4.7 — Hypothesis Testing (প্রকল্প পরীক্ষা)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "data কি একটা দাবির বিরুদ্ধে যথেষ্ট প্রমাণ দেয়?"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
Part IV-এর এ পর্যন্ত আমরা estimation (অনুমান) শিখেছি — অজানা parameter \(\theta\)-র জন্য data থেকে একটা সংখ্যা (\(\hat\theta\), point estimate, 4.2–4.5) বা একটা ব্যবধান (confidence interval, 4.6) বানানো। সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়ের গল্প ঠিক সেখান থেকেই ডালপালা মেলে:
- 4.1-এ শিখেছি কোথাও একটা population (সমগ্রক) আছে, যার ভেতরে একটা স্থির কিন্তু অজানা সংখ্যা — parameter \(\theta\) ("থিটা")। আমরা পুরো population দেখি না; পাই কেবল একটা sample (নমুনা) \(X_1, X_2, \dots, X_n\) — \(n\)টি পর্যবেক্ষণ। data-র যেকোনো function (যেমন নমুনা গড় \(\bar X\)) নিজেও random, তার একটা sampling distribution (স্যাম্পলিং বণ্টন) আছে।
- 4.6-এ (Confidence Intervals) আমরা \(\hat\theta\)-কে ঘিরে একটা ব্যবধান \(\hat\theta \pm z_{\alpha/2}\,\mathrm{SE}\) বানাতে শিখেছি, যা confidence level \(1-\alpha\) নিয়ে সত্য \(\theta\)-কে "ধরে" — pivot ও critical value \(z_{\alpha/2}\) ব্যবহার করে।
কিন্তু লক্ষ করুন, estimation একটা খোলা প্রশ্নের উত্তর দেয়: "\(\theta\)-র মান কত?" বাস্তবে বহু সময় আমাদের সামনে একটা বদ্ধ প্রশ্ন আসে — একটা নির্দিষ্ট দাবি (claim), যার শুধু "হ্যাঁ/না"-জাতীয় বিচার চাই:
- একটা ওষুধ কোম্পানি দাবি করছে তাদের নতুন ওষুধ রক্তচাপ কমায়। data কি সেই দাবির পক্ষে যথেষ্ট প্রমাণ দেয়, নাকি যে হ্রাস দেখা গেছে তা নিছক নমুনার এলোমেলোতা (random fluctuation)?
- একটা website-এর নতুন design চালু করে দেখা গেল click-হার একটু বাড়ল। সেটা কি সত্যিই design-এর গুণ, নাকি কাকতালীয়?
এই "data কি একটা দাবির বিরুদ্ধে যথেষ্ট প্রমাণ দেয়?" — এটাই hypothesis testing-এর কেন্দ্রীয় প্রশ্ন, আর এই অধ্যায়ের একমাত্র বিষয়। estimation যেখানে বলে "\(\theta\) কত", hypothesis testing সেখানে বলে "\(\theta\) সম্পর্কে এই নির্দিষ্ট দাবিটা data-র আলোয় টেকে কি না"।
১.২ Hook — দুটি বাস্তব দৃশ্য¶
দুটো concrete দৃশ্য দিয়ে শুরু করি; পুরো অধ্যায় জুড়ে এরাই (আরো দুটো সহ) চলমান উদাহরণ হিসেবে ফিরবে।
দৃশ্য ১ — drug trial (ওষুধ-পরীক্ষা)। একটা ওষুধ গড় রক্তচাপ কতটা বদলায় তা মাপতে \(n\) জন রোগীর ওপর পরীক্ষা হলো। ধরা যাক "ওষুধের কোনো প্রভাব নেই" মানে গড় পরিবর্তন \(\mu = 0\)। data-তে নমুনা গড় হ্রাস পাওয়া গেল, ধরা যাক \(\bar X = 5\) mmHg। এখন আসল প্রশ্ন: এই \(5\) কি যথেষ্ট বড় যে "প্রভাব নেই" দাবিটাকে অবিশ্বাস্য করে তোলে? নাকি প্রভাব শূন্য হলেও নিছক random ওঠানামায় এমন \(\bar X\) অহরহ আসতে পারে? — শুধু \(\bar X\)-এর সংখ্যামান দেখে এর উত্তর দেওয়া যায় না; জানতে হবে "প্রভাব নেই" সত্য ধরে নিলে এমন (বা আরো বড়) \(\bar X\) আসা কতটা সম্ভব। ঠিক এই হিসাবটাই hypothesis testing।
দৃশ্য ২ — A/B test (এ/বি পরীক্ষা)। একটা অ্যাপে পুরোনো (A) আর নতুন (B) দুটো version দেখানো হলো ব্যবহারকারীদের। ধরা যাক A-তে click-হার \(p_A\), B-তে \(p_B\)। নমুনায় B-র হার একটু বেশি দেখা গেল। দাবি: "B আসলে A-র চেয়ে ভালো (\(p_B > p_A\))।" আবার সেই একই কাঠামো: পার্থক্যটা কি যথেষ্ট বড় যে "দুটো আসলে সমান (\(p_A=p_B\))" দাবিটাকে নাকচ করে, নাকি এটুকু পার্থক্য নিছক sampling-এর এলোমেলোতা?
এই দুই দৃশ্যেই গঠনটা একই: একটা default দাবি ("কোনো প্রভাব নেই", "দুটো সমান") আর data-তে দেখা একটা বিচ্যুতি — আর সিদ্ধান্ত নিতে হবে, বিচ্যুতিটা "default সত্য হলে স্বাভাবিকভাবে ঘটার মতো ছোট", নাকি "এত বড় যে default-টাকে অবিশ্বাস করতে হয়"।
১.৩ মূল রূপক — আদালত (courtroom): \(H_0 =\) নির্দোষ¶
hypothesis testing-এর পুরো যুক্তি-কাঠামোটা একটা পরিচিত রূপকে নিখুঁতভাবে ধরা পড়ে — ফৌজদারি আদালত। এই রূপকটা গোটা অধ্যায়ের মেরুদণ্ড, তাই গোড়াতেই ভালো করে গেঁথে নিন।
আদালতে একজন আসামির বিচার হচ্ছে। বিচারব্যবস্থার একটা মৌলিক নীতি: "যতক্ষণ না দোষ প্রমাণিত, ততক্ষণ আসামি নির্দোষ" (innocent until proven guilty)। লক্ষ করুন এর ভেতরের অসমতা:
- শুরুর default অবস্থান হলো নির্দোষ — এটাই বিনা-প্রমাণে ধরে নেওয়া হয়। একে বলব null hypothesis \(H_0\): আসামি নির্দোষ।
- প্রসিকিউশনের দাবি হলো দোষী — এটাই প্রমাণ করতে হবে। একে বলব alternative hypothesis \(H_1\): আসামি দোষী।
- বিচারক/জুরি কেবল তখনই \(H_0\) (নির্দোষ) বাতিল করে দোষী রায় দেয় যখন প্রমাণ "যুক্তিসঙ্গত সন্দেহের ঊর্ধ্বে" (beyond reasonable doubt) দোষের দিকে যায়। প্রমাণ দুর্বল হলে রায় হয় "দোষী নয়" (not guilty) — লক্ষ করুন, এটা "নির্দোষ প্রমাণিত" নয়; এটা শুধু "দোষ প্রমাণে যথেষ্ট প্রমাণ মেলেনি"।
এই অসমতা hypothesis testing-এর প্রাণ। এখান থেকে পাঁচটা গুরুত্বপূর্ণ শিক্ষা, যা §২-এ আনুষ্ঠানিক হবে:
- \(H_0\) আর \(H_1\) সমান মর্যাদার নয়। \(H_0\) হলো "সন্দেহাতীত না-হওয়া পর্যন্ত যা ধরে রাখি" — সাধারণত "কোনো প্রভাব নেই / কোনো পার্থক্য নেই / status quo"। \(H_1\) হলো সেই দাবি যা প্রমাণের ভার বহন করে (যা আমরা data দিয়ে প্রতিষ্ঠা করতে চাই)।
- প্রমাণের ভার \(H_1\)-এর ঘাড়ে। আমরা \(H_0\) সত্য ধরে নিয়ে শুরু করি, আর তখনই কেবল তা ছাড়ি যখন data \(H_0\)-কে যথেষ্ট অসম্ভাব্য করে তোলে। data নীরব থাকলে \(H_0\) টিকে থাকে — "প্রমাণের অভাব" নিজে "প্রভাব-অভাবের প্রমাণ" নয়।
- আমরা কখনো \(H_0\) "প্রমাণ" করি না। ঠিক যেমন আদালত কাউকে "নির্দোষ প্রমাণিত" ঘোষণা করে না, hypothesis test-ও \(H_0\) "সত্য" প্রমাণ করে না। দুটো-ই সম্ভাব্য রায়: "\(H_0\) বাতিল" (reject \(H_0\)) অথবা "\(H_0\) বাতিল করতে ব্যর্থ" (fail to reject \(H_0\)) — দ্বিতীয়টা "\(H_0\) গ্রহণ করলাম" নয়।
- দুই ধরনের ভুল সম্ভব, আর তারা অসম। নির্দোষকে দোষী সাব্যস্ত করা (সত্য \(H_0\) বাতিল) — এক ধরনের ভুল; দোষীকে ছেড়ে দেওয়া (মিথ্যা \(H_0\) মেনে নেওয়া) — আরেক ধরনের ভুল। সমাজ প্রথমটাকে (নির্দোষের সাজা) বেশি গুরুতর ধরে, তাই বিচারে তার সম্ভাবনা কঠোরভাবে ছোট রাখা হয় ("একজন নির্দোষের সাজার চেয়ে দশজন দোষীর মুক্তি ভালো")। ঠিক একইভাবে hypothesis test-এ প্রথম ভুলের সম্ভাবনাকেই আমরা আগে থেকে একটা ছোট সংখ্যায় (\(\alpha\)) বেঁধে দিই — এ-ই type I error ও significance level-এর উৎস (§২.৩)।
- "কতটা প্রমাণ যথেষ্ট" তা আগে থেকে ঠিক করতে হয়। "যুক্তিসঙ্গত সন্দেহের ঊর্ধ্বে" — এই মানদণ্ড বিচার শুরুর আগেই স্থির। পরিসংখ্যানে এই মানদণ্ডই significance level \(\alpha\) (যেমন \(0.05\)), আর data দেখার পর কতটা প্রমাণ জমল তার মাপ হলো p-value (§২.৫)।
এক বাক্যে রূপকটা: hypothesis test একটা পরিসংখ্যানিক বিচার — \(H_0\) (নির্দোষ/"কোনো প্রভাব নেই") সত্য ধরে নিয়ে শুরু, আর data যদি \(H_0\)-কে "যুক্তিসঙ্গত সন্দেহের ঊর্ধ্বে" অসম্ভাব্য করে তোলে, কেবল তবেই \(H_0\) বাতিল করে \(H_1\)-এর পক্ষে রায়। প্রমাণের ভার \(H_1\)-এর; নীরবতায় \(H_0\) টেকে।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — testing-এর শব্দভাণ্ডার from scratch: \(H_0\)/\(H_1\), test statistic \(T\), rejection region \(R\), type I error (\(\alpha\)) ও type II error (\(\beta\)), power \(=1-\beta\); p-value-র precise সংজ্ঞা ও সঠিক/ভুল ব্যাখ্যা; one- বনাম two-sided; Neyman–Pearson lemma (most powerful test); এবং CI–test duality। প্রতিটি প্রতীক খোলা হবে।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 z-test for mean (σ known), E2 t-test (σ unknown), E3 proportion test, E4 Neyman–Pearson most powerful test — প্রতিটিতে test statistic, critical value, p-value ও decision।
- §৪–৫ — power ও type II error-এর পূর্ণ গণিত, power function ও sample-size, Neyman–Pearson lemma-র যুক্তি/প্রমাণ, এবং CI–test duality-র আনুষ্ঠানিক প্রতিষ্ঠা।
- §৬–৮ — চিত্র (
4-7-error-types,4-7-pvalue,4-7-power-curve,4-7-ci-test-duality), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর গুরুত্বপূর্ণ ধাপ। estimation দেয় "\(\theta\) কত" (4.2–4.6); hypothesis testing দেয় "\(\theta\) সম্পর্কে একটা দাবি data-র আলোয় টেকে কি না" — বিজ্ঞান, চিকিৎসা ও ব্যবসায় সিদ্ধান্তের মূল যন্ত্র। আর এই অধ্যায়ের কাঠামোই পরের অধ্যায় 4.8 (likelihood ratio / Wald / score test)-এর ভিত্তি, যেখানে এখানকার এক-parameter test-কে আরো সাধারণ পরিস্থিতিতে বাড়ানো হবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামোটা স্থির: আমাদের কাছে একটি i.i.d. নমুনা \(X_1, X_2, \dots, X_n\) আছে (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা) একটি common distribution থেকে, যার ভেতরে একটি অজানা স্থির parameter \(\theta\) আছে। আমরা \(\theta\) সম্পর্কে একটা নির্দিষ্ট দাবি যাচাই করতে চাই।
২.১ Null ও alternative hypothesis — \(H_0\) আর \(H_1\)¶
প্রথম ধাপ: প্রশ্নটাকে দুটো প্রতিদ্বন্দ্বী hypothesis (প্রকল্প)-এ ভাগ করা। একটা hypothesis হলো parameter-জগৎ সম্পর্কে একটা দাবি — অর্থাৎ "\(\theta\) এই মানগুলোর একটা" ধরনের একটা বিবৃতি।
সংজ্ঞা (Null hypothesis — শূন্য প্রকল্প, \(H_0\))। null hypothesis \(H_0\) হলো সেই default দাবি, যা আমরা সত্য ধরে নিয়ে শুরু করি এবং কেবল যথেষ্ট প্রমাণ পেলেই ছাড়ি — সাধারণত "কোনো প্রভাব নেই / কোনো পার্থক্য নেই / status quo"। প্রতীকে এটা parameter-এর একটা নির্দিষ্ট মান বা মান-সমষ্টিকে বেছে নেয়, যেমন
যেখানে \(\theta_0\) ("থিটা-নট") হলো একটা পূর্বনির্ধারিত নির্দিষ্ট সংখ্যা — null-এর দাবি করা মান। (drug trial-এ \(\theta=\mu\) আর \(\theta_0=0\): "কোনো প্রভাব নেই"।)
সংজ্ঞা (Alternative hypothesis — বিকল্প প্রকল্প, \(H_1\))। alternative hypothesis \(H_1\) (অনেক বইয়ে \(H_a\)) হলো সেই দাবি যা \(H_0\) মিথ্যা হলে সত্য হয় — অর্থাৎ "যা প্রমাণ করতে চাই"। সাধারণ তিনটি রূপ:
| রূপ | \(H_1\) | কখন | নাম |
|---|---|---|---|
| দুই-পাশ | \(\theta \ne \theta_0\) | "কোনো পার্থক্য আছে" (দিক জানি না) | two-sided |
| ডান-পাশ | \(\theta > \theta_0\) | "বেড়েছে / বড়" | one-sided (right) |
| বাঁ-পাশ | \(\theta < \theta_0\) | "কমেছে / ছোট" | one-sided (left) |
এখানে দুটো গুরুত্বপূর্ণ পরিভাষা:
- একটা hypothesis simple (সরল) যদি সে parameter-কে একটিমাত্র নির্দিষ্ট মানে বাঁধে (যেমন \(H_0:\theta=\theta_0\), বা \(H_1:\theta=\theta_1\) একটা নির্দিষ্ট \(\theta_1\)-তে)। তখন distribution-টা সম্পূর্ণ নির্দিষ্ট।
- একটা hypothesis composite (যৌগিক) যদি সে একাধিক মান অনুমোদন করে (যেমন \(H_1:\theta>\theta_0\) — অসংখ্য মান)।
এই পার্থক্য §২.৬-এ Neyman–Pearson lemma-তে কেন্দ্রীয় হবে (lemma-টা মূলত simple-বনাম-simple ক্ষেত্রের)।
এক বাক্যে: \(H_0\) = সন্দেহাতীত না-হওয়া পর্যন্ত যা ধরে রাখি (default, "প্রভাব নেই"); \(H_1\) = যা প্রমাণ করতে চাই। কোনটা \(H_0\) আর কোনটা \(H_1\) সেটা গবেষকই ঠিক করেন — সাধারণত "প্রভাব নেই"-ই \(H_0\), কারণ আমরা চাই data নিজে থেকে প্রভাবের পক্ষে কথা বলুক।
২.২ Test statistic ও rejection region — সিদ্ধান্তের যন্ত্র¶
দাবি দুটো সাজানো হলো। এবার data থেকে একটা সংখ্যা গণনা করতে হবে যা \(H_0\) আর \(H_1\)-এর মধ্যে রায় দিতে সাহায্য করবে।
সংজ্ঞা (Test statistic — পরীক্ষা-পরিসংখ্যান, \(T\))। একটি test statistic \(T = T(X_1,\dots,X_n)\) হলো data-র একটা function (অর্থাৎ একটা সংখ্যা যা শুধু নমুনা থেকে গণনা করা যায়, কোনো অজানা parameter ছাড়াই), যা এমনভাবে বানানো যে \(H_0\) সত্য হলে \(T\)-র distribution জানা থাকে এবং \(H_1\)-এর দিকে গেলে \(T\) আলাদা (চরম) মান নেয়। অর্থাৎ \(T\) হলো "\(H_0\)-এর বিরুদ্ধে প্রমাণের পরিমাপক" — এর মান যত চরম, \(H_0\)-এর বিপক্ষে প্রমাণ তত জোরালো।
সবচেয়ে চেনা উদাহরণ (E1-এ সরাসরি লাগবে): \(\theta=\mu\), \(H_0:\mu=\mu_0\), σ জানা। তখন test statistic
প্রতীক খুলি: লব \(\bar X - \mu_0\) মাপে নমুনা গড় null-এর দাবি করা \(\mu_0\) থেকে কত দূরে; হর \(\sigma/\sqrt n = \mathrm{SE}(\bar X)\) সেই দূরত্বকে "কত standard error দূরে"-তে রূপ দেয়। মূল কথা: \(H_0\) সত্য হলে (\(\mu\) সত্যিই \(\mu_0\)) এই \(Z \sim \mathcal{N}(0,1)\) (4.1) — তাই "\(Z\) কত বড়" দেখে বুঝি বিচ্যুতিটা null-এর অধীনে স্বাভাবিক না অস্বাভাবিক।
সংজ্ঞা (Rejection region — বাতিল-অঞ্চল, \(R\))। rejection region (বা critical region) \(R\) হলো test statistic-এর মানগুলোর সেই সংগ্রহ যেখানে \(T\) পড়লে আমরা \(H_0\) বাতিল করি। সিদ্ধান্ত-নিয়ম সরল:
\(R\)-এর আকৃতি \(H_1\)-এর দিকের ওপর নির্ভর করে — কারণ \(R\)-কে \(H_1\)-এর "চরম" দিকেই বসাতে হয়:
- two-sided (\(H_1:\theta\ne\theta_0\)): \(R = \{\,\lvert T \rvert > c\,\}\) — দুই লেজেই (যেমন \(\lvert Z \rvert > 1.96\))।
- right one-sided (\(H_1:\theta>\theta_0\)): \(R = \{\,T > c\,\}\) — শুধু ডান লেজে।
- left one-sided (\(H_1:\theta<\theta_0\)): \(R = \{\,T < -c\,\}\) — শুধু বাঁ লেজে।
এখানে \(c\) একটা critical value (সংকট-মান) — সেই সীমা যার ওপারে গেলে "প্রমাণ যথেষ্ট চরম" ধরি। \(c\)-র মান কীভাবে বাছি? — ঠিক যেন \(H_0\) সত্য হলে ভুল করে বাতিল করার সম্ভাবনা একটা পূর্বনির্ধারিত ছোট সংখ্যায় (significance level \(\alpha\)) আটকে থাকে। সেটাই পরের উপবিভাগ।
এক বাক্যে: test statistic \(T\) data-কে একটা সংখ্যায় গুটিয়ে দেয় যা \(H_0\)-এর বিরুদ্ধে প্রমাণ মাপে; rejection region \(R\) ঠিক করে \(T\) কতটা চরম হলে \(H_0\) বাতিল হবে। test = "\(T\) গণনা করো, \(R\)-এ পড়লে \(H_0\) ছাড়ো"।
২.৩ দুই ধরনের ভুল — type I (\(\alpha\)) ও type II (\(\beta\))¶
