অধ্যায় ২.৪ · Continuous Distributions¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
গত অধ্যায়ে (2.3) আমরা discrete random variable নিয়ে কাজ করেছি — যেখানে সম্ভাব্য মানগুলো গোনা যায় (০, ১, ২, …), আর প্রতিটি মানের নিজস্ব probability থাকে, যা probability mass function (PMF) দিয়ে লেখা। কয়েন টস, পাশার দান, ভোটে "হ্যাঁ/না" — এসব discrete।
কিন্তু পৃথিবীর অনেক রাশি গোনা যায় না, মাপা যায় — উচ্চতা, ওজন, তাপমাত্রা, কোনো বাসের জন্য অপেক্ষার সময়, একটা যন্ত্রের আয়ু। এদের মান একটা গোটা ব্যবধান (interval) জুড়ে অবিচ্ছিন্নভাবে (continuously) ছড়িয়ে থাকে — ১৭০ ও ১৭১ cm-এর মাঝে অসীম-সংখ্যক সম্ভাব্য উচ্চতা আছে (১৭০.৫, ১৭০.৫০০৩, …)। এমন রাশিকে বলে continuous random variable (অবিচ্ছিন্ন দৈব চলক)।
এখানেই একটা চমক অপেক্ষা করছে। জিজ্ঞেস করুন: "একজন মানুষের উচ্চতা ঠিক ১৭০.০০০০… cm হওয়ার probability কত?" উত্তর — শূন্য। কারণ অসীম-সংখ্যক সম্ভাব্য মান, আর তাদের সবার probability যোগ করে ১ হতে হলে কোনো একটি নির্দিষ্ট মানের ভাগে কিছুই পড়ে না। তাহলে continuous রাশির probability কীভাবে বর্ণনা করব?
0.4-এ আমরা এর উত্তর তৈরি করেছিলাম, একটাই বাক্যে যা মনে রাখার মতো:
probability = density curve-এর নিচের area।
আমরা প্রতিটি বিন্দুতে probability বসাই না; বরং একটা মসৃণ curve \(f(x)\) আঁকি — probability density function (PDF, সম্ভাব্যতার ঘনত্ব) — আর একটা ব্যবধান জুড়ে probability পরিমাপ করি সেই curve-এর নিচের area দিয়ে: $$ P(a \le X \le b) = \int_a^b f(x)\,dx. $$ এটাই 0.4-এর integral-এর সরাসরি ফল। "ঠিক একটি বিন্দু" মানে \(a=b\) — শূন্য-প্রস্থের ব্যবধান, শূন্য-প্রস্থ rectangle, area শূন্য — তাই \(P(X=x)=0\)।
Hook — density (ঘনত্ব) মানে কী? "density" শব্দটা ভৌত ঘনত্বের মতোই ভাবুন। একটা পাতলা ধাতব দণ্ডের কথা ভাবুন যার কোথাও বেশি, কোথাও কম ভর জমা। কোনো একটি বিন্দুতে ভর কত? কার্যত শূন্য (বিন্দুর প্রস্থ নেই)। কিন্তু একটা টুকরো জুড়ে (যেমন ২ থেকে ৫ cm) ভর কত? সেটা বের করা যায় — density-কে দৈর্ঘ্য বরাবর integrate করে। PDF ঠিক তা-ই: \(f(x)\) মানে \(x\)-বিন্দুতে probability নয়, বরং সেখানে probability কত ঘন হয়ে জমছে তার হার। আর সেই হারকে একটা ব্যবধান জুড়ে যোগ (integrate) করলে পাই সেই ব্যবধানের probability।
এই অধ্যায়ে আমরা পাঁচটি সবচেয়ে গুরুত্বপূর্ণ continuous distribution চিনব — Uniform, Exponential, Normal, Gamma, Beta — প্রত্যেকটির আকৃতি, প্যারামিটার আর গল্প সহ। এর মধ্যে Normal distribution (Gaussian) সবচেয়ে গভীরভাবে দেখব, কারণ Part III-এর Central Limit Theorem (CLT) ও Part IV-এর প্রায় সব inference এই bell curve-কে ঘিরে আবর্তিত হয়।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ probability density function (PDF) ও কেন \(P(X=x)=0\)¶
একটি random variable \(X\)-কে continuous বলা হয় যদি এমন একটি function \(f(x) \ge 0\) থাকে — যাকে probability density function (PDF) বলে — যা দিয়ে যেকোনো ব্যবধানের probability লেখা যায়: $$ \boxed{\ P(a \le X \le b) = \int_a^b f(x)\,dx\ } $$
দুটো শর্ত PDF-কে বৈধ করে:
- অঋণাত্মকতা: \(f(x) \ge 0\) সর্বত্র (negative density হয় না — area ঋণাত্মক হলে probability ঋণাত্মক হত)।
- normalization (মোট area \(=1\)): $$ \int_{-\infty}^{\infty} f(x)\,dx = 1. $$ পুরো রেখার নিচের মোট area অবশ্যই \(1\) — কারণ "\(X\) কোনো-না-কোনো মান নেবেই" এই ঘটনার probability \(1\)। (এটি 0.4-এর normalization শর্তের পুনরাবৃত্তি।)
এখন গুরুত্বপূর্ণ পার্থক্যটা স্পষ্ট করি — PDF ≠ probability। discrete-এ PMF \(p(x)\) সরাসরি probability (\(P(X=x)\)), তাই \(0 \le p(x) \le 1\)। কিন্তু PDF \(f(x)\) একটা হার (density), probability নয় — তাই \(f(x)\) অনায়াসে \(1\)-এর চেয়ে বড় হতে পারে! যেমন Uniform(0, 0.5)-এ density \(=2\) (নিচে দেখব)। কেবল area-ই probability, density নয়।
কেন \(P(X=x)=0\)? যেকোনো একটি বিন্দু \(c\)-তে: $$ P(X = c) = P(c \le X \le c) = \int_c^c f(x)\,dx = 0, $$ কারণ একই উপর-নিচ সীমার integral সবসময় শূন্য (শূন্য প্রস্থ)। এর একটা সরাসরি ও সুবিধাজনক ফল:
continuous ক্ষেত্রে প্রান্ত \(<\) না \(\le\) — কিছু যায় আসে না: $\(P(a \le X \le b) = P(a < X < b) = P(a < X \le b) = P(a \le X < b).\)$ কারণ এক-একটা প্রান্তবিন্দু যোগ/বিয়োগ করলে শূন্যই যোগ/বিয়োগ হয়।
(discrete-এ এই কথাটা মিথ্যা — সেখানে প্রান্তবিন্দুর mass গুরুত্বপূর্ণ। এটাই দুই জগতের একটা বড় ব্যবহারিক পার্থক্য।)
২.২ cumulative distribution function (CDF) ও PDF-এর সম্পর্ক¶
cumulative distribution function (CDF, সঞ্চিত বণ্টন ফাংশন) সংজ্ঞা discrete ও continuous — দুই জগতে একই: $$ F(x) = P(X \le x). $$ continuous ক্ষেত্রে এটি PDF-এর "বাঁ দিক পর্যন্ত জমা area": $$ \boxed{\ F(x) = P(X \le x) = \int_{-\infty}^{x} f(t)\,dt\ } $$
এখানে 0.4-এর Fundamental Theorem of Calculus (FTC) সরাসরি কাজে লাগে। FTC বলে: "area জমা হওয়ার তাৎক্ষণিক হার = সেই বিন্দুর function-মান।" তাই CDF-কে differentiate করলে ফিরে পাই PDF: $$ \boxed{\ F'(x) = f(x)\ } $$
এটাই PDF আর CDF-এর হৃদয়ের সম্পর্ক — দুটো একই বস্তুর দুই রূপ:
- PDF → CDF: integrate করো (area জমাও)।
- CDF → PDF: differentiate করো (slope নাও)।
CDF-এর কয়েকটি ধর্ম (continuous ক্ষেত্রে):
- \(F\) মসৃণ ও continuous (লাফ নেই — কারণ কোনো বিন্দুতে mass নেই)।
- \(F\) monotone non-decreasing (কখনো নামে না, কারণ area যোগ হতে থাকে), এবং \(0 \le F(x) \le 1\)।
- প্রান্তে: \(\lim_{x\to-\infty} F(x) = 0\), \(\lim_{x\to+\infty} F(x) = 1\)।
CDF দিয়ে যেকোনো ব্যবধানের probability সহজে বের হয় (subtraction দিয়ে): $$ P(a \le X \le b) = F(b) - F(a) = \int_a^b f(x)\,dx. $$
আর একটা দরকারি পরিমাণ — survival function (টিকে থাকার ফাংশন): \(S(x) = P(X > x) = 1 - F(x)\)। "যন্ত্রটা \(x\) সময়ের পরও টিকে আছে" — এই probability, যা reliability ও memorylessness আলোচনায় লাগবে।
২.৩ quantile ও density-র শৃঙ্গ¶
