3.1 — Probability Inequalities (প্রবাবিলিটি অসমতা)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
আগের Part (2.5) আমরা একটি random variable \(X\)-এর দুটি মূল সারসংখ্যা শিখেছি — expectation (প্রত্যাশা) \(\mathbb{E}[X]=\mu\) এবং variance (ভেদাঙ্ক) \(\mathrm{Var}(X)=\sigma^2\)। এই অধ্যায়ে আমরা একটা চমৎকার প্রশ্নের উত্তর খুঁজব: শুধু এই দুটি সংখ্যা জেনে, পুরো distribution না জেনেও, \(X\) কতটা বড় বা কতটা দূরে যেতে পারে তা নিয়ে আমরা কী বলতে পারি?
এক মিনিট থেমে বুঝে নিই কেন প্রশ্নটা গুরুত্বপূর্ণ।
বাস্তব hook — distribution জানা বিলাসিতা। ভাবুন আপনি একটি অনলাইন দোকানের ম্যানেজার। আপনি জানেন গড়ে প্রতি গ্রাহক মাসে ৫০ টাকা খরচ করেন (\(\mathbb{E}[X]=50\))। কিন্তু আপনি গ্রাহকদের খরচের পুরো distribution জানেন না — কেউ ০ টাকা, কেউ হয়তো ১০,০০০ টাকা; আকৃতিটা অজানা। এখন প্রশ্ন: "কত শতাংশ গ্রাহক মাসে ২০০ টাকার বেশি খরচ করেন?" পুরো distribution না জানলে কি কিছুই বলা যায় না? অবাক করা উত্তর: যায়। শুধু "গড় ৫০" আর "খরচ কখনো ঋণাত্মক নয়" — এই দুই তথ্যেই আমরা একটা উপরের সীমা (upper bound) দিতে পারি: ২০০ টাকার বেশি খরচকারী সর্বোচ্চ ২৫%। এটাই Markov's inequality।
কেন এমন সীমা দেওয়া আদৌ সম্ভব? insight-টা সরল। গড় যদি মাত্র ৫০ হয়, তাহলে খুব বেশি মানুষ ২০০ (গড়ের ৪ গুণ) খরচ করতে পারে না — করলে গড় ৫০-এ থাকত না, অনেক উপরে উঠে যেত। অর্থাৎ mean একটা "বাজেট"-এর মতো কাজ করে: বড় মান বেশি লোকের হলে সেই বাজেট ফুরিয়ে যায়। এই সহজ ভাবনাই গাণিতিক রূপ নেবে।
কেন এই ধারণা পরিসংখ্যানে মেরুদণ্ড? দুটি কারণ।
প্রথমত, distribution প্রায়ই অজানা থাকে। বাস্তব dataset-এ আমরা সবসময় জানি না data ঠিক কোন distribution মেনে চলে — কিন্তু mean ও variance estimate করা সহজ। তাই distribution-মুক্ত (distribution-free) সীমা — যা শুধু \(\mu\) ও \(\sigma^2\)-এর ওপর নির্ভর করে — অসম্ভব মূল্যবান। এগুলোকে বলে probability inequality (প্রবাবিলিটি অসমতা) বা tail bound (প্রান্ত-সীমা), কারণ এরা distribution-এর tail (প্রান্ত — কেন্দ্র থেকে দূরের চরম মান) কতটা ভারী হতে পারে তার সীমা বেঁধে দেয়।
দ্বিতীয়ত, এই অসমতাগুলোই concentration (কেন্দ্রীভবন) ধারণার বীজ। concentration বলতে বোঝায়: অনেকগুলো random variable-এর গড় (sample mean \(\bar X_n\)) তার expectation-এর চারপাশে জড়ো হয়ে থাকে — যত বেশি data, তত শক্ত করে জড়ো হয়। ভাবুন একটা fair coin বহুবার ছুঁড়লে heads-এর অনুপাত \(0.5\)-এর কাছে থিতু হয় — এটাই concentration। এই অধ্যায়ের অসমতাগুলো (বিশেষত Chebyshev ও Hoeffding) দিয়ে আমরা সংখ্যায় দেখাতে পারব \(\bar X_n\) কত শক্ত করে \(\mu\)-এর চারপাশে জড়ো হয়। আর ঠিক সেখান থেকেই 3.3-এর Law of Large Numbers (LLN) — "বেশি data মানে বেশি নির্ভরযোগ্য গড়" — গাণিতিকভাবে প্রমাণিত হবে। অর্থাৎ আজকের অসমতাগুলো হলো পরের কয়েকটি অধ্যায়ের ভিত্তি-পাথর।
এই অধ্যায়ে আমরা চারটি ক্লাসিক অসমতা শিখব, ক্রমশ শক্তিশালী হতে হতে:
- Markov — শুধু mean লাগে; দুর্বল কিন্তু সর্বজনীন (এমনকি variance না জানলেও খাটে)।
- Chebyshev — mean + variance লাগে; দুই দিকের (two-sided) tail bound দেয়, Markov-এর চেয়ে শক্ত।
- Jensen — convexity ব্যবহার করে \(\mathbb{E}[g(X)]\) ও \(g(\mathbb{E}[X])\)-এর মধ্যে দিক ঠিক করে (যেমন \(\mathbb{E}[X^2]\ge(\mathbb{E}[X])^2\) কেন সত্য তা ব্যাখ্যা করে)।
- Hoeffding — bounded random variable-এর যোগ/গড়ের জন্য exponentially শক্ত bound; এটাই আধুনিক concentration-এর প্রবেশদ্বার।
চলুন প্রতিটির statement ও তার পেছনের insight একে একে গড়ি।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে চারটি অসমতার statement ও from-scratch intuition — প্রতিটি symbol খুলে বলা হবে। (প্রমাণ এ অধ্যায়ের পরের অংশে; এখানে "কী বলছে ও কেন বিশ্বাসযোগ্য" তা-ই লক্ষ্য।)
২.১ Markov's inequality — শুধু mean দিয়ে tail bound¶
ধরা যাক \(X\) একটি nonnegative (অঋণাত্মক — মানে \(X\ge 0\) সর্বদা) random variable, এবং তার expectation \(\mathbb{E}[X]\) সসীম (finite)। তখন যেকোনো ধ্রুবক \(a>0\)-এর জন্য:
প্রতিটি অংশ খুলে বলি:
- \(X\ge 0\) — শর্ত: \(X\) কখনো ঋণাত্মক হতে পারে না (যেমন আয়, উচ্চতা, সময় — যা ঋণাত্মক হয় না)। এই শর্ত অপরিহার্য; ছাড়া অসমতা ভেঙে পড়ে।
- \(a>0\) — একটি threshold (চৌকাঠ — যে মানের "বেশি" হওয়ার probability জানতে চাই)। যেমন "২০০ টাকার বেশি" হলে \(a=200\)।
- \(P(X\ge a)\) — \(X\) অন্তত \(a\) হওয়ার probability, অর্থাৎ ডান-প্রান্তের (right tail) ওজন।
- \(\mathbb{E}[X]/a\) — উপরের সীমা: mean-কে threshold দিয়ে ভাগ।
From-scratch intuition — "বাজেট" যুক্তি। mean \(\mathbb{E}[X]\) হলো সব মানের probability-ওজন-করা গড় (2.5)। এখন কল্পনা করুন একটা বড় অংশ probability \(a\) বা তার বেশি মানে বসে আছে। প্রতিটি এমন মান গড়কে অন্তত \(a\) পরিমাণে "টানে"। তাই যদি \(P(X\ge a)\) বড় হতো, গড় \(\mathbb{E}[X]\)-ও বড় হতে বাধ্য — অন্তত \(a\cdot P(X\ge a)\)। উল্টে লিখলে: \(a\cdot P(X\ge a)\le \mathbb{E}[X]\), অর্থাৎ \(P(X\ge a)\le \mathbb{E}[X]/a\)। সংক্ষেপে — নির্দিষ্ট গড় একটা সীমিত বাজেট; বড় মান বেশি জায়গায় বসালে বাজেট ফুরিয়ে যায়, তাই বড় মানের probability ছোট হতেই হবে।
লক্ষণীয় দুটি বৈশিষ্ট্য। (ক) Markov-এর জন্য variance লাগে না — শুধু mean জানলেই হয়; তাই এটি সবচেয়ে কম-চাহিদার, সবচেয়ে সর্বজনীন অসমতা। (খ) বিনিময়ে এটি প্রায়ই আলগা (loose — সত্যের চেয়ে অনেক বড় সীমা দেয়), কারণ এত কম তথ্য দিয়ে এর বেশি আশা করা যায় না। Markov আসলে পরের সব অসমতার ভিত্তি-ইট: Chebyshev ও Hoeffding দুটোই Markov-কে চতুরভাবে প্রয়োগ করে পাওয়া যায়।
সতর্কতা — \(X\ge 0\) ভুলবেন না। Markov শুধু nonnegative \(X\)-এ খাটে। \(X\) ঋণাত্মক হতে পারলে সরাসরি Markov প্রয়োগ ভুল। তখন কৌশল: একটি nonnegative রূপ বানান — যেমন \(\lvert X-\mu\rvert\) বা \((X-\mu)^2\) — তারপর তার ওপর Markov প্রয়োগ করুন। ঠিক এই কৌশলেই Chebyshev আসে (নিচে)।
(এই অসমতার চিত্র: 3-1-markov — threshold \(a\)-এর ডানে tail-area ও তার ওপর Markov-সীমা।)
২.২ Chebyshev's inequality — variance দিয়ে দুই-দিকের bound¶
Markov শুধু এক দিকের (ডান tail) কথা বলে এবং variance ব্যবহার করে না। কিন্তু আমরা প্রায়ই জানতে চাই: \(X\) তার গড় \(\mu\) থেকে — যেদিকেই হোক — কতটা দূরে যেতে পারে? এখানেই Chebyshev's inequality, যা variance \(\sigma^2\) ব্যবহার করে দুই দিকেরই (two-sided) সীমা দেয়।
ধরা যাক \(X\)-এর mean \(\mathbb{E}[X]=\mu\) এবং variance \(\mathrm{Var}(X)=\sigma^2\) (সসীম)। তখন যেকোনো \(k>0\)-এর জন্য:
symbol-গুলো খুলি:
- \(\mu=\mathbb{E}[X]\) — কেন্দ্র (center)।
- \(\sigma=\sqrt{\sigma^2}\) — standard deviation (মান বিচ্যুতি), "গড়ে কতটা ছড়ানো" (2.5)।
- \(\lvert X-\mu\rvert\) — \(X\) গড় থেকে কত দূরে (চিহ্ন উপেক্ষা করে দূরত্ব; তাই \(\lvert\cdot\rvert\) — absolute value, কখনো raw bar নয়)।
- \(k\) — দূরত্বকে \(\sigma\)-এর কত "গুণ"-এ মাপছি (যেমন \(k=2\) মানে "\(2\sigma\) বা তার বেশি দূরে")।
- \(1/k^2\) — উপরের সীমা: \(k\) বাড়লে এই সীমা দ্রুত (বর্গ-হারে) ছোট হয়।
কথায়: "\(X\) তার গড় থেকে \(k\) standard deviation বা তার বেশি দূরে থাকার probability কখনো \(1/k^2\)-এর বেশি নয়।" যেমন \(k=2\) হলে সীমা \(1/4=25\%\), \(k=3\) হলে \(1/9\approx 11\%\), \(k=5\) হলে মাত্র \(1/25=4\%\)। অর্থাৎ গড় থেকে যত দূর, তত কম probability — এবং এটা যেকোনো distribution-এ সত্য, শুধু variance জানলেই।
From-scratch intuition — Markov-এর বুদ্ধিমান প্রয়োগ। \(X-\mu\) ঋণাত্মক হতে পারে, তাই সরাসরি Markov চলবে না। কিন্তু একটা কৌশল আছে: বর্গ করুন। লক্ষ করুন দুটি ঘটনা অভিন্ন: $$ \lvert X-\mu\rvert \ge k\sigma \quad\Longleftrightarrow\quad (X-\mu)^2 \ge k^2\sigma^2. $$ ডান পাশের \((X-\mu)^2\) একটি nonnegative random variable — এর ওপর Markov খাটে! আর তার expectation আমরা চিনি: \(\mathbb{E}[(X-\mu)^2]=\mathrm{Var}(X)=\sigma^2\) (এটাই তো variance-এর সংজ্ঞা, 2.5)। Markov প্রয়োগ করে (\(a=k^2\sigma^2\)): $$ P\big((X-\mu)^2\ge k^2\sigma^2\big)\le \frac{\sigma^2}{k^2\sigma^2}=\frac{1}{k^2}. $$ ব্যস — Chebyshev পাওয়া গেল। অর্থাৎ Chebyshev = "\((X-\mu)^2\)-এর ওপর Markov"। এই কারণে variance ছোট হলে সীমা শক্ত হয়: কম variance মানে data গড়ের কাছে জড়ো (concentrated), তাই দূরে যাওয়ার probability কম।
