অধ্যায় ২.৬ · Joint, Marginal & Conditional Distributions; Covariance¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
এতক্ষণ (2.3–2.5) আমরা একটিমাত্র random variable নিয়ে কাজ করেছি — একটা \(X\), তার distribution, তার গড় ও variance। কিন্তু বাস্তবে কোনো কিছুই একা থাকে না। একজন মানুষের উচ্চতা ও ওজন একসাথে চলে; একটা শেয়ারের আজকের দাম ও কালকের দাম পরস্পরে জড়ানো; একটা ই-মেইলে শব্দসংখ্যা ও spam হওয়ার সম্ভাবনা একে অপরকে টানে। এই অধ্যায়ের মূল প্রশ্ন:
দুটি (বা ততোধিক) random variable একসাথে কীভাবে আচরণ করে, এবং একটির মান জানলে অন্যটি সম্পর্কে আমাদের জ্ঞান কতটুকু বদলায়?
এই প্রশ্নের উত্তরই গোটা পরিসংখ্যানের মেরুদণ্ড। কেন? কারণ inference (Part IV) মানেই হলো: data দেখে parameter সম্পর্কে শেখা — অর্থাৎ data ও parameter-এর joint আচরণ থেকে parameter-এর conditional distribution বের করা। আর regression (Part V) মানেই হলো একটা variable-এর গড়কে অন্যটির শর্তে দেখা — ঠিক যে বস্তুটি আমরা এই অধ্যায়ে \(\mathbb{E}[Y \mid X]\) নামে চিনব। তাই এই অধ্যায়টি Part II-এর ভিতরের সবচেয়ে "সংযোগকারী" অধ্যায়।
একটি গল্প — ওজন আর উচ্চতা। ধরুন একটা ঘরে অনেক মানুষ। আমি যদি আপনাকে শুধু বলি "এই মানুষটির ওজন অনুমান করুন", আপনি গোটা জনগোষ্ঠীর গড় ওজন বলবেন — সেটাই আপনার সেরা অনুমান। কিন্তু আমি যদি আগে বলি "এই মানুষটির উচ্চতা ৬ ফুট", তখন আপনার অনুমান বদলে যাবে — আপনি বেশি ওজন আশা করবেন। নতুন তথ্য (উচ্চতা) আপনার ওজনের distribution-কে সংকুচিত ও সরিয়ে দিল। এই "সরে যাওয়া ও সংকুচিত হওয়া" গাণিতিকভাবে ধরা পড়ে conditional distribution-এ; আর "উচ্চতা জানলে ওজনের গড় কী দাঁড়ায়" — সেটাই conditional expectation। যদি উচ্চতা জানার পরেও ওজনের distribution একটুও না বদলাত, তবে বলতাম দুটি variable independent।
0.4-এর double integral এখানে probability হয়ে যায়। Part 0-তে আপনি \(\iint_R f(x,y)\,dx\,dy\) শিখেছিলেন একটা surface-এর নিচের volume হিসেবে। এই অধ্যায়ে সেই volume-ই হয়ে যায় probability: \(P\big((X,Y)\in R\big)\)। ঠিক যেমন এক variable-এ "probability = density curve-এর নিচের area" (0.4), দুই variable-এ "probability = density surface-এর নিচের volume"। গাণিতিক যন্ত্রটা একই; শুধু ব্যাখ্যাটা সম্ভাব্যতার।
এই অধ্যায়ে আমরা ধাপে ধাপে গড়ব: joint distribution (একসাথে), marginal (একটাকে আলাদা করে দেখা), conditional (শর্তসাপেক্ষে), independence, covariance ও correlation, তারপর conditional expectation ও দুটি শক্তিশালী সূত্র — law of total expectation ও law of total variance — এবং সবশেষে এই সবকিছুর সবচেয়ে সুন্দর উদাহরণ, bivariate Normal।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Joint distribution — একসাথের বর্ণনা¶
দুটি random variable \(X\) ও \(Y\) একই random experiment থেকে আসছে (যেমন একজন মানুষ বাছাই করে তার উচ্চতা \(X\) ও ওজন \(Y\) মাপলাম)। তাদের একসাথের আচরণ ধরা পড়ে joint distribution-এ (যৌথ বণ্টন)।
Discrete ক্ষেত্র — joint PMF. যদি \(X, Y\) দুটোই discrete হয়, তাদের joint probability mass function (যৌথ PMF): $$ p_{X,Y}(x, y) = P(X = x,\ Y = y), $$ অর্থাৎ \(X\)-এর মান ঠিক \(x\) এবং একই সাথে \(Y\)-এর মান ঠিক \(y\) হওয়ার probability (কমা মানে "এবং")। দুটি স্বাভাবিক শর্ত: $$ p_{X,Y}(x, y) \ge 0, \qquad \sum_x \sum_y p_{X,Y}(x, y) = 1. $$ অর্থাৎ সব ঘর অঋণাত্মক, আর সব ঘরের যোগফল ১ (কোথাও না কোথাও তো পড়তেই হবে)।
Continuous ক্ষেত্র — joint PDF. যদি \(X, Y\) continuous হয়, তাদের joint probability density function (যৌথ PDF) হলো একটি function \(f_{X,Y}(x, y) \ge 0\) যা দিয়ে কোনো অঞ্চলে পড়ার probability হয় একটি double integral: $$ P\big((X, Y) \in R\big) = \iint_R f_{X,Y}(x, y)\,dx\,dy, $$ এবং পুরো সমতলে integral ১: $$ \int_{-\infty}^{\infty}!!\int_{-\infty}^{\infty} f_{X,Y}(x, y)\,dx\,dy = 1. $$ এক variable-এ density curve-এর নিচের area ছিল probability; এখানে density surface-এর নিচের volume probability। লক্ষ করুন, এক বিন্দুর probability শূন্য (যেমন এক variable-এও ছিল) — তাই \(f_{X,Y}\) নিজে probability নয়, প্রতি-একক-ক্ষেত্রফলে probability-র density (ঘনত্ব)।
২.২ Marginal distribution — একটাকে আলাদা করে দেখা¶
joint distribution-এ দুটো variable একসাথে আছে। যদি আমি শুধু \(X\) নিয়ে ভাবতে চাই, \(Y\)-কে "ভুলে যেতে" চাই? তখন আমি \(Y\)-এর সব সম্ভাব্য মানের ওপর যোগ/integrate করে ফেলি — ফলটি marginal distribution (প্রান্তিক বণ্টন, কারণ পুরোনো দিনে কাগজের ছকের "প্রান্তে" এই যোগফল লেখা হতো)।
Discrete: $$ p_X(x) = \sum_y p_{X,Y}(x, y), \qquad p_Y(y) = \sum_x p_{X,Y}(x, y). $$
Continuous: $$ f_X(x) = \int_{-\infty}^{\infty} f_{X,Y}(x, y)\,dy, \qquad f_Y(y) = \int_{-\infty}^{\infty} f_{X,Y}(x, y)\,dx. $$
স্বজ্ঞা: \(X = x\) ঘটতে পারে \(Y\)-এর যেকোনো মানের সাথে; তাই \(X = x\)-এর মোট probability পেতে \(Y\)-এর সব রাস্তা যোগ করি। এক variable-এ ফিরে গেলে \(X\)-এর marginal-ই আগের অধ্যায়ের সেই সাধারণ distribution।
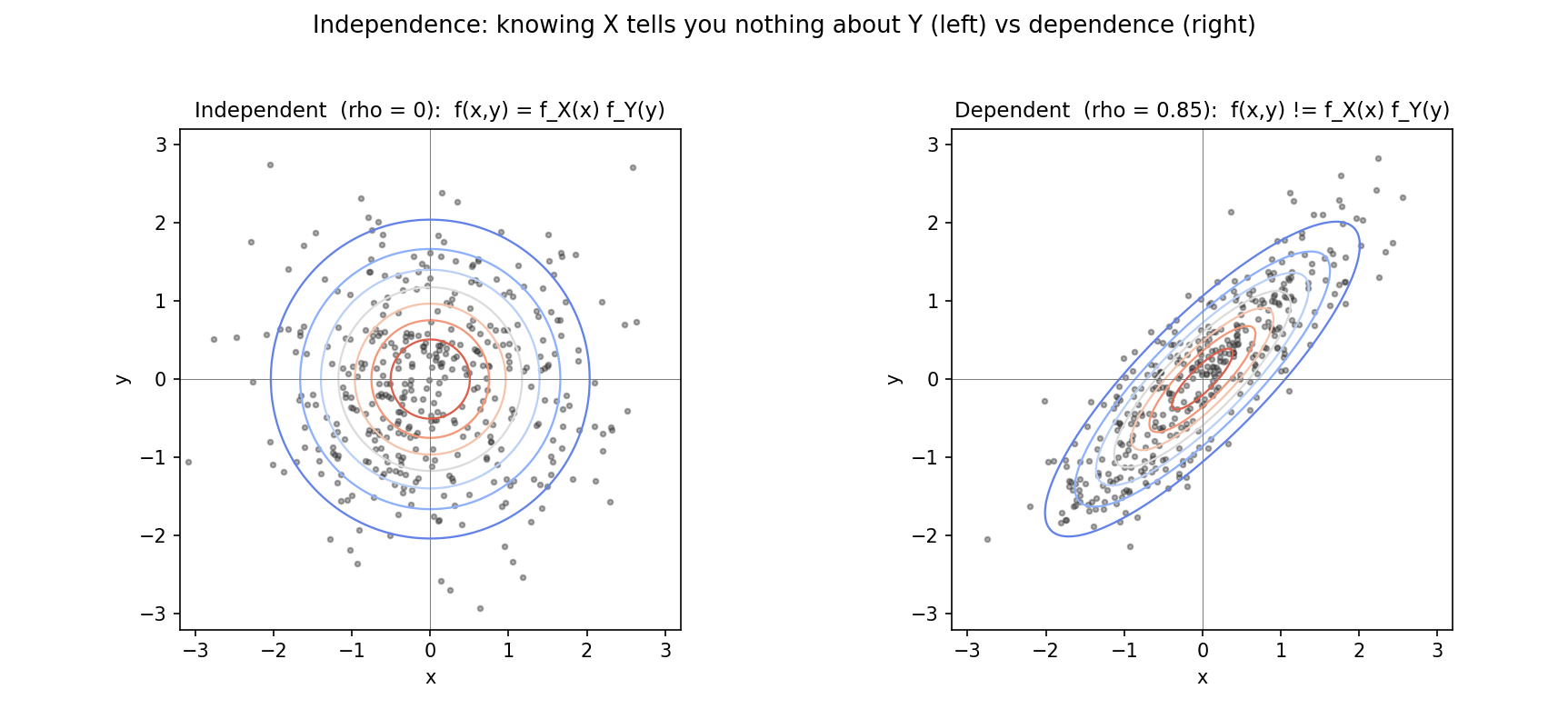
সতর্কতা। marginal থেকে joint ফিরে পাওয়া যায় না সাধারণভাবে। দুটি marginal একই হলেও joint ভিন্ন হতে পারে (§৬-এ independent বনাম dependent ছবিতে দুটোরই একই marginal, অথচ joint আলাদা)। marginal-গুলো joint-এর "ছায়া" — ছায়া দেখে আসল ত্রিমাত্রিক আকৃতি অনন্যভাবে পুনর্গঠন করা যায় না।
২.৩ Conditional distribution — শর্তসাপেক্ষ বণ্টন¶
