Calculus I: Limits, Derivatives, Optimization¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
ধরা যাক, আপনি একটি model fit করছেন। আপনার হাতে একটা সংখ্যা আছে — যাকে বলে loss (ভুলের পরিমাপ) — আর আপনি চান সেটা যতটা সম্ভব ছোট করতে। প্রশ্ন হলো: model-এর parameter-গুলো কোন দিকে একটু নাড়লে loss কমবে? এই "কোন দিকে নাড়লে কী হবে" — এটাই derivative (তাৎক্ষণিক পরিবর্তনের হার)। আর "সবচেয়ে ভালো parameter খুঁজে বের করা" — এটাই optimization (সর্বোত্তম মান খোঁজা)। পুরো আধুনিক statistics ও machine learning এই দুটো ধারণার উপর দাঁড়িয়ে আছে।
কেন এই topic statistics-এ এত গুরুত্বপূর্ণ? দুটো জায়গায় calculus সরাসরি প্রাণভোমরা:
-
Maximum Likelihood Estimation (MLE) — Part IV-এ আমরা দেখব, কোনো distribution-এর parameter estimate করার সবচেয়ে প্রচলিত পদ্ধতি হলো: যে parameter-এর জন্য পাওয়া data-টা সবচেয়ে "সম্ভাব্য" (likely), সেটাকেই বেছে নাও। গাণিতিকভাবে এর মানে — একটা function (log-likelihood) কে maximize করা, যা করা হয় derivative শূন্য করে: \(\frac{d}{d\theta}\,\ell(\theta) = 0\) সমাধান করে।
-
Gradient descent — Part VI ও deep learning-এ যেকোনো জটিল model train করা হয় এই algorithm দিয়ে: loss function-এর gradient (একাধিক direction-এ derivative-এর vector) হিসাব করে, তার বিপরীত দিকে ছোট ছোট পা ফেলে নিচে নামতে নামতে minimum-এ পৌঁছানো।
Hook। কল্পনা করুন একটা পাহাড়ি উপত্যকায় ঘন কুয়াশার মধ্যে আপনি দাঁড়িয়ে আছেন, চোখে কিছু দেখা যাচ্ছে না, কিন্তু নিচের উপত্যকার একদম তলায় (minimum) পৌঁছাতে হবে। আপনি কী করবেন? পায়ের নিচের ঢাল (slope) অনুভব করবেন, আর যেদিকে নিচে নামছে সেদিকে এক পা ফেলবেন — বারবার। এই "slope অনুভব করা" হলো derivative, আর এই পুরো কৌশলটাই gradient descent। এই অধ্যায়ে আমরা slope অনুভব করতে শিখব।
এই অধ্যায়ে আমরা পূর্ণ real-analysis rigor-এ যাব না (সেটা Part VII-এর কাজ) — বরং intuition-first ভাবে, পরবর্তী probability ও statistics-কে যতটুকু support করতে দরকার, ঠিক ততটুকু শিখব।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Limit (সীমা) — একটি বিন্দুর "কাছে গেলে" কী হয়¶
Limit (limit, "সীমা" — কোনো বিন্দুর দিকে এগোলে function কোন মানের দিকে যায়) হলো calculus-এর মূল ভিত্তি। intuitively (অন্তর্দৃষ্টিগতভাবে):
এর অর্থ — "\(x\) কে \(a\)-এর যত কাছে নিয়ে যাই (কিন্তু ঠিক \(a\) নয়), \(f(x)\) তত \(L\)-এর কাছে চলে যায়।" এখানে দুটো শব্দ বাংলায় খুলে নিই:
- \(x \to a\) পড়া হয় "\(x\) tends to \(a\)" — অর্থাৎ \(x\), \(a\)-এর দিকে এগোচ্ছে।
- \(L\) হলো সেই limiting value (সীমান্ত মান) — যার দিকে \(f(x)\) ছুটছে।
মজার ব্যাপার: limit বের করতে \(f(a)\)-এর মান জানা লাগে না, এমনকি \(f(a)\) অসংজ্ঞায়িত হলেও limit থাকতে পারে। যেমন:
এখানে \(x=2\)-তে function-টা \(\frac{0}{0}\) আকারে অসংজ্ঞায়িত, তবু limit চমৎকারভাবে \(4\)।
২.২ Continuity (অবিচ্ছিন্নতা)¶
একটি function \(f\) কে \(x=a\) বিন্দুতে continuous (continuous, "অবিচ্ছিন্ন" — কলম না তুলে আঁকা যায়) বলা হয় যদি তিনটি শর্ত মেলে:
insight (অন্তর্দৃষ্টি): graph-এ কোনো লাফ (jump), ফাঁক (gap) বা ছিদ্র (hole) নেই — কাগজ থেকে কলম না তুলে আঁকা যায়। আমরা যে function-গুলো নিয়ে কাজ করব (polynomial, \(\sin\), \(\cos\), \(e^x\), \(\log\) ইত্যাদি) সেগুলো তাদের domain-এ continuous।
২.৩ Derivative (অন্তরজ) — slope-এর limit¶
এবার মূল সংজ্ঞা। একটা curve-এর দুটো বিন্দু \((x, f(x))\) ও \((x+h, f(x+h))\) যোগ করা সরলরেখাকে বলে secant line (secant, "ছেদক রেখা")। এর slope (ঢাল):
এটা হলো \(x\) থেকে \(x+h\) পর্যন্ত average rate of change (গড় পরিবর্তনের হার)। এখন যদি \(h\) কে ক্রমশ ছোট, আরও ছোট, শূন্যের দিকে নিয়ে যাই — তাহলে secant line ঘুরতে ঘুরতে গিয়ে ঐ বিন্দুতে curve-কে স্পর্শ করা tangent line (tangent, "স্পর্শক রেখা")-এ রূপ নেয়। সেই tangent-এর slope-ই হলো derivative:
বাংলায় notation খুলে নিই:
- \(f'(x)\) পড়া হয় "f prime of x" — এটি \(f\)-এর derivative function, যা প্রতিটি \(x\)-এ tangent-এর slope দেয়।
- \(h\) হলো একটা ছোট ব্যবধান (step), যাকে আমরা \(0\)-এর দিকে নিচ্ছি।
- \(\frac{f(x+h)-f(x)}{h}\) হলো difference quotient (পার্থক্যের ভাগফল) — secant-এর slope।
derivative-এর সমার্থক কয়েকটি notation: \(f'(x)\), \(\dfrac{df}{dx}\), \(\dfrac{dy}{dx}\), \(Df\)। এদের অর্থ একই।
দুই অর্থ — একই জিনিস: - জ্যামিতিক: নির্দিষ্ট বিন্দুতে curve-এর tangent line-এর slope। - ভৌত/গতিশীল: instantaneous rate of change — ঠিক ঐ মুহূর্তে \(f\) কত দ্রুত বদলাচ্ছে। (যেমন position-এর derivative = velocity।)
