১.১ · Data Types, Populations & Samples¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
Part 0-তে আমরা গণিতের ভাষা (set, function, calculus, linear algebra) আর Python-এর scientific stack শিখেছি। এখন সেই হাতিয়ার নিয়ে আমরা আসল পরিসংখ্যানে ঢুকছি। আর পরিসংখ্যানের সবচেয়ে গোড়ার প্রশ্নটি হলো খুব সহজ:
আমরা যা জানতে চাই তা একটা বিশাল গোষ্ঠী সম্পর্কে, কিন্তু আমরা যা দেখতে পাই তা সেই গোষ্ঠীর একটা ছোট অংশ। ছোট অংশ থেকে পুরোটা সম্পর্কে কীভাবে শিখব?
ধরা যাক আপনি জানতে চান "বাংলাদেশের সব প্রাপ্তবয়স্ক মানুষের গড় উচ্চতা কত?"। আদর্শভাবে সবাইকে মেপে ফেলতে পারলে উত্তর নিশ্চিত। কিন্তু কোটি কোটি মানুষকে মাপা অসম্ভব — সময়, খরচ, লোকবল কুলোবে না। তাই বাস্তবে আমরা হয়তো ২,০০০ জনকে মাপি, তাদের গড় বের করি, আর সেই গড় থেকে পুরো দেশের গড় সম্পর্কে একটা আন্দাজ (estimate) করি।
এই গোটা প্রক্রিয়ার দুটি মূল চরিত্র:
- Population (জনসমষ্টি — আমরা যাদের সম্পর্কে জানতে চাই): দেশের সব প্রাপ্তবয়স্ক।
- Sample (নমুনা — যাদের আমরা আসলে দেখি): মাপা ওই ২,০০০ জন।
পুরো inferential statistics (অনুমান-ভিত্তিক পরিসংখ্যান) — যা এই curriculum-এর Part IV থেকে শুরু হবে — দাঁড়িয়ে আছে এই একটাই ভিত্তির উপর: sample থেকে population সম্পর্কে শেখা। তাই এই অধ্যায়ে আমরা ওই দুই চরিত্র, তাদের সংখ্যাগত বৈশিষ্ট্য (parameter বনাম statistic), এবং data কত রকম হতে পারে (data type) — সব নিচ থেকে গড়ে তুলব।
Insight (অন্তর্দৃষ্টি): statistics কোনো জাদু নয়। এটি একটা ঝুঁকি-নিয়ন্ত্রিত অনুমানের কাঠামো: একটা ছোট, এলোমেলোভাবে বাছাই করা অংশ যদি পুরো গোষ্ঠীকে ঠিকমতো "প্রতিনিধিত্ব" করে, তবে অল্প তথ্য থেকেও পুরোটা সম্পর্কে যুক্তিসঙ্গত (এবং কতটা অনিশ্চিত তা মাপা সহ) সিদ্ধান্ত নেওয়া যায়।
নিচের ছবিতে এই গোটা loop-টা একনজরে: population থেকে আমরা একটা sample draw করি (sampling), আর sample থেকে population সম্পর্কে শিখি (inference)।
এই অধ্যায়ের শেষে আপনি জানবেন: কারা population, কারা sample; কোনটা parameter, কোনটা statistic; data কোন কোন ধরনের হয়; ভালো sample মানে কী; আর সবটা pandas-এ কীভাবে সঠিকভাবে সাজাতে হয়।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Population ও Sample¶
Population (জনসমষ্টি — আমরা যে গোটা গোষ্ঠী সম্পর্কে সিদ্ধান্ত নিতে চাই) হলো আগ্রহের সব unit-এর (একক — যেমন মানুষ, পণ্য, লেনদেন) সমষ্টি। গাণিতিকভাবে population-কে একটা set হিসেবে ভাবা যায়; এর আকার সাধারণত \(N\) দিয়ে লেখা হয় (যা খুব বড়, এমনকি ধারণাগতভাবে অসীমও হতে পারে)।
Sample (নমুনা — যে অংশটি আমরা আসলে পর্যবেক্ষণ করি) হলো population থেকে নেওয়া একটা উপসেট (subset)। এর আকার \(n\) দিয়ে লেখা হয়, এবং প্রায় সবসময় \(n \ll N\) (অনেক ছোট)।
| বিষয় | Population | Sample |
|---|---|---|
| কী | আগ্রহের পুরো গোষ্ঠী | তার পর্যবেক্ষিত অংশ |
| আকার | \(N\) (বড়/অসীম) | \(n\) (ছোট) |
| পাওয়া যায়? | প্রায় কখনোই পুরোটা নয় | হ্যাঁ, এটাই হাতে থাকে |
| বৈশিষ্ট্যের নাম | parameter | statistic |
সূক্ষ্ম কিন্তু জরুরি পার্থক্য: "population" সবসময় বিশাল জনগোষ্ঠী মানে নয়। এটি নির্ভর করে প্রশ্নের উপর। যদি প্রশ্ন হয় "এই কারখানার আজকের উৎপাদিত সব bulb-এর গড় আয়ু কত?", তবে population = আজকের সব bulb; sample = তার থেকে পরীক্ষা করা ৫০টি bulb। প্রশ্ন বদলালে population-ও বদলায়।
২.২ Parameter ও Statistic¶
একই ধরনের সংখ্যা (যেমন গড়) population আর sample — দুই জায়গাতেই থাকতে পারে, কিন্তু এদের ভূমিকা সম্পূর্ণ আলাদা।
