4.2 — Point Estimation: The Method of Moments (বিন্দু-অনুমান: মোমেন্ট পদ্ধতি)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — একটা সংখ্যায় parameter আন্দাজ; কেন moment matching স্বাভাবিক¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল, আর এখন কোন প্রশ্ন¶
অধ্যায় 4.1-এ আমরা inference-এর কেন্দ্রীয় ছবিটা গেঁথেছি। সংক্ষেপে মনে করিয়ে দিই: পৃথিবীতে কোথাও একটা population (সমগ্রক) আছে — ধরা যাক, বাংলাদেশের সব প্রাপ্তবয়স্কের উচ্চতা, কিংবা একটা কারখানার সব বাল্বের আয়ু। এই population-এর আচরণ একটা probability distribution দিয়ে বর্ণিত, আর সেই distribution-এর ভেতরে এক বা একাধিক অজানা সংখ্যা লুকিয়ে আছে — যেমন গড় উচ্চতা, বা গড় আয়ু। এই অজানা সংখ্যাটাকে আমরা বলি parameter (প্যারামিটার / প্রাচল), আর সাধারণভাবে তাকে চিহ্নিত করি গ্রিক অক্ষর \(\theta\) ("থিটা") দিয়ে।
সমস্যা হলো — আমরা পুরো population দেখতে পারি না (কোটি মানুষের উচ্চতা মাপা, বা সব বাল্ব পুড়িয়ে আয়ু দেখা অসম্ভব)। আমরা পাই কেবল একটা sample (নমুনা): population থেকে এলোমেলোভাবে তোলা \(n\)টি পর্যবেক্ষণ, যাদের লিখি
এখানে প্রতিটি \(X_i\) একটি random variable (যাদৃচ্ছিক চলক) — কোন মানটা আসবে তা আগে থেকে নিশ্চিত নয়; আর সাধারণভাবে আমরা ধরে নিই এরা i.i.d. (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা), অর্থাৎ প্রত্যেকটা একই অজানা distribution থেকে, একে অপরের ওপর প্রভাব ছাড়া তোলা।
এতক্ষণে 4.1-এর সব জানা। এই অধ্যায়ের একটিমাত্র প্রশ্ন, এবং সেটা ভয়ানক ব্যবহারিক:
হাতে এই \(n\)টি সংখ্যা \(X_1, \dots, X_n\) আছে। এখান থেকে অজানা \(\theta\)-র জন্য আমার সেরা একটিমাত্র আন্দাজ-সংখ্যা কী হবে?
লক্ষ করুন শব্দটা — "একটিমাত্র সংখ্যা"। আমরা চাইছি না "\(\theta\) হয়তো ৫ থেকে ৭-এর মধ্যে" (সেটা interval estimation, পরে 4.5-এ); আমরা চাইছি একটামাত্র best-guess: "\(\theta\) আনুমানিক \(6.2\)।" একটিমাত্র বিন্দু (point) দিয়ে অজানা parameter আন্দাজ করা — এই কাজটারই নাম point estimation (বিন্দু-অনুমান)।
১.২ Hook — দাঁড়িপাল্লা মেলানোর স্বজ্ঞা¶
একটা ছোট দৃশ্য কল্পনা করুন। আপনার সামনে একটা বাক্সভর্তি অজানা মুদ্রা — কিন্তু এগুলো ন্যায্য (fair) নাও হতে পারে; "head" আসার একটা অজানা probability \(\theta\) আছে। আপনি জানেন না \(\theta\) কত। কী করবেন? স্বাভাবিক প্রবৃত্তি: মুদ্রাটা অনেকবার ছুঁড়ুন, আর দেখুন কত ভাগ বার head এল। ধরা যাক ১০০ বারে ৬২ বার head — আপনি প্রায় না-ভেবেই বলবেন "\(\theta\) মোটামুটি \(0.62\)।"
এই সহজ সিদ্ধান্তের ভেতরে যে যুক্তিটা লুকিয়ে আছে, সেটাই এই গোটা অধ্যায়ের প্রাণভোমরা। আপনি আসলে কী করলেন? আপনি দুটো জিনিসকে সমান ধরে নিলেন:
- একদিকে তত্ত্ব যা বলে: একটা ছোঁড়ায় head আসার গড় (theoretical গড় বা প্রত্যাশা) ঠিক \(\theta\) — কারণ head-কে \(1\) আর tail-কে \(0\) ধরলে \(\mathbb{E}[X] = \theta\)।
- অন্যদিকে data যা দেখাল: ১০০টা ছোঁড়ার বাস্তব গড় হলো \(62/100 = 0.62\)।
আপনি বললেন: "তত্ত্বের গড় = data-র গড়", অর্থাৎ \(\theta = 0.62\)। ব্যস — আপনি method of moments প্রয়োগ করে ফেললেন, এর নাম না জেনেই!
এই দাঁড়িপাল্লা-মেলানোর ছবিটা মাথায় গেঁথে নিন। বাঁ পাল্লায় বসে population-এর গড় (যা parameter \(\theta\)-র ওপর নির্ভর করে, একটা সূত্র), ডান পাল্লায় বসে sample-এর গড় (data থেকে গোনা একটা সংখ্যা)। দুই পাল্লা সমান করে দিলে \(\theta\)-র মান বেরিয়ে আসে। "গড়" বলতে এখানে যা বোঝালাম, তার সাধারণ নাম moment — আর সেখানেই আমরা এখন যাচ্ছি।
১.৩ কেন "moment matching" এতটা স্বাভাবিক — LLN-এর গল্প¶
কিন্তু একটা সংশয় থেকেই যায়: data-র গড়কে তত্ত্বের গড়ের সমান ধরে দেওয়াটা কি নিছক একটা সুবিধাজনক ফিকির, নাকি এর পেছনে শক্ত ভিত্তি আছে? ভিত্তিটা আছে, আর সেটা আমরা Part III-এ ইতিমধ্যে প্রমাণ করে এসেছি — তার নাম Law of Large Numbers (LLN, বৃহৎ সংখ্যার সূত্র)।
মনে করুন 3.3 কী বলেছিল। যদি \(X_1, X_2, \dots\) i.i.d. হয় এবং প্রত্যেকের expectation (প্রত্যাশা) \(\mathbb{E}[X_i] = \mu\) হয়, তবে sample mean (নমুনা গড়)
বড় \(n\)-এর জন্য প্রকৃত গড় \(\mu\)-তে গিয়ে থিতু হয় (\(\bar X_n \to \mu\))। অর্থাৎ — data থেকে গোনা গড় হলো তত্ত্বের গড়ের একটা ভালো প্রতিনিধি, এবং data যত বেশি, প্রতিনিধিত্ব তত নিখুঁত। ঠিক এই কারণেই "sample-এর গড় ≈ population-এর গড়" ধরে নেওয়া একটা যুক্তিসঙ্গত পদক্ষেপ, কোনো হাতসাফাই নয়।
আর সবচেয়ে সুন্দর ব্যাপারটা হলো — LLN শুধু সাধারণ গড়েই থেমে থাকে না। \(X\)-এর জায়গায় যদি \(X^2\) বসাই, তবে \(\frac1n\sum X_i^2\) গিয়ে থিতু হবে \(\mathbb{E}[X^2]\)-তে; \(X^3\) বসালে \(\frac1n\sum X_i^3 \to \mathbb{E}[X^3]\); এবং সাধারণভাবে যেকোনো শক্তি \(k\)-র জন্য
বাঁ দিকের রাশিটাকে আমরা বলব \(k\)-th sample moment (data থেকে গোনা), আর ডান দিকেরটাকে \(k\)-th population moment (তত্ত্ব যা বলে)। LLN-এর এই সম্প্রসারিত রূপটাই method of moments-কে বৈধতা দেয়: প্রতিটি sample moment তার সংশ্লিষ্ট population moment-এর কাছাকাছি থাকে, তাই দুটোকে সমান ধরে parameter solve করা স্বাভাবিক ও নির্ভরযোগ্য।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই:
- Point estimator কী, আর population vs sample moment-এর precise সংজ্ঞা (§২.১–২.২)।
- সেই দুটোকে সমান ধরার নিয়ম → method of moments-এর recipe (§২.৩): যতগুলো অজানা parameter, ততগুলো moment equation।
- কেন এই recipe কাজ করে → consistency-র স্বজ্ঞা (§২.৪), সরাসরি LLN থেকে।
- recipe-টা চারটি বাস্তব distribution-এ সংখ্যাসহ চালিয়ে দেখা — E1 Normal, E2 Exponential, E3 Uniform, E4 Gamma/Binomial (§৩)।
- তারপর properties, sampling distribution, কোড, MLE-র সাথে তুলনা ও অনুশীলনী (§৪ থেকে — পরবর্তী অংশে)।
এক বাক্যে ধরে রাখুন: method of moments বলে — "তত্ত্বের moment আর data-র moment সমান হওয়া উচিত"; এই সমতা থেকে parameter বের করো, আর LLN নিশ্চিত করে যে বেশি data-য় এই আন্দাজ সত্যের কাছে যায়।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো অধ্যায়ের সাধারণ কাঠামোটা একবারে স্থির করি: আমাদের কাছে একটি i.i.d. sample \(X_1, X_2, \dots, X_n\) আছে, একটি common distribution থেকে আসা, যার ভেতরে এক বা একাধিক অজানা parameter আছে — সাধারণভাবে \(\theta\) (একাধিক হলে \(\theta_1, \theta_2, \dots\))। লক্ষ্য: এই data থেকে \(\theta\)-র একটি একক আন্দাজ-সংখ্যা তৈরি করা।
২.১ Point estimator — একটি best-guess তৈরির যন্ত্র¶
প্রথমেই দুটি কাছাকাছি কিন্তু আলাদা ধারণা পরিষ্কার করি, কারণ এদের গুলিয়ে ফেলা পরে বিভ্রান্তি ডেকে আনে।
সংজ্ঞা (Point estimator — বিন্দু-আনুমানক)। একটি point estimator হলো sample-এর একটা function — অর্থাৎ data \(X_1, \dots, X_n\)-কে ইনপুট দিলে যা একটা সংখ্যা ফেরত দেয় — যাকে আমরা অজানা parameter \(\theta\)-র আন্দাজ হিসেবে ব্যবহার করি। একে লিখি "টুপি" (hat) চিহ্ন দিয়ে:
প্রতিটি প্রতীক খুলি:
- \(\theta\) — অজানা, কিন্তু স্থির (fixed) সত্য parameter। এটা প্রকৃতির একটা ধ্রুবক; এর কোনো randomness নেই, আমরা শুধু এর মান জানি না।
- \(\hat\theta\) ("থিটা-হ্যাট") — \(\theta\)-র আনুমানক। মাথার উপর টুপি (hat) চিহ্নটাই সর্বত্র মানে "এটা একটা estimate / data থেকে বানানো আন্দাজ"। যেহেতু \(\hat\theta\) random data \(X_i\)-দের ওপর নির্ভর করে, \(\hat\theta\) নিজেও একটি random variable — নমুনা বদলালে এর মানও বদলায়।
- \(\hat\theta(X_1, \dots, X_n)\) — মনে করায় যে \(\hat\theta\) আসলে data-র একটা সূত্র; data বসালে তবেই সংখ্যা মেলে।
একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ ভাষাগত পার্থক্য (4.1-এর পুনরাবৃত্তি, কিন্তু এখানে কাজে লাগবে):
- Estimator হলো সূত্রটা — যেমন "\(\bar X_n\)" বা "\(\frac1n\sum X_i\)"। এটা data হাতে আসার আগে একটা random variable, একটা নিয়ম।
- Estimate হলো একটা নির্দিষ্ট সংখ্যা — যখন বাস্তব data বসিয়ে দিই, যেমন "\(\bar X_n = 6.2\)"। এটা একটা স্থির সংখ্যা, একটা পরিমাপ।
(একই সূত্র "\(\bar X_n\)" — data আসার আগে estimator, data বসানোর পরে estimate। সাদা চোখে এক, কিন্তু একটা random একটা স্থির।)
পুরো অধ্যায়ের কাজ একটাই: একটা ভালো \(\hat\theta\) লেখার নিয়ম খুঁজে বের করা। এই অধ্যায়ের নিয়মটার নাম method of moments। কিন্তু সেটা বলার আগে দরকার "moment" শব্দটার দুই রূপ পরিষ্কার করা।
২.২ Population moment বনাম sample moment — তত্ত্বের পাল্লা ও data-র পাল্লা¶
§১.২-এর দাঁড়িপাল্লার দুই পাল্লাকে এবার গাণিতিক ভাষা দিই। "Moment" আসলে "গড়"-এর একটা সাধারণীকরণ — শুধু \(X\)-এর গড় নয়, \(X^2\)-এর গড়, \(X^3\)-এর গড়, ইত্যাদি (2.5-এ এদের পরিচয় হয়েছিল)।
সংজ্ঞা (\(k\)-th population moment — সমগ্রক ভ্রামক)। distribution-এর \(k\)-th population moment (বা \(k\)-th raw moment, তত্ত্বের moment) হলো \(X^k\)-এর প্রত্যাশা:
প্রতিটি প্রতীক খুলি:
- \(\mu_k'\) ("mu-\(k\)-prime") — \(k\)-তম population moment। নিচের \(k\) মানে "কত শক্তিতে তুলেছি"; উপরের prime (′) চিহ্নটা ঐতিহ্যগতভাবে বোঝায় এটা raw (origin থেকে মাপা) moment, central (গড় থেকে মাপা) নয়।
- \(\mathbb{E}[\,\cdot\,]\) — প্রত্যাশা / expectation (2.5)। discrete হলে \(\sum_x x^k\,p(x)\), continuous হলে \(\int x^k f(x)\,dx\)।
- \(X\) — population-এর একটি typical random variable (যেকোনো একটা \(X_i\), যেহেতু সবাই একই distribution-এর)।
এই \(\mu_k'\) একটা তত্ত্বের রাশি: এটা distribution-এর সূত্র থেকে আসে, তাই এটা parameter \(\theta\)-র ওপর নির্ভর করে — যেমন আমরা §৩-এ দেখব। বিশেষ করে \(k=1\)-এ এটা চেনা গড়: \(\mu_1' = \mathbb{E}[X] = \mu\) (সাধারণ population mean)।
এবার data-র পাল্লা।
সংজ্ঞা (\(k\)-th sample moment — নমুনা ভ্রামক)। data \(X_1, \dots, X_n\) থেকে গোনা \(k\)-th sample moment হলো \(X_i^k\)-দের গড়:
প্রতিটি প্রতীক খুলি:
- \(\hat\mu_k'\) ("mu-\(k\)-prime-hat") — \(k\)-তম sample moment। টুপি (hat) চিহ্নটা মনে করায় এটা data থেকে বানানো, একটা estimate। (অনেক বই একে \(m_k\)-ও লেখে; আমরা hat-ভাষায় থাকব, যাতে "data থেকে আসা" ব্যাপারটা চোখে পড়ে।)
- \(\frac1n\sum_{i=1}^n\) — \(n\)টি পদের গড়: প্রতিটি \(X_i\)-কে \(k\) শক্তিতে তুলে যোগ করে \(n\) দিয়ে ভাগ।
- \(X_i^{\,k}\) — \(i\)-তম পর্যবেক্ষণের \(k\)-তম শক্তি।
বিশেষ করে \(k=1\)-এ এটা চেনা sample mean: \(\hat\mu_1' = \frac1n\sum X_i = \bar X_n\)।
দুটোকে পাশাপাশি রাখুন (পুরো অধ্যায়ের কেন্দ্রীয় জোড়া):
| প্রতীক | কী | প্রকৃতি | |
|---|---|---|---|
| Population moment | \(\mu_k' = \mathbb{E}[X^k]\) | তত্ত্ব যা বলে | \(\theta\)-র সূত্র, স্থির কিন্তু অজানা |
| Sample moment | \(\hat\mu_k' = \frac1n\sum X_i^k\) | data যা দেখায় | একটি সংখ্যা, data থেকে গোনা |
