অধ্যায় ২.১ · Sample Spaces, Axioms & Counting-Based Probability¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
Part 0-তে আমরা গণিতের ভাষা শিখেছি — set, subset, function, আর counting। এবার সেই ভাষায় প্রথম সত্যিকারের গল্প বলব: probability (সম্ভাবনা)-র গল্প। পুরো statistics — আগামী সব অধ্যায়, random variable থেকে শুরু করে hypothesis testing, regression, machine learning পর্যন্ত — দাঁড়িয়ে আছে এই একটিমাত্র ভিত্তির ওপর। তাই এই অধ্যায়টা মনোযোগ দিয়ে পড়া দরকার; এটাই Part II-এর শিকড়।
কল্পনা করো তুমি একটা fair coin (ন্যায্য মুদ্রা) একবার toss করছ। ফলাফল কী হবে — head না tail — সেটা নিশ্চিতভাবে আগে থেকে বলা যায় না। এই "আগে থেকে বলা যায় না কিন্তু সম্ভাব্য ফলাফলগুলো জানা আছে" — এমন প্রক্রিয়াকেই বলে random experiment (দৈব পরীক্ষা)। অথচ আশ্চর্যের ব্যাপার: একটা toss-এ অনিশ্চিত হলেও, হাজার hাজার toss-এ head পড়ার হার আশ্চর্যজনকভাবে স্থির হয়ে \(0.5\)-এর কাছে চলে আসে। অনিশ্চয়তার ভেতরে এই লুকানো নিয়ম-ই probability theory-র মূল বিষয়।
Hook — তিনটি প্রশ্ন, একটাই কাঠামো। এই তিন প্রশ্ন আপাতদৃষ্টিতে আলাদা, কিন্তু সবগুলোর উত্তর একই তিন ধাপে আসবে:
- দুটো পাশা (dice) ছুড়লে যোগফল ঠিক \(7\) হওয়ার সম্ভাবনা কত?
- \(52\)টা তাস থেকে \(2\)টা তুললে দুটোই টেক্কা (ace) হওয়ার সম্ভাবনা কত?
- দুটো পাশায় "প্রথমটায় \(6\)" অথবা "যোগফল \(7\)" — এর সম্ভাবনা কত?
তিনটিতেই আমরা প্রথমে ঠিক করব সব সম্ভাব্য ফলাফলের set কী (sample space), তারপর প্রশ্নের ঘটনাটিকে একটা subset হিসেবে লিখব (event), তারপর একটা নিয়ম মেনে (axioms) সেই subset-এ সম্ভাবনা বসাব। এই তিন ধাপ — \(\Omega\), event, \(P\) — হলো এই অধ্যায়ের পুরো কাঠামো।
0.1-এর সাথে সরাসরি সেতু। 0.1-এ একটা টেবিল দেখেছিলে; সেটাই এখন জীবন্ত হবে:
| Probability-র ধারণা | আসলে যা (0.1 থেকে) | এই অধ্যায়ে |
|---|---|---|
| sample space \(\Omega\) | সব সম্ভাব্য outcome-এর set | §২.১ |
| event | \(\Omega\)-এর একটা subset | §২.২ |
| "A এবং B" | \(A \cap B\) (intersection) | §২.২ |
| "A অথবা B" | \(A \cup B\) (union) | §২.২ |
| "A ঘটল না" | \(A^c\) (complement) | §২.২ |
| mutually exclusive | \(A \cap B = \varnothing\) (disjoint) | §২.২ |
অর্থাৎ probability শেখা মানে নতুন কিছু না — set-এর ভাষাতেই অনিশ্চয়তা মাপা। শুধু একটা নতুন জিনিস যোগ হবে: প্রতিটি subset-এ একটা সংখ্যা (তার "ওজন" বা probability) বসানোর নিয়ম।
💡 এই অধ্যায়ে আমরা পূর্ণ measure-theoretic rigor-এ যাব না — সেটা Part VII-এর জন্য তোলা থাকল। এখানে \(\Omega\) হয় সসীম (finite) বা গণনাযোগ্য (countable) ধরে নেব, যাতে "প্রতিটি subset একটা event" — এই সরল ছবিটা খাটে। তবু axiom-গুলো ঠিক যেভাবে Kolmogorov লিখেছিলেন, সেভাবেই লিখব, এবং properties-গুলো ঠিকঠাক প্রমাণ করব।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Random experiment, outcome ও sample space \(\Omega\)¶
একটা random experiment (দৈব পরীক্ষা) হলো এমন একটা প্রক্রিয়া যার (১) সম্ভাব্য ফলাফলগুলো আগে থেকে জানা, কিন্তু (২) কোন ফলাফলটা আসবে তা নিশ্চিতভাবে আগে বলা যায় না, এবং (৩) নীতিগতভাবে বারবার একই অবস্থায় চালানো যায়।
প্রতিটি একক সম্ভাব্য ফলাফলকে বলে একটা outcome (ফলাফল), সাধারণত \(\omega\) (ছোট omega) দিয়ে লেখা হয়। সব outcome-এর সংগ্রহ — অর্থাৎ একটা set — কে বলে sample space (নমুনাক্ষেত্র), লেখা হয় \(\Omega\) (বড় omega) দিয়ে।
কিছু উদাহরণ (লক্ষ করো \(\Omega\) প্রতিবারই একটা set):
| Random experiment | Sample space \(\Omega\) | \(\lvert \Omega \rvert\) |
|---|---|---|
| এক মুদ্রা toss | \(\{H, T\}\) | \(2\) |
| দুই মুদ্রা toss | \(\{HH, HT, TH, TT\}\) | \(4\) |
| এক পাশা roll | \(\{1,2,3,4,5,6\}\) | \(6\) |
| দুই পাশা roll | \(\{(i,j): 1\le i,j\le 6\}\) | \(36\) |
| প্রথম head না আসা পর্যন্ত toss | \(\{H, TH, TTH, TTTH, \dots\}\) | অসীম (countable) |
| একটা বাল্বের আয়ুষ্কাল | \([0, \infty)\) | অসীম (uncountable) |
প্রথম চারটা finite, পঞ্চমটা countably infinite, শেষটা uncountable (পুরো একটা ব্যবধি)। এই অধ্যায়ে আমরা মূলত finite ও countable \(\Omega\) নিয়ে কাজ করব; uncountable \(\Omega\) (যেমন density, continuous distribution) আসবে 2.4 থেকে।
