4.4 — Properties of Estimators (অনুমানকের গুণাবলি)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — একই parameter, অনেক estimator: কোনটা "ভালো"?¶
১.১ আগের অধ্যায়গুলো কোথায় রেখে এসেছিল — আর এখন কোন প্রশ্ন¶
গত তিনটি অধ্যায়ে আমরা inference-এর কাঠামো ও তার দুটি যন্ত্র গড়ে তুলেছি। সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়ের পুরো গল্পটাই এর উপরে দাঁড়িয়ে।
- 4.1-এ আমরা শিখেছি যে কোথাও একটা population (সমগ্রক / জনসমষ্টি) আছে, যার ভেতরে একটা স্থির কিন্তু অজানা সংখ্যা লুকিয়ে — তার নাম parameter (প্যারামিটার / প্রাচল), প্রতীকে \(\theta\) ("থিটা")। আমরা পুরো population দেখতে পাই না; পাই কেবল একটা sample (নমুনা) — \(n\)টি পর্যবেক্ষণ \(X_1, X_2, \dots, X_n\)। এই data থেকে \(\theta\)-র একটা আন্দাজ বানানোর সূত্রকে বলি estimator (আনুমানক), প্রতীকে "টুপি" চিহ্ন দিয়ে \(\hat\theta\)। যেহেতু \(\hat\theta\) random data-র ওপর নির্ভর করে, \(\hat\theta\) নিজেও একটা random variable — নমুনা বদলালে এর মানও বদলায়, আর তার নিজস্ব একটা বণ্টন আছে, যাকে বলেছিলাম sampling distribution (স্যাম্পলিং বণ্টন)।
- 4.2-এ (Method of Moments) আর 4.3-এ (Maximum Likelihood) আমরা শিখেছি দুটো আলাদা recipe — data থেকে \(\hat\theta\) লেখার দুটো ভিন্ন নিয়ম। যেমন Uniform\((0,\theta)\) distribution-এর জন্য MoM দিল \(\hat\theta = 2\bar X\) (নমুনা গড়ের দ্বিগুণ)।
তাহলে এখন আমাদের হাতে কী আছে? একটা অজানা \(\theta\), আর সেটা আন্দাজ করার একাধিক পদ্ধতি। আর ঠিক এখানেই এই অধ্যায়ের প্রশ্নটা জন্ম নেয় — একটা প্রশ্ন যা গত তিন অধ্যায়ে আমরা সযত্নে এড়িয়ে গেছি:
একই অজানা \(\theta\)-র জন্য আমার কাছে যদি একাধিক estimator থাকে, তবে কোনটা "ভালো"? আর "ভালো" বলতে আমরা ঠিক কী বোঝাব — কোন সংখ্যায় তা মাপব?
লক্ষ করুন, এতদিন আমরা শুধু \(\hat\theta\) বানানো শিখেছি — বিচার করিনি। এই অধ্যায়ের একমাত্র কাজ সেই বিচার: estimator-এর মান পরিমাপ করার একটা গাণিতিক কাঠামো গড়ে তোলা।
১.২ একটা ছোট ধাক্কা — একই parameter-এর জন্য সত্যিই অনেক estimator¶
"একাধিক estimator" কথাটা বিমূর্ত শোনাতে পারে, তাই একটা concrete দৃশ্য দিই। ধরুন একটা population থেকে নমুনা নিয়েছেন, আর আপনি জানেন population-টা প্রতিসম (symmetric) — তার একটা সত্য কেন্দ্র \(\theta\) আছে (গড় = মধ্যমা), সেটাই অনুমান করতে চান। আপনার সামনে অন্তত তিনটে স্বাভাবিক পথ:
- নমুনা গড় (sample mean): \(\hat\theta_1 = \bar X_n = \frac1n\sum_{i=1}^n X_i\) — সব মান যোগ করে \(n\) দিয়ে ভাগ।
- নমুনা মধ্যমা (sample median): $\hat\theta_2 = $ মানগুলো সাজিয়ে ঠিক মাঝেরটা।
- মাঝ-পরিসর (midrange): \(\hat\theta_3 = \frac{\min_i X_i + \max_i X_i}{2}\) — সবচেয়ে ছোট ও সবচেয়ে বড় মানের গড়।
তিনটেই "কেন্দ্র"-এর সৎ আন্দাজ; তিনটেই data থেকে গণনাযোগ্য; তিনটেই বৈধ estimator। অথচ একই নমুনায় এরা সাধারণত তিনটে আলাদা সংখ্যা দেবে। কোনটা বেছে নেব? "যেটা সত্যের কাছে থাকার সম্ভাবনা বেশি" — কিন্তু সেটাকে পরিমাপ করব কীভাবে? এই অধ্যায় তারই উত্তর।
আরও জোরালো একটা উদাহরণ, যেটা গোটা অধ্যায়ে ফিরে আসবে: population variance \(\sigma^2\) অনুমানের দুটো প্রায়-অভিন্ন সূত্র —
দুটোর মধ্যে পার্থক্য কেবল ভাজক — একটায় \(n\), অন্যটায় \(n-1\)। দেখতে তুচ্ছ। অথচ 1.2-এ আমরা ইঙ্গিত দিয়েছিলাম যে \(n-1\)-ওয়ালা \(S^2\)-কেই "ঠিক" ধরা হয়। কেন? \(n\) দিয়ে ভাগ করলে তো আরও স্বাভাবিক মনে হয় (variance তো "গড় বর্গ-দূরত্ব")! এই "কেন \(n-1\)" প্রশ্নের নিখুঁত উত্তর — যা এতদিন স্থগিত ছিল — এই অধ্যায়ের bias ধারণা দিয়ে আমরা অবশেষে দেব (§৩, E1)।
১.৩ Hook — ডার্টবোর্ডের রূপক: নিশানা বনাম ছড়ানো¶
estimator-এর মান বিচারের পুরো অন্তর্দৃষ্টিটা একটা ছবিতে ধরা যায় — ডার্টবোর্ড (dartboard)। কল্পনা করুন, board-এর একদম কেন্দ্রের লাল বিন্দুটাই হলো সত্য parameter \(\theta\) — যেখানে আমরা মারতে চাই। আর প্রতিবার নতুন নমুনা টেনে \(\hat\theta\) হিসাব করা মানে একটা ডার্ট ছোঁড়া। অনেকবার নমুনা = অনেকগুলো ডার্ট, board-এ ছড়িয়ে।
এবার দুটো আলাদা জিনিস লক্ষ করুন — এরা স্বাধীন, একটার ভালো হলেই অন্যটা ভালো হয় না:
- নিশানা ঠিক আছে কি না (bias)। আপনার ডার্টগুলোর গড় অবস্থান কি কেন্দ্রে, নাকি একটা দিকে সরে আছে? যদি গড়ে আপনি কেন্দ্রের ডানদিকে মারেন, তবে আপনার লক্ষ্যে একটা পদ্ধতিগত ভুল (systematic error) আছে — এটাই bias (পক্ষপাত / নতি)। গড় অবস্থান ঠিক কেন্দ্রে হলে bias শূন্য — estimator-টা unbiased (নিরপেক্ষ)।
- ছড়ানো কতটা (variance)। আপনার ডার্টগুলো কি একে অপরের কাছাকাছি গুচ্ছ হয়ে পড়ছে, নাকি board জুড়ে এলোমেলো ছিটিয়ে? এই ছড়ানোটাই variance (ভেদ) — নমুনা-থেকে-নমুনায় \(\hat\theta\) কতটা ওঠানামা করে তার মাপ।
চারটে সম্ভাবনা তাই দাঁড়ায়, আর প্রতিটাই বাস্তব estimator-এ ঘটে:
| কম variance (গুচ্ছ) | বেশি variance (ছড়ানো) | |
|---|---|---|
| bias শূন্য (গড়ে কেন্দ্রে) | আদর্শ — গড়েও ঠিক, প্রতিবারও কাছে | গড়ে ঠিক, কিন্তু একক নমুনা দূরে যেতে পারে |
| bias আছে (গড়ে সরা) | প্রতিবার একই জায়গায়, কিন্তু ভুল জায়গায় | দুই দিক থেকেই খারাপ |
এই ছকটা মাথায় গেঁথে নিন — এটাই গোটা অধ্যায়ের কঙ্কাল। একটা estimator "কতটা ভালো" তা একটামাত্র সংখ্যায় ধরতে হলে এই দুই উৎসের ভুল একসাথে মাপতে হবে: কেন্দ্র থেকে গড় সরণ (bias), আর কেন্দ্রের চারপাশে ছড়ানো (variance)। সেই একত্রিত মাপটার নাম mean squared error (MSE, গড় বর্গ-ত্রুটি), আর এই অধ্যায়ের সবচেয়ে সুন্দর সমীকরণটা বলবে: MSE = bias² + variance — অর্থাৎ মোট ভুল = (নিশানার ভুল)² + (ছড়ানোর ভুল)। (Figure 4-4-bias-variance এই চারটে ডার্টবোর্ড চোখে দেখাবে।)
একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ কথা — bias আর variance প্রায়ই পরস্পরবিরোধী। অনেক সময় একটা কমাতে গেলে অন্যটা বাড়ে। bias শূন্য করতে গিয়ে variance এত বড় হতে পারে যে estimator কার্যত খারাপ; আবার সামান্য bias মেনে নিয়ে variance অনেকখানি কমালে মোট MSE কমে যেতে পারে। এই টানাপোড়েনের নাম bias–variance tradeoff (পক্ষপাত–ভেদ আপস), আর এটি কেবল এই অধ্যায়ের নয় — গোটা পরিসংখ্যান ও মেশিন লার্নিং-এর একটি কেন্দ্রীয় থিম (Part VI-এ আবার বড় করে আসবে)।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — estimator-এর মান মাপার শব্দভাণ্ডার from scratch: bias, variance, MSE; কেন্দ্রীয় পরিচিতি MSE = bias² + variance; unbiased estimator; consistency (এবং LLN-এর সাথে এর সংযোগ); সবশেষে (asymptotic) efficiency ও standard error-এর স্বজ্ঞা। প্রতিটি প্রতীক খোলা হবে।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 (\(\hat\sigma^2\) vs \(S^2\)-এর bias গণনা — "কেন \(n-1\)" প্রশ্নের উত্তর), E2 (একটি estimator-এর bias–variance decomposition হাতে-কলমে সংখ্যায়), E3 (\(\bar X\)-এর consistency, সরাসরি LLN থেকে), E4 (Uniform\((0,\theta)\)-তে \(2\bar X\) বনাম \(\max\)-এর MSE তুলনা — কোনটা জেতে?)।
- §৪–৫ — bias–variance decomposition-এর পূর্ণ প্রমাণ, consistency-র নিখুঁত শর্ত, asymptotic efficiency ও Cramér–Rao-র দিকে সেতু, এবং tradeoff-এর গভীরতর আলোচনা।
- §৬–৮ — চিত্র (চারটি ডার্টবোর্ড/decomposition/consistency/তুলনা), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর মেরুদণ্ড। 4.2–4.3 আমাদের দিয়েছে estimator বানানোর হাতিয়ার; এই অধ্যায় দেয় estimator বিচারের হাতিয়ার — bias, variance, MSE, consistency, efficiency। এই মানদণ্ডগুলো ছাড়া পরের অধ্যায় 4.5 (sufficiency, Fisher information, Cramér–Rao lower bound — "সবচেয়ে দক্ষ estimator কতটা ভালো হতে পারে তার তাত্ত্বিক সীমা") দাঁড়াতেই পারে না।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর ডার্টবোর্ড-স্বজ্ঞাকে আমরা আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামোটা স্থির: আমাদের কাছে একটি i.i.d. নমুনা \(X_1, X_2, \dots, X_n\) আছে (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা), একটি common distribution থেকে, যার ভেতরে একটি অজানা স্থির parameter \(\theta\) আছে। আমরা একটি estimator \(\hat\theta = \hat\theta(X_1,\dots,X_n)\) বেছেছি — data-র একটা function, তাই নিজেই random। প্রশ্ন: এই \(\hat\theta\) কতটা ভালো?
মনে রাখার মতো মূল কাঠামো, যা সবকিছুর গোড়ায়:
\(\theta\) একটা স্থির সংখ্যা (random নয়, শুধু অজানা — board-এর কেন্দ্র); \(\hat\theta\) একটা random variable (নমুনা বদলালে বদলায় — প্রতিটি ডার্টের অবস্থান)। তাই \(\hat\theta\)-র উপর আমরা \(\mathbb{E}[\cdot]\) (প্রত্যাশা) ও \(\mathrm{Var}(\cdot)\) (ভেদ) প্রয়োগ করতে পারি — এরা \(\hat\theta\)-র sampling distribution-এর উপর গণনা করা হয়, অর্থাৎ "সব সম্ভাব্য নমুনার গড়ে"।
এখানে \(\mathbb{E}[\hat\theta]\) বলতে কী বোঝায়, সেটা একবার স্পষ্ট করি — কারণ এটাই পরের সব সংজ্ঞার ভিত্তি। কল্পনা করুন একই population থেকে বারবার (ধারণাগতভাবে অসীমবার) আকার-\(n\) নমুনা টানছেন, প্রতিবার \(\hat\theta\) হিসাব করছেন, আর সেই অসংখ্য \(\hat\theta\)-মানের গড় নিচ্ছেন — সেটাই \(\mathbb{E}[\hat\theta]\), \(\hat\theta\)-র দীর্ঘমেয়াদি গড় অবস্থান (ডার্টগুলোর গড় জায়গা)। এটা একটা স্থির সংখ্যা (random নয়), যা \(\theta\) ও \(n\)-এর উপর নির্ভর করে।
২.১ Bias — নিশানা কতটা সরে আছে¶
প্রথম স্তম্ভ: estimator-টা কি গড়ে সত্যের দিকেই তাক করে, নাকি একটা পদ্ধতিগত দিকে সরে আছে?
সংজ্ঞা (Bias — পক্ষপাত / নতি)। estimator \(\hat\theta\)-র bias হলো তার গড় অবস্থান ও সত্য parameter-এর মধ্যে পার্থক্য:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta\) — আমাদের estimator (data-র function, random variable)।
- \(\theta\) — সত্য, স্থির, অজানা parameter (board-এর কেন্দ্র)।
- \(\mathbb{E}[\hat\theta]\) — \(\hat\theta\)-র expected value (প্রত্যাশা), অর্থাৎ তার sampling distribution-এর গড় (ডার্টগুলোর গড় অবস্থান, একটা স্থির সংখ্যা)।
- \(b(\hat\theta)\) — bias; নিজেও একটা স্থির সংখ্যা (random নয়), যা ধনাত্মক, ঋণাত্মক বা শূন্য হতে পারে।
পড়ার নিয়ম: - \(b(\hat\theta) = 0\) হলে গড়ে estimator ঠিক কেন্দ্রে — কোনো পদ্ধতিগত ভুল নেই। - \(b(\hat\theta) > 0\) হলে estimator গড়ে \(\theta\)-কে বেশি করে অনুমান করে (গড়ে কেন্দ্রের ডানে — overestimate)। - \(b(\hat\theta) < 0\) হলে গড়ে কম করে অনুমান করে (underestimate)।
সাবধান — bias মানে "এই নমুনায় ভুল" নয়। bias একটা নমুনার বৈশিষ্ট্য নয়, এটা estimator-পদ্ধতির গড় বৈশিষ্ট্য। একটা unbiased estimator-ও যেকোনো একটা নির্দিষ্ট নমুনায় সত্য থেকে অনেক দূরে যেতে পারে (যদি variance বড় হয়); bias শুধু বলে — অসংখ্য নমুনার গড়ে কি সে কেন্দ্রে বসে কি না। ঠিক যেমন একজন তীরন্দাজের তীর গড়ে কেন্দ্রে পড়লেও কোনো একটা তীর কেন্দ্র থেকে দূরে পড়তে পারে।
২.২ Unbiased estimator — গড়ে নিখুঁত¶
bias-এর সবচেয়ে আকাঙ্ক্ষিত মান শূন্য, আর তার একটা আলাদা নাম আছে।
সংজ্ঞা (Unbiased estimator — নিরপেক্ষ আনুমানক)। একটি estimator \(\hat\theta\)-কে unbiased বলা হয় যদি তার bias শূন্য হয়, অর্থাৎ
— সব সম্ভাব্য নমুনার গড়ে estimator ঠিক সত্য parameter-এ বসে। অর্থাৎ unbiased estimator কোনো পদ্ধতিগত দিকে সরে নেই; গড়ে সে নিখুঁত।
দুটো পরিচিত উদাহরণ (4.1 ও পরে প্রমাণ-সহ):
- নমুনা গড় \(\bar X_n\) সবসময় population গড় \(\mu\)-র একটি unbiased estimator: \(\mathbb{E}[\bar X_n] = \mu\) (linearity of expectation থেকে সহজে — §৩, E3-এ দেখব)।
- নমুনা variance \(S^2\) (n−1-ভাজক) population variance \(\sigma^2\)-র unbiased estimator: \(\mathbb{E}[S^2] = \sigma^2\) — অথচ \(\hat\sigma^2\) (n-ভাজক) নয়। ঠিক এই পার্থক্যটাই E1-এ "কেন \(n-1\)" প্রশ্নের উত্তর দেবে।
একটা সতর্কতা যা পরে বড় হয়ে উঠবে: unbiased হওয়া মানেই "সেরা" নয়। একটা estimator unbiased হয়েও বিশাল variance বহন করতে পারে, ফলে যেকোনো একটা নমুনায় ভয়ংকর ভুল দিতে পারে। অন্যদিকে একটা সামান্য-biased estimator অনেক কম variance নিয়ে গড়ে সত্যের আরও কাছে থাকতে পারে। তাই unbiasedness একটা গুণ, কিন্তু একমাত্র মানদণ্ড নয় — এজন্যই আমাদের একটা একত্রিত মাপ চাই, যা পরের দুটো উপবিভাগে আসছে।
২.৩ Variance — ছড়ানো কতটা¶
দ্বিতীয় স্তম্ভ: estimator কি নমুনা-থেকে-নমুনায় স্থির থাকে, নাকি বুনোভাবে লাফায়?
