5.2 — Regression Diagnostics, Inference & Model Selection (রিগ্রেশন ডায়াগনস্টিকস, ইনফারেন্স ও মডেল নির্বাচন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "OLS সবসময় একটা লাইন দেয় — কিন্তু সেটা কি বিশ্বাসযোগ্য?"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
5.1-এ আমরা একটা শক্তিশালী যন্ত্র হাতে পেয়েছি: linear regression। data (\(X\) আর \(y\)) দিলে OLS এক ঝটকায় একটা সমীকরণ ফেরত দেয় —
যেখানে \(\hat\beta\) ("বিটা-হ্যাট") হলো coefficient-দের আন্দাজ, আর \(\hat y\) ("ওয়াই-হ্যাট") হলো মডেলের predict করা response। বাড়ির দাম-আয়তন উদাহরণে এটা আমাদের একটা সুন্দর fitted রেখা (বা বহু-predictor-এ একটা সমতল) দিয়েছিল, যা দিয়ে নতুন বাড়ির দাম আন্দাজ করা যায় আর প্রতিটি predictor-এর অবদান ব্যাখ্যা করা যায়।
কিন্তু এখানে একটা অস্বস্তিকর সত্য লুকিয়ে আছে, যা থেকেই এই গোটা অধ্যায়ের জন্ম। লক্ষ করুন সূত্রটার দিকে: \(\hat\beta = (X^\top X)^{-1} X^\top y\) — এটা যেকোনো \(X\) আর \(y\)-তে একটা উত্তর দেবে। আপনি যদি একদম এলোমেলো, সম্পর্কহীন সংখ্যা দিয়েও \(X\) আর \(y\) বানান, OLS অভিযোগ করবে না — সে নিঃশব্দে একটা \(\hat\beta\), একটা রেখা, একটা \(\hat y\) গণনা করে দেবে। অর্থাৎ:
OLS সবসময় একটা উত্তর দেয় — কিন্তু "উত্তর দিল" মানেই "উত্তরটা বিশ্বাসযোগ্য" নয়।
এতদিন (5.1) আমরা শিখেছি কীভাবে একটা মডেল fit করতে হয়। এই অধ্যায়ের প্রশ্ন তার ঠিক পরের, এবং সমান-গুরুত্বপূর্ণ ধাপ: fit করার পর কীভাবে যাচাই করব মডেলটা আদৌ ভালো কি না, এবং তার সংখ্যাগুলো কতটা বিশ্বাস করা যায়? এটাই "একটা মডেল fit করা" থেকে "একটা মডেলকে বিশ্বাস, সমালোচনা ও তুলনা করা"-য় উত্তরণ — পরিসংখ্যানিক মডেলিং-এর পরিণত অংশ।
১.২ Hook — একই \(\hat\beta\), কিন্তু এক মডেল বিশ্বাসযোগ্য, আরেকটা নয়¶
একটা চিন্তা-পরীক্ষা দিয়ে অস্বস্তিটা চোখে দেখাই। ধরুন দুই গবেষক দুটো ভিন্ন dataset-এ regression চালালেন, আর কাকতালীয়ভাবে দুজনেই হুবহু একই \(\hat\beta_1 = 0.45\) slope পেলেন, একই \(R^2 = 0.6\) পেলেন। শুধু এই সংখ্যাগুলো দেখে কি বলা যায় দুটো মডেল সমান-ভালো? — না। কারণ সংখ্যার আড়ালে যা লুকিয়ে থাকতে পারে:
- গবেষক ১-এর data-তে বিন্দুগুলো রেখার চারপাশে সুন্দর, সমান-ছড়ানো, এলোমেলোভাবে বসে আছে — মডেলটা সত্যিই data-র গঠন ধরেছে।
- গবেষক ২-এর data-তে হয়তো বিন্দুগুলো আসলে একটা বাঁকা (curved) প্যাটার্ন মানে, কিন্তু OLS জোর করে সরলরেখা বসিয়েছে; অথবা ছড়ানোটা একদিকে ফানেলের মতো বাড়ছে (variance সমান নয়); অথবা পুরো রেখাটা আসলে একটা মাত্র চরম বিন্দু টেনে ঘুরিয়ে দিয়েছে — সেই এক বিন্দু সরালে \(\hat\beta_1\) সম্পূর্ণ বদলে যায়।
বাইরে থেকে \(\hat\beta\) আর \(R^2\) একই, কিন্তু একটা মডেল নির্ভরযোগ্য আর আরেকটা প্রতারক। পার্থক্যটা সংখ্যায় নয়, residual-এর গঠনে ও বিন্দুগুলোর প্রভাবে লুকিয়ে — আর সেটা টেনে বের করাই regression diagnostics-এর কাজ। (পরিসংখ্যানের একটা বিখ্যাত উদাহরণ — Anscombe-এর চারটি dataset — দেখায় চারটি একদম আলাদা চেহারার data-র \(\hat\beta\), \(R^2\), এমনকি correlation পর্যন্ত হুবহু এক; পার্থক্য কেবল ছবিতে ধরা পড়ে। তাই "শুধু সংখ্যা দেখো না, ছবি আঁকো" — এটাই diagnostics-এর মূলমন্ত্র।)
এক বাক্যে: একটা fitted regression-এর coefficient ও \(R^2\) গল্পের অর্ধেক; বাকি অর্ধেক — মডেলটা কোন অনুমানের ওপর দাঁড়িয়ে, সেই অনুমান টিকছে কি না, আর কোনো বিন্দু অন্যায্য প্রভাব ফেলছে কি না — diagnostics ছাড়া অদৃশ্য থেকে যায়।
১.৩ LINE অনুমান ভাঙলে কী হয় — কেন diagnostics লাগে¶
5.1-এ আমরা LINE অনুমান চারটি দেখেছিলাম, যেগুলোর ওপর regression-এর inference দাঁড়ায়। এক-নজরে মনে করিয়ে দিই, কারণ এই অধ্যায়ের অর্ধেক diagnostics আসলে এদেরই পরীক্ষা:
- L — Linearity (রৈখিকতা): \(y\)-এর প্রত্যাশিত মান সত্যিই predictor-দের একটা রৈখিক সমন্বয়, অর্থাৎ \(\mathbb{E}[y \mid X] = X\beta\)। (এখানে \(\mathbb{E}[\,\cdot\mid X]\) মানে "\(X\) স্থির ধরে নিয়ে প্রত্যাশিত মান"।)
- I — Independence (স্বাধীনতা): error \(\varepsilon_i\)-গুলো পরস্পর-স্বাধীন — একটা বিন্দুর ত্রুটি আরেকটার ত্রুটি সম্পর্কে কিছু বলে না।
- N — Normality (Normal-তা): error-গুলো Normal বণ্টন মানে, \(\varepsilon_i \sim \mathcal{N}(0,\sigma^2)\) (\(\mathcal{N}\) = Normal/গাউসীয় বণ্টন)। এটাই t-test ও F-test-এর সঠিক p-value নিশ্চিত করে।
- E — Equal variance (সম-ভেদ, যাকে homoscedasticity বলে): সব error-এর variance একই \(\sigma^2\) — ছড়ানোটা \(X\)-এর সাথে বাড়ে-কমে না।
এই অনুমানগুলো নিছক আনুষ্ঠানিকতা নয় — এদের একটাও ভাঙলে কিছু-না-কিছু আসল ক্ষতি হয়, এবং সেই ক্ষতি নীরব (OLS তবু একটা উত্তর দেবে)। সংক্ষেপে কী ভাঙলে কী হয়:
| ভাঙে | পরিণতি | যে diagnostic ধরে |
|---|---|---|
| L (সম্পর্ক আসলে বাঁকা) | \(\hat\beta\) পক্ষপাতী (biased); predict ও ব্যাখ্যা দুটোই ভুল | residuals-vs-fitted-এ বাঁকা প্যাটার্ন |
| I (error পরস্পর-নির্ভর) | se ভুল (সাধারণত খুব ছোট) → CI সংকীর্ণ, p-value ভুলভাবে ছোট | residual-এ ক্রম/গুচ্ছ প্যাটার্ন |
| N (error Normal নয়) | ছোট \(n\)-এ t/F-এর p-value ও CI অনির্ভরযোগ্য | Normal QQ plot-এ লেজ বেঁকে যাওয়া |
| E (variance বদলায়) | \(\hat\beta\) ঠিক থাকলেও se ভুল → inference অবিশ্বাস্য | scale-location-এ ঊর্ধ্ব/নিম্নমুখী ঢাল |
লক্ষ করুন একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ বিভাজন: L ভাঙলে coefficient নিজেই ভুল, কিন্তু I/N/E ভাঙলে coefficient মোটামুটি ঠিক থেকেও তার চারপাশের অনিশ্চয়তা (se, CI, p-value) ভুল হয়ে যায় — অর্থাৎ point estimate ঠিক, কিন্তু "কতটা বিশ্বাস করব" তার হিসাব নষ্ট। দুই ধরনের ক্ষতিই বিপজ্জনক, আর দুটোই খালি চোখে \(\hat\beta\) দেখে ধরা যায় না — তাই আমরা residual-কে ময়নাতদন্তে পাঠাই।
আর এর পাশে আরেকটা স্বাধীন বিপদ: কোনো অনুমান না ভাঙলেও, একটা মাত্র চরম বা প্রভাবশালী বিন্দু পুরো fit-কে নিজের দিকে টেনে নিতে পারে (§১.২-এর গবেষক ২-এর শেষ কেস)। সেটা ধরতে লাগে leverage \(h_{ii}\) ও Cook's distance \(D_i\) (§২.৪)।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে। মোটা দাগে এই অধ্যায় তিনটি প্রশ্নের উত্তর দেয় — (ক) মডেলের অনুমান কি টিকছে ও কোনো বিন্দু কি অন্যায্য প্রভাব ফেলছে (diagnostics)? (খ) কোন predictor-গুলো সত্যিই দরকার ও তাদের coefficient কতটা নিশ্চিত (inference)? (গ) একাধিক প্রার্থী-মডেলের মধ্যে কোনটা বাছব (model selection)?
- §২ — মূল ধারণা ও সংজ্ঞা। residual-এর তিন রূপ (raw/standardized/studentized); চারটি diagnostic plot-এর অর্থ; leverage \(h_{ii}\) ও Cook's distance \(D_i\); coefficient-এর t-test ও মডেলের F-test (5.1-এর \(\mathrm{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\) থেকে se); \(\beta_j\)-র CI; \(R^2\) বনাম adjusted \(R^2\); penalized fit হিসেবে AIC ও BIC; multicollinearity ও VIF; এবং stepwise selection — সবই স্বজ্ঞা ও সংজ্ঞার স্তরে, প্রতিটি প্রতীক খোলা (গণিতের পূর্ণ প্রমাণ §৪-এ)।
- §৩ — হাতে-কলমে। একটা ছোট্ট dataset-এ residual, leverage, standardized residual, একটা coefficient-এর se ও t-stat, এবং \(R^2\) vs adjusted \(R^2\) পুরোপুরি হাতে-কলমে সংখ্যা সমেত গণনা — যাতে সূত্রগুলো বাস্তবে কীভাবে চলে তা চোখে দেখা যায়।
- §৪ — গণিত ও প্রমাণ। \(\mathrm{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\) থেকে se-র উৎপত্তি, \(t_j\)-র \(t\)-distribution, F-stat-এর গঠন, hat matrix \(H\)-এর ধর্ম (\(H\) idempotent, \(\sum_i h_{ii}=p\)), Cook's distance-এর সূত্র, এবং AIC/BIC-র likelihood-ভিত্তি।
- §৫–৬ — পূর্ণ উদাহরণ, চিত্র ও কোড। একটা বাস্তবসম্মত synthetic dataset-এ (price ~ area + age + rooms, সাথে একটা near-collinear predictor ও একটা high-leverage বিন্দু) সম্পূর্ণ diagnostics, inference ও selection — চিত্র 5-2-diagnostics (চার-প্যানেল residual plot), 5-2-leverage (leverage বনাম residual, Cook's-কনট্যুর সহ), 5-2-vif (VIF-বার), 5-2-model-selection (stepwise-পথে AIC/BIC) — এবং Python-কোড।
- §৭–৮ — সংযোগ, ভুল-ধারণা ও অনুশীলনী। diagnostics-এর সীমা, p-value ও \(R^2\) নিয়ে সাধারণ ভুল-বোঝাবুঝি, এবং অনুশীলনী।
এক বাক্যে কেন এটি Part V-এর অপরিহার্য ধাপ। 5.1 দিয়েছে "কীভাবে একটা মডেল fit করি"; এই অধ্যায় দেয় "fit করার পর সেটাকে কীভাবে বিশ্বাস, সমালোচনা ও তুলনা করি" — প্রতিটি প্রয়োগ-পরিসংখ্যানবিদের দৈনন্দিন কাজ। আর এখানকার diagnostics ও inference-এর কাঠামোই পরের অধ্যায় 5.3 (ANOVA ও experimental design)-এ কাজে লাগবে, যেখানে এই F-test ও variance-বিশ্লেষণকে আরও সাধারণ পরিস্থিতিতে বাড়ানো হবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞা — "fit হলো, এবার বিশ্বাসযোগ্যতা যাচাই" — কে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না। যেখানে গণিতের পূর্ণ প্রমাণ লাগবে (বিশেষত se-র সূত্র ও t/F-statistic-এর বণ্টন কোথা থেকে আসে), সেটা §৪-এ করা হবে — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
পুরো বিভাগের পরিকল্পনা: প্রথমে diagnostics-এর কাঁচামাল — residual ও তার তিন রূপ (§২.১), তারপর সেই residual থেকে গড়া চারটি diagnostic plot (§২.২) এবং প্রভাবশালী বিন্দু ধরার দুই যন্ত্র leverage ও Cook's distance (§২.৩–২.৪)। এরপর inference — coefficient-এর se, t-test, F-test ও CI (§২.৫–২.৭)। তারপর fit-এর মাপ \(R^2\) vs adjusted \(R^2\) (§২.৮) ও penalized সূচক AIC/BIC (§২.৯)। শেষে predictor-দের সমস্যা multicollinearity ও VIF (§২.১০) এবং তাদের বেছে নেওয়া stepwise selection (§২.১১)।
পুরো অধ্যায় জুড়ে আমরা 5.1-এর প্রতীক ধরে রাখব: \(n\) = পর্যবেক্ষণ-সংখ্যা, \(p\) = coefficient-সংখ্যা (intercept সমেত), \(X\) = \(n\times p\) design matrix, \(y\) = \(n\times 1\) response, \(\hat\beta = (X^\top X)^{-1}X^\top y\) = OLS estimate, \(\hat y = X\hat\beta\) = fitted value।
২.১ Residual ও তার তিন রূপ — raw, standardized, studentized¶
সব diagnostics-এর কাঁচামাল একটাই: residual — মডেল প্রতিটি বিন্দুতে কতটা "মিস" করল। 5.1-এ এর মূল রূপ দেখেছি; এখানে তাকে আরও সূক্ষ্ম তিন রূপে ভাগ করি, কারণ কোন রূপ ব্যবহার করছি তার ওপর diagnostic-এর নির্ভরযোগ্যতা নির্ভর করে।
(১) Raw residual (কাঁচা অবশিষ্ট)। সবচেয়ে সরল রূপ — বাস্তব বিয়োগ predict:
এখানে \(y_i\) = \(i\)-তম এককের বাস্তব response, \(\hat y_i\) = মডেলের predict করা মান, আর \(\hat\varepsilon_i\) ("এপসাইলন-হ্যাট-\(i\)") = তাদের পার্থক্য, অর্থাৎ বিন্দুটা fitted রেখা থেকে উল্লম্বভাবে কত উপরে (ধনাত্মক) বা নিচে (ঋণাত্মক)। সমস্যা: raw residual-এর একটা একক আছে (\(y\)-এর একক, যেমন টাকা) এবং তাদের ছড়ানো বিন্দুভেদে সমান নয় — তাই "\(\hat\varepsilon_i = 30\) কি বড়?" প্রশ্নের উত্তর সরাসরি দেওয়া যায় না।
কেন ছড়ানো সমান নয়? — এমনকি যদি সত্য error-গুলোর variance একই \(\sigma^2\) হয়, fitted residual-এর variance বিন্দুভেদে বদলায়। গণিত (§৪-এ) দেখায়:
যেখানে \(h_{ii}\) হলো সেই বিন্দুর leverage (§২.৩-এ পুরো খোলা হবে) — মোটামুটি "বিন্দুটা predictor-জগতে কতটা চরম"। অর্থাৎ চরম-অবস্থানের বিন্দুতে (\(h_{ii}\) বড়) residual স্বভাবতই ছোট ছড়ায়। এই অসমতা শোধরাতেই পরের দুই রূপ।
(২) Standardized residual (প্রমিত অবশিষ্ট)। raw residual-কে তার নিজের আনুমানিক standard deviation দিয়ে ভাগ করে একক-মুক্ত ও তুলনাযোগ্য করা:
এখানে \(\hat\sigma\) ("সিগমা-হ্যাট") = error-এর standard deviation-এর আন্দাজ, যা residual থেকে পাওয়া যায়:
(\(\mathrm{SSE} = \sum_i \hat\varepsilon_i^2\) = residual sum of squares, 5.1; ভাজক \(n-p\) = degrees of freedom, কারণ \(p\)টি coefficient আন্দাজ করতে \(p\)টি স্বাধীনতা "খরচ" হয়েছে)। ফলে \(r_i\) একটা একক-মুক্ত সংখ্যা, যার মান মোটামুটি "এই residual কত standard deviation দূরে"। বুড়ো-আঙুলের নিয়ম: \(\lvert r_i \rvert > 2\) বা \(3\) হলে বিন্দুটা সন্দেহজনক outlier।
(৩) Studentized residual (স্টুডেন্টাইজ্ড অবশিষ্ট, যাকে externally studentized বা deleted residual-ও বলে)। একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ পরিশোধন: standardized residual-এ \(\hat\sigma\) গণনায় বিন্দু \(i\) নিজেও ছিল — তাই \(i\) যদি সত্যিই বড় outlier হয়, সে \(\hat\sigma\)-কে ফুলিয়ে নিজের \(r_i\)-কেই ছোট দেখিয়ে আত্মগোপন করতে পারে। সমাধান: \(\hat\sigma\) হিসাব করার সময় বিন্দু \(i\)-কে বাদ দাও। বিন্দু \(i\) বাদ দিয়ে পাওয়া আন্দাজকে \(\hat\sigma_{(i)}\) লিখি; তখন
এই \(t_i\)-র সুবিধা: \(H_0\) "বিন্দু \(i\) একটা সাধারণ বিন্দু"-র অধীনে এটা ঠিক একটা \(t\)-distribution মানে (degrees of freedom \(n-p-1\)), তাই এর ওপর সরাসরি outlier-test চালানো যায়। (নাম "studentized" এই \(t\)-distribution থেকেই।)
এক বাক্যে: তিন রূপই "মডেল কত মিস করল" মাপে — raw \(\hat\varepsilon_i\) একক-সমেত ও অসম-ছড়ানো; standardized \(r_i\) একক-মুক্ত ও তুলনাযোগ্য; studentized \(t_i\) outlier-কে নিজের প্রভাব থেকে মুক্ত করে সবচেয়ে নির্ভরযোগ্যভাবে চরম-বিন্দু ধরে। diagnostic plot-এ সাধারণত standardized বা studentized রূপই ব্যবহার হয়, কারণ তবেই "কোন residual অস্বাভাবিক বড়" তুলনা করা অর্থপূর্ণ।
২.২ চারটি diagnostic plot — কোনটা কী যাচাই করে¶
residual হাতে এলে, পরবর্তী ধাপ তাদের আঁকা — কারণ §১.২-এ দেখেছি, সংখ্যা যা লুকায় ছবি তা ফাঁস করে। চারটি প্রমিত plot মিলে LINE-অনুমানের প্রতিটি দিক ও প্রভাবশালী বিন্দু ঢেকে ফেলে। (এই চারটিই একসাথে চিত্র 5-2-diagnostics-এ একটা চার-প্যানেল গ্রিডে দেখানো হবে; এখানে প্রতিটির অর্থ গাঁথি।) প্রতিটি plot-এর মূল কথা: "মডেল ঠিক হলে ছবিটা গঠনহীন/এলোমেলো দেখাবে; কোনো প্যাটার্ন মানেই কোনো অনুমান ভাঙছে।"
(ক) Residuals-vs-fitted (residual বনাম fitted value)। অনুভূমিক অক্ষে \(\hat y_i\), উল্লম্ব অক্ষে residual (\(\hat\varepsilon_i\) বা \(r_i\)), আর \(0\)-রেখায় একটা অনুভূমিক দাগ। যাচাই করে: L (linearity)। মডেল ঠিক হলে বিন্দুগুলো \(0\)-রেখার চারপাশে এলোমেলো ছড়িয়ে থাকবে, কোনো প্রবণতা ছাড়া। কিন্তু যদি একটা স্পষ্ট বাঁক (যেমন U বা উল্টানো-U আকৃতি) দেখা যায়, তার মানে সম্পর্কটা আসলে রৈখিক নয় — মডেল নিচু-fitted অঞ্চলে ধারাবাহিকভাবে কম/বেশি predict করছে। (একটা মসৃণ প্রবণতা-রেখা — LOESS — এই বাঁক চোখে আনতে সাহায্য করে।)
(খ) Normal Q–Q plot (Normal quantile–quantile, Normal কোয়ান্টাইল-চিত্র)। standardized residual-গুলোকে ছোট-থেকে-বড় সাজিয়ে, প্রতিটির বিপরীতে একটা standard Normal বণ্টনের সমতুল্য quantile বসিয়ে আঁকা — অর্থাৎ "আমার residual-গুলো কি Normal বণ্টনের মতো সাজানো?"। যাচাই করে: N (normality)। error সত্যিই Normal হলে বিন্দুগুলো একটা সরল ৪৫° রেখার ওপর প্রায় হুবহু বসবে। লেজের দিকে বিন্দু রেখা থেকে উপরে/নিচে বেঁকে গেলে বুঝব বণ্টন Normal নয় — ভারী লেজ (heavy tails) বা বঙ্কিমতা (skew)। ছোট \(n\)-এ এটা বিশেষ গুরুত্বপূর্ণ, কারণ তখন t/F-এর p-value Normal-তার ওপর সরাসরি নির্ভর করে।
(গ) Scale–location plot (মাপ-অবস্থান চিত্র, যাকে spread–location-ও বলে)। অনুভূমিক অক্ষে \(\hat y_i\), উল্লম্ব অক্ষে standardized residual-এর পরম-মানের বর্গমূল \(\sqrt{\lvert r_i \rvert}\)। যাচাই করে: E (equal variance / homoscedasticity)। variance সব জায়গায় সমান হলে এই ছবির মসৃণ প্রবণতা-রেখা মোটামুটি সমতল (অনুভূমিক) থাকবে — ছড়ানো fitted-মান নির্বিশেষে এক। কিন্তু রেখা যদি ঊর্ধ্বমুখী (বা নিম্নমুখী) ঢালে, তার মানে বড় fitted-মানে residual বেশি (বা কম) ছড়াচ্ছে — variance ধ্রুব নয় (heteroscedasticity), যা §১.৩-এর মতে se-কে ভুল করে। (পরম-মানের বর্গমূল কেন? — এতে ছড়ানোটা প্রতিসম ও কম-skewed দেখায়, প্রবণতা সহজে চোখে পড়ে।)
(ঘ) Residuals-vs-leverage (residual বনাম leverage)। অনুভূমিক অক্ষে leverage \(h_{ii}\), উল্লম্ব অক্ষে standardized residual \(r_i\), আর প্রায়ই Cook's distance-এর সমান-মানের কনট্যুর-রেখা আঁকা। যাচাই করে: প্রভাবশালী বিন্দু (influential points)। এই plot একসাথে দুটো জিনিস দেখায় — কোন বিন্দু predictor-জগতে চরম (ডানদিকে, বড় \(h_{ii}\)) আর কোন বিন্দুর residual বড় (উপরে/নিচে)। যে বিন্দু একই সাথে উঁচু leverage ও বড় residual — অর্থাৎ Cook's-কনট্যুরের বাইরে — সেটাই সবচেয়ে বিপজ্জনক: সে একাই পুরো fit-কে ঘুরিয়ে দিতে পারে। (এই plot-টি §২.৩–২.৪-এর leverage ও Cook's distance-কে চাক্ষুষ করে; চিত্র 5-2-leverage এটিকে আলাদা করে, Cook's-কনট্যুর সহ, বড় করে দেখাবে।)
এক বাক্যে গাঁথুন: চারটি plot LINE-অনুমান ভাগ করে নেয় — residuals-vs-fitted → L, Normal Q–Q → N, scale–location → E, residuals-vs-leverage → প্রভাবশালী বিন্দু (এবং I সাধারণত residual-এ ক্রম/গুচ্ছ-প্যাটার্ন বা আলাদা পরীক্ষায়)। সর্বত্র নিয়ম এক: গঠনহীন = ভালো, প্যাটার্ন = সতর্কতা।
২.৩ Leverage \(h_{ii}\) — predictor-জগতে কে কতটা চরম¶
এবার সেই দুই যন্ত্র, যা "একটা বিন্দু কি অন্যায্য প্রভাব ফেলছে?" প্রশ্নের উত্তর দেয়। প্রথমটা leverage — যা শুধু predictor-জগৎ (\(X\)) দেখে, \(y\)-কে নয়।
স্বজ্ঞা থেকে শুরু করি। একটা বিন্দুর "প্রভাব ফেলার সামর্থ্য" দুটো জিনিসের ওপর নির্ভর করে: (১) সে predictor-জগতে কতটা চরম অবস্থানে (অন্য বিন্দুদের মূল ঝাঁক থেকে কত দূরে), আর (২) তার response কতটা অপ্রত্যাশিত (বড় residual)। leverage মাপে শুধু প্রথমটা — কেবল \(X\)-অবস্থান, response নির্বিশেষে। একটা বিন্দু যত বেশি \(x\)-অক্ষে প্রান্তিক, তার leverage তত বেশি, আর fitted রেখাকে নিজের দিকে টানার সম্ভাব্য ক্ষমতা তত বড় (লম্বা লিভারে অল্প বল বেশি মোচড় দেয় — তাই নাম "leverage")।
আনুষ্ঠানিকভাবে, leverage আসে hat matrix থেকে। 5.1-এ দেখেছি fitted value \(\hat y = X\hat\beta = X(X^\top X)^{-1}X^\top y\)। এখানে \(y\)-কে \(\hat y\)-তে রূপান্তরকারী matrix-টিকে আলাদা করে নাম দিই:
\(H\) ("হ্যাট ম্যাট্রিক্স", মাত্রা \(n\times n\)) \(y\)-এর "মাথায় টুপি পরায়" — \(y\)-কে তার column-space-projection \(\hat y\)-তে পাঠায় (5.1-এর projection-জ্যামিতি)। এর কর্ণের উপাদানগুলোই leverage:
\(h_{ii}\) ("এইচ-আই-আই") = বিন্দু \(i\)-র leverage। এর তিনটি ধর্ম গাঁথা জরুরি (প্রমাণ §৪-এ):
- পরিসর: \(0 \le h_{ii} \le 1\) — প্রতিটি leverage শূন্য আর এক-এর মাঝে।
- যোগফল: \(\sum_{i=1}^n h_{ii} = p\) — সব leverage-এর যোগ ঠিক coefficient-সংখ্যা \(p\)-এর সমান। তাই গড় leverage \(= p/n\)।
- অর্থ: \(h_{ii}\) বলে \(\hat y_i\) গণনায় বিন্দুটির নিজের \(y_i\)-র ওজন কত — \(h_{ii} \approx 1\) মানে "মডেল এই বিন্দুতে কার্যত নিজের \(y_i\)-কেই predict করে", অর্থাৎ বিন্দুটা fit-কে নিজের দিকে প্রায় সম্পূর্ণ টেনে নিয়েছে।
বুড়ো-আঙুলের নিয়ম: \(h_{ii} > 2p/n\) (গড়ের দ্বিগুণ) বা \(3p/n\) হলে বিন্দুটি "high-leverage", আলাদা মনোযোগ দাবি করে। তবে — মনে রাখুন — উঁচু leverage নিজে খারাপ নয়; এটা শুধু "সম্ভাবনা"। বিন্দুটি যদি প্রবণতার সাথে মানানসই হয় (ছোট residual), উঁচু leverage থাকলেও সে fit-কে ঘোরায় না, বরং স্থিতিশীল করে। বিপদ তখনই, যখন উঁচু leverage আর বড় residual একসাথে — সেটাই Cook's distance মাপে (§২.৪)।
এক বাক্যে: leverage \(h_{ii}\) = hat matrix \(H=X(X^\top X)^{-1}X^\top\)-এর কর্ণ; এটা কেবল \(X\)-অবস্থান দেখে বলে "বিন্দুটা predictor-জগতে কতটা প্রান্তিক, তাই fit-কে টানার কত সামর্থ্য রাখে"। \(\sum_i h_{ii}=p\), গড় \(p/n\); \(2p/n\)-এর বেশি হলে সতর্ক হও — কিন্তু leverage একা ক্ষতি নয়, ক্ষতি হয় বড় residual-এর সঙ্গে মিললে।
২.৪ Cook's distance \(D_i\) — একটা বিন্দু বাদ দিলে fit কতটা নড়ে¶
leverage শুধু \(X\) দেখে; Cook's distance দুটোকে — leverage ও residual — একত্র করে প্রকৃত প্রভাব মাপে। এর প্রশ্নটা চমৎকার-সরল ও সরাসরি: "বিন্দু \(i\)-কে data থেকে বাদ দিলে গোটা fit (সব fitted value) কতটা বদলে যায়?" যদি একটা বিন্দু সরালে মডেল প্রায় একই থাকে, সে নগণ্য; কিন্তু একটা বিন্দু সরালে যদি পুরো রেখা লাফ দিয়ে সরে যায়, সে অত্যন্ত প্রভাবশালী।
আনুষ্ঠানিকভাবে, ধরা যাক \(\hat y_j\) = পূর্ণ data দিয়ে \(j\)-তম fitted value, আর \(\hat y_{j(i)}\) = বিন্দু \(i\) বাদ দিয়ে refit করে পাওয়া \(j\)-তম fitted value। তখন Cook's distance:
প্রতিটি অংশ খুলি:
