০.৬ · Python On-ramp for Scientific Computing¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
এই অধ্যায়টি পুরো curriculum-এর coding foundation (কোডিং ভিত্তি)। Part 0-এর আগের অধ্যায়গুলোতে আমরা গণিতের ভাষা — set, function, derivative, integral, vector — শিখেছি। কিন্তু পরিসংখ্যান শুধু কাগজ-কলমের বিষয় নয়; বাস্তবে আমরা data নিয়ে কাজ করি, আর data নিয়ে কাজ করতে দরকার একটা computational tool। সেই tool-ই হলো Python ও তার scientific stack (বৈজ্ঞানিক গণনার প্যাকেজ-সমষ্টি)।
কেন Python? তিনটি সহজ কারণ:
- পড়তে সহজ, লিখতে সহজ — Python-এর syntax প্রায় ইংরেজি বাক্যের মতো। গণিতের ধারণা থেকে কোডে যাওয়ার দূরত্ব কম।
- scientific stack তৈরি — NumPy (দ্রুত সংখ্যাগত গণনা), pandas (tabular data), matplotlib (গ্রাফ), scipy (পরিসংখ্যান ও বিজ্ঞান), seaborn (সুন্দর plot)। এগুলো একসাথে মিলে data science-এর প্রায় সবকিছু সামলায়।
- সর্বজনীন — গবেষণা, industry, interview — সব জায়গায় এই stack-ই standard।
এই অধ্যায়ে আমরা যে চারটি স্তম্ভ শিখব, পরবর্তী প্রতিটি অধ্যায়ের code lab ঠিক এই একই stack ব্যবহার করবে:
| স্তম্ভ | কাজ | এই অধ্যায়ে যা শিখব |
|---|---|---|
| NumPy | সংখ্যার array, দ্রুত গণনা | array, vectorization, broadcasting, random |
| pandas | tabular data (সারি-কলাম) | Series, DataFrame, groupby |
| matplotlib | ছবি/গ্রাফ | line, scatter, histogram, subplots |
| Jupyter | interactive workflow | cell-by-cell চালানো, reproducibility |
insight: এই অধ্যায় কোনো নতুন গণিত শেখায় না — এটি শেখায় গণিতকে মেশিনে কথা বলানো। একবার এই ভাষা রপ্ত হলে, descriptive statistics থেকে শুরু করে machine learning — সবই কোডে অনুবাদ করা সহজ হয়ে যাবে।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Python basics (দ্রুত ঝালাই)¶
আমাদের focus scientific stack, তাই Python basics সংক্ষিপ্তভাবে দেখি। চারটি জিনিস জানলেই চলবে।
Variable (চলক) ও type (ধরন): একটি নামে একটি মান রাখা। Python-এ type আগে থেকে ঘোষণা করতে হয় না; মান দেখেই type ঠিক হয় — একে বলে dynamic typing।
n = 5 # int (পূর্ণসংখ্যা)
pi = 3.14159 # float (দশমিক সংখ্যা)
name = "Dhaka" # str (string, অর্থাৎ লেখা)
is_ok = True # bool (সত্য/মিথ্যা)
print(type(n), type(pi), type(name), type(is_ok))
# <class 'int'> <class 'float'> <class 'str'> <class 'bool'>
List (তালিকা) ও dict (অভিধান): list হলো ক্রমিক মানের সংগ্রহ (index ০ থেকে শুরু); dict হলো key → value জোড়ার সংগ্রহ।
