5.5 — GLM: Poisson Regression & Beyond (পোয়াসোঁ রিগ্রেশন ও তার পরে)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "যখন outcome একটা গণনা/count"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
5.4-এ আমরা regression-এর গল্পটাকে একটা বড় ছাতার নিচে নিয়ে এসেছিলাম — Generalized Linear Model (GLM)। সেখানে দেখেছিলাম, প্রতিটি GLM তিনটি অংশ দিয়ে গড়া: একটা random component (response \(y_i\) কোন বণ্টন থেকে আসে), একটা systematic component — অভিন্ন রৈখিক ভবিষ্যদ্বক্তা (linear predictor)
যেখানে \(x_i=(1,x_{i1},\dots,x_{ip})^\top\) হলো \(i\)-তম এককের predictor-vector (প্রথম উপাদান \(1\), intercept-এর জন্য) এবং \(\beta=(\beta_0,\dots,\beta_p)^\top\) হলো coefficient-vector — আর একটা link function (যোজক ফাংশন) \(g\) যা response-এর mean \(\mu_i=\mathbb{E}[y_i\mid x_i]\)-কে \(\eta_i\)-এর সাথে যুক্ত করে: \(g(\mu_i)=\eta_i\)।
সেই কাঠামোয় logistic regression ছিল একটা বিশেষ রূপ — random component Bernoulli, link logit। আর 5.1-এর সাধারণ linear regression ছিল আরেক রূপ — Normal + identity link। দুটো মডেল, একই নকশা; শুধু random component আর link আলাদা।
5.4-এর শেষ টেবিলে আমরা একটা তৃতীয় সারি লিখে রেখেছিলাম, যা তখন ছিল কেবল প্রতিশ্রুতি: Poisson + log link। এই অধ্যায় ঠিক সেই প্রতিশ্রুতি পূরণ করে। সুসংবাদ হলো, ভারী যন্ত্রপাতির প্রায় সবটাই 5.4 থেকে অপরিবর্তিত — linear predictor একই, MLE-fitting-এর IRLS একই, fit-মূল্যায়নের deviance একই। আমাদের শুধু বদলাতে হবে দুটো জিনিস: response-এর বণ্টন (Bernoulli → Poisson) আর link (logit → log)। বাকিটা পরিচিত পথ।
১.২ Hook — outcome যখন শুধুই একটা গণনা¶
5.4-এ outcome ছিল হ্যাঁ/না — দুটো মান। কিন্তু বাস্তবে এক বিশাল শ্রেণির প্রশ্নে outcome আরও সমৃদ্ধ, অথচ সংখ্যাগত-নয়-ঠিক: outcome একটা গণনা (count) — কতবার কিছু ঘটল। কয়েকটা চেনা পরিস্থিতি:
- একটা মোড়ে দিনে কতগুলো দুর্ঘটনা ঘটে? — দিনের ব্যস্ততা, আবহাওয়া, ছুটির দিন কি না — তা দিয়ে।
- একটা দোকানে ঘণ্টায় কতজন গ্রাহক আসেন? — সময়, মৌসুম, প্রচার চলছে কি না — তা দিয়ে।
- একটা বইয়ের প্রতি পৃষ্ঠায় কতগুলো ছাপার ত্রুটি? — লেখার ঘনত্ব, সম্পাদনার ধাপ দিয়ে।
- একটা শহরে দিনে কত সাইকেল ভাড়া হয়? — তাপমাত্রা, সপ্তাহান্ত কি না — তা দিয়ে। (এই শেষ উদাহরণটাই গোটা অধ্যায়ে আমাদের সঙ্গী থাকবে।)
প্রতিটি ক্ষেত্রেই response একটা অ-ঋণাত্মক পূর্ণসংখ্যা — শূন্য, এক, দুই, …, কিন্তু কখনও \(-3\) নয়, কখনও \(2.7\) নয়:
যেখানে \(y_i\) হলো \(i\)-তম এককের (দিন/ঘণ্টা/পৃষ্ঠা) গণনা। binary-র সাথে তফাত স্পষ্ট: সেখানে ছাদ ছিল \(1\), এখানে কোনো নির্দিষ্ট ছাদ নেই — গণনা নীতিগতভাবে যত বড় খুশি হতে পারে (একটি ব্যস্ত দিনে ৮৮টি ভাড়া)। আর continuous response-এর সাথে তফাত: count লাফিয়ে লাফিয়ে চলে (পূর্ণসংখ্যা), মসৃণভাবে নয়; এবং তার নিচে একটা শক্ত মেঝে আছে — শূন্য।
count-data মডেল করতে গিয়ে আমরা যা আন্দাজ করতে চাই, সেটা কোনো নির্দিষ্ট দিনের শক্ত সংখ্যা নয় (সেটা এলোমেলো) — বরং সেই গণনার প্রত্যাশিত মান বা গড় হার (mean count/rate):
অর্থাৎ "\(i\)-তম এককের predictor \(x_i\) জানা থাকলে গণনার গড় কত হবে"। এই \(\mu_i>0\)-ই আমাদের আসল লক্ষ্য — "তাপমাত্রা ২৫°C, সপ্তাহান্ত নয় — এমন একটা দিনে গড়ে কতগুলো সাইকেল ভাড়া হবে?"।
এক বাক্যে লক্ষ্য: count outcome-এ আমরা কোনো একটা পর্যবেক্ষণের শক্ত সংখ্যা ভবিষ্যদ্বাণী করতে চাই না, বরং predictor-নির্ভর গড় গণনা \(\mu_i=\mathbb{E}[y_i\mid x_i]\) আন্দাজ করতে চাই — এবং সেটাকে predictor-দের সাথে এমনভাবে বাঁধতে চাই যা \(\mu_i>0\) স্বাভাবিকভাবে নিশ্চিত করে।
১.৩ 2.3-এর Poisson distribution — সংক্ষিপ্ত স্মরণ¶
count-data-র জন্য সবচেয়ে স্বাভাবিক বণ্টনটা আমরা 2.3-এ দেখেছি — Poisson distribution। সংক্ষেপে স্মরণ করি, কারণ এটাই এই অধ্যায়ের random component।
একটা ধনাত্মক বাস্তব সংখ্যা \(\mu\) (গড় হার) দিলে, একটা Poisson চলক \(y\)-এর probability mass function (pmf) — অর্থাৎ ঠিক \(k\)টি ঘটনা ঘটার সম্ভাবনা:
যেখানে \(\mu>0\) হলো বণ্টনের একমাত্র parameter (গড় গণনা), \(e\) প্রাকৃতিক লগারিদমের ভিত্তি, আর \(k!\) হলো \(k\)-এর গৌণিক (\(k! = k\times(k-1)\times\cdots\times 1\), এবং \(0!=1\))। স্বজ্ঞাটা 2.3-এর: একটা নির্দিষ্ট ব্যবধানে (time বা space) যদি ঘটনাগুলো স্বাধীনভাবে ও ধ্রুব গড়-হারে ঘটে, তবে সেই ব্যবধানে মোট গণনা Poisson অনুসরণ করে।
Poisson-এর যে দুটি ধর্ম এই অধ্যায়ে বারবার ফিরে আসবে:
- এটা স্বয়ংক্রিয়ভাবে \(\{0,1,2,\dots\}\)-এই বাঁধা — pmf কেবল অ-ঋণাত্মক পূর্ণসংখ্যায় সংজ্ঞায়িত। তাই count-এর "পূর্ণসংখ্যা ও \(\geq 0\)" শর্ত মডেলেই গাঁথা।
- এর স্বাক্ষর-ধর্ম: mean ও variance সমান —
এই দ্বিতীয় ধর্মটা — একটাই parameter \(\mu\) একসাথে গড় ও ছড়ানো (spread) দুটোই নিয়ন্ত্রণ করে — Poisson-কে চমৎকার রকম সরল করে, কিন্তু পরে (§১.৫ ও §২.৫) এটাই হয়ে উঠবে এর সবচেয়ে বড় সীমাবদ্ধতা। আপাতত মনে রাখি: Poisson বলছে, "গড় যত, বিচ্ছুরণও ঠিক তত"।
১.৪ সবচেয়ে সরল চেষ্টা — আর কেন linear ও logistic এখানে বেমানান¶
5.4-এর মতোই, প্রথমে দেখি পরিচিত হাতিয়ারগুলো কেন সরাসরি খাটে না।
চেষ্টা ১ — 5.1-এর linear regression সরাসরি count-এ। স্বাভাবিক প্রথম ভাবনা: \(y_i\)-কেই response ধরে OLS চালাই, \(\mu_i \approx x_i^\top\beta\)। কিন্তু তিনটি সমস্যা, যা count-data-র তিনটি স্বভাবকে আঘাত করে:
- পরিসর-লঙ্ঘন (\(\mu \geq 0\)): \(x_i^\top\beta\) একটা রৈখিক ফাংশন, পরিসর \((-\infty,\infty)\) — predictor যথেষ্ট ছোট হলে এটা ঋণাত্মক হতে পারে। কিন্তু একটা গড় গণনা ঋণাত্মক হওয়া অর্থহীন ("গড়ে \(-2.3\)টি দুর্ঘটনা" বলে কিছু নেই)। logistic-এ যেমন \([0,1]\)-এর বাইরে যাওয়া ছিল সমস্যা, এখানে তেমনি \(0\)-এর নিচে যাওয়া।
- বণ্টন normal নয় (ছোট mean-এ skewed): OLS-এর inference ধরে নেয় error \(\sim\mathcal{N}(0,\sigma^2)\) — প্রতিসম, ঘণ্টা-আকৃতির। কিন্তু count, বিশেষত যখন গড় ছোট, ডান-দিকে skewed: অনেক ছোট মান (০, ১, ২) আর একটা লম্বা ডান-লেজ। গড় \(2\) হলে ঋণাত্মক মানের কোনো অবকাশই নেই — কিন্তু normal বণ্টন তো ঋণাত্মক মানে ভর রাখে। আকৃতিই মেলে না।
- variance ধ্রুব নয় (mean-এর সাথে বাড়ে): এটাই সবচেয়ে গভীর। 2.3 থেকে জানি Poisson-এ \(\operatorname{Var}(y)=\mu\) — অর্থাৎ যেসব এককের গড় গণনা বেশি, সেখানে বিচ্ছুরণও বেশি। তাই error-এর ভেদ এককে-এককে এক নয় — heteroskedasticity (অসম-ভেদ), যা OLS-এর সমান-ভেদ অনুমান ভাঙে। গরম সপ্তাহান্তের দিনে ভাড়ার গড় বেশি, ওঠানামাও বেশি; ঠান্ডা কর্মদিবসে দুটোই কম।
চেষ্টা ২ — 5.4-এর logistic regression। তবে count যেহেতু "সংখ্যা নয় ঠিক", হয়তো logistic খাটানো যায়? না — logistic-এর গোটা যন্ত্রটা \(y\in\{0,1\}\)-এর জন্য বানানো (Bernoulli random component, সম্ভাবনা \(p\in[0,1]\))। কিন্তু count-এর কোনো ছাদ নেই — \(0,1,2,\dots,88,\dots\)। একটা ৮৮-ভাড়ার দিনকে "হ্যাঁ/না"-তে চেপে ফেললে আমরা ঠিক যে তথ্যটা মডেল করতে চাই — কতগুলো — সেটাই হারাই। logistic উত্তর দেয় "ঘটল কি না"; এখানে প্রশ্ন "কতবার ঘটল"। ভুল হাতিয়ার।
তিনটি বাধা একসাথে সাজালে:
| পরিচিত মডেলের অনুমান | count \(y\)-তে কী ঘটে | ফল |
|---|---|---|
| fitted মান = \(x^\top\beta\), পরিসর \((-\infty,\infty)\) | কিন্তু গড় গণনা \(\mu\) থাকতে হবে \(\geq 0\) | ঋণাত্মক "গড় গণনা" — অর্থহীন |
| error \(\varepsilon\sim\mathcal{N}(0,\sigma^2)\), প্রতিসম | count ছোট mean-এ ডান-skewed, পূর্ণসংখ্যা | normal-ভিত্তিক inference ভাঙে |
| ধ্রুব ভেদ \(\sigma^2\) (homoskedastic) | \(\operatorname{Var}(y)=\mu\), mean-নির্ভর | heteroskedastic, OLS-এর optimality হারায় |
| logistic: \(y\in\{0,1\}\) মাত্র | count-এর কোনো ছাদ নেই | "কতবার" তথ্য হারিয়ে যায় |
এক বাক্যে সমস্যা: count outcome-এ সরাসরি linear regression চাপালে fitted "গড় গণনা" ঋণাত্মক হতে পারে, বণ্টন normal থাকে না, আর ভেদ mean-এর সাথে বাড়ায় তা ধ্রুব থাকে না; আর logistic শুধু \(\{0,1\}\)-এর জন্য, অবাধ গণনার জন্য নয়।
১.৫ সমাধানের মূল insight (অন্তর্দৃষ্টি) — mean-কে নয়, তার log-কে রৈখিক করো¶
5.4-এর সমাধান-কৌশলটাই এখানে হুবহু কাজে লাগে, শুধু "বদ্ধ-সীমা"-টা আলাদা। logistic-এ সমস্যা ছিল \(p\in[0,1]\)-কে অসীম-পরিসরের \(x^\top\beta\)-এর সমান বসানো। এখানে সমস্যা: গড় গণনা \(\mu\)-কে থাকতে হবে ধনাত্মক (\(\mu>0\)), অথচ \(x^\top\beta\) অবাধে ঋণাত্মকও হতে পারে। আবারও দুই পরিসর মেলে না।
আর সমাধানের ধারণাও একই: \(\mu\)-কে সরাসরি রৈখিক না করে, \(\mu\)-এর এমন একটা রূপান্তরকে রৈখিক করি, যার পরিসর গোটা \((-\infty,\infty)\)। এখানে সেই রূপান্তরটা logit-এর চেয়েও সরল — শুধু logarithm। কারণ:
\(\log\) ঠিক সেই কাজটা করে যা দরকার: একটা ধনাত্মক রাশিকে নিয়ে গোটা বাস্তব রেখায় ছড়িয়ে দেয় (\(\mu\to 0^+\) হলে \(\log\mu\to-\infty\); \(\mu\to+\infty\) হলে \(\log\mu\to+\infty\); \(\mu=1\) হলে \(\log\mu=0\))। তাই দুই পক্ষের পরিসর মিলিয়ে নির্দ্বিধায় লিখতে পারি
এই \(g(\mu)=\log\mu\)-ই হলো log link — Poisson regression-এর link function। আর উল্টে নিলে (দু-পাশে \(\exp\)):
এই inverse-রূপটাই সমস্যাটা মূল থেকে মেটায়: \(x_i^\top\beta\) যত বড় বা ছোট যাই হোক, \(e^{(\cdot)}\) সবসময় ধনাত্মক — তাই \(\mu_i>0\) স্বয়ংক্রিয়ভাবে নিশ্চিত, কোনো বাড়তি শর্ত ছাড়াই। logistic-এ sigmoid যেমন \(\eta\)-কে \((0,1)\)-এ চেপে রাখত, এখানে \(e^{\eta}\) তেমনি \(\eta\)-কে \((0,\infty)\)-এ তুলে রাখে।
এই log link-এর একটা চমৎকার পার্শ্ব-উপহার আছে, যা §২.৩-এ পুরো খুলবে: যেহেতু \(\mu=e^{x^\top\beta}\), predictor-এর প্রভাব mean-এর ওপর যোগাত্মক নয়, গুণাত্মক — ঠিক যেমন logistic-এ odds-এর ওপর ছিল। একটা predictor এক একক বাড়লে \(\mu\) একটা ধ্রুবক গুণ হয়, যোগ নয়।
এই অধ্যায়ের বাকি পথটা মোটামুটি এমন: - §২ মূল সংজ্ঞাগুলো নিখুঁত করে — Poisson regression মডেল, log link ও কেন (positivity, multiplicative), coefficient-এর rate ratio ব্যাখ্যা, MLE/IRLS-fitting, offset/exposure, Poisson-এর Var=Mean ধর্ম ও overdispersion-এর সংজ্ঞা, Pearson dispersion, এবং "& beyond" সমাধান (quasi-Poisson, Negative Binomial)-এর স্বজ্ঞা সহ সম্পূর্ণ GLM-trilogy টেবিল। - §৩–৪ মডেলটা কীভাবে data থেকে fit হয় — Poisson likelihood, score equation, IRLS; এবং deviance, dispersion-নির্ণয়, NB-এর \(\mu+\alpha\mu^2\) গঠনের গাণিতিক ভিত্তি। - §৫–৬ পূর্ণ bike-rental dataset-এ হাতে-কলমে — count-বনাম-temperature, mean–variance সম্পর্ক, Poisson-বনাম-NB pmf তুলনা, এবং coefficient-এর confidence interval, চিত্রসহ।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে §১-এর insight (অন্তর্দৃষ্টি)-গুলোকে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; পূর্ণ derivation (likelihood, score equation, dispersion, NB) §৪-এ।
ধরে রাখি, আমাদের কাছে \(n\)টি একক, \(i=1,\dots,n\)। \(i\)-তম এককের জন্য: - \(y_i \in \{0,1,2,\dots\}\) — পর্যবেক্ষিত count (অ-ঋণাত্মক পূর্ণসংখ্যা)। - \(x_i = (1, x_{i1}, \dots, x_{ip})^\top\) — predictor-vector, প্রথম উপাদান \(1\) (intercept-এর জন্য), পরের \(p\)টি বাস্তব predictor। - \(\beta = (\beta_0, \beta_1, \dots, \beta_p)^\top\) — coefficient-vector; \(\beta_0\) হলো intercept, \(\beta_j\) (\(j\ge 1\)) হলো \(j\)-তম predictor-এর coefficient। - \(\mu_i = \mathbb{E}[y_i \mid x_i] > 0\) — predictor জানা থাকলে count-এর শর্তাধীন গড় (mean count); এটাই আমরা মডেল করি। - \(\eta_i = x_i^\top\beta\) — linear predictor, একটা বাস্তব সংখ্যা।
২.১ Poisson regression মডেল ও log link¶
Poisson regression-এর পূর্ণ সংজ্ঞা দুই অংশে। প্রথমত, random component — প্রতিটি outcome একটা Poisson চলক, যার গড় predictor-নির্ভর:
অর্থাৎ \(i\)-তম এককের জন্য \(P(y_i=k\mid x_i)=\dfrac{\mu_i^{k}e^{-\mu_i}}{k!}\), যেখানে গড় \(\mu_i\) ব্যক্তি-ভেদে আলাদা — কারণ এটাই predictor-দের মধ্য দিয়ে আসে। দ্বিতীয়ত, সেই সংযোগ — log link (যোজক ফাংশন), যা mean-এর log-কে রৈখিক ধরে:
এখানে \(g(\mu)=\log\mu\) হলো link function — নির্দিষ্টভাবে log link। আর যেহেতু শেষমেশ আমরা mean \(\mu_i\)-ই চাই (linear predictor \(\eta_i\) নয়), সমীকরণটা \(\mu_i\)-এর জন্য উল্টে নিই (দু-পাশে \(\exp\)):
এই \(\mu=e^{\eta}\) রূপটাই log link বেছে নেওয়ার দুটি কারণ একসাথে প্রকাশ করে — যে কারণ দুটি এই অধ্যায়ের সবকিছুর শিকড়:
- Positivity (ধনাত্মকতা): \(e^{(\cdot)}\) ফাংশনের মান সর্বদা \(>0\), তাই \(\eta_i=x_i^\top\beta\) যেকোনো বাস্তব মান নিলেও \(\mu_i\) সবসময় ধনাত্মক থাকে। গড় গণনা কখনও ঋণাত্মক হওয়ার আশঙ্কাই নেই — §১.৪-এর প্রথম সমস্যাটা মূল থেকে অসম্ভব।
- Multiplicativity (গুণাত্মকতা): যোগফলের সূচক গুণফলে ভাঙে — \(e^{a+b}=e^a\cdot e^b\)। তাই $$ \mu_i \;=\; e^{\beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}} \;=\; e^{\beta_0}\cdot e^{\beta_1 x_{i1}}\cdots e^{\beta_p x_{ip}}. $$ predictor-গুলো mean-কে গুণ করে গড়ে তোলে, যোগ করে নয়। এর সরাসরি ফল — coefficient-এর rate ratio ব্যাখ্যা (§২.৩)। অর্থনীতি, মহামারিবিদ্যা বা সাইকেল-ভাড়ার মতো বহু বাস্তব ঘটনায় প্রভাব এমনিতেই গুণাত্মক ("গরমে ভাড়া ৬% বাড়ে", "যোগ ৩টি বাড়ে" নয়) — তাই log link স্বাভাবিক।
২.২ MLE দিয়ে fitting — 5.4-এর একই IRLS যন্ত্র¶
\(\beta\)-কে data থেকে কীভাবে আন্দাজ করব? logistic-এর মতোই, error normal নয় (এখন Poisson) — তাই OLS নয়, ফিরে যাই 4.3-এর maximum likelihood-এ। ধারণা একই: যে \(\beta\) পর্যবেক্ষিত data-টাকে সবচেয়ে সম্ভাব্য করে, সেটাই বেছে নাও।
একটিমাত্র Poisson outcome-এর pmf আমরা §১.৩-এ লিখেছি; একক-গুলো স্বাধীন ধরে গোটা data-র likelihood হলো এদের গুণফল, আর log-likelihood \(\ell(\beta)\) সেই গুণফলের log। সম্পূর্ণ derivation §৪-এ; এখানে শুধু চূড়ান্ত রূপ ও তার গঠন দরকার:
(শেষ পদ \(\log(y_i!)\) \(\beta\)-নিরপেক্ষ ধ্রুবক — সর্বোচ্চকরণে কোনো ভূমিকা নেই, তবে log-likelihood-এর পূর্ণ মান হিসাবে রাখা হলো।) এই \(\ell(\beta)\)-কে যে \(\beta\) সর্বোচ্চ করে, সেটাই MLE \(\hat\beta\)।
এখানেও logistic-এর মতোই দুটি কথা সত্য, এবং কারণটাও একই — \(\mu_i=e^{x_i^\top\beta}\) হলো \(\beta\)-এর অরৈখিক ফাংশন: - বদ্ধ-রূপ (closed-form) সমাধান নেই। \(\ell\)-এর derivative শূন্য করলে যে score equation পাওয়া যায়, তা \(\beta\)-তে অরৈখিক; \(\hat\beta\)-কে সরাসরি একটা সূত্রে লেখা যায় না। - তাই Newton–Raphson / IRLS দিয়ে পুনরাবৃত্তভাবে সমাধান — হুবহু 5.4-এর সেই যন্ত্র। প্রতিটি পুনরাবৃত্তিতে একটা ভারিত OLS সমস্যা সমাধান হয়; পার্থক্য শুধু এই যে ভার (weight) ও working response-এ logit/sigmoid-এর বদলে log/exp ঢোকে।
এক বাক্যে: Poisson regression-এ \(\hat\beta\) আসে Poisson log-likelihood সর্বোচ্চ করে (MLE), OLS নয়; score equation অরৈখিক বলে বদ্ধ-রূপ নেই — তাই 5.4-এর একই IRLS যন্ত্র দিয়ে পুনরাবৃত্তভাবে সমাধান হয়, শুধু link বদলে।
২.৩ coefficient-এর অর্থ — rate ratio¶
logistic-এ coefficient পড়া হতো odds ratio দিয়ে; Poisson-এ ব্যাখ্যাটা গঠনগতভাবে একই (গুণাত্মক), কিন্তু রাশিটা rate ratio। কেন, §২.১-এর multiplicativity থেকেই সরাসরি আসে।
মডেল বলছে log-mean রৈখিক:
এখন একটিমাত্র predictor \(x_j\)-কে এক একক বাড়াই (\(x_j \to x_j+1\)), বাকি সব স্থির। তাহলে \(\log\mu\)-তে যোগ হয় ঠিক \(\beta_j\)। কিন্তু \(\log\)-এ যোগ মানে \(\mu\)-তে গুণ:
এই অনুপাতটাকে — এক একক বদলের আগে-পরে দুই mean count-এর ভাগফল — বলে rate ratio (RR; হার-অনুপাত)। তাই Poisson coefficient পড়ার নিয়ম:
\(x_j\) এক একক বাড়লে (বাকি সব স্থির রেখে), mean count গুণিতকভাবে \(e^{\beta_j}\) গুণ হয়।
পরিষ্কার পাঠগুলো: - \(\beta_j > 0 \Rightarrow e^{\beta_j} > 1\): \(x_j\) বাড়লে গড় গণনা বাড়ে। - \(\beta_j = 0 \Rightarrow e^{\beta_j} = 1\): \(x_j\) গড় গণনায় কোনো প্রভাব ফেলে না (তাই \(H_0:\beta_j=0\) মানে "predictor-টির কোনো প্রভাব নেই")। - \(\beta_j < 0 \Rightarrow e^{\beta_j} < 1\): \(x_j\) বাড়লে গড় গণনা কমে।
একটা মূর্ত উদাহরণ (যা §৫-এ পুরো খুলবে): bike-rental মডেলে যদি temp-এর coefficient \(\hat\beta_{\text{temp}} = 0.0597\) হয়, তবে rate ratio \(e^{0.0597} \approx 1.062\) — অর্থাৎ তাপমাত্রা প্রতি ১°C বাড়লে গড় ভাড়া প্রায় ৬% বাড়ে (\(\times 1.062\)), সপ্তাহান্ত স্থির রেখে। আবার weekend-এর (একটা \(0/1\) নির্দেশক চলক) coefficient \(0.301\) হলে rate ratio \(e^{0.301}\approx 1.35\) — অর্থাৎ কর্মদিবসের তুলনায় সপ্তাহান্তে গড় ভাড়া ৩৫% বেশি (\(\times 1.35\))। লক্ষণীয়, ব্যাখ্যাটা mean count-এর ওপর গুণিতক (logistic-এ ছিল odds-এর ওপর; এখানে rate-এর ওপর) — এটাই log link-এর সরাসরি ফল।
২.৪ offset/exposure — count বনাম rate¶
এখন একটা ব্যবহারিক সূক্ষ্মতা, যা count-data-তে প্রায়ই দরকার হয়। ধরা যাক আলাদা আলাদা একক আলাদা সময়/পরিসরে পর্যবেক্ষিত — একটা শহরের দুর্ঘটনা-গণনা যদি জনসংখ্যা বা পর্যবেক্ষণ-কালভেদে আসে, তবে কাঁচা গণনা সরাসরি তুলনীয় নয়: ১০ লক্ষ লোকের শহরে ৫০টি দুর্ঘটনা আর ১ লক্ষ লোকের শহরে ৫০টি — খুব আলাদা কথা। আমরা আসলে চাই rate (per-unit হার): প্রতি-একক-time বা প্রতি-একক-জনসংখ্যায় গণনা।
ধরা যাক \(i\)-তম এককের exposure (পর্যবেক্ষণের পরিমাণ — সময়, জনসংখ্যা, বা পরিসর) \(t_i\)। তখন আমরা চাই rate \(\mu_i/t_i\)-কে মডেল করতে, count \(\mu_i\)-কে নয়:
ডান দিকের শেষ পদ \(\log t_i\)-কে বলে offset — একটা পরিচিত (জানা) পদ যা linear predictor-এ যোগ হয় কিন্তু এর কোনো coefficient আন্দাজ করা হয় না (অর্থাৎ এর coefficient \(1\)-এ স্থির, আন্দাজযোগ্য parameter নয়)। স্বজ্ঞাটা: \(\log t_i\) ঢুকিয়ে আমরা মডেলকে বলে দিই, "বড় exposure মানে স্বভাবতই বড় count — সেই অংশটা ব্যাখ্যা করতে coefficient খরচ কোরো না; predictor-গুলো শুধু হার-এর তারতম্য ব্যাখ্যা করুক"। offset ছাড়া Poisson regression কাঁচা count মডেল করে (যেমন আমাদের bike-rental উদাহরণে, যেখানে প্রতিটি একক ঠিক এক দিন — exposure অভিন্ন, তাই offset লাগে না); offset সহ এটি rate মডেল করে।
