2.3 · Random Variables Discrete
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
Part 2.1-এ আমরা probability-কে একটা set (sample space \(\Omega\))-এর উপর সংজ্ঞায়িত করেছি, আর event-কে দেখেছি \(\Omega\)-এর একটা subset হিসেবে। কিন্তু বাস্তবে আমরা প্রায় সময়ই পুরো outcome-টা নিয়ে মাথা ঘামাই না — আমরা চাই একটা number (সংখ্যা)। ১০ বার coin ছুড়লে কতগুলো head পড়ল? একটা call center-এ ঘণ্টায় কয়টা call এল? একটা machine-এর প্রথম failure পেতে কতবার চালাতে হলো? প্রতিটি প্রশ্নই একটা random outcome-কে একটা সংখ্যায় রূপান্তর করছে।
এই "outcome → সংখ্যা" রূপান্তরই হলো random variable (দৈব চলক)। আর এখানেই Part 0-এর সবচেয়ে সুন্দর সেতুটা স্পষ্ট হয়: ০.১-এ আমরা শিখেছিলাম একটা function হলো এমন একটা নিয়ম যা এক set-এর প্রতিটি উপাদানকে আরেক set-এর ঠিক একটা উপাদানে পাঠায়। Random variable ঠিক তাই — sample space \(\Omega\) থেকে বাস্তব সংখ্যা \(\mathbb{R}\)-তে একটা function:
💡 এক বাক্যে মূল কথা: sample space একটা set, event একটা subset, আর random variable একটা function। ০.১-এর এই তিন-শব্দের ছকটাই Part II-এর গোটা ব্যাকরণ।
একটা ছোট উদাহরণ (০.১-এর সাথে হুবহু মিল)। দুবার fair coin ছুড়লে \(\Omega = \{HH, HT, TH, TT\}\)। ধরা যাক $X(\omega) = $ (head-এর সংখ্যা)। তাহলে \(X(HH)=2\), \(X(HT)=X(TH)=1\), \(X(TT)=0\) — অর্থাৎ \(X:\Omega\to\{0,1,2\}\subset\mathbb{R}\)। লক্ষ করো \(X\) injective নয় (\(HT\) ও \(TH\) দুটোই \(1\)-এ যায়), আর সেটাই স্বাভাবিক — random variable-কে injective হতে হয় না।
এবার মজার ব্যাপারটা: "\(X=1\)" লিখলে আমরা আসলে একটা event বোঝাই — \(\{\omega \mid X(\omega)=1\} = \{HT, TH\}\), যা \(\Omega\)-এর একটা subset। তাই
এই \(k\mapsto P(X=k)\) নিয়মটাই random variable-এর probability mass function (PMF), আর এটাই হবে এই অধ্যায়ের কেন্দ্র।
Statistics-এ এর ভূমিকা। এই অধ্যায় Part II-এর মেরুদণ্ড, কারণ যত data আমরা পরে modeling করব তার বেশিরভাগই কোনো-না-কোনো distribution থেকে আসা random variable হিসেবে ধরা হয়:
- একটা A/B test-এ "conversion হলো কি না" — Bernoulli; \(n\) জন user-এর মধ্যে কতজন convert করল — Binomial।
- ঘণ্টায় website hit-সংখ্যা, দিনে দুর্ঘটনা-সংখ্যা, পৃষ্ঠায় typo-সংখ্যা — Poisson।
- সফলতা পেতে কতবার চেষ্টা — Geometric।
আর Part IV-এ যখন likelihood ও estimation আসবে, তখন এই PMF-গুলোই হবে কাঁচামাল: data দেখে আমরা জিজ্ঞেস করব "কোন parameter এই data-কে সবচেয়ে সম্ভাব্য করে তোলে?" — সেই প্রশ্নের ভিত্তি এখানেই বসছে। বিশেষ করে binomial distribution সরাসরি ০.২-এর \(\binom{n}{k}\)-এর উপর দাঁড়িয়ে — counting থেকে probability-তে এটাই সরাসরি সেতু।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ Random variable ও তার দুই ধরন¶
Random variable (দৈব চলক) হলো একটা function \(X:\Omega\to\mathbb{R}\) যা sample space-এর প্রতিটি outcome \(\omega\)-কে একটা বাস্তব সংখ্যা \(X(\omega)\)-তে পাঠায়।
দুই বড় শ্রেণি:
- Discrete (বিচ্ছিন্ন): \(X\)-এর সম্ভাব্য মানগুলো গণনাযোগ্য (countable) — হয় সসীম \(\{0,1,\dots,n\}\), নয়তো গণনাযোগ্য-অসীম \(\{0,1,2,\dots\}\)। যেমন head-সংখ্যা, call-সংখ্যা। এই অধ্যায় শুধু discrete নিয়ে।
- Continuous (অবিচ্ছিন্ন): \(X\) একটা ব্যবধির (interval) সব মান নিতে পারে, যেমন উচ্চতা, সময়। এদের নিয়ে 2.4-এ।
Random variable-এর সম্ভাব্য মানগুলোর set-কে তার support (সমর্থন) বলে, লেখা হয় \(\mathcal{X}\) বা \(\mathrm{supp}(X)\)।
Notation convention (পুরো Part II জুড়ে): বড় হাতের অক্ষর (\(X, Y\)) random variable বোঝায়; ছোট হাতের অক্ষর (\(x, k\)) তার একটা নির্দিষ্ট মান বোঝায়। তাই "\(P(X=k)\)" পড়ো "random variable \(X\)-এর মান \(k\) হওয়ার probability"।
২.২ Probability mass function (PMF)¶
Discrete random variable \(X\)-এর probability mass function (সম্ভাব্যতা ভর-অপেক্ষক) হলো function $$ p_X(k) = P(X = k), \qquad k \in \mathbb{R}. $$ এখানে \(P(X=k)\) মানে event \(\{\omega\in\Omega \mid X(\omega)=k\}\)-এর probability।
PMF-এর দুটো অপরিহার্য ধর্ম (axioms থেকে সরাসরি, §৪.১):
- অঋণাত্মকতা: \(p_X(k) \ge 0\) সব \(k\)-এর জন্য।
- মোট ভর \(1\): \(\displaystyle\sum_{k \in \mathcal{X}} p_X(k) = 1\) — অর্থাৎ সব সম্ভাব্য মানের probability যোগ করলে ঠিক \(1\)।
"Mass" (ভর) শব্দটা স্বজ্ঞাময়: কল্পনা করো মোট \(1\) একক ভরকে সংখ্যারেখার কতগুলো বিন্দুতে টুকরো টুকরো করে বসানো হয়েছে; প্রতিটি বিন্দুতে কতটুকু ভর বসল, সেটাই \(p_X(k)\)। (Continuous ক্ষেত্রে ভর ছড়িয়ে যায় density-তে — 2.4।)
যেকোনো event \(A\subseteq\mathbb{R}\)-এর probability পেতে শুধু সংশ্লিষ্ট মানগুলোর ভর যোগ করো:
২.৩ Cumulative distribution function (CDF)¶
\(X\)-এর cumulative distribution function (ক্রমযোজিত বণ্টন-অপেক্ষক) হলো $$ F_X(x) = P(X \le x), \qquad x \in \mathbb{R}. $$
CDF "এ পর্যন্ত জমা হওয়া মোট probability" মাপে। Discrete ক্ষেত্রে এটা পাওয়া যায় ভর জমিয়ে:
ফলে discrete CDF একটা step function (ধাপ-অপেক্ষক): সমর্থনের প্রতিটি মান \(k\)-এ এটা ঠিক \(p_X(k)\) পরিমাণ লাফ দেয়, আর দুই মানের মাঝে সমতল থাকে (§৬-এর চিত্র দেখো)। যেকোনো CDF-এর সর্বজনীন ধর্ম:
- অ-হ্রাসমান (non-decreasing): \(x_1 \le x_2 \Rightarrow F_X(x_1) \le F_X(x_2)\)।
- সীমা: \(\displaystyle\lim_{x\to-\infty}F_X(x)=0\) এবং \(\displaystyle\lim_{x\to+\infty}F_X(x)=1\)।
- ডান-অবিচ্ছিন্ন (right-continuous): \(\le\) চিহ্নের কারণে প্রতিটি লাফে উপরের মানটাই ধরা হয়।
