অধ্যায় ১.৪ — Correlation & Bivariate Exploration¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
এতক্ষণ আমরা একটি variable নিয়ে কথা বলেছি — তার mean কত, কতটা ছড়ানো (১.২), তার distribution-এর আকৃতি কেমন (১.৩)। কিন্তু বাস্তব data-র মজা শুরু হয় যখন আমরা জিজ্ঞেস করি: দুটি variable একসাথে কীভাবে চলে? পড়ার সময় বাড়লে কি পরীক্ষার নম্বর বাড়ে? তাপমাত্রা বাড়লে কি আইসক্রিম বিক্রি বাড়ে? বিজ্ঞাপন খরচ আর বিক্রির মধ্যে কি কোনো টান আছে? এই "একসাথে চলা"-কে পরিমাপ করার বিদ্যাই bivariate analysis (দ্বি-চলক বিশ্লেষণ) — এই অধ্যায়ের বিষয়।
সবচেয়ে সরল হাতিয়ার হলো scatterplot (বিক্ষেপ চিত্র): প্রতিটি observation-কে \((x, y)\) সমতলে একটি বিন্দু হিসেবে আঁকা। বিন্দুগুলোর "আকৃতি" দেখলেই অনেক কিছু বোঝা যায় — তারা কি উপরের দিকে ঢালু একটি মেঘ তৈরি করেছে (একটি বাড়লে অন্যটি বাড়ে), নাকি নিচের দিকে, নাকি কোনো নকশাই নেই? এই চোখে-দেখা সম্পর্ককে একটি সংখ্যায় ধরার চেষ্টাই হলো correlation (সহসম্বন্ধ)।
কিন্তু এই সংখ্যায় নামানোর পথে দুটি বড় শিক্ষা আছে, যা এই অধ্যায়ের মেরুদণ্ড:
Hook ১ — Anscombe's quartet (figure 3)। চারটি সম্পূর্ণ আলাদা চেহারার dataset, যাদের mean, variance, correlation, এমনকি best-fit লাইন হুবহু এক — কিন্তু scatterplot আঁকলে একটি সরল, একটি বাঁকা, একটিতে একটি outlier, আরেকটিতে পুরো নকশা একটি বিন্দু ঠিক করে দিচ্ছে। শিক্ষা: আগে ছবি আঁকো, তারপর সংখ্যায় বিশ্বাস করো।
Hook ২ — correlation ≠ causation। আইসক্রিম বিক্রি আর পানিতে ডুবে মৃত্যু — দুটোই গরমকালে বাড়ে, তাই তাদের correlation প্রবল। তার মানে কি আইসক্রিম খেলে মানুষ ডোবে? না — দুটোরই পেছনে লুকানো তৃতীয় কারণ: গরম (একটি confounder)। correlation কেবল বলে "একসাথে চলে", কখনো বলে না "একটি অন্যটিকে ঘটায়"।
এই দুই সতর্কবাণী মাথায় রেখে আমরা গড়ব: covariance → তার একক-সমস্যা → standardize করে Pearson \(r\) → rank দিয়ে Spearman → ছবির সীমাবদ্ধতা → categorical data-র জন্য contingency table → বড় data-র জন্য hexbin। সবশেষে দেখব এই covariance/correlation আসলে Part 0.5-এর covariance matrix-এরই হৃদয়, এবং Part V-এর regression-এর সরাসরি ভিত্তি।
২ · মূল ধারণা ও সংজ্ঞা¶
ধরা যাক আমাদের কাছে \(n\)টি জোড়া observation আছে: \((x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\) — যেমন \(n\) জন ছাত্রের (পড়ার ঘণ্টা, নম্বর)। তাদের mean যথাক্রমে \(\bar{x}\) ও \(\bar{y}\) (১.২ থেকে)।
২.১ Scatterplot — সম্পর্কের প্রথম ছবি¶
Scatterplot হলো \(xy\)-সমতলে \(n\)টি বিন্দু \(\{(x_i, y_i)\}\) আঁকা। কোনো সংখ্যা গণনার আগে এটিই প্রথম এবং সবচেয়ে জরুরি কাজ। একটি scatterplot থেকে আমরা একসাথে চারটি জিনিস পড়ি:
- Direction (দিক): মেঘ কি উপরে-ডানে ঢালু (positive সম্পর্ক), নাকি নিচে-ডানে (negative)?
- Form (রূপ): সম্পর্ক কি সরলরেখার মতো (linear), নাকি বাঁকা (nonlinear)?
- Strength (প্রবলতা): বিন্দুগুলো কি একটি রেখার গায়ে ঘন হয়ে আছে, নাকি ছড়িয়ে-ছিটিয়ে?
- Outlier ও cluster: কোনো বিন্দু কি বাকিদের থেকে অনেক দূরে? data কি দলে দলে ভাগ হয়ে আছে?
মনে রাখা জরুরি: correlation যে একটিমাত্র সংখ্যা দেবে, সেটি কেবল উপরের প্রথম ও তৃতীয় বিন্দু (linear direction ও strength) ধরে — form বা outlier ধরে না। তাই ছবি কখনো বাদ দেওয়া যায় না।
২.২ Covariance — একসাথে কতটা সরে¶
দুটি variable একসাথে কীভাবে চলে, তা মাপার প্রথম গাণিতিক চেষ্টা হলো covariance (সহভেদ)। ধারণাটি সরল: প্রতিটি বিন্দুর জন্য দেখি, \(x\) তার নিজের mean থেকে যেদিকে সরেছে, \(y\) কি একই দিকে সরেছে?