২.৪ Differentiation rules (অন্তরীকরণের নিয়ম)¶
প্রতিবার limit ধরে derivative বের করা কষ্টকর। কিছু নিয়ম মুখস্থ থাকলে কাজ সহজ। নিচে \(c\) ধ্রুবক, \(u=u(x)\), \(v=v(x)\) function:
| নিয়ম (rule) | সূত্র | উদাহরণ |
|---|---|---|
| Constant | \(\dfrac{d}{dx}c = 0\) | \(\dfrac{d}{dx}7 = 0\) |
| Power rule | \(\dfrac{d}{dx}x^{n} = n\,x^{\,n-1}\) | \(\dfrac{d}{dx}x^5 = 5x^4\) |
| Constant multiple | \(\dfrac{d}{dx}\big(c\,u\big) = c\,u'\) | \(\dfrac{d}{dx}3x^2 = 6x\) |
| Sum / difference | \((u \pm v)' = u' \pm v'\) | \((x^2+\sin x)' = 2x+\cos x\) |
| Product rule | \((u\,v)' = u'v + u\,v'\) | \((x^2\sin x)' = 2x\sin x + x^2\cos x\) |
| Quotient rule | \(\left(\dfrac{u}{v}\right)' = \dfrac{u'v - u\,v'}{v^2}\) | \(\left(\dfrac{x}{\,x+1\,}\right)' = \dfrac{1}{(x+1)^2}\) |
| Chain rule | \(\big(f(g(x))\big)' = f'(g(x))\cdot g'(x)\) | \(\big(\sin(x^2)\big)' = \cos(x^2)\cdot 2x\) |
আর কিছু গুরুত্বপূর্ণ standard derivative — যেগুলো statistics-এ বারবার লাগবে:
মনে রাখার মন্ত্র — chain rule। "বাইরের function-এর derivative (ভেতরটা অপরিবর্তিত রেখে) গুণ ভেতরের function-এর derivative।" log-likelihood-এ \(\ln\)-এর ভেতরে আরেকটা function থাকে — তাই chain rule MLE-তে অপরিহার্য।
২.৫ Higher-order derivative (উচ্চতর অন্তরজ)¶
derivative-এর আবার derivative নেওয়া যায়। একে বলে second derivative \(f''(x) = \dfrac{d^2 f}{dx^2}\), যা মাপে — slope নিজে কত দ্রুত বদলাচ্ছে, অর্থাৎ curve-এর বক্রতা (curvature)। physically: position \(\to\) (১ম derivative) velocity \(\to\) (২য় derivative) acceleration। statistics-এ \(f''\) আমাদের বলবে কোনো critical point আসলে maximum না minimum, আর curve convex না concave।
২.৬ Optimization — critical point, derivative test, convexity¶
Optimization মানে function-এর সর্বোচ্চ (maximum) বা সর্বনিম্ন (minimum) মান ও তার অবস্থান খোঁজা।
-
Critical point (সংকট বিন্দু): যে \(x\)-এ \(f'(x) = 0\) (অথবা \(f'\) অসংজ্ঞায়িত)। insight (অন্তর্দৃষ্টি) — চূড়ায় (peak) বা খাদের তলায় (valley) tangent line অনুভূমিক, slope \(=0\)।
-
First derivative test (প্রথম derivative পরীক্ষা): critical point \(x_0\)-এর আশেপাশে \(f'\)-এর চিহ্ন দেখো।
- \(f'\): ধনাত্মক \(\to\) ঋণাত্মক (বাড়া থেকে কমা) হলে local maximum।
-
\(f'\): ঋণাত্মক \(\to\) ধনাত্মক (কমা থেকে বাড়া) হলে local minimum।
-
Second derivative test (দ্বিতীয় derivative পরীক্ষা): critical point \(x_0\)-এ (\(f'(x_0)=0\)): $\(f''(x_0) > 0 \;\Rightarrow\; \text{local minimum}, \qquad f''(x_0) < 0 \;\Rightarrow\; \text{local maximum}, \qquad f''(x_0)=0 \;\Rightarrow\; \text{inconclusive}.\)$
-
Convexity / concavity (উত্তলতা / অবতলতা):
- \(f'' > 0\) সর্বত্র \(\Rightarrow\) function convex (নিচের দিকে বাঁকা, বাটির মতো \(\smile\))। convex function-এর যেকোনো local minimum-ই global minimum — gradient descent-এর জন্য এটা স্বর্গ।
- \(f'' < 0\) সর্বত্র \(\Rightarrow\) function concave (উপরের দিকে বাঁকা, গম্বুজের মতো \(\frown\))। MLE-তে log-likelihood প্রায়ই concave হয়, তাই তার একটা সুন্দর global maximum থাকে।
২.৭ Partial derivative ও gradient (multivariable পরিচয়)¶
বাস্তবে function-এ একাধিক variable থাকে — যেমন \(f(x, y)\)। তখন আমরা একবারে একটা variable নিয়ে derivative নিই, বাকিগুলো ধ্রুবক ধরে। একে বলে partial derivative (আংশিক অন্তরজ):
(এখানে \(\partial\) চিহ্নটি পড়া হয় "partial" — সাধারণ \(d\)-এর বদলে multivariable ক্ষেত্রে ব্যবহৃত।) এই সব partial derivative একসাথে সাজিয়ে যে vector পাই, তাকে বলে gradient (gradient, "নতিমাত্রা" — সবচেয়ে দ্রুত বৃদ্ধির দিক):
(\(\nabla\) চিহ্নটি পড়া হয় "del" বা "nabla"।) gradient-এর দুটো গুরুত্বপূর্ণ অর্থ:
- gradient \(\nabla f\) যেদিকে দেখায়, সেদিকে \(f\) সবচেয়ে দ্রুত বাড়ে।
- তাই \(-\nabla f\) (negative gradient) যেদিকে দেখায়, সেদিকে \(f\) সবচেয়ে দ্রুত কমে — এটাই gradient descent-এর "নামার দিক"।
gradient descent-এর update নিয়ম (যা Part VI-তে বিস্তারিত আসবে):
যেখানে \(\eta\) (পড়া হয় "eta") হলো learning rate (শেখার হার — প্রতি পদক্ষেপের আকার)।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ১ — limit সংজ্ঞা থেকে derivative (হাতে-কলমে)¶
