3.6 — Markov Chains & Introduction to MCMC (মার্কভ চেইন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "ভবিষ্যৎ শুধু বর্তমানের উপর নির্ভর করে, অতীতের উপর নয়"¶
১.১ একটা নতুন ধরনের randomness — যেখানে গতকালের কথা মনে থাকে, কিন্তু অল্পটুকুই¶
এতদিন (Part II ও Part III-এর প্রথম দিকে) আমরা প্রায় সবসময় ধরে নিয়েছি আমাদের random variable-গুলো স্বাধীন (independent) — একটার ফল জানলে অন্যটা সম্পর্কে নতুন কিছু জানা যায় না। i.i.d. নমুনা, coin toss-এর ক্রম, এসবের মূল ভিত্তি ছিল এই স্বাধীনতা। কিন্তু বাস্তব জগতের বেশিরভাগ "ক্রমে ঘটতে থাকা" ঘটনা মোটেও স্বাধীন নয় — আজকের আবহাওয়া কালকের আবহাওয়ার সাথে সম্পর্কিত, আজকের শেয়ারের দাম গতকালের দামের কাছাকাছি, একটা গান শোনার পর পরের গান কোনটা বাজবে তা আগেরটার উপর নির্ভর করে।
তাহলে কি আমরা পুরো অতীত মনে রাখতে বাধ্য? একটা প্রক্রিয়ার আজকের অবস্থা বুঝতে কি গত একশো দিনের সব তথ্য লাগবে? — এখানেই একটা চমৎকার সরলীকরণ আসে, যা অসংখ্য বাস্তব ব্যবস্থায় আশ্চর্যজনকভাবে ভালো কাজ করে। সেটি হলো:
"ভবিষ্যৎ শুধু বর্তমানের উপর নির্ভর করে, অতীতের উপর নয়।"
মানে: আজকের পুরো অবস্থা যদি আমি জানি, তাহলে আগামীকাল কী হবে তা ঠিক করতে গতকাল বা তারও আগের কথা অতিরিক্ত কোনো তথ্য দেয় না। অতীত যা বলত, তার সবটুকু ইতিমধ্যেই "বর্তমান অবস্থা"-র ভেতর ধরা আছে। এই একটিমাত্র সরল নিয়মই হলো Markov property (মার্কভ ধর্ম — রুশ গণিতবিদ Andrey Markov-এর নামে), আর যে random process এই নিয়ম মানে তাকে বলে Markov chain (মার্কভ চেইন)।
লক্ষ করুন এটা দুই চরমের মাঝখানের একটা সুন্দর অবস্থান:
- একদিকে পূর্ণ স্বাধীনতা (independence): ভবিষ্যৎ বর্তমানের উপরও নির্ভর করে না — অতি সরল, কিন্তু বাস্তবের নির্ভরশীলতা ধরতে পারে না।
- অন্যদিকে পূর্ণ স্মৃতি (full history dependence): ভবিষ্যৎ পুরো অতীতের উপর নির্ভর করে — অত্যন্ত সাধারণ, কিন্তু সামলানো প্রায় অসম্ভব।
- মাঝখানে Markov chain: ভবিষ্যৎ শুধু একধাপ পেছনের (বর্তমান) উপর নির্ভর করে — নির্ভরশীলতা ধরে, অথচ গাণিতিকভাবে সামলানো যায়।
এই "অল্পটুকু স্মৃতি" (এক ধাপের স্মৃতি) থাকাটাকে অনেক সময় বলা হয় memoryless dependence — নির্ভরশীল, কিন্তু পুরো অতীত মনে রাখে না। শব্দ দুটো প্রথমে স্ববিরোধী শোনায় ("memoryless" অথচ "dependence"?), কিন্তু মানেটা সুনির্দিষ্ট: বর্তমানকে দেওয়া হলে ভবিষ্যৎ অতীত থেকে স্বাধীন।
১.২ তিনটি hook — কোথায় এই ধারণা লুকিয়ে আছে¶
ধারণাটা কেন এত গুরুত্বপূর্ণ, তা তিনটি বাস্তব দৃষ্টান্তে দেখি। এই তিনটিই অধ্যায় জুড়ে ফিরে আসবে।
(ক) আবহাওয়া (weather). ধরুন প্রতিটি দিন হয় "রোদেলা" (sunny) নয় "বৃষ্টি" (rainy) — দুটো মাত্র সম্ভাব্য অবস্থা (state)। কালকের আবহাওয়া আজকের আবহাওয়ার উপর নির্ভর করে: রোদেলা দিনের পরদিন রোদেলা থাকার প্রবণতা বেশি, বৃষ্টির পরদিন বৃষ্টির প্রবণতা বেশি। কিন্তু একটা সরল (ও মোটামুটি বাস্তবসম্মত) ধারণা: আজকের আবহাওয়া জানলে কালকেরটা সম্পর্কে যা বলার বলা হয়ে গেছে — গত সপ্তাহের রোজকার আবহাওয়া আর নতুন কিছু যোগ করে না। এটাই একটা Markov chain, আর এটাই হবে আমাদের চলমান উদাহরণ E1।
(খ) ওয়েবে হাঁটা ও PageRank. কল্পনা করুন একজন "এলোমেলো সার্ফার" (random surfer) ওয়েবে ঘুরছে: এক পৃষ্ঠায় থাকা অবস্থায় সে ওই পৃষ্ঠার কোনো একটা লিংকে এলোমেলোভাবে ক্লিক করে পরের পৃষ্ঠায় যায়। পরের পৃষ্ঠা কোনটা হবে তা শুধু বর্তমান পৃষ্ঠার উপর নির্ভর করে (কোন কোন লিংক আছে), আগে কোথায় কোথায় ছিল তার উপর নয় — আবার Markov property। Google-এর বিখ্যাত PageRank অ্যালগরিদমের মূলে আছে ঠিক এই random walk-এর stationary distribution (§২.৬-এ সংজ্ঞা): দীর্ঘ সময় ধরে সার্ফার কোন পৃষ্ঠায় কত ভাগ সময় কাটায় — সেটাই সেই পৃষ্ঠার "গুরুত্ব"। ওয়েব-graph-এর ছোট সংস্করণ আমাদের উদাহরণ E2 (graph-এ random walk)।
(গ) MCMC — কঠিন distribution থেকে নমুনা। এটি সবচেয়ে বিস্ময়কর hook, আর এই অধ্যায়ের শেষ গন্তব্য। ভাবুন Bayesian পরিসংখ্যানে (Part IV-এ আসবে) আমরা প্রায়ই একটা জটিল posterior distribution পাই, যেখান থেকে গড়, probability ইত্যাদি বের করতে নমুনা (sample) দরকার — কিন্তু সরাসরি নমুনা নেওয়া অসম্ভব বা ভয়াবহ কঠিন। চমকপ্রদ সমাধান: এমন একটা Markov chain বুদ্ধি করে বানাও যার stationary distribution ঠিক ওই target distribution-টাই। তারপর শুধু chain-টা অনেকক্ষণ চালাও — তার গতিপথে যে অবস্থাগুলোতে সে যায়, সেগুলোই (একটু থিতু হওয়ার পর) target থেকে নেওয়া নমুনার মতো আচরণ করে! এই কৌশলের নাম Markov Chain Monte Carlo (MCMC), আর তার সরলতম রূপ Metropolis অ্যালগরিদম হবে আমাদের উদাহরণ E4। কেন এটি বিপ্লবী, তা §২.৭-এ ও পরে বিশদে।
১.৩ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Markov property — "ভবিষ্যৎ ⟂ অতীত | বর্তমান" — নিয়মটা precise করা (§২.১)।
- সেই নিয়মকে এক ধাপে ধরে রাখা সংখ্যাগুলো → transition matrix \(P\) (§২.২)।
- এক ধাপ নয়, \(n\) ধাপ পরে কোথায়? → \(n\)-step transition \(P^n\) ও Chapman–Kolmogorov সমীকরণ (§২.৩)।
- বহুদিন পর distribution কি কোথাও থিতু হয়? → stationary distribution \(\pi=\pi P\) (§২.৪) এবং কোন শর্তে সত্যিই থিতু হয় → irreducibility, aperiodicity, convergence theorem (§২.৫)।
- এই থিতু-হওয়ার ধর্মকে উল্টো কাজে লাগানো → MCMC-র মূল ধারণা (§২.৬–২.৭)।
- সব কিছু সংখ্যাসহ চারটি উদাহরণে (§৩), তারপর গভীরতর তত্ত্ব, প্রমাণ-অন্তর্দৃষ্টি, কোড ও অনুশীলনী (§৪ থেকে — পরবর্তী অংশে)।
এক বাক্যে: আগের অধ্যায়গুলো একটিমাত্র random variable বা স্বাধীন ক্রম নিয়ে ভেবেছে; এই অধ্যায় ভাবে নির্ভরশীল ক্রম নিয়ে — এবং শেখায় কীভাবে সেই নির্ভরশীলতাকেই আমরা কঠিন distribution থেকে নমুনা টানার হাতিয়ার বানাই।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে আমরা §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
প্রথমে কিছু সাধারণ notation একবারে স্থির করি (পুরো অধ্যায়ে এক থাকবে):
- State (অবস্থা) — প্রক্রিয়াটি কোনো এক মুহূর্তে যে সম্ভাব্য পরিস্থিতিগুলোর একটিতে থাকতে পারে। আমরা ধরব মোট state-সংখ্যা সসীম (finite) \(S\)টি, এবং তাদের সংখ্যা দিয়ে নাম দিই: state-সেট \(\{1,2,\dots,S\}\)। (E1-এ \(S=2\): \(1=\) sunny, \(2=\) rainy।)
- \(X_n\) — process-টির \(n\)-তম ধাপে (time step \(n\)-এ) অবস্থা; এটি একটি random variable যার মান \(\{1,\dots,S\}\)-এর একটি। এখানে \(n=0,1,2,\dots\) পূর্ণসংখ্যা সময়-সূচক (discrete time)। \(X_0\) হলো শুরুর অবস্থা।
- \(P(\cdot)\) — যথারীতি probability; \(P(A\mid B)\) হলো \(B\) দেওয়া থাকলে \(A\)-এর conditional probability (2.2)।
২.১ Markov property — আনুষ্ঠানিক সংজ্ঞা¶
§১-এর বাক্য "ভবিষ্যৎ শুধু বর্তমানের উপর নির্ভর করে"-কে এবার সমীকরণে লিখি। একটি random process \(X_0,X_1,X_2,\dots\) (প্রতিটি \(X_n\in\{1,\dots,S\}\)) Markov chain যদি যেকোনো ধাপ \(n\) এবং যেকোনো state \(i_0,i_1,\dots,i_{n-1},i,j\)-এর জন্য হয়:
প্রতিটি অংশ খুলে বলি:
- বাঁদিকে যা শর্ত (condition) দেওয়া আছে: \(X_n=i\) (বর্তমান state \(i\)) এবং \(X_{n-1}=i_{n-1},\dots,X_0=i_0\) (পুরো অতীতের পথ) — অর্থাৎ আমরা পুরো ইতিহাস জানি।
- ডানদিকে শর্ত শুধু একটাই: \(X_n=i\) (শুধু বর্তমান)।
- সমীকরণ বলছে এই দুটো probability সমান। মানে: পুরো অতীত জানা থাকলেও, ভবিষ্যৎ \(X_{n+1}\)-এর probability বদলায় না — বর্তমান \(X_n=i\) জেনে ফেললে অতীত আর কোনো অতিরিক্ত তথ্য দেয় না।
একই কথা শর্তসাপেক্ষ-স্বাধীনতার ভাষায় (conditional independence, 2.2-এর সম্প্রসারণ): বর্তমানকে দেওয়া হলে, ভবিষ্যৎ অতীত থেকে স্বাধীন — সংক্ষেপে "future \(\perp\) past \(\mid\) present"। এটাই Markov property-র প্রাণ।
একটা সূক্ষ্ম কিন্তু জরুরি ধারণা: আমরা ধরে নেব chain-টি time-homogeneous (সময়-সমসত্ত্ব) — মানে \(i\) থেকে \(j\)-তে যাওয়ার probability \(n\)-এর উপর নির্ভর করে না, যে সময়েই হোক একই:
অর্থাৎ "রোদেলা দিনের পরদিন বৃষ্টি হওয়ার সম্ভাবনা" সোমবার আর শুক্রবার — সব দিন একই। এই \(P_{ij}\) সংখ্যাগুলোই এবার একটা matrix-এ সাজাব।
২.২ Transition matrix \(P\) — এক ধাপের সব probability এক টেবিলে¶
\(i\) থেকে \(j\)-তে এক ধাপে যাওয়ার probability \(P_{ij}=P(X_{n+1}=j\mid X_n=i)\)-গুলো \(i\) ও \(j\) উভয়ই \(\{1,\dots,S\}\)-এ ঘোরে। এদের একটা \(S\times S\) বর্গাকার (square) matrix-এ সাজাই, নাম transition matrix (স্থানান্তর ম্যাট্রিক্স) \(P\):
পড়ার নিয়ম (মুখস্থ রাখার মতো): "সারি থেকে, কলামে" — \(P_{ij}\) মানে সারি \(i\) থেকে কলাম \(j\)-তে যাওয়ার probability। অর্থাৎ প্রতিটি সারি একটা "এখান থেকে কোথায় যাব" বিতরণ।
এর দুটো অপরিহার্য ধর্ম, সরাসরি probability-র নিয়ম থেকেই আসে:
- প্রতিটি entry probability, তাই \(0\le P_{ij}\le 1\)।
- প্রতিটি সারির যোগফল ঠিক \(1\)। কারণ বর্তমান state \(i\)-তে থাকলে পরের ধাপে কোথাও-না-কোথাও তো যেতেই হবে (নিজের জায়গায় থেকে যাওয়াও একটা "যাওয়া"), আর সব সম্ভাবনার যোগ \(1\): $$ \sum_{j=1}^{S} P_{ij}=1\qquad\text{প্রতিটি সারি } i\text{-এর জন্য}. $$
এই দ্বিতীয় ধর্মটি (প্রতিটি সারি একটা probability distribution) থাকায় \(P\)-কে বলে row-stochastic matrix (সারি-স্টোক্যাস্টিক)। সাবধান: কলামগুলোর যোগ \(1\) হতে বাধ্য নয় — শুধু সারিগুলোর। এই "সারি বনাম কলাম" পার্থক্যটি পরে \(\pi=\pi P\) (row-vector বাঁদিকে) বোঝার সময় গুরুত্বপূর্ণ হবে।
Distribution-কে row-vector ভাবা। এক মুহূর্তে process-টি কোন state-এ আছে, তা প্রায়ই নিশ্চিত জানি না — আমরা জানি একটা probability distribution। যেমন: "আজ ৭০% সম্ভাবনা রোদেলা, ৩০% বৃষ্টি।" এই distribution-কে একটা row-vector (সারি-ভেক্টর) হিসেবে লিখি:
এখানে \(\mu_i\) হলো এই মুহূর্তে state \(i\)-তে থাকার probability।
এক ধাপ পরে distribution — কেন \(\mu P\)। যদি এখন distribution \(\mu\) হয়, তবে পরের ধাপে state \(j\)-তে থাকার probability কত? state \(j\)-তে পৌঁছানো যায় যেকোনো \(i\) থেকে: "এখন \(i\)-তে থাকার সম্ভাবনা" \(\times\) "\(i\) থেকে \(j\)-তে যাওয়ার সম্ভাবনা", সব \(i\)-এর উপর যোগ। এটি ঠিক total probability-র নিয়ম (2.2):
ডানদিকটা ঠিক row-vector \(\mu\) আর matrix \(P\)-এর গুণফল \(\mu P\)-এর \(j\)-তম উপাদান। তাই সংক্ষেপে:
এই একটিমাত্র সূত্রই সব কিছুর চালিকা: এক ধাপ এগোনো মানে row-vector-কে \(P\) দিয়ে ডানদিক থেকে গুণ করা। (এজন্যই distribution-কে row-vector ধরা সুবিধাজনক, আর \(P\) row-stochastic।)
২.৩ \(n\)-step transition \(P^n\) ও Chapman–Kolmogorov¶
এক ধাপ এগোলে \(\mu\to\mu P\)। তাহলে দু'ধাপ এগোলে \(\mu\to(\mu P)P=\mu P^2\), তিন ধাপে \(\mu P^3\), … সাধারণভাবে \(n\) ধাপ পরে:
এখানে \(P^n\) মানে matrix \(P\)-কে নিজের সাথে \(n\) বার গুণ (\(P^n=\underbrace{P\,P\cdots P}_{n\ \text{বার}}\)), আর \(\mu_0=(\mu_{0,1},\dots,\mu_{0,S})\) হলো শুরুর (time \(0\)-এর) distribution।
এবার \(P^n\)-এর entry-গুলোর অর্থ। আমরা লিখি \(P^{(n)}_{ij}\) = ঠিক \(n\) ধাপে \(i\) থেকে \(j\)-তে পৌঁছানোর probability:
অর্থাৎ "\(n\)-step transition matrix" আর "\(P\)-এর \(n\)-তম ঘাত" — একই জিনিস। (\(n=1\)-এ \(P^{(1)}=P\); প্রথা অনুযায়ী \(P^{(0)}=I\), identity matrix — "শূন্য ধাপে যেখানে ছিলে সেখানেই থাকো"।)
কেন এটা সত্যি, তার পেছনের ছোট হিসাবটাই Chapman–Kolmogorov সমীকরণ। \(i\) থেকে \(m+k\) ধাপে \(j\)-তে যেতে হলে, মাঝপথে (ঠিক \(m\) ধাপ পরে) process কোনো এক state \(\ell\)-তে থাকবেই; সব সম্ভাব্য মধ্যবর্তী \(\ell\)-এর উপর যোগ করি (আবার total probability + Markov property):
প্রতিটি প্রতীক: \(P^{(m)}_{i\ell}\) = \(i\) থেকে \(m\) ধাপে মধ্যবর্তী state \(\ell\)-তে যাওয়া; \(P^{(k)}_{\ell j}\) = সেখান থেকে বাকি \(k\) ধাপে \(j\)-তে যাওয়া; যোগচিহ্ন সব \(\ell\)-এর উপর। ডানদিকটা ঠিক matrix গুণফল \(P^{(m)}P^{(k)}\)-এর \((i,j)\) entry — যা প্রমাণ করে \(P^{(m+k)}=P^{(m)}P^{(k)}=P^m P^k=P^{m+k}\)। (এই সমীকরণটি Markov property-র সরাসরি ফল; পূর্ণ যুক্তি §৪-এ।)
সারাংশ — দুই দৃষ্টিভঙ্গি, একই সত্য। distribution-কেন্দ্রিক: এক ধাপ = "\(P\) দিয়ে গুণ", \(n\) ধাপ = "\(P^n\) দিয়ে গুণ"। entry-কেন্দ্রিক: \(i\to j\)-তে ঠিক \(n\) ধাপে যাওয়ার probability = \(P^n\)-এর \((i,j)\) ঘর। দুটোই আমরা §৩-এ সংখ্যায় যাচাই করব।
২.৪ Stationary distribution — যে distribution আর বদলায় না: \(\pi=\pi P\)¶
এখন কেন্দ্রীয় প্রশ্ন: chain-টা বহুদিন চললে distribution কি কোথাও থিতু হয়? অর্থাৎ এমন কোনো distribution \(\pi\) আছে কি, যা একবার পেলে আর বদলায় না — এক ধাপ চললেও একই থাকে?