PMF ↔ CDF সম্পর্ক। Discrete ক্ষেত্রে PMF-কে CDF-এর "লাফের উচ্চতা" থেকে পুনরুদ্ধার করা যায়:
যেখানে \(F_X(k^-)\) মানে বাঁদিক থেকে সীমা। আরেকটা খুব দরকারি সূত্র — দুই মানের মধ্যবর্তী probability:
২.৪ Expectation (প্রত্যাশা) ও variance (ভেদাঙ্ক)¶
Discrete random variable \(X\)-এর expectation বা mean (প্রত্যাশিত মান) হলো ভর দিয়ে ভারিত গড়: $$ \mathbb{E}[X] = \mu = \sum_{k\in\mathcal{X}} k\, p_X(k). $$
স্বজ্ঞা: যদি একই experiment (পরীক্ষা) বহুবার করো, \(X\)-এর মানগুলোর গড় দীর্ঘমেয়াদে \(\mathbb{E}[X]\)-এর দিকে যায় (এটাই law of large numbers, Part III; §৬-এ চাক্ষুষ)। ছক্কার ক্ষেত্রে \(\mathbb{E}[X]=(1+2+\cdots+6)/6=3.5\) — খেয়াল করো mean নিজে support-এর মান নাও হতে পারে।
যেকোনো function \(g\)-এর জন্য (law of the unconscious statistician, §৪.২):
Linearity (রৈখিকতা) — অসম্ভব দরকারি, যেকোনো \(X,Y\) ও constant (ধ্রুবক) \(a,b\)-এর জন্য (independence লাগে না):
\(X\)-এর variance (ভেদাঙ্ক) হলো mean থেকে গড় squared deviation (বর্গ-বিচ্যুতি): $$ \mathrm{Var}(X) = \sigma^2 = \mathbb{E}\big[(X-\mu)^2\big] = \sum_{k} (k-\mu)^2\, p_X(k). $$
Variance হলো spread (ছড়ানো)-এর পরিমাপ; এর বর্গমূল \(\sigma = \sqrt{\mathrm{Var}(X)}\) হলো standard deviation (পরিমিত ব্যবধান)। হিসাবের জন্য একটা সহজ formula (সূত্র) (§৪.৩-এ প্রমাণ):
স্কেলিং-এর নিয়ম: \(\mathrm{Var}(aX+b) = a^2\,\mathrm{Var}(X)\) (ধ্রুবক \(b\) ছড়ানো বদলায় না)।
২.৫ চারটি core discrete distribution¶
নিচের চারটি distribution (বণ্টন) statistics-এ সবচেয়ে বেশি আসে। প্রতিটির একটা সৃষ্টিগল্প (generative story) আছে — সেটা মনে রাখলে সূত্র মুখস্থ করতে হয় না।
(ক) Bernoulli\((p)\) — একটামাত্র "হ্যাঁ/না" পরীক্ষা (যেমন একবার coin toss, success চিহ্ন \(1\), ব্যর্থতা \(0\)):
এটাই সব discrete distribution-এর মৌলিক ইট — Binomial, Geometric সব এর উপর গড়া।
(খ) Binomial\((n,p)\) — \(n\)টি independent (স্বাধীন) Bernoulli\((p)\) trial-এ মোট success-সংখ্যা। সমর্থন \(\{0,1,\dots,n\}\):
এখানে \(\binom{n}{k}\) ঠিক ০.২-এ শেখা — "\(n\) trial-এর মধ্যে কোন \(k\)টিতে success" তার গণনা। \(p^k(1-p)^{n-k}\) অংশটা একটা নির্দিষ্ট ক্রমের probability (independence), আর \(\binom{n}{k}\) সব সমান-সম্ভাব্য ক্রম গোনে। (Bernoulli আসলে \(n=1\)-এর Binomial।)
(গ) Poisson\((\lambda)\) — একটা স্থির ব্যবধি (সময়/স্থান)-তে বিরল, independent event (ঘটনা)-এর সংখ্যা; \(\lambda>0\) হলো গড় হার। সমর্থন \(\{0,1,2,\dots\}\):
Poisson-এর স্বাক্ষর ধর্ম: mean ও variance সমান (\(=\lambda\))। উদাহরণ: ঘণ্টায় গড়ে \(\lambda\)টা call এলে, কোনো ঘণ্টায় ঠিক \(k\)টা call আসার probability।
(ঘ) Geometric\((p)\) — independent Bernoulli\((p)\) trial-এ প্রথম success পেতে কত trial লাগল। সমর্থন \(\{1,2,3,\dots\}\) (এই কনভেনশনে \(k\) = trial-সংখ্যা):
স্বজ্ঞা: প্রথম \(k-1\)টা trial ব্যর্থ (প্রতিটির probability \(1-p\), independent), \(k\)-তম trial success (probability \(p\))। Geometric-এর বিখ্যাত memoryless (স্মৃতিহীন) ধর্ম: ইতিমধ্যে যতগুলো ব্যর্থতা হোক, পরবর্তী success-এর জন্য অপেক্ষা একইরকম থাকে (§৪.৫)।
⚠️ কনভেনশন সতর্কতা: কিছু বই Geometric-কে "প্রথম success-এর আগে কতগুলো ব্যর্থতা" হিসেবে নেয়, তখন support \(\{0,1,2,\dots\}\) ও \(\mathbb{E}[X]=(1-p)/p\)।
scipy.stats.geomআমাদের মতোই trial-সংখ্যা (\(k\ge1\)) ব্যবহার করে। সবসময় কোন কনভেনশন তা মিলিয়ে নিও।
২.৬ সংক্ষেপে আরও দুটি: Negative Binomial ও Hypergeometric¶
Negative Binomial\((r,p)\) — Geometric-এর সাধারণীকরণ: \(r\)-তম success পেতে কত trial লাগল (সমর্থন \(k=r, r+1,\dots\)):
\(r=1\) হলে এটা ঠিক Geometric। Data science-এ এটা overdispersed count data (যেখানে variance > mean, তাই Poisson খাটে না) modeling-এ লাগে।
Hypergeometric\((N,K,n)\) — \(N\)টা জিনিসের মধ্যে \(K\)টা "success" আছে; প্রতিস্থাপন ছাড়া (without replacement) \(n\)টা টানলে কতগুলো success পাওয়া যায়:
Binomial-এর সাথে পার্থক্য: Binomial-এ প্রতি trial independent (স্বাধীন) (with replacement / অসীম population), Hypergeometric-এ টান নির্ভরশীল (finite population, যেমন তাস বা গুণমান-পরীক্ষায় lot থেকে sample (নমুনা) নেওয়া)। \(N\) অনেক বড় হলে দুটো প্রায় মিলে যায়।
এই দুটি এখন শুধু চিনে রাখো; এরা মূলত Part IV–V (modeling)-এ ফিরবে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ৩.১ — PMF ও CDF হাতে গড়া: তিন coin toss¶
তিনবার fair coin (\(p=0.5\)) ছুড়ছি; \(X=\) head-সংখ্যা। এটা Binomial\((3, 0.5)\)। ০.২-এ শেখা \(\binom{n}{k}\) দিয়ে PMF:
| \(k\) | \(\binom{3}{k}\) | \(p_X(k)\) | \(F_X(k)=P(X\le k)\) |
|---|---|---|---|
| \(0\) | \(1\) | \(1/8 = 0.125\) | \(0.125\) |
| \(1\) | \(3\) | \(3/8 = 0.375\) | \(0.500\) |
| \(2\) | \(3\) | \(3/8 = 0.375\) | \(0.875\) |
| \(3\) | \(1\) | \(1/8 = 0.125\) | \(1.000\) |
যাচাই: \(\sum p_X(k) = (1+3+3+1)/8 = 1\) ✓ (মোট ভর \(1\))। আর \(F_X(3)=1\) ✓।
একটা event-এর হিসাব: "অন্তত \(2\) head" মানে \(P(X\ge2) = p_X(2)+p_X(3) = 0.375+0.125 = 0.5\)। অথবা CDF দিয়ে: \(P(X\ge2)=1-F_X(1)=1-0.5=0.5\) ✓।
উদাহরণ ৩.২ — Binomial: A/B test-এ conversion¶
একটা website-এ নতুন button-এর conversion rate \(p=0.2\)। \(n=10\) জন independent (স্বাধীন) visitor এলে, ঠিক \(3\) জন convert করার probability?