\(f(x) = x^2\)-এর derivative limit সংজ্ঞা থেকে বের করি:
সুতরাং \(f'(x) = 2x\)। বিশেষভাবে \(x=3\)-এ tangent-এর slope \(f'(3) = 2\cdot 3 = 6\)। অর্থাৎ \(x=3\) বিন্দুতে curve-টি প্রতি ১ একক horizontal গমনে ৬ একক উপরে ওঠার হারে বাড়ছে। (§৫-এ আমরা finite difference দিয়ে এটি যাচাই করব — সেখানে \(h\) ছোট করতে করতে \(6\) পাব।)
উদাহরণ ২ — optimization (critical point + second derivative test)¶
\(f(x) = x^3 - 3x\)-এর সর্বোচ্চ/সর্বনিম্ন খুঁজি।
ধাপ ১: derivative নিই — \(f'(x) = 3x^2 - 3\)।
ধাপ ২: critical point — \(f'(x)=0 \Rightarrow 3x^2 - 3 = 0 \Rightarrow x^2 = 1 \Rightarrow x = \pm 1\)।
ধাপ ৩: দ্বিতীয় derivative — \(f''(x) = 6x\)।
ধাপ ৪: test প্রয়োগ: - \(x = -1\): \(f''(-1) = -6 < 0 \Rightarrow\) local maximum, মান \(f(-1) = (-1)^3 - 3(-1) = -1+3 = 2\)। - \(x = +1\): \(f''(1) = 6 > 0 \Rightarrow\) local minimum, মান \(f(1) = 1 - 3 = -2\)।
লক্ষ করুন, এটি cubic বলে কোনো global max/min নেই (\(x\to\pm\infty\)-এ function \(\pm\infty\)); কিন্তু local extrema-গুলো ঠিক এই দুটো। §৬-এর প্রথম figure-এ এই দুটো বিন্দু দেখানো আছে।
উদাহরণ ৩ — statistics সংযোগ: Normal mean-এর MLE¶
ধরা যাক \(n\)টি observation \(x_1, \dots, x_n\) একটি Normal distribution (গড় \(\mu\), পরিচিত variance \(\sigma^2\)) থেকে এসেছে। log-likelihood (constant বাদ দিয়ে, কেবল \(\mu\)-নির্ভর অংশ):
MLE মানে — যে \(\mu\) এই \(\ell(\mu)\) কে maximize করে। derivative নিয়ে শূন্য করি (chain rule প্রয়োগ করে \((x_i-\mu)^2\)-এর derivative হয় \(-2(x_i-\mu)\)):
অর্থাৎ Normal-এর mean-এর MLE হলো simple sample mean \(\bar{x}\)! আর \(\ell'' = -n/\sigma^2 < 0\) বলে এটা সত্যিই maximum (concave function-এর শীর্ষ)। এই একটামাত্র উদাহরণ থেকেই বোঝা যায় — "derivative = 0 সমাধান" কীভাবে পরিসংখ্যানের estimator-কে জন্ম দেয়। §৫-এ আমরা সংখ্যা দিয়ে দেখাব data-র \(\bar{x}=5\)-এই log-likelihood সর্বোচ্চ।
৪ · প্রমাণ ও derivation (উৎপাদন)¶
৪.১ Power rule (positive integer \(n\)) · কাঠিন্য ★¶
দাবি: \(\dfrac{d}{dx}x^n = n\,x^{n-1}\) (যেখানে \(n\) একটি ধনাত্মক পূর্ণসংখ্যা)।
প্রমাণ (binomial expansion দিয়ে):
limit সংজ্ঞা থেকে শুরু করি —
binomial theorem দিয়ে \((x+h)^n\) খুলি:
প্রথম পদ \(x^n\) বিয়োগ হয়ে যায়:
এবার \(h\) দিয়ে ভাগ করি (প্রতিটি পদে অন্তত একটা \(h\) আছে):
এখন \(h \to 0\) নিলে চিহ্নিত সব পদ শূন্য হয়ে যায়, পড়ে থাকে শুধু প্রথম পদ:
৪.২ Product rule · কাঠিন্য ★★¶
দাবি: \(\big(u(x)\,v(x)\big)' = u'(x)\,v(x) + u(x)\,v'(x)\)।
প্রমাণ (add-subtract কৌশল):
মূল কৌশল — লব-এ একটা পদ যোগ ও বিয়োগ করি (\(-u(x+h)v(x) + u(x+h)v(x)\)), যাতে দুটো অর্থপূর্ণ অংশে ভাঙা যায়:
এবার দুই দলে সাজাই:
limit ভাগ করি। \(h\to 0\)-এ: \(u(x+h) \to u(x)\) (\(u\) continuous), \(\frac{v(x+h)-v(x)}{h} \to v'(x)\), এবং \(\frac{u(x+h)-u(x)}{h} \to u'(x)\)। ফলে:
৪.৩ Second derivative test-এর insight (অন্তর্দৃষ্টি) · কাঠিন্য ★★¶
পূর্ণ প্রমাণ Taylor expansion চায় (Part VII), কিন্তু insight elementary। ধরা যাক \(x_0\) একটা critical point, অর্থাৎ \(f'(x_0)=0\)। \(x_0\)-এর কাছাকাছি \(f'\)-কে তার নিজের tangent দিয়ে approximate করি:
- যদি \(f''(x_0) > 0\): তখন \(x < x_0\)-এ \((x-x_0)<0\) তাই \(f'(x)<0\) (function কমছে), আর \(x > x_0\)-এ \(f'(x)>0\) (function বাড়ছে)। কমা-থেকে-বাড়া \(\Rightarrow\) local minimum (\(\smile\) আকার)।
- যদি \(f''(x_0) < 0\): ঠিক উল্টো — বাড়া-থেকে-কমা \(\Rightarrow\) local maximum (\(\frown\) আকার)।
এভাবেই \(f''\)-এর চিহ্ন critical point-এর প্রকৃতি ঠিক করে দেয়। \(\blacksquare\)
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা দুই পথে derivative বের করব — প্রথমে from scratch (NumPy finite-difference) দিয়ে, তারপর symbolic (sympy.diff) দিয়ে — এবং computation দিয়ে §৩–৪-এর theory যাচাই করব।
৫.১ From scratch — finite-difference দিয়ে derivative¶
derivative-এর limit সংজ্ঞায় \(h\to 0\) নিতে পারি না (computer-এ সঠিক শূন্য সম্ভব নয়), কিন্তু খুব ছোট \(h\) নিয়ে আনুমানিক মান বের করতে পারি। দুই রকম:
- Forward difference: \(\dfrac{f(x+h)-f(x)}{h}\) — সরাসরি সংজ্ঞা।
- Central difference: \(\dfrac{f(x+h)-f(x-h)}{2h}\) — দুপাশ ব্যবহার করে, অনেক বেশি নির্ভুল।
import numpy as np
def f(x):
return x**2
def numeric_derivative(f, x, h=1e-5):
"""Forward-difference approximation of f'(x)."""
