3.5 — Random Processes; Poisson & Gaussian Processes (দৈব প্রক্রিয়া)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — একটিমাত্র random variable নয়, সময় বরাবর গোটা একটা random "পথ"¶
১.১ এতদিন যা দেখেছি — একটিমাত্র random snapshot¶
এ পর্যন্ত পুরো Part II ও Part III-জুড়ে আমাদের মৌলিক বস্তুটি ছিল একটি random variable (দৈব চলক) — প্রতীকে \(X\) — অথবা বড়জোর একটি গুচ্ছ random variable একসাথে, \(X_1, X_2, \dots, X_n\) (2.6-এ joint distribution হিসেবে দেখা)। মনে করিয়ে দিই প্রতীকগুলো:
- \(X\) — একটি random variable, অর্থাৎ একটি দৈব পরীক্ষার ফলকে একটি সংখ্যায় রূপান্তরকারী রাশি (যেমন একটিবার ছক্কা ছুড়ে পাওয়া মান, বা একজন মানুষের উচ্চতা)।
- \(X_1, \dots, X_n\) — এমন \(n\)টি random variable একসাথে, সাধারণত একই পরীক্ষার \(n\)বার পুনরাবৃত্তি (যেমন \(n\)বার ছক্কা)।
লক্ষ করুন এই পুরো ছবিতে সময়ের কোনো ভূমিকা নেই। ছক্কা একবার ছুড়ি, একটা সংখ্যা পাই — গল্প শেষ। যেন একটিমাত্র snapshot (স্থিরচিত্র) নিলাম: এক মুহূর্তের একটি দৈব মান। এমনকি \(X_1,\dots,X_n\)-ও মূলত \(n\)টি বিচ্ছিন্ন snapshot, যাদের মধ্যে স্বাভাবিক কোনো ক্রম বা "আগে-পরে" সম্পর্ক ধরে নিই না (i.i.d. ধরলে তো তারা একে অপরের থেকে সম্পূর্ণ স্বাধীন)।
কিন্তু বাস্তব পৃথিবীর বহু ঘটনা ঠিক এমন নয় — সেখানে দৈবতা সময় বরাবর গড়িয়ে চলে।
১.২ insight — হঠাৎ করেই, আমাদের একটা গোটা পথ দরকার¶
তিনটি বাস্তব দৃশ্য ভাবি, যেখানে একটিমাত্র সংখ্যা যথেষ্ট নয়:
- শেয়ারের দাম (stock price)। একটা কোম্পানির শেয়ারের দাম আজ সকাল ৯টায় একটা মান, ৯:০১-এ আরেকটা, ৯:০২-এ আরেকটা — সারাদিন ধরে দৈবভাবে ওঠানামা করে একটা আঁকাবাঁকা রেখা তৈরি করে। আমরা শুধু "দুপুর ১২টায় দাম কত" জানতে চাই না; পুরো দিনের গতিপথ-টাই আমাদের আগ্রহের বিষয় (কখন উঠল, কখন পড়ল, কতটা দুলল)।
- সারিতে অপেক্ষমাণ গ্রাহক (queue)। একটা ব্যাংকের কাউন্টারে এই মুহূর্তে \(3\) জন দাঁড়িয়ে, দু-মিনিট পরে হয়তো \(5\) জন, তারপর \(2\) জন — সংখ্যাটা সময়ের সাথে দৈবভাবে বদলায়। কখন নতুন গ্রাহক আসবে, কখন একজন সেবা পেয়ে বেরিয়ে যাবে — সবই দৈব, এবং পুরো দিনের সারির দৈর্ঘ্যের ইতিহাসটাই একটা random গতিপথ।
- সেন্সরের গোলমাল (sensor noise)। একটা তাপমাত্রা-সেন্সর প্রতি সেকেন্ডে একটা মান পাঠায়, কিন্তু প্রতিটি মানের সাথে সামান্য দৈব ত্রুটি (noise) মিশে থাকে। তাই রিডিং-গুলো সময় বরাবর একটা দৈবভাবে কাঁপতে-থাকা রেখা।
এই তিনটিরই সাধারণ বৈশিষ্ট্য: প্রতিটি সময়-বিন্দুতে একটি করে random variable আছে, আর আমরা চাই এই সবগুলোকে একসাথে, একটি গোটা বস্তু হিসেবে ধরতে। অর্থাৎ আমাদের দরকার এমন একটা ধারণা যা একটিমাত্র random variable নয়, বরং সময় (বা অন্য কোনো সূচক) বরাবর সাজানো random variable-এর একটি গোটা পরিবার। এই পরিবারটিকেই বলে random process বা stochastic process (দৈব প্রক্রিয়া) — এবং এটাই এই অধ্যায়ের কেন্দ্রীয় বস্তু।
এক বাক্যে insight-টা ধরে রাখুন:
একটি random variable আমাদের দেয় একটিমাত্র দৈব সংখ্যা; একটি random process আমাদের দেয় একটি গোটা দৈব পথ (function) — সময়ের প্রতিটি বিন্দুতে একটি করে দৈব মান, সব একসাথে।
১.৩ একটা ছবি — random variable থেকে random process-এ লাফ¶
পার্থক্যটা মনে গাঁথতে একটা সরল চিত্র ভাবুন। একটি random variable \(X\)-এর একটি বাস্তবায়ন (realization) মানে অক্ষরেখার ওপর একটিমাত্র বিন্দু — যেমন \(X=4.2\)। বারবার পরীক্ষা চালালে এই বিন্দুটা একেকবার একেক জায়গায় পড়ে, আর তার ছড়িয়ে-পড়ার ধরনটাই \(X\)-এর distribution।
কিন্তু একটি random process \(\{X_t\}\)-এর একটি বাস্তবায়ন মানে একটিমাত্র বিন্দু নয় — মানে একটি গোটা বক্ররেখা (curve): অনুভূমিক অক্ষে সময় \(t\), উল্লম্ব অক্ষে সেই সময়ের মান \(X_t\)। একবার পুরো পরীক্ষা চালালে (যেমন একটা গোটা ট্রেডিং-দিন দেখলে) একটা গোটা আঁকাবাঁকা রেখা পাই। আরেকবার চালালে (আরেকটা দিন) — সম্পূর্ণ আলাদা আরেকটা রেখা। এই প্রতিটি গোটা রেখাকে বলে process-এর একটি sample path (নমুনা-পথ)।
তাই ধারণাগত লাফটা এই: random variable-এ দৈবতা একটি সংখ্যায় বাস করে; random process-এ দৈবতা একটি গোটা function-এ (পথে) বাস করে। এই একটিমাত্র উপলব্ধি পুরো অধ্যায়ের চাবিকাঠি — বাকি সবকিছু (mean function, autocovariance, Poisson ও Gaussian process, stationarity) এই ধারণাটিকে নিখুঁত ও পরিমাপযোগ্য করার চেষ্টা মাত্র।
১.৪ এই অধ্যায় কোথা থেকে আসছে, কোথায় যাচ্ছে¶
এই অধ্যায়টা শূন্য থেকে আসছে না — এর দুটো সরাসরি স্তম্ভ আছে:
- 2.6 (joint distributions ও covariance) থেকে। যেহেতু একটি process মানে অনেকগুলো random variable একসাথে, তাদের পারস্পরিক সম্পর্ক বোঝাটা কেন্দ্রীয়। বিশেষত দুটো ভিন্ন সময়ের মান \(X_s\) ও \(X_t\) কতটা একসাথে চলে — তা মাপতে আমরা সরাসরি 2.6-এর covariance \(\mathrm{Cov}(X_s,X_t)\) ব্যবহার করব (§২-এ একে autocovariance বলব)।
- 3.4 (CLT) থেকে। আমাদের প্রথম মুখ্য উদাহরণ random walk — i.i.d. পদের যোগফল \(S_n=\sum_{i=1}^n X_i\)। যোগফলের আচরণ (বিশেষত বড় \(n\)-এ Normal হয়ে আসা) ঠিক CLT-এরই বিষয়, তাই 3.4-এর ফল এখানে সরাসরি কাজে লাগবে।
আর এই অধ্যায় পরের অধ্যায়ের (3.6 — Markov chains ও MCMC) ভিত্তি। Markov chain হলো একধরনের বিশেষ random process যেখানে "ভবিষ্যৎ কেবল বর্তমানের ওপর নির্ভর করে, অতীত ভুলে যায়" — সেই বিশেষ গঠন বোঝার আগে এখানে আমরা random process-এর সাধারণ ভাষা ও কাঠামোটাই দাঁড় করাব।
পুরো অধ্যায় চারটি ধাপে এগোবে:
- §২ — মূল সংজ্ঞা: stochastic process, index set, state space, sample path; mean function \(m(t)\) ও autocovariance \(C(s,t)\); (weak/strict) stationarity; এবং চার মৌলিক উদাহরণের (i.i.d. sequence, random walk, Poisson process, Gaussian process) আনুষ্ঠানিক সংজ্ঞা।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ (E1 random walk, E2 Poisson process, E3 Gaussian process, E4 stationarity-যাচাই), সংখ্যাসহ।
- §৪–৫ — process-এর ধর্ম, Poisson ও Gaussian process-এর গভীরতর বিশ্লেষণ, ও stationarity-র আরও প্রয়োগ।
- §৬–৮ — চিত্র, common ভুল-ধারণা, ও অনুশীলন।
এক বাক্যে কেন এটা গুরুত্বপূর্ণ। Static random variable-এর জগৎ থেকে এই অধ্যায়েই আমরা প্রথম সময়-নির্ভর দৈবতা-র জগতে পা রাখছি — যেখানে শেয়ারের দাম, সারির দৈর্ঘ্য, সংকেতের গোলমাল, এমনকি (3.6-এ) Markov chain ও MCMC বাস করে। ভাষাটা একবার তৈরি হলে, এই সবগুলো একই কাঠামোর বিশেষ রূপ হয়ে ধরা দেয়।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে আমরা ধাপে ধাপে গড়ব: প্রথমে stochastic process-এর সংজ্ঞা ও তার সঙ্গী তিনটি ধারণা — index set, state space, sample path (§২.১)। তারপর একটি process-কে সংখ্যায় ধরার দুটি মূল হাতিয়ার — mean function ও autocovariance function (§২.২)। এরপর stationarity (§২.৩)। শেষে চার মৌলিক উদাহরণের আনুষ্ঠানিক সংজ্ঞা (§২.৪)। প্রতিটি প্রতীক প্রথম ব্যবহারেই খুলব।
২.১ Stochastic process, index set, state space, sample path¶
আগে অন্তর্দৃষ্টিটা সংখ্যায় না গিয়ে: একটি stochastic process মানে "একটা সূচকের প্রতিটি মানের জন্য একটি করে random variable"। সেই সূচকটাকে আমরা সাধারণত সময় ভাবি, কিন্তু এটা স্থানও হতে পারে (যেমন একটা মাঠের প্রতিটি বিন্দুতে তাপমাত্রা)। এবার আনুষ্ঠানিকভাবে।
সংজ্ঞা (stochastic process / random process — দৈব প্রক্রিয়া)। একটি stochastic process হলো random variable-এর একটি পরিবার (collection) $$ {X_t}_{t\in T}, $$ যেখানে সূচক \(t\) একটি নির্দিষ্ট সেট \(T\)-এর ওপর দিয়ে চলে, এবং প্রতিটি \(t\in T\)-এর জন্য \(X_t\) একটি random variable (সবগুলো একই probability space-এ সংজ্ঞায়িত)।
প্রতিটি প্রতীক খুলে বলি:
- \(\{X_t\}_{t\in T}\) — গোটা process-টিকে বোঝানো প্রতীক; পড়ুন "\(T\)-এর প্রতিটি \(t\)-এর জন্য একটি করে \(X_t\) নিয়ে গঠিত পরিবার"। (কখনো একে \(\{X(t)\}\) বা \(X_t\) লেখা হয়; একই জিনিস।)
- \(t\) — index (সূচক)। বেশিরভাগ সময় এটি সময় বোঝায়, তাই "\(t\)"; কিন্তু আনুষ্ঠানিকভাবে এটা শুধু একটা label, যা \(T\) থেকে আসে।
- \(T\) — index set (সূচক-সেট): যেসব মান \(t\) নিতে পারে তাদের সেট। এটাই process-এর "সময়-অক্ষ"।
- \(X_t\) — process-টির সময় \(t\)-এ মান; এটি একটি random variable (প্রতিটি স্থির \(t\)-এ একটি দৈব সংখ্যা)।
Index set \(T\) — discrete না continuous। \(T\) কেমন, তার ওপর process-এর চরিত্র অনেকটা নির্ভর করে। দুটো প্রধান ধরন:
- Discrete-time (বিচ্ছিন্ন সময়): \(T=\{0,1,2,\dots\}\) (বা \(\{1,2,\dots\}\), বা পূর্ণসংখ্যা)। তখন process একটি ক্রম (sequence): \(X_0, X_1, X_2, \dots\)। সূচক প্রায়ই \(n\) লেখা হয় (\(t\)-এর বদলে), তাই \(\{X_n\}_{n\ge 0}\)। উদাহরণ: প্রতিদিনের শেয়ার-বন্ধের দাম, \(n\)তম পদক্ষেপে random walk-এর অবস্থান।
- Continuous-time (অবিচ্ছিন্ন সময়): \(T=[0,\infty)\) (বা \([0,T_{\max}]\), বা সমস্ত বাস্তব সংখ্যা)। তখন প্রতিটি বাস্তব মুহূর্তে একটি মান আছে। উদাহরণ: যেকোনো মুহূর্তে একটা সেন্সরের রিডিং, যেকোনো মুহূর্ত পর্যন্ত মোট আগত গ্রাহক-সংখ্যা।
State space (অবস্থা-পরিসর)। যেমন index set বলে \(t\) কোথা থেকে আসে, তেমনি state space \(S\) বলে \(X_t\)-এর মান কোথা থেকে আসে — অর্থাৎ process কোন কোন মান নিতে পারে। এটিও discrete হতে পারে (যেমন \(S=\{0,1,2,\dots\}\) — সারিতে গ্রাহক-সংখ্যা, বা মোট গণনা) বা continuous (যেমন \(S=\mathbb{R}\) — শেয়ারের দাম, তাপমাত্রা)। সংক্ষেপে: index set = "কখন", state space = "কী মান"।
Sample path (নমুনা-পথ) — সবচেয়ে গুরুত্বপূর্ণ insight (অন্তর্দৃষ্টি)। এবার §১.৩-এর ছবিটা আনুষ্ঠানিক করি। ধরুন আমরা একবার পুরো দৈব পরীক্ষাটা চালালাম (যেমন একটা গোটা দিন শেয়ার-দাম দেখলাম)। তখন প্রতিটি \(t\in T\)-এর জন্য \(X_t\) একটি নির্দিষ্ট সংখ্যায় থিতু হয়। এই সব মান একসাথে নিলে \(t\)-এর একটি function তৈরি হয়:
অর্থাৎ একটি গোটা গতিপথ। এই function-কেই বলে process-এর একটি sample path (বা realization, trajectory)। মূল কথা:
একটি random variable-এর একটি বাস্তবায়ন = একটি সংখ্যা; একটি random process-এর একটি বাস্তবায়ন = একটি গোটা function (sample path)।
তাই একটি process-কে দুভাবে দেখা যায়, আর দুটোই দরকারি: (ক) প্রতিটি স্থির \(t\)-এ এটি একটি random variable \(X_t\) (উল্লম্বভাবে কাটা — "এই মুহূর্তে মান কেমন ছড়ায়"); (খ) গোটা \(t\) বরাবর এটি একটি random function — তার একেকটি নমুনা একেকটি sample path (অনুভূমিকভাবে দেখা — "একটা গোটা গতিপথ কেমন দেখায়")। এই দ্বৈত দৃষ্টিভঙ্গি গোটা অধ্যায়জুড়ে কাজে লাগবে।
২.২ একটি process-কে সংখ্যায় ধরা — mean function ও autocovariance function¶
একটি গোটা random function ভয়ংকর জটিল বস্তু (অসংখ্য random variable একসাথে)। ভাগ্যিস, একে পুরোপুরি না জেনেও তার দুটো সবচেয়ে দরকারি বৈশিষ্ট্য গুটিকয়েক সংখ্যায় ধরা যায়: প্রতিটি সময়ে এর গড় কোথায়, আর দুটো সময়ের মান কতটা একসাথে চলে। এই দুটোই যথাক্রমে mean function ও autocovariance function।
সংজ্ঞা (mean function — গড়-অপেক্ষক)। একটি process \(\{X_t\}_{t\in T}\)-এর mean function হলো $$ m(t) \;=\; \mathbb{E}[X_t], \qquad t\in T. $$
প্রতিটি প্রতীক:
- \(m(t)\) — process-টির সময় \(t\)-এ গড় মান; এটি \(t\)-এর একটি সাধারণ (non-random) function, কারণ গড় নেওয়ার পর দৈবতা মুছে যায়।
- \(\mathbb{E}[X_t]\) — random variable \(X_t\)-এর expectation (প্রত্যাশা, 2.5)। প্রতিটি স্থির \(t\)-এ এটি একটি সংখ্যা।
স্বজ্ঞা: mean function হলো process-এর "কেন্দ্রীয় প্রবণতা" সময় বরাবর — যদি বহুবার পুরো পরীক্ষা চালিয়ে সব sample path পাশাপাশি রেখে প্রতিটি সময় \(t\)-এ গড় করি, সেই গড়-রেখাটাই \(m(t)\)। শেয়ার-দামের ক্ষেত্রে এটা হতে পারে দিনের প্রত্যাশিত প্রবণতা; অনেক process-এ এটা ধ্রুবক (যেমন নিচে random walk-এ \(m(n)=0\))।
কিন্তু \(m(t)\) একা যথেষ্ট নয়। দুটো process-এর mean function এক হতে পারে, অথচ একটা মসৃণভাবে গড়ায় আর আরেকটা বুনোভাবে লাফায় — পার্থক্যটা থাকে বিভিন্ন সময়ের মানগুলো একে অপরের সাথে কতটা বাঁধা তাতে। এটাই মাপে autocovariance।
