Part V — পরিসংখ্যানিক মডেলিং · Integrative Demos¶
Part V পরিসংখ্যানের সেই স্তম্ভগুলো ধরে যেখানে data থেকে একটা structured সম্পর্ক শেখা ও যাচাই করা হয়: linear regression, regression diagnostics ও model selection, ANOVA, logistic regression, Poisson GLM, mixed-effects (random intercept), nonparametric regression, cross-validation, এবং PCA ও clustering। প্রতিটি ধারণা চারভাবে দেখানো — (b) scratch (শুধু numpy), (c) library check (statsmodels/sklearn), (d) demonstrate/"prove" (ছাপা real সংখ্যা), (e) visualization — সবই real open data (diabetes, iris, breast_cancer, sunspots, co2, wine)-এর উপর, fixed seed 20260619 সহ। নিচের সব সংখ্যা executed notebook (notebooks/05-modeling.ipynb) থেকে সরাসরি নেওয়া।
চালানো:
cd notebooks && python3 -m nbconvert --to notebook --execute --inplace 05-modeling.ipynb --ExecutePreprocessor.timeout=1200
5.1 — Linear regression (OLS from scratch on diabetes)¶
ধারণা। Linear regression ধরে নেয় target \(y\) হলো features-এর একটা linear combination যোগ noise: \(y = X\beta + \varepsilon\)। Ordinary Least Squares (OLS) সেই \(\beta\) বেছে নেয় যা residual sum of squares \(\lVert y - X\beta\rVert^2\) ন্যূনতম করে; এর closed-form normal equations \(\hat\beta = (X^\top X)^{-1} X^\top y\)। সংখ্যাগত দিক থেকে \(X^\top X\) inverse করা খারাপ হতে পারে, তাই একই সমাধান QR decomposition (\(X=QR\), তখন \(R\hat\beta = Q^\top y\)) দিয়ে বেশি নির্ভরযোগ্য।
Scratch-এর মূল ধারণা। diabetes-এর \(10\) feature + intercept (\(n=442\)) দিয়ে design matrix \(X\) গড়ে (১) np.linalg.solve দিয়ে normal equations এবং (২) np.linalg.qr দিয়ে QR — দুই পথে \(\hat\beta\); তারপর \(R^2 = 1 - \mathrm{SS}_{\text{res}}/\mathrm{SS}_{\text{tot}}\)।
Demonstrated result (প্রমাণ)। intercept \(\hat\beta_0 = 152.1335\), প্রথম তিন slope \(=[-10.01,\ -239.82,\ 519.85]\); normal-eq ও QR হুবহু মেলে (True)। \(R^2 = 0.517748\), residual std error \(=54.15\)। statsmodels ও sklearn-এর coefficient হুবহু একই (\(\hat\beta[:4]\) তিন-ভাবেই সমান, True/True), \(R^2\)-ও True। OLS-এর first-order optimality