অধ্যায় ০.৫ — Linear Algebra Essentials¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
ধরুন আপনার কাছে ১০০ জন মানুষের তথ্য আছে — প্রত্যেকের উচ্চতা, ওজন, বয়স আর আয়। এটিকে কাগজে লিখলে আপনি একটি table বানাবেন: ১০০টি row (প্রতি row একজন মানুষ), ৪টি column (প্রতি column একটি বৈশিষ্ট্য)। পরিসংখ্যানে এই table-টিই একটি matrix (সংখ্যার আয়তাকার সাজানো ছক)। আর একজন মানুষের ৪টি সংখ্যা একসাথে — সেটি একটি vector (মান ও দিকসম্পন্ন রাশি, বা সংখ্যার ক্রমিক তালিকা)।
তাহলে statistics-এ পুরো dataset = একটি matrix, একটি observation = একটি vector। এটি নিছক সাজানো-গোছানোর সুবিধা নয়; এর ফলে আমরা সমস্ত data-র উপর একসাথে গণিত করতে পারি। একটিমাত্র সমীকরণ \(\hat{\mathbf{y}} = X\boldsymbol{\beta}\) দিয়ে হাজার হাজার row-র জন্য prediction বের হয়ে যায় — এটাই linear regression (Part V)। আবার data কোন দিকে সবচেয়ে বেশি ছড়িয়ে আছে তা খুঁজে বের করা — সেটাই PCA (Part VI), আর সেটি আসলে একটি eigenvalue problem।
কেন এই অধ্যায় জরুরি, তা একটি বাক্যে: আধুনিক পরিসংখ্যান ও machine learning-এর ভাষাই হলো linear algebra। Mean, variance, regression coefficient, covariance, principal component — এগুলোর সবকিছু vector আর matrix-এর operation। তাই এখানে আমরা ঠিক ততটুকু linear algebra শিখব যতটুকু পরবর্তী probability ও statistics বুঝতে লাগবে — পূর্ণ rigor নয় (সেটি Part VII), বরং intuition + হাতে-কলমে হিসাব + Python।
Hook. নিচের একটিমাত্র ছবি (figure 3, section ৬) মনে রাখলে অর্ধেক linear algebra মনে থাকবে: একটি matrix পুরো সমতলকে টেনে-বাঁকিয়ে দেয়, কিন্তু কিছু বিশেষ দিক (eigenvector) থাকে যেগুলো বাঁকে না — কেবল লম্বা বা খাটো হয়। ওই দিকগুলোই data-র "প্রাকৃতিক অক্ষ", আর PCA সেগুলোই খুঁজে বের করে।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Vector¶
একটি vector হলো সংখ্যার একটি ক্রমিক তালিকা। \(n\)টি সংখ্যা থাকলে সেটি \(\mathbb{R}^n\) (n-মাত্রিক বাস্তব space)-এর একটি vector। আমরা একে column হিসেবে লিখি এবং bold অক্ষরে চিহ্নিত করি:
এখানে \(u_1, u_2, \dots\) হলো vector-এর component (উপাংশ)। জ্যামিতিকভাবে \(\mathbb{R}^2\)-এ একটি vector হলো origin (মূলবিন্দু) থেকে \((u_1, u_2)\) বিন্দুর দিকে একটি তীর — তার একটি দৈর্ঘ্য (length) ও একটি দিক (direction) আছে।
Operation ১ — addition (যোগ): দুটি vector-এর component ধরে ধরে যোগ। $$ \mathbf{u} + \mathbf{v} = \begin{bmatrix} u_1 + v_1 \ u_2 + v_2 \end{bmatrix}. $$ জ্যামিতিকভাবে এটি parallelogram rule (সামান্তরিক নিয়ম): \(\mathbf{u}\)-এর শেষ থেকে \(\mathbf{v}\) আঁকলে যেখানে পৌঁছায়, সেটিই \(\mathbf{u}+\mathbf{v}\)।
Operation ২ — scalar multiplication (scalar দিয়ে গুণ): একটি সংখ্যা \(c\) (যাকে scalar বলি) দিয়ে প্রতিটি component গুণ। $$ c\,\mathbf{u} = \begin{bmatrix} c\,u_1 \ c\,u_2 \end{bmatrix}. $$ এতে দিক একই থাকে (যদি \(c>0\)), কেবল দৈর্ঘ্য \(|c|\) গুণ হয়; \(c<0\) হলে দিক উল্টে যায়।
Operation ৩ — dot product (বিন্দু গুণফল): দুটি vector-কে নিয়ে একটি সংখ্যা তৈরি করে (vector নয়): $$ \mathbf{u}\cdot\mathbf{v} \;=\; \mathbf{u}^\top\mathbf{v} \;=\; \sum_{i=1}^{n} u_i\,v_i \;=\; u_1 v_1 + u_2 v_2 + \dots + u_n v_n . $$ এই একটিমাত্র operation থেকেই length, angle, orthogonality, এমনকি statistics-এর mean ও covariance — সব আসে।
Norm / length (দৈর্ঘ্য): dot product দিয়ে vector-এর দৈর্ঘ্য মাপি (Pythagoras-এর সাধারণীকরণ): $$ |\mathbf{u}| \;=\; \sqrt{\mathbf{u}\cdot\mathbf{u}} \;=\; \sqrt{u_1^2 + u_2^2 + \dots + u_n^2}. $$ একে Euclidean norm (\(L^2\) norm) বলে। \(\|\mathbf{u}\| = 1\) হলে \(\mathbf{u}\)-কে unit vector (একক vector) বলি।
Angle ও orthogonality (লম্বত্ব): dot product ও angle-এর সম্পর্ক: $$ \mathbf{u}\cdot\mathbf{v} = |\mathbf{u}|\,|\mathbf{v}|\cos\theta , $$ যেখানে \(\theta\) হলো দুই vector-এর মধ্যবর্তী কোণ। তাই $$ \mathbf{u}\cdot\mathbf{v} = 0 \quad\Longleftrightarrow\quad \mathbf{u} \perp \mathbf{v}\ \ (\text{lম্ব / orthogonal}), $$ ধরে নিচ্ছি কোনোটিই zero vector নয়। statistics-এ সংযোগ: দুটি (centered) variable-এর dot product শূন্য মানে তারা uncorrelated — orthogonality আর uncorrelatedness আসলে একই জিনিস।
২.২ Matrix¶
একটি matrix হলো সংখ্যার আয়তাকার ছক — \(m\)টি row ও \(n\)টি column থাকলে তার shape \(m\times n\)। আমরা capital অক্ষরে লিখি: $$ A = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n}\ a_{21} & a_{22} & \cdots & a_{2n}\ \vdots & & \ddots & \vdots\ a_{m1} & a_{m2} & \cdots & a_{mn}\end{bmatrix}, $$ যেখানে \(a_{ij}\) মানে \(i\)-তম row ও \(j\)-তম column-এর উপাদান (entry)। একটি column vector হলো \(n\times 1\) matrix-এর বিশেষ ক্ষেত্র।
Transpose (স্থানান্তর): row আর column অদলবদল। \(A\) যদি \(m\times n\) হয়, \(A^\top\) হবে \(n\times m\), এবং \((A^\top)_{ij} = a_{ji}\)। $$ A = \begin{bmatrix} 1 & 2 & 3\ 4 & 5 & 6\end{bmatrix} \ \Longrightarrow\ A^\top = \begin{bmatrix} 1 & 4\ 2 & 5\ 3 & 6\end{bmatrix}. $$