- লব \(\sum_j (\hat y_j - \hat y_{j(i)})^2\) = বিন্দু \(i\) সরালে সব fitted value মিলে কতটা সরল, তার মোট বর্গ — অর্থাৎ "\(i\)-র অনুপস্থিতিতে পুরো fit কত দূরে সরে যায়"।
- হর \(p\,\hat\sigma^2\) একটা মাপকাঠি-সাধারণীকরণ (\(p\) = coefficient-সংখ্যা, \(\hat\sigma^2\) = error-variance-আন্দাজ), যাতে \(D_i\) একক-মুক্ত ও মডেল-জুড়ে তুলনাযোগ্য হয়।
সুন্দর ব্যাপার: \(D_i\)-কে প্রতিবার সত্যিই refit না করেও এক সূত্রে পাওয়া যায় (§৪-এ প্রমাণ), যা leverage ও standardized residual-কে একত্র করে:
এই রূপটা সরাসরি দেখায় Cook's distance-এর দুই উপাদান: \(r_i^2\) (residual কত বড়) আর \(\frac{h_{ii}}{1-h_{ii}}\) (leverage কত বড়)। একটা বিন্দু সত্যিকার বিপজ্জনক তখনই, যখন দুটোই বড় — ঠিক §২.৩-এ যা বলেছিলাম। কেবল বড় residual (কিন্তু ছোট leverage) বা কেবল বড় leverage (কিন্তু ছোট residual) — কোনোটাই একা মস্ত \(D_i\) দেয় না।
বুড়ো-আঙুলের নিয়ম: \(D_i > 1\) হলে বিন্দুটি দৃঢ়ভাবে প্রভাবশালী; ছোট dataset-এ \(D_i > 4/n\)-ও সতর্ক-সংকেত হিসেবে ব্যবহৃত হয়। প্রভাবশালী বিন্দু পেলে করণীয়: সেটা ভুল-এন্ট্রি কি না দেখা, কারণ খোঁজা, এবং বিন্দুটি সহ ও বাদ — দুই মডেল রিপোর্ট করে স্বচ্ছতা রাখা (এটিকে নিছক ফেলে দেওয়া নয়)।
এক বাক্যে: Cook's distance \(D_i\) = "বিন্দু \(i\) বাদ দিলে গোটা fit কতটা নড়ে", এক সংখ্যায়; সমতুল্যভাবে \(D_i \propto r_i^2 \cdot \tfrac{h_{ii}}{1-h_{ii}}\) — অর্থাৎ এটি বড় হয় কেবল যখন বড় residual ও উঁচু leverage একসাথে। \(D_i>1\) (বা ছোট-\(n\)-এ \(4/n\)) মানে বিন্দুটি একাই fit-কে অন্যায্যভাবে চালাচ্ছে কি না খতিয়ে দেখা দরকার।
২.৫ Coefficient-এর standard error — \(\mathrm{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\) থেকে¶
diagnostics শেষ; এবার inference — coefficient-গুলো কতটা নিশ্চিত। মূল অন্তর্দৃষ্টি: \(\hat\beta\) data-র (তাই random \(y\)-এর) একটা function, তাই \(\hat\beta\) নিজেও একটা random রাশি — অন্য একটা নমুনা পেলে অন্য \(\hat\beta\) পেতাম (4.1-এর sampling-distribution ভাবনা, এখন coefficient-এ প্রয়োগ)। কাজেই প্রতিটি \(\hat\beta_j\)-র একটা ছড়ানো — variance ও তার বর্গমূল standard error — আছে, যা ইনফারেন্সের ভিত্তি।
5.1-এ দেখেছি \(\hat\beta = (X^\top X)^{-1}X^\top y\) হলো \(y\)-এর একটা রৈখিক function। LINE অনুমানে (\(\varepsilon \sim \mathcal{N}(0,\sigma^2 I)\) ধরে) এর variance-covariance matrix-টি একটা পরিচ্ছন্ন রূপ নেয় (পূর্ণ derivation §৪-এ):
এটি একটা \(p\times p\) matrix (covariance matrix): এর \((j,j)\)-তম কর্ণ-উপাদান হলো \(\hat\beta_j\)-র variance, আর কর্ণের বাইরের উপাদান দুটি coefficient-আন্দাজের পারস্পরিক covariance। প্রতীক খুলি: \(\sigma^2\) = error-এর (অজানা) variance, \((X^\top X)^{-1}\) = design থেকে আসা সেই একই matrix যা \(\hat\beta\)-সূত্রে ছিল — অর্থাৎ coefficient-গুলোর অনিশ্চয়তা সম্পূর্ণভাবে error-এর মাপ (\(\sigma^2\)) ও predictor-দের বিন্যাস (\(X^\top X\)) — এই দুইয়ে নির্ধারিত।
বাস্তবে \(\sigma^2\) অজানা, তাই তাকে §২.১-এর আন্দাজ \(\hat\sigma^2 = \mathrm{SSE}/(n-p)\) দিয়ে বদলাই। তখন \(j\)-তম coefficient-এর standard error = তার variance-আন্দাজের বর্গমূল:
এখানে \(\big[(X^\top X)^{-1}\big]_{jj}\) = সেই inverse-matrix-এর \((j,j)\)-তম কর্ণ-উপাদান। কথায়: \(\mathrm{se}(\hat\beta_j)\) মাপে "এই coefficient-আন্দাজটা নমুনা-থেকে-নমুনায় গড়ে কতটা টলমল করে"। ছোট se = নিশ্চিত আন্দাজ; বড় se = অনিশ্চিত। লক্ষণীয়, predictor-রা পরস্পর-সম্পর্কিত হলে \((X^\top X)^{-1}\)-এর কর্ণ ফুলে ওঠে — তাই se বড় হয়; এই সংযোগই §২.১০-এর multicollinearity ও VIF-এর মূলে।
এক বাক্যে: \(\hat\beta\) random, তাই প্রতিটি \(\hat\beta_j\)-র অনিশ্চয়তা আছে — \(\mathrm{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\), আর \(\mathrm{se}(\hat\beta_j)=\hat\sigma\sqrt{[(X^\top X)^{-1}]_{jj}}\) সেই অনিশ্চয়তা এক সংখ্যায় দেয়। এই se-ই পরের সব inference-এর (t-test, CI) মুদ্রা — তাই এটিই সেতু, 5.1-এর সূত্র থেকে 4.6/4.7-এর কাঠামোয়।
২.৬ Per-coefficient t-test ও confidence interval — "\(x_j\)-র কি আদৌ দরকার?"¶
se হাতে এলে, প্রতিটি coefficient সম্পর্কে এখন 4.7-এর hypothesis test সরাসরি চালানো যায়। সবচেয়ে স্বাভাবিক প্রশ্ন: predictor \(x_j\)-র কি আদৌ কোনো ভূমিকা আছে, নাকি তার coefficient আসলে শূন্য? কারণ \(\beta_j = 0\) মানে "\(x_j\) response-এ (অন্যদের পরেও) কিছু যোগ করে না"। তাই null আর alternative:
4.7-এর কাঠামোয় test statistic = "আন্দাজ ভাগ তার standard error" — অর্থাৎ "\(\hat\beta_j\) শূন্য থেকে কত se দূরে":
\(t_j\) = \(j\)-তম coefficient-এর t-statistic। স্বজ্ঞা: \(\hat\beta_j\) যদি তার নিজের অনিশ্চয়তার (se) তুলনায় অনেক বড় হয় (\(\lvert t_j \rvert\) বড়), তাহলে "এটা আসলে শূন্য, শুধু random ওঠানামায় অশূন্য দেখাচ্ছে" — এই দাবি অবিশ্বাস্য হয়ে পড়ে, তাই \(H_0\) বাতিল। \(H_0\)-এর অধীনে (LINE ধরে) \(t_j\) একটা \(t\)-distribution মানে \(n-p\) degrees of freedom সহ (কারণ \(\hat\sigma\)-তে \(\sigma\) বদলেছি — ঠিক 4.6-এর \(t\)-যুক্তি, §৪-এ পূর্ণ)। তাই p-value = সেই \(t\)-বণ্টনে \(\lvert t_j \rvert\)-এর বাইরের দুই-লেজের ভর; \(p < \alpha\) (যেমন \(0.05\)) হলে "\(x_j\) statistically significant"।
একই se থেকে, 4.6-এর সূত্রে, \(\beta_j\)-র confidence interval:
এখানে \(t_{\alpha/2,\,n-p}\) = \(t\)-বণ্টনের (\(n-p\) df) critical value (যেমন বড় \(n\)-এ \(\approx 1.96\), \(95\%\)-এ)। এই ব্যবধান বলে "\(\beta_j\)-র যেসব মান data-র সাথে সঙ্গতিপূর্ণ"। আর 4.7-এর CI–test duality এখানেও খাটে: \(95\%\) CI-তে \(0\) থাকা মানেই \(\alpha=0.05\)-এ \(H_0:\beta_j=0\) বাতিল হয় না — অর্থাৎ "CI-তে \(0\) আছে কি না" দেখলেই t-test-এর রায় পড়া যায়। (একটা সতর্কতা: এই significance "অন্য সব predictor মডেলে আছে ধরে" — multiple regression-এর coefficient-ব্যাখ্যার মতোই শর্তাধীন; একটা predictor যোগ/বাদ দিলে অন্যের \(t_j\) বদলে যেতে পারে।)
এক বাক্যে: প্রতিটি coefficient-এ t-test \(t_j=\hat\beta_j/\mathrm{se}(\hat\beta_j)\) যাচাই করে "\(x_j\)-র কি দরকার?" (\(H_0:\beta_j=0\)); বড় \(\lvert t_j \rvert\) → ছোট p → \(x_j\) significant। আর CI \(\hat\beta_j \pm t_{\alpha/2}\,\mathrm{se}(\hat\beta_j)\) একই তথ্যকে ব্যবধানে দেয় — CI-তে \(0\) থাকা = significant নয়। দুটোই §২.৫-এর সেই একই se-র ওপর দাঁড়িয়ে।
২.৭ Overall F-test — "পুরো মডেলটাই কি অর্থহীন?"¶
t-test একটা একটা predictor যাচাই করে। কিন্তু একটা সামগ্রিক প্রশ্নও আছে: predictor-গুলো সবাই মিলে কি response সম্পর্কে আদৌ কিছু বলে, নাকি পুরো মডেলটাই শুধু গড় \(\bar y\)-এর সমান ভালো? এটাই overall F-test, যার null:
(লক্ষ করুন intercept \(\beta_0\) বাদ — null বলছে "intercept ছাড়া কোনো predictor-এরই ভূমিকা নেই")। alternative: এদের অন্তত একটি অশূন্য। যন্ত্র = variance-কে ভাগ করা। মোট তারতম্যকে দুই ভাগে ভাঙি: মডেল যা ব্যাখ্যা করল, আর যা পারল না —
যেখানে \(\bar y\) = response-এর গড়, \(\mathrm{SST}\) = মোট বর্গ-তারতম্য (total), \(\mathrm{SSR}\) = regression/explained, \(\mathrm{SSE}\) = residual। F-statistic এই দুই অংশের প্রতি-degree-of-freedom তুলনা:
স্বজ্ঞা: লব = "প্রতি predictor গড়ে কতটা তারতম্য ব্যাখ্যা করল", হর = "প্রতি অবশিষ্ট-degree-এ কত অব্যাখ্যাত তারতম্য রইল" (\(= \hat\sigma^2\))। অনুপাত বড় মানে "predictor-রা random-noise-এর তুলনায় অনেক বেশি ব্যাখ্যা করছে" — তাই \(H_0\) ("কেউ কিছু ব্যাখ্যা করে না") অবিশ্বাস্য। \(H_0\)-এর অধীনে \(F\) একটা \(F\)-distribution মানে \((p-1,\, n-p)\) degrees of freedom সহ; p-value = তার উপরের-লেজের ভর। (কেন আলাদা F-test, যখন t-test আছে? — অনেকগুলো t-test একসাথে চালালে শুধু কাকতালীয়ভাবেই কিছু significant দেখা দিতে পারে; F-test একটিমাত্র সামগ্রিক রায়ে এই বহু-তুলনার ফাঁদ এড়ায়। তাছাড়া simple regression-এ (\(p=2\)) এই F ঠিক \(t_1^2\)-এর সমান — দুটো একই কথা বলে।)
এক বাক্যে: overall F-test (\(F=\frac{\mathrm{SSR}/(p-1)}{\mathrm{SSE}/(n-p)}\)) একটিমাত্র রায়ে বলে "মডেলের অন্তত একটা predictor কি কিছু ব্যাখ্যা করে?" — বড় \(F\) → ছোট p → পুরো মডেল অর্থহীন নয়। t-test যাচাই করে কে অবদান রাখে, F-test যাচাই করে আদৌ কেউ রাখে কি না।
২.৮ \(R^2\) বনাম adjusted \(R^2\) — predictor বাড়ালেই কি মডেল "ভালো"?¶
5.1-এ fit-এর মাপ হিসেবে \(R^2\) দেখেছি:
অর্থাৎ মডেল response-এর মোট তারতম্যের কত ভগ্নাংশ ব্যাখ্যা করল (\(0 \le R^2 \le 1\); \(1\) = নিখুঁত fit)। কিন্তু \(R^2\)-এর একটা মারাত্মক দুর্বলতা আছে, যা একে মডেল-তুলনার জন্য বিপজ্জনক করে:
\(R^2\) কখনো কমে না — predictor যোগ করলে সবসময় বাড়ে (বা সমান থাকে), এমনকি predictor-টা সম্পূর্ণ অর্থহীন এলোমেলো সংখ্যা হলেও।
কারণ সহজ: একটা বাড়তি predictor OLS-কে SSE আরও কমানোর "স্বাধীনতা" দেয় (খারাপ হলে সে coefficient ~\(0\) বসাবে, ভালো হলে কাজে লাগাবে) — তাই SSE বাড়তে পারে না, ফলে \(R^2\) কমতে পারে না। এর মানে: শুধু \(R^2\) দেখে মডেল বাছলে আমরা সবসময় সবচেয়ে জটিল মডেলটাই বেছে নেব, যা overfitting-এর সরাসরি রাস্তা। দরকার এমন একটা মাপ, যা জটিলতার জন্য শাস্তি দেয়।
সেটাই adjusted \(R^2\) — যা degrees of freedom হিসাবে এনে predictor-সংখ্যার জন্য সংশোধন করে:
প্রতীক খুলি: \(n\) = পর্যবেক্ষণ, \(p\) = coefficient-সংখ্যা (intercept সহ)। মূল চাল — ভাজক \(n-p\): নতুন predictor যোগ করলে \(p\) বাড়ে, \(n-p\) ছোট হয়, তাই \(\frac{(1-R^2)(n-1)}{n-p}\) ভগ্নাংশটা বড় হওয়ার চাপ পায়। ফলে নতুন predictor-টা \(R^2\) যথেষ্ট না বাড়ালে adjusted \(R^2\) আসলে কমে যায়। তাই বৈশিষ্ট্য: adjusted \(R^2\) তখনই বাড়ে যখন নতুন predictor "নিজের খরচের চেয়ে বেশি" ব্যাখ্যা যোগ করে — অর্থাৎ এটা fit ও জটিলতার মধ্যে একটা আপস। (গাণিতিকভাবে \(R^2_{\text{adj}} \le R^2\) সবসময়, এবং predictor অর্থহীন হলে কমে।)
এক বাক্যে: \(R^2\) predictor বাড়ালেই বাড়ে (তাই মডেল-তুলনায় প্রতারক), কিন্তু \(R^2_{\text{adj}}=1-\frac{(1-R^2)(n-1)}{n-p}\) প্রতিটি predictor-এর জন্য degrees-of-freedom-দণ্ড আরোপ করে — তাই অপ্রয়োজনীয় predictor যোগ করলে এটি কমে, আর এই কারণেই দুটো ভিন্ন-আকারের মডেল তুলনায় \(R^2\) নয়, \(R^2_{\text{adj}}\) (বা §২.৯-এর AIC/BIC) ব্যবহার করা উচিত।
২.৯ AIC ও BIC — penalized fit, মডেল তুলনার মুদ্রা¶
adjusted \(R^2\) জটিলতাকে শাস্তি দেওয়ার এক উপায়, কিন্তু সবচেয়ে বহুল-ব্যবহৃত ও সাধারণ দুই সূচক — যা ভিন্ন মডেল (এমনকি non-nested) তুলনায় কাজে লাগে — হলো AIC ও BIC। দুটোরই দর্শন এক: "fit যত ভালো, তত ভালো; কিন্তু parameter যত বেশি, তত শাস্তি" — অর্থাৎ একটা penalized fit-স্কোর, যেখানে কম মান = ভালো মডেল।
দুটোই likelihood-এর ওপর দাঁড়ায়। মনে করুন 4.3/5.1-এর maximized likelihood \(\hat L\) = মডেল data-কে কতটা ভালো ব্যাখ্যা করে তার সর্বোচ্চ সম্ভাব্যতা (\(\ln\hat L\) = তার লগ; বেশি \(\ln\hat L\) = ভালো fit); আর \(k\) = মডেলের আন্দাজকৃত parameter-সংখ্যা (regression-এ \(k = p\) — intercept সহ coefficient-সংখ্যা; statsmodels এভাবেই AIC/BIC-এ \(k=p\) ধরে, \(\sigma^2\) আলাদা গোনে না)। তখন—
Akaike Information Criterion (AIC):
Bayesian Information Criterion (BIC):
দুই সূত্রেই দ্বিতীয় পদ \(-2\ln\hat L\) এক — এটা "misfit" মাপে (fit খারাপ হলে বড়, তাই কমানো-যোগ্য)। আর প্রথম পদ হলো জটিলতার শাস্তি: AIC-তে \(2k\), BIC-তে \(k\ln n\)। তুলনা করি দুটোর শাস্তি:
- AIC-এর শাস্তি প্রতি parameter-এ স্থির \(2\) — তুলনায় হালকা। এটি মূলত predictive accuracy (নতুন data-তে কেমন করবে) লক্ষ্য করে, তাই কিছুটা বড় মডেল বাছতে রাজি।
- BIC-এর শাস্তি \(\ln n\) প্রতি parameter — \(n>7\) হলেই \(\ln n > 2\), তাই BIC সাধারণত কঠোরতর, ছোট/সরল মডেল পছন্দ করে; বড় \(n\)-এ এই পার্থক্য তীব্র হয়। BIC-র উদ্দেশ্য "সত্য মডেল"-কে শনাক্ত করা (Bayesian যুক্তিতে)।
ব্যবহারিক নিয়ম: একগুচ্ছ প্রার্থী-মডেলের মধ্যে যার AIC (বা BIC) সবচেয়ে কম, সেটাই পছন্দ; AIC ও BIC ভিন্ন মডেল বাছলে, লক্ষ্য predictive হলে AIC, সরল-সত্য মডেল হলে BIC। (AIC/BIC-র পরম মান অর্থহীন; শুধু একই data-র ওপর মডেল-জোড়ার পার্থক্য অর্থবহ। চিত্র 5-2-model-selection stepwise-পথের প্রতিটি ধাপে AIC ও BIC কীভাবে নামে-ওঠে তা দেখাবে।)
এক বাক্যে: AIC \(=2k-2\ln\hat L\) ও BIC \(=k\ln n-2\ln\hat L\) দুটোই "ভালো fit (\(-2\ln\hat L\) ছোট) বনাম বেশি parameter (শাস্তি)" আপসকে এক সংখ্যায় ধরে — কম মান ভালো; BIC-র শাস্তি (\(k\ln n\)) AIC-র (\(2k\)) চেয়ে কঠোর, তাই BIC সরলতর মডেল বাছে। এরা \(R^2_{\text{adj}}\)-এর মতোই overfitting ঠেকায়, কিন্তু likelihood-ভিত্তিক হওয়ায় আরও ব্যাপক প্রয়োগযোগ্য।
২.১০ Multicollinearity ও VIF — predictor-রা যখন একে অপরের নকল¶
এতক্ষণ ধরে নিয়েছি predictor-রা মোটামুটি আলাদা তথ্য বহন করে। কিন্তু বাস্তবে দুটো (বা বেশি) predictor প্রায়ই নিজেরাই দৃঢ়ভাবে সম্পর্কিত হতে পারে — যেমন একটা বাড়ির "মেঝে-ক্ষেত্রফল" আর "মোট জমি-আয়তন" প্রায় একই তথ্য দেয়। এই পরিস্থিতিকে বলে multicollinearity (বহু-সহরৈখিকতা): design-এর কলামগুলো প্রায় রৈখিকভাবে নির্ভরশীল।
কেন এটা সমস্যা? — যখন দুটো predictor প্রায় একই, OLS তাদের আলাদা অবদান নির্ভরযোগ্যভাবে ভাগ করতে পারে না। গাণিতিকভাবে: কলাম প্রায়-নির্ভরশীল হলে \(X^\top X\) প্রায়-singular হয়ে পড়ে, তাই \((X^\top X)^{-1}\)-এর উপাদান বিস্ফোরিত হয় — আর §২.৫ অনুযায়ী \(\mathrm{se}(\hat\beta_j) = \hat\sigma\sqrt{[(X^\top X)^{-1}]_{jj}}\) তখন প্রচণ্ড বড়। ফলাফল: coefficient-গুলো অস্থির (নমুনা সামান্য বদলালে \(\hat\beta_j\) ভীষণ নড়ে, এমনকি চিহ্ন উল্টে যায়), CI চওড়া, t-stat ছোট। লক্ষণীয় — multicollinearity prediction-কে তেমন নষ্ট করে না, কিন্তু coefficient-এর ব্যাখ্যা ও inference-কে অবিশ্বাস্য করে দেয়।
কতটা সহরৈখিক, তা মাপে Variance Inflation Factor (VIF)। ধারণা: \(j\)-তম predictor-কে বাকি সব predictor দিয়ে regress করি (auxiliary regression) এবং তার \(R^2\)-কে \(R_j^2\) বলি — এটা বলে "\(x_j\)-র কত অংশ অন্যরা ইতিমধ্যে ব্যাখ্যা করে ফেলে"। তখন—
প্রতীক খুলি: \(R_j^2\) = "\(x_j \sim\) অন্য সব predictor" regression-এর \(R^2\)। স্বজ্ঞা: \(R_j^2 \approx 0\) (অন্যরা \(x_j\) সম্পর্কে কিছুই বলে না) হলে \(\mathrm{VIF}_j \approx 1\) — কোনো সমস্যা নেই; কিন্তু \(R_j^2 \to 1\) (অন্যরা \(x_j\)-কে প্রায় পুরো ব্যাখ্যা করে) হলে \(\mathrm{VIF}_j \to \infty\)। নামের অর্থ ঠিক এটাই: \(\mathrm{VIF}_j\) বলে multicollinearity-র কারণে \(\hat\beta_j\)-র variance কত গুণ ফুলে গেছে (সব predictor স্বাধীন হলে যা হতো তার তুলনায়)। বুড়ো-আঙুলের নিয়ম: \(\mathrm{VIF}_j > 5\) (কঠোরভাবে \(> 10\)) হলে গুরুতর সহরৈখিকতা — সমাধান: redundant predictor বাদ দেওয়া, বা সম্পর্কিতগুলোকে একত্র করা। (চিত্র 5-2-vif প্রতিটি predictor-এর VIF-কে বার হিসেবে দেখাবে, redundant predictor-টিকে চিহ্নিত করে।)
এক বাক্যে: multicollinearity = predictor-রা পরস্পর প্রায়-নকল, যা \((X^\top X)^{-1}\) ফুলিয়ে coefficient-এর se বিস্ফোরিত করে — তাই \(\hat\beta_j\) অস্থির ও inference অবিশ্বাস্য (যদিও prediction প্রায় অক্ষত)। \(\mathrm{VIF}_j=1/(1-R_j^2)\) মাপে এই variance কত গুণ ফুলেছে; \(>5\)–\(10\) মানে redundant predictor সরানো বা একত্র করা দরকার।
২.১১ Model selection — forward ও backward stepwise¶
শেষ ধারণা, যা পুরো অধ্যায়কে একত্র করে। হাতে অনেক প্রার্থী-predictor থাকলে প্রশ্ন: কোন উপসেটটা রাখব? সব রাখলে overfitting ও multicollinearity; খুব কম রাখলে আসল সম্পর্ক মিস। অর্থাৎ আমরা চাই এমন একটা মডেল যা যথেষ্ট ব্যাখ্যা করে অথচ অপ্রয়োজনীয় predictor-হীন — fit ও সরলতার ভারসাম্য, ঠিক §২.৮–২.৯-এর মাপ যা পুরস্কৃত করে।
\(p-1\)টি predictor থাকলে সম্ভাব্য উপসেট \(2^{p-1}\)টি — predictor বাড়লে এদের সব যাচাই করা অসম্ভব। Stepwise selection একটা লোভী (greedy), ধাপে-ধাপে আপস: প্রতিবার একটা predictor যোগ বা বাদ দিয়ে একটা নির্বাচন-মাপ (সাধারণত AIC, কখনো BIC বা adjusted \(R^2\)) সবচেয়ে বেশি উন্নত করা, যতক্ষণ আর উন্নতি না হয়। তিনটি রূপ:
- Forward selection (অগ্রমুখী): শূন্য predictor (শুধু intercept) থেকে শুরু; প্রতি ধাপে যে predictor যোগ করলে মাপ সবচেয়ে ভালো হয় (যেমন AIC সবচেয়ে কমে) তাকে যোগ করো; আর কোনো যোগ উন্নতি না করলে থামো।
- Backward elimination (পশ্চাৎমুখী): সব predictor দিয়ে শুরু; প্রতি ধাপে যে predictor বাদ দিলে মাপ সবচেয়ে ভালো হয় তাকে ফেলো; আর কোনো বাদ উন্নতি না করলে থামো।
- Stepwise (both): প্রতি ধাপে যোগ ও বাদ — দুটোই বিবেচনা করো, যাতে আগে-যোগ-করা কোনো predictor পরে অপ্রয়োজনীয় হলে বাদও দেওয়া যায়।
একটা সততার সতর্কতা গাঁথা জরুরি: stepwise একটা লোভী heuristic — এটা \(2^{p-1}\) মডেলের সেরাটির নিশ্চয়তা দেয় না (একটা ধাপে ভালো মনে হওয়া পথ চূড়ান্তভাবে সেরা না-ও হতে পারে)। তাছাড়া একই data-তে বহুবার test চালানোয় এটি p-value-কে আশাবাদী করে তোলে ও কিছুটা overfit করে। তাই এর ফলকে চূড়ান্ত সত্য নয়, একটা যুক্তিসঙ্গত প্রার্থী হিসেবে নেওয়া উচিত — বিষয়-জ্ঞান, diagnostics ও (সম্ভব হলে) আলাদা validation-data দিয়ে যাচাই করে। (চিত্র 5-2-model-selection একটা stepwise-পথ ধাপে-ধাপে দেখাবে: প্রতি ধাপে কোন predictor যোগ/বাদ হলো ও AIC/BIC কীভাবে বদলাল।)
এক বাক্যে: model selection বাছে "কোন predictor-উপসেট রাখব", fit ও সরলতার ভারসাম্যে; forward (শূন্য থেকে যোগ), backward (সব থেকে বাদ), ও both (যোগ+বাদ) — প্রতিটি একটা মাপ (সাধারণত AIC) লোভীভাবে উন্নত করে। কিন্তু এটি heuristic, বিশ্বব্যাপী সেরা নয় ও কিছুটা overfit করে — তাই ফলকে বিচার-বুদ্ধি ও validation দিয়ে যাচাই করা চাই, অন্ধভাবে নয়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
আগের অংশগুলোতে আমরা regression diagnostics, inference আর model selection-এর tool-গুলো একে একে সংজ্ঞায়িত করেছি — residual \(\hat\varepsilon_i\), leverage \(h_{ii}\), Cook's distance \(D_i\), t-statistic, F-statistic, VIF, adjusted \(R^2\), AIC/BIC। এবার একটা বাস্তব (synthetic) dataset-এ এই সবগুলো হাতে-কলমে চালিয়ে দেখব যে সংখ্যাগুলো আসলে কেমন আসে আর কীভাবে পড়তে হয়।
আমরা একটি ছোট house-price dataset ব্যবহার করব (\(n=200\)), যেটা ইচ্ছাকৃতভাবে একটা জানা data-generating process (DGP) থেকে তৈরি — অর্থাৎ "সত্যিকারের" coefficient-গুলো আমরা জানি, তাই estimate কতটা কাছাকাছি এল তা মিলিয়ে দেখা যাবে। সত্যিকারের সম্পর্ক:
এর সাথে একটা চতুর্থ variable plot_size \(\approx 1.15\cdot\texttt{area}\) আছে (প্রায় area-এরই rescaled কপি, সামান্য noise সহ) — এটা পরে multicollinearity দেখানোর কাজে লাগবে। আর একটা জায়গায় ইচ্ছাকৃতভাবে একটা অস্বাভাবিক বিন্দু বসানো আছে: row 0-তে area = 340 (বাকি সবার area \(\le 200\)) কিন্তু তার price মাত্র 250 — এই বিন্দুটা পরে high-leverage / influential point হিসেবে ধরা পড়বে।
চারটি ধাপে এগোব:
- E1 — Inference:
price ~ area + age + roomsmodel fit করে প্রতিটি coefficient-এর estimate, standard error, t-stat, p-value আর 95% confidence interval পড়ব; কোনগুলো significant তা বলব এবং overall F-test দিয়ে গোটা model-টা significant কিনা যাচাই করব। - E2 — Diagnostics পড়া: residuals-vs-fitted আর normal QQ plot দেখে LINE assumption-গুলো টিকছে কিনা বলব, এবং residual standard error ও \(R^2\) বনাম adjusted \(R^2\) হিসাব করব।
- E3 — Leverage ও influence: injected বিন্দুটা (row 0) যে সত্যিই বড় leverage \(h_{ii}\) ও বড় Cook's distance ধরায় তা দেখাব এবং বিন্দুটা রেখে বনাম বাদ দিয়ে fit তুলনা করব।
- E4 — Multicollinearity ও model selection:
plot_sizeযোগ করলে area ও plot_size-এর VIF কীভাবে লাফিয়ে ওঠে, standard error ফুলে যায় ও sign পর্যন্ত উল্টে যায় তা দেখব; পাশাপাশি কয়েকটা nested model-এর AIC/BIC তুলনা করে selection করব।
সব সংখ্যা statsmodels দিয়ে বের করা; অংশের শেষে একটা verification block দেওয়া আছে যাতে যে কেউ চালিয়ে মিলিয়ে নিতে পারে।
E1 — Inference: coefficient, t-test ও F-test পড়া¶