সংজ্ঞা (Variance of an estimator — আনুমানকের ভেদ)। \(\hat\theta\)-র variance হলো তার নিজের গড়ের চারপাশে গড় বর্গ-বিচ্যুতি:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta - \mathbb{E}[\hat\theta]\) — একটা নির্দিষ্ট নমুনার estimate তার নিজের গড় অবস্থান থেকে কতটা সরে (লক্ষ করুন: সত্য \(\theta\) থেকে নয়, নিজের গড় \(\mathbb{E}[\hat\theta]\) থেকে — variance শুধু ছড়ানো মাপে, নিশানার ভুল নয়)।
- বর্গ \((\cdot)^2\) — ধনাত্মক-ঋণাত্মক বিচ্যুতি যাতে একে অপরকে কেটে শূন্য না করে, এবং বড় বিচ্যুতিকে বেশি গুরুত্ব দিতে।
- বাইরের \(\mathbb{E}[\cdot]\) — সব সম্ভাব্য নমুনার উপর সেই বর্গ-বিচ্যুতির গড়।
\(\mathrm{Var}(\hat\theta)\) যত ছোট, ডার্টগুলো তত শক্ত গুচ্ছ — estimator তত নির্ভরযোগ্য (একটা নমুনা থেকেই সত্যের কাছাকাছি থাকার ভরসা বেশি, যদি bias-ও কম হয়)। আর variance-এর বর্গমূল \(\sqrt{\mathrm{Var}(\hat\theta)}\) হলো \(\hat\theta\)-র standard deviation, যার একটা বিশেষ নাম আছে inference-এ — standard error (§২.৭-এ ফিরছি)।
২.৪ Mean Squared Error — দুই উৎসের ভুল এক সংখ্যায়¶
bias একা যথেষ্ট নয় (variance উপেক্ষা করে), variance একাও যথেষ্ট নয় (নিশানা উপেক্ষা করে)। আমাদের একটা একত্রিত মাপ চাই — যা একটামাত্র সংখ্যায় বলে দেবে "\(\hat\theta\) গড়ে সত্য \(\theta\) থেকে কতটা দূরে"। সেটাই MSE।
সংজ্ঞা (Mean Squared Error — গড় বর্গ-ত্রুটি, MSE)। \(\hat\theta\)-র MSE হলো সত্য \(\theta\) থেকে তার গড় বর্গ-দূরত্ব:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta - \theta\) — একটা নির্দিষ্ট নমুনায় estimate-এর প্রকৃত ভুল (সত্য কেন্দ্র থেকে দূরত্ব — এবার সত্যিই \(\theta\) থেকে, নিজের গড় থেকে নয়)।
- \((\cdot)^2\) — সেই ভুলের বর্গ (চিহ্ন মুছে, বড় ভুলকে বেশি শাস্তি)।
- \(\mathbb{E}[\cdot]\) — সব সম্ভাব্য নমুনার উপর গড় ভুল-বর্গ।
লক্ষ করুন variance ও MSE-র সূক্ষ্ম পার্থক্য: variance-এ আমরা \(\hat\theta\)-কে তার নিজের গড় \(\mathbb{E}[\hat\theta]\) থেকে মাপি, কিন্তু MSE-তে সত্য \(\theta\) থেকে। এই একটিমাত্র পার্থক্যই MSE-কে bias-সচেতন করে তোলে — আর সেখান থেকেই অধ্যায়ের সবচেয়ে সুন্দর পরিচিতিটা বেরোয়।
কেন্দ্রীয় পরিচিতি (MSE decomposition — statement)। যেকোনো estimator \(\hat\theta\)-র জন্য:
কথায়: গড় বর্গ-ত্রুটি = (পক্ষপাত)² + ভেদ = (নিশানার ভুল)² + (ছড়ানোর ভুল)। ঠিক ডার্টবোর্ডের সেই দুই উৎস — কেন্দ্র থেকে গড় সরণ, আর গড়ের চারপাশে ছড়ানো — একটা সমীকরণে মিলে যায়।
এই পরিচিতির তাৎক্ষণিক ফল:
- unbiased হলে (\(b(\hat\theta)=0\)): \(\mathrm{MSE}(\hat\theta) = \mathrm{Var}(\hat\theta)\) — তখন MSE আর variance অভিন্ন, তাই দুই unbiased estimator-এর মধ্যে যেটার variance কম, সেটাই ভালো।
- biased হলেও estimator-টা জিততে পারে — যদি তার variance এত কম হয় যে \([b]^2 + \mathrm{Var}\) একটা unbiased প্রতিদ্বন্দ্বীর (বড়) variance-এর চেয়েও ছোট। এটাই bias–variance tradeoff-এর গাণিতিক চেহারা: সামান্য \([b]^2\) মেনে নিয়ে অনেকখানি \(\mathrm{Var}\) কমানো লাভজনক হতে পারে।
(এই পরিচিতির পূর্ণ প্রমাণ — \(\theta\)-কে \(\pm\,\mathbb{E}[\hat\theta]\) যোগ-বিয়োগ করে বর্গ ভেঙে cross-term শূন্য দেখানো — §৪-এ দেওয়া হবে। এখানে আমরা statement হিসেবে গ্রহণ করছি এবং §৩-এ সংখ্যায় যাচাই করব।)
স্বজ্ঞায় কেন cross-term মিলিয়ে যায়। ভুল \((\hat\theta - \theta)\)-কে দুই টুকরো করুন: "গড় থেকে কত দূরে" \((\hat\theta - \mathbb{E}[\hat\theta])\) — এটা random, গড়ে শূন্য — আর "গড় নিজে সত্য থেকে কত দূরে" \((\mathbb{E}[\hat\theta] - \theta) = b(\hat\theta)\) — এটা একটা স্থির সংখ্যা। বর্গ করলে দুটো বর্গ-পদ আর একটা ক্রস-পদ; ক্রস-পদে random টুকরোটার গড় শূন্য বলে সে মুছে যায়, পড়ে থাকে variance (\(=\) random টুকরোর বর্গের গড়) আর bias² (\(=\) স্থির টুকরোর বর্গ)।
২.৫ Consistency — বেশি data-য় সত্যে থিতু হওয়া¶
এতক্ষণের সব মাপ (bias, variance, MSE) একটা নির্দিষ্ট নমুনা-আকার \(n\)-এ estimator-এর আচরণ মাপে। কিন্তু একটা ভিন্ন, সমান গুরুত্বপূর্ণ প্রশ্ন: নমুনা যত বড় করি, estimator কি সত্যের দিকে গুটিয়ে যায়? এটাই consistency।
সংজ্ঞা (Consistency — সংগতি)। একটি estimator-ক্রম \(\hat\theta_n\) (নমুনা-আকার \(n\)-এর উপর সূচীবদ্ধ — প্রতিটি \(n\)-এর জন্য একটা estimator) parameter \(\theta\)-র জন্য consistent যদি \(n\) বাড়ার সাথে \(\hat\theta_n\) সম্ভাবনার অর্থে \(\theta\)-তে converge করে:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta_n\) — নমুনা-আকার \(n\)-এর estimator; \(n\) বাড়লে নতুন (বড়) নমুনায় নতুন estimate।
- \(\xrightarrow{P}\) — "converges in probability" তীর (3.2-এর সংজ্ঞা)। পূর্ণরূপে এর মানে: যেকোনো ছোট সহনশীলতা \(\varepsilon > 0\)-র জন্য $$ \lim_{n\to\infty} P\big(\lvert \hat\theta_n - \theta \rvert > \varepsilon\big) = 0 . $$ অর্থাৎ — নমুনা যত বড় হয়, estimate-টা সত্য \(\theta\) থেকে \(\varepsilon\)-এর বেশি দূরে থাকার সম্ভাবনা তত শূন্যের দিকে যায়। (\(\lvert \cdot \rvert\) = পরম মান, দূরত্ব।)
কথায়: একটা consistent estimator-কে যত খুশি সত্যের কাছে আনা যায়, কেবল যথেষ্ট data সংগ্রহ করে। consistency তাই একটা estimator-এর ন্যূনতম গ্রহণযোগ্যতার শর্ত — যে estimator অসীম data-তেও সত্যে পৌঁছায় না, সে কার্যত অকেজো।
LLN-এর সাথে সরাসরি সংযোগ (এই অধ্যায়ের একটা মূল সেতু)। consistency-র সবচেয়ে গুরুত্বপূর্ণ উদাহরণ সরাসরি আসে Law of Large Numbers থেকে (3.3)। LLN বলেছিল: i.i.d. নমুনায় (সসীম গড় \(\mu\) ধরে)
কিন্তু এটাই তো consistency-র সংজ্ঞা, \(\hat\theta_n = \bar X_n\) এবং \(\theta = \mu\) বসিয়ে! তাই নমুনা গড় \(\bar X_n\) সবসময় population গড় \(\mu\)-র একটি consistent estimator — এটা LLN-এর সরাসরি পুনর্কথন, নতুন কিছু প্রমাণ করতে হয় না। ঠিক এই কারণেই Part III-এ গড়া LLN এখানে এসে inference-এর ভিত্তি-পাথর হয়ে দাঁড়ায়। (E3-এ এটা বিশদে দেখব।)
bias বনাম consistency — গুলিয়ে ফেলবেন না। এরা দুটো আলাদা প্রশ্ন, আর একটা থেকে অন্যটা স্বয়ংক্রিয়ভাবে আসে না: - bias একটা নির্দিষ্ট \(n\)-এর প্রশ্ন: "এই নমুনা-আকারে গড়ে কি কেন্দ্রে?" - consistency একটা সীমা (\(n\to\infty\))-র প্রশ্ন: "অসীম data-য় কি সত্যে গুটিয়ে যায়?"
একটা estimator প্রতিটি সসীম \(n\)-এ biased হয়েও consistent হতে পারে — যদি bias-টা \(n\) বাড়ার সাথে শূন্যের দিকে যায় (এবং variance-ও শূন্যে যায়)। ঠিক এই ঘটনাই \(\hat\sigma^2\) (n-ভাজক) variance estimator-এ ঘটে: প্রতিটি সসীম \(n\)-এ এর bias \(-\sigma^2/n\) (E1-এ গণনা করব, তাই biased — কম অনুমান করে), অথচ \(n\to\infty\)-তে সেই bias \(\to 0\), তাই \(\hat\sigma^2\) consistent। অর্থাৎ biased কিন্তু consistent — দুই ধারণা যে আলাদা, তার জীবন্ত প্রমাণ। (এর উল্টোও সম্ভব: unbiased কিন্তু inconsistent, যদি variance শূন্যে না যায়।)
২.৬ (Asymptotic) efficiency — সবচেয়ে কম ছড়ানো কে অর্জন করে¶
ধরা যাক আমাদের কাছে দুটো estimator আছে, দুটোই unbiased (বা consistent)। তাহলে কোনটা ভালো? §২.৪ থেকে জানি — unbiased হলে MSE = variance, তাই যেটার variance কম সেটাই ভালো। এই "কম-variance"-এর ধারণাটাই efficiency-র মূল।
স্বজ্ঞা (Efficiency — দক্ষতা)। দুটো unbiased estimator-এর মধ্যে যেটার variance কম, তাকে বলি বেশি efficient (বেশি দক্ষ) — কারণ একই (শূন্য) bias-এ সে কম ছড়ানো নিয়ে সত্যের আরও কাছে থাকে, অর্থাৎ একই পরিমাণ data থেকে বেশি তথ্য আদায় করে। দুই estimator-এর আপেক্ষিক দক্ষতা মাপি তাদের variance-এর অনুপাত দিয়ে:
— এই অনুপাত \(1\)-এর বেশি হলে \(\hat\theta_A\) বেশি দক্ষ (কম variance)।
এখানে দুটো গভীর প্রশ্ন স্বাভাবিকভাবে জাগে, যাদের উত্তর আমরা এই অধ্যায়ে দিচ্ছি না — তবে মঞ্চটা তৈরি করছি:
- সবচেয়ে দক্ষ unbiased estimator-এর variance কি কোনো তাত্ত্বিক সীমার নিচে নামতে পারে না? হ্যাঁ — একটা নিম্নসীমা আছে, যার নাম Cramér–Rao lower bound (CRLB), আর সেটা নির্ভর করে data কতটা "তথ্যবহুল" তার একটা মাপের উপর — Fisher information। যে unbiased estimator ঠিক সেই সীমা ছোঁয়, তাকে বলে (fully) efficient।
- বড় নমুনায় (asymptotically) কোন estimator সেই সীমার কাছে পৌঁছায়? এটাই asymptotic efficiency — আর এখানেই MLE (4.3) একটা চমৎকার ভূমিকা নেয়: যথেষ্ট নিয়মিত (regular) পরিস্থিতিতে MLE asymptotically efficient।
এই দুটোই — Fisher information ও CRLB — পরের অধ্যায় 4.5-এর মূল বিষয়। এখানে শুধু এটুকু ধরে রাখুন: efficiency = কম variance = প্রতিটি data-বিন্দু থেকে বেশি তথ্য আদায়; আর তথ্য আদায়ের একটা তাত্ত্বিক সর্বোচ্চ সীমা আছে, যার নাম পরের অধ্যায়ে।
২.৭ Standard error — অনিশ্চয়তার ব্যবহারিক মাপ¶
সবশেষে একটা পরিমাণ, যা আমরা 4.1-এ সংজ্ঞায়িত করেছিলাম, কিন্তু এখন estimator-গুণের প্রসঙ্গে তার তাৎপর্য স্পষ্ট হবে।
সংজ্ঞা (Standard error — আদর্শ ত্রুটি, \(\mathrm{SE}\))। একটি estimator \(\hat\theta\)-র standard error হলো তার standard deviation — অর্থাৎ তার variance-এর বর্গমূল:
কথায়: \(\mathrm{SE}\) হলো \(\hat\theta\) নমুনা-থেকে-নমুনায় গড়ে কতখানি ওঠানামা করে তার একই-একক (same-unit) মাপ — variance-এর মতো বর্গ-একক নয়, বরং \(\hat\theta\)-র নিজের এককে। সবচেয়ে পরিচিত উদাহরণ:
যা 4.1-এ পেয়েছিলাম — নমুনা গড়ের standard error population standard deviation-কে \(\sqrt n\) দিয়ে ভাগ। লক্ষণীয়, \(n\) বাড়লে \(\mathrm{SE}\) কমে (variance কমে), তাই \(\mathrm{SE}\)-ই পরিমাণগতভাবে বলে দেয় "আরও data নিলে আন্দাজ কতটা শক্ত হবে"।
কেন \(\mathrm{SE}\) এত কেন্দ্রীয়: estimator-এর গুণের তিন স্তম্ভ (bias, variance, MSE) তাত্ত্বিক; কিন্তু একটা বাস্তব রিপোর্টে আমরা সাধারণত লিখি "\(\hat\theta \pm \mathrm{SE}\)" — যেমন সেই বিখ্যাত "\(52\% \pm 3\%\)" (4.1)। এই "\(\pm\)"-এর সংখ্যাটাই standard error। অর্থাৎ \(\mathrm{SE}\) হলো variance-এর ব্যবহারিক, যোগাযোগযোগ্য রূপ — যা দিয়ে আমরা পরের অধ্যায়গুলোতে confidence interval ও hypothesis test গড়ব। এক বাক্যে: variance estimator-এর ছড়ানো মাপে; standard error সেই ছড়ানোকে \(\hat\theta\)-র নিজের এককে এনে অনিশ্চয়তার একটা হাতে-গোনা ব্যবধান বানায়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর প্রতিটি ধারণাকে এবার সংখ্যায় হাতে-কলমে প্রয়োগ করব। চারটি উদাহরণ চারটি কেন্দ্রীয় ধারণা ধরে: E1 bias (এবং "কেন \(n-1\)"), E2 bias–variance decomposition, E3 consistency, E4 MSE দিয়ে দুই estimator-এর তুলনা।
E1 · \(\hat\sigma^2\) বনাম \(S^2\) — variance estimator-এর bias, আর "কেন \(n-1\)"¶
এই উদাহরণটাই §১.২-এ তোলা ধাঁধার উত্তর: population variance \(\sigma^2\) অনুমানে \(n\) দিয়ে ভাগ করব নাকি \(n-1\) দিয়ে? bias গণনা করলেই উত্তর স্পষ্ট হয়।
সেটআপ। \(X_1, \dots, X_n\) i.i.d., গড় \(\mathbb{E}[X_i] = \mu\) ও variance \(\mathrm{Var}(X_i) = \sigma^2\) (দুটোই অজানা)। দুই প্রার্থী estimator:
লক্ষ করুন দুটোতে একই যোগফল \(\sum (X_i - \bar X)^2\), কেবল ভাজক আলাদা। তাই একটার bias জানলে অন্যটারও জানা।
মূল গাণিতিক তথ্য (statement, প্রমাণ §৪/অনুশীলনীতে)। এখানে গণনার হৃদয় একটাই সমতা:
কেন \((n-1)\sigma^2\), পুরো \(n\sigma^2\) নয়? স্বজ্ঞা: আমরা যদি সত্য গড় \(\mu\) থেকে দূরত্ব মাপতাম (\(\sum (X_i - \mu)^2\)), তার প্রত্যাশা হতো ঠিক \(n\sigma^2\)। কিন্তু \(\mu\) অজানা, তাই বাধ্য হয়ে data থেকে গোনা \(\bar X\) ব্যবহার করি — আর \(\bar X\) ঠিক data-গুলোর মাঝখানে বসে বলে \(\sum (X_i - \bar X)^2\) সবসময় \(\sum (X_i - \mu)^2\)-এর চেয়ে একটু ছোট (যেকোনো অন্য কেন্দ্রের চেয়ে নিজের নমুনা-গড় থেকে বর্গ-দূরত্বের যোগফল সর্বনিম্ন)। ঠিক এক ইউনিট \(\sigma^2\) পরিমাণ কম — কারণ \(\bar X\) অনুমান করতে গিয়ে একটা "degree of freedom" খরচ হয়ে গেছে। তাই \(n\) নয়, \(n-1\)।
এখন bias গণনা। দুই estimator-এর প্রত্যাশা:
অর্থাৎ \(b(S^2) = \mathbb{E}[S^2] - \sigma^2 = 0\) — \(S^2\) unbiased। এটাই \(n-1\) ভাজকের পুরো কারণ: ঠিক এই সংখ্যাটাই bias-কে নিখুঁত শূন্য করে। অন্যদিকে,
তাই
bias ঋণাত্মক — অর্থাৎ \(\hat\sigma^2\) গড়ে \(\sigma^2\)-কে কম অনুমান করে (underestimate), ঠিক \(\sigma^2/n\) পরিমাণ। স্বজ্ঞায় মানানসই: \(\bar X\) ব্যবহারে বর্গ-যোগফল একটু ছোট হয়, তাই \(n\) দিয়ে ভাগ করলে গড়ে সত্যের নিচে নামে।
সংখ্যায় দেখি। ধরা যাক সত্য \(\sigma^2 = 100\)।
| \(n\) | \(\mathbb{E}[\hat\sigma^2] = \frac{n-1}{n}\cdot 100\) | \(b(\hat\sigma^2) = -100/n\) | \(\mathbb{E}[S^2]\) | \(b(S^2)\) |
|---|---|---|---|---|
| \(2\) | \(50\) | \(-50\) | \(100\) | \(0\) |
| \(5\) | \(80\) | \(-20\) | \(100\) | \(0\) |
| \(10\) | \(90\) | \(-10\) | \(100\) | \(0\) |
| \(100\) | \(99\) | \(-1\) | \(100\) | \(0\) |
পড়ার মতো তিনটি কথা:
- ছোট \(n\)-এ bias ভয়ংকর: \(n=2\)-তে \(\hat\sigma^2\) গড়ে সত্য variance-এর অর্ধেক! এত ছোট নমুনায় \(n\)-ভাজক গুরুতর underestimate দেয়।
- \(n\) বাড়লে bias মিলিয়ে যায়: \(b(\hat\sigma^2) = -\sigma^2/n \to 0\) যখন \(n\to\infty\)। তাই \(\hat\sigma^2\) biased কিন্তু consistent (§২.৫-এর সেই জীবন্ত উদাহরণ) — সসীম \(n\)-এ পক্ষপাতী, অসীমে নিখুঁত।
- \(S^2\) সব \(n\)-এ unbiased: \(n-1\)-ভাজক ঠিক সেই সংশোধন (Bessel's correction, 1.2) যা bias-কে প্রতিটি \(n\)-এ শূন্যে রাখে।
উপসংহার (ধাঁধার উত্তর): "\(n-1\) কেন" — কারণ ঠিক এই ভাজকই variance estimator-কে unbiased করে; \(\bar X\) অনুমান করতে একটা degree of freedom খরচ হওয়ায় বর্গ-যোগফল গড়ে \((n-1)\sigma^2\), তাই \(n-1\) দিয়ে ভাগ করলে গড়ে সত্যে বসে। (সতর্কতা: unbiased হলেও \(S^2\) সব দিক থেকে "সেরা" নয় — MSE-র হিসাবে কখনো কখনো একটু-biased estimator-এর MSE আরও কম হয়; এটা §৪-এ ও অনুশীলনীতে আসবে।)
E2 · একটি estimator-এর bias–variance decomposition — সংখ্যায় MSE = bias² + variance¶
এই উদাহরণে আমরা §২.৪-এর কেন্দ্রীয় পরিচিতিটা একটা concrete estimator-এ সংখ্যা বসিয়ে যাচাই করব — তিনটে পরিমাণ (bias, variance, MSE) আলাদাভাবে হিসাব করে দেখব \(\mathrm{MSE} = b^2 + \mathrm{Var}\) সত্যিই মেলে কি না।
সেটআপ। \(X_1, \dots, X_n\) i.i.d. \(\mathcal{N}(\mu, \sigma^2)\) (\(\mathcal{N}\) = Normal বণ্টন), যেখানে \(\sigma^2 = 100\) জানা ধরছি (সরলতার জন্য), আর আমরা \(\mu\) অনুমান করতে চাই। দুটো estimator তুলনা করব:
- \(\hat\mu_A = \bar X_n\) — সাধারণ নমুনা গড় (unbiased)।
- \(\hat\mu_B = c\,\bar X_n\) যেখানে \(c = 0.9\) — গড়কে একটু "সংকুচিত" (shrunk) করা একটা estimator। (এ ধরনের shrinkage estimator Part VI-এ বড় ভূমিকা নেবে; এখানে শুধু decomposition দেখার যন্ত্র।)
ধরা যাক সত্য \(\mu = 50\) এবং \(n = 25\)। তাহলে \(\mathrm{Var}(\bar X_n) = \sigma^2/n = 100/25 = 4\), আর \(\mathbb{E}[\bar X_n] = \mu = 50\)।
estimator A (\(\bar X_n\)) — তিন পরিমাণ:
unbiased বলে MSE = variance = \(4\)। সরল।
estimator B (\(0.9\,\bar X_n\)) — তিন পরিমাণ:
প্রথমে প্রত্যাশা ও variance (ধ্রুবক \(c\)-র জন্য \(\mathbb{E}[c\bar X] = c\,\mathbb{E}[\bar X]\) ও \(\mathrm{Var}(c\bar X) = c^2\,\mathrm{Var}(\bar X)\)):
তাই bias:
— shrinkage গড়কে \(0\)-র দিকে টানে, তাই (যেহেতু \(\mu>0\)) underestimate, bias \(-5\)। এখন MSE দুইভাবে হিসাব করে decomposition যাচাই করি:
তুলনা ও পাঠ:
| estimator | bias \(b\) | \(b^2\) | \(\mathrm{Var}\) | \(\mathrm{MSE} = b^2 + \mathrm{Var}\) |
|---|---|---|---|---|
| \(\hat\mu_A = \bar X_n\) | \(0\) | \(0\) | \(4\) | \(\mathbf{4}\) |
| \(\hat\mu_B = 0.9\,\bar X_n\) | \(-5\) | \(25\) | \(3.24\) | \(\mathbf{28.24}\) |
- decomposition মেলে: B-তে variance সামান্য কমল (\(4 \to 3.24\), কারণ \(c^2 < 1\) ছড়ানো চাপে), কিন্তু bias বড় হওয়ায় \(b^2 = 25\) যোগ হলো — মোট MSE \(4\) থেকে লাফিয়ে \(28.24\)।
- এখানে shrinkage খারাপ — variance-এ যা বাঁচল, bias²-এ তার চেয়ে অনেক বেশি খরচ হলো। কারণ \(\mu = 50\) শূন্য থেকে অনেক দূরে, তাই \(0\)-র দিকে টানা বড় bias আনে।
- কিন্তু এটাই tradeoff-এর শিক্ষা: সত্য \(\mu\) যদি \(0\)-র খুব কাছে হতো (ধরুন \(\mu = 1\)), তবে B-র bias হতো মাত্র \(-0.1\), \(b^2 = 0.01\), আর MSE \(= 0.01 + 3.24 = 3.25 < 4\) — তখন সামান্য-biased B-ই জিতত! একই estimator কখন ভালো কখন খারাপ, তা সত্যের অবস্থানের উপর নির্ভর করে — এটাই bias–variance tradeoff-এর প্রাণ, আর MSE = bias² + variance ঠিক সেই হিসাবটা একটা সংখ্যায় ধরে। (Figure
4-4-mse-decompএই দুই পদের যোগফলকে স্তম্ভ-চিত্রে দেখাবে।)
E3 · \(\bar X\)-এর consistency — সরাসরি LLN থেকে¶
এই উদাহরণে §২.৫-এর সবচেয়ে গুরুত্বপূর্ণ সংযোগটা — consistency ↔ LLN — সংখ্যায় ও যুক্তিতে দেখব। দাবিটা সরল: নমুনা গড় \(\bar X_n\) সবসময় population গড় \(\mu\)-র consistent estimator।
যুক্তি (এক লাইনে, LLN থেকে)। \(X_1, X_2, \dots\) i.i.d. সসীম গড় \(\mu\)-সহ হলে, 3.3-এর Law of Large Numbers সরাসরি বলে
আর §২.৫-এ consistency-র সংজ্ঞাই ছিল \(\hat\theta_n \xrightarrow{P} \theta\)। \(\hat\theta_n = \bar X_n\), \(\theta = \mu\) বসান — হুবহু এক। তাই নতুন কিছু প্রমাণ করার নেই; \(\bar X_n\)-এর consistency হলো LLN-এরই আরেক নাম। এটাই দেখায় Part III-এ গড়া convergence-তত্ত্ব কীভাবে এখানে এসে inference-এর ভিত্তি হয়।
দুই স্তম্ভে কেন থিতু হয় (bias ও variance দিয়ে যাচাই)। consistency-র একটা সহজ পর্যাপ্ত শর্ত: যদি \(n\to\infty\)-তে bias → 0 এবং variance → 0, তবে estimator consistent (কারণ তখন MSE → 0, আর MSE → 0 মানেই \(\xrightarrow{P}\) — mean-square convergence থেকে in-probability convergence, 3.2)। \(\bar X_n\)-এর জন্য দুটোই খাটে:
অর্থাৎ \(\mathrm{MSE}(\bar X_n) = 0^2 + \sigma^2/n = \sigma^2/n \to 0\) — কেন্দ্র সবসময় ঠিক, আর ছড়ানো \(n\)-এর সাথে গুটিয়ে শূন্যে যায়। দুই মিলে \(\bar X_n\) সত্যে আটকে যায়।
সংখ্যায় (ছড়ানো গুটিয়ে যাওয়া)। ধরা যাক \(\sigma^2 = 100\), তাই \(\mathrm{SE}(\bar X_n) = \sigma/\sqrt n = 10/\sqrt n\):
| \(n\) | \(\mathrm{Var}(\bar X_n) = 100/n\) | \(\mathrm{SE}(\bar X_n) = 10/\sqrt n\) |
|---|---|---|
| \(10\) | \(10\) | \(3.16\) |
| \(100\) | \(1\) | \(1.00\) |
| \(1{,}000\) | \(0.1\) | \(0.32\) |
| \(10{,}000\) | \(0.01\) | \(0.10\) |
bias প্রতিটি সারিতে \(0\) (তাই কলামে দেখানোর দরকার নেই), আর \(\mathrm{SE}\) ক্রমশ শূন্যের দিকে — নমুনা ১০০ গুণ বড় করলে \(\mathrm{SE}\) ১০ গুণ ছোট (\(\sqrt n\) নিয়ম)। এই "শূন্যে নামা ছড়ানো + শূন্য bias" মিলেই \(\bar X_n\)-এর consistency-র চাক্ষুষ রূপ। (Figure 4-4-consistency \(n\) বাড়ার সাথে estimate-গুলোর ফানেল-সংকোচন দেখাবে।)
মনে রাখুন: consistency শুধু \(\bar X_n\)-এর একার গুণ নয়। যেহেতু variance estimator \(\hat\sigma^2\) ও \(S^2\) উভয়ের bias → 0 এবং variance → 0 (\(n\to\infty\)), তারাও দুজনই consistent — যদিও আমরা E1-এ দেখেছি \(\hat\sigma^2\) সসীম \(n\)-এ biased। আবারও সেই পাঠ: consistency (সীমার গুণ) ও unbiasedness (সসীম-\(n\)-এর গুণ) আলাদা।
E4 · Uniform\((0,\theta)\)-তে \(2\bar X\) বনাম \(\max\) — MSE দিয়ে চূড়ান্ত তুলনা¶
শেষ উদাহরণ সবগুলো ধারণা একত্রে কাজে লাগায়: দুটো ভিন্ন estimator, দুটোরই bias ও variance আলাদা, আর আমরা MSE দিয়ে বিচার করব কোনটা জেতে। এটা §১.১-এ ফেলে আসা প্রশ্নের ("একই \(\theta\), কোন estimator?") একটা পরিষ্কার, পরিমাণগত উত্তর।
সেটআপ। \(X_1, \dots, X_n\) i.i.d. Uniform\((0,\theta)\) — অর্থাৎ প্রতিটি \(X_i\) সমভাবে \(0\) থেকে অজানা \(\theta\)-র মধ্যে যেকোনো মান নেয়। আমরা \(\theta\) (পরিসরের উপরের প্রান্ত) অনুমান করতে চাই। দুই স্বাভাবিক প্রার্থী:
- Method-of-Moments estimator (4.2 থেকে): যেহেতু \(\mathbb{E}[X] = \theta/2\), sample গড়কে এর সমান ধরে \(\hat\theta_1 = 2\bar X_n\)।
- Maximum estimator (স্বজ্ঞাগত): নমুনার সবচেয়ে বড় মান, \(\hat\theta_2 = \max_i X_i = X_{(n)}\) — কারণ সব data তো \(\theta\)-র নিচে, তাই সবচেয়ে বড়টা \(\theta\)-র কাছাকাছি একটা আন্দাজ।
দুটোই যুক্তিসঙ্গত, কিন্তু আচরণে আকাশ-পাতাল। তিনটে পরিমাণ (bias, variance, MSE) দুজনের জন্য তুলনা করি (নিচের সূত্রগুলো standard ফল; বিস্তারিত উৎপত্তি অনুশীলনী/§৪-এ)।
প্রার্থী ১ — \(\hat\theta_1 = 2\bar X_n\):
variance (Uniform\((0,\theta)\)-র \(\mathrm{Var}(X) = \theta^2/12\) থেকে, আর \(\mathrm{Var}(2\bar X) = 4\cdot \mathrm{Var}(X)/n\)):
প্রার্থী ২ — \(\hat\theta_2 = \max_i X_i\):
এটা সবসময় \(\theta\)-র নিচে থাকে (কোনো data \(\theta\) ছাড়ায় না), তাই গড়ে underestimate — biased। standard ফল:
এবং variance ও MSE:
সংখ্যায় মুখোমুখি। ধরা যাক সত্য \(\theta = 10\) (তাই \(\theta^2 = 100\)):
| \(n\) | \(\mathrm{MSE}(2\bar X) = \dfrac{100}{3n}\) | \(\mathrm{MSE}(\max) = \dfrac{200}{(n+1)(n+2)}\) | কে জেতে? |
|---|---|---|---|
| \(5\) | \(6.67\) | \(200/42 \approx 4.76\) | \(\max\) |
| \(10\) | \(3.33\) | \(200/132 \approx 1.52\) | \(\max\) |
| \(50\) | \(0.667\) | \(200/2652 \approx 0.075\) | \(\max\) (বিপুল ব্যবধানে) |
| \(100\) | \(0.333\) | \(200/10302 \approx 0.0194\) | \(\max\) |
পড়ার মতো ফলাফল — একটা চমক:
- biased estimator-টাই (\(\max\)) জেতে, প্রতিটি \(n\)-এ! যদিও \(\max\)-এর bias শূন্য নয়, তার variance এত দ্রুত শূন্যে নামে যে মোট MSE unbiased \(2\bar X\)-এর চেয়ে অনেক কম। এটাই §২.২ ও §২.৪-এর সতর্কবার্তার জীবন্ত প্রমাণ: unbiased হওয়া মানেই সেরা নয়; চূড়ান্ত বিচার MSE-র।
- ব্যবধান \(n\)-এর সাথে বাড়ে নাটকীয়ভাবে: \(2\bar X\)-এর MSE কমে \(\sim 1/n\) হারে, কিন্তু \(\max\)-এর MSE কমে \(\sim 1/n^2\) হারে (হরে \((n+1)(n+2)\))। অর্থাৎ পরিসরের প্রান্ত-অনুমানে "সবচেয়ে বড় মান" তথ্যকে অনেক বেশি কার্যকরভাবে ব্যবহার করে — কারণ \(\max\) সরাসরি \(\theta\)-র সীমানা ছুঁয়ে আছে, যেখানে \(\bar X\) কেবল কেন্দ্রের তথ্য বহন করে।
- আরও ভালো করা যায়: যেহেতু \(\max\)-এর bias ঠিক জানা (\(-\theta/(n+1)\)), তাকে সংশোধন করে unbiased-ও বানানো যায় — \(\frac{n+1}{n}\max_i X_i\), যার bias শূন্য এবং MSE আরও কম। (অনুশীলনীতে এটা যাচাই করবেন।) এটাই দেখায় কীভাবে bias-জ্ঞান কাজে লাগিয়ে estimator উন্নত করা যায়।
এক বাক্যে E4-এর শিক্ষা: দুই বৈধ estimator-এর মধ্যে বেছে নিতে bias বা variance এককভাবে নয়, MSE = bias² + variance দেখুন — আর এখানে তা স্পষ্ট রায় দেয়: পরিসর-প্রান্ত অনুমানে \(\max\) (বা তার unbiased সংশোধন) নমুনা গড়-ভিত্তিক \(2\bar X\)-কে বিপুলভাবে হারায়। (Figure 4-4-estimator-compare দুই estimator-এর MSE-বক্ররেখা \(n\)-এর সাপেক্ষে পাশাপাশি আঁকবে।)