- Parameter (প্যারামিটার — population-এর একটি সাংখ্যিক বৈশিষ্ট্য): এটি population-কে বর্ণনা করে। এটি একটা fixed (নির্দিষ্ট) সংখ্যা, কিন্তু সাধারণত unknown (অজানা) — কারণ পুরো population আমরা দেখতেই পারি না। যেমন:
- population mean \(\mu\) (গড়),
- population standard deviation \(\sigma\) (পরিবর্তনশীলতা),
-
population proportion \(p\) (কোনো বৈশিষ্ট্যের অনুপাত)।
-
Statistic (স্ট্যাটিস্টিক — sample থেকে গণনা করা একটি সংখ্যা): এটি sample-কে বর্ণনা করে, এবং সম্পূর্ণভাবে হাতের data থেকে গণনাযোগ্য। কিন্তু এটি random (এলোমেলো) — কারণ ভিন্ন sample নিলে ভিন্ন মান পাওয়া যায়। যেমন:
- sample mean \(\bar{x}\),
- sample standard deviation \(s\),
- sample proportion \(\hat{p}\)।
দুটি data set \(x_1,\dots,x_n\) দেওয়া থাকলে sample mean-এর সংজ্ঞা: $$ \bar{x} \;=\; \frac{1}{n}\sum_{i=1}^{n} x_i . $$
মূল ধারণাটি হলো: আমরা statistic (\(\bar{x}\)) ব্যবহার করি অজানা parameter (\(\mu\))-কে আন্দাজ (estimate) করতে। তখন \(\bar{x}\)-কে \(\mu\)-এর একটি estimator বলা হয়, এবং প্রায়ই লেখা হয় \(\hat{\mu} = \bar{x}\) (টুপি/hat চিহ্ন মানে "আন্দাজকৃত")।
স্মরণে রাখার নিয়ম: Greek অক্ষর → parameter (population), Roman/Latin অক্ষর → statistic (sample)। তাই \(\mu, \sigma, p\) population-এর; \(\bar{x}, s, \hat{p}\) sample-এর। এই কনভেনশন পুরো পরিসংখ্যানজুড়ে অপরিবর্তিত — এখনই মুখস্থ করে নিন।
২.৩ Data Type-এর Taxonomy¶
আমরা যে variable (চলক — পরিমাপযোগ্য বৈশিষ্ট্য) নিয়ে কাজ করি তা প্রধানত দুই ভাগে পড়ে: numeric ও categorical। কোন ধরন তা ঠিক করে দেয় আমরা কোন summary, কোন plot, কোন method ব্যবহার করতে পারব — তাই এটি চেনা অত্যন্ত গুরুত্বপূর্ণ।
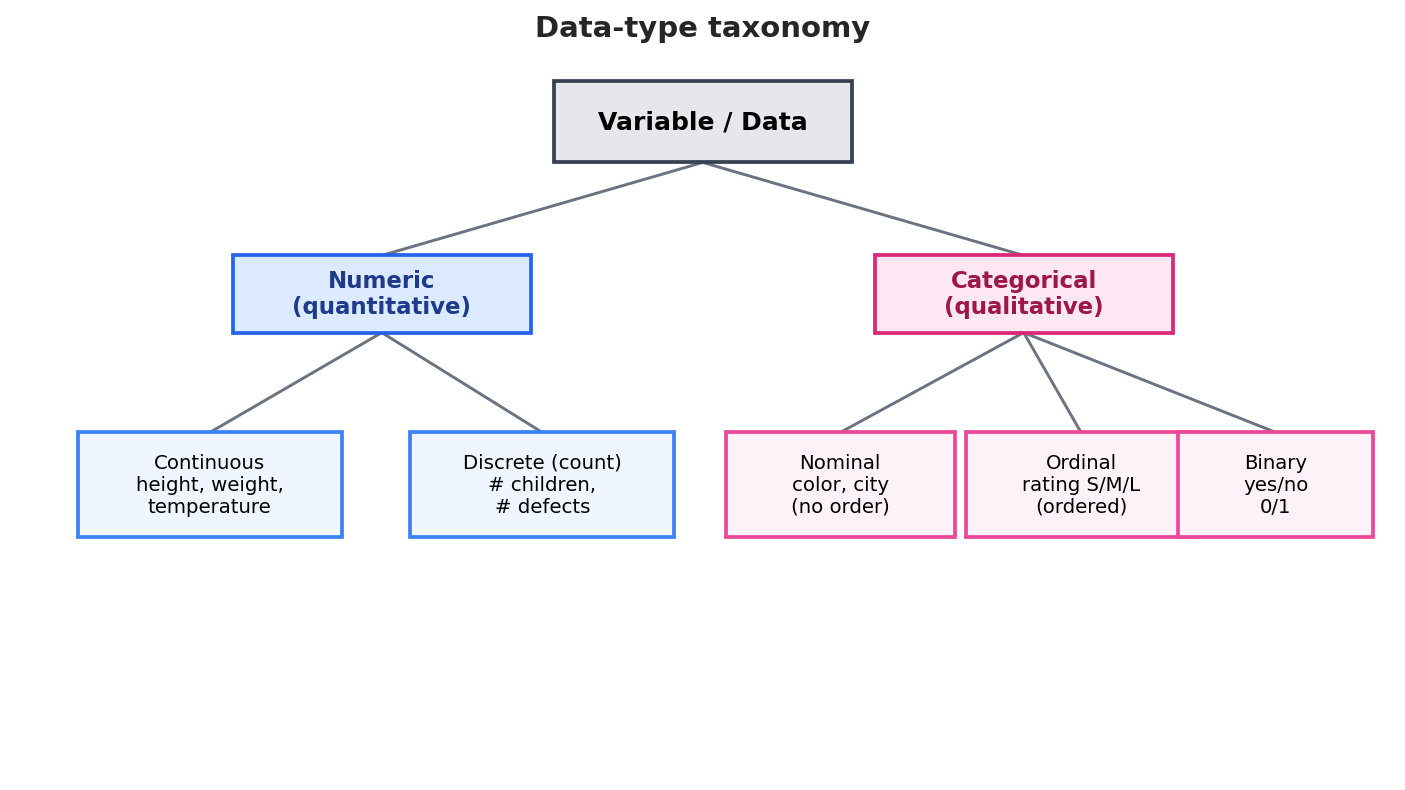
Numeric / quantitative (সংখ্যাগত — যার উপর অর্থপূর্ণ গাণিতিক কাজ করা যায়):
- Continuous (অবিচ্ছিন্ন — যেকোনো ভগ্নাংশ মান নিতে পারে, একটি interval-এ): উচ্চতা (\(172.4\) cm), ওজন, তাপমাত্রা, আয়। দুটি মানের মধ্যে সবসময় আরেকটি মান কল্পনা করা যায়।
- Discrete (বিচ্ছিন্ন/গণনাযোগ্য — সাধারণত পূর্ণসংখ্যা, প্রায়ই "কতগুলো" গোছের): সন্তানের সংখ্যা, একটি ব্যাচে ত্রুটিপূর্ণ পণ্যের সংখ্যা, ওয়েবসাইটে click-এর সংখ্যা। \(2.5\)টি সন্তান হয় না।
Categorical / qualitative (শ্রেণিগত — যা শ্রেণি/লেবেল নির্দেশ করে, সংখ্যা নয়):
- Nominal (নামমাত্র — শুধু নাম, কোনো ক্রম নেই): রং (লাল/নীল/সবুজ), শহর (Dhaka/Khulna), রক্তের গ্রুপ। এদের মধ্যে "বড়/ছোট" নেই; "লাল > নীল" অর্থহীন।
- Ordinal (ক্রমবাচক — শ্রেণিগুলোর একটা স্বাভাবিক ক্রম আছে, কিন্তু ব্যবধান অর্থপূর্ণ নয়): সন্তুষ্টি (Low < Medium < High), শিক্ষাগত স্তর, পোশাকের সাইজ (S < M < L)। ক্রম আছে, কিন্তু "Medium − Low" সংখ্যাটা অর্থহীন।
- Binary (দ্বিমিক — ঠিক দুটি শ্রেণি): হ্যাঁ/না, পাস/ফেল, subscribed (\(1\))/not (\(0\))। এটি categorical-এর একটি বিশেষ (অতি সাধারণ ও দরকারি) ক্ষেত্র; প্রায়ই \(0/1\) দিয়ে কোড করা হয় বলে অনেক হিসাব সহজ হয়ে যায় (যেমন গড় = অনুপাত)।
সতর্কতা — "সংখ্যা" সবসময় numeric নয়। ZIP code, ফোন নম্বর, jersey নম্বর দেখতে সংখ্যা, কিন্তু এদের গড় নেওয়া অর্থহীন — এগুলো আসলে nominal। একইভাবে সন্তুষ্টিকে যদি \(1,2,3\) দিয়ে কোড করি, তা automatically continuous হয়ে যায় না; এটি ordinal-ই থাকে। data-র ধরন ঠিক করে তার অর্থ, তার সংরক্ষণ-রূপ নয়।
২.৪ Structured / Rectangular Data¶
পরিসংখ্যানের কাজের প্রধান ফরম্যাট হলো structured বা rectangular data (গঠিত/আয়তাকার data — সারি-কলামের টেবিল), যাকে প্রোগ্রামিংয়ে DataFrame বলে:
- প্রতিটি row (সারি) = একটি record বা একটি observation (পর্যবেক্ষণ — যেমন একজন গ্রাহক)।
