১.৩ · Distributions & Visualization¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
গত অধ্যায়ে আমরা একগুচ্ছ সংখ্যাকে দুই-তিনটি সারাংশ-সংখ্যায় চেপে ধরেছিলাম — mean, median, standard deviation, IQR। এটা শক্তিশালী, কিন্তু একটা বড় বিপদও বটে: সারাংশ-সংখ্যা সত্য লুকাতে পারে। ক্লাসিক উদাহরণ — দুটি সম্পূর্ণ ভিন্ন data-র mean এক, std এক, এমনকি correlation পর্যন্ত এক হতে পারে, অথচ একটার ভেতরে লুকিয়ে আছে দুটো আলাদা দল আর অন্যটায় একটা সরল ঝাঁক। সংখ্যা দেখলে ধরা পড়বে না; ছবি আঁকলে এক সেকেন্ডে ধরা পড়বে।
Insight (অন্তর্দৃষ্টি): একটি distribution (বণ্টন) হলো একটি variable-এর সম্পূর্ণ গল্প — কোন মান কত ঘন ঘন আসে, তার পুরো ছবি। location আর variability সেই গল্পের মাত্র দুটি বাক্য; distribution হলো গোটা অনুচ্ছেদ।
এই অধ্যায়ের মূল প্রশ্ন বদলে যাচ্ছে। আগে জিজ্ঞেস করতাম "data সাধারণত কত, কতটা ছড়ানো?"। এখন জিজ্ঞেস করব — "data-র আকৃতি (shape) কেমন?"। কি এটি একটিমাত্র শৃঙ্গবিশিষ্ট ও symmetric (প্রতিসম) (যেমন উচ্চতা), নাকি একদিকে লম্বা লেজ-টানা (যেমন আয় বা সম্পদ), নাকি দুটো আলাদা চূড়া (যেমন একটি যন্ত্রে নারী-পুরুষ মিশ্র উচ্চতা)? এই আকৃতিই বলে দেয় কোন সারাংশ-সংখ্যা বিশ্বাসযোগ্য, কোন probability (সম্ভাব্যতা)-model (Part II) data-র সাথে খাপ খাবে, আর কোন inference-পদ্ধতি (Part IV) বৈধ হবে।
statistics-এর সাথে যোগসূত্র এখানে সরাসরি ও গভীর। প্রায় প্রতিটি classical পরিসংখ্যান-পদ্ধতি কোনো-না-কোনো অনুমান করে data-র আকৃতি নিয়ে — সবচেয়ে বিখ্যাত অনুমান হলো "data approximately normal"। সেই অনুমান সত্যি কিনা তা যাচাইয়ের প্রথম হাতিয়ার হলো ছবি — histogram, QQ-plot। আবার ECDF (empirical CDF) নামের যে curve-টি এখানে শিখব, সেটি কেবল একটা ছবি নয়; এটি একটি গাণিতিক বস্তু যা Part IV-তে nonparametric statistics-এ (Kolmogorov–Smirnov test, bootstrap) মূল ভূমিকা নেবে। তাই এই অধ্যায় EDA (exploratory data analysis)-এর হৃদয় এবং একইসাথে পরবর্তী সমস্ত inference-এর প্রবেশদ্বার।
একটি অভ্যাস এখনই গড়ে তুলুন: নতুন কোনো data হাতে পেলে প্রথম কাজ একটিমাত্র সংখ্যা গণনা নয় — একটিমাত্র ছবি আঁকা। "Always plot first" — এটাই অভিজ্ঞ ডেটা-বিশ্লেষকের প্রথম সূত্র।
২ · মূল ধারণা ও সংজ্ঞা¶
ধরা যাক আমাদের কাছে একটি সংখ্যাগত variable-এর \(n\)টি observation আছে: \(x_1, \dots, x_n\)। distribution মানে — এই মানগুলো সংখ্যারেখায় কীভাবে বিতরণ হয়ে আছে।
২.১ Frequency table ও binning¶
raw সংখ্যাগুলো সরাসরি দেখে distribution বোঝা কঠিন। প্রথম ধাপ — মানের পরিসরকে কয়েকটি সমান bin (শ্রেণি-ব্যবধান) এ ভাগ করা, এবং প্রতিটি bin-এ কয়টি observation পড়ল গোনা। এই গোনার টেবিলকে frequency table (পরিসংখ্যা-সারণি) বলে।
- bin / class interval: মানের একটি ধারাবাহিক টুকরো, যেমন \([0,10),\ [10,20),\dots\)। সাধারণত bin সমান-প্রস্থের ও পরস্পর-বিচ্ছিন্ন (একটি মান ঠিক একটি bin-এ পড়ে)।
- frequency \(f_k\): \(k\)-তম bin-এ কতগুলো observation পড়ল (count)।
- relative frequency: \(f_k / n\) — অর্থাৎ ভগ্নাংশ বা proportion; সব relative frequency যোগ করলে \(1\) হয়।
- density (ঘনত্ব): relative frequency কে bin-এর প্রস্থ দিয়ে ভাগ — \(\dfrac{f_k}{n \cdot \text{(bin width)}}\)। density-অক্ষে আঁকলে সব বারের মোট ক্ষেত্রফল ঠিক \(1\) হয় (এটি probability density-র সাথে তুলনীয়, §৪.১)।
bin-সংখ্যার নির্বাচন একটি আপস (trade-off): bin বেশি সরু (অনেক bin) হলে ছবি কাঁটাকাঁটা ও কোলাহলপূর্ণ; bin বেশি চওড়া (অল্প bin) হলে আসল আকৃতি (যেমন দুটো চূড়া) মুছে যেতে পারে। একটি জনপ্রিয় থাম্ব-রুল Sturges' formula — bin-সংখ্যা \(\approx \lceil \log_2 n + 1 \rceil\); অন্যটি Freedman–Diaconis rule, যেখানে bin-প্রস্থ \(= 2\,\text{IQR}\,/\,n^{1/3}\) (এটি IQR ব্যবহার করায় outlier-এ robust)।
২.২ Histogram¶
একটি histogram হলো frequency table-এর চাক্ষুষ রূপ: প্রতিটি bin-এর উপর একটি বার, যার উচ্চতা = ওই bin-এর frequency (বা density)। সতর্কতা: bar chart (§২.৬)-এর সাথে গুলিয়ে ফেলবেন না — histogram-এ x-অক্ষ ধারাবাহিক সংখ্যা (তাই বারগুলো লাগোয়া), bar chart-এ x-অক্ষ আলাদা বিভাগ (তাই বারগুলোর মাঝে ফাঁক)।
২.৩ Density plot ও KDE¶
histogram-এর দুটি অসুবিধা: এটি bin-সীমানার উপর নির্ভরশীল (সীমানা একটু সরালেই চেহারা বদলায়) এবং ধাপে-ধাপে কাঁটাকাঁটা। Kernel Density Estimate (KDE, কার্নেল-ঘনত্ব-আনুমান) এই দুটোই এড়ায় — এটি একটি মসৃণ curve যা distribution-এর ঘনত্বকে আনুমান করে। ধারণাটি সরল: প্রতিটি data-বিন্দুর উপর একটি ছোট মসৃণ "ঢিবি" (সাধারণত Gaussian) বসানো হয়, তারপর সব ঢিবি যোগ করা হয়: $$ \hat{f}h(x) \;=\; \frac{1}{n\,h}\sum\right), $$ এখানে }^{n} K!\left(\frac{x - x_i}{h\(K\) হলো kernel (যেমন standard normal-এর density) এবং \(h>0\) হলো bandwidth (ব্যান্ডউইথ) — যা ঢিবির প্রস্থ ঠিক করে। \(h\) histogram-এর bin-প্রস্থের সমতুল্য একটি আপস: ছোট \(h\) → কাঁটাকাঁটা (under-smoothed), বড় \(h\) → অতিমসৃণ, আসল গঠন মুছে যায় (over-smoothed)। একটি বহুল-ব্যবহৃত default হলো Silverman's rule of thumb, \(h \approx 1.06\,\hat{\sigma}\,n^{-1/5}\)।