নোট — দুটি রূপ একই কথা। কখনো Chebyshev সরাসরি threshold \(a\)-তে লেখা হয়: \(P(\lvert X-\mu\rvert\ge a)\le \sigma^2/a^2\)। এটা উপরের রূপেরই অনুবাদ — \(a=k\sigma\) বসালে \(\sigma^2/a^2 = \sigma^2/(k\sigma)^2 = 1/k^2\)। দুটো একই; \(k\)-রূপটা "কত \(\sigma\) দূরে" ভাবতে সুবিধাজনক, \(a\)-রূপটা সরাসরি দূরত্ব দিলে সুবিধাজনক।
Markov-এর সাথে তুলনা: Chebyshev বেশি তথ্য (variance) চায়, বিনিময়ে (i) দুই দিকের সীমা দেয় এবং (ii) সাধারণত শক্ত সীমা দেয়। এটি 3.3-এ Weak Law of Large Numbers প্রমাণের সরাসরি হাতিয়ার।
(চিত্র: 3-1-chebyshev — \(\mu\)-কে কেন্দ্র করে \(\pm k\sigma\) ব্যান্ড ও বাইরের দুই tail-এর ওপর \(1/k^2\) সীমা।)
২.৩ Convex function ও Jensen's inequality¶
পরের অসমতা একটু ভিন্ন স্বাদের — এটি tail bound নয়, বরং expectation ও function-এর ক্রম (order) নিয়ে। আগে দরকারি যন্ত্র convex function চিনি।
Convex function (উত্তল ফাংশন) — একটি function \(g\) convex তখনই যখন তার graph সর্বত্র "নিচের দিকে বাটির মতো" বাঁকা (যেমন \(g(x)=x^2\), \(g(x)=e^x\), \(g(x)=\lvert x\rvert\))। আনুষ্ঠানিক সংজ্ঞা: যেকোনো দুই বিন্দু \(x_1, x_2\) এবং যেকোনো \(\lambda\in[0,1]\)-এর জন্য $$ g\big(\lambda x_1 + (1-\lambda)x_2\big) \;\le\; \lambda\, g(x_1) + (1-\lambda)\, g(x_2). $$ এর সরল ছবি: graph-এর দুই বিন্দু জোড়া দিলে যে রেখাংশ (chord — জ্যা) পাওয়া যায়, সেটি সবসময় graph-এর উপরে বা সমান থাকে। অর্থাৎ বাটির মাঝখানটা চেপে নিচে, প্রান্ত দুটো উপরে — তাই যেকোনো গড়-অবস্থানে (chord) function-এর প্রকৃত মান নিচে থাকে। (যদি অসমতা উল্টো হয়, অর্থাৎ chord graph-এর নিচে থাকে, তখন \(g\)-কে বলে concave (অবতল — উপুড় বাটি), যেমন \(g(x)=\log x\), \(g(x)=\sqrt{x}\)।)
একটি সহজ পরীক্ষা (যদি \(g\) দুবার অন্তরকলনযোগ্য): \(g''(x)\ge 0\) সর্বত্র হলে \(g\) convex (যেমন \(g(x)=x^2 \Rightarrow g''(x)=2\ge 0\))। \(g''(x)\le 0\) হলে concave।
এবার মূল ফল। Jensen's inequality বলে: যদি \(g\) একটি convex function হয়, তবে $$ \boxed{\ \mathbb{E}\big[g(X)\big] \;\ge\; g\big(\mathbb{E}[X]\big)\ } $$ (আর \(g\) concave হলে অসমতা উল্টো: \(\mathbb{E}[g(X)]\le g(\mathbb{E}[X])\)।)
খুলে বলি দুই পাশ:
- \(\mathbb{E}[g(X)]\) — আগে \(g\) লাগান প্রতিটি মানে, তারপর গড় নিন।
- \(g(\mathbb{E}[X])\) — আগে গড় নিন, তারপর \(g\) লাগান।
Jensen বলছে convex \(g\)-এর জন্য এই দুটোর ক্রম গুরুত্বপূর্ণ: "আগে function, পরে গড়" সবসময় "আগে গড়, পরে function"-এর চেয়ে বড় বা সমান।
From-scratch intuition — chord সর্বদা উপরে। ধরুন \(X\) মাত্র দুটি মান নেয়: \(x_1\) (probability \(\lambda\)) ও \(x_2\) (probability \(1-\lambda\))। তাহলে \(\mathbb{E}[X]=\lambda x_1+(1-\lambda)x_2\) — এটা \(x_1, x_2\)-এর মাঝামাঝি একটা বিন্দু। এখন: - \(g(\mathbb{E}[X])\) = সেই মাঝবিন্দুতে graph-এর উচ্চতা। - \(\mathbb{E}[g(X)]=\lambda g(x_1)+(1-\lambda)g(x_2)\) = সেই মাঝবিন্দুতে chord-এর উচ্চতা।
convexity-র সংজ্ঞা ঠিক বলছে chord ≥ graph — তাই \(\mathbb{E}[g(X)]\ge g(\mathbb{E}[X])\)। দুইয়ের বেশি মান বা continuous \(X\)-এর ক্ষেত্রেও একই যুক্তি গড় করে খাটে (এটাকে বলে গড় নেওয়া = chord-এর ভারিত গড়, যা graph-এর উপরে)। মূল ছবি একটাই: বাটির আকারের graph-এ, গড়-অবস্থানে প্রকৃত graph নিচে থাকে, তাই গড়-করা function উপরে থাকে।
কেন এটা কাজের? কারণ এটি বহু সূক্ষ্ম ফলের দিক ঠিক করে দেয়। উদাহরণ: \(g(x)=x^2\) convex, তাই Jensen সরাসরি দেয় \(\mathbb{E}[X^2]\ge(\mathbb{E}[X])^2\) — যার মানে \(\mathrm{Var}(X)=\mathbb{E}[X^2]-(\mathbb{E}[X])^2\ge 0\), অর্থাৎ variance কখনো ঋণাত্মক হয় না (2.5-এ যা আমরা ধরে নিয়েছিলাম, Jensen তা প্রমাণ করে)। এই ফলটি §৩-এর E3-এ সংখ্যাসহ দেখব।
(চিত্র: 3-1-jensen — convex \(g(x)=x^2\)-এর graph, এক chord, এবং তার ওপর \(g(\mathbb{E}[X])\) vs \(\mathbb{E}[g(X)]\)।)
২.৪ Hoeffding's inequality — bounded যোগফলের exponential bound¶
এখন সবচেয়ে শক্তিশালী হাতিয়ার, যা concentration-কে সরাসরি সংখ্যায় ধরে। Chebyshev একটা মাত্র \(X\)-এর জন্য ভালো, কিন্তু পরিসংখ্যানে আমরা প্রায়ই অনেকগুলো random variable-এর গড় নিয়ে কাজ করি — sample mean \(\bar X_n\)। Chebyshev \(\bar X_n\)-এর tail-কে \(1/n\)-হারে কমায়, যা ভালো কিন্তু ধীর। Hoeffding's inequality দেখায় random variable-গুলো যদি bounded (সীমাবদ্ধ — একটা নির্দিষ্ট পরিসরে আটকে) হয়, তবে tail exponentially (সূচকীয় হারে — অনেক দ্রুত) কমে।
ধরা যাক \(X_1, X_2, \dots, X_n\) স্বাধীন (independent) random variable, এবং প্রত্যেকটি bounded: \(X_i\in[a_i, b_i]\) (অর্থাৎ \(a_i\le X_i\le b_i\) নিশ্চিত)। sample mean সংজ্ঞায়িত করি $$ \bar X_n = \frac{1}{n}\sum_{i=1}^n X_i. $$ তখন যেকোনো \(t>0\)-এর জন্য (two-sided রূপ):
symbol-গুলো খুলি:
- \(X_i\in[a_i,b_i]\) — \(i\)-তম variable-এর নিশ্চিত নিম্ন ও ঊর্ধ্ব সীমা (যেমন coin toss-এ প্রতিটি \(X_i\in[0,1]\))। এই boundedness-ই Hoeffding-এর প্রধান শর্ত।
- \(\bar X_n\) — \(n\)টি variable-এর গড় (sample mean)।
- \(\mathbb{E}[\bar X_n]\) — সেই গড়ের expectation (যা linearity থেকে প্রতিটি \(\mathbb{E}[X_i]\)-এর গড়)।
- \(t>0\) — কত দূরে সরছি (deviation threshold)।
- \(\sum_i (b_i-a_i)^2\) — প্রতিটি variable-এর "পরিসর-প্রস্থ" (\(b_i-a_i\), এক range কত চওড়া) বর্গ করে যোগফল; এটি কত বিচরণ-সুযোগ আছে তা মাপে।
- \(\exp(\cdot)\) — exponential function \(e^{(\cdot)}\); এই \(e^{-(\dots)}\) অংশটাই tail-কে exponentially ছোট করে।
- সামনের \(2\) — দুই দিকের (উপরে ও নিচে) tail মেলানোর জন্য।
সবচেয়ে গুরুত্বপূর্ণ যেটি লক্ষ করার: bound-এ \(n\) আছে exponent-এর ভেতরে (\(-2n^2t^2/\sum(\dots)\))। অর্থাৎ \(n\) বাড়লে সীমা exponentially ছোট হয়, Chebyshev-এর \(1/n\)-এর চেয়ে অনেক দ্রুত। এটাই concentration-এর শক্তি: bounded data-র গড় তার expectation-এর চারপাশে প্রচণ্ড শক্ত করে জড়ো হয়।
From-scratch intuition — boundedness কেন এত সাহায্য করে। এক লাইনে: প্রতিটি \(X_i\) যদি \([a_i,b_i]\)-তে আটকা থাকে, তবে কোনো একটি \(X_i\) একা গড়কে বেশি দূর টানতে পারে না (চরম মান নিষিদ্ধ)। তাই গড় খুব দূরে যেতে হলে অনেক \(X_i\)-কে একসাথে একই দিকে "ষড়যন্ত্র" করতে হবে — আর independent variable-দের একযোগে এক দিকে যাওয়ার probability exponentially ছোট। এই boundedness-ই Chebyshev-এর শুধু-variance তথ্যের চেয়ে বেশি কিছু দেয়, তাই bound-ও বেশি শক্ত হয়। (গাণিতিকভাবে Hoeffding-ও Markov থেকেই আসে — তবে \(X\)-এর বদলে \(e^{sX}\)-এর ওপর Markov, যাকে বলে Chernoff কৌশল; বিস্তারিত পরের অংশে।)
কেন এটি 3.3-এর সেতু: Hoeffding সরাসরি বলে দেয় \(\bar X_n\) কত দ্রুত \(\mathbb{E}[\bar X_n]\)-এ জড়ো হয় — এবং \(n\to\infty\) নিলে ডান পাশ \(\to 0\), যা LLN-এরই একটি শক্তিশালী (exponential-হারে) সংস্করণ।
(চিত্র: 3-1-hoeffding — coin-toss \(\bar X_n\)-এর tail কীভাবে \(n\) বাড়লে Chebyshev-এর চেয়ে দ্রুত শূন্যে নামে।)
৩ · পূর্ণাঙ্গ উদাহরণ¶
এবার চারটি running example (E1–E4) হাতে-কলমে, সংখ্যাসহ। প্রতিটিতে আগে কোন অসমতা, কেন; তারপর symbol বসিয়ে গণনা; শেষে ফল কী বলছে।
উদাহরণ E1 (Markov) — আয়ের tail¶
সমস্যা। একজন গ্রাহকের মাসিক খরচ \(X\) অঋণাত্মক (\(X\ge 0\), কেউ ঋণাত্মক খরচ করে না) এবং \(\mathbb{E}[X]=50\) টাকা। distribution-এর আকৃতি অজানা। প্রশ্ন: \(P(X\ge 200)\) — অর্থাৎ ২০০ টাকার বেশি খরচ করার probability — সর্বোচ্চ কত হতে পারে?
