4.5 — Sufficiency, Fisher Information & the Cramér–Rao Bound (সাফিসিয়েন্সি, ফিশার তথ্য ও ক্রামার–রাও সীমা)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "data-র কতটা আসলে θ সম্পর্কে তথ্য?" আর "কত ছোট variance সম্ভব?"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন প্রশ্ন এখনও খোলা¶
গত দুটো অধ্যায়ে আমরা inference-এর দুই স্তম্ভ গড়েছি — সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়ের পুরো গল্প ঠিক এখান থেকেই শুরু।
- 4.3-এ (Maximum Likelihood) আমরা data থেকে best-guess বানানোর একটা শক্তিশালী recipe শিখেছি: হাতে-পাওয়া data \(X_1,\dots,X_n\) স্থির রেখে likelihood \(L(\theta)=\prod_{i=1}^n f(X_i;\theta)\) লিখি, log নিয়ে log-likelihood \(\ell(\theta)=\sum_{i=1}^n \log f(X_i;\theta)\) বানাই, তার derivative (score, প্রতীকে \(\ell'(\theta)=\partial_\theta\ell\)) শূন্য করে চূড়া খুঁজি — সেই চূড়ার অবস্থানই \(\hat\theta_{\text{MLE}}\)। এখানে \(f(x;\theta)\) মানে একটি observation-এর density/mass, \(\theta\) ("থিটা") অজানা parameter, আর \(\partial_\theta\) মানে "\(\theta\)-র সাপেক্ষে derivative"।
- 4.4-এ (Properties of Estimators) আমরা একটা estimator-এর মান বিচার করার ভাষা পেয়েছি: bias \(b(\hat\theta)=\mathbb{E}[\hat\theta]-\theta\) (গড়ে কত সরা), variance \(\mathrm{Var}(\hat\theta)\) (কত ছড়ানো), তাদের একত্রিত MSE \(=b^2+\mathrm{Var}\), এবং unbiased, consistent, efficient-এর সংজ্ঞা।
কিন্তু 4.4 ঠিক যেখানে থেমেছিল, সেখানেই দুটো প্রশ্ন খোলা রয়ে গিয়েছিল — দুটো প্রশ্ন যা আমরা সযত্নে "পরের অধ্যায়ে" বলে স্থগিত রেখেছিলাম:
প্রশ্ন A (তথ্যের প্রশ্ন)। আমার হাতে \(n\)টা কাঁচা সংখ্যা \(X_1,\dots,X_n\)। কিন্তু \(\theta\) আন্দাজ করতে কি সত্যিই সবগুলো আলাদা সংখ্যা দরকার, নাকি কয়েকটা সারাংশ-সংখ্যা (যেমন শুধু তাদের যোগফল) জানলেই \(\theta\) সম্পর্কে সব তথ্য হাতে এসে যায়? "তথ্য ধরে রাখা" কথাটার একটা নিখুঁত মানে কি দেওয়া যায়?
প্রশ্ন B (সীমার প্রশ্ন)। 4.4 বলেছিল efficient estimator মানে "সবচেয়ে কম variance"। কিন্তু কত কম? variance কি ইচ্ছেমতো ছোট করা যায়, নাকি একটা তাত্ত্বিক মেঝে আছে যার নিচে কোনো (নিরপেক্ষ) estimator-ই নামতে পারে না? থাকলে সেই মেঝে কীসের উপর নির্ভর করে?
এই অধ্যায়ের একমাত্র কাজ — এই দুটো প্রশ্নের নিখুঁত উত্তর দেওয়া। আর মজার কথা: দুটো উত্তরই একটা একই বস্তুর চারপাশে ঘোরে — log-likelihood কতটা "তথ্যবহুল" তার একটা পরিমাপ, যার নাম Fisher information \(I(\theta)\)।
১.২ Hook ১ — "data-র কতটা আসলে θ সম্পর্কে তথ্য?" (sufficiency-র স্বজ্ঞা)¶
একটা concrete দৃশ্য দিয়ে শুরু করি। ধরুন আপনি একটা মুদ্রা \(n=10\) বার ছুঁড়লেন, head-হার \(p\) (অজানা) আন্দাজ করবেন। আপনার বন্ধু পুরো ক্রম মুখস্থ বলল:
এখন প্রশ্ন: \(p\) আন্দাজ করতে আপনার কি পুরো ক্রমটা দরকার — কোনটা কত নম্বরে এল, সেই সাজানো-তথ্য সহ? নাকি শুধু এটুকু জানলেই চলে যে "১০ বারে ৭টা head"?
একটু ভাবলেই টের পাবেন — শুধু "৭টা head" সংখ্যাটাই \(p\) সম্পর্কে সব তথ্য বহন করে। কোন বিশেষ ক্রমে head-গুলো এল (HTHH... নাকি HHHH...TTT) — তা \(p\) নিয়ে নতুন কিছুই বলে না, কারণ প্রতিটি toss স্বাধীন ও একই \(p\)-যুক্ত। অর্থাৎ যোগফল \(T(X)=\sum_{i=1}^{10} X_i = 7\) (যেখানে \(X_i=1\) মানে head) জানার পর কাঁচা ক্রমটা \(p\)-র দৃষ্টিতে অপ্রাসঙ্গিক আবর্জনা।
এটাই sufficiency-র হৃদয়। এক বাক্যে:
একটি statistic \(T(X)\)-কে \(\theta\)-র জন্য "sufficient" (পর্যাপ্ত) বলি যদি \(T\)-র মান জানার পর কাঁচা data \(X_1,\dots,X_n\) আর \(\theta\) সম্পর্কে নতুন কোনো তথ্য না দেয় — অর্থাৎ \(T\) একাই data-র মধ্যেকার \(\theta\)-সংক্রান্ত সব তথ্য গুটিয়ে ধরে রাখে।
এর ব্যবহারিক তাৎপর্য বিরাট: \(10\)টা সংখ্যার বদলে \(1\)টা সংখ্যা (\(\sum X_i\)) রাখলেই \(p\)-অনুমানের সব কাঁচামাল হাতে — কোনো তথ্য হারায় না। এ যেন data-র একটা lossless compression (ক্ষতিহীন সংকোচন), কিন্তু কেবল \(\theta\)-সম্পর্কিত তথ্যের জন্য। §২-এ আমরা এর নিখুঁত সংজ্ঞা দেব, আর তা যাচাইয়ের একটা যান্ত্রিক যন্ত্র — factorization theorem — শিখব।
১.৩ Hook ২ — "কত ছোট variance সম্ভব?" (Fisher information ও CRLB-র স্বজ্ঞা)¶
এবার দ্বিতীয় hook — যা সরাসরি 4.4-এর efficiency-প্রশ্নের ধারাবাহিকতা। 4.4-এ আমরা দেখেছি, একই \(\theta\)-র জন্য একাধিক unbiased estimator থাকতে পারে, আর তাদের মধ্যে যেটার variance কম, সেটাই বেশি দক্ষ। স্বাভাবিক পরের প্রশ্ন: variance-এর কি কোনো তলদেশ আছে?
এর উত্তর পেতে একটা সুন্দর স্বজ্ঞা কাজে লাগে — log-likelihood-এর চূড়ার আকার। মনে করুন data হাতে আসার পর আপনি \(\ell(\theta)\)-কে \(\theta\)-র বিপরীতে এঁকেছেন; MLE হলো তার চূড়া। এখন দুটো পরিস্থিতি কল্পনা করুন:
- তীক্ষ্ণ (sharp) চূড়া: \(\ell(\theta)\) চূড়ার দু-পাশে খুব দ্রুত নিচে নামে — মানে চূড়া থেকে একটু সরলেই likelihood হুড়মুড় করে পড়ে যায়। তাহলে data খুব জোর গলায় বলছে "\(\theta\) ঠিক এইখানে, অন্য কোথাও নয়" — অর্থাৎ \(\theta\) নিয়ে আমাদের অনিশ্চয়তা কম, আন্দাজ শক্ত।
- চ্যাপ্টা (flat) চূড়া: \(\ell(\theta)\) চূড়ার চারপাশে প্রায় সমতল — চূড়া থেকে অনেকখানি সরলেও likelihood বিশেষ কমে না। তাহলে data দুর্বল গলায় বলছে "\(\theta\) মোটামুটি এই অঞ্চলে, ঠিক কোথায় নিশ্চিত নই" — অনিশ্চয়তা বেশি, আন্দাজ নড়বড়ে।
তাহলে চূড়ার তীক্ষ্ণতা = data-র তথ্যের পরিমাণ। আর তীক্ষ্ণতার গাণিতিক মাপ হলো চূড়ায় বক্রতা (curvature) — অর্থাৎ second derivative কতটা ঋণাত্মক। ঠিক এই পরিমাণটাকেই বলে Fisher information \(I(\theta)\) ("ফিশার তথ্য", R. A. Fisher-এর নামে)। মোটা দাগে:
Fisher information \(I(\theta)\) = log-likelihood-এর চূড়া গড়ে কতটা তীক্ষ্ণ (বক্র)। বেশি \(I(\theta)\) = তীক্ষ্ণ চূড়া = প্রতিটি observation থেকে \(\theta\) সম্পর্কে বেশি তথ্য = কম অনিশ্চয়তা সম্ভব।
আর এখান থেকেই প্রশ্ন B-র উত্তর বেরোয়, একটা চমকপ্রদ অসমতায়। দেখা যায় — যেকোনো unbiased estimator \(\hat\theta\)-র জন্য
এটাই Cramér–Rao lower bound (CRLB) — variance-এর সেই ভাঙা-যায়-না মেঝে। কথায়: যত বেশি তথ্য (\(nI(\theta)\) বড়), তত নিচে variance নামতে পারে (মেঝে নিচে নামে); কিন্তু কখনোই এর নিচে নয়। data যতই চালাকি করে ব্যবহার করুন, একটা unbiased estimator-এর ছড়ানো এই সীমার নিচে নামবে না। (এখানে \(n\) = নমুনা-আকার, কারণ \(n\)টা স্বাধীন observation-এর মোট তথ্য একটার \(n\) গুণ — §২-এ দেখব।)
১.৪ দুই hook এক সুতোয় — আর MLE-র চমৎকার ভূমিকা¶
লক্ষ করুন, দুটো hook আসলে একই বস্তুর দুই মুখ। Fisher information \(I(\theta)\) একদিকে বলে "প্রতিটি data-বিন্দুতে কতটা তথ্য" (Hook ২-এর চূড়া-তীক্ষ্ণতা), আবার সেই একই \(I(\theta)\)-ই variance-এর মেঝে \(\frac{1}{nI(\theta)}\) ঠিক করে দেয়। আর sufficiency (Hook ১) এই গল্পের প্রস্তুতি-পর্ব: যদি data-র সব তথ্য কয়েকটা সংখ্যায় গুটিয়ে রাখা যায়, তবে সেই গুটানো-সংখ্যাগুলোর উপরেই ভালো estimator গড়া স্বাভাবিক।
আর গল্পের সবচেয়ে সুন্দর মোড়টা আসে MLE-কে নিয়ে (4.3)। দেখা যায়, বড় নমুনায় MLE শুধু consistent-ই নয়, সে প্রায়-নিখুঁতভাবে normal হয়ে যায়, এবং তার variance asymptotically ঠিক CRLB-র মেঝে ছোঁয়:
এখানে \(\xrightarrow{d}\) মানে "converges in distribution" (3.4) আর \(\mathcal N\) = Normal বণ্টন। কথায়: যথেষ্ট data থাকলে MLE-ই কার্যত সেরা সম্ভাব্য estimator — সে তথ্যের শেষবিন্দু পর্যন্ত নিংড়ে নেয়। এই ফলটাই 4.3 ও 4.4-এর সুতো দুটোকে এক গিঁটে বাঁধে, আর এই অধ্যায়কে Part IV-এর তাত্ত্বিক শিখর করে তোলে।
১.৫ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — চারটি কেন্দ্রীয় ধারণা from scratch, প্রতিটি প্রতীক খুলে: (ক) sufficiency ও তা যাচাইয়ের factorization theorem; (খ) Fisher information \(I(\theta)\) — তার দুই সমতুল্য রূপ ও curvature-অর্থ; (গ) Cramér–Rao lower bound ও efficiency-র সংজ্ঞা; (ঘ) MLE-র asymptotic normality।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 Bernoulli (\(\sum X_i\) কেন sufficient, \(I(p)=\frac{1}{p(1-p)}\)), E2 Normal mean (\(I(\mu)=1/\sigma^2\)), E3 Poisson (\(I(\lambda)=1/\lambda\)), E4 MLE asymptotic variance (CRLB ছোঁয়া)।
- §৪–৫ — factorization theorem ও CRLB-র উৎপাদন/প্রমাণ, score-এর মৌলিক ধর্ম (\(\mathbb{E}[\text{score}]=0\)), দুই Fisher-রূপের সমতা, এবং MLE asymptotics-এর গভীরতর যুক্তি।
- §৬–৮ — চিত্র (Fisher info, CRLB, MLE asymptotic, sufficiency), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর শিখর। 4.3 দিয়েছিল estimator বানানোর সেরা recipe (MLE), 4.4 দিয়েছিল estimator বিচারের মানদণ্ড (bias, variance, efficiency); এই অধ্যায় সেই দুইকে মিলিয়ে বলে — data-র তথ্য পরিমাপযোগ্য (Fisher information), variance-এর একটা ভাঙা-যায়-না মেঝে আছে (CRLB), আর MLE বড় নমুনায় ঠিক সেই মেঝে ছুঁয়ে সর্বোত্তম হয়ে ওঠে। এই ভিত্তি ছাড়া পরের অধ্যায় 4.6 (confidence intervals — "estimate-এর চারপাশে কত চওড়া ব্যবধান") দাঁড়াতে পারে না, কারণ সেই ব্যবধানের প্রস্থ সরাসরি এখানকার variance/\(I(\theta)\) থেকে আসে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর দুই স্বজ্ঞাকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামো স্থির: আমাদের কাছে একটি i.i.d. নমুনা \(X_1,\dots,X_n\) আছে (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা), একটি common distribution থেকে, যার pdf/pmf \(f(x;\theta)\) — এখানে \(f\) মানে continuous হলে density, discrete হলে probability mass, আর \(\theta\) ("থিটা") অজানা স্থির parameter। মনে রাখি (4.3 থেকে):
- likelihood \(L(\theta)=\prod_{i=1}^n f(X_i;\theta)\) — data স্থির, \(\theta\) চলক;
- log-likelihood \(\ell(\theta)=\log L(\theta)=\sum_{i=1}^n \log f(X_i;\theta)\);
- score = log-likelihood-এর derivative, \(\partial_\theta \log f\) এক observation-এর জন্য বা \(\ell'(\theta)=\partial_\theta\ell\) পুরো নমুনার জন্য, যেখানে \(\partial_\theta\) মানে "\(\theta\)-র সাপেক্ষে partial derivative"।
২.১ Statistic ও sufficiency — তথ্য না হারিয়ে data গুটানো¶
প্রথমে একটা শব্দ পরিষ্কার করি, যা 4.1-এ এসেছিল কিন্তু এখানে কেন্দ্রীয়।
সংজ্ঞা (Statistic — পরিসংখ্যান)। একটি statistic হলো data-র যেকোনো function \(T = T(X_1,\dots,X_n)\) যা \(\theta\)-কে ব্যবহার করে না — কেবল হাতে-পাওয়া সংখ্যাগুলো থেকে গণনা করা যায়। যেমন \(\bar X\), \(\sum_i X_i\), \(\max_i X_i\) — সবই statistic। (যেহেতু \(T\) random data-র function, \(T\) নিজেও একটা random variable।)
এখন মূল ধারণা — §১.২-এর "তথ্য না হারিয়ে গুটানো"-কে নিখুঁত করি।
সংজ্ঞা (Sufficient statistic — পর্যাপ্ত পরিসংখ্যান)। একটি statistic \(T(X)\)-কে parameter \(\theta\)-র জন্য sufficient বলা হয় যদি — \(T\)-র মান একবার জানা থাকলে — data \(X_1,\dots,X_n\)-এর শর্তাধীন বণ্টন (conditional distribution) আর \(\theta\)-র উপর নির্ভর করে না। প্রতীকে: \(T(X)\) sufficient যদি
প্রতিটি প্রতীক/ধারণা খুলি:
- \(T(X)=t\) — statistic-টির একটা নির্দিষ্ট মান \(t\) (যেমন "৭টা head")।
- "\(X_1,\dots,X_n\)-এর conditional distribution given \(T=t\)" — \(T\)-র মান \(t\) জেনে নেওয়ার পর, কাঁচা data কোন কোন রূপে আসতে পারত তার সম্ভাবনা-বণ্টন।
- "\(\theta\) থাকে না" — এই conditional distribution-এর সূত্রে \(\theta\) একটাও জায়গায় ঢোকে না।
কেন এটাই "সব তথ্য ধরে রাখা": যদি \(T\) জানার পর data-র অবশিষ্ট এলোমেলোভাব \(\theta\)-র উপর নির্ভরই না করে, তবে সেই অবশিষ্ট অংশে \(\theta\) সম্পর্কে কোনো তথ্য নেই — সব তথ্য \(T\)-তেই চলে এসেছে। তাই \(\theta\)-অনুমানে \(T\) জানা = পুরো data জানা; কাঁচা \(X_i\)-গুলো ফেলে দিলেও \(\theta\) সম্পর্কে কিছু হারায় না।
স্বজ্ঞা (মুদ্রার উদাহরণে)। "৭টা head" (\(T=\sum X_i=7\)) জানার পর, ঠিক কোন ৭টা অবস্থানে head পড়েছিল — তার সব সম্ভাব্য বিন্যাস সমান-সম্ভাব্য, আর সেই সমান-সম্ভাব্যতা \(p\)-র উপর মোটেও নির্ভর করে না (যেকোনো নির্দিষ্ট বিন্যাসের probability \(p^7(1-p)^3\), যা ভাগ করলে \(p\) কেটে যায়)। তাই \(\sum X_i\) Bernoulli-র জন্য sufficient — E1-এ সংখ্যাসহ দেখব।