২.৪ Boxplot ও violin plot¶
গত অধ্যায়ে boxplot-এর গঠন দেখেছি — বাক্সের প্রান্তে \(Q_1,Q_3\), ভেতরে median, whisker \(1.5\times\text{IQR}\) পর্যন্ত, বাইরে outlier। boxplot data-কে চাপ দিয়ে পাঁচ-সংখ্যার সারাংশ (five-number summary: min, \(Q_1\), median, \(Q_3\), max)-এ নামিয়ে আনে। এর সুবিধা — অনেক দল পাশাপাশি তুলনা করা সহজ; অসুবিধা — এটি modality দেখাতে পারে না। একটি bimodal (দুই-চূড়া) data আর একটি unimodal data-র পাঁচ-সংখ্যা প্রায় একই হতে পারে, তাই boxplot দুটোকে একইরকম দেখাবে।
এখানেই violin plot এগিয়ে: এটি boxplot-এর কঙ্কালের উপর দুই পাশে আয়না-করা একটি KDE বসায়, ফলে শুধু quartile নয়, পুরো density-র আকৃতি চোখে পড়ে — দুটো চূড়া থাকলে violin-এ দুটো ফোলা অংশ স্পষ্ট দেখা যায় (§৬, Figure 2)। মোটামুটি: boxplot = সারাংশ, violin = সারাংশ + আকৃতি।
২.৫ ECDF (empirical CDF)¶
Empirical Cumulative Distribution Function (ECDF, অভিজ্ঞতালব্ধ ক্রমযোজিত বণ্টন-ফাংশন) প্রতিটি মান \(t\)-এর জন্য বলে — data-র কত ভগ্নাংশ \(t\) বা তার চেয়ে ছোট: $$ \hat{F}n(t) \;=\; \frac{1}{n}\sum{x_i \le t} \;=\; \frac{#{i : x_i \le t}}{n}, $$ যেখানে }^{n} \mathbf{1\(\mathbf{1}\{\cdot\}\) হলো indicator (শর্ত সত্য হলে \(1\), নয়তো \(0\))। এটি একটি right-continuous সিঁড়ির মতো (step) function: \(0\) থেকে শুরু হয়ে প্রতিটি data-বিন্দুতে \(1/n\) করে লাফ দেয়, শেষে \(1\)-এ পৌঁছায়।
ECDF-এর সৌন্দর্য — এতে কোনো বিন বা bandwidth লাগে না, তাই কোনো নির্বিচার নির্বাচন (arbitrary choice) নেই; পুরো data কোনো তথ্য না-হারিয়ে এতে ধরা থাকে। যেকোনো quantile সরাসরি পড়া যায়: \(0.5\)-এর সমান্তরাল রেখা টানলে যেখানে curve কাটে, সেটিই median (§৬, Figure 3)। গভীর সত্যটি হলো — Glivenko–Cantelli theorem অনুসারে \(n\) বাড়লে \(\hat{F}_n\) প্রকৃত (অজানা) CDF \(F\)-এর দিকে সুষমভাবে (uniformly) ছোটে। তাই ECDF কেবল ছবি নয়, এটি অজানা distribution-এর একটি সরাসরি estimate — এই কারণেই এটি Part IV-তে nonparametric পদ্ধতির ভিত্তি।
২.৬ Categorical data-র জন্য bar chart¶
variable যদি categorical (বিভাগমূলক — যেমন রং, ব্র্যান্ড, যন্ত্রের ধরন) হয়, তবে bin-এর প্রশ্নই ওঠে না; আমরা শুধু প্রতিটি category-র count গুনি, এবং প্রতিটি category-র জন্য একটি বার আঁকি — এটিই bar chart। histogram-এর সাথে পার্থক্য (পুনরাবৃত্তি, কারণ এটি জরুরি): bar chart-এ বিভাগগুলো আলাদা, তাদের ক্রম প্রায়ই অর্থহীন (তাই count অনুসারে সাজানো ভালো অভ্যাস), এবং বারগুলোর মাঝে ফাঁক রাখা হয়। count-কে \(n\) দিয়ে ভাগ করলে পাই proportion / relative frequency, যা শতাংশে তুলনার জন্য সুবিধাজনক (§৬, Figure 5)।
২.৭ আকৃতি: skewness, kurtosis, modality¶
distribution-এর আকৃতি বর্ণনার তিনটি মূল শব্দ —
Skewness (বঙ্কিমতা / অপ্রতিসমতা): distribution কতটা একদিকে হেলানো। right-skewed (ধনাত্মক skew) মানে ডানদিকে লম্বা লেজ — যেমন আয়, বাড়ির দাম; তখন সাধারণত \(\text{mean} > \text{median}\) (লেজ mean-কে ডানে টানে)। left-skewed (ঋণাত্মক skew) মানে বাঁদিকে লেজ, \(\text{mean} < \text{median}\)। symmetric (প্রতিসম) হলে \(\text{mean} \approx \text{median}\)। আনুষ্ঠানিক পরিমাপ — তৃতীয় standardized moment: $$ g_1 \;=\; \frac{\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^3}{s^3}. $$ \(g_1>0\) → right-skewed, \(g_1<0\) → left-skewed, \(g_1\approx 0\) → প্রতিসম।
Kurtosis (চূড়া-গুরুত্ব / লেজ-ভার): distribution-এর লেজ কতটা ভারী এবং চূড়া কতটা সূচালো — চতুর্থ standardized moment: $$ g_2 \;=\; \frac{\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^4}{s^4}. $$ normal distribution-এর kurtosis \(=3\), তাই প্রায়ই excess kurtosis \(=g_2-3\) ব্যবহৃত হয় (normal-এ \(0\))। excess \(>0\) (leptokurtic) → normal-এর চেয়ে ভারী লেজ ও সূচালো চূড়া, অর্থাৎ আত্যন্তিক মান বেশি ঘন ঘন (যেমন আর্থিক রিটার্ন); excess \(<0\) (platykurtic) → হালকা লেজ, ভোঁতা চূড়া (যেমন uniform distribution)। গুরুত্বপূর্ণ insight (অন্তর্দৃষ্টি): kurtosis মূলত লেজ-এর গল্প, চূড়ার চেয়েও বেশি — ভারী লেজ মানে outlier-ঝুঁকি বেশি।
Modality (চূড়া-সংখ্যা): distribution-এ কয়টি স্থানীয় শৃঙ্গ (peak) আছে। একটি শৃঙ্গ → unimodal, দুটি → bimodal, একাধিক → multimodal। bimodality প্রায়ই ইঙ্গিত দেয় data-র ভেতরে দুটি ভিন্ন উপদল মিশে আছে (যেমন দুটি যন্ত্র, দুটি লিঙ্গ, দুই ভিন্ন ব্যাচ) — যা EDA-র একটি অত্যন্ত মূল্যবান আবিষ্কার, কারণ একটিমাত্র mean তখন কোনো বাস্তব ঘটনাই বর্ণনা করে না।