হাতে-কলমে যাচাই: \(\max\lvert X^\top(y-\hat y)\rvert = 3.3\times10^{-12}\approx 0\) (normal equations), residual-এর গড় \(=6.2\times10^{-15}\)। geometric identity \(R^2 = \operatorname{corr}(y,\hat y)^2 = 0.517748\) (True), এবং variance decomposition \(\mathrm{SS}_{\text{tot}} = \mathrm{SS}_{\text{reg}} + \mathrm{SS}_{\text{res}}\) হুবহু ধরে (\(2621009.1 = 1357023.3 + 1263985.8\))।
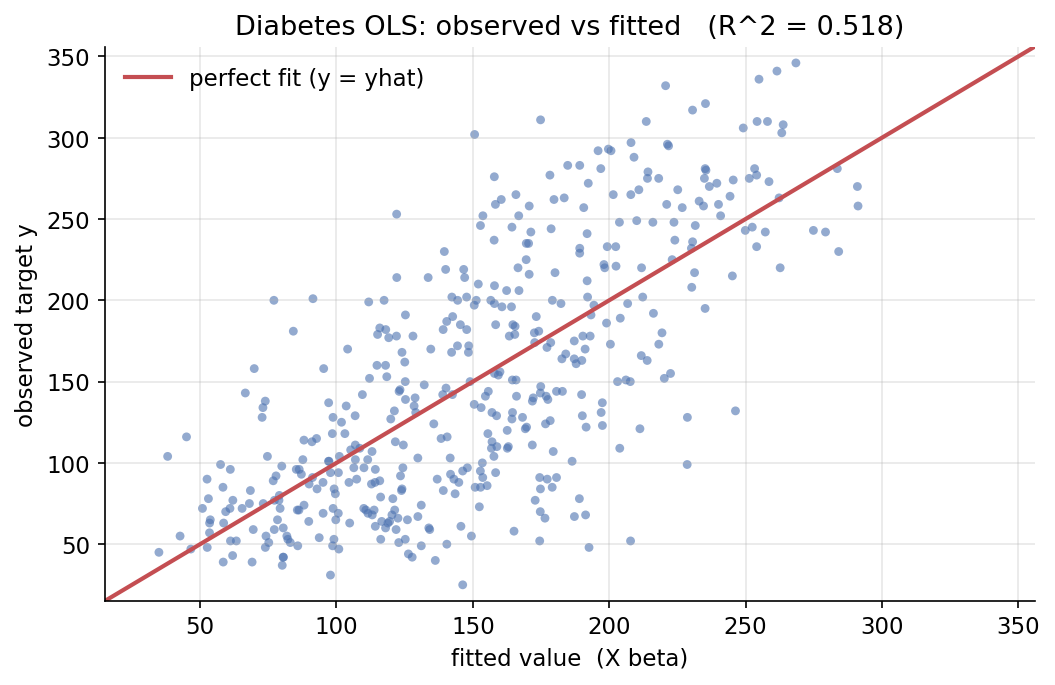
চিত্র: diabetes OLS-এ observed target বনাম fitted মান, \(45^\circ\) perfect-fit রেখাসহ (\(R^2 = 0.52\))।
5.2 — Regression diagnostics & model selection¶
ধারণা। একটা OLS fit "ভালো" কি না তা যাচাই করতে diagnostics দরকার। residual-vs-fitted plot linearity ও সম-variance দেখায়; leverage (\(h_{ii}\), hat matrix \(H = X(X^\top X)^{-1}X^\top\)-এর diagonal) বলে কোন observation feature-space-এ চরম; Cook's distance মাপে একটা point বাদ দিলে fit কতটা নড়ে; VIF \(=1/(1-R_j^2)\) multicollinearity মাপে। মডেল বাছাইয়ে AIC \(=2k-2\hat\ell\) ও BIC \(=k\ln n-2\hat\ell\) — ছোট মান ভালো।
Scratch-এর মূল ধারণা। 5.1-এর diabetes design পুনর্ব্যবহার করে \(h_{ii}=x_i^\top(X^\top X)^{-1}x_i\) (einsum, পুরো \(n\times n\) hat matrix না গড়েই), Cook's \(D\), প্রতিটি feature-কে বাকিদের উপর regress করে VIF, এবং দুটি nested model-এর Gaussian log-likelihood থেকে AIC/BIC।
Demonstrated result (প্রমাণ)। leverage-দের যোগফল \(=11.0000\) — ঠিক parameter সংখ্যার (=11) সমান (trace identity)। সর্বোচ্চ leverage \(h_{ii}=0.1276\) (obs 322), সর্বোচ্চ Cook's \(D=0.0245\) (obs 382)। VIF: \(s1\)-এ \(59.20\), \(s2\)-এ \(39.19\) — lipid feature-গুলো তীব্রভাবে collinear; বাকিরা ছোট (\(\text{bmi}\approx1.5\))। scratch-এর leverage/Cook/VIF তিনটাই statsmodels-এর সাথে মেলে (True/True/True; যেমন \(\text{VIF}[s1]=59.203\) দুই দিকেই)। model selection: Model A (bmi, s5) — \(\text{AIC}=4828.40,\ \text{BIC}=4840.67\); Model B (সব 10) — \(\text{AIC}=4793.99,\ \text{BIC}=4838.99\)। AIC ও BIC দুটোই full model-কে পছন্দ করে (নিচু); full-model AIC statsmodels-এর সাথে হুবহু মেলে (\(4793.99\))।