- প্রতিটি column (কলাম) = একটি feature বা variable (বৈশিষ্ট্য — যেমন বয়স, আয়)।
- প্রতিটি column-এর একটি নির্দিষ্ট data type থাকে (পুরো কলামজুড়ে একই ধরন)।
| city | age | income_k | satisfaction | subscribed |
|---|---|---|---|---|
| Dhaka | 38 | 77.8 | High | 1 |
| Khulna | 39 | 12.6 | Low | 0 |
| … | … | … | … | … |
এই "একটি row = একটি unit, একটি column = একটি variable" নিয়মটিকে প্রায়ই tidy data বলা হয়; প্রায় সব statistical method ও plotting library এই গঠনই প্রত্যাশা করে। pandas-এ এই টেবিল হলো একটি DataFrame, আর প্রতিটি column একটি Series যার নিজস্ব dtype (data type) থাকে।
২.৫ Random Sample, Bias ও Representativeness¶
sample থেকে population সম্পর্কে নির্ভরযোগ্যভাবে শিখতে হলে sample-টা population-কে ঠিকমতো প্রতিনিধিত্ব করতে হবে। এটি নিশ্চিত করার সবচেয়ে মৌলিক উপায়:
-
Simple Random Sample (SRS) (সরল এলোমেলো নমুনা): population-এর প্রতিটি unit-এর নির্বাচিত হওয়ার সম্ভাবনা সমান, এবং নির্বাচনগুলো একে অপরকে প্রভাবিত করে না। এটিই হলো "fair" বাছাই — যেমন একটা বড় বাক্স থেকে চোখ বন্ধ করে চিরকুট তোলা।
-
Representative sample (প্রতিনিধিত্বমূলক নমুনা): যে sample-এর গঠন (বয়স-বণ্টন, আয়-বণ্টন, ইত্যাদি) population-এর গঠনের কাছাকাছি। SRS গড়ে representative sample দেয়, কারণ এটি কোনো বিশেষ ধরনের unit-কে বেশি/কম বাছাই করে না।
-
Sampling bias (নমুনাজনিত পক্ষপাত): যখন বাছাইয়ের পদ্ধতিই কিছু unit-কে পদ্ধতিগতভাবে (systematically) বেশি বা কম প্রতিনিধিত্ব দেয়, ফলে statistic পদ্ধতিগতভাবে parameter থেকে সরে যায়। উদাহরণ: শুধু premium গ্রাহকদের জরিপ করে "গড় আয়" বের করলে তা সত্যিকারের গড়ের চেয়ে বেশি আসবে — কারণ গরিব গ্রাহকেরা sample-এ ঢুকছেনই না।
মূল বার্তা: বড় sample size bias দূর করে না। ১০ লক্ষ মানুষকেও যদি পক্ষপাতদুষ্টভাবে বাছাই করেন, উত্তর ১০ লক্ষবার একই ভুল দিকে নির্দেশ করবে — শুধু বেশি "আত্মবিশ্বাসের সাথে" ভুল। নির্ভুলতার চাবি size নয়, randomness ও representativeness। (ইতিহাসের বিখ্যাত উদাহরণ: ১৯৩৬-এর Literary Digest জরিপ ২৩ লক্ষ উত্তরদাতা নিয়েও নির্বাচনের ফল ভুল predict করেছিল, কারণ sample-টা ধনী গাড়ি/টেলিফোন-মালিকদের দিকে পক্ষপাতদুষ্ট ছিল।)
এই পার্থক্যটা আমরা §৬-এ একটি সিমুলেশনে চোখে দেখব: একই population থেকে একটা SRS আর একটা income-পক্ষপাতদুষ্ট sample নিলে তাদের গড় কতটা আলাদা হয়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
ধরা যাক একটি কোম্পানির গ্রাহক-জরিপ। Population = কোম্পানির সব নিবন্ধিত গ্রাহক (ধরা যাক \(N = 50{,}000\))। বাজেট সীমিত, তাই আমরা \(n = 200\) জনকে SRS-এ বেছে নিয়ে জরিপ করলাম। প্রতিজনের জন্য পাঁচটি variable নথিভুক্ত করা হলো — প্রতিটি একটি ভিন্ন data type, যাতে taxonomy পরিষ্কার হয়:
| column | অর্থ | data type |
|---|---|---|
city |
গ্রাহকের শহর | nominal (Dhaka/Chattogram/Khulna) |
age |
বয়স (বছর) | discrete numeric |
income_k |
মাসিক আয় (হাজার BDT) | continuous numeric |
satisfaction |
সন্তুষ্টি | ordinal (Low < Medium < High) |
subscribed |
প্রিমিয়াম নিয়েছেন? | binary (0/1) |
ধাপ ১ — population vs sample চিহ্নিত করা। আমরা জানতে চাই সব ৫০,০০০ গ্রাহকের গড় আয় (\(\mu\), একটি parameter — অজানা)। হাতে আছে শুধু ২০০ জনের data, যা থেকে আমরা গণনা করি sample mean \(\bar{x}\) (একটি statistic)।
ধাপ ২ — statistic গণনা। §৫-এ আমরা এই data তৈরি করে দেখব, এখানে শুধু ফলাফল উদ্ধৃত করছি (reproducible, seed \(=42\)):
$$
\bar{x}{\text{income}} \approx 44.9 \text{ (হাজার BDT)}, \qquad s \approx 20.2.