expected (প্রত্যাশিত) conversion: \(\mathbb{E}[X]=np = 10\times0.2 = 2\) জন; spread (ছড়ানো) \(\mathrm{Var}(X)=np(1-p)=10(0.2)(0.8)=1.6\), তাই \(\sigma=\sqrt{1.6}\approx1.26\)। "অন্তত একজন convert করবে" এর probability হিসাব করা সহজ পরিপূরক দিয়ে: \(P(X\ge1)=1-P(X=0)=1-(0.8)^{10}\approx1-0.107=0.893\)।
উদাহরণ ৩.৩ — Poisson: call center¶
একটা call center-এ গড়ে ঘণ্টায় \(\lambda=4\)টা call আসে। একটা নির্দিষ্ট ঘণ্টায় ঠিক \(2\)টা call আসার probability?
কোনো call না আসার probability \(P(X=0)=e^{-4}\approx0.0183\)। এখানে mean \(=\) variance \(=4\), তাই \(\sigma=2\) — মোটামুটি \(4\pm2\) call প্রত্যাশিত। (পরে §৭ Q5-এ দেখবে এই same hour-rate দিয়ে অন্য ব্যবধি, যেমন আধ ঘণ্টার, hisab কীভাবে scaling করে।)
উদাহরণ ৩.৪ — Geometric: প্রথম সফলতা¶
একটা পাশা ছুড়ছি; "\(6\) পড়া" = success, তাই \(p=1/6\)। প্রথম \(6\) পেতে ঠিক \(4\) বার ছুড়তে হওয়ার probability (অর্থাৎ প্রথম তিনবার \(6\) নয়, চতুর্থবার \(6\))?
average (গড়)-এ কতবার লাগবে? \(\mathbb{E}[X]=1/p = 6\) বার — স্বজ্ঞাময়, \(1/6\) probability-র জন্য গড়ে \(6\) চেষ্টা। "\(3\) বারের মধ্যেই \(6\) পড়বে" এর probability CDF দিয়ে: \(P(X\le3)=1-(5/6)^3 = 1-0.5787 = 0.4213\) (এটাই Geometric-এর CDF-এর বদ্ধ রূপ, §৪.৪)।
উদাহরণ ৩.৫ — Variance দুই উপায়ে: Bernoulli দিয়ে যাচাই¶
Bernoulli\((p)\)-এর variance §২.৫-এ লেখা সূত্র \(\mathrm{Var}(X)=\mathbb{E}[X^2]-(\mathbb{E}[X])^2\) দিয়ে যাচাই করি। সমর্থন \(\{0,1\}\), তাই \(X^2=X\) (কারণ \(0^2=0,1^2=1\)):
§২.৫-এর Bernoulli variance-এর সাথে হুবহু মিলল।
৪ · প্রমাণ ও উৎপাদন¶
Intro-probability স্তরের প্রমাণ — যেখানে measure theory লাগে (যেমন CDF-এর সাধারণ গঠন) তা Part VII-এ। তারা চিহ্ন: ★ সহজ, ★★ মাঝারি, ★★★ গভীর।
৪.১ PMF axioms সন্তুষ্ট করে ★¶
দাবি: \(p_X(k)=P(X=k)\) অঋণাত্মক এবং \(\sum_k p_X(k)=1\)।
প্রমাণ: probability axiom থেকে যেকোনো event-এর probability \(\ge0\), তাই \(p_X(k)=P(\{X=k\})\ge0\)। আবার event-গুলো \(\{X=k\}\) (ভিন্ন \(k\)-এর জন্য) পরস্পর-বিচ্ছিন্ন (একটা outcome \(\omega\) ঠিক একটাই মান \(X(\omega)\) দেয়, কারণ \(X\) একটা function — ০.১), এবং তাদের সংযোগ পুরো \(\Omega\)। তাই countable additivity axiom দিয়ে
লক্ষ করো: "\(X\) একটা function" এই একটামাত্র ধর্মই নিশ্চিত করছে event-গুলো বিচ্ছিন্ন — ০.১-এর function-সংজ্ঞা সরাসরি কাজে লাগল।
৪.২ Binomial PMF যোগফল \(1\) ★★¶
দাবি: \(\displaystyle\sum_{k=0}^{n}\binom{n}{k}p^k(1-p)^{n-k}=1\)।
প্রমাণ: ০.২-এর binomial theorem \((x+y)^n=\sum_{k=0}^n\binom{n}{k}x^k y^{n-k}\)-তে \(x=p,\;y=1-p\) বসাও:
এই একটা লাইন দেখায় কেন binomial distribution নামটা সার্থক — এর PMF-গুলো ঠিক binomial theorem-এর পদ। ০.২ আর ২.৩-এর সেতু এখানে দৃশ্যমান।
৪.৩ Variance-এর সংক্ষিপ্ত সূত্র ★¶
দাবি: \(\mathrm{Var}(X)=\mathbb{E}[X^2]-(\mathbb{E}[X])^2\)।
প্রমাণ: সংজ্ঞা থেকে শুরু করে বর্গ খুলি, তারপর expectation-এর linearity (§২.৪) প্রয়োগ করি (ধরা যাক \(\mu=\mathbb{E}[X]\) একটা ধ্রুবক):
৪.৪ Binomial mean ও Poisson PMF যোগফল ★★¶
(ক) Binomial mean \(\mathbb{E}[X]=np\) (linearity-র সুন্দর প্রয়োগ): Binomial\((n,p)\) হলো \(n\)টা স্বাধীন Bernoulli\((p)\)-র যোগফল, \(X=\sum_{i=1}^n Y_i\), প্রতিটি \(\mathbb{E}[Y_i]=p\)। তাই linearity (§২.৪, independence লাগে না) দিয়ে:
(এই Bernoulli-যোগ কৌশলেই variance-ও \(np(1-p)\) পাওয়া যায়, তবে তাতে independence ও variance-এর additivity লাগে — Part 2.5।)
(খ) Poisson PMF যোগফল \(1\): পরিচিত exponential series \(\sum_{k=0}^{\infty}\frac{\lambda^k}{k!}=e^{\lambda}\) ব্যবহার করে (০.৩-০.৪-এ Taylor series দেখা):
৪.৫ Geometric CDF ও memoryless ধর্ম ★★¶
(ক) CDF-এর বদ্ধ রূপ: \(P(X>k)\) মানে প্রথম \(k\)টা trial-ই ব্যর্থ, যার probability (independence) \((1-p)^k\)। তাই
(এটা geometric series-এর যোগফল হিসেবেও পাওয়া যায়, তাই নাম "Geometric"।)
(খ) Memoryless ধর্ম ★★★: দাবি — যেকোনো \(s,t\ge0\)-এর জন্য \(P(X>s+t \mid X>s)=P(X>t)\)। প্রমাণ conditional probability (2.2)-এর সংজ্ঞা দিয়ে:
(এখানে \(\{X>s+t\}\subseteq\{X>s\}\), তাই joint (যৌথ) event ঠিক \(\{X>s+t\}\)।) \(\blacksquare\) অর্থ: এতবার ব্যর্থ হয়েছ — তাতে "এবার নিশ্চয় হবে" নয়; পরবর্তী সফলতার অপেক্ষা একদম নতুন করে শুরুর মতোই। Geometric হলো একমাত্র discrete distribution যার এই ধর্ম আছে।
৪.৬ Binomial → Poisson approximation ★★★¶
দাবি (Poisson limit theorem): যদি \(n\to\infty\) এবং \(p\to0\) এমনভাবে যে \(np\to\lambda\) স্থির থাকে, তবে Binomial\((n,p)\)-এর PMF Poisson\((\lambda)\)-এর PMF-এ convergent (অভিসারী) হয়।
প্রমাণ-রূপরেখা: \(p=\lambda/n\) বসিয়ে Binomial PMF লিখি ও \(n\to\infty\) নিই:
তিনটি সীমা: (১) প্রথম গুণনীয়কে \(k\)টি পদ, প্রতিটি \(\to1\); (২) বিখ্যাত সীমা \((1-\lambda/n)^n\to e^{-\lambda}\) (০.৩); (৩) শেষেরটি \(\to1\) যেহেতু \(k\) স্থির। গুণফল:
ব্যবহারিক নিয়ম: \(n\ge20,\;p\le0.05\) (বা \(n\ge100,\;np\le10\)) হলে Poisson একটা চমৎকার আসন্ন মান দেয়। এজন্যই Poisson-কে বলা হয় "law of rare events (বিরল ঘটনার নিয়ম)" — অনেক trial, প্রতিটিতে সামান্য success-probability। §৬-এর overlay চিত্রে এই convergence চোখে দেখা যায়।