📝 দুই পাশার ক্ষেত্রে \(\Omega = \{1,\dots,6\} \times \{1,\dots,6\}\) — এটা ঠিক 0.1-এর Cartesian product! আর \(\lvert \Omega \rvert = 6 \times 6 = 36\) — এটা ঠিক 0.2-এর multiplication principle। দেখো, কিছুই নতুন নয়।
২.২ Event — \(\Omega\)-এর subset¶
একটা event (ঘটনা) হলো sample space \(\Omega\)-এর যেকোনো একটা subset \(A \subseteq \Omega\)। আমরা বলি "event \(A\) ঘটেছে" যদি পরীক্ষার আসল outcome \(\omega\) ওই subset \(A\)-এর সদস্য হয় (\(\omega \in A\))।
এটাই 2.1-এর সবচেয়ে গুরুত্বপূর্ণ ধারণাগত লাফ: ঘটনা = উপসেট। প্রতিটি দৈনন্দিন "ঘটনা" আসলে কিছু outcome-এর সংগ্রহ।
এক পাশা roll, \(\Omega = \{1,2,3,4,5,6\}\) — কিছু event:
- "জোড় সংখ্যা পড়ল" \(\;\Rightarrow\; A = \{2,4,6\}\)।
- "\(5\) বা তার বেশি পড়ল" \(\;\Rightarrow\; B = \{5,6\}\)।
- "\(3\) পড়ল" \(\;\Rightarrow\; \{3\}\) — একটিমাত্র outcome-এর event, একে simple/elementary event বলে।
- "\(7\) পড়ল" \(\;\Rightarrow\; \varnothing\) — অসম্ভব, তাই empty set; একে impossible event বলে।
- "১ থেকে ৬-এর মধ্যে কিছু পড়ল" \(\;\Rightarrow\; \Omega\) নিজেই — নিশ্চিত, একে sure/certain event বলে।
যেহেতু event মানেই set, set-এর সব অপারেশন এখন ঘটনার ভাষা হয়ে যায় (এটাই 0.1 থেকে সরাসরি আসছে):
| ঘটনার কথা | Set-এর ভাষা | চিত্র (Figure 1) |
|---|---|---|
| "\(A\) এবং \(B\) দুটোই ঘটল" | \(A \cap B\) | দুই circle-এর overlap |
| "\(A\) অথবা \(B\) ঘটল" (বা দুটোই) | \(A \cup B\) | দুই circle-এর মিলন |
| "\(A\) ঘটল না" | \(A^c = \Omega \setminus A\) | \(A\)-এর বাইরের অংশ |
| "\(A\) ঘটল কিন্তু \(B\) নয়" | \(A \setminus B = A \cap B^c\) | \(A\)-only অংশ |
| "\(A\) ও \(B\) একসাথে ঘটতে পারে না" | \(A \cap B = \varnothing\) (mutually exclusive) | দুই circle আলাদা |
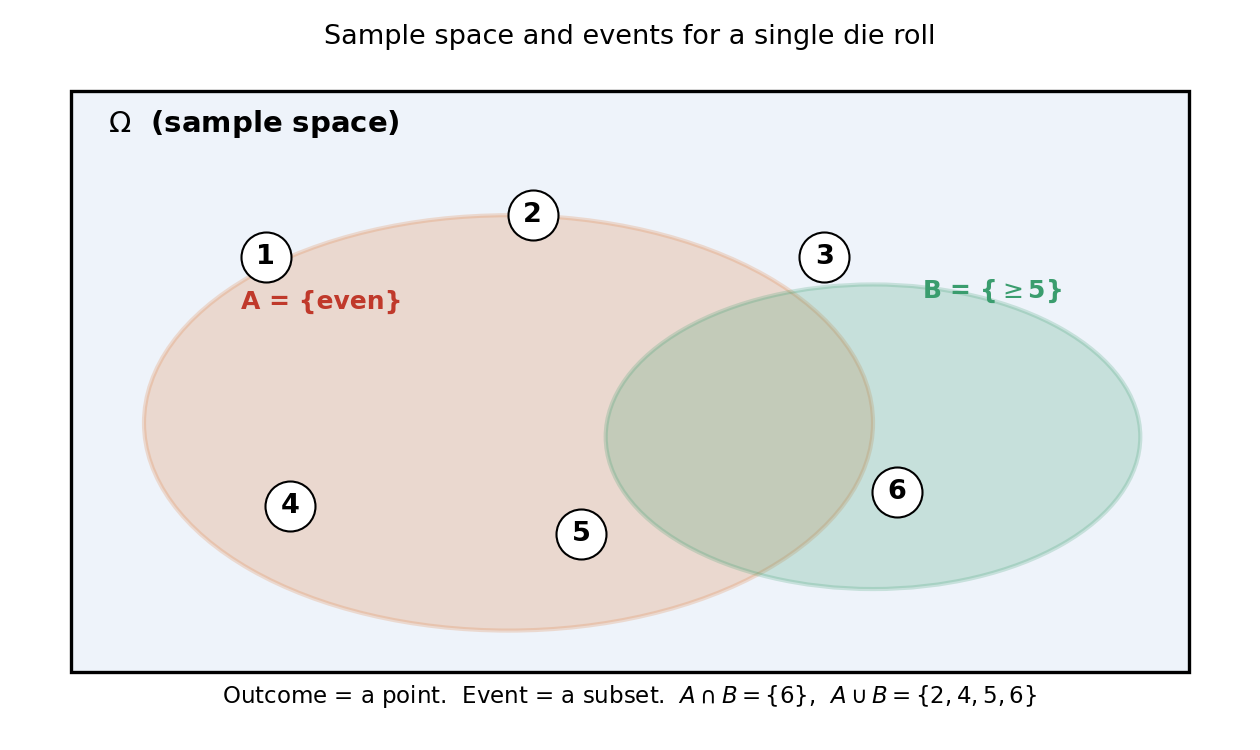
পাশার উদাহরণে \(A = \{2,4,6\}\) (জোড়), \(B=\{5,6\}\) (≥5):
আর \(A=\{2,4,6\}\) ও \(C=\{1,3,5\}\) (বিজোড়) — এদের \(A \cap C = \varnothing\), তাই এরা mutually exclusive।
💡 0.1-এর De Morgan এখানেই কাজে লাগবে। "অন্তত একটা ঘটল না" = "সব ঘটল-এর উল্টো": \((A \cup B)^c = A^c \cap B^c\)। অর্থাৎ "\(A\) বা \(B\) ঘটল না" মানে "\(A\)-ও ঘটল না এবং \(B\)-ও ঘটল না"। complement rule (§৪) দিয়ে কঠিন event-কে সহজ event-এ অনুবাদ করার মূল হাতিয়ার এটাই।
২.৩ Probability axioms (Kolmogorov, 1933)¶
এতক্ষণ শুধু set গুছিয়েছি, কোনো সংখ্যা বসাইনি। এবার মূল কাজ: প্রতিটি event \(A\)-কে একটা সংখ্যা \(P(A)\) দেওয়া, যাকে আমরা "\(A\) ঘটার probability" বলব। কিন্তু যেকোনো সংখ্যা বসালেই তো হবে না — তা যুক্তিসঙ্গত হতে হবে। ১৯৩৩ সালে আন্দ্রেই Kolmogorov দেখালেন যে মাত্র তিনটি সরল নিয়ম (axiom — স্বতঃসিদ্ধ, যা প্রমাণ ছাড়াই মেনে নেওয়া হয়) থেকে probability-র সমস্ত পরিচিত ধর্ম যৌক্তিকভাবে বেরিয়ে আসে।
Probability measure হলো একটা function \(P\) যা প্রতিটি event \(A \subseteq \Omega\)-কে একটা বাস্তব সংখ্যা \(P(A)\)-তে পাঠায়, এবং নিচের তিনটি axiom মানে:
Axiom 1 (Non-negativity): যেকোনো event \(A\)-এর জন্য $$ P(A) \ge 0. $$
Axiom 2 (Normalization): নিশ্চিত event-এর probability \(1\): $$ P(\Omega) = 1. $$
Axiom 3 (Countable additivity): যদি \(A_1, A_2, A_3, \dots\) পরস্পর mutually exclusive হয় (\(i \ne j\) হলে \(A_i \cap A_j = \varnothing\)), তবে তাদের union-এর probability প্রতিটির probability-র যোগফল: $$ P!\left(\bigcup_{i=1}^{\infty} A_i\right) = \sum_{i=1}^{\infty} P(A_i). $$
তিনটিকেই খুব স্বাভাবিক মনে হওয়া উচিত:
- Axiom 1: সম্ভাবনা কখনো ঋণাত্মক হতে পারে না — "\(-0.3\) সম্ভাবনা" কথাটারই কোনো মানে নেই।
- Axiom 2: কিছু-না-কিছু তো ঘটবেই; "যেকোনো একটা outcome আসবে" — এই নিশ্চিত ঘটনার সম্ভাবনা পুরো \(1\) (অর্থাৎ \(100\%\))।
- Axiom 3: যদি দুটো ঘটনা একসাথে ঘটতে না পারে, তবে "এদের যেকোনো একটা" ঘটার সম্ভাবনা শুধু যোগ করলেই হয়। যেমন এক পাশায় "\(2\) পড়া" আর "\(5\) পড়া" — একসাথে অসম্ভব; তাই \(P(\{2\} \text{ বা } \{5\}) = P(\{2\}) + P(\{5\}) = \tfrac16 + \tfrac16 = \tfrac13\)।