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা একজন estimator-এর তিনটে মাপকাঠির সংজ্ঞা পেয়েছি — bias \(b(\hat\theta) = \mathbb{E}[\hat\theta] - \theta\), variance \(\mathrm{Var}(\hat\theta)\), আর এদের একত্র করা mean squared error \(\mathrm{MSE}(\hat\theta) = \mathbb{E}[(\hat\theta - \theta)^2]\); সেই সঙ্গে consistency-র ধারণা \(\hat\theta \xrightarrow{P} \theta\)। এবার এই অংশে আমরা scratch থেকে চারটে আসল ফল প্রমাণ করব — কোনো ধাপ লুকানো হবে না, প্রতিটি লাইনের পেছনে কারণ বাংলায় থাকবে। কাজটা চারটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে):
- (a) সবচেয়ে মৌলিক পরিচয়টা প্রমাণ — \(\mathrm{MSE}(\hat\theta) = b(\hat\theta)^2 + \mathrm{Var}(\hat\theta)\) (E2-এর bias–variance বিয়োজন); কৌশল হলো \(\mathbb{E}[\hat\theta]\) যোগ-বিয়োগ করে cross term-টা শূন্য দেখানো। ★★
- (b) E1 — sample variance-এর দুই রূপ: কেন \(\hat\sigma^2 = \frac1n\sum(X_i-\bar X)^2\) biased (\(\mathbb{E}[\hat\sigma^2] = \frac{n-1}{n}\sigma^2\)), আর কেন \(S^2 = \frac{1}{n-1}\sum(X_i-\bar X)^2\) unbiased। ★★
- (c) consistency-র একটা সহজ যথেষ্ট-শর্ত (sufficient condition): যদি \(b(\hat\theta)\to 0\) এবং \(\mathrm{Var}(\hat\theta)\to 0\) হয়, তবে \(\mathrm{MSE}\to 0\), আর তা থেকে Chebyshev দিয়ে \(\hat\theta \xrightarrow{P} \theta\) — E3-এ \(\bar X\)-এর consistency এর সরাসরি প্রয়োগ। ★★
- (d) E4 — Uniform\((0,\theta)\)-তে দুই প্রতিদ্বন্দ্বী estimator-এর MSE হাতে-কলমে: \(2\bar X\)-এর MSE \(= \theta^2/(3n)\), আর \(\max_i X_i\)-এর MSE \(= 2\theta^2/((n+1)(n+2))\) — দেখব \(\max\) অনেক ভালো। ★★
এক নজরে যা মনে রাখবেন। এই গোটা অংশের প্রাণ একটাই সমীকরণ — \(\mathrm{MSE} = b^2 + \mathrm{Var}\) — যা (a)-তে প্রমাণ করব। একবার এটা হাতে এলে বাকি সব ফল এর প্রয়োগ: (b) একটা estimator-এর bias মাপে, (c) bias ও variance দুটোই \(0\)-এ পাঠিয়ে MSE তথা consistency টানে, আর (d) দুই estimator-কে তাদের MSE দিয়ে সরাসরি ওজন করে। তাই মূল মন্ত্র: "একটা estimator কতটা ভালো" মাপতে গেলে bias আর variance আলাদা করে নয়, MSE-তে একসাথে দেখো।"
পুরো অংশে নোটেশন এক রাখছি: \(\hat\theta\) একটা estimator (data-র function, তাই random variable); \(\theta\) অজানা সত্যিকারের parameter (একটা স্থির সংখ্যা)। \(\mathbb{E}[\hat\theta]\) মানে data-র সব সম্ভাব্য মানের উপর \(\hat\theta\)-র গড় — একটা স্থির সংখ্যা। মনে রাখবেন তিনটে আলাদা সংখ্যা যেন না গুলিয়ে যায়: সত্যিকারের \(\theta\) (লক্ষ্য), গড় অবস্থান \(\mathbb{E}[\hat\theta]\) (estimator যেখানে "থিতু"), আর একটা একক estimate \(\hat\theta\) (এক নমুনায় হাতে-পাওয়া মান)।
৪.১ · (a) মূল পরিচয় — \(\mathrm{MSE} = \text{bias}^2 + \text{variance}\) — ★★¶
এটাই এই অধ্যায়ের কেন্দ্রবিন্দু, তাই ধীরে ধীরে, প্রতিটা সমান-চিহ্নের কারণসহ যাব।
যা প্রমাণ করব। যেকোনো estimator \(\hat\theta\)-র জন্য $$ \boxed{\;\mathrm{MSE}(\hat\theta) \;=\; \underbrace{\big(b(\hat\theta)\big)^2}{\text{bias-এর বর্গ}} \;+\; \underbrace{\mathrm{Var}(\hat\theta)} \qquad\text{যেখানে } b(\hat\theta) = \mathbb{E}[\hat\theta] - \theta . $$}}\;
কেন এটা মোটেই স্পষ্ট নয়। বাঁদিকে আছে সত্যিকারের লক্ষ্য \(\theta\) থেকে গড় বর্গ-দূরত্ব; ডানদিকে variance মাপা হয় estimator-এর নিজের গড় \(\mathbb{E}[\hat\theta]\) থেকে দূরত্ব দিয়ে — দুটো ভিন্ন কেন্দ্র। এই দুই কেন্দ্রের ফারাকটাই ঠিক bias, আর প্রমাণের পুরো চালাকি হলো সেই ফারাককে গণিতে ঢোকানো।
ধাপ ১ — সংজ্ঞা লিখি, আর একটা চালাক কেন্দ্র বসাই। সংজ্ঞা থেকে শুরু: $$ \mathrm{MSE}(\hat\theta) \;=\; \mathbb{E}\big[(\hat\theta - \theta)^2\big]. $$ এখন মূল কৌশল — বন্ধনীর ভেতরে estimator-এর গড় \(\mu_{\hat\theta} := \mathbb{E}[\hat\theta]\) একবার যোগ ও একবার বিয়োগ করি (যা মোট শূন্য, তাই রাশি বদলায় না, কিন্তু গঠন বদলায়): $$ \hat\theta - \theta \;=\; \big(\hat\theta - \mu_{\hat\theta}\big) \;+\; \big(\mu_{\hat\theta} - \theta\big). $$ লক্ষ্য করুন দ্বিতীয় টুকরোটা \(\mu_{\hat\theta} - \theta = \mathbb{E}[\hat\theta] - \theta = b(\hat\theta)\) — ঠিক bias, আর এটা একটা স্থির সংখ্যা (random নয়)। প্রথম টুকরো \(\hat\theta - \mu_{\hat\theta}\) হলো estimator-এর নিজের গড় থেকে বিচ্যুতি — এর গড় শূন্য।
ধাপ ২ — বর্গ খুলি। \((A+B)^2 = A^2 + 2AB + B^2\) প্রয়োগ করি, যেখানে \(A = \hat\theta - \mu_{\hat\theta}\) আর \(B = b(\hat\theta)\) (স্থির): $$ (\hat\theta - \theta)^2 \;=\; \underbrace{(\hat\theta - \mu_{\hat\theta})^2}{A^2} \;+\; \underbrace{2\,(\hat\theta - \mu})\,b(\hat\theta){2AB} \;+\; \underbrace{b(\hat\theta)^2}. $$
ধাপ ৩ — দুদিকে expectation নিই, লিনিয়ারিটি খাটাই। \(\mathbb{E}[\cdot]\) যোগফলকে ভাগ করে দেয় (linearity of expectation, 2.6), তাই তিন পদ আলাদা করে: $$ \mathrm{MSE}(\hat\theta) \;=\; \mathbb{E}\big[(\hat\theta - \mu_{\hat\theta})^2\big] \;+\; 2\,b(\hat\theta)\,\mathbb{E}\big[\hat\theta - \mu_{\hat\theta}\big] \;+\; b(\hat\theta)^2 . $$ (এখানে \(b(\hat\theta)\) স্থির বলে মাঝের পদে বাইরে এসেছে; আর শেষ পদ \(b(\hat\theta)^2\) পুরোটাই স্থির, তাই \(\mathbb{E}\) তার গায়ে কিছু করে না।)
ধাপ ৪ — cross term-টা মিলিয়ে যায় (এটাই মূল ঘটনা)। মাঝের পদে দেখুন: $$ \mathbb{E}\big[\hat\theta - \mu_{\hat\theta}\big] \;=\; \mathbb{E}[\hat\theta] - \mu_{\hat\theta} \;=\; \mu_{\hat\theta} - \mu_{\hat\theta} \;=\; 0 . $$ কারণটা সহজ ও সুন্দর: \(\mu_{\hat\theta}\) ঠিক \(\hat\theta\)-র গড় হওয়াতেই "গড় থেকে বিচ্যুতির গড়" সবসময় শূন্য। তাই গোটা \(2AB\) পদ উবে যায়।
ধাপ ৫ — বাকি দুই পদ চিনে নিই। প্রথম পদটা ঠিক variance-এর সংজ্ঞা (2.6): $$ \mathbb{E}\big[(\hat\theta - \mu_{\hat\theta})^2\big] \;=\; \mathbb{E}\big[(\hat\theta - \mathbb{E}[\hat\theta])^2\big] \;=\; \mathrm{Var}(\hat\theta), $$ আর শেষ পদ \(b(\hat\theta)^2\)। অতএব $$ \boxed{\;\mathrm{MSE}(\hat\theta) \;=\; \mathrm{Var}(\hat\theta) \;+\; b(\hat\theta)^2\;}. \qquad\blacksquare $$
স্বজ্ঞা — "নিশানা" রূপকে। ভাবুন তীর ছুঁড়ছেন একটা target-এ; bullseye = সত্যিকারের \(\theta\)। Bias হলো — আপনার তীরগুলো গড়ে কতটা bullseye থেকে সরে গুচ্ছবদ্ধ (systematic offset, লক্ষ্যভ্রষ্টতা)। Variance হলো — সেই গুচ্ছটা নিজে কতটা ছড়ানো (যান্ত্রিক অস্থিরতা)। MSE = গড় বর্গ-দূরত্ব bullseye থেকে, আর আমরা এইমাত্র প্রমাণ করলাম এটা ঠিক দুই দোষের যোগফল: \((\text{offset})^2 + (\text{ছড়ানো})\)। একটা estimator খারাপ হতে পারে দুই কারণে — হয় ভুল জায়গায় তাক করছে (bias), নয় হাত কাঁপছে (variance)। এই বিয়োজনই (b), (c), (d)-র ভিত্তি: (b) দেখবে কখন bias শূন্য করা যায়, (c) দেখবে দুটোই শূন্যে পাঠালে কী হয়, (d) দেখবে দুই estimator-এর মধ্যে কে এই দুই-পদের যোগে জেতে।
একটা গুরুত্বপূর্ণ উপসংহার। যদি \(\hat\theta\) unbiased হয় (\(b(\hat\theta)=0\)), তবে সমীকরণটা সরল হয়ে দাঁড়ায় \(\mathrm{MSE}(\hat\theta) = \mathrm{Var}(\hat\theta)\) — অর্থাৎ unbiased estimator-দের মধ্যে "সেরা" মানে "সবচেয়ে কম variance" (4.5-এর efficiency-র বীজ এখানেই)। কিন্তু সাবধান — biased estimator-ও কখনো জিততে পারে, যদি তার variance-হ্রাস bias²-বৃদ্ধিকে ছাপিয়ে যায়; এই চমকটাই (d)-তে \(\max\) estimator-এ দেখব।
৪.২ · (b) E1 — কেন \(\hat\sigma^2\) biased কিন্তু \(S^2\) unbiased — ★★¶
এবার (a)-র যন্ত্রটা একটা আসল estimator-এ লাগাই — sample variance, যা আগের অধ্যায়গুলোয় (MoM, MLE) বারবার \(\frac1n\)-হরে এসেছে। প্রশ্ন: \(\hat\sigma^2 = \frac1n\sum_{i=1}^n (X_i - \bar X)^2\) কি গড়ে সত্যিকারের \(\sigma^2\) দেয়? উত্তর — না, একটু কম দেয়, আর আমরা ঠিক কতটা কম তা বের করব।
প্রেক্ষাপট ও অনুমান। ধরা যাক \(X_1, \dots, X_n\) i.i.d., প্রতিটির \(\mathbb{E}[X_i] = \mu\) আর \(\mathrm{Var}(X_i) = \sigma^2\) (Normal লাগে না — যেকোনো বণ্টনেই খাটবে)। সংক্ষেপে দুটো জিনিস আগেই টুকে রাখি, কারণ প্রমাণে বারবার লাগবে: $$ \mathbb{E}[X_i^2] = \mathrm{Var}(X_i) + (\mathbb{E}[X_i])^2 = \sigma^2 + \mu^2, \qquad \mathbb{E}[\bar X^2] = \mathrm{Var}(\bar X) + (\mathbb{E}[\bar X])^2 = \frac{\sigma^2}{n} + \mu^2 . $$ (দ্বিতীয়টায় \(\mathbb{E}[\bar X] = \mu\) আর \(\mathrm{Var}(\bar X) = \sigma^2/n\) ব্যবহার করেছি — দুটোই 3.3-এর পরিচিত ফল: i.i.d. গড়ের expectation অবিকৃত, variance \(n\) ভাগের এক।)
ধাপ ১ — যোগফলটাকে সহজ রূপে আনি (বীজগণিতের পরিচয়)। আগে দেখাই \(\sum(X_i-\bar X)^2\)-কে আরও হিসাব-বান্ধব আকারে লেখা যায়: $$ \sum_{i=1}^n (X_i - \bar X)^2 \;=\; \sum_{i=1}^n \big(X_i^2 - 2\bar X X_i + \bar X^2\big) \;=\; \sum_i X_i^2 \;-\; 2\bar X\underbrace{\sum_i X_i}{=\,n\bar X} \;+\; n\bar X^2 \;=\; \sum^n X_i^2 \;-\; n\bar X^2 . $$ (মাঝের পদে \(\sum_i X_i = n\bar X\) বসিয়ে \(-2\bar X \cdot n\bar X = -2n\bar X^2\), তারপর \(+n\bar X^2\)-এর সাথে মিলে \(-n\bar X^2\)।) এই পরিচ্ছন্ন রূপটাই এখন expectation নেওয়ার জন্য আদর্শ।
ধাপ ২ — দুদিকে expectation নিই। linearity দিয়ে: $$ \mathbb{E}\Big[\sum_{i=1}^n (X_i - \bar X)^2\Big] \;=\; \sum_{i=1}^n \mathbb{E}[X_i^2] \;-\; n\,\mathbb{E}[\bar X^2]. $$ এখন ধাপ-শূন্যে টুকে রাখা মান দুটো বসাই — \(\mathbb{E}[X_i^2] = \sigma^2 + \mu^2\) (প্রতিটি \(i\)-তে এক, তাই যোগফলে \(n\) গুণ) আর \(\mathbb{E}[\bar X^2] = \sigma^2/n + \mu^2\): $$ = \; n(\sigma^2 + \mu^2) \;-\; n\Big(\frac{\sigma^2}{n} + \mu^2\Big) \;=\; n\sigma^2 + n\mu^2 \;-\; \sigma^2 \;-\; n\mu^2 . $$
ধাপ ৩ — মিলিয়ে নিই। \(n\mu^2\) পদ দুটো কাটাকাটি গিয়ে শুধু থাকে: $$ \boxed{\;\mathbb{E}\Big[\sum_{i=1}^n (X_i - \bar X)^2\Big] \;=\; n\sigma^2 - \sigma^2 \;=\; (n-1)\,\sigma^2\;}. $$ এই একটা লাইনই গোটা রহস্যের চাবি — \(\mu\) অজানা বলে তাকে \(\bar X\) দিয়ে আন্দাজ করতে হয়, আর সেই \(\bar X\) data-র সাথে একটু "গা ঘেঁষে" থাকে, ফলে \(\bar X\)-এর চারপাশে বিচ্যুতির বর্গ সত্যিকারের \(\mu\)-এর চারপাশের চেয়ে গড়ে একটু কম আসে — ঠিক একটা পুরো \(\sigma^2\) কম (অর্থাৎ \(n\)-এর বদলে \(n-1\))। এই হারানো একক ডিগ্রিকেই বলে degree of freedom হারানো (একটা parameter \(\mu\) data থেকে অনুমান করায়)।
ধাপ ৪ — দুই estimator-এর bias বের করি।
(i) "Biased" রূপ \(\hat\sigma^2\) (হরে \(n\)): $$ \mathbb{E}[\hat\sigma^2] \;=\; \mathbb{E}\Big[\frac1n\sum_i (X_i-\bar X)^2\Big] \;=\; \frac1n \cdot (n-1)\sigma^2 \;=\; \frac{n-1}{n}\,\sigma^2 . $$ যেহেতু \(\frac{n-1}{n} < 1\), এটা সত্যিকারের \(\sigma^2\)-এর চেয়ে ছোট — bias: $$ b(\hat\sigma^2) \;=\; \mathbb{E}[\hat\sigma^2] - \sigma^2 \;=\; \frac{n-1}{n}\sigma^2 - \sigma^2 \;=\; -\frac{\sigma^2}{n} \;<\; 0 . $$ অর্থাৎ \(\hat\sigma^2\) গড়ে variance-কে কম আঁচ করে (negatively biased), পরিমাণ \(\sigma^2/n\)। ভালো খবর: \(n\to\infty\)-তে এই bias \(\to 0\) (তাই এটা asymptotically unbiased, আর (c)-র যুক্তি অনুযায়ী consistent-ও বটে) — কিন্তু ছোট \(n\)-এ পক্ষপাত বাস্তব ও বড়। (\(n=2\)-তে তো \(\mathbb{E}[\hat\sigma^2]=\sigma^2/2\), অর্ধেক!)