৫ · কোড ল্যাব (Python)¶
প্রথমে from-scratch PMF/CDF, তারপর scipy.stats দিয়ে যাচাই, শেষে reproducible simulation। সব seed স্থির (default_rng(2025))।
৫.১ From scratch — PMF, CDF, mean, variance¶
import numpy as np
from math import comb, factorial, exp
# --- PMF গুলো সরাসরি সংজ্ঞা থেকে ---
def binom_pmf(k, n, p):
return comb(n, k) * p**k * (1 - p)**(n - k)
def poisson_pmf(k, lam):
return lam**k * exp(-lam) / factorial(k)
def geom_pmf(k, p): # k = trial-সংখ্যা, k >= 1
return (1 - p)**(k - 1) * p
# --- support-এর উপর PMF থেকে CDF, mean, variance ---
def summarize(pmf_func, support):
ks = np.array(support, dtype=float)
pmf = np.array([pmf_func(int(k)) for k in ks])
cdf = np.cumsum(pmf)
mean = np.sum(ks * pmf)
ex2 = np.sum(ks**2 * pmf)
var = ex2 - mean**2 # §৪.৩ সূত্র
return pmf, cdf, mean, var
# Binomial(10, 0.4)
pmf, cdf, mean, var = summarize(lambda k: binom_pmf(k, 10, 0.4), range(0, 11))
print("Binomial(10,0.4):")
print(" sum(pmf) =", round(pmf.sum(), 10)) # 1.0
print(" mean =", round(mean, 4), " (np = 4.0)")
print(" var =", round(var, 4), " (np(1-p) = 2.4)")
print(" P(X<=3) =", round(cdf[3], 4))
আউটপুট:
theory-র সাথে হুবহু মিলল: \(\mathbb{E}[X]=np=4\), \(\mathrm{Var}(X)=np(1-p)=2.4\)।
৫.২ scipy.stats দিয়ে যাচাই¶
scipy.stats-এ প্রতিটা distribution একটা object; .pmf, .cdf, .mean, .var, .rvs সব আছে।
from scipy import stats
import numpy as np
# Binomial
b = stats.binom(n=10, p=0.4)
print("scipy Binomial pmf(3) =", round(b.pmf(3), 6), "| scratch =", round(binom_pmf(3, 10, 0.4), 6))
print("scipy mean, var =", b.mean(), b.var())
# Poisson(4): mean == var == 4
po = stats.poisson(mu=4)
print("Poisson(4) mean, var =", po.mean(), po.var()) # 4.0 4.0
print("Poisson P(X=2) =", round(po.pmf(2), 6), "| scratch =", round(poisson_pmf(2, 4), 6))
# Geometric(1/6): scipy-ও trial-সংখ্যা (k>=1) ব্যবহার করে
g = stats.geom(p=1/6)
print("Geometric mean =", round(g.mean(), 4), " (1/p = 6)")
print("Geometric P(X=4) =", round(g.pmf(4), 6), "| scratch =", round(geom_pmf(4, 1/6), 6))
# from-scratch ও scipy একমত কিনা assert দিয়ে নিশ্চিত
assert np.isclose(b.pmf(3), binom_pmf(3, 10, 0.4))
assert np.isclose(po.pmf(2), poisson_pmf(2, 4))
assert np.isclose(g.pmf(4), geom_pmf(4, 1/6))
print("✓ from-scratch ও scipy একমত")
আউটপুট:
scipy Binomial pmf(3) = 0.214991 | scratch = 0.214991
scipy mean, var = 4.0 2.4
Poisson(4) mean, var = 4.0 4.0
Poisson P(X=2) = 0.146525 | scratch = 0.146525
Geometric mean = 6.0 (1/p = 6)
Geometric P(X=4) = 0.096451 | scratch = 0.096451
✓ from-scratch ও scipy একমত
৫.৩ Reproducible simulation — empirical বনাম theoretical¶
বড় সংখ্যক draw নিয়ে দেখি empirical relative frequency theory-র PMF-এর কাছে যায় কিনা (law of large numbers-এর ঝলক)।
import numpy as np
from scipy import stats
rng = np.random.default_rng(2025) # স্থির seed → পুনরুৎপাদনযোগ্য
N = 100_000
n, p = 12, 0.35
samples = rng.binomial(n, p, size=N) # N বার Binomial(12,0.35) draw
ks = np.arange(0, n + 1)
emp = np.array([(samples == k).mean() for k in ks]) # empirical P(X=k)
theo = stats.binom.pmf(ks, n, p) # theoretical
print(f"{'k':>2} {'empirical':>11} {'theory':>10} {'|diff|':>9}")
for k in ks:
print(f"{k:>2} {emp[k]:>11.4f} {theo[k]:>10.4f} {abs(emp[k]-theo[k]):>9.4f}")
print("\nempirical mean =", round(samples.mean(), 3), " theory np =", n * p)
print("empirical var =", round(samples.var(), 3), " theory np(1-p) =", round(n*p*(1-p), 3))
print("max |emp - theory| =", round(np.max(np.abs(emp - theo)), 4))
আউটপুট (সংক্ষেপিত):
k empirical theory |diff|
0 0.0057 0.0057 0.0001
1 0.0375 0.0368 0.0007
2 0.1101 0.1088 0.0013
3 0.1951 0.1954 0.0002
4 0.2387 0.2367 0.0020
5 0.2022 0.2039 0.0017
...
empirical mean = 4.189 theory np = 4.2
empirical var = 2.733 theory np(1-p) = 2.73
max |emp - theory| = 0.0020
\(100{,}000\) draw-তে empirical ও theoretical PMF সর্বত্র \(0.002\)-এর মধ্যে মিলছে — এটাই §৬-এর শেষ চিত্রের সংখ্যাগত রূপ। seed স্থির থাকায় এই আউটপুট প্রতিবার একই।
৫.৪ Binomial → Poisson approximation সংখ্যায়¶
import numpy as np
from scipy import stats
lam = 4.0
ks = np.arange(0, 11)
pois = stats.poisson.pmf(ks, lam)
print(f"{'k':>2} {'Poisson':>9} {'Bin n=10':>9} {'Bin n=100':>10} {'Bin n=1000':>11}")
for k in ks:
row = [stats.binom.pmf(k, n, lam / n) for n in (10, 100, 1000)]
print(f"{k:>2} {pois[k]:>9.4f} {row[0]:>9.4f} {row[1]:>10.4f} {row[2]:>11.4f}")
# মোট পরম পার্থক্য n বাড়লে কমছে কিনা
for n in (10, 100, 1000):
b = stats.binom.pmf(ks, n, lam / n)
print(f"n={n:>4}: sum|Binom - Poisson| = {np.sum(np.abs(b - pois)):.5f}")
আউটপুট (সংক্ষেপিত):
k Poisson Bin n=10 Bin n=100 Bin n=1000
0 0.0183 0.0060 0.0169 0.0182
1 0.0733 0.0403 0.0703 0.0730
2 0.1465 0.1209 0.1450 0.1464
...