visual intuition (ভিজ্যুয়াল স্বজ্ঞা) — mass হিসেবে probability। finite \(\Omega\)-তে probability-কে ভাবো এক কেজি "ধুলো" \(\Omega\)-র outcome-গুলোর ওপর ছড়িয়ে দেওয়া হলো। Axiom 1: কোথাও ঋণাত্মক ধুলো নেই। Axiom 2: মোট ধুলোর ভর ঠিক \(1\) কেজি। Axiom 3: একটা subset-এর ভর = তার সদস্য-outcome-গুলোর ভরের যোগফল। একটা event-এর probability মানে ওই subset-এ জমে থাকা মোট ভর।
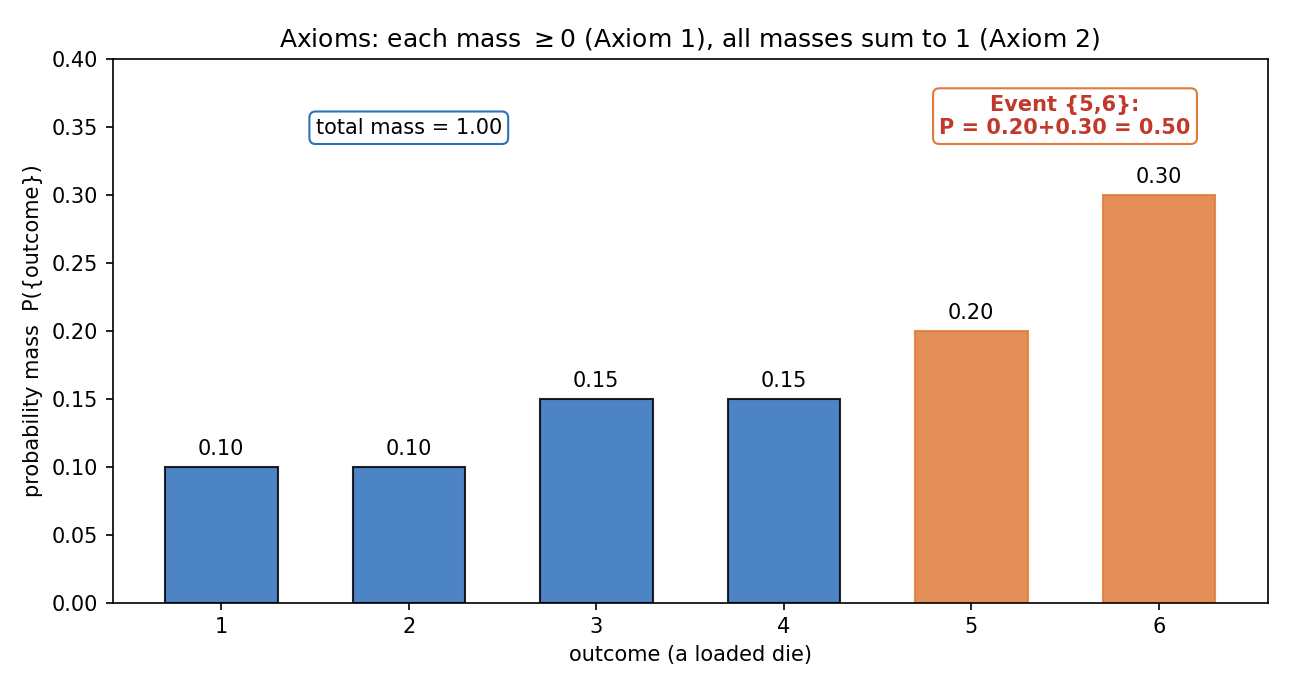
📝 Finite additivity। Axiom 3 অসীম union নিয়ে বলা, কিন্তু finite ক্ষেত্রে সরাসরি বেরোয়: দুটো disjoint event \(A, B\)-এর জন্য \(P(A \cup B) = P(A) + P(B)\) (বাকি \(A_i\)-গুলোকে \(\varnothing\) ধরে নিলেই হয়, যেহেতু পরে দেখব \(P(\varnothing)=0\))। আমরা proofs-এ এই finite রূপটাই বেশি ব্যবহার করব।
২.৪ Equally-likely (classical) probability — 0.2-এর প্রয়োগ¶
অনেক চেনা পরীক্ষায় (ন্যায্য মুদ্রা, পাশা, ভালোভাবে রাঙানো তাস, লটারি) ধরে নেওয়া যায় সব outcome সমসম্ভাব্য (equally likely)। তখন axiom থেকেই একটা চমৎকার সরল সূত্র বেরোয়।
ধরো \(\Omega\) finite, \(\lvert \Omega \rvert = N\), এবং প্রতিটি outcome সমসম্ভাব্য — অর্থাৎ প্রত্যেকটার probability \(p\)। Axiom 2 + 3 বলে \(N\)টা single-outcome event-এর যোগফল \(1\): $$ \underbrace{p + p + \cdots + p}_{N \text{ বার}} = 1 \;\Rightarrow\; p = \frac{1}{N}. $$ তাহলে একটা event \(A\) (যাতে \(\lvert A \rvert\)টি outcome আছে)-এর probability:
এটাই classical probability — যেটা 0.2-তে আগেই দেখেছিলে, এখন axiom থেকে যৌক্তিকভাবে প্রতিষ্ঠিত হলো। লক্ষ করো এখানে probability বের করা মানে আসলে দুটো সংখ্যা গোনা — \(\lvert A \rvert\) আর \(\lvert \Omega \rvert\) — অর্থাৎ 0.2-এর পুরো counting-machinery (permutation, \(\binom{n}{k}\)) এখন সরাসরি probability-র যন্ত্র।
⚠️ এই সূত্র কেবল equally-likely ক্ষেত্রে খাটে। পক্ষপাতদুষ্ট (loaded) পাশা বা অসম-সম্ভাব্য outcome-এ "favorable/total" ভুল উত্তর দেবে — তখন আবার আসল axiom-এ (mass যোগ) ফিরতে হবে।
২.৫ Frequentist interpretation — relative frequency¶
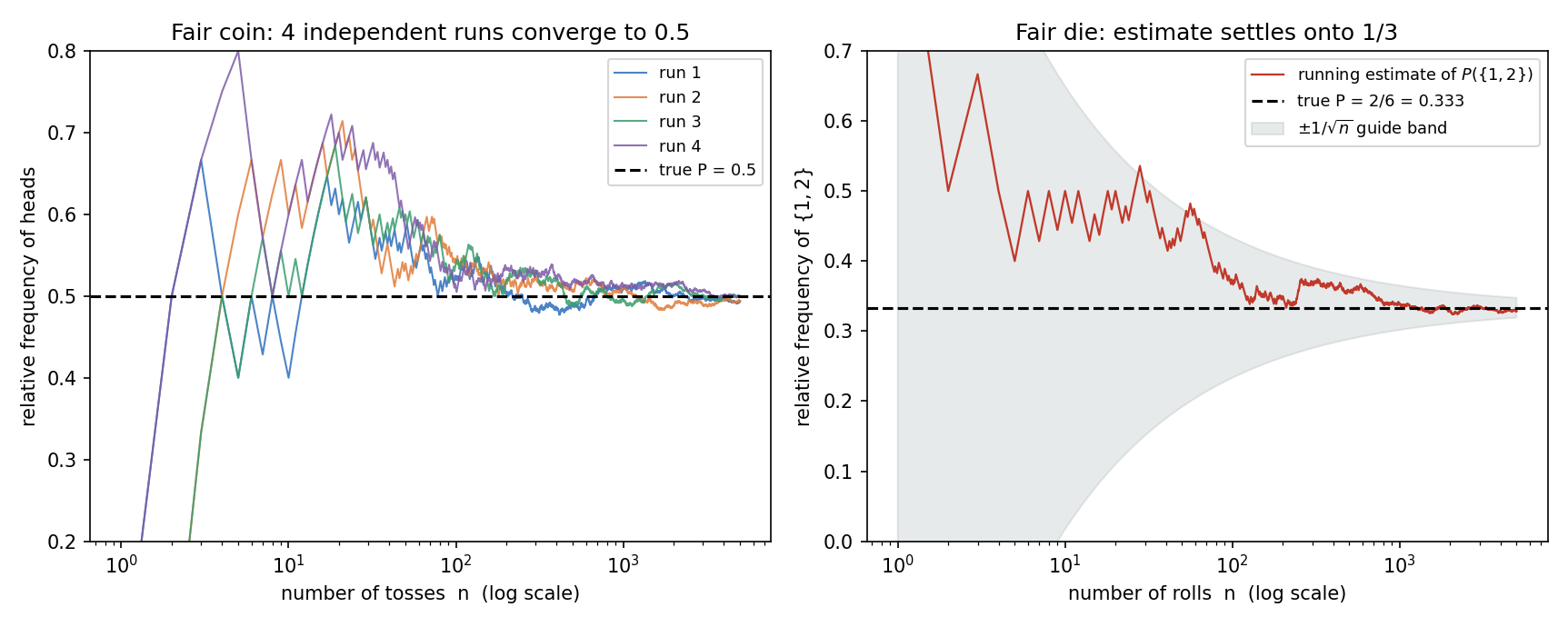
Axiom-গুলো বলে probability কীভাবে আচরণ করে, কিন্তু একটা সংখ্যা \(P(A) = 0.5\)-এর মানে কী? সবচেয়ে প্রচলিত ব্যাখ্যা frequentist (পৌনঃপুনিক): probability হলো একই পরীক্ষা বহুবার চালালে event-টির আপেক্ষিক হার (relative frequency)-এর সীমা।
পরীক্ষাটা \(n\) বার চালালে \(A\) যদি \(n_A\) বার ঘটে, তবে relative frequency হলো $$ \hat{P}_n(A) = \frac{n_A}{n}. $$ Frequentist দাবি: \(n\) বড় হতে থাকলে এই হার একটা স্থির সংখ্যায় থিতু হয়, আর সেটাই \(P(A)\): $$ \hat{P}_n(A) = \frac{n_A}{n} \;\longrightarrow\; P(A) \qquad (n \to \infty). $$
এটা শুধু দর্শন নয় — গভীর একটা গাণিতিক theorem (উপপাদ্য) — Law of Large Numbers, Part III — এই convergence-কে (অভিসৃতি) সঠিকভাবে প্রতিষ্ঠা করে। এই অধ্যায়ে আমরা সেটা simulation দিয়ে চোখে দেখব (§৫, §৬): মুদ্রা ছোড়ার সংখ্যা বাড়লে head-এর হার সত্যিই \(0.5\)-এ এসে স্থির হয়। লক্ষণীয়, relative frequency সবসময় Kolmogorov axiom মানে — \(n_A/n \ge 0\) (Axiom 1), \(n_\Omega/n = 1\) (Axiom 2), আর disjoint event-এর গণনা যোগ হয় (Axiom 3)। তাই axiom-গুলো frequency-র অভিজ্ঞতাকেই গাণিতিকভাবে ধরে রাখে।
📝 আরেকটা ব্যাখ্যা — Bayesian। Probability-কে "বিশ্বাসের মাত্রা" (degree of belief) হিসেবেও দেখা যায়, যা পুনরাবৃত্তি ছাড়া এককালীন ঘটনাতেও ("আগামীকাল বৃষ্টি হওয়ার সম্ভাবনা") অর্থপূর্ণ। মজার ব্যাপার: ব্যাখ্যা যা-ই হোক, গণিত (axiom) একই থাকে। Bayesian দৃষ্টিভঙ্গি 2.2 (Bayes' theorem) ও Part IV-এ ফিরবে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§১-এর তিনটি hook-প্রশ্নের উত্তর — প্রতিটিতে একই তিন ধাপ: (১) \(\Omega\) লেখা, (২) event-কে subset হিসেবে লেখা, (৩) probability হিসাব।
উদাহরণ ৩.১ — দুই পাশার যোগফল \(7\) (classical)¶
ধাপ ১. দুই পাশা (একটা লাল, একটা নীল ভাবো — তাহলে \((2,5)\) ও \((5,2)\) আলাদা): $$ \Omega = {(i,j) : 1 \le i,j \le 6}, \qquad \lvert \Omega \rvert = 6 \times 6 = 36. $$ সব outcome সমসম্ভাব্য (ন্যায্য পাশা)।