কোন অসমতা? শুধু mean জানা, \(X\ge 0\), এক দিকের (ডান) tail চাই — ঠিক Markov-এর জন্য তৈরি।
গণনা। Markov-এ \(a=200\) বসাই: $$ P(X\ge 200) \;\le\; \frac{\mathbb{E}[X]}{a} \;=\; \frac{50}{200} \;=\; \frac{1}{4} \;=\; 0.25. $$
ফল কী বলছে। distribution-এর কিছুই না জেনে, শুধু "গড় ৫০, অঋণাত্মক" — এই দুই তথ্যেই আমরা নিশ্চিত: সর্বোচ্চ ২৫% গ্রাহক ২০০ টাকার বেশি খরচ করেন। লক্ষণীয়, এটি একটি upper bound — প্রকৃত শতাংশ অনেক কম হতে পারে (যেমন distribution বেশি কেন্দ্রীভূত হলে), কিন্তু কখনো ২৫%-এর বেশি নয়। এই "আলগা কিন্তু নিশ্চিত" সীমাই Markov-এর চরিত্র।
উদাহরণ E2 (Chebyshev) — পরীক্ষার নম্বর¶
সমস্যা। একটি পরীক্ষায় নম্বর \(X\)-এর mean \(\mu=70\) ও standard deviation \(\sigma=10\) (অর্থাৎ \(\sigma^2=100\))। distribution অজানা। প্রশ্ন: একজন শিক্ষার্থীর নম্বর গড় থেকে ২০ নম্বর বা তার বেশি দূরে (যেকোনো দিকে — অর্থাৎ ৫০-এর নিচে বা ৯০-এর উপরে) থাকার probability সর্বোচ্চ কত? এটা \(P(\lvert X-70\rvert\ge 20)\)।
কোন অসমতা? mean ও variance দুটোই জানা, এবং দুই দিকের (গড় থেকে দূরত্ব) tail চাই — Chebyshev আদর্শ।
গণনা। প্রথমে \(k\) বের করি: দূরত্ব \(20 = k\sigma = k\cdot 10\), তাই \(k=2\)। এবার Chebyshev: $$ P\big(\lvert X-70\rvert \ge 20\big) \;=\; P\big(\lvert X-\mu\rvert \ge 2\sigma\big) \;\le\; \frac{1}{k^2} \;=\; \frac{1}{2^2} \;=\; \frac{1}{4} \;=\; 0.25. $$ (সরাসরি \(a\)-রূপেও মেলে: \(\sigma^2/a^2 = 100/20^2 = 100/400 = 1/4\)। দুই পথ একই উত্তর।)
ফল কী বলছে। distribution অজানা থাকলেও আমরা নিশ্চিত: সর্বোচ্চ ২৫% শিক্ষার্থী গড় থেকে ২০ নম্বরের বেশি দূরে (৫০-এর নিচে বা ৯০-এর উপরে)। উল্টোভাবে, অন্তত ৭৫% শিক্ষার্থী \([50, 90]\) পরিসরে — শুধু \(\mu\) ও \(\sigma\) থেকেই এই গ্যারান্টি। (তুলনা: যদি data সত্যিই normal হতো, তবে \(2\sigma\)-এর বাইরে মাত্র ~৫% থাকত; Chebyshev-এর ২৫% আলগা, কারণ এটি সব distribution-এর জন্য নিরাপদ থাকতে হয়।)
উদাহরণ E3 (Jensen) — \(\mathbb{E}[X^2]\ge(\mathbb{E}[X])^2\)¶
সমস্যা। দেখাও যে convex \(g(x)=x^2\)-এর জন্য \(\mathbb{E}[X^2]\ge(\mathbb{E}[X])^2\), এবং একটি concrete সংখ্যায় তা যাচাই করো।
কোন অসমতা ও কেন। \(g(x)=x^2\) convex (\(g''(x)=2\ge 0\) সর্বত্র — §২.৩-এর পরীক্ষা)। Jensen সরাসরি বলে convex \(g\)-এর জন্য \(\mathbb{E}[g(X)]\ge g(\mathbb{E}[X])\)। এখানে \(g(X)=X^2\), তাই $$ \mathbb{E}[X^2] \;=\; \mathbb{E}[g(X)] \;\ge\; g(\mathbb{E}[X]) \;=\; (\mathbb{E}[X])^2. $$ ব্যস — প্রমাণ হয়ে গেল। এর সরাসরি ফল: \(\mathrm{Var}(X)=\mathbb{E}[X^2]-(\mathbb{E}[X])^2\ge 0\) — variance কখনো ঋণাত্মক নয়।
সংখ্যায় যাচাই। ধরা যাক \(X\) সমান probability (\(\tfrac12\) করে) দুটি মান নেয়: \(X=2\) বা \(X=4\)। তাহলে $$ \mathbb{E}[X] = \tfrac12\cdot 2 + \tfrac12\cdot 4 = 3, \qquad (\mathbb{E}[X])^2 = 3^2 = 9, $$ $$ \mathbb{E}[X^2] = \tfrac12\cdot 2^2 + \tfrac12\cdot 4^2 = \tfrac12\cdot 4 + \tfrac12\cdot 16 = 2 + 8 = 10. $$ সত্যিই \(\mathbb{E}[X^2]=10 \;\ge\; 9=(\mathbb{E}[X])^2\) — Jensen মিলে গেল। পার্থক্য \(10-9=1\) ঠিক \(\mathrm{Var}(X)\), যা positive। (সমতা ধরা পড়ে কেবল যখন \(X\) ধ্রুবক — তখন ছড়ানো নেই, তাই variance \(0\)।)
উদাহরণ E4 (Hoeffding) — ন্যায্য মুদ্রার heads-অনুপাত¶
সমস্যা। একটি ন্যায্য (fair) মুদ্রা \(n\) বার ছুঁড়লাম। প্রতিবার \(X_i=1\) যদি heads, \(X_i=0\) যদি tails — তাই প্রতিটি \(X_i\in[0,1]\) (অর্থাৎ \(a_i=0, b_i=1\))। sample mean \(\bar X_n=\frac1n\sum_i X_i\) = heads-এর অনুপাত। fair coin-এ \(\mathbb{E}[X_i]=0.5\), তাই \(\mathbb{E}[\bar X_n]=0.5\)। প্রশ্ন: heads-অনুপাত \(0.5\) থেকে \(t\) বা বেশি দূরে যাওয়ার probability, \(P(\lvert\bar X_n-0.5\rvert\ge t)\), কত দ্রুত ছোট হয়?
কোন অসমতা? স্বাধীন, bounded (\([0,1]\)) variable-এর গড়ের tail — Hoeffding ঠিক এর জন্য।
গণনা। প্রতিটি পরিসর-প্রস্থ \(b_i-a_i = 1-0 = 1\), তাই \(\sum_{i=1}^n (b_i-a_i)^2 = n\cdot 1^2 = n\)। Hoeffding-এ বসাই: $$ P\big(\lvert\bar X_n - 0.5\rvert \ge t\big) \;\le\; 2\exp!\left(-\frac{2n^2 t^2}{n}\right) \;=\; 2\exp!\left(-2n t^2\right). $$ এই পরিষ্কার রূপটি — \(2e^{-2nt^2}\) — fair-coin-এর জন্য মনে রাখার মতো।
সংখ্যায় দেখি — concentration কত দ্রুত। ধরা যাক আমরা \(t=0.1\) নিলাম (অর্থাৎ heads-অনুপাত \(0.4\)–\(0.6\)-এর বাইরে যাওয়ার probability):
| tosses \(n\) | bound \(2e^{-2nt^2} = 2e^{-0.02n}\) |
|---|---|
| \(n=100\) | \(2e^{-2}\approx 0.27\) |
| \(n=500\) | \(2e^{-10}\approx 9.1\times 10^{-5}\) |
| \(n=1000\) | \(2e^{-20}\approx 4.1\times 10^{-9}\) |
ফল কী বলছে। \(n=100\)-এ সীমা এখনো বড় (~২৭%), কিন্তু \(n\) মাত্র ১০ গুণ বাড়িয়ে \(1000\) করতেই সীমা \(4\times 10^{-9}\)-এ নেমে যায় — কার্যত শূন্য। অর্থাৎ ১০০০ বার ছুঁড়লে heads-অনুপাত \(0.4\)–\(0.6\)-এর বাইরে যাওয়া প্রায় অসম্ভব। এটাই exponential concentration: bounded data-র গড় তার expectation-এর চারপাশে \(n\)-এর সাথে exponentially শক্ত করে জড়ো হয়। (তুলনার জন্য: একই ক্ষেত্রে Chebyshev দিত \(\mathrm{Var}(\bar X_n)/t^2 = (0.25/n)/0.01 = 25/n\), যা \(n=1000\)-এ \(0.025\) — Hoeffding-এর \(4\times 10^{-9}\)-এর চেয়ে কোটি গুণ আলগা!) এই \(n\to\infty\)-তে \(\to 0\) আচরণই 3.3-এর Law of Large Numbers-এর শক্তিশালী রূপ।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে আমরা চারটি অসমতা scratch থেকে (একদম শুরু থেকে) প্রমাণ করব। প্রতিটি লাইনের পেছনে কারণ বাংলায় লেখা থাকবে, কোনো বীজগণিতের ধাপ লুকানো হবে না। প্রমাণগুলো কঠিনতা অনুযায়ী ট্যাগ করা: ★ = সহজ, ★★ = মাঝারি, ★★★ = উন্নত।
মূল কৌশল একটাই, এবং সেটা আগে বুঝে নেওয়া জরুরি: indicator function (নির্দেশক ফাংশন) \(\mathbf{1}\{\cdot\}\)-কে একটা সাধারণ random variable দিয়ে ওপর থেকে চেপে ধরা (bound করা), তারপর দুই পাশে expectation (প্রত্যাশা) নেওয়া। মনে রাখুন — expectation একটি monotone (একমুখী/ক্রমরক্ষাকারী) operation: যদি দুটো random variable \(U, V\)-এর জন্য সবসময় \(U \le V\) হয়, তবে \(\mathbb{E}[U] \le \mathbb{E}[V]\)। এই একটি ধর্মই আমাদের সব প্রমাণের ইঞ্জিন।
আরও একটা ছোট জিনিস মনে করিয়ে দিই: indicator \(\mathbf{1}\{A\}\) মানে এমন একটা সংখ্যা যা ঘটনা \(A\) ঘটলে \(1\), না ঘটলে \(0\)। এর সবচেয়ে গুরুত্বপূর্ণ ধর্ম হলো
অর্থাৎ একটি indicator-এর expectation মানে সেই ঘটনার probability। এটাই সেতু — কারণ আমরা একটা probability (\(P(X \ge a)\)) সম্পর্কে জানতে চাই, কিন্তু আমাদের হাতিয়ার expectation।
৪.১ · Markov inequality — ★¶
দাবি (claim): যদি \(X \ge 0\) একটি অঋণাত্মক (non-negative) random variable হয় এবং \(a > 0\) হয়, তবে
প্রমাণের মূল ধারণা। আমরা একটা সহজ বীজগাণিতিক অসমতা বানাব যা প্রতিটি সম্ভাব্য মান \(x \ge 0\)-এর জন্য সত্য, তারপর দুই পাশে expectation নিয়ে নেব।
ধাপ ১ — pointwise (বিন্দুভিত্তিক) অসমতা। দাবি করছি যে প্রতিটি \(x \ge 0\)-এর জন্য
এটা কেন সত্য? দুটো ক্ষেত্র (case) আলাদা করে দেখি — কারণ indicator-এর মান কেবল \(0\) বা \(1\) হয়, তাই কেস ভাগ করাই স্বাভাবিক।
- কেস A: \(x \ge a\). তখন বাঁ পাশ \(\mathbf{1}\{x \ge a\} = 1\)। ডান পাশ \(\dfrac{x}{a}\); যেহেতু \(x \ge a\) এবং \(a > 0\), তাই \(\dfrac{x}{a} \ge \dfrac{a}{a} = 1\)। সুতরাং বাঁ পাশ \(= 1 \le \dfrac{x}{a} =\) ডান পাশ। ✓
- কেস B: \(0 \le x < a\). তখন বাঁ পাশ \(\mathbf{1}\{x \ge a\} = 0\)। ডান পাশ \(\dfrac{x}{a} \ge 0\) (কারণ \(x \ge 0, a > 0\))। সুতরাং বাঁ পাশ \(= 0 \le \dfrac{x}{a} =\) ডান পাশ। ✓