n= 10: sum|Binom - Poisson| = 0.25061
n= 100: sum|Binom - Poisson| = 0.01988
n=1000: sum|Binom - Poisson| = 0.00195
\(n\) দশগুণ বাড়লে মোট পার্থক্যও মোটামুটি দশগুণ কমছে — §৪.৬-এর limit theorem সংখ্যায় নিশ্চিত।
৬ · ভিজ্যুয়ালাইজেশন¶
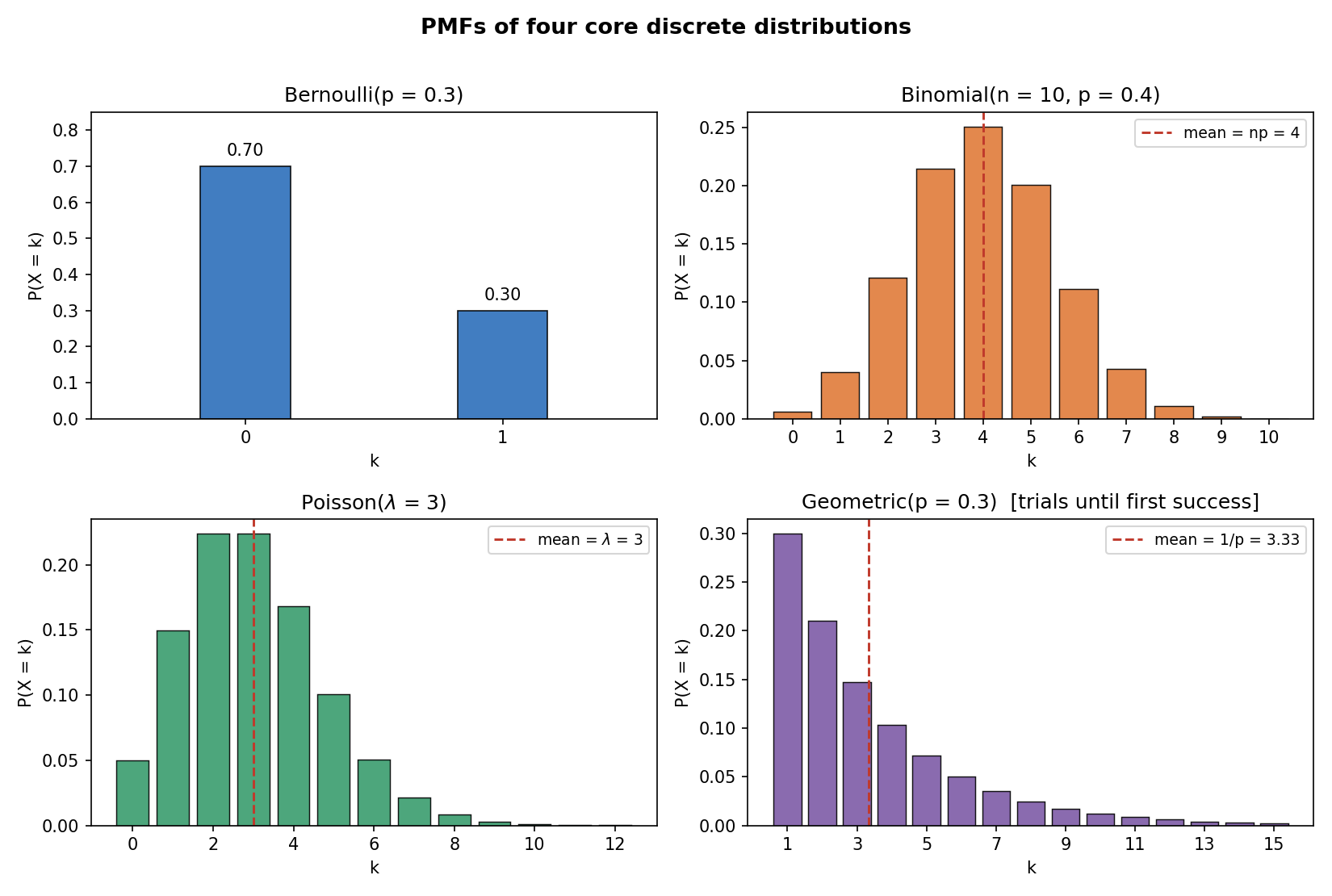
চিত্র ১ — চারটি core distribution-এর PMF¶
নিচে Bernoulli, Binomial, Poisson, Geometric-এর PMF bar chart। লক্ষ করো আকৃতি: Bernoulli-তে মাত্র দুটো bar; Binomial প্রায় symmetric (প্রতিসম) শিখর (\(np\)-এর কাছে); Poisson ডানদিকে লেজ-টানা; Geometric একঘেয়ে কমছে (সবচেয়ে বড় ভর \(k=1\)-এ)। প্রতিটিতে লাল ছেদরেখা mean দেখাচ্ছে।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
fig, axes = plt.subplots(2, 2, figsize=(11, 7.4))
# (a) Bernoulli(0.3)
ax = axes[0, 0]; xs = np.array([0, 1]); pmf = stats.bernoulli.pmf(xs, 0.3)
ax.bar(xs, pmf, width=0.35, color="#2c6fbb", edgecolor="black", alpha=0.9)
ax.set_title("Bernoulli(p = 0.3)"); ax.set_xticks([0, 1]); ax.set_xlabel("k"); ax.set_ylabel("P(X = k)")
# (b) Binomial(10, 0.4)
ax = axes[0, 1]; xs = np.arange(0, 11); pmf = stats.binom.pmf(xs, 10, 0.4)
ax.bar(xs, pmf, color="#e07b39", edgecolor="black", alpha=0.9)
ax.axvline(4, color="#c0392b", ls="--", label="mean = np = 4")
ax.set_title("Binomial(n = 10, p = 0.4)"); ax.legend(fontsize=9); ax.set_xlabel("k"); ax.set_ylabel("P(X = k)")
# (c) Poisson(3)
ax = axes[1, 0]; xs = np.arange(0, 13); pmf = stats.poisson.pmf(xs, 3.0)
ax.bar(xs, pmf, color="#3a9d6e", edgecolor="black", alpha=0.9)
ax.axvline(3, color="#c0392b", ls="--", label=r"mean = $\lambda$ = 3")
ax.set_title(r"Poisson($\lambda$ = 3)"); ax.legend(fontsize=9); ax.set_xlabel("k"); ax.set_ylabel("P(X = k)")
# (d) Geometric(0.3)
ax = axes[1, 1]; xs = np.arange(1, 16); pmf = stats.geom.pmf(xs, 0.3)
ax.bar(xs, pmf, color="#7d5ba6", edgecolor="black", alpha=0.9)
ax.axvline(1/0.3, color="#c0392b", ls="--", label="mean = 1/p = 3.33")
ax.set_title("Geometric(p = 0.3)"); ax.legend(fontsize=9); ax.set_xlabel("k"); ax.set_ylabel("P(X = k)")
fig.suptitle("PMFs of four core discrete distributions", fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.97])
fig.savefig("../_assets/2-3-pmf-grid.png", dpi=150)
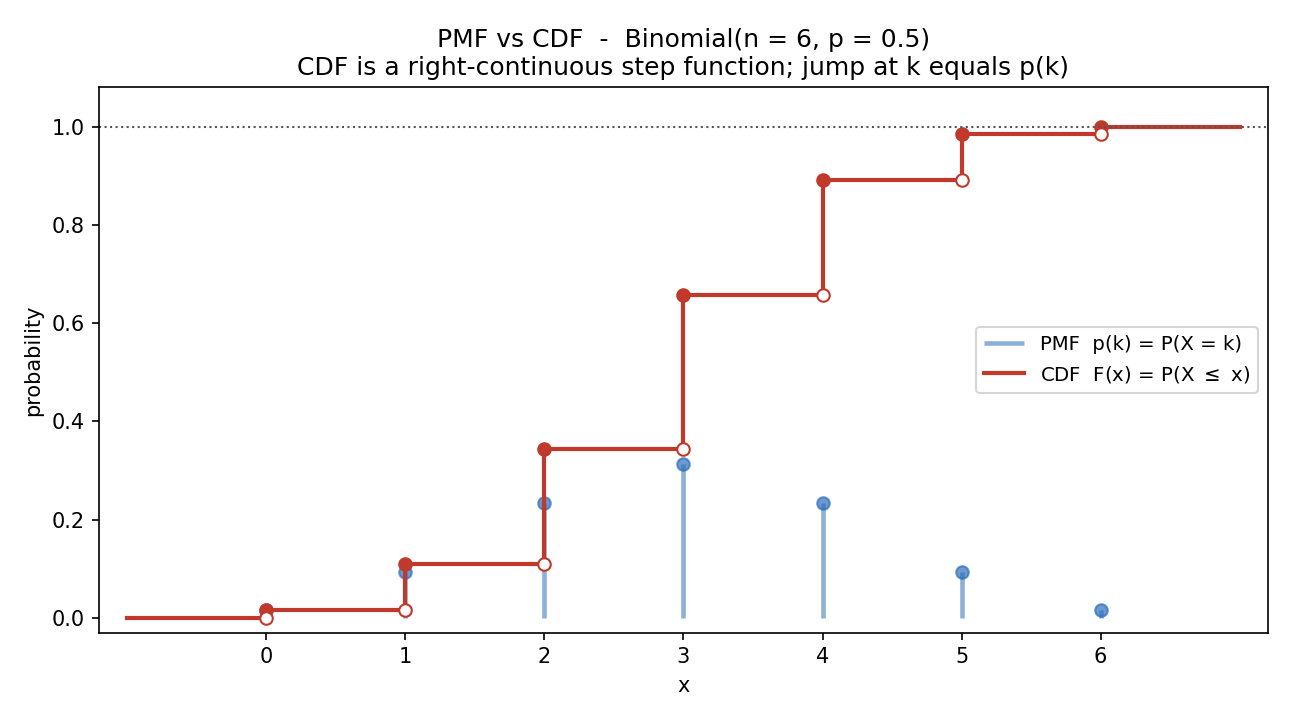
চিত্র ২ — PMF বনাম CDF: একটা step function¶
একই Binomial\((6,0.5)\)-এর PMF (নীল দণ্ড) ও CDF (লাল ধাপ) একসাথে। CDF প্রতিটি পূর্ণসংখ্যা \(k\)-এ ঠিক \(p_X(k)\) পরিমাণ লাফ দেয় — ভরা বিন্দু (•) লাফের পরের মান (attained, কারণ ডান-অবিচ্ছিন্ন), ফাঁকা বিন্দু (○) আগের মান। CDF \(0\) থেকে শুরু হয়ে \(1\)-এ পৌঁছায়, কখনো কমে না — §২.৩-এর সব ধর্মের চাক্ষুষ রূপ।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
n, p = 6, 0.5
xs = np.arange(0, n + 1)
pmf = stats.binom.pmf(xs, n, p); cdf = stats.binom.cdf(xs, n, p)
fig, ax = plt.subplots(figsize=(8.6, 4.8))
ax.vlines(xs, 0, pmf, color="#2c6fbb", lw=2.2, alpha=0.55, label="PMF p(k) = P(X = k)")
ax.plot(xs, pmf, "o", color="#2c6fbb", ms=6, alpha=0.7)
x_ext = np.concatenate(([-1], xs, [n + 1])); F_ext = np.concatenate(([0.], cdf, [1.]))
ax.step(x_ext, F_ext, where="post", color="#c0392b", lw=2.0, label=r"CDF F(x) = P(X $\leq$ x)")