$$
city-র বণ্টন: Dhaka }\(104\) জন, Chattogram \(61\) জন, Khulna \(35\) জন (মোট \(200\))। binary subscribed-এর গড় \(= \hat{p} = 90/200 = 0.45\) — অর্থাৎ sample-এ \(45\%\) গ্রাহক premium।
ধাপ ৩ — interpretation (ব্যাখ্যা)। আমরা বলি: "population-এর গড় আয় \(\mu\)-এর আমাদের সেরা একক-আন্দাজ (point estimate) হলো \(\hat{\mu} = \bar{x} \approx 44.9\) হাজার BDT।" এটি একটি সাহসী লাফ — ২০০ থেকে ৫০,০০০-এ — যা শুধু তখনই বৈধ যখন (ক) sample-টা SRS, এবং (খ) আমরা \(\bar{x}\)-এর চারপাশের অনিশ্চয়তা (uncertainty) মাপি। এই অনিশ্চয়তা মাপার যন্ত্রপাতি (standard error, confidence interval) আসবে Part IV-এ; এই অধ্যায়ের কাজ ভিত্তিটা পরিষ্কার করা।
ধাপ ৪ — কেন data type জরুরি। লক্ষ করুন: income_k-এর জন্য গড়+histogram অর্থপূর্ণ (continuous), কিন্তু city-র "গড়" অর্থহীন (nominal — সেখানে আমরা count/proportion নিই)। satisfaction-এ আমরা ক্রম রক্ষা করে (Low→Medium→High) bar আঁকি, কিন্তু "গড় সন্তুষ্টি = 2.05" বলা বিভ্রান্তিকর (ordinal — ব্যবধান অর্থহীন)। প্রতিটি data type তার নিজস্ব বৈধ summary ও plot নির্ধারণ করে — এটিই EDA-র প্রথম শৃঙ্খলা।
৪ · প্রমাণ ও উৎপাদন¶
এই অধ্যায়টি মূলত ধারণাগত, তবে দুটি ভিত্তিমূলক সত্য সহজ গণিতে প্রমাণযোগ্য — যা আমরা পরে বারবার ব্যবহার করব।
৪.১ ★ Binary variable-এর গড় = অনুপাত (proportion)¶
দাবি: যদি প্রতিটি \(x_i \in \{0, 1\}\) হয় (binary, যেখানে \(1\) = "বৈশিষ্ট্যটি আছে"), তবে sample mean \(\bar{x}\) ঠিক সেই বৈশিষ্ট্যের অনুপাত \(\hat{p}\)-এর সমান।
প্রমাণ। ধরা যাক \(n\)টি মানের মধ্যে \(k\)টি \(1\) এবং বাকি \((n-k)\)টি \(0\)। তাহলে:
$$
\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i
= \frac{1}{n}\big(\underbrace{1 + \cdots + 1}{k\text{ বার}} + \underbrace{0 + \cdots + 0}\big)
= \frac{k}{n} = \hat{p}. \qquad \blacksquare
$$
}কেন গুরুত্বপূর্ণ: এই ছোট সমীকরণটিই categorical (yes/no) আর numeric দুনিয়ার মধ্যে সেতু বানায়। আমাদের উদাহরণে \(\hat{p} = 90/200 = 0.45\) মানে subscribed-এর গড়ও ঠিক \(0.45\) — দুটি একই সংখ্যা। এর ফলেই অনুপাত নিয়ে inference (Part IV-এর proportion test) আর গড় নিয়ে inference একই কাঠামোতে পড়ে।
৪.২ ★★ SRS-এ sample mean হলো population mean-এর unbiased estimator¶
দাবি: ধরা যাক population-এর mean \(\mu\)। একটি SRS থেকে প্রতিটি পর্যবেক্ষণ \(X_i\) এমন যে \(\mathbb{E}[X_i] = \mu\) (প্রতিটি unit সমান সম্ভাবনায় বাছাই হওয়ায় গড়ে এটি population-এর একটি "টিপিক্যাল" মান)। তাহলে sample mean \(\bar{X} = \frac{1}{n}\sum_i X_i\) গড়ে \(\mu\)-ই দেয়: $$ \mathbb{E}[\bar{X}] = \mu . $$
উৎপাদন। expectation-এর linearity (রৈখিকতা — \(\mathbb{E}[A+B] = \mathbb{E}[A] + \mathbb{E}[B]\) এবং \(\mathbb{E}[cA] = c\,\mathbb{E}[A]\)) ব্যবহার করে: $$ \mathbb{E}[\bar{X}] = \mathbb{E}!\left[\frac{1}{n}\sum_{i=1}^{n} X_i\right] = \frac{1}{n}\sum_{i=1}^{n} \mathbb{E}[X_i] = \frac{1}{n}\sum_{i=1}^{n} \mu = \frac{1}{n}\cdot n\mu = \mu. \qquad \blacksquare $$
অর্থ ও সতর্কতা। "Unbiased" (পক্ষপাতহীন) মানে: যদিও যেকোনো একটি sample-এ \(\bar{X}\) হয়তো \(\mu\) থেকে একটু এদিক-ওদিক, কিন্তু এমন অসংখ্য sample-এর গড় ঠিক \(\mu\)-তেই বসে — পদ্ধতিতে কোনো systematic ঝোঁক নেই। এটি শুধু SRS-এর জন্য সত্য। §২.৫-এর income-পক্ষপাতদুষ্ট sampling-এ এই শর্ত ভাঙে: সেখানে বেশি-আয়ের unit বেশি সম্ভাবনায় বাছাই হয়, তাই \(\mathbb{E}[X_i] > \mu\), এবং \(\mathbb{E}[\bar{X}] > \mu\) — sample mean পদ্ধতিগতভাবে বেশি দেখায়। §৬-এর সিমুলেশন ঠিক এটাই সংখ্যায় দেখাবে: SRS-এর গড় ভুল মাত্র \(\approx -1.2\), কিন্তু পক্ষপাতদুষ্টটির ভুল \(\approx +14\) (হাজার BDT)। (এই \(\bar{X}\) কতটা ছড়ায় — তার পরিমাপ variance ও পরবর্তী convergence তত্ত্ব Part III-এ।)