Matrix multiplication (গুণ): এটি linear algebra-র হৃদয়। \(A\) যদি \(m\times n\) এবং \(B\) যদি \(n\times p\) হয় (অর্থাৎ \(A\)-এর column সংখ্যা = \(B\)-এর row সংখ্যা), তবে \(C = AB\) হবে \(m\times p\), এবং $$ c_{ij} \;=\; \sum_{k=1}^{n} a_{ik}\,b_{kj} \;=\; (\text{\(A\)-এর \(i\)-তম row}) \cdot (\text{\(B\)-এর \(j\)-তম column}). $$ অর্থাৎ output-এর প্রতিটি entry আসলে একটি dot product। মনে রাখুন: সাধারণভাবে \(AB \neq BA\) — matrix multiplication commutative নয়।
Identity matrix (অভেদ matrix): কর্ণে (diagonal) ১ আর বাকি সব ০ — একে \(I\) বলি। এটি গুণের "১"-এর মতো: \(AI = IA = A\)। $$ I_2 = \begin{bmatrix} 1 & 0\ 0 & 1\end{bmatrix}. $$
Inverse (বিপরীত matrix): একটি বর্গ (square) matrix \(A\)-এর inverse \(A^{-1}\) হলো এমন matrix যেন $$ A A^{-1} = A^{-1} A = I . $$ এটি সংখ্যার "ভাগ"-এর equivalent (সমতুল্য): সমীকরণ \(A\mathbf{x} = \mathbf{b}\)-এর সমাধান \(\mathbf{x} = A^{-1}\mathbf{b}\) (যদি \(A^{-1}\) থাকে)। \(2\times2\) matrix-এর জন্য সূত্রটি সরল: $$ A = \begin{bmatrix} a & b\ c & d\end{bmatrix} \ \Longrightarrow\ A^{-1} = \frac{1}{ad - bc}\begin{bmatrix} d & -b\ -c & a\end{bmatrix}. $$ এখানে \(ad-bc\)-ই হলো determinant, যা পরের অংশে।
২.৩ Matrix = linear transformation¶
এটিই সবচেয়ে গুরুত্বপূর্ণ intuition। একটি \(m\times n\) matrix \(A\)-কে একটি function ভাবুন: এটি একটি vector \(\mathbf{x}\in\mathbb{R}^n\) নেয় এবং আরেকটি vector \(A\mathbf{x}\in\mathbb{R}^m\) ফেরত দেয়। এই function-টি linear — মানে দুটি সরল নিয়ম মানে: $$ A(\mathbf{x}+\mathbf{y}) = A\mathbf{x} + A\mathbf{y}, \qquad A(c\,\mathbf{x}) = c\,(A\mathbf{x}). $$ জ্যামিতিকভাবে: \(A\) পুরো space-কে টেনে, ঘুরিয়ে, বাঁকিয়ে নতুন জায়গায় বসায়, কিন্তু origin স্থির রাখে এবং সরলরেখা সরলরেখাই থাকে, সমান্তরাল রেখা সমান্তরালই থাকে। section ৬-এর figure 2-তে দেখবেন একটি unit square কীভাবে rotated/stretched parallelogram হয়ে যায়। এই দৃষ্টিভঙ্গিতে \(A\)-এর column গুলো বলে দেয় basis vector \(\mathbf{e}_1, \mathbf{e}_2\) "কোথায় গিয়ে পড়ে"।
২.৪ System of linear equations (সংক্ষিপ্ত)¶
কয়েকটি একসাথের linear (রৈখিক) সমীকরণ, যেমন $$ \begin{aligned} 2x + \phantom{3}y &= 5,\ \phantom{2}x + 3y &= 10, \end{aligned} $$ কে matrix আকারে এক লাইনে লেখা যায়: $$ A\mathbf{x} = \mathbf{b}, \qquad A = \begin{bmatrix} 2 & 1\ 1 & 3\end{bmatrix},\ \mathbf{x} = \begin{bmatrix} x\ y\end{bmatrix},\ \mathbf{b} = \begin{bmatrix} 5\ 10\end{bmatrix}. $$ \(A\) invertible হলে অনন্য সমাধান \(\mathbf{x} = A^{-1}\mathbf{b}\)। (বাস্তবে inverse না বানিয়ে দ্রুততর ও সংখ্যায় স্থিতিশীল পদ্ধতিতে solve করা হয় — section ৫।) statistics-এ সংযোগ: linear regression-এর normal equation \(X^\top X\,\boldsymbol{\beta} = X^\top\mathbf{y}\) ঠিক এই রূপের একটি system।
২.৫ Determinant — area/volume scaling¶
একটি বর্গ matrix-এর determinant \(\det(A)\) একটি একক সংখ্যা যা বলে: \(A\) transformation-এর অধীনে আয়তন কত গুণ বাড়ে বা কমে। \(2\times2\)-এ এটি ক্ষেত্রফলের স্কেল: $$ \det!\begin{bmatrix} a & b\ c & d\end{bmatrix} = ad - bc . $$ - \(\det(A) = 3\) মানে যেকোনো region-এর ক্ষেত্রফল \(3\) গুণ হয়ে যায়। - \(\det(A) = 0\) মানে space একটি নিম্নমাত্রায় চেপ্টে যায় (২D → একটি রেখা), তথ্য হারায় — তখন \(A^{-1}\) থাকে না। - \(\det(A) < 0\) মানে orientation উল্টে যায় (যেমন আয়না-প্রতিফলন)।
২.৬ Eigenvalue ও eigenvector¶
বেশিরভাগ vector-কে \(A\) টানার পাশাপাশি ঘুরিয়েও দেয়। কিন্তু কিছু বিশেষ vector আছে যেগুলোর দিক \(A\) বদলায় না — কেবল দৈর্ঘ্য বদলায়। এমন এক নন-zero vector \(\mathbf{v}\)-কে eigenvector (নিজস্ব দিক) এবং সংশ্লিষ্ট scaling factor \(\lambda\)-কে eigenvalue (নিজস্ব মান) বলি: $$ \boxed{\,A\mathbf{v} = \lambda\mathbf{v}, \qquad \mathbf{v} \neq \mathbf{0}.\,} $$ পড়ুন: "\(A\) দিয়ে \(\mathbf{v}\)-কে রূপান্তর করলে ফল হয় ঠিক \(\mathbf{v}\)-কেই \(\lambda\) গুণ করা।" এই \(\lambda\) বের করতে হলে \((A-\lambda I)\mathbf{v}=\mathbf{0}\)-এর non-trivial সমাধান চাই, যা সম্ভব কেবল যখন $$ \det(A - \lambda I) = 0 \qquad (\text{characteristic equation}). $$ statistics-এ সংযোগ: covariance matrix-এর eigenvector গুলোই data-র principal axis, আর eigenvalue গুলো সেই দিকে variance — এটাই PCA-র সারমর্ম (Part VI)।
২.৭ Symmetric ও positive-definite matrix (সংক্ষিপ্ত)¶
একটি বর্গ matrix symmetric যদি \(A = A^\top\) (কর্ণের সাপেক্ষে আয়না-প্রতিসম)। Symmetric matrix-এর দুটি সুন্দর ধর্ম: তার সব eigenvalue বাস্তব, এবং eigenvector গুলো পরস্পর orthogonal — তাই এরা data-র জন্য নিখুঁত "অক্ষ" দেয়।
একটি symmetric matrix positive-definite (PD) যদি প্রতিটি non-zero vector \(\mathbf{x}\)-এর জন্য $$ \mathbf{x}^\top A\,\mathbf{x} > 0 , $$ equivalently (সমতুল্যভাবে) যদি তার সব eigenvalue \(> 0\)। statistics-এ সংযোগ: যেকোনো (পূর্ণ-পদমর্যাদার) covariance matrix symmetric এবং positive-(semi)definite — কারণ variance কখনো ঋণাত্মক হয় না। এই ধর্মই অনেক algorithm-এর (Cholesky decomposition, Gaussian likelihood) ভিত্তি।
২.৮ Covariance matrix — preview¶