return (f(x + h) - f(x)) / h
def central_derivative(f, x, h=1e-5):
"""Central-difference approximation of f'(x) — more accurate."""
return (f(x + h) - f(x - h)) / (2*h)
x0 = 3.0
print("forward f'(3) approx:", numeric_derivative(f, x0))
print("central f'(3) approx:", central_derivative(f, x0))
print("exact f'(3) = 2*3 =", 2*x0)
# h ছোট করতে করতে forward-difference error কমে আসে
print("\n--- forward-difference error shrinks with h ---")
for h in [1e-1, 1e-2, 1e-3, 1e-4]:
approx = numeric_derivative(f, x0, h)
print(f"h={h:<7} approx={approx:.6f} error={abs(approx-6):.6f}")
আউটপুট:
forward f'(3) approx: 6.000009999951316
central f'(3) approx: 6.000000000039306
exact f'(3) = 2*3 = 6.0
--- forward-difference error shrinks with h ---
h=0.1 approx=6.100000 error=0.100000
h=0.01 approx=6.010000 error=0.010000
h=0.001 approx=6.001000 error=0.001000
h=0.0001 approx=6.000100 error=0.000100
লক্ষ করুন — \(h\) যত ছোট, error তত ছোট, আর forward-difference-এর error প্রায় ঠিক \(h\)-এর সমানুপাতে কমছে। এটাই limit সংজ্ঞা "জীবন্ত" — §৩-এর উদাহরণ ১-এর \(f'(3)=6\) computation-এই যাচাই হলো।
৫.২ Symbolic — sympy দিয়ে নির্ভুল derivative ও optimization¶
import sympy as sp
x = sp.symbols('x')
expr = x**3 - 3*x
d1 = sp.diff(expr, x) # first derivative
d2 = sp.diff(expr, x, 2) # second derivative
print("f(x) =", expr)
print("f'(x) =", d1)
print("f''(x) =", d2)
# critical points: f'(x) = 0 সমাধান
crit = sp.solve(d1, x)
print("critical points (f'=0):", crit)
for c in crit:
val = d2.subs(x, c)
kind = "min" if val > 0 else ("max" if val < 0 else "inconclusive")
print(f" x={c}: f''={val} -> {kind}")
আউটপুট:
f(x) = x**3 - 3*x
f'(x) = 3*x**2 - 3
f''(x) = 6*x
critical points (f'=0): [-1, 1]
x=-1: f''=-6 -> max
x=1: f''=6 -> min
ঠিক §৩-এর উদাহরণ ২-এর হাতে-করা ফল — \(x=-1\) local max, \(x=1\) local min। sympy-র solve ও diff মিলে পুরো second-derivative-test স্বয়ংক্রিয় করে দিল। chain rule-ও যাচাই করি:
৫.৩ MLE যাচাই — log-likelihood maximize করলে μ̂ = x̄¶
§৩-এর উদাহরণ ৩-এর তত্ত্ব computation দিয়ে যাচাই করি: data-র উপর log-likelihood-কে \(\mu\)-এর একটা grid-এ হিসাব করে দেখি কোথায় সর্বোচ্চ।
import numpy as np
data = np.array([2.0, 4.0, 4.0, 4.0, 5.0, 5.0, 7.0, 9.0])
print("data:", data, " sample mean =", data.mean())
def loglik(mu, sigma, d):
return np.sum(-0.5*np.log(2*np.pi*sigma**2) - (d - mu)**2 / (2*sigma**2))
sigma_hat = data.std() # σ-এর MLE (n দিয়ে ভাগ)
grid = np.linspace(0, 10, 100001)
lls = np.array([loglik(mu, sigma_hat, data) for mu in grid])
best_mu = grid[np.argmax(lls)]
print("argmax(log-likelihood) for mu approx:", round(best_mu, 3))
আউটপুট:
grid-search-এ পাওয়া সর্বোত্তম \(\mu \approx 5.0\) — ঠিক sample mean \(\bar{x}=5.0\)। অর্থাৎ "derivative = 0" থেকে পাওয়া বিশ্লেষণাত্মক ফল \(\hat\mu=\bar{x}\) সংখ্যাগতভাবেও মিলে গেল।