ধাপ ২. "যোগফল \(7\)" event: $$ A = {(1,6),(2,5),(3,4),(4,3),(5,2),(6,1)}, \qquad \lvert A \rvert = 6. $$
ধাপ ৩. classical সূত্র (§২.৪): $$ P(A) = \frac{\lvert A \rvert}{\lvert \Omega \rvert} = \frac{6}{36} = \frac{1}{6} \approx 0.1667. $$
§৫-এ আমরা ২ লক্ষ বার পাশা ছুড়ে simulation দিয়ে এই \(1/6\) যাচাই করব (পেয়েছিলাম \(0.1658\) — দারুণ মিল)।
উদাহরণ ৩.২ — দুটো টেক্কা (counting দিয়ে classical)¶
ধাপ ১. \(52\) তাস থেকে একসাথে \(2\)টা তোলা; ক্রম গোনা হয় না (হাত একটাই)। 0.2-এর combination: $$ \lvert \Omega \rvert = \binom{52}{2} = \frac{52 \times 51}{2} = 1326. $$
ধাপ ২. "দুটোই ace" — \(4\)টা ace থেকে \(2\)টা বাছা: $$ \lvert A \rvert = \binom{4}{2} = \frac{4\times3}{2} = 6. $$
ধাপ ৩. $$ P(A) = \frac{\binom{4}{2}}{\binom{52}{2}} = \frac{6}{1326} = \frac{1}{221} \approx 0.00452. $$
দেখো কীভাবে 0.2-এর \(\binom{n}{k}\) সরাসরি probability-র লব ও হর হয়ে গেল — এটাই 0.2 → 2.1 সেতুর প্রাণ।
উদাহরণ ৩.৩ — "প্রথমে \(6\)" অথবা "যোগফল \(7\)" (addition rule)¶
দুই পাশা, \(\lvert \Omega \rvert = 36\)। দুটো event: $$ F = {\text{প্রথম পাশায় } 6} = {(6,1),\dots,(6,6)}, \quad \lvert F \rvert = 6, \quad P(F) = \tfrac{6}{36}; $$ $$ S = {\text{যোগফল } 7}, \quad \lvert S \rvert = 6, \quad P(S) = \tfrac{6}{36}. $$ এরা mutually exclusive নয় — overlap আছে: \(F \cap S = \{(6,1)\}\), তাই \(P(F \cap S) = \tfrac{1}{36}\)। তাই সরাসরি যোগ করলে \((6,1)\) দুবার গোনা হবে। Inclusion–exclusion (§৪.৪) ঠিক এই double-counting শোধরায়:
(§৫-এ brute-force গণনায় ঠিক \(11/36 \approx 0.3056\) মিলবে।)
উদাহরণ ৩.৪ — "অন্তত একটা \(6\)" (complement rule)¶
দুই পাশায় "অন্তত একটা \(6\) পড়া" event \(A\) সরাসরি গোনা ক্লান্তিকর (\(\{(6,1),\dots\}\) অনেক কেস)। Complement rule (§৪.১) দিয়ে উল্টোটা গোনাই সহজ। "অন্তত একটা \(6\)"-এর উল্টো হলো "কোনো \(6\) নেই" — প্রতিটি পাশায় \(5\)টা অ-৬ option: $$ P(A^c) = \frac{5 \times 5}{36} = \frac{25}{36}. $$ তাহলে $$ P(A) = 1 - P(A^c) = 1 - \frac{25}{36} = \frac{11}{36} \approx 0.3056. $$
💡 "অন্তত একটা" (at least one) দেখলেই complement rule-এর কথা ভাবো — প্রায় সবসময় উল্টোটা ("একটাও না") গোনা সহজ। এটা probability-র সবচেয়ে কাজের একটা কৌশল।
৪ · প্রমাণ ও উৎপাদন¶
এবার Kolmogorov-এর তিন axiom থেকে probability-র চেনা ধর্মগুলো প্রমাণ করব। লক্ষ করো — এগুলো অতিরিক্ত নিয়ম নয়, axiom থেকেই অবশ্যম্ভাবীভাবে বেরোয়। (finite ক্ষেত্রে finite additivity ব্যবহার করছি; difficulty ★/★★।)
৪.১ Complement rule: \(P(A^c) = 1 - P(A)\) ★¶
দাবি. যেকোনো event \(A\)-এর জন্য \(P(A^c) = 1 - P(A)\)।
প্রমাণ. \(A\) ও \(A^c\) পরস্পর disjoint (\(A \cap A^c = \varnothing\), সংজ্ঞা থেকে), এবং তাদের union পুরো sample space (\(A \cup A^c = \Omega\))। তাই finite additivity (Axiom 3): $$ P(A) + P(A^c) = P(A \cup A^c) = P(\Omega) = 1 \quad (\text{Axiom 2}). $$ দুপাশ থেকে \(P(A)\) বিয়োগ করলেই \(P(A^c) = 1 - P(A)\). \(\;\blacksquare\)
দুটি তাৎক্ষণিক ফল:
- \(A = \Omega\) বসালে \(A^c = \varnothing\), তাই \(P(\varnothing) = 1 - P(\Omega) = 1 - 1 = 0\) — impossible event-এর probability \(0\)।
- যেহেতু \(P(A^c) \ge 0\) (Axiom 1), তাই \(1 - P(A) \ge 0\), অর্থাৎ \(P(A) \le 1\)। Axiom 1-এর সাথে মিলিয়ে: প্রতিটি probability \(0 \le P(A) \le 1\)।
৪.২ Monotonicity: \(A \subseteq B \Rightarrow P(A) \le P(B)\) ★¶
দাবি. যদি \(A \subseteq B\), তবে \(P(A) \le P(B)\) এবং \(P(B \setminus A) = P(B) - P(A)\)।
প্রমাণ. \(A \subseteq B\) হলে \(B\)-কে দুটো disjoint টুকরোয় ভাঙা যায়: \(A\) আর "\(B\)-তে আছে কিন্তু \(A\)-তে নেই", অর্থাৎ $$ B = A \cup (B \setminus A), \qquad A \cap (B \setminus A) = \varnothing. $$ finite additivity দিলে $$ P(B) = P(A) + P(B \setminus A). $$ এখন Axiom 1 বলে \(P(B \setminus A) \ge 0\), তাই \(P(B) \ge P(A)\), অর্থাৎ \(P(A) \le P(B)\)। আর উপরের সমীকরণ পুনর্বিন্যাস করলে \(P(B \setminus A) = P(B) - P(A)\). \(\;\blacksquare\)