ধরা যাক একটি dataset \(X\), যার \(n\)টি row (observation) ও \(d\)টি column (variable)। প্রতিটি column থেকে তার mean বিয়োগ করে center করার পর centered data \(X_c\)-র জন্য covariance matrix $$ \Sigma \;=\; \frac{1}{n-1}\, X_c^\top X_c $$ একটি \(d\times d\) symmetric matrix। এর \((i,i)\) entry হলো variable \(i\)-এর variance, আর \((i,j)\) entry হলো variable \(i\) ও \(j\)-এর covariance। লক্ষ করুন \(X_c^\top X_c\)-র প্রতিটি entry আসলে দুটি column-এর dot product — তাই covariance = কেন্দ্রীভূত column-দের dot product। section ৬-এর figure 4-এ দেখব এই matrix-এর eigenvector গুলো ঠিক সেই দিকে ইঙ্গিত করে যেদিকে data সবচেয়ে বেশি ছড়িয়ে আছে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ৩.১ — dot product, length, orthogonality¶
ধরা যাক \(\mathbf{u} = \begin{bmatrix}3\\4\end{bmatrix}\), \(\mathbf{v} = \begin{bmatrix}1\\2\end{bmatrix}\)।
dot product: \(\mathbf{u}\cdot\mathbf{v} = (3)(1) + (4)(2) = 3 + 8 = 11.\)
length: \(\|\mathbf{u}\| = \sqrt{3^2 + 4^2} = \sqrt{9+16} = \sqrt{25} = 5.\) (চিরচেনা ৩-৪-৫ ত্রিভুজ।)
angle: \(\|\mathbf{v}\| = \sqrt{1+4} = \sqrt5\), তাই $$ \cos\theta = \frac{\mathbf{u}\cdot\mathbf{v}}{|\mathbf{u}|\,|\mathbf{v}|} = \frac{11}{5\sqrt5} \approx 0.984 \ \Rightarrow\ \theta \approx 10.3^\circ . $$
orthogonality পরীক্ষা: \(\mathbf{a} = \begin{bmatrix}1\\2\end{bmatrix}\) ও \(\mathbf{b} = \begin{bmatrix}2\\-1\end{bmatrix}\) নিলে \(\mathbf{a}\cdot\mathbf{b} = (1)(2) + (2)(-1) = 2 - 2 = 0\) — অর্থাৎ \(\mathbf{a}\perp\mathbf{b}\), তারা পরস্পর লম্ব।
উদাহরণ ৩.২ — matrix multiplication ও \(AB\neq BA\)¶
\(A = \begin{bmatrix}1 & 2\\ 3 & 4\end{bmatrix}\), \(B = \begin{bmatrix}5 & 6\\ 7 & 8\end{bmatrix}\)।
\(AB\)-এর প্রতিটি entry = (\(A\)-র row) · (\(B\)-র column): $$ AB = \begin{bmatrix} 1\cdot5+2\cdot7 & 1\cdot6+2\cdot8\ 3\cdot5+4\cdot7 & 3\cdot6+4\cdot8\end{bmatrix} = \begin{bmatrix} 19 & 22\ 43 & 50\end{bmatrix}. $$ উল্টো ক্রমে: $$ BA = \begin{bmatrix} 5\cdot1+6\cdot3 & 5\cdot2+6\cdot4\ 7\cdot1+8\cdot3 & 7\cdot2+8\cdot4\end{bmatrix} = \begin{bmatrix} 23 & 34\ 31 & 46\end{bmatrix}. $$ স্পষ্টতই \(AB \neq BA\) — তাই ক্রম গুরুত্বপূর্ণ।
উদাহরণ ৩.৩ — determinant, inverse ও system সমাধান¶
\(M = \begin{bmatrix}4 & 7\\ 2 & 6\end{bmatrix}\)।
determinant: \(\det(M) = (4)(6) - (7)(2) = 24 - 14 = 10 \neq 0\), তাই inverse আছে।
inverse: সূত্র প্রয়োগ করে $$ M^{-1} = \frac{1}{10}\begin{bmatrix} 6 & -7\ -2 & 4\end{bmatrix} = \begin{bmatrix} 0.6 & -0.7\ -0.2 & 0.4\end{bmatrix}. $$ যাচাই: \(M M^{-1} = \begin{bmatrix}4(0.6)+7(-0.2) & 4(-0.7)+7(0.4)\\ 2(0.6)+6(-0.2) & 2(-0.7)+6(0.4)\end{bmatrix} = \begin{bmatrix}1 & 0\\ 0 & 1\end{bmatrix} = I.\) ✓
system সমাধান: \(2x+y=5,\ x+3y=10\) অর্থাৎ \(A=\begin{bmatrix}2&1\\1&3\end{bmatrix}\), \(\mathbf{b}=\begin{bmatrix}5\\10\end{bmatrix}\)। \(\det(A)=2\cdot3-1\cdot1=5\), তাই $$ A^{-1} = \frac15\begin{bmatrix}3 & -1\ -1 & 2\end{bmatrix}, \qquad \mathbf{x} = A^{-1}\mathbf{b} = \frac15\begin{bmatrix}3\cdot5 + (-1)\cdot10\ (-1)\cdot5 + 2\cdot10\end{bmatrix} = \frac15\begin{bmatrix}5\ 15\end{bmatrix} = \begin{bmatrix}1\ 3\end{bmatrix}. $$ অর্থাৎ \(x=1,\ y=3\)। মূল সমীকরণে বসিয়ে দেখুন: \(2(1)+3=5\) ✓ এবং \(1+3(3)=10\) ✓।
উদাহরণ ৩.৪ — eigenvalue ও eigenvector হাতে¶
\(A = \begin{bmatrix}2 & 1\\ 1 & 2\end{bmatrix}\) (symmetric)। characteristic equation: $$ \det(A - \lambda I) = \det!\begin{bmatrix}2-\lambda & 1\ 1 & 2-\lambda\end{bmatrix} = (2-\lambda)^2 - 1 = 0 . $$ \((2-\lambda)^2 = 1 \Rightarrow 2-\lambda = \pm1 \Rightarrow \lambda = 1\) অথবা \(\lambda = 3\)।
\(\lambda=3\)-এর eigenvector: \((A-3I)\mathbf{v}=\mathbf{0}\) দেয় \(\begin{bmatrix}-1 & 1\\ 1 & -1\end{bmatrix}\mathbf{v}=\mathbf{0}\), অর্থাৎ \(-v_1+v_2=0 \Rightarrow v_1=v_2\)। তাই \(\mathbf{v}\propto\begin{bmatrix}1\\1\end{bmatrix}\)।
\(\lambda=1\)-এর eigenvector: একইভাবে \(v_1+v_2=0 \Rightarrow \mathbf{v}\propto\begin{bmatrix}1\\-1\end{bmatrix}\)।
লক্ষ করুন দুই eigenvector পরস্পর orthogonal (\(1\cdot1 + 1\cdot(-1)=0\)) — symmetric matrix-এর প্রতিশ্রুত ধর্ম। যাচাই: \(A\begin{bmatrix}1\\1\end{bmatrix} = \begin{bmatrix}3\\3\end{bmatrix} = 3\begin{bmatrix}1\\1\end{bmatrix}\) ✓।
৪ · প্রমাণ ও derivation (উৎপাদন)¶
৪.১ ★ Cauchy–Schwarz inequality ও cosine সূত্র¶
দাবি: যেকোনো \(\mathbf{u},\mathbf{v}\in\mathbb{R}^n\)-এর জন্য \(|\mathbf{u}\cdot\mathbf{v}| \le \|\mathbf{u}\|\,\|\mathbf{v}\|\)।
এই inequality-ই নিশ্চিত করে যে \(\cos\theta = \dfrac{\mathbf{u}\cdot\mathbf{v}}{\|\mathbf{u}\|\|\mathbf{v}\|}\) সবসময় \([-1,1]\)-এর মধ্যে থাকে, ফলে "কোণ"-এর সংজ্ঞা অর্থবহ হয়। (statistics-এ এর সরাসরি ফল: correlation coefficient সবসময় \([-1,1]\)-এ থাকে।)