যেহেতু সিদ্ধান্ত random data-র ওপর দাঁড়ানো, আমরা মাঝে মাঝে ভুল করব। দুটো ভিন্ন ভুল সম্ভব — আদালত-রূপকের সেই দুই অসম ভুল (§১.৩)। সব সম্ভাবনা একটা \(2\times2\) ছকে:
| \(H_0\) সত্য (আসামি নির্দোষ) | \(H_0\) মিথ্যা (আসামি দোষী) | |
|---|---|---|
| reject \(H_0\) (দোষী রায়) | ❌ Type I error (নির্দোষের সাজা) — সম্ভাবনা \(\alpha\) | ✅ সঠিক (দোষীর সাজা) — সম্ভাবনা \(1-\beta\) = power |
| fail to reject \(H_0\) (খালাস) | ✅ সঠিক (নির্দোষের খালাস) | ❌ Type II error (দোষীর মুক্তি) — সম্ভাবনা \(\beta\) |
দুই ভুল নিখুঁতভাবে সংজ্ঞায়িত করি:
সংজ্ঞা (Type I error ও significance level \(\alpha\))। Type I error হলো সত্য \(H_0\)-কে বাতিল করা (প্রথম ধরনের ভুল — নির্দোষকে দোষী বলা)। এর সম্ভাবনাকে বলি significance level (তাৎপর্য-মাত্রা), প্রতীকে \(\alpha\) ("আলফা"):
এখানে \(P(\,\cdot \mid H_0)\) মানে "\(H_0\) সত্য ধরে নিয়ে হিসাব করা সম্ভাবনা" (উল্লম্ব দাগ \(\mid\) = conditional, "...শর্তে")। \(\alpha\) আমরা আগে থেকে বেছে নিই (সাধারণত \(0.05\), কখনো \(0.01\) বা \(0.10\)) — এটাই "কত বার নির্দোষকে ভুল করে শাস্তি দিতে রাজি" তার সীমা। তারপর critical value \(c\)-কে ঠিক এমনভাবে বসাই যেন এই সমীকরণ মেটে। (যেমন two-sided z-test-এ \(\alpha=0.05\) চাইলে \(c=z_{\alpha/2}=z_{0.025}=1.96\) — কারণ তখন দুই লেজে মোট \(0.05\) ভর।)
সংজ্ঞা (Type II error, \(\beta\))। Type II error হলো মিথ্যা \(H_0\)-কে মেনে নেওয়া (দ্বিতীয় ধরনের ভুল — দোষীকে ছেড়ে দেওয়া)। এর সম্ভাবনা \(\beta\) ("বিটা"):
লক্ষ করুন একটা গুরুত্বপূর্ণ অপ্রতিসমতা: \(\alpha\) হিসাব করতে \(H_0\) যথেষ্ট (\(\theta=\theta_0\) নির্দিষ্ট), কিন্তু \(\beta\) হিসাব করতে \(H_1\)-এর একটা নির্দিষ্ট মান লাগে — কারণ "\(H_0\) মিথ্যা" নিজে অস্পষ্ট (\(\theta\) ঠিক কত?)। \(\theta\) যত \(\theta_0\)-র কাছে, \(\beta\) তত বড় (কাছের পার্থক্য ধরা কঠিন); যত দূরে, \(\beta\) তত ছোট। তাই \(\beta\) আসলে \(\theta\)-র একটা function (§২.৪)।
মূল আপস (trade-off) — কেন দুটোকে একসাথে শূন্য করা যায় না। \(R\)-কে ছোট করলে (বাতিল করা কঠিন করলে) \(\alpha\) কমে কিন্তু \(\beta\) বাড়ে; \(R\)-কে বড় করলে উল্টো। স্থির \(n\)-এ একটাকে কমাতে গেলে অন্যটা বাড়ে — ঠিক যেমন আদালতে প্রমাণের মান খুব কঠোর করলে নির্দোষের সাজা কমে কিন্তু দোষীর মুক্তি বাড়ে। তাই কাঠামোটা অপ্রতিসম: আমরা আগে \(\alpha\)-কে একটা ছোট মানে বেঁধে দিই (টাইপ I ভুলকেই বেশি গুরুতর ধরে), তারপর সেই সীমার মধ্যে \(\beta\) যতটা সম্ভব ছোট করার (power বাড়ানোর) চেষ্টা করি। \(\alpha\) ও \(\beta\) একসাথে ছোট করার একমাত্র সৎ উপায় — \(n\) বাড়ানো। (চিত্র
4-7-error-typesএই দুই ভুলকে দুটি overlapping বণ্টনের ছায়াকৃত লেজ হিসেবে দেখাবে।)
২.৪ Power — মিথ্যা \(H_0\) ধরার সামর্থ্য¶
type II error-এর পরিপূরক ধারণাটাই বাস্তবে সবচেয়ে বেশি ব্যবহৃত, কারণ এটা "ভালো"-র মাপ (ভুলের নয়)।
সংজ্ঞা (Power — সামর্থ্য)। একটা test-এর power হলো মিথ্যা \(H_0\)-কে ঠিকঠাক বাতিল করার সম্ভাবনা — অর্থাৎ "প্রভাব সত্যিই থাকলে তা ধরে ফেলার" ক্ষমতা:
আদালত-রূপকে: power = সত্যিকারের দোষীকে দোষী সাব্যস্ত করার হার। power \(=0.80\) মানে "যদি প্রভাব সত্যিই থাকে, এই test ৮০% বার তা ধরবে (আর ২০% বার ফসকাবে, কারণ \(\beta=0.20\))"।
যেহেতু \(\beta\) (তাই power-ও) \(H_1\)-এর নির্দিষ্ট মানের ওপর নির্ভর করে, power আসলে \(\theta\)-র একটা function:
সংজ্ঞা (Power function — সামর্থ্য-অপেক্ষক)। \(\beta(\theta) = P(\text{reject } H_0 \mid \theta)\) হলো power function — প্রতিটি সত্য \(\theta\)-মানের জন্য বাতিল করার সম্ভাবনা। এর আচরণ:
- \(\theta = \theta_0\)-তে (অর্থাৎ \(H_0\) সত্য) power \(= \alpha\) — কারণ তখন "reject" করাটাই type I error।
- \(\theta\) যত \(\theta_0\) থেকে দূরে (\(H_1\)-এর গভীরে), power তত \(1\)-এর দিকে — বড় প্রভাব ধরা সহজ।
- power বাড়ে যখন: (ক) প্রকৃত প্রভাব বড় (effect size বেশি), (খ) \(n\) বড়, (গ) \(\sigma\) ছোট, (ঘ) \(\alpha\) বড় (কম কঠোর)।
(চিত্র 4-7-power-curve এই power function-কে \(\theta\)-র বিপরীতে এঁকে দেখাবে: \(\theta_0\)-তে \(\alpha\) ছুঁয়ে, দূরে গিয়ে \(1\)-এর দিকে S-আকারে ওঠা।)
এক বাক্যে: power = "প্রভাব থাকলে ধরতে পারার" সম্ভাবনা (\(=1-\beta\))। ভালো test = নির্দিষ্ট \(\alpha\) ধরে রেখেও বেশি power — আর power বাড়ানোর সবচেয়ে নির্ভরযোগ্য পথ বেশি data। (পরীক্ষা design করার সময় "কত \(n\) লাগবে কাঙ্ক্ষিত power পেতে" — এটাই sample-size calculation, §৪–৫-এ।)
২.৫ p-value — প্রমাণের পরিমাণ, ও তার সঠিক/ভুল ব্যাখ্যা¶
এতক্ষণ সিদ্ধান্ত নিয়েছি "\(T \in R\) কি না" (হ্যাঁ/না) দিয়ে। কিন্তু এটা একটা তথ্য লুকিয়ে ফেলে: \(T\) কি সবে-সবে \(R\)-এ ঢুকল, নাকি অনেক গভীরে? p-value ঠিক সেই "কতটা চরম" মাপে — একটা ধারাবাহিক প্রমাণ-পরিমাপক। এই অধ্যায়ের সবচেয়ে বেশি ভুল-বোঝা ধারণা, তাই খুব যত্নে।
সংজ্ঞা (p-value)। একটা পর্যবেক্ষণ থেকে test statistic-এর মান \(T_{\text{obs}}\) (observed) পেলে, p-value হলো:
অর্থাৎ: "\(H_0\) সত্য ধরে নিলে, নিছক random chance-এ এত (বা তার চেয়ে বেশি) চরম data দেখার সম্ভাবনা কত?" "চরম"-এর মানে \(H_1\)-এর দিক অনুযায়ী —
- two-sided: \(p = P(\lvert T \rvert \ge \lvert T_{\text{obs}} \rvert \mid H_0)\) (দুই লেজ),
- right one-sided: \(p = P(T \ge T_{\text{obs}} \mid H_0)\),
- left one-sided: \(p = P(T \le T_{\text{obs}} \mid H_0)\)।
স্বজ্ঞা। ছোট p-value মানে: "\(H_0\) সত্য হলে এমন data প্রায় আসেই না — অথচ এল; তাহলে হয় বিরল ঘটনা ঘটেছে, নয় \(H_0\) ভুল।" আমরা দ্বিতীয়টা বেছে \(H_0\) বাতিল করি। বড় p-value মানে: "\(H_0\) সত্য হলেও এমন data দিব্যি আসে — কাজেই \(H_0\) অবিশ্বাস করার কারণ নেই।"
সিদ্ধান্ত-নিয়ম ও \(\alpha\)-র সাথে সম্পর্ক। p-value আর rejection region আসলে একই সিদ্ধান্তের দুই ভাষা:
অর্থাৎ p-value হলো "যে ক্ষুদ্রতম \(\alpha\)-তে এই data দিয়ে \(H_0\) বাতিল হতো"। তাই p-value রিপোর্ট করা শুধু "reject/fail" বলার চেয়ে বেশি তথ্য দেয় — পাঠক নিজের পছন্দের \(\alpha\) বসিয়ে রায় দেখে নিতে পারেন। (চিত্র 4-7-pvalue \(H_0\)-এর বণ্টনে \(T_{\text{obs}}\)-এর ওপারের ছায়াকৃত লেজ হিসেবে p-value দেখাবে।)
সঠিক বনাম ভুল ব্যাখ্যা — সবচেয়ে গুরুত্বপূর্ণ অংশ। p-value নিয়ে কিছু ভুল-ধারণা এত সাধারণ যে আলাদা করে গেঁথে দিচ্ছি:
| বিবৃতি | |
|---|---|
| ✅ সঠিক | "\(H_0\) সত্য ধরলে, এত-চরম-বা-আরো-চরম data দেখার সম্ভাবনা।" |
| ❌ ভুল ১ | "\(H_0\) সত্য হওয়ার সম্ভাবনা।" — না। p-value হলো \(P(\text{data}\mid H_0)\), \(P(H_0\mid\text{data})\) নয়। \(H_0\) স্থির সত্য/মিথ্যা, frequentist কাঠামোয় তার "সম্ভাবনা" নেই। |
| ❌ ভুল ২ | "\(1-p\) = \(H_1\) সত্য হওয়ার সম্ভাবনা।" — না, একই কারণে। |
| ❌ ভুল ৩ | "p-value = type I error করার সম্ভাবনা।" — না; type I error-এর সম্ভাবনা হলো পূর্বনির্ধারিত \(\alpha\), একটা নির্দিষ্ট data-র p-value নয়। |
| ❌ ভুল ৪ | "বড় p-value মানে \(H_0\) সত্য প্রমাণিত।" — না; এটা শুধু "\(H_0\) বাতিলের যথেষ্ট প্রমাণ নেই" (আদালতের "not guilty", "innocent প্রমাণিত" নয়)। |
| ❌ ভুল ৫ | "p-value প্রভাবের আকার বা গুরুত্ব মাপে।" — না; ছোট p-value মানে "প্রভাব শূন্য নয় বলে আত্মবিশ্বাস", "প্রভাব বড়" নয়। বিশাল \(n\)-এ তুচ্ছ প্রভাবও ক্ষুদ্র p দিতে পারে। (effect size আলাদা জিনিস।) |
এক বাক্যে গাঁথুন: p-value \(= P(\text{এত-চরম data} \mid H_0)\) — "\(H_0\) সত্য হওয়ার সম্ভাবনা" নয়। ছোট p = "\(H_0\) সত্য হলে এই data বিস্ময়কর", তাই \(H_0\)-কে সন্দেহ করি; কিন্তু p কখনোই \(H_0\)-এর সত্যতার সম্ভাবনা বা প্রভাবের আকার দেয় না।
২.৬ Neyman–Pearson lemma — সবচেয়ে শক্তিশালী test¶
এতক্ষণ ধরে নিয়েছি test statistic ও rejection region আমাদের দেওয়া আছে। কিন্তু একটা গভীর প্রশ্ন: নির্দিষ্ট \(\alpha\)-তে অজস্র সম্ভাব্য test-এর মধ্যে কোনটা সেরা — অর্থাৎ সবচেয়ে বেশি power? simple-বনাম-simple ক্ষেত্রে এর নিখুঁত উত্তর দেয় Neyman–Pearson lemma।
প্রেক্ষাপট: ধরা যাক দুটোই simple hypothesis (§২.১) — null density সম্পূর্ণ নির্দিষ্ট \(H_0:\theta=\theta_0\), আর alternative-ও একটামাত্র নির্দিষ্ট মানে \(H_1:\theta=\theta_1\)। তখন data \(x=(x_1,\dots,x_n)\)-এর likelihood দুই hypothesis-এর অধীনে নির্দিষ্ট:
- \(L(\theta_0) = \prod_{i=1}^n f(x_i;\theta_0)\) — "\(H_0\) সত্য হলে এই data দেখার সম্ভাব্যতা" (likelihood, 4.3)।
- \(L(\theta_1) = \prod_{i=1}^n f(x_i;\theta_1)\) — "\(H_1\) সত্য হলে এই data দেখার সম্ভাব্যতা"।
এখানে \(f(x;\theta)\) হলো একটি observation-এর density/mass।
মূল ধারণা। কোন data \(H_1\)-এর পক্ষে আর কোন \(H_0\)-এর পক্ষে বেশি কথা বলে? — স্বাভাবিক পরিমাপক দুটো likelihood-এর অনুপাত:
এই অনুপাত বড় মানে "\(H_1\)-এর অধীনে data অনেক বেশি সম্ভাব্য" — তাই \(H_0\)-এর বিপক্ষে জোরালো প্রমাণ। স্বজ্ঞা বলছে: \(\Lambda\) বড় হলেই \(H_0\) বাতিল করা উচিত। Neyman–Pearson lemma এই স্বজ্ঞাকে সর্বোত্তম বলে প্রমাণ করে।
Neyman–Pearson lemma (statement)। simple \(H_0:\theta=\theta_0\) বনাম simple \(H_1:\theta=\theta_1\) পরীক্ষায়, নির্দিষ্ট significance level \(\alpha\)-তে সবচেয়ে শক্তিশালী (most powerful) test হলো likelihood ratio test — অর্থাৎ যে test এই rejection region ব্যবহার করে:
যেখানে threshold \(k\)-কে ঠিক এমনভাবে বাছা হয় যেন \(P(\Lambda > k \mid H_0) = \alpha\)। কোনো অন্য test যার type I error \(\le \alpha\), তার power এই likelihood-ratio test-এর power-এর চেয়ে বেশি হতে পারে না।
কথায়: নির্দিষ্ট "নির্দোষের সাজার হার" (\(\alpha\)) ধরে রাখলে, likelihood-অনুপাতকে threshold-এর সাথে তুলনা করাই "দোষী ধরার হার" (power) সর্বোচ্চ করে। likelihood ratio-ই সেই সেরা প্রমাণ-পরিমাপক — অন্য কোনো নিয়ম এর চেয়ে ভালো করতে পারে না।
কেন এটা গুরুত্বপূর্ণ। (১) এটা একটা অপ্টিমালিটি ফল — কেবল একটা test দেয় না, বলে দেয় ওটাই সেরা। (২) আমরা E1-এ দেখব Normal mean-এর ক্ষেত্রে এই likelihood-ratio নিয়মটা সরল হয়ে গিয়ে ঠিক চেনা z-test-এ দাঁড়ায় — অর্থাৎ z-test দৈবচয়ন নয়, এটা most powerful। (৩) composite \(H_1\)-এর জন্য lemma সরাসরি খাটে না; সেখান থেকেই 4.8-এর generalized likelihood ratio test-এর জন্ম।
এক বাক্যে: Neyman–Pearson lemma বলে — simple বনাম simple ক্ষেত্রে, নির্দিষ্ট \(\alpha\)-তে সর্বোচ্চ power পাওয়ার একমাত্র পথ likelihood ratio \(L(\theta_1)/L(\theta_0)\)-কে একটা threshold-এর সাথে তুলনা করা। "সেরা প্রমাণ = likelihood-অনুপাত" — এটাই hypothesis testing-এর তাত্ত্বিক ভিত্তিপ্রস্তর। (পূর্ণ যুক্তি §৪–৫-এ।)
২.৭ CI–test duality — একই মুদ্রার দুই পিঠ¶
শেষ মূল ধারণা — যা 4.6-কে এই অধ্যায়ের সাথে সরাসরি জোড়ে। দেখা যায়, confidence interval আর hypothesis test আসলে একই তথ্যের দুই রূপ।
Duality (statement)। parameter \(\theta\)-র একটা \((1-\alpha)\) confidence interval \(C(X)\) আর একটা level-\(\alpha\) two-sided test (যা \(H_0:\theta=\theta_0\) বনাম \(H_1:\theta\ne\theta_0\) যাচাই করে) এই সম্পর্কে বাঁধা:
কথায়: একটা মান \(\theta_0\) ৯৫% CI-তে আছে — ঠিক তখনই, যখন সেই \(\theta_0\)-কে \(H_0\) ধরে \(\alpha=0.05\) test চালালে \(H_0\) বাতিল হয় না। উল্টোভাবে, \(\theta_0\) CI-র বাইরে থাকা মানেই \(H_0:\theta=\theta_0\) ওই level-এ বাতিল।
কেন এটা সত্য (স্বজ্ঞা): দুটোই একই pivot (\(Z\) বা \(T\)) থেকে আসে। CI হলো "\(\lvert (\bar X-\theta_0)/\mathrm{SE} \rvert \le z_{\alpha/2}\) যেসব \(\theta_0\)-র জন্য খাটে তাদের সংগ্রহ", আর test হলো "\(\lvert (\bar X-\theta_0)/\mathrm{SE} \rvert > z_{\alpha/2}\) হলে \(H_0\) বাতিল" — একই অসমতার দুই দিক। তাই একটা \(\theta_0\) CI-তে থাকা আর তা নিয়ে \(H_0\) বাতিল না-হওয়া হুবহু সমার্থক।
ব্যবহারিক তাৎপর্য। এর ফলে CI প্রায়ই test-এর চেয়ে বেশি তথ্যবহুল: শুধু "বাতিল কি না" নয়, CI দেখায় কোন কোন মান data-র সাথে সঙ্গতিপূর্ণ। বিশেষত, "\(H_0:\mu=0\)" ধরনের কোনো null পরীক্ষায় শুধু দেখুন CI-তে \(0\) আছে কি না: \(0\) বাইরে থাকলে \(\mu\ne0\) statistically significant। (চিত্র 4-7-ci-test-duality একটা CI ও null-মান \(\theta_0\)-এর অবস্থান পাশাপাশি দেখিয়ে এই সমতা চাক্ষুষ করবে; পূর্ণ প্রমাণ §৪–৫-এ।)
এক বাক্যে: CI ও hypothesis test একই pivot-যুক্তির দুই পিঠ — "\(\theta_0\) ৯৫% CI-তে আছে" আর "\(\alpha=0.05\)-এ \(H_0:\theta=\theta_0\) বাতিল হয় না" হুবহু একই কথা। তাই CI দেখলেই একগুচ্ছ test-এর ফল একসাথে পড়া যায়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর কাঠামো এবার চারটি বাস্তব পরিস্থিতিতে সংখ্যাসহ চালাব। প্রতিটিতে একই পাঁচ-ধাপ ছন্দ: (১) \(H_0,H_1\) লেখো → (২) test statistic \(T\) বাছো ও \(H_0\)-এর অধীনে তার বণ্টন বলো → (৩) \(\alpha\) ও critical value ঠিক করো (rejection region) → (৪) \(T_{\text{obs}}\) ও p-value গণনা করো → (৫) সিদ্ধান্ত ও ব্যাখ্যা। চারটি উদাহরণ চারটি কেন্দ্রীয় কেস ধরে: E1 z-test (σ known), E2 t-test (σ unknown), E3 proportion test, E4 Neyman–Pearson most powerful test।
E1 · z-test for mean (σ known)¶
এই উদাহরণ §২.২-এর \(Z\)-statistic-এর সরাসরি সংখ্যা-প্রয়োগ।
সেটআপ। একটা কারখানার যন্ত্র প্যাকেটে চিনি ভরে; দীর্ঘ ইতিহাস থেকে population standard deviation জানা: \(\sigma = 10\) গ্রাম, এবং লক্ষ্য (label) গড় ওজন \(\mu_0 = 50\) গ্রাম। সন্দেহ হলো যন্ত্রটা মাত্রাতিরিক্ত ভরছে। আজ \(n = 100\)টি প্যাকেট মেপে নমুনা গড় \(\bar X = 53\) গ্রাম। প্রকৃত গড় \(\mu\) কি \(50\) থেকে আলাদা?