এমন distribution-কে বলে stationary distribution (স্থিতিশীল/অপরিবর্তনীয় বণ্টন)। সংজ্ঞা: একটি row-vector \(\pi=(\pi_1,\dots,\pi_S)\) stationary, যদি সে এক ধাপে নিজেতেই ফিরে আসে:
প্রতিটি অংশ:
- \(\pi=(\pi_1,\dots,\pi_S)\) একটি row-vector (distribution); \(\pi_i\) = stationary অবস্থায় state \(i\)-তে থাকার probability।
- শর্ত \(\pi_i\ge 0\) ও \(\sum_i\pi_i=1\) নিশ্চিত করে এটি সত্যিই একটি বৈধ probability distribution।
- সমীকরণ \(\pi=\pi P\) বলছে: distribution যদি এখন \(\pi\) হয়, তবে এক ধাপ পরেও (\(\pi P\)) সেটি \(\pi\)-ই থাকে — কোনো পরিবর্তন নেই। তাই \(n\) ধাপ পরেও \(\pi P^n=\pi\)।
একটা সহজ ভৌত ছবি: কল্পনা করুন বহু কণা (particle) state-গুলোতে \(\pi\) অনুপাতে ছড়িয়ে আছে, আর প্রত্যেকে \(P\) অনুযায়ী লাফাচ্ছে। \(\pi\) stationary হলে — প্রতিটি ধাপে state \(i\) ছেড়ে যত কণা বেরোয়, ঠিক তত কণা \(i\)-তে ঢোকে; মোট চিত্রটা স্থির, যদিও আলাদা আলাদা কণা ঘুরছেই। এটাকে বলে equilibrium (সাম্যাবস্থা)।
\(\pi=\pi P\) আসলে একটা linear সমীকরণ-সংহতি। \(\pi=\pi P\) মানে প্রতিটি \(j\)-এর জন্য \(\pi_j=\sum_{i}\pi_i P_{ij}\) — \(S\)টি linear সমীকরণ, \(S\)টি অজানা (\(\pi_1,\dots,\pi_S\))। সাথে normalization \(\sum_i\pi_i=1\) যোগ করলে সাধারণত একটিমাত্র সমাধান মেলে। অর্থাৎ stationary distribution বের করা = হাতে একটা সরল linear system সমাধান করা — যা আমরা E3-তে সংখ্যাসহ করব।
সতর্কতা — symbol-confusion এড়াই। এখানে \(\pi\) মানে বৃত্তের ৩.১৪১৬ নয়; এটি stationary distribution-এর প্রচলিত নাম মাত্র (একটি probability row-vector)। আর \(\pi=\pi P\) লেখায় \(\pi\) বাঁদিকে (row-vector বাঁ থেকে \(P\)-কে গুণ করছে) — eigenvalue-ভাষায় \(\pi\) হলো \(P\)-এর left eigenvector, eigenvalue \(1\)-এর সাথে। (এই eigen-সংযোগ ঐচ্ছিক; §৪-এ।)
২.৫ কখন distribution সত্যিই \(\pi\)-তে যায়? — irreducibility, aperiodicity, convergence theorem (intro)¶
stationary distribution-এর সংজ্ঞা (\(\pi=\pi P\)) শুধু বলে "এমন একটা \(\pi\) আছে যা বদলায় না"। কিন্তু আরও জোরালো প্রশ্ন: শুরু যেখান থেকেই করি না কেন, distribution কি শেষমেশ ওই \(\pi\)-তেই গিয়ে পৌঁছায়? এটাই MCMC-র গোটা ভিত্তি, তাই এখানে স্বজ্ঞা-পর্যায়ে দুটো শর্ত ও একটা উপপাদ্য পরিচয় করিয়ে দিই (পূর্ণ আলোচনা §৪–৫-এ)।
দুটো শর্ত দরকার, প্রত্যেকটির পেছনে একটা সরল "যা ভুল হতে পারে" ছবি আছে:
- Irreducibility (অবিভাজ্যতা) — যেকোনো state থেকে যেকোনো state-এ (যথেষ্ট ধাপে, positive probability-তে) পৌঁছানো যায়; chain-টা আলাদা আলাদা অংশে আটকে যায় না। যদি ভাঙে: ধরুন state-সেট দুই দলে বিভক্ত আর এক দল থেকে অন্য দলে কখনো যাওয়া যায় না — তাহলে কোথা থেকে শুরু করলেন তার উপরই চূড়ান্ত distribution নির্ভর করবে, একটা সর্বজনীন \(\pi\) থাকবে না।
- Aperiodicity (অপর্যাবৃত্তি) — chain কোনো নির্দিষ্ট ছন্দে (period) আটকে দোলে না। যদি ভাঙে: কল্পনা করুন এমন chain যা state \(1\) আর \(2\)-এর মধ্যে কেবল \(1\to2\to1\to2\) এভাবে লাফায় (period \(2\))। distribution তখন দুই রূপের মধ্যে চিরকাল দুলবে, কখনো একটিতে থিতু হবে না — যদিও stationary \(\pi\) থেকে যায়। ছোট্ট self-loop (যেমন \(P_{ii}>0\)) থাকলেই সাধারণত এই দোলন ভেঙে যায়।
এই দুই শর্ত একসাথে থাকলে chain-কে বলে ergodic (এর্গডিক)। আর তখন মূল ফল:
Convergence theorem (অভিসারণ উপপাদ্য — intro রূপ). একটি সসীম, irreducible ও aperiodic (অর্থাৎ ergodic) Markov chain-এর একটিমাত্র stationary distribution \(\pi\) থাকে, এবং যে initial distribution \(\mu_0\) থেকেই শুরু করি, \(n\) বড় হলে $$ \mu_0\,P^{n}\;\longrightarrow\;\pi\qquad(n\to\infty). $$ অর্থাৎ chain "ভুলে যায়" সে কোথা থেকে শুরু হয়েছিল, আর সবাই একই equilibrium \(\pi\)-তে এসে মেলে।
এই "শুরু ভুলে যাওয়া এবং \(\pi\)-তে স্থির হওয়া"-র ছবিটাই হবে Figure 3-6-convergence: একাধিক ভিন্ন শুরুর রেখা ধাপে ধাপে একই অনুভূমিক স্তরে (অর্থাৎ \(\pi\)-তে) মিশে যাচ্ছে।
এখানে দুটো গভীর ফলের ইঙ্গিত দিয়ে রাখি (বিশদ §৪–৫-এ): এই ergodic chain-এ (ক) দীর্ঘকালীন distribution \(\pi\), এবং (খ) একটা চমৎকার "ergodic average" — chain যত ভাগ সময় state \(i\)-তে কাটায়, \(n\to\infty\)-তে তা \(\pi_i\)-তে যায়। এই দ্বিতীয় কথাটাই PageRank-এ "গুরুত্ব" আর MCMC-তে "নমুনা থেকে গড় হিসাব" — দুটোরই ভিত্তি।
২.৬ MCMC-র মূল ধারণা — target-কে stationary বানিয়ে নমুনা টানা¶
এবার অধ্যায়ের মুকুট-রত্ন। §২.৫-এ আমরা একটা দেওয়া chain (\(P\)) থেকে তার ফলস্বরূপ \(\pi\) বের করছিলাম — এটা ছিল "\(P\) দাও, \(\pi\) পাও" দিকে চলা। MCMC ঠিক উল্টোদিকে হাঁটে।
পরিস্থিতিটা এই: আমাদের একটা target distribution (লক্ষ্য বণ্টন) \(\pi\) দেওয়া আছে — যেটি থেকে আমরা নমুনা টানতে চাই (Part IV-এ এটি প্রায়ই Bayesian posterior হবে)। কিন্তু \(\pi\) এত জটিল যে সরাসরি নমুনা নেওয়া যায় না। প্রায়ই আমরা \(\pi\)-কে শুধু একটা ধ্রুবক-গুণিতক পর্যন্ত জানি — মানে কোনো একটা না-নর্মালাইজড ফাংশন জানি, কিন্তু পুরো distribution জুড়ে যোগফল \(1\) বানানোর normalizing constant-টা জানি না (এই constant হিসাব করা প্রায়ই অসম্ভব)।
MCMC-র উল্টানো প্রশ্ন: "\(\pi\) দাও — আমাকে এমন একটা সহজ-চালানো chain \(P\) বানিয়ে দাও যার stationary distribution ঠিক এই \(\pi\)।" যদি এমন \(P\) বানানো যায়, তবে §২.৫-এর convergence theorem অনুযায়ী: শুধু যেকোনো জায়গা থেকে chain চালাতে থাকো; কিছুক্ষণ পর তার ভ্রমণ-পথের অবস্থাগুলো \(\pi\) থেকে নেওয়া নমুনার মতো আচরণ করবে। তখন কঠিন \(\pi\) থেকে সরাসরি নমুনা না নিয়েও, chain-এর গতিপথ থেকে আমরা \(\pi\)-এর গড়, probability, ইত্যাদি আন্দাজ করতে পারি (ওই ergodic-average ধর্ম কাজে লাগিয়ে)।
দুটো ব্যবহারিক শব্দ এখানেই পরিচয় করিয়ে রাখি (বিশদ §৬–৮-এ):
- Burn-in (গা-গরম পর্ব) — chain শুরুর কিছু ধাপ এখনো \(\pi\)-তে থিতু হয়নি (শুরুর জায়গা "ভুলতে" সময় লাগে); সাধারণত প্রথম কিছু নমুনা বাদ দিই।
- Mixing (মিশে যাওয়া) — chain কত দ্রুত \(\pi\)-তে এসে state-জুড়ে ভালোভাবে ঘোরে; দ্রুত mixing মানে কম ধাপেই ভালো নমুনা।
কিন্তু মূল প্রশ্ন বাকি: দেওয়া \(\pi\)-র জন্য এমন \(P\) আমরা সত্যিই বানাব কীভাবে? — এর একটা অসাধারণ সরল সর্বজনীন উত্তর আছে, Metropolis–Hastings অ্যালগরিদম। পরের উপ-অংশে তার মূল কৌশলটুকু, আর সংখ্যাসহ এক ধাপ E4-তে।
২.৭ Metropolis-এর মূল কৌশল — কেন এটি বিপ্লবী (sketch)¶
Metropolis অ্যালগরিদমের প্রতিভা একটা সরল দুই-ধাপ চক্রে: "প্রস্তাব দাও, তারপর মেনে-নাও-বা-প্রত্যাখ্যান-করো" (propose, then accept/reject)। ধরুন এই মুহূর্তে chain state \(i\)-তে। তখন:
- Propose (প্রস্তাব)। একটা সহজ, symmetric (প্রতিসম) নিয়মে একটা সম্ভাব্য পরের অবস্থা \(j\) প্রস্তাব করো (যেমন প্রতিবেশী state থেকে এলোমেলো একটা বাছো) — এই বাছাই-নিয়মটা ইচ্ছেমতো সহজ রাখা যায়।
- Accept/Reject (গ্রহণ/বর্জন)। acceptance probability হিসাব করো $$ a=\min!\left(1,\ \frac{\pi_j}{\pi_i}\right), $$ তারপর সম্ভাবনা \(a\)-তে \(j\)-তে যাও (accept), নয়তো \(i\)-তেই থাকো (reject)।
এখানে কেন এটা চমৎকার, তা দুটো লক্ষ্যণীয় বিন্দুতে:
- শুধু অনুপাত \(\pi_j/\pi_i\) লাগে — পুরো \(\pi\) নয়। এই অনুপাতে \(\pi\)-এর সেই অজানা normalizing constant-টা কাটাকাটি হয়ে যায় (লব-হরে একই থাকে)। ঠিক এই কারণেই MCMC Bayesian computation-এ বিপ্লবী: posterior-কে আমরা সাধারণত শুধু normalizing-constant পর্যন্ত জানি, আর Metropolis-এর ঠিক ততটুকুই দরকার!
