4.10 — Bayesian Inference (বেইসীয় অনুমান)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — parameter-কে একটা সংখ্যা নয়, একটা বিশ্বাস-বণ্টন ভাবা¶
১.১ এতদিন আমরা যা করেছি — আর কোন প্রশ্নটা গোড়াতেই অস্বস্তিকর ছিল¶
Part IV-এর এতগুলো অধ্যায় (4.1 থেকে 4.9) জুড়ে আমরা একটা অলিখিত ধারণা ধরে রেখেছিলাম — এতই স্বাভাবিক মনে হয়েছে যে কখনো প্রশ্নও তুলিনি। ধারণাটা এই:
সত্য parameter \(\theta\) ("থিটা") একটা fixed (স্থির) কিন্তু আমাদের অজানা সংখ্যা। সব এলোমেলোতা (randomness) আসে data থেকে — আমরা যদি আবার নমুনা নিই, ভিন্ন data পাব, ভিন্ন estimate \(\hat\theta\) পাব। কিন্তু \(\theta\) নিজে নড়ে না; সে আকাশে স্থির একটা তারা, যাকে আমরা কেবল অস্পষ্ট দূরবিনে (data) দেখার চেষ্টা করছি।
এই দৃষ্টিভঙ্গির নাম frequentist (পৌনঃপুনিক) — কারণ এখানে probability মানে "বহুবার পুনরাবৃত্তিতে কত ভগ্নাংশ বার"। এই কাঠামোতেই আমরা MLE (\(\hat\theta\), 4.3), estimator-এর ধর্ম (4.4), confidence interval (4.6), আর hypothesis test (4.7–4.8) বানিয়েছি। এটা শক্তিশালী, আর বহু ক্ষেত্রে ঠিক যা দরকার।
কিন্তু একটা জায়গায় এই কাঠামো গোড়াতেই অস্বস্তিকর — আর সেই অস্বস্তি থেকেই এই অধ্যায়ের গল্প শুরু:
-
(ক) ব্যাখ্যার অস্বস্তি। 4.6-এ মনে আছে — "৯৫% confidence interval \([49\%,\ 55\%]\)" শোনার পর সবার প্রথম যে কথাটা মনে আসে — "তাহলে সত্য \(\theta\) এই ব্যবধানে থাকার সম্ভাবনা ৯৫%" — সেটা frequentist কাঠামোয় ভুল! কারণ \(\theta\) fixed, সে হয় ভেতরে নয় বাইরে, কোনো "৯৫% সম্ভাবনা" নেই। ৯৫% থাকে পদ্ধতির উপর, \(\theta\)-র উপর নয়। কিন্তু মানুষ যা বলতে চায় সেটাই তো বেশি স্বাভাবিক — তাহলে কি কোনো কাঠামো আছে যেখানে ওই স্বজ্ঞাত বাক্যটাই বৈধ?
-
(খ) পূর্ব-জ্ঞানের অস্বস্তি। ধরুন একটা মুদ্রা পরীক্ষা করছি। আমি জানি বেশিরভাগ মুদ্রাই প্রায় ন্যায্য — \(p\) (\(=\) head-এর সম্ভাবনা) সাধারণত \(0.5\)-এর কাছেই থাকে। frequentist MLE কিন্তু এই পূর্ব-জ্ঞান পুরোপুরি উপেক্ষা করে: \(n=10\) টসে \(7\)টা head এলে সে সোজা বলে \(\hat p=0.7\), যেন আগের কোনো জ্ঞানই নেই। কিন্তু আমার তো আছে! এই বৈধ পূর্ব-বিশ্বাসকে হিসাবে আনার কি কোনো নিয়ম-নিষ্ঠ উপায় আছে?
দুটো অস্বস্তিরই একটাই সমাধান — আর সেটা এতই সরল ও আমূল যে পুরো ছবিটাই বদলে দেয়।
১.২ মূল মোড় — parameter-এর উপরই probability বসাও¶
Bayesian (বেইসীয়) দৃষ্টিভঙ্গির পুরো নতুনত্ব একটিমাত্র বাক্যে:
\(\theta\)-কে fixed-কিন্তু-অজানা একটা সংখ্যা না ভেবে, \(\theta\)-র উপরই একটা probability distribution (সম্ভাবনা-বণ্টন) রাখি — যা আমাদের বিশ্বাস প্রকাশ করে: \(\theta\)-র কোন মান কতটা যুক্তিযুক্ত মনে করি।
এখানে probability-র অর্থ বদলে গেল। frequentist-এ probability ছিল "দীর্ঘমেয়াদি পুনরাবৃত্তির ভগ্নাংশ"। Bayesian-এ probability হলো বিশ্বাসের মাত্রা (degree of belief) — "আমি কতটা নিশ্চিত"। মুদ্রার উদাহরণে: data দেখার আগে আমি বলতে পারি "\(p\) সম্ভবত \(0.5\)-এর কাছে, \(0.9\) বা \(0.1\) হওয়ার সম্ভাবনা কম" — এটাই একটা বণ্টন, \(\theta\)-র উপর।
এই এক পদক্ষেপ ঠিক ওই দুই অস্বস্তি মেটায়:
- যেহেতু \(\theta\)-র উপর এখন সত্যিকারের probability আছে, "\(\theta\) এই ব্যবধানে থাকার সম্ভাবনা ৯৫%" বাক্যটা এবার বৈধ ও সরাসরি — এটাই হবে credible interval (§২.৪)।
- পূর্ব-বিশ্বাসটা হবে আমাদের শুরুর বণ্টন — prior (§২.১)। তাই পূর্ব-জ্ঞান আর উপেক্ষিত নয়; সে হিসাবের আনুষ্ঠানিক অংশ।
১.৩ data এলে কী হয় — 2.2-এর Bayes-ই, এবার parameter-এ¶
কিন্তু বিশ্বাস তো স্থির থাকার জিনিস নয় — data এলে বিশ্বাস বদলায়। আর বিশ্বাস বদলানোর নিয়ম আমরা 2.2-এই শিখেছি: Bayes' theorem। সেখানে আমরা event-এর জন্য লিখেছিলাম (2.2-এর মূল মন্ত্র):
এখানে \(B_k\) ছিল প্রতিদ্বন্দ্বী hypothesis, \(A\) ছিল পর্যবেক্ষিত evidence, আর "\(\propto\)" ("সমানুপাতিক") মানে "ডান পাশকে একটা স্থির সংখ্যা দিয়ে গুণ করলে বাঁ পাশ" — সেই স্থির সংখ্যাই normalizing constant (হরের যোগফল)। 2.2-এর §৩.৪-এ আমরা আরও দেখেছিলাম sequential updating: একটা positive test-এর পর posterior বের করে, সেটাকেই পরের test-এর prior ধরে আবার update — বিশ্বাস ধাপে ধাপে পরিমার্জিত হয়।
এই অধ্যায়ের পুরো কথা একটাই — ঠিক সেই নিয়মটা, কিন্তু \(B_k\) (একটা event)-এর জায়গায় parameter \(\theta\) (একটা সংখ্যা/রাশি):
অর্থাৎ:
- শুরুতে \(\theta\) সম্পর্কে আমার বিশ্বাস — prior \(\pi(\theta)\) ("পাই-অফ-থিটা")।
- data এলো; data কতটা \(\theta\)-র সঙ্গে মানানসই, তা মাপে likelihood \(L(\theta)=p(\text{data}\mid\theta)\) — যা আমাদের 4.3 থেকেই চেনা।
- দুটো গুণ করে (ও normalize করে) পাই হালনাগাদ বিশ্বাস — posterior \(p(\theta\mid\text{data})\)।
এক বাক্যে যা সারা অধ্যায় ধরে রাখবে: Bayesian inference মানে — \(\theta\)-র উপর একটা শুরুর বিশ্বাস (prior) নাও, data কতটা প্রতিটি \(\theta\)-কে সমর্থন করে তা দিয়ে (likelihood) গুণ করো, normalize করো — ফল হলো data-পরবর্তী বিশ্বাস (posterior)। গোটা inference এই এক লাইনেই: \(\text{posterior} \propto \text{prior} \times \text{likelihood}\)।
১.৪ দুই দর্শন পাশাপাশি — frequentist বনাম Bayesian¶
পার্থক্যটা যন্ত্রের নয়, দর্শনের — কী জিনিসকে এলোমেলো (random) ভাবা হচ্ছে, তার। নিচের তুলনাটা পুরো অধ্যায়ের কম্পাস:
| প্রশ্ন | Frequentist (4.1–4.9) | Bayesian (এই অধ্যায়) |
|---|---|---|
| \(\theta\) কী? | fixed কিন্তু অজানা সংখ্যা | একটা random চলক — তার উপর বিশ্বাস-বণ্টন |
| probability-র অর্থ | দীর্ঘমেয়াদি ভগ্নাংশ (frequency) | বিশ্বাসের মাত্রা (degree of belief) |
| পূর্ব-জ্ঞান? | কাঠামোয় ঢোকে না | prior \(\pi(\theta)\)-তে আনুষ্ঠানিকভাবে ঢোকে |
| মূল ফলাফল | point estimate \(\hat\theta\) + confidence interval | পুরো posterior বণ্টন \(p(\theta\mid\text{data})\) |
| interval-এর ব্যাখ্যা | "পদ্ধতি ৯৫% বার \(\theta\) ধরে" (পরোক্ষ) | "\(\theta\) এখানে থাকার সম্ভাবনা ৯৫%" (সরাসরি) |
| data এলে | নতুন estimate গণনা | prior → posterior update |
লক্ষ করুন — Bayesian-এর আউটপুট কোনো একটামাত্র সংখ্যা নয়, বরং একটা পুরো বণ্টন (posterior)। চাইলে তা থেকে একটা সংখ্যা (posterior mean বা MAP, §২.৫) বা একটা ব্যবধান (credible interval) বের করা যায় — কিন্তু মূল ধন হলো বণ্টনটাই, কারণ সে \(\theta\) সম্পর্কে আমাদের সম্পূর্ণ অনিশ্চয়তা একসাথে ধরে রাখে।
একটা ভারসাম্যের কথা (যাতে ভুল ধারণা না হয়): Bayesian "ভালো" আর frequentist "খারাপ" — এমন নয়। দুটোই বৈধ, পরিপূরক হাতিয়ার। Bayesian-এর সুবিধা: পূর্ব-জ্ঞান ব্যবহার, স্বজ্ঞাত ব্যাখ্যা, ছোট নমুনায়ও পূর্ণ অনিশ্চয়তা-হিসাব। দাম: prior বাছতে হয় (যা বিতর্কিত হতে পারে), আর posterior-এর integral প্রায়ই কঠিন (তখন MCMC লাগে, §৩-এর E4)। কোনটা কখন — সেটা সমস্যা ও দর্শনের উপর।
১.৫ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — কেন্দ্রীয় ধারণা from scratch, প্রতিটি প্রতীক খুলে: (ক) prior \(\pi(\theta)\), likelihood \(L(\theta)\), posterior \(p(\theta\mid\text{data})\) ও তাদের সম্পর্ক \(\text{posterior}\propto\text{prior}\times\text{likelihood}\); (খ) normalizing constant (evidence) \(\int L\pi\,d\theta\); (গ) conjugate prior — Beta–Binomial ও Normal–Normal; (ঘ) credible interval ও CI-র সঙ্গে ব্যাখ্যার পার্থক্য; (ঙ) MAP ও posterior mean; (চ) posterior predictive।
- §৩ — চারটি পূর্ণাঙ্গ উদাহরণ সংখ্যাসহ: E1 Beta–Binomial (মুদ্রা/proportion), E2 Normal–Normal (mean), E3 credible বনাম confidence interval (একই data, দুই ব্যাখ্যা), E4 conjugacy না থাকলে MCMC-র স্বজ্ঞা ও posterior predictive।
- §৪–৫ — posterior-এর integral-উৎপত্তি ও conjugacy-র প্রমাণ, prior বাছাইয়ের আলোচনা (informative/noninformative, Jeffreys), decision theory (loss function থেকে Bayes estimate), এবং MCMC-র গভীরতর সংযোগ (3.6)।
- §৬–৮ — চিত্র (
4-10-prior-posterior,4-10-conjugate-update,4-10-credible-vs-ci,4-10-bayes-mcmc), সাধারণ ভুল-ধারণা, কোড ও অনুশীলনী।
এক বাক্যে কেন এটি Part IV-এর সমাপ্তি-অধ্যায়। Part IV পুরোটা ছিল frequentist inference-এর গল্প — point estimate, interval, test, সব ধরে নিয়ে \(\theta\) fixed। এই অধ্যায় সেই ভিত্তিটাকেই উল্টে দিয়ে দেখায় একই প্রশ্নের (\(\theta\) কী?) সম্পূর্ণ বিকল্প উত্তর-কাঠামো — যেখানে data থেকে আমরা একটা সংখ্যা নয়, একটা পরিমার্জিত বিশ্বাস শিখি। এই Bayesian চিন্তা সরাসরি Part V (Statistical Modeling)-এ গিয়ে কাজে লাগবে — যেখানে জটিল মডেলের parameter-গুলোর উপর prior রেখে posterior থেকে শেখাই হবে আধুনিক statistical ও probabilistic modeling-এর মেরুদণ্ড।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
পুরো বিভাগ জুড়ে কাঠামোটা স্থির: আমাদের কাছে data আছে (প্রায়ই একটি নমুনা \(X_1,\dots,X_n\) — independent and identically distributed, অর্থাৎ স্বাধীন ও একই বণ্টন থেকে আসা, সংক্ষেপে i.i.d.), যার বণ্টন একটি অজানা parameter \(\theta\)-র উপর নির্ভর করে। frequentist-এ \(\theta\) ছিল fixed সংখ্যা; এখানে \(\theta\)-র উপর আমরা probability বসাই।
২.১ Prior, likelihood, posterior — তিন স্তম্ভ¶
সংজ্ঞা (Prior — পূর্ব-বণ্টন, \(\pi(\theta)\))। prior হলো data দেখার আগে \(\theta\) সম্পর্কে আমাদের বিশ্বাস, একটা probability distribution হিসেবে প্রকাশিত:
- \(\pi(\theta)\) ("পাই-অফ-থিটা") — \(\theta\)-র একটা pdf (continuous \(\theta\) হলে) বা pmf (discrete হলে)। এটা বলে: data আসার আগে কোন \(\theta\)-মান কতটা যুক্তিযুক্ত মনে করি। (মুদ্রার উদাহরণে: "\(p\) সম্ভবত \(0.5\)-এর কাছে" — এমন একটা আকৃতির বণ্টন।)
- এটি একটি বৈধ বণ্টন, তাই \(\pi(\theta)\ge 0\) এবং \(\int \pi(\theta)\,d\theta = 1\) (সব \(\theta\)-র উপর সমাকল \(1\))।
সংজ্ঞা (Likelihood — সম্ভাব্যতা-ফলন, \(L(\theta)\))। likelihood হলো data যদি একটা নির্দিষ্ট \(\theta\) থেকে আসত, তবে এই data পাওয়ার সম্ভাবনা — কিন্তু \(\theta\)-র function হিসেবে দেখা (data স্থির):
- \(p(\text{data}\mid\theta)\) — শর্তাধীন সম্ভাবনা: "\(\theta\) দেওয়া থাকলে এই পুরো data-র সম্ভাবনা"। এটি ঠিক 4.3-এর likelihood — কেবল নোটেশনে \(p(\cdot\mid\theta)\) লিখলাম, যাতে Bayes-এর সঙ্গে মেলে।
- \(f(X_i;\theta)\) — একটি observation \(X_i\)-র pdf/pmf, parameter \(\theta\)-তে; i.i.d. বলে সবগুলোর গুণফল।
- মনে রাখুন: likelihood কোনো বণ্টন নয় \(\theta\)-র উপর — \(\int L(\theta)\,d\theta\) সাধারণত \(1\) নয়। এটি কেবল "প্রতিটি \(\theta\) data-কে কতটা সমর্থন করে" তার মাপ।
সংজ্ঞা (Posterior — উত্তর-বণ্টন, \(p(\theta\mid\text{data})\))। posterior হলো data দেখার পর \(\theta\) সম্পর্কে আমাদের পরিমার্জিত বিশ্বাস। Bayes' theorem (2.2)-এর continuous সংস্করণ দিয়ে:
প্রতিটি অংশ খুলি:
- লব \(L(\theta)\,\pi(\theta)\) — likelihood গুণ prior। এটাই 2.2-এর "likelihood × prior"।
- হর \(\int L(\theta')\,\pi(\theta')\,d\theta'\) — লবটাকে সব সম্ভাব্য \(\theta'\)-র উপর যোগ/সমাকল করা (এখানে \(\theta'\) কেবল integration-চলক, যাতে লবের \(\theta\)-র সঙ্গে গুলিয়ে না যায়)। এটি একটি সংখ্যা (\(\theta\)-নিরপেক্ষ), যা নিশ্চিত করে posterior একটা বৈধ বণ্টন (সমাকল \(1\))। এর নাম normalizing constant বা evidence (নিচে §২.২)।
সংজ্ঞা (proportionality form — সবচেয়ে কাজের রূপ)। যেহেতু হর \(\theta\)-র উপর নির্ভর করে না, posterior-এর আকৃতি (\(\theta\) বরাবর) পুরোটা লব থেকেই আসে। তাই আমরা লিখি:
এখানে "\(\propto\)" ("সমানুপাতিক") মানে "একটা \(\theta\)-নিরপেক্ষ ধ্রুবক দিয়ে গুণ করলে সমান"। এই রূপটাই বাস্তবে সবচেয়ে বেশি ব্যবহার হয়: প্রায়ই আমরা \(L(\theta)\pi(\theta)\) গণনা করে, তার আকৃতি দেখে চিনে ফেলি কোন পরিচিত বণ্টন — তারপর normalizing constant এমনিতেই বসে যায় (ঠিক এটাই conjugacy, §২.৩)।
স্বজ্ঞা — তিন স্তম্ভ একসাথে। prior \(\pi(\theta)\) হলো আমার শুরুর মতামত; likelihood \(L(\theta)\) হলো data-র সাক্ষ্য; posterior হলো দুইয়ের আপস। যেখানে prior জোরালো (সংকীর্ণ) ও data কম, সেখানে posterior prior-এর কাছে; যেখানে data প্রচুর, সেখানে likelihood জিতে যায়, posterior MLE-র কাছে চলে আসে — prior-এর ছাপ মুছে যায়। (§৬-এর চিত্র
4-10-prior-posteriorএই তিন বক্ররেখা — prior, likelihood, ও তাদের গুণফল posterior — একই অক্ষে পাশাপাশি দেখাবে।)
২.২ Normalizing constant (evidence) — হরটা কী করছে¶
posterior-এর হর \(\int L(\theta)\pi(\theta)\,d\theta\)-কে আলাদা করে বোঝা দরকার, কারণ এটাই Bayesian হিসাবের সবচেয়ে কঠিন অংশ হয়ে দাঁড়ায়।
সংজ্ঞা (Evidence / marginal likelihood, \(Z\))।
- কেন একে \(p(\text{data})\) বলি: এটি data-র প্রান্তিক (marginal) সম্ভাবনা — সব সম্ভাব্য \(\theta\)-র উপর গড় করা ("\(\theta\) যা-ই হোক, এই data পাওয়ার মোট সম্ভাবনা")। তাই নাম marginal likelihood বা evidence।
- এর একমাত্র কাজ posterior-এ: normalization — posterior-কে \(1\)-এ সমাকলিত করা। আকৃতিতে এর কোনো ভূমিকা নেই (যেহেতু \(\theta\)-নিরপেক্ষ)।
- কেন এটা কঠিন: \(Z\) একটা integral, যা প্রায়ই হাতে কষা যায় না (বিশেষত \(\theta\) বহুমাত্রিক হলে)। দুটো রক্ষাকবচ আছে: (১) conjugate prior বাছলে integral এমনিতেই বেরিয়ে আসে (§২.৩); (২) না বেরোলে, posterior থেকে সরাসরি নমুনা তুলে আনি MCMC দিয়ে (3.6) — যেখানে \(Z\) গণনা করতেই হয় না (§৩-এর E4)।
২.৩ Conjugate prior — যেখানে posterior হাতে-কলমে বেরোয়¶
