,4.8,5.6,4.1,5.3,4.7])
obs = A.mean() - B.mean()
pool = np.concatenate([A, B]); nA = A.size; P = 10000
diffs = np.empty(P)
for i in range(P):
rng.shuffle(pool)
diffs[i] = pool[:nA].mean() - pool[nA:].mean()
p_perm = (np.abs(diffs) >= abs(obs)).mean()
print("perm p =", p_perm, " t-test p =", stats.ttest_ind(A, B).pvalue)
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- bootstrap-এর মূলমন্ত্র (Figure 1)। sampling distribution জানতে অনেক নমুনা লাগত, কিন্তু হাতে একটাই; তাই মূল নমুনার empirical distribution \(\hat F_n\)-কেই population ধরে replacement-সহ \(n\)বার টেনে একটা resample \(X^*\) বানাই, আর তা থেকে \(\hat\theta^*_b\) হিসাব করি। \(B\)টা replicate মিলে যে বণ্টন = sampling distribution-এর নকল; তার standard deviation = bootstrap standard error \(\widehat{\mathrm{se}}_{\text{boot}}\)। বণ্টন \(\hat\theta\)-কে কেন্দ্র করে, তাই শেখা আসে কেন্দ্র থেকে নয়, বিস্তার থেকে।
- percentile CI (Figure 2)। bootstrap বণ্টনের \(\alpha/2\) ও \(1-\alpha/2\) quantile-এ কাটলেই একটা \((1-\alpha)\) confidence interval — কোনো normality বা \(\widehat{\mathrm{se}}\)-সূত্র ছাড়াই। median-এর মতো সূত্র-কঠিন statistic-এও একই রেসিপি খাটে, আর বণ্টনের skew সরাসরি CI-তে ধরা পড়ে (অসম interval)।
- jackknife (Figure 3)। নির্ধারক (deterministic) পূর্বসূরি: একটা একটা করে বিন্দু বাদ দিয়ে \(n\)টা leave-one-out estimate \(\hat\theta_{(i)}\); তাদের ছড়ানো থেকে \(\widehat{\mathrm{se}}_{\text{jack}}=\sqrt{\frac{n-1}{n}\sum_i(\hat\theta_{(i)}-\bar\theta_{(\cdot)})^2}\) আর bias\(_{\text{jack}}=(n-1)(\bar\theta_{(\cdot)}-\hat\theta)\)। গড়ের ক্ষেত্রে \(\widehat{\mathrm{se}}_{\text{jack}}=s/\sqrt n\) ও bias \(=0\) (§৭ Q9); nonlinear statistic-এ bias ধরে ও সংশোধন করে। outlier বাদ দিলে estimate সবচেয়ে লাফায় — influence-ও দেখায়। (সীমা: median-এর মতো অ-মসৃণ statistic-এ jackknife দুর্বল, bootstrap ভালো।)
- permutation test (Figure 4)। দুই দলের তুলনায় resampling-এর তৃতীয় রূপ: \(H_0\) (label অর্থহীন) ধরে label বারবার এলোমেলো করে গড়ের তফাতের null distribution বানাই; p-value = লেজের ভগ্নাংশ = shuffle-গুলোর কত ভাগ observed-এর মতো চরম। কোনো বণ্টন-অনুমান নেই, একমাত্র শর্ত exchangeability (§৭ Q11)।
- তিন পদ্ধতির বিভাজন। bootstrap (with replacement, random) → estimate-এর অনিশ্চয়তা (SE/CI); jackknife (leave-one-out, deterministic) → SE ও bias; permutation (label-shuffle, random) → null hypothesis-এর p-value। প্রথম দুটো "কত নিশ্চিত", শেষটা "কতটা আশ্চর্যজনক"।
- একটা সাধারণ চিন্তা। চারটা ছবিই একই দর্শন: তত্ত্বের closed-form সূত্র না থাকলে বা না খাটলে, data থেকেই বারবার resample/relabel করে উত্তর সিমুলেশনে বানিয়ে নাও — computation দিয়ে formula-র অভাব পূরণ।