- নিয়মটা "উঁচুর দিকে টানে, কিন্তু নিচেও নামতে দেয়।" প্রস্তাবিত \(j\) যদি বেশি সম্ভাব্য হয় (\(\pi_j\ge\pi_i\)), তবে \(a=1\) — নিশ্চিত গ্রহণ। আর \(j\) কম সম্ভাব্য হলে (\(\pi_j<\pi_i\)) মাঝে মাঝে তবু গ্রহণ করি (সম্ভাবনা \(\pi_j/\pi_i\))। এই ভারসাম্যই chain-কে \(\pi\)-এর উঁচু অঞ্চলে বেশি সময় কাটাতে বাধ্য করে — ঠিক যতটা \(\pi\) চায় — অথচ কোনো অঞ্চল পুরো বাদ পড়ে না।
কেন এই বিশেষ acceptance-নিয়মে গড়া chain-এর stationary distribution ঠিক \(\pi\) হয় (এর পেছনে আছে detailed balance নামের সুন্দর শর্ত), তার পূর্ণ যুক্তি, Hastings-এর সাধারণীকরণ, ও বাস্তব কোড — সবই §৬–৮-এ। এখানে আমরা শুধু কৌশলটুকু চিনলাম; পরের অংশে (E4) এক ধাপ সংখ্যাসহ করে স্বজ্ঞাটা পাকা করব।
৩ · পূর্ণাঙ্গ উদাহরণ — সংখ্যাসহ¶
এবার §২-এর প্রতিটি ধারণা সংখ্যায় খাটিয়ে দেখি। চারটি চলমান উদাহরণ: E1 weather chain, E2 graph random walk, E3 \(\pi\) নির্ণয়, E4 Metropolis-এর এক ধাপ।
৩.১ E1 — 2-state weather chain (sunny/rainy)¶
দুটো state: \(1=\) sunny (রোদেলা), \(2=\) rainy (বৃষ্টি), অর্থাৎ \(S=2\)। ধরা যাক observation থেকে পাওয়া transition-নিয়ম:
- রোদেলা দিনের পরদিন: \(0.8\) সম্ভাবনায় রোদেলা, \(0.2\) সম্ভাবনায় বৃষ্টি।
- বৃষ্টির দিনের পরদিন: \(0.4\) সম্ভাবনায় রোদেলা, \(0.6\) সম্ভাবনায় বৃষ্টি।
transition matrix (সারি = আজ, কলাম = কাল; ক্রম: sunny, rainy):
যাচাই (row-stochastic): সারি ১ যোগ \(0.8+0.2=1\) ✓, সারি ২ যোগ \(0.4+0.6=1\) ✓। লক্ষ করুন কলাম-যোগ (\(0.8+0.4=1.2\)) \(1\) নয় — হওয়ারও দরকার নেই। (এই \(P\)-এর ছবি — দুই state, তীরে লেখা \(0.8,0.2,0.4,0.6\) — হবে Figure 3-6-transition-graph।)
দুই ধাপের transition \(P^2\)। আজ থেকে দু'দিন পরের আবহাওয়া। matrix-গুণ করি (\(P^2=P\cdot P\)):
প্রতিটি ঘর "সারি থেকে নাও \(\times\) কলাম থেকে নাও, যোগ করো":
- \((1,1):\ 0.8\cdot0.8+0.2\cdot0.4=0.64+0.08=0.72\)
- \((1,2):\ 0.8\cdot0.2+0.2\cdot0.6=0.16+0.12=0.28\)
- \((2,1):\ 0.4\cdot0.8+0.6\cdot0.4=0.32+0.24=0.56\)
- \((2,2):\ 0.4\cdot0.2+0.6\cdot0.6=0.08+0.36=0.44\)
পড়া: \(P^{(2)}_{11}=0.72\) মানে আজ রোদেলা হলে ঠিক দুই দিন পরও রোদেলা হওয়ার probability \(0.72\)। (যাচাই: প্রতিটি সারি এখনও যোগে \(1\) — \(0.72+0.28=1\) ✓।)
একটা concrete forecast। ধরুন আজ নিশ্চিত রোদেলা, অর্থাৎ আজকের distribution \(\mu_0=(1,\ 0)\) (state ১-এ পুরো ভর)। তাহলে—
আগামীকাল: \(\mu_1=\mu_0 P=(1,0)\begin{pmatrix}0.8&0.2\\0.4&0.6\end{pmatrix}=(0.8,\ 0.2)\) — কাল ৮০% রোদেলা, ২০% বৃষ্টি।
পরশু: \(\mu_2=\mu_0 P^2=(1,0)\begin{pmatrix}0.72&0.28\\0.56&0.44\end{pmatrix}=(0.72,\ 0.28)\) — পরশু ৭২% রোদেলা, ২৮% বৃষ্টি।
লক্ষ করুন distribution আস্তে আস্তে \((1,0)\) থেকে সরে একটা ভারসাম্যের দিকে যাচ্ছে — সেই ভারসাম্য (\(\pi\)) ঠিক কত, তা বের করব E3-তে। (এই chain irreducible — দু'দিক থেকেই যাওয়া যায় — আর aperiodic — self-loop \(P_{11},P_{22}>0\); তাই §২.৫ অনুযায়ী distribution একটা একক \(\pi\)-তে থিতু হবে।)
৩.২ E2 — ছোট graph-এ random walk¶
এবার একটা graph (নকশা) নিই — কয়েকটা বিন্দু (node) আর তাদের সংযোগ-রেখা (edge)। Random walk মানে: এক node-এ থাকা অবস্থায়, তার যত প্রতিবেশী (যে যে node-এর সাথে সরাসরি edge আছে) তাদের মধ্যে থেকে সমান সম্ভাবনায় একটা বেছে সেখানে চলে যাও। (এটাই PageRank-এর random surfer-এর সরল সংস্করণ।)
ধরা যাক তিনটি node: \(A, B, C\), এবং edge আছে — \(A\!-\!B\), \(B\!-\!C\), \(A\!-\!C\) (অর্থাৎ তিনটি node একটা ত্রিভুজ, প্রত্যেকেই বাকি দুজনের প্রতিবেশী)। তাহলে প্রতিটি node-এর ২টি প্রতিবেশী, তাই প্রতিটি প্রতিবেশীতে যাওয়ার probability \(\tfrac12\)। state ক্রম \((A,B,C)\) ধরে transition matrix:
পড়া: \(A\)-তে থাকলে \(\tfrac12\) সম্ভাবনায় \(B\), \(\tfrac12\) সম্ভাবনায় \(C\) (নিজের জায়গায় থাকা নেই, তাই \(P_{AA}=0\))। প্রতিটি সারি যোগে \(1\) ✓ (row-stochastic)।
এক ধাপ। ধরুন এখন আমরা নিশ্চিত \(A\)-তে: \(\mu_0=(1,0,0)\)। এক ধাপ পরে—
অর্থাৎ এক ধাপ পরে \(\tfrac12\) সম্ভাবনায় \(B\), \(\tfrac12\) সম্ভাবনায় \(C\) — যা সরাসরি দেখাই যাচ্ছিল। symmetry (প্রতিসাম্য) থেকেই অনুমান করা যায় দীর্ঘকালে তিন node সমান — stationary \(\pi=(\tfrac13,\tfrac13,\tfrac13)\); এটি E3-এর পদ্ধতিতে যাচাই করা যায় (\(\sum\) প্রতিবেশী সমান হলে uniform \(\pi\) আসে)। (এই triangle-graph ও তার তীরগুলোও Figure 3-6-transition-graph-এর অংশ হতে পারে।)
৩.৩ E3 — stationary distribution \(\pi=\pi P\) হাতে নির্ণয়¶
E1-এর weather chain-এ ফিরি; এবার তার ভারসাম্য \(\pi=(\pi_1,\pi_2)\) আসলে কত, সংখ্যায় বের করি। সংজ্ঞা \(\pi=\pi P\) মানে:
ডানদিকের গুণফল উপাদান-অনুযায়ী লিখি (row-vector \(\times\) matrix):
প্রথম সমীকরণ গোছাই: \(\pi_1-0.8\pi_1=0.4\pi_2\Rightarrow 0.2\,\pi_1=0.4\,\pi_2\Rightarrow \pi_1=2\,\pi_2\)। (দ্বিতীয় সমীকরণও একই তথ্য দেয় — \(0.4\pi_2=0.2\pi_1\) — তাই দুটো সমীকরণ আলাদা কিছু বলে না; এজন্যই normalization লাগে।)
এবার normalization \(\pi_1+\pi_2=1\) ব্যবহার করি, \(\pi_1=2\pi_2\) বসিয়ে:
অর্থাৎ
ব্যাখ্যা: দীর্ঘকালে প্রায় \(\tfrac23\) দিন রোদেলা, \(\tfrac13\) দিন বৃষ্টি — শুরু রোদেলা না বৃষ্টি, তাতে চূড়ান্ত অনুপাত বদলায় না (irreducible + aperiodic বলে)। মিলিয়ে দেখুন E1-এর forecast: \(\mu_1=(0.8,0.2)\), \(\mu_2=(0.72,0.28)\) — ক্রমে \((0.667,0.333)\)-এর দিকেই এগোচ্ছে। যাচাই: \(\pi P=(\tfrac23,\tfrac13)P=\big(\tfrac23\cdot0.8+\tfrac13\cdot0.4,\ \tfrac23\cdot0.2+\tfrac13\cdot0.6\big)\) — সংখ্যায়: \(\tfrac23(0.8)+\tfrac13(0.4)=0.5333+0.1333=0.6667=\tfrac23\) ✓ এবং দ্বিতীয় উপাদান \(\tfrac23(0.2)+\tfrac13(0.6)=0.1333+0.2=0.3333=\tfrac13\) ✓। সত্যিই \(\pi=\pi P\)।
পদ্ধতিটা মনে রাখুন (যেকোনো ছোট chain-এ): (১) \(\pi=\pi P\) থেকে \(S\)টি সমীকরণ লেখো; (২) একটা অতিরিক্ত (redundant) বাদ দিয়ে বাকিগুলোয় \(\pi\)-গুলোর অনুপাত বের করো; (৩) \(\sum_i\pi_i=1\) দিয়ে স্কেল ঠিক করো। বড় chain-এ কম্পিউটারে একই linear system সমাধান হয় (কোড §৬–৮-এ)।
৩.৪ E4 — Metropolis-এর এক ধাপ (intuition, সংখ্যাসহ)¶
§২.৭-এর "propose, then accept/reject" এক ধাপ সংখ্যায় চালিয়ে দেখি। ধরুন আমাদের target distribution তিনটি state \(\{1,2,3\}\)-এর উপর, কিন্তু আমরা শুধু একটা না-নর্মালাইজড ওজন (unnormalized weight) \(w\) জানি:
(সত্যিকারের \(\pi\) হবে এদের ভাগ-যোগ-করা রূপ: \(\pi=(1/6,\ 3/6,\ 2/6)\), যোগফল \(w_1+w_2+w_3=6\)। কিন্তু খেয়াল করুন — Metropolis-এ এই \(6\) জানা লাগবেই না; এটাই মূল সুবিধা।)
ধরা যাক এই মুহূর্তে chain state \(i=2\)-তে।
ধাপ ১ — Propose. প্রতিসম নিয়মে একটা প্রতিবেশী state প্রস্তাব করি — ধরুন সমান সম্ভাবনায় \(\{1,2,3\}\) থেকে একটা বাছি, এবং এবার প্রস্তাব এলো \(j=1\)।
ধাপ ২ — Accept/Reject. acceptance probability:
এখানে দুটো জিনিস লক্ষণীয়:
- normalizing constant \(6\) কেটে গেল: \(\dfrac{\pi_1}{\pi_2}=\dfrac{w_1/6}{w_2/6}=\dfrac{w_1}{w_2}=\dfrac13\) — হিসাবে শুধু অনুপাত \(w_1/w_2\) লাগল, পুরো \(\pi\) নয়।
- প্রস্তাবিত state (\(1\)) বর্তমানের (\(2\)) চেয়ে কম সম্ভাব্য (\(w_1=1<3=w_2\)), তাই \(a=\tfrac13<1\) — চলে যাওয়া নিশ্চিত নয়, মাত্র \(\tfrac13\) সম্ভাবনা।
সিদ্ধান্ত। একটা \(\text{Uniform}(0,1)\) সংখ্যা \(u\) তুলি; \(u\le \tfrac13\) হলে state \(1\)-এ যাই (accept), নয়তো state \(2\)-তেই থাকি (reject)। ধরুন \(u=0.7>\tfrac13\) → reject → পরের state আবার \(2\)।
বিপরীত দিকটাও দেখি (কেন এটা \(\pi\)-কে সম্মান করে)। এবার ধরুন chain state \(1\)-এ, আর প্রস্তাব এলো \(j=2\) (বেশি সম্ভাব্য)। তখন
অর্থাৎ উঁচুতে (\(w_2>w_1\)) যাওয়ার প্রস্তাব সবসময় গ্রহণ। ফল: chain উঁচু-ওজনের state-এ টানে কিন্তু নিচুতেও মাঝে মাঝে নামে — দীর্ঘকালে প্রতিটি state-এ কাটানো সময়ের অনুপাত ঠিক \(w\)-এর অনুপাতে (অর্থাৎ \(\pi\)-তে) দাঁড়ায়। এই বহু ধাপ চালানোর গতিপথ ও তার histogram হবে Figure 3-6-mcmc-trace ও Figure 3-6-mcmc-hist: trace-এ chain-এর লাফ, আর hist-এ জমা নমুনা যে \(w=(1,3,2)\)-এর আকৃতি (অর্থাৎ \(\pi\)) ধরে ফেলেছে — সবই §৬–৮-এ কোডসহ।
এক বাক্যে E4-এর শিক্ষা: Metropolis target-এর শুধু অনুপাত দেখে "উঁচুতে নিশ্চিত, নিচুতে মাঝে মাঝে" — আর এই সরল নিয়মেই গড়া chain-এর stationary distribution হয়ে যায় ঠিক target \(\pi\)। কেন (detailed balance), পূর্ণ অ্যালগরিদম, Hastings-সাধারণীকরণ ও বাস্তব কোড — §৬–৮; convergence-এর শর্ত ও proof-অন্তর্দৃষ্টি — §৪–৫।
৪ · প্রমাণ ও উৎপাদন¶
এই অধ্যায়ের তিনটে স্তম্ভ — Chapman–Kolmogorov (\(n\)-step = matrix power), stationary distribution (\(\pi=\pi P\)), আর detailed balance — এখানে আমরা scratch থেকে দাঁড় করাব। প্রতিটি বীজগণিতের ধাপের পেছনে কারণ বাংলায় থাকবে, কোনো লাফ লুকানো থাকবে না। তিনটে ফলকে কঠিনতা অনুযায়ী ট্যাগ করছি (★ = সরাসরি · ★★ = কিছু কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে, একটা অংশ সৎ-ভাবে sketch হিসেবে নেওয়া হবে):
- (a) Chapman–Kolmogorov — \(n\)-step transition probability ঠিক matrix power \(P^n\)-এর entry; law of total probability (2.2) থেকে ধাপে ধাপে বের করব। ★★
- (b) Stationary distribution \(\pi=\pi P\) — সংজ্ঞা, অস্তিত্ব ও একত্ব (irreducible + aperiodic finite chain → একমাত্র \(\pi\), আর convergence \(P^n_{ij}\to\pi_j\)) — একটা সৎ বিবৃতি ও proof-sketch। ★★★
- (c) Detailed balance \(\pi_i P_{ij}=\pi_j P_{ji}\) ⇒ stationarity, এবং Metropolis–Hastings কেন target distribution-কে stationary রাখে — acceptance ratio-র পূর্ণ derivation। ★★
পুরো অংশের ভিত্তি দুটো জিনিস, যা আগের অধ্যায়ে শেখা: (i) law of total probability — \(P(A)=\sum_k P(A\mid B_k)\,P(B_k)\) যখন \(\{B_k\}\) একটা partition (2.2); আর (ii) Markov property — ভবিষ্যৎ শুধু বর্তমানের উপর নির্ভর করে, অতীত ভুলে যায়: \(P(X_{n+1}=j\mid X_n=i, X_{n-1}=\dots)=P(X_{n+1}=j\mid X_n=i)=P_{ij}\) (3.5)। এই দুই হাতিয়ার দিয়েই পুরো অধ্যায়ের গাণিতিক মেরুদণ্ড দাঁড়াবে।
৪.১ · (a) Chapman–Kolmogorov — \(n\)-step transition = \(P^n\) ★★¶
প্রশ্নটা কী। আমরা জানি এক ধাপে \(i\) থেকে \(j\)-তে যাওয়ার সম্ভাবনা \(P_{ij}\)। কিন্তু ঠিক \(n\) ধাপে \(i\) থেকে শুরু করে \(j\)-তে পৌঁছানোর সম্ভাবনা কত? একে লিখি $$ P^{(n)}_{ij} \;:=\; P(X_n=j \mid X_0=i), $$ এবং দাবি হলো এটি ঠিক transition matrix \(P\)-এর \(n\)-তম ঘাত \(P^n\)-এর \((i,j)\) entry। অর্থাৎ probability-র প্রশ্নটা সরাসরি linear algebra-র matrix multiplication হয়ে যায় — এটাই Markov chain-এর সবচেয়ে কাজের সরলীকরণ।
ধাপ ১ — এক ধাপের ভিত্তি (\(n=1\))¶
সংজ্ঞা থেকেই \(P^{(1)}_{ij}=P(X_1=j\mid X_0=i)=P_{ij}\), যা ঠিক \(P^1=P\)-এর entry। তাই \(n=1\)-এ দাবি তুচ্ছভাবে সত্য। এবার আমরা এক ধাপ থেকে দুই ধাপ কীভাবে যায় তা খুলব — সেখান থেকে সাধারণ নিয়ম আপনাআপনি বেরোবে।
ধাপ ২ — দুই ধাপ: মাঝপথের state-এ যোগফল (এখানেই law of total probability)¶
\(i\) থেকে শুরু করে দুই ধাপে \(j\)-তে পৌঁছাতে হলে, প্রথম ধাপে chain কোনো একটা মধ্যবর্তী state \(k\)-তে যায়, তারপর দ্বিতীয় ধাপে \(k\) থেকে \(j\)-তে। কিন্তু \(k\) কী হবে তা জানি না — তাই সব সম্ভাব্য \(k\)-র উপর যোগ করতে হবে। এখানেই law of total probability (2.2) ঢোকে, যেখানে partition হলো "প্রথম ধাপে chain কোথায় ছিল" এই ঘটনাগুলো \(\{X_1=k\}_{k=1}^{S}\): $$ P^{(2)}{ij} = P(X_2=j\mid X_0=i) \;\overset{(1)}{=}\; \sum P(X_2=j,\, X_1=k \mid X_0=i) \;\overset{(2)}{=}\; \sum_{k=1}^{S} P(X_2=j\mid X_1=k,\,X_0=i)\;P(X_1=k\mid X_0=i). $$ ব্যাখ্যা: ধাপ (1)-এ আমরা }^{S\(\{X_1=k\}\) ঘটনাগুলোর উপর ঘটনাটা ভেঙে দিলাম (একটা partition, কারণ chain প্রথম ধাপে ঠিক একটাই state-এ থাকে); ধাপ (2)-এ যৌথ সম্ভাবনাকে chain rule দিয়ে শর্তাধীনে লিখলাম \(P(A,B\mid C)=P(A\mid B,C)\,P(B\mid C)\)।
