অধ্যায় ২.৭ · Transformations ও Order Statistics¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
এই অধ্যায়টি Part II-র শেষ অধ্যায়, এবং এক অর্থে এটি একটি সেতু। এতদিন আমরা একেকটা random variable-এর distribution আলাদাভাবে চিনেছি — Uniform, Exponential, Normal (2.4), তাদের expectation-variance (2.5), একাধিক variable-এর joint আচরণ (2.6)। এবার প্রশ্ন পাল্টাবে: একটি random variable নিয়ে যদি আমরা কিছু করি — তাকে নতুন কোনো সূত্রে ফেলি — তাহলে ফলাফলের distribution কী হবে?
কেন এটা এত জরুরি? কারণ বাস্তবে আমরা প্রায় কখনোই "কাঁচা" random variable নিয়ে থামি না। আমরা তার transformation (রূপান্তর) করি।
একটি গল্প দিয়ে শুরু করি। ধরুন একটি কারখানায় বৃত্তাকার ধাতব চাকতি (disc) বানানো হয়, আর প্রতিটি চাকতির ব্যাসার্ধ (radius) \(R\) একটি random variable — মেশিনের সূক্ষ্ম তারতম্যে এটি একটু এদিক-ওদিক হয়। আপনি জানেন \(R\)-এর distribution। এখন গুণমান নিয়ন্ত্রণের জন্য আপনার দরকার চাকতির ক্ষেত্রফল (area) \(A = \pi R^2\)-এর distribution — গড় area কত, কতটা ছড়িয়ে আছে। লক্ষ করুন, \(A\) নিজেও একটি random variable, কিন্তু এটি \(R\)-এর একটি function: \(A = g(R)\) যেখানে \(g(r)=\pi r^2\)। \(R\)-এর distribution থেকে \(A\)-এর distribution কীভাবে বের করব? এটাই transformation of a random variable-এর কেন্দ্রীয় প্রশ্ন।
আরও তিনটি দৃশ্য, যা এই অধ্যায়ের চারটি স্তম্ভকে ছুঁয়ে যায়:
- sum (যোগফল)। দুজন স্বাধীন গ্রাহকের সেবা-সময় \(X\) ও \(Y\) — মোট সময় \(X+Y\)-এর distribution কী? দুটি random variable যোগ করলে তাদের density-গুলো একটি বিশেষ ক্রিয়ায় মিশে যায়, যার নাম convolution (কনভল্যুশন)। এটি Part III-এর Central Limit Theorem-এর সরাসরি প্রস্তুতি — কারণ CLT-ই বলে অনেক স্বাধীন random variable যোগ করলে কী হয়।
- extremes (চরম মান)। একটি বাঁধ ডিজাইন করতে গেলে দরকার "আগামী ১০০ বছরে সর্বোচ্চ বন্যার মাত্রা" — অর্থাৎ \(n\)টি বার্ষিক মানের মধ্যে maximum-এর distribution। আবার একটি শিকল ঠিক ততটাই শক্ত যতটা তার সবচেয়ে দুর্বল কড়িটা — অর্থাৎ minimum। এই min, max, median — সাজানো নমুনার এই বিশেষ মানগুলোকে বলে order statistics।
- simulation (নমুনা তৈরি)। কম্পিউটার তো শুধু \(\text{Uniform}(0,1)\) random সংখ্যা দিতে পারে। তাহলে Exponential বা Normal নমুনা আসে কোথা থেকে? উত্তর একটি সুন্দর transformation — probability integral transform — যা এই অধ্যায়ের শেষে দেখব।
মূল অন্তর্দৃষ্টি (পুরো অধ্যায়ের সুতো)। একটি random variable-কে কোনো function দিয়ে রূপান্তর করলে তার "ভর" (probability mass/density) নতুনভাবে ছড়িয়ে পড়ে — কোথাও জমাট বাঁধে, কোথাও পাতলা হয়। কেন? কারণ function কোথাও ইনপুট-অক্ষকে সংকুচিত করে, কোথাও প্রসারিত করে। যেখানে \(g\) একটা ছোট ইনপুট-পরিসরকে বড় আউটপুট-পরিসরে ছড়ায়, সেখানে density পাতলা হয়; যেখানে চাপায়, সেখানে ঘন হয়। এই "কতটা টানছে/চাপছে"-র পরিমাপই হলো Jacobian (\(\lvert dx/dy \rvert\)) — derivative-এর absolute value। আর যেহেতু মোট probability সবসময় \(1\), ভর শুধু পুনর্বণ্টিত হয়, হারায় না। এই একটিমাত্র ছবি — "ভর সংরক্ষিত, ঘনত্ব পুনর্বণ্টিত" — মনে রাখলে এই অধ্যায়ের প্রতিটি সূত্র স্বাভাবিক মনে হবে।
২ · মূল ধারণা ও সংজ্ঞা¶
২.১ একটি random variable-এর function: সমস্যাটা কী¶
ধরা যাক \(X\) একটি random variable যার distribution আমরা জানি (CDF \(F_X\), density \(f_X\))। একটি (deterministic) function \(g\) নিয়ে আমরা নতুন random variable বানাই: $$ Y = g(X). $$ \(Y\) random, কারণ \(X\) random — \(X\) যে মান নেয় তার ওপর \(Y=g(X)\) নির্ভর করে। আমাদের লক্ষ্য \(Y\)-এর distribution (CDF \(F_Y\) বা density \(f_Y\)) বের করা। দুটি মূল পদ্ধতি আছে — একটি সর্বজনীন, একটি দ্রুত।
২.২ পদ্ধতি ১ — CDF method (সব ক্ষেত্রে কাজ করে)¶
সবচেয়ে নির্ভরযোগ্য কৌশল: সরাসরি \(Y\)-এর CDF লেখো, তারপর দরকারে derivative নিয়ে density পাও। সংজ্ঞা থেকে শুরু— $$ F_Y(y) = P(Y \le y) = P\big(g(X) \le y\big). $$ এখন \(\{g(X)\le y\}\) ঘটনাটিকে \(X\)-এর ভাষায় অনুবাদ করো — অর্থাৎ \(X\)-এর কোন কোন মানে \(g(X)\le y\) হয়, সেই সেট বের করো — এবং সেই সেটের probability \(F_X\) বা \(f_X\) দিয়ে লেখো। শেষে continuous ক্ষেত্রে $$ f_Y(y) = \frac{d}{dy} F_Y(y). $$
উদাহরণ (monotone increasing \(g\))। ধরা যাক \(g\) কঠোরভাবে বাড়ন্ত (strictly increasing) ও invertible (উল্টানো যায়), inverse \(g^{-1}\)। তাহলে \(g(X)\le y \iff X \le g^{-1}(y)\), সুতরাং $$ F_Y(y) = P\big(X \le g^{-1}(y)\big) = F_X\big(g^{-1}(y)\big). $$ উদাহরণ (monotone decreasing \(g\))। তখন অসমতা উল্টে যায়: \(g(X)\le y \iff X \ge g^{-1}(y)\), তাই $$ F_Y(y) = P\big(X \ge g^{-1}(y)\big) = 1 - F_X\big(g^{-1}(y)\big). $$
CDF method-এর শক্তি: \(g\) monotone না হলেও কাজ করে। যেমন \(Y=X^2\)-তে \(\{X^2\le y\}=\{-\sqrt{y}\le X\le \sqrt{y}\}\), তাই \(F_Y(y)=F_X(\sqrt y)-F_X(-\sqrt y)\) — দুই শাখা মিলিয়ে (§৩-এ পূর্ণ গণনা)।
২.৩ পদ্ধতি ২ — change of variables (Jacobian সূত্র, monotone \(g\))¶
monotone (এবং differentiable) \(g\)-র জন্য density সরাসরি লেখা যায়, CDF-এর মধ্য দিয়ে না গিয়ে। উপরের CDF-সূত্রকে chain rule দিয়ে differentiate করলে—