scores = [88, 72, 95, 60] # list
scores[0] # 88 (প্রথম উপাদান)
scores.append(77) # শেষে যোগ → [88, 72, 95, 60, 77]
person = {"name": "Rina", "age": 23} # dict
person["age"] # 23 (key দিয়ে value তোলা)
Loop (পুনরাবৃত্তি): একই কাজ বারবার করা।
Function (ফাংশন): input নিয়ে output দেয় এমন পুনঃব্যবহারযোগ্য কোড-খণ্ড।
এটুকুই Python-এর প্রয়োজনীয় ভিত্তি। এবার আসল শক্তি — scientific stack।
২.২ NumPy array¶
array (সমজাতীয় সংখ্যার গ্রিড) হলো NumPy-র মূল object। সাধারণ Python list-এর সাথে পার্থক্য: array-র সব উপাদান একই type-এর এবং memory-তে পাশাপাশি সাজানো — তাই গণনা অনেক দ্রুত।
a.shape→ array-র আকার (এখানে(5,)মানে ৫টি উপাদানের 1D array)a.dtype→ উপাদানের type (এখানেint64)a.ndim→ মাত্রার সংখ্যা (1D হলে 1, 2D হলে 2)
দ্বিমাত্রিক array (matrix-এর মতো):
২.৩ Vectorization (ভেক্টরায়ন)¶
vectorization মানে loop না লিখে পুরো array-র উপর একসাথে operation চালানো। গণিতে যেমন আমরা \(2\mathbf{a}\) লিখলে vector-এর প্রতিটি উপাদান ২ দিয়ে গুণ বোঝায়, NumPy ঠিক তা-ই করে — কিন্তু C-এর গতিতে।
a * 2 # প্রতিটি উপাদান ২ গুণ: [4, 8, 12, 16, 20]
a + a # উপাদান-ভিত্তিক যোগ: [4, 8, 12, 16, 20]
a > 5 # উপাদান-ভিত্তিক তুলনা: [False, False, True, True, True]
a[a > 5] # boolean mask দিয়ে নির্বাচন: [6, 8, 10]
কেন দ্রুত — তা Section 4-এ benchmark দিয়ে দেখাব।
২.৪ Broadcasting (সম্প্রসারণ)¶
broadcasting হলো NumPy-র সেই নিয়ম যা ভিন্ন আকারের দুটি array-কে স্বয়ংক্রিয়ভাবে মিলিয়ে operation চালাতে দেয় — ছোট array-টিকে "সম্প্রসারিত" করে বড়টির আকারে এনে। নিয়মটি সরল: দুটি array-র shape ডান দিক থেকে মেলানো হয়; প্রতিটি মাত্রায় হয় সংখ্যা সমান হতে হবে, নয়তো একটি \(1\) হতে হবে।
উদাহরণ — একটি column vector \(\mathbf{a}\) (shape \((6,1)\)) আর একটি row vector \(\mathbf{b}\) (shape \((1,6)\)) যোগ করলে \((6,6)\) গ্রিড তৈরি হয়:
এটি গণিতের outer sum (বাহ্যিক যোগফল); এর figure Section 6-এ আছে।
২.৫ Random number generation (এলোমেলো সংখ্যা)¶
পরিসংখ্যানে আমরা প্রায়ই সিমুলেশন করি — যেমন একটি distribution থেকে নমুনা টানা। NumPy-র আধুনিক উপায়:
rng = np.random.default_rng(seed=42) # Generator object তৈরি
rng.normal(loc=0, scale=1, size=5) # standard normal থেকে ৫টি মান
rng.integers(0, 10, size=5) # 0–9 থেকে ৫টি পূর্ণসংখ্যা
seed (বীজ) একটি নির্দিষ্ট সংখ্যা দিলে প্রতিবার একই এলোমেলো ক্রম পাওয়া যায় — একে বলে reproducibility (পুনরুৎপাদনযোগ্যতা)। কেন এটি জরুরি, Section 4-এ ব্যাখ্যা করা আছে।