স্বজ্ঞা. বড় event-এ বেশি outcome (বেশি mass) — তাই তার probability ছোট event-এর চেয়ে কম হতে পারে না। mass-এর ছবিতে: বড় subset-এ অন্তত যত ধুলো, ছোট subset-এ তার চেয়ে বেশি নয়।
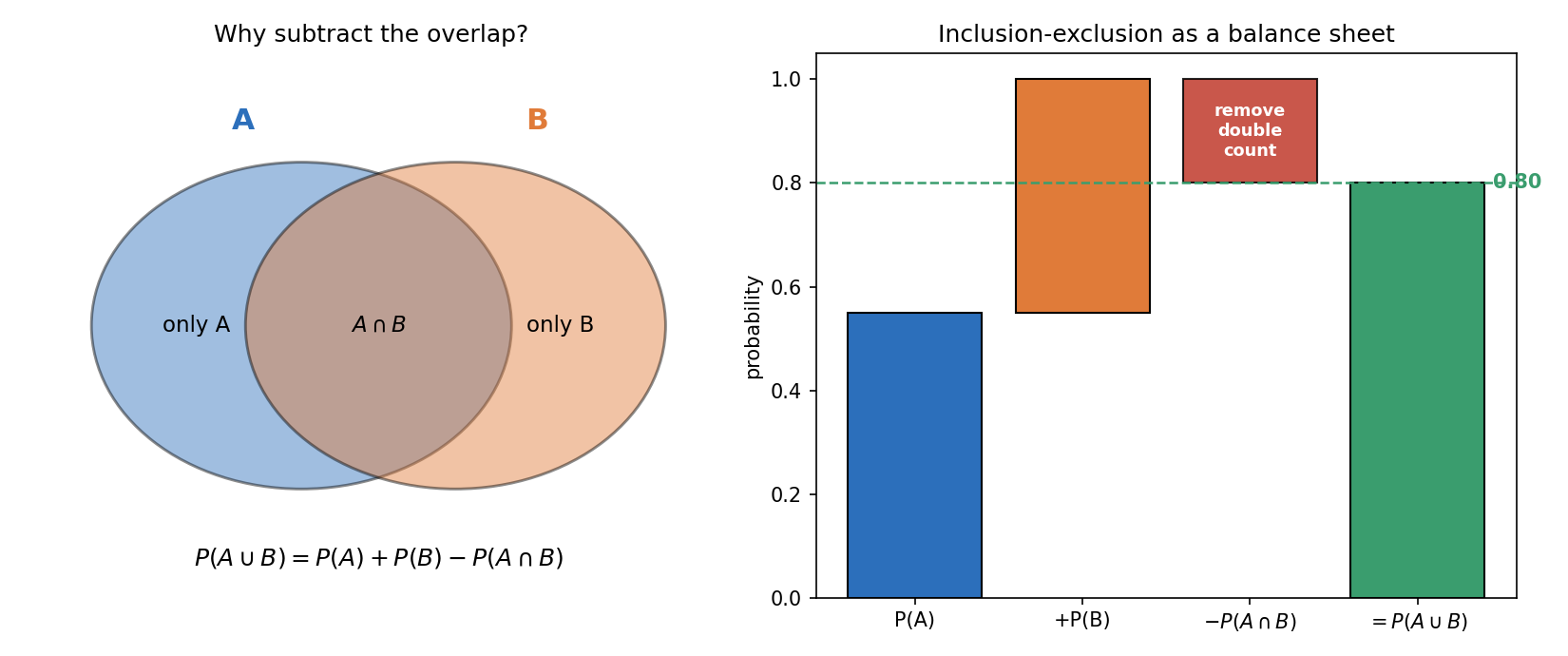
৪.৩ Addition rule (দুই event): \(P(A \cup B) = P(A) + P(B) - P(A \cap B)\) ★★¶
দাবি. যেকোনো দুই event \(A, B\)-এর জন্য (mutually exclusive হোক বা না হোক) $$ P(A \cup B) = P(A) + P(B) - P(A \cap B). $$
প্রমাণ. কৌশল: \(A \cup B\)-কে disjoint টুকরোয় ভেঙে তবেই additivity প্রয়োগ করা (Axiom 3 শুধু disjoint হলে যোগ করতে দেয়)। দুটো disjoint decomposition লিখি:
(i) ও (ii)-তে finite additivity: $$ P(A \cup B) = P(A) + P(B \setminus A), \tag{i\('\)} $$ $$ P(B) = P(A \cap B) + P(B \setminus A) \;\Rightarrow\; P(B \setminus A) = P(B) - P(A \cap B). \tag{ii\('\)} $$
(ii\('\))-এর \(P(B \setminus A)\)-কে (i\('\))-এ বসালে: $$ P(A \cup B) = P(A) + P(B) - P(A \cap B). \qquad \blacksquare $$
কেন বিয়োগ? \(P(A) + P(B)\)-তে overlap \(A \cap B\) অংশটা দুবার গোনা হয় (একবার \(A\)-তে, একবার \(B\)-তে); তাই একবার বিয়োগ করে শোধ করা হয়। mutually exclusive হলে \(A \cap B = \varnothing\), \(P(A \cap B) = 0\), আর সূত্রটা সরল \(P(A \cup B) = P(A) + P(B)\)-তে নেমে আসে — Axiom 3-এর সাথে সঙ্গতিপূর্ণ।
৪.৪ Inclusion–exclusion (তিন event) ★★¶
দুই event-এর সূত্রকে সাধারণীকরণ করা যায়। তিন event-এর জন্য:
প্রমাণ-স্কেচ. \(A \cup B \cup C = (A \cup B) \cup C\) ধরে §৪.৩-এর দুই-event সূত্র দুবার প্রয়োগ করো: $$ P\big((A\cup B)\cup C\big) = P(A \cup B) + P(C) - P\big((A \cup B) \cap C\big). $$ এখন \(P(A \cup B)\)-তে §৪.৩ বসাও, আর distributive law \((A \cup B) \cap C = (A \cap C) \cup (B \cap C)\)-তে আবার §৪.৩ প্রয়োগ করো (এই দুই-পদের union-এর intersection \((A\cap C)\cap(B\cap C) = A\cap B\cap C\))। সব মিলিয়ে গুছালে উপরের সাত-পদ সূত্র পাওয়া যায়। \(\;\blacksquare\)
নিদর্শন (pattern): এক-এক করে যোগ, জোড়ায়-জোড়ায় বিয়োগ, তিন-তিন করে যোগ — পর্যায়ক্রমে চিহ্ন বদলায়। সাধারণ \(n\) event-এর সূত্র (এখানে শুধু উল্লেখ): $$ P!\left(\bigcup_{i=1}^n A_i\right) = \sum_i P(A_i) - \sum_{i<j} P(A_i \cap A_j) + \sum_{i<j<k} P(A_i \cap A_j \cap A_k) - \cdots + (-1)^{n+1} P!\left(\bigcap_{i=1}^n A_i\right). $$
📝 0.2-এর "set-এর inclusion–exclusion" (cardinality \(\lvert A \cup B \rvert = \lvert A \rvert + \lvert B \rvert - \lvert A \cap B \rvert\)) আর এখানকার probability-র সূত্র আসলে একই জিনিস: equally-likely ক্ষেত্রে দুপাশকে \(\lvert \Omega \rvert\) দিয়ে ভাগ করলেই cardinality-সূত্র থেকে probability-সূত্র বেরোয়। গোনা আর সম্ভাবনা — একই মুদ্রার দুই পিঠ।
৪.৫ Union bound (Boole's inequality) ★★ — সংক্ষিপ্ত¶
inclusion–exclusion-এর একটা কাজের পরিণতি, যা পরে (concentration, ML) বহুবার লাগবে। যেকোনো event \(A_1, \dots, A_n\) (disjoint হোক বা না হোক): $$ P!\left(\bigcup_{i=1}^n A_i\right) \le \sum_{i=1}^n P(A_i). $$ স্বজ্ঞা/প্রমাণ-ভাব: overlap থাকলে union-এ mass একবারই গোনা হয়, কিন্তু ডানদিকে প্রতিটি overlap বারবার যোগ হয় — তাই ডানদিক কখনো ছোট হতে পারে না। (formal induction: §৭, Q8।)
৫ · কোড ল্যাব (Python)¶
লক্ষ্য: classical probability (গণনা) আর frequentist estimate (simulation) মিলিয়ে দেখানো যে তত্ত্ব ও পরীক্ষা একমত। reproducibility-র জন্য numpy-র default_rng এবং fixed seed ব্যবহার করছি — তাই তোমার মেশিনেও ঠিক একই সংখ্যা আসবে।
৫.১ Sample space গুনে classical probability¶
ছোট \(\Omega\) পুরোটা enumerate করে "favorable/total" সরাসরি যাচাই করি:
import numpy as np
from itertools import product
from math import comb
# দুই পাশার sample space — 0.1-এর Cartesian product
omega = list(product(range(1, 7), repeat=2)) # [(1,1),(1,2),...,(6,6)]
assert len(omega) == 36 # multiplication principle: 6*6
def classical_P(event_fn):
"""event_fn(outcome) -> True/False হলে P = favorable / total."""
favorable = [o for o in omega if event_fn(o)]
return len(favorable) / len(omega)