এবার মূল প্রশ্নে: \(X = x\) জানা গেলে \(Y\)-এর distribution কী দাঁড়ায়? এটাই conditional distribution (শর্তাধীন বণ্টন)। 2.2-এর \(P(A \mid B) = P(A \cap B)/P(B)\)-এর সরাসরি বর্ধিত রূপ:
Discrete: $$ p_{Y \mid X}(y \mid x) = \frac{p_{X,Y}(x, y)}{p_X(x)}, \qquad p_X(x) > 0. $$
Continuous: $$ f_{Y \mid X}(y \mid x) = \frac{f_{X,Y}(x, y)}{f_X(x)}, \qquad f_X(x) > 0. $$
এটি \(y\)-এর একটি বৈধ distribution: প্রতিটি fixed \(x\)-এর জন্য \(\int f_{Y \mid X}(y \mid x)\,dy = \int f_{X,Y}(x,y)\,dy \big/ f_X(x) = f_X(x)/f_X(x) = 1\)। জ্যামিতিকভাবে: joint surface-কে \(X = x\) রেখা বরাবর কেটে একটা slice নিলাম; সেই slice-এর আকৃতিই \(Y\)-এর conditional আকৃতি, শুধু area ১ করার জন্য \(f_X(x)\) দিয়ে normalize করা (§৬, Figure 3)।
এই তিনটি সংজ্ঞা একসাথে দিলে পাই multiplication rule ও Bayes-এর density রূপ: $$ f_{X,Y}(x, y) = f_{Y \mid X}(y \mid x)\,f_X(x) = f_{X \mid Y}(x \mid y)\,f_Y(y), $$ $$ f_{X \mid Y}(x \mid y) = \frac{f_{Y \mid X}(y \mid x)\,f_X(x)}{f_Y(y)}. $$ শেষ সূত্রটি Bayes' theorem-এর continuous রূপ — Part IV-এ এটিই posterior \(\propto\) likelihood \(\times\) prior-এর ভিত্তি।
২.৪ Independence — স্বাধীনতা¶
\(X\) ও \(Y\) independent (স্বাধীন) বলা হয় যদি একটির মান জানলে অন্যটির distribution একটুও না বদলায়। equivalent (সমতুল্য) তিনটি শর্ত: $$ \underbrace{f_{X,Y}(x, y) = f_X(x)\,f_Y(y)}{\text{joint = marginal-দের গুণফল}} \quad\Longleftrightarrow\quad f(x \mid y) = f_X(x), $$ সব }(y \mid x) = f_Y(y) \quad\Longleftrightarrow\quad f_{X \mid Y\(x, y\)-এর জন্য (discrete-এ \(p\) দিয়ে একই)। মূল রূপটি factorization (গুণফলে বিভাজন): joint ভেঙে দুই marginal-এর গুণফল হয়ে গেলে independent। স্বজ্ঞা: \(Y \mid X\)-এর distribution যদি \(X\)-এর ওপর নির্ভরই না করে, তবে \(X\) জানা মানে \(Y\) সম্পর্কে নতুন কিছুই জানা নয়।
পরীক্ষা করার সহজ উপায়। একটিমাত্র ঘরে যদি \(p_{X,Y}(x,y) \ne p_X(x)\,p_Y(y)\) হয়, তবেই dependent প্রমাণিত — সব ঘর মেলানোর দরকার নেই।
২.৫ Covariance ও correlation — random-variable স্তরে¶
দুটি variable একই দিকে চলে নাকি বিপরীত দিকে — তা মাপে covariance (সহভেদাঙ্ক)। 1.4-এ আপনি data-র উপর descriptive covariance দেখেছিলেন (\(\frac{1}{n-1}\sum (x_i-\bar x)(y_i-\bar y)\))। এখন সেটিরই জনসংখ্যা-স্তরের (population) সংজ্ঞা, যেখানে গড়ের জায়গায় expectation: $$ \boxed{\ \operatorname{Cov}(X, Y) = \mathbb{E}\big[(X - \mu_X)(Y - \mu_Y)\big] = \mathbb{E}[XY] - \mu_X \mu_Y\ } $$ যেখানে \(\mu_X = \mathbb{E}[X],\ \mu_Y = \mathbb{E}[Y]\)। ডান রূপটি (shortcut) প্রায়ই গণনায় সহজ — §৪-এ প্রমাণ। মূল বৈশিষ্ট্য:
- \(\operatorname{Cov}(X, X) = \operatorname{Var}(X)\) — covariance variance-এর সাধারণীকরণ।
- \(\operatorname{Cov}(X, Y) > 0\): একসাথে বড়/ছোট হওয়ার প্রবণতা; \(< 0\): একটি বড় হলে অন্যটি ছোট; \(= 0\): linear (রৈখিক) সম্পর্ক নেই (uncorrelated)।
- bilinear: \(\operatorname{Cov}(aX + b,\ cY + d) = ac\,\operatorname{Cov}(X, Y)\) (constant সরে যায়, স্কেল গুণ হয়)।
covariance-এর সমস্যা: তার একক \(X\) ও \(Y\)-এর এককের গুণফল (cm·kg), তাই মান একক-নির্ভর ও তুলনা কঠিন। তাই একে আদর্শায়িত (standardize) করে পাই correlation (সহসম্পর্ক), যা একক-মুক্ত ও \([-1, 1]\)-এ আবদ্ধ: $$ \boxed{\ \rho_{X,Y} = \operatorname{Corr}(X, Y) = \frac{\operatorname{Cov}(X, Y)}{\sigma_X\,\sigma_Y}\ } \qquad -1 \le \rho_{X,Y} \le 1. $$ \(\rho = \pm 1\) ঠিক তখনই যখন \(Y\) হুবহু \(X\)-এর একটি রৈখিক function (\(Y = aX + b\))। সীমাবদ্ধতা \([-1,1]\) আসে Cauchy–Schwarz inequality থেকে (§৪, এবং 0.5-এর dot-product দৃষ্টিভঙ্গির সাথে মেলে)।
অতি গুরুত্বপূর্ণ ফাঁদ। independent \(\Rightarrow\) uncorrelated (\(\operatorname{Cov} = 0\)), কিন্তু উল্টোটা সাধারণভাবে সত্য নয়। correlation শুধু রৈখিক সম্পর্ক মাপে; অরৈখিক নির্ভরতা থাকলেও \(\operatorname{Cov} = 0\) হতে পারে। ক্লাসিক উদাহরণ §৩.৩-এ। (ব্যতিক্রম: bivariate Normal-এ uncorrelated \(\Rightarrow\) independent — §২.৭।)
২.৬ Conditional expectation ও দুটি total সূত্র¶
\(Y \mid X = x\) একটি distribution; তার গড়ই conditional expectation: $$ \mathbb{E}[Y \mid X = x] = \sum_y y\, p_{Y \mid X}(y \mid x) \quad\text{(discrete)}, \qquad \mathbb{E}[Y \mid X = x] = \int_{-\infty}^{\infty} y\, f_{Y \mid X}(y \mid x)\,dy \quad\text{(continuous)}. $$ এটি \(x\)-এর একটি function, \(g(x) = \mathbb{E}[Y \mid X = x]\)। যখন \(x\)-কে নিজেই random variable \(X\) ভাবি, \(g(X) = \mathbb{E}[Y \mid X]\) হয়ে যায় একটি random variable। এই বস্তুটিই Part V-এ regression function — "\(X\) জানলে \(Y\)-এর সেরা অনুমান"।
দুটি সূত্র এই অধ্যায়ের সবচেয়ে কাজের যন্ত্র:
Law of total expectation (পূর্ণ প্রত্যাশার সূত্র; "tower rule"): $$ \boxed{\ \mathbb{E}[Y] = \mathbb{E}\big[\,\mathbb{E}[Y \mid X]\,\big]\ } $$ স্বজ্ঞা: প্রতিটি \(X = x\) গোষ্ঠীর গড় \(\mathbb{E}[Y \mid X = x]\) নিয়ে, তারপর সেগুলোকে \(X\)-এর distribution দিয়ে ওজনে গড় করলে গোটা \(Y\)-এর গড় ফিরে পাই। (গোষ্ঠী-গড়ের গড় = সামগ্রিক গড়।)
Law of total variance (পূর্ণ ভেদাঙ্কের সূত্র): $$ \boxed{\ \operatorname{Var}(Y) = \underbrace{\mathbb{E}\big[\operatorname{Var}(Y \mid X)\big]}{\text{within-group (ভেতরের)}} + \underbrace{\operatorname{Var}\big(\mathbb{E}[Y \mid X]\big)} $$ স্বজ্ঞা: }}\ \(Y\)-এর মোট অনিশ্চয়তা ভাঙে দুই ভাগে — (১) প্রতিটি \(X\)-গোষ্ঠীর ভেতরের গড় ছড়ানো, আর (২) গোষ্ঠী-গড়গুলো নিজেদের মধ্যে কতটা আলাদা। এই বিভাজনই ANOVA (Part IV) ও mixed model-এর হৃৎপিণ্ড।