CDF-এর "উল্টো" হলো quantile function \(Q(p) = F^{-1}(p)\): কোন মান \(x\)-এর নিচে probability \(p\) জমে? যেমন median হলো \(Q(0.5)\) — যে বিন্দুর দু'পাশে সমান area (\(0.5\) করে)। percentile, quartile — সবই quantile। (simulation ও inference-এ এর ভূমিকা পরে।)
density curve-এর সর্বোচ্চ বিন্দু (শৃঙ্গ) হলো mode — যেখানে probability সবচেয়ে ঘন। symmetric distribution-এ (যেমন Normal) mean = median = mode, কিন্তু skewed distribution-এ (যেমন Exponential, কিছু Gamma/Beta) এরা আলাদা।
২.৪ পাঁচটি মূল continuous distribution¶
নিচে প্রতিটির PDF, প্যারামিটার, support (যেখানে \(f>0\)), আর সংক্ষিপ্ত গল্প। (mean/variance Section 4 ও 2.5-এ আসবে, কয়েকটি এখানে দেওয়া হলো অন্তর্দৃষ্টির জন্য।)
(ক) Uniform — সমবণ্টন (সবচেয়ে সরল)। \(X \sim \text{Uniform}(a, b)\) মানে \([a, b]\)-এর সব মান সমান-সম্ভাব্য। PDF একটা সমতল বাক্স: $$ f(x) = \begin{cases} \dfrac{1}{b-a}, & a \le x \le b \[4pt] 0, & \text{অন্যত্র} \end{cases} $$ উচ্চতা \(\frac{1}{b-a}\) এমনভাবে বাছা যাতে বাক্সের area \(= \frac{1}{b-a} \times (b-a) = 1\)। লক্ষ করুন: \(b-a < 1\) হলে density \(1\)-এর বেশি! যেমন Uniform(0, 0.5)-এ \(f = 2\)। CDF একটা সরলরেখা: \(F(x) = \frac{x-a}{b-a}\) for \(x\in[a,b]\)। mean \(= \frac{a+b}{2}\) (কেন্দ্র)। ব্যবহার: "কিছুই জানি না, সমান সুযোগ" — random number generation-এর ভিত্তি (এ থেকে যেকোনো distribution বানানো যায়, Section 5)।
(খ) Exponential — সূচকীয় (অপেক্ষার সময়)। \(X \sim \text{Exponential}(\lambda)\) — কোনো একটা ঘটনার জন্য অপেক্ষার সময়, যখন ঘটনা ধ্রুব হার (rate) \(\lambda > 0\)-তে ঘটে। PDF: $$ f(x) = \lambda e^{-\lambda x}, \quad x \ge 0. $$ CDF: \(F(x) = 1 - e^{-\lambda x}\) (\(x\ge 0\))। mean \(= \frac{1}{\lambda}\) — হার যত বেশি, গড় অপেক্ষা তত কম (স্বাভাবিক)। শৃঙ্গ \(x=0\)-তে, তারপর সূচকীয়ভাবে কমে — তাই ডান দিকে লম্বা লেজ (right-skewed)। ব্যবহার: পরের ফোন কল আসতে কত সময়, একটা bulb কত দিন চলবে, radioactive ক্ষয়। এর সবচেয়ে বিখ্যাত ধর্ম memorylessness (২.৫-এ)।
scale বনাম rate — সাবধান! Exponential দুইভাবে লেখা হয়: rate \(\lambda\) দিয়ে (\(f=\lambda e^{-\lambda x}\)) অথবা scale \(\theta = 1/\lambda\) দিয়ে।
scipy.stats.exponscale চায় — তাই rate \(\lambda\) হলে কোড লিখুনexpon(scale=1/lam)। এই একটা ভুল সবচেয়ে বেশি হয়।
(গ) Normal / Gaussian — স্বাভাবিক বণ্টন (bell curve, সবচেয়ে গুরুত্বপূর্ণ)। \(X \sim \mathcal{N}(\mu, \sigma^2)\), দুটি প্যারামিটার: mean \(\mu\) (কেন্দ্র/location) ও standard deviation \(\sigma > 0\) (বিস্তার/scale)। PDF: $$ f(x) = \frac{1}{\sigma\sqrt{2\pi}}\, \exp!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right), \quad -\infty < x < \infty. $$ এটা একটা symmetric (প্রতিসম) ঘণ্টা-আকৃতি, \(x=\mu\)-তে শৃঙ্গ। \(\mu\) পাল্টালে পুরো curve ডানে-বামে সরে; \(\sigma\) পাল্টালে curve সরু/চওড়া হয়। ব্যবহার: উচ্চতা, পরিমাপের ভুল (measurement error), পরীক্ষার নম্বর, আর — সবচেয়ে গভীর কারণ — অনেক ছোট independent (স্বাধীন) প্রভাবের যোগফল প্রায়ই Normal হয় (Central Limit Theorem, Part III)। এজন্যই Normal সর্বত্র, আর এজন্যই inference-এর কেন্দ্রে। এর গভীর গঠন (standardization, z-score, 68–95–99.7 rule) ২.৬-এ আলাদাভাবে।
(ঘ) Gamma — গামা (কয়েকটি অপেক্ষার যোগফল)। \(X \sim \text{Gamma}(k, \theta)\) — shape \(k>0\) ও scale \(\theta>0\)। PDF: $$ f(x) = \frac{1}{\Gamma(k)\,\theta^{k}}\, x^{\,k-1} e^{-x/\theta}, \quad x > 0, $$ যেখানে \(\Gamma(k) = \int_0^\infty t^{k-1}e^{-t}\,dt\) হলো gamma function (factorial-এর continuous সম্প্রসারণ: পূর্ণসংখ্যা \(n\)-এ \(\Gamma(n)=(n-1)!\))। মূল অন্তর্দৃষ্টি: shape পূর্ণসংখ্যা \(k\) হলে, Gamma হলো \(k\)টি স্বাধীন Exponential(\(1/\theta\))-এর যোগফল — অর্থাৎ "\(k\)-তম ঘটনা ঘটতে মোট কত সময়"। তাই \(k=1\)-এ Gamma ঠিক Exponential হয়ে যায়। \(k\) বাড়লে আকৃতি ডান দিকে সরে ও কম-skewed হয় (যোগফল বলে CLT-র দিকে ঝোঁকে)। ব্যবহার: queue-তে \(k\)টি গ্রাহক সেবা পেতে সময়, rainfall মডেল; Bayesian statistics-এ অত্যন্ত গুরুত্বপূর্ণ (Part IV)।
(ঙ) Beta — বিটা (একটা অনুপাত \([0,1]\)-এ)। \(X \sim \text{Beta}(\alpha, \beta)\) — দুটি shape প্যারামিটার \(\alpha, \beta > 0\); support সবসময় \([0,1]\)। PDF: $$ f(x) = \frac{x^{\,\alpha-1}(1-x)^{\,\beta-1}}{B(\alpha, \beta)}, \quad 0 \le x \le 1, $$ যেখানে \(B(\alpha,\beta) = \frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha+\beta)}\) — normalization ধ্রুবক (beta function)। আকৃতি অসাধারণ নমনীয়: \(\alpha=\beta=1\)-এ সমতল (= Uniform(0,1)!); \(\alpha=\beta>1\)-এ মাঝে শৃঙ্গযুক্ত প্রতিসম; \(\alpha<1,\beta<1\)-এ U-আকৃতি (দুই প্রান্তে ঘন); \(\alpha\ne\beta\)-তে এক দিকে হেলানো। mean \(= \frac{\alpha}{\alpha+\beta}\)। ব্যবহার: যেকোনো proportion/probability (অনুপাত/সম্ভাব্যতা) মডেল করতে — যেমন "একটা কয়েন head পড়ার সত্যিকারের probability কত" — তাই Bayesian inference-এ Binomial-এর সঙ্গী (conjugate prior, Part IV)।
২.৫ Exponential-এর memorylessness¶
Exponential-এর সবচেয়ে চমকপ্রদ ধর্ম — memorylessness (স্মৃতিহীনতা): "এতক্ষণ অপেক্ষা করেছি" — এই তথ্য ভবিষ্যৎ অপেক্ষা সম্পর্কে কিছুই বলে না। গাণিতিকভাবে, যেকোনো \(s, t \ge 0\)-র জন্য: $$ \boxed{\ P(X > s + t \mid X > s) = P(X > t)\ } $$
বাংলায়: "ইতিমধ্যে \(s\) সময় টিকে গেছে, আরও অন্তত \(t\) টিকবে" — এর probability ঠিক "শূন্য থেকে শুরু করে অন্তত \(t\) টিকবে"-এর সমান। বাস যদি Exponential অনুযায়ী আসে, ১০ মিনিট দাঁড়িয়ে থাকার পরও "আর কতক্ষণ লাগবে?" — উত্তর একদম শুরুর মতোই; অপেক্ষা আপনার ভাগ্য বদলায়নি। (এটা একটু অস্বস্তিকর কিন্তু গাণিতিকভাবে সত্য — Section 4-এ প্রমাণ।) Exponential-ই একমাত্র continuous distribution যার এই ধর্ম আছে। এজন্য এটা "ক্ষয় হয় না এমন" ঘটনার (ধ্রুব hazard rate) আদর্শ মডেল।