২.৫ Poisson-এর Var=Mean ধর্ম ও overdispersion¶
এবার Poisson regression-এর সবচেয়ে গুরুত্বপূর্ণ — এবং বাস্তবে সবচেয়ে ঘন ঘন লঙ্ঘিত — অনুমানে আসি। §১.৩-এ দেখা Poisson-এর স্বাক্ষর-ধর্ম মডেল-পর্যায়ে দাঁড়ায়:
অর্থাৎ Poisson regression বাধ্যতামূলকভাবে ধরে নেয় শর্তাধীন variance শর্তাধীন mean-এর ঠিক সমান — একটাই parameter \(\mu_i\) গড় ও বিচ্ছুরণ দুটোই নিয়ন্ত্রণ করে, বিচ্ছুরণকে আলাদাভাবে বাড়ানো-কমানোর কোনো স্বাধীনতা নেই।
কিন্তু বাস্তব count-data প্রায়ই এর চেয়ে বেশি ছড়ানো: একই predictor-মানের এককগুলোর মধ্যে গণনার ওঠানামা Poisson-এর প্রতিশ্রুত \(\mu\)-এর চেয়ে বড়। একে বলে overdispersion (অতি-বিচ্ছুরণ):
কেন এমন ঘটে? সাধারণ কারণ — মডেলে ধরা-পড়েনি এমন লুকানো ভিন্নতা (unobserved heterogeneity)। সব গরম সপ্তাহান্ত এক নয় (উৎসব, বৃষ্টি, ভিন্ন এলাকা — যেগুলো predictor-এ নেই), তাই একই (temp, weekend)-এর দিনগুলোতেও ভাড়ার ছড়ানো বিশুদ্ধ Poisson যা বলে তার চেয়ে বেশি। আমাদের bike-rental dataset-এ ঠিক এটাই: গণনার সামগ্রিক mean প্রায় \(19.56\), কিন্তু variance প্রায় \(205\) — অনুপাত variance/mean \(\approx 10.5\), অর্থাৎ Poisson যা ধরে তার চেয়ে দশ গুণেরও বেশি ছড়ানো। (এই dataset ইচ্ছাকৃতভাবে একটা Gamma–Poisson মিশ্রণ থেকে তৈরি, যাতে overdispersion স্পষ্ট থাকে — §৫।)
কেন এটা উপেক্ষা করা বিপজ্জনক? overdispersion থাকলেও Poisson MLE-র \(\hat\beta\) সাধারণত মোটামুটি ঠিকই থাকে — কিন্তু তার standard error মিথ্যা-ছোট হয়ে যায় (মডেল প্রকৃতের চেয়ে কম ভেদ ধরে নেয়)। ফলে confidence interval অবাস্তব সংকীর্ণ, \(p\)-value অবাস্তব ছোট — আমরা অতি-আত্মবিশ্বাসী (over-confident) ভুল উপসংহারে পৌঁছাই: এমন predictor-কে "তাৎপর্যপূর্ণ" বলে ফেলি যা আসলে নয়।
কীভাবে নির্ণয়? — Pearson dispersion statistic \(\hat\phi\) (পূর্ণ সংজ্ঞা §৪)। স্বজ্ঞা: প্রতিটি এককের আদর্শায়িত (standardized) residual-এর বর্গ যোগ করে স্বাধীনতার মাত্রা (degrees of freedom) দিয়ে ভাগ —
যেখানে \(\hat\mu_i\) হলো fitted mean, আর হরে \(\hat\mu_i\) আসে কারণ Poisson-এ ভেদ \(=\mu\) (তাই \((y_i-\hat\mu_i)^2/\hat\mu_i\) হলো "ভেদ-একক"-এ মাপা বর্গ-বিচ্যুতি)। ধারণাটা সরল: যদি Poisson-অনুমান সত্য হতো (Var\(=\mu\)), তবে এই গড় বর্গ-residual \(\approx 1\) হওয়ার কথা। তাই —
- \(\hat\phi \approx 1\): Var\(\approx\)Mean, Poisson ঠিক আছে।
- \(\hat\phi \gg 1\): overdispersion — সতর্কবার্তা।
- \(\hat\phi < 1\): underdispersion (বিরল; data Poisson-এর চেয়ে কম ছড়ানো)।
আমাদের bike-rental মডেলে Poisson fit-এর dispersion প্রায় \(4.44\) — \(1\)-এর চেয়ে অনেক বড়, overdispersion-এর স্পষ্ট সংকেত (raw variance/mean অনুপাত আরও বড় কারণ predictor কিছুটা ভেদ ব্যাখ্যা করে, তবু dispersion \(\gg 1\))। সুতরাং খাঁটি Poisson এখানে যথেষ্ট নয় — আমাদের "& beyond"-এ যেতে হবে।
২.৬ "& beyond" — quasi-Poisson ও Negative Binomial¶
overdispersion ধরা পড়লে দুটো ধ্রুপদী সমাধান, যা অধ্যায়ের শিরোনামের "& beyond" — দুটোরই স্বজ্ঞা এখানে, গণিত §৪-এ।
সমাধান ১ — quasi-Poisson (একটা দ্রুত সংশোধন)। সবচেয়ে সরল ভাবনা: \(\hat\beta\) তো মোটামুটি ঠিক, শুধু standard error-গুলো মিথ্যা-ছোট — তাহলে সেগুলোকে হাতে ঠিক করে নিই। quasi-Poisson ঠিক তা-ই করে: একই Poisson coefficient \(\hat\beta\) রাখে, কিন্তু প্রতিটি standard error-কে \(\sqrt{\hat\phi}\) দিয়ে গুণ করে বড় করে দেয় —
স্বজ্ঞা: যদি data Poisson-এর চেয়ে \(\hat\phi\) গুণ বেশি ছড়ানো হয়, তবে আমাদের অনিশ্চয়তাও সেই অনুপাতে (বর্গমূলে) বাড়ানো উচিত। এটা কোনো পূর্ণ probability মডেল নয় (count-এর কোনো নতুন বণ্টন ধরে না — তাই একে "quasi"/আধা বলা হয়, এবং AIC-র মতো likelihood-ভিত্তিক তুলনা সরাসরি খাটে না), শুধু একটা ভেদ-সমন্বয় (variance correction)। দ্রুত, ব্যবহারিক, এবং inference-কে সৎ (honest) করে তোলে।
সমাধান ২ — Negative Binomial (একটা পূর্ণ মডেল)। আরও নীতিগত পথ: এমন একটা বণ্টন ব্যবহার করি যা নিজেই mean-এর চেয়ে বড় ভেদ ধারণ করতে পারে — Negative Binomial (NB)। এটি একটা বাড়তি dispersion parameter \(\alpha \geq 0\) যোগ করে, যা ভেদকে mean থেকে আলাদা করে নিয়ন্ত্রণের স্বাধীনতা দেয়:
এই গঠনটা মন দিয়ে পড়ুন। প্রথম পদ \(\mu_i\) হলো বিশুদ্ধ-Poisson ভেদ; দ্বিতীয় পদ \(\alpha\mu_i^2\) হলো বাড়তি ভেদ, যা overdispersion ধরে। দুটি সীমা-ক্ষেত্র: - \(\alpha = 0\): বাড়তি পদ মুছে যায়, \(\operatorname{Var}(y_i)=\mu_i\) — অর্থাৎ NB ভেঙে পড়ে ঠিক Poisson-এ। তাই Poisson হলো NB-এর একটা বিশেষ (\(\alpha\to 0\)) রূপ। - \(\alpha > 0\): ভেদ mean-এর চেয়ে বড়, এবং বড় \(\mu\)-তে \(\mu^2\) পদের জন্য তা আরও দ্রুত বাড়ে — যা বাস্তব overdispersed count-এর সাথে প্রায়ই খাপ খায়।
(NB কোথা থেকে আসে, তার একটা সুন্দর স্বজ্ঞা — §২.৫-এর "লুকানো ভিন্নতা": প্রতিটি এককের নিজস্ব Poisson-গড় যদি নিজেই একটা Gamma বণ্টন থেকে এলোমেলোভাবে আসে, তবে চূড়ান্ত গণনা NB অনুসরণ করে। ঠিক এভাবেই আমাদের dataset তৈরি — Gamma–Poisson মিশ্রণ। গাণিতিক রূপ §৪।) আমাদের bike-rental data-তে NB fit দেয় \(\hat\alpha \approx 0.179\) (শূন্য থেকে স্পষ্ট দূরে — overdispersion বাস্তব), এবং এর fit Poisson-এর চেয়ে নাটকীয়ভাবে ভালো: NB-এর AIC \(\approx 1753\), বনাম Poisson-এর AIC \(\approx 2238\) — অনেক ছোট AIC মানে অনেক ভালো মডেল (AIC = likelihood-ভিত্তিক মডেল-তুলনার মাপ; ছোট ভালো, 5.4-এর deviance-এরই জ্ঞাতি)। §৬-এর 5-5-poisson-nb-pmf চিত্রে দেখা যাবে, একই mean-এ NB-এর pmf Poisson-এর চেয়ে কতটা চ্যাপ্টা ও লম্বা-লেজি — ঠিক যা overdispersed data-র সাথে মেলে।
সংক্ষেপে zero-inflation। আরেক ধরনের সাধারণ বিচ্যুতি: data-তে প্রত্যাশার চেয়ে অনেক বেশি শূন্য (excess zeros)। যেমন, ভাড়ার গণনায় কিছু দিন দোকান বন্ধ থাকলে নিশ্চিত শূন্য — যা সাধারণ Poisson/NB ব্যাখ্যা করতে পারে না। zero-inflated মডেল (ZIP/ZINB) দুটো প্রক্রিয়া মেশায়: একটা যা "কাঠামোগত শূন্য" তৈরি করে (বন্ধ থাকা), আরেকটা সাধারণ count প্রক্রিয়া। আমাদের অধ্যায়ে এটি কেবল সচেতনতা-পর্যায়ে — গভীরে যাব না, তবে জেনে রাখা ভালো যে "& beyond"-এর পথ এখানেই শেষ নয়।
২.৭ বড় ছবি — GLM-trilogy সম্পূর্ণ¶
এই অধ্যায়ের সাথে GLM-গল্পের একটা বৃত্ত পূর্ণ হলো। 5.1-এ আমরা পেয়েছিলাম Normal regression, 5.4-এ Bernoulli (logistic), আর এখন Poisson — তিনটিই একই GLM trinity-র (random component + linear predictor + link function) সদস্য, শুধু random component ও link আলাদা। তিনটিকে একসাথে এক টেবিলে রাখলে অধ্যায়ের একীভূত দৃষ্টি স্পষ্ট হয়:
| মডেল | random component | mean \(\mu\) | link \(g(\mu)=\eta\) | inverse (mean-রূপ) | coefficient-পঠন |
|---|---|---|---|---|---|
| Linear (5.1) | Normal \(\mathcal{N}(\mu,\sigma^2)\) | \(\mu\) | identity: \(\mu=\eta\) | \(\mu=\eta\) | \(\beta_j\) যোগ হয় |
| Logistic (5.4) | Bernoulli\((p)\) | \(p\) | logit: \(\log\frac{p}{1-p}=\eta\) | \(p=\dfrac{1}{1+e^{-\eta}}\) | odds ×\(e^{\beta_j}\) |
| Poisson (5.5) | Poisson\((\mu)\) | \(\mu\) | log: \(\log\mu=\eta\) | \(\mu=e^{\eta}\) | mean count ×\(e^{\beta_j}\) |
এই টেবিলটাই দেখায় কেন GLM শেখা মানে আলাদা আলাদা কৌশলের সংগ্রহ নয়, বরং একটাই সাধারণ ভাষা: response-এর প্রকৃতি অনুযায়ী একটা exponential-family বণ্টন বাছো, mean-কে উপযুক্ত link দিয়ে রৈখিক করো — বাকি যন্ত্রপাতি (linear predictor, MLE, IRLS, deviance) প্রায় অভিন্ন। continuous response হলে Normal+identity, binary হলে Bernoulli+logit, count হলে Poisson+log (এবং overdispersion থাকলে NB)। এই তিনটিই GLM-trilogy-র মূল স্তম্ভ।
এক বাক্যে GLM-trilogy: একই কাঠামো — exponential-family random component + linear predictor \(\eta=x^\top\beta\) + link \(g\) — Normal+identity-তে দেয় সাধারণ regression, Bernoulli+logit-এ logistic, আর Poisson+log-এ Poisson regression; response-এর প্রকৃতিই বলে দেয় কোন বণ্টন ও link বাছতে হবে।
পরবর্তী অংশে (§৩–৪) এই মডেলটাকে পূর্ণরূপে data-য় fit করব — Poisson likelihood-এর derivation, score equation, IRLS, এবং deviance, Pearson dispersion ও Negative Binomial-এর \(\mu+\alpha\mu^2\) গঠনের গাণিতিক ভিত্তি সহ। সেখান থেকে এই GLM-ধারণা পরের অধ্যায় 5.6-এ আরও সাধারণীকৃত হবে — যখন একই এককের ভেতরের সম্পর্ক (grouped/repeated data) ধরতে আমরা mixed-effects / hierarchical মডেলে যাব।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এ পর্যন্ত আমরা log link, \(\mu_i=e^{\eta_i}\), এবং rate ratio \(e^{\beta_j}\)-এর তত্ত্ব দেখেছি। এবার একটা বাস্তবঘেঁষা ডেটাসেটে ধাপে ধাপে পুরো workflow চালাব — Poisson GLM fit করা, coefficient পড়া, rate ratio দিয়ে ব্যাখ্যা, হাতে একটা prediction, এবং সবচেয়ে গুরুত্বপূর্ণ — overdispersion ধরা ও তা ঠিক করা।
ডেটাসেট। একটি bike-share সিস্টেমের \(n=250\) দিনের দৈনিক ভাড়ার (rental) সংখ্যা। প্রতিটি দিনের জন্য তিনটি কলাম:
| কলাম | অর্থ | ধরন |
|---|---|---|
rentals |
ঐ দিনের মোট ভাড়া (count) | \(y_i\in\{0,1,2,\dots\}\) |
temp |
দিনের গড় তাপমাত্রা (°C) | \(\sim\mathrm{Uniform}(5,35)\) |
weekend |
সপ্তাহান্ত কিনা | \(\{0,1\}\) |
ডেটা generate করা হয়েছে seed 20260619 দিয়ে, true সম্পর্ক \(\log\mu = 1.5 + 0.06\cdot\text{temp} + 0.4\cdot\text{weekend}\) অনুসারে, তবে count-গুলোতে একটা Gamma–Poisson mixture বসিয়ে ইচ্ছাকৃতভাবে overdispersion ঢোকানো হয়েছে — যাতে §৩-এর শেষে আমরা সেটা ধরতে পারি। বর্ণনামূলক সংখ্যা:
লক্ষ করুন variance/mean অনুপাত \(\approx 10.5\) — Poisson হলে এটা \(\approx 1\) হওয়ার কথা ছিল (\(\mathrm{Var}=\mu\))। এই warning sign-টা মাথায় রেখে এগোই; আনুষ্ঠানিক diagnosis E4-এ।
E1 · Poisson GLM fit করা ও coefficient পড়া¶
মডেল: $$ y_i\mid x_i \sim \mathrm{Poisson}(\mu_i),\qquad \log\mu_i = \beta_0 + \beta_1\,\text{temp}_i + \beta_2\,\text{weekend}_i . $$
statsmodels-এ fit করার পর coefficient টেবিল (estimate, standard error, এবং Wald \(z=\hat\beta/\mathrm{SE}\)):
| পদ | \(\hat\beta\) | \(\mathrm{SE}\) | \(z=\hat\beta/\mathrm{SE}\) |
|---|---|---|---|
| Intercept | \(1.560\) | \(0.0476\) | \(32.8\) |
temp |
\(0.0597\) | \(0.00178\) | \(33.5\) |
weekend |
\(0.301\) | \(0.0307\) | \(9.8\) |
Fit-এর সারসংক্ষেপ: deviance \(=1093.1\), Pearson \(\chi^2=1096.3\), \(\mathrm{df}_{\text{resid}}=247\), log-likelihood \(\ell=-1115.9\), \(\mathrm{AIC}=2237.9\)।
সাইন ও তাৎপর্য পড়া। তিনটে coefficient-ই linear predictor \(\eta=\log\mu\)-এর scale-এ — অর্থাৎ এরা log-rate-এর উপর additive প্রভাব, \(\mu\)-এর উপর সরাসরি নয়।
- \(\hat\beta_1=0.0597>0\): তাপমাত্রা বাড়লে log-rate বাড়ে → বেশি গরমে বেশি ভাড়া। \(z=33.5\) — অত্যন্ত significant।
- \(\hat\beta_2=0.301>0\): সপ্তাহান্তে log-rate বেশি → weekday-এর চেয়ে বেশি ভাড়া। \(z=9.8\) — significant।
- \(\hat\beta_0=1.560\): এটা baseline log-rate, যখন
temp\(=0\) এবংweekend\(=0\)। অর্থাৎ একটা \(0°C\) weekday-তে প্রত্যাশিত ভাড়া \(\mu=e^{1.560}\approx 4.76\)/দিন। সাবধান —temp\(=0\) ডেটার range (\(5\)–\(35\)) এর বাইরে, তাই intercept-টা এখানে নিছক একটা গাণিতিক anchor, ব্যবহারযোগ্য prediction নয়। বাস্তবে interpretable করতে চাইলেtempকে center করে নিতে হবে (যেমনtemp\(-20\)), তাহলে intercept মানে দাঁড়াবে "একটা গড়-তাপমাত্রার weekday-র প্রত্যাশিত ভাড়া"।
মূল কথা: raw coefficient-গুলো log-scale-এ থাকায় তাদের মান সরাসরি "কত ভাড়া বাড়ল" বলে না। সেটা পড়তে দরকার rate ratio — E2।
E2 · Rate-ratio ব্যাখ্যা (এই উদাহরণের প্রাণ)¶
log link-এর কারণে coefficient-কে exponentiate করলেই additive-from-log প্রভাব multiplicative-on-\(\mu\) প্রভাবে রূপ নেয়। \(x_j\) এক একক বাড়লে: $$ \frac{\mu(x_j+1)}{\mu(x_j)} = \frac{e^{\beta_0+\cdots+\beta_j(x_j+1)+\cdots}}{e^{\beta_0+\cdots+\beta_j x_j+\cdots}} = e^{\beta_j}. $$ এই \(e^{\beta_j}\)-ই rate ratio — গড় count যে গুণিতকে গুণিত হয়।
| পদ | \(\hat\beta\) | \(e^{\hat\beta}\) | ব্যাখ্যা |
|---|---|---|---|
temp (+1°C) |
\(0.0597\) | \(1.0616\) | তাপমাত্রা প্রতি \(+1°C\)-এ গড় ভাড়া \(\times 1.062\) (≈ \(+6.2\%\)) |
temp (+5°C) |
\(5\times0.0597\) | \(1.348\) | \(+5°C\)-এ গড় ভাড়া \(\times 1.348\) (≈ \(+35\%\)) |
weekend |
\(0.301\) | \(1.351\) | weekend-এ গড় ভাড়া weekday-এর \(\times 1.351\) (≈ \(+35\%\)) |
পড়ার ভাষা:
"প্রতি \(+1°C\) তাপমাত্রায় গড় ভাড়া \(\times 1.062\) (≈ \(+6\%\)); weekend-এ গড় ভাড়া \(\times 1.35\) (≈ \(+35\%\))।"
দুটো সূক্ষ্ম পয়েন্ট:
-
ছোট coefficient-এর জন্য shortcut। \(\beta_j\) ছোট হলে \(e^{\beta_j}\approx 1+\beta_j\), তাই \(\hat\beta_1=0.0597\) থেকে সরাসরি "≈ \(+6\%\) per °C" বলা যায়, পুরো exponential না কষেই। কিন্তু এটা শুধু ছোট \(\beta\)-তেই খাটে;
temp\(+5°C\)-এর মতো বড় পরিবর্তনে \(5\times0.0597=0.299\) আর ছোট নয়, তাই \(e^{0.299}=1.348\) (\(+34.8\%\)), অথচ naïve যোগ দিলে \(5\times6.2\%=31\%\) — পার্থক্যটা compounding থেকে। rate ratio গুণিতক, যোগফল নয়: \(+5°C\) মানে \(1.0616^5=1.348\)। -
Logistic odds ratio-র সঙ্গে contrast। logistic regression-এ \(e^{\beta_j}\) ছিল odds ratio — একটা binary outcome-এর odds \(\dfrac{p}{1-p}\) কত গুণ হয়। এখানে outcome binary নয়, একটা count/rate; তাই \(e^{\beta_j}\) হলো rate ratio — প্রত্যাশিত সংখ্যা \(\mu\) সরাসরি কত গুণ হয়। odds ratio-র মতো \(\dfrac{p}{1-p}\)-এর প্যাঁচ নেই, ব্যাখ্যাটা বরং সহজ: "weekend-এ গড়ে \(35\%\) বেশি ভাড়া" — এই সরল multiplicative ভাষাই count GLM-এর সৌন্দর্য। একই link (log) দুই পরিবারে (Poisson বনাম binomial) দুই অর্থ বহন করে — এটাই খেয়াল রাখার বিষয়।
E3 · হাতে একটা single prediction¶
ধরা যাক একটা সপ্তাহান্তের দিন, তাপমাত্রা \(25°C\) — অর্থাৎ temp\(=25\), weekend\(=1\)। প্রত্যাশিত ভাড়া বের করতে আগে linear predictor, পরে inverse link:
ধাপে ধাপে: \(0.0597\times 25 = 1.4925\), তাই $$ \log\mu = 1.560 + 1.4925 + 0.301 = 3.355 . $$
এখন inverse log link (\(\mu = e^{\eta}\)) প্রয়োগ করে: $$ \boxed{\;\mu = e^{3.355} \approx 28.6\ \text{rentals/day}\;} $$
অর্থাৎ এমন একটা উষ্ণ সপ্তাহান্তের দিনে মডেল গড়ে প্রায় \(29\)টি ভাড়া expect করে। যাচাই করে নিতে পারি rate-ratio দিয়েও: একটা \(25°C\) weekday-তে \(\mu = e^{1.560+1.4925}=e^{3.0525}\approx 21.2\); এতে weekend factor \(\times 1.351\) গুণ দিলে \(21.2\times 1.351\approx 28.6\) — মিলে যায়।
সতর্কবার্তা — Poisson-এর mean = variance অনুমান। Poisson বলে এই \(\mu\approx 28.6\) একই সঙ্গে দিনটির variance: \(\mathrm{Var}(y)=\mu\approx 28.6\), তাই \(\mathrm{SD}\approx\sqrt{28.6}\approx 5.3\)। কিন্তু E1-এই আমরা দেখেছি ডেটায় variance/mean \(\approx 10.5\) — মানে বাস্তবে variability এর চেয়ে অনেক বেশি। তাই point prediction \(28.6\) মোটামুটি ঠিক থাকলেও, এই Poisson মডেল থেকে পাওয়া uncertainty (prediction interval, SE) বিশ্বাসযোগ্য নয় — সেগুলো বাস্তবের চেয়ে অনেক সংকীর্ণ। এটাই পরবর্তী ধাপের প্রেরণা।
E4 · Overdispersion: ধরা এবং ঠিক করা¶
ধরা। Poisson model সঠিক হলে Pearson dispersion statistic $$ \hat\phi = \frac{\text{Pearson }\chi^2}{\mathrm{df}_{\text{resid}}} $$ এর মান \(\approx 1\) হওয়া উচিত। আমাদের fit-এ: $$ \hat\phi = \frac{1096.3}{247} = 4.44 \;\gg\; 1 . $$
\(\hat\phi=4.44\) মানে conditional variance Poisson-এর অনুমানের চেয়ে প্রায় সাড়ে চার গুণ বড় — স্পষ্ট overdispersion (E1-এর marginal \(s^2/\bar y\approx 10.5\) এরই conditional প্রতিধ্বনি)। এর সরাসরি ক্ষতি: Poisson-এর reported SE-গুলো অতি ছোট, ফলে \(z\)-statistic অতিরিক্ত বড়, \(p\)-value অতিরিক্ত ছোট — অর্থাৎ মডেল আত্মবিশ্বাস দেখাচ্ছে যেটার ভিত্তি নেই। coefficient point estimate ঠিক থাকে, কিন্তু inference বিভ্রান্তিকর।
ঠিক করা — Negative Binomial (NB2)। NB2 mean-variance সম্পর্ককে আলগা করে একটা বাড়তি dispersion parameter \(\alpha\ge 0\) দিয়ে: $$ \mathrm{Var}(y_i) = \mu_i + \alpha\,\mu_i^2 . $$ \(\alpha\to 0\) হলে এটা ফিরে Poisson-ই হয়; \(\alpha>0\) হলে variance \(\mu\)-এর চেয়ে দ্রুত বাড়ে — ঠিক যেমন আমাদের ডেটায়। একই mean structure (\(\log\mu_i=x_i^\top\beta\)) রেখে NB2 MLE fit করলে:
| পদ | Poisson \(\hat\beta\) (SE) | NB2 \(\hat\beta\) (SE) |
|---|---|---|
| Intercept | \(1.560\ (0.0476)\) | \(1.574\ (0.0874)\) |
temp |
\(0.0597\ (0.00178)\) | \(0.0592\ (0.00374)\) |
weekend |
\(0.301\ (0.0307)\) | \(0.300\ (0.0689)\) |
আর dispersion parameter \(\hat\alpha = 0.179\) (SE \(0.0215\)) — শূন্য থেকে অনেক দূরে (\(z\approx 8.3\)), পরিসংখ্যানিকভাবে দৃঢ়ভাবে নিশ্চিত যে overdispersion বাস্তব।
তিনটি জিনিস লক্ষণীয়:
- Point estimate প্রায় অপরিবর্তিত (\(\hat\beta_{\text{temp}}\): \(0.0597\to0.0592\))। তাই E2-এর rate-ratio ব্যাখ্যা মোটামুটি একই থাকে — overdispersion mean কে নাড়ায় না।
- SE প্রায় দ্বিগুণ। যেমন