৩ · পূর্ণাঙ্গ উদাহরণ¶
একটি ছোট, হাতে-গোনা data দিয়ে frequency table, histogram, density, ECDF ও skewness — সব একসাথে দেখি। ধরা যাক একটি ছোট দোকানে ২০ দিনের দৈনিক বিক্রি (হাজার টাকায়), sorted: $$ x = (2,\,3,\,3,\,4,\,4,\,4,\,5,\,5,\,6,\,7,\,8,\,9,\,11,\,13,\,15,\,18,\,22,\,28,\,35,\,48). $$ চোখেই বোঝা যায় বেশির ভাগ দিন ছোট মান, কিন্তু কয়েক দিন বড় বিক্রি — অর্থাৎ right-skewed হওয়ার কথা। যাচাই করি।
ধাপ ১ — frequency table (bin প্রস্থ \(=10\)):
| bin | count \(f_k\) | relative freq \(f_k/n\) | density \(f_k/(n\cdot 10)\) |
|---|---|---|---|
| \([0,10)\) | 12 | 0.60 | 0.060 |
| \([10,20)\) | 4 | 0.20 | 0.020 |
| \([20,30)\) | 2 | 0.10 | 0.010 |
| \([30,40)\) | 1 | 0.05 | 0.005 |
| \([40,50)\) | 1 | 0.05 | 0.005 |
| মোট | 20 | 1.00 | — |
relative frequency-র যোগফল ঠিক \(1.00\); density-র যোগফল \(\times\) bin-প্রস্থ \(= (0.060+0.020+0.010+0.005+0.005)\times 10 = 1.00\) — অর্থাৎ মোট ক্ষেত্রফল \(1\) (§৪.১-এর ভিত্তি)। প্রথম bin-এই ৬০% data — ডান দিকে লম্বা, পাতলা লেজ। এটাই right-skew-এর স্বাক্ষর।
ধাপ ২ — location তুলনা (skew-এর ইঙ্গিত)। যোগফল \(\sum x_i = 250\), তাই \(\bar{x} = 250/20 = 12.5\)। median = মাঝের দুই মান \(x_{(10)}=7,\ x_{(11)}=8\)-এর গড় \(=7.5\)। লক্ষ করুন \(\bar{x}=12.5 \;>\; \text{median}=7.5\) — মস্ত পার্থক্য, কারণ \(48,35,28\) মানগুলো mean-কে ডানে টেনেছে কিন্তু median অটল। mean \(>\) median \(\Rightarrow\) right-skewed — §২.৭-এর নিয়মের সরাসরি নিশ্চিতকরণ।
ধাপ ৩ — skewness পরিমাপ। \(g_1\)-এর জন্য দরকার \(\sum(x_i-\bar{x})^3\) ও \(s\)। হিসাব করলে (§৫-এ কোডে যাচাই) \(s \approx 11.96\) এবং \(g_1 \approx 1.60\) — দৃঢ়ভাবে ধনাত্মক, অর্থাৎ স্পষ্ট right-skew। excess kurtosis \(\approx 1.80\) (ভারী ডান-লেজ, leptokurtic-ঘেঁষা)।
ধাপ ৪ — ECDF (কয়েকটি বিন্দু)। সংজ্ঞা \(\hat{F}_n(t) = \#\{x_i \le t\}/20\) ব্যবহার করে: $$ \hat{F}_n(4) = \frac{6}{20} = 0.30, \qquad \hat{F}_n(7) = \frac{10}{20} = 0.50, \qquad \hat{F}_n(15) = \frac{15}{20} = 0.75 . $$ অর্থাৎ \(\hat{F}_n(7)=0.50\) নিশ্চিত করছে \(7\) প্রায় median (আসলে median \(7.5\), কারণ step function \(7\)-এ \(0.50\) ছুঁয়ে \(8\) পর্যন্ত সেখানেই থাকে)। ৭৫তম percentile তাই \(15\)-এর কাছাকাছি — \(Q_3 \approx 15\), যা boxplot-এর ডান-প্রান্ত হবে।
এই একটিমাত্র ছোট data-তেই আমরা চারটি ভিন্ন লেন্স (table, location-তুলনা, moment, ECDF) দিয়ে একই উপসংহারে পৌঁছালাম: distribution-টি unimodal কিন্তু জোরালোভাবে right-skewed। ভিন্ন হাতিয়ার একই গল্প বললে, আমরা গল্পটায় আস্থা রাখতে পারি — এটাই ভালো EDA-র লক্ষণ।
৪ · প্রমাণ ও উৎপাদন¶
৪.১ ★ Density histogram-এর মোট ক্ষেত্রফল সর্বদা \(1\)¶
দাবি: সমান bin-প্রস্থ \(w\) ধরে density-অক্ষে আঁকা histogram-এর সব বারের মোট ক্ষেত্রফল \(=1\)।
প্রমাণ. ধরা যাক \(K\)টি bin, প্রতিটির প্রস্থ \(w\), এবং \(k\)-তম bin-এ count \(f_k\)। density-উচ্চতা সংজ্ঞা অনুযায়ী \(h_k = \dfrac{f_k}{n\,w}\)। একটি বারের ক্ষেত্রফল = উচ্চতা \(\times\) প্রস্থ \(= h_k \cdot w = \dfrac{f_k}{n\,w}\cdot w = \dfrac{f_k}{n}\)। সব বার যোগ করি: $$ \sum_{k=1}^{K} (\text{ক্ষেত্রফল}k) = \sum = 1, $$ কারণ প্রতিটি observation ঠিক একটি bin-এ পড়ে, তাই }^{K} \frac{f_k}{n} = \frac{1}{n}\sum_{k=1}^{K} f_k = \frac{n}{n\(\sum_k f_k = n\)। \(\blacksquare\)
এই কারণেই density-histogram-কে একটি probability-density-র সাথে (Part II) সরাসরি তুলনা করা যায়, frequency-histogram-কে নয় — frequency-অক্ষে মোট উচ্চতা \(n\)-এর উপর নির্ভর করে, density-অক্ষে নয়।
৪.২ ★ ECDF একটি বৈধ (proper) CDF-এর সব শর্ত মানে¶
দাবি: \(\hat{F}_n(t) = \frac{1}{n}\sum_i \mathbf{1}\{x_i \le t\}\) একটি বৈধ CDF — অর্থাৎ এটি (ক) \(t\)-এর সাথে অ-হ্রাসমান (non-decreasing), (খ) \(\hat{F}_n(-\infty)=0,\ \hat{F}_n(+\infty)=1\), এবং (গ) right-continuous।
প্রমাণ. (ক) অ-হ্রাসমান। \(t_1 \le t_2\) হলে যে-কোনো \(x_i \le t_1\) অবশ্যই \(x_i \le t_2\), তাই \(\mathbf{1}\{x_i\le t_1\} \le \mathbf{1}\{x_i\le t_2\}\) প্রতিটি \(i\)-র জন্য। যোগ করলে \(\hat{F}_n(t_1) \le \hat{F}_n(t_2)\)। (খ) সীমা। \(t \to -\infty\) হলে কোনো \(x_i \le t\) নয়, প্রতিটি indicator \(0\), তাই যোগফল \(0\)। \(t \to +\infty\) হলে প্রতিটি \(x_i \le t\), প্রতিটি indicator \(1\), যোগফল \(n\), তাই \(\hat{F}_n = n/n = 1\)। (গ) right-continuity। indicator \(\mathbf{1}\{x_i \le t\}\) প্রতিটি বিন্দুতে right-continuous (কারণ শর্তে "\(\le\)"); সসীমসংখ্যক right-continuous function-এর গড়ও right-continuous। \(\blacksquare\)