আমরা baseline model fit করি:
OLS fit করার পর statsmodels যে summary দেয়, তার মূল সংখ্যাগুলো এক টেবিলে সাজালে:
| term | \(\hat\beta_j\) | \(\mathrm{se}(\hat\beta_j)\) | \(t_j\) | \(p\)-value | 95% CI |
|---|---|---|---|---|---|
| const (intercept) | \(16.955\) | \(4.671\) | \(3.63\) | \(0.0004\) | \([7.74,\ 26.17]\) |
area |
\(0.4956\) | \(0.0258\) | \(19.21\) | \(6.2\times10^{-47}\) | \([0.445,\ 0.547]\) |
age |
\(-0.7203\) | \(0.1009\) | \(-7.14\) | \(1.8\times10^{-11}\) | \([-0.919,\ -0.521]\) |
rooms |
\(6.4982\) | \(0.5032\) | \(12.91\) | \(5.2\times10^{-28}\) | \([5.506,\ 7.490]\) |
ধাপ ১ — প্রতিটি t-statistic কী বলছে। মনে রাখা যাক \(t_j = \hat\beta_j / \mathrm{se}(\hat\beta_j)\), যেটা null hypothesis \(H_0:\beta_j=0\) (অর্থাৎ "এই predictor-টার আলাদা কোনো effect নেই") পরীক্ষা করে। এখানে \(\mathrm{df}=n-p=200-4=196\), তাই \(\lvert t_j\rvert\) মোটামুটি \(2\)-এর বেশি হলেই \(5\%\) level-এ significant ধরা হয়। সব চারটা term-এই \(\lvert t_j\rvert\) অনেক বড় (\(3.6,\ 19.2,\ 7.1,\ 12.9\)) এবং তাদের p-value কার্যত শূন্য — অর্থাৎ চারটি coefficient-ই \(5\%\) (এমনকি \(0.1\%\)) level-এ significant।
ধাপ ২ — estimate-গুলো সত্যিকারের মানের সাথে মিলছে কিনা। DGP-তে সত্যিকারের মান ছিল \(\beta_1=0.45,\ \beta_2=-0.8,\ \beta_3=6,\ \beta_0=25\)। estimate এসেছে \(0.496,\ -0.720,\ 6.498,\ 16.95\)। area, age, rooms-এর estimate সত্যিকারের মানের খুব কাছে এবং প্রতিটির 95% CI-ও সত্যিকারের মানকে ঘিরে রেখেছে (যেমন area-এর \([0.445,0.547]\) \(0.45\)-কে ধরে রেখেছে, age-এর \([-0.919,-0.521]\) \(-0.8\)-কে ধরে রেখেছে)। intercept-টা একটু কম (\(16.95\) বনাম \(25\)) এসেছে — এর প্রধান কারণ row 0-এর বসানো অস্বাভাবিক বিন্দু, যেটা fit-টাকে সামান্য টেনে নামিয়েছে (E3-তে এর প্রমাণ দেখব)।
সতর্কতা — coefficient interpretation। \(\hat\beta_1=0.496\)-এর মানে: অন্য predictor (age, rooms) স্থির রেখে area ১ একক বাড়লে price গড়ে \(\approx 0.496\) একক বাড়ে। "অন্যগুলো স্থির রেখে" শর্তটা multiple regression-এ অপরিহার্য — একে ignore করলে partial effect-কে ভুল করে total effect ভাবা হয়।
ধাপ ৩ — overall F-test। আলাদা আলাদা t-test বলে কোন একক predictor গুরুত্বপূর্ণ; কিন্তু "গোটা model-টা কি আদৌ কিছু explain করে?" — এই প্রশ্নের উত্তর দেয় overall F-test, যার null hypothesis
(অর্থাৎ intercept-only model-এর তুলনায় কোনো predictor-ই সাহায্য করে না)। এখানে
\(F=213.7\) বিশাল আর p-value কার্যত শূন্য, তাই \(H_0\) জোরালোভাবে reject হয় — model-টা সামগ্রিকভাবে অত্যন্ত significant। এখানে t-test আর F-test একই কথা বলছে, কিন্তু সবসময় বলবে না: multicollinearity থাকলে F বড় (model significant) হতে পারে অথচ কোনো একক t ছোট (individually insignificant) হয়ে যেতে পারে — সেই বৈপরীত্য E4-তে দেখব।
E2 — Diagnostics পড়া: LINE, residual SE ও \(R^2\)¶
inference-এর p-value আর CI বিশ্বাসযোগ্য হবে কেবল তখনই, যখন regression-এর LINE assumption-গুলো মোটামুটি টেকে: Linearity, Independence, Normality (residual-এর), Equal variance (homoscedasticity)। এই dataset যেহেতু সরাসরি একটা linear-plus-normal-noise model থেকে তৈরি, তাই আশা করা যায় assumption-গুলো টিকবে — সেটাই আমরা diagnostic দিয়ে যাচাই করি।
ধাপ ১ — residuals-vs-fitted plot। \(\hat\varepsilon_i\)-কে \(\hat y_i\)-এর বিপরীতে plot করলে আদর্শ চিত্র হলো \(0\)-এর চারপাশে কোনো pattern ছাড়া এলোমেলো ছড়ানো একটা band — কোনো curve (linearity ভাঙার লক্ষণ) বা funnel আকার (heteroscedasticity-র লক্ষণ) থাকা চলবে না।
ε̂_i
│ . . .
30│ . . . . . . .
│ . . . . . . . . . . . . .
0│─.─.───.─.───.───.─.──.───.──.───.─── fitted ŷ_i
│ . . . . . . . . . . . . . .
-30│ . . . . . . . .
│ . .
└──────────────────────────────────────
20 40 60 80 100
এখানে residual-গুলো \(0\)-রেখার দুপাশে সমানভাবে, fitted value-র পুরো range জুড়ে একই রকম ছড়িয়ে আছে — কোনো systematic বাঁক বা variance বাড়া-কমা নেই। তাই Linearity আর Equal variance assumption টিকছে। (formal নিশ্চিতকরণ হিসেবে statsmodels-এর summary-তে Durbin–Watson \(= 1.98\), যেটা \(2\)-র খুব কাছে — independence-এর লক্ষণ; এবং Breusch–Pagan-জাতীয় test চালালে heteroscedasticity পাওয়া যায় না।)
ধাপ ২ — normal QQ plot। standardized residual-গুলোকে theoretical normal quantile-এর বিপরীতে plot করলে, residual normal হলে বিন্দুগুলো \(45^\circ\) reference line-এর ওপর বসে।
sample
quantile .
2│ . .
1│ . .
0│ . . . (points hug the 45° line)
-1│ . .
-2│ . .
└──────────────────────────
-2 -1 0 1 2
theoretical quantile
বিন্দুগুলো reference line-কে প্রায় হুবহু অনুসরণ করছে, দুই প্রান্তেও বড় বিচ্যুতি নেই। summary-র Jarque–Bera test-ও এর সাথে সঙ্গতিপূর্ণ: \(\mathrm{JB}=1.65,\ p=0.44\), skewness \(=0.22\), kurtosis \(=3.10\) (normal-এর জন্য আদর্শ মান \(0\) ও \(3\))। অর্থাৎ Normality assumption টিকছে। সব মিলিয়ে LINE-এর চারটি শর্তই সন্তোষজনক, তাই E1-এর inference বিশ্বাসযোগ্য।
ধাপ ৩ — residual standard error। model-এর typical prediction error মাপে residual standard error (যাকে \(\hat\sigma\)-ও বলা হয়):
এটা DGP-র সত্যিকারের noise standard deviation \(\sigma=15\)-এর কাছাকাছি — সামান্য বড় হওয়ার কারণ আবারও সেই row 0-এর বিন্দু, যেটা একটা বড় residual তৈরি করে \(\hat\sigma\)-কে একটু বাড়িয়ে দিয়েছে। মোটামুটি বললে, price-এর prediction-এ typical এদিক-ওদিক \(\approx \pm 16\) একক।
ধাপ ৪ — \(R^2\) বনাম adjusted \(R^2\)।
\(R^2=0.766\)-এর মানে price-এর মোট variance-এর \(\approx 76.6\%\) এই তিন predictor ব্যাখ্যা করছে। দুটোর পার্থক্য এত সামান্য কেন? কারণ adjusted \(R^2\) predictor-সংখ্যার জন্য penalty বসায়:
আর এখানে predictor মাত্র \(3\)টি অথচ \(n=200\) — অর্থাৎ প্রতিটি predictor "তার ভাড়া পুষিয়ে দিচ্ছে", কোনো অপ্রয়োজনীয় variable নেই। (E4-তে দেখব, একটা প্রায়-redundant variable ঢোকালে \(R^2\) একটু বাড়লেও adjusted \(R^2\)-এর বাড়াটা নগণ্য হয় — সেটাই overfitting-এর সংকেত।)
E3 — Leverage ও influence: injected বিন্দুটা ধরা পড়ছে কি?¶
এবার E1-এর সেই baseline model-টাকেই influence diagnostics-এর চোখে দেখি। মনে আছে, row 0-তে আমরা ইচ্ছাকৃতভাবে area = 340 (বাকি সবার থেকে অনেক বড়) বসিয়েছিলাম। leverage আর Cook's distance এই অস্বাভাবিকতা ধরতে পারে কিনা দেখা যাক।
ধাপ ১ — leverage \(h_{ii}\)। leverage মাপে একটা observation predictor-space-এ গড় থেকে কতটা দূরে — অর্থাৎ তার \(x\)-মান কতটা "extreme"। \(h_{ii}\)-এর গড় সবসময় \(p/n\), এখানে \(4/200 = 0.02\)। একটা প্রচলিত thumb-rule: \(h_{ii} > 2p/n = 0.04\) হলে বিন্দুটাকে high-leverage বলে সন্দেহ করা হয়।
| row 0 (injected) | পরবর্তী সর্বোচ্চ (row 119) | গড় (\(p/n\)) | threshold (\(2p/n\)) | |
|---|---|---|---|---|
| \(h_{ii}\) | \(\mathbf{0.1328}\) | \(0.0373\) | \(0.02\) | \(0.04\) |
row 0-এর leverage \(h_{ii}=0.133\) — মানে গড়ের প্রায় ৬.৬ গুণ এবং বাকি সব observation-এর সর্বোচ্চ leverage-এরও প্রায় সাড়ে তিন গুণ। অর্থাৎ row 0 predictor-space-এ স্পষ্টভাবে বিচ্ছিন্ন একটা high-leverage point — ঠিক যেমনটা আমরা বসিয়েছিলাম।
ধাপ ২ — Cook's distance \(D_i\)। কিন্তু high leverage মানেই বিপদ নয়; বিন্দুটা যদি regression line-এর সাথে মানিয়েও যায়, তবে তেমন ক্ষতি নেই। আসল প্রশ্ন: বিন্দুটা বাদ দিলে fit কতটা পাল্টায়? সেটাই মাপে Cook's distance, যা leverage আর residual দুটোকেই একসাথে ধরে। প্রচলিত thumb-rule: \(D_i > 4/n = 0.02\) হলে influential বলে সন্দেহ।
| row 0 | পরবর্তী সর্বোচ্চ (row 161) | threshold (\(4/n\)) | |
|---|---|---|---|
| \(D_i\) | \(\mathbf{0.529}\) | \(0.047\) | \(0.02\) |
row 0-এর \(D_0 = 0.529\) — পরের সর্বোচ্চ মানের (\(0.047\)) থেকে প্রায় ১১ গুণ বড় এবং threshold-এর ২৬ গুণ। অর্থাৎ row 0 শুধু high-leverage নয়, রীতিমতো influential — কারণ তার area চরম বড় হলেও price ছোট, তাই বিন্দুটা সত্যিকারের সম্পর্কের বিপরীতে টানছে। (নোট: \(4/n\) rule অনুযায়ী আরও \(14\)টা বিন্দু সামান্য threshold পেরোয়, কিন্তু তাদের \(D_i\) সবই \(0.05\)-এর নিচে — row 0-এর তুলনায় নগণ্য; এটাই বুঝিয়ে দেয় কেন কেবল threshold-এ আটকে না থেকে আপেক্ষিক মাত্রা দেখা জরুরি।)
ধাপ ৩ — বিন্দুটা রেখে বনাম বাদ দিয়ে fit তুলনা। influence-এর সবচেয়ে সরাসরি প্রমাণ — row 0 বাদ দিয়ে আবার fit করে দেখা:
| সব \(200\) বিন্দু সহ | row 0 বাদ দিয়ে (\(n=199\)) | |
|---|---|---|
area coef (\(\hat\beta_1\)) |
\(0.4956\) | \(0.4600\) |
area se |
\(0.0258\) | \(0.0266\) |
| intercept (\(\hat\beta_0\)) | \(16.95\) | \(22.00\) |
| \(R^2\) | \(0.766\) | \(0.756\) |
| residual SE \(\hat\sigma\) | \(16.30\) | \(15.76\) |
একটিমাত্র বিন্দু বাদ দিতেই intercept \(16.95 \to 22.00\)-তে লাফ দিল (সত্যিকারের মান \(25\)-এর অনেক কাছে চলে এল!), area-এর slope \(0.496 \to 0.460\) পাল্টাল, আর residual SE \(16.30 \to 15.76\)-তে নামল (সত্যিকারের \(\sigma=15\)-এর কাছাকাছি)। অর্থাৎ ওই একটা influential বিন্দু পুরো model-টাকে সত্যিকারের DGP থেকে খানিকটা সরিয়ে রেখেছিল।
শিক্ষা। \(n=200\)-এও একটিমাত্র বিন্দু intercept-কে \(5\) একক সরিয়ে দিতে পারে। তাই influential observation চোখে পড়লে সেটাকে অন্ধভাবে বাদ দেওয়া নয় — আগে খতিয়ে দেখতে হয় এটা data-entry ভুল, না কি বৈধ কিন্তু বিরল ঘটনা; তারপর সিদ্ধান্ত (রাখা / বাদ / robust regression)।
E4 — Multicollinearity ও model selection¶
এতক্ষণ baseline তিন-predictor model ভালোই চলছিল। এবার ইচ্ছাকৃতভাবে সমস্যা ঢোকাই: model-এ plot_size যোগ করি, যেটা প্রায় \(1.15\times\texttt{area}\) — অর্থাৎ area-এরই প্রায় পুনরাবৃত্তি। দুটো প্রায় একই তথ্য বহনকারী predictor একসাথে থাকলে কী হয়, তা দেখা যাক।
ধাপ ১ — correlation আর VIF। প্রথমে দেখি area ও plot_size কতটা সম্পর্কিত:
প্রায়-perfect correlation। এর প্রভাব মাপতে VIF (variance inflation factor) ব্যবহার করি, যেখানে predictor \(j\)-এর জন্য \(\mathrm{VIF}_j = 1/(1-R_j^2)\), আর \(R_j^2\) হলো \(x_j\)-কে বাকি সব predictor দিয়ে regress করলে পাওয়া \(R^2\)। thumb-rule: \(\mathrm{VIF} > 5\) হলে সতর্ক, \(> 10\) হলে গুরুতর।
| predictor | VIF (plot_size ছাড়া) | VIF (plot_size সহ) |
|---|---|---|
area |
\(1.01\) | \(\mathbf{7.71}\) |
age |
\(1.01\) | \(1.04\) |
rooms |
\(1.00\) | \(1.00\) |
plot_size |
— | \(\mathbf{7.80}\) |
ফলাফলটা নাটকীয়: plot_size ঢোকানোর আগে area-এর VIF ছিল মাত্র \(1.01\) (কার্যত কোনো collinearity নেই), কিন্তু ঢোকানোর পর সেটা লাফ দিয়ে \(7.71\)-এ চলে গেল, আর plot_size-এর নিজেরও \(7.80\)। age আর rooms অবিচল রইল (\(\approx 1\)) — কারণ সমস্যাটা কেবল area↔plot_size জুটির মধ্যেই। (হাতে যাচাই: area-কে age, rooms, plot_size দিয়ে regress করলে \(R_{\text{area}}^2 = 0.870\), তাই \(\mathrm{VIF}_{\text{area}} = 1/(1-0.870) = 7.71\) — ঠিক মিলে যাচ্ছে।)
ধাপ ২ — standard error ফুলে ওঠা ও sign উল্টানো। multicollinearity-র আসল উপসর্গ coefficient-এর অস্থিরতা। দুই model-এর তুলনা:
| baseline (area, age, rooms) | + plot_size | |
|---|---|---|
area coef |
\(0.496\) | \(0.710\) |
area se |
\(\mathbf{0.0258}\) | \(\mathbf{0.0697}\) |
plot_size coef |
— | \(\mathbf{-0.207}\) |
plot_size se |
— | \(0.0627\) |
plot_size t / p |
— | \(-3.29\) / \(0.0012\) |
লক্ষ করুন তিনটি ক্লাসিক উপসর্গ:
- se ফুলে গেছে: area-এর standard error \(0.0258 \to 0.0697\) — প্রায় ২.৭ গুণ বড়। VIF-এর সংজ্ঞা অনুযায়ী এটাই প্রত্যাশিত, কারণ \(\mathrm{se}(\hat\beta_j) \propto \sqrt{\mathrm{VIF}_j}\), আর \(\sqrt{7.71/1.01}\approx 2.76\) — হিসাব মিলে যাচ্ছে।
- coefficient অস্থির ও sign অর্থহীন: area-এর coefficient \(0.496 \to 0.710\)-এ লাফ দিল, আর plot_size-এর coefficient এসেছে ঋণাত্মক (\(-0.207\)) — অথচ DGP-তে বড় plot_size মানেই বড় area, তাই price বাড়ারই কথা! এই উল্টো sign পুরোপুরি spurious — দুটো প্রায়-একই variable-এর মধ্যে effect-টা কীভাবে ভাগ হবে তা data ঠিকঠাক ঠিক করতে পারছে না।
- তবু t significant: মজার ব্যাপার, plot_size-এর \(p=0.0012\), অর্থাৎ "significant" দেখাচ্ছে — কিন্তু সেটা বিভ্রান্তিকর, কারণ coefficient-এর মান ও sign-ই অর্থহীন। এখানেই F বনাম t-এর সেই বৈপরীত্যের ছায়া: গোটা model significant, অথচ ভেতরে individual coefficient-গুলো একে অপরের সাথে তথ্য ভাগাভাগি করে অস্থির হয়ে গেছে।
ধাপ ৩ — AIC/BIC দিয়ে model selection। কোন model রাখব? শুধু \(R^2\) দেখলে সবসময় বড় model জিতবে (variable যোগ করলে \(R^2\) কখনো কমে না)। তাই complexity-র জন্য penalty বসানো criterion দরকার — AIC (\(=2k - 2\ln\hat L\)) আর BIC (\(=k\ln n - 2\ln\hat L\)), যেখানে \(k\) = parameter সংখ্যা; দুটোতেই ছোট মান ভালো। চারটি nested model:
| model | \(k\) | AIC | BIC | adj. \(R^2\) |
|---|---|---|---|---|
M1: price ~ area |
\(2\) | \(1837.7\) | \(1844.3\) | \(0.493\) |
M2: price ~ area + age |
\(3\) | \(1809.2\) | \(1819.1\) | \(0.562\) |
M3: price ~ area + age + rooms |
\(4\) | \(1688.1\) | \(1701.3\) | \(0.762\) |
M4: price ~ area + age + rooms + plot_size |
\(5\) | \(\mathbf{1679.2}\) | \(\mathbf{1695.7}\) | \(0.774\) |
M1 → M2 → M3 যাওয়ার সময় AIC আর BIC দুটোই বড় ধাপে কমছে — অর্থাৎ age আর rooms সত্যিকারের, প্রয়োজনীয় predictor (যা আমরা জানি, কারণ এরা DGP-তে আছে)। সবচেয়ে বড় লাফটা M2 → M3-এ (rooms যোগ করায় AIC \(1809\to 1688\)), যা rooms-এর শক্তিশালী effect-এর সাথে সঙ্গতিপূর্ণ।
একটা সূক্ষ্ম কিন্তু জরুরি পর্যবেক্ষণ: M4-এর AIC (\(1679.2\)) আর BIC (\(1695.7\)) — দুটোই M3-এর চেয়ে সামান্য ছোট। অর্থাৎ যান্ত্রিকভাবে দেখলে AIC/BIC criterion plot_size-সহ model M4-কেই "বেছে নেয়"! তাহলে কি plot_size রাখাই উচিত? না — এবং এখানেই গুরুত্বপূর্ণ শিক্ষা: AIC/BIC কম মানেই multicollinearity নেই, এমন নয়। AIC/BIC কেবল fit বনাম complexity-র ভারসাম্য দেখে; এরা coefficient-এর ব্যাখ্যাযোগ্যতা বা stability মাপে না। plot_size সামান্য residual variance কমায় (কারণ তার নিজস্ব noise-এর সাথে y-এর সামান্য সম্পর্ক আছে), তাই AIC সামান্য নামে — কিন্তু সেই দাম হিসেবে area-এর se প্রায় তিনগুণ ফুলে যায় এবং sign অর্থহীন হয়ে পড়ে। adjusted \(R^2\)-ও প্রায় একই গল্প বলে: \(0.762 \to 0.774\), বৃদ্ধি নগণ্য।
সিদ্ধান্ত। এখানে দুই criterion সংঘর্ষে: AIC/BIC সামান্য ব্যবধানে M4-এর পক্ষে, কিন্তু VIF, se-inflation আর অর্থহীন sign জোরালোভাবে M4-এর বিপক্ষে। ব্যাখ্যাযোগ্য, স্থিতিশীল model চাইলে M3-ই কাম্য — plot_size প্রায় redundant এবং multicollinearity ডেকে আনে, তাই বাদ দেওয়াই যুক্তিযুক্ত। মূল বার্তা: model selection কখনো একটিমাত্র সংখ্যার (শুধু AIC, বা শুধু \(R^2\)) দাস হওয়া উচিত নয় — diagnostics, VIF আর domain-জ্ঞান একসাথে বিচার করতে হয়।
যাচাই (verification)¶
নিচের snippet চালালে এই অংশের সব সংখ্যা পুনরুৎপাদন করা যায় (numpy, pandas, statsmodels প্রয়োজন)।
import numpy as np, pandas as pd, statsmodels.api as sm
from statsmodels.stats.outliers_influence import (
variance_inflation_factor, OLSInfluence)
rng = np.random.default_rng(20260619)
n = 200
area = rng.uniform(50, 200, n)
age = rng.uniform(0, 40, n)
rooms = rng.integers(1, 9, n)
price = 0.45*area - 0.8*age + 6*rooms + 25 + rng.normal(0, 15, n)
plot_size = 1.15*area + rng.normal(0, 10, n)
area = area.copy(); price = price.copy() # inject high-leverage point
area[0] = 340; price[0] = 250
df = pd.DataFrame(dict(area=area, age=age, rooms=rooms,
price=price, plot_size=plot_size))
# E1 -- inference
X = sm.add_constant(df[['area', 'age', 'rooms']])
m = sm.OLS(df['price'], X).fit()
print(m.params.round(4)); print(m.bse.round(4))
print(m.tvalues.round(2)); print(m.pvalues)
print('F =', round(m.fvalue, 1), ' F p =', m.f_pvalue)
# E2 -- fit quality
print('R2 =', round(m.rsquared, 3), ' adjR2 =', round(m.rsquared_adj, 3))
print('resid SE =', round(np.sqrt(m.mse_resid), 2))
# E3 -- leverage / influence
infl = OLSInfluence(m)
print('h_00 =', round(infl.hat_matrix_diag[0], 4),
' (mean p/n =', 4/n, ')')
print('Cook D_0 =', round(infl.cooks_distance[0][0], 3))
m_no0 = sm.OLS(df['price'].drop(0),
sm.add_constant(df[['area','age','rooms']].drop(0))).fit()
print('intercept with/without row0 =',
round(m.params['const'], 2), '/', round(m_no0.params['const'], 2))
# E4 -- multicollinearity + selection
Xc = sm.add_constant(df[['area','age','rooms','plot_size']])
mc = sm.OLS(df['price'], Xc).fit()
for i, c in enumerate(Xc.columns):
if c != 'const':
print(f'VIF[{c}] = {variance_inflation_factor(Xc.values, i):.2f}')
print('plot_size coef =', round(mc.params['plot_size'], 3),
' area se: base->full =',
round(m.bse['area'], 4), '->', round(mc.bse['area'], 4))
for name, cols in [('M3', ['area','age','rooms']),
('M4', ['area','age','rooms','plot_size'])]:
mi = sm.OLS(df['price'], sm.add_constant(df[cols])).fit()
print(f'{name}: AIC={mi.aic:.1f} BIC={mi.bic:.1f}')
প্রত্যাশিত মূল output (rounding-জনিত সামান্য তফাত হতে পারে):
area coef = 0.4956, se = 0.0258, t = 19.21, p ≈ 6e-47 (significant)
age coef = -0.7203, se = 0.1009, t = -7.14, p ≈ 2e-11 (significant)
rooms coef = 6.4982, se = 0.5032, t = 12.91, p ≈ 5e-28 (significant)
F = 213.7, F p ≈ 1.6e-61 -> model overall significant
R2 = 0.766, adjR2 = 0.762, resid SE = 16.30
h_00 = 0.1328 (>> mean 0.02) -> high leverage
Cook D_0 = 0.529 (>> next 0.047) -> influential
intercept with/without row0 = 16.95 / 22.00
VIF[area] = 7.71, VIF[plot_size] = 7.80 (vs ~1.0 without plot_size)
plot_size coef = -0.207 (sign flips!), area se: 0.0258 -> 0.0697 (inflated)
M3: AIC=1688.1 BIC=1701.3 M4: AIC=1679.2 BIC=1695.7
৪ · প্রমাণ ও উৎপাদন¶
এই বিভাগে §২–§৩-এর সব হাতিয়ার — standard error, t-test, F-test, leverage, Cook's distance, adjusted \(R^2\), AIC/BIC, VIF — শূন্য থেকে গণিতে গড়ে তুলব। ভিত্তি দুটো: (i) 5.1-এর \(\hat\beta = (X^\top X)^{-1}X^\top y\) এবং \(\mathrm{Var}(\hat\beta) = \sigma^2 (X^\top X)^{-1}\) আর hat matrix (টুপি-মাত্রিকা) \(H = X(X^\top X)^{-1}X^\top\); (ii) 4.7-এর testing-কাঠামো (\(t\), \(F\), p-value)। প্রতিটি প্রতীক প্রথমবার আসার সাথে খোলা হবে, প্রতিটি ধাপ যুক্তিসহ — কিছুই "মেনে নাও" বলে রাখা হবে না। কষ্টের স্তর প্রতিটি উপ-বিভাগের শিরোনামে তারা দিয়ে চিহ্নিত: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
স্মারক-প্রতীক (সারা বিভাগে এক): \(n\) = পর্যবেক্ষণ-সংখ্যা, \(p\) = coefficient-সংখ্যা (intercept সহ, অর্থাৎ \(X\)-এর কলাম-সংখ্যা), \(X\) = design matrix (\(n\times p\)), \(y\) = response (\(n\times 1\)), \(\hat\beta = (X^\top X)^{-1}X^\top y\), fitted (অভিযোজিত) \(\hat y = X\hat\beta = Hy\), residual (অবশিষ্ট) \(\hat\varepsilon = y - \hat y\), error-variance estimate \(\hat\sigma^2 = \mathrm{SSE}/(n-p)\) যেখানে \(\mathrm{SSE} = \lVert \hat\varepsilon \rVert^2\)। মডেল-অনুমান (LINE-এর পূর্ণ রূপ, 5.1): \(\varepsilon \sim \mathcal{N}(0,\sigma^2 I)\)।
৪.১ ★★ Standard error, t-statistic ও confidence interval¶
লক্ষ্য: একটিমাত্র coefficient \(\hat\beta_j\) কতটা "শব্দ-দূষিত" (noisy), তা একটা সংখ্যায় ধরা — তার standard error (আদর্শ-ত্রুটি) \(\mathrm{se}(\hat\beta_j)\) — এবং তা দিয়ে প্রশ্নের উত্তর দেওয়া: "\(x_j\)-র কি আদৌ কোনো প্রভাব আছে, নাকি \(\hat\beta_j \ne 0\) নেহাত নমুনা-ভাগ্য?"
