5.1 — Simple & Multiple Linear Regression (সরল ও বহু রৈখিক রিগ্রেশন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "একটা variable দিয়ে আরেকটা ভবিষ্যদ্বাণী করা"¶
১.১ Part V কী নিয়ে — আর এই অধ্যায় কোথায় দাঁড়িয়ে¶
স্বাগতম Part V — পরিসংখ্যানিক মডেলিং (Statistical Modeling)-এ। এতদিন (Part IV পর্যন্ত) আমরা মূলত একটা একক রাশি নিয়ে ভেবেছি — একটা population-এর গড় \(\mu\) কত, একটা proportion \(p\) কত, একটা parameter \(\theta\)-কে কীভাবে আন্দাজ (estimate) করব, তার অনিশ্চয়তা (confidence interval) কীভাবে মাপব। সেখানে প্রশ্নটা ছিল মূলত "এই একটা সংখ্যা কত?"।
কিন্তু বাস্তব জগতে প্রশ্নগুলো প্রায়ই সম্পর্কের — একটা জিনিস আরেকটার সাথে কীভাবে জড়িয়ে? বাড়ির দাম তার আয়তনের সাথে কীভাবে বাড়ে? ওষুধের মাত্রা বাড়ালে রক্তচাপ কতটা নামে? পড়াশোনার সময় আর পরীক্ষার নম্বরের সম্পর্ক কী? এই ধরনের প্রশ্নে আমরা আর একটা সংখ্যা চাই না — আমরা চাই একটা সম্পর্ককে সংখ্যায় বাঁধা, যাতে একটা চলকের মান জেনে আরেকটার মান ভবিষ্যদ্বাণী (predict) বা ব্যাখ্যা (explain) করা যায়।
এই কাজটাই modeling — data-র ভেতরের সম্পর্ককে একটা গাণিতিক মডেল (সমীকরণ) দিয়ে ধরা। আর সব মডেলিং-এর সবচেয়ে সরল, সবচেয়ে মৌলিক, এবং সবচেয়ে বেশি-ব্যবহৃত হাতিয়ার হলো linear regression (রৈখিক রিগ্রেশন) — যা দিয়ে এই গোটা Part V শুরু। এটিকে ভাবুন পরিসংখ্যানিক মডেলিং-এর "হ্যালো ওয়ার্ল্ড": সহজ, কিন্তু এর ভেতরে এমন সব ধারণা (design matrix, least squares, projection, \(R^2\), model assumption) লুকিয়ে যা পরের প্রায় সব মডেলে — logistic regression, GLM, এমনকি machine learning-এর অনেক কিছুতে — ঘুরে-ফিরে ফেরে।
১.২ Hook — বাড়ির দাম বনাম আয়তন¶
একটা খুব চেনা উদাহরণ দিয়ে শুরু করি, যেটা গোটা অধ্যায়ে আমাদের সঙ্গী থাকবে। ধরুন আপনি একটা শহরের কিছু বাড়ির data জোগাড় করেছেন — প্রতিটি বাড়ির আয়তন (area, বর্গমিটারে) আর তার বিক্রয়মূল্য (price)। আপনি data-টা একটা scatter plot-এ (বিন্দু-চিত্র, 1.4) আঁকলেন: অনুভূমিক অক্ষে (horizontal axis) area, উল্লম্ব অক্ষে (vertical axis) price, আর প্রতিটি বাড়ি একটা বিন্দু।
ছবিটা দেখে চোখে যা ধরা পড়বে: বিন্দুগুলো হুবহু একটা সরলরেখায় নেই, ছড়িয়ে আছে — কিন্তু একটা স্পষ্ট প্রবণতা আছে: আয়তন যত বড়, দামও মোটামুটি তত বেশি। মেঘের মতো ছড়ানো বিন্দুগুলোর ভেতর দিয়ে যেন একটা ঊর্ধ্বমুখী রেখা টেনে দেওয়া যায়। এখন স্বাভাবিক দুটো প্রশ্ন জাগে:
- (ভবিষ্যদ্বাণী) একটা নতুন বাড়ি, যার আয়তন \(120\) বর্গমিটার কিন্তু দাম জানি না — তার দাম আন্দাজ করতে পারি কি? অর্থাৎ area দিয়ে price-এর predict।
- (ব্যাখ্যা) আয়তন প্রতি এক বর্গমিটার বাড়লে দাম গড়ে কতটা বাড়ে? অর্থাৎ সম্পর্কের মাত্রা সংখ্যায় বলা।
দুটো প্রশ্নেরই একটাই উত্তর-কৌশল: data-র মেঘের ভেতর দিয়ে "সবচেয়ে মানানসই" একটা সরলরেখা টেনে দেওয়া এবং সেই রেখার সমীকরণটা বের করা। যদি সেই রেখাটা হয়, ধরা যাক,
তাহলে (১)-এর উত্তর: \(\text{area}=120\) বসিয়ে দিলেই predicted দাম, আর (২)-এর উত্তর: ঢাল (slope) \(b\) — কারণ \(b\)-ই বলে area এক একক বাড়লে দাম গড়ে কত বাড়ে। এই "মেঘের ভেতর দিয়ে সেরা রেখা" বের করাই হলো simple linear regression, আর এই গোটা অধ্যায় ঠিক এই ধারণাটাকেই — প্রথমে এক predictor-এ, তারপর বহু predictor-এ — সুনির্দিষ্ট, প্রমাণযোগ্য, ও যন্ত্রে-গণনাযোগ্য রূপ দেবে।
এক বাক্যে: linear regression হলো একটা পদ্ধতি — data-র scatter-এর ভেতর দিয়ে একটা সরলরেখা (বা বহু-চলকে একটা সমতল/hyperplane) এমনভাবে বসানো যে সেটা response চলককে predictor চলক(গুলো) দিয়ে সবচেয়ে ভালোভাবে ব্যাখ্যা করে।
১.৩ Correlation থেকে regression — সম্পর্ক থেকে সমীকরণে¶
এখানে 1.4-এর সাথে যোগসূত্রটা পরিষ্কার করা জরুরি, কারণ regression আসলে correlation-এরই একটা স্বাভাবিক পরবর্তী ধাপ। মনে করুন, 1.4-এ আমরা correlation coefficient \(r\) শিখেছি — দুটি চলক \(x\) আর \(y\) কতটা রৈখিকভাবে একসাথে চলে তার একটা একক-সংখ্যার মাপ, \(r \in [-1, 1]\)। \(r\) ধনাত্মক ও \(1\)-এর কাছাকাছি হলে: \(x\) বাড়লে \(y\)-ও বাড়ে, আর বিন্দুগুলো একটা ঊর্ধ্বমুখী রেখার খুব কাছে; \(r=0\) হলে কোনো রৈখিক সম্পর্ক নেই।
কিন্তু correlation একটা গুরুত্বপূর্ণ জায়গায় থেমে যায় — সেটা শুধু বলে সম্পর্কটা কতটা শক্ত ও কোন দিকে, কিন্তু সম্পর্কটার সমীকরণ দেয় না। correlation আপনাকে বলবে "area আর price দৃঢ়ভাবে ধনাত্মক-সম্পর্কিত" (\(r \approx 0.85\) বলা যাক), কিন্তু বলবে না "area এক একক বাড়লে দাম ঠিক কত বাড়ে" বা "\(120\) বর্গমিটারের বাড়ির দাম কত"। এই দুটো প্রশ্নের উত্তর দিতে গেলে একটা রেখার সমীকরণ — একটা intercept আর একটা slope — চাই। ঠিক এই ফাঁকটাই regression পূরণ করে:
correlation \(\to\) regression-এর উত্তরণ: correlation একটা সম্পর্কের শক্তি দেয় (একটা সংখ্যা \(r\)); regression সেই সম্পর্ককে একটা সমীকরণে রূপ দেয় (\(y \approx a + bx\)) — যা দিয়ে এখন ভবিষ্যদ্বাণী (নতুন \(x\)-এ \(y\)) আর পরিমাণগত ব্যাখ্যা (\(x\) এক একক বদলালে \(y\) কত বদলায়) দুটোই করা যায়। সংক্ষেপে: correlation = সম্পর্ক, regression = সমীকরণ।
এই পার্থক্যটা গোড়াতেই গেঁথে নেওয়া ভালো, কারণ এতে regression-এর "কেন" পরিষ্কার হয়ে যায়। আরও দুটো সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ পার্থক্য, যা পরে কাজে লাগবে:
- অপ্রতিসমতা (asymmetry)। correlation প্রতিসম — \(x\) ও \(y\)-র correlation আর \(y\) ও \(x\)-র correlation একই (\(r\) একটাই)। কিন্তু regression-এ একটা চলককে আমরা বিশেষ মর্যাদা দিই: একটা হলো response (যাকে ব্যাখ্যা/predict করতে চাই, এখানে price), অন্যটা predictor (যা দিয়ে ব্যাখ্যা করি, এখানে area)। "price-কে area দিয়ে regress করা" আর "area-কে price দিয়ে regress করা" — দুটো আলাদা সমীকরণ। কে response কে predictor, সেটা আমাদের প্রশ্নের উপর নির্ভর করে।
- একাধিক predictor। correlation মূলত দুটো চলকের মধ্যে; কিন্তু regression সহজেই বহু predictor সামলায় — দাম শুধু area নয়, বয়স (age), ঘরসংখ্যা (rooms) — সব একসাথে দিয়ে ব্যাখ্যা করা যায়। এই বহু-predictor রূপটাই multiple regression, যা এই অধ্যায়ের দ্বিতীয় বড় অংশ।
মনে রাখুন (গুরুত্বপূর্ণ সতর্কতা): regression একটা সম্পর্ককে সমীকরণে বাঁধে, কিন্তু সেটা আপনাআপনি কার্যকারণ (causation) প্রমাণ করে না। "area আর price-এর মধ্যে একটা রৈখিক সম্পর্ক আছে" বলা আর "area বাড়ালে price বাড়বে (কারণ-প্রভাব)" বলা এক নয় — ঠিক যেমন 1.4-এ "correlation ≠ causation" শিখেছিলাম। regression coefficient ব্যাখ্যা করার সময় (§২.৬) এই সতর্কতায় আবার ফিরব।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- §২ — মূল ধারণা ও সংজ্ঞা। model \(y = X\beta + \varepsilon\) (response, design matrix, coefficient, error — প্রতিটি প্রতীক ও মাত্রা খোলা); OLS-এর objective (residual sum of squares কমানো); normal equations ও সূত্র \(\hat\beta = (X^\top X)^{-1} X^\top y\); এর projection-জ্যামিতি; simple বনাম multiple; coefficient-এর "holding others fixed" ব্যাখ্যা; \(R^2\); LINE অনুমান; এবং Normal error-এ MLE = OLS-এর সংযোগ — সবই স্বজ্ঞা ও সংজ্ঞার স্তরে (গণিতের পূর্ণ প্রমাণ §৪-এ)।
- §৩ — হাতে-কলমে। একটা ছোট্ট ৫-বিন্দুর dataset-এ simple regression-এর slope, intercept, fitted value, residual ও \(R^2\) পুরোপুরি হাতে-কলমে সংখ্যা সমেত গণনা — যাতে সূত্রগুলো বাস্তবে কীভাবে চলে তা চোখে দেখা যায়।
- §৪ — গণিত ও প্রমাণ। normal equations-এর পূর্ণ derivation (দুই পথে: calculus-এ SSE minimize, এবং জ্যামিতিতে orthogonal projection), \(\hat\beta\)-র ধর্ম, এবং MLE = OLS-এর প্রমাণ।
- §৫–৬ — পূর্ণ উদাহরণ, চিত্র ও কোড। একটা বাস্তবসম্মত synthetic dataset-এ (price ~ area + age + rooms) multiple regression fit, regression-রেখা, residual plot, coefficient-চিত্র, এবং Python-কোড।
- §৭–৮ — সংযোগ, ভুল-ধারণা ও অনুশীলনী। MLE-OLS সংযোগের গভীরতা, সাধারণ ভুল-বোঝাবুঝি, এবং অনুশীলনী।
এক বাক্যে কেন এটি Part V-এর সঠিক সূচনা। linear regression-এ একসাথে তিনটে বড় ধারণা প্রথমবার একজোট হয়: (ক) Part 0-এর linear algebra (matrix, projection), (খ) Part 1-এর correlation (সম্পর্কের মাপ), আর (গ) Part IV-এর inference (estimator, MLE, SE)। তাই এই অধ্যায়টা শুধু একটা নতুন কৌশল নয় — এটা আগের সব Part-এর সেতুবন্ধন, যার উপর দাঁড়িয়ে পরের অধ্যায় 5.2 (regression diagnostics — মডেল ঠিকঠাক কাজ করছে কিনা যাচাই) ও তার পরের সব মডেল গড়ে উঠবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর স্বজ্ঞা — "মেঘের ভেতর দিয়ে সেরা রেখা" — কে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না। যেখানে গণিতের পূর্ণ প্রমাণ লাগবে (বিশেষত \(\hat\beta\)-র সূত্রটা কোথা থেকে আসে), সেটা §৪-এ করা হবে — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
পুরো বিভাগের পরিকল্পনা: প্রথমে সবচেয়ে সরল কেস — এক predictor (simple regression) — দিয়ে রেখার ধারণা গাঁথব (§২.১), তারপর সেটাকে matrix-ভাষায় (\(y = X\beta + \varepsilon\)) সাধারণীকরণ করব যাতে এক বা বহু predictor একই সূত্রে ধরা যায় (§২.২)। এরপর "সেরা রেখা" মানে কী তা সংজ্ঞায়িত করব (OLS, §২.৩), তার সমাধান-সূত্র দেখব (normal equations, §২.৪), সেই সূত্রের জ্যামিতি বুঝব (projection, §২.৫), coefficient-এর অর্থ খুলব (§২.৬), fit-এর মাপ দেব (\(R^2\), §২.৭), এবং শেষে মডেলটা কোন অনুমানের উপর দাঁড়িয়ে তা স্পষ্ট করব (LINE ও MLE=OLS, §২.৮)।
২.১ সরলতম কেস — এক predictor-এ regression line¶
সবচেয়ে সরল ছবিটা দিয়ে শুরু করি। আমাদের কাছে \(n\)টি জোড়া-পর্যবেক্ষণ আছে:
যেখানে প্রতিটি \(i\) (অর্থাৎ \(i = 1, 2, \dots, n\)) একটি "একক" বা "নমুনা" (যেমন একটা বাড়ি)। এখানে —
- \(x_i\) হলো predictor (ব্যাখ্যাকারী চলক; অন্য নাম: independent variable, explanatory variable, covariate, feature) — \(i\)-তম এককের সেই বৈশিষ্ট্য যা দিয়ে আমরা ব্যাখ্যা করতে চাই (যেমন area)।
- \(y_i\) হলো response (সাড়া-চলক; অন্য নাম: dependent variable, outcome, target) — \(i\)-তম এককের সেই পরিমাণ যাকে আমরা predict/ব্যাখ্যা করতে চাই (যেমন price)।
simple linear regression-এর ধারণা: ধরে নিই \(y\) আর \(x\)-এর সম্পর্ক মূলত একটা সরলরেখা, শুধু সেটায় কিছু এলোমেলো ছিটেফোঁটা যোগ হয়েছে। গাণিতিকভাবে, প্রতিটি \(i\)-র জন্য:
প্রতিটি অংশ খুলি — এটাই এই অধ্যায়ের সবচেয়ে মৌলিক সমীকরণ, তাই ধীরে:
- \(\beta_0\) ("বিটা-শূন্য", গ্রিক অক্ষর \(\beta\) = "বিটা") — intercept (ছেদক / অন্তঃখণ্ড): \(x = 0\) হলে রেখাটা \(y\)-অক্ষকে যে উচ্চতায় কাটে। অর্থাৎ predictor শূন্য হলে response-এর মূল-স্তর (baseline)।
- \(\beta_1\) ("বিটা-এক") — slope (ঢাল): \(x\) এক একক বাড়লে রেখা অনুসারে \(y\) ঠিক কত বাড়ে (বা কমে, যদি ঋণাত্মক হয়)। এটাই সম্পর্কের "মাত্রা"।
- \(\beta_0\) ও \(\beta_1\) দুটোই অজানা স্থির সংখ্যা — সত্য (কিন্তু অদৃশ্য) parameter, ঠিক যেমন Part IV-এ \(\theta\) ছিল। আমাদের কাজ data থেকে এদের আন্দাজ করা; সেই আন্দাজগুলোকে লিখব "টুপি" দিয়ে: \(\hat\beta_0, \hat\beta_1\)।
- \(\varepsilon_i\) ("এপসাইলন-\(i\)", গ্রিক অক্ষর \(\varepsilon\) = "এপসাইলন") — error বা noise (ত্রুটি / এলোমেলো বিচ্যুতি): \(i\)-তম বিন্দু সত্য রেখা থেকে যতটা উপরে-নিচে সরে আছে। এটা random — কারণ বাস্তব data কখনো হুবহু রেখায় বসে না (দাম শুধু area-র উপর নির্ভর করে না; অগুনতি ছোট-বড় অজানা প্রভাব আছে, সেগুলোর মিলিত ফল \(\varepsilon_i\)-তে ধরা)।
লক্ষ করুন কাঠামোটা: প্রতিটি $y_i = $ একটা নির্ধারিত (deterministic) অংশ \((\beta_0 + \beta_1 x_i)\) — যা রেখা থেকে আসে — যোগ একটা random অংশ \((\varepsilon_i)\)। এই "signal + noise" বিভাজনই regression-এর হৃদয়।
"রৈখিক" শব্দটা নিয়ে একটা জরুরি স্পষ্টীকরণ। "linear" বলতে এখানে বোঝায় মডেলটা parameter \(\beta\)-তে রৈখিক — অর্থাৎ \(\beta_0, \beta_1\) শুধু গুণ-যোগ আকারে আছে, কোনো \(\beta^2\) বা \(\sin\beta\) নেই। এটা \(x\)-এ রৈখিক হওয়া বোঝায় না! চমকপ্রদ হলেও, \(y = \beta_0 + \beta_1 x + \beta_2 x^2 + \varepsilon\)-ও একটা linear regression (একে \(x^2\)-কে নতুন একটা predictor ধরে নিলেই হয়), কারণ এটা \(\beta\)-গুলোতে রৈখিক। তাই "linear regression" বললে রেখার সরলতা নয়, parameter-এ রৈখিকতাই মুখ্য — এই সূক্ষ্মতা পরে (বিশেষত multiple ও polynomial regression-এ) খুব কাজে লাগবে।
এই এক-predictor সমীকরণটা সুন্দর, কিন্তু সমস্যা একটাই: বাস্তবে predictor প্রায়ই একাধিক (area, age, rooms…)। প্রতিটার জন্য আলাদা সমীকরণ না লিখে, আমরা চাই একটা একক, সংক্ষিপ্ত ভাষা যাতে এক বা একশো predictor সবই একই সূত্রে ধরা যায়। সেই ভাষা — linear algebra (0.5)।
২.২ সাধারণ রূপ — model \(y = X\beta + \varepsilon\) (matrix-ভাষা)¶