২.২ Factorization theorem — sufficiency যাচাইয়ের যন্ত্র¶
উপরের সংজ্ঞা সুন্দর, কিন্তু সরাসরি conditional distribution হিসাব করে যাচাই করা কষ্টকর। সৌভাগ্যবশত একটা চমৎকার শর্টকাট আছে, যা কেবল likelihood-এর আকৃতি দেখে sufficiency বলে দেয় — কোনো conditional হিসাব ছাড়াই।
Factorization theorem (গুণনীকরণ উপপাদ্য — Fisher–Neyman)। একটি statistic \(T(X)\) parameter \(\theta\)-র জন্য sufficient যদি এবং কেবল যদি যৌথ density/likelihood-কে দুই গুণনীয়াংশে ভাঙা যায় — একটা যা data-তে \(\theta\)-কে স্পর্শ করে কেবল \(T(X)\)-এর মধ্য দিয়ে, আরেকটা যাতে \(\theta\) একদমই নেই:
প্রতিটি অংশ খুলি:
- \(f(x_1,\dots,x_n;\theta)=\prod_i f(x_i;\theta)\) — পুরো নমুনার যৌথ density (= likelihood, \(\theta\)-র function হিসেবে দেখলে)।
- \(g(T(x),\theta)\) — এমন একটা function যেখানে \(\theta\) data-কে স্পর্শ করে শুধু \(T(x)\)-এর মাধ্যমে; অর্থাৎ data থেকে \(\theta\)-নির্ভর সব কিছু \(T(x)\)-এর ভেতর দিয়েই যায়।
- \(h(x_1,\dots,x_n)\) — data-র উপর নির্ভরশীল, কিন্তু \(\theta\)-মুক্ত একটা function (এতে \(\theta\) নেই)।
কীভাবে কাজে লাগাই (recipe): likelihood লিখে দেখুন \(\theta\)-কে কেবল কোন data-সারাংশের সাথে জড়িয়ে আছে। যদি likelihood-কে "(\(\theta\) আর শুধু \(T\)-এর জোড়া) × (\(\theta\)-হীন বাকিটা)" রূপে লেখা যায়, তবে সেই \(T\)-ই sufficient। এক কথায়: likelihood-এ \(\theta\) যে data-পরিমাণের গায়ে লেগে থাকে, সেটাই sufficient statistic। (এর "if and only if" প্রমাণ §৪-এ; এখানে আমরা যন্ত্রটা ব্যবহার করব।)
২.৩ Fisher information — log-likelihood-এর তীক্ষ্ণতা (দুই রূপ)¶
এবার §১.৩-এর "চূড়ার তীক্ষ্ণতা = তথ্য" স্বজ্ঞাকে নিখুঁত সংজ্ঞায় বাঁধি। প্রথমে এক observation-এর জন্য, পরে \(n\)-এ স্কেল করব।
আগে একটা সহায়ক রাশি — score (এক observation-এর জন্য):
অর্থাৎ এক observation-এর log-density-র \(\theta\)-সাপেক্ষ derivative। (এই score-কে একাধিক প্রতীকে লেখা হয় — per-term $s(\theta;x)$, এবং মোট রূপ $S_n(\theta)=\sum_i s(\theta;X_i)$; §৭–৮ ও glossary-তে এটিকে $U$-ও লেখা হয়েছে, সবই একই জিনিস।) চূড়ায় (MLE-তে) এই score শূন্য — তাই score বলে "\(\theta\) ঠিক জায়গা থেকে কোন দিকে, কতটা সরে আছে"। একটা মৌলিক ও সুন্দর ধর্ম (§৪-এ প্রমাণ করা হবে): সত্য \(\theta\)-তে score-এর গড় শূন্য, \(\mathbb{E}[s(\theta;X)]=0\)।
সংজ্ঞা (Fisher information — ফিশার তথ্য, প্রথম রূপ: score-এর variance)। এক observation-এর Fisher information হলো score-এর variance (= বর্গের প্রত্যাশা, যেহেতু গড় শূন্য):
প্রতিটি প্রতীক খুলি:
- \(\partial_\theta \log f(X;\theta)\) — score; এখানে \(X\) random (নমুনা থেকে), তাই এটা একটা random variable।
- \((\cdot)^2\) — বর্গ (চিহ্ন মুছে, কারণ score গড়ে শূন্য কিন্তু ছড়ানো আছে)।
- \(\mathbb{E}[\cdot]\) — সত্য \(\theta\)-তে \(X\)-এর বণ্টনের উপর গড়।
পড়ার নিয়ম: score যত বেশি ওঠানামা করে (variance বড়), data তত তীব্রভাবে \(\theta\)-র পরিবর্তনে সাড়া দেয় — তাই বেশি \(I(\theta)\) মানে বেশি তথ্য। এটাই §১.৩-এর "তীক্ষ্ণ চূড়া"-র এক মুখ।
সংজ্ঞা (Fisher information — দ্বিতীয় রূপ: গড় ঋণাত্মক বক্রতা)। নিয়মিত (regular) পরিস্থিতিতে একই \(I(\theta)\) লেখা যায় log-density-র second derivative-এর গড় ঋণাত্মক রূপে:
এখানে \(\partial_\theta^2 \log f\) মানে log-density-র দ্বিতীয় derivative — অর্থাৎ চূড়ার curvature (বক্রতা)। চূড়ায় function নিচের দিকে বাঁকা (concave), তাই \(\partial_\theta^2\log f<0\); সামনে ঋণচিহ্ন বসিয়ে \(I(\theta)\) ধনাত্মক হয়। মান যত বড়, চূড়া তত তীক্ষ্ণভাবে বাঁকা — ঠিক §১.৩-এর ছবি।
দুই রূপ এক কেন (স্বজ্ঞা)। প্রথম রূপ বলে "score কত ছড়ানো", দ্বিতীয় রূপ বলে "চূড়া কত বাঁকা" — আশ্চর্যজনকভাবে এরা সমান। কারণ score-এর ঢাল (= \(\partial_\theta\) score = \(\partial_\theta^2\log f\)) যত খাড়াভাবে শূন্য পেরোয়, score তত দ্রুত বদলায়, তত তার variance বড়। অর্থাৎ "খাড়া বক্রতা" আর "বড় score-variance" একই ঘটনার দুই বর্ণনা। (এই সমতার পূর্ণ প্রমাণ — score identity ব্যবহার করে — §৪-এ।) ব্যবহারিক টিপ: দ্বিতীয় রূপ (\(-\mathbb{E}[\partial_\theta^2\log f]\)) প্রায়ই হিসাব করা সহজ, তাই §৩-এ বেশিরভাগ সময় সেটাই ব্যবহার করব।
\(n\) observation-এ স্কেলিং (যোগাত্মকতা)। যেহেতু observation-গুলো স্বাধীন, তাদের log-likelihood যোগ হয়, তাই তথ্যও যোগ হয়: পুরো নমুনার Fisher information \(= n\,I(\theta)\)। অর্থাৎ \(n\)টা স্বাধীন data-বিন্দু মিলে একটার \(n\) গুণ তথ্য দেয় — সরল ও স্বজ্ঞাসম্মত (দ্বিগুণ data = দ্বিগুণ তথ্য)। ঠিক এই \(n\)-গুণই পরের CRLB-তে \(\frac{1}{nI(\theta)}\) হয়ে দেখা দেবে।
২.৪ Cramér–Rao lower bound — variance-এর তাত্ত্বিক মেঝে¶
এবার §১.৩-এর সেই অসমতাকে আনুষ্ঠানিক বিবৃতি দিই — প্রশ্ন B-র উত্তর।
Cramér–Rao lower bound (CRLB — ক্রামার–রাও নিম্নসীমা)। কিছু নিয়মিততা-শর্তে (regularity conditions), একটি i.i.d. নমুনার যেকোনো unbiased estimator \(\hat\theta\)-র জন্য তার variance নিচের মেঝে মানে না:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta\) — \(\theta\)-র একটি unbiased estimator (অর্থাৎ \(\mathbb{E}[\hat\theta]=\theta\); এই শর্ত অপরিহার্য — biased estimator-এর variance এর নিচেও নামতে পারে, কারণ তখন MSE-তে bias-পদ যোগ হয়)।
- \(n\) — নমুনা-আকার।
- \(I(\theta)\) — এক observation-এর Fisher information (§২.৩)।
- \(n\,I(\theta)\) — পুরো নমুনার মোট তথ্য; তাই মেঝে \(=\dfrac{1}{\text{মোট তথ্য}}\)।
কীভাবে পড়ব:
- বেশি তথ্য → নিচু মেঝে। \(nI(\theta)\) যত বড় (বেশি data, বা প্রতিটি data বেশি তথ্যবহুল), মেঝে \(\frac{1}{nI(\theta)}\) তত নিচে — তত ছোট variance সম্ভব। স্বজ্ঞাসম্মত।
- \(n\) বাড়লে মেঝে \(\sim 1/n\) হারে নামে। তাই বড় নমুনায় খুব ছোট variance তাত্ত্বিকভাবে অর্জনযোগ্য।
- মেঝে ভাঙা অসম্ভব। কোনো unbiased estimator যতই চতুর হোক, তার variance এই সীমার নিচে নামবে না — এটাই data-র তথ্যসীমার চূড়ান্ত উচ্চারণ।
(CRLB-র উৎপাদন — Cauchy–Schwarz অসমতা ও score-এর ধর্ম ব্যবহার করে — §৪-এ দেওয়া হবে। এখানে statement হিসেবে নিচ্ছি ও §৩-এ সংখ্যায় প্রয়োগ করব।)
২.৫ Efficiency — মেঝে যে ছোঁয়, সে সেরা¶
CRLB হাতে এলে 4.4-এর "efficiency" শব্দটা অবশেষে নিখুঁত মানে পায়।
সংজ্ঞা (Efficient estimator — দক্ষ আনুমানক)। একটি unbiased estimator \(\hat\theta\)-কে efficient বলা হয় যদি তার variance ঠিক CRLB-র মেঝে স্পর্শ করে, অর্থাৎ অসমতাটা সমতায় পরিণত হয়:
অর্থাৎ efficient estimator হলো সম্ভাব্য সবচেয়ে কম-variance-যুক্ত unbiased estimator — সে data-র তথ্য শেষবিন্দু পর্যন্ত নিংড়ে নেয়, আর কিছু আদায় করার বাকি থাকে না। একটি estimator কতটা efficient তা মাপি efficiency অনুপাত দিয়ে:
যা সবসময় \(\le 1\) (কারণ CRLB মেঝে); ঠিক \(1\) হলে \(\hat\theta\) পূর্ণ efficient। (4.4-এর relative efficiency দুই estimator তুলনা করত; এখানে আমরা একটা চূড়ান্ত মানদণ্ড — CRLB মেঝে — পেলাম, যার সাপেক্ষে absolute efficiency মাপা যায়।)
২.৬ MLE-র asymptotic normality — বড় নমুনায় MLE মেঝে ছোঁয়¶
সবশেষে গল্পের সেই সুন্দর সমাপ্তি — যা 4.3-এর MLE আর এই অধ্যায়ের Fisher information/CRLB-কে এক গিঁটে বাঁধে।
MLE-র asymptotic normality (large-sample উপপাদ্য — statement)। নিয়মিত পরিস্থিতিতে, \(n\to\infty\) হলে maximum likelihood estimator \(\hat\theta_{\text{MLE}}\) নিচের আচরণ দেখায়:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta_{\text{MLE}} - \theta\) — MLE-র ভুল (সত্য \(\theta\) থেকে দূরত্ব)।
- \(\sqrt n\) গুণক — ভুলটা \(1/\sqrt n\) হারে শূন্যে যায়, তাই \(\sqrt n\) দিয়ে গুণ করলে একটা স্থিতিশীল (non-degenerate) বণ্টন পাওয়া যায় (ঠিক CLT-র মতো, 3.4)।
- \(\xrightarrow{d}\) — "converges in distribution" (3.4); বাঁ পাশের রাশির বণ্টন \(n\) বাড়ার সাথে ডান পাশের Normal-এ গুটিয়ে যায়।
- \(\mathcal N\!\big(0,\frac{1}{I(\theta)}\big)\) — গড় \(0\) (তাই MLE asymptotically unbiased), variance \(\frac{1}{I(\theta)}\)।
এর তিনটি গভীর ফল (এই অধ্যায়ের চূড়া):
- MLE প্রায়-normal: বড় নমুনায় \(\hat\theta_{\text{MLE}}\)-র বণ্টন প্রায় \(\mathcal N\!\big(\theta,\ \frac{1}{nI(\theta)}\big)\) — কারণ \(\sqrt n(\hat\theta-\theta)\sim\mathcal N(0,1/I(\theta))\) মানে \(\hat\theta\approx\theta+\frac{1}{\sqrt n}\,\mathcal N(0,1/I(\theta))\), যার variance \(\frac{1}{nI(\theta)}\)।
- MLE asymptotically efficient: লক্ষ করুন এই asymptotic variance \(\frac{1}{nI(\theta)}\) ঠিক CRLB-র মেঝে (§২.৪)! অর্থাৎ বড় নমুনায় MLE সেই তাত্ত্বিক সীমা ছুঁয়ে ফেলে — আর ভালো করা সম্ভব নয়। এটাই "MLE বড় নমুনায় সেরা" দাবির নিখুঁত অর্থ।
- ব্যবহারিক সেতু (4.6-এর দিকে): যেহেতু \(\hat\theta_{\text{MLE}}\approx\mathcal N\!\big(\theta,\frac{1}{nI(\theta)}\big)\), তার standard error \(\approx \frac{1}{\sqrt{nI(\theta)}}\) — আর Normal-আকৃতি জানা থাকায় আমরা "\(\hat\theta\pm 1.96\cdot\mathrm{SE}\)" ধরনের confidence interval গড়তে পারব (পরের অধ্যায়, 4.6)। এই কারণেই Fisher information শুধু তাত্ত্বিক সৌন্দর্য নয় — এটি অনিশ্চয়তা-পরিমাপের ব্যবহারিক যন্ত্র।
এক বাক্যে §২-এর সার। sufficiency বলে কোন সারাংশে data-র \(\theta\)-তথ্য সম্পূর্ণ গুটিয়ে থাকে; Fisher information \(I(\theta)\) সেই তথ্যকে একটা সংখ্যায় পরিমাপ করে (log-likelihood-এর তীক্ষ্ণতা); CRLB সেই তথ্য থেকে variance-এর একটা ভাঙা-যায়-না মেঝে \(\frac{1}{nI(\theta)}\) টানে; efficient estimator সেই মেঝে ছোঁয়; আর MLE বড় নমুনায় ঠিক তাই করে — asymptotically normal, unbiased, ও efficient।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর প্রতিটি ধারণাকে এবার সংখ্যায় হাতে-কলমে প্রয়োগ করব। চারটি উদাহরণ চারটি কেন্দ্রীয় ধারণা ধরে: E1 Bernoulli (\(\sum X_i\) sufficient + \(I(p)\)), E2 Normal mean (\(I(\mu)\)), E3 Poisson (\(I(\lambda)\)), E4 MLE asymptotic variance (CRLB ছোঁয়া)। সর্বত্র \(\bar X=\frac1n\sum_{i=1}^n X_i\) মানে sample mean।
প্রতিটি Fisher-information হিসাবে একই ছন্দ রাখব: log-density লেখো → একবার derivative (score) → আবার derivative (\(\partial_\theta^2\log f\)) → ঋণচিহ্নসহ প্রত্যাশা নাও → \(I(\theta)\)। (§২.৩-এর দ্বিতীয় রূপ \(I(\theta)=-\mathbb{E}[\partial_\theta^2\log f]\) ব্যবহার করছি, কারণ হিসাব সহজ।)
৩.১ E1 — Bernoulli\((p)\): \(\sum X_i\) sufficient, আর \(I(p)=\dfrac{1}{p(1-p)}\)¶
এই উদাহরণ §১.২-এর মুদ্রা-স্বজ্ঞাকে সংখ্যায় বাঁধে — দুই অংশে: প্রথমে sufficiency (factorization দিয়ে), পরে Fisher information।
পরিস্থিতি। \(X_1,\dots,X_n\) i.i.d. Bernoulli\((p)\), প্রতিটি \(X_i\in\{0,1\}\) (head \(=1\), tail \(=0\)), অজানা head-হার \(p=P(X_i=1)\)। pmf এক লাইনে:
অংশ ক — \(\sum X_i\) sufficient (factorization theorem, §২.২)। likelihood:
ধরি \(T(X)=\sum_{i=1}^n X_i\) (মোট head)। তাহলে likelihood লেখা যায়
লক্ষ করুন: \(p\) data-কে স্পর্শ করছে কেবল \(T=\sum X_i\)-এর মধ্য দিয়ে (আর \(\theta\)-হীন অংশ \(h(x)=1\))। factorization theorem অনুযায়ী এটাই sufficiency-র শর্ত — তাই \(T=\sum X_i\) sufficient। কোন বিশেষ ক্রমে head এল তা likelihood-এ ঢোকেই না; ঠিক §১.২-এর স্বজ্ঞা — "৭টা head" জানাই \(p\)-র জন্য যথেষ্ট, ক্রম অপ্রাসঙ্গিক। ✓
অংশ খ — Fisher information \(I(p)\)। এক observation-এর log-density:
প্রথম derivative (score), \(p\)-র সাপেক্ষে (\(\partial_p\log p=1/p\), \(\partial_p\log(1-p)=-1/(1-p)\)):
দ্বিতীয় derivative:
এখন ঋণচিহ্নসহ প্রত্যাশা নিই — মূল কথা \(\mathbb{E}[X]=p\) (Bernoulli-র গড়), তাই \(\mathbb{E}[1-X]=1-p\):
ভগ্নাংশ মিলিয়ে:
সংখ্যা ও পাঠ। ধরা যাক \(p=0.5\): \(I(0.5)=\frac{1}{0.5\cdot 0.5}=\frac{1}{0.25}=4\)। এখন \(p=0.1\): \(I(0.1)=\frac{1}{0.1\cdot 0.9}=\frac{1}{0.09}\approx 11.1\)। দুটো কথা পড়ার মতো:
- \(p\) প্রান্তের দিকে গেলে তথ্য বাড়ে: \(p\) যত \(0\) বা \(1\)-এর কাছে, \(p(1-p)\) তত ছোট, তাই \(I(p)\) তত বড় — কারণ প্রান্তে (যেমন \(p\approx0.05\)) কয়েকটা head/tail-ই \(p\)-র মান নিয়ে অনেক জোরালো ইঙ্গিত দেয়।
- CRLB যাচাই (§২.৪): এক observation-এর Bernoulli-তে আমরা জানি \(\mathrm{Var}(\bar X)=\frac{p(1-p)}{n}\), আর CRLB মেঝে \(=\frac{1}{nI(p)}=\frac{p(1-p)}{n}\) — হুবহু সমান! অর্থাৎ \(\hat p=\bar X\) ঠিক CRLB মেঝে ছোঁয় — এটি একটি efficient estimator (§২.৫)। সুন্দরভাবে সব মিলে গেল।
৩.২ E2 — Normal mean: \(I(\mu)=\dfrac{1}{\sigma^2}\)¶
পরিস্থিতি। \(X_1,\dots,X_n\) i.i.d. \(\mathcal N(\mu,\sigma^2)\), যেখানে variance \(\sigma^2\) জানা ধরছি, আর parameter হলো গড় \(\mu\) (\(\mathcal N\) = Normal বণ্টন)। pdf:
log-density। log নিয়ে (\(\log\frac{1}{\sqrt{2\pi\sigma^2}}\) একটা \(\mu\)-হীন ধ্রুবক, \(\log\exp(\cdot)=(\cdot)\)):
score ও second derivative। \(\mu\)-র সাপেক্ষে প্রথম derivative (chain rule-এ \(\partial_\mu(x-\mu)^2 = 2(x-\mu)(-1)\)):
দ্বিতীয় derivative (এবার \(x-\mu\)-এর \(\mu\)-derivative \(=-1\)):
লক্ষণীয় — এটা ধ্রুবক, \(x\)-এর উপর নির্ভরই করে না! তাই প্রত্যাশা নেওয়া তুচ্ছ:
পাঠ ও CRLB যাচাই। এক observation-এর তথ্য \(\frac{1}{\sigma^2}\) — স্বজ্ঞাসম্মত: কম বিক্ষেপ (ছোট \(\sigma^2\)) = বেশি তথ্য, কারণ data টানটান হলে গড় \(\mu\) আরও নিশ্চিতভাবে ধরা যায়। CRLB মেঝে \(=\frac{1}{nI(\mu)}=\frac{\sigma^2}{n}\) — আর আমরা 4.1/4.4 থেকে জানি \(\mathrm{Var}(\bar X)=\frac{\sigma^2}{n}\), হুবহু সমান। তাই \(\hat\mu=\bar X\) Normal mean-এর একটি efficient estimator — তথ্যের শেষবিন্দু পর্যন্ত নিংড়ানো, আর ভালো করা অসম্ভব।
৩.৩ E3 — Poisson\((\lambda)\): \(I(\lambda)=\dfrac{1}{\lambda}\)¶
পরিস্থিতি। \(X_1,\dots,X_n\) i.i.d. Poisson\((\lambda)\) — যেমন এক ঘণ্টায় একটা কল-সেন্টারে আসা ফোনের সংখ্যা; \(\lambda>0\) = গড় হার (rate), \(X_i\in\{0,1,2,\dots\}\)। pmf:
log-density। \(\log f = -\lambda + x\log\lambda - \log(x!)\), যেখানে \(\log(x!)\) একটা \(\lambda\)-হীন পদ:
score ও second derivative। \(\lambda\)-র সাপেক্ষে প্রথম derivative (\(\partial_\lambda(-\lambda)=-1\), \(\partial_\lambda(x\log\lambda)=x/\lambda\), \(\log(x!)\)-এর derivative \(0\)):
দ্বিতীয় derivative:
ঋণচিহ্নসহ প্রত্যাশা — মূল কথা \(\mathbb{E}[X]=\lambda\) (Poisson-এর গড়):
পাঠ ও CRLB যাচাই। তথ্য \(\frac{1}{\lambda}\) — অর্থাৎ ছোট হারে (rare events, ছোট \(\lambda\)) প্রতিটি observation বেশি তথ্যবহুল। CRLB মেঝে \(=\frac{1}{nI(\lambda)}=\frac{\lambda}{n}\)। আর Poisson-এ \(\mathrm{Var}(X)=\lambda\), তাই \(\mathrm{Var}(\bar X)=\frac{\lambda}{n}\) — আবারও হুবহু সমান। কাজেই \(\hat\lambda=\bar X\) (\(\lambda\)-র MLE, 4.3) একটি efficient estimator। তিনটি উদাহরণেই (E1–E3) একই চমৎকার নিদর্শন: সাধারণ গড়-ভিত্তিক estimator ঠিক CRLB মেঝে ছোঁয়।
৩.৪ E4 — MLE-র asymptotic variance: \(\sqrt n(\hat\theta-\theta)\xrightarrow{d}\mathcal N(0,1/I(\theta))\) সংখ্যায়¶
আগের তিনটি উদাহরণ এক observation-এর তথ্য \(I(\theta)\) বের করল। এই শেষ উদাহরণ §২.৬-এর asymptotic normality-কে সংখ্যায় দেখায় — বড় নমুনায় MLE-র variance ঠিক \(\frac{1}{nI(\theta)}\), অর্থাৎ CRLB মেঝে।
সেটআপ। ধরা যাক Poisson\((\lambda)\) মডেল (E3), সত্য \(\lambda=4\) (গড়ে ঘণ্টায় ৪টা কল), নমুনা-আকার \(n=100\)। MLE হলো \(\hat\lambda=\bar X\) (4.3)। §২.৬ বলছে বড় \(n\)-এ
কারণ E3-তে \(I(\lambda)=1/\lambda\), তাই \(\frac{1}{I(\lambda)}=\lambda\)।
asymptotic variance সংখ্যায়। উপরের statement-এর মানে \(\hat\lambda\) প্রায় \(\mathcal N\!\big(\lambda,\ \frac{1}{nI(\lambda)}\big)=\mathcal N\!\big(\lambda,\ \frac{\lambda}{n}\big)\) বণ্টন মানে। সংখ্যা বসাই (\(\lambda=4,\ n=100\)):
যাচাই (ঠিক, asymptotic নয় — মেলে কি?)। এখানে সুবিধা: \(\hat\lambda=\bar X\)-এর প্রকৃত variance আমরা সরাসরিও জানি — \(\mathrm{Var}(\bar X)=\frac{\mathrm{Var}(X)}{n}=\frac{\lambda}{n}=\frac{4}{100}=0.04\)। হুবহু একই! অর্থাৎ এই ক্ষেত্রে asymptotic সূত্র আর প্রকৃত হিসাব মিলে যায় — আর তা ঠিক CRLB মেঝে \(\frac{1}{nI(\lambda)}=0.04\)। তিনটে জিনিস এক বিন্দুতে মিলল: (১) MLE-র asymptotic variance, (২) তার প্রকৃত variance, (৩) CRLB মেঝে — তাই \(\hat\lambda=\bar X\) পূর্ণ efficient।
পাঠ (এই অধ্যায়ের চূড়া সংখ্যায়)। asymptotic normality বলে: বড় নমুনায় \(\hat\lambda\approx\mathcal N(4,\,0.04)\) — অর্থাৎ MLE প্রায়-unbiased (গড়ে \(4\)), প্রায়-normal (ঘণ্টার আকৃতি), আর তার ছড়ানো ঠিক তাত্ত্বিক ন্যূনতম। ব্যবহারিকভাবে এটাই বলে দেয় \(\hat\lambda\) গড়ে সত্য \(\lambda\) থেকে \(\pm 0.2\)-র মধ্যে থাকার কথা — আর Normal-আকৃতি জানা থাকায় পরের অধ্যায়ে (4.6) আমরা এই \(\mathrm{SE}=0.2\) ব্যবহার করে "\(\hat\lambda\pm 1.96\times 0.2\)" ধরনের confidence interval গড়তে পারব। এভাবেই Fisher information তাত্ত্বিক তথ্য-পরিমাপ থেকে ব্যবহারিক অনিশ্চয়তা-ব্যবধানে রূপ নেয়।
§৩-এর সার: E1–E3 দেখাল কীভাবে log-density-র দ্বিতীয় derivative থেকে \(I(\theta)\) বের করি — Bernoulli \(\frac{1}{p(1-p)}\), Normal mean \(\frac{1}{\sigma^2}\), Poisson \(\frac{1}{\lambda}\) — আর প্রতিবার সাধারণ গড়-estimator ঠিক CRLB মেঝে ছুঁয়ে efficient প্রমাণিত হলো। E4 সেই ছবিকে বড় নমুনায় MLE-র asymptotic normality-তে গেঁথে দিল: \(\sqrt n(\hat\theta-\theta)\xrightarrow{d}\mathcal N(0,1/I(\theta))\) — যেখানে variance ঠিক তাত্ত্বিক মেঝে। এই তিন সুতো — sufficiency (E1-এর factorization), Fisher information (E1–E3), আর CRLB-ছোঁয়া MLE (E4) — মিলেই এই অধ্যায়ের গল্প।
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা এই অধ্যায়ের চারটে মূল ধারণার সংজ্ঞা পেয়েছি — sufficient statistic \(T(X)\) (যা data-র মধ্যে \(\theta\) সম্পর্কে সব তথ্য ধরে রাখে), score \(\partial_\theta \log f\) (log-likelihood-এর ঢাল), Fisher information \(I(\theta)\) (data \(\theta\) সম্পর্কে কতটা "তথ্য" বহন করে তার পরিমাপ), আর Cramér–Rao lower bound (CRLB) (যেকোনো unbiased estimator-এর variance-এর তলদেশ)। এবার এই অংশে আমরা scratch থেকে সেই ধারণাগুলোর পেছনের ফলগুলো প্রমাণ করব — কোনো ধাপ লুকানো হবে না, প্রতিটি লাইনের পেছনে কারণ বাংলায় থাকবে। কাজটা চারটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে, sketch দিই):
- (a) Factorization theorem (গুণনীকরণ উপপাদ্য)-এর statement, আর তা দিয়ে E1 Bernoulli-তে দেখানো যে \(\sum X_i\) একটি sufficient statistic। ★★
- (b) Fisher information দুই উপায়ে হিসাব — (i) score-এর variance \(\mathbb{E}[(\partial_\theta\log f)^2]\) আর (ii) ঋণাত্মক প্রত্যাশিত দ্বিতীয় অন্তরজ \(-\mathbb{E}[\partial_\theta^2\log f]\) — E1/E2/E3-এর প্রতিটিতে, আর দেখানো দুটো মিলে যায়। ★★
- (c) CRLB-এর statement আর তার প্রমাণ score ও estimator-এর ওপর Cauchy–Schwarz অসমতা প্রয়োগ করে (সৎ sketch; সঙ্গে \(\mathbb{E}[\text{score}]=0\) regularity-র ভূমিকা)। ★★★
- (d) MLE-র asymptotic normality — \(\sqrt n(\hat\theta-\theta)\xrightarrow{d}\mathcal N(0,1/I(\theta))\) — statement + অন্তর্দৃষ্টি (score-এর Taylor expansion)। ★★★
পুরোটা জুড়ে চারটে running example ব্যবহার করব: E1 Bernoulli\((p)\), E2 Normal\((\mu,\sigma^2)\) (\(\sigma\) জানা), E3 Poisson\((\lambda)\), আর E4 MLE-র সীমান্ত আচরণ।
একটা সাধারণ পরিভাষা আগে স্থির করে নিই, কারণ পুরো §৪ এর ওপর দাঁড়িয়ে। \(n\)টি i.i.d. (independent and identically distributed — স্বাধীন ও সমবণ্টিত) পর্যবেক্ষণ \(X_1,\dots,X_n\) আছে, প্রতিটির density (বা probability mass function, pmf) \(f(x;\theta)\)। যৌথ density গুণফল হয় (স্বাধীনতার জন্য): $$ f(x_1,\dots,x_n;\theta) \;=\; \prod_{i=1}^n f(x_i;\theta). $$ Log-likelihood হলো এর লগারিদম, যেটাকে \(\theta\)-র function হিসেবে দেখি: $$ \ell_n(\theta) \;=\; \log \prod_{i=1}^n f(X_i;\theta) \;=\; \sum_{i=1}^n \log f(X_i;\theta). $$ গুণফল লগে যোগফলে ভেঙে যায় — এটাই log নেওয়ার মূল সুবিধা, আর এই "যোগফল" গঠনই Fisher information-এর additivity (\(n\) পর্যবেক্ষণে মোট information \(= nI(\theta)\)) আর CRLB-র \(1/(nI)\) রূপের জন্ম দেবে।
৪.১ · (a) Factorization theorem — আর E1-এ \(\sum X_i\) sufficient — ★★¶
৪.১.১ · "Sufficient" মানে কী, এক বাক্যে মনে করিয়ে¶
§১–৩-এ বলা হয়েছে: একটা statistic \(T(X)=T(X_1,\dots,X_n)\) (data-র একটা function, যেমন যোগফল বা গড়) sufficient for \(\theta\) যদি, \(T\)-এর মান জানা থাকলে, বাকি data \(\theta\) সম্পর্কে আর কোনো অতিরিক্ত তথ্য না দেয়। আনুষ্ঠানিকভাবে: \(T(X)=t\) শর্তে data \(X\)-এর conditional distribution \(\theta\)-র উপর নির্ভর করে না।
স্বজ্ঞাটা এমন: \(T\) যদি sufficient হয়, তবে \(\theta\) আন্দাজ করতে কাঁচা data-র দরকার নেই — শুধু \(T\)-এর মানটুকুই যথেষ্ট; \(T\) যেন data-টাকে \(\theta\) সম্পর্কে কোনো তথ্য না হারিয়েই একটা ছোট সংখ্যায় সংকুচিত করে দিয়েছে। কিন্তু conditional distribution সরাসরি বের করা প্রায়ই কঠিন। সৌভাগ্যবশত একটা চমৎকার শর্ট-কাট আছে।
৪.১.২ · Factorization theorem (statement)¶
Fisher–Neyman Factorization Theorem. একটি statistic \(T(X)\) তখনই \(\theta\)-র জন্য sufficient যখন যৌথ density/pmf-কে এমন দুটি গুণনীয়াংশের গুণফল হিসেবে লেখা যায়: $$ f(x_1,\dots,x_n;\theta) \;=\; g\big(T(x);\,\theta\big)\,\cdot\,h(x), $$ যেখানে — প্রথম গুণনীয়াংশ \(g\) data-র উপর নির্ভর করে শুধুমাত্র \(T(x)\)-এর মাধ্যমে (এবং \(\theta\)-র উপর নির্ভর করে), আর দ্বিতীয় গুণনীয়াংশ \(h\) \(\theta\)-মুক্ত (data-র উপর নির্ভর করতে পারে, কিন্তু \(\theta\)-র উপর নয়)।
কেন এই factorization sufficiency-র সমান, তার স্বজ্ঞা: যৌথ density-তে \(\theta\) যা-কিছু "কথা বলে", সব ঢুকে আছে \(g(T(x);\theta)\)-এর ভেতরে — আর \(g\) data-কে দেখে কেবল \(T(x)\)-এর জানালা দিয়ে। তাই \(T(x)\) জানা থাকলে, \(\theta\) সম্পর্কে আর জানার কিছু বাকি থাকে না; \(h(x)\) অংশটা \(\theta\)-নিরপেক্ষ ধ্রুবক-সদৃশ, যা likelihood-এর আকৃতিতে \(\theta\)-বরাবর কিছু যোগ করে না। (পূর্ণ "if and only if" প্রমাণ — বিশেষত অবিচ্ছিন্ন ক্ষেত্রে measure-theoretic সূক্ষ্মতা — এই পর্যায়ের বাইরে ★★★; statement-টাই আমাদের হাতিয়ার, Wasserman §9.13।)
ব্যবহারিক রেসিপি। Sufficiency দেখাতে আমরা শুধু যৌথ density লিখব, তারপর \(\theta\)-নির্ভর সব টুকরো একটা গুণনীয়াংশে জড়ো করব, আর দেখব সেই গুণনীয়াংশে data ঢোকে কেবল কোনো একটা সংক্ষিপ্ত সংখ্যা \(T(x)\) দিয়ে। সেই \(T(x)\)-ই sufficient।
৪.১.৩ · E1 প্রয়োগ — Bernoulli\((p)\)-তে \(\sum X_i\) sufficient¶
ধরা যাক \(X_1,\dots,X_n \overset{iid}{\sim} \text{Bernoulli}(p)\), অর্থাৎ প্রতিটি \(X_i\in\{0,1\}\) আর $$ f(x_i;p) \;=\; p^{x_i}(1-p)^{1-x_i}, \qquad x_i\in{0,1}. $$ (যাচাই: \(x_i=1\) হলে এটা \(p\); \(x_i=0\) হলে \((1-p)\) — ঠিক যা চাই।) যৌথ pmf হলো গুণফল: $$ f(x;p) \;=\; \prod_{i=1}^n p^{x_i}(1-p)^{1-x_i}. $$ এবার একই ভিত্তির ঘাতগুলো যোগ করি (এটাই মূল বীজগণিতের ধাপ — \(a^{u}a^{v}=a^{u+v}\)): $$ \prod_{i=1}^n p^{x_i} \;=\; p^{\sum_i x_i}, \qquad \prod_{i=1}^n (1-p)^{1-x_i} \;=\; (1-p)^{\sum_i (1-x_i)} \;=\; (1-p)^{\,n-\sum_i x_i}. $$ শেষ ধাপে \(\sum_{i=1}^n (1-x_i) = n - \sum_i x_i\) ব্যবহার করেছি (১-এর যোগফল \(n\), বিয়োগ মোট \(\sum x_i\))। তাই, লিখি \(t = \sum_{i=1}^n x_i\): $$ \boxed{\,f(x;p) \;=\; p^{\,t}\,(1-p)^{\,n-t}\,}, \qquad t = \sum_{i=1}^n x_i. $$ এখন factorization theorem-এর সাঁচে ফেলি: $$ f(x;p) \;=\; \underbrace{p^{\,t}(1-p)^{\,n-t}}{\displaystyle g(T(x);\,p)} \;\cdot\; \underbrace{1}, \qquad T(x) = \sum_{i=1}^n x_i . $$ লক্ষ করুন — সমস্ত \(p\)-নির্ভরতা প্রথম গুণনীয়াংশে, আর সেই গুণনীয়াংশে data ঢোকে একমাত্র \(t=\sum x_i\)-এর মাধ্যমে; দ্বিতীয় গুণনীয়াংশ এখানে নিছক \(h(x)=1\) (কোনো \(p\)-মুক্ত data-অংশই অবশিষ্ট নেই, কারণ Bernoulli-তে কোনো combinatorial বা normalizing টুকরো লেগে নেই)। factorization theorem অনুযায়ী তাই —