ধাপ ১ (hypotheses)। \(H_0:\mu = 50\) বনাম \(H_1:\mu \ne 50\) (two-sided — "আলাদা কি না", দিক ধরে নিচ্ছি না)।
ধাপ ২ (test statistic)। σ জানা, তাই $$ Z = \frac{\bar X - \mu_0}{\sigma/\sqrt n}, \qquad H_0 \text{-এর অধীনে } Z \sim \mathcal{N}(0,1). $$
ধাপ ৩ (α ও rejection region)। \(\alpha = 0.05\), two-sided, তাই critical value \(z_{\alpha/2} = z_{0.025} = 1.96\); rejection region \(R = \{\lvert Z \rvert > 1.96\}\)।
ধাপ ৪ (observed statistic ও p-value)। প্রথমে standard error: $$ \mathrm{SE}(\bar X) = \frac{\sigma}{\sqrt n} = \frac{10}{\sqrt{100}} = \frac{10}{10} = 1 \ \text{গ্রাম}, $$ তাই $$ Z_{\text{obs}} = \frac{53 - 50}{1} = 3.0 . $$ two-sided p-value (standard normal-এ \(\lvert Z \rvert \ge 3\)-এর ভর): $$ p = 2\,P(Z > 3.0) = 2 \times 0.00135 = 0.0027 . $$
ধাপ ৫ (সিদ্ধান্ত ও ব্যাখ্যা)। \(\lvert Z_{\text{obs}} \rvert = 3.0 > 1.96\) (অথবা সমতুল্যভাবে \(p = 0.0027 < 0.05\)) → \(H_0\) বাতিল। ব্যাখ্যা: "যন্ত্রটা সত্যিই \(50\) গ্রামে কেন্দ্রিত হলে, নিছক random ওঠানামায় \(\bar X\) লক্ষ্য থেকে এত দূরে (≥ ৩ SE) যাওয়ার সম্ভাবনা মাত্র \(0.27\%\) — এত বিরল যে আমরা 'কেন্দ্র \(50\)' দাবিটাকে অবিশ্বাস করি। data ইঙ্গিত দেয় প্রকৃত গড় \(50\) গ্রামের বেশি।" (সঠিক p-ব্যাখ্যা মেনে: \(0.0027\) হলো "\(H_0\) সত্য হলে এমন-চরম data-র সম্ভাবনা", "\(H_0\) সত্য হওয়ার সম্ভাবনা" নয়।)
CI-র সাথে মিল (duality, §২.৭)। ৯৫% CI \(= 53 \pm 1.96\times 1 = [51.04,\ 54.96]\)। লক্ষ করুন null-মান \(50\) এই ব্যবধানের বাইরে — ঠিক যেমন duality বলে, তাই \(H_0:\mu=50\) বাতিল। একই সিদ্ধান্ত, দুই পথে।
E2 · t-test (σ unknown)¶
বাস্তবসম্মত কেস: σ জানা নয়, data থেকে \(S\) অনুমান করতে হবে — তাই \(z\) নয়, \(t\) (4.6-এর CI-তে যেমন)।
সেটআপ। একটা প্রমিত পরীক্ষায় গড় স্কোর ঐতিহাসিকভাবে \(\mu_0 = 100\)। একটা নতুন শিক্ষণ-পদ্ধতির পর \(n = 16\) জন শিক্ষার্থীর নমুনা গড় \(\bar X = 105\), sample standard deviation \(S = 8\) (population \(\sigma\) অজানা)। নতুন পদ্ধতি কি গড় স্কোর বদলেছে?
ধাপ ১ (hypotheses)। \(H_0:\mu = 100\) বনাম \(H_1:\mu \ne 100\) (two-sided)।
ধাপ ২ (test statistic)। σ অজানা, \(S\) দিয়ে প্রতিস্থাপিত, তাই $$ T = \frac{\bar X - \mu_0}{S/\sqrt n}, \qquad H_0 \text{-এর অধীনে } T \sim t_{n-1} = t_{15} $$ (degrees of freedom \(= n-1 = 15\), কারণ \(S\) গণনায় একটা df খরচ হয়, 4.4/4.6)।
ধাপ ৩ (α ও rejection region)। \(\alpha = 0.05\), two-sided, \(t\)-ছক থেকে critical value \(t_{15,\,0.025} = 2.131\) (লক্ষণীয়: \(z_{0.025}=1.96\)-এর চেয়ে বড় — \(t\) ভারী-লেজ, তাই একটু কঠোর); \(R = \{\lvert T \rvert > 2.131\}\)।
ধাপ ৪ (observed statistic ও p-value)। estimated standard error: $$ \widehat{\mathrm{SE}}(\bar X) = \frac{S}{\sqrt n} = \frac{8}{\sqrt{16}} = \frac{8}{4} = 2 , $$ তাই $$ T_{\text{obs}} = \frac{105 - 100}{2} = 2.5 . $$ two-sided p-value (\(t_{15}\)-বণ্টনে \(\lvert T \rvert \ge 2.5\)): $$ p = 2\,P(t_{15} > 2.5) \approx 2 \times 0.0123 = 0.0245 . $$
ধাপ ৫ (সিদ্ধান্ত ও ব্যাখ্যা)। \(\lvert T_{\text{obs}} \rvert = 2.5 > 2.131\) (এবং \(p = 0.0245 < 0.05\)) → \(H_0\) বাতিল। ব্যাখ্যা: "পুরোনো গড় \(100\) সত্য হলে \(16\)-জনের নমুনায় এমন বিচ্যুতির সম্ভাবনা মাত্র ~\(2.45\%\); তাই নতুন পদ্ধতি গড় স্কোরকে statistically significant-ভাবে বদলেছে বলে ধরছি।"
t বনাম z-এর তাৎপর্য। যদি ভুল করে (σ জানা ভেবে) \(z_{0.025}=1.96\) ব্যবহার করতাম, p হতো ছোট (\(2P(Z>2.5)=0.0124\)) — অর্থাৎ \(t\) ব্যবহার না করলে প্রমাণকে অতি-আত্মবিশ্বাসী ভাবে দেখানো হতো। ছোট \(n\)-এ \(t\)-ই সৎ; এখানে দুই পথেই বাতিল হলেও সীমান্ত ক্ষেত্রে পার্থক্যটা সিদ্ধান্ত উল্টে দিতে পারত।
E3 · proportion test¶
একটা অনুপাত (proportion) নিয়ে test — §১.২-এর A/B-ধরনের প্রশ্ন।
সেটআপ। একটা মুদ্রা/মুদ্রার-মতো প্রক্রিয়া (যেমন একটা coin সুষম কি না, বা একটা click-through ৫০% কি না) নিয়ে দাবি: সাফল্য-হার \(p_0 = 0.5\)। \(n = 400\) বার চালিয়ে \(220\)টি সাফল্য পাওয়া গেল, অর্থাৎ নমুনা-অনুপাত \(\hat p = 220/400 = 0.55\)। প্রকৃত \(p\) কি \(0.5\) থেকে আলাদা?
ধাপ ১ (hypotheses)। \(H_0:p = 0.5\) বনাম \(H_1:p \ne 0.5\) (two-sided)।
ধাপ ২ (test statistic)। প্রতিটি ফল Bernoulli\((p)\), তাই \(\hat p\) একটা নমুনা গড়; বড় \(n\)-এ CLT-র জোরে \(\hat p \approx \mathcal{N}(p,\ p(1-p)/n)\) (3.4)। মূল সূক্ষ্মতা: test statistic-এ standard error হিসাব করি \(H_0\)-এর মান \(p_0\) দিয়ে (কারণ \(H_0\) সত্য ধরে নিয়েই null distribution চাই — CI-র মতো \(\hat p\) দিয়ে নয়): $$ Z = \frac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}}, \qquad H_0 \text{-এর অধীনে } Z \approx \mathcal{N}(0,1). $$
ধাপ ৩ (α ও rejection region)। \(\alpha = 0.05\), two-sided → \(z_{0.025} = 1.96\); \(R = \{\lvert Z \rvert > 1.96\}\)।
ধাপ ৪ (observed statistic ও p-value)। null SE: $$ \mathrm{SE}0 = \sqrt{\frac{p_0(1-p_0)}{n}} = \sqrt{\frac{0.5 \times 0.5}{400}} = \sqrt{\frac{0.25}{400}} = \sqrt{0.000625} = 0.025 , $$ তাই $$ Z = 2.0 . $$ two-sided p-value: $$ p = 2\,P(Z > 2.0) = 2 \times 0.02275 = 0.0455 . $$}} = \frac{0.55 - 0.50}{0.025
ধাপ ৫ (সিদ্ধান্ত ও ব্যাখ্যা)। \(\lvert Z_{\text{obs}} \rvert = 2.0 > 1.96\) (এবং \(p = 0.0455 < 0.05\)) → \(H_0\) বাতিল (কেবলমাত্র — সীমান্ত-ঘেঁষা)। ব্যাখ্যা: "প্রকৃত হার \(0.5\) হলে \(400\) চেষ্টায় \(\hat p\) এত দূরে যাওয়ার সম্ভাবনা ~\(4.55\%\); \(0.05\)-এর সামান্য নিচে, তাই \(0.05\)-মানদণ্ডে \(H_0\) অল্পের জন্য বাতিল। data দুর্বলভাবে ইঙ্গিত দেয় \(p > 0.5\)।" লক্ষ করুন p প্রায় \(\alpha\)-র গায়ে — এমন সীমান্ত ফলকে "নিশ্চিত প্রমাণ" ভাবা ঠিক নয়; এখানেই p-value (শুধু হ্যাঁ/না নয়) রিপোর্ট করার মূল্য।
একটি লক্ষণীয় ফারাক (CI বনাম test SE)। CI-তে (4.6) SE হিসাব করতাম \(\hat p\) দিয়ে: \(\sqrt{0.55\cdot0.45/400}\approx0.0249\) — এখানে test-এ \(p_0\) দিয়ে \(0.025\)। মান কাছাকাছি বলে এখানে দুই পথ মোটামুটি মেলে, কিন্তু নীতিগতভাবে test-এ null-মান \(p_0\), CI-তে estimate \(\hat p\) — কারণ test "\(H_0\) সত্য ধরে" আর CI "estimate ঘিরে" কাজ করে।
E4 · Neyman–Pearson most powerful test¶
শেষ উদাহরণ §২.৬-এর lemma-কে সংখ্যায় দেখায়: simple বনাম simple ক্ষেত্রে likelihood ratio থেকে most powerful test, এবং তার power।
সেটআপ। একটা সংকেত (signal) মাপা হচ্ছে; প্রতিটি পরিমাপ \(X_i \sim \mathcal{N}(\mu, 1)\) (variance \(1\), জানা)। দুটো simple দাবি: \(H_0:\mu = 0\) ("সংকেত নেই, কেবল noise") বনাম \(H_1:\mu = 0.5\) ("নির্দিষ্ট-শক্তির সংকেত আছে")। \(n = 25\)টি পরিমাপ নেওয়া হবে; \(\alpha = 0.05\)-এ most powerful test ও তার power চাই।
ধাপ ১ (likelihood ratio গঠন)। Normal density বসিয়ে likelihood ratio: $$ \Lambda(x) = \frac{L(\mu=0.5)}{L(\mu=0)} = \frac{\prod_i \exp!\big(-\tfrac12 (x_i-0.5)^2\big)}{\prod_i \exp!\big(-\tfrac12 x_i^2\big)} . $$ log নিয়ে সরল করলে (exponent-এ \(-\tfrac12[(x_i-0.5)^2 - x_i^2] = -\tfrac12[-x_i + 0.25] = 0.5\,x_i - 0.125\)): $$ \log \Lambda(x) = \sum_{i=1}^{n} (0.5\,x_i - 0.125) = 0.5\sum_i x_i - 0.125\,n . $$ লক্ষ করুন এটা শুধু \(\sum x_i\) (তাই \(\bar X\))-এর বাড়তি function। কাজেই "\(\Lambda > k\)" শর্ত হুবহু "\(\bar X > c\)" শর্তে রূপ নেয় — অর্থাৎ Neyman–Pearson-এর most powerful test এখানে সরল হয়ে দাঁড়ায় "\(\bar X\) যথেষ্ট বড় হলে \(H_0\) বাতিল", ঠিক এক-পাশের z-test! (এটাই §২.৬-এর সেই বার্তা: z-test দৈবচয়ন নয়, NP-অর্থে optimal।)
ধাপ ২–৩ (critical value, \(\alpha=0.05\))। \(H_0:\mu=0\)-এর অধীনে \(\bar X \sim \mathcal{N}(0,\ 1/n) = \mathcal{N}(0,\ 1/25)\), অর্থাৎ \(\mathrm{SE} = 1/\sqrt{25} = 0.2\)। right one-sided test, তাই critical value \(c\) এমন যে \(P(\bar X > c \mid \mu=0) = 0.05\): $$ c = z_{0.05}\times \mathrm{SE} = 1.645 \times 0.2 = 0.329 . $$ rejection region: reject \(H_0 \iff \bar X > 0.329\)।
ধাপ ৪ (power \(=1-\beta\))। power = \(H_1\) (\(\mu=0.5\)) সত্য হলে \(\bar X > 0.329\) হওয়ার সম্ভাবনা। \(H_1\)-এর অধীনে \(\bar X \sim \mathcal{N}(0.5,\ 0.2^2)\), তাই standardize করে: $$ \text{power} = P\big(\bar X > 0.329 \,\mid\, \mu=0.5\big) = P!\left(Z > \frac{0.329 - 0.5}{0.2}\right) = P(Z > -0.855) \approx 0.80 . $$ অর্থাৎ \(\beta = 1 - 0.80 = 0.20\)।
ধাপ ৫ (সিদ্ধান্ত-অর্থ)। এই test-এর মানে: "\(\bar X > 0.329\) হলে 'সংকেত আছে' (\(H_1\)) রায়।" Neyman–Pearson lemma গ্যারান্টি দেয় — \(\alpha=0.05\) ধরে রাখা যেকোনো test-এর মধ্যে এই likelihood-ratio (= এক-পাশের z) test-এরই power সর্বোচ্চ, এখানে \(0.80\)। কোনো বিকল্প নিয়ম \(\alpha\le0.05\) রেখে \(0.80\)-র বেশি power দিতে পারবে না। (power বাড়াতে চাইলে — \(n\) বাড়ান: \(n\) বড় করলে \(\mathrm{SE}\) কমে, দুই বণ্টনের overlap কমে, power \(1\)-এর দিকে যায়; চিত্র 4-7-power-curve এই নির্ভরতা দেখাবে।)
§৩-এর সার: চারটি উদাহরণই একই পাঁচ-ধাপ কঙ্কাল — \(H_0,H_1\) → test statistic ও তার null-বণ্টন → \(\alpha\) ও rejection region → \(T_{\text{obs}}\) ও p-value → সিদ্ধান্ত। শুধু (ক) test statistic-এর রূপ আর (খ) তার null-বণ্টন পরিস্থিতি-ভেদে বদলায়: σ জানা → \(Z\), \(\mathcal{N}(0,1)\) (E1); σ অজানা → \(T\), \(t_{n-1}\) (E2); proportion → \(Z\) (null SE \(p_0\) দিয়ে), \(\mathcal{N}(0,1)\) (E3); simple-vs-simple → likelihood ratio, যা প্রায়ই চেনা statistic-এ সরল হয় (E4)। আর প্রতিটিরই একই সাবধানতা: p-value = "\(H_0\) সত্য হলে এত-চরম data-র সম্ভাবনা", "\(H_0\) সত্য হওয়ার সম্ভাবনা" নয়।
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা hypothesis testing (পরিকল্পনা-পরীক্ষা / প্রকল্প-যাচাই) কী, কেন দরকার, আর তার দৈনন্দিন রূপ — z-test, t-test, proportion test — স্বজ্ঞাগতভাবে দেখেছি; পরিচয় হয়েছে \(H_0\) (null hypothesis, শূন্য-প্রকল্প), \(H_1\) (alternative, বিকল্প-প্রকল্প), test statistic \(T\), significance level \(\alpha\), এবং rejection region \(R\)-এর সঙ্গে। এবার এই অংশে আমরা scratch থেকে সেই যন্ত্রগুলো উৎপাদন করব: কোথা থেকে rejection region \(\lvert Z\rvert > z_{\alpha/2}\) আসে আর কেন তা ঠিক \(\alpha\)-হারে type I error ধরে রাখে; একটা নির্দিষ্ট বিকল্পে power কীভাবে গুনি; p-value আসলে কী জিনিসের সংখ্যা; কেন likelihood-ratio test সবচেয়ে শক্তিশালী (Neyman–Pearson lemma); আর CI ও test একই মুদ্রার দুই পিঠ কেন (CI–test duality)। কোনো ধাপ লুকানো হবে না; প্রতিটি সমান-চিহ্নের পেছনে বাংলায় কারণ থাকবে। কাজটা পাঁচটি অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের সামান্য ওপরে, statement + proof-sketch দেব):
- (a) z-test নির্মাণ — \(H_0:\mu=\mu_0\) ধরে pivot \(Z=\dfrac{\bar X-\mu_0}{\sigma/\sqrt n}\sim\mathcal N(0,1)\), তারপর rejection region \(\lvert Z\rvert>z_{\alpha/2}\) ঠিক কেন type I error-কে \(\alpha\)-তে আটকায় তার পূর্ণ যুক্তি (E1)। ★★
- (b) একটা নির্দিষ্ট বিকল্প \(\mu_1\)-এ power \(=1-\beta\) গণনা — \(H_1\) সত্য হলে \(Z\)-এর বণ্টন সরে যায়, আর সেই সরে-যাওয়া বণ্টনে rejection region-এর ভর-ই power। ★★
- (c) p-value = "যত ছোট \(\alpha\)-তে এখনও reject করতাম তার সর্বনিম্ন", আর সে কীভাবে test statistic থেকে সরাসরি বেরোয় ও decision rule-এ মেলে। ★★
- (d) Neyman–Pearson lemma — simple-vs-simple-এ likelihood-ratio test-ই most powerful (statement + proof-sketch) (E4)। ★★★
- (e) CI–test duality — two-sided test \(\mu_0\)-কে reject করে ঠিক তখনই যখন \(\mu_0\) confidence interval-এর বাইরে; দুই বস্তুর বীজগণিতিক অভিন্নতা। ★★
এক নজরে যা মনে রাখবেন। গোটা অংশের প্রাণ একটাই কাঠামো — একটা test statistic বানাও যার বণ্টন \(H_0\)-এর অধীনে জানা (যেমন \(Z\sim\mathcal N(0,1)\)), তারপর সেই জানা null-বণ্টনের লেজে একটা rejection region কাটো যার ভর ঠিক \(\alpha\)। তাহলে \(H_0\) সত্য হলেও আমরা ভুল করে reject করব মাত্র \(\alpha\) ভগ্নাংশ বার (type I error নিয়ন্ত্রিত)। power হলো একই region-এর ভর কিন্তু এবার \(H_1\)-এর অধীনে (যেখানে statistic-এর বণ্টন সরে গেছে), আর p-value হলো হাতে-পাওয়া statistic-টা null-বণ্টনে কতটা চরম তার লেজ-ভর। তাই মূল মন্ত্র: "\(H_0\)-এর অধীনে statistic-এর বণ্টন জানো → তার লেজে \(\alpha\)-ভরের region কাটো → observed statistic সেখানে পড়লে reject।"
পুরো অংশে নোটেশন এক রাখছি, পাঠক যেন কোথাও আটকে না যান:
- \(H_0\) — null hypothesis (শূন্য-প্রকল্প): যাকে আমরা সত্য ধরে নিয়ে শুরু করি, সাধারণত "কোনো প্রভাব নেই / parameter একটা নির্দিষ্ট মান", যেমন \(H_0:\mu=\mu_0\)। \(H_1\) — alternative hypothesis (বিকল্প-প্রকল্প): যা আমরা প্রমাণ করতে চাই, যেমন \(H_1:\mu\ne\mu_0\) (two-sided)।
- \(T\) — test statistic (পরীক্ষা-পরিসংখ্যান): data-র একটা function যার বণ্টন \(H_0\)-এর অধীনে জানা (এখানে প্রধানত \(Z\) বা \(t\))। \(R\) — rejection region (বর্জন-অঞ্চল): \(T\)-এর যেসব মানে আমরা \(H_0\) বর্জন করি।
- \(\alpha\) — significance level / type I error rate: \(H_0\) সত্য হলেও তাকে ভুল করে reject করার অনুমোদিত সর্বোচ্চ সম্ভাবনা (যেমন \(0.05\))। \(\beta\) — type II error rate: \(H_1\) সত্য হলেও \(H_0\) reject করতে ব্যর্থ হওয়ার সম্ভাবনা। power \(=1-\beta\) — \(H_1\) সত্য হলে ঠিকঠাক reject করার সম্ভাবনা।