print("P(sum = 7) =", classical_P(lambda o: o[0] + o[1] == 7)) # 6/36
print("P(sum >= 10) =", classical_P(lambda o: o[0] + o[1] >= 10)) # 6/36
# তাসের দুটো ace — 0.2-এর combination সরাসরি probability-তে
p_two_aces = comb(4, 2) / comb(52, 2)
print("P(two aces) =", p_two_aces, "=", comb(4, 2), "/", comb(52, 2))
আউটপুট:
P(sum = 7) = 0.16666666666666666
P(sum >= 10) = 0.16666666666666666
P(two aces) = 0.004524886877828055 = 6 / 1326
§৩.১ ও §৩.২-এর হাতে-কষা \(\tfrac{6}{36}\) ও \(\tfrac{6}{1326}\) হুবহু মিলল।
৫.২ Axiom ও properties সংখ্যায় যাচাই¶
# Addition rule (§4.3): P(F u S) = P(F) + P(S) - P(F n S)
F = lambda o: o[0] == 6 # প্রথম পাশায় 6
S = lambda o: o[0] + o[1] == 7 # যোগফল 7
pF, pS = classical_P(F), classical_P(S)
pFS = classical_P(lambda o: F(o) and S(o)) # F n S
pF_or_S = classical_P(lambda o: F(o) or S(o)) # F u S
print("addition rule:", round(pF_or_S, 6), "==", round(pF + pS - pFS, 6),
"->", abs(pF_or_S - (pF + pS - pFS)) < 1e-12) # 11/36
# Complement rule (§4.1): P(at least one 6) = 1 - P(no 6)
p_no6 = classical_P(lambda o: o[0] != 6 and o[1] != 6)
print("complement:", round(1 - p_no6, 4), "= 11/36 =", round(11/36, 4))
# Monotonicity (§4.2): {sum=12} ⊆ {sum>=10} => P bigger for superset
p_small = classical_P(lambda o: o[0] + o[1] == 12)
p_big = classical_P(lambda o: o[0] + o[1] >= 10)
print("monotonicity:", p_small, "<=", p_big, "->", p_small <= p_big)
আউটপুট:
addition rule: 0.305556 == 0.305556 -> True
complement: 0.3056 = 11/36 = 0.3056
monotonicity: 0.027777777777777776 <= 0.16666666666666666 -> True
তিনটি প্রমাণিত property-ই computation-এ ঠিকঠাক ধরা পড়ল।
৫.৩ Frequentist: simulation দিয়ে probability estimate¶
এবার তত্ত্ব ভুলে গিয়ে পরীক্ষা করি — পাশা \(200{,}000\) বার ছুড়ে "যোগফল \(7\)"-এর relative frequency বের করি, আর classical \(1/6\)-এর সাথে মেলাই:
rng = np.random.default_rng(7) # fixed seed -> reproducible
N = 200_000
d1 = rng.integers(1, 7, size=N) # 1..6
d2 = rng.integers(1, 7, size=N)
estimate = np.mean((d1 + d2) == 7) # relative frequency = n_A / n
true_p = 6 / 36
print(f"frequentist estimate P(sum=7) = {estimate:.4f}")
print(f"classical (true) P(sum=7) = {true_p:.4f}")
print(f"absolute error = {abs(estimate - true_p):.4f}")
আউটপুট:
মাত্র \(0.0009\) ফারাক — frequentist relative frequency সত্যিই classical probability-র দিকে এগোচ্ছে। এটাই Law of Large Numbers-এর প্রথম প্রত্যক্ষ প্রমাণ, যা §৬-এ চোখে দেখব এবং Part III-এ কঠোরভাবে প্রমাণ করব।
৬ · ভিজ্যুয়ালাইজেশন¶
চিত্র ১ — Sample space ও event (Venn-চিত্র)¶
§২.২-এ দেখানো চিত্রটি (এক পাশার \(\Omega\), event \(A=\{\text{even}\}\) ও \(B=\{\ge 5\}\)): outcome হলো বিন্দু, event হলো subset, আর intersection \(A \cap B = \{6\}\) দুই অঞ্চলের overlap। এটাই 0.1-এর Venn diagram-এর probability-রূপ — set আর event এক জিনিস।
চিত্র ২ — Inclusion–exclusion¶
§৪.৩-এর চিত্র: বাঁয়ে দুই overlapping circle, ডানে একটা "balance sheet" bar — \(P(A) + P(B)\) থেকে double-counted overlap একবার বিয়োগ করে \(P(A \cup B)\) পাওয়া যায়। সংখ্যাগুলো illustrative (\(P(A)=0.55\), \(P(B)=0.45\), \(P(A\cap B)=0.20\), ফল \(0.80\))।
চিত্র ৩ — Relative frequency স্থিত হওয়া (frequentist-এর হৃদয়)¶
এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ চিত্র। বাঁয়ে: ন্যায্য মুদ্রার \(4\)টি independent (স্বাধীন) run — শুরুতে head-এর হার এদিক-ওদিক লাফায়, কিন্তু toss বাড়ার সাথে (log scale-এ \(x\)-অক্ষ) সবগুলোই \(0.5\)-এর দিকে এসে স্থির হয়। ডানে: ন্যায্য পাশায় event \(\{1,2\}\)-এর running estimate \(2/6 = \tfrac13\)-এ থিতু হচ্ছে; ধূসর \(\pm 1/\sqrt{n}\) ব্যান্ড দেখায় ভুল কত দ্রুত কমে (এই \(1/\sqrt{n}\) হার Part III-এ ফিরবে)।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(42)
N = 5000
fig, axes = plt.subplots(1, 2, figsize=(11.5, 4.6))
# বাঁ-প্যানেল: মুদ্রা, 4টি স্বাধীন run -> 0.5
ax = axes[0]