\[\boxed{\,T(X) = \sum_{i=1}^n X_i \ \text{ একটি sufficient statistic for } p\,.}\]
পাঠোদ্ধার। এর তাৎপর্য বিশাল: \(n=1000\)টি ০/১ মান হাতে থাকলেও, \(p\) অনুমান করতে আপনার পুরো ক্রমটা লাগে না — শুধু কতগুলো ১ পড়ল, সেই একটা সংখ্যা \(\sum X_i\)-ই \(p\) সম্পর্কে সব তথ্য বহন করে। কোন কোন অবস্থানে ১ পড়ল (অর্থাৎ data-র ক্রম) তা \(p\) সম্পর্কে অতিরিক্ত কিছুই বলে না। আর যেহেতু \(\bar X = \frac1n\sum X_i\) হলো \(\sum X_i\)-এর এক-এক (one-to-one) function, \(\bar X\)-ও sufficient — এটাই ঠিক Bernoulli-র MLE \(\hat p=\bar X\) (4.3), যা সুন্দরভাবে দেখায় MLE প্রায়ই sufficient statistic-এর উপরেই দাঁড়ায়।
পাশের নোট (★). একই কৌশলে E3 Poisson-এও \(\sum X_i\) sufficient: \(f(x;\lambda)=\prod e^{-\lambda}\lambda^{x_i}/x_i! = e^{-n\lambda}\lambda^{\sum x_i}\cdot \big(\prod 1/x_i!\big)\) — এখানে \(g(T;\lambda)=e^{-n\lambda}\lambda^{t}\) (\(t=\sum x_i\)) আর \(h(x)=\prod 1/x_i!\) (বিশুদ্ধ \(\lambda\)-মুক্ত)। তাই \(T=\sum X_i\) sufficient। E2 Normal-এ (\(\sigma\) জানা) \(\mu\)-র জন্য \(\sum X_i\) (বা \(\bar X\)) sufficient — exponent-এ \(\mu\) ঢোকে কেবল \(\sum x_i\) দিয়ে। এই তিনটেরই গভীর কারণ: এরা exponential family, যেখানে sufficient statistic সবসময় density-র exponent-এ লুকিয়ে থাকে (4.6-এ বিস্তৃত হবে)।
৪.২ · (b) Fisher information দুই উপায়ে — E1/E2/E3 — ★★¶
৪.২.১ · দুটো সংজ্ঞা, আর কেন এরা একই¶
একটি একক পর্যবেক্ষণের Fisher information সংজ্ঞায়িত করা হয় score-এর variance হিসেবে: $$ I(\theta) \;=\; \mathbb{E}!\left[\left(\frac{\partial}{\partial\theta}\log f(X;\theta)\right)^{!2}\right] \qquad\text{(সংজ্ঞা I — score-এর দ্বিতীয় ভ্রামক)} . $$ এখানে \(\partial_\theta \log f\) হলো score — log-density-র \(\theta\)-বরাবর ঢাল। নিচে (৪.৩.১-এ) আমরা দেখব \(\mathbb{E}[\partial_\theta\log f]=0\) (regularity), তাই score-এর mean শূন্য, ফলে এর "second moment" আর "variance" একই জিনিস — অর্থাৎ \(I(\theta)=\mathrm{Var}(\text{score})\)।
আশ্চর্যজনকভাবে আরেকটা, প্রায়ই হিসাবে সহজতর, রূপ আছে: $$ I(\theta) \;=\; -\,\mathbb{E}!\left[\frac{\partial^2}{\partial\theta^2}\log f(X;\theta)\right] \qquad\text{(সংজ্ঞা II — ঋণাত্মক প্রত্যাশিত curvature)} . $$ এটা log-likelihood-এর বক্রতা (curvature, দ্বিতীয় অন্তরজ) মাপে: log-likelihood যত তীক্ষ্ণভাবে চূড়ার চারপাশে নিচে নামে (বেশি ঋণাত্মক দ্বিতীয় অন্তরজ), \(\theta\) সম্পর্কে data তত বেশি "নিশ্চিত" — তত বেশি information।
কেন দুটো সমান (sketch ★★)। ধরি density সঠিকভাবে normalize করা: \(\int f(x;\theta)\,dx = 1\) সব \(\theta\)-র জন্য। দুপাশে \(\theta\)-বরাবর অন্তরীকরণ করি (integral ও derivative-এর ক্রম বদলানো যায় ধরে নিই — এটাই "regularity condition"): $$ \frac{\partial}{\partial\theta}\int f\,dx = 0 \;\;\Rightarrow\;\; \int \frac{\partial f}{\partial\theta}\,dx = 0. $$ এখন একটা মূল পরিচয়: \(\dfrac{\partial}{\partial\theta}\log f = \dfrac{1}{f}\dfrac{\partial f}{\partial\theta}\), অর্থাৎ \(\dfrac{\partial f}{\partial\theta} = f\cdot \dfrac{\partial}{\partial\theta}\log f\) (chain rule)। তাই উপরের সমীকরণ দাঁড়ায় \(\int f\,(\partial_\theta\log f)\,dx = 0\), যা মানে \(\mathbb{E}[\partial_\theta\log f]=0\) (regularity, যা ৪.৩-এও কাজে লাগবে)। আবার একবার \(\theta\)-বরাবর অন্তরীকরণ করি \(\int f\,(\partial_\theta\log f)\,dx = 0\) সমীকরণটিকে; product rule দিয়ে: $$ \int \Big[ \underbrace{(\partial_\theta f)(\partial_\theta\log f)}{=\,f\,(\partial\theta\log f)^2} + f\,(\partial_\theta^2\log f) \Big]dx = 0, $$ যেখানে প্রথম পদে আবার \(\partial_\theta f = f\,\partial_\theta\log f\) বসিয়েছি। পদ দুটো integral-এ আলাদা করলে: $$ \mathbb{E}\big[(\partial_\theta\log f)^2\big] + \mathbb{E}\big[\partial_\theta^2\log f\big] = 0 \;\;\Longrightarrow\;\; \underbrace{\mathbb{E}\big[(\partial_\theta\log f)^2\big]}{I(\theta)\ \text{(সংজ্ঞা I)}} = \underbrace{-\,\mathbb{E}\big[\partial\theta^2\log f\big]}_{I(\theta)\ \text{(সংজ্ঞা II)}} . $$ দুটো সংজ্ঞা সমান — প্রমাণিত। এবার তিনটে উদাহরণে দুপথেই হিসাব করে এই সমতা চোখে দেখি।
৪.২.২ · E1 — Bernoulli\((p)\), \(\quad I(p)=\dfrac{1}{p(1-p)}\)¶
এক পর্যবেক্ষণে \(\log f(x;p) = x\log p + (1-x)\log(1-p)\)।
Score (প্রথম অন্তরজ, \(p\)-বরাবর): $$ \frac{\partial}{\partial p}\log f = \frac{x}{p} - \frac{1-x}{1-p}. $$ (\(\log p\)-র অন্তরজ \(1/p\), আর \(\log(1-p)\)-র অন্তরজ \(-1/(1-p)\) — chain rule-এ ভেতরের \(-1\)।)
পথ I — score-এর second moment. \(X\in\{0,1\}\) হওয়ায় \(X^2=X\) এবং \((1-X)^2=(1-X)\), আর cross term-এ \(X(1-X)=0\) (একটা শূন্য না হলে অন্যটা শূন্য)। তাই $$ \Big(\tfrac{X}{p}-\tfrac{1-X}{1-p}\Big)^2 = \frac{X}{p^2} + \frac{1-X}{(1-p)^2} $$ (cross term অন্তর্হিত)। প্রত্যাশা নিই, \(\mathbb{E}[X]=p\) ব্যবহার করে: $$ I(p) = \mathbb{E}!\left[\frac{X}{p^2}+\frac{1-X}{(1-p)^2}\right] = \frac{p}{p^2} + \frac{1-p}{(1-p)^2} = \frac1p + \frac{1}{1-p}. $$ সাধারণ হর নিয়ে যোগ করি: \(\dfrac1p+\dfrac1{1-p}=\dfrac{(1-p)+p}{p(1-p)}=\dfrac{1}{p(1-p)}\)।
পথ II — ঋণাত্মক প্রত্যাশিত দ্বিতীয় অন্তরজ. score-কে আবার অন্তরীকরণ করি: $$ \frac{\partial^2}{\partial p^2}\log f = -\frac{x}{p^2} - \frac{1-x}{(1-p)^2}. $$ (\(\frac{x}{p}=xp^{-1}\)-র অন্তরজ \(-xp^{-2}\); \(-\frac{1-x}{1-p}\)-র অন্তরজ \(-\frac{1-x}{(1-p)^2}\)।) ঋণ-চিহ্ন দিয়ে প্রত্যাশা নিই: $$ -\mathbb{E}!\left[\frac{\partial^2}{\partial p^2}\log f\right] = \mathbb{E}!\left[\frac{X}{p^2}+\frac{1-X}{(1-p)^2}\right] = \frac1p+\frac1{1-p} = \frac{1}{p(1-p)}. $$ দুই পথ মিলে গেল: $$ \boxed{\,I(p) = \frac{1}{p(1-p)}\,}. $$ লক্ষণীয় — \(p\) যত \(0\) বা \(1\)-এর কাছে, \(I(p)\) তত বড়: প্রান্তিক \(p\)-তে data বেশি information দেয়। আর \(n\) পর্যবেক্ষণে মোট information \(nI(p)=\dfrac{n}{p(1-p)}\), যা CRLB-তে \(\bar X\)-এর variance \(\dfrac{p(1-p)}{n}\)-এর ঠিক অন্যোন্যক — অর্থাৎ Bernoulli-র MLE বাউন্ড ছোঁয় (§৫ Part 2-এ সংখ্যায় দেখব)।
৪.২.৩ · E2 — Normal\((\mu,\sigma^2)\), \(\sigma\) জানা, \(\quad I(\mu)=\dfrac{1}{\sigma^2}\)¶
এক পর্যবেক্ষণে $$ \log f(x;\mu) = -\tfrac12\log(2\pi\sigma^2) - \frac{(x-\mu)^2}{2\sigma^2}. $$ (\(\mu\)-বরাবর) প্রথম পদ ধ্রুবক, তাই score: $$ \frac{\partial}{\partial\mu}\log f = -\frac{1}{2\sigma^2}\cdot 2(x-\mu)\cdot(-1) = \frac{x-\mu}{\sigma^2}. $$ পথ I. \(\mathbb{E}\big[(\tfrac{X-\mu}{\sigma^2})^2\big]=\dfrac{1}{\sigma^4}\mathbb{E}[(X-\mu)^2]=\dfrac{1}{\sigma^4}\cdot\sigma^2=\dfrac{1}{\sigma^2}\), কারণ \(\mathbb{E}[(X-\mu)^2]=\mathrm{Var}(X)=\sigma^2\)।
পথ II. দ্বিতীয় অন্তরজ: \(\dfrac{\partial^2}{\partial\mu^2}\log f = \dfrac{\partial}{\partial\mu}\dfrac{x-\mu}{\sigma^2} = -\dfrac{1}{\sigma^2}\) (একটা ধ্রুবক, data-নিরপেক্ষ!)। তাই \(-\mathbb{E}[\partial_\mu^2\log f] = -(-\tfrac{1}{\sigma^2}) = \dfrac{1}{\sigma^2}\)।
দুই পথ মিলে: $$ \boxed{\,I(\mu) = \frac{1}{\sigma^2}\,}. $$ সুন্দর স্বজ্ঞা — variance যত ছোট, তথ্য তত বেশি (\(I\propto 1/\sigma^2\)): কম ছড়ানো data কেন্দ্র সম্পর্কে বেশি নিশ্চিত। আর Normal-এ দ্বিতীয় অন্তরজ ধ্রুবক হওয়ায় curvature সর্বত্র সমান — তাই log-likelihood নিখুঁত প্যারাবোলা, যা Normal-কে CRLB তত্ত্বের আদর্শ উদাহরণ বানায়।
৪.২.৪ · E3 — Poisson\((\lambda)\), \(\quad I(\lambda)=\dfrac{1}{\lambda}\)¶
এক পর্যবেক্ষণে \(f(x;\lambda)=e^{-\lambda}\lambda^x/x!\), তাই $$ \log f(x;\lambda) = -\lambda + x\log\lambda - \log(x!). $$ Score: \(\dfrac{\partial}{\partial\lambda}\log f = -1 + \dfrac{x}{\lambda} = \dfrac{x-\lambda}{\lambda}\) (\(\log(x!)\) পদ \(\lambda\)-মুক্ত, তাই অন্তরজে অদৃশ্য)।
পথ I. \(\mathbb{E}\big[(\tfrac{X-\lambda}{\lambda})^2\big] = \dfrac{1}{\lambda^2}\mathbb{E}[(X-\lambda)^2] = \dfrac{1}{\lambda^2}\cdot\mathrm{Var}(X) = \dfrac{1}{\lambda^2}\cdot\lambda = \dfrac{1}{\lambda}\), কারণ Poisson-এ mean ও variance উভয়ই \(\lambda\) (\(\mathbb{E}[X]=\lambda\), \(\mathrm{Var}(X)=\lambda\))।
পথ II. দ্বিতীয় অন্তরজ: \(\dfrac{\partial^2}{\partial\lambda^2}\log f = \dfrac{\partial}{\partial\lambda}\big(-1+\tfrac{x}{\lambda}\big) = -\dfrac{x}{\lambda^2}\)। ঋণ-চিহ্নে প্রত্যাশা: \(-\mathbb{E}\big[-\tfrac{X}{\lambda^2}\big] = \dfrac{\mathbb{E}[X]}{\lambda^2} = \dfrac{\lambda}{\lambda^2} = \dfrac{1}{\lambda}\)।
দুই পথ মিলে: $$ \boxed{\,I(\lambda) = \frac{1}{\lambda}\,}. $$
সারণি — তিন উদাহরণ এক নজরে (per observation):
উদাহরণ \(\log f\) score \(\partial_\theta\log f\) \(-\partial_\theta^2\log f\) \(I(\theta)\) E1 Bernoulli\((p)\) \(x\log p+(1-x)\log(1-p)\) \(\dfrac{x}{p}-\dfrac{1-x}{1-p}\) \(\dfrac{x}{p^2}+\dfrac{1-x}{(1-p)^2}\) \(\dfrac{1}{p(1-p)}\) E2 Normal\((\mu)\) \(-\dfrac{(x-\mu)^2}{2\sigma^2}+c\) \(\dfrac{x-\mu}{\sigma^2}\) \(\dfrac{1}{\sigma^2}\) \(\dfrac{1}{\sigma^2}\) E3 Poisson\((\lambda)\) \(-\lambda+x\log\lambda-\log x!\) \(\dfrac{x-\lambda}{\lambda}\) \(\dfrac{x}{\lambda^2}\) \(\dfrac{1}{\lambda}\) তিনটেতেই দুই সংজ্ঞা একই উত্তর দেয় — §৫ Part 1-এ এই সমতা Monte-Carlo সিমুলেশনে সংখ্যায়ও যাচাই করব। (Figure
4-5-fisher-infocurvature-হিসেবে-তথ্য ছবিতে দেখাবে।)
৪.৩ · (c) Cramér–Rao Lower Bound — Cauchy–Schwarz দিয়ে — ★★★¶
৪.৩.১ · Statement আর দুই regularity শর্ত¶
Cramér–Rao Lower Bound (CRLB). ধরা যাক \(\hat\theta = \hat\theta(X_1,\dots,X_n)\) একটি unbiased estimator (\(\mathbb{E}[\hat\theta]=\theta\)), আর density যথেষ্ট "মসৃণ" (regularity, নিচে)। তবে $$ \boxed{\,\mathrm{Var}(\hat\theta) \;\ge\; \frac{1}{n\,I(\theta)}\,}. $$
এটি একটা মৌলিক তলদেশ: কোনো unbiased estimator যত চতুরই হোক, তার variance \(\frac{1}{nI(\theta)}\)-এর নিচে নামতে পারে না। Information \(I(\theta)\) যত বেশি (data যত বেশি বলে), বাউন্ড তত নিচে — তত নিখুঁত অনুমান সম্ভব। আর সাম্য (\(=\)) যে estimator অর্জন করে, তাকে বলি efficient (দক্ষ)।
প্রমাণের জন্য দুটো ভিত্তি লাগবে, দুটোই regularity থেকে আসা:
- Score-এর mean শূন্য: total score \(S_n(\theta):=\partial_\theta\ell_n(\theta)=\sum_{i=1}^n \partial_\theta\log f(X_i;\theta)\)-এর প্রত্যাশা \(\mathbb{E}[S_n(\theta)]=0\)। (৪.২.১-এ এক পর্যবেক্ষণে \(\mathbb{E}[\partial_\theta\log f]=0\) দেখিয়েছি; \(n\)টি যোগ করলেও যোগফল \(0\)।)
- Score-এর variance \(=nI(\theta)\): স্বাধীনতার জন্য variance যোগ হয়, আর প্রতিটি পদের variance \(=I(\theta)\) (mean শূন্য বলে \(\mathrm{Var}=\mathbb{E}[(\cdot)^2]=I\))। তাই \(\mathrm{Var}(S_n)=\mathbb{E}[S_n^2]=nI(\theta)\)।
৪.৩.২ · প্রমাণের মূল হাতিয়ার — Cauchy–Schwarz / covariance অসমতা¶
আমরা covariance ও variance-এর Cauchy–Schwarz ব্যবহার করব: যেকোনো দুই random variable \(U,V\)-এর জন্য $$ \big(\mathrm{Cov}(U,V)\big)^2 \;\le\; \mathrm{Var}(U)\,\mathrm{Var}(V). $$ (এটি স্বীকৃত: correlation \(\rho_{U,V}\in[-1,1]\), আর \(\rho^2 = \mathrm{Cov}^2/(\mathrm{Var}\,U\cdot\mathrm{Var}\,V)\le 1\) — তা থেকে সরাসরি।) আমরা \(U=\hat\theta\) (estimator) আর \(V=S_n(\theta)\) (total score) বসাব। কৌশলটা হলো — এদের covariance আমরা ঠিক \(1\)-এ বাঁধতে পারব, আর variance দুটোও জানা, ফলে অসমতা সাজালেই বাউন্ড বেরিয়ে আসে।
৪.৩.৩ · মূল লেমা — \(\mathrm{Cov}(\hat\theta,\,S_n) = 1\) (unbiased হলে)¶