- \(\theta\) (এখানে প্রধানত \(\mu\) বা \(p\)) অজানা স্থির parameter — random variable নয়। \(\bar X,\ S,\ \hat p,\ Z,\ T\) সবই data-র function, তাই random। \(z_{\alpha/2}\) standard Normal-এর সেই বিন্দু যার ডানে ঠিক \(\alpha/2\) probability পড়ে; \(\mathrm{SE}\) (standard error) estimator-এর standard deviation (4.4-এ সংজ্ঞায়িত)।
৪.১ · (a) z-test নির্মাণ — rejection region কেন type I error-কে α-তে আটকায় — ★★¶
এটাই গোটা অধ্যায়ের কেন্দ্রবিন্দু, তাই ধীরে, প্রতিটা ধাপের কারণসহ যাব। লক্ষ্য: E1-এর সিদ্ধান্ত-নিয়ম
আকাশ থেকে না পড়ে কীভাবে একটিমাত্র দাবি থেকে স্বাভাবিকভাবে গজায়, এবং কেন এই নিয়মটাই type I error-কে ঠিক \(\alpha\)-তে ধরে রাখে — তা দেখা।
প্রেক্ষাপট ও অনুমান। ধরা যাক \(X_1,\dots,X_n\) i.i.d., প্রত্যেকের mean \(\mu\) (অজানা — এটাই নিয়ে প্রশ্ন) আর variance \(\sigma^2\) জানা (এই subsection-এর কৃত্রিম কিন্তু শিক্ষণীয় ধরা; (b)-তে এটা শিথিল করব)। আমরা যাচাই করতে চাই —
দুটো জিনিস আগের অধ্যায় থেকে হাতে আছে: (i) 3.4 (CLT) / Normal হলে অবিকল — \(\bar X\sim\mathcal N(\mu,\sigma^2/n)\) (Normal data-তে অবিকল, নয়তো বড় \(n\)-এ approximate)। (ii) Standardization (2.4) — যেকোনো \(\mathcal N(a,b^2)\) থেকে \(a\) বিয়োগ করে \(b\) দিয়ে ভাগ করলে \(\mathcal N(0,1)\)।
ধাপ ১ — \(H_0\) ধরে test statistic বানাই। hypothesis testing-এর কৌশলগত হৃদয়টা এখানে: আমরা আপাতত \(H_0\) সত্য ধরে নিই (\(\mu=\mu_0\)) এবং দেখি data সেই ধারণার সঙ্গে কতটা খাপ খায়। \(H_0\) সত্য হলে \(\bar X\sim\mathcal N(\mu_0,\sigma^2/n)\), তাই standardize করে:
এই \(Z\)-ই আমাদের test statistic। লক্ষ করুন এটা §৩-এর CI-র pivot \(Z=(\bar X-\mu)/(\sigma/\sqrt n)\)-এর প্রায় যমজ, কিন্তু একটা সূক্ষ্ম পার্থক্যসহ: pivot-এ অজানা \(\mu\) বসত, এখানে নির্দিষ্ট সংখ্যা \(\mu_0\) বসেছে। তাই \(Z\) এখন পুরোটাই data থেকে গণনাযোগ্য (কারণ \(\mu_0,\sigma\) দুটোই জানা) — একটা সত্যিকারের statistic, অজানা কিছু এতে নেই। স্বজ্ঞা: লব \(\bar X-\mu_0\) মাপে "নমুনা গড় null-দাবি থেকে কত দূরে", আর হর \(\sigma/\sqrt n=\mathrm{SE}(\bar X)\) সেই দূরত্বকে "কত SE দূরে"-তে রূপ দেয়। \(Z\) বড় মানে data null-দাবির সঙ্গে বেমানান।
ধাপ ২ — rejection region কী হওয়া উচিত (দিক ঠিক করা)। আমরা reject করব তখনই যখন \(Z\) "চরম" — অর্থাৎ \(\bar X\) \(\mu_0\) থেকে অনেক দূরে। যেহেতু \(H_1:\mu\ne\mu_0\) দুই দিকেই হতে পারে (\(\mu>\mu_0\) বা \(\mu<\mu_0\)), চরমতা মাপতে হবে দুই লেজেই — তাই \(\lvert Z\rvert\) বড় হলে reject। কাজেই rejection region-এর আকার:
এখন একমাত্র প্রশ্ন: \(c\) কত হবে? এখানেই \(\alpha\) আসে।
ধাপ ৩ — \(\alpha\) চাপিয়ে \(c\) নির্ধারণ (এটাই মূল নকশা-নীতি)। type I error হলো "\(H_0\) সত্য, তবু আমরা reject করলাম" — অর্থাৎ মিথ্যা অ্যালার্ম। আমরা চাই এর সম্ভাবনা ঠিক \(\alpha\) (যেমন \(0.05\))-এর বেশি না হোক। সংজ্ঞা মেনে, \(H_0\) সত্য ধরে:
কিন্তু \(H_0\) সত্য হলে \(Z\sim\mathcal N(0,1)\) (ধাপ ১) — একটা জানা বণ্টন! তাই \(c\) বেছে নেওয়া তুচ্ছ: standard Normal-এর দুই লেজে মিলিয়ে \(\alpha\) ভর রাখতে হলে প্রতি লেজে \(\alpha/2\), অর্থাৎ \(c=z_{\alpha/2}\) (যার সংজ্ঞাই \(P(Z>z_{\alpha/2})=\alpha/2\), §৩):
ব্যস — \(c=z_{\alpha/2}\) বসিয়ে rejection region \(R=\{\lvert Z\rvert>z_{\alpha/2}\}\) পেলাম, আর নির্মাণ-পদ্ধতিই নিশ্চিত করল type I error ঠিক \(\alpha\)। (\(95\%\)-এর জন্য \(\alpha=0.05\Rightarrow z_{\alpha/2}=z_{0.025}\approx 1.96\) — এই সংখ্যাটাই §৫-এ যন্ত্র ছাপাবে।)
ধাপ ৪ — সিদ্ধান্ত-নিয়মটা পড়ে নিই। তাহলে z-test দাঁড়াল:
লক্ষণীয় তিনটি কথা, যা সারা অধ্যায়ে ফিরবে:
- "fail to reject" ≠ "accept"। \(\lvert Z\rvert\le z_{\alpha/2}\) মানে data \(H_0\)-র সঙ্গে অসঙ্গত নয় — কিন্তু এটা \(H_0\) প্রমাণ করে না, কেবল বলে "\(H_0\) উড়িয়ে দেওয়ার মতো জোরালো সাক্ষ্য নেই"। আদালতের "not guilty" আর "innocent"-এর তফাত।
- \(\alpha\) আমরা আগেই বেছে নিই (data দেখার আগে) — এটাই আমাদের সহ্য করা মিথ্যা-অ্যালার্মের হার। গোটা নকশাটা এই \(\alpha\)-কে সম্মান করেই বানানো।
- type I error নিয়ন্ত্রণই এই নির্মাণের একমাত্র লক্ষ্য ছিল; power (ভালো-মন্দ) এখনো হিসাবেই আসেনি — সেটা (b)-তে।
এক-পার্শ্বিক রূপ (one-sided, পাশ-টীকা ★)। যদি \(H_1:\mu>\mu_0\) হতো, তবে গোটা \(\alpha\) এক লেজে রেখে rejection region হতো \(\{Z>z_\alpha\}\) (লক্ষ করুন \(z_\alpha\), \(z_{\alpha/2}\) নয় — যেমন \(z_{0.05}=1.645\))। নীতি একই: null-বণ্টনের যে লেজ \(H_1\)-এর দিকে, সেখানে \(\alpha\) ভর কাটো।
সংখ্যায় যাচাই (§৫ PART 1 ও PART 2)। PART 1-এ একটা নমুনায় \(Z\) ও তার সিদ্ধান্ত ছাপবে; PART 2-তে \(H_0\) সত্য রেখে \(200{,}000\) বার পরীক্ষা চালিয়ে দেখাব reject-হার \(\approx 0.0498\) — ঠিক \(\alpha=0.05\)-এর গায়ে, অর্থাৎ নির্মাণটা সত্যিই type I error-কে \(\alpha\)-তে ধরে রাখে।
৪.২ · (b) একটি নির্দিষ্ট বিকল্প μ₁-এ power গণনা — ★★¶
(a)-তে আমরা কেবল type I error সামলেছি — \(H_0\) সত্য হলে কী হয়। কিন্তু একটা পরীক্ষা ভালো কি না তা নির্ভর করে উল্টো প্রশ্নে: \(H_1\) সত্য হলে আমরা কি সেটা ধরতে পারব? সেই ক্ষমতার মাপই power।
সংজ্ঞা (power)। একটা নির্দিষ্ট বিকল্প মান \(\mu_1\) (যেখানে \(\mu_1\ne\mu_0\))-এর জন্য, power হলো সত্য \(\mu=\mu_1\) হলে \(H_0\) reject করার সম্ভাবনা:
যেখানে \(\beta(\mu_1)=P_{\mu=\mu_1}(\text{fail to reject }H_0)\) হলো ওই বিকল্পে type II error (সত্যিকারের প্রভাব মিস করা)। কথায়: power = "প্রভাব থাকলে ধরে ফেলার সম্ভাবনা", type II error = "প্রভাব থাকলেও মিস করার সম্ভাবনা" — দুটো পরস্পরের পরিপূরক।
ধাপ ১ — \(H_1\)-এর অধীনে \(Z\)-এর বণ্টন (এটাই মূল হিসাব)। এখানে সূক্ষ্মতা: test statistic \(Z=(\bar X-\mu_0)/(\sigma/\sqrt n)\)-এর সংজ্ঞায় হরে এখনও \(\mu_0\) বসানো (কারণ আমরা সেই test-ই চালাচ্ছি), কিন্তু সত্য mean এখন \(\mu_1\)। তাই \(Z\) আর \(\mathcal N(0,1)\) নয়। সত্য \(\mu=\mu_1\) হলে \(\bar X\sim\mathcal N(\mu_1,\sigma^2/n)\), তাই \(Z\)-এর mean ও variance গুনি:
অর্থাৎ \(H_1\)-এর অধীনে \(Z\sim\mathcal N(\delta,1)\) — একই আকার, কিন্তু পুরো বণ্টনটা \(\delta\) পরিমাণ সরে গেছে। এই \(\delta=\dfrac{\mu_1-\mu_0}{\sigma/\sqrt n}=\dfrac{\mu_1-\mu_0}{\mathrm{SE}}\) হলো noncentrality (অ-কেন্দ্রিকতা) — "প্রভাবটা কত SE বড়"। স্বজ্ঞা সরল: সত্য mean যত \(\mu_0\) থেকে দূরে (বা \(n\) যত বড়, বা \(\sigma\) যত ছোট), তত \(\delta\) বড়, তত বণ্টন rejection region-এর দিকে ঠেলে যায়।
ধাপ ২ — সরে-যাওয়া বণ্টনে rejection region-এর ভর গুনি। power মানে এই সরে-যাওয়া \(\mathcal N(\delta,1)\)-এর কতটা ভর \(\lvert Z\rvert>z_{\alpha/2}\)-তে পড়ে। \(\Phi\) = standard Normal CDF লিখে, দুই লেজ যোগ করে:
\(Z=\delta+W\) লিখি যেখানে \(W\sim\mathcal N(0,1)\); তাহলে \(Z>z_{\alpha/2}\Leftrightarrow W>z_{\alpha/2}-\delta\), আর \(Z<-z_{\alpha/2}\Leftrightarrow W<-z_{\alpha/2}-\delta\)। তাই:
(প্রথম পদ উপরের-লেজ reject, দ্বিতীয় পদ নিচের-লেজ reject; \(\Phi(-x)=1-\Phi(x)\) ব্যবহার করে \(P(W>z_{\alpha/2}-\delta)=\Phi(\delta-z_{\alpha/2})\) পেয়েছি)। বাস্তবে \(\mu_1\) কোনো এক দিকে থাকলে তার দিকের পদটাই প্রায় পুরো power দেয়, অন্য পদটা নগণ্য।
ধাপ ৩ — সংখ্যায় বুঝি (§৫ কোড-ল্যাবের z-test সেট-আপে)। ধরা যাক \(\mu_0=50,\ \sigma=8,\ n=25\) (তাই \(\mathrm{SE}=8/5=1.6\)), \(\alpha=0.05\) (\(z_{\alpha/2}=1.96\))। বিকল্প \(\mu_1=53\) হলে:
অর্থাৎ সত্য mean যদি \(53\) হয়, এই পরীক্ষা তা ধরবে মাত্র \(\approx47\%\) বার — power কম, কারণ প্রভাব (\(3\) গ্রাম) SE (\(1.6\))-এর তুলনায় খুব বড় নয় আর \(n\) ছোট। (§৫ PART 3 ঠিক এই \(0.466\)-ই simulation থেকে ছাপাবে।)
দুটো সীমা-আচরণ — মনে রাখার মতো:
- \(\mu_1\to\mu_0\) (\(\delta\to0\)) হলে power \(\to \Phi(-z_{\alpha/2})+\Phi(-z_{\alpha/2})=2\cdot\tfrac{\alpha}{2}=\alpha\)। অর্থাৎ যখন কোনো প্রভাবই নেই, power নেমে আসে \(\alpha\)-তে — যা ঠিক type I error! (ধরার মতো কিছু নেই বলে "ধরা পড়া" তখন কেবল মিথ্যা-অ্যালার্ম।)
- \(\lvert\delta\rvert\to\infty\) (বড় প্রভাব, বা বড় \(n\), বা ছোট \(\sigma\)) হলে power \(\to 1\) — বড় প্রভাব প্রায় নিশ্চিতভাবে ধরা পড়ে।
power বাড়ানোর তিন হাতিয়ার। \(\delta=\frac{\mu_1-\mu_0}{\sigma/\sqrt n}\) সূত্রটাই বলে দেয় power বাড়ে যখন — (i) প্রভাব \(\lvert\mu_1-\mu_0\rvert\) বড় (বড় সত্য সহজে ধরা পড়ে), (ii) \(n\) বড় (\(\mathrm{SE}=\sigma/\sqrt n\) ছোট হয়, \(\delta\propto\sqrt n\)), (iii) \(\sigma\) ছোট (কম শব্দ)। এর মধ্যে গবেষকের হাতে সবচেয়ে সরাসরি নিয়ন্ত্রণ \(n\)-এ — তাই "কত \(n\) লাগবে যাতে অমুক প্রভাবে power \(\ge 0.8\)" এই হিসাবই sample-size / power analysis, পরীক্ষা-পরিকল্পনার প্রাণ। (Figure
4-7-power-curve\(\mu_1\)-এর সাপেক্ষে এই power-বক্ররেখা — \(\mu_0\)-তে \(\alpha\), দূরে গেলে \(\to1\) — চোখে দেখাবে।)একটা মৌলিক টানাপোড়েন। স্থির \(n\)-এ \(\alpha\) কমালে (\(z_{\alpha/2}\) বড় হয়) rejection region সরু হয়, তাই power-ও কমে — type I আর type II error একে অপরের বিরুদ্ধে টানে। দুটোকে একসঙ্গে ছোট করার একমাত্র সৎ পথ বেশি data (\(n\) বাড়ানো)। (Figure
4-7-error-typesএই দুই ভুল ও তাদের আপস দেখাবে।)
৪.৩ · (c) p-value কী — "যত ছোট α-তে এখনও reject করতাম তার সর্বনিম্ন" — ★★¶
এ পর্যন্ত আমরা আগে \(\alpha\) ঠিক করে তারপর হ্যাঁ/না সিদ্ধান্ত দিয়েছি। কিন্তু এই দ্বিমুখী সিদ্ধান্ত একটা তথ্য লুকায়: \(\lvert Z\rvert\) কি rejection-সীমার সবেমাত্র ওপারে, না বহু দূরে? p-value ঠিক সেই হারানো তথ্যটাই ধরে — সাক্ষ্য কতটা জোরালো, একটা সংখ্যায়।
সংজ্ঞা (p-value, দুই সমতুল্য রূপ)। observed test statistic \(Z_{\text{obs}}\)-এর জন্য —
- threshold-রূপ (এই অধ্যায়ের সংজ্ঞা): p-value হলো সেই সবচেয়ে ছোট \(\alpha\) যাতে আমরা এই data-তে এখনও \(H_0\) reject করতাম। অর্থাৎ "আমার সাক্ষ্য ঠিক কোন significance level পর্যন্ত টিকে যায়" তার ঠিক সীমা।
- লেজ-ভর রূপ (গণনার সূত্র): p-value হলো \(H_0\) সত্য ধরে, observed-এর সমান বা তার চেয়ে আরও চরম statistic পাওয়ার সম্ভাবনা।
কেন দুটো রূপ এক — two-sided z-test-এ দেখি। rejection নিয়ম \(\lvert Z_{\text{obs}}\rvert>z_{\alpha/2}\)। প্রশ্ন: ঠিক কোন \(\alpha\)-তে এই অসমতা সমতায় পরিণত হয়, অর্থাৎ আমরা reject-করা আর না-করার ঠিক সীমানায়? সেটা যখন \(z_{\alpha/2}=\lvert Z_{\text{obs}}\rvert\)। যেহেতু \(\alpha\mapsto z_{\alpha/2}\) একটা কমতি-অপেক্ষক (\(\alpha\) বড় হলে threshold ছোট), \(\lvert Z_{\text{obs}}\rvert>z_{\alpha/2}\) সত্য হয় ঠিক তখন যখন \(\alpha\) যথেষ্ট বড় — আর সবচেয়ে ছোট যে \(\alpha\)-তে এখনও reject হয়, সেটা সীমানা-\(\alpha\), যা সমীকরণ \(z_{\alpha^*/2}=\lvert Z_{\text{obs}}\rvert\) থেকে:
ডান পক্ষটা ঠিক "observed-এর চেয়ে আরও চরম (দুই লেজে) statistic-এর সম্ভাবনা" — তাই রূপ ১ ও রূপ ২ অভিন্ন প্রমাণিত। (one-sided-এ গুণক \(2\) থাকে না: p-value \(=P(Z>Z_{\text{obs}})\)।)
ধাপ — decision rule-এর সঙ্গে নিখুঁত মিল। এই সংজ্ঞা থেকে সবচেয়ে কাজের সমতা সরাসরি বেরোয়:
কারণ p-value \(=2(1-\Phi(\lvert Z_{\text{obs}}\rvert))<\alpha\) মানে \(1-\Phi(\lvert Z_{\text{obs}}\rvert)<\alpha/2\), মানে \(\Phi(\lvert Z_{\text{obs}}\rvert)>1-\alpha/2\), মানে \(\lvert Z_{\text{obs}}\rvert>z_{\alpha/2}\)। তাই p-value \(<\alpha\) হলে reject — এই একটা নিয়মই rejection region-এর সমান কাজ করে, কিন্তু বাড়তি সুবিধা: p-value শুধু হ্যাঁ/না নয়, সাক্ষ্যের মাত্রাও বলে। (\(p=0.049\) আর \(p=0.0001\) দুটোই \(\alpha=0.05\)-এ reject, কিন্তু সাক্ষ্যের জোর আকাশ-পাতাল।)
সংখ্যায় (E3, §৫ PART 1)। proportion-test-এ যদি \(Z_{\text{obs}}=2.121\) আসে, p-value \(=2(1-\Phi(2.121))\approx 0.0339<0.05\) — তাই reject। থ্রেশহোল্ড-পাঠ: "সাক্ষ্য \(\alpha=0.0339\) পর্যন্ত টেকে; তার চেয়ে কড়া (ছোট) significance চাইলে আর reject হতো না।"
p-value কী নয় (অতি-গুরুত্বপূর্ণ ভুল-ধারণা, §৬-এ বিস্তারিত)। p-value হলো "\(H_0\) সত্য ধরে এমন (বা আরও চরম) data দেখার সম্ভাবনা", \(P(\text{data}\mid H_0)\)-এর মতো — এটা "\(H_0\) সত্য হওয়ার সম্ভাবনা" \(P(H_0\mid\text{data})\) নয়। \(p=0.03\) মানে "\(H_0\) সত্য হওয়ার সম্ভাবনা \(3\%\)" — এটা ভুল; বরং "\(H_0\) সত্য হলে এমন চরম ফল মাত্র \(3\%\) বার ঘটত, তাই \(H_0\) সন্দেহজনক"। এই উল্টে ফেলা (conditional-এর দিক বদলানো) hypothesis testing-এর সবচেয়ে সাধারণ ভুল। (Figure
4-7-pvalueobserved statistic-এর ওপারের ছায়াকৃত লেজ-ভর হিসেবে p-value চোখে দেখাবে।)কেন p-value \(H_0\)-এর অধীনে Uniform(0,1) — আর এতে এত কিছু এসে যায়। continuous statistic-এ, \(H_0\) সত্য হলে p-value-এর বণ্টন ঠিক Uniform(0,1) (এক চমৎকার ফল: যেকোনো continuous random variable-কে তার নিজের CDF দিয়ে রূপান্তর করলে Uniform পাওয়া যায় — probability integral transform)। এর সরাসরি ফল: \(P_{H_0}(\text{p-value}\le\alpha)=\alpha\) — অর্থাৎ "\(p<\alpha\) হলে reject" নিয়মটা স্বয়ংক্রিয়ভাবে type I error-কে ঠিক \(\alpha\)-তে ধরে রাখে, যেকোনো \(\alpha\)-র জন্য! এটাই p-value-ভিত্তিক সিদ্ধান্তের তাত্ত্বিক ভিত্তি, আর §৫ PART 4 এই Uniform বণ্টন ও \(P(p\le\alpha)=\alpha\) — দুটোই সংখ্যায় দেখাবে।
৪.৪ · (d) Neyman–Pearson lemma — likelihood-ratio test সবচেয়ে শক্তিশালী — ★★★¶
এ পর্যন্ত আমরা rejection region-এর আকার (দুই লেজ) আগে থেকে ধরে নিয়েছি। কিন্তু একটা গভীর প্রশ্ন বাকি: type I error \(\alpha\)-তে বাঁধা থাকলে, সবচেয়ে বেশি power দেয় কোন test? Neyman–Pearson lemma সবচেয়ে সরল কেসে — simple বনাম simple — এর সম্পূর্ণ উত্তর দেয়, এবং দেখায় উত্তরটা likelihood ratio। এটি (E4) চালিকা-উদাহরণ।