২.৭ Bivariate Normal distribution¶
একাধিক variable-এর সবচেয়ে গুরুত্বপূর্ণ joint distribution — bivariate Normal (দ্বিচলকীয় normal), অর্থাৎ multivariate Normal-এর দুই-মাত্রিক রূপ। parameter: গড় \(\boldsymbol{\mu} = (\mu_X, \mu_Y)\), ভেদ \(\sigma_X^2, \sigma_Y^2\) এবং correlation \(\rho\)। covariance matrix (0.5-এর সেই \(\Sigma\)): $$ \Sigma = \begin{bmatrix} \sigma_X^2 & \rho\,\sigma_X \sigma_Y \ \rho\,\sigma_X \sigma_Y & \sigma_Y^2 \end{bmatrix}. $$ density (vector রূপে, \(\mathbf{z} = (x, y)\)): $$ f_{X,Y}(x, y) = \frac{1}{2\pi\,\sqrt{\det \Sigma}}\,\exp!\left[-\tfrac{1}{2}(\mathbf{z} - \boldsymbol{\mu})^\top \Sigma^{-1} (\mathbf{z} - \boldsymbol{\mu})\right]. $$ তিনটি সুন্দর বৈশিষ্ট্য, যা একে inference ও regression-এর প্রিয় করে তুলেছে:
- Marginal-ও Normal: \(X \sim \mathcal{N}(\mu_X, \sigma_X^2)\), \(Y \sim \mathcal{N}(\mu_Y, \sigma_Y^2)\)।
- Conditional-ও Normal, এবং তার গড় \(x\)-এ রৈখিক — ঠিক linear regression-এর সূত্র: $$ \mathbb{E}[Y \mid X = x] = \mu_Y + \rho\,\frac{\sigma_Y}{\sigma_X}(x - \mu_X), \qquad \operatorname{Var}(Y \mid X = x) = \sigma_Y^2 (1 - \rho^2). $$ লক্ষণীয়: conditional variance \(x\)-এর ওপর নির্ভর করে না (homoscedasticity), আর \(\lvert \rho \rvert\) বড় হলে conditional variance ছোট — \(X\) জানলে \(Y\) সম্পর্কে বেশি নিশ্চয়তা।
- uncorrelated \(\Rightarrow\) independent: শুধু bivariate Normal-এ \(\rho = 0\) হলেই density factorize করে দুই Normal-এর গুণফল হয়ে যায়, অর্থাৎ independent। (সাধারণ ফাঁদটি এখানে খাটে না।)
contour (সম-density রেখা) সর্বদা উপবৃত্ত (ellipse); \(\rho\) বদলালে উপবৃত্ত হেলে যায় (§৬, Figure 2)।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ৩.১ — একটি discrete joint PMF: marginal, conditional, covariance (হাতে)¶
দুটি discrete random variable \(X, Y \in \{0, 1, 2\}\)-এর joint PMF (প্রতিটি ঘর \(/20\); Figure 1-এর টেবিল):
| \(p_{X,Y}\) | \(y=0\) | \(y=1\) | \(y=2\) | \(p_X(x)\) |
|---|---|---|---|---|
| \(x=0\) | \(3/20\) | \(2/20\) | \(1/20\) | \(6/20\) |
| \(x=1\) | \(2/20\) | \(3/20\) | \(2/20\) | \(7/20\) |
| \(x=2\) | \(1/20\) | \(2/20\) | \(4/20\) | \(7/20\) |
| \(p_Y(y)\) | \(6/20\) | \(7/20\) | \(7/20\) | \(1\) |
(ক) Marginal. প্রতিটি row যোগ করে \(p_X\), প্রতিটি column যোগ করে \(p_Y\) (ছকের প্রান্তে লেখা)। যাচাই: সব ঘর যোগ \(= 20/20 = 1\)। ✓
(খ) Conditional \(Y \mid X = 2\). শেষ row-কে তার যোগফল \(p_X(2) = 7/20\) দিয়ে ভাগ করি: $$ p_{Y \mid X}(0 \mid 2) = \frac{1/20}{7/20} = \tfrac{1}{7}, \quad p_{Y \mid X}(1 \mid 2) = \tfrac{2}{7}, \quad p_{Y \mid X}(2 \mid 2) = \tfrac{4}{7}. $$ যোগফল \(\tfrac{1}{7}+\tfrac{2}{7}+\tfrac{4}{7} = 1\) ✓। লক্ষ করুন এটি marginal \(p_Y = (6/20, 7/20, 7/20) = (0.30, 0.35, 0.35)\) থেকে আলাদা — তাই \(X, Y\) dependent।
(গ) Independence পরীক্ষা। একটি ঘরই যথেষ্ট: \(p_{X,Y}(0,0) = 3/20 = 0.15\), কিন্তু \(p_X(0)\,p_Y(0) = \tfrac{6}{20}\cdot\tfrac{6}{20} = \tfrac{36}{400} = 0.09 \ne 0.15\)। অমিল \(\Rightarrow\) dependent। ✓
(ঘ) Covariance ও correlation. প্রথমে গড়: $$ \mathbb{E}[X] = 0\cdot\tfrac{6}{20} + 1\cdot\tfrac{7}{20} + 2\cdot\tfrac{7}{20} = \tfrac{21}{20} = 1.05, \qquad \mathbb{E}[Y] = \tfrac{21}{20} = 1.05 $$ (symmetry-তে একই)। \(\mathbb{E}[XY] = \sum_{x,y} xy\,p_{X,Y}(x,y)\); শুধু \(x,y \ge 1\) ঘরগুলো অবদান রাখে: $$ \mathbb{E}[XY] = (1)(1)\tfrac{3}{20} + (1)(2)\tfrac{2}{20} + (2)(1)\tfrac{2}{20} + (2)(2)\tfrac{4}{20} = \tfrac{3 + 4 + 4 + 16}{20} = \tfrac{27}{20} = 1.35. $$ $$ \operatorname{Cov}(X, Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y] = 1.35 - 1.05^2 = 1.35 - 1.1025 = \tfrac{99}{400} = 0.2475 > 0. $$ ভেদ: \(\mathbb{E}[X^2] = 0 + 1\cdot\tfrac{7}{20} + 4\cdot\tfrac{7}{20} = \tfrac{35}{20} = 1.75\), তাই \(\operatorname{Var}(X) = 1.75 - 1.1025 = \tfrac{259}{400} = 0.6475\) (symmetry-তে \(\operatorname{Var}(Y)\) একই)। ফলে $$ \rho_{X,Y} = \frac{0.2475}{\sqrt{0.6475 \times 0.6475}} = \frac{0.2475}{0.6475} \approx 0.382. $$ ধনাত্মক, মাঝারি — \(X\) বড় হলে \(Y\)-ও বড় হওয়ার প্রবণতা, যা ছকের কর্ণে ভারী মান দেখেই বোঝা যায়।
উদাহরণ ৩.২ — Law of total expectation ও total variance (একই ছক)¶
প্রতিটি \(X = x\)-এর জন্য \(\mathbb{E}[Y \mid X = x]\) বের করি (row-কে normalize করে \(\sum y\, p_{Y\mid X}\)): $$ \mathbb{E}[Y \mid X=0] = \frac{0\cdot 3 + 1\cdot 2 + 2\cdot 1}{6} = \tfrac{4}{6} = \tfrac{2}{3}, \quad \mathbb{E}[Y \mid X=1] = \frac{0\cdot 2 + 1\cdot 3 + 2\cdot 2}{7} = \tfrac{7}{7} = 1, \quad \mathbb{E}[Y \mid X=2] = \frac{0\cdot 1 + 1\cdot 2 + 2\cdot 4}{7} = \tfrac{10}{7}. $$ লক্ষ করুন এই তিনটি মান \(x\)-এর সাথে বাড়ছে (\(\tfrac{2}{3} < 1 < \tfrac{10}{7}\)) — ধনাত্মক সম্পর্কের সরাসরি প্রতিফলন।
Law of total expectation যাচাই: $$ \mathbb{E}\big[\mathbb{E}[Y\mid X]\big] = \tfrac{2}{3}\cdot\tfrac{6}{20} + 1\cdot\tfrac{7}{20} + \tfrac{10}{7}\cdot\tfrac{7}{20} = \tfrac{2}{20} + \tfrac{7}{20} + \tfrac{10}{20} = \tfrac{21}{20} = 1.05 = \mathbb{E}[Y]. \;\checkmark $$