এটাই প্রমাণের প্রাণভোমরা। যেহেতু \(\mathbb{E}[S_n]=0\), আমরা পাই \(\mathrm{Cov}(\hat\theta,S_n)=\mathbb{E}[\hat\theta\,S_n] - \mathbb{E}[\hat\theta]\underbrace{\mathbb{E}[S_n]}_{0} = \mathbb{E}[\hat\theta\,S_n]\)। এখন \(\mathbb{E}[\hat\theta\,S_n]\) হিসাব করি। লিখি যৌথ density \(f_n(x;\theta)=\prod_i f(x_i;\theta)\); মনে রাখি \(S_n=\partial_\theta\log f_n = \dfrac{\partial_\theta f_n}{f_n}\), তাই \(\hat\theta\,S_n\,f_n = \hat\theta\,\partial_\theta f_n\)। তাহলে $$ \mathbb{E}[\hat\theta\,S_n] = \int \hat\theta(x)\,S_n(x)\,f_n(x;\theta)\,dx = \int \hat\theta(x)\,\frac{\partial f_n}{\partial\theta}\,dx = \frac{\partial}{\partial\theta}\int \hat\theta(x)\,f_n(x;\theta)\,dx, $$ যেখানে শেষ ধাপে আবার integral–derivative-এর ক্রম বদলেছি (regularity)। কিন্তু ভেতরের integral হলো ঠিক \(\mathbb{E}[\hat\theta]\), আর unbiased বলে \(\mathbb{E}[\hat\theta]=\theta\)। তাই $$ \mathbb{E}[\hat\theta\,S_n] = \frac{\partial}{\partial\theta}\,\theta = 1 \;\;\Longrightarrow\;\; \boxed{\,\mathrm{Cov}(\hat\theta,\,S_n) = 1\,}. $$ ঠিক এই জায়গাতেই "unbiased" ধরা অপরিহার্য — \(\mathbb{E}[\hat\theta]=\theta\) না হলে ডানপাশে \(1\)-এর বদলে \(\partial_\theta\mathbb{E}[\hat\theta]\neq 1\) আসত, আর বাউন্ডের রূপ বদলে যেত (biased ক্ষেত্রে এর সাধারণীকরণ আছে, কিন্তু সেটা ★★★-এর বাইরে)।
৪.৩.৪ · টুকরো জোড়া — বাউন্ড বেরিয়ে আসে¶
এবার Cauchy–Schwarz-এ \(U=\hat\theta,\ V=S_n\) বসাই: $$ \underbrace{\big(\mathrm{Cov}(\hat\theta,S_n)\big)^2}{=\,1^2\,=\,1} \;\le\; \mathrm{Var}(\hat\theta)\cdot \underbrace{\mathrm{Var}(S_n)} . $$ অর্থাৎ \(1 \le \mathrm{Var}(\hat\theta)\cdot nI(\theta)\)। দুপাশে \(nI(\theta)>0\) দিয়ে ভাগ করলেই — $$ \boxed{\,\mathrm{Var}(\hat\theta) \;\ge\; \frac{1}{nI(\theta)}\,} \qquad\blacksquare $$ সৎ সীমাবদ্ধতার নোট (★★★)। এই প্রমাণে আমরা দুবার "integral ও derivative-এর ক্রম বদলানো যায়" ধরে নিয়েছি (৪.২.১ ও ৪.৩.৩-এ)। এটাই মূল regularity condition — যা ধরে নেয় support \(\theta\)-র উপর নির্ভর করে না (যেমন Uniform\((0,\theta)\)-তে এটা ভাঙে, তাই সেখানে CRLB সরাসরি খাটে না — সেজন্যই \(\max X_i\) "অতি-দক্ষ" দেখায়, 4.4 E4 স্মরণ করুন), আর প্রয়োজনীয় অন্তরজ ও প্রত্যাশা সসীম। সম্পূর্ণ rigor-এ এই বদলগুলো dominated convergence দিয়ে ন্যায্য করতে হয়; আমাদের তিনটে exponential-family উদাহরণে (E1/E2/E3) শর্তগুলো অনায়াসে মেটে। (Wasserman §9.10, Rice §8.7।)
সাম্য কখন? Cauchy–Schwarz-এ সাম্য তখনই, যখন \(\hat\theta-\theta\) আর \(S_n\) একে অপরের ধ্রুবক-গুণিতক (linearly dependent) — অর্থাৎ \(\hat\theta-\theta = c(\theta)\,S_n\) আকারে। ঠিক এই শর্ত exponential family-তে মেটে, তাই সেখানকার সহজ MLE-রা CRLB ছুঁয়ে ফেলে (§৫ Part 2-এ efficiency \(\approx 1.00\) দেখব)। (Figure 4-5-crlb variance-floor হিসেবে CRLB আঁকবে।)
৪.৪ · (d) MLE-র Asymptotic Normality — \(\sqrt n(\hat\theta-\theta)\xrightarrow{d}\mathcal N(0,1/I(\theta))\) — ★★★¶
৪.৪.১ · Statement¶
MLE Asymptotic Normality. "মসৃণ" (regular) parametric model-এ, সত্য মান \(\theta_0\)-এ, maximum likelihood estimator \(\hat\theta_n\) বড় \(n\)-এ মোটামুটি Normal: $$ \boxed{\,\sqrt{n}\,(\hat\theta_n - \theta_0) \;\xrightarrow{\ d\ }\; \mathcal N!\Big(0,\ \frac{1}{I(\theta_0)}\Big)\,} \qquad(\text{eq. E4}), $$ অর্থাৎ আনুমানিকভাবে \(\hat\theta_n \approx \mathcal N\!\big(\theta_0,\ \tfrac{1}{nI(\theta_0)}\big)\) বড় \(n\)-এ।
এর দুটো অসাধারণ বার্তা: (১) MLE consistent (\(\hat\theta_n\xrightarrow{P}\theta_0\), কারণ এর variance \(\sim \frac{1}{nI}\to 0\))। (২) MLE asymptotically efficient — তার সীমান্ত variance ঠিক CRLB \(\frac{1}{nI}\), অর্থাৎ বড় \(n\)-এ কোনো (regular) unbiased estimator MLE-র চেয়ে ভালো করতে পারে না। CRLB ছিল একটা তলদেশ; এই ফল বলছে MLE সেই তলদেশ ছুঁয়ে ফেলে (asymptotically)।
৪.৪.২ · কেন — score-এর Taylor expansion দিয়ে অন্তর্দৃষ্টি¶
পূর্ণ প্রমাণ এই পর্যায়ের বাইরে (★★★), কিন্তু মূল যন্ত্রটা চমৎকার সরল, আর তা CLT (3.4) ও LLN (3.3)-কে এক করে — তাই স্বজ্ঞাটা দিই।
MLE \(\hat\theta_n\) সংজ্ঞা অনুযায়ী log-likelihood-এর চূড়া, অর্থাৎ সেখানে score শূন্য: $$ S_n(\hat\theta_n) = \ell_n'(\hat\theta_n) = 0. $$ এবার score-কে সত্য মান \(\theta_0\)-র চারপাশে Taylor (প্রথম ক্রম) expand করি (mean value theorem): $$ 0 = S_n(\hat\theta_n) \;\approx\; S_n(\theta_0) + (\hat\theta_n-\theta_0)\,S_n'(\theta_0), $$ যেখানে \(S_n'(\theta_0)=\ell_n''(\theta_0)\) হলো log-likelihood-এর দ্বিতীয় অন্তরজ। \((\hat\theta_n-\theta_0)\)-এর জন্য সমাধান করি, আর \(\sqrt n\) দিয়ে স্কেল করি: $$ \sqrt n\,(\hat\theta_n-\theta_0) \;\approx\; \frac{\tfrac{1}{\sqrt n}\,S_n(\theta_0)}{-\tfrac1n\,\ell_n''(\theta_0)} \;=\; \frac{\text{(লব)}}{\text{(হর)}}. $$ এবার লব ও হরকে আলাদা করে দেখি — দুটো ভিন্ন সীমা-উপপাদ্য এখানে একসাথে কাজ করে:
- লব — CLT। \(S_n(\theta_0)=\sum_{i=1}^n \partial_\theta\log f(X_i;\theta_0)\) হলো i.i.d. score-গুলোর যোগফল, প্রতিটির mean \(0\) (৪.৩.১) আর variance \(I(\theta_0)\) (৪.২)। তাই Central Limit Theorem অনুযায়ী $$ \frac{1}{\sqrt n}\,S_n(\theta_0) \;\xrightarrow{\ d\ }\; \mathcal N\big(0,\ I(\theta_0)\big). $$
- হর — LLN. \(-\tfrac1n\ell_n''(\theta_0) = \tfrac1n\sum_{i=1}^n\big(-\partial_\theta^2\log f(X_i;\theta_0)\big)\) হলো i.i.d. পদগুলোর গড়, প্রতিটির mean \(\mathbb{E}[-\partial_\theta^2\log f]=I(\theta_0)\) (৪.২-র সংজ্ঞা II!)। তাই Law of Large Numbers অনুযায়ী $$ -\frac1n\,\ell_n''(\theta_0) \;\xrightarrow{\ P\ }\; I(\theta_0). $$
দুটো একসাথে বসিয়ে (Slutsky-র উপপাদ্য — একটা \(\xrightarrow{d}\) Normal-কে একটা \(\xrightarrow{P}\) ধ্রুবক দিয়ে ভাগ করলে অনুপাত Normal থাকে, ভাগফলের ধ্রুবকটি স্কেল করে): $$ \sqrt n\,(\hat\theta_n-\theta_0) \;\xrightarrow{\ d\ }\; \frac{\mathcal N(0,\,I(\theta_0))}{I(\theta_0)} \;=\; \mathcal N!\Big(0,\ \frac{I(\theta_0)}{I(\theta_0)^2}\Big) \;=\; \mathcal N!\Big(0,\ \frac{1}{I(\theta_0)}\Big). $$ (শেষ ধাপে variance-এর স্কেলিং: \(\mathrm{Var}(aY)=a^2\mathrm{Var}(Y)\) দিয়ে \(a=1/I\) বসিয়ে \(I/I^2 = 1/I\)।) ঠিক eq. E4 — অন্তর্দৃষ্টি সম্পূর্ণ। (যা skip করলাম ★★★: \(\hat\theta_n\xrightarrow{P}\theta_0\) আগে প্রমাণ করা, Taylor-এর অবশিষ্ট পদ নগণ্য দেখানো, আর \(\ell''\)-কে \(\hat\theta_n\) নয় \(\theta_0\)-তে মূল্যায়নের ন্যায্যতা — Wasserman §9.4, Rice §8.5.2।)
এক বাক্যে গল্প। MLE-র এলোমেলোতার উৎস score-এর এলোমেলোতা (লব, CLT-তে Normal), আর তা কতটা \(\hat\theta\)-তে অনুবাদ হবে তা ঠিক করে log-likelihood-এর curvature (হর, LLN-এ \(I\)-তে স্থির)। তীক্ষ্ণ চূড়া (বড় \(I\)) = score-এর ওঠানামা কম \(\hat\theta\)-তে গড়ায় = ছোট variance \(1/(nI)\)। এভাবেই Fisher information, CRLB ও MLE — তিনটে আলাদা ধারণা একই সূত্রে গাঁথা পড়ে। (Figure
4-5-mle-asymptoticএই অভিসরণ ছবিতে দেখাবে; §৫ Part 3-এ সংখ্যায় যাচাই।)
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর তিনটে স্তম্ভকে আমরা সংখ্যায় যাচাই করব — যাতে Fisher information, CRLB ও MLE-র asymptotic আচরণ কাগজে নয় শুধু, computer-এও বিশ্বাসযোগ্য হয়। তিনটে অংশ, §৪-এর কাঠামো অনুসরণ করে:
- Part 1 — Fisher information = curvature (§৪.২)। প্রতিটি উদাহরণে (E1/E2/E3) এক পর্যবেক্ষণের Fisher information তিন উপায়ে বের করব — (a) হাতে-derive করা closed form, (b) ঋণাত্মক দ্বিতীয় অন্তরজের Monte-Carlo গড় \(\mathbb{E}[-\partial_\theta^2\log f]\), আর (c) score-এর বর্গের গড় \(\mathbb{E}[(\partial_\theta\log f)^2]\) — তারপর দেখব তিনটে এক জায়গায় মেলে (দুই information identity), আর \(\mathbb{E}[\text{score}]\approx 0\)।
- Part 2 — Var(MLE) বনাম CRLB (§৪.৩)। প্রতিটি model-এ হাজার-হাজার স্বাধীন নমুনায় MLE হিসাব করে তার sampling variance বের করব, তারপর CRLB \(\frac{1}{nI}\)-এর সাথে তুলনা — efficiency \(=\frac{\text{CRLB}}{\mathrm{Var}(\text{MLE})}\) মেপে দেখব তা \(\approx 1\) (MLE বাউন্ড ছোঁয়)।
- Part 3 — Asymptotic normality (§৪.৪)। \(n\) বাড়ার সাথে দেখব \(\sqrt n(\hat\theta-\theta)\)-এর sampling distribution Normal-এর দিকে যায় — তার variance \(\frac{1}{I}\)-তে স্থির থাকে, আর skewness ও excess-kurtosis \(0\)-এর দিকে নামে।
সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয়।)
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.5 — Sufficiency, Fisher Information & the Cramer-Rao Bound : Code Lab
# Numerically illustrates / verifies (sections 4 & 5):
# PART 1 — Fisher information as CURVATURE of the log-likelihood:
# compute I(theta) THREE ways and compare to the closed form, for
# E1 Bernoulli I(p) = 1 / (p(1-p))
# E2 Normal I(mu) = 1 / sigma^2
# E3 Poisson I(lambda) = 1 / lambda
# PART 2 — MLE sampling distribution vs the CRLB 1/(n I(theta)):
# simulate the MLE, compare Var(MLE) to 1/(n I) (efficiency).
# PART 3 — Asymptotic normality: sqrt(n)(thetahat - theta) -> Normal(0, 1/I)
# as n grows (variance -> 1/I; skewness/kurtosis -> 0).
# Reproducible: numpy default_rng with a fixed seed.
import numpy as np
from scipy import stats
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=6, suppress=True)
# ===========================================================================
# PART 1 — FISHER INFORMATION = CURVATURE OF THE LOG-LIKELIHOOD
# For one observation, I(theta) = E[ -d^2/dtheta^2 log f ] = E[(score)^2].
# Verify the closed forms for E1/E2/E3 via Monte-Carlo over both identities.
# ===========================================================================
print("=" * 74)
print("PART 1 - Fisher information I(theta) for ONE observation: three routes agree")
print(" (a) closed form (b) E[-d2/dth2 log f] (c) E[(d/dth log f)^2]")
print("=" * 74)
REP_I = 2_000_000 # huge sample so Monte-Carlo means are tight
# ---- E1 : Bernoulli(p). score = x/p - (1-x)/(1-p); -2nd = x/p^2 + (1-x)/(1-p)^2
p = 0.30
Xb = (rng.random(REP_I) < p).astype(float)
score_b = Xb / p - (1 - Xb) / (1 - p)
neg2nd_b = Xb / p**2 + (1 - Xb) / (1 - p)**2
print(f"\n E1 Bernoulli(p={p}): closed 1/(p(1-p)) = {1.0/(p*(1-p)):.5f}")
print(f" (b) mean[-2nd deriv] = {neg2nd_b.mean():.5f}")
print(f" (c) mean[ score^2 ] = {(score_b**2).mean():.5f}")
print(f" mean[score] (should be ~0) = {score_b.mean():.5f}")
# ---- E2 : Normal(mu, sigma^2). score = (x-mu)/s^2; -2nd = 1/s^2 (constant)
mu, sigma = 1.5, 2.0
Xn = rng.normal(mu, sigma, REP_I)
score_n = (Xn - mu) / sigma**2
neg2nd_n = np.full_like(Xn, 1.0 / sigma**2)
print(f"\n E2 Normal(mu, sigma^2={sigma**2:.1f}): closed 1/sigma^2 = {1.0/sigma**2:.5f}")
print(f" (b) mean[-2nd deriv] = {neg2nd_n.mean():.5f}")
print(f" (c) mean[ score^2 ] = {(score_n**2).mean():.5f}")
print(f" mean[score] (should be ~0) = {score_n.mean():.5f}")
# ---- E3 : Poisson(lambda). score = x/lam - 1; -2nd = x/lam^2
lam = 4.0
Xp = rng.poisson(lam, REP_I).astype(float)
score_p = Xp / lam - 1.0
neg2nd_p = Xp / lam**2
print(f"\n E3 Poisson(lambda={lam}): closed 1/lambda = {1.0/lam:.5f}")
print(f" (b) mean[-2nd deriv] = {neg2nd_p.mean():.5f}")
print(f" (c) mean[ score^2 ] = {(score_p**2).mean():.5f}")
print(f" mean[score] (should be ~0) = {score_p.mean():.5f}")
print("\n Read-off: for each example (a)=(b)=(c) to ~3 dp => the two information")
print(" identities I = E[-d2 log f] = E[(score)^2] hold, and E[score] = 0.")