ax.plot(xs, cdf, "o", color="#c0392b", ms=6)
ax.plot(xs, np.concatenate(([0.], cdf[:-1])), "o", mfc="white", mec="#c0392b", ms=6)
ax.set_xticks(xs); ax.set_xlabel("x"); ax.set_ylabel("probability")
ax.set_title("PMF vs CDF — Binomial(n = 6, p = 0.5)")
ax.legend(loc="center right", fontsize=9.5)
fig.tight_layout(); fig.savefig("../_assets/2-3-cdf-step.png", dpi=150)
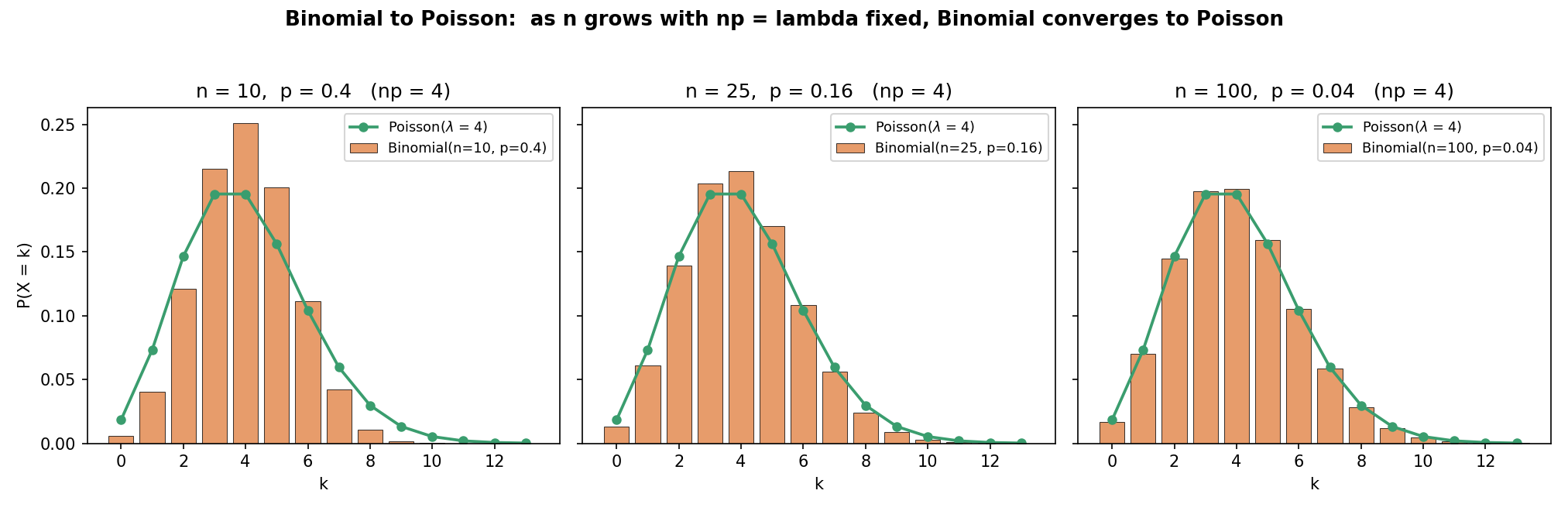
চিত্র ৩ — Binomial → Poisson approximation¶
\(\lambda=np=4\) স্থির রেখে \(n\) বাড়ালে (\(n=10,25,100\)) Binomial-এর bar ক্রমশ Poisson\((4)\)-এর সবুজ বক্ররেখার সাথে মিশে যায়। \(n=100\)-এ পার্থক্য প্রায় অদৃশ্য — §৪.৬-এর limit theorem-এর চাক্ষুষ প্রমাণ। এটাই কেন বিরল-ঘটনা (large \(n\), small \(p\)) Binomial-কে Poisson দিয়ে আসন্ন করা যায়।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
fig, axes = plt.subplots(1, 3, figsize=(13.5, 4.4), sharey=True)
lam = 4.0; xs = np.arange(0, 14); pois = stats.poisson.pmf(xs, lam)
for ax, (n, p) in zip(axes, [(10, lam/10), (25, lam/25), (100, lam/100)]):
ax.bar(xs, stats.binom.pmf(xs, n, p), color="#e07b39", edgecolor="black",
alpha=0.75, label=f"Binomial(n={n}, p={p:.3g})")
ax.plot(xs, pois, "o-", color="#3a9d6e", lw=1.8, ms=5, label=r"Poisson($\lambda$ = 4)")
ax.set_title(f"n = {n}, p = {p:.3g} (np = 4)"); ax.set_xlabel("k"); ax.legend(fontsize=8.5)
axes[0].set_ylabel("P(X = k)")
fig.suptitle("Binomial to Poisson: n grows with np fixed", fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95]); fig.savefig("../_assets/2-3-binom-poisson.png", dpi=150)
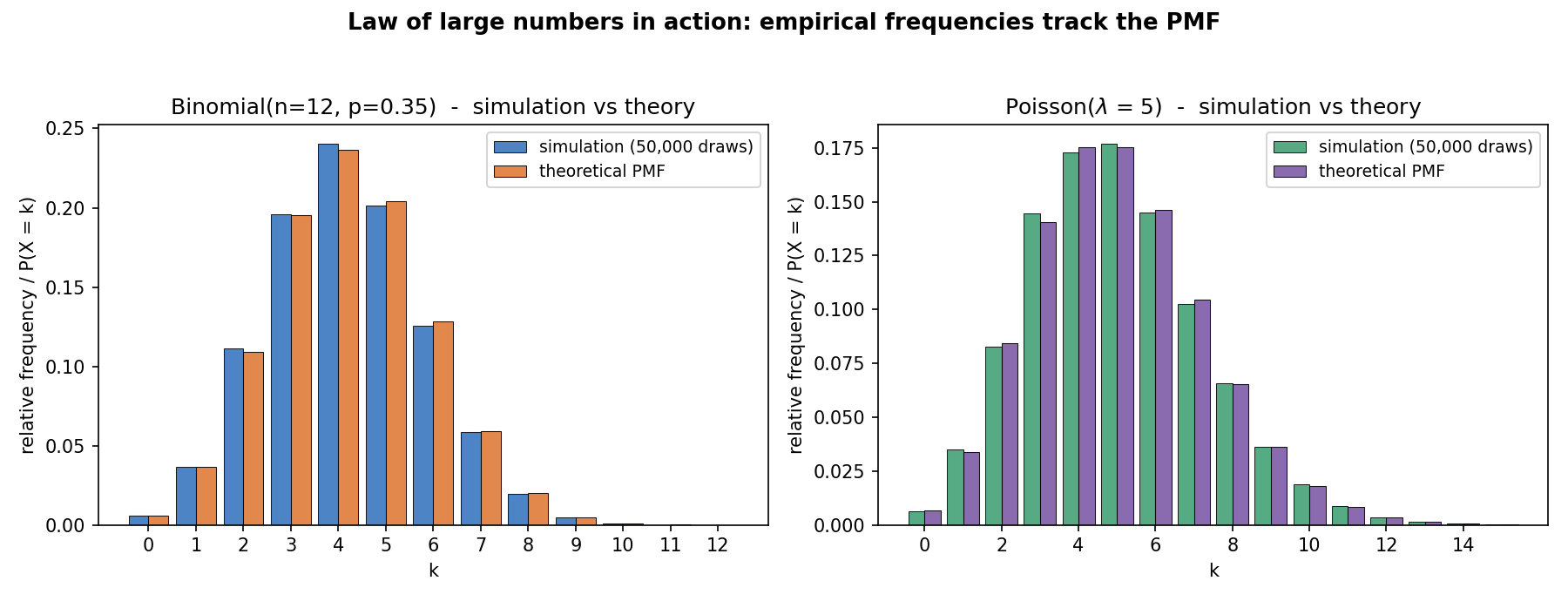
চিত্র ৪ — Simulation বনাম theoretical PMF¶
বাঁদিকে Binomial\((12,0.35)\), ডানে Poisson\((5)\) — প্রতিটিতে \(50{,}000\) বার simulation-এর empirical frequency (নীল/সবুজ) আর theoretical PMF (কমলা/বেগুনি) পাশাপাশি। দুটো প্রায় অভিন্ন: যথেষ্ট নমুনায় empirical frequency theoretical probability-র দিকে যায় (law of large numbers, Part III)। এটাই §৫.৩-এর সংখ্যাগত ফলের ছবি।
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
rng = np.random.default_rng(2025); N = 50_000; w = 0.42
fig, axes = plt.subplots(1, 2, figsize=(12, 4.6))
# Binomial
ax = axes[0]; n, p = 12, 0.35; s = rng.binomial(n, p, N); xs = np.arange(0, n + 1)
emp = np.array([(s == k).mean() for k in xs]); theo = stats.binom.pmf(xs, n, p)
ax.bar(xs - w/2, emp, width=w, color="#2c6fbb", alpha=0.85, label=f"simulation ({N:,})")
ax.bar(xs + w/2, theo, width=w, color="#e07b39", alpha=0.9, label="theoretical PMF")
ax.set_title(f"Binomial(n={n}, p={p}) — sim vs theory"); ax.set_xticks(xs); ax.legend(fontsize=9)
ax.set_xlabel("k"); ax.set_ylabel("relative frequency / P(X = k)")
# Poisson
ax = axes[1]; lam = 5.0; s = rng.poisson(lam, N); xs = np.arange(0, 16)
emp = np.array([(s == k).mean() for k in xs]); theo = stats.poisson.pmf(xs, lam)
ax.bar(xs - w/2, emp, width=w, color="#3a9d6e", alpha=0.85, label=f"simulation ({N:,})")
ax.bar(xs + w/2, theo, width=w, color="#7d5ba6", alpha=0.9, label="theoretical PMF")
ax.set_title(r"Poisson($\lambda$ = 5) — sim vs theory"); ax.legend(fontsize=9)