প্রমাণ (elementary). যদি \(\mathbf{v}=\mathbf{0}\) হয়, দুই পক্ষই \(0\) — দাবি সত্য। ধরা যাক \(\mathbf{v}\neq\mathbf{0}\)। যেকোনো বাস্তব সংখ্যা \(t\)-এর জন্য একটি norm কখনো ঋণাত্মক হতে পারে না: $$ 0 \;\le\; |\mathbf{u} - t\,\mathbf{v}|^2 \;=\; (\mathbf{u}-t\mathbf{v})\cdot(\mathbf{u}-t\mathbf{v}) \;=\; |\mathbf{u}|^2 - 2t\,(\mathbf{u}\cdot\mathbf{v}) + t^2|\mathbf{v}|^2 . $$ ডান পক্ষ \(t\)-এর একটি quadratic (দ্বিঘাত) রাশি, যা সব \(t\)-এর জন্য \(\ge 0\)। একটি quadratic \(at^2+bt+c\) (\(a>0\)) সর্বত্র অঋণাত্মক হওয়ার শর্ত হলো তার discriminant \(\le 0\): $$ \big(2(\mathbf{u}\cdot\mathbf{v})\big)^2 - 4|\mathbf{v}|^2|\mathbf{u}|^2 \le 0 \;\Longrightarrow\; (\mathbf{u}\cdot\mathbf{v})^2 \le |\mathbf{u}|^2|\mathbf{v}|^2 . $$ দুই পক্ষের বর্গমূল নিয়ে \(|\mathbf{u}\cdot\mathbf{v}| \le \|\mathbf{u}\|\|\mathbf{v}\|\)। \(\blacksquare\)
৪.২ ★★ Eigenvector-এর দিক transformation-এ অপরিবর্তিত — কেন¶
দাবি: যদি \(A\mathbf{v}=\lambda\mathbf{v}\) হয়, তবে \(\mathbf{v}\)-এর span (অর্থাৎ ওই vector বরাবর পুরো রেখা) \(A\)-এর অধীনে নিজের মধ্যেই থাকে — কেবল \(\lambda\) গুণে scale হয়।
derivation (উৎপাদন)। ধরা যাক \(\mathbf{v}\) একটি eigenvector, eigenvalue \(\lambda\) সহ। ওই রেখার যেকোনো বিন্দু \(c\mathbf{v}\) (যেখানে \(c\) যেকোনো scalar) নিন। linearity ব্যবহার করে: $$ A(c\mathbf{v}) = c\,(A\mathbf{v}) = c\,(\lambda\mathbf{v}) = \lambda\,(c\mathbf{v}). $$ অর্থাৎ ওই রেখার প্রতিটি বিন্দু একই রেখার উপর \(\lambda\) গুণ দূরত্বে গিয়ে পড়ে — রেখাটি ঘোরে না, বাঁকে না। এজন্যই figure 3-এ eigenvector-এর dashed রেখা transformation-এর পরেও একই রেখা থাকে, শুধু তীরটি \(\lambda\) গুণ লম্বা/খাটো হয়।
\(2\times2\)-এ characteristic equation কোথা থেকে আসে। \(A\mathbf{v}=\lambda\mathbf{v}\) লিখুন $ (A-\lambda I)\mathbf{v} = \mathbf{0}$। যদি \((A-\lambda I)\) invertible হতো, একমাত্র সমাধান হতো \(\mathbf{v}=\mathbf{0}\) — কিন্তু eigenvector সংজ্ঞা অনুযায়ী non-zero। তাই \((A-\lambda I)\) অবশ্যই non-invertible, যার শর্ত \(\det(A-\lambda I)=0\)। এটিই characteristic equation; এর মূলগুলোই eigenvalue। \(\blacksquare\)
৪.৩ ★★ Covariance matrix সর্বদা symmetric ও positive-semidefinite¶
দাবি ১ (symmetric). \(\Sigma = \frac{1}{n-1}X_c^\top X_c\) symmetric। প্রমাণ. transpose-এর নিয়ম \((BC)^\top = C^\top B^\top\) ও \((B^\top)^\top = B\) ব্যবহার করে: $$ \Sigma^\top = \frac{1}{n-1}\,(X_c^\top X_c)^\top = \frac{1}{n-1}\,X_c^\top (X_c^\top)^\top = \frac{1}{n-1}\,X_c^\top X_c = \Sigma. \ \blacksquare $$
দাবি ২ (positive-semidefinite). প্রতিটি \(\mathbf{w}\)-এর জন্য \(\mathbf{w}^\top \Sigma\,\mathbf{w} \ge 0\)। প্রমাণ. \(\mathbf{z} = X_c\mathbf{w}\) ধরুন (এটি একটি vector)। তাহলে $$ \mathbf{w}^\top \Sigma\,\mathbf{w} = \frac{1}{n-1}\,\mathbf{w}^\top X_c^\top X_c\,\mathbf{w} = \frac{1}{n-1}\,(X_c\mathbf{w})^\top (X_c\mathbf{w}) = \frac{1}{n-1}\,|\mathbf{z}|^2 \ge 0, $$ কারণ যেকোনো norm-এর বর্গ অঋণাত্মক। \(\blacksquare\) — এজন্যই variance (যা \(\mathbf{w}\) একক হলে এই রাশিরই মান) কখনো ঋণাত্মক হয় না।
৫ · কোড ল্যাব (Python)¶
প্রথমে from scratch (শুধু NumPy array operation দিয়ে) ধারণাগুলো বানাব, তারপর numpy.linalg-এর তৈরি function দিয়ে মিলিয়ে নেব।
import numpy as np
# ---------- vector: dot, norm, orthogonality (from scratch) ----------
u = np.array([3.0, 4.0])
v = np.array([1.0, 2.0])
dot_scratch = sum(ui * vi for ui, vi in zip(u, v)) # হাতে: 3*1 + 4*2
dot_numpy = u @ v # @ = matrix/dot product
norm_scratch = (u @ u) ** 0.5 # sqrt(u·u)
norm_numpy = np.linalg.norm(u)
print("u·v scratch =", dot_scratch, " numpy =", dot_numpy) # 11.0 11.0
print("||u|| scratch =", norm_scratch, " numpy =", norm_numpy) # 5.0 5.0
a = np.array([1.0, 2.0]); b = np.array([2.0, -1.0])
print("a·b =", a @ b, "-> orthogonal?", np.isclose(a @ b, 0)) # 0.0 True
# ---------- matrix multiply from scratch vs numpy ----------
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
def matmul_scratch(P, Q):
m, n = P.shape
n2, p = Q.shape
assert n == n2, "inner dimensions must match"
C = np.zeros((m, p))
for i in range(m):
for j in range(p):
C[i, j] = sum(P[i, k] * Q[k, j] for k in range(n)) # row·column
return C
print("AB scratch =\n", matmul_scratch(A, B))
print("AB numpy =\n", A @ B)
print("BA numpy =\n", B @ A) # ≠ AB : multiplication is not commutative
print("A^T =\n", A.T) # transpose
# ---------- determinant, inverse, solving a system ----------
M = np.array([[4.0, 7.0], [2.0, 6.0]])
detM_scratch = M[0,0]*M[1,1] - M[0,1]*M[1,0] # ad - bc
print("det scratch =", detM_scratch, " numpy =", np.linalg.det(M)) # 10.0
Minv = np.linalg.inv(M)
print("M^{-1} =\n", Minv)
print("M @ M^{-1} =\n", np.round(M @ Minv, 10)) # identity (rounded)
# system 2x + y = 5, x + 3y = 10
Acoef = np.array([[2.0, 1.0], [1.0, 3.0]])
bvec = np.array([5.0, 10.0])
x_inv = np.linalg.inv(Acoef) @ bvec # via inverse (illustrative)
x_solve = np.linalg.solve(Acoef, bvec) # preferred: faster & stabler
print("solution via inverse:", x_inv) # [1. 3.]
print("solution via solve :", x_solve) # [1. 3.]