পূর্ববর্তী সংযোগ (← 4.6 Confidence Intervals; 4.7 Hypothesis Testing; এবং 4.4): 4.6-এ আমরা confidence interval-এর ধারণা ও সূত্র-ভিত্তিক (\(\hat\theta\pm z\,\widehat{\mathrm{se}}\)) construction শিখেছিলাম — যা normality বা পরিচিত sampling distribution ধরে নেয়। এই অধ্যায়ের percentile CI (Figure 2) সেই ধারণাকেই সূত্র ছাড়াই দেয়: bootstrap বণ্টন কেটে interval — যেখানে 4.6-এর সূত্র কঠিন বা অবৈধ (median, ছোট \(n\), skewed data), সেখানে এটাই বাঁচায়। আবার 4.7-এ p-value ও hypothesis testing-এর কাঠামো গড়েছিলাম; এই অধ্যায়ের permutation test (Figure 4) সেই p-value-কে তার সবচেয়ে স্বচ্ছ, সূত্রহীন রূপে দেখায় — "label এলোমেলো করলে কত ভাগ ক্ষেত্রে observed-এর মতো চরম তফাত পাই" = ঠিক p-value-র সংজ্ঞা, কোনো \(t\)- বা \(\chi^2\)-বণ্টন ছাড়াই। আর গোটা bootstrap-যুক্তির শিকড় 4.4-এর sampling distribution ও CLT-এ: Figure 1-এর bell-আকৃতি ঠিক CLT-এর প্রতিধ্বনি, আর bootstrap আসলে sampling distribution-কে সিমুলেশনে দেখানোর একটা যন্ত্র। অর্থাৎ 4.6–4.7 ছিল inference-এর সূত্র-ভিত্তিক পথ; 4.9 হলো সেই একই লক্ষ্যের simulation-ভিত্তিক পথ — যখন সূত্র নীরব।
পরবর্তী সংযোগ (→ 4.10 — Bayesian inference: অনিশ্চয়তার ভিন্ন দর্শন): এ পর্যন্ত (4.1–4.9) আমরা পুরোটাই frequentist দৃষ্টিভঙ্গিতে থেকেছি — \(\theta\) একটা স্থির-কিন্তু-অজানা সংখ্যা, আর অনিশ্চয়তা আসে data-র random ওঠানামা থেকে (তাই "যদি বারবার নমুনা নিতাম..." ধরনের কথা: SE, CI, p-value, এবং bootstrap-এর resample)। পরের অধ্যায় দর্শনটাই উল্টে দেয়: Bayesian ভাবনায় \(\theta\)-কেই একটা random variable ভাবা হয়, যার ওপর আগে থেকে একটা prior বিশ্বাস থাকে, আর data এসে Bayes' theorem দিয়ে সেটাকে posterior-এ হালনাগাদ করে — অনিশ্চয়তা মাপা হয় সরাসরি \(\theta\)-র বণ্টন দিয়ে (credible interval), "কাল্পনিক পুনঃনমুনা" দিয়ে নয়। মজার মিল: এই অধ্যায়ের bootstrap ও পরের অধ্যায়ের Bayesian posterior — দুটোই প্রায়ই computation-চালিত (resampling বনাম MCMC/simulation) এবং দুটোই closed-form সূত্রের নির্ভরতা কমায়; পার্থক্য দর্শনে — bootstrap data-র randomness নকল করে (frequentist), Bayesian \(\theta\)-র ওপর বিশ্বাস হালনাগাদ করে। তাই 4.9 হলো frequentist-জগতের শেষ বড় হাতিয়ার, আর 4.10 খোলে inference-এর সম্পূর্ণ ভিন্ন একটা দরজা।
বৃহত্তর স্থান (where this sits): 4.9 হলো Part IV-এর resampling/computational inference অধ্যায় — point estimation (4.1–4.5), confidence intervals (4.6), hypothesis testing (4.7), likelihood-ভিত্তিক ও \(\chi^2\) tests (4.8)-এর পর এটি দেখায় কীভাবে এই সবকিছুর (SE, CI, p-value) simulation-ভিত্তিক, অনুমান-হালকা বিকল্প বানানো যায়। এর পরে দৃষ্টিভঙ্গি বদলে Bayesian (4.10)-এ যায়। তাই এই অধ্যায়ের সাথে frequentist parametric inference-এর গল্প পূর্ণ হয় — শেষ সংযোজন হিসেবে সেই সর্বজনীন হাতিয়ার যা তত্ত্ব নীরব হলেও কাজ করে; আর পরের অধ্যায় থেকে অনিশ্চয়তা-চিন্তার দ্বিতীয় মহাধারা (Bayesian) শুরু।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 8 (The Bootstrap — §8.1 simulation, §8.2 bootstrap variance estimation ও \(\widehat{\mathrm{se}}_{\text{boot}}\), §8.3 bootstrap confidence intervals: normal, pivotal ও percentile interval); B. Bruce, P. Bruce & P. Gedeck, Practical Statistics for Data Scientists, Ch. 2 (Data and Sampling Distributions — "The Bootstrap" ও "Confidence Intervals" অংশ: resampling, bootstrap distribution, percentile CI), এবং Ch. 3-এর permutation/randomization test (two-group difference ও p-value as tail area)। jackknife-এর আদিরূপ Quenouille (১৯৪৯) ও Tukey (১৯৫৮), bootstrap-এর আদিরূপ Efron (১৯৭৯)।