দুই কেসেই অসমতা \((৪.১)\) সত্য, কাজেই এটা সব \(x \ge 0\)-এর জন্য সত্য। (লক্ষ্য করুন, এখানে \(X \ge 0\) শর্তটা কেস B-তে দরকার হলো — না হলে ঋণাত্মক \(x\)-এর জন্য \(\frac{x}{a}\) ঋণাত্মক হয়ে অসমতা ভেঙে যেত।)
ধাপ ২ — random variable-এ তুলে ধরা। যেহেতু \((৪.১)\) সম্ভাব্য প্রতিটি মানে সত্য, তাই random variable \(X\) বসিয়ে আমরা পাই দুটো random variable-এর মধ্যে একটা অসমতা যা সর্বদা (probability 1-এ) ধরে:
ধাপ ৩ — expectation নেওয়া। এখন দুই পাশে expectation নিই। monotonicity বলে অসমতার দিক বজায় থাকবে:
ধাপ ৪ — দুই পাশ সরল করা।
- বাঁ পাশ: উপরে আলোচিত সেতু-সূত্র অনুযায়ী \(\mathbb{E}\big[\mathbf{1}\{X \ge a\}\big] = P(X \ge a)\)।
- ডান পাশ: \(a\) একটি ধ্রুবক (constant), আর expectation linear (রৈখিক), তাই ধ্রুবক বাইরে আনা যায়: \(\mathbb{E}\!\left[\dfrac{X}{a}\right] = \dfrac{1}{a}\,\mathbb{E}[X] = \dfrac{\mathbb{E}[X]}{a}\)।
দুটো একসাথে বসিয়ে:
উদাহরণ E1-এ যাচাই। আয় \(X \ge 0\), \(\mathbb{E}[X] = 50\), threshold \(a = 200\)। সরাসরি বসিয়ে:
অর্থাৎ "আয় গড়ের অন্তত চারগুণ" — এমন লোক সর্বোচ্চ ২৫% হতে পারে, distribution-এর আকার যা-ই হোক। §৫-এর LAB 1-এ আমরা দেখব আসল মান এর চেয়ে অনেক ছোট (~\(0.018\)); Markov ঢিলা (loose) কিন্তু সবসময় বৈধ।
৪.২ · Chebyshev inequality — ★★¶
দাবি (claim): যদি \(X\)-এর মানে \(\mathbb{E}[X] = \mu\) এবং সসীম variance \(\mathrm{Var}(X) = \sigma^2 < \infty\) থাকে, তবে প্রতিটি \(k > 0\)-এর জন্য
প্রমাণের মূল ধারণা। Chebyshev আসলে Markov-এরই একটা corollary (অনুসিদ্ধান্ত) — কোনো নতুন কৌশল লাগে না। চালাকিটা হলো: Markov শুধু অঋণাত্মক variable-এ খাটে, তাই আমরা \((X - \mu)\)-কে সরাসরি না নিয়ে তার বর্গ \((X - \mu)^2\) নেব, যা সর্বদা \(\ge 0\)।
ধাপ ১ — ঘটনাটিকে বর্গের ভাষায় লেখা। লক্ষ্য করুন, যেহেতু দুই পাশই অঋণাত্মক, বর্গ করলে অসমতার দিক বদলায় না:
দুটো ঘটনা হুবহু একই (equivalent), তাই তাদের probability-ও সমান:
ধাপ ২ — Markov প্রয়োগ। এখন নতুন random variable ধরি \(Y = (X - \mu)^2\)। এটা একটা বর্গ, তাই \(Y \ge 0\) — Markov-এর শর্ত পূরণ। আর threshold ধরি \(a = k^2 \sigma^2 > 0\)। Markov (§৪.১) সরাসরি দেয়:
ধাপ ৩ — variance চিনে নেওয়া। এখানে লব \(\mathbb{E}\big[(X - \mu)^2\big]\) ঠিক variance-এর সংজ্ঞা (definition) — মনে করুন \(\mathrm{Var}(X) = \mathbb{E}\big[(X - \mu)^2\big] = \sigma^2\) (২.৫ থেকে)। কাজেই লব \(= \sigma^2\):
ধাপ ৪ — \((৪.২)\) দিয়ে ফিরিয়ে আনা। বাঁ পাশটা ধাপ ১-এ দেখানো equivalence অনুযায়ী মূল ঘটনার probability-র সমান:
মন্তব্য (variance বাতিল হওয়া)। খেয়াল করুন \(\sigma^2\) লব-হর দুজায়গাতেই এসে কাটাকুটি হয়ে গেল — তাই চূড়ান্ত bound-এ \(\sigma\) থাকে না, শুধু \(k\) থাকে। এজন্যই Chebyshev-কে "\(k\) standard deviation দূরে যাওয়ার সম্ভাবনা" হিসেবে মনে রাখা সুবিধাজনক।
উদাহরণ E2-এ যাচাই। পরীক্ষার স্কোর, \(\mu = 70\), \(\sigma = 10\), আর আমরা চাই \(P(\lvert X - 70 \rvert \ge 20)\)। এখানে deviation \(= 20 = k\sigma\), অর্থাৎ \(k = 20/10 = 2\)। বসিয়ে:
অর্থাৎ গড় থেকে অন্তত \(2\sigma\) দূরে স্কোর সর্বোচ্চ ২৫% শিক্ষার্থীর। §৫-এর LAB 2-এ Normal ডেটায় আসল মান ~\(0.045\) পাব — আবারও bound ঢিলা কিন্তু বৈধ। (Chebyshev কোনো distribution অনুমান করে না, তাই Normal-এর তুলনায় ঢিলা হওয়াই স্বাভাবিক।)
৪.৩ · Jensen inequality — ★★¶
দাবি (claim): যদি \(g\) একটি convex (উত্তল) ফাংশন হয় এবং \(\mathbb{E}[X] = \mu\) ও \(\mathbb{E}[g(X)]\) বিদ্যমান থাকে, তবে
(convex ফাংশন বাঁকা থাকে নিচ থেকে উপরের দিকে — যেমন \(g(x) = x^2\)। স্মৃতিসহায়ক: "smile is convex" — হাসিমুখের বাঁক উত্তল।)
প্রমাণের মূল ধারণা — supporting line (অবলম্বন-রেখা)। convex ফাংশনের একটা চমৎকার জ্যামিতিক ধর্ম: যেকোনো বিন্দু \(x_0\)-তে এমন একটা সরলরেখা টানা যায় যা \(x_0\)-তে গ্রাফকে ছোঁয় এবং সর্বত্র গ্রাফের নিচে বা গ্রাফেই থাকে। এই রেখাকে বলে \(x_0\)-তে supporting line। আমরা রেখাটা ঠিক \(\mu = \mathbb{E}[X]\) বিন্দুতে টানব, কারণ ওখানেই শেষে সমতা ধরবে।
ধাপ ১ — \(\mu\)-তে supporting line। convexity-র সংজ্ঞা থেকে এটা পরিচিত তথ্য (২.৪-এ আলোচিত; এখানে কারণসহ ব্যবহার করছি): বিন্দু \(\mu\)-তে এমন একটা ঢাল (slope) \(c\) আছে যেন প্রতিটি \(x\)-এর জন্য
ডান পাশটা একটা সরলরেখা: এটা \(\mu\)-তে \(g(\mu)\) মানে শুরু করে এবং \(c\) ঢালে চলে। (\(g\) অন্তরযোগ্য (differentiable) হলে \(c = g'(\mu)\); না হলেও যেকোনো subgradient নিলে চলে — convex হওয়াই \(c\)-র অস্তিত্ব নিশ্চিত করে।) মূল কথা: convex গ্রাফ তার যেকোনো স্পর্শক-রেখার উপরে বা রেখাতেই থাকে — সেটাই \((৪.৩)\)।
ধাপ ২ — random variable বসানো। যেহেতু \((৪.৩)\) প্রতিটি \(x\)-এ সত্য, তাই \(x\)-এর জায়গায় \(X\) বসিয়ে দুই random variable-এর মধ্যে সর্বদা-সত্য অসমতা পাই:
ধাপ ৩ — expectation নেওয়া। দুই পাশে expectation নিই; monotonicity-তে দিক বজায়:
ধাপ ৪ — ডান পাশ সরল করা (linearity)। ডান পাশের প্রতিটি অংশ আলাদা করি, কারণ expectation যোগ ও ধ্রুবক-গুণে রৈখিক:
এখানে \(g(\mu)\) একটা সংখ্যা (random নয়), তাই তার expectation সে নিজেই; আর \(\mathbb{E}[X] = \mu\) বসানোয় বন্ধনী শূন্য হয়ে গেল — এই কারণেই রেখাটা ঠিক \(\mu\)-তে টানা হয়েছিল।
উপসংহার। দুই পাশ মিলিয়ে:
(যদি \(g\) concave (অবতল, যেমন \(\log\)) হতো, অসমতার দিক উল্টে যেত: \(\mathbb{E}[g(X)] \le g(\mathbb{E}[X])\) — কারণ তখন গ্রাফ স্পর্শক-রেখার নিচে থাকে।)
উদাহরণ E3-এ যাচাই। নিই \(g(x) = x^2\)। এটা convex (দ্বিতীয় অন্তরজ \(g''(x) = 2 > 0\), তাই সর্বত্র উত্তল)। Jensen সরাসরি দেয়:
আর এই দুইয়ের ফারাকটা ঠিক variance — কারণ সংজ্ঞা থেকে \(\mathrm{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 \ge 0\)। অর্থাৎ এখানে Jensen-এর অসমতা আসলে "variance কখনো ঋণাত্মক নয়" — এই সত্যেরই আরেক রূপ। §৫-এর LAB 3-এ সংখ্যায় এই gap = Var দেখব।
৪.৪ · Hoeffding inequality — ★★★¶
এটি সবচেয়ে উন্নত ফলাফল। আগের তিনটি ছিল এক-পদক্ষেপের; Hoeffding-এর প্রমাণে কয়েকটা স্তর আছে। আমরা পূর্ণ কাঠামোটা সৎভাবে দেখাব, একটা মাঝারি ধাপ (Hoeffding's lemma) নির্ভরযোগ্য sketch হিসেবে রেখে — পুরো বীজগণিত করলে অধ্যায় দীর্ঘ হয়ে যেত, কিন্তু কোথাও ফাঁকি নেই, সব দাবি সৎ।
দাবি (statement)। ধরুন \(X_1, \dots, X_n\) স্বাধীন (independent), এবং প্রতিটি bounded (সীমাবদ্ধ): \(X_i \in [a_i, b_i]\)। নমুনা-গড় \(\bar X_n = \frac{1}{n}\sum_{i=1}^{n} X_i\) ধরি। তবে প্রতিটি \(t > 0\)-এর জন্য (এক-পাশ, one-sided):
বিশেষ ভাবে যদি প্রতিটি \(X_i \in [0, 1]\) হয় (তাই \(b_i - a_i = 1\), এবং হর \(= n\)), তবে দুই-পাশের (two-sided) রূপ দাঁড়ায়:
লক্ষ্য করুন — Markov/Chebyshev-এর মতো এখানে bound \(t\)-তে শুধু বহুপদীয় ভাবে নয়, exponentially (সূচকীয়ভাবে) দ্রুত শূন্যের দিকে যায়। এটাই Hoeffding-কে শক্তিশালী করে তোলে।
কৌশলের নাম: Chernoff পদ্ধতি। মূল চালাকি — সরাসরি \(\bar X_n\)-এ Markov না লাগিয়ে, আগে একটা \(\lambda > 0\) দিয়ে গুণ করে সূচকীকরণ (exponentiate) করি, তারপর Markov লাগাই। কেন? কারণ exponentiation tail-কে অনেক জোরে চেপে ধরে, ফলে অনেক ভালো (টাইট) bound আসে।
ধাপ ১ — সূচকীয় Markov (Chernoff)। ধরি \(S = \sum_{i=1}^n \big(X_i - \mathbb{E}[X_i]\big)\) (কেন্দ্রীকৃত যোগফল)। তখন \(\bar X_n - \mathbb{E}[\bar X_n] \ge t\) ঘটনাটি \(S \ge nt\)-এর সমান। যেকোনো \(\lambda > 0\) ধরি। যেহেতু \(u \mapsto e^{\lambda u}\) কঠোরভাবে বর্ধমান (strictly increasing), তাই অসমতার দিক বদলায় না:
এখন \(Y = e^{\lambda S} \ge 0\) অঋণাত্মক, তাই এতে Markov (§৪.১) লাগাই, threshold \(e^{\lambda n t}\):