for run, col in zip(range(4), ["#2c6fbb", "#e07b39", "#3a9d6e", "#7d5ba6"]):
flips = rng.integers(0, 2, size=N) # 1 = head
running = np.cumsum(flips) / np.arange(1, N + 1) # relative frequency
ax.plot(np.arange(1, N + 1), running, color=col, lw=1.0, alpha=0.85,
label=f"run {run + 1}")
ax.axhline(0.5, color="black", ls="--", lw=1.5, label="true P = 0.5")
ax.set_xscale("log"); ax.set_ylim(0.2, 0.8)
ax.set_xlabel("number of tosses n (log scale)")
ax.set_ylabel("relative frequency of heads")
ax.set_title("Fair coin: 4 independent runs converge to 0.5")
ax.legend(fontsize=8.5, loc="upper right")
# ডান-প্যানেল: পাশা, event {1,2} -> 1/3
ax = axes[1]
true_p = 2 / 6
rolls = rng.integers(1, 7, size=N)
running = np.cumsum(rolls <= 2) / np.arange(1, N + 1)
ax.plot(np.arange(1, N + 1), running, color="#c0392b", lw=1.1,
label=r"running estimate of $P(\{1,2\})$")
ax.axhline(true_p, color="black", ls="--", lw=1.5,
label=f"true P = 2/6 = {true_p:.3f}")
nn = np.arange(1, N + 1)
ax.fill_between(nn, true_p - 1/np.sqrt(nn), true_p + 1/np.sqrt(nn),
color="#7f8c8d", alpha=0.18, label=r"$\pm 1/\sqrt{n}$ guide band")
ax.set_xscale("log"); ax.set_ylim(0.0, 0.7)
ax.set_xlabel("number of rolls n (log scale)")
ax.set_ylabel(r"relative frequency of $\{1,2\}$")
ax.set_title("Fair die: estimate settles onto 1/3")
ax.legend(fontsize=8.5, loc="upper right")
fig.tight_layout()
fig.savefig("../_assets/2-1-relative-frequency.png", dpi=150)
চিত্র ৪ — Axioms চিত্র: probability mass হিসেবে¶
§২.৩-এর চিত্র (একটা loaded পাশা): প্রতিটি bar এক outcome-এর probability mass — সব mass অঋণাত্মক (Axiom 1), যোগফল ঠিক \(1.00\) (Axiom 2), আর event \(\{5,6\}\)-এর probability হলো তার সদস্যদের mass-এর যোগফল \(0.20+0.30=0.50\) (Axiom 3)। এই ছবিটাই axiom-গুলোকে দৃশ্যমান করে।
৭ · অনুশীলনী¶
difficulty: ★ সহজ, ★★ মাঝারি, ★★★ কঠিন। পূর্ণ সমাধান: _solutions/02-01-sample-spaces-axioms-solutions.md।
৭.১ Conceptual (ধারণাগত)¶
Q1 (★) নিচের প্রতিটি random experiment-এর sample space \(\Omega\) লেখো এবং \(\lvert \Omega \rvert\) বলো: (ক) একটা মুদ্রা \(3\) বার toss; (খ) দুটো আলাদা পাশার যোগফল; (গ) প্রথম head না আসা পর্যন্ত toss। Hint: (খ)-তে \(\Omega\) কি যোগফলের set, না জোড়ার set — সাবধান।
Q2 (★) এক পাশায় \(A=\{2,4,6\}\), \(B=\{1,2,3\}\)। set-এর ভাষায় লেখো ও তালিকা করো: (ক) "\(A\) এবং \(B\) দুটোই", (খ) "\(A\) অথবা \(B\)", (গ) "\(A\) ঘটল কিন্তু \(B\) নয়", (ঘ) "\(A\)-ও না, \(B\)-ও না"। (ঘ)-তে De Morgan ব্যবহার করে যাচাই করো। Hint: §২.২ টেবিল; "\(A\)-ও না \(B\)-ও না" \(=(A\cup B)^c = A^c \cap B^c\)।
Q3 (★★) ব্যাখ্যা করো কেন classical সূত্র \(P(A)=\lvert A\rvert/\lvert\Omega\rvert\) একটা loaded (পক্ষপাতদুষ্ট) পাশায় খাটে না, অথচ Kolmogorov-এর তিন axiom তখনও মানে। একটা loaded পাশার উদাহরণ দাও যেখানে \(P(\{6\})=0.5\)। Hint: classical সূত্রের কোন অনুমান ভাঙছে? axiom কোনটাই "সমসম্ভাব্য" দাবি করে না।
৭.২ Computational (গণনামূলক)¶
Q4 (★) দুই পাশা। classical probability বের করো: (ক) যোগফল \(\le 4\); (খ) দুটো একই সংখ্যা (doubles); (গ) যোগফল জোড়। Hint: \(\lvert \Omega \rvert = 36\); প্রতিটি favorable outcome গোনো।
Q5 (★★) \(52\) তাস থেকে \(5\)টা তোলা (poker hand)। (ক) সম্ভাব্য hand-সংখ্যা (\(\lvert\Omega\rvert\))? (খ) ঠিক \(4\)টা ace-সহ একটা hand-এর probability? (গ) flush ছাড়া — শুধু "চারটা ace" event-এর probability। Hint: \(\binom{52}{5}\); চারটা ace fixed, পঞ্চম তাস বাকি \(48\) থেকে।
Q6 (★★) একটা ক্লাসে \(25\) জন ছাত্র, সবার জন্মদিন \(365\) দিনের যেকোনোটিতে সমসম্ভাব্য। complement rule দিয়ে দেখাও যে "অন্তত দুজনের একই জন্মদিন"-এর probability \(1 - \dfrac{365 \cdot 364 \cdots (365-24)}{365^{25}}\), এবং সংখ্যাটা আনুমানিক বের করো (calculator/Python)। Hint: "অন্তত দুজন একই" — উল্টোটা ("সবার আলাদা") গোনো; permutation \(P(365,25)\)।
৭.৩ Proof-based (প্রমাণভিত্তিক)¶