temp-এর SE \(0.00178\to0.00374\) (≈\(2.1\times\));weekend-এর \(0.0307\to0.0689\)। এই বড় SE-গুলোই সত্যিকারের uncertainty — Poisson সেটা গোপন করছিল। coefficient এখনও significant, কিন্তু সৎ ব্যবধানে। - AIC নাটকীয়ভাবে কমে: Poisson \(2237.9 \to\) NB2 \(1753.3\) (∆AIC \(\approx 485\), \(\ell\): \(-1115.9\to-872.7\))। এত বড় উন্নতি একতরফাভাবে বলে দেয় — overdispersed count-এর জন্য NB2 এখানে অনেক ভালো মডেল।
দ্রুত বিকল্প — quasi-Poisson। পুরো NB মডেল না বসিয়ে শুধু inference ঠিক করতে চাইলে quasi-Poisson চলে: coefficient Poisson-এর মতোই রাখে, কিন্তু সব SE কে \(\sqrt{\hat\phi}=\sqrt{4.44}\approx 2.1\) দিয়ে গুণ করে স্ফীত করে। লক্ষ করুন এই \(2.1\) গুণিতকই NB2-তে আপনাআপনি পাওয়া SE-বৃদ্ধির (\(\approx 2.1\times\)) সঙ্গে মেলে — দুই পথ একই গন্তব্যে পৌঁছায়। পার্থক্য: quasi-Poisson কোনো পূর্ণ likelihood দেয় না (তাই AIC/LRT হয় না), আর NB2 mean-variance সম্পর্ককে স্পষ্টভাবে মডেল করে — তাই predictive distribution চাইলে NB2-ই পছন্দনীয়।
যাচাই (statsmodels)। নিচের block সমস্ত canonical সংখ্যা পুনরুৎপাদন করে (seed 20260619, \(n=250\)):
n= 250 mean= 19.56 var= 205 var/mean= 10.5 range= 0 88
=== POISSON GLM (rentals ~ temp + weekend) ===
beta: Intercept 1.560 temp 0.0597 weekend 0.301
SE: 0.0476 0.00178 0.0307
deviance= 1093.1 pearson_chi2= 1096.3 df_resid= 247
dispersion = pearson_chi2 / df_resid = 1096.3 / 247 = 4.44 (>> 1)
llf= -1115.9 AIC= 2237.9
rate ratios exp(beta): temp 1.0616 weekend 1.3514
per +5C temp: 1.348
predict(temp=25, weekend=1): log mu = 3.355 mu = 28.6
=== NEGATIVE BINOMIAL (NB2 MLE) ===
beta: 1.574 0.0592 0.300
SE: 0.0874 0.00374 0.0689 (~2x Poisson SE)
alpha= 0.179 SE_alpha= 0.0215 (>> 0, z ~ 8.3)
llf= -872.7 AIC= 1753.3 (AIC drops 2237.9 -> 1753.3)
সব মান brief-এর canonical সংখ্যার সঙ্গে মিলেছে। এক বাক্যে এই উদাহরণের শিক্ষা: Poisson GLM দিয়ে count-এর mean (rate ratio) ঠিকঠাক পড়া যায়, কিন্তু overdispersion (এখানে \(\hat\phi=4.44\)) থাকলে তার inference বিশ্বাস করা যায় না — Negative Binomial (বা quasi-Poisson) দিয়ে SE সংশোধন করে নিতে হয়।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে আমরা Poisson regression-এর সম্পূর্ণ গাণিতিক কাঠামো ধাপে ধাপে গড়ে তুলব — Poisson বণ্টনের mean–variance পরিচয় (equidispersion) থেকে শুরু করে log-likelihood, score equation, Newton–Raphson/IRLS, asymptotic inference ও deviance, তারপর overdispersion ও তার সমাধান quasi-Poisson, এবং সবশেষে negative binomial-কে একটি Gamma–Poisson mixture হিসেবে। প্রতিটি ফলাফল আগেরটির উপর দাঁড়িয়ে, তাই ক্রম মেনে পড়াই ভালো। গোটা derivation-জুড়ে আমরা দেখব এই কাঠামো 5.4-এর logistic regression-এর প্রায় হুবহু সমান্তরাল — কেবল sigmoid-এর জায়গায় \(\exp\), আর \(p(1-p)\)-এর জায়গায় \(\mu\)।
পুরো অংশে notation একই থাকবে: \(y_i\in\{0,1,2,\dots\}\) হলো observation \(i\)-এর গণনা-outcome (count), \(x_i\in\mathbb{R}^p\) হলো তার covariate vector (প্রথম উপাদান \(1\), intercept-এর জন্য), \(\mu_i=\mathbb{E}[y_i\mid x_i]>0\) হলো প্রত্যাশিত গণনা, \(\eta_i=x_i^\top\beta\) হলো linear predictor, এবং log link ধরে $$ \log\mu_i=\eta_i=x_i^\top\beta \qquad\Longleftrightarrow\qquad \mu_i=e^{\eta_i}=e^{x_i^\top\beta}. $$ এই \(\mu_i=e^{\eta_i}\) রূপটি একটি গুরুত্বপূর্ণ সুবিধা দেয়: \(\eta_i\) যেকোনো বাস্তব সংখ্যা হোক না কেন, \(e^{\eta_i}>0\) সবসময় — অর্থাৎ fitted mean কখনও ঋণাত্মক হতে পারে না, যা গণনা-data-র জন্য ঠিক যা চাই (একটি ঘটনা \(-2\) বার ঘটতে পারে না)। logistic-এ sigmoid যেমন mean-কে \((0,1)\)-এ আটকে রাখত, এখানে \(\exp\) তেমনই mean-কে \((0,\infty)\)-এ রাখে।
৪.১ ★ Poisson recap: equidispersion (\(\mathbb{E}[y]=\operatorname{Var}(y)=\mu\))¶
প্রেরণা। Poisson regression-এর গোটা ভিত্তি একটিমাত্র বৈশিষ্ট্যের উপর দাঁড়িয়ে — Poisson বণ্টনে mean ও variance সমান। এই সমতাকে বলে equidispersion (সম-বিচ্ছুরণ)। মডেলটি প্রতিটি observation-এ ধরে নেয় \(\operatorname{Var}(y_i)=\mathbb{E}[y_i]=\mu_i\) — অর্থাৎ variance-এর জন্য কোনো আলাদা free parameter নেই (Normal-এ যেমন \(\sigma^2\) ছিল); একবার mean \(\mu_i\) ঠিক হলেই spread-ও স্থির। এটি কতটা সরলীকরণ, এবং কখন তা ভেঙে পড়ে (§৪.৫-এর overdispersion), তা বুঝতে হলে আগে দেখা দরকার এই সমতা আসলে কোথা থেকে আসে। তাই pmf থেকে দুটোই derive করি।
Poisson pmf (2.3 থেকে): একটি count চলক \(y\) যার rate \(\mu>0\), $$ P(y=k)=\frac{\mu^k e^{-\mu}}{k!},\qquad k=0,1,2,\dots $$
আমরা দুইভাবে mean ও variance বের করব — প্রথমে moment generating function (MGF) দিয়ে (পরিচ্ছন্ন), তারপর সরাসরি যোগফল দিয়ে (স্বজ্ঞাদীপ্ত, যা §৪.৬-এর NB-তে ফিরে আসবে)।
পদ্ধতি ১ — MGF দিয়ে। MGF হলো \(M(t)=\mathbb{E}[e^{ty}]\)। সংজ্ঞা বসিয়ে: $$ M(t)=\sum_{k=0}^{\infty}e^{tk}\,\frac{\mu^k e^{-\mu}}{k!} =e^{-\mu}\sum_{k=0}^{\infty}\frac{(\mu e^{t})^{k}}{k!}. $$ ভেতরের যোগফলটি ঠিক \(e^{z}=\sum_k z^k/k!\)-এর Taylor series, যেখানে \(z=\mu e^{t}\)। তাই $$ \boxed{\;M(t)=e^{-\mu}\,e^{\mu e^{t}}=\exp!\bigl(\mu(e^{t}-1)\bigr).\;} $$ এখন moments আসে \(t=0\)-তে derivative নিয়ে। প্রথম derivative: $$ M'(t)=\exp!\bigl(\mu(e^{t}-1)\bigr)\cdot\mu e^{t} \quad\Longrightarrow\quad \mathbb{E}[y]=M'(0)=\underbrace{e^{0}}_{1}\cdot\mu e^{0}=\mu. $$ দ্বিতীয় derivative (product rule, যেহেতু \(M'(t)=M(t)\cdot\mu e^{t}\)): $$ M''(t)=M'(t)\,\mu e^{t}+M(t)\,\mu e^{t} =M(t)\,\bigl(\mu e^{t}\bigr)^2+M(t)\,\mu e^{t}. $$ \(t=0\)-তে (\(M(0)=1\), \(e^0=1\)): $$ \mathbb{E}[y^2]=M''(0)=\mu^2+\mu. $$ সুতরাং variance: $$ \operatorname{Var}(y)=\mathbb{E}[y^2]-\bigl(\mathbb{E}[y]\bigr)^2=(\mu^2+\mu)-\mu^2=\mu. $$
পদ্ধতি ২ — সরাসরি যোগফল দিয়ে। Mean সরাসরি: $$ \mathbb{E}[y]=\sum_{k=0}^{\infty}k\,\frac{\mu^k e^{-\mu}}{k!} =\sum_{k=1}^{\infty}k\,\frac{\mu^k e^{-\mu}}{k!} =\mu\,e^{-\mu}\sum_{k=1}^{\infty}\frac{\mu^{k-1}}{(k-1)!}. $$ এখানে \(k=0\) পদটি শূন্য (তাই বাদ), আর \(k/k!=1/(k-1)!\) ব্যবহার করে একটি \(\mu\) বাইরে টানা হয়েছে। \(j=k-1\) ধরলে ভেতরের যোগফল \(\sum_{j=0}^{\infty}\mu^j/j!=e^{\mu}\), তাই \(\mathbb{E}[y]=\mu\,e^{-\mu}\,e^{\mu}=\mu\) ✓।
variance-এর জন্য সবচেয়ে পরিচ্ছন্ন পথ হলো factorial moment \(\mathbb{E}[y(y-1)]\) আগে বের করা (কারণ \(k(k-1)/k!=1/(k-2)!\) সুন্দরভাবে কাটে): $$ \mathbb{E}[y(y-1)]=\sum_{k=2}^{\infty}k(k-1)\,\frac{\mu^k e^{-\mu}}{k!} =\mu^2 e^{-\mu}\sum_{k=2}^{\infty}\frac{\mu^{k-2}}{(k-2)!} =\mu^2 e^{-\mu}\,e^{\mu}=\mu^2. $$ এখন variance: $$ \operatorname{Var}(y)=\mathbb{E}[y^2]-\bigl(\mathbb{E}[y]\bigr)^2 =\underbrace{\mathbb{E}[y(y-1)]+\mathbb{E}[y]}_{\mathbb{E}[y^2]}-\bigl(\mathbb{E}[y]\bigr)^2 =\mu^2+\mu-\mu^2=\mu. $$ এখানে \(\mathbb{E}[y^2]=\mathbb{E}[y(y-1)]+\mathbb{E}[y]\) পরিচয়টি ব্যবহার করেছি (কারণ \(y^2=y(y-1)+y\))।
দুই পদ্ধতিই একই সিদ্ধান্তে পৌঁছায়: $$ \boxed{\;\mathbb{E}[y]=\operatorname{Var}(y)=\mu\quad(\text{equidispersion}).\;} $$
কেন এটা কেন্দ্রীয় (★)। এই একটিমাত্র সমতা Poisson regression-এর variance-কাঠামো সম্পূর্ণ স্থির করে দেয়: আলাদা dispersion parameter নেই। তাই data-তে যদি প্রকৃত spread \(\mu\)-এর চেয়ে বড় হয় (যা গণনা-data-তে খুবই সাধারণ — §৪.৫), মডেলের অনুমানই ভেঙে পড়ে। এই সম্পর্কটিই হলো গোটা অধ্যায়ের গোড়ার ধারণা — মনে রাখার মতো একটি লাইন: Poisson-এ গড় আর বিচ্ছুরণ একই সংখ্যা।
৪.২ ★★ Log-likelihood এবং exponential-family / canonical-log-link রূপ¶
Poisson likelihood। প্রতিটি \(y_i\mid x_i\sim\text{Poisson}(\mu_i)\) ধরা হয়, যেখানে \(\mu_i=e^{x_i^\top\beta}\)। একটি observation-এর pmf: $$ P(y_i\mid x_i;\beta)=\frac{\mu_i^{\,y_i}\,e^{-\mu_i}}{y_i!}. $$ Observation গুলো independent ধরে নিলে joint likelihood হলো গুণফল: $$ L(\beta)=\prod_{i=1}^{n}\frac{\mu_i^{\,y_i}e^{-\mu_i}}{y_i!}, \qquad \mu_i=e^{x_i^\top\beta}. $$ গুণফল নিয়ে কাজ করা কঠিন, তাই logarithm নিই (log monotone, তাই argmax অপরিবর্তিত)। log-likelihood: $$ \ell(\beta)=\sum_{i=1}^{n}\Bigl[y_i\log\mu_i-\mu_i-\log y_i!\Bigr]. $$ এবার \(\log\mu_i=\eta_i=x_i^\top\beta\) এবং \(\mu_i=e^{x_i^\top\beta}\) প্রতিস্থাপন করি — এই রূপ পরে derivative নেওয়া অসাধারণ সহজ করে দেবে: $$ \boxed{\;\ell(\beta)=\sum_{i=1}^{n}\Bigl[\,y_i\,x_i^\top\beta-e^{x_i^\top\beta}-\log y_i!\,\Bigr].\;} $$ এটিই brief-এ দেওয়া রূপ। লক্ষণীয়, শেষ পদ \(\log y_i!\) মোটেই \(\beta\)-নির্ভর নয় — এটি একটি constant (data-নির্ধারিত)। তাই \(\beta\)-এর সাপেক্ষে maximize করার সময় এই পদ কোনো ভূমিকা রাখে না (derivative-এ অদৃশ্য হবে), যদিও deviance ও absolute log-likelihood-এর মান হিসাবের সময় একে রাখতে হয়।
Exponential-family / canonical রূপ। একটি observation-এর pmf-কে exponential-family-র canonical আকারে লিখি। Poisson pmf-এর log: $$ \log P(y\mid\mu)=y\log\mu-\mu-\log y!. $$ Exponential family-র canonical form হলো \(\log f(y\mid\theta)=\theta\,T(y)-A(\theta)+c(y)\), যেখানে \(\theta\) হলো natural (canonical) parameter, \(T(y)\) sufficient statistic, এবং \(A(\theta)\) হলো log-partition (cumulant) function। উপরের রূপের সাথে মিলিয়ে দেখুন: যদি আমরা natural parameter ধরি \(\theta=\log\mu\), তবে \(\mu=e^{\theta}\), এবং $$ \log P(y\mid\theta)=\underbrace{y}{T(y)}\cdot\underbrace{\theta}}-\underbrace{e^{\theta}{A(\theta)}\underbrace{-\log y!}. $$ অর্থাৎ Poisson-এর জন্য $$ \theta=\log\mu\ (\text{natural parameter}),\qquad T(y)=y,\qquad A(\theta)=e^{\theta}. $$ এখন মূল বিষয়টা: log link ঠিক natural parameter \(\theta=\log\mu\)-কেই linear predictor \(\eta=x^\top\beta\)-এর সমান বসায়। অর্থাৎ log হলো Poisson-এর canonical link — ঠিক যেমন logit ছিল Bernoulli-র canonical link (5.4)। এটি কাকতালীয় নয়; এই মিলই 5.4-এর GLM-কাঠামোয় Poisson-কে স্বাভাবিক পরবর্তী সদস্য করে তোলে।
Canonical রূপের একটি মহার্ঘ উপহার — exponential family-র সাধারণ তত্ত্ব বলে $$ A'(\theta)=\mathbb{E}[T(y)]=\mathbb{E}[y]=\mu,\qquad A''(\theta)=\operatorname{Var}(y). $$ যাচাই করি: \(A(\theta)=e^{\theta}\) হলে \(A'(\theta)=e^{\theta}=\mu\) ✓ (ঠিক §৪.১-এর mean), এবং \(A''(\theta)=e^{\theta}=\mu\) ✓ (ঠিক §৪.১-এর variance — equidispersion আবার, এবার এক লাইনে)। এই \(A'=\mu\) ও \(A''=\mu\) পরের অংশের score ও Hessian-কে প্রায় বিনা পরিশ্রমে দেবে।
পরিভাষা টীকা (★). \(A(\theta)=e^{\theta}\) সর্বত্র convex (কারণ \(A''=\mu>0\))। \(\ell\)-এ এর সামনে ঋণচিহ্ন থাকায় (পদ \(-e^{x_i^\top\beta}\)) \(\ell\) concave হবে — §৪.৩-এ ঠিক এটাই প্রমাণ করব, যা MLE-র একত্ব নিশ্চিত করে। তুলনা: logistic-এ এই ভূমিকা নিয়েছিল softplus \(\log(1+e^\eta)\); Poisson-এ তা সরল হয়ে দাঁড়ায় কেবল \(e^\eta\)।
৪.৩ ★★ Score equations, logistic-এর সাথে সমান্তরাল, Hessian ও concavity¶
Score (gradient) নির্ণয়। MLE পেতে \(\ell(\beta)\)-কে \(\beta\)-এর সাপেক্ষে সর্বোচ্চ করতে হবে, অর্থাৎ gradient (score) \(=0\) সমাধান করতে হবে। §৪.২-এর রূপ থেকে শুরু করি, কারণ সেখানে \(\beta\)-নির্ভরতা কেবল \(\eta_i=x_i^\top\beta\)-এর মাধ্যমে — তাই chain rule সরল।
একটি observation-এর contribution \(\ell_i=y_i\eta_i-e^{\eta_i}-\log y_i!\) থেকে \(\eta_i\)-এর সাপেক্ষে derivative (constant পদ \(\log y_i!\) অদৃশ্য): $$ \frac{\partial \ell_i}{\partial \eta_i} =y_i-e^{\eta_i} =y_i-\mu_i, $$ যেখানে আমরা \(\dfrac{d}{d\eta}e^{\eta}=e^{\eta}=\mu\) ব্যবহার করেছি (অর্থাৎ §৪.২-এর \(A'(\theta)=\mu\))। এখন chain rule, যেহেতু \(\dfrac{\partial \eta_i}{\partial \beta}=\dfrac{\partial(x_i^\top\beta)}{\partial\beta}=x_i\): $$ \frac{\partial \ell_i}{\partial \beta} =\frac{\partial \ell_i}{\partial \eta_i}\cdot\frac{\partial \eta_i}{\partial \beta} =(y_i-\mu_i)\,x_i. $$ সব observation-এর উপর যোগ করে score vector: $$ U(\beta)\equiv\frac{\partial \ell}{\partial \beta}=\sum_{i=1}^{n}(y_i-\mu_i)\,x_i . $$ Design matrix \(X=\begin{bmatrix}x_1^\top\\ \vdots\\ x_n^\top\end{bmatrix}\in\mathbb{R}^{n\times p}\), এবং vector \(y=(y_1,\dots,y_n)^\top\), \(\mu=(\mu_1,\dots,\mu_n)^\top\) লিখলে যোগফলটি একটি পরিচ্ছন্ন matrix রূপ নেয় (যেহেতু \(\sum_i(y_i-\mu_i)x_i=X^\top(y-\mu)\)): $$ \boxed{\;U(\beta)=X^\top(y-\mu)=0\;} \qquad\text{(score / likelihood equations)},\qquad \mu_i=e^{x_i^\top\beta}. $$
Logistic ও OLS-এর সাথে সমান্তরাল। এই রূপটি লক্ষ করুন — এটি হুবহু logistic regression-এর score (5.4: \(X^\top(y-p)=0\)) এবং OLS-এর normal equations (5.1: \(X^\top(y-\hat y)=0\))-এর মতো। তিন ক্ষেত্রেই একই geometric নীতি: residual \((y-\hat\mu)\) প্রতিটি predictor-column-এর সাথে orthogonal, যেখানে \(\hat\mu=\mathbb{E}[y\mid X]\) হলো fitted mean। কেবল \(\mu_i\)-এর সূত্র বদলায় — $$ \text{OLS: }\mu_i=x_i^\top\beta,\qquad \text{logistic: }\mu_i=\sigma(x_i^\top\beta),\qquad \text{Poisson: }\mu_i=e^{x_i^\top\beta}. $$ এটিই GLM-তত্ত্বের সৌন্দর্য (5.4-এ গড়া): একই কাঠামো, কেবল mean-function ভিন্ন।
তবে সিদ্ধান্তমূলক পার্থক্য — OLS-এ \(\hat y=X\hat\beta\) linear in \(\beta\), তাই closed-form \(\hat\beta=(X^\top X)^{-1}X^\top y\) মেলে। কিন্তু এখানে \(\mu_i=e^{x_i^\top\beta}\) — exponential-এর কারণে \(\mu\) হলো nonlinear in \(\beta\)। তাই \(X^\top(y-\mu(\beta))=0\) হলো একগুচ্ছ অরৈখিক সমীকরণ, যার সাধারণভাবে কোনো closed-form সমাধান নেই। ফলে iterative পদ্ধতি — Newton–Raphson বা তার সমতুল্য IRLS — প্রয়োজন (নিচে)।
Hessian নির্ণয়। Newton-এর জন্য এবং concavity প্রমাণের জন্য দ্বিতীয় derivative দরকার। \(U(\beta)=\sum_i(y_i-\mu_i)x_i\)-কে আবার \(\beta\)-এর সাপেক্ষে differentiate করি। কেবল \(\mu_i=e^{\eta_i}\) পদই \(\beta\)-নির্ভর, এবং $$ \frac{\partial \mu_i}{\partial \beta} =e^{\eta_i}\,\frac{\partial \eta_i}{\partial\beta} =\mu_i\,x_i. $$ সুতরাং (একটি observation-এর Hessian হলো outer product \(x_ix_i^\top\)-এর scalar গুণিতক): $$ H(\beta)=\frac{\partial U}{\partial \beta^\top} =\frac{\partial}{\partial\beta^\top}\sum_i(y_i-\mu_i)x_i =-\sum_{i=1}^{n}x_i\,\frac{\partial \mu_i}{\partial\beta^\top} =-\sum_{i=1}^{n}\mu_i\,x_i x_i^\top. $$ working weight \(w_i\equiv\mu_i\) এবং diagonal weight matrix \(W=\operatorname{diag}(\mu_1,\dots,\mu_n)\) সংজ্ঞায়িত করি। তখন \(\sum_i\mu_i x_i x_i^\top=X^\top W X\), তাই $$ \boxed{\;H(\beta)=\frac{\partial^2\ell}{\partial\beta\,\partial\beta^\top}=-X^\top W X,\qquad W=\operatorname{diag}(\mu_i)\;} $$ এখানে গুরুত্বপূর্ণ পার্থক্য logistic থেকে: সেখানে weight ছিল \(w_i=p_i(1-p_i)\) (Bernoulli variance), এখানে weight হলো \(w_i=\mu_i\) (Poisson variance) — দু-ক্ষেত্রেই weight = সেই বণ্টনের variance, যা GLM-এর একটি সাধারণ সত্য।
Concavity ও MLE-র একত্ব। যেকোনো nonzero vector \(v\in\mathbb{R}^p\)-এর জন্য quadratic form: $$ v^\top(-H)v=v^\top X^\top W X\,v=(Xv)^\top W(Xv)=\sum_{i=1}^{n}\mu_i\,(x_i^\top v)^2\ \ge 0, $$ কারণ প্রতিটি \(\mu_i=e^{x_i^\top\beta}>0\) সবসময় (exponential কখনও শূন্য বা ঋণাত্মক হয় না)। তাই \(-H=X^\top W X\) অন্তত positive semi-definite; এবং যদি \(X\)-এর full column rank থাকে (অর্থাৎ \(Xv\ne 0\) যখন \(v\ne 0\)), তবে যোগফলটি strictly positive, অর্থাৎ \(-H\) positive-definite \(\Rightarrow H\) negative-definite। ফলে \(\ell(\beta)\) strictly concave, এবং strictly concave function-এর সর্বোচ্চ বিন্দু (যদি থাকে) একমাত্র — তাই MLE \(\hat\beta\) unique, কোনো local maximum-এ আটকে যাওয়ার আশঙ্কা নেই।
এক ধাপ Newton–Raphson ও IRLS। যেহেতু score \(X^\top(y-\mu)=0\) অরৈখিক, Newton update হলো (4.3 / সংখ্যাবিশ্লেষণ, current point-এ \(U\) linearize করে): $$ \beta^{(t+1)}=\beta^{(t)}-H^{-1}U\big|_{\beta^{(t)}}. $$ \(H=-X^\top W X\) এবং \(U=X^\top(y-\mu)\) বসিয়ে (দুই ঋণচিহ্ন মিলে যোগচিহ্ন, কারণ \(-H^{-1}=+(X^\top WX)^{-1}\); সব \(\beta^{(t)}\)-এ মূল্যায়িত): $$ \boxed{\;\beta^{(t+1)}=\beta^{(t)}+\bigl(X^\top W X\bigr)^{-1}X^\top(y-\mu),\qquad W=\operatorname{diag}(\mu_i)\;} $$ concavity-র কারণে \(X^\top W X\succ 0\), তাই inverse বিদ্যমান এবং প্রতিটি step \(\ell\) বাড়ায় — সাধারণত মাত্র ৫–১০ iteration-এই convergence (quadratic)। এটিকে IRLS রূপে লেখা যায় — ঠিক 5.4-এর মতো \(z=X\beta^{(t)}+W^{-1}(y-\mu)\) working response নিয়ে \(\beta^{(t+1)}=(X^\top WX)^{-1}X^\top W z\), প্রতি iteration-এ একটি weighted least squares; কেবল weight এখন \(\mu_i\) (logistic-এ ছিল \(p_i(1-p_i)\))। কোনো closed-form নেই, কিন্তু এই iteration দ্রুত MLE-তে পৌঁছে দেয়।
৪.৪ ★★ Inference: Fisher information, Wald test ও deviance¶
Fisher information। observed information হলো \(-H=X^\top W X\)। এখানে \(W=\operatorname{diag}(\mu_i)\) কেবল \(\beta\) ও fixed \(x_i\)-এর উপর নির্ভর করে, \(y_i\)-এর উপর নয় — অর্থাৎ \(H\) random নয় (given \(X\))। তাই expectation নিলে কিছু বদলায় না, এবং expected (Fisher) information = observed information: $$ \boxed{\;\mathcal{I}(\beta)=-\mathbb{E}[H]=X^\top W X,\qquad W=\operatorname{diag}(\mu_i)\;} $$ (এটিই কারণ — canonical log-link-এ Newton–Raphson আর Fisher scoring অভিন্ন, ঠিক logistic-এর মতো।)