সংজ্ঞা (autocovariance function — স্ব-সহভেদাঙ্ক অপেক্ষক)। একটি process \(\{X_t\}_{t\in T}\)-এর autocovariance function হলো দুটি সময়-বিন্দুর function: $$ C(s,t) \;=\; \mathrm{Cov}(X_s, X_t) \;=\; \mathbb{E}!\big[(X_s - m(s))(X_t - m(t))\big], \qquad s,t\in T. $$
প্রতিটি প্রতীক:
- \(C(s,t)\) — সময় \(s\) ও সময় \(t\)-এর মানদুটো কতটা একসাথে ওঠানামা করে তার মাপ; দুটো সময়ের function (non-random সংখ্যা প্রতিটি \((s,t)\)-এ)।
- \(s, t\) — দুটি (সম্ভবত ভিন্ন) সময়-বিন্দু, দুটোই \(T\) থেকে।
- \(\mathrm{Cov}(X_s,X_t)\) — random variable \(X_s\) ও \(X_t\)-এর covariance, ঠিক 2.6-এর সংজ্ঞা।
- \(m(s)=\mathbb{E}[X_s]\), \(m(t)=\mathbb{E}[X_t]\) — যথাক্রমে \(s\) ও \(t\)-এ mean function (উপরে সংজ্ঞায়িত)।
দুটো জরুরি লক্ষণীয় দিক, যা পরে বারবার লাগবে:
- স্ব-সহভেদাঙ্ক ("auto") কেন? সাধারণ covariance দুটো আলাদা random variable \(X\) ও \(Y\)-এর মধ্যে। এখানে \(X_s\) ও \(X_t\) আসলে একই process-এর দুই সময়ের মান — তাই process নিজের সাথেই নিজের covariance, এজন্য "auto" (স্ব-)। এটাই বলে process-এর "স্মৃতি": অতীতের মান ভবিষ্যতের মানের সাথে কতটা সম্পর্কিত।
- \(s=t\) হলে variance। সংজ্ঞায় \(s=t\) বসালে \(C(t,t)=\mathrm{Cov}(X_t,X_t)=\mathrm{Var}(X_t)\) — অর্থাৎ autocovariance-এর "কর্ণ" (diagonal) দিলে প্রতিটি সময়ে process-এর variance (ছড়ানোর মাপ)। তাই একটিমাত্র function \(C(s,t)\) প্রতিটি সময়ের variance এবং প্রতিটি জোড়া সময়ের সম্পর্ক — দুটোই ধরে রাখে।
একসাথে: mean function বলে process গড়ে কোথায়; autocovariance বলে কতটা ছড়ায় ও কতটা স্মৃতি ধরে রাখে। এই দুটোই পরে stationarity ও Gaussian process-এর সংজ্ঞার ভিত্তি।
পরিভাষাগত নোট (autocorrelation)। autocovariance-কে প্রতিটি সময়ের standard deviation দিয়ে ভাগ করে \(-1\) থেকে \(+1\)-এ এনে normalize করলে পাওয়া যায় autocorrelation — ঠিক যেমন 2.6-এ covariance থেকে correlation এসেছিল। এর সংজ্ঞা ও ব্যবহার §৪-এ; এখানে আমরা autocovariance-ই কেন্দ্রীয় রাখছি।
২.৩ Stationarity — যখন "নিয়মকানুন" সময়ের সাথে বদলায় না¶
বহু গুরুত্বপূর্ণ process-এর একটি বিশেষ সরলকারী ধর্ম আছে: তাদের পরিসংখ্যানগত আচরণ সময়ের সাথে বদলায় না। অর্থাৎ আজ যে নিয়মে দৈবতা চলছে, কাল-পরশুও ঠিক সেই নিয়মে চলবে — শুধু সময়-অক্ষে সরে গিয়ে দেখলে কোনো পার্থক্য নেই। এই ধর্মকে বলে stationarity (স্থিতিশীলতা)। এর দুটো রূপ — একটি কড়া, একটি শিথিল।
সংজ্ঞা (strict / strong stationarity — কঠোর স্থিতিশীলতা)। একটি process \(\{X_t\}\) strictly stationary যদি যেকোনো সময়-বিন্দু-গুচ্ছ \(t_1,\dots,t_k\) এবং যেকোনো সরণ (shift) \(h\)-এর জন্য, \((X_{t_1},\dots,X_{t_k})\)-এর joint distribution আর \((X_{t_1+h},\dots,X_{t_k+h})\)-এর joint distribution একদম এক হয়।
কথায়: process-এর গোটা সম্ভাব্যতা-আচরণ সময়-সরণে অপরিবর্তিত — যেকোনো "জানালা" দিয়ে দেখা দৃশ্য তার অবস্থানের ওপর নির্ভর করে না, শুধু জানালার আকার ও ভেতরের আপেক্ষিক ব্যবধানের ওপর নির্ভর করে। এটি একটি খুব শক্তিশালী শর্ত (পুরো joint distribution নিয়ে কথা বলে), তাই বাস্তবে প্রায়ই এর একটি দুর্বল, কিন্তু অনেক বেশি ব্যবহারিক সংস্করণ ব্যবহার করা হয় — যা কেবল প্রথম দুটো moment (mean ও autocovariance) নিয়ে কথা বলে।
সংজ্ঞা (weak / wide-sense stationarity — দুর্বল বা প্রসারিত-অর্থে স্থিতিশীলতা)। একটি process \(\{X_t\}\) weakly stationary (সংক্ষেপে WSS) যদি দুটো শর্ত মেনে চলে: 1. mean function ধ্রুবক: \(m(t)=\mathbb{E}[X_t]=\mu\) প্রতিটি \(t\)-এর জন্য একই (সময়-নিরপেক্ষ একটি সংখ্যা \(\mu\)); 2. autocovariance কেবল ব্যবধানের ওপর নির্ভর করে: \(C(s,t)\) কেবল পার্থক্য \(t-s\)-এর ওপর নির্ভর করে, \(s\) ও \(t\)-এর আলাদা মানের ওপর নয়। অর্থাৎ একটি function \(\gamma\) আছে যেন $$ C(s,t) \;=\; \gamma(t-s) \qquad \text{প্রতিটি } s,t. $$
প্রতিটি প্রতীক/শর্ত খুলে:
- \(\mu\) — process-এর সাধারণ (ধ্রুব) গড়; WSS-এ mean function কোনো নির্দিষ্ট সময়ে ওঠে-নামে না, সর্বত্র সমান।
- শর্ত ২-এর অর্থ: \(X_s\) ও \(X_t\)-এর সম্পর্ক কেবল তারা কত দূরে (ব্যবধান \(\tau=t-s\)) তার ওপর নির্ভর করে, তারা কোথায় (\(s\) সকালে না বিকেলে) তার ওপর নয়। তাই দুই-চলকের \(C(s,t)\) আসলে এক-চলকের \(\gamma(\tau)\)-তে গুটিয়ে যায়, যেখানে \(\tau=t-s\) হলো lag (ব্যবধান)।
স্বজ্ঞা: weak stationarity বলে process-এর "গড় উচ্চতা" ও "ছড়ানো-ও-স্মৃতির গঠন" সময়ের সাথে স্থির — শুধু সময়ের ব্যবধানটাই গুরুত্বপূর্ণ, পরম সময় নয়। (নাম দুটো মনে রাখুন: strict = পুরো distribution shift-invariant; weak = কেবল mean ও autocovariance shift-invariant। strict হলে — variance সসীম থাকলে — সবসময় weak-ও হয়; উল্টোটা সাধারণত নয়। এই সম্পর্ক ও কেন weak-ই বাস্তবে যথেষ্ট, তা §৪–৫-এ।)
একটি process stationary কি না যাচাই করার ব্যবহারিক রেসিপি তাই দাঁড়ায়: (১) \(m(t)\) বের করো — তা কি \(t\)-নিরপেক্ষ ধ্রুবক? (২) \(C(s,t)\) বের করো — তা কি কেবল \(t-s\)-এর ওপর নির্ভর করে? দুটোই "হ্যাঁ" হলে weakly stationary। ঠিক এই রেসিপিই §৩.৪-এর E4-এ সংখ্যাসহ চালাব।
২.৪ চার মৌলিক উদাহরণের সংজ্ঞা¶
এবার এই অধ্যায়ের চারটি দৌড়-উদাহরণের (running example) আনুষ্ঠানিক সংজ্ঞা দিই। §৩-এ এদের প্রত্যেকটি সংখ্যাসহ বিশ্লেষণ করব।
(ক) i.i.d. sequence (স্বাধীন-সমবণ্টিত ক্রম) — সবচেয়ে সরল process। ধরা যাক \(X_1, X_2, X_3, \dots\) একটি i.i.d. (independent and identically distributed — স্বাধীন ও অভিন্নভাবে বণ্টিত) ক্রম, প্রত্যেকের একই distribution, mean \(\mu\) ও variance \(\sigma^2\)। এটিকে discrete-time process \(\{X_n\}_{n\ge 1}\) হিসেবে দেখলে, এর সংজ্ঞার্থক বৈশিষ্ট্য: ভিন্ন সময়ের মান সম্পূর্ণ স্বাধীন — অতীতের কোনো স্মৃতি নেই। এটি process-জগতের সবচেয়ে সরল ও স্মৃতিহীন সদস্য, এবং বাকি তিনটি বোঝার রেফারেন্স-বিন্দু (এবং random walk-এর কাঁচামাল)।
(খ) Random walk (দৈব পদচারণা) — i.i.d. পদের চলমান যোগফল। একই i.i.d. পদ \(X_1, X_2, \dots\) নিয়ে (প্রতিটি মান একেকটি দৈব "পদক্ষেপ") তাদের চলমান যোগফল সংজ্ঞায়িত করি:
প্রতিটি প্রতীক:
- \(X_i\) — \(i\)তম পদক্ষেপ (step); একটি i.i.d. random variable, mean \(\mu\), variance \(\sigma^2\) (যেমন প্রতি পদে \(+1\) বা \(-1\) সমসম্ভাব্যে)।
- \(S_n\) — \(n\)টি পদক্ষেপের পর process-এর অবস্থান (position): প্রথম \(n\)টি পদের যোগফল।
- \(S_0=0\) — শুরুর অবস্থান (সাধারণত উৎসবিন্দু)।
তাহলে \(\{S_n\}_{n\ge 0}\) একটি discrete-time process — index set \(\{0,1,2,\dots\}\), state space সাধারণত \(\mathbb{R}\) (বা \(\pm 1\)-পদের ক্ষেত্রে পূর্ণসংখ্যা)। এর একটি sample path একটি আঁকাবাঁকা সিঁড়ি-রেখা, যা প্রতি ধাপে একটি দৈব পরিমাণ ওঠে বা নামে। (এই অধ্যায়ের একটি sample path-চিত্র হবে Figure 3-5-random-walk।)
(গ) Poisson process (পয়সঁ প্রক্রিয়া) — দৈব ঘটনার গণনা সময় বরাবর। এটি একটি continuous-time, integer-valued counting process (গণনা-প্রক্রিয়া): এটি সময়ের সাথে দৈবভাবে ঘটতে-থাকা ঘটনাগুলো (events) গুনে চলে — যেমন একটা কল-সেন্টারে আসা কল, একটা ওয়েবসাইটে hit, বা একটা গাইগার-কাউন্টারে ক্লিক।
সংজ্ঞা (Poisson process, rate \(\lambda\))। \(N(t)\) = সময় \(0\) থেকে \(t\) পর্যন্ত ঘটে-যাওয়া মোট ঘটনার সংখ্যা। তাহলে \(\{N(t)\}_{t\ge 0}\) একটি Poisson process rate (হার) \(\lambda>0\)-সহ যদি: 1. \(N(0)=0\) (শুরুতে শূন্যটি ঘটনা); 2. যেকোনো ব্যবধি \([s, s+t]\)-তে ঘটনার সংখ্যা \(N(s+t)-N(s) \sim \text{Poisson}(\lambda t)\) — অর্থাৎ দৈর্ঘ্য-\(t\) ব্যবধিতে গণনা Poisson বণ্টিত, গড় \(\lambda t\); 3. অসংলগ্ন (non-overlapping) ব্যবধিগুলোর গণনা পরস্পর স্বাধীন (independent increments)।
প্রতিটি প্রতীক:
- \(N(t)\) — \([0,t]\) সময়ে মোট ঘটনার গণনা; একটি integer-valued random variable, state space \(\{0,1,2,\dots\}\)।
- \(\lambda\) — rate (হার): প্রতি একক সময়ে গড় ঘটনা-সংখ্যা (যেমন ঘণ্টায় গড় কতটা কল)।
- \(\lambda t\) — দৈর্ঘ্য-\(t\) ব্যবধিতে গড় ঘটনা-সংখ্যা; তাই গণনা \(\sim\text{Poisson}(\lambda t)\), যার PMF (2.3 থেকে) \(P(N(t)=k)=\dfrac{(\lambda t)^k e^{-\lambda t}}{k!}\)।
এই process-এর একটি মূল সঙ্গী-ধর্ম (§৩.২-এ বিস্তারিত): পরপর দুই ঘটনার মধ্যবর্তী অপেক্ষা-সময় (interarrival time) \(\sim\text{Exponential}(\lambda)\) — ঠিক 2.4-এ দেখা সেই memoryless অপেক্ষা-বণ্টন। তাই Poisson process হলো "যেখানে ঘটনা ধ্রুব হারে, স্বাধীনভাবে, স্মৃতিহীনভাবে ঘটে" তার আদর্শ মডেল। এর একটি sample path একটি সিঁড়ি-ফাংশন — প্রতিটি ঘটনায় ঠিক \(1\) লাফিয়ে ওঠা, মাঝে সমতল। (চিত্র হবে Figure 3-5-poisson-process।)
(ঘ) Gaussian process (গাউসীয় প্রক্রিয়া) — প্রতিটি finite গুচ্ছ jointly Normal। এটি Normal/Gaussian distribution-এর process-জগতে স্বাভাবিক সম্প্রসারণ।
সংজ্ঞা (Gaussian process — গাউসীয় প্রক্রিয়া)। একটি process \(\{X_t\}_{t\in T}\) একটি Gaussian process যদি যেকোনো সসীম সংখ্যক সময়-বিন্দু \(t_1, t_2, \dots, t_k\) বেছে নিলে, সংশ্লিষ্ট random variable-গুচ্ছ \((X_{t_1}, X_{t_2}, \dots, X_{t_k})\)-এর joint distribution একটি multivariate Normal (বহুমাত্রিক প্রসামান্য) হয়।
প্রতিটি প্রতীক/ধারণা:
- \(t_1,\dots,t_k\) — যেকোনোভাবে বাছা সসীম সংখ্যক সময়-বিন্দু (\(T\) থেকে)।
- \((X_{t_1},\dots,X_{t_k})\) — সেই সময়গুলোর মান নিয়ে গঠিত random vector।
- multivariate Normal — Normal-এর বহুমাত্রিক রূপ; একটি random vector jointly Gaussian হলে তার পুরো বণ্টন কেবল দুটো জিনিসে সম্পূর্ণ নির্ধারিত হয়: তার mean-vector ও covariance-matrix। (এই বহুমাত্রিক Normal-এর পূর্ণ বিবরণ Part IV-এ; এখানে মূল ধারণাটুকুই দরকার।)
এর সবচেয়ে সুন্দর দিকটি ঠিক এখান থেকেই আসে: যেহেতু jointly Gaussian বণ্টন কেবল mean ও covariance-এ নির্ধারিত, একটি Gaussian process সম্পূর্ণভাবে কেবল তার mean function \(m(t)\) ও autocovariance function \(C(s,t)\) দিয়েই নির্দিষ্ট হয়ে যায় — আর কিছু লাগে না। অর্থাৎ §২.২-এর ঐ দুটো হাতিয়ারই Gaussian process-কে পুরোপুরি বর্ণনা করে ফেলে। (Brownian motion — একটি বিখ্যাত Gaussian process — এর প্রাকদর্শন §৩.৩-এ; চিত্র Figure 3-5-gaussian-process।)
৩ · পূর্ণাঙ্গ উদাহরণ¶
এবার §২-এর ধারণাগুলো চারটি concrete উদাহরণে সংখ্যাসহ চালাই: E1 random walk (mean ও variance), E2 Poisson process (গণনা ও interarrival), E3 Gaussian process, E4 stationarity-যাচাই।
৩.১ E1 — Random walk: mean \(0\), variance \(n\sigma^2\)¶
সবচেয়ে পরিচিত random walk-টি নিই — সরল প্রতিসম random walk (simple symmetric random walk)। এখানে প্রতিটি পদক্ষেপ \(X_i\) সমসম্ভাব্যে \(+1\) বা \(-1\):
প্রথমে এক-পদের mean ও variance বের করি (2.3/2.5-এর সূত্রে):
তাই এখানে \(\mu=0\) ও \(\sigma^2=1\)। (অন্য random walk-এ এরা অন্য মান হতে পারে; সূত্রগুলো নিচে সাধারণভাবে \(\mu,\sigma^2\) দিয়ে রাখছি।)
এবার অবস্থান \(S_n=\sum_{i=1}^n X_i\)-এর mean function। যোগফলের প্রত্যাশা = প্রত্যাশার যোগফল (2.5, যেকোনো নির্ভরতাতেই খাটে):
আমাদের প্রতিসম ক্ষেত্রে \(\mu=0\), তাই \(\boxed{\,\mathbb{E}[S_n]=0\,}\) — গড়ে walk উৎসবিন্দুতেই থাকে, কোনো দিকেই ঝোঁক নেই।
এবার variance। যেহেতু \(X_i\)-রা স্বাধীন, স্বাধীন পদের যোগফলের variance = variance-গুলোর যোগফল (2.6-এর মূল ফল — covariance পদগুলো শূন্য):
প্রতিসম ক্ষেত্রে \(\sigma^2=1\), তাই \(\boxed{\,\mathrm{Var}(S_n)=n\,}\)। লক্ষ করুন এটাই random walk-এর স্বাক্ষর: গড় স্থির (\(0\)) থাকলেও ছড়ানো \(n\)-এর সাথে বাড়ে — তাই walk উৎস থেকে ক্রমে দূরে সরে যাওয়ার প্রবণতা দেখায়, এবং typical দূরত্ব \(\sqrt{\mathrm{Var}(S_n)}=\sqrt n\) হারে বাড়ে (standard deviation \(\sigma\sqrt n\))। এই "\(\sqrt n\) হারে ছড়ানো" ঠিক 3.4-এর CLT-র সাথে মেলে: বড় \(n\)-এ \(S_n\) approximately \(\mathcal{N}(n\mu,\, n\sigma^2)\), অর্থাৎ এখানে \(\mathcal{N}(0,n)\)।