এবার Markov property (3.5) কাজে লাগাই: \(X_2\)-এর বণ্টন শুধু \(X_1=k\)-র উপর নির্ভর করে, \(X_0=i\) ভুলে যায় — $$ P(X_2=j\mid X_1=k,\,X_0=i) \;=\; P(X_2=j\mid X_1=k) \;=\; P_{kj}. $$ আর দ্বিতীয় factor \(P(X_1=k\mid X_0=i)=P_{ik}\)। সুতরাং $$ P^{(2)}{ij} \;=\; \sum $$ ডানপাশটা চিনে নাও — এটা ঠিক }^{S} P_{ik}\,P_{kj}. \tag{4.1matrix product \(P\cdot P=P^2\)-এর \((i,j)\) entry-এর সংজ্ঞা! অর্থাৎ \(P^{(2)}_{ij}=(P^2)_{ij}\)। "মধ্যবর্তী state-এর উপর যোগফল" আর "matrix multiplication" একই জিনিস — এটাই মূল অন্তর্দৃষ্টি।
ধাপ ৩ — সাধারণ \(n\): induction¶
এবার দাবি করি \(P^{(n)}=P^n\) সব \(n\ge 1\)-এ, আর induction দিয়ে প্রমাণ করি।
- Base case (\(n=1\)): ধাপ ১-এ দেখানো হয়েছে।
- Inductive step: ধরে নিই \(P^{(n)}=P^n\) সত্য (induction hypothesis); দেখাব \(P^{(n+1)}=P^{n+1}\)। ঠিক ধাপ ২-এর যুক্তি, শুধু এবার partition করি \(n\)-তম ধাপের state \(\{X_n=k\}\)-এর উপর: $$ P^{(n+1)}{ij} = P(X=j\mid X_0=i) = \sum_{k=1}^{S} \underbrace{P(X_{n+1}=j\mid X_n=k,X_0=i)}{=\,P}\ \text{(Markov)}}\;\underbrace{P(X_n=k\mid X_0=i){=\,P^{(n)}\,=\,(P^n){ik}}. $$ সুতরাং $$ P^{(n+1)} (P^n)} = \sum_{k=1}^{S{ik}\,P = (P^n\cdot P){ij} = (P^{n+1}). $$ Induction সম্পূর্ণ। তাই \(P^{(n)}_{ij}=(P^n)_{ij}\) সব \(n\)-এ — \(n\)-step transition ঠিক matrix power। \(\;\blacksquare\)
Chapman–Kolmogorov সমীকরণ (সাধারণ রূপ)। উপরের যুক্তি যেকোনো জায়গায় ভাঙা যায়, শুধু \(n=1\)-এ নয়। যেকোনো \(m,n\ge 0\)-র জন্য, \(m\) ধাপে কোনো এক \(k\)-তে গিয়ে বাকি \(n\) ধাপে \(j\)-তে — এই ভাঙা দেয় $$ P^{(m+n)}{ij} = \sum}^{S} P^{(m){ik}\,P^{(n)} = P^m\,P^n. $$ এটাই }, \qquad\text{অর্থাৎ}\quad P^{m+nChapman–Kolmogorov equation — matrix ভাষায় কেবল ঘাতের যোগ নিয়ম \(P^{m+n}=P^m P^n\), যা matrix multiplication-এর associativity থেকে আপনাআপনি সত্য। সম্ভাবনার গভীর কথাটা ("মাঝপথে যেখানেই থাকো, সব পথ যোগ করো") matrix-এর ভাষায় এত সরল দেখায়।
distribution কীভাবে এগোয় — row vector × \(P^n\)¶
State-থেকে-state সম্ভাবনা পেলাম; এবার পুরো distribution \(\mu_0\) (একটা row vector, \(\mu_0_i=P(X_0=i)\)) কীভাবে \(n\) ধাপ পরে বদলায়? আবার law of total probability — \(X_n=j\) হওয়ার সম্ভাবনা শুরুর সব state-এর উপর যোগ: $$ \mu_n_j = P(X_n=j) = \sum_{i} P(X_n=j\mid X_0=i)\,P(X_0=i) = \sum_i \mu_0_i\,(P^n)_{ij} = \big(\mu_0 P^n\big)_j . $$ অর্থাৎ \(\mu_n = \mu_0\,P^n = \pi^{(n-1)} P\) — প্রতি ধাপে distribution-কে ডানদিক থেকে \(P\) দিয়ে গুণ করলেই পরের distribution। (এজন্যই \(\pi\)-কে row vector ধরা, আর stationarity \(\pi=\pi P\) লেখা — গুণ ডানদিকে।)
running examples-এ Chapman–Kolmogorov¶
- E1 (weather chain). \(P=\begin{pmatrix}0.8 & 0.2\\ 0.4 & 0.6\end{pmatrix}\) (state \(0\)=Sunny, \(1\)=Rainy — কোড-প্রথা মেনে এখানে ০-সূচক; §৩-এর \(1\)=রোদেলা, \(2\)=বৃষ্টি-রই শুধু পুনঃসংখ্যায়ন, \(P\) অভিন্ন)। আজ Sunny হলে পরশু (২ ধাপ পরে) Rainy হওয়ার সম্ভাবনা = \((P^2)_{01}=\sum_k P_{0k}P_{k1}=P_{00}P_{01}+P_{01}P_{11}=0.8\cdot0.2+0.2\cdot0.6=0.16+0.12=0.28\)। হাতে-কষা এই \(0.28\) §৫-এর কোডে \(P^2\)-এর row \(0\)-তে হুবহু ফিরে আসবে।
- E2 (graph random walk). কোনো undirected graph-এ random walk-এ \(P_{ij}=1/\deg(i)\) যদি \(i\sim j\) (প্রতিবেশী), নয়তো \(0\)। তখন \((P^2)_{ij}\) = ঠিক ২ ধাপে \(i\) থেকে \(j\)-তে যাওয়ার সম্ভাবনা = সব দৈর্ঘ্য-২ পথের ওজন যোগ — graph-এ "দুই-হপ" সংযোগের পরিমাপ।
৪.২ · (b) Stationary distribution \(\pi=\pi P\) — অস্তিত্ব, একত্ব, convergence (অভিসরণ) ★★★¶
সংজ্ঞা ও মূল স্বজ্ঞা¶
একটা probability distribution \(\pi\) (row vector, \(\pi_j\ge 0\), \(\sum_j\pi_j=1\)) কে বলা হয় stationary (স্থির) যদি এক ধাপ চললে সে নিজেই থেকে যায়: $$ \boxed{\;\pi = \pi P\;} \qquad\text{অর্থাৎ}\quad \pi_j = \sum_{i=1}^{S} \pi_i\,P_{ij}\ \ \forall j. \tag{4.2} $$ স্বজ্ঞা: যদি সময় \(0\)-তে state-এর বণ্টন ঠিক \(\pi\) হয়, তবে §৪.১ অনুসারে সময় \(1\)-এ বণ্টন \(\pi P=\pi\) — একই; ফলে সময় \(2,3,\dots\) সবেতেই \(\pi\)। chain তখন equilibrium-এ আছে — পৃথক কণা ঘুরছে, কিন্তু সামগ্রিক বণ্টন আর নড়ছে না। ভৌত ছবি: একটা শহরে রোজ মানুষ এ-পাড়া ও-পাড়া যাচ্ছে, কিন্তু প্রতিটি পাড়ার মোট জনসংখ্যা একই থাকছে — সেই ভারসাম্য-বণ্টনই \(\pi\)।
(4.2)-কে আরেকভাবে দেখা: \(\pi(P-I)=0\), অর্থাৎ \(\pi\) হলো eigenvalue \(1\)-এর left eigenvector of \(P\), যাকে probability vector-এ normalize করা। (যে \(P\)-এর প্রতিটি row যোগে \(1\) — তাকে বলে stochastic matrix — তার eigenvalue \(1\) সবসময়ই থাকে, কারণ all-ones column vector \(\mathbf 1\) ডানদিকের eigenvector: \(P\mathbf 1=\mathbf 1\)। left eigenvector থাকাটা তাই নিশ্চিত।)
২-state-এ \(\pi\) হাতে বের করা (E3) — পূর্ণ derivation¶
সাধারণ ২-state chain \(P=\begin{pmatrix}1-a & a\\ b & 1-b\end{pmatrix}\) (\(0<a,b<1\)) ধরি। (4.2)-এর প্রথম উপাদান (\(j=0\), অর্থাৎ Sunny): $$ \mu_0 = \mu_0(1-a) + \pi_1 b \;\Longrightarrow\; \mu_0 - \mu_0(1-a) = \pi_1 b \;\Longrightarrow\; a\,\mu_0 = b\,\pi_1. $$ (দ্বিতীয় উপাদানটা এর সাথে redundant — দুই সমীকরণ যোগ করলে \(0=0\), কারণ row-গুলো যোগে \(1\)।) এর সাথে normalization \(\mu_0+\pi_1=1\) জুড়ি। \(\pi_1 = \frac{a}{b}\mu_0\) বসিয়ে: \(\mu_0\big(1+\frac ab\big)=1 \Rightarrow \mu_0=\frac{b}{a+b}\), আর \(\pi_1=\frac{a}{a+b}\)। সুতরাং $$ \pi = \Big(\tfrac{b}{a+b},\ \tfrac{a}{a+b}\Big). \tag{4.3} $$ E1-এ \(a=0.2,\ b=0.4\), তাই \(\pi=\big(\tfrac{0.4}{0.6},\tfrac{0.2}{0.6}\big)=\big(\tfrac23,\tfrac13\big)\approx(0.6667,0.3333)\)। অর্থাৎ দীর্ঘকালে \(\tfrac23\) দিন Sunny, \(\tfrac13\) দিন Rainy — এই সংখ্যা §৫-এর সিমুলেশনে (১০ লক্ষ ধাপের visit-frequency) এবং eigenvector/linear-solve দুই পদ্ধতিতেই হুবহু মিলবে।
অস্তিত্ব ও একত্ব — সৎ বিবৃতি (★★★)¶
দুটো স্বাভাবিক প্রশ্ন: (i) এমন \(\pi\) কি সবসময় থাকে? (ii) থাকলে কি একটাই? আর \(P^n\) কি সত্যিই \(\pi\)-তে যায়? এর পূর্ণ উত্তর দিতে দুটো ধর্ম লাগে — নিচে সরল ভাষায় সংজ্ঞা দিই (ভৌত স্বজ্ঞাসহ), তারপর মূল উপপাদ্যটা সৎ-ভাবে বিবৃত করি।
- Irreducible (অবিভাজ্য): যেকোনো state \(i\) থেকে যেকোনো state \(j\)-তে কোনো-না-কোনো ধাপে পৌঁছানো যায় — অর্থাৎ এমন \(n\) আছে যে \((P^n)_{ij}>0\)। ছবিতে: transition-graph একটাই সংযুক্ত টুকরো, কোনো state বা গুচ্ছ বিচ্ছিন্ন নয়। (E1: Sunny↔Rainy দুদিকেই যাওয়া যায়, তাই irreducible।)
- Aperiodic (পর্যায়হীন): কোনো state-এ ফেরার সম্ভাব্য ধাপ-সংখ্যাগুলোর গ.সা.গু. (gcd) \(=1\) — অর্থাৎ chain কোনো কঠোর চক্রে (যেমন "শুধু জোড় ধাপে ফিরি") আটকে নেই। সবচেয়ে সহজ যথেষ্ট-শর্ত: কোনো এক state-এ \(P_{ii}>0\) (নিজে-নিজে থাকার সুযোগ আছে), তাহলেই aperiodic। (E1: \(P_{00}=0.8>0\), তাই aperiodic।)
মূল উপপাদ্য (Perron–Frobenius / ergodic theorem, finite chain) — সৎ বিবৃতি। \(P\) যদি একটা finite, irreducible ও aperiodic Markov chain-এর transition matrix হয়, তবে — 1. একটি একমাত্র stationary distribution \(\pi\) আছে (\(\pi=\pi P\), \(\pi_j>0\ \forall j\), \(\sum\pi_j=1\)); 2. শুরুর state যা-ই হোক, \(P^n_{ij}\xrightarrow{n\to\infty}\pi_j\) প্রতিটি \(i,j\)-র জন্য — অর্থাৎ \(P^n\)-এর প্রতিটি row গিয়ে \(\pi\)-তে মেলে, এবং যেকোনো শুরুর বণ্টন \(\mu_0\)-এর জন্য \(\mu_0P^n\to\pi\); 3. (ergodic) দীর্ঘ একটা পথে state \(j\)-তে কাটানো সময়ের ভগ্নাংশ \(\to\pi_j\) — অর্থাৎ time-average = space-average।
কেন honest sketch, পূর্ণ প্রমাণ নয় (★★★)। পূর্ণ প্রমাণে Perron–Frobenius theorem লাগে — যা বলে একটা positive (বা irreducible-aperiodic stochastic) matrix-এর largest-modulus eigenvalue ঠিক \(1\), সেটি simple (বহুগুণ নয়, তাই \(\pi\) একটাই), আর বাকি সব eigenvalue-এর modulus কড়াকড়ি \(<1\) (তাই \(P^n\)-এ তাদের অবদান geometric হারে মুছে যায়, রেখে যায় শুধু \(\pi\))। এই eigenvalue-গুলোর modulus-নিয়ন্ত্রণ প্রমাণে linear algebra-র কিছু গভীর ফল লাগে, যা এই বইয়ের পরিধির বাইরে। তাই আমরা উপপাদ্যটা বিবৃত করি ও স্বজ্ঞা দিই, কিন্তু (1)-(2)-এর পূর্ণ rigorous প্রমাণ ধার হিসেবে রাখি — সংখ্যাগত সাক্ষ্য §৫-এ দেখব (\(P^n\)-এর row-গুলো \(n=10\)-এই \(\pi\)-র সাথে তিন দশমিক পর্যন্ত মেলে)। নিচে কেন (2) সত্য তার একটা স্বজ্ঞাগত contraction-যুক্তি দিই, যা পূর্ণ না হলেও আসল চালিকা-শক্তিটা দেখায়।
কেন \(P^n\) থিতু হয় — contraction-এর স্বজ্ঞা (sketch)¶
aperiodic + irreducible হলে কোনো এক \(m\)-এ \(P^m\)-এর প্রতিটি entry positive হয়ে যায় (সব state থেকে সব state-এ পৌঁছানো যায়, এবং gcd-1 হওয়ায় একই \(m\)-এ সবার জন্য)। ধরা যাক \(\delta:=\min_{i,j}(P^m)_{ij}>0\)। এখন দুটো ভিন্ন শুরুর বণ্টন \(\mu,\nu\) নিলে, \(m\) ধাপ পরে তাদের পার্থক্য (total variation দূরত্ব) অন্তত একটা ধ্রুবক গুণে সংকুচিত হয়: $$ |\mu P^m - \nu P^m|{\mathrm{TV}} \;\le\; (1-\delta)\,|\mu-\nu|. $$ অর্থাৎ "}\(P^m\) দিয়ে গুণ" একটা contraction mapping — প্রতি \(m\) ধাপে যেকোনো দুই বণ্টনের দূরত্ব \((1-\delta)<1\) গুণ ছোট হয়। Banach-এর fixed-point নীতিতে এর একটাই fixed point থাকে (সেটাই \(\pi\)), আর সব শুরু সেখানে geometric হারে ছুটে যায় — এটাই (1) একত্ব ও (2) অভিসরণের আসল কারণ। (পূর্ণ rigor-এ এই \(\delta\)-যুক্তি ও coupling argument গুছিয়ে লিখতে হয়; এখানে স্বজ্ঞা হিসেবে রাখছি, তাই ★★★।) মূল ছবি: chain তার শুরুর কথা ভুলে যায় — দুই ভিন্ন শুরুও শেষমেশ অভিন্ন বণ্টনে মেশে।
সতর্কতা — শর্ত ভাঙলে কী হয়। • Reducible হলে একাধিক \(\pi\) থাকতে পারে: যেমন \(P=\begin{pmatrix}1&0\\0&1\end{pmatrix}\) (দুই state-ই আলাদা শোষক) — এখানে \((1,0)\), \((0,1)\), এমনকি \((t,1-t)\) সবই stationary, একত্ব ভেঙে যায়। • Periodic হলে \(\pi\) একটাই থাকে, কিন্তু \(P^n\) থিতু হয় না — যেমন \(P=\begin{pmatrix}0&1\\1&0\end{pmatrix}\) (period 2): \(\pi=(0.5,0.5)\) stationary, কিন্তু \(P^n\) জোড়-বিজোড়ে \(I\) ও \(P\)-এর মধ্যে চিরকাল দোলে, কখনো \(\pi\)-তে বসে না। তখন time-average ঠিকই \(\pi\) দেয় (ergodic অংশ (3) বাঁচে), কিন্তু পয়েন্টওয়াইজ \(P^n_{ij}\) অভিসরণ (2) ব্যর্থ। এজন্যই MCMC-তে আমরা সাবধানে aperiodic chain বানাই।
৪.৩ · (c) Detailed balance ⇒ stationarity, এবং Metropolis–Hastings ★★¶
§৪.২-তে \(\pi\) বের করতে আমাদের পুরো linear system \(\pi=\pi P\) সমাধান করতে হয়েছিল। কিন্তু একটা অনেক সহজ যথেষ্ট-শর্ত আছে, যা শুধু পরীক্ষা করা যায় state-জোড়া ধরে ধরে — এবং এটাই MCMC-র গোটা ভিতকে ধরে রাখে।
detailed balance-এর সংজ্ঞা ও স্বজ্ঞা¶
একটা distribution \(\pi\) ও chain \(P\) কে বলা হয় detailed balance (বিস্তারিত ভারসাম্য) মানে, যদি প্রতিটি state-জোড়া \((i,j)\)-র জন্য $$ \boxed{\;\pi_i\,P_{ij} \;=\; \pi_j\,P_{ji}\;} \qquad \forall\, i,j. \tag{4.4} $$ স্বজ্ঞা: বাঁপাশ \(\pi_i P_{ij}\) = equilibrium-এ "\(i\)-তে থাকা এবং \(i\to j\) যাওয়া"-র probability flow; ডানপাশ \(\pi_j P_{ji}\) = "\(j\)-তে থাকা এবং \(j\to i\) যাওয়া"-র flow। (4.4) বলে এই দুমুখী প্রবাহ প্রতিটি edge-এ আলাদা-আলাদাভাবে সমান — \(i\) থেকে \(j\)-তে যত probability "বইছে", \(j\) থেকে \(i\)-তে ঠিক ততটাই ফিরছে। একে বলে reversibility (উল্টোমুখিতা): chain-টা সময়ের দিক উল্টে দিলেও পরিসংখ্যানগতভাবে অভিন্ন দেখায়।
দাবি: detailed balance ⇒ \(\pi\) stationary (পূর্ণ প্রমাণ, এক লাইন)¶