২.৬ Normal-এর গভীর গঠন: standardization, z-score, 68–95–99.7 rule¶
Normal এত গুরুত্বপূর্ণ যে একে আলাদা মনোযোগ দিই।
standard Normal ও z-score। যেকোনো Normal-কে একটা সর্বজনীন রূপে আনা যায়। যদি \(X \sim \mathcal{N}(\mu, \sigma^2)\), তবে $$ Z = \frac{X - \mu}{\sigma} \sim \mathcal{N}(0, 1) $$ হলো standard Normal (mean \(0\), sd \(1\))। এই \(Z\)-কে বলে z-score — "\(X\) তার গড় থেকে কত \(\sigma\) দূরে"। উদাহরণ: গড় ১৬৪, sd ৬ — কেউ ১৭৬ cm লম্বা হলে \(z = (176-164)/6 = 2\), অর্থাৎ "গড়ের ২ standard deviation উপরে"। এই standardization ছাড়া আলাদা আলাদা Normal নিয়ে কাজ করা কঠিন; z-score সব Normal-কে একই মাপকাঠিতে আনে, আর তখন একটাই table/function (standard Normal CDF \(\Phi\)) দিয়ে সব probability বের করা যায়: $$ P(X \le x) = P!\left(Z \le \tfrac{x-\mu}{\sigma}\right) = \Phi!\left(\tfrac{x-\mu}{\sigma}\right). $$
68–95–99.7 (empirical) rule। যেকোনো Normal-এ — \(\mu, \sigma\) যা-ই হোক — প্রায় নিশ্চিতভাবে:
| পরিসর | probability (area) |
|---|---|
| \(\mu \pm 1\sigma\) | \(\approx 68\%\) |
| \(\mu \pm 2\sigma\) | \(\approx 95\%\) |
| \(\mu \pm 3\sigma\) | \(\approx 99.7\%\) |
অর্থাৎ Normal রাশির প্রায় সব মান গড়ের ৩ standard deviation-এর মধ্যে থাকে; ২\(\sigma\)-র বাইরে যাওয়া বিরল (~৫%), ৩\(\sigma\)-র বাইরে অতি-বিরল (~০.৩%)। এই নিয়মটা মাথায় থাকলে কোনো হিসাব ছাড়াই দ্রুত আন্দাজ করা যায় — "এই মানটা কি স্বাভাবিক, না অস্বাভাবিক?" quality control, outlier-শনাক্তকরণ, hypothesis testing — সব জায়গায় এটা কাজের। (Section 6-এ ছবি; Section 4-এ একটা সংখ্যা প্রমাণ।)
২.৭ এদের পারস্পরিক সম্পর্ক (সংক্ষেপে)¶
এই পাঁচটা বিচ্ছিন্ন নয় — একটা পরিবারের মতো জড়ানো:
- Uniform(0,1) → যেকোনো distribution। inverse-CDF কৌশলে (Section 5) Uniform থেকে যেকোনো distribution বানানো যায় — তাই Uniform সব simulation-এর ভিত্তি।
- Exponential = Gamma(shape \(=1\))। Exponential হলো Gamma-র সবচেয়ে সরল সদস্য।
- Gamma(shape \(=k\)) = \(k\)টি স্বাধীন Exponential-এর যোগফল (পূর্ণসংখ্যা \(k\))। "\(k\)-তম ঘটনার অপেক্ষা"।
- Beta(1, 1) = Uniform(0, 1)। Beta-পরিবারের সমতল সদস্য।
- যোগফল → Normal (CLT)। অনেক স্বাধীন রাশির যোগফল/গড় প্রায় Normal হয় — Part III-এর সবচেয়ে বড় উপপাদ্য, যা Normal-কে কেন্দ্রীয় বানায়।
(এদের আরও সম্পর্ক — যেমন Normal-এর বর্গ থেকে chi-square, যা Part IV-এ — পরে আসবে।)
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ A — বাসের অপেক্ষা (Uniform): সংজ্ঞা থেকে probability¶
সমস্যা: একটা বাস প্রতি ১৫ মিনিট অন্তর আসে, আর আপনি যেকোনো এলোমেলো মুহূর্তে স্টপে পৌঁছান। অপেক্ষার সময় \(X \sim \text{Uniform}(0, 15)\) (মিনিট)। (ক) PDF লিখুন। (খ) ৫ মিনিটের কম অপেক্ষার probability? (গ) ৫ থেকে ১০ মিনিটের মধ্যে? (ঘ) median অপেক্ষা?
সমাধান।
(ক) \(f(x) = \dfrac{1}{15-0} = \dfrac{1}{15}\) for \(0 \le x \le 15\), নয়তো \(0\)। (উচ্চতা \(\frac{1}{15}\approx 0.067\) — সমতল।)
(খ) area = বাক্সের একটা টুকরো (rectangle): $$ P(X < 5) = \int_0^5 \frac{1}{15}\,dx = \frac{5}{15} = \frac{1}{3} \approx 0.333. $$
(গ) $$ P(5 \le X \le 10) = \int_5^{10}\frac{1}{15}\,dx = \frac{10-5}{15} = \frac{5}{15} = \frac{1}{3} \approx 0.333. $$ (Uniform-এ সমান-প্রস্থ যেকোনো টুকরোর probability সমান — এটাই "uniform" হওয়ার অর্থ।)
(ঘ) median \(m\): \(F(m) = 0.5 \Rightarrow \frac{m}{15} = 0.5 \Rightarrow m = 7.5\) মিনিট (ঠিক মাঝখানে, যেমন আশা করা যায়)।
উদাহরণ B — bulb-এর আয়ু (Exponential) ও memorylessness¶
সমস্যা: একটা LED bulb-এর আয়ু \(X \sim \text{Exponential}(\lambda)\) যেখানে গড় আয়ু \(\frac{1}{\lambda} = 10{,}000\) ঘণ্টা (তাই \(\lambda = 10^{-4}\) প্রতি ঘণ্টা)। (ক) ৫,০০০ ঘণ্টার আগেই নষ্ট হওয়ার probability? (খ) bulb-টা ইতিমধ্যে ৮,০০০ ঘণ্টা চলেছে; আরও অন্তত ৫,০০০ ঘণ্টা চলার probability?
সমাধান।
(ক) CDF \(F(x) = 1 - e^{-\lambda x}\) ব্যবহার করি: $$ P(X < 5000) = F(5000) = 1 - e^{-10^{-4}\cdot 5000} = 1 - e^{-0.5} \approx 1 - 0.6065 = 0.3935. $$
(খ) এখানে memorylessness! চাই \(P(X > 13000 \mid X > 8000)\)। memoryless ধর্ম অনুযায়ী এটি \(= P(X > 5000)\) — যেন bulb নতুন: $$ P(X > 5000) = e^{-\lambda \cdot 5000} = e^{-0.5} \approx 0.6065. $$ যাচাই (সংজ্ঞা থেকে, যাতে আস্থা হয়): $$ P(X>13000 \mid X>8000) = \frac{P(X>13000)}{P(X>8000)} = \frac{e^{-1.3}}{e^{-0.8}} = e^{-0.5} \approx 0.6065. \checkmark $$ "৮,০০০ ঘণ্টা চলেছে" — এই তথ্য বাড়তি কোনো সুবিধা/অসুবিধা দেয় না।
উদাহরণ C — পরীক্ষার নম্বর (Normal): z-score ও empirical rule¶
সমস্যা: একটা বড় পরীক্ষায় নম্বর \(X \sim \mathcal{N}(\mu=70, \sigma=8)\)। (ক) ৮৬ নম্বর পাওয়া একজনের z-score? (খ) empirical rule দিয়ে আন্দাজ করুন কত শতাংশ ৫৪ থেকে ৮৬-এর মধ্যে। (গ) \(P(X > 86)\) আনুমানিক? (ঘ) ঠিক কত নম্বরের উপরে থাকলে কেউ "টপ ২.৫%"-এ পড়বে?
সমাধান।
(ক) \(z = \dfrac{86 - 70}{8} = \dfrac{16}{8} = 2\) — গড়ের ২ standard deviation উপরে।
(খ) \(54 = 70 - 2(8) = \mu - 2\sigma\) এবং \(86 = \mu + 2\sigma\)। তাই পরিসরটা ঠিক \(\mu \pm 2\sigma\) — empirical rule অনুযায়ী \(\approx 95\%\) শিক্ষার্থী এখানে।
(গ) \(86 = \mu + 2\sigma\)-র উপরে। \(\mu\pm2\sigma\)-এ ৯৫% থাকলে, বাইরে ৫%, আর প্রতিসমতার জন্য এক প্রান্তে অর্ধেক: $$ P(X > 86) \approx \frac{1 - 0.95}{2} = 0.025 \;(\approx 2.5\%). $$
(ঘ) "টপ ২.৫%" মানে ঠিক \(\mu + 2\sigma\)-র উপরে (গ থেকে): \(70 + 2(8) = 86\) নম্বর। (৮৬ ও তার উপরে ≈ উপরের ২.৫%।)
উদাহরণ D — Beta দিয়ে একটা অনুপাত মডেল¶
সমস্যা: একটা নতুন ওয়েবসাইটে ক্লিক-করার হার (proportion) \(p\) অজানা। অতীত অভিজ্ঞতা বলছে \(p\) সম্ভবত ছোট (২০%-এর কাছাকাছি), কিন্তু অনিশ্চিত। আমরা \(p \sim \text{Beta}(2, 5)\) ধরলাম। এই বাছাই কতটা যুক্তিসঙ্গত?