autocovariance (এক ঝলক)। \(s\le t\) ধরে \(C(s,t)=\mathrm{Cov}(S_s,S_t)\) বের করা যায়: যেহেতু \(S_t=S_s+(X_{s+1}+\dots+X_t)\) এবং পরের যোগটি \(S_s\)-এর থেকে স্বাধীন, পাওয়া যায় \(C(s,t)=\mathrm{Var}(S_s)=s\sigma^2=\min(s,t)\,\sigma^2\)। অর্থাৎ random walk-এর autocovariance \(\min(s,t)\)-এর সমানুপাতিক — এটি \(s,t\)-এর আলাদা মানের ওপর নির্ভর করে (কেবল \(t-s\)-এর ওপর নয়), তাই random walk weakly stationary নয় (variance \(n\sigma^2\) নিজেই \(n\)-এর সাথে বাড়ছে — §৩.৪-এ এই সুরটাই ফিরবে)। (পূর্ণ বিশ্লেষণ §৪-এ।)
ছোট্ট সিমুলেশনে mean ও variance যাচাই:
import numpy as np
rng = np.random.default_rng(0)
n, reps = 100, 200_000
steps = rng.choice([-1, 1], size=(reps, n)) # প্রতিবার n টি ±1 পদক্ষেপ
S_n = steps.sum(axis=1) # S_100 = পদক্ষেপের যোগফল
print(round(S_n.mean(), 3)) # ≈ 0 = E[S_100]
print(round(S_n.var(), 3)) # ≈ 100 = Var(S_100) = n·σ² = 100·1
আউটপুট: গড় \(\approx 0\) ও variance \(\approx 100\) — ঠিক \(\mathbb{E}[S_{100}]=0\) ও \(\mathrm{Var}(S_{100})=100\)।
৩.২ E2 — Poisson process: \(P(N(t)=k)\) ও interarrival time¶
একটা কল-সেন্টার ধরি যেখানে কল আসে rate \(\lambda = 3\) প্রতি ঘণ্টা (গড়ে ঘণ্টায় \(3\)টা কল)। গণনা-প্রক্রিয়া \(N(t)\) = প্রথম \(t\) ঘণ্টায় মোট আগত কল।
গণনার বণ্টন। §২.৪(গ) অনুযায়ী, দৈর্ঘ্য-\(t\) ব্যবধিতে \(N(t)\sim\text{Poisson}(\lambda t)\), PMF:
সংখ্যায় (ক)। প্রথম \(2\) ঘণ্টায় ঠিক \(4\)টি কল আসার probability? এখানে \(\lambda t = 3\times 2 = 6\), \(k=4\):
অর্থাৎ ২ ঘণ্টায় ঠিক ৪টি কল আসার সম্ভাবনা প্রায় \(13.4\%\)। (যাচাই: এই ব্যবধিতে গড় কল \(\lambda t = 6\), তাই \(4\)টি গড়ের একটু নিচে — যুক্তিসঙ্গত।)
সংখ্যায় (খ)। প্রথম আধ ঘণ্টায় (অর্থাৎ \(t=0.5\)) একটিও কল না আসার probability? এখন \(\lambda t = 3\times 0.5 = 1.5\), \(k=0\):
interarrival time (আন্তঃআগমন সময়)। Poisson process-এর সঙ্গী-ধর্ম: পরপর দুই কলের মধ্যবর্তী অপেক্ষা-সময় \(\sim\text{Exponential}(\lambda)\)। কেন তা একটিমাত্র সুন্দর সংযোগে দেখা যায় — "পরের কল আসতে \(t\)-এর বেশি সময় লাগে" মানে ঠিক "দৈর্ঘ্য-\(t\) ব্যবধিতে শূন্যটি কল"। তাই অপেক্ষা-সময় \(W\) ধরলে, উপরের (খ)-এর যুক্তিতেই:
যা ঠিক Exponential\((\lambda)\)-এর survival function (2.4-এ দেখা: \(P(W>t)=e^{-\lambda t}\), তাই CDF \(1-e^{-\lambda t}\))। তাই \(W\sim\text{Exponential}(\lambda)\), গড় অপেক্ষা \(\mathbb{E}[W]=1/\lambda\)। আমাদের ক্ষেত্রে \(1/3\) ঘণ্টা \(=20\) মিনিট — গড়ে প্রতি \(20\) মিনিটে একটা কল, যা rate \(3\)/ঘণ্টার সাথে নিখুঁত সামঞ্জস্যপূর্ণ।
ছোট্ট সিমুলেশনে দুটোই যাচাই:
import numpy as np
rng = np.random.default_rng(1)
lam, T, reps = 3.0, 2.0, 200_000
# (ক) [0, T]-তে গণনা: Poisson(λT)
counts = rng.poisson(lam * T, size=reps)
print(round((counts == 4).mean(), 4)) # ≈ 0.1339 = P(N(2)=4)
# interarrival time: Exponential(λ) → scipy/numpy scale = 1/λ
gaps = rng.exponential(1/lam, size=reps)
print(round(gaps.mean(), 4)) # ≈ 0.3333 ঘণ্টা = 1/λ = 20 মিনিট
আউটপুট: \(P(N(2)=4)\approx 0.1339\) ও গড় interarrival \(\approx 0.333\) ঘণ্টা — হাতে-করা হিসাবের সাথে মেলে।
৩.৩ E3 — Gaussian process: প্রতিটি গুচ্ছ jointly Normal, এবং Brownian motion-এর ঝলক¶
একটি Gaussian process হাতে-কলমে বুঝতে, এর সবচেয়ে বিখ্যাত উদাহরণ Brownian motion (ব্রাউনীয় গতি, প্রতীকে \(\{W_t\}_{t\ge 0}\))-এর প্রাকদর্শন নিই। একে ভাবা যায় random walk-এর "অবিচ্ছিন্ন-সময় সীমা" হিসেবে — পদক্ষেপগুলো অসীম ছোট ও অসীম ঘন করে দিলে যে মসৃণ-অথচ-কাঁপা পথ পাওয়া যায়। এর সংজ্ঞাদায়ক বৈশিষ্ট্য (যা §২.৪(ঘ)-এর সংজ্ঞা মেনে এটিকে একটি Gaussian process বানায়):
- \(B_0 = 0\);
- প্রতিটি স্থির \(t\)-এর জন্য \(W_t \sim \mathcal{N}(0,\, t)\) — অর্থাৎ mean \(0\), variance ঠিক \(t\) (লক্ষ করুন random walk-এর \(\mathrm{Var}(S_n)=n\)-এর সাথে নিখুঁত মিল, \(n\)-এর জায়গায় অবিচ্ছিন্ন \(t\));
- যেকোনো সময়-গুচ্ছ \((B_{t_1},\dots,B_{t_k})\) jointly Normal (multivariate Normal)।
এখান থেকে এর mean ও autocovariance function সরাসরি পড়ে নেওয়া যায়:
(autocovariance \(\min(s,t)\) আসে random walk-এর \(\min(s,t)\sigma^2\)-এর সরাসরি অবিচ্ছিন্ন প্রতিরূপ হিসেবে, এখানে \(\sigma^2=1\)।) আর যেহেতু এটি একটি Gaussian process, §২.৪(ঘ)-এর মূল কথা অনুযায়ী এই \(m(t)=0\) ও \(C(s,t)=\min(s,t)\) জোড়াই Brownian motion-কে সম্পূর্ণভাবে নির্দিষ্ট করে দেয় — আর কোনো তথ্যের দরকার নেই।
সংখ্যায়। ধরা যাক \(s=1\) ও \(t=4\)। তাহলে:
এদের correlation (2.6-এর সংজ্ঞা — covariance-কে দুই standard deviation দিয়ে ভাগ):
অর্থাৎ \(W_1\) ও \(W_4\) ধনাত্মকভাবে সম্পর্কিত (correlation \(0.5\)) — স্বজ্ঞাত, কারণ \(W_4 = W_1 + (W_4 - W_1)\), অর্থাৎ সময় \(4\)-এর অবস্থান সময় \(1\)-এর অবস্থানকে নিজের ভেতরে বহন করে। লক্ষ করুন এই correlation \(s,t\)-এর পরম মানের ওপর নির্ভর করে (কেবল \(t-s\)-এর ওপর নয়) — তাই Brownian motion-ও weakly stationary নয় (random walk-এর মতোই)। (একটি Brownian sample path হবে Figure 3-5-gaussian-process।)
ছোট্ট সিমুলেশনে \((W_1, W_4)\)-এর mean, variance ও covariance যাচাই (পথটিকে সূক্ষ্ম পদক্ষেপে গড়ে তুলে):
import numpy as np
rng = np.random.default_rng(2)
reps, m = 200_000, 400 # m = [0,4] কে m ভাগে ভাগ
dt = 4.0 / m
incr = rng.normal(0, np.sqrt(dt), size=(reps, m)) # স্বাধীন N(0, dt) বৃদ্ধি
B = np.cumsum(incr, axis=1) # B পথ (সঞ্চিত যোগ)
B1 = B[:, m//4 - 1] # t = 1
B4 = B[:, m - 1] # t = 4
print(round(B1.var(), 3), round(B4.var(), 3)) # ≈ 1, ≈ 4 = Var(B_t) = t
print(round(np.cov(B1, B4)[0, 1], 3)) # ≈ 1 = min(1,4)
আউটপুট: \(\mathrm{Var}(W_1)\approx 1\), \(\mathrm{Var}(W_4)\approx 4\), \(\mathrm{Cov}(W_1,W_4)\approx 1\) — ঠিক \(\mathrm{Var}(W_t)=t\) ও \(C(s,t)=\min(s,t)\)।
৩.৪ E4 — Stationarity যাচাই: একটি stationary বনাম একটি non-stationary process¶
শেষ উদাহরণে §২.৩-এর weak-stationarity যাচাই-রেসিপি দুটো process-এ চালাই, পাশাপাশি — একটি যা stationary, একটি যা নয়। প্রতিটিতে দুটো প্রশ্নই করব: (১) \(m(t)\) কি ধ্রুবক? (২) \(C(s,t)\) কি কেবল \(t-s\)-এর ওপর নির্ভর করে?
Process A — i.i.d. sequence (stationary)। ধরা যাক \(\{X_n\}_{n\ge 1}\) i.i.d., প্রত্যেকে \(\mathcal{N}(0,\sigma^2)\), \(\sigma^2=4\) ধরি।
- mean function: \(m(n)=\mathbb{E}[X_n]=0\) প্রতিটি \(n\)-এ — ধ্রুবক। শর্ত ১ ✓।
- autocovariance: \(X_s, X_t\) স্বাধীন (i.i.d.) যখন \(s\ne t\), তাই \(\mathrm{Cov}(X_s,X_t)=0\); আর \(s=t\) হলে \(\mathrm{Cov}(X_t,X_t)=\mathrm{Var}(X_t)=\sigma^2=4\)। সংক্ষেপে
এটি কেবল ব্যবধান \(\tau=t-s\)-এর ওপর নির্ভর করে (\(s,t\)-এর আলাদা মানের ওপর নয়)। শর্ত ২ ✓। দুটো শর্তই মেটায় — তাই i.i.d. sequence weakly stationary। (স্বজ্ঞাত: সম্পূর্ণ স্মৃতিহীন ও সময়-সমসত্ত্ব process; এটি আসলে strictly stationary-ও।)
Process B — random walk (non-stationary)। ধরা যাক \(S_n=\sum_{i=1}^n X_i\), একই \(\pm 1\) পদ (§৩.১), \(\sigma^2=1\)।
- mean function: \(m(n)=\mathbb{E}[S_n]=0\) — এটা ধ্রুবক, শর্ত ১ পেরিয়ে গেল ✓।
- autocovariance: §৩.১-এ পেয়েছি \(C(s,t)=\min(s,t)\cdot\sigma^2 = \min(s,t)\)। এটা \(s,t\)-এর পরম মানের ওপর নির্ভর করে, কেবল \(t-s\)-এর ওপর নয় — যেমন \(C(1,2)=\min(1,2)=1\) কিন্তু \(C(5,6)=\min(5,6)=5\); দুটো জোড়ারই ব্যবধান \(\tau=1\), তবু autocovariance আলাদা (\(1\) বনাম \(5\))। শর্ত ২ ব্যর্থ ✗।
শর্ত ২ ভাঙায় random walk weakly stationary নয়। মূল কারণটা সরল: variance \(\mathrm{Var}(S_n)=n\sigma^2\) নিজেই সময়ের সাথে বাড়ছে (কর্ণে \(C(n,n)=n\)), তাই process-এর ছড়ানো "সময়-সমসত্ত্ব" নয় — এটিই non-stationarity-র জীবন্ত ছবি (walk যত এগোয়, তত বেশি ছড়ায়)।
ছোট্ট সিমুলেশনে দুটোর পার্থক্য — দুই lag-\(1\) জোড়ার autocovariance:
import numpy as np
rng = np.random.default_rng(3)
reps = 300_000
# Process A: i.i.d. N(0,4) → autocov(s,t)=0 for s≠t (shift-invariant)
X = rng.normal(0, 2, size=(reps, 7))
covA_12 = np.cov(X[:, 1], X[:, 2])[0, 1] # lag 1, কাছাকাছি বিন্দু
covA_56 = np.cov(X[:, 5], X[:, 6])[0, 1] # lag 1, দূরবর্তী বিন্দু
print(round(covA_12, 3), round(covA_56, 3)) # ≈ 0, ≈ 0 → একই, তাই stationary
# Process B: random walk → autocov(s,t)=min(s,t) (NOT shift-invariant)
S = np.cumsum(rng.choice([-1, 1], size=(reps, 7)), axis=1) # S_1..S_7
covB_12 = np.cov(S[:, 0], S[:, 1])[0, 1] # ≈ min(1,2)=1
covB_56 = np.cov(S[:, 4], S[:, 5])[0, 1] # ≈ min(5,6)=5
print(round(covB_12, 2), round(covB_56, 2)) # ≈ 1, ≈ 5 → আলাদা, তাই NON-stationary
আউটপুট: Process A-তে দুই lag-\(1\) জোড়ার autocovariance প্রায় সমান (\(\approx 0\) ও \(\approx 0\)) — shift-invariant, তাই stationary। Process B-তে তারা স্পষ্ট আলাদা (\(\approx 1\) বনাম \(\approx 5\)) — shift-invariant নয়, তাই non-stationary। ঠিক যেমন রেসিপি ভবিষ্যদ্বাণী করল। (এই দুই autocovariance-এর তুলনামূলক ছবি হবে Figure 3-5-autocovariance।)
৪ · প্রমাণ ও উৎপাদন¶
এই উপধারায় আমরা §১–৩-এ পরিচয় করানো তিনটে প্রধান random process-কে ধাপে ধাপে খুলব — প্রতিটা সূত্রের পেছনে কোন স্বাধীনতা-ধর্ম বা ছোট-ব্যবধান-স্বতঃসিদ্ধ কাজ করছে তা স্পষ্ট করে। চারটে ফল প্রমাণ/উৎপাদন করব, প্রতিটার পাশে difficulty-tag বসিয়ে (★ = সরাসরি, ★★ = কিছু কৌশল লাগে, ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে — কাঠামো পুরো, একটা ধাপ সততার সাথে honest sketch হিসেবে নেওয়া):
- (a) random walk \(S_n=\sum_{i=1}^n X_i\)-এর জন্য \(\mathbb{E}[S_n]=0\), \(\mathrm{Var}(S_n)=n\sigma^2\), এবং autocovariance \(C(m,n)=\sigma^2\min(m,n)\) — পুরোটাই independent increments থেকে। ★★
- (b) Poisson process: ছোট-ব্যবধান স্বতঃসিদ্ধ + independent increments থেকে বের করব count \(N(t)\sim\text{Poisson}(\lambda t)\) এবং interarrival time \(\sim\text{Exponential}(\lambda)\)। ★★★
- (c) Gaussian process-এর সংজ্ঞা — mean function \(m(t)\) ও covariance function \(C(s,t)\) দিয়ে সম্পূর্ণভাবে নির্ধারিত। ★★
- (d) weak (covariance) stationarity-এর শর্ত আর তা যাচাইয়ের নিয়ম। ★
এক নজরে সততা-নোট। (a), (c), (d) এখানে সম্পূর্ণভাবে যুক্তিসিদ্ধ — কেবল 2.6-এর প্রত্যাশা/ভ্যারিয়েন্সের রৈখিকতা, covariance-এর bilinearity, আর independent increments লাগে, কোনো ফাঁক নেই। (b)-তে কাঠামোটা পুরো দেওয়া হবে, কিন্তু একটিমাত্র গাঁট — ছোট-ব্যবধান স্বতঃসিদ্ধ থেকে একটা ordinary differential equation (ODE)-এ পৌঁছে তা সমাধান করা, যেখানে limit ও \(o(h)\)-পদ সামলাতে হয় — আমরা honest sketch হিসেবে নেব; পূর্ণ rigor-এ measure-theoretic process-construction লাগে, যা এই বইয়ের পরিধির বাইরে। তাই (b)-কে ★★★ ট্যাগ দিলাম: কঙ্কাল পুরো বুঝে নাও, ওই একটি গাঁট পরে শক্ত হবে।
৪.১ · (a) Random walk-এর mean, variance ও autocovariance ★★¶
মঞ্চ সাজাই। ধরা যাক \(X_1,X_2,\dots\) একগুচ্ছ i.i.d. (independent and identically distributed) step, প্রতিটার $$ \mathbb{E}[X_i]=0,\qquad \mathrm{Var}(X_i)=\mathbb{E}[X_i^2]=\sigma^2 . $$ (কেন্দ্রায়িত ধাপ ধরছি — \(\mathbb{E}[X_i]=0\) — যাতে মূল সূত্রগুলো পরিষ্কার আসে; অশূন্য গড়ের ক্ষেত্রটা শেষে এক লাইনে যোগ করব।) random walk হলো এদের ক্রমযোগফল: $$ S_n \;=\; \sum_{i=1}^{n} X_i, \qquad S_0 := 0 . $$ এটাই আমাদের চলমান উদাহরণ E1। আমরা তিনটে জিনিস বের করব: গড় \(m(n)=\mathbb{E}[S_n]\), ভ্যারিয়েন্স \(\mathrm{Var}(S_n)\), আর autocovariance \(C(m,n)=\mathrm{Cov}(S_m,S_n)\)।
ধাপ ১ — গড় \(\mathbb{E}[S_n]=0\)¶