# ---------- eigenvalues / eigenvectors + verification ----------
S = np.array([[2.0, 1.0], [1.0, 2.0]])
# eigh: for SYMMETRIC matrices -> real eigenvalues, orthonormal eigenvectors
eigvals, eigvecs = np.linalg.eigh(S)
print("eigenvalues :", eigvals) # [1. 3.]
print("eigenvectors (columns):\n", eigvecs)
# verify the defining relation A v = lambda v for each pair
for i in range(2):
lam = eigvals[i]
vec = eigvecs[:, i]
print(f" λ={lam:.0f}: A v - λ v =", np.round(S @ vec - lam * vec, 12))
# symmetric => eigenvectors orthogonal
print("v1 · v2 =", np.round(eigvecs[:, 0] @ eigvecs[:, 1], 12)) # 0
# positive-definite check: all eigenvalues > 0
print("S positive-definite?", np.all(eigvals > 0))
# ---------- covariance matrix: from scratch vs numpy ----------
X = np.array([[1.0, 2.0],
[3.0, 6.0],
[5.0, 4.0]]) # 3 observations, 2 variables (columns)
Xc = X - X.mean(axis=0) # center each column
n = X.shape[0]
cov_scratch = (Xc.T @ Xc) / (n - 1) # (1/(n-1)) X_c^T X_c
cov_numpy = np.cov(X, rowvar=False)
print("covariance scratch =\n", cov_scratch)
print("covariance numpy =\n", cov_numpy)
# eigen-decomposition of covariance = principal directions (preview of PCA)
pc_vals, pc_vecs = np.linalg.eigh(cov_scratch)
print("variances along principal axes:", pc_vals)
Output (সংক্ষেপে): dot ও norm দু'ভাবেই \(11.0\) ও \(5.0\); matmul_scratch ও @ একই \(\begin{bmatrix}19&22\\43&50\end{bmatrix}\) দেয়; \(\det M = 10\), \(MM^{-1}=I\); system-এর সমাধান \([1,3]\) দুই পদ্ধতিতেই মেলে; eigenvalue \(\{1,3\}\), প্রতিটি জোড়ার জন্য \(A\mathbf{v}-\lambda\mathbf{v}=\mathbf{0}\) এবং eigenvector দুটি orthogonal; covariance scratch ও np.cov হুবহু এক — theory সংখ্যায় যাচাই হলো।
৬ · ভিজ্যুয়ালাইজেশন¶
Figure 1 — vector addition (parallelogram rule)¶
দুটি vector যোগ করলে ফল কোথায় পড়ে — সামান্তরিক নিয়মে।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
u = np.array([3.0, 1.0])
v = np.array([1.0, 2.0])
w = u + v
fig, ax = plt.subplots(figsize=(6, 6))
ax.quiver(0, 0, u[0], u[1], angles="xy", scale_units="xy", scale=1,
color="#1f77b4", width=0.012, label="u = (3, 1)")
ax.quiver(0, 0, v[0], v[1], angles="xy", scale_units="xy", scale=1,
color="#2ca02c", width=0.012, label="v = (1, 2)")
ax.quiver(0, 0, w[0], w[1], angles="xy", scale_units="xy", scale=1,
color="#d62728", width=0.012, label="u + v = (4, 3)")
ax.plot([u[0], w[0]], [u[1], w[1]], "k--", lw=1, alpha=0.6)
ax.plot([v[0], w[0]], [v[1], w[1]], "k--", lw=1, alpha=0.6)
ax.set_xlim(-0.5, 5); ax.set_ylim(-0.5, 4)
ax.axhline(0, color="gray", lw=0.8); ax.axvline(0, color="gray", lw=0.8)
ax.set_aspect("equal"); ax.grid(True, alpha=0.3)
ax.set_xlabel("x-axis"); ax.set_ylabel("y-axis")
ax.set_title("Vector Addition: Parallelogram Rule")
ax.legend(loc="upper left", fontsize=10)
plt.tight_layout()
plt.savefig("../_assets/0-5-vector-addition.png", dpi=150)
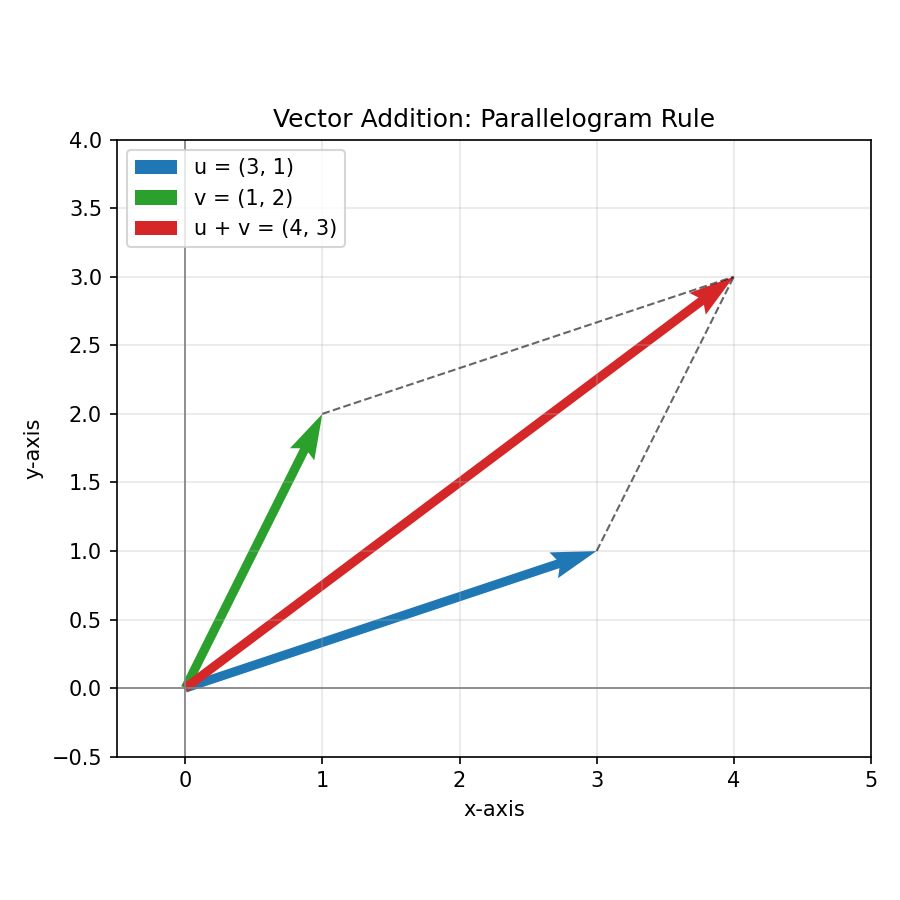
Figure 2 — matrix একটি linear transformation¶
বাঁয়ে মূল grid ও unit square (ক্ষেত্রফল ১); ডানে \(A=\begin{bmatrix}2&1\\0&1.5\end{bmatrix}\) প্রয়োগের পর — grid টেনে-বেঁকে গেছে, square হয়ে গেছে parallelogram। নতুন ক্ষেত্রফল \(=\det(A)=3\), ঠিক যেমন তত্ত্ব বলে।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