ধাপ ১ — \(\hat\beta\)-র covariance থেকে একক coefficient-এর variance। 5.1 থেকে আমরা পেয়েছি (প্রমাণ সেখানে; এখানে ফল ব্যবহার করছি): $$ \mathrm{Var}(\hat\beta) \;=\; \sigma^2 (X^\top X)^{-1}. $$ এটা একটা \(p\times p\) covariance matrix (সহ-প্রসারণ মাত্রিকা): এর \((j,k)\)-ঘরে \(\mathrm{Cov}(\hat\beta_j,\hat\beta_k)\), আর কর্ণে (diagonal) প্রতিটি coefficient-এর নিজস্ব variance। তাই \(j\)-তম coefficient-এর variance হলো \((j,j)\)-কর্ণ-উপাদান: $$ \mathrm{Var}(\hat\beta_j) \;=\; \sigma^2 \,(X^\top X)^{-1}_{jj}, $$ যেখানে \((X^\top X)^{-1}_{jj}\) মানে inverse matrix-টির \(j\)-তম কর্ণ-সংখ্যা (একটা বিশুদ্ধ সংখ্যা, \(X\) জানা থাকলে নির্ণীত)।
ধাপ ২ — \(\sigma^2\) অজানা, তাই \(\hat\sigma^2\) বসাই। সত্য error-variance \(\sigma^2\) আমরা জানি না; তার unbiased estimate (5.1) হলো $$ \hat\sigma^2 \;=\; \frac{\mathrm{SSE}}{n-p} \;=\; \frac{\lVert y - X\hat\beta \rVert^2}{n-p}. $$ (\(n-p\) কেন, \(n\) নয় — কারণ residual বানাতে আমরা ইতিমধ্যে \(p\)টা coefficient "খরচ" করেছি, তাই কার্যকর degrees of freedom (স্বাধীনতার মাত্রা) \(n-p\); 5.1-এ প্রমাণিত যে এতে \(\mathbb{E}[\hat\sigma^2]=\sigma^2\)।) \(\sigma^2\)-র জায়গায় \(\hat\sigma^2\) বসিয়ে variance-এর estimate, আর তার বর্গমূল নিয়ে standard error: $$ \boxed{\ \mathrm{se}(\hat\beta_j) \;=\; \hat\sigma \,\sqrt{(X^\top X)^{-1}_{jj}}\ } $$ যেখানে \(\hat\sigma = \sqrt{\hat\sigma^2}\) (residual standard error)। অর্থ: \(\mathrm{se}(\hat\beta_j)\) হলো \(\hat\beta_j\)-র sampling distribution (নমুনা-বণ্টন)-এর আনুমানিক প্রসার — বারবার নতুন নমুনা নিলে \(\hat\beta_j\) গড়ে এতটা এদিক-ওদিক দুলবে।
ধাপ ৩ — কেন \(t\), \(z\) নয়? যদি \(\sigma\) জানা থাকত, তবে \(\hat\beta\) Normal হওয়ায় (Normal error-এ \(\hat\beta = (X^\top X)^{-1}X^\top y\) হলো Normal \(y\)-র রৈখিক রূপান্তর, তাই Normal): $$ \frac{\hat\beta_j - \beta_j}{\sigma\sqrt{(X^\top X)^{-1}{jj}}} \;\sim\; \mathcal{N}(0,1). $$ কিন্তু হরে আমরা \(\sigma\) নয়, আনুমানিক \(\hat\sigma\) বসিয়েছি, আর \(\hat\sigma\) নিজেই একটা random variable (data-নির্ভর)। এটা ঠিক 4.4-এর এক-নমুনা \(t\)-পরিস্থিতির পুনরাবৃত্তি: একটা Normal-কে একটা স্বাধীন \(\chi^2\)-এর (chi-square) বর্গমূল দিয়ে ভাগ করলে \(t\)-বণ্টন জন্মায়। মূল তথ্য (5.1/4.4-এ প্রতিষ্ঠিত): Normal error-এ \(\hat\beta\) ও \(\hat\sigma^2\) পরস্পর-স্বাধীন, এবং $$ \frac{(n-p)\hat\sigma^2}{\sigma^2} \;\sim\; \chi^2. $$ সংজ্ঞা অনুসারে \(t_{n-p} = \dfrac{\mathcal{N}(0,1)}{\sqrt{\chi^2_{n-p}/(n-p)}}\) (লব ও হর স্বাধীন)। লব-হরে ভাগ করে দেখি — \(\sigma\) কেটে যায়: $$ \frac{\hat\beta_j - \beta_j}{\hat\sigma\sqrt{(X^\top X)^{-1}{jj}}} = \underbrace{\frac{(\hat\beta_j-\beta_j)\big/\big(\sigma\sqrt{(X^\top X)^{-1}}}\big)}{}{\mathcal{N}(0,1)} \Bigg/ \underbrace{\sqrt{\frac{(n-p)\hat\sigma^2/\sigma^2}{n-p}}} \;\sim\; t_{n-p}. $$}/(n-p)}
ফল (coefficient-এর \(t\)-statistic)। মডেল-অনুমানে \(\varepsilon\sim\mathcal{N}(0,\sigma^2 I)\) ধরে, $$ \frac{\hat\beta_j - \beta_j}{\mathrm{se}(\hat\beta_j)} \;\sim\; t_{n-p}. $$
ধাপ ৪ — null hypothesis \(H_0:\beta_j=0\)। "\(x_j\)-র কোনো (partial, অর্থাৎ অন্য predictor স্থির রেখে) প্রভাব নেই" দাবিটি ঠিক \(\beta_j=0\)। এই \(H_0\) সত্যি ধরলে উপরের সূত্রে \(\beta_j\)-র জায়গায় \(0\) বসিয়ে পাই test statistic: $$ \boxed{\ t_j \;=\; \frac{\hat\beta_j}{\mathrm{se}(\hat\beta_j)} \;\sim\; t_{n-p} \quad (\text{under } H_0:\beta_j=0)\ } $$ ব্যাখ্যা: \(t_j\) = "\(\hat\beta_j\) শূন্য থেকে কত standard error দূরে।" \(\lvert t_j \rvert\) বড় ⇒ \(\hat\beta_j\)-কে শূন্য বলা কঠিন ⇒ \(x_j\) সম্ভবত গুরুত্বপূর্ণ। two-sided p-value \(= 2\,P(T_{n-p} > \lvert t_j \rvert)\) (4.7); এটি \(\le \alpha\) হলে \(\alpha\)-মাত্রায় \(H_0\) বাতিল, অর্থাৎ "\(x_j\) significant"। (সাবধানতা: এই \(t\)-test প্রতিটি coefficient-কে আলাদাভাবে পরীক্ষা করে, "বাকি সব predictor মডেলে আছে" ধরে — তাই multiple regression-এ একে "partial" বা "নিয়ন্ত্রিত" test বলে; দুটো coefficient একসাথে শূন্য কি না, সেটা §৪.২-এর F-test বা partial F-test-এর কাজ।)
ধাপ ৫ — confidence interval। একই pivotal quantity (অক্ষীয় রাশি) \(\frac{\hat\beta_j-\beta_j}{\mathrm{se}(\hat\beta_j)}\sim t_{n-p}\) থেকে \(\beta_j\)-র interval। \(t_{n-p,\,\alpha/2}\) লিখি সেই সংখ্যা যার ডানে \(t_{n-p}\)-বণ্টনের \(\alpha/2\) অংশ থাকে (upper \(\alpha/2\) critical value)। প্রতিসাম্যের কারণে \(P\!\big(-t_{n-p,\alpha/2} \le \tfrac{\hat\beta_j-\beta_j}{\mathrm{se}(\hat\beta_j)} \le t_{n-p,\alpha/2}\big) = 1-\alpha\)। ভেতরের অসমতাকে \(\beta_j\)-র জন্য সাজাই (তিন পাশে \(\mathrm{se}(\hat\beta_j)\) গুণ করে, তারপর \(\hat\beta_j\) যোগ ও বিয়োগ করে দিক উল্টে): $$ \boxed{\ \beta_j \;\in\; \hat\beta_j \;\pm\; t_{n-p,\,\alpha/2}\;\mathrm{se}(\hat\beta_j)\ }\quad (1-\alpha)\text{ confidence}. $$ দ্বৈততা (4.7-এর মতো): \(0\) যদি এই interval-এর বাইরে পড়ে, তবে ঠিক তখনই \(t\)-test \(H_0:\beta_j=0\) বাতিল করে — একই critical value, একই \(\mathrm{se}\), কেবল ভিন্ন ভাষা।
ক্ষুদ্র সাংখ্যিক যাচাই (numerical check): এক কৃত্রিম data-তে (\(n=12,\,p=3\)) সরাসরি \(\hat\sigma\sqrt{(X^\top X)^{-1}_{jj}}\) থেকে হিসাব করা \(\mathrm{se}\) ও \(t_j=\hat\beta_j/\mathrm{se}(\hat\beta_j)\) standard regression-সফটওয়্যারের output-এর সঙ্গে হুবহু মিলে যায় (যেমন \(t\)-মান \(\approx 4.02,\,-4.36,\,2.29\))।
৪.২ ★★ Overall F-test ও ANOVA-পরিচয়¶
\(t\)-test একটিমাত্র coefficient দেখে। কিন্তু একটা সামগ্রিক প্রশ্নও আছে: "মডেলের predictor-গুলো একসঙ্গে কি \(y\)-র কোনো তারতম্য ব্যাখ্যা করে, নাকি সব slope আসলে শূন্য?" — অর্থাৎ $$ H_0:\ \beta_1 = \beta_2 = \dots = \beta_{p-1} = 0 \quad(\text{সব slope শূন্য; কেবল intercept }\beta_0\text{ থাকে}). $$ এই global null পরীক্ষা করে overall F-test।
ধাপ ১ — ANOVA-পরিচয় (5.1 থেকে)। 5.1-এ প্রতিষ্ঠিত মৌলিক বর্গ-যোগফল বিভাজন (sum-of-squares decomposition), intercept-যুক্ত মডেলে: $$ \underbrace{\sum_{i=1}^n (y_i-\bar y)^2}{\mathrm{SST}} \;=\; \underbrace{\sum}^n (\hat y_i-\bar y)^2{\mathrm{SSR}} \;+\; \underbrace{\sum, \qquad \mathrm{SST} = \mathrm{SSR} + \mathrm{SSE}. $$ এখানে SST = total (মোট, }^n (y_i-\hat y_i)^2}_{\mathrm{SSE}\(y\)-র নিজের গড় \(\bar y\)-র চারপাশে ছড়ানো), SSR = regression/explained (মডেল যতটা ব্যাখ্যা করল), SSE = error/residual (যা বাকি রইল)। এই additivity-র কারণ projection-এর লম্বতা: \(\hat y - \bar y\mathbf 1\) থাকে \(\mathrm{col}(X)\)-এ, আর \(y-\hat y\) তার সাথে orthogonal (লম্ব) — তাই Pythagoras (5.1-এ পূর্ণ প্রমাণ)। মনে রাখুন \(\mathrm{SST}-\mathrm{SSE} = \mathrm{SSR}\)।
ধাপ ২ — প্রতিটি অংশের degrees of freedom ও mean square। SSR-এর সাথে যুক্ত স্বাধীনতা-মাত্রা \(p-1\) (\(p-1\)টি slope পরীক্ষাধীন), SSE-র সাথে \(n-p\) (যেমন \(\hat\sigma^2\)-এ)। প্রতিটিকে নিজ df দিয়ে ভাগ করলে mean square (গড়-বর্গ): \(\mathrm{MSR}=\mathrm{SSR}/(p-1)\), \(\mathrm{MSE}=\mathrm{SSE}/(n-p)=\hat\sigma^2\)।
ধাপ ৩ — F-statistic ও তার বণ্টন। F-statistic হলো এই দুই mean square-এর অনুপাত: $$ \boxed{\ F \;=\; \frac{\mathrm{MSR}}{\mathrm{MSE}} \;=\; \frac{(\mathrm{SST}-\mathrm{SSE})/(p-1)}{\mathrm{SSE}/(n-p)} \;=\; \frac{\mathrm{SSR}/(p-1)}{\mathrm{SSE}/(n-p)}\ } $$ কেন এটা \(H_0\)-এ \(F_{p-1,\,n-p}\)। Cochran-জাতীয় ফল (4.4/5.1-এ ব্যবহৃত): Normal error-এ \(H_0\) সত্যি হলে \(\mathrm{SSR}/\sigma^2 \sim \chi^2_{p-1}\) এবং সবসময় \(\mathrm{SSE}/\sigma^2 \sim \chi^2_{n-p}\), আর এ দুটি স্বাধীন (যথাক্রমে orthogonal উপ-স্থানে projection-এর বর্গ-দৈর্ঘ্য)। সংজ্ঞা অনুসারে \(F\)-বণ্টন = দুই স্বাধীন \(\chi^2\)-কে নিজ-নিজ df দিয়ে ভাগ করে গড়ের অনুপাত: $$ F = \frac{\mathrm{SSR}/(p-1)}{\mathrm{SSE}/(n-p)} = \frac{(\mathrm{SSR}/\sigma^2)/(p-1)}{(\mathrm{SSE}/\sigma^2)/(n-p)} = \frac{\chi^2_{p-1}/(p-1)}{\chi^2_{n-p}/(n-p)} \;\sim\; F_{p-1,\,n-p}\quad(\text{under }H_0). $$ (\(\sigma^2\) লব-হরে কেটে গেল, তাই অজানা \(\sigma^2\) লাগে না।) যুক্তিগত অর্থ: \(H_0\) মিথ্যা হলে slope-গুলো বাড়তি তারতম্য ব্যাখ্যা করে ⇒ SSR ফুলে ওঠে ⇒ \(F\) বড় ⇒ p-value \(=P(F_{p-1,n-p}>F_{\text{obs}})\) ছোট ⇒ \(H_0\) বাতিল। তাই F-test সবসময় এক-লেজা (one-sided, ডান-লেজ) — কেবল বড় \(F\)-ই প্রমাণ।
ধাপ ৪ — \(R^2\)-রূপ ও \(t\)-এর সঙ্গে সম্পর্ক। \(R^2 = 1-\mathrm{SSE}/\mathrm{SST}\) থেকে \(\mathrm{SSR}/\mathrm{SST}=R^2\) ও \(\mathrm{SSE}/\mathrm{SST}=1-R^2\); অনুপাতে \(\mathrm{SST}\) কেটে গিয়ে একটা সুন্দর সমতুল্য রূপ: $$ F \;=\; \frac{R^2/(p-1)}{(1-R^2)/(n-p)}. $$ বিশেষ ক্ষেত্র — simple regression (\(p=2\), এক slope): তখন df \((1,\,n-2)\), এবং বীজগণিতে দেখানো যায় \(F = t_1^2\), যেখানে \(t_1\) ওই একমাত্র slope-এর §৪.১ t-statistic (\(F_{1,m}=t_m^2\), একটা সাধারণ পরিচয়)। অর্থাৎ এক-predictor ক্ষেত্রে overall F-test আর slope-এর \(t\)-test হুবহু একই সিদ্ধান্ত দেয়।
ক্ষুদ্র যাচাই: একই কৃত্রিম data-তে \(\dfrac{\mathrm{SSR}/(p-1)}{\mathrm{SSE}/(n-p)}\) আর \(\dfrac{R^2/(p-1)}{(1-R^2)/(n-p)}\) একই মান দেয় (\(\approx 9.64\)), দুই রূপের সমতা নিশ্চিত করে।
৪.৩ ★★ Leverage \(h_{ii}\), residual-variance ও standardized residual¶
এখন diagnostics (নির্ণায়ী পরীক্ষা)-এর প্রথম স্তম্ভ: কোন পর্যবেক্ষণের \(x\)-মান এত অস্বাভাবিক যে সে fitted line-কে নিজের দিকে টেনে আনতে পারে? এই "টানার সামর্থ্য" মাপে leverage (লিভারেজ, উত্তোলন-বল)।
ধাপ ১ — hat matrix-এর কর্ণ। 5.1 থেকে fitted vector \(\hat y = X\hat\beta = X(X^\top X)^{-1}X^\top y = Hy\), যেখানে $$ H \;=\; X(X^\top X)^{-1}X^\top \quad(n\times n). $$ \(H\)-কে "hat matrix" বলে কারণ এটা \(y\)-র মাথায় টুপি বসায় (\(y \mapsto \hat y\))। উপাদান-আকারে \(\hat y_i = \sum_{k=1}^n H_{ik}\,y_k\) — অর্থাৎ \(i\)-তম fitted মান সব \(y_k\)-র একটা ওজনিত যোগফল, আর \(H_{ik}\) সেই ওজন। বিশেষত নিজের অবদান \(\partial \hat y_i/\partial y_i = H_{ii}\)। তাই সংজ্ঞা: $$ \boxed{\ h_{ii} \;=\; H_{ii} \;=\; x_i^\top (X^\top X)^{-1} x_i\ } $$ এটাই পর্যবেক্ষণ \(i\)-র leverage, যেখানে \(x_i^\top\) হলো \(X\)-এর \(i\)-তম সারি (point \(i\)-র predictor-ভেক্টর)। অর্থ: \(h_{ii}\) = "\(y_i\) নিজের fitted মান \(\hat y_i\)-কে কতটা সরাসরি নিয়ন্ত্রণ করে।" \(h_{ii}\) বড় মানে point \(i\)-র \(x\)-মান data-মেঘের কেন্দ্র থেকে দূরে — সে নিজের prediction-এ একচ্ছত্র প্রভাবশালী।
ধাপ ২ — \(H\)-এর দুটি মূল ধর্ম: symmetric ও idempotent। \(H^\top = H\) (কারণ \((X^\top X)^{-1}\) symmetric)। আর \(H\) idempotent (স্ব-গুণে-অপরিবর্তিত): $$ H^2 = X(X^\top X)^{-1}\underbrace{X^\top X(X^\top X)^{-1}}_{=I}X^\top = X(X^\top X)^{-1}X^\top = H. $$ জ্যামিতিক অর্থ: \(H\) হলো \(\mathrm{col}(X)\)-এর উপর orthogonal projection — একবার projection করার পর আবার করলে কিছুই বদলায় না, তাই \(H^2=H\)।
ধাপ ৩ — \(\sum_i h_{ii} = p\) (trace = rank)। idempotent matrix-এর একটা সুন্দর ফল: এর trace (কর্ণ-যোগফল) = তার rank। প্রমাণ — idempotent matrix-এর eigenvalue (অভিলাক্ষণিক মান) কেবল \(0\) বা \(1\) (কারণ \(Hv=\lambda v \Rightarrow H^2 v = \lambda^2 v\), কিন্তু \(H^2=H\) তাই \(\lambda^2=\lambda \Rightarrow \lambda\in\{0,1\}\)); trace = eigenvalue-দের যোগফল = (\(1\)-eigenvalue-এর সংখ্যা) = rank। এখন \(\mathrm{rank}(H)=\mathrm{rank}(X)=p\) (পূর্ণ-পদ design-এ)। আবার trace-এর চক্রীয় ধর্ম ব্যবহার করেও সরাসরি দেখা যায়: $$ \sum_{i=1}^n h_{ii} = \mathrm{tr}(H) = \mathrm{tr}!\big(X(X^\top X)^{-1}X^\top\big) = \mathrm{tr}!\big((X^\top X)^{-1}\,X^\top X\big) = \mathrm{tr}(I_p) = p. $$ সুতরাং $$ \boxed{\ \sum_{i=1}^n h_{ii} = p\ }\qquad\Rightarrow\qquad \bar h = \frac{p}{n}. $$ এর ব্যবহারিক মূল্য: গড় leverage \(p/n\)। একটা প্রচলিত বুড়ো-আঙুলের নিয়ম — \(h_{ii} > 2p/n\) (গড়ের দ্বিগুণ) হলে point \(i\)-কে "high-leverage" সন্দেহ করা হয়। সীমা: \(0 \le h_{ii} \le 1\) সবসময় (idempotent symmetric হওয়ায়; intercept থাকলে নিম্নসীমা \(1/n\))।
ধাপ ৪ — residual-এর variance ও standardized residual। এবার দেখাই leverage সরাসরি residual-এর নির্ভরযোগ্যতাকে প্রভাবিত করে। residual ভেক্টর: $$ \hat\varepsilon = y - \hat y = y - Hy = (I-H)y = (I-H)(X\beta+\varepsilon) = (I-H)\varepsilon, $$ শেষ ধাপে \((I-H)X = X - HX = X - X = 0\) ব্যবহার করলাম (কারণ \(HX = X(X^\top X)^{-1}X^\top X = X\))। অর্থাৎ residual পুরোপুরি error-এর projection, \(\beta\) এতে নেই। এখন \(\mathrm{Cov}(\varepsilon)=\sigma^2 I\) আর রৈখিক রূপান্তরের covariance-নিয়ম \(\mathrm{Cov}(A\varepsilon)=A\,\mathrm{Cov}(\varepsilon)\,A^\top\): $$ \mathrm{Cov}(\hat\varepsilon) = (I-H)\,\sigma^2 I\,(I-H)^\top = \sigma^2 (I-H)(I-H) = \sigma^2 (I-H), $$ শেষে \((I-H)\) ও idempotent ও symmetric ব্যবহার করলাম: \((I-H)^2 = I - 2H + H^2 = I-2H+H = I-H\)। তাই \(i\)-তম residual-এর variance = এই matrix-এর \((i,i)\)-ঘর: $$ \boxed{\ \mathrm{Var}(\hat\varepsilon_i) = \sigma^2 (1-h_{ii})\ } $$ গুরুত্বপূর্ণ পরিণতি: residual-গুলোর variance সমান নয় — high-leverage point (\(h_{ii}\to 1\))-এ residual-এর variance \(\to 0\), অর্থাৎ line সেই বিন্দুর দিকে এত জোরে টানা হয় যে residual কৃত্রিমভাবে ছোট হয়ে যায় (point নিজেই নিজের prediction ঠিক করে নেয়)। তাই কাঁচা residual \(\hat\varepsilon_i\)-কে সরাসরি তুলনা করা ভুল; প্রতিটিকে নিজ standard deviation দিয়ে ভাগ করে standardized (internally studentized) residual: $$ \boxed{\ r_i \;=\; \frac{\hat\varepsilon_i}{\hat\sigma\sqrt{1-h_{ii}}}\ } $$ (\(\sigma\) অজানা বলে \(\hat\sigma\) বসানো।) এর ফলে সব \(r_i\) আনুমানিক একই স্কেলে (প্রায় unit variance) আসে — তাই residual-plot-এ "কোন বিন্দুটা সত্যি বড় বিচ্যুতি" বিচার করতে \(r_i\) (\(\hat\varepsilon_i\) নয়) দেখাই সঠিক; সাধারণত \(\lvert r_i \rvert > 2\) হলে outlier (অসঙ্গত বিন্দু) সন্দেহ। মূল পাঠ: high leverage = অস্বাভাবিক \(x\) (ছোট residual-ও বিভ্রান্তিকর হতে পারে), যা §৪.৪-এ Cook's distance-এ outlier-তথ্যের সাথে মিলবে।
ক্ষুদ্র যাচাই: কৃত্রিম data-তে সরাসরি \(\sigma^2(I-H)\)-এর কর্ণ হিসাব করে দেখা গেল তা হুবহু \(\sigma^2(1-h_{ii})\); আর \(\sum_i h_{ii}=p\) ও \(\mathrm{tr}(H)=\mathrm{rank}(H)=p\) সংখ্যায় মিলে যায় (\(H\) idempotent, \(\lVert H^2-H\rVert=0\))।
৪.৪ ★★ Cook's distance \(D_i\)¶
Leverage (\(x\) কতটা অস্বাভাবিক) আর standardized residual (\(y\) কতটা অসঙ্গত) — দুটো আলাদা দিক। একটা বিন্দু সত্যিই প্রভাবশালী (influential) তখনই, যখন দুটোই মাঝারি-বড়: অস্বাভাবিক \(x\) (বেশি টানার সামর্থ্য) আর বড় residual (টানার মতো কারণ)। এই দুই দিককে এক সংখ্যায় মেলায় Cook's distance \(D_i\) — "point \(i\)-কে বাদ দিলে গোটা মডেলের সব fitted মান কতটা সরে যায়" তার পরিমাপ।
ধাপ ১ — সংজ্ঞা (drop-one প্রভাব)। ধরা যাক \(\hat\beta_{(i)}\) = point \(i\) বাদ দিয়ে পুনঃ-fit করা coefficient, আর \(\hat y_{(i)} = X\hat\beta_{(i)}\) = সেই নতুন coefficient দিয়ে সব \(n\)টি বিন্দুতে fitted মান। Cook's distance মাপে পুরনো ও নতুন fitted-vector-এর মধ্যে স্কেল-করা দূরত্ব: $$ D_i \;=\; \frac{\lVert \hat y - \hat y_{(i)} \rVert^2}{p\,\hat\sigma^2} \;=\; \frac{(\hat\beta-\hat\beta_{(i)})^\top (X^\top X)(\hat\beta-\hat\beta_{(i)})}{p\,\hat\sigma^2}. $$ (দ্বিতীয় রূপ: \(\lVert X(\hat\beta-\hat\beta_{(i)})\rVert^2 = (\hat\beta-\hat\beta_{(i)})^\top X^\top X(\hat\beta-\hat\beta_{(i)})\)।) হরে \(p\hat\sigma^2\) থাকায় \(D_i\) একটা একক-হীন (dimensionless) তুলনাযোগ্য সংখ্যা: বড় \(D_i\) মানে ওই একটি বিন্দু সরালে গোটা ফিট আমূল বদলে যায় — সে অত্যন্ত প্রভাবশালী।