নোট: পুরনো
np.random.seed()+np.random.rand()এখনও কাজ করে, কিন্তু আধুনিক ও প্রস্তাবিত উপায় হলোdefault_rng। আমরা পুরো curriculum-এ এটাই ব্যবহার করব।
২.৬ pandas: Series ও DataFrame¶
- Series (নামাঙ্কিত 1D array) — একটি index-যুক্ত কলাম। array-র মতো, কিন্তু প্রতিটি মানের একটি label থাকে।
- DataFrame (সারি-কলামের টেবিল) — অনেকগুলো Series পাশাপাশি; অনেকটা Excel শিট বা SQL টেবিলের মতো। এটি data science-এ সবচেয়ে বেশি ব্যবহৃত object।
import pandas as pd
s = pd.Series([10, 20, 30], index=["a", "b", "c"]) # Series
df = pd.DataFrame({"city": ["Dhaka", "Khulna"],
"age": [23, 35]}) # DataFrame
groupby (দল করে সারাংশ): কোনো কলামের মান অনুযায়ী সারিগুলোকে দলে ভাগ করে প্রতিটি দলের উপর সারাংশ (mean, count…) বের করা। এটি split → apply → combine নীতিতে কাজ করে এবং EDA-র (পরবর্তী Part I) মেরুদণ্ড।
২.৭ matplotlib essentials¶
matplotlib.pyplot (সংক্ষেপে plt) দিয়ে আমরা গ্রাফ আঁকি। মূল প্যাটার্ন: fig, ax = plt.subplots() দিয়ে একটি Figure (পুরো ছবি) ও Axes (একক plot-এর ক্ষেত্র) তৈরি করি, তারপর ax.plot(...), ax.scatter(...), ax.hist(...), ax.bar(...) দিয়ে আঁকি।
In-figure text সবসময় ইংরেজিতে রাখব (Bengali font সমস্যা এড়াতে); বাংলা ব্যাখ্যা থাকবে চারপাশের লেখায় ও caption-এ।
৩ · পূর্ণাঙ্গ উদাহরণ¶
নিচের তিনটি ছোট উদাহরণ হাতে চালালে NumPy-র মূল ধারণা পরিষ্কার হবে। প্রতিটিতে input → output দেওয়া আছে; নিজে চালিয়ে মিলিয়ে নিন।
উদাহরণ ১ — array basics ও vectorization¶
import numpy as np
a = np.array([2, 4, 6, 8, 10])
print("a =", a)
print("a.mean() =", a.mean())
print("a.std() =", round(float(a.std()), 4))
print("a * 2 =", a * 2)
print("a[a > 5] =", a[a > 5])
Output:
লক্ষ করুন: a * 2 কোনো loop ছাড়াই প্রতিটি উপাদানে কাজ করল (vectorization), আর a[a > 5] boolean mask দিয়ে শর্ত-অনুযায়ী উপাদান বেছে নিল।
উদাহরণ ২ — broadcasting দিয়ে দাম + কর¶
ধরা যাক তিনটি পণ্যের দাম আর প্রতিটির আলাদা কর-হার:
prices = np.array([100, 250, 80])
tax = np.array([0.05, 0.10, 0.15])
total = prices * (1 + tax)
print("total =", total)
Output:
এখানে 1 + tax প্রতিটি উপাদানে কাজ করল, তারপর prices-এর সাথে উপাদান-ভিত্তিক গুণ — সবই broadcasting-এর সৌজন্যে, এক লাইনে।
উদাহরণ ৩ — 2D array-তে axis বরাবর mean¶
axis argument ঠিক করে কোন দিক বরাবর সারাংশ নেওয়া হবে: axis=0 → কলাম বরাবর (প্রতি কলামের গড়), axis=1 → সারি বরাবর (প্রতি সারির গড়)।
M = np.array([[1, 2, 3],