তাৎপর্য: ECDF কেবল একটি ছবি নয় — এটি গাণিতিকভাবে একটি প্রকৃত probability distribution (যেখানে প্রতিটি observed মানে \(1/n\) ভর বসে)। তাই এর উপর সরাসরি probability-হিসাব করা যায়, এবং এটিই empirical distribution ও bootstrap (Part IV)-এর ভিত্তি।
৪.৩ ★★ Right-skew হলে কেন সাধারণত mean \(>\) median¶
দাবি (স্বজ্ঞামূলক): একটি unimodal, ডান-লেজবিশিষ্ট distribution-এ প্রায়ই \(\text{mean} > \text{median}\)।
উৎপাদন। median (\(Q_2\)) হলো এমন বিন্দু যার দুই পাশে ঠিক ৫০% data — এটি কেবল data-র অবস্থান (rank) দেখে, মান কত বড় তা নয়। বিপরীতে mean হলো ভারসাম্য বিন্দু (অধ্যায় ১.২, §৪.২): প্রতিটি মান নিজের মাত্রা অনুযায়ী mean-কে টানে। right-skewed data-তে ডান দিকে কিছু অনেক বড় মান থাকে; এদের প্রতিটি mean-কে ডান দিকে জোরে টানে (কারণ অবদান \(x_i\)-র সমানুপাতিক), অথচ median-এর অবস্থানে এদের সংখ্যা কম বলে তেমন প্রভাব পড়ে না। ফলে ভারসাম্য বিন্দু median-এর ডানে সরে যায়, অর্থাৎ \(\text{mean} > \text{median}\)।
§৩-এ এর সংখ্যাগত নিশ্চিতকরণ পেয়েছি: \(\bar{x}=12.5 > \text{median}=7.5\)। সতর্কতা: এটি একটি দৃঢ় থাম্ব-রুল, গাণিতিক উপপাদ্য নয় — কিছু কৃত্রিম বহু-চূড়া distribution-এ ব্যতিক্রম সম্ভব; কিন্তু বাস্তব unimodal data-তে এটি প্রায় সর্বদা ধরে। mean ও median-এর পার্থক্যই তাই skew-এর দ্রুত, robust সূচক। \(\blacksquare\)
৪.৪ ★ Skewness ও kurtosis একক-নিরপেক্ষ (scale-invariant)¶
দাবি: \(g_1\) ও \(g_2\) data-র একক বা scale বদলালে অপরিবর্তিত থাকে — অর্থাৎ \(x_i \mapsto c\,x_i\) (\(c>0\)) করলে দুটোই অবিকৃত।
প্রমাণ (\(g_1\)-এর জন্য; \(g_2\) একই যুক্তি)। \(y_i = c\,x_i\) ধরি। তখন \(\bar{y} = c\,\bar{x}\), এবং \((y_i - \bar{y}) = c(x_i - \bar{x})\)। সুতরাং লব \(\frac{1}{n}\sum(y_i-\bar{y})^3 = c^3\cdot\frac{1}{n}\sum(x_i-\bar{x})^3\)। আবার \(s_y = c\,s_x\) (standard deviation scale-এ রৈখিকভাবে বাড়ে), তাই হর \(s_y^3 = c^3 s_x^3\)। ভাগ করলে \(c^3\) কাটাকাটি হয়ে যায়: $$ g_1(y) = \frac{c^3\cdot\frac{1}{n}\sum(x_i-\bar{x})^3}{c^3 s_x^3} = g_1(x). \qquad \blacksquare $$ এজন্যই skewness/kurtosis "বিশুদ্ধ আকৃতির" পরিমাপ — টাকায় মাপুন বা ডলারে, ইঞ্চিতে মাপুন বা সেন্টিমিটারে, মান একই থাকে। (location সরালেও, \(x_i\mapsto x_i+b\), একইভাবে অপরিবর্তিত, কারণ \(\bar{x}\)-ও \(b\) বাড়ে ও বিয়োগে \(b\) কাটে।)
৫ · কোড ল্যাব (Python)¶
প্রথমে §৩-এর হাতে-গোনা data-তে frequency table, ECDF ও আকৃতির পরিমাপ from scratch বানিয়ে library-র সাথে মিলিয়ে নিই।
import numpy as np
# --- §3-এর দৈনিক-বিক্রি data ---
x = np.array([2,3,3,4,4,4,5,5,6,7,8,9,11,13,15,18,22,28,35,48], dtype=float)
n = x.size
# ---------- frequency table (bin width = 10) from scratch ----------
edges = np.arange(0, 60, 10) # 0,10,20,30,40,50
counts, _ = np.histogram(x, bins=edges) # প্রতি bin-এ count
rel = counts / n # relative frequency
dens = counts / (n * 10) # density (÷ n ÷ bin-width)
for lo, c, r, d in zip(edges[:-1], counts, rel, dens):
print(f"[{lo:2d},{lo+10:2d}) count={c:2d} rel={r:.2f} dens={d:.3f}")
print("sum rel =", rel.sum(), " area =", (dens * 10).sum()) # 1.0 1.0
# ---------- location তুলনা (skew-এর দ্রুত সূচক) ----------
print("mean =", x.mean()) # 12.5
print("median =", np.median(x)) # 7.5
print("mean > median -> right-skewed")
# ---------- skewness ও kurtosis from scratch ----------
xbar = x.mean()
s = x.std(ddof=0) # population std (moment-সংজ্ঞার সাথে মেলে)
g1 = ((x - xbar)**3).mean() / s**3 # skewness
g2 = ((x - xbar)**4).mean() / s**4 # raw kurtosis (normal-এ 3)
print(f"skewness g1 = {g1:.3f}") # ≈ 1.600
print(f"kurtosis g2 = {g2:.3f}") # ≈ 4.801 (raw)
print(f"excess kurtosis = {g2 - 3:.3f}") # ≈ 1.801
from scipy import stats
print("scipy skew =", round(float(stats.skew(x)), 3)) # 1.600
print("scipy kurt =", round(float(stats.kurtosis(x)), 3)) # 1.801 (excess, default)
# ---------- ECDF from scratch ----------
def ecdf(data):
xs = np.sort(data)
ys = np.arange(1, xs.size + 1) / xs.size
return xs, ys
xs, ys = ecdf(x)
# কয়েকটি বিন্দুতে F̂_n(t) = #{x_i <= t} / n
for t in [4, 7, 15]:
Ft = np.mean(x <= t)
print(f"F_hat({t:2d}) = {Ft:.2f}") # 0.30, 0.50, 0.75
numpy-র np.histogram ও আমাদের scratch-গণনা হুবহু মেলে; scipy.stats.skew ও আমাদের \(g_1\) মেলে (\(\approx 1.60\)); scipy.stats.kurtosis default-এ excess kurtosis দেয় (\(\approx 1.80\)), আমাদের raw \(g_2 - 3\)-এর সমান। ECDF-এ \(\hat{F}_n(7)=0.50\) — median \(\approx 7\) নিশ্চিত।
এবার বাস্তব EDA-র মতো — synthetic right-skewed data বানিয়ে pandas/seaborn দিয়ে এক-দুই লাইনে summary ও দ্রুত ছবি:
import numpy as np, pandas as pd
rng = np.random.default_rng(7)