সমাধান। Beta(2, 5)-এর mean \(= \dfrac{\alpha}{\alpha+\beta} = \dfrac{2}{2+5} = \dfrac{2}{7} \approx 0.286\) — অর্থাৎ গড় ধারণা ~২৯% ক্লিক-হার, ছোট মানের দিকে হেলানো (right-skew, কারণ \(\beta>\alpha\))। support \([0,1]\) — proportion-এর জন্য ঠিক। mode (শৃঙ্গ) \(= \dfrac{\alpha-1}{\alpha+\beta-2} = \dfrac{1}{5} = 0.2\) — সবচেয়ে সম্ভাব্য মান ২০%, আমাদের প্রাথমিক অনুমানের সঙ্গে মেলে। তাই Beta(2, 5) "ছোট কিন্তু অনিশ্চিত অনুপাত"-এর একটা বুদ্ধিদীপ্ত মডেল। (Part IV-এ এই Beta হবে Bayesian inference-এর prior।)
৪ · প্রমাণ ও উৎপাদন¶
intro-probability স্তরের প্রমাণ। rigor (কোন function-এর density আছে, measure-theoretic ভিত্তি) → Part VII।
প্রমাণ ১ (★) — Uniform PDF বৈধ ও তার CDF¶
দাবি: \(f(x) = \frac{1}{b-a}\) on \([a,b]\) একটি বৈধ PDF, এবং \(F(x) = \frac{x-a}{b-a}\) on \([a,b]\)।
প্রমাণ। \(f \ge 0\) স্পষ্ট (\(b>a\))। normalization: $$ \int_{-\infty}^{\infty} f = \int_a^b \frac{1}{b-a}\,dx = \frac{1}{b-a}\big[x\big]_a^b = \frac{b-a}{b-a} = 1.\ \checkmark $$ CDF, \(a \le x \le b\)-এ (0.4-এর FTC প্রয়োগে): $$ F(x) = \int_a^x \frac{1}{b-a}\,dt = \frac{t}{b-a}\Big|_a^x = \frac{x-a}{b-a}. \qquad \blacksquare $$ (\(x<a\)-এ \(F=0\), \(x>b\)-এ \(F=1\)।) যাচাই: \(F'(x) = \frac{1}{b-a} = f(x)\) — সম্পর্ক ঠিক।
প্রমাণ ২ (★) — Exponential PDF বৈধ, CDF, এবং survival function¶
দাবি: \(f(x)=\lambda e^{-\lambda x}\) (\(x\ge0\), \(\lambda>0\)) বৈধ; \(F(x)=1-e^{-\lambda x}\); \(S(x)=e^{-\lambda x}\)।
প্রমাণ। \(f\ge0\) স্পষ্ট। normalization (0.4-এর improper integral): $$ \int_0^\infty \lambda e^{-\lambda x}\,dx = \lambda\cdot\left[\frac{-1}{\lambda}e^{-\lambda x}\right]_0^\infty = \big[-e^{-\lambda x}\big]_0^\infty = (0) - (-1) = 1.\ \checkmark $$ CDF: $$ F(x) = \int_0^x \lambda e^{-\lambda t}\,dt = \big[-e^{-\lambda t}\big]_0^x = 1 - e^{-\lambda x}. $$ তাই survival \(S(x) = 1 - F(x) = e^{-\lambda x}\)। \(\blacksquare\)
প্রমাণ ৩ (★★) — Exponential-এর memorylessness¶
দাবি: \(X \sim \text{Exponential}(\lambda)\) হলে যেকোনো \(s,t\ge0\)-র জন্য \(P(X>s+t \mid X>s) = P(X>t)\)।
প্রমাণ। conditional probability-র সংজ্ঞা থেকে (লক্ষ করুন \(\{X>s+t\}\subseteq\{X>s\}\), তাই যৌথ ঘটনা \(=\{X>s+t\}\)): $$ P(X>s+t \mid X>s) = \frac{P(X>s+t)}{P(X>s)} = \frac{S(s+t)}{S(s)}. $$ প্রমাণ ২ থেকে \(S(x)=e^{-\lambda x}\), তাই: $$ = \frac{e^{-\lambda(s+t)}}{e^{-\lambda s}} = e^{-\lambda(s+t)+\lambda s} = e^{-\lambda t} = S(t) = P(X>t). \qquad \blacksquare $$ মূল কারণ: exponential function-এর \(e^{a+b}=e^a e^b\) ধর্ম — যোগফলকে গুণফলে ভাঙে, আর \(s\)-অংশ কাটাকাটি হয়ে যায়। (উল্টোটাও সত্য: continuous, memoryless ধর্মযুক্ত একমাত্র distribution-ই Exponential — Section 7, প্রশ্ন ৯।)
প্রমাণ ৪ (★★) — standardization: \(Z=\frac{X-\mu}{\sigma}\) standard Normal¶
দাবি: \(X\sim\mathcal{N}(\mu,\sigma^2)\) হলে \(Z=\frac{X-\mu}{\sigma}\sim\mathcal{N}(0,1)\)।
প্রমাণ (CDF কৌশল)। \(Z\)-এর CDF বের করি, তারপর differentiate করে PDF পাই (\(\sigma>0\)): $$ F_Z(z) = P(Z\le z) = P!\left(\frac{X-\mu}{\sigma}\le z\right) = P(X \le \mu+\sigma z) = F_X(\mu+\sigma z). $$ এখন chain rule-এ differentiate (0.4): $$ f_Z(z) = F_Z'(z) = f_X(\mu+\sigma z)\cdot\frac{d}{dz}(\mu+\sigma z) = f_X(\mu+\sigma z)\cdot \sigma. $$ \(f_X\) বসাই — exponent-এ \(x=\mu+\sigma z\) দিলে \((x-\mu)^2/(2\sigma^2) = (\sigma z)^2/(2\sigma^2) = z^2/2\): $$ f_Z(z) = \frac{1}{\sigma\sqrt{2\pi}}\,e^{-z^2/2}\cdot\sigma = \frac{1}{\sqrt{2\pi}}\,e^{-z^2/2}. $$ এটা ঠিক \(\mathcal{N}(0,1)\)-এর PDF। \(\blacksquare\) (এজন্যই z-score সব Normal-কে একই সর্বজনীন রূপে আনে।)
উৎপাদন ৫ (★★★) — একটা area-প্রমাণ: \(\mu\pm1\sigma\)-এ ~৬৮%¶
empirical rule-এর সংখ্যা কোথা থেকে আসে দেখাই (standard Normal-এ, কারণ standardization-এ পরিসর \(\pm1\)-এ পরিণত হয়):
$$
P(\mu-\sigma \le X \le \mu+\sigma) = P(-1\le Z\le 1) = \Phi(1)-\Phi(-1).
$$
standard Normal CDF \(\Phi(1)\approx 0.8413\), আর প্রতিসমতায় \(\Phi(-1)=1-\Phi(1)\approx 0.1587\)। তাই:
$$
\Phi(1)-\Phi(-1) \approx 0.8413 - 0.1587 = 0.6826 \approx 68.3\%. \ \checkmark
$$
একইভাবে \(\pm2\): \(\Phi(2)-\Phi(-2)\approx 0.9772-0.0228 = 0.9544 \approx 95.4\%\); \(\pm3\): \(\approx 0.9973 \approx 99.7\%\)। (এই \(\Phi\)-মানগুলো closed-form-এ পাওয়া যায় না — \(\int e^{-z^2/2}\)-এর কোনো elementary antiderivative নেই — তাই numeric/table দিয়ে বের করা হয়, যা Section 5-এ scipy করে দেখাবে।) \(\blacksquare\)
৫ · কোড ল্যাব (Python)¶
scipy.stats দিয়ে PDF/CDF গণনা ও reproducible simulation। সব ক্ষেত্রে default_rng(seed) ব্যবহার করি যাতে ফল বারবার একই আসে।
৫.১ পাঁচটি distribution: PDF, CDF, mean — এক নজরে¶
import numpy as np
from scipy import stats
# প্রতিটি distribution scipy-তে: পছন্দের প্যারামিটার সহ একটি "frozen" object
dists = {
"Uniform(0,1)" : stats.uniform(loc=0, scale=1), # [loc, loc+scale]
"Exponential(rate=1)": stats.expon(scale=1/1.0), # scale = 1/rate (সাবধান!)