বেশিরভাগ সময় ওই integral \(Z\) ভয়ের কারণ। কিন্তু কিছু সৌভাগ্যজনক জুটি আছে, যেখানে prior আর likelihood এমনভাবে মেলে যে posterior prior-এর মতো একই পরিবারে থাকে — শুধু parameter বদলায়। তখন কোনো integral কষতে হয় না; posterior-এর নাম-ঠিকানা সূত্র দিয়েই জানা যায়।
সংজ্ঞা (Conjugate prior — অনুবন্ধী prior)। একটি likelihood-পরিবারের জন্য prior-পরিবার \(\pi(\theta)\)-কে conjugate বলি যদি, সেই likelihood-এর সঙ্গে গুণ করার পর, posterior \(p(\theta\mid\text{data})\) একই prior-পরিবারে থাকে (শুধু parameter আলাদা)। সুবিধা: posterior পেতে কেবল prior-এর parameter-কে data দিয়ে update করলেই হয় — integral লাগে না।
দুটি মুখ্য জুটি (যা §৩-এ সংখ্যায় চালাব):
(ক) Beta–Binomial conjugacy (proportion/মুদ্রার জন্য)। ধরুন \(\theta=p\in[0,1]\) একটা সাফল্যের সম্ভাবনা (যেমন head), আর data হলো \(n\) trial-এ \(k\)টা সাফল্য — অর্থাৎ \(k\sim\text{Binomial}(n,p)\)।
- prior: \(\pi(p)=\text{Beta}(a,b)\) — Beta বণ্টন (2.4), যার pdf \(\propto p^{a-1}(1-p)^{b-1}\)। এখানে \(a>0,b>0\) দুটো আকৃতি-parameter (shape parameters); স্বজ্ঞা — \(a\) যেন "আগে দেখা সাফল্যের সংখ্যা \(+1\)", \(b\) যেন "আগে দেখা ব্যর্থতার সংখ্যা \(+1\)" (pseudo-counts, ছদ্ম-গণনা)। \(a=b=1\) দিলে Beta\((1,1)\) = uniform = "কোনো পক্ষপাত নেই"।
- likelihood: \(L(p)=p^{k}(1-p)^{n-k}\) (\(p\)-নির্ভর অংশ, ধ্রুবক \(\binom{n}{k}\) বাদ)।
- posterior: গুণ করি — \(\pi(p)L(p)\propto p^{a-1}(1-p)^{b-1}\cdot p^{k}(1-p)^{n-k} = p^{(a+k)-1}(1-p)^{(b+n-k)-1}\)। এটি ঠিক আরেকটা Beta-র আকৃতি! তাই $$ \boxed{\ p\mid\text{data} \;\sim\; \text{Beta}\big(a+k,\; b+n-k\big)\ } $$ কথায়: prior Beta\((a,b)\)-তে সাফল্য-গণনা \(k\) যোগ হয় প্রথম parameter-এ, ব্যর্থতা-গণনা \(n-k\) যোগ হয় দ্বিতীয়টায়। data যেন prior-এর pseudo-count-এ আসল count যোগ করছে — ঠিক sequential updating (2.2-§৩.৪)-এর সুন্দর রূপ।
(খ) Normal–Normal conjugacy (known variance-এ mean-এর জন্য)। ধরুন data \(X_1,\dots,X_n \sim \mathcal{N}(\mu,\sigma^2)\), যেখানে variance \(\sigma^2\) জানা, আর অজানা parameter কেবল mean \(\mu\)।
- prior: \(\mu \sim \mathcal{N}(\mu_0,\tau_0^2)\) — mean-এর উপর Normal prior, যেখানে \(\mu_0\) ("মিউ-নট") prior-গড় (আমার আগের অনুমান \(\mu\) কোথায়) আর \(\tau_0^2\) ("টাউ-নট-বর্গ") prior-variance (কতটা অনিশ্চিত — বড় \(\tau_0^2\) = দুর্বল/ছড়ানো prior)।
- likelihood: \(L(\mu)\propto \exp\!\big(-\frac{n}{2\sigma^2}(\bar X-\mu)^2\big)\), যেখানে \(\bar X=\frac1n\sum_i X_i\) sample mean (গণনা §৪-এ)।
- posterior: দুটো Normal-এর exponent যোগ করলে আবার একটা Normal বেরোয় (বর্গপূরণ, §৪-এ): $$ \boxed{\ \mu\mid\text{data} \;\sim\; \mathcal{N}\big(\mu_n,\ \tau_n^2\big),\quad \mu_n=\frac{\frac{1}{\tau_0^2}\mu_0+\frac{n}{\sigma^2}\bar X}{\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}},\quad \frac{1}{\tau_n^2}=\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}\ } $$ কথায় (সবচেয়ে সুন্দর স্বজ্ঞা): posterior mean \(\mu_n\) হলো prior-গড় \(\mu_0\) আর data-গড় \(\bar X\)-এর একটা ওজনযুক্ত গড় (weighted average) — ওজন হলো প্রতিটির precision (নির্ভুলতা = \(1/\text{variance}\))। prior-এর precision \(1/\tau_0^2\), data-র precision \(n/\sigma^2\)। যে পক্ষ বেশি নিশ্চিত (বেশি precision), posterior তার দিকে বেশি হেলে। আর posterior-এর precision হলো দুই precision-এর যোগফল — অর্থাৎ data যোগ করলে নিশ্চয়তা সবসময় বাড়ে (variance কমে)।
এক বাক্যে conjugacy-র মর্ম: ঠিকঠাক prior বাছলে "prior × likelihood" আবার একই চেনা বণ্টন হয়ে যায়, তাই posterior পেতে শুধু parameter-update সূত্র লাগে, কোনো integral নয় — Beta-তে count যোগ, Normal-এ precision-ওজনে গড়। (§৬-এর চিত্র
4-10-conjugate-updateদেখাবে কীভাবে data বাড়ার সঙ্গে Beta বা Normal posterior ধাপে ধাপে সরু ও তীক্ষ্ণ হয়।)
২.৪ Credible interval — এবং CI-র সঙ্গে ব্যাখ্যার পার্থক্য¶
posterior একটা পুরো বণ্টন; কিন্তু রিপোর্টে প্রায়ই একটা ব্যবধান চাই — "\(\theta\) মোটামুটি কোথায়"। Bayesian-এ এটাই credible interval, আর এর ব্যাখ্যাই হলো §১.১-এর প্রথম অস্বস্তির সমাধান।
সংজ্ঞা (Credible interval — বিশ্বাসযোগ্য ব্যবধান)। একটি \(1-\alpha\) স্তরের credible interval হলো এমন একটি ব্যবধান \([L,U]\), যার মধ্যে \(\theta\) থাকার posterior সম্ভাবনা \(1-\alpha\):
- \(1-\alpha\) — কাঙ্ক্ষিত স্তর (যেমন \(0.95\) হলে ৯৫%)।
- এখানে probability-টা posterior-এর উপর — অর্থাৎ "\(\theta\) এই ব্যবধানে থাকার সম্ভাবনা \(1-\alpha\)" বাক্যটা সরাসরি ও বৈধ, কারণ Bayesian-এ \(\theta\) random ও তার একটা বণ্টন আছে।
- একটা সাধারণ পছন্দ: equal-tailed interval — দুই লেজে \(\alpha/2\) করে রেখে posterior-এর \(\alpha/2\) ও \(1-\alpha/2\) quantile নেওয়া। (আরেকটা: highest posterior density interval — সবচেয়ে উঁচু-ঘনত্বের অঞ্চল; §৪-এ।)
মূল পার্থক্য — credible interval বনাম confidence interval। দুটো দেখতে এক (একটা \([L,U]\), একটা শতাংশ), কিন্তু ব্যাখ্যা সম্পূর্ণ আলাদা:
| Confidence interval (4.6, frequentist) | Credible interval (এই অধ্যায়, Bayesian) | |
|---|---|---|
| \(\theta\) ধরা হয় | fixed সংখ্যা (random নয়) | random চলক (posterior বণ্টন আছে) |
| random কে? | ব্যবধানটা (\(L,U\) data-নির্ভর, তাই random) | \(\theta\) (ব্যবধানটা data পেলে fixed) |
| "৯৫%" মানে | পদ্ধতিটা বারবার চালালে ৯৫% বার সত্য \(\theta\) ধরবে | এই data-র পর \(\theta\) ব্যবধানে থাকার posterior সম্ভাবনা ৯৫% |
| "\(\theta\) এই ব্যবধানে থাকার সম্ভাবনা ৯৫%" | ভুল ব্যাখ্যা | সঠিক ব্যাখ্যা |
অর্থাৎ মানুষ confidence interval শুনে যা বলতে চায় (4.6-এর সেই স্বজ্ঞাত-কিন্তু-ভুল বাক্য), Bayesian credible interval ঠিক সেটাকেই বৈধ করে তোলে। দাম: এর জন্য একটা prior বাছতে হয়েছে। (§৬-এর চিত্র 4-10-credible-vs-ci একই data-তে দুই ব্যবধান ও তাদের ভিন্ন ব্যাখ্যা পাশাপাশি দেখাবে; বিস্তারিত §৩-এর E3-এ।)
২.৫ Point estimate — MAP ও posterior mean¶
posterior পুরো বণ্টন দেয়, কিন্তু কখনো একটামাত্র "সেরা অনুমান" সংখ্যা চাই। posterior থেকে দুটো স্বাভাবিক পছন্দ:
সংজ্ঞা (MAP estimate — Maximum A Posteriori, \(\hat\theta_{\text{MAP}}\))। posterior-কে সর্বোচ্চ করে যে \(\theta\), সেটাই MAP:
- \(\arg\max_\theta\) — "যে \(\theta\)-তে সর্বোচ্চ" (posterior-এর চূড়ার অবস্থান, posterior-mode)।
- দ্বিতীয় সমতা: normalizing constant \(Z\) যেহেতু \(\theta\)-নিরপেক্ষ, max-এ ভূমিকা নেই — তাই MAP কেবল লব \(L(\theta)\pi(\theta)\) সর্বোচ্চ করলেই হয় (integral লাগে না — এই কারণেই MAP প্রায়ই হিসাব-সহজ)।
- MLE-র সঙ্গে সম্পর্ক: যদি prior uniform (সমতল, \(\pi(\theta)=\) ধ্রুবক) হয়, তবে \(\hat\theta_{\text{MAP}}=\arg\max_\theta L(\theta)=\hat\theta_{\text{MLE}}\) — অর্থাৎ flat prior-এ MAP ঠিক MLE! তাই MLE-কে "prior-হীন Bayesian"-ও বলা যায়। prior যত জোরালো, MAP তত MLE থেকে prior-চূড়ার দিকে সরে।
সংজ্ঞা (Posterior mean — উত্তর-গড়, \(\mathbb{E}[\theta\mid\text{data}]\))। posterior বণ্টনের গড়:
- \(\mathbb{E}[\cdot\mid\text{data}]\) — posterior-এর সাপেক্ষে expectation (প্রত্যাশা)।
- এটাই সবচেয়ে বেশি ব্যবহৃত Bayesian point estimate, কারণ (§৪-এ দেখা যাবে) এটি squared-error loss-এর অধীনে সর্বোত্তম — decision theory-র প্রথম ফল।
- conjugate ক্ষেত্রে এটি সহজ: Beta\((a',b')\)-র গড় \(\frac{a'}{a'+b'}\); Normal posterior-এর গড় ঠিক \(\mu_n\) (§২.৩)।
MAP নাকি mean? posterior symmetric (যেমন Normal) হলে দুটো সমান। skewed হলে আলাদা — MAP চূড়া (mode), mean ভরকেন্দ্র (যা লম্বা লেজের দিকে একটু টানে)। কোনটা — নির্ভর করে কোন loss-কে গুরুত্ব দিচ্ছেন তার উপর (§৪, decision theory)।
২.৬ Posterior predictive — পরের observation-এর ভবিষ্যদ্বাণী¶
এতক্ষণ \(\theta\) নিয়ে ছিলাম। কিন্তু প্রায়ই আসল প্রশ্ন — "পরের observation কী হবে?" (যেমন: এই মুদ্রার পরের টস head হবে কি?) এর উত্তর দেয় posterior predictive।
সংজ্ঞা (Posterior predictive distribution — উত্তর-ভবিষ্যদ্বাণী বণ্টন)। একটি নতুন observation \(\tilde x\) ("x-টিল্ডা") সম্পর্কে data-পরবর্তী ভবিষ্যদ্বাণী:
প্রতিটি অংশ খুলি:
- \(p(\tilde x\mid\theta)\) — একটা নির্দিষ্ট \(\theta\) ধরলে নতুন observation-এর বণ্টন (মডেল নিজেই, যেমন Bernoulli\((\theta)\))।
- \(p(\theta\mid\text{data})\) — posterior, যা প্রতিটি \(\theta\)-কে তার বর্তমান বিশ্বাস-ওজন দেয়।
- \(\int(\cdots)\,d\theta\) — সব \(\theta\)-র উপর গড়: প্রতিটি \(\theta\)-এর ভবিষ্যদ্বাণীকে তার posterior-সম্ভাবনা দিয়ে ওজন দিয়ে যোগ।
মূল স্বজ্ঞা — কেন এটা frequentist plug-in-এর চেয়ে ভালো: সরল পথ হতো একটা estimate \(\hat\theta\) বসিয়ে \(p(\tilde x\mid\hat\theta)\) বলা ("plug-in")। কিন্তু তাতে \(\theta\)-র অনিশ্চয়তা উপেক্ষিত — যেন আমরা \(\theta\) নিশ্চিত জানি। posterior predictive তার বদলে \(\theta\)-র সব সম্ভাব্য মান গড়ে নেয়, তাই \(\theta\)-র অনিশ্চয়তা ভবিষ্যদ্বাণীতেও ঢোকে — ফলে এটি বেশি সৎ (সাধারণত একটু চওড়া, বিশেষত কম data-তে)। (E4-এ এর সংখ্যা।)
এক বাক্যে §২-এর সার। Bayesian inference = prior \(\pi(\theta)\) (পূর্ব-বিশ্বাস) \(\times\) likelihood \(L(\theta)=p(\text{data}\mid\theta)\) (সাক্ষ্য) \(\to\) posterior \(p(\theta\mid\text{data})\propto L\pi\) (পরিমার্জিত বিশ্বাস), হরে normalizing constant \(Z=\int L\pi\,d\theta\); conjugate জুটিতে (Beta–Binomial, Normal–Normal) posterior একই পরিবারে, parameter-update সূত্রে; posterior থেকে credible interval (সরাসরি "\(\theta\) এখানে থাকার সম্ভাবনা") এবং point estimate MAP (\(\arg\max\), flat prior-এ = MLE) বা posterior mean (\(\mathbb{E}[\theta\mid\text{data}]\)); আর পরের observation-এর জন্য posterior predictive (posterior-এর উপর গড়)।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§২-এর প্রতিটি যন্ত্র এবার সংখ্যায় হাতে-কলমে চালাব। চারটি উদাহরণ চারটি কেন্দ্রীয় বিষয় ধরে: E1 Beta–Binomial conjugacy, E2 Normal–Normal conjugacy, E3 credible বনাম confidence interval, E4 conjugacy না থাকলে MCMC-র স্বজ্ঞা ও posterior predictive। সর্বত্র \(\bar X=\frac1n\sum_{i=1}^n X_i\) মানে sample mean।
৩.১ E1 — Beta–Binomial: একটা মুদ্রা কতটা পক্ষপাতী?¶
এই উদাহরণ §২.১–২.৩ ও ২.৫-এর Beta–Binomial conjugacy, MAP ও posterior mean সরাসরি সংখ্যায় প্রয়োগ করে।
পরিস্থিতি। একটা মুদ্রার head-সম্ভাবনা \(p\) অজানা। আমরা মুদ্রাকে \(n=10\) বার ছুঁড়ে \(k=7\)টা head পেলাম। অজানা \(\theta=p\)।
ধাপ ১ — prior বাছাই। ধরা যাক আগে কোনো জোরালো ধারণা নেই, তাই uniform prior: \(\pi(p)=\text{Beta}(1,1)\) (সমতল, \(a=b=1\) — প্রতিটি \(p\in[0,1]\) সমান-সম্ভাব্য)।
ধাপ ২ — posterior (conjugacy সূত্র)। §২.৩-এর Beta–Binomial সূত্রে — সাফল্য \(k=7\) প্রথম parameter-এ, ব্যর্থতা \(n-k=3\) দ্বিতীয়টায় যোগ:
কোনো integral কষতে হলো না — শুধু count যোগ করেই posterior পেলাম।
ধাপ ৩ — posterior summary। Beta\((a',b')\)-র সূত্র (2.4) থেকে, এখানে \(a'=8,\ b'=4\):
- posterior mean \(=\dfrac{a'}{a'+b'}=\dfrac{8}{12}\approx 0.667\)।
- MAP (Beta-র mode, \(a',b'>1\) হলে) \(=\dfrac{a'-1}{a'+b'-2}=\dfrac{7}{10}=0.70\) — যা ঠিক MLE \(\hat p=k/n=7/10=0.7\) (কারণ prior uniform, §২.৫)।
- লক্ষ করুন posterior mean (\(0.667\)) MLE (\(0.7\)) থেকে সামান্য \(0.5\)-এর দিকে টানা — কারণ uniform prior-ও দুর্বলভাবে মাঝ-মান টানে (যেন \(1\) ছদ্ম-head ও \(1\) ছদ্ম-tail যোগ হয়েছে)। data বাড়লে এই টান মিলিয়ে যাবে।
ধাপ ৪ — informative prior-এর প্রভাব (তুলনা)। ধরা যাক বদলে আমরা জানতাম মুদ্রাটা প্রায় ন্যায্য — একটা জোরালো prior \(\text{Beta}(50,50)\) (মাঝে তীক্ষ্ণভাবে কেন্দ্রিত, যেন আগে \(98\) বার দেখে প্রায় সমান head/tail পেয়েছি)। তখন posterior \(=\text{Beta}(50+7,\ 50+3)=\text{Beta}(57,53)\), posterior mean \(=57/110\approx 0.518\) — data-র \(0.7\) সত্ত্বেও বিশ্বাস \(0.5\)-এর কাছেই, কারণ prior জোরালো আর data (\(n=10\)) কম। এই তুলনাই Bayesian-এর হৃদয়: একই data, ভিন্ন prior → ভিন্ন posterior; data বাড়লে দুই posterior-ই MLE-তে মিলবে। (4-10-conjugate-update চিত্রে এই দুই prior-এর posterior-এর তীক্ষ্ণতার তফাত দেখা যাবে।)
৩.২ E2 — Normal–Normal: known variance-এ গড় অনুমান¶
এই উদাহরণ §২.৩-এর Normal–Normal conjugacy প্রয়োগ করে।
পরিস্থিতি। একটা যন্ত্রের তৈরি বস্তুর ওজন \(X\sim\mathcal{N}(\mu,\sigma^2)\), যেখানে \(\sigma^2=4\) (অর্থাৎ \(\sigma=2\)) জানা, কিন্তু গড় \(\mu\) অজানা। আমরা \(n=16\)টা বস্তু মেপে পেলাম \(\bar X = 10.5\)।
ধাপ ১ — prior। আগের জ্ঞান থেকে \(\mu\) সম্ভবত \(10\)-এর কাছে, কিন্তু খুব নিশ্চিত নই — তাই prior \(\mu\sim\mathcal{N}(\mu_0,\tau_0^2)\) with \(\mu_0=10,\ \tau_0^2=1\)।
ধাপ ২ — posterior precision ও mean (conjugacy সূত্র)। §২.৩-এর সূত্রে। আগে দুই precision:
- prior precision \(=1/\tau_0^2 = 1/1 = 1\)।
- data precision \(=n/\sigma^2 = 16/4 = 4\)।
posterior precision \(=1+4=5\), তাই posterior variance \(\tau_n^2 = 1/5 = 0.2\)। আর posterior mean (precision-ওজনযুক্ত গড়):
তাই \(\mu\mid\text{data}\sim\mathcal{N}(10.4,\ 0.2)\)।