# ===========================================================================
# PART 2 — MLE SAMPLING DISTRIBUTION vs THE CRAMER-RAO BOUND 1/(n I(theta))
# Draw REP independent samples of size n, compute the MLE on each, compare
# empirical Var(MLE) to CRLB 1/(nI). efficiency = CRLB / Var(MLE) in [0,1].
# ===========================================================================
print("\n" + "=" * 74)
print("PART 2 - Var(MLE) vs CRLB 1/(nI): the MLE essentially attains the bound")
print("=" * 74)
REP = 60_000
n = 50
def report(name, theta, mle_samples, I_theta):
var_mle = mle_samples.var(ddof=1)
crlb = 1.0 / (n * I_theta)
bias = mle_samples.mean() - theta
print(f" {name:<22} n={n}")
print(f" true theta = {theta:.5f}")
print(f" mean(MLE) = {mle_samples.mean():.5f} (bias = {bias:+.5f})")
print(f" Var(MLE) [empirical] = {var_mle:.6f}")
print(f" CRLB = 1/(n I) = {crlb:.6f}")
print(f" efficiency CRLB/Var = {crlb / var_mle:.4f}")
# E1 Bernoulli: MLE phat = mean(X); I(p) = 1/(p(1-p))
phat = ((rng.random((REP, n)) < p).astype(float)).mean(axis=1)
report("E1 Bernoulli(p=0.30)", p, phat, 1.0 / (p * (1 - p)))
# E2 Normal mean: MLE muhat = mean(X); I(mu) = 1/sigma^2
muhat = rng.normal(mu, sigma, (REP, n)).mean(axis=1)
report("E2 Normal(mu=1.5)", mu, muhat, 1.0 / sigma**2)
# E3 Poisson: MLE lamhat = mean(X); I(lambda) = 1/lambda
lamhat = rng.poisson(lam, (REP, n)).astype(float).mean(axis=1)
report("E3 Poisson(lambda=4)", lam, lamhat, 1.0 / lam)
print("\n Read-off: in all three, empirical Var(MLE) sits right on CRLB 1/(nI),")
print(" so efficiency ~ 1.00 => these MLEs are (finite-sample) EFFICIENT.")
# ===========================================================================
# PART 3 — ASYMPTOTIC NORMALITY: sqrt(n)(thetahat - theta) -> N(0, 1/I(theta))
# E3 Poisson(lambda=4) => limiting variance 1/I(lambda) = lambda = 4.
# As n grows: variance -> 1/I, and skewness/excess-kurtosis -> 0.
# ===========================================================================
print("\n" + "=" * 74)
print("PART 3 - MLE asymptotic normality: sqrt(n)(lamhat - lambda) -> N(0, 1/I)")
print(f" Poisson(lambda={lam}): target limiting variance 1/I = lambda = {lam:.1f}")
print("=" * 74)
print(f"\n {'n':>6} {'mean':>9} {'Var[sqrt(n)(lamhat-lam)]':>26} {'1/I':>7} {'skew':>8} {'exkurt':>8}")
print(" " + "-" * 70)
REP3 = 120_000
for nn in [5, 20, 100, 1000]:
lamhat = rng.poisson(lam, (REP3, nn)).astype(float).mean(axis=1)
z = np.sqrt(nn) * (lamhat - lam) # standardized statistic
print(f" {nn:>6} {z.mean():>9.4f} {z.var(ddof=1):>26.4f} {lam:>7.2f} "
f"{stats.skew(z):>8.4f} {stats.kurtosis(z):>8.4f}")
print("\n Read-off: Var[sqrt(n)(lamhat-lam)] stays ~ 1/I = 4 for every n (exact here),")
print(" while skewness and excess-kurtosis shrink toward 0 as n grows -> the sampling")
print(" distribution of the MLE approaches N(theta, 1/(nI)) (eq. E4).")
৫.২ · বাস্তব আউটপুট ও পাঠোদ্ধার¶
স্ক্রিপ্টটা চালালে নিচের আউটপুট পাওয়া যায় (হুবহু, seed 20260619):
==========================================================================
PART 1 - Fisher information I(theta) for ONE observation: three routes agree
(a) closed form (b) E[-d2/dth2 log f] (c) E[(d/dth log f)^2]
==========================================================================
E1 Bernoulli(p=0.3): closed 1/(p(1-p)) = 4.76190
(b) mean[-2nd deriv] = 4.76009
(c) mean[ score^2 ] = 4.76009
mean[score] (should be ~0) = -0.00095
E2 Normal(mu, sigma^2=4.0): closed 1/sigma^2 = 0.25000
(b) mean[-2nd deriv] = 0.25000
(c) mean[ score^2 ] = 0.24933
mean[score] (should be ~0) = -0.00018
E3 Poisson(lambda=4.0): closed 1/lambda = 0.25000
(b) mean[-2nd deriv] = 0.25021
(c) mean[ score^2 ] = 0.25028
mean[score] (should be ~0) = 0.00086
Read-off: for each example (a)=(b)=(c) to ~3 dp => the two information
identities I = E[-d2 log f] = E[(score)^2] hold, and E[score] = 0.
==========================================================================
PART 2 - Var(MLE) vs CRLB 1/(nI): the MLE essentially attains the bound
==========================================================================
E1 Bernoulli(p=0.30) n=50
true theta = 0.30000
mean(MLE) = 0.30015 (bias = +0.00015)
Var(MLE) [empirical] = 0.004193
CRLB = 1/(n I) = 0.004200
efficiency CRLB/Var = 1.0017
E2 Normal(mu=1.5) n=50
true theta = 1.50000
mean(MLE) = 1.50090 (bias = +0.00090)
Var(MLE) [empirical] = 0.080219
CRLB = 1/(n I) = 0.080000
efficiency CRLB/Var = 0.9973
E3 Poisson(lambda=4) n=50
true theta = 4.00000
mean(MLE) = 4.00062 (bias = +0.00062)
Var(MLE) [empirical] = 0.081188
CRLB = 1/(n I) = 0.080000
efficiency CRLB/Var = 0.9854
Read-off: in all three, empirical Var(MLE) sits right on CRLB 1/(nI),
so efficiency ~ 1.00 => these MLEs are (finite-sample) EFFICIENT.
==========================================================================
PART 3 - MLE asymptotic normality: sqrt(n)(lamhat - lambda) -> N(0, 1/I)
Poisson(lambda=4.0): target limiting variance 1/I = lambda = 4.0
==========================================================================
n mean Var[sqrt(n)(lamhat-lam)] 1/I skew exkurt
----------------------------------------------------------------------
5 0.0003 4.0357 4.00 0.2272 0.0692
20 -0.0038 3.9849 4.00 0.1112 0.0094
100 0.0079 3.9990 4.00 0.0617 0.0206
1000 -0.0027 3.9914 4.00 0.0179 -0.0064
Read-off: Var[sqrt(n)(lamhat-lam)] stays ~ 1/I = 4 for every n (exact here),
while skewness and excess-kurtosis shrink toward 0 as n grows -> the sampling
distribution of the MLE approaches N(theta, 1/(nI)) (eq. E4).
পাঠোদ্ধার — কী শিখলাম।
-
Part 1 (Fisher information = দুই পরিচয়, §৪.২ যাচাই). তিনটে উদাহরণেই closed form (a), curvature-গড় (b), আর score-বর্গের গড় (c) — তিনটে স্তম্ভ তিন দশমিক স্থান পর্যন্ত মিলে যায়: E1-এ তিনটেই \(\approx 4.760\), E2-তে তিনটেই \(\approx 0.250\), E3-এ তিনটেই \(\approx 0.250\)। এটাই \(I(\theta)=\mathbb{E}[-\partial_\theta^2\log f]=\mathbb{E}[(\partial_\theta\log f)^2]\)-এর সংখ্যাগত প্রমাণ। সঙ্গে
mean[score]প্রতিটিতে \(\approx 0\) (\(\pm 0.001\)-এর ভেতরে) — অর্থাৎ score-এর প্রত্যাশা শূন্য (৪.৩.১-এর regularity), যেটা CRLB প্রমাণের ভিত্তি ছিল। (লক্ষণীয়: E2 Normal-এ(b) -2nd derivঠিক \(0.25000\) — কারণ Normal-এ দ্বিতীয় অন্তরজ \(1/\sigma^2\) একটা ধ্রুবক, data-নিরপেক্ষ, তাই কোনো Monte-Carlo error নেই; পথ (c)-তে সামান্য \(\approx 0.249\) এসেছে এলোমেলো নমুনার জন্য।) -
Part 2 (CRLB ও efficiency, §৪.৩ যাচাই). তিনটে model-এই, \(n=50\)-এ MLE-র empirical variance আর তাত্ত্বিক CRLB \(\frac{1}{nI}\) কার্যত অভিন্ন: E1-এ \(0.004193\) বনাম \(0.004200\); E2-তে \(0.0802\) বনাম \(0.0800\); E3-এ \(0.0812\) বনাম \(0.0800\)। ফলে efficiency \(=\frac{\text{CRLB}}{\mathrm{Var}}\) তিনটেতেই \(\approx 1.00\) (0.985–1.002)। অর্থাৎ এই তিনটে MLE বাউন্ডটা ছুঁয়ে ফেলেছে — এরা (finite-sample) efficient, যা ৪.৩.৪-এর সাম্য-শর্তের (exponential family) সরাসরি ফল। bias-ও নগণ্য (\(\lvert\text{bias}\rvert<0.001\)), তাই unbiased-CRLB তুলনা ন্যায্য।
-
Part 3 (Asymptotic normality, §৪.৪ যাচাই). standardized statistic \(\sqrt n(\hat\lambda-\lambda)\)-এর variance প্রতিটি \(n\)-এই \(\approx 4.0\) — ঠিক \(1/I(\lambda)=\lambda=4\) (Poisson-এ এটা সব \(n\)-এ হুবহু সত্য, কারণ \(\bar X\)-এর variance \(\lambda/n\), তাই \(\sqrt n\)-স্কেলে \(\lambda\))। আসল গল্পটা শেষ দুই কলামে: skewness \(0.227\to0.111\to0.062\to0.018\) আর excess-kurtosis \(0\)-র দিকে নামছে \(n\) বাড়ার সাথে। অর্থাৎ ছোট \(n\)-এ sampling distribution বাঁকা/অপ্রতিসম (Poisson-এর ছাপ), কিন্তু \(n\) বড় হলে তা ক্রমে নিখুঁত Normal \(\mathcal N(0,1/I)\)-এর আকার নেয় — এটাই eq. E4-র দৃশ্যমান রূপ: \(\sqrt n(\hat\theta-\theta)\xrightarrow{d}\mathcal N(0,1/I(\theta))\)।
তিনটে Part একসাথে §৪-এর পুরো শৃঙ্খল সংখ্যায় বেঁধে দেয়: Fisher information (দুই পরিচয়) → তা থেকে CRLB (variance-floor, যা MLE ছোঁয়) → আর বড় \(n\)-এ MLE-র Normal sampling distribution যার variance ঠিক সেই floor \(\frac{1}{nI(\theta)}\)-এ বসে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-5.py-তে তৈরি; PNG_assets/-এ (prefix4-5, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 Bernoulli (\(I(p)=\frac1{p(1-p)}\)); E2 Normal (\(I(\mu)=1/\sigma^2\)); E3 Poisson (\(I(\lambda)=1/\lambda\)); E4 MLE-র asymptotic normality।
এই অধ্যায়ের চারটি মূল ধারণা — Fisher information, Cramér–Rao bound (CRLB), MLE-র asymptotic normality, আর sufficiency — প্রত্যেকটার একটা করে ছবি আছে, আর চারটে মিলে একটাই গল্প বলে: data প্যারামিটার সম্পর্কে কতটা "জানে", সেই জানাটা কীভাবে variance-এর একটা মেঝে তৈরি করে, কোন estimator সেই মেঝে ছোঁয়, আর data-র কোন অংশটুকু আসলে সব তথ্য বহন করে। প্রথম ছবিটা তথ্যের উৎস (log-likelihood কতটা বাঁকা = curvature), দ্বিতীয়টা সেই তথ্য থেকে আসা variance-এর মেঝে (\(1/[nI(\theta)]\)), তৃতীয়টা বড় নমুনায় MLE-র আচরণ (ঠিক সেই মেঝে-variance-সহ Normal), আর চতুর্থটা দেখায় সব তথ্য কীভাবে একটা সংখ্যায় (sufficient statistic) গুটিয়ে আসে। চারটে ছবি একসাথে পড়লে "information → bound → efficient estimator → sufficient statistic"-এর পুরো শৃঙ্খলটা চোখে ধরা পড়ে।
Figure 1 — Fisher information = log-likelihood-এর বক্রতা (curvature)¶
এই অধ্যায়ের কেন্দ্রীয় অন্তর্দৃষ্টি একটাই ছবিতে: Fisher information মানে log-likelihood তার চূড়ায় কতটা তীক্ষ্ণভাবে বাঁকা। দুই প্যানেলেই অনুভূমিক অক্ষ প্যারামিটার \(\theta\), উল্লম্ব অক্ষ log-likelihood \(\ell(\theta)\) (তুলনার সুবিধার্থে দুটোরই চূড়া \(0\)-তে সরানো), আর ধূসর ভাঙা-রেখা MLE \(\hat\theta\) (যেখানে \(\ell\) সর্বোচ্চ)। বাঁ প্যানেল (নীল): একটা তীক্ষ্ণ, সরু চূড়া — চূড়ার চারপাশে \(\ell\) খুব দ্রুত নামে, curvature \(\lvert\ell''(\hat\theta)\rvert=28\) বড়; এর মানে data বলছে "\(\theta\) এই বিন্দুর আশেপাশেই, একটু সরলেই likelihood ধপ করে পড়ে যায়" — তাই HIGH Fisher information। ডান প্যানেল (লাল): একটা চ্যাপ্টা, চওড়া চূড়া — \(\ell\) ধীরে নামে, curvature মাত্র \(2.8\); অনেকগুলো \(\theta\)-মান প্রায় সমান likelihood দেয়, data প্যারামিটার সম্পর্কে কম নিশ্চিত — তাই LOW Fisher information। আনুষ্ঠানিকভাবে \(I(\theta)=-\mathbb{E}[\ell''(\theta)]=\mathbb{E}[(\text{score})^2]\), যেখানে score \(=\frac{\partial}{\partial\theta}\ell(\theta)\)।
যা লক্ষ করতে হবে: (ক) "তথ্য" মানে এখানে তীক্ষ্ণতা — চূড়া যত সরু ও খাড়া, তত বেশি information, কারণ data তত জোর দিয়ে একটা \(\theta\)-কে অন্যগুলো থেকে আলাদা করছে। (খ) curvature হলো দ্বিতীয় অন্তরকলজ \(\ell''\); তীক্ষ্ণ চূড়ায় \(\ell''\) বড় (ঋণাত্মক), চ্যাপ্টা চূড়ায় ছোট — তাই \(I(\theta)=-\ell''\) ঠিক এই তীক্ষ্ণতাকেই সংখ্যায় ধরে। (গ) বেশি information মানেই পরে দেখবেন কম variance সম্ভব (Figure 2): তীক্ষ্ণ চূড়া ⇒ MLE নমুনাভেদে কম নড়ে। (ঘ) চলমান উদাহরণে এই curvature-গুলোর সুন্দর বদ্ধ-রূপ আছে: E2 Normal-এ \(I(\mu)=1/\sigma^2\) (ছোট \(\sigma\) = তীক্ষ্ণ = বেশি তথ্য), E1 Bernoulli-তে \(I(p)=1/[p(1-p)]\), E3 Poisson-এ \(I(\lambda)=1/\lambda\)।