§১.৩-এ দেখা LLN ঠিক এই দুই সারিকে জোড়া লাগায়: প্রতিটি \(\hat\mu_k' \to \mu_k'\) যখন \(n \to \infty\)। অর্থাৎ ডান কলামের গোনা-সংখ্যা বাঁ কলামের তত্ত্ব-সংখ্যার ভালো প্রতিনিধি — আর এই প্রতিনিধিত্বই পরের ধাপের ভিত্তি।
২.৩ Method of Moments-এর recipe — "যতগুলো parameter, ততগুলো সমীকরণ"¶
এবার মূল যন্ত্র। ধারণাটা §১.২-তেই বলা হয়েছে: population moment-কে তার সংশ্লিষ্ট sample moment-এর সমান ধরো, তারপর সেই সমীকরণ থেকে parameter solve করো। শুধু একটা হিসাব রাখতে হয় — কয়টা সমীকরণ লাগবে।
মূল নীতিটা সহজ: অজানা যতগুলো parameter, ঠিক ততগুলো সমীকরণ দরকার। একটা মাত্র অজানা (\(\theta\)) থাকলে একটা সমীকরণই (সাধারণত প্রথম moment) যথেষ্ট। দুটো অজানা (\(\theta_1, \theta_2\), যেমন Normal-এর \(\mu\) ও \(\sigma^2\)) থাকলে দুটো সমীকরণ লাগবে — প্রথম ও দ্বিতীয় moment। এটা ঠিক বীজগণিতের সেই চেনা নিয়ম: \(m\)টা অজানা solve করতে \(m\)টা স্বাধীন সমীকরণ চাই।
সংজ্ঞা (Method of Moments — মোমেন্ট পদ্ধতি; সংক্ষেপে MoM)। ধরা যাক distribution-এ \(m\)টি অজানা parameter \(\theta_1, \dots, \theta_m\) আছে। তাহলে নিচের ধাপগুলো অনুসরণ করো।
ধাপ ১ — population moment-গুলো parameter-এর সূত্রে লেখো। প্রথম \(m\)টি population moment বের করো, প্রতিটি অজানা parameter-এর function হিসেবে: $$ \mu_1' = g_1(\theta_1, \dots, \theta_m), \quad \mu_2' = g_2(\theta_1, \dots, \theta_m), \quad \dots, \quad \mu_m' = g_m(\theta_1, \dots, \theta_m). $$ এখানে \(g_1, g_2, \dots\) হলো distribution থেকে পাওয়া নির্দিষ্ট সূত্র (যেমন Exponential-এ \(\mu_1' = 1/\lambda\) — §৩-এ দেখব)।
ধাপ ২ — sample moment-গুলো গোনো। data থেকে প্রথম \(m\)টি sample moment হিসাব করো: $$ \hat\mu_1' = \frac1n\sum X_i, \quad \hat\mu_2' = \frac1n\sum X_i^2, \quad \dots, \quad \hat\mu_m' = \frac1n\sum X_i^{\,m}. $$
ধাপ ৩ — সমান ধরো (moment matching)। তত্ত্বের moment-কে data-র moment-এর সমান বসিয়ে দাও — এই \(m\)টি সমীকরণই MoM-এর হৃদয়: $$ \boxed{\ \mu_k'(\theta_1, \dots, \theta_m) \;=\; \hat\mu_k' \qquad (k = 1, 2, \dots, m).\ } $$
ধাপ ৪ — parameter-এর জন্য solve করো। এই \(m\)টি সমীকরণ থেকে \(\theta_1, \dots, \theta_m\)-এর মান বের করো। যে সমাধান পাও, সেগুলোকে টুপি দিয়ে লিখে বলি method of moments estimator: $$ \hat\theta_{1,\text{MoM}}, \quad \hat\theta_{2,\text{MoM}}, \quad \dots, \quad \hat\theta_{m,\text{MoM}}. $$
প্রতীকটা একবার খুলি: \(\hat\theta_{\text{MoM}}\) মানে "method of moments দিয়ে পাওয়া \(\theta\)-র আনুমানক" — অর্থাৎ উপরের সমীকরণ-জোড়া সমাধান করে পাওয়া সূত্র। যেহেতু এটা sample moment \(\hat\mu_k'\) (যা random) থেকে আসে, \(\hat\theta_{\text{MoM}}\) নিজেও একটা random variable — §২.১-এর সাধারণ estimator-এরই একটা নির্দিষ্ট রূপ।
এক বাক্যে recipe: যতগুলো অজানা parameter, ততগুলো "তত্ত্ব-moment = data-moment" সমীকরণ লেখো, আর parameter-এর জন্য solve করো। — এত সহজ যে অনেক সময় এটাই inference-এর প্রথম হাতিয়ার, এবং পরের অধ্যায়ের MLE-র জন্য একটা ভালো শুরুর আন্দাজ (starting value) দেয়।
একটা ছোট সতর্কতা (পরে §৪-এ বিশদে)। MoM প্রায় সবসময় কাজ করে এবং হিসাব সহজ, কিন্তু এটাই সবসময় "সেরা" estimator নয় — কখনো এটা যুক্তিসঙ্গত সীমার বাইরে মান দিতে পারে (যেমন একটা probability-র জন্য \(1.2\)), বা MLE-র চেয়ে বেশি ছড়ানো (কম efficient) হতে পারে। তবু এর সরলতা ও নির্ভরযোগ্য consistency একে অমূল্য করে তোলে — বিশেষত প্রথম আন্দাজ হিসেবে।
২.৪ কেন MoM কাজ করে — consistency-র স্বজ্ঞা (LLN-এর সাথে সংযোগ)¶
recipe তো পেলাম, কিন্তু একটা গভীর প্রশ্ন: এভাবে পাওয়া \(\hat\theta_{\text{MoM}}\) কি আসলেই সত্য \(\theta\)-র কাছাকাছি থাকে? উত্তর — হ্যাঁ, আর এর কারণটা আমরা ইতিমধ্যে হাতে নিয়ে বসে আছি: Law of Large Numbers (3.3)।
যুক্তিটা সরল রেখায় সাজাই।
প্রথম ধাপ — sample moment তার population moment-এ যায়। §১.৩-এ দেখেছি, LLN বলে প্রতিটি \(k\)-র জন্য $$ \hat\mu_k' \;=\; \frac{1}{n}\sum_{i=1}^{n} X_i^{\,k} \;\xrightarrow{\;n\to\infty\;}\; \mathbb{E}[X^k] \;=\; \mu_k'. $$ অর্থাৎ data যত বাড়ে, ডান পাল্লা (sample moment) বাঁ পাল্লার (population moment) সত্য মানে গিয়ে বসে।
দ্বিতীয় ধাপ — তাই সমীকরণের সমাধানও সত্য মানে যায়। MoM estimator \(\hat\theta_{\text{MoM}}\) হলো "\(\mu_k'(\theta) = \hat\mu_k'\)" সমীকরণের সমাধান, আর সত্য \(\theta\) হলো "\(\mu_k'(\theta) = \mu_k'\)" (অর্থাৎ তত্ত্ব = তত্ত্ব)-এর সমাধান। যেহেতু ডান পাশ \(\hat\mu_k'\) ক্রমশ \(\mu_k'\)-এর কাছে যাচ্ছে, এবং solve-করা সূত্রটা (function \(g\)-এর বিপরীত) যথেষ্ট মসৃণ (continuous), তাই সমাধান \(\hat\theta_{\text{MoM}}\)-ও ক্রমশ সত্য \(\theta\)-র কাছে যায়: $$ \hat\theta_{\text{MoM}} \;\xrightarrow{\;n\to\infty\;}\; \theta . $$
এই ধর্মটারই একটা নাম আছে।
সংজ্ঞা (Consistency — সঙ্গতি)। একটি estimator \(\hat\theta\)-কে consistent (সঙ্গত) বলা হয় যদি \(n\) বাড়ার সাথে সাথে এটা সত্য parameter \(\theta\)-তে থিতু হয় (formal-ভাবে: \(\hat\theta \to \theta\) in probability, 3.2-এর অর্থে)। সোজা কথায় — বেশি data দিলে consistent estimator সত্যের কাছে চলে আসে।
তাহলে এক বাক্যে: MoM estimator consistent, কারণ তা গড়ে নেওয়া sample moment থেকে তৈরি, আর LLN-ই নিশ্চিত করে যে এই গড়গুলো সত্য population moment-এ থিতু হয়। এটাই MoM-এর সবচেয়ে শক্ত ভরসা — পদ্ধতিটা যত সরলই হোক, এর consistency-র পেছনে দাঁড়িয়ে আছে Part III-এর কঠিন-অর্জিত LLN।
(এই consistency-র ছবিটা — কীভাবে \(n\) বাড়লে \(\hat\theta_{\text{MoM}}\) সত্য \(\theta\)-র চারপাশে শক্ত হয়ে আসে — আমরা §৬-এর একটা চিত্রে চোখে দেখব; এবং পুরোদস্তুর প্রমাণ ও আরও কিছু property §৪–৫-এ।)
৩ · পূর্ণাঙ্গ উদাহরণ — হাতে-কলমে MoM solve¶
এবার §২.৩-এর চার-ধাপি recipe-টা চারটি বাস্তব distribution-এ চালাই। প্রতিটিতে একই ছন্দ: (১) population moment-কে parameter-এর সূত্রে লেখা, (২) sample moment গোনা, (৩) সমান ধরা, (৪) solve করা — শেষে একটা ছোট সংখ্যা-উদাহরণ। এগুলো অধ্যায়জুড়ে ফিরে আসবে, তাই লেবেল মনে রাখুন: E1 Normal, E2 Exponential, E3 Uniform\((0,\theta)\), E4 Gamma/Binomial।
৩.১ E1 — Normal \((\mu, \sigma^2)\): দুই parameter, দুই moment¶
ধরা যাক \(X_1, \dots, X_n\) i.i.d. \(\mathcal{N}(\mu, \sigma^2)\) থেকে — অর্থাৎ একটি normal (গাউসীয়) distribution, যার গড় \(\mu\) ও variance \(\sigma^2\) দুটোই অজানা। এখানে \(m = 2\)টি parameter, তাই দুটি moment equation লাগবে।
ধাপ ১ — population moment। Normal distribution-এর moment আমরা 2.5 থেকে জানি: $$ \mu_1' = \mathbb{E}[X] = \mu, \qquad \mu_2' = \mathbb{E}[X^2] = \sigma^2 + \mu^2 . $$ (দ্বিতীয়টা মনে করার সূত্র: \(\mathbb{E}[X^2] = \mathrm{Var}(X) + (\mathbb{E}[X])^2 = \sigma^2 + \mu^2\) — variance ও mean থেকে। এটা যেকোনো distribution-এর জন্যই সত্য, শুধু Normal-এর নয়।)
ধাপ ২ — sample moment। $$ \hat\mu_1' = \frac1n\sum_{i=1}^n X_i = \bar X, \qquad \hat\mu_2' = \frac1n\sum_{i=1}^n X_i^2 . $$ (এখান থেকে \(\bar X\) লিখছি \(\bar X_n\)-এর সংক্ষেপে, যখন \(n\) স্পষ্ট।)
ধাপ ৩ — সমান ধরো। $$ \mu = \bar X, \qquad \sigma^2 + \mu^2 = \frac1n\sum X_i^2 . $$
ধাপ ৪ — solve করো। প্রথম সমীকরণ থেকে সরাসরি: $$ \boxed{\ \hat\mu_{\text{MoM}} = \bar X\ } . $$ এই \(\hat\mu = \bar X\)-কে দ্বিতীয় সমীকরণে বসিয়ে \(\sigma^2\)-এর জন্য solve করি: $$ \hat\sigma^2_{\text{MoM}} = \frac1n\sum X_i^2 - \bar X^2 . $$ এই রাশিটাকে একটু সাজিয়ে নিলে আরও চেনা চেহারা পাই (বীজগণিতিক পরিচয় \(\frac1n\sum X_i^2 - \bar X^2 = \frac1n\sum (X_i - \bar X)^2\) ব্যবহার করে): $$ \boxed{\ \hat\sigma^2_{\text{MoM}} = \frac{1}{n}\sum_{i=1}^{n}(X_i - \bar X)^2\ } . $$ অর্থাৎ MoM আমাদের দেয় ঠিক সেই স্বাভাবিক আন্দাজ যা আশা করি: গড়ের আন্দাজ = sample mean, আর variance-এর আন্দাজ = data-র গড় থেকে গড়-বর্গ-বিচ্যুতি।
(একটা সূক্ষ্ম খটকা — খেয়াল করুন এখানে ভাগটা \(n\) দিয়ে, \(n-1\) দিয়ে নয়। ফলে MoM-এর \(\hat\sigma^2\) সামান্য পক্ষপাতদুষ্ট (biased) — এই bias ও কেন অনেকে \(n-1\) ব্যবহার করেন, তা §৪-এ আলোচিত হবে। আপাতত মূল বার্তা: recipe সরাসরি \(n\)-ভাগ দেয়।)
ছোট সংখ্যা-উদাহরণ। ধরা যাক ৫টি পর্যবেক্ষণ: \(2, 4, 4, 4, 6\) (ধরে নিই এরা একটা normal থেকে)। - \(\bar X = \dfrac{2+4+4+4+6}{5} = \dfrac{20}{5} = 4\). তাই \(\hat\mu_{\text{MoM}} = 4\)। - বিচ্যুতিগুলো: \((2-4)^2, (4-4)^2, (4-4)^2, (4-4)^2, (6-4)^2 = 4, 0, 0, 0, 4\). যোগফল \(= 8\)। - \(\hat\sigma^2_{\text{MoM}} = \dfrac{8}{5} = 1.6\)।
অর্থাৎ এই data থেকে MoM বলে: \(\mu \approx 4\), \(\sigma^2 \approx 1.6\) (তাই \(\sigma \approx 1.26\))।
৩.২ E2 — Exponential\((\lambda)\): এক parameter, এক moment¶
ধরা যাক \(X_1, \dots, X_n\) i.i.d. Exponential\((\lambda)\) থেকে — যেমন একটা সার্ভারে পরপর দুটো request-এর মধ্যেকার অপেক্ষা-সময়, বা একটা যন্ত্রাংশের আয়ু। এখানে একটিমাত্র অজানা parameter, rate \(\lambda\) ("ল্যামডা", \(\lambda > 0\)); তাই একটিমাত্র moment equation লাগবে।
ধাপ ১ — population moment। Exponential-এর গড় (2.4/2.5 থেকে): $$ \mu_1' = \mathbb{E}[X] = \frac{1}{\lambda} . $$ (স্বজ্ঞা: rate \(\lambda\) বড় হলে ঘটনা ঘন ঘন ঘটে, তাই গড় অপেক্ষা-সময় ছোট — তাই গড় \(= 1/\lambda\), rate-এর উল্টো।)
ধাপ ২ — sample moment। \(\hat\mu_1' = \bar X\).
ধাপ ৩ — সমান ধরো। $$ \frac{1}{\lambda} = \bar X . $$
ধাপ ৪ — solve করো। দুই পাশ উল্টে: $$ \boxed{\ \hat\lambda_{\text{MoM}} = \frac{1}{\bar X}\ } . $$ চমৎকার রকম স্বজ্ঞাময়: rate-এর আন্দাজ হলো গড় অপেক্ষা-সময়ের উল্টো। যদি গড়ে প্রতি \(2\) মিনিটে একটা request আসে (\(\bar X = 2\)), তবে rate-এর আন্দাজ \(\hat\lambda = 1/2 = 0.5\) request প্রতি মিনিট।
ছোট সংখ্যা-উদাহরণ। পরপর চারটি অপেক্ষা-সময় (মিনিটে): \(1, 2, 2, 3\)। - \(\bar X = \dfrac{1+2+2+3}{4} = \dfrac{8}{4} = 2\)। - \(\hat\lambda_{\text{MoM}} = \dfrac{1}{2} = 0.5\) (প্রতি মিনিটে গড়ে \(0.5\)টি ঘটনা)।
৩.৩ E3 — Uniform\((0, \theta)\): এক parameter, এক moment (একটা চমকসহ)¶
ধরা যাক \(X_1, \dots, X_n\) i.i.d. Uniform\((0, \theta)\) থেকে — অর্থাৎ \(0\) থেকে \(\theta\)-র মধ্যে সমভাবে ছড়ানো, যেখানে উপরের সীমা \(\theta\) (\(\theta > 0\)) অজানা। (কল্পনা করুন একটা স্কেলে এলোমেলো বিন্দু, যার দৈর্ঘ্য \(\theta\) জানা নেই।) একটিমাত্র অজানা, তাই একটি moment equation।
ধাপ ১ — population moment। Uniform\((0,\theta)\)-এর গড় হলো মাঝবিন্দু: $$ \mu_1' = \mathbb{E}[X] = \frac{0 + \theta}{2} = \frac{\theta}{2} . $$ (স্বজ্ঞা: \(0\) আর \(\theta\)-র মধ্যে সমভাবে ছড়ানো হলে গড় ঠিক মাঝখানে — \(\theta/2\)।)
ধাপ ২ — sample moment। \(\hat\mu_1' = \bar X\).