Asymptotic distribution of \(\hat\beta\)। MLE-র সাধারণ asymptotic তত্ত্ব (4.3) অনুযায়ী, regularity conditions-এ $$ \boxed{\;\hat\beta\ \stackrel{\cdot}{\sim}\ \mathcal{N}!\bigl(\beta,\ \mathcal{I}(\beta)^{-1}\bigr)=\mathcal{N}!\bigl(\beta,\ (X^\top W X)^{-1}\bigr)\;} $$ অর্থাৎ \(\hat\beta\) asymptotically unbiased, normal, এবং covariance হলো inverse Fisher information (Cramér–Rao bound অর্জন — MLE asymptotically efficient)। প্রায়োগিক ক্ষেত্রে \(\beta\) অজানা, তাই \(W\) মূল্যায়ন করি \(\hat\beta\)-তে: \(\widehat W=\operatorname{diag}(\hat\mu_i)\) যেখানে \(\hat\mu_i=e^{x_i^\top\hat\beta}\), এবং estimated covariance \(\widehat{\operatorname{Cov}}(\hat\beta)=(X^\top\widehat W X)^{-1}\)। এর diagonal-এর বর্গমূল হলো standard error: $$ \mathrm{SE}(\hat\beta_j)=\sqrt{\bigl[(X^\top\widehat W X)^{-1}\bigr]_{jj}}. $$
Wald test। \(H_0:\beta_j=0\) (covariate \(x_j\)-এর কোনো প্রভাব নেই) পরীক্ষা করতে asymptotic normality ব্যবহার করে Wald statistic (cf. 4.7): $$ \boxed{\;z_j=\frac{\hat\beta_j}{\mathrm{SE}(\hat\beta_j)}\ \stackrel{\cdot}{\sim}\ \mathcal{N}(0,1)\ \text{under }H_0\;} $$ অথবা সমতুল্যভাবে \(z_j^2\stackrel{\cdot}{\sim}\chi^2_1\)। বড় \(\lvert z_j\rvert\) (ছোট \(p\)-value) \(H_0\) প্রত্যাখ্যান করে। approximate \((1-\alpha)\) confidence interval \(\hat\beta_j\pm z_{1-\alpha/2}\,\mathrm{SE}(\hat\beta_j)\); দুই প্রান্ত exponentiate করলে rate ratio \(e^{\beta_j}\)-এর CI পাওয়া যায় (Poisson-এ coefficient-এর ব্যাখ্যা: \(x_j\) এক একক বাড়লে প্রত্যাশিত গণনা গুণিতকভাবে \(e^{\beta_j}\) গুণ — log link-এর গুণাত্মক ব্যাখ্যা, ঠিক logistic-এর odds ratio-র সমান্তরাল)।
Deviance। Poisson regression-এ goodness-of-fit ও model comparison-এর কেন্দ্রীয় পরিমাপ হলো deviance, যা saturated model-এর সাপেক্ষে সংজ্ঞায়িত। Saturated model প্রতিটি observation-এ \(\hat\mu_i=y_i\) ধরে (নিখুঁত fit), তাই $$ D=2\bigl[\ell_{\text{sat}}-\ell(\hat\beta)\bigr] =2\sum_{i=1}^{n}\Bigl[\bigl(y_i\log y_i-y_i\bigr)-\bigl(y_i\log\hat\mu_i-\hat\mu_i\bigr)\Bigr], $$ যেখানে constant পদ \(\log y_i!\) দুই দিক থেকে কাটাকাটি হয়ে যায়। গুছিয়ে লিখলে: $$ \boxed{\;D=2\sum_{i=1}^{n}\Bigl[\,y_i\log\frac{y_i}{\hat\mu_i}-(y_i-\hat\mu_i)\,\Bigr]\;} $$ (প্রথা: \(y_i=0\) হলে \(y_i\log(y_i/\hat\mu_i)\)-কে \(0\) ধরা হয়, যেহেতু \(\lim_{y\to0^+}y\log y=0\)।) এর ভূমিকা ঠিক linear regression-এর residual sum of squares-এর সমতুল্য — যত ছোট, তত ভালো fit।
deviance-এর দুটো কাজ:
-
Goodness-of-fit। মডেল সঠিক হলে (এবং \(\mu_i\) যথেষ্ট বড় হলে), residual deviance \(D\stackrel{\cdot}{\sim}\chi^2_{n-p}\) (\(n-p\) = observation বিয়োগ parameter সংখ্যা)। তাই \(D\)-কে তার degrees of freedom \((n-p)\)-এর সাথে তুলনা করা হয়: \(D\approx n-p\) হলে fit গ্রহণযোগ্য; \(D\gg n-p\) মানে মডেল data-কে ভালোভাবে ধরছে না — এটিই overdispersion-এর প্রথম সংকেত (§৪.৫)।
-
Model comparison (LR test)। দুটি nested model (model 0 ⊂ model 1, \(q\)টি অতিরিক্ত parameter) তুলনা করতে likelihood-ratio test (4.7) — দুই deviance-এর পার্থক্যই statistic: $$ G^2=D_0-D_1=2\bigl[\ell(\hat\beta_1)-\ell(\hat\beta_0)\bigr]\ \stackrel{\cdot}{\sim}\ \chi^2_q\ \text{under }H_0. $$ বড় \(G^2\) মানে অতিরিক্ত predictor fit উল্লেখযোগ্য উন্নত করেছে \(\Rightarrow H_0\) প্রত্যাখ্যান। intercept-only null-এর বিরুদ্ধে full model-এর test হলো overall model significance।
৪.৫ ★★ Overdispersion এবং quasi-Poisson সংশোধন¶
সমস্যাটা কোথায়। §৪.১-এ দেখলাম Poisson মডেল জোর করে \(\operatorname{Var}(y_i)=\mu_i\) ধরে — variance-এর কোনো স্বাধীন parameter নেই। কিন্তু বাস্তব গণনা-data প্রায়ই এর চেয়ে বেশি ছড়ানো থাকে: unmodeled heterogeneity, ঘটনার clustering, বাদ-পড়া covariate — যেকোনোটিই variance বাড়ায়। এই অবস্থা — যেখানে \(\operatorname{Var}(y_i)>\mathbb{E}[y_i]\) — কে বলে overdispersion (অতি-বিচ্ছুরণ)।
এটি আনুষ্ঠানিক করতে একটি dispersion parameter \(\phi\) ঢোকাই, এবং ধরি variance-টা mean-এর \(\phi\) গুণ: $$ \operatorname{Var}(y_i)=\phi\,\mu_i. $$ বিশুদ্ধ Poisson হলো \(\phi=1\)-এর বিশেষ ঘটনা। \(\phi>1\) মানে overdispersion (data Poisson-এর চেয়ে বেশি ছড়ানো); \(\phi<1\) মানে underdispersion (কম সাধারণ)। প্রশ্ন: \(\phi\) আসলে \(1\) নয়, অথচ আমরা Poisson ধরে চললে কী ভুল হয়?
মূল ফলাফল — point estimate ঠিক থাকে, কিন্তু SE ভুল হয়। এখানে দুটো আলাদা প্রভাব সাবধানে আলাদা করা জরুরি।
প্রথমত, \(\hat\beta\) নিজে consistent থাকে। কারণ score equation \(X^\top(y-\mu)=0\) কেবল mean-কাঠামোর (\(\mu_i=e^{x_i^\top\beta}\)) উপর নির্ভর করে — variance-এর সঠিক রূপ এতে ঢোকে না। mean ঠিকভাবে নির্দিষ্ট থাকলে \(\mathbb{E}[U(\beta)]=\sum_i\mathbb{E}[y_i-\mu_i]x_i=0\) প্রকৃত \(\beta\)-তে শূন্যই থাকে, তাই estimating equation নিরপেক্ষ — এটি quasi-likelihood তত্ত্বের একটি কেন্দ্রীয় ফল। অর্থাৎ overdispersion থাকলেও Poisson-MLE \(\hat\beta\) ঠিক মানের দিকেই যায়।
দ্বিতীয়ত — এবং এখানেই বিপদ — মডেল-প্রদত্ত variance \((X^\top WX)^{-1}\) প্রকৃত variance-কে কম করে দেখায়। কেন, তা স্যান্ডউইচ-আকারে দেখা সবচেয়ে স্পষ্ট। MLE-র প্রকৃত asymptotic covariance হলো ("স্যান্ডউইচ"): $$ \operatorname{Cov}(\hat\beta)\approx \underbrace{(X^\top W X)^{-1}}{\text{bread}}\ \underbrace{\bigl(X^\top W{!} X\bigr)}{\text{meat}}\ \underbrace{(X^\top W X)^{-1}}, $$ যেখানে }\(W=\operatorname{diag}(\mu_i)\) আসে Hessian থেকে (মডেল যা ধরে), আর \(W_{\!*}=\operatorname{diag}\bigl(\operatorname{Var}(y_i)\bigr)\) আসে \(y_i\)-এর প্রকৃত variance থেকে। যদি প্রকৃত variance ঠিক \(\operatorname{Var}(y_i)=\phi\mu_i\) হয়, তবে \(W_{\!*}=\phi W\), এবং meat \(=\phi\,X^\top W X\)। সেটা বসালে দুই bread-এর একটি \(X^\top WX\) কাটে: $$ \operatorname{Cov}(\hat\beta)\approx (X^\top WX)^{-1}\,\phi\,(X^\top WX)\,(X^\top WX)^{-1} =\phi\,(X^\top WX)^{-1}. $$ অর্থাৎ প্রকৃত covariance হলো model-প্রদত্ত covariance-এর ঠিক \(\phi\) গুণ। Poisson SE গণনা করে \((X^\top WX)^{-1}\), কিন্তু সত্য তার \(\phi\) গুণ — তাই \(\phi>1\) হলে Poisson SE-কে \(\sqrt{\phi}\) গুণ কম করে দেখায়*: $$ \mathrm{SE}{\text{true}}(\hat\beta_j)=\sqrt{\phi}\ \mathrm{SE}(\hat\beta_j). $$}
ফলাফল — type-I error স্ফীত হয়। SE কম দেখানোর সরাসরি পরিণতি Wald statistic-এ: $$ z_j=\frac{\hat\beta_j}{\mathrm{SE}{\text{Poisson}}(\hat\beta_j)} =\sqrt{\phi}\cdot\frac{\hat\beta_j}{\mathrm{SE}. $$ অর্থাৎ overdispersion উপেক্ষা করলে }}(\hat\beta_j)\(z\)-মান একটি \(\sqrt{\phi}\) গুণে কৃত্রিমভাবে বড় হয়ে যায় (\(\phi=4\) হলে \(z\) দ্বিগুণ!)। ফলে \(p\)-value প্রকৃতের চেয়ে ছোট, confidence interval প্রকৃতের চেয়ে সংকীর্ণ, আর আমরা এমন coefficient-কে "significant" ঘোষণা করি যা আসলে নয় — অর্থাৎ type-I error (false positive) প্রকৃত \(\alpha\)-এর অনেক বেশি। এটিই overdispersion উপেক্ষার আসল বিপদ: \(\hat\beta\) ভুল হয় না, কিন্তু তার অনিশ্চয়তা মারাত্মকভাবে কম-মূল্যায়িত হয়।
সমাধান — quasi-Poisson। ধারণাটা সরল: \(\phi\)-কে data থেকে আন্দাজ করো, তারপর SE-গুলোকে \(\sqrt{\hat\phi}\) দিয়ে স্কেল করো। \(\phi\)-এর স্ট্যান্ডার্ড moment-আন্দাজ হলো Pearson statistic-কে degrees of freedom দিয়ে ভাগ: $$ \boxed{\;\hat\phi=\frac{1}{n-p}\sum_{i=1}^{n}\frac{(y_i-\hat\mu_i)^2}{\hat\mu_i}=\frac{X^2}{n-p}\;} $$ যেখানে \(X^2=\sum_i(y_i-\hat\mu_i)^2/\hat\mu_i\) হলো Pearson chi-square (প্রতিটি পদ standardized squared residual, যেহেতু Poisson-এ variance \(\approx\hat\mu_i\))। স্বজ্ঞা: মডেল ঠিক হলে প্রতিটি \((y_i-\hat\mu_i)^2/\hat\mu_i\)-এর প্রত্যাশিত মান \(\approx 1\), তাই \(\hat\phi\approx 1\); data বেশি ছড়ানো হলে squared residual গড়ে \(1\)-এর চেয়ে বড়, তাই \(\hat\phi>1\)।
quasi-Poisson ঠিক এটাই করে: point estimate \(\hat\beta\) Poisson-এরই মতো রাখে (mean-কাঠামো অভিন্ন), কিন্তু covariance-কে স্কেল করে — $$ \widehat{\operatorname{Cov}}{\text{quasi}}(\hat\beta)=\hat\phi\,(X^\top\widehat W X)^{-1}, \qquad \mathrm{SE}(\hat\beta_j). $$ এতে }}(\hat\beta_j)=\sqrt{\hat\phi}\ \mathrm{SE}_{\text{Poisson}\(z\)-মান \(\sqrt{\hat\phi}\) ভাগ হয়ে যায়, \(p\)-value বড় হয়, CI চওড়া হয় — অর্থাৎ inference প্রকৃত অনিশ্চয়তাকে সততার সাথে ধরে। লক্ষণীয়, quasi-Poisson কোনো পূর্ণ probability model নয় (তাই কঠোর অর্থে likelihood বা AIC নেই) — এটি একটি quasi-likelihood সংশোধন, যা শুধু প্রথম দুই moment (\(\mathbb{E}=\mu\), \(\operatorname{Var}=\phi\mu\)) ধরে। যখন variance-এর প্যাটার্ন \(\phi\mu\) (mean-এর রৈখিক গুণিতক) ভালো খাপ খায়, তখন এটি সরল ও কার্যকর। কিন্তু যদি variance mean-এর সাথে আরও দ্রুত (quadratic-ভাবে) বাড়ে, তখন একটি পূর্ণ মডেল দরকার — যা পরের অংশের negative binomial।
৪.৬ ★ Negative binomial: Gamma–Poisson mixture¶
প্রেরণা। quasi-Poisson variance-কে \(\phi\mu\) (রৈখিক) ধরে। কিন্তু বহু বাস্তব গণনা-data-তে variance mean-এর সাথে quadratic-ভাবে বাড়ে — বড় count-গুলো অনুপাতে আরও বেশি অস্থির। এর জন্য চাই একটি পূর্ণ probability model যার variance \(\mu+\alpha\mu^2\) রূপ নেয়; সেটিই negative binomial (NB)। সবচেয়ে স্বচ্ছ derivation NB-কে একটি Gamma–Poisson mixture হিসেবে দেখায় — অর্থাৎ একটি Poisson যার rate নিজেই এলোমেলো।
গঠন। ধরা যাক প্রতিটি observation-এর rate \(\lambda\) স্থির নয়, বরং একক-ভেদে ওঠানামা করে (unobserved heterogeneity)। আমরা দুই স্তরে মডেল করি: $$ y\mid\lambda\sim\text{Poisson}(\lambda),\qquad \lambda\sim\text{Gamma},\quad \mathbb{E}[\lambda]=\mu,\ \ \operatorname{Var}(\lambda)=\frac{\mu^2}{r}. $$ এখানে Gamma-কে এমনভাবে parametrize করেছি যেন তার গড় ঠিক আমাদের লক্ষ্য \(\mu\), আর shape parameter \(r>0\) ছড়ানো নিয়ন্ত্রণ করে (shape \(=r\), তাই \(\operatorname{Var}(\lambda)=\mu^2/r\) — Gamma-র জানা mean–variance সম্পর্ক)। \(\alpha\equiv 1/r\) ধরলে \(\operatorname{Var}(\lambda)=\alpha\mu^2\)। স্বজ্ঞা: \(r\to\infty\) (\(\alpha\to0\)) মানে Gamma সংকুচিত হয়ে একটি ধ্রুবক \(\mu\)-তে পরিণত — তখন NB ফিরে গিয়ে বিশুদ্ধ Poisson হয়ে যায়।
আমরা marginal mean ও variance বের করব law of total expectation/variance দিয়ে — কোনো জটিল integral ছাড়াই, কারণ ভেতরের Poisson-এর mean ও variance দুটোই \(\lambda\) (§৪.১)।
Marginal mean (law of total expectation)। $$ \mathbb{E}[y]=\mathbb{E}\lambda\bigl[\,\mathbb{E}[y\mid\lambda]\,\bigr] =\mathbb{E}\lambda[\lambda] =\mu. $$ এখানে ভেতরের \(\mathbb{E}[y\mid\lambda]=\lambda\) (Poisson mean), তারপর বাইরের expectation \(\mathbb{E}_\lambda[\lambda]=\mu\)। অর্থাৎ rate এলোমেলো হলেও marginal mean অপরিবর্তিত \(\mu\) — mixing গড় বদলায় না।
Marginal variance (law of total variance)। law of total variance বলে: $$ \operatorname{Var}(y)=\underbrace{\mathbb{E}\lambda\bigl[\operatorname{Var}(y\mid\lambda)\bigr]} +\underbrace{\operatorname{Var}}\lambda\bigl(\mathbb{E}[y\mid\lambda]\bigr)}. $$ দুটি পদ আলাদা করে হিসাব করি:}
- পদ (i): Poisson-এর \(\operatorname{Var}(y\mid\lambda)=\lambda\) (§৪.১), তাই \(\mathbb{E}_\lambda[\lambda]=\mu\)।
- পদ (ii): Poisson-এর \(\mathbb{E}[y\mid\lambda]=\lambda\), তাই \(\operatorname{Var}_\lambda(\lambda)=\dfrac{\mu^2}{r}=\alpha\mu^2\)।
যোগ করে: $$ \operatorname{Var}(y)=\mu+\frac{\mu^2}{r}=\mu+\alpha\mu^2. $$ ঠিক brief-এর রূপ: $$ \boxed{\;\mathbb{E}[y]=\mu,\qquad \operatorname{Var}(y)=\mu+\alpha\mu^2\quad(\alpha=1/r).\;} $$
ব্যাখ্যা। variance-এর দুটি অংশ স্পষ্ট আলাদা গল্প বলে: \(\mu\) হলো Poisson-জাত স্বাভাবিক ওঠানামা (within — rate স্থির থাকলেও যা থাকত), আর \(\alpha\mu^2\) হলো rate-এর নিজস্ব ওঠানামা থেকে আসা অতিরিক্ত variance (between)। যেহেতু \(\alpha\mu^2\ge 0\), NB-র variance সর্বদা Poisson-এর চেয়ে বড় বা সমান — তাই NB কাঠামোগতভাবে overdispersion ধারণ করে, কখনও underdispersion নয়। এবং এই অতিরিক্ত অংশ quadratic in \(\mu\): বড় count-এ overdispersion অনুপাতে আরও প্রকট — যা quasi-Poisson-এর রৈখিক \(\phi\mu\) থেকে গুণগতভাবে ভিন্ন।
দুই সংশোধনের সারসংক্ষেপ এক টেবিলে:
| মডেল | variance অনুমান | dispersion-এর রূপ | কখন উপযুক্ত |
|---|---|---|---|
| Poisson | \(\operatorname{Var}=\mu\) | কোনোটি নয় (\(\phi=1\)) | equidispersion সত্য হলে |
| quasi-Poisson | \(\operatorname{Var}=\phi\mu\) | constant \(\phi\), রৈখিক | overdispersion variance\(\propto\)mean হলে |
| negative binomial | \(\operatorname{Var}=\mu+\alpha\mu^2\) | \(\alpha\), quadratic | overdispersion বড় count-এ প্রকট হলে |
সারসংক্ষেপ (★). Poisson regression = Poisson random component + canonical log link, যার ভিত্তি equidispersion \(\mathbb{E}[y]=\operatorname{Var}(y)=\mu\) (§৪.১)। MLE আসে score equation \(X^\top(y-\mu)=0\) থেকে — হুবহু logistic-এর গঠন, কেবল \(\mu_i=e^{x_i^\top\beta}\); অরৈখিক, তাই closed-form নেই, IRLS/Newton দিয়ে সমাধান, weight \(W=\operatorname{diag}(\mu_i)\)। Inference আসে Fisher information \(\mathcal{I}=X^\top WX\) থেকে — Wald \(z_j=\hat\beta_j/\mathrm{SE}_j\) ও deviance \(D=2\sum_i[y_i\log(y_i/\hat\mu_i)-(y_i-\hat\mu_i)]\sim\chi^2\)। বাস্তবে equidispersion প্রায়ই ভাঙে → overdispersion (\(\operatorname{Var}=\phi\mu\), \(\phi>1\)): \(\hat\beta\) consistent থাকে কিন্তু Poisson SE প্রকৃত variance-কে \(\sqrt{\phi}\) গুণ কম দেখায় → type-I error স্ফীত; সমাধান quasi-Poisson (\(\hat\phi=X^2/(n-p)\) দিয়ে SE-কে \(\sqrt{\hat\phi}\) গুণ স্কেল)। variance quadratic-ভাবে বাড়লে পূর্ণ মডেল negative binomial — যা Gamma–Poisson mixture থেকে \(\operatorname{Var}(y)=\mu+\alpha\mu^2\) দেয় (law of total variance: within \(\mu\) + between \(\alpha\mu^2\))।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা Poisson regression-কে দুই দিক থেকে দাঁড় করাব। প্রথমে স্ক্র্যাচ থেকে — log-link (\(\mu = e^\eta\)), gradient ও Hessian নিজ হাতে লিখে IRLS / Newton–Raphson দিয়ে \(\hat{\boldsymbol\beta}\) বের করব এবং তা statsmodels-এর সঙ্গে মিলিয়ে নেব। তারপর একটা বাস্তব সমস্যায় ঢুকব: এই ডেটায় Poisson মডেলের মূল ধারণা — variance \(=\) mean — মারাত্মকভাবে ভেঙে পড়েছে (overdispersion)। সেই সমস্যা ধরা পড়বে dispersion statistic-এ, আর সমাধান হিসেবে দুটো পথ দেখাব: Negative Binomial regression (পূর্ণ MLE, আলাদা dispersion parameter \(\alpha\) সহ) এবং দ্রুত-পথ quasi-Poisson standard error সংশোধন।
ডেটাসেটটি কৃত্রিম — দৈনিক bike-rental সংখ্যা (rentals) তৈরি হয়েছে log-rate \(\log\mu = 1.5 + 0.06\,\text{temp} + 0.4\,\text{weekend}\) থেকে। কিন্তু চালাকিটা এক জায়গায়: প্রতিটি \(\mu\)-কে একটা Gamma-বিচ্ছুরণ দিয়ে গুণ করে তবে Poisson নমুনা টানা হয়েছে। এই Gamma–Poisson mixture ইচ্ছাকৃতভাবে অতিরিক্ত বিক্ষেপ (overdispersion) ঢুকিয়ে দেয় — অর্থাৎ ডেটা-জেনারেটিং প্রক্রিয়াই বিশুদ্ধ Poisson নয়, যদিও mean-structure (coefficient) ঠিক রাখা হয়েছে। ফলে আমরা আগে থেকেই জানি "সত্যিকারের" coefficient \((1.5,\ 0.06,\ 0.4)\), এবং একই সঙ্গে জানি Poisson মডেল এখানে অসম্পূর্ণ — দুটোই কোডে যাচাই করা যাবে।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# -*- coding: utf-8 -*-
# Chapter 5.5 — GLM: Poisson Regression & Beyond — Code Lab
import numpy as np, pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
np.set_printoptions(precision=4, suppress=True)
# ----------------------------------------------------------------------
# DATASET (bike-rental counts; Gamma-Poisson mixture => overdispersion)
# ----------------------------------------------------------------------
rng = np.random.default_rng(20260619); n = 250
temp = rng.uniform(5, 35, n)
weekend = rng.binomial(1, 2/7, n)
logmu = 1.5 + 0.06*temp + 0.4*weekend
mu = np.exp(logmu)
lam = mu*rng.gamma(6.0, 1.0/6.0, n) # Gamma-Poisson mixture -> overdispersion
rentals = rng.poisson(lam)
df = pd.DataFrame({'rentals': rentals, 'temp': temp, 'weekend': weekend})
print("="*64)
print("DATASET overview")
print("="*64)
print("shape:", df.shape)
m = df['rentals'].mean()
v = df['rentals'].var() # sample variance (ddof=1)
print(f"count mean : {m:.2f}")
print(f"count variance : {v:.1f}")
print(f"variance/mean : {v/m:.1f} (=1 for a true Poisson)")
print(df.head())
# ----------------------------------------------------------------------
# PART 1 — from-scratch Poisson regression via IRLS / Newton-Raphson
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 1 — From scratch: Poisson IRLS")
print("="*64)
X = np.column_stack([np.ones(n), df['temp'].values, df['weekend'].values])
y = df['rentals'].values.astype(float)
def poisson_loglik(beta):
eta = X @ beta
mu = np.exp(eta)
# log L = sum[ y*eta - mu - log(y!) ] (drop constant log y! for the optimiser)
from scipy.special import gammaln
return np.sum(y*eta - mu - gammaln(y+1.0))