প্রতিটি observation-এ দুটি deviation (বিচ্যুতি): \((x_i - \bar{x})\) এবং \((y_i - \bar{y})\)। তাদের গুণফল নিই:
- দুটোই mean-এর উপরে (\(+,+\)) বা দুটোই নিচে (\(-,-\)) → গুণফল ধনাত্মক;
- একটি উপরে আরেকটি নিচে (\(+,-\) বা \(-,+\)) → গুণফল ঋণাত্মক।
এই গুণফলগুলোর গড়ই covariance:
(এখানে \(n-1\) — sample covariance-এর জন্য Bessel-এর সংশোধন, ১.২-এর sample variance-এর মতোই; population-এ \(n\) দিয়ে ভাগ।) লক্ষ করুন একটি সুন্দর সংযোগ: যদি \(y = x\) হয়, তবে \(\operatorname{cov}(x, x) = \frac{1}{n-1}\sum (x_i-\bar x)^2 = s_x^2\) — অর্থাৎ variance হলো নিজের সাথে নিজের covariance। আর ০.৫-এর ভাষায়, centered column দুটিকে vector ভাবলে \(\operatorname{cov}(x,y)\) আসলে তাদের dot product (একটি \(\tfrac{1}{n-1}\) গুণক সহ)।
Covariance-এর প্রাণঘাতী সমস্যা — একক। covariance-এর চিহ্ন (positive/negative) অর্থপূর্ণ, কিন্তু তার মান ব্যাখ্যা করা প্রায় অসম্ভব। কেন? কারণ তার একক হলো \(x\)-এর একক \(\times\) \(y\)-এর একক। উচ্চতা (cm) ও ওজন (kg)-এর covariance-এর একক "cm·kg"। উচ্চতা মিটারে মাপলে covariance ১০০ গুণ ছোট হয়ে যাবে — অথচ সম্পর্ক তো বদলায়নি! তাই \(\operatorname{cov} = 250\) বড় না ছোট, তা বলার কোনো উপায় নেই। এই সমস্যার সমাধানই correlation।
২.৩ Pearson correlation coefficient \(r\) — একক-মুক্ত করা¶
সমাধান সহজ: covariance-কে দুই variable-এর standard deviation দিয়ে ভাগ করে একক বাতিল করে দাও। এতে পাওয়া যায় Pearson correlation coefficient (পিয়ারসন সহসম্বন্ধ গুণাঙ্ক), চিহ্ন \(r\):
(দ্বিতীয় রূপে \(n-1\) উপরে-নিচে কাটাকাটি হয়ে গেছে।) এর একটি সমান-সুন্দর রূপ আছে z-score (১.৩) দিয়ে: যদি \(z_{x_i} = (x_i-\bar x)/s_x\) হয়, তবে
অর্থাৎ \(r\) হলো standardized \(x\) ও standardized \(y\)-এর গুণফলের গড় — সম্পূর্ণ একক-মুক্ত, খাঁটি সংখ্যা।
\(r\)-এর তিনটি মূল ধর্ম, যা মুখস্থ রাখতে হবে:
- পরিসর \(-1 \le r \le 1\) (প্রমাণ section ৪)। \(r=+1\): বিন্দুগুলো ঠিক একটি উপরে-ঢালু সরলরেখায়; \(r=-1\): ঠিক একটি নিচে-ঢালু সরলরেখায়; \(r=0\): কোনো linear সম্পর্ক নেই।
- একক-নিরপেক্ষ ও scale-নিরপেক্ষ। \(x \to ax+b\) (যেকোনো \(a>0\)) করলে \(r\) বদলায় না। তাই সেন্টিমিটার-কিলোগ্রামের সমস্যা মিটে গেল।
- প্রতিসম: \(r_{xy} = r_{yx}\)। কে "কারণ" কে "ফল" — \(r\) তা জানে না (Hook ২ মনে আছে?)।
ব্যাখ্যার মোটামুটি নিয়ম (rule of thumb): \(\lvert r \rvert\) এর মান \(0.0\)–\(0.2\) খুব দুর্বল, \(0.2\)–\(0.4\) দুর্বল, \(0.4\)–\(0.6\) মাঝারি, \(0.6\)–\(0.8\) প্রবল, \(0.8\)–\(1.0\) খুব প্রবল। তবে এ কেবল আঙুলের মাপ — ক্ষেত্রভেদে (পদার্থবিজ্ঞান বনাম সমাজবিজ্ঞান) মানদণ্ড বদলায়। figure 1-এ বিভিন্ন \(r\)-মানের scatter একসাথে দেখলে চোখ তৈরি হয়ে যায়।
২.৪ Spearman rank correlation — যখন সম্পর্ক বাঁকা কিন্তু একমুখী¶
Pearson \(r\) কেবল linear সম্পর্ক ধরে। কিন্তু অনেক সম্পর্ক monotonic (একমুখী — \(x\) বাড়লে \(y\) সবসময় বাড়ে) অথচ সরলরেখা নয় (যেমন \(y=e^x\))। সেখানে Pearson \(r\) ১-এর চেয়ে কম দেখাবে, যদিও সম্পর্ক নিখুঁতভাবে একমুখী।
সমাধান: মূল মানের বদলে তাদের rank (ক্রম) ব্যবহার করো। সবচেয়ে ছোট মান পায় rank ১, পরেরটি ২, …। তারপর সেই rank-এর উপর সাধারণ Pearson \(r\) বের করলেই পাওয়া যায় Spearman rank correlation (চিহ্ন \(\rho\), "rho")। সমান মান (tie) না থাকলে এর একটি সরল রূপ:
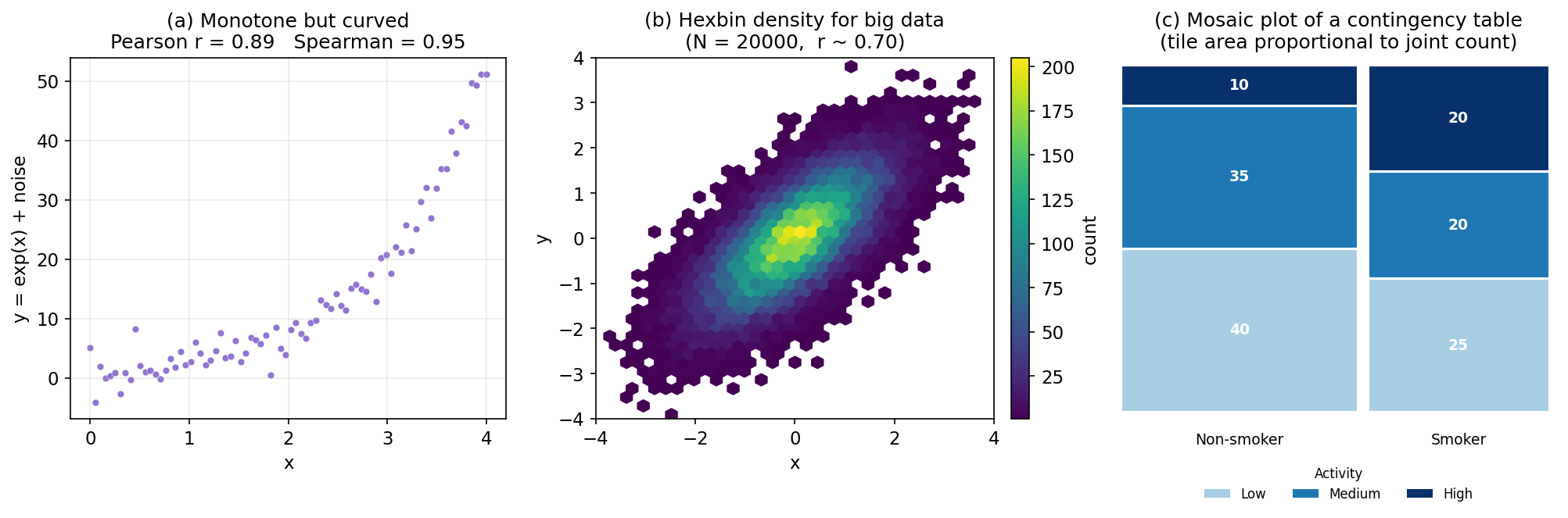
Spearman-এর তিন সুবিধা: (ক) যেকোনো monotonic সম্পর্ক (বাঁকা হলেও) ১ বা −১ দেখায়; (খ) outlier-এ অনেক কম স্পর্শকাতর (কারণ চরম মান কেবল একটি rank পায়, বিশাল সংখ্যা নয়); (গ) ordinal data-তেও (যেমন রেটিং ১–৫) কাজ করে। figure 4(a)-তে একই বাঁকা data-র Pearson (\(\approx 0.89\)) ও Spearman (\(\approx 0.95\)) তুলনা করলে পার্থক্যটা স্পষ্ট হয়।
২.৫ Correlation বনাম Causation — সবচেয়ে জরুরি সতর্কতা¶
correlation মানে causation নয় — পরিসংখ্যানের একক বাক্যের সবচেয়ে গুরুত্বপূর্ণ পাঠ। \(x\) ও \(y\)-এর প্রবল correlation দেখলে অন্তত চারটি সম্ভাবনা থাকে:
- \(x\) আসলেই \(y\)-কে ঘটায় (\(x \to y\));
- উল্টোটা (\(y \to x\));
- একটি confounder (গুপ্ত চলক) \(z\) আছে যা দুটোকেই ঘটায় (\(z \to x\) এবং \(z \to y\)) — আইসক্রিম/ডুবে-মৃত্যুর "গরম";
- নিছক coincidence — যথেষ্ট variable ঘাঁটলে এমনিতেই কাকতালীয় correlation মেলে (spurious correlation)।
correlation একা এই চারটির মধ্যে পার্থক্য করতে পারে না। কারণ প্রমাণ করতে হলে দরকার randomized experiment বা যত্নশীল causal inference (Part V ও তার পরে)। তাই EDA-তে correlation দেখে কখনো "অতএব \(x\) করলে \(y\) হবে" — এমন সিদ্ধান্ত নয়; বড়জোর "এখানে একটি সম্পর্ক আছে, কারণ খুঁজে দেখা দরকার।"
২.৬ Categorical–Categorical: Contingency Table¶