ধাপ ৩ — পড়া। posterior গড় \(10.4\) — prior-গড় \(10\) আর data-গড় \(10.5\)-এর মাঝে, কিন্তু data-র দিকে বেশি কাছে (কারণ data-precision \(4\) > prior-precision \(1\), তাই data-র ওজন \(4/5\))। আর posterior variance \(0.2\) — prior-variance \(1\) ও data-variance (\(\sigma^2/n=4/16=0.25\)) দুটোর চেয়েই ছোট: দুই সাক্ষ্য মিলে নিশ্চয়তা বেড়েছে। posterior mean \(=\) MAP \(=10.4\) (Normal symmetric, §২.৫)।
৩.৩ E3 — Credible interval বনাম Confidence interval: একই data, দুই ব্যাখ্যা¶
এই উদাহরণ §২.৪-এর কেন্দ্রীয় পার্থক্য — একই সংখ্যায় — হাতে দেখায়। আমরা E2-এরই posterior \(\mu\mid\text{data}\sim\mathcal{N}(10.4,\ 0.2)\) ব্যবহার করি।
ধাপ ১ — ৯৫% credible interval (Bayesian)। posterior Normal, তাই equal-tailed ৯৫% credible interval \(=\mu_n\pm 1.96\,\tau_n\), যেখানে \(\tau_n=\sqrt{0.2}\approx 0.447\):
ব্যাখ্যা (সরাসরি ও বৈধ): "data দেখার পর, সত্য \(\mu\) এই \([9.52,\ 11.28]\) ব্যবধানে থাকার posterior সম্ভাবনা ০.৯৫।" — এই বাক্যটা Bayesian-এ পুরোপুরি সঠিক, কারণ \(\mu\) random ও তার posterior আছে।
ধাপ ২ — ৯৫% confidence interval (frequentist, 4.6)। σ জানা, তাই z-interval \(\bar X\pm z_{0.025}\,\sigma/\sqrt n = 10.5\pm 1.96\times (2/\sqrt{16}) = 10.5\pm 1.96\times 0.5 = 10.5\pm 0.98 \Rightarrow [\,9.52,\ 11.48\,]\)।
ব্যাখ্যা (পরোক্ষ): "এই পদ্ধতি বারবার চালালে, এভাবে-গড়া ব্যবধানের ৯৫% সত্য \(\mu\) ধরবে।" — এখানে "\(\mu\) এই নির্দিষ্ট ব্যবধানে থাকার সম্ভাবনা ৯৫%" বলা যাবে না (4.6), কারণ frequentist-এ \(\mu\) fixed।
ধাপ ৩ — তুলনা। দুটো ব্যবধান কাছাকাছি কিন্তু এক নয়: credible \([9.52,11.28]\) একটু সরু ও prior-গড় \(10\)-এর দিকে সামান্য টানা (prior-এর তথ্য যোগ হয়েছে); confidence \([9.52,11.48]\) কেবল data-র উপর। মূল শিক্ষা ব্যাখ্যায়, সংখ্যায় নয়: একই রকম দেখতে দুই ব্যবধানের অর্থ মৌলিকভাবে আলাদা — একটা \(\theta\)-র সম্ভাবনার কথা বলে, অন্যটা পদ্ধতির দীর্ঘমেয়াদি আচরণের। (4-10-credible-vs-ci চিত্রে দুই ব্যবধান ও তাদের ভিন্ন ব্যাখ্যা পাশাপাশি।)
সতর্কতা: prior dominant বা data কম হলে credible ও confidence interval অনেক আলাদা হতে পারে — এখানে কাছাকাছি কারণ prior দুর্বল আর data যথেষ্ট। মিলটা সর্বজনীন নিয়ম নয়।
৩.৪ E4 — conjugacy না থাকলে: MCMC-র স্বজ্ঞা ও posterior predictive¶
এই উদাহরণ §২.২ (কঠিন \(Z\)), 3.6-র MCMC-সংযোগ, ও §২.৬-র posterior predictive ছুঁয়ে যায় — সংখ্যায় সরল রেখে।
কেন সমস্যা। E1–E2-এ conjugacy ছিল, তাই posterior সূত্রেই বেরিয়েছে। কিন্তু ধরুন মডেলটা এমন যেখানে কোনো conjugate prior নেই — যেমন logistic-জাতীয় likelihood-এ একটা skewed prior, বা একাধিক parameter জটিলভাবে জড়ানো। তখন posterior
-এর হরের integral \(Z\) হাতে কষা যায় না (বহুমাত্রিক, বন্ধ-রূপহীন)। তাহলে posterior থেকে mean বা credible interval বের করব কীভাবে?
সমাধানের স্বজ্ঞা — নমুনা তোলো, integral এড়াও (MCMC, 3.6)। চমৎকার কৌশল: posterior-এর সূত্র (সংখ্যা) না জেনেও, আমরা posterior থেকে নমুনা \(\theta^{(1)},\theta^{(2)},\dots,\theta^{(M)}\) টানতে পারি — 3.6-এর MCMC (Markov chain Monte Carlo) দিয়ে। মূল ধারণা (3.6 থেকে): এমন একটা Markov chain বানাই যার stationary distribution ঠিক posterior \(p(\theta\mid\text{data})\); chain যথেষ্টক্ষণ চালালে তার ভ্রমণ-বিন্দুগুলোই posterior-থেকে নমুনা হয়ে যায়। মুখ্য সুবিধা: chain-টা চালাতে কেবল লব \(L(\theta)\pi(\theta)\)-র অনুপাত লাগে — কঠিন \(Z\) কেটে যায়, কখনো গণনাই করতে হয় না।
নমুনা পেলে সব summary সহজ (Monte Carlo)। একবার \(M\)টা posterior-নমুনা হাতে এলে, যেকোনো posterior পরিমাণ কেবল নমুনা-গড়/quantile:
- posterior mean \(\approx \frac1M\sum_{m=1}^M \theta^{(m)}\) (নমুনার গড়)।
- ৯৫% credible interval \(\approx\) নমুনার \(2.5\) ও \(97.5\) percentile।
ছোট সংখ্যা-উদাহরণ (ধারণা পরিষ্কার করতে)। ধরুন MCMC থেকে \(\theta\)-র (sorted) \(M=8\)টা প্রতিনিধি-নমুনা পেলাম: \(0.55, 0.58, 0.60, 0.62, 0.63, 0.65, 0.68, 0.71\)। তবে posterior mean \(\approx \frac{0.55+0.58+0.60+0.62+0.63+0.65+0.68+0.71}{8} = \frac{5.02}{8}\approx 0.628\), আর একটা মোটা ৯৫% credible interval প্রান্ত-নমুনা থেকে \(\approx[0.55,\ 0.71]\)। (বাস্তবে \(M\) কয়েক হাজার, যাতে অনুমান মসৃণ হয় — এখানে কেবল পদ্ধতি দেখানো।)
posterior predictive (§২.৬) নমুনা দিয়ে। নতুন observation-এর ভবিষ্যদ্বাণীও নমুনা থেকে সহজ — প্রতিটি posterior-নমুনা \(\theta^{(m)}\)-এর জন্য একটা নকল observation \(\tilde x^{(m)}\sim p(\tilde x\mid\theta^{(m)})\) টানি; এই \(\tilde x^{(m)}\)-গুলোর সমষ্টিই posterior predictive বণ্টন (integral-টা স্বয়ংক্রিয়ভাবে নমুনায় গড় হয়ে যায়)। উদাহরণ — E1-এর মুদ্রায় posterior \(\text{Beta}(8,4)\): পরের টস head হওয়ার posterior-predictive সম্ভাবনা ঠিক posterior mean \(=\frac{8}{12}\approx 0.667\) (কারণ \(P(\text{পরের head}\mid\text{data})=\int p\, \cdot p(p\mid\text{data})\,dp=\mathbb{E}[p\mid\text{data}]\)) — plug-in MLE \(0.7\)-এর বদলে \(\theta\)-র অনিশ্চয়তা গড়ে নেওয়া, তাই সামান্য নরম। (4-10-bayes-mcmc চিত্রে MCMC-নমুনার histogram কীভাবে সত্য posterior বক্ররেখায় বসে তা দেখা যাবে।)
৪ · প্রমাণ ও উৎপাদন¶
§১–৩-এ আমরা Bayesian চিন্তার নীতিটা পেয়েছি এক বাক্যে: "data দেখার পর parameter সম্পর্কে আমাদের বিশ্বাস হালনাগাদ করো — prior থেকে posterior-এ।" এই অংশে সেই নীতিকে scratch থেকে কাজে লাগিয়ে আসল সূত্রগুলো বের করব — কোনো বীজগণিতের ধাপ লুকানো থাকবে না, প্রতিটি লাইনের পেছনে কারণ বাংলায় থাকবে। চারটে অংশে ভাগ করেছি, প্রতিটি কঠিনতা অনুযায়ী ট্যাগ করা (★ = সরাসরি · ★★ = কিছু বীজগণিত/কৌশল লাগে · ★★★ = পূর্ণ rigor এই পর্যায়ের বাইরে, একটা অংশ সৎ-ভাবে স্বজ্ঞা হিসেবে নেওয়া হবে):
- (a) parameter-এর জন্য Bayes — posterior \(\propto\) likelihood \(\times\) prior, সরাসরি 2.2-এর Bayes' theorem থেকে; আর হরের normalizing constant \(\int L\pi\,d\theta\) আসলে marginal likelihood (evidence) — কেন এটাই সবচেয়ে কঠিন অংশ, কেন প্রায়ই এড়িয়ে যাওয়া যায়। ★
- (b) Beta–Binomial conjugacy — prior Beta\((a,b)\) × Binomial likelihood → posterior Beta\((a+k,\,b+n-k)\); kernel মেলানোর কৌশলে integral না কষেই বের করা। ★★
- (c) Normal–Normal conjugacy (known variance) — posterior mean = prior mean ও data mean-এর precision-weighted average; বর্গ-পূরণ (completing the square) দিয়ে পূর্ণ derivation। ★★★
- (d) posterior থেকে point summary — MAP (mode) ও posterior mean; credible interval; আর Bernstein–von Mises স্বজ্ঞা (বড় data → posterior ≈ MLE, Bayesian ≈ frequentist)। ★★
পুরো অংশে নোটেশন এক রাখছি, ঠিক §১-এর মতো: prior \(\pi(\theta)\) (data দেখার আগের বিশ্বাস); likelihood \(L(\theta)=p(\text{data}\mid\theta)\) (এই \(\theta\) হলে data কতটা সম্ভব); posterior $$ p(\theta\mid\text{data}) \;=\; \frac{L(\theta)\,\pi(\theta)}{\displaystyle\int L(\theta)\,\pi(\theta)\,d\theta} $$ (data দেখার পরের হালনাগাদ বিশ্বাস)। লক্ষ করুন এক সূক্ষ্ম কিন্তু গভীর পার্থক্য frequentist-দৃষ্টির সাথে: এখানে \(\theta\)-কে একটা random variable ধরা হচ্ছে যার একটা distribution আছে — অজানা কিন্তু স্থির একটা সংখ্যা নয়। এই এক ধারণাগত লাফই Bayesian পরিসংখ্যানের প্রাণ, আর এটাই credible interval-কে confidence interval থেকে আলাদা করে (যা §(d)-তে স্পষ্ট হবে)।
৪.১ · (a) parameter-এর জন্য Bayes: posterior \(\propto\) likelihood \(\times\) prior — ★¶
2.2-এর Bayes' theorem থেকে শুরু¶
2.2-এ আমরা event-এর জন্য Bayes' theorem প্রমাণ করেছিলাম: দুটো event \(A, B\)-এ $$ P(A\mid B) \;=\; \frac{P(B\mid A)\,P(A)}{P(B)}. $$ এর প্রমাণ ছিল এক লাইন — conditional probability-র সংজ্ঞা \(P(A\mid B)=\frac{P(A\cap B)}{P(B)}\) আর multiplication rule \(P(A\cap B)=P(B\mid A)P(A)\) মিলিয়ে। এখন আমরা ঠিক এই সূত্রটাকেই parameter \(\theta\) ও observed data-র উপর প্রয়োগ করব — শুধু "\(A\)"-র জায়গায় "\(\theta\) এই মান" আর "\(B\)"-র জায়গায় "data যা দেখলাম"। প্রতিস্থাপন করলে: $$ \underbrace{p(\theta\mid\text{data})}{\text{posterior}} \;=\; \frac{\overbrace{p(\text{data}\mid\theta)}^{\text{likelihood }L(\theta)}\;\overbrace{\pi(\theta)}^{\text{prior}}} {\underbrace{p(\text{data})} $$ এটাই }}}. \tag{4.1Bayesian inference-এর মূল সমীকরণ — 2.2-এর event-Bayes-এর সরাসরি পুনঃপ্রয়োগ, শুধু এবার অজানাটা একটা parameter। তিনটে নাম মনে রাখুন: লব-এ \(L(\theta)\pi(\theta)\), হর-এ \(p(\text{data})\)।
সূক্ষ্মতা — discrete বনাম continuous \(\theta\)। \(\theta\) যদি discrete হয় (গুটিকয় সম্ভাব্য মান), তবে \(\pi,p(\cdot\mid\theta),p(\theta\mid\text{data})\) সব probability; হরে যোগফল \(p(\text{data})=\sum_\theta L(\theta)\pi(\theta)\)। আর \(\theta\) continuous হলে (আমাদের চলমান উদাহরণগুলোর মতো) এরা density, হরে integral \(p(\text{data})=\int L(\theta)\pi(\theta)\,d\theta\)। দুই ক্ষেত্রেই কাঠামো অভিন্ন — তাই আমরা একই সূত্র (4.1) লিখি, প্রসঙ্গভেদে যোগ/integral বুঝে নিই।
হরটা \(\theta\)-নিরপেক্ষ — তাই proportionality¶
এবার মূল পর্যবেক্ষণ, যা গোটা Bayesian বীজগণিতকে সহজ করে দেয়। (4.1)-এর হর \(p(\text{data})\)-এর দিকে তাকান — এটা law of total probability (2.2) দিয়ে লেখা যায়: $$ p(\text{data}) \;=\; \int p(\text{data}\mid\theta)\,\pi(\theta)\,d\theta \;=\; \int L(\theta)\,\pi(\theta)\,d\theta. \tag{4.2} $$ লক্ষ করুন ডানপাশে \(\theta\) একটা integration variable — যোগ/integral করার পর \(\theta\) আর থাকে না! অর্থাৎ \(p(\text{data})\) একটা স্থির সংখ্যা (data দিলেই নির্দিষ্ট), \(\theta\)-র উপর মোটেই নির্ভর করে না। তাই posterior-কে \(\theta\)-র function হিসেবে দেখলে হরটা নিছক একটা ধ্রুবক scaling factor। এজন্য আমরা প্রায়ই লিখি $$ \boxed{\;p(\theta\mid\text{data}) \;\propto\; L(\theta)\,\pi(\theta)\;} \tag{4.3} $$ পড়ুন: "posterior সমানুপাতিক likelihood গুণ prior"। চিহ্ন "\(\propto\)" বলছে — ডানপাশটা \(\theta\)-তে posterior-এর আকার ঠিকঠাক দেয়, শুধু একটা সামগ্রিক ধ্রুবক বাদ। আর সেই ধ্রুবকটা সবসময় শেষে পুনরুদ্ধার করা যায় একটাই শর্ত থেকে: posterior একটা বৈধ distribution, তাই তার মোট ভর/ক্ষেত্রফল \(1\) — $$ \int p(\theta\mid\text{data})\,d\theta = 1 \quad\Longrightarrow\quad \text{ধ্রুবক} = \frac{1}{\int L(\theta)\pi(\theta)\,d\theta}. $$ এটাই (b)-এর গোটা কৌশলের ভিত্তি: \(L\pi\)-র আকার চিনে নিয়ে বলে দেওয়া এটা কোন পরিচিত distribution-এর kernel, তারপর normalizing constant ওই distribution-এর জানা সূত্র থেকে তুলে নেওয়া — কোনো integral না কষেই।
normalizing constant = marginal likelihood (evidence) — কেন কঠিন¶
হর \(p(\text{data})=\int L(\theta)\pi(\theta)\,d\theta\)-এর একটা গুরুত্বপূর্ণ নাম আছে: marginal likelihood বা evidence। "marginal" কারণ এটা \(\theta\)-কে integrate-out করে পাওয়া — অর্থাৎ prior-অনুযায়ী সব সম্ভাব্য \(\theta\)-র উপর গড় করা data-র সম্ভাবনা। এটা কেবল normalizer নয়; model comparison-এ (Bayes factor) এর স্বাধীন গুরুত্ব আছে, যা পরে দেখা যাবে।
কিন্তু এখানেই Bayesian হিসাবের আসল কাঁটা: এই integral সাধারণত বন্ধ-রূপে (closed form) কষা যায় না। \(\theta\) যদি উঁচু-মাত্রিক হয় (যেমন একটা নিউরাল-মডেলের হাজারো parameter), তবে \(\int\cdots d\theta\) একটা উঁচু-মাত্রিক integral — বিশ্লেষণে অসাধ্য, এমনকি সংখ্যাগত grid-এও অসাধ্য (মাত্রার অভিশাপ)। দুটো পথ এই কাঁটা এড়ায়:
- Conjugacy (সংযোজ্যতা): prior-কে এমন বেছে নাও যে \(L\pi\)-র আকার আবার একই family-র distribution হয় — তখন normalizer বিনা integration-এ জানা সূত্র থেকে পাওয়া যায়। ঠিক এটাই (b) Beta–Binomial ও (c) Normal–Normal করবে।
- MCMC (যখন conjugacy নেই): posterior থেকে সরাসরি নমুনা তোলো (যেমন 3.6-এর Metropolis), যেখানে শুধু অ-normalized \(L(\theta)\pi(\theta)\) লাগে — কারণ acceptance-ratio-তে normalizer কাটাকাটি যায় (3.6-এ দেখানো)। তাই \(p(\text{data})\) না জেনেও posterior-এর mean/quantile সব আঁচ করা যায়। ঠিক এটাই §৫-এর Part 4 করবে।
এক নজরে। Bayes-এর মূল সমীকরণ (4.1) হলো 2.2-এর event-Bayes-এর parameter-সংস্করণ। লব \(L(\theta)\pi(\theta)\) posterior-এর আকার সম্পূর্ণ ঠিক করে দেয় (4.3); হর \(p(\text{data})\) শুধু একটা \(\theta\)-নিরপেক্ষ ধ্রুবক যা ভর-কে \(1\)-এ স্বাভাবিক করে। এই ধ্রুবকই evidence — তাত্ত্বিকভাবে অপরিহার্য, ব্যবহারিকভাবে কঠিন, আর সেটাই conjugacy ও MCMC-র জন্ম দেয়।
৪.২ · (b) Beta–Binomial conjugacy — kernel মেলানো — ★★¶
এবার (a)-র "আকার চিনে নাও" কৌশলটা প্রথমবার কাজে লাগাই — চলমান উদাহরণ E1-এ। প্রসঙ্গ: একটা অজানা success-সম্ভাবনা \(\theta\in(0,1)\) (যেমন কোনো মুদ্রার পক্ষপাত, বা কোনো বোতামে ক্লিক-হার)। আমরা \(n\) বার চেষ্টা করে \(k\) বার success দেখলাম।
ধাপ ১ — likelihood লিখি (Binomial)। \(n\)টা স্বাধীন Bernoulli\((\theta)\) চেষ্টায় ঠিক \(k\)টা success-এর সম্ভাবনা (2.3 থেকে): $$ L(\theta) \;=\; p(k\mid\theta) \;=\; \binom{n}{k}\,\theta^k\,(1-\theta)^{\,n-k}. $$ \(\theta\)-র function হিসেবে দেখলে \(\binom{n}{k}\) একটা \(\theta\)-নিরপেক্ষ ধ্রুবক, তাই kernel (আকার-নির্ধারক অংশ) হলো $$ L(\theta) \;\propto\; \theta^k\,(1-\theta)^{\,n-k}. $$