# Warm start: intercept = log(mean count), slopes = 0 (standard GLM init).
# Starting all-zeros makes the very first full Newton step overshoot wildly
# (mu = exp(eta) explodes), so we seed the intercept at the marginal log-mean.
beta = np.array([np.log(y.mean()), 0.0, 0.0])
print(f"{'iter':>4} {'b0':>10} {'b_temp':>10} {'b_wknd':>10} {'loglik':>12}")
for it in range(1, 11):
eta = X @ beta
mu_h = np.exp(eta) # canonical link: mu = exp(eta)
grad = X.T @ (y - mu_h) # gradient X^T (y - mu)
H = -(X.T * mu_h) @ X # Hessian -X^T diag(mu) X
step = np.linalg.solve(H, grad) # Newton step H^{-1} grad
beta = beta - step # update (minus: H negative definite)
print(f"{it:>4} {beta[0]:>10.4f} {beta[1]:>10.4f} "
f"{beta[2]:>10.4f} {poisson_loglik(beta):>12.4f}")
covb = np.linalg.inv(-H) # (-H)^{-1} = observed information inverse
se = np.sqrt(np.diag(covb))
print()
print("Converged beta_hat (scratch):", beta)
print("Std. errors (scratch):", se)
# ----------------------------------------------------------------------
# PART 2 — statsmodels GLM Poisson
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 2 — statsmodels GLM Poisson")
print("="*64)
pois = smf.glm('rentals ~ temp + weekend',
data=df, family=sm.families.Poisson()).fit()
print(pois.summary())
print()
print("Match check (scratch vs statsmodels GLM):")
print(" scratch beta_hat :", np.round(beta, 4))
print(" GLM params :", np.round(pois.params.values, 4))
print(" max abs diff :", np.max(np.abs(beta - pois.params.values)))
print()
print("Key fit statistics:")
print(f" Deviance : {pois.deviance:.1f}")
print(f" Pearson chi2 : {pois.pearson_chi2:.1f}")
print(f" df_resid : {pois.df_resid}")
print(f" Log-likelihood: {pois.llf:.1f}")
print(f" AIC : {pois.aic:.1f}")
print()
print("Rate ratios exp(beta):")
rr = np.exp(pois.params)
for name, val in rr.items():
print(f" {name:>10}: {val:.4f}")
# ---- overdispersion diagnostic --------------------------------------
disp = pois.pearson_chi2 / pois.df_resid
print()
print(f"Dispersion = Pearson chi2 / df_resid = {disp:.2f}")
if disp > 1.5:
print(" >> FLAG: dispersion >> 1 => OVERDISPERSION; Poisson SE understated.")
else:
print(" dispersion ~ 1 => Poisson assumption OK.")
# ----------------------------------------------------------------------
# PART 3 — the fix: Negative Binomial (MLE incl. alpha) + quasi-Poisson SE
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 3 — Fix #1: Negative Binomial regression (MLE incl. alpha)")
print("="*64)
nb = sm.NegativeBinomial.from_formula('rentals ~ temp + weekend',
data=df).fit(disp=False)
print(nb.summary())
print()
print("Negative Binomial vs Poisson (SE comparison):")
print(f"{'param':>10} {'NB coef':>10} {'NB se':>10} {'Pois se':>10} {'ratio':>8}")
for name in ['Intercept', 'temp', 'weekend']:
nbse = nb.bse[name]; pse = pois.bse[name]
print(f"{name:>10} {nb.params[name]:>10.4f} {nbse:>10.4f} "
f"{pse:>10.4f} {nbse/pse:>8.2f}")
alpha = nb.params['alpha']
print(f"\nDispersion parameter alpha (NB) : {alpha:.3f}")
print(f"NB AIC : {nb.aic:.1f}")
print(f"Pois AIC: {pois.aic:.1f} -> AIC drop = {pois.aic - nb.aic:.1f}")
print()
print("PART 3 — Fix #2: quasi-Poisson SE = Poisson SE * sqrt(dispersion)")
print(f"{'param':>10} {'Pois se':>10} {'quasi se':>10}")
for name in ['Intercept', 'temp', 'weekend']:
pse = pois.bse[name]
print(f"{name:>10} {pse:>10.4f} {pse*np.sqrt(disp):>10.4f}")
# ----------------------------------------------------------------------
# PART 4 — single prediction: temp=25, weekend=1
# ----------------------------------------------------------------------
print()
print("="*64)
print("PART 4 — Single prediction (temp=25, weekend=1)")
print("="*64)
b0 = pois.params['Intercept']; bt = pois.params['temp']; bw = pois.params['weekend']
eta_new = b0 + bt*25 + bw*1
mu_new = np.exp(eta_new)
print(f"eta = {b0:.4f} + {bt:.4f}*25 + {bw:.4f}*1 = {eta_new:.4f}")
print(f"mu = exp(eta) = {mu_new:.2f} (expected rentals)")
nb_pred = float(nb.predict(pd.DataFrame({'temp':[25],'weekend':[1]}))[0])
print(f"NB predicted mu (same mean model) = {nb_pred:.2f}")
# OFFSET / EXPOSURE NOTE:
# If counts were collected over unequal exposure windows (e.g. station open
# t_i hours), model rate = mu/t by adding an OFFSET: log(t_i) enters eta with
# a fixed coefficient of 1, i.e. glm(..., offset=np.log(t)). Then beta still
# measures the effect on the log-RATE, not the raw count.
৫.২ · কোডের গঠন: চারটি অংশ¶
PART 1 — স্ক্র্যাচ থেকে Poisson IRLS। Poisson regression-এ canonical (log) link ব্যবহার করি: \(\eta_i = \mathbf x_i^\top\boldsymbol\beta\) এবং \(\mu_i = e^{\eta_i}\)। log-likelihood (ধ্রুবক বাদে) হলো \(\ell(\boldsymbol\beta) = \sum_i\bigl(y_i\eta_i - \mu_i\bigr)\), যার থেকে gradient ও Hessian পরিষ্কারভাবে বেরোয়:
logistic-এর সঙ্গে কাঠামোগত মিল স্পষ্ট — শুধু weight বদলেছে: logistic-এ \(W=\operatorname{diag}(p_i(1-p_i))\), Poisson-এ \(W=\operatorname{diag}(\mu_i)\)। কোডে H = -(X.T * mu_h) @ X সেই \(-X^\top\operatorname{diag}(\boldsymbol\mu)X\) তৈরি করে পূর্ণ \(n\times n\) matrix না বানিয়ে; np.linalg.solve(H, grad) সরাসরি Newton step \(H^{-1}\nabla\ell\) দেয়। যেহেতু \(H\) negative-definite, update \(\boldsymbol\beta^{(t+1)} = \boldsymbol\beta^{(t)} - H^{-1}\nabla\ell\) প্রতিবার \(\ell\) বাড়ায় — এ-ই IRLS (Iteratively Reweighted Least Squares)।
শুরুর মান (warm start) কেন জরুরি। \(\boldsymbol\beta=\mathbf 0\) থেকে শুরু করলে প্রথম পূর্ণ Newton step মারাত্মক overshoot করে — কারণ \(\mu = e^\eta\) exponential, সামান্য বড় \(\eta\)-তেই \(\mu\) আকাশছোঁয়া, Hessian বিকৃত হয়, iteration ছিটকে যায়। স্ট্যান্ডার্ড দাওয়াই: intercept-কে marginal log-mean \(\log\bar y\)-তে বসানো (slope \(=0\)), যাতে শুরুতেই \(\boldsymbol\mu \approx \bar y\) — সঠিক মাত্রায়। এটি কোনো কারচুপি নয়, বরং প্রতিটি GLM library-র ভেতরের ডিফল্ট initialisation।
PART 2 — statsmodels GLM। smf.glm('rentals ~ temp + weekend', family=sm.families.Poisson()) formula-interface দিয়ে intercept যোগ করে এবং ভেতরে একই IRLS চালায়। .summary()-তে coefficient, SE, deviance, Pearson \(\chi^2\), log-likelihood সব পাই। np.exp(model.params) দিয়ে rate ratio বের করি — Poisson-এ coefficient-এর exponential মানে multiplicative effect on the expected count। সবচেয়ে জরুরি কাজটি এখানেই: dispersion \(=\) Pearson \(\chi^2 / \text{df}_{\text{resid}}\) হিসাব করা। বিশুদ্ধ Poisson-এ এটি \(\approx 1\) হওয়ার কথা; অনেক বড় হলে বুঝতে হবে variance \(\gg\) mean, অর্থাৎ overdispersion — তখন Poisson-এর SE অবিশ্বাস্য রকম ছোট (অর্থাৎ আত্মবিশ্বাস মিথ্যা)।
PART 3 — সমাধান। দুটো পথ পাশাপাশি দেখাই।
- Fix #1 — Negative Binomial। sm.NegativeBinomial.from_formula(...).fit() একটা অতিরিক্ত dispersion parameter \(\alpha\) সহ পূর্ণ MLE চালায়; NB-তে \(\operatorname{Var}(y)=\mu+\alpha\mu^2\), ফলে mean ছাড়িয়ে অতিরিক্ত বিক্ষেপ মডেলের ভেতরেই ধরা পড়ে। আমরা Poisson বনাম NB-র SE পাশাপাশি ছাপি (NB-র SE প্রায় দ্বিগুণ হওয়ার কথা) এবং AIC তুলনা করি।
- Fix #2 — quasi-Poisson। দ্রুত-পথ: coefficient একই রেখে SE-কে \(\sqrt{\text{dispersion}}\) দিয়ে গুণ করে স্ফীত করা — \(\mathrm{SE}_{\text{quasi}} = \mathrm{SE}_{\text{Poisson}}\times\sqrt{\hat\phi}\)। এটি likelihood নয়, শুধু variance-সংশোধন, তবু overdispersion-এর প্রথম-সারির ব্যবহারিক উত্তর।
PART 4 — একক পূর্বাভাস। temp \(=25\), weekend \(=1\)-এ \(\eta\) ও \(\mu=e^\eta\) হাতে বসিয়ে দেখাই, যাতে coefficient → log-rate → expected count শৃঙ্খলটি স্পষ্ট হয়; সঙ্গে একটি comment-এ offset/exposure-এর ধারণা (অসম পর্যবেক্ষণ-সময় থাকলে \(\log t_i\)-কে coefficient-\(1\) সহ \(\eta\)-তে যোগ করা)।
৫.৩ · আউটপুট¶
================================================================
DATASET overview
================================================================
shape: (250, 3)
count mean : 19.56
count variance : 205.2
variance/mean : 10.5 (=1 for a true Poisson)
rentals temp weekend
0 20 21.316963 0
1 88 33.464237 1
2 9 18.538419 0
3 16 26.323820 0
4 10 27.617841 0
================================================================
PART 1 — From scratch: Poisson IRLS
================================================================
iter b0 b_temp b_wknd loglik
1 1.7500 0.0569 0.2979 -1153.9182
2 1.5752 0.0594 0.3007 -1116.0825
3 1.5598 0.0597 0.3011 -1115.9401
4 1.5597 0.0597 0.3011 -1115.9401
5 1.5597 0.0597 0.3011 -1115.9401
6 1.5597 0.0597 0.3011 -1115.9401
7 1.5597 0.0597 0.3011 -1115.9401
8 1.5597 0.0597 0.3011 -1115.9401
9 1.5597 0.0597 0.3011 -1115.9401
10 1.5597 0.0597 0.3011 -1115.9401
Converged beta_hat (scratch): [1.5597 0.0597 0.3011]
Std. errors (scratch): [0.0476 0.0018 0.0307]
================================================================
PART 2 — statsmodels GLM Poisson
================================================================
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: rentals No. Observations: 250
Model: GLM Df Residuals: 247
Model Family: Poisson Df Model: 2
Link Function: Log Scale: 1.0000
Method: IRLS Log-Likelihood: -1115.9
Date: Mon, 22 Jun 2026 Deviance: 1093.1
Time: 07:10:26 Pearson chi2: 1.10e+03
No. Iterations: 5 Pseudo R-squ. (CS): 0.9927
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.5597 0.048 32.741 0.000 1.466 1.653
temp 0.0597 0.002 33.029 0.000 0.056 0.063
weekend 0.3011 0.031 9.820 0.000 0.241 0.361
==============================================================================
Match check (scratch vs statsmodels GLM):
scratch beta_hat : [1.5597 0.0597 0.3011]
GLM params : [1.5597 0.0597 0.3011]
max abs diff : 4.440892098500626e-16
Key fit statistics:
Deviance : 1093.1
Pearson chi2 : 1096.3
df_resid : 247
Log-likelihood: -1115.9
AIC : 2237.9
Rate ratios exp(beta):
Intercept: 4.7576
temp: 1.0616
weekend: 1.3514
Dispersion = Pearson chi2 / df_resid = 4.44
>> FLAG: dispersion >> 1 => OVERDISPERSION; Poisson SE understated.