[4, 5, 6]])
print("M.mean(axis=0) =", M.mean(axis=0)) # প্রতি কলামের গড়
print("M.mean(axis=1) =", M.mean(axis=1)) # প্রতি সারির গড়
Output:
axis-এর এই ধারণা পরবর্তীতে DataFrame-এও একইভাবে কাজ করে — তাই এখনই রপ্ত করে নেওয়া জরুরি।
৪ · "প্রমাণ" ও derivation (উৎপাদন): vectorization কেন দ্রুত, seed কেন জরুরি¶
এই অধ্যায়ে গাণিতিক proof-এর বদলে আমরা যুক্তি + পরিমাপ দিয়ে দুটি গুরুত্বপূর্ণ দাবি প্রতিষ্ঠা করব।
৪.১ Vectorization কেন দ্রুত — benchmark দিয়ে [difficulty: easy]¶
দাবি: একই গণনা NumPy vectorization-এ করলে তা Python loop-এর চেয়ে নাটকীয়ভাবে দ্রুত।
কেন (যুক্তি): Python একটি interpreted ভাষা — প্রতিটি loop iteration-এ interpreter অনেক overhead সামলায় (type যাচাই, object তৈরি ইত্যাদি)। NumPy array-র উপর operation আসলে আগে থেকে compile করা C কোডে চলে এবং সব উপাদান memory-তে পাশাপাশি থাকায় CPU দক্ষভাবে কাজ করে। তাই loop-এর per-element overhead পুরোপুরি বাদ যায়।
পরিমাপ (benchmark): \(N = 10^6\) সংখ্যার বর্গের যোগফল — একবার Python loop-এ, একবার NumPy-তে:
import numpy as np, time
N = 1_000_000
xs = list(range(N))
arr = np.arange(N)
t0 = time.perf_counter()
s = 0
for v in xs:
s += v * v # pure Python loop
loop_time = time.perf_counter() - t0
t0 = time.perf_counter()
s2 = np.sum(arr * arr) # NumPy vectorized
vec_time = time.perf_counter() - t0
print(f"Python loop : {loop_time*1000:8.2f} ms")
print(f"NumPy vector: {vec_time*1000:8.2f} ms")
print(f"Speedup : {loop_time/vec_time:7.1f}x")
একটি সাধারণ মেশিনে Output (আনুমানিক):
অর্থাৎ একই উত্তর, কিন্তু vectorization প্রায় ৩০–৪০ গুণ দ্রুত (সঠিক সংখ্যা মেশিনভেদে বদলায়)। data যত বড় হবে, এই ব্যবধান তত গুরুত্বপূর্ণ। এ কারণেই পুরো curriculum-এ আমরা loop এড়িয়ে vectorization-কে প্রাধান্য দেব।
৪.২ Reproducibility: seed কেন জরুরি [difficulty: easy]¶
দাবি: seed নির্দিষ্ট করলে এলোমেলো ফলাফলও পুনরুৎপাদনযোগ্য হয়।
কেন (যুক্তি): কম্পিউটারের "random" সংখ্যা আসলে pseudo-random — একটি নির্ধারক (deterministic) algorithm একটি শুরুর অবস্থা (seed) থেকে সংখ্যা তৈরি করে। একই seed দিলে একই ক্রম পাওয়া যায়। বিজ্ঞানে এটি অপরিহার্য: অন্য কেউ (বা ভবিষ্যতের আপনি) যেন হুবহু একই ফলাফল পায়, debug করা যায়, এবং পরীক্ষার ফল যাচাই করা যায়।
rng1 = np.random.default_rng(0)
print("draw1 =", rng1.integers(0, 10, 5))
rng2 = np.random.default_rng(0) # একই seed
print("draw2 =", rng2.integers(0, 10, 5))