৫ · কোড ল্যাব (Python)¶
আমরা §৩-এর গ্রাহক-dataset টি নিজে তৈরি করব (reproducible synthetic data), তারপর pandas-এ data type ঠিকমতো উপস্থাপন করব এবং statistic বনাম parameter হাতে-কলমে দেখব। প্রথমে from-scratch ধারণা, তারপর library সুবিধা।
৫.১ Setup ও reproducible dataset তৈরি¶
import numpy as np
import pandas as pd
rng = np.random.default_rng(42) # reproducible: একই seed → একই data
n = 200 # sample size
city = rng.choice(["Dhaka", "Chattogram", "Khulna"],
size=n, p=[0.5, 0.3, 0.2]) # nominal
age = rng.integers(18, 60, size=n) # discrete numeric
income = np.round(rng.lognormal(mean=10.6, sigma=0.45, # continuous numeric
size=n) / 1000, 1) # → হাজার BDT
satisfaction = rng.choice(["Low", "Medium", "High"],
size=n, p=[0.25, 0.45, 0.30]) # ordinal
subscribed = rng.integers(0, 2, size=n) # binary (0/1)
লক্ষ করুন lognormal ব্যবহার করেছি income-এর জন্য — কারণ বাস্তবে আয় সাধারণত right-skewed (ডানদিকে লেজ-টানা): বেশিরভাগ মানুষের আয় কম-মাঝারি, অল্প কিছু মানুষের অনেক বেশি। এটি §৬-এর histogram-এ চোখে পড়বে।
৫.২ DataFrame বানানো ও dtype ঠিক করা (from raw → typed)¶
pandas নিজে থেকে city/satisfaction-কে সাধারণ object (string) ভাবে। কিন্তু আমরা ইচ্ছাকৃতভাবে এদের সঠিক categorical dtype দিই — বিশেষত satisfaction-কে ordered categorical বানাই, যাতে Low < Medium < High ক্রম pandas-ই মনে রাখে।
df = pd.DataFrame({
"city": pd.Categorical(city), # nominal categorical
"age": age, # int64
"income_k": income, # float64
"satisfaction": pd.Categorical( # ORDERED categorical
satisfaction, categories=["Low", "Medium", "High"], ordered=True),
"subscribed": subscribed, # int64 (binary)
})
print(df.head(3))
print(df.dtypes)
print("shape:", df.shape)
প্রকৃত output:
city age income_k satisfaction subscribed
0 Chattogram 59 35.2 High 1
1 Dhaka 50 38.3 Medium 1
2 Khulna 31 35.8 Low 1
city category
age int64
income_k float64
satisfaction category
subscribed int64
dtype: object
shape: (200, 5)
df.shape = (200, 5) মানে ২০০টি row (observation) × ৫টি column (variable) — ঠিক rectangular data-র সংজ্ঞা। dtype-গুলো আমাদের taxonomy-র সাথে মিলে যাচ্ছে: numeric → int64/float64, categorical → category।
ordered categorical-এর সুবিধা — pandas এখন ক্রম "জানে", তাই তুলনা বৈধ:
print(df["satisfaction"].cat.categories.tolist()) # ['Low', 'Medium', 'High']
print((df["satisfaction"] >= "Medium").sum()) # Medium বা High কতজন
৫.৩ Statistic হাতে গণনা — parameter আমরা জানি না¶
মনে রাখুন: এই \(\bar{x}\) একটি statistic (sample থেকে গণনাযোগ্য); সত্যিকারের \(\mu\) population-এর parameter যা আমরা সাধারণত জানি না।
# from scratch: sample mean = (যোগফল) / n
x = df["income_k"].to_numpy()
xbar_scratch = x.sum() / len(x)
# library: একই জিনিস
xbar_pandas = df["income_k"].mean()
print(f"sample mean income (scratch) = {xbar_scratch:.2f}")
print(f"sample mean income (pandas) = {xbar_pandas:.2f}")
print(f"sample std income (s) = {df['income_k'].std():.2f}")
প্রকৃত output:
sample mean income (scratch) = 44.88
sample mean income (pandas) = 44.88
sample std income (s) = 20.17
দুই পথ একই — from-scratch সংজ্ঞা আর pandas-এর .mean() হুবহু মেলে। তাই \(\hat{\mu} = \bar{x} \approx 44.88\) হাজার BDT।
৫.৪ Data type অনুযায়ী সঠিক summary¶
প্রতিটি data type-এর জন্য আলাদা ধরনের summary বৈধ — pandas এই পার্থক্য সম্মান করে:
# numeric → describe (mean, std, quartiles ইত্যাদি)
print(df[["age", "income_k"]].describe().round(2))