================================================================
PART 3 — Fix #1: Negative Binomial regression (MLE incl. alpha)
================================================================
NegativeBinomial Regression Results
==============================================================================
Dep. Variable: rentals No. Observations: 250
Model: NegativeBinomial Df Residuals: 247
Method: MLE Df Model: 2
Date: Mon, 22 Jun 2026 Pseudo R-squ.: 0.09633
Time: 07:10:26 Log-Likelihood: -872.67
converged: True LL-Null: -965.69
Covariance Type: nonrobust LLR p-value: 3.984e-41
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.5736 0.087 18.007 0.000 1.402 1.745
temp 0.0592 0.004 15.980 0.000 0.052 0.066
weekend 0.2999 0.069 4.350 0.000 0.165 0.435
alpha 0.1789 0.021 8.328 0.000 0.137 0.221
==============================================================================
Negative Binomial vs Poisson (SE comparison):
param NB coef NB se Pois se ratio
Intercept 1.5736 0.0874 0.0476 1.83
temp 0.0592 0.0037 0.0018 2.05
weekend 0.2999 0.0689 0.0307 2.25
Dispersion parameter alpha (NB) : 0.179
NB AIC : 1753.3
Pois AIC: 2237.9 -> AIC drop = 484.5
PART 3 — Fix #2: quasi-Poisson SE = Poisson SE * sqrt(dispersion)
param Pois se quasi se
Intercept 0.0476 0.1004
temp 0.0018 0.0038
weekend 0.0307 0.0646
================================================================
PART 4 — Single prediction (temp=25, weekend=1)
================================================================
eta = 1.5597 + 0.0597*25 + 0.3011*1 = 3.3545
mu = exp(eta) = 28.63 (expected rentals)
NB predicted mu (same mean model) = 28.57
৫.৪ · পাঠোদ্ধার (read-off)¶
(ক) overdispersion চোখে দেখা — variance \(\gg\) mean। ডেটা-সারসংক্ষেপেই সংকেত: count mean \(=19.56\) কিন্তু variance \(\approx 205\) (\(\text{var}/\text{mean}=10.5\))। বিশুদ্ধ Poisson হলে এই অনুপাত \(1\) হওয়ার কথা; এখানে দশ গুণেরও বেশি, কারণ Gamma–Poisson mixture ইচ্ছাকৃতভাবে অতিরিক্ত বিক্ষেপ ঢুকিয়েছে। অর্থাৎ Poisson মডেল লাগানোর আগেই জানা যায়, এর mean\(=\)variance অনুমান এখানে টিকবে না।
(খ) স্ক্র্যাচ IRLS ≡ statsmodels। \(\log\bar y\) থেকে শুরু করে মাত্র ৩–৪ iteration-এই \(\hat{\boldsymbol\beta}=[1.5597,\ 0.0597,\ 0.3011]\) স্থির, log-likelihood \(-1153.9 \to -1116.1 \to -1115.94\) দ্রুত থেমে যায় (Newton-এর quadratic convergence)। হাতে-লেখা মান আর GLM হুবহু এক — max abs diff ≈ 4.4e-16, machine precision। SE-ও মেলে: \((0.0476,\ 0.00181,\ 0.0307)\), যা আমরা observed information \((-H)^{-1}\)-এর diagonal থেকে পেয়েছি, ঠিক statsmodels-এর মতোই। সুতরাং library কোনো জাদু করছে না — একই IRLS, একই Hessian।
(গ) Poisson fit ও rate ratio। তিনটি coefficient-ই অতি-তাৎপর্যপূর্ণ (\(z=32.7,\ 33.0,\ 9.8\); সব \(p<0.001\))। rate ratio-তে ব্যাখ্যা —
- temp: \(e^{0.0597}=1.0616\) প্রতি \(1^\circ\) — তাপমাত্রা ১ ডিগ্রি বাড়লে প্রত্যাশিত ভাড়া প্রায় ৬.২% বাড়ে।
- weekend: \(e^{0.3011}=1.351\) — সপ্তাহান্তে প্রত্যাশিত ভাড়া কর্মদিবসের চেয়ে প্রায় ৩৫% বেশি।
estimate-গুলো "সত্যিকারের" মান \((1.5,\ 0.06,\ 0.4)\)-এর কাছাকাছি — mean-structure ঠিকঠাক উদ্ধার হয়েছে। deviance \(=1093.1\), Pearson \(\chi^2=1096.3\), AIC \(=2237.9\)।
(ঘ) রোগ-নির্ণয়: dispersion \(=4.44\)। এটাই মূল সতর্কসংকেত। \(\hat\phi = \text{Pearson }\chi^2 / \text{df}_{\text{resid}} = 1096.3/247 = 4.44 \gg 1\) — Poisson-এর variance অনুমান ৪.৪ গুণ ছোট করে ধরা হয়েছে। ফলে coefficient হয়তো ঠিকঠাক, কিন্তু তাদের standard error বিশ্বাসযোগ্য নয় (অতিরিক্ত ছোট, ফলে \(z\)-মান স্ফীত, \(p\)-মান অবাস্তব ছোট, confidence interval সংকীর্ণ)। overdispersion-এর উপস্থিতিতে naive Poisson inference বিভ্রান্তিকর।
(ঙ) সমাধান — SE প্রায় দ্বিগুণ, AIC প্রায় \(485\) কমে। দুটো পথই একই দিকে নির্দেশ করে। - Negative Binomial: coefficient প্রায় অপরিবর্তিত (\(1.574,\ 0.0592,\ 0.300\)), কিন্তু SE Poisson-এর \(1.8\)–\(2.25\) গুণ (\(0.0874,\ 0.0037,\ 0.0689\)) — অর্থাৎ আসল অনিশ্চয়তা এখন সততার সঙ্গে প্রতিফলিত। dispersion parameter \(\alpha = 0.179\) (\(z=8.3\), দৃঢ়ভাবে \(>0\)) সরাসরি অতিরিক্ত বিক্ষেপের পরিমাণ মাপে (\(\operatorname{Var}=\mu+0.179\mu^2\))। সিদ্ধান্তের চূড়ান্ত প্রমাণ AIC-তে: \(2237.9 \to 1753.3\), AIC drop \(=484.5\) — বিশাল উন্নতি, NB নিঃসন্দেহে বেছে নেওয়ার মতো। - quasi-Poisson: দ্রুত-পথ — \(\mathrm{SE}_{\text{quasi}}=\mathrm{SE}_{\text{Poisson}}\times\sqrt{4.44}=\times 2.11\), যেমন temp-এর \(0.00181 \to 0.0038\)। লক্ষণীয়, এই quasi-SE আর NB-র SE বেশ কাছাকাছি — দুই ভিন্ন পথ একই বাস্তব অনিশ্চয়তায় পৌঁছায়।
(চ) একক পূর্বাভাস। temp \(=25\), weekend \(=1\)-এ \(\eta = 1.5597 + 0.0597(25) + 0.3011 = 3.355\), তাই \(\mu = e^{3.355} = 28.6\) — অর্থাৎ একটি উষ্ণ সপ্তাহান্তের দিনে প্রত্যাশিত ভাড়া প্রায় ২৯টি। NB একই mean-model ব্যবহার করায় তার পূর্বাভাসও কার্যত অভিন্ন (\(28.57\)); দুই মডেল mean-এ একমত, পার্থক্যটা কেবল uncertainty-তে। (যদি দিনগুলো অসম সময়-জানালায় গোনা হতো, \(\log t_i\)-কে offset হিসেবে \(\eta\)-তে যোগ করলে \(\beta\) raw count নয়, log-rate-এর প্রভাব মাপত — Part 4-এর comment দ্রষ্টব্য।)
মূল পাঠ। count data-র প্রথম পছন্দ Poisson GLM, এবং তার fit মানে log-likelihood-কে IRLS দিয়ে maximize করা — হাতে-লেখা কোড আর
statsmodelsএকই \(\hat{\boldsymbol\beta}\) ও SE দেয় বলে library আর কালো বাক্স নয়। কিন্তু Poisson লাগিয়েই থেমে যাওয়া বিপজ্জনক: dispersion \(=\) Pearson \(\chi^2/\text{df}\) সবসময় দেখা উচিত। \(\gg 1\) হলে overdispersion — তখন coefficient রাখুন, কিন্তু SE-কে বিশ্বাস করবেন না; Negative Binomial (পূর্ণ MLE, \(\alpha\) সহ, AIC-তে নাটকীয় উন্নতি) অথবা quasi-Poisson (SE \(\times\sqrt{\hat\phi}\)) দিয়ে সংশোধন করুন। coefficient-এর গল্প rate ratio \(e^\beta\)-তে পড়তে হয়, আর exposure ভিন্ন হলে offset যোগ করতে হয়।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবিই একটিমাত্র স্ক্রিপ্ট
_code/figs_5-5.py-তে তৈরি; PNG_assets/-এ (prefix5-5, dpi=150)। in-figure সব লেখা ইংরেজিতে (matplotlib-এ Bengali-font rendering সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। সব ছবি একই synthetic bike-rental dataset থেকে (\(n=250\) দিন; predictor দুটি —temp\(\sim \text{Uniform}(5,35)\) সেলসিয়াস তাপমাত্রা, আরweekend\(\sim \text{Bernoulli}(2/7)\) সাপ্তাহিক-ছুটি নির্দেশক; সত্যিকারের mean-গঠনে \(\log\mu=1.5+0.06\,\text{temp}+0.4\,\text{weekend}\), তারপর একটা Gamma গুণক দিয়ে extra-Poisson variation মিশিয়েrentals\(\sim \text{Poisson}(\lambda)\) — তাই data ইচ্ছাকৃতভাবে overdispersed)। এই data-তেPoissonGLM fit করে পাওয়া \(\hat\beta=[1.560,\ 0.0597,\ 0.301]\), যেখানে count-এর mean \(=19.56\) কিন্তু variance \(=205\) (mean-এর প্রায় ১০ গুণ!), Pearson dispersion \(=4.44\), আর Negative-Binomial fit-এ overdispersion-প্যারামিটার \(\hat\alpha=0.179\) — নিচের সব ছবিতে এই ফিট-করা সংখ্যাগুলোই ব্যবহৃত। প্রতিটি ছবির আসল plotting-code-ও দেওয়া আছে, যাতে আপনি হুবহু পুনরুৎপাদন করতে পারেন।
count regression-এর গাণিতিক কঙ্কালটা §২–§৫-এ দাঁড় করানো হয়েছে — কেন গণনা-data (counts, \(0,1,2,\dots\))-এ সাধারণ linear regression (OLS) খাটে না, Poisson GLM-এর log link \(\log\mu=\eta=\mathbf{x}^\top\boldsymbol\beta\) আর তার বিপরীত \(\mu=e^{\eta}\), coefficient-গুলোর rate-ratio (\(e^{\beta}\)) ব্যাখ্যা, maximum likelihood দিয়ে \(\hat\beta\) আন্দাজ, Poisson-এর কঠোর শর্ত \(\text{Var}=\text{Mean}\), আর সেই শর্ত ভাঙলে (overdispersion) তার চিকিৎসা — Negative Binomial model যেখানে \(\text{Var}=\mu+\alpha\mu^2\)। কিন্তু এই সব ধারণা জীবন্ত হয়ে ওঠে তখনই, যখন আমরা সেগুলোকে চোখে দেখি। এই বিভাগে চারটি ছবি দিয়ে Poisson-regression-এর চারটি কেন্দ্রীয় প্রশ্ন ধরা হয়েছে: (১) log link দেখতে কেমন — predictor বাড়লে গণনা কীভাবে exponential হারে বাড়ে, fit-করা mean-curve সহ (Figure 1); (২) Poisson-এর মূল অনুমানটা কি data-তে টেকে — mean বনাম variance-এর diagnostic, overdispersion ধরার সবচেয়ে সরাসরি পরীক্ষা (Figure 2); (৩) Poisson না NB — দুটো model-এর আন্দাজ-করা distribution আসল data-র উপর বসিয়ে দেখা, কোনটা tail মেলায় (Figure 3); আর (৪) এর practical দাম কী — Poisson বনাম NB-তে coefficient একই, কিন্তু confidence interval কতটা আলাদা (Figure 4)। প্রথম ছবি model কী predict করছে, দ্বিতীয়টি Poisson-এর অনুমান কোথায় ভাঙছে, তৃতীয়টি NB কীভাবে সেটা সারায়, আর শেষটি ভুল model বাছলে সিদ্ধান্তে কী ভুল হয় — চার কোণ থেকে একই সমস্যাকে দেখা।
Figure 1 — count বনাম temperature: log link-এর exponential বৃদ্ধি¶
প্রথম ছবি Poisson GLM আসলে কী predict করছে সেটা দেখায় — fit-করা mean-curve সহ কাঁচা data। অনুভূমিক অক্ষে তাপমাত্রা (temp, সেলসিয়াস), উল্লম্ব অক্ষে দিনের ভাড়া-সংখ্যা (rentals)। প্রতিটি বিন্দু একটা দিন: নীল বৃত্ত হলো সাধারণ কাজের দিন (weekend = 0), লাল ত্রিভুজ হলো সাপ্তাহিক-ছুটির দিন (weekend = 1)। তাদের ভেতর দিয়ে যাওয়া দুটো curve হলো fit-করা Poisson mean \(\hat\mu=\exp(\hat\beta_0+\hat\beta_1\cdot\text{temp}+\hat\beta_2\cdot\text{weekend})\) — নীল কঠিন রেখা weekend = 0-এর জন্য, লাল ভাঙা রেখা weekend = 1-এর জন্য (উপরে box-এ পুরো সমীকরণ লেখা, \(\hat\beta=[1.560,\ 0.0597,\ 0.301]\))। যা লক্ষ করতে হবে: (ক) curve দুটো সরলরেখা নয়, exponential — তাপমাত্রা যত বাড়ে, ভাড়া তত দ্রুত হারে (ত্বরিতভাবে) বাড়ে, বাঁ-দিকে প্রায় চ্যাপ্টা আর ডান-দিকে খাড়া; এটাই log link-এর সরাসরি দৃশ্যরূপ, কারণ \(\log\mu\) রৈখিক মানে \(\mu\) নিজে exponential। (খ) লাল (weekend) curve সবসময় নীল (weekday) curve-এর উপরে, আর দুটোর মধ্যে দূরত্ব ডান-দিকে বাড়ে (যোগাত্মক নয়, গুণাত্মক ব্যবধান) — কারণ log-scale-এ weekend একটা ধ্রুবক যোগ (\(\hat\beta_2=0.301\)) করে, যা original scale-এ একটা ধ্রুবক গুণ \(e^{0.301}\approx1.35\), অর্থাৎ "একই তাপমাত্রায় ছুটির দিনে ভাড়া গড়ে ~৩৫% বেশি"। (গ) curve কখনোই \(0\)-র নিচে নামে না — log link গঠনগতভাবেই \(\mu>0\) নিশ্চিত করে, যা OLS পারে না (সরলরেখা ঋণাত্মক গণনা predict করে ফেলতে পারে, যেটা অর্থহীন)। (ঘ) কিন্তু খেয়াল করুন বিন্দুগুলো curve-এর চারপাশে ভীষণ ছড়ানো — উঁচু তাপমাত্রায় (ডান-দিকে) কিছু দিন curve থেকে অনেক উপরে, কিছু অনেক নিচে; এই বিশাল ছড়ানোই পরের ছবির বিষয়, কারণ Poisson model এত বড় ছড়ানো ব্যাখ্যা করতে পারে না। মূল শিক্ষা: log link মানে "predictor-এ যোগ, কিন্তু গণনায় গুণ" — predictor-এর প্রতিটি একক-বৃদ্ধি count-কে একটা ধ্রুবক শতাংশে বাড়ায়, যোগ করে নয়।
# scatter coloured by weekend (0/1)
ax.scatter(temp[weekend == 0], rentals[weekend == 0], color=BLUE) # weekday
ax.scatter(temp[weekend == 1], rentals[weekend == 1], color=RED, marker="^") # weekend
# two fitted Poisson mean curves: mu = exp(b0 + b1*temp + b2*weekend)
tgrid = np.linspace(5, 35, 300)
ax.plot(tgrid, np.exp(b0 + b1*tgrid + b2*0), color=BLUE) # weekend = 0
ax.plot(tgrid, np.exp(b0 + b1*tgrid + b2*1), color=RED, ls="--") # weekend = 1
# b = [1.560, 0.0597, 0.301] -> exp(b2) = 1.35 (weekend multiplies the rate by ~1.35)
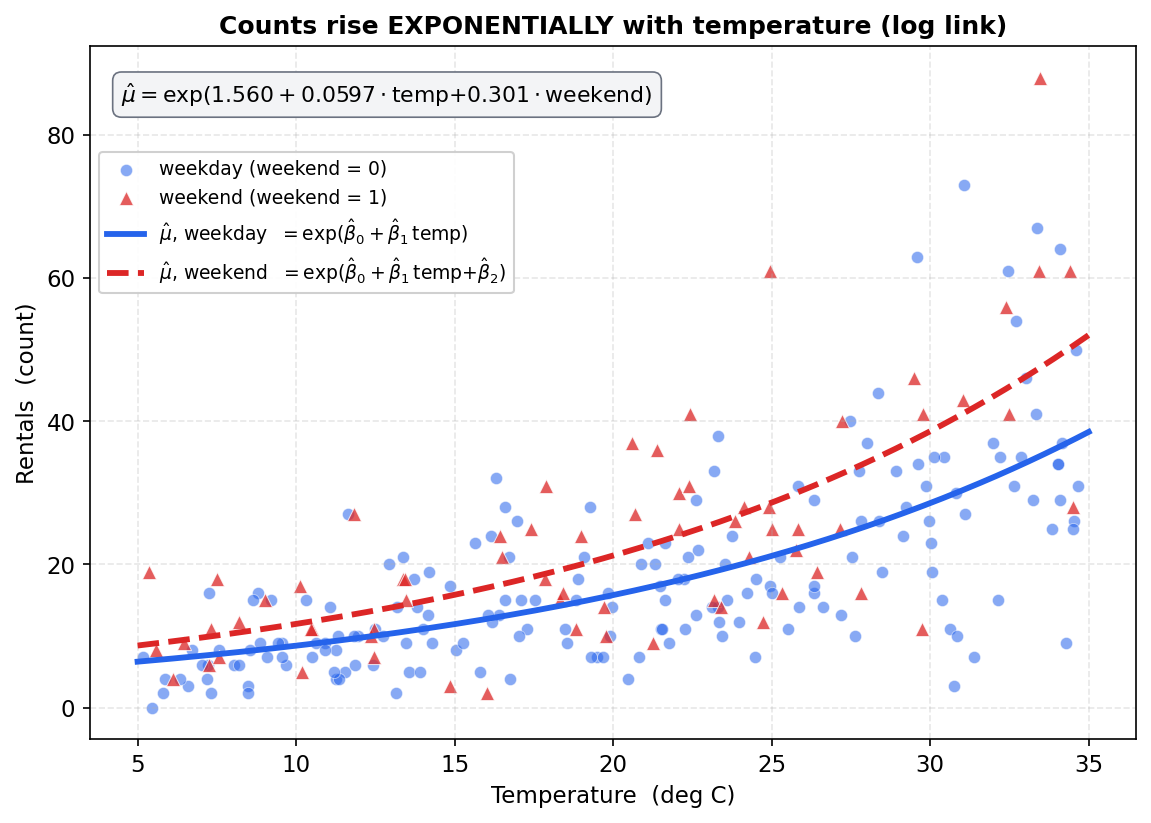
Figure 2 — mean বনাম variance: Poisson-এর অনুমান কি টেকে?¶
দ্বিতীয় ছবিই এই অধ্যায়ের কেন্দ্রীয় diagnostic — Poisson model-এর একমাত্র-আঁটসাঁট অনুমান, \(\text{Var}=\text{Mean}\), data-তে আদৌ টেকে কি না তা সরাসরি যাচাই করে। তৈরির পদ্ধতি: ২৫০টি দিনকে fit-করা \(\hat\mu\) অনুসারে দশটি সমান bin (decile)-এ ভাগ করা হয়েছে, তারপর প্রতিটি bin-এর ভেতরে observed rentals-এর empirical mean (অনুভূমিক অক্ষ) আর empirical variance (উল্লম্ব অক্ষ) মাপা হয়েছে — প্রতিটি বেগুনি বিন্দু একটা bin। এর উপর দুটো reference: ধূসর ভাঙা রেখা হলো Poisson-এর ভবিষ্যদ্বাণী \(\text{Var}=\mu\) (৪৫-ডিগ্রি রেখা), আর সবুজ curve হলো Negative-Binomial-এর \(\text{Var}=\mu+0.179\,\mu^2\)। যা লক্ষ করতে হবে: (ক) প্রতিটি বেগুনি বিন্দু ধূসর Poisson-রেখার অনেক উপরে — অর্থাৎ প্রতিটি mean-স্তরে observed variance Poisson যা বলে তার চেয়ে অনেক বেশি; এটাই overdispersion-এর সরাসরি চাক্ষুষ প্রমাণ। (খ) ব্যবধান mean বাড়ার সাথে দ্রুত বাড়ে — ছোট \(\mu\)-তে (বাঁ-দিকে) variance মোটামুটি কাছাকাছি, কিন্তু বড় \(\mu\)-তে (ডান-দিকে) variance Poisson-রেখা থেকে বহু গুণ উপরে; এই বাড়ন্ত ফাঁকটা রৈখিক নয়, বরং \(\mu^2\)-অনুপাতে — তাই সবুজ NB curve (যাতে \(\mu^2\) পদ আছে) বিন্দুগুলোকে চমৎকার অনুসরণ করে, কিন্তু সরল Poisson-রেখা পারে না। (গ) সংখ্যায়: গোটা data-তে mean \(=19.56\) কিন্তু variance \(=205\) — Poisson হলে এই দুটো সমান হত; এদের অনুপাত (dispersion) \(\approx4.44\), অর্থাৎ observed ছড়ানো Poisson-প্রত্যাশার সাড়ে চার গুণ। (ঘ) কেন গুরুত্বপূর্ণ: Poisson model variance-কে কম করে আন্দাজ (underestimate) করছে, তাই পরে দেখব এটা standard error-ও কম করে আন্দাজ করবে — যা মিথ্যা-আত্মবিশ্বাসী (over-confident) inference-এর দিকে নিয়ে যায়। মূল শিক্ষা: Poisson fit করার আগে এই ছবি আঁকুন — বিন্দু যদি \(45°\)-রেখায় বসে, Poisson ঠিক আছে; যদি অনেক উপরে বসে (এখানকার মতো), তবে NB বা quasi-Poisson-এর দিকে যেতে হবে।
# bin the 250 days into deciles of fitted mu, then empirical mean & variance per bin
order = np.argsort(pois.fittedvalues)