scatterplot, covariance, Pearson — সবই numeric variable-এর জন্য। কিন্তু দুটিই যদি categorical হয় (যেমন ধূমপায়ী/অধূমপায়ী বনাম শারীরিক সক্রিয়তা low/medium/high)? তখন ব্যবহার করি contingency table (আনুষঙ্গিকতা ছক, বা cross-tabulation): এক variable-এর শ্রেণি row-তে, অন্যটির column-এ, আর প্রতিটি ঘরে সেই দুই শ্রেণির joint (যৌথ) গণনা।
| Low | Medium | High | মোট | |
|---|---|---|---|---|
| Non-smoker | 40 | 35 | 10 | 85 |
| Smoker | 25 | 20 | 20 | 65 |
| মোট | 65 | 55 | 30 | 150 |
দুই categorical variable independent (স্বাধীন) কিনা তা পরীক্ষা করা যায় chi-square test দিয়ে (পূর্ণ তত্ত্ব Part IV): প্রতিটি ঘরের প্রকৃত গণনাকে "স্বাধীন হলে যা হতো" (expected) তার সাথে তুলনা করা হয়। ছবিতে দেখাতে চাইলে mosaic plot ব্যবহৃত হয় — প্রতিটি টালির ক্ষেত্রফল সেই ঘরের যৌথ অনুপাতের সমানুপাতিক (figure 4(c))।
২.৭ বড় data: hexbin ও 2D density¶
যখন বিন্দুসংখ্যা হাজার-লক্ষ, সাধারণ scatterplot-এ বিন্দুগুলো একে অপরের উপর জমাট বেঁধে (overplotting) কালো দলায় পরিণত হয় — ঘনত্ব বোঝা যায় না। তখন সমতলকে ছোট ছোট hexagon ঘরে ভাগ করে প্রতিটিতে কয়টি বিন্দু পড়ল তা রঙ দিয়ে দেখানো হয় — এটিই hexbin plot (figure 4(b))। বিকল্পে 2D kernel density দিয়ে মসৃণ density-র contour আঁকা যায়। দুটোতেই সম্পর্কের আকৃতি ও ঘনত্ব দুটোই ফুটে ওঠে — যা ১.৫-এর EDA workflow-এ কাজে লাগবে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ৩.১ — হাতে covariance ও Pearson \(r\)¶
পাঁচ জোড়া observation নিই: \(x = (1, 2, 3, 4, 5)\), \(y = (2, 4, 5, 4, 5)\)।
ধাপ ১ — mean। \(\bar{x} = \frac{1+2+3+4+5}{5} = 3\), \(\quad \bar{y} = \frac{2+4+5+4+5}{5} = 4\)।
ধাপ ২ — deviation ও তাদের গুণফল। একটি ছক বানাই:
| \(x_i\) | \(y_i\) | \(x_i-\bar x\) | \(y_i-\bar y\) | গুণফল | \((x_i-\bar x)^2\) | \((y_i-\bar y)^2\) |
|---|---|---|---|---|---|---|
| 1 | 2 | \(-2\) | \(-2\) | \(4\) | \(4\) | \(4\) |
| 2 | 4 | \(-1\) | \(0\) | \(0\) | \(1\) | \(0\) |
| 3 | 5 | \(0\) | \(1\) | \(0\) | \(0\) | \(1\) |
| 4 | 4 | \(1\) | \(0\) | \(0\) | \(1\) | \(0\) |
| 5 | 5 | \(2\) | \(1\) | \(2\) | \(4\) | \(1\) |
| যোগ | \(\mathbf{6}\) | \(\mathbf{10}\) | \(\mathbf{6}\) |
ধাপ ৩ — covariance। \(\displaystyle \operatorname{cov}(x,y) = \frac{1}{n-1}\sum (x_i-\bar x)(y_i-\bar y) = \frac{6}{5-1} = \frac{6}{4} = 1.5\)।
ধাপ ৪ — standard deviation। \(\displaystyle s_x = \sqrt{\frac{10}{4}} = \sqrt{2.5} \approx 1.581\), \(\quad s_y = \sqrt{\frac{6}{4}} = \sqrt{1.5} \approx 1.225\)।
ধাপ ৫ — Pearson \(r\)। $$ r = \frac{\operatorname{cov}(x,y)}{s_x s_y} = \frac{1.5}{1.581 \times 1.225} = \frac{1.5}{1.936} \approx 0.775 . $$ অথবা সরাসরি যোগফল দিয়ে: \(r = \dfrac{6}{\sqrt{10}\,\sqrt{6}} = \dfrac{6}{\sqrt{60}} = \dfrac{6}{7.746} \approx 0.775\)। মাঝারি-প্রবল positive linear সম্পর্ক — section ৫-এ NumPy দিয়ে হুবহু \(0.7746\) মিলবে।
উদাহরণ ৩.২ — Spearman যখন Pearson-কে ছাড়িয়ে যায়¶
ধরা যাক \(x = (1, 2, 3, 4, 5)\) এবং \(y = (1, 4, 9, 16, 25) = x^2\)। এটি নিখুঁতভাবে monotonic (x বাড়লে y সবসময় বাড়ে), কিন্তু সরলরেখা নয়।
- Pearson: হিসাব করলে \(r \approx 0.981\) — ১-এর কাছাকাছি, কিন্তু ঠিক ১ নয়, কারণ সম্পর্ক বাঁকা।
- Spearman: \(x\)-এর rank \((1,2,3,4,5)\), \(y\)-এরও rank \((1,2,3,4,5)\) — হুবহু এক, তাই সব \(d_i = 0\): $$ \rho = 1 - \frac{6 \cdot 0}{5(25-1)} = 1 . $$
Spearman নিখুঁতভাবে \(1\) ধরল কারণ সে কেবল ক্রম দেখে, আকৃতি নয়। শিক্ষা: সম্পর্ক একমুখী কিন্তু বাঁকা হলে Spearman বেশি সৎ উত্তর দেয়। (figure 4(a)-তে noisy \(e^x\)-data-তেও একই প্রবণতা: Spearman > Pearson।)
উদাহরণ ৩.৩ — Anscombe's quartet পড়া (figure 3)¶
১৯৭৩ সালে পরিসংখ্যানবিদ Francis Anscombe চারটি dataset বানান, প্রতিটিতে ১১টি বিন্দু। চারটিরই সারসংক্ষেপ পরিসংখ্যান প্রায় হুবহু এক:
| পরিমাপ | I | II | III | IV |
|---|---|---|---|---|
| \(\bar{x}\) | 9.0 | 9.0 | 9.0 | 9.0 |
| \(\bar{y}\) | 7.50 | 7.50 | 7.50 | 7.50 |
| Pearson \(r\) | 0.816 | 0.816 | 0.816 | 0.817 |
| best-fit line | \(y=3.00+0.50x\) | একই | একই | একই |
অথচ ছবি আঁকলে (figure 3): - I — সত্যিকারের noisy linear সম্পর্ক; \(r=0.82\) যথার্থ। - II — নিখুঁত বাঁকা (parabolic); linear \(r\) এখানে অর্থহীন। - III — নিখুঁত সরলরেখা, কিন্তু একটি outlier পুরো \(r\)-কে টেনে নামিয়েছে। - IV — \(x\) প্রায় সবসময় ৮, একটিমাত্র দূরবর্তী বিন্দু একা পুরো correlation ও লাইন তৈরি করছে।
মোক্ষম শিক্ষা: correlation একটি সংকীর্ণ লেন্স — কেবল linear strength মাপে। mean, variance, \(r\) মিলে গেলেও data সম্পূর্ণ আলাদা হতে পারে। তাই সবসময় আগে scatterplot।