ধাপ ৩ — সমান ধরো। $$ \frac{\theta}{2} = \bar X . $$
ধাপ ৪ — solve করো। দুই পাশে \(2\) গুণ: $$ \boxed{\ \hat\theta_{\text{MoM}} = 2\bar X\ } . $$ স্বজ্ঞাময়: গড় যদি পরিসরের মাঝখানে বসে, তবে উপরের সীমা গড়ের দ্বিগুণ। গড় \(3\) হলে \(\theta\)-র আন্দাজ \(6\)।
ছোট সংখ্যা-উদাহরণ। পাঁচটি মান: \(1, 2, 3, 4, 5\) (ধরে নিই Uniform\((0,\theta)\) থেকে)। - \(\bar X = \dfrac{1+2+3+4+5}{5} = \dfrac{15}{5} = 3\)। - \(\hat\theta_{\text{MoM}} = 2 \times 3 = 6\)।
একটা শিক্ষণীয় চমক (পরে কাজে লাগবে)। এই data-য় সবচেয়ে বড় পর্যবেক্ষণ \(5\) — কিন্তু MoM বলছে \(\theta \approx 6\), যা ঠিক আছে (\(\theta\) অবশ্যই সব data-র চেয়ে বড়, তাই \(6 > 5\) যুক্তিসঙ্গত)। কিন্তু এমন data কল্পনা করুন: \(1, 1, 1, 9\)। তখন \(\bar X = 3\), তাই \(\hat\theta_{\text{MoM}} = 6\) — অথচ একটা পর্যবেক্ষণ (\(9\)) ইতিমধ্যে \(6\)-এর চেয়ে বড়! অর্থাৎ MoM এমন \(\hat\theta\) দিল যা অসম্ভব (\(\theta \geq 9\) না হলে \(9\) আসতেই পারত না)। এটাই §২.৩-এর সতর্কতার একটা জীবন্ত উদাহরণ: MoM সরল ও consistent, কিন্তু সবসময় "যুক্তিসঙ্গত" উত্তর দেয় না — এখানে \(\hat\theta = \max_i X_i\) অনেক ভালো হতো। এই তুলনা MLE-র (4.3) সাথে আবার ফিরে আসবে।
৩.৪ E4 — দুই-moment উদাহরণ: Gamma ও Binomial¶
শেষ উদাহরণে এমন distribution নিই যেখানে দুটো parameter একসাথে নির্ণয় করতে হয় — তাই দুটো moment equation লাগবে। দুটো ভিন্ন স্বাদ দেখাই: একটা continuous (Gamma), একটা discrete (Binomial)।
(ক) Gamma\((\alpha, \beta)\) — shape ও rate, দুই-moment¶
ধরা যাক \(X_1, \dots, X_n\) i.i.d. Gamma\((\alpha, \beta)\) থেকে, যেখানে shape \(\alpha\) ও rate \(\beta\) দুটোই অজানা (\(\alpha, \beta > 0\))। Gamma-র moment (2.5/distribution-তালিকা থেকে): $$ \mu_1' = \mathbb{E}[X] = \frac{\alpha}{\beta}, \qquad \mu_2' = \mathbb{E}[X^2] = \frac{\alpha(\alpha+1)}{\beta^2} . $$ (এখানে \(\mathbb{E}[X^2] = \mathrm{Var}(X) + (\mathbb{E}[X])^2\), আর Gamma-র \(\mathrm{Var}(X) = \dfrac{\alpha}{\beta^2}\); তাই \(\mu_2' = \dfrac{\alpha}{\beta^2} + \dfrac{\alpha^2}{\beta^2} = \dfrac{\alpha(\alpha+1)}{\beta^2}\)।)
সমান ধরে solve। sample moment দিয়ে: $$ \frac{\alpha}{\beta} = \bar X, \qquad \frac{\alpha(\alpha+1)}{\beta^2} = \frac1n\sum X_i^2 . $$ সুবিধার জন্য একটা সংক্ষেপ ব্যবহার করি — sample variance-জাতীয় রাশি \(\hat\sigma^2 = \frac1n\sum X_i^2 - \bar X^2 = \frac1n\sum (X_i - \bar X)^2\)। লক্ষ করুন দ্বিতীয় সমীকরণটা লেখা যায় $$ \underbrace{\frac{\alpha}{\beta^2}}{\mathrm{Var}} \;=\; \frac1n\sum X_i^2 - \Big(\frac{\alpha}{\beta}\Big)^2 \;=\; \frac1n\sum X_i^2 - \bar X^2 \;=\; \hat\sigma^2 , $$ যেখানে আমরা \(\alpha/\beta = \bar X\) বসিয়েছি। এখন দুটো পরিষ্কার সম্পর্ক: $$ \frac{\alpha}{\beta} = \bar X \quad(\text{mean}), \qquad \frac{\alpha}{\beta^2} = \hat\sigma^2 \quad(\text{variance}). $$ প্রথমটাকে দ্বিতীয়টা দিয়ে ভাগ করলে \(\alpha\) কেটে গিয়ে \(\beta\) একা পড়ে যায় (\(\frac{\alpha/\beta}{\alpha/\beta^2} = \beta\)): $$ \boxed{\ \hat\beta, \qquad \boxed{\ \hat\alpha_{\text{MoM}} = \hat\beta_{\text{MoM}}\cdot\bar X = \frac{\bar X^2}{\hat\sigma^2}\ } . $$ (শেষ ধাপে }} = \frac{\bar X}{\hat\sigma^2}\ \(\hat\alpha = \bar X \cdot \hat\beta = \bar X^2/\hat\sigma^2\) এসেছে \(\alpha = \beta\,\bar X\) থেকে — অর্থাৎ \(\alpha/\beta = \bar X\)।) সুন্দর সরল ফলাফল — মাত্র \(\bar X\) আর \(\hat\sigma^2\) গুনেই দুটো parameter মিলে গেল।
ছোট সংখ্যা-উদাহরণ। ধরা যাক \(\bar X = 4\) ও \(\hat\sigma^2 = 8\) (data থেকে গোনা)। তাহলে $$ \hat\beta_{\text{MoM}} = \frac{4}{8} = 0.5, \qquad \hat\alpha_{\text{MoM}} = \frac{4^2}{8} = \frac{16}{8} = 2 . $$ অর্থাৎ MoM আন্দাজ: Gamma\((\alpha \approx 2,\ \beta \approx 0.5)\)। (যাচাই: mean \(= \alpha/\beta = 2/0.5 = 4 = \bar X\) ✓, variance \(= \alpha/\beta^2 = 2/0.25 = 8 = \hat\sigma^2\) ✓।)
(খ) Binomial\((k, p)\) — একই দুই-moment কৌশল (এক ঝলক)¶
discrete জগতেও কৌশল হুবহু এক। ধরা যাক প্রতিটি \(X_i \sim\) Binomial\((k, p)\), যেখানে trial-সংখ্যা \(k\) ও সাফল্যের probability \(p\) — দুটোই অজানা। Binomial-এর moment: $$ \mu_1' = \mathbb{E}[X] = kp, \qquad \mathrm{Var}(X) = kp(1-p) \;\Rightarrow\; \mu_2' = kp(1-p) + (kp)^2 . $$ আগের মতোই mean ও variance সমান ধরে (\(kp = \bar X\), \(kp(1-p) = \hat\sigma^2\)):
প্রথম সমীকরণকে দ্বিতীয়তে ভাগ করলে — \(\frac{kp(1-p)}{kp} = 1-p\) — তাই \(1 - \hat p = \hat\sigma^2/\bar X\), অর্থাৎ $$ \boxed{\ \hat p_{\text{MoM}} = 1 - \frac{\hat\sigma^2}{\bar X}\ }, \qquad \boxed{\ \hat k_{\text{MoM}} = \frac{\bar X}{\hat p_{\text{MoM}}}\ } . $$ (\(\hat k\) এসেছে \(kp = \bar X\) থেকে — যদিও \(k\) পূর্ণসংখ্যা হওয়ার কথা, MoM ভগ্নাংশ দিতে পারে, যা §২.৩-এর সতর্কতার আরেকটা ছোঁয়া; বাস্তবে নিকটতম পূর্ণসংখ্যায় গোল করা হয়।)
এই চারটি উদাহরণ থেকে যা ধরে রাখবেন: এক parameter হোক বা দুই, continuous হোক বা discrete — recipe একই থাকে। moment-গুলো parameter-এর সূত্রে লেখো, sample moment-এর সমান ধরো, solve করো। পার্থক্য শুধু বীজগণিতে, ধারণায় নয়। §৪ থেকে আমরা এই estimator-গুলোর ভালো-মন্দ (bias, variance, sampling distribution) ও কোড-প্রয়োগ দেখব।
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা Method of Moments (MoM)-এর নীতি পেয়েছি একটাই বাক্যে: "sample moment-গুলোকে theoretical moment-এর সমান বসিয়ে parameter-এর জন্য সমাধান করো।" এই অংশে সেই নীতিকে scratch থেকে কাজে লাগিয়ে আসল estimator গুলো বের করব — কোনো বীজগণিতের ধাপ লুকানো হবে না, প্রতিটি লাইনের পেছনে কারণ বাংলায় থাকবে। কাজটা তিনটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে):
- (a) চারটে চলমান উদাহরণ E1–E4-এর জন্য MoM estimator উৎপাদন করা — moment-equation \(\hat\mu_k' = \mu_k'(\theta)\) বসিয়ে \(\theta\)-র জন্য সমাধান (Normal ও Exponential ও Uniform\((0,\theta)\) প্রথম moment দিয়ে, Gamma প্রথম দুই moment দিয়ে)। ★★
- (b) consistency — কেন MoM estimator \(\hat\theta_{\text{MoM}} \xrightarrow{P} \theta\): ভিত্তি হলো 3.3-এর LLN (\(\hat\mu_k' \xrightarrow{P} \mu_k'\)) আর তার উপর continuous mapping। ★★
- (c) একটা সৎ স্বীকারোক্তি — MoM সবসময় ভালো নয়: biased বা inefficient হতে পারে; Uniform\((0,\theta)\)-তে \(2\bar X\) বনাম অনেক ভালো \(\max\)-এর তুলনা। ★
এক নজরে যা মনে রাখবেন। MoM-এর গোটা যন্ত্রটাই দুই স্তম্ভের উপর দাঁড়িয়ে — (i) population moment \(\mu_k'(\theta)\) কে \(\theta\)-র function হিসেবে লেখা (এটা 2.5-এর কাজ: প্রতিটি distribution-এর moment আমরা সেখানে বের করেছি), আর (ii) sample moment \(\hat\mu_k'\) যে সেই population moment-এ থিতু হয় (এটা 3.3-এর LLN)। (a)-তে প্রথম স্তম্ভ খাটাই, (b)-তে দ্বিতীয়টা।
পুরো অংশে নোটেশন এক রাখছি: \(\theta\) হলো অজানা parameter (একটা সংখ্যা হতে পারে, বা একাধিক সংখ্যার vector); \(k\)-তম theoretical (population) moment $$ \mu_k' \;=\; \mathbb{E}[X^k] \qquad(\text{2.5-এ সংজ্ঞায়িত, raw moment}), $$ যা সাধারণত \(\theta\)-র উপর নির্ভর করে — তাই লিখব \(\mu_k'(\theta)\); আর \(k\)-তম sample (empirical) moment $$ \hat\mu_k' \;=\; \frac1n\sum_{i=1}^n X_i^k $$ — হাতে-পাওয়া \(n\)টা data-র \(k\)-তম ঘাতের গড়। লক্ষ্য করুন \(\mu_k'\) একটা স্থির সংখ্যা (অজানা \(\theta\)-র উপর নির্ভর) আর \(\hat\mu_k'\) একটা random variable (data বদলালে বদলায়) — এই পার্থক্যটাই (b)-এর প্রাণ।
৪.১ · (a) E1–E4-এর জন্য MoM estimator উৎপাদন — ★★¶
সাধারণ রেসিপি (recipe)। ধরা যাক parameter-এ \(p\)টা অজানা সংখ্যা আছে (\(\theta = (\theta_1,\dots,\theta_p)\))। তবে \(p\)টা সমীকরণ লাগবে। আমরা প্রথম \(p\)টা moment নিই আর প্রতিটার theoretical রূপকে sample রূপের সমান বসাই: $$ \boxed{\;\hat\mu_1' = \mu_1'(\theta),\quad \hat\mu_2' = \mu_2'(\theta),\quad\dots,\quad \hat\mu_p' = \mu_p'(\theta)\;} $$ এই \(p\)টা সমীকরণ \(p\)টা অজানা \(\theta_j\)-তে সমাধান করলে যা পাই তা-ই Method of Moments estimator \(\hat\theta_{\text{MoM}}\)। নিচে চারটে উদাহরণে ঠিক এটাই করব — তবে প্রতিবার ডান দিকের \(\mu_k'(\theta)\) কোথা থেকে এল, সেটা 2.5 থেকে স্পষ্ট মনে করিয়ে নেব।
E1 — Normal\((\mu, \sigma^2)\): দুই parameter, দুই moment¶
এখানে অজানা \(\theta = (\mu, \sigma^2)\) — দুটো সংখ্যা, তাই প্রথম দুই moment লাগবে।
ধাপ ১ — theoretical moment দুটো লিখি (2.5 থেকে)। Normal-এর সংজ্ঞা থেকেই $$ \mu_1' \;=\; \mathbb{E}[X] \;=\; \mu, \qquad \mu_2' \;=\; \mathbb{E}[X^2]. $$ দ্বিতীয়টা সরাসরি না জানলেও variance-এর সংজ্ঞা দিয়ে পাই (2.5-এর মূল পরিচয়): \(\mathrm{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2\), অর্থাৎ $$ \mu_2' \;=\; \mathrm{Var}(X) + (\mathbb{E}[X])^2 \;=\; \sigma^2 + \mu^2 . $$
ধাপ ২ — moment-equation বসাই। $$ \hat\mu_1' = \mu_1'(\theta):\quad \bar X = \mu, \qquad\qquad \hat\mu_2' = \mu_2'(\theta):\quad \frac1n\sum_{i=1}^n X_i^2 = \sigma^2 + \mu^2 . $$ (এখানে \(\hat\mu_1' = \frac1n\sum X_i = \bar X\)।)
ধাপ ৩ — সমাধান। প্রথম সমীকরণ থেকে সরাসরি $$ \boxed{\;\hat\mu_{\text{MoM}} \;=\; \bar X\;}. $$ এটাকে দ্বিতীয়তে বসিয়ে \(\sigma^2\) বের করি: $$ \hat\sigma^2_{\text{MoM}} \;=\; \frac1n\sum_{i=1}^n X_i^2 \;-\; \hat\mu^2 \;=\; \frac1n\sum_{i=1}^n X_i^2 \;-\; \bar X^2 . $$ এই শেষ রাশিটা চেনা — বীজগণিতের পরিচিত পরিচয় \(\frac1n\sum X_i^2 - \bar X^2 = \frac1n\sum (X_i - \bar X)^2\) ব্যবহার করলে (নিচে এক লাইনে যাচাই): $$ \frac1n\sum_i (X_i-\bar X)^2 = \frac1n\sum_i\big(X_i^2 - 2\bar X X_i + \bar X^2\big) = \frac1n\sum_i X_i^2 - 2\bar X\underbrace{\tfrac1n\sum_i X_i}{=\bar X} + \bar X^2 = \frac1n\sum_i X_i^2 - \bar X^2 , $$ তাই পরিচ্ছন্ন রূপে $$ \boxed{\;\hat\sigma^2. $$}} \;=\; \frac1n\sum_{i=1}^n (X_i - \bar X)^2\;
খেয়াল করুন — হরে \(n\), \(n-1\) নয়। MoM সরাসরি \(\frac1n\) দেয় (sample variance-এর "biased" রূপ), কারণ moment-matching-এ কোনো জায়গায় "\(-1\)" ঢোকার সুযোগ নেই। 4.3-এ MLE-ও ঠিক এই \(\frac1n\)-ই দেবে; অথচ unbiased estimator-এ \(\frac{1}{n-1}\) লাগে। তাই MoM আর "নিরপেক্ষতা (unbiasedness)" এক জিনিস নয় — এটা (c)-এর সততা-নোটের প্রথম আভাস।
E2 — Exponential\((\lambda)\): এক parameter, এক moment¶
অজানা একটাই: rate \(\lambda\)। তাই একটা moment-equation যথেষ্ট।
ধাপ ১ — theoretical moment (2.5)। Exponential\((\lambda)\)-এর জন্য (rate-parametrization) $$ \mu_1' \;=\; \mathbb{E}[X] \;=\; \frac1\lambda . $$ (স্মরণ: rate \(\lambda\) বড় হলে ঘটনা ঘন ঘন ঘটে, তাই গড় অপেক্ষা-সময় \(1/\lambda\) ছোট — সংজ্ঞাটা স্বজ্ঞার সাথে মেলে।)
ধাপ ২ — moment-equation। $$ \hat\mu_1' = \mu_1'(\lambda):\qquad \bar X = \frac1\lambda . $$
ধাপ ৩ — সমাধান। দুদিক উল্টে $$ \boxed{\;\hat\lambda_{\text{MoM}} \;=\; \frac{1}{\bar X}\;}. $$ চমৎকার সরল: গড় অপেক্ষা-সময়ের উল্টোটাই rate-এর আন্দাজ। (লক্ষ্য করুন এটা \(\bar X\)-এর একটা non-linear function — \(1/\bar X\) — যা (b)-তে গুরুত্বপূর্ণ হবে: linearity ছাড়াই consistency পেতে হবে।)
E3 — Uniform\((0,\theta)\): এক parameter, প্রথম moment দিয়ে¶
অজানা একটাই: উপরের প্রান্ত \(\theta\)। আবার একটা moment-equation।
ধাপ ১ — theoretical moment (2.5)। \([0,\theta]\)-তে সমভাবে ছড়ানো বণ্টনের গড় ঠিক মাঝখানে: $$ \mu_1' \;=\; \mathbb{E}[X] \;=\; \frac{0+\theta}{2} \;=\; \frac{\theta}{2} . $$