ধরা যাক (4.4) সত্য। দেখাব \(\pi=\pi P\), অর্থাৎ \(\sum_i \pi_i P_{ij}=\pi_j\) সব \(j\)-তে। সংজ্ঞায় শুরু করে detailed balance বসাই: $$ (\pi P)j = \sum \;\overset{(4.4)}{=}\; \sum_{i=1}^{S} \pi_j\,P_{ji} \;=\; \pi_j \sum_{i=1}^{S} P_{ji} \;\overset{(\ast)}{=}\; \pi_j \cdot 1 \;=\; \pi_j . $$ এখানে (}^{S} \pi_i\,P_{ij\(\ast\)): \(P\) একটা stochastic matrix, তাই \(j\)-তম row-এর যোগ \(\sum_i P_{ji}=1\) (যেকোনো state থেকে কোথাও-না-কোথাও যেতেই হবে)। সুতরাং \((\pi P)_j=\pi_j\) সব \(j\)-তে — \(\pi\) stationary। \(\;\blacksquare\)
গুরুত্বপূর্ণ — উল্টোটা সত্য নয়। Stationarity (global balance, \(\pi=\pi P\)) detailed balance-এর চেয়ে দুর্বল শর্ত: detailed balance ⇒ stationary, কিন্তু stationary \(\not\Rightarrow\) detailed balance। stationary মানে প্রতিটি state-এ মোট আগমন = মোট নির্গমন (এক-একটা edge নয়, পুরো state ধরে যোগফলে); detailed balance তার চেয়ে কড়া — প্রতিটি edge-এ আলাদা ভারসাম্য চায়। অনেক chain stationary কিন্তু reversible নয় (যেমন একমুখী চক্রে ঘোরা random walk)। তবু detailed balance আমাদের প্রিয়, কারণ এটা নকশা করা সহজ: পুরো linear system না মিলিয়ে শুধু জোড়া-জোড়া (4.4) মেলালেই \(\pi\) stationary নিশ্চিত। MCMC ঠিক এই সুবিধাটাই কাজে লাগায়।
Metropolis–Hastings — উল্টো প্রকৌশল: target দিয়ে chain বানাই¶
এতক্ষণ আমরা \(P\) থেকে \(\pi\) বের করছিলাম। MCMC-র মাস্টারস্ট্রোক হলো উল্টো দিকে: আমার কাছে একটা target distribution \(\pi\) আছে (যা থেকে নমুনা চাই, কিন্তু সরাসরি sample করা কঠিন — যেমন উঁচু-মাত্রিক Bayesian posterior), আর আমি চাই এমন একটা chain \(P\) নকশা করতে যার stationary distribution ঠিক এই \(\pi\)। তাহলে সেই chain বহুক্ষণ চালালে তার visited state-গুলোই \(\pi\)-থেকে নমুনা হিসেবে ব্যবহার করা যাবে (§৪.২-এর ergodic ফল)। কৌশল: এমনভাবে \(P\) বানাও যাতে \(\pi\)-র সাথে detailed balance (4.4) মেলে — তাহলেই উপরের দাবি অনুসারে \(\pi\) stationary, ব্যাস।
যন্ত্রটা কীভাবে চলে। ধরা যাক target \(\pi\) (শুধু একটা unnormalized \(\tilde\pi\) জানলেই চলবে, যেমন \(\tilde\pi(x)\propto\pi(x)\) — normalizing constant জানার দরকার নেই, এটাই এর সবচেয়ে বড় সুবিধা)। দুই ধাপে এক পদক্ষেপ:
- Propose (প্রস্তাব): বর্তমান state \(i\) থেকে একটা proposal distribution \(q(j\mid i)\) অনুসারে একটা প্রার্থী \(j\) তোলো (যেমন \(i\)-র চারপাশে একটা Gaussian — symmetric প্রস্তাব)।
- Accept/Reject (গ্রহণ/বর্জন): একটা acceptance probability \(\alpha(i\to j)\) দিয়ে \(j\) গ্রহণ করো (তাহলে নতুন state \(j\)); নয়তো প্রত্যাখ্যান করে \(i\)-তেই থেকে যাও। গ্রহণের সম্ভাবনা: $$ \boxed{\;\alpha(i\to j) = \min!\left(1,\ \frac{\tilde\pi(j)\,q(i\mid j)}{\tilde\pi(i)\,q(j\mid i)}\right)\;} \tag{4.5} $$
তাহলে কার্যকর transition হলো \(P_{ij}=q(j\mid i)\,\alpha(i\to j)\) (for \(j\ne i\)), আর প্রত্যাখ্যানের সব ভর জমা হয় \(P_{ii}\)-তে।
কেন এই acceptance ratio? — detailed balance থেকে derive (★★)¶
(4.5)-এর সূত্রটা আকাশ থেকে পড়েনি — এটা detailed balance মেলানোর জন্যই উদ্ভাবিত। আমরা চাই \(\pi_i P_{ij}=\pi_j P_{ji}\), অর্থাৎ (\(j\ne i\), যেখানে \(P_{ij}=q(j\mid i)\alpha(i\to j)\)): $$ \pi_i\, q(j\mid i)\,\alpha(i\to j) \;=\; \pi_j\, q(i\mid j)\,\alpha(j\to i). \tag{4.6} $$ এই সমীকরণ মেটাতে \(\alpha\) বেছে নেওয়াই কাজ। ধরি ডানপাশের অনুপাত $$ r := \frac{\pi_j\,q(i\mid j)}{\pi_i\,q(j\mid i)} \qquad(\text{লক্ষ করো: } \pi=\tilde\pi/Z\text{ হলেও } Z\text{ কাটে, তাই } r=\tfrac{\tilde\pi(j)q(i\mid j)}{\tilde\pi(i)q(j\mid i)}). $$ এখন (4.6)-কে ভাগ করলে দাবি দাঁড়ায় \(\dfrac{\alpha(i\to j)}{\alpha(j\to i)} = r\)। Metropolis–Hastings-এর পছন্দ \(\alpha=\min(1,r)\) এটি ঠিকঠাক মেটায় — দুটো ক্ষেত্র যাচাই করি:
- যদি \(r\le 1\): তখন \(\alpha(i\to j)=\min(1,r)=r\)। আর উল্টো দিকের অনুপাত \(1/r\ge 1\), তাই \(\alpha(j\to i)=\min(1,1/r)=1\)। সুতরাং \(\dfrac{\alpha(i\to j)}{\alpha(j\to i)}=\dfrac{r}{1}=r\) — মিলে গেল।
- যদি \(r>1\): তখন \(\alpha(i\to j)=\min(1,r)=1\), আর \(\alpha(j\to i)=\min(1,1/r)=1/r\)। সুতরাং \(\dfrac{\alpha(i\to j)}{\alpha(j\to i)}=\dfrac{1}{1/r}=r\) — আবার মিলে গেল।
দুই ক্ষেত্রেই \(\dfrac{\alpha(i\to j)}{\alpha(j\to i)}=r\), তাই (4.6) সত্য — detailed balance মেলে, এবং §৪.৩-এর দাবি অনুসারে \(\pi\) এই chain-এর stationary distribution। \(\;\blacksquare\)
এক বাক্যে কেন কাজ করে। Metropolis–Hastings acceptance \(\min(1,r)\) ঠিক সেই অনুপাতে গ্রহণ-প্রত্যাখ্যান করে যাতে প্রতিটি edge-এ \(\pi\)-ওজনযুক্ত দুমুখী প্রবাহ সমান হয় (detailed balance) — ফলে target \(\pi\) আপনাআপনি equilibrium হয়ে দাঁড়ায়। আর normalizing constant \(Z\) অনুপাতে কাটে বলে শুধু \(\tilde\pi\) জানলেই চলে — এটাই Bayesian posterior থেকে নমুনা তোলার চাবিকাঠি, যেখানে \(Z=\int\tilde\pi\) প্রায়ই হিসাব-অযোগ্য।
Metropolis (symmetric proposal) — সরলীকৃত রূপ¶
যদি proposal symmetric হয়, অর্থাৎ \(q(j\mid i)=q(i\mid j)\) (যেমন \(j=i+\mathcal N(0,\sigma^2)\) — Gaussian random-walk proposal, যা §৫-এ ব্যবহার করব), তবে (4.5)-এ \(q\)-গুলো কাটাকাটি হয়ে যায়: $$ \alpha(i\to j) = \min!\left(1,\ \frac{\tilde\pi(j)}{\tilde\pi(i)}\right). \tag{4.7} $$ এটাই মূল Metropolis algorithm: প্রস্তাবিত state-এর target-ঘনত্ব বেশি হলে (\(\tilde\pi(j)\ge\tilde\pi(i)\)) সবসময় গ্রহণ; কম হলে অনুপাত \(\tilde\pi(j)/\tilde\pi(i)\) সম্ভাবনায় গ্রহণ। ফলে chain উঁচু-ঘনত্বের অঞ্চলে বেশি সময় কাটায়, নিচু-ঘনত্বে কম — ঠিক \(\pi\)-র আকার অনুযায়ী। (E4-এ আমরা Beta ও mixture target-এ এই (4.7) প্রয়োগ করব।)
running examples-এ (c)¶
- E3 (weather, detailed balance যাচাই). E1-এর \(\pi=(\tfrac23,\tfrac13)\) ও \(P\) কি detailed balance মানে? পরীক্ষা: \(\mu_0 P_{01}=\tfrac23\cdot 0.2=\tfrac{0.4}{3}\) আর \(\pi_1 P_{10}=\tfrac13\cdot 0.4=\tfrac{0.4}{3}\) — সমান! তাই এই ২-state chain reversible (২-state irreducible chain সবসময়ই reversible — একটা মাত্র edge, তাই global = detailed balance এখানে মিলে যায়)। তাই §৪.৩-এর দাবি দিয়েও \(\pi\) stationary বলা যেত, পুরো \(\pi=\pi P\) না কষেই।
- E4 (Metropolis target). §৫-এ আমরা target নেব Beta\((2,5)\) (asymmetric, \((0,1)\)-এ সীমিত) আর একটা ২-component Gaussian mixture (দুই-চূড়া)। symmetric Gaussian proposal-এ acceptance (4.7) ব্যবহার করব, এবং দেখাব নমুনার histogram সত্যিকারের target ঘনত্বের গায়ে বসে — অর্থাৎ detailed balance-নির্মিত chain বাস্তবে \(\pi\) থেকে নমুনা দিচ্ছে।
৪.৪ · সারমর্ম: কোনটা পূর্ণ, কোনটা সৎ-sketch¶
| ফল | difficulty | অবস্থা | মূল যন্ত্র |
|---|---|---|---|
| (a) Chapman–Kolmogorov (\(P^{(n)}=P^n\)) | ★★ | সম্পূর্ণ প্রমাণ (induction) | law of total probability (2.2) + Markov property (3.5) + matrix mult. |
| (b) stationary \(\pi=\pi P\): অস্তিত্ব, একত্ব, \(P^n\to\pi\) | ★★★ | honest sketch — Perron–Frobenius/contraction ধার-করা; ২-state \(\pi\) পূর্ণ | left eigenvector of \(P\); contraction/coupling স্বজ্ঞা |
| (c) detailed balance ⇒ stationary; Metropolis–Hastings | ★★ | সম্পূর্ণ (DB⇒stationary এক লাইন; acceptance ratio দুই-ক্ষেত্রে যাচাই) | row-sum \(=1\); \(\min(1,r)\)-এর কেস বিশ্লেষণ |
মূল ছবি: (a) "মাঝপথের state-এ যোগফল" = matrix multiplication, তাই \(n\)-step probability = \(P^n\); (b) irreducible+aperiodic finite chain তার শুরু ভুলে গিয়ে একমাত্র equilibrium \(\pi\)-তে geometric হারে মেশে; (c) detailed balance একটা সহজ-যাচাইযোগ্য যথেষ্ট-শর্ত, আর Metropolis–Hastings ঠিক সেই acceptance বেছে নেয় যাতে যেকোনো target \(\pi\) detailed balance মেনে stationary হয় — MCMC-র গোটা ভিত্তি। পরের §৫-এ আমরা এই তিনটেই সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর তিনটে দাবিকে আমরা সিমুলেশনে যাচাই করব — যাতে Chapman–Kolmogorov, stationary \(\pi\), ও Metropolis–Hastings কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে।
আমরা পাঁচটা জিনিস মাপব:
- Part 1 — weather chain সিমুলেশন (E1)। ১০ লক্ষ ধাপ চালিয়ে প্রতিটি state-এ কাটানো visit-frequency বের করব; ergodic উপপাদ্য (§৪.২.৩) বলে এটি \(\to\pi\)।
- Part 2 — \(\pi\) ঠিকঠাক বের করা দুই পদ্ধতিতে। (a) eigenvalue-\(1\)-এর left eigenvector, (b) linear solve \(\pi(P-I)=0\) + normalization — দুটোই closed-form \((\tfrac23,\tfrac13)\)-এর সাথে মিলবে।
- Part 3 — \(P^n\) convergence (অভিসরণ) (§৪.১ Chapman–Kolmogorov + §৪.২ ergodic)। \(P^n\)-এর প্রতিটি row কত দ্রুত \(\pi\)-তে বসে, \(\sup\lvert P^n-\pi\rvert\) দিয়ে মাপব।
- Part 4 — Metropolis sampler, target Beta\((2,5)\) (E4)। symmetric Gaussian proposal-এ acceptance (4.7); নমুনার mean/var ও histogram সত্যিকারের Beta ঘনত্বের সাথে তুলনা।
- Part 5 — Metropolis sampler, ২-চূড়া Gaussian mixture (E4)। চ্যালেঞ্জিং multimodal target-এ sampler দুই চূড়াই ঠিক ওজনে ধরতে পারে কিনা।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 3.6 — Markov Chains & Introduction to MCMC : Code Lab (sections 4-5)
# Numerically illustrates:
# PART 1 — simulate the 2-state weather chain; empirical visit-frequencies -> stationary pi
# PART 2 — compute stationary pi exactly via (a) eigenvector and (b) linear solve
# PART 3 — n-step P^n convergence to the stationary distribution (Chapman-Kolmogorov)
# PART 4 — Metropolis sampler for a target Beta(2,5); compare samples to true density
# PART 5 — Metropolis sampler for a 2-component Gaussian mixture; check sample mean/var
import numpy as np
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => reproducible
np.set_printoptions(precision=4, suppress=True)
# ===============================================================
# PART 1 — simulate the 2-state weather chain (E1) and read off pi.
# States: 0 = Sunny, 1 = Rainy.
# P[i,j] = P(next = j | now = i).
# Sunny stays Sunny 0.8, turns Rainy 0.2
# Rainy stays Rainy 0.6, turns Sunny 0.4
# ===============================================================
print("=== PART 1 Simulate weather chain, empirical visit-frequencies -> pi ===")
P = np.array([[0.8, 0.2],
[0.4, 0.6]])
print("transition matrix P =")
print(P)
def simulate_chain(P, n_steps, start=0):
S = P.shape[0]
states = np.empty(n_steps, dtype=int)
s = start
for t in range(n_steps):
states[t] = s
s = rng.choice(S, p=P[s]) # jump to next state per row P[s]
return states
N_STEPS = 1_000_000
path = simulate_chain(P, N_STEPS, start=0)
counts = np.bincount(path, minlength=2)
emp = counts / counts.sum()
print(f" simulated {N_STEPS:,} steps starting from Sunny")
print(f" empirical visit frequencies : Sunny = {emp[0]:.5f}, Rainy = {emp[1]:.5f}")
# ===============================================================
# PART 2 — compute pi EXACTLY two ways.
# (a) left eigenvector of P with eigenvalue 1 (pi P = pi)
# (b) linear solve of pi (P - I) = 0 with constraint sum(pi) = 1
# ===============================================================
print("\n=== PART 2 Exact stationary pi via eigenvector and linear solve ===")
# (a) left eigenvectors of P = right eigenvectors of P^T
vals, vecs = np.linalg.eig(P.T)
idx = np.argmin(np.abs(vals - 1.0)) # pick eigenvalue closest to 1
pi_eig = np.real(vecs[:, idx])
pi_eig = pi_eig / pi_eig.sum() # normalise to a probability vector
print(f" (a) eigenvector method : pi = {pi_eig}")