উদাহরণ ৩.৪ — contingency table পড়া¶
section ২.৬-এর ছক দেখুন। অধূমপায়ীদের মধ্যে high-activity-র অনুপাত \(10/85 \approx 12\%\), কিন্তু ধূমপায়ীদের মধ্যে \(20/65 \approx 31\%\)। অনুপাত দুটি আলাদা — ইঙ্গিত যে ধূমপান ও সক্রিয়তা স্বাধীন নয়। chi-square test চালালে (section ৫) \(\chi^2 \approx 8.37\), \(p \approx 0.015\) — অর্থাৎ এই সম্পর্ক \(5\%\) স্তরে পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ (পূর্ণ ব্যাখ্যা Part IV)। তবু সাবধান: এটিও association, causation নয়।
৪ · প্রমাণ ও উৎপাদন¶
৪.১ ★ কেন \(-1 \le r \le 1\) (Cauchy–Schwarz)¶
centered vector দুটি ধরি: \(\mathbf{a} = (x_1-\bar x, \dots, x_n-\bar x)\) এবং \(\mathbf{b} = (y_1-\bar y, \dots, y_n-\bar y)\)। তাহলে সংজ্ঞা থেকে $$ r = \frac{\mathbf{a}\cdot\mathbf{b}}{\lVert \mathbf{a}\rVert\, \lVert \mathbf{b}\rVert}. $$ ০.৫-এর Cauchy–Schwarz inequality বলে \(\lvert \mathbf{a}\cdot\mathbf{b}\rvert \le \lVert \mathbf{a}\rVert\,\lVert \mathbf{b}\rVert\)। দুই পাশকে \(\lVert \mathbf{a}\rVert\,\lVert \mathbf{b}\rVert\) দিয়ে ভাগ করলেই সরাসরি $$ \lvert r \rvert \le 1 \quad\Longleftrightarrow\quad -1 \le r \le 1. \qquad \blacksquare $$ আবার ০.৫ থেকে: \(\mathbf{a}\cdot\mathbf{b} = \lVert\mathbf{a}\rVert\,\lVert\mathbf{b}\rVert\cos\theta\), তাই \(r = \cos\theta\) — দুই centered vector-এর মধ্যবর্তী কোণের cosine। এটিই কেন \(r\) সবসময় \([-1,1]\)-এ: cosine কখনো এই সীমা ছাড়ায় না। আর \(r=\pm 1\) ঠিক তখনই, যখন \(\mathbf{a}\) ও \(\mathbf{b}\) একই (বা বিপরীত) দিকে — অর্থাৎ \(y_i = \alpha x_i + \beta\) নিখুঁত সরলরেখা।
৪.২ ★ \(r\) scale ও shift-এ অপরিবর্তিত — কেন¶
ধরুন প্রতিটি \(x_i\)-কে রূপান্তর করি \(x_i' = a x_i + b\) (\(a>0\))। তাহলে নতুন mean \(\bar{x}' = a\bar x + b\), এবং deviation $$ x_i' - \bar{x}' = (a x_i + b) - (a\bar x + b) = a(x_i - \bar x). $$ shift (\(b\)) সম্পূর্ণ বাতিল, scale (\(a\)) deviation-এ গুণ হয়। ফলে numerator-এ \(\operatorname{cov}(x', y) = a\,\operatorname{cov}(x, y)\), আর denominator-এ \(s_{x'} = a\, s_x\)। ভাগ করলে \(a\) কাটাকাটি: $$ r' = \frac{a\,\operatorname{cov}(x,y)}{(a\,s_x)\,s_y} = \frac{\operatorname{cov}(x,y)}{s_x s_y} = r. \qquad \blacksquare $$ এই কারণেই একক বদলালে (cm→m, °C→°F ধনাত্মক scale-এ) \(r\) বদলায় না — covariance-এর প্রধান দুর্বলতা \(r\)-এ নিরাময় হয়ে যায়।
৪.৩ ★★ Covariance থেকে covariance matrix — Part 0.5-এর সাথে সেতু¶
\(d\)টি variable থাকলে প্রতিটি জোড়ার covariance একসাথে সাজিয়ে পাই covariance matrix \(\Sigma\), যার \((i,j)\) entry হলো \(\operatorname{cov}(X_i, X_j)\): $$ \Sigma = \begin{bmatrix} \operatorname{var}(X_1) & \operatorname{cov}(X_1,X_2) & \cdots \ \operatorname{cov}(X_2,X_1) & \operatorname{var}(X_2) & \cdots \ \vdots & & \ddots \end{bmatrix} = \frac{1}{n-1} X_c^\top X_c, $$ যেখানে \(X_c\) হলো column-wise centered data matrix (০.৫-এ দেখা)। কর্ণে variance, কর্ণের বাইরে covariance। যেহেতু \(\operatorname{cov}(X_i,X_j)=\operatorname{cov}(X_j,X_i)\), তাই \(\Sigma\) সর্বদা symmetric; আর \(X_c^\top X_c\) রূপ থেকে এটি positive-semidefinite (০.৫-এর প্রমাণ)। প্রতিটি covariance-কে \(s_i s_j\) দিয়ে ভাগ করলে পাই correlation matrix \(R\) — যার সব entry \([-1,1]\)-এ, কর্ণে \(1\)। figure 2 ঠিক এই \(R\)-কেই heatmap হিসেবে দেখায়।
এই বিন্দুতেই Part I-এর descriptive statistics আর Part 0.5-এর linear algebra হাত মেলায়: correlation কেবল একটি জোড়ার সংখ্যা নয়, বরং একটি সম্পূর্ণ matrix-এর entry — যার eigenstructure পরে PCA (Part VI) ও regression (Part V)-কে চালায়।
৫ · কোড ল্যাব (Python)¶
প্রথমে from scratch (শুধু NumPy দিয়ে সূত্র বসিয়ে) covariance ও \(r\) বানাব, তারপর তৈরি function (np.corrcoef, scipy.stats, pandas) দিয়ে মিলিয়ে নেব।
import numpy as np
from scipy import stats
# ---------- covariance ও Pearson r: from scratch vs library ----------
x = np.array([1.0, 2, 3, 4, 5])
y = np.array([2.0, 4, 5, 4, 5])
n = len(x)
xc, yc = x - x.mean(), y - y.mean() # center (deviation থেকে mean)
cov_scratch = (xc @ yc) / (n - 1) # dot product / (n-1) -> উদাহরণ ৩.১
sx = np.sqrt((xc @ xc) / (n - 1))
sy = np.sqrt((yc @ yc) / (n - 1))
r_scratch = cov_scratch / (sx * sy)
cov_numpy = np.cov(x, y, ddof=1)[0, 1] # 2x2 covariance matrix, off-diagonal
r_numpy = np.corrcoef(x, y)[0, 1]
print("cov scratch =", round(cov_scratch, 4), " numpy =", round(cov_numpy, 4)) # 1.5 1.5
print("r scratch =", round(r_scratch, 4), " numpy =", round(r_numpy, 4)) # 0.7746 ...