Output:
দুটি ক্রম হুবহু এক। নিয়ম: যেকোনো সিমুলেশন বা random-নির্ভর কোডের শুরুতে একটি rng = np.random.default_rng(<seed>) তৈরি করে নিন এবং সর্বত্র সেটাই ব্যবহার করুন। এই curriculum-এর প্রতিটি code lab এই অভ্যাস মেনে চলবে।
৫ · কোড ল্যাব (Python)¶
নিচের সব snippet runnable। ক্রমান্বয়ে চালান; প্রতিটি ব্লকের নিচে প্রকৃত output দেওয়া।
৫.১ NumPy: array, vectorization, broadcasting, random¶
import numpy as np
# --- array তৈরি ---
a = np.arange(1, 6) # [1 2 3 4 5]
b = np.linspace(0, 1, 5) # [0. 0.25 0.5 0.75 1. ]
z = np.zeros((2, 3)) # 2x3 শূন্য array
# --- vectorization ---
print("a**2 =", a**2) # [ 1 4 9 16 25]
print("a + 10 =", a + 10) # [11 12 13 14 15]
# --- broadcasting: column + row -> grid ---
col = np.arange(1, 4).reshape(3, 1) # shape (3,1)
row = np.arange(1, 4).reshape(1, 3) # shape (1,3)
print("grid =\n", col + row) # (3,3) outer sum
# --- random (reproducible) ---
rng = np.random.default_rng(0)
print("normals =", rng.normal(0, 1, 4).round(3))
Output:
a**2 = [ 1 4 9 16 25]
a + 10 = [11 12 13 14 15]
grid =
[[2 3 4]
[3 4 5]
[4 5 6]]
normals = [ 0.126 -0.132 0.64 0.105]
৫.২ pandas: Series, DataFrame, describe, groupby¶
import pandas as pd
df = pd.DataFrame({
"city": ["Dhaka", "Khulna", "Dhaka", "Khulna", "Dhaka"],
"age": [23, 35, 31, 28, 45],
"score": [88, 72, 95, 60, 77],
})
print(df)
print("\ngroupby city mean:")
print(df.groupby("city")[["age", "score"]].mean().round(2))
Output:
city age score
0 Dhaka 23 88
1 Khulna 35 72
2 Dhaka 31 95
3 Khulna 28 60
4 Dhaka 45 77
groupby city mean:
age score
city
Dhaka 33.0 86.67
Khulna 31.5 66.00
df.groupby("city") সারিগুলোকে শহর অনুযায়ী দলে ভাগ করল, তারপর প্রতিটি দলের age ও score-এর গড় বের করল — split → apply → combine।
৫.৩ End-to-end mini-workflow: build → summarize → visualize¶
এবার একটি ছোট পূর্ণ workflow — যা পরবর্তী প্রতিটি অধ্যায়ের code lab-এর কঙ্কাল। আমরা একটি কৃত্রিম experiment তৈরি করব (control বনাম treatment গ্রুপ), সারাংশ বের করব, পরে Section 6-এ ছবি আঁকব।
import numpy as np
import pandas as pd
rng = np.random.default_rng(123) # reproducibility
n = 200
# build: কৃত্রিম data তৈরি
data = pd.DataFrame({
"group": rng.choice(["control", "treatment"], size=n),
"value": rng.normal(50, 10, size=n),
})
data.loc[data["group"] == "treatment", "value"] += 5 # treatment effect