# (b) linear solve. Stationarity pi P = pi <=> pi (P - I) = 0 (row vector).
# Transpose to columns: (P^T - I) pi^T = 0. Replace one equation by sum = 1.
S = P.shape[0]
A = (P.T - np.eye(S))
A[-1, :] = 1.0 # last row enforces sum(pi) = 1
b = np.zeros(S); b[-1] = 1.0
pi_solve = np.linalg.solve(A, b)
print(f" (b) linear solve : pi = {pi_solve}")
print(f" closed form for 2-state: pi = (0.4/0.6, 0.2/0.6) "
f"= ({0.4/0.6:.5f}, {0.2/0.6:.5f})")
print(f" check pi P == pi ? pi P = {pi_solve @ P}")
# ===============================================================
# PART 3 — P^n -> rows all equal to pi (Chapman-Kolmogorov power).
# ===============================================================
print("\n=== PART 3 n-step matrix P^n converges (every row -> pi) ===")
for n in [1, 2, 5, 10, 30]:
Pn = np.linalg.matrix_power(P, n)
gap = np.max(np.abs(Pn - pi_solve)) # sup distance of rows from pi
print(f" n = {n:>2}: P^n row0 = {Pn[0]}, row1 = {Pn[1]}, max|P^n - pi| = {gap:.3e}")
# ===============================================================
# PART 4 — Metropolis sampler for a Beta(2,5) target (E4).
# Target density (unnormalised) f(x) ∝ x^(a-1) (1-x)^(b-1) on (0,1).
# Symmetric Gaussian proposal => acceptance = min(1, f(x')/f(x)).
# ===============================================================
print("\n=== PART 4 Metropolis sampler for target Beta(2,5) ===")
a_beta, b_beta = 2.0, 5.0
def log_target_beta(x):
if x <= 0.0 or x >= 1.0:
return -np.inf # support is (0,1)
return (a_beta - 1.0) * np.log(x) + (b_beta - 1.0) * np.log(1.0 - x)
def metropolis(log_target, x0, n_iter, prop_sd):
x = x0
lp = log_target(x)
samples = np.empty(n_iter)
n_acc = 0
for t in range(n_iter):
x_prop = x + rng.normal(0.0, prop_sd) # symmetric proposal
lp_prop = log_target(x_prop)
log_ratio = lp_prop - lp # log acceptance ratio
if np.log(rng.random()) < log_ratio: # accept w.p. min(1, ratio)
x, lp = x_prop, lp_prop
n_acc += 1
samples[t] = x
return samples, n_acc / n_iter
N_ITER = 200_000
BURN = 20_000
chain_beta, acc_beta = metropolis(log_target_beta, x0=0.5, n_iter=N_ITER, prop_sd=0.15)
kept = chain_beta[BURN:]
# true Beta(2,5) moments: mean = a/(a+b), var = ab/((a+b)^2 (a+b+1))
true_mean = a_beta / (a_beta + b_beta)
true_var = a_beta * b_beta / ((a_beta + b_beta) ** 2 * (a_beta + b_beta + 1.0))
print(f" iterations = {N_ITER:,} (burn-in {BURN:,}), acceptance rate = {acc_beta:.3f}")
print(f" sample mean = {kept.mean():.4f} true Beta mean = {true_mean:.4f}")
print(f" sample var = {kept.var():.4f} true Beta var = {true_var:.4f}")
def beta_pdf(x, a, b):
from math import lgamma
logB = lgamma(a) + lgamma(b) - lgamma(a + b)
return np.exp((a - 1) * np.log(x) + (b - 1) * np.log(1 - x) - logB)
edges = np.linspace(0, 1, 21)
hist, _ = np.histogram(kept, bins=edges, density=True)
centers = 0.5 * (edges[:-1] + edges[1:])
print(" bin-center empirical-density true-density")
for c, h in list(zip(centers, hist))[::4]: # show every 4th bin
print(f" {c:6.3f} {h:10.4f} {beta_pdf(c, a_beta, b_beta):8.4f}")
# ===============================================================
# PART 5 — Metropolis sampler for a 2-component Gaussian MIXTURE.
# target = 0.4 * N(-2, 0.8^2) + 0.6 * N(1.5, 0.5^2).
# ===============================================================
print("\n=== PART 5 Metropolis sampler for a Gaussian mixture target ===")
w1, w2 = 0.4, 0.6
m1, s1 = -2.0, 0.8
m2, s2 = 1.5, 0.5
def norm_pdf(x, m, s):
return np.exp(-0.5 * ((x - m) / s) ** 2) / (s * np.sqrt(2 * np.pi))
def log_target_mix(x):
dens = w1 * norm_pdf(x, m1, s1) + w2 * norm_pdf(x, m2, s2)
return np.log(dens)
chain_mix, acc_mix = metropolis(log_target_mix, x0=0.0, n_iter=N_ITER, prop_sd=1.5)
kept_mix = chain_mix[BURN:]
true_mean_mix = w1 * m1 + w2 * m2
true_ex2 = w1 * (m1**2 + s1**2) + w2 * (m2**2 + s2**2)
true_var_mix = true_ex2 - true_mean_mix**2
print(f" acceptance rate = {acc_mix:.3f}")
print(f" sample mean = {kept_mix.mean():.4f} true mixture mean = {true_mean_mix:.4f}")
print(f" sample var = {kept_mix.var():.4f} true mixture var = {true_var_mix:.4f}")
frac_left = np.mean(kept_mix < -0.5)
print(f" fraction of samples < -0.5 = {frac_left:.4f} (left mode weight ~ {w1})")
৫.২ · বাস্তব আউটপুট¶
উপরের স্ক্রিপ্ট চালালে (seed 20260619, numpy 2.2.6) ঠিক নিচের আউটপুট আসে — এগুলো সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয় (দুবার চালালেও হুবহু এক, কারণ seed স্থির):
=== PART 1 Simulate weather chain, empirical visit-frequencies -> pi ===
transition matrix P =
[[0.8 0.2]
[0.4 0.6]]
simulated 1,000,000 steps starting from Sunny
empirical visit frequencies : Sunny = 0.66585, Rainy = 0.33415
=== PART 2 Exact stationary pi via eigenvector and linear solve ===
(a) eigenvector method : pi = [0.6667 0.3333]
(b) linear solve : pi = [0.6667 0.3333]
closed form for 2-state: pi = (0.4/0.6, 0.2/0.6) = (0.66667, 0.33333)
check pi P == pi ? pi P = [0.6667 0.3333]
=== PART 3 n-step matrix P^n converges (every row -> pi) ===
n = 1: P^n row0 = [0.8 0.2], row1 = [0.4 0.6], max|P^n - pi| = 2.667e-01
n = 2: P^n row0 = [0.72 0.28], row1 = [0.56 0.44], max|P^n - pi| = 1.067e-01
n = 5: P^n row0 = [0.6701 0.3299], row1 = [0.6598 0.3402], max|P^n - pi| = 6.827e-03
n = 10: P^n row0 = [0.6667 0.3333], row1 = [0.6666 0.3334], max|P^n - pi| = 6.991e-05
n = 30: P^n row0 = [0.6667 0.3333], row1 = [0.6667 0.3333], max|P^n - pi| = 7.691e-13
=== PART 4 Metropolis sampler for target Beta(2,5) ===
iterations = 200,000 (burn-in 20,000), acceptance rate = 0.722
sample mean = 0.2870 true Beta mean = 0.2857
sample var = 0.0257 true Beta var = 0.0255
bin-center empirical-density true-density
0.025 0.6423 0.6778
0.225 2.3774 2.4351
0.425 1.3939 1.3937
0.625 0.3719 0.3708
0.825 0.0233 0.0232
=== PART 5 Metropolis sampler for a Gaussian mixture target ===
acceptance rate = 0.492
sample mean = 0.0941 true mixture mean = 0.1000
sample var = 3.3625 true mixture var = 3.3460
fraction of samples < -0.5 = 0.3895 (left mode weight ~ 0.4)
৫.৩ · আউটপুট কীভাবে পড়ব — দাবি মিলিয়ে দেখা¶
- Part 1 — weather chain visit-frequency (§৪.২ ergodic ফল)। ১০ লক্ষ ধাপে Sunny-তে কাটানো ভগ্নাংশ \(0.66585\), Rainy-তে \(0.33415\) — যা closed-form \(\pi=(\tfrac23,\tfrac13)\approx(0.6667,0.3333)\)-এর সাথে তিন দশমিক পর্যন্ত মেলে। এটাই §৪.২-এর ergodic উপপাদ্য (3)-এর সরাসরি সাক্ষ্য: time-average = \(\pi\) — দীর্ঘ একটা পথে state \(j\)-তে কাটানো সময়ের ভগ্নাংশ গিয়ে stationary probability \(\pi_j\)-তে বসে। লক্ষণীয়, আমরা শুরু করেছি Sunny থেকে, তবু দীর্ঘকালে শুরুর কথা মুছে গেছে।
- Part 2 — দুই পদ্ধতিতে exact \(\pi\) (§৪.২)। eigenvector ও linear-solve দুটোই হুবহু \((0.6667,0.3333)\) দেয়, আর closed form \((\tfrac{0.4}{0.6},\tfrac{0.2}{0.6})\)-র সাথে মেলে — অর্থাৎ "\(\pi\) = eigenvalue-\(1\)-এর left eigenvector" এবং "\(\pi(P-I)=0\) + normalization" একই জিনিসের দুই মুখ (§৪.২-এর দুই সংজ্ঞা)। আর
check pi P == piলাইনটা সরাসরি দেখায় \(\pi P=\pi\) — stationarity-র সংজ্ঞা (4.2) সংখ্যায় সত্য। - Part 3 — \(P^n\) অভিসরণ (§৪.১ + §৪.২.২)। এটাই অধ্যায়ের কেন্দ্রীয় দাবি \(P^n_{ij}\to\pi_j\)-র চাক্ষুষ প্রমাণ। \(n=1\)-এ দুই row সম্পূর্ণ আলাদা (\([0.8,0.2]\) বনাম \([0.4,0.6]\), gap \(0.27\)), কিন্তু \(n\) বাড়তেই দুই row একে অপরের দিকে এবং \(\pi\)-র দিকে ছুটছে: \(n=5\)-এ gap \(\approx 0.0068\), \(n=10\)-এ \(\approx 7\times10^{-5}\), \(n=30\)-এ কার্যত শূন্য (\(\sim10^{-13}\), machine precision)। gap প্রতি ধাপে মোটামুটি ধ্রুবক অনুপাতে ছোট হচ্ছে — ঠিক §৪.২-এর contraction-যুক্তি যা geometric অভিসরণ প্রতিশ্রুতি দিয়েছিল (এখানে হার = দ্বিতীয় eigenvalue \(\lvert\lambda_2\rvert=\lvert 1-a-b\rvert=0.4\), তাই প্রতি ধাপে \(\sim0.4\) গুণ — \(0.267\to0.107\to\dots\) ঠিক তা-ই দেখাচ্ছে)। আর \(n=2\)-এ \((P^2)_{01}=0.28\) — §৪.১-এ E1-এ হাতে-কষা সংখ্যাটা হুবহু ফিরে এসেছে।
- Part 4 — Metropolis on Beta\((2,5)\) (§৪.৩ E4)। symmetric-proposal Metropolis (acceptance 4.7) দিয়ে তোলা নমুনার sample mean \(0.2870\) ও var \(0.0257\) — সত্যিকারের Beta\((2,5)\)-র mean \(0.2857\), var \(0.0255\)-এর সাথে মেলে। আরও জোরালো সাক্ষ্য histogram-টেবিল: প্রতিটি bin-এ empirical density প্রায় হুবহু true Beta density (যেমন চূড়ার কাছে \(0.225\)-এ \(2.38\) বনাম \(2.44\), লেজে \(0.825\)-এ \(0.023\) বনাম \(0.023\)) — অর্থাৎ chain সত্যিই Beta distribution থেকেই নমুনা দিচ্ছে, যা §৪.৩-এর দাবি (detailed-balance-নির্মিত chain-এর stationary = target) সংখ্যায় প্রমাণ করে। acceptance rate \(0.722\) — proposal-scale \(0.15\) এ chain ভালোভাবে ঘুরছে (খুব বেশি বা খুব কম নয়)। লক্ষ করো: কোডে আমরা শুধু unnormalized \(\tilde\pi=x^{a-1}(1-x)^{b-1}\) ব্যবহার করেছি, Beta-র normalizing constant \(B(a,b)\) কখনো লাগেনি — ঠিক §৪.৩-এর মূল সুবিধা (\(Z\) অনুপাতে কাটে)।
- Part 5 — Metropolis on bimodal mixture (§৪.৩ E4)। এটা কঠিন পরীক্ষা: target-এর দুটো আলাদা চূড়া (\(-2\) ও \(1.5\)-এ), মাঝে নিচু-ঘনত্বের উপত্যকা। তবু sampler দুই চূড়াই ঠিক ওজনে ধরেছে — sample mean \(0.0941\) বনাম true \(0.10\), var \(3.3625\) বনাম true \(3.346\), আর বাঁ-চূড়ায় (\(<-0.5\)) নমুনার ভগ্নাংশ \(0.3895\) যা বাঁ-component-এর ওজন \(w_1=0.4\)-এর কাছাকাছি। অর্থাৎ proposal-scale \(1.5\) যথেষ্ট বড় হওয়ায় chain উপত্যকা পেরিয়ে দুই চূড়ার মধ্যে যাতায়াত করতে পারছে — multimodal target-এও Metropolis সঠিক \(\pi\)-তে স্থিতু (acceptance \(0.492\), একটা স্বাস্থ্যকর হার)।