# ---------- Pearson বনাম Spearman: একমুখী কিন্তু বাঁকা সম্পর্ক ----------
x = np.array([1.0, 2, 3, 4, 5])
y = x**2 # নিখুঁত monotonic, কিন্তু non-linear
r_pearson = stats.pearsonr(x, y).statistic # বাঁকা বলে 1-এর চেয়ে কম
rho_spear = stats.spearmanr(x, y).statistic # rank একই বলে ঠিক 1
print("Pearson r =", round(r_pearson, 4)) # ~0.9811
print("Spearman ρ =", round(rho_spear, 4)) # 1.0 (উদাহরণ ৩.২)
# ---------- correlation matrix (multivariate) ----------
rng = np.random.default_rng(7)
m = 300
study = rng.normal(5, 1.5, m)
sleep = rng.normal(7, 1.0, m)
score = 50 + 6*study + 2.5*sleep + 4*rng.normal(0, 1, m)
absent = np.clip(20 - 1.8*study + rng.normal(0, 2, m), 0, None)
X = np.column_stack([study, sleep, score, absent])
R = np.corrcoef(X, rowvar=False) # 4x4 correlation matrix; rowvar=False: columns=variables
print("correlation matrix:\n", np.round(R, 2))
# study↔score প্রবল positive (~0.86), study↔absent প্রবল negative (~-0.76)
# ---------- Anscombe's quartet: একই r, ভিন্ন চিত্র ----------
x123 = np.array([10,8,13,9,11,14,6,4,12,7,5.])
ys = {
"I": [8.04,6.95,7.58,8.81,8.33,9.96,7.24,4.26,10.84,4.82,5.68],
"II": [9.14,8.14,8.74,8.77,9.26,8.10,6.13,3.10,9.13,7.26,4.74],
"III": [7.46,6.77,12.74,7.11,7.81,8.84,6.08,5.39,8.15,6.42,5.73],
}
x4 = np.array([8,8,8,8,8,8,8,19,8,8,8.])
y4 = np.array([6.58,5.76,7.71,8.84,8.47,7.04,5.25,12.50,5.56,7.91,6.89])
for name, yv in {**{k: np.array(v) for k, v in ys.items()}, "IV": y4}.items():
xv = x4 if name == "IV" else x123
r = np.corrcoef(xv, yv)[0, 1]
b, a = np.polyfit(xv, yv, 1) # slope b, intercept a
print(f"{name}: mean_y={yv.mean():.2f} r={r:.3f} line: y={a:.2f}+{b:.2f}x")
# চারটিরই: mean_y=7.50, r≈0.816, line y=3.00+0.50x — অথচ ছবি সম্পূর্ণ আলাদা
# ---------- categorical–categorical: contingency table + chi-square ----------
import pandas as pd
# raw data থেকে pandas crosstab বানানোর সাধারণ pattern:
df = pd.DataFrame({
"smoker": (["no"]*85) + (["yes"]*65),
"activity": (["Low"]*40 + ["Medium"]*35 + ["High"]*10) # non-smokers
+ (["Low"]*25 + ["Medium"]*20 + ["High"]*20), # smokers
})
table = pd.crosstab(df["smoker"], df["activity"])
print(table)