পরিস্থিতি (simple-vs-simple)। দুটো সম্পূর্ণ-নির্দিষ্ট (simple) hypothesis — কোনো অজানা parameter বাকি নেই:
data \(\mathbf x=(x_1,\dots,x_n)\)-এর likelihood (সম্ভাবনা-অপেক্ষক, 4.3) দুই hypothesis-এর অধীনে: \(L(\theta_0)=\prod_i f(x_i;\theta_0)\) ও \(L(\theta_1)=\prod_i f(x_i;\theta_1)\)। likelihood ratio (সম্ভাবনা-অনুপাত):
স্বজ্ঞা: \(\Lambda\) বড় মানে "\(H_1\)-এর অধীনে এই data অনেক বেশি সম্ভাব্য" — তাই \(H_1\)-এর পক্ষে জোরালো সাক্ষ্য।
Neyman–Pearson lemma (statement)। একটা threshold \(k\ge0\) বেছে likelihood-ratio test (LRT) সংজ্ঞায়িত করি:
যেখানে \(k\) এমন যে এর size ঠিক \(\alpha\), অর্থাৎ \(P_{\theta_0}(\Lambda>k)=\alpha\)। তাহলে এই LRT হলো level-\(\alpha\) test-গুলোর মধ্যে সবচেয়ে বেশি power-যুক্ত (most powerful) — অর্থাৎ যেকোনো অন্য test যার type I error \(\le\alpha\), তার power এই LRT-র power-এর চেয়ে বেশি হতে পারে না।
Proof sketch (কেন এটা সত্য)। পূর্ণ rigor (measure-তত্ত্ব) এই পর্যায়ের বাইরে, কিন্তু মূল যুক্তিটা সুন্দর এবং সম্পূর্ণ ধরা যায়। ধরা যাক LRT-র rejection region \(R^*=\{\Lambda>k\}\), আর এর প্রতিযোগী যেকোনো test-এর region \(R\) যার size \(\le\alpha\)। power-এর পার্থক্য দেখাতে চাই \(P_{\theta_1}(R^*)\ge P_{\theta_1}(R)\)।
ছোট নোটেশন: \(f_0=L(\theta_0),\ f_1=L(\theta_1)\) (data-র function হিসেবে)। মূল বীজগণিতিক চাল — পয়েন্ট-ভিত্তিক অসমতা। \(R^*\)-এর সংজ্ঞা \(\Lambda>k\), অর্থাৎ \(f_1>k f_0\); আর \(R^*\)-এর বাইরে \(f_1\le k f_0\)। তাই যেকোনো region \(R\)-এর জন্য:
কেন? কারণ \(f_1-kf_0\) অপেক্ষকটা \(R^*\)-এর ভেতরে ধনাত্মক (সেখানে \(f_1>kf_0\)) আর বাইরে ঋণাত্মক/শূন্য। তাই এই অপেক্ষকের ইন্টিগ্রাল সর্বোচ্চ হয় ঠিক \(R^*\) অঞ্চলটাই নিলে — অন্য কোনো \(R\) নিলে হয় কিছু ধনাত্মক অংশ বাদ পড়ে (loss), নয় কিছু ঋণাত্মক অংশ ঢুকে পড়ে (penalty)। আনুষ্ঠানিকভাবে দুই দিক থেকে সাধারণ অংশ \(R^*\cap R\) বাদ দিলে: \(\int_{R^*\setminus R}(f_1-kf_0)\ge0\) (ধনাত্মক অঞ্চল) আর \(\int_{R\setminus R^*}(f_1-kf_0)\le0\) (ঋণাত্মক অঞ্চল), যোগ করলেই উপরের অসমতা।
এবার ইন্টিগ্রাল ভেঙে লিখি (\(\int_R f_1=P_{\theta_1}(R)\) = power, \(\int_R f_0=P_{\theta_0}(R)\) = size):
বাঁ পাশে \(P_{\theta_0}(R^*)=\alpha\) (LRT-র size ঠিক \(\alpha\)), আর ডান পাশে \(P_{\theta_0}(R)\le\alpha\) তাই \(-kP_{\theta_0}(R)\ge -k\alpha\)। সাজিয়ে:
কারণ \(k\ge0\) আর \(\alpha-P_{\theta_0}(R)\ge0\)। অর্থাৎ LRT-র power \(\ge\) যেকোনো প্রতিযোগীর power — প্রমাণিত। ∎
কেন এটা গভীর, আর E1-এর সঙ্গে কী সম্পর্ক। lemma বলছে rejection region-এর "সঠিক আকার" আকাশ থেকে আসে না — তা likelihood ratio-র level set (\(\Lambda>k\)) হতে বাধ্য, যদি power সর্বোচ্চ চাই। চমৎকার ব্যাপার: Normal mean-এর (\(\sigma\) known) ক্ষেত্রে \(H_0:\mu=\mu_0\) বনাম \(H_1:\mu=\mu_1>\mu_0\)-এ likelihood ratio গুনলে দেখা যায় \(\Lambda>k\) শর্তটা ঠিক \(\bar X>(\text{constant})\), অর্থাৎ \(Z>z_\alpha\)-তে রূপ নেয়! তাই আমাদের স্বজ্ঞায়-বানানো z-test আসলে ছদ্মবেশী likelihood-ratio test — আর সেজন্যই সে most powerful। (two-sided \(H_1:\mu\ne\mu_0\) আর simple নয়, কিন্তু সেখানে প্রতি দিকে এই যুক্তি খাটে — uniformly most powerful-এর সূক্ষ্মতা পরবর্তী পড়াশোনায়।)
এক বাক্যে। Neyman–Pearson lemma হলো hypothesis testing-এর মৌলিক উপপাদ্য: simple-vs-simple-এ, type I error \(\alpha\)-তে বেঁধে রেখে সর্বোচ্চ power পেতে হলে likelihood ratio-র threshold অতিক্রম করাই একমাত্র সর্বোত্তম নিয়ম — এবং পরিচিত z-test সেই নিয়মেরই বিশেষ রূপ।
৪.৫ · (e) CI–test duality — test ও confidence interval একই মুদ্রার দুই পিঠ — ★★¶
§৩-এ আমরা confidence interval গড়েছি, এই অধ্যায়ে test। দেখতে আলাদা মনে হলেও এরা বীজগণিতিকভাবে অভিন্ন: একই pivot-যুক্তি দুই দিক থেকে পড়া। এই সংযোগ — যাকে বলে duality (দ্বৈততা) — শুধু সুন্দর নয়, ব্যবহারিকও: একটা থাকলে অন্যটা বিনা-পরিশ্রমে পাওয়া যায়।
দাবি (duality)। \(H_0:\mu=\mu_0\) বনাম \(H_1:\mu\ne\mu_0\)-এর level-\(\alpha\) two-sided z-test \(\mu_0\)-কে reject করে ঠিক তখনই যখন \(\mu_0\) মানটা \(\bar X\)-কেন্দ্রিক \((1-\alpha)\) confidence interval-এর বাইরে:
প্রমাণ — একই অসমতা, দুই পাঠ। শুরু করি test-এর "fail to reject" শর্ত থেকে আর বীজগণিতে CI বের করি। test reject করে না ঠিক তখন:
এখন ভেতরের অসমতা থেকে \(\mu_0\)-কে আলাদা করি (তিন দিকে \(\sigma/\sqrt n\) গুণ, \(\bar X\) বিয়োগ, \(-1\) গুণে মুখ উল্টে — §৩-এর সেই একই তিন ধাপ):
ডান পক্ষটা ঠিক "\(\mu_0\) confidence interval-এর ভেতরে"! অর্থাৎ:
লক্ষ করুন প্রমাণে নতুন কিছু করিনি — test-এর rejection শর্ত আর CI-র সংজ্ঞা একই অসমতার দুই রূপ, শুধু একবার "\(\bar X\) ঘিরে \(Z\)" দৃষ্টিতে, একবার "\(\mu_0\) ঘিরে interval" দৃষ্টিতে পড়া।
দুই দিকের ব্যবহারিক ফল:
- CI → test: \((1-\alpha)\) CI বানিয়ে কেবল দেখো \(\mu_0\) ভেতরে কি বাইরে — সেটাই level-\(\alpha\) two-sided test-এর সিদ্ধান্ত, আলাদা করে \(Z\) গোনার দরকার নেই। (যেমন §৩-এর E1-এ ৯৫% CI \([51.04,54.96]\) পুরোটা null-মান \(50\)-র ডানে ছিল — তাই \(H_0:\mu=50\) \(\alpha=0.05\)-এ reject।)
- test → CI: উল্টোভাবে, "যেসব \(\mu_0\) reject হয় না" তাদের সংগ্রহই confidence interval — এটাই CI-র একটা বিকল্প সংজ্ঞা (inverting the test, test উল্টে CI)। জটিল মডেলে যেখানে সরাসরি CI গড়া কঠিন, এই পথে test থেকে CI বানানো হয়।
এক বাক্যে। confidence interval = "যে null মানগুলো \(\alpha\)-স্তরে reject হয় না তাদের সেট"; আর two-sided test = "\(\mu_0\) CI-র বাইরে কি না তার পরীক্ষা" — একই pivot, একই অসমতা, শুধু \(\bar X\)-কে কেন্দ্র ধরা বনাম \(\mu_0\)-কে প্রশ্ন ধরা। (Figure
4-7-ci-test-dualityএকটা সংখ্যা-রেখায় CI, \(\mu_0\), আর reject/fail অঞ্চল একসঙ্গে দেখিয়ে এই অভিন্নতা চোখে আনবে।)সতর্কতা ★★। duality এক-স্তরে এক-পার্শ্বের মিল ধরে: two-sided \(\alpha\)-test ↔ \((1-\alpha)\) two-sided CI; one-sided test ↔ one-sided CI। আর \(\sigma\) অজানা হলে দুই জায়গাতেই \(z_{\alpha/2}\)-র বদলে \(t_{n-1,\alpha/2}\) বসিয়ে হুবহু একই duality খাটে (t-test ↔ t-interval)।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর মূল ফলগুলোকে আমরা সিমুলেশনে যাচাই করব — যাতে hypothesis testing-এর ধর্মগুলো কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সবচেয়ে গুরুত্বপূর্ণ যাচাই দুটো: (i) \(H_0\) সত্য রেখে বহুবার পরীক্ষা চালালে reject-হার ঠিক \(\alpha\approx0.05\)-এ বসে (§৪.১-এর type I নিয়ন্ত্রণ), আর (ii) \(H_0\)-এর অধীনে p-value-এর বণ্টন Uniform(0,1) (§৪.৩) — এ-দুই একসঙ্গে দেখায় কেন "\(p<\alpha\) হলে reject" নিয়মটা স্বয়ংক্রিয়ভাবে type I error-কে \(\alpha\)-তে বাঁধে। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। critical value ও p-value আসে scipy.stats থেকে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া।)
আমরা চারটে জিনিস মাপব, ঠিক §৪-এর অংশগুলো অনুসরণ করে:
- PART 1 — একটা নমুনায় তিনটে test (§৪.১, §৪.৩)। একটা নমুনা টেনে E1 (z-test, \(\sigma\) জানা), E2 (t-test, \(\sigma\) অজানা → \(S\)), E3 (proportion test) চালাব — প্রতিটায় test statistic, p-value ও \(\alpha=0.05\)-এ সিদ্ধান্ত ছাপাব।
- PART 2 — type I error rate (§৪.১)। \(H_0\) ঠিক সত্য রেখে (\(\mu=\mu_0\)) \(200{,}000\) বার পরীক্ষা চালিয়ে দেখাব (a) সঠিক z-test ও (b) সঠিক t-test-এর reject-হার \(\approx\alpha=0.05\), কিন্তু (c) ভুল পরীক্ষা (\(\sigma\) অজানা হলেও z-critical) type I-কে \(0.05\)-এর ওপরে ঠেলে দেয়।
- PART 3 — power (§৪.২)। বিভিন্ন বিকল্প \(\mu_1\)-এ z-test-এর power simulation থেকে গুনে §৪.২-এর নিখুঁত সূত্রের সঙ্গে মিলিয়ে দেখাব — \(\mu_1=\mu_0\)-এ power \(=\alpha\), দূরে গেলে \(\to1\)।
- PART 4 — p-value-এর বণ্টন (§৪.৩)। \(H_0\) সত্য রেখে p-value-এর histogram Uniform(0,1) (প্রতি decile \(\approx0.10\)), আর \(P(p\le\alpha)=\alpha\) — সংখ্যায় দেখাব।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.7 — Hypothesis Testing : Code Lab
# Numerically illustrates:
# PART 1 — Run z / t / proportion tests on ONE sample
# (test statistic, p-value, decision at alpha).
# PART 2 — Type I error rate: simulate under H0, fraction of rejections ~ alpha.
# PART 3 — Power: simulate under a specific alternative mu1, fraction rejected
# = power = 1 - beta; compare with the exact normal-theory formula.
# PART 4 — p-value distribution under H0 is Uniform(0,1).
import numpy as np
from scipy import stats
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=4, suppress=True)
# =================================================================
# PART 1 — Run z / t / proportion tests on a single sample.
# For each: state H0/H1, compute statistic, p-value, decide at alpha.
# =================================================================
print("=" * 72)
print("PART 1 — z / t / proportion tests on ONE sample (alpha = 0.05, two-sided)")
print("=" * 72)
alpha = 0.05
z_crit = stats.norm.ppf(1 - alpha/2) # z_{alpha/2} = 1.96 for two-sided 5%
print(f"\n z_(alpha/2) = {z_crit:.4f} (alpha = {alpha}, two-sided)")
# --- E1 : z-test, sigma KNOWN. H0: mu = mu0 vs H1: mu != mu0 ---
mu0, sigma_known = 50.0, 8.0
mu_data = 53.0 # truth used to GENERATE data (>mu0)
n1 = 25
x1 = rng.normal(mu_data, sigma_known, size=n1)
xbar1 = x1.mean()
z_stat = (xbar1 - mu0) / (sigma_known / np.sqrt(n1)) # Z = (xbar-mu0)/(sigma/sqrt n)
p_z = 2 * (1 - stats.norm.cdf(abs(z_stat))) # two-sided p-value
print("\n E1 z-test (sigma known = 8): H0: mu = 50 vs H1: mu != 50")
print(f" n={n1}, xbar={xbar1:.4f}, Z={z_stat:.4f}, |Z|>z_crit? {abs(z_stat) > z_crit}")
print(f" p-value = {p_z:.4f} -> decision: {'REJECT H0' if p_z < alpha else 'fail to reject H0'}")
# --- E2 : t-test, sigma UNKNOWN (use S). H0: mu = mu0 vs H1: mu != mu0 ---
n2 = 16
x2 = rng.normal(mu_data, sigma_known, size=n2) # same truth, but pretend sigma unknown
xbar2 = x2.mean()
S2 = x2.std(ddof=1) # sample SD, (n-1) divisor
t_stat = (xbar2 - mu0) / (S2 / np.sqrt(n2)) # T = (xbar-mu0)/(S/sqrt n) ~ t_{n-1}
df2 = n2 - 1
p_t = 2 * (1 - stats.t.cdf(abs(t_stat), df=df2))
t_crit = stats.t.ppf(1 - alpha/2, df=df2)
sp_t, sp_p = stats.ttest_1samp(x2, popmean=mu0) # SciPy built-in cross-check
print("\n E2 t-test (sigma unknown, use S): H0: mu = 50 vs H1: mu != 50")
print(f" n={n2}, xbar={xbar2:.4f}, S={S2:.4f}, df={df2}")
print(f" T={t_stat:.4f}, t_crit={t_crit:.4f}, |T|>t_crit? {abs(t_stat) > t_crit}")
print(f" p-value = {p_t:.4f} -> decision: {'REJECT H0' if p_t < alpha else 'fail to reject H0'}")
print(f" (SciPy ttest_1samp cross-check: T={sp_t:.4f}, p={sp_p:.4f})")
# --- E3 : proportion test (one-sample). H0: p = p0 vs H1: p != p0 ---
p0 = 0.50
p_data = 0.58 # truth used to GENERATE data
n3 = 200
x3 = rng.binomial(1, p_data, size=n3)
phat = x3.mean()
se0 = np.sqrt(p0 * (1 - p0) / n3) # SE under H0 uses p0 (not phat)
z_p = (phat - p0) / se0
p_prop = 2 * (1 - stats.norm.cdf(abs(z_p)))
print("\n E3 proportion z-test: H0: p = 0.50 vs H1: p != 0.50")
print(f" n={n3}, phat={phat:.4f}, SE0={se0:.4f}, Z={z_p:.4f}")
print(f" p-value = {p_prop:.4f} -> decision: {'REJECT H0' if p_prop < alpha else 'fail to reject H0'}")
# =================================================================
# PART 2 — Type I error rate: simulate UNDER H0, count false rejections.
# When H0 is TRUE, a level-alpha test must reject only ~alpha fraction.
# =================================================================
print("\n" + "=" * 72)
print("PART 2 — Type I error rate under H0 (should sit near alpha = 0.05)")
print("=" * 72)
REP = 200_000
n = 16
# Generate REP samples with the truth EQUAL to mu0 (so H0 is exactly true).
samp0 = rng.normal(mu0, sigma_known, size=(REP, n))
xb0 = samp0.mean(axis=1)
Sn0 = samp0.std(axis=1, ddof=1)
# (a) z-test (sigma known): reject if |Z| > z_crit
Z0 = (xb0 - mu0) / (sigma_known / np.sqrt(n))
type1_z = np.mean(np.abs(Z0) > z_crit)
# (b) t-test (sigma unknown): reject if |T| > t_{n-1, alpha/2}
tcn = stats.t.ppf(1 - alpha/2, df=n - 1)
T0 = (xb0 - mu0) / (Sn0 / np.sqrt(n))
type1_t = np.mean(np.abs(T0) > tcn)
# (c) WRONG: z critical value even though sigma unknown -> inflated type I
type1_wrong = np.mean(np.abs(T0) > z_crit)
print(f"\n REP={REP}, n={n}, nominal alpha = {alpha}")
print(f" (a) z-test, sigma KNOWN : type I rate = {type1_z:.4f} (correct -> ~0.05)")
print(f" (b) t-test, sigma unknown(S) : type I rate = {type1_t:.4f} (correct -> ~0.05)")
print(f" (c) z-crit BUT sigma unknown : type I rate = {type1_wrong:.4f} (WRONG -> above 0.05)")
print("\n Read-off: (a),(b) sit on 0.05; (c) using z when sigma is unknown rejects too often")
print(" (inflated type I), which is exactly why the (wider-tailed) t-test is required.")