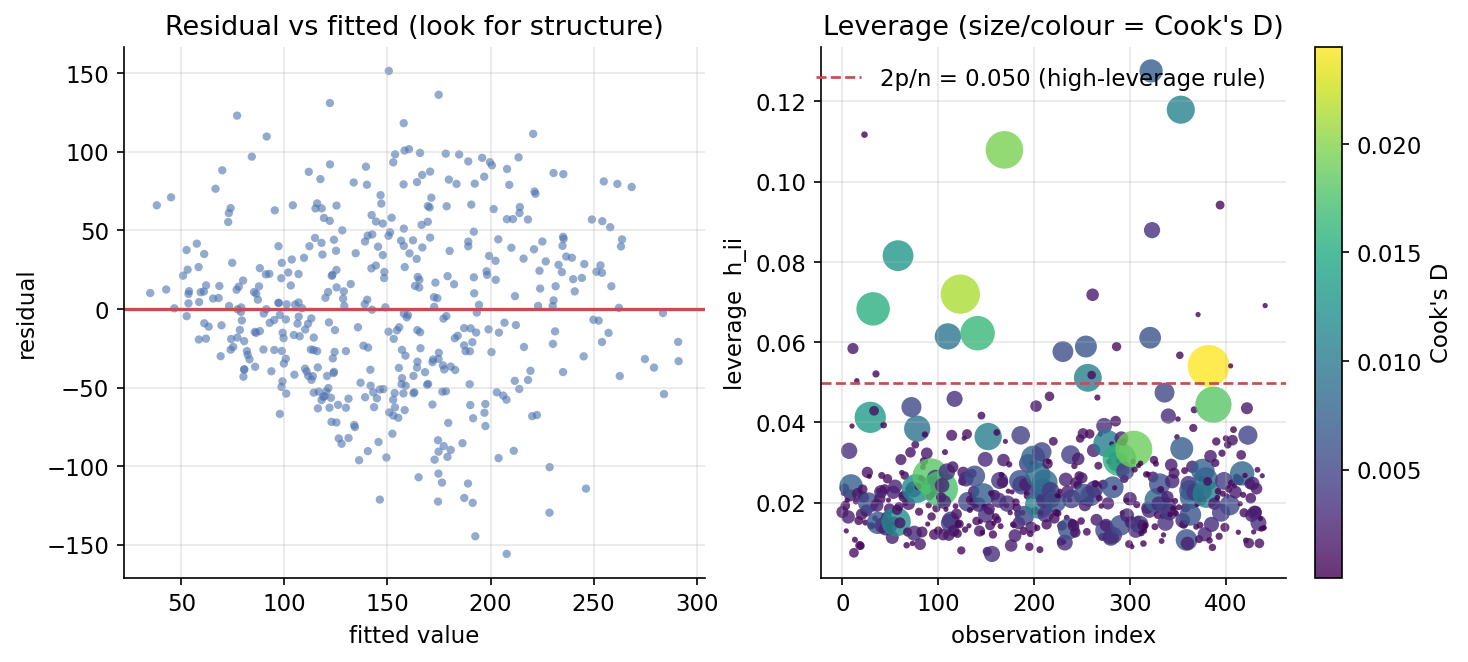
চিত্র: বাঁয়ে residual-vs-fitted (structure খোঁজা), ডানে leverage বনাম observation index (point-এর আকার/রং = Cook's \(D\)), \(2p/n\) high-leverage রেখাসহ।
5.3 — One-way ANOVA (iris petal length across 3 species)¶
ধারণা। One-way ANOVA একাধিক group-এর mean সমান কি না পরীক্ষা করে। মোট variability ভাঙা হয় between-group (\(\mathrm{SSB}\)) ও within-group (\(\mathrm{SSW}\)) অংশে; test statistic \(F = \dfrac{\mathrm{SSB}/(k-1)}{\mathrm{SSW}/(N-k)}\) — বড় হলে group-mean-এর পার্থক্য noise-এর তুলনায় বড়। \(H_0\) সত্য হলে \(F \sim F_{k-1,\,N-k}\)।
Scratch-এর মূল ধারণা। iris-এর petal length তিন species (setosa/versicolor/virginica) অনুযায়ী ভাগ করে \(\mathrm{SSB},\mathrm{SSW}\), \(F\) ও upper-tail \(p\); scipy-র f.sf দিয়ে \(p\)।
Demonstrated result (প্রমাণ)। group mean \(=[1.462,\ 4.260,\ 5.552]\); \(\mathrm{SSB}=437.10\) (df \(2\)), \(\mathrm{SSW}=27.22\) (df \(147\)), \(\mathrm{MSB}=218.55\), \(\mathrm{MSW}=0.1852\) → \(F = 1180.16\), \(p = 2.857\times10^{-91}\)। scipy.stats.f_oneway হুবহু একই \(F,p\) দেয় (True/True)। SS decomposition \(\mathrm{SST} = \mathrm{SSB} + \mathrm{SSW}\) হুবহু (\(464.33 = 437.10 + 27.22\)); effect size \(\eta^2 = \mathrm{SSB}/\mathrm{SST} = 0.9414\) — species মাত্রই \(94.1\%\) variance ব্যাখ্যা করে। \(\eta^2\) থেকে \(F\) পুনর্গঠন করলে আবার \(1180.16\) (True); \(F_{\text{crit}}(0.05,2,147)=3.058\), তাই \(F \gg F_{\text{crit}}\) → \(H_0\) বাতিল।
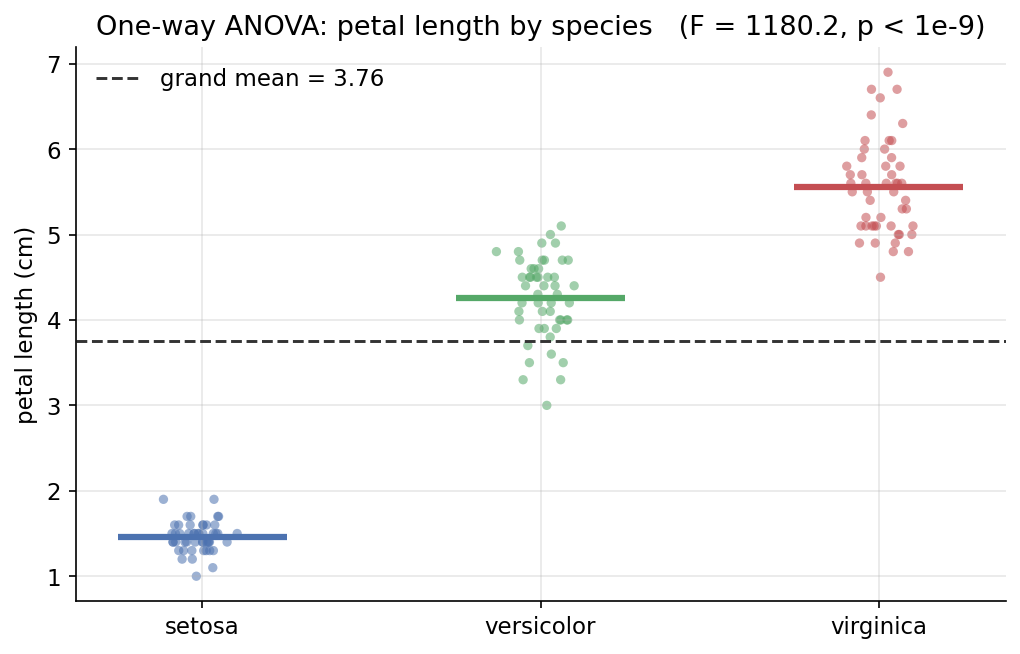
চিত্র: species-ভিত্তিক petal length (jittered points), প্রতিটি group-mean মোটা দাগে ও grand mean ড্যাশ রেখায় (\(F=1180\), \(p<10^{-9}\))।
5.4 — Logistic regression (IRLS from scratch on breast_cancer)¶
ধারণা। Logistic regression binary target-এর জন্য \(P(y=1\mid x)=\sigma(x^\top\beta)\), \(\sigma(t)=1/(1+e^{-t})\)। parameter fit হয় maximum likelihood-এ, কিন্তু closed form নেই। IRLS (Iteratively Reweighted Least Squares) — Newton–Raphson-এরই রূপ — বারবার weighted least squares সমাধান করে: \(\beta \leftarrow \beta + (X^\top W X)^{-1}X^\top(y-\mu)\), \(\mu=\sigma(X\beta)\), \(W=\operatorname{diag}(\mu(1-\mu))\)। মান মাপে ROC curve ও তার নিচের ক্ষেত্রফল AUC।