ধাপ ২ — prior বাছি (Beta)। \(\theta\) যেহেতু \((0,1)\)-এ থাকে, তার জন্য স্বাভাবিক prior হলো Beta\((a,b)\) distribution, যার density (2.4 থেকে) $$ \pi(\theta) \;=\; \frac{1}{B(a,b)}\,\theta^{a-1}\,(1-\theta)^{b-1}, \qquad 0<\theta<1, $$ যেখানে \(B(a,b)=\int_0^1\theta^{a-1}(1-\theta)^{b-1}\,d\theta\) হলো Beta function (normalizing constant)। আবার kernel-টাই গুরুত্বপূর্ণ: $$ \pi(\theta) \;\propto\; \theta^{a-1}\,(1-\theta)^{b-1}. $$ (স্বজ্ঞা: \(a\) যেন "আগে থেকে দেখা success-সংখ্যা \(+1\)" আর \(b\) যেন "আগে থেকে দেখা failure-সংখ্যা \(+1\)" — prior-টা একটা কাল্পনিক পূর্ব-পরীক্ষার সারাংশ।)
ধাপ ৩ — posterior = likelihood × prior, kernel গুণ করি। (4.3) অনুসারে $$ p(\theta\mid k) \;\propto\; L(\theta)\,\pi(\theta) \;\propto\; \underbrace{\theta^k(1-\theta)^{n-k}}{\text{likelihood kernel}}\cdot \underbrace{\theta^{a-1}(1-\theta)^{b-1}}. $$ একই ভিত্তির ঘাত যোগ করি (এটাই পুরো কৌশলের একমাত্র বীজগণিত): $$ p(\theta\mid k) \;\propto\; \theta^{\,k+a-1}\,(1-\theta)^{\,(n-k)+b-1} \;=\; \theta^{\,(a+k)-1}\,(1-\theta)^{\,(b+n-k)-1}. \tag{4.4} $$}
ধাপ ৪ — kernel চিনে নাও (এখানেই integration এড়াই)। (4.4)-এর ডানপাশের দিকে তাকান — এটা ঠিক Beta distribution-এর kernel \(\theta^{a'-1}(1-\theta)^{b'-1}\), যেখানে $$ a' = a+k, \qquad b' = b + n - k. $$ যেহেতু একটা density তার kernel দিয়ে সম্পূর্ণরূপে নির্ধারিত (normalizing constant kernel থেকেই বাঁধা, কারণ মোট ক্ষেত্রফল \(1\) হতে হবে), আমরা integral না কষেই সিদ্ধান্তে পৌঁছাই: $$ \boxed{\;\theta\mid k \;\sim\; \mathrm{Beta}(a+k,\; b+n-k)\;} \tag{4.5} $$ আর normalizing constant আপনাআপনি \(B(a+k,\,b+n-k)\) — Beta function-এর জানা সূত্র, কোনো নতুন integral নয়। এটাই conjugacy-র জাদু: Beta prior × Binomial likelihood → আবার Beta posterior, শুধু parameter দুটো হালনাগাদ হলো — \(a\to a+k\) (দেখা success যোগ), \(b\to b+n-k\) (দেখা failure যোগ)। এই বৈশিষ্ট্যের নাম conjugate prior: Beta হলো Binomial likelihood-এর conjugate family।
কেন এত স্বজ্ঞাময় হালনাগাদ। Beta\((a,b)\) prior-কে "\(a-1\) কাল্পনিক success ও \(b-1\) কাল্পনিক failure" ভাবলে, posterior Beta\((a+k,\,b+n-k)\) মানে — কাল্পনিক গোনার সাথে আসল \(k\) success ও \(n-k\) failure যোগ করে দাও। data ঠিক যেভাবে গোনা বাড়ায়, posterior সেভাবেই prior-কে ঠেলে। এই "pseudo-count যোগ" ছবিটাই Beta–Binomial-কে শেখানোর জন্য আদর্শ প্রথম উদাহরণ করে তোলে — §৫-এর Part 1 ও Part 2 এটাই সংখ্যায় দেখাবে (sequential updating-এ প্রতিটি batch ঠিক এভাবে \(a,b\)-তে যোগ হয়)।
৪.৩ · (c) Normal–Normal conjugacy (known variance): precision-weighted mean — ★★★¶
দ্বিতীয় conjugate জোড়া — চলমান উদাহরণ E2। প্রসঙ্গ: একটা অজানা গড় \(\theta\) আঁচ করা, যখন data-র variance \(\sigma^2\) জানা (একটা সরলীকরণী ধারণা, যা গণিতকে পরিষ্কার রাখে)। এটাই সবচেয়ে শিক্ষণীয় conjugacy, কারণ ফলাফলটা — posterior mean হলো prior ও data-র precision-weighted average — গোটা Bayesian shrinkage-এর হৃদয়।
সেটআপ। Prior \(\theta\sim\mathcal{N}(\mu_0,\tau_0^2)\) (data দেখার আগে \(\theta\) সম্পর্কে বিশ্বাস, কেন্দ্র \(\mu_0\), ছড়ানো \(\tau_0\))। Data \(x_1,\dots,x_n\) i.i.d. \(\mathcal{N}(\theta,\sigma^2)\), \(\sigma^2\) জানা।
ধাপ ১ — likelihood (Gaussian)। স্বাধীনতার গুণফল: $$ L(\theta) \;=\; \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}}\exp!\Big(-\frac{(x_i-\theta)^2}{2\sigma^2}\Big) \;\propto\; \exp!\Big(-\frac{1}{2\sigma^2}\sum_{i=1}^n (x_i-\theta)^2\Big), $$ যেখানে \(\theta\)-নিরপেক্ষ ধ্রুবক \((2\pi\sigma^2)^{-n/2}\) ফেলে দিলাম। এখন exponent-এর যোগফলটা \(\theta\)-তে গুছিয়ে নিই — একটা পরিচিত পরিচয় (2.5-এ ব্যবহৃত): \(\sum_i(x_i-\theta)^2=\sum_i(x_i-\bar x)^2+n(\bar x-\theta)^2\), যার প্রথম পদ \(\theta\)-নিরপেক্ষ। তাই $$ L(\theta) \;\propto\; \exp!\Big(-\frac{n}{2\sigma^2}(\theta-\bar x)^2\Big). \tag{4.6} $$ পড়ুন: \(\theta\)-র function হিসেবে likelihood নিজেই একটা Gaussian-আকৃতির, কেন্দ্র \(\bar x\), "variance" \(\sigma^2/n\) — অর্থাৎ data যেন একটা \(\mathcal{N}(\bar x,\sigma^2/n)\) বিবৃতি দিচ্ছে \(\theta\) সম্পর্কে।
ধাপ ২ — prior kernel। $$ \pi(\theta) \;\propto\; \exp!\Big(-\frac{1}{2\tau_0^2}(\theta-\mu_0)^2\Big). $$
ধাপ ৩ — posterior ∝ likelihood × prior; exponent যোগ করি। (4.3) দিয়ে $$ p(\theta\mid\text{data}) \;\propto\; \exp!\Big(-\frac{n}{2\sigma^2}(\theta-\bar x)^2 \;-\; \frac{1}{2\tau_0^2}(\theta-\mu_0)^2\Big). \tag{4.7} $$ exponent-এ দুটো বর্গপদের যোগফল — একে \(\theta\)-তে একটা মাত্র বর্গে গোছাতে হবে (completing the square)। এখানে নোটেশন সহজ করতে precision ধারণা আনি: precision = \(1/\text{variance}\), অর্থাৎ "কতটা নিশ্চিত"। লিখি data-precision \(\;b:=n/\sigma^2\) আর prior-precision \(\;a:=1/\tau_0^2\)। তবে exponent-এর ভেতরের রাশি (বাইরের \(-\tfrac12\) বাদ দিয়ে): $$ Q(\theta) \;=\; b\,(\theta-\bar x)^2 + a\,(\theta-\mu_0)^2. $$
ধাপ ৪ — বর্গ-পূরণ (completing the square)। \(\theta^2,\theta,\) ধ্রুবক — এই তিন ভাগে খুলি: $$ Q(\theta) = (a+b)\,\theta^2 \;-\; 2\big(a\mu_0 + b\bar x\big)\theta \;+\; \big(a\mu_0^2 + b\bar x^2\big). $$ \(\theta^2\)-এর সহগ \((a+b)\) বাইরে নিয়ে গুছাই: $$ Q(\theta) = (a+b)\Big[\theta^2 - 2\,\frac{a\mu_0+b\bar x}{a+b}\,\theta\Big] + \text{const} = (a+b)\Big(\theta - \underbrace{\tfrac{a\mu_0+b\bar x}{a+b}}_{=:~\mu_n}\Big)^2 + \text{const}', $$ যেখানে "const" সব \(\theta\)-নিরপেক্ষ পদ (posterior-এর আকারে অপ্রাসঙ্গিক, normalizer-এ মিশে যাবে)। এই বর্গ-পূরণ থেকেই দুটো ফল সরাসরি পড়া যায়।
ধাপ ৫ — posterior চিনে নাও। (4.7)-এ ফিরে বসালে $$ p(\theta\mid\text{data}) \;\propto\; \exp!\Big(-\tfrac{1}{2}(a+b)\,(\theta-\mu_n)^2\Big), $$ যা ঠিক একটা Gaussian kernel — কেন্দ্র \(\mu_n\), precision \((a+b)\), অর্থাৎ variance \(1/(a+b)\)। তাই (আবার kernel-চেনা, কোনো integral না কষে): $$ \boxed{\;\theta\mid\text{data} \;\sim\; \mathcal{N}\big(\mu_n,\ \tau_n^2\big),\qquad \frac{1}{\tau_n^2} = \underbrace{\frac{1}{\tau_0^2}}{\text{prior prec.}} + \underbrace{\frac{n}{\sigma^2}},\qquad \mu_n = \tau_n^2\Big(\frac{\mu_0}{\tau_0^2} + \frac{n\bar x}{\sigma^2}\Big)\;} \tag{4.8} $$ অর্থাৎ Normal prior × Normal likelihood → আবার Normal posterior — Normal হলো (known-variance) Normal likelihood-এর conjugate family।}
দুটো গভীর পাঠ (4.8) থেকে।
- (i) Precision যোগ হয়। posterior-precision = prior-precision + data-precision: \(\;1/\tau_n^2 = 1/\tau_0^2 + n/\sigma^2\)। অর্থাৎ "নিশ্চয়তা যোগ করো" — data যত বাড়ে (\(n\uparrow\)), data-precision \(n/\sigma^2\) তত বড়, posterior তত সরু (নিশ্চিত)। variance নয়, precision যোগ হওয়াই Gaussian-জগতে স্বাভাবিক বীজগণিত।
- (ii) Posterior mean = precision-weighted average। \(\mu_n\)-কে দুই weight-এর ভারিত গড় হিসেবে লেখা যায়: $$ \mu_n \;=\; \frac{\frac{1}{\tau_0^2}}{\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}}\,\mu_0 \;+\; \frac{\frac{n}{\sigma^2}}{\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}}\,\bar x \;=\; w\,\mu_0 + (1-w)\,\bar x, \qquad w=\frac{1/\tau_0^2}{1/\tau_0^2 + n/\sigma^2}. $$ পড়ুন: posterior mean হলো prior mean \(\mu_0\) ও data mean \(\bar x\)-এর মাঝামাঝি একটা টানাপোড়েন, যেখানে যার precision বেশি সে তত বেশি টানে। তিনটে সীমা দেখুন — (১) prior দুর্বল হলে (\(\tau_0\to\infty\), অর্থাৎ \(1/\tau_0^2\to0\)): \(w\to0\), তাই \(\mu_n\to\bar x\) — posterior পুরো data-চালিত (frequentist MLE)। (২) data বেশি হলে (\(n\to\infty\)): data-precision \(n/\sigma^2\) বিপুল, আবার \(w\to0\), \(\mu_n\to\bar x\) — বড় data prior-কে চাপা দেয়। (৩) data কম ও prior কড়া হলে: \(\mu_n\) \(\mu_0\)-র কাছে থাকে। এই "data বাড়লে posterior MLE-তে গড়িয়ে যায়" প্রবণতাই (d)-র Bernstein–von Mises-এর বীজ, আর §৫-এর Part 3 এটা সংখ্যায় দেখাবে (সেখানে \(n=25,\sigma=1,\tau_0=2\)-তে data-weight \(\approx0.99\), তাই \(\mu_n\approx\bar x\))।
কেন ★★★। এখানে গণিত (বর্গ-পূরণ) এই পর্যায়ের ছাত্রের নাগালে, তাই derivation পূর্ণ দিলাম। ★★★ ট্যাগটা বিষয়ের গভীরতা-র জন্য: variance \(\sigma^2\)-ও অজানা হলে conjugate prior হয় Normal–Inverse-Gamma (একটা joint prior), আর posterior হয় Student-\(t\) — সেই সাধারণ কেসের পূর্ণ derivation এখানে দিচ্ছি না (পরে আসবে)। known-variance কেসটাই precision-weighting-এর সারকথা পরিষ্কারতম রূপে দেখায়, তাই সেটাই বেছে নিলাম।
৪.৪ · (d) posterior থেকে সারাংশ: MAP, posterior mean, credible interval, ও Bernstein–von Mises — ★★¶
§৪.২–৪.৩-এ পুরো posterior distribution পেলাম। কিন্তু রিপোর্ট করার সময় প্রায়ই একটা সংখ্যা (point estimate) আর একটা ব্যাপ্তি (interval) চাই। posterior থেকে এদের কীভাবে নিষ্কাশন করি — আর কেন এই Bayesian interval frequentist-এরটার চেয়ে আলাদা — তা এই অংশে।
point estimate: MAP (mode) বনাম posterior mean¶
posterior-কে একটামাত্র সংখ্যায় সংকুচিত করার দুটো স্বাভাবিক পথ:
- MAP (Maximum A Posteriori) estimate — posterior-এর mode (সর্বোচ্চ-ঘনত্বের বিন্দু): $$ \hat\theta_{\text{MAP}} \;=\; \arg\max_\theta\, p(\theta\mid\text{data}) \;=\; \arg\max_\theta\, L(\theta)\,\pi(\theta). $$ (দ্বিতীয় সমতা (4.3) থেকে — normalizer \(\theta\)-নিরপেক্ষ, তাই argmax-এ অপ্রাসঙ্গিক, এবং এটাই MAP-কে গণনায় সহজ করে: evidence না জেনেও বের করা যায়।) স্বজ্ঞা: MAP হলো MLE-র Bayesian জ্ঞাতি — MLE \(L(\theta)\)-কে সর্বোচ্চ করে, MAP করে \(L(\theta)\pi(\theta)\)-কে; অর্থাৎ MAP = "prior-দিয়ে নিয়ন্ত্রিত (regularized) MLE"। flat prior হলে দুটো মিলে যায়।
- Posterior mean — posterior-এর গড়: $$ \hat\theta_{\text{mean}} \;=\; \mathbb{E}[\theta\mid\text{data}] \;=\; \int \theta\,p(\theta\mid\text{data})\,d\theta. $$ স্বজ্ঞা: mean পুরো posterior-এর ভর-কেন্দ্র, তাই লেজের আকার-ও হিসেবে নেয় (mode শুধু চূড়া দেখে)। decision-theory-গতভাবে posterior mean হলো squared-error loss-এর সেরা estimate (Bayes estimator) — একটা গুরুত্বপূর্ণ ফল যা পরে আসবে।
E1-এ দুটো একসাথে। posterior Beta\((a+k,\,b+n-k)\) থেকে (2.4-এর Beta-সূত্র দিয়ে): posterior mean \(=\dfrac{a+k}{a+b+n}\), আর MAP (mode) \(=\dfrac{a+k-1}{a+b+n-2}\) (যখন parameter \(>1\))। দুটো কাছাকাছি কিন্তু এক নয় — §৫-এর Part 1-এ \(a{=}b{=}2,n{=}20,k{=}13\)-তে mean \(=15/24=0.625\) আর MAP \(=14/22\approx0.636\), সংখ্যায় এই ছোট পার্থক্য দেখা যাবে। (লক্ষ করুন দুটোই MLE \(k/n=0.65\) থেকে সামান্য \(0.5\)-র দিকে টানা — prior Beta\((2,2)\) কেন্দ্রে \(0.5\) পছন্দ করে বলে।)
credible interval — এবং confidence interval থেকে এর মৌলিক পার্থক্য (E3)¶
একটা \((1-\alpha)\) credible interval হলো parameter-space-এর এমন একটা অঞ্চল \(C\) যাতে posterior অনুযায়ী \(\theta\)-র থাকার সম্ভাবনা \(1-\alpha\): $$ P\big(\theta\in C \,\big\mid\, \text{data}\big) \;=\; \int_C p(\theta\mid\text{data})\,d\theta \;=\; 1-\alpha. $$
সবচেয়ে প্রচলিত রূপ equal-tailed interval — দুই লেজে \(\alpha/2\) করে ছেঁটে, অর্থাৎ posterior-এর \(\alpha/2\) ও \(1-\alpha/2\) quantile দুটো প্রান্ত। (আরেকটা রূপ HPD — highest-posterior-density — সবচেয়ে সরু অঞ্চল; symmetric posterior-এ দুটো মেলে।)
এখানেই E3-এর মূল শিক্ষা — credible বনাম confidence (4.6-এর সাথে তুলনা):
| দিক | credible interval (Bayesian, এই অধ্যায়) | confidence interval (frequentist, 4.6) |
|---|---|---|
| \(\theta\) কী | একটা random variable (distribution আছে) | একটা স্থির অজানা ধ্রুবক |
| interval কী | data দিলে একটা স্থির অঞ্চল | data-নির্ভর, তাই একটা random অঞ্চল |
| ব্যাখ্যা | "এই data-র শর্তে \(\theta\) এই অঞ্চলে থাকার সম্ভাবনা \(95\%\)" | "এই পদ্ধতি বারবার চালালে উৎপন্ন interval-গুলোর \(95\%\) আসল \(\theta\)-কে ঢাকে" |
| কোথায় randomness | \(\theta\)-তে (data দেওয়া) | interval-এ (অর্থাৎ data-তে); \(\theta\) স্থির |
মূল ফারাকটা এক বাক্যে: credible interval সরাসরি বলে "\(\theta\) এখানে থাকার সম্ভাবনা \(95\%\)" — ঠিক যা মানুষ স্বজ্ঞায় চায়; অথচ confidence interval সেটা বলে না — সেখানে \(95\%\) হলো পদ্ধতির দীর্ঘকালীন coverage, কোনো একটা নির্দিষ্ট interval সম্পর্কে সম্ভাব্যতা-বিবৃতি নয় (\(\theta\) স্থির বলে একটা নির্দিষ্ট interval হয় ঢাকে নয় ঢাকে না, মাঝামাঝি "৯৫% সম্ভাবনা" বলা frequentist কাঠামোয় অর্থহীন)। দুটো প্রায়ই সংখ্যায় কাছাকাছি আসে (বিশেষত বড় data-তে, নিচের Bernstein–von Mises অনুসারে), কিন্তু অর্থ ভিন্ন — এই সূক্ষ্ম পার্থক্যই বহু বিভ্রান্তির উৎস, তাই E3 এটাকে সামনে রাখে। §৫-এ আমরা একটা সংখ্যাগত credible interval বের করব ([0.43, 0.80] E1-তে); চাইলে একই data-তে 4.6-র Wald confidence interval পাশে রেখে দেখা যায় দুটো কত কাছাকাছি অথচ ব্যাখ্যায় কত আলাদা।
Bernstein–von Mises: বড় data-তে Bayesian ≈ frequentist (স্বজ্ঞা)¶
একটা সুন্দর ও আশ্বস্তকর ফল দিয়ে Part IV শেষ করি, যা দুই দর্শনকে জোড়ে। আমরা §৪.৩-এ এক ঝলক দেখেছি — data বাড়লে posterior mean MLE-তে গড়ায়। এর সাধারণ রূপ:
Bernstein–von Mises উপপাদ্য (স্বজ্ঞাগত বিবৃতি)। যথেষ্ট নিয়মিত (regular) মডেলে, data যত বাড়ে (\(n\to\infty\)), posterior distribution-টা prior ভুলে গিয়ে একটা Normal-এ গড়ায়, যার কেন্দ্র MLE \(\hat\theta_{\text{MLE}}\) আর ছড়ানো ঠিক MLE-র sampling-distribution-এর সমান (4.3-এর asymptotic variance, inverse Fisher information): $$ p(\theta\mid\text{data}) \;\approx\; \mathcal{N}\Big(\hat\theta_{\text{MLE}},\ \tfrac{1}{n}\,I(\theta)^{-1}\Big) \qquad (n \text{ বড়}). $$
তিনটে পরিণতি, স্বজ্ঞাসহ:
- prior ধুয়ে যায় (washout)। যেকোনো (যুক্তিসঙ্গত, non-zero) prior থেকে শুরু করুন — যথেষ্ট data পেলে posterior প্রায় একই জায়গায় এসে দাঁড়ায়। অর্থাৎ prior-এর প্রভাব \(O(1/n)\) হারে মিলিয়ে যায়, data-ই শেষমেশ কথা বলে। (Normal–Normal-এ এটা হুবহু সত্য — §৪.৩-এ \(w\to0\); সাধারণ মডেলে আসন্নভাবে সত্য।)
- Bayesian point estimate ≈ MLE। posterior mean, MAP, MLE — তিনটেই বড় data-তে একে অপরের কাছে চলে আসে (পার্থক্য \(O(1/n)\))। তাই বড় নমুনায় "কোন দর্শন" প্রশ্নটা সংখ্যাগতভাবে গৌণ হয়ে পড়ে।
- credible interval ≈ confidence interval। posterior যেহেতু MLE-র sampling-distribution-এর মতোই Normal হয়ে যায়, তাই \(95\%\) credible interval আর \(95\%\) confidence interval সংখ্যায় প্রায় মিলে যায় — যদিও (উপরের টেবিল অনুযায়ী) তাদের ব্যাখ্যা চিরকাল ভিন্ন থাকে। এটাই E3-এর গল্পের সুন্দর সমাপ্তি: ছোট data-তে দুই interval অর্থে ও মানে আলাদা হতে পারে, বড় data-তে মানে মেলে কিন্তু অর্থ আলাদাই থাকে।
Part IV-এর সমাপ্তি-সুর। Bayesian inference কোনো বিচ্ছিন্ন দ্বীপ নয় — Bernstein–von Mises দেখায়, যথেষ্ট data-র সীমায় Bayesian ও frequentist উত্তর একই বিন্দুতে মেশে। পার্থক্যটা সবচেয়ে বেশি গুরুত্বপূর্ণ যখন data কম বা prior-জ্ঞান মূল্যবান — তখন prior সততার সাথে পূর্ব-তথ্য ঢোকায় আর credible interval সরাসরি, স্বজ্ঞাগত সম্ভাব্যতা-বিবৃতি দেয়। এই বোঝাপড়া নিয়েই আমরা Part V (পরিসংখ্যানিক মডেলিং)-এ ঢুকব, যেখানে এই দুই কাঠামোই বারবার পাশাপাশি কাজে লাগবে।
৪.৫ · সারমর্ম: কোনটা পূর্ণ, কোনটা স্বজ্ঞা¶
| ফল | difficulty | অবস্থা | মূল যন্ত্র |
|---|---|---|---|
| (a) posterior \(\propto L\cdot\pi\); evidence = normalizer | ★ | সম্পূর্ণ (2.2 event-Bayes-এর পুনঃপ্রয়োগ) | conditional probability + law of total probability (2.2) |
| (b) Beta–Binomial → Beta\((a+k,b+n-k)\) | ★★ | সম্পূর্ণ প্রমাণ (kernel মেলানো, integration এড়িয়ে) | ঘাত-যোগ + Beta-kernel চেনা (2.4) |
| (c) Normal–Normal: precision-weighted mean | ★★★ | সম্পূর্ণ (known-variance কেস; বর্গ-পূরণ) | completing the square + Gaussian-kernel চেনা |
| (d) MAP/mean, credible interval, Bernstein–von Mises | ★★ | point/CI সম্পূর্ণ; BvM স্বজ্ঞাগত বিবৃতি (প্রমাণ ধার) | argmax/quantile of posterior; asymptotic Normal (4.3) |
মূল ছবি: (a) Bayes মানে posterior \(\propto\) likelihood × prior, হরটা শুধু \(\theta\)-নিরপেক্ষ normalizer (= evidence); (b)-(c) সঠিক prior বাছলে posterior একই family-তে থাকে, তাই kernel চিনেই উত্তর — integration লাগে না (conjugacy); (d) posterior থেকে MAP/mean ও credible interval বের করা সরল, আর Bernstein–von Mises আশ্বাস দেয় বড় data-তে Bayesian ও frequentist এক বিন্দুতে মেশে। পরের §৫-এ এই চারটেই সংখ্যায় যাচাই করব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে §৪-এর দাবিগুলোকে আমরা সিমুলেশনে যাচাই করব — যাতে Bayesian updating কাগজে নয় শুধু, সংখ্যাতেও বিশ্বাসযোগ্য হয়। সব এলোমেলোতা আসে numpy-র আধুনিক generator default_rng থেকে, একটা স্থির seed (20260619) বসিয়ে — তাই ফলাফল পুনরুৎপাদনযোগ্য (reproducible): যে যতবার চালাবে হুবহু একই সংখ্যা পাবে। posterior-এর distribution ও quantile-এর জন্য scipy.stats ব্যবহার করছি। (নিচে ছাপানো সব সংখ্যা স্ক্রিপ্টটা সত্যিই চালিয়ে পাওয়া।)
আমরা চারটে জিনিস মাপব, ঠিক §৪-এর অংশগুলো অনুসরণ করে:
- Part 1 — Beta–Binomial update (§৪.২, §৪.৪)। prior Beta\((2,2)\) ও data (\(k{=}13\) in \(n{=}20\)) থেকে posterior Beta\((15,9)\); এর posterior mean, MAP, ও \(95\%\) credible interval বের করব, আর MLE \(k/n\)-এর সাথে তুলনা করব।
- Part 2 — sequential updating (§৪.২)। একই data \(40\)টা flip-এ, \(10\)টা করে ৪ batch-এ খাইয়ে দেখব posterior কীভাবে ধাপে ধাপে সরু (নিশ্চিত) হয় — আর batch-করা বনাম একসাথে-করা যে একই posterior দেয় তা cross-check করব।
- Part 3 — Normal–Normal posterior (§৪.৩)। prior \(\mathcal{N}(0,2^2)\), known \(\sigma{=}1\), \(n{=}25\) data থেকে posterior mean-কে precision-weighted average হিসেবে যাচাই করব, সংখ্যায় দেখব data-weight \(\approx0.99\) (তাই posterior \(\approx\) MLE — Bernstein–von Mises-এর আভাস)।
- Part 4 — non-conjugate posterior + Metropolis (§৪.১.৩, E4)। Gaussian likelihood × Cauchy prior (conjugacy নেই, closed-form নেই) — 3.6-এর Metropolis sampler দিয়ে posterior থেকে নমুনা তুলে, একটা fine-grid সংখ্যাগত "সত্য"-র সাথে mean ও credible interval মিলিয়ে দেখব।
৫.১ · সম্পূর্ণ স্ক্রিপ্ট¶
# Chapter 4.10 - Bayesian Inference : Code Lab (sections 4-5)
# Numerically illustrates:
# PART 1 - Beta-Binomial conjugate update: posterior, posterior mean, 95% credible interval
# PART 2 - Sequential updating: posterior tightens as data arrives one batch at a time
# PART 3 - Normal-Normal conjugacy (known variance): posterior mean = precision-weighted avg
# PART 4 - Metropolis sampler for a NON-conjugate posterior; compare to a fine-grid "truth"
import numpy as np
from scipy import stats
SEED = 20260619
rng = np.random.default_rng(SEED) # fixed seed => fully reproducible
np.set_printoptions(precision=4, suppress=True)
# ===============================================================
# PART 1 - BETA-BINOMIAL CONJUGATE UPDATE (E1).
# Model: theta ~ Beta(a, b) (prior); k successes in n trials ~ Binomial(n, theta).
# Posterior (proved in section 4): theta | data ~ Beta(a + k, b + n - k).
# ===============================================================
print("=" * 66)
print("PART 1 - Beta-Binomial conjugate update (E1)")
print("=" * 66)
a0, b0 = 2.0, 2.0 # prior Beta(2,2): symmetric, mild
n, k = 20, 13 # observed: 13 successes in 20 trials
aT, bT = a0 + k, b0 + (n - k) # posterior Beta(a+k, b+n-k)
post = stats.beta(aT, bT)
post_mean = aT / (aT + bT) # mean of Beta(aT,bT)
post_mode = (aT - 1) / (aT + bT - 2) # MAP = mode (valid since aT,bT > 1)
lo, hi = post.ppf(0.025), post.ppf(0.975) # equal-tailed 95% credible interval
mle = k / n # frequentist MLE for comparison
print(f" prior : Beta(a={a0}, b={b0})")
print(f" data : k={k} successes in n={n} trials (MLE = k/n = {mle:.4f})")
print(f" posterior : Beta(a+k={aT}, b+n-k={bT})")
print(f" posterior mean : {post_mean:.4f}")
print(f" posterior MAP : {post_mode:.4f} (mode of the posterior)")
print(f" 95% credible interval : [{lo:.4f}, {hi:.4f}]")
print(f" P(theta > 0.5 | data) = {1 - post.cdf(0.5):.4f}")
# ===============================================================
# PART 2 - SEQUENTIAL UPDATING (E1).
# Bayes is naturally online: yesterday's posterior is today's prior.
# ===============================================================
print("\n" + "=" * 66)
print("PART 2 - Sequential updating: posterior tightens as data arrives")
print("=" * 66)
theta_true = 0.7
flips = rng.binomial(1, theta_true, size=40) # 40 Bernoulli(0.7) flips
a, b = 1.0, 1.0 # start from flat Uniform = Beta(1,1) prior
print(f" true bias theta = {theta_true}; flat prior Beta(1,1)")
print(f" {'after':>7} {'k/n':>7} {'post a':>8} {'post b':>8} {'mean':>8} "
f"{'sd':>8} {'95% credible interval':>24}")
seen_k, seen_n = 0, 0
for batch in range(4):
chunk = flips[batch * 10:(batch + 1) * 10]
kk = int(chunk.sum()); seen_k += kk; seen_n += len(chunk)
a += kk; b += (len(chunk) - kk) # conjugate update with this batch
d = stats.beta(a, b)
lo_b, hi_b = d.ppf(0.025), d.ppf(0.975)
print(f" {seen_n:>7} {str(seen_k)+'/'+str(seen_n):>7} {a:>8.1f} {b:>8.1f} {a/(a+b):>8.4f} "
f"{d.std():>8.4f} [{lo_b:.4f}, {hi_b:.4f}]")
print(" note: batching vs. all-at-once gives the SAME final posterior (order-free).")
k_all = int(flips.sum())
print(f" one-shot Beta(1+{k_all}, 1+{40 - k_all}) = Beta({1 + k_all}, {1 + 40 - k_all})"
f" -> matches final row: {a == 1 + k_all and b == 1 + 40 - k_all}")
# ===============================================================
# PART 3 - NORMAL-NORMAL CONJUGACY, known variance (E2).
# Prior: theta ~ N(mu0, tau0^2). Data: x_1..x_n ~ N(theta, sigma^2), sigma known.
# Posterior precision 1/tau_n^2 = 1/tau0^2 + n/sigma^2 ;
# posterior mean mu_n = tau_n^2 * ( mu0/tau0^2 + (n*xbar)/sigma^2 ).
# ===============================================================
print("\n" + "=" * 66)
print("PART 3 - Normal-Normal conjugacy (known variance) (E2)")
print("=" * 66)
mu0, tau0 = 0.0, 2.0 # prior N(0, 2^2)
sigma = 1.0 # KNOWN data sd
theta_true_n = 1.5
nN = 25
data = rng.normal(theta_true_n, sigma, size=nN)
xbar = data.mean()
prior_prec = 1.0 / tau0**2
data_prec = nN / sigma**2
post_prec = prior_prec + data_prec # precisions ADD
tau_n2 = 1.0 / post_prec
mu_n = tau_n2 * (mu0 * prior_prec + xbar * data_prec) # precision-weighted average
w_data = data_prec / post_prec
loN, hiN = stats.norm(mu_n, np.sqrt(tau_n2)).ppf([0.025, 0.975])
print(f" prior : N(mu0={mu0}, tau0^2={tau0**2:.1f}) known sigma={sigma}")
print(f" data : n={nN}, xbar={xbar:.4f} (true theta={theta_true_n}, MLE=xbar)")
print(f" posterior precision 1/tau_n^2 = 1/tau0^2 + n/sigma^2 = "
f"{prior_prec:.4f} + {data_prec:.4f} = {post_prec:.4f}")
print(f" posterior mean mu_n = {mu_n:.4f} (a {w_data:.3f}:{1 - w_data:.3f} "
f"data:prior weighting)")
print(f" posterior sd = {np.sqrt(tau_n2):.4f}")
print(f" 95% credible interval : [{loN:.4f}, {hiN:.4f}]")
print(f" for contrast, xbar alone (MLE) = {xbar:.4f}; posterior pulled "
f"slightly toward prior mean {mu0}")
# ===============================================================
# PART 4 - METROPOLIS for a NON-CONJUGATE posterior (E4).
# Likelihood: x_1..x_n ~ N(theta, 1) (known var). Prior: theta ~ Cauchy(0,1)
# (heavy-tailed prior -> NO conjugacy, no closed-form posterior).
# log posterior (up to const) = -0.5*sum (x_i - theta)^2 - log(1 + theta^2).
# ===============================================================
print("\n" + "=" * 66)
print("PART 4 - Metropolis sampler for a NON-conjugate posterior (E4)")
print("=" * 66)
n4 = 10
theta_true4 = 3.0
x4 = rng.normal(theta_true4, 1.0, size=n4)
xbar4 = x4.mean()
def log_post(theta):
loglik = -0.5 * np.sum((x4 - theta) ** 2) # N(theta,1) likelihood up to const
logprior = -np.log1p(theta ** 2) # standard Cauchy(0,1) prior up to const
return loglik + logprior
def metropolis(logf, x0, n_iter, prop_sd):
x = x0; lp = logf(x)
out = np.empty(n_iter); n_acc = 0
for t in range(n_iter):
xp = x + rng.normal(0.0, prop_sd) # symmetric proposal (3.6 idea)
lpp = logf(xp)
if np.log(rng.random()) < lpp - lp: # accept w.p. min(1, ratio)
x, lp = xp, lpp; n_acc += 1
out[t] = x
return out, n_acc / n_iter
N_ITER, BURN = 120_000, 20_000
chain, acc = metropolis(log_post, x0=0.0, n_iter=N_ITER, prop_sd=0.6)
kept = chain[BURN:]
# high-resolution grid "truth" for the SAME posterior (normalize numerically)
grid = np.linspace(-2, 7, 9001)
logvals = np.array([log_post(t) for t in grid])
w = np.exp(logvals - logvals.max())
w /= np.trapezoid(w, grid) # normalized posterior density on grid
grid_mean = np.trapezoid(grid * w, grid)
cdf = np.cumsum(w) * (grid[1] - grid[0])
grid_lo = grid[np.searchsorted(cdf, 0.025)]
grid_hi = grid[np.searchsorted(cdf, 0.975)]
print(f" data: n={n4}, xbar={xbar4:.4f} (true theta={theta_true4})")
print(f" prior = Cauchy(0,1) => NON-conjugate, no closed-form posterior")
print(f" Metropolis: {N_ITER:,} iters (burn {BURN:,}), acceptance = {acc:.3f}")
print(f" {'quantity':<22}{'Metropolis':>12}{'grid truth':>12}")
print(f" {'posterior mean':<22}{kept.mean():>12.4f}{grid_mean:>12.4f}")
print(f" {'2.5% quantile':<22}{np.quantile(kept, 0.025):>12.4f}{grid_lo:>12.4f}")
print(f" {'97.5% quantile':<22}{np.quantile(kept, 0.975):>12.4f}{grid_hi:>12.4f}")
print(f" => 95% credible interval (Metropolis) = "
f"[{np.quantile(kept, 0.025):.4f}, {np.quantile(kept, 0.975):.4f}]")
print(f" note: posterior mean {kept.mean():.3f} sits BELOW xbar {xbar4:.3f} - the heavy")
print(f" Cauchy prior gently pulls the estimate toward 0 (robust shrinkage).")