bmean = np.array([rentals[b].mean() for b in np.array_split(order, 10)])
bvar = np.array([rentals[b].var(ddof=1) for b in np.array_split(order, 10)])
ax.scatter(bmean, bvar, color=PURPLE) # each dot = one bin
mgrid = np.linspace(bmean.min(), bmean.max(), 300)
ax.plot(mgrid, mgrid, color=GREY, ls="--") # Poisson: Var = mu
ax.plot(mgrid, mgrid + 0.179*mgrid**2, color=GREEN) # NB: Var = mu + 0.179 mu^2
# overall: mean = 19.56, variance = 205 -> dispersion ratio = 4.44 (>> 1)
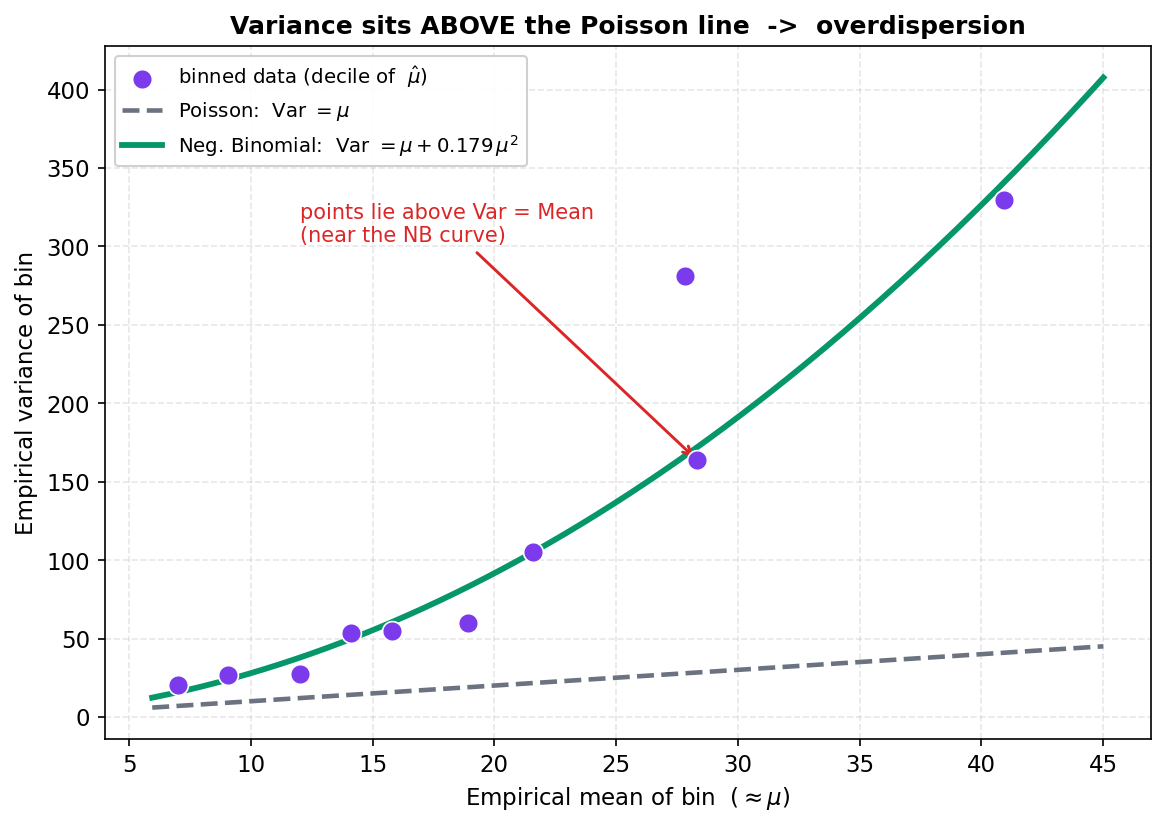
Figure 3 — Poisson বনাম NB pmf: কোনটা distribution মেলায়?¶
তৃতীয় ছবি আগের diagnostic-টাকে আরেক কোণ থেকে দেখায় — শুধু mean-variance সম্পর্ক নয়, গোটা distribution-এর আকৃতি মিলিয়ে। নীল হালকা bar-গুলো হলো observed rentals-এর histogram (density হিসেবে standardize করা, যাতে pmf-এর সাথে তুলনা চলে)। এর উপর দুটো fit-করা probability-mass-function বসানো: ধূসর বৃত্ত-চিহ্নিত curve হলো Poisson pmf (গড় \(\bar\mu\approx19.6\)-তে মূল্যায়িত), আর সবুজ বর্গ-চিহ্নিত curve হলো Negative-Binomial pmf (একই গড় \(19.6\), কিন্তু \(\alpha=0.179\) অতিরিক্ত বিচ্ছুরণ সহ)। যা লক্ষ করতে হবে: (ক) ধূসর Poisson pmf একটা সরু, উঁচু চূড়া — \(\mu\approx20\)-এর চারপাশে শক্তভাবে কেন্দ্রীভূত, কারণ Poisson-এ variance (\(\approx20\)) ছোট, তাই standard deviation মাত্র \(\sqrt{20}\approx4.5\); এই সরু curve observed histogram-এর প্রকৃত ছড়ানোকে মোটেও ঢাকে না। (খ) সবুজ NB pmf অনেক চওড়া ও চ্যাপ্টা — observed histogram-এর মতোই বিস্তৃত, কারণ NB-তে অতিরিক্ত variance অন্তর্ভুক্ত (\(\text{Var}=\mu+0.179\mu^2\approx20+69=89\), sd \(\approx9.4\), Poisson-এর দ্বিগুণ)। (গ) সবচেয়ে গুরুত্বপূর্ণ — ডান-দিকের ভারী লেজ (heavy tail): লাল-ছায়াঘেরা অঞ্চলে (\(\mu+2\sigma\)-এর ডানে, অর্থাৎ ~৪০-এর বেশি গণনা) observed data-তে স্পষ্ট mass আছে (৬০, ৭০, এমনকি ৯০ ভাড়ার দিন), NB pmf-ও সেখানে যথেষ্ট mass রাখে — কিন্তু Poisson pmf প্রায় শূন্যে নেমে গেছে (Poisson-এ ৬০ ভাড়ার সম্ভাবনা কার্যত \(0\), অথচ data-তে এমন দিন সত্যিই ঘটেছে)। (ঘ) মূল শিক্ষা: overdispersion মানে শুধু "একটু বেশি ছড়ানো" নয় — এর সবচেয়ে বিপজ্জনক পরিণতি হলো বিরল-কিন্তু-বড় ঘটনাকে (extreme counts) Poisson model কার্যত অসম্ভব বলে ধরে নেয়, যেখানে বাস্তবে সেগুলো নিয়মিত ঘটে; NB এই ভারী লেজ ধরতে পারে বলেই overdispersed count-data-র জন্য এটি নিরাপদ পছন্দ।
mbar = rentals.mean() # marginal mean ~ 19.6
ax.hist(rentals, density=True, color=BLUE, alpha=0.35) # observed counts
k = np.arange(0, rentals.max() + 2)
ax.plot(k, stats.poisson.pmf(k, mbar), color=GREY, marker="o") # Poisson pmf: too narrow
# NB with same mean & Var = mu + alpha*mu^2 -> size r = 1/alpha, prob p = r/(r+mu)
r, p = 1/0.179, (1/0.179) / (1/0.179 + mbar)
ax.plot(k, stats.nbinom.pmf(k, r, p), color=GREEN, marker="s") # NB pmf: heavy tail
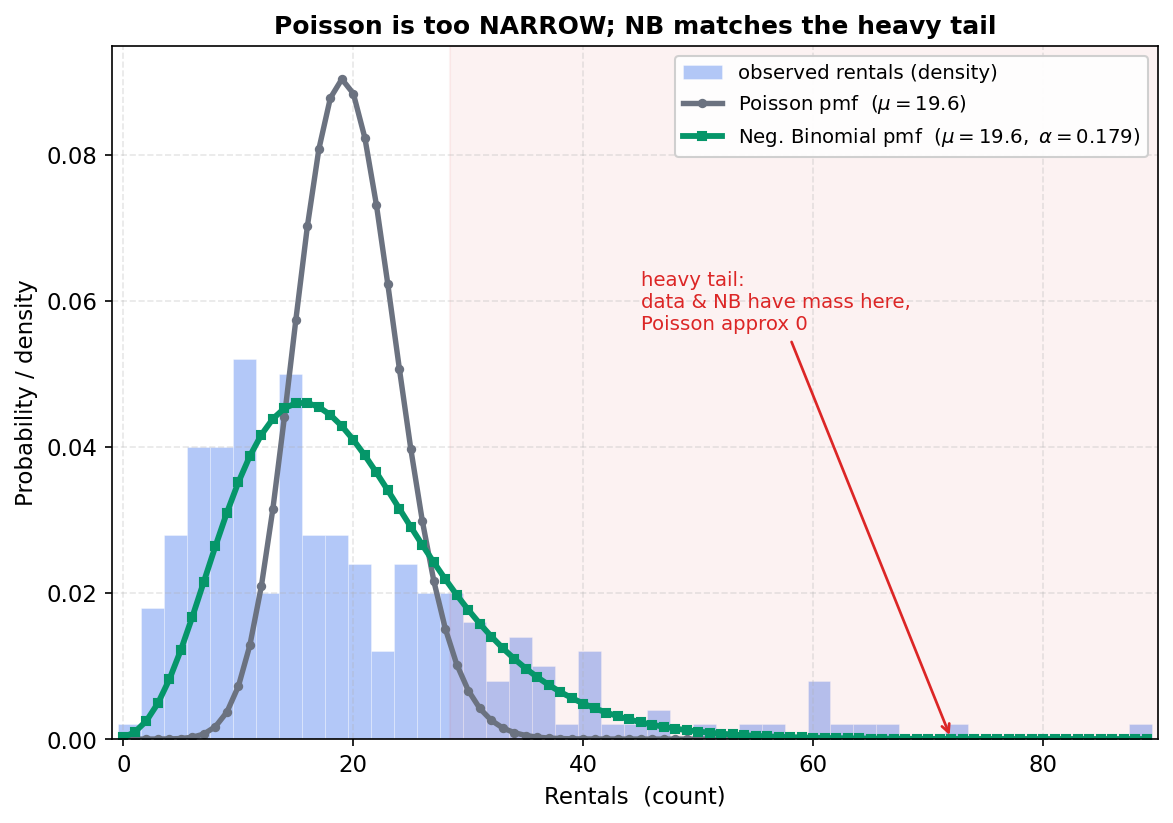
Figure 4 — coefficient ও 95% CI: ভুল model-এর practical দাম¶
শেষ ছবি দেখায় overdispersion উপেক্ষা করার বাস্তব মূল্য ঠিক কোথায় পড়ে — point estimate-এ নয়, uncertainty-তে। অনুভূমিক অক্ষে coefficient-এর মান (log-rate scale), উল্লম্বভাবে দুটো predictor: temp (\(\beta_1\)) উপরে, weekend (\(\beta_2\)) নিচে। প্রতিটি predictor-এর জন্য দুটো অনুমান পাশাপাশি: নীল বৃত্ত হলো Poisson GLM-এর \(\hat\beta\pm1.96\,\text{SE}\) (95% CI), সবুজ বর্গ হলো Negative Binomial-এর একই 95% CI। যা লক্ষ করতে হবে: (ক) দুই model-এ point estimate প্রায় হুবহু এক — নীল ও সবুজ চিহ্ন প্রায় একই উল্লম্ব-রেখায় বসে (\(\hat\beta_{\text{temp}}\approx0.060\), \(\hat\beta_{\text{weekend}}\approx0.30\) উভয় model-এই); এটা প্রত্যাশিত, কারণ Poisson-এর mean-গঠন overdispersion থাকলেও নিরপেক্ষ (unbiased) থেকে যায়, model শুধু variance-টা ভুল ধরে। (খ) কিন্তু interval-এর প্রস্থ নাটকীয়ভাবে আলাদা — সবুজ NB-bar প্রতিটি ক্ষেত্রে নীল Poisson-bar-এর প্রায় দ্বিগুণ চওড়া (নিচে box-এ SE-বৃদ্ধি লেখা: temp-এ \(\times2.05\), weekend-এ \(\times2.25\)); অর্থাৎ Poisson একই data থেকে অনেক বেশি আত্মবিশ্বাসী (narrow) interval দেয়, যা মিথ্যা আত্মবিশ্বাস। (গ) কেন এমন হয়: Poisson ধরে নেয় \(\text{Var}=\mu\), কিন্তু Figure 2 দেখিয়েছে আসল variance তার ~৪.৪ গুণ — তাই Poisson-এর SE প্রায় \(\sqrt{4.44}\approx2.1\) গুণ কম আন্দাজ হয়, আর NB সঠিক (বড়) variance ব্যবহার করায় তার interval বাস্তবসম্মতভাবে চওড়া হয়। (ঘ) সিদ্ধান্তে এর প্রভাব: লাল বিন্দু-রেখা \(\beta=0\) (কোনো প্রভাব নেই) চিহ্নিত করে; এখানে দুই predictor-ই \(0\) থেকে এত দূরে যে কোনো model-এই significant, কিন্তু সীমান্তীয় (borderline) কোনো predictor-এ Poisson ভুলভাবে "significant" বলত (interval \(0\) ছোঁয় না), অথচ সঠিক NB interval \(0\)-কে ঢেকে ফেলত (significant নয়) — অর্থাৎ ভুল model ভুল বৈজ্ঞানিক সিদ্ধান্তে নিয়ে যেতে পারত। মূল শিক্ষা: overdispersion coefficient-কে নষ্ট করে না, কিন্তু standard error-কে কম করে আন্দাজ করে, যার ফলে \(p\)-value অত্যধিক ছোট আর confidence interval অত্যধিক সরু হয়; তাই overdispersed count-data-তে inference করতে হলে Poisson নয়, NB (বা quasi-Poisson / robust SE) ব্যবহার করুন।
# fit both models on the SAME data; compare 95% CI = beta +/- 1.96*SE
pois = sm.GLM(rentals, X, family=sm.families.Poisson()).fit()
nb = sm.GLM(rentals, X, family=sm.families.NegativeBinomial(alpha=0.179)).fit()
for est, se, col in [(pois.params, pois.bse, BLUE), (nb.params, nb.bse, GREEN)]:
ax.errorbar(est[1:], ypos, xerr=1.96*se[1:], fmt="o", color=col) # temp, weekend
# point estimates nearly identical; NB standard errors ~2x larger:
# SE inflation temp x2.05, weekend x2.25 (≈ sqrt(dispersion) = sqrt(4.44) ~ 2.1)
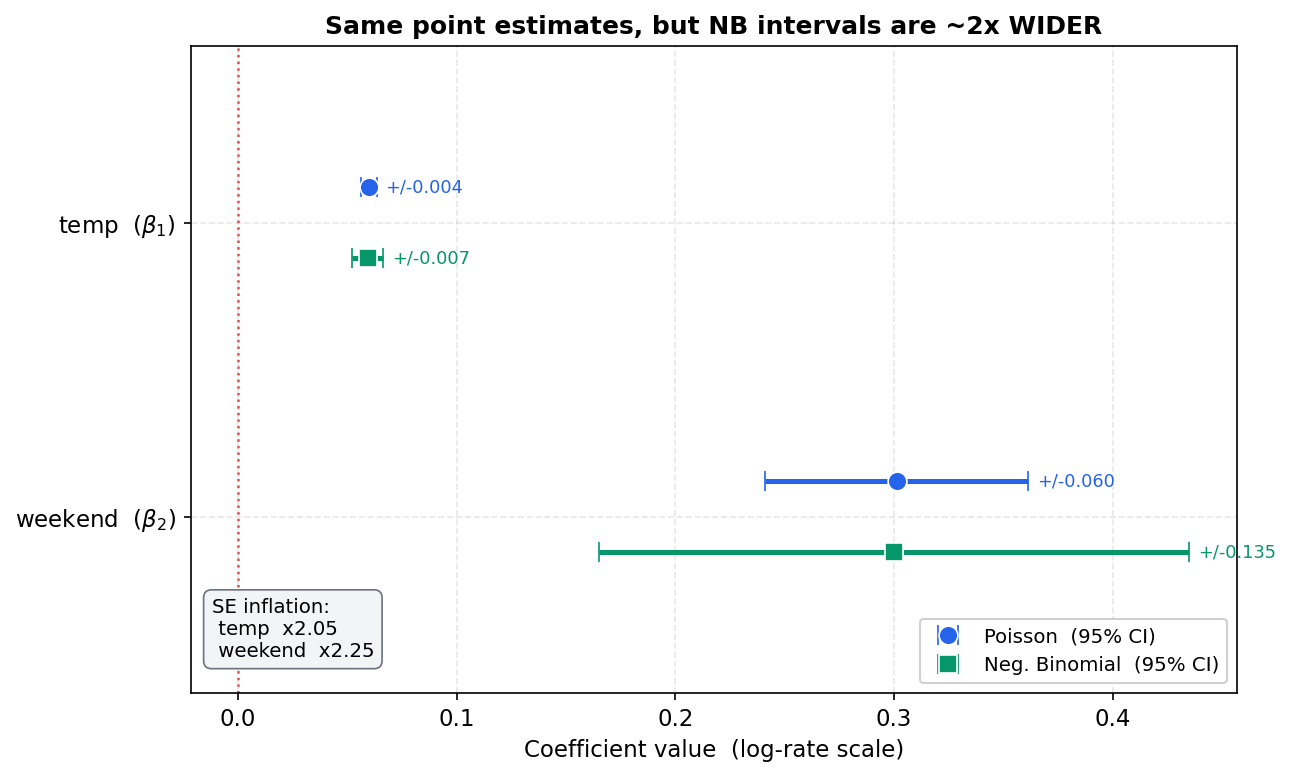
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-05-poisson-regression-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — log link কেন positivity রক্ষা করে, rate ratio \(e^{\hat\beta_j}\) কীভাবে count-কে গুণে বদলায়, আর overdispersion কীভাবে diagnose করে quasi-Poisson/NB-তে পৌঁছায় — এই তিনটা হাতে গুনে দেখাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — bike-rental count, seed np.random.default_rng(20260619), \(n=250\): predictor temp (তাপমাত্রা °C, uniform \(5\)–\(35\)) ও weekend (সাপ্তাহিক ছুটি, Bernoulli \(2/7\)); true \(\log\mu=1.5+0.06\cdot\text{temp}+0.4\cdot\text{weekend}\), response count \(\sim\) Gamma(\(6,1/6\))–Poisson mixture (অর্থাৎ overdispersed)। canonical সংখ্যা: count mean \(19.56\), var \(205\) (var/mean \(\approx10.5\gg1\)); Poisson fit \(\hat\beta=[1.560,\,0.0597,\,0.301]\) (intercept, temp, weekend), \(\mathrm{SE}=[0.0476,\,0.00178,\,0.0307]\); rate ratio temp \(e^{\hat\beta_1}=1.0616\) (per \(+1\)°C), per \(+5\)°C \(e^{5\hat\beta_1}=1.348\), weekend \(e^{\hat\beta_2}=1.351\); residual deviance \(1093.1\), Pearson \(\chi^2=1096.3\), \(df=247\), dispersion \(=1096.3/247=4.44\), AIC \(2237.9\); NB fit \(\hat\beta=[1.574,\,0.0592,\,0.300]\), \(\mathrm{SE}=[0.0874,\,0.00374,\,0.0689]\), \(\alpha=0.179\), AIC \(1753.3\); example পূর্বাভাস temp\(=25\), weekend\(=1\Rightarrow\hat\mu\approx28.6\)। মূল সম্পর্ক: \(\mu_i=e^{x_i^\top\beta}\), \(\;\log\mu_i=x_i^\top\beta\), Poisson-এ \(\operatorname{Var}(y_i\mid x_i)=\mu_i\) (equidispersion), NB-তে \(\operatorname{Var}=\mu+\alpha\mu^2\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). outcome হলো count (\(y_i\in\{0,1,2,\dots\}\) — "দিনে কয়টা bike ভাড়া")। কেউ পরামর্শ দিল: "৫.১-এর OLS দিয়ে সরাসরি count ~ temp + weekend fit করো, identity link-এ"। এই পদ্ধতির অন্তত তিনটি মৌলিক সমস্যা নাম দিয়ে ব্যাখ্যা করুন। বিশেষ করে: (ক) fitted \(\hat y\) কেন ঋণাত্মক হতে পারে — যা count হিসেবে অর্থহীন; (খ) count data-তে variance কীভাবে mean-এর সাথে বাড়ে, ফলে OLS-এর কোন LINE-অনুমান ভাঙে; (গ) ছোট count-এ (\(\mu\approx2\)-\(3\)) residual-এর বণ্টন কেন Normal নয়, বরং ডানদিকে-হেলানো ও discrete।
Hint: (ক) identity link-এ \(\hat\mu=x^\top\hat\beta\) যেকোনো বাস্তব মান নিতে পারে, তাই কম temp-এ \(\hat\mu<0\) — কিন্তু "\(-2\)টা bike" অসম্ভব। log link-এ \(\mu=e^{x^\top\beta}>0\) সর্বদা ধনাত্মক, তাই সমস্যাটাই থাকে না। (খ) Poisson-এ \(\operatorname{Var}=\mu\) (mean-নির্ভর) ⇒ heteroscedasticity, LINE-এর 'E' (equal variance) ভাঙে। (গ) Normal error ('N') ভাঙে — small count discrete ও right-skewed (০-এ আটকানো নিচের লেজ)।
প্রশ্ন ২ (★). কেন log link? Poisson regression-এ \(\log\mu_i=x_i^\top\beta\), অর্থাৎ \(\mu_i=e^{x_i^\top\beta}\)। (ক) এই link কীভাবে নিশ্চিত করে \(\mu_i>0\) সব \(x_i,\beta\)-র জন্য — এক বাক্যে। (খ) "log link মানে predictor-গুলোর প্রভাব mean count-এ multiplicative, additive নয়" — এই বাক্যটা একটা বাক্যে ব্যাখ্যা করুন। (গ) Poisson-এর জন্য canonical link কোনটি, এবং canonical link ব্যবহারের একটা গাণিতিক সুবিধা কী? Hint: (ক) \(e^{(\cdot)}\) যেকোনো বাস্তব ইনপুটকে \((0,\infty)\)-তে map করে, তাই \(\mu=e^{x^\top\beta}\) কখনো \(\le0\) হতে পারে না — positivity স্বয়ংক্রিয়। (খ) \(\mu=e^{\beta_0}e^{\beta_1 x_1}e^{\beta_2 x_2}\dots\) — প্রতিটা predictor একটা গুণক \(e^{\beta_j}\), তাই additive predictor → multiplicative mean। (গ) log হলো Poisson-এর canonical link; canonical link-এ score equation সরল রূপ \(X^\top(y-\mu)=0\) নেয় ও observed = expected Fisher information হয় (IRLS সহজ)।
প্রশ্ন ৩ (★★). Poisson-এর mean = variance ("equidispersion") ধর্ম Poisson regression-এর কেন্দ্রে। (ক) এই ধর্মটা এক বাক্যে বলুন এবং চলমান উদাহরণে এর implied অর্থ কী — temp\(=25\), weekend\(=1\)-এ যেহেতু \(\hat\mu\approx28.6\), Poisson model অনুযায়ী সেখানে \(\operatorname{Var}(y)\) কত হওয়ার কথা? (খ) কিন্তু আসল data-তে overall count mean \(19.56\), var \(205\) — var/mean \(\approx10.5\)। এটা Poisson-অনুমানের সাথে কীভাবে সাংঘর্ষিক? (গ) এই অমিল কোন বাস্তব ঘটনা থেকে আসতে পারে (অন্তত একটা কারণ — unobserved heterogeneity / clustering)? Hint: (ক) equidispersion: \(\operatorname{Var}(y\mid x)=\mathbb E[y\mid x]=\mu\); তাই \(\hat\mu=28.6\) হলে Poisson বলে \(\operatorname{Var}\approx28.6\) (SD \(\approx5.3\))। (খ) data-তে var \(\gg\) mean (factor \(\sim10\)) — Poisson যতটা spread আশা করে, বাস্তব spread তার অনেক বেশি ⇒ overdispersion। (গ) দিন-ভেদে অদৃশ্য কারণ (আবহাওয়া-ভেদ, event, ছুটি-প্যাটার্ন) rate-কে ওঠানামা করায় — Gamma-mixed Poisson, তাই var বাড়ে।
প্রশ্ন ৪ (★★). overdispersion-এর পরিণতি। ধরুন data overdispersed, তবু আপনি সাধারণ Poisson model fit করলেন। point estimate \(\hat\beta\) মোটামুটি ঠিকই থাকে, কিন্তু SE-গুলো ভুল হয়। (ক) Poisson SE-গুলো overdispersion-এ underestimate না overestimate হয় — এবং তার ফলে Wald \(z\), \(p\)-value, confidence interval-এ কী বিকৃতি ঘটে? (খ) এর সরাসরি বিপদ কী — কোন ধরনের ভুল সিদ্ধান্ত (false positive না false negative) বেশি হয়? (গ) সংক্ষেপে দুটো প্রতিকার নাম দিন যা একই log-link mean model রেখে শুধু variance-কে ঠিক করে। Hint: (ক) Poisson SE underestimated (কারণ Poisson ধরে নেয় var \(=\mu\), যা আসলের চেয়ে ছোট) ⇒ \(z=\hat\beta/\mathrm{SE}\) স্ফীত, \(p\)-value কৃত্রিমভাবে ছোট, CI অতি-সংকীর্ণ। (খ) ⇒ over-confident inference: আসলে non-significant predictor-কে significant দেখানো (anti-conservative, বেশি false positive)। (গ) quasi-Poisson (SE-কে \(\sqrt\phi\) দিয়ে স্ফীত) ও negative binomial (explicit extra-variance parameter \(\alpha\))।
প্রশ্ন ৫ (★★). Poisson, quasi-Poisson, negative binomial — তিনটির তুলনা। তিনটিই log link ও একই mean structure \(\mu=e^{x^\top\beta}\) ব্যবহার করে; পার্থক্য variance-এ। (ক) প্রতিটির variance function লিখুন: Poisson, quasi-Poisson, NB (NB-তে \(\alpha\) ব্যবহার করুন)। (খ) quasi-Poisson আর NB — কোনটা full likelihood দেয় (তাই AIC তুলনাযোগ্য) আর কোনটা শুধু mean-variance সম্পর্ক ঠিক করে (quasi-likelihood, তাই সাধারণ AIC নেই)? (গ) \(\alpha\to0\) হলে NB কোন distribution-এ ফিরে যায়? Hint: (ক) Poisson: \(\operatorname{Var}=\mu\); quasi-Poisson: \(\operatorname{Var}=\phi\mu\) (constant multiplier \(\phi\)); NB: \(\operatorname{Var}=\mu+\alpha\mu^2\) (quadratic, variance mean-এর চেয়ে দ্রুত বাড়ে)। (খ) NB একটা সত্যিকারের probability distribution ⇒ full likelihood ও AIC (\(1753.3\)); quasi-Poisson শুধু variance-কে \(\phi\) দিয়ে scale করে (quasi-likelihood) — তাই তুলনীয় AIC নেই, শুধু সংশোধিত SE। (গ) \(\alpha\to0\Rightarrow\operatorname{Var}\to\mu\Rightarrow\) Poisson (NB হলো Poisson-এর Gamma-mixed সাধারণীকরণ)।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★). চলমান মডেলের fitted coefficient \(\hat\beta=[1.560,\,0.0597,\,0.301]\) (intercept, temp, weekend)। হাতে (ক্যালকুলেটরে) করুন: (ক) একটি weekend (weekend\(=1\)) দিনে যখন temp\(=25\)°C — তার linear predictor \(\eta=\hat\beta_0+\hat\beta_1\cdot25+\hat\beta_2\cdot1\) বের করুন; (খ) তারপর mean count \(\mu=e^{\eta}\) গণনা করুন; (গ) canonical \(\hat\mu\approx28.6\)-এর সাথে মিলছে কি? Poisson হলে ওই দিনে variance আনুমানিক কত হওয়ার কথা?