"Normal(0,1)" : stats.norm(loc=0, scale=1), # loc=mu, scale=sigma
"Gamma(k=3, th=1)" : stats.gamma(a=3, scale=1), # a = shape k
"Beta(2,5)" : stats.beta(a=2, b=5), # a, b shape params
}
print(f"{'distribution':22s} {'pdf(0.5)':>10s} {'cdf(0.5)':>10s} {'mean':>8s} {'var':>8s}")
for name, d in dists.items():
print(f"{name:22s} {d.pdf(0.5):10.4f} {d.cdf(0.5):10.4f} {d.mean():8.4f} {d.var():8.4f}")
প্রতিটি frozen distribution-এ আছে .pdf(x), .cdf(x), .ppf(p) (quantile = inverse CDF), .mean(), .var(), .rvs(size, random_state) (নমুনা)। একই ইন্টারফেস সব distribution-এ — এটাই scipy.stats-এর শক্তি।
৫.২ area = probability: \(\int f\) বনাম \(F(b)-F(a)\) (এবং normalization)¶
import numpy as np
from scipy import stats
from scipy.integrate import quad
d = stats.norm(loc=2, scale=1.5) # Normal(mu=2, sigma=1.5)
# (১) ব্যবধানের probability — দুইভাবে, একই হওয়া উচিত
a, b = 1.0, 4.0
area_integral = quad(d.pdf, a, b)[0] # সরাসরি integral (0.4-এর সংজ্ঞা)
area_cdf = d.cdf(b) - d.cdf(a) # CDF subtraction
print(f"P({a} <= X <= {b}): integral = {area_integral:.6f}, F(b)-F(a) = {area_cdf:.6f}")
# (২) normalization: মোট area = 1
total = quad(d.pdf, -np.inf, np.inf)[0]
print(f"মোট area (normalization) = {total:.6f}") # ~1.000000
# (৩) P(X = c) = 0 — শূন্য-প্রস্থ
print(f"P(X = 2) = {d.cdf(2) - d.cdf(2):.6f}") # ঠিক 0.0
quad (0.4-এর numeric integration) আর CDF-subtraction — দুটোই একই উত্তর দেয়, কারণ \(F(b)-F(a)=\int_a^b f\)। এটাই PDF↔CDF সম্পর্কের কোড-যাচাই।
৫.৩ Normal: z-score ও 68–95–99.7 rule সংখ্যায় যাচাই¶
import numpy as np
from scipy import stats
# z-score: X=86 in Normal(70, 8)
mu, sigma, x = 70, 8, 86
z = (x - mu) / sigma
print(f"z-score of {x} = {z:.2f} (গড়ের {z:.0f} sigma উপরে)")
# empirical rule — যেকোনো Normal-এ একই (standard normal দিয়ে হিসাব)
Z = stats.norm(0, 1)
for k in (1, 2, 3):
p = Z.cdf(k) - Z.cdf(-k)
print(f"mu +/- {k} sigma -> P = {p*100:.2f}%")
# 68.27%, 95.45%, 99.73%
z-score of 86 = 2.00 (গড়ের 2 sigma উপরে)
mu +/- 1 sigma -> P = 68.27%
mu +/- 2 sigma -> P = 95.45%
mu +/- 3 sigma -> P = 99.73%
(Section 4-এর হাতে-করা প্রমাণের সাথে হুবহু মেলে।) Z.ppf(0.975) ≈ 1.96 — inference-এ সবচেয়ে বিখ্যাত সংখ্যা (৯৫% confidence interval-এর সহগ, Part IV)।
৫.৪ reproducible simulation: histogram বনাম theoretical PDF¶
import numpy as np
from scipy import stats