এই \(\mathbb{E}[e^{\lambda S}]\)-কে বলে MGF (moment generating function, ভ্রামক উৎপাদক ফাংশন)। মূল কাজ এখন একে bound করা।
ধাপ ২ — MGF-কে গুণফলে ভাঙা (স্বাধীনতা)। যেহেতু \(X_i\)-রা স্বাধীন, তাদের কেন্দ্রীকৃত রূপও স্বাধীন, আর স্বাধীন variable-এর exponential-এর product-এর expectation = expectation-এর product:
এতে \(n\)-মাত্রার একটা সমস্যা \(n\)টি এক-মাত্রার সমস্যায় ভেঙে গেল — এখন শুধু একটা পদ bound করলেই হবে।
ধাপ ৩ — Hoeffding's lemma (★★★, নির্ভরযোগ্য sketch)।
Hoeffding's lemma। যদি \(Z\) একটা random variable হয় যার \(\mathbb{E}[Z] = 0\) এবং \(Z \in [a, b]\) (সীমাবদ্ধ), তবে প্রতিটি \(\lambda \in \mathbb{R}\)-এর জন্য $$ \mathbb{E}\big[e^{\lambda Z}\big] \;\le\; \exp!\Big(\tfrac{1}{8}\,\lambda^2 (b - a)^2\Big). $$
lemma-র ধারণা (sketch, সৎ)। এর পূর্ণ প্রমাণ এভাবে এগোয় — সংক্ষেপে কিন্তু কোনো মিথ্যা নয়:
- \(z \mapsto e^{\lambda z}\) convex। তাই \([a,b]\) ব্যবধির ভেতরে যেকোনো \(z\)-কে দুই প্রান্ত \(a, b\)-এর উত্তল সংযোগ (convex combination) হিসেবে লিখে convexity প্রয়োগ করলে \(e^{\lambda z}\)-এর একটা রৈখিক উপরি-সীমা (linear upper bound) পাওয়া যায়।
- সেই রৈখিক bound-এ expectation নিলে এবং \(\mathbb{E}[Z] = 0\) ব্যবহার করলে ডান পাশটা দাঁড়ায় \(e^{\varphi(\lambda)}\) আকারে, যেখানে \(\varphi\) একটা স্পষ্ট ফাংশন (প্রান্ত \(a, b\) আর \(\lambda\)-নির্ভর)।
- এরপর \(\varphi(\lambda)\)-কে Taylor-এ বিস্তার করে দেখানো হয় \(\varphi''(\lambda) \le \tfrac{1}{4}(b-a)^2\) সর্বত্র। দুইবার সংযোজন (integrate) করে, \(\varphi(0) = \varphi'(0) = 0\) ব্যবহার করলে পাওয়া যায় \(\varphi(\lambda) \le \tfrac{1}{8}\lambda^2 (b-a)^2\) — ঠিক lemma-র দাবি।
(ধাপ ৩-এর ঐ \(\varphi'' \le \frac14 (b-a)^2\) অংশটুকুই সবচেয়ে কারিগরি; সেটাই আমরা গণনা না করে সৎভাবে উদ্ধৃত করছি। ধারণাটা: এক প্রান্ত \(a\) আর অন্য প্রান্ত \(b\)-তে ভরযুক্ত একটা Bernoulli-সদৃশ চলকের variance সর্বোচ্চ \(\frac14(b-a)^2\) — যা \(z\mapsto e^{\lambda z}\)-এর "tilted" বণ্টনের variance-কে সীমায় বাঁধে।)
ধাপ ৪ — lemma বসিয়ে যোগফলে আনা। প্রতিটি \(Z_i = X_i - \mathbb{E}[X_i]\) সন্তুষ্ট করে \(\mathbb{E}[Z_i] = 0\) এবং \(Z_i \in [a_i - \mathbb{E}[X_i],\, b_i - \mathbb{E}[X_i]]\) — যার দৈর্ঘ্য \((b_i - a_i)\), প্রান্ত সরালেও অপরিবর্তিত। তাই lemma দেয়:
ধাপ ২-এর গুণফলে বসিয়ে (exponential-এর product মানে সূচকের যোগ):
সংক্ষেপে লিখি \(D := \sum_{i=1}^{n}(b_i - a_i)^2\)।
ধাপ ৫ — \(\lambda\)-এর সর্বোত্তম মান বেছে নেওয়া। ধাপ ১-এর \((৪.৪)\)-এ এই bound বসাই:
এই bound প্রতিটি \(\lambda > 0\)-এর জন্য সত্য, তাই আমরা সবচেয়ে ছোট (সবচেয়ে টাইট) bound পেতে \(h(\lambda)\)-কে \(\lambda\)-এর সাপেক্ষে minimize করব। \(h\) একটা উর্ধ্বমুখী parabola, তাই \(h'(\lambda) = 0\) বসাই:
এই \(\lambda^\star\) ফিরিয়ে বসিয়ে (সরল বীজগণিত):
উপসংহার (এক-পাশ)। তাই
দুই-পাশ ও \([0,1]\) বিশেষ রূপ। নিচের প্রান্ত \(P(\bar X_n - \mathbb{E}[\bar X_n] \le -t)\)-এর জন্য একই যুক্তি \(-S\)-এ চালালে অভিন্ন bound পাই; দুটো union bound (যোগফল) দিয়ে মিলিয়ে factor \(2\) আসে। আর \(X_i \in [0,1]\) হলে \(D = \sum_i 1 = n\), তাই \(\frac{2n^2 t^2}{D} = \frac{2 n^2 t^2}{n} = 2 n t^2\)। ফল:
উদাহরণ E4-এ যাচাই। ন্যায্য মুদ্রা (fair coin): \(X_i \in \{0, 1\}\), তাই \([0,1]\)-bounded এবং \(\mathbb{E}[\bar X_n] = 0.5\)। সরাসরি:
উদাহরণস্বরূপ \(n = 100, t = 0.1\) হলে bound \(= 2 e^{-2\cdot100\cdot0.01} = 2 e^{-2} \approx 0.271\)। §৫-এর LAB 4-এ সিমুলেশনে আসল মান ~\(0.036\) পাব — bound ঢিলা কিন্তু বৈধ, এবং \(n\) বাড়লে দুটোই দ্রুত শূন্যে নামে।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা চারটি bound-কেই simulation-এর বিপরীতে যাচাই করব: প্রতিবার বহু-সংখ্যক নমুনা টেনে empirical (পরীক্ষালব্ধ) tail probability বের করে তাকে theoretical bound-এর সাথে মেলাব। সঠিক প্রমাণ হলে empirical মান সবসময় bound-এর নিচে বা সমান থাকবে।
পুনরুৎপাদনযোগ্যতার (reproducibility) জন্য আমরা numpy-র আধুনিক default_rng ব্যবহার করছি একটা স্থির seed (seed=42) দিয়ে — তাই কোড চালালে প্রতিবার একই সংখ্যা আসবে। নিচের আউটপুটগুলো বাস্তবে কোড চালিয়ে পাওয়া (printed output সরাসরি দেওয়া)।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 3.1 Probability Inequalities -- Code Lab
# Verifies Markov, Chebyshev, Jensen, and Hoeffding bounds against simulation.
import numpy as np
rng = np.random.default_rng(seed=42) # fixed seed for reproducibility
N = 1_000_000 # number of Monte Carlo samples
# ---- LAB 1: Markov (X >= 0, E[X] = 50, threshold a = 200) ----
mu_exp = 50.0
X = rng.exponential(scale=mu_exp, size=N) # E[X] = mu_exp (so E[X] = 50)
a = 200.0
emp_tail = np.mean(X >= a) # empirical P(X >= a)
markov_bnd = mu_exp / a # Markov upper bound = E[X]/a
print("LAB 1 Markov")
print(f" empirical P(X >= {a:.0f}) = {emp_tail:.6f}")
print(f" Markov bound E[X]/a = {markov_bnd:.6f}")
print(f" bound holds? {emp_tail <= markov_bnd}")
# ---- LAB 2: Chebyshev (mu = 70, sigma = 10, k*sigma = 20) ----
mu_s, sigma_s = 70.0, 10.0
S = rng.normal(loc=mu_s, scale=sigma_s, size=N)
dev = 20.0 # = k*sigma with k = 2
k = dev / sigma_s
emp_dev = np.mean(np.abs(S - mu_s) >= dev) # empirical P(|S-mu| >= 20)
cheb_bnd = 1.0 / k**2 # Chebyshev bound = 1/k^2
print("LAB 2 Chebyshev")
print(f" empirical P(|S-70| >= {dev:.0f}) = {emp_dev:.6f}")
print(f" Chebyshev bound 1/k^2 = {cheb_bnd:.6f}")
print(f" bound holds? {emp_dev <= cheb_bnd}")
# ---- LAB 3: Jensen (g(x) = x^2 convex => E[X^2] >= (E[X])^2) ----
Xj = rng.uniform(0.0, 10.0, size=N)
lhs = np.mean(Xj**2) # E[g(X)] = E[X^2]
rhs = (np.mean(Xj))**2 # g(E[X]) = (E[X])^2
print("LAB 3 Jensen")
print(f" E[X^2] (LHS) = {lhs:.6f}")
print(f" (E[X])^2 (RHS) = {rhs:.6f}")
print(f" gap = Var(X) = {lhs - rhs:.6f} (>= 0)")
print(f" Jensen holds? {lhs >= rhs}")
# ---- LAB 4: Hoeffding (fair coin, P(|Xbar_n - 0.5| >= t)) ----
print("LAB 4 Hoeffding")
print(f" {'n':>5} {'t':>5} {'empirical':>11} {'2e^-2nt^2':>11} {'holds?':>7}")
n_trials = 200_000
for n in (10, 50, 100):
for t in (0.1, 0.2):
flips = rng.integers(0, 2, size=(n_trials, n)) # Bernoulli(0.5)
xbar = flips.mean(axis=1) # Xbar_n per trial
emp = np.mean(np.abs(xbar - 0.5) >= t) # two-sided tail
hoeff = 2.0 * np.exp(-2.0 * n * t**2) # Hoeffding bound
print(f" {n:>5} {t:>5.2f} {emp:>11.6f} {hoeff:>11.6f} {str(emp <= hoeff):>7}")
৫.২ · বাস্তব আউটপুট¶
কোডটি চালালে (seed=42) নিচের আউটপুট আসে — হুবহু পুনরুৎপাদনযোগ্য:
LAB 1 Markov
empirical P(X >= 200) = 0.018325
Markov bound E[X]/a = 0.250000
bound holds? True
LAB 2 Chebyshev
empirical P(|S-70| >= 20) = 0.045284
Chebyshev bound 1/k^2 = 0.250000
bound holds? True
LAB 3 Jensen
E[X^2] (LHS) = 33.315288
(E[X])^2 (RHS) = 24.977608
gap = Var(X) = 8.337680 (>= 0)
Jensen holds? True
LAB 4 Hoeffding
n t empirical 2e^-2nt^2 holds?
10 0.10 0.344445 1.637462 True
10 0.20 0.227045 0.898658 True
50 0.10 0.118530 0.735759 True
50 0.20 0.004905 0.036631 True
100 0.10 0.035565 0.270671 True
100 0.20 0.000075 0.000671 True
৫.৩ · আউটপুট পড়ার নির্দেশিকা¶