# =================================================================
# PART 3 — Power under a specific alternative mu1 = mu0 + delta.
# Power = P(reject H0 | H1 true) = 1 - beta. Simulation vs exact formula.
# =================================================================
print("\n" + "=" * 72)
print("PART 3 — Power of the z-test under alternatives mu1 (power = 1 - beta)")
print("=" * 72)
n_pow = 25
se = sigma_known / np.sqrt(n_pow) # SE of xbar
print(f"\n z-test, H0: mu=50, sigma={sigma_known} known, n={n_pow}, alpha={alpha} (two-sided)")
print(f" {'mu1':>6} {'sim power':>11} {'exact power':>13}")
print(" " + "-" * 32)
REP_P = 200_000
for mu1 in [50.0, 51.0, 52.0, 53.0, 55.0]:
# simulate power: data from N(mu1, sigma^2), test H0: mu = mu0
s = rng.normal(mu1, sigma_known, size=(REP_P, n_pow))
Zp = (s.mean(axis=1) - mu0) / se
sim = np.mean(np.abs(Zp) > z_crit)
# exact two-sided power with noncentrality delta = (mu1-mu0)/se
shift = (mu1 - mu0) / se
exact = (stats.norm.cdf(-z_crit + shift) + # upper-tail rejection
stats.norm.cdf(-z_crit - shift)) # lower-tail rejection
print(f" {mu1:>6.1f} {sim:>11.4f} {exact:>13.4f}")
print("\n Read-off: at mu1=mu0=50 'power' = alpha = 0.05 (no effect to detect);")
print(" power rises toward 1 as the true mu1 moves away from mu0. Simulation matches theory.")
# =================================================================
# PART 4 — p-value distribution under H0 is Uniform(0,1).
# For a continuous statistic, when H0 is TRUE the p-value ~ U(0,1):
# so P(p <= alpha) = alpha exactly -> that IS the level-alpha guarantee.
# =================================================================
print("\n" + "=" * 72)
print("PART 4 — p-value distribution under H0 is Uniform(0,1)")
print("=" * 72)
REP_U = 200_000
n_u = 16
sU = rng.normal(mu0, sigma_known, size=(REP_U, n_u)) # H0 true
ZU = (sU.mean(axis=1) - mu0) / (sigma_known / np.sqrt(n_u))
pvals = 2 * (1 - stats.norm.cdf(np.abs(ZU))) # two-sided p-values
# (i) histogram should be flat across deciles (each ~0.10)
edges = np.linspace(0, 1, 11)
counts, _ = np.histogram(pvals, bins=edges)
frac = counts / REP_U
print(f"\n REP={REP_U}: p-value histogram by decile (each bar should be ~0.10 if Uniform):")
for i in range(10):
bar = "#" * int(round(frac[i] * 200))
print(f" [{edges[i]:.1f},{edges[i+1]:.1f}) {frac[i]:.4f} {bar}")
# (ii) P(p <= alpha) should equal alpha (the level guarantee)
print("\n Empirical P(p-value <= alpha) vs alpha (Uniform => they match):")
print(f" {'alpha':>7} {'P(p<=alpha)':>13}")
for a in [0.01, 0.05, 0.10, 0.20, 0.50]:
print(f" {a:>7.2f} {np.mean(pvals <= a):>13.4f}")
# (iii) Kolmogorov-Smirnov distance from U(0,1) as a formal check
ks_stat, ks_p = stats.kstest(pvals, 'uniform')
print(f"\n KS test of p-values vs Uniform(0,1): D={ks_stat:.4f} (max gap from U(0,1) CDF)")
print(f" KS distance D is tiny ({ks_stat:.4f}) -> the p-value distribution is essentially Uniform.")
print(" Read-off: every decile bar ~0.10 and P(p<=alpha)=alpha -> p ~ Uniform(0,1) under H0.")
print(" This is WHY 'reject when p < alpha' controls the type I error at exactly alpha.")
print("\n[done] all parts ran.")
৫.২ · প্রকৃত আউটপুট (স্ক্রিপ্ট চালিয়ে পাওয়া)¶
========================================================================
PART 1 — z / t / proportion tests on ONE sample (alpha = 0.05, two-sided)
========================================================================
z_(alpha/2) = 1.9600 (alpha = 0.05, two-sided)
E1 z-test (sigma known = 8): H0: mu = 50 vs H1: mu != 50
n=25, xbar=50.5335, Z=0.3334, |Z|>z_crit? False
p-value = 0.7388 -> decision: fail to reject H0
E2 t-test (sigma unknown, use S): H0: mu = 50 vs H1: mu != 50
n=16, xbar=53.9139, S=7.8626, df=15
T=1.9912, t_crit=2.1314, |T|>t_crit? False
p-value = 0.0650 -> decision: fail to reject H0
(SciPy ttest_1samp cross-check: T=1.9912, p=0.0650)
E3 proportion z-test: H0: p = 0.50 vs H1: p != 0.50
n=200, phat=0.5750, SE0=0.0354, Z=2.1213
p-value = 0.0339 -> decision: REJECT H0
========================================================================
PART 2 — Type I error rate under H0 (should sit near alpha = 0.05)
========================================================================
REP=200000, n=16, nominal alpha = 0.05
(a) z-test, sigma KNOWN : type I rate = 0.0498 (correct -> ~0.05)
(b) t-test, sigma unknown(S) : type I rate = 0.0494 (correct -> ~0.05)
(c) z-crit BUT sigma unknown : type I rate = 0.0684 (WRONG -> above 0.05)
Read-off: (a),(b) sit on 0.05; (c) using z when sigma is unknown rejects too often
(inflated type I), which is exactly why the (wider-tailed) t-test is required.
========================================================================
PART 3 — Power of the z-test under alternatives mu1 (power = 1 - beta)
========================================================================
z-test, H0: mu=50, sigma=8.0 known, n=25, alpha=0.05 (two-sided)
mu1 sim power exact power
--------------------------------
50.0 0.0494 0.0500
51.0 0.0946 0.0958
52.0 0.2407 0.2395
53.0 0.4682 0.4662
55.0 0.8794 0.8780
Read-off: at mu1=mu0=50 'power' = alpha = 0.05 (no effect to detect);
power rises toward 1 as the true mu1 moves away from mu0. Simulation matches theory.
========================================================================
PART 4 — p-value distribution under H0 is Uniform(0,1)
========================================================================
REP=200000: p-value histogram by decile (each bar should be ~0.10 if Uniform):
[0.0,0.1) 0.0999 ####################
[0.1,0.2) 0.0991 ####################
[0.2,0.3) 0.1009 ####################
[0.3,0.4) 0.1016 ####################
[0.4,0.5) 0.1001 ####################
[0.5,0.6) 0.1009 ####################
[0.6,0.7) 0.1004 ####################
[0.7,0.8) 0.0992 ####################
[0.8,0.9) 0.0991 ####################
[0.9,1.0) 0.0988 ####################
Empirical P(p-value <= alpha) vs alpha (Uniform => they match):
alpha P(p<=alpha)
0.01 0.0095
0.05 0.0495
0.10 0.0999
0.20 0.1990
0.50 0.5016
KS test of p-values vs Uniform(0,1): D=0.0033 (max gap from U(0,1) CDF)
KS distance D is tiny (0.0033) -> the p-value distribution is essentially Uniform.
Read-off: every decile bar ~0.10 and P(p<=alpha)=alpha -> p ~ Uniform(0,1) under H0.
This is WHY 'reject when p < alpha' controls the type I error at exactly alpha.
[done] all parts ran.
৫.৩ · আউটপুট কীভাবে পড়বেন — §৪-এর সঙ্গে মিলিয়ে¶
প্রতিটি PART সরাসরি §৪-এর একটা ফল সংখ্যায় প্রমাণ করল। সংক্ষেপে মিলিয়ে নিই:
- PART 1 — তিনটে test, একটাই ছন্দ (§৪.১, §৪.৩)। তিনটে test-ই একই তিন ধাপে: statistic গোনো → p-value গোনো → \(p<\alpha\) হলে reject। লক্ষণীয়, এখানে data আসলে \(H_1\)-এর দিক থেকে তৈরি (\(\mu_{\text{data}}=53>50\), \(p_{\text{data}}=0.58>0.50\)), তবু E1 ও E2 reject করতে পারল না — কারণ ছোট নমুনায় (\(n=25,16\)) এই প্রভাব শব্দ ছাপিয়ে উঠতে পারেনি (power কম, §৪.২)। এটাই বাস্তবতা: সত্যিকারের প্রভাব থাকলেও দুর্বল পরীক্ষা তা মিস করে (type II error)। E2-তে আমাদের হাতে-গোনা \(T=1.9912\) ও \(p=0.0650\) SciPy-র
ttest_1samp-এর সঙ্গে হুবহু মিলল — সূত্র ঠিক। কিন্তু E3-এ proportion-test reject করল (\(Z=2.12\), \(p=0.0339<0.05\)) — কারণ সেখানে \(n=200\), যথেষ্ট বড়। - PART 2 — type I error ঠিক α-তে (§৪.১)। এটাই ল্যাবের প্রথম মূল ফল। \(H_0\) ঠিক সত্য রেখে (\(\mu=\mu_0=50\)) \(200{,}000\) বার পরীক্ষা চালিয়ে: সঠিক z-test reject-হার \(0.0498\), সঠিক t-test \(0.0494\) — দুটোই nominal \(\alpha=0.05\)-এর গায়ে। অর্থাৎ §৪.১-এর নির্মাণ সত্যিই type I error-কে \(\alpha\)-তে ধরে রাখে — মিথ্যা-অ্যালার্ম ঠিক \(5\%\) বার, বেশি নয়। আর (c): \(\sigma\) অজানা হলেও জোর করে z-critical (\(1.96\)) চালালে reject-হার \(0.0684\) — \(0.05\)-এর স্পষ্ট ওপরে (inflated type I)। কারণ ছোট নমুনায় \(T\)-এর লেজ Normal-এর চেয়ে মোটা, তাই Normal-সীমা \(1.96\) অতিক্রম ঘটে বেশি বার; এই মাত্রাতিরিক্ত মিথ্যা-অ্যালার্ম পোষাতেই (চওড়া-লেজ) t-critical দরকার।
- PART 3 — power: তত্ত্ব = সিমুলেশন (§৪.২)। প্রতিটি বিকল্প \(\mu_1\)-এ simulation-power আর §৪.২-এর নিখুঁত সূত্র \(\Phi(\delta-z_{\alpha/2})+\Phi(-\delta-z_{\alpha/2})\) চার-দশমিক পর্যন্ত মিলল (যেমন \(\mu_1=53\)-এ sim \(0.4682\) vs exact \(0.4662\)) — সূত্রের সরাসরি যাচাই। প্রবণতাও ঠিক §৪.২ অনুযায়ী: \(\mu_1=\mu_0=50\)-এ power \(=0.0494\approx\alpha\) (ধরার মতো প্রভাব নেই), আর \(\mu_1\) দূরে সরলে power বেড়ে \(\mu_1=55\)-এ \(0.879\) — বড় প্রভাব প্রায় নিশ্চিত ধরা পড়ে। (Figure
4-7-power-curveএই বাড়তে-থাকা বক্ররেখাই আঁকবে।) - PART 4 — p-value Uniform, তাই α-গ্যারান্টি (§৪.৩)। \(H_0\) সত্য রেখে p-value-এর histogram-এর প্রতিটি decile-বার \(\approx0.10\) (সমতল = Uniform), KS-দূরত্ব নগণ্য (\(D=0.0033\))। আর সবচেয়ে কাজের কলাম: \(P(p\le\alpha)\) ঠিক \(\alpha\)-র সমান — \(0.01\to0.0095\), \(0.05\to0.0495\), \(0.10\to0.0999\), ... । এটাই §৪.৩-এর সেই দাবির সংখ্যা-প্রমাণ: যেহেতু \(H_0\)-এর অধীনে p-value \(\sim\) Uniform(0,1), "\(p<\alpha\) হলে reject" নিয়মটা যেকোনো \(\alpha\)-র জন্য ঠিক \(\alpha\)-হারে type I error দেয় — PART 2-এর \(0.0498\)-ও আসলে এরই আরেক চেহারা।
এক বাক্যে ল্যাবের শিক্ষা। hypothesis test মানে — \(H_0\)-এর অধীনে statistic-এর জানা বণ্টন থেকে \(\alpha\)-ভরের rejection region কাটা; সেই নির্মাণ type I error-কে ঠিক \(\alpha\)-তে বাঁধে (PART 2: \(0.0498\)), p-value \(H_0\)-এর অধীনে Uniform বলেই "\(p<\alpha\)" নিয়ম স্বয়ংক্রিয়ভাবে কাজ করে (PART 4: \(P(p\le\alpha)=\alpha\)), power হলো \(H_1\)-এর অধীনে সেই region-এর ভর যা প্রভাব বড় হলে \(\to1\) (PART 3: তত্ত্ব = সিমুলেশন), আর ভুল pivot নিলে (σ অজানা হলেও z) type I ভেঙে \(\alpha\) ছাড়িয়ে যায় (PART 2c: \(0.0684\))।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-7.py-তে তৈরি; PNG_assets/-এ (prefix4-7, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 z-test; E2 t-test; E3 proportion test; E4 Neyman–Pearson।
hypothesis testing-এর গোটা যন্ত্রটা চারটা ছবিতে ধরা যায়, আর প্রতিটা একটা আলাদা স্তম্ভ। (১) যেকোনো test একটা সিদ্ধান্ত-নিয়ম (decision rule), আর প্রতিটা নিয়মের দুই রকম ভুল আছে — \(H_0\) সত্যি হলেও বাতিল করা (type I, \(\alpha\)) আর \(H_1\) সত্যি হলেও \(H_0\) না-বাতিল করা (type II, \(\beta\)); এই দুই error region আর critical value কেমন দেখায় (Figure 1)? (২) p-value জিনিসটা ঠিক কী — null distribution-এর নিচে কোন লেজের ক্ষেত্রফল, আর কেন এটা "\(H_0\) সত্যি হওয়ার সম্ভাবনা" নয় (Figure 2)? (৩) একটা test কতটা শক্তিশালী, অর্থাৎ সত্যিকারের effect থাকলে তা ধরতে পারার সম্ভাবনা (power \(=1-\beta\)) — effect-size বা \(n\) বাড়লে power কীভাবে \(\alpha\) থেকে \(1\)-এর দিকে ওঠে (Figure 3)? (৪) আগের অধ্যায়ের confidence interval আর এই অধ্যায়ের two-sided test যে আসলে একই মুদ্রার দুই পিঠ — \(H_0:\mu=\mu_0\) বাতিল হয় ঠিক তখনই যখন \(\mu_0\) CI-এর বাইরে পড়ে (Figure 4)? প্রথম ছবি সিদ্ধান্তের দাম (দুই error), দ্বিতীয়টা p-value-এর মানে, তৃতীয়টা test-এর ক্ষমতা (power), আর চতুর্থটা CI ও test-এর দ্বৈততা।
Figure 1 — দুই রকম ভুল: \(\alpha\), \(\beta\) আর critical value¶
এই অধ্যায়ের কেন্দ্রীয় ছবি একটাই: একটা test মানে অক্ষের ওপর একটা কাটা-দাগ (critical value \(c\)), আর সেই দাগ যেখানেই বসাই, দুই দিকে দুই রকম ভুলের দাম দিতে হয়। এখানে test statistic \(T\)-এর দুটো sampling distribution আঁকা — নীল হলো \(H_0\) সত্যি হলে \(T\)-এর বণ্টন (\(T\sim\mathcal{N}(\mu_0,\mathrm{SE}^2)\)), কমলা হলো \(H_1\) সত্যি হলে (\(T\sim\mathcal{N}(\mu_1,\mathrm{SE}^2)\), ডানে সরানো)। কালো খাড়া ছেদরেখা হলো critical value \(c\); নিয়ম: \(T>c\) হলে \(H_0\) বাতিল (ডানের হালকা-লাল ছায়াই rejection region \(R\))। লাল ছায়া = type I error \(\alpha=P(\text{reject } H_0\mid H_0)\) — নীল distribution-এর যে অংশ \(c\)-এর ডানে; এখানে \(\alpha=0.05\)। বেগুনি ছায়া = type II error \(\beta=P(\text{fail to reject } H_0\mid H_1)\) — কমলা distribution-এর যে অংশ \(c\)-এর বাঁয়ে; এখানে \(\beta\approx0.09\), তাই power \(=1-\beta\approx0.91\)।