A = np.array([[2.0, 1.0], [0.0, 1.5]])
fig, axes = plt.subplots(1, 2, figsize=(11, 5.2))
def draw_grid(ax, M, title):
lim = 3
for k in range(-lim, lim + 1):
pts_v = np.array([[k, t] for t in np.linspace(-lim, lim, 50)]).T
pts_h = np.array([[t, k] for t in np.linspace(-lim, lim, 50)]).T
mv = M @ pts_v; mh = M @ pts_h
ax.plot(mv[0], mv[1], color="#cccccc", lw=0.8, zorder=1)
ax.plot(mh[0], mh[1], color="#cccccc", lw=0.8, zorder=1)
square = np.array([[0,0],[1,0],[1,1],[0,1],[0,0]]).T
ms = M @ square
ax.fill(ms[0], ms[1], color="#ff9999", alpha=0.5, zorder=2)
ax.plot(ms[0], ms[1], color="#d62728", lw=2, zorder=3)
e1 = M @ np.array([1, 0]); e2 = M @ np.array([0, 1])
ax.quiver(0, 0, e1[0], e1[1], angles="xy", scale_units="xy", scale=1,
color="#1f77b4", width=0.015, zorder=4)
ax.quiver(0, 0, e2[0], e2[1], angles="xy", scale_units="xy", scale=1,
color="#2ca02c", width=0.015, zorder=4)
ax.set_xlim(-4, 5); ax.set_ylim(-4, 5)
ax.axhline(0, color="gray", lw=0.6); ax.axvline(0, color="gray", lw=0.6)
ax.set_aspect("equal"); ax.set_title(title)
ax.set_xlabel("x"); ax.set_ylabel("y")
draw_grid(axes[0], np.eye(2), "Before: original grid + unit square (area = 1)")
draw_grid(axes[1], A, "After: A applied (det(A) = 3, area = 3)")
plt.suptitle("Matrix as a Linear Transformation A = [[2, 1], [0, 1.5]]", fontsize=13)
plt.tight_layout()
plt.savefig("../_assets/0-5-linear-transformation.png", dpi=150)
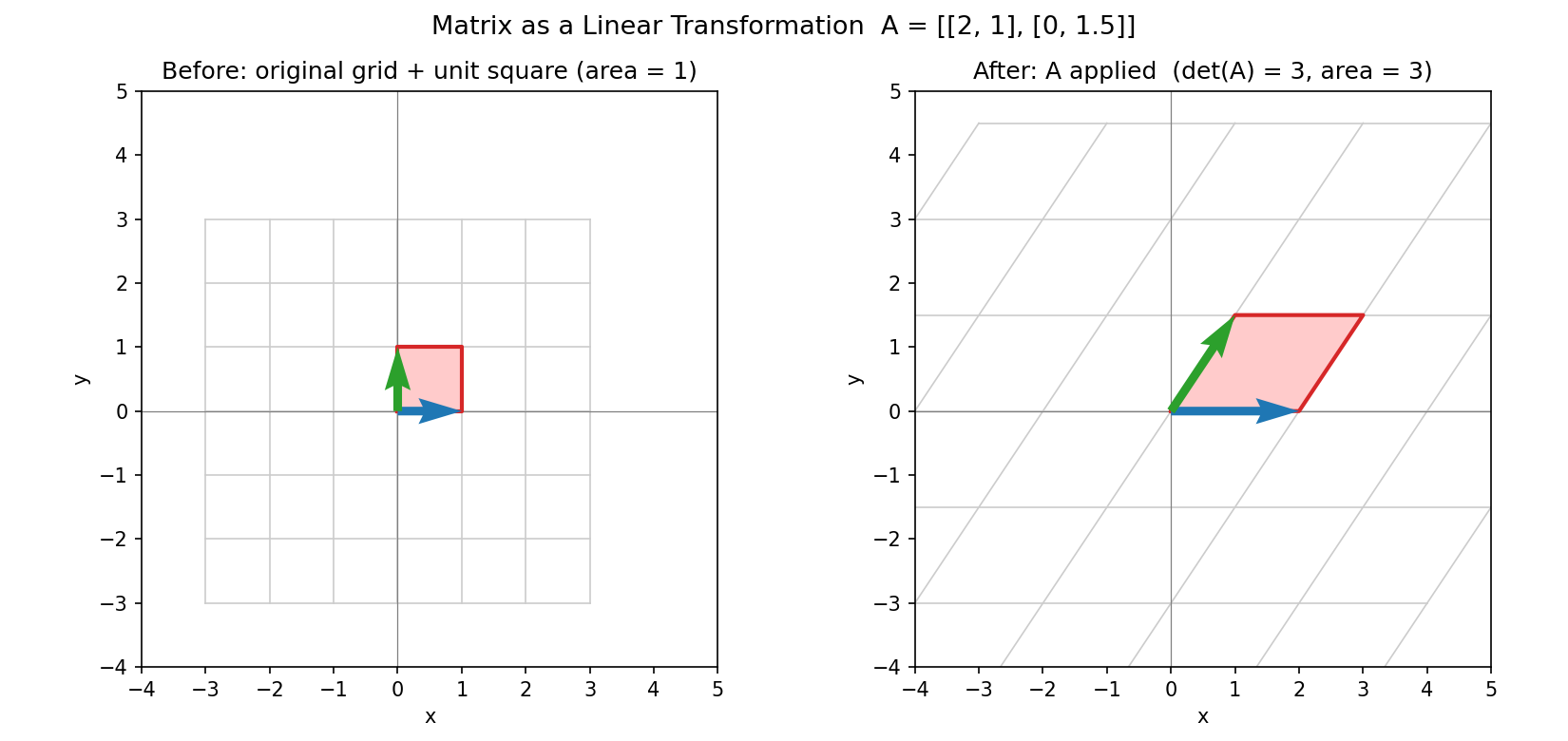
Figure 3 — eigenvector: যে দিক বদলায় না¶
\(A=\begin{bmatrix}2&1\\1&2\end{bmatrix}\)-এর দুই eigenvector (ভাঙা রেখা)। transformation-এর পরেও তীর দুটি একই রেখায় থাকে — শুধু \(\lambda=3\) ও \(\lambda=1\) গুণে লম্বা/খাটো হয়। এই "নিজস্ব দিক"-গুলোই পরে data-র principal axis হবে।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
A = np.array([[2.0, 1.0], [1.0, 2.0]])
eigvals, eigvecs = np.linalg.eigh(A)
order = np.argsort(eigvals)[::-1]
eigvals = eigvals[order]; eigvecs = eigvecs[:, order]
fig, axes = plt.subplots(1, 2, figsize=(11, 5.2))
def draw_grid(ax, M, title, show_eig=False):
lim = 3
for k in range(-lim, lim + 1):
pts_v = np.array([[k, t] for t in np.linspace(-lim, lim, 50)]).T
pts_h = np.array([[t, k] for t in np.linspace(-lim, lim, 50)]).T
mv = M @ pts_v; mh = M @ pts_h
ax.plot(mv[0], mv[1], color="#dddddd", lw=0.7, zorder=1)
ax.plot(mh[0], mh[1], color="#dddddd", lw=0.7, zorder=1)
colors = ["#d62728", "#1f77b4"]
for i in range(2):
vv = eigvecs[:, i]; mv = M @ vv
ax.plot([-4*vv[0], 4*vv[0]], [-4*vv[1], 4*vv[1]],
color=colors[i], lw=1, ls="--", alpha=0.5, zorder=2)
ax.quiver(0, 0, mv[0], mv[1], angles="xy", scale_units="xy", scale=1,
color=colors[i], width=0.015, zorder=4,
label=f"lambda_{i+1} = {eigvals[i]:.0f}: v lands at {eigvals[i]:.0f}*v")
ax.quiver(0, 0, vv[0], vv[1], angles="xy", scale_units="xy", scale=1,
color=colors[i], width=0.010, alpha=0.45, zorder=3)
ax.set_xlim(-5, 5); ax.set_ylim(-5, 5)
ax.axhline(0, color="gray", lw=0.6); ax.axvline(0, color="gray", lw=0.6)
ax.set_aspect("equal"); ax.set_title(title)
ax.set_xlabel("x"); ax.set_ylabel("y")
if show_eig:
ax.legend(loc="upper left", fontsize=8)
draw_grid(axes[0], np.eye(2), "Eigenvector directions (dashed) on original grid")