Scratch-এর মূল ধারণা। breast_cancer-এর তিনটি standardized feature (mean radius, texture, area) + intercept-এ Newton/IRLS iteration চালিয়ে \(\hat\beta\); তারপর predicted probability থেকে threshold sweep করে ROC ও np.trapezoid-এ AUC।
Demonstrated result (প্রমাণ)। IRLS \(9\) iteration-এ converge; \(\hat\beta = [0.1809,\ 1.3564,\ -0.8989,\ -5.7525]\) (intercept, radius, texture, area)। log-likelihood \(=-144.41\), in-sample accuracy \(=0.8910\)। sklearn-এর সাথে coefficient মেলে (tol \(2\times10^{-2}\), True; scratch Newton vs lbfgs-এ শেষ digit-এ সামান্য পার্থক্য), accuracy হুবহু \(0.8910\) (True)। AUC \(=0.951734\) — scratch trapezoid ও sklearn.roc_auc_score হুবহু মেলে (True)। \(0.5\) threshold-এ confusion: \(\text{TP}=336,\ \text{TN}=171,\ \text{FP}=41,\ \text{FN}=21\)।
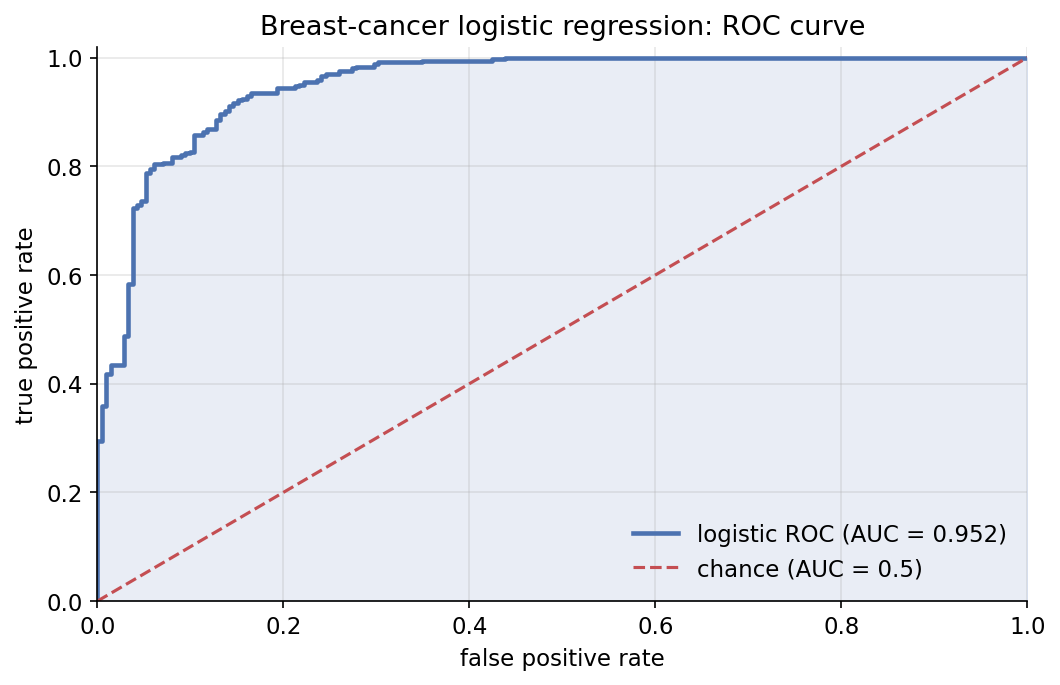
চিত্র: logistic regression-এর ROC curve (AUC \(=0.952\)), chance-রেখা (\(\text{AUC}=0.5\)) ও নিচের ক্ষেত্র ছায়াসহ।
5.5 — Poisson regression (GLM with log link, IRLS from scratch)¶
ধারণা। count data মডেল করতে Poisson GLM: \(y_i \sim \text{Poisson}(\mu_i)\), log link \(\log\mu_i = x_i^\top\beta\), তাই \(\mu_i = e^{x_i^\top\beta}\)। এটাও IRLS দিয়ে fit — Poisson-এ working weight \(W=\operatorname{diag}(\mu)\)। একটা coefficient-এর \(e^{\beta_j}\) হলো rate ratio। Poisson ধরে variance \(=\) mean; বাস্তবে variance বেশি হলে overdispersion।
Scratch-এর মূল ধারণা। sunspots-এর SUNACTIVITY (integer-এ round) count হিসেবে, predictor centred-scaled YEAR; IRLS-এ working response \(z = \eta + (y-\mu)/\mu\) দিয়ে weighted least squares; তারপর Pearson \(\chi^2/\text{dof}\) দিয়ে dispersion।