প্রত্যাশা রৈখিক (linearity of expectation, 2.6) — যোগফলের প্রত্যাশা = প্রত্যাশার যোগফল, স্বাধীনতা লাগে না: $$ \mathbb{E}[S_n] \;=\; \mathbb{E}!\Big[\sum_{i=1}^n X_i\Big] \;=\; \sum_{i=1}^n \mathbb{E}[X_i] \;=\; \sum_{i=1}^n 0 \;=\; 0 . \tag{4.1} $$ অর্থাৎ যেকোনো \(n\)-এ walk-টা গড়ে শূন্যেই থাকে — এদিক-ওদিক যাওয়ার সম্ভাবনা ভারসাম্যপূর্ণ, তাই কোনো drift নেই।
ধাপ ২ — ভ্যারিয়েন্স \(\mathrm{Var}(S_n)=n\sigma^2\) (এখানেই স্বাধীনতা ঢোকে)¶
ভ্যারিয়েন্স রৈখিক নয়; স্বাধীন চলকের যোগফলের ভ্যারিয়েন্সের সাধারণ সূত্র (2.6): $$ \mathrm{Var}!\Big(\sum_{i=1}^n X_i\Big) \;=\; \sum_{i=1}^n \mathrm{Var}(X_i) \;+\; \underbrace{\sum_{i\ne j}\mathrm{Cov}(X_i,X_j)}{\text{cross terms}} . $$ এখানে \(X_i\)-রা স্বাধীন, তাই \(i\ne j\) হলে \(\mathrm{Cov}(X_i,X_j)=0\) — সব cross-term মুছে যায়। পড়ে থাকে কেবল diagonal পদগুলো: $$ \mathrm{Var}(S_n) \;=\; \sum $$ }^n \mathrm{Var}(X_i) \;=\; \sum_{i=1}^n \sigma^2 \;=\; n\,\sigma^2 . \tag{4.2মূল ছবিটা পড়ে নাও। ভ্যারিয়েন্স \(n\)-এর সাথে রৈখিকভাবে বাড়ে, তাই standard deviation বাড়ে \(\sqrt n\) হারে: \(\mathrm{sd}(S_n)=\sigma\sqrt n\)। অর্থাৎ \(n\) ধাপ পরে walk সাধারণত উৎস থেকে \(\sim\sigma\sqrt n\) দূরে থাকে — \(n\)-এর সমানুপাতিক নয়, তার বর্গমূলের সমানুপাতিক। এটাই diffusion-এর স্বাক্ষর (একই \(\sqrt n\) স্কেল 3.4-এর CLT-তেও দেখেছ — কাকতালীয় নয়)।
ধাপ ৩ — autocovariance \(C(m,n)=\sigma^2\min(m,n)\) (এখানে independent increments-এর কৌশল)¶
ধরা যাক \(m\le n\) (সাধারণতা না হারিয়ে; সমমিত বলে অন্য ক্রমও একই)। আমরা চাই \(C(m,n)=\mathrm{Cov}(S_m,S_n)\)। মূল কৌশল হলো বড়ের চলককে ছোটের চলক + একটা increment-এ ভাঙা: $$ S_n \;=\; S_m \;+\; \underbrace{(S_n - S_m)}{=\,\sum, $$ যেখানে }^{n} X_i \,=:\, I\(I=X_{m+1}+\cdots+X_n\) হলো \(m\)-এর পরের ধাপগুলোর যোগফল। এখন covariance bilinear (প্রতিটা argument-এ রৈখিক, 2.6), তাই $$ C(m,n)=\mathrm{Cov}(S_m,\,S_n)=\mathrm{Cov}(S_m,\,S_m+I) =\underbrace{\mathrm{Cov}(S_m,S_m)}{=\,\mathrm{Var}(S_m)}+\underbrace{\mathrm{Cov}(S_m,\,I)} $$ দুটো পদ আলাদা করে দেখি:} . \tag{4.3
- প্রথম পদ ধাপ ২ থেকেই জানা: \(\mathrm{Cov}(S_m,S_m)=\mathrm{Var}(S_m)=m\sigma^2\)।
- দ্বিতীয় পদ — এখানেই independent increments। \(S_m=X_1+\cdots+X_m\) গড়া হয়েছে প্রথম \(m\)টা ধাপ থেকে, আর \(I=X_{m+1}+\cdots+X_n\) গড়া হয়েছে সম্পূর্ণ আলাদা ধাপ থেকে। যেহেতু সব \(X_i\) পরস্পর স্বাধীন, দুই গুচ্ছ ধাপ অ-অধিক্রমী (disjoint), তাই \(S_m\) ও \(I\) স্বাধীন — অতএব \(\mathrm{Cov}(S_m,I)=0\)।
বসিয়ে: $$ \boxed{\,C(m,n) \;=\; m\,\sigma^2 \;=\; \sigma^2\min(m,n)\,} \qquad (m\le n). \tag{4.4} $$ ক্রম উল্টে দিলে (\(n\le m\)) একইভাবে \(\sigma^2 n\) পেতাম, তাই সাধারণ রূপে \(\sigma^2\min(m,n)\) — দুটোই \(\min\)।
স্বজ্ঞা — কেন \(\min\)। \(S_m\) ও \(S_n\) একই প্রথম \(\min(m,n)\)টা ধাপ ভাগ করে নেয়; এই ভাগ-করা অংশই তাদের একসাথে নড়ায়, তাই covariance ঠিক ওই ভাগ-করা ভ্যারিয়েন্স \(\sigma^2\min(m,n)\)। তার পরের ধাপগুলো (শুধু \(S_n\)-এ আছে, \(S_m\)-এ নেই) স্বাধীন, তাই covariance-এ কিছু যোগ করে না। দুটো লক একই উৎস ভাগ করলে যতক্ষণ একসাথে চলে, ততক্ষণই তাদের মিল।
নন-stationary, কিন্তু independent increments। লক্ষ করো — \(C(m,n)\) কেবল ব্যবধান \(\lvert m-n\rvert\)-এর উপর নির্ভর করে না, বরং \(\min(m,n)\)-এর উপর; আর \(\mathrm{Var}(S_n)=n\sigma^2\) সময়ের সাথে বাড়ে। তাই random walk weakly stationary নয় (§৪.৪-এ এর সাথে তুলনা করব)। অথচ এর increments stationary ও independent — এটাই Poisson process ও Brownian motion-এর সাথে এর গভীর মিল।
(অশূন্য drift: যদি \(\mathbb{E}[X_i]=\mu\ne 0\) হতো, তবে \(\mathbb{E}[S_n]=n\mu\) — একটা রৈখিক trend; কিন্তু ভ্যারিয়েন্স ও autocovariance অপরিবর্তিত, কারণ covariance ধ্রুবক-যোগে বদলায় না। প্রমাণে শুধু \(X_i\)-কে \(X_i-\mu\) দিয়ে বদলে দিলেই হয়।)
৪.২ · (b) Poisson process: \(N(t)\sim\text{Poisson}(\lambda t)\) ও interarrival \(\sim\text{Exponential}(\lambda)\) ★★★¶
এটাই চলমান উদাহরণ E2। লক্ষ্য: কেবল কয়েকটা স্বাভাবিক স্বতঃসিদ্ধ থেকে শুরু করে দেখানো যে গণনা-চলক \(N(t)\) ঠিক Poisson, আর পরপর দুই ঘটনার মধ্যবর্তী সময় (interarrival) ঠিক Exponential। এখানে rigor-এর গাঁটটা সততার সাথে চিহ্নিত করব।
স্বতঃসিদ্ধ — একটা "বিশৃঙ্খল কিন্তু সমসত্ত্ব" গণনা-প্রক্রিয়ার তিন শর্ত¶
\(N(t)\) = সময় \([0,t]\)-এ ঘটে যাওয়া ঘটনার সংখ্যা (\(N(0)=0\))। rate \(\lambda>0\)-এর Poisson process-কে সংজ্ঞায়িত করে তিনটে স্বতঃসিদ্ধ:
- (Independent increments) অ-অধিক্রমী সময়-ব্যবধানে ঘটনাসংখ্যা পরস্পর স্বাধীন। অর্থাৎ disjoint \([a,b)\) ও \([c,d)\)-তে \(N(b)-N(a)\) আর \(N(d)-N(c)\) স্বাধীন।
- (Stationary, ছোট-ব্যবধানে একটি ঘটনা) খুব ছোট ব্যবধান \(h\)-এ ঠিক একটি ঘটনার সম্ভাবনা rate-এর সমানুপাতিক: $$ P\big(N(t+h)-N(t)=1\big) \;=\; \lambda h + o(h). $$
- (ছোট-ব্যবধানে দুই-বা-বেশি ঘটনা প্রায় অসম্ভব) $$ P\big(N(t+h)-N(t)\ge 2\big) \;=\; o(h). $$
এখানে \(o(h)\) মানে "\(h\)-এর তুলনায় উপেক্ষ্য", অর্থাৎ \(o(h)/h\to 0\) যখন \(h\to 0\)। স্বতঃসিদ্ধ ২ ও ৩ একসাথে বলে: এত ছোট জানালায় হয় কিছুই ঘটে না, নয়তো ঠিক একটি ঘটনা — যমজ ঘটনা কার্যত নিষিদ্ধ। তিনটে একত্রে মিলে শূন্য-ঘটনার সম্ভাবনাও পাওয়া যায়: $$ P\big(N(t+h)-N(t)=0\big) = 1 - \lambda h + o(h). \tag{4.5} $$ (কেন: তিনটে ঘটনা — \(0,1,\ge 2\) — সম্ভাবনার যোগফল \(1\); স্বতঃসিদ্ধ ২ থেকে "\(=1\)"-এর ভাগ \(\lambda h+o(h)\), স্বতঃসিদ্ধ ৩ থেকে "\(\ge 2\)"-এর ভাগ \(o(h)\), তাই "\(=0\)"-এর ভাগ \(1-\lambda h+o(h)\)।)
অংশ I — \(N(t)\sim\text{Poisson}(\lambda t)\) উৎপাদন (ODE পদ্ধতি) (honest sketch — গাঁট এখানে)¶
লিখি \(p_k(t):=P\big(N(t)=k\big)\)। আমরা ছোট-ব্যবধান যুক্তি দিয়ে \(p_k(t)\)-এর একটা পার্থক্য-সমীকরণ বানাব, তারপর \(h\to 0\) নিয়ে ODE-তে রূপান্তর করব।
ধাপ ১ — শূন্য-ঘটনার সমীকরণ \(p_0(t)\)। \([0,t+h]\)-এ শূন্য ঘটনা ঘটতে হলে \([0,t]\)-এও শূন্য এবং \([t,t+h]\)-এও শূন্য ঘটতে হবে। independent increments (স্বতঃসিদ্ধ ১) বলে এই দুটো স্বাধীন, তাই সম্ভাবনা গুণ হয়; আর (4.5) ব্যবহার করি: $$ p_0(t+h) = p_0(t)\cdot P(\text{next }h\text{ has 0}) = p_0(t)\,\big(1-\lambda h + o(h)\big). $$ পুনর্বিন্যাস করে \(p_0(t)\) বিয়োগ ও \(h\) দিয়ে ভাগ: $$ \frac{p_0(t+h)-p_0(t)}{h} = -\lambda\,p_0(t) + \frac{o(h)}{h}. $$ এখন \(h\to 0\) নিই — এখানেই honest-sketch-এর গাঁট: বামপাশ derivative-এর সংজ্ঞায় গিয়ে দাঁড়ায়, আর \(o(h)/h\to 0\): $$ p_0'(t) = -\lambda\,p_0(t). \tag{4.6} $$ \(p_0(0)=1\) (শুরুতে নিশ্চিত শূন্য ঘটনা) শর্তে এই ODE-র সমাধান: $$ p_0(t) = e^{-\lambda t}. \tag{4.7} $$ (যাচাই: \(\frac{d}{dt}e^{-\lambda t}=-\lambda e^{-\lambda t}\), আর \(e^0=1\) — দুই শর্তই মেলে।)
ধাপ ২ — সাধারণ \(k\)-এর সমীকরণ। \([0,t+h]\)-এ ঠিক \(k\)টা ঘটনা ঘটার দুটো প্রধান পথ (দুই-বা-বেশি ঘটনা \(h\)-এ \(o(h)\), তাই বাদ): (i) \([0,t]\)-এ \(k\)টা, আর \([t,t+h]\)-এ \(0\)টা; অথবা (ii) \([0,t]\)-এ \(k-1\)টা, আর \([t,t+h]\)-এ ঠিক \(1\)টা। independent increments দিয়ে গুণ করে যোগ করি: $$ p_k(t+h) = p_k(t)\underbrace{(1-\lambda h+o(h))}{0\text{ in }h} + p}(t)\underbrace{(\lambda h+o(h)){1\text{ in }h} + o(h). $$ আগের মতো বিয়োগ–ভাগ–\(h\to 0\) করে পাই ODE-সংসার (system): $$ p_k'(t) = -\lambda\,p_k(t) + \lambda\,p $$}(t), \qquad k\ge 1, \qquad p_k(0)=0. \tag{4.8
ধাপ ৩ — সমাধান induction-এ। দাবি: \(p_k(t)=e^{-\lambda t}\dfrac{(\lambda t)^k}{k!}\)। \(k=0\)-তে এটা ঠিক (4.7)। ধরে নিই \(k-1\)-এর জন্য সত্য; (4.8)-এ বসাই। একটা পরিচ্ছন্ন কৌশল — \(q_k(t):=e^{\lambda t}p_k(t)\) ধরলে \(q_k'(t)=e^{\lambda t}(p_k'+\lambda p_k)=e^{\lambda t}\lambda p_{k-1}(t)=\lambda\cdot\frac{(\lambda t)^{k-1}}{(k-1)!}\) (induction অনুমান)। সুতরাং \(q_k(t)=\int_0^t \lambda\frac{(\lambda s)^{k-1}}{(k-1)!}ds=\frac{(\lambda t)^k}{k!}\) (যেহেতু \(q_k(0)=0\))। তাই $$ \boxed{\,p_k(t)=P\big(N(t)=k\big)=e^{-\lambda t}\,\frac{(\lambda t)^k}{k!}\,}\qquad k=0,1,2,\dots \tag{4.9} $$ এটাই ঠিক Poisson\((\lambda t)\)-এর pmf (2.x)। অতএব \(\mathbb{E}[N(t)]=\mathrm{Var}(N(t))=\lambda t\) — গড় ঘটনাসংখ্যা rate \(\times\) সময়, ঠিক যেমন স্বজ্ঞা বলে।
স্কেচ কোথায়। ধাপ ২–৩-এর বীজগণিত ও induction সম্পূর্ণ ও প্রাথমিক। একমাত্র ধার-করা গাঁট ধাপ ১-এর "\(h\to 0\) নিলে পার্থক্য-অনুপাত derivative হয় আর \(o(h)/h\to 0\)" — এটা অন্তর্নিহিতভাবে ধরে নেয় যে \(p_k(t)\) সত্যিই differentiable এবং limit ও সম্ভাবনার ক্রম অদলবদল বৈধ। পূর্ণ rigor-এ দেখাতে হয় এমন একটা process আদৌ আছে (measure-theoretic construction) ও এই নিয়মিততা ধর্মগুলো ধরে — তা একটা stochastic-process কোর্সের বিষয়। তাই ★★★: যুক্তির কাঠামো পুরো, ওই একটি analytic গাঁট পরে শক্ত হবে।
অংশ II — interarrival time \(\sim\text{Exponential}(\lambda)\)¶
এবার ঘটনার সংখ্যা নয়, পরপর দুই ঘটনার মধ্যবর্তী সময় দেখি। ধরা যাক \(\tau_1\) = প্রথম ঘটনার সময়। মূল লক্ষ্য \(\tau_1\)-এর বণ্টন বের করা; এর জন্য সবচেয়ে সহজ পথ survival function \(P(\tau_1>t)\)।
মূল সংযোগ (count ↔ time)। "প্রথম ঘটনা \(t\)-এর পরে" — এই বাক্য আর "\([0,t]\)-এ একটাও ঘটনা ঘটেনি" — এই বাক্য হুবহু একই ঘটনা: $$ {\tau_1 > t} \;=\; {N(t)=0}. $$ তাই (4.7) সরাসরি দেয়: $$ P(\tau_1>t) = P\big(N(t)=0\big) = e^{-\lambda t}, \qquad t\ge 0. \tag{4.10} $$ এখন CDF আর density: $$ F_{\tau_1}(t) = P(\tau_1\le t) = 1 - e^{-\lambda t}, \qquad f_{\tau_1}(t) = F_{\tau_1}'(t) = \lambda e^{-\lambda t}\quad (t\ge 0). \tag{4.11} $$ এটাই ঠিক Exponential\((\lambda)\)-এর density। তাই \(\mathbb{E}[\tau_1]=1/\lambda\) — গড় অপেক্ষার সময় rate-এর বিপরীত, স্বজ্ঞাসম্মত (rate বেশি হলে অপেক্ষা কম)।
পরবর্তী interarrival-গুলোও একই, এবং স্বাধীন। \(k\)-তম ঘটনার পর process যেন "নতুন করে শুরু" হয় — কারণ independent + stationary increments বলে \(k\)-তম ঘটনার পরের ব্যবধানে যা ঘটে তা আগের থেকে স্বাধীন এবং একই আইন মানে। তাই interarrival times \(\tau_1,\tau_2,\tau_3,\dots\) পরস্পর i.i.d. \(\text{Exponential}(\lambda)\) — Poisson process-এর এটাই সবচেয়ে কাজে-লাগা রূপ (সিমুলেশনেও §৫-এ এটাই ব্যবহার করব: Exp gap পরপর যোগ করে arrival বানানো)।
memoryless সংযোগ। Exponential-এর স্মৃতিহীনতা (\(P(T>s+t\mid T>s)=P(T>t)\)) আর Poisson-এর independent increments আসলে একই মুদ্রার দুই পিঠ: যেহেতু অতীত গণনা ভবিষ্যৎ গণনাকে প্রভাবিত করে না, পরবর্তী ঘটনার জন্য অপেক্ষাও অতীতকে "মনে রাখে না"। তাই এই দুই বণ্টন (Poisson count, Exponential gap) সবসময় জোড়ায় আসে।
৪.৩ · (c) Gaussian process — mean ও covariance function দিয়ে সংজ্ঞা ★★¶
এটাই চলমান উদাহরণ E3। Gaussian process হলো random process-এর জগতে সবচেয়ে "নিয়ন্ত্রণযোগ্য" শ্রেণি — কারণ একে সম্পূর্ণভাবে নির্ধারণ করতে মাত্র দুটো অপেক্ষক লাগে।
সংজ্ঞা — finite-dimensional distribution সব joint Gaussian¶
একটা process \(\{X_t\}_{t\in T}\)-কে Gaussian process বলা হয় যদি যেকোনো সসীমসংখ্যক সময়-বিন্দু \(t_1,\dots,t_k\) বাছলে সংশ্লিষ্ট vector $$ \big(X_{t_1}, X_{t_2}, \dots, X_{t_k}\big) $$ একটা multivariate Normal বণ্টন মানে (2.x — joint Gaussian)। অর্থাৎ process-এর যেকোনো "স্ন্যাপশট" সবসময় বহুমাত্রিক ঘণ্টা-আকৃতির।
কেন কেবল mean ও covariance যথেষ্ট¶
মূল কথাটা multivariate Normal-এর একটা চেনা ধর্ম থেকে আসে: একটা multivariate Normal বণ্টন সম্পূর্ণভাবে নির্ধারিত হয় তার mean vector ও covariance matrix দিয়ে — আর কোনো তথ্য লাগে না (higher moments সব এই দুটো থেকেই বেরোয়)। এখন process-এর ক্ষেত্রে এই দুটো হয়ে যায় দুটো অপেক্ষক: $$ m(t)=\mathbb{E}[X_t]\ \ (\text{mean function}), \qquad C(s,t)=\mathrm{Cov}(X_s,X_t)\ \ (\text{covariance function / kernel}). $$ যেকোনো সময়-বিন্দু-গুচ্ছ \(t_1,\dots,t_k\)-এর জন্য snapshot vector-টির mean vector হলো \(\big(m(t_1),\dots,m(t_k)\big)\) আর covariance matrix-এর \((i,j)\)-ঘর হলো \(C(t_i,t_j)\)। যেহেতু snapshot-টা Gaussian, এই দুই তথ্যই তার পূর্ণ বণ্টন ঠিক করে দেয়। তাই: $$ \boxed{\,m(\cdot)\ \text{ও}\ C(\cdot,\cdot)\ \text{জানা মানেই পুরো Gaussian process জানা}\,.} $$