৫.৪ Gradient descent — হাতে-লেখা minimizer¶
def fc(x): return (x - 3)**2 + 1 # convex, minimum at x=3
def dfc(x): return 2*(x - 3) # derivative
x = 8.0 # শুরুর বিন্দু
lr = 0.25 # learning rate (eta)
for i in range(13):
if i in (0, 1, 2, 5, 12):
print(f"step {i:2d}: x={x:.5f} f(x)={fc(x):.5f} grad={dfc(x):.5f}")
x = x - lr * dfc(x) # update: theta <- theta - eta * grad
আউটপুট:
step 0: x=8.00000 f(x)=26.00000 grad=10.00000
step 1: x=5.50000 f(x)=7.25000 grad=5.00000
step 2: x=4.25000 f(x)=2.56250 grad=2.50000
step 5: x=3.15625 f(x)=1.02441 grad=0.31250
step 12: x=3.00122 f(x)=1.00000 grad=0.00244
প্রতিটি ধাপে \(x\) ক্রমশ \(3\)-এর দিকে এগোচ্ছে, gradient ছোট হতে হতে প্রায় শূন্য — মানে আমরা minimum-এ পৌঁছে গেছি। এই কয়েক লাইনই হলো সমস্ত deep learning-এর হৃদয়।
৬ · ভিজ্যুয়ালাইজেশন¶
নিচের তিনটি (+ একটি optional) figure §২–৫-এর ধারণাগুলো চোখে দেখায়। প্রতিটি figure-এর নিচে ঠিক যে code সেটি তৈরি করেছে তা দেওয়া আছে।
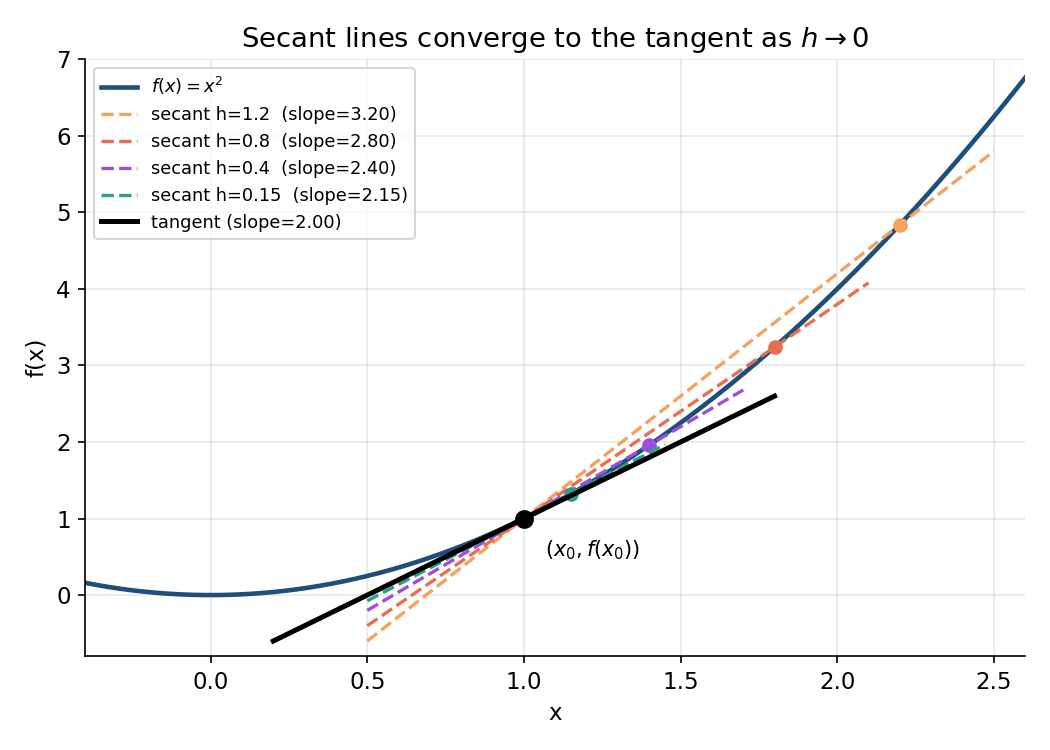
Figure ১ — secant থেকে tangent: limit সংজ্ঞা দৃশ্যমান¶
\(h\) ছোট করতে করতে secant line কীভাবে tangent-এ রূপ নেয় — এটাই derivative-এর সংজ্ঞা।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
plt.rcParams.update({"figure.dpi":150,"axes.grid":True,"grid.alpha":0.3,
"axes.spines.top":False,"axes.spines.right":False})
def f1(x): return x**2
x0 = 1.0
fig, ax = plt.subplots(figsize=(7, 5))
xs = np.linspace(-0.4, 2.6, 400)
ax.plot(xs, f1(xs), color="#1f4e79", lw=2.2, label=r"$f(x)=x^2$")
for h, c in zip([1.2, 0.8, 0.4, 0.15], ["#f4a261","#e76f51","#9d4edd","#2a9d8f"]):
x1 = x0 + h
slope = (f1(x1) - f1(x0)) / h
xx = np.linspace(x0 - 0.5, x1 + 0.3, 50)
ax.plot(xx, f1(x0) + slope*(xx - x0), "--", color=c, lw=1.6,
label=f"secant h={h} (slope={slope:.2f})")
ax.plot([x1], [f1(x1)], "o", color=c, ms=6)
slope_t = 2*x0
xt = np.linspace(x0 - 0.8, x0 + 0.8, 50)
ax.plot(xt, f1(x0) + slope_t*(xt - x0), color="black", lw=2.4,
label=f"tangent (slope={slope_t:.2f})")
ax.plot([x0], [f1(x0)], "ko", ms=8)
ax.annotate(r"$(x_0, f(x_0))$", (x0, f1(x0)), textcoords="offset points",
xytext=(10, -18), fontsize=10)
ax.set_title("Secant lines converge to the tangent as $h \\to 0$")
ax.set_xlabel("x"); ax.set_ylabel("f(x)")
ax.legend(fontsize=8.5, loc="upper left")
ax.set_xlim(-0.4, 2.6); ax.set_ylim(-0.8, 7)
fig.tight_layout(); fig.savefig("../_assets/0-3-secant-to-tangent.png")
লক্ষ করুন legend-এ — \(h=1.2\)-এ slope \(3.20\), \(h=0.4\)-এ \(2.40\), \(h=0.15\)-এ \(2.15\)… ক্রমশ tangent-এর true slope \(2.00\)-এর দিকে নামছে।
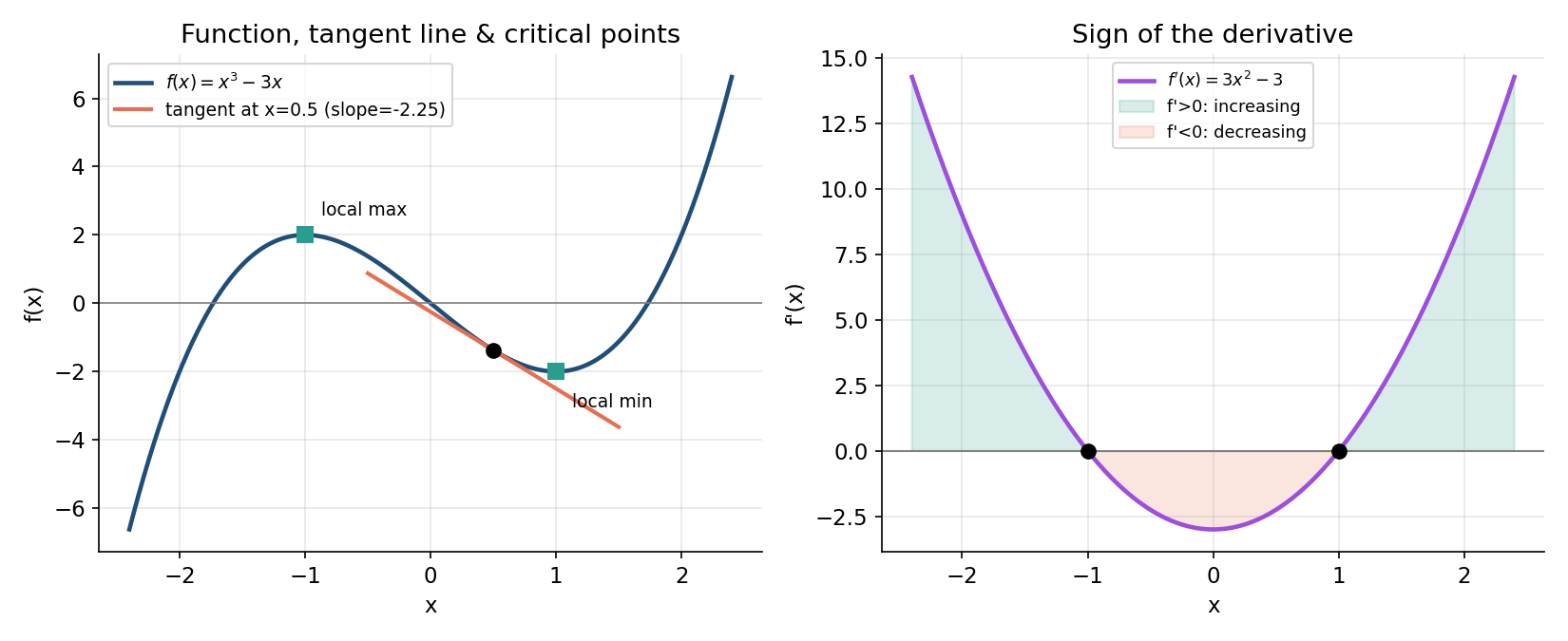
Figure ২ — function, tangent line ও derivative-এর চিহ্ন¶
বাঁয়ে \(f(x)=x^3-3x\), একটা বিন্দুতে tangent, আর critical point দুটো; ডানে \(f'(x)\)-এর চিহ্ন কীভাবে increasing/decreasing ঠিক করে।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