draw_grid(axes[1], A, "After A: eigenvectors keep direction, scaled by lambda", show_eig=True)
plt.suptitle("Eigenvectors of A = [[2, 1], [1, 2]] stay on their own line", fontsize=13)
plt.tight_layout()
plt.savefig("../_assets/0-5-eigvec.png", dpi=150)
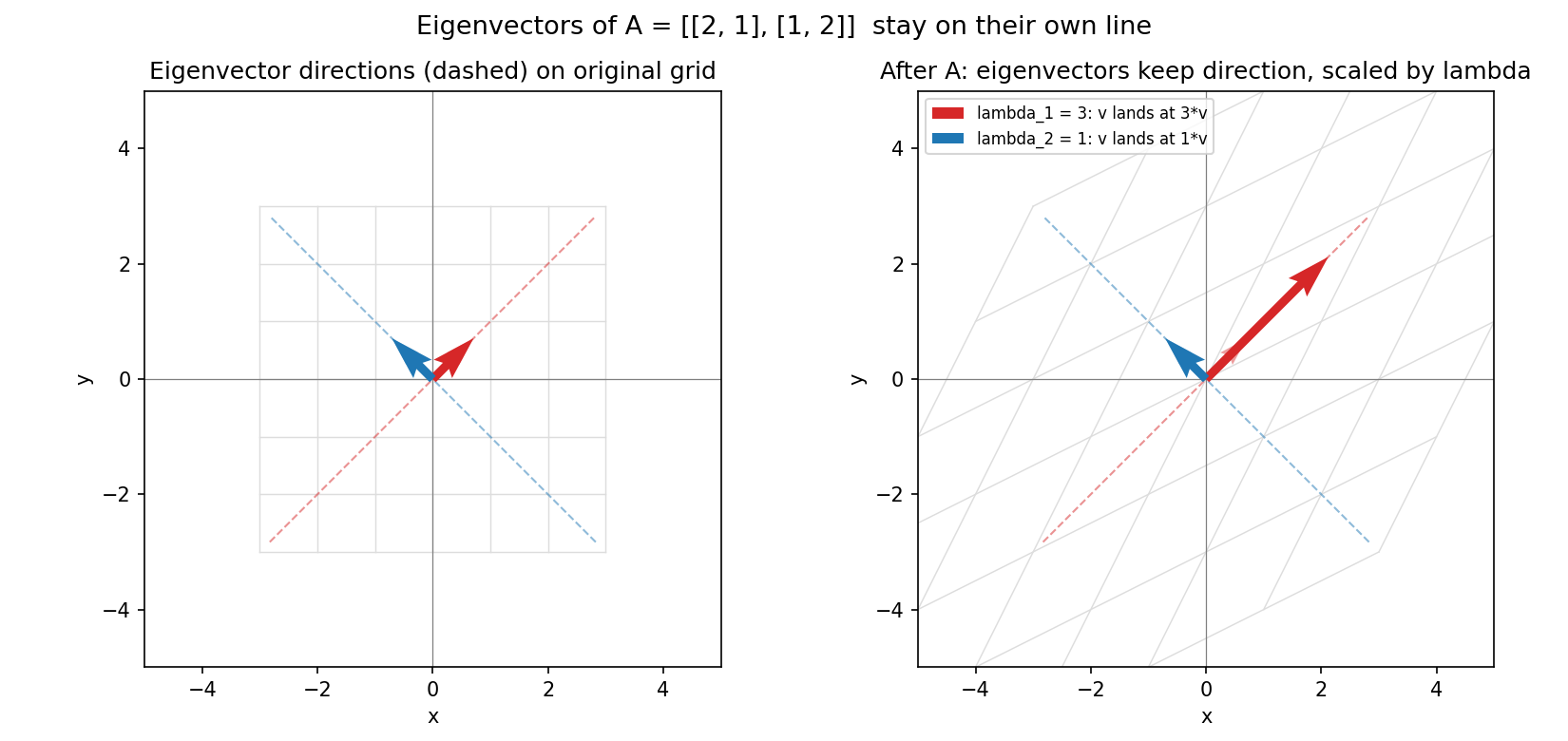
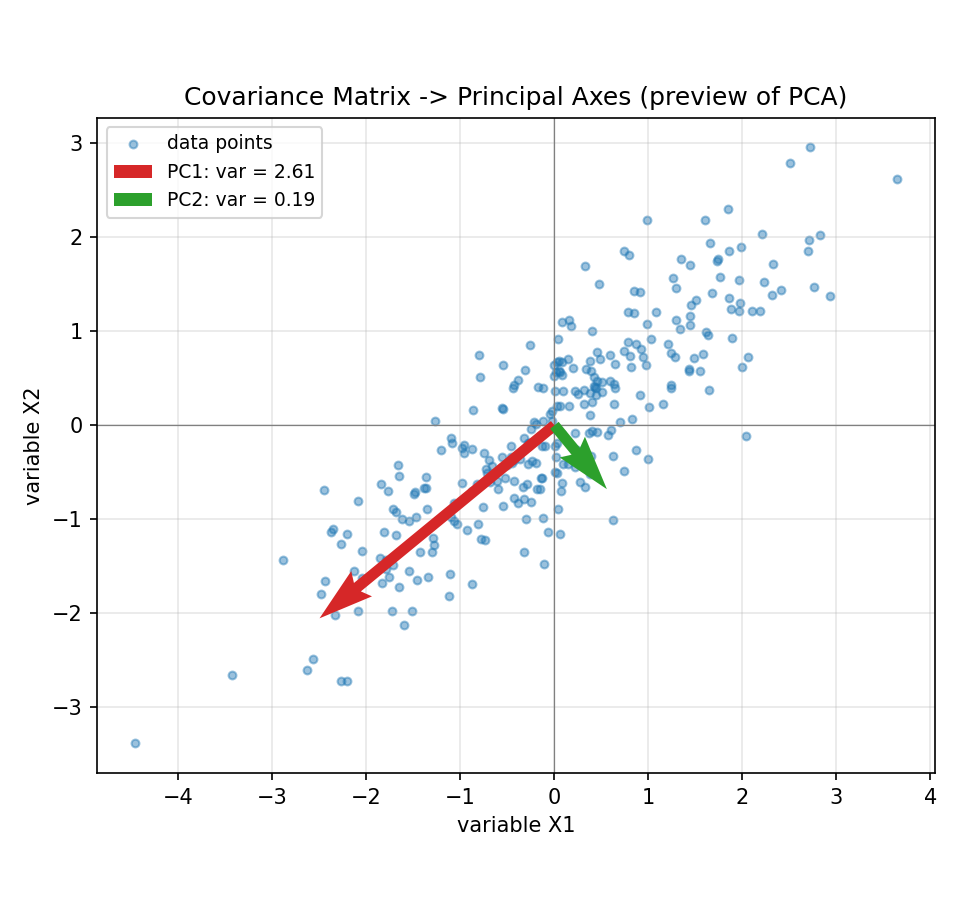
Figure 4 — covariance matrix → principal axes (PCA-র preview)¶
correlated 2D data; দুই তীর হলো covariance matrix-এর eigenvector, \(\sqrt{\text{eigenvalue}}\) অনুপাতে লম্বা। লম্বা তীর (PC1) সেই দিক যেদিকে variance সবচেয়ে বেশি — PCA ঠিক এই দিকটিই বেছে নেয়।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(7)
base = rng.normal(size=(300, 2))
T = np.array([[1.4, 0.0], [1.0, 0.6]])
X = base @ T.T
X = X - X.mean(axis=0)
C = np.cov(X, rowvar=False)
vals, vecs = np.linalg.eigh(C)
order = np.argsort(vals)[::-1]
vals = vals[order]; vecs = vecs[:, order]
fig, ax = plt.subplots(figsize=(6.4, 6))
ax.scatter(X[:, 0], X[:, 1], s=14, alpha=0.45, color="#1f77b4", label="data points")
colors = ["#d62728", "#2ca02c"]
for i in range(2):
vv = vecs[:, i] * np.sqrt(vals[i]) * 2.0
ax.quiver(0, 0, vv[0], vv[1], angles="xy", scale_units="xy", scale=1,
color=colors[i], width=0.013, zorder=5,
label=f"PC{i+1}: var = {vals[i]:.2f}")
ax.set_aspect("equal")
ax.axhline(0, color="gray", lw=0.6); ax.axvline(0, color="gray", lw=0.6)
ax.grid(True, alpha=0.3)
ax.set_xlabel("variable X1"); ax.set_ylabel("variable X2")
ax.set_title("Covariance Matrix -> Principal Axes (preview of PCA)")
ax.legend(loc="upper left", fontsize=9)
plt.tight_layout()
plt.savefig("../_assets/0-5-covariance.png", dpi=150)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নের পূর্ণ সমাধান আছে
_solutions/00-05-linear-algebra-solutions.md-এ। difficulty: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
Conceptual (ধারণাভিত্তিক)¶
৭.১ ★ এক বাক্যে ব্যাখ্যা করুন কেন একই dataset-কে "একটি matrix" এবং "vector-দের সংগ্রহ" — দুই ভাবেই দেখা যায়। (hint: row vs column-এর অর্থ ভাবুন।)
৭.২ ★★ \(\det(A)=0\) হলে \(A^{-1}\) কেন থাকে না — geometry-র ভাষায় বলুন। (hint: figure 2-এর ক্ষেত্রফল-scaling এবং "তথ্য হারানো"-র কথা ভাবুন।)
৭.৩ ★★ "orthogonality" আর "uncorrelated" — statistics-এ এই দুটি কীভাবে একই ধারণা? (hint: centered variable-দের dot product।)
Computational (গণনাভিত্তিক)¶
৭.৪ ★ \(\mathbf{u}=\begin{bmatrix}2\\-1\\2\end{bmatrix}\), \(\mathbf{v}=\begin{bmatrix}1\\2\\2\end{bmatrix}\)-এর জন্য \(\mathbf{u}\cdot\mathbf{v}\), \(\|\mathbf{u}\|\), \(\|\mathbf{v}\|\) বের করুন এবং \(\cos\theta\) নির্ণয় করুন। (hint: \(\|\mathbf{u}\|=\sqrt{\mathbf{u}\cdot\mathbf{u}}\)।)
৭.৫ ★★ \(A=\begin{bmatrix}3&0\\0&2\end{bmatrix}\), \(B=\begin{bmatrix}1&1\\0&1\end{bmatrix}\)-এর জন্য \(AB\) ও \(BA\) বের করে দেখান তারা সমান কিনা। তারপর \(\det(A)\), \(\det(B)\), \(\det(AB)\) বের করে \(\det(AB)=\det(A)\det(B)\) যাচাই করুন। (hint: diagonal matrix-এর det = কর্ণের গুণফল।)
৭.৬ ★★ \(M=\begin{bmatrix}1&2\\3&4\end{bmatrix}\)-এর \(\det(M)\) ও \(M^{-1}\) হাতে বের করুন, এবং \(MM^{-1}=I\) দেখান। (hint: \(2\times2\) inverse সূত্র।)
Proof-based (প্রমাণভিত্তিক)¶
৭.৭ ★★ দেখান যে যেকোনো square matrix \(A\)-এর জন্য \(A + A^\top\) সবসময় symmetric। (hint: \((B+C)^\top=B^\top+C^\top\) এবং \((A^\top)^\top=A\)।)