![A two-panel figure illustrating that Fisher information is the curvature of the log-likelihood at its peak. Both panels plot the log-likelihood ell(theta) against the parameter theta, with each curve's peak shifted to zero for comparison, and a grey dashed vertical line marking the maximum-likelihood estimate theta-hat. LEFT panel "High information: sharply-peaked log-likelihood": a blue parabola with a narrow, steep peak; a cream annotation box reads "Sharp peak, large curvature |ell''(theta-hat)| = 28, HIGH Fisher information, data pins down theta tightly". RIGHT panel "Low information: flat log-likelihood": a red parabola with a broad, shallow peak; a cream annotation box reads "Flat / broad peak, small curvature |ell''(theta-hat)| = 2.8, LOW Fisher information, many theta fit almost equally". The shared title states "Fisher information = curvature of the log-likelihood at its peak: I(theta) = -E[ell''(theta)]". The viewer should notice that a sharper, steeper peak corresponds to more information because the data strongly distinguishes one theta from its neighbours, that curvature is measured by the second derivative ell'' so I(theta) = -ell'' captures exactly this sharpness, and that more information will translate into a smaller achievable variance for the estimator.](../_assets/4-5-fisher-info.png)
Figure 2 — Cramér–Rao bound: variance-এর শক্ত মেঝে¶
Figure 1 দেখাল তথ্য কোথা থেকে আসে; এই ছবি দেখায় সেই তথ্য কীভাবে একটা ভাঙা-না-যাওয়া মেঝে তৈরি করে যার নিচে কোনো unbiased estimator-এর variance যেতে পারে না। মডেল E1 Bernoulli(\(p=0.3\)), যার per-observation Fisher information \(I(p)=1/[p(1-p)]\approx4.76\)। অনুভূমিক অক্ষে নমুনা-আকার \(n\) (log scale), উল্লম্ব অক্ষে estimator-এর variance (log scale)। লাল রেখা হলো Cramér–Rao floor \(\frac{1}{nI(p)}=\frac{p(1-p)}{n}\) — তাত্ত্বিক সর্বনিম্ন। নীল ফাঁপা বর্গ হলো MLE \(\hat p=\bar X\)-এর তাত্ত্বিক variance, যা ঠিক মেঝের উপরেই বসে (\(\mathrm{Var}(\hat p)=p(1-p)/n=\) floor) — তাই MLE এখানে efficient। নীল বিন্দুগুলো Monte-Carlo সিমুলেশন থেকে পাওয়া variance, লাল রেখার গায়ে। সবুজ ভাঙা-রেখা একটা inefficient estimator (যে শুধু অর্ধেক data ব্যবহার করে): তার variance floor-এর ঠিক \(2\times\) — মেঝের উপরে, কিন্তু মেঝে ছোঁয় না। হালকা লাল ছায়াঘেরা FORBIDDEN region হলো মেঝের নিচের এলাকা, যেখানে কোনো unbiased estimator পৌঁছাতে পারে না।
যা লক্ষ করতে হবে: (ক) CRLB হলো \(\mathrm{Var}(\hat\theta)\ge\frac{1}{nI(\theta)}\) — একটা hard floor: যত চালাকিই করুন, একটা unbiased estimator-এর variance এর নিচে নামানো অসম্ভব (লাল ছায়া এলাকা সম্পূর্ণ নিষিদ্ধ)। (খ) দুটো অক্ষই log-scale, তাই floor একটা সরল রেখা যার ঢাল \(-1\): \(n\) দশগুণ হলে variance দশভাগের এক — মেঝে \(1/n\) হারে নামে। (গ) MLE (নীল বর্গ) মেঝের উপরেই বসে — এটাই "efficient" হওয়ার দৃশ্যরূপ, আর Monte-Carlo বিন্দুগুলো তা যাচাই করে। (ঘ) সবুজ inefficient estimator সবসময় floor-এর \(2\times\) উপরে: একই \(n\)-এ সে MLE-র দ্বিগুণ variance দেয়, অর্থাৎ একই নির্ভুলতা পেতে তার দ্বিগুণ data লাগবে — এটাই "তথ্য নষ্ট করা"-র মূল্য। (এই floor-ই 4.4-এ Figure 4-এ দেখা "\(\max\) বনাম \(2\bar X\)"-এর অনানুষ্ঠানিক efficiency-তুলনাকে এখন একটা সুনির্দিষ্ট, প্রমাণযোগ্য সীমায় পরিণত করল।)
![A log-log line plot showing the Cramér–Rao lower bound as a hard floor on estimator variance for the Bernoulli(p=0.3) model, with Fisher information I(p) = 1/[p(1-p)] ≈ 4.76. The horizontal axis is sample size n on a log scale from 5 to 320; the vertical axis is the variance of the estimator on a log scale. A solid red line with circular markers shows the Cramér–Rao floor 1/(n I(p)) = p(1-p)/n, descending as a straight line of slope minus one. Open blue squares show the theoretical variance of the MLE p-hat = X-bar, which lies exactly on the red floor line, and filled blue dots show Monte-Carlo estimates of that variance, also on the line — so the MLE is efficient. A dashed green line with triangular markers shows an inefficient estimator that uses only half the data, whose variance is exactly twice the floor and stays above it at every n. The region below the floor is shaded pale red and labelled "FORBIDDEN region (no unbiased estimator can have variance here)". The viewer should notice that the Cramér–Rao bound Var(theta-hat) ≥ 1/(n I(theta)) is a hard floor that no unbiased estimator can cross, that on log-log axes the floor is a straight line of slope -1 so variance falls like 1/n, that the MLE sits exactly on the floor (this is what "efficient" looks like), and that the inefficient half-data estimator pays for wasting information by needing twice the sample size for the same precision.](../_assets/4-5-crlb.png)
Figure 3 — MLE-র asymptotic normality (E4)¶
এবার চলমান উদাহরণ E4: বড় নমুনায় MLE-র sampling distribution দেখতে কেমন? উত্তর — এটা একটা Normal-এর দিকে এগোয় যার variance ঠিক Cramér–Rao floor-এ বসে: \(\hat\theta\approx\mathcal{N}\!\big(\theta,\,\frac{1}{nI(\theta)}\big)\)। মডেল Poisson(\(\lambda=4\)), \(I(\lambda)=1/\lambda\), MLE \(=\bar X\)। অনুভূমিক অক্ষে MLE-র মান, উল্লম্ব অক্ষে sampling density। হালকা থেকে গাঢ় কমলা histogram-গুলো \(n=5,20,80\)-এ MLE-র প্রকৃত (সিমুলেটেড) বণ্টন; প্রতিটির উপর একই রঙের নিরেট রেখা হলো তাত্ত্বিক Normal-অনুমান \(\mathcal{N}(\lambda,\,\lambda/n)\)। লাল ভাঙা-রেখা সত্যি \(\theta=\lambda=4\)। প্রতিটা \(n\)-এ standard error \(\mathrm{SE}=\sqrt{\lambda/n}\) লেখা আছে: \(0.89\to0.45\to0.22\)।
যা লক্ষ করতে হবে: (ক) histogram আর নিরেট রেখা প্রায় মিলে যায় — এমনকি \(n=20\)-তেও MLE-র বণ্টন Normal-এর খুব কাছে, আর \(n\) বাড়লে মিল আরও নিখুঁত হয় (এটাই "asymptotic" শব্দের অর্থ)। (খ) তিনটে curve-ই সত্যি \(4\)-এ কেন্দ্রীভূত (MLE asymptotically unbiased), কিন্তু \(n\) বাড়ার সাথে লম্বা ও সরু হয় — কারণ variance \(=\lambda/n=1/[nI(\lambda)]\) মানে ঠিক CRLB floor, যা \(n\) বাড়লে কমে। (গ) SE পড়ছে \(0.89\to0.45\to0.22\) — \(n\) চারগুণ হলে SE অর্ধেক (\(\sqrt n\)-এর জন্য), হুবহু Figure 2-র floor-এর সাথে সঙ্গতিপূর্ণ। (ঘ) এটাই MLE-র গভীরতম গুণ: বড় নমুনায় MLE (i) approximately Normal, (ii) approximately unbiased, এবং (iii) efficient (variance CRLB ছোঁয়) — তাই MLE-কে "asymptotically সেরা" বলা যায়, আর এই Normal-রূপই পরের অধ্যায়ে confidence interval বানানোর ভিত্তি হবে।
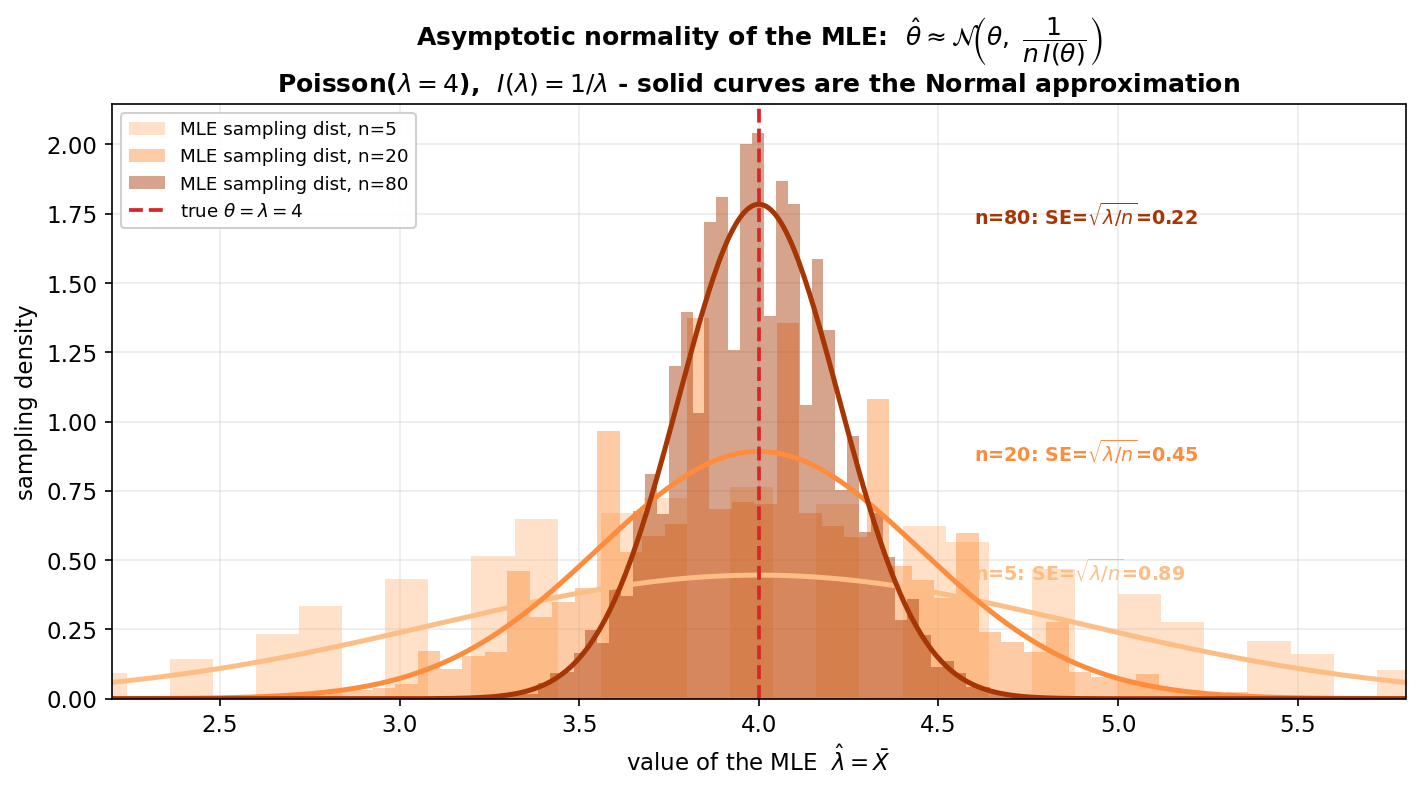
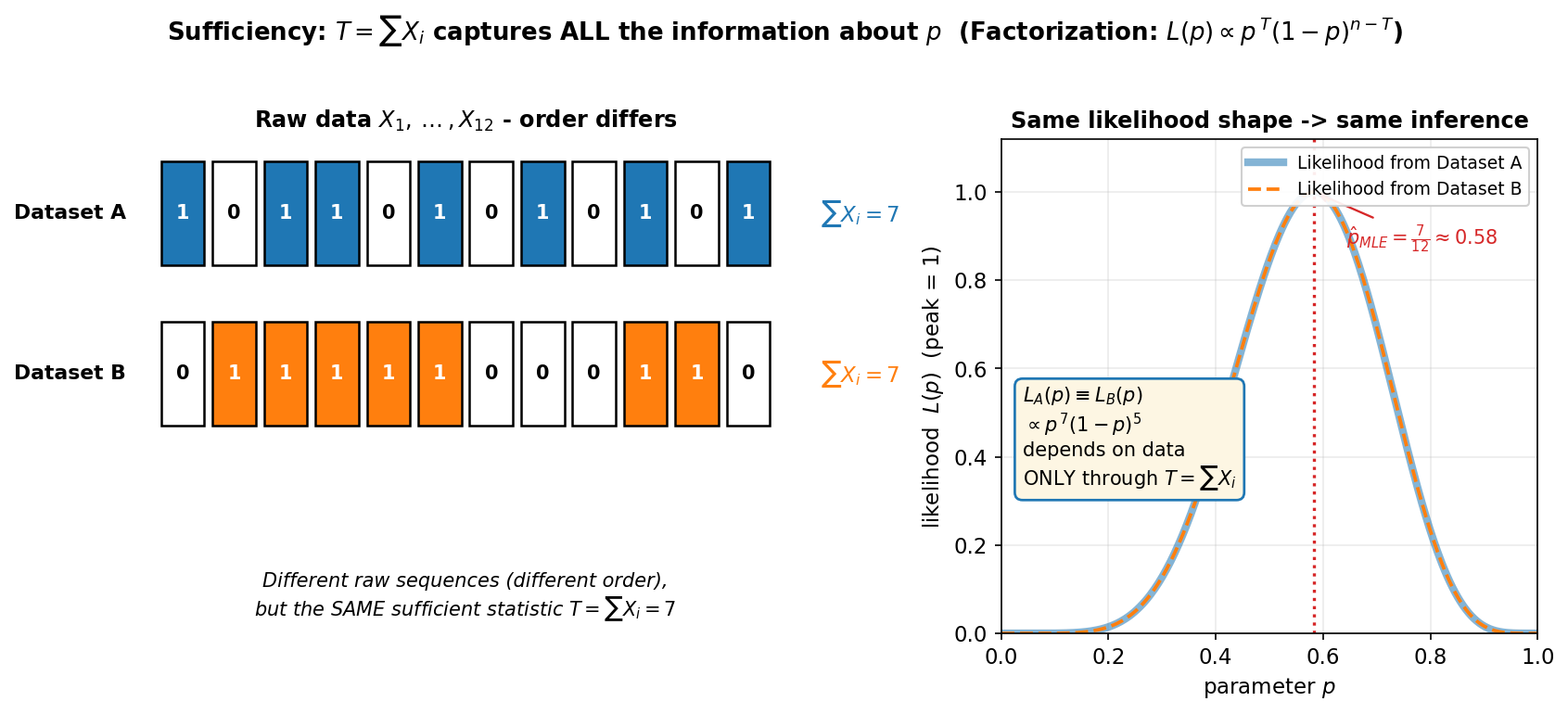
Figure 4 — sufficiency: \(T=\sum X_i\) সব তথ্য ধরে রাখে (E1)¶
শেষ ছবি sufficiency-র ধারণাটা সবচেয়ে সরলভাবে দেখায়: একটা sufficient statistic হলো data-র এমন একটা সংক্ষিপ্তসার যা প্যারামিটার সম্পর্কে পুরো information ধরে রাখে — raw data আর সেই statistic একই inference দেয়। মডেল E1 Bernoulli। বাঁ প্যানেলে দুটো আলাদা কাঁচা data-ক্রম: Dataset A ও Dataset B, ১২টা করে \(0/1\) (নীল/কমলা ঘর = \(1\), সাদা = \(0\))। দুটোর ক্রম আলাদা, কিন্তু দুটোতেই ঠিক ৭টা ১ — অর্থাৎ একই sufficient statistic \(T=\sum X_i=7\)। ডান প্যানেলে দুটো dataset থেকে \(p\)-এর likelihood \(L(p)\) আঁকা: মোটা হালকা-নীল রেখা Dataset A-র, ভাঙা-কমলা রেখা Dataset B-র — দুটো হুবহু একে অপরের উপর বসে, কারণ উভয়েই \(L(p)\propto p^{7}(1-p)^{5}\)। MLE \(\hat p=7/12\approx0.58\) দুটোতেই এক।
যা লক্ষ করতে হবে: (ক) ক্রম (order) অপ্রাসঙ্গিক — Bernoulli-তে \(p\) সম্পর্কে সব তথ্য কেবল "কতগুলো ১" (অর্থাৎ \(\sum X_i\))-তে; কোন ক্রমে এল তাতে কিছু যায়-আসে না। তাই দুই ভিন্ন raw dataset একই \(T\) দিলে একই likelihood, একই MLE, একই উপসংহার। (খ) দুটো likelihood-রেখা আলাদা করা যায় না — এটাই sufficiency-র দৃশ্যরূপ: \(T\) জানলেই যথেষ্ট, পুরো raw data রাখার দরকার নেই (১২টা সংখ্যা → ১টা সংখ্যা, কোনো তথ্য হারানো ছাড়াই)। (গ) এর পিছনে factorization theorem: \(L(p)=p^{\sum x_i}(1-p)^{n-\sum x_i}\) — likelihood data-র উপর নির্ভর করে কেবল \(T=\sum x_i\)-এর মাধ্যমে, তাই \(T\) sufficient। (ঘ) sufficiency আর information একই গল্পের দুই দিক: \(T\) যদি সব তথ্য ধরে, তবে \(T\)-র উপর ভিত্তি করা estimator-ই (যেমন MLE) সেই তথ্যের সবটুকু কাজে লাগায় — আর সেজন্যই সে Figure 2-র মেঝে ছুঁতে পারে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-05-sufficiency-fisher-crlb-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: score \(U(\theta)=\frac{\partial}{\partial\theta}\log f(X;\theta)\); Fisher information \(I(\theta)=\mathbb{E}[U(\theta)^2]=-\mathbb{E}[\ell''(\theta)]\); CRLB \(\mathrm{Var}(\hat\theta)\ge\frac{1}{nI(\theta)}\) (unbiased \(\hat\theta\)-র জন্য); efficiency \(e(\hat\theta)=\frac{1/[nI(\theta)]}{\mathrm{Var}(\hat\theta)}\); MLE asymptotic: \(\hat\theta\approx\mathcal{N}(\theta,\frac{1}{nI(\theta)})\)। চলমান উদাহরণ: E1 \(I(p)=\frac1{p(1-p)}\); E2 \(I(\mu)=1/\sigma^2\); E3 \(I(\lambda)=1/\lambda\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় Fisher information কী বলুন, এবং Figure 1-এর দুই প্যানেল ব্যবহার করে ব্যাখ্যা করুন কেন "তীক্ষ্ণ log-likelihood = বেশি তথ্য"। একটা flat log-likelihood প্যারামিটার সম্পর্কে কী বলে? Hint: \(I(\theta)\) মাপে log-likelihood তার চূড়ায় কত বাঁকা (curvature \(-\ell''\))। তীক্ষ্ণ চূড়া ⇒ একটু সরলেই likelihood পড়ে যায় ⇒ data দৃঢ়ভাবে একটা \(\theta\) বলছে ⇒ বেশি তথ্য। Flat ⇒ অনেক \(\theta\) প্রায় সমান likelihood ⇒ কম তথ্য।
প্রশ্ন ২ (★). Cramér–Rao bound নিজের কথায় বলুন। Figure 2-এর "FORBIDDEN region" কী নির্দেশ করে? একটা unbiased estimator কি ইচ্ছেমতো ছোট variance অর্জন করতে পারে — কেন/কেন নয়? Hint: CRLB: \(\mathrm{Var}(\hat\theta)\ge\frac{1}{nI(\theta)}\) যেকোনো unbiased \(\hat\theta\)-র জন্য। মেঝের নিচের এলাকা (FORBIDDEN) অর্জন-অসম্ভব। তাই variance-এর একটা শক্ত নিচের সীমা আছে — ইচ্ছেমতো ছোট করা যায় না।
প্রশ্ন ৩ (★★). একটা estimator-কে efficient বলতে কী বোঝায়? Figure 2-এর কোন রেখা efficient আর কোনটা নয়, ব্যাখ্যা করুন। সবুজ (অর্ধেক-data) estimator-এর efficiency \(e\) কত, আর সেটা ব্যবহারিকভাবে কী অর্থ বহন করে? Hint: efficient = variance ঠিক CRLB floor-এ (\(e=1\))। MLE (নীল বর্গ) efficient; সবুজ floor-এর \(2\times\), তাই \(e=\frac12=50\%\) — একই precision পেতে দ্বিগুণ নমুনা লাগে।
প্রশ্ন ৪ (★★). sufficient statistic কী, Figure 4 দিয়ে ব্যাখ্যা করুন। কেন Bernoulli-তে \(\sum X_i\) sufficient কিন্তু observation-গুলোর ক্রম নয়? "sufficient" শব্দটার আক্ষরিক অর্থ এখানে কীভাবে খাটে? Hint: \(T\) sufficient যদি \(T\) দেওয়া থাকলে data-র বাকি অংশ \(\theta\) সম্পর্কে আর কিছু না বলে। Figure 4-এ দুই ভিন্ন-ক্রম dataset একই \(T=7\) ⇒ একই likelihood ⇒ ক্রম অপ্রাসঙ্গিক। "sufficient" = inference-এর জন্য \(T\)-ই যথেষ্ট।
প্রশ্ন ৫ (★★★). MLE-র asymptotic normality (\(\hat\theta\approx\mathcal{N}(\theta,\frac{1}{nI(\theta)})\)) তিনটি পৃথক ভালো-গুণকে একসাথে বহন করে — সেগুলো চিহ্নিত করুন এবং Figure 3-এর কোন বৈশিষ্ট্য প্রতিটিকে দেখায় তা বলুন। কেন এই ফলাফল CRLB-র সাথে সরাসরি জড়িত? Hint: (i) approximately Normal (histogram ≈ নিরেট রেখা), (ii) asymptotically unbiased (সব curve \(\theta\)-তে কেন্দ্রীভূত), (iii) efficient (variance \(=\frac{1}{nI}=\) CRLB floor, তাই curve সরু হয়)। MLE বড় নমুনায় floor ছোঁয় — তাই asymptotically সেরা।