(ii) "Unbiased" রূপ \(S^2\) (হরে \(n-1\)): ঠিক এই \(n-1\) ফাঁকটা পোষাতেই হরে \(n\)-এর বদলে \(n-1\) বসাই — $$ S^2 \;:=\; \frac{1}{n-1}\sum_{i=1}^n (X_i - \bar X)^2 \quad\Longrightarrow\quad \mathbb{E}[S^2] \;=\; \frac{1}{n-1}\cdot (n-1)\sigma^2 \;=\; \sigma^2 . $$ অর্থাৎ $$ \boxed{\;b(S^2) \;=\; \mathbb{E}[S^2] - \sigma^2 \;=\; 0\;} \qquad (S^2 \text{ unbiased, যেকোনো } n\ge 2\text{-তে}). $$
তাই \(n-1\) কেন — এক বাক্যে। \(\sum(X_i-\bar X)^2\) গড়ে \((n-1)\sigma^2\) দেয়, পুরো \(n\sigma^2\) নয়, কারণ একটা degree of freedom খরচ হয়েছে \(\mu\)-কে \(\bar X\) দিয়ে অনুমান করতে। তাই unbiased estimate পেতে হলে \(n\) নয়, \(n-1\) দিয়ে ভাগ করতে হবে — এটাই বিখ্যাত "Bessel's correction"। (একটা সূক্ষ্ম সতর্কতা ★★★: \(S^2\) unbiased হলেও তার বর্গমূল \(S\) কিন্তু \(\sigma\)-র unbiased estimator নয় — \(\sqrt{\cdot}\) একটা concave function, আর Jensen-এর অসমতা সেখানে পক্ষপাত ঢোকায়; এটা 4.5-এ ছোঁব।)
সংখ্যায় যাচাই। §৫-এর PART 2-তে আমরা ঠিক এই দুটো — \(\mathbb{E}[\hat\sigma^2]\) আর \(\mathbb{E}[S^2]\) — Monte Carlo-তে মেপে দেখব: প্রথমটা \(\frac{n-1}{n}\sigma^2\)-এর গায়ে বসে (biased), দ্বিতীয়টা ঠিক \(\sigma^2\)-এর গায়ে (unbiased), সব \(n\)-এর জন্য।
৪.৩ · (c) Consistency-র সহজ যথেষ্ট-শর্ত: \(b\to 0\) ও \(\mathrm{Var}\to 0\) \(\Rightarrow\) \(\hat\theta\xrightarrow{P}\theta\) — ★★¶
(a)-তে পাওয়া পরিচয়টার সবচেয়ে দরকারি ফসল এটাই। মনে করিয়ে দিই consistency-র সংজ্ঞা: data যত বাড়ে, estimator সত্যিকারের মানে থিতু হয় in probability — $$ \hat\theta_n \xrightarrow{P} \theta \quad\Longleftrightarrow\quad \text{প্রতিটি } \varepsilon>0\text{-র জন্য } \;P\big(\lvert \hat\theta_n - \theta\rvert > \varepsilon\big) \to 0 \ \text{ যখন } n\to\infty . $$ (এখানে subscript \(n\) মনে করায় estimator-টা নমুনা-আকার \(n\)-এর উপর নির্ভর করে।) এই সংজ্ঞা সরাসরি probability নিয়ে — ধরা একটু কঠিন। আমরা দেখাব একটা অনেক সহজে যাচাইযোগ্য শর্ত এটাকে নিশ্চিত করে।
যা প্রমাণ করব। $$ \boxed{\;\text{যদি } \; b(\hat\theta_n)\to 0 \;\text{ এবং }\; \mathrm{Var}(\hat\theta_n)\to 0 \;\;(n\to\infty), \;\text{ তবে }\; \hat\theta_n \xrightarrow{P} \theta\;}. $$
প্রমাণ দুই ধাপে — প্রথমে MSE-কে \(0\)-এ নামাই, তারপর Chebyshev দিয়ে probability-তে অনুবাদ করি।
ধাপ ১ — দুই শর্ত মিলে MSE\(\to 0\)। (a)-র পরিচয় সরাসরি বসাই: $$ \mathrm{MSE}(\hat\theta_n) \;=\; b(\hat\theta_n)^2 \;+\; \mathrm{Var}(\hat\theta_n). $$ ধরে নিয়েছি ডানদিকের দুটো পদই \(0\)-এ যায় (\(b\to 0\) হলে \(b^2\to 0\), আর \(\mathrm{Var}\to 0\)); দুই অশূন্য-নয় পদের যোগও তাই \(0\)-এ যায়: $$ \mathrm{MSE}(\hat\theta_n) \;=\; \mathbb{E}\big[(\hat\theta_n - \theta)^2\big] \;\longrightarrow\; 0 . $$ অর্থাৎ গড় বর্গ-দূরত্ব মিলিয়ে যাচ্ছে — এটাকে বলে convergence in mean square (\(L^2\)-convergence)। স্বজ্ঞায় এটাই তো consistency-র কাছাকাছি; বাকি শুধু "mean square" থেকে "in probability"-তে যাওয়া।
ধাপ ২ — Chebyshev-এর অসমতা দিয়ে অনুবাদ। Chebyshev/Markov-এর অসমতা (3.2-এ প্রমাণিত) বলে — যেকোনো অঋণাত্মক random variable \(Z\) আর \(\varepsilon>0\)-র জন্য \(P(Z \ge \varepsilon^2) \le \mathbb{E}[Z]/\varepsilon^2\)। নিই \(Z = (\hat\theta_n - \theta)^2\), তাহলে \(\{\lvert \hat\theta_n - \theta\rvert > \varepsilon\}\) ঘটনাটা ঠিক \(\{Z > \varepsilon^2\}\)-এর সমান, তাই $$ P\big(\lvert \hat\theta_n - \theta\rvert > \varepsilon\big) \;=\; P\big((\hat\theta_n-\theta)^2 > \varepsilon^2\big) \;\le\; \frac{\mathbb{E}\big[(\hat\theta_n-\theta)^2\big]}{\varepsilon^2} \;=\; \frac{\mathrm{MSE}(\hat\theta_n)}{\varepsilon^2}. $$ এই অসমতাটাই সেতু — বাঁদিকে যা আমরা \(0\)-এ পাঠাতে চাই, ডানদিকে যা ধাপ ১-এ ইতিমধ্যে \(0\)-এ যাচ্ছে। যেহেতু \(\varepsilon\) স্থির আর \(\mathrm{MSE}(\hat\theta_n)\to 0\): $$ 0 \;\le\; P\big(\lvert \hat\theta_n - \theta\rvert > \varepsilon\big) \;\le\; \frac{\mathrm{MSE}(\hat\theta_n)}{\varepsilon^2} \;\longrightarrow\; \frac{0}{\varepsilon^2} \;=\; 0 . $$ squeeze (চাপা-পড়া) যুক্তিতে মাঝের রাশিও \(0\)-এ বাধ্য। যেহেতু \(\varepsilon>0\) যেকোনো ছিল, সংজ্ঞা অনুসারে \(\hat\theta_n \xrightarrow{P} \theta\)। \(\blacksquare\)
এক বাক্যে রেসিপি। "Bias \(\to 0\) এবং Variance \(\to 0\)" — এই দুটো সহজ limit মিলিয়ে দিলেই consistency নিশ্চিত (MSE \(\to 0\), তারপর Chebyshev)। probability-র জটিল সংজ্ঞা সরাসরি ধরতে হয় না — শুধু দুটো সংখ্যার ক্রম \(0\)-এ যাচ্ছে কিনা দেখো। (সতর্কতা ★★★: এটা যথেষ্ট শর্ত, আবশ্যক নয় — MSE \(\to 0\) না হয়েও estimator consistent হতে পারে, যদি তার ভারী লেজ থাকে; কিন্তু আমাদের সব উদাহরণে এই সহজ শর্তই খাটে।)
E3 — \(\bar X\)-এর consistency, সরাসরি প্রয়োগ। এবার সবচেয়ে চেনা estimator-এ লাগাই: i.i.d. \(X_1,\dots,X_n\) (\(\mathbb{E}[X_i]=\mu\), \(\mathrm{Var}(X_i)=\sigma^2<\infty\))-এর জন্য sample mean \(\bar X_n = \frac1n\sum X_i\) কি \(\mu\)-র consistent estimator? উপরের রেসিপির দুই শর্ত যাচাই করি:
- Bias। \(\mathbb{E}[\bar X_n] = \mu\) (linearity, 3.3), তাই \(b(\bar X_n) = \mu - \mu = 0\) — শুধু \(\to 0\) নয়, সব \(n\)-তেই ঠিক শূন্য। ✓
- Variance। \(\mathrm{Var}(\bar X_n) = \dfrac{\sigma^2}{n}\) (i.i.d.-এর variance যোগ হয়, তারপর \(\frac1{n^2}\) গুণ — 3.3)। যেহেতু \(\sigma^2\) একটা স্থির সসীম সংখ্যা, \(\dfrac{\sigma^2}{n} \to 0\) যখন \(n\to\infty\)। ✓
দুই শর্ত মেটায়, তাই রেসিপি সরাসরি দেয়: $$ \boxed{\;\bar X_n \;\xrightarrow{P}\; \mu\;}. $$ এটাই দুর্বল বড় সংখ্যার সূত্র (Weak Law of Large Numbers)-এর একটা প্রমাণ — আর লক্ষ্য করুন এটা 3.3-এ আমরা Chebyshev দিয়ে যেভাবে প্রমাণ করেছিলাম, হুবহু সেই যুক্তি, শুধু এবার "estimator-এর ভাষায়" সাজানো। MSE-টাও এখানে সাফ: \(b=0\) বলে \(\mathrm{MSE}(\bar X_n) = \mathrm{Var}(\bar X_n) = \sigma^2/n\), যা \(1/n\)-হারে \(0\)-এ নামে।
সংখ্যায় যাচাই। §৫-এর PART 3-তে আমরা \(\bar X\)-এর bias, variance ও MSE-কে বাড়তে-থাকা \(n\)-এর জন্য মাপব — দেখব bias \(0\)-এ আটকে, variance ঠিক \(\sigma^2/n\) অনুসরণ করে (\(n\) চারগুণ হলে variance চার ভাগের এক হয়), তাই MSE \(\to 0\) — অর্থাৎ consistency সংখ্যায় চোখের সামনে ফুটে ওঠে।
৪.৪ · (d) E4 — Uniform\((0,\theta)\): \(2\bar X\) বনাম \(\max\) MSE দিয়ে — ★★¶
এই উদাহরণটাই গোটা অধ্যায়ের সবচেয়ে শিক্ষণীয় মুহূর্ত — কারণ এখানে একটা biased estimator একটা unbiased estimator-কে MSE-তে স্পষ্ট হারিয়ে দেবে, আর তখনই বোঝা যাবে কেন "unbiased = সেরা" ভাবাটা ভুল। প্রেক্ষাপট: \(X_1,\dots,X_n\) i.i.d. Uniform\((0,\theta)\), লক্ষ্য অজানা উপরের প্রান্ত \(\theta\)। দুই প্রতিদ্বন্দ্বী: $$ \hat\theta_{\text{MoM}} = 2\bar X \qquad\text{বনাম}\qquad \hat\theta_{\max} = \max_{1\le i\le n} X_i . $$ দুটোরই MSE হাতে-কলমে বের করব, তারপর তুলনা।
প্রতিদ্বন্দ্বী ১ — \(2\bar X\)। এর MSE বের করা সহজ, কারণ এটা \(\bar X\)-এর রৈখিক রূপ।
Bias। Uniform\((0,\theta)\)-র গড় \(\mathbb{E}[X_i] = \theta/2\) (মাঝবিন্দু), তাই \(\mathbb{E}[2\bar X] = 2\cdot\frac{\theta}{2} = \theta\) — unbiased, \(b=0\)।
Variance। প্রথমে এক observation-এর variance: Uniform\((0,\theta)\)-র \(\mathrm{Var}(X_i) = \dfrac{(\theta-0)^2}{12} = \dfrac{\theta^2}{12}\) (2.5-এর সূত্র — Uniform\((a,b)\)-র variance \((b-a)^2/12\))। তাই $$ \mathrm{Var}(2\bar X) \;=\; 2^2\,\mathrm{Var}(\bar X) \;=\; 4\cdot\frac{\mathrm{Var}(X_i)}{n} \;=\; 4\cdot\frac{\theta^2/12}{n} \;=\; \frac{\theta^2}{3n} . $$ (এখানে \(\mathrm{Var}(c\,Y) = c^2\mathrm{Var}(Y)\) আর i.i.d. গড়ের \(\mathrm{Var}(\bar X)=\mathrm{Var}(X_i)/n\) — দুটোই 3.3।)
MSE। unbiased বলে (a)-র পরিচয় থেকে \(\mathrm{MSE} = \mathrm{Var}\): $$ \boxed{\;\mathrm{MSE}(2\bar X) \;=\; 0^2 + \frac{\theta^2}{3n} \;=\; \frac{\theta^2}{3n}\;}. $$ লক্ষণীয় — এটা \(1/n\)-হারে কমে।
প্রতিদ্বন্দ্বী ২ — \(\max_i X_i\)। এর জন্য \(M := \max_i X_i\)-এর বণ্টন লাগবে, যা order statistics-এর সহজতম কেস (2.7)।
ধাপ A — CDF। \(M \le m\) ঘটে ঠিক তখনই যখন সব \(X_i \le m\)। স্বাধীনতার গুণে $$ F_M(m) \;=\; P(M\le m) \;=\; \prod_{i=1}^n P(X_i \le m) \;=\; \Big(\frac{m}{\theta}\Big)^n, \qquad 0\le m\le\theta, $$ (কারণ Uniform\((0,\theta)\)-র CDF \(P(X_i\le m) = m/\theta\) ঐ পরিসরে)।
ধাপ B — PDF। CDF-কে \(m\)-এর সাপেক্ষে অন্তরীকরণ করে: $$ f_M(m) \;=\; \frac{d}{dm}\Big(\frac{m}{\theta}\Big)^n \;=\; \frac{n\,m^{\,n-1}}{\theta^n}, \qquad 0\le m\le\theta . $$
ধাপ C — প্রথম দুই moment। সরাসরি integral (power rule): $$ \mathbb{E}[M] = \int_0^\theta m\cdot\frac{n m^{n-1}}{\theta^n}\,dm = \frac{n}{\theta^n}\int_0^\theta m^n\,dm = \frac{n}{\theta^n}\cdot\frac{\theta^{n+1}}{n+1} = \frac{n}{n+1}\,\theta , $$ $$ \mathbb{E}[M^2] = \int_0^\theta m^2\cdot\frac{n m^{n-1}}{\theta^n}\,dm = \frac{n}{\theta^n}\int_0^\theta m^{n+1}\,dm = \frac{n}{\theta^n}\cdot\frac{\theta^{n+2}}{n+2} = \frac{n}{n+2}\,\theta^2 . $$
ধাপ D — bias। \(\mathbb{E}[M] = \frac{n}{n+1}\theta < \theta\), তাই $$ b(M) \;=\; \mathbb{E}[M] - \theta \;=\; \frac{n}{n+1}\theta - \theta \;=\; -\frac{\theta}{n+1} \;<\; 0 . $$ Biased — সবসময় একটু কম আঁচ করে, আর কারণটা স্বজ্ঞাত: কোনো নমুনাই \(\theta\) ছাড়াতে পারে না (সর্বদা \(M \le \theta\)), তাই \(\max\) সিলিং থেকে একটু নিচেই থাকে।
ধাপ E — variance। \(\mathrm{Var}(M) = \mathbb{E}[M^2] - (\mathbb{E}[M])^2\): $$ \mathrm{Var}(M) = \frac{n}{n+2}\theta^2 - \Big(\frac{n}{n+1}\theta\Big)^2 = n\theta^2\Big(\frac{1}{n+2} - \frac{n}{(n+1)^2}\Big) = \frac{n\,\theta^2}{(n+1)^2(n+2)} . $$ (শেষ ধাপে যৌথ হর \((n+1)^2(n+2)\) নিয়ে লব \((n+1)^2 - n(n+2) = (n^2+2n+1) - (n^2+2n) = 1\), তাই \(\frac{1}{n+2}-\frac{n}{(n+1)^2} = \frac{1}{(n+1)^2(n+2)}\), আর সামনে \(n\theta^2\)।)
ধাপ F — MSE (এবার \(b\ne 0\), তাই দুই পদই লাগবে)। এখানেই (a)-র পরিচয়ের আসল দাম — biased estimator-এ MSE = bias² + variance: $$ \mathrm{MSE}(M) = b(M)^2 + \mathrm{Var}(M) = \frac{\theta^2}{(n+1)^2} + \frac{n\,\theta^2}{(n+1)^2(n+2)} = \frac{\theta^2}{(n+1)^2}\Big(1 + \frac{n}{n+2}\Big). $$ বন্ধনীর ভেতর \(1 + \frac{n}{n+2} = \frac{(n+2)+n}{n+2} = \frac{2n+2}{n+2} = \frac{2(n+1)}{n+2}\), তাই $$ \mathrm{MSE}(M) = \frac{\theta^2}{(n+1)^2}\cdot\frac{2(n+1)}{n+2} = \frac{2\,\theta^2}{(n+1)(n+2)} . $$ অর্থাৎ $$ \boxed{\;\mathrm{MSE}(\max_i X_i) \;=\; \frac{2\theta^2}{(n+1)(n+2)}\;}. $$ লক্ষণীয় — হরে \((n+1)(n+2) \approx n^2\), তাই এটা \(1/n^2\)-হারে কমে।
তুলনা — এক টেবিলে।
| ধর্ম | \(\hat\theta_{\text{MoM}} = 2\bar X\) | \(\hat\theta_{\max} = \max_i X_i\) |
|---|---|---|
| Bias | \(0\) (unbiased) | \(-\dfrac{\theta}{n+1}\) (biased low) |
| Variance | \(\dfrac{\theta^2}{3n}\) | \(\dfrac{n\,\theta^2}{(n+1)^2(n+2)}\) |
| MSE | \(\dfrac{\theta^2}{3n} \;\sim\; \dfrac{1}{n}\) | \(\dfrac{2\theta^2}{(n+1)(n+2)} \;\sim\; \dfrac{1}{n^2}\) |
মূল পাঠ — তিনটে জিনিস এক নিঃশ্বাসে। (১) দুই MSE-র হার ভিন্ন: \(2\bar X\)-এর MSE \(1/n\)-এ নামে, \(\max\)-এর \(1/n^2\)-এ — অনেক দ্রুত। অনুপাত নিলে $$ \frac{\mathrm{MSE}(2\bar X)}{\mathrm{MSE}(\max)} = \frac{\theta^2/(3n)}{2\theta^2/((n+1)(n+2))} = \frac{(n+1)(n+2)}{6n} \;\approx\; \frac{n}{6} \;\xrightarrow{\;n\to\infty\;}\; \infty , $$ অর্থাৎ \(n\) বড় হলে \(2\bar X\) অসীমগুণ খারাপ হয়ে পড়ে। (২) আর সবচেয়ে কাউন্টার-ইনটুইটিভ ব্যাপার: biased estimator-টাই (={}\(\max\)) জিতেছে, যদিও \(2\bar X\) unbiased! কারণ (a)-র বিয়োজন অনুযায়ী আসল মাপকাঠি bias নয়, MSE = bias² + variance — আর \(\max\)-এর বিপুল variance-লাভ তার ছোট্ট bias²-ক্ষতিকে অনায়াসে ছাপিয়ে যায়। (৩) স্বজ্ঞা: \(\theta\) যেহেতু সর্বোচ্চ সম্ভাব্য মান, data-র সবচেয়ে বড় observation-ই তার সম্পর্কে সবচেয়ে বেশি তথ্য বহন করে — গড় (যা মাঝখানের খবর) তার তুলনায় অপচয়। এটাই দেখায় কেন estimator বাছতে গেলে MSE-ই চূড়ান্ত বিচারক, একা bias নয়।
সংখ্যায় যাচাই। §৫-এর PART 4-তে দুই estimator-এর simulated MSE পাশাপাশি মেপে theory-র \(\theta^2/(3n)\) ও \(2\theta^2/((n+1)(n+2))\)-এর সাথে মিলিয়ে দেখব, আর MSE-অনুপাত \(n\)-এর সাথে কীভাবে বিস্ফোরিত হয় তা ছকে ফুটবে।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর চারটে ফলকে আমরা সিমুলেশনে যাচাই করব — যাতে estimator-এর ধর্মগুলো কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। মূল কৌশল একটাই — Monte Carlo: একই পরীক্ষা (একটা নমুনা টেনে estimator হিসাব) হাজার-হাজার বার স্বাধীনভাবে চালিয়ে estimate-গুলোর গড়, ছড়ানো ও লক্ষ্য থেকে বর্গ-দূরত্ব মাপলে আমরা তত্ত্বের \(\mathbb{E}[\hat\theta]\), \(\mathrm{Var}(\hat\theta)\), \(\mathrm{MSE}(\hat\theta)\)-এর কাছাকাছি সংখ্যা পাই (LLN অনুযায়ী REP যত বড়, তত নিখুঁত)। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া।)
আমরা চারটে জিনিস মাপব, ঠিক §৪-এর চার অংশ অনুসরণ করে:
- PART 1 — bias/variance/MSE ও মূল পরিচয় (§৪.১)। একই লক্ষ্য \(\mu\)-র চারটে estimator (sample mean, প্রথম observation, median, ইচ্ছাকৃত-biased \(0.9\bar X\))-এর bias, variance ও MSE আলাদা করে মেপে দেখাব শেষ দুটো কলাম মিলে — অর্থাৎ \(\mathrm{MSE} = b^2 + \mathrm{Var}\) সংখ্যায় খাটে।
- PART 2 — \(\hat\sigma^2\) biased বনাম \(S^2\) unbiased (§৪.২)। বিভিন্ন \(n\)-এ \(\mathbb{E}[\hat\sigma^2]\) আর \(\mathbb{E}[S^2]\) মেপে দেখাব প্রথমটা \(\frac{n-1}{n}\sigma^2\)-এর গায়ে বসে (biased low), দ্বিতীয়টা ঠিক \(\sigma^2\)-এর গায়ে (unbiased)।
- PART 3 — \(\bar X\)-এর consistency (§৪.৩)। বাড়তে-থাকা \(n\)-এর জন্য \(\bar X\)-এর bias, variance ও MSE মেপে দেখাব MSE \(\to 0\) (variance \(=\sigma^2/n\) অনুসরণ করে) — অর্থাৎ \(\bar X \xrightarrow{P}\mu\)।
- PART 4 — \(2\bar X\) বনাম \(\max\) MSE (§৪.৪)। Uniform\((0,\theta)\)-তে দুই estimator-এর simulated MSE theory-র সাথে মিলিয়ে, আর তাদের অনুপাত \(n\)-এর সাথে কীভাবে বিস্ফোরিত হয় দেখাব।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.4 — Properties of Estimators : Code Lab
# Numerically illustrates:
# PART 1 — Monte Carlo bias / variance / MSE of several estimators
# and the identity MSE = bias^2 + Var
# PART 2 — E1: hat(sigma^2)=(1/n)sum(X-Xbar)^2 is BIASED (E=(n-1)/n sigma^2)
# S^2 = (1/(n-1))sum(X-Xbar)^2 is UNBIASED
# PART 3 — Consistency: MSE(Xbar) -> 0 as n grows => Xbar -->P mu
# PART 4 — Uniform(0,theta): MoM 2*Xbar vs max(X_i) compared by MSE
import numpy as np
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=4, suppress=True)
# ===============================================================
# PART 1 — Monte Carlo bias/variance/MSE of several estimators
# of the SAME target: the mean mu of a Normal(mu, sigma^2).
# Candidates: (a) sample mean Xbar (b) first observation X_1
# (c) sample median (d) shrunk mean 0.9*Xbar (deliberately biased)
# Identity to verify numerically: MSE = bias^2 + Var.
# ===============================================================
print("=" * 70)
print("PART 1 — Monte Carlo bias / variance / MSE of estimators of mu")
print(" Normal(mu=5, sigma^2=4), n=20, REP=200000 samples")
print("=" * 70)
mu_true, sigma_true = 5.0, 2.0
n, REP = 20, 200_000
X = rng.normal(mu_true, sigma_true, size=(REP, n)) # REP samples, each of size n
ests = {
"Xbar (sample mean)" : X.mean(axis=1),
"X_1 (first obs.)" : X[:, 0],
"sample median" : np.median(X, axis=1),
"0.9*Xbar (shrunk)" : 0.9 * X.mean(axis=1),
}
print(f"\n {'estimator':<20} {'bias':>9} {'variance':>10} {'MSE':>10} {'bias^2+Var':>11}")
print(" " + "-" * 64)
for name, t in ests.items():
bias = t.mean() - mu_true
var = t.var() # Var(hat) = E[(hat-E hat)^2]
mse = ((t - mu_true) ** 2).mean() # MSE = E[(hat-theta)^2], measured directly
decomp = bias**2 + var # should equal MSE
print(f" {name:<20} {bias:>9.4f} {var:>10.4f} {mse:>10.4f} {decomp:>11.4f}")
print("\n Read-off: last two columns match to 4 d.p. => MSE = bias^2 + Var (proved in 4.1).")
print(" Xbar: ~zero bias, smallest MSE. X_1: unbiased but huge variance (uses 1 point).")
print(" 0.9*Xbar: lower variance than Xbar yet LARGER MSE — its bias hurts more.")