ax.set_xlabel("k"); ax.set_ylabel("relative frequency / P(X = k)")
fig.suptitle("Empirical frequencies track the PMF", fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95]); fig.savefig("../_assets/2-3-sim-vs-theory.png", dpi=150)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty: ★ সহজ, ★★ মাঝারি, ★★★ কঠিন। পূর্ণ সমাধান: _solutions/02-03-random-variables-discrete-solutions.md।
৭.১ Conceptual (ধারণাগত)¶
Q1 (★) নিচের কোনগুলো discrete random variable, ব্যাখ্যা করো: (ক) একটা দিনে কোনো দোকানে আসা ক্রেতার সংখ্যা; (খ) একজন মানুষের ঠিক উচ্চতা; (গ) ১০ বার coin toss-এ head-সংখ্যা; (ঘ) একটা bus আসতে অপেক্ষার সময় (মিনিটে)। Hint: সম্ভাব্য মানগুলো গণনাযোগ্য (countable) কিনা দেখো।
Q2 (★) \(X:\Omega\to\mathbb{R}\) random variable-কে কেন একটা function বলা হয়, ০.১-এর সংজ্ঞার সাথে মিলিয়ে এক-দুই বাক্যে লেখো। "\(X=2\)" আসলে কোন গাণিতিক বস্তু (object) বোঝায়? Hint: function = এক set-এর প্রতিটি উপাদানের জন্য আরেক set-এ ঠিক একটা মান; "\(X=2\)" একটা subset।
Q3 (★★) একটা বন্ধু বলল "যেহেতু Poisson distribution-এ mean \(=\) variance, তাই সব count data Poisson দিয়ে model করা যায়।" এই যুক্তির ভুল কোথায়? কোন distribution তখন বেশি উপযুক্ত? Hint: §২.৬ Negative Binomial; overdispersion (variance > mean)।
৭.২ Computational (গণনামূলক)¶
Q4 (★) একটা biased coin-এ \(P(\text{head})=0.7\), একবার ছোড়া হচ্ছে; \(X=1\) যদি head, নাহলে \(0\)। (ক) PMF লেখো, (খ) \(\mathbb{E}[X]\) ও \(\mathrm{Var}(X)\) বের করো। Hint: Bernoulli\((0.7)\); §২.৫।
Q5 (★★) §৩.৩-এর call center-এ ঘণ্টায় গড়ে \(\lambda=4\) call। (ক) ঠিক \(5\)টা call আসার probability? (খ) \(2\)টার বেশি call আসার probability? (গ) যদি এখন আধ ঘণ্টা ধরো, সেই ব্যবধির জন্য \(\lambda'\) কত, এবং সেই আধ ঘণ্টায় কোনো call না আসার probability কত? Hint: (খ) \(P(X>2)=1-P(X\le2)\); (গ) Poisson rate সময়ের সাথে সমানুপাতিক, \(\lambda'=2\)।
Q6 (★★) একটা পরীক্ষায় প্রতিটা প্রশ্নের সঠিক উত্তরের probability স্বাধীনভাবে \(p=0.6\)। (ক) \(8\)টা প্রশ্নের মধ্যে ঠিক \(5\)টা সঠিক হওয়ার probability? (খ) গড়ে কয়টা সঠিক হবে ও তার standard deviation কত? (গ) প্রথম ভুল উত্তর \(4\)নং প্রশ্নে হওয়ার probability? Hint: (ক)(খ) Binomial\((8,0.6)\); (গ) Geometric — "ভুল" কে success ধরো, \(p_{\text{fail}}=0.4\)।
৭.৩ Proof-based (প্রমাণভিত্তিক)¶
Q7 (★★) Geometric\((p)\)-এর জন্য §৪.৪-এর exponential-series কৌশলের অনুরূপ পথে দেখাও যে \(\sum_{k=1}^{\infty}(1-p)^{k-1}p = 1\)। Hint: geometric series \(\sum_{j=0}^{\infty}r^j = 1/(1-r)\) যেখানে \(r=1-p\)।
Q8 (★★★) Linearity of expectation (§২.৪) ধরে নিয়ে, \(X\sim\) Binomial\((n,p)\)-কে \(n\)টা স্বাধীন Bernoulli\((p)\)-র যোগফল \(X=\sum_{i=1}^n Y_i\) হিসেবে লিখে প্রমাণ করো \(\mathbb{E}[X]=np\) (§৪.৪ক)। তারপর ব্যাখ্যা করো কেন \(\mathrm{Var}(X)=np(1-p)\) পেতে অতিরিক্ত একটা ধর্ম (independence) লাগে যেটা mean-এর জন্য লাগেনি। Hint: mean-এ linearity যথেষ্ট; variance-এর additivity শুধু independent হলে খাটে (Part 2.5)।
৭.৪ Coding (কোডিং)¶
Q9 (★★) একটা function discrete_summary(pmf_dict) লেখো যা একটা dict (key = মান \(k\), value = \(p_X(k)\)) নিয়ে ফেরত দেয় \((\text{sum}, \mathbb{E}[X], \mathrm{Var}(X))\)। প্রথমে assert করো যোগফল \(\approx1\)। ছক্কার uniform PMF ({1:1/6, ..., 6:1/6})-তে চালিয়ে \(\mathbb{E}[X]=3.5\), \(\mathrm{Var}(X)=35/12\approx2.9167\) পাও কিনা দেখো।