খ · গাণনিক (computational)¶
প্রশ্ন ৬ (★). E1 Bernoulli(\(p\))। single observation-এর log-pmf \(\log f(x;p)=x\log p+(1-x)\log(1-p)\) থেকে শুরু করে দেখান \(I(p)=\frac{1}{p(1-p)}\)। তারপর \(p=0.3\) ও \(n=50\)-এ unbiased estimator-এর জন্য CRLB কত — সংখ্যায় বের করুন। Hint: \(\ell'=\frac{x}{p}-\frac{1-x}{1-p}\), \(\ell''=-\frac{x}{p^2}-\frac{1-x}{(1-p)^2}\); \(\mathbb{E}[X]=p\) বসিয়ে \(I(p)=-\mathbb{E}[\ell'']=\frac1p+\frac1{1-p}=\frac{1}{p(1-p)}\)। CRLB \(=\frac{p(1-p)}{n}=\frac{0.21}{50}=0.0042\)।
প্রশ্ন ৭ (★). E2 Normal(\(\mu,\sigma^2\)), \(\sigma^2\) জানা। single observation থেকে \(I(\mu)=1/\sigma^2\) বের করুন, এবং দেখান \(\bar X\) ঠিক CRLB অর্জন করে (অর্থাৎ efficient)। Hint: \(\log f=-\frac{(x-\mu)^2}{2\sigma^2}+c\); \(\ell''=-1/\sigma^2\), তাই \(I(\mu)=1/\sigma^2\)। CRLB \(=\frac{1}{nI}=\sigma^2/n\); আর \(\mathrm{Var}(\bar X)=\sigma^2/n\) — সমান, তাই efficient (\(e=1\))।
প্রশ্ন ৮ (★★). E3 Poisson(\(\lambda\))। (ক) দেখান \(I(\lambda)=1/\lambda\)। (খ) \(\hat\lambda=\bar X\)-এর জন্য CRLB লিখুন ও দেখান \(\bar X\) efficient। (গ) \(\lambda=4,n=20\)-এ asymptotic SE \(\sqrt{1/[nI(\lambda)]}\) বের করুন — Figure 3-এর \(n=20\) মানের সাথে মিলিয়ে দেখুন। Hint: \(\log f=x\log\lambda-\lambda-\log x!\); \(\ell''=-x/\lambda^2\), \(\mathbb{E}[X]=\lambda\) ⇒ \(I=1/\lambda\)। CRLB \(=\lambda/n\); \(\mathrm{Var}(\bar X)=\lambda/n\) ⇒ efficient। SE \(=\sqrt{4/20}=\sqrt{0.2}=0.447\) — Figure 3-এর \(0.45\)-এর সাথে মেলে।
প্রশ্ন ৯ (★★). Figure 4-এর সংখ্যাগুলো যাচাই: \(n=12\), \(\sum x_i=7\)। (ক) likelihood \(L(p)\propto p^7(1-p)^5\) থেকে MLE \(\hat p\) বের করুন (log নিয়ে অন্তরকলন)। (খ) এই \(\hat p\)-এর জন্য asymptotic variance \(\frac{1}{nI(\hat p)}=\frac{\hat p(1-\hat p)}{n}\) বের করুন। Hint: \(\ell(p)=7\log p+5\log(1-p)\); \(\ell'=\frac7p-\frac5{1-p}=0\Rightarrow\hat p=7/12\approx0.583\)। variance \(=\frac{0.583\cdot0.417}{12}\approx0.0203\), SE \(\approx0.142\)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১০ (★★). score-এর গড় শূন্য প্রমাণ করুন: \(\mathbb{E}[U(\theta)]=\mathbb{E}\!\left[\frac{\partial}{\partial\theta}\log f(X;\theta)\right]=0\) (নিয়মিত শর্তে, যেখানে differentiation ও integration বিনিময়যোগ্য)। এরপর এ থেকে দেখান \(I(\theta)=\mathrm{Var}(U(\theta))=\mathbb{E}[U(\theta)^2]\)। Hint: \(\frac{\partial}{\partial\theta}\log f=\frac{f'}{f}\); \(\mathbb{E}[U]=\int\frac{f'}{f}f\,dx=\int f'\,dx=\frac{d}{d\theta}\int f\,dx=\frac{d}{d\theta}1=0\)। মান \(0\) বলে \(\mathrm{Var}(U)=\mathbb{E}[U^2]=I(\theta)\)।
প্রশ্ন ১১ (★★★). Cramér–Rao অসমতা প্রমাণ করুন: একটি unbiased estimator \(\hat\theta\) (\(n=1\), single observation) ও score \(U(\theta)\)-র জন্য, Cauchy–Schwarz ব্যবহার করে দেখান \(\mathrm{Var}(\hat\theta)\ge\frac{1}{I(\theta)}\)। (\(n\) iid নমুনায় \(I\to nI\) হয়ে \(\mathrm{Var}\ge\frac{1}{nI(\theta)}\)।) Hint: unbiasedness \(\mathbb{E}[\hat\theta]=\theta\) অন্তরকলন করলে \(\mathrm{Cov}(\hat\theta,U)=1\) পাওয়া যায় (\(\mathbb{E}[U]=0\) ব্যবহার করে)। Cauchy–Schwarz: \(1=\mathrm{Cov}(\hat\theta,U)^2\le\mathrm{Var}(\hat\theta)\,\mathrm{Var}(U)=\mathrm{Var}(\hat\theta)\,I(\theta)\) ⇒ \(\mathrm{Var}(\hat\theta)\ge1/I(\theta)\)।
প্রশ্ন ১২ (★★). Factorization theorem (Fisher–Neyman) প্রয়োগ করে প্রমাণ করুন যে Bernoulli(\(p\))-তে \(T=\sum_{i=1}^n X_i\) একটি sufficient statistic। তারপর E3 Poisson(\(\lambda\))-তেও দেখান \(\sum X_i\) sufficient। Hint: joint pmf \(\prod p^{x_i}(1-p)^{1-x_i}=p^{\sum x_i}(1-p)^{n-\sum x_i}=g(T,p)\cdot h(x)\) যেখানে \(h(x)=1\) — data-র উপর নির্ভরতা কেবল \(T\)-র মাধ্যমে। Poisson: \(\prod\frac{\lambda^{x_i}e^{-\lambda}}{x_i!}=\lambda^{\sum x_i}e^{-n\lambda}\cdot\frac{1}{\prod x_i!}=g(\sum x_i,\lambda)h(x)\)।
প্রশ্ন ১৩ (★★★). additivity of Fisher information: যদি \(X_1,\dots,X_n\) iid হয়, প্রমাণ করুন মোট নমুনার Fisher information \(I_n(\theta)=nI_1(\theta)\), যেখানে \(I_1\) হলো single observation-এর information। এই additivity-ই কেন CRLB-তে \(1/[nI(\theta)]\)-এ \(n\) আসে, ব্যাখ্যা করুন। Hint: \(\ell_n(\theta)=\sum_i\log f(X_i;\theta)\), তাই score \(U_n=\sum_i U_1^{(i)}\) — iid বলে স্বাধীন, প্রতিটির গড় \(0\)। \(\mathrm{Var}(U_n)=\sum\mathrm{Var}(U_1^{(i)})=nI_1\)। তাই CRLB \(=1/\mathrm{Var}(U_n)=1/[nI_1]\) — বেশি data = বেশি (যোগফল) তথ্য = নিচু floor।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৪ (★★). Monte Carlo দিয়ে CRLB যাচাই (Figure 2): Bernoulli(\(p=0.3\)) থেকে বিভিন্ন \(n\in\{10,40,160\}\)-এ ৫০,০০০ বার \(\hat p=\bar X\) হিসাব করে empirical variance বের করুন এবং তাত্ত্বিক CRLB \(\frac{p(1-p)}{n}\)-এর সাথে মেলান। দেখান MLE-র variance floor-এ বসে (অনুপাত \(\approx1\))। Hint:
import numpy as np
rng = np.random.default_rng(0); p, R = 0.3, 50000
for n in [10, 40, 160]:
phat = rng.binomial(n, p, size=R) / n
crlb = p*(1-p)/n
print(n, "emp var", round(phat.var(), 5), "CRLB", round(crlb, 5),
"ratio", round(phat.var()/crlb, 3))
প্রশ্ন ১৫ (★★). Fisher information-এর দুই রূপ সংখ্যায় মিলিয়ে দেখুন (E2 বা E3): একটা \(\theta\) বেছে, log-likelihood-এর দ্বিতীয় অন্তরকলজের গড় \(-\mathbb{E}[\ell'']\) আর score-এর বর্গের গড় \(\mathbb{E}[U^2]\) — দুটো numerically সমান কি না যাচাই করুন (Poisson(\(\lambda=4\)) দিয়ে)। Hint: Poisson-এ \(U=x/\lambda-1\), \(\ell''=-x/\lambda^2\)। \(\mathbb{E}[U^2]=\mathrm{Var}(X)/\lambda^2=\lambda/\lambda^2=1/\lambda\); \(-\mathbb{E}[\ell'']=\mathbb{E}[X]/\lambda^2=\lambda/\lambda^2=1/\lambda\) — সমান। সিমুলেশনে নমুনা টেনে দুটো গড় ছাপান, \(1/\lambda=0.25\)-এর কাছে আসা উচিত।
প্রশ্ন ১৬ (★★★). MLE-র asymptotic normality পুনঃনির্মাণ (Figure 3): Poisson(\(\lambda=4\)) থেকে \(n\in\{5,20,80\}\)-এ ৪০,০০০ বার \(\hat\lambda=\bar X\) হিসাব করুন, প্রতিটির histogram (density) আঁকুন, আর উপরে \(\mathcal{N}(\lambda,\lambda/n)\)-এর pdf বসান। empirical SD আর \(\sqrt{\lambda/n}\) মিলিয়ে দেখুন।
Hint: est = rng.poisson(4, size=(40000, n)).mean(1); plt.hist(est, bins=60, density=True, alpha=0.45); se = np.sqrt(4/n); overlay norm.pdf(xs, 4, se)। est.std() ≈ se (০.৮৯, ০.৪৫, ০.২২)।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- score function। যেকোনো parametric model-এ score \(U(\theta)=\frac{\partial}{\partial\theta}\log f(X;\theta)\) — log-likelihood কত দ্রুত \(\theta\)-র সাথে বদলায়। নিয়মিত শর্তে \(\mathbb{E}[U(\theta)]=0\) (§৭ Q10)।
- Fisher information। \(\boxed{I(\theta)=\mathbb{E}[U(\theta)^2]=-\mathbb{E}[\ell''(\theta)]}\) — log-likelihood তার চূড়ায় কতটা তীক্ষ্ণ (curvature, Figure 1)। তীক্ষ্ণ চূড়া = বেশি তথ্য = data দৃঢ়ভাবে \(\theta\) আলাদা করছে। iid নমুনায় তথ্য যোগ হয়: \(I_n(\theta)=nI_1(\theta)\) (§৭ Q13)। চলমান উদাহরণে: E1 \(I(p)=\frac1{p(1-p)}\), E2 \(I(\mu)=\frac1{\sigma^2}\), E3 \(I(\lambda)=\frac1\lambda\)।
- Cramér–Rao lower bound (CRLB)। যেকোনো unbiased estimator-এর জন্য \(\boxed{\mathrm{Var}(\hat\theta)\ge\frac{1}{nI(\theta)}}\) — একটা শক্ত মেঝে যার নিচে যাওয়া অসম্ভব (Figure 2-র FORBIDDEN region; প্রমাণ §৭ Q11, Cauchy–Schwarz)। বেশি তথ্য ⇒ নিচু মেঝে ⇒ আরও নির্ভুল অনুমান সম্ভব।
- efficiency। যে unbiased estimator ঠিক CRLB ছোঁয় (\(\mathrm{Var}=\frac{1}{nI}\)) তাকে efficient বলে (\(e=1\), Figure 2-র নীল MLE)। E2 \(\bar X\), E3 \(\bar X\) — দুটোই efficient। অর্ধেক-data estimator \(e=0.5\) (একই precision-এ দ্বিগুণ নমুনা লাগে)।
- MLE-র asymptotic normality। বড় নমুনায় \(\boxed{\hat\theta\approx\mathcal{N}\!\big(\theta,\,\frac{1}{nI(\theta)}\big)}\) (Figure 3) — MLE একসাথে (i) approximately Normal, (ii) asymptotically unbiased, (iii) efficient (variance CRLB ছোঁয়)। তাই MLE-কে "asymptotically সেরা" estimator বলা যায়। SE \(=\sqrt{\frac{1}{nI(\hat\theta)}}\)।
- sufficiency ও factorization theorem। একটা statistic \(T(X)\) sufficient যদি \(T\) দেওয়া থাকলে raw data আর \(\theta\) সম্পর্কে কিছু না বলে; সমতুল্যভাবে (Fisher–Neyman) যদি \(L(\theta)=g(T,\theta)h(x)\) — likelihood data-র উপর নির্ভর করে কেবল \(T\)-র মাধ্যমে (§৭ Q12)। E1/E3-তে \(\sum X_i\) sufficient (Figure 4): দুই ভিন্ন-ক্রম dataset একই \(T\) দিলে একই likelihood, একই inference।
পূর্ববর্তী সংযোগ (← 4.4 Properties of Estimators, 4.3 MLE): 4.4-এ আমরা estimator-কে bias, variance, MSE, consistency দিয়ে বিচার করতে শিখেছি, আর বারবার এসেছিল "variance কম মানে ভালো" — Figure 4-এ (4.4) \(\max\)-এর variance \(2\bar X\)-এর চেয়ে অনেক ছোট ছিল, যাকে আমরা অনানুষ্ঠানিকভাবে "efficiency" বলেছিলাম। কিন্তু সেখানে একটা প্রশ্ন খোলা ছিল: variance কত ছোট হওয়া আদৌ সম্ভব? এই অধ্যায় সেই প্রশ্নের চূড়ান্ত উত্তর দিল — Fisher information \(I(\theta)\) মাপে data কতটা তথ্য বহন করে, আর Cramér–Rao bound সেই তথ্যকে variance-এর একটা শক্ত মেঝে \(\frac{1}{nI(\theta)}\)-তে রূপান্তরিত করে। অর্থাৎ 4.4-এর অস্পষ্ট "efficiency"-তুলনা এখন একটা সুনির্দিষ্ট, প্রমাণযোগ্য সীমা পেল: একটা estimator-কে "efficient" বলা যায় ঠিক যখন সে এই মেঝে ছোঁয়। আবার 4.3-এর MLE এখানে দুবার ফিরে এল — (i) Fisher information আসলে log-likelihood-এর curvature, যা MLE খোঁজারই হাতিয়ার; (ii) MLE বড় নমুনায় ঠিক CRLB-variance-সহ Normal হয় (asymptotic normality), অর্থাৎ MLE asymptotically efficient। তাই 4.3–4.4-এ "estimator বানানো ও বিচার করা" এখানে পূর্ণতা পেল — আমরা এখন জানি সর্বোত্তম সম্ভব estimator কেমন দেখতে।
পরবর্তী সংযোগ (→ 4.6 — Confidence Intervals): এই অধ্যায়ে আমরা পেয়েছি estimator-এর variance-এর floor (\(\frac{1}{nI}\)) আর MLE-র asymptotic Normal-রূপ — এই দুটোই পরের অধ্যায় 4.6-এর সরাসরি ভিত্তি। এতদিন আমরা শুধু একটা point estimate \(\hat\theta\) দিয়েছি (একটা সংখ্যা); কিন্তু সেই সংখ্যা কতটা নির্ভরযোগ্য, সেই অনিশ্চয়তা প্রকাশ করতে চাই একটা interval দিয়ে: "\(\theta\) সম্ভবত এই দুই সীমার মধ্যে"। 4.6 দেখাবে কীভাবে standard error \(\mathrm{SE}=\sqrt{\frac{1}{nI(\hat\theta)}}\) (এই অধ্যায়ের CRLB/Fisher থেকে পাওয়া) আর MLE-র asymptotic normality ব্যবহার করে একটা confidence interval বানানো যায় — যেমন \(\hat\theta\pm z_{\alpha/2}\cdot\mathrm{SE}\) (৯৫% interval-এ \(z\approx1.96\))। অর্থাৎ এই অধ্যায়ের "variance কত ছোট হতে পারে" আর "MLE Normal" — এই দুই ফলাফল মিলে পরের অধ্যায়ে অনিশ্চয়তা পরিমাপের যন্ত্র হয়ে উঠবে, আর point estimation থেকে আমরা interval estimation-এ পা রাখব।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 9 (Parametric Inference — §9.4–9.6: score function, Fisher information, Cramér–Rao inequality, sufficiency, এবং MLE-র asymptotic normality ও efficiency); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 8 (Estimation of Parameters — §8.5 efficiency ও Cramér–Rao lower bound, §8.7 sufficiency ও factorization theorem, §8.5.2 large-sample theory of MLE)।