# summarize: গ্রুপভিত্তিক সারাংশ
summary = data.groupby("group")["value"].agg(["mean", "std", "count"]).round(2)
print(summary)
Output:
treatment গ্রুপের গড় (~56.8) control-এর (~49.1) চেয়ে বেশি — কারণ আমরা ৫ মান যোগ করেছিলাম। এই build → summarize প্যাটার্নই পরিসংখ্যানগত বিশ্লেষণের শুরু; এর সাথে visualize যোগ করলেই EDA সম্পূর্ণ।
৬ · ভিজ্যুয়ালাইজেশন¶
নিচের প্রতিটি figure-এর সাথে হুবহু সেই কোড দেওয়া যা ছবিটি তৈরি করেছে। মনে রাখুন: figure-এর ভেতরের লেখা ইংরেজি, ব্যাখ্যা বাংলায়।
Figure 1 — generated data থেকে histogram¶
rng.normal দিয়ে ২০০০টি কাল্পনিক উচ্চতা তৈরি করে তার histogram (পরিসংখ্যান চিত্র, যা প্রতিটি মানের পরিসরে কয়টি data পড়ল তা দেখায়) আঁকা। লাল ভাঙা রেখাটি গড়।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(42)
heights = rng.normal(loc=165, scale=8, size=2000) # cm
fig, ax = plt.subplots(figsize=(7, 4.2))
ax.hist(heights, bins=30, color="#4C72B0", edgecolor="white", alpha=0.9)
ax.axvline(heights.mean(), color="#C44E52", linestyle="--", linewidth=2,
label=f"mean = {heights.mean():.1f} cm")
ax.set_xlabel("Height (cm)"); ax.set_ylabel("Count")
ax.set_title("Histogram of 2000 simulated heights")
ax.legend(); fig.tight_layout()
fig.savefig("../_assets/0-6-histogram.png", dpi=150)
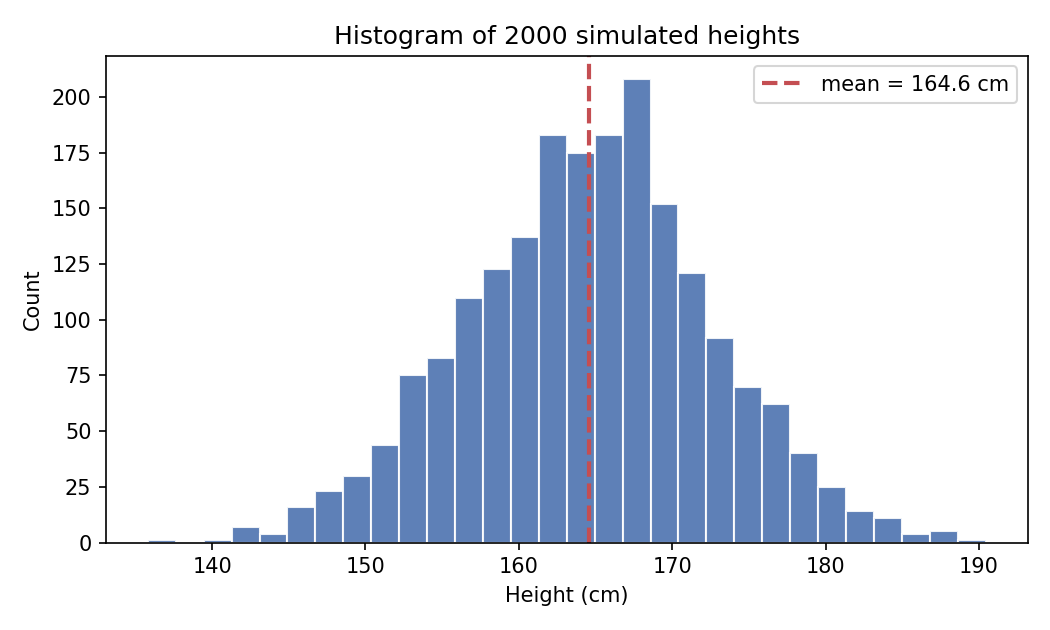
Figure 2 — broadcasting illustration (outer-sum grid)¶
একটি column vector আর একটি row vector যোগ করলে কীভাবে \((6,6)\) গ্রিড তৈরি হয় — broadcasting-এর ছবি। প্রতিটি ঘরে \(a_i + b_j\) লেখা; রঙ মান অনুযায়ী।
import numpy as np
import matplotlib.pyplot as plt
a = np.arange(1, 7).reshape(6, 1) # column vector (6, 1)
b = np.arange(1, 7).reshape(1, 6) # row vector (1, 6)
grid = a + b # broadcasts to (6, 6)
fig, ax = plt.subplots(figsize=(5.6, 5.0))
im = ax.imshow(grid, cmap="viridis", origin="lower")
for i in range(6):
for j in range(6):
ax.text(j, i, str(grid[i, j]), ha="center", va="center",
color="white", fontsize=10)
ax.set_xticks(range(6)); ax.set_xticklabels(range(1, 7))
ax.set_yticks(range(6)); ax.set_yticklabels(range(1, 7))
ax.set_xlabel("row vector b = [1..6]")
ax.set_ylabel("column vector a = [1..6]")
ax.set_title("Broadcasting: a[:,None] + b[None,:]")
fig.colorbar(im, ax=ax, label="a + b")
fig.tight_layout(); fig.savefig("../_assets/0-6-broadcasting.png", dpi=150)