Law of total variance যাচাই (সংখ্যায়, §৫-এ কোডে নিশ্চিত)। প্রতিটি গোষ্ঠীর conditional variance ও গোষ্ঠী-গড়ের variance বের করলে: $$ \mathbb{E}[\operatorname{Var}(Y \mid X)] = \tfrac{58}{105} \approx 0.5524, \qquad \operatorname{Var}(\mathbb{E}[Y \mid X]) = \tfrac{799}{8400} \approx 0.0951, $$ $$ 0.5524 + 0.0951 = 0.6475 = \operatorname{Var}(Y). \;\checkmark $$ অর্থাৎ \(Y\)-এর মোট ছড়ানোর প্রায় ৮৫% আসে গোষ্ঠীর ভেতরের অনিশ্চয়তা থেকে, আর ~১৫% গোষ্ঠী-গড়গুলোর পারস্পরিক পার্থক্য থেকে। \(X\) জানা মোট অনিশ্চয়তার এই ১৫% "ব্যাখ্যা" করে — যা পরে \(R^2\) ধারণার বীজ।
উদাহরণ ৩.৩ — uncorrelated কিন্তু dependent (ফাঁদ)¶
ধরা যাক \(X\) একটি symmetric distribution থেকে আসে যেখানে \(\mathbb{E}[X] = 0\) ও \(\mathbb{E}[X^3] = 0\) (যেমন \(X \sim \mathcal{N}(0,1)\), বা \(X \in \{-1, 0, 1\}\) সমসম্ভাব্য)। ধরা যাক \(Y = X^2\)। তাহলে \(Y\) সম্পূর্ণভাবে \(X\)-নির্ভর — চূড়ান্ত dependent। অথচ: $$ \operatorname{Cov}(X, Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y] = \mathbb{E}[X \cdot X^2] - 0\cdot\mathbb{E}[Y] = \mathbb{E}[X^3] = 0. $$ সুতরাং \(\operatorname{Cov}(X, Y) = 0\), \(\rho = 0\) — uncorrelated, তবু dependent। শিক্ষা: correlation কেবল রৈখিক সম্পর্ক দেখে; এখানে সম্পর্কটি নিখুঁত প্যারাবোলা, রৈখিক অংশ শূন্য, তাই correlation অন্ধ। "\(\rho = 0\) মানেই স্বাধীন" — এই ভুল ধারণা পরিসংখ্যানে সবচেয়ে সাধারণ ভুলগুলোর একটি।
উদাহরণ ৩.৪ — bivariate Normal-এ conditional (regression-এর পূর্বাভাস)¶
ধরা যাক উচ্চতা \(X\) ও ওজন \(Y\) একসাথে bivariate Normal, যেখানে \(\mu_X = 168\) cm, \(\sigma_X = 8\), \(\mu_Y = 65\) kg, \(\sigma_Y = 10\), এবং \(\rho = 0.7\)। কেউ \(X = 180\) cm লম্বা হলে তার ওজনের conditional distribution?
\(\S 2.7\)-এর সূত্রে: $$ \mathbb{E}[Y \mid X = 180] = 65 + 0.7 \cdot \tfrac{10}{8}(180 - 168) = 65 + 0.7 \cdot 1.25 \cdot 12 = 65 + 10.5 = 75.5 \text{ kg}, $$ $$ \operatorname{Var}(Y \mid X = 180) = 10^2 (1 - 0.7^2) = 100 \cdot 0.51 = 51, \quad \text{তাই } \mathrm{sd} = \sqrt{51} \approx 7.14 \text{ kg}. $$ অর্থাৎ "১৮০ cm লম্বা" জানার পরে ওজনের সেরা অনুমান ৭৫.৫ kg (গড় ৬৫ থেকে উপরে সরে গেছে), আর অনিশ্চয়তা ১০ kg থেকে কমে ৭.১৪ kg-এ নেমেছে (\(X\) তথ্য variance-এর \(1 - 0.7^2 = 51\%\) রেখে দিল)। এই সরল-রেখা সম্পর্ক \(\mathbb{E}[Y \mid X=x] = 65 + 0.875(x - 168)\)-ই Part V-এর linear regression।
৪ · প্রমাণ ও উৎপাদন¶
৪.১ ★ Covariance-এর shortcut সূত্র ও bilinearity¶
দাবি: \(\operatorname{Cov}(X, Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y]\)।
প্রমাণ. সংজ্ঞা থেকে শুরু করে গুণফল খুলি; \(\mu_X, \mu_Y\) ধ্রুবক, তাই linearity of expectation (2.5) প্রয়োগ: $$ \operatorname{Cov}(X, Y) = \mathbb{E}[(X - \mu_X)(Y - \mu_Y)] = \mathbb{E}[XY - \mu_Y X - \mu_X Y + \mu_X \mu_Y] $$ $$ = \mathbb{E}[XY] - \mu_Y \mathbb{E}[X] - \mu_X \mathbb{E}[Y] + \mu_X \mu_Y = \mathbb{E}[XY] - \mu_Y \mu_X - \mu_X \mu_Y + \mu_X \mu_Y = \mathbb{E}[XY] - \mu_X \mu_Y. \qquad \blacksquare $$
ফলস্বরূপ — independent \(\Rightarrow\) uncorrelated. যদি \(X \perp Y\), তবে \(\mathbb{E}[XY] = \mathbb{E}[X]\mathbb{E}[Y]\) (independent হলে product-এর expectation = expectation-দের product; continuous-এ \(\iint xy f_X(x)f_Y(y)\,dx\,dy = (\int x f_X)(\int y f_Y)\) factorize করে)। তাই \(\operatorname{Cov}(X,Y) = \mathbb{E}[X]\mathbb{E}[Y] - \mu_X\mu_Y = 0\)। উল্টোটা §৩.৩-এ মিথ্যা প্রমাণিত। \(\blacksquare\)
Bilinearity (\(\operatorname{Cov}(aX+b, cY+d) = ac\,\operatorname{Cov}(X,Y)\)) একইভাবে: \(aX+b\)-এর গড় \(a\mu_X+b\), তাই deviation (বিচ্যুতি) \(aX+b - (a\mu_X+b) = a(X-\mu_X)\); অনুরূপ \(Y\)-এ। গুণ করে expectation নিলে \(\mathbb{E}[a(X-\mu_X)\cdot c(Y-\mu_Y)] = ac\,\operatorname{Cov}(X,Y)\) — constant \(b, d\) উবে যায়।
৪.২ ★★ Variance of a sum: covariance কেন দরকার¶
দাবি: \(\operatorname{Var}(X + Y) = \operatorname{Var}(X) + \operatorname{Var}(Y) + 2\operatorname{Cov}(X, Y)\)।
প্রমাণ. \(\operatorname{Var}(X+Y) = \operatorname{Cov}(X+Y, X+Y)\)। covariance bilinear ও symmetric, তাই চারটি পদে খুলি: $$ = \operatorname{Cov}(X,X) + \operatorname{Cov}(X,Y) + \operatorname{Cov}(Y,X) + \operatorname{Cov}(Y,Y) = \operatorname{Var}(X) + \operatorname{Var}(Y) + 2\operatorname{Cov}(X,Y). \qquad \blacksquare $$ গুরুত্ব: শুধু independent (বা অন্তত uncorrelated) হলেই "variance যোগ হয়" (\(\operatorname{Var}(X+Y) = \operatorname{Var}(X)+\operatorname{Var}(Y)\))। নয়তো cross-term \(2\operatorname{Cov}\) থাকে — portfolio risk, error propagation সবখানে এটি কেন্দ্রীয়। (\(\operatorname{Var}(X-Y) = \operatorname{Var}X + \operatorname{Var}Y - 2\operatorname{Cov}(X,Y)\), চিহ্ন বদলে।)
৪.৩ ★★ Law of total expectation¶
দাবি: \(\mathbb{E}[Y] = \mathbb{E}\big[\mathbb{E}[Y \mid X]\big]\) (discrete রূপ; continuous-এ যোগ → integral)।