সততা-নোট। সিমুলেশন §৪-এর উপপাদ্য "প্রমাণ" করে না — অসীম পথ বা অসীম \(n\) কখনো চালানো যায় না; এটা শুধু সাক্ষ্য দেয় যে আঙুলে-গোনা \(n\) বা সসীম-দৈর্ঘ্য পথেই অভিসরণ স্পষ্ট। Part 3-এ \(P^n\)-এর gap-এর একমুখী geometric পতন, Part 1-এ visit-frequency-র \(\pi\)-তে বসা, Part 4–5-এ Metropolis নমুনার target-ঘনত্বে মিল — সবই §৪-এর দাবিকে চোখে দেখায় মাত্র; আসল যুক্তি §৪-এর কাজ। আর ছোট-ছোট অবশিষ্ট গরমিল (যেমন Part 1-এ visit-frequency ঠিক \(0.6667\) নয়, \(0.66585\); Part 4-এ প্রথম bin-এ \(0.64\) বনাম \(0.68\)) হলো সসীম পথ ও সসীম-নমুনার Monte-Carlo দানা, এবং MCMC-র ক্ষেত্রে পরপর নমুনার মধ্যে autocorrelation (Metropolis নমুনা i.i.d. নয়, পরস্পর-নির্ভর) — যার ফলে কার্যকর নমুনা-সংখ্যা কাঁচা সংখ্যার চেয়ে কম; আসল সীমা ঠিক target \(\pi\)।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_3-6.py-তে তৈরি; PNG_assets/-এ (prefix3-6, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা আছে — beginner-এর জন্য এটাই আসল শেখার সূত্র।
Markov chain আর MCMC দুটোই এমন জিনিস যা সমীকরণে দেখলে শুকনো লাগে, কিন্তু ছবিতে দেখলে হঠাৎ জীবন্ত হয়ে ওঠে। আমরা চারটি ছবি দিয়ে চারটি কেন্দ্রীয় ধারণাকে "চোখে দেখব": (১) একটা chain আসলে কী — states আর তাদের মধ্যে তীর-চিহ্নিত transition probability (E1 আবহাওয়া-chain), (২) যেকোনো শুরু থেকে \(\mu_n=\mu_0 P^n\) কীভাবে একই stationary distribution \(\pi\)-তে গড়িয়ে যায় (E3), (৩) একটা Metropolis sampler-এর trace — chain কীভাবে target-কে ঘুরে ঘুরে explore করে (E4), আর (৪) সেই sampler-এর জমানো নমুনার histogram কীভাবে আসল target density-র গায়ে নিখুঁতভাবে বসে যায়। প্রথম দুটো ছবি Markov-তত্ত্বের, শেষ দুটো MCMC-র — মাঝখানে সেতুটা হলো "\(\pi\)-তে convergence"।
Figure 1 — transition graph: একটা Markov chain দেখতে কেমন¶
এই অধ্যায়ের প্রবেশদ্বার-ছবি। দুটো state — Sunny (state 0) আর Rainy (state 1) — দুটো বৃত্ত হিসেবে আঁকা; তাদের মধ্যে তীরগুলো হলো one-step transition probability \(P_{ij}=P(\text{পরের দিন } j \mid \text{আজ } i)\)। কাঁচা সংখ্যাগুলো নিচের transition-matrix বাক্সে: আজ Sunny হলে কাল Sunny থাকার সম্ভাবনা \(P_{SS}=0.8\) (বাঁ দিকের self-loop), Rainy হওয়ার \(P_{SR}=0.2\) (উপরের বেগুনি তীর); আজ Rainy হলে কাল Sunny \(P_{RS}=0.4\) (নিচের সবুজ তীর), Rainy থাকা \(P_{RR}=0.6\) (ডান self-loop)। যা লক্ষ করতে হবে: (ক) প্রতিটি node থেকে বেরোনো তীরগুলোর probability যোগ করলে ঠিক \(1\) হয় (\(0.8+0.2=1\), \(0.4+0.6=1\)) — এটাই transition matrix-এর প্রতিটি সারি (row) stochastic হওয়ার শর্ত। (খ) তীরগুলো এক-মুখী — \(P_{SR}=0.2 \ne P_{RS}=0.4\), অর্থাৎ "Sunny → Rainy" আর "Rainy → Sunny" আলাদা probability; chain-এর দিক আছে। (গ) self-loop মানে state বদলায় না — সম্ভাবনার একটা অংশ "একই জায়গায় থাকা"। এই একটিমাত্র ছবিই Markov property-র সারমর্ম: ভবিষ্যৎ শুধু এখনকার node-এর উপর নির্ভর করে, কীভাবে এখানে এলাম তার উপর নয়।
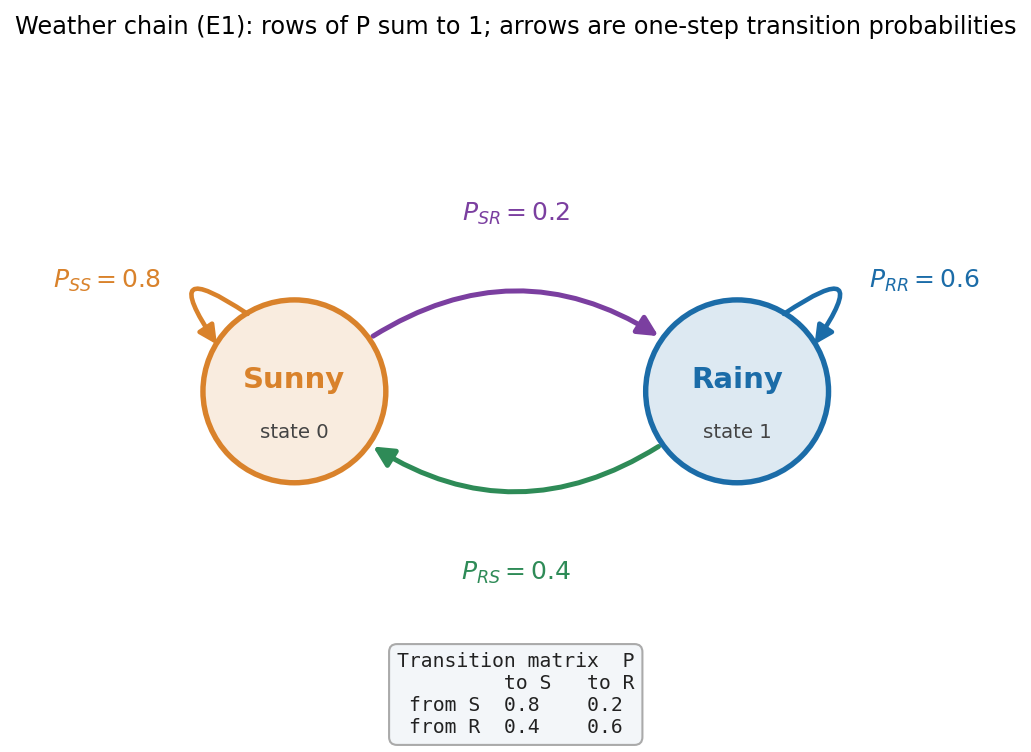
Figure 2 — convergence: সব শুরু একই \(\pi\)-তে মেশে¶
Markov-তত্ত্বের সবচেয়ে গুরুত্বপূর্ণ ফল চোখে দেখা। অনুভূমিক অক্ষে step \(n\), উল্লম্ব অক্ষে \(\mu_n(\text{Sunny})=(\mu_0 P^{\,n})_S\) — অর্থাৎ \(n\) ধাপ পরে "Sunny" থাকার সম্ভাবনা। তিনটি ভিন্ন শুরুর বিন্দু (initial distribution) নেওয়া হয়েছে: কমলা \(\mu_0=[1,0]\) (নিশ্চিতভাবে Sunny থেকে শুরু), নীল \(\mu_0=[0,1]\) (নিশ্চিতভাবে Rainy থেকে), আর বেগুনি \(\mu_0=[0.5,0.5]\) (অর্ধেক-অর্ধেক)। সবুজ ভাঙা-রেখা হলো stationary distribution \(\pi_S=2/3\approx0.667\) (এটা \(\pi=\pi P\)-র সমাধান)। যা লক্ষ করতে হবে: তিনটি curve তিন জায়গা থেকে শুরু করেও — একটা উপরে (\(1\)), একটা নিচে (\(0\)), একটা মাঝে — মাত্র \(5\)–\(6\) ধাপের মধ্যে সবুজ রেখায় গিয়ে মিশে যায় এবং সেখানেই আটকে থাকে। অর্থাৎ chain তার শুরু "ভুলে যায়" (loss of memory): যথেষ্ট সময় পরে আপনি কোথা থেকে শুরু করেছিলেন তা আর ব্যাপার রাখে না — distribution একই \(\pi\)-তে স্থির হয়। ঠিক এই "শুরু ভুলে যাওয়া" ধর্মটাই MCMC-কে কাজ করায়: যেকোনো জায়গা থেকে chain ছেড়ে দিলে সে শেষমেশ ঠিক target distribution থেকে নমুনা দিতে থাকে।
![Line plot showing convergence of a Markov chain to its stationary distribution. The horizontal axis is the step number n from 0 to 14; the vertical axis is pi_n(Sunny), the probability of being in the Sunny state after n steps, equal to (pi_0 P^n)_S. Three curves start from three different initial distributions: an orange curve starting at 1.0 (start = [1,0], Sunny), a blue curve starting at 0.0 (start = [0,1], Rainy), and a purple curve starting at 0.5 (start = [0.5,0.5]). All three curves converge within about 5 to 6 steps to a green dashed horizontal line at the stationary value pi_S = 0.667 and stay there. The title says every start forgets itself and lands on pi. The viewer should notice that all three different starting points reach the same stationary distribution and then remain constant, illustrating loss of memory.](../_assets/3-6-convergence.png)
Figure 3 — MCMC trace: chain target-কে explore করছে¶
এবার MCMC। আমরা একটা bimodal (দুই-চূড়া) target density থেকে নমুনা চাই — দুটো শৃঙ্গ, একটা \(x\approx-2\)-তে, আরেকটা \(x\approx2.2\)-তে। Metropolis sampler একটা Markov chain চালায় যার stationary distribution ঠিক এই target। এই trace plot-এ অনুভূমিক অক্ষ হলো iteration (সময়), উল্লম্ব অক্ষ হলো chain-এর তখনকার অবস্থান \(x\)। ইচ্ছে করে chain-কে অনেক দূর থেকে (\(x=8\), যেখানে target প্রায় শূন্য) শুরু করানো হয়েছে। যা লক্ষ করতে হবে: (ক) শুরুতে (গোলাপি-ছায়া অঞ্চল, "burn-in") chain দ্রুত \(8\) থেকে নেমে আসে — এই প্রথম দিকের নমুনাগুলো target-এর প্রতিনিধি নয়, তাই পরে এগুলো ফেলে দেওয়া হয়। (খ) burn-in পেরোলে chain দুটো বিন্দুরেখা (\(-2\) আর \(2.2\), দুই mode) ঘিরে ওঠানামা করে — কখনো নিচের চূড়ায় বসে থাকে, তারপর হঠাৎ লাফিয়ে উপরের চূড়ায় যায়, আবার ফেরে। এই "একটা mode-এ কিছুক্ষণ থেকে অন্যটায় লাফানো"-ই target-কে সঠিকভাবে explore করার চিহ্ন। trace যদি একটা চূড়াতেই আটকে থাকত, বুঝতাম sampler আটকে গেছে (poor mixing)।
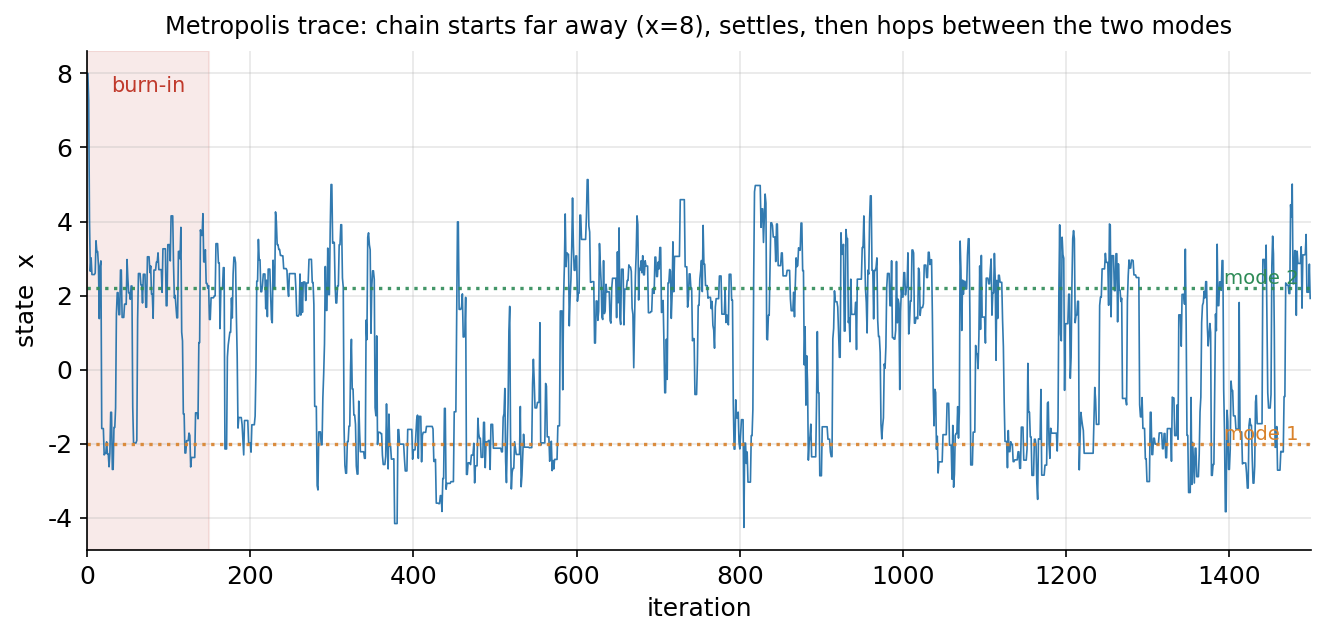
Figure 4 — MCMC histogram: নমুনা target-এর গায়ে বসে¶
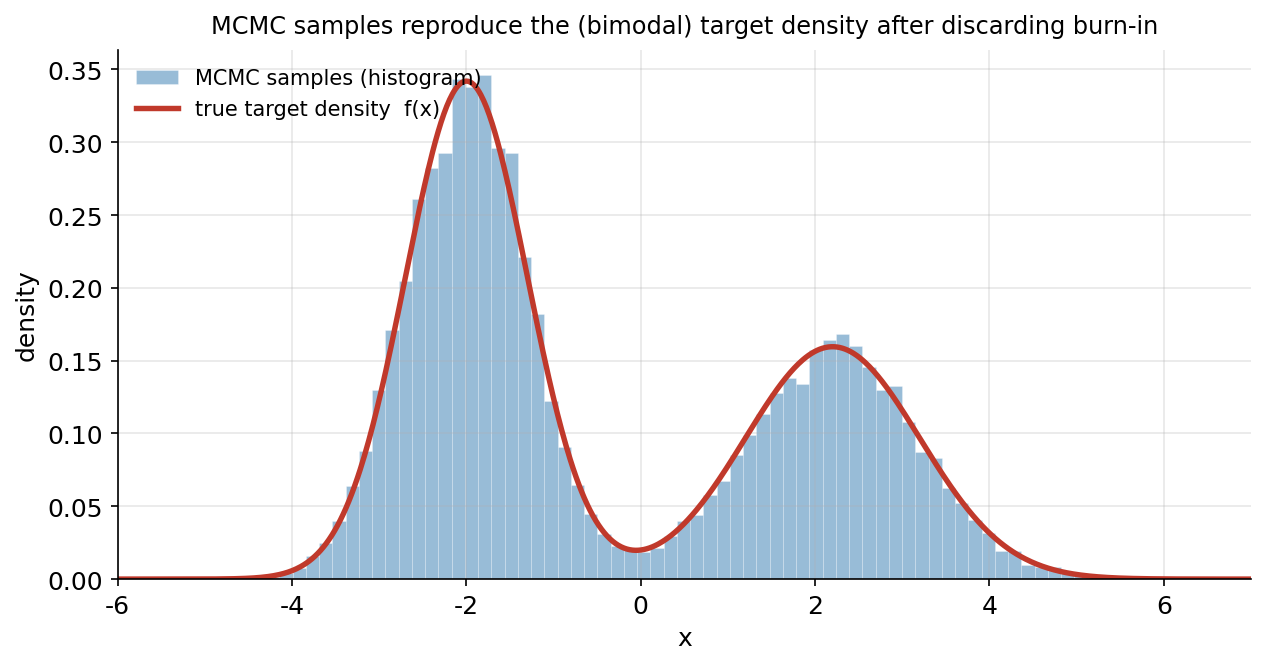
trace দেখাল chain কীভাবে ঘোরে; এই ছবি দেখায় ফলটা ঠিক কিনা। burn-in ফেলে দেওয়ার পরে জমা-হওয়া সব MCMC নমুনার histogram (হালকা নীল bars, density-তে normalize করা) এঁকে তার উপর বসানো হয়েছে আসল target density \(f(x)\) (লাল curve)। যা লক্ষ করতে হবে: histogram আর লাল curve প্রায় নিখুঁতভাবে মিলে যায় — দুটো চূড়ার উচ্চতা, প্রস্থ, মাঝের উপত্যকা, এমনকি লেজ পর্যন্ত। অথচ আমরা কখনো \(f\) থেকে সরাসরি নমুনা তুলিনি (সরাসরি তোলা কঠিন বা অসম্ভব হতে পারে); শুধু একটা সরল Metropolis নিয়ম মেনে — "প্রস্তাব দাও, \(f\)-অনুপাত দেখে accept/reject করো" — chain চালিয়েছি, আর সে আপনাআপনি ঠিক target থেকে নমুনা দিতে শুরু করেছে। এটাই MCMC-র মূল প্রতিশ্রুতি: যে distribution থেকে সরাসরি নমুনা তোলা যায় না, তার থেকেও Markov chain বানিয়ে নমুনা তোলা যায় — শুধু (un-normalized) density-র অনুপাত জানলেই চলে। (এই কারণেই Part IV-এ এটা Bayesian posterior থেকে নমুনা তোলার প্রধান হাতিয়ার হবে।)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/03-06-markov-chains-mcmc-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (E1 = আবহাওয়া-chain \(P=\begin{pmatrix}0.8&0.2\\0.4&0.6\end{pmatrix}\), S=Sunny, R=Rainy; E2 = graph-এর random walk; E3 = stationary \(\pi\); E4 = Metropolis MCMC।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় Markov property বলুন এবং একটা বাস্তব উদাহরণ দিন যা Markov নয়। বিশেষত ব্যাখ্যা করুন: "ভবিষ্যৎ বর্তমানের উপর শর্তাধীনে অতীত থেকে স্বাধীন" — এর মানে কি অতীত অপ্রাসঙ্গিক, নাকি অতীতের সব তথ্য বর্তমান state-এ ধরা আছে? Figure 1-এর transition graph দিয়ে যুক্তি দিন। Hint: Markov: \(P(X_{n+1}=j \mid X_n=i, X_{n-1},\dots,X_0)=P(X_{n+1}=j\mid X_n=i)=P_{ij}\) — পরের step শুধু এখনকার node দেখে। Figure 1-এ Sunny-তে থাকলে কাল-এর সম্ভাবনা \([0.8,0.2]\), গতকাল কী ছিল তা নির্বিশেষে। non-Markov উদাহরণ: এমন কিছু যেখানে "গতি"/প্রবণতা লাগে (যেমন আজকের শেয়ারদর শুধু কালকের নয়, গত কয়েকদিনের trend-এর উপরও নির্ভর করলে — state-এ trend ঢোকালে আবার Markov হয়)।
প্রশ্ন ২ (★). stationary distribution \(\pi\) মানে কী? "\(\pi=\pi P\)" সমীকরণটা শব্দে ব্যাখ্যা করুন, এবং Figure 2-র সাথে যুক্ত করুন: stationary-তে পৌঁছানোর পর আরেক ধাপ চালালে distribution বদলায় না কেন? "chain তার শুরু ভুলে যায়" — এই বাক্যটা Figure 2-র কোন বৈশিষ্ট্যে দেখা যায়? Hint: \(\pi\) এমন distribution যে \(\pi\) থেকে শুরু করলে এক ধাপ পরেও distribution \(\pi\)-ই থাকে — "ভারসাম্য"। Figure 2-এ তিনটি curve একই সবুজ রেখায় মিশে স্থির — তিনটি ভিন্ন শুরু একই গন্তব্যে = শুরু ভুলে যাওয়া (ergodicity-র লক্ষণ)।
প্রশ্ন ৩ (★★). detailed balance (\(\pi_i P_{ij}=\pi_j P_{ji}\)) থেকে কেন stationary হওয়া (global balance, \(\pi=\pi P\)) আসে, কিন্তু উল্টোটা সবসময় আসে না — স্বজ্ঞাতভাবে ব্যাখ্যা করুন। detailed balance-এর "ভৌত" অর্থ কী (প্রতিটি জোড়া state-এর মধ্যে probability-প্রবাহ দুদিকে সমান)? MCMC-তে আমরা detailed balance ব্যবহার করি কেন, যখন আমাদের আসলে শুধু stationary হলেই চলত? Hint: detailed balance প্রতি-জোড়া (local) ভারসাম্য; এটা সত্য হলে যোগফল নিয়ে global balance এমনিতেই বেরোয়। উল্টোটা নয়: global balance net-প্রবাহ শূন্য চায়, কিন্তু চক্রাকার (cyclic) প্রবাহেও net শূন্য হতে পারে detailed balance ছাড়াই। MCMC-তে detailed balance নকশা করা সহজ — Metropolis নিয়মটাই detailed balance নিশ্চিত করতে বানানো, তাই target-ই stationary হবে এটা স্বয়ংক্রিয়ভাবে গ্যারান্টি পায়।