# categorical → value_counts (গণনা/অনুপাত)
print("\ncity counts:\n", df["city"].value_counts())
# binary → গড় = অনুপাত (§৪.১-এর প্রমাণ অনুযায়ী)
phat = df["subscribed"].mean()
print(f"\nsubscribed proportion p̂ = {phat:.3f} "
f"(= {int(df['subscribed'].sum())}/{len(df)})")
প্রকৃত output (সংক্ষেপে):
income_k-এর describe() দেয় mean \(\approx 44.88\), std \(\approx 20.17\), median (50%) \(\approx 41.8\) — median < mean হওয়া right-skew-এর ইঙ্গিত (পরের অধ্যায় 1.2-এ এর গভীরে যাব)। আর §৪.১-এর প্রমাণ মিলে গেল: subscribed-এর গড় ঠিক অনুপাত \(0.45\)।
৬ · ভিজ্যুয়ালাইজেশন¶
দুটি ছবি আঁকব: (ক) এক dataset, চার data type — প্রতিটির জন্য সঠিক plot; (খ) representative বনাম biased sampling — কেন randomness জরুরি তা চোখে দেখানো। নিচের কোড ঠিক যা figure দুটি তৈরি করেছে।
৬.১ এক dataset, চার data type¶
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("whitegrid")
fig, axes = plt.subplots(2, 2, figsize=(10, 7))
# (a) nominal → bar of counts
counts = df["city"].value_counts()
axes[0, 0].bar(counts.index.astype(str), counts.values,
color=["#2563eb", "#16a34a", "#d97706"])
axes[0, 0].set_title("(a) Nominal: customers per city")
axes[0, 0].set_ylabel("count")
# (b) continuous → histogram + mean line
axes[0, 1].hist(df["income_k"], bins=22, color="#3b82f6",
edgecolor="white", alpha=0.85)
axes[0, 1].axvline(df["income_k"].mean(), color="#dc2626", ls="--", lw=2,
label=f"mean = {df['income_k'].mean():.1f}k")
axes[0, 1].set_title("(b) Continuous: income (k BDT)")
axes[0, 1].set_xlabel("income (thousand BDT)"); axes[0, 1].set_ylabel("count")
axes[0, 1].legend()
# (c) discrete → histogram over integer bins
axes[1, 0].hist(df["age"], bins=range(18, 62, 3), color="#16a34a",
edgecolor="white", alpha=0.85)
axes[1, 0].set_title("(c) Discrete: age (years)")
axes[1, 0].set_xlabel("age"); axes[1, 0].set_ylabel("count")
# (d) ordinal → bar in the CORRECT order
sat_order = ["Low", "Medium", "High"]
sat_counts = df["satisfaction"].value_counts().reindex(sat_order)
axes[1, 1].bar(sat_order, sat_counts.values,
color=["#f87171", "#fbbf24", "#34d399"])
axes[1, 1].set_title("(d) Ordinal: satisfaction level")
axes[1, 1].set_ylabel("count")
fig.suptitle("One synthetic dataset, four data types (n = 200)",
fontsize=14, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.96])
fig.savefig("../_assets/1-1-dataset-preview.png", dpi=150, bbox_inches="tight")
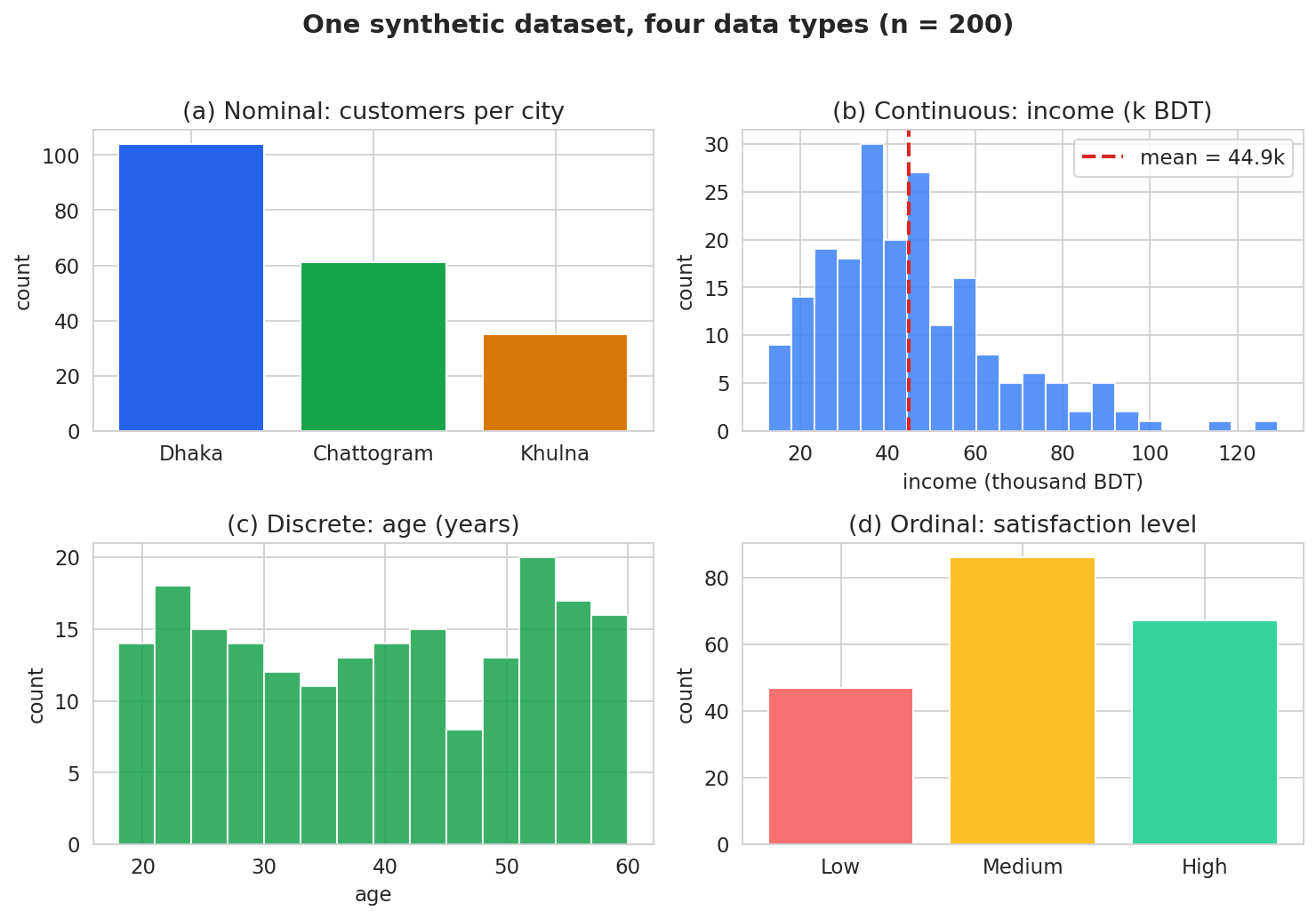
কীভাবে data type plot ঠিক করল: nominal/ordinal-এ আমরা bar of counts আঁকলাম (অর্থপূর্ণ "গড়" নেই); ordinal-এ যত্ন করে reindex দিয়ে Low→Medium→High ক্রম রক্ষা করলাম (alphabetical-এ "High" আগে চলে আসত, যা বিভ্রান্তিকর)। continuous/discrete-এ histogram আঁকলাম — income-এর histogram স্পষ্ট right-skew দেখাচ্ছে।
৬.২ Representative বনাম biased sampling¶
এবার সবচেয়ে গুরুত্বপূর্ণ ধারণাটি সিমুলেশনে। একটা বড় population (income, lognormal) বানাই যার জানা mean আছে (এটি আমাদের "satya parameter")। তারপর দুইভাবে \(300\)টি unit নিই: (১) SRS, (২) income-এর সমানুপাতিক ওজনে (বেশি-আয় বেশি সম্ভাবনায় — মানে শুধু ধনী গ্রাহকদের পৌঁছানো জরিপের নকল)।
rng3 = np.random.default_rng(7)
N = 20_000
pop_income = rng3.lognormal(mean=10.6, sigma=0.5, size=N) / 1000 # population
pop_mean = pop_income.mean() # TRUE parameter μ
# (1) representative: simple random sample
srs = rng3.choice(pop_income, size=300, replace=False)