প্রমাণ. ডান পক্ষে \(g(X) = \mathbb{E}[Y \mid X]\)-এর expectation, যা \(X\)-এর marginal-এর ওপর গড়: $$ \mathbb{E}\big[\mathbb{E}[Y \mid X]\big] = \sum_x \Big(\underbrace{\sum_y y\, p_{Y \mid X}(y \mid x)}{\mathbb{E}[Y \mid X=x]}\Big) p_X(x) = \sum_x \sum_y y\, \underbrace{p}(y \mid x)\,p_X(x){=\,p. $$ ভেতরের গুণফলটি ঠিক joint PMF (§২.৩-এর multiplication rule)। যোগের ক্রম পাল্টে: $$ = \sum_y y \sum_x p_{X,Y}(x, y) = \sum_y y\, p_Y(y) = \mathbb{E}[Y]. \qquad \blacksquare $$ মূল কৌশল: }(x,y)\(p_{Y\mid X}\,p_X = p_{X,Y}\), তারপর \(x\)-এর ওপর যোগ করে marginal \(p_Y\) ফিরে পাওয়া।
৪.৪ ★★★ Law of total variance¶
দাবি: \(\operatorname{Var}(Y) = \mathbb{E}[\operatorname{Var}(Y \mid X)] + \operatorname{Var}(\mathbb{E}[Y \mid X])\)।
প্রমাণ. \(g(X) = \mathbb{E}[Y \mid X]\) লিখি। দুই অংশ পৃথকভাবে গড়ব। conditional variance-এর shortcut: \(\operatorname{Var}(Y \mid X) = \mathbb{E}[Y^2 \mid X] - g(X)^2\)। দুই পক্ষে expectation নিয়ে (4.3 প্রয়োগ করে \(\mathbb{E}[\mathbb{E}[Y^2\mid X]] = \mathbb{E}[Y^2]\)): $$ \mathbb{E}[\operatorname{Var}(Y \mid X)] = \mathbb{E}[Y^2] - \mathbb{E}[g(X)^2]. \tag{i} $$ আবার \(g(X)\)-এর নিজের variance: $$ \operatorname{Var}(\mathbb{E}[Y \mid X]) = \operatorname{Var}(g(X)) = \mathbb{E}[g(X)^2] - \big(\mathbb{E}[g(X)]\big)^2 = \mathbb{E}[g(X)^2] - \big(\mathbb{E}[Y]\big)^2, \tag{ii} $$ যেখানে শেষ ধাপে 4.3: \(\mathbb{E}[g(X)] = \mathbb{E}[\mathbb{E}[Y\mid X]] = \mathbb{E}[Y]\)। এখন (i) + (ii) যোগ করলে \(\mathbb{E}[g(X)^2]\) পদ কাটাকাটি যায়: $$ \mathbb{E}[\operatorname{Var}(Y\mid X)] + \operatorname{Var}(\mathbb{E}[Y\mid X]) = \mathbb{E}[Y^2] - (\mathbb{E}[Y])^2 = \operatorname{Var}(Y). \qquad \blacksquare $$ \(\mathbb{E}[g(X)^2]\)-এর কাটাকাটিই এই সূত্রের সৌন্দর্য — within ও between ভাগ ঠিক মোটে যোগ হয়।
৫ · কোড ল্যাব (Python)¶
নিচের কোড §৩-এর হাতে-করা ফলগুলো reproducibly যাচাই করে (default_rng, fixed seed) এবং bivariate Normal থেকে simulate করে। প্রতিটি ব্লক স্বতন্ত্রভাবে চালানো যায়।
৫.১ Discrete joint: marginal, conditional, covariance যাচাই¶
import numpy as np
# §৩.১-এর joint PMF (প্রতিটি ঘর /20), rows = x ∈ {0,1,2}, cols = y ∈ {0,1,2}
P = np.array([[3, 2, 1],
[2, 3, 2],
[1, 2, 4]], dtype=float) / 20.0
x_vals = np.array([0, 1, 2])
y_vals = np.array([0, 1, 2])
assert np.isclose(P.sum(), 1.0) # বৈধ joint PMF
pX = P.sum(axis=1) # marginal of X (row-যোগ)
pY = P.sum(axis=0) # marginal of Y (col-যোগ)
print("p_X =", pX, " p_Y =", pY) # [0.3 0.35 0.35] দুটোই
# conditional Y | X = 2 (শেষ row / তার যোগফল)
cond_Y_given_X2 = P[2] / pX[2]
print("P(Y | X=2) =", cond_Y_given_X2) # [1/7, 2/7, 4/7] ≈ [0.143 0.286 0.571]
# Covariance ও correlation
EX = (x_vals * pX).sum()
EY = (y_vals * pY).sum()
EXY = sum(x_vals[i] * y_vals[j] * P[i, j]
for i in range(3) for j in range(3))
cov = EXY - EX * EY
varX = (x_vals**2 * pX).sum() - EX**2
varY = (y_vals**2 * pY).sum() - EY**2
corr = cov / np.sqrt(varX * varY)
print(f"E[X]={EX:.4f} E[Y]={EY:.4f} Cov={cov:.4f} Corr={corr:.4f}")
# E[X]=1.0500 E[Y]=1.0500 Cov=0.2475 Corr=0.3822 ← §৩.১-এর সাথে মেলে
# independence পরীক্ষা (একটি ঘর যথেষ্ট)
print("p(0,0)=", P[0, 0], " vs pX(0)pY(0)=", pX[0] * pY[0]) # 0.15 vs 0.09 → dependent
৫.২ Law of total expectation ও total variance যাচাই¶
import numpy as np
P = np.array([[3, 2, 1], [2, 3, 2], [1, 2, 4]], dtype=float) / 20.0
x_vals = np.array([0, 1, 2]); y_vals = np.array([0, 1, 2])
pX = P.sum(axis=1); pY = P.sum(axis=0)
EY = (y_vals * pY).sum()
varY = (y_vals**2 * pY).sum() - EY**2
# প্রতিটি x-এর জন্য E[Y|X=x] ও Var(Y|X=x)
cond = P / pX[:, None] # row-গুলো normalize → P(Y|X=x)
EY_given_x = (cond * y_vals).sum(axis=1) # [2/3, 1, 10/7]
EY2_given_x = (cond * y_vals**2).sum(axis=1)
Var_given_x = EY2_given_x - EY_given_x**2
print("E[Y|X=x] =", np.round(EY_given_x, 4)) # [0.6667 1. 1.4286]
# Law of total expectation
lte = (EY_given_x * pX).sum()
print(f"E[E[Y|X]] = {lte:.4f} vs E[Y] = {EY:.4f}") # 1.0500 == 1.0500 ✓
# Law of total variance
E_of_Var = (Var_given_x * pX).sum() # within-group
Var_of_E = (EY_given_x**2 * pX).sum() - lte**2 # between-group
print(f"E[Var(Y|X)]={E_of_Var:.4f} + Var(E[Y|X])={Var_of_E:.4f}"
f" = {E_of_Var + Var_of_E:.4f} vs Var(Y)={varY:.4f}")
# 0.5524 + 0.0951 = 0.6475 == 0.6475 ✓
৫.৩ Bivariate Normal: simulate, conditional সূত্র, empirical মিল¶
import numpy as np
from scipy.stats import multivariate_normal
rng = np.random.default_rng(2606) # reproducible
mu = np.array([168.0, 65.0]) # (উচ্চতা, ওজন): §৩.৪
sX, sY, rho = 8.0, 10.0, 0.7
Sigma = np.array([[sX**2, rho*sX*sY],
[rho*sX*sY, sY**2]])
# theoretical conditional at X = 180 (§৩.৪)
x0 = 180.0
cond_mean = mu[1] + rho * (sY / sX) * (x0 - mu[0])
cond_var = sY**2 * (1 - rho**2)
print(f"E[Y|X=180]={cond_mean:.3f} Var={cond_var:.2f} sd={np.sqrt(cond_var):.3f}")
# E[Y|X=180]=75.500 Var=51.00 sd=7.141 ← §৩.৪-এর হিসাবের সাথে মেলে
# simulation দিয়ে যাচাই: X≈180 (±0.5) উপগোষ্ঠীর ওজনের গড় ও sd
samples = multivariate_normal(mean=mu, cov=Sigma).rvs(size=400_000, random_state=rng)
near = np.abs(samples[:, 0] - x0) < 0.5
print(f"empirical mean={samples[near,1].mean():.3f} sd={samples[near,1].std():.3f}"
f" (n={near.sum()})")