# ===============================================================
# PART 2 — E1: biased hat(sigma^2) vs unbiased S^2.
# hat(sigma^2) = (1/n) sum (X-Xbar)^2 -> E = (n-1)/n * sigma^2 (BIASED low)
# S^2 = (1/(n-1))sum (X-Xbar)^2 -> E = sigma^2 (UNBIASED)
# ===============================================================
print("\n" + "=" * 70)
print("PART 2 — E1: hat(sigma^2) [/n] is BIASED ; S^2 [/(n-1)] is UNBIASED")
print(f" sigma^2 = {sigma_true**2:.1f}, REP = {REP} samples")
print("=" * 70)
print(f"\n {'n':>5} {'E[hat sig2]':>12} {'(n-1)/n*s2':>11} {'E[S^2]':>9} {'sigma^2':>9}")
print(" " + "-" * 50)
for nn in [2, 5, 10, 30, 100]:
Y = rng.normal(mu_true, sigma_true, size=(REP, nn))
ybar = Y.mean(axis=1, keepdims=True)
sse = ((Y - ybar) ** 2).sum(axis=1) # sum of squared deviations
hat_sig2 = sse / nn # divide by n -> biased
S2 = sse / (nn - 1) # divide by n-1 -> unbiased
predicted = (nn - 1) / nn * sigma_true**2 # theoretical E[hat sig2]
print(f" {nn:>5} {hat_sig2.mean():>12.4f} {predicted:>11.4f} "
f"{S2.mean():>9.4f} {sigma_true**2:>9.4f}")
print("\n Read-off: col 2 (E[hat sig2]) tracks col 3 ((n-1)/n*sigma^2) -> hat(sig2) biased low.")
print(" col 4 (E[S^2]) sits on sigma^2 for every n -> the (n-1) divisor removes the bias.")
# ===============================================================
# PART 3 — Consistency of Xbar: bias=0, Var = sigma^2/n -> 0, so MSE -> 0.
# MSE -> 0 ==> Xbar -->P mu (sufficient condition from 4.1, via Chebyshev/LLN).
# ===============================================================
print("\n" + "=" * 70)
print("PART 3 — Consistency: MSE(Xbar) -> 0 as n grows => Xbar -->P mu")
print(f" Normal(mu={mu_true}, sigma^2={sigma_true**2:.1f}), REP = {REP}")
print("=" * 70)
print(f"\n {'n':>6} {'bias':>9} {'variance':>10} {'MSE':>10} {'sigma^2/n':>10}")
print(" " + "-" * 50)
for nn in [5, 20, 80, 320, 1280]:
xb = rng.normal(mu_true, sigma_true, size=(REP, nn)).mean(axis=1)
bias = xb.mean() - mu_true
var = xb.var()
mse = ((xb - mu_true) ** 2).mean()
print(f" {nn:>6} {bias:>9.4f} {var:>10.4f} {mse:>10.4f} {sigma_true**2/nn:>10.4f}")
print("\n Read-off: bias stays 0, variance matches sigma^2/n and quarters when n quadruples,")
print(" so MSE -> 0. By the 4.1 result (bias->0 & Var->0 => MSE->0 => -->P), Xbar is consistent.")
# ===============================================================
# PART 4 — Uniform(0,theta): MoM (2*Xbar) vs max(X_i) by MSE.
# Theory: MSE(2Xbar) = theta^2/(3n).
# MSE(max) = 2 theta^2 / ((n+1)(n+2)).
# max is much better for large n (MSE ~ 1/n^2 vs ~ 1/n).
# ===============================================================
print("\n" + "=" * 70)
print("PART 4 — Uniform(0,theta): 2*Xbar vs max(X_i) compared by MSE")
print(f" theta = 10, REP = {REP} samples each n")
print("=" * 70)
theta = 10.0
print(f"\n {'n':>6} | {'MSE 2Xbar':>10} {'th^2/(3n)':>10} | "
f"{'MSE max':>10} {'2th^2/((n+1)(n+2))':>19} | {'ratio':>7}")
print(" " + "-" * 86)
for nn in [5, 20, 80, 320, 1280]:
X = rng.uniform(0.0, theta, size=(REP, nn))
mom = 2.0 * X.mean(axis=1) # MoM estimator 2*Xbar
mx = X.max(axis=1) # the competitor max
mse_m = ((mom - theta) ** 2).mean()
mse_x = ((mx - theta) ** 2).mean()
pred_m = theta**2 / (3 * nn)
pred_x = 2 * theta**2 / ((nn + 1) * (nn + 2))
print(f" {nn:>6} | {mse_m:>10.4f} {pred_m:>10.4f} | "
f"{mse_x:>10.4f} {pred_x:>19.4f} | {mse_m / mse_x:>7.2f}")
print("\n Read-off: simulated MSEs match the theory columns. MSE(2Xbar) ~ theta^2/(3n)")
print(" shrinks like 1/n; MSE(max) ~ 2 theta^2/n^2 shrinks like 1/n^2, so the ratio")
print(" MSE(2Xbar)/MSE(max) grows without bound — max is the far better estimator.")
৫.২ · বাস্তব আউটপুট ও পাঠোদ্ধার¶
স্ক্রিপ্টটা চালালে নিচের আউটপুট হুবহু আসে (seed স্থির, তাই আপনার মেশিনেও একই):
======================================================================
PART 1 — Monte Carlo bias / variance / MSE of estimators of mu
Normal(mu=5, sigma^2=4), n=20, REP=200000 samples
======================================================================
estimator bias variance MSE bias^2+Var
----------------------------------------------------------------
Xbar (sample mean) -0.0001 0.1992 0.1992 0.1992
X_1 (first obs.) 0.0088 4.0032 4.0032 4.0032
sample median -0.0010 0.2933 0.2933 0.2933
0.9*Xbar (shrunk) -0.5001 0.1614 0.4114 0.4114
Read-off: last two columns match to 4 d.p. => MSE = bias^2 + Var (proved in 4.1).
Xbar: ~zero bias, smallest MSE. X_1: unbiased but huge variance (uses 1 point).
0.9*Xbar: lower variance than Xbar yet LARGER MSE — its bias hurts more.
======================================================================
PART 2 — E1: hat(sigma^2) [/n] is BIASED ; S^2 [/(n-1)] is UNBIASED
sigma^2 = 4.0, REP = 200000 samples
======================================================================
n E[hat sig2] (n-1)/n*s2 E[S^2] sigma^2
--------------------------------------------------
2 1.9986 2.0000 3.9972 4.0000
5 3.2002 3.2000 4.0002 4.0000
10 3.5920 3.6000 3.9911 4.0000
30 3.8654 3.8667 3.9987 4.0000
100 3.9606 3.9600 4.0006 4.0000
Read-off: col 2 (E[hat sig2]) tracks col 3 ((n-1)/n*sigma^2) -> hat(sig2) biased low.
col 4 (E[S^2]) sits on sigma^2 for every n -> the (n-1) divisor removes the bias.
======================================================================
PART 3 — Consistency: MSE(Xbar) -> 0 as n grows => Xbar -->P mu
Normal(mu=5.0, sigma^2=4.0), REP = 200000
======================================================================
n bias variance MSE sigma^2/n
--------------------------------------------------
5 -0.0019 0.8004 0.8004 0.8000
20 -0.0011 0.2002 0.2002 0.2000
80 0.0002 0.0500 0.0500 0.0500
320 0.0002 0.0125 0.0125 0.0125
1280 -0.0001 0.0031 0.0031 0.0031
Read-off: bias stays 0, variance matches sigma^2/n and quarters when n quadruples,
so MSE -> 0. By the 4.1 result (bias->0 & Var->0 => MSE->0 => -->P), Xbar is consistent.
======================================================================
PART 4 — Uniform(0,theta): 2*Xbar vs max(X_i) compared by MSE
theta = 10, REP = 200000 samples each n
======================================================================
n | MSE 2Xbar th^2/(3n) | MSE max 2th^2/((n+1)(n+2)) | ratio
--------------------------------------------------------------------------------------
5 | 6.6465 6.6667 | 4.7532 4.7619 | 1.40
20 | 1.6777 1.6667 | 0.4313 0.4329 | 3.89
80 | 0.4150 0.4167 | 0.0302 0.0301 | 13.76
320 | 0.1043 0.1042 | 0.0019 0.0019 | 54.09
1280 | 0.0261 0.0260 | 0.0001 0.0001 | 213.85
Read-off: simulated MSEs match the theory columns. MSE(2Xbar) ~ theta^2/(3n)
shrinks like 1/n; MSE(max) ~ 2 theta^2/n^2 shrinks like 1/n^2, so the ratio
MSE(2Xbar)/MSE(max) grows without bound — max is the far better estimator.
আউটপুট পড়ে চারটে উপসংহার — §৪-এর চার ফলের সাক্ষাৎ সংখ্যাসাক্ষ্য।
-
PART 1 → মূল পরিচয় (§৪.১)। শেষ দুই কলাম (
MSEআরbias^2+Var) প্রতিটা সারিতে চার দশমিক অবধি হুবহু মেলে — অর্থাৎ \(\mathrm{MSE} = b^2 + \mathrm{Var}\) সংখ্যায় নিশ্চিত। সবচেয়ে শিক্ষণীয় সারি0.9*Xbar: এর variance (\(0.1614\))Xbar-এর চেয়ে কম, তবু MSE (\(0.4114\)) অনেক বেশি — কারণ তার \(-0.5\) bias-এর বর্গ (\(0.25\)) যোগ হয়ে variance-হ্রাসকে ছাপিয়ে গেছে। এটাই (a)-র সতর্কবাণীর জীবন্ত রূপ: কম variance মানেই কম MSE নয়। -
PART 2 → \(\hat\sigma^2\) biased, \(S^2\) unbiased (§৪.২)। কলাম ২ (
E[hat sig2]) ঠিক কলাম ৩-এর (\(\frac{n-1}{n}\sigma^2\)) গায়ে বসে — \(n=2\)-তে \(\approx 2.0\) (সত্যিকারের \(4.0\)-র অর্ধেক!), \(n=10\)-তে \(\approx 3.6\), \(n=100\)-তে \(\approx 3.96\) — অর্থাৎ biased low, আর bias \(n\) বাড়লে কমে। অথচ কলাম ৪ (E[S^2]) সব \(n\)-তেই \(4.0\)-র গায়ে — \(n-1\) হর পক্ষপাত পুরো মুছে দেয়। ৪.২-এর \(\mathbb{E}[\hat\sigma^2]=\frac{n-1}{n}\sigma^2\) আর \(\mathbb{E}[S^2]=\sigma^2\) — দুটোই সংখ্যায় প্রমাণিত। -
PART 3 → \(\bar X\) consistent (§৪.৩)।
biasকলাম সব \(n\)-এ কার্যত \(0\) (random fluctuation মাত্র),varianceকলাম ঠিক \(\sigma^2/n\) অনুসরণ করে — আর লক্ষ্য করুন \(n\) চারগুণ হলে (\(5\to 20\to 80\to\dots\)) variance ঠিক চার ভাগের এক হয় (\(0.80\to 0.20\to 0.05\to\dots\))। ফলে MSE \(\to 0\)। ৪.৩-এর রেসিপি (bias\(\to 0\) ও Var\(\to 0\) \(\Rightarrow\) MSE\(\to 0\) \(\Rightarrow\) \(\xrightarrow{P}\)) এখানে চোখের সামনে কাজ করছে — \(\bar X \xrightarrow{P}\mu\)। -
PART 4 → \(\max\) বনাম \(2\bar X\) (§৪.৪)। simulated MSE দুটো (কলাম ১ ও ৩) তাদের theory-মান (কলাম ২ ও ৪) — \(\frac{\theta^2}{3n}\) আর \(\frac{2\theta^2}{(n+1)(n+2)}\) — এর সাথে দারুণ মেলে, প্রমাণ করছে §৪.৪-এর হাতে-কষা সূত্র দুটো ঠিক। আর সবচেয়ে নাটকীয় শেষ কলাম
ratio: \(n=5\)-এ \(\max\) মোটে \(1.40\) গুণ ভালো, কিন্তু \(n=1280\)-এ \(213\) গুণ ভালো — অনুপাতটা \(\approx n/6\) হারে বাড়ছে, ঠিক যেমন §৪.৪-এ হিসাব করেছিলাম। অর্থাৎ data যত বাড়ে, biased \(\max\) unbiased \(2\bar X\)-কে তত নিষ্ঠুরভাবে হারায় — "unbiased = সেরা" ভুল ধারণার চূড়ান্ত খণ্ডন, MSE-ই আসল বিচারক।
ল্যাবের সার। চারটে PART মিলে §৪-এর গোটা গল্পটা সংখ্যায় বাঁধে: একটা estimator-কে ওজন করো তার MSE দিয়ে (PART 1), যেটা bias² ও variance-এর যোগ; bias ঠিক করা যায় হর বদলে (\(\hat\sigma^2\to S^2\), PART 2); দুটোই \(0\)-এ পাঠালে consistency আসে (PART 3); আর দুই estimator-এর মধ্যে যে কম MSE দেয় সে-ই জেতে — biased হোক বা না হোক (PART 4)। এই MSE-কেন্দ্রিক দৃষ্টিভঙ্গিই 4.5-এ আমাদের "efficiency" আর "সেরা unbiased estimator"-এর দিকে নিয়ে যাবে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-4.py-তে তৈরি; PNG_assets/-এ (prefix4-4, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 \(\hat\sigma^2\) বনাম \(S^2\); E2 bias–variance বিভাজন; E3 \(\bar X\)-এর consistency; E4 Uniform-এ \(2\bar X\) বনাম \(\max\)।