Q7 (★★) axiom থেকে প্রমাণ করো: যেকোনো event \(A, B\)-এর জন্য \(P(A \cap B) \ge P(A) + P(B) - 1\) (Bonferroni inequality)। Hint: §৪.৩-এর addition rule + \(P(A \cup B) \le 1\)।
Q8 (★★★) mathematical induction দিয়ে প্রমাণ করো union bound (§৪.৫): \(P\!\left(\bigcup_{i=1}^n A_i\right) \le \sum_{i=1}^n P(A_i)\) যেকোনো \(n\) event-এর জন্য। Hint: base case \(n=1\) তুচ্ছ; inductive step-এ \(\bigcup_{i=1}^{n+1} A_i = \left(\bigcup_{i=1}^{n} A_i\right) \cup A_{n+1}\) ধরে দুই-event addition rule + monotonicity।
৭.৪ Coding (কোডিং)¶
Q9 (★★) একটা ফাংশন estimate_prob(event_fn, n, seed) লেখো যা দুই পাশা \(n\) বার simulate করে (numpy default_rng) এবং event_fn-এর relative frequency ফেরত দেয়। n = 1000, 10000, 100000-এ "যোগফল \(=7\)"-এ চালিয়ে দেখাও estimate কীভাবে \(1/6\)-এর দিকে যায়।
Hint: §৫.৩-এর কাঠামো; np.mean(event_fn(d1, d2))।
Q10 (★★★) §৪.৪-এর তিন-event inclusion–exclusion সংখ্যায় যাচাই করো। দুই পাশায় তিনটি event নাও: \(A=\{\)প্রথমে \(6\}\), \(B=\{\)যোগফল \(\ge 10\}\), \(C=\{\)দ্বিতীয়টা জোড়\(\}\)। itertools.product-এ পুরো \(\Omega\) enumerate করে বাঁদিক \(P(A\cup B\cup C)\) ও ডানদিকের সাত-পদ সূত্র — দুটো হিসাব মিলিয়ে দেখাও সমান।
Hint: §৫.১-এর classical_P পুনর্ব্যবহার; সাত-পদ আলাদা আলাদা গোনো।
৮ · সারসংক্ষেপ ও সংযোগ¶
যা শিখলাম (recap):
| ধারণা | সংজ্ঞা / সূত্র | মূল কথা |
|---|---|---|
| Random experiment | অনিশ্চিত ফলাফল, জানা সম্ভাবনা-সেট | অনিশ্চয়তার মডেল |
| Sample space \(\Omega\) | সব outcome-এর set | 0.1-এর set |
| Event | \(\Omega\)-এর subset \(A\) | 0.1-এর subset |
| Axiom 1 | \(P(A) \ge 0\) | ঋণাত্মক নয় |
| Axiom 2 | \(P(\Omega) = 1\) | মোট mass \(1\) |
| Axiom 3 | disjoint হলে \(P(\bigcup A_i)=\sum P(A_i)\) | যোগ্যতা |
| Complement rule | \(P(A^c) = 1 - P(A)\) | "অন্তত একটা" |
| Monotonicity | \(A\subseteq B \Rightarrow P(A)\le P(B)\) | বড় event, বেশি mass |
| Addition rule | \(P(A\cup B)=P(A)+P(B)-P(A\cap B)\) | overlap শোধ |
| Inclusion–exclusion | পর্যায়ক্রমে \(\pm\) | তিন/\(n\) event |
| Classical probability | \(P(A)=\lvert A\rvert/\lvert\Omega\rvert\) | equally-likely; 0.2-এর counting |
| Frequentist | \(n_A/n \to P(A)\) | relative frequency-এর সীমা |
মূল ধারণাগত লাফ: outcome = বিন্দু, event = subset, probability = subset-এর ওপর জমা mass; সব property মাত্র তিনটি axiom থেকে যৌক্তিকভাবে বেরোয়।
পূর্ববর্তী সংযোগ (0.1, 0.2): এই অধ্যায়ে \(\Omega\) হলো 0.1-এর set, event হলো subset, "এবং/অথবা/না" হলো intersection/union/complement, mutually exclusive হলো disjoint, আর De Morgan সরাসরি complement-যুক্তিতে কাজে লাগল। classical probability-তে \(\lvert A\rvert\) ও \(\lvert\Omega\rvert\) গোনা মানে 0.2-এর permutation ও \(\binom{n}{k}\)-এর সরাসরি প্রয়োগ — গোনা ও সম্ভাবনা একই মুদ্রার দুই পিঠ (inclusion–exclusion-এ এটা স্পষ্ট)।
পরবর্তী সংযোগ (2.2 — Conditional probability ও Bayes): এখন আমরা probability-কে অবস্থাবিহীনভাবে মেপেছি। পরের অধ্যায়ে প্রশ্ন: "\(B\) ঘটেছে — এই তথ্য জানলে \(A\)-এর probability কীভাবে বদলায়?" সেই \(P(A \mid B) = P(A \cap B)/P(B)\) ঠিক এই অধ্যায়ের \(P(A\cap B)\) ও \(P(B)\)-র ওপর দাঁড়ায়; independence ও বিখ্যাত Bayes' theorem সেখান থেকেই আসবে।
Statistics-এ এর গন্তব্য (source pointer — Rice Ch.1, Wasserman Ch.1, Fernández-Granda Ch.1): এই তিন axiom পুরো statistics-এর শিকড়। 2.3-এ আমরা একটা random variable \(X\) সংজ্ঞায়িত করব — 0.1-এর সেই function যা outcome-কে সংখ্যায় পাঠায় (\(\omega \mapsto X(\omega)\)) — আর তার distribution মাপব ঠিক এই \(P\) দিয়েই (\(P(X = k)\) মানে \(P(\{\omega : X(\omega)=k\})\), একটা event-এর probability)। Part IV (inference)-এ আমরা উল্টো পথে হাঁটব: data থেকে অজানা \(P\) সম্পর্কে সিদ্ধান্ত নেব — আর সেই inference-এর প্রতিটি p-value, confidence interval, posterior এই axiom-গুলোকে মেনেই গণিত করবে। অর্থাৎ এই ছোট্ট অধ্যায়টাই সেই ভিত্তি, যার ওপর গোটা বিল্ডিং দাঁড়া