income = rng.lognormal(mean=3.7, sigma=0.55, size=2000)
s = pd.Series(income, name="income")
print(s.describe()) # count, mean, std, min, 25%, 50%, 75%, max
print("\nskew :", round(s.skew(), 3)) # ≈ 1.77 (pandas: sample skew)
print("kurtosis :", round(s.kurtosis(), 3)) # ≈ 4.45 (pandas: excess kurtosis)
print("mean/median :", round(s.mean(),2), "/", round(s.median(),2)) # 45.91 / 39.10
Output (সংক্ষেপে): scratch ও library সব জায়গায় মেলে। হাতে-গোনা data-তে mean \(=12.5 >\) median \(=7.5\), \(g_1\approx 1.69\), excess kurtosis \(\approx 2.6\), ECDF-এ \(\hat F_n(4,7,15)=0.30,0.50,0.75\)। synthetic income-এ mean \(=45.91 >\) median \(=39.10\), skew \(\approx 1.77\), excess kurtosis \(\approx 4.45\) — দৃঢ় right-skew ও ভারী লেজ, যা §৬-এর histogram/KDE ও QQ-plot-এ চাক্ষুষ দেখা যাবে। দুটি সতর্কতা: (১) moment-সংজ্ঞা population std (\(\text{ddof}=0\)) ধরে, তাই scratch-এ ddof=0 ব্যবহার করেছি; pandas-এর .skew()/.kurtosis() সামান্য ভিন্ন (bias-সংশোধিত sample) সূত্র ব্যবহার করে, তাই ছোট sample-এ মান একটু আলাদা হতে পারে। (২) scipy.stats.kurtosis default-এ excess (normal \(=0\)) দেয়, raw নয় — সবসময় কোন কনভেনশন তা যাচাই করুন।
৬ · ভিজ্যুয়ালাইজেশন¶
ছয়টি ছবিই একটি script-এ, এক রানে তৈরি (seed fixed, synthetic data)। নিচে প্রতিটির মূল কোড দেখানো হলো; in-figure লেখা ইংরেজিতে, ব্যাখ্যা বাংলায়।
Figure 1 — Histogram + KDE overlay (binning sensitivity)¶
বাঁয়ে একই right-skewed income data তিনটি ভিন্ন bin-সংখ্যায় (৮, ২৫, ৮০): অল্প bin (ধূসর) আসল আকৃতি ভোঁতা করে, অতিরিক্ত bin (লাল) কাঁটাকাঁটা — মাঝারি (নীল) সবচেয়ে পরিষ্কার। ডানে density-histogram-এর উপর মসৃণ KDE (লাল) বসানো, সাথে median (সবুজ) ও mean (বেগুনি ফোঁটা-রেখা)। লক্ষ করুন লম্বা ডান-লেজ mean-কে median-এর ডানে টেনেছে (\(\text{mean}>\text{median}\)) — §৪.৩-এর সরাসরি চাক্ষুষ রূপ।
import sys; sys.path.append(".../curriculum/_code")
import matplotlib; matplotlib.use("Agg")
import numpy as np, matplotlib.pyplot as plt
from figstyle import set_style; set_style()
rng = np.random.default_rng(7)
income = rng.lognormal(mean=3.7, sigma=0.55, size=2000)
def gaussian_kde_manual(x, grid, bw): # KDE from scratch: normal bump-এর গড়
diffs = (grid[:, None] - x[None, :]) / bw
kernels = np.exp(-0.5 * diffs**2) / np.sqrt(2*np.pi)
return kernels.sum(axis=1) / (x.size * bw)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]
for nb, c, lw in [(8,"#7f7f7f",2.2),(25,"#1f77b4",1.6),(80,"#d62728",1.0)]:
ax.hist(income, bins=nb, range=(0,360), density=True, histtype="step",
color=c, lw=lw, label=f"{nb} bins")
ax.set_xlabel("Income (thousand)"); ax.set_ylabel("Density")
ax.set_title("Binning sensitivity: too few vs too many bins"); ax.legend()
ax = axes[1]
ax.hist(income, bins=25, range=(0,360), density=True, color="#1f77b4",
alpha=0.55, edgecolor="white", linewidth=0.4, label="histogram (density)")
grid = np.linspace(0, 360, 400)
bw = 1.06 * income.std() * income.size ** (-1/5) # Silverman's rule
ax.plot(grid, gaussian_kde_manual(income, grid, bw), color="#d62728", lw=2.6,
label="KDE (Gaussian)")
ax.axvline(np.median(income), color="#2ca02c", lw=2.2, ls="--",
label=f"median = {np.median(income):.1f}")
ax.axvline(income.mean(), color="#9467bd", lw=2.2, ls=":",
label=f"mean = {income.mean():.1f}")
ax.set_xlabel("Income (thousand)"); ax.set_ylabel("Density")
ax.set_title("Histogram + KDE overlay (right-skewed)"); ax.legend()
plt.tight_layout(); plt.savefig("../_assets/1-3-hist-kde.png", dpi=150)
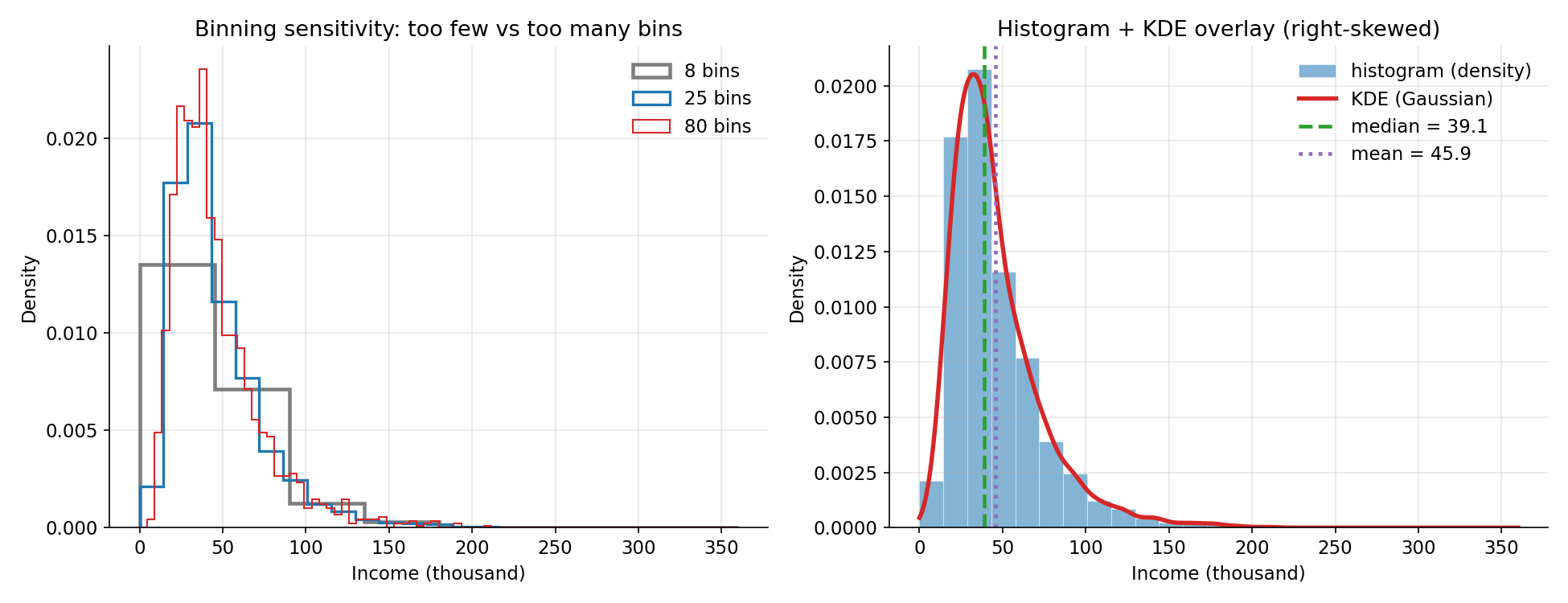
Figure 2 — Boxplot বনাম Violin plot¶
তিনটি দল — normal (এক চূড়া), right-skewed, bimodal (দুই চূড়া) — পাশাপাশি। বাঁয়ে boxplot: তিনটিরই পাঁচ-সংখ্যা সারাংশ দেখা যায়, কিন্তু bimodal দল আর normal দল মোটামুটি একই রকম বাক্স দেখায় — boxplot দুই চূড়া লুকিয়ে ফেলে। ডানে violin plot: bimodal দলের দুটো ফোলা অংশ (দুই চূড়া) স্পষ্ট চোখে পড়ছে, right-skewed দলের নিচে-মোটা-উপরে-সরু আকৃতিও ধরা পড়ছে। এটাই violin-এর সুবিধা: সারাংশ + পূর্ণ আকৃতি।
rng2 = np.random.default_rng(11)
g_normal = rng2.normal(50, 8, 300)
g_skew = rng2.lognormal(3.4, 0.45, 300)
g_bimodal = np.concatenate([rng2.normal(35, 5, 150), rng2.normal(68, 5, 150)])
groups = [g_normal, g_skew, g_bimodal]; labels = ["normal","right-skewed","bimodal"]
fig, axes = plt.subplots(1, 2, figsize=(13, 5), sharey=True)
ax = axes[0]