chi2, p, dof, expected = stats.chi2_contingency(table.values)
print(f"chi2 = {chi2:.3f}, p = {p:.4f}, dof = {dof}") # 8.368, 0.0152, 2
# p < 0.05 -> smoker ও activity স্বাধীন নয় (association আছে)
Output (সংক্ষেপে): scratch ও np.cov/np.corrcoef হুবহু মেলে — \(\operatorname{cov}=1.5\), \(r=0.7746\) (উদাহরণ ৩.১ যাচাই)। \(y=x^2\)-এ Pearson \(\approx 0.981\) কিন্তু Spearman \(=1.0\) (উদাহরণ ৩.২)। correlation matrix-এ study↔score \(\approx 0.86\), study↔absent \(\approx -0.76\)। Anscombe-এর চারটিরই mean \(7.50\), \(r\approx 0.816\), line \(y=3.00+0.50x\) — সংখ্যায় এক, ছবিতে ভিন্ন। contingency-তে \(\chi^2=8.368\), \(p=0.0152\) — association নিশ্চিত।
৬ · ভিজ্যুয়ালাইজেশন¶
নিচের সব চিত্র
/tmp/figs_1-4.py-তে একসাথে তৈরি (synthetic data, fixed seed; in-figure text English)। প্রতিটি../_assets/-এ সংরক্ষিত।
Figure 1 — বিভিন্ন \(r\)-মানের scatter সিরিজ¶
np.corrcoef দিয়ে চোখ তৈরি করার জন্য \(r = +1.0\) থেকে \(-0.9\) পর্যন্ত ছয়টি scatter। লক্ষ করুন \(r\) যত \(0\)-র কাছে, মেঘ তত গোলাকার ও দিশাহীন; \(\pm 1\)-এর কাছে তত সরু রেখার মতো।
def make_corr(rng, n, target_r):
x = rng.standard_normal(n); z = rng.standard_normal(n)
return x, (target_r*x + np.sqrt(1-target_r**2)*z)
rng = np.random.default_rng(14)
# targets = [1.0, 0.8, 0.4, 0.0, -0.5, -0.9] -> 2x3 grid, প্রতিটির sample r শিরোনামে
plt.savefig("../_assets/1-4-scatter-r-series.png", dpi=150)
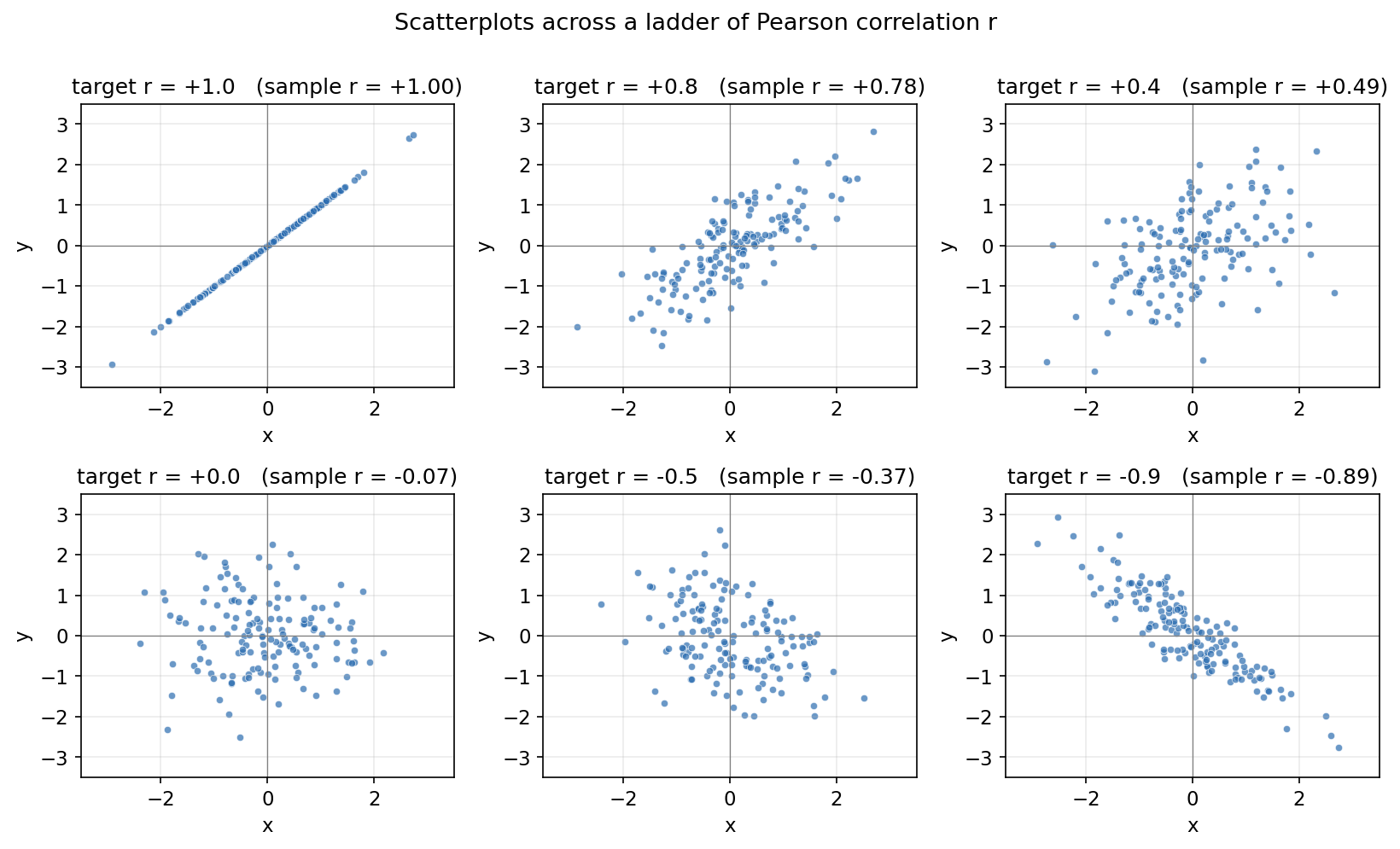
Figure 2 — correlation matrix heatmap¶
পাঁচটি variable (study, sleep, score, absent, height)-এর সব জোড়ার Pearson \(r\) একটি রঙিন matrix-এ। লাল = প্রবল positive, নীল = প্রবল negative, সাদা ≈ ০। study↔score (লাল \(0.86\)) ও study↔absent (নীল \(-0.76\)) চোখে পড়ে; height বাকিদের সাথে প্রায় সাদা (uncorrelated nuisance variable)।
C = np.corrcoef(data, rowvar=False) # 5x5
# imshow + diverging colormap (blue–white–red), প্রতিটি ঘরে মান লেখা
plt.savefig("../_assets/1-4-corr-heatmap.png", dpi=150)
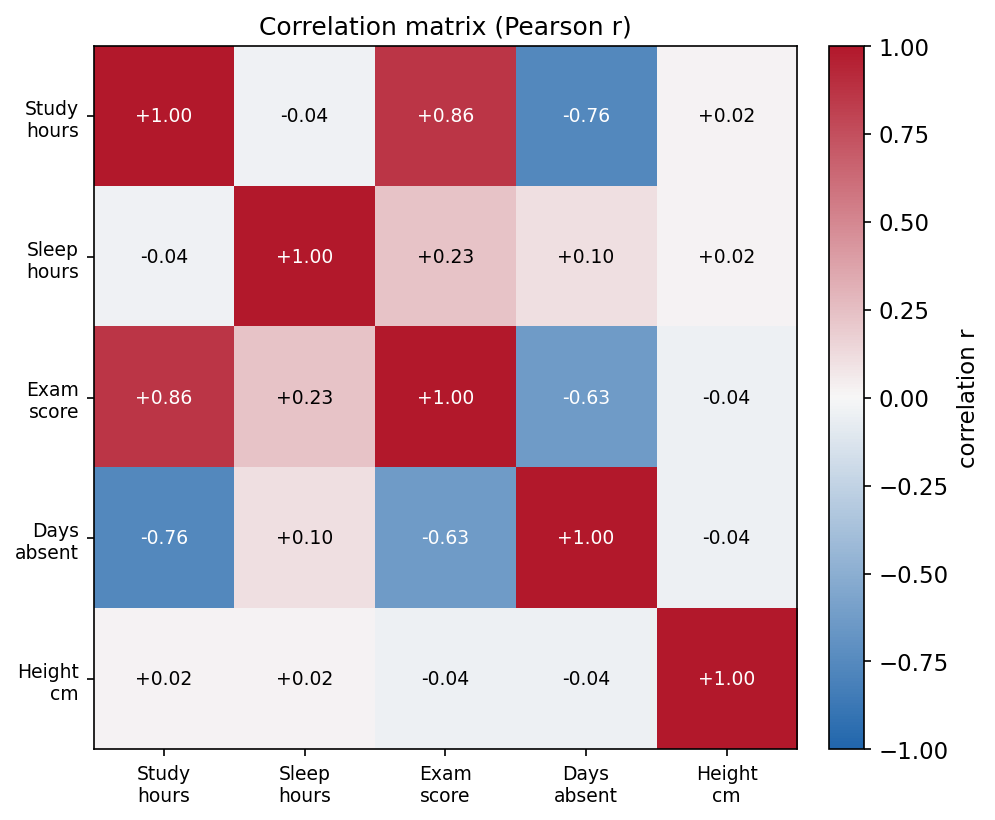
Figure 3 — Anscombe's quartet (২×২)¶
correlation-এর সীমাবদ্ধতার চূড়ান্ত প্রদর্শন: চারটি dataset, একই \(r=0.82\), একই লাইন \(y=3+0.5x\), কিন্তু সম্পূর্ণ আলাদা চিত্র — linear, parabolic, outlier-চালিত, ও একক-বিন্দু-চালিত।