plt.rcParams.update({"figure.dpi":150,"axes.grid":True,"grid.alpha":0.3,
"axes.spines.top":False,"axes.spines.right":False})
def f2(x): return x**3 - 3*x
def df2(x): return 3*x**2 - 3
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 4.5))
xs = np.linspace(-2.4, 2.4, 500)
ax1.plot(xs, f2(xs), color="#1f4e79", lw=2.2, label=r"$f(x)=x^3-3x$")
xp = 0.5; m = df2(xp); xt = np.linspace(xp-1.0, xp+1.0, 50)
ax1.plot(xt, f2(xp) + m*(xt - xp), color="#e76f51", lw=2.0,
label=f"tangent at x={xp} (slope={m:.2f})")
ax1.plot([xp], [f2(xp)], "ko", ms=7)
for xc, lab in [(-1, "local max"), (1, "local min")]:
ax1.plot([xc], [f2(xc)], "s", color="#2a9d8f", ms=8)
ax1.annotate(lab, (xc, f2(xc)), textcoords="offset points",
xytext=(8, 10 if lab=="local max" else -18), fontsize=9)
ax1.axhline(0, color="gray", lw=0.8)
ax1.set_title("Function, tangent line & critical points")
ax1.set_xlabel("x"); ax1.set_ylabel("f(x)"); ax1.legend(fontsize=9, loc="upper left")
ax2.plot(xs, df2(xs), color="#9d4edd", lw=2.2, label=r"$f'(x)=3x^2-3$")
ax2.axhline(0, color="gray", lw=1.0)
ax2.fill_between(xs, df2(xs), 0, where=(df2(xs) > 0), alpha=0.18,
color="#2a9d8f", label="f'>0: increasing")
ax2.fill_between(xs, df2(xs), 0, where=(df2(xs) < 0), alpha=0.18,
color="#e76f51", label="f'<0: decreasing")
for xc in [-1, 1]: ax2.plot([xc], [0], "ko", ms=7)
ax2.set_title("Sign of the derivative")
ax2.set_xlabel("x"); ax2.set_ylabel("f'(x)"); ax2.legend(fontsize=8.5, loc="upper center")
fig.tight_layout(); fig.savefig("../_assets/0-3-derivative-sign.png")
ডানের প্যানেলে সবুজ অঞ্চলে \(f'>0\) (function বাড়ছে), লাল অঞ্চলে \(f'<0\) (কমছে); যেখানে \(f'\) চিহ্ন বদলায়, ঠিক সেখানেই বাঁয়ের max/min।
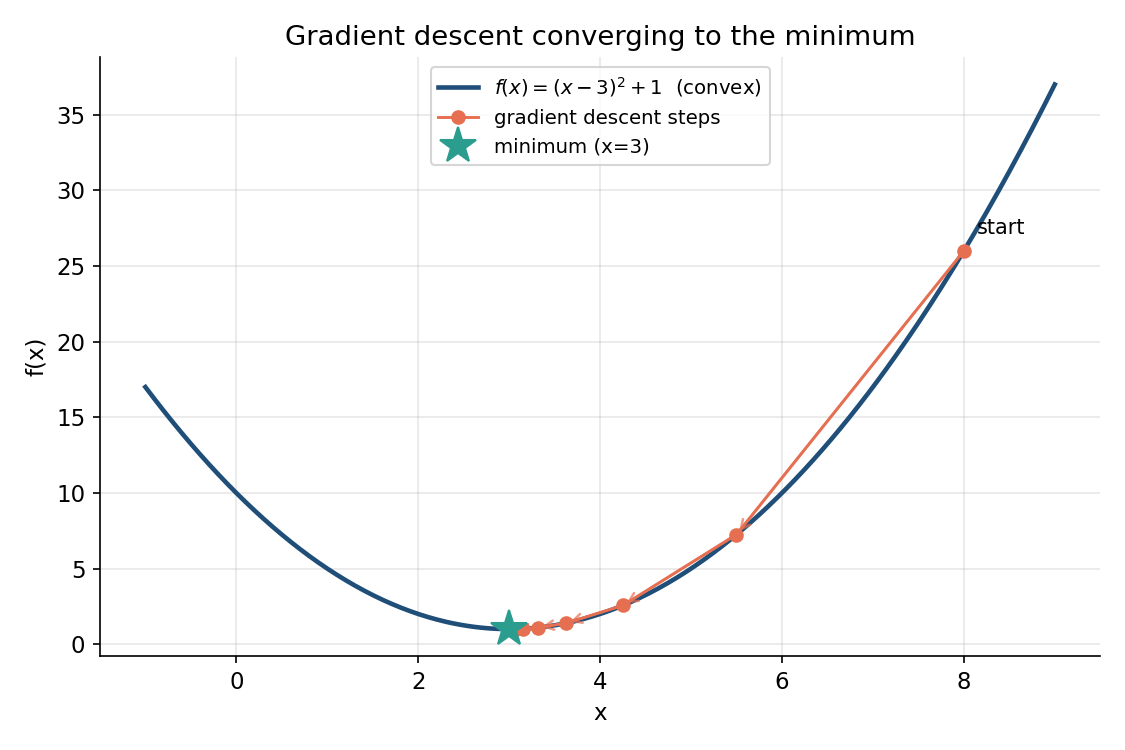
Figure ৩ — convex curve-এ gradient descent minimum-এ converge করছে¶
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
plt.rcParams.update({"figure.dpi":150,"axes.grid":True,"grid.alpha":0.3,
"axes.spines.top":False,"axes.spines.right":False})
def fc(x): return (x - 3)**2 + 1
def dfc(x): return 2*(x - 3)
x = 8.0; lr = 0.25; path = [x]
for _ in range(12):
x = x - lr*dfc(x); path.append(x)
path = np.array(path)
fig, ax = plt.subplots(figsize=(7.5, 5))
xs = np.linspace(-1, 9, 400)
ax.plot(xs, fc(xs), color="#1f4e79", lw=2.2, label=r"$f(x)=(x-3)^2+1$ (convex)")
ax.plot(path, fc(path), "o-", color="#e76f51", lw=1.4, ms=6, label="gradient descent steps")
for i in range(len(path) - 1):
ax.annotate("", xy=(path[i+1], fc(path[i+1])), xytext=(path[i], fc(path[i])),
arrowprops=dict(arrowstyle="->", color="#e76f51", lw=1.2, alpha=0.7))
ax.plot([3], [fc(3)], "*", color="#2a9d8f", ms=18, label="minimum (x=3)", zorder=5)