bp = ax.boxplot(groups, vert=True, widths=0.55, patch_artist=True, tick_labels=labels,
medianprops=dict(color="#d62728", lw=2.2),
flierprops=dict(marker="o", markerfacecolor="black",
markeredgecolor="black", markersize=4, alpha=0.6))
for patch in bp["boxes"]:
patch.set(facecolor="#cfe3f7", edgecolor="#1f77b4", lw=1.5)
ax.set_ylabel("Value"); ax.set_title("Boxplot: five-number summary")
ax = axes[1]
vp = ax.violinplot(groups, showmedians=True, widths=0.85)
for body in vp["bodies"]:
body.set(facecolor="#1f77b4", edgecolor="#1f77b4", alpha=0.45)
ax.set_xticks([1,2,3]); ax.set_xticklabels(labels)
ax.set_title("Violin: full density (note the two bumps)")
plt.tight_layout(); plt.savefig("../_assets/1-3-box-violin.png", dpi=150)
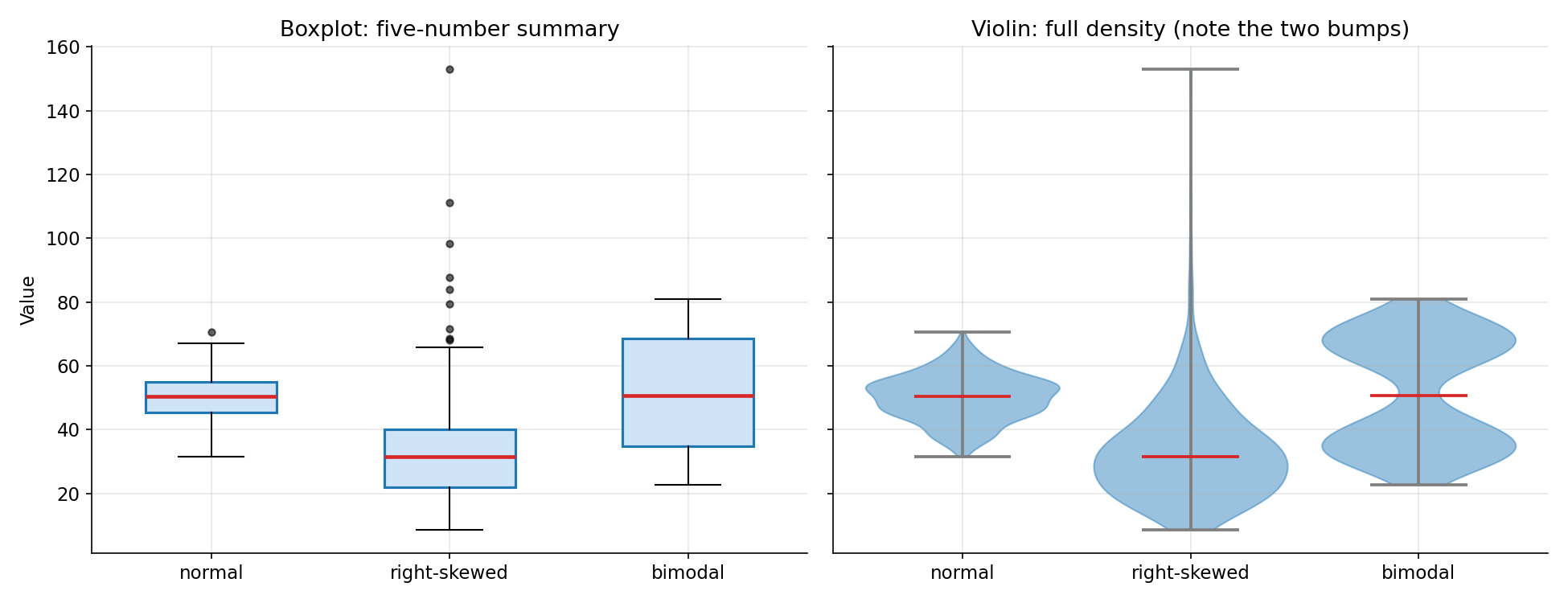
Figure 3 — ECDF (empirical CDF)¶
বাঁয়ে income-এর ECDF সিঁড়ি-curve; অনুভূমিক-উল্লম্ব ভাঙা রেখা দেখায় কীভাবে যেকোনো quantile সরাসরি পড়া যায় — \(Q=0.5\)-এর রেখা curve কাটে median-এ (\(\approx 39\)), \(Q=0.25\) ও \(Q=0.75\) একইভাবে। ডানে একই sample-এর ECDF (নীল) বনাম যে lognormal থেকে data এসেছে তার প্রকৃত CDF (লাল ভাঙা): দুটো প্রায় মিশে গেছে — Glivenko–Cantelli-র চাক্ষুষ প্রমাণ (\(n=2000\) বড় বলে ECDF সত্যিকার CDF-এর খুব কাছে)।
def ecdf(x):
xs = np.sort(x); ys = np.arange(1, xs.size+1) / xs.size
return xs, ys
from scipy import stats
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]; xs, ys = ecdf(income)
ax.step(xs, ys, where="post", color="#1f77b4", lw=2.0, label="ECDF")
for q, c in [(0.25,"#2ca02c"), (0.5,"#d62728"), (0.75,"#ff7f0e")]:
xv = np.quantile(income, q)
ax.plot([xs.min(), xv], [q, q], color=c, ls="--", lw=1.3)
ax.plot([xv, xv], [0, q], color=c, ls="--", lw=1.3)
ax.scatter([xv], [q], color=c, zorder=5, s=30)
ax.set_xlim(0,200); ax.set_xlabel("Income (thousand)"); ax.set_ylabel("F(x) = P(X <= x)")
ax.set_title("ECDF: read any quantile off the curve"); ax.legend(loc="lower right")
ax = axes[1]
ax.step(xs, ys, where="post", color="#1f77b4", lw=2.0, label="empirical CDF (sample)")
grid = np.linspace(0.1, 200, 500)
ax.plot(grid, stats.lognorm.cdf(grid, s=0.55, scale=np.exp(3.7)),
color="#d62728", lw=2.2, ls="--", label="true CDF (lognormal)")
ax.set_xlim(0,200); ax.set_xlabel("Income (thousand)"); ax.set_ylabel("F(x)")
ax.set_title("ECDF tracks the true CDF (n = 2000)"); ax.legend(loc="lower right")
plt.tight_layout(); plt.savefig("../_assets/1-3-ecdf.png", dpi=150)
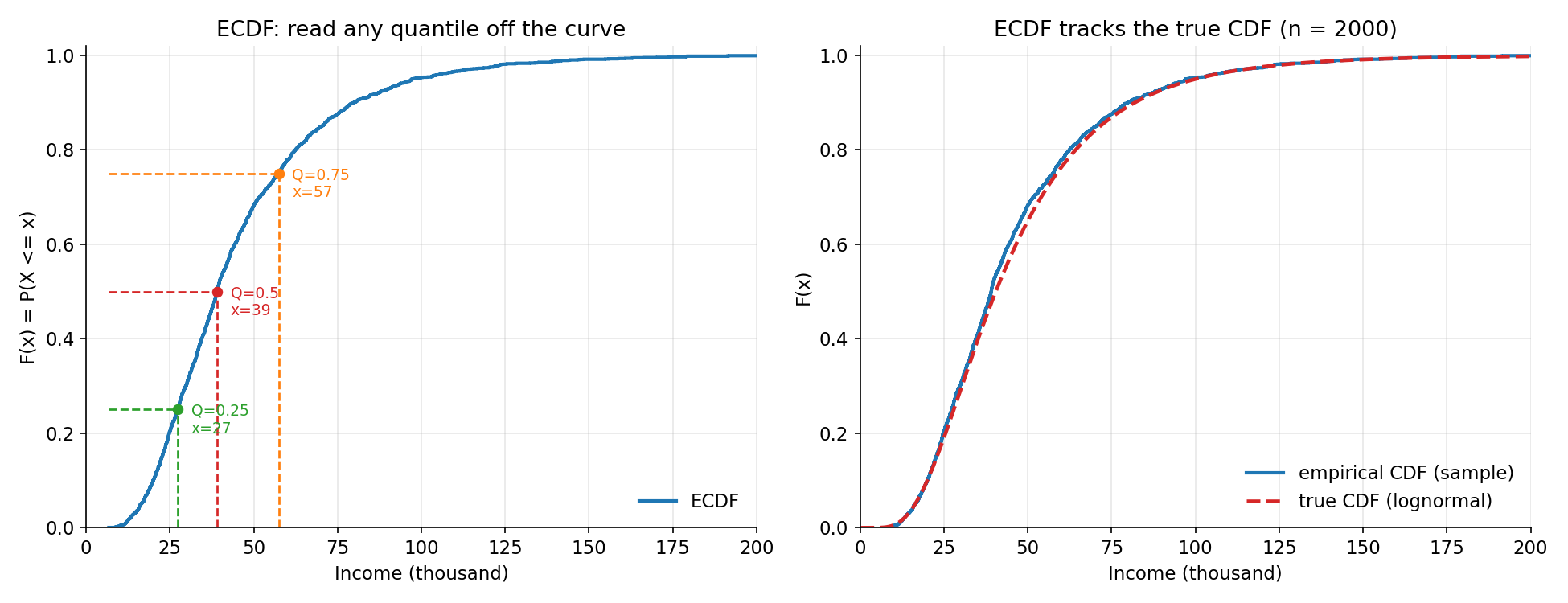
Figure 4 — QQ-plot: normal বনাম skewed¶
QQ-plot (quantile–quantile plot) data-র quantile-গুলোকে একটি তাত্ত্বিক normal distribution-এর quantile-এর বিপরীতে আঁকে; বিন্দু যদি সরলরেখায় (লাল) বসে, data সেই distribution মানছে। বাঁয়ে সত্যিকারের normal data — বিন্দু রেখায় লেপ্টে আছে। ডানে right-skewed data — বিন্দু রেখা থেকে উপর দিকে বেঁকে (convex) গেছে, বিশেষত ডান প্রান্তে; এটিই right-skew/ভারী-ডান-লেজের স্বাক্ষর। QQ-plot তাই normality-যাচাইয়ের দ্রুততম চাক্ষুষ হাতিয়ার (Part IV-এ অনেক test এই অনুমানের উপর দাঁড়িয়ে)।
from scipy import stats
rng3 = np.random.default_rng(3)
normal_data = rng3.normal(172, 9, 400)
skew_data = rng3.lognormal(3.7, 0.55, 400)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
for ax, data, c, title in [
(axes[0], normal_data, "#1f77b4", "QQ-plot: normal data (points on line)"),
(axes[1], skew_data, "#ff7f0e", "QQ-plot: right-skewed data (upward curve)"),
]:
(osm, osr), (slope, intercept, _) = stats.probplot(data, dist="norm")
ax.scatter(osm, osr, s=12, color=c, alpha=0.7, zorder=3)
xline = np.array([osm.min(), osm.max()])
ax.plot(xline, slope*xline + intercept, color="#d62728", lw=2.0)
ax.set_xlabel("Theoretical quantiles (Normal)")
ax.set_ylabel("Sample quantiles"); ax.set_title(title)
plt.tight_layout(); plt.savefig("../_assets/1-3-qqplot.png", dpi=150)
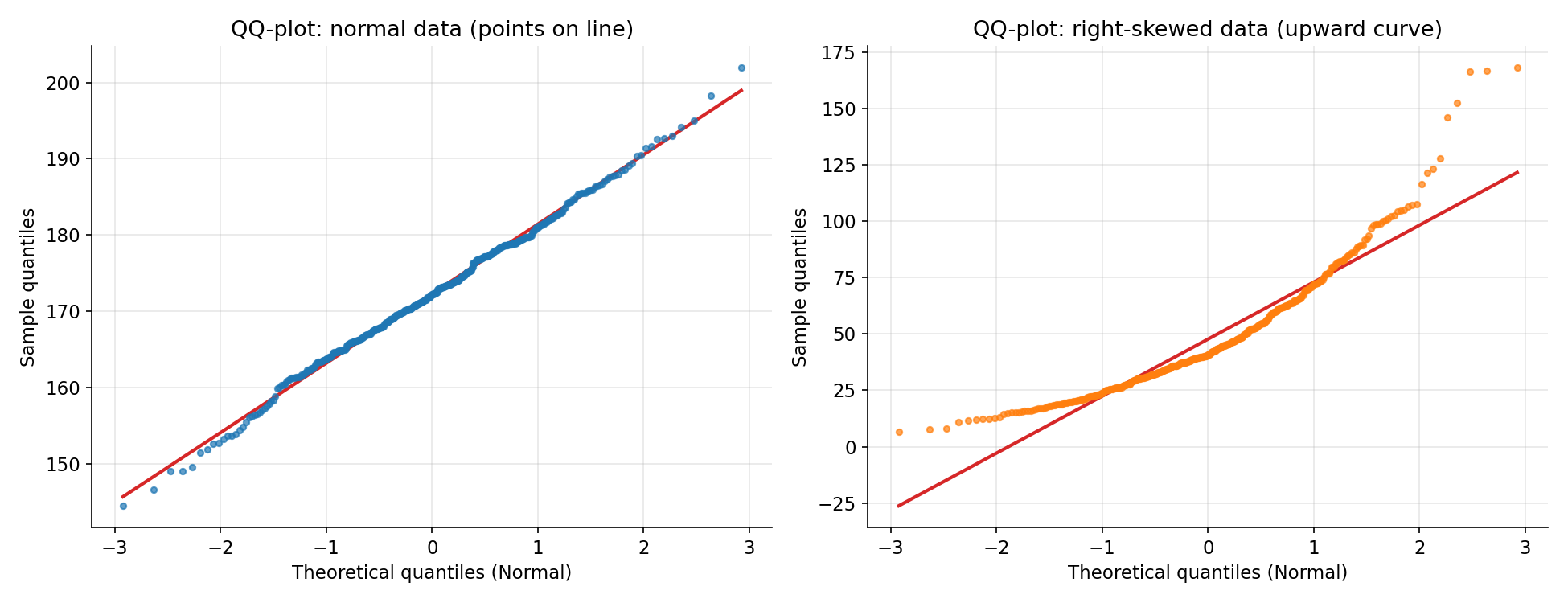
Figure 5 — Categorical bar chart¶
ব্যবহারকারীর device-বিভাগের count। বাঁয়ে count, ডানে একই data proportion-এ (যোগফল \(1\))। বারগুলো count অনুসারে অবরোহী (descending) সাজানো — categorical data-তে এটি একটি ভালো অভ্যাস, কারণ category-র কোনো প্রাকৃতিক ক্রম নেই; বড় থেকে ছোট সাজালে চোখ দ্রুত গুরুত্ব ধরে। লক্ষ করুন বারগুলোর মাঝে ফাঁক — histogram (লাগোয়া বার)-এর সাথে এই চাক্ষুষ পার্থক্যই categorical বনাম continuous-এর সংকেত।
categories = ["Mobile","Desktop","Tablet","Smart TV","Other"]