প্রতিটি ফলাফল §৪-এর প্রমাণকে সংখ্যায় সমর্থন করছে — খেয়াল করুন কীভাবে:
-
LAB 1 (Markov). empirical tail \(\approx 0.0183\), আর Markov bound \(= 0.25\)। bound বৈধ (\(0.0183 \le 0.25\)) কিন্তু প্রায় ১৪ গুণ ঢিলা — কারণ Markov কেবল \(\mathbb{E}[X]\) জানে, distribution-এর আকার নয়। এখানে Exponential-এর tail দ্রুত ক্ষয়ে যায়, তাই আসল মান অনেক ছোট।
-
LAB 2 (Chebyshev). empirical \(\approx 0.0453\) বনাম bound \(0.25\) (\(k = 2\) হওয়ায় \(1/k^2 = 0.25\))। Normal ডেটায় \(2\sigma\)-এর বাইরে যাওয়ার আসল সম্ভাবনা \(\approx 0.045\) — Chebyshev এর চেয়ে অনেক বড় সীমা দেয়, কারণ সে distribution-নিরপেক্ষ (যেকোনো \(\sigma\)-সসীম distribution-এ খাটে)।
-
LAB 3 (Jensen). LHS \(= \mathbb{E}[X^2] \approx 33.32 \ge\) RHS \(= (\mathbb{E}[X])^2 \approx 24.98\), আর তাদের ফারাক \(\approx 8.34\)। মনে করুন Uniform\((0,10)\)-এর তাত্ত্বিক variance \(= \frac{(10-0)^2}{12} = \frac{100}{12} \approx 8.333\) — সিমুলেশনের gap ঠিক সেটাই (~\(8.338\))। অর্থাৎ "Jensen-এর ফাঁক = variance" তত্ত্বটা সংখ্যায় মিলে গেল।
-
LAB 4 (Hoeffding). প্রতিটি সারিতে empirical tail \(\le 2e^{-2nt^2}\) — bound সর্বত্র বৈধ। দুটো গুরুত্বপূর্ণ পর্যবেক্ষণ:
- \(n = 10\)-এর সারিতে bound \(> 1\) (যেমন \(1.637\), \(0.899\))। একটা probability কখনো \(1\) ছাড়ায় না, তাই এসব ক্ষেত্রে Hoeffding-bound vacuous (তুচ্ছ-বৈধ) — সত্য, কিন্তু কোনো কাজের তথ্য দেয় না। Hoeffding তখনই অর্থবহ হয় যখন \(2e^{-2nt^2} < 1\), অর্থাৎ \(n\) যথেষ্ট বড় বা \(t\) যথেষ্ট বড়।
- \(n\) বা \(t\) বাড়লে bound ও empirical — দুটোই সূচকীয়ভাবে দ্রুত শূন্যে নামে। যেমন \(n=100, t=0.2\)-তে আসল মান \(\approx 0.000075\), bound \(\approx 0.00067\) — এই দ্রুত ক্ষয়ই Hoeffding-কে Chebyshev-এর চেয়ে অনেক শক্তিশালী করে (Chebyshev এখানে \(t\)-তে কেবল \(1/(\cdots)\) হারে কমত, exponentially নয়)।
সারকথা। চারটি ক্ষেত্রেই bound holds? True — অসমতাগুলো ঢিলা হতে পারে, কিন্তু কখনো লঙ্ঘিত হয় না। ঠিক এটাই একটা valid upper bound-এর প্রতিশ্রুতি: সে আসল probability-কে সর্বদা ওপর থেকে ঢেকে রাখে, distribution যা-ই হোক।
৬ · ভিজ্যুয়ালাইজেশন¶
এই চারটি ছবি §১–§৫-এর চারটি প্রধান inequality-কে চোখে দেখায় — কীভাবে প্রতিটি bound (সীমা) সত্য probability-কে ঢেকে রাখে (upper-bound করে), এবং কতটা "ঢিলা" (loose) বা "আঁটসাঁট" (tight)। নিচের প্রতিটি figure-এর কোড ঠিক যা দিয়ে ছবিটি বানানো হয়েছে তা-ই (একটি script _code/figs_3-1.py থেকে)। in-figure লেখা English; ব্যাখ্যা বাংলায়। সব simulation reproducible — numpy এর default_rng ও fixed seed।
Figure 1 — Markov: একটি ঢিলা কিন্তু সর্বজনীন ছাদ¶
বাঁয়ে একটি nonnegative random variable-এর (Exponential, rate \(1\), তাই \(\mathbb{E}[X]=1\)) density; threshold \(a=3\)-এর ডানের tail-mass (কমলা) হলো সত্য \(P(X\ge 3)=e^{-3}\approx 0.050\), আর Markov bound \(\mathbb{E}[X]/a = 1/3 \approx 0.333\)। ডানে বহু threshold জুড়ে দুই রেখা: লাল হলো Markov bound \(1/a\), নীল হলো সত্য tail \(e^{-a}\) — bound সবসময় সত্য tail-এর উপরে থাকে (ফাঁকটাই "slack")। এটাই §২-এর মূল বার্তা: শুধু গড় জানলে tail-এর একটি নিরাপদ কিন্তু রক্ষণশীল ছাদ পাওয়া যায়।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
C = {"blue":"#2f6db5","red":"#c0392b","orange":"#e67e22","grey":"#34495e"}
fig, axes = plt.subplots(1, 2, figsize=(12, 4.6))
lam = 1.0; EX = 1.0/lam
# Left: density with one threshold a, tail shaded
ax = axes[0]
x = np.linspace(0, 7, 700); y = stats.expon.pdf(x, scale=1/lam)
ax.plot(x, y, color=C["grey"], lw=2.3, label="Exponential(rate=1) pdf, E[X]=1")
a0 = 3.0; m = x >= a0
ax.fill_between(x[m], 0, y[m], color=C["orange"], alpha=0.55,
label=f"true tail P(X>={a0:.0f}) = {np.exp(-a0):.3f}")
ax.axvline(a0, color=C["red"], ls="--", lw=1.5)
ax.text(a0+0.1, 0.5, f"a = {a0:.0f}\nMarkov bound = E[X]/a = {EX/a0:.3f}",
fontsize=10, color=C["red"], va="center")
ax.set_title("Markov: tail mass past a is bounded by E[X]/a")
ax.set_xlabel("x"); ax.set_ylabel("density f(x)"); ax.legend(loc="upper right", fontsize=9)
# Right: bound vs true tail across thresholds
ax = axes[1]
a = np.linspace(1.0, 6.0, 300)
bound = EX/a; true_tail = np.exp(-lam*a)
ax.plot(a, bound, color=C["red"], lw=2.4, label="Markov bound E[X]/a = 1/a")
ax.plot(a, true_tail, color=C["blue"], lw=2.4, label="true tail P(X >= a) = e^{-a}")
ax.fill_between(a, true_tail, bound, color=C["red"], alpha=0.12, label="slack (bound - truth)")
ax.scatter([a0],[EX/a0], color=C["red"], zorder=5); ax.scatter([a0],[np.exp(-a0)], color=C["blue"], zorder=5)
ax.set_title("The bound always sits above the true tail")
ax.set_xlabel("threshold a"); ax.set_ylabel("probability")
ax.set_ylim(0, 1.05); ax.legend(loc="upper right", fontsize=9)
fig.suptitle("Markov inequality: a loose but universal ceiling on the right tail", fontsize=14)
fig.tight_layout(rect=[0,0,1,0.95]); fig.savefig("../_assets/3-1-markov.png", dpi=150)
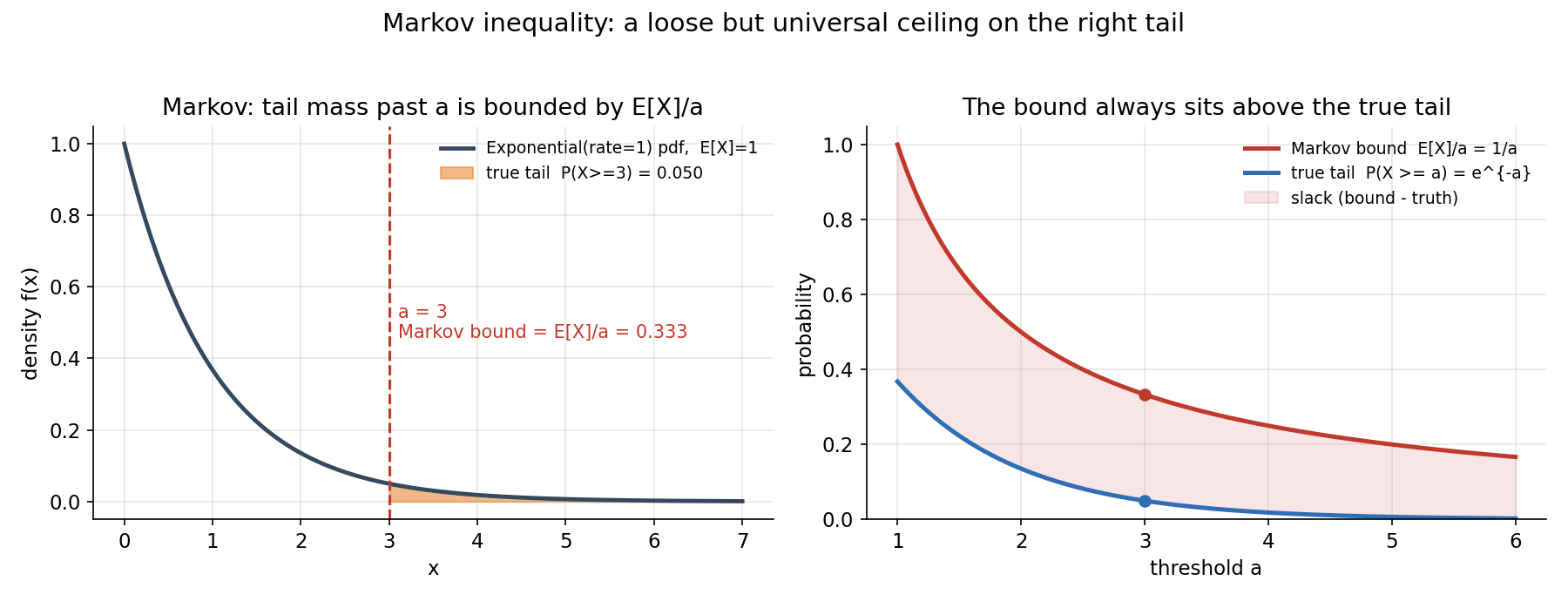
Figure 2 — Chebyshev: \(1-1/k^2\) মেঝে সব distribution-এ খাটে¶
প্রতিটি \(k\)-এর জন্য (এখানে \(k=1,2,3\)) Chebyshev নিশ্চয়তা দেয় যে mass-এর অন্তত \(1-1/k^2\) অংশ \(\mu\pm k\sigma\)-এর মধ্যে থাকবে — distribution যা-ই হোক। তিনটি খুবই ভিন্ন distribution (Normal, Uniform, Exponential, সবকটি \(\mu=0,\sigma=1\)-এ standardize করা) থেকে simulation-এ মাপা প্রকৃত অংশ (রঙিন bar) প্রতিটি ক্ষেত্রেই কালো হীরা-চিহ্নিত Chebyshev মেঝের উপরে — অর্থাৎ গ্যারান্টি লঙ্ঘিত হয় না, তবে বেশ রক্ষণশীল (বিশেষত \(k=1\)-এ মেঝে \(0\), যা সবসময়ই খাটে কিন্তু অর্থহীন)। এটাই §৩-এর বার্তা: Chebyshev কোনো distribution-আকৃতি না জেনেও একটি সর্বজনীন floor দেয়।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
C = {"blue":"#2f6db5","green":"#27ae60","purple":"#7d3c98"}
rng = np.random.default_rng(31)
N = 2_000_000
ks = np.array([1, 2, 3])
samples = {
"Normal": rng.normal(0, 1, N),
"Uniform": rng.uniform(-np.sqrt(3), np.sqrt(3), N), # var 1
"Exponential": rng.exponential(1.0, N) - 1.0, # mean 0, var 1
}
frac = {name: [] for name in samples}
for name, s in samples.items():
mu, sd = s.mean(), s.std(); z = np.abs(s - mu)/sd
for k in ks: frac[name].append(np.mean(z <= k))
cheb_floor = 1.0 - 1.0/ks**2
fig, ax = plt.subplots(figsize=(9.5, 5.0))
width = 0.2; xpos = np.arange(len(ks))
colors = {"Normal":C["blue"], "Uniform":C["green"], "Exponential":C["purple"]}
for i,(name,vals) in enumerate(frac.items()):
ax.bar(xpos+(i-1)*width, vals, width=width, color=colors[name], alpha=0.8,
edgecolor="white", label=f"actual: {name}")
ax.plot(xpos, cheb_floor, "D", color="black", ms=11, zorder=6, label="Chebyshev floor 1 - 1/k^2")
for xp, cf in zip(xpos, cheb_floor):
ax.hlines(cf, xp-0.36, xp+0.36, color="black", lw=2.0, zorder=5)
ax.text(xp, cf-0.07, f"{cf:.2f}", ha="center", fontsize=10, color="black")
ax.set_xticks(xpos); ax.set_xticklabels([f"k = {k}" for k in ks])
ax.set_ylabel("fraction of mass within k standard deviations"); ax.set_ylim(0, 1.08)
ax.set_title("Chebyshev: at least 1 - 1/k^2 of any distribution lies within k*sigma")