ax.annotate("start", (path[0], fc(path[0])), textcoords="offset points",
xytext=(6, 8), fontsize=10)
ax.set_title("Gradient descent converging to the minimum")
ax.set_xlabel("x"); ax.set_ylabel("f(x)"); ax.legend(fontsize=9.5, loc="upper center")
fig.tight_layout(); fig.savefig("../_assets/0-3-gradient-descent.png")
শুরুতে (\(x=8\)) ধাপগুলো বড় (slope খাড়া), minimum-এর কাছে এসে ধাপ ছোট হয়ে যায় (slope কম) — gradient descent স্বয়ংক্রিয়ভাবে "ধীরে থামে"।
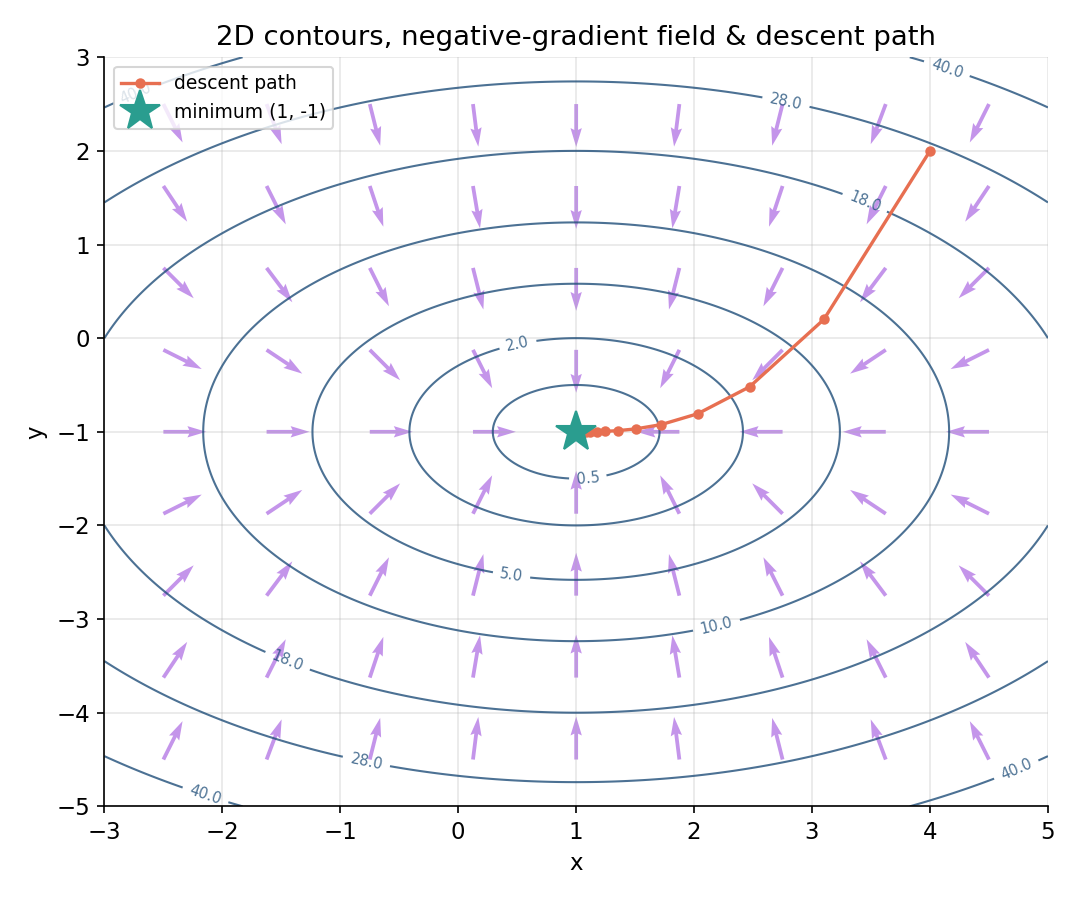
Figure ৪ (optional) — 2D contour, gradient field ও descent path¶
multivariable function \(g(x,y)=(x-1)^2 + 2(y+1)^2\)-এর contour, প্রতিটি বিন্দুতে \(-\nabla g\) তীর (নামার দিক), আর একটা descent path minimum \((1,-1)\)-এ পৌঁছাচ্ছে।
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
plt.rcParams.update({"figure.dpi":150,"axes.grid":True,"grid.alpha":0.3,
"axes.spines.top":False,"axes.spines.right":False})
def g(X, Y): return (X - 1)**2 + 2*(Y + 1)**2
def grad_g(x, y): return np.array([2*(x - 1), 4*(y + 1)])
xs = np.linspace(-3, 5, 300); ys = np.linspace(-5, 3, 300)
X, Y = np.meshgrid(xs, ys); Z = g(X, Y)
fig, ax = plt.subplots(figsize=(7.2, 6))
cs = ax.contour(X, Y, Z, levels=[0.5,2,5,10,18,28,40], colors="#1f4e79", linewidths=1.0, alpha=0.8)
ax.clabel(cs, inline=True, fontsize=7)
gx = np.linspace(-2.5, 4.5, 9); gy = np.linspace(-4.5, 2.5, 9)
GX, GY = np.meshgrid(gx, gy)
U = -(2*(GX - 1)); V = -(4*(GY + 1)); N = np.sqrt(U**2 + V**2) + 1e-9
ax.quiver(GX, GY, U/N, V/N, color="#9d4edd", alpha=0.6, scale=22, width=0.004)
p = np.array([4.0, 2.0]); lr = 0.15; px, py = [p[0]], [p[1]]
for _ in range(25):
p = p - lr*grad_g(p[0], p[1]); px.append(p[0]); py.append(p[1])
ax.plot(px, py, "o-", color="#e76f51", ms=4, lw=1.6, label="descent path")
ax.plot([1], [-1], "*", color="#2a9d8f", ms=20, label="minimum (1, -1)", zorder=5)
ax.set_title("2D contours, negative-gradient field & descent path")
ax.set_xlabel("x"); ax.set_ylabel("y"); ax.legend(fontsize=9, loc="upper left")
fig.tight_layout(); fig.savefig("../_assets/0-3-contour-gradient.png")
তীরগুলো সবসময় contour-এর সাথে লম্বভাবে কেন্দ্রের দিকে দেখাচ্ছে — এটাই gradient-এর ধর্ম: সবচেয়ে খাড়া নামার দিক।
৭ · অনুশীলনী¶
প্রতিটি সমস্যার পূর্ণ সমাধান আলাদা ফাইলে: _solutions/00-03-calculus-1-derivatives-solutions.md। আগে নিজে চেষ্টা করুন, তারপর মিলিয়ে নিন।
ক · ধারণাগত (Conceptual)¶
Q1 ★ নিজের ভাষায় ব্যাখ্যা করুন: secant line ও tangent line-এর মধ্যে পার্থক্য কী, এবং derivative-এর সংজ্ঞায় \(h\to 0\) নেওয়ার তাৎপর্য কী? Hint: §২.৩-এর secant→tangent ছবিটি ভাবুন।
Q2 ★ একটি function-এর graph দেখে যদি কোনো বিন্দুতে \(f'(x)=0\) কিন্তু সেটা max-ও নয় min-ও নয়, এমন বিন্দুকে কী বলা যায়? একটি উদাহরণ function দিন। Hint: \(f(x)=x^3\), \(x=0\)-এ কী ঘটে?