বৈধ covariance function-এর শর্ত — positive semidefinite¶
যেকোনো দুই-চলকের অপেক্ষক \(C(s,t)\) covariance function হতে পারে না; একে symmetric (\(C(s,t)=C(t,s)\)) এবং positive semidefinite (PSD) হতে হবে: যেকোনো \(t_1,\dots,t_k\) ও বাস্তব \(a_1,\dots,a_k\)-এর জন্য $$ \sum_{i=1}^{k}\sum_{j=1}^{k} a_i\,a_j\,C(t_i,t_j) \;\ge\; 0 . \tag{4.12} $$ কেন এই শর্ত (এক লাইনের প্রমাণ)। বামপাশ আসলে একটা রৈখিক সমাবেশের ভ্যারিয়েন্স, যা কখনো ঋণাত্মক হতে পারে না: $$ \sum_{i,j} a_i a_j\,\mathrm{Cov}(X_{t_i},X_{t_j}) = \mathrm{Cov}!\Big(\sum_i a_i X_{t_i},\ \sum_j a_j X_{t_j}\Big) = \mathrm{Var}!\Big(\sum_i a_i X_{t_i}\Big) \ge 0 . $$ এটাই (4.12) — অর্থাৎ PSD শর্ত স্রেফ "যেকোনো ভ্যারিয়েন্স \(\ge 0\)"-এর পুনরুচ্চারণ। ব্যবহারিকভাবে এর মানে: snapshot-এর covariance matrix সবসময় PSD, তাই তার Cholesky factorization \(C=LL^\top\) বিদ্যমান — যা §৫-এ Gaussian process সিমুলেট করতে ঠিক এই কাজে লাগবে (\(X=Lz\), \(z\sim\mathcal{N}(0,I)\))।
চলমান উদাহরণ E3 (squared-exponential kernel)। §৫-এ আমরা নেব \(m(t)=0\) আর $$ C(s,t)=\exp!\Big(-\frac{(s-t)^2}{2\ell^2}\Big), $$ যেখানে \(\ell\) একটা length-scale। এর তিনটে স্বজ্ঞাগত ধর্ম: (i) \(C(t,t)=1\) — প্রতিটা বিন্দুর ভ্যারিয়েন্স \(1\); (ii) \(\lvert s-t\rvert\) ছোট হলে \(C\approx 1\) — কাছাকাছি সময়ের মান প্রায় সমান (মসৃণ পথ); (iii) \(\lvert s-t\rvert\) বড় হলে \(C\to 0\) — দূরের মান প্রায় স্বাধীন। এই kernel symmetric ও PSD (একটা জানা ফল), তাই বৈধ।
random walk-এর সাথে সম্পর্ক। §৪.১-এর random walk-ও একটা Gaussian process হয়ে যায় যদি ধাপগুলো \(X_i\sim\mathcal{N}(0,\sigma^2)\) হয় (তখন \(S_n\)-গুলো joint Gaussian, যেহেতু স্বাধীন Normal-এর রৈখিক সমাবেশ Normal)। তখন এর mean function \(m(n)=0\) আর covariance function ঠিক (4.4): \(C(m,n)=\sigma^2\min(m,n)\)। অর্থাৎ Gaussian random walk = "Gaussian process with kernel \(\sigma^2\min(m,n)\)" — এটাই Brownian motion-এর বিচ্ছিন্ন-সময় পূর্বসূরি।
৪.৪ · (d) Weak (covariance) stationarity-এর শর্ত ★¶
দুই ধরনের stationarity, আর কেন দুর্বলটা ব্যবহারিক¶
এটাই চলমান উদাহরণ E4। স্থূলভাবে, একটা process stationary যদি তার পরিসাংখ্যিক আচরণ সময়ের সাথে না বদলায় — সময়-অক্ষ বরাবর সরালেও ছবি একই থাকে। এর দুটো রূপ:
- strict (strong) stationarity: যেকোনো সময়-গুচ্ছ \(t_1,\dots,t_k\) ও যেকোনো shift \(\tau\)-এর জন্য \(\big(X_{t_1},\dots,X_{t_k}\big)\) আর \(\big(X_{t_1+\tau},\dots,X_{t_k+\tau}\big)\)-এর সম্পূর্ণ joint বণ্টন অভিন্ন। এটা শক্ত শর্ত — পুরো বণ্টন মেলাতে হয়, যা বাস্তবে যাচাই করা কঠিন।
- weak (covariance / second-order) stationarity: শুধু প্রথম দুই moment shift-নিরপেক্ষ হলেই চলবে। ঠিক তিনটে শর্ত:
(S3)-এর মানে: একটা অপেক্ষক \(\gamma(\cdot)\) আছে যেন \(C(s,t)=\gamma(t-s)\) — covariance নির্ভর করে দুই বিন্দু কত দূরে তার উপর, কোন জায়গায় তার উপর নয়। (এই \(\gamma\)-কে বলে autocovariance function; §৫-এ আমরা এর empirical রূপ মাপব।) লক্ষ করো (S2) আসলে (S3)-এর বিশেষ ক্ষেত্র (\(s=t\), ব্যবধান \(0\)): \(\gamma(0)=\mathrm{Var}(X_t)\), যা সব \(t\)-তে এক — তাই ভ্যারিয়েন্সও ধ্রুবক।
কেন "weak"-ই যথেষ্ট, কখন "weak = strong"। বহু প্রয়োগে (signal processing, time-series forecasting) কেবল mean ও autocovariance লাগে — পুরো বণ্টন নয়; তাই weak stationarity-ই ব্যবহারিক মানদণ্ড। আর একটা সুন্দর সংযোগ: Gaussian process-এর জন্য weak ⟺ strong, কারণ Gaussian-এর পুরো বণ্টন তো শুধু mean ও covariance দিয়েই ঠিক হয় (§৪.৩) — তাই প্রথম দুই moment shift-নিরপেক্ষ হওয়া মানেই পুরো বণ্টন shift-নিরপেক্ষ।
চলমান উদাহরণে শর্ত যাচাই¶
- E1 — random walk weakly stationary নয়। §৪.১ থেকে \(\mathrm{Var}(S_n)=n\sigma^2\) — সময়ের সাথে বাড়ে, তাই (S2) ভাঙে; আর \(C(m,n)=\sigma^2\min(m,n)\) ব্যবধান \(\lvert m-n\rvert\)-এর অপেক্ষক নয় (\(\min(m,n)\) স্থানের উপর নির্ভর করে), তাই (S3)-ও ভাঙে। সিদ্ধান্ত: random walk non-stationary (যদিও এর increments stationary)।
- E2 — Poisson process-ও stationary নয়। \(\mathbb{E}[N(t)]=\lambda t\) সময়ের সাথে বাড়ে, (S1) ভাঙে। তবে এর increments (\(N(t+\tau)-N(t)\)) stationary — distribution কেবল \(\tau\)-এর উপর নির্ভর করে।
- E4 — একটি weakly stationary উদাহরণ (white noise)। ধরো \(\{X_t\}\) i.i.d. প্রতিটা \(\mathcal{N}(0,\sigma^2)\) (discrete white noise)। তখন \(\mathbb{E}[X_t]=0\) (S1 ✓), \(\mathrm{Var}(X_t)=\sigma^2\) (S2 ✓), আর $$ C(s,t)=\mathrm{Cov}(X_s,X_t)=\begin{cases}\sigma^2 & s=t\[2pt]0 & s\ne t\end{cases}=\sigma^2\,\mathbf{1}{s=t}=\gamma(s-t),\quad \gamma(h)=\sigma^2\mathbf{1}{h=0}, $$ যা কেবল ব্যবধান \(h=s-t\)-এর অপেক্ষক (S3 ✓)। তিন শর্তই পূরণ — white noise weakly stationary। (এটা Gaussian-ও, তাই strongly stationary-ও।)
এক বাক্যে মন্ত্র। Weak stationarity = "গড় ও ভ্যারিয়েন্স ধ্রুবক, আর covariance শুধু ব্যবধানের উপর নির্ভরশীল।" — এই তিনটে box টিক করলেই process weakly stationary; random walk ও Poisson দুটোই প্রথম বা দ্বিতীয় box-এ আটকে যায়।
৪.৫ · সারমর্ম: কোনটা পূর্ণ, কোনটা ধার-করা গাঁট¶
| ফল | difficulty | অবস্থা | মূল যন্ত্র |
|---|---|---|---|
| (a) random walk \(\mathbb{E}[S_n]=0,\ \mathrm{Var}=n\sigma^2,\ C=\sigma^2\min(m,n)\) | ★★ | সম্পূর্ণ যুক্তি | প্রত্যাশার রৈখিকতা, ভ্যারিয়েন্স-যোগ, covariance bilinearity, independent increments |
| (b) Poisson count \(\sim\text{Poisson}(\lambda t)\), gap \(\sim\text{Exp}(\lambda)\) | ★★★ | honest sketch — ১টি গাঁট (\(h\to 0\) ODE-রূপান্তর) ধার-করা | ছোট-ব্যবধান স্বতঃসিদ্ধ, independent increments, ODE + induction |
| (c) Gaussian process = mean + covariance function | ★★ | সম্পূর্ণ | multivariate Normal-এর mean+cov যথেষ্টতা; PSD = "ভ্যারিয়েন্স \(\ge 0\)" |
| (d) weak stationarity (S1–S3) | ★ | সম্পূর্ণ | প্রত্যাশা/ভ্যারিয়েন্স/covariance-এর shift-নিরপেক্ষতা |
মূল ছবি: (a) independent increments-এর দরুন সব cross-term মুছে যায়, তাই variance যোগ হয় ও covariance \(\min(m,n)\)-এ দাঁড়ায়; (b) ছোট-ব্যবধান স্বতঃসিদ্ধ → ODE → Poisson count, আর "প্রথম ঘটনা \(>t\) ⟺ \([0,t]\)-এ শূন্য" সংযোগ → Exponential gap; (c) Gaussian বলে snapshot-এর mean ও covariance-ই পুরো process ঠিক করে; (d) stationarity = প্রথম দুই moment-এর shift-নিরপেক্ষতা। পরের §৫-এ এই চারটেই সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর চারটে দাবিকে আমরা সিমুলেশনে যাচাই করব — যাতে random walk, Poisson process ও Gaussian process কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে।
আমরা চারটে জিনিস মাপব:
- Part 1 — random walk (E1, §৪.১)। ধাপ \(X_i\in\{-1,+1\}\) (Rademacher, \(\sigma^2=1\))। বহু path সিমুলেট করে দেখব
mean(S_n)\(\approx 0\) আরvar(S_n)\(\approx n\sigma^2\) — অর্থাৎ ভ্যারিয়েন্স \(n\)-এর সাথে রৈখিকভাবে বাড়ে। - Part 2 — Poisson process (E2, §৪.২)। rate \(\lambda=2\), পর্যবেক্ষণ \([0,T]\), \(T=5\)। Exp\((\lambda)\) gap পরপর যোগ করে path বানিয়ে দেখব count \(N(T)\)-এর বণ্টন Poisson\((\lambda T)=\) Poisson\((10)\)-এর সাথে মেলে, আর interarrival time-এর mean/var/CDF Exponential\((\lambda)\)-এর সাথে মেলে।
- Part 3 — Gaussian process via Cholesky (E3, §৪.৩)। \(m(t)=0\), squared-exponential kernel। covariance matrix-এর Cholesky factor \(L\) নিয়ে \(X=Lz\) (\(z\sim\mathcal{N}(0,I)\)) দিয়ে বহু sample বানিয়ে দেখব empirical mean\(\approx 0\) আর empirical covariance\(\approx C(s,t)\)।
- Part 4 — empirical autocovariance (§৪.১)। একই random-walk path থেকে \(\mathrm{Cov}(S_m,S_n)\) মেপে তত্ত্বের \(\sigma^2\min(m,n)\)-এর সাথে মেলানো।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 3.5 — Random Processes; Poisson & Gaussian Processes : Code Lab
# Numerically illustrates:
# PART 1 — Random walk S_n: E[S_n]=0, Var(S_n)=n*sigma^2
# PART 2 — Poisson process: N(t) ~ Poisson(lambda*t), interarrival ~ Exponential(lambda)
# PART 3 — Gaussian process via covariance matrix + Cholesky; check mean & cov
# PART 4 — Empirical autocovariance of the random walk vs theory sigma^2*min(m,n)
import numpy as np
from math import factorial, exp
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => reproducible
# ===============================================================
# PART 1 — RANDOM WALK S_n = sum_{i=1}^n X_i, X_i iid, E[X]=0, Var=sigma^2.
# Theory: E[S_n] = 0, Var(S_n) = n*sigma^2, Cov(S_m,S_n) = sigma^2*min(m,n).
# Use Rademacher steps X_i in {-1,+1} (sigma^2 = 1) so theory is clean.
# ===============================================================
print("=== PART 1 Random walk S_n = sum X_i, X_i in {-1,+1} (sigma^2 = 1) ===")
REP = 200_000
N_MAX = 50
steps = rng.integers(0, 2, size=(REP, N_MAX)) * 2 - 1 # {-1,+1} Rademacher
S = np.cumsum(steps, axis=1) # S[:,k] = S_{k+1}
sigma2 = 1.0
print(f"{'n':>4} {'mean(S_n)':>10} {'var(S_n)':>10} {'theory n*s2':>12}")
for n in [1, 5, 10, 25, 50]:
col = S[:, n-1]
print(f"{n:>4} {col.mean():>10.4f} {col.var():>10.4f} {n*sigma2:>12.1f}")
print(" mean stays ~0; var(S_n) tracks n*sigma^2 (variance grows linearly in n)")
# ===============================================================
# PART 2 — POISSON PROCESS, rate lambda.
# (a) count N(t) ~ Poisson(lambda*t): compare empirical pmf to Poisson pmf.
# (b) interarrival times ~ Exponential(lambda): compare mean/var & a CDF check.
# ===============================================================
print("\n=== PART 2 Poisson process rate lambda = 2.0 ===")
lam = 2.0
T = 5.0 # observe on [0, T]; N(T) ~ Poisson(lam*T)=Poisson(10)
M = 300_000 # number of independent realizations
# Build each path by drawing Exp(lambda) interarrivals; cumulative-sum; count those <= T.
BUF = 40 # generous buffer of gaps per path (E[N]=10)
gaps = rng.exponential(scale=1.0/lam, size=(M, BUF)) # Exp(rate=lam): scale = 1/lam
arr = np.cumsum(gaps, axis=1) # arrival times
Ncount = (arr <= T).sum(axis=1) # N(T) per path
saturated = int((arr[:, -1] <= T).sum()) # safety: buffer must not run out
print(f" (buffer check: {saturated} of {M} paths saturated the {BUF}-gap buffer; want 0)")
print(f" count N(T): empirical mean = {Ncount.mean():.4f}, var = {Ncount.var():.4f}"
f" theory Poisson(lam*T) mean=var={lam*T:.1f}")
muP = lam * T
print(f" {'k':>3} {'emp P(N=k)':>11} {'Poisson pmf':>12}")
for k in [6, 8, 10, 12, 14]:
emp = np.mean(Ncount == k)
pois = exp(-muP) * muP**k / factorial(k)
print(f" {k:>3} {emp:>11.5f} {pois:>12.5f}")
g = gaps.ravel() # all interarrival gaps ~ Exp(lambda)
print(f" interarrival ~ Exponential(lambda): mean = {g.mean():.4f} (theory 1/lam = {1/lam:.4f}),"
f" var = {g.var():.4f} (theory 1/lam^2 = {1/lam**2:.4f})")
xchk = 0.5
emp_cdf = np.mean(g <= xchk)
print(f" P(gap <= {xchk}): empirical = {emp_cdf:.4f}, theory 1-e^(-lam*x) = {1-exp(-lam*xchk):.4f}")