increasing ক্ষেত্রে \(f_Y(y)=f_X(g^{-1}(y))\cdot \frac{d}{dy}g^{-1}(y)\), এবং decreasing ক্ষেত্রে একটি ঋণচিহ্ন আসে। দুটিকে এক সূত্রে absolute value দিয়ে বাঁধা যায়:
ভেতরের রাশি \(\lvert \frac{d}{dy} g^{-1}(y)\rvert = \lvert dx/dy\rvert\)-কে এই (এক-মাত্রিক) রূপান্তরের Jacobian বলে। \(x=g^{-1}(y)\) বসিয়ে আরও স্মরণযোগ্যভাবে: $$ f_Y(y) = f_X(x)\,\left\lvert \frac{dx}{dy}\right\rvert , \qquad x = g^{-1}(y). $$
কেন absolute value? density কখনো ঋণাত্মক নয়। decreasing \(g\)-তে \(dx/dy<0\), কিন্তু ভর তো নেগেটিভ হতে পারে না — তাই আমরা মাত্রা (magnitude) নিই। কেন এই Jacobian factor? §১-এর "ভর সংরক্ষণ" অন্তর্দৃষ্টি: \(x\)-অক্ষের ছোট টুকরো \(dx\)-এ যত ভর (\(f_X(x)\,dx\)), \(y\)-অক্ষের সংশ্লিষ্ট টুকরো \(dy\)-তেও ঠিক তত ভর (\(f_Y(y)\,dy\))। সমান বসিয়ে \(f_Y(y)=f_X(x)\,\lvert dx/dy\rvert\)। Jacobian-ই বলে দেয় \(g\) এখানে অক্ষকে কতটা টানছে বা চাপছে।
সতর্কতা। এই সূত্র শুধু monotone \(g\)-তে সরাসরি খাটে। \(g\) না-monotone হলে (যেমন \(Y=X^2\) পুরো \(\mathbb{R}\)-তে) inverse এক-মান নয়; তখন প্রতিটি monotone শাখার অবদান যোগ করতে হয়, অথবা নিরাপদে CDF method ব্যবহার করতে হয়।
২.৪ সরলরৈখিক রূপান্তর — location-scale (বিশেষ ক্ষেত্র)¶
সবচেয়ে বেশি ব্যবহৃত transformation: \(Y=aX+b\) (\(a\neq 0\))। এখানে \(x=g^{-1}(y)=(y-b)/a\) এবং \(\lvert dx/dy\rvert = 1/\lvert a\rvert\)। সূত্রে বসিয়ে $$ f_Y(y) = \frac{1}{\lvert a\rvert}\, f_X!\left(\frac{y-b}{a}\right). $$ এটিই location-scale family-র ভিত্তি: \(b\) density-কে সরায় (location/অবস্থান), \(a\) একে টানে-চাপে (scale/মাপ), আর \(1/\lvert a\rvert\) factor মোট area \(1\) রাখে। এর সরাসরি ফল (2.5 মনে করুন): \(\mathbb{E}[Y]=a\,\mathbb{E}[X]+b\), \(\operatorname{Var}(Y)=a^2\operatorname{Var}(X)\)। Normal-এর standardization \(Z=(X-\mu)/\sigma\) এরই বিশেষ রূপ।
২.৫ দুই independent random variable-এর sum — convolution¶
ধরা যাক \(X\) ও \(Y\) independent (স্বাধীন), density \(f_X,f_Y\), এবং \(S=X+Y\)। \(S\)-এর density দুই density-র convolution:
কোথা থেকে এলো? \(S\le s\) মানে joint density-কে \(\{x+y\le s\}\) অঞ্চলে integrate করা (2.6-এর double integral)। independence-এ joint \(=f_X(x)f_Y(y)\)। CDF-কে \(s\)-এর সাপেক্ষে differentiate করলে ভেতরের integral-এ \(y=s-x\) বসে যায় — তাই উপরের সূত্র। স্বজ্ঞাত পাঠ: "\(S=s\) হওয়ার সব উপায় যোগ করছি — \(X=x\) হলে \(Y\)-কে ঠিক \(s-x\) হতে হবে; সব \(x\)-এর ওপর যোগ।" discrete ক্ষেত্রে integral হয়ে যায় sum: \(P(S=s)=\sum_x P(X=x)\,P(Y=s-x)\)।
ধ্রুপদী ফল — দুই Uniform → Triangular। \(X,Y\sim\text{Uniform}(0,1)\) independent হলে \(S=X+Y\)-এর density একটি ত্রিভুজ (triangular): $$ f_S(s)=\begin{cases} s, & 0\le s\le 1,\ 2-s, & 1<s\le 2,\ 0,&\text{অন্যত্র.}\end{cases} $$ সমতল দুটি density যোগ করলে চূড়াযুক্ত ত্রিভুজ আসে — এটাই "যোগফল কেন্দ্রের দিকে জমে" ধারণার প্রথম আভাস, যা CLT-তে পূর্ণতা পাবে (§৪ ও §৬-এ ছবি)।
২.৬ Order statistics — সাজানো নমুনা¶
ধরা যাক \(X_1,\dots,X_n\) একটি i.i.d. (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত) নমুনা, সাধারণ CDF \(F\) ও density \(f\)। এদের ছোট-থেকে-বড় সাজালে যে ক্রম পাই, তাদের বলে order statistics: $$ X_{(1)} \le X_{(2)} \le \cdots \le X_{(n)}, $$ যেখানে \(X_{(1)}=\min_i X_i\) (সর্বনিম্ন) এবং \(X_{(n)}=\max_i X_i\) (সর্বোচ্চ)। \(X_{(k)}\) হলো \(k\)-তম ক্ষুদ্রতম মান। লক্ষ করুন order statistics-গুলো independent নয় (সাজানোই তাদের জুড়ে দেয়), যদিও মূল \(X_i\)-গুলো ছিল।
maximum-এর distribution। চাবিকাঠি: \(\max\le x\) ঘটে তখনই ও কেবল তখনই যদি সবগুলো \(X_i\le x\) হয়। independence-এ probability গুণ হয়: $$ F_{X_{(n)}}(x)=P(\text{সব } X_i\le x)=\big[F(x)\big]^n,\qquad f_{X_{(n)}}(x)=n\,[F(x)]^{n-1}f(x). $$
minimum-এর distribution। একইভাবে, \(\min> x\) ঘটে তখনই যদি সবগুলো \(X_i>x\) হয়: $$ F_{X_{(1)}}(x)=1-P(\text{সব } X_i> x)=1-[1-F(x)]^n,\qquad f_{X_{(1)}}(x)=n\,[1-F(x)]^{n-1}f(x). $$
সাধারণ \(k\)-তম order statistic। \(X_{(k)}\le x\) মানে "\(n\)টির মধ্যে অন্তত \(k\)টি \(\le x\)" — এটি একটি Binomial-গণনা, যার থেকে density: $$ \boxed{\ f_{X_{(k)}}(x)=\frac{n!}{(k-1)!\,(n-k)!}\,[F(x)]^{k-1}\,[1-F(x)]^{n-k}\,f(x)\ } $$ স্বজ্ঞাত পাঠ: একটি observation ঠিক \(x\)-তে (\(f(x)\)), তার বাঁয়ে \(k-1\)টি (\([F(x)]^{k-1}\)), ডানে \(n-k\)টি (\([1-F(x)]^{n-k}\)), আর কোন observation কোথায় যাবে তার গণনা multinomial গুণাঙ্ক \(\frac{n!}{(k-1)!(n-k)!}\)। (median হলো \(n\) বিজোড় হলে \(X_{((n+1)/2)}\)।)
Uniform-এ সুন্দর রূপ। \(X_i\sim\text{Uniform}(0,1)\) হলে \(F(x)=x\), তাই \(f_{X_{(k)}}(x)=\frac{n!}{(k-1)!(n-k)!}x^{k-1}(1-x)^{n-k}\) — অর্থাৎ \(X_{(k)}\sim\text{Beta}(k,\,n-k+1)\)। বিশেষভাবে \(\max\sim\text{Beta}(n,1)\), \(\min\sim\text{Beta}(1,n)\)। এজন্যই 2.4-এর Beta distribution এখানে স্বাভাবিকভাবে ফিরে আসে।
২.৭ Probability Integral Transform (PIT)¶
একটি চমৎকার, প্রায় জাদুকরী ফল। ধরা যাক \(X\) একটি continuous random variable যার CDF \(F_X\) (কঠোরভাবে বাড়ন্ত)। নিজের CDF দিয়েই \(X\)-কে রূপান্তর করো: $$ U = F_X(X). $$ তখন সবসময় \(U\sim\text{Uniform}(0,1)\) — \(X\)-এর distribution যাই হোক না কেন!