Demonstrated result (প্রমাণ)। IRLS \(5\) iteration; \(\hat\beta = [\text{intercept}=3.8917,\ \text{slope}=0.17885]\), rate ratio \(e^{\text{slope}} = 1.1958\) (time \(+1\) SD-এ গড় count \(\approx1.2\times\)); fitted mean count range \([35.98,\ 66.72]\)। statsmodels GLM Poisson-এর সাথে coefficient হুবহু মেলে (True; rate ratio দুই দিকেই \(1.19584\))। overdispersion স্পষ্ট: raw counts-এর mean \(=49.78\) কিন্তু variance \(=1637.67\) (var/mean \(=32.90\)); Pearson \(\chi^2/\text{dof} = 30.634\) (\(\gg1\)), statsmodels-এর সাথে মেলে (True)। অর্থাৎ naive Poisson SE খুব ছোট — Negative-Binomial / quasi-Poisson ভালো হতো।
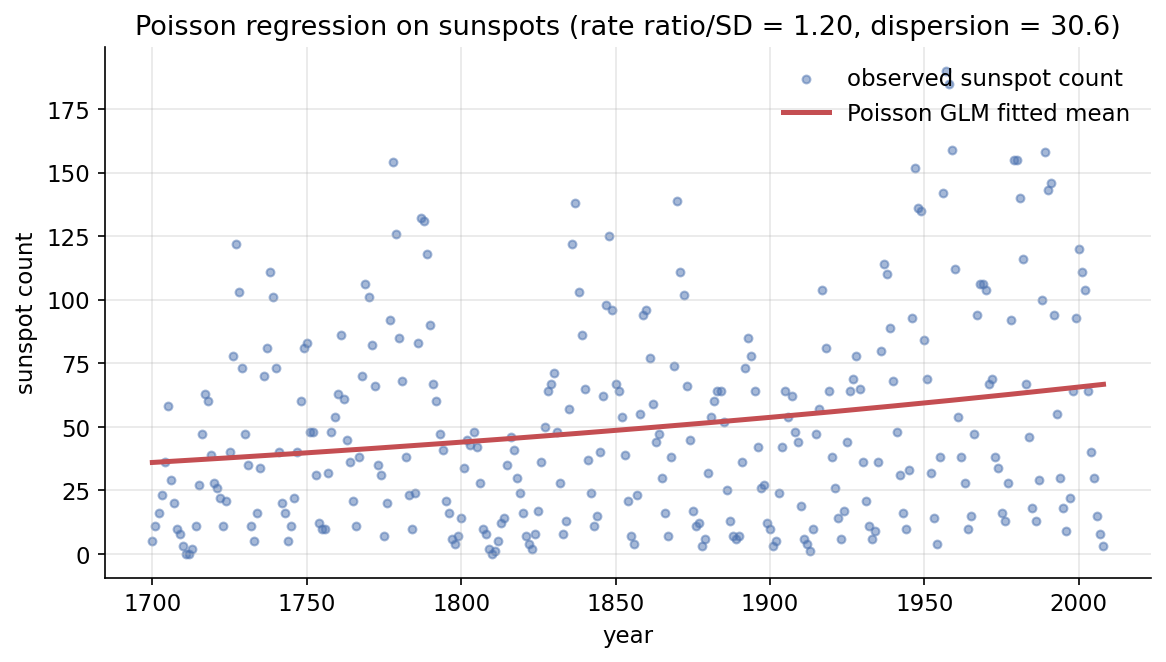
চিত্র: বছরভিত্তিক sunspot count (bindu) ও Poisson GLM fitted mean (রেখা); rate ratio \(=1.20\)/SD, dispersion \(=30.6\)।
5.6 — Mixed-effects: random-intercept model (iris feature by species)¶
ধারণা। grouped data-য় একটা random-intercept model প্রতিটি group-কে নিজের baseline দেয়: \(y_{ij} = \mu + u_j + \varepsilon_{ij}\), group effect \(u_j \sim N(0,\sigma_u^2)\), noise \(\varepsilon_{ij}\sim N(0,\sigma_e^2)\)। between-group (\(\sigma_u^2\)) ও within-group (\(\sigma_e^2\)) variance আলাদা করা যায়; ICC \(=\sigma_u^2/(\sigma_u^2+\sigma_e^2)\) বলে variance-এর কত অংশ group-স্তরের। group-mean-এর BLUP হলো grand mean-এর দিকে shrunk estimate।
Scratch-এর মূল ধারণা। iris sepal width species দিয়ে group করে balanced one-way random-effects ANOVA estimator: \(\sigma_e^2 = \mathrm{MSW}\), \(\sigma_u^2 = (\mathrm{MSB}-\mathrm{MSW})/n_0\); shrinkage factor \(\lambda_j = \sigma_u^2/(\sigma_u^2 + \sigma_e^2/n_j)\) দিয়ে BLUP; statsmodels MixedLM-এর সাথে তুলনা।
Demonstrated result (প্রমাণ)। grand mean \(=3.0573\), raw group mean \(=[3.428,\ 2.770,\ 2.974]\); \(\mathrm{MSB}=5.6725,\ \mathrm{MSW}=0.1154,\ n_0=50\) → \(\sigma_u^2=0.1111,\ \sigma_e^2=0.1154\), ICC \(=0.4906\) (variance-এর \(\approx49\%\) species-এর মধ্যে)। MixedLM হুবহু একই \(\sigma_u^2=0.1111,\ \sigma_e^2=0.1154,\ \text{ICC}=0.4906\) দেয়; \(\sigma_e^2\) MSW-এর সাথে মেলে (True)। shrinkage factor \(\lambda\approx0.9797\) (বড় group, তাই সামান্য shrink); প্রতিটি BLUP তার raw mean ও grand mean-এর মাঝে থাকে (True) — যেমন setosa \(3.4280 \to 3.4205\) (\(2.0\%\) grand-এর দিকে টানা)।
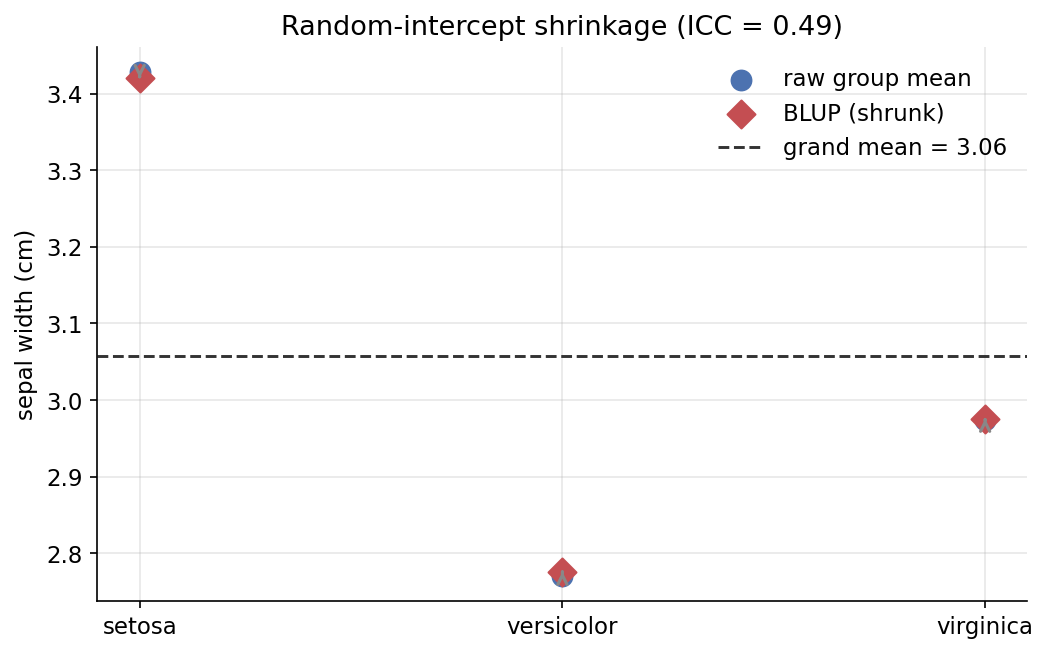