rng = np.random.default_rng(42) # নির্দিষ্ট seed -> বারবার একই ফল
N = 100_000
# নমুনা টানি (rvs) এবং নমুনা-গড় বনাম তাত্ত্বিক গড় মেলাই
checks = [
("Uniform(0,15)", stats.uniform(0, 15)),
("Exponential(rate=0.5)", stats.expon(scale=1/0.5)),
("Normal(2,1.5)", stats.norm(2, 1.5)),
("Gamma(k=3,th=1)", stats.gamma(a=3, scale=1)),
("Beta(2,5)", stats.beta(a=2, b=5)),
]
print(f"{'distribution':22s} {'sample mean':>12s} {'true mean':>10s}")
for name, d in checks:
s = d.rvs(size=N, random_state=rng)
print(f"{name:22s} {s.mean():12.4f} {d.mean():10.4f}")
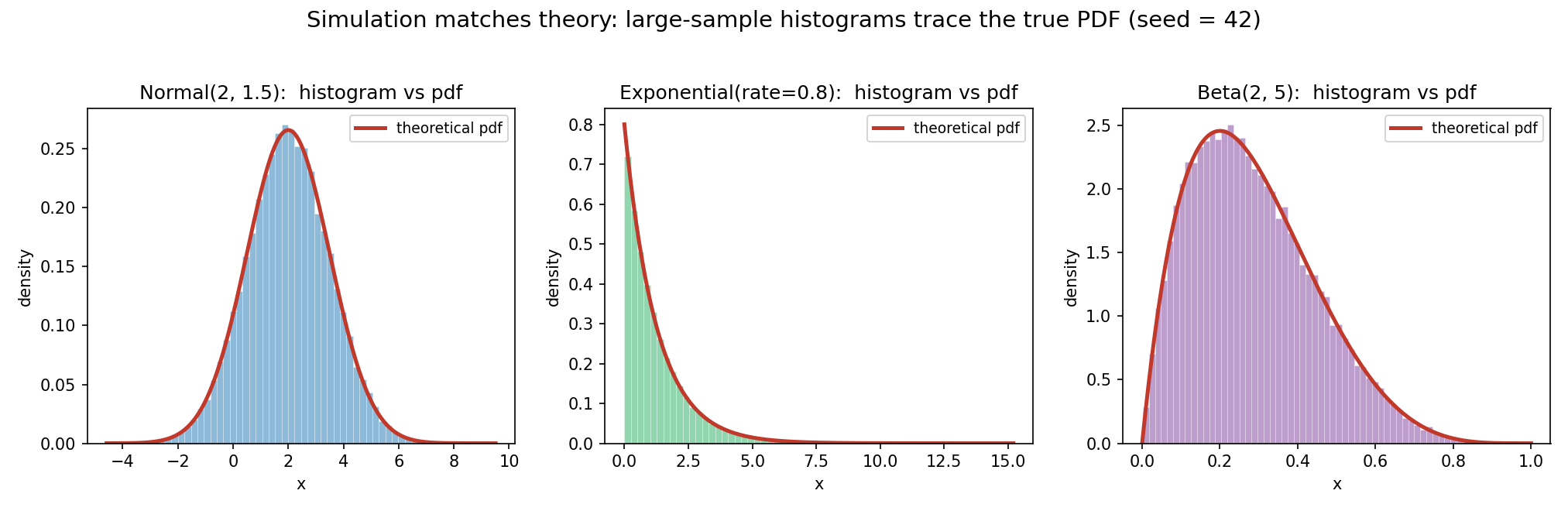
বড় \(N\)-এ নমুনা-গড় তাত্ত্বিক গড়ের খুব কাছে আসে (Law of Large Numbers, Part III-এর পূর্বাভাস)। random_state=rng দেওয়ায় ফল reproducible।
৫.৫ inverse-CDF কৌশল: Uniform থেকে Exponential বানানো¶
কীভাবে Uniform random number থেকে অন্য distribution তৈরি হয় (২.৭-এর সম্পর্ক) — Exponential-এ CDF উল্টে (\(F(x)=1-e^{-\lambda x}\) থেকে \(x=-\frac{1}{\lambda}\ln(1-u)\)):
import numpy as np
from scipy import stats
rng = np.random.default_rng(7)
lam = 0.5
u = rng.uniform(0, 1, size=200_000) # Uniform(0,1)
x = -np.log(1 - u) / lam # inverse-CDF -> Exponential(lam)
print(f"বানানো নমুনার গড় = {x.mean():.4f}")
print(f"তাত্ত্বিক গড় (1/lam) = {1/lam:.4f}")
# scipy-র নিজস্ব generator-এর সাথেও মেলে:
print(f"scipy expon গড় = {stats.expon(scale=1/lam).rvs(200_000, rng).mean():.4f}")
তিনটি গড়ই ~২.০-এর কাছাকাছি — হাতে-বানানো ও built-in দুই পথ একমত। এটাই দেখায় কেন Uniform সব simulation-এর বীজ।
৬ · ভিজ্যুয়ালাইজেশন¶
সব ছবি একটি স্ক্রিপ্ট
_code/figs_2-4.py-তে; PNG_assets/-এ (prefix2-4)। in-figure লেখা ইংরেজিতে।
Figure 1 — পাঁচটি PDF-এর "চিড়িয়াখানা"¶
পাঁচটি মূল distribution-এর আকৃতি একসাথে: Uniform (সমতল বাক্স), Exponential (ক্ষয়ী লেজ), Normal (ঘণ্টা), Gamma (shape বাড়লে যোগফল-আকৃতি), Beta (নমনীয়, \([0,1]\)-এ)। শেষ প্যানেলে এদের পারস্পরিক সম্পর্কের মানচিত্র।
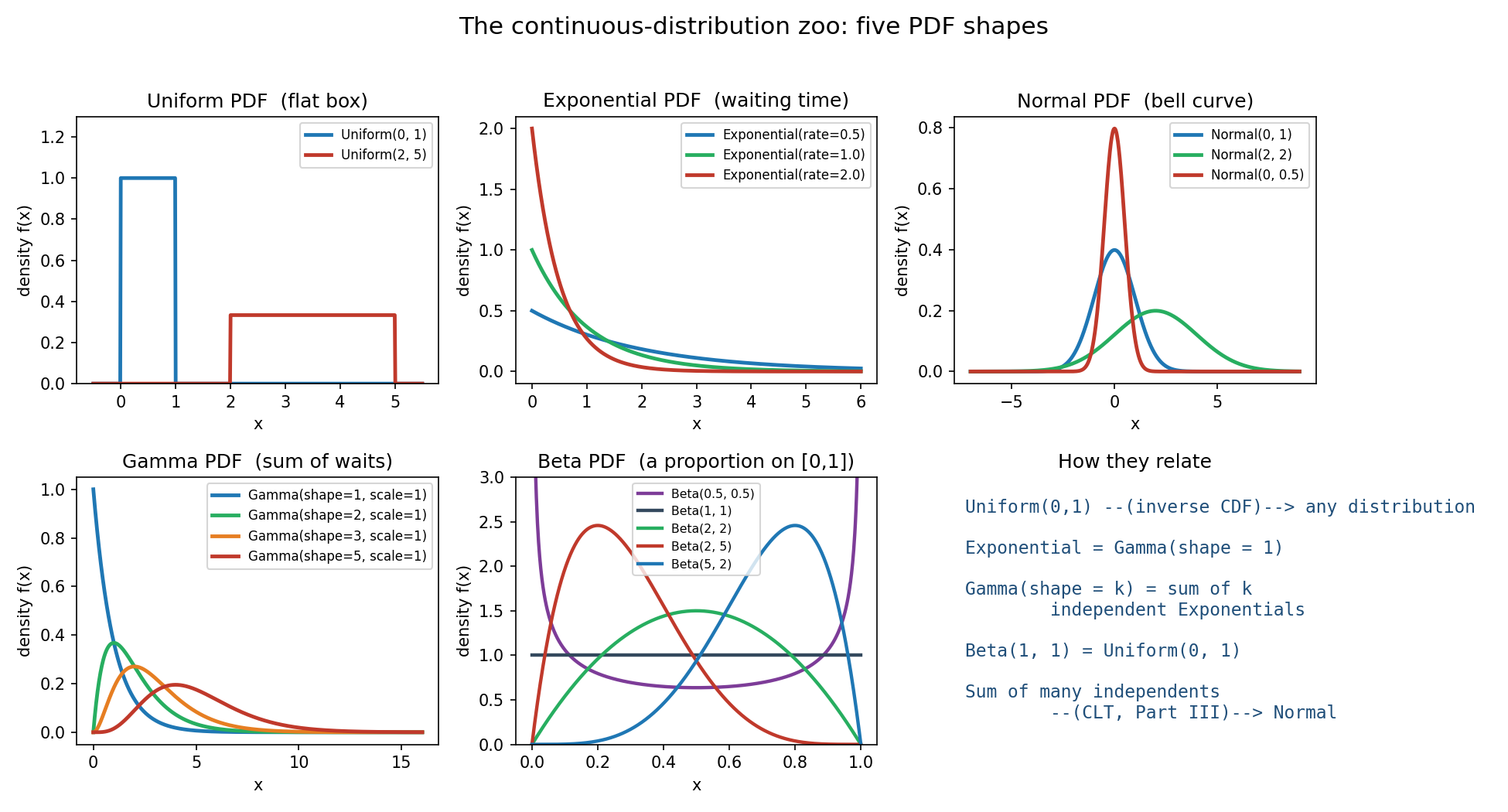
Figure 2 — probability = density-র নিচের area (Normal)¶
অধ্যায়ের কেন্দ্রীয় ছবি: standard Normal curve, আর নিচে \(-1 \le Z \le 1.5\) অঞ্চলের shaded area = সেই range-এ থাকার probability। density নিজে probability নয়; কেবল এই area-ই probability।
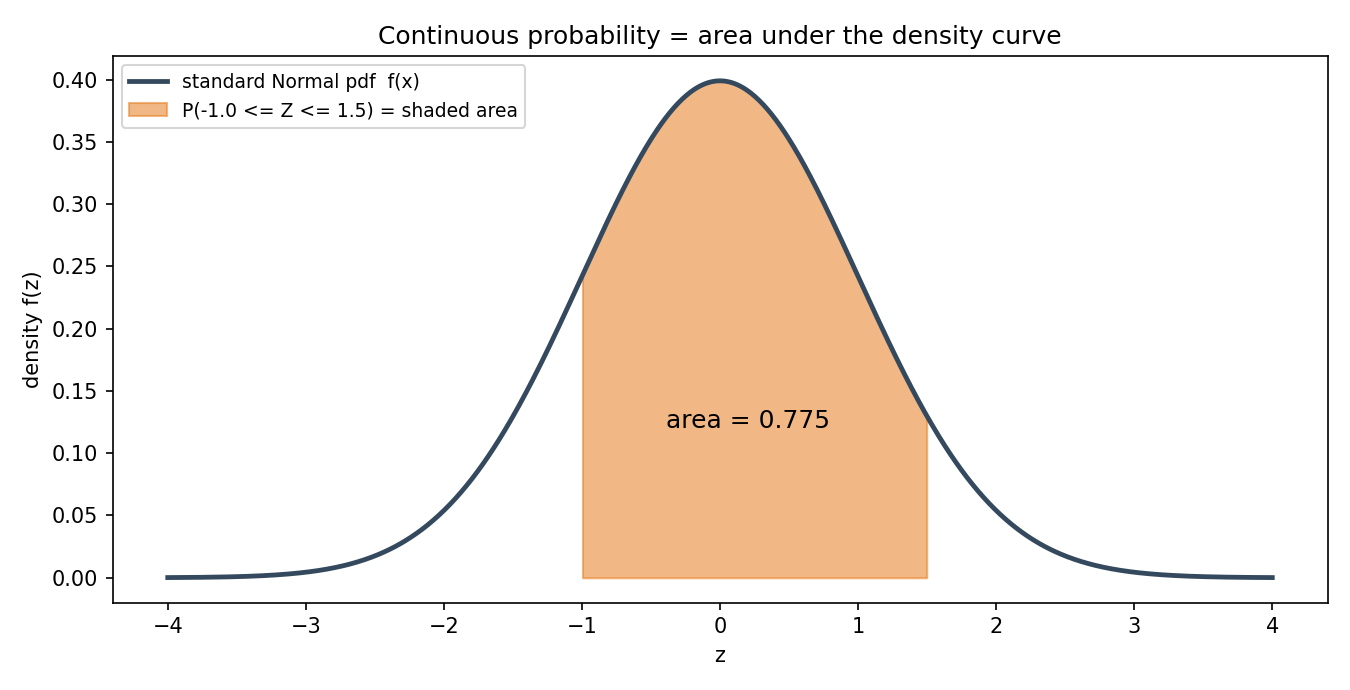
Figure 3 — Normal পরিবার: \(\mu\) সরায়, \(\sigma\) ছড়ায়¶