৫.২ · বাস্তব আউটপুট¶
স্ক্রিপ্টটা চালালে (seed 20260619, numpy 2.2.6, scipy 1.15.3) ঠিক নিচের আউটপুট আসে — এগুলো সত্যিই চালিয়ে পাওয়া, হাতে-বানানো নয় (দুবার চালালেও হুবহু এক, কারণ seed স্থির):
==================================================================
PART 1 - Beta-Binomial conjugate update (E1)
==================================================================
prior : Beta(a=2.0, b=2.0)
data : k=13 successes in n=20 trials (MLE = k/n = 0.6500)
posterior : Beta(a+k=15.0, b+n-k=9.0)
posterior mean : 0.6250
posterior MAP : 0.6364 (mode of the posterior)
95% credible interval : [0.4273, 0.8029]
P(theta > 0.5 | data) = 0.8950
==================================================================
PART 2 - Sequential updating: posterior tightens as data arrives
==================================================================
true bias theta = 0.7; flat prior Beta(1,1)
after k/n post a post b mean sd 95% credible interval
10 4/10 5.0 7.0 0.4167 0.1367 [0.1675, 0.6921]
20 13/20 14.0 8.0 0.6364 0.1003 [0.4303, 0.8189]
30 22/30 23.0 9.0 0.7188 0.0783 [0.5539, 0.8578]
40 31/40 32.0 10.0 0.7619 0.0650 [0.6239, 0.8764]
note: batching vs. all-at-once gives the SAME final posterior (order-free).
one-shot Beta(1+31, 1+9) = Beta(32, 10) -> matches final row: True
==================================================================
PART 3 - Normal-Normal conjugacy (known variance) (E2)
==================================================================
prior : N(mu0=0.0, tau0^2=4.0) known sigma=1.0
data : n=25, xbar=1.3365 (true theta=1.5, MLE=xbar)
posterior precision 1/tau_n^2 = 1/tau0^2 + n/sigma^2 = 0.2500 + 25.0000 = 25.2500
posterior mean mu_n = 1.3233 (a 0.990:0.010 data:prior weighting)
posterior sd = 0.1990
95% credible interval : [0.9332, 1.7133]
for contrast, xbar alone (MLE) = 1.3365; posterior pulled slightly toward prior mean 0.0
==================================================================
PART 4 - Metropolis sampler for a NON-conjugate posterior (E4)
==================================================================
data: n=10, xbar=3.4893 (true theta=3.0)
prior = Cauchy(0,1) => NON-conjugate, no closed-form posterior
Metropolis: 120,000 iters (burn 20,000), acceptance = 0.521
quantity Metropolis grid truth
posterior mean 3.4370 3.4353
2.5% quantile 2.8069 2.8110
97.5% quantile 4.0581 4.0590
=> 95% credible interval (Metropolis) = [2.8069, 4.0581]
note: posterior mean 3.437 sits BELOW xbar 3.489 - the heavy
Cauchy prior gently pulls the estimate toward 0 (robust shrinkage).
৫.৩ · আউটপুট কীভাবে পড়ব — দাবি মিলিয়ে দেখা¶
- Part 1 — Beta–Binomial update (§৪.২, §৪.৪)। prior Beta\((2,2)\)-তে \(k{=}13\) in \(n{=}20\) যোগ করে posterior ঠিক Beta\((15,9)\) — হুবহু (4.5)-এর \(a{+}k=2{+}13,\ b{+}n{-}k=2{+}7\)। এর posterior mean \(=15/24=0.6250\) আর MAP (mode) \(=14/22\approx0.6364\) — §৪.৪-এর দুই সূত্রের সংখ্যাচিত রূপ, আর দেখুন দুটোই MLE \(0.65\) থেকে সামান্য \(0.5\)-র দিকে টানা (prior Beta\((2,2)\) কেন্দ্রে \(0.5\) পছন্দ করে বলে — ঠিক §৪.৪-এর "regularized MLE" স্বজ্ঞা)। \(95\%\) credible interval \([0.4273,0.8029]\) — সরাসরি posterior-এর \(2.5\%\) ও \(97.5\%\) quantile, যার Bayesian অর্থ: "এই data-র শর্তে \(\theta\) এই ব্যাপ্তিতে থাকার সম্ভাবনা \(95\%\)" (§৪.৪-এর E3-পার্থক্য মনে রাখুন — confidence interval এটা বলে না)। আর \(P(\theta>0.5\mid\text{data})=0.895\) — Bayesian কাঠামোয় এমন সরাসরি সম্ভাব্যতা-বিবৃতি করা যায়, frequentist-এ যা করা যায় না।
- Part 2 — sequential updating (§৪.২)। এটাই Bayes-এর "online" চরিত্রের জীবন্ত ছবি: প্রতিটি batch-এর \(k\) success ও \(n{-}k\) failure সরাসরি \(a,b\)-তে যোগ হচ্ছে (Beta\((1,1)\to(5,7)\to(14,8)\to(23,9)\to(32,10)\)) — ঠিক §৪.২-এর "pseudo-count যোগ" স্বজ্ঞা। দুটো প্যাটার্ন স্পষ্ট: (১) data বাড়তেই posterior সরু হচ্ছে — sd নামছে \(0.1367\to0.1003\to0.0783\to0.0650\), আর credible interval সংকুচিত হচ্ছে (\([0.17,0.69]\to[0.62,0.88]\)); (২) posterior mean সত্যিকারের \(\theta=0.7\)-র দিকে গড়াচ্ছে (\(0.42\to0.64\to0.72\to0.76\))। আর শেষ লাইনের cross-check
Trueপ্রমাণ করে — চার batch-এ ভেঙে হালনাগাদ করা আর পুরো \(40\) একসাথে হালনাগাদ করা হুবহু একই posterior Beta\((32,10)\) দেয় (Bayes order-free), যা §৪.২-এর conjugate-update-এর associativity-র সংখ্যাচিত নিশ্চিতি। - Part 3 — Normal–Normal precision-weighting (§৪.৩)। আউটপুট (4.8) লাইন-বাই-লাইন যাচাই করে: posterior precision \(=1/\tau_0^2+n/\sigma^2=0.25+25=25.25\) (precision যোগ হলো)। posterior mean \(\mu_n=1.3233\), আর কোডের গণিত দেখায় এটা \(0.990:0.010\) data:prior ভারিত গড় — অর্থাৎ এখানে data-precision (\(25\)) prior-precision (\(0.25\))-কে বিপুলভাবে ছাপিয়ে যায়, তাই \(\mu_n\) প্রায় পুরোপুরি \(\bar x=1.3365\)-এ, শুধু সামান্য prior mean \(0\)-র দিকে টানা। এটাই §৪.৩-এর পাঠ (ii) ও §৪.৪-এর Bernstein–von Mises-এর সংখ্যাচিত আভাস: data যথেষ্ট হলে posterior প্রায় MLE-তে বসে, prior ধুয়ে যায়। credible interval \([0.933,1.713]\) সত্যিকারের \(\theta=1.5\)-কে ঢাকে।
- Part 4 — non-conjugate posterior + Metropolis (§৪.১.৩, E4)। এখানে prior Cauchy\((0,1)\) — heavy-tailed, conjugate নয়, তাই posterior-এর closed form নেই ও normalizer \(\int L\pi\) বিশ্লেষণে কষা যায় না। তবু 3.6-এর symmetric-proposal Metropolis (acceptance \(\min(1,\text{ratio})\), যেখানে normalizer কাটে বলে শুধু অ-normalized \(L\pi\) লাগে — §৪.১.৩-এর মূল কথা) posterior থেকে নমুনা তুলে দেয়। ফল একটা স্বাধীন fine-grid সংখ্যাগত "সত্য"-র সাথে মিলিয়ে দেখুন: posterior mean Metropolis \(3.4370\) বনাম grid \(3.4353\); credible interval Metropolis \([2.807,4.058]\) বনাম grid \([2.811,4.059]\) — তিন দশমিক পর্যন্ত মিল, অর্থাৎ sampler সত্যিই ঠিক posterior থেকেই নমুনা দিচ্ছে। শেষ নোটটা শিক্ষণীয়: posterior mean \(3.437\) data-গড় \(\bar x=3.489\)-এর নিচে — heavy-tailed Cauchy prior estimate-কে আলতো করে \(0\)-র দিকে টানে (robust shrinkage), conjugate কেসের চেয়ে সূক্ষ্ম এক আচরণ যা শুধু MCMC দিয়েই ধরা গেল।
সততা-নোট। সিমুলেশন §৪-এর সূত্র "প্রমাণ" করে না — Part 1–3-এ আমরা closed-form posterior-ই (4.5)/(4.8) কোডে বসিয়েছি, তাই মিল প্রত্যাশিত; এটা শুধু পাটিগণিত যাচাই ও দাবিগুলোকে চোখে দেখায় (posterior কীভাবে সরু হয়, mean কীভাবে গড়ায়)। Part 4-এ Metropolis-আর-grid মিল দেখায় MCMC সঠিক distribution-কে আঁচ করছে, কিন্তু MCMC নমুনা i.i.d. নয় (পরপর মান autocorrelated, 3.6-এর মতো) — তাই কার্যকর নমুনা-সংখ্যা কাঁচা সংখ্যার চেয়ে কম, আর Metropolis বনাম grid-এর শেষ-দশমিকের ছোট গরমিল সেই Monte-Carlo দানারই ছাপ; আসল উত্তর ঠিক target posterior। বড় ছবিতে — চারটে Part মিলে §৪-এর গোটা যাত্রা সংখ্যায় ফুটিয়ে তোলে: conjugacy (Part 1–3) যেখানে খাটে সেখানে integration-হীন ঝটপট posterior, আর যেখানে খাটে না (Part 4) সেখানে MCMC — ঠিক যেমন Part V-এর জটিলতর মডেলগুলোতে বারবার লাগবে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
figs_4-10_C.py-তে তৈরি; PNG_assets/-এ (prefix4-10, dpi=150)। in-figure লেখা সব ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। চলমান উদাহরণ: E1 Beta–Binomial; E2 Normal–Normal; E3 credible vs confidence interval; E4 MCMC / posterior predictive।
Bayesian inference-এর গোটা গল্পটা চারটা ছবিতে ধরা যায়, আর প্রতিটা একটা মূল প্রশ্নের উত্তর দেয়। (১) prior \(\pi(\theta)\) আর likelihood \(L(\theta)\) মিলে কীভাবে posterior \(p(\theta\mid\text{data})\) বানায় — তিনটা বক্ররেখা এক অক্ষে রাখলে কেমন দেখায়, আর posterior কেন দুটোর মাঝে বসে অথচ দুটোর চেয়ে সরু (Figure 1)? (২) data ফোঁটায় ফোঁটায় এলে posterior ধাপে ধাপে কীভাবে ধারালো হয় — প্রতিটা posterior পরের ধাপের prior হয়ে গেলে অনিশ্চয়তা কীভাবে কমে (Figure 2)? (৩) একটা \(95\%\) credible interval posterior-এর নিচে ছায়া দিয়ে দেখালে তা ঠিক কী বলে, আর সেটা frequentist confidence interval-এর ব্যাখ্যা থেকে কীভাবে আলাদা (Figure 3)? (৪) posterior-এর কোনো সুন্দর সূত্র না থাকলে (non-conjugate) MCMC দিয়ে নমুনা টেনে কীভাবে posterior-কে আঁকা যায় — trace আর histogram মিলে কী দেখায় (Figure 4)? প্রথম ছবিটা আপডেটের জ্যামিতি, দ্বিতীয়টা আপডেটের ধারাবাহিকতা, তৃতীয়টা credible বনাম confidence, আর চতুর্থটা যখন সূত্র নেই — sampling।
Figure 1 — prior × likelihood → posterior: একটাই ছবিতে Bayes' rule¶
এই অধ্যায়ের কেন্দ্রীয় সমীকরণ \(p(\theta\mid\text{data})\propto \pi(\theta)\,L(\theta)\) একটাই ছবিতে: নীল prior \(\pi(\theta)\), কমলা likelihood \(L(\theta)\), আর সবুজ posterior \(p(\theta\mid\text{data})\) — তিনটাই এক অক্ষে। চলমান উদাহরণ E1 (Beta–Binomial): prior \(\pi(\theta)=\text{Beta}(2,2)\) (একটা মৃদু "\(\theta\) সম্ভবত মাঝামাঝি" বিশ্বাস), data = \(20\) চেষ্টায় \(14\) সাফল্য, তাই likelihood-এর শিখর MLE \(\hat\theta=k/n=0.70\)-তে। conjugate update-এর নিয়মে posterior হয় \(\text{Beta}(2+14,\,2+6)=\text{Beta}(16,8)\) (চিত্রের জন্য illustrative count \(14/20\); §৩/§৫-এ একই E1-এর সংখ্যা \(13/20\) — পদ্ধতি অভিন্ন) — সবুজ মোটা রেখা; তার posterior mean \(0.67\) আর MAP \(\hat\theta_{\text{MAP}}=0.68\) (শিখরের অবস্থান)। নীল prior চওড়া ও নিচু (অনেক অনিশ্চয়তা), কমলা likelihood data-র কথা বলে, আর সবুজ posterior দুটোকে গুণ করে তৈরি।
যা লক্ষ করতে হবে: (ক) posterior (সবুজ) prior আর likelihood-এর মাঝে বসে — তার শিখর \(0.68\), যা prior-এর কেন্দ্র \(0.50\) আর likelihood-এর শিখর \(0.70\)-এর মাঝামাঝি (data-র দিকে বেশি হেলানো, কারণ \(20\)টা পর্যবেক্ষণ মৃদু prior-কে ছাড়িয়ে যায়)। এটাই Bayes-এর "compromise": উত্তর = পূর্ব-বিশ্বাস ও নতুন তথ্যের ভারিত মিশ্রণ। (খ) posterior দুটোর চেয়েই সরু (ধারালো) — গুণফলে অনিশ্চয়তা কমে, কারণ prior আর data দুই উৎস মিলে \(\theta\)-কে বেশি নিশ্চিতভাবে আটকায়। (গ) prior দুর্বল (চওড়া) হলে posterior প্রায় likelihood-কেই অনুসরণ করত, আর posterior mean MLE-র কাছে চলে আসত — অর্থাৎ যথেষ্ট data থাকলে prior-এর প্রভাব ম্লান হয় (পরের ছবিতে এটাই চরমে দেখা যাবে)। (ঘ) likelihood-কে এখানে একটা density হিসেবে rescale করে আঁকা হয়েছে কেবল একই অক্ষে তুলনার জন্য; likelihood নিজে \(\theta\)-এর density নয়, এটা data-র সম্ভাবনাকে \(\theta\)-র ফাংশন হিসেবে দেখা।
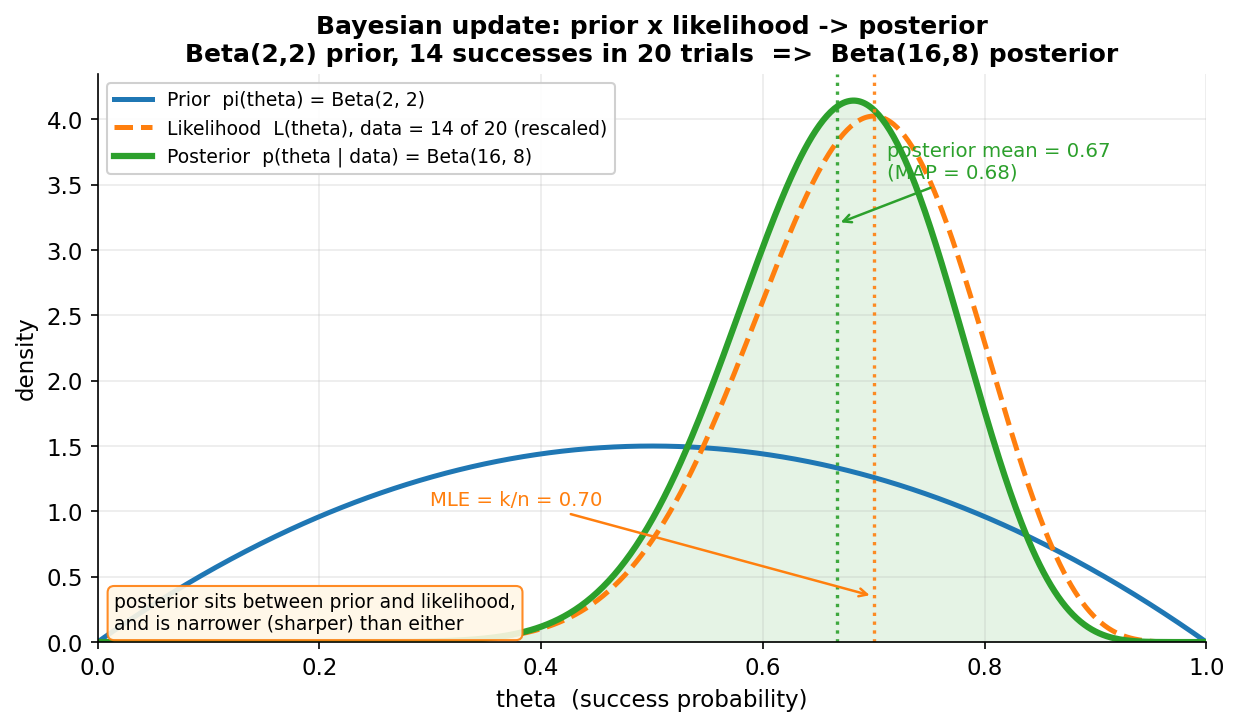
Figure 2 — sequential updating: posterior ধাপে ধাপে ধারালো হয়¶
Figure 1 একবারের আপডেট দেখাল; এই ছবি দেখায় data যত বাড়ে posterior তত ধারালো হয় — Bayesian inference-এর সবচেয়ে স্বজ্ঞাত (intuitive) ছবি। এখানে prior শুরুতে \(\text{Beta}(1,1)\) (সমতল uniform — "\(\theta\) নিয়ে কোনো পূর্ব-ঝোঁক নেই"), আর সত্য \(\theta=0.7\) থেকে data ফোঁটায় ফোঁটায় আসছে। কয়েকটা checkpoint-এ posterior আঁকা: \(n=0\) (prior, সমতল ভাঙা রেখা) → \(n=5\) (\(\text{Beta}(4,3)\), এখনও চওড়া) → \(n=20\) (\(\text{Beta}(13,9)\)) → \(n=80\) (\(\text{Beta}(60,22)\)) → \(n=320\) (\(\text{Beta}(222,100)\), সরু ও আকাশছোঁয়া শিখর)। conjugate update-এর মূল সৌন্দর্য: প্রতিটা ধাপে আগের posterior পরের ধাপের prior হয়ে যায়, আর Beta পরিবার থেকে বেরোয় না — শুধু \(a\leftarrow a+(\text{নতুন সাফল্য})\), \(b\leftarrow b+(\text{নতুন ব্যর্থতা})\)।
যা লক্ষ করতে হবে: (ক) \(n\) বাড়লে বক্ররেখা লম্বা ও সরু হয় — অর্থাৎ \(\theta\) নিয়ে অনিশ্চয়তা কমে; \(n=5\)-এ posterior প্রায় পুরো \([0.3,0.95]\) জুড়ে ছড়ানো, কিন্তু \(n=320\)-এ তা একটা সরু চূড়ায় গুটিয়ে আসে। বেশি data ⇒ কম অনিশ্চয়তা — credible interval সরু হয়। (খ) শিখরটা সত্য \(\theta=0.7\)-এর দিকে স্থির হয় (লাল ভাঙা রেখা): শুরুতে শিখর data-র এলোমেলো ওঠানামায় একটু এদিক-ওদিক, কিন্তু \(n\) বাড়লে সত্য মানে থিতু হয় — এটাই Bayesian consistency (frequentist LLN-এর সমান্তরাল, 3.3)। (গ) প্রথম দিকে (ছোট \(n\)) uniform prior-এর সমতল প্রভাব দেখা যায়, কিন্তু data জমলে posterior সম্পূর্ণভাবে data-চালিত হয়ে যায় — prior-এর প্রভাব data-র সাথে ম্লান হয়, যা ছোট-data ছাড়া সব ক্ষেত্রে আশ্বাসজনক। (ঘ) এই "online" আপডেট মানে নতুন পর্যবেক্ষণ এলে শূন্য থেকে শুরু করতে হয় না — পুরোনো posterior-ই নতুন prior, তাই streaming data-য় Bayesian পদ্ধতি স্বাভাবিকভাবে খাপ খায়।
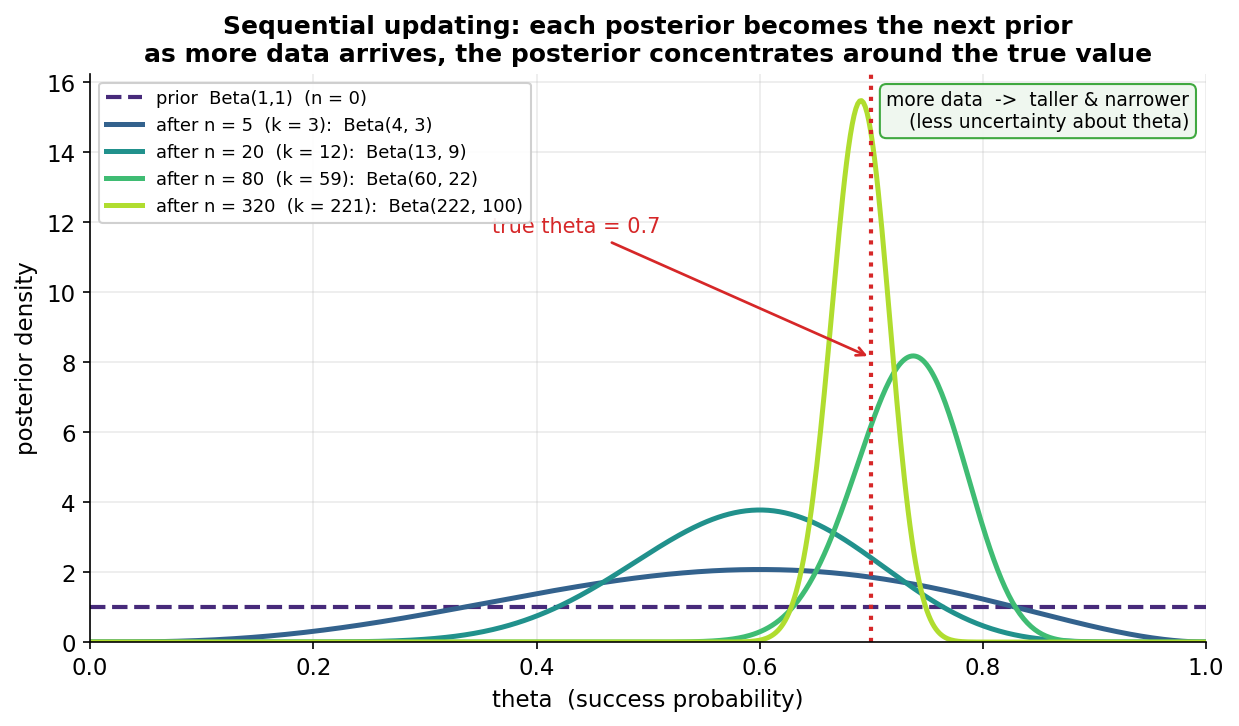
Figure 3 — credible interval বনাম confidence interval: একই সংখ্যা, ভিন্ন অর্থ¶