প্রমাণের স্কেচ (§৪-এ পূর্ণ)। \(U=F_X(X)\) সবসময় \([0,1]\)-এ। \(0\le u\le 1\)-এর জন্য \(F_U(u)=P(F_X(X)\le u)=P(X\le F_X^{-1}(u))=F_X(F_X^{-1}(u))=u\) — যা ঠিক \(\text{Uniform}(0,1)\)-এর CDF।
উল্টো দিক — inverse transform sampling। PIT উল্টে দিলে নমুনা তৈরির যন্ত্র পাই: \(U\sim\text{Uniform}(0,1)\) নাও, তারপর \(X=F_X^{-1}(U)\) বসাও — এই \(X\)-এর CDF ঠিক \(F_X\)। অর্থাৎ যেকোনো distribution-এর inverse-CDF জানলে, শুধু uniform random সংখ্যা থেকে সেই distribution-এর নমুনা বানানো যায়। উদাহরণ: Exponential(\(1\))-এর \(F(x)=1-e^{-x}\), inverse \(F^{-1}(u)=-\ln(1-u)\); তাই \(-\ln(1-U)\) সবসময় Exponential(\(1\)) (§৩, §৫)।
৩ · পূর্ণাঙ্গ উদাহরণ¶
উদাহরণ ১ — \(Y=X^2\) যখন \(X\sim\text{Uniform}(0,1)\) (CDF method ও Jacobian, দুই পথে মিলিয়ে)¶
\(X\sim\text{Uniform}(0,1)\), তাই \(f_X(x)=1\) for \(0\le x\le 1\) এবং \(F_X(x)=x\)। চাই \(Y=X^2\)-এর density।
CDF method। যেহেতু \(0\le X\le 1\), এই পরিসরে \(g(x)=x^2\) বাড়ন্ত, আর \(0\le Y\le 1\)। \(0\le y\le 1\)-এর জন্য $$ F_Y(y)=P(X^2\le y)=P(0\le X\le \sqrt{y})=F_X(\sqrt y)=\sqrt y. $$ differentiate করে density: $$ f_Y(y)=\frac{d}{dy}\sqrt y=\frac{1}{2\sqrt y},\qquad 0<y\le 1. $$
Jacobian method (যাচাই)। \(x=g^{-1}(y)=\sqrt y\), তাই \(\frac{dx}{dy}=\frac{1}{2\sqrt y}\)। সূত্রে বসাও: $$ f_Y(y)=f_X(\sqrt y)\left\lvert \frac{1}{2\sqrt y}\right\rvert = 1\cdot \frac{1}{2\sqrt y}=\frac{1}{2\sqrt y}. \checkmark $$ দুই পথ এক উত্তর। ব্যাখ্যা: \(f_Y\) \(y\to 0\)-তে অসীমের দিকে যায় — মানে ভর \(0\)-র কাছে জমে। কারণ \(g(x)=x^2\) ছোট \(x\)-গুলোকে আরও ছোট করে চেপে আনে (যেমন \(0.1\mapsto 0.01\)), তাই সেখানে density ঘন হয়। যাচাই (§৬ Figure 1b): \(X\sim\text{Uniform}(0,1)\) নমুনার বর্গ নিলে histogram ঠিক \(\frac{1}{2\sqrt y}\) curve-কে অনুসরণ করে; এবং \(P(Y\le 0.25)=\sqrt{0.25}=0.5\) — অর্থাৎ অর্ধেক ভর \([0,0.25]\)-এ, কারণ ছোট মানে জমাট।
উদাহরণ ২ — দুই Uniform-এর sum (convolution হাতে-কলমে)¶
\(X,Y\sim\text{Uniform}(0,1)\) independent, \(S=X+Y\)। convolution সূত্রে \(f_X(x)=1\) on \([0,1]\), শূন্য অন্যত্র; একইভাবে \(f_Y\)। $$ f_S(s)=\int_{-\infty}^{\infty} f_X(x)\,f_Y(s-x)\,dx=\int (\text{integrand}=1)\,dx \quad\text{সেই }x\text{-এ যেখানে দুটোই nonzero}. $$ integrand \(1\) হয় শুধু যখন একসাথে \(0\le x\le 1\) এবং \(0\le s-x\le 1\) (অর্থাৎ \(s-1\le x\le s\))। তাই \(x\)-এর পরিসর \([\max(0,s-1),\ \min(1,s)]\), আর \(f_S(s)\) = সেই পরিসরের দৈর্ঘ্য।
- \(0\le s\le 1\): পরিসর \([0,s]\), দৈর্ঘ্য \(s\). সুতরাং \(f_S(s)=s\).
- \(1< s\le 2\): পরিসর \([s-1,1]\), দৈর্ঘ্য \(1-(s-1)=2-s\). সুতরাং \(f_S(s)=2-s\).
এটাই triangular density, চূড়া \(s=1\)-এ যেখানে \(f_S(1)=1\)। যাচাই: \(\mathbb{E}[S]=\mathbb{E}[X]+\mathbb{E}[Y]=\tfrac12+\tfrac12=1\) (চূড়াও সেখানে, ঠিক), আর \(\operatorname{Var}(S)=\tfrac{1}{12}+\tfrac{1}{12}=\tfrac16\)। (§৫.২-এ simulation এই সংখ্যাগুলো হুবহু মেলায়।)
উদাহরণ ৩ — \(n\)টি Uniform-এর maximum (order statistic)¶
\(X_1,\dots,X_n\sim\text{Uniform}(0,1)\) i.i.d., \(M=X_{(n)}=\max\)। এখানে \(F(x)=x\) on \([0,1]\), তাই $$ F_M(x)=[F(x)]^n=x^n,\qquad f_M(x)=n\,x^{n-1}\quad(0\le x\le 1), $$ অর্থাৎ \(M\sim\text{Beta}(n,1)\)। গড়: $$ \mathbb{E}[M]=\int_0^1 x\cdot n x^{n-1}\,dx=n\int_0^1 x^n\,dx=\frac{n}{n+1}. $$ ব্যাখ্যা: \(n\) বাড়লে \(\frac{n}{n+1}\to 1\) — যত বেশি নমুনা, maximum তত \(1\)-এর কাছে ঠেলে যায়, এবং density \(x=1\)-এর দিকে আরও তীক্ষ্ণভাবে জমে (§৬ Figure 3, বাঁ পাশ)। একইভাবে \(\min\)-এর গড় \(\frac{1}{n+1}\to 0\)। সংখ্যাগত যাচাই (\(n=20\)): theory \(\mathbb{E}[M]=20/21\approx0.9524\); §৫.৩-এর simulation দেয় \(0.9525\) — চমৎকার মিল। আর \(P(M\le 0.9)=0.9^{20}\approx0.1216\), simulation \(0.1210\)।