ধাপ ২ — moment-equation। $$ \hat\mu_1' = \mu_1'(\theta):\qquad \bar X = \frac{\theta}{2} . $$
ধাপ ৩ — সমাধান। \(\theta\)-র জন্য সমাধান করে $$ \boxed{\;\hat\theta_{\text{MoM}} \;=\; 2\bar X\;}. $$ স্বজ্ঞা পরিষ্কার: যদি গড় \(\bar X\) হয়, আর ডেটা \(0\) থেকে \(\theta\) অবধি সমভাবে ছড়ানো, তবে ছাদ \(\theta\) গড়ের দ্বিগুণের কাছে থাকবে। কিন্তু এই estimator-এই MoM-এর দুর্বলতা সবচেয়ে স্পষ্ট ফুটে ওঠে — কারণ এটা একটা সমস্যাও ডেকে আনে: \(2\bar X\) অনায়াসে কোনো এক observed \(X_i\)-এর চেয়েও ছোট হতে পারে, যদিও \(\theta \ge \max_i X_i\) অবশ্যই সত্য। এই অস্বস্তিটাই (c)-তে গভীরভাবে দেখব এবং §৫-এ সংখ্যায় ধরব।
E4 — Gamma\((\alpha, \beta)\): দুই parameter, প্রথম দুই moment¶
অজানা দুটো: shape \(\alpha\) আর rate \(\beta\) (অর্থাৎ \(\theta=(\alpha,\beta)\))। তাই প্রথম দুই moment চাই — এটাই সবচেয়ে শিক্ষণীয় উদাহরণ, কারণ এখানে দুটো অজানা একসাথে সমাধান করতে হয়।
ধাপ ১ — theoretical moment দুটো (2.5)। Gamma\((\alpha,\beta)\) (shape–rate) থেকে $$ \mu_1' \;=\; \mathbb{E}[X] \;=\; \frac{\alpha}{\beta}, \qquad \mathrm{Var}(X) \;=\; \frac{\alpha}{\beta^2} . $$ এবং আগের মতোই \(\mu_2' = \mathrm{Var}(X) + (\mathbb{E}[X])^2 = \dfrac{\alpha}{\beta^2} + \dfrac{\alpha^2}{\beta^2} = \dfrac{\alpha(\alpha+1)}{\beta^2}\)।
ধাপ ২ — moment-equation দুটো। সংক্ষেপে \(m_1 := \hat\mu_1' = \bar X\) আর \(m_2 := \hat\mu_2' = \frac1n\sum X_i^2\) লিখলে: $$ m_1 = \frac{\alpha}{\beta}, \qquad\qquad m_2 = \frac{\alpha(\alpha+1)}{\beta^2} . $$
ধাপ ৩ — সমাধান (কৌশল: variance বিয়োগ করো)। দুটো অজানা একসাথে — সরাসরি না ভেবে একটা চালাকি খাটাই। §৩-এর সেই একই sample variance-জাতীয় রাশি \(\hat\sigma^2 = \frac1n\sum (X_i-\bar X)^2\) বানাই (এখানে \(n\)-হর, তাই §৩ আর §৪-এর প্রতীক এক): $$ \hat\sigma^2 \;:=\; m_2 - m_1^2 \;=\; \frac{\alpha(\alpha+1)}{\beta^2} - \frac{\alpha^2}{\beta^2} \;=\; \frac{\alpha^2 + \alpha - \alpha^2}{\beta^2} \;=\; \frac{\alpha}{\beta^2} . $$ এখন আমাদের হাতে দুটো পরিষ্কার সমীকরণ: $$ \underbrace{m_1 = \frac{\alpha}{\beta}}{(\text{I})}, \qquad \underbrace{\hat\sigma^2 = \frac{\alpha}{\beta^2}}. $$ (I)-কে (II) দিয়ে ভাগ করলে })\(\alpha\) কাটাকাটি গিয়ে শুধু \(\beta\) থাকে: $$ \frac{m_1}{\hat\sigma^2} \;=\; \frac{\alpha/\beta}{\alpha/\beta^2} \;=\; \frac{\beta^2}{\beta} \;=\; \beta \quad\Longrightarrow\quad \boxed{\;\hat\beta_{\text{MoM}} \;=\; \frac{m_1}{\hat\sigma^2} \;=\; \frac{\bar X}{\,\frac1n\sum (X_i-\bar X)^2\,}\;}. $$ এবার (I)-তে ফিরে \(\alpha = \beta\, m_1 = \hat\beta\, m_1\), অর্থাৎ $$ \boxed{\;\hat\alpha_{\text{MoM}} \;=\; \hat\beta\, m_1 \;=\; \frac{m_1^2}{\hat\sigma^2} \;=\; \frac{\bar X^2}{\,\frac1n\sum (X_i-\bar X)^2\,}\;}. $$ সুন্দর ব্যাখ্যা: \(\hat\alpha = \bar X^2 / \hat\sigma^2\) মানে — গড়ের বর্গ যত ভ্যারিয়েন্সের চেয়ে বড়, shape তত বড় (বণ্টন তত কম ছড়ানো ও বেশি প্রতিসম)। MoM-এর এই দুই-parameter সমাধানই দেখায় কেন রেসিপিটা শক্তিশালী: যেখানে likelihood-সমীকরণ (4.3-এ MLE) Gamma-র জন্য digamma-function-এ গিয়ে closed form দেয় না, সেখানে MoM সরল বীজগণিতেই উত্তর দিয়ে দেয়।
চার উদাহরণ এক টেবিলে।
উদাহরণ অজানা \(\theta\) লাগানো moment \(\hat\theta_{\text{MoM}}\) E1 Normal \((\mu,\sigma^2)\) ১ম, ২য় \(\hat\mu=\bar X,\ \ \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\) E2 Exponential \(\lambda\) ১ম \(\hat\lambda = 1/\bar X\) E3 Uniform\((0,\theta)\) \(\theta\) ১ম \(\hat\theta = 2\bar X\) E4 Gamma \((\alpha,\beta)\) ১ম, ২য় \(\hat\beta=\bar X/\hat\sigma^2,\ \ \hat\alpha=\bar X^2/\hat\sigma^2\) (\(\hat\sigma^2 = \frac1n\sum(X_i-\bar X)^2\), §৩-এর মতোই \(n\)-হর।) — এই ছকটাই §৪.১-এর সারাংশ; §৫-এ এদের প্রত্যেকটা কোডে যাচাই করব।
৪.২ · (b) Consistency — কেন \(\hat\theta_{\text{MoM}} \xrightarrow{P} \theta\) — ★★¶
এতক্ষণ estimator বানালাম; এবার প্রশ্ন — এগুলো কি কাজ করে? অর্থাৎ data যত বাড়ে (\(n\to\infty\)), \(\hat\theta_{\text{MoM}}\) কি সত্যিকারের \(\theta\)-র দিকে যায়? এই ধর্মটার নাম consistency (সঙ্গতি/সাবলীলতা), আর এটাই একটা estimator-এর সবচেয়ে ন্যূনতম দাবি: অসীম data পেলে অন্তত সঠিক উত্তরে পৌঁছানো উচিত। সুসংবাদ — MoM estimator সাধারণ পরিস্থিতিতে consistent, আর তার প্রমাণ আশ্চর্য রকম পরিষ্কার, মাত্র দুটো ইট দিয়ে গাঁথা।
ইট ১ — sample moment নিজে consistent (LLN, 3.3)। স্থির করি যেকোনো \(k\)। লক্ষ্য করুন \(\hat\mu_k' = \frac1n\sum_{i=1}^n X_i^k\) আসলে নতুন কিছু নয় — এটা \(Y_i := X_i^k\) নামের নতুন i.i.d. random variable-গুলোর sample mean! কারণ \(X_i\)-রা i.i.d. হলে তাদের যেকোনো (fixed) function \(X_i^k\)-ও i.i.d.। আর এই নতুন variable-এর population mean ঠিক \(\mathbb{E}[Y] = \mathbb{E}[X^k] = \mu_k'\)। তাই Weak Law of Large Numbers (3.3-এ প্রমাণিত: i.i.d.-এর sample mean তার expectation-এ converge করে in probability) সরাসরি প্রয়োগ করে পাই: $$ \boxed{\;\hat\mu_k' \;=\; \frac1n\sum_{i=1}^n X_i^k \;\xrightarrow{\;P\;}\; \mathbb{E}[X^k] \;=\; \mu_k'\;} \qquad(\text{যদি } \mu_k' \text{ সসীম, যা আমাদের চার উদাহরণেই সত্য}). $$ অর্থাৎ প্রতিটা sample moment তার আসল (population) moment-এ থিতু হয়। এটাই ভিত্তি — বাকিটা শুধু "function লাগানো"।
ইট ২ — continuous mapping (3.2/3.3)। §৪.১-এ আমরা দেখেছি প্রতিটা MoM estimator আসলে sample moment-গুলোর একটা function: যেমন \(\hat\lambda = 1/\hat\mu_1'\), বা \(\hat\theta = 2\hat\mu_1'\), বা Gamma-র \(\hat\alpha = (\hat\mu_1')^2/(\hat\mu_2' - (\hat\mu_1')^2)\)। সাধারণভাবে যদি লিখি $$ \hat\theta_{\text{MoM}} \;=\; g\big(\hat\mu_1', \dots, \hat\mu_p'\big) $$ যেখানে \(g\) হলো সেই (একই) function যা সত্যিকারের moment-এ লাগালে সত্যিকারের parameter দেয়: $$ \theta \;=\; g\big(\mu_1', \dots, \mu_p'\big), $$ তবে দরকার শুধু continuous mapping theorem (3.2-এ বিবৃত): যদি \(T_n \xrightarrow{P} c\) এবং \(g\) ওই বিন্দু \(c\)-তে continuous হয়, তবে \(g(T_n) \xrightarrow{P} g(c)\)। স্বজ্ঞায় এটা স্পষ্ট — continuous function "কাছের input-কে কাছের output-এ পাঠায়", তাই input থিতু হলে output-ও থিতু হয়। ইট ১ থেকে আমরা জানি ভেতরের প্রতিটা \(\hat\mu_k' \xrightarrow{P} \mu_k'\); তাই \(g\) ওই point-এ continuous হলে $$ \boxed{\;\hat\theta_{\text{MoM}} \;=\; g(\hat\mu_1',\dots,\hat\mu_p') \;\xrightarrow{\;P\;}\; g(\mu_1',\dots,\mu_p') \;=\; \theta\;}. $$ এই দুই লাইনেই consistency-র পুরো প্রমাণ শেষ। খেয়াল করুন, কোনো জায়গায় \(g\)-র linearity লাগেনি — শুধু continuity; তাই \(1/\bar X\)-এর মতো non-linear estimator-ও সমানভাবে ঢাকা পড়ে।
উদাহরণে যাচাই — continuity-র শর্তটা কোথায় খাটে। তত্ত্ব সুন্দর, কিন্তু "\(g\) ওই point-এ continuous" শর্তটা ঠিক কী মানে, উদাহরণে দেখি:
- E2 (Exponential): \(g(m) = 1/m\), যা \(m = \mu_1' = 1/\lambda > 0\)-তে continuous (কারণ আসল গড় ধনাত্মক, তাই \(0\)-তে ভাগের বিপদ নেই)। সুতরাং \(\hat\lambda = 1/\bar X \xrightarrow{P} 1/(1/\lambda) = \lambda\)। ✓
- E3 (Uniform): \(g(m) = 2m\) — সর্বত্র continuous (linear)। তাই \(\hat\theta = 2\bar X \xrightarrow{P} 2\cdot(\theta/2) = \theta\)। ✓ (Consistent — যদিও §(c)-তে দেখব consistent মানেই ভালো নয়।)
- E4 (Gamma): \(g(m_1,m_2) = \big(m_1^2/(m_2-m_1^2),\ m_1/(m_2-m_1^2)\big)\), যা continuous যতক্ষণ হর \(m_2 - m_1^2 = \mathrm{Var}(X) = \alpha/\beta^2 > 0\) — আর কোনো অ-অবক্ষয়ী (non-degenerate) Gamma-তে variance ধনাত্মক, তাই শর্ত মেটে। অতএব \(\hat\alpha \xrightarrow{P} \alpha\), \(\hat\beta \xrightarrow{P} \beta\)। ✓
- E1 (Normal): \(\hat\mu = \bar X \xrightarrow{P} \mu\) (সরাসরি LLN), আর \(\hat\sigma^2 = \hat\mu_2' - (\hat\mu_1')^2 \xrightarrow{P} \mu_2' - (\mu_1')^2 = \sigma^2\) (continuous mapping: \(g(m_1,m_2)=m_2 - m_1^2\) সর্বত্র continuous)। ✓
এক বাক্যে। "\(\hat\mu_k' \xrightarrow{P} \mu_k'\) (LLN, ইট ১) \(\;+\;\) continuous \(g\) (continuous mapping, ইট ২) \(\;\Rightarrow\;\) \(\hat\theta_{\text{MoM}} \xrightarrow{P} \theta\)।" — এটাই MoM-এর সার্বজনীন consistency-যুক্তি; §৫-এ চারটে উদাহরণেই এটা সংখ্যায় ফুটতে দেখব (mean absolute error \(\to 0\))।
একটা সতর্কতা (rigor-এর সীমা, ★★★)। আমরা শুধু convergence in probability (\(\xrightarrow{P}\)) দেখালাম, যা consistency-র সংজ্ঞা। Almost-sure consistency (\(\xrightarrow{a.s.}\)) পেতে Strong Law আর continuous mapping-এর a.s.-সংস্করণ লাগে — যুক্তির কাঠামো হুবহু এক, শুধু LLN-এর strong রূপটা বসাতে হয়। আর consistency কিন্তু গতি (rate) বা বণ্টন কিছুই বলে না — শুধু বলে "শেষমেশ ঠিক জায়গায় পৌঁছায়।" কত দ্রুত পৌঁছায় (asymptotic variance, efficiency) সে এক স্বতন্ত্র, গভীরতর প্রশ্ন, যার একটা ঝলক এক্ষুনি (c)-তে পাব।
৪.৩ · (c) সততা-নোট — MoM biased ও/বা inefficient হতে পারে — ★¶
Consistency একটা ন্যূনতম শংসাপত্র, সর্বোচ্চ নয়। একজন সৎ পরিসংখ্যানবিদ হিসেবে এবার MoM-এর সীমাবদ্ধতা খোলাখুলি বলা দরকার — যাতে এটাকে অন্ধভাবে ব্যবহার না করি। দুটো আলাদা দুর্বলতা:
(i) MoM প্রায়ই biased (পক্ষপাতদুষ্ট)। "Bias" মানে — গড়ে estimator আসল মান থেকে সরে থাকে: \(\mathrm{bias}(\hat\theta) = \mathbb{E}[\hat\theta] - \theta \ne 0\)। উদাহরণ আমরা §৪.১-এই দেখেছি: E1-এ \(\hat\sigma^2 = \frac1n\sum(X_i-\bar X)^2\), যার \(\mathbb{E}[\hat\sigma^2] = \frac{n-1}{n}\sigma^2 \ne \sigma^2\) (2.5/পরের অধ্যায়ের পরিচিত ফল) — অর্থাৎ MoM variance-কে গড়ে একটু কম আন্দাজ করে (factor \(\frac{n-1}{n} < 1\))। ভালো খবর: \(n\to\infty\)-তে \(\frac{n-1}{n}\to 1\), তাই bias মিলিয়ে যায় (consistent-ই থাকে, asymptotically unbiased); কিন্তু ছোট \(n\)-এ এই পক্ষপাত বাস্তব।
(ii) MoM প্রায়ই inefficient (অদক্ষ) — Uniform\((0,\theta)\) একটা নাটকীয় উদাহরণ। "Inefficient" মানে — estimator-টা consistent ও (প্রায়) unbiased হলেও, একই data থেকে আরেকটা estimator অনেক কম ভ্যারিয়েন্সে একই কাজ করতে পারে। সবচেয়ে শিক্ষণীয় কেসটা E3:
আমাদের MoM estimator \(\hat\theta_{\text{MoM}} = 2\bar X\)। এটা unbiased (\(\mathbb{E}[2\bar X] = 2\cdot\frac{\theta}{2} = \theta\)) ও consistent। কিন্তু একটা প্রতিদ্বন্দ্বী আছে যা অনেক ভালো: সবচেয়ে বড় observation, $$ \hat\theta_{\max} \;=\; \max_{1\le i\le n} X_i . $$ দুটোর তুলনা (variance/MSE-র সূত্র 2.7-এর order-statistics থেকে আসে; এখানে ফল উদ্ধৃত করছি, §৫-এ সংখ্যায় যাচাই করব):
| ধর্ম | \(\hat\theta_{\text{MoM}} = 2\bar X\) | \(\hat\theta_{\max} = \max_i X_i\) |
|---|---|---|
| Bias | \(0\) (unbiased) | \(-\dfrac{\theta}{n+1}\) (একটু কম আঁচ, কারণ \(\max \le \theta\) সর্বদা) |
| Variance | \(\dfrac{\theta^2}{3n}\) | \(\dfrac{n\,\theta^2}{(n+1)^2(n+2)} \approx \dfrac{\theta^2}{n^2}\) |
| MSE (\(\approx\)) | \(\dfrac{\theta^2}{3n}\ \sim\ \dfrac1n\) | \(\dfrac{2\theta^2}{(n+1)(n+2)}\ \sim\ \dfrac{1}{n^2}\) |
মূল পাঠ — দুটো জিনিস এক নিঃশ্বাসে। MoM-এর variance \(\theta^2/(3n)\) কমে \(1/n\)-হারে; কিন্তু \(\max\)-এর MSE কমে \(1/n^2\)-হারে — অনেক দ্রুত। অর্থাৎ \(n\) বড় হলে \(\max\) আসল \(\theta\)-র চারপাশে অসম্ভব শক্ত করে জড়ো হয়, \(2\bar X\) তুলনায় ঢিলেঢালা। মজার প্যারাডক্স: \(\max\) biased (সর্বদা একটু কম আঁচ করে, কারণ কোনো নমুনাই \(\theta\) ছাড়াতে পারে না) — তবু তার MSE ঢের ছোট, কারণ ভ্যারিয়েন্স-লাভটা bias-ক্ষতিকে বিপুলভাবে ছাপিয়ে যায়। এটাই দেখায় "unbiased = ভালো" ভাবাটা ভুল; আসল মাপকাঠি MSE = bias² + variance, আর সেখানে \(\max\) স্পষ্ট বিজয়ী।