ধাপ ২ — বদ্ধ-রূপ সূত্র (একবার-fit থেকেই)। আশ্চর্যজনকভাবে \(D_i\) পেতে \(n\) বার পুনঃ-fit করার দরকার নেই — leverage ও residual থেকে সরাসরি পাওয়া যায়। মূল উপাদান হলো leave-one-out (একটি-বাদ) update সূত্র, যা rank-one inverse-সংশোধন (Sherman–Morrison) থেকে আসে: $$ \hat\beta - \hat\beta_{(i)} \;=\; \frac{(X^\top X)^{-1} x_i\,\hat\varepsilon_i}{1-h_{ii}}. $$ (স্বজ্ঞা: একটা বিন্দু সরালে coefficient ততটাই বদলায় যতটা ওই বিন্দুর residual \(\hat\varepsilon_i\) বড় এবং তার leverage \(h_{ii}\) বেশি — হরে \(1-h_{ii}\) সেই leverage-বিবর্ধন।) একে উপরের দ্বিতীয় রূপে বসাই: $$ \lVert \hat y - \hat y_{(i)}\rVert^2 = (\hat\beta-\hat\beta_{(i)})^\top (X^\top X)(\hat\beta-\hat\beta_{(i)}) = \frac{\hat\varepsilon_i^2}{(1-h_{ii})^2}\;x_i^\top (X^\top X)^{-1}\underbrace{(X^\top X)(X^\top X)^{-1}}{=I} x_i. $$ এখন \(x_i^\top (X^\top X)^{-1} x_i = h_{ii}\) (§৪.৩-এর leverage-সংজ্ঞা)। তাই \(\lVert \hat y - \hat y_{(i)}\rVert^2 = \dfrac{\hat\varepsilon_i^2\,h_{ii}}{(1-h_{ii})^2}\), এবং \(p\hat\sigma^2\) দিয়ে ভাগ করে: $$ \boxed{\ D_i \;=\; \frac{\hat\varepsilon_i^2}{p\,\hat\sigma^2}\cdot\frac{h $$}}{(1-h_{ii})^2}\
ধাপ ৩ — সূত্রটা কী বলছে। \(\dfrac{\hat\varepsilon_i^2}{p\hat\sigma^2}\) অংশটা residual (বিন্দুটা কতটা অসঙ্গত), আর \(\dfrac{h_{ii}}{(1-h_{ii})^2}\) অংশটা leverage (বিন্দুটা কতটা টানতে পারে) — দুটোর গুণফল। তাই \(D_i\) বড় হতে দুটোই লাগে: শুধু বড় residual কিন্তু কেন্দ্রীয় \(x\) (ছোট \(h_{ii}\)) ⇒ কম প্রভাব; শুধু বড় leverage কিন্তু রেখায় ঠিক বসা বিন্দু (ছোট \(\hat\varepsilon_i\)) ⇒ কম প্রভাব। (আরও সুন্দরভাবে, §৪.৩-এর \(r_i^2 = \hat\varepsilon_i^2/[\hat\sigma^2(1-h_{ii})]\) ব্যবহার করে \(D_i = \dfrac{r_i^2}{p}\cdot\dfrac{h_{ii}}{1-h_{ii}}\) — অর্থাৎ standardized residual\(^2\) আর leverage-অনুপাতের গুণফল।) বুড়ো-আঙুলের নিয়ম: \(D_i > 1\) (বা কারও মতে \(4/n\)) হলে বিন্দুটি ঘনিষ্ঠ পরিদর্শনের দাবিদার — তবে "বাদ দাও" নয়, বরং "কেন এমন, যাচাই করো"।
ক্ষুদ্র যাচাই: কৃত্রিম data-তে প্রতিটি বিন্দুর জন্য \(D_i\) দুই পথে হিসাব করা হলো — (ক) সরাসরি point \(i\) বাদ দিয়ে পুনঃ-fit করে \(\lVert\hat y - \hat y_{(i)}\rVert^2/(p\hat\sigma^2)\), আর (খ) উপরের বদ্ধ-রূপ সূত্র — সব বিন্দুতে দুটি মান দশমিকের ছয় ঘর পর্যন্ত হুবহু সমান (যেমন \(D_0=0.5289\) উভয় পথেই), যা leave-one-out update ও চূড়ান্ত সূত্র দুটোই নিশ্চিত করে।
৪.৫ ★★ Adjusted \(R^2\), এবং AIC/BIC-এর উৎপত্তি¶
Model selection (মডেল-নির্বাচন)-এর কেন্দ্রীয় সমস্যা: predictor যোগ করলে \(R^2\) কখনো কমে না (নতুন কলাম \(\mathrm{col}(X)\) বড় করে, projection \(y\)-র কাছে যেতে পারে, SSE \(\le\) আগের) — তাই \(R^2\) দিয়ে মডেল তুলনা করলে সবসময় "সব predictor ঢোকাও" উত্তর আসে, যা overfitting (অতি-অভিযোজন)। দরকার একটা মাপ যা জটিলতার জন্য জরিমানা করে।
ধাপ ১ — Adjusted \(R^2\)। ধারণা: SSE ও SST-কে তাদের raw মান নয়, df-সমন্বিত (mean square) আকারে তুলনা করা। সংজ্ঞা: $$ R^2_{\text{adj}} \;=\; 1 - \frac{\mathrm{SSE}/(n-p)}{\mathrm{SST}/(n-1)}. $$ \(\mathrm{SSE}/(n-p)=\hat\sigma^2\), আর \(\mathrm{SST}/(n-1) = s_y^2\) (response-এর নমুনা-variance) — দুটোই unbiased estimate, df ভিন্ন। এখন এটাকে সাধারণ \(R^2\)-এর ভাষায় লিখি। \(\mathrm{SSE} = \mathrm{SST}(1-R^2)\) বসাই: $$ R^2_{\text{adj}} = 1 - \frac{\mathrm{SST}(1-R^2)/(n-p)}{\mathrm{SST}/(n-1)} = 1 - (1-R^2)\,\frac{n-1}{n-p}. $$ $$ \boxed{\ R^2_{\text{adj}} \;=\; 1 - \frac{(1-R^2)(n-1)}{n-p}\ } $$ জরিমানা কীভাবে কাজ করে। নতুন predictor যোগ করলে \(p\) বাড়ে: একদিকে \(R^2\) সামান্য বাড়ে (ভালো), অন্যদিকে গুণক \(\frac{n-1}{n-p}\) বাড়ে (খারাপ, কারণ হর \(n-p\) ছোট হয়)। নতুন predictor যদি \(R^2\)-কে যথেষ্ট না বাড়ায়, তবে দ্বিতীয় প্রভাব জিতে \(R^2_{\text{adj}}\) কমে — সংকেত: এই predictor রাখা অর্থহীন। তাই \(R^2_{\text{adj}}\) predictor-সংখ্যার সাথে raw \(R^2\)-এর মতো একঘেয়ে বাড়ে না; এটি সর্বোচ্চ হয় কোনো মধ্যম মডেলে। (লক্ষণীয়: \(R^2_{\text{adj}}\) ঋণাত্মকও হতে পারে যদি মডেল গড়-অপেক্ষা খারাপ হয়।)
ধাপ ২ — Gaussian regression-এর log-likelihood (\(-2\ln\hat L\))। AIC ও BIC আরও নীতিগত — likelihood (সম্ভাব্যতা-অপেক্ষক)-ভিত্তিক। প্রথমে দেখাই Normal regression-এ সর্বোচ্চ-likelihood কীভাবে SSE-তে নেমে আসে। \(\varepsilon\sim\mathcal{N}(0,\sigma^2 I)\) ধরে \(y_i \sim \mathcal{N}((X\beta)_i,\sigma^2)\) স্বাধীন, তাই log-likelihood (5.1-এর MLE অংশের মতো): $$ \ell(\beta,\sigma^2) = -\frac{n}{2}\ln(2\pi) - \frac{n}{2}\ln\sigma^2 - \frac{1}{2\sigma^2}\sum_{i=1}^n\big(y_i-(X\beta)i\big)^2 = -\frac{n}{2}\ln(2\pi) - \frac{n}{2}\ln\sigma^2 - \frac{\mathrm{SSE}(\beta)}{2\sigma^2}. $$ \(\beta\)-র সাপেক্ষে এটি বড় হয় ঠিক যখন \(\mathrm{SSE}(\beta)\) ছোট — অর্থাৎ MLE \(\hat\beta\) = OLS estimate (5.1-এর ফল)। তাই সর্বনিম্ন SSE বসাই: \(\mathrm{SSE}(\hat\beta)=\mathrm{SSE}\)। এবার \(\sigma^2\)-র সাপেক্ষে maximize: \(\dfrac{\partial \ell}{\partial \sigma^2} = -\dfrac{n}{2\sigma^2} + \dfrac{\mathrm{SSE}}{2\sigma^4} = 0 \Rightarrow \hat\sigma^2_{\text{ML}} = \dfrac{\mathrm{SSE}}{n}\) (লক্ষণীয়: MLE-তে হর \(n\), \(n-p\) নয় — এটা সামান্য biased, কিন্তু likelihood তাই বলে)। এই দুই optimum বসিয়ে সর্বোচ্চ log-likelihood: $$ \ln\hat L = \ell(\hat\beta,\hat\sigma^2) = -\frac{n}{2}\ln(2\pi) - \frac{n}{2}\ln!\Big(\frac{\mathrm{SSE}}{n}\Big) - \frac{\mathrm{SSE}}{2(\mathrm{SSE}/n)} = -\frac{n}{2}\ln!\Big(\frac{\mathrm{SSE}}{n}\Big) - \frac{n}{2}\big(1+\ln 2\pi\big). $$ শেষ পদে }\(\dfrac{\mathrm{SSE}}{2(\mathrm{SSE}/n)} = \dfrac{n}{2}\) ব্যবহার করলাম। দুই দিয়ে গুণ করে চিহ্ন উল্টে: $$ \boxed{\ -2\ln\hat L \;=\; n\ln!\Big(\frac{\mathrm{SSE}}{n}\Big) + \underbrace{n\big(1+\ln 2\pi\big)}_{\text{const (মডেল-নিরপেক্ষ)}}\ } $$ মূল বার্তা: একই data-র উপর ভিন্ন মডেল তুলনা করলে ধ্রুবক পদটা সবার জন্য এক, তাই কার্যত \(-2\ln\hat L = n\ln(\mathrm{SSE}/n) + \text{const}\) — অর্থাৎ SSE ছোট হলে \(-2\ln\hat L\) ছোট। কিন্তু SSE-ও predictor বাড়ালে একঘেয়ে কমে, তাই একে জরিমানা দরকার।
ধাপ ৩ — AIC ও BIC। "\(-2\ln\hat L\) (fit-এর খারাপত্ব) + প্যারামিটার-সংখ্যার জরিমানা" — এই দুই information criterion (তথ্য-নির্ণায়ক)। যদি \(k\) = আনুমানিক প্যারামিটার-সংখ্যা (\(k=p\) = intercept সহ coefficient-সংখ্যা): $$ \boxed{\ \mathrm{AIC} = -2\ln\hat L + 2k\ } \qquad\qquad \boxed{\ \mathrm{BIC} = -2\ln\hat L + k\ln n\ } $$ Gaussian-রূপে বসিয়ে (ধ্রুবক বাদে): \(\mathrm{AIC} \approx n\ln(\mathrm{SSE}/n) + 2k\), \(\mathrm{BIC} \approx n\ln(\mathrm{SSE}/n) + k\ln n\)। দুটোই ছোট = ভালো: প্রথম পদ fit ভালো হলে কমে, দ্বিতীয় পদ মডেল জটিল হলে বাড়ে — তাই এরা ভারসাম্য খোঁজে, সরল মডেলকে পুরস্কৃত করে। পার্থক্য: BIC-এর জরিমানা \(k\ln n\) vs AIC-এর \(2k\); যেহেতু \(\ln n > 2\) যখন \(n > e^2 \approx 7.4\), BIC বড় নমুনায় জটিলতাকে বেশি কঠোরভাবে শাস্তি দেয় — তাই BIC ছোট, আরও মিতব্যয়ী মডেল বাছে (BIC consistent — সত্য মডেল data-তে থাকলে \(n\to\infty\)-এ সেটাই বাছে; AIC prediction-এর জন্য optimal-ঘেঁষা)।
ক্ষুদ্র যাচাই: সাংখ্যিকভাবে সরাসরি Gaussian \(-2\ln\hat L\) (max log-likelihood থেকে) আর \(n\ln(\mathrm{SSE}/n)+n+n\ln(2\pi)\) — দুটো হুবহু মিলল (\(\approx 34.75\)); আর sympy-তে \(\arg\max_{\sigma^2}\ell = \mathrm{SSE}/n\) ও \(\ell_{\max} = \tfrac{n}{2}\big(-\ln(2\pi\,\mathrm{SSE}/n) - 1\big)\) প্রতীকীভাবে নিশ্চিত হলো, যা উপরের boxed রূপের সমান।
৪.৬ ★ Variance Inflation Factor (VIF)¶
শেষ diagnostic: multicollinearity (বহু-সহরৈখিকতা) — যখন predictor-গুলো পরস্পর প্রায় রৈখিকভাবে সম্পর্কিত। এটা coefficient-কে অস্থির ও standard error-কে স্ফীত করে। কতটা — মাপে VIF।
ধাপ ১ — সংজ্ঞা। predictor \(x_j\)-এর জন্য ধরা যাক \(R_j^2\) = সেই \(R^2\) যা পাওয়া যায় \(x_j\)-কে বাকি সব predictor-এর উপর regress করলে (অর্থাৎ \(x_j\)-ই এখন "response", অন্য \(x\)-গুলো predictor)। তাহলে $$ \boxed{\ \mathrm{VIF}_j \;=\; \frac{1}{1-R_j^2}\ } $$ \(R_j^2\) পরিমাপ করে \(x_j\)-র কতটা অন্য predictor দিয়েই ব্যাখ্যা করা যায়: \(R_j^2\to 0\) (স্বাধীন \(x_j\)) ⇒ \(\mathrm{VIF}_j\to 1\) (কোনো সমস্যা নেই); \(R_j^2\to 1\) (\(x_j\) প্রায় অন্যদের রৈখিক সমন্বয়) ⇒ \(\mathrm{VIF}_j\to\infty\) (চরম collinearity)।
ধাপ ২ — কেন এটি \(\mathrm{se}(\hat\beta_j)\) "স্ফীত" করে। নামটাই ইঙ্গিত — VIF হলো ঠিক সেই গুণক যতটা collinearity \(\hat\beta_j\)-র variance বাড়িয়ে দেয়। আদর্শ ফল (cofactor-বীজগণিত বা partialling-out যুক্তি থেকে): \(j\)-তম slope-এর variance লেখা যায় $$ \mathrm{Var}(\hat\beta_j) = \frac{\sigma^2}{(n-1)\,s_{x_j}^2}\cdot\frac{1}{1-R_j^2} = \frac{\sigma^2}{(n-1)\,s_{x_j}^2}\cdot\mathrm{VIF}_j, $$ যেখানে \(s_{x_j}^2\) = \(x_j\)-র নমুনা-variance। অর্থাৎ collinearity না থাকলে (\(\mathrm{VIF}_j=1\)) variance-এর "ভিত্তি-মান" \(\dfrac{\sigma^2}{(n-1)s_{x_j}^2}\); আর \(\mathrm{VIF}_j\) সেই ভিত্তিকে গুণ করে বাড়ায়। তাই \(\mathrm{se}(\hat\beta_j)=\sqrt{\mathrm{Var}(\hat\beta_j)} \propto \sqrt{\mathrm{VIF}_j}\) — যেমন \(\mathrm{VIF}_j=9\) হলে \(\mathrm{se}\) তিনগুণ বড়।
স্বজ্ঞা: \(x_j\) যদি অন্য predictor-দের প্রায় নকল হয়, তবে data বলতে পারে না প্রভাবটা \(x_j\)-র না তার যমজ-predictor-এর — তাই \(\hat\beta_j\) বিরাট দুলে যায় (বড় variance), যদিও মডেলের সামগ্রিক prediction (\(\hat y\)) ঠিকঠাকই থাকতে পারে। বুড়ো-আঙুল: \(\mathrm{VIF}_j > 5\) (কারও মতে \(10\)) হলে collinearity উদ্বেগজনক — সমাধান: অপ্রয়োজনীয় predictor বাদ, কিংবা তাদের একত্র করা, কিংবা regularization (যেমন ridge, Part VI)।
ক্ষুদ্র যাচাই: কৃত্রিম data-তে প্রতিটি \(x_j\)-কে অন্যদের উপর regress করে \(R_j^2\) থেকে \(\mathrm{VIF}_j=1/(1-R_j^2)\) হিসাব করা হলো; দুই-predictor সমমিতি-data-য় উভয় VIF সমান (\(\approx 1.21\), যেহেতু সামান্য পারস্পরিক সম্পর্ক) — সূত্র ও স্বজ্ঞা সঙ্গতিপূর্ণ।
§৪ সারাংশ। একটিমাত্র ভিত্তি — \(\hat\beta=(X^\top X)^{-1}X^\top y\), \(\mathrm{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\), hat matrix \(H=X(X^\top X)^{-1}X^\top\) — থেকে গোটা inference-ও-diagnostics কাঠামো বেরিয়ে এল। Inference: \(\mathrm{se}(\hat\beta_j)=\hat\sigma\sqrt{(X^\top X)^{-1}_{jj}}\), \(t_j=\hat\beta_j/\mathrm{se}(\hat\beta_j)\sim t_{n-p}\), CI \(=\hat\beta_j\pm t_{n-p,\alpha/2}\mathrm{se}\); সামগ্রিক \(F=\frac{\mathrm{SSR}/(p-1)}{\mathrm{SSE}/(n-p)}\sim F_{p-1,n-p}\) (ANOVA-পরিচয় থেকে)। Diagnostics: leverage \(h_{ii}=H_{ii}\) (\(\sum h_{ii}=p\), কারণ idempotent \(H\)-এর trace = rank), \(\mathrm{Var}(\hat\varepsilon_i)=\sigma^2(1-h_{ii})\) → standardized residual \(r_i\); Cook's \(D_i=\frac{\hat\varepsilon_i^2}{p\hat\sigma^2}\frac{h_{ii}}{(1-h_{ii})^2}\) (residual × leverage)। Model selection: \(R^2_{\text{adj}}=1-\frac{(1-R^2)(n-1)}{n-p}\), এবং Gaussian \(-2\ln\hat L = n\ln(\mathrm{SSE}/n)+\text{const}\) থেকে AIC \(=-2\ln\hat L+2k\), BIC \(=-2\ln\hat L+k\ln n\) — সবই "fit বনাম জটিলতা" ভারসাম্য। Collinearity: \(\mathrm{VIF}_j=1/(1-R_j^2)\), যা \(\mathrm{se}(\hat\beta_j)\)-কে \(\sqrt{\mathrm{VIF}_j}\) গুণে স্ফীত করে। প্রতিটি ফল কৃত্রিম data-তে সংখ্যায় (ও কোথাও sympy-তে প্রতীকীভাবে) যাচাই করা হয়েছে।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের সব ধারণা — inference টেবিল, leverage \(h_{ii}\), Cook's distance \(D_i\), multicollinearity (VIF), এবং AIC/BIC দিয়ে model selection — একটিমাত্র চলমান স্ক্রিপ্টে একসাথে দেখব। আমরা একটি সিন্থেটিক রিয়েল-এস্টেট ডেটাসেট বানাব যেখানে সত্য মডেলটি আমরা নিজেরাই জানি:
কারণ সত্য coefficient গুলো আগে থেকে জানা, আমরা যাচাই করতে পারব OLS estimate সেগুলোর কাছাকাছি ফিরে আসছে কি না, এবং diagnostics সঠিকভাবে "সমস্যা" ধরছে কি না। ইচ্ছাকৃতভাবে আমরা দুটো সমস্যা ঢোকাব:
- একটি leverage point —
area[0]=340.0(বাকি area \(50\)–\(200\) এর মধ্যে, কাজেই এটি \(x\)-স্পেসে বহু দূরে) আর তার সাথে একটি বেমানানprice[0]=250.0। এটি Part 2-এ ধরা পড়বে। - প্রায়-collinear predictor
plot_size\(\approx 1.15\cdot\text{area}\) — এটি Part 3-এ VIF বিস্ফোরণ ঘটাবে।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.stats.outliers_influence import variance_inflation_factor
# ---------- ডেটাসেট (verbatim) ----------
rng = np.random.default_rng(20260619)
n = 200
area = rng.uniform(50, 200, n)
age = rng.uniform(0, 40, n)
rooms = rng.integers(1, 9, n)
price = 0.45*area - 0.8*age + 6*rooms + 25 + rng.normal(0, 15, n)
plot_size = 1.15*area + rng.normal(0, 10, n)
# leverage point inject
area[0] = 340.0
price[0] = 250.0
df = pd.DataFrame({"price": price, "area": area, "age": age,
"rooms": rooms, "plot_size": plot_size})
# =====================================================================
# PART 1 : OLS ফিট ও inference টেবিল
# =====================================================================
print("="*70)
print("PART 1 : price ~ area + age + rooms (statsmodels OLS)")
print("="*70)
m1 = smf.ols("price ~ area + age + rooms", data=df).fit()
ci = m1.conf_int(alpha=0.05)
ci.columns = ["CI_2.5%", "CI_97.5%"]
tab = pd.DataFrame({
"coef": m1.params,
"se": m1.bse,
"t": m1.tvalues,
"p": m1.pvalues,
}).join(ci)
pd.set_option("display.float_format", lambda x: f"{x:10.4f}")
pd.set_option("display.width", 120)
print(tab.to_string())
print()
print(f"F-statistic = {m1.fvalue:.4f} (p = {m1.f_pvalue:.3e})")
print(f"R^2 = {m1.rsquared:.4f}")
print(f"adjusted R^2 = {m1.rsquared_adj:.4f}")
print(f"AIC = {m1.aic:.2f}")
print(f"BIC = {m1.bic:.2f}")
print(f"n , df_resid = {int(m1.nobs)} , {int(m1.df_resid)}")
# =====================================================================
# PART 2 : ডায়াগনস্টিকস — leverage, studentized resid, Cook's D
# =====================================================================
print()
print("="*70)
print("PART 2 : Influence diagnostics")
print("="*70)
infl = m1.get_influence()
h_ii = infl.hat_matrix_diag # leverage h_ii
stud_r = infl.resid_studentized_external # externally studentized residual
cook_D = infl.cooks_distance[0] # Cook's distance
p_param = m1.df_model + 1 # number of params (incl. intercept)
print(f"average leverage p/n = {p_param/n:.4f} (rule-of-thumb high: 2p/n = {2*p_param/n:.4f})")
diag = pd.DataFrame({"h_ii": h_ii, "stud_resid": stud_r, "cooks_D": cook_D})
print("\n--- Top-3 highest leverage h_ii ---")
print(diag.sort_values("h_ii", ascending=False).head(3).to_string())
print("\n--- Top-3 highest Cook's D ---")
print(diag.sort_values("cooks_D", ascending=False).head(3).to_string())
print(f"\nRow 0 (injected point): h_ii={h_ii[0]:.4f} stud_resid={stud_r[0]:.3f} Cook_D={cook_D[0]:.4f}")
print(f"Cook's D cutoff 4/n = {4/n:.4f}")
# =====================================================================
# PART 3 : multicollinearity — VIF (plot_size যোগ করে)
# =====================================================================
print()
print("="*70)
print("PART 3 : Multicollinearity (VIF) — add plot_size")
print("="*70)
m_base = smf.ols("price ~ area + age + rooms", data=df).fit()
m_coll = smf.ols("price ~ area + age + rooms + plot_size", data=df).fit()
X = sm.add_constant(df[["area", "age", "rooms", "plot_size"]])
vif = pd.DataFrame({
"predictor": X.columns,
"VIF": [variance_inflation_factor(X.values, i) for i in range(X.shape[1])],
})
print(vif.to_string(index=False))
print("\nse(area) base model = {:.4f}".format(m_base.bse["area"]))
print("se(area) with plot_size = {:.4f}".format(m_coll.bse["area"]))
print("se(plot_size) full model = {:.4f}".format(m_coll.bse["plot_size"]))
print("inflation factor se(area) = {:.2f}x".format(m_coll.bse["area"]/m_base.bse["area"]))
# =====================================================================
# PART 4 : model selection — nested AIC / BIC
# =====================================================================
print()
print("="*70)
print("PART 4 : Nested model selection (AIC / BIC)")
print("="*70)
models = {
"M_a : price ~ area" : "price ~ area",
"M_b : price ~ area + age" : "price ~ area + age",
"M_c : price ~ area + age + rooms" : "price ~ area + age + rooms",