উদাহরণ ৪ — PIT দিয়ে Exponential নমুনা তৈরি¶
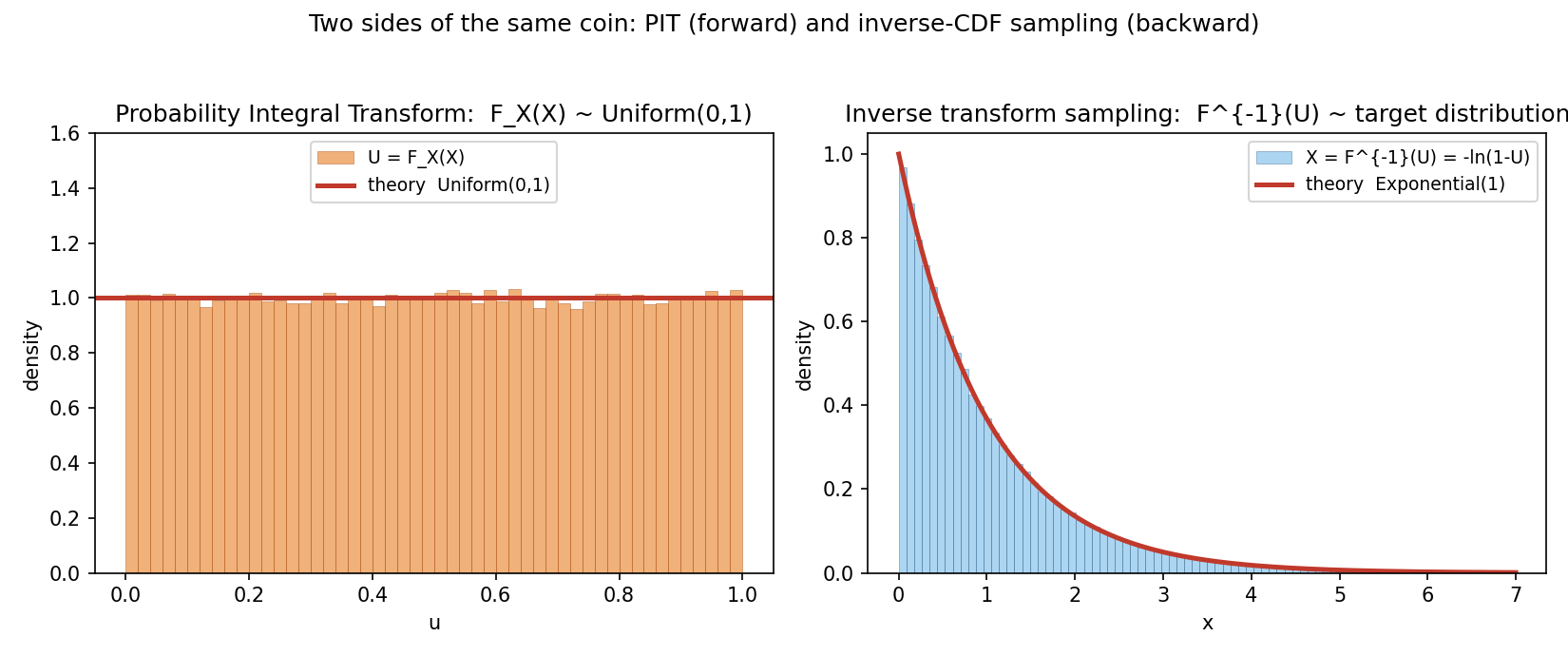
কম্পিউটার \(U\sim\text{Uniform}(0,1)\) দেয়। চাই Exponential(\(\lambda\)) নমুনা। Exponential-এর CDF \(F(x)=1-e^{-\lambda x}\); এর inverse: $$ u=1-e^{-\lambda x}\ \Rightarrow\ x=F^{-1}(u)=-\frac{1}{\lambda}\ln(1-u). $$ তাই \(X=-\frac{1}{\lambda}\ln(1-U)\) সবসময় Exponential(\(\lambda\))। (\(1-U\)-ও Uniform, তাই বাস্তবে অনেকে \(-\frac1\lambda\ln U\) লেখে।) যাচাই (\(\lambda=1\)): §৫.৪-এ এই সূত্রে বানানো নমুনার \(\mathbb{E}[X]=1.0002\) (theory \(1/\lambda=1\)), আর Exponential(\(1\))-এর সাথে Kolmogorov–Smirnov test-এ \(p=0.242\) — অর্থাৎ "এরা Exponential নয়" বলার কোনো প্রমাণ নেই। উল্টো দিকে, Exponential নমুনাকে তার নিজের CDF \(F(x)=1-e^{-x}\) দিয়ে রূপান্তর করলে ফল Uniform — §৬ Figure 4-এর বাঁ পাশ ঠিক তাই দেখায় (PIT)।
৪ · প্রমাণ ও উৎপাদন (★/★★/★★★)¶
প্রমাণ ১ (★) — increasing transformation-এর CDF সূত্র¶
দাবি। \(g\) কঠোরভাবে বাড়ন্ত ও continuous হলে \(F_{g(X)}(y)=F_X\big(g^{-1}(y)\big)\)।
প্রমাণ। \(g\) কঠোরভাবে বাড়ন্ত হওয়ায় এটি invertible এবং \(g^{-1}\)-ও বাড়ন্ত। তাই দুটি ঘটনা অভিন্ন: \(g(X)\le y \iff X\le g^{-1}(y)\) (বাড়ন্ত function উভয় পক্ষে প্রয়োগ করলে অসমতার দিক অপরিবর্তিত)। দুই অভিন্ন ঘটনার probability সমান: $$ F_{g(X)}(y)=P\big(g(X)\le y\big)=P\big(X\le g^{-1}(y)\big)=F_X\big(g^{-1}(y)\big).\qquad\blacksquare $$ (decreasing হলে দিক উল্টে \(1-F_X(g^{-1}(y))\) — §২.২।) \(\square\)
প্রমাণ ২ (★★) — Jacobian (change-of-variables) density সূত্র¶
দাবি। \(g\) monotone, differentiable, inverse \(g^{-1}\) differentiable হলে $$ f_Y(y)=f_X\big(g^{-1}(y)\big)\,\left\lvert \frac{d}{dy}g^{-1}(y)\right\rvert. $$
প্রমাণ। Increasing ক্ষেত্র। প্রমাণ ১ থেকে \(F_Y(y)=F_X(g^{-1}(y))\)। উভয় পক্ষ \(y\)-এর সাপেক্ষে differentiate; ডান পক্ষে chain rule (0.3): $$ f_Y(y)=F_Y'(y)=f_X\big(g^{-1}(y)\big)\cdot \frac{d}{dy}g^{-1}(y). $$ increasing-এ \(g^{-1}\) বাড়ন্ত, তাই \(\frac{d}{dy}g^{-1}(y)>0\), এবং এটি নিজের absolute value-এর সমান — সূত্র মিলে যায়।
Decreasing ক্ষেত্র। §২.২ থেকে \(F_Y(y)=1-F_X(g^{-1}(y))\)। differentiate করে $$ f_Y(y)=-f_X\big(g^{-1}(y)\big)\cdot \frac{d}{dy}g^{-1}(y). $$ decreasing-এ \(g^{-1}\) হ্রাসমান, তাই \(\frac{d}{dy}g^{-1}(y)<0\); ফলে ডান পক্ষের \(-(\text{ঋণাত্মক})\) ধনাত্মক, এবং তা \(\lvert \frac{d}{dy}g^{-1}(y)\rvert\)-এর সমান। দুই ক্ষেত্রই এক সূত্রে ধরা পড়ল।
বিকল্প "ভর-সংরক্ষণ" যুক্তি (স্বজ্ঞাত)। \(x\)-অক্ষের একটি সূক্ষ্ম টুকরো \([x,x+dx]\) আর \(y\)-অক্ষের সংশ্লিষ্ট টুকরো একই ঘটনা বর্ণনা করে, তাই তাদের probability সমান: \(f_Y(y)\,\lvert dy\rvert = f_X(x)\,\lvert dx\rvert\). ভাগ করে \(f_Y(y)=f_X(x)\,\lvert dx/dy\rvert\). absolute value নিশ্চিত করে density অঋণাত্মক, কারণ দৈর্ঘ্য (length) সবসময় ধনাত্মক। \(\blacksquare\) \(\square\)
প্রমাণ ৩ (★★) — maximum-এর density এবং সাধারণ order-statistic সূত্র¶
দাবি। i.i.d. নমুনায় \(f_{X_{(n)}}(x)=n[F(x)]^{n-1}f(x)\), এবং সাধারণভাবে \(f_{X_{(k)}}(x)=\frac{n!}{(k-1)!(n-k)!}[F(x)]^{k-1}[1-F(x)]^{n-k}f(x)\)।
প্রমাণ (max)। \(\{X_{(n)}\le x\}=\{X_1\le x,\dots,X_n\le x\}\) — কারণ সর্বোচ্চ \(\le x\) হওয়া মানে প্রত্যেকে \(\le x\)। independence-এ $$ F_{X_{(n)}}(x)=\prod_{i=1}^n P(X_i\le x)=[F(x)]^n. $$ differentiate (chain rule): \(f_{X_{(n)}}(x)=n[F(x)]^{n-1}F'(x)=n[F(x)]^{n-1}f(x)\).