চিত্র: raw group mean (নীল) থেকে BLUP (লাল হীরা)-এ shrinkage তীর, grand mean ড্যাশ রেখায় (ICC \(=0.49\))।
5.7 — Nonparametric regression (Nadaraya–Watson on the co2 series)¶
ধারণা। fixed functional form ধরে না নিয়ে nonparametric regression data-কেই আকার ঠিক করতে দেয়। Nadaraya–Watson smoother একটা point \(x_0\)-এ prediction দেয় কাছের observation-দের weighted average হিসেবে: \(\hat m(x_0)=\dfrac{\sum_i K_h(x_0-x_i)\,y_i}{\sum_i K_h(x_0-x_i)}\), Gaussian kernel \(K_h(u)\propto e^{-u^2/2h^2}\)। bandwidth \(h\) মসৃণতা নিয়ন্ত্রণ করে: ছোট \(h\) → under-smoothing, বড় \(h\) → over-smoothing — এটাই bias–variance tradeoff।
Scratch-এর মূল ধারণা। Mauna Loa co2 (weekly ppm, dropna) time-index scale করে তিনটি bandwidth (\(h=0.02,0.10,0.60\))-এ NW smoother; তুলনায় statsmodels lowess ও একটা global cubic polynomial; bandwidth-এর প্রভাব training RMSE ও roughness দিয়ে।
Demonstrated result (প্রমাণ)। series \(n=2225\) weekly point, ppm range \([313.0,\ 373.9]\); mid bandwidth (\(h=0.10\))-এ training RMSE \(=2.1082\) ppm, series-শেষে fitted \(=369.91\) (raw শেষ \(=371.50\))। NW-mid ও lowess প্রায় অভিন্ন: grid-এ \(\operatorname{corr}=0.99996\)। bias–variance tradeoff সংখ্যায়: \(h=0.02\) → RMSE \(1.5436\), roughness \(1.95\times10^{-1}\) (wiggly, low train error); \(h=0.10\) → RMSE \(2.1082\), roughness \(1.47\times10^{-5}\); \(h=0.60\) → RMSE \(3.9198\), roughness \(8.85\times10^{-7}\) (মসৃণ, বেশি train error)। অর্থাৎ \(h\) বাড়লে training error বাড়ে কিন্তু roughness কমে — ঠিক তত্ত্ব অনুযায়ী।
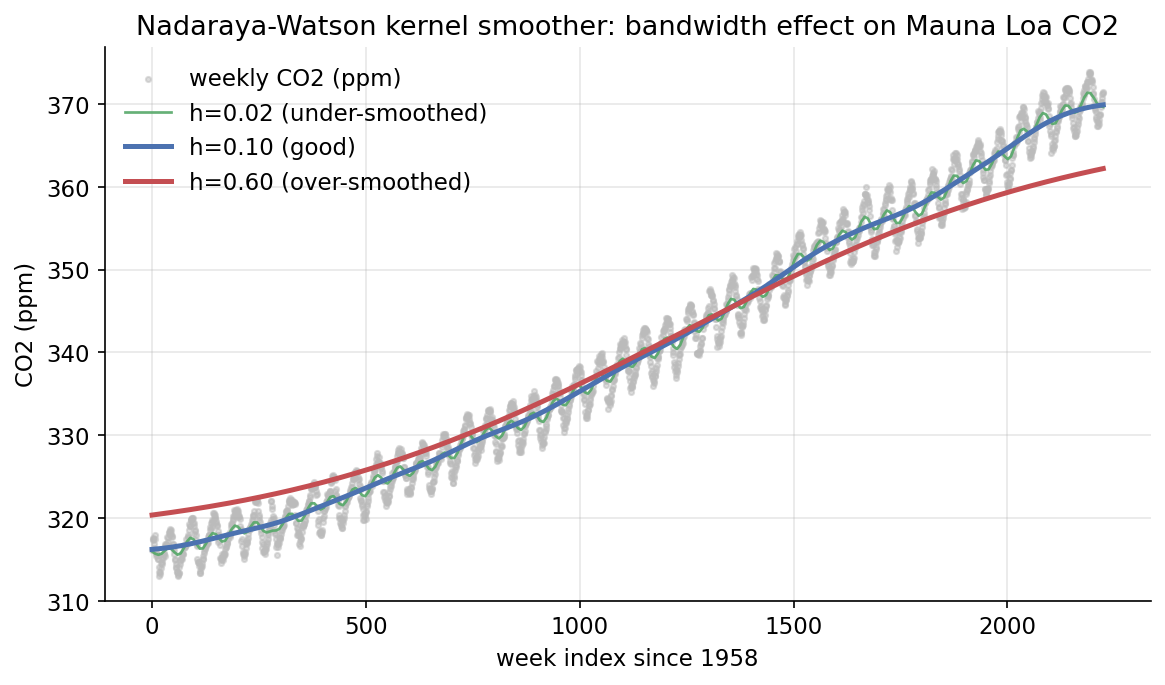
চিত্র: weekly CO2 (ধূসর bindu)-র উপর তিন bandwidth-এর NW smoother — \(h=0.02\) (under), \(h=0.10\) (good), \(h=0.60\) (over)।
5.8 — Cross-validation to select the ridge penalty (diabetes)¶
ধারণা। Ridge regression OLS-এ penalty যোগ করে: \(\hat\beta_\lambda=(X^\top X+\lambda I)^{-1}X^\top y\) — বড় \(\lambda\) coefficient ছোট করে (variance \(\downarrow\), bias \(\uparrow\))। সঠিক \(\lambda\) বাছতে cross-validation: data \(K\) ভাগ, প্রতিবার এক fold test — K-fold CV; \(K=n\) হলে LOOCV। one-standard-error rule — সেরা মডেলের এক SE-র মধ্যে থাকা সবচেয়ে simple (বড় \(\lambda\)) মডেল বেছে অতি-fit এড়ায়।