কেন তবু MoM শিখি? কারণ এর গুণ অন্যত্র: (১) সরলতা — শুধু গড় (ও বর্গের গড়) লাগে, কোনো optimization নয়; (২) সার্বজনীনতা — যেখানে MLE (4.3) closed form দেয় না বা likelihood জটিল, MoM তবু চটজলদি একটা উত্তর দেয়; (৩) ভালো সূচনাবিন্দু — অনেক সময় MoM-estimate-কে শুরু ধরে iterative MLE চালানো হয়। তাই MoM-কে ভাবুন "দ্রুত, নির্ভরযোগ্য খসড়া উত্তর" হিসেবে — চূড়ান্ত নয়, কিন্তু প্রায়ই যথেষ্ট, আর সবসময় শুরু করার সহজ জায়গা। 4.3-এ আমরা MLE দেখব, যা সাধারণত efficient — আর তখন এই MoM-বনাম-MLE তুলনাটাই পুরো ছবিটা সম্পূর্ণ করবে।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর তিনটে দাবিকে আমরা সিমুলেশনে যাচাই করব — যাতে Method of Moments কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া।)
আমরা তিনটে জিনিস মাপব, ঠিক §৪-এর তিন অংশ অনুসরণ করে:
- Part 1 — চারটে MoM estimator এক নমুনায় (§৪.১)। Normal, Exponential, Uniform\((0,\theta)\), Gamma — প্রতিটার জন্য একটা বড় নমুনা (\(n=2000\)) টেনে \(\hat\theta_{\text{MoM}}\) হিসাব করে দেখব estimate সত্যিকারের parameter-এর কত কাছে।
- Part 2 — consistency (§৪.২)। প্রতিটা \(n \in \{10,50,200,1000,5000\}\)-এর জন্য \(REP=2000\)টা স্বাধীন নমুনা টেনে গড় পরম-ত্রুটি (mean absolute error, \(\mathbb{E}\lvert\hat\theta-\theta\rvert\)) মাপব — \(n\) বাড়লে এটা \(0\)-এর দিকে নামছে দেখলেই \(\hat\theta_{\text{MoM}}\xrightarrow{P}\theta\) চোখে ধরা পড়বে।
- Part 3 — \(2\bar X\) বনাম \(\max\) (§৪.৩)। Uniform\((0,\theta)\)-তে MoM estimator \(2\bar X\) আর প্রতিদ্বন্দ্বী \(\max_i X_i\)-এর bias, variance ও MSE পাশাপাশি মেপে দেখব MSE-অনুপাত \(n\)-এর সাথে কীভাবে বিস্ফোরিত হয় — অর্থাৎ \(\max\) কতটা ভালো।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.2 — Point Estimation: Method of Moments (MoM) : Code Lab
# Numerically illustrates:
# PART 1 — MoM estimators for Normal, Exponential, Uniform(0,theta), Gamma
# PART 2 — Consistency: hat(theta)_MoM -> theta as n grows (LLN + continuous mapping)
# PART 3 — Uniform(0,theta): MoM 2*Xbar vs the better estimator max(X_i)
# (bias, variance, MSE — an honest comparison)
import numpy as np
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=4, suppress=True)
# ===============================================================
# PART 1 — MoM ESTIMATORS ON ONE SAMPLE EACH.
# Recipe: set sample moment hat(mu_k') = (1/n) sum X_i^k equal to the
# theoretical moment mu_k'(theta), then solve for theta.
# ===============================================================
print("=" * 64)
print("PART 1 — MoM estimators on one sample each (n = 2000)")
print("=" * 64)
n = 2000
# ---- E1 Normal(mu, sigma^2) : hat(mu)=Xbar, hat(sigma^2)=(1/n) sum (X-Xbar)^2
mu_true, sigma_true = 5.0, 2.0
x = rng.normal(mu_true, sigma_true, size=n)
mom_mu = x.mean()
mom_sigma2 = x.var() # np.var = (1/n) sum (x-xbar)^2 (ddof=0)
print(f"\n[E1] Normal(mu={mu_true}, sigma^2={sigma_true**2:.1f})")
print(f" hat(mu) = Xbar = {mom_mu:.4f} (true {mu_true})")
print(f" hat(sigma^2)= (1/n)sum(X-Xbar)^2 = {mom_sigma2:.4f} (true {sigma_true**2:.1f})")
# ---- E2 Exponential(lambda) : E[X]=1/lambda => hat(lambda)=1/Xbar
lam_true = 0.5
x = rng.exponential(scale=1.0 / lam_true, size=n) # numpy 'scale' = 1/lambda = mean
mom_lam = 1.0 / x.mean()
print(f"\n[E2] Exponential(lambda={lam_true})")
print(f" hat(lambda) = 1 / Xbar = {mom_lam:.4f} (true {lam_true})")
# ---- E3 Uniform(0,theta) : E[X]=theta/2 => hat(theta)=2 Xbar
theta_true = 10.0
x = rng.uniform(0.0, theta_true, size=n)
mom_theta = 2.0 * x.mean()
print(f"\n[E3] Uniform(0, theta={theta_true})")
print(f" hat(theta) = 2 * Xbar = {mom_theta:.4f} (true {theta_true})")
# ---- E4 Gamma(alpha, beta) [shape alpha, rate beta]:
# E[X] = alpha/beta = m1 ; Var = alpha/beta^2 = m2 - m1^2
# Solve: beta_hat = m1/(m2-m1^2), alpha_hat = m1^2/(m2-m1^2)
alpha_true, beta_true = 3.0, 2.0 # mean = 1.5
x = rng.gamma(shape=alpha_true, scale=1.0 / beta_true, size=n) # numpy 'scale' = 1/rate
m1 = x.mean()
m2 = (x**2).mean()
sigma2_hat = m2 - m1**2 # = (1/n) sum (X-Xbar)^2 (same as sigma^2 in section 3)
beta_hat = m1 / sigma2_hat
alpha_hat = m1**2 / sigma2_hat
print(f"\n[E4] Gamma(alpha={alpha_true}, beta={beta_true}) [shape, rate]")
print(f" m1=Xbar={m1:.4f}, m2=(1/n)sumX^2={m2:.4f}, sigma_hat^2=m2-m1^2={sigma2_hat:.4f}")
print(f" hat(alpha) = m1^2/(m2-m1^2) = {alpha_hat:.4f} (true {alpha_true})")
print(f" hat(beta) = m1/(m2-m1^2) = {beta_hat:.4f} (true {beta_true})")
# ===============================================================
# PART 2 — CONSISTENCY: as n grows, hat(theta)_MoM -> theta.
# For each n we average |hat - true| over MANY independent samples to see
# the estimator settle onto the truth (convergence in probability in action).
# ===============================================================
print("\n" + "=" * 64)
print("PART 2 — Consistency: estimate -> true as n grows")
print(" (mean absolute error over REP=2000 independent samples)")
print("=" * 64)
REP = 2000
ns = [10, 50, 200, 1000, 5000]
# E2 Exponential: hat(lambda) = 1/Xbar
lam_true = 0.5
print(f"\n[E2] Exponential(lambda={lam_true}) : hat(lambda)=1/Xbar")
print(f" {'n':>6} {'mean hat':>10} {'mean |err|':>11}")
for nn in ns:
xb = rng.exponential(1.0 / lam_true, size=(REP, nn)).mean(axis=1)
est = 1.0 / xb
print(f" {nn:>6} {est.mean():>10.4f} {np.abs(est - lam_true).mean():>11.4f}")
# E3 Uniform(0,theta): hat(theta) = 2 Xbar
theta_true = 10.0
print(f"\n[E3] Uniform(0,theta={theta_true}) : hat(theta)=2 Xbar")
print(f" {'n':>6} {'mean hat':>10} {'mean |err|':>11}")
for nn in ns:
xb = rng.uniform(0.0, theta_true, size=(REP, nn)).mean(axis=1)
est = 2.0 * xb
print(f" {nn:>6} {est.mean():>10.4f} {np.abs(est - theta_true).mean():>11.4f}")
# E4 Gamma: hat(alpha), hat(beta) from first two moments
alpha_true, beta_true = 3.0, 2.0
print(f"\n[E4] Gamma(alpha={alpha_true}, beta={beta_true}) : hat(alpha)=m1^2/(m2-m1^2)")
print(f" {'n':>6} {'mean a_hat':>11} {'mean b_hat':>11} {'|a_err|':>9} {'|b_err|':>9}")
for nn in ns:
xx = rng.gamma(alpha_true, 1.0 / beta_true, size=(REP, nn))
m1 = xx.mean(axis=1)
m2 = (xx**2).mean(axis=1)
s2 = m2 - m1**2
a_hat = m1**2 / s2
b_hat = m1 / s2
print(f" {nn:>6} {a_hat.mean():>11.4f} {b_hat.mean():>11.4f}"
f" {np.abs(a_hat - alpha_true).mean():>9.4f} {np.abs(b_hat - beta_true).mean():>9.4f}")
# ===============================================================
# PART 3 — Uniform(0,theta): MoM (2*Xbar) vs max(X_i).
# Both are consistent, but max is far better. We compare bias, var, MSE.
# Theory: 2Xbar -> unbiased, Var = theta^2/(3n).
# max -> biased low, E[max]=n/(n+1)*theta, Var=n*theta^2/((n+1)^2(n+2)).
# ===============================================================
print("\n" + "=" * 64)
print("PART 3 — Uniform(0,theta): MoM 2*Xbar vs max(X_i)")
print(f" theta = {theta_true}, REP = {REP} samples each n")
print("=" * 64)
theta_true = 10.0
print(f"\n {'n':>6} | {'2Xbar: bias':>11} {'var':>9} {'MSE':>9} | "
f"{'max: bias':>10} {'var':>9} {'MSE':>9} | {'MSE ratio':>9}")
print(" " + "-" * 86)
for nn in ns:
X = rng.uniform(0.0, theta_true, size=(REP, nn))
mom = 2.0 * X.mean(axis=1) # MoM estimator
mx = X.max(axis=1) # the competitor
b_mom = mom.mean() - theta_true; v_mom = mom.var(); mse_m = b_mom**2 + v_mom
b_mx = mx.mean() - theta_true; v_mx = mx.var(); mse_x = b_mx**2 + v_mx
ratio = mse_m / mse_x
print(f" {nn:>6} | {b_mom:>11.4f} {v_mom:>9.4f} {mse_m:>9.4f} | "
f"{b_mx:>10.4f} {v_mx:>9.4f} {mse_x:>9.4f} | {ratio:>9.2f}")
print("\n Read-off: 2Xbar is ~unbiased but Var ~ theta^2/(3n) shrinks only like 1/n;")
print(" max is biased LOW (it can never exceed theta) yet its MSE shrinks like 1/n^2,")
print(" so for large n MSE(2Xbar)/MSE(max) blows up — max is the far better estimator.")
print(" Honest moral: Method of Moments is simple & consistent, but NOT always efficient.")
৫.২ · বাস্তব আউটপুট ও পাঠোদ্ধার¶
স্ক্রিপ্টটা চালালে নিচের আউটপুট হুবহু আসে (seed স্থির, তাই আপনার মেশিনেও একই):
================================================================
PART 1 — MoM estimators on one sample each (n = 2000)
================================================================
[E1] Normal(mu=5.0, sigma^2=4.0)
hat(mu) = Xbar = 5.1345 (true 5.0)
hat(sigma^2)= (1/n)sum(X-Xbar)^2 = 4.1115 (true 4.0)
[E2] Exponential(lambda=0.5)
hat(lambda) = 1 / Xbar = 0.5063 (true 0.5)
[E3] Uniform(0, theta=10.0)
hat(theta) = 2 * Xbar = 9.8782 (true 10.0)
[E4] Gamma(alpha=3.0, beta=2.0) [shape, rate]
m1=Xbar=1.4873, m2=(1/n)sumX^2=2.9355, sigma_hat^2=m2-m1^2=0.7236
hat(alpha) = m1^2/(m2-m1^2) = 3.0569 (true 3.0)
hat(beta) = m1/(m2-m1^2) = 2.0554 (true 2.0)
================================================================
PART 2 — Consistency: estimate -> true as n grows
(mean absolute error over REP=2000 independent samples)
================================================================
[E2] Exponential(lambda=0.5) : hat(lambda)=1/Xbar
n mean hat mean |err|
10 0.5505 0.1386
50 0.5105 0.0576
200 0.5010 0.0281
1000 0.5005 0.0125
5000 0.5000 0.0055
[E3] Uniform(0,theta=10.0) : hat(theta)=2 Xbar
n mean hat mean |err|
10 10.0575 1.4743
50 9.9836 0.6492
200 10.0059 0.3258
1000 10.0047 0.1447
5000 10.0010 0.0656
[E4] Gamma(alpha=3.0, beta=2.0) : hat(alpha)=m1^2/(m2-m1^2)
n mean a_hat mean b_hat |a_err| |b_err|
10 4.4482 3.0605 1.8851 1.3610
50 3.2765 2.2065 0.6222 0.4500
200 3.0607 2.0455 0.2769 0.1990
1000 3.0082 2.0064 0.1228 0.0875
5000 3.0018 2.0014 0.0559 0.0398
================================================================
PART 3 — Uniform(0,theta): MoM 2*Xbar vs max(X_i)
theta = 10.0, REP = 2000 samples each n
================================================================
n | 2Xbar: bias var MSE | max: bias var MSE | MSE ratio
--------------------------------------------------------------------------------------
10 | 0.0016 3.2571 3.2571 | -0.9191 0.6667 1.5114 | 2.16
50 | 0.0095 0.6453 0.6454 | -0.1963 0.0377 0.0762 | 8.47
200 | -0.0032 0.1640 0.1640 | -0.0505 0.0026 0.0051 | 32.07
1000 | -0.0005 0.0325 0.0325 | -0.0098 0.0001 0.0002 | 171.86
5000 | 0.0025 0.0066 0.0066 | -0.0020 0.0000 0.0000 | 809.98
Read-off: 2Xbar is ~unbiased but Var ~ theta^2/(3n) shrinks only like 1/n;
max is biased LOW (it can never exceed theta) yet its MSE shrinks like 1/n^2,
so for large n MSE(2Xbar)/MSE(max) blows up — max is the far better estimator.