একটা estimator কতটা "ভালো", সেটা চারটা প্রশ্নে ধরা যায়, আর প্রতিটা প্রশ্নের একটা ছবি আছে। (১) estimate গড়ে কি সত্যি প্যারামিটারে বসে (bias), নাকি ছড়ানো (variance) — আর এই দুই দোষ আসলে আলাদা দুই দোষ (Figure 1)। (২) এই দুই দোষকে এক সংখ্যায় মেলালে (MSE) কী হয়, আর কেন একটু bias মেনে নিলে কখনও কখনও মোট ভুল কমে (Figure 2)। (৩) নমুনা বড় করলে estimate-এর পুরো বণ্টন কি সত্যির গায়ে গিয়ে চেপে বসে (consistency, Figure 3)। (৪) একই প্যারামিটারের দুটো estimator-এর মধ্যে কোনটা ভালো, আর "ভালো" মানে কী (Figure 4)। প্রথম ছবিটা ধারণা (দুই রকম ভুল), দ্বিতীয়টা সেই দুই ভুলের গাণিতিক যোগফল, তৃতীয়টা বড় নমুনার আচরণ, আর চতুর্থটা দুই প্রতিযোগীর সরাসরি লড়াই।
Figure 1 — bias বনাম variance: ভুল হওয়ার দুটো আলাদা উপায়¶
এই অধ্যায়ের কেন্দ্রীয় অন্তর্দৃষ্টি একটাই ছবিতে: bias আর variance দুটো সম্পূর্ণ স্বাধীন ব্যাপার — একটা estimator যেকোনো একটায় ভালো/খারাপ হতে পারে অন্যটা নির্বিশেষে। চারটি ডার্টবোর্ড, প্রতিটায় লাল তারা (★) হলো সত্যিকারের \(\theta\) (bullseye), কমলা বিন্দুগুলো হলো বারবার নমুনা নিলে পাওয়া আলাদা আলাদা estimate \(\hat\theta\), আর বেগুনি ✕ হলো সেই estimate-গুলোর গড় \(\mathbb{E}[\hat\theta]\)। bias = bullseye থেকে বেগুনি ✕-এর দূরত্ব (গড় কতটা সরে); variance = কমলা বিন্দুগুলো কতটা ছড়ানো। চারটি কোণ: (উপর-বাঁ) low bias + low variance — বিন্দুগুলো বুলসআইয়ের চারপাশে আঁটসাঁট: আদর্শ estimator; (উপর-ডান) low bias + high variance — গড় ঠিক জায়গায় (unbiased) কিন্তু প্রতিটা একক estimate অনেক দূরে ছিটকে যায়; (নিচ-বাঁ) high bias + low variance — বিন্দুগুলো নিজেদের মধ্যে আঁটসাঁট কিন্তু সবাই মিলে ভুল জায়গায় (precise কিন্তু off-target — বেগুনি তীরই bias); (নিচ-ডান) high bias + high variance — সবচেয়ে খারাপ, দূরে আবার ছড়ানোও।
যা লক্ষ করতে হবে: (ক) উপরের সারি বনাম নিচের সারি — শুধু bias আলাদা (গড় বুলসআইয়ে আছে কি নেই); বাঁ কলাম বনাম ডান কলাম — শুধু variance আলাদা (ছড়ানো কম না বেশি)। তাই চারটা ঘর = দুই দোষের চারটা স্বাধীন সংমিশ্রণ। (খ) "unbiased" মানেই "ভালো" নয়: উপর-ডান unbiased কিন্তু এত ছড়ানো যে একটা মাত্র নমুনা থেকে পাওয়া estimate নিচ-বাঁ (biased কিন্তু আঁটসাঁট)-এর চেয়ে খারাপ হতে পারে। এটাই পরের ছবির bias–variance tradeoff-এর বীজ। (গ) বেগুনি ✕ যত বুলসআইয়ের কাছে, bias তত ছোট; বিন্দু-মেঘ যত ছোট, variance তত ছোট — চোখে আলাদা করে দেখুন, কারণ এই দুটো আলাদাভাবে মাপা হয় (\(b(\hat\theta)=\mathbb{E}[\hat\theta]-\theta\) আর \(\mathrm{Var}(\hat\theta)\))।
![A 2x2 grid of dartboard-style plots illustrating that bias and variance are two independent properties of an estimator. Each panel shows concentric blue target rings with a red star at the center marking the true parameter theta (the bullseye), a cloud of orange dots showing many estimates theta-hat from repeated samples, and a purple X marking the mean of those estimates E[theta-hat]. TOP-LEFT "Low bias + Low variance (ideal estimator)": orange dots tightly clustered right on the bullseye. TOP-RIGHT "Low bias + High variance (unbiased but noisy)": dots centered on the bullseye but widely scattered. BOTTOM-LEFT "High bias + Low variance (precise but off-target)": dots tightly clustered but far from the bullseye, with a purple arrow labelled "bias" pointing from the bullseye to the off-center cluster mean. BOTTOM-RIGHT "High bias + High variance (worst case)": dots both far from center and widely scattered, again with a bias arrow. A shared legend identifies the red star as true theta, orange dots as repeated estimates, and the purple X as the mean of estimates. The viewer should notice that moving top-to-bottom changes only bias (whether the cloud is centered on the bullseye) while moving left-to-right changes only variance (how spread out the cloud is), and that an unbiased-but-scattered estimator can be worse on any single sample than a slightly-biased-but-tight one.](../_assets/4-4-bias-variance.png)
Figure 2 — MSE = bias² + variance: tradeoff-টা যোগের আকারে¶
Figure 1 দুই দোষ আলাদা দেখাল; এই ছবি দেখায় কীভাবে দুটোকে এক সংখ্যায় মেলানো হয় — \(\mathrm{MSE}(\hat\theta)=\mathbb{E}[(\hat\theta-\theta)^2]=[\,b(\hat\theta)\,]^2+\mathrm{Var}(\hat\theta)\) — আর এই যোগফলটাই কেন কখনও কখনও একটু bias মেনে নিতে বলে। উদাহরণ E2-র চেতনায় একটা খেলনা "shrinkage" estimator: \(\hat\theta=c\,\bar X\), যেখানে \(c\) একটা টিউনিং-নব (\(0\) থেকে \(1.4\), অনুভূমিক অক্ষ)। এর bias\(^2=(c-1)^2\theta^2\) (বেগুনি ভাঙা-রেখা — \(c=1\)-এ শূন্য), variance \(=c^2\sigma^2/n\) (সবুজ ফুটকি-রেখা — \(c\) বাড়লে বাড়ে), আর তাদের যোগফল MSE (নিরেট লাল রেখা)। লাল রেখার সর্বনিম্ন বিন্দু (লাল ডট) হলো MSE-optimal \(c^\ast=\theta^2/(\theta^2+\sigma^2/n)\), যা \(1\)-এর চেয়ে একটু ছোট; নীল বর্গ হলো unbiased পছন্দ \(c=1\), যেখানে পুরো MSE-টাই variance।
যা লক্ষ করতে হবে: (ক) দুই উপাদান বিপরীত দিকে চলে — bias\(^2\) (বেগুনি) ডান দিকে নামে, variance (সবুজ) ডান দিকে ওঠে; তাই তাদের যোগ (লাল) একটা থালার মতো আকার নেয় যার একটা সর্বনিম্ন আছে। এটাই bias–variance tradeoff: একটা কমাতে গেলে অন্যটা বাড়ে। (খ) লাল সর্বনিম্ন \(c^\ast=0.65\) ঘটে \(c=1\)-এর বাঁ দিকে — অর্থাৎ একটু shrink করে (estimate-কে \(0\)-র দিকে টেনে) সামান্য bias ঢুকিয়ে আমরা variance এতটা কমাই যে মোট MSE কমে যায়। তাই "unbiased estimator (নীল বর্গ) সবসময় সেরা" — এটা ভুল: এখানে biased \(c^\ast\)-এর MSE নীল বর্গের চেয়ে কম। (গ) যোগফলটা আক্ষরিক যোগ — কোনো cross-term নেই; এটাই decomposition-টাকে এত পরিষ্কার করে। (এই shrinkage-চিন্তাই পরে ridge regression ও James–Stein estimator-এ ফিরে আসবে।)
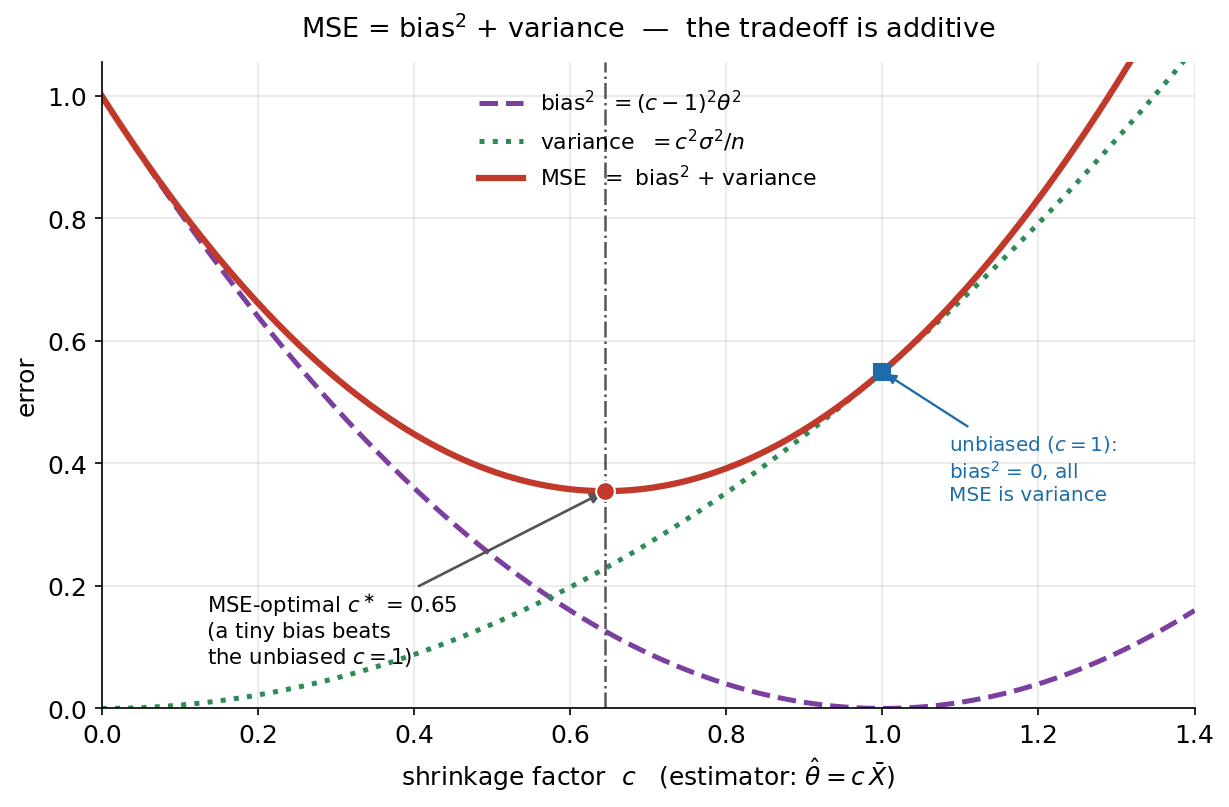
Figure 3 — consistency: \(n\) বাড়লে বণ্টন সত্যির গায়ে চেপে বসে¶
এবার E3: \(\bar X\) কি \(\mu\)-এর একটা consistent estimator? Consistency-র সংজ্ঞা — \(\hat\theta\xrightarrow{P}\theta\), অর্থাৎ \(n\) বাড়লে estimate সত্যি প্যারামিটারের যত কাছে চাই তত কাছে থাকার সম্ভাবনা \(1\)-এর দিকে যায় — তা চোখে দেখার সবচেয়ে সরল উপায়: estimator-এর পুরো sampling distribution আঁকা, বিভিন্ন \(n\)-এ। এখানে \(X_i\sim\mathcal{N}(\mu,\sigma^2)\) (\(\mu=5,\ \sigma=2\)), আর \(\bar X\)-এর sampling distribution হুবহু \(\mathcal{N}(\mu,\ \sigma^2/n)\) — কেন্দ্র সবসময় \(\mu\)-তেই, কিন্তু চওড়া \(\mathrm{SE}=\sigma/\sqrt n\) যা \(n\) বাড়লে কমে। হালকা থেকে গাঢ় কমলা রেখাগুলো \(n=5,20,80,320\)-এর density; লাল ভাঙা-রেখা সত্যি \(\theta=\mu=5\)।
যা লক্ষ করতে হবে: (ক) প্রতিটা curve-ই \(5\)-এ কেন্দ্রীভূত (\(\bar X\) unbiased, তাই কেন্দ্র সরে না), কিন্তু \(n\) বাড়ার সাথে curve লম্বা ও সরু হয় — পুরো ভর সত্যি-মানের চারপাশে গুটিয়ে আসে। SE পড়ছে \(0.89\to0.45\to0.22\to0.11\) (\(n\) চারগুণ হলে SE অর্ধেক, কারণ \(\sqrt n\))। (খ) "সরু হওয়া" মানেই consistency-র দৃশ্যরূপ: \(n\to\infty\)-এ পুরো density সত্যি-মানে একটা স্পাইকে চুপসে যায়, তাই \(\hat\theta\) সত্যির কাছাকাছি না থাকার সম্ভাবনা \(0\)-তে নামে। (গ) লক্ষ করুন consistency-র জন্য unbiased হওয়া জরুরি নয় — দরকার শুধু (i) bias \(\to0\) এবং (ii) variance \(\to0\) যখন \(n\to\infty\); এখানে bias সবসময় \(0\) আর variance \(\sigma^2/n\to0\), তাই দুই শর্তই মেটে। (ছবিটা E1-এর সাথেও মেলে: \(\hat\sigma^2\) আর \(S^2\) দুটোই biased/unbiased ভিন্নভাবে, কিন্তু দুটোই consistent, কারণ উভয়ের variance \(\to0\)।)
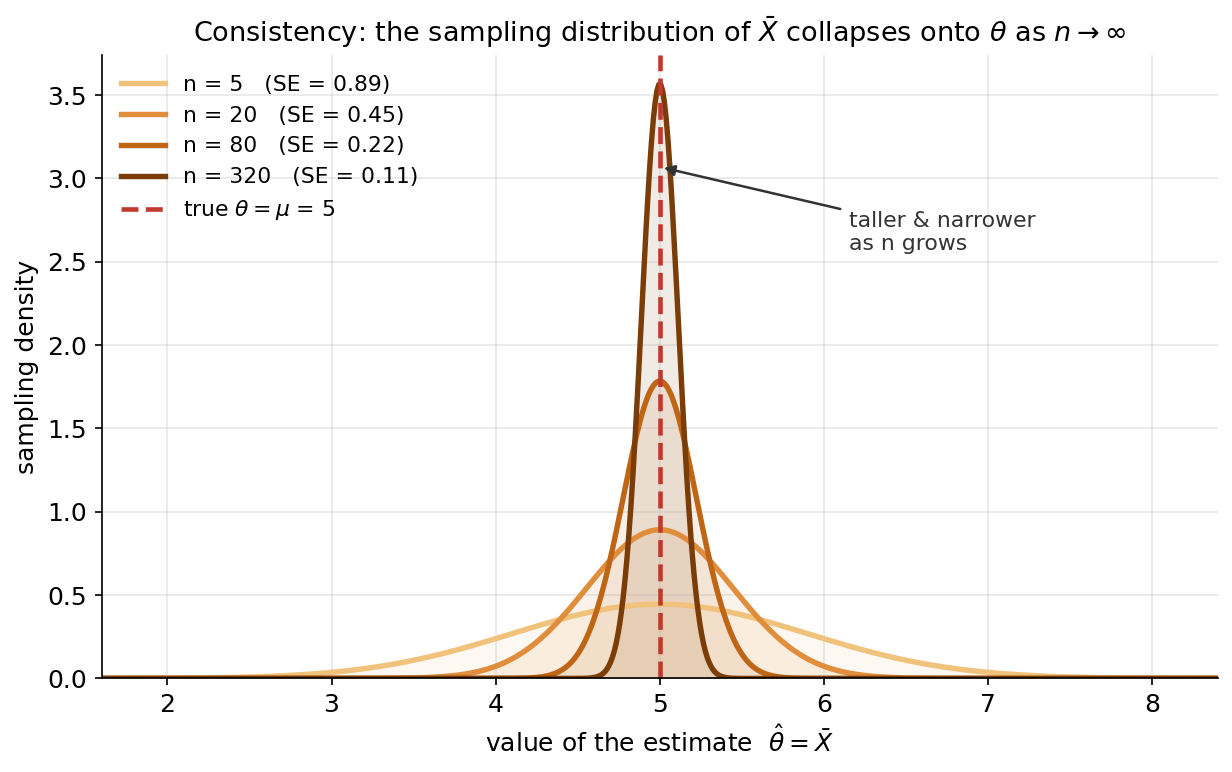
Figure 4 — দুই estimator-এর লড়াই: \(2\bar X\) বনাম \(\max\) (E4)¶
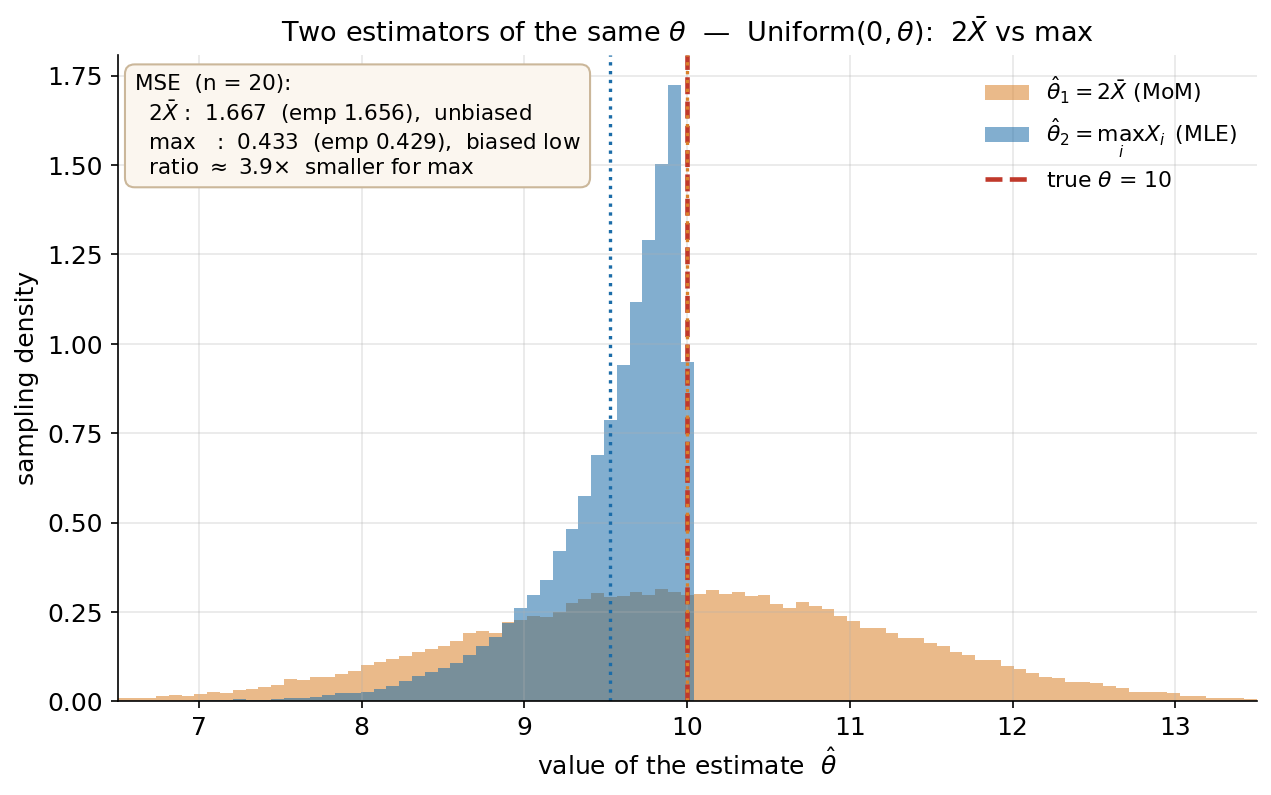
শেষ ছবি দুটো বড় ধারণাকে এক জায়গায় আনে: একই প্যারামিটারের দুটো ভিন্ন estimator-কে তাদের sampling distribution দিয়ে তুলনা, আর "কোনটা ভালো" প্রশ্নের উত্তর MSE দিয়ে। মডেল Uniform\((0,\theta)\), \(\theta=10\), \(n=20\); দুই প্রতিযোগী — কমলা \(\hat\theta_1=2\bar X\) (Method of Moments) আর নীল \(\hat\theta_2=\max_i X_i\) (Maximum Likelihood)। ৬০,০০০ বার নমুনা টেনে দুটোরই sampling distribution histogram হিসেবে আঁকা; লাল ভাঙা-রেখা সত্যি \(\theta=10\), আর ফুটকি-রেখা দুটো estimator-এর গড়। বক্সে তাত্ত্বিক ও empirical MSE।
যা লক্ষ করতে হবে: (ক) আকৃতি একদম আলাদা। \(2\bar X\) (কমলা) সত্যি \(10\)-এর চারপাশে প্রায় প্রতিসম ও চওড়া — গড় ঠিক \(10\) (unbiased), কিন্তু অনেক ছড়ানো। \(\max\) (নীল) সরু ও \(10\)-এর গায়ে ঠেসে, কিন্তু পুরোটাই \(10\)-এর বাঁ দিকে (কারণ \(\max\le\theta\) সবসময়) — অর্থাৎ এটা biased low, গড় \(\approx\frac{n}{n+1}\theta=9.52\)। (খ) তবু MSE-তে \(\max\) স্পষ্ট বিজয়ী: \(\mathrm{MSE}(2\bar X)=\theta^2/(3n)=1.667\) বনাম \(\mathrm{MSE}(\max)=2\theta^2/[(n+1)(n+2)]=0.433\) — প্রায় ৩.৯ গুণ ছোট (empirical-ও মিলেছে: \(1.66\) বনাম \(0.43\))। তাহলে শিক্ষা: bias থাকা সত্ত্বেও \(\max\) ভালো, কারণ তার variance এত ছোট যে bias²-সহ যোগফলও \(2\bar X\)-এর variance-এর চেয়ে কম। (গ) এটাই Figure 1–2-র পাঠের চূড়ান্ত উদাহরণ: "unbiased" (কমলা) ⇏ "সেরা"; সঠিক মানদণ্ড MSE, যেখানে \(\max\) জেতে। (লক্ষ করুন \(\max\)-এর MSE \(\sim\theta^2/n^2\), \(2\bar X\)-এর \(\sim\theta^2/n\) — তাই \(n\) বাড়লে ব্যবধান আরও নাটকীয় হয়; এটাই efficiency-র গল্প, যা 4.5-এ Cramér–Rao bound দিয়ে পূর্ণতা পাবে।)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-04-properties-of-estimators-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: \(b(\hat\theta)=\mathbb{E}[\hat\theta]-\theta\); \(\mathrm{MSE}(\hat\theta)=\mathbb{E}[(\hat\theta-\theta)^2]=[b(\hat\theta)]^2+\mathrm{Var}(\hat\theta)\); consistency \(\hat\theta\xrightarrow{P}\theta\)। চলমান উদাহরণ: E1 \(\hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\) বনাম \(S^2=\frac1{n-1}\sum(X_i-\bar X)^2\); E3 \(\bar X\); E4 Uniform\((0,\theta)\): \(2\bar X\) বনাম \(\max\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় bias ও variance-এর পার্থক্য বলুন, এবং Figure 1-এর চারটি ডার্টবোর্ডকে নিজের কথায় বর্ণনা করুন। একটা estimator কি একই সাথে low-bias আর high-variance হতে পারে? উদাহরণ দিন। Hint: bias = \(\mathbb{E}[\hat\theta]\) সত্যি \(\theta\) থেকে কত দূরে (গড়ের ভুল); variance = \(\hat\theta\) নিজে নমুনাভেদে কতটা ওঠানামা করে (ছড়ানো)। দুটো স্বাধীন — Figure 1-এর উপর-ডান ঘরটাই low-bias + high-variance।
প্রশ্ন ২ (★). "একটা estimator unbiased হলেই সেটা সবচেয়ে ভালো" — এই দাবিটা কেন ভুল? Figure 2 ও Figure 4 থেকে একটি করে যুক্তি দিন। Hint: "ভালো"-র সঠিক মাপ MSE, bias নয়। Figure 2-এ biased \(c^\ast\)-এর MSE unbiased \(c=1\)-এর চেয়ে কম; Figure 4-এ biased \(\max\) unbiased \(2\bar X\)-কে MSE-তে হারায়।
প্রশ্ন ৩ (★★). consistency-র সংজ্ঞা (\(\hat\theta\xrightarrow{P}\theta\)) দিন। দেখান যে "\(\mathrm{MSE}(\hat\theta_n)\to0\)" থেকে consistency বেরিয়ে আসে। এরপর ব্যাখ্যা করুন কেন unbiased হওয়া consistency-র জন্য জরুরি নয় — Figure 3 ও E1-এর \(\hat\sigma^2\) উদাহরণ দিন। Hint: Markov/Chebyshev: \(P(\lvert\hat\theta_n-\theta\rvert\ge\varepsilon)\le \mathrm{MSE}/\varepsilon^2\to0\)। আর \(\mathrm{MSE}=\text{bias}^2+\text{variance}\); দুটোই \(0\)-তে গেলেই চলে, bias শুরুতে \(0\) হতে হবে না (যেমন \(\hat\sigma^2\) biased কিন্তু consistent)।