Scratch-এর মূল ধারণা। diabetes standardize করে (intercept penalize না করে) \(30\)-point \(\lambda\)-grid (\(10^{-2}\) থেকে \(10^{3}\))-এ 10-fold CV MSE ও তার SE; LOOCV-এর জন্য hat-matrix shortcut \(r_i/(1-H_{ii})\); sklearn RidgeCV-এর সাথে তুলনা।
Demonstrated result (প্রমাণ)। 10-fold CV: best \(\lambda = 28.07\) (CV MSE \(=3021.02\)); one-SE rule \(\lambda = 204.34\) (CV MSE \(=3135.19\) — বেশি shrink, তবু সেরার এক SE-র মধ্যে)। LOOCV: scratch best \(\lambda = 1.7433\), sklearn RidgeCV \(\alpha = 1.7433\) — হুবহু একই grid-point (True)। (LOOCV ও 10-fold ভিন্ন \(\lambda\) দেয়, এটা স্বাভাবিক — LOOCV কম bias, বেশি variance।) ridge coefficient shrink হয় একঘেয়েভাবে: \(\lVert\beta_{\text{slopes}}\rVert\) \(=65.54\ (\lambda{=}0)\to 39.35\ (28.07)\to 34.75\ (100)\to 17.35\ (1000)\) — non-increasing (True)। CV MSE: OLS (\(\lambda\approx0\)) \(=3037.83\) বনাম best-\(\lambda\) \(=3021.02\) — ridge out-of-sample-এ OLS-কে হারায় (True)।
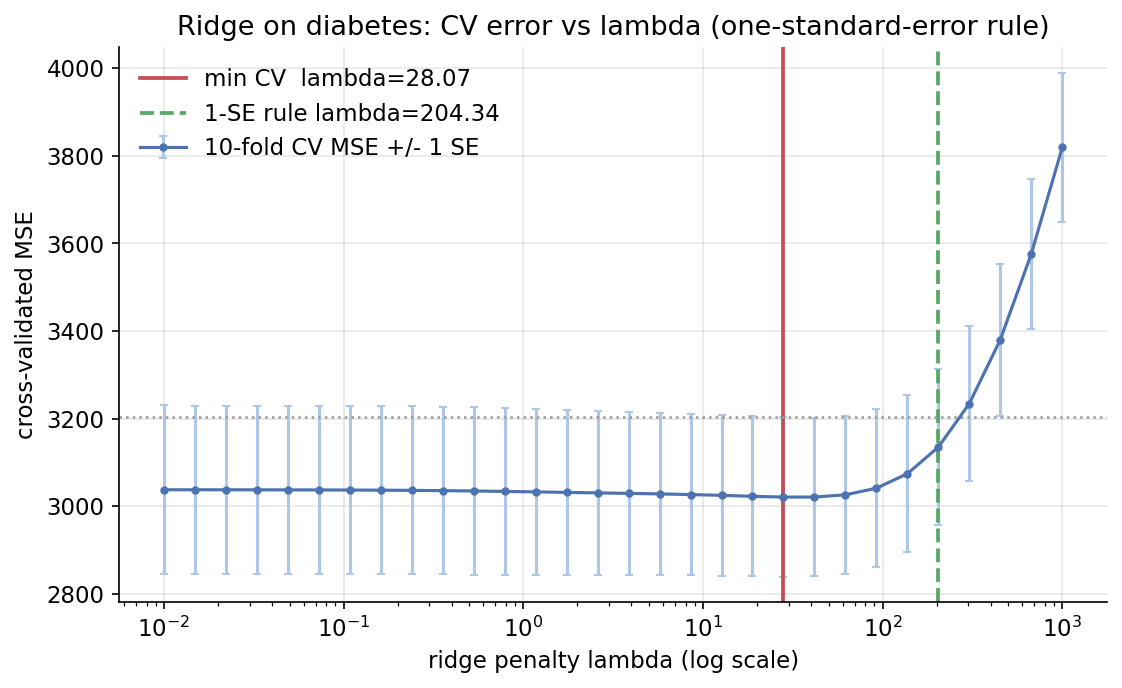
চিত্র: 10-fold CV MSE বনাম \(\lambda\) (log-scale, \(\pm1\) SE band); min-CV (\(\lambda=28\)) ও 1-SE rule (\(\lambda=204\)) রেখা চিহ্নিত।
5.9 — PCA & k-means clustering (wine)¶
ধারণা। PCA standardized data-র dimension কমায় সবচেয়ে বেশি variance রাখা orthogonal দিক (principal component) খুঁজে; সংখ্যাগতভাবে এটা centred data-র SVD \(X = U\Sigma V^\top\) থেকে (\(V\)-এর column = component, \(\sigma_i^2/(n-1)\) = explained variance)। k-means point-দের \(k\) cluster-এ ভাগ করে within-cluster squared distance (inertia) ন্যূনতম করে (Lloyd's algorithm)। \(k\) বাছতে elbow ও silhouette (\([-1,1]\))।
Scratch-এর মূল ধারণা। wine-এর \(13\) feature standardize করে np.linalg.svd-এ PCA (explained-variance ratio), এবং scratch Lloyd's k-means (assign→update) দিয়ে inertia; \(k=2..6\)-এ elbow ও silhouette; sklearn PCA/KMeans-এর সাথে তুলনা এবং true label-এর সাথে Adjusted Rand Index।