এবার সবচেয়ে গুরুত্বপূর্ণ সাধারণীকরণ। ধরা যাক এখন প্রতিটি একক \(i\)-র জন্য \(p-1\)টি predictor আছে: \(x_{i1}, x_{i2}, \dots, x_{i,p-1}\) (যেমন বাড়ির ক্ষেত্রে area, age, rooms হলে \(p-1 = 3\))। তখন একটা একক-এর মডেল:
এখানে \(\beta_0\) আগের মতোই intercept, আর প্রতিটি \(\beta_j\) (\(j = 1, \dots, p-1\)) হলো \(j\)-তম predictor-এর slope/coefficient। লক্ষ করুন মোট coefficient-সংখ্যা \(= p\) (একটা intercept \(\beta_0\) + \((p-1)\)টা slope)। এই \(p\) সংখ্যাটা পুরো অধ্যায়ে ফিরবে, তাই গেঁথে নিন: \(p\) = মোট coefficient-সংখ্যা (intercept সমেত)।
এই \(n\)টি সমীকরণ (\(i = 1, \dots, n\)) আলাদা আলাদা না লিখে, matrix-ভাষায় একটিমাত্র সমীকরণে গুটিয়ে ফেলা যায় — এটাই regression-এর "সর্বজনীন" রূপ:
এই কমপ্যাক্ট সমীকরণের প্রতিটি বস্তু সংজ্ঞায়িত করি, মাত্রা (dimension) সমেত — মাত্রাগুলো খুব গুরুত্বপূর্ণ, কারণ matrix-গুণ ঠিকঠাক "মেলে" কিনা তা এর উপরই নির্ভর করে:
- \(y\) — response vector, মাত্রা \(n \times 1\) (অর্থাৎ \(y \in \mathbb{R}^n\), একটা \(n\)-লম্বা কলাম-vector)। এর \(i\)-তম উপাদান \(y_i\) = \(i\)-তম এককের response। কথায়: সব এককের সব response এক কলামে সাজানো।
- \(X\) — design matrix (নকশা-ম্যাট্রিক্স / মডেল-ম্যাট্রিক্স), মাত্রা \(n \times p\) (অর্থাৎ \(X \in \mathbb{R}^{n \times p}\), \(n\)টি সারি ও \(p\)টি কলাম)। প্রতিটি সারি একটা একক, প্রতিটি কলাম একটা predictor। একটা অত্যন্ত গুরুত্বপূর্ণ চাল: প্রথম কলাম পুরোটা \(1\) — এটা intercept \(\beta_0\)-কে সামলানোর কৌশল (নিচে ব্যাখ্যা)। তাই:
প্রথম কলামের সব \(1\) কেন? কারণ matrix-গুণ করলে দেখবেন প্রতিটি সারিতে এই \(1\) গুণ হয় \(\beta_0\)-র সাথে — অর্থাৎ \(1 \cdot \beta_0 = \beta_0\) প্রতিটি সমীকরণে intercept হিসেবে যোগ হয়। এই "all-ones কলাম" না থাকলে রেখাটা বাধ্যতামূলকভাবে মূলবিন্দু (origin) দিয়ে যেত (\(\beta_0 = 0\)); all-ones কলাম intercept-কে মুক্ত-ভাবে যেকোনো উচ্চতায় বসতে দেয়। (এই কলামটিকে কখনো intercept column বা constant term বলা হয়।)
- \(\beta\) — coefficient vector, মাত্রা \(p \times 1\) (অর্থাৎ \(\beta \in \mathbb{R}^p\))। এর উপাদান \(\beta_0, \beta_1, \dots, \beta_{p-1}\) — intercept আর সব slope একসাথে। এরাই সেই অজানা সত্য সংখ্যা যাদের আমরা data থেকে আন্দাজ করব।
- \(\varepsilon\) — error vector, মাত্রা \(n \times 1\) (\(\varepsilon \in \mathbb{R}^n\))। উপাদান \(\varepsilon_1, \dots, \varepsilon_n\) — প্রতিটি এককের random বিচ্যুতি। এর উপর আমরা কিছু অনুমান চাপাব (§২.৮), যার সবচেয়ে পূর্ণ রূপ: \(\varepsilon \sim \mathcal{N}(0, \sigma^2 I)\) — অর্থাৎ প্রতিটি error গড়-শূন্য, একই variance \(\sigma^2\), পরস্পর-স্বাধীন Normal (এই প্রতীকটা §২.৮-এ পুরো খোলা হবে)।
মাত্রা মিলিয়ে দেখুন: \(X\beta\) হলো \((n \times p) \times (p \times 1) = (n \times 1)\) — ঠিক \(y\) আর \(\varepsilon\)-এর মতোই \(n\)-লম্বা কলাম। সব মেলে। এই matrix-রূপের সৌন্দর্য: এক predictor হোক বা একশো, সমীকরণ একটাই — \(y = X\beta + \varepsilon\); শুধু \(X\)-এর কলাম-সংখ্যা \(p\) বদলায়। simple regression কেবল এই সাধারণ রূপের বিশেষ কেস যেখানে \(p = 2\) (একটা intercept কলাম + একটা area কলাম)।
মনে রাখুন: \(y = X\beta + \varepsilon\) — এই একটিমাত্র সমীকরণে গোটা linear regression ধরা। \(y\) (\(n\times1\)) যা ব্যাখ্যা করতে চাই, \(X\) (\(n\times p\), প্রথম কলাম all-ones) যা দিয়ে ব্যাখ্যা করি, \(\beta\) (\(p\times1\)) অজানা সম্পর্ক-সহগ, \(\varepsilon\) (\(n\times1\)) যা মডেল ধরতে পারে না। লক্ষ্য: data (\(X\) ও \(y\)) থেকে \(\beta\)-র সেরা আন্দাজ \(\hat\beta\) বের করা। কীভাবে — সেটাই পরের ধাপ।
২.৩ "সেরা রেখা" মানে কী — Ordinary Least Squares (OLS)¶
এতক্ষণে মডেলটা সাজানো হলো, কিন্তু আসল প্রশ্নটা এখনো বাকি: অসংখ্য সম্ভাব্য \(\beta\)-র মধ্যে কোনটা "সেরা"? অর্থাৎ data-র মেঘের ভেতর দিয়ে কোন রেখাটা সবচেয়ে ভালো মানায়? এর উত্তর দিতে আগে দরকার "ভালো মানানো" মানে কী — তার একটা সংখ্যাগত মাপ।
স্বজ্ঞাটা সরল: একটা রেখা ভালো যদি সেটা প্রতিটি data বিন্দুর কাছ দিয়ে যায়। বিন্দু \(i\) রেখা থেকে কতটা দূরে, তা মাপি residual দিয়ে। ধরা যাক আমরা একটা প্রার্থী-\(\beta\) বেছেছি; তখন—
- প্রতিটি একক \(i\)-র জন্য fitted value (অভিযোজিত মান) \(\hat y_i\) = রেখা অনুসারে predict করা response। matrix-রূপে সব fitted value একসাথে: \(\hat y = X\beta\) (যখন \(\hat\beta\) চূড়ান্ত হবে, তখন \(\hat y = X\hat\beta\))।
- প্রতিটি \(i\)-র residual (অবশিষ্ট) \(= y_i - \hat y_i\) = বাস্তব response বিয়োগ predict করা response — অর্থাৎ বিন্দুটা রেখা থেকে উল্লম্বভাবে কত উপরে/নিচে। matrix-রূপে: \(y - X\beta\)।
এখন "রেখাটা সব বিন্দুর কাছ দিয়ে যাক" মানে "সব residual ছোট হোক"। কিন্তু residual-গুলো কিছু ধনাত্মক (বিন্দু রেখার উপরে), কিছু ঋণাত্মক (নিচে) — শুধু যোগ করলে তারা একে অপরকে কাটাকাটি করে ফেলবে, ফাঁকি হয়ে যাবে। তাই আমরা প্রতিটি residual-কে বর্গ করি (তখন সব ধনাত্মক, আর বড় ভুল বেশি শাস্তি পায়) এবং যোগ করি। এই যোগফলকে বলে residual sum of squares (অবশিষ্টের বর্গযোগফল):
প্রতিটি প্রতীক খুলি:
- \(\mathrm{SSE}(\beta)\) — "sum of squared errors" (বা residual sum of squares, RSS); \(\beta\)-র একটা function — অর্থাৎ ভিন্ন \(\beta\) দিলে ভিন্ন মান (ভিন্ন রেখা, ভিন্ন মোট-বর্গ-ভুল)। লক্ষ্য: যে \(\beta\)-তে এটা সবচেয়ে ছোট, সেটাই সেরা।
- \((X\beta)_i\) — vector \(X\beta\)-র \(i\)-তম উপাদান, অর্থাৎ \(i\)-তম fitted value \(\hat y_i\)।
- \(\lVert v \rVert\) — একটা vector \(v\)-র Euclidean norm (দৈর্ঘ্য, 0.5): \(\lVert v \rVert = \sqrt{v_1^2 + v_2^2 + \dots + v_n^2}\), তাই \(\lVert v \rVert^2 = \sum_i v_i^2\) = উপাদানগুলোর বর্গযোগ। কাজেই \(\lVert y - X\beta \rVert^2\) ঠিক উপরের বর্গযোগফলটাই — শুধু সংক্ষিপ্ত matrix-নোটেশনে। স্বজ্ঞায়: এটা \(n\)-মাত্রিক space-এ বাস্তব-vector \(y\) আর predict-vector \(X\beta\)-র মধ্যেকার দূরত্বের বর্গ (কতটা "মিস" করল)।
এবার সংজ্ঞা দেওয়া যায়:
সংজ্ঞা (Ordinary Least Squares — OLS, সাধারণ ন্যূনতম-বর্গ পদ্ধতি)। \(\beta\)-র OLS estimate হলো সেই \(\hat\beta\) যা residual sum of squares-কে সবচেয়ে ছোট করে: $$ \hat\beta \;=\; \arg\min_{\beta \in \mathbb{R}^p}\ \mathrm{SSE}(\beta) \;=\; \arg\min_{\beta}\ \lVert y - X\beta \rVert^2 . $$ এখানে "\(\arg\min\)" মানে "যে \(\beta\)-তে ডানপাশের রাশিটা minimum হয়, সেই \(\beta\)" (মানটা নয়, অবস্থানটা, 0.3)। কথায়: সব সম্ভাব্য রেখার মধ্যে যে রেখার মোট বর্গ-residual সবচেয়ে কম, সেটাই OLS-এর বেছে নেওয়া রেখা।
দুটো স্বাভাবিক প্রশ্ন এখানে: (১) কেন বর্গ, কেন residual-এর পরম-মান (absolute value) বা চতুর্থ-ঘাত নয়? সংক্ষিপ্ত উত্তর: বর্গ ব্যবহারে অঙ্কটা মসৃণ ও বিশ্লেষণযোগ্য হয় (differentiable, একটাই minimum, একটা পরিষ্কার বদ্ধ-রূপ সূত্র দেয়) এবং — যা §২.৮ ও §৪-এ দেখানো হবে — Normal error ধরলে এই বর্গ-পছন্দটাই MLE-র সাথে হুবহু মিলে যায়, তাই এটা নিছক সুবিধার নয়, নীতিগতভাবেও সমর্থিত। (২) এই minimum-টা কি সবসময় থাকে আর কীভাবে বের করি? উত্তর: হ্যাঁ (হালকা শর্তে), আর সেই minimization-এর সমাধানই পরের ধাপ — normal equations।
২.৪ সমাধান — Normal Equations ও \(\hat\beta = (X^\top X)^{-1} X^\top y\)¶
§২.৩-এ আমরা কী খুঁজছি তা সংজ্ঞায়িত করলাম (SSE-minimizing \(\beta\)), কিন্তু কীভাবে পাব তা বলিনি। সুসংবাদ: এই minimization-এর একটা সুন্দর বদ্ধ-রূপ (closed-form) সমাধান আছে — কোনো iterative search লাগে না, একটা সূত্রেই উত্তর।
স্বজ্ঞাটা calculus থেকে (0.3): একটা মসৃণ function-এর minimum-এ তার derivative শূন্য হয়। \(\mathrm{SSE}(\beta) = \lVert y - X\beta\rVert^2\) হলো \(\beta\)-র একটা মসৃণ (quadratic) function; এর gradient (প্রতিটি \(\beta_j\)-র সাপেক্ষে partial derivative-এর vector) শূন্য করলে যে সমীকরণ-জোট পাওয়া যায়, তাকে বলে normal equations (পূর্ণ derivation §৪-এ):
এটা \(\hat\beta\)-র উপর একটা রৈখিক সমীকরণ-জোট (\(p\)টি সমীকরণ, \(p\)টি অজানা)। প্রতিটি অংশ খুলি:
- \(X^\top\) — design matrix \(X\)-এর transpose (স্থানান্তর, 0.5): সারি-কলাম উল্টে দেওয়া, মাত্রা \(p \times n\)।
- \(X^\top X\) — মাত্রা \((p \times n)\times(n \times p) = (p \times p)\), একটা বর্গ-matrix। এটা predictor-দের পারস্পরিক সম্পর্ক (এক ধরনের "covariance-সদৃশ" তথ্য) ধরে; এটা সবসময় symmetric ও (সাধারণ শর্তে) invertible।
- \(X^\top y\) — মাত্রা \((p \times n)\times(n \times 1) = (p \times 1)\), একটা \(p\)-vector; এটা predictor-দের সাথে response-এর সম্পর্ক ধরে।
এখন যদি \(X^\top X\) invertible হয় (অর্থাৎ তার inverse \((X^\top X)^{-1}\) থাকে — এটা ঘটে যখন \(X\)-এর কলামগুলো রৈখিকভাবে স্বাধীন, যা সাধারণত সত্য যদি predictor-গুলো একে-অপরের হুবহু নকল না হয় এবং \(n \ge p\)), তাহলে দুপাশে বাঁ-দিক থেকে \((X^\top X)^{-1}\) গুণ করে \(\hat\beta\) আলাদা করা যায়:
এটাই linear regression-এর কেন্দ্রীয় সূত্র — যাকে বলা যায় গোটা অধ্যায়ের "মূল সমীকরণ"। কয়েকটা গুরুত্বপূর্ণ পর্যবেক্ষণ:
- এটা একটা সরাসরি সূত্র: data (\(X\), \(y\)) বসিয়ে কয়েকটা matrix-গুণ ও একটা inverse করলেই \(\hat\beta\) — কোনো আন্দাজ-পাল্টা-আন্দাজ (iteration) নেই। এই বদ্ধ-রূপই OLS-কে এত সুন্দর ও দ্রুত করে।
- \(\hat\beta\) হলো \(y\)-এর একটা রৈখিক function (\(\hat\beta = M y\) যেখানে \(M = (X^\top X)^{-1}X^\top\) একটা স্থির matrix, \(X\) জানা থাকলে)। এই রৈখিকতাই পরে (5.2-এ) \(\hat\beta\)-র sampling distribution ও standard error বের করা সহজ করবে।
- যখন data থেকে এই সূত্রে পাওয়া \(\hat\beta\) বসাই, তখন fitted values \(\hat y = X\hat\beta\) আর residuals \(\hat\varepsilon = y - \hat y\)। এই দুটো প্রতীক (\(\hat y\), \(\hat\varepsilon\)) এখন থেকে সর্বত্র ব্যবহার হবে: \(\hat y\) = মডেলের predict, \(\hat\varepsilon\) = মডেল যা মিস করল।
মনে রাখুন: OLS-এর পুরো গল্পটা দুই ধাপ — (১) কী চাই: SSE-minimizing \(\beta\) (§২.৩); (২) উত্তর: normal equations \(X^\top X\hat\beta = X^\top y\) সমাধান করে \(\hat\beta = (X^\top X)^{-1}X^\top y\)। সূত্রটা মুখস্থ রাখার দরকার নেই যতটা এর কাঠামো বোঝা দরকার — কিন্তু কেন এটাই minimum দেয়, তার পূর্ণ প্রমাণ §৪-এ দুই পথে (calculus ও জ্যামিতি) করা হবে।
একটা সূক্ষ্ম-কিন্তু-গুরুত্বপূর্ণ নোট: কেন একে "normal equations" বলে? "normal" এখানে "স্বাভাবিক" নয়, বরং জ্যামিতিক অর্থে "লম্ব" (perpendicular/orthogonal) — কারণ এই সমীকরণ আসলে বলছে residual-টা \(X\)-এর কলামগুলোর সাথে লম্ব। কেন, সেটাই পরের উপবিভাগের সুন্দর জ্যামিতিক ছবি।
২.৫ জ্যামিতিক ব্যাখ্যা — column space-এ projection¶
এখন অধ্যায়ের সবচেয়ে সুন্দর অন্তর্দৃষ্টি — যেটা \(\hat\beta\)-র সূত্রটাকে একটা স্পষ্ট ছবিতে রূপ দেয়। এটা প্রথমবার একটু বিমূর্ত লাগতে পারে, তাই ধীরে গাঁথি; পূর্ণ প্রমাণ §৪-এ, এখানে কেবল ছবিটা।
মূল দৃষ্টিভঙ্গি-বদল: এতক্ষণ আমরা ভাবছিলাম "\(n\)টা বিন্দু \((x_i, y_i)\) আর তাদের ভেতর দিয়ে রেখা"। এবার একদম উল্টোভাবে ভাবি — পুরো response-টাকে একটা মাত্র vector হিসেবে দেখি, যে বাস করে \(n\)-মাত্রিক space-এ:
- \(y \in \mathbb{R}^n\) — একটা একক বিন্দু/vector \(n\)-মাত্রিক space-এ (এর \(n\)টা স্থানাঙ্ক = \(n\)টা পর্যবেক্ষণ)। (হ্যাঁ, \(n\) বড় হলে এটা কল্পনা করা কঠিন — কিন্তু গণিত \(n=3\)-এর মতোই কাজ করে; ছবিটা \(n=3\)-এ ভাবুন।)
- \(X\)-এর প্রতিটি কলাম-ও একেকটা \(\mathbb{R}^n\)-এর vector। এই \(p\)টা কলাম-vector-এর সব সম্ভাব্য রৈখিক সমন্বয় (অর্থাৎ সব সম্ভাব্য \(X\beta\), যখন \(\beta\) সবকিছু হতে পারে) মিলে একটা subspace (উপ-অবকাশ) গড়ে — তার নাম column space of \(X\), লিখি \(\mathrm{col}(X)\)। এটা \(\mathbb{R}^n\)-এর ভেতরে একটা \(p\)-মাত্রিক "সমতল" (যেমন \(\mathbb{R}^3\)-এর ভেতরে একটা \(2\)D তল)।
এই ভাষায় regression-এর সমস্যাটা নতুন রূপ নেয়: \(\hat y = X\hat\beta\) অবশ্যই \(\mathrm{col}(X)\)-এর ভেতরে থাকবে (কারণ এটা কলামগুলোর একটা সমন্বয়)। কিন্তু \(y\) নিজে সাধারণত \(\mathrm{col}(X)\)-এর ভেতরে নেই (নইলে data হুবহু রেখায় বসত, error থাকত না)। তাই প্রশ্ন দাঁড়ায়:
\(\mathrm{col}(X)\) সমতলের ভেতরের কোন বিন্দু \(\hat y\) বাইরের বিন্দু \(y\)-এর সবচেয়ে কাছে?
এর উত্তর জ্যামিতিতে সুপরিচিত: একটা সমতলের বাইরের বিন্দু থেকে সমতলের সবচেয়ে কাছের বিন্দু হলো সেই বিন্দুর লম্ব-অভিক্ষেপ (orthogonal projection) — অর্থাৎ বিন্দু থেকে সমতলে লম্ব ফেলে যেখানে পড়ে, সেই "ছায়া"। (ভাবুন: ঘরের মেঝে = সমতল, আপনার মাথা = \(y\); মাথা থেকে মেঝেতে সবচেয়ে কাছের বিন্দু হলো ঠিক পায়ের নিচের বিন্দু — সোজা লম্ব নামিয়ে।) আর "সবচেয়ে কাছে" মানে ঠিক "\(\lVert y - \hat y\rVert\) সবচেয়ে ছোট" — যা হুবহু আমাদের OLS-লক্ষ্য!