# ===============================================================
# PART 3 — GAUSSIAN PROCESS on a finite grid via covariance matrix + Cholesky.
# Mean m(t)=0; covariance C(s,t) = exp(-(s-t)^2 / (2 ell^2)) (squared-exponential).
# Draw X = L z, L L^T = C, z ~ N(0, I). Check empirical mean ~ m, cov ~ C.
# ===============================================================
print("\n=== PART 3 Gaussian process (mean 0, squared-exp covariance) ===")
ell = 1.0
t = np.linspace(0.0, 5.0, 11) # 11 time points on [0,5]
S2, T2 = np.meshgrid(t, t, indexing="ij")
Cmat = np.exp(-(S2 - T2)**2 / (2 * ell**2)) # covariance matrix C(s,t)
Cmat += 1e-10 * np.eye(t.size) # tiny jitter for numerical PD-ness
L = np.linalg.cholesky(Cmat) # lower-triangular, L L^T = C
K = 200_000
z = rng.standard_normal(size=(t.size, K)) # each column z ~ N(0, I)
Xgp = L @ z # each column is one GP sample on the grid
emp_mean = Xgp.mean(axis=1)
emp_cov = np.cov(Xgp) # 11x11 empirical covariance
print(f" grid t = {np.round(t,2)}")
print(f" max |empirical mean - 0| = {np.max(np.abs(emp_mean)):.5f}")
print(f" max |empirical cov - C(s,t)| = {np.max(np.abs(emp_cov - Cmat)):.5f}")
print(f" C(t0,t0) emp/theory = {emp_cov[0,0]:.4f} / {Cmat[0,0]:.4f} (variance, should be 1)")
print(f" C(t0,t1) emp/theory = {emp_cov[0,1]:.4f} / {Cmat[0,1]:.4f} (|s-t|=0.5)")
print(f" C(t0,t5) emp/theory = {emp_cov[0,5]:.4f} / {Cmat[0,5]:.4f} (|s-t|=2.5, nearly 0)")
# ===============================================================
# PART 4 — EMPIRICAL AUTOCOVARIANCE of the random walk (reuse PART 1 paths).
# Theory: C(m,n) = Cov(S_m, S_n) = sigma^2 * min(m,n).
# ===============================================================
print("\n=== PART 4 Random-walk autocovariance C(m,n) = sigma^2*min(m,n) ===")
print(f" {'m':>3} {'n':>3} {'emp Cov(Sm,Sn)':>15} {'theory min(m,n)':>16}")
for (m, n) in [(5, 5), (5, 10), (10, 10), (10, 25), (25, 50)]:
Sm = S[:, m-1]
Sn = S[:, n-1]
emp = np.mean((Sm - Sm.mean()) * (Sn - Sn.mean()))
print(f" {m:>3} {n:>3} {emp:>15.4f} {sigma2*min(m,n):>16.1f}")
print(" empirical Cov(S_m,S_n) tracks sigma^2*min(m,n) (independent increments)")
৫.২ · বাস্তব আউটপুট¶
উপরের স্ক্রিপ্ট চালালে (seed 20260619, numpy 2.2.6) ঠিক নিচের আউটপুট আসে — এগুলো সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয় (দুবার চালালেও হুবহু এক, কারণ seed স্থির):
=== PART 1 Random walk S_n = sum X_i, X_i in {-1,+1} (sigma^2 = 1) ===
n mean(S_n) var(S_n) theory n*s2
1 -0.0034 1.0000 1.0
5 -0.0059 5.0108 5.0
10 -0.0160 10.0076 10.0
25 -0.0165 24.8909 25.0
50 -0.0034 50.1006 50.0
mean stays ~0; var(S_n) tracks n*sigma^2 (variance grows linearly in n)
=== PART 2 Poisson process rate lambda = 2.0 ===
(buffer check: 0 of 300000 paths saturated the 40-gap buffer; want 0)
count N(T): empirical mean = 9.9975, var = 10.0031 theory Poisson(lam*T) mean=var=10.0
k emp P(N=k) Poisson pmf
6 0.06257 0.06306
8 0.11274 0.11260
10 0.12475 0.12511
12 0.09426 0.09478
14 0.05221 0.05208
interarrival ~ Exponential(lambda): mean = 0.5002 (theory 1/lam = 0.5000), var = 0.2501 (theory 1/lam^2 = 0.2500)
P(gap <= 0.5): empirical = 0.6320, theory 1-e^(-lam*x) = 0.6321
=== PART 3 Gaussian process (mean 0, squared-exp covariance) ===
grid t = [0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. ]
max |empirical mean - 0| = 0.00515
max |empirical cov - C(s,t)| = 0.00702
C(t0,t0) emp/theory = 1.0067 / 1.0000 (variance, should be 1)
C(t0,t1) emp/theory = 0.8886 / 0.8825 (|s-t|=0.5)
C(t0,t5) emp/theory = 0.0487 / 0.0439 (|s-t|=2.5, nearly 0)
=== PART 4 Random-walk autocovariance C(m,n) = sigma^2*min(m,n) ===
m n emp Cov(Sm,Sn) theory min(m,n)
5 5 5.0108 5.0
5 10 5.0028 5.0
10 10 10.0076 10.0
10 25 9.9881 10.0
25 50 25.0019 25.0
empirical Cov(S_m,S_n) tracks sigma^2*min(m,n) (independent increments)
৫.৩ · আউটপুট কীভাবে পড়ব — দাবি মিলিয়ে দেখা¶
- Part 1 — random walk mean ও variance (§৪.১, ফল a)। এটা §৪.১-এর (4.1) ও (4.2)-এর সরাসরি সাক্ষ্য।
mean(S_n)সব \(n\)-এ \(\approx 0\) (সবচেয়ে বড় বিচ্যুতি \(-0.0165\), যা \(200{,}000\)-নমুনার Monte-Carlo দানা মাত্র) — অর্থাৎ কোনো drift নেই, ঠিক (4.1)। আরvar(S_n)কলামটা theory কলামের (\(n\sigma^2\)) গায়ে বসে আছে: \(n=50\)-এ empirical \(50.10\) বনাম theory \(50.0\)। লক্ষ করো ভ্যারিয়েন্স \(n\)-এর সাথে রৈখিকভাবে বাড়ছে (১, ৫, ১০, ২৫, ৫০) — দ্বিগুণ-চতুর্গুণ নয়, ঠিক \(n\) গুণ; এটাই \(\mathrm{sd}(S_n)=\sigma\sqrt n\) তথা diffusion-স্কেলের সংখ্যাগত রূপ। - Part 2 — Poisson process (§৪.২, ফল b)। এটাই অধ্যায়ের সবচেয়ে ঘন দাবির যাচাই, দুই অংশে:
- count \(N(T)\)। empirical mean \(9.9975\) ও var \(10.0031\) — দুটোই তত্ত্বের \(\lambda T=10\)-এর কাছে, আর mean\(\approx\)var হওয়াটাই Poisson-এর স্বাক্ষর। pmf টেবিলে প্রতিটা \(k\)-তে empirical \(P(N=k)\) আর Poisson\((10)\) pmf তিন-চার দশমিক পর্যন্ত মেলে (যেমন \(k=10\): \(0.12475\) বনাম \(0.12511\)) — অর্থাৎ (4.9) সংখ্যায় সত্য। (buffer-check \(0\) মানে কোনো path-ই \(40\)-gap সীমা ছাড়ায়নি, তাই count নিম্নমুখী পক্ষপাতহীন।)
- interarrival gap। mean \(0.5002\) বনাম তত্ত্ব \(1/\lambda=0.5\), var \(0.2501\) বনাম \(1/\lambda^2=0.25\) — Exponential\((\lambda)\)-এর mean ও variance হুবহু মিলছে। আর CDF-যাচাই \(P(\text{gap}\le 0.5)=0.6320\) বনাম \(1-e^{-\lambda\cdot 0.5}=0.6321\) — কার্যত অভিন্ন, যা (4.11) নিশ্চিত করে। অর্থাৎ "count Poisson, gap Exponential" জোড়াটা সংখ্যায় ধরা পড়ল।
- Part 3 — Gaussian process via Cholesky (§৪.৩, ফল c)। এটা দেখায় কীভাবে কেবল একটা covariance function \(C(s,t)\) থেকে পুরো process জন্মায়।
max |empirical mean - 0| = 0.00515— সব ১১টা বিন্দুতে গড় কার্যত \(0\), ঠিক \(m(t)=0\)।max |empirical cov - C(s,t)| = 0.00702— পুরো \(11\times 11\) empirical covariance matrix তত্ত্বের kernel matrix-এর গায়ে বসেছে (সর্বোচ্চ ঘর-বিচ্যুতি \(0.007\))। নির্দিষ্ট ঘরগুলো kernel-এর আকৃতি দেখায়: diagonal \(C(t_0,t_0)\approx 1\) (প্রতি বিন্দুর ভ্যারিয়েন্স \(1\)); \(\lvert s-t\rvert=0.5\)-এ \(\approx 0.88\) (কাছের বিন্দু জোরালো-সম্পর্কিত); \(\lvert s-t\rvert=2.5\)-এ \(\approx 0.04\) (দূরের বিন্দু প্রায় স্বাধীন)। এটাই §৪.৩-র মূল বার্তা — mean ও covariance function জানলেই Gaussian process পুরো নির্ধারিত, আর Cholesky (\(C=LL^\top\), PSD বলে সম্ভব) সেই সংজ্ঞাকে নমুনায় রূপ দেয়। - Part 4 — empirical autocovariance (§৪.১, ফল a-র শেষ অংশ)। এটা (4.4)-এর — autocovariance \(C(m,n)=\sigma^2\min(m,n)\)-এর — সরাসরি যাচাই, এবং এটাই
3-5-autocovarianceছবির সংখ্যাগত ভিত্তি। প্রতিটা জোড়ায় empirical \(\mathrm{Cov}(S_m,S_n)\) ঠিক \(\min(m,n)\)-এ বসছে: \((5,10)\)-এ \(5.00\) (= \(\min=5\), যদিও \(n=10\)), \((10,25)\)-এ \(9.99\) (= \(\min=10\)), \((25,50)\)-এ \(25.00\) (= \(\min=25\))। মূল চমক — covariance বড় index-এর (\(n\)) উপর নির্ভর করছে না, কেবল ছোট index-এর (\(\min\)) উপর — ঠিক §৪.১-এর "ভাগ-করা ধাপই কেবল covariance গড়ে" স্বজ্ঞা। (Part 1-এর diagonal ঘর \(m=n\) আর Part 4-এর \(m=n\) ঘর একই সংখ্যা দেয়, যেমন \((10,10)\to 10.0076\) — সামঞ্জস্য নিশ্চিত।)
সততা-নোট। সিমুলেশন §৪-এর সূত্র "প্রমাণ" করে না — অসীম replication কখনো চালানো যায় না; এটা শুধু সাক্ষ্য দেয় যে আঙুলে-গোনা \(n\) ও সসীম নমুনাতেই তত্ত্ব স্পষ্টভাবে ধরা পড়ে। ছোট-ছোট অবশিষ্ট গরমিল (যেমন Part 1-এ \(n=25\)-এ var \(24.89\), ঠিক \(25\) নয়; বা Part 3-এ \(C(t_0,t_5)\) empirical \(0.0487\) বনাম theory \(0.0439\)) হলো সসীম-replication Monte-Carlo দানা — replication বাড়ালে এগুলো আরও সঙ্কুচিত হয়, আসল সীমা §৪-এর সঠিক মান। আসল যুক্তি §৪-এর কাজ; §৫ তাকে চোখে দেখায় মাত্র।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_3-5.py-তে তৈরি; PNG_assets/-এ (prefix3-5, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font rendering সমস্যা এড়াতে) — বাংলা ব্যাখ্যা prose-এ। প্রতিটি ছবির ক্যাপশনে আলাদা করে কী লক্ষ করতে হবে বলা আছে; beginner-এর জন্য এটাই আসল শেখার সূত্র।
random process-এর ধারণাগুলো ভাষায় শক্ত শোনায়, কিন্তু ছবিতে "এক outcome = এক গোটা ফাংশন" দেখলে স্বচ্ছ হয়ে যায়। আমরা চারটি ছবি দিয়ে আমাদের চারটি running example চোখে দেখব: (১) random walk \(S_n\) কীভাবে \(0\)-র চারপাশে \(\sqrt{n}\)-হারে ছড়ায় (E1); (২) Poisson process \(N(t)\) কীভাবে একটা সিঁড়ির মতো লাফ দিয়ে বাড়ে আর তার interarrival gap-গুলো Exponential (E2); (৩) Gaussian process / Brownian motion তার covariance matrix থেকেই কীভাবে জন্ম নেয় (E3); আর (৪) stationarity মানে কী — সময়ের সাথে পরিসংখ্যান বদলায় না বনাম বদলায়, আর autocovariance কেবল lag-এর উপর নির্ভর করে (E4)।
Figure 1 — random walk: পথগুলো \(\sqrt{n}\)-হারে ছড়ায়¶
E1-এর মূল ছবি। প্রতিটি হালকা নীল রেখা একটা sample path — একটা পৃথক "ইতিহাস" \(S_n=\sum_{i=1}^{n} X_i\), যেখানে প্রতিটি ধাপ \(X_i=\pm1\) সমসম্ভাব্য। তিনটি path রঙিন করে আলাদা করা, যাতে একটা একক পথের এলোমেলো চলন দেখা যায়। লাল ড্যাশ-রেখা দুটি হলো \(\pm\sqrt{n}\) (এক standard deviation, কারণ \(\operatorname{Var}(S_n)=n\)), আর বিন্দুযুক্ত রেখা \(\pm2\sqrt{n}\)।
যা লক্ষ করতে হবে: (ক) গড় রেখা শূন্যেই থাকে — \(\mathbb{E}[S_n]=0\), path-গুলো উপরে-নিচে সমানভাবে ছড়ায়। (খ) ছড়ানোটা \(n\)-হারে নয়, \(\sqrt{n}\)-হারে — তাই envelope-টা সরলরেখা নয়, একটা ধীরে-চওড়া-হওয়া প্যারাবোলিক মুখ। (গ) প্রায় সব path বেশিরভাগ সময় \(\pm2\sqrt{n}\) ব্যান্ডের ভেতরে থাকে — এটাই "typical distance from 0 is about \(\sqrt{n}\)" কথাটার চাক্ষুষ রূপ। এই \(\sqrt{n}\)-ছড়ানোই পরে CLT (3.4) আর Brownian motion-এর সাথে random walk-কে জোড়ে।
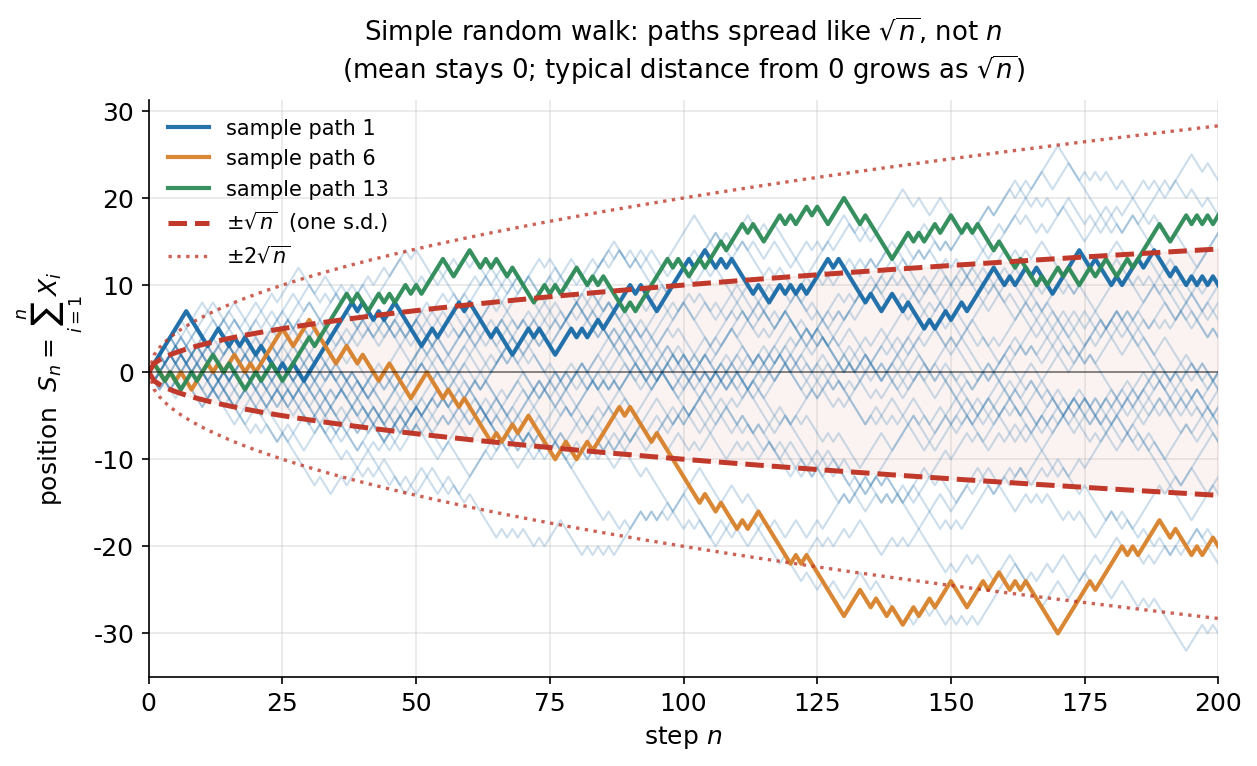
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(7)
N, M = 200, 30
steps = rng.choice([-1, 1], size=(M, N))
walks = np.hstack([np.zeros((M, 1)), np.cumsum(steps, axis=1)]) # start at 0
n = np.arange(N + 1)
fig, ax = plt.subplots(figsize=(9.2, 5.0))
for i in range(M):
ax.plot(n, walks[i], color="#1b6ca8", alpha=0.22, lw=1.0)
for i, c in zip([0, 5, 12], ["#1b6ca8", "#d9822b", "#2e8b57"]):
ax.plot(n, walks[i], color=c, lw=2.0, label=f"sample path {i+1}")
ax.plot(n, np.sqrt(n), "--", color="#c0392b", lw=2.4, label=r"$\pm\sqrt{n}$ (one s.d.)")