Demonstrated result (প্রমাণ)। explained variance ratio (প্রথম \(5\)) \(=[0.362,\ 0.192,\ 0.111,\ 0.071,\ 0.066]\); cumulative প্রথম \(2\) \(=0.5541\), প্রথম \(3\) \(=0.6653\)। sklearn PCA-র সাথে ratio হুবহু মেলে (True; \([:3]\) দুই দিকেই \([0.362,0.192,0.111]\))। k-means (\(k=3\)) inertia \(=1277.93\) — sklearn-এর \(1277.93\)-এর সাথে \(<1\%\)-এ মেলে (True)। model selection: silhouette সর্বোচ্চ \(k=3\)-এ (\(0.2849\); \(k{=}2{:}0.2597\), \(k{=}4{:}0.2608\)), যা wine-এর \(3\) cultivar-এর সাথে সঙ্গতিপূর্ণ; Adjusted Rand Index \(=0.8975\) (k=3 বনাম true class — প্রায় নিখুঁত)। PC1+PC2 মিলে \(55.4\%\) variance ধরে, তাই 2-D-তে পরিষ্কার বিভাজন।
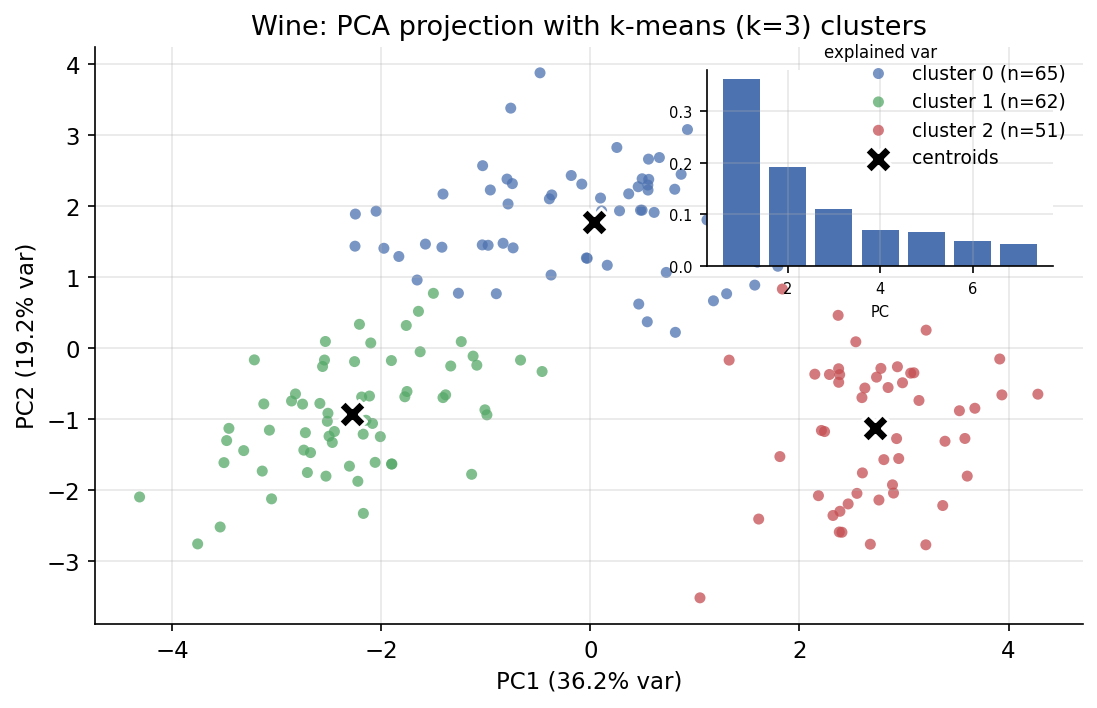
চিত্র: wine-এর PC1–PC2 projection, k-means (k=3) cluster অনুযায়ী রঙানো, centroid (\(\times\)) ও explained-variance scree inset সহ।
সারসংক্ষেপ (Part V)¶
| Demo | scratch যা প্রমাণ করে | key real number | library মিল |
|---|---|---|---|
| 5.1 OLS | normal-eq = QR; \(R^2=\operatorname{corr}^2\) | \(R^2 = 0.5177\) | statsmodels/sklearn ✓ |
| 5.2 diagnostics | \(\sum h_{ii}=k\); VIF collinearity | \(\text{VIF}_{s1}=59.2\), AIC \(=4794\) | statsmodels ✓ |
| 5.3 ANOVA | \(\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}\) | \(F=1180\), \(p<10^{-90}\) | f_oneway ✓ |
| 5.4 logistic | IRLS = Newton; ROC/AUC | AUC \(=0.9517\), acc \(=0.891\) | sklearn ✓ |
| 5.5 Poisson | log link; overdispersion | RR \(=1.196\), disp \(=30.6\) | statsmodels GLM ✓ |
| 5.6 mixed | variance components; BLUP shrink | ICC \(=0.491\) | MixedLM ✓ |
| 5.7 nonparam | bandwidth = bias–variance | RMSE \(1.54\!\to\!3.92\) | lowess ✓ |
| 5.8 CV | ridge shrink; 1-SE rule | \(\lambda_{\text{LOO}}=1.743\) | RidgeCV ✓ |
| 5.9 PCA/k-means | SVD variance; silhouette | ARI \(=0.898\), \(k=3\) | PCA/KMeans ✓ |
সব সংখ্যা notebooks/05-modeling.ipynb (seed 20260619) execute করে পাওয়া; প্রতিটি scratch implementation তার library counterpart-এর সাথে close(...) দিয়ে যাচাই করা।