Hint: \(\mathrm{Var}=\sum k^2 p_X(k) - (\sum k\,p_X(k))^2\) (§৪.৩)।
Q10 (★★★) numpy-র default_rng(0) দিয়ে Geometric\((p=0.2)\) থেকে \(100{,}000\)টা নমুনা টানো (rng.geometric(0.2, size=...))। (ক) empirical mean ও variance বের করে theory (\(1/p=5\), \((1-p)/p^2=20\))-র সাথে মেলাও। (খ) memoryless ধর্ম যাচাই করো: নমুনা থেকে empirical-ভাবে \(P(X>5+3 \mid X>5)\) আর \(P(X>3)\) হিসাব করে দেখো প্রায় সমান কিনা।
Hint: (খ) s[s>5] থেকে কতগুলো >8 তা গোনো; আলাদাভাবে সব নমুনায় >3-এর অনুপাত।
৮ · সারসংক্ষেপ ও সংযোগ¶
যা শিখলাম (recap):
- Random variable \(X:\Omega\to\mathbb{R}\) একটা function (০.১) — outcome-কে সংখ্যায় পাঠায়; "\(X=k\)" আসলে একটা event।
- PMF \(p_X(k)=P(X=k)\): অঋণাত্মক, যোগফল \(1\)। CDF \(F_X(x)=P(X\le x)\): অ-হ্রাসমান step function, \(0\to1\), ডান-অবিচ্ছিন্ন। সম্পর্ক: \(p_X(k)=F_X(k)-F_X(k^-)\)।
- Expectation \(\mathbb{E}[X]=\sum k\,p_X(k)\) (রৈখিক); Variance \(\mathrm{Var}(X)=\mathbb{E}[X^2]-(\mathbb{E}[X])^2\)।
চারটি core distribution (মুখস্থ-যোগ্য ছক):
| Distribution | সৃষ্টিগল্প | PMF | Mean | Variance |
|---|---|---|---|---|
| Bernoulli\((p)\) | একটা হ্যাঁ/না | \(p^k(1-p)^{1-k},\;k\in\{0,1\}\) | \(p\) | \(p(1-p)\) |
| Binomial\((n,p)\) | \(n\) স্বাধীন trial-এ success | \(\binom{n}{k}p^k(1-p)^{n-k}\) | \(np\) | \(np(1-p)\) |
| Poisson\((\lambda)\) | ব্যবধিতে বিরল ঘটনা | \(\dfrac{\lambda^k e^{-\lambda}}{k!}\) | \(\lambda\) | \(\lambda\) |
| Geometric\((p)\) | প্রথম success-এর trial | \((1-p)^{k-1}p,\;k\ge1\) | \(1/p\) | \((1-p)/p^2\) |
আরও: Negative Binomial\((r,p)\) (\(r\)-তম success, mean \(r/p\)); Hypergeometric (without-replacement sampling)।
মূল সম্পর্কগুলো: Bernoulli \(=\) Binomial\((1,p)\); Geometric \(=\) Negative Binomial\((1,p)\); Binomial\((n,p)\xrightarrow{n\to\infty,\,np\to\lambda}\) Poisson\((\lambda)\) (§৪.৬)। Poisson-এর স্বাক্ষর: mean \(=\) variance। Geometric-এর স্বাক্ষর: memoryless।
পূর্ববর্তী সংযোগ: ০.১-এর function ধারণাই random variable-এর সংজ্ঞা; ০.২-এর \(\binom{n}{k}\) ও binomial theorem সরাসরি Binomial distribution গড়ে ও তার PMF-যোগফল \(1\) প্রমাণ করে (§৪.২)। ০.৩-০.৪-এর Taylor series (\(e^\lambda\), \((1-\lambda/n)^n\to e^{-\lambda}\)) Poisson-এর ভিত্তি। 2.1-এর axioms থেকেই PMF-এর দুই ধর্ম আসে (§৪.১), আর 2.2-এর conditional probability দিয়ে memoryless প্রমাণ হয় (§৪.৫)।
পরবর্তী সংযোগ (2.4 Continuous Distributions): পরের অধ্যায়ে support একটা interval হয়ে যাবে; PMF-এর জায়গায় আসবে probability density function (PDF), আর যোগফল \(\sum\)-এর জায়গায় integral \(\int\) (০.৪)। CDF ধারণাটা একই থাকবে — শুধু step function-এর বদলে মসৃণ বক্ররেখা। সেখানে Uniform, Exponential (Geometric-এর continuous সহোদর, এটাও memoryless), Normal, Gamma, Beta দেখবে।
Statistics-এ গন্তব্য (source pointer): এই PMF-গুলো Part IV-এ likelihood ও maximum likelihood estimation-এর কাঁচামাল — data দেখে \(p\) বা \(\lambda\) আন্দাজ করা। Part V-এ Binomial → logistic regression, Poisson → Poisson/count regression-এর ভিত্তি হবে। বিস্তারিত প্রমাণ Rice Ch.2, Wasserman Ch.2 ও Fernández-Granda Ch