# চারটি hard-coded dataset; প্রতিটির r ও polyfit লাইন শিরোনামে
# 2x2 subplot, একই রঙের লাইন ও বিন্দু
plt.savefig("../_assets/1-4-anscombe.png", dpi=150)
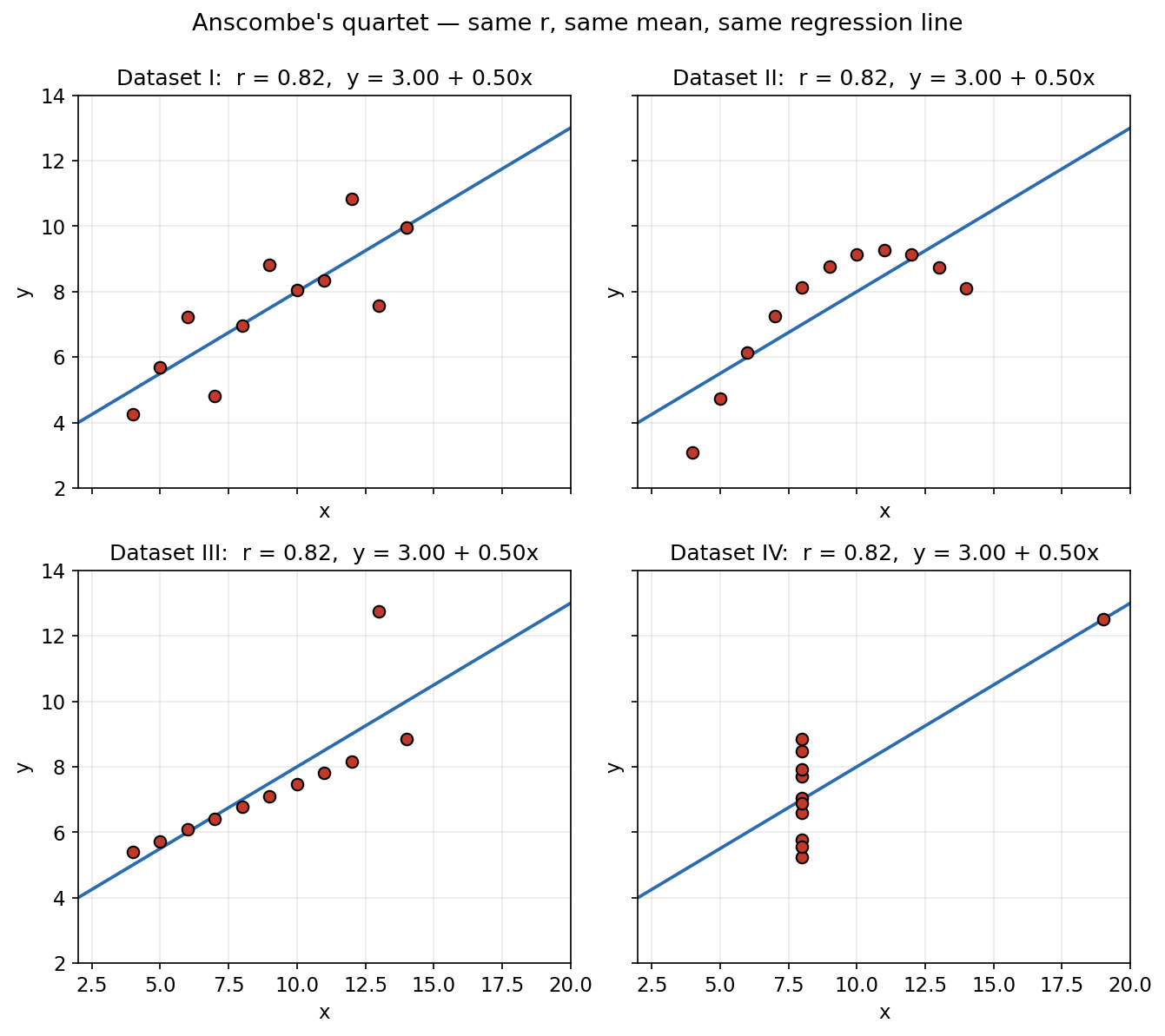
Figure 4 — Spearman বনাম Pearson, hexbin, ও mosaic¶
তিন প্যানেলে অধ্যায়ের তিন বাকি ধারণা: (a) একমুখী কিন্তু বাঁকা data-তে Pearson (\(\approx 0.89\)) Spearman (\(\approx 0.95\))-এর চেয়ে কম; (b) ২০,০০০ বিন্দুর জন্য hexbin density (overplotting এড়িয়ে); (c) contingency table-এর mosaic plot, যেখানে টালির ক্ষেত্রফল যৌথ গণনার সমানুপাতিক।
# (a) scatter of exp(x)+noise: pearsonr vs spearmanr
# (b) plt.hexbin(bx, by, gridsize=35) for N=20000 correlated points
# (c) stacked rectangles: width ∝ row total, height ∝ conditional proportion
plt.savefig("../_assets/1-4-spearman-hexbin-mosaic.png", dpi=150)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নের পূর্ণ সমাধান আছে
_solutions/01-04-correlation-bivariate-solutions.md-এ। difficulty: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
Conceptual (ধারণাভিত্তিক)¶
৭.১ ★ scatterplot থেকে আমরা যে চারটি জিনিস পড়ি (direction, form, strength, outlier) তার মধ্যে Pearson \(r\) কোন দুটি ধরে, আর কোন দুটি ধরে না? (hint: \(r\) কেবল linear ও strength-সংক্রান্ত।)
৭.২ ★ কেন covariance-এর "মান" ব্যাখ্যা করা কঠিন কিন্তু correlation-এর মান সহজ? এক বাক্যে একক-এর ভূমিকা ব্যাখ্যা করুন। (hint: cov-এর একক $= $ x-একক \(\times\) y-একক।)
৭.৩ ★★ "শীতকালে যে শহরে বেশি কম্বল বিক্রি হয়, সেখানে বেশি মানুষ ঠান্ডায় অসুস্থ হয় — অতএব কম্বল অসুস্থতা ঘটায়।" এই যুক্তির ভুল ধরিয়ে দিন এবং সম্ভাব্য confounder নির্দেশ করুন। (hint: section ২.৫-এর চারটি সম্ভাবনা।)
৭.৪ ★★ Anscombe's quartet-এর Dataset III-এ একটি outlier আছে। সেটি বাদ দিলে \(r\) বাড়বে না কমবে? কেন? (hint: বাকি ১০ বিন্দু প্রায় নিখুঁত রেখায়।)
Computational (গণনাভিত্তিক)¶
৭.৫ ★ \(x=(2,4,6,8)\), \(y=(1,3,2,4)\)-এর জন্য হাতে \(\bar x, \bar y\), \(\operatorname{cov}(x,y)\) (ব্যবহার করুন \(n-1\)) ও Pearson \(r\) বের করুন। (hint: উদাহরণ ৩.১-এর ছক-পদ্ধতি।)
৭.৬ ★★ \(x=(1,2,3,4,5)\), \(y=(10,8,6,4,2)\) — অর্থাৎ \(y=12-2x\), একটি নিখুঁত নিম্নমুখী রেখা। হিসাব না করেই \(r\)-এর মান অনুমান করুন, তারপর সূত্রে যাচাই করুন। (hint: নিখুঁত নিম্নমুখী রেখা মানে কী?)