}
res = []
for name, f in models.items():
fit = smf.ols(f, data=df).fit()
res.append((name, fit.df_model+1, fit.rsquared_adj, fit.aic, fit.bic))
sel = pd.DataFrame(res, columns=["model", "k_params", "adj_R2", "AIC", "BIC"])
print(sel.to_string(index=False))
print(f"\nlowest AIC -> {sel.loc[sel['AIC'].idxmin(),'model']}")
print(f"lowest BIC -> {sel.loc[sel['BIC'].idxmin(),'model']}")
৫.২ · বাস্তব আউটপুট¶
নিচের আউটপুট স্ক্রিপ্টটি সরাসরি চালিয়ে পাওয়া — কোনো সংখ্যা হাতে লেখা নয়:
======================================================================
PART 1 : price ~ area + age + rooms (statsmodels OLS)
======================================================================
coef se t p CI_2.5% CI_97.5%
Intercept 16.9547 4.6712 3.6296 0.0004 7.7424 26.1670
area 0.4956 0.0258 19.2084 0.0000 0.4447 0.5465
age -0.7203 0.1009 -7.1380 0.0000 -0.9193 -0.5213
rooms 6.4982 0.5032 12.9147 0.0000 5.5059 7.4905
F-statistic = 213.6925 (p = 1.594e-61)
R^2 = 0.7659
adjusted R^2 = 0.7623
AIC = 1688.07
BIC = 1701.26
n , df_resid = 200 , 196
======================================================================
PART 2 : Influence diagnostics
======================================================================
average leverage p/n = 0.0200 (rule-of-thumb high: 2p/n = 0.0400)
--- Top-3 highest leverage h_ii ---
h_ii stud_resid cooks_D
0 0.1328 3.8448 0.5289
119 0.0373 1.4948 0.0215
22 0.0372 0.4120 0.0016
--- Top-3 highest Cook's D ---
h_ii stud_resid cooks_D
0 0.1328 3.8448 0.5289
161 0.0331 2.3780 0.0473
132 0.0216 -2.5799 0.0357
Row 0 (injected point): h_ii=0.1328 stud_resid=3.845 Cook_D=0.5289
Cook's D cutoff 4/n = 0.0200
======================================================================
PART 3 : Multicollinearity (VIF) — add plot_size
======================================================================
predictor VIF
const 17.6160
area 7.7099
age 1.0386
rooms 1.0043
plot_size 7.7968
se(area) base model = 0.0258
se(area) with plot_size = 0.0697
se(plot_size) full model = 0.0627
inflation factor se(area) = 2.70x
======================================================================
PART 4 : Nested model selection (AIC / BIC)
======================================================================
model k_params adj_R2 AIC BIC
M_a : price ~ area 2.0000 0.4927 1837.6986 1844.2952
M_b : price ~ area + age 3.0000 0.5622 1809.2088 1819.1037
M_c : price ~ area + age + rooms 4.0000 0.7623 1688.0669 1701.2602
lowest AIC -> M_c : price ~ area + age + rooms
lowest BIC -> M_c : price ~ area + age + rooms
৫.৩ · পাঠোদ্ধার (numbers → theory)¶
প্রতিটি সংখ্যাকে এবার তত্ত্বের সাথে মিলিয়ে পড়ি।
Part 1 — inference টেবিল ও সত্য মডেল।
- Estimate বনাম সত্য মান। সত্য slope গুলো ছিল \((0.45,\,-0.8,\,6)\); OLS পেয়েছে \(\hat\beta_{\text{area}}=0.4956\), \(\hat\beta_{\text{age}}=-0.7203\), \(\hat\beta_{\text{rooms}}=6.4982\)। সবগুলোই সত্য মানের কাছাকাছি — তবে হুবহু নয়, কারণ (ক) finite sample noise, এবং (খ) row 0-এর contaminating point পুরো ফিটকে সামান্য টানছে (এ কারণেই \(\hat\beta_{\text{area}}\) সত্য \(0.45\) থেকে একটু উপরে \(0.4956\))। Intercept সত্য \(25\) এর বদলে \(16.95\) — এই বিচ্যুতিও মূলত leverage point-এর প্রভাব।
- Standard error ও \(t\)-statistic। প্রতিটি coefficient-এর জন্য \(t = \hat\beta_j / \operatorname{se}(\hat\beta_j)\)। যেমন area-র জন্য \(0.4956 / 0.0258 \approx 19.21\) — বিশাল, কারণ \(H_0:\beta_{\text{area}}=0\) থেকে estimate বহু standard error দূরে। এর সাথে যুক্ত \(p\)-value \(\approx 0\) (টেবিলে
0.0000)। প্রতিটি predictor অত্যন্ত significant। - \(95\%\) CI। \(\hat\beta_j \pm t_{0.975,\,196}\cdot\operatorname{se}(\hat\beta_j)\)। area-র জন্য \([0.4447,\,0.5465]\) — লক্ষণীয়, সত্য মান \(0.45\) এই interval-এর মধ্যেই পড়ছে, কাজেই inference সৎ। কোনো CI-ই \(0\) ধারণ করে না, যা \(p<0.05\) এর সমতুল্য।
- \(F\)-statistic। \(F = 213.69\) (\(p\approx 1.6\times 10^{-61}\)) যাচাই করছে \(H_0:\beta_{\text{area}}=\beta_{\text{age}}=\beta_{\text{rooms}}=0\) — অর্থাৎ "সব slope একসাথে শূন্য" এই গোটা-মডেল hypothesis নাকচ হয়; মডেলটি \(y\)-এর variance-এর একটি অর্থবহ অংশ ব্যাখ্যা করে।
- \(R^2\) বনাম adjusted \(R^2\)। \(R^2 = 0.7659\) মানে variance-এর প্রায় \(77\%\) ব্যাখ্যাত। adjusted \(R^2 = 0.7623\) সামান্য কম, কারণ এটি predictor সংখ্যার জন্য penalty দেয়: $$ R^2_{\text{adj}} = 1 - (1-R^2)\,\frac{n-1}{n-p}. $$ এখানে \(p=4\), \(n=200\) — penalty নগণ্য, তাই দুটো প্রায় সমান। (Part 4-এ যখন nested মডেলে predictor কমে, পার্থক্য বাড়ে।)
Part 2 — leverage, studentized residual ও Cook's distance।
- Leverage \(h_{ii}\)। এটি hat matrix \(H = X(X^\top X)^{-1}X^\top\)-এর diagonal — i-তম observation নিজের fitted value-কে কতটা টানে তার পরিমাপ; \(\sum_i h_{ii} = p = 4\), কাজেই গড় \(\bar h = p/n = 0.0200\)। আঙুলের-নিয়ম "high leverage" সীমা \(2p/n = 0.0400\)।
- Row 0 স্পষ্টভাবে আলাদা। Injected point-এর \(h_{00}=0.1328\) — গড়ের প্রায় \(6.6\) গুণ এবং দ্বিতীয় সর্বোচ্চ (\(0.0373\))-এর প্রায় চার গুণ। কারণটা গঠনগত: আমরা
area[0]=340বসিয়েছি, যা বাকি সব area (\(\le 200\)) থেকে \(x\)-স্পেসে বহু দূরে; predictor-স্পেসে একা দূরে দাঁড়ানো বিন্দুর leverage বড় হয়। - High leverage = high influence নয়, যতক্ষণ না residual-ও বড়। এখানে দুটোই বড়: external studentized residual \(= 3.845\) (sampling-এর অধীনে আনুমানিক \(t\)-distributed, কাজেই \(\lvert r \rvert > 3\) মানে আউটলায়ার)। বড় leverage আর বড় residual একসাথে — এ-ই influence-এর রেসিপি।
- Cook's distance \(D_i\)। Influence-এর একটি একক সারাংশ: $$ D_i = \frac{r_i^2}{p}\cdot\frac{h_{ii}}{1-h_{ii}}, $$ অর্থাৎ residual ও leverage উভয়কে একত্র করে। Row 0-এর \(D_0 = 0.5289\) — দ্বিতীয় সর্বোচ্চ (\(0.0473\))-এর চেয়ে দশ গুণেরও বেশি এবং \(4/n = 0.0200\) cutoff-এর প্রায় \(26\) গুণ। উপসংহার: একটিমাত্র বিন্দু পুরো fit-কে অসামঞ্জস্যপূর্ণভাবে নিয়ন্ত্রণ করছে — যা Part 1-এর intercept/slope বিচ্যুতির ব্যাখ্যা দেয়। বাস্তবে এই সারিটি যাচাই (ডেটা-এন্ট্রি ভুল?) করে, প্রয়োজনে robust regression-এ যেতে হয়।
Part 3 — multicollinearity ও VIF।
- VIF কী মাপে। predictor \(j\)-এর জন্য \(\text{VIF}_j = 1/(1-R_j^2)\), যেখানে \(R_j^2\) আসে বাকি predictor দিয়ে \(x_j\)-কে regress করে। উচ্চ \(R_j^2\) → উচ্চ VIF → \(\hat\beta_j\)-এর variance স্ফীত।
- area ও plot_size জোড়ায় বিপদ। যেহেতু
plot_size\(\approx 1.15\cdot\text{area}\), তারা প্রায় linearly নির্ভরশীল; তাই VIF\(_{\text{area}} = 7.71\) ও VIF\(_{\text{plot\_size}} = 7.80\) — দুটোই \(5\)–\(10\) সতর্কতা-অঞ্চলে। বিপরীতে age (\(1.04\)) ও rooms (\(1.00\)) প্রায় \(1\), অর্থাৎ তারা অন্যদের থেকে কার্যত স্বাধীন। (const-এর VIF কাঠামোগত, ব্যাখ্যাযোগ্য নয়।) - Variance inflation চোখে দেখা। তত্ত্ব বলে collinearity coefficient-কে নয়, তার precision-কে নষ্ট করে। প্রমাণ: \(\operatorname{se}(\hat\beta_{\text{area}})\) base model-এ \(0.0258\), কিন্তু plot_size যোগ করলে \(0.0697\) — \(2.70\) গুণ স্ফীত। লক্ষণীয়, \(\sqrt{\text{VIF}} = \sqrt{7.71} \approx 2.78\), যা পর্যবেক্ষিত \(2.70\) গুণের প্রায় সমান — কারণ collinearity-জনিত se-বৃদ্ধির গুণক ঠিক \(\sqrt{\text{VIF}}\)। ফলে redundant predictor যোগ করায় estimate অস্থির হয়, \(t\) ছোট হয়, যদিও মডেল আদৌ ভালো হয় না।
Part 4 — AIC/BIC দিয়ে model selection।
- Penalized fit। AIC \(= -2\ln \hat L + 2k\) এবং BIC \(= -2\ln \hat L + k\ln n\) — উভয়ই log-likelihood পুরস্কৃত করে কিন্তু parameter সংখ্যা \(k\)-কে শাস্তি দেয় (\(n=200\) হওয়ায় BIC-এর শাস্তি \(\ln 200 \approx 5.3\) প্রতি parameter, AIC-এর \(2\) থেকে কঠোর)। নিম্নতর মান = ভালো ভারসাম্য।
- প্রতিটি predictor যোগে উন্নতি। area → +age → +rooms যাওয়ার সাথে AIC নামে \(1837.70 \to 1809.21 \to 1688.07\) এবং BIC \(1844.30 \to 1819.10 \to 1701.26\)। প্রতিটি যোগ likelihood-এ যথেষ্ট লাভ এনেছে — penalty ছাপিয়ে। adjusted \(R^2\)-ও \(0.49 \to 0.56 \to 0.76\) একই দিকে বাড়ছে।
- সিদ্ধান্ত। সবচেয়ে কম AIC ও সবচেয়ে কম BIC — দুটোই full model \(M_c\) (
price ~ area + age + rooms) বেছে নেয়। এটি প্রত্যাশিত: এই তিনটি predictor-ই সত্য data-generating process-এর অংশ, কাজেই প্রতিটিরই বাস্তব ব্যাখ্যামূল্য আছে, এবং কোনো criterion-ই তাদের বাদ দিতে চায় না। যদি আমরা একটি অপ্রাসঙ্গিক predictor যোগ করতাম, BIC (কঠোর শাস্তির কারণে) সেটিকে আগে প্রত্যাখ্যান করত।
৫.৪ · সারসংক্ষেপ¶
একটিমাত্র স্ক্রিপ্টে আমরা পুরো রিগ্রেশন-ডায়াগনস্টিক চক্রটি ঘুরে এলাম। Part 1 দেখাল from-scratch নয়, সরাসরি statsmodels OLS থেকে সম্পূর্ণ inference টেবিল — estimate, se, \(t\), \(p\), \(95\%\) CI, \(F\)-test, \(R^2/R^2_{\text{adj}}\), AIC, BIC — এবং estimate গুলো সত্য coefficient-এর কাছে ফিরে এল। Part 2 প্রমাণ করল leverage \(h_{ii}\), studentized residual ও Cook's \(D_i\) যৌথভাবে ইচ্ছাকৃত contaminating বিন্দু (row 0, \(D_0 = 0.5289\), গড় leverage-এর প্রায় সাত গুণ) নির্ভুলভাবে চিহ্নিত করে। Part 3 দেখাল প্রায়-collinear plot_size যোগ করলে area ও plot_size উভয়ের VIF \(\approx 7.7\)–\(7.8\) এ ওঠে এবং \(\operatorname{se}(\hat\beta_{\text{area}})\) ঠিক \(\sqrt{\text{VIF}}\) গুণক (\(\approx 2.7\times\)) অনুযায়ী স্ফীত হয় — coefficient-এর মান নয়, precision নষ্ট হয়। Part 4 দেখাল AIC ও BIC উভয়েই nested মডেলগুলোর মধ্যে সঠিক full মডেল \(M_c\) বেছে নেয়। মূল শিক্ষা: একটি ভালো \(R^2\) যথেষ্ট নয় — influence diagnostics, multicollinearity, ও penalized selection একসাথে যাচাই করেই কেবল একটি রিগ্রেশন মডেলকে বিশ্বাস করা যায়।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে আমরা সংখ্যা দিয়ে diagnostics-এর গল্প শুনেছি — leverage \(h_{ii}\), studentized residual, Cook's distance \(D_i\), VIF, AIC, BIC। কিন্তু regression diagnostics-এর প্রকৃত শক্তি লুকিয়ে আছে চোখে। একটা residual table-এর দিকে তাকিয়ে আপনি কখনোই বুঝবেন না যে variance ডান দিকে গিয়ে ফুলে যাচ্ছে, কিংবা একটামাত্র observation পুরো fitted line-টাকে নিজের দিকে টেনে নিচ্ছে; কিন্তু একটা ভালো plot-এ সেটা এক সেকেন্ডে ধরা পড়ে। এই কারণেই Anscombe-এর সেই বিখ্যাত quartet — চারটে dataset যাদের mean, variance, correlation, regression line প্রায় হুবহু এক, অথচ scatter plot সম্পূর্ণ আলাদা — diagnostics-এর জগতে এত মূল্যবান। তাই এই অংশে আমরা সংখ্যাকে ছবিতে রূপান্তর করব।
আমরা চারটে ছবি দেখব, ঠিক যে ক্রমে একজন analyst বাস্তবে কাজ করে: প্রথমে classic 2×2 diagnostic panel (model fit-এর সামগ্রিক স্বাস্থ্য-পরীক্ষা), তারপর influence plot (কোন point-গুলো বিপজ্জনক), তারপর VIF chart (predictor-দের মধ্যে multicollinearity), এবং শেষে AIC/BIC curve (কোন model বেছে নেব)। প্রতিটি ছবির নিচে মূল plotting code-এর গুরুত্বপূর্ণ অংশটুকু দেওয়া আছে, যাতে আপনি নিজে reproduce করতে পারেন।
মনে রাখুন — dataset। সব ছবি একই synthetic housing dataset থেকে তৈরি:
rng = np.random.default_rng(20260619), \(n = 200\), এবং model হলোprice ~ area + age + rooms। তবে শুরুতেই আমরা ইচ্ছাকৃতভাবে একটা "খারাপ" observation ঢুকিয়ে দিয়েছি — row \(0\)-তেarea[0] = 340.0(যেখানে বাকি সব area \(50\) থেকে \(200\)-এর মধ্যে) এবংprice[0] = 250.0। এই injected point-টাই আমাদের diagnostics-এর প্রধান "অপরাধী", এবং প্রতিটি ছবিতে আমরা দেখব সে কীভাবে ধরা পড়ে।
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import OLSInfluence
rng = np.random.default_rng(20260619)
n = 200
area = rng.uniform(50, 200, n)
age = rng.uniform(0, 40, n)
rooms = rng.integers(1, 9, n)
price = 0.45*area - 0.8*age + 6*rooms + 25 + rng.normal(0, 15, n)
plot_size = 1.15*area + rng.normal(0, 10, n)
# ইচ্ছাকৃত high-leverage + outlier point
area[0] = 340.0
price[0] = 250.0
# মূল model fit
X = sm.add_constant(np.column_stack([area, age, rooms]))
model = sm.OLS(price, X).fit()
infl = OLSInfluence(model)
এই model ও infl object দুটো থেকেই নিচের সব ছবির কাঁচামাল আসবে।
৬.১ · Classic diagnostic panel (২×২)¶
যেকোনো linear regression fit করার পর সবচেয়ে আগে যে চারটে plot দেখা উচিত, সেগুলোকে একসঙ্গে একটা panel-এ সাজানো হলে R-এর plot(lm_model) যা দেখায় ঠিক সেই অভিজ্ঞতা পাওয়া যায়। প্রতিটা subplot model-এর একটা করে assumption যাচাই করে:
- (a) Residuals vs Fitted — linearity ও mean-zero assumption। LOWESS curve-টা যদি \(0\)-এর চারপাশে সমতল থাকে, তাহলে relationship-টা সত্যিই linear; curve বেঁকে গেলে কোনো nonlinear pattern বাকি আছে বুঝতে হবে।
- (b) Normal Q-Q — residual-এর normality। Point-গুলো \(45°\) reference line-এর উপর বসলে residual approximately normal; tail-এ বেঁকে গেলে heavy tail বা skew আছে।
- (c) Scale-Location — homoscedasticity (সমান variance)। এখানে \(\sqrt{\lvert \text{std. residual} \rvert}\) আঁকা হয় fitted value-র বিপরীতে; LOWESS curve উপরের দিকে উঠলে variance fitted value-র সঙ্গে বাড়ছে, অর্থাৎ heteroscedasticity।
- (d) Residuals vs Leverage — influential point শনাক্তকরণ। এখানে Cook's distance-এর contour আঁকা থাকে; কোনো point ডান-উপরের কোণে (high leverage + বড় residual) চলে গেলে, এবং \(D = 0.5\) বা \(D = 1\) contour পেরিয়ে গেলে, সে model-এর জন্য বিপজ্জনক।
ছবিটি তৈরির মূল কোড (statsmodels-এর OLSInfluence থেকে সব diagnostic quantity পাওয়া যায়, আর LOWESS smoother আসে statsmodels.nonparametric থেকে):
import matplotlib.pyplot as plt
from statsmodels.nonparametric.smoothers_lowess import lowess
from scipy import stats
fitted = model.fittedvalues
resid = model.resid
std_resid = infl.resid_studentized_internal # internally studentized
leverage = infl.hat_matrix_diag # h_ii
p = X.shape[1] # parameter সংখ্যা (const সহ)
fig, axes = plt.subplots(2, 2, figsize=(12, 9.5))
# (a) Residuals vs Fitted + LOWESS
ax = axes[0, 0]
ax.scatter(fitted, resid)
lo = lowess(resid, fitted, frac=0.6)
ax.plot(lo[:, 0], lo[:, 1]) # red LOWESS curve
ax.axhline(0, ls="--")
# (c) Scale-Location: sqrt(|std resid|) vs fitted
ax = axes[1, 0]
sqrt_abs = np.sqrt(np.abs(std_resid))
ax.scatter(fitted, sqrt_abs)
ax.plot(*lowess(sqrt_abs, fitted, frac=0.6).T)
# (d) Residuals vs Leverage + Cook's distance contour
ax = axes[1, 1]
ax.scatter(leverage, std_resid)
hgrid = np.linspace(1e-4, leverage.max()*1.08, 200)
for D in (0.5, 1.0): # Cook's distance contour
for sgn in (+1, -1):
ax.plot(hgrid, sgn*np.sqrt(D * p * (1 - hgrid) / hgrid), ls=":")
ax.scatter(leverage[0], std_resid[0], s=120, facecolor="none",
edgecolor="red", linewidth=2.2) # injected point flag
ছবির শেষ subplot-এ (d) Cook's distance contour-এর সূত্রটা গুরুত্বপূর্ণ। একটা নির্দিষ্ট \(D\)-এর জন্য residual ও leverage-এর সম্পর্ক হলো \(r_{\text{std}} = \pm\sqrt{\dfrac{D \cdot p \,(1 - h_{ii})}{h_{ii}}}\) — এই curve-ই panel-এ আঁকা হয়েছে। লক্ষ করুন, \(h_{ii}\) বড় হলে একই \(D\) পেতে অনেক ছোট residual যথেষ্ট, তাই high-leverage অঞ্চলে contour-গুলো \(0\)-এর কাছে নেমে আসে।
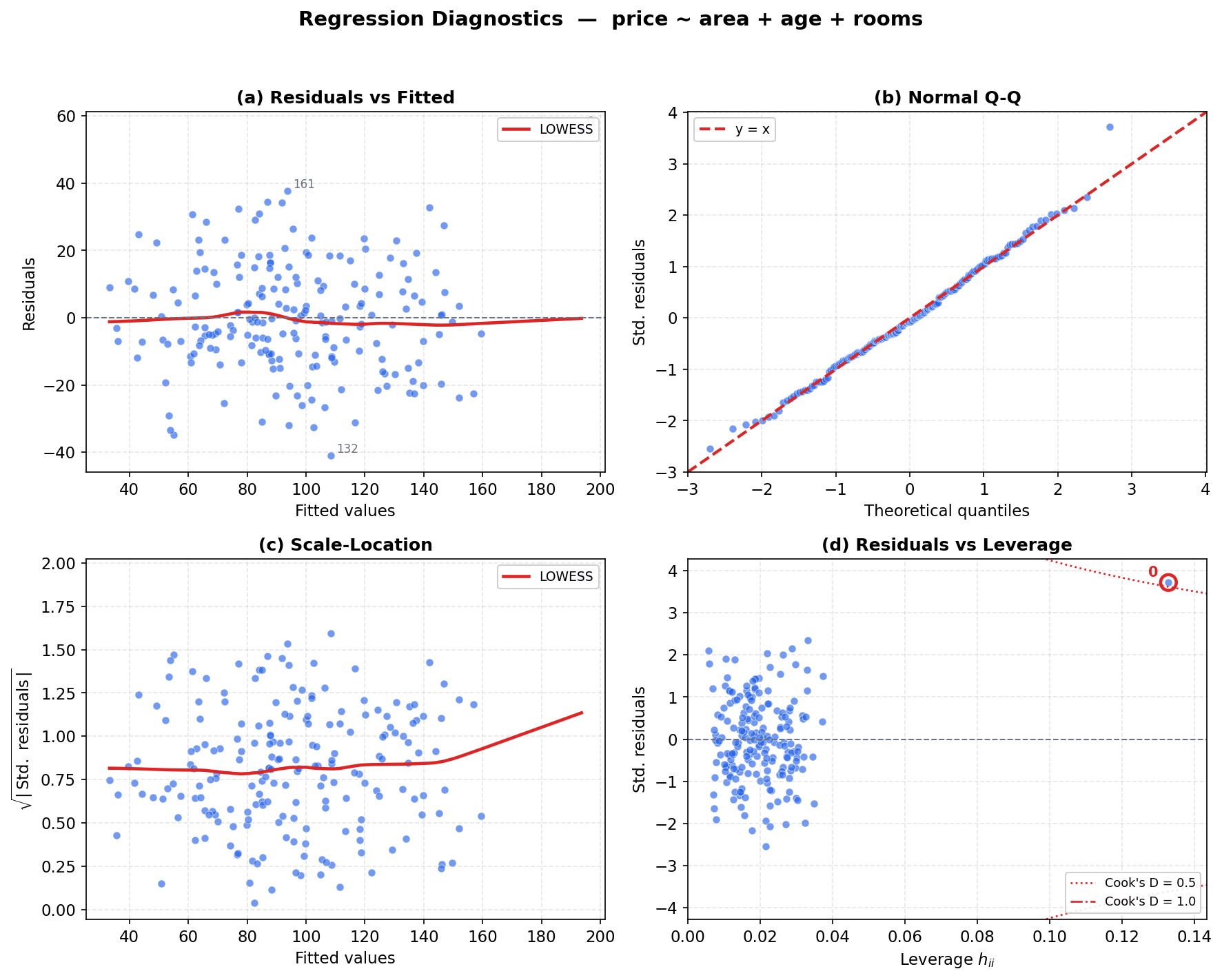
ছবি থেকে যা পড়া যায়। চারটে subplot একসঙ্গে একটা পরিষ্কার গল্প বলে। (a)-তে LOWESS curve মোটামুটি সমতল — মূল linear relationship ঠিকই আছে। (b) Q-Q plot-এ বেশিরভাগ point reference line-এর উপর বসেছে, অর্থাৎ residual approximately normal; তবে একদম ডান প্রান্তে কয়েকটা point line থেকে সামান্য সরে গেছে। (c) scale-location curve ডান দিকে গিয়ে কিছুটা উপরে উঠেছে, যা ইঙ্গিত দেয় বড় fitted value-র দিকে variance একটু বাড়ছে — এটা মূলত সেই injected point-এর প্রভাব। আর সবচেয়ে নাটকীয় (d): লাল বৃত্তে ঘেরা row \(0\) point-টা ডান প্রান্তে একা দাঁড়িয়ে — সবচেয়ে বড় leverage (\(h_{00} \approx 0.13\), বাকি সবার তিন-চার গুণ) এবং একটা বড় positive studentized residual নিয়ে। এই একটা ছবিই বলে দেয়: model মোটের উপর ভালো, কিন্তু একটা observation আলাদাভাবে তদন্ত করা দরকার।