৭.৮ ★★★ ধরুন \(\mathbf{v}\) একটি eigenvector, eigenvalue \(\lambda\) সহ (\(A\mathbf{v}=\lambda\mathbf{v}\))। দেখান যে \(\mathbf{v}\) একই সাথে \(A^2\)-এরও eigenvector, এবং তার eigenvalue \(\lambda^2\)। আরও সাধারণভাবে \(A^k\)-এর জন্য eigenvalue কত? (hint: \(A^2\mathbf{v}=A(A\mathbf{v})\)।)
Coding (Python)¶
৭.৯ ★★ NumPy-তে একটি function is_orthogonal(u, v, tol=1e-9) লিখুন যা dot product ব্যবহার করে \(\mathbf{u}\perp\mathbf{v}\) কিনা True/False দেয়। \(\begin{bmatrix}1\\2\end{bmatrix}\) ও \(\begin{bmatrix}2\\-1\end{bmatrix}\)-এ পরীক্ষা করুন। (hint: np.isclose।)
৭.১০ ★★★ \(50\times2\) random correlated dataset বানান (নিজের পছন্দের mixing matrix দিয়ে), centered covariance matrix np.cov দিয়ে বের করুন, তার eigenvalue ও eigenvector np.linalg.eigh দিয়ে নির্ণয় করুন, এবং বৃহত্তম eigenvalue-র eigenvector data-র উপর তীর হিসেবে plot করুন (figure 4-এর মতো)। (hint: base @ T.T দিয়ে correlation আনুন; তীরের দৈর্ঘ্য \(\sqrt{\lambda}\) অনুপাতে নিন।)
৮ · সারসংক্ষেপ ও সংযোগ¶
যা শিখলাম (recap):
- vector = সংখ্যার তালিকা; addition (parallelogram rule), scaling, dot product \(\mathbf{u}\cdot\mathbf{v}=\sum u_i v_i\)। dot product থেকে norm \(\|\mathbf{u}\|=\sqrt{\mathbf{u}\cdot\mathbf{u}}\), কোণ, ও orthogonality (\(\mathbf{u}\cdot\mathbf{v}=0\))।
- matrix = সংখ্যার ছক; transpose (\(A^\top\)), multiplication (প্রতিটি entry = row·column, \(AB\neq BA\)), identity \(I\), inverse \(A^{-1}\) (থাকে যদি \(\det\neq0\))।
- matrix = linear transformation: space-কে টেনে-বাঁকিয়ে দেয়; column গুলো বলে basis কোথায় যায়।
- system \(A\mathbf{x}=\mathbf{b}\), সমাধান \(A^{-1}\mathbf{b}\) (বা দ্রুততর
solve)। - determinant = area/volume scaling; \(0\) মানে চেপ্টে যাওয়া, inverse নেই।
- eigenvalue/eigenvector: \(A\mathbf{v}=\lambda\mathbf{v}\) — যে দিক transformation-এ বদলায় না, কেবল \(\lambda\) গুণে scale হয়।
- symmetric (\(A=A^\top\)) ⇒ বাস্তব eigenvalue ও orthogonal eigenvector; positive-definite ⇒ সব eigenvalue \(>0\)।
- covariance matrix \(\Sigma=\frac{1}{n-1}X_c^\top X_c\) — symmetric ও positive-semidefinite; এর eigenvector গুলো data-র principal axis।
আগের সাথে সংযোগ (০.১): এখানে vector আর matrix আসলে বিশেষ ধরনের function ও সাজানো set — ০.১-এ শেখা set/function-এর ভিত্তির উপরই দাঁড়িয়ে। linearity-র দুটি নিয়মই function-এর একটি বিশেষ শ্রেণি সংজ্ঞায়িত করে।
পরের সাথে সংযোগ (০.৬): পরের অধ্যায় Python on-ramp — NumPy, pandas, matplotlib, Jupyter দিয়ে scientific computing workflow। এই অধ্যায়ে আমরা যে array-operation আর numpy.linalg ছুঁয়ে গেছি, ০.৬ সেগুলোকে গুছিয়ে পূর্ণ toolkit হিসেবে শেখাবে — যাতে Part I থেকে data নিয়ে কাজ শুরু করা যায়।
দূরবর্তী সংযোগ (source pointer): এই অধ্যায় self-contained, এবং সরাসরি দুটি স্তম্ভকে support করে — - Part V (linear regression): \(\hat{\boldsymbol{\beta}} = (X^\top X)^{-1}X^\top\mathbf{y}\) — পুরোটাই matrix operation; \(X^\top X\) আসলে (uncentered) covariance-সদৃশ। - Part VI (PCA): covariance matrix-এর eigen-decomposition — যে eigenvector-এর eigenvalue বড়, সেদিকেই data সবচেয়ে বেশি ছড়ানো; ওই দিকগুলোই principal component।
এক বাক্যে: statistics-এর data হলো matrix, তার গঠন (variance, correlation, প্রধান দিক) লুকিয়ে আছে covariance matrix-এর eigenvalue ও eigenvector-এ — যা এই অধ্যায়ের ভাষাতেই পড়া যায়।