ax.plot(n, -np.sqrt(n), "--", color="#c0392b", lw=2.4)
ax.plot(n, 2*np.sqrt(n), ":", color="#c0392b", lw=1.6, alpha=0.8, label=r"$\pm 2\sqrt{n}$")
ax.plot(n, -2*np.sqrt(n), ":", color="#c0392b", lw=1.6, alpha=0.8)
ax.fill_between(n, -np.sqrt(n), np.sqrt(n), color="#c0392b", alpha=0.06)
ax.axhline(0, color="black", lw=0.8, alpha=0.5)
ax.set_xlabel(r"step $n$"); ax.set_ylabel(r"position $S_n=\sum_{i=1}^{n}X_i$")
ax.legend(loc="upper left"); ax.set_xlim(0, N)
fig.savefig("3-5-random-walk.png", dpi=150, bbox_inches="tight")
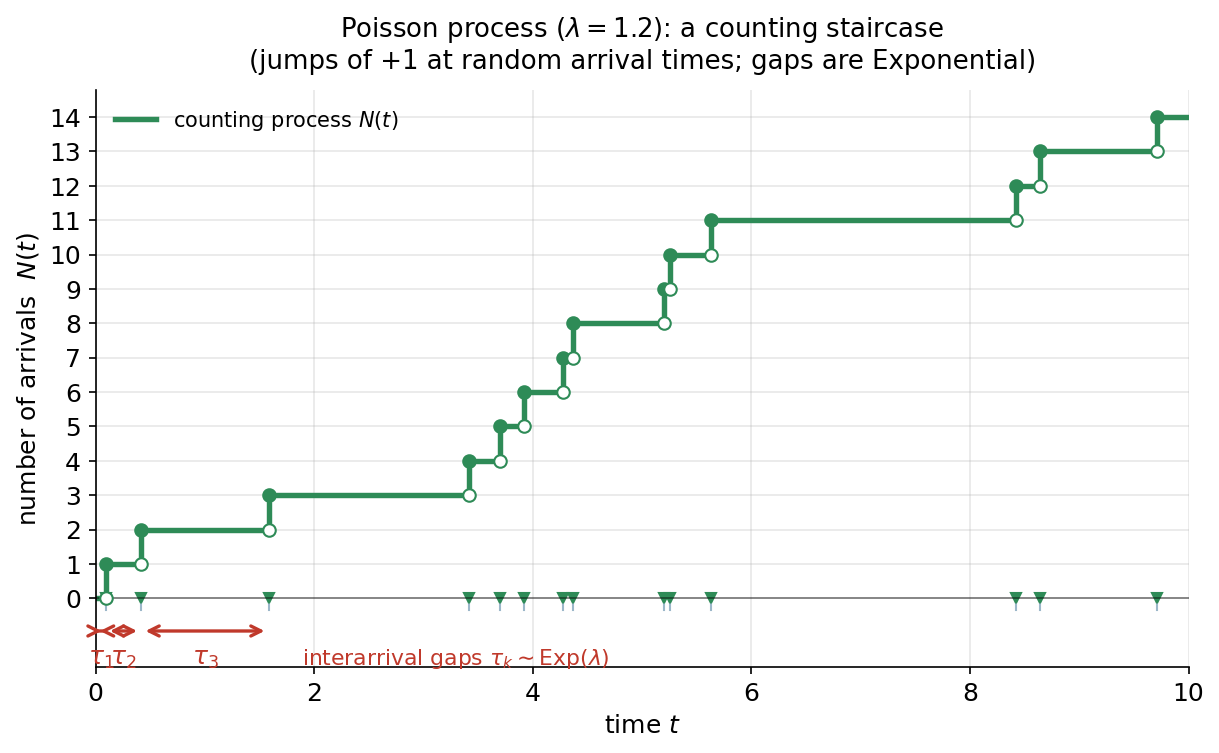
Figure 2 — Poisson process: গণনার সিঁড়ি¶
E2-এর প্রতিকৃতি। সবুজ সিঁড়ি-ফাংশন হলো counting process \(N(t)\) — সময় \([0,t]\)-এ এ পর্যন্ত ঘটে যাওয়া event-সংখ্যা (\(\lambda=1.2\))। প্রতিটি লাফ ঠিক \(+1\) উঁচু, আর লাফ ঘটে একটা random arrival time-এ। প্রতিটি লাফের নিচে একটা ভরা বৃত্ত (নতুন মান, right-continuous) আর তার ঠিক নিচে একটা ফাঁপা বৃত্ত (পুরোনো মান, ওই বিন্দুতে আর নেই) — এই open/filled জোড়াই "ডানদিক-সন্তত সিঁড়ি"-র সঠিক চিত্র। x-অক্ষে ছোট ত্রিভুজ-চিহ্নগুলো arrival time, আর নিচের লাল দ্বিমুখী তীরগুলো প্রথম তিনটি interarrival gap \(\tau_1,\tau_2,\tau_3\) চিহ্নিত করে।
যা লক্ষ করতে হবে: (ক) \(N(t)\) কখনো কমে না, শুধু \(+1\) লাফে বাড়ে — গণনা বলেই। (খ) লাফগুলোর মধ্যে ফাঁক অসমান — কোথাও পরপর তিনটে event কাছাকাছি, কোথাও দীর্ঘ নীরবতা; এই ফাঁকগুলোই \(\tau_k\sim\text{Exp}(\lambda)\), iid ও memoryless। (গ) লম্বা সমতল অংশ (যেমন \(t\approx6\) থেকে \(8.4\)) মানে দীর্ঘ interarrival gap — Exponential-এর লম্বা লেজের সরাসরি ফল। এই দুই রূপ — "\(N(t)\)-এর গণনা" আর "gap-গুলোর Exponential" — একই Poisson process-এর দুই মুখ।
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(3)
lam, T = 1.2, 10.0
gaps, t = [], 0.0
while True: # draw iid Exp(lam) gaps until we pass T
g = rng.exponential(1.0 / lam); t += g
if t > T: break
gaps.append(g)
arrivals = np.cumsum(gaps) # arrival times = running sum of gaps
counts = np.arange(1, len(arrivals) + 1) # N jumps to 1,2,3,... at each arrival
fig, ax = plt.subplots(figsize=(9.4, 5.0))
xs = np.concatenate([[0], arrivals, [T]]); ys = np.concatenate([[0], counts, [counts[-1]]])
ax.step(xs, ys, where="post", color="#2e8b57", lw=2.6, label=r"counting process $N(t)$")
ax.plot(arrivals, counts, "o", color="#2e8b57", ms=6) # filled = new value
ax.plot(arrivals, counts - 1, "o", color="white", mec="#2e8b57", ms=6) # open = old value
edges = np.concatenate([[0], arrivals])
for k in range(min(3, len(arrivals))): # mark first 3 gaps
ax.annotate("", xy=(edges[k+1], -0.95), xytext=(edges[k], -0.95),
arrowprops=dict(arrowstyle="<->", color="#c0392b", lw=1.6))
ax.set_xlabel(r"time $t$"); ax.set_ylabel(r"number of arrivals $N(t)$")
ax.legend(loc="upper left"); ax.set_xlim(0, T)
fig.savefig("3-5-poisson-process.png", dpi=150, bbox_inches="tight")
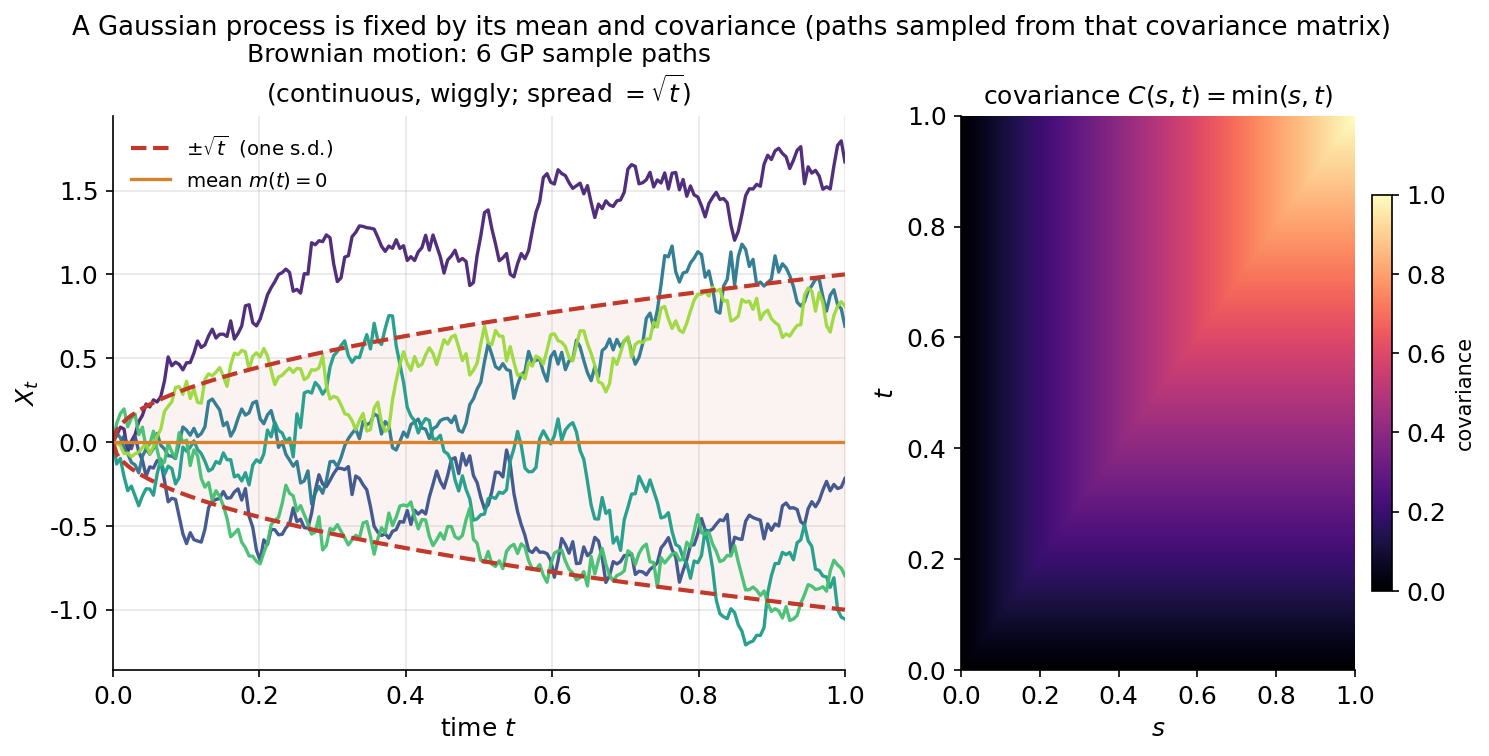
Figure 3 — Gaussian process: covariance থেকেই path¶
E3-এর কেন্দ্রীয় ছবি — দুটি প্যানেল। বাঁ প্যানেলে ছয়টি Gaussian-process sample path: এগুলো Brownian motion (\(m(t)=0\), \(C(s,t)=\min(s,t)\))। এদের আঁকা হয়েছে সরাসরি covariance matrix থেকে — \(K_{ij}=\min(t_i,t_j)\) নিয়ে Cholesky factor \(L\) (\(K=LL^{\top}\)) বের করে \(X=Lz\) (যেখানে \(z\) iid standard Normal); এটাই "একটা GP মানে শুধু একটা বিশাল multivariate Normal" কথাটার যন্ত্র। কমলা রেখা \(m(t)=0\), লাল ড্যাশ \(\pm\sqrt{t}\) envelope (কারণ \(\operatorname{Var}(W_t)=t\))। ডান প্যানেলে সেই covariance matrix \(C(s,t)=\min(s,t)\) নিজেই — একটা heatmap, কোণে (বড় \(s,t\)) উজ্জ্বল, কারণ সেখানে covariance বেশি।
যা লক্ষ করতে হবে: (ক) path-গুলো সন্তত কিন্তু কাঁটা-কাঁটা (nowhere-smooth) — Brownian motion-এর স্বাক্ষর। (খ) সবগুলো \(t=0\)-তে এক বিন্দু (\(0\)) থেকে শুরু, তারপর সময়ের সাথে \(\sqrt{t}\)-envelope-এর ভেতরে ফ্যানের মতো ছড়ায় — random walk-এর \(\sqrt{n}\)-ছড়ানোরই সন্তত (continuous-time) যমজ। (গ) ডান heatmap-এ কর্ণের কাছে মান সবচেয়ে বড় (\(C(t,t)=t\)) আর কোণ থেকে দূরে কম — মানে দূরের দুই সময় কম সম্পর্কিত। মূল বার্তা: mean function \(m(t)\) আর covariance \(C(s,t)\) জানা থাকলেই পুরো Gaussian process জানা — path-গুলো ওই matrix থেকেই বেরোয়।
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(11)
t = np.linspace(0.0, 1.0, 200)
S, Tg = np.meshgrid(t, t)
K = np.minimum(S, Tg) + 1e-10*np.eye(len(t)) # Brownian cov C(s,t)=min(s,t) (+jitter)
L = np.linalg.cholesky(K) # K = L L^T
paths = L @ rng.standard_normal((len(t), 6)) # each column is a GP sample path X=Lz
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 4.8),
gridspec_kw={"width_ratios": [1.7, 1]})
for j in range(6):
ax1.plot(t, paths[:, j], lw=1.6)
ax1.plot(t, np.sqrt(t), "--", color="#c0392b", lw=2.0, label=r"$\pm\sqrt{t}$ (one s.d.)")
ax1.plot(t, -np.sqrt(t), "--", color="#c0392b", lw=2.0)
ax1.plot(t, np.zeros_like(t), color="#d9822b", lw=1.6, label=r"mean $m(t)=0$")
ax1.set_xlabel(r"time $t$"); ax1.set_ylabel(r"$X_t$"); ax1.legend(loc="upper left")
im = ax2.imshow(K, origin="lower", extent=[0,1,0,1], cmap="magma", aspect="auto")
ax2.set_xlabel(r"$s$"); ax2.set_ylabel(r"$t$"); fig.colorbar(im, ax=ax2)
fig.savefig("3-5-gaussian-process.png", dpi=150, bbox_inches="tight")
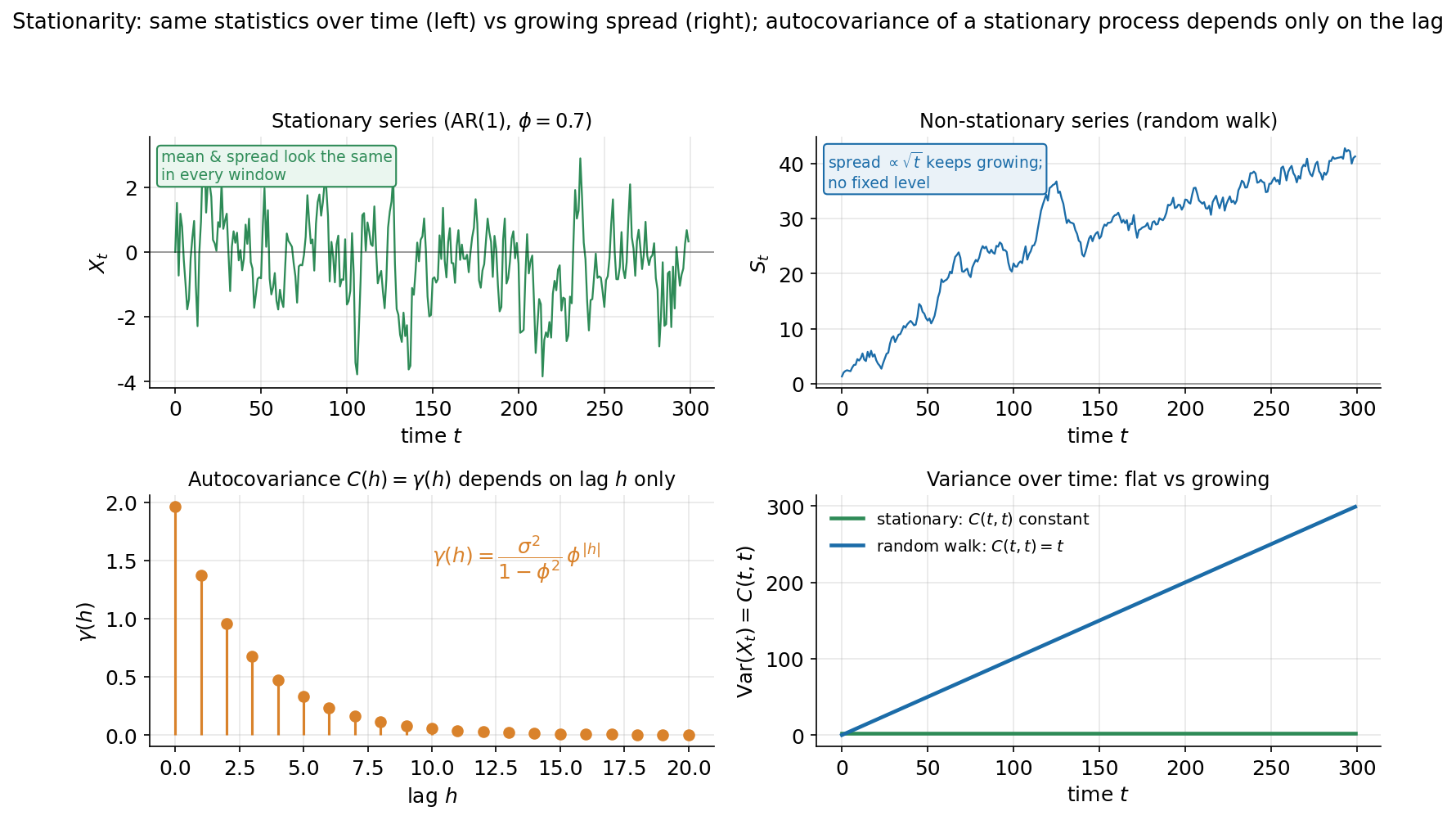
Figure 4 — stationarity ও autocovariance¶
E4-এর চার-প্যানেল সারসংক্ষেপ। উপরে-বাঁয়ে একটা stationary ক্রম — AR(1), \(X_t=0.7\,X_{t-1}+\varepsilon_t\): যেকোনো জানালায় মান ও ছড়ানো একই রকম দেখায়, কোনো trend নেই। উপরে-ডানে একটা non-stationary ক্রম — random walk \(S_t\): কোনো স্থির স্তর নেই, ছড়ানো (\(\propto\sqrt{t}\)) সময়ের সাথে বাড়তেই থাকে। নিচে-বাঁয়ে stationary process-এর তাত্ত্বিক autocovariance \(\gamma(h)=\frac{\sigma^2}{1-\phi^2}\phi^{\lvert h\rvert}\) — একটা stem plot, lag \(h\) বাড়লে দ্রুত শূন্যের দিকে নামে। নিচে-ডানে variance-বনাম-সময়: stationary-তে \(C(t,t)\) সমতল (অনুভূমিক), random walk-এ \(C(t,t)=t\) — সরলরেখায় উপরে।
যা লক্ষ করতে হবে: (ক) চোখেই আলাদা — বাঁ ক্রমটা "একই রকম থেকে যায়", ডানটা "ভেসে যায়"; এটাই stationary বনাম non-stationary-র স্বজ্ঞা। (খ) stationary process-এর \(C(s,t)\) আসলে দুই সময়ের পার্থক্যের (lag \(h=t-s\)) উপরই নির্ভর করে, \(s,t\)-এর আলাদা মানে নয় — তাই autocovariance একটা একচলকীয় ফাংশন \(\gamma(h)\) হিসেবে আঁকা যায় (নিচে-বাঁ)। (গ) \(\gamma(h)\) lag-এর সাথে কমা মানে process-এর memory ক্ষীণ হওয়া — দূরের অতীত বর্তমানকে কম প্রভাবিত করে। (ঘ) সমতল-বনাম-বাড়তি variance (নিচে-ডান) হলো stationarity-র সবচেয়ে দ্রুত পরীক্ষা: variance সময়ের সাথে বাড়লে process stationary নয়।
import numpy as np, matplotlib.pyplot as plt
rng = np.random.default_rng(21)
n = 300; tt = np.arange(n); phi, sigma = 0.7, 1.0
x_stat = np.zeros(n); eps = rng.standard_normal(n)*sigma
for k in range(1, n): # stationary AR(1)
x_stat[k] = phi*x_stat[k-1] + eps[k]
x_walk = np.cumsum(rng.standard_normal(n)) # non-stationary random walk
fig, ax = plt.subplots(2, 2, figsize=(11, 6.6))
ax[0,0].plot(tt, x_stat, color="#2e8b57", lw=1.1); ax[0,0].set_title("Stationary (AR(1))")
ax[0,1].plot(tt, x_walk, color="#1b6ca8", lw=1.1); ax[0,1].set_title("Non-stationary (random walk)")
h = np.arange(21); g0 = sigma**2/(1-phi**2); gamma = g0*phi**h # autocovariance gamma(h)
ax[1,0].stem(h, gamma); ax[1,0].set_xlabel(r"lag $h$"); ax[1,0].set_ylabel(r"$\gamma(h)$")
ax[1,1].plot(tt, np.full_like(tt, g0, float), color="#2e8b57", lw=2.2, label=r"stationary: $C(t,t)$ const")
ax[1,1].plot(tt, tt.astype(float), color="#1b6ca8", lw=2.2, label=r"random walk: $C(t,t)=t$")
ax[1,1].legend(); fig.tight_layout()
fig.savefig("3-5-autocovariance.png", dpi=150, bbox_inches="tight")
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint দেওয়া আছে। পূর্ণ সমাধান _solutions/03-05-random-processes-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ।
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন একটা random variable আর একটা stochastic process \(\{X_t\}\)-এর পার্থক্য কী। "এক outcome ধরলে একটা random variable একটা সংখ্যা দেয়, কিন্তু একটা process একটা গোটা ফাংশন (sample path) দেয়" — Figure 1 (random walk) দিয়ে এটা ব্যাখ্যা করুন: ছবিতে একটা random variable কোথায়, আর একটা sample path কোথায়? Hint: স্থির \(n\)-এ উল্লম্ব এক-একটা কলাম = এক-একটা random variable \(S_n\); একটা পুরো বাঁকা রেখা = এক outcome \(\omega\)-র sample path \(n\mapsto S_n(\omega)\)।
প্রশ্ন ২ (★). Poisson process (Figure 2)-এর দুটি সমতুল্য বর্ণনা আছে: (ক) "\(N(t)\sim\text{Poisson}(\lambda t)\) ও independent increments", আর (খ) "interarrival time \(\tau_k\) iid \(\text{Exp}(\lambda)\)"। ছবি দেখে বলুন কোন বৈশিষ্ট্য কোন বর্ণনার সাথে মেলে, এবং কেন লম্বা সমতল অংশগুলো বর্ণনা (খ)-এর "Exponential-এর লম্বা লেজ"-এর প্রমাণ। Hint: সিঁড়ির উচ্চতা = গণনা (বর্ণনা ক); দুই লাফের মধ্যে অনুভূমিক ফাঁক = interarrival gap (বর্ণনা খ)।
প্রশ্ন ৩ (★★). "Gaussian process মানে শুধু mean function \(m(t)\) আর covariance function \(C(s,t)\)" — এই দাবিটা ব্যাখ্যা করুন। কেন এটা সাধারণ (non-Gaussian) process-এর জন্য সত্য নয়? Figure 3-এর দুই প্যানেল (path বনাম covariance heatmap) দিয়ে দেখান কীভাবে covariance থেকেই path তৈরি হয়। Hint: multivariate Normal পুরোপুরি তার mean vector ও covariance matrix দিয়ে নির্ধারিত; অন্য distribution-এ একই \(m,C\) থেকেও আলাদা higher moment থাকতে পারে।