এটি এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ ধারণাগত ছবি (E3): Bayesian credible interval আর frequentist confidence interval দেখতে একইরকম সংখ্যা দিতে পারে, কিন্তু তাদের অর্থ মৌলিকভাবে আলাদা। বাঁ প্যানেল (Bayesian): Figure 1-এর posterior \(\text{Beta}(16,8)\)-এর নিচে সবুজ ছায়া হলো \(95\%\) equal-tailed credible interval \([0.47,0.84]\) — যার মধ্যে posterior-এর ঠিক \(95\%\) ভর; অর্থাৎ \(P(0.47\le\theta\le0.84\mid\text{data})=0.95\)। এখানে \(\theta\)-ই অনিশ্চিত (একটা random quantity আমাদের বিশ্বাসে), আর interval-টা স্থির — তাই বলা যায় "এই interval-এর মধ্যে \(\theta\) আছে—এই সম্ভাবনা \(0.95\)"। ডান প্যানেল (frequentist): সত্য \(\theta=0.67\) একটা স্থির (কিন্তু অজানা) সংখ্যা (কালো ভাঙা রেখা); \(20\)টা ভিন্ন নমুনা থেকে \(20\)টা random confidence interval বানানো — কিছু সত্য মানকে ঢাকে, কিছু ফসকায় (গড়ে \(\sim95\%\) ঢাকবে)। এখানে interval random, \(\theta\) স্থির — তাই বলা যায় না "এই একটা interval-এ \(\theta\) থাকার সম্ভাবনা \(0.95\)"; বরং "এমন \(95\%\) interval সত্য মানকে ঢাকবে" (4.6-এর সূক্ষ্ম ব্যাখ্যা)।
যা লক্ষ করতে হবে: (ক) কোনটা random, কোনটা fixed — এটাই আসল পার্থক্য। Bayesian: \(\theta\) random (বিশ্বাসের density), interval fixed → সম্ভাবনাটা \(\theta\) সম্পর্কে। Frequentist: \(\theta\) fixed, interval random → সম্ভাবনাটা পদ্ধতি (long-run coverage) সম্পর্কে, এই বিশেষ interval সম্পর্কে নয়। (খ) বাঁ প্যানেলের একটামাত্র interval বনাম ডান প্যানেলের অনেক interval — এই ছবির পার্থক্যই দুই দর্শনের পার্থক্য: Bayesian একটা data-set থেকে \(\theta\)-র সরাসরি সম্ভাব্যতা-বিবৃতি দেয়; frequentist কল্পিত পুনরাবৃত্ত নমুনায় পদ্ধতির আচরণ বর্ণনা করে। (গ) তবু সংখ্যাগতভাবে দুটো প্রায়ই কাছাকাছি (বিশেষত flat prior ও বড় নমুনায়) — তাই ভুল করে অনেকে confidence interval-কে "\(\theta\) এখানে থাকার \(95\%\) সম্ভাবনা" বলে ফেলে, যা আসলে credible interval-এর ব্যাখ্যা; এই ছবি ঠিক সেই বিভ্রান্তি ঠেকাতে। (ঘ) Bayesian ব্যাখ্যাটা স্বজ্ঞার বেশি কাছের (মানুষ স্বাভাবিকভাবেই "\(\theta\) এখানে থাকার সম্ভাবনা" ভাবতে চায়) — কিন্তু তার দাম হলো একটা prior বাছতে হয়।
![A two-panel figure contrasting a Bayesian credible interval with a frequentist confidence interval, under the overall title "Credible interval vs confidence interval: same numbers, different meaning". The LEFT panel, titled "Bayesian: 95 percent credible interval, shaded region holds 95 percent of posterior probability", plots the posterior Beta(16,8) as a green curve with the central region from 0.47 to 0.84 shaded; dashed green vertical lines mark the 2.5 percent and 97.5 percent quantiles, a dotted red line marks the posterior mean 0.67, and a double-headed arrow spans the interval labelled "95 percent credible interval [0.47, 0.84]". A boxed note reads "P(0.47 less-or-equal theta less-or-equal 0.84 given data) equals 0.95; theta is in here with probability 0.95". The RIGHT panel, titled "Frequentist: 95 percent confidence interval, random intervals, about 95 percent of them cover the fixed theta", shows a vertical stack of twenty horizontal interval bars from twenty simulated samples drawn at a fixed true theta equals 0.67 (a black dashed vertical line); intervals are coloured blue when they cover the true value and red when they miss, with a legend giving the counts. A boxed note reads "theta is FIXED, the interval is random: 95 percent of such intervals would cover theta (NOT a probability about this one theta)". The viewer should notice that the essential difference is which quantity is random: in the Bayesian view theta is random and the interval fixed so the probability is a statement about theta, whereas in the frequentist view theta is fixed and the interval random so the probability describes the long-run coverage of the procedure, not this particular interval; and that although the two intervals can be numerically close, only the credible interval may be read as the probability that theta lies inside it.](../_assets/4-10-credible-vs-ci.png)
Figure 4 — MCMC: সূত্র না থাকলে নমুনা টানো (non-conjugate posterior)¶
Beta–Binomial-এর মতো conjugate ক্ষেত্রে posterior-এর সুন্দর closed-form আছে। কিন্তু বাস্তবে প্রায়ই posterior-এর কোনো নাম-জানা সূত্র থাকে না (non-conjugate) — তখন কী? MCMC (Markov chain Monte Carlo): posterior থেকে সরাসরি নমুনা টেনে, সেই নমুনাগুলো দিয়েই posterior-কে আঁকা ও সারাংশ করা। এই চিত্রের উদাহরণটি §৫-এর Cauchy উদাহরণ থেকে স্বতন্ত্র (ধারণা এক, কেবল সংখ্যা ভিন্ন) — একটা ছোট logistic-style মডেল — একটা প্যারামিটার \(\theta\), prior \(\mathcal{N}(0,2^2)\), likelihood Bernoulli-logit — যার posterior conjugate নয়, তাই closed-form নেই। একটা সরল Metropolis sampler চালানো হয়েছে। বাঁ প্যানেল (trace): \(\theta\)-এর মান প্রতি iteration-এ কীভাবে ঘুরছে — শুরুর "burn-in" অংশ (ধূসর, বাদ দেওয়া) chain যখন এখনও থিতু হয়নি; তারপর একটা স্থির "fuzzy caterpillar" (লোমশ শুঁয়োপোকা) চেহারা — ভালো mixing-এর চিহ্ন; accept rate \(0.66\)। ডান প্যানেল (histogram): burn-in বাদ দেওয়া নমুনাগুলোর histogram — এটাই posterior-এর আনুমানিক রূপ; সবুজ KDE তার মসৃণ আকৃতি, আর \(95\%\) credible interval \([0.59,2.11]\) সরাসরি নমুনার \(2.5\%\)–\(97.5\%\) percentile থেকে; সত্য \(\theta=1.3\) (কালো বিন্দু-রেখা) আনুমানিক posterior-এর ভেতরেই।
যা লক্ষ করতে হবে: (ক) histogram-ই posterior — কোনো সূত্র লাগেনি; যথেষ্ট নমুনা টানলে তাদের histogram posterior density-কে যত খুশি কাছ থেকে নকল করে (Monte Carlo নীতি, 3.6 MCMC-র ফল)। posterior mean, credible interval — সব কেবল নমুনার গড়/percentile নিয়ে বের করা যায়, কঠিন integral করতে হয় না। (খ) trace-এর "fuzzy caterpillar" চেহারাটা ভালো চিহ্ন: chain দ্রুত গোটা posterior চষে বেড়াচ্ছে (ভালো mixing); উল্টো, trace যদি লম্বা সময় এক জায়গায় আটকে থাকত বা ধীরে গড়াত, তাহলে আরও iteration বা ভালো sampler লাগত। (গ) burn-in বাদ দেওয়া জরুরি: শুরুর কয়েকটা ধাপে chain এখনও prior থেকে posterior-এ "হেঁটে" যাচ্ছে, তাই সেগুলো posterior-এর প্রতিনিধি নয় — বাদ দিলে তবেই histogram নিরপেক্ষ। (ঘ) এই sampling-ভিত্তিক চিন্তাই আধুনিক Bayesian computation-এর হৃদয় (Stan, PyMC ইত্যাদি): conjugate বিলাসিতা ছাড়া যেকোনো মডেলে posterior টানা যায় — এটাই Bayesian পদ্ধতিকে বাস্তবে সর্বব্যাপী করেছে।
![A two-panel figure illustrating MCMC sampling from a non-conjugate posterior, under the overall title "MCMC for a non-conjugate posterior: sampling instead of solving". The LEFT panel, titled "MCMC trace (Metropolis), accept rate equals 0.66; chain explores the posterior, fuzzy caterpillar equals good mixing", is a trace plot of the parameter theta against MCMC iteration from 0 to 6000; the early portion up to iteration 1000 is shaded grey and labelled "burn-in (discarded)", and the rest is a dense fuzzy band oscillating around a dashed red horizontal line marking the posterior mean of about 1.29. The RIGHT panel, titled "Histogram of samples approximates the posterior; no formula needed, just summarise the draws", shows a purple density histogram of the post-burn-in theta samples with a green smooth KDE curve overlaid labelled "posterior (KDE of samples)"; dashed green vertical lines and a double-headed arrow mark the 95 percent credible interval [0.59, 2.11], and a dotted black vertical line marks the true theta equals 1.3, which lies inside the bulk of the histogram. The viewer should notice that the histogram of the samples is itself the approximate posterior so no closed-form formula is needed (summaries like the mean and credible interval come straight from the draws), that the fuzzy-caterpillar appearance of the trace signals good mixing (the chain explores the whole posterior), and that the early burn-in iterations are discarded because the chain has not yet settled onto the posterior.](../_assets/4-10-bayes-mcmc.png)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/04-10-bayesian-inference-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — হোঁচট খাওয়াটাই শেখার অংশ। (স্মারক: Bayes' rule \(p(\theta\mid\text{data})\propto \pi(\theta)\,L(\theta)\); prior \(\pi(\theta)\), likelihood \(L(\theta)\), posterior \(p(\theta\mid\text{data})\); conjugate prior — posterior একই পরিবারে থাকে [Beta–Binomial: prior \(\text{Beta}(a,b)\), \(k\) সাফল্য/\(n\) চেষ্টা ⇒ posterior \(\text{Beta}(a+k,b+n-k)\); Normal–Normal নিচে]; credible interval — posterior-এর \((1-\alpha)\) ভর ধরা ব্যবধান; MAP \(\hat\theta_{\text{MAP}}=\arg\max_\theta p(\theta\mid\text{data})\); posterior predictive \(p(\tilde y\mid\text{data})=\int p(\tilde y\mid\theta)\,p(\theta\mid\text{data})\,d\theta\)। চলমান উদাহরণ: E1 Beta–Binomial; E2 Normal–Normal; E3 credible vs confidence; E4 MCMC / posterior predictive।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). নিজের ভাষায় বলুন prior \(\pi(\theta)\), likelihood \(L(\theta)\), আর posterior \(p(\theta\mid\text{data})\) কী, আর Bayes' rule \(p(\theta\mid\text{data})\propto\pi(\theta)L(\theta)\) এদের কীভাবে জোড়ে। Figure 1 থেকে ব্যাখ্যা করুন posterior কেন prior আর likelihood-এর মাঝে বসে এবং দুটোর চেয়ে সরু হয়। Hint: prior = data দেখার আগে \(\theta\) নিয়ে বিশ্বাস; likelihood = এই \(\theta\)-তে observed data-র সম্ভাবনা; posterior = data দেখার পরে আপডেটেড বিশ্বাস। গুণফল \(\pi\cdot L\) দুই উৎসকে মেলায়, তাই posterior তাদের মাঝে; দুই উৎস মিলে অনিশ্চয়তা কমায়, তাই সরু (Figure 1)।
প্রশ্ন ২ (★★) — [credible interval বনাম confidence interval]। একটা \(95\%\) credible interval আর একটা \(95\%\) confidence interval-এর ব্যাখ্যাগত পার্থক্য সাবধানে লিখুন। প্রতিটিতে কী random আর কী fixed? "\(\theta\) এই interval-এ থাকার সম্ভাবনা \(0.95\)" — এই বাক্যটা কোনটার জন্য বৈধ, কোনটার জন্য নয়, এবং কেন? Figure 3-এর দুই প্যানেল ব্যবহার করুন। Hint: credible (Bayesian): \(\theta\) random (posterior density), interval fixed ⇒ \(P(\theta\in[\,\cdot\,]\mid\text{data})=0.95\) — বাক্যটা বৈধ। confidence (frequentist): \(\theta\) fixed, interval random ⇒ "এমন \(95\%\) interval সত্য \(\theta\)-কে ঢাকে" — বাক্যটা এই একটা interval-এর জন্য অবৈধ (Figure 3-ডান: অনেক random interval, সত্য \(\theta\) স্থির)।
প্রশ্ন ৩ (★★). conjugate prior বলতে কী বোঝায়, আর Beta–Binomial একটা conjugate জোড়া কেন? এর ব্যবহারিক সুবিধা কী (Figure 2-এর sequential updating-এর সাথে যোগ করুন)? কোন ক্ষেত্রে conjugate prior পাওয়া যায় না, তখন কী করতে হয় (Figure 4)? Hint: conjugate = prior ও posterior একই পরিবারে। Beta prior × Binomial likelihood ⇒ আবার Beta posterior (শুধু parameter আপডেট: \(a\!+\!k\), \(b\!+\!n\!-\!k\))। সুবিধা: closed-form, সহজ online আপডেট (Figure 2)। না পাওয়া গেলে (non-conjugate) MCMC দিয়ে নমুনা টানতে হয় (Figure 4)।
প্রশ্ন ৪ (★★). MAP estimate \(\hat\theta_{\text{MAP}}\) আর posterior mean কীভাবে আলাদা, আর MAP কীভাবে MLE-র সাথে সম্পর্কিত? কোন বিশেষ ক্ষেত্রে \(\hat\theta_{\text{MAP}}=\hat\theta_{\text{MLE}}\) হয়? (Figure 1-এর posterior \(\text{Beta}(16,8)\) ব্যবহার করুন: কোনটা \(0.67\), কোনটা \(0.68\)?) Hint: MAP = posterior-এর শিখর (\(\arg\max\)); mean = posterior-এর ভারকেন্দ্র (\(\mathbb{E}[\theta\mid\text{data}]\)) — skewed posterior-এ দুটো আলাদা। MAP \(=\arg\max\pi(\theta)L(\theta)\); flat (uniform) prior-এ \(\pi\) ধ্রুবক, তাই MAP \(=\arg\max L=\) MLE। Figure 1: MAP \(=0.68\) (শিখর), mean \(=0.67\)।
খ · গাণনিক (computational)¶
প্রশ্ন ৫ (★) — E1 (Beta–Binomial)। একটা মুদ্রার head-সম্ভাবনা \(\theta\)-তে prior \(\pi(\theta)=\text{Beta}(3,3)\)। \(n=12\) বার ছুঁড়ে \(x=9\) head এলো। (ক) posterior কী? (খ) posterior mean ও MAP বের করুন। Hint: posterior \(=\text{Beta}(3+9,\,3+3)=\text{Beta}(12,6)\)। mean \(=\frac{12}{12+6}=\frac{12}{18}=0.667\); MAP \(=\frac{12-1}{12+6-2}=\frac{11}{16}=0.688\)।
প্রশ্ন ৬ (★★) — E1 (Beta–Binomial, credible interval)। প্রশ্ন ৫-এর posterior \(\text{Beta}(12,6)\) থেকে একটা \(95\%\) equal-tailed credible interval বের করুন (numerically), আর তার অর্থ এক বাক্যে লিখুন। Hint: equal-tailed = posterior-এর \(2.5\%\) ও \(97.5\%\) quantile।