বাঁ প্যানেলে \(\mu\) বদলালে পুরো ঘণ্টা ডানে-বামে সরে (location); ডান প্যানেলে \(\sigma\) বদলালে ঘণ্টা সরু/চওড়া হয় (scale)। আকৃতি একই, কেবল অবস্থান ও বিস্তার বদলায়।
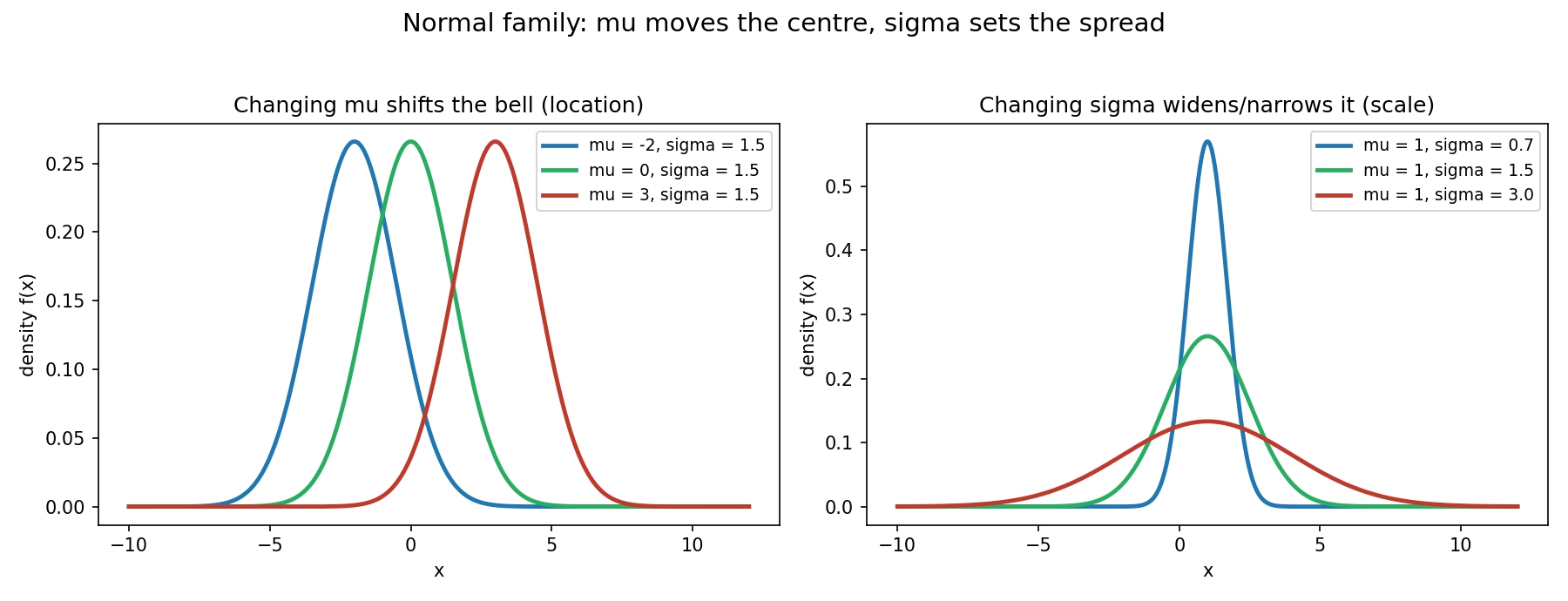
Figure 4 — 68–95–99.7 (empirical) rule¶
যেকোনো Normal-এ গড় থেকে \(1\sigma\)-এ ~৬৮%, \(2\sigma\)-এ ~৯৫%, \(3\sigma\)-এ ~৯৯.৭% area। চোখে দেখলেই "এই মান কি স্বাভাবিক, না বিরল?" আন্দাজ করা যায়।
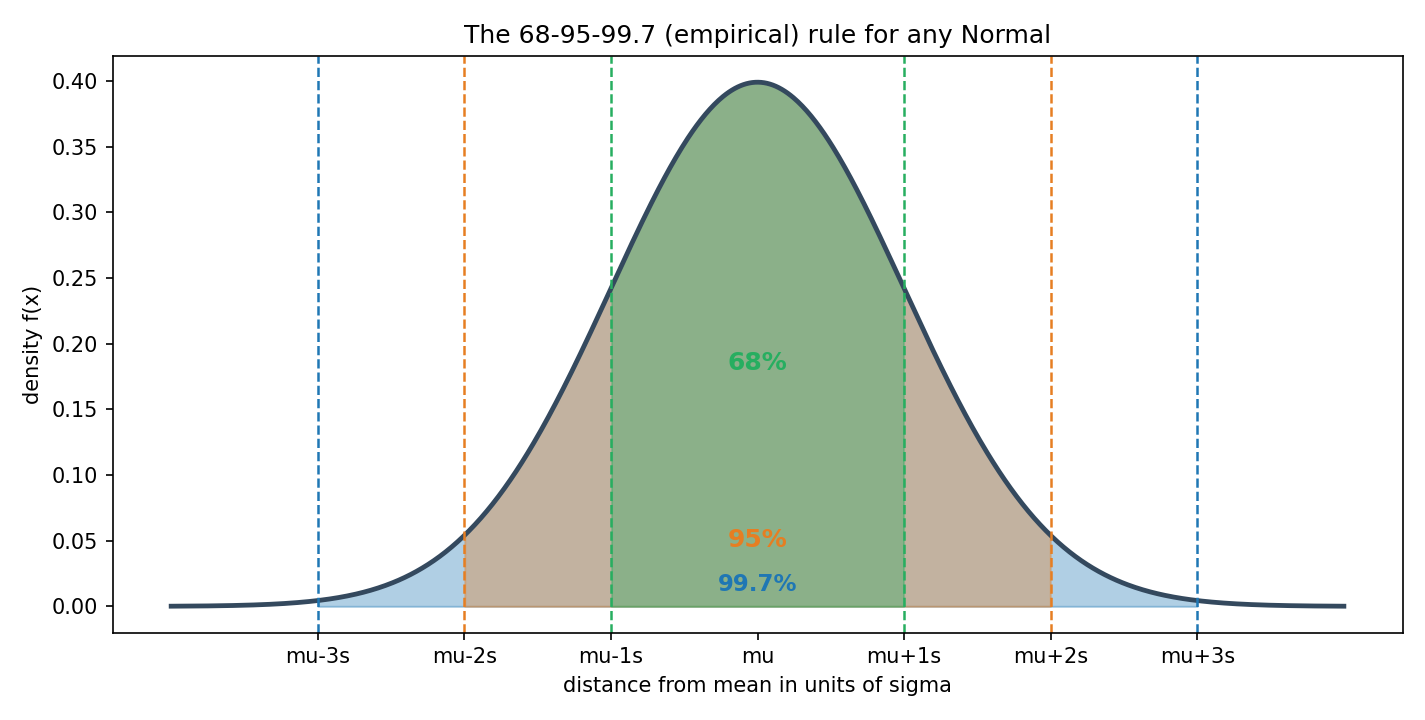
Figure 5 — Exponential-এর memorylessness¶
বাঁ প্যানেলে \(t=2\) অবধি অপেক্ষার পরের অংশ (survival) চিহ্নিত। ডান প্যানেলে চমক: "অবশিষ্ট অপেক্ষা" (\(X-t \mid X>t\))-এর density আদি Exponential-এর density-র সাথে হুবহু মিলে যায় — অতীত ভবিষ্যৎকে বদলায় না।
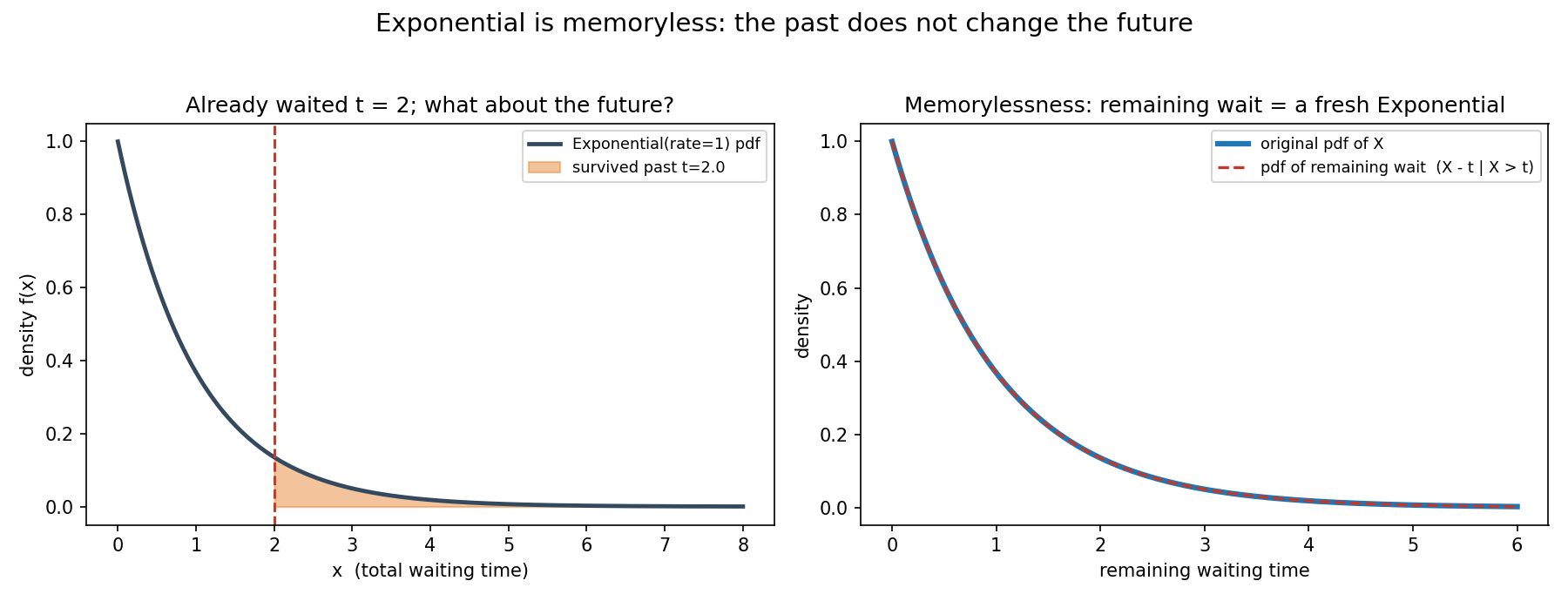
Figure 6 — PDF ও CDF: একই বস্তুর দুই রূপ (\(F'=f\))¶
বাঁ প্যানেলে PDF-এর \(x_0=1\) পর্যন্ত বাঁ-দিকের area = \(F(x_0)\)। ডান প্যানেলে সেই CDF: \(x_0\)-তে CDF-এর মান = ওই area, আর CDF-এর slope = সেখানকার density \(f(x_0)\)। এটাই \(F'=f\) ও area=probability-র একসাথে ছবি।
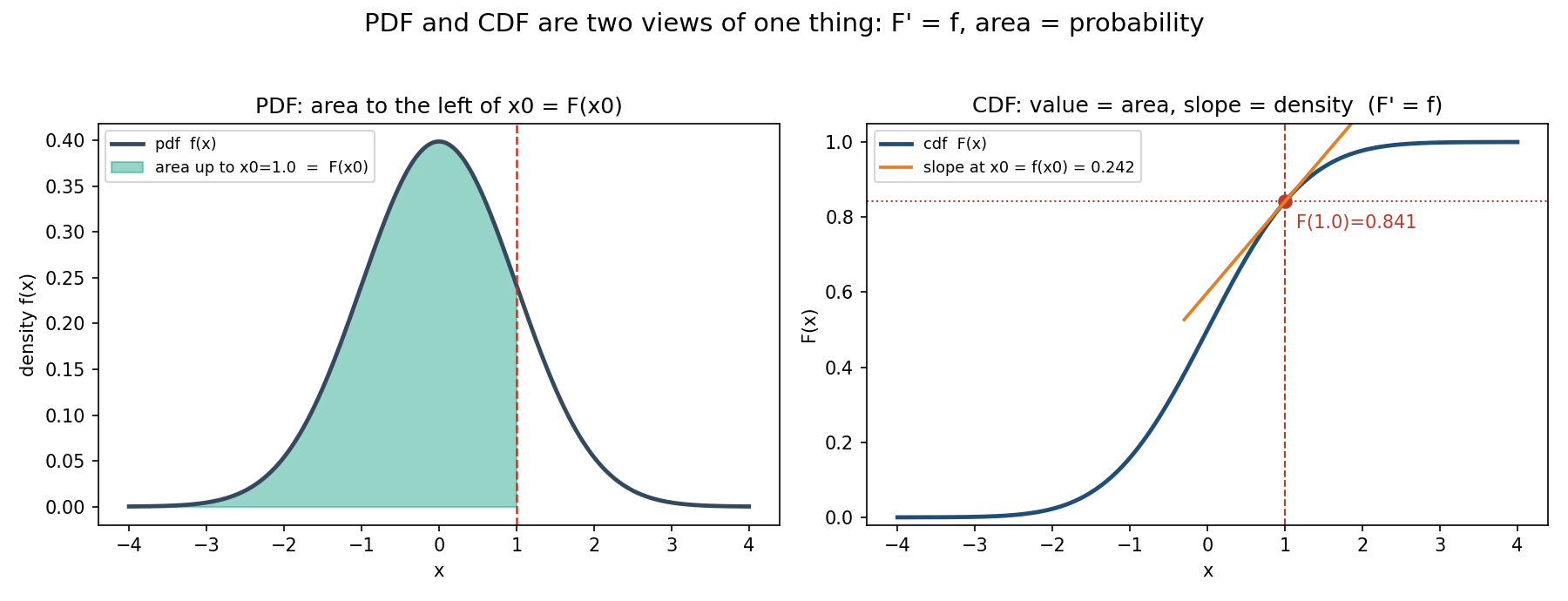
Figure 7 — simulation বনাম theory (seed = 42)¶
reproducible simulation-এ ৫০,০০০ নমুনার density-histogram তাত্ত্বিক PDF-এর গায়ে বসে যায় — Normal, Exponential, Beta তিনটিতেই। সংজ্ঞা ও বাস্তব নমুনা একমত।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও hint। পূর্ণ সমাধান _solutions/02-04-continuous-distributions-solutions.md-এ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় ব্যাখ্যা করুন কেন continuous ক্ষেত্রে \(P(X=c)=0\), অথচ \(X\) একটা মান নেবেই। তাহলে \(P(a\le X\le b)\) আর \(P(a<X<b)\) কেন সমান? Hint: শূন্য-প্রস্থ rectangle-এর area; প্রান্তবিন্দুর mass কত।
প্রশ্ন ২ (★). PDF \(f(x)\) আর PMF \(p(x)\)-এর মৌলিক পার্থক্য কী? কেন PDF \(1\)-এর চেয়ে বড় হতে পারে কিন্তু PMF পারে না? একটা সংখ্যাগত উদাহরণ দিন যেখানে \(f(x)>1\)। Hint: density বনাম probability; Uniform(0, 0.5)।
প্রশ্ন ৩ (★★). PDF আর CDF-এর সম্পর্ক (\(F'=f\) এবং \(F(x)=\int_{-\infty}^x f\)) এক প্যারাগ্রাফে ব্যাখ্যা করুন, 0.4-এর FTC-র সাথে যুক্ত করে। CDF সবসময় non-decreasing কেন? Hint: area জমা হলে কখনো কমে না; slope = density \(\ge 0\)।
প্রশ্ন ৪ (★★). memorylessness-এর বাক্যটা (\(P(X>s+t\mid X>s)=P(X>t)\)) সাধারণ ভাষায় ব্যাখ্যা করুন একটা bus-উদাহরণ দিয়ে। এটা কি স্বজ্ঞাত (intuitive) মনে হয়, না অস্বস্তিকর? কেন একটা ক্ষয়িষ্ণু যন্ত্রের জন্য এটা ভুল মডেল হবে? Hint: পুরোনো যন্ত্রের নষ্ট হওয়ার ঝুঁকি কি ধ্রুব?