Honest moral: Method of Moments is simple & consistent, but NOT always efficient.
পাঠ ১ — estimator গুলো সত্যিই কাজ করে (Part 1)। এক নমুনাতেই (n=2000) চারটে \(\hat\theta_{\text{MoM}}\) আসল মানের খুব কাছে: \(\hat\mu=5.13\) (সত্য \(5\)), \(\hat\lambda=0.506\) (সত্য \(0.5\)), \(\hat\theta=9.88\) (সত্য \(10\)), Gamma-তে \(\hat\alpha=3.06,\ \hat\beta=2.06\) (সত্য \(3,2\))। §৪.১-এর বীজগণিত আর কোডের আউটপুট মিলে গেল — রেসিপি বৈধ।
পাঠ ২ — consistency চোখে দেখা যায় (Part 2)। তিনটে উদাহরণেই "mean |err|" কলামটা \(n\) বাড়ার সাথে নামছে: E2-তে \(0.1386 \to 0.0055\), E3-তে \(1.4743 \to 0.0656\), Gamma-তে \(\hat\alpha\)-এর ত্রুটি \(1.8851 \to 0.0559\)। এটাই \(\hat\theta_{\text{MoM}}\xrightarrow{P}\theta\)-র সংখ্যাচিত মূর্তি। আরও সূক্ষ্ম একটা প্যাটার্ন: \(n\) চারগুণ হলে ত্রুটি মোটামুটি অর্ধেক হয় (যেমন E2-তে \(n{:}50\to200\)-এ \(0.0576\to0.0281\)) — অর্থাৎ ত্রুটি \(\propto 1/\sqrt n\), যা পরের অধ্যায়ের asymptotic-তত্ত্বের সাথে খাপে খাপ। (খেয়াল করুন Gamma-তে ছোট \(n\)-এ \(\hat\alpha\) গড়ে একটু বড় — \(n{=}10\)-এ \(4.45\) — এটা MoM-এর finite-sample bias-এর জীবন্ত উদাহরণ, §৪.৩(i)-এর কথামতোই, আর \(n\) বাড়লে মিলিয়ে যায়।)
পাঠ ৩ — "consistent" আর "ভালো" এক নয় (Part 3)। এটাই ল্যাবের সবচেয়ে শিক্ষণীয় টেবিল। দুটো estimator-ই \(\theta=10\)-এ থিতু হয়, কিন্তু কত আঁটসাঁটভাবে — সেখানেই আকাশ-পাতাল ফারাক:
- \(2\bar X\): bias কার্যত \(0\) (সব সারিতে \(\approx \pm 0.01\)) — unbiased, যেমন তত্ত্ব বলেছিল। কিন্তু MSE নামে ধীরে: \(3.26 \to 0.0066\) যখন \(n\) যায় \(10\to5000\) (মোটামুটি \(1/n\)-হার)।
- \(\max\): bias ঋণাত্মক (সব সারিতে, যেমন \(n{=}10\)-এ \(-0.92\)) — সর্বদা একটু কম আঁচ, কারণ কোনো নমুনাই \(\theta=10\) ছাড়াতে পারে না; কিন্তু MSE নামে অনেক দ্রুত (\(1.51 \to 0.0000\), মোটামুটি \(1/n^2\)-হার)।
- MSE অনুপাত \(= \mathrm{MSE}(2\bar X)/\mathrm{MSE}(\max)\) বাড়ে \(2.16 \to 8.47 \to 32.07 \to 171.86 \to 809.98\) — অর্থাৎ \(n=5000\)-এ MoM estimator-এর গড়-বর্গ-ত্রুটি \(\max\)-এর চেয়ে প্রায় ৮১০ গুণ বড়! এটাই §৪.৩(ii)-এর inefficiency-দাবির নাটকীয় সংখ্যাচিত প্রমাণ।
সারমর্ম: Method of Moments একটা সরল, সার্বজনীন ও consistent যন্ত্র — কোনো optimization ছাড়াই চটজলদি একটা নির্ভরযোগ্য খসড়া উত্তর দেয়, আর প্রায়ই MLE-র মতো ভারী পদ্ধতির ভালো সূচনাবিন্দু। কিন্তু এটা সবসময় unbiased বা efficient নয় — Uniform\((0,\theta)\)-তে \(\max\) একে ৮০০ গুণে হারায়। এই সততা-নোটটাই 4.3-এ Maximum Likelihood-এর দিকে স্বাভাবিক সেতু: সেখানে আমরা এমন estimator খুঁজব যা শুধু consistent নয়, সাধারণভাবে efficient-ও।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-2.py-তে তৈরি; PNG_assets/-এ (prefix4-2, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E2 Exponential (\(\hat\lambda=1/\bar X\)), E3 Uniform\((0,\theta)\) (\(\hat\theta=2\bar X\)), E4 Gamma।
Method of Moments-এর পুরো গল্পটা আসলে একটা ছবিতেই ধরা যায়: "নমুনার গড় (sample moment) আর জনসংখ্যার গড় (population moment) মিলিয়ে দাও, তারপর parameter-এর জন্য সমীকরণটা সমাধান করো।" কিন্তু সমীকরণে এটা যত শুকনো শোনায়, ছবিতে তত জীবন্ত। আমরা চারটি ছবি দিয়ে চারটি কেন্দ্রীয় ব্যাপার "চোখে দেখব": (১) matching-এর মুহূর্ত — sample moment আর population moment কীভাবে একটা সমীকরণে বসে \(\hat\theta\) দেয় (Figure 1); (২) consistency — \(n\) বাড়লে \(\hat\theta_{\text{MoM}}\) কীভাবে সত্যিকারের \(\theta\)-তে গড়িয়ে যায় (Figure 2); (৩) একটা MoM estimator-এর sampling distribution বহু নমুনার উপর কেমন দেখায় (প্রায় Normal — Figure 3); আর (৪) MoM-এ পাওয়া parameter দিয়ে আঁকা distribution কীভাবে আসল data-র histogram-এর গায়ে নিখুঁতভাবে বসে (Figure 4)। প্রথম ছবিটা পদ্ধতি, পরের তিনটা সেই পদ্ধতির ফল কতটা ভালো — তিনটা ভিন্ন কোণ থেকে।
Figure 1 — moment matching: MoM আসলে কী করে¶
এই অধ্যায়ের কেন্দ্রীয় ছবি। বাঁ দিকে একটা সত্যিকারের Exponential নমুনা (\(n=60\), true \(\lambda=0.5\)) সংখ্যা-রেখায় কমলা বিন্দু হিসেবে ছড়ানো; এর উপর দুটো উল্লম্ব রেখা — নিরেট কমলা রেখা sample mean \(\bar x=1.65\) (অর্থাৎ প্রথম sample moment \(\hat\mu_1'\)), আর ভাঙা নীল রেখা সত্যিকারের population mean \(1/\lambda=2.00\)। MoM-এর চাল: population-এর সূত্র \(\mathbb{E}[X]=1/\lambda\)-কে আমরা sample-এর মান \(\bar x\)-এর সমান ধরি — "\(\bar x = 1/\lambda\)" — আর তা থেকে \(\lambda\)-এর জন্য সমাধান করি: \(\hat\lambda_{\text{MoM}}=1/\bar x=0.607\)। ডান দিকে এই matching-টাই bar-চিত্রে: প্রথম moment-এ sample-bar (\(\hat\mu_1'\)) আর model-bar (পাওয়া \(\hat\lambda\)-তে \(\mathbb{E}[X]\)) ঠিক সমান উচ্চতায় (১.৬৫ = ১.৬৫) — কারণ ওটাই তো আমরা মিলিয়ে দিয়েছি। যা লক্ষ করতে হবে: (ক) আমরা শুধু একটি moment (এখানে প্রথমটি) মিলিয়েছি, তাই ঠিক ওই moment-টাই হুবহু মেলে — দ্বিতীয় moment-এ দুই bar সামান্য আলাদা (৫.২৫ বনাম ৫.৪২), কারণ সেটা আমরা ব্যবহার করিনি, শুধু "উপহার হিসেবে" কাছাকাছি এসেছে। (খ) \(\hat\lambda=0.607\) আসল \(0.5\) থেকে একটু দূরে — কারণ \(n=60\), নমুনায় ওঠানামা (sampling variability) আছে; পরের ছবি দেখাবে \(n\) বাড়লে এই দূরত্ব মিলিয়ে যায়। (গ) মূল মন্ত্রটা মনে রাখুন: population moment-এর সূত্রে \(\theta\) বসিয়ে = sample moment, তারপর \(\theta\)-র জন্য সমাধান — এক প্যারামিটার, এক moment।
![Two-panel figure illustrating the core idea of the method of moments using an Exponential sample (E2, n = 60, true lambda = 0.5). LEFT panel: a horizontal number line in x from 0 to 8 with 60 orange data dots scattered in a lower band. A solid orange vertical line marks the sample mean x-bar = 1.65 (the first sample moment), and a dashed blue vertical line marks the true population mean 1/lambda = 2.00. A small callout above the lines reads "set x-bar = 1/lambda, solve => lambda-hat = 1/x-bar" with an arrow pointing down to the orange line. A cream box in the top-left corner reports lambda-hat_MoM = 0.607 (true lambda = 0.5). RIGHT panel: a grouped bar chart comparing the sample moment (orange) and the model moment evaluated at lambda-hat (green) for the 1st moment E[X] and the 2nd moment E[X^2]. For the 1st moment both bars are exactly equal at 1.65, while for the 2nd moment the bars differ slightly (5.25 vs 5.42). The viewer should notice that only the matched (first) moment coincides exactly because that is the equation we solved, that the estimate 0.607 differs from the truth 0.5 due to sampling variability at n = 60, and that the whole method is "set population moment = sample moment, solve for the parameter".](../_assets/4-2-moment-matching.png)
Figure 2 — consistency: \(n\) বাড়লে \(\hat\theta\to\theta\)¶
MoM-এর সবচেয়ে গুরুত্বপূর্ণ গুণটা চোখে দেখা। দুটো প্যানেল, দুটো চলমান উদাহরণ। অনুভূমিক অক্ষে sample size \(n\) (log-scale, \(5\) থেকে \(5000\)), উল্লম্ব অক্ষে estimate। প্রতিটি \(n\)-এ আমরা \(400\) বার নতুন নমুনা টেনে \(\hat\theta_{\text{MoM}}\) হিসাব করেছি; সবুজ রেখা সেই estimate-গুলোর গড়, আর সবুজ-ছায়া ব্যান্ড estimate-গুলোর মাঝের ৮০% (অর্থাৎ ওঠানামার পরিসর)। লাল ভাঙা-রেখা সত্যিকারের প্যারামিটার। বাঁ প্যানেল: E2 Exponential, \(\hat\lambda=1/\bar X\), true \(\lambda=0.5\)। ডান প্যানেল: E3 Uniform\((0,\theta)\), \(\hat\theta=2\bar X\), true \(\theta=10\)। যা লক্ষ করতে হবে: (ক) ছোট \(n\)-এ (বাঁ দিকে) সবুজ ব্যান্ড চওড়া — যেকোনো একটা নমুনা থেকে পাওয়া estimate সত্যি থেকে অনেক দূরে হতে পারে; কিন্তু \(n\) বাড়ার সাথে সাথে ব্যান্ডটা একটা ফানেলের মতো সরু হয়ে লাল রেখায় আটকে যায়। (খ) সবুজ গড়-রেখা লাল সত্যি-রেখায় গিয়ে মেলে ও সেখানেই থাকে — অর্থাৎ বড় \(n\)-এ \(\hat\theta_{\text{MoM}}\) সত্যিকারের \(\theta\)-র চারপাশে নিখুঁতভাবে কেন্দ্রীভূত ও সংকুচিত। এটাই consistency: \(\hat\theta_{\text{MoM}}\xrightarrow{P}\theta\) যখন \(n\to\infty\) (যা 3.3-এর LLN-এর সরাসরি ফল — sample moment → population moment)। (গ) লক্ষ করুন Exponential-এ ছোট \(n\)-এ সবুজ গড় সামান্য উপরে (\(\lambda\)-কে একটু বেশি অনুমান করে — কারণ \(1/\bar X\) একটা nonlinear রূপ, finite-sample bias আছে), কিন্তু \(n\) বাড়লে সেটাও মিলিয়ে যায়; Uniform-এ \(2\bar X\) সব \(n\)-এই গড়ে নিখুঁত (unbiased), শুধু spread কমে।
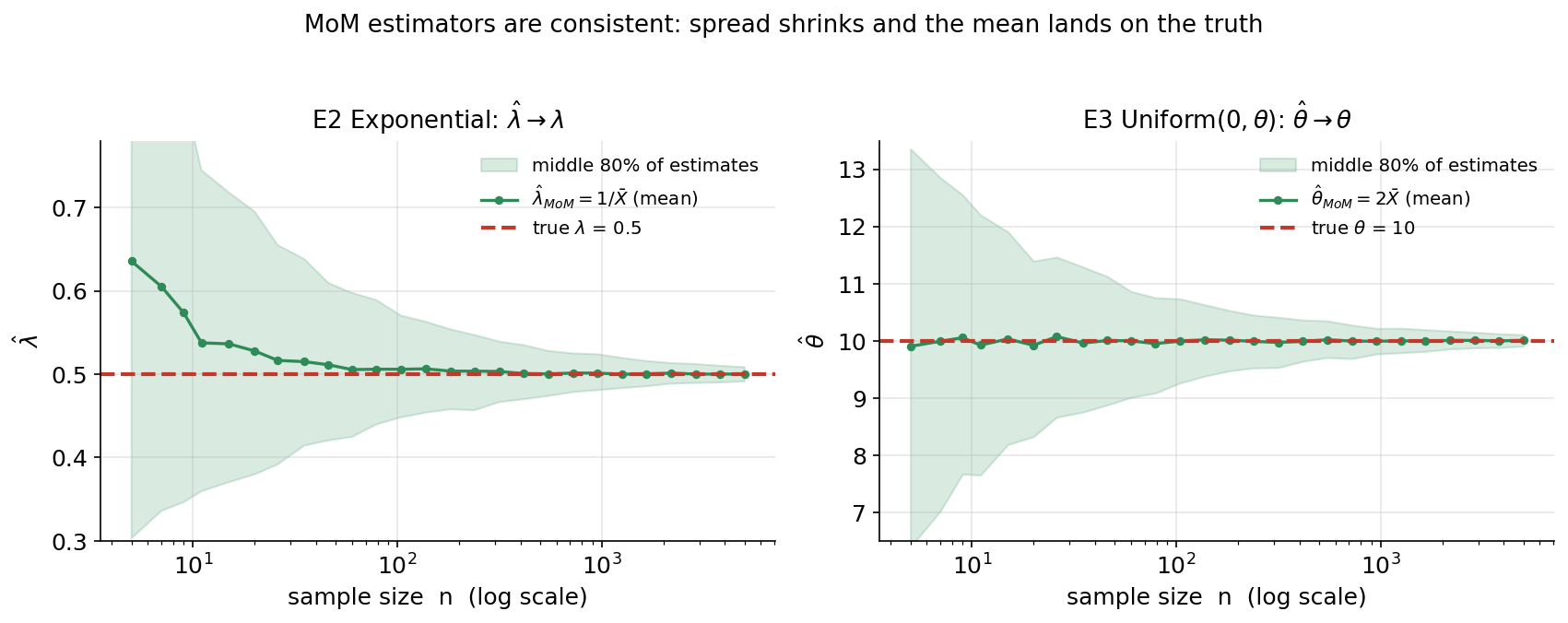
Figure 3 — sampling distribution: একটা MoM estimate কতটা ওঠানামা করে¶