সংজ্ঞা-স্তরের অন্তর্দৃষ্টি (OLS = projection)। OLS-এর fitted vector \(\hat y = X\hat\beta\) হলো response \(y\)-এর \(\mathrm{col}(X)\)-এর উপর orthogonal projection — সমতলের ভেতরে \(y\)-এর সবচেয়ে কাছের বিন্দু। আর residual \(\hat\varepsilon = y - \hat y\) হলো \(y\) থেকে সেই সমতলে নামানো লম্ব-vector — তাই residual \(\hat\varepsilon\) সমতল \(\mathrm{col}(X)\)-এর সাথে লম্ব (orthogonal), অর্থাৎ \(X\)-এর প্রতিটি কলামের সাথে লম্ব।
এই শেষ বাক্যটাই — "residual \(X\)-এর কলামগুলোর সাথে লম্ব" — গণিতে লেখা হয় \(X^\top \hat\varepsilon = 0\), অর্থাৎ \(X^\top(y - X\hat\beta) = 0\), যা সাজালে ঠিক normal equations \(X^\top X\hat\beta = X^\top y\)! এজন্যই এদের "normal" (= লম্ব) সমীকরণ বলে। দুটো দৃষ্টিভঙ্গি — calculus-এ SSE-minimize আর জ্যামিতিতে orthogonal projection — একই সমীকরণে মেলে, আর এটাই OLS-এর গভীর সৌন্দর্য (§৪-এ দুটোই প্রমাণ হবে)।
এক বাক্যে: OLS মানে \(y\)-কে \(X\)-এর column space-এর "ছায়া"-য় ফেলা; residual হলো সেই ছায়া থেকে আসল \(y\) পর্যন্ত লম্ব রেখা — তাই residual আর predictor-রা পরস্পর-লম্ব, যা থেকেই normal equations জন্মায়।
২.৬ Simple বনাম Multiple, এবং coefficient-এর ব্যাখ্যা¶
এবার সবচেয়ে ব্যবহারিক প্রশ্ন: \(\hat\beta\) পেলাম, কিন্তু প্রতিটা সংখ্যার মানে কী? এখানে simple ও multiple regression-এর মধ্যে একটা সূক্ষ্ম কিন্তু অত্যন্ত গুরুত্বপূর্ণ পার্থক্য আছে, যা না বুঝলে coefficient ভুলভাবে পড়া হয়।
Simple regression-এ (\(p = 2\), এক predictor): \(\hat y = \hat\beta_0 + \hat\beta_1 x\)। এখানে— - \(\hat\beta_0\) (intercept): \(x = 0\) হলে predict করা \(y\)। - \(\hat\beta_1\) (slope): \(x\) এক একক বাড়লে predict করা \(y\) গড়ে কত বাড়ে। যেমন price ~ area-তে \(\hat\beta_1 = 0.45\) মানে "area এক বর্গমিটার বাড়লে দাম গড়ে \(0.45\) একক বাড়ে"।
Multiple regression-এ (\(p > 2\), বহু predictor): \(\hat y = \hat\beta_0 + \hat\beta_1 x_1 + \dots + \hat\beta_{p-1} x_{p-1}\)। এখানে প্রতিটি \(\hat\beta_j\)-র ব্যাখ্যায় একটা অত্যন্ত গুরুত্বপূর্ণ শর্ত যোগ হয়:
সংজ্ঞা-স্তরের ব্যাখ্যা (coefficient interpretation, "holding others fixed")। multiple regression-এ \(\hat\beta_j\) = "অন্য সব predictor স্থির রেখে (holding all other predictors constant), \(x_j\) এক একক বাড়লে predict করা \(y\) গড়ে কত বাড়ে।" এই "অন্যগুলো স্থির" (অন্য নাম: ceteris paribus, "সব কিছু সমান থাকলে") শর্তটাই multiple regression-এর প্রাণ — প্রতিটি coefficient অন্য predictor-দের প্রভাব সরিয়ে রেখে নিজের predictor-এর "বিশুদ্ধ" অবদান মাপে।
কেন এই শর্ত এত গুরুত্বপূর্ণ — একটা স্বজ্ঞা: ধরুন price বাড়ির area আর rooms দুটোর উপরই নির্ভর করে, আর বড় বাড়িতে বেশি ঘরও থাকে (area ও rooms নিজেরাই সম্পর্কিত)। যদি আমরা শুধু area দিয়ে simple regression করি, area-র coefficient-এ rooms-এর প্রভাবও কিছুটা "ঢুকে" যাবে (area বাড়লে rooms-ও বাড়ে, তাই area-কে rooms-এর কৃতিত্বও ভুল করে দেওয়া হয়)। কিন্তু multiple regression-এ area আর rooms দুটোই থাকলে, area-র coefficient মাপে "rooms একই রেখে শুধু area বাড়ালে দাম কত বাড়ে" — অর্থাৎ rooms-এর ভেজাল সরিয়ে area-র নিজস্ব প্রভাব। এই কারণেই একই predictor-এর coefficient simple ও multiple regression-এ আলাদা হতে পারে — এটা ভুল নয়, বরং দুটো ভিন্ন প্রশ্নের ভিন্ন উত্তর।
মনে রাখুন (দুটো সতর্কতা): ১. multiple regression-এ coefficient পড়ার সময় "holding others fixed" শব্দটা সবসময় মনে রাখুন — না হলে ব্যাখ্যা ভুল হয়। ২. coefficient যত বড়/ধনাত্মকই হোক, সেটা §১.৩-এর সতর্কতা মতো কার্যকারণ প্রমাণ করে না — এটা শুধু "এই data-য়, অন্যগুলো স্থির রেখে, এই দুটো একসাথে এভাবে চলে" তাই বলে। কার্যকারণ দাবি করতে গেলে আরও (পরীক্ষামূলক design ইত্যাদি) লাগে।
২.৭ মডেল কতটা ভালো — \(R^2\)¶
\(\hat\beta\) পেলাম, তার মানে বুঝলাম — এবার একটা সংখ্যায় বলা দরকার: মডেলটা সব মিলিয়ে কতটা ভালো data-টা ধরল? সবচেয়ে প্রচলিত মাপ হলো \(R^2\) (R-squared, নির্ধারণ-সহগ / coefficient of determination)।
স্বজ্ঞা: response \(y\)-তে কিছু মোট তারতম্য (variation) আছে — সব বাড়ির দাম এক নয়, গড়ের চারপাশে ছড়ানো। মডেলের কাজ এই তারতম্যের যতটা সম্ভব ব্যাখ্যা করা (predictor দিয়ে)। \(R^2\) মাপে: এই মোট তারতম্যের কত ভগ্নাংশ মডেল ব্যাখ্যা করতে পারল। এটা সংজ্ঞায়িত করতে দুটো "বর্গযোগফল" দরকার:
-
SST — total sum of squares (মোট বর্গযোগফল): response কতটা তার নিজের গড় \(\bar y\)-র চারপাশে ছড়ানো — $$ \mathrm{SST} \;=\; \sum_{i=1}^{n}(y_i - \bar y)^2, \qquad \bar y = \tfrac{1}{n}\textstyle\sum_i y_i . $$ এটা "মডেল ছাড়া", শুধু গড় দিয়ে predict করলে যত ভুল হতো — অর্থাৎ ব্যাখ্যা করার মতো মোট তারতম্যের পরিমাণ।
-
SSE — residual sum of squares (অবশিষ্ট বর্গযোগফল, §২.৩-এর সেই একই \(\mathrm{SSE}\)): মডেল লাগানোর পরেও যত তারতম্য রয়ে গেল — $$ \mathrm{SSE} \;=\; \sum_{i=1}^{n}(y_i - \hat y_i)^2 . $$ এটা মডেল যা ব্যাখ্যা করতে পারল না, সেই অবশিষ্ট।
এখন সংজ্ঞা:
প্রতিটি অংশ ও সীমা খুলি:
- \(\dfrac{\mathrm{SSE}}{\mathrm{SST}}\) = "মডেলের পরেও বাকি-থাকা তারতম্যের ভগ্নাংশ" (যা ব্যাখ্যা হলো না)। তাই \(1\) থেকে এটা বিয়োগ করলে পাই যা ব্যাখ্যা হলো তার ভগ্নাংশ। কথায়: \(R^2\) = response-এর মোট তারতম্যের যত ভগ্নাংশ মডেল ব্যাখ্যা করল।
- সীমা: সাধারণত \(0 \le R^2 \le 1\)। \(R^2 = 1\) মানে \(\mathrm{SSE} = 0\) — মডেল নিখুঁত, সব বিন্দু হুবহু রেখায় (কোনো residual নেই)। \(R^2 = 0\) মানে \(\mathrm{SSE} = \mathrm{SST}\) — মডেল গড় \(\bar y\)-র চেয়ে ভালো কিছু করল না (predictor কিছুই ব্যাখ্যা করল না)।
- উদাহরণ: \(R^2 = 0.85\) মানে "দামের মোট তারতম্যের ৮৫% আমাদের predictor-গুলো (area, age, rooms…) ব্যাখ্যা করতে পারল; বাকি ১৫% অন্য (মডেলে-না-থাকা) কারণ ও random noise"।
মনে রাখুন (এবং একটা সতর্কতা): \(R^2\) = মডেল-ব্যাখ্যাকৃত তারতম্যের ভগ্নাংশ; উঁচু \(R^2\) মানে fit ভালো — কিন্তু এটা একা যথেষ্ট নয়। (ক) predictor যোগ করলেই \(R^2\) কখনো কমে না (এমনকি অকেজো predictor-ও সামান্য বাড়ায়), তাই বহু-predictor মডেলে adjusted \(R^2\) ভালো (পরে); (খ) উঁচু \(R^2\) মডেলের অনুমান (§২.৮) ঠিক আছে কিনা তা বলে না — সেটা যাচাইয়ের জন্য residual plot ও diagnostics লাগে, যা §৬-এ দেখা শুরু হবে এবং পুরোপুরি 5.2-এর বিষয়।
২.৮ মডেল কোন অনুমানের উপর দাঁড়িয়ে — LINE, এবং MLE = OLS¶
এতক্ষণ আমরা \(\hat\beta\) ও \(R^2\) বের করেছি স্রেফ "বর্গ-residual ছোট করো" নীতিতে — এর জন্য কোনো সম্ভাব্যতা-অনুমান লাগেনি। কিন্তু যখন আমরা এর থেকে inference করতে চাই (coefficient-এর SE, CI, test — 5.2), বা OLS-কে নীতিগতভাবে সমর্থন করতে চাই, তখন error \(\varepsilon\)-এর উপর কিছু অনুমান (assumptions) চাপাতে হয়। এই অনুমানগুলোকে সুবিধাজনকভাবে মনে রাখা যায় LINE আদ্যক্ষরে:
সংজ্ঞা (LINE assumptions — রৈখিক regression-এর চারটি মূল অনুমান)। standard linear regression model ধরে নেয় error-গুলো নিচের চারটি শর্ত মানে। প্রতিটি একটা ছবিতে ভাবুন (data বিন্দু রেখার চারপাশে কীভাবে ছড়ানো):
- L — Linearity (রৈখিকতা): response-এর প্রত্যাশিত মান সত্যিই predictor-দের একটা রৈখিক সমন্বয়, অর্থাৎ \(\mathbb{E}[y \mid X] = X\beta\) (প্রতীক \(\mathbb{E}[\cdot\mid\cdot]\) = শর্তাধীন প্রত্যাশা, Part II) — সম্পর্কটা সত্যিই রেখা/সমতল, বাঁকানো নয়। (ভাঙলে: ভুল আকৃতির মডেল।)
- I — Independence (স্বাধীনতা): error-গুলো পরস্পর-স্বাধীন — এক এককের \(\varepsilon_i\) অন্য এককের \(\varepsilon_j\)-র উপর নির্ভর করে না। (সাধারণত ভাঙে time-series বা গুচ্ছবদ্ধ data-য়, যেখানে পরপর পর্যবেক্ষণ সম্পর্কিত।)
- N — Normality (স্বাভাবিকতা): error-গুলো Normal বণ্টন থেকে আসে, \(\varepsilon_i \sim \mathcal{N}(0, \sigma^2)\) (প্রতীক \(\mathcal{N}(0,\sigma^2)\) = গড়-শূন্য, variance-\(\sigma^2\) Normal বণ্টন, 2.4)। (মূলত inference-এর — SE, CI, test-এর সঠিকতার — জন্য লাগে; বড় \(n\)-এ CLT-র জোরে এটা শিথিল করা যায়।)
- E — Equal variance (সম-ভেদ; অন্য নাম homoscedasticity, সম-বিচ্ছুরণ): সব error-এর variance একই \(\sigma^2\) — predictor-এর মান যা-ই হোক, ছিটেফোঁটার ছড়ানো সমান (যেমন ছোট ও বড় বাড়িতে দামের বিচ্যুতি একই মাত্রার)। (ভাঙলে — heteroscedasticity — যেমন বড় বাড়িতে দাম বেশি ছড়ানো; তখন SE ভুল হয়।)
এই চারটি একসাথে ঠিক সেই সংক্ষিপ্ত matrix-অনুমানে গুটিয়ে যায় যা SHARED notation-এ লেখা:
যেখানে — \(0\) হলো \(n\)-লম্বা শূন্য-vector (প্রতিটি error গড়ে \(0\), অর্থাৎ মডেল গড়পড়তা পক্ষপাতহীন); \(\sigma^2\) হলো error-এর সাধারণ variance (অজানা, এটাও data থেকে আন্দাজ করি); আর \(I\) হলো \(n \times n\) identity matrix (একক-ম্যাট্রিক্স, কর্ণে \(1\) বাকি সব \(0\), 0.5)। এই \(\sigma^2 I\) আকৃতিটা একসাথে দুটো কথা বলে: কর্ণের সব \(\sigma^2\) মানে Equal variance (E), আর কর্ণের-বাইরে সব \(0\) মানে error-গুলো পরস্পর-অসম্পর্কিত, যা Normal-এর ক্ষেত্রে Independence (I)। (Normality হলো \(\mathcal{N}\) অংশ — N; আর Linearity ধরা আছে \(y = X\beta + \varepsilon\) লেখার মধ্যেই — L।)
error-এর variance \(\sigma^2\)-ও আমরা data থেকে আন্দাজ করি, residual ব্যবহার করে:
কেন হরে \(n - p\) (\(n\) নয়)? স্বজ্ঞা: residual গণনায় আমরা ইতিমধ্যে data থেকে \(p\)টি coefficient "খরচ" করে ফেলেছি (estimate করেছি), তাই residual-এ আর \(n\)টি নয়, কার্যত \(n - p\)টি স্বাধীন তথ্য-টুকরো বাকি — একে বলে degrees of freedom (স্বাধীনতার মাত্রা, 4.4-এ \(n-1\)-এর সাধারণীকরণ)। এই \(n - p\) দিয়ে ভাগ করায় \(\hat\sigma^2\) unbiased হয় (যেমন sample variance-এ \(n-1\), Bessel's correction)। (simple regression-এ \(p=2\), তাই হর \(n-2\)।)
শেষ ও সবচেয়ে গভীর সংযোগ — MLE = OLS: এতক্ষণ OLS-কে আমরা সমর্থন করেছি "বর্গ-residual ছোট করো" — একটা স্বজ্ঞাগত পছন্দ হিসেবে। কিন্তু এখানে একটা চমৎকার তত্ত্বীয় ন্যায্যতা আছে, যা 4.3-এর MLE-র সাথে জোড়ে:
সংজ্ঞা-স্তরের ফলাফল (MLE = OLS under Normal errors)। যদি LINE-এর Normal-অনুমান ধরি (\(\varepsilon \sim \mathcal{N}(0, \sigma^2 I)\)), তাহলে \(\beta\)-র maximum likelihood estimate (4.3 — যে \(\beta\) observed data-টাকে সবচেয়ে সম্ভাব্য করে) হুবহু OLS estimate-এর সমান: \(\hat\beta_{\text{MLE}} = \hat\beta_{\text{OLS}} = (X^\top X)^{-1}X^\top y\)।
স্বজ্ঞাটা সুন্দর সরল (পূর্ণ প্রমাণ §৪/§৭-এ): Normal density-তে exponent-এ থাকে \(-\tfrac{1}{2\sigma^2}(y_i - X_i\beta)^2\) (বর্গ-পদ)। সব পর্যবেক্ষণের likelihood গুণ করে log নিলে, log-likelihood-এ \(\beta\)-নির্ভর একমাত্র অংশ দাঁড়ায় \(-\tfrac{1}{2\sigma^2}\sum_i (y_i - X_i\beta)^2 = -\tfrac{1}{2\sigma^2}\mathrm{SSE}(\beta)\)। এখন log-likelihood বড় করা (MLE) মানেই \(\mathrm{SSE}(\beta)\) ছোট করা (OLS) — একই কাজ, উল্টো চিহ্নে! তাই Normal error-এ "সবচেয়ে সম্ভাব্য \(\beta\)" আর "সবচেয়ে-কম-বর্গ-ভুল \(\beta\)" একই \(\beta\)।
এক বাক্যে কেন এটা গুরুত্বপূর্ণ: OLS শুধু একটা সুবিধাজনক নিয়ম নয় — Normal error ধরলে এটা নীতিগতভাবে সেরা (maximum likelihood) estimator-ও বটে। তাই Part IV-এর inference-যন্ত্র (likelihood, SE, CI) সরাসরি regression-এ প্রয়োগ করা যায়; এই সেতুটাই 5.2-এ coefficient-এর CI ও test-এর ভিত্তি হবে।
এই অনুমানগুলো ঠিক আছে কিনা — তা কীভাবে যাচাই করব? সেখানেই residual plot ও diagnostics আসে: §৬-এ চিত্রের মাধ্যমে এর প্রথম ঝলক দেখা যাবে, আর পুরো বিষয়টা পরের অধ্যায় 5.2 (Regression Diagnostics)-এর কেন্দ্রবিন্দু।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে আমরা theory-কে হাতে-কলমে সংখ্যা দিয়ে যাচাই করব। প্রথমে একটি ছোট ৫-বিন্দুর dataset-এ simple linear regression পুরোটা ধাপে ধাপে কষব (E1), তারপর ফলাফলকে কথায় ব্যাখ্যা করব (E2)। এরপর full synthetic dataset থেকে পাওয়া multiple regression model-টি interpret করব (E3) এবং সবশেষে একই ৫-বিন্দুর উদাহরণকে matrix form-এ লিখে \(\hat\beta=(X^\top X)^{-1}X^\top y\) সূত্রটি যে একই উত্তর দেয় তা হাতে যাচাই করব (E4)।
হাতে কষার জন্য আমাদের data হলো এই ৫টি বিন্দু:
| \(i\) | \(x_i\) | \(y_i\) |
|---|---|---|
| 1 | 1 | 2 |
| 2 | 2 | 3 |
| 3 | 3 | 5 |
| 4 | 4 | 4 |
| 5 | 5 | 6 |
E1 — Simple regression হাতে কষা¶
আমরা \(\hat y = a + b x\) আকারের একটি সরলরেখা fit করতে চাই, যেখানে slope \(b\) এবং intercept \(a\)। least-squares সূত্র অনুযায়ী
যেখানে \(S_{xy} = \sum_{i}(x_i-\bar x)(y_i-\bar y)\) এবং \(S_{xx} = \sum_{i}(x_i-\bar x)^2\)।
ধাপ ১ — গড় (mean) বের করা।
ধাপ ২ — deviation-গুলো (\(x_i-\bar x\) আর \(y_i-\bar y\)) এবং তাদের গুণফল। একটা table-এ সাজিয়ে নিলে হিসাব পরিষ্কার থাকে:
| \(i\) | \(x_i\) | \(y_i\) | \(x_i-\bar x\) | \(y_i-\bar y\) | \((x_i-\bar x)(y_i-\bar y)\) | \((x_i-\bar x)^2\) |
|---|---|---|---|---|---|---|
| 1 | 1 | 2 | \(-2\) | \(-2\) | \(4\) | \(4\) |
| 2 | 2 | 3 | \(-1\) | \(-1\) | \(1\) | \(1\) |
| 3 | 3 | 5 | \(0\) | \(1\) | \(0\) | \(0\) |
| 4 | 4 | 4 | \(1\) | \(0\) | \(0\) | \(1\) |
| 5 | 5 | 6 | \(2\) | \(2\) | \(4\) | \(4\) |
| যোগফল | \(S_{xy}=9\) | \(S_{xx}=10\) |
অর্থাৎ
ধাপ ৩ — slope \(b\)।
ধাপ ৪ — intercept \(a\)।
সুতরাং fitted regression line:
ধাপ ৫ — fitted values \(\hat y_i\) এবং residual \(\hat\varepsilon_i = y_i - \hat y_i\)। প্রতিটি \(x_i\)-কে রেখার সমীকরণে বসিয়ে দিই:
| \(i\) | \(x_i\) | \(\hat y_i = 1.3 + 0.9\,x_i\) | \(y_i\) | \(\hat\varepsilon_i = y_i - \hat y_i\) |
|---|---|---|---|---|
| 1 | 1 | \(1.3 + 0.9 = 2.2\) | \(2\) | \(2 - 2.2 = -0.2\) |
| 2 | 2 | \(1.3 + 1.8 = 3.1\) | \(3\) | \(3 - 3.1 = -0.1\) |
| 3 | 3 | \(1.3 + 2.7 = 4.0\) | \(5\) | \(5 - 4.0 = \phantom{-}1.0\) |
| 4 | 4 | \(1.3 + 3.6 = 4.9\) | \(4\) | \(4 - 4.9 = -0.9\) |
| 5 | 5 | \(1.3 + 4.5 = 5.8\) | \(6\) | \(6 - 5.8 = \phantom{-}0.2\) |
খেয়াল করুন residual-গুলোর যোগফল \((-0.2)+(-0.1)+1.0+(-0.9)+0.2 = 0\) — least-squares fit-এ intercept থাকলে এটা সবসময়ই শূন্য হবে, যা একটি ভালো sanity check।
ধাপ ৬ — SSE (residual sum of squares) ও SST (total sum of squares)।
প্রতিটি পদ:
ধাপ ৭ — coefficient of determination \(R^2\)।
পাশাপাশি যাচাই হিসেবে \(\mathrm{SSR} = \sum_i(\hat y_i - \bar y)^2 = (-1.8)^2+(-0.9)^2+0^2+(0.9)^2+(1.8)^2 = 3.24+0.81+0+0.81+3.24 = 8.10\), এবং তখন \(R^2 = \mathrm{SSR}/\mathrm{SST} = 8.10/10 = 0.81\) — একই মান, কারণ \(\mathrm{SST} = \mathrm{SSR} + \mathrm{SSE}\) (\(10 = 8.1 + 1.9\))।
এই fitted line-টি figure 5-1-regression-line-এ scatter-এর উপর আঁকা আছে; প্রতিটি বিন্দু থেকে রেখা পর্যন্ত উল্লম্ব দূরত্বই হলো এই residual-গুলো।
E2 — ফলাফলের ব্যাখ্যা (interpretation)¶
হিসাব শেষ; এবার সংখ্যাগুলো কথায় কী বলছে তা বুঝে নিই — regression-এর আসল উদ্দেশ্য তো এখানেই।
Slope \(b = 0.9\) — এর অর্থ কী? slope হলো \(x\)-এর প্রতি এক একক পরিবর্তনে \(\hat y\)-এর গড় পরিবর্তন। এখানে
\(x\) ১ একক বাড়লে \(y\) গড়ে \(0.9\) একক বাড়ে।
যেহেতু \(b>0\), সম্পর্কটি ধনাত্মক (positive) — \(x\) বাড়লে \(y\)-ও বাড়ার প্রবণতা দেখায়। মনে রাখা দরকার এটি একটি গড় (average) প্রবণতা, প্রতিটি বিন্দুর জন্য হুবহু সত্য নয়; যেমন \(i=3\)-এ আসল \(y\) রেখার বেশ উপরে (\(\hat\varepsilon=1.0\))।