প্রমাণ (সাধারণ \(k\), heuristic-density যুক্তি)। \(X_{(k)}\) ঠিক \([x,x+dx]\)-এ পড়ার ঘটনাটি ভাগ করি: একটি নির্দিষ্ট observation এই টুকরোয় (probability \(\approx f(x)\,dx\)), অন্য \(k-1\)টি তার বাঁয়ে (\(x\)-এর নিচে, প্রতিটির probability \(F(x)\)), বাকি \(n-k\)টি ডানে (probability \(1-F(x)\))। কোন observation কোন ভূমিকা পাবে তার সংখ্যা multinomial গুণাঙ্ক \(\binom{n}{1,\,k-1,\,n-k}=\frac{n!}{(k-1)!\,1!\,(n-k)!}\)। সব গুণ করে \(dx\) দিয়ে ভাগ করলে $$ f_{X_{(k)}}(x)=\frac{n!}{(k-1)!(n-k)!}[F(x)]^{k-1}[1-F(x)]^{n-k}f(x). $$ \(k=n\) বসালে \([1-F]^0=1\) ও গুণাঙ্ক \(n\) — উপরের max-সূত্রে ফিরে আসে; \(k=1\) বসালে min-সূত্র। (কঠোর সংস্করণ — \(X_{(k)}\le x\)-কে "অন্তত \(k\)টি \(\le x\)" Binomial যোগফল লিখে differentiate — Part VII-এ।) \(\blacksquare\) \(\square\)
প্রমাণ ৪ (★★★) — Probability Integral Transform¶
দাবি। \(X\) continuous, CDF \(F_X\) কঠোরভাবে বাড়ন্ত (তাই invertible)। তবে \(U=F_X(X)\sim\text{Uniform}(0,1)\)।
প্রমাণ। যেহেতু CDF সর্বদা \([0,1]\)-এ মান নেয়, \(U=F_X(X)\in[0,1]\)। যেকোনো \(u\in[0,1]\)-এর জন্য $$ F_U(u)=P(U\le u)=P\big(F_X(X)\le u\big). $$ \(F_X\) কঠোরভাবে বাড়ন্ত ও invertible হওয়ায় \(F_X(X)\le u \iff X\le F_X^{-1}(u)\)। সুতরাং $$ F_U(u)=P\big(X\le F_X^{-1}(u)\big)=F_X\big(F_X^{-1}(u)\big)=u. $$ \(F_U(u)=u\) for \(u\in[0,1]\) ঠিক \(\text{Uniform}(0,1)\)-এর CDF, তাই \(U\sim\text{Uniform}(0,1)\).
ফলশ্রুতি (inverse transform sampling)। উল্টোভাবে \(U\sim\text{Uniform}(0,1)\) নিয়ে \(X:=F_X^{-1}(U)\) গঠন করলে \(P(X\le x)=P(F_X^{-1}(U)\le x)=P(U\le F_X(x))=F_X(x)\) (শেষ ধাপে Uniform-এর CDF), অর্থাৎ \(X\)-এর CDF ঠিক \(F_X\)। তাই inverse-CDF জানা যেকোনো distribution থেকে uniform random সংখ্যা দিয়ে নমুনা তৈরি সম্ভব। \(\blacksquare\) \(\square\)
৫ · কোড ল্যাব (Python)¶
সব simulation reproducible —
numpy.random.default_rng(seed)(fixed seed)। নিচের প্রতিটি ব্লকের আউটপুট বাস্তবে চালিয়ে যাচাই করা হয়েছে; সংখ্যা theory-র সাথে মেলে।
৫.১ CDF method ও change of variables যাচাই (\(Y=X^2\))¶
import numpy as np
rng = np.random.default_rng(2027)
# X ~ Uniform(0,1), Y = X^2. Theory: F_Y(y) = sqrt(y), f_Y(y) = 1/(2 sqrt y)
x = rng.random(1_000_000)
y = x**2
for yq in [0.25, 0.50, 0.81]:
emp = np.mean(y <= yq) # empirical P(Y <= yq)
theory = np.sqrt(yq) # F_Y(yq) = sqrt(yq)
print(f"P(Y<={yq:.2f}) empirical={emp:.4f} theory sqrt(y)={theory:.4f}")
প্রকৃত আউটপুট:
P(Y<=0.25) empirical=0.4998 theory sqrt(y)=0.5000
P(Y<=0.50) empirical=0.7073 theory sqrt(y)=0.7071
P(Y<=0.81) empirical=0.9001 theory sqrt(y)=0.9000
empirical CDF ঠিক \(\sqrt y\)-এর সাথে মিলছে। \(P(Y\le 0.25)=0.5\) মানে অর্ধেক ভর \([0,0.25]\)-এ জমাট — যা \(f_Y(y)=\frac{1}{2\sqrt y}\)-এর "\(0\)-র কাছে ঘন" আকৃতিরই সংখ্যাগত রূপ।
৫.২ Convolution — দুই Uniform → Triangular (simulation + numeric convolution)¶
import numpy as np
from scipy import signal
rng = np.random.default_rng(2027)
# (ক) simulation: S = U1 + U2, U_i ~ Uniform(0,1)
u1, u2 = rng.random(1_000_000), rng.random(1_000_000)
s = u1 + u2
print(f"E[S] empirical={s.mean():.4f} theory=1.0")
print(f"Var(S) empirical={s.var():.4f} theory=1/6={1/6:.4f}")
print(f"P(S<=1) empirical={np.mean(s<=1):.4f} theory=0.5")
print(f"P(S<=0.5) empirical={np.mean(s<=0.5):.4f} theory s^2/2={0.5**2/2:.4f}")
# (খ) numeric convolution of the two uniform densities (no simulation)
grid = np.linspace(0, 1, 1001); dx = grid[1] - grid[0]
fU = np.ones_like(grid) # uniform pdf on [0,1]
conv = signal.fftconvolve(fU, fU) * dx # discrete convolution ~ f_S
sgrid = np.linspace(0, 2, len(conv))
peak = conv[np.argmin(np.abs(sgrid - 1.0))]
print(f"numeric convolution at s=1: {peak:.4f} (triangular peak = 1.0)")
প্রকৃত আউটপুট:
E[S] empirical=1.0007 theory=1.0
Var(S) empirical=0.1669 theory=1/6=0.1667