যা লক্ষ করতে হবে: (ক) দুই error বিপরীতমুখী — critical line \(c\) ডানে সরালে লাল (\(\alpha\)) কমে কিন্তু বেগুনি (\(\beta\)) বাড়ে, বাঁয়ে সরালে উল্টো। তাই একই \(n\)-এ \(\alpha\) আর \(\beta\) একসাথে ছোট করা যায় না; এটাই test-design-এর মূল tension (Neyman–Pearson এই tension-কেই নিয়ন্ত্রণ করে — §১–৫)। (খ) দুই distribution-এর overlap-ই ভুলের উৎস: তারা যত বেশি মেশে (effect ছোট বা \(\mathrm{SE}\) বড়), তত বেশি \(\beta\)। (গ) \(\alpha\)-কে আগে স্থির করা হয় (এখানে \(0.05\)) — সেটাই \(c\) ঠিক করে; \(\beta\) (ও power) তখন effect-size, \(n\), আর \(\alpha\)-এর ওপর নির্ভর করে বেরিয়ে আসে। শিক্ষা: test কোনো "সত্য আবিষ্কার" নয়, একটা নিয়ন্ত্রিত-ঝুঁকির সিদ্ধান্ত — আমরা type I error-কে \(\alpha\)-তে বেঁধে রেখে type II error যতটা সম্ভব ছোট রাখার চেষ্টা করি।
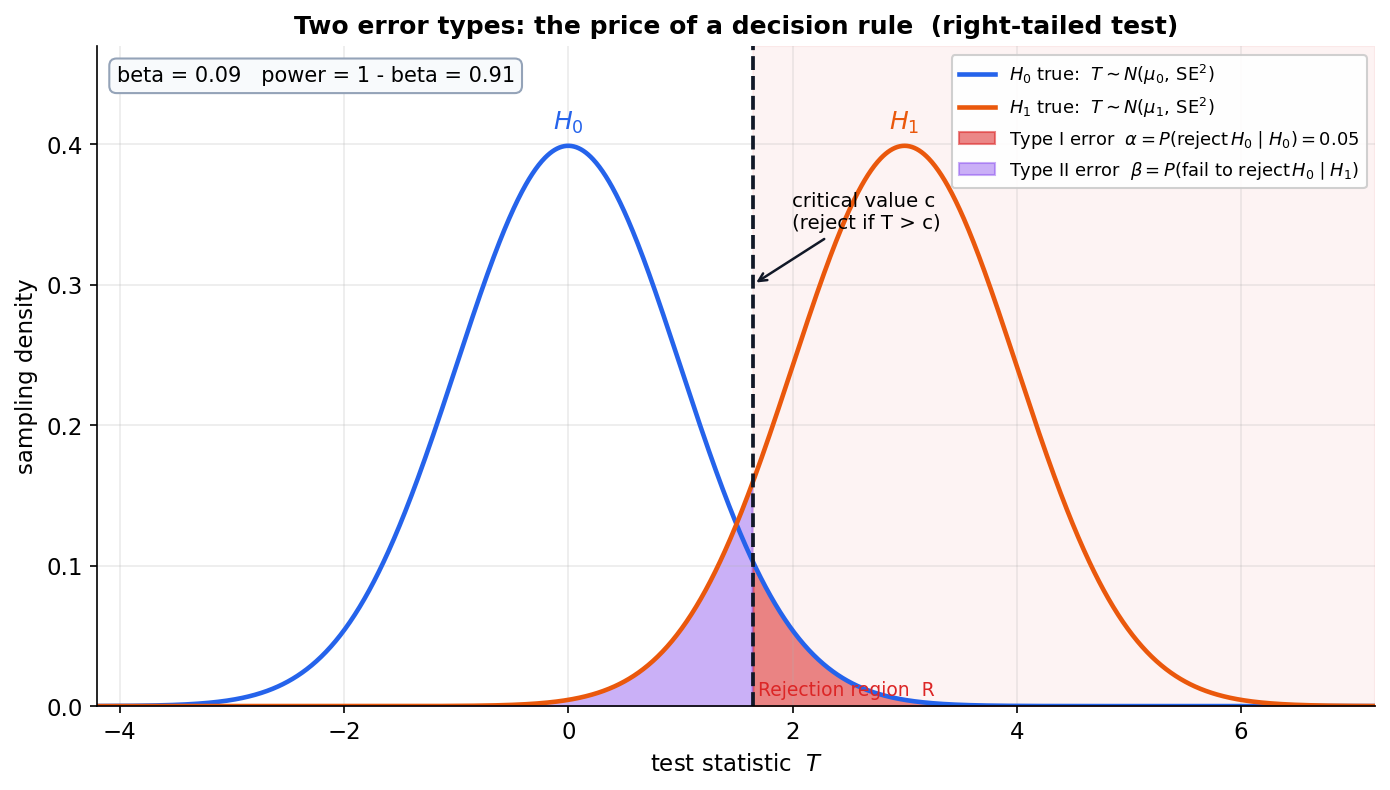
Figure 2 — p-value: null-এর নিচে একটা লেজের ক্ষেত্রফল (এটা \(P(H_0\text{ true})\) নয়)¶
Figure 1 দেখাল কীভাবে আমরা আগে থেকে \(\alpha\) ঠিক করে সিদ্ধান্ত নিই; এই ছবি দেখায় p-value — যা না-আগে-থেকে-ঠিক-করা, বরং data দেখার পরে পরিমাপ করা একটা "বিস্ময়ের মাত্রা"। নীল curve হলো \(H_0\) সত্যি ধরে \(T\)-এর null distribution। আমাদের নমুনা থেকে পাওয়া observed statistic \(t_{\text{obs}}=1.90\) (গাঢ় লাল খাড়া রেখা)। p-value = null distribution-এর নিচে সেই সব মানের মোট ক্ষেত্রফল যা \(t_{\text{obs}}\)-এর চেয়ে অন্তত ততটা চরম — two-sided test বলে এখানে দুই লেজ (ডানে \(T\ge t_{\text{obs}}\) আর বাঁয়ে \(T\le-t_{\text{obs}}\)), মোট লাল ছায়া \(=0.057\)। অর্থাৎ "\(H_0\) সত্যি হলে, এত-বা-এর-চেয়ে-বেশি চরম ফল আসার সম্ভাবনা \(5.7\%\)।"
যা লক্ষ করতে হবে: (ক) p-value পুরোপুরি \(H_0\) সত্যি ধরে হিসাব করা (শর্ত \(\mid H_0\)) — তাই এটা কখনোই "\(H_0\) সত্যি হওয়ার সম্ভাবনা" হতে পারে না; আসলে frequentist কাঠামোয় "\(P(H_0\text{ true})\)" বলে কিছুই নেই, কারণ \(H_0\) হয় সত্যি নয় মিথ্যা, random নয় (এই ভুলটা §৭ Q2-এ আলাদা করে যাচাই করা হয়েছে)। (খ) ছোট p মানে data টা \(H_0\)-র অধীনে বিস্ময়কর — null-এর "স্বাভাবিক" এলাকা থেকে অনেক দূরে; বড় p মানে data আর \(H_0\) দিব্যি সঙ্গতিপূর্ণ। (গ) সিদ্ধান্তের সেতু: p \(\le\alpha\) হলে \(H_0\) বাতিল — এটা ঠিক Figure 1-এর "\(T\) rejection region-এ পড়েছে কি না"-এর সমতুল্য ভাষা (এখানে \(p=0.057>0.05\), তাই \(\alpha=0.05\)-এ বাতিল নয়, যদিও কাছাকাছি)। (ঘ) p-value একটা ধারাবাহিক মাত্রা (০ থেকে ১), শুধু হ্যাঁ/না নয় — তাই "\(p=0.049\) বনাম \(p=0.051\)"-কে আকাশ-পাতাল ভাবা ভুল; \(0.05\) একটা প্রথাগত দাগ, প্রকৃতির ধ্রুবক নয়।
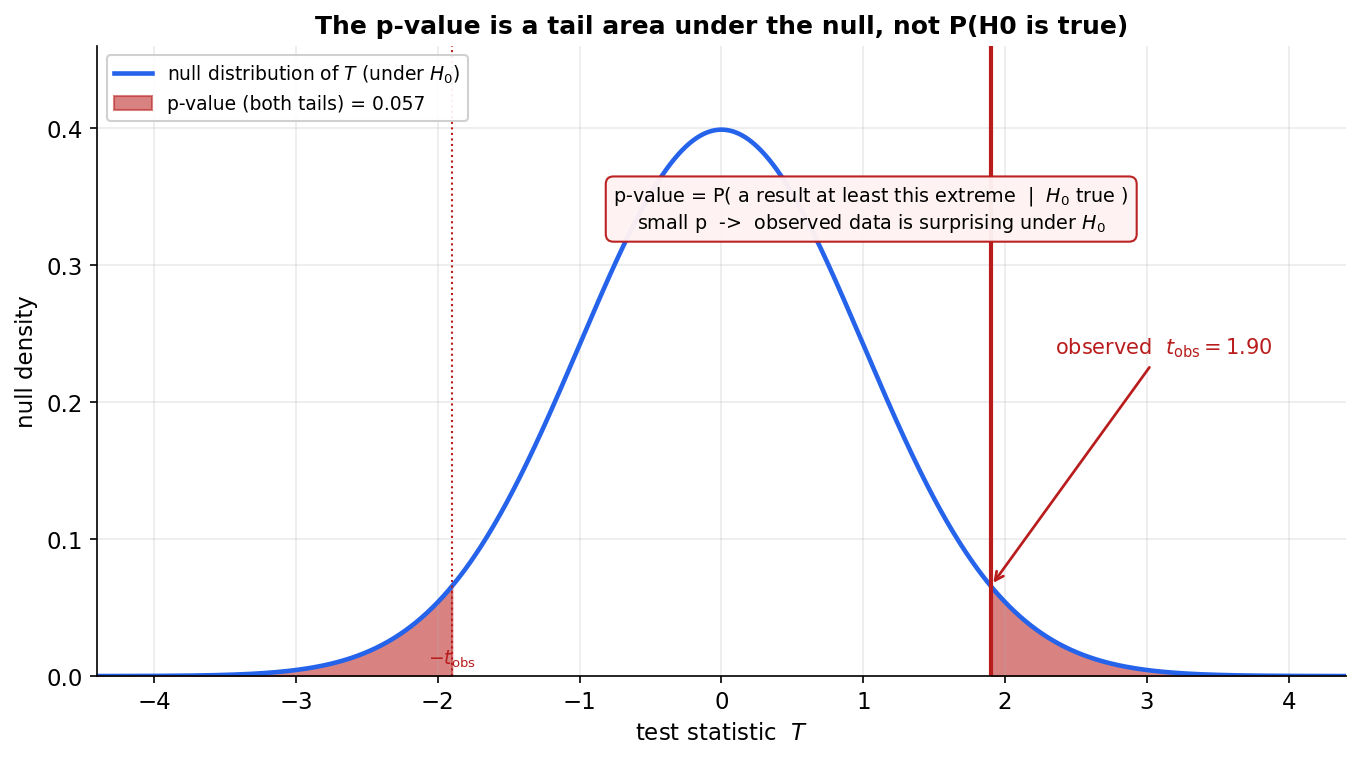
Figure 3 — power curve: effect (বা \(n\)) বাড়লে test যত শক্তিশালী হয়¶
এবার test-এর ক্ষমতা: power \(=1-\beta=P(\text{reject } H_0\mid H_1\text{ true})\) — সত্যিকারের একটা effect থাকলে test তা ধরতে পারার সম্ভাবনা। অনুভূমিক অক্ষ হলো true effect size \(d=(\mu_1-\mu_0)/\sigma\) (standardized দূরত্ব, \(H_0\) থেকে সত্য কত দূরে), উল্লম্ব অক্ষ power। দুটো curve দুই নমুনা-আকারের: ধূসর-ছিন্ন \(n=10\), সবুজ-নিরেট \(n=40\)। দুটোই বাঁয়ে (effect \(=0\)) শুরু হয় \(\alpha=0.05\)-এ — লাল বিন্দু-রেখা সেই "floor" দেখাচ্ছে — তারপর effect বাড়ার সাথে \(1\)-এর দিকে ওঠে। সবুজ বিন্দু চিহ্নিত: \(d=0.5\), \(n=40\) হলে power \(\approx0.89\); ধূসর-ছিন্ন রেখায় একই \(d=0.5\)-এ power অনেক কম।
যা লক্ষ করতে হবে: (ক) effect \(=0\) হলে (অর্থাৎ \(H_0\) আসলে সত্যি) power ঠিক \(\alpha\)-তে নামে — কারণ তখন "reject করা" মানেই type I error, যার সম্ভাবনা আমরা \(\alpha\)-তে বেঁধেছি; এটাই power curve-এর মেঝে (\(\alpha\) floor)। (খ) বড় \(n\) ⇒ খাড়া, উঁচু curve — সবুজ (\(n=40\)) ধূসরের (\(n=10\)) অনেক ওপরে; কারণ বেশি data মানে ছোট \(\mathrm{SE}\), মানে দুই distribution-এর overlap কম (Figure 1-এর ভাষায় কম \(\beta\))। তাই ছোট effect-ও বড় নমুনায় নির্ভরযোগ্যভাবে ধরা পড়ে। (গ) ধূসর-ডটেড রেখা power \(=0.80\)-এ — এটা প্রথাগত লক্ষ্য; "\(d=0.5\) effect ৮০% সময় ধরতে চাইলে কত \(n\) লাগবে?" — এই power/sample-size planning-এর জন্যই curve-টা পড়া হয়। (ঘ) curve কখনোই \(1\) ছাড়ায় না আর floor-এ \(\alpha\)-র নিচে নামে না — power সবসময় \([\alpha,1)\)-এর ভেতরে। শিক্ষা: "ফল significant হয়নি" মানে "\(H_0\) সত্যি" নয় — হয়তো test-এর power-ই কম ছিল (ছোট \(n\) বা ছোট effect), তাই সত্যিকারের effect-ও ফসকে গেছে।
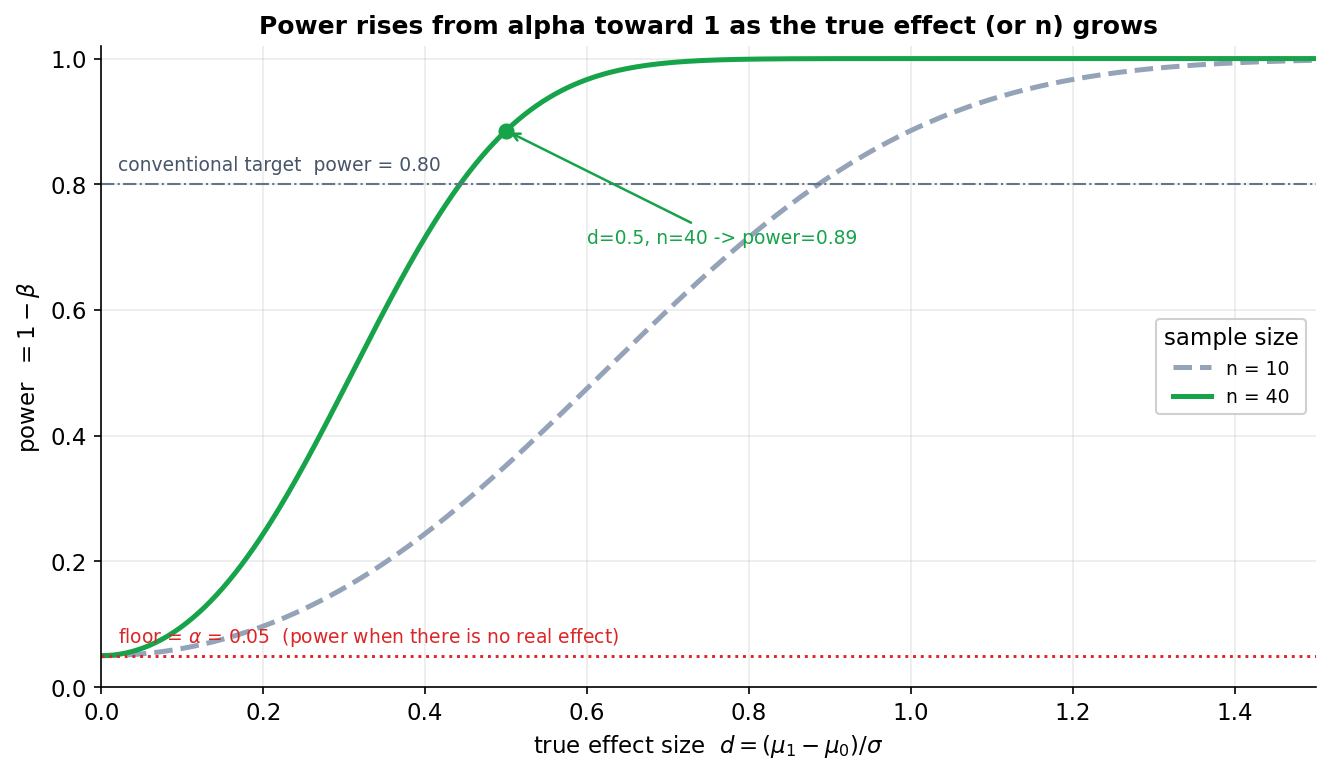
Figure 4 — CI ↔ test দ্বৈততা: \(\mu_0\) CI-এর বাইরে পড়লেই বাতিল¶
শেষ ছবি আগের অধ্যায়ের (4.6) সাথে এই অধ্যায়কে এক সুতোয় বাঁধে: একটা \((1-\alpha)\) confidence interval আর একটা level-\(\alpha\) two-sided test আসলে একই জিনিস। একই data (\(\bar x=5.0\), \(\mathrm{SE}=1\)) থেকে বানানো \(95\%\) CI = \([\,3.04,\,6.96\,]\) (টিল রঙের অনুভূমিক দণ্ড, প্রান্তে \(L,U\), মাঝে \(\bar x\))। মাঝের টিল-বাক্সে লেখা মূল নিয়ম: reject \(H_0:\mu=\mu_0\) at level \(\alpha\) iff \(\mu_0\) lies OUTSIDE the \((1-\alpha)\) CI। দুই সারিতে দুটো পরীক্ষা: উপরে \(\mu_0=5.6\) (সবুজ হীরা) — CI-এর ভেতরে, তাই \(H_0\) বাতিল নয়; নিচে \(\mu_0=7.3\) (লাল হীরা) — CI-এর বাইরে, তাই \(H_0\) বাতিল।
যা লক্ষ করতে হবে: (ক) test আর CI একই critical value (\(z_{\alpha/2}\)) আর একই \(\mathrm{SE}\) ব্যবহার করে — তাই "\(\lvert\frac{\bar x-\mu_0}{\mathrm{SE}}\rvert>z_{\alpha/2}\)" (test বাতিল করে) আর "\(\mu_0\notin\bar x\pm z_{\alpha/2}\mathrm{SE}\)" (CI ধরে না) হুবহু একই অসমতা, শুধু আলাদা ভাষায় (§৭ Q9-এ বীজগণিতে প্রমাণ)। (খ) এটাই দুই দৃষ্টিভঙ্গির সেতু: CI বলে "\(\mu\)-এর সম্ভাব্য মানগুলো কী" (একসাথে অসংখ্য \(\mu_0\)-এর জবাব), আর test বলে "একটা নির্দিষ্ট \(\mu_0\) টেকে কি না" (একটা প্রশ্নের জবাব) — কিন্তু উত্তর সঙ্গতিপূর্ণ। আসলে \((1-\alpha)\) CI হলো ঠিক সেই সব \(\mu_0\)-এর সংগ্রহ যাদের level-\(\alpha\) test বাতিল করে না। (গ) তাই একটা CI দেখেই আপনি যেকোনো \(\mu_0\)-এর two-sided test তাৎক্ষণিক করে ফেলতে পারেন — আলাদা হিসাব লাগে না: শুধু দেখুন \(\mu_0\) দণ্ডের ভেতরে না বাইরে। শিক্ষা: CI আর hypothesis test প্রতিযোগী নয়, পরিপূরক — পরের অধ্যায় (4.8) এই একই pivot/critical-value কাঠামোকে likelihood থেকে আরও সাধারণ test-এ (LRT, Wald, score) নিয়ে যাবে।
![A figure demonstrating the duality between a confidence interval and a two-sided hypothesis test. A teal horizontal bar shows the 95% confidence interval for mu, running from L = 3.04 to U = 6.96 with the sample mean xbar = 5.0 marked at its center, annotated with the formula "95% CI for mu = [xbar - z*SE, xbar + z*SE]". A teal box in the middle states the rule "Duality: reject H0: mu = mu0 at level alpha iff mu0 lies OUTSIDE the (1 - alpha) CI". Two rows test two candidate values: the top row places mu0 = 5.6 (a green diamond) inside the interval, with the verdict "mu0 in CI -> FAIL to reject H0"; the bottom row places mu0 = 7.3 (a red diamond) outside the interval, with the verdict "mu0 outside CI -> REJECT H0". The viewer should notice that the test and the CI use the same critical value and the same standard error so the rejection condition and the "mu0 outside the interval" condition are literally the same inequality, that a CI answers "which values of mu are plausible" while a test answers "does one specific mu0 survive", and that a confidence interval is exactly the set of null values a level-alpha test does not reject, so any two-sided test can be read straight off the interval.](../_assets/4-7-ci-test-duality.png)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-07-hypothesis-testing-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: \(H_0\) null, \(H_1\) alternative; test statistic \(T\); \(\alpha=P(\text{type I})\), \(\beta=P(\text{type II})\), power \(=1-\beta\); p-value \(=P(\text{at least as extreme}\mid H_0)\); rejection region \(R\)। z-test: \(T=\frac{\bar x-\mu_0}{\sigma/\sqrt n}\) (\(\sigma\) জানা); t-test: \(T=\frac{\bar x-\mu_0}{s/\sqrt n}\sim t_{n-1}\) (\(\sigma\) অজানা); proportion test: \(T=\frac{\hat p-p_0}{\sqrt{p_0(1-p_0)/n}}\)। চলমান উদাহরণ: E1 z-test; E2 t-test; E3 proportion test; E4 Neyman–Pearson।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন \(H_0\), \(H_1\), test statistic \(T\), rejection region \(R\), significance level \(\alpha\), এবং power — এই ছয়টা কী। একটা right-tailed z-test-এ \(\alpha=0.05\) হলে rejection region কোথায় (critical value-সহ)? Hint: \(H_0\) = "কিছু ঘটেনি"/status-quo দাবি; \(H_1\) = বিকল্প/গবেষণা-দাবি; \(T\) = data-কে একটা সংখ্যায় চাপানো যার null distribution জানা; \(R\) = \(T\)-এর যে মানে \(H_0\) বাতিল; \(\alpha=P(T\in R\mid H_0)\); power \(=P(T\in R\mid H_1)=1-\beta\)। right-tailed: \(R=\{T>z_{0.05}=1.645\}\) (Figure 1)।
প্রশ্ন ২ (★★) — [p-value-এর সঠিক ব্যাখ্যা যাচাই]. একজন গবেষক একটা test-এ \(p=0.03\) পেয়ে লিখলেন: "\(H_0\) সত্যি হওয়ার সম্ভাবনা মাত্র \(3\%\)।" এই বাক্যটা কেন ভুল? p-value আসলে কীসের শর্তে কীসের সম্ভাবনা? Figure 2 থেকে যুক্তি টানুন, এবং নিচের প্রতিটি বিবৃতি সত্য না মিথ্যা বলুন: (i) "\(p=\) data দেখার পরে \(H_0\) সত্যি হওয়ার সম্ভাবনা"; (ii) "\(p=H_0\) সত্যি ধরে এত-বা-বেশি চরম ফল আসার সম্ভাবনা"; (iii) "\(p=\) ভুল করে \(H_0\) বাতিল করার সম্ভাবনা"; (iv) "\(1-p=H_1\) সত্যি হওয়ার সম্ভাবনা"। Hint: p-value \(H_0\) সত্যি ধরে (\(\mid H_0\)) হিসাব করা একটা tail-probability — তাই এটা "\(H_0\) সত্যি হওয়ার সম্ভাবনা" হতে পারে না; frequentist-এ \(H_0\) random নয়, তাই \(P(H_0\text{ true})\) সংজ্ঞায়িতই নয় ("\(P(H_0\text{ true})\)"-এর জন্য Bayesian posterior লাগে)। (i) মিথ্যা; (ii) সত্য; (iii) মিথ্যা (\(\alpha\), p-value নয়); (iv) মিথ্যা।
প্রশ্ন ৩ (★★). type I error (\(\alpha\)) আর type II error (\(\beta\))-এর পার্থক্য একটা বাস্তব উদাহরণে (যেমন একটা medical screening test) ব্যাখ্যা করুন: কোনটা "false positive", কোনটা "false negative"? Figure 1 থেকে দেখান কেন critical value সরালে একটা কমলে অন্যটা বাড়ে, এবং কীভাবে দুটোই একসাথে কমানো যায়। Hint: type I = \(H_0\) সত্যি (রোগ নেই) তবু "রোগ আছে" বলা = false positive; type II = \(H_1\) সত্যি (রোগ আছে) তবু "নেই" বলা = false negative। Figure 1-এ \(c\) ডানে সরালে লাল (\(\alpha\))↓ বেগুনি (\(\beta\))↑। একই \(n\)-এ tradeoff; দুটোই কমাতে \(n\) বাড়াতে হয় (overlap কমে, Figure 3-এর power↑)।
প্রশ্ন ৪ (★★). "ফল statistically significant নয়" — এর মানে কি "\(H_0\) প্রমাণিত / সত্যি"? Figure 3 (power curve) ব্যবহার করে ব্যাখ্যা করুন কেন নয়, এবং "absence of evidence is not evidence of absence" কথাটা এখানে কীভাবে খাটে। এছাড়া statistical significance আর practical significance-এর পার্থক্য একটা বড়-\(n\) উদাহরণে বলুন। Hint: significant নয় = "\(H_0\) বাতিল করার যথেষ্ট প্রমাণ পাইনি", "\(H_0\) সত্যি" নয়; কম power (ছোট \(n\)/effect) হলে সত্যি effect-ও ফসকায় (Figure 3-এর নিচু ধূসর curve)। বিশাল \(n\)-এ তুচ্ছ effect-ও significant হতে পারে (p ছোট) অথচ practically অর্থহীন — তাই effect size ও CI দেখা জরুরি, শুধু p নয়।
খ · গাণনিক (computational)¶
প্রশ্ন ৫ (★) — E1 (z-test). একটা কারখানার দাবি প্যাকেটের গড় ওজন \(\mu_0=500\) গ্রাম, \(\sigma=4\) গ্রাম জানা। \(n=16\) প্যাকেটে \(\bar x=502.5\)। \(H_0:\mu=500\) বনাম \(H_1:\mu\neq500\) (two-sided)। (ক) test statistic \(z\) বের করুন; (খ) \(\alpha=0.05\)-এ critical value-এর সাথে তুলনা করে সিদ্ধান্ত দিন; (গ) two-sided p-value বের করুন। Hint: \(\mathrm{SE}=\sigma/\sqrt n=4/4=1\); \(z=\frac{502.5-500}{1}=2.5\)। two-sided critical \(z_{0.025}=1.96\); \(\lvert2.5\rvert>1.96\) ⇒ reject \(H_0\)। p \(=2\,P(Z>2.5)=2(0.0062)=0.0124\)।