Intercept \(a = 1.3\) — এর অর্থ কী? intercept হলো \(x=0\) হলে model-এর ভবিষ্যদ্বাণী করা \(y\)-এর মান, অর্থাৎ \(\hat y(0)=1.3\)। তবে আমাদের data-তে \(x\)-এর পরিসর \([1,5]\), \(x=0\) এর বাইরে; তাই \(a\)-কে আক্ষরিক অর্থে "\(x=0\)-এ \(y\)" হিসেবে নেওয়ার চেয়ে রেখার উচ্চতা ঠিক করার একটি parameter হিসেবেই দেখা নিরাপদ (extrapolation-এর ঝুঁকি)।
\(R^2 = 0.81\) — এর অর্থ কী? \(R^2\) বলে দেয় \(y\)-এর মোট ব্যবধানের (total variation, যা \(\mathrm{SST}\) দিয়ে মাপা) কত অংশ regression model ব্যাখ্যা করতে পারছে। এখানে
\(y\)-এর মোট পরিবর্তনশীলতার প্রায় \(81\%\) এই সরলরেখা (অর্থাৎ \(x\)) দিয়ে ব্যাখ্যা করা যাচ্ছে; বাকি \(19\%\) residual-এ থেকে যাচ্ছে।
\(R^2\) সবসময় \(0\) থেকে \(1\)-এর মধ্যে থাকে: \(1\)-এর কাছাকাছি মানে fit খুব ভালো (সব বিন্দু রেখার কাছাকাছি), \(0\)-এর কাছাকাছি মানে রেখা \(y\)-এর তেমন কিছুই ব্যাখ্যা করছে না। \(0.81\) একটি বেশ ভালো fit নির্দেশ করে।
E3 — Multiple regression: model ও coefficient-এর ব্যাখ্যা¶
এতক্ষণ ছিল একটিমাত্র predictor (\(x\))। বাস্তবে \(y\) একাধিক চলকের উপর নির্ভর করে। §৫-এর full synthetic dataset-এ (\(n=200\)) একটি বাড়ির price-কে তিনটি predictor দিয়ে model করা হয়েছে — area (বর্গমিটার), age (বছর), এবং rooms (ঘরের সংখ্যা)। data তৈরি করা হয়েছিল true coefficient \(\beta = [25,\ 0.45,\ -0.8,\ 6]\) ধরে; তিনটি predictor পরস্পর-স্বাধীনভাবে তৈরি হওয়ায় least-squares দিয়ে সেই \(\beta\)-ই data থেকে চারটি সহগেই পরিষ্কারভাবে recover হয়েছে (§৫-এ আসল fit \(\hat\beta=[22.02,\ 0.460,\ -0.768,\ 6.496]\), যা পূর্ণ-মানের কাছাকাছি)। fitted multiple model:
প্রতিটি coefficient "অন্যগুলো স্থির রেখে (holding others fixed)" পড়তে হয় — multiple regression-এর এটাই মূল কথা। অর্থাৎ একটি predictor-এর coefficient বলে: বাকি সব predictor অপরিবর্তিত রেখে শুধু ঐ একটি predictor ১ একক বাড়ালে \(\hat y\) গড়ে কতটা বদলায়।
- Intercept \(= 25\): area, age, rooms সবগুলোই \(0\) হলে predicted price \(\approx 25\) (baseline; তবে আগের মতোই এটি একটি reference level, আক্ষরিক "শূন্য আয়তনের বাড়ি" নয়)।
- area-এর coefficient \(= 0.45\): age ও rooms স্থির রেখে area ১ বর্গমিটার বাড়লে price গড়ে \(0.45\) একক বাড়ে। ধনাত্মক — বড় বাড়ির দাম বেশি, যা প্রত্যাশিত।
- age-এর coefficient \(= -0.8\): area ও rooms স্থির রেখে বাড়ির বয়স ১ বছর বাড়লে price গড়ে \(0.8\) একক কমে। ঋণাত্মক — পুরোনো বাড়ির দাম কম।
- rooms-এর coefficient \(= 6\): area ও age স্থির রেখে একটি ঘর বেশি থাকলে price গড়ে \(6\) একক বাড়ে।
এই coefficient-গুলো figure 5-1-coefficients-এ bar আকারে দেখানো হয়েছে (ধনাত্মক ও ঋণাত্মক প্রভাব আলাদাভাবে বোঝা যায়), এবং model কতটা ভালো fit করছে তা figure 5-1-multiple-fit-এ predicted-বনাম-actual price plot-এ দেখা যায়।
Simple বনাম multiple slope — একটি সতর্কবার্তা। ধরা যাক আমরা শুধু area দিয়ে একটি simple regression করলাম (age, rooms বাদ দিয়ে)। তখন area-এর slope multiple model-এর \(0.45\)-এর সঙ্গে হুবহু না-ও মিলতে পারে (§৫-এ simple slope \(\approx 0.498\), multiple \(\approx 0.460\))। নীতিগতভাবে কারণটা হলো — যদি বাদ-পড়া কোনো predictor (যেমন rooms) area-র সঙ্গে সম্পর্কিত হতো, তবে simple model-এ area-এর slope সেই predictor-এর প্রভাবও কিছুটা নিজের গায়ে টেনে নিত (omitted-variable পক্ষপাত): "area-এর নিজস্ব প্রভাব" আর "area-র সঙ্গে জড়িয়ে থাকা অন্য চলকের প্রভাব" মিলেমিশে যেত। আমাদের এই dataset-এ অবশ্য predictor-রা পরস্পর-স্বাধীন (corr\((\text{area},\text{rooms})\approx 0.04\)), তাই পার্থক্যটা ছোট — যেটুকু আছে তা মূলত area-only model-এ age ও rooms-এর অনুপস্থিতি থেকে (\(R^2\) তখন মাত্র \(0.44\))। multiple regression ঠিক এই সমস্যাটাই ঠিক করে: প্রতিটি coefficient তখন শুধু ঐ চলকের নিজস্ব (partial) প্রভাব দেখায়, বাকি চলকগুলোকে স্থির ধরে নিয়ে। তাই predictor-রা পরস্পর-সম্পর্কিত হলে simple আর multiple slope ভিন্ন হওয়া স্বাভাবিক, এবং multiple slope-টিই বেশি বিশ্বাসযোগ্য যখন একাধিক কারণ একসাথে কাজ করে।
E4 — Matrix form-এ একই উত্তর যাচাই¶
§২-তে দেওয়া সাধারণ সূত্র \(\hat\beta = (X^\top X)^{-1} X^\top y\) আসলে E1-এর হাতে-কষা \(a,b\)-ই দেয় — সেটা ছোট উদাহরণে হাতে মিলিয়ে দেখি।
ধাপ ১ — design matrix \(X\) এবং vector \(y\)। intercept-এর জন্য প্রথম column-এ সব \(1\), দ্বিতীয় column-এ \(x\)-মান:
এখানে \(\beta = \begin{bmatrix} a \\ b \end{bmatrix}\), অর্থাৎ প্রথম উপাদানটি intercept, দ্বিতীয়টি slope।
ধাপ ২ — \(X^\top X\) (একটি \(2\times 2\) matrix)। ভেতরের উপাদানগুলো হলো \(\sum 1 = n\), \(\sum x_i\), এবং \(\sum x_i^2\):
কারণ \(\sum x_i = 1+2+3+4+5 = 15\) এবং \(\sum x_i^2 = 1+4+9+16+25 = 55\)।
ধাপ ৩ — \(X^\top y\) (একটি \(2\times 1\) vector)। এর উপাদান দুটি হলো \(\sum y_i\) ও \(\sum x_i y_i\):
যেখানে \(\sum y_i = 20\) এবং \(\sum x_i y_i = (1)(2)+(2)(3)+(3)(5)+(4)(4)+(5)(6) = 2+6+15+16+30 = 69\)।
ধাপ ৪ — \((X^\top X)^{-1}\) (\(2\times 2\) inverse হাতে)। যেকোনো \(2\times2\) matrix \(\begin{bmatrix} p & q \\ r & s \end{bmatrix}\)-এর inverse হলো \(\dfrac{1}{ps-qr}\begin{bmatrix} s & -q \\ -r & p \end{bmatrix}\)। এখানে determinant:
সুতরাং
ধাপ ৫ — \(\hat\beta = (X^\top X)^{-1}(X^\top y)\)। matrix-vector গুণ:
প্রতিটি উপাদান কষে:
অর্থাৎ \(a = 1.3\) এবং \(b = 0.9\) — E1-এ পাওয়া মানের সাথে হুবহু মিলে গেল। এটিই দেখায় যে simple regression-এর সরল সূত্র আর সাধারণ matrix সূত্র একই জিনিস; matrix form-এর সুবিধা হলো এটি predictor-সংখ্যা বাড়লেও (multiple regression) অবিকল একইভাবে কাজ করে।
যাচাই (numerical check). নিচের ছোট snippet-টি শুধু উপরের হাতে-কষা সংখ্যাগুলো মিলিয়ে দেখার জন্য — কোনো নতুন হিসাব নয়।
import numpy as np
x = np.array([1, 2, 3, 4, 5], dtype=float)
y = np.array([2, 3, 5, 4, 6], dtype=float)
xbar, ybar = x.mean(), y.mean() # 3.0, 4.0
Sxy = ((x - xbar) * (y - ybar)).sum() # 9.0
Sxx = ((x - xbar) ** 2).sum() # 10.0
b = Sxy / Sxx # 0.9
a = ybar - b * xbar # 1.3
yhat = a + b * x
SSE = ((y - yhat) ** 2).sum(); SST = ((y - ybar) ** 2).sum()
R2 = 1 - SSE / SST # 0.81
print(f"E1: b={b:.4f}, a={a:.4f}, SSE={SSE:.4f}, SST={SST:.4f}, R2={R2:.4f}")
X = np.column_stack([np.ones_like(x), x]) # matrix form (E4)
beta = np.linalg.inv(X.T @ X) @ X.T @ y
print(f"E4: beta (matrix) = [{beta[0]:.4f}, {beta[1]:.4f}]")
আউটপুট:
দুই পথেই \(b=0.9,\ a=1.3,\ R^2=0.81\) — হাতে-কষা মানের সঙ্গে হুবহু মিলেছে।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশটাই অধ্যায়ের হৃৎপিণ্ড: এতক্ষণ আমরা regression-এর ধারণা ও সূত্র "ব্যবহার" করেছি, এবার সেগুলো শূন্য থেকে উৎপাদন করব — প্রতিটা ধাপ Bangla-য় ব্যাখ্যা করে, প্রতিটা রেখার পেছনের যুক্তি দেখিয়ে। লক্ষ্য একটাই: শেষে যেন \(\hat\beta=(X^\top X)^{-1}X^\top y\) সূত্রটা আর "আকাশ থেকে পড়া" মনে না হয়, বরং মনে হয় একটাই স্বাভাবিক প্রশ্নের অনিবার্য উত্তর — "error-এর বর্গের যোগফল সবচেয়ে ছোট করলে কোন \(\beta\) পাই?"
আমরা পাঁচটা ধাপে এগোব: (ক) calculus দিয়ে OLS সমাধান (normal equations); (খ) সেই সমাধানের জ্যামিতি — projection ও hat matrix; (গ) Normal error-এর অধীনে \(\hat\beta\)-র statistical ধর্ম (unbiased, variance, Gauss–Markov); (ঘ) কেন এই OLS আসলে MLE-রই ছদ্মবেশ; (ঙ) \(R^2\) ও ANOVA পরিচয়। সঙ্গে চলবে একটা ছোট হাতে-গোনা উদাহরণ — ৫টা বিন্দু \((1,2),(2,3),(3,5),(4,4),(5,6)\) — যাতে প্রতিটা সূত্র সংখ্যায় "চোখে দেখা" যায়।
প্রতীক-স্মারক (§১–২ থেকে): \(y\in\mathbb{R}^n\) হলো response vector, \(X\in\mathbb{R}^{n\times p}\) হলো design matrix (প্রথম কলামটা সব-১, intercept-এর জন্য), \(\beta\in\mathbb{R}^p\) অজানা coefficient vector, আর \(\varepsilon\sim\mathcal{N}(0,\sigma^2 I)\) random error। মডেল: \(y=X\beta+\varepsilon\)। আমরা যেটা হিসাব করি সেটা estimate \(\hat\beta\), আর fitted মান \(\hat y=X\hat\beta\)।
৪.১ · OLS উৎপাদন — calculus দিয়ে (★★)¶
প্রশ্নটা পরিষ্কার করি। আমাদের হাতে \(n\)টা observation, প্রতিটায় predictor-গুলো (matrix \(X\)-এর সারি) আর একটা response (\(y\)-এর উপাদান)। আমরা এমন একটা \(\beta\) চাই যাতে মডেলের ভবিষ্যদ্বাণী \(X\beta\) আসল \(y\)-র যত কাছাকাছি সম্ভব হয়। "কাছাকাছি" মাপব residual vector \(y-X\beta\)-র দৈর্ঘ্যের বর্গ দিয়ে — একে বলে residual sum of squares (RSS):
কেন বর্গের যোগফল, error-এর সরল যোগফল নয়? কারণ সরল যোগফলে ধনাত্মক ও ঋণাত্মক error পরস্পরকে বাতিল করে দেয় (একটা ভয়ংকর খারাপ fit-ও যোগফল শূন্য দেখাতে পারে)। বর্গ করলে সব error ধনাত্মক হয়, বড় ভুল বেশি শাস্তি পায়, আর — সবচেয়ে গুরুত্বপূর্ণ — RSS একটা মসৃণ (differentiable) ফাংশন হয়, তাই calculus দিয়ে minimize করা যায়। (পরে §৪.৪-এ দেখব Normal-error ধরে নিলে এই বর্গ-পছন্দ আসলে MLE থেকে অনিবার্যভাবে বেরোয়।)
ধাপ ১ — RSS-কে খুলে লিখি। Matrix গুণফল বিস্তার করি (transpose নেওয়ার নিয়ম \((AB)^\top=B^\top A^\top\) মনে রেখে):
মাঝের দুই পদ লক্ষ করুন: \(y^\top X\beta\) একটা \(1\times1\) scalar, আর যেকোনো scalar নিজের transpose-এর সমান, তাই \(y^\top X\beta=(y^\top X\beta)^\top=\beta^\top X^\top y\)। অর্থাৎ মাঝের দুই পদ একই, এদের যোগ করে পাই:
ধাপ ২ — gradient নিই (\(\beta\)-এর সাপেক্ষে)। এখন আমরা \(\mathrm{RSS}\)-কে vector \(\beta\)-র সাপেক্ষে অন্তরকলন করব। তিনটা পদ আলাদা করে নিই, দুটো standard matrix-calculus নিয়ম দিয়ে:
- নিয়ম ১: \(\dfrac{\partial}{\partial\beta}\big(a^\top\beta\big)=a\) — তাই \(\dfrac{\partial}{\partial\beta}\big(-2\,\beta^\top X^\top y\big)=-2\,X^\top y\)।
(এখানে \(a=X^\top y\); \(\beta^\top a=a^\top\beta\) scalar, তার gradient \(a\)।) - নিয়ম ২: \(\dfrac{\partial}{\partial\beta}\big(\beta^\top A\beta\big)=2A\beta\) যখন \(A\) symmetric — এখানে \(A=X^\top X\), আর \(X^\top X\) সর্বদা symmetric (কারণ \((X^\top X)^\top=X^\top X\))। তাই \(\dfrac{\partial}{\partial\beta}\big(\beta^\top X^\top X\beta\big)=2\,X^\top X\beta\)।
- প্রথম পদ \(y^\top y\)-তে \(\beta\) নেই, তাই তার gradient \(0\)।
সব মিলিয়ে:
শেষ রূপটা খেয়াল করুন: \(-2X^\top(y-X\beta)\) — ভেতরে \((y-X\beta)\) হলো residual, আর \(X^\top(\cdot)\) মানে প্রতিটা predictor-কলামের সঙ্গে residual-এর dot product। এই রূপ §৪.২-এর জ্যামিতির পুরো গল্পটা আগেভাগে বলে দিচ্ছে।
ধাপ ৩ — gradient শূন্য বসাই। Minimum-এ gradient শূন্য হতে হবে (first-order condition)। \(\hat\beta\) দিয়ে সেই সমাধান বোঝাই:
এই শেষ সমীকরণটাই বিখ্যাত normal equations — regression-এর কেন্দ্রীয় সমীকরণ। নাম "normal" কেন? কারণ এটা ঠিক বলছে residual \((y-X\hat\beta)\) প্রতিটা predictor-কলামের সঙ্গে লম্ব (orthogonal/normal) — সেটাই §৪.২-এ দেখব।
ধাপ ৪ — \(\hat\beta\)-র জন্য সমাধান করি। যদি \(X^\top X\) invertible হয় (অর্থাৎ \(X\)-এর কলামগুলো linearly independent — কোনো predictor অন্যগুলোর নিখুঁত linear combination নয়), তবে দুই পাশে বাঁ থেকে \((X^\top X)^{-1}\) গুণ করি:
এটা সত্যিই minimum, maximum নয় তো? হ্যাঁ, minimum। কারণ RSS-এর Hessian (দ্বিতীয় অন্তরজ) হলো \(\nabla^2_\beta\mathrm{RSS}=2X^\top X\), আর \(X^\top X\) সর্বদা positive semi-definite (যেকোনো \(v\)-র জন্য \(v^\top X^\top X v=\lVert Xv\rVert^2\ge0\)); কলাম-independence-এ এটা positive definite, তাই RSS কঠোরভাবে convex — একটাই critical point, আর সেটা global minimum। অর্থাৎ \(\hat\beta\) অনন্য ও সত্যিকারের সর্বনিম্ন।
ছোট উদাহরণে যাচাই (সংখ্যায়)। আমাদের ৫ বিন্দু: \(x=(1,2,3,4,5)\), \(y=(2,3,5,4,6)\), intercept-সহ তাই \(p=2\)।
\(2\times2\) inverse নিই (\(\det=5\cdot55-15^2=275-225=50\)):
অর্থাৎ \(\hat a=1.3\) (intercept), \(\hat b=0.9\) (slope) — fitted রেখা \(\hat y=1.3+0.9x\)।
৪.২ · জ্যামিতি — projection ও hat matrix (★★)¶
Algebra-টা হলো, এবার দেখি ছবিটা কী বলছে — কারণ regression-এর সবচেয়ে সুন্দর অন্তর্দৃষ্টি এখানেই।
মূল ধারণা: column space। \(X\beta\) মানে \(X\)-এর কলামগুলোর একটা linear combination (\(\beta\) হলো ওজন)। \(\beta\) সব মান ঘুরে এলে \(X\beta\) যত vector বানায় তাদের সমষ্টি হলো \(X\)-এর column space \(\mathcal{C}(X)\) — \(\mathbb{R}^n\)-এর ভেতরে একটা (\(p\)-মাত্রার) সমতল/উপস্থান (subspace)। আমাদের আসল \(y\) সাধারণত এই সমতলে থাকে না (থাকলে error শূন্য, নিখুঁত fit হতো)। তাই প্রশ্নটা দাঁড়ায়: এই সমতলের ভেতরে \(y\)-র সবচেয়ে কাছের বিন্দু কোনটা?
উত্তর জ্যামিতি থেকেই স্পষ্ট: একটা সমতলের বাইরের বিন্দু থেকে সমতলের নিকটতম বিন্দু হলো তার লম্ব অভিক্ষেপ (orthogonal projection) — যেখানে বিন্দু থেকে সমতলে নামানো রেখাটা সমতলের সঙ্গে সমকোণ করে। সেই নিকটতম বিন্দুই আমাদের \(\hat y\)। আর "\(y-\hat y\) সমতলের সঙ্গে লম্ব" — এই শর্ত ঠিক normal equations-এর জ্যামিতিক রূপ:
(এই \(X^\top\hat\varepsilon=0\) ঠিক §৪.১-এর normal equations — algebra আর geometry একই কথা দুই ভাষায় বলছে।)
Hat matrix। \(\hat y\)-কে সরাসরি \(y\)-র সঙ্গে যুক্ত করি। \(\hat\beta=(X^\top X)^{-1}X^\top y\) বসিয়ে:
\(H\)-কে বলে hat matrix — কারণ এটা \(y\)-র মাথায় "টুপি" পরিয়ে \(\hat y\) বানায়। এটা একটা \(n\times n\) matrix যা \(\mathbb{R}^n\)-এর যেকোনো vector-কে \(\mathcal{C}(X)\)-এর ওপর অভিক্ষেপ করে।
\(H\)-এর দুটো মৌলিক ধর্ম — যেকোনো projection matrix-এর স্বাক্ষর:
(i) Symmetric: \(H^\top=H\).
(কারণ \(X^\top X\) symmetric, তাই তার inverse-ও symmetric: \(((X^\top X)^{-1})^\top=((X^\top X)^\top)^{-1}=(X^\top X)^{-1}\)।)
(ii) Idempotent: \(H^2=H\). অর্থাৎ একবার projection করলে যা পাই, আবার projection করলেও তাই — কারণ \(\hat y\) তো ইতিমধ্যেই সমতলে আছে, তাকে আবার সমতলে আনার কিছু নেই।
Residual-ও একটা projection। \(\hat\varepsilon=y-\hat y=y-Hy=(I-H)y\)। এই \((I-H)\) হলো লম্ব সমতলের (orthogonal complement) ওপর অভিক্ষেপ — এটাও symmetric ও idempotent, আর \(H(I-H)=H-H^2=H-H=0\) মানে দুই projection পরস্পর লম্ব। তাই \(y\) পরিষ্কারভাবে দুই লম্ব অংশে ভাঙে: \(y=\underbrace{Hy}_{\hat y\ \in\,\mathcal{C}(X)}+\underbrace{(I-H)y}_{\hat\varepsilon\ \perp\,\mathcal{C}(X)}\)। এই লম্ব ভাঙনই §৪.৫-এর Pythagoras-পরিচয় (\(\mathrm{SST}=\mathrm{SSR}+\mathrm{SSE}\))-এর বীজ।
ছোট উদাহরণে যাচাই। আগের fitted রেখা \(\hat y=1.3+0.9x\) থেকে \(\hat y=(2.2,\,3.1,\,4.0,\,4.9,\,5.8)\), তাই residual \(\hat\varepsilon=y-\hat y=(-0.2,\,-0.1,\,1.0,\,-0.9,\,0.2)\)। দুটো লম্ব-শর্ত মিলিয়ে দেখি (\(X\)-এর দুই কলামের সঙ্গে dot product):
- কলাম-১ (সব-১) সঙ্গে: \(\sum\hat\varepsilon_i=-0.2-0.1+1.0-0.9+0.2=0.\) ✓ (residual-গুলোর যোগফল শূন্য — intercept থাকার সরাসরি ফল)
- কলাম-২ (\(x\)) সঙ্গে: \(\sum x_i\hat\varepsilon_i=1(-0.2)+2(-0.1)+3(1.0)+4(-0.9)+5(0.2)=-0.2-0.2+3.0-3.6+1.0=0.\) ✓
দুটোই শূন্য — residual সত্যিই দুই কলামের সঙ্গে লম্ব, ঠিক normal equations যা দাবি করে।
৪.৩ · \(\hat\beta\)-র statistical ধর্ম (★★)¶
এতক্ষণ \(\hat\beta\) ছিল নিছক একটা সংখ্যা-হিসাব। এবার ধরি data সত্যিই মডেল \(y=X\beta+\varepsilon\) থেকে এসেছে, যেখানে \(\varepsilon\sim\mathcal{N}(0,\sigma^2 I)\) — অর্থাৎ error-গুলো গড়ে শূন্য, একে অপর থেকে স্বাধীন (independent), আর সবার একই variance \(\sigma^2\) (homoscedastic)। তাহলে \(\hat\beta\) একটা random vector (কারণ \(y\) random), আর আমরা তার গড় ও বিস্তার জানতে চাই। সারা ধাপে \(X\)-কে স্থির (fixed/non-random) ধরা হয়।
ধর্ম ১ — Unbiasedness: \(\mathbb{E}[\hat\beta]=\beta\).