Figure 2 দেখাল estimate-এর গড় ও পরিসর কীভাবে কমে; এই ছবি একটা নির্দিষ্ট \(n\)-এ estimate-এর পুরো আকৃতি দেখায়। আমরা E2 Exponential থেকে \(n=50\)-এর নমুনা ৮০০০ বার টেনে প্রতিবার \(\hat\lambda_{\text{MoM}}=1/\bar X\) হিসাব করেছি; কমলা histogram সেই ৮০০০ estimate-এর বণ্টন — অর্থাৎ estimator-টির sampling distribution। তার উপর নীল curve হলো একটা Normal আনুমান \(\mathcal{N}(\lambda,\ \lambda^2/n)\) (এই variance-টা delta method থেকে আসে — \(g(\bar X)=1/\bar X\)-এর আনুমানিক variance; বিস্তারিত §৫-এ)। লাল ভাঙা-রেখা সত্যি \(\lambda=0.5\), সবুজ বিন্দু-রেখা ৮০০০ estimate-এর গড় (\(0.510\))। যা লক্ষ করতে হবে: (ক) histogram-এর আকৃতি ঘণ্টার মতো এবং নীল Normal curve প্রায় নিখুঁতভাবে তার গায়ে বসে — অর্থাৎ যথেষ্ট \(n\)-এ একটা MoM estimator-ও আনুমানিক Normal (CLT-জাত, কারণ \(\hat\lambda\) আসলে \(\bar X\)-এর একটা মসৃণ ফাংশন)। (খ) box-এ দেখুন delta-method-এর তাত্ত্বিক \(\text{SE}=\lambda/\sqrt{n}=0.071\) আর data থেকে মাপা empirical SD \(=0.073\) — প্রায় হুবহু মিলেছে, মানে আমাদের variance-সূত্র কাজ করছে। (গ) তবু বণ্টনটা একদম প্রতিসম নয় — ডান দিকে সামান্য লেজ (right-skew), আর গড় \(0.510\) সত্যি \(0.5\)-এর সামান্য উপরে: এটাই সেই finite-sample bias, কারণ \(1/\bar X\) একটা উত্তল (convex) ফাংশন (Jensen-এর অসমতা)। বড় \(n\)-এ skew আর bias দুটোই \(0\)-র দিকে যায়।
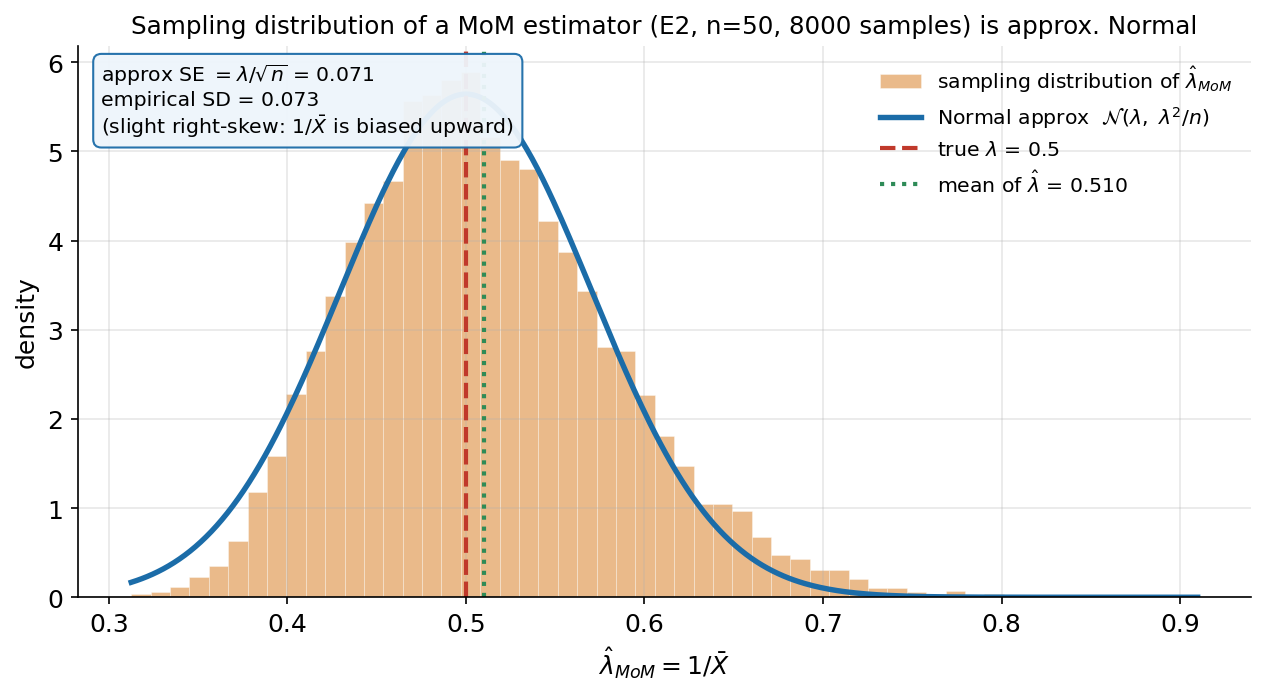
Figure 4 — MoM fit বনাম data: পদ্ধতিটা কি সত্যিই ভালো?¶
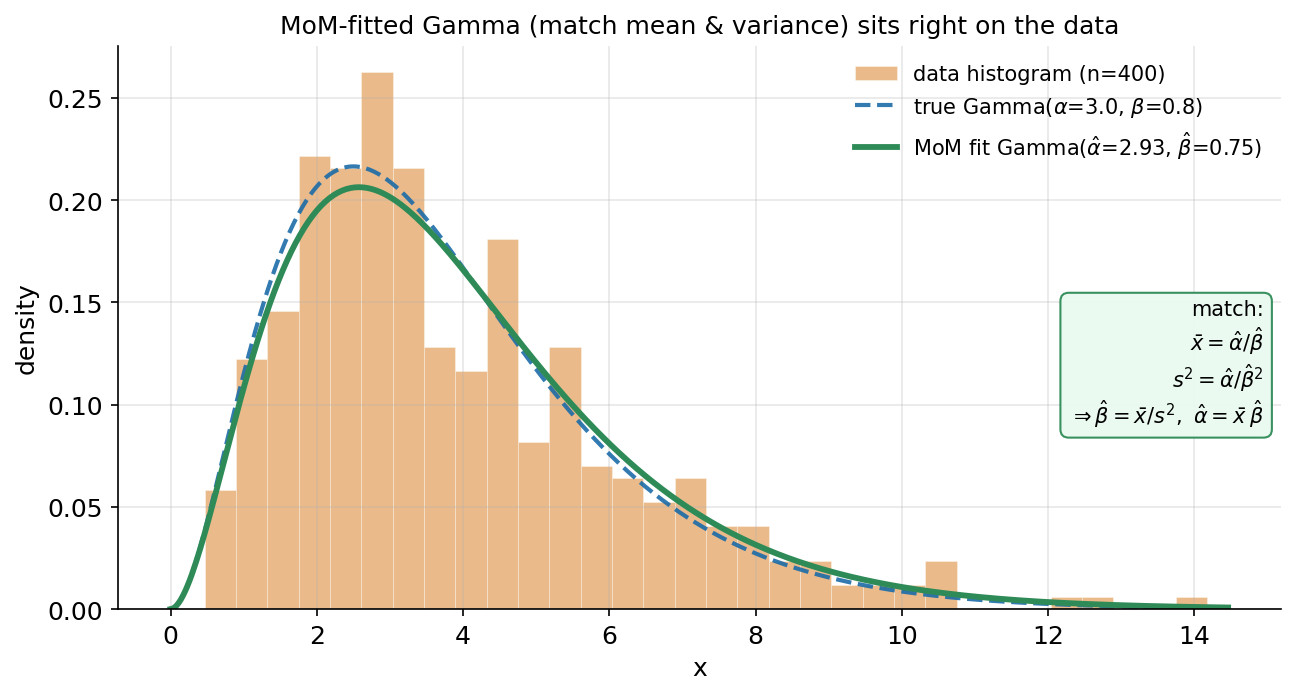
শেষ ছবি একটা ব্যবহারিক "sanity check": MoM দিয়ে পাওয়া parameter বসিয়ে যে distribution আঁকা যায়, সেটা কি সত্যিই data-র মতো দেখতে? আমরা E4 Gamma নিয়েছি (দুটো parameter — shape \(\alpha\), rate \(\beta\)), কারণ এখানে দুটো moment মেলাতে হয়। \(n=400\)-এর একটা Gamma নমুনা (true \(\alpha=3.0,\ \beta=0.8\)) থেকে আমরা প্রথম দুটো moment মিলিয়েছি: \(\bar x=\hat\alpha/\hat\beta\) আর \(s^2=\hat\alpha/\hat\beta^2\), যা সমাধান করে \(\hat\beta=\bar x/s^2\) ও \(\hat\alpha=\bar x\,\hat\beta\) (সূত্রটা ছবির সবুজ box-এ)। কমলা histogram হলো আসল data; সবুজ নিরেট curve হলো MoM-fitted Gamma (\(\hat\alpha=2.93,\ \hat\beta=0.75\)); তুলনার জন্য নীল ভাঙা curve হলো সত্যিকারের Gamma। যা লক্ষ করতে হবে: (ক) সবুজ MoM-fit curve histogram-এর আকৃতিকে চমৎকারভাবে ধরে — চূড়ার অবস্থান, উচ্চতা, ডান দিকের লম্বা লেজ সব মিলে যায়; অথচ আমরা মাত্র দুটো সংখ্যা (\(\bar x\) আর \(s^2\)) থেকে পুরো curve-টা বের করেছি। (খ) সবুজ (fitted) আর নীল (true) curve প্রায় গায়ে-গায়ে — \(\hat\alpha=2.93\approx3.0\), \(\hat\beta=0.75\approx0.8\), মানে MoM সত্যিকারের parameter খুব কাছাকাছি ধরেছে। (গ) এটাই MoM-এর বড় আকর্ষণ: দ্রুত, সরল, বন্ধ-রূপ (closed-form) — কোনো optimization বা iteration ছাড়াই কয়েকটা গড় হিসাব করেই একটা পুরো distribution data-য় ফিট করে ফেলা যায়। (পরের অধ্যায় 4.3-এ দেখব MLE প্রায়ই এর চেয়ে আরও নিখুঁত fit দেয় — কিন্তু তার দাম হলো বেশি গণনা।)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-02-method-of-moments-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (চলমান উদাহরণ: E1 Normal\((\mu,\sigma^2)\); E2 Exponential\((\lambda)\), \(\hat\lambda=1/\bar X\); E3 Uniform\((0,\theta)\), \(\hat\theta=2\bar X\); E4 Gamma/Binomial। স্মারক: \(\mu_k'=\mathbb{E}[X^k]\), \(\hat\mu_k'=\frac1n\sum_i X_i^k\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় Method of Moments-এর মূল ধাপগুলো বলুন (population moment, sample moment, সমীকরণ, সমাধান)। বিশেষত ব্যাখ্যা করুন: একটা প্যারামিটার থাকলে কয়টা moment মেলাতে হয়, আর দুটো প্যারামিটার থাকলে কয়টা? Figure 1 দিয়ে যুক্তি দিন কেন আমরা ঠিক "এতগুলো" moment বাছি। Hint: যত প্যারামিটার, তত সমীকরণ লাগে — তাই \(p\) প্যারামিটারের জন্য প্রথম \(p\)টা moment মেলানো হয় (\(\mu_1'=\hat\mu_1',\dots,\mu_p'=\hat\mu_p'\))। Figure 1-এ এক প্যারামিটার (\(\lambda\)), তাই এক সমীকরণ (\(\bar x=1/\lambda\))। কম মেলালে সমাধান অনন্য হয় না, বেশি মেলালে সমীকরণ-সংখ্যা প্যারামিটার-সংখ্যাকে ছাড়িয়ে যায় (over-determined)।
প্রশ্ন ২ (★). plug-in principle বলতে কী বোঝায় এবং MoM কীভাবে তার একটা উদাহরণ? "population-এর অজানা পরিমাণকে তার sample-প্রতিরূপ দিয়ে প্রতিস্থাপন" — এই ধারণাটা ব্যাখ্যা করুন, আর বলুন কেন এটা যুক্তিসঙ্গত (LLN-এর সাথে যোগসূত্র)। Hint: plug-in: যেখানেই তত্ত্বে population moment \(\mu_k'=\mathbb{E}[X^k]\) দরকার, সেখানে তার estimate \(\hat\mu_k'=\frac1n\sum X_i^k\) "বসিয়ে দাও"। যুক্তি: LLN বলে \(\hat\mu_k'\xrightarrow{P}\mu_k'\), তাই বড় \(n\)-এ প্রতিস্থাপনের ভুল ছোট — এটাই MoM-এর consistency-র ভিত্তি (Figure 2)।
প্রশ্ন ৩ (★★). Figure 1-এর ডান প্যানেলে প্রথম moment-এ দুই bar হুবহু সমান, কিন্তু দ্বিতীয় moment-এ আলাদা — কেন? এর থেকে MoM সম্পর্কে কী সাধারণ সত্য বেরোয়? (ইঙ্গিত: আমরা কোন moment ব্যবহার করেছি?) Hint: আমরা শুধু প্রথম moment মিলিয়েছি (\(\bar x=1/\hat\lambda\)), তাই গঠনগতভাবে ঠিক ওটাই সমান হতে বাধ্য; দ্বিতীয় moment ব্যবহার করা হয়নি, তাই সেটা মেলার কোনো নিশ্চয়তা নেই — শুধু কাছাকাছি আসে। সাধারণ সত্য: MoM যেগুলো মেলায় সেগুলো হুবহু মেলে, বাকিগুলো আনুমানিক।
প্রশ্ন ৪ (★★). MoM estimator কি সবসময় valid parameter দেয়? এমন একটা পরিস্থিতির কথা ভাবুন যেখানে MoM এমন একটা মান দেয় যা প্যারামিটার-স্থানের বাইরে (যেমন ঋণাত্মক variance, বা সম্ভাবনা \(>1\))। কেন এটা ঘটতে পারে, আর MLE-র তুলনায় এটা MoM-এর একটা দুর্বলতা কীভাবে? Hint: MoM শুধু moment-সমীকরণ সমাধান করে — সমাধান প্যারামিটার-স্থানে পড়বে তার নিশ্চয়তা নেই। উদাহরণ: কোনো নমুনায় \(\hat\mu_2'-(\hat\mu_1')^2<0\) হতে পারে না (নমুনা-variance সর্বদা \(\ge0\)), কিন্তু আরও জটিল মডেলে (যেমন কিছু mixture বা negative-binomial-এ moment দিয়ে dispersion) MoM ঋণাত্মক বা অসম্ভব মান দিতে পারে; MLE likelihood সর্বোচ্চ করে বলে সাধারণত বৈধ সীমানায় থাকে।
খ · গণনামূলক (computational)¶
প্রশ্ন ৫ (★). E2 Exponential\((\lambda)\), নমুনা \(\{0.8,\ 1.2,\ 2.0,\ 0.5,\ 1.5\}\) (\(n=5\))। (ক) \(\bar x\) বের করুন। (খ) MoM দিয়ে \(\hat\lambda_{\text{MoM}}\) হিসাব করুন। (গ) এই \(\hat\lambda\)-তে \(\mathbb{E}[X]\) কত, আর সেটা \(\bar x\)-এর সাথে মেলে কি? Hint: (ক) \(\bar x=(0.8+1.2+2.0+0.5+1.5)/5=6.0/5=1.2\)। (খ) \(\bar x=1/\lambda\Rightarrow\hat\lambda=1/1.2\approx0.833\)। (গ) \(\mathbb{E}[X]=1/\hat\lambda=1.2=\bar x\) — হুবহু মেলে (এটাই matching)।
প্রশ্ন ৬ (★). E3 Uniform\((0,\theta)\), নমুনা \(\{2.1,\ 5.4,\ 3.3,\ 7.8,\ 1.4\}\)। (ক) MoM দিয়ে \(\hat\theta_{\text{MoM}}\) বের করুন। (খ) লক্ষ করুন নমুনায় সবচেয়ে বড় মান \(7.8\) — আপনার \(\hat\theta\) কি তার চেয়ে বড়, না ছোট? এটা কি সমস্যা? Hint: (ক) \(\bar x=(2.1+5.4+3.3+7.8+1.4)/5=20.0/5=4.0\); \(\hat\theta=2\bar x=8.0\)। (খ) \(8.0>7.8\) — এবার ঠিক আছে; কিন্তু সাবধান: অন্য নমুনায় \(2\bar x\) সবচেয়ে বড় observation-এর চেয়ে ছোট হতে পারে, যা অসম্ভব (যেহেতু সব \(x_i\le\theta\))! এটাই MoM-এর একটা পরিচিত দুর্বলতা (§৫/৭ Q4, Q11 দ্রষ্টব্য)।
প্রশ্ন ৭ (★★). E1 Normal\((\mu,\sigma^2)\) — দুটো প্যারামিটার। MoM estimator বের করুন। (ক) প্রথম দুটো population moment লিখুন (\(\mu_1'=\mathbb{E}[X]\), \(\mu_2'=\mathbb{E}[X^2]\)) \(\mu,\sigma^2\)-এর মাধ্যমে। (খ) এদের sample moment-এর সমান ধরে \(\hat\mu_{\text{MoM}}\) ও \(\hat\sigma^2_{\text{MoM}}\) সমাধান করুন। (গ) দেখান \(\hat\sigma^2_{\text{MoM}}=\frac1n\sum_i(X_i-\bar X)^2\)। Hint: (ক) \(\mu_1'=\mu\), \(\mu_2'=\sigma^2+\mu^2\)। (খ) \(\hat\mu=\hat\mu_1'=\bar X\); \(\hat\sigma^2+\hat\mu^2=\hat\mu_2'\Rightarrow\hat\sigma^2=\hat\mu_2'-\bar X^2\)। (গ) \(\hat\mu_2'-\bar X^2=\frac1n\sum X_i^2-\bar X^2=\frac1n\sum(X_i-\bar X)^2\) (পরিচিত পরিচয়); লক্ষ করুন হরে \(n\) (না \(n-1\)), তাই এটা সামান্য biased।
প্রশ্ন ৮ (★★). E4 Gamma\((\alpha,\beta)\) (shape–rate), যেখানে \(\mathbb{E}[X]=\alpha/\beta\) ও \(\mathrm{Var}(X)=\alpha/\beta^2\)। একটা নমুনায় \(\bar x=3.75\) আর \(s^2=\frac1n\sum(x_i-\bar x)^2=4.7\) মাপা হলো। MoM দিয়ে \(\hat\alpha,\hat\beta\) বের করুন (Figure 4-এর সূত্র ব্যবহার করুন)। Hint: দুটো moment-সমীকরণ ভাগ করুন: \(\frac{\mathbb{E}[X]^2}{\mathrm{Var}(X)}=\frac{(\alpha/\beta)^2}{\alpha/\beta^2}=\alpha\), আর \(\frac{\mathbb{E}[X]}{\mathrm{Var}(X)}=\frac{\alpha/\beta}{\alpha/\beta^2}=\beta\)। তাই \(\hat\beta=\bar x/s^2=3.75/4.7\approx0.798\) এবং \(\hat\alpha=\bar x\,\hat\beta=3.75\times0.798\approx2.99\) (Figure 4-এর \(\approx(2.93,0.75)\)-এর সমধর্মী)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). MoM estimator consistent — যুক্তি দিন। ধরুন একক প্যারামিটার \(\theta\), আর moment-সম্পর্ক \(\mu_1'(\theta)=g(\theta)\) যেখানে \(g\) একটা সন্তত (continuous) ও বিপরীতযোগ্য (invertible) ফাংশন, তাই \(\hat\theta_{\text{MoM}}=g^{-1}(\hat\mu_1')\)। প্রমাণ করুন \(\hat\theta_{\text{MoM}}\xrightarrow{P}\theta\) যখন \(n\to\infty\)। Hint: দুই ধাপ: (১) LLN বলে \(\hat\mu_1'=\frac1n\sum X_i\xrightarrow{P}\mathbb{E}[X]=g(\theta)\) (3.3)। (২) \(g^{-1}\) সন্তত বলে continuous mapping theorem খাটে: \(\hat\theta_{\text{MoM}}=g^{-1}(\hat\mu_1')\xrightarrow{P}g^{-1}(g(\theta))=\theta\)। (একাধিক প্যারামিটারে: vector LLN + vector-এ continuous mapping।)