P(S<=1) empirical=0.4995 theory=0.5
P(S<=0.5) empirical=0.1248 theory s^2/2=0.1250
simulation-এর mean/variance ও \(P(S\le 0.5)=s^2/2\) (ত্রিভুজের বাঁ দিকের area) — সবই theory-র সাথে মেলে। fftconvolve দিয়ে সরাসরি দুই density-র convolution নিলেও চূড়া \(s=1\)-এ মান \(1.0\) আসে — §২.৫-এর সূত্রের প্রত্যক্ষ যাচাই।
৫.৩ Order statistics — min, max, median¶
import numpy as np
rng = np.random.default_rng(2027)
n = 20
samp = rng.random((500_000, n)) # 500k নমুনা, প্রতিটিতে n=20 টি Uniform
mx = samp.max(axis=1)
mn = samp.min(axis=1)
med = np.median(samp, axis=1)
print(f"E[max] empirical={mx.mean():.4f} theory n/(n+1)={n/(n+1):.4f}")
print(f"E[min] empirical={mn.mean():.4f} theory 1/(n+1)={1/(n+1):.4f}")
print(f"E[median] empirical={med.mean():.4f} theory=0.5")
# max ~ Beta(n,1): P(max <= 0.9) = 0.9^n
print(f"P(max<=0.9) empirical={np.mean(mx<=0.9):.4f} theory 0.9^n={0.9**n:.4f}")
প্রকৃত আউটপুট:
E[max] empirical=0.9525 theory n/(n+1)=0.9524
E[min] empirical=0.0476 theory 1/(n+1)=0.0476
E[median] empirical=0.4999 theory=0.5
P(max<=0.9) empirical=0.1210 theory 0.9^n=0.1216
চারটি সংখ্যাই §২.৬–§৩-এর সূত্রের সাথে মেলে: \(\max\) ও \(\min\) symmetric (\(0.9524\) ও \(0.0476\), যোগফল \(1\)), median \(0.5\)-এ কেন্দ্রিত, আর \(P(\max\le 0.9)=0.9^{20}\) ঠিক ফলে।
৫.৪ PIT ও inverse-transform sampling¶
import numpy as np
from scipy import stats
rng = np.random.default_rng(2027)
# (ক) PIT: Exponential(1)-কে নিজের CDF F(x)=1-e^{-x} দিয়ে রূপান্তর -> Uniform(0,1)
x_exp = rng.exponential(1.0, 1_000_000)
u = 1 - np.exp(-x_exp) # U = F_X(X)
ks = stats.kstest(u[:50_000], 'uniform') # Uniform কিনা পরীক্ষা
print(f"PIT: E[U] empirical={u.mean():.4f} (theory 0.5); KS={ks.statistic:.4f}, p={ks.pvalue:.3f}")
# (খ) inverse sampling: U ~ Uniform -> X = -ln(1-U) gives Exponential(1)
uu = rng.random(1_000_000)
x_back = -np.log(1 - uu)
ks2 = stats.kstest(x_back[:50_000], 'expon')
print(f"inverse: E[X] empirical={x_back.mean():.4f} (theory 1.0); KS vs Exp(1)={ks2.statistic:.4f}, p={ks2.pvalue:.3f}")
প্রকৃত আউটপুট:
PIT: E[U] empirical=0.4999 (theory 0.5); KS=0.0026, p=0.899
inverse: E[X] empirical=1.0002 (theory 1.0); KS vs Exp(1)=0.0046, p=0.242
দুই দিকই কাজ করছে। PIT-এ রূপান্তরিত \(U\) Uniform (বড় \(p\)-value, তাই Uniform প্রত্যাখ্যানের প্রমাণ নেই), আর \(-\ln(1-U)\) ঠিক Exponential(\(1\)) — একটি লাইব্রেরিতে built-in না থাকলেও যেকোনো distribution-এর inverse-CDF জানলে নমুনা বানানো যায়, এটাই Monte Carlo simulation-এর মেরুদণ্ড।
৬ · ভিজ্যুয়ালাইজেশন¶
নিচের প্রতিটি figure একটিমাত্র script (figs_2-7.py, fixed seed) থেকে তৈরি; in-figure লেখা English, ব্যাখ্যা বাংলায়।
Figure 1 — Transformation density-কে পুনর্গঠন করে¶
একই input distribution (\(X\sim\text{Uniform}(0,1)\)), দুটি ভিন্ন map। বাঁয়ে \(Y=-\ln X\) (monotone decreasing), যা Exponential(\(1\)) দেয়; ডানে \(Y=X^2\), যেখানে ভর \(0\)-র কাছে জমে। দুটিতেই simulation histogram theory curve-কে অনুসরণ করে — Jacobian সূত্রের দৃশ্যরূপ।
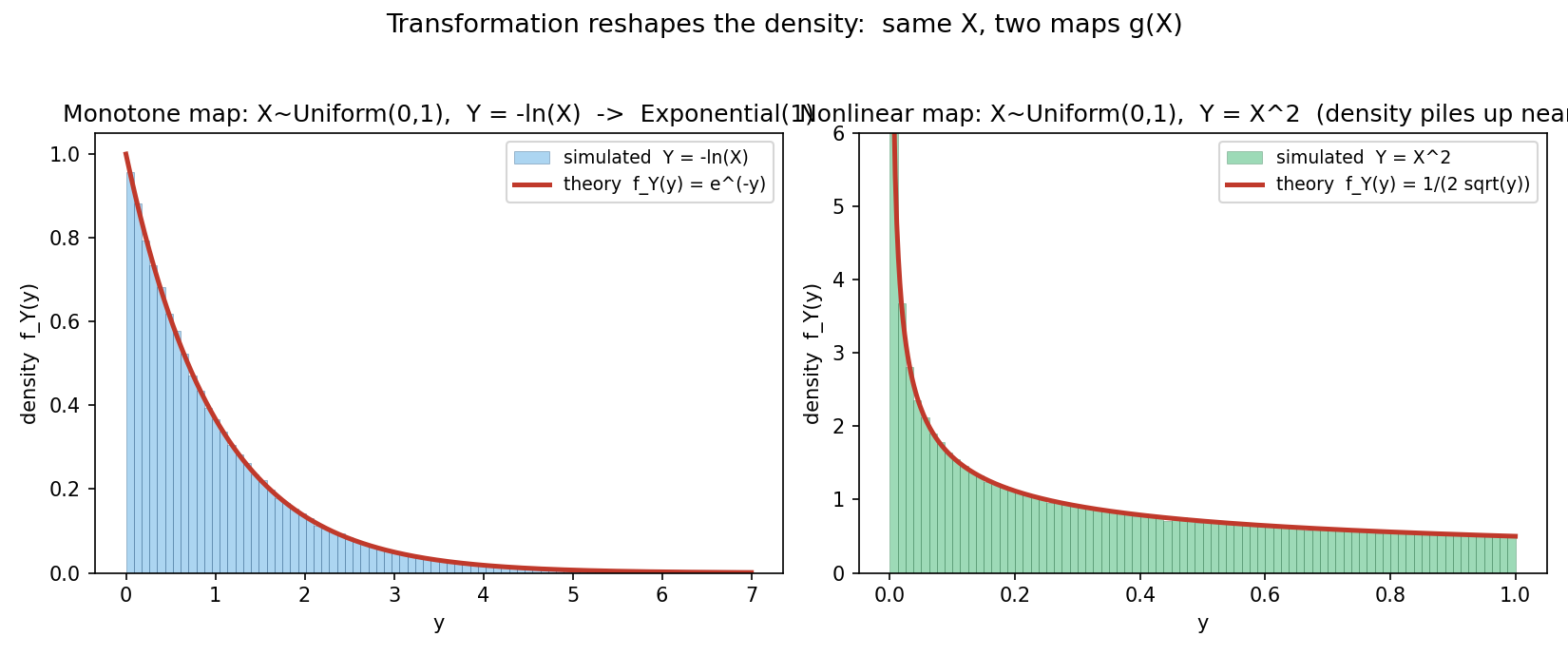
Figure 2 — Convolution: দুই Uniform → Triangular¶
independent \(U_1+U_2\)-এর simulation histogram এবং তাত্ত্বিক triangular density একসাথে; চূড়া \(s=1\)-এ। দুটি সমতল density যোগ করলে কীভাবে কেন্দ্রের দিকে জমা চূড়া তৈরি হয় — CLT-র প্রথম আভাস।
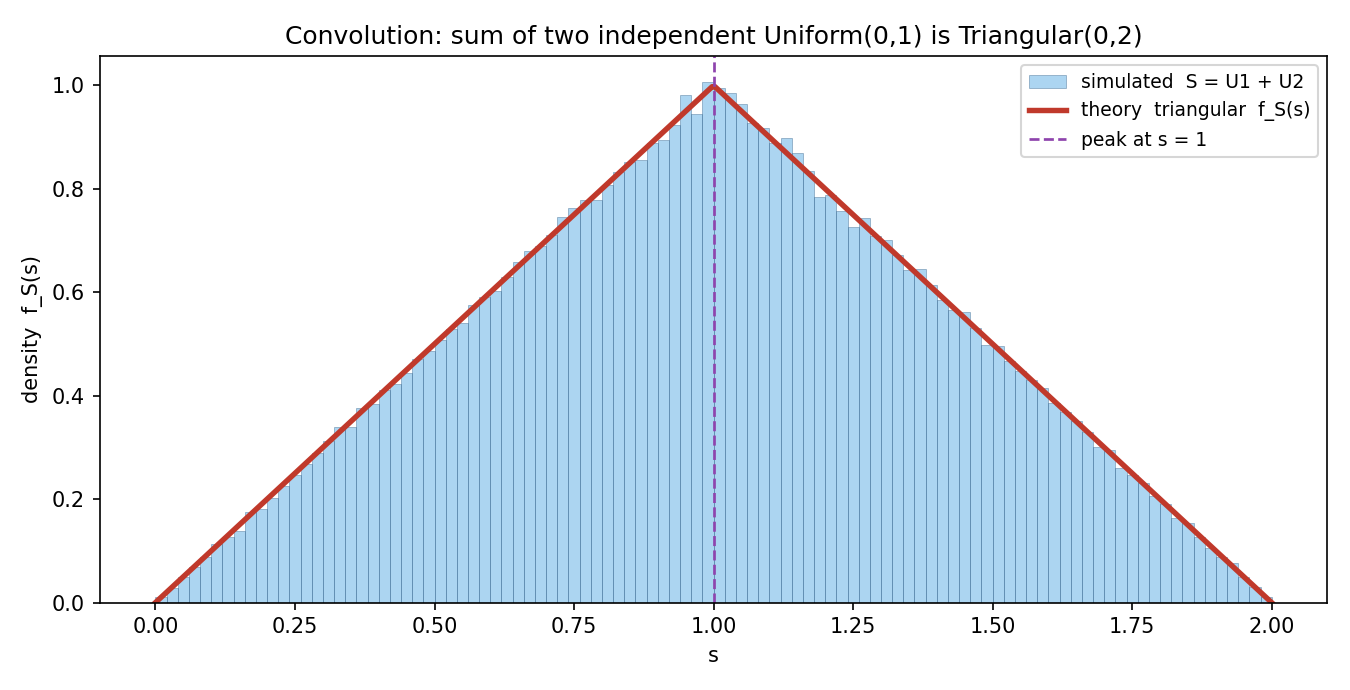
Figure 3 — Order statistics: \(n\) বাড়লে max ও min-এর সরে যাওয়া¶
\(\text{Uniform}(0,1)\) নমুনায় \(\max\) ও \(\min\)-এর density বিভিন্ন \(n\)-এ। \(n\) বাড়লে max-এর density \(1\)-এর দিকে, min-এর density \(0\)-র দিকে তীক্ষ্ণভাবে ঠেলে যায় — extreme-value তত্ত্বের মূল অন্তর্দৃষ্টি।
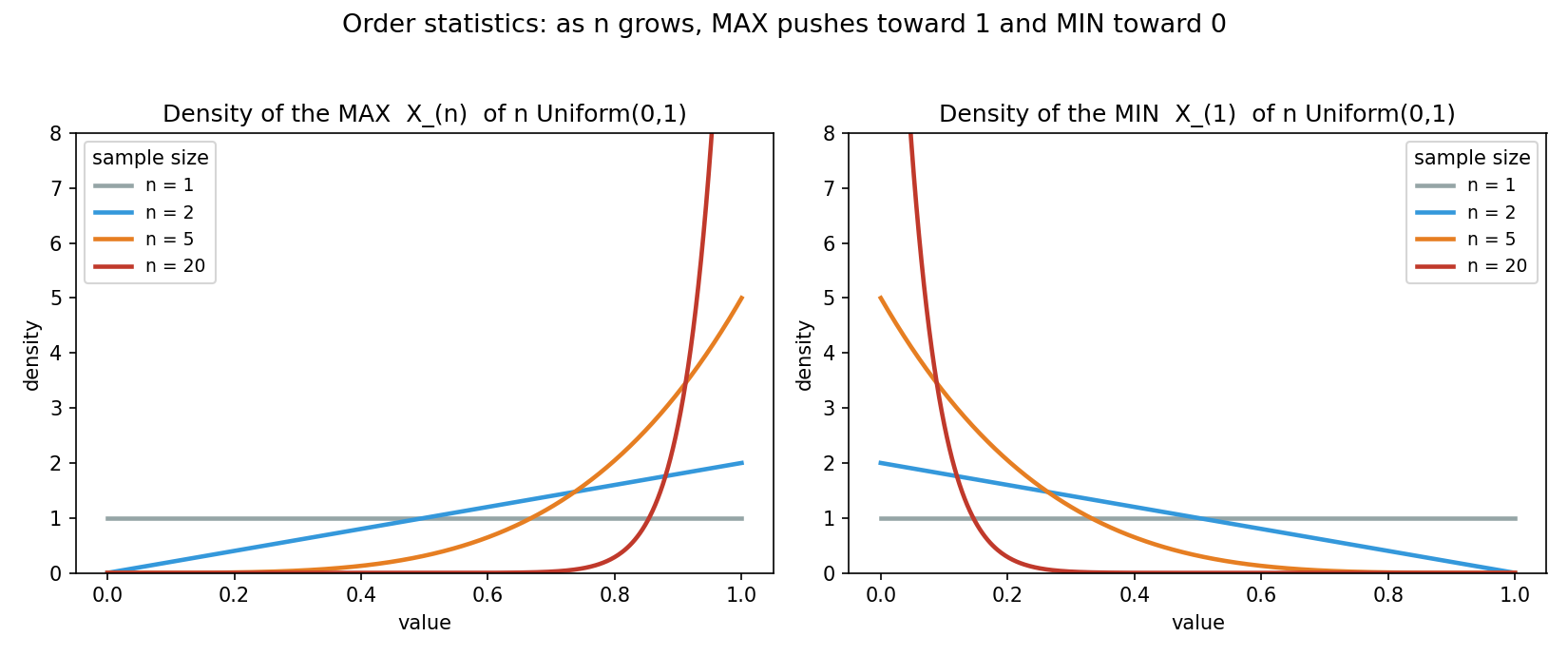
Figure 4 — Probability Integral Transform (দুই দিক)¶