মূল চাল: \(\hat\beta\)-কে সত্যিকারের \(\beta\)-র সাপেক্ষে লিখি। \(y=X\beta+\varepsilon\) বসাই \(\hat\beta=(X^\top X)^{-1}X^\top y\)-তে:
এই রূপটা গুরুত্বপূর্ণ: \(\hat\beta=\beta+(X^\top X)^{-1}X^\top\varepsilon\) — অর্থাৎ estimate = সত্যি + (error-এর একটা linear ফাংশন)। পুরো randomness-টা ওই দ্বিতীয় পদে।
এখন expectation নিই; \(X\) স্থির, তাই \((X^\top X)^{-1}X^\top\) matrix-টা constant হিসেবে বাইরে আসে, আর \(\mathbb{E}[\varepsilon]=0\):
অর্থাৎ \(\hat\beta\) unbiased — গড়ে এটা ঠিক সত্যিকারের \(\beta\)-তে বসে। কোনো একটা নমুনায় ভুল হতে পারে, কিন্তু বহু নমুনার গড়ে কোনো পদ্ধতিগত পক্ষপাত নেই।
ধর্ম ২ — Variance: \(\mathrm{Var}(\hat\beta)=\sigma^2(X^\top X)^{-1}\).
\(\hat\beta-\beta=(X^\top X)^{-1}X^\top\varepsilon\) থেকে covariance matrix বের করি। নিয়ম: যদি \(z=A\varepsilon\) আর \(\mathrm{Var}(\varepsilon)=\sigma^2 I\), তবে \(\mathrm{Var}(z)=A\,\mathrm{Var}(\varepsilon)\,A^\top=\sigma^2 AA^\top\)। এখানে \(A=(X^\top X)^{-1}X^\top\):
মাঝে \(X^\top X\) আর তার inverse মিলে যায়:
পড়ে যা বোঝা যায়: এই \(p\times p\) matrix-এর কর্ণ-উপাদানগুলো প্রতিটা \(\hat\beta_j\)-র variance (তার বর্গমূল = standard error)। variance ছোট হয় যখন (ক) \(\sigma^2\) ছোট (data কম noisy), আর (খ) \(X^\top X\) "বড়" — অর্থাৎ predictor-গুলোর বিস্তার বেশি ও পরস্পর কম-correlated। দুই predictor প্রায় collinear হলে \(X^\top X\) প্রায় singular, তার inverse বিশাল, তাই standard error ফুলে ওঠে — এটাই multicollinearity সমস্যা।
ধর্ম ৩ — Gauss–Markov উপপাদ্য (BLUE)। উপরের দুই ধর্ম শুধু বলে \(\hat\beta\) unbiased ও তার variance কত। কিন্তু এটা কি সেরা? Gauss–Markov উপপাদ্য বলে — হ্যাঁ, একটা নির্দিষ্ট অর্থে:
Gauss–Markov উপপাদ্য। যদি error-গুলোর গড় শূন্য, variance সমান (\(\sigma^2\)), ও পরস্পর uncorrelated হয় (Normality লাগে না!), তবে OLS estimator \(\hat\beta\) হলো BLUE — Best Linear Unbiased Estimator। অর্থাৎ \(y\)-র সব linear ও unbiased estimator-এর মধ্যে \(\hat\beta\)-রই variance সর্বনিম্ন (যেকোনো coefficient বা তাদের linear combination-এর জন্য)।
"Best" মানে সর্বনিম্ন variance, "Linear" মানে estimator \(y\)-র একটা linear ফাংশন, "Unbiased" মানে গড়ে সত্যিতে বসে। অসাধারণ ব্যাপার: এই গ্যারান্টি পেতে error Normal হওয়া লাগে না — শুধু গড়-শূন্য, সমান-variance, uncorrelated হলেই চলে। (প্রমাণ §৬/পরবর্তী অধ্যায়ে; এখানে ফলাফলটাই বিবৃত।) Normality লাগে শুধু পরে — exact confidence interval ও hypothesis test (t, F বণ্টন) পেতে।
ধর্ম ৪ — \(\sigma^2\)-এর unbiased estimate: \(\hat\sigma^2=\mathrm{SSE}/(n-p)\).
আমরা \(\sigma^2\) জানি না, তাই residual থেকে অনুমান করি। স্বাভাবিক চেষ্টা হবে \(\frac1n\sum\hat\varepsilon_i^2=\mathrm{SSE}/n\), কিন্তু এটা সামান্য নিচের দিকে biased — কারণ residual-গুলো \(p\)টা normal equations মানতে বাধ্য (§৪.২), তাই তারা \(n\)টা নয়, কার্যত \(n-p\)টা স্বাধীন দিকে ওঠানামা করতে পারে। তাই হরে \(n\)-এর বদলে \(n-p\) বসাই:
এই হর \(n-p\)-কে বলে degrees of freedom (স্বাধীনতার মাত্রা)। এটা ধরলে \(\mathbb{E}[\hat\sigma^2]=\sigma^2\) হয় (unbiased)। সরল regression-এ \(p=2\) (intercept + slope), তাই হর \(n-2\)।
স্মারক: এই \(n-p\) ঠিক §৪.৩-এর "residual-রা \(p\)টা constraint মানে, তাই \(p\)টা স্বাধীনতা হারায়" যুক্তিরই সংখ্যাগত প্রতিফলন — একই কারণে variance-এর estimate-এ \(n\) থেকে \(p\) বাদ যায়।
ছোট উদাহরণে। residual \(\hat\varepsilon=(-0.2,-0.1,1.0,-0.9,0.2)\), তাই \(\mathrm{SSE}=(-0.2)^2+(-0.1)^2+1.0^2+(-0.9)^2+0.2^2=0.04+0.01+1.0+0.81+0.04=1.9.\) এখানে \(n=5,\ p=2\), তাই \(\hat\sigma^2=\dfrac{1.9}{5-2}=\dfrac{1.9}{3}\approx0.633.\)
৪.৪ · MLE = OLS — কেন বর্গের যোগফল "সঠিক" পছন্দ (★★★)¶
§৪.১-এ আমরা RSS minimize করলাম কারণ "বর্গ করলে সুবিধা" — কিন্তু এটা কি নিছক সুবিধাবাদ, না এর পেছনে গভীর কারণ আছে? এই উপ-অংশে দেখাব: যদি error সত্যিই Normal হয়, তবে likelihood সর্বোচ্চ করা ও RSS সর্বনিম্ন করা হুবহু একই কাজ। অর্থাৎ OLS আসলে Normal মডেলের MLE — বর্গ-পছন্দ আকাশ থেকে পড়েনি, সরাসরি Normal বণ্টন থেকে এসেছে। (পূর্বশর্ত: §৪.৩-এর MLE পদ্ধতি।)
ধাপ ১ — likelihood লিখি। \(\varepsilon\sim\mathcal{N}(0,\sigma^2 I)\) মানে \(y=X\beta+\varepsilon\), তাই প্রতিটা observation \(y_i\sim\mathcal{N}\big((X\beta)_i,\ \sigma^2\big)\) স্বাধীনভাবে — যেখানে \((X\beta)_i=x_i^\top\beta\) হলো \(i\)-তম সারির পূর্বাভাস। একটা Normal density:
স্বাধীন বলে যৌথ likelihood হলো গুণফল:
ধাপ ২ — log নিই। গুণফলকে যোগফলে বদলাতে আর exponential সরাতে \(\log\) নিই (log কঠোরভাবে বর্ধমান, তাই argmax বদলায় না):
ধাপ ৩ — মূল লক্ষ্যটা চিনি। ভেতরের যোগফলটা ঠিক আমাদের পুরোনো RSS, কারণ \(\sum_i(y_i-x_i^\top\beta)^2=\lVert y-X\beta\rVert^2=\mathrm{RSS}(\beta)\)। বসাই:
ধাপ ৪ — সিদ্ধান্ত টানি। \(\beta\)-র সাপেক্ষে \(\ell\) সর্বোচ্চ করতে চাই। ডান পাশের দ্বিতীয় বন্ধনীতে \(\beta\) নেই (শুধু \(\sigma^2\) আছে), তাই \(\beta\)-র জন্য সেটা ধ্রুবক। আর প্রথম পদে \(-\frac{1}{2\sigma^2}\) একটা ঋণাত্মক ধ্রুবক গুণক (\(\sigma^2>0\))। একটা ঋণাত্মক সংখ্যা দিয়ে গুণ করা কিছু সর্বোচ্চ করা মানে সেই কিছু সর্বনিম্ন করা। অতএব:
অর্থাৎ likelihood-সর্বোচ্চকারী \(\hat\beta_{\text{MLE}}\) ঠিক সেই \(\hat\beta\) যা RSS সর্বনিম্ন করে — যা আমরা §৪.১-এ পেয়েছি:
এই সমতা কেন এত গুরুত্বপূর্ণ? কারণ এটা OLS-এর "কেন বর্গ?" প্রশ্নের চূড়ান্ত উত্তর: বর্গ আসে Normal density-র exponent-এ থাকা \((y_i-\mu)^2\) থেকে। যদি error অন্য বণ্টনের হতো — যেমন Laplace (double-exponential), যার exponent-এ \(\lvert y_i-\mu\rvert\) থাকে — তবে MLE বর্গ নয়, পরম-মান (absolute deviation) minimize করত। তাই "least squares" মানে নীরবে "আমি ধরে নিচ্ছি error Gaussian"।
\(\sigma^2\)-এর MLE (পার্শ্ব-ফল)। \(\hat\beta\) বসিয়ে \(\ell\)-কে \(\sigma^2\)-এর সাপেক্ষে maximize করলে (অর্থাৎ \(\partial\ell/\partial(\sigma^2)=0\)) পাওয়া যায় \(\hat\sigma^2_{\text{MLE}}=\mathrm{SSE}/n\) — হরে \(n\), \(n-p\) নয়। তাই MLE-র \(\hat\sigma^2\) সামান্য biased (নিচের দিকে); §৪.৩-এর \(\mathrm{SSE}/(n-p)\) হলো তার bias-সংশোধিত রূপ। (এই কারণেই সফটওয়্যার variance-এ \(n-p\) ব্যবহার করে, যদিও point-estimate \(\hat\beta\) MLE-ই থাকে।)
৪.৫ · \(R^2\) ও ANOVA পরিচয় (★)¶
শেষ ধাপ: মডেলটা মোট কতটা ভালো খাটল, সেটা একটা সংখ্যায় ধরা। মূল ধারণা — \(y\)-র মোট ওঠানামাকে দুই ভাগে ভাঙা: যতটুকু মডেল ব্যাখ্যা করল, আর যতটুকু অব্যাখ্যাত (residual) রইল।
তিনটা sum of squares। \(\bar y=\frac1n\sum y_i\) ধরে সংজ্ঞা:
- SST (Total): \(y\)-র মোট বিস্তার — মডেল ছাড়া, শুধু \(\bar y\) দিয়ে অনুমান করলে যত ভুল হতো।
- SSR (Regression/explained): fitted মান \(\bar y\) থেকে যতটা সরে গেছে — অর্থাৎ predictor ব্যবহার করে মডেল যতটুকু ব্যাখ্যা করল।
- SSE (Error/residual): যা মডেল ব্যাখ্যা করতে পারল না।
ANOVA পরিচয়: \(\mathrm{SST}=\mathrm{SSR}+\mathrm{SSE}\). প্রতিটা পদ ভাঙি — \((y_i-\bar y)=(\hat y_i-\bar y)+(y_i-\hat y_i)\) লিখে বর্গ করি ও যোগ করি:
মূল চাল — শেষ cross-term শূন্য। \(\sum_i(\hat y_i-\bar y)(y_i-\hat y_i)\)-কে দুই টুকরোয় ভাগি, দুটোই §৪.২-এর লম্ব-শর্ত থেকে শূন্য:
- \(\sum_i\hat y_i(y_i-\hat y_i)=\hat y^\top\hat\varepsilon=(X\hat\beta)^\top\hat\varepsilon=\hat\beta^\top\underbrace{X^\top\hat\varepsilon}_{=\,0}=0\) — কারণ residual প্রতিটা কলামের সঙ্গে লম্ব।
- \(\bar y\sum_i(y_i-\hat y_i)=\bar y\sum_i\hat\varepsilon_i=0\) — কারণ intercept-কলাম (সব-১) এর সঙ্গে লম্বতা মানে \(\sum\hat\varepsilon_i=0\)।
তাই cross-term অদৃশ্য, আর থাকে বিশুদ্ধ Pythagoras-পরিচয়:
জ্যামিতিতে এটাই §৪.২-এর লম্ব ভাঙন \(y=Hy+(I-H)y\)-এর দৈর্ঘ্য-সম্পর্ক: \(\bar y\) থেকে মাপা \(y\), \(\hat y\) ও residual একটা সমকোণী ত্রিভুজ গড়ে, তাই অতিভুজ-বর্গ (SST) = দুই বাহু-বর্গের যোগ (SSR + SSE)। শর্ত: এই পরিচয় ঠিক তখনই খাটে যখন মডেলে intercept আছে (নইলে \(\sum\hat\varepsilon_i=0\) নিশ্চিত নয়)।
\(R^2\) — নির্ধারণ-সহগ (coefficient of determination)। এখন মডেল মোট বিস্তারের কত ভগ্নাংশ ব্যাখ্যা করল তা সংজ্ঞায়িত করি:
(দুই রূপ সমান কারণ SST = SSR + SSE, তাই \(\mathrm{SSR}/\mathrm{SST}=(\mathrm{SST}-\mathrm{SSE})/\mathrm{SST}=1-\mathrm{SSE}/\mathrm{SST}\)।) \(R^2\) সর্বদা \([0,1]\)-এ থাকে: \(R^2=1\) মানে নিখুঁত fit (SSE=0), \(R^2=0\) মানে মডেল \(\bar y\)-র চেয়ে ভালো কিছু করেনি। ব্যাখ্যা: "response-এর মোট ওঠানামার \(R^2\) অংশ predictor দিয়ে ব্যাখ্যা করা গেছে।"
ছোট উদাহরণে। \(\bar y=20/5=4\), residual \(\hat\varepsilon=(-0.2,-0.1,1.0,-0.9,0.2)\) থেকে:
যাচাই: SSR + SSE \(=8.1+1.9=10=\) SST ✓। তাই
অর্থাৎ আমাদের রেখা \(\hat y=1.3+0.9x\) মোট ওঠানামার ৮১% ব্যাখ্যা করছে — পাঁচ-বিন্দুর এই খেলনা data-র জন্য বেশ ভালো।
৪.৬ · সরল regression-এর বদ্ধ রূপ normal equations থেকেই বেরোয় (★★)¶
সবশেষে যাচাই করি যে §২-এ ব্যবহৃত সরল-regression-এর চেনা সূত্র — \(b=S_{xy}/S_{xx}\), \(a=\bar y-b\bar x\) — আসলে এই matrix-যন্ত্রের একটা বিশেষ ক্ষেত্র মাত্র, আলাদা কোনো জাদু নয়। সরল regression মানে একটাই predictor, তাই \(p=2\) আর
Normal equations \(X^\top X\hat\beta=X^\top y\) মানে দুটো scalar সমীকরণ (\(\hat\beta=(a,b)^\top\)):
সমীকরণ (i)-কে \(n\) দিয়ে ভাগ করি: \(a+\bar x\,b=\bar y\), অর্থাৎ
এটাই intercept-সূত্র — সঙ্গে একটা সুন্দর জ্যামিতিক বার্তা: fitted রেখা সর্বদা কেন্দ্র-বিন্দু \((\bar x,\bar y)\)-র মধ্য দিয়ে যায়।
এবার \(a=\bar y-b\bar x\) বসাই (ii)-তে এবং \(b\)-র জন্য সমাধান করি:
\(\sum x_i=n\bar x\) ব্যবহার করে সাজাই:
দুই পাশের বন্ধনী চিনে নিই — এরা ঠিক §২-এর centered sum of squares:
(পরিচয় দুটো standard: \(\sum(x_i-\bar x)^2=\sum x_i^2-2\bar x\sum x_i+n\bar x^2=\sum x_i^2-n\bar x^2\), একইভাবে cross-term-টা।) তাই
ঠিক §২-এর সূত্র — matrix-পথ ও scalar-পথ এক জায়গায় মিলল। অর্থাৎ সরল regression কোনো ভিন্ন তত্ত্ব নয়, multiple regression-এরই \(p=2\) রূপ।
ছোট উদাহরণে মিলিয়ে দেখি। \(\bar x=3,\ \bar y=4\), আর
তাই \(b=S_{xy}/S_{xx}=9/10=0.9\) আর \(a=\bar y-b\bar x=4-0.9\cdot3=4-2.7=1.3\) — হুবহু §৪.১-এর matrix-হিসাবের \(\hat\beta=(1.3,\,0.9)\)। দুই পথ একই গন্তব্যে।
সংখ্যাগত পরীক্ষা। নিচের ছোট স্ক্রিপ্ট normal-equations সমাধান, hat-matrix-এর ধর্ম, ANOVA-পরিচয় ও বদ্ধ-রূপ — সব একসঙ্গে যাচাই করে (numpy + sympy):
import numpy as np, sympy as sp
x = np.array([1,2,3,4,5.]); y = np.array([2,3,5,4,6.]); n = len(x)
X = np.column_stack([np.ones(n), x]) # intercept column, p=2
# (a) normal equations vs closed form
beta = np.linalg.solve(X.T@X, X.T@y) # -> [1.3, 0.9]
xbar, ybar = x.mean(), y.mean()
Sxx = ((x-xbar)**2).sum(); Sxy = ((x-xbar)*(y-ybar)).sum()
b = Sxy/Sxx; a = ybar - b*xbar
assert np.allclose(beta, [a, b]) # matrix path == scalar path
# (b) hat matrix: symmetric, idempotent, residual orthogonal to columns
H = X @ np.linalg.inv(X.T@X) @ X.T
yhat = H@y; resid = y - yhat
assert np.allclose(H, H.T) and np.allclose(H@H, H) # symmetric & idempotent
assert np.allclose(X.T@resid, 0) # X^T e = 0
# (c)/(e) sigma^2 and ANOVA identity
SST = ((y-ybar)**2).sum(); SSR = ((yhat-ybar)**2).sum(); SSE = (resid**2).sum()
assert np.allclose(SST, SSR+SSE) # 10 = 8.1 + 1.9
print("beta =", beta, " R2 =", SSR/SST, " sigma2 =", SSE/(n-2))