৭.৭ ★★ \(x=(1,2,3,4,5)\), \(y=(1,2,3,4,5)\) — এবার \(y\)-এর শেষ মান \(5\)-কে \(50\) করুন (একটি outlier)। Pearson \(r\) ও Spearman \(\rho\) আগে কত ছিল এবং পরে আনুমানিক কত হবে — কোনটি বেশি বদলায় ও কেন? (hint: Spearman কেবল rank দেখে।)
Proof-based (প্রমাণভিত্তিক)¶
৭.৮ ★★ দেখান যে \(\operatorname{cov}(x, x) = s_x^2\) এবং তাই \(r_{xx} = 1\) — অর্থাৎ যেকোনো variable নিজের সাথে নিখুঁতভাবে correlated। (hint: covariance-এর সংজ্ঞায় \(y=x\) বসান।)
৭.৯ ★★★ ধরুন \(y_i = a x_i + b\) ঠিক একটি সরলরেখা (\(a \ne 0\))। প্রমাণ করুন \(r = +1\) যদি \(a>0\) এবং \(r=-1\) যদি \(a<0\)। (hint: deviation \(y_i-\bar y = a(x_i-\bar x)\) বসিয়ে \(r\)-এর সূত্রে \(a\) ও \(\lvert a\rvert\)-এর ভূমিকা দেখুন।)
Coding (Python)¶
৭.১০ ★★ একটি function pearson_from_scratch(x, y) লিখুন যা NumPy array নিয়ে শুধু সূত্র (centering + dot product) দিয়ে Pearson \(r\) ফেরত দেয়, এবং np.corrcoef-এর সাথে np.isclose দিয়ে মিলিয়ে দেখান। (hint: \(r = (\mathbf{x}_c\cdot\mathbf{y}_c)/(\lVert\mathbf{x}_c\rVert\,\lVert\mathbf{y}_c\rVert)\)।)
৭.১১ ★★★ default_rng(0) দিয়ে \(n=2000\) এমন data বানান যেখানে \(y\) আসলে \(x^3\)-এর সাথে noise — একটি প্রবল monotonic কিন্তু অরৈখিক সম্পর্ক। Pearson ও Spearman দুটোই বের করুন, একটি scatter ও একটি hexbin আঁকুন (figure 4-এর ধরনে), এবং কেন Spearman বেশি তা ব্যাখ্যা করুন। (hint: stats.spearmanr, plt.hexbin।)
৮ · সারসংক্ষেপ ও সংযোগ¶
যা শিখলাম (recap):
- scatterplot — দুই numeric variable-এর সম্পর্কের প্রথম ও অপরিহার্য ছবি; এতে direction, form, strength, outlier — চারটিই পড়া যায়।
- covariance \(\operatorname{cov}(x,y)=\frac{1}{n-1}\sum (x_i-\bar x)(y_i-\bar y)\) — একসাথে চলার পরিমাপ; চিহ্ন অর্থপূর্ণ কিন্তু মান একক-নির্ভর বলে ব্যাখ্যাহীন। \(\operatorname{cov}(x,x)=s_x^2\)।
- Pearson \(r = \operatorname{cov}(x,y)/(s_x s_y)\) — covariance-কে standardize করে পাওয়া একক-মুক্ত সংখ্যা; পরিসর \([-1,1]\) (Cauchy–Schwarz), scale/shift-নিরপেক্ষ, প্রতিসম; কেবল linear সম্পর্ক ধরে। জ্যামিতিকভাবে \(r=\cos\theta\)।
- Spearman \(\rho\) — rank-এর উপর Pearson; যেকোনো monotonic সম্পর্ক ধরে, outlier-এ কম স্পর্শকাতর, ordinal data-তে চলে।
- correlation ≠ causation — confounder ও spurious correlation-এর ফাঁদ; correlation কেবল association বলে, কারণ নয়।
- Anscombe's quartet — একই \(r\)/mean/line, সম্পূর্ণ ভিন্ন data: correlation-এর সীমাবদ্ধতার প্রমাণ → আগে ছবি, পরে সংখ্যা।
- contingency table (+ chi-square) — categorical–categorical সম্পর্কের জন্য; hexbin/2D density — বড় data-র overplotting এড়াতে।
আগের সাথে সংযোগ (১.২, ১.৩): এই অধ্যায় ১.২-এর mean/variance/standard deviation-কে দুই-চলকে সম্প্রসারিত করল — covariance আসলে "যৌথ variance", আর \(r\)-এর সূত্রে \(s_x, s_y\) সরাসরি ১.২ থেকে। ১.৩-এর z-score দিয়েই \(r\)-কে standardized variable-দের গুণফলের গড় হিসেবে লেখা যায়।
পরের সাথে সংযোগ (১.৫): পরের অধ্যায় EDA Workflow — এখানকার scatterplot, correlation matrix heatmap, hexbin সব একত্র করে একটি dataset-কে শুরু থেকে শেষ পর্যন্ত পরীক্ষা করার সুশৃঙ্খল পদ্ধতি গড়বে; "আগে ছবি আঁকো" নীতিটি সেখানে কেন্দ্রীয় হবে।
দূরবর্তী সংযোগ (source pointer): - Part 0.5 (linear algebra): সব covariance একসাথে = covariance matrix \(\Sigma=\frac{1}{n-1}X_c^\top X_c\) (symmetric, positive-semidefinite); সব correlation = correlation matrix \(R\)। এই অধ্যায়ের একটি-জোড়ার সংখ্যা সেই matrix-এর একেকটি entry মাত্র। - Part V (regression): best-fit রেখার slope সরাসরি correlation থেকে — \(\hat{\beta}_1 = r\,\dfrac{s_y}{s_x}\); অর্থাৎ Pearson \(r\) হলো simple linear regression-এর গাণিতিক বীজ। Anscombe-এর শিক্ষা সেখানে "model diagnostics কেন জরুরি" হিসেবে ফিরে আসবে। - Part VI (PCA): correlation/covariance matrix-এর eigen-decomposition থেকেই principal component — অর্থাৎ এই অধ্যায়ের সম্পর্ক-মাপা শেষমেশ data-র প্রধান দিক খোঁজায় গিয়ে মেলে।
এক বাক্যে: scatterplot দিয়ে চোখে দেখো, covariance দিয়ে দিক মাপো, Pearson \(r\) দিয়ে একক-মুক্ত শক্তি মাপো, Spearman দিয়ে বাঁকা-একমুখী ধরো — কিন্তু কখনো ভুলো না যে correlation একটি সংকীর্ণ সংখ্যা, আর সম্পর্ক মানেই কারণ নয়।