# empirical mean ≈ 75.5, sd ≈ 7.14 → তত্ত্বের কাছাকাছি ✓
# পুরো sample-এর covariance matrix theoretical Σ-এর কাছাকাছি?
print("empirical cov:\n", np.round(np.cov(samples.T), 2))
print("theoretical Σ:\n", Sigma)
scipy টিপ:
multivariate_normal(mean, cov)দিয়ে.pdf(points),.rvs(size, random_state),.logpdf(...)সব পাওয়া যায়। conditional distribution scipy সরাসরি দেয় না — উপরের রৈখিক সূত্র হাতে প্রয়োগ করতে হয়, যা bivariate Normal-এ সবসময় Normal।
৬ · ভিজ্যুয়ালাইজেশন¶
Figure 1 — joint PMF heatmap + দুটি marginal¶
§৩.১-এর joint PMF। মাঝের তাপচিত্রে (heatmap) প্রতিটি ঘরের probability; উপরে \(X\)-এর marginal \(p_X\), ডানে \(Y\)-এর marginal \(p_Y\) (joint-এর row/column যোগফল)। কর্ণ বরাবর ভারী রং ধনাত্মক covariance-এর চাক্ষুষ ইঙ্গিত।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
xs = np.array([0, 1, 2]); ys = np.array([0, 1, 2])
P = np.array([[3, 2, 1], [2, 3, 2], [1, 2, 4]], dtype=float) / 20.0
pX = P.sum(axis=1); pY = P.sum(axis=0)
fig = plt.figure(figsize=(8.2, 6.6))
gs = GridSpec(2, 2, width_ratios=[4, 1.1], height_ratios=[1.1, 4],
wspace=0.05, hspace=0.05)
ax_h = fig.add_subplot(gs[1, 0])
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_h)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_h)
im = ax_h.imshow(P.T, origin="lower", aspect="auto", cmap="viridis",
extent=[-0.5, 2.5, -0.5, 2.5])
ax_h.set_xticks(xs); ax_h.set_yticks(ys)
ax_h.set_xlabel("x (values of X)"); ax_h.set_ylabel("y (values of Y)")
for i, x in enumerate(xs):
for j, y in enumerate(ys):
ax_h.text(x, y, f"{P[i, j]:.2f}", ha="center", va="center",
color="white" if P[i, j] < 0.12 else "black", fontsize=10)
ax_top.bar(xs, pX, color="#4C72B0", width=0.6); ax_top.set_ylabel("p_X(x)")
ax_top.set_title("Joint PMF p(x, y) with Marginals", fontsize=13)
plt.setp(ax_top.get_xticklabels(), visible=False)
ax_right.barh(ys, pY, color="#C44E52", height=0.5); ax_right.set_xlabel("p_Y(y)")
plt.setp(ax_right.get_yticklabels(), visible=False)
cbar = fig.colorbar(im, ax=ax_right, fraction=0.5, pad=0.35)
cbar.set_label("probability")
plt.savefig("../_assets/2-6-joint-pmf.png", dpi=150, bbox_inches="tight")
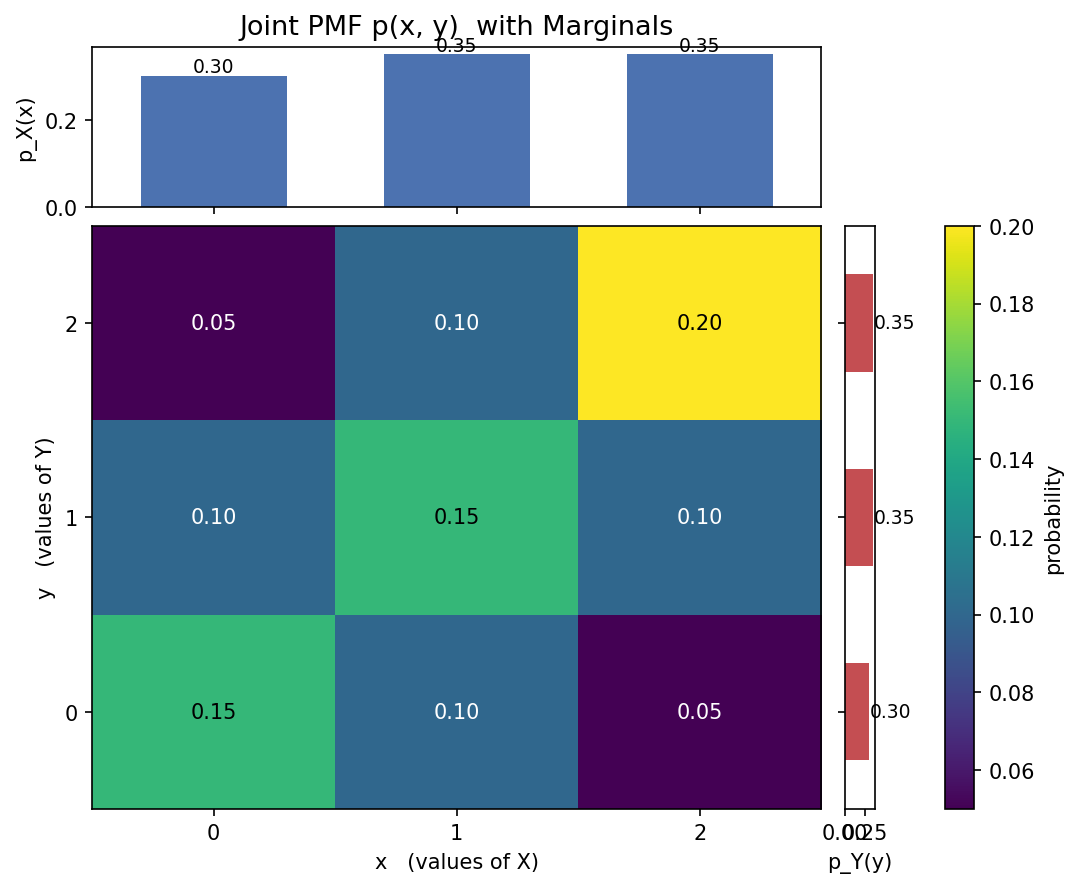
Figure 2 — bivariate Normal: correlation \(\rho\) বদলালে আকৃতি¶
চারটি প্যানেলে একই marginal (\(\sigma_X = \sigma_Y = 1\)) কিন্তু ভিন্ন \(\rho \in \{-0.8, 0, 0.5, 0.9\}\)। contour সর্বদা উপবৃত্ত; \(\rho > 0\)-তে মেঘ ডান-উপরে হেলে, \(\rho < 0\)-তে বাম-উপরে, \(\rho = 0\)-তে গোলাকার (independent)। \(\lvert \rho \rvert\) বাড়লে উপবৃত্ত সরু হয় — variable দুটি কঠিনভাবে একসাথে বাঁধা।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
rng = np.random.default_rng(2606)
rhos = [-0.8, 0.0, 0.5, 0.9]
fig, axes = plt.subplots(1, 4, figsize=(15, 4.1))
gx = np.linspace(-3.2, 3.2, 220); gy = np.linspace(-3.2, 3.2, 220)
GX, GY = np.meshgrid(gx, gy); grid = np.dstack((GX, GY))
for ax, r in zip(axes, rhos):
cov = np.array([[1.0, r], [r, 1.0]])
Z = multivariate_normal(mean=[0, 0], cov=cov).pdf(grid)
ax.contourf(GX, GY, Z, levels=14, cmap="magma")
ax.contour(GX, GY, Z, levels=6, colors="white", linewidths=0.5, alpha=0.6)
s = multivariate_normal(mean=[0, 0], cov=cov).rvs(size=260, random_state=rng)
ax.scatter(s[:, 0], s[:, 1], s=4, color="#7FDBFF", alpha=0.35)
ax.set_title(f"rho = {r:+.1f}", fontsize=12)
ax.set_xlabel("x"); ax.set_aspect("equal")
ax.set_xlim(-3.2, 3.2); ax.set_ylim(-3.2, 3.2)
axes[0].set_ylabel("y")
fig.suptitle("Bivariate Normal Density: effect of correlation rho (sigma_X = sigma_Y = 1)",
fontsize=13)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig("../_assets/2-6-bivariate-normal-rho.png", dpi=150)
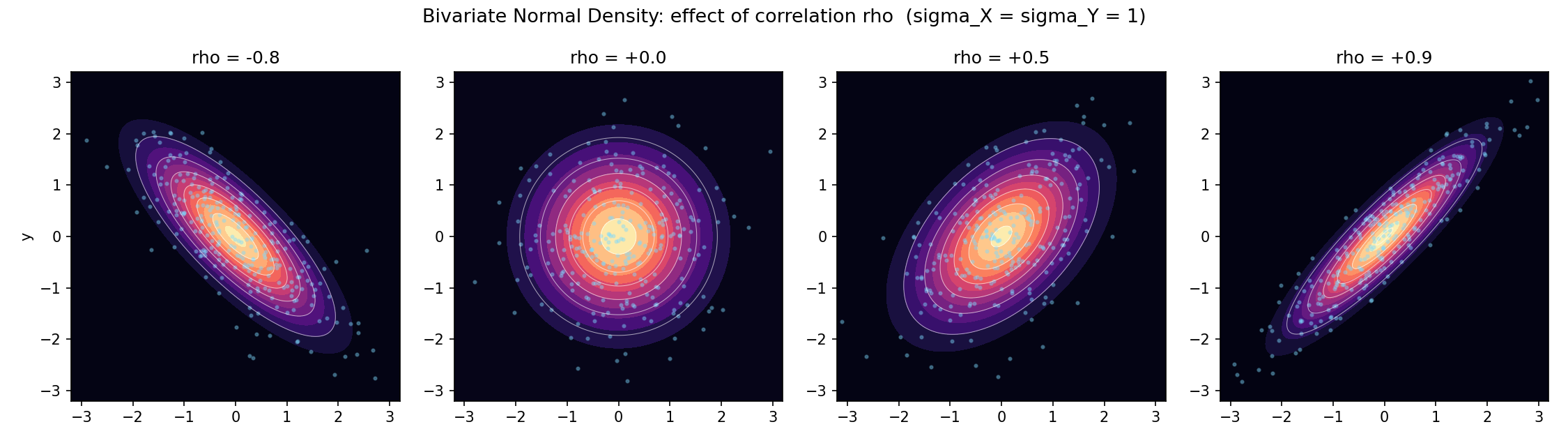
Figure 3 — conditional slice ও \(\mathbb{E}[Y \mid X]\) রেখা¶