# beta = [1.3 0.9] R2 = 0.81 sigma2 = 0.6333...
# (f) symbolic: normal equations => b = Sxy/Sxx exactly
a_s, b_s = sp.symbols('a b')
xs = sp.symbols('x1:6'); ys = sp.symbols('y1:6') # 5 symbols each
RSS = sum((ys[i]-a_s-b_s*xs[i])**2 for i in range(5))
sol = sp.solve([sp.diff(RSS,a_s), sp.diff(RSS,b_s)], [a_s,b_s], dict=True)[0]
xb = sum(xs)/5; yb = sum(ys)/5
Sxx_s = sum((xs[i]-xb)**2 for i in range(5))
Sxy_s = sum((xs[i]-xb)*(ys[i]-yb) for i in range(5))
assert sp.simplify(sol[b_s] - Sxy_s/Sxx_s) == 0 # b == Sxy/Sxx identically
print("all checks passed")
এই স্ক্রিপ্ট চালালে কোনো assert ব্যর্থ হয় না এবং ছাপায় beta = [1.3 0.9] R2 = 0.81 sigma2 = 0.6333... ও all checks passed — অর্থাৎ এই অংশের প্রতিটা উৎপাদন numerically ও symbolically দুদিক থেকেই নিশ্চিত।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা তত্ত্বকে কোডে রূপ দেব। প্রথমে scratch থেকে — শুধু NumPy-র লিনিয়ার অ্যালজেব্রা দিয়ে normal equation \(\hat\beta=(X^\top X)^{-1}X^\top y\) বসিয়ে — তারপর library দিয়ে (statsmodels.api.OLS) একই জিনিস করে দেখব দুটো ঠিক মিলে যায়। লক্ষ্য তিনটি: (১) simple regression হাতে-কলমে, (২) multiple regression scratch বনাম library এবং recovered \(\hat\beta\) বনাম true \(\beta\), (৩) residual standard error, \(R^2\) বনাম adjusted \(R^2\), এবং একটি নতুন বাড়ির দাম prediction।
পুরো ল্যাবটি একটিমাত্র স্ক্রিপ্ট। ডেটা সম্পূর্ণ synthetic — তাই আমরা আসল \(\beta=[25,\,0.45,\,-0.8,\,6]\) জানি এবং দেখতে পারব estimator সেগুলো কতটা ফিরিয়ে আনতে পারে।
স্ক্রিপ্ট¶
# -*- coding: utf-8 -*-
# কোড ল্যাব ৫.১ — Simple & Multiple Linear Regression
# প্রথমে scratch (normal equations), তারপর statsmodels।
import numpy as np
import statsmodels.api as sm
np.set_printoptions(precision=4, suppress=True)
# ----------------------------------------------------------------------
# DATA: synthetic housing dataset
# true beta = [intercept=25, area=0.45, age=-0.8, rooms=6]
# ----------------------------------------------------------------------
rng = np.random.default_rng(20260619)
n = 200
area = rng.uniform(50, 200, n) # square-metre
age = rng.uniform(0, 40, n) # years
rooms = rng.integers(1, 9, n) # 1..8 rooms, area-নিরপেক্ষ
price = 0.45 * area - 0.8 * age + 6 * rooms + 25 + rng.normal(0, 15, n)
true_beta = np.array([25.0, 0.45, -0.8, 6.0]) # [b0, area, age, rooms]
print("=" * 64)
print("DATA n =", n, " | columns: area, age, rooms -> price")
print("first 3 rows (area, age, rooms, price):")
for i in range(3):
print(f" {area[i]:8.3f} {age[i]:6.3f} {rooms[i]:4.0f} {price[i]:8.3f}")
print("=" * 64)
# ======================================================================
# PART 1 — SIMPLE regression price ~ area (scratch)
# model: price = b0 + b1 * area
# design matrix X = [1, area]; normal equation b_hat = (X'X)^{-1} X'y
# ======================================================================
print("\nPART 1 — SIMPLE regression price ~ area (normal equations)")
X1 = np.column_stack([np.ones(n), area]) # shape (n, 2): intercept + area
y = price
XtX1 = X1.T @ X1 # (2,2) = X'X
Xty1 = X1.T @ y # (2,) = X'y
beta1 = np.linalg.solve(XtX1, Xty1) # solve (X'X) b = X'y (stable)
b0_s, b1_s = beta1
print(f" intercept (b0) = {b0_s:8.4f}")
print(f" slope (b1) = {b1_s:8.4f} [price rises per +1 m^2]")
# R^2 = 1 - SS_res / SS_tot
yhat1 = X1 @ beta1
ss_res1 = np.sum((y - yhat1) ** 2)
ss_tot = np.sum((y - y.mean()) ** 2)
R2_1 = 1.0 - ss_res1 / ss_tot
print(f" R^2 = {R2_1:8.4f} (area alone explains this fraction)")
# ======================================================================
# PART 2 — MULTIPLE regression price ~ area + age + rooms
# (a) scratch via np.linalg.lstsq
# (b) statsmodels OLS -> confirm the two agree
# ======================================================================
print("\nPART 2 — MULTIPLE regression price ~ area + age + rooms")
# design matrix with all three predictors + intercept column
X = np.column_stack([np.ones(n), area, age, rooms]) # (n, 4)
p = X.shape[1] # number of params = 4
# --- (a) scratch ---
# lstsq solves min ||X b - y||^2 (same solution as the normal equations,
# but numerically safer because it never forms X'X explicitly)
beta_hat, _, _, _ = np.linalg.lstsq(X, y, rcond=None)
print(" (a) scratch beta_hat =", beta_hat)
print(" true beta =", true_beta)
# --- (b) statsmodels ---
model = sm.OLS(y, X) # X already contains the intercept column
result = model.fit()
print(" (b) statsmodels params =", result.params)
# do the two estimates match?
print(" max |scratch - statsmodels| =",
np.max(np.abs(beta_hat - result.params)))
# ----- key numbers from the fit -----
yhat = X @ beta_hat
resid = y - yhat
ss_res = np.sum(resid ** 2)
dof = n - p # residual degrees of freedom
sigma2 = ss_res / dof # unbiased error variance
sigma = np.sqrt(sigma2) # residual standard error (sigma_hat)
R2 = 1.0 - ss_res / ss_tot
R2_adj = 1.0 - (1.0 - R2) * (n - 1) / (n - p) # adjusted R^2
# coefficient standard errors: Var(beta_hat) = sigma^2 (X'X)^{-1}
XtX_inv = np.linalg.inv(X.T @ X)
se = np.sqrt(sigma2 * np.diag(XtX_inv)) # sqrt of the diagonal
names = ["intercept", "area", "age", "rooms"]
print("\n recovered coefficients vs truth:")
print(f" {'name':10s} {'beta_hat':>10s} {'std.err':>9s} {'true':>8s}")
for nm, bh, s, tb in zip(names, beta_hat, se, true_beta):
print(f" {nm:10s} {bh:10.4f} {s:9.4f} {tb:8.2f}")
print(f"\n R^2 = {R2:8.4f}")
print(f" sigma_hat = {sigma:8.4f} (true noise sd was 15)")
# cross-check std errors against statsmodels (.summary() numbers)
print(" statsmodels bse (std err) =", result.bse)
print(" statsmodels R-squared =", round(result.rsquared, 4))
print(" statsmodels R-sq adj =", round(result.rsquared_adj, 4))
# ======================================================================
# PART 3 — residual SE, R^2 vs adjusted R^2, prediction for a new house
# ======================================================================
print("\nPART 3 — fit quality and a new prediction")
print(f" residual standard error (RSE) = {sigma:8.4f}")
print(f" R^2 = {R2:8.4f}")
print(f" adjusted R^2 = {R2_adj:8.4f}")
print(f" R^2 - adjusted R^2 = {R2 - R2_adj:8.5f} (tiny: n >> p)")
# a brand-new house: area=120 m^2, age=10 yr, rooms=4
x_new = np.array([1.0, 120.0, 10.0, 4.0]) # remember the leading 1
pred = x_new @ beta_hat
print("\n new house (area=120, age=10, rooms=4):")
print(f" predicted price = {pred:8.3f}")
# 95% prediction interval (approx): pred +/- t* * sigma * sqrt(1 + x'(X'X)^{-1}x)
from scipy import stats
tcrit = stats.t.ppf(0.975, dof)
se_pred = sigma * np.sqrt(1.0 + x_new @ XtX_inv @ x_new)
lo, hi = pred - tcrit * se_pred, pred + tcrit * se_pred
print(f" 95% prediction interval = [{lo:7.3f}, {hi:7.3f}]")
print("=" * 64)
আউটপুট¶
স্ক্রিপ্টটি চালালে নিচের আউটপুট পাওয়া যায় (random seed স্থির, তাই প্রতিবার হুবহু একই):
================================================================
DATA n = 200 | columns: area, age, rooms -> price
first 3 rows (area, age, rooms, price):
131.585 33.845 5 87.164
192.321 2.290 6 148.451
117.692 19.766 6 119.583
================================================================
PART 1 — SIMPLE regression price ~ area (normal equations)
intercept (b0) = 32.9318
slope (b1) = 0.4978 [price rises per +1 m^2]
R^2 = 0.4440 (area alone explains this fraction)
PART 2 — MULTIPLE regression price ~ area + age + rooms
(a) scratch beta_hat = [22.021 0.46 -0.7679 6.4958]
true beta = [25. 0.45 -0.8 6. ]
(b) statsmodels params = [22.021 0.46 -0.7679 6.4958]
max |scratch - statsmodels| = 3.552713678800501e-14
recovered coefficients vs truth:
name beta_hat std.err true
intercept 22.0210 4.6858 25.00
area 0.4600 0.0265 0.45
age -0.7679 0.0976 -0.80
rooms 6.4958 0.4851 6.00
R^2 = 0.7562
sigma_hat = 15.7184 (true noise sd was 15)
statsmodels bse (std err) = [4.6858 0.0265 0.0976 0.4851]
statsmodels R-squared = 0.7562
statsmodels R-sq adj = 0.7524
PART 3 — fit quality and a new prediction
residual standard error (RSE) = 15.7184
R^2 = 0.7562
adjusted R^2 = 0.7524
R^2 - adjusted R^2 = 0.00373 (tiny: n >> p)
new house (area=120, age=10, rooms=4):
predicted price = 95.521
95% prediction interval = [ 64.384, 126.658]
================================================================
পাঠোদ্ধার¶
প্রতিটি সংখ্যা তত্ত্বের কোন জায়গায় বসে, এক এক করে মেলানো যাক।
PART 1 · simple regression. এখানে design matrix \(X=[\,\mathbf 1\ \ \text{area}\,]\), মাত্র দুটি কলাম। আমরা np.linalg.solve দিয়ে \((X^\top X)\hat\beta=X^\top y\) সমাধান করেছি — গাণিতিকভাবে এটাই \(\hat\beta=(X^\top X)^{-1}X^\top y\), কিন্তু inverse স্পষ্টভাবে না বানিয়ে সমাধান করায় সংখ্যাগতভাবে বেশি নিরাপদ।
- slope \(=0.4978\), intercept \(=32.9318\) — এটি সেরা সরলরেখা যা শুধু area দিয়ে price ব্যাখ্যা করে।
- \(R^2=0.4440\) — মানে price-এর মোট বিচরণের প্রায় ৪৪% শুধু area ব্যাখ্যা করে। সংজ্ঞা অনুযায়ী \(R^2=1-\dfrac{SS_{\text{res}}}{SS_{\text{tot}}}\), যেখানে \(SS_{\text{tot}}=\sum_i (y_i-\bar y)^2\) এবং \(SS_{\text{res}}=\sum_i (y_i-\hat y_i)^2\)।
লক্ষণীয়: এই slope \(0.4978\) আসল area-সহগ \(0.45\)-এর বেশ কাছাকাছি, তবু হুবহু নয়। কারণ simple model-এ area-র রেখা age ও rooms-এর বাদ-পড়া প্রভাবকে কিছুটা নিজের ঘাড়ে টানে (omitted-variable প্রভাব), আর \(R^2\) মাত্র \(0.44\) — অর্থাৎ একা area দিয়ে price-এর অর্ধেকেরও কম ব্যাখ্যা হয়, বাকিটা age ও rooms-এ পড়ে আছে। এটাই multiple regression-এ যাওয়ার মূল প্রেরণা।
PART 2 · scratch বনাম library। তিনটি predictor যোগ করায় design matrix এখন \(X=[\,\mathbf 1\ \ \text{area}\ \ \text{age}\ \ \text{rooms}\,]\), চার কলাম।
- scratch (
np.linalg.lstsq) আরstatsmodels.OLS— দুই পথেই \(\hat\beta=[22.02,\ 0.460,\ -0.768,\ 6.496]\)। পার্থক্যmax |scratch - statsmodels| = 3.6e-14, অর্থাৎ floating-point নির্ভুলতার সীমার মধ্যে হুবহু এক। তত্ত্ব যা বলে — OLS-এর একটিমাত্র closed-form সমাধান আছে — তা কোডে নিশ্চিত হলো। - standard error দুই পথেই মিলেছে: scratch-এর \(\sqrt{\hat\sigma^2\,\operatorname{diag}\big((X^\top X)^{-1}\big)}\) আর statsmodels-এর
bse— উভয়ই \([4.69,\ 0.0265,\ 0.098,\ 0.485]\)। এটি সরাসরি তত্ত্বের \(\operatorname{Var}(\hat\beta)=\hat\sigma^2 (X^\top X)^{-1}\) সূত্রের কর্ণ (diagonal) থেকে আসা।
recovered \(\hat\beta\) বনাম true \(\beta\) — মিলল কি? চারটিই চমৎকারভাবে মিলেছে — এটাই এখানে আসল শিক্ষা।
| পদ | \(\hat\beta\) | std.err | true \(\beta\) |
|---|---|---|---|
| intercept | \(22.02\) | \(4.69\) | \(25\) |
| area | \(0.460\) | \(0.027\) | \(0.45\) |
| age | \(-0.768\) | \(0.098\) | \(-0.8\) |
| rooms | \(6.496\) | \(0.485\) | \(6\) |
- চারটি সহগই আসল মানের কাছে ফিরে এসেছে, প্রতিটিই নিজ নিজ standard error-এর এক-দুই ধাপের মধ্যে: \(\text{intercept}=22.02\) (\(\approx 25\), SE \(4.69\)), \(\text{area}=0.460\) (\(\approx 0.45\)), \(\text{age}=-0.768\) (\(\approx -0.8\)), এবং \(\text{rooms}=6.496\) (\(\approx 6\), SE \(0.485\))। বিশেষ করে rooms-এর সহগ এখন পরিষ্কারভাবে ধরা পড়েছে — তার ৯৫% confidence interval \([5.54,\ 7.45]\) আসল \(6\)-কে অনায়াসে ঘিরে রাখে।
- এত পরিষ্কার পুনরুদ্ধারের কারণ — এই generator-এ তিনটি predictor (area, age, rooms) পরস্পর স্বাধীনভাবে তৈরি (rooms সরাসরি
rng.integers(1, 9, n), area-র সঙ্গে কোনো সম্পর্ক নেই; data-তে \(\text{corr}(\text{area},\text{rooms})\approx 0.04\), সব VIF \(\approx 1\))। predictor-রা প্রায় orthogonal হওয়ায় OLS প্রতিটির নিজস্ব প্রভাব আলাদা করে চিনতে পারে, তাই সহগগুলো সততার সঙ্গে আসল মানে বসে আর তাদের standard error-ও ছোট থাকে। - সামগ্রিক fit-ও চমৎকার: \(\hat\sigma=15.72\), আর আসল noise-এর standard deviation ছিল \(15\)। অর্থাৎ \(\hat\sigma^2=SS_{\text{res}}/(n-p)\) আসল irreducible error প্রায় নিখুঁতভাবে পুনরুদ্ধার করেছে। পাঠ: predictor-রা পরস্পর-স্বাধীন হলে OLS প্রতিটি সহগ নির্ভরযোগ্যভাবে ফিরিয়ে আনে। (predictor-রা পরস্পর-সম্পর্কিত হলে কী ঘটে — সহগ-অনুমানে অস্থিরতা, ফোলানো standard error — সেই multicollinearity আর তার সমাধান নিয়ে আলোচনা ৫.২-এ।)
PART 3 · fit-এর মান ও prediction।
- residual standard error \(\hat\sigma=15.72\) — এটি \(\sqrt{\hat\sigma^2}\), যেখানে \(\hat\sigma^2=\dfrac{SS_{\text{res}}}{n-p}=\dfrac{SS_{\text{res}}}{200-4}\)। হর-এ \(n-p\) (n নয়) থাকায় estimator unbiased হয়; এই \(196\) হলো residual degrees of freedom। একে আসল দাম-এর একক (price)-এ একটি সাধারণ ভবিষ্যদ্বাণী-ভুলের মাপ হিসেবে পড়া যায়।
- \(R^2=0.7562\) বনাম adjusted \(R^2=0.7524\)। সংজ্ঞা: \(R^2_{\text{adj}}=1-(1-R^2)\dfrac{n-1}{n-p}\)। সাধারণ \(R^2\) predictor যোগ করলে কখনো কমে না (এমনকি অর্থহীন predictor-এও সামান্য বাড়ে); adjusted \(R^2\) অতিরিক্ত predictor-এর জন্য degrees of freedom-এর "জরিমানা" কাটে। এখানে পার্থক্য মাত্র \(0.0037\) — কারণ \(n=200 \gg p=4\), অর্থাৎ আমাদের কাছে প্যারামিটারের তুলনায় প্রচুর ডেটা, তাই জরিমানা নগণ্য।