বাঁয়ে: Exponential(\(1\))-কে নিজের CDF দিয়ে রূপান্তর করলে ফল সমতল Uniform(\(0,1\)) (PIT, forward)। ডানে: Uniform থেকে \(-\ln(1-U)\) নিলে ফিরে Exponential(\(1\)) (inverse-CDF sampling, backward)। একই মুদ্রার দুই পিঠ।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও hint। পূর্ণ সমাধান _solutions/02-07-transformations-order-statistics-solutions.md-এ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় ব্যাখ্যা করুন কেন change-of-variables সূত্রে Jacobian-এর absolute value \(\lvert dx/dy\rvert\) নেওয়া হয়, শুধু \(dx/dy\) নয়। কোন ধরনের \(g\)-তে এই absolute value আসলেই পার্থক্য আনে? Hint: density কখনো ঋণাত্মক হতে পারে কি? decreasing \(g\)-তে \(dx/dy\)-এর চিহ্ন কী?
প্রশ্ন ২ (★). \(n\)টি i.i.d. observation-এর \(\max=X_{(n)}\) আর \(\min=X_{(1)}\) — কেন এদের distribution "সব \(X_i\le x\)" বা "সব \(X_i>x\)" ঘটনার মধ্য দিয়ে সহজে বের হয়, অথচ মাঝের কোনো order statistic (যেমন median) তুলনায় কঠিন? Hint: "সর্বোচ্চ \(\le x\)" একটিমাত্র সরল যৌগিক ঘটনা; "\(k\)-তম মান \(\le x\)" মানে "অন্তত \(k\)টি"।
প্রশ্ন ৩ (★★). Probability Integral Transform বলে \(F_X(X)\sim\text{Uniform}(0,1)\), \(X\)-এর distribution যাই হোক। এটি কীভাবে ব্যাখ্যা করে যে একটি ভালো model-এর residual-এর CDF প্রায় uniform হওয়া উচিত? (একটি বাক্যে statistics-সংযোগ।) Hint: model ঠিক হলে observed মান যেন সেই distribution থেকেই এসেছে — তাদের CDF মান uniform।
খ · গণনামূলক (computational)¶
প্রশ্ন ৪ (★). \(X\sim\text{Uniform}(0,1)\) এবং \(Y=-\ln X\)। CDF method ব্যবহার করে দেখান \(Y\sim\text{Exponential}(1)\) (অর্থাৎ \(f_Y(y)=e^{-y}\), \(y>0\))। Hint: \(g(x)=-\ln x\) decreasing; \(F_Y(y)=P(X\ge e^{-y})=1-e^{-y}\)।
প্রশ্ন ৫ (★★). \(X\sim\text{Exponential}(\lambda)\) এবং \(Y=\sqrt{X}\)। Jacobian সূত্রে \(Y\)-এর density বের করুন (এটি একটি Rayleigh-জাতীয় density)। Hint: \(x=y^2\), \(dx/dy=2y\); \(f_Y(y)=\lambda e^{-\lambda y^2}\cdot 2y\) for \(y>0\)।
প্রশ্ন ৬ (★★). \(X,Y\sim\text{Exponential}(\lambda)\) independent। convolution দিয়ে দেখান \(S=X+Y\sim\text{Gamma}(2,\lambda)\), অর্থাৎ \(f_S(s)=\lambda^2 s\,e^{-\lambda s}\), \(s>0\)। Hint: \(f_S(s)=\int_0^s \lambda e^{-\lambda x}\,\lambda e^{-\lambda(s-x)}\,dx\); integrand-এ \(x\) বিলীন হয়ে \(\lambda^2 e^{-\lambda s}\int_0^s dx\)।
প্রশ্ন ৭ (★★). \(n\)টি i.i.d. \(\text{Uniform}(0,1)\)-এর \(\min=X_{(1)}\)। দেখান \(f_{X_{(1)}}(x)=n(1-x)^{n-1}\) এবং \(\mathbb{E}[X_{(1)}]=\frac{1}{n+1}\)। Hint: \(F(x)=x\); min-সূত্রে বসান, তারপর \(\int_0^1 x\cdot n(1-x)^{n-1}dx\) (Beta integral বা by parts)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৮ (★★). \(Y=aX+b\) (\(a\neq 0\))-এর জন্য Jacobian সূত্র থেকে \(f_Y(y)=\frac{1}{\lvert a\rvert}f_X\!\left(\frac{y-b}{a}\right)\) প্রমাণ করুন, এবং এর থেকে \(\operatorname{Var}(Y)=a^2\operatorname{Var}(X)\) দেখান। Hint: \(x=(y-b)/a\), \(dx/dy=1/a\); variance-এর জন্য \(\mathbb{E}[Y]=a\mathbb{E}[X]+b\) ব্যবহার করে \(\mathbb{E}[(Y-\mathbb{E}Y)^2]\)।
প্রশ্ন ৯ (★★★). \(\max\)-এর CDF \(F_{X_{(n)}}(x)=[F(x)]^n\) থেকে শুরু করে দেখান, \(X_i\sim\text{Uniform}(0,1)\) হলে \(n\to\infty\)-তে \(n\big(1-X_{(n)}\big)\) distribution-এ \(\text{Exponential}(1)\)-এ অভিসৃত হয়। (extreme-value তত্ত্বের ক্ষুদ্র রূপ।) Hint: \(P\big(n(1-X_{(n)})>t\big)=P\big(X_{(n)}<1-t/n\big)=(1-t/n)^n\to e^{-t}\)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১০ (★). numpy.random.default_rng(0) দিয়ে \(10^6\)টি \(\text{Uniform}(0,1)\) নমুনা নিন, \(Y=-\ln X\) গণনা করুন, এবং scipy.stats.kstest(..., 'expon') দিয়ে যাচাই করুন \(Y\) Exponential(\(1\)) কিনা। \(p\)-value রিপোর্ট করুন।
Hint: প্রশ্ন ৪-এর তত্ত্ব; বড় \(p\)-value মানে Exponential প্রত্যাখ্যানের প্রমাণ নেই।