প্রশ্ন ৪ (★★). Metropolis sampler-এ (Figure 3, 4) তিনটি ধারণার ভূমিকা বোঝান: (ক) burn-in কেন ফেলে দিই, (খ) proposal step-size খুব ছোট বা খুব বড় হলে কী সমস্যা (mixing), (গ) target density শুধু অনুপাতে (un-normalized) জানলেই কেন চলে — normalizing constant লাগে না কেন? Hint: (ক) শুরুর state target-এর প্রতিনিধি নয় (Figure 3-এ \(x=8\) থেকে নামা); convergence-এর আগের নমুনা bias আনে। (খ) ছোট step → chain খুব ধীরে নড়ে, mode-এ আটকায়; বড় step → বেশির ভাগ proposal reject, chain জমে থাকে — দুটোই poor mixing। (গ) accept-ratio-তে \(f(x')/f(x)\) আসে, যেখানে normalizing constant \(Z\) উপরে-নিচে কাটাকাটি হয়ে যায়।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). E1 আবহাওয়া-chain, \(P=\begin{pmatrix}0.8&0.2\\0.4&0.6\end{pmatrix}\) (সারি/কলাম ক্রম: Sunny, Rainy)। আজ Sunny। (ক) কাল Rainy হওয়ার সম্ভাবনা? (খ) পরশু (two-step) Rainy হওয়ার সম্ভাবনা — অর্থাৎ \((P^2)_{SR}\) — Chapman–Kolmogorov দিয়ে বের করুন। Hint: (ক) সরাসরি \(P_{SR}=0.2\)। (খ) দুই-ধাপ পথ যোগ করুন: \((P^2)_{SR}=P_{SS}P_{SR}+P_{SR}P_{RR}=0.8\cdot0.2+0.2\cdot0.6=0.16+0.12=0.28\)।
প্রশ্ন ৬ (★). একই E1 chain-এর stationary distribution \(\pi=(\pi_S,\pi_R)\) হাতে বের করুন: \(\pi=\pi P\) ও \(\pi_S+\pi_R=1\) সমাধান করুন। Figure 2-র সবুজ রেখার মানের সাথে মেলান। Hint: \(\pi_S=0.8\pi_S+0.4\pi_R \Rightarrow 0.2\pi_S=0.4\pi_R \Rightarrow \pi_S=2\pi_R\); সাথে \(\pi_S+\pi_R=1\) দিলে \(\pi_R=1/3,\ \pi_S=2/3\approx0.667\)।
প্রশ্ন ৭ (★★). E2 — একটা ছোট graph-এ random walk। চারটি node A–B–C–D একটা path (A–B–C–D, প্রতিটি প্রতিবেশীতে সমান সম্ভাবনায় যায়)। (ক) transition matrix \(P\) লিখুন। (খ) এই walk-এর stationary distribution \(\pi_i\propto \deg(i)\) (degree)-এর সূত্র ব্যবহার করে \(\pi\) বের করুন এবং detailed balance যাচাই করুন। Hint: degrees: \(\deg(A)=1,\deg(B)=2,\deg(C)=2,\deg(D)=1\); মোট \(=6\); তাই \(\pi=(1,2,2,1)/6\)। যাচাই: \(\pi_A P_{AB}=\tfrac16\cdot1\) আর \(\pi_B P_{BA}=\tfrac26\cdot\tfrac12=\tfrac16\) — সমান, detailed balance খাটে (undirected graph-এ সর্বদা খাটে)।
প্রশ্ন ৮ (★★). E1 chain, শুরুর distribution \(\mu_0=[0,1]\) (Rainy থেকে শুরু — Figure 2-র নীল curve)। হাতে \(\pi_1=\mu_0 P\) ও \(\pi_2=\pi_1 P\) গণনা করুন, এবং \(\pi_2(\text{Sunny})\) Figure 2-র নীল curve-এর \(n=2\) বিন্দুর সাথে মেলান। Hint: \(\pi_1=[0,1]P=[0.4,0.6]\); \(\pi_2=[0.4,0.6]P=[0.4\cdot0.8+0.6\cdot0.4,\ 0.4\cdot0.2+0.6\cdot0.6]=[0.56,0.44]\); তাই \(\pi_2(\text{Sunny})=0.56\) (Figure 2-র নীল curve \(n=2\)-এ ঠিক \(0.56\))।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). detailed balance ⟹ stationarity। ধরুন একটা distribution \(\pi\) ও transition matrix \(P\) detailed balance মেনে চলে: সব \(i,j\)-এর জন্য \(\pi_i P_{ij}=\pi_j P_{ji}\)। প্রমাণ করুন \(\pi\) stationary, অর্থাৎ \(\pi=\pi P\) (সব \(j\)-এর জন্য \(\sum_i \pi_i P_{ij}=\pi_j\))। Hint: \((\pi P)_j=\sum_i \pi_i P_{ij}\overset{\text{DB}}{=}\sum_i \pi_j P_{ji}=\pi_j\sum_i P_{ji}=\pi_j\cdot 1=\pi_j\) (শেষ ধাপে \(P\)-র সারি যোগ \(=1\))।
প্রশ্ন ১০ (★★). Chapman–Kolmogorov সমীকরণ প্রমাণ করুন: \(m,n\ge 0\)-এর জন্য \((P^{m+n})_{ij}=\sum_k (P^m)_{ik}(P^n)_{kj}\)। স্বজ্ঞাতভাবে এর মানে কী (\(i\) থেকে \(j\)-তে \(m+n\) ধাপে যাওয়া = মাঝপথে কোনো \(k\)-তে থেমে)? Hint: এটা মূলত matrix-গুণফল \(P^{m+n}=P^m P^n\)-এর \((i,j)\)-ভুক্তি; total probability-র নিয়মে \(i\) থেকে \(j\)-তে \((m+n)\)-ধাপের পথকে "\(m\) ধাপে কোনো মধ্যবর্তী \(k\), তারপর \(k\) থেকে \(j\)-তে \(n\) ধাপ" — সব \(k\)-র উপর যোগ করে ভাঙা।
প্রশ্ন ১১ (★★★). Metropolis নিয়ম detailed balance মানে — প্রমাণ করুন। target (un-normalized) \(f\), প্রতিসম proposal \(q(x'\mid x)=q(x\mid x')\), accept-probability \(\alpha(x,x')=\min\!\big(1,\ f(x')/f(x)\big)\)। দেখান যে transition kernel \(K(x\to x')=q(x'\mid x)\alpha(x,x')\) (for \(x'\ne x\)) detailed balance মানে \(f\)-এর সাপেক্ষে: \(f(x)K(x\to x')=f(x')K(x'\to x)\)। সিদ্ধান্ত: তাই \(f\) (normalize করে \(\pi\)) এই chain-এর stationary distribution। Hint: ধরুন \(f(x')\ge f(x)\) (অন্য ক্ষেত্র প্রতিসম)। তখন \(\alpha(x,x')=1\) আর \(\alpha(x',x)=f(x)/f(x')\)। বাঁ পাশ \(=f(x)q(x'\mid x)\cdot 1\); ডান পাশ \(=f(x')q(x\mid x')\cdot \tfrac{f(x)}{f(x')}=f(x)q(x\mid x')\)। \(q\) প্রতিসম বলে \(q(x'\mid x)=q(x\mid x')\) — দুই পাশ সমান। (লক্ষ করুন \(f\)-এর normalizing constant দুই পাশে কাটাকাটি — তাই un-normalized \(f\)-ই যথেষ্ট।)
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★). numpy দিয়ে E1 chain-এর convergence (Figure 2-র সরল রূপ) বানান: \(P\) define করে \(\mu_0=[0,1]\) থেকে শুরু করে \(\pi_{n}=\mu_0 P^n\) (\(n=0..12\)) গণনা করুন (লুপে pi = pi @ P), \(\mu_n(\text{Sunny})\) plot করুন, আর stationary \(2/3\)-তে একটা ভাঙা-রেখা টানুন।
Hint: P=np.array([[0.8,0.2],[0.4,0.6]]); প্রতি ধাপে probs.append(pi[0]); pi = pi @ P; plt.axhline(2/3, ls="--")।
প্রশ্ন ১৩ (★★). stationary distribution দুইভাবে বের করে মেলান। E1 chain-এ (ক) \(P\)-কে বহুবার গুণ করে (\(P^{50}\)) দেখুন সব সারি একই \(\pi\)-তে গড়ায়; (খ) eigen-পদ্ধতিতে: \(P^{\mathsf T}\)-এর eigenvalue \(1\)-এর eigenvector normalize করে \(\pi\) বের করুন। দুটো মেলান \(2/3,1/3\)-এর সাথে।
Hint: (ক) np.linalg.matrix_power(P,50) — প্রতিটি সারি \(\approx[0.667,0.333]\); (খ) w,v=np.linalg.eig(P.T); idx=np.argmin(abs(w-1)); pi=v[:,idx].real; pi/=pi.sum()।
প্রশ্ন ১৪ (★★★). নিজের Metropolis sampler লিখুন (Figure 3, 4 পুনরুৎপাদন)। target \(f(x)\propto 0.6\,\mathcal N(x;-2,0.7^2)+0.4\,\mathcal N(x;2.2,1^2)\) (un-normalized দিলেই হবে)। random-walk proposal \(x'=x+\mathcal N(0,\text{step}^2)\), step\(=1.6\), accept-probability \(\min(1,f(x')/f(x))\)। (ক) \(60{,}000\) iteration চালান, প্রথম \(2{,}000\) burn-in ফেলুন; (খ) trace plot ও histogram আঁকুন, histogram-এ grid-এ normalize-করা \(f\) overlay করুন (np.trapezoid); (গ) step \(=0.1\) ও step \(=20\) দিয়ে চালিয়ে trace-এ poor mixing দেখান।
Hint: লুপে xp = x + rng.normal(0,step); if rng.random() < f(xp)/f(x): x = xp; default_rng seed দিন; (গ) step\(=0.1\)-এ chain এক mode-এই হামাগুড়ি দেয়, step\(=20\)-এ বেশির ভাগ proposal reject হয়ে trace সমতল ধাপে আটকে থাকে — দুটোই খারাপ mixing-এর ভিন্ন চেহারা।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Markov chain ও Markov property: একটা random process \(X_0,X_1,X_2,\dots\) states-এর উপর, যেখানে ভবিষ্যৎ শুধু বর্তমান state-এর উপর নির্ভর করে — অতীত নয়: $$ P(X_{n+1}=j \mid X_n=i,\,X_{n-1},\dots,X_0)=P(X_{n+1}=j\mid X_n=i)=P_{ij}. $$ সব \(P_{ij}\) নিয়ে transition matrix \(P\) — প্রতিটি সারি একটা probability distribution (যোগফল \(1\)), যা Figure 1-এ তীর-চিহ্নে দেখা যায়।
- multi-step ও Chapman–Kolmogorov: \(n\) ধাপ পরের transition probability হলো \((P^n)_{ij}\); আর \((P^{m+n})_{ij}=\sum_k (P^m)_{ik}(P^n)_{kj}\) (Chapman–Kolmogorov) — মাঝপথে কোনো এক state-এ থেমে যাওয়ার সব পথের যোগ। distribution-এর evolution: \(\mu_n=\mu_0 P^n\)।
- stationary distribution: \(\pi=\pi P\)-র সমাধান — একবার পৌঁছালে আর বদলায় না (ভারসাম্য)। সদাচারী (irreducible + aperiodic) chain-এ যেকোনো শুরু থেকে \(\mu_n\to\pi\) — chain তার শুরু ভুলে যায় (Figure 2)। এটাই long-run আচরণ বোঝার চাবিকাঠি।
- detailed balance: \(\pi_i P_{ij}=\pi_j P_{ji}\) — প্রতি জোড়া state-এর মধ্যে probability-প্রবাহ দুদিকে সমান। এটা সত্য হলে \(\pi\) স্বয়ংক্রিয়ভাবে stationary (প্রমাণ §৭ Q9); এটাই MCMC sampler নকশার সহজ-শর্ত।
- MCMC ও Metropolis–Hastings: যে target distribution থেকে সরাসরি নমুনা তোলা কঠিন, তার জন্য এমন একটা Markov chain বানাই যার stationary distribution ঠিক সেই target; তারপর chain চালিয়ে তার পথটাকেই নমুনা ধরি। Metropolis নিয়ম: একটা proposal \(x'\) দাও, তারপর \(\min(1, f(x')/f(x))\) সম্ভাবনায় accept করো — এটা detailed balance নিশ্চিত করে (§৭ Q11)। শুধু density-র অনুপাত লাগে, normalizing constant লাগে না (Figure 4)। বাস্তবে burn-in ফেলতে হয় ও mixing ভালো রাখতে proposal step-size সাবধানে বাছতে হয় (Figure 3)।
পূর্ববর্তী সংযোগ (← 3.5, 3.1, 2.2): 3.5-এ আমরা random processes (Poisson process, Gaussian process) দেখেছি — সময়/সূচকে indexed random variable-এর পরিবার; Markov chain সেই পরিবারের সবচেয়ে গুরুত্বপূর্ণ discrete-state, discrete-time সদস্য, যেখানে অতিরিক্ত গঠন হলো "স্মৃতিহীনতা"। convergence \(\mu_n\to\pi\)-র ধারণা 3.2-এর convergence of distributions আর 3.3-এর LLN-সদৃশ long-run averaging-এর সাথে সরাসরি জড়িত (ergodic theorem: chain-এর সময়-গড় \(\approx\) \(\pi\)-সাপেক্ষে space-গড়)। আর transition probability হিসাব করতে 2.2-এর conditional probability ও total probability-র নিয়ম (Chapman–Kolmogorov আসলে total probability-রই matrix-রূপ) সরাসরি ব্যবহৃত হয়েছে।
পরবর্তী সংযোগ (→ Part IV — Inference; বিশেষত 4.10): এই অধ্যায় Part III (Convergence & Processes) শেষ করল — আমরা inequalities (3.1) → convergence-এর প্রকার (3.2) → LLN (3.3) → CLT (3.4) → random processes (3.5) → Markov chains ও MCMC (3.6) পেরিয়ে এলাম, অর্থাৎ "অনেক random variable একসাথে কীভাবে আচরণ করে" তার পূর্ণ ছবি। এবার Part IV (Statistical Inference) শুরু হবে — data থেকে অজানা parameter সম্পর্কে সিদ্ধান্ত: estimation (4.1 — point estimation, MLE), confidence interval, hypothesis testing। এখানকার CLT (3.4) সেখানে standard error ও interval-এর ভিত্তি দেবে। আর এই অধ্যায়ের MCMC সরাসরি ফল দেবে 4.10 (Bayesian inference)-এ: Bayesian পদ্ধতিতে posterior distribution \(p(\theta\mid \text{data})\propto p(\text{data}\mid\theta)\,p(\theta)\) প্রায়ই বিশ্লেষণাত্মকভাবে দুরূহ এবং তার normalizing constant অজানা — কিন্তু আমরা এখন জানি, শুধু un-normalized posterior জানলেই Metropolis–Hastings দিয়ে তার থেকে নমুনা তোলা যায়। তাই 3.6-এর Markov chain হলো ঠিক সেই সেতু যা probability-তত্ত্বকে আধুনিক Bayesian computation-এর সাথে যুক্ত করে — Part III-এর তত্ত্ব Part IV-এর হাতিয়ার হয়ে ওঠে।
সূত্র (sources): C. Fernández-Granda, Probability and Statistics for Data Science (NYU), Markov Chains অধ্যায় (transition matrix, stationary distribution, Chapman–Kolmogorov) ও Monte Carlo / MCMC অংশ; L. Wasserman, All of Statistics, Ch. 23 (Stochastic Processes — Markov Chains) ও Ch. 24 (Simulation Methods — MCMC, Metropolis–Hastings)।