প্রশ্ন ৪ (★★). strict stationarity আর weak (wide-sense) stationarity-র পার্থক্য বলুন। কোনটা কোনটাকে imply করে? এবং ব্যাখ্যা করুন কেন Gaussian process-এর ক্ষেত্রে দুটো সমতুল্য হয়ে যায়। Figure 4-এর বাঁ (stationary) ও ডান (random walk) ক্রম দিয়ে স্বজ্ঞাটা বোঝান। Hint: strict = পুরো joint distribution শিফট-নিরপেক্ষ; weak = কেবল \(m(t)\) ধ্রুবক ও \(C(s,t)=\gamma(t-s)\)। Gaussian-এ joint distribution শুধু \(m,C\) দিয়েই ঠিক হয়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). simple random walk \(S_n=\sum_{i=1}^{n}X_i\), \(X_i=\pm1\) সমসম্ভাব্য (E1)। (ক) \(\mathbb{E}[S_n]\) ও \(\operatorname{Var}(S_n)\) বের করুন। (খ) autocovariance \(C(s,t)=\operatorname{Cov}(S_s,S_t)\) গণনা করে দেখান এটা \(\min(s,t)\)-এর সমান। (গ) এর থেকে যুক্তি দিন কেন random walk stationary নয়। Hint: \(\operatorname{Var}(X_i)=1\); \(s\le t\) হলে \(S_t=S_s+(X_{s+1}+\dots+X_t)\), আর প্রথম অংশই কেবল \(S_s\)-এর সাথে সম্পর্কিত।
প্রশ্ন ৬ (★). rate \(\lambda=2\) (per hour)-এর Poisson process (E2)। (ক) \(N(3)\)-এর distribution, mean ও variance কী? (খ) প্রথম event-এর জন্য অপেক্ষার গড় সময় কত? (গ) \(P(N(1)=0)\) বের করুন এবং interarrival-ভিত্তিতে একই উত্তর যাচাই করুন। Hint: \(N(3)\sim\text{Poisson}(\lambda\cdot3)\); \(\tau_1\sim\text{Exp}(\lambda)\), mean \(1/\lambda\); \(P(N(1)=0)=e^{-\lambda}=P(\tau_1>1)\)।
প্রশ্ন ৭ (★★). Brownian motion \(\{W_t\}\): \(m(t)=0\), \(C(s,t)=\min(s,t)\) (E3)। (ক) \(\operatorname{Var}(W_t)\) ও \(\operatorname{Var}(W_t-W_s)\) (\(s<t\)) বের করুন। (খ) \(\operatorname{Corr}(W_s,W_t)\) গণনা করুন। (গ) \((W_1,W_2)\)-এর joint distribution লিখুন (mean vector ও \(2\times2\) covariance matrix)। Hint: increment-এর variance \(=t-s\); \(\operatorname{Corr}=\min(s,t)/\sqrt{st}=\sqrt{s/t}\) (\(s<t\)); covariance matrix-এর entry \(C(i,j)=\min(i,j)\)।
প্রশ্ন ৮ (★★). AR(1) process \(X_t=\phi X_{t-1}+\varepsilon_t\), \(\varepsilon_t\) iid \(\mathcal N(0,\sigma^2)\), \(\lvert\phi\rvert<1\) (E4, Figure 4)। (ক) stationary variance \(\gamma(0)=\operatorname{Var}(X_t)\) বের করুন। (খ) autocovariance \(\gamma(h)\) ও autocorrelation \(\rho(h)\) লিখুন। (গ) \(\phi=0.7,\sigma^2=1\) হলে \(\gamma(0),\gamma(1),\rho(2)\) সংখ্যায় বের করুন। Hint: stationarity ধরে \(\gamma(0)=\phi^2\gamma(0)+\sigma^2\); \(\gamma(h)=\phi^{\lvert h\rvert}\gamma(0)\); \(\rho(h)=\phi^{\lvert h\rvert}\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). প্রমাণ করুন random walk-এর autocovariance \(C(s,t)=\operatorname{Cov}(S_s,S_t)=\min(s,t)\cdot\sigma^2\) (যেখানে \(\sigma^2=\operatorname{Var}(X_i)\))। ধাপগুলো iid, mean \(0\) ধরুন। এর থেকে দেখান \(C(t,t)=\operatorname{Var}(S_t)\) সময়ের সাথে বাড়ে, তাই process stationary নয়। Hint: \(s\le t\) ধরুন; \(\operatorname{Cov}\big(\sum_{i\le s}X_i,\sum_{j\le t}X_j\big)=\sum_{i\le s}\sum_{j\le t}\operatorname{Cov}(X_i,X_j)\), আর iid বলে কেবল \(i=j\) পদ টেকে।
প্রশ্ন ১০ (★★). Poisson process-এর superposition: \(N_1,N_2\) স্বাধীন Poisson process, rate \(\lambda_1,\lambda_2\)। প্রমাণ করুন \(N(t)=N_1(t)+N_2(t)\) একটা Poisson process, rate \(\lambda_1+\lambda_2\)। (অর্থাৎ দুটি স্বাধীন event-স্রোত মিশলে আবার Poisson, rate যোগ হয়।) Hint: স্বাধীন Poisson-এর যোগফল Poisson (\(N(t)\sim\text{Poisson}((\lambda_1+\lambda_2)t)\)); independent increments দুটোরই থাকায় যোগফলেরও থাকে।
প্রশ্ন ১১ (★★★). প্রমাণ করুন Brownian motion-এর increment-গুলো stationary: \(W_t-W_s\)-এর distribution কেবল \(t-s\)-এর উপর নির্ভর করে, \(\mathcal N(0,t-s)\) — যদিও process \(\{W_t\}\) নিজে stationary নয়। তারপর দেখান increment-process \(Y_k=W_k-W_{k-1}\) (\(k=1,2,\dots\)) একটা white-noise (iid \(\mathcal N(0,1)\)) ক্রম, তাই stationary। Hint: increment-এর mean \(0\), variance \(t-s\) (প্রশ্ন ৭); independent increments বলে \(Y_k\)-রা স্বাধীন; প্রতিটি \(\mathcal N(0,1)\) বলে identically distributed।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে simple random walk-এর \(500\)টি sample path (\(n=0,\dots,200\)) সিমুলেট করুন (default_rng(0)), Figure 1-এর মতো এঁকে \(\pm\sqrt{n}\) envelope বসান। তারপর প্রতিটি \(n\)-এ empirical \(\operatorname{Var}(S_n)\) বের করে দেখান এটা তাত্ত্বিক রেখা \(n\)-এর গায়ে বসে।
Hint: steps = rng.choice([-1,1], size=(500, 200)); walks = np.cumsum(steps, axis=1); walks.var(axis=0) বনাম np.arange(1,201)।
প্রশ্ন ১৩ (★★). rate \(\lambda=1.5\)-এর Poisson process সিমুলেট করুন interarrival পদ্ধতিতে (iid rng.exponential(1/lam) জমিয়ে cumsum) সময় \(T=20\) পর্যন্ত। (ক) \(N(20)\) গণনা করুন এবং বহুবার চালিয়ে এর গড় \(\approx\lambda T=30\) যাচাই করুন। (খ) interarrival gap-গুলোর histogram এঁকে তাত্ত্বিক \(\text{Exp}(\lambda)\) density-র সাথে মেলান।
Hint: gaps = rng.exponential(1/lam, size=large); arr = np.cumsum(gaps); N20 = (arr <= 20).sum(); histogram-এ density=True, তুলনা lam*np.exp(-lam*x)-এর সাথে।
প্রশ্ন ১৪ (★★★). Brownian motion-কে covariance matrix থেকে সিমুলেট করুন (Figure 3-এর পদ্ধতি): \(t\in[0,1]\)-এ grid নিয়ে \(K_{ij}=\min(t_i,t_j)\) বানান, Cholesky \(L\) বের করে \(X=Lz\) দিয়ে ১০টি path আঁকুন। তারপর empirical covariance \(\widehat{\operatorname{Cov}}(W_s,W_t)\) (\(s=0.3,t=0.7\), অনেক path-এ) বের করে তাত্ত্বিক \(\min(0.3,0.7)=0.3\)-এর সাথে মেলান।
Hint: K = np.minimum.outer(t, t) + 1e-10*np.eye(len(t)); L = np.linalg.cholesky(K); paths = L @ rng.standard_normal((len(t), Npaths)); দুই row নিয়ে np.cov।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- একটা stochastic process \(\{X_t\}\) হলো এক probability space-এ সংজ্ঞায়িত random variable-এর একটা সংগ্রহ, \(t\) (সময়/স্থান) দিয়ে index করা। একটা outcome স্থির করলে একটা sample path (\(t\mapsto X_t(\omega)\)) — একটা গোটা ফাংশন — পাওয়া যায়। দুটি বর্ণনাকারী রাশি: mean function \(m(t)=\mathbb{E}[X_t]\) আর autocovariance function \(C(s,t)=\operatorname{Cov}(X_s,X_t)\) — যা process-এর memory/নির্ভরতার গঠন ধরে।
- E1 — random walk \(S_n=\sum_{i=1}^{n}X_i\) (iid \(\pm1\)): discrete-time process, \(\mathbb{E}[S_n]=0\), \(\operatorname{Var}(S_n)=n\), \(C(s,t)=\min(s,t)\)। তাই \(0\) থেকে দূরত্ব \(\sqrt{n}\)-হারে বাড়ে (Figure 1) — stationary নয়।
- E2 — Poisson process \(N(t)\): rate \(\lambda\)-র counting process; \(N(t)\sim\text{Poisson}(\lambda t)\), independent increments, interarrival time iid \(\text{Exp}(\lambda)\) (Figure 2)। "গণনার সিঁড়ি" আর "Exponential gap" একই জিনিসের দুই রূপ।
- E3 — Gaussian process: যেকোনো সসীম সংগ্রহ \((X_{t_1},\dots,X_{t_k})\) multivariate Normal — তাই সম্পূর্ণরূপে \(m(t)\) ও \(C(s,t)\) দিয়ে নির্ধারিত। Brownian motion এর প্রধান উদাহরণ (\(m=0\), \(C(s,t)=\min(s,t)\)): সন্তত, কোথাও-অন্তরকলনযোগ্য-নয়, \(\sqrt{t}\)-হারে ছড়ায় (Figure 3)। path covariance matrix থেকেই তৈরি (\(X=Lz\), \(K=LL^\top\))।
- E4 — stationarity: process-এর পরিসংখ্যান সময়-শিফটে অপরিবর্তিত। strict = পুরো joint distribution শিফট-নিরপেক্ষ; weak = \(m(t)\) ধ্রুবক ও \(C(s,t)=\gamma(t-s)\) (কেবল lag-নির্ভর)। Gaussian process-এ দুটো সমতুল্য। stationary হলে autocovariance একচলকীয় \(\gamma(h)\); AR(1)-এ \(\gamma(h)=\frac{\sigma^2}{1-\phi^2}\phi^{\lvert h\rvert}\) (Figure 4)। random walk/Brownian motion stationary নয় (variance বাড়ে), কিন্তু এদের increment-গুলো stationary।
statistics/ML-এর সাথে সংযোগ (কেন এত গুরুত্বপূর্ণ):
| ধারণা | statistics/ML-এ ভূমিকা |
|---|---|
| random walk / Brownian motion | finance-এ asset-price মডেল; bootstrap/MCMC-র convergence-তত্ত্ব; diffusion-ভিত্তিক generative model-এর ভিত্তি |
| Poisson process | queueing, arrival/event মডেল (call center, web traffic, নিউরন-spike); Poisson regression ও point-process-এর কাঠামো |
| Gaussian process | GP regression/kernel method — ML-এ অনিশ্চয়তাসহ nonparametric prediction; Bayesian optimization-এর হৃদয় |
| stationarity ও autocovariance | time-series বিশ্লেষণের ভিত্তি (ARMA, forecasting); spectral analysis; signal processing-এ noise-মডেল |
পূর্ববর্তী সংযোগ (← 3.4, 2.6): 3.4-এর Central Limit Theorem এখানে দুইভাবে ফিরে আসে — random walk \(S_n\)-কে \(\sqrt{n}\) দিয়ে স্কেল করলে তা Normal-এ যায় (CLT), আর সেই \(\sqrt{n}\)-ছড়ানোই Brownian motion-এর সন্তত রূপের জন্ম দেয় (Donsker-এর invariance principle-এর বীজ)। 2.6-এর joint distribution ও covariance (\(\operatorname{Cov}\)) সরাসরি \(C(s,t)\)-তে রূপ নেয়; Gaussian process আসলে multivariate Normal-এরই (2.6) অসীম-মাত্রিক সম্প্রসারণ — তাই mean vector → \(m(t)\), covariance matrix → \(C(s,t)\)।
পরবর্তী সংযোগ (→ 3.6 Markov chains): এই অধ্যায়ে process-গুলোর নির্ভরতা হয় খুব সরল (Poisson/Brownian-এ independent increments) নয়তো সম্পূর্ণ-Normal (Gaussian)। পরের অধ্যায় 3.6-এ আসে একটা বিশেষ ও শক্তিশালী নির্ভর process — Markov chain, যেখানে "ভবিষ্যৎ অতীত থেকে স্বাধীন, শুধু বর্তমান জানলেই চলে" (Markov property)। AR(1) (এই অধ্যায়ের Figure 4) আসলে একটা সরল continuous-state Markov process — তাই 3.6 এই অধ্যায়েরই স্বাভাবিক ধারাবাহিকতা: random walk হলো integer-line-এ সরলতম Markov chain, আর Markov chain-ই MCMC, PageRank ও hidden-Markov-model-এর ভিত্তি।
সূত্র (sources): Wasserman, All of Statistics, Ch. 23 (Stochastic Processes — Markov chains, Poisson processes); Fernández-Granda, Probability and Statistics for Data Science, "Random Processes" অধ্যায় (random walk, Poisson ও Gaussian process, stationarity ও autocovariance)।