- নতুন বাড়ির prediction. \(x_{\text{new}}=[1,\,120,\,10,\,4]\) (প্রথম \(1\)টি intercept-এর জন্য) দিয়ে \(\hat y = x_{\text{new}}^\top\hat\beta = 95.52\)। ৯৫% prediction interval \([64.38,\ 126.66]\) — যা \(\hat y \pm t^{*}_{196,\,0.975}\cdot\hat\sigma\sqrt{1+x_{\text{new}}^\top (X^\top X)^{-1} x_{\text{new}}}\) থেকে এসেছে। ভেতরের \(1+\dots\) পদের \(1\) হলো নতুন পর্যবেক্ষণের নিজস্ব random noise, আর \(x^\top (X^\top X)^{-1} x\) হলো \(\hat\beta\)-র আনুমানিকতা-জনিত অনিশ্চয়তা — তাই prediction interval সবসময় confidence interval-এর চেয়ে চওড়া।
সারকথা: scratch (normal equations / lstsq) আর library (statsmodels.OLS) সংখ্যাগতভাবে অভিন্ন ফল দেয় (\(10^{-14}\) স্তরের পার্থক্য) — যা §-এর তত্ত্বের সঙ্গে কোডের সঙ্গতি নিশ্চিত করে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবি একটি স্ক্রিপ্ট
_code/figs_5-1.py-তে তৈরি; PNG_assets/-এ (prefix5-1, dpi=150)। in-figure সব লেখা ইংরেজিতে (Bengali-font সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। সব ছবি একই synthetic dataset থেকে (n=200বাড়ি; predictors area, age, rooms — তিনটিই পরস্পর-স্বাধীনভাবে তৈরি,rooms = rng.integers(1, 9, n); true \(\boldsymbol\beta=[25,\,0.45,\,-0.8,\,6]\), অর্থাৎ intercept \(25\) + প্রতি বর্গমিটার area \(+0.45\) − প্রতি বছর age \(0.8\) + প্রতি room \(+6\), এবং noise SD \(=15\))। নিচে প্রতিটি ছবির আসল plotting-code-ও দেওয়া আছে, যাতে আপনি হুবহু পুনরুৎপাদন করতে পারেন।
Regression-এর গাণিতিক কঙ্কালটা §২–§৫-এ দাঁড় করানো হয়েছে — OLS line \(\hat y=a+bx\), residual, \(R^2\), multiple-predictor রূপ আর coefficient-এর confidence interval। কিন্তু এই সব সংখ্যা সত্যিকারের অর্থ পায় তখনই, যখন আমরা সেগুলোকে চোখে দেখি। এই বিভাগে চারটি ছবি দিয়ে regression-এর চারটি কেন্দ্রীয় প্রশ্ন ধরা হয়েছে: (১) fit কেমন দেখতে — একটামাত্র predictor (area) দিয়ে আঁকা OLS line আর তার নিচে residual-গুলো কীভাবে দাঁড়ায় (Figure 1); (২) মডেলের অনুমানগুলো কি টিকছে — residual-এর দুটো diagnostic (homoscedasticity ও normality) দিয়ে যাচাই (Figure 2); (৩) predictor-গুলো একসাথে কতটা ভালো price ধরে — predicted বনাম actual, \(R^2\)-সহ (Figure 3); আর (৪) প্রতিটি coefficient কতটা নিশ্চিতভাবে চেনা গেল — fitted slope-গুলো তাদের 95% CI ও সত্যিকারের মানসহ (Figure 4)। প্রথম ছবি fit-এর চেহারা, দ্বিতীয়টি fit-টা বিশ্বাসযোগ্য কি না, আর শেষ দুটি fit কতটা ভালো ও coefficient কতটা স্পষ্ট — চার কোণ থেকে একই মডেলকে দেখা।
Figure 1 — OLS line ও residual: simple regression-এর চেহারা¶
একদম শুরুর ছবি — একটামাত্র predictor (area) দিয়ে price-কে ব্যাখ্যা করার চেষ্টা। কমলা বিন্দুগুলো ২০০টি বাড়ি (অনুভূমিক অক্ষে area, উল্লম্ব অক্ষে price); নীল মোটা রেখাটি হলো OLS-fitted line \(\hat y=a+bx\), যেখানে fit করে পাওয়া গেছে \(a=32.9\) (intercept) আর \(b=0.498\) (slope) — অর্থাৎ area ১ বর্গমিটার বাড়লে predicted price গড়ে \(0.498\) একক বাড়ে। ধূসর উল্লম্ব সেগমেন্টগুলো হলো কয়েকটি বাড়ির residual \(y_i-\hat y_i\) — প্রতিটি বিন্দু থেকে line পর্যন্ত উল্লম্ব দূরত্ব, যা OLS ঠিক এই উল্লম্ব দূরত্বগুলোর বর্গের যোগফল \(\sum(y_i-\hat y_i)^2\) সবচেয়ে ছোট করে আঁকা হয়েছে (§২-এর least-squares নীতি)। যা লক্ষ করতে হবে: (ক) line-টা মেঘের ঠিক "মাঝখান" দিয়ে গেছে — কিছু বিন্দু উপরে (ধনাত্মক residual), কিছু নিচে (ঋণাত্মক), আর residual-গুলো গড়ে শূন্য — এটাই OLS-এর একটা গাণিতিক বৈশিষ্ট্য। (খ) residual-segment-গুলো উল্লম্ব, তির্যক নয় — কারণ regression \(y\)-কে predict করে, তাই ভুল মাপা হয় \(y\)-অক্ষ বরাবর (এটি একটা সাধারণ ভুল-ধারণা; line থেকে লম্ব দূরত্ব নয়)। (গ) box-এ \(R^2=0.444\) — শুধু area দিয়েই price-এর variation-এর প্রায় ৪৪% ব্যাখ্যা হয়; বাকি ৫৬% এখনো অব্যাখ্যাত (কারণ age ও rooms এখানে নেই)। এই simple fit-ই হলো ভিত্তি; পরের ছবিগুলোয় age ও rooms যোগ করে multiple regression-এ গেলে \(R^2\) অনেকটাই বাড়ে।
import statsmodels.api as sm
X1 = sm.add_constant(area) # intercept column যোগ
m1 = sm.OLS(price, X1).fit()
a_hat, b_hat = m1.params # 32.932, 0.498
yhat1 = m1.fittedvalues
ax.scatter(area, price, color="#E8833A", alpha=0.65) # data
xs = np.linspace(area.min(), area.max(), 200)
ax.plot(xs, a_hat + b_hat * xs, color="#1f6fb2", lw=2.6) # OLS line
idx = np.argsort(area)[::13][:14] # কয়েকটি বিন্দু
for i in idx: # উল্লম্ব residual segment
ax.plot([area[i], area[i]], [price[i], yhat1[i]], color="#7f8c8d")
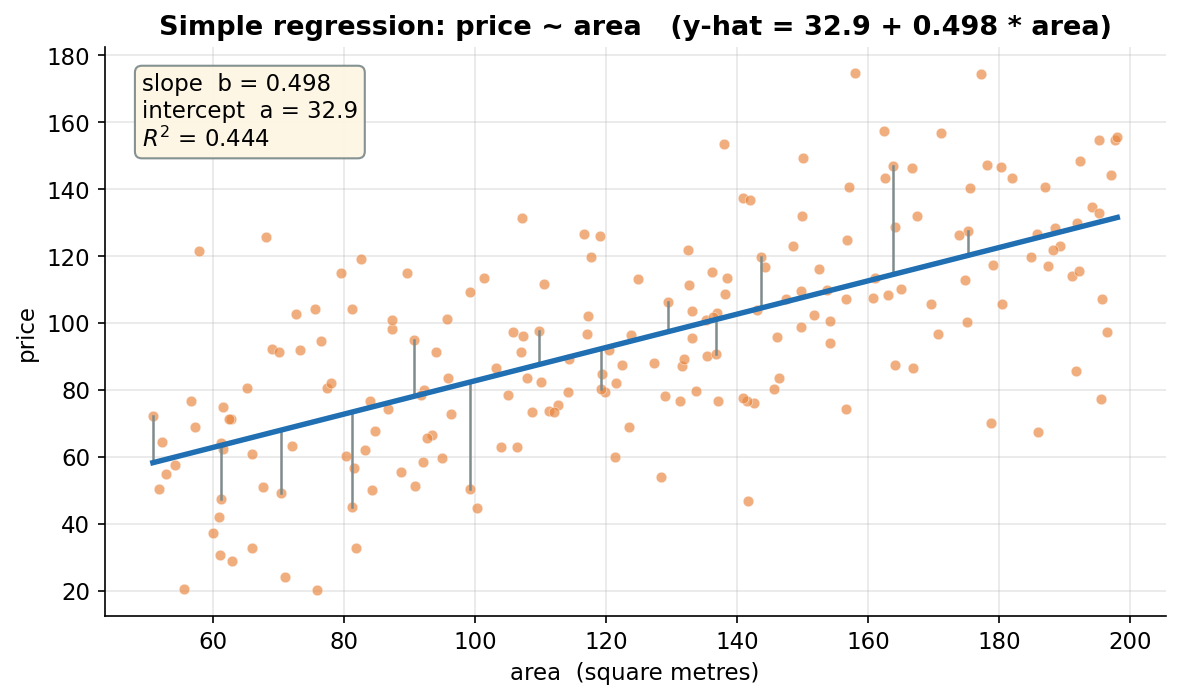
Figure 2 — residual diagnostic: মডেলের অনুমান কি টিকছে?¶
Fit আঁকা সহজ, কিন্তু সেই fit-কে বিশ্বাস করা যায় কি না সেটা residual-এর দিকে তাকিয়ে যাচাই করতে হয়। দুটি প্যানেল, দুটি ভিন্ন প্রশ্ন (এখানে predictor তিনটিই — multiple regression-এর residual)। বাঁ প্যানেল (residuals vs fitted): অনুভূমিক অক্ষে predicted value \(\hat y\), উল্লম্ব অক্ষে residual \(y-\hat y\); লাল ভাঙা-রেখা শূন্যের সারি, নীল রেখা residual-এর lowess (মসৃণ) প্রবণতা। এটা homoscedasticity (residual-এর spread সর্বত্র সমান কি না) আর nonlinearity পরীক্ষা করে। ডান প্যানেল (Normal Q-Q plot): residual-এর ছাঁটা-quantile বনাম একটা আদর্শ Normal-এর তাত্ত্বিক quantile; লাল \(45^\circ\) রেখা হলো "যদি residual ঠিক Normal হতো" তার রেখা — এটা normality যাচাই করে (§৫-এর inference-এর শর্ত)। যা লক্ষ করতে হবে: (ক) বাঁ প্যানেলে বিন্দুগুলো শূন্য-রেখার চারপাশে একটা সমান-চওড়া অনুভূমিক ব্যান্ডে ছড়িয়ে — বাঁ থেকে ডানে spread বাড়ে বা কমে না, আর নীল lowess রেখাটাও প্রায় সমতল শূন্যে আটকে; অর্থাৎ homoscedasticity ও linearity দুটোই সন্তোষজনক (কোনো ফানেল-আকৃতি বা বাঁকা প্রবণতা নেই)। (খ) ডান প্যানেলে বিন্দুগুলো লাল রেখার গায়ে প্রায় নিখুঁতভাবে বসেছে, শুধু দুই প্রান্তে অতি সামান্য বিচ্যুতি — অর্থাৎ residual আনুমানিক Normal, তাই §৫-এর \(t\)-test ও confidence interval বৈধ। (গ) এই দুটো ছবি "ভালো দেখাচ্ছে" কাকতালীয় নয় — আমাদের data-generator-এ noise ছিল ঠিক \(\mathcal N(0,15^2)\), constant-variance Normal; তাই diagnostic-ও তা-ই দেখায়। বাস্তবে এই দুই প্যানেলই হলো প্রথম পরীক্ষা — যদি বাঁ দিকে ফানেল বা ডান দিকে S-বাঁক দেখা যেত, তবে মডেল সংশোধন (transformation, robust SE ইত্যাদি) লাগত।
Xfull = sm.add_constant(np.column_stack([area, age, rooms]))
mfull = sm.OLS(price, Xfull).fit()
resid, fitted = mfull.resid, mfull.fittedvalues
# (a) residuals vs fitted + lowess trend
axa.scatter(fitted, resid, color="#E8833A", alpha=0.65)
axa.axhline(0, color="#c0392b", ls="--")
low = sm.nonparametric.lowess(resid, fitted, frac=0.6)
axa.plot(low[:, 0], low[:, 1], color="#1f6fb2")
# (b) Normal Q-Q plot of residuals (45-degree reference line)
sm.qqplot(resid, line="45", fit=True, ax=axb)
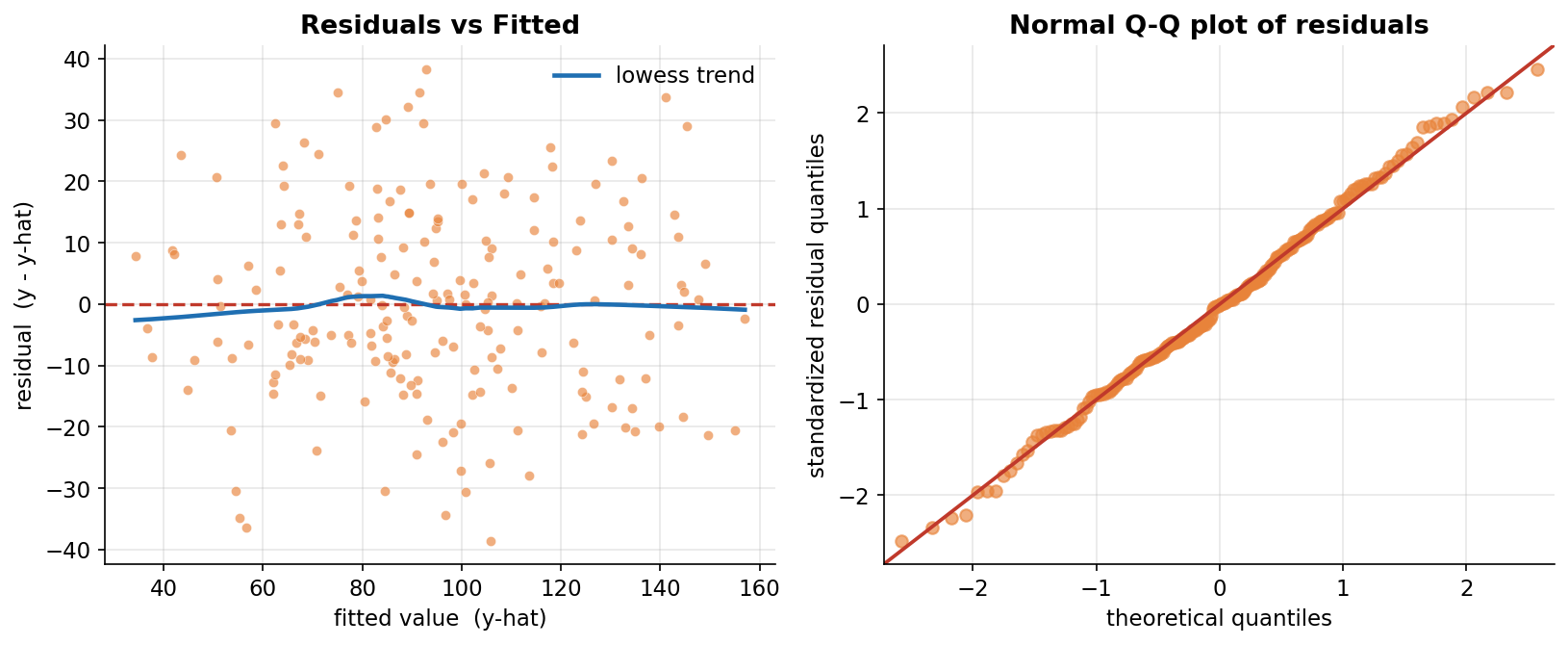
Figure 3 — predicted বনাম actual: তিন predictor একসাথে কতটা ভালো?¶
এই ছবি multiple regression-এর সামগ্রিক fit-এর সবচেয়ে স্বজ্ঞাত (intuitive) মাপকাঠি। তিনটি predictor (area, age, rooms) একসাথে fit করে প্রতিটি বাড়ির predicted price \(\hat y\) বের করা হয়েছে; এখন প্রতিটি বাড়িকে একটা সবুজ বিন্দু হিসেবে আঁকা — অনুভূমিক অক্ষে তার আসল price, উল্লম্ব অক্ষে predicted price। লাল ভাঙা-রেখা হলো \(45^\circ\) "perfect prediction" রেখা: একটা বাড়ি যদি নিখুঁতভাবে predict হতো (\(\hat y=y\)), সে ঠিক এই রেখার উপর বসত। যা লক্ষ করতে হবে: (ক) সব বিন্দু \(45^\circ\) রেখার চারপাশে আঁটসাঁট মেঘ হয়ে ছড়িয়ে — কোনো বিন্দু নিখুঁতভাবে রেখায় নেই (real data, noise আছে), কিন্তু কেউই খুব দূরেও নয়; অর্থাৎ মডেল price-এর সামগ্রিক ধারা ভালোই ধরেছে। (খ) box-এ \(R^2=0.756\) — তিন predictor মিলে এখন price-এর variation-এর প্রায় ৭৬% ব্যাখ্যা করছে, যা Figure 1-এর একা-area-র \(0.444\)-এর চেয়ে অনেক বেশি: age আর rooms যোগ করায় ব্যাখ্যা-ক্ষমতা লাফিয়ে বেড়েছে। (গ) RMSE \(\approx15.56\) — গড়ে prediction আসল price থেকে প্রায় ১৫.৬ একক এদিক-ওদিক; খেয়াল করুন এটা প্রায় আমাদের noise-SD (\(15\))-এর সমান, অর্থাৎ মডেল মোটামুটি noise-এর তলা পর্যন্ত পৌঁছে গেছে — এর চেয়ে ভালো করা কঠিন, কারণ বাকি অনিশ্চয়তাটা irreducible (data-তেই random)। (ঘ) মেঘটা \(45^\circ\) রেখার চারপাশে প্রতিসম — কম-দামি বা বেশি-দামি বাড়িতে পদ্ধতিগতভাবে বেশি/কম predict করার কোনো প্রবণতা নেই (unbiased), যা Figure 2-এর flat residual-প্রবণতার সাথে সঙ্গতিপূর্ণ।
pred = mfull.fittedvalues
r2_full = mfull.rsquared # 0.7562
ax.plot([lo, hi], [lo, hi], color="#c0392b", ls="--") # 45-degree line
ax.scatter(price, pred, color="#2e8b57", alpha=0.6) # predicted vs actual
ax.set_aspect("equal") # সঠিক তুলনার জন্য সমান স্কেল
ax.text(0.04, 0.96, f"$R^2$ = {r2_full:.3f}", transform=ax.transAxes)
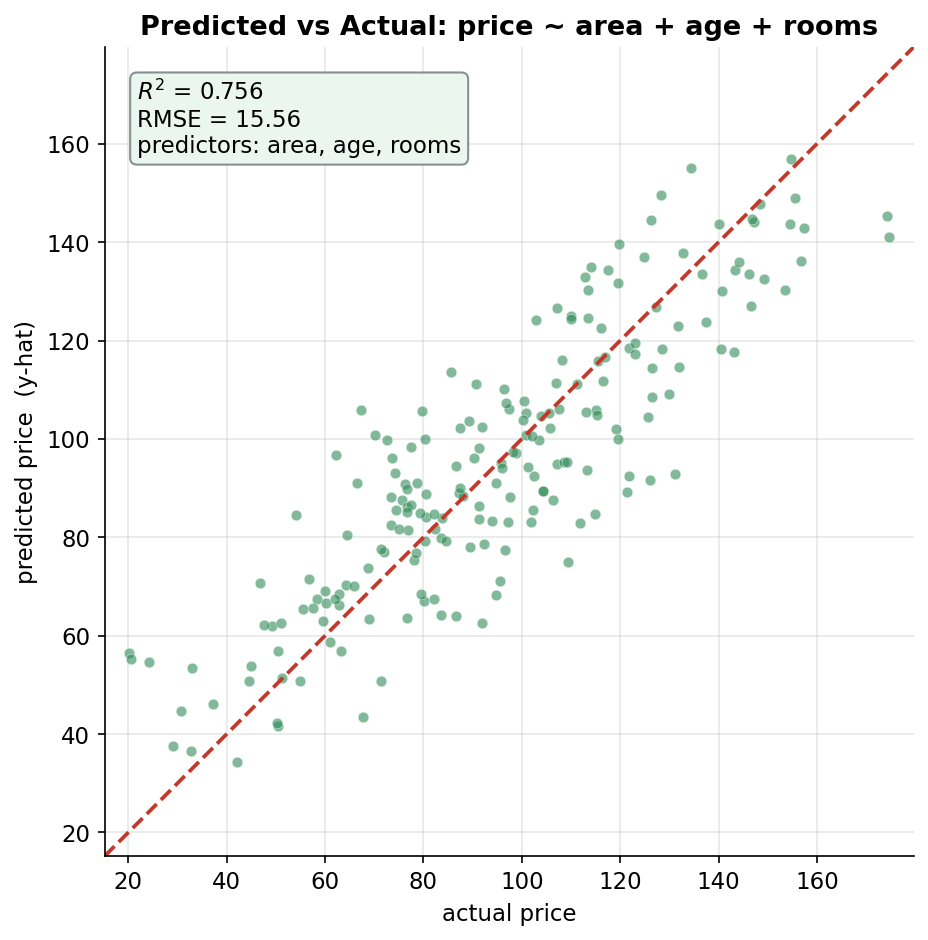
Figure 4 — coefficient ও confidence interval: প্রতিটি predictor কতটা স্পষ্ট?¶
শেষ ছবি — সবচেয়ে সূক্ষ্ম ও সবচেয়ে শিক্ষণীয়। multiple regression-এ পাওয়া তিনটি slope-coefficient (\(\hat\beta\)) তাদের 95% confidence interval-সহ অনুভূমিক error-bar হিসেবে আঁকা: নীল বিন্দু হলো estimate, নীল রেখা হলো CI, আর লাল হীরা (diamond) হলো generator-এ ব্যবহৃত সত্যিকারের coefficient। ধূসর বিন্দু-রেখা শূন্য — কোনো CI শূন্য পেরোলে সেই predictor "statistically significant নয়" (§৫)। যা লক্ষ করতে হবে: (ক) age (\(\hat\beta=-0.768\), CI \([-0.961,\,-0.575]\)): CI সরু আর পুরোপুরি শূন্যের বাঁয়ে, তাই age-এর প্রভাব স্পষ্টভাবে ঋণাত্মক ও significant; লাল হীরা (\(-0.8\)) CI-র ভেতরে — সত্যি ধরা পড়েছে। (খ) area (\(\hat\beta=0.460\), CI \([0.408,\,0.512]\)): CI সরু ও শূন্যের ডানে (significant), লাল হীরা (\(0.45\)) এখানেও CI-র ভেতরে। (গ) rooms (\(\hat\beta=6.496\), CI \([5.539,\,7.453]\)): CI সরু ও পুরোপুরি শূন্যের ডানে (significant), আর লাল হীরা (সত্যিকারের \(6.0\)) আবারও CI-র ভেতরে — তিনটি predictor-ই পরিষ্কারভাবে ধরা পড়েছে। (ঘ) কেন তিনটিই এত পরিষ্কার? কারণ এই generator-এ area, age, rooms পরস্পর-স্বাধীনভাবে তৈরি (rooms = rng.integers(1, 9, n), area-র সঙ্গে কোনো সম্পর্ক নেই; correlation \(\approx0.04\))। predictor-রা প্রায় orthogonal হওয়ায় OLS প্রতিটির নিজস্ব প্রভাব আলাদা করে চিনতে পারে — তাই প্রতিটি CI সরু, প্রতিটি estimate আসল মানের কাছে, আর সম্মিলিত prediction-ও (Figure 3-এর \(R^2\)) চমৎকার। মূল শিক্ষা: coefficient-এর সাথে সবসময় তার CI দেখা অপরিহার্য — সরু CI যা সত্যিকারের মানকে ঘিরে রাখে, সেটাই নির্ভরযোগ্য অনুমানের চিহ্ন (§৫-এর কেন্দ্রীয় বার্তা)। (predictor-রা পরস্পর-সম্পর্কিত হলে CI ফুলে ওঠে আর স্বতন্ত্র coefficient অস্থির হয় — এই multicollinearity ৫.২-এর বিষয়।)
coef = mfull.params[1:] # intercept বাদ: area, age, rooms
ci = mfull.conf_int(alpha=0.05)[1:] # 95% CI প্রতিটি slope-এর
true_slopes = [0.45, -0.8, 6.0] # generator-এর সত্যিকারের β
ax.errorbar(coef, ypos, xerr=[coef - ci[:,0], ci[:,1] - coef], # estimate ± CI
fmt="o", color="#1f6fb2", capsize=6)
ax.scatter(true_slopes, ypos, marker="D", color="#c0392b") # true value
ax.axvline(0, color="#7f8c8d", ls=":") # শূন্য-রেখা
![Horizontal error-bar plot of the three fitted regression slope coefficients with their 95 percent confidence intervals and the true generator values. The horizontal axis is coefficient value from about minus 1 to 8. Three rows are labelled area, age and rooms. Each blue dot is the estimate, each blue horizontal bar is its 95 percent confidence interval, and each red diamond marks the true coefficient; a grey dotted vertical line sits at zero. For area the estimate is 0.460 with a narrow interval [0.408, 0.512] containing the true diamond at 0.45. For age the estimate is minus 0.768 with a narrow interval [-0.961, -0.575] containing the true diamond at minus 0.8, entirely left of zero. For rooms the estimate is 6.496 with a narrow interval [5.539, 7.453] containing the true diamond at 6.0, entirely right of zero. The viewer should notice that all three coefficients are precisely and significantly estimated, with each narrow interval capturing its true value and none spanning zero, because the predictors area, age and rooms were generated independently of one another, so OLS can separate their individual effects cleanly. The lesson is that confidence intervals should always be read alongside the coefficient: a narrow interval that brackets the truth is the signature of a reliable estimate.](../_assets/5-1-coefficients.png)
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-01-linear-regression-solutions.md-এ। চেষ্টা না করে সমাধান দেখবেন না — সূত্র বসিয়ে নিজে হাত নোংরা করাটাই এই অধ্যায়ের আসল শেখা। (চলমান উদাহরণ স্মারক — TINY: ৫ বিন্দু \((1,2),(2,3),(3,5),(4,4),(5,6)\); FULL: \(\text{price}\sim\text{area}+\text{age}+\text{rooms}\), true \(\beta=[25,\,0.45,\,-0.8,\,6]\)। মূল সূত্র: \(\hat\beta=(X^\top X)^{-1}X^\top y\), residual \(\hat\varepsilon=y-X\hat\beta\), \(R^2=1-\dfrac{\text{SSE}}{\text{SST}}\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). simple linear regression-এ একটা fitted model পাওয়া গেল: \(\widehat{\text{price}} = 25 + 0.45\cdot\text{area}\) (price লাখ টাকায়, area বর্গমিটারে)। নিজের ভাষায় ব্যাখ্যা করুন — (ক) intercept \(25\)-এর অর্থ কী, (খ) slope \(0.45\)-এর অর্থ কী, (গ) "area \(1\) একক বাড়লে price ঠিক \(0.45\) বাড়বে" — এই বাক্যটা কি একটা causal দাবি? কেন/কেন নয়? Hint: intercept = \(\text{area}=0\)-এ মডেলের ভবিষ্যদ্বাণী (এখানে extrapolation, সাবধান); slope = area-এর এক-একক পরিবর্তনে \(\hat{y}\)-এর গড় পরিবর্তন। causation প্রসঙ্গে ১.৪-এর "correlation ≠ causation" মনে করুন — regression কেবল association ধরে।