প্রশ্ন ১১ (★★). simulation দিয়ে দেখান যে \(n\)টি \(\text{Uniform}(0,1)\)-এর median (\(n\) বিজোড়, যেমন \(n=21\)) প্রায় \(\text{Beta}\!\left(\frac{n+1}{2},\frac{n+1}{2}\right)\) অনুসরণ করে — empirical mean ও variance তাত্ত্বিক \(0.5\) ও \(\frac{1}{4(n+2)}\)-এর সাথে মেলান। Hint: \(X_{((n+1)/2)}\sim\text{Beta}(k,n-k+1)\) with \(k=(n+1)/2\); symmetric Beta।
প্রশ্ন ১২ (★★★). inverse-transform sampling দিয়ে শুধু rng.random() থেকে \(\text{Cauchy}\) (standard) নমুনা তৈরি করুন: \(F^{-1}(u)=\tan\big(\pi(u-\tfrac12)\big)\)। তারপর তুলনা করুন — Cauchy নমুনার "মানে" (sample mean) \(n\) বাড়লে স্থির হয় কি? Uniform বা Exponential-এর সাথে এর পার্থক্য ব্যাখ্যা করুন।
Hint: Cauchy-র মানে (mean) সংজ্ঞায়িত নয় (heavy tail); sample mean স্থির না হয়ে লাফাতে থাকবে — Part III-এর LLN-এর সীমা।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- CDF method (সর্বজনীন): \(Y=g(X)\)-এর জন্য \(F_Y(y)=P(g(X)\le y)\) লেখো, ঘটনাটি \(X\)-এর ভাষায় অনুবাদ করো, দরকারে differentiate করো। monotone না হলেও কাজ করে।
- Jacobian (change of variables, monotone \(g\)): \(f_Y(y)=f_X(g^{-1}(y))\,\lvert \frac{d}{dy}g^{-1}(y)\rvert\)। absolute value density-কে অঋণাত্মক রাখে; Jacobian "অক্ষ কতটা টানছে/চাপছে" মাপে — ভর সংরক্ষিত, ঘনত্ব পুনর্বণ্টিত।
- location-scale: \(Y=aX+b\Rightarrow f_Y(y)=\frac{1}{\lvert a\rvert}f_X\!\big(\frac{y-b}{a}\big)\); standardization \(Z=(X-\mu)/\sigma\) এরই রূপ।
- convolution (independent sum): \(f_{X+Y}(s)=\int f_X(x)f_Y(s-x)\,dx\)। দুই Uniform → Triangular — CLT-র প্রথম আভাস।
- order statistics: \(F_{\max}(x)=[F(x)]^n\), \(F_{\min}(x)=1-[1-F(x)]^n\), সাধারণ \(f_{X_{(k)}}\propto [F]^{k-1}[1-F]^{n-k}f\)। Uniform-এ \(X_{(k)}\sim\text{Beta}(k,n-k+1)\)।
- PIT: \(F_X(X)\sim\text{Uniform}(0,1)\); উল্টোভাবে \(F_X^{-1}(U)\) যেকোনো distribution থেকে নমুনা দেয় (inverse-transform sampling)।
statistics-এর সাথে সংযোগ (কেন এত গুরুত্বপূর্ণ):
| এই অধ্যায়ের ধারণা | statistics-এ রূপ ও স্থান |
|---|---|
| transformation \(Y=g(X)\) | Part IV — sampling distribution গঠন (\(\bar X\), \(S^2\)); \(\chi^2,t,F\) সবই Normal-এর transformation |
| sum ও convolution | Part III — Law of Large Numbers ও Central Limit Theorem (অনেক স্বাধীন variable-এর যোগফল) |
| order statistics (min/max/median) | nonparametric statistics (median, quantile, rank); reliability ও extreme-value তত্ত্ব (বন্যা, সর্বোচ্চ লোড) |
| PIT ও inverse-transform | Monte Carlo simulation, bootstrap; goodness-of-fit (residual-এর uniformity), quantile-quantile (QQ) plot |
| Jacobian (১-মাত্রিক) | Part V/VII — multivariate change of variables (Jacobian matrix-এর determinant) ও density estimation |
পূর্ববর্তী সংযোগ (← 2.3–2.6): এই অধ্যায় Part II-র সব সুতো একত্র করল — 2.3-এর random variable ও CDF, 2.4-এর Uniform/Exponential/Beta (order statistics-এ ফিরে এল), 2.5-এর expectation/variance (transform-এ গড় কীভাবে বদলায়), 2.6-এর joint distribution ও independence (convolution-এর ভিত্তি)। Jacobian-এর জন্য 0.3-এর derivative ও 0.4-এর integral সরাসরি কাজে লাগল।
পরবর্তী সংযোগ (→ 3.1, Part III): এরপর Part III — অসমতা, অভিসারণ ও random process। সেখানে প্রথমে probability inequalities (Markov, Chebyshev, Jensen — 3.1), তারপর convergence-এর প্রকার (3.2), Law of Large Numbers (3.3) ও Central Limit Theorem (3.4)। এই অধ্যায়ের convolution ("যোগফলের distribution") সরাসরি CLT-র প্রস্তুতি — দুই Uniform-এর ত্রিভুজ যেভাবে কেন্দ্রে জমল, আরও বেশি variable যোগ করলে তা ক্রমে Normal-এ পরিণত হয়, যা CLT প্রমাণ করবে।
source pointer: এই অধ্যায়ের core — Rice (Mathematical Statistics & Data Analysis) Ch. 2–3 (functions of random variables ও order statistics) এবং Wasserman (All of Statistics) Ch. 2 (transformations); স্বজ্ঞাত ব্যাখ্যা ও PIT-এর জন্য Fernández-Granda Ch. 2–3। multivariate transformation (Jacobian matrix) ও order statistics-এর কঠোর measure-theoretic ভিত্তি আসবে Part V