Q3 ★★ কেন convex function-এ gradient descent global minimum পাওয়ার নিশ্চয়তা দেয়, কিন্তু non-convex function-এ দেয় না — সংক্ষেপে যুক্তি দিন। Hint: convex-এ local minimum = global minimum; non-convex-এ একাধিক local minimum থাকতে পারে।
খ · গণনামূলক (Computational)¶
Q4 ★ নিচের প্রতিটির derivative বের করুন: (a) \(x^4\), (b) \(\sqrt{x}\), (c) \(\dfrac{1}{x}\), (d) \(e^x\), (e) \(\ln x\), (f) \(x^3 \sin x\)। Hint: (b),(c) কে \(x^{1/2}, x^{-1}\) লিখে power rule; (f)-এ product rule।
Q5 ★★ chain rule দিয়ে \(\dfrac{d}{dx}(3x^2 + 1)^5\) বের করুন। Hint: বাইরের function \(u^5\), ভেতরের \(u = 3x^2+1\)।
Q6 ★★ \(f(x) = x^3 - 6x^2 + 9x + 1\)-এর সব local maxima ও minima খুঁজুন (অবস্থান ও মান সহ), second derivative test ব্যবহার করে। Hint: \(f'=0\) থেকে দুটো critical point পাবেন; প্রতিটিতে \(f''\)-এর চিহ্ন দেখুন।
গ · প্রমাণভিত্তিক (Proof-based)¶
Q7 ★★ limit সংজ্ঞা থেকে দেখান যে \(\dfrac{d}{dx}\dfrac{1}{x} = -\dfrac{1}{x^2}\)। Hint: difference quotient-এ \(\frac{1/(x+h) - 1/x}{h}\) কে এক ভগ্নাংশে এনে সরল করুন।
Q8 ★★★ Quotient rule-কে product rule ও chain rule থেকে উৎপন্ন করুন। অর্থাৎ \(\dfrac{u}{v} = u\cdot v^{-1}\) লিখে শুরু করুন। Hint: \(\frac{d}{dx}v^{-1} = -v^{-2}v'\) (chain rule), তারপর product rule।
ঘ · কোডিং (Coding)¶
Q9 ★★ একটি Python function লিখুন second_derivative(f, x, h=1e-4) যা central difference দিয়ে \(f''(x)\) আনুমানিক বের করে। সূত্র: \(f''(x) \approx \dfrac{f(x+h) - 2f(x) + f(x-h)}{h^2}\)। \(f(x)=x^3\)-এর জন্য \(x=2\)-এ পরীক্ষা করুন (exact \(f''(2)=12\))।
Hint: সরাসরি সূত্রটি কোডে বসান; তিনটি function-call লাগবে।
Q10 ★★★ \(f(x) = x^4 - 3x^3 + 2\)-এর জন্য gradient descent লিখে এর minimum খুঁজুন। শুরু করুন \(x_0=4\), learning rate \(0.01\), ২০০০ ধাপ। ফলকে বিশ্লেষণাত্মক critical point-এর সাথে মিলিয়ে দেখুন। Hint: \(f'(x)=4x^3-9x^2\); \(f'=0 \Rightarrow x=0\) বা \(x=9/4\); কোনটিতে GD থামবে?
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে যা শিখলাম¶
- Limit হলো calculus-এর ভিত্তি: \(x\to a\)-এ function কোন মানের দিকে যায়। Continuity মানে graph-এ কোনো লাফ/ফাঁক নেই।
- Derivative \(f'(x) = \lim_{h\to0}\frac{f(x+h)-f(x)}{h}\) = tangent-এর slope = instantaneous rate of change। secant line \(\xrightarrow{h\to0}\) tangent line।
- Differentiation rules — power, sum, constant-multiple, product, quotient, chain — দিয়ে limit ছাড়াই দ্রুত derivative; standard derivative (\(e^x, \ln x, \sin, \cos\)) মনে রাখা।
- Higher-order derivative: \(f''\) মাপে curvature; second-derivative test-এ max/min ও convex/concave নির্ণয়।
- Optimization: critical point (\(f'=0\)) → first/second derivative test। Convex function-এ যেকোনো local min = global min।
- Partial derivative ও gradient \(\nabla f\) = সবচেয়ে দ্রুত বৃদ্ধির দিক; \(-\nabla f\) = নামার দিক → gradient descent।
- Statistics সংযোগ: MLE = log-likelihood maximize (\(\ell'=0\) সমাধান, যেমন Normal mean-এর \(\hat\mu=\bar{x}\)); gradient descent = সর্বত্র ব্যবহৃত optimizer।
পূর্ববর্তী ও পরবর্তী সংযোগ¶
- ← পূর্ববর্তী (0.1 Functions): derivative হলো একটি function-এর উপর ক্রিয়া; domain, range, graph-এর ধারণা এখানে অপরিহার্য ছিল।
- → পরবর্তী (0.4 Calculus II — Integration): derivative-এর বিপরীত ক্রিয়া হলো integration — বক্ররেখার নিচের ক্ষেত্রফল ও সঞ্চয়। probability density-কে integrate করে probability পাওয়া যায়, তাই 0.4 probability-র (Part II) সরাসরি ভিত্তি।
Source pointer¶
এই অধ্যায় self-contained (Part 0 just-in-time math)। এটি বিশেষভাবে support করে — - Part IV — Statistical Inference (MLE): "derivative = 0" দিয়ে estimator উৎপাদনের পূর্ণ যন্ত্রপাতি এখানেই তৈরি হলো। - Part VI — Statistical ML (optimization): gradient ও gradient descent-এর গভীর আলোচনার বীজ এখানে বপন করা হলো।