প্রশ্ন ৪ (★★). "biased কিন্তু ছোট variance" বনাম "unbiased কিন্তু বড় variance" — কোন বাস্তব পরিস্থিতিতে আপনি প্রথমটা বেছে নেবেন? bias–variance tradeoff-এর ভাষায় ব্যাখ্যা করুন, এবং Figure 4-এর \(\max\)-কে এই আলোকে ব্যাখ্যা করুন। Hint: MSE-ই চূড়ান্ত বিচারক। যদি variance-এ লাভ bias²-এ ক্ষতির চেয়ে বড় হয়, biased estimator-ই কম MSE দেয় — ঠিক যেমন \(\max\)।
খ · গাণনিক (computational)¶
প্রশ্ন ৫ (★). \(X_1,\dots,X_n \overset{iid}{\sim}\mathcal{N}(\mu,\sigma^2)\)। \(\bar X\)-এর জন্য (ক) \(\mathbb{E}[\bar X]\), (খ) bias, (গ) \(\mathrm{Var}(\bar X)\), (ঘ) \(\mathrm{MSE}(\bar X)\) — চারটিই \(\mu,\sigma^2,n\)-এর মাধ্যমে লিখুন। Hint: \(\mathbb{E}[\bar X]=\mu\) (তাই bias \(=0\)), \(\mathrm{Var}(\bar X)=\sigma^2/n\); unbiased হলে MSE = variance।
প্রশ্ন ৬ (★★). E1। জানা আছে \(\mathbb{E}[S^2]=\sigma^2\) যেখানে \(S^2=\frac1{n-1}\sum(X_i-\bar X)^2\)। ধরুন \(\hat\sigma^2=\frac1n\sum(X_i-\bar X)^2=\frac{n-1}{n}S^2\)। (ক) \(\mathbb{E}[\hat\sigma^2]\) ও তার bias বের করুন। (খ) \(n=10\)-এ bias শতকরা কত? (গ) \(n\to\infty\)-এ bias-এর কী হয়? Hint: \(\mathbb{E}[\hat\sigma^2]=\frac{n-1}{n}\sigma^2\), তাই bias \(=-\sigma^2/n\) (নিচের দিকে)। \(n=10\)-এ \(-10\%\); \(n\to\infty\)-এ \(\to0\) (asymptotically unbiased)।
প্রশ্ন ৭ (★★). E4, Uniform\((0,\theta)\), \(\hat\theta_1=2\bar X\)। (ক) \(\mathbb{E}[2\bar X]\) দেখিয়ে unbiased প্রমাণ করুন। (খ) \(\mathrm{Var}(2\bar X)\) বের করুন (ব্যবহার করুন \(\mathrm{Var}(X_i)=\theta^2/12\))। (গ) তাই \(\mathrm{MSE}(2\bar X)\) লিখুন। Hint: \(\mathbb{E}[X_i]=\theta/2\Rightarrow\mathbb{E}[2\bar X]=\theta\)। \(\mathrm{Var}(2\bar X)=4\cdot\frac{\theta^2/12}{n}=\theta^2/(3n)\); unbiased তাই MSE \(=\theta^2/(3n)\) — Figure 4-এর বক্সের সাথে মিলিয়ে দেখুন।
প্রশ্ন ৮ (★★★). E4, \(\hat\theta_2=\max_i X_i=X_{(n)}\)। জানা: \(X_{(n)}\)-এর CDF \(F(t)=(t/\theta)^n\) (\(0\le t\le\theta\))। (ক) density বের করে \(\mathbb{E}[X_{(n)}]=\frac{n}{n+1}\theta\) দেখান, তাই bias \(=-\theta/(n+1)\)। (খ) \(\mathbb{E}[X_{(n)}^2]=\frac{n}{n+2}\theta^2\) ব্যবহার করে \(\mathrm{Var}(X_{(n)})=\frac{n\theta^2}{(n+1)^2(n+2)}\) বের করুন। (গ) তাই \(\mathrm{MSE}(X_{(n)})=\frac{2\theta^2}{(n+1)(n+2)}\) দেখান, এবং \(n=20,\theta=10\)-এ এই MSE আর প্রশ্ন ৭-এর \(2\bar X\)-এর MSE-র অনুপাত বের করুন। Hint: density \(f(t)=nt^{n-1}/\theta^n\)। MSE \(=\) variance \(+\) bias²; বীজগণিতে \(\frac{n}{(n+1)^2(n+2)}+\frac1{(n+1)^2}=\frac{2}{(n+1)(n+2)}\) (গুণ \(\theta^2\))। অনুপাত \(\approx 3.85\) — Figure 4-এর "৩.৯×"।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★). যেকোনো estimator \(\hat\theta\)-র জন্য bias–variance পচন প্রমাণ করুন: $\(\mathrm{MSE}(\hat\theta)=\mathbb{E}[(\hat\theta-\theta)^2]=[\,b(\hat\theta)\,]^2+\mathrm{Var}(\hat\theta).\)$ Hint: \(\hat\theta-\theta=(\hat\theta-\mathbb{E}[\hat\theta])+(\mathbb{E}[\hat\theta]-\theta)\) লিখে বর্গ করুন; মাঝের cross-term \(2\,\mathbb{E}[(\hat\theta-\mathbb{E}\hat\theta)]\cdot b=0\) কারণ \(\mathbb{E}[\hat\theta-\mathbb{E}\hat\theta]=0\)।
প্রশ্ন ১০ (★★). ধরুন \(\hat\theta_n\) এমন যে \(b(\hat\theta_n)\to0\) এবং \(\mathrm{Var}(\hat\theta_n)\to0\) যখন \(n\to\infty\)। Chebyshev/Markov অসমতা ব্যবহার করে প্রমাণ করুন \(\hat\theta_n\xrightarrow{P}\theta\) (অর্থাৎ এই দুই শর্ত consistency-র জন্য যথেষ্ট)। Hint: \(P(\lvert\hat\theta_n-\theta\rvert\ge\varepsilon)\le\frac{\mathbb{E}[(\hat\theta_n-\theta)^2]}{\varepsilon^2}=\frac{\mathrm{MSE}(\hat\theta_n)}{\varepsilon^2}=\frac{b^2+\mathrm{Var}}{\varepsilon^2}\to0\)।
প্রশ্ন ১১ (★★★). ধরুন \(\hat\theta\) unbiased, variance \(\sigma_0^2\)। বিবেচনা করুন shrinkage estimator \(\tilde\theta=c\hat\theta\) (\(0\le c\le1\))। (ক) \(\tilde\theta\)-র bias ও variance \(c,\theta,\sigma_0^2\)-এর মাধ্যমে লিখুন। (খ) \(\mathrm{MSE}(\tilde\theta)\)-কে \(c\)-এর ফাংশন হিসেবে লিখে ন্যূনতমকারী \(c^\ast\) বের করুন, এবং দেখান \(c^\ast<1\) যখন \(\theta\ne0\)। (গ) এর তাৎপর্য Figure 2-র সাথে মেলান। Hint: bias \(=(c-1)\theta\), \(\mathrm{Var}=c^2\sigma_0^2\); \(\mathrm{MSE}(c)=(c-1)^2\theta^2+c^2\sigma_0^2\); \(\frac{d}{dc}=0\Rightarrow c^\ast=\frac{\theta^2}{\theta^2+\sigma_0^2}<1\)। অর্থাৎ একটু shrink করলেই MSE কমে — Figure 2-র লাল সর্বনিম্ন \(c=1\)-এর বাঁয়ে।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★★). Monte Carlo দিয়ে Figure 4 যাচাই: Uniform\((0,10)\) থেকে \(n=20\)-এর নমুনা ৫০,০০০ বার টেনে প্রতিবার \(2\bar X\) ও \(\max\) হিসাব করুন। দুটোর empirical bias, variance, MSE ছাপান এবং তাত্ত্বিক মান (\(\theta^2/(3n)\) ও \(2\theta^2/((n+1)(n+2))\))-এর সাথে মেলান। Hint:
import numpy as np
rng = np.random.default_rng(0); theta, n, R = 10.0, 20, 50000
s = rng.uniform(0, theta, size=(R, n))
for name, est in [("2*Xbar", 2*s.mean(1)), ("max", s.max(1))]:
b = est.mean()-theta; v = est.var(); print(name, "bias", round(b,3),
"var", round(v,3), "MSE", round(b**2+v,3))
প্রশ্ন ১৩ (★★). E1। \(\mathcal{N}(0,4)\) থেকে (\(\sigma^2=4\)) \(n=8\)-এর নমুনা ২০,০০০ বার টেনে \(\hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\) ও \(S^2=\frac1{n-1}\sum(\cdot)\)-এর empirical গড় বের করুন। দেখান \(\hat\sigma^2\) গড়ে \(\sigma^2\)-এর নিচে (\(\approx\frac{n-1}{n}\sigma^2=3.5\)) কিন্তু \(S^2\) গড়ে \(\approx4\)। তারপর দুটোর empirical MSE তুলনা করুন — biased \(\hat\sigma^2\)-ই কি কম MSE দেয়?
Hint: s.var(axis=1, ddof=0) দেয় \(\hat\sigma^2\), ddof=1 দেয় \(S^2\)। ছোট \(n\)-এ biased \(\hat\sigma^2\) প্রায়ই কম MSE দেয় — bias–variance tradeoff-এর আরেকটা বাস্তব উদাহরণ।
প্রশ্ন ১৪ (★★★). consistency নিজের চোখে: \(\mathcal{N}(5,4)\) থেকে \(n=2,5,20,100,500\)-এ ৫,০০০ বার \(\bar X\) হিসাব করে প্রতিটির empirical SD ছাপান, দেখান তা \(\sigma/\sqrt n\)-এর সাথে মেলে, আর একটা ছবিতে পাঁচটা sampling distribution-এর histogram বসিয়ে Figure 3-এর "সরু হওয়া" পুনঃনির্মাণ করুন।
Hint: প্রতিটা \(n\)-এ est = rng.normal(5,2,size=(5000,n)).mean(1); est.std() ≈ 2/np.sqrt(n)। plt.hist(..., density=True, alpha=0.5) লুপে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- estimator-এর তিন মূল গুণ। একটা point estimator \(\hat\theta\) একটা র্যান্ডম পরিমাণ (নমুনার ফাংশন), তাই তার নিজস্ব sampling distribution আছে; সেই distribution-কে তিনটা সংখ্যায় বিচার করি — bias \(b(\hat\theta)=\mathbb{E}[\hat\theta]-\theta\) (গড়ে কত সরে), variance \(\mathrm{Var}(\hat\theta)\) (নমুনাভেদে কত ওঠানামা), আর MSE \(\mathbb{E}[(\hat\theta-\theta)^2]\) (সব মিলিয়ে গড় বর্গ-ভুল)।
- bias আর variance আলাদা দোষ (Figure 1)। একটা estimator unbiased হয়েও খুব ছড়ানো হতে পারে, বা আঁটসাঁট হয়েও সরে-যাওয়া। ডার্টবোর্ডের চার কোণ এই স্বাধীনতা দেখায়।
- bias–variance পচন: \(\boxed{\mathrm{MSE}(\hat\theta)=[\,b(\hat\theta)\,]^2+\mathrm{Var}(\hat\theta)}\) — কোনো cross-term নেই (প্রমাণ §৭ Q9)। এটাই estimator-তত্ত্বের কেন্দ্রীয় সমীকরণ: ভালো মানে কম MSE, আর MSE-কে কমাতে গেলে bias² ও variance-এর মধ্যে tradeoff সামলাতে হয় (Figure 2)। তাই unbiased ≠ best: সামান্য bias মেনে variance অনেক কমালে মোট MSE কমতে পারে (shrinkage, §৭ Q11)।
- consistency (Figure 3): \(\hat\theta_n\xrightarrow{P}\theta\) — \(n\) বাড়লে estimate সত্যিতে গড়ায়; যথেষ্ট শর্ত হলো bias \(\to0\) ও variance \(\to0\) (Chebyshev দিয়ে, §৭ Q10)। তাই biased estimator-ও consistent হতে পারে (E1-এর \(\hat\sigma^2\) — biased কিন্তু consistent)।
- চলমান উদাহরণে সারাংশ। E1: \(\hat\sigma^2=\frac1n\sum(X_i-\bar X)^2\) biased (\(\mathbb{E}=\frac{n-1}{n}\sigma^2\), তাই \(-\sigma^2/n\)), \(S^2=\frac1{n-1}\sum(\cdot)\) unbiased — তবু ছোট \(n\)-এ biased \(\hat\sigma^2\) প্রায়ই কম MSE দেয়। E3: \(\bar X\) unbiased ও consistent, \(\mathrm{MSE}=\sigma^2/n\)। E4 (Uniform): \(2\bar X\) unbiased, \(\mathrm{MSE}=\theta^2/(3n)\); \(\max\) biased low কিন্তু \(\mathrm{MSE}=\frac{2\theta^2}{(n+1)(n+2)}\sim\theta^2/n^2\) — অনেক ছোট, তাই MSE-তে বিজয়ী (Figure 4)। দুই estimator-এর variance-হার (\(n\) বনাম \(n^2\)) থেকেই efficiency-র প্রশ্ন জন্ম নেয়।
পূর্ববর্তী সংযোগ (← 4.3 MLE, 4.1–4.2): 4.1-এ point estimation-এর কাঠামো, 4.2-এ Method of Moments, আর 4.3-এ Maximum Likelihood Estimation — এই অধ্যায় সেই সব পদ্ধতিতে-পাওয়া estimator-গুলোকে বিচার করার মানদণ্ড দিল। 4.3-এ আমরা MLE কীভাবে বানাতে হয় শিখেছি; এখন জানলাম কোন প্রশ্নে তাকে যাচাই করি — biased কি না, variance কত, MSE কত, consistent কি না। Figure 4-এর \(\max\) আসলে Uniform-এর MLE, আর \(2\bar X\) তার MoM-প্রতিদ্বন্দ্বী: এই অধ্যায় দেখাল কেন MLE-টা এখানে এত ভালো (নাটকীয়ভাবে ছোট MSE)। অর্থাৎ 4.2–4.3 ছিল "estimator বানানো", 4.4 হলো "estimator-এর গুণ মাপা" — দুটো মিলে point estimation-এর পূর্ণ ছবি। আর consistency-র পুরো ভিত্তি Part III-এর convergence-তত্ত্ব (LLN, \(\xrightarrow{P}\), Chebyshev)।
পরবর্তী সংযোগ (→ 4.5 — Fisher Information ও Cramér–Rao Bound): এই অধ্যায়ে বারবার এসেছে "variance কম মানে ভালো" আর Figure 4-এ \(\max\)-এর variance \(2\bar X\)-এর চেয়ে অনেক ছোট ছিল। স্বাভাবিক প্রশ্ন: variance কত ছোট হওয়া আদৌ সম্ভব? কোনো একটা unbiased estimator কি ইচ্ছেমতো ছোট variance পেতে পারে, নাকি একটা মেঝে (lower bound) আছে? পরের অধ্যায় 4.5 ঠিক এই প্রশ্নের উত্তর দেবে — Fisher information \(I(\theta)\) মাপে data প্যারামিটার সম্পর্কে কতটা "তথ্য" বহন করে, আর Cramér–Rao bound বলে যেকোনো unbiased estimator-এর variance \(\ge 1/[nI(\theta)]\) — অর্থাৎ একটা ভাঙা-না-যাওয়া মেঝে। যে estimator এই মেঝে ছোঁয় তাকে বলে efficient। এই অধ্যায়ের "efficiency"-র অনানুষ্ঠানিক তুলনা (কোনটা কম variance) 4.5-এ একটা সুনির্দিষ্ট, প্রমাণযোগ্য সীমায় রূপ নেবে — আর তখন বোঝা যাবে কেন কিছু estimator-কে "সেরা সম্ভব" বলা যায়।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 6 (Models, Statistical Inference — §6.3 bias, se, MSE; bias–variance decomposition) ও Ch. 9 (Parametric Inference — consistency, MSE তুলনা, Uniform উদাহরণ); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 8 (Estimation of Parameters — §8.4 MoM বনাম MLE, sampling distribution, mean squared error ও efficiency-র ভূমিকা)।