প্রশ্ন ১০ (★★). E2 Exponential-এ \(\hat\lambda=1/\bar X\) একটা biased estimator — দেখান \(\mathbb{E}[\hat\lambda]>\lambda\) (সসীম \(n\)-এ)। (ইঙ্গিত: \(1/x\) একটা উত্তল ফাংশন, Jensen-এর অসমতা ব্যবহার করুন।) Hint: \(\bar X\)-এর প্রত্যাশা \(\mathbb{E}[\bar X]=1/\lambda\)। \(\phi(x)=1/x\) কঠোরভাবে উত্তল (\(x>0\)-তে), তাই Jensen: \(\mathbb{E}[\phi(\bar X)]>\phi(\mathbb{E}[\bar X])\), অর্থাৎ \(\mathbb{E}[1/\bar X]>1/\mathbb{E}[\bar X]=\lambda\)। তাই \(\mathbb{E}[\hat\lambda]>\lambda\) — Figure 3-এর গড় \(0.510>0.5\) ঠিক এটাই দেখায়। (\(n\to\infty\)-এ \(\bar X\)-এর variance \(\to0\), তাই bias \(\to0\) — asymptotically unbiased ও consistent।)
প্রশ্ন ১১ (★★★). E3 Uniform\((0,\theta)\), \(\hat\theta_{\text{MoM}}=2\bar X\)। (ক) দেখান এটা unbiased: \(\mathbb{E}[2\bar X]=\theta\)। (খ) এর variance বের করুন: \(\mathrm{Var}(2\bar X)=\frac{\theta^2}{3n}\)। (গ) তুলনা করুন MLE \(\hat\theta_{\text{MLE}}=X_{(n)}=\max_i X_i\)-এর সাথে, যার \(\mathrm{Var}(X_{(n)})=\frac{n\,\theta^2}{(n+1)^2(n+2)}\approx\frac{\theta^2}{n^2}\) (বড় \(n\)-এ)। কোনটা ভালো এবং কত গুণ? Hint: (ক) \(\mathbb{E}[X]=\theta/2\Rightarrow\mathbb{E}[2\bar X]=2\cdot\theta/2=\theta\)। (খ) \(\mathrm{Var}(X)=\theta^2/12\); \(\mathrm{Var}(\bar X)=\theta^2/(12n)\); \(\mathrm{Var}(2\bar X)=4\cdot\theta^2/(12n)=\theta^2/(3n)\)। (গ) MoM variance \(\sim\theta^2/n\) মাত্রায়, MLE variance \(\sim\theta^2/n^2\) — MLE প্রায় \(n\) গুণ ছোট variance, অর্থাৎ অনেক বেশি কার্যকর (efficient)। এটাই 4.3-এর মূল বার্তার পূর্বাভাস: MoM সরল কিন্তু সবসময় সবচেয়ে নিখুঁত নয়।
প্রশ্ন ১২ (★★). একক প্যারামিটার \(\theta\)-এ ধরুন \(\hat\theta_{\text{MoM}}=g^{-1}(\hat\mu_1')\) যেখানে \(g\) মসৃণ ও \(g'(\theta)\ne0\)। delta method ব্যবহার করে \(\hat\theta_{\text{MoM}}\)-এর আনুমানিক sampling variance বের করুন \(\mathrm{Var}(X)\) ও \(g'\)-এর মাধ্যমে, এবং দেখান E2-তে এটা \(\lambda^2/n\) দেয় (Figure 3-এর সূত্র)। Hint: delta method: \(\mathrm{Var}(g^{-1}(\hat\mu_1'))\approx[(g^{-1})'(\mu_1')]^2\,\mathrm{Var}(\hat\mu_1')=\frac{\mathrm{Var}(X)}{n\,[g'(\theta)]^2}\)। E2-তে \(\mu_1'=g(\lambda)=1/\lambda\), \(g'(\lambda)=-1/\lambda^2\), \(\mathrm{Var}(X)=1/\lambda^2\); বসিয়ে \(\frac{1/\lambda^2}{n\,(1/\lambda^2)^2}=\frac{1/\lambda^2}{n/\lambda^4}=\frac{\lambda^2}{n}\) — অর্থাৎ \(\text{SE}\approx\lambda/\sqrt n\) (Figure 3-এ যাচাই)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৩ (★). numpy দিয়ে E3 Uniform\((0,\theta)\)-এর MoM estimate বানান। true \(\theta=10\) ধরে \(n=200\)-এর একটা নমুনা টানুন (rng.uniform(0,10,200)), \(\hat\theta_{\text{MoM}}=2\bar X\) হিসাব করুন, আর সবচেয়ে বড় observation \(X_{(n)}\)-এর সাথে ছাপান। দুটোর কোনটা সত্যি \(10\)-এর কাছাকাছি?
Hint: rng=np.random.default_rng(0); x=rng.uniform(0,10,200); theta_mom=2*x.mean(); print(theta_mom, x.max())। সাধারণত \(2\bar X\) ও \(X_{(n)}\) দুটোই \(10\)-এর কাছাকাছি, তবে \(X_{(n)}\) একটু কম (নিচ থেকে), \(2\bar X\) দুদিকেই হেলতে পারে।
প্রশ্ন ১৪ (★★). Figure 2-র consistency নিজে পুনরুৎপাদন করুন (Exponential)। true \(\lambda=0.5\)। \(n\in\{5,10,50,100,500,2000\}\)-এর প্রতিটির জন্য \(300\) বার নমুনা টেনে \(\hat\lambda=1/\bar X\)-এর গড় ও standard deviation বের করুন; দেখান \(n\) বাড়লে গড় \(\to0.5\) ও SD \(\to0\)। ছকে/plot-এ দেখান।
Hint: ভেক্টরাইজ করুন: ests = 1/rng.exponential(1/0.5, size=(300,n)).mean(axis=1); তারপর ests.mean(), ests.std()। লুপে \(n\) ঘুরিয়ে দুটো তালিকা বানিয়ে plt.plot/print — SD প্রায় \(\lambda/\sqrt n\) অনুসরণ করবে।
প্রশ্ন ১৫ (★★★). নিজের MoM-fitter লিখুন এবং histogram-এ overlay করুন (Figure 4 পুনরুৎপাদন, Gamma)। (ক) true \((\alpha,\beta)=(3,0.8)\) থেকে \(n=400\) Gamma নমুনা টানুন (rng.gamma(shape=3, scale=1/0.8, size=400))। (খ) MoM দিয়ে \(\hat\beta=\bar x/s^2\), \(\hat\alpha=\bar x\,\hat\beta\) বের করুন (\(s^2=\) x.var())। (গ) data-র density-histogram-এর উপর scipy.stats.gamma.pdf(grid, a=alpha_hat, scale=1/beta_hat) overlay করুন। (ঘ) বোনাস: একই data-য় MLE fit (scipy.stats.gamma.fit(x, floc=0)) overlay করে MoM-fit-এর সাথে তুলনা করুন — কোনটা data-র সাথে একটু ভালো মেলে?
Hint: m1=x.mean(); s2=x.var(); beta=m1/s2; alpha=m1*beta। overlay: grid=np.linspace(0,x.max(),400); plt.plot(grid, stats.gamma.pdf(grid,a=alpha,scale=1/beta))। MLE: a_ml,loc,scale_ml=stats.gamma.fit(x,floc=0) — সাধারণত MoM ও MLE দুটোই ভালো fit দেয়, MLE একটু কম "noisy", বিশেষত ছোট \(n\)-এ পার্থক্য স্পষ্ট হয়।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Method of Moments-এর সারমর্ম: population moment-এর তাত্ত্বিক সূত্রে প্যারামিটার বসাও, তাকে sample moment-এর সমান ধরো, আর প্যারামিটারের জন্য সমাধান করো। \(p\)টা অজানা প্যারামিটারের জন্য প্রথম \(p\)টা moment মেলাও: $$ \mu_1'(\theta)=\hat\mu_1',\quad \mu_2'(\theta)=\hat\mu_2',\quad\dots,\quad \mu_p'(\theta)=\hat\mu_p', \qquad \hat\mu_k'=\frac1n\sum_{i=1}^n X_i^k . $$ সমাধান \(\hat\theta_{\text{MoM}}\) (Figure 1)। এটা একটা plug-in estimator — population-এর অজানা \(\mu_k'\)-এর জায়গায় তার sample-প্রতিরূপ \(\hat\mu_k'\) "বসিয়ে দেওয়া"।
- চলমান উদাহরণগুলো (closed-form): E1 Normal — \(\hat\mu=\bar X,\ \hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\); E2 Exponential — \(\hat\lambda=1/\bar X\); E3 Uniform\((0,\theta)\) — \(\hat\theta=2\bar X\); E4 Gamma — \(\hat\beta=\bar X/s^2,\ \hat\alpha=\bar X\,\hat\beta\)। প্রতিটিতেই শুধু কয়েকটা গড় হিসাব করলেই estimator পাওয়া যায়, কোনো iteration লাগে না।
- কেন কাজ করে — consistency: LLN বলে \(\hat\mu_k'\xrightarrow{P}\mu_k'\) (3.3), আর moment→প্যারামিটার রূপান্তর সন্তত হলে continuous mapping theorem দিয়ে \(\hat\theta_{\text{MoM}}\xrightarrow{P}\theta\)। অর্থাৎ \(n\) বাড়লে estimate সত্যিকারের প্যারামিটারে গড়িয়ে যায় (Figure 2)।
- sampling distribution: যথেষ্ট \(n\)-এ একটা MoM estimator আনুমানিক Normal (কারণ এটা sample moment-এর মসৃণ ফাংশন — CLT + delta method), যার standard error delta method দিয়ে আনুমান করা যায় (E2-তে \(\text{SE}\approx\lambda/\sqrt n\) — Figure 3)। তবে nonlinear রূপান্তরে সসীম \(n\)-এ সামান্য bias থাকতে পারে (যেমন \(1/\bar X\) উপরে হেলে — Jensen)।
- সুবিধা ও সীমাবদ্ধতা: সুবিধা — সরল, দ্রুত, প্রায়ই বন্ধ-রূপ; প্রাথমিক estimate বা MLE-র starting point হিসেবে চমৎকার; data-য় ভালো fit দেয় (Figure 4)। সীমাবদ্ধতা — (১) সবসময় বৈধ প্যারামিটার দেয় না (যেমন \(2\bar X\) সবচেয়ে বড় observation-এর চেয়ে ছোট হতে পারে); (২) সাধারণত MLE-র চেয়ে কম efficient (বড় variance — Uniform-এ MLE প্রায় \(n\) গুণ ভালো); (৩) কোন moment বাছব তাতে কিছুটা স্বেচ্ছাচার।
পূর্ববর্তী সংযোগ (← 4.1, 3.3): 4.1-এ আমরা point estimation-এর কাঠামো শিখেছি — estimator, bias, variance, MSE, consistency — এই অধ্যায় সেই কাঠামোর ভেতরে প্রথম একটা concrete পদ্ধতি ভরল: MoM হলো একটা নির্দিষ্ট নিয়ম যা data থেকে \(\hat\theta\) বানায়, আর আমরা 4.1-এর মানদণ্ডেই (consistent? biased? কত variance?) তাকে যাচাই করলাম। আর এর তাত্ত্বিক ভিত্তি পুরোটাই 3.3 (Law of Large Numbers) — sample moment যে population moment-এ গড়ায়, সেটাই MoM-কে অর্থপূর্ণ করে; delta method ও Normal-আকৃতির পেছনে আছে 3.4-এর CLT। অর্থাৎ Part III-এ গড়া convergence-তত্ত্ব এখানে সরাসরি estimation-এর হাতিয়ার হয়ে উঠল।
পরবর্তী সংযোগ (→ 4.3 — Maximum Likelihood Estimation): MoM একটা estimate বানানোর প্রথম ও সহজতম উপায়; পরের অধ্যায় 4.3-এ আসছে MLE — আরেকটি, প্রায়ই উন্নততর, estimation পদ্ধতি। MoM moment মেলায়; MLE বদলে জিজ্ঞেস করে — "কোন প্যারামিটার-মান এই observed data-কে সবচেয়ে সম্ভাব্য (most likely) করে?" — অর্থাৎ likelihood function \(L(\theta)=\prod_i f(X_i;\theta)\) সর্বোচ্চ করে। এই অধ্যায়ে আমরা দুটো ইঙ্গিত রেখে এলাম যা 4.3-এ পূর্ণতা পাবে: (১) Figure 4-এ MoM-fit আর true curve প্রায় মিলেছিল, কিন্তু §৭ Q11/Q15 দেখাল MLE প্রায়ই আরও কম variance (বেশি efficient) দেয় — Uniform-এ নাটকীয়ভাবে; (২) MoM মাঝে মাঝে অবৈধ মান দেয়, MLE সাধারণত বৈধ সীমানায় থাকে। তাই 4.3 MLE-কে "default" estimation পদ্ধতি হিসেবে প্রতিষ্ঠা করবে, আর MoM থাকবে তার সরল-সঙ্গী ও প্রায়ই-starting-point হিসেবে। এই দুই পদ্ধতির তুলনাই Part IV-এর estimation-যাত্রার মূল সুর — সরলতা বনাম দক্ষতা।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 9 (Parametric Inference — §9.2 The Method of Moments: moment equations, consistency, asymptotic normality); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 8 (Estimation of Parameters — §8.4 The Method of Moments, Gamma ও অন্যান্য উদাহরণ, MoM বনাম MLE তুলনা)।