# (2) biased: probability ∝ income (ধনীরা বেশি বাছাই হয়)
weights = pop_income / pop_income.sum()
biased_idx = rng3.choice(np.arange(N), size=300, replace=False, p=weights)
biased = pop_income[biased_idx]
print(f"pop mean (μ) = {pop_mean:.2f}")
print(f"SRS mean = {srs.mean():.2f} (error {srs.mean()-pop_mean:+.2f})")
print(f"biased mean = {biased.mean():.2f} (error {biased.mean()-pop_mean:+.2f})")
fig, axes = plt.subplots(1, 2, figsize=(10.5, 4.6), sharey=True)
for ax, samp, c, name in [(axes[0], srs, "#2563eb", "random sample"),
(axes[1], biased, "#dc2626", "biased sample")]:
ax.hist(pop_income, bins=60, color="#d1d5db", density=True, label="population")
ax.hist(samp, bins=40, color=c, density=True, alpha=0.55, label=name)
ax.axvline(pop_mean, color="#111827", lw=1.6) # true μ (solid)
ax.axvline(samp.mean(), color=c, ls="--", lw=2) # sample mean (dashed)
ax.set_xlim(0, 200); ax.set_xlabel("income (k BDT)"); ax.legend()
axes[0].set_ylabel("density")
axes[0].set_title(f"Representative (SRS)\nsample mean {srs.mean():.0f} vs pop {pop_mean:.0f}")
axes[1].set_title(f"Biased (income-weighted)\nsample mean {biased.mean():.0f} vs pop {pop_mean:.0f}")
fig.suptitle("Why representativeness matters: same population, two sampling schemes",
fontsize=13, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
fig.savefig("../_assets/1-1-sampling-bias.png", dpi=150, bbox_inches="tight")
প্রকৃত output:
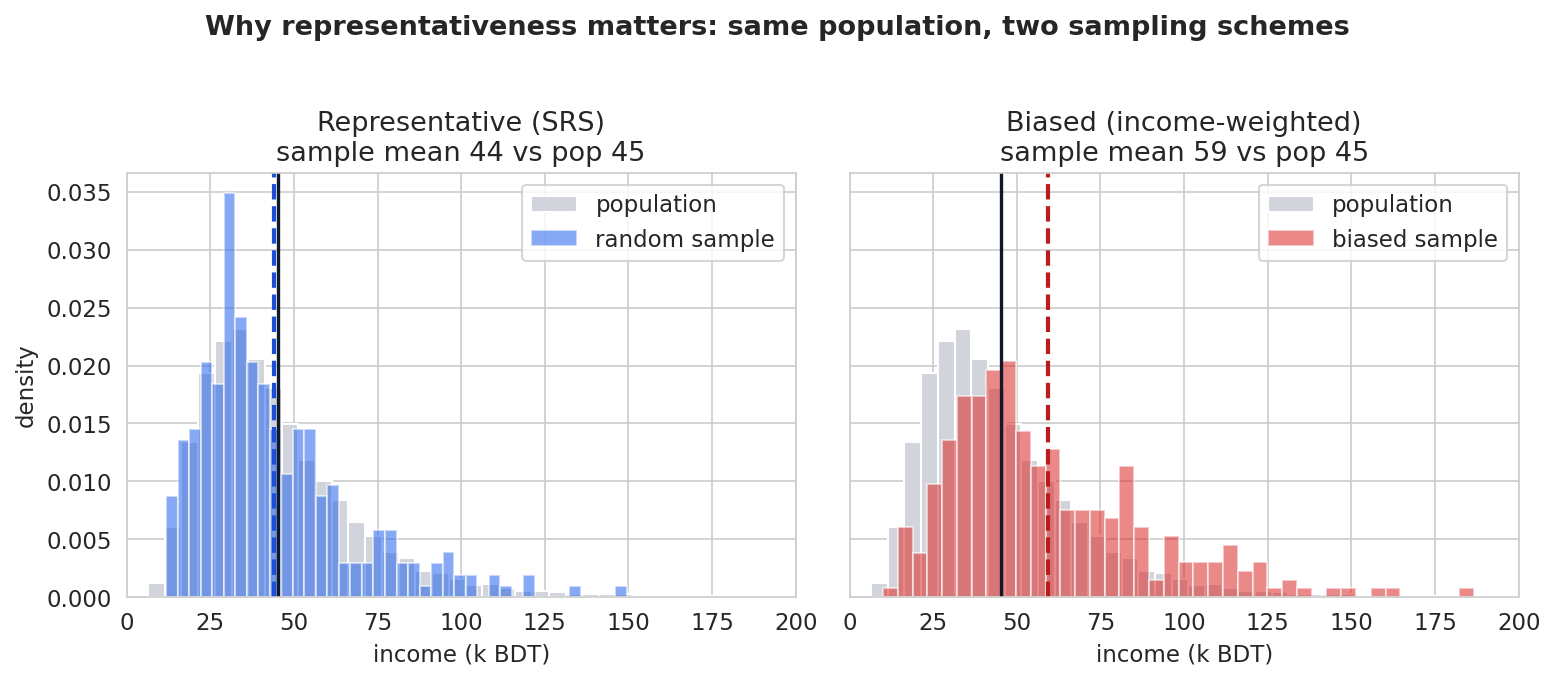
ব্যাখ্যা: SRS-এর ভুল মাত্র \(-1.18\) (random fluctuation, যা sample বদলালে এদিক-ওদিক হয়), কিন্তু biased sample-এর ভুল \(+14.06\) — এটি random নয়, systematic: পদ্ধতিটাই ধনীদের বেশি টানছে, তাই উত্তর সবসময় বেশি দিকে। এটিই §৪.২-এর তত্ত্বের জীবন্ত রূপ — SRS unbiased, পক্ষপাতদুষ্ট sampling biased। আর গুরুত্বপূর্ণ: biased sample-এর size বাড়ালেও এই \(+14\) ভুল কমবে না।
৭ · অনুশীলনী¶
প্রতিটি অনুশীলনীর difficulty tag ও hint দেওয়া। পূর্ণ সমাধান আছে _solutions/01-01-data-types-populations-samples-solutions.md ফাইলে।
Conceptual (ধারণাগত)¶
প্র. ১ [difficulty: easy] নিচের প্রতিটিকে population নাকি sample হিসেবে শনাক্ত করুন এবং সংশ্লিষ্ট unit কী বলুন:
(ক) "বাংলাদেশের সব ভোটার"-এর মতামত জানতে জরিপ করা ১,২০০ জন;
(খ) একটি কারখানার আজকের উৎপাদিত সব \(10{,}000\)টি bulb;
(গ) ওই bulb থেকে পরীক্ষা করা \(50\)টি।
Hint: "যাদের সম্পর্কে জানতে চাই" = population; "যাদের আসলে দেখি" = sample।
প্র. ২ [difficulty: easy] নিচের প্রতিটি সংখ্যা parameter নাকি statistic — বলুন এবং উপযুক্ত চিহ্ন (\(\mu, \sigma, p\) বা \(\bar{x}, s, \hat{p}\)) বসান:
(ক) দেশের সব পরিবারের প্রকৃত গড় আয়;
(খ) জরিপ করা ৫০০ পরিবারের গড় আয়;
(গ) এক ব্যাচের সব পণ্যের সত্যিকারের ত্রুটি-অনুপাত।
Hint: Greek → population/parameter; Roman → sample/statistic।
প্র. ৩ [difficulty: medium] নিচের প্রতিটি variable-এর data type বলুন (numeric continuous / numeric discrete / nominal / ordinal / binary) এবং এক বাক্যে কারণ:
(ক) ঢাকার একটি বাড়ির ZIP/postal code; (খ) একজন রোগীর শরীরের তাপমাত্রা; (গ) একটি সিনেমার \(1\)–\(5\) তারকা রেটিং; (ঘ) একটি ইমেল spam কিনা; (ঙ) একটি পরিবারের সদস্য সংখ্যা।
Hint: §২.৩-এর সতর্কতা মনে রাখুন — "সংখ্যা দেখতে" আর "numeric হওয়া" এক নয়।
প্র. ৪ [difficulty: medium] একটি অনলাইন জরিপ "গড়ে মানুষ দিনে কত ঘণ্টা ইন্টারনেট ব্যবহার করে" জানতে শুধু একটি টেক-ব্লগে লিঙ্ক বসিয়ে \(1{,}00{,}000\) উত্তর সংগ্রহ করল। কেন এই বিশাল sample-ও পক্ষপাতদুষ্ট হতে পারে? বড় \(n\) কি সমস্যা মেটায়?