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). \(X\sim\text{Uniform}(2, 10)\)। বের করুন: (ক) \(f(x)\); (খ) \(P(X<5)\); (গ) \(P(4\le X\le 7)\); (ঘ) median। Hint: উচ্চতা \(\frac{1}{b-a}\); area = প্রস্থ × উচ্চতা।
প্রশ্ন ৬ (★★). একটা call center-এ পরের কল আসতে সময় \(X\sim\text{Exponential}(\lambda)\), গড় ৪ মিনিট। (ক) \(\lambda=?\) (খ) \(P(X<2)\); (গ) \(P(X>6)\); (ঘ) ইতিমধ্যে ৩ মিনিট গেছে — আরও অন্তত ৪ মিনিট লাগার probability (memorylessness ব্যবহার করুন, তারপর সংজ্ঞা দিয়ে যাচাই)। Hint: \(\lambda=1/\text{mean}\); \(F(x)=1-e^{-\lambda x}\); \(S(x)=e^{-\lambda x}\)।
প্রশ্ন ৭ (★★). \(X\sim\mathcal{N}(100, 15^2)\) (IQ-র মতো)। (ক) IQ ১৩০-এর z-score; (খ) empirical rule দিয়ে আন্দাজ করুন কত শতাংশ ৭০–১৩০-এ; (গ) \(P(X>130)\) আনুমানিক; (ঘ) "টপ ১৬%" হতে অন্তত কত IQ লাগবে? Hint: \(z=(x-\mu)/\sigma\); ৭০ ও ১৩০ হলো \(\mu\pm2\sigma\); ১৬% ≈ \(\mu+1\sigma\)-র উপরে।
প্রশ্ন ৮ (★★). Beta(2, 5)-এর mean ও mode বের করুন (\(\text{mean}=\frac{\alpha}{\alpha+\beta}\), \(\text{mode}=\frac{\alpha-1}{\alpha+\beta-2}\) যখন \(\alpha,\beta>1\))। এই distribution একটা proportion-এর জন্য কেন যুক্তিসঙ্গত (skew কোন দিকে)? Hint: \(\alpha<\beta\) হলে কোন দিকে হেলানো; mean ও mode-র অবস্থান তুলনা করুন।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★★). ধরুন একটি continuous random variable \(X>0\) memoryless: সব \(s,t\ge0\)-তে \(S(s+t)=S(s)S(t)\) যেখানে \(S(x)=P(X>x)\)। দেখান এর একমাত্র (continuous, \(S(0)=1\)) সমাধান \(S(x)=e^{-\lambda x}\) — অর্থাৎ \(X\) অবশ্যই Exponential। Hint: \(g(x)=\ln S(x)\) ধরলে \(g(s+t)=g(s)+g(t)\) (Cauchy functional equation); continuous সমাধান \(g(x)=cx\)।
প্রশ্ন ১০ (★★). standard Normal PDF \(\phi(z)=\frac{1}{\sqrt{2\pi}}e^{-z^2/2}\) প্রতিসম প্রমাণ করুন (\(\phi(-z)=\phi(z)\)), এবং এর থেকে দেখান \(\Phi(-z)=1-\Phi(z)\) (যা empirical-rule হিসাবে আমরা ব্যবহার করেছি)। Hint: exponent-এ \((-z)^2=z^2\); প্রতিসম PDF-এর area-যুক্তি বা \(u=-t\) substitution।
ঘ · কোডিং (coding)¶
প্রশ্ন ১১ (★). scipy.stats দিয়ে যাচাই করুন Normal(0,1)-এ cdf(1)-cdf(-1), cdf(2)-cdf(-2), cdf(3)-cdf(-3) সত্যিই ~৬৮/৯৫/৯৯.৭%। তারপর ppf(0.975) ছাপিয়ে দেখুন কেন এটা ~১.৯৬।
Hint: stats.norm(0,1); .cdf, .ppf।
প্রশ্ন ১২ (★★). default_rng(0) দিয়ে Exponential(rate=1) থেকে ১০০,০০০ নমুনা টেনে: (ক) নমুনা-গড় বনাম তাত্ত্বিক গড় ১; (খ) নমুনা থেকে \(P(X>2)\) (অর্থাৎ (x>2).mean()) বনাম তাত্ত্বিক \(e^{-2}\) মেলান।
Hint: stats.expon(scale=1).rvs(100_000, rng); survival \(=e^{-\lambda x}\)।
প্রশ্ন ১৩ (★★★). inverse-CDF কৌশলে (§৫.৫-এর মতো) শুধু rng.uniform ব্যবহার করে Uniform(0,1) থেকে ৫,০০০ Exponential(rate=2) নমুনা বানান, তারপর তাদের density-histogram-এর উপর তাত্ত্বিক PDF এঁকে (matplotlib) মিল দেখান। (চাইলে নিজের স্ক্রিপ্টে, shared ফাইলে নয়।)
Hint: \(x=-\frac{1}{\lambda}\ln(1-u)\); plt.hist(..., density=True) + stats.expon(scale=1/2).pdf।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- continuous random variable-এর probability বিন্দুতে নয়, density curve-এর নিচের area-তে: \(P(a\le X\le b)=\int_a^b f(x)\,dx\) (0.4-এর সরাসরি ফল)। তাই \(P(X=c)=0\) এবং প্রান্ত \(<\) না \(\le\) — যায় আসে না।
- PDF \(f(x)\ge0\) একটা density (হার), probability নয় — \(1\)-এর বেশি হতে পারে; কেবল \(\int f=1\) (normalization) ও area-ই অর্থপূর্ণ।
- CDF \(F(x)=P(X\le x)=\int_{-\infty}^x f\); FTC-র ফলে \(F'=f\) — PDF ও CDF একই বস্তুর দুই রূপ (integrate ↔ differentiate)। \(P(a\le X\le b)=F(b)-F(a)\)।
- পাঁচটি distribution: Uniform (সমান-সম্ভাব্য বাক্স), Exponential (অপেক্ষার সময়, \(\lambda e^{-\lambda x}\), memoryless), Normal (ঘণ্টা, \(\mu\)=location, \(\sigma\)=scale, z-score ও 68–95–99.7 rule), Gamma (\(k\)টি Exponential-এর যোগফল), Beta (একটা অনুপাত \([0,1]\)-এ, নমনীয়)।
- সম্পর্ক: Exponential = Gamma(shape 1); Gamma(\(k\)) = \(k\) Exponential-এর যোগফল; Beta(1,1) = Uniform(0,1); Uniform → inverse-CDF → যেকোনো distribution; যোগফল → Normal (CLT)।
statistics-এর সাথে সংযোগ (কেন এত গুরুত্বপূর্ণ):
| ধারণা | statistics/ML-এ রূপ |
|---|---|
| Normal distribution | Central Limit Theorem (Part III); অধিকাংশ inference (CI, t/z-test) এর ভিত্তি |
| z-score, standardization | কোনো মান কত "অস্বাভাবিক" তা মাপা; feature scaling |
| 68–95–99.7 rule | outlier-শনাক্তকরণ, quality control, দ্রুত আন্দাজ |
| Exponential / Gamma | waiting time, reliability, survival analysis; Poisson process (পরে) |
| Beta | Bayesian inference-এ proportion-এর prior (Part IV; Binomial-এর conjugate) |
| PDF/CDF, \(\int f=1\) | maximum likelihood, density estimation — সব continuous মডেলের ভিত্তি |
পূর্ববর্তী সংযোগ (← 2.3, 0.4): discrete-এর PMF → continuous-এর PDF; যোগফল (\(\sum\)) → integral (\(\int\)); mass → density; "area=probability" ও normalization 0.4-এর integral থেকেই এসেছে, আর \(F'=f\) হলো 0.4-এর FTC-র প্রয়োগ।
পরবর্তী সংযোগ (→ 2.5): এরপর Expectation, Variance, Moments ও Moment-Generating Function (MGF) — অর্থাৎ এই distribution-গুলোর "গড় কোথায়", "কতটা ছড়ানো", আকৃতি (skew, kurtosis) কীভাবে সংখ্যায় ধরা হয়। আমরা যেসব mean/variance এখানে কেবল বলে দিয়েছি (যেমন Exponential-এর mean \(1/\lambda\), Beta-র \(\frac{\alpha}{\alpha+\beta}\)), 2.5-এ সেগুলো integral \(\mathbb{E}[X]=\int x f(x)\,dx\) থেকে উৎপন্ন করব — যা সরাসরি Part III-এর CLT-র দিকে নিয়ে যা