4.8 — Likelihood Ratio, Wald & Score Tests; Goodness-of-Fit (লাইকলিহুড-অনুপাত, ওয়াল্ড ও স্কোর পরীক্ষা)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — একটিমাত্র পাহাড়, তিন দিক থেকে মাপা¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন প্রশ্ন এখনও খোলা¶
গত অধ্যায়ে (4.7) আমরা hypothesis testing (প্রকল্প-পরীক্ষা)-এর পুরো কাঠামো গড়েছি। সংক্ষেপে মনে করিয়ে দিই, কারণ এই অধ্যায়ের গল্প ঠিক সেখান থেকেই শুরু:
- আমরা দুটো প্রতিদ্বন্দ্বী দাবি দাঁড় করাই — null hypothesis (শূন্য প্রকল্প) \(H_0\) (সাধারণত "কিছু ঘটেনি / parameter একটা নির্দিষ্ট মান", যেমন \(\theta=\theta_0\)) আর alternative hypothesis (বিকল্প প্রকল্প) \(H_1\) (যেমন \(\theta\neq\theta_0\))। এখানে \(\theta\) ("থিটা") হলো অজানা parameter, আর \(\theta_0\) ("থিটা-নট") হলো \(H_0\) যে নির্দিষ্ট মান দাবি করে।
- তারপর data থেকে একটা test statistic (পরীক্ষা-পরিসংখ্যান) গণনা করি — একটা সংখ্যা যা মাপে data কতটা \(H_0\)-র বিরুদ্ধে যায়। সেই statistic যথেষ্ট চরম হলে আমরা \(H_0\) বাতিল করি (reject)। কত চরম হলে বাতিল করব, তা ঠিক করে significance level \(\alpha\) ("আলফা", টাইপ I error-এর অনুমোদিত হার), আর কতটা চরম তা summarise করে p-value।
- 4.7-এ আমরা দুটো নির্দিষ্ট test হাতে-কলমে শিখেছি — Normal গড়ের জন্য z-test আর σ অজানা হলে t-test।
কিন্তু এখানেই একটা বড় সীমাবদ্ধতা রয়ে গেছে — আর সেই সীমাবদ্ধতা থেকেই এই অধ্যায়ের প্রশ্ন জন্ম নেয়:
z-test, t-test — এগুলো তো বিশেষ বিশেষ পরিস্থিতির জন্য হাতে গড়া (Normal গড়, একটা parameter)। কিন্তু পৃথিবীতে তো হাজার রকম মডেল আর parameter — Poisson-এর rate \(\lambda\), Exponential-এর \(\lambda\), একটা বণ্টনের আকৃতি-parameter, একসাথে কয়েকটা parameter। প্রতিটার জন্য কি আলাদা আলাদা test আবিষ্কার করতে হবে? নাকি একটা সর্বজনীন কারখানা আছে — যেখানে যেকোনো মডেল ঢোকালেই একটা বৈধ test বেরিয়ে আসে?
উত্তর — হ্যাঁ, এমন কারখানা আছে, আর তার কাঁচামাল আমাদের পরিচিত: likelihood। এই অধ্যায়ের পুরো কাজ — likelihood থেকে test বানানোর তিনটি সর্বজনীন উপায় শেখা, যাদের যেকোনো parametric মডেলে প্রায় যান্ত্রিকভাবে প্রয়োগ করা যায়।
১.২ মূল ছবি — likelihood একটা পাহাড়, \(H_0\) একটা বিন্দু¶
পুরো অধ্যায়ের insight (অন্তর্দৃষ্টি)-টা একটামাত্র ছবিতে ধরা যায়, তাই ধীরে গড়ি। 4.3 থেকে মনে করুন: data হাতে আসার পর log-likelihood \(\ell(\theta)=\sum_{i=1}^n\log f(X_i;\theta)\) হলো \(\theta\)-র একটা function — প্রতিটি সম্ভাব্য \(\theta\)-মানের জন্য একটা সংখ্যা, যা বলে "এই \(\theta\) ধরলে হাতে-পাওয়া data কতটা যুক্তিযুক্ত"। এই function-টা আঁকলে সাধারণত একটা পাহাড়ের আকার — কোথাও সর্বোচ্চ (চূড়া), দুপাশে নিচু।
- পাহাড়ের চূড়ার অবস্থান (যে \(\theta\)-তে \(\ell\) সর্বোচ্চ) = MLE, \(\hat\theta\) — data যাকে সবচেয়ে বেশি সমর্থন করে।
- পাহাড়ের চূড়ার উচ্চতা = \(\ell(\hat\theta)\) — data-র সঙ্গে সবচেয়ে ভালো মানানসই মডেলের "ফিট-স্কোর"।
এখন \(H_0\) আসে দৃশ্যে। \(H_0:\theta=\theta_0\) মানে আমরা পাহাড়ের একটা নির্দিষ্ট বিন্দু \(\theta_0\)-তে দাঁড়িয়ে জিজ্ঞেস করছি: "সত্য \(\theta\) কি এখানেই (চূড়ার অবস্থান যা-ই হোক)?" স্বাভাবিক স্বজ্ঞা: যদি \(\theta_0\) চূড়ার কাছেই হয়, তবে \(H_0\) যুক্তিসঙ্গত; আর যদি \(\theta_0\) চূড়া থেকে অনেক দূরে, নিচু ঢালে, তবে data \(H_0\)-র বিরুদ্ধে — বাতিল করা উচিত।
এই "\(\theta_0\) চূড়া থেকে কতটা দূরে / খাপছাড়া" — এটাই মাপার তিনটি স্বাভাবিক উপায় আছে, আর সেই তিনটিই এই অধ্যায়ের তিন test:
- উচ্চতার তুলনা (LRT)। চূড়ার উচ্চতা \(\ell(\hat\theta)\)-র সঙ্গে \(H_0\)-বিন্দুর উচ্চতা \(\ell(\theta_0)\)-র পার্থক্য মাপো। পার্থক্য বড় মানে \(\theta_0\) চূড়ার চেয়ে অনেক নিচে — data \(H_0\) পছন্দ করছে না। → likelihood ratio test।
- অনুভূমিক দূরত্ব (Wald)। চূড়ার অবস্থান \(\hat\theta\) আর \(H_0\)-বিন্দু \(\theta_0\)-র মধ্যে অনুভূমিক দূরত্ব \(\hat\theta-\theta_0\) মাপো (এবং সেটাকে তার standard error দিয়ে স্কেল করো — "কত SE দূরে")। → Wald test।
- \(H_0\)-বিন্দুতে ঢাল (score)। চূড়ায় না গিয়ে, কেবল \(\theta_0\)-বিন্দুতে দাঁড়িয়ে পাহাড়ের ঢাল (slope = score \(\ell'(\theta_0)\)) মাপো। চূড়ায় ঢাল শূন্য; তাই \(\theta_0\)-তে ঢাল যত খাড়া, \(\theta_0\) চূড়া থেকে তত দূরে। → score (Rao) test।
এক বাক্যে যা সারা অধ্যায় ধরে রাখবে: তিনটি test একই পাহাড়ের (\(\ell(\theta)\)-র) তিনটি ভিন্ন বৈশিষ্ট্য মাপে — উচ্চতার ফারাক (LRT), চূড়ার অনুভূমিক দূরত্ব (Wald), আর \(H_0\)-বিন্দুতে ঢাল (score)। তিনটিই একই প্রশ্নের ("\(\theta_0\) কি চূড়ার কাছে?") উত্তর দেয়, আর বড় নমুনায় প্রায় একই সিদ্ধান্তে পৌঁছায় (asymptotic equivalence)।
(§৬-এর চিত্র 4-8-three-tests এই এক-পাহাড়-তিন-পরিমাপ ছবিটা — উচ্চতার ফারাক, অনুভূমিক দূরত্ব, ও \(\theta_0\)-তে স্পর্শক-ঢাল — পাশাপাশি চোখে দেখাবে।)
১.৩ কেন তিনটিই দরকার — প্রত্যেকের আলাদা সুবিধা¶
তিনটি test যদি প্রায় একই উত্তর দেয়, তবে তিনটি কেন? কারণ হিসাবের সুবিধা তিন ক্ষেত্রে তিন রকম — পরিস্থিতিভেদে একটা অন্যটার চেয়ে অনেক সহজ:
- LRT-র জন্য দুটো জায়গায় likelihood সর্বোচ্চ করতে হয় — একবার \(H_0\)-র সীমার মধ্যে, একবার পুরো জায়গায়। সবচেয়ে নীতিগতভাবে সুন্দর ও প্রায়ই সবচেয়ে শক্তিশালী, কিন্তু দুটো optimization লাগে।
- Wald test-এর জন্য কেবল MLE \(\hat\theta\) আর তার standard error লাগে — \(\theta_0\)-তে আলাদা করে কিছু হিসাব করতে হয় না। MLE হাতে থাকলে সবচেয়ে সহজ; তাই software-এ ডিফল্ট রিপোর্ট প্রায়ই Wald।
- Score test-এর সবচেয়ে বড় চমৎকারিতা: MLE হিসাব করতেই হয় না! কেবল \(H_0\)-বিন্দু \(\theta_0\)-তে score ও Fisher information লাগে। যখন \(H_0\)-র অধীনে হিসাব সহজ কিন্তু পূর্ণ MLE বের করা কঠিন (যেমন জটিল মডেল), তখন score test সোনার খনি।
তাই তিনটি একসঙ্গে শেখা মানে একটা পূর্ণ টুলবক্স — হাতে যা সহজে আছে (MLE? নাকি \(H_0\)-তে সহজ হিসাব? নাকি দুটো likelihood?) তার ভিত্তিতে সেরা যন্ত্রটা বেছে নেওয়া।
১.৪ দ্বিতীয় সুতো — "মডেলটা কি আদৌ মানানসই?" (goodness-of-fit hook)¶
এতক্ষণ আমরা ধরে নিয়েছি মডেলটা (যেমন Normal, বা একটা নির্দিষ্ট ছক্কার বণ্টন) ঠিক, শুধু তার parameter \(\theta\) নিয়ে প্রশ্ন। কিন্তু একটা আরও মৌলিক প্রশ্ন আছে:
আমি যে বণ্টনটা ধরে নিয়েছি — সেটাই কি আদৌ data-র সঙ্গে খাপ খায়? ছক্কাটা কি সত্যিই ন্যায্য (প্রতিটি মুখ \(1/6\))? চোখের রঙ আর হাতের-দিক (বাঁ/ডান) কি স্বাধীন? এই দুই categorical চলকের পর্যবেক্ষিত গণনা কি তত্ত্বের প্রত্যাশিত গণনার সঙ্গে মেলে?
এই প্রশ্নের নাম goodness-of-fit (সদৃশতা / মানানসইতা-যাচাই)। আর এর উত্তর দেয় পরিসংখ্যানের সবচেয়ে বিখ্যাত test-গুলোর একটি — Pearson's chi-square test, যার হৃদয়ে একটামাত্র সরল রাশি:
যেখানে \(O_i\) ("observed") হলো \(i\)-তম শ্রেণিতে পর্যবেক্ষিত গণনা, আর \(E_i\) ("expected") হলো \(H_0\) সত্য হলে যা প্রত্যাশিত ছিল। স্বজ্ঞা সরল: পর্যবেক্ষণ আর প্রত্যাশা যত আলাদা (লব বড়), মডেল তত খারাপ; আর এই পার্থক্য যথেষ্ট বড় হলে মডেল বাতিল। চমৎকার ব্যাপার — এই Pearson \(\chi^2\) আসলে likelihood-চিন্তার (বিশেষত multinomial-এর LRT-র) একটা সরাসরি ফল, তাই এটি এই অধ্যায়ের প্রথম সুতোর সঙ্গে গভীরভাবে বাঁধা (এই সংযোগ §৪–৫-এ খোলা হবে)।
১.৫ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — পাঁচটি কেন্দ্রীয় ধারণা from scratch, প্রতিটি প্রতীক খুলে: (ক) likelihood ratio \(\Lambda\) ও LRT; (খ) Wilks' theorem (\(-2\log\Lambda\xrightarrow{d}\chi^2_k\), df = \(H_0\) যত parameter বাঁধে); (গ) Wald test (MLE কত SE দূরে); (ঘ) score test (MLE-তে না গিয়ে \(H_0\)-তে ঢাল); (ঙ) তিনটির geometric intuition ও asymptotic equivalence; (চ) Pearson \(\chi^2\) goodness-of-fit ও test of independence।
- §৩ — পাঁচটি/চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 LRT, E2 Wald test, E3 score test, E4 Pearson \(\chi^2\) — ছক্কার ন্যায্যতা (goodness-of-fit) ও contingency table-এ independence।
- §৪–৫ — তিন test-এর asymptotic equivalence-এর যুক্তি, Wilks' theorem-এর উৎপত্তি (\(-2\log\Lambda\) কেন \(\chi^2\)), Pearson \(\chi^2\)-কে multinomial LRT থেকে পাওয়া, এবং degrees-of-freedom গোনার সাধারণ নিয়ম।
- §৬–৮ — চিত্র (three-tests, Wilks, chi2-gof, test-equivalence), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর গুরুত্বপূর্ণ ধাপ। 4.7 দিয়েছিল testing-এর ব্যাকরণ (\(H_0/H_1\), \(\alpha\), p-value) কিন্তু কেবল কয়েকটি হাতে-গড়া test; এই অধ্যায় সেই ব্যাকরণে likelihood থেকে test বানানোর সর্বজনীন যন্ত্র জুড়ে দেয় — তিনটি general test (LRT, Wald, score) যা যেকোনো parametric মডেলে খাটে, আর Pearson \(\chi^2\) যা মডেলের আকৃতিই যাচাই করে। ঠিক এই asymptotic-\(\chi^2\) যন্ত্রপাতি পরের অধ্যায় 4.9 (bootstrap)-এ একটা বিকল্প — যখন asymptotic আনুমানিকতা যথেষ্ট নয়, তখন data পুনঃনমুনায়ন (resampling) দিয়ে সরাসরি বণ্টন আঁকা — পথ খুলে দেয়।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামোটা স্থির: আমাদের কাছে একটি i.i.d. নমুনা \(X_1,\dots,X_n\) আছে (independent and identically distributed — স্বাধীন ও একই বণ্টন থেকে আসা), যার pdf/pmf \(f(x;\theta)\), এবং একটি অজানা parameter \(\theta\) যা একটি parameter-জগৎ (parameter space) \(\Theta\) ("বড় থিটা")-র সদস্য। 4.3 থেকে মনে রাখি:
- likelihood \(L(\theta)=\prod_{i=1}^n f(X_i;\theta)\) — data স্থির, \(\theta\) চলক;
- log-likelihood \(\ell(\theta)=\log L(\theta)=\sum_{i=1}^n\log f(X_i;\theta)\);
- score \(\ell'(\theta)=\partial_\theta\ell(\theta)\) — log-likelihood-এর derivative (পাহাড়ের ঢাল);
- MLE \(\hat\theta=\arg\max_{\theta\in\Theta}\ell(\theta)\) — পাহাড়ের চূড়ার অবস্থান।
আমরা একটা null hypothesis পরীক্ষা করছি, যেটা parameter-জগতের একটা উপ-অংশ \(\Theta_0\subseteq\Theta\) দিয়ে প্রকাশ করা যায় — \(H_0:\theta\in\Theta_0\)। সবচেয়ে সরল ক্ষেত্রে \(\Theta_0\) একটামাত্র বিন্দু, \(H_0:\theta=\theta_0\)।
২.১ Likelihood ratio ও likelihood ratio test (LRT)¶
§১.২-এর "দুই উচ্চতার তুলনা"-কে নিখুঁত করি। মূল ধারণা: \(H_0\)-র সীমার মধ্যে data যতটা ভালো ব্যাখ্যা করা যায়, আর কোনো সীমা ছাড়া (পুরো \(\Theta\)-তে) যতটা ভালো ব্যাখ্যা করা যায় — এ-দুইয়ের অনুপাত।
সংজ্ঞা (Likelihood ratio — লাইকলিহুড-অনুপাত, \(\Lambda\))। likelihood ratio হলো
প্রতিটি অংশ খুলি:
- \(\sup_{\theta\in\Theta_0} L(\theta)\) — "supremum" (সর্বোচ্চ মান) \(L(\theta)\)-র, কিন্তু \(\theta\)-কে কেবল \(H_0\)-র অনুমোদিত অঞ্চল \(\Theta_0\)-র মধ্যে রেখে। কথায়: "\(H_0\) মানলে data-র সর্বোচ্চ সম্ভাব্যতা"। (সরল ক্ষেত্রে \(\Theta_0=\{\theta_0\}\) হলে এটা শুধুই \(L(\theta_0)\)।)
- \(\sup_{\theta\in\Theta} L(\theta)=L(\hat\theta)\) — পুরো \(\Theta\)-তে সর্বোচ্চ, অর্থাৎ চূড়ার উচ্চতা — MLE-তে likelihood। কথায়: "কোনো বাধা ছাড়াই data-র সর্বোচ্চ সম্ভাব্যতা"।
- \(\Lambda\) ("ল্যামডা") — উপরের ভাগ নিচের দিয়ে। যেহেতু লব হরের একটা সীমাবদ্ধ (কম-স্বাধীনতার) সংস্করণ, লব কখনো হরের চেয়ে বড় হতে পারে না; তাই \(0\le\Lambda\le 1\)।
\(\Lambda\) কীভাবে পড়ব (স্বজ্ঞা):
- \(\Lambda\) \(1\)-এর কাছে → \(H_0\)-র সেরা ব্যাখ্যা প্রায় বাধাহীন সেরা ব্যাখ্যার সমান ভালো → \(H_0\) যুক্তিসঙ্গত, বাতিল করার কারণ নেই। (পাহাড়-ছবিতে: \(\theta_0\) চূড়ার প্রায় সমান উঁচুতে।)
- \(\Lambda\) \(0\)-র কাছে (ছোট) → \(H_0\)-র সীমা মানলে data অনেক কম সম্ভাব্য → data \(H_0\)-র বিরুদ্ধে → \(H_0\) বাতিল করা উচিত। (পাহাড়-ছবিতে: \(\theta_0\) চূড়ার চেয়ে অনেক নিচে।)
সংজ্ঞা (Likelihood ratio test — LRT)। ছোট \(\Lambda\) দেখলে \(H_0\) বাতিল করার test-ই LRT। সমতুল্যভাবে — এবং এটাই ব্যবহারিক রূপ — আমরা একটা রূপান্তরিত statistic ব্যবহার করি:
এই রূপটা মন দিয়ে দেখুন — এটাই §১.২-এর "দুই উচ্চতার ফারাক" সংখ্যায়:
- \(\log\Lambda=\log\frac{\sup_{\Theta_0}L}{\sup_\Theta L}=\sup_{\Theta_0}\ell-\ell(\hat\theta)\) (log নিলে ভাগ → বিয়োগ, আর \(\log L=\ell\))। এটা সবসময় \(\le 0\) (যেহেতু \(\Lambda\le 1\))।
- সামনে \(-2\) গুণ বসিয়ে: \(-2\log\Lambda=2[\ell(\hat\theta)-\sup_{\Theta_0}\ell]\ge 0\) — অর্থাৎ চূড়ার উচ্চতা বিয়োগ \(H_0\)-বিন্দুর উচ্চতা, দ্বিগুণ করা। কেন ঠিক "\(2\)" আর কেন এই রূপ — তার রহস্য পরের উপবিভাগের Wilks' theorem-এ।
- ছোট \(\Lambda\) ⇔ বড় \(-2\log\Lambda\)। তাই LRT-র নিয়ম দাঁড়ায়: \(-2\log\Lambda\) যথেষ্ট বড় হলে \(H_0\) বাতিল।
২.২ Wilks' theorem — LRT-র সর্বজনীন nul-বণ্টন¶
একটা গুরুতর সমস্যা এখনও বাকি: "\(-2\log\Lambda\) যথেষ্ট বড়" — কিন্তু কত বড়? সিদ্ধান্ত নিতে হলে আমাদের জানতে হবে, \(H_0\) সত্য হলে \(-2\log\Lambda\) কেমন মান নেয় (তার null distribution) — তবেই বলতে পারব কোন মান "অস্বাভাবিক বড়"। এখানেই এই অধ্যায়ের সবচেয়ে শক্তিশালী ফল।
Wilks' theorem (উইল্কসের উপপাদ্য — statement)। কিছু নিয়মিততা-শর্তে (regularity conditions), যদি \(H_0:\theta\in\Theta_0\) সত্য হয়, তবে নমুনা-আকার \(n\to\infty\) হলে
প্রতিটি প্রতীক খুলি:
- \(\xrightarrow{d}\) — "converges in distribution" (3.4); বাঁ পাশের statistic-এর বণ্টন \(n\) বাড়লে ডান পাশের বণ্টনে গুটিয়ে যায়।