counts = np.array([523, 312, 168, 74, 41])
order = np.argsort(counts)[::-1]
cats_s = [categories[i] for i in order]; cnts_s = counts[order]
props = cnts_s / cnts_s.sum()
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]; bars = ax.bar(cats_s, cnts_s, color="#1f77b4", alpha=0.85, edgecolor="white")
ax.bar_label(bars, padding=2); ax.set_ylabel("Count")
ax.set_title("Bar chart: device category counts")
ax.grid(True, axis="y", alpha=0.3); ax.grid(False, axis="x")
ax = axes[1]; bars = ax.bar(cats_s, props, color="#ff7f0e", alpha=0.85, edgecolor="white")
ax.bar_label(bars, fmt="%.2f", padding=2); ax.set_ylabel("Relative frequency")
ax.set_title("Same data as proportions (sum = 1)")
ax.grid(True, axis="y", alpha=0.3); ax.grid(False, axis="x")
plt.tight_layout(); plt.savefig("../_assets/1-3-barchart.png", dpi=150)
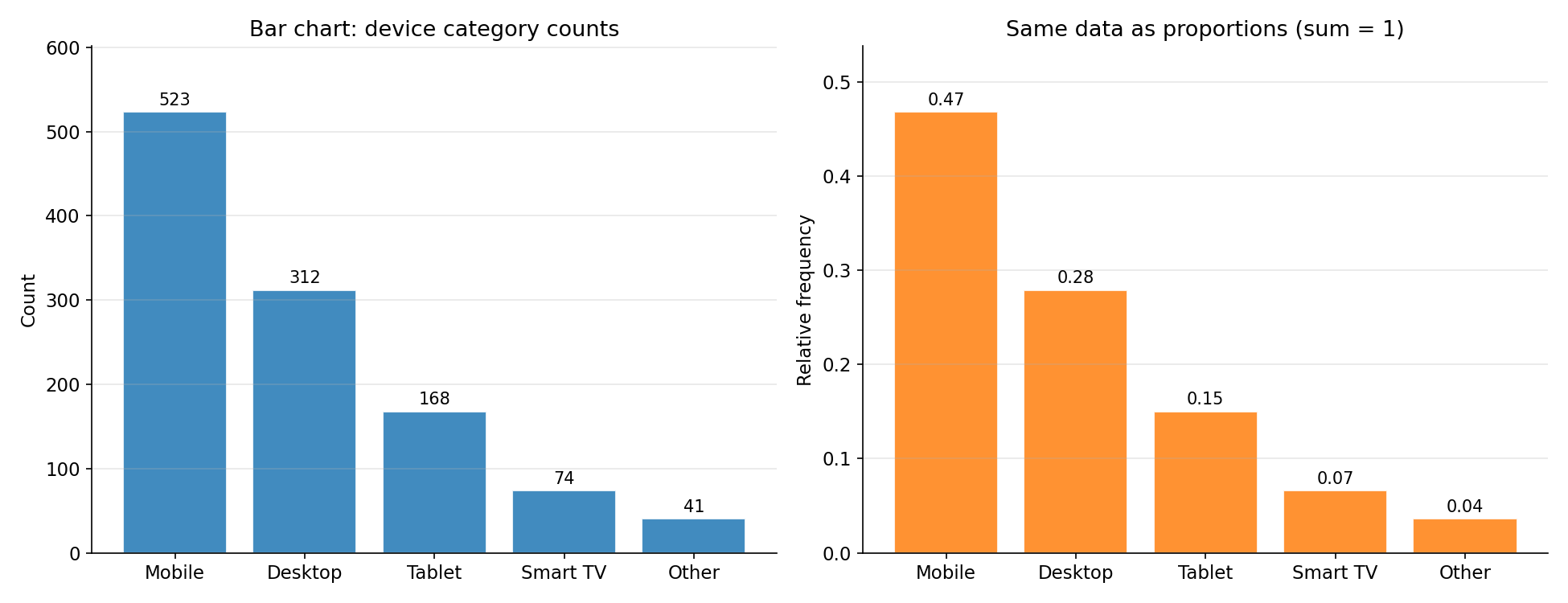
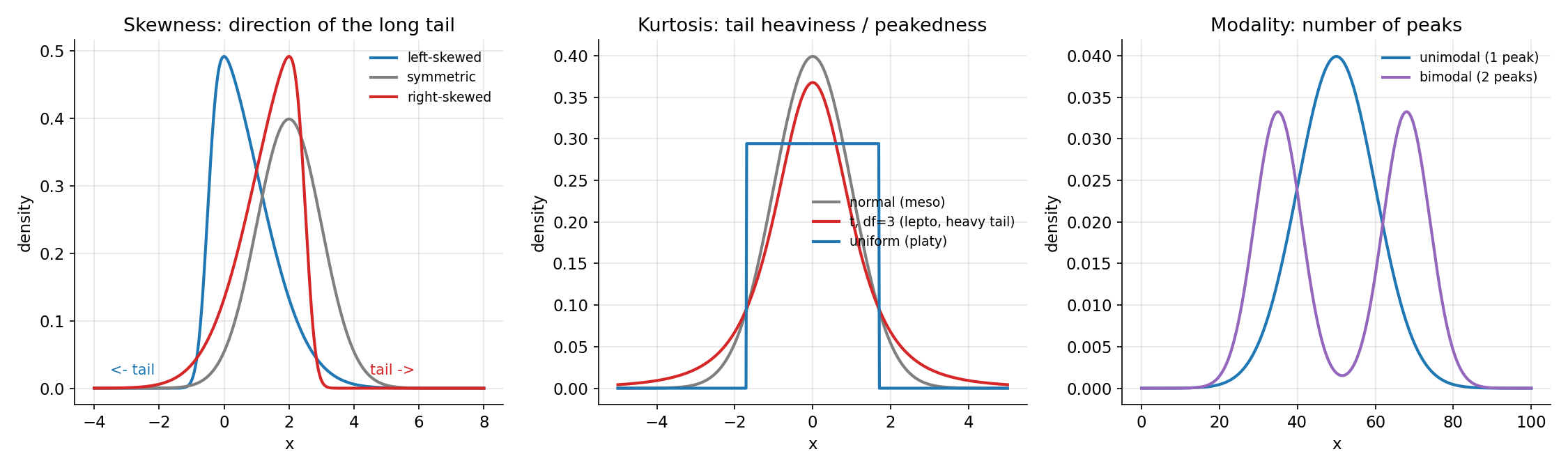
Figure 6 — Shape explainer: skewness, kurtosis, modality¶
আকৃতির তিন ভাষা এক ছবিতে। বাঁ প্যানেল (skewness): left-skewed (লেজ বাঁয়ে), প্রতিসম, right-skewed (লেজ ডানে) — তীরচিহ্ন দেখায় লেজ কোন দিকে। মাঝ প্যানেল (kurtosis): normal (meso), Student-\(t\) df=3 (lepto — সূচালো চূড়া + ভারী লেজ), uniform (platy — সমতল, হালকা লেজ)। ডান প্যানেল (modality): unimodal (এক চূড়া) বনাম bimodal (দুই চূড়া)। এই একটি ছবি §২.৭-এর পুরো শব্দভাণ্ডারের চাক্ষুষ অভিধান।
from scipy import stats
fig, axes = plt.subplots(1, 3, figsize=(15, 4.5))
ax = axes[0]; xg = np.linspace(-4, 8, 600)
ax.plot(xg, stats.skewnorm.pdf(xg, a=6, loc=-0.5, scale=1.5), color="#1f77b4", lw=2, label="left-skewed")
ax.plot(xg, stats.norm.pdf(xg, loc=2, scale=1), color="#7f7f7f", lw=2, label="symmetric")
ax.plot(xg, stats.skewnorm.pdf(xg, a=-6, loc=2.5, scale=1.5), color="#d62728", lw=2, label="right-skewed")
ax.text(-3.5, 0.02, "<- tail", color="#1f77b4"); ax.text(4.5, 0.02, "tail ->", color="#d62728")
ax.set_xlabel("x"); ax.set_ylabel("density")
ax.set_title("Skewness: direction of the long tail"); ax.legend(fontsize=9)
ax = axes[1]; xg = np.linspace(-5, 5, 600)
ax.plot(xg, stats.norm.pdf(xg), color="#7f7f7f", lw=2, label="normal (meso)")
ax.plot(xg, stats.t.pdf(xg, df=3), color="#d62728", lw=2, label="t, df=3 (lepto, heavy tail)")
ax.plot(xg, stats.uniform.pdf(xg, -1.7, 3.4), color="#1f77b4", lw=2, label="uniform (platy)")
ax.set_xlabel("x"); ax.set_ylabel("density")
ax.set_title("Kurtosis: tail heaviness / peakedness"); ax.legend(fontsize=9)
ax = axes[2]; xg = np.linspace(0, 100, 600)
ax.plot(xg, stats.norm.pdf(xg, 50, 10), color="#1f77b4", lw=2, label="unimodal (1 peak)")
ax.plot(xg, 0.5*stats.norm.pdf(xg,35,6) + 0.5*stats.norm.pdf(xg,68,6),
color="#9467bd", lw=2, label="bimodal (2 peaks)")
ax.set_xlabel("x"); ax.set_ylabel("density")
ax.set_title("Modality: number of peaks"); ax.legend(fontsize=9)
plt.tight_layout(); plt.savefig("../_assets/1-3-shape-explainer.png", dpi=150)
৭ · অনুশীলনী¶
সমাধান
_solutions/01-03-distributions-visualization-solutions.md-এ। আগে নিজে চেষ্টা করুন; কোড-প্রশ্নে seed দিলে আপনার সংখ্যা সমাধানের সাথে মিলবে।
Conceptual¶
১. [easy] histogram আর bar chart-এর মধ্যে দুটি মৌলিক পার্থক্য লিখুন — একটি x-অক্ষের data-ধরন নিয়ে, একটি বারের মাঝের ফাঁক নিয়ে। প্রতিটির জন্য একটি করে উপযুক্ত উদাহরণ-variable দিন।
২. [easy] একটি distribution-এর \(\text{mean} = 50\), \(\text{median} = 38\) দেওয়া আছে। (ক) এটি কোন দিকে skewed? (খ) histogram-এর লেজ কোন দিকে লম্বা হবে? (গ) এমন কোন বাস্তব variable-এর নাম বলুন যার distribution এ-রকম দেখায়।
৩. [medium] KDE-তে bandwidth \(h\) খুব ছোট নিলে কী সমস্যা, খুব বড় নিলে কী সমস্যা? histogram-এর কোন প্যারামিটার \(h\)-এর সমতুল্য, এবং কেন দুটোই একটি "smoothing trade-off" বলে বিবেচিত? (§২.৩ ব্যবহার করুন।)
৪. [medium] আপনাকে চারটি ভিন্ন কারখানার একই যন্ত্রাংশের ওজনের distribution তুলনা করতে বলা হলো এবং সন্দেহ আছে কোনো কারখানায় দুটি আলাদা মেশিন থেকে অংশ মিশছে। boxplot না violin plot — কোনটি বেছে নেবেন এবং কেন? উত্তরে modality-র ভূমিকা স্পষ্ট করুন।
৫. [hard] ECDF "কোনো arbitrary নির্বাচন ছাড়াই পুরো data ধরে রাখে" — এই দাবি ব্যাখ্যা করুন histogram/KDE-এর সাথে তুলনা করে। তারপর §৪.২-এর তিনটি শর্তের যেকোনো একটি (অ-হ্রাসমানতা, সীমা, বা right-continuity) নিজের ভাষায় কেন সত্য তা বুঝিয়ে বলুন।
Computational¶