প্রশ্ন ৬ (★★) — E2 (t-test). এক নতুন শিক্ষণ-পদ্ধতির পরীক্ষায় \(n=10\) ছাত্রের উন্নতি (পয়েন্ট): \(\bar x=6\), \(s=8\) (\(\sigma\) অজানা)। \(H_0:\mu=0\) বনাম \(H_1:\mu>0\) (right-tailed)। (ক) \(t\) statistic; (খ) \(t_{9,0.05}=1.833\)-এর সাথে তুলনা করে সিদ্ধান্ত; (গ) এই সিদ্ধান্ত z-test ব্যবহার করলে বদলাত কি না, এবং কেন t সঠিক। Hint: \(\mathrm{SE}=s/\sqrt n=8/\sqrt{10}=2.530\); \(t=\frac{6-0}{2.530}=2.372\)। \(2.372>1.833\) ⇒ reject \(H_0\)। z হলে critical \(1.645\) ব্যবহার করত (আরও সহজে reject), কিন্তু \(\sigma\) অজানা বলে null distribution \(t_9\), normal নয় — ছোট \(n\)-এ t না নিলে type I error স্ফীত হয়।
প্রশ্ন ৭ (★★) — E3 (proportion test). একটা ওয়েবসাইটের পুরোনো click-rate \(p_0=0.20\)। নতুন ডিজাইনে \(n=500\) ব্যবহারকারীর \(120\) জন ক্লিক করল (\(\hat p=0.24\))। \(H_0:p=0.20\) বনাম \(H_1:p>0.20\)। (ক) test statistic (null-এর \(\mathrm{SE}=\sqrt{p_0(1-p_0)/n}\) ব্যবহার করে); (খ) \(\alpha=0.05\)-এ সিদ্ধান্ত; (গ) p-value। Hint: \(\mathrm{SE}_0=\sqrt{0.20\times0.80/500}=\sqrt{0.00032}=0.01789\); \(z=\frac{0.24-0.20}{0.01789}=2.236\)। \(2.236>1.645\) ⇒ reject \(H_0\)। p \(=P(Z>2.236)=0.0127\)। (লক্ষ: null-এর \(\mathrm{SE}\)-তে \(p_0\) ব্যবহার, \(\hat p\) নয় — কারণ \(H_0\) সত্যি ধরে হিসাব।)
প্রশ্ন ৮ (★★) — power হিসাব। প্রশ্ন ৫-এর z-test-এ (\(\sigma=4\), \(n=16\), two-sided \(\alpha=0.05\)) সত্যিকারের গড় যদি \(\mu_1=502\) হয়, power \(=1-\beta\) কত? (one-sided approximation: ডান লেজ ধরুন।) Hint: \(\mathrm{SE}=1\); critical (ডান) \(\bar x_c=500+1.96\times1=501.96\)। power \(\approx P(\bar X>501.96\mid\mu=502)=P\big(Z>\frac{501.96-502}{1}\big)=P(Z>-0.04)=0.516\)। অর্থাৎ এই effect ও \(n\)-এ test প্রায় অর্ধেক সময় ধরবে — power বাড়াতে \(n\) বাড়ান (Figure 3)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★) — CI ↔ test দ্বৈততা প্রমাণ। \(X_1,\dots,X_n\overset{iid}{\sim}\mathcal{N}(\mu,\sigma^2)\), \(\sigma\) জানা। দেখান যে two-sided z-test (\(H_0:\mu=\mu_0\), level \(\alpha\)) \(H_0\) বাতিল করে ঠিক তখনই যখন \(\mu_0\) নির্দিষ্ট \((1-\alpha)\) z-CI \(\bar X\pm z_{\alpha/2}\,\sigma/\sqrt n\)-এর বাইরে পড়ে। অর্থাৎ test ও CI একই অসমতা (Figure 4)। Hint: test বাতিল করে \(\iff\big\lvert\frac{\bar X-\mu_0}{\sigma/\sqrt n}\big\rvert>z_{\alpha/2}\iff\lvert\bar X-\mu_0\rvert>z_{\alpha/2}\frac{\sigma}{\sqrt n}\iff\mu_0<\bar X-z_{\alpha/2}\frac{\sigma}{\sqrt n}\) অথবা \(\mu_0>\bar X+z_{\alpha/2}\frac{\sigma}{\sqrt n}\iff\mu_0\notin\) CI। তাই CI = \(\{\mu_0:\text{test বাতিল করে না}\}\)।
প্রশ্ন ১০ (★★) — p-value-এর null distribution। দেখান যে একটা continuous test statistic-এর জন্য, \(H_0\) সত্যি হলে p-value-এর বণ্টন \(\text{Uniform}(0,1)\)। এর ফলে কেন "\(p\le\alpha\) হলে reject" নিয়মটা ঠিক \(\alpha\) type I error দেয়, তা ব্যাখ্যা করুন। Hint: এক-লেজা ক্ষেত্রে \(p=1-F_0(T)\) যেখানে \(F_0\) = null CDF; \(H_0\)-তে \(F_0(T)\sim\text{Uniform}(0,1)\) (probability integral transform), তাই \(1-F_0(T)\)-ও Uniform। তখন \(P(p\le\alpha\mid H_0)=\alpha\) — অর্থাৎ p-threshold \(\alpha\) ঠিক \(\alpha\)-মাত্রার type I error দেয়, সংজ্ঞা মেলে।
প্রশ্ন ১১ (★★★) — E4 (Neyman–Pearson lemma)। সরল-বনাম-সরল test \(H_0:\theta=\theta_0\) বনাম \(H_1:\theta=\theta_1\)-এ likelihood ধরুন \(L(\theta)=\prod f(x_i;\theta)\)। Neyman–Pearson lemma বলে level-\(\alpha\) test-গুলোর মধ্যে সবচেয়ে শক্তিশালী (most powerful) test হলো likelihood-ratio test: reject \(H_0\) যদি \(\Lambda=\frac{L(\theta_1)}{L(\theta_0)}>k\), যেখানে \(k\) এমন যাতে \(P(\Lambda>k\mid H_0)=\alpha\)। (ক) এই rejection region-এর গঠন লিখুন। (খ) \(\mathcal{N}(\theta,1)\)-এ \(\theta_1>\theta_0\) হলে দেখান যে \(\Lambda>k\) অসমতা \(\bar x>c\)-তে নেমে আসে (অর্থাৎ NP-optimal test আসলে স্বাভাবিক z-test)। (গ) এটা §১–৫-এর power-ধারণার সাথে কীভাবে মেলে? Hint: (ক) \(R=\{x:\Lambda(x)>k\}\), \(k\) ঠিক হয় size-condition \(P_{\theta_0}(\Lambda>k)=\alpha\) থেকে। (খ) \(\log\Lambda=\sum\big[(\theta_1-\theta_0)x_i-\tfrac12(\theta_1^2-\theta_0^2)\big]\); \(\theta_1>\theta_0\) হওয়ায় এটা \(\sum x_i\) (তথা \(\bar x\))-এ monotone increasing, তাই \(\Lambda>k\iff\bar x>c\) — exactly right-tailed z-test। (গ) NP lemma নিশ্চিত করে এই z-test প্রতিটি বিকল্পে সর্বোচ্চ power দেয় (Figure 3-এর সবচেয়ে উঁচু সম্ভাব্য curve) — তাই z-test শুধু সুবিধাজনক নয়, এই কাঠামোয় optimal।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★★) — type I error simulation। \(H_0\) সত্যি ধরে (\(\mathcal{N}(\mu_0=0,\sigma^2=1)\), \(n=30\)) \(10{,}000\) বার নমুনা টেনে প্রতিবার two-sided z-test (\(\alpha=0.05\)) চালান, এবং কত ভাগ ক্ষেত্রে (ভুল করে) \(H_0\) বাতিল হয় গুনুন। এই হার কি \(\approx\alpha=0.05\)? এটাই কি type I error-এর অভিজ্ঞতামূলক যাচাই? Hint:
import numpy as np
from scipy import stats
rng = np.random.default_rng(0)
mu0, sigma, n, R = 0.0, 1.0, 30, 10000
zc = stats.norm.ppf(0.975)
X = rng.normal(mu0, sigma, size=(R, n))
z = (X.mean(1) - mu0) / (sigma / np.sqrt(n))
reject = np.abs(z) > zc
print("empirical type I error:", reject.mean()) # ~0.05
প্রশ্ন ১৩ (★★) — power ও p-value distribution। (ক) এখন \(\mu=0.5\) (অর্থাৎ \(H_1\) সত্যি, effect \(d=0.5\)), \(n=30\)-এ একই two-sided z-test \(10{,}000\) বার চালিয়ে empirical power (\(=\) reject-হার) বের করুন; প্রশ্ন ৮-এর তত্ত্বের সাথে মেলান। (খ) \(H_0\) সত্যি ধরে (\(\mu=0\)) p-value-গুলোর histogram আঁকুন — দেখান তা \(\text{Uniform}(0,1)\) (§৭ Q10-এর যাচাই)।
Hint: (ক) z = (X.mean(1)-0)/(1/np.sqrt(30)); power \(=\) (np.abs(z)>1.96).mean() \(\approx0.75\) (effect \(0.5\), \(n=30\))। (খ) p = 2*(1-stats.norm.cdf(np.abs(z0))) যেখানে z0 \(\mu=0\)-এর নমুনা থেকে; plt.hist(p, bins=20) প্রায় সমতল — null-এ p-value uniform, তাই \(P(p\le0.05)\approx0.05\)।
প্রশ্ন ১৪ (★★★) — t বনাম z, ছোট \(n\)-এ type I error। \(\sigma\) অজানা ধরে (\(s\) দিয়ে অনুমান) \(H_0:\mu=0\) সত্যি রেখে (\(\mathcal{N}(0,1)\), \(n=5\)) \(10{,}000\) বার (ক) ভুলভাবে z-test (\(\lvert T\rvert>1.96\), \(T=\bar x/(s/\sqrt n)\)) ও (খ) সঠিক t-test (\(\lvert T\rvert>t_{4,0.025}=2.776\)) চালিয়ে দুটোর empirical type I error তুলনা করুন। দেখান z-test ভুলভাবে \(0.05\)-এর বেশি reject করে (inflated type I), কিন্তু t-test \(\approx0.05\) ফিরিয়ে দেয়। Hint:
s = X.std(axis=1, ddof=1)
T = X.mean(1) / (s / np.sqrt(n))
print("z-rule type I:", (np.abs(T) > 1.96).mean()) # ~0.07-0.08 (inflated)
print("t-rule type I:", (np.abs(T) > stats.t.ppf(0.975, n-1)).mean()) # ~0.05
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- hypothesis test = নিয়ন্ত্রিত-ঝুঁকির সিদ্ধান্ত (Figure 1)। দুটো প্রতিদ্বন্দ্বী দাবি — null \(H_0\) (status quo) আর alternative \(H_1\) — এবং একটা test statistic \(T\) যার null distribution জানা। একটা rejection region \(R\): \(T\in R\) হলে \(H_0\) বাতিল। দুই রকম ভুল: type I (\(\alpha=P(\text{reject}\mid H_0)\), false positive) আর type II (\(\beta=P(\text{fail to reject}\mid H_1)\), false negative); একই \(n\)-এ একটা কমালে অন্যটা বাড়ে (critical value সরানোর tradeoff)।
- \(\alpha\) আগে স্থির, power বেরিয়ে আসে। আমরা type I error-কে \(\alpha\)-তে (যেমন \(0.05\)) বেঁধে রাখি — সেটাই critical value ঠিক করে; তারপর power \(=1-\beta=P(\text{reject}\mid H_1)\) নির্ভর করে effect-size, \(n\), ও \(\alpha\)-এর ওপর (Figure 3)। effect \(=0\)-তে power \(=\alpha\) (floor); \(n\) বা effect বাড়লে power \(\to1\)।
- p-value মানে কী, আর কী নয় (Figure 2, §৭ Q2)। p-value \(=P(\text{observed-এর চেয়ে অন্তত ততটা চরম}\mid H_0\text{ সত্যি})\) — null distribution-এর নিচে একটা লেজের ক্ষেত্রফল। ছোট p = data টা \(H_0\)-র অধীনে বিস্ময়কর; নিয়ম: \(p\le\alpha\) হলে reject (rejection-region-নিয়মের সমতুল্য)। এটা \(P(H_0\text{ true})\) নয় — frequentist-এ \(H_0\) random নয়, p-value পুরোটাই \(H_0\) সত্যি ধরে হিসাব করা। continuous statistic-এ null-এ p-value \(\sim\text{Uniform}(0,1)\) (§৭ Q10)।
- চলমান উদাহরণে test-এর গঠন। E1 (z-test): \(\sigma\) জানা, \(T=\frac{\bar x-\mu_0}{\sigma/\sqrt n}\sim\mathcal{N}(0,1)\)। E2 (t-test): \(\sigma\) অজানা, \(T=\frac{\bar x-\mu_0}{s/\sqrt n}\sim t_{n-1}\) — ছোট \(n\)-এ z ব্যবহার করলে type I error স্ফীত হয় (§৭ Q14)। E3 (proportion): \(T=\frac{\hat p-p_0}{\sqrt{p_0(1-p_0)/n}}\) (null-এর \(\mathrm{SE}\)-তে \(p_0\))। E4 (Neyman–Pearson lemma): simple-vs-simple-এ likelihood-ratio test \(\Lambda=L(\theta_1)/L(\theta_0)>k\) হলো most powerful; normal-এ তা স্বাভাবিক z-test-এ নেমে আসে — অর্থাৎ z-test শুধু সুবিধাজনক নয়, optimal (§৭ Q11)।
- CI ↔ test দ্বৈততা (Figure 4, §৭ Q9)। একটা \((1-\alpha)\) CI আর একটা level-\(\alpha\) two-sided test একই critical value ও \(\mathrm{SE}\) ব্যবহার করে: reject \(H_0:\mu=\mu_0\) iff \(\mu_0\) CI-এর বাইরে। তাই \((1-\alpha)\) CI = সেই সব \(\mu_0\)-এর সংগ্রহ যাদের test বাতিল করে না — CI "সম্ভাব্য মান" বলে, test "একটা দাবি টেকে কি না" বলে, উত্তর সঙ্গতিপূর্ণ।
- সতর্কতা। "significant নয়" ≠ "\(H_0\) সত্যি/প্রমাণিত" — হয়তো power কম ছিল (§৭ Q4)। আর বিশাল \(n\)-এ তুচ্ছ effect-ও significant হতে পারে, তাই statistical significance ≠ practical significance — effect size ও CI দেখুন, শুধু p নয়।
পূর্ববর্তী সংযোগ (← 4.6 Confidence Intervals; এবং 4.1, 3.4): 4.6-এ আমরা data থেকে \(\theta\)-এর একটা সম্ভাব্য পরিসর বানিয়েছিলাম এবং সেখানকার শেষ ইঙ্গিতই ছিল এই অধ্যায়ের দ্বৈততা। এখানে সেটাই পূর্ণতা পেল: 4.6-এর pivot \(\frac{\bar X-\mu}{\sigma/\sqrt n}\sim\mathcal{N}(0,1)\) সরাসরি এই অধ্যায়ের test statistic হয়ে গেল, আর 4.6-এর critical value \(z_{\alpha/2}/t_{n-1,\alpha/2}\)-গুলোই হলো test-এর rejection boundary (Figure 4, §৭ Q9)। 4.1-এর point estimation, standard error আর sampling distribution এই test-এর কাঁচামাল — \(T\)-এর null distribution তো 4.1/3.4-এর sampling-distribution তত্ত্ব থেকেই আসে; আর \(1/\sqrt n\) হারের কারণে বড় নমুনায় power বাড়ে (Figure 3) তার শিকড় 3.4-এর CLT-তে। সংক্ষেপে: 4.6 অনিশ্চয়তাকে interval-এ অনুবাদ করল; 4.7 সেই একই কাঠামোকে একটা হ্যাঁ/না সিদ্ধান্তে রূপ দিল — দুটো একই গণিতের দুই মুখ।
পরবর্তী সংযোগ (→ 4.8 — Likelihood-based tests: LRT, Wald, Score): এই অধ্যায়ের test-গুলো (z, t, proportion) একেকটা বিশেষ ক্ষেত্রে হাতে-গড়া, আর Neyman–Pearson lemma (E4) আমাদের simple-vs-simple-এর optimal test দিল — কিন্তু composite hypothesis (\(H_0:\theta\in\Theta_0\), একাধিক প্যারামিটার) আর সাধারণ মডেলে কী করব? পরের অধ্যায় NP-এর likelihood-ratio ধারণাকে সাধারণীকরণ করবে তিনটি মহাক্ষমতাশালী, likelihood থেকে-উদ্ভূত test-পরিবারে: Likelihood-Ratio Test (LRT) (\(\Lambda=\frac{\sup_{\Theta_0}L}{\sup_\Theta L}\), যার \(-2\log\Lambda\xrightarrow{d}\chi^2\) — Wilks), Wald test (MLE \(\hat\theta\) ও Fisher information থেকে, 4.5-এর asymptotic normality-র সরাসরি ফসল), আর Score test (log-likelihood-এর ঢাল থেকে)। তিনটেই বড় নমুনায় সমতুল্য, আর এই অধ্যায়ের z-test/t-test তাদের সরল বিশেষ ঘটনা। অর্থাৎ 4.7 ছিল testing-এর অন্তর্দৃষ্টি ও শব্দভাণ্ডার (\(\alpha,\beta\), power, p-value, rejection region, NP-optimality); 4.8 হবে সেই অন্তর্দৃষ্টিকে likelihood-চালিত একটা সাধারণ যন্ত্রে পরিণত করা, যা প্রায় যেকোনো parametric মডেলে test বানাতে পারে।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 10 ("Hypothesis Testing and p-values" — Wald test, p-value-এর সংজ্ঞা ও ভুল-ব্যাখ্যা, Neyman–Pearson, §10.1–10.4) ও Ch. 6.3 (CI–test দ্বৈততা); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 9 ("Testing Hypotheses and Assessing Goodness of Fit" — Neyman–Pearson paradigm, type I/II error ও power, likelihood-ratio, §9.1–9.4); পরিপূরক স্বজ্ঞার জন্য P. Bruce, A. Bruce & P. Gedeck, Practical Statistics for Data Scientists, Ch. 3 ("Statistical Experiments and Significance Testing" — p-value, significance, power-এর ব্যবহারিক দিক)।