- \(\chi^2_k\) ("কাই-স্কোয়ার", \(k\) degrees of freedom) — chi-square বণ্টন (3.5); মনে রাখুন, \(k\)টা স্বাধীন standard normal-এর বর্গের যোগফল \(\sum_{j=1}^k Z_j^2\) ঠিক \(\chi^2_k\) বণ্টন মানে। এটা ধনাত্মক, ডান দিকে লেজ-টানা, আর তার গড় ঠিক \(k\)।
- \(k\) — degrees of freedom, যা গোনে: \(H_0\) মোট কতগুলো parameter "বেঁধে দেয়", অর্থাৎ $$ k \;=\; (\text{পূর্ণ মডেলে স্বাধীন parameter সংখ্যা}) - (H_0\text{-র অধীনে স্বাধীন parameter সংখ্যা}) \;=\; \dim(\Theta)-\dim(\Theta_0). $$ সরল ক্ষেত্রে \(H_0:\theta=\theta_0\) একটামাত্র parameter বাঁধে, তাই \(k=1\)।
কেন এটা এত গুরুত্বপূর্ণ: লক্ষ করুন nul-বণ্টন \(\chi^2_k\) মডেলের বিস্তারিত-এর উপর নির্ভর করে না — Normal হোক, Poisson হোক, যা-ই হোক, কেবল df \(k\) জানলেই সীমা-বণ্টন এক। তাই LRT হয়ে ওঠে সর্বজনীন: যেকোনো মডেলে \(-2\log\Lambda\) গণনা করো, \(\chi^2_k\)-ছক থেকে সংকট-মান (বা p-value) নাও, সিদ্ধান্ত দাও। এই "এক ছাঁচ, সব মডেল" ব্যাপারটাই Wilks' theorem-কে inference-এর স্তম্ভ করে তোলে।
সিদ্ধান্তের নিয়ম। significance level \(\alpha\)-তে: \(-2\log\Lambda > \chi^2_{k,\alpha}\) হলে \(H_0\) বাতিল, যেখানে \(\chi^2_{k,\alpha}\) হলো \(\chi^2_k\) বণ্টনের upper-\(\alpha\) সংকট-মান (\(P(\chi^2_k>\chi^2_{k,\alpha})=\alpha\))। সমতুল্যভাবে \(\text{p-value}=P(\chi^2_k > -2\log\Lambda_{\text{obs}})\)।
(§৬-এর চিত্র 4-8-wilks দেখাবে কীভাবে অনেক নমুনার \(-2\log\Lambda\)-র histogram \(\chi^2_k\) বক্ররেখায় বসে যায়, আর ডান-লেজের \(\alpha\)-অঞ্চলটাই rejection region।)
২.৩ Wald test — MLE সত্য থেকে কত SE দূরে¶
দ্বিতীয় পরিমাপ — §১.২-এর "অনুভূমিক দূরত্ব"। ধারণা সরল: যদি \(\hat\theta\) (চূড়ার অবস্থান) \(\theta_0\) থেকে অনেক দূরে, তবে \(H_0:\theta=\theta_0\) সম্ভবত মিথ্যা। কিন্তু "অনেক দূরে" আপেক্ষিক — তাই দূরত্বটা estimator-এর নিজের ওঠানামার মাপ, অর্থাৎ standard error দিয়ে স্কেল করি।
সংজ্ঞা (Wald statistic)। \(H_0:\theta=\theta_0\)-র জন্য Wald statistic:
প্রতিটি প্রতীক খুলি:
- \(\hat\theta\) — MLE (চূড়ার অবস্থান)।
- \(\hat\theta-\theta_0\) — MLE \(H_0\)-র দাবি-মান থেকে কত দূরে (কাঁচা অনুভূমিক দূরত্ব)।
- \(\widehat{\mathrm{Var}}(\hat\theta)\) — \(\hat\theta\)-র আনুমানিক variance। 4.5 থেকে MLE asymptotically \(\mathcal{N}\big(\theta,\,1/(nI(\theta))\big)\), তাই \(\widehat{\mathrm{Var}}(\hat\theta)=\dfrac{1}{n\,I(\hat\theta)}\) (অজানা \(\theta\)-র জায়গায় \(\hat\theta\) বসানো \(I\))। আর \(\mathrm{SE}(\hat\theta)=\sqrt{\widehat{\mathrm{Var}}(\hat\theta)}=1/\sqrt{n I(\hat\theta)}\) — সেই পরিচিত standard error।
- ভাগ করার ফলে \(W\) একক-হীন — "MLE কত-গুণ-SE দূরে"-র বর্গ।
null বণ্টন ও স্বজ্ঞা। \(H_0\) সত্য হলে (4.5-এর asymptotic normality থেকে) \(Z_W=(\hat\theta-\theta_0)/\mathrm{SE}\xrightarrow{d}\mathcal{N}(0,1)\), তাই তার বর্গ \(W=Z_W^2\xrightarrow{d}\chi^2_1\)। অর্থাৎ এক-parameter Wald test-ও বড় নমুনায় \(\chi^2_1\) (বা সমতুল্যভাবে standard normal) ব্যবহার করে — ঠিক LRT-র df=1 ক্ষেত্রের মতো। স্বজ্ঞা: \(\hat\theta\) যদি \(\theta_0\) থেকে \(2\)-৩টা SE-র বেশি দূরে হয়, \(W\) বড় হয়, \(H_0\) বাতিল।
মনে রাখুন: Wald test-এর সবচেয়ে বড় ব্যবহারিক সুবিধা — এতে \(\theta_0\)-তে আলাদা করে কিছু সর্বোচ্চ করতে হয় না; কেবল MLE আর তার SE হাতে থাকলেই হলো। তাই অধিকাংশ পরিসংখ্যান-software রিপোর্টে "estimate ± SE" আর তার p-value আসলে Wald test-এর ফল। (একটা সতর্কতা §৪-এ আসবে: \(\hat\theta\) সীমার কাছে হলে Wald-এর SE আনুমানিকতা দুর্বল হতে পারে।)
২.৪ Score (Rao) test — MLE-তে না গিয়ে \(H_0\)-তে ঢাল¶
তৃতীয় পরিমাপ — §১.২-এর "\(\theta_0\)-বিন্দুতে ঢাল"। এর চমৎকারিতা: এতে MLE হিসাব করতেই হয় না। মূল স্বজ্ঞা পাহাড়-ছবি থেকে সরাসরি: চূড়ায় ঢাল (score) শূন্য। তাই \(\theta_0\)-তে যদি ঢাল শূন্যের কাছে হয়, \(\theta_0\) চূড়ার কাছেই (\(H_0\) ঠিক); আর ঢাল যদি খাড়া হয় (ধনাত্মক বা ঋণাত্মক, মানে চূড়া অন্যদিকে অনেক দূরে), তবে \(\theta_0\) চূড়া থেকে দূরে (\(H_0\) সন্দেহজনক)।
সংজ্ঞা (Score / Rao statistic)। \(H_0:\theta=\theta_0\)-র জন্য score statistic:
প্রতিটি প্রতীক খুলি:
- \(\ell'(\theta_0)=\partial_\theta\ell(\theta)\big\rvert_{\theta=\theta_0}\) — score, অর্থাৎ log-likelihood-এর ঢাল, কিন্তু \(\theta_0\)-বিন্দুতে মাপা (MLE-তে নয়!)। এই ঢাল মাপতে শুধু \(\theta_0\) জানলেই হয় — পূর্ণ optimization লাগে না।
- \([\ell'(\theta_0)]^2\) — ঢালের বর্গ (চিহ্ন মুছে কেবল মাত্রা; ঢাল ধনাত্মক হোক বা ঋণাত্মক, খাড়া মানেই \(H_0\)-র বিরুদ্ধে প্রমাণ)।
- \(n\,I(\theta_0)\) — পুরো নমুনার Fisher information, কিন্তু \(\theta_0\)-তে মাপা (\(I(\theta_0)\) এক observation-এর Fisher information, 4.5)। এটা score-এর variance-এর মাপ — তাই ঢালটাকে এর দিয়ে ভাগ করে আমরা "score কত-গুণ-তার-স্বাভাবিক-ওঠানামা দূরে"-তে রূপ দিই।
null বণ্টন ও স্বজ্ঞা। 4.5-এর একটা মৌলিক ধর্ম: \(H_0\) সত্য হলে score \(\ell'(\theta_0)\)-র গড় \(0\) আর variance \(nI(\theta_0)\), এবং বড় নমুনায় এটি প্রায় Normal — \(\ell'(\theta_0)\xrightarrow{d}\mathcal{N}(0,\,nI(\theta_0))\)। তাই standardize করা ঢালের বর্গ \(U=\dfrac{[\ell'(\theta_0)]^2}{nI(\theta_0)}\xrightarrow{d}\chi^2_1\)। আবারও সেই একই \(\chi^2_1\) সীমা।
মনে রাখুন: score test-এর হিসাব পুরোটাই \(\theta_0\)-তে (\(\ell'(\theta_0)\) আর \(I(\theta_0)\)) — MLE \(\hat\theta\) কোথাও লাগে না। তাই যখন \(H_0\)-র অধীনে সব কিছু সরল কিন্তু পূর্ণ MLE বের করা কঠিন/অসম্ভব, তখন score test সবচেয়ে সহজ যন্ত্র। (পরে দেখা যাবে, বিখ্যাত Pearson \(\chi^2\) goodness-of-fit আসলে multinomial মডেলের একটা score-জাতীয় test।)
২.৫ তিন test এক ছবিতে — geometric intuition ও asymptotic equivalence¶
এবার তিনটিকে পাশাপাশি রেখে §১.২-এর পাহাড়-ছবিটা পূর্ণ করি। তিনটিই একই log-likelihood পাহাড়ের তিন বৈশিষ্ট্য, একই \(\theta_0\)-বিন্দুতে:
| test | পাহাড়ের কোন বৈশিষ্ট্য মাপে | কী লাগে | statistic | null বণ্টন (df=1) |
|---|---|---|---|---|
| LRT | চূড়া ও \(\theta_0\)-র উচ্চতার ফারাক (উল্লম্ব) | দুই জায়গায় \(\sup\ell\) | \(-2\log\Lambda=2[\ell(\hat\theta)-\ell(\theta_0)]\) | \(\chi^2_1\) |
| Wald | চূড়ার অবস্থান \(\hat\theta\) কত দূরে (অনুভূমিক) | MLE \(\hat\theta\) ও তার SE | \(W=(\hat\theta-\theta_0)^2/\widehat{\mathrm{Var}}\) | \(\chi^2_1\) |
| Score | \(\theta_0\)-বিন্দুতে ঢাল কত খাড়া | \(\theta_0\)-তে \(\ell'\) ও \(I\) | \(U=[\ell'(\theta_0)]^2/(nI(\theta_0))\) | \(\chi^2_1\) |
Asymptotic equivalence (বড় নমুনায় তিনটি প্রায় সমান)। কেন তিনটির null বণ্টন একই \(\chi^2_1\) (বা সাধারণভাবে \(\chi^2_k\))? কারণ বড় নমুনায় log-likelihood পাহাড়টা চূড়ার কাছে প্রায় একটা উল্টানো প্যারাবোলা (quadratic) হয়ে যায় (Taylor-প্রসারণ, যা §৪-এ খোলা হবে)। একটা প্যারাবোলার ক্ষেত্রে — তিনটে পরিমাপ গাণিতিকভাবে একই তথ্য বহন করে:
- উচ্চতার ফারাক (LRT), অনুভূমিক দূরত্ব² × বক্রতা (Wald), আর ঢাল² ÷ বক্রতা (score) — একটা প্যারাবোলায় এই তিনটি সমান হয়ে যায় (parabola-র জ্যামিতি)।
তাই \(\theta_0\) যদি \(\hat\theta\)-র কাছাকাছি হয় (যা \(H_0\) সত্য হলে বড় নমুনায় ঘটে), তিনটি statistic একে অপরের প্রায় সমান এবং একই \(\chi^2\) সিদ্ধান্ত দেয় — এটাই asymptotic equivalence। ছোট নমুনায় বা \(\theta_0\) চূড়া থেকে দূরে হলে এরা একটু আলাদা হতে পারে (তখন কোনটা বাছবেন তা হিসাবের সুবিধা ও §৪-এর সূক্ষ্মতা মতে)।
এক বাক্যে: বড় নমুনায় likelihood-পাহাড় চূড়ার কাছে প্যারাবোলা হয়ে যায়, আর প্যারাবোলায় "উচ্চতার ফারাক" (LRT), "অনুভূমিক দূরত্ব" (Wald), ও "\(\theta_0\)-তে ঢাল" (score) একই কথা বলে — তাই তিন test একই \(\chi^2\)-সিদ্ধান্তে মেলে। (§৬-এর চিত্র
4-8-test-equivalenceএই তিন পরিমাপ একই প্যারাবোলায় কীভাবে মেলে তা দেখাবে।)
২.৬ Pearson's chi-square goodness-of-fit ও test of independence¶
এবার §১.৪-এর দ্বিতীয় সুতো — মডেলের আকৃতি যাচাই। ধরা যাক data কয়েকটা শ্রেণিতে (category) পড়ে — যেমন ছক্কার ৬টা মুখ, বা চোখের রঙের কয়েকটা ভাগ। প্রতিটি শ্রেণিতে কতগুলো পর্যবেক্ষণ পড়ল তা গুনি।
সংজ্ঞা (Observed ও expected counts)। ধরুন \(c\)টা শ্রেণি (\(i=1,\dots,c\)), মোট \(n\)টা পর্যবেক্ষণ।
- \(O_i\) — observed count (পর্যবেক্ষিত গণনা): \(i\)-তম শ্রেণিতে আসলে যতগুলো পড়ল। (যোগফল \(\sum_i O_i=n\)।)
- \(E_i\) — expected count (প্রত্যাশিত গণনা): \(H_0\) সত্য হলে \(i\)-তম শ্রেণিতে গড়ে যতগুলো পড়ার কথা, অর্থাৎ \(E_i = n\,p_i^{(0)}\), যেখানে \(p_i^{(0)}\) হলো \(H_0\)-র দাবি-অনুযায়ী \(i\)-শ্রেণিতে পড়ার সম্ভাবনা। (যেমন ন্যায্য ছক্কায় প্রতিটি মুখের \(p_i^{(0)}=1/6\)।)
সংজ্ঞা (Pearson's chi-square statistic — goodness-of-fit)।
প্রতিটি অংশ খুলি:
- \((O_i-E_i)\) — \(i\)-শ্রেণিতে পর্যবেক্ষণ আর প্রত্যাশার ফারাক (residual)।
- \((O_i-E_i)^2\) — বর্গ (চিহ্ন মুছে, বড় বিচ্যুতিকে বেশি ওজন)।
- ভাজক \(E_i\) — প্রত্যাশিত গণনা দিয়ে ভাগ একটা normalization: একই কাঁচা ফারাক বড় \(E_i\)-র শ্রেণিতে কম তাৎপর্যপূর্ণ, ছোট \(E_i\)-তে বেশি। (গভীর কারণ: প্রতিটি count আনুমানিকভাবে Poisson/Binomial, যার variance \(\approx E_i\); তাই \((O_i-E_i)/\sqrt{E_i}\) একটা standardize-করা বিচ্যুতি, আর তার বর্গের যোগই \(X^2\) — §৪-এ খোলা হবে কেন এতে \(\chi^2\) আসে।)
null বণ্টন ও df। \(H_0\) সত্য হলে বড় নমুনায় \(X^2\xrightarrow{d}\chi^2_{\mathrm{df}}\), যেখানে df গোনার নিয়ম:
- কেন "\(-1\)": \(c\)টা গণনা স্বাধীন নয় — তাদের যোগ স্থির (\(\sum O_i=n\)), তাই একটা স্বাধীনতা হারায়।
- কেন "\(-\) অনুমিত parameter সংখ্যা": যদি \(H_0\)-র সম্ভাবনাগুলো (\(p_i^{(0)}\)) সম্পূর্ণ নির্দিষ্ট থাকে (যেমন ন্যায্য ছক্কা, কোনো parameter অনুমান করতে হয় না), তবে এই পদ \(0\); কিন্তু যদি \(E_i\) গণনায় data থেকে কোনো parameter অনুমান করতে হয় (যেমন একটা Poisson rate fit করা), প্রতিটি অনুমিত parameter আরেকটা df কাড়ে। (সরল \(c\)-মুখ ছক্কায় কোনো parameter অনুমান নেই, তাই \(\mathrm{df}=c-1\)।)
Test of independence (contingency table)। এবার দুটো categorical চলক একসাথে — যেমন (চোখের রঙ) × (হাতের-দিক)। data সাজাই একটা contingency table (আনুষঙ্গিকতা-সারণি)-তে, \(r\)টা সারি ও \(c\)টা কলাম। \(H_0\): দুই চলক স্বাধীন (independent)। স্বাধীনতা ধরলে কোষ-\((i,j)\)-র প্রত্যাশিত গণনা:
(স্বজ্ঞা: স্বাধীন হলে \(P(\text{সারি } i,\ \text{কলাম } j)=P(\text{সারি } i)\,P(\text{কলাম } j)\), আর প্রতিটি প্রান্তিক সম্ভাবনা অনুমান করি তার মোট ÷ \(n\) দিয়ে; গুণ করে \(n\) দিয়ে গুণলে উপরের সূত্র।) তারপর একই Pearson রাশি:
df এখানে \((r-1)(c-1)\) — কারণ সারি-মোট ও কলাম-মোট স্থির রাখলে স্বাধীনভাবে বসানো যায় এমন কোষের সংখ্যা ঠিক \((r-1)(c-1)\) (বাকি কোষ মোট থেকে নির্ধারিত)।
এক বাক্যে §২-এর সার। likelihood-পাহাড়ের তিন বৈশিষ্ট্য তিনটি general test দেয় — LRT (উচ্চতার ফারাক, \(-2\log\Lambda\)), Wald (চূড়ার দূরত্ব, SE-তে মাপা), score (Wald\(/\)LRT-র বিকল্প, \(\theta_0\)-তে ঢাল); তিনটিরই null বণ্টন \(\chi^2_k\) (Wilks' theorem ও asymptotic equivalence), df = \(H_0\) যত parameter বাঁধে। আর likelihood-চিন্তারই সরাসরি ফল Pearson \(\chi^2\) (\(\sum(O-E)^2/E\)) মডেলের আকৃতি যাচাই করে — goodness-of-fit (\(\mathrm{df}=c-1-\#\)অনুমিত) ও independence (\(\mathrm{df}=(r-1)(c-1)\))।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর প্রতিটি যন্ত্র এবার সংখ্যায় হাতে-কলমে চালাব। চারটি উদাহরণ চারটি কেন্দ্রীয় যন্ত্র ধরে: E1 LRT, E2 Wald test, E3 score test, E4 Pearson \(\chi^2\) — goodness-of-fit (ছক্কা) ও independence (contingency)। সর্বত্র \(\bar X=\frac1n\sum_{i=1}^n X_i\) মানে sample mean।
প্রথম তিনটি উদাহরণ (E1–E3) ইচ্ছাকৃতভাবে একই পরিস্থিতি — Binomial/Bernoulli-র \(p\) পরীক্ষা — তিন যন্ত্রে চালায়, যাতে আপনি §২.৫-এর asymptotic equivalence নিজের চোখে সংখ্যায় মিলিয়ে দেখতে পারেন।
৩.১ E1 — Likelihood Ratio Test: একটা মুদ্রা/ছক্কা কি ন্যায্য?¶
এই উদাহরণ §২.১–২.২-এর LRT ও Wilks' theorem সরাসরি সংখ্যায় প্রয়োগ করে।
পরিস্থিতি। একটা মুদ্রা \(n=100\) বার ছুঁড়ে \(X=60\)টা head পাওয়া গেল। প্রতিটি toss Bernoulli\((p)\) (\(1\) = head), মোট head \(X=\sum X_i\sim\text{Binomial}(n,p)\)। পরীক্ষা: \(H_0:p=p_0=0.5\) (ন্যায্য) বনাম \(H_1:p\neq 0.5\)।
ধাপ ১ — দুই likelihood সর্বোচ্চ। Binomial log-likelihood (\(\theta\)-নির্ভর অংশ): \(\ell(p)=X\log p+(n-X)\log(1-p)\) (ধ্রুবক \(\binom{n}{X}\) বাদ, যেহেতু \(p\)-নিরপেক্ষ)।
- হর (পুরো \(\Theta\)-তে সর্বোচ্চ): MLE \(\hat p=X/n=60/100=0.6\)। তাই $$ \ell(\hat p)=60\log 0.6+40\log 0.4 = 60(-0.5108)+40(-0.9163) = -30.65 - 36.65 = -67.30 . $$
- লব (\(\Theta_0=\{0.5\}\)-তে): $$ \ell(p_0)=60\log 0.5+40\log 0.5 = 100\log 0.5 = 100(-0.6931) = -69.31 . $$
ধাপ ২ — \(-2\log\Lambda\)। §২.১-এর রূপে:
ধাপ ৩ — Wilks দিয়ে সিদ্ধান্ত। \(H_0\) একটামাত্র parameter বাঁধে, তাই df \(k=1\); Wilks' theorem মতে null-এ \(-2\log\Lambda\approx\chi^2_1\)। সংকট-মান \(\chi^2_{1,\,0.05}=3.84\)। যেহেতু \(4.02 > 3.84\), আমরা \(H_0\) বাতিল করি (\(\alpha=0.05\)-এ) — data ন্যায্যতার বিরুদ্ধে যথেষ্ট প্রমাণ দেয়। (p-value \(=P(\chi^2_1>4.02)\approx 0.045\), যা \(0.05\)-এর সামান্য নিচে।)