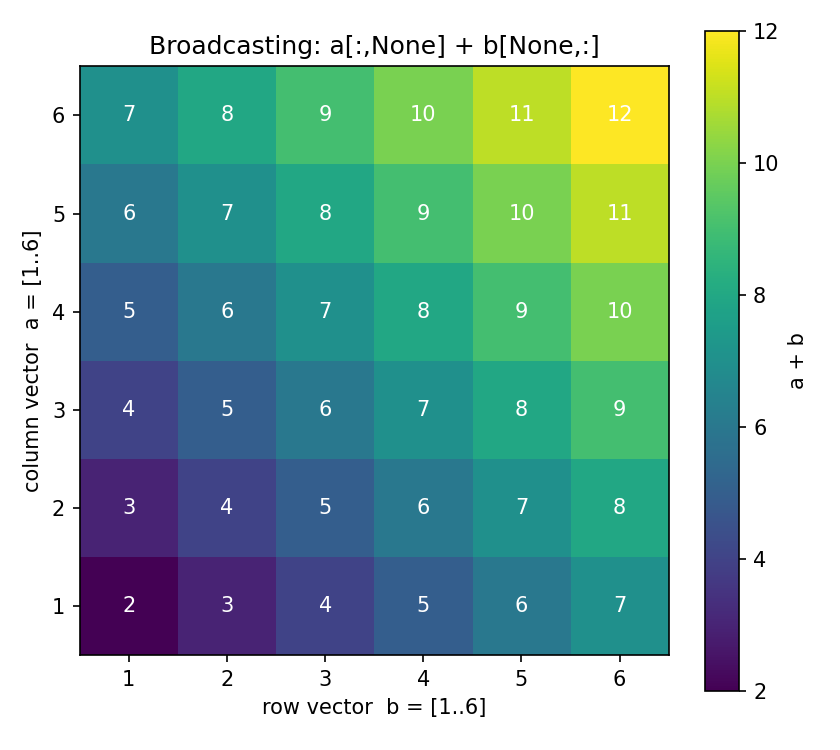
Figure 3 — 2×2 subplots: চার ধরনের plot¶
একটি Figure-এ চারটি Axes — line, scatter, histogram, bar — একসাথে। subplots দিয়ে একাধিক গ্রাফ পাশাপাশি সাজানো শেখা জরুরি, কারণ EDA-তে বহু চিত্র একসাথে দেখতে হয়।
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(7)
x = np.linspace(0, 2*np.pi, 100)
fig, axes = plt.subplots(2, 2, figsize=(9, 6.5))
axes[0, 0].plot(x, np.sin(x), color="#4C72B0")
axes[0, 0].set_title("Line: sin(x)")
xs = rng.normal(0, 1, 120); ys = 2*xs + rng.normal(0, 1, 120)
axes[0, 1].scatter(xs, ys, s=18, color="#55A868", alpha=0.7)
axes[0, 1].set_title("Scatter: y ~ 2x + noise")
axes[1, 0].hist(rng.normal(0, 1, 1000), bins=25,
color="#C44E52", edgecolor="white")
axes[1, 0].set_title("Histogram: standard normal")
axes[1, 1].bar(["A", "B", "C", "D"], [23, 17, 35, 12], color="#8172B3")
axes[1, 1].set_title("Bar: category counts")
fig.suptitle("matplotlib subplots: four plot types", fontsize=13)
fig.tight_layout(); fig.savefig("../_assets/0-6-subplots.png", dpi=150)
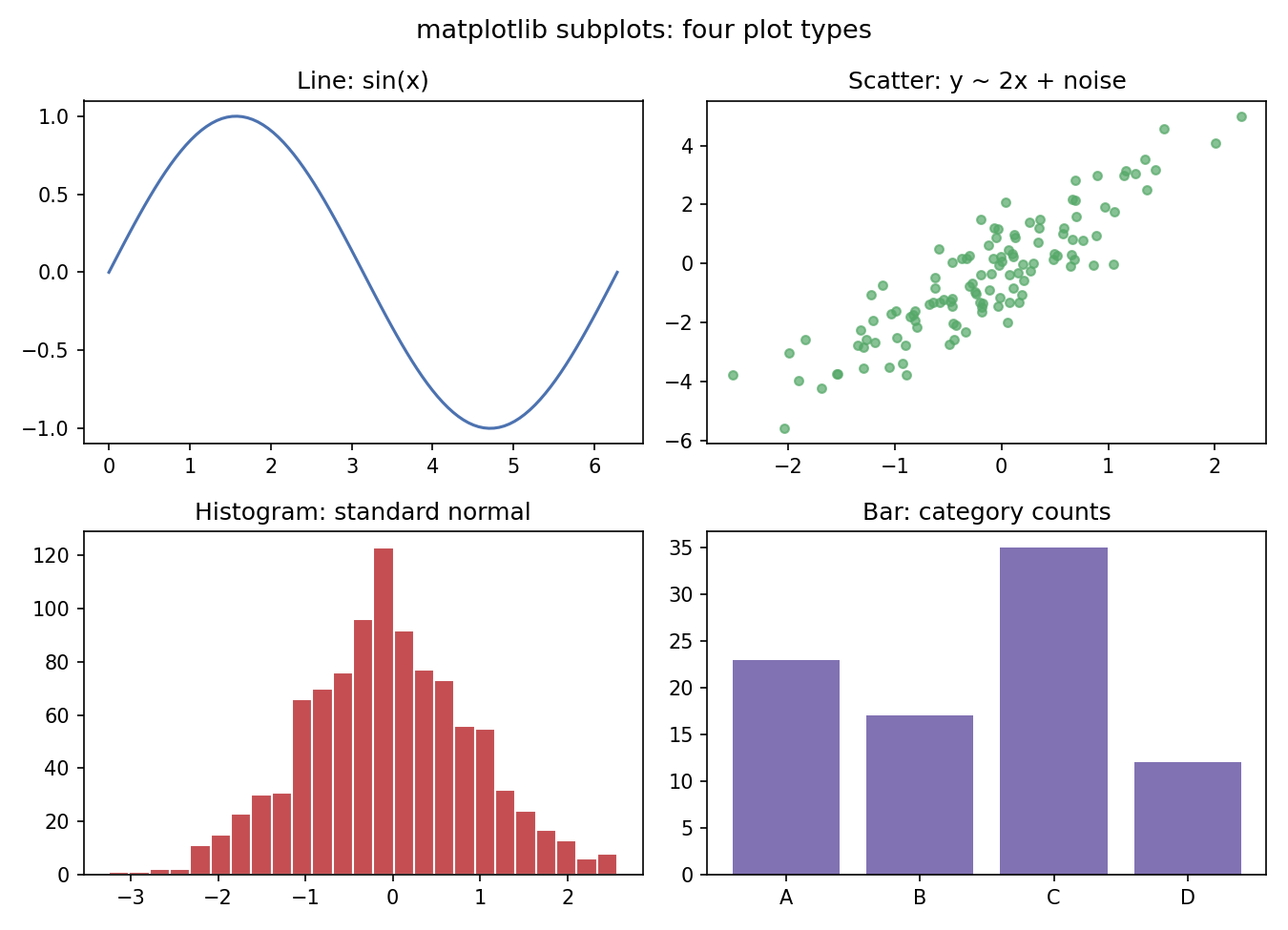
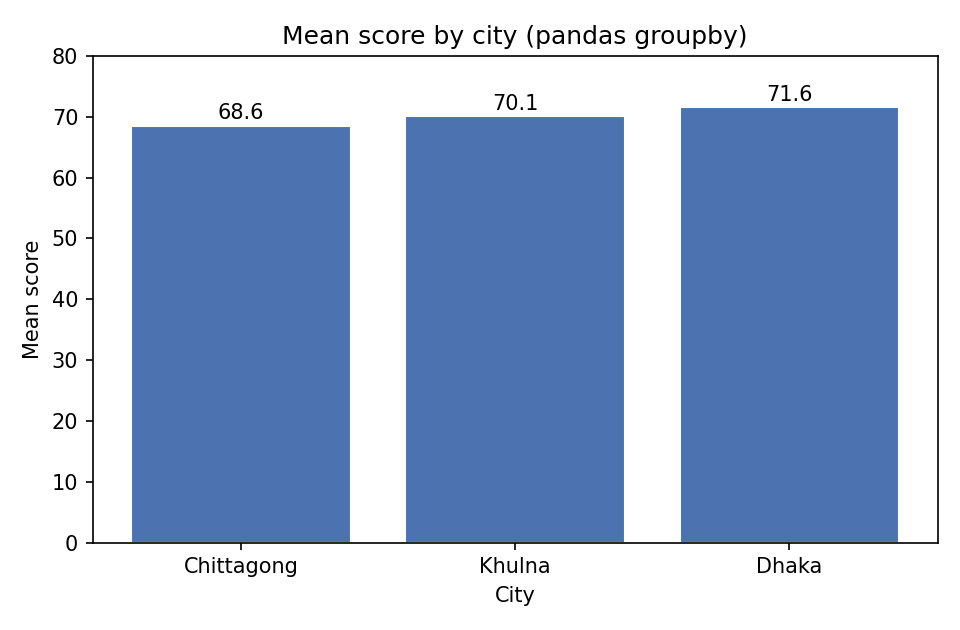
Figure 4 — pandas groupby bar chart¶
Section 2-এর groupby ধারণাকে ছবিতে: তিন শহরের গড় score। আগে groupby(...).mean() দিয়ে সারাংশ, তারপর সরাসরি bar chart।
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
rng = np.random.default_rng(2024)
df = pd.DataFrame({
"city": rng.choice(["Dhaka", "Chittagong", "Khulna"], size=300),
"score": rng.normal(70, 12, size=300),
})
means = df.groupby("city")["score"].mean().sort_values()
fig, ax = plt.subplots(figsize=(6.4, 4.2))
ax.bar(means.index, means.values, color="#4C72B0", edgecolor="white")
ax.set_ylabel("Mean score"); ax.set_xlabel("City")
ax.set_title("Mean score by city (pandas groupby)")
ax.set_ylim(0, 80)
for i, v in enumerate(means.values):
ax.text(i, v + 1, f"{v:.1f}", ha="center", fontsize=10)
fig.tight_layout(); fig.savefig("../_assets/0-6-groupby.png", dpi=150)
৭ · অনুশীলনী¶
প্রতিটি অনুশীলনীর difficulty tag ও hint দেওয়া। পূর্ণ সমাধান আছে _solutions/00-06-python-onramp-solutions.md ফাইলে।
Conceptual (ধারণাগত)¶
প্র. ১ [difficulty: easy] নিজের ভাষায় ব্যাখ্যা করুন: vectorization আর Python for-loop-এর মধ্যে মূল পার্থক্য কী, এবং কেন প্রথমটি দ্রুত?