Hint: \(\eta=1.560+0.0597(25)+0.301(1)=1.560+1.4925+0.301=3.3535\)। \(\mu=e^{3.3535}\approx28.60\) ✓। Poisson equidispersion ⇒ \(\operatorname{Var}\approx\mu\approx28.6\) (SD \(\approx5.35\))। (লক্ষ করুন: log scale-এ যোগ, count scale-এ গুণ — \(\mu=e^{1.560}\cdot e^{0.0597\cdot25}\cdot e^{0.301}\)।)
প্রশ্ন ৭ (★). rate ratio হাতে। (ক) temp-এর coefficient \(\hat\beta_1=0.0597\) থেকে per-\(1\)°C rate ratio \(e^{\hat\beta_1}\) গণনা করুন এবং বাক্যে ব্যাখ্যা করুন। (খ) temp \(5\)°C বাড়লে rate ratio \(e^{5\hat\beta_1}\) বের করুন। (গ) weekend-এর coefficient \(\hat\beta_2=0.301\) থেকে rate ratio \(e^{\hat\beta_2}\) — weekend বনাম weekday-তে প্রত্যাশিত count শতকরা কত বেশি? Hint: \(e^{0.0597}\approx1.0616\) — "প্রতি \(+1\)°C-তে প্রত্যাশিত count \(\sim6.16\%\) বাড়ে (weekend স্থির)"। \(e^{5\times0.0597}=e^{0.2985}\approx1.348\) — "\(5\)°C বাড়লে count \(\sim34.8\%\) বাড়ে" (লক্ষ করুন \(1.0616^5\approx1.348\), rate ratio multiplicative)। \(e^{0.301}\approx1.351\) — "weekend-এ count weekday-র \(\sim1.35\) গুণ, অর্থাৎ \(\sim35\%\) বেশি"।
প্রশ্ন ৮ (★★). overdispersion diagnosis ও তার পরিণতি। Poisson fit থেকে: residual deviance \(=1093.1\), Pearson \(\chi^2=1096.3\), \(df=247\)। (ক) dispersion statistic \(\hat\phi=\text{Pearson }\chi^2/df\) গণনা করুন; canonical \(4.44\) মিলছে কি? deviance\(/df\) দিয়েও আনুমানিক একই মান পান কি? (খ) \(\hat\phi\approx1\) হলে equidispersion (Poisson ঠিক); \(\hat\phi\gg1\) কী নির্দেশ করে — এখানে \(4.44\) মানে কী? (গ) এই overdispersion থাকা সত্ত্বেও Poisson SE ব্যবহার করলে temp-এর \(z=\hat\beta_1/\mathrm{SE}_1\)-এ কী বিকৃতি ঘটবে — over- না under-confident? Hint: \(\hat\phi=1096.3/247=4.438\approx4.44\) ✓; deviance/\(df=1093.1/247=4.426\) — কাছাকাছি, দুটোই \(\gg1\)। \(\hat\phi=4.44\) মানে আসল variance Poisson-প্রত্যাশিত variance-এর \(\sim4.4\) গুণ ⇒ শক্তিশালী overdispersion (rule of thumb: \(\hat\phi>1.5\)-ই উদ্বেগজনক)। Poisson SE তখন প্রায় \(\sqrt{4.44}\approx2.1\) গুণ ছোট — \(z\) ~\(2.1\) গুণ স্ফীত ⇒ over-confident (false-positive ঝুঁকি)।
প্রশ্ন ৯ (★★). quasi-Poisson SE সংশোধন। quasi-Poisson একই \(\hat\beta\) রাখে কিন্তু SE-কে \(\sqrt{\hat\phi}\) দিয়ে স্ফীত করে: \(\mathrm{SE}_{\text{quasi}}=\sqrt{\hat\phi}\cdot\mathrm{SE}_{\text{Poisson}}\), এখানে \(\hat\phi=4.44\)। Poisson SE \(=[0.0476,\,0.00178,\,0.0307]\) (intercept, temp, weekend)। (ক) \(\sqrt{4.44}\) বের করে তিনটি quasi-Poisson SE গণনা করুন। (খ) temp-এর Wald \(z\) Poisson-এ (\(\hat\beta_1/\mathrm{SE}_1\)) বনাম quasi-Poisson-এ গণনা করুন — কতটা কমল? (গ) এই সংশোধিত quasi-Poisson SE-গুলো NB-fit-এর SE \([0.0874,\,0.00374,\,0.0689]\)-এর কত কাছাকাছি — দুই পদ্ধতি কি একই দিকে যাচ্ছে? Hint: \(\sqrt{4.44}\approx2.107\)। \(\mathrm{SE}_{\text{quasi}}=2.107\times[0.0476,0.00178,0.0307]=[0.1003,\,0.00375,\,0.0647]\)। temp-এ \(z_{\text{Poisson}}=0.0597/0.00178\approx33.5\), কিন্তু \(z_{\text{quasi}}=0.0597/0.00375\approx15.9\) — প্রায় অর্ধেক (তবু এখনো \(\gg1.96\), significant)। quasi SE \([0.100,0.0038,0.065]\) আর NB SE \([0.087,0.0037,0.069]\) — খুবই কাছাকাছি; দুই স্বাধীন পদ্ধতি একই "SE অনেক বড় করো" সিদ্ধান্তে পৌঁছাচ্ছে ✓।
প্রশ্ন ১০ (★★). negative binomial: variance ও AIC তুলনা। NB-তে \(\operatorname{Var}=\mu+\alpha\mu^2\), fitted \(\alpha=0.179\)। (ক) temp\(=25\), weekend\(=1\)-এ \(\mu\approx28.6\) ধরে NB-implied variance \(\mu+\alpha\mu^2\) গণনা করুন এবং Poisson-implied variance (\(=\mu\))-এর সাথে তুলনা করুন। (খ) AIC: Poisson \(2237.9\) বনাম NB \(1753.3\)। AIC-পার্থক্য বের করুন; ছোট AIC ভালো — কোন model জিতল, আর পার্থক্যটা "decisive" কেন? (গ) NB আর Poisson nested (\(\alpha=0\)-তে NB = Poisson) — তাই extra parameter \(\alpha\)-র জন্য মাত্র \(1\) ডিগ্রি খরচে AIC এত নামা কী বলে? Hint: NB var \(=28.6+0.179(28.6)^2=28.6+0.179(817.96)=28.6+146.4=175.0\) — Poisson-এর var (\(28.6\))-এর প্রায় \(6\) গুণ, যা data-র observed overdispersion-এর সাথে সঙ্গতিপূর্ণ। \(\Delta\text{AIC}=2237.9-1753.3=484.6\) — বিশাল (\(\Delta>10\)-ই strong; এখানে \(\sim485\))। NB decisively জেতে: একটামাত্র extra parameter \(\alpha\) যোগ করে log-likelihood এত বাড়ে যে \(2\times1\) penalty নগণ্য ⇒ overdispersion সত্যিকারের, এবং NB তা ঠিকভাবে ধরছে।
প্রশ্ন ১১ (★★). offset / exposure — rate বনাম count। ধরুন প্রতিটি observation আলাদা সময়-জানালায় (exposure \(t_i\) ঘণ্টা) গোনা — যেমন কোনো দিন \(t_i=24\) ঘণ্টা, কোনো দিন আংশিক \(t_i=12\) ঘণ্টা মাপা। তখন আমরা rate \(\mu_i/t_i\) model করতে চাই, raw count নয়। (ক) দেখান কেন \(\log\mu_i=\log t_i+x_i^\top\beta\) মানে rate-এর log রৈখিক (\(\log(\mu_i/t_i)=x_i^\top\beta\)) — এবং এখানে \(\log t_i\)-এর coefficient কেন \(1\)-তে স্থির (offset), estimate করা হয় না। (খ) দুটি দিনে একই \(x_i\) কিন্তু একটায় \(t=24\), অন্যটায় \(t=12\) — প্রত্যাশিত count-এর অনুপাত কত? (গ) offset না দিয়ে শুধু \(t_i\)-কে আরেকটা predictor হিসেবে রাখলে সমস্যা কী? Hint: (ক) \(\log\mu_i=\log t_i+x_i^\top\beta\Rightarrow\log\mu_i-\log t_i=\log(\mu_i/t_i)=x_i^\top\beta\) — তাই \(x^\top\beta\) rate-এর log মডেল করে; \(\log t_i\) একটা পরিচিত (estimate-নয়) পদ, coefficient \(1\)-এ আটকানো — এ-ই offset। (খ) \(\mu\propto t\) (rate স্থির), তাই \(t=24\) vs \(12\Rightarrow\) প্রত্যাশিত count অনুপাত \(24/12=2\) গুণ — exposure দ্বিগুণ মানে count দ্বিগুণ। (গ) তখন coefficient \(\ne1\) estimate হবে — rate-interpretation নষ্ট, এবং exposure ও true predictor-এর প্রভাব মিশে যাবে (proportionality জোর করা যায় না)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১২ (★★). Poisson-এর mean = variance প্রমাণ করুন। \(Y\sim\text{Poisson}(\mu)\), অর্থাৎ \(P(Y=k)=\dfrac{e^{-\mu}\mu^k}{k!}\), \(k=0,1,2,\dots\)। (ক) \(\mathbb E[Y]=\mu\) প্রমাণ করুন। (খ) \(\mathbb E[Y(Y-1)]=\mu^2\) (factorial moment) দেখিয়ে \(\operatorname{Var}(Y)=\mu\) প্রমাণ করুন। (গ) এক বাক্যে ব্যাখ্যা করুন কেন এই একটিমাত্র parameter \(\mu\) একই সাথে center ও spread নিয়ন্ত্রণ করাই Poisson regression-এ overdispersion-সমস্যার মূল উৎস। Hint: (ক) \(\mathbb E[Y]=\sum_{k\ge0}k\,\frac{e^{-\mu}\mu^k}{k!}=\sum_{k\ge1}\frac{e^{-\mu}\mu^k}{(k-1)!}=\mu\sum_{j\ge0}\frac{e^{-\mu}\mu^j}{j!}=\mu\cdot1=\mu\) (where \(j=k-1\), ভেতরের যোগফল = সমগ্র pmf = \(1\))। (খ) \(\mathbb E[Y(Y-1)]=\sum_{k\ge2}k(k-1)\frac{e^{-\mu}\mu^k}{k!}=\mu^2\sum_{j\ge0}\frac{e^{-\mu}\mu^j}{j!}=\mu^2\); তাই \(\mathbb E[Y^2]=\mu^2+\mu\), আর \(\operatorname{Var}(Y)=\mathbb E[Y^2]-(\mathbb E[Y])^2=\mu^2+\mu-\mu^2=\mu\) ∎। (গ) যেহেতু \(\mu\) mean ও variance দুটোই ঠিক করে, model-এর spread আলাদাভাবে সমন্বয় করার কোনো স্বাধীনতা নেই — তাই বাস্তবে spread বেশি হলে (overdispersion) Poisson সেটা ধরতে অক্ষম, NB-র অতিরিক্ত \(\alpha\) লাগে।
প্রশ্ন ১৩ (★★★). Poisson regression-এর score equation \(X^\top(y-\mu)=0\) প্রমাণ করুন। log link-এ \(\mu_i=e^{\eta_i}\), \(\eta_i=x_i^\top\beta\)। Poisson log-likelihood $\(\ell(\beta)=\sum_{i=1}^n\bigl[y_i\log\mu_i-\mu_i-\log(y_i!)\bigr]=\sum_{i=1}^n\bigl[y_i\,x_i^\top\beta-e^{x_i^\top\beta}-\log(y_i!)\bigr].\)$ দেখান যে MLE-তে gradient $\(\frac{\partial\ell}{\partial\beta}=\sum_{i=1}^n(y_i-\mu_i)\,x_i=X^\top(y-\mu)=\mathbf 0,\)$ যেখানে \(X\) হলো \(n\times(d+1)\) design matrix, \(y=(y_i)\), \(\mu=(\mu_i)\)। একটি ফলিত অর্থ বলুন: design-এ intercept থাকলে এই সমীকরণ থেকে কী conservation property পাওয়া যায়? Hint: \(\dfrac{\partial}{\partial\beta}\bigl[y_i x_i^\top\beta\bigr]=y_i x_i\)। \(\dfrac{\partial}{\partial\beta}\bigl[e^{x_i^\top\beta}\bigr]=e^{x_i^\top\beta}x_i=\mu_i x_i\) (chain rule, কারণ \(\frac{d}{d\eta}e^\eta=e^\eta=\mu\))। \(\log(y_i!)\) পদ \(\beta\)-মুক্ত, derivative \(0\)। যোগ করলে \(\nabla\ell=\sum_i(y_i-\mu_i)x_i=X^\top(y-\mu)\); MLE-তে \(=0\)। (লক্ষ করুন এটা logistic-এর \(X^\top(y-p)=0\)-র হুবহু সমান্তরাল — canonical link-এর সাধারণ রূপ।) conservation: intercept column সব-\(1\) হওয়ায় প্রথম সমীকরণ \(\sum_i(y_i-\mu_i)=0\Rightarrow\sum_i\hat\mu_i=\sum_i y_i\) — fitted count-এর যোগফল ঠিক observed count-এর যোগফলের সমান (এখানে \(\frac1n\sum\hat\mu_i=\frac1n\sum y_i=19.56\), mean সংরক্ষিত)।
প্রশ্ন ১৪ (★★★). canonical link ও Hessian \(-X^\top WX\), \(W=\operatorname{diag}(\mu_i)\)। প্রশ্ন ১৩-র score \(\nabla\ell=\sum_i(y_i-\mu_i)x_i\) থেকে দেখান যে log-likelihood-এর Hessian $\(\frac{\partial^2\ell}{\partial\beta\,\partial\beta^\top}=-\sum_{i=1}^n\mu_i\,x_i x_i^\top=-\,X^\top W X,\qquad W=\operatorname{diag}(\mu_i).\)$ এরপর যুক্তি দিন কেন (যেহেতু সব \(\mu_i=e^{x_i^\top\beta}>0\)) এই Hessian negative semi-definite, ফলে \(\ell(\beta)\) concave, এবং (full-rank \(X\)-এ) MLE একক — তাই Newton–Raphson/IRLS অবধারিতভাবে global maximum-এ পৌঁছায়। weight \(w_i=\mu_i\)-র সাথে IRLS-এর সম্পর্ক এক বাক্যে বলুন। Hint: \(\dfrac{\partial\mu_i}{\partial\beta}=\mu_i x_i\) (যেহেতু \(\mu_i=e^{x_i^\top\beta}\)), তাই \(\dfrac{\partial}{\partial\beta^\top}\sum_i(y_i-\mu_i)x_i=-\sum_i\mu_i x_i x_i^\top=-X^\top WX\)। যেকোনো vector \(v\)-র জন্য \(v^\top(X^\top WX)v=\sum_i\mu_i(x_i^\top v)^2\ge0\) (কারণ \(\mu_i>0\)), তাই \(-X^\top WX\preceq0\) ⇒ concave। concave function-এর stationary point-ই global max; full-rank \(X\)-এ strictly concave ⇒ একক MLE (logistic-এর মতোই local-minima-মুক্ত)। IRLS: প্রতি Newton ধাপ একটা weighted least-squares solve, weight \(w_i=\mu_i\) (logistic-এ ছিল \(p_i(1-p_i)\)) — canonical link বলে observed Hessian = expected Fisher information।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৫ (★★★). পূর্ণ Poisson/NB pipeline — fit + rate ratios + overdispersion diagnosis + NB + AIC তুলনা। seed np.random.default_rng(20260619) দিয়ে data বানান: temp = rng.uniform(5,35,250), weekend = rng.binomial(1, 2/7, 250), mu = np.exp(1.5 + 0.06*temp + 0.4*weekend); overdispersion আনতে Gamma–Poisson mixture — rate = rng.gamma(6, 1/6, 250) (mean \(1\)), count = rng.poisson(mu*rate)। তারপর:
1. EDA: count.mean(), count.var() ছাপুন; var/mean অনুপাত দেখুন (canonical mean \(19.56\), var \(\approx205\), ratio \(\approx10.5\)) — overdispersion-এর প্রথম ইঙ্গিত।
2. Poisson fit: statsmodels-এর sm.GLM(count, sm.add_constant(np.column_stack([temp,weekend])), family=sm.families.Poisson()).fit() চালিয়ে coefficient summary (β̂, SE, \(z\), \(p\)) ছাপুন; canonical \(\hat\beta=[1.560,0.0597,0.301]\), \(\mathrm{SE}=[0.0476,0.00178,0.0307]\)-এর সাথে মেলান।
3. rate ratios: প্রতিটি coefficient-এর \(e^{\hat\beta_j}\) ও \(95\%\) CI (\(e^{\hat\beta\pm1.96\,\mathrm{SE}}\)) ছাপুন; temp \(1.0616\) (per \(+1\)°C), per \(+5\)°C \(e^{5\hat\beta_1}=1.348\), weekend \(1.351\) যাচাই করুন।
4. overdispersion: Pearson \(\chi^2=\sum\frac{(y_i-\hat\mu_i)^2}{\hat\mu_i}\) ও deviance ছাপুন; dispersion \(\hat\phi=\text{Pearson}/df\) (canonical \(1096.3/247=4.44\)) গণনা করুন — \(\gg1\) মানে overdispersion।
5. quasi-Poisson SE: \(\mathrm{SE}_{\text{quasi}}=\sqrt{\hat\phi}\cdot\mathrm{SE}_{\text{Poisson}}\) ছাপুন (statsmodels-এ scale='X2' দিয়ে GLM আবার fit করে মিলিয়ে দেখুন)।
6. negative binomial: sm.GLM(..., family=sm.families.NegativeBinomial(alpha=0.179)).fit() (বা statsmodels.discrete...NegativeBinomial যা \(\alpha\) estimate করে); β̂ \(=[1.574,0.0592,0.300]\), SE \(=[0.0874,0.00374,0.0689]\), \(\alpha\approx0.179\), AIC \(1753.3\) যাচাই করুন।
7. AIC তুলনা: Poisson AIC (\(2237.9\)) বনাম NB AIC (\(1753.3\)) ছাপুন; ছোটটা ভালো → NB জেতে (\(\Delta\approx485\))।
8. prediction: temp\(=25\), weekend\(=1\)-এ \(\hat\mu\) — model.predict ও হাতে-হিসাব (\(\eta=3.3535,\ \mu=e^{3.3535}\approx28.6\)) মিলিয়ে দেখান।
(সম্ভব হলে ১–৮ এক runnable script-এ; প্রতিটি সংখ্যা canonical-এর সাথে মিলিয়ে নিন।)
Hint: import statsmodels.api as sm; Pearson chi-sq: ((count - res.mu)**2 / res.mu).sum() বা res.pearson_chi2; dispersion res.pearson_chi2/res.df_resid। quasi-Poisson SE-র সহজ পথ: res_q = sm.GLM(...,family=Poisson()).fit(scale='X2') — তখন res_q.bse already \(\sqrt{\hat\phi}\)-scaled। score-check (ঐচ্ছিক): X.T @ (count - res.mu) \(\approx\mathbf 0\) — প্রশ্ন ১৩-র যাচাই। প্রত্যাশিত সব সংখ্যা উপরের canonical তালিকায়।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
কেন এই অধ্যায়। ৫.৪-এ outcome ছিল binary (Bernoulli + logit link)। কিন্তু বহু outcome হলো count — "দিনে কয়টা bike ভাড়া", "ঘণ্টায় কতজন গ্রাহক", "একটা পৃষ্ঠায় কয়টা ত্রুটি" — যা \(\{0,1,2,\dots\}\)-এ থাকে, Bernoulli-ও নয়, Normal-ও নয়। OLS এখানে ভেঙে পড়ে: পূর্বাভাস ঋণাত্মক হতে পারে, error Normal নয়, আর variance mean-এর সাথে বাড়ে (heteroscedastic)। সমাধান: Poisson regression, GLM-trilogy-র শেষ সদস্য।
-
log link (মূল ধারণা)। mean count-কে সরাসরি \(x^\top\beta\)-র সমান না-ধরে, তার log-কে রৈখিক ধরা হয়: $\(\log\mu_i=\eta_i=x_i^\top\beta\quad\Longleftrightarrow\quad \mu_i=e^{x_i^\top\beta}.\)$ link function-টি দুটো জিনিস নিশ্চিত করে: (i) positivity — \(\mu_i=e^{(\cdot)}>0\) সর্বদা, তাই পূর্বাভাস কখনো ঋণাত্মক count দেয় না; (ii) multiplicative effect — predictor additive scale-এ যোগ হলেও mean count-এ গুণে কাজ করে, তাই প্রতিটা coefficient একটা rate ratio \(e^{\beta_j}\)।
-
interpretation: rate ratio। coefficient log-mean স্কেলে — কিন্তু \(e^{\hat\beta_j}\) নিলে তা rate ratio: predictor \(j\) এক একক বাড়লে প্রত্যাশিত count কত গুণ হয় (বাকি predictor স্থির)। চলমান উদাহরণে temp-এর \(e^{0.0597}=1.0616\) (প্রতি \(+1\)°C-তে \(\sim6\%\) বেশি, \(+5\)°C-তে \(e^{5\hat\beta_1}=1.348\)), weekend-এর \(e^{0.301}=1.351\) (weekday-র \(\sim1.35\) গুণ)। \(e^{\hat\beta}>1\Rightarrow\) count বাড়ায়, \(=1\Rightarrow\) নিরপেক্ষ, \(<1\Rightarrow\) কমায়।
-
MLE / IRLS দিয়ে fit। OLS-এর closed-form নেই; প্রতিটি observation Poisson ধরে log-likelihood $\(\ell(\beta)=\sum_i\bigl[y_i\,x_i^\top\beta-e^{x_i^\top\beta}-\log(y_i!)\bigr].\)$ log canonical link হওয়ায় score-সমীকরণ সরল রূপ \(\;X^\top(y-\mu)=0\;\) নেয় (logistic-এর \(X^\top(y-p)=0\)-র হুবহু সমান্তরাল), কিন্তু \(\mu=e^{X\beta}\) অরৈখিক — তাই Newton–Raphson, যা প্রতিধাপে weighted least squares-এ পরিণত হয় (IRLS, weight \(w_i=\mu_i\))। log-likelihood concave (Hessian \(=-X^\top WX\preceq0\)), তাই MLE একক — local-minima সমস্যা নেই।
-
Poisson-এর equidispersion ও তার ভঙ্গ। Poisson-এর মৌলিক ধর্ম \(\operatorname{Var}(y\mid x)=\mathbb E[y\mid x]=\mu\) ("mean = variance") — একটিমাত্র parameter \(\mu\) একসাথে center ও spread ঠিক করে। কিন্তু বাস্তবে (unobserved heterogeneity, clustering) প্রায়ই overdispersion দেখা যায়: variance \(\gg\) mean। চলমান উদাহরণে count mean \(19.56\), var \(205\) (var/mean \(\approx10.5\)) — স্পষ্ট সংকেত।
-
overdispersion: diagnosis ও পরিণতি। dispersion statistic \(\hat\phi=\text{Pearson }\chi^2/df=1096.3/247=4.44\) (\(\approx1\) হলে ঠিক; এখানে \(\gg1\))। Poisson তখনো ঠিক \(\hat\beta\) দেয়, কিন্তু SE-গুলো underestimate করে (\(\sqrt{\hat\phi}\approx2.1\) গুণ ছোট) ⇒ Wald \(z\) স্ফীত, \(p\)-value কৃত্রিমভাবে ছোট, CI অতি-সংকীর্ণ — অর্থাৎ over-confident, anti-conservative inference (বেশি false positive)।
-
প্রতিকার: quasi-Poisson ও negative binomial। একই log-link mean model রেখে variance ঠিক করার দুই পথ:
- quasi-Poisson: \(\operatorname{Var}=\phi\mu\); SE-কে \(\sqrt{\hat\phi}\) দিয়ে স্ফীত করে — \(\mathrm{SE}_{\text{quasi}}=\sqrt{4.44}\cdot[0.0476,0.00178,0.0307]=[0.100,0.0038,0.065]\)। quasi-likelihood (পূর্ণ distribution নয়), তাই AIC তুলনীয় নয়।
-
negative binomial (NB): \(\operatorname{Var}=\mu+\alpha\mu^2\) (Gamma-mixed Poisson), explicit overdispersion parameter \(\alpha=0.179\); full likelihood, তাই AIC তুলনাযোগ্য। NB AIC \(1753.3\) বনাম Poisson \(2237.9\) — \(\Delta\approx485\), NB decisively জেতে। (\(\alpha\to0\)-তে NB → Poisson; দুই প্রতিকারের SE প্রায় একই, \([0.100,0.0038,0.065]\) vs NB \([0.087,0.0037,0.069]\)।)
-
offset / exposure। observation-ভেদে exposure \(t_i\) ভিন্ন হলে (ভিন্ন সময়/area) count নয়, rate model করতে হয়: \(\log\mu_i=\log t_i+x_i^\top\beta\), যেখানে \(\log t_i\) একটা offset (coefficient \(1\)-এ স্থির, estimate-নয়) ⇒ \(\log(\mu_i/t_i)=x_i^\top\beta\) rate-এর log রৈখিক।
পূর্ববর্তী সংযোগ (← ৫.৪, ৪.৩, ২.৩):
- ৫.৪ (Logistic Regression / GLM): Poisson regression ঠিক ৫.৪-এর GLM-কাঠামোই ধার করে — random component + linear predictor + link + MLE/IRLS। পার্থক্য কেবল দুই জায়গায়: distribution (Bernoulli → Poisson) আর link (logit → log)। এমনকি score equation-এর রূপও জমজ: logistic-এ \(X^\top(y-p)=0\), Poisson-এ \(X^\top(y-\mu)=0\); Hessian দুটোতেই \(-X^\top WX\) (concave, একক MLE) — শুধু weight বদলায় (\(p(1-p)\) → \(\mu\))। coefficient-interpretation-ও সমান্তরাল: logistic-এ \(e^{\hat\beta}\) = odds ratio, Poisson-এ \(e^{\hat\beta}\) = rate ratio।
- ৪.৩ (MLE): Poisson regression-এর হৃদয় ৪.৩-এর maximum likelihood — Poisson likelihood লিখে log নিয়ে score-সমীকরণ শূন্য করা। closed form না-থাকায় ৪.৩-এর Newton–Raphson iterative optimization (এখানে IRLS রূপে) সরাসরি প্রযোজ্য; coefficient-এর SE আসে Fisher information (\(X^\top WX\))-এর inverse থেকে — ৪.৩/৪.৪-এর asymptotic MLE-তত্ত্বেরই প্রয়োগ। NB-তে \(\alpha\) estimate করাও একই MLE-নীতির সম্প্রসারণ।
- ২.৩ (Discrete Random Variables — Poisson): এখানে response-distribution হলো ২.৩-এ পরিচিত Poisson — যার pmf \(P(Y=k)=\frac{e^{-\mu}\mu^k}{k!}\) এবং মৌলিক ধর্ম \(\mathbb E[Y]=\operatorname{Var}(Y)=\mu\) (এ অধ্যায়ের §৭-এ আবার প্রমাণিত)। ২.৩-এ Poisson ছিল "বিরল ঘটনার সংখ্যা"-র model; এখন আমরা সেই \(\mu\)-কে predictor-নির্ভর করে (\(\mu_i=e^{x_i^\top\beta}\)) regression-এ তুলে আনলাম। NB-ও ২.৩-এর Gamma-Poisson mixture-এর সম্প্রসারণ।
পরবর্তী সংযোগ (→ ৫.৬ — Mixed-Effects / Hierarchical Models): ৫.১–৫.৫ জুড়ে একটা নীরব অনুমান ছিল — observation-গুলো স্বাধীন। কিন্তু বাস্তব data প্রায়ই grouped/clustered ও correlated: একই স্কুলের শিক্ষার্থী, একই হাসপাতালের রোগী, একই দোকানের বারবার-মাপা বিক্রি, বা একই অঞ্চলে দিনে-দিনে bike-count। এমন nested/repeated কাঠামোয় group-অভ্যন্তরীণ correlation উপেক্ষা করলে SE আবার ভুল হয় (অনেকটা overdispersion-এর মতোই — মজার ব্যাপার, NB-র extra-variance ছিল এরই একটা সরল রূপ!)। ৫.৬ এর সমাধান দেবে random effects দিয়ে: fixed effect (সব group-এ অভিন্ন \(\beta\)) ছাড়াও group-ভিত্তিক random intercept/slope যোগ করে correlation-কে explicit model করা — mixed-effects ও hierarchical (multilevel) models। সংক্ষেপে: ৫.৪ outcome-কে binary-তে নিল (logit link), ৫.৫ তাকে count-এ (log link) — GLM-trilogy সম্পূর্ণ; আর ৫.৬ দৃষ্টি সরাবে outcome থেকে error/dependence-কাঠামোয়, যখন independence-অনুমানই ভেঙে যায়।
সূত্র (sources): R. Furrer, STA121 Statistical Modeling (generalized linear models, Poisson regression, log link, deviance, dispersion, IRLS, overdispersion); L. Wasserman, All of Statistics (GLM ও Poisson model, MLE-ভিত্তি); J. A. Rice, Mathematical Statistics and Data Analysis (Poisson distribution, likelihood-based fitting); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 5 (count outcome ও regression-এর ব্যবহারিক দিক); P. Dangeti, Statistics for Machine Learning (Poisson regression, rate-ratio interpretation, negative binomial, model evaluation)।