ax.legend(loc="lower right", fontsize=9)
fig.tight_layout(); fig.savefig("../_assets/3-1-chebyshev.png", dpi=150)
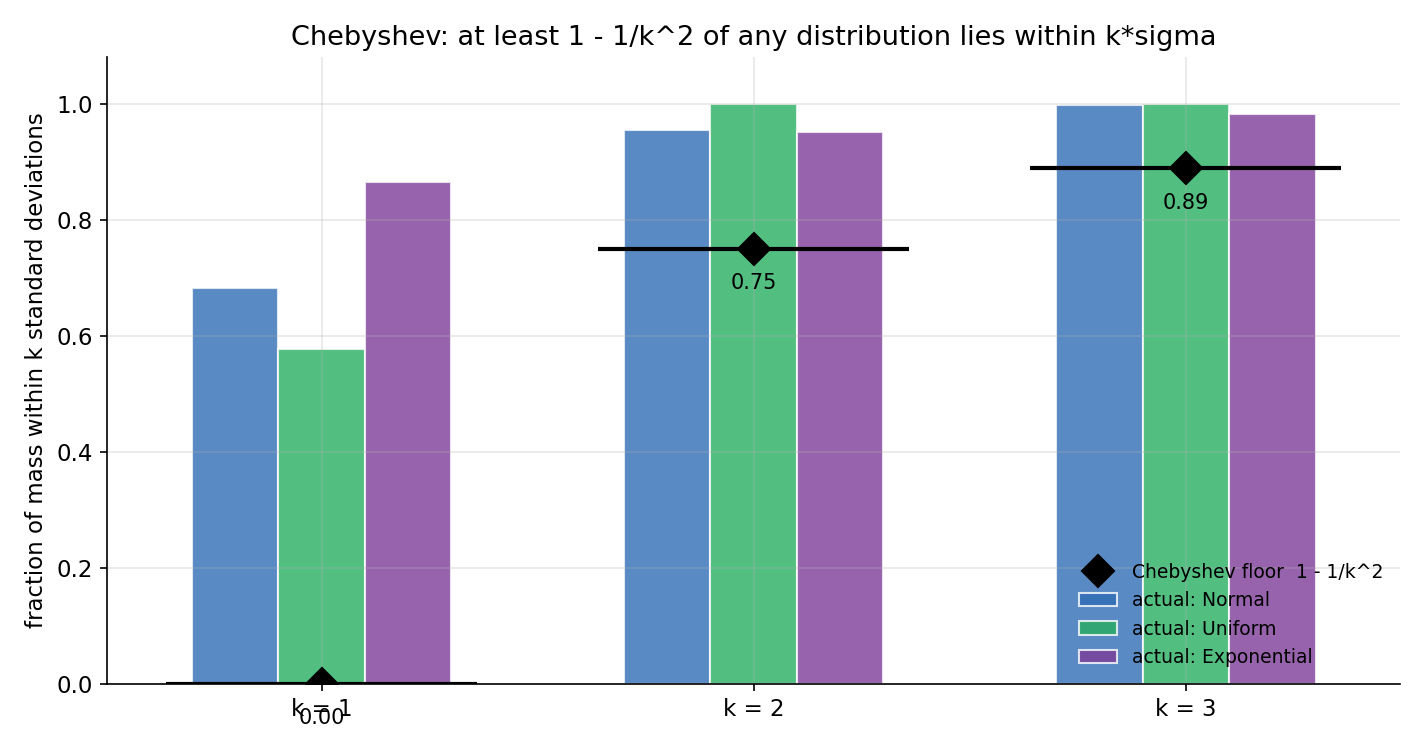
Figure 3 — Jensen: chord curve-এর উপরে, তাই \(g(\mathbb{E}X)\le\mathbb{E}[g(X)]\)¶
convex function \(g(x)=x^2\) (নীল)। একটি two-point random variable নিই: \(X=0.5\) বা \(X=4\), প্রতিটি probability \(0.5\)। দুই বিন্দু \((x_1,g(x_1))\) ও \((x_2,g(x_2))\) জুড়ে chord (লাল ড্যাশ) পুরোটাই curve-এর উপরে। \(x=\mathbb{E}[X]=2.25\)-এ: curve-এর মান \(g(\mathbb{E}X)=5.06\) (সবুজ বিন্দু) আর chord-এর মান \(\mathbb{E}[g(X)]=8.12\) (কমলা বিন্দু) — তাই \(g(\mathbb{E}X)\le\mathbb{E}[g(X)]\), আর তাদের পার্থক্যই "Jensen gap"। এই ছবিই §৪-এর Jensen's inequality-র জ্যামিতিক হৃদয়: convexity মানে "গড়ের ছবি \(\le\) ছবির গড়"।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
C = {"red":"#c0392b","green":"#27ae60","orange":"#e67e22","grey":"#34495e","navy":"#1f4e79"}
fig, ax = plt.subplots(figsize=(9.0, 5.2))
x = np.linspace(-1, 5, 400)
ax.plot(x, x**2, color=C["navy"], lw=2.6, label="convex g(x) = x^2")
x1, x2, p = 0.5, 4.0, 0.5
EX = p*x1 + (1-p)*x2 # 2.25
Eg = p*x1**2 + (1-p)*x2**2 # chord midpoint at E[X]
gEX = EX**2 # curve value at E[X]
ax.plot([x1, x2], [x1**2, x2**2], color=C["red"], lw=2.2, ls="--",
label="chord through (x1, g(x1)) and (x2, g(x2))")
ax.scatter([x1, x2], [x1**2, x2**2], color=C["red"], zorder=6)
ax.scatter([EX],[Eg], color=C["orange"], s=80, zorder=7)
ax.scatter([EX],[gEX], color=C["green"], s=80, zorder=7)
ax.vlines(EX, gEX, Eg, color=C["grey"], lw=1.6, ls=":"); ax.axvline(EX, color=C["grey"], lw=1.0, ls=":")
ax.annotate(f"E[g(X)] = {Eg:.2f} (on chord)", xy=(EX, Eg), xytext=(EX+0.25, Eg+0.6),
fontsize=10, color=C["orange"], arrowprops=dict(arrowstyle="->", color=C["orange"]))
ax.annotate(f"g(E[X]) = {gEX:.2f} (on curve)", xy=(EX, gEX), xytext=(EX+0.25, gEX-2.6),
fontsize=10, color=C["green"], arrowprops=dict(arrowstyle="->", color=C["green"]))
ax.text(EX, -1.4, "x = E[X]", ha="center", fontsize=10, color=C["grey"])
ax.text(3.1, 6.0, f"Jensen gap = E[g(X)] - g(E[X]) = {Eg-gEX:.2f}", fontsize=10, color=C["red"])
ax.set_title("Jensen (convex): the chord lies above the curve, so g(E[X]) <= E[g(X)]")
ax.set_xlabel("x"); ax.set_ylabel("g(x)"); ax.set_ylim(-2, 18); ax.legend(loc="upper left", fontsize=9)
fig.tight_layout(); fig.savefig("../_assets/3-1-jensen.png", dpi=150)
![convex parabola g(x)=x² (নীল) ও দুই বিন্দু (0.5, 0.25) এবং (4, 16) জুড়ে লাল ড্যাশ chord, যা পুরোটাই curve-এর উপরে। x=E[X]=2.25-এ সবুজ বিন্দু g(E[X])=5.06 curve-এ, কমলা বিন্দু E[g(X)]=8.12 chord-এ; খাড়া ফাঁকা Jensen gap=3.06। convexity-তে গড়ের ছবি ছবির গড়ের চেয়ে ছোট বা সমান।](../_assets/3-1-jensen.png)
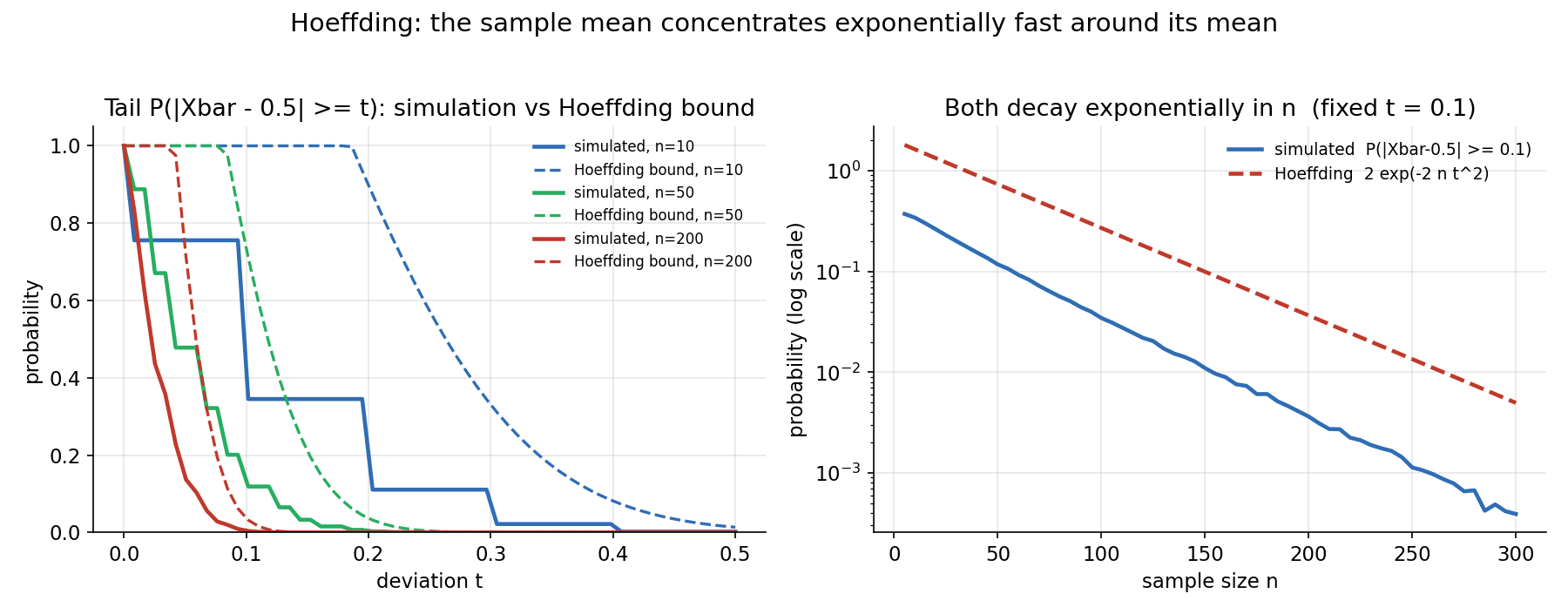
Figure 4 — Hoeffding: sample mean exponentially দ্রুত কেন্দ্রীভূত¶
একটি fair coin (\(p=0.5\)) \(n\) বার ছোঁড়া হয়; \(\bar X_n\) হলো heads-এর ভগ্নাংশ। বাঁ প্যানেলে deviation \(t\)-এর সাপেক্ষে সত্য tail \(P(\lvert\bar X_n-0.5\rvert\ge t)\) (নিরেট রেখা, simulation) ও Hoeffding bound \(2e^{-2nt^2}\) (ড্যাশ) তিনটি \(n\)-এর জন্য — \(n\) বাড়লে দুটোই দ্রুত নামে, আর bound সবসময় সত্যের উপরে। ডান প্যানেলে \(t=0.1\) স্থির রেখে \(n\) বাড়ানো হয় (log y-axis): সত্য tail ও Hoeffding bound দুটোই \(n\)-এর সাথে exponentially নামে (log-scale-এ প্রায় সরলরেখা)। এটাই §৫-এর concentration-এর মূল কথা: আরও data মানে \(\bar X_n\) আরও আঁটসাঁটভাবে \(\mu\)-র চারপাশে — এবং বিচ্যুতির probability জ্যামিতিক হারে নয়, exponential হারে শূন্যের দিকে যায়।
import matplotlib; matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
C = {"blue":"#2f6db5","green":"#27ae60","red":"#c0392b"}
rng = np.random.default_rng(314)
fig, axes = plt.subplots(1, 2, figsize=(12, 4.7))
TRIALS = 200_000
# Left: tail prob vs t, for a few n
ax = axes[0]
ts = np.linspace(0.0, 0.5, 60)
for n, c in zip([10, 50, 200], [C["blue"], C["green"], C["red"]]):
draws = rng.binomial(1, 0.5, size=(TRIALS, n)); xbar = draws.mean(axis=1)
dev = np.abs(xbar - 0.5)
emp = np.array([np.mean(dev >= t) for t in ts])
hoef = np.minimum(2*np.exp(-2*n*ts**2), 1.0)
ax.plot(ts, emp, color=c, lw=2.2, label=f"simulated, n={n}")
ax.plot(ts, hoef, color=c, lw=1.6, ls="--", label=f"Hoeffding bound, n={n}")
ax.set_title("Tail P(|Xbar - 0.5| >= t): simulation vs Hoeffding bound")
ax.set_xlabel("deviation t"); ax.set_ylabel("probability")
ax.set_ylim(0, 1.05); ax.legend(fontsize=8, loc="upper right")
# Right: fix t=0.1, watch both decay as n grows (log y)
ax = axes[1]
t_fix = 0.1; ns = np.arange(5, 305, 5); emp_curve, hoef_curve = [], []
for n in ns:
draws = rng.binomial(1, 0.5, size=(TRIALS, n)); dev = np.abs(draws.mean(axis=1) - 0.5)
emp_curve.append(max(np.mean(dev >= t_fix), 1.0/TRIALS))
hoef_curve.append(2*np.exp(-2*n*t_fix**2))
ax.plot(ns, emp_curve, color=C["blue"], lw=2.2, label=f"simulated P(|Xbar-0.5| >= {t_fix})")
ax.plot(ns, hoef_curve, color=C["red"], lw=2.2, ls="--", label="Hoeffding 2 exp(-2 n t^2)")
ax.set_yscale("log")
ax.set_title(f"Both decay exponentially in n (fixed t = {t_fix})")
ax.set_xlabel("sample size n"); ax.set_ylabel("probability (log scale)"); ax.legend(fontsize=9, loc="upper right")
fig.suptitle("Hoeffding: the sample mean concentrates exponentially fast around its mean", fontsize=14)
fig.tight_layout(rect=[0,0,1,0.95]); fig.savefig("../_assets/3-1-hoeffding.png", dpi=150)
চারটি ছবি একসাথে কী বলে। Markov ও Chebyshev (Figure 1–2) এক-দুটি moment থেকে একটি ঢিলা কিন্তু সর্বজনীন ছাদ দেয় — distribution যা-ই হোক। Jensen (Figure 3) convexity-র দিকনির্দেশী অসমতা দেয় (গড় ও function-এর বিনিময়)। Hoeffding (Figure 4) bounded random variable-এর যোগফল/গড়ের জন্য একটি exponentially আঁটসাঁট ছাদ দেয় — যেটা Chebyshev-এর polynomial (\(1/k^2\)) decay-কে বহুগুণ ছাপিয়ে যায়। এই "ঢিলা থেকে আঁটসাঁট"-এর যাত্রাই §৭-এর অনুশীলনী ও §৮-এর Law of Large Numbers-এর সেতু।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও সংক্ষিপ্ত hint। (★ সহজ, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং।) পূর্ণ সমাধান _solutions/03-01-probability-inequalities-solutions.md-এ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). Markov inequality শুধু nonnegative random variable-এ খাটে কেন? একটি random variable কল্পনা করুন যেটা ঋণাত্মক মান নিতে পারে এবং তাতে \(\mathbb{E}[X]/a\) "bound" কেন অর্থহীন বা ভুল হয়ে যেতে পারে দেখান। Hint: প্রমাণে \(X \ge a\cdot\mathbf{1}\{X\ge a\}\) ধাপটি কোথায় nonnegativity ব্যবহার করে? \(X\) ঋণাত্মক হলে কী ভাঙে?
প্রশ্ন ২ (★). Chebyshev inequality বলে \(\mu\pm 2\sigma\)-এর মধ্যে অন্তত \(75\%\) mass থাকে। কিন্তু Normal distribution-এ আসলে \(\approx 95\%\) থাকে (empirical rule, 2.4)। এই দুই সংখ্যা কি পরস্পরবিরোধী? কেন Chebyshev এত রক্ষণশীল? Hint: Chebyshev সব distribution-এর জন্য একটিই মেঝে দেয়; কোন distribution সেই মেঝে প্রায় ছুঁয়ে ফেলে?