বাঁয়ে \(\rho = 0.7\)-এর joint density; লাল রেখাটি \(\mathbb{E}[Y \mid X = x]\) (regression line), আর তিনটি ভাঙা উল্লম্ব রেখা তিনটি \(x\)-এ slice। ডানে সেই slice-গুলোর conditional density \(f(y \mid x)\) — প্রতিটি Normal, এবং তাদের গড় বাঁয়ের লাল রেখা বরাবর সরে। conditional density-ই "X জানার পরে Y-এর হালনাগাদ বিশ্বাস"।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
from scipy.stats import multivariate_normal, norm
mu = np.array([0.0, 0.0]); sX, sY, rho = 1.0, 1.0, 0.7
cov = np.array([[sX**2, rho*sX*sY], [rho*sX*sY, sY**2]])
mvn = multivariate_normal(mean=mu, cov=cov)
gx = np.linspace(-3.2, 3.2, 260); gy = np.linspace(-3.2, 3.2, 260)
GX, GY = np.meshgrid(gx, gy); Z = mvn.pdf(np.dstack((GX, GY)))
fig = plt.figure(figsize=(12, 5.0))
gs = GridSpec(1, 2, width_ratios=[1.25, 1.0], wspace=0.28)
ax0 = fig.add_subplot(gs[0, 0]); ax1 = fig.add_subplot(gs[0, 1])
cf = ax0.contourf(GX, GY, Z, levels=14, cmap="viridis")
fig.colorbar(cf, ax=ax0, fraction=0.046, pad=0.04, label="f(x, y)")
xline = np.linspace(-3.0, 3.0, 100)
ax0.plot(xline, mu[1] + rho*(sY/sX)*(xline - mu[0]),
color="#FF4136", lw=2.4, label="E[Y | X = x]")
x_slices = [-1.5, 0.0, 1.5]; cols = ["#FFDC00", "#FF851B", "#B10DC9"]
for xs_, c in zip(x_slices, cols):
ax0.axvline(xs_, color=c, lw=1.8, ls="--")
ax0.set_xlabel("x"); ax0.set_ylabel("y"); ax0.set_aspect("equal")
ax0.set_title("Joint f(x, y): conditional slices + regression line E[Y | X]")
ax0.legend(loc="upper left", fontsize=9)
yy = np.linspace(-3.2, 3.2, 300)
for xs_, c in zip(x_slices, cols):
m = mu[1] + rho*(sY/sX)*(xs_ - mu[0]); sd = sY*np.sqrt(1 - rho**2)
ax1.plot(yy, norm.pdf(yy, m, sd), color=c, lw=2.2, label=f"f(y | x={xs_:+.1f})")
ax1.axvline(m, color=c, lw=1.0, ls=":")
ax1.set_xlabel("y"); ax1.set_ylabel("conditional density f(y | x)")
ax1.set_title("Conditionals are Normal; means slide along E[Y | X]")
ax1.legend(fontsize=9)
plt.savefig("../_assets/2-6-conditional-slice.png", dpi=150, bbox_inches="tight")
![বাঁয়ে rho=0.7 joint density-তে regression line E[Y|X] ও তিনটি উল্লম্ব slice; ডানে সেই slice-গুলোর conditional density f(y|x) — প্রতিটি Normal এবং গড় regression line বরাবর সরছে।](../_assets/2-6-conditional-slice.png)
Figure 4 — independent বনাম dependent joint¶
দুটি প্যানেলে একই marginal (দুটোই standard Normal) কিন্তু আলাদা joint: বাঁয়ে \(\rho = 0\) (independent, গোলাকার contour, \(X\) জানলে \(Y\) সম্পর্কে কিছুই জানা যায় না), ডানে \(\rho = 0.85\) (dependent, সরু হেলানো মেঘ)। এই ছবিই §২.২-এর সতর্কতা চাক্ষুষ করে: marginal এক হলেও joint ভিন্ন হতে পারে — marginal joint-কে নির্ধারণ করে না।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
rng = np.random.default_rng(2606)
fig, axes = plt.subplots(1, 2, figsize=(11.5, 5.2))
covs = [np.array([[1.0, 0.0], [0.0, 1.0]]),
np.array([[1.0, 0.85], [0.85, 1.0]])]
titles = ["Independent (rho = 0): f(x,y) = f_X(x) f_Y(y)",
"Dependent (rho = 0.85): f(x,y) != f_X(x) f_Y(y)"]
gx = np.linspace(-3.2, 3.2, 200); gy = np.linspace(-3.2, 3.2, 200)
GX, GY = np.meshgrid(gx, gy); grid = np.dstack((GX, GY))
for ax, cov_, title in zip(axes, covs, titles):
Z = multivariate_normal(mean=[0, 0], cov=cov_).pdf(grid)
ax.contour(GX, GY, Z, levels=7, cmap="coolwarm", linewidths=1.1)
s = multivariate_normal(mean=[0, 0], cov=cov_).rvs(size=400, random_state=rng)
ax.scatter(s[:, 0], s[:, 1], s=7, color="#333333", alpha=0.4)
ax.set_title(title, fontsize=11); ax.set_xlabel("x"); ax.set_ylabel("y")
ax.set_aspect("equal"); ax.set_xlim(-3.2, 3.2); ax.set_ylim(-3.2, 3.2)
fig.suptitle("Same marginals, different joints: independence (left) vs dependence (right)",
fontsize=12.5)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig("../_assets/2-6-independent-vs-dependent.png", dpi=150)
৭ · অনুশীলনী¶
তারকা: ★ সরাসরি, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং। সমাধান _solutions/02-06-...-এ।
Conceptual (ধারণাভিত্তিক)¶
৭.১ ★ এক বাক্যে বলুন: joint, marginal ও conditional distribution-এর মধ্যে সম্পর্ক কী? কোনটি থেকে কোনটি পাওয়া যায়, আর কোনটি থেকে কোনটি পাওয়া যায় না?