৬. [easy] হাতে (ক্যালকুলেটর চলবে, কোড নয়) data \(\{1,2,2,3,3,3,4,9\}\)-এর জন্য বের করুন: (ক) bin-প্রস্থ \(2\) ধরে frequency table (\([0,2),[2,4),\dots\)) এবং প্রতিটি bin-এর relative frequency; (খ) \(\hat{F}_n(3)\) ও \(\hat{F}_n(4)\); (গ) mean ও median তুলনা করে skew-এর দিক অনুমান করুন।
৭. [medium] নিচের seed-fixed data-তে from scratch ECDF বানান এবং np.quantile-এর সাথে median, \(Q_1\), \(Q_3\) মিলিয়ে দেখুন:
import numpy as np
rng = np.random.default_rng(2025)
data = rng.gamma(shape=2.0, scale=10.0, size=200)
scipy.stats.skew-এর সাথে মেলান।
৮. [medium] একটি ওয়েবসাইটে চারটি browser-এর ব্যবহারকারী-সংখ্যা: Chrome \(640\), Safari \(210\), Firefox \(90\), Edge \(60\)। (ক) প্রতিটির proportion বের করুন; (খ) কোডে একটি bar chart বানান যেখানে বার count অনুসারে অবরোহী সাজানো এবং প্রতিটি বারের উপর count লেখা। (গ) এই data-তে histogram কেন অর্থহীন হতো, এক বাক্যে লিখুন।
৯. [hard] skewness আর location-পরিমাপের সম্পর্ক। প্রশ্ন ৭-এর gamma data-র জন্য \(\bar{x}\), median, এবং skewness \(g_1\) — তিনটিই বের করুন। তারপর প্রতিটি মানকে \(\log\)-রূপান্তর করুন (np.log(data)) এবং রূপান্তরিত data-র skewness আবার বের করুন। log নেওয়ার পর skew কমল না বাড়ল, এবং কেন — সংক্ষেপে ব্যাখ্যা করুন।
১০. [hard] QQ-plot ব্যাখ্যা ও যাচাই। নিচের তিনটি sample বানান (একই seed) — একটি normal, একটি right-skewed (exponential), একটি heavy-tailed (Student-\(t\), df=3):
import numpy as np
rng = np.random.default_rng(99)
a = rng.normal(0, 1, 500)
b = rng.exponential(1.0, 500)
c = rng.standard_t(df=3, size=500)
scipy.stats.probplot দিয়ে normal-QQ আঁকুন (একটি figure, তিনটি subplot)। তিনটি ছবি কীভাবে আলাদা দেখাবে — সরল রেখা থেকে কোনটি কোন দিকে, কীভাবে বেঁকবে — তা আগে অনুমান করুন, তারপর ছবি এঁকে যাচাই করুন। (heavy-tailed ক্ষেত্রে দুই প্রান্ত কীভাবে আচরণ করে, বিশেষ লক্ষ্য করুন।)
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল কথাগুলো একনজরে:
- একটি distribution হলো variable-এর সম্পূর্ণ গল্প — কোন মান কত ঘন; সারাংশ-সংখ্যা সেই গল্পের অংশমাত্র, তাই নতুন data পেলে প্রথমে ছবি আঁকুন।
- Frequency table ও binning raw data-কে distribution-এ রূপ দেয়; histogram তার ছবি (continuous, লাগোয়া বার)। density-অক্ষে মোট ক্ষেত্রফল সর্বদা \(1\) (§৪.১)।
- KDE একটি মসৃণ, bin-নিরপেক্ষ density-আনুমান; bandwidth \(h\) smoothing নিয়ন্ত্রণ করে (ছোট=কাঁটাকাঁটা, বড়=অতিমসৃণ)।
- Boxplot = পাঁচ-সংখ্যা সারাংশ (modality লুকায়); violin = সারাংশ + পূর্ণ density (দুই চূড়া ধরে)।
- ECDF \(\hat{F}_n(t)=\#\{x_i\le t\}/n\) — bin/bandwidth ছাড়াই পুরো data ধরে; একটি বৈধ CDF (§৪.২), এবং \(n\) বাড়লে প্রকৃত CDF-এ ছোটে (Glivenko–Cantelli)।
- QQ-plot data-র quantile বনাম normal-quantile আঁকে; সরল রেখা = normality, উপরে-বাঁক = right-skew/ভারী লেজ।
- Categorical data-তে bar chart (গ্যাপ-সহ বার, count অনুসারে সাজানো); count \(\div n\) = proportion।
- আকৃতি: skewness (লেজের দিক — right-skew হলে সাধারণত mean\(>\)median, §৪.৩), kurtosis (লেজ-ভার/চূড়া; normal=3, excess=0), modality (চূড়ার সংখ্যা; bimodality = লুকানো উপদলের ইঙ্গিত)। skewness/kurtosis একক-নিরপেক্ষ (§৪.৪)।
প্রমাণ থেকে যা শিখলাম: density-histogram-এর ক্ষেত্রফল গঠনগতভাবে \(1\) (তাই density-র সাথে তুলনাযোগ্য); ECDF গাণিতিকভাবে একটি প্রকৃত distribution; right-skew → mean\(>\)median আসে ভারসাম্য-বনাম-অবস্থানের যুক্তি থেকে; আকৃতি-পরিমাপ scale বদলে অপরিবর্তিত।
পেছনের সাথে সংযোগ (1.2): ১.২-এর mean/median/quartile/IQR/boxplot এখানে পূর্ণ distribution-এর কাঠামোয় বসল — mean বনাম median-এর পার্থক্য এখন skewness-এর ভাষায় ধরা পড়ল, আর boxplot-এর সীমাবদ্ধতা (modality না-দেখানো) violin দিয়ে পূরণ হলো।
সামনের সাথে সংযোগ: পরের অধ্যায় 1.4 — Correlation & Bivariate এক variable থেকে দুই variable-এ যাবে — দুটি variable একসাথে কীভাবে চলে (scatter plot, correlation)। এই অধ্যায়ের আকৃতি-সচেতনতা সেখানে অপরিহার্য, কারণ correlation-এর অনেক পরিমাপ অন্তর্নিহিতভাবে distribution-এর আকৃতি (যেমন রৈখিকতা, outlier) ধরে নেয়। আর গভীর যোগসূত্র দুই দিকে: (১) Part II-তে আমরা শিখব কোন তাত্ত্বিক distribution (normal, lognormal, exponential…) কোন আকৃতির data-র সাথে মেলে — তখন histogram/QQ-plot হবে model-নির্বাচনের প্রথম হাতিয়ার; (২) Part IV-তে ECDF ফিরে আসবে nonparametric statistics-এর কেন্দ্রে (Kolmogorov–Smirnov test, bootstrap), এবং QQ-plot-এর normality-যাচাই অনেক test-এর বৈধতার পূর্বশর্ত হিসেবে কাজ করবে।
এক বাক্যে: distribution-এর আকৃতি — কোথায় চূড়া, কোন দিকে লেজ, কত ভারী লেজ, ক'টা চূড়া — এই প্রশ্নগুলোর উত্তর জানা মানে inference ও model-নির্বাচনের প্রথম ও সবচেয়ে গুরুত্বপূর্ণ ধাপটি সারা।