প্রশ্ন ৩ (★★). "Jensen's inequality বলে \(\mathbb{E}[X^2]\ge(\mathbb{E}[X])^2\)" — এই বিশেষ ক্ষেত্রটি আসলে কোন পরিচিত রাশি অঋণাত্মক হওয়ার সমতুল্য? convex-এর বদলে \(g\) concave (যেমন \(\log\) বা \(\sqrt{\cdot}\)) হলে অসমতার দিক কী হয়? Hint: \(\mathbb{E}[X^2]-(\mathbb{E}[X])^2 = \mathrm{Var}(X)\) (2.5)। concave মানে \(-g\) convex।
প্রশ্ন ৪ (★★). Hoeffding bound \(2e^{-2nt^2}\)-এ \(n\) exponent-এ বসে, কিন্তু Chebyshev দিলে \(\bar X_n\)-এর tail bound যায় \(\sigma^2/(nt^2)\) — অর্থাৎ \(1/n\) হারে। দুটোর decay-হার তুলনা করুন: বড় \(n\)-এ কোনটা অনেক ছোট, এবং কেন এটা concentration inequality-কে এত শক্তিশালী করে? Hint: exponential বনাম polynomial decay; \(n=100, t=0.1\) বসিয়ে দুটো সংখ্যা মেলান।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★) [E1]. একটি শহরের গড় মাসিক আয় \(\mathbb{E}[X]=50\) (হাজার টাকা), আয় কখনো ঋণাত্মক নয়। Markov দিয়ে দেখান \(P(X\ge 200)\le \tfrac14\)। এই bound কেন সম্ভবত প্রকৃত ভগ্নাংশের তুলনায় অনেক বড়, এক বাক্যে বলুন। Hint: \(P(X\ge a)\le \mathbb{E}[X]/a\); এখানে \(a=200\)।
প্রশ্ন ৬ (★★) [E2]. একটি পরীক্ষায় নম্বরের \(\mu=70,\ \sigma=10\)। Chebyshev দিয়ে নিচের দুটি বের করুন: (ক) \(P(\lvert X-70\rvert\ge 20)\)-এর একটি ঊর্ধ্বসীমা; (খ) এমন একটি প্রতিসম পরিসর \([70-c,\,70+c]\) যাতে Chebyshev গ্যারান্টি দেয় অন্তত \(90\%\) শিক্ষার্থী পড়ে। Hint: (ক) \(k=20/\sigma=2\); (খ) \(1-1/k^2\ge 0.9 \Rightarrow k\ge\sqrt{10}\), তারপর \(c=k\sigma\)।
প্রশ্ন ৭ (★★) [E3]. \(X\)-এর মান সমান-সম্ভাব্যভাবে \(\{1,3\}\) (প্রতিটি \(0.5\))। \(g(x)=x^2\) নিয়ে \(g(\mathbb{E}[X])\) ও \(\mathbb{E}[g(X)]\) আলাদা গণনা করে Jensen যাচাই করুন, এবং Jensen gap বের করুন। এই gap কি \(\mathrm{Var}(X)\)-এর সমান? কেন (এই বিশেষ \(g\)-এ)? Hint: \(\mathbb{E}[X]=2\); \(\mathbb{E}[g(X)]-g(\mathbb{E}[X]) = \mathbb{E}[X^2]-(\mathbb{E}X)^2\)।
প্রশ্ন ৮ (★★) [E4]. একটি fair coin \(n=100\) বার ছোঁড়া হয়, \(\bar X_n\) heads-এর ভগ্নাংশ (\(\mathbb{E}[\bar X_n]=0.5\), প্রতিটি \(X_i\in[0,1]\))। Hoeffding দিয়ে \(P(\lvert\bar X_n-0.5\rvert\ge 0.1)\)-এর একটি ঊর্ধ্বসীমা বের করুন। একই tail-এর জন্য Chebyshev bound (\(\sigma^2=0.25\)) বের করে দুটো তুলনা করুন। Hint: Hoeffding (\(a_i=0,b_i=1\)): \(2\exp(-2n t^2)\) with \(n=100,t=0.1\). Chebyshev: \(\mathrm{Var}(\bar X_n)/t^2 = (0.25/100)/0.01\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). Markov থেকে Chebyshev উৎপাদন করুন: \(Y=(X-\mu)^2\) একটি nonnegative random variable — এতে threshold \(k^2\sigma^2\)-এ Markov প্রয়োগ করে \(P(\lvert X-\mu\rvert\ge k\sigma)\le 1/k^2\) পান। Hint: \(P(\lvert X-\mu\rvert\ge k\sigma) = P(Y\ge k^2\sigma^2)\); Markov-এ \(\mathbb{E}[Y]=\sigma^2\)।
প্রশ্ন ১০ (★★). \(g\) convex এবং differentiable ধরে Jensen প্রমাণ করুন supporting-line কৌশলে: \(\mu=\mathbb{E}[X]\)-এ tangent line \(\ell(x)=g(\mu)+g'(\mu)(x-\mu)\) পুরো curve-এর নিচে থাকে, অর্থাৎ \(g(X)\ge \ell(X)\); দুই পাশে expectation নিন। Hint: \(\mathbb{E}[\ell(X)] = g(\mu)+g'(\mu)(\mathbb{E}[X]-\mu) = g(\mu)\), কারণ \(\mathbb{E}[X]-\mu=0\)।
প্রশ্ন ১১ (★★★). Hoeffding-এর পথে একটি মূল ধাপ — Hoeffding's lemma — প্রমাণ করুন (সরলীকৃত): যদি \(X\in[a,b]\) এবং \(\mathbb{E}[X]=0\), তবে যেকোনো \(s>0\)-এর জন্য \(\mathbb{E}[e^{sX}]\le e^{s^2(b-a)^2/8}\)। তারপর এক বাক্যে বলুন এই lemma কীভাবে Chernoff-পদ্ধতির সাথে মিলে পূর্ণ Hoeffding inequality দেয়। Hint: convexity দিয়ে \(e^{sx}\le \frac{b-x}{b-a}e^{sa}+\frac{x-a}{b-a}e^{sb}\); expectation নিয়ে \(\psi(s)=\log\mathbb{E}[e^{sX}]\) ফাংশনে \(\psi(0)=\psi'(0)=0\) ও \(\psi''(s)\le (b-a)^2/4\) দেখান, তারপর Taylor।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে Exponential(rate=1) থেকে \(10^6\) নমুনা টানুন। threshold \(a\in\{2,3,4,5\}\)-এর প্রতিটির জন্য empirical \(P(X\ge a)\) মাপুন এবং Markov bound \(\mathbb{E}[X]/a=1/a\)-এর সাথে একটি টেবিলে তুলনা করুন। bound কি সবসময় বড়?
Hint: rng=np.random.default_rng(0); np.mean(samples>=a)।
প্রশ্ন ১৩ (★★). একটি ফাংশন chebyshev_check(sample, k) লিখুন যা empirical \(P(\lvert X-\bar x\rvert\ge k s)\) (\(s\) = sample std) ফেরত দেয়, এবং তা Chebyshev bound \(1/k^2\)-এর নিচে কিনা যাচাই করে। তিনটি ভিন্ন distribution (Normal, Uniform, Exponential) ও \(k=1.5,2,3\)-এ চালিয়ে দেখান bound কখনো লঙ্ঘিত হয় না।
Hint: Figure 2-এর গঠন অনুসরণ করুন; np.mean(np.abs(s-s.mean()) >= k*s.std())।
প্রশ্ন ১৪ (★★★) [E4]. fair coin-এর জন্য \(n\)-কে \(\{10,50,100,500,1000\}\)-এ পরিবর্তন করে প্রতিটির জন্য empirical \(P(\lvert\bar X_n-0.5\rvert\ge 0.05)\) (বড় TRIALS দিয়ে) মাপুন, এবং একই অক্ষে Hoeffding bound \(2e^{-2n(0.05)^2}\) আঁকুন (log y-axis)। দুটো কি \(n\)-এর সাথে exponentially নামে? bound কি সবসময় উপরে?
Hint: Figure 4-এর ডান প্যানেলের কোড পুনঃব্যবহার করুন; খুব ছোট empirical-এর জন্য log-plot-এ একটি floor (max(p, 1/TRIALS)) রাখুন।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Markov inequality (nonnegative \(X\), \(a>0\)): \(P(X\ge a)\le \dfrac{\mathbb{E}[X]}{a}\) — শুধু গড় থেকে tail-এর একটি সর্বজনীন কিন্তু ঢিলা ছাদ। সব probability inequality-র ভিত্তি-ইট।
- Chebyshev inequality (\(k>0\)): \(P(\lvert X-\mu\rvert\ge k\sigma)\le \dfrac{1}{k^2}\), সমতুল্যভাবে অন্তত \(1-1/k^2\) mass \(\mu\pm k\sigma\)-এর মধ্যে। মানে ও ভেদাঙ্ক থেকে, distribution-আকৃতি না জেনেও — Markov-কে \((X-\mu)^2\)-এ প্রয়োগ করেই পাওয়া যায়।
- Jensen's inequality: \(g\) convex হলে \(g(\mathbb{E}[X])\le \mathbb{E}[g(X)]\); concave হলে দিক উল্টো। জ্যামিতি: chord curve-এর উপরে। বিশেষ ক্ষেত্র \(\mathbb{E}[X^2]\ge(\mathbb{E}X)^2\) মানেই \(\mathrm{Var}(X)\ge0\)।
- Hoeffding inequality (independent \(X_i\in[a_i,b_i]\)): \(P\!\big(\lvert\bar X_n-\mathbb{E}[\bar X_n]\rvert\ge t\big)\le 2\exp\!\Big(\dfrac{-2n^2t^2}{\sum (b_i-a_i)^2}\Big)\) — bounded সমান-পরিসর হলে \(2e^{-2nt^2}\)। একটি exponentially আঁটসাঁট tail bound; Markov→Chernoff পদ্ধতি + Hoeffding's lemma থেকে আসে।
- concentration inequality হলো সেই inequality যা দেখায় random variable (বিশেষত sample mean) তার expectation-এর চারপাশে কতটা ঘনীভূত — Chebyshev ও Hoeffding দুটোই এই পরিবারের, কিন্তু Hoeffding-এর decay (\(e^{-2nt^2}\)) Chebyshev-এর (\(1/(nt^2)\)) চেয়ে নাটকীয়ভাবে দ্রুত।
inequality-গুলোর দ্রুত তুলনা:
| Inequality | কী লাগে (input) | ছাদ (bound) | decay-হার | আঁটসাঁটতা |
|---|---|---|---|---|
| Markov | \(X\ge0\), mean | \(\mathbb{E}[X]/a\) | — | সবচেয়ে ঢিলা, সর্বজনীন |
| Chebyshev | mean, variance | \(1/k^2\) | polynomial (\(1/n\) via \(\bar X_n\)) | মাঝারি |
| Jensen | \(g\)-এর convexity | দিকনির্দেশী (bound নয়, সম্পর্ক) | — | সমতা \(g\) রৈখিক/অবিচল হলে |
| Hoeffding | bounded, independent | \(2e^{-2nt^2}\) | exponential | সবচেয়ে আঁটসাঁট |
পূর্ববর্তী সংযোগ (← 2.5): এই পুরো অধ্যায় দাঁড়িয়ে আছে 2.5-এর expectation (\(\mu\)) ও variance (\(\sigma^2\))-এর উপর। Markov শুধু \(\mathbb{E}[X]\) ব্যবহার করে; Chebyshev \((X-\mu)^2\)-এর expectation অর্থাৎ variance ব্যবহার করে; Jensen-এর \(\mathbb{E}[X^2]\ge(\mathbb{E}X)^2\) ক্ষেত্রটি সরাসরি 2.5-এর গণনা-সূত্র \(\mathrm{Var}=\mathbb{E}[X^2]-(\mathbb{E}X)^2\); আর Hoeffding-এ \(\bar X_n\)-এর \(\mathbb{E}\) ও bounded-ness (\(X_i\in[a_i,b_i]\)) লাগে। convexity ও tangent-line যুক্তি 0.3-এর derivative থেকে এসেছে।
পরবর্তী সংযোগ (→ 3.3 — Law of Large Numbers): এই inequality-গুলোই LLN-এর প্রমাণযন্ত্র। Weak Law of Large Numbers বলে \(\bar X_n \xrightarrow{P} \mu\) — অর্থাৎ যেকোনো \(\varepsilon>0\)-এর জন্য \(P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\to0\)। এর সরলতম প্রমাণ ঠিক Chebyshev: যেহেতু \(\mathrm{Var}(\bar X_n)=\sigma^2/n\), তাই $$ P(\lvert\bar X_n-\mu\rvert\ge\varepsilon)\le \frac{\mathrm{Var}(\bar X_n)}{\varepsilon^2}=\frac{\sigma^2}{n\varepsilon^2}\;\xrightarrow[n\to\infty]{}\;0. $$ আর Hoeffding একই tail-কে exponentially ছোট bound দেয় (\(2e^{-2n\varepsilon^2}\)), যা শুধু "শূন্যে যায়" নয়, "কত দ্রুত যায়" তা-ও বলে — এটাই finite-sample / non-asymptotic statistics-এর ভিত্তি (Part IV–VI: confidence interval, generalization bound, PAC learning)। অর্থাৎ আজকের ঢিলা-থেকে-আঁটসাঁট ছাদগুলোই পরের অধ্যায়ে "data বাড়লে গড় সত্যে স্থির হয়" — এই কেন্দ্রীয় প্রতিজ্ঞাকে প্রমাণ করে দেয়।
source pointer: এই অধ্যায়ের মূল উৎস Wasserman, All of Statistics — Ch. 4 (Inequalities) — Markov, Chebyshev, Hoeffding ও Cauchy–Schwarz/Jensen-এর সংক্ষিপ্ত, statistics-অভিমুখী উপস্থাপনা। intuition ও concentration-এর আধুনিক দৃষ্টিভঙ্গি Fernández-Granda, Probability and Statistics for Data Science (concentration ও tail bound অধ্যায়)। Hoeffding's lemma ও Chernoff পদ্ধতির পূর্ণ rigorous রূপ এবং sub-Gaussian তত্ত্ব আসবে measure-theoretic ও high-dimensional অংশে (Part VII এবং Part VI-এর learning-theory অধ্যায়)।