Hint: interpreter overhead ও compiled C কোডের কথা ভাবুন।
প্র. ২ [difficulty: medium] কোনো সিমুলেশনের কোডে seed না দিলে কী সমস্যা হতে পারে গবেষণা বা debugging-এর সময়? default_rng(0) কীভাবে তা সমাধান করে?
Hint: pseudo-random ও reproducibility।
Computational (গণনামূলক)¶
প্র. ৩ [difficulty: easy] একটি array x = np.array([10, 12, 14, 16, 18])-কে z-score-এ রূপান্তর করুন: \(z = \dfrac{x - \bar{x}}{\sigma}\)। যাচাই করুন z.mean() ≈ 0 ও z.std() ≈ 1।
Hint: x.mean() ও x.std() ব্যবহার করুন; পুরো array-তে vectorization আপনাআপনি হবে।
প্র. ৪ [difficulty: medium] একটি \(4\times3\) random integer matrix M তৈরি করুন (rng.integers(1, 10, size=(4,3)))। প্রতিটি কলাম থেকে সেই কলামের গড় বিয়োগ করে "column-centered" matrix বানান। যাচাই করুন প্রতিটি কলামের নতুন গড় ≈ 0।
Hint: M.mean(axis=0) shape (3,); broadcasting নিজেই মিলিয়ে নেবে।
Debugging / coding¶
প্র. ৫ [difficulty: medium] নিচের কোড সারি বরাবর center করতে গিয়ে error দেয়। কারণ খুঁজে বের করুন ও ঠিক করুন:
M = rng.integers(1, 10, size=(4, 3))
row_centered = M - M.mean(axis=1) # ValueError: operands could not be broadcast
Hint: M.mean(axis=1)-এর shape (4,); broadcasting-এর জন্য একে (4,1) করা দরকার — keepdims=True খুঁজুন।
Mini-project (ছোট প্রকল্প)¶
প্র. ৬ [difficulty: hard] একটি কৃত্রিম exam dataset (১৫০ জন শিক্ষার্থী, কলাম: section ∈ {A,B,C}, hours, score) তৈরি করুন যেখানে score মোটামুটি hours-এর উপর নির্ভর করে (যোগ-সম্পর্ক + কিছু noise + section-ভিত্তিক bonus)। তারপর:
(ক) প্রতি section-এর গড়/std/count বের করুন (groupby);
(খ) hours ও score-এর correlation বের করুন;
(গ) একটি scatter plot (hours বনাম score) আঁকুন।
Hint: df["section"].map({...}) দিয়ে section bonus; df["hours"].corr(df["score"]); reproducibility-র জন্য default_rng ব্যবহার করুন।
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে যা শিখলাম¶
- Python basics: variable, type, list, dict, loop, function — scientific stack-এ ঢোকার ন্যূনতম ভিত্তি।
- NumPy:
arrayহলো দ্রুত সংখ্যাগত গণনার মূল object। vectorization (loop-হীন উপাদান-ভিত্তিক operation) ও broadcasting (ভিন্ন আকারের array মেলানো) কোডকে ছোট ও দ্রুত করে।np.random.default_rng(seed)দেয় reproducible random। - pandas:
SeriesওDataFrameদিয়ে tabular data;groupbyদিয়ে split → apply → combine সারাংশ। - matplotlib:
fig, ax = plt.subplots()প্যাটার্নে line, scatter, histogram, bar ও subplots। - প্রমাণ-অংশে benchmark দিয়ে দেখলাম vectorization প্রায় ৩০–৪০ গুণ দ্রুত, আর seed কেন reproducibility-র জন্য অপরিহার্য।
- একটি end-to-end mini-workflow (build → summarize → visualize) চালালাম — যা পরবর্তী সব code lab-এর কাঠামো।
সংযোগ¶
- পূর্ববর্তী: 0.1 (set, function, notation) থেকে আসা ধারণাগুলো এখানে কোডে রূপ নিল; 0.5-এর vector/matrix সরাসরি NumPy
arrayহিসেবে ফিরে এলো। - পরবর্তী: 1.1 — Data types, population vs sample (Part I — Descriptive Statistics)। সেখান থেকে শুরু করে পুরো curriculum-এ আমরা ঠিক এই stack (NumPy + pandas + matplotlib,
default_rngদিয়ে reproducible) ব্যবহার করব। এই অধ্যায়টি তাই বারবার ফিরে দেখার reference।
Source pointer¶
এই অধ্যায় self-contained এবং পুরো curriculum-এর coding foundation। স্পিরিট ও applied code-on-ramp ভঙ্গিতে এটি Practical Statistics for Data Scientists (Bruce, Bruce & Gedeck)-এর সাথে সঙ্গতিপূর্ণ; NumPy/pandas/matplotlib-এর official documentation (numpy.org, pandas.pydata.org, matplotlib.org) গভীরতর refere