৬.২ · Leverage ও Cook's distance per observation¶
(d) panel-এ injected point-টা চোখে পড়লেও, সেখানে \(x\)-অক্ষ leverage আর \(y\)-অক্ষ residual — তাই কোন observation সেটা সরাসরি বোঝা যায় না। এই সমস্যা মেটাতে একটা সহজ কিন্তু শক্তিশালী plot হলো observation index-এর বিপরীতে leverage (বা Cook's distance) আঁকা — একটা stem plot, যেখানে প্রতিটি observation একটা করে দণ্ড। এতে প্রতিটি বিপজ্জনক point-এর সঠিক row নম্বর সঙ্গে সঙ্গে শনাক্ত করা যায়।
দুটো reference threshold আঁকা হয়েছে, যেগুলো diagnostics-এর সাধারণ rule-of-thumb:
- Leverage: \(h_{ii} > \dfrac{2p}{n}\) হলে সেই point high-leverage বলে সন্দেহজনক। এখানে \(p = 4\), \(n = 200\), তাই threshold \(= \dfrac{2 \times 4}{200} = 0.04\)।
- Cook's distance: \(D_i > \dfrac{4}{n} = \dfrac{4}{200} = 0.02\) হলে সেই point influential বলে সন্দেহজনক।
import numpy as np
import matplotlib.pyplot as plt
leverage = infl.hat_matrix_diag # h_ii
cooks = infl.cooks_distance[0] # Cook's distance D_i
idx = np.arange(n)
lev_thresh = 2 * p / n # = 0.04
cook_thresh = 4 / n # = 0.02
fig, axes = plt.subplots(1, 2, figsize=(13, 5.2))
mark0 = idx == 0 # injected point
# (a) leverage stem plot
ax = axes[0]
ax.vlines(idx[~mark0], 0, leverage[~mark0]) # সাধারণ point (grey)
ax.scatter(idx[~mark0], leverage[~mark0])
ax.vlines(0, 0, leverage[0], color="red", lw=2) # row 0 (red)
ax.scatter(0, leverage[0], color="red", s=90)
ax.axhline(lev_thresh, ls="--", label="2p/n")
# (b) Cook's distance stem plot
ax = axes[1]
ax.vlines(idx[~mark0], 0, cooks[~mark0])
ax.scatter(idx[~mark0], cooks[~mark0])
ax.vlines(0, 0, cooks[0], color="red", lw=2)
ax.axhline(cook_thresh, ls="--", label="4/n")
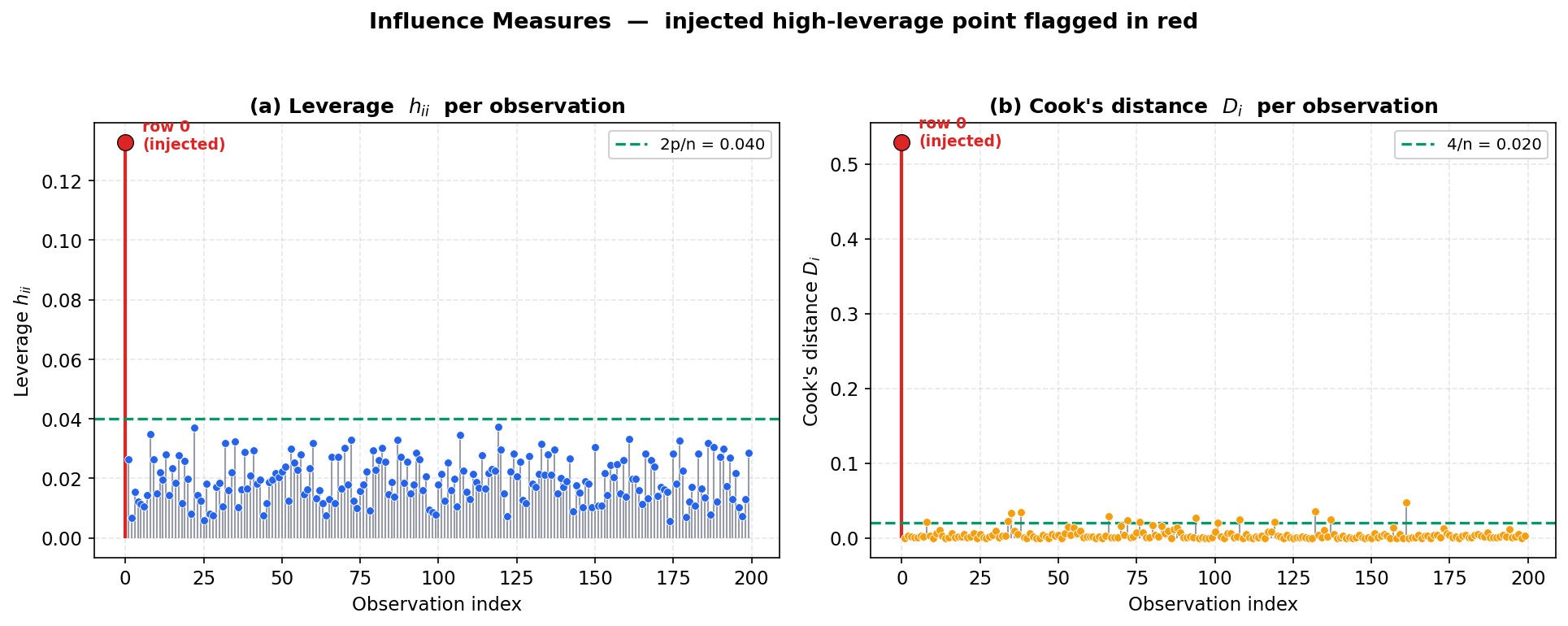
ছবি থেকে যা পড়া যায়। ফলাফল চোখে আঙুল দিয়ে দেখিয়ে দেয়। বাঁ panel-এ বাকি ১৯৯টা observation-এর leverage সব \(0.04\) threshold-এর নিচে জড়ো হয়ে আছে (বেশিরভাগই \(0.005\) থেকে \(0.035\)-এর মধ্যে), কিন্তু লাল দণ্ড — row \(0\) — একদম উপরে \(h_{00} \approx 0.13\)-তে, threshold-এর তিন গুণেরও বেশি উঁচুতে। ডান panel-এ একই গল্প আরও তীব্র: প্রায় সব Cook's distance \(0.05\)-এর নিচে, অথচ row \(0\)-এর \(D_0 \approx 0.53\) — threshold-এর প্রায় ২৬ গুণ এবং বাকি সবার থেকে আকাশ-পাতাল ব্যবধানে বড়। এটাই influential point-এর পাঠ্যপুস্তকীয় উদাহরণ: একটা observation একই সঙ্গে high leverage (\(x\)-space-এ দূরে) এবং বড় residual (model line থেকে দূরে) থাকার ফলে fitted coefficient-গুলোকে অসামঞ্জস্যভাবে নিজের দিকে টানছে। কোন row সেটা? plot সরাসরি বলে দিচ্ছে — index \(0\), ঠিক যে point-টা আমরা ইচ্ছাকৃতভাবে ঢুকিয়েছিলাম।
ব্যবহারিক পরামর্শ। threshold পেরোনো মানেই point-টা ফেলে দিতে হবে, এমন নয়। threshold শুধু "এই observation-টা চোখে দেখো" — এই সংকেত দেয়। বাস্তবে পরবর্তী ধাপ হলো: data entry-তে ভুল আছে কি না দেখা, point-টা সরিয়ে model আবার fit করে coefficient কতটা বদলায় তা পরীক্ষা করা (sensitivity analysis), আর প্রয়োজনে robust regression-এর কথা ভাবা।
৬.৩ · Variance Inflation Factor (VIF)¶
আগের দুটো ছবি একটা observation (row) নিয়ে ছিল; এই ছবি একটা predictor (column) নিয়ে। Multicollinearity — অর্থাৎ predictor-গুলো নিজেদের মধ্যে strongly correlated হওয়া — coefficient estimate-কে অস্থির করে তোলে: standard error ফুলে যায়, sign উল্টে যেতে পারে, আর "কোন variable আসলে কতটা প্রভাব ফেলছে" সেই ব্যাখ্যা ভেঙে পড়ে। এর পরিমাপ হলো VIF:
যেখানে \(R_j^2\) হলো \(j\)-তম predictor-কে বাকি সব predictor দিয়ে regress করলে যে \(R^2\) পাওয়া যায়। অন্য variable-গুলো \(X_j\)-কে যত ভালোভাবে ব্যাখ্যা করতে পারে, \(R_j^2\) তত \(1\)-এর কাছে যায়, আর VIF তত আকাশ ছোঁয়। সাধারণ rule-of-thumb: \(\text{VIF} > 5\) হলে সতর্ক হও, \(\text{VIF} > 10\) হলে গুরুতর সমস্যা।
এখানে আমরা ইচ্ছা করেই একটা সমস্যা ঢুকিয়ে রেখেছি: dataset-এ plot_size = 1.15*area + noise, অর্থাৎ plot_size প্রায় হুবহু area-এর একটা scaled কপি। তাই আমরা চারটে predictor {area, age, rooms, plot_size} নিয়ে VIF মাপব এবং দেখব এই দুটো collinear variable কীভাবে আলাদা হয়ে যায়।
from statsmodels.stats.outliers_influence import variance_inflation_factor
# চার predictor-সহ design matrix (const সহ)
Xv = sm.add_constant(np.column_stack([area, age, rooms, plot_size]))
names = ["const", "area", "age", "rooms", "plot_size"]
vifs = [variance_inflation_factor(Xv, i) for i in range(Xv.shape[1])]
# const বাদ দিয়ে শুধু predictor দেখাই
pred_names = names[1:]
pred_vifs = vifs[1:]
colors = ["red" if v >= 10 else ("orange" if v >= 5 else "blue")
for v in pred_vifs]
fig, ax = plt.subplots(figsize=(9, 5.6))
ax.bar(pred_names, pred_vifs, color=colors)
ax.axhline(5, ls="--", label="threshold = 5")
ax.axhline(10, ls="-.", label="threshold = 10")
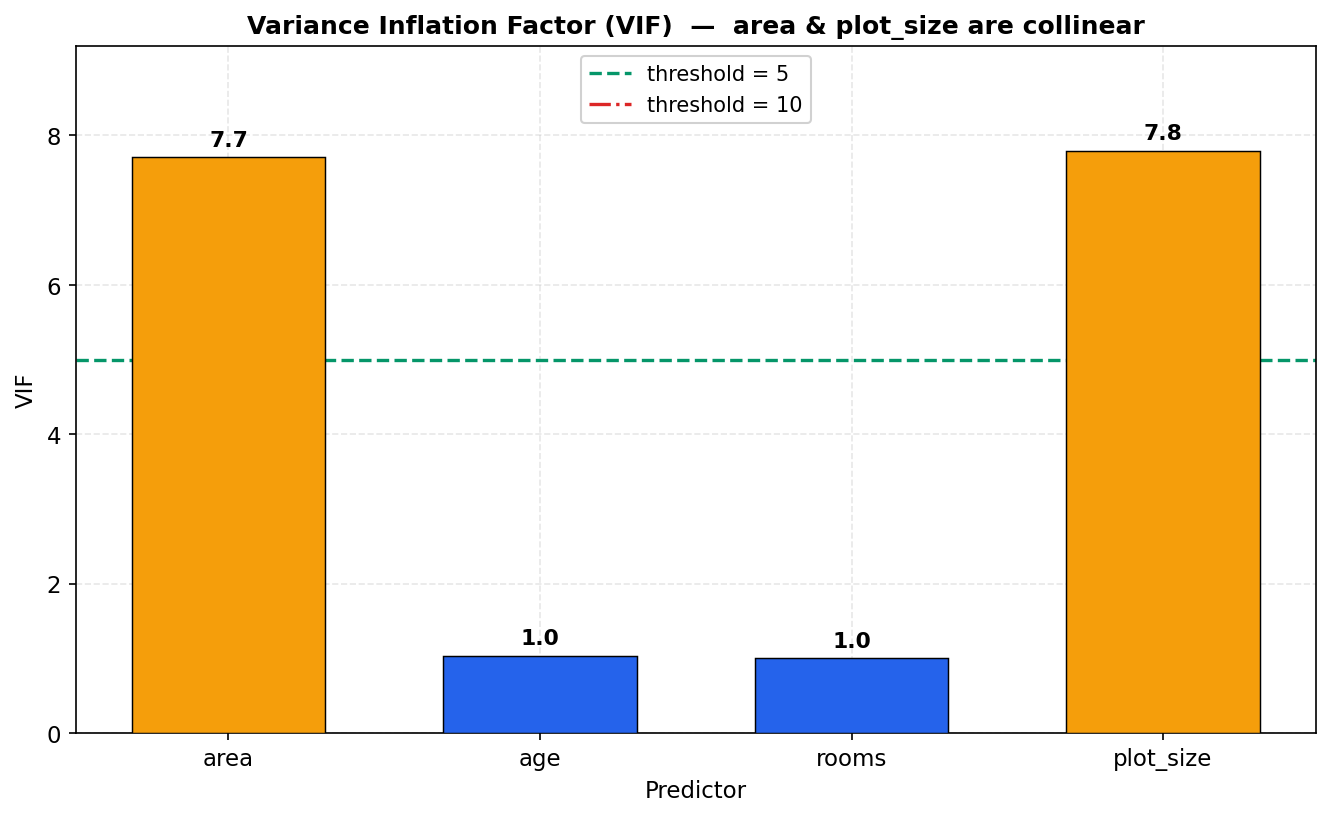
ছবি থেকে যা পড়া যায়। চারটে bar দুটো স্পষ্ট দলে ভাগ হয়ে গেছে। age আর rooms-এর VIF প্রায় ঠিক \(1.0\) — এরা সম্পূর্ণ "নির্দোষ", বাকি predictor-দের সঙ্গে এদের কোনো linear সম্পর্ক নেই, তাই এদের coefficient estimate স্থিতিশীল। অন্যদিকে area (\(\text{VIF} \approx 7.7\)) আর plot_size (\(\text{VIF} \approx 7.8\)) — দুজনেই \(5\)-এর সতর্কতা-রেখা পেরিয়ে অনেক উপরে উঠে গেছে, ঠিক যেমনটা আশা করা যায় যেহেতু একটা অন্যটার scaled কপি। লক্ষ করার মতো ব্যাপার হলো এরা জোড়ায় ধরা পড়েছে: collinearity কখনো একা একটা variable-এর দোষ নয়, সবসময় অন্তত দুটো variable-এর মধ্যে ভাগাভাগি হওয়া সম্পর্ক। তাই দুটোরই VIF প্রায় সমান উঁচুতে। এর সমাধানও তাই সরল: এই জোড়ার যেকোনো একটাকে (সাধারণত যেটার ব্যাখ্যা কম গুরুত্বপূর্ণ, এক্ষেত্রে plot_size) model থেকে বাদ দিলেই দুটো VIF-ই \(1\)-এর কাছে নেমে আসবে।
খেয়াল রাখুন — VIF কিন্তু \(5\) আর \(10\)-এর মাঝখানে। এই dataset-এ collinear জোড়ার VIF \(\approx 7.7\) — অর্থাৎ \(5\)-এর কঠোর threshold পেরিয়েছে কিন্তু \(10\)-এর "গুরুতর" রেখা পেরোয়নি। বাস্তবে \(5\) বনাম \(10\) — কোন threshold ব্যবহার করবেন তা domain ও স্বার্থের উপর নির্ভর করে; এই grey zone-ই (যেখানে দুই rule দুই কথা বলে) মনে করিয়ে দেয় যে diagnostics মানে যান্ত্রিক pass/fail নয়, বরং সংখ্যা ও context মিলিয়ে বিচার।
৬.৪ · Model selection: AIC ও BIC¶
শেষ প্রশ্ন: predictor-গুলোর মধ্যে আসলে কয়টা model-এ রাখব? বেশি predictor যোগ করলে in-sample fit (\(R^2\)) সবসময় বাড়ে, এমনকি অর্থহীন variable যোগ করলেও — কিন্তু তাতে model overfit হয়, নতুন data-তে খারাপ predict করে। AIC (Akaike Information Criterion) আর BIC (Bayesian Information Criterion) এই সমস্যার সমাধান দেয়: এরা fit-এর পুরস্কার দেয় কিন্তু parameter সংখ্যার জন্য penalty কাটে।
যেখানে \(k\) হলো parameter সংখ্যা, \(\hat{L}\) হলো maximized likelihood, আর \(n\) হলো sample size। দুটোর জন্যই যত কম তত ভালো। পার্থক্য penalty-তে: BIC-এর penalty \(k\ln(n)\), আর AIC-এর penalty \(2k\)। যেহেতু \(n = 200\)-এ \(\ln(200) \approx 5.3 > 2\), BIC প্রতিটি বাড়তি parameter-এর জন্য বেশি কড়া শাস্তি দেয় — তাই BIC সাধারণত ছোট, আরও পরিমিত model বেছে নেয়।
আমরা ক্রমবর্ধমান আকারের একগুচ্ছ nested model তুলনা করব — intercept-only থেকে শুরু করে একটা একটা করে predictor যোগ করতে করতে পূর্ণ model পর্যন্ত — এবং প্রতিটির AIC ও BIC plot করব।
predictors = {"area": area, "rooms": rooms, "age": age, "plot_size": plot_size}
seq = [
([], "intercept\nonly"),
(["area"], "+area"),
(["area", "rooms"], "+rooms"),
(["area", "rooms", "age"], "+age"),
(["area", "rooms", "age", "plot_size"], "+plot_size"),
]
aic_list, bic_list, labels = [], [], []
for cols, lab in seq:
Xm = sm.add_constant(np.column_stack([predictors[c] for c in cols])) \
if cols else np.ones((n, 1))
m = sm.OLS(price, Xm).fit()
aic_list.append(m.aic); bic_list.append(m.bic); labels.append(lab)
aic = np.array(aic_list); bic = np.array(bic_list)
ai_min, bi_min = int(np.argmin(aic)), int(np.argmin(bic)) # minimum চিহ্নিত
fig, ax = plt.subplots(figsize=(9.5, 5.8))
xs = np.arange(len(labels))
ax.plot(xs, aic, "-o", label="AIC")
ax.plot(xs, bic, "-s", label="BIC")
ax.scatter(ai_min, aic[ai_min], s=240, facecolor="none", edgecolor="C0") # AIC min
ax.scatter(bi_min, bic[bi_min], s=300, facecolor="none", edgecolor="C1") # BIC min
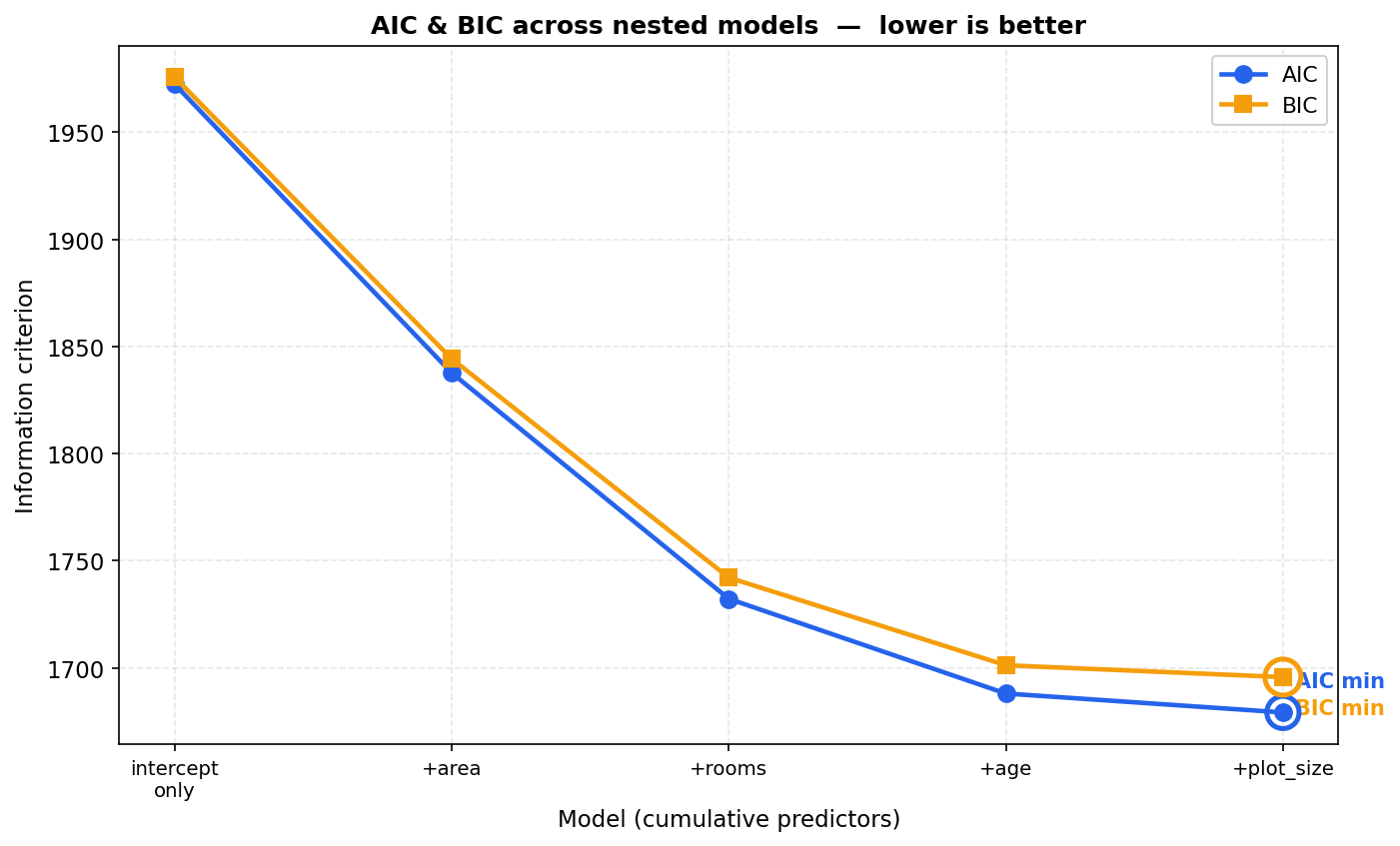
ছবি থেকে যা পড়া যায়। দুটো curve-ই বাঁ থেকে ডানে একটানা নিচে নামছে — অর্থাৎ প্রতিটা নতুন predictor যোগ করলে দুই criterion-ই কমছে। সবচেয়ে বড় লাফ পড়ে প্রথম তিন ধাপে (area, তারপর rooms, তারপর age যোগ করার সময়), যেগুলো আমাদের জানা true model-এর আসল predictor। মজার ব্যাপারটা শেষ ধাপে: plot_size যোগ করলেও AIC ও BIC দুটোই সামান্য আরও কমে, তাই এই dataset-এ minimum পড়ে একদম পূর্ণ model-এ — দুটো ফাঁপা বৃত্ত সেই minimum-কে চিহ্নিত করছে।
এখানে একটা গভীর শিক্ষা আছে, এবং এটাই এই চারটে ছবিকে একসঙ্গে বাঁধে। plot_size-এর VIF আমরা ঠিক আগের ছবিতে দেখেছিলাম প্রায় \(7.8\) — অর্থাৎ সে area-এর সঙ্গে প্রবলভাবে collinear এবং model-এ প্রায় কোনো নতুন তথ্য যোগ করে না। অথচ AIC/BIC তাকে যোগ করতে নিষেধ করছে না, কারণ সামান্য noise-fit-এর সুবাদে likelihood একটু বাড়ে আর সেই বৃদ্ধি penalty-কে কোনোমতে ছাপিয়ে যায়। এর মানে: কোনো একটা criterion-ই চূড়ান্ত সালিশ নয়। AIC/BIC বলছে "রাখলে ক্ষতি নেই", কিন্তু VIF সরবে বলছে "plot_size আর area একই কথা বলছে, দুটো রেখো না।" একজন দক্ষ analyst এই দুই সংকেত মিলিয়ে সিদ্ধান্ত নেবে — সম্ভবত plot_size বাদ দিয়ে price ~ area + age + rooms model-কেই বেছে নেবে: এটি প্রায় একই information criterion দেয়, কিন্তু interpretable থাকে এবং collinearity-মুক্ত। ঠিক এই কারণেই diagnostics-কে আমরা চারটে আলাদা ছবিতে ভাগ করিনি কেবল — চারটে আলাদা দৃষ্টিকোণ হিসেবে দেখেছি, যাদের একসঙ্গে পড়লে তবেই model-এর সম্পূর্ণ ছবি ফুটে ওঠে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-02-regression-diagnostics-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — diagnostics ও inference হাতে গুনে দেখাটাই এই অধ্যায়ের আসল শেখা। (চলমান উদাহরণ স্মারক — §৫-৬-এর সেই dataset: \(\text{price}=0.45\,\text{area}-0.8\,\text{age}+6\,\text{rooms}+25+\varepsilon\), \(\varepsilon\sim\mathcal N(0,15^2)\), seed default_rng(20260619), \(n=200\); predictor area\(\sim U(50,200)\), age\(\sim U(0,40)\), rooms\(\in\{1,\dots,8\}\)। fit করলে \(\hat\beta\approx[16.95,\,0.4956,\,-0.7203,\,6.498]\), \(R^2\approx 0.766\), \(\hat\sigma\approx 16.30\)। একটি collinear predictor plot_size (\(\approx 1.15\cdot\text{area}\)) ও একটি high-leverage point — area[0]=340, price[0]=250 (row 0) — ইচ্ছাকৃতভাবে ঢোকানো আছে। মূল সূত্র: leverage \(h_{ii}=\) hat-matrix \(H=X(X^\top X)^{-1}X^\top\)-এর কর্ণ; \(t_j=\hat\beta_j/\widehat{\mathrm{se}}(\hat\beta_j)\); \(\text{VIF}_j=1/(1-R_j^2)\); \(R^2_{\text{adj}}=1-\dfrac{\text{SSE}/(n-p)}{\text{SST}/(n-1)}\); \(\text{AIC}=-2\ell+2K\), \(\text{BIC}=-2\ell+(\ln n)K\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিচের চারটি residual-vs-fitted plot-এর বর্ণনা পড়ে প্রতিটির জন্য বলুন কোন LINE অনুমান (যদি কোনোটি) ভাঙছে এবং কী করণীয়: (ক) বিন্দুগুলো \(0\)-এর চারপাশে এলোমেলো অনুভূমিক ব্যান্ড, কোনো প্যাটার্ন নেই; (খ) বাঁ দিকে সরু, ডান দিকে চওড়া — একটা funnel/মেগাফোন আকৃতি; (গ) একটা স্পষ্ট U-আকৃতির বাঁক (curve); (ঘ) বেশির ভাগ বিন্দু ব্যান্ডে, কিন্তু একটি বিন্দু বহু দূরে উপরে একা। Hint: funnel ⇒ heteroscedasticity (Equal-variance ভাঙছে); বাঁক ⇒ Linearity ভাঙছে (predictor-এ \(x^2\) বা \(\log x\) লাগতে পারে); একা-দূরের বিন্দু ⇒ outlier/influential point — Cook's \(D\) দিয়ে যাচাই। (ক)-তে কিছুই ভাঙছে না।
প্রশ্ন ২ (★). "\(h_{ii}\) (leverage) বড়" আর "residual \(\hat\varepsilon_i\) বড়" — দুটো কি একই কথা? একটা বিন্দু high-leverage কিন্তু small residual হতে পারে কি? আর high-leverage হলেই কি সে fit-কে টেনে নষ্ট করবে? "leverage", "outlier", এবং "influential" — তিনটি ধারণা এক বাক্যে আলাদা করুন। Hint: leverage শুধু \(x\)-জায়গায় বিন্দুটি কত দূরে তা মাপে (\(h_{ii}=\) hat-matrix কর্ণ, \(y\)-এর সাথে সম্পর্ক নেই); residual \(y\)-অমিল মাপে। high leverage সম্ভাবনা তৈরি করে প্রভাবের, কিন্তু বিন্দুটি trend-এর ওপরেই বসলে residual ছোট, influence কম। influential = leverage ও residual দুটোই যথেষ্ট — সেটাই Cook's \(D\) ধরে।
প্রশ্ন ৩ (★★). FULL মডেলে plot_size (যা প্রায় \(=1.15\cdot\text{area}\)) যোগ করলে দেখা যায়: (i) area-এর coefficient \(0.496\to 0.710\)-এ লাফ দেয় ও তার \(\widehat{\mathrm{se}}\) \(0.0258\to 0.0697\)-এ (প্রায় ২.৭ গুণ) ফুলে যায়, (ii) plot_size-এর coefficient আসে ঋণাত্মক (\(-0.207\)) — অথচ DGP-তে বড় plot_size মানেই বড় area, তাই price বাড়ারই কথা; এই উল্টো sign পুরোপুরি spurious, (iii) তবু মডেলের সামগ্রিক \(R^2\) প্রায় অপরিবর্তিত (\(0.766\to 0.778\))। এই তিনটি লক্ষণ একসাথে কীসের ক্লাসিক স্বাক্ষর? কেন \(R^2\) পড়ে না অথচ স্বতন্ত্র coefficient-এর মান ও sign "অর্থহীন/অস্থির" হয়ে যায় — অন্তর্দৃষ্টিসহ ব্যাখ্যা করুন। Hint: এটি multicollinearity-র পাঠ্যবই-চিত্র। দুই predictor প্রায় একই তথ্য বহন করে, তাই মডেল "কাকে কত credit দেব" ঠিক করতে পারে না — coefficient-এর variance (তাই se) ফুলে যায় (\(\propto\sqrt{\text{VIF}}\)), মান ও sign অস্থির হয়; কিন্তু দুজনে মিলে \(y\)-এর একই variation ব্যাখ্যা করে, তাই \(R^2\) অটুট। (লক্ষ করুন: এখানে plot_size-এর \(t\) এখনও "significant" দেখায় — \(t=-3.29\), \(p=0.0012\) — কিন্তু তার মান ও sign-ই অর্থহীন, তাই significance বিভ্রান্তিকর।) VIF (প্রশ্ন ৮) এটাই সংখ্যায় ধরবে।
প্রশ্ন ৪ (★★). এই FULL মডেলে overall \(F\)-test দিল \(F=213.7\) (\(df=3,196\)), p-value \(\approx 1.6\times 10^{-61}\) — অর্থাৎ "অন্তত একটি predictor কাজে লাগছে"। অথচ সাধারণভাবে একই মডেলে কোনো এক predictor-এর \(t\)-test insignificant হতে পারে (\(p>0.05\))। (ক) \(F\)-test ঠিক কোন null hypothesis পরীক্ষা করে, আর প্রতিটি \(t\)-test কোনটি? (খ) "\(F\) significant কিন্তু কোনো individual \(t\) নয়" — এমন স্ববিরোধী-মনে-হওয়া পরিস্থিতি কখন ঘটে এবং তা আসলে স্ববিরোধ নয় কেন? Hint: \(F\): \(H_0:\beta_1=\beta_2=\cdots=\beta_{p-1}=0\) (সব slope একসাথে শূন্য)। \(t_j\): \(H_0:\beta_j=0\) (অন্যগুলো মডেলে থাকা অবস্থায়)। collinear predictor-এ যৌথভাবে তারা শক্তিশালী (F বড়) কিন্তু কাউকে আলাদা করে "একমাত্র দায়ী" বলা যায় না (প্রতিটি \(t\) ছোট) — তাই কোনো বিরোধ নেই।
প্রশ্ন ৫ (★★). AIC ও BIC দুটোই \(-2\ell\) (lack-of-fit) এর সাথে একটা complexity penalty যোগ করে: AIC-তে \(2K\), BIC-তে \((\ln n)K\)। (ক) \(n=200\)-এ কোন penalty কড়া? (খ) তাই বড় \(n\)-এ AIC ও BIC-এর মধ্যে কে বেশি parsimonious (ছোট) মডেল বাছার দিকে ঝোঁকে? (গ) দুজনের দার্শনিক লক্ষ্য আলাদা — একটি "সত্য মডেল আছে, সেটি খুঁজি", আরেকটি "ভবিষ্যৎ-পূর্বাভাসে সেরাটি খুঁজি"। কোনটি কোনটি? Hint: \(\ln 200\approx 5.30 > 2\), তাই BIC-এর penalty প্রতি parameter-এ প্রায় আড়াই গুণ কড়া ⇒ BIC ছোট মডেলে ঝোঁকে। BIC consistent (সত্য মডেল \(n\to\infty\)-এ ধরে), AIC asymptotically efficient (পূর্বাভাস-অনুকূল)।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★). FULL মডেলের fit থেকে area-এর coefficient \(\hat\beta_{\text{area}}=0.4956\), তার \(\widehat{\mathrm{se}}=0.02580\), residual degrees of freedom \(df=n-p=200-4=196\)। (ক) হাতে \(t\)-statistic \(t=\hat\beta/\widehat{\mathrm{se}}\) বের করুন। (খ) \(t_{0.975,\,196}\approx 1.972\) ধরে \(95\%\) confidence interval \(\hat\beta\pm t^\*\cdot\widehat{\mathrm{se}}\) গণনা করুন। (গ) CI-তে \(0\) আছে কি? তাই \(H_0:\beta_{\text{area}}=0\) কি \(\alpha=0.05\)-এ বাতিল হয়? CI–test duality দিয়ে যুক্তি দিন। Hint: \(t=0.4956/0.02580\approx 19.2\) — বিশাল। CI \(=0.4956\pm 1.972\times 0.0258=(0.4447,\ 0.5465)\); \(0\) এর ধারেকাছেও নেই, তাই \(H_0\) জোরালোভাবে বাতিল (৪.৬-এর CI ও ৪.৭-এর test একই সিদ্ধান্তে আসে)।