Hint: কারা ওই ব্লগ পড়ে ও লিঙ্কে ক্লিক করে? §২.৫-এর মূল বার্তা।
Computational (গণনামূলক)¶
প্র. ৫ [difficulty: easy] rng = np.random.default_rng(0) দিয়ে \(n = 500\) আকারের একটি binary array তৈরি করুন (rng.integers(0, 2, 500))। (ক) এর গড় বের করুন; (খ) এতে কতগুলো \(1\) আছে গুনুন; (গ) যাচাই করুন গড় ঠিক (১-এর সংখ্যা)/500 — অর্থাৎ §৪.১-এর সমতা।
Hint: .mean() ও .sum()।
প্র. ৬ [difficulty: medium] §৫.১-এর df পুনরায় তৈরি করুন (seed 42)। তারপর: (ক) df.dtypes ছাপুন এবং প্রতিটি column-এর data type taxonomy-অনুযায়ী লেবেল করুন; (খ) satisfaction-কে ordered categorical বানিয়ে দেখান (df["satisfaction"] > "Low").sum() কত দেয় এবং তা কী বোঝায়।
Hint: pd.Categorical(..., ordered=True); ordered হলে > তুলনা বৈধ।
Coding (কোডিং)¶
প্র. ৭ [difficulty: medium] একটি ফাংশন summarize_column(s) লিখুন যা একটি pandas Series নেয় এবং তার dtype দেখে স্বয়ংক্রিয়ভাবে সঠিক summary ফেরত দেয়: numeric হলে (mean, std), নাহলে value_counts()। আপনার df-এর income_k ও city-তে চালিয়ে দেখান।
Hint: pd.api.types.is_numeric_dtype(s) দিয়ে যাচাই করুন।
প্র. ৮ [difficulty: hard] §৬.২-এর সিমুলেশন সম্প্রসারণ করুন। একই population থেকে SRS ও biased — উভয়ের জন্য \(n = 300\)-এর sampling ৫০০ বার পুনরাবৃত্তি করুন (প্রতিবার নতুন sample), প্রতিবারের sample mean জমা করুন। তারপর: (ক) দুটি সেট sample-mean-এর histogram একই অক্ষে আঁকুন, population mean-এ একটি উল্লম্ব রেখা দিন; (খ) দুটি সেটের গড় ছাপুন। SRS-এর গড় কেন \(\mu\)-এর কাছে, biased-এর গড় কেন দূরে — §৪.২ দিয়ে ব্যাখ্যা করুন।
Hint: একটি loop-এ rng.choice(...).mean() জমা করুন; p=weights দিলে biased। এটি sampling distribution-এর প্রথম ঝলক (Part III/IV-এ বিস্তারিত)।
Proof (প্রমাণ)¶
প্র. ৯ [difficulty: medium] ★ দেখান যে যদি প্রতিটি পর্যবেক্ষণে একই ধ্রুবক \(c\) যোগ করা হয় (\(y_i = x_i + c\)), তবে নতুন গড় \(\bar{y} = \bar{x} + c\)। (এটি §৪.১–৪.২-এর মতোই linearity-নির্ভর; পরের অধ্যায়ের standardization-এর ভিত্তি।)
Hint: \(\bar{y} = \frac{1}{n}\sum (x_i + c)\) — যোগফল ভাঙুন।
প্র. ১০ [difficulty: hard] ★★ ধরা যাক একটি population-এ \(M\)টি unit আছে যাদের \(K\)টির একটি নির্দিষ্ট বৈশিষ্ট্য আছে (proportion \(p = K/M\))। SRS-এ একটিমাত্র unit তুলে তার indicator \(X \in \{0,1\}\) (\(X=1\) যদি বৈশিষ্ট্যটি থাকে) বিবেচনা করুন। প্রমাণ করুন \(\mathbb{E}[X] = p\), এবং এর থেকে যুক্তি দিন কেন SRS-এ \(\hat{p} = \bar{X}\) হলো \(p\)-এর unbiased estimator।
Hint: \(X\) একটি Bernoulli(\(p\))-এর মতো: \(P(X=1) = K/M = p\); \(\mathbb{E}[X] = 1\cdot p + 0\cdot(1-p)\)। তারপর §৪.২-এর linearity।
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে যা শিখলাম¶
- Population vs Sample: population (\(N\) একক) হলো আগ্রহের পুরো গোষ্ঠী — সাধারণত পুরোটা দেখা যায় না; sample (\(n\) একক) হলো তার পর্যবেক্ষিত অংশ। পুরো inference-এর লক্ষ্য: sample থেকে population সম্পর্কে শেখা।
- Parameter vs Statistic: parameter (\(\mu, \sigma, p\) — Greek) population-এর fixed কিন্তু unknown বৈশিষ্ট্য; statistic (\(\bar{x}, s, \hat{p}\) — Roman) sample থেকে গণনাযোগ্য কিন্তু random। আমরা statistic দিয়ে parameter আন্দাজ (estimate) করি: \(\hat{\mu} = \bar{x}\)।
- Data-type taxonomy: numeric (continuous, discrete) ও categorical (nominal, ordinal, binary)। ধরনই ঠিক করে কোন summary ও plot বৈধ — "সংখ্যা দেখতে" মানেই numeric নয়।
- Structured/rectangular data: এক row = এক observation, এক column = এক variable, প্রতিটির নিজস্ব dtype — এটিই statistics ও pandas
DataFrame-এর মূল ফরম্যাট। - Random sample, bias, representativeness: SRS গড়ে representative sample দেয় এবং sample mean-কে unbiased করে (\(\mathbb{E}[\bar{X}] = \mu\), §৪.২); sampling bias systematic ভুল আনে যা বড় \(n\)-এও মেটে না।
- Code lab-এ synthetic গ্রাহক-dataset (seed 42) তৈরি করে dtype ঠিক করলাম, statistic from-scratch ও pandas দুইভাবে মিলিয়ে দেখলাম (\(\bar{x} \approx 44.88\)), এবং সিমুলেশনে representative (\(-1.2\) ভুল) বনাম biased (\(+14\) ভুল) sampling চোখে দেখলাম।
সংযোগ¶
- পূর্ববর্তী: 0.6 (Python on-ramp) — সেখানকার NumPy
default_rng, pandasSeries/DataFrame/value_counts, matplotlib এখানে সরাসরি কাজে লাগল; এটিই প্রতিটি code lab-এর ভিত্তি। - পরবর্তী: 1.2 — Location & Variability। এই অধ্যায়ে আমরা data চিনলাম ও সাজালাম; পরের অধ্যায়ে সেই data-কে কয়েকটি সংখ্যায় সারাংশ করব — center (mean, median, mode) ও spread (variance, standard deviation, IQR)। আজকের income histogram-এর "right-skew" আর "median < mean" পর্যবেক্ষণ ঠিক সেখানেই গভীরভাবে ব্যাখ্যা পাবে। আর parameter-statistic পার্থক্য থেকে শুরু হওয়া "অনিশ্চয়তা মাপা"-র গল্প পূর্ণতা পাবে Part IV (Inference)-এ।
Source pointer¶
এই অধ্যায়ের কাঠামো ও প্রায়োগিক ভঙ্গি অনুসরণ করে Practical Statistics for Data Scientists (Bruce, Bruce & Gedeck)-এর Ch.1 (Exploratory Data Analysis) — বিশেষত structured data ও data-type taxonomy অংশ। population/sample ও estimation-এর তাত্ত্বিক ভিত্তি দেখুন All of Statistics (Wasserman) এবং descriptive statistics ও sampling-এর জন্য Probability and Statistics for Data Science (Fernández-Granda)।