৭.২ ★ "\(\operatorname{Cov}(X, Y) = 0\) হলে \(X\) ও \(Y\) সবসময় independent" — সত্য না মিথ্যা? একটি উদাহরণ বা প্রতি-উদাহরণ দিন।
৭.৩ ★★ correlation \(\rho\) একক-মুক্ত ও \([-1,1]\)-এ আবদ্ধ, কিন্তু covariance নয় — কেন? এই দুই বৈশিষ্ট্য correlation-কে covariance-এর তুলনায় কোথায় বেশি কাজের করে তোলে?
৭.৪ ★★ law of total variance-এর দুই পদ ("within-group" \(\mathbb{E}[\operatorname{Var}(Y\mid X)]\) ও "between-group" \(\operatorname{Var}(\mathbb{E}[Y\mid X])\)) একটি বাস্তব উদাহরণে (যেমন: ভিন্ন স্কুলের ছাত্রদের পরীক্ষার নম্বর, \(X =\) স্কুল) ব্যাখ্যা করুন।
Computational (গণনাভিত্তিক)¶
৭.৫ ★ নিচের joint PMF-এ (\(X,Y \in \{0,1\}\)): \(p(0,0)=0.4,\ p(0,1)=0.1,\ p(1,0)=0.2,\ p(1,1)=0.3\)। (ক) দুটি marginal বের করুন। (খ) \(X, Y\) কি independent? (গ) \(p_{Y\mid X}(1 \mid 1)\) বের করুন।
৭.৬ ★★ §৩.৫-এর joint PMF-এ \(\operatorname{Cov}(X,Y)\) ও \(\rho_{X,Y}\) হাতে গণনা করুন।
৭.৭ ★★ একটি bivariate Normal-এ \(\mu_X=0, \mu_Y=0, \sigma_X=2, \sigma_Y=3, \rho=-0.5\)। (ক) \(\mathbb{E}[Y \mid X = 4]\) ও \(\operatorname{Var}(Y \mid X = 4)\) বের করুন। (খ) covariance matrix \(\Sigma\) লিখুন।
৭.৮ ★★ \(X \sim \mathcal{N}(0,1)\) এবং \(Y = 3X + Z\), যেখানে \(Z \sim \mathcal{N}(0, 4)\) এবং \(Z \perp X\)। \(\operatorname{Var}(Y)\), \(\operatorname{Cov}(X,Y)\) ও \(\rho_{X,Y}\) বের করুন।
Proof-based (প্রমাণভিত্তিক)¶
৭.৯ ★★ দেখান \(\operatorname{Cov}(aX + bY,\ Z) = a\operatorname{Cov}(X,Z) + b\operatorname{Cov}(Y,Z)\) (covariance-এর প্রথম argument-এ linearity)।
৭.১০ ★★★ \(X, Y\) independent হলে \(\operatorname{Var}(XY) = \mathbb{E}[X^2]\mathbb{E}[Y^2] - (\mathbb{E}[X])^2(\mathbb{E}[Y])^2\) প্রমাণ করুন। (ইঙ্গিত: independence → \(\mathbb{E}[X^2Y^2] = \mathbb{E}[X^2]\mathbb{E}[Y^2]\)।)
Coding (Python)¶
৭.১১ ★★ §৫.৩-এর কোড সম্প্রসারিত করে \(\rho \in \{0, 0.3, 0.6, 0.9\}\)-এর প্রতিটির জন্য ৫,০০,০০০ sample নিন এবং empirical correlation theoretical \(\rho\)-র কাছাকাছি কিনা যাচাই করুন।
৭.১২ ★★★ \(X \sim \mathcal{N}(0,1)\), \(Y = X^2 + 0.3\,\varepsilon\) (\(\varepsilon \sim \mathcal{N}(0,1)\) স্বাধীন) — simulate করে empirical \(\operatorname{Cov}(X,Y) \approx 0\) দেখান, অথচ scatter plot স্পষ্ট (অরৈখিক) নির্ভরতা দেখায়। §৩.৩-এর ফাঁদ চাক্ষুষ করুন।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল ধারণাগুলো এক নজরে:
| ধারণা | সংজ্ঞা / সূত্র | এক-লাইন স্বজ্ঞা |
|---|---|---|
| Joint PMF/PDF | \(p_{X,Y}(x,y)\) / \(f_{X,Y}(x,y)\) | দুই variable একসাথে |
| Marginal | \(\sum_y p_{X,Y}\) / \(\int f_{X,Y}\,dy\) | একটাকে আলাদা করে দেখা |
| Conditional | \(f_{Y\mid X}(y\mid x)=f_{X,Y}/f_X\) | \(X\) জানার পরে \(Y\)-এর distribution |
| Independence | \(f_{X,Y} = f_X f_Y\) | \(X\) জানা মানে \(Y\) সম্পর্কে নতুন কিছু নয় |
| Covariance | \(\mathbb{E}[XY]-\mu_X\mu_Y\) | একই/বিপরীত দিকে চলা (রৈখিক) |
| Correlation | \(\operatorname{Cov}/(\sigma_X\sigma_Y)\in[-1,1]\) | একক-মুক্ত covariance |
| \(\mathbb{E}[Y\mid X]\) | \(\int y f_{Y\mid X}\,dy\) | \(X\) জানলে \(Y\)-এর সেরা অনুমান (regression!) |
| Total expectation | \(\mathbb{E}[Y]=\mathbb{E}[\mathbb{E}[Y\mid X]]\) | গোষ্ঠী-গড়ের গড় = সামগ্রিক গড় |
| Total variance | \(\operatorname{Var}Y = \mathbb{E}[\operatorname{Var}(Y\mid X)] + \operatorname{Var}(\mathbb{E}[Y\mid X])\) | within + between |
| Bivariate Normal | \(\Sigma\), conditional রৈখিক ও Normal | multivariate জগতের আদর্শ মডেল |
পেছনের দিকে সংযোগ। - 0.4 (double integral): "surface-এর নিচের volume" এখানে \(P((X,Y)\in R)\) — probability হয়ে গেল। - 0.5 (covariance matrix): সেই \(\Sigma\)-ই bivariate Normal-এর parameter; symmetric, positive-semidefinite। - 1.4 (descriptive covariance/correlation): data-র \(\frac{1}{n-1}\sum(x_i-\bar x)(y_i-\bar y)\) ছিল sample estimate; এখানে population সংজ্ঞা \(\mathbb{E}[(X-\mu_X)(Y-\mu_Y)]\) — sample সেটিরই আনুমানিক রূপ। - 2.5 (expectation, variance): covariance variance-এর সাধারণীকরণ (\(\operatorname{Cov}(X,X)=\operatorname{Var}X\)); linearity of expectation ছিল সব প্রমাণের যন্ত্র।
সামনের দিকে সংযোগ। - 2.7 (পরবর্তী): Transformations ও functions of random variables; order statistics — একাধিক variable-এর function-এর distribution বের করা, যেখানে এই joint distribution-ই কাঁচামাল। - Part III: \(X_1 + \dots + X_n\)-এর variance-এ covariance-পদ; CLT-তে joint Normal limit। - Part IV (inference): data ও parameter-এর joint থেকে parameter-এর conditional (posterior) — Bayes-এর density রূপ এখানকার সরাসরি প্রয়োগ। - Part V (regression): \(\mathbb{E}[Y\mid X]\)-ই regression function; bivariate Normal-এর রৈখিক conditional mean-ই linear regression-এর তাত্ত্বিক ভিত্তি, আর law of total variance-এর within/between বিভাজন \(R^2\) ও ANOVA-র মূলে।
এক বাক্যে অধ্যায়: একাধিক random variable-এর গল্প বলে তাদের joint distribution; সেখান থেকে marginal (একা) ও conditional (শর্তে) বের হয়, independence ও covariance/correlation তাদের সম্পর্ক মাপে, আর \(\mathbb{E}[Y\mid X]\) ও দুটি total সূত্র সেই সম্পর্ককে inference ও regression-এর ভাষায় অনুবাদ ক