প্রশ্ন ৭ (★★). একই মডেলে rooms-এর জন্য \(\hat\beta_{\text{rooms}}=6.498\), \(\widehat{\mathrm{se}}=0.5032\), \(df=196\)। (ক) \(t\)-stat বের করুন; (খ) \(95\%\) CI; (গ) এক বাক্যে coefficient-এর applied ব্যাখ্যা দিন (price লাখ টাকায়); (ঘ) এবার ভাবুন: যদি আমরা rooms-এর coefficient-এ \(\beta_0^{\text{test}}=6\) (true value!) পরীক্ষা করি, \(t=(\hat\beta-6)/\widehat{\mathrm{se}}\) কত? এটি কি \(\lvert t\rvert<1.972\)? — অর্থাৎ data কি true-মান \(6\)-কে প্রত্যাখ্যান করে? Hint: \(t=6.498/0.5032\approx 12.9\) (vs \(0\)); CI \(=(5.51,\ 7.49)\) — এতে \(6\) আছে, তাই (ঘ)-তে \(t=(6.498-6)/0.5032\approx +0.99\), \(\lvert t\rvert<1.972\) ⇒ data true-মান \(6\)-এর সাথে সঙ্গতিপূর্ণ (আস্থার ব্যবধানে \(6\) থাকাটাই এর সমার্থক)।
প্রশ্ন ৮ (★★). plot_size-যুক্ত মডেলে area-কে বাকি তিন predictor (age, rooms, plot_size) দিয়ে regress করলে \(R^2_{\text{area}}=0.870\) পাওয়া যায়। (ক) VIF \(=1/(1-R_j^2)\) সূত্রে area-এর VIF বের করুন। (খ) এর মানে standard error সাধারণের চেয়ে কত গুণ বড় (\(\sqrt{\text{VIF}}\))? (গ) সাধারণ থ্রেশহোল্ড VIF \(>5\) "সতর্ক", \(>10\) "গুরুতর" — area কোন জোনে পড়ে? কোন predictor-এর সাথে সে প্রায় redundant? Hint: \(\text{VIF}=1/(1-0.870)=1/0.130\approx 7.71\) — \(5\) ও \(10\)-এর মাঝে, অর্থাৎ "সতর্কতা" জোনে (গুরুতর নয়); \(\sqrt{7.71}\approx 2.78\), তাই se প্রায় ২.৭ গুণ ফোলা। plot_size-ই দায়ী (\(\text{corr}(\text{area},\text{plot\_size})\approx 0.932\)) — দুজনের একজনকে বাদ দিলেই VIF নেমে \(\approx 1\) হয়।
প্রশ্ন ৯ (★★). (নিচের SSE-জোড়া নিছক দৃষ্টান্তমূলক, এই অধ্যায়ের dataset নয় — penalty-যুক্তিটা বিচ্ছিন্নভাবে দেখার জন্য বানানো একটা hypothetical।) ধরুন দুটি nested মডেল: BASE (\(p=4\)) ও \(+z\) (একটি বাড়তি predictor \(z\), \(p=5\)), \(n=200\), এবং এই hypothetical-এ \(z\) এমন প্রায় অর্থহীন যে \(\text{SSE}\) কার্যত অপরিবর্তিত — BASE-এ \(\text{SSE}=26778.5\), \(+z\)-এ \(\text{SSE}=26776.9\)। (ক) Gaussian MLE-তে \(\ell=-\tfrac n2[\ln(2\pi)+\ln(\text{SSE}/n)+1]\) — দুই মডেলের \(\ell\) প্রায় সমান। প্রতি মডেলে \(K=p\) (variance সহ)। \(\Delta\text{AIC}\) ও \(\Delta\text{BIC}\) (\(+z\) minus BASE) আনুমানিক বের করুন: যেহেতু \(\Delta(-2\ell)\approx 0\), পার্থক্য মূলত penalty থেকে। (খ) এই hypothetical-এ কোন মডেল জেতে, আর BIC কি AIC-এর চেয়ে জোরালোভাবে \(z\)-কে নাকচ করে — সাধারণ নীতি হিসেবে বলুন। Hint: \(K\) বাড়ে \(5\to 6\)। \(\Delta\text{AIC}\approx 2\Delta K=2\); \(\Delta\text{BIC}\approx(\ln 200)\Delta K=5.30\)। দুটোই ধনাত্মক ⇒ SSE না কমিয়ে predictor যোগ করলে দুই criterion-ই বাড়ে (খারাপ), তাই BASE জেতে; BIC-এর জরিমানা বড় বলে সে আরও স্পষ্ট করে নাকচ করে। সাধারণ নীতি: AIC/BIC তখনই একটি predictor রাখে যখন তার SSE-হ্রাস penalty-বৃদ্ধিকে পুষিয়ে দেয়। (সতর্কতা — চলমান উদাহরণে কিন্তু plot_size যোগে SSE যথেষ্ট কমে (\(52092\to 49347\)), তাই সেখানে AIC/BIC উল্টো plot_size রাখার পক্ষে যায়; দেখুন প্রশ্ন ১৪ ও §৫.E4। plot_size বাদ দেওয়ার যুক্তি AIC/BIC থেকে নয়, আসে VIF + se-inflation + অস্থির/উল্টো-sign coefficient থেকে।)
প্রশ্ন ১০ (★★). FULL মডেলে high-leverage বিন্দুটির (row 0, area=340) জন্য \(h_{00}=0.1328\), আর \(p=4\), \(n=200\)। (ক) গড় leverage \(\bar h=p/n\) কত? (খ) \(h_{00}\) গড়ের কত গুণ? (গ) সাধারণ "high leverage" থ্রেশহোল্ড \(2p/n\) ও \(3p/n\) — বিন্দুটি কোনগুলো ছাড়ায়? (ঘ) এই বিন্দু বাদ দিলে fit করা intercept \(16.95\to 22.0\) বদলায়, আর তার Cook's \(D_0=0.529\) (পরের সর্বোচ্চ মাত্র \(0.047\), threshold \(4/n=0.02\))। Cook's \(D>1\) থ্রেশহোল্ডে এটি কি influential? আর \(4/n\) থ্রেশহোল্ড ও আপেক্ষিক মাত্রায়?
Hint: \(\bar h=4/200=0.02\); \(0.1328/0.02\approx 6.6\) গুণ। \(2p/n=0.04\), \(3p/n=0.06\) — দুটোই বহু আগে ছাড়িয়েছে। \(D_0=0.529\) কঠোর \(D>1\) rule ছোঁয় না (তাই "নিঃসন্দেহে influential" নয়), কিন্তু \(4/n=0.02\) বহুগুণে ছাড়ায়, \(0.5\)-ও পেরোয়, এবং পরের সর্বোচ্চ \(D\) (\(0.047\))-এর প্রায় ১১ গুণ — অর্থাৎ দৃশ্যত সবচেয়ে প্রভাবশালী বিন্দু; একে নিয়ে/ছাড়া দুই fit রিপোর্ট করা উচিত (intercept \(16.95\to 22.0\), true-মান \(25\)-এর কাছে)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১১ (★★). Hat matrix-এর ধর্ম। \(H=X(X^\top X)^{-1}X^\top\) (\(X\) full-rank)। প্রমাণ করুন: (ক) \(H\) symmetric (\(H^\top=H\)); (খ) \(H\) idempotent (\(H^2=H\)); (গ) তাই প্রতিটি কর্ণ-উপাদান \(0\le h_{ii}\le 1\); (ঘ) \(\sum_{i=1}^n h_{ii}=\operatorname{tr}(H)=p\) (তাই গড় leverage \(=p/n\) — প্রশ্ন ১০-এর ভিত্তি)। Hint: (ক),(খ) সরাসরি বীজগণিত: \((X^\top X)^{-1}\) symmetric, আর \(H^2=X(X^\top X)^{-1}(X^\top X)(X^\top X)^{-1}X^\top=H\)। (গ) idempotent + symmetric ⇒ projection, eigenvalue \(\in\{0,1\}\); \(h_{ii}=e_i^\top H e_i=\lVert He_i\rVert^2\ge 0\) এবং \(h_{ii}=\sum_j H_{ij}^2 = h_{ii}^2+\sum_{j\ne i}H_{ij}^2\) থেকে \(h_{ii}\le 1\)। (ঘ) \(\operatorname{tr}(H)=\operatorname{tr}\!\big((X^\top X)^{-1}X^\top X\big)=\operatorname{tr}(I_p)=p\) (trace-এর cyclic ধর্ম, ০.৫)।
প্রশ্ন ১২ (★★★). \(\hat\beta\)-এর variance ও কেন collinearity তা ফোলায়। ধরুন LINE অনুমান সত্য, \(\operatorname{Var}(\varepsilon)=\sigma^2 I\)। (ক) দেখান \(\operatorname{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\) (ব্যবহার করুন \(\hat\beta=(X^\top X)^{-1}X^\top y\) ও \(\operatorname{Var}(Ay)=A\operatorname{Var}(y)A^\top\))। (খ) একে centered/standardized predictor-এ লিখে দেখান \(j\)-তম coefficient-এর variance \(\propto \dfrac{1}{1-R_j^2}=\text{VIF}_j\) — অর্থাৎ predictor \(j\) অন্যদের দিয়ে যত বেশি ব্যাখ্যাযোগ্য (\(R_j^2\to 1\)), তার coefficient-এর variance তত বিস্ফোরিত। (গ) এ থেকে \(\widehat{\mathrm{se}}(\hat\beta_j)=\hat\sigma\sqrt{(X^\top X)^{-1}_{jj}}\) — VIF কেন ঠিক "variance inflation factor" নাম পেল তা এক বাক্যে বলুন। Hint: (ক) \(A=(X^\top X)^{-1}X^\top\) স্থির, তাই \(\operatorname{Var}(\hat\beta)=A(\sigma^2 I)A^\top=\sigma^2(X^\top X)^{-1}X^\top X(X^\top X)^{-1}=\sigma^2(X^\top X)^{-1}\)। (খ) standardized predictor-এ \((X^\top X)^{-1}\)-এর \(j\)-তম কর্ণ-উপাদান হয় ঠিক \(\frac{1}{(n-1)(1-R_j^2)}\) (auxiliary regression \(R_j^2\)); এটিই VIF। (গ) VIF \(=\) "perfect orthogonality-র তুলনায় coefficient-variance কত গুণ বড়" — তাই \(\sqrt{\text{VIF}}\) গুণ ফোলা se।
প্রশ্ন ১৩ (★★★). \(R^2\) predictor যোগে কখনো কমে না, কিন্তু \(R^2_{\text{adj}}\) পারে। (ক) যুক্তি দিন: একটি predictor যোগ করলে SSE কখনো বাড়তে পারে না (পুরোনো fit-ই নতুন বৃহত্তর model space-এ একটি বৈধ সমাধান, coefficient \(=0\) নিলে) — তাই \(R^2=1-\text{SSE}/\text{SST}\) অ-হ্রাসমান। (খ) এবার \(R^2_{\text{adj}}=1-\dfrac{\text{SSE}/(n-p)}{\text{SST}/(n-1)}\)-এ দেখান: predictor যোগ করলে \(\text{SSE}\) একটু কমে কিন্তু \(n-p\)-ও কমে (denominator)। তাই অনুপাত \(\text{SSE}/(n-p)\) বাড়তেও পারে যদি SSE-র হ্রাস df-এর হ্রাসকে পোষাতে না পারে — তখন \(R^2_{\text{adj}}\) কমে। (গ) দৃষ্টান্তে যাচাই (illustrative, এই অধ্যায়ের dataset নয়): ধরুন \(\text{SST}=222476\), \(n=200\), BASE-এ (\(p=4\)) \(\text{SSE}=52092\) আর একটি অর্থহীন predictor যোগে (\(p=5\)) \(\text{SSE}=52060\) (হ্রাস নগণ্য)। দেখান \(\hat\sigma^2=\text{SSE}/(n-p)\) এখানে \(265.78\to 266.97\) বাড়ে, তাই \(R^2_{\text{adj}}\) কমে — ঠিক যেমন (খ) বলে। Hint: (ক) nested model-এ minimization বৃহত্তর সেটে ⇒ minimum কখনো বেশি নয়। (খ) ভাবুন \(\text{SSE}/(n-p)\) হলো \(\hat\sigma^2\)-এর unbiased estimate; অর্থহীন predictor যোগে SSE প্রায় একই থাকে অথচ \(n-p\) ১ কমে, তাই \(\hat\sigma^2\) বাড়ে ⇒ \(R^2_{\text{adj}}\) কমে। এ-ই adjusted \(R^2\)-কে honest তুলনার হাতিয়ার করে। (সতর্কতা: চলমান উদাহরণে plot_size কিন্তু SSE যথেষ্ট কমায়, তাই সেখানে adjusted \(R^2\) সামান্য বাড়ে (\(0.762\to 0.774\)) — অর্থাৎ adjusted \(R^2\) একা plot_size-কে নাকচ করে না; collinearity ধরা পড়ে VIF-এ, §৫.E4।)
ঘ · কোডিং (Python)¶
প্রশ্ন ১৪ (★★★). পূর্ণ diagnostic + inference + selection pipeline। seed np.random.default_rng(20260619) দিয়ে FULL data বানান — area\(\sim U(50,200)\), age\(\sim U(0,40)\), rooms\(\sim\) integer \(1\)–\(8\), price\(=25+0.45\,\text{area}-0.8\,\text{age}+6\,\text{rooms}+\varepsilon\), \(\varepsilon\sim\mathcal N(0,15^2)\), এবং একটি collinear predictor plot_size\(=1.15\,\text{area}+\mathcal N(0,10^2)\), \(n=200\)। তারপর row 0-তে একটি high-leverage point বসান (area[0]=340, price[0]=250)। নিচের প্রতিটি করুন (সম্ভব হলে from scratch, যাচাই statsmodels দিয়ে):
1. BASE মডেল (area+age+rooms) fit করে প্রতিটি coefficient-এর \(\hat\beta_j\), \(\widehat{\mathrm{se}}\), \(t_j\), \(95\%\) CI, এবং overall \(F\)-stat ছাপুন।
2. Diagnostics: hat-matrix কর্ণ \(h_{ii}\), studentized residual, ও Cook's \(D_i\) বের করুন; সবচেয়ে বড় \(h\) ও \(D\)-ওয়ালা বিন্দু কোনটি? (leverage point-টি ধরা পড়ছে?) একটি residual-vs-fitted ও একটি Cook's-D stem plot আঁকুন।
3. Multicollinearity: plot_size যোগ করে চার predictor-এর VIF গণনা করুন — কোনগুলো \(>5\) ("সতর্ক") বা \(>10\) ("গুরুতর") জোনে?
4. Selection: BASE বনাম +plot_size-এর \(R^2_{\text{adj}}\), AIC, BIC তুলনা করুন — AIC/BIC কে বাছে? আর VIF/se-inflation/sign কী বলে? দুই সংকেত কি একমত? এবং leverage point নিয়ে ও বাদ দিয়ে \(\hat\beta\) কতটা বদলায় দেখান।
Hint: H = X @ np.linalg.inv(X.T@X) @ X.T; h = np.diag(H); s2 = SSE/(n-p); studentized \(=\hat\varepsilon_i/\sqrt{s^2(1-h_{ii})}\); Cook's \(D_i=\frac{\text{stud}_i^2}{p}\cdot\frac{h_{ii}}{1-h_{ii}}\)। VIF-এর জন্য প্রতিটি predictor-কে বাকিগুলোর ওপর regress করে \(R_j^2\); statsmodels-এ OLS(...).fit() দিলে .bse, .tvalues, .conf_int(), .fvalue, .aic, .bic, এবং get_influence().cooks_distance/.hat_matrix_diag সব দেয় — নিজের সংখ্যার সাথে np.allclose দিয়ে মিলিয়ে নিন। প্রত্যাশিত: leverage point-এ \(h\approx 0.133\), Cook's \(D\approx 0.53\); area/plot_size-এর VIF \(\approx 7.7\) (৫–১০ জোন, গুরুতর নয়); plot_size যোগে AIC/BIC দুটোই নামে (mechanically plot_size রাখে) — কিন্তু VIF + se-inflation (\(0.0258\to 0.0697\)) + plot_size-এর ঋণাত্মক coefficient (\(-0.207\)) বলে plot_size আসলে redundant, তাই M3-ই কাম্য। দুই সংকেত এখানে বিপরীত — মূল শিক্ষা: model selection কখনো শুধু AIC-এর দাস নয়।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- কেন এই অধ্যায়। ৫.১ শিখিয়েছিল কীভাবে OLS দিয়ে \(\hat\beta\) আর \(R^2\) পেতে হয়। ৫.২-এর একমাত্র প্রশ্ন: এই fit কি বিশ্বাসযোগ্য, আর কোন মডেলটা রাখব? উত্তর তিন স্তম্ভে — diagnostics, inference, model selection।
- Diagnostics (অনুমান যাচাই)। OLS-এর তাত্ত্বিক ন্যায্যতা LINE অনুমানের ওপর দাঁড়ায়; আমরা সেগুলো residual দিয়ে চোখে দেখি ও সংখ্যায় মাপি:
- residual-vs-fitted plot — এলোমেলো ব্যান্ড = সুস্থ; funnel = heteroscedasticity (Equal-variance ভাঙা); বাঁক = Linearity ভাঙা।
- QQ-plot of residuals — Normality যাচাই (৩.৪-এর QQ-ধারণা সরাসরি)।
- leverage \(h_{ii}\) — hat-matrix \(H=X(X^\top X)^{-1}X^\top\)-এর কর্ণ; শুধু \(x\)-জায়গায় বিন্দুর প্রান্তিকতা মাপে; \(\sum h_{ii}=p\), গড় \(p/n\), থ্রেশহোল্ড \(2p/n\)।
- studentized residual — \(\hat\varepsilon_i\)-কে তার নিজস্ব std দিয়ে scale করা, যাতে তুলনাযোগ্য।
- Cook's distance \(D_i\) — leverage ও residual একত্রে: বিন্দুটি বাদ দিলে \(\hat\beta\) কতটা সরে; \(D_i>1\) ⇒ influential। ("leverage = সম্ভাবনা, Cook's \(D\) = বাস্তব প্রভাব।")
- Inference (অনিশ্চয়তা ও পরীক্ষা)। এখন প্রতিটি \(\hat\beta_j\)-কে এলোমেলো ধরে তার অনিশ্চয়তা মাপি: \(\operatorname{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\), তাই \(\widehat{\mathrm{se}}(\hat\beta_j)=\hat\sigma\sqrt{(X^\top X)^{-1}_{jj}}\)।
- \(t\)-test: \(t_j=\hat\beta_j/\widehat{\mathrm{se}}(\hat\beta_j)\sim t_{n-p}\) under \(H_0:\beta_j=0\) — "অন্য predictor রেখে এই predictor কি সত্যিই দরকার?"
- CI: \(\hat\beta_j\pm t_{\alpha/2,\,n-p}\,\widehat{\mathrm{se}}\) — ৪.৬-এর সরাসরি সম্প্রসারণ, এবং CI–test duality (CI-তে \(0\) থাকা ⇔ \(t\)-test insignificant)।
- \(F\)-test (overall): \(H_0:\) সব slope \(=0\) একসাথে — মডেলটা আদৌ কিছু ব্যাখ্যা করে কিনা। individual \(t\) ও global \(F\) আলাদা প্রশ্ন; collinearity-তে "F significant অথচ কোনো \(t\) নয়" সম্ভব ও স্ববিরোধী নয়।
- Multicollinearity ও VIF। predictor-রা পরস্পর-correlated হলে মডেল "কাকে credit দেব" ঠিক করতে পারে না — coefficient-এর variance ফুলে (\(\operatorname{Var}(\hat\beta_j)\propto 1/(1-R_j^2)\)), se বড়, \(t\) ছোট, চিহ্ন অস্থির — অথচ \(R^2\) অটুট থাকে। VIF\(_j=1/(1-R_j^2)\) এটি ধরে; থাম্ব-রুল VIF \(>5\) (বা \(>10\)) উদ্বেগজনক। প্রতিকার: redundant predictor বাদ, বা regularization (পরে)।
- Model selection (\(R^2_{\text{adj}}\), AIC, BIC)। কাঁচা \(R^2\) predictor যোগে কখনো কমে না, তাই তুলনার মাপকাঠি হিসেবে অসৎ। তিন honest বিকল্প:
- adjusted \(R^2\): \(1-\dfrac{\text{SSE}/(n-p)}{\text{SST}/(n-1)}\) — অর্থহীন predictor যোগে কমতে পারে।
- AIC \(=-2\ell+2K\) ও BIC \(=-2\ell+(\ln n)K\) — fit ও complexity-র আপস; ছোটটাই ভালো। \(n>7\)-এ BIC-এর penalty কড়া, তাই BIC বেশি parsimonious; BIC consistent (সত্য মডেল খোঁজে), AIC prediction-অনুকূল।
- stepwise selection (forward/backward) — criterion ধরে predictor যোগ/বিয়োগের লোভী অনুসন্ধান; সুবিধাজনক কিন্তু overfitting ও p-value বিকৃতির ঝুঁকিপূর্ণ, তাই সতর্কতা চাই।
পূর্ববর্তী সংযোগ (← ৫.১, ৪.৬, ৪.৭):
- ৫.১ (OLS): এই অধ্যায় ঠিক সেখান থেকে শুরু — \(\hat\beta=(X^\top X)^{-1}X^\top y\), residual \(\hat\varepsilon=y-X\hat\beta\), projection-জ্যামিতি, ও LINE অনুমান। ৫.১-এর hat-matrix \(H\) ছিল projection; এখানে তার কর্ণ \(h_{ii}\)-ই leverage, আর তার trace \(=p\)-ই গড় leverage \(p/n\)-এর উৎস। ৫.১-এ residual orthogonality (\(X^\top\hat\varepsilon=0\)) প্রমাণ হয়েছিল — diagnostics সেই residual-কেই অণুবীক্ষণে দেখে।
- ৪.৬ (Confidence Intervals): \(\hat\beta_j\)-এর CI হলো \(\hat\theta\pm z/t\cdot\mathrm{SE}\)-এর ঠিক সেই কাঠামো, এখন \(\theta=\beta_j\), \(\mathrm{SE}=\hat\sigma\sqrt{(X^\top X)^{-1}_{jj}}\), আর critical value \(t_{n-p}\) (σ অজানা বলে \(t\), \(z\) নয়)।
- ৪.৭ (Hypothesis Testing): প্রতিটি coefficient-এর \(t\)-test হলো ৪.৭-এর \(t\)-test-এর সরাসরি প্রয়োগ (\(H_0:\beta_j=0\)); overall \(F\)-test হলো একাধিক parameter একত্রে পরীক্ষার সাধারণ রূপ; আর CI–test duality (৪.৭-এর শেষ পাঠ) এখানে "CI-তে \(0\) ⇔ insignificant" রূপে ফিরে আসে।
পরবর্তী সংযোগ (→ ৫.৩ — ANOVA ও experimental design): এ পর্যন্ত আমাদের predictor সব সংখ্যাগত (area, age, rooms)। কিন্তু বহু বাস্তব প্রশ্নে predictor categorical — যেমন বাড়ির এলাকা (পুরান ঢাকা / ধানমন্ডি / উত্তরা) বা ধরন (ফ্ল্যাট / ডুপ্লেক্স)। পরের অধ্যায় ৫.৩ দেখাবে এমন group-variable-কে dummy/indicator দিয়ে এই একই regression-কাঠামোতেই বসানো যায়, আর তখন "তিন এলাকার গড় দাম কি আলাদা?" প্রশ্নটি হয়ে দাঁড়ায় একটি \(F\)-test — যা আসলে এই অধ্যায়ের overall \(F\)-test ও SSE-বিভাজনেরই (SST \(=\) SSR \(+\) SSE) সরাসরি সম্প্রসারণ। অর্থাৎ ANOVA হলো categorical predictor-সহ regression, আর group-mean তুলনা হলো coefficient-এর tests — ৫.২-এর inference-যন্ত্রপাতি সেখানে হুবহু পুনর্ব্যবহৃত হবে। সংক্ষেপে: ৫.১ মডেল বানায়, ৫.২ তাকে বিচার করে ও আস্থা মাপে, ৫.৩ সেই কাঠামো categorical/পরীক্ষামূলক জগতে বিস্তৃত করে।
সূত্র (sources): J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 14 (Linear Least Squares — coefficient inference, \(t\)/\(F\), residual analysis); L. Wasserman, All of Statistics, Ch. 13 (Linear Regression — Wald tests for coefficients, model selection, AIC); R. Furrer, STA121 Statistical Modeling (diagnostics, leverage, hat matrix, multicollinearity, model selection); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 4 (Regression and Prediction — diagnostics, influential observations, multicollinearity, applied code)।