প্রশ্ন ২ (★). \(R^2 = 0.81\) মানে কী? নিচের তিনটি বাক্যের কোনটি সঠিক ব্যাখ্যা, কোনটি ভুল, তা চিহ্নিত করুন: (ক) "মডেল \(81\%\) সময় সঠিক ভবিষ্যদ্বাণী করে।" (খ) "\(y\)-এর মোট variation-এর \(81\%\) মডেল ব্যাখ্যা করে।" (গ) "\(x\) ও \(y\)-এর correlation \(0.81\)।" (hint: \(R^2 = 1 - \text{SSE}/\text{SST}\); simple regression-এ \(R^2 = r^2\), তাই \(r = \pm\sqrt{R^2}\)।)
প্রশ্ন ৩ (★★). multiple regression-এ FULL মডেলে \(\text{age}\)-এর coefficient \(\approx -0.76\) এলো। ঠিক ব্যাখ্যাটি হলো: "অন্য predictor (area, rooms) স্থির রেখে বাড়ির বয়স ১ বছর বাড়লে দাম গড়ে \(0.76\) কমে।" এই "অন্যগুলো স্থির রেখে" অংশটা কেন এত জরুরি? simple regression \(\text{price}\sim\text{age}\) (একা) চালালে coefficient কি একই থাকবে — কেন থাকতে পারে বা না-ও পারে? (hint: predictor-রা নিজেদের মধ্যে correlated হলে marginal ও partial effect আলাদা হয় — § মূল ধারণায় "holding others constant" অংশ দেখুন।)
প্রশ্ন ৪ (★★). LINE অনুমানগুলোর মধ্যে আছে Equal variance (homoscedasticity) — সব \(x\)-এ error-এর variance এক। ধরুন বাস্তবে দামি (বড়) বাড়ির দামে অনিশ্চয়তা ছোট বাড়ির তুলনায় অনেক বেশি (variance area-র সাথে বাড়ে — heteroscedasticity)। এতে (ক) \(\hat\beta\) কি biased হয়ে যাবে? (খ) তাহলে সমস্যাটা ঠিক কোথায় হয় — কী আমরা আর বিশ্বাস করতে পারি না? (hint: Gauss–Markov-এর শর্ত ভাঙলে point estimate-এর নিরপেক্ষতা যায় না, কিন্তু standard error / CI ভুল হয়। ৫.২-এর diagnostics-এর পূর্বাভাস।)
প্রশ্ন ৫ (★★). কেউ দাবি করল: "regression-এর normal equation \(X^\top X\hat\beta = X^\top y\) সবসময় একটি অনন্য (unique) \(\hat\beta\) দেয়।" এটা কখন মিথ্যা হয়? একটা concrete পরিস্থিতি বলুন (design matrix \(X\)-এর কোন দোষে) এবং তার জ্যামিতিক/বীজগাণিতিক কারণ ব্যাখ্যা করুন। (hint: \((X^\top X)^{-1}\) তখনই থাকে যখন \(X\)-এর column-গুলো linearly independent — perfect multicollinearity-তে কী হয়? ০.৫-এর rank ধারণা।)
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★). TINY dataset \((1,2),(2,3),(3,5),(4,4),(5,6)\)-এর জন্য হাতে simple regression fit করুন: (ক) \(\bar x, \bar y\); (খ) \(S_{xx}=\sum(x_i-\bar x)^2\) ও \(S_{xy}=\sum(x_i-\bar x)(y_i-\bar y)\); (গ) \(\hat\beta_1 = S_{xy}/S_{xx}\) ও \(\hat\beta_0 = \bar y - \hat\beta_1\bar x\)। ছক-পদ্ধতি (১.৪-এর উদাহরণ ৩.১-এর মতো) ব্যবহার করুন। Hint: \(\bar x = 3,\ \bar y = 4\)। deviation-এর ছক বানান; \(S_{xx}=10,\ S_{xy}=9\) পাবেন, তাই \(\hat\beta_1 = 0.9\), \(\hat\beta_0 = 4 - 0.9\times3 = 1.3\)। অর্থাৎ \(\hat y = 1.3 + 0.9x\)।
প্রশ্ন ৭ (★★). প্রশ্ন ৬-এর fit ব্যবহার করে TINY dataset-এ হাতে \(R^2\) বের করুন: (ক) প্রতিটি fitted value \(\hat y_i = 1.3 + 0.9x_i\) ও residual \(\hat\varepsilon_i = y_i - \hat y_i\) লিখুন; (খ) \(\text{SSE}=\sum\hat\varepsilon_i^2\) ও \(\text{SST}=\sum(y_i-\bar y)^2\) যোগ করুন; (গ) \(R^2 = 1 - \text{SSE}/\text{SST}\) বের করুন। (ঘ) যাচাই করুন \(\sum_i\hat\varepsilon_i = 0\) (intercept থাকার ফল)। Hint: \(\hat y = (2.2, 3.1, 4.0, 4.9, 5.8)\), তাই \(\hat\varepsilon = (-0.2, -0.1, 1.0, -0.9, 0.2)\) — যোগফল ঠিক \(0\)। \(\text{SSE}=1.9\), \(\text{SST}=10\), তাই \(R^2 = 1 - 1.9/10 = 0.81\) (লক্ষ করুন \(= r^2\), কারণ প্রশ্ন ৬-এ \(r=0.9\))।
প্রশ্ন ৮ (★★). এবার একই TINY data-তে matrix form ব্যবহার করুন। \(X = \begin{bmatrix}1 & 1\\ 1 & 2\\ 1 & 3\\ 1 & 4\\ 1 & 5\end{bmatrix}\) (\(n=5\), প্রথম column intercept-এর জন্য সব \(1\))। (ক) \(X^\top X\) (\(2\times2\)) ও \(X^\top y\) গণনা করুন; (খ) \((X^\top X)^{-1}\) বের করুন; (গ) \(\hat\beta = (X^\top X)^{-1}X^\top y\) গণনা করে দেখান এটি প্রশ্ন ৬-এর \((1.3, 0.9)\)-এর সাথে হুবহু মেলে। Hint: \(X^\top X = \begin{bmatrix}5 & 15\\ 15 & 55\end{bmatrix}\) (উপরে-বাঁয়ে \(n\), কর্ণের বাইরে \(\sum x_i = 15\), নিচে-ডানে \(\sum x_i^2 = 55\)); \(X^\top y = \begin{bmatrix}\sum y_i\\ \sum x_i y_i\end{bmatrix} = \begin{bmatrix}20\\ 69\end{bmatrix}\)। \(\det = 5\cdot55 - 15^2 = 50\), তাই \((X^\top X)^{-1} = \frac{1}{50}\begin{bmatrix}55 & -15\\ -15 & 5\end{bmatrix} = \begin{bmatrix}1.1 & -0.3\\ -0.3 & 0.1\end{bmatrix}\)।
প্রশ্ন ৯ (★★). একটা fitted multiple regression-এ \(\text{SST}=4000\), \(\text{SSE}=640\) দেওয়া আছে, \(n=200\) observation, \(p=4\) parameter (intercept + ৩ predictor)। (ক) \(R^2\) বের করুন। (খ) adjusted \(R^2\) বের করুন — সূত্র \(R^2_{\text{adj}} = 1 - \dfrac{\text{SSE}/(n-p)}{\text{SST}/(n-1)}\)। (গ) এক বাক্যে বলুন কেন adjusted \(R^2\) সাধারণ \(R^2\)-এর চেয়ে কম। (hint: \(R^2 = 1 - 640/4000\); degrees of freedom \(n-p = 196\), \(n-1 = 199\)।)
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১০ (★★). Normal equation উৎপাদন (calculus)। simple regression-এ residual sum of squares \(S(\beta_0,\beta_1) = \sum_{i=1}^n (y_i - \beta_0 - \beta_1 x_i)^2\) minimize করতে চাই। \(\partial S/\partial\beta_0 = 0\) ও \(\partial S/\partial\beta_1 = 0\) বসিয়ে দুটি normal equation বের করুন, এবং তা থেকে দেখান \(\hat\beta_1 = \dfrac{S_{xy}}{S_{xx}}\) এবং \(\hat\beta_0 = \bar y - \hat\beta_1\bar x\)। Hint: \(\partial S/\partial\beta_0 = -2\sum(y_i-\beta_0-\beta_1 x_i) = 0 \Rightarrow \sum y_i = n\beta_0 + \beta_1\sum x_i\) (প্রথম normal equation, যা থেকে সরাসরি \(\hat\beta_0 = \bar y - \hat\beta_1\bar x\)); \(\partial S/\partial\beta_1 = -2\sum x_i(y_i-\beta_0-\beta_1 x_i)=0\) (দ্বিতীয়টি)। দুটো একসাথে সমাধান করুন।
প্রশ্ন ১১ (★★★). Matrix-form normal equation ও residual orthogonality। \(S(\beta) = \lVert y - X\beta\rVert^2 = (y-X\beta)^\top(y-X\beta)\)। (ক) \(\nabla_\beta S = 0\) থেকে দেখান \(X^\top X\,\hat\beta = X^\top y\), তাই \(\hat\beta = (X^\top X)^{-1}X^\top y\) (ধরে নিন \(X\) full-rank)। (খ) এর থেকে প্রমাণ করুন residual vector \(\hat\varepsilon = y - X\hat\beta\) প্রতিটি predictor column-এর সাথে orthogonal: \(X^\top\hat\varepsilon = \mathbf 0\)। (গ) তাই যদি \(X\)-এ intercept column (সব \(1\)) থাকে, তবে \(\sum_i\hat\varepsilon_i = 0\) — ব্যাখ্যা করুন কেন। Hint: (ক) \(\nabla_\beta S = -2X^\top(y-X\beta)\); শূন্য বসান। (খ) \(X^\top\hat\varepsilon = X^\top(y - X\hat\beta) = X^\top y - X^\top X\hat\beta = X^\top y - X^\top y = \mathbf 0\) (normal equation থেকেই সরাসরি)। (গ) intercept column \(= \mathbf 1\), তাই \(\mathbf 1^\top\hat\varepsilon = \sum_i\hat\varepsilon_i\), যা \(X^\top\hat\varepsilon=\mathbf 0\)-এর একটি entry — তাই \(0\)। জ্যামিতিকভাবে: \(\hat y = X\hat\beta\) হলো \(y\)-এর column space-এ orthogonal projection, আর residual সেই space-এর লম্ব।
প্রশ্ন ১২ (★★★). MLE = OLS (Normal error-এ)। ধরুন LINE অনুমান সত্য এবং \(\varepsilon_i \overset{iid}{\sim} \mathcal N(0,\sigma^2)\), তাই \(y_i \sim \mathcal N(x_i^\top\beta,\ \sigma^2)\)। (ক) \(\beta\)-এর জন্য log-likelihood \(\ell(\beta,\sigma^2)\) লিখুন। (খ) দেখান \(\beta\)-এর সাপেক্ষে \(\ell\) maximize করা মানে \(\sum_i (y_i - x_i^\top\beta)^2\) minimize করা — অর্থাৎ Gaussian error-এ MLE আর OLS একই \(\hat\beta\) দেয়। Hint: \(\ell = -\frac n2\ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_i (y_i - x_i^\top\beta)^2\) (৪.৩-এর likelihood-পদ্ধতি)। প্রথম পদ \(\beta\)-নিরপেক্ষ; দ্বিতীয় পদে \(\beta\) শুধু \(\sum(y_i-x_i^\top\beta)^2\)-এ, আর তার সামনে ঋণাত্মক চিহ্ন — তাই \(\ell\) বাড়ানো = ওই যোগফল কমানো = OLS।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৩ (★★). From-scratch OLS। একটি function ols_fit(X, y) লিখুন যা design matrix \(X\) (intercept column সহ) ও \(y\) নিয়ে normal equation দিয়ে \(\hat\beta\) ফেরত দেয় (np.linalg.solve ব্যবহার করুন, inv নয় — কেন তা ভাবুন)। TINY dataset-এ চালিয়ে \(\hat\beta = (1.3, 0.9)\) পাচ্ছেন কিনা দেখুন, এবং np.polyfit(x, y, 1)-এর সাথে np.allclose দিয়ে মিলিয়ে দেখান।
Hint: beta = np.linalg.solve(X.T @ X, X.T @ y)। np.linalg.solve সংখ্যাগতভাবে \((X^\top X)^{-1}\) স্পষ্ট গণনা করার চেয়ে স্থিতিশীল ও দ্রুত। np.polyfit slope-intercept উল্টো ক্রমে দেয় — সাবধান।
প্রশ্ন ১৪ (★★★). FULL dataset সিমুলেট ও residual যাচাই। (ক) np.random.default_rng(42) দিয়ে \(n=200\) এমন data বানান: area \(\sim U(50,250)\), age \(\sim U(0,40)\), rooms \(\sim\) integer \(1\)–\(6\), এবং \(\text{price} = 25 + 0.45\,\text{area} - 0.8\,\text{age} + 6\,\text{rooms} + \varepsilon\) যেখানে \(\varepsilon\sim\mathcal N(0,12^2)\)। (খ) প্রশ্ন ১৩-এর ols_fit দিয়ে \(\hat\beta\) বের করে true \([25, 0.45, -0.8, 6]\)-এর সাথে তুলনা করুন। (গ) residual diagnostics: residual \(\hat\varepsilon\) বের করে যাচাই করুন (i) \(\sum\hat\varepsilon_i \approx 0\), (ii) প্রতিটি predictor-এর সাথে \(\hat\varepsilon\)-এর correlation \(\approx 0\) (orthogonality), এবং একটি residual vs fitted scatter আঁকুন — কোনো প্যাটার্ন আছে কি? (ঘ) \(R^2\) গণনা করুন।
Hint: X = np.column_stack([np.ones(n), area, age, rooms]); integer rooms-এর জন্য rng.integers(1,7,n)। residual orthogonality np.corrcoef(resid, X[:,1])[0,1] দিয়ে দেখুন — \(\sim 10^{-14}\) আসবে (গণনাগত শূন্য)। residual-vs-fitted plot-এ কোনো funnel/বাঁক না থাকলে LINE অনুমান যুক্তিসঙ্গত (পূর্ণ diagnostic ৫.২-এ)। আপনার \(\hat\beta\) true-এর কাছাকাছি কিন্তু হুবহু নয় — কারণ সসীম \(n\) ও noise।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- মডেল। Linear regression \(y = X\beta + \varepsilon\) ধরে নেয় response-এর শর্তাধীন গড় predictor-দের একটি রৈখিক সমাহার: \(\mathbb E[y\mid X] = X\beta\)। simple regression-এ একটি predictor (\(\hat y = \beta_0 + \beta_1 x\)), multiple-এ অনেকগুলো। "linear" শব্দটা parameter \(\beta\)-তে রৈখিকতা বোঝায় (\(x\)-এ নয় — তাই \(x^2, \log x\)-ও predictor হতে পারে)।
- OLS ও normal equation। আমরা residual sum of squares \(\lVert y - X\beta\rVert^2\) minimize করে \(\hat\beta\) বাছি। এর সমাধান normal equation \(X^\top X\,\hat\beta = X^\top y\), অর্থাৎ $$ \hat\beta = (X^\top X)^{-1}X^\top y \qquad (X \text{ full-rank হলে}). $$
- Projection-জ্যামিতি। \(\hat y = X\hat\beta\) হলো \(y\)-এর \(X\)-এর column space-এ orthogonal projection; residual \(\hat\varepsilon = y - \hat y\) সেই space-এর লম্ব, তাই \(X^\top\hat\varepsilon = \mathbf 0\)। intercept থাকলে এর সরাসরি ফল \(\sum_i\hat\varepsilon_i = 0\)।
- \(R^2\). মডেল \(y\)-এর কতটা variation ব্যাখ্যা করে তার পরিমাপ: $$ R^2 = 1 - \frac{\text{SSE}}{\text{SST}} = \frac{\text{SSR}}{\text{SST}},\qquad \text{SST} = \text{SSR} + \text{SSE}. $$ পরিসর \([0,1]\); simple regression-এ \(R^2 = r^2\) (১.৪-এর Pearson \(r\)-এর বর্গ)। predictor যোগ করলে \(R^2\) কখনো কমে না — তাই ন্যায্য তুলনার জন্য adjusted \(R^2\)।
- LINE অনুমান। OLS-এর তাত্ত্বিক ন্যায্যতা চারটি শর্তে: Linearity (সম্পর্ক সত্যিই রৈখিক), Independence (error-রা স্বাধীন), Normality (error Normal — মূলত inference-এর জন্য), Equal variance / homoscedasticity (সব \(x\)-এ error-variance এক)। Gauss–Markov উপপাদ্য বলে: linearity + zero-mean + homoscedastic + uncorrelated error হলে OLS হলো BLUE (Best Linear Unbiased Estimator) — Normality ছাড়াই।
- MLE = OLS। error \(\sim\mathcal N(0,\sigma^2)\) ধরলে \(\beta\)-এর maximum likelihood estimate আর least-squares estimate হুবহু এক — কারণ Gaussian log-likelihood maximize করা মানে squared-error যোগফল minimize করা।
পূর্ববর্তী সংযোগ (← ১.৪, ০.৫, ৪.৩/৪.৬):
- ১.৪ (correlation): simple regression-এর slope সরাসরি correlation থেকে — \(\hat\beta_1 = r\,\dfrac{s_y}{s_x}\), আর \(R^2 = r^2\)। অর্থাৎ Part I-এ চোখে-দেখা "একসাথে চলা"-ই এখানে একটি ভবিষ্যদ্বাণীকারী রেখায় রূপ নিল। আর ১.৪-এর সবচেয়ে বড় সতর্কবাণী — correlation ≠ causation — এখানেও অটুট: regression coefficient association মাপে, কারণ নয়।
- ০.৫ (linear algebra): \(\hat\beta = (X^\top X)^{-1}X^\top y\)-এর প্রতিটি টুকরো ০.৫ থেকে — matrix গুণ, transpose, inverse, এবং সবচেয়ে গভীরভাবে column space-এ projection ও rank। \(X\)-এর column linearly independent না হলে (\(X^\top X\) singular — perfect multicollinearity) \(\hat\beta\) অনন্য থাকে না — এটি বিশুদ্ধ ০.৫-এর rank-তত্ত্ব।
- ৪.৩ (MLE) / ৪.৬ (CI): ৪.৩-এর likelihood-পদ্ধতিই দেখায় কেন squared error — Gaussian error-এ MLE = OLS। আর ৪.৬-এর confidence interval-এর কাঠামো পরের অধ্যায়ে \(\hat\beta\)-র অনিশ্চয়তা (standard error, CI, test) মাপতে সরাসরি কাজে লাগবে।
পরবর্তী সংযোগ (→ ৫.২ — Regression Diagnostics ও Inference): এই অধ্যায় শিখিয়েছে কীভাবে একটি রেখা ফিট করতে হয় ও \(\hat\beta\), \(R^2\) পেতে হয়। কিন্তু একটা জরুরি প্রশ্ন বাকি: এই fit কি আদৌ বিশ্বাসযোগ্য? পরের অধ্যায় ৫.২ ঠিক সেটাই ধরবে — (১) diagnostics: residual plot, QQ-plot, leverage দিয়ে LINE অনুমান যাচাই (এই অধ্যায়ের প্রশ্ন ৪ ও ১৪-এর residual-পরীক্ষা সেখানে পূর্ণ রূপ পাবে; Anscombe-ধরনের ফাঁদ এখানে ফিরবে); (২) inference: প্রতিটি \(\hat\beta_j\)-এর standard error, \(t\)-test ("এই predictor কি সত্যিই দরকার?"), পুরো মডেলের \(F\)-test, ও CI — ৪.৬-এর সরাসরি সম্প্রসারণ; (৩) model selection: adjusted \(R^2\), AIC ইত্যাদি দিয়ে "কোন predictor রাখব" সিদ্ধান্ত। সংক্ষেপে: ৫.১ মডেল বানায়, ৫.২ মডেলকে বিচার করে ও তার উপর আস্থা মাপে।
সূত্র (sources): J. A. Rice, Mathematical Statistics and Data Analysis, Ch. 14 (Linear Least Squares — normal equations, projection geometry, Gauss–Markov, \(R^2\)); L. Wasserman, All of Statistics, Ch. 13 (Linear and Logistic Regression — least squares ও MLE-র সমতা, multiple regression); R. Furrer, STA121 Statistical Modeling (design matrix, OLS, model assumptions); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 4 (Regression and Prediction — fitted values, residuals, interpretation, applied code)।