অর্থ: "data দেখার পর, \(P(0.44\le\theta\le0.87\mid\text{data})=0.95\)।"প্রশ্ন ৭ (★★) — E2 (Normal–Normal)। একটা পরিমাণ \(\mu\)-এর prior \(\pi(\mu)=\mathcal{N}(\mu_0=100,\ \tau_0^2=25)\)। জানা \(\sigma^2=16\) সহ \(n=10\) পর্যবেক্ষণের গড় \(\bar x=108\)। conjugate Normal–Normal সূত্রে posterior mean ও variance বের করুন। (সূত্র: posterior precision \(=\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}\); posterior mean \(=\big(\frac{\mu_0}{\tau_0^2}+\frac{n\bar x}{\sigma^2}\big)\big/\big(\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}\big)\)।) Hint: \(\frac{1}{\tau_0^2}=0.04\), \(\frac{n}{\sigma^2}=\frac{10}{16}=0.625\); posterior precision \(=0.665\), posterior var \(=1/0.665=1.504\)। posterior mean \(=\frac{0.04\cdot100+0.625\cdot108}{0.665}=\frac{4+67.5}{0.665}=\frac{71.5}{0.665}=107.5\) — data-র দিকে হেলানো (data বেশি তথ্যবহুল)।
প্রশ্ন ৮ (★★) — E4 (posterior predictive)। প্রশ্ন ৫-এর posterior \(\text{Beta}(12,6)\)-এর অধীনে, পরের একটা ছোঁড়ায় head আসার posterior predictive সম্ভাবনা কত? (সূত্র: একটা Bernoulli-র জন্য \(P(\tilde y=1\mid\text{data})=\mathbb{E}[\theta\mid\text{data}]=\frac{a}{a+b}\)।) Hint: posterior predictive একটা ভবিষ্যৎ ছোঁড়ার জন্য posterior mean-এই সমান: \(\frac{12}{12+6}=\frac{12}{18}=0.667\)। (লক্ষ্য করুন এটি \(\theta\)-কে এক মানে আটকায় না, বরং পুরো posterior-এর ওপর গড় নেয় — তাই point-estimate-এর চেয়ে সৎভাবে অনিশ্চয়তা বহন করে।)
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ৯ (★★) — Beta–Binomial conjugacy। দেখান যে prior \(\pi(\theta)=\text{Beta}(a,b)\) আর Binomial likelihood (\(n\) চেষ্টায় \(k\) সাফল্য) মিলে posterior \(\text{Beta}(a+k,\ b+n-k)\) দেয়। অর্থাৎ Beta হলো Binomial-এর conjugate prior। Hint: \(p(\theta\mid\text{data})\propto\pi(\theta)L(\theta)\propto \big[\theta^{a-1}(1-\theta)^{b-1}\big]\cdot\big[\theta^{k}(1-\theta)^{n-k}\big]=\theta^{(a+k)-1}(1-\theta)^{(b+n-k)-1}\) — ঠিক \(\text{Beta}(a+k,b+n-k)\)-এর kernel। normalizing constant Beta function থেকে আসে; \(\propto\) লেখায় constant ফেলে দেওয়া যায়।
প্রশ্ন ১০ (★★★) — Normal–Normal conjugacy। \(X_1,\dots,X_n\overset{iid}{\sim}\mathcal{N}(\mu,\sigma^2)\) (\(\sigma^2\) জানা), prior \(\mu\sim\mathcal{N}(\mu_0,\tau_0^2)\)। দেখান যে posterior \(p(\mu\mid\text{data})\) আবার Normal, এবং তার precision \(=\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}\) (precision যোগ হয়) আর mean হলো prior-mean ও sample-mean-এর precision-ভারিত গড়। Hint: posterior \(\propto\exp\!\big(-\frac{(\mu-\mu_0)^2}{2\tau_0^2}\big)\exp\!\big(-\frac{\sum(x_i-\mu)^2}{2\sigma^2}\big)\); \(\mu\)-তে exponent-এর quadratic অংশ \(-\frac12\big(\frac{1}{\tau_0^2}+\frac{n}{\sigma^2}\big)\mu^2+\big(\frac{\mu_0}{\tau_0^2}+\frac{n\bar x}{\sigma^2}\big)\mu\) — "complete the square" করলে Normal kernel পড়ে, যার precision = \(\mu^2\)-এর সহগ, mean = (linear সহগ)/(precision)।
প্রশ্ন ১১ (★★) — flat prior-এ MAP = MLE। দেখান যে prior \(\pi(\theta)\) ধ্রুবক (uniform/flat) হলে \(\hat\theta_{\text{MAP}}=\hat\theta_{\text{MLE}}\)। তারপর ব্যাখ্যা করুন কেন সাধারণভাবে (informative prior-এ) MAP MLE থেকে prior-mode-এর দিকে "টেনে" সরে যায়। Hint: \(\hat\theta_{\text{MAP}}=\arg\max_\theta\pi(\theta)L(\theta)=\arg\max_\theta[\log\pi(\theta)+\log L(\theta)]\)। flat \(\pi\)-তে \(\log\pi\) ধ্রুবক (যোগে শুধু constant), তাই \(\arg\max=\arg\max\log L=\) MLE। informative prior-এ \(\log\pi\) যোগ হয় — তা শিখরকে prior-এর ঘন অঞ্চলের দিকে সরায় (regularization-এর সমতুল্য, যেমন ridge = Gaussian prior)।
ঘ · কোডিং (coding)¶
প্রশ্ন ১২ (★★) — sequential updating অ্যানিমেশন (Figure 2 পুনর্নির্মাণ)। \(\text{Beta}(1,1)\) prior থেকে শুরু করে সত্য \(\theta=0.7\)-এর Bernoulli data এক এক করে যোগ করতে করতে কয়েকটা checkpoint (\(n=5,20,80,320\))-এ posterior \(\text{Beta}(a,b)\) প্লট করুন। posterior কীভাবে সরু হয় ও \(0.7\)-এ থিতু হয় তা দেখান। Hint:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
rng = np.random.default_rng(0)
th = np.linspace(0, 1, 500)
a0, b0, true_p = 1, 1, 0.7
stream = rng.binomial(1, true_p, 320)
for n in [0, 5, 20, 80, 320]:
k = int(stream[:n].sum())
a, b = a0 + k, b0 + (n - k)
plt.plot(th, stats.beta.pdf(th, a, b), label=f"n={n}")
plt.axvline(true_p, ls=":"); plt.legend(); plt.show()
প্রশ্ন ১৩ (★★) — Beta–Binomial credible vs Wald CI তুলনা (E1 + E3)। \(n=40\), \(x=28\) সাফল্য। (ক) \(\text{Beta}(1,1)\) prior-এ posterior থেকে \(95\%\) credible interval বের করুন; (খ) একই data-য় frequentist Wald CI (\(\hat p\pm1.96\sqrt{\hat p(1-\hat p)/n}\)) বের করুন; (গ) দুটো সংখ্যাগতভাবে তুলনা করুন — কাছাকাছি কি? অর্থে কীভাবে আলাদা? Hint:
import numpy as np
from scipy import stats
n, x = 40, 28
a, b = 1 + x, 1 + (n - x) # posterior Beta(29, 13)
cred = stats.beta.ppf([0.025, 0.975], a, b) # ~ [0.555, 0.825]
ph = x / n; se = np.sqrt(ph*(1-ph)/n)
wald = (ph - 1.96*se, ph + 1.96*se) # ~ [0.557, 0.843]
print("credible", np.round(cred,3), "Wald", np.round(wald,3))
প্রশ্ন ১৪ (★★★) — MCMC দিয়ে non-conjugate posterior (Figure 4-এর ধাঁচে)। একটা মুদ্রার \(\theta\)-তে একটা non-conjugate prior \(\pi(\theta)\propto\theta\,(1-\theta)\,\big[1+\sin(6\pi\theta)\big]\) (\(0<\theta<1\), একটা ঢেউখেলানো prior), data = \(n=30\)-এ \(k=21\) সাফল্য। একটা random-walk Metropolis sampler লিখে posterior থেকে নমুনা টানুন, histogram আঁকুন, আর posterior mean ও \(95\%\) credible interval (percentile থেকে) বের করুন। Hint:
import numpy as np
rng = np.random.default_rng(1)
n, k = 30, 21
def log_post(t):
if t <= 0 or t >= 1: return -np.inf
log_prior = np.log(t) + np.log(1-t) + np.log(1 + np.sin(6*np.pi*t))
log_lik = k*np.log(t) + (n-k)*np.log(1-t)
return log_prior + log_lik
N, t, cur = 20000, 0.5, None
cur = log_post(t); chain = []
for _ in range(N):
prop = t + rng.normal(0, 0.08)
lp = log_post(prop)
if np.log(rng.uniform()) < lp - cur:
t, cur = prop, lp
chain.append(t)
s = np.array(chain[2000:]) # drop burn-in
print("mean", s.mean().round(3), "95% CI", np.percentile(s,[2.5,97.5]).round(3))
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Bayes' rule = বিশ্বাস আপডেট (Figure 1)। \(p(\theta\mid\text{data})\propto\pi(\theta)\,L(\theta)\) — posterior হলো prior \(\pi(\theta)\) (পূর্ব-বিশ্বাস) আর likelihood \(L(\theta)\) (data-র সাক্ষ্য)-এর গুণফল। posterior দুটোর মাঝে বসে আর দুটোর চেয়ে সরু: উত্তর = বিশ্বাস ও তথ্যের ভারিত মিশ্রণ, অনিশ্চয়তা কমে।
- Conjugate updating (Figure 2)। conjugate prior-এ posterior একই পরিবারে থাকে — Beta–Binomial: \(\text{Beta}(a,b)\) prior, \(k\) সাফল্য/\(n\) চেষ্টা ⇒ \(\text{Beta}(a+k,b+n-k)\) posterior। তাই data ফোঁটায় ফোঁটায় এলে আগের posterior পরের prior হয়ে যায়; \(n\) বাড়লে posterior ধারালো হয়ে সত্য মানে থিতু হয় (Bayesian consistency), আর prior-এর প্রভাব ম্লান হয়।
- Credible বনাম confidence interval (Figure 3)। \(95\%\) credible interval = posterior-এর \(95\%\) ভর ধরা ব্যবধান; \(P(\theta\in[\,\cdot\,]\mid\text{data})=0.95\) — এখানে \(\theta\) random, interval fixed। confidence interval (4.6) = পদ্ধতির long-run coverage; \(\theta\) fixed, interval random। সংখ্যা প্রায়ই কাছাকাছি, কিন্তু কেবল credible interval-কেই "\(\theta\) এখানে থাকার সম্ভাবনা" বলা বৈধ।
- MAP ও point summaries। \(\hat\theta_{\text{MAP}}=\arg\max_\theta p(\theta\mid\text{data})\) = posterior-এর শিখর; posterior mean = ভারকেন্দ্র — skewed posterior-এ দুটো আলাদা। flat prior-এ MAP = MLE; informative prior MAP-কে prior-mode-এর দিকে টানে (regularization-এর সমতুল্য)।
- Posterior predictive। ভবিষ্যৎ পর্যবেক্ষণের পূর্বাভাস \(p(\tilde y\mid\text{data})=\int p(\tilde y\mid\theta)\,p(\theta\mid\text{data})\,d\theta\) — \(\theta\)-কে এক মানে না আটকে পুরো posterior-এর ওপর গড় নেয়, তাই অনিশ্চয়তা সৎভাবে বহন করে।
- MCMC: সূত্র না থাকলে নমুনা (Figure 4)। non-conjugate posterior-এ closed-form নেই; তখন MCMC posterior থেকে নমুনা টানে, আর সেই নমুনার histogram-ই posterior, mean/credible interval নমুনার গড়/percentile। trace-এর "fuzzy caterpillar" = ভালো mixing; burn-in বাদ দিতে হয়। এটাই আধুনিক Bayesian computation-এর হৃদয়।
পূর্ববর্তী সংযোগ (← 4.9 Bootstrap; এবং 2.2 Bayes, 3.6 MCMC): এই অধ্যায়ের সরাসরি বীজ পড়েছিল 2.2-তে — conditional probability ও Bayes' theorem (\(P(A\mid B)=\frac{P(B\mid A)P(A)}{P(B)}\)): সেখানে আমরা একটা event-এর সম্ভাবনা উল্টে দিতাম, এখানে সেই একই যুক্তি একটা parameter \(\theta\)-তে টেনে এনে prior → posterior আপডেট পেলাম (Bayes' rule = density-র ভাষায় 2.2-এর theorem)। গণনার দিকটা এসেছে 3.6 (Markov Chains & MCMC) থেকে — Figure 4-এর Metropolis sampler ঠিক সেই Markov chain যার stationary distribution আমরা posterior বানিয়ে রাখি, আর LLN/Monte Carlo (3.3, 3.4) নিশ্চিত করে নমুনার histogram সত্যিকারের posterior-এ মেলে। আর ঠিক আগের 4.9 (bootstrap) ও এই অধ্যায় একই বড় বার্তা ভাগ করে: যখন তত্ত্বের closed-form সূত্র কঠিন বা অজানা, তখন computation/simulation দিয়ে অনিশ্চয়তা মাপা — bootstrap data-কে resample করে frequentist sampling distribution বানায়, MCMC posterior থেকে নমুনা টেনে Bayesian posterior বানায়; দুটোই "সূত্রের বদলে সংখ্যা"। সাথে এই অধ্যায় টেনে আনে 4.3-এর likelihood \(L(\theta)\) ও MLE (posterior-এর likelihood অংশ; flat prior-এ MAP = MLE) এবং 4.6-এর confidence interval (যার সাথে credible interval-কে Figure 3-এ মুখোমুখি রাখা হলো)।
পরবর্তী সংযোগ (→ Part V — Statistical Modeling): এতক্ষণ আমরা মূলত একটা-দুটো প্যারামিটার অনুমান করছিলাম (একটা \(\theta\), একটা \(\mu\))। Part V (Statistical Modeling) এই সব হাতিয়ারকে মডেলে জোড়ে — regression, GLM, ইত্যাদি — যেখানে অনেক প্যারামিটার একসাথে, আর প্রতিটা অনুমানের পেছনে এই Part-এর কোনো-না-কোনো নীতি কাজ করে: MLE দিয়ে coefficient fit, confidence/credible interval দিয়ে অনিশ্চয়তা, hypothesis test দিয়ে কোন predictor তাৎপর্যপূর্ণ। বিশেষভাবে, এই অধ্যায়ের Bayesian দৃষ্টিভঙ্গি Part V-তে Bayesian regression ও hierarchical models-এ ফিরে আসবে, যেখানে prior দিয়ে regularization আর MCMC দিয়ে posterior — ঠিক যা এখানে শিখলাম, কিন্তু বহু-প্যারামিটারে। অর্থাৎ Part IV দিয়েছে inference-এর মূলনীতি; Part V সেগুলো বাস্তব মডেলে প্রয়োগ করবে।
বৃহত্তর স্থান — এই অধ্যায় Part IV (Inference) শেষ করে। এটি ছিল Inference অধ্যায়ের শেষ অধ্যায়, আর এর সাথে পরিসংখ্যানিক অনুমানের পুরো যাত্রা সম্পূর্ণ হলো। সেই যাত্রাটা এক নজরে: প্রথমে estimation — কীভাবে data থেকে একটা প্যারামিটার আঁচ করি (method of moments, MLE; 4.2–4.3) আর একটা ভালো estimator কী (unbiasedness, efficiency, sufficiency, CRLB; 4.4–4.5); তারপর confidence interval — point estimate-এর চারপাশে অনিশ্চয়তা মাপা (4.6); তারপর hypothesis testing — একটা দাবি data-র সাথে খাটে কিনা যাচাই, আর তার তিন মহাপদ্ধতি LRT/Wald/score + \(\chi^2\) (4.7–4.8); তারপর resampling — সূত্র যেখানে নীরব, সেখানে bootstrap দিয়ে simulation-ভিত্তিক inference (4.9); আর শেষে Bayesian inference — অনিশ্চয়তাকে সরাসরি প্রায়িকতা (posterior) দিয়ে প্রকাশ, prior-এ পূর্ব-জ্ঞান যোগ করে, MCMC দিয়ে গণনা (4.10)। এই পাঁচটা স্তম্ভ — estimation → confidence interval → testing → resampling → Bayesian — একসাথে মিলে আধুনিক পরিসংখ্যানিক inference-এর সম্পূর্ণ ছবি: frequentist ও Bayesian দুই দর্শন, closed-form ও computation দুই পথ। এর ওপর দাঁড়িয়েই Part V-এর মডেলিং, আর তারপরের statistical ML গড়ে উঠবে।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 11 (Bayesian Inference — §11.1 Bayesian philosophy, §11.2 the Bayesian method ও conjugate priors, §11.3 functions of parameters, §11.4 simulation, §11.5 large-sample properties, §11.6 flat priors ও credible vs confidence intervals); J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 8 (§8.6 Bayesian approach to parameter estimation — prior/posterior, conjugacy, Beta–Binomial ও Normal–Normal); P. Bruce, A. Bruce & P. Gedeck, Practical Statistics for Data Scientists, Ch. 2–3 (Bayesian thinking, credible intervals ও resampling-এর সাথে তুলনা)।