ব্যাখ্যা। "ন্যায্য-মুদ্রা (\(p=0.5\)) মডেলে data-র সর্বোচ্চ সম্ভাব্যতা, পূর্ণ মডেলের (\(\hat p=0.6\)) সর্বোচ্চ সম্ভাব্যতার তুলনায় যথেষ্ট কম — এতটাই যে \(-2\log\Lambda\) একটা \(\chi^2_1\) থেকে আসা মানের জন্য অস্বাভাবিক বড়।" তাই ন্যায্যতার ধারণা বাতিল।
৩.২ E2 — Wald Test: একই মুদ্রা, MLE কত SE দূরে?¶
এবার §২.৩-এর Wald test — একই data (\(n=100,\ X=60,\ H_0:p_0=0.5\)), যাতে LRT-র সঙ্গে তুলনা করা যায়।
ধাপ ১ — MLE ও তার SE। MLE \(\hat p=0.6\)। Bernoulli-র Fisher information \(I(p)=\dfrac{1}{p(1-p)}\) (4.5-এর E1), তাই MLE-তে আনুমানিক variance:
আর \(\mathrm{SE}(\hat p)=\sqrt{0.0024}\approx 0.0490\)।
ধাপ ২ — Wald statistic। §২.৩-এর সূত্রে:
ধাপ ৩ — সিদ্ধান্ত। \(W\approx 4.17\xrightarrow{d}\chi^2_1\); সংকট-মান \(3.84\)। \(4.17>3.84\), তাই \(H_0\) বাতিল। (সমতুল্যভাবে \(\lvert Z_W\rvert = 2.04 > 1.96=z_{0.025}\); p-value \(\approx 0.041\)।)
LRT-র সঙ্গে তুলনা (asymptotic equivalence সংখ্যায়)। লক্ষ করুন — LRT দিল \(-2\log\Lambda=4.02\), Wald দিল \(W=4.17\)। দুটো প্রায় সমান (দুটোই \(\chi^2_1\), একই "বাতিল" সিদ্ধান্ত), কিন্তু হুবহু এক নয় — ঠিক §২.৫ যা বলেছিল: বড় নমুনায় কাছাকাছি, কিন্তু সসীম \(n\)-এ সামান্য ভিন্ন। (এখানে Wald-এর variance MLE \(\hat p=0.6\)-তে মাপা; পরের score test \(p_0=0.5\)-তে মাপবে — সেটাই মূল পার্থক্য।)
৩.৩ E3 — Score (Rao) Test: MLE-তে না গিয়ে \(H_0\)-তে ঢাল¶
এবার §২.৪-এর score test — আবার একই data, কিন্তু এবার আমরা MLE ব্যবহারই করব না; সব হিসাব \(p_0=0.5\)-তে।
ধাপ ১ — \(p_0\)-তে score। Bernoulli/Binomial-এ score \(\ell'(p)=\dfrac{X}{p}-\dfrac{n-X}{1-p}\)। \(p_0=0.5\)-তে বসাই:
(লক্ষণীয়: \(\ell'(p_0)\neq 0\), অর্থাৎ \(p_0=0.5\)-এ পাহাড়ের ঢাল শূন্য নয় — চূড়া অন্যত্র; এটাই \(H_0\)-র বিরুদ্ধে ইঙ্গিত।)
ধাপ ২ — \(p_0\)-তে Fisher information ও statistic। \(n\,I(p_0)=\dfrac{n}{p_0(1-p_0)}=\dfrac{100}{0.5\times 0.5}=\dfrac{100}{0.25}=400\)। তাই score statistic:
ধাপ ৩ — সিদ্ধান্ত। \(U=4.0\xrightarrow{d}\chi^2_1\); সংকট-মান \(3.84\)। \(4.0>3.84\), তাই \(H_0\) বাতিল। (p-value \(\approx 0.046\)।)
তিন test পাশাপাশি (asymptotic equivalence-এর চূড়ান্ত মিল)। একই data (\(n=100,\ X=60\)), একই \(H_0:p=0.5\) — তিন যন্ত্রের ফল:
| test | statistic | মান | সংকট-মান (\(\chi^2_{1,0.05}\)) | সিদ্ধান্ত |
|---|---|---|---|---|
| LRT (E1) | \(-2\log\Lambda\) | \(4.02\) | \(3.84\) | বাতিল |
| Wald (E2) | \(W\) | \(4.17\) | \(3.84\) | বাতিল |
| Score (E3) | \(U\) | \(4.00\) | \(3.84\) | বাতিল |
তিনটিই \(\approx 4\), একই সিদ্ধান্ত — §২.৫-এর asymptotic equivalence-এর জীবন্ত উদাহরণ। (পার্থক্য কেবল কোথায় variance মাপা: Wald \(\hat p\)-তে, score \(p_0\)-তে, LRT উচ্চতার ফারাকে — তাই সামান্য আলাদা সংখ্যা, কিন্তু একই গল্প।)
৩.৪ E4 — Pearson's chi-square: ছক্কা ন্যায্য কি না, ও দুই চলক স্বাধীন কি না¶
শেষ উদাহরণ §২.৬-এর দুই Pearson \(\chi^2\) — প্রথমে goodness-of-fit (এক চলক), পরে independence (দুই চলক)।
অংশ ক — Goodness-of-fit: ছক্কা ন্যায্য কি? একটা ছক্কা \(n=120\) বার গড়িয়ে প্রতিটি মুখ যতবার এল:
| মুখ (\(i\)) | 1 | 2 | 3 | 4 | 5 | 6 | মোট |
|---|---|---|---|---|---|---|---|
| \(O_i\) (observed) | 16 | 18 | 25 | 17 | 22 | 22 | 120 |
| \(E_i\) (expected) | 20 | 20 | 20 | 20 | 20 | 20 | 120 |
\(H_0\): ছক্কা ন্যায্য, প্রতিটি মুখের \(p_i^{(0)}=1/6\), তাই \(E_i=n p_i^{(0)}=120\times\frac16=20\) (সব শ্রেণিতে সমান)। Pearson statistic:
লব গুনি: \((-4)^2+(-2)^2+5^2+(-3)^2+2^2+2^2 = 16+4+25+9+4+4 = 62\)। তাই
df ও সিদ্ধান্ত। কোনো parameter অনুমান করতে হয়নি (\(p_i^{(0)}\) সম্পূর্ণ নির্দিষ্ট), তাই \(\mathrm{df}=c-1=6-1=5\)। সংকট-মান \(\chi^2_{5,\,0.05}=11.07\)। যেহেতু \(3.1 < 11.07\), আমরা \(H_0\) বাতিল করি না — এই data ছক্কা-অন্যায্যতার পক্ষে যথেষ্ট প্রমাণ দেয় না (এই পরিমাণ বিচ্যুতি একটা ন্যায্য ছক্কাতেও স্বাভাবিক)। (p-value \(=P(\chi^2_5>3.1)\approx 0.68\) — মোটেও ছোট নয়।)
অংশ খ — Independence: চিকিৎসা ও আরোগ্য কি স্বাধীন? \(n=200\) রোগীকে দুই দলে (ওষুধ / placebo) ভাগ করে ফল (সুস্থ / অসুস্থ) লিপিবদ্ধ — একটা \(2\times 2\) contingency table:
| সুস্থ | অসুস্থ | সারি-মোট | |
|---|---|---|---|
| ওষুধ | \(O_{11}=50\) | \(O_{12}=30\) | \(80\) |
| placebo | \(O_{21}=40\) | \(O_{22}=80\) | \(120\) |
| কলাম-মোট | \(90\) | \(110\) | \(n=200\) |
\(H_0\): চিকিৎসা ও ফল স্বাধীন। §২.৬-এর সূত্রে প্রতিটি \(E_{ij}=\dfrac{(\text{সারি-মোট})(\text{কলাম-মোট})}{n}\):
Pearson statistic:
প্রতিটি পদ (লক্ষ করুন প্রতিটি লব \(14^2=196\), যেহেতু \(2\times2\)-তে চারটি residual সমান-মাপের):
df ও সিদ্ধান্ত। \(r=2,\ c=2\), তাই \(\mathrm{df}=(r-1)(c-1)=1\times 1=1\)। সংকট-মান \(\chi^2_{1,\,0.05}=3.84\)। যেহেতু \(16.50 \gg 3.84\), আমরা \(H_0\) জোরালোভাবে বাতিল করি — চিকিৎসা ও ফল স্বাধীন নয়; ওষুধের সঙ্গে সুস্থ-হওয়ার একটা স্পষ্ট সম্পর্ক আছে। (p-value \(\approx 0.00005\) — অত্যন্ত ছোট।)
§৩-এর সার: E1–E3 দেখাল কীভাবে একই \(H_0:p=0.5\) তিন যন্ত্রে — LRT (উচ্চতার ফারাক, \(-2\log\Lambda=4.02\)), Wald (চূড়ার দূরত্ব, \(W=4.17\)), score (\(\theta_0\)-তে ঢাল, \(U=4.00\)) — পরীক্ষা করা যায়, আর তিনটি প্রায় একই মানে (≈4) মিলে একই \(\chi^2_1\)-সিদ্ধান্ত দেয় (asymptotic equivalence)। E4 দেখাল Pearson \(\chi^2=\sum(O-E)^2/E\) কীভাবে মডেল-আকৃতি যাচাই করে — ছক্কার ন্যায্যতা (goodness-of-fit, df \(=c-1=5\), বাতিল হয় না) ও দুই চলকের স্বাধীনতা (independence, df \(=(r-1)(c-1)=1\), জোরালোভাবে বাতিল)। সর্বত্র এক সুর: একটা statistic গণনা করো, তার \(\chi^2\) null-বণ্টন থেকে সংকট-মান নাও, সিদ্ধান্ত দাও।
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা এই অধ্যায়ের কেন্দ্রীয় তিনটে test — likelihood ratio test (LRT), Wald test, ও score test (Rao test) — এবং Pearson-এর \(\chi^2\) goodness-of-fit (GOF) ও independence test-এর সংজ্ঞা ও স্বজ্ঞা পেয়েছি। এবার এই অংশে scratch থেকে সেই test-গুলোর পেছনের ফলগুলো উৎপাদন করব — কোথা থেকে \(-2\log\Lambda\) আসে আর কেন তা \(\chi^2_k\) হয় (Wilks), Wald ও score statistic কীভাবে MLE-র asymptotic normality (4.5) থেকে স্বাভাবিকভাবে গজায়, কেন তিনটে test বড় নমুনায় একই, আর Pearson-এর \(\chi^2\) আসলে LRT-রই একটা approximation। কোনো ধাপ লুকানো হবে না; প্রতিটি সমান-চিহ্নের পেছনে বাংলায় কারণ থাকবে। কাজটা পাঁচটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে, sketch দিই):
- (a) LRT-এর নির্মাণ (\(\Lambda=\frac{\sup_{\Theta_0}L}{\sup_\Theta L}\), \(-2\log\Lambda\)) আর Wilks-এর উপপাদ্য — কেন \(H_0\)-র অধীনে \(-2\log\Lambda\xrightarrow{d}\chi^2_k\) (df = restriction-সংখ্যা), log-likelihood-এর MLE-র চারপাশে দ্বিতীয়-ক্রম Taylor expansion থেকে অন্তর্দৃষ্টি। ★★★
- (b) Wald statistic — MLE-র asymptotic normality (4.5) থেকে: \(W=\dfrac{(\hat\theta-\theta_0)^2}{1/(nI)}\xrightarrow{d}\chi^2_1\)। ★★
- (c) Score (Rao) test — সত্য মানে score-এর asymptotic normality থেকে, কোনো MLE না খুঁজেই \(H_0\)-তে। ★★
- (d) তিনটে test (LRT, Wald, score) asymptotically সমতুল্য — তিনটেই একই quadratic approximation-এর তিন মুখ। ★★
- (e) Pearson-এর \(\chi^2=\sum_i (O_i-E_i)^2/E_i\) — multinomial likelihood থেকে LRT-র approximation হিসেবে, আর df-এর নিয়ম (GOF বনাম independence)। ★★
পুরোটা জুড়ে চারটে running example ব্যবহার করব: E1 LRT (Normal mean, \(\sigma\) জানা), E2 Wald, E3 score, আর E4 Pearson \(\chi^2\) GOF + independence।
একটা সাধারণ পরিভাষা আগে স্থির করি, কারণ পুরো §৪ এর ওপর দাঁড়িয়ে। আমাদের কাছে \(n\)টি i.i.d. পর্যবেক্ষণ \(X_1,\dots,X_n\), প্রতিটির density/pmf \(f(x;\theta)\), আর parameter \(\theta\) একটা প্যারামিটার-জগৎ \(\Theta\)-তে থাকে। দুটো hypothesis:
- null \(H_0:\theta\in\Theta_0\) — একটা ছোট (restricted) উপ-জগৎ \(\Theta_0\subset\Theta\) (যেমন \(\Theta_0=\{\theta_0\}\), একটিমাত্র বিন্দু);
- alternative \(H_1:\theta\in\Theta\setminus\Theta_0\) — বাকিটা।
আর likelihood ও log-likelihood (4.3 থেকে): $$ L(\theta)=\prod_{i=1}^n f(X_i;\theta),\qquad \ell(\theta)=\log L(\theta)=\sum_{i=1}^n \log f(X_i;\theta). $$ এখানে \(\sup_{\Theta_0}L\) মানে "\(\Theta_0\)-র ভেতরে \(L\)-কে যতটা বড় করা যায়" (অর্থাৎ restricted MLE-তে likelihood-এর মান), আর \(\sup_\Theta L\) মানে "পুরো \(\Theta\)-জুড়ে \(L\)-এর সর্বোচ্চ" (unrestricted MLE-তে)।
এক নজরে যা মনে রাখবেন। এই গোটা অংশের প্রাণ একটাই বস্তু — log-likelihood-এর চূড়ার আকার (4.5-এর Fisher information যা মাপে)। তিনটে test আসলে একই প্রশ্ন তিন দিক থেকে জিজ্ঞেস করে: "\(\theta_0\) চূড়া থেকে কতটা দূরে?" — LRT মাপে উচ্চতার ব্যবধান (\(\theta_0\)-তে likelihood চূড়ার চেয়ে কতটা নিচে), Wald মাপে অনুভূমিক দূরত্ব (\(\hat\theta\) থেকে \(\theta_0\) কত দূর), আর score মাপে ঢাল (\(\theta_0\)-তে log-likelihood কতটা খাড়া — চূড়ায় ঢাল শূন্য বলে \(\theta_0\)-তে বড় ঢাল মানে \(\theta_0\) চূড়া থেকে দূরে)। চূড়াটা প্রায়-প্যারাবোলা (Taylor-এর দ্বিতীয় ক্রম) হওয়ায় তিন মাপ একে অপরের সাথে বাঁধা — তাই তিনটে test বড় নমুনায় একই সংখ্যা, আর সেই সংখ্যার বণ্টন \(\chi^2_k\)। মূল মন্ত্র: "তিন test = একই প্যারাবোলিক চূড়ার উচ্চতা/দূরত্ব/ঢাল; df = কতগুলো parameter \(H_0\) আটকে রাখে।"
৪.১ · (a) LRT-এর নির্মাণ ও Wilks-এর উপপাদ্য — ★★★¶
৪.১.১ · Likelihood ratio statistic কেন এই রূপ¶
স্বজ্ঞা থেকে শুরু (যা §১–৩-এ এসেছে)। data হাতে এলে আমরা জানতে চাই — \(H_0\) (সীমিত মডেল) কি data-কে প্রায় ততটাই ভালো ব্যাখ্যা করে যতটা পূর্ণ মডেল করে? "ভালো ব্যাখ্যা" মাপার সবচেয়ে স্বাভাবিক মাপকাঠি likelihood (4.3): যে \(\theta\)-তে likelihood বড়, সে data-কে বেশি সম্ভাব্য করে তোলে। তাই দুটো সর্বোচ্চ likelihood-এর অনুপাত নিই:
প্রতিটি অংশ খুলি:
- লব \(\sup_{\Theta_0}L\) — \(H_0\) মানলে likelihood সর্বোচ্চ যতটা হতে পারে (restricted MLE \(\hat\theta_0\)-তে \(L\)-এর মান)।
- হর \(\sup_\Theta L\) — কোনো বাধা ছাড়াই likelihood-এর সর্বোচ্চ (unrestricted MLE \(\hat\theta\)-তে \(L\)-এর মান)।
দুটো মৌলিক ধর্ম এখনই চোখে পড়ে। প্রথমত, \(\Theta_0\subset\Theta\) হওয়ায় হরের sup লবের sup-এর চেয়ে ছোট হতে পারে না (বড় সেট-এ সর্বোচ্চ আরও বড়/সমান), তাই \(0\le\Lambda\le 1\)। দ্বিতীয়ত, \(\Lambda\) \(1\)-এর কাছে মানে — \(H_0\) মেনেও প্রায় একই likelihood পাওয়া যায়, অর্থাৎ data \(H_0\)-র সাথে মানানসই; আর \(\Lambda\) ছোট (০-র দিকে) মানে — বাধা আরোপ করলে likelihood হুড়মুড় করে পড়ে, অর্থাৎ data \(H_0\)-র বিরুদ্ধে সাক্ষ্য দিচ্ছে। তাই সিদ্ধান্ত-নিয়ম: \(\Lambda\) যথেষ্ট ছোট হলে \(H_0\) বাতিল।
৪.১.২ · কেন \(-2\log\Lambda\) — আর কেন তার বণ্টন জানা দরকার¶
\(\Lambda\) দিয়ে সরাসরি কাজ করার দুটো অসুবিধা: (i) এর বণ্টন (sampling distribution) জটিল, তাই "কত ছোট হলে যথেষ্ট ছোট" বলা কঠিন; (ii) likelihood-গুলো গুণফল, তাই log নিলে যোগফলে ভাঙে (4.3-এর মতোই সুবিধা)। তাই আমরা একটা monotone রূপান্তর নিই:
যেখানে \(\hat\theta\) unrestricted MLE আর \(\hat\theta_0\) restricted MLE (অর্থাৎ \(\ell(\hat\theta)=\log\sup_\Theta L\), \(\ell(\hat\theta_0)=\log\sup_{\Theta_0}L\))। দুটো কথা লক্ষ করুন: যেহেতু \(\Lambda\le1\), তাই \(\log\Lambda\le0\), তাই \(-2\log\Lambda\ge0\) — একটা অঋণাত্মক রাশি। আর \(\Lambda\) ছোট \(\Leftrightarrow\) \(-2\log\Lambda\) বড়; তাই সিদ্ধান্ত-নিয়ম উল্টে দাঁড়ায়: \(-2\log\Lambda\) যথেষ্ট বড় হলে \(H_0\) বাতিল। আর \(-2\log\Lambda=2[\ell(\hat\theta)-\ell(\hat\theta_0)]\) রূপটা সরাসরি বলে — এটা log-likelihood-এর চূড়ার উচ্চতা আর \(H_0\)-তে সর্বোচ্চ উচ্চতার ব্যবধান, দ্বিগুণ। (\(2\)-গুণটা কেন, তা ৪.১.৪-এ পরিষ্কার হবে — ঠিক ওই গুণকেই বণ্টন \(\chi^2\) হয়।)
এখন একমাত্র যে জিনিসটা বাকি — "যথেষ্ট বড়" মানে কী, তা ঠিক করতে হলে \(H_0\)-র অধীনে \(-2\log\Lambda\)-র বণ্টন চাই। সেটাই Wilks-এর উপপাদ্য দেয়।
৪.১.৩ · Wilks-এর উপপাদ্য (statement)¶
Wilks' Theorem. "মসৃণ" (regular) parametric মডেলে, যদি \(H_0:\theta\in\Theta_0\) সত্য হয়, তবে \(n\to\infty\)-তে $$ \boxed{\;-2\log\Lambda \;\xrightarrow{\ d\ }\; \chi^2_k\;} $$ যেখানে \(k\) = restriction-সংখ্যা = (পূর্ণ মডেলে free parameter-সংখ্যা) \(-\) (\(H_0\)-র অধীনে free parameter-সংখ্যা) = \(\dim(\Theta)-\dim(\Theta_0)\)।
এখানে \(\xrightarrow{d}\) মানে "converges in distribution" (3.4), আর \(\chi^2_k\) হলো \(k\) degrees of freedom-যুক্ত chi-square বণ্টন। df-এর নিয়মটা মনে রাখার সহজ উপায়: \(H_0\) পূর্ণ মডেলের কতগুলো স্বাধীন parameter "আটকে" (fix করে) দিচ্ছে — ঠিক ততগুলোই \(k\)।
df-এর তিনটে দৃষ্টান্ত। (১) Normal mean (E1): পূর্ণ মডেলে \(\mu\) একটাই free parameter (\(\sigma\) জানা), \(H_0:\mu=\mu_0\) সেটিকে আটকায় — তাই \(k=1-0=1\), বণ্টন \(\chi^2_1\)। (২) যদি \(\theta=(\mu_1,\mu_2)\) আর \(H_0:\mu_1=\mu_2\) (একটা সমতা-শর্ত), তাহলে \(\dim\Theta=2\), \(\dim\Theta_0=1\) — তাই \(k=1\)। (৩) Multinomial-এ \(m\)টা category (\(m-1\) free probability), GOF \(H_0\) সবগুলো ঠিক করে দিলে \(\dim\Theta_0=0\) — তাই \(k=(m-1)-0=m-1\) (E4-এ দেখব)।
লক্ষণীয় — Wilks-এর সৌন্দর্য হলো ডানপাশের বণ্টন \(\chi^2_k\) কোনো অজানা parameter-এর উপর নির্ভর করে না (শুধু \(k\)-র উপর)। তাই critical value একবার \(\chi^2_k\)-টেবিল থেকে নিলেই হয় — সত্য \(\theta\) না জেনেও। (\(\alpha\)-স্তরে test: \(-2\log\Lambda>\chi^2_{k,\,1-\alpha}\) হলে \(H_0\) বাতিল।)
৪.১.৪ · কেন \(\chi^2_k\) — দ্বিতীয়-ক্রম Taylor expansion থেকে অন্তর্দৃষ্টি (★★★)¶
পূর্ণ প্রমাণ এই পর্যায়ের বাইরে, কিন্তু মূল যন্ত্রটা চমৎকার সরল — log-likelihood-কে MLE-র চারপাশে প্যারাবোলা দিয়ে আনুমানিক করা — আর তা সরাসরি (b)/(c)-র Wald/score-এর সাথে যুক্ত। সরলতার জন্য একটা scalar parameter \(\theta\) আর \(H_0:\theta=\theta_0\) ধরি (তখন \(k=1\))।
ধাপ ১ — চূড়ার চারপাশে log-likelihood-কে Taylor expand করি। unrestricted MLE \(\hat\theta\)-তে log-likelihood-এর ঢাল শূন্য (\(\ell'(\hat\theta)=0\), কারণ ওটাই চূড়া)। তাই \(\ell(\theta)\)-কে \(\hat\theta\)-র চারপাশে দ্বিতীয় ক্রম পর্যন্ত খুলি:
মাঝের পদ বাদ পড়ল কারণ চূড়ায় ঢাল শূন্য — এটাই MLE ব্যবহারের মূল সুবিধা। ফলে চূড়ার কাছে log-likelihood একটা উল্টানো প্যারাবোলা, যার "প্রস্থ" নির্ধারণ করে curvature \(\ell''(\hat\theta)\)।
ধাপ ২ — \(H_0\)-তে (অর্থাৎ \(\theta=\theta_0\)-তে) উচ্চতার ব্যবধান। এখানে scalar \(H_0:\theta=\theta_0\) হলে restricted MLE নিজেই \(\hat\theta_0=\theta_0\) (কারণ \(\Theta_0\) একটিমাত্র বিন্দু)। উপরের approximation-এ \(\theta=\theta_0\) বসাই:
দ্বিগুণ করি (LRT-র সংজ্ঞা মতো):
(এখানেই দেখা গেল কেন সংজ্ঞায় ঠিক \(2\)-গুণ — তাতে \(\tfrac12\) কেটে গিয়ে পরিষ্কার quadratic form দাঁড়ায়।)
ধাপ ৩ — curvature-কে Fisher information দিয়ে বদলাই (4.5)। 4.5 থেকে জানি, observed curvature \(-\ell''(\hat\theta)\) বড় নমুনায় expected curvature-এ স্থির হয়: \(-\ell''(\hat\theta)\approx nI(\theta_0)\) (LLN, কারণ \(-\ell''=\sum_i(-\partial_\theta^2\log f)\) আর প্রতিটির গড় \(I(\theta_0)\))। বসাই:
ধাপ ৪ — এখানেই \(\chi^2_1\) জন্মায়। কিন্তু 4.5-এর MLE asymptotic normality ঠিক বলে যে \(\sqrt n(\hat\theta-\theta_0)\xrightarrow{d}\mathcal N(0,1/I(\theta_0))\), অর্থাৎ \(\sqrt{nI(\theta_0)}\,(\hat\theta-\theta_0)\xrightarrow{d}\mathcal N(0,1)\) — তাই \(Z_n\xrightarrow{d}\mathcal N(0,1)\)। আর একটা standard Normal-এর বর্গ হলো সংজ্ঞা-অনুসারে \(\chi^2_1\) (3.x-এ দেখা: \(Z\sim\mathcal N(0,1)\Rightarrow Z^2\sim\chi^2_1\))। তাই
এক বাক্যে কেন। log-likelihood চূড়ার কাছে প্যারাবোলা; LRT মাপে চূড়া আর \(\theta_0\)-র উচ্চতা-ব্যবধান, যা প্যারাবোলার জ্যামিতিতে হয় \((\text{curvature})\times(\hat\theta-\theta_0)^2\); curvature \(\to nI\), আর \(\sqrt{nI}(\hat\theta-\theta_0)\to\mathcal N(0,1)\) — তাই উচ্চতা-ব্যবধানের দ্বিগুণ \(\to\) এক standard-Normal-এর বর্গ \(=\chi^2_1\)। \(k\) restriction হলে একই যুক্তি \(k\) মাত্রায় চলে: \(k\)টা স্বাধীন standard-Normal-এর বর্গের যোগফল, যা সংজ্ঞা-অনুসারে \(\chi^2_k\) — তাই df ঠিক restriction-সংখ্যা। (যা skip করলাম ★★★: multi-parameter \(\hat\theta_0\ne\theta_0\) ক্ষেত্রে restricted/unrestricted MLE দুটোর যৌথ Taylor, আর Taylor-অবশিষ্ট নগণ্য দেখানো — Wasserman §10.6.)
সতর্কতা — কখন df গোনায় ভুল হয়। Wilks-এ df free parameter-এর সংখ্যার পার্থক্য, প্রতীকের সংখ্যা নয়। আর শর্তটা "interior" হতে হবে — \(\theta_0\) যদি প্যারামিটার-জগতের সীমানায় থাকে (যেমন variance \(=0\) test), Wilks ভেঙে যায় এবং বণ্টন \(\chi^2\)-এর mixture হয়; এই সূক্ষ্মতা পরের অধ্যায়/উন্নত কোর্সে।
৪.২ · (b) Wald statistic — MLE-র asymptotic normality থেকে — ★★¶
LRT-তে দুটো MLE (restricted ও unrestricted) দরকার হয়। Wald test একটা শর্টকাট: শুধু unrestricted MLE \(\hat\theta\) আর তার estimated variance দিয়ে কাজ সারে — restricted মডেল fit করার দরকারই পড়ে না।
ধাপ ১ — 4.5-এর asymptotic normality স্মরণ। 4.5-এ প্রমাণিত হয়েছিল, regular মডেলে MLE বড় নমুনায় Normal:
যেখানে \(I(\theta)\) এক-পর্যবেক্ষণের Fisher information, আর \(\frac{1}{nI(\theta)}\) হলো MLE-র asymptotic variance (= CRLB মেঝে)।
ধাপ ২ — \(H_0:\theta=\theta_0\) ধরে standardize করি। যদি \(H_0\) সত্য হয় (সত্য \(\theta=\theta_0\)), তবে উপরের statement-এ \(\theta=\theta_0\) বসিয়ে \(\hat\theta\approx\mathcal N(\theta_0,\,\frac{1}{nI(\theta_0)})\)। তাই একে standardize করলে (mean বিয়োগ, sd দিয়ে ভাগ — 2.4):
ধাপ ৩ — variance-এ plug-in, আর বর্গ করি। বাস্তবে \(I(\theta_0)\)-এর জায়গায় আমরা একটা estimate বসাই — সবচেয়ে সাধারণ পছন্দ \(\widehat{\mathrm{Var}}=\frac{1}{nI(\hat\theta)}\) (MLE-তে মূল্যায়িত Fisher info) বা observed information \(-1/\ell''(\hat\theta)\)। যেহেতু \(\hat\theta\xrightarrow{P}\theta_0\) (consistency), Slutsky (3.2) বলে এই বদল asymptotic বণ্টন নষ্ট করে না, অনুপাত এখনও \(\mathcal N(0,1)\)। এবার বর্গ করি (যাতে দুই-দিকের বিচ্যুতি এক ধনাত্মক রাশিতে আসে এবং \(\chi^2\) পাই):
কারণ ধাপ ২-৩-এ ভেতরের রাশি \(\to\mathcal N(0,1)\), আর তার বর্গ \(\to\chi^2_1\) (ঠিক ৪.১.৪-এর ধাপ ৪-এর মতো)।
স্বজ্ঞা — Wald মাপে "অনুভূমিক দূরত্ব"। \(W\) আসলে "MLE \(\hat\theta\) থেকে null-মান \(\theta_0\) কত standard-error দূরে" — তার বর্গ। \(\hat\theta\) যদি \(\theta_0\)-র কাছে (কম SE দূরত্ব) হয়, \(W\) ছোট, \(H_0\) মানানসই; অনেক দূরে হলে \(W\) বড়, \(H_0\) বাতিল। ৪.১.৪-এর ছবিতে: Wald মাপছে প্যারাবোলার অক্ষ থেকে \(\theta_0\)-র অনুভূমিক দূরত্ব, curvature দিয়ে ওজন করে।
E2 — Normal mean (\(\sigma\) জানা), সংখ্যায় (§৫ PART 1)। এখানে \(I(\mu)=1/\sigma^2\) (4.5 E2), তাই \(\widehat{\mathrm{Var}}=\frac{1}{n\cdot(1/\sigma^2)}=\sigma^2/n\) — যা \(\hat\mu=\bar X\)-এর সঠিক variance, কোনো approximation ছাড়াই। তাই $$ W=\frac{(\bar X-\mu_0)^2}{\sigma^2/n}=\frac{n(\bar X-\mu_0)^2}{\sigma^2}=\Big(\frac{\bar X-\mu_0}{\sigma/\sqrt n}\Big)^2=Z^2, $$ অর্থাৎ Wald statistic ঠিক পরিচিত \(z\)-statistic-এর বর্গ — §৫ PART 1 দেখাবে এটা LRT ও score-এর সাথে হুবহু মেলে (\(W=Z^2=4.928\))। সতর্কতা ★★: Wald variance \(\hat\theta\)-তে মূল্যায়িত (null-এ নয়), তাই \(\hat\theta\) সীমানার কাছে হলে বা মডেল reparametrize করলে Wald-এর মান বদলায় — এটাই Wald-এর পরিচিত দুর্বলতা (LRT এই সমস্যায় ভোগে না)।
৪.৩ · (c) Score (Rao) test — null-এ score-এর asymptotic normality থেকে — ★★¶
তৃতীয় test আরও বড় শর্টকাট: এটা কোনো MLE-ই খোঁজে না। শুধু null-মান \(\theta_0\)-তে log-likelihood-এর ঢাল (score) আর Fisher information দিয়ে কাজ সারে — তাই যখন restricted মডেল fit করা সহজ কিন্তু full মডেল কঠিন, score test সবচেয়ে সুবিধাজনক।
ধাপ ১ — score-এর মৌলিক ধর্ম (4.5)। এক-পর্যবেক্ষণ-score \(\partial_\theta\log f(X_i;\theta)\)-এর সত্য \(\theta\)-তে গড় শূন্য আর variance \(I(\theta)\) (4.5-এ প্রমাণিত)। মোট score \(U(\theta)=\ell'(\theta)=\sum_{i=1}^n\partial_\theta\log f(X_i;\theta)\) তাই \(n\)টা i.i.d., mean-শূন্য রাশির যোগফল, যার
ধাপ ২ — CLT প্রয়োগ, \(H_0\)-তে মূল্যায়ন। যেহেতু \(U(\theta_0)\) i.i.d. mean-শূন্য পদের যোগফল, Central Limit Theorem (3.4) অনুযায়ী \(H_0\) সত্য হলে (সত্য \(\theta=\theta_0\)):
লক্ষ করুন — এই রাশিটা পুরোপুরি \(\theta_0\)-তে গণনাযোগ্য (\(U(\theta_0)\) আর \(I(\theta_0)\) দুটোই null-মানে, কোনো MLE লাগে না)।
ধাপ ৩ — বর্গ করি। ঠিক আগের মতোই, \(\mathcal N(0,1)\)-এর বর্গ \(\chi^2_1\):
স্বজ্ঞা — score মাপে "ঢাল"। চূড়ায় (MLE-তে) log-likelihood-এর ঢাল শূন্য। তাই \(\theta_0\)-তে ঢাল \(\ell'(\theta_0)\) যত বড় (শূন্য থেকে যত দূর), \(\theta_0\) চূড়া থেকে তত দূরে — তত বেশি \(H_0\)-বিরোধী সাক্ষ্য। score statistic ঠিক এই ঢালকেই বর্গ করে, তার "স্বাভাবিক স্কেল" \(nI(\theta_0)\) দিয়ে normalize করে। ৪.১.৪-এর ছবিতে: score মাপছে প্যারাবোলার \(\theta_0\)-বিন্দুতে স্পর্শকের খাড়াই।
E3 — Normal mean (\(\sigma\) জানা), সংখ্যায় (§৫ PART 1)। \(\log f=-\frac{(x-\mu)^2}{2\sigma^2}+c\), তাই score \(\ell'(\mu)=\sum_i\frac{X_i-\mu}{\sigma^2}=\frac{n(\bar X-\mu)}{\sigma^2}\)। \(\mu_0\)-তে: \(U(\mu_0)=\frac{n(\bar X-\mu_0)}{\sigma^2}\), আর \(nI(\mu_0)=n/\sigma^2\)। তাই $$ U_{\text{score}}=\frac{\big(n(\bar X-\mu_0)/\sigma^2\big)^2}{n/\sigma^2}=\frac{n(\bar X-\mu_0)^2}{\sigma^2}=Z^2, $$ আবার সেই একই \(Z^2\)! তিনটে test এখানে হুবহু মেলে — §৫ PART 1-এ সংখ্যায় (\(U_{\text{score}}=4.928\))। এই কাকতালীয়তা Normal-known-\(\sigma\)-র বিশেষত্ব (নিচে (d)); সাধারণভাবে তিনটে সামান্য আলাদা।
৪.৪ · (d) তিন test asymptotically সমতুল্য — একই quadratic approximation — ★★¶
এবার দেখাই কেন LRT, Wald, ও score বড় নমুনায় একই সিদ্ধান্ত দেয় — তিনটেই log-likelihood-এর একই প্যারাবোলিক approximation থেকে আসে। scalar \(\theta\), \(H_0:\theta=\theta_0\) ধরি।
৪.১.৪-এর Taylor approximation-টাই কেন্দ্র। তিনটে statistic-কে সেই একই প্যারাবোলার ভাষায় লিখি — সবগুলোতে curvature \(-\ell''\approx nI\) ব্যবহার করে (\(I\) মানে \(I(\theta_0)\), আর \(\hat\theta\approx\theta_0\) বলে \(I(\hat\theta)\approx I(\theta_0)\) asymptotically):
প্রথম দুটোর সমতা সরাসরি — দুটোই \(nI\,(\hat\theta-\theta_0)^2\) (asymptotically \(I(\hat\theta)\approx I\))। তৃতীয়টা মেলানোর জন্য score-কে Taylor করি: চূড়ায় \(\ell'(\hat\theta)=0\), তাই \(\theta_0\)-তে ঢাল
এটা \(U_{\text{score}}\)-তে বসাই:
তিনটেই একই রাশি \(nI\,(\hat\theta-\theta_0)^2\)-তে গিয়ে মিলল — তাই
আর তিনটেরই সীমান্ত-বণ্টন একই \(\chi^2_1\) (scalar; সাধারণভাবে \(\chi^2_k\))।
এক বাক্যে গল্প। তিন test = একই প্যারাবোলিক চূড়াকে তিন দিক থেকে দেখা — LRT উচ্চতা-ব্যবধান, Wald অনুভূমিক দূরত্ব (\(\hat\theta\to\theta_0\)), score ঢাল (\(\theta_0\)-তে)। প্যারাবোলায় উচ্চতা \(=\tfrac12\times\)curvature\(\times\)দূরত্ব\(^2\), আর ঢাল \(=\) curvature\(\times\)দূরত্ব — তাই তিন মাপ বীজগণিতে একে অপরের সমান হয়ে যায়। পার্থক্য কোথায়: ছোট/মাঝারি নমুনায় তিনটে সামান্য আলাদা সংখ্যা দেয়, কারণ Wald curvature মাপে \(\hat\theta\)-তে, score মাপে \(\theta_0\)-তে, আর LRT পুরো ব্যবধান নেয় (কোনো এক বিন্দুর curvature নয়) — তাই LRT-কে প্রায়ই সবচেয়ে নির্ভরযোগ্য ধরা হয়। কিন্তু Normal-known-\(\sigma\)-তে log-likelihood ঠিক প্যারাবোলা (approximation নয়), curvature সর্বত্র সমান \(n/\sigma^2\) — তাই সেখানে তিনটে হুবহু সমান (\(=Z^2\)), যা §৫ PART 1 সংখ্যায় দেখাবে।
কোনটা কখন। তিনটেই asymptotically সমান, তাই পছন্দ সুবিধার উপর নির্ভরশীল: score — যখন শুধু restricted মডেল fit সহজ (\(\hat\theta\) লাগে না); Wald — যখন unrestricted MLE ও তার SE হাতে আছে (CI-র সাথে সরাসরি যুক্ত, 4.6); LRT — যখন দুটো MLE-ই পাওয়া যায় এবং সবচেয়ে ভালো ছোট-নমুনা আচরণ চাই।
৪.৫ · (e) Pearson-এর \(\chi^2\) — multinomial LRT-র approximation — ★★¶
এতক্ষণ continuous parameter দেখলাম। এবার categorical data: \(n\)টা পর্যবেক্ষণ \(m\)টা category-তে পড়ে, observed count \(O_1,\dots,O_m\) (যোগফল \(n\))। প্রশ্ন: এগুলো কি নির্দিষ্ট সম্ভাবনা \(p_1,\dots,p_m\) (যেমন "সব মুখ সমান", die-fairness) মেনে এসেছে? এই goodness-of-fit প্রশ্নের ক্লাসিক উত্তর Pearson-এর statistic — দেখাই এটাও আসলে LRT-রই একটা approximation।
ধাপ ১ — multinomial likelihood ও দুটো hypothesis। count-গুলোর যৌথ বণ্টন multinomial; তার log-likelihood (ধ্রুবক বাদে)
\(H_0\): \(p_i=p_i^0\) (নির্দিষ্ট, যেমন die-তে \(p_i^0=1/6\)); \(H_1\): \(p_i\) মুক্ত। expected count সংজ্ঞায়িত করি \(E_i:=n\,p_i^0\) ("\(H_0\) সত্য হলে গড়ে কতটা পড়ার কথা")। unrestricted MLE হলো \(\hat p_i=O_i/n\) (observed অনুপাত — গণনা করলেই পাওয়া যায়)।
ধাপ ২ — LRT statistic লিখি। restricted sup-এ \(p_i=p_i^0\), unrestricted sup-এ \(p_i=O_i/n\) বসাই:
কারণ \(\frac{\hat p_i}{p_i^0}=\frac{O_i/n}{E_i/n}=\frac{O_i}{E_i}\)। এটাই \(G\)-statistic (likelihood-ratio GOF) — সঠিক, কিন্তু log-এর জন্য হাতে-হিসাবে কষ্টকর।
ধাপ ৩ — log-কে Taylor approximate করে Pearson-এ পৌঁছাই। লিখি \(O_i=E_i+\delta_i\), যেখানে \(\delta_i=O_i-E_i\) হলো "observed বনাম expected"-এর ব্যবধান (বড় \(n\)-এ \(E_i\)-র তুলনায় ছোট)। তাহলে \(\frac{O_i}{E_i}=1+\frac{\delta_i}{E_i}\), আর \(\log(1+u)\approx u-\frac{u^2}{2}\) (ছোট \(u\)-র Taylor):
গুণ করে শুধু \(\delta_i\)-তে দ্বিতীয় ক্রম পর্যন্ত রাখি (উচ্চতর পদ ফেলে):
এবার \(2\sum_i\) নিই। মূল কথা \(\sum_i\delta_i=\sum_i(O_i-E_i)=n-n=0\) (দুই দিকেই মোট \(n\)) — তাই প্রথম পদ মুছে যায়:
অর্থাৎ Pearson-এর \(\chi^2\) হলো multinomial LRT-র দ্বিতীয়-ক্রম Taylor approximation — তাই তারা একই সীমান্ত-বণ্টন \(\chi^2_k\)-এ যায় (Wilks), আর বড় \(n\)-এ সংখ্যাতেও কাছাকাছি। Pearson-রূপটাই জনপ্রিয় কারণ এতে log নেই — শুধু গুণ-ভাগ-যোগ।
ধাপ ৪ — df-এর নিয়ম। Wilks অনুযায়ী df \(=\dim\Theta-\dim\Theta_0\):
- Goodness-of-fit (\(m\) category): পূর্ণ মডেলে free parameter \(m-1\) (যেহেতু \(\sum p_i=1\) একটা constraint)। \(H_0\) সব \(p_i\) ঠিক করে দিলে \(\dim\Theta_0=0\)। তাই $$ \boxed{\;\mathrm{df}=(m-1)-0=m-1\;} $$ (die: \(m=6\), df \(=5\) — E4/§৫ PART 3 দেখাবে।) যদি \(H_0\)-র অধীনে \(q\)টা parameter data থেকে estimate করতে হয় (যেমন Poisson fit-এ \(\hat\lambda\)), তখন df \(=(m-1)-q\) — প্রতিটি estimated parameter একটা df খরচ করে।
- Independence (\(r\times c\) contingency table): এখানে \(E_{ij}=\frac{(\text{row}_i\ \text{total})(\text{col}_j\ \text{total})}{n}\), আর row/column marginal probability data থেকে estimate করতে হয় — হিসাব করলে $$ \boxed{\;\mathrm{df}=(r-1)(c-1)\;} $$ (\(2\times3\) table: df \(=(2-1)(3-1)=2\) — E4/§৫ PART 4 দেখাবে)।
E4 — Pearson \(\chi^2\) স্বজ্ঞা। \(\frac{(O_i-E_i)^2}{E_i}\) পদটা পড়ুন এভাবে: প্রতিটি cell-এ "observed কত দূরে expected থেকে" (\(O_i-E_i\)), বর্গ করে (চিহ্ন মুছে), আর \(E_i\) দিয়ে ভাগ করে স্কেল করা (কারণ বড় \(E_i\)-তে স্বাভাবিক ওঠানামাও বড়, তাই ভাগ করে ন্যায্য তুলনা)। মোট statistic বড় \(\Rightarrow\) observed সামগ্রিকভাবে expected থেকে অনেক দূরে \(\Rightarrow\) \(H_0\) বাতিল। সিদ্ধান্ত: \(\chi^2_{\text{Pearson}}>\chi^2_{\mathrm{df},\,1-\alpha}\) হলে \(H_0\) বাতিল। শর্ত ★★: approximation ভালো কাজ করে যদি সব \(E_i\) যথেষ্ট বড় (বুড়ো-আঙুলের নিয়ম \(E_i\ge5\)); ছোট \(E_i\)-তে category মেলানো বা exact test দরকার। (Figure
4-8-chi2-gof-এ এই \(O\) বনাম \(E\) তুলনা চোখে দেখানো হয়েছে।)
§৪-এর সার (Figure
4-8-three-tests,4-8-wilks,4-8-test-equivalenceদেখাবে)। তিনটে test একই log-likelihood-চূড়ার তিন মাপ — LRT উচ্চতা-ব্যবধান (\(-2\log\Lambda=2[\ell(\hat\theta)-\ell(\hat\theta_0)]\)), Wald অনুভূমিক দূরত্ব (\(W=(\hat\theta-\theta_0)^2/\widehat{\mathrm{Var}}\)), score ঢাল (\(U(\theta_0)^2/nI\)); চূড়া প্রায়-প্যারাবোলা বলে তিনটে asymptotically সমান, সীমান্ত-বণ্টন \(\chi^2_k\) (\(k=\) restriction-সংখ্যা, Wilks)। categorical data-য় একই LRT multinomial-এ Pearson-এর \(\sum(O_i-E_i)^2/E_i\)-তে রূপ নেয় (df: GOF \(m-1\), independence \((r-1)(c-1)\))। পরের §৫-এ এই সব ফল সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর ফলগুলো আমরা সংখ্যায় যাচাই করব — যাতে তিন test-এর সমতা, Wilks-এর \(\chi^2_k\), আর Pearson-এর GOF/independence কাগজে নয় শুধু, computer-এও বিশ্বাসযোগ্য হয়। চারটে অংশ, §৪-এর কাঠামো অনুসরণ করে:
- PART 1 — তিন statistic এক নমুনায় (§৪.১–৪.৪)। একটা Normal নমুনায় (\(\sigma\) জানা, \(H_0:\mu=\mu_0\)) LRT \(-2\log\Lambda\), Wald \(W\), ও score \(U\) হিসাব করব, \(\chi^2_1\) critical value-র সাথে তুলনা করব, আর দেখব এই বিশেষ ক্ষেত্রে তিনটে হুবহু \(Z^2\)-এ মেলে — (d)-র সমতার সরাসরি সংখ্যা।
- PART 2 — Wilks (§৪.১)। \(H_0\) সত্য রেখে হাজার-হাজার নমুনায় \(-2\log\Lambda\) সিমুলেট করব, তার বণ্টনকে \(\chi^2_k\) (\(k=1\))-এর সাথে মেলাব (mean, variance, quantile), আর দেখব \(H_0\) সত্য হলে test ঠিক \(\alpha\approx5\%\) বার বাতিল করে।
- PART 3 — Pearson \(\chi^2\) GOF, die-fairness (§৪.৫)। একটা সামান্য-পক্ষপাতী die ছুঁড়ে \(\sum(O_i-E_i)^2/E_i\) হাতে হিসাব করব,
scipy.stats.chisquare-এর সাথে মিলিয়ে p-value নেব, আর \(\chi^2_5\) critical-এর সাথে তুলনা করব। - PART 4 — contingency-table independence (§৪.৫)। একটা \(2\times3\) table-এ \(E_{ij}=\frac{\text{row}\cdot\text{col}}{n}\) আর \(\chi^2=\sum(O-E)^2/E\) হাতে হিসাব করব,
scipy.stats.chi2_contingency-র সাথে মিলিয়ে \(\chi^2_2\)-এ সিদ্ধান্ত নেব।
সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। critical value ও p-value আসে scipy.stats থেকে। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয়।)
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.8 — Likelihood Ratio, Wald & Score Tests; Goodness-of-Fit : Code Lab
# Numerically illustrates / verifies (sections 4 & 5):
# PART 1 — Compute LRT (-2 log Lambda), Wald, and Score statistics on ONE
# sample (Normal mean, sigma known) and compare to chi2_1 critical
# value; show all three coincide here and give the same decision.
# PART 2 — Wilks' theorem: simulate -2 log Lambda under H0 many times and show
# its sampling distribution matches chi2_k (here k = 1).
# PART 3 — Pearson chi-square GOODNESS-OF-FIT: test a die for fairness
# (sum (O-E)^2 / E) with a p-value via scipy.stats.chisquare.
# PART 4 — Contingency-table INDEPENDENCE chi-square (Pearson) on a 2x3 table.
# Reproducible: numpy default_rng with a fixed seed; criticals from scipy.stats.
import numpy as np
from scipy import stats
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=6, suppress=True)
# ===========================================================================
# PART 1 — LRT / WALD / SCORE on ONE sample, then compare to chi2_1 critical.
# Model: X_1..X_n ~ Normal(mu, sigma^2), sigma KNOWN. Test H0: mu = mu0.
# Closed forms (all functions of Z = (xbar - mu0)/(sigma/sqrt(n))):
# -2 log Lambda = n (xbar - mu0)^2 / sigma^2 = Z^2
# Wald W = (muhat - mu0)^2 / Var_hat = Z^2 (Var_hat = sigma^2/n)
# Score U = [score(mu0)]^2 / (n I) = Z^2
# => in this Normal-known-sigma case the three are ALGEBRAICALLY identical.
# ===========================================================================
print("=" * 74)
print("PART 1 - LRT / Wald / Score statistics on ONE sample, vs chi2_1 critical")
print(" Model: Normal(mu, sigma^2), sigma known. H0: mu = mu0")
print("=" * 74)
mu_true, sigma = 5.0, 2.0
mu0 = 4.0 # null value (deliberately != mu_true so H0 is FALSE)
n1 = 40
alpha = 0.05
crit1 = stats.chi2.ppf(1 - alpha, df=1) # chi2_1 critical value (=3.8415)
x1 = rng.normal(mu_true, sigma, size=n1)
xbar = x1.mean()
muhat = xbar # MLE of mu (sigma known)
# (a) Likelihood ratio: -2 log Lambda = n (xbar - mu0)^2 / sigma^2
lrt = n1 * (xbar - mu0)**2 / sigma**2
# (b) Wald: W = (muhat - mu0)^2 / Var_hat, Var_hat = sigma^2 / n (= 1/(nI))
var_hat = sigma**2 / n1
wald = (muhat - mu0)**2 / var_hat
# (c) Score (Rao): U = [U(mu0)]^2 / (n I), score U(mu0) = sum(x - mu0)/sigma^2,
# Fisher info I(mu) = 1/sigma^2, so n I = n/sigma^2.
score_at_mu0 = np.sum(x1 - mu0) / sigma**2
nI = n1 / sigma**2
score = score_at_mu0**2 / nI
zval = (xbar - mu0) / (sigma / np.sqrt(n1)) # the common Z; all stats = Z^2
print(f"\n n={n1}, sigma={sigma} (known), mu0={mu0}, true mu={mu_true}, alpha={alpha}")
print(f" xbar = {xbar:.5f} Z=(xbar-mu0)/(sigma/sqrt n) = {zval:.5f} Z^2 = {zval**2:.5f}")
print(f"\n {'statistic':<26}{'value':>12}{'crit chi2_1':>14}{'reject H0?':>12}")
print(" " + "-" * 62)
for name, val in [("-2 log Lambda (LRT)", lrt), ("Wald W", wald), ("Score U (Rao)", score)]:
print(f" {name:<26}{val:>12.5f}{crit1:>14.5f}{str(val > crit1):>12}")
# p-values (all from chi2_1 survival function)
print(f"\n p-values (chi2_1 sf): LRT={stats.chi2.sf(lrt,1):.5f} "
f"Wald={stats.chi2.sf(wald,1):.5f} Score={stats.chi2.sf(score,1):.5f}")
print(" Read-off: for Normal mean with sigma known the three statistics are")
print(" ALGEBRAICALLY equal (all = Z^2); each exceeds chi2_1=3.84, so H0: mu=4")
print(" is rejected. In general the three differ but agree asymptotically.")
# ===========================================================================
# PART 2 — WILKS' THEOREM: under H0, -2 log Lambda -> chi2_k (here k = 1).
# Simulate many samples WITH H0 TRUE (mu = mu0), recompute -2 log Lambda each
# time, and compare the empirical distribution to chi2_1 (quantiles + tail).
# ===========================================================================
print("\n" + "=" * 74)
print("PART 2 - Wilks' theorem: distribution of -2 log Lambda under H0 vs chi2_k")
print(f" k = 1 restriction; H0 TRUE (mu = mu0 = {mu0})")
print("=" * 74)
REP = 200_000
nW = 40
# Under H0 the data ARE generated with mu = mu0:
samp = rng.normal(mu0, sigma, size=(REP, nW))
xbarW = samp.mean(axis=1)
lam2 = nW * (xbarW - mu0)**2 / sigma**2 # -2 log Lambda for each sample
k = 1
print(f"\n REP={REP}, n={nW}, sigma={sigma} known.")
print(f" empirical mean of -2logLambda = {lam2.mean():.4f} (chi2_{k} mean = {k})")
print(f" empirical var of -2logLambda = {lam2.var(ddof=1):.4f} (chi2_{k} var = {2*k})")
print(f"\n {'quantile':>9}{'empirical':>12}{'chi2_1 theory':>16}")
print(" " + "-" * 37)
for q in [0.50, 0.90, 0.95, 0.99]:
print(f" {q:>9.2f}{np.quantile(lam2, q):>12.4f}{stats.chi2.ppf(q, k):>16.4f}")
rej = np.mean(lam2 > crit1)
print(f"\n rejection rate at alpha={alpha} (i.e. P(-2logLambda > {crit1:.4f})) = {rej:.4f}")
print(" Read-off: mean ~ 1, var ~ 2, quantiles match chi2_1, and the test rejects")
print(" H0 about alpha=5% of the time when H0 is TRUE -> Wilks' chi2_k holds.")
# ===========================================================================
# PART 3 — PEARSON chi-square GOODNESS-OF-FIT: is a die fair?
# chi2 = sum (O_i - E_i)^2 / E_i, df = (#categories - 1) = 5 for a 6-faced die.
# We roll a SLIGHTLY loaded die, then test H0: all faces equally likely (1/6).
# ===========================================================================
print("\n" + "=" * 74)
print("PART 3 - Pearson chi-square goodness-of-fit: testing a die for fairness")
print("=" * 74)
n_rolls = 600
# A slightly loaded die: face 6 a bit more likely, face 1 a bit less.
p_loaded = np.array([0.13, 0.17, 0.17, 0.17, 0.17, 0.19])
faces = rng.choice(np.arange(1, 7), size=n_rolls, p=p_loaded)
O = np.array([np.sum(faces == f) for f in range(1, 7)]) # observed counts O_i
E = np.full(6, n_rolls / 6.0) # expected under fairness
chi2_gof = np.sum((O - E)**2 / E) # Pearson statistic
df_gof = 6 - 1
crit_gof = stats.chi2.ppf(1 - alpha, df_gof)
# scipy cross-check (same statistic + p-value):
chi2_sp, p_sp = stats.chisquare(f_obs=O, f_exp=E)
print(f"\n rolls = {n_rolls}; H0: every face has probability 1/6 (E_i = {E[0]:.1f})")
print(f" {'face':>5}{'O_i':>7}{'E_i':>8}{'(O-E)^2/E':>12}")
print(" " + "-" * 32)
for f in range(6):
print(f" {f+1:>5}{O[f]:>7}{E[f]:>8.1f}{(O[f]-E[f])**2/E[f]:>12.4f}")
print(" " + "-" * 32)
print(f" Pearson chi2 (by hand) = {chi2_gof:.4f} df = {df_gof}")
print(f" scipy.stats.chisquare : chi2 = {chi2_sp:.4f}, p-value = {p_sp:.4f}")
print(f" chi2_{df_gof} critical (alpha={alpha}) = {crit_gof:.4f} "
f"=> reject H0? {chi2_gof > crit_gof}")
print(" Read-off: by-hand statistic equals scipy's exactly; compare to chi2_5 and")
print(" to the p-value to decide whether the observed counts are 'too far' from fair.")
# ===========================================================================
# PART 4 — CONTINGENCY-TABLE INDEPENDENCE (Pearson chi-square).
# 2x3 table. H0: row and column variables are independent.
# E_ij = (row_i total)(col_j total) / grand total; chi2 = sum (O-E)^2/E;
# df = (r-1)(c-1). Cross-checked with scipy.stats.chi2_contingency.
# ===========================================================================
print("\n" + "=" * 74)
print("PART 4 - Contingency-table independence: Pearson chi-square on a 2x3 table")
print("=" * 74)
# Observed counts (e.g. treatment {A,B} x outcome {worse, same, better}); a real
# (non-independent) association is baked in.
Otab = np.array([[30, 40, 50],
[50, 35, 20]], dtype=float)
row = Otab.sum(axis=1, keepdims=True) # row totals
col = Otab.sum(axis=0, keepdims=True) # column totals
N = Otab.sum() # grand total
Etab = row @ col / N # expected counts under independence
chi2_ind = np.sum((Otab - Etab)**2 / Etab)
r, c = Otab.shape
df_ind = (r - 1) * (c - 1)
crit_ind = stats.chi2.ppf(1 - alpha, df_ind)
chi2_c, p_c, dof_c, exp_c = stats.chi2_contingency(Otab, correction=False)
print("\n Observed O_ij:")
print(" ", str(Otab.astype(int)).replace("\n", "\n "))
print(" Expected E_ij under independence (row*col/N):")
print(" ", np.array2string(Etab, precision=3).replace("\n", "\n "))
print(f"\n Pearson chi2 (by hand) = {chi2_ind:.4f} df = (r-1)(c-1) = {df_ind}")
print(f" scipy.chi2_contingency : chi2 = {chi2_c:.4f}, p = {p_c:.6f}, dof = {dof_c}")
print(f" chi2_{df_ind} critical (alpha={alpha}) = {crit_ind:.4f} "
f"=> reject independence? {chi2_ind > crit_ind}")
print(" Read-off: by-hand chi2 matches scipy; small p-value => reject H0, i.e. the")
print(" row and column variables are NOT independent (there is an association).")
print("\n[done] all parts ran.")
৫.২ · বাস্তব আউটপুট ও পাঠোদ্ধার¶
স্ক্রিপ্টটা চালালে নিচের আউটপুট পাওয়া যায় (হুবহু, seed 20260619):
==========================================================================
PART 1 - LRT / Wald / Score statistics on ONE sample, vs chi2_1 critical
Model: Normal(mu, sigma^2), sigma known. H0: mu = mu0
==========================================================================
n=40, sigma=2.0 (known), mu0=4.0, true mu=5.0, alpha=0.05
xbar = 4.70200 Z=(xbar-mu0)/(sigma/sqrt n) = 2.21991 Z^2 = 4.92800
statistic value crit chi2_1 reject H0?
--------------------------------------------------------------
-2 log Lambda (LRT) 4.92800 3.84146 True
Wald W 4.92800 3.84146 True
Score U (Rao) 4.92800 3.84146 True
p-values (chi2_1 sf): LRT=0.02642 Wald=0.02642 Score=0.02642
Read-off: for Normal mean with sigma known the three statistics are
ALGEBRAICALLY equal (all = Z^2); each exceeds chi2_1=3.84, so H0: mu=4
is rejected. In general the three differ but agree asymptotically.
==========================================================================
PART 2 - Wilks' theorem: distribution of -2 log Lambda under H0 vs chi2_k
k = 1 restriction; H0 TRUE (mu = mu0 = 4.0)
==========================================================================
REP=200000, n=40, sigma=2.0 known.
empirical mean of -2logLambda = 0.9951 (chi2_1 mean = 1)
empirical var of -2logLambda = 1.9834 (chi2_1 var = 2)
quantile empirical chi2_1 theory
-------------------------------------
0.50 0.4524 0.4549
0.90 2.6920 2.7055
0.95 3.8286 3.8415
0.99 6.6281 6.6349
rejection rate at alpha=0.05 (i.e. P(-2logLambda > 3.8415)) = 0.0495
Read-off: mean ~ 1, var ~ 2, quantiles match chi2_1, and the test rejects
H0 about alpha=5% of the time when H0 is TRUE -> Wilks' chi2_k holds.
==========================================================================
PART 3 - Pearson chi-square goodness-of-fit: testing a die for fairness
==========================================================================
rolls = 600; H0: every face has probability 1/6 (E_i = 100.0)
face O_i E_i (O-E)^2/E
--------------------------------
1 76 100.0 5.7600
2 103 100.0 0.0900
3 103 100.0 0.0900
4 100 100.0 0.0000
5 111 100.0 1.2100
6 107 100.0 0.4900
--------------------------------
Pearson chi2 (by hand) = 7.6400 df = 5
scipy.stats.chisquare : chi2 = 7.6400, p-value = 0.1772
chi2_5 critical (alpha=0.05) = 11.0705 => reject H0? False
Read-off: by-hand statistic equals scipy's exactly; compare to chi2_5 and
to the p-value to decide whether the observed counts are 'too far' from fair.
==========================================================================
PART 4 - Contingency-table independence: Pearson chi-square on a 2x3 table
==========================================================================
Observed O_ij:
[[30 40 50]
[50 35 20]]
Expected E_ij under independence (row*col/N):
[[42.667 40. 37.333]
[37.333 35. 32.667]]
Pearson chi2 (by hand) = 17.2672 df = (r-1)(c-1) = 2
scipy.chi2_contingency : chi2 = 17.2672, p = 0.000178, dof = 2
chi2_2 critical (alpha=0.05) = 5.9915 => reject independence? True
Read-off: by-hand chi2 matches scipy; small p-value => reject H0, i.e. the
row and column variables are NOT independent (there is an association).
[done] all parts ran.
পাঠোদ্ধার — কী শিখলাম।
-
PART 1 (তিন test এক নমুনায়, §৪.১–৪.৪ যাচাই)। এই নমুনায় \(\bar X=4.702\), তাই \(Z=(4.702-4)/(2/\sqrt{40})=2.220\), আর \(Z^2=4.928\)। তিনটে statistic — LRT \(-2\log\Lambda\), Wald \(W\), score \(U\) — তিনটেই হুবহু \(4.92800\), এবং তিনটেরই p-value \(=0.02642\)। এটাই §৪.৪-এর সমতার সবচেয়ে পরিষ্কার দৃষ্টান্ত: Normal-known-\(\sigma\)-তে log-likelihood ঠিক প্যারাবোলা, তাই Taylor approximation নিখুঁত হয়ে যায় এবং তিন test বীজগণিতে অভিন্ন (\(=Z^2\))। তিনটেই \(\chi^2_1\) critical \(3.841\) ছাড়িয়ে গেছে, তাই \(H_0:\mu=4\) বাতিল — যা সঠিক, কারণ সত্য \(\mu=5\)। (সাধারণ মডেলে তিনটে সামান্য আলাদা সংখ্যা দিত, কিন্তু একই সিদ্ধান্তে আসত।)
-
PART 2 (Wilks, §৪.১ যাচাই)। \(H_0\) সত্য রেখে (\(\mu=\mu_0=4\)) \(200{,}000\) বার \(-2\log\Lambda\) সিমুলেট করায়: empirical mean \(0.9951\) (\(\chi^2_1\)-এর তাত্ত্বিক mean \(=k=1\)), variance \(1.9834\) (\(\chi^2_1\)-এর variance \(=2k=2\)) — মিলে গেছে। quantile-গুলোও কাছাকাছি: median \(0.4524\) বনাম \(0.4549\), \(95\)-তম percentile \(3.8286\) বনাম \(3.8415\)। সবচেয়ে গুরুত্বপূর্ণ — \(\alpha=0.05\)-এ rejection rate \(0.0495\), অর্থাৎ \(H_0\) সত্য হলে test ঠিক \(\approx5\%\) বার ভুল করে বাতিল করে (Type I error nominal-এর গায়ে)। এটাই §৪.১.৩-এর \(-2\log\Lambda\xrightarrow{d}\chi^2_k\)-এর সংখ্যাগত প্রমাণ। (Figure
4-8-wilks-এ এই histogram-এর উপর \(\chi^2_1\) curve overlay করা হয়েছে।) -
PART 3 (Pearson GOF, die-fairness, §৪.৫ যাচাই)। \(600\) বার ছোঁড়ায় observed count \([76,103,103,100,111,107]\), expected সব \(100\)। হাতে-হিসাব \(\chi^2=\sum(O_i-E_i)^2/E_i=5.76+0.09+0.09+0+1.21+0.49=7.64\), আর
scipy.stats.chisquareহুবহু একই \(7.6400\) (p \(=0.1772\)) — অর্থাৎ §৪.৫-এর সূত্রটাই scipy ভেতরে চালায়। df \(=6-1=5\), critical \(11.07\); \(7.64<11.07\) (p \(>0.05\)), তাই \(H_0\) বাতিল হয় না। শিক্ষণীয় বিন্দু: die আসলে সামান্য পক্ষপাতী ছিল (face 1 কম, face 6 বেশি), কিন্তু \(n=600\)-এ সেই ছোট পক্ষপাত ধরা পড়ার মতো যথেষ্ট শক্তিশালী সাক্ষ্য জমেনি — test বাতিল-না-করা মানে "\(H_0\) প্রমাণিত" নয়, কেবল "যথেষ্ট সাক্ষ্য নেই" (power-এর প্রশ্ন, 4.7/4.9)। -
PART 4 (contingency-table independence, §৪.৫ যাচাই)। \(2\times3\) table-এ \(E_{ij}=\frac{\text{row}_i\cdot\text{col}_j}{n}\) সূত্রে expected বের করে (যেমন cell \((1,1)\): \(\frac{120\times80}{225}=42.667\)), হাতে-হিসাব \(\chi^2=17.2672\), আর
scipy.stats.chi2_contingencyহুবহু একই (\(17.2672\), p \(=0.000178\), dof \(=2\))। df \(=(2-1)(3-1)=2\), critical \(5.99\); \(17.27\gg5.99\) (p অতি ছোট), তাই independence বাতিল — row ও column চলকের মধ্যে স্পষ্ট সম্পর্ক আছে। (correction=Falseদিলাম যাতে scipy Yates-সংশোধন ছাড়া ঠিক আমাদের raw Pearson-সূত্রই ব্যবহার করে — তাই সংখ্যা হুবহু মেলে।)
চারটে PART একসাথে §৪-এর পুরো শৃঙ্খল সংখ্যায় বেঁধে দেয়: তিন test একই \(Z^2\)-এ মেলে (PART 1, §৪.৪) → \(H_0\)-র অধীনে \(-2\log\Lambda\)-এর বণ্টন ঠিক \(\chi^2_k\) (PART 2, §৪.১, Wilks) → আর categorical data-য় সেই একই \(\chi^2\)-যন্ত্র Pearson-এর \(\sum(O_i-E_i)^2/E_i\) রূপে GOF (PART 3) ও independence (PART 4) test চালায়, df যথাক্রমে \(m-1\) ও \((r-1)(c-1)\)।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_4-8.py-তে তৈরি; PNG_assets/-এ (prefix4-8, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 LRT; E2 Wald; E3 score; E4 Pearson \(\chi^2\) goodness-of-fit ও independence।
এই অধ্যায়ের গোটা গল্পটা চারটা প্রশ্নে ধরা যায়, আর প্রতিটার একটা ছবি আছে। (১) likelihood ratio, Wald আর score — এই তিনটা test আসলে একই log-likelihood পাহাড়ের তিনটা ভিন্ন দিক থেকে মাপ; কোনটা কী মাপে তা জ্যামিতিকভাবে দেখতে কেমন (Figure 1)? (২) LRT-এর statistic \(-2\log\Lambda\) কেন \(H_0\)-র অধীনে একটা \(\chi^2_k\) বণ্টন মেনে চলে — অর্থাৎ Wilks' theorem-টা সিমুলেশনে কেমন দেখায় (Figure 2)? (৩) categorical data-য় observed গণনা \(O_i\) আর প্রত্যাশিত গণনা \(E_i\)-এর তফাত কীভাবে একটা Pearson \(\chi^2\) goodness-of-fit statistic-এ রূপ নেয়, আর সেটা \(\chi^2\)-table-এর সাথে তুলনা করলে কী সিদ্ধান্ত আসে (Figure 3)? (৪) তিনটা test (LRT, Wald, score) ছোট নমুনায় আলাদা মান দিলেও বড় নমুনায় কেন একই জায়গায় মিলে যায় (Figure 4)? প্রথম ছবিটা জ্যামিতি (তিন test-এর ছবি), দ্বিতীয়টা কেন \(\chi^2\) (Wilks), তৃতীয়টা categorical \(\chi^2\) (GOF-এর প্রয়োগ), আর চতুর্থটা তিন test-এর সমতা (asymptotic equivalence)।
Figure 1 — একই পাহাড়ের তিন দৃষ্টি: LRT, Wald, score¶
এই অধ্যায়ের কেন্দ্রীয় অন্তর্দৃষ্টি একটাই ছবিতে: তিনটা test একই log-likelihood বক্ররেখা \(\ell(\theta)\)-র ওপর তিনটা ভিন্ন দূরত্ব মাপে — কিন্তু সবাই একই প্রশ্নের উত্তর খোঁজে: null মান \(\theta_0\) কি পাহাড়ের চূড়া (MLE \(\hat\theta\)) থেকে অনেক দূরে? নীল বক্ররেখাটা log-likelihood (এখানে normal mean, \(\sigma\) জানা, তাই একটা মসৃণ উল্টানো parabola); চূড়ায় নীল বিন্দু MLE \(\hat\theta\), আর \(\theta_0\)-তে লাল বিন্দু। সবুজ (LRT): \(\theta_0\)-তে বক্ররেখা চূড়া থেকে কতটা নিচে নেমেছে — উল্লম্ব ড্রপ \(\ell(\hat\theta)-\ell(\theta_0)\); এই ড্রপ-ই \(\tfrac12(-2\log\Lambda)\)। কমলা (Wald): চূড়ার \(\theta\)-অবস্থান আর \(\theta_0\)-এর মধ্যে অনুভূমিক দূরত্ব \(\hat\theta-\theta_0\) (পরে variance দিয়ে scale করা হয়)। বেগুনি (score): \(\theta_0\)-তে বক্ররেখার ঢাল (tangent), \(U(\theta_0)=\ell'(\theta_0)\) — চূড়ায় ঢাল \(0\), তাই \(\theta_0\)-তে ঢাল যত খাড়া, \(\theta_0\) চূড়া থেকে তত দূরে।
যা লক্ষ করতে হবে: (ক) তিনটা রঙিন চিহ্ন তিন দিক থেকে একই ফাঁক মাপছে — উল্লম্ব (উচ্চতার তফাত), অনুভূমিক (অবস্থানের তফাত), আর ঢাল (চূড়ার দিকে কত জোরে টানছে)। ছোট ফাঁক ⇒ তিনটাই ছোট ⇒ \(H_0\) গ্রহণযোগ্য; বড় ফাঁক ⇒ তিনটাই বড় ⇒ \(H_0\) প্রত্যাখ্যান। (খ) LRT-এর দুই প্রান্তে fit লাগে (চূড়া \(\hat\theta\) আর \(\theta_0\) — দুটোতেই log-lik হিসাব), Wald-এর শুধু চূড়ায় (\(\hat\theta\) ও সেখানকার curvature), score-এর শুধু \(\theta_0\)-তে (null-এ ঢাল ও information — MLE বের করাই লাগে না)। এই "কোথায় হিসাব করতে হয়" পার্থক্যটাই কোন test কখন সুবিধাজনক তা ঠিক করে। (গ) চূড়াটা মসৃণ ও গোলাকার বলেই তিনটা মাপ পরস্পর সম্পর্কিত: একটা quadratic approximation-এ উল্লম্ব ড্রপ, অনুভূমিক দূরত্বের বর্গ, আর ঢাল — সবাই একই curvature (Fisher information) দিয়ে বাঁধা, আর সেখান থেকেই Figure 4-এর সমতা আসে।
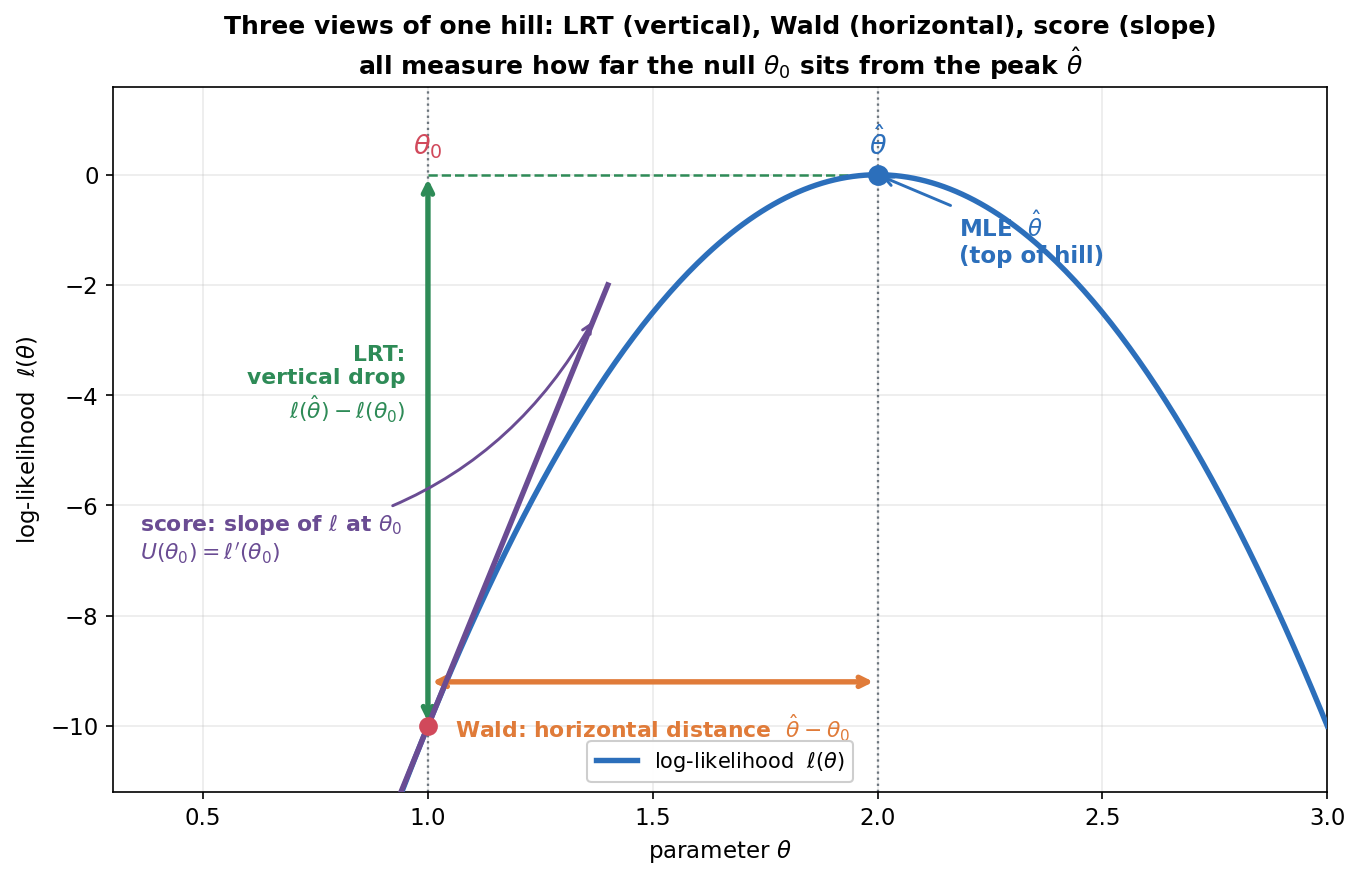
Figure 2 — Wilks' theorem: \(-2\log\Lambda\) কেন \(\chi^2_k\)¶
Figure 1 দেখাল LRT হলো log-likelihood-এর উল্লম্ব ড্রপ; এই ছবি দেখায় সেই ড্রপ থেকে বানানো statistic \(-2\log\Lambda\) \(H_0\)-র অধীনে কোন বণ্টন মেনে চলে — এটাই Wilks' theorem: বড় নমুনায় \(-2\log\Lambda \xrightarrow{d} \chi^2_k\), যেখানে \(k\) = কতগুলো প্যারামিটার \(H_0\) আটকে রাখে (restrictions বা degrees of freedom)। দুটো প্যানেল। বাঁ (k = 1): একটা প্যারামিটার আটকানো (\(H_0:\theta=\theta_0\)); \(H_0\) সত্য ধরে ৩০,০০০ বার নমুনা টেনে প্রতিবার \(-2\log\Lambda\) হিসাব করে নীল histogram বানানো, আর তার ওপর লাল \(\chi^2_1\) density বসানো — দুটো প্রায় হুবহু মিলে যায়। ডান (k = 2): দুটো প্যারামিটার আটকানো; এবার histogram \(\chi^2_2\) density-র সাথে মেলে। প্রতিটিতে সবুজ ভাঙা রেখা \(95\%\) critical value (\(\chi^2_{1,0.95}=3.84\), \(\chi^2_{2,0.95}=5.99\)) — যার ডানে \(5\%\) rejection region।
যা লক্ষ করতে হবে: (ক) histogram (সিমুলেটেড সত্য) আর লাল curve (তত্ত্বের \(\chi^2_k\)) একে অপরের ওপর বসে যায় — অর্থাৎ Wilks' theorem-টা শুধু সূত্র নয়, সিমুলেশনে সত্যিই খাটে। এটাই LRT-কে practical করে তোলে: \(-2\log\Lambda\) বের করে সরাসরি \(\chi^2_k\)-table-এ দেখলেই p-value পাওয়া যায়, আলাদা করে কঠিন বণ্টন বের করতে হয় না। (খ) \(k\) বদলালে আকার বদলায়: \(\chi^2_1\) শূন্যের কাছে আকাশছোঁয়া (চূড়াহীন, ডানে দ্রুত নামে), \(\chi^2_2\) একটা মসৃণ ক্ষয়িষ্ণু (exponential-আকৃতি) — তাই সঠিক \(k\) (df) গোনা জরুরি, নইলে ভুল critical value আসবে। (গ) critical value-র ডানে যে \(5\%\) অঞ্চল, \(H_0\) সত্য হলেও statistic ঘটনাক্রমে সেখানে পড়তে পারে — এটাই test-এর type I error rate \(\alpha=0.05\), পদ্ধতির অনিবার্য অংশ (4.7-এর ধারণা)। (ঘ) এই approximation বড় নমুনার; ছোট \(n\)-এ histogram \(\chi^2\) থেকে একটু সরে যেতে পারে — তখন exact বা simulation-ভিত্তিক পদ্ধতি (4.9) লাগে।
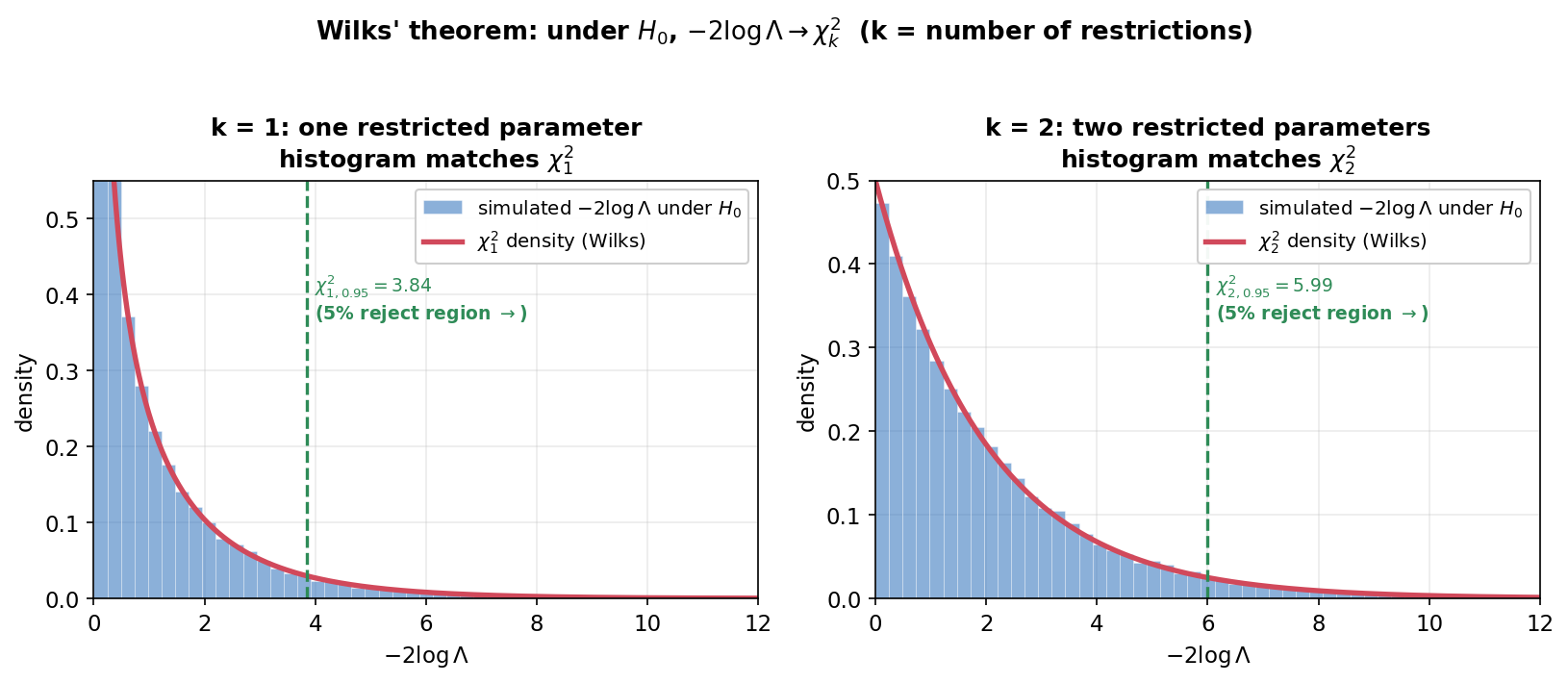
Figure 3 — Pearson \(\chi^2\) goodness-of-fit: observed বনাম expected¶
এবার categorical data-র জন্য সবচেয়ে চেনা test (E4): একটা ঝোঁকহীন (fair) ছক্কা কি সত্যিই ঝোঁকহীন? \(n=120\) বার গড়ানো হলো; \(H_0\) (fair) সত্য হলে প্রতিটা মুখ আশা করি \(E_i=120/6=20\) বার। বাঁ প্যানেল: নীল দণ্ড observed গণনা \(O_i\) (মুখপিছু সত্যিকারের ফল: \(16,25,18,14,29,18\)), কমলা দণ্ড expected \(E_i=20\) (কমলা ডটেড রেখায় সমান উচ্চতা)। ওপরের বাক্সে Pearson statistic \(\chi^2=\sum_i\frac{(O_i-E_i)^2}{E_i}=8.30\) (\(df=k-1=5\))। ডান প্যানেল: বেগুনি \(\chi^2_5\) reference density; লাল ভাঙা রেখা ও ছায়া \(95\%\) critical value \(\chi^2_{5,0.95}=11.07\)-এর ডানে \(5\%\) rejection region; নীল মোটা রেখা আমাদের observed statistic \(8.30\) — যা critical value-এর বাঁয়ে (rejection region-এর বাইরে)।
যা লক্ষ করতে হবে: (ক) প্রতিটা \(\frac{(O_i-E_i)^2}{E_i}\) আসলে একটা scaled squared mismatch — দণ্ড-জোড়ার উচ্চতার তফাত যত বড়, সেই মুখের অবদান তত বড় (এখানে মুখ "৫": \(O=29\) বনাম \(E=20\), অবদান \(\frac{81}{20}=4.05\) — সবচেয়ে বড়)। সব অবদান যোগ করে মোট \(\chi^2=8.30\)। তফাত যত বড়, statistic তত বড়, \(H_0\) তত অবিশ্বাস্য। (খ) সিদ্ধান্তের নিয়ম: observed $8.30 < 11.07 = $ critical value (p \(=0.14 > 0.05\)), তাই \(H_0\) প্রত্যাখ্যান করা যায় না — এই ওঠানামা \(120\) বার গড়ানোয় কেবল randomness দিয়েই ব্যাখ্যা করা যায়, ছক্কাটা ঝোঁকওয়ালা বলার যথেষ্ট প্রমাণ নেই। (গ) \(df=k-1=5\) (৬টা মুখ, ১টা constraint: গণনাগুলোর যোগফল \(n\)-এ স্থির), \(6\) নয় — এই df-গোনা না-পারলে ভুল critical value আসবে। (ঘ) একই \(\chi^2\) যন্ত্র test of independence-এও খাটে: তখন \(E_i\) আসে row-total × column-total ÷ grand-total থেকে, আর \(df=(r-1)(c-1)\) — observed বনাম "independence ধরলে যা হতো" তার তফাত মাপা।
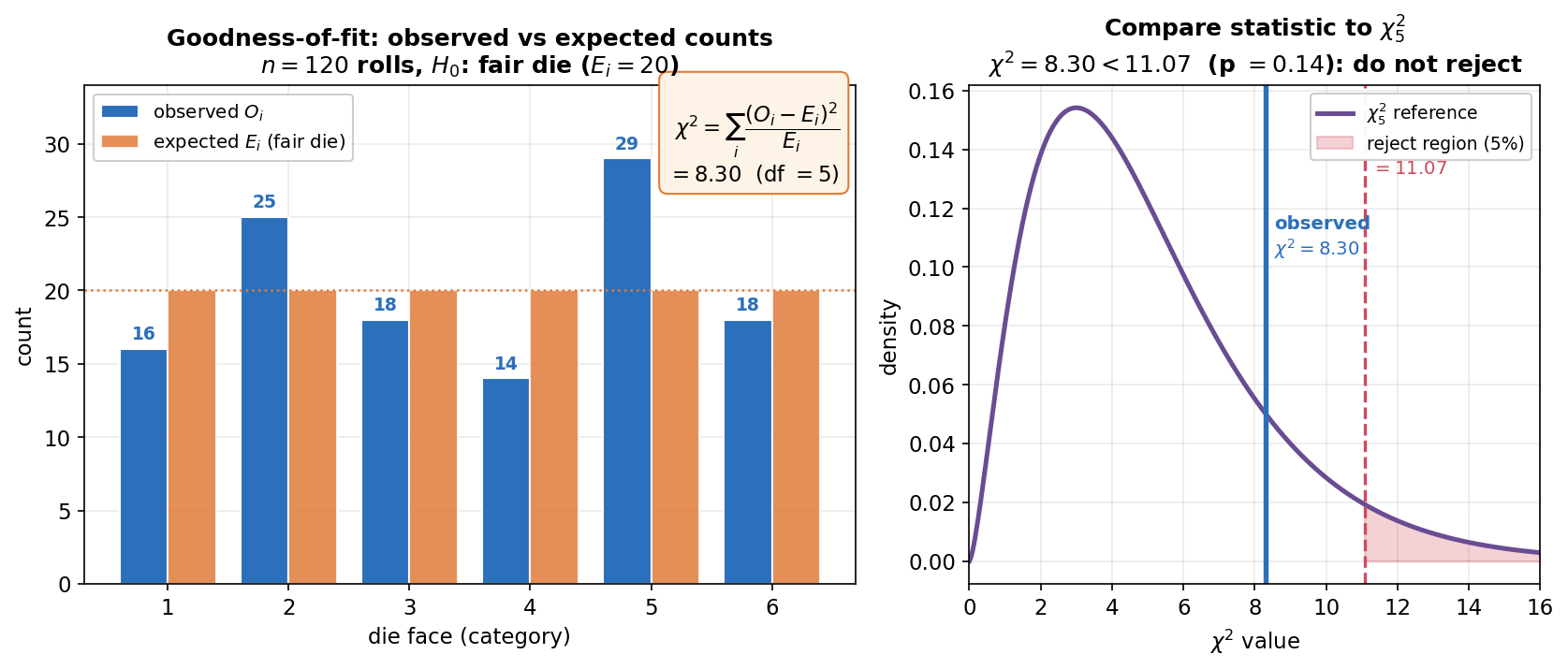
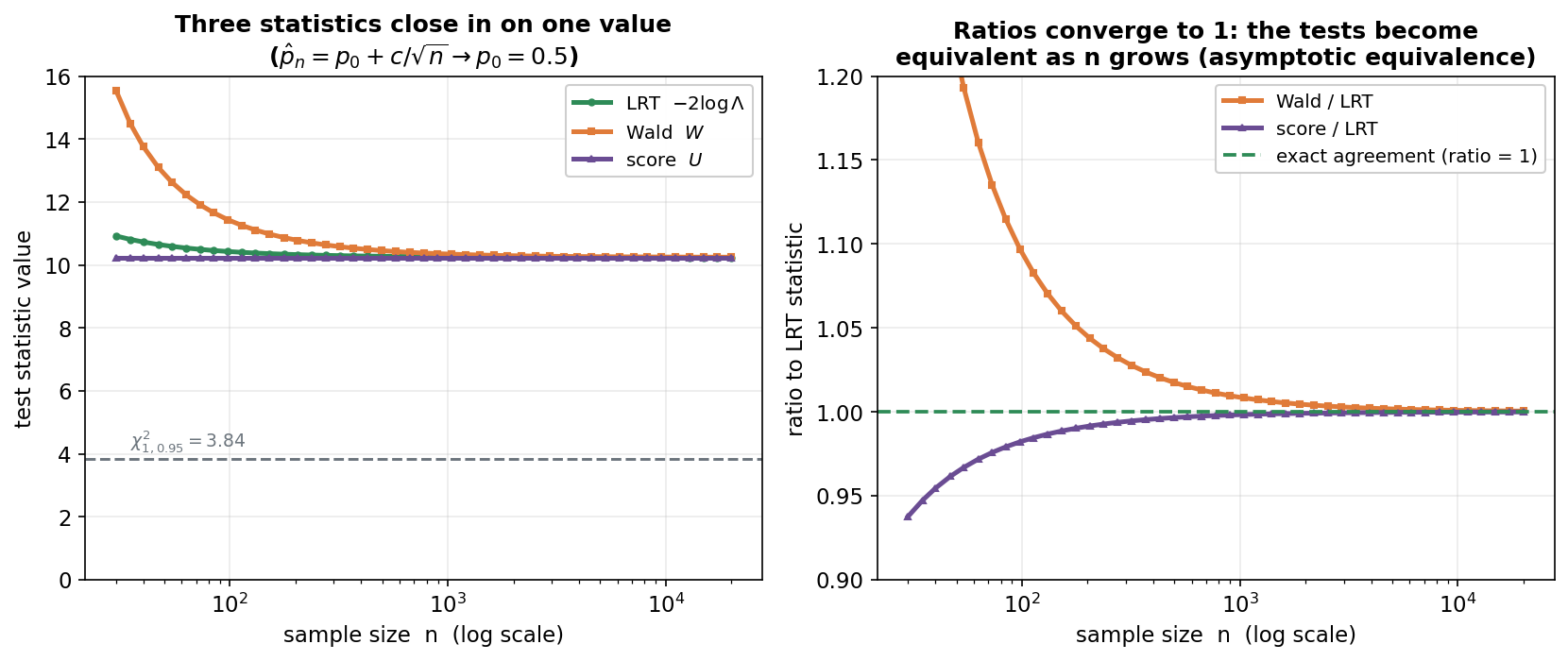
Figure 4 — তিন test-এর সমতা: \(n\) বাড়লে এক বিন্দুতে মিলন¶
শেষ ছবি Figure 1-এর তিন test-কে আবার একসাথে আনে, কিন্তু এবার প্রশ্ন: এরা কি একই উত্তর দেয়? ছোট নমুনায় LRT, Wald, score তিনটা আলাদা সংখ্যা দিতে পারে (কারণ তারা পাহাড়ের ভিন্ন জায়গায় হিসাব করে — Figure 1), কিন্তু বড় নমুনায় তিনটাই একই মানে মিলে যায় — এটাই তাদের asymptotic equivalence। উদাহরণ: Bernoulli\((p)\), \(H_0:p=0.5\), আর data এমন যে \(\hat p_n=p_0+c/\sqrt n\) (একটা "local alternative", যা \(n\) বাড়লে \(p_0\)-এর দিকে আসে)। বাঁ প্যানেল: অনুভূমিক অক্ষ \(n\) (log-scale); সবুজ LRT, কমলা Wald, বেগুনি score তিনটা curve — ছোট \(n\)-এ স্পষ্ট আলাদা (Wald সবার ওপরে), \(n\) বাড়লে একটা সাধারণ মানে (~\(10.2\)) গুটিয়ে আসে; ধূসর রেখা \(\chi^2_{1,0.95}=3.84\)। ডান প্যানেল: LRT-এর সাপেক্ষে অনুপাত — কমলা Wald/LRT উপর থেকে, বেগুনি score/LRT নিচ থেকে, দুটোই \(n\) বাড়লে \(1\)-এ মিলে যায় (সবুজ রেখা)।
যা লক্ষ করতে হবে: (ক) ছোট \(n\)-এ তিনটা curve আলাদা — তাই ছোট নমুনায় কোন test বাছছেন তা সিদ্ধান্ত বদলে দিতে পারে (Wald এখানে সবচেয়ে বড়, একটু liberal)। কিন্তু বড় \(n\)-এ পার্থক্য মুছে যায়। (খ) ডান প্যানেলে অনুপাত \(\to 1\): \(n=30\)-এ Wald/LRT \(\approx 1.42\), score/LRT \(\approx 0.94\) (বেশ আলাদা); \(n\) কয়েক হাজার হলে দুটোই \(1.00\)-এর গায়ে — অর্থাৎ তিন test কার্যত একই। এই সমতার কারণ Figure 1-এর জ্যামিতি: বড় নমুনায় log-likelihood চূড়ার কাছে প্রায়-নিখুঁত parabola (quadratic), আর parabola-র জন্য উল্লম্ব ড্রপ, অনুভূমিক দূরত্বের বর্গ, আর ঢাল-ভিত্তিক মাপ — তিনটাই একই curvature (Fisher information) দিয়ে হুবহু মিলে যায়। (গ) তাহলে কোনটা ব্যবহার করব? বড় নমুনায় যেটা সুবিধাজনক: score (MLE বের করা লাগে না, শুধু \(\theta_0\)-তে হিসাব), Wald (CI বানানো সহজ, MLE ও তার se থেকে), LRT (প্রায়ই সবচেয়ে নির্ভরযোগ্য ছোট-নমুনা আচরণ)। তিনটাই বৈধ; শুধু ছোট নমুনায় ফল আলাদা হতে পারে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-08-likelihood-ratio-wald-score-gof-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: likelihood ratio \(\Lambda=\dfrac{\sup_{\theta\in\Theta_0}L(\theta)}{\sup_{\theta\in\Theta}L(\theta)}=\dfrac{L(\theta_0)}{L(\hat\theta)}\) [simple null]; LRT statistic \(-2\log\Lambda \xrightarrow{d}\chi^2_k\) (Wilks); Wald \(W=\dfrac{(\hat\theta-\theta_0)^2}{\widehat{\mathrm{se}}^{\,2}}\); score \(U(\theta_0)=\ell'(\theta_0)\), score statistic \(\dfrac{U(\theta_0)^2}{I(\theta_0)}\xrightarrow{d}\chi^2_1\); Pearson \(\chi^2=\sum_i\dfrac{(O_i-E_i)^2}{E_i}\), GOF df \(=k-1-(\text{আঁচ-করা প্যারামিটার})\), independence df \(=(r-1)(c-1)\)। চলমান উদাহরণ: E1 LRT; E2 Wald; E3 score; E4 Pearson \(\chi^2\) GOF + independence।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন likelihood ratio \(\Lambda\), \(-2\log\Lambda\), আর Wilks' theorem কী। \(\Lambda\) সবসময় \(0\) আর \(1\)-এর মধ্যে থাকে কেন, আর \(\Lambda\) ছোট হওয়া মানে \(H_0\)-এর পক্ষে না বিপক্ষে প্রমাণ? Hint: \(\Lambda=L(\theta_0)/L(\hat\theta)\); লব হলো null-এ best likelihood, হর হলো সর্বত্র best (MLE)-এ — তাই লব \(\le\) হর, মানে \(0\le\Lambda\le1\) (Figure 1-এ \(\ell(\theta_0)\le\ell(\hat\theta)\))। \(\Lambda\) ছোট ⇒ null model অনেক খারাপ fit করে ⇒ \(H_0\)-এর বিপক্ষে প্রমাণ। Wilks: \(H_0\)-র অধীনে \(-2\log\Lambda\xrightarrow{d}\chi^2_k\)।
প্রশ্ন ২ (★★) — [তিন test-এর তুলনা]. LRT, Wald, আর score test — তিনটা কোথায় (কোন \(\theta\)-মানে) likelihood-এর হিসাব করে, আর প্রতিটার সুবিধা কী? Figure 1 থেকে ব্যাখ্যা করুন কোনটা MLE \(\hat\theta\) বের না করেও চালানো যায়। Hint: LRT: \(\hat\theta\) আর \(\theta_0\) দুটোতেই (উল্লম্ব ড্রপ)। Wald: শুধু \(\hat\theta\)-তে (অনুভূমিক দূরত্ব + সেখানকার curvature)। score: শুধু \(\theta_0\)-তে (ঢাল ও information) — তাই score-এ MLE বের করা লাগে না, \(H_0\) যখন simple ও MLE বের করা কঠিন তখন সুবিধাজনক।
প্রশ্ন ৩ (★★). Pearson goodness-of-fit test-এ \(O_i\) ও \(E_i\) কী, আর statistic \(\chi^2=\sum_i\frac{(O_i-E_i)^2}{E_i}\)-এ ভাগফলে \(E_i\) থাকে কেন (শুধু \((O_i-E_i)^2\) নয়)? Figure 3 থেকে বলুন কোন category সবচেয়ে বেশি অবদান রাখল ও কেন। Hint: \(O_i\) = সত্যিকারের গণনা, \(E_i=n p_i^{(0)}\) = \(H_0\) সত্য হলে প্রত্যাশিত গণনা। \(E_i\) দিয়ে ভাগ করায় তফাতটা আপেক্ষিক হয় (বড় \(E_i\)-তে বড় ওঠানামা স্বাভাবিক, তাই কম শাস্তি — এটি Poisson-style variance scaling)। Figure 3-এ মুখ "৫": \((29-20)^2/20=4.05\) সবচেয়ে বড়।
প্রশ্ন ৪ (★★). "তিনটা test বড় নমুনায় equivalent" — এই কথার মানে কী, আর Figure 4 অনুসারে ছোট নমুনায় কী ঘটে? equivalence-এর পেছনে log-likelihood-এর কোন আকৃতিগত (geometric) কারণ আছে (Figure 1-এর সাথে যোগ করুন)? Hint: asymptotic equivalence = \(n\to\infty\)-এ তিন statistic-এর অনুপাত \(\to1\) (একই \(\chi^2_k\) limit)। ছোট \(n\)-এ তিনটা আলাদা সংখ্যা (Figure 4-বাঁ, অনুপাত \(\ne1\))। কারণ: বড় নমুনায় log-lik চূড়ার কাছে প্রায়-নিখুঁত parabola (quadratic), যেখানে উল্লম্ব/অনুভূমিক/ঢাল-মাপ একই Fisher information দিয়ে মেলে।
খ · গাণনিক (computational)¶
প্রশ্ন ৫ (★) — E1 (LRT)। একটা মুদ্রা \(n=100\) বার ছুঁড়ে \(x=62\) বার head এলো। \(H_0:p=0.5\) বনাম \(H_1:p\ne0.5\) টেস্ট করতে \(-2\log\Lambda\) বের করুন এবং \(\chi^2_{1,0.95}=3.84\)-এর সাথে তুলনা করে সিদ্ধান্ত নিন। (সূত্র: \(-2\log\Lambda=2n\big[\hat p\log\frac{\hat p}{p_0}+(1-\hat p)\log\frac{1-\hat p}{1-p_0}\big]\), \(\hat p=0.62\)।) Hint: \(2\times100\big[0.62\ln\frac{0.62}{0.5}+0.38\ln\frac{0.38}{0.5}\big]=200[0.62(0.2151)+0.38(-0.2744)]=200(0.02909)=5.82\)। \(5.82>3.84\) ⇒ \(H_0\) প্রত্যাখ্যান (p \(\approx0.016\))।
প্রশ্ন ৬ (★★) — E2 (Wald)। একই data (\(n=100\), \(\hat p=0.62\), \(H_0:p=0.5\))। Wald statistic \(W=\frac{(\hat p-p_0)^2}{\hat p(1-\hat p)/n}\) বের করুন, \(\chi^2_{1,0.95}\)-এর সাথে তুলনা করুন, এবং প্রশ্ন ৫-এর LRT মানের সাথে মিলিয়ে দেখুন — কাছাকাছি কি? Hint: \(\widehat{\mathrm{var}}=\hat p(1-\hat p)/n=0.62\times0.38/100=0.002356\); \(W=(0.12)^2/0.002356=0.0144/0.002356=6.11\)। \(6.11>3.84\) ⇒ প্রত্যাখ্যান। LRT \(5.82\)-র কাছাকাছি (Wald একটু বড়, Figure 4-এর মতো) — \(n=100\)-এ এখনও পুরো মিল নয়।
প্রশ্ন ৭ (★★) — E3 (score)। একই data। score statistic \(S=\frac{(\hat p-p_0)^2}{p_0(1-p_0)/n}\) বের করুন (লক্ষ করুন variance এখন \(p_0\)-তে হিসাব, \(\hat p\)-তে নয়)। তিনটা মান (LRT \(5.82\), Wald \(6.11\), score) পাশাপাশি রাখুন — কোনটা সবচেয়ে ছোট/বড়? Hint: \(p_0(1-p_0)/n=0.5\times0.5/100=0.0025\); \(S=(0.12)^2/0.0025=0.0144/0.0025=5.76\)। ক্রম: score \(5.76<\) LRT \(5.82<\) Wald \(6.11\) — তিনটাই \(>3.84\), একই সিদ্ধান্ত, মানে কাছাকাছি (এটাই Figure 4-এর ছোট-\(n\) ছবি; এখানে score = Pearson \(\chi^2\)-এর সমতুল্য)।
প্রশ্ন ৮ (★★) — E4 (Pearson \(\chi^2\) GOF)। একটা ছক্কা \(n=60\) বার গড়ানো: মুখ ১–৬-এর গণনা \(O=(8,10,9,12,7,14)\)। ছক্কাটা fair কিনা (\(H_0:p_i=1/6\)) Pearson \(\chi^2\) দিয়ে টেস্ট করুন। \(E_i\), \(\chi^2\), df ও সিদ্ধান্ত দিন (\(\chi^2_{5,0.95}=11.07\))। Hint: \(E_i=60/6=10\) সবার। \(\chi^2=\frac{(8\!-\!10)^2+(10\!-\!10)^2+(9\!-\!10)^2+(12\!-\!10)^2+(7\!-\!10)^2+(14\!-\!10)^2}{10}=\frac{4+0+1+4+9+16}{10}=\frac{34}{10}=3.4\)। df \(=6-1=5\); \(3.4<11.07\) ⇒ fair প্রত্যাখ্যান করা যায় না (p \(\approx0.64\))।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★) — score = Pearson \(\chi^2\) (multinomial)। \(k\)-শ্রেণির multinomial-এ \(H_0:p_i=p_i^{(0)}\) টেস্টে দেখান যে score statistic-টি ঠিক Pearson \(\chi^2=\sum_i\frac{(O_i-E_i)^2}{E_i}\)-এ পরিণত হয় (যেখানে \(O_i\) = observed গণনা, \(E_i=np_i^{(0)}\))। অর্থাৎ E3 (score) আর E4 (Pearson GOF) আসলে একই জিনিস। Hint: multinomial log-lik \(\ell(p)=\sum_i O_i\log p_i\) (constraint \(\sum p_i=1\)); \(\theta_0=p^{(0)}\)-তে score vector ও Fisher information বের করে quadratic form \(U^\top I^{-1}U\) গঠন করুন। বীজগণিতে সরলীকরণে \(\sum_i\frac{(O_i-np_i^{(0)})^2}{np_i^{(0)}}\) পড়ে — ঠিক Pearson \(\chi^2\) (df \(=k-1\), constraint-এর জন্য)।
প্রশ্ন ১০ (★★) — Wilks (normal mean ক্ষেত্রে exact)। \(X_1,\dots,X_n\overset{iid}{\sim}\mathcal{N}(\theta,\sigma^2)\), \(\sigma\) জানা; \(H_0:\theta=\theta_0\)। দেখান যে এখানে \(-2\log\Lambda=\frac{n(\bar X-\theta_0)^2}{\sigma^2}\), এবং \(H_0\)-র অধীনে এটি ঠিক (asymptotic নয়) \(\chi^2_1\) — অর্থাৎ এই বিশেষ ক্ষেত্রে Wilks' theorem হুবহু খাটে। Hint: \(\ell(\theta)=-\frac{1}{2\sigma^2}\sum(X_i-\theta)^2+\)const; MLE \(\hat\theta=\bar X\)। \(-2\log\Lambda=2[\ell(\hat\theta)-\ell(\theta_0)]=\frac{1}{\sigma^2}[\sum(X_i-\theta_0)^2-\sum(X_i-\bar X)^2]=\frac{n(\bar X-\theta_0)^2}{\sigma^2}\)। \(H_0\)-তে \(\frac{\bar X-\theta_0}{\sigma/\sqrt n}\sim\mathcal{N}(0,1)\), তাই তার বর্গ \(\sim\chi^2_1\) exactly। (এটাই Figure 1-এর উল্লম্ব ড্রপ, আর Figure 2-বাঁয়ের \(k=1\) histogram-এর তাত্ত্বিক ভিত্তি।)
প্রশ্ন ১১ (★★★) — তিন test-এর asymptotic equivalence। smooth log-likelihood-এ \(\theta_0\)-র কাছে দ্বিতীয়-ক্রম (Taylor) প্রসারণ ব্যবহার করে দেখান যে LRT statistic \(-2\log\Lambda\), Wald \(W\), আর score statistic \(S\) — তিনটাই বড় নমুনায় একই limit-এ যায় (\(\xrightarrow{d}\chi^2_k\)), অর্থাৎ Figure 4-এর অনুপাত-অভিসরণ। (single-parameter ক্ষেত্রে যথেষ্ট।) Hint: \(\ell(\theta)\approx\ell(\hat\theta)-\frac12 I(\hat\theta)(\theta-\hat\theta)^2\) (চূড়ায় ঢাল \(0\), curvature \(\approx I\))। এখান থেকে: \(-2\log\Lambda\approx I(\hat\theta)(\hat\theta-\theta_0)^2\) (উল্লম্ব ড্রপ); \(W=(\hat\theta-\theta_0)^2 I(\hat\theta)\) (একই!); score \(U(\theta_0)\approx I(\hat\theta)(\hat\theta-\theta_0)\), তাই \(S=U^2/I\approx I(\hat\theta)(\hat\theta-\theta_0)^2\)। তিনটাই \(\approx I\cdot(\hat\theta-\theta_0)^2\), পার্থক্য শুধু \(I\) কোথায় হিসাব (\(\hat\theta\) না \(\theta_0\)) — যা \(\hat\theta\xrightarrow{P}\theta_0\) হওয়ায় মুছে যায়।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★★) — Wilks সিমুলেশন (Figure 2 পুনর্নির্মাণ)। \(\mathcal{N}(\theta_0=0,1)\) থেকে \(n=40\)-এর নমুনা \(20{,}000\) বার টেনে প্রতিবার \(H_0:\theta=0\)-এর জন্য \(-2\log\Lambda=n\bar x^2\) হিসাব করুন। (ক) histogram আর \(\chi^2_1\) density পাশাপাশি প্লট করুন — মেলে কি? (খ) সিমুলেটেড statistic-এর কত ভাগ \(\chi^2_{1,0.95}=3.84\) ছাড়িয়ে যায় — \(\approx0.05\) কি (type I error)? Hint:
import numpy as np
from scipy import stats
rng = np.random.default_rng(0)
n, R = 40, 20000
xbar = rng.normal(0, 1/np.sqrt(n), size=R)
lr = n * xbar**2 # -2 log Lambda, exact chi^2_1 under H0
print("reject rate:", (lr > stats.chi2.ppf(0.95, 1)).mean()) # ~0.05
প্রশ্ন ১৩ (★★) — তিন test পাশাপাশি (Bernoulli)। Bernoulli\((p)\), \(H_0:p=0.5\)। একটা ফাংশন লিখুন যা \(n\) ও observed \(\hat p\) নিয়ে LRT, Wald, score তিনটা statistic ফেরত দেয়। \(n=100,\hat p=0.62\)-তে চালিয়ে প্রশ্ন ৫–৭-এর হাতে-হিসাব (\(5.82,6.11,5.76\)) যাচাই করুন; তারপর \(n\) বড় করে (একই \(\hat p\)) দেখান তিনটা মান কাছাকাছি আসে। Hint:
import numpy as np
def three_tests(n, phat, p0=0.5):
lrt = 2*n*(phat*np.log(phat/p0) + (1-phat)*np.log((1-phat)/(1-p0)))
wald = n*(phat-p0)**2 / (phat*(1-phat)) # var at MLE
score = n*(phat-p0)**2 / (p0*(1-p0)) # var at p0
return lrt, wald, score
print(three_tests(100, 0.62)) # ~ (5.82, 6.11, 5.76)
প্রশ্ন ১৪ (★★★) — \(\chi^2\) test of independence (E4-এর দ্বিতীয় রূপ)। একটা \(2\times2\) contingency table ([[30, 20], [25, 45]], যেমন treatment×outcome) থেকে \(H_0:\) row ও column স্বাধীন টেস্ট করুন। (ক) row/column total থেকে \(E_{ij}=\frac{\text{row}_i\times\text{col}_j}{n}\) হিসাব করে Pearson \(\chi^2\) ও df \(=(r-1)(c-1)=1\) বের করুন; (খ) scipy.stats.chi2_contingency-র ফলের সাথে মিলিয়ে দেখুন।
Hint:
import numpy as np
from scipy import stats
O = np.array([[30, 20], [25, 45]])
chi2, p, dof, E = stats.chi2_contingency(O, correction=False)
print(f"chi2={chi2:.3f}, df={dof}, p={p:.4f}") # df=1
# হাতে: E = row_totals[:,None]*col_totals[None,:]/n; sum((O-E)**2/E)
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- এক পাহাড়, তিন test (Figure 1)। likelihood ratio, Wald, আর score — তিনটাই একই log-likelihood বক্ররেখায় "\(\theta_0\) চূড়া থেকে কত দূরে" মাপে, তিন ভিন্ন দিক থেকে: LRT = উল্লম্ব ড্রপ \(-2\log\Lambda=2[\ell(\hat\theta)-\ell(\theta_0)]\) (\(\hat\theta\) ও \(\theta_0\) দুটোতেই fit); Wald \(W=(\hat\theta-\theta_0)^2/\widehat{\mathrm{se}}^{\,2}\) (শুধু MLE-তে); score \(S=U(\theta_0)^2/I(\theta_0)\) (শুধু \(\theta_0\)-তে, MLE বের না করেই)।
- Wilks' theorem (Figure 2)। বড় নমুনায় \(H_0\)-র অধীনে \(-2\log\Lambda\xrightarrow{d}\chi^2_k\), যেখানে \(k\) = \(H_0\) যতগুলো প্যারামিটার আটকায় (restrictions/df)। এটাই LRT-কে practical করে: statistic বের করে সরাসরি \(\chi^2_k\)-table-এ দেখলেই p-value। সিমুলেশনে histogram ঠিক \(\chi^2_k\)-এ বসে (§৭ Q10, Q12)।
- Pearson \(\chi^2\) goodness-of-fit (Figure 3)। categorical data-য় \(\chi^2=\sum_i\frac{(O_i-E_i)^2}{E_i}\) — observed \(O_i\) বনাম \(H_0\)-প্রত্যাশিত \(E_i=np_i^{(0)}\)-এর scaled squared mismatch-এর যোগফল; বড় হলে \(H_0\) খারিজ। GOF df \(=k-1-(\text{আঁচ-করা প্যারামিটার সংখ্যা})\); test of independence-এ \(E_{ij}=\frac{\text{row}_i\,\text{col}_j}{n}\), df \(=(r-1)(c-1)\) — একই যন্ত্র, ভিন্ন \(E\) (§৭ Q8, Q14)।
- score = Pearson (§৭ Q9)। multinomial-এ score statistic বীজগণিতে ঠিক Pearson \(\chi^2\)-এ পরিণত হয় — অর্থাৎ E3 আর E4 গভীরভাবে এক; Pearson \(\chi^2\) আসলে multinomial-এর score test।
- তিন test-এর সমতা (Figure 4)। ছোট নমুনায় LRT, Wald, score আলাদা সংখ্যা দিতে পারে, কিন্তু বড় নমুনায় তিনটাই একই \(\chi^2_k\) limit-এ মিলে যায় (অনুপাত \(\to1\))। কারণ: বড় \(n\)-এ log-lik চূড়ার কাছে প্রায়-নিখুঁত parabola, যেখানে উল্লম্ব/অনুভূমিক/ঢাল-মাপ একই Fisher information দিয়ে বাঁধা (§৭ Q11)। তাই কোনটা ব্যবহার করবেন তা সুবিধার প্রশ্ন: score (MLE লাগে না), Wald (CI-র সাথে সুসংগত), LRT (প্রায়ই সেরা ছোট-নমুনা আচরণ)।
- CI ↔ test দ্বৈততা (4.6 থেকে)। Wald statistic-এর \(\sqrt{}\) ঠিক 4.6-এর Wald CI-র z-অনুপাত; একটা \((1-\alpha)\) Wald CI হলো সেই সব \(\theta_0\)-এর সংগ্রহ যাদের Wald test \(\alpha\)-level-এ প্রত্যাখ্যান করে না।
পূর্ববর্তী সংযোগ (← 4.7 Hypothesis Testing; এবং 4.3, 4.5): 4.7-এ আমরা hypothesis testing-এর কাঠামো গড়েছি — \(H_0\) বনাম \(H_1\), type I/II error, p-value, power, আর Neyman–Pearson lemma যা বলে simple বনাম simple ক্ষেত্রে likelihood ratio-ই সবচেয়ে শক্তিশালী (most powerful) test। এই অধ্যায় সেই likelihood-ratio ধারণাকে composite ও বহুমাত্রিক ক্ষেত্রে সাধারণীকরণ করল (\(\Lambda=\sup_{\Theta_0}L/\sup_{\Theta}L\), \(-2\log\Lambda\sim\chi^2_k\)) আর তার সাথে দুটো সহগামী test (Wald, score) যোগ করল। ভিত্তিগত উপাদান এসেছে আগে থেকে: 4.3-এর MLE ও log-likelihood (\(\hat\theta\), \(\ell(\theta)\) — Figure 1-এর পাহাড়), আর 4.5-এর Fisher information \(I(\theta)\) ও MLE-র asymptotic normality — যেখান থেকে Wald-এর \(\widehat{\mathrm{se}}\), score-এর \(I(\theta_0)\), আর তিন test-এর \(\chi^2\)-limit সবই আসে। অর্থাৎ 4.7 ছিল testing-এর সাধারণ নীতি; 4.8 হলো সেই নীতি প্রয়োগের তিনটা সর্বজনীন পদ্ধতি এবং categorical data-র \(\chi^2\) পরিবার।
পরবর্তী সংযোগ (→ 4.9 — Bootstrap: simulation-ভিত্তিক inference): এই অধ্যায়ের পুরো শক্তি একটা সূত্রের ওপর দাঁড়িয়ে — "\(-2\log\Lambda\) বা Wald বা \(\chi^2\) statistic-এর বণ্টন (asymptotically) \(\chi^2_k\)।" কিন্তু এই \(\chi^2\) approximation বড় নমুনার, আর অনেক বাস্তব সমস্যায় (ছোট \(n\), জটিল estimator, অদ্ভুত statistic) এমন কোনো সুন্দর সূত্র জানাই থাকে না বা ভালো খাটে না। পরের অধ্যায় উল্টো পথে যায়: যখন formula কঠিন বা অজানা, তখন data থেকেই বারবার resample করে (bootstrap) statistic-এর sampling distribution সিমুলেশনে বানিয়ে নেওয়া — standard error, confidence interval, এমনকি p-value পর্যন্ত। যেমন Figure 2-তে আমরা সিমুলেশনে \(-2\log\Lambda\)-এর বণ্টন দেখলাম (কিন্তু সেখানে সত্য \(H_0\) জানা ছিল), bootstrap সেই simulation-ভিত্তিক চিন্তাকে হাতের data দিয়ে করে যখন তত্ত্ব নীরব। এটি এই অধ্যায়ের চমৎকার পরিপূরক: classical theory দেয় ঝকঝকে সূত্র যেখানে সেগুলো খাটে, bootstrap দেয় সাধারণ-উদ্দেশ্য হাতিয়ার যেখানে সূত্র নেই।
বৃহত্তর স্থান (where this sits): 4.8 হলো Part IV-এর শেষ "classical/parametric inference" অধ্যায় — point estimation (4.1–4.5), confidence intervals (4.6), hypothesis testing (4.7), আর testing-এর তিন মহাপদ্ধতি + \(\chi^2\) (4.8) মিলে frequentist parametric inference-এর কাঠামো সম্পূর্ণ। এর পরে দৃষ্টিভঙ্গি বদলায়: 4.9 (bootstrap) নিয়ে আসে resampling/simulation-ভিত্তিক inference, এবং তারপর Bayesian দৃষ্টিভঙ্গি — যেখানে অনিশ্চয়তা আঁকা হয় formula-নির্ভরতা কমিয়ে, computation দিয়ে। অর্থাৎ এই অধ্যায়ের সাথে এক যুগ (closed-form, large-sample \(\chi^2\) তত্ত্ব) শেষ, আর পরের অধ্যায় থেকে computation-চালিত inference-এর যুগ শুরু।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 10 (Hypothesis Testing and p-values — §10.5 Wald test, §10.6 likelihood ratio test ও Wilks' theorem, §10.7 multinomial ও goodness-of-fit, §10.8 Pearson \(\chi^2\) ও test of independence); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 9 (Testing Hypotheses — §9.4–9.5 likelihood ratio tests ও generalized LRT, §9.5 Pearson